|
|
2012年4月17日
需求描述:一个表已经上线,但是上线之后发现该表的数据量很大,而且会删除历史数据,该表上要建立多个唯一索引,现在的问题就是在建表的时候是建立了一个普通表,现在需要将普通表转化为分区表,并尽量减少对应用的影响1、使用ctas的方式来建立create table t1(ID VARCHAR2(60) not null,a VARCHAR2(60) not null,b VARCHAR2(60) not null,create_time TIMESTAMP(6) not null,d NUMBER(2) not null,e VARCHAR2(400) not null,OUTER_ID VARCHAR2(100))----原表---建立分区表:create table t1_new(ID_1 ,a ,b ,create_time ,d ,e ,OUTER_ID )partition by range (ID_1)(partition p_t1_new values less than ('201204'),partition p_t2_new values less than ('201205'))asselect * from t1;----此时应用还是不断的往t1表中插入数据-alter table t1_new add constraints pk_t1_new primary key (id) using tablespace local index_tablespace;----建立本地索引为了删除历史数据/alter table t1_new add constraints pk_t1_new primary key (id_1) using index local ;但是应用还在outer_id上建立唯一索引create unique index IDX_t1_new_2 on t1_new (OUTER_ID) LOCAL ;此时报ORA-14039: 分区列必须构成 UNIQUE 索引的关键字列子集原来oracle不支持在分区表上创建PK主键时主键列不包含分区列,创建另外的约束(unique)也不可以。为了解决这个问题,两种方法1、将分区键加到唯一索引里面2、将local索引变为global索引----此时当进行历史数据删除的时候会导致索引失效权衡之后在outer_id上建立普通索引alter table t1 rename to t1_bak;alter table t1_new rename to t1;在进行ctas之后需要进行数据完整新检查,而且在进行rename的时候会导致应用连接失效(也有可能在进行alter的时候获取不到表锁而失败)---适用于修改不很频繁的表2、使用交换分区的方式----原表create table t1(ID VARCHAR2(60) not null,a VARCHAR2(60) not null,b VARCHAR2(60) not null,create_time TIMESTAMP(6) not null,d NUMBER(2) not null,e VARCHAR2(400) not null,OUTER_ID VARCHAR2(100))alter table t1 add constraints pk_t1 primary key(id) ;新表create table t1_new(ID_1 ,a ,b ,create_time ,d ,e ,OUTER_ID )partition by range (ID_1)(partition p_t1_new values less than ('201204'),partition p_t2_new values less than ('201205'))alter table t1_new add constraints pk_t1_new primary key (id_1) using index local ;ALTER TABLE t1_new EXCHANGE PARTITION p_t1_new WITH TABLE t1 without validation;----要不要加上without validation(加上的话就是不验证数据是否有效,直接全部放在p_t1_new分区中)然后进行rename操作优点:只是对数据字典中分区和表的定义进行了修改,没有数据的修改或复制,效率最高。如果对数据在分区中的分布没有进一步要求的话,实现比较简单。在执行完RENAME操作后,可以检查T_OLD中是否存在数据,如果存在的话,直接将这些数据插入到T中,可以保证对T插入的操作不会丢失。不足:仍然存在一致性问题,交换分区之后RENAME T_NEW TO T之前,查询、更新和删除会出现错误或访问不到数据。如果要求数据分布到多个分区中,则需要进行分区的SPLIT操作,会增加操作的复杂度,效率也会降低。适用于包含大数据量的表转到分区表中的一个分区的操作。应尽量在闲时进行操作。3、在线重定义----原表create table t1(ID VARCHAR2(60) not null,a VARCHAR2(60) not null,b VARCHAR2(60) not null,create_time TIMESTAMP(6) not null,d NUMBER(2) not null,e VARCHAR2(400) not null,OUTER_ID VARCHAR2(100))alter table t1 add constraints pk_t1 primary key(id) ;新表create table t1_new(ID_1 ,a ,b ,create_time ,d ,e ,OUTER_ID )partition by range (ID_1)(partition p_t1_new values less than ('201204'),partition p_t2_new values less than ('201205'))alter table t1_new add constraints pk_t1_new primary key (id_1) using index local ;EXEC DBMS_REDEFINITION.CAN_REDEF_TABLE(USER, 'T1', DBMS_REDEFINITION.CONS_USE_PK);
EXEC DBMS_REDEFINITION.START_REDEF_TABLE(USER, 'T1', 'T1_NEW',DBMS_REDEFINITION.CONS_USE_PK);
(转载请注明出处:[url=http://www.k6567.com]e世博[/url] [url=http://www.d9732.com]澳门博彩[/url])
尽管httpservletresponse.sendredirect方法和requestdispatcher.forward方法都可以让浏览器获得另外一个url所指向的资源,但两者的内部运行机制有着很大的区别。下面是httpservletresponse.sendredirect方法实现的请求重定向与requestdispatcher.forward方法实现的请求转发的总结比较:
(1)requestdispatcher.forward方法只能将请求转发给同一个web应用中的组件;而httpservletresponse.sendredirect 方法不仅可以重定向到当前应用程序中的其他资源,还可以重定向到同一个站点上的其他应用程序中的资源,甚至是使用绝对url重定向到其他站点的资源。如果传递给httpservletresponse.sendredirect 方法的相对url以“/”开头,它是相对于整个web站点的根目录;如果创建requestdispatcher对象时指定的相对url以“/”开头,它是相对于当前web应用程序的根目录。
(2)调用httpservletresponse.sendredirect方法重定向的访问过程结束后,浏览器地址栏中显示的url会发生改变,由初始的url地址变成重定向的目标url;而调用requestdispatcher.forward 方法的请求转发过程结束后,浏览器地址栏保持初始的url地址不变。
(3)httpservletresponse.sendredirect方法对浏览器的请求直接作出响应,响应的结果就是告诉浏览器去重新发出对另外一个url的 访问请求,这个过程好比有个绰号叫“浏览器”的人写信找张三借钱,张三回信说没有钱,让“浏览器”去找李四借,并将李四现在的通信地址告诉给了“浏览器”。于是,“浏览器”又按张三提供通信地址给李四写信借钱,李四收到信后就把钱汇给了“浏览器”。可见,“浏览器”一共发出了两封信和收到了两次回复, “浏览器”也知道他借到的钱出自李四之手。requestdispatcher.forward方 法在服务器端内部将请求转发给另外一个资源,浏览器只知道发出了请求并得到了响应结果,并不知道在服务器程序内部发生了转发行为。这个过程好比绰号叫“浏览器”的人写信找张三借钱,张三没有钱,于是张三找李四借了一些钱,甚至还可以加上自己的一些钱,然后再将这些钱汇给了“浏览器”。可见,“浏览器”只发 出了一封信和收到了一次回复,他只知道从张三那里借到了钱,并不知道有一部分钱出自李四之手。
(4)requestdispatcher.forward方法的调用者与被调用者之间共享相同的request对象和response对象,它们属于同一个访问请求和响应过程;而httpservletresponse.sendredirect方法调用者与被调用者使用各自的request对象和response对象,它们属于两个独立的访问请求和响应过程。对于同一个web应用程序的内部资源之间的跳转,特别是跳转之前要对请求进行一些前期预处理,并要使用httpservletrequest.setattribute方法传递预处理结果,那就应该使用requestdispatcher.forward方法。不同web应用程序之间的重定向,特别是要重定向到另外一个web站点上的资源的情况,都应该使用httpservletresponse.sendredirect方法。
(5)无论是requestdispatcher.forward方法,还是httpservletresponse.sendredirect方法,在调用它们之前,都不能有内容已经被实际输出到了客户端。如果缓冲区中已经有了一些内容,这些内容将被从缓冲区中清除。 (转载请注明出处:[url=http://www.a9832.com]博彩网[/url][url=http://www.tswa.org]博彩通[/url])
在java.lang包当中定义了一个Runtime类,在java中对于Runtime类的定义如下:public class Runtimeextends Object每个 Java 应用程序都有一个 Runtime 类实例,使应用程序能够与其运行的环境相连接。可以通过 getRuntime 方法获取当前运行时。应用程序不能创建自己的 Runtime 类实例。根据上面的话,我们知道对于每一个java程序来说都只有一个Runtime类实例,而且不能由用户创建一个Runtime实例,既然不能创建那么这个类的实例的作用是什么呢?它提供了应用程序和应用程序正在运行的环境的一个接口。Runtime不能由我们创建,我们可以通过Runtime类的一个静态方法,得到一个Runtime类的实例。获取了这个实例之后我们就可以获取java虚拟机的自由内存、也可以获取这个java虚拟机的总的内存等(具体的方法可以参照java帮助文档Runtime类的方法学习),也就是说这个类提供了应用程序了环境的接口。下面我们举一个例子程序:Runtime rt=Runtime.getRuntime();System.out.println(rt.freeMemory());System.out.println(rt.totalMemory());//结果返回的是数字Runtime类还有一个好处就是可以执行一个外部的程序,可以调用Runtime类的exec()方法传入一个命令(exec()方法有几个重载的方法,可以自己学习),创建一个子进程,结果返货一个Process类的实例,通过这个实例我们可以管理创建的子进程。对于Process类在java帮助文档中描述如下:public abstract class Processextends ObjectProcessBuilder.start() 和 Runtime.exec 方法创建一个本机进程,并返回 Process 子类的一个实例,该实例可用来控制进程并获得相关信息。Process 类提供了执行从进程输入、执行输出到进程、等待进程完成、检查进程的退出状态以及销毁(杀掉)进程的方法。public abstract class Processextends ObjectProcessBuilder.start() 和 Runtime.exec 方法创建一个本机进程,并返回 Process 子类的一个实例,该实例可用来控制进程并获得相关信息。Process 类提供了执行从进程输入、执行输出到进程、等待进程完成、检查进程的退出状态以及销毁(杀掉)进程的方法。下面我们接着上面的代码继续写:try{rt.exec("notepad");}catch(Exception e){e.printStackTrace;}//在使用exec()方法的时候会抛出一个异常,我们需要捕获这段代码,是运行在windows上的,它调用了windows系统的记事本程序。举一反三我们同样可以用这个方法去编译java的文件,只是传入的参数是“javac ***.java”。对于Process类的实例主要作用是创建一个可以管理的进程,并对它进行管理。Process类还有几个方法分别是destroy() 杀掉子进程、exitValue()返回子进程的出口值、getErrorStream()获取子进程的错误流,错误流获得由该 Process 对象表示的进程的错误输出流传送的数据,还有获取输入流输出流请读者自己参照java帮助文档学习。这是自己在接触Runtime类和Process类的时候学到的一些东西,分享出来希望对大家有用,大家看见了若是有不对的地方,请指出来。 (转载请注明出处:[url=http://www.live588.org]淘金盈[/url][url=http://www.10086money.com]时尚资讯[/url])
许多人对于程序、进程、线程这几个概念许多人都分的不是很清楚,下面我们就简单的介绍一下它们的区别。 程序是计算机指令的集合,它以文件的形式存储在磁盘上。程序是通常我们所写好的存储于计算机上没有执行的指令的集合,通俗的讲就是我们自己写的代码。我们写的代码不可能只是为了存储吧,必须运行才不会浪费我们的辛苦,等到我们将我们的代码运行了,就产生了进程。 进程:是一个程序在其自身的地址空间中的一次执行活动。通常的程序是不能并发执行的。为了使程序能够独立运行,应该为之配置一些进程控制块,即PCB;而由程序段,相关数据段和PCB三部分构成了进程实体。通常我们并不区分进程和进程实体,基本上就代表同一事物。进程是资源申请、调度和独立运行的单位,因此,它使用系统中的运行资源;而程序不能申请系统资源,不能被系统调度,也不能作为独立运行的单位,因此,它不占用系统的运行资源。 20世纪60年代人们提出了进程的概念,在OS中一直都是以进程作为能独立运行和拥有资源的基本单位。但是进程间的切换比较麻烦费时,所以在20世纪80年代人们为了提高系统内程序并发执行的程度,进一步提高系统的吞吐量,提出了比进程更小的能独立运行的基本单位。线程又称为轻量级进程,它和进程一样拥有独立的执行控制,由操作系统负责调度,区别在于线程没有独立的存储空间,而是和所属进程中的其它线程共享一个存储空间,这使得线程间的通信远较进程简单。一个进程可以同时拥有一个或者多个线程,这几个线程共享同样的数据。 现在的CPU几乎都是多核的了,这样多线程的程序,运行起来就更加流畅。下面我们通过图片来比较一下单线程和多线程: 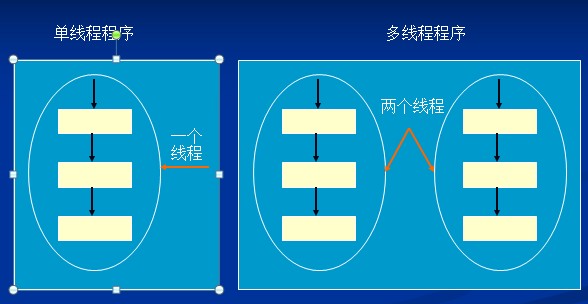
这个就好比我们算一道数学题(2+3)*(5-3),如果我们使用左边的单线程,只能是先算2+3然后算5-3,最后结果相加。但是如果我们使用右边的多线程,我们可以同时对2+3和5-3进行运算,然后再对最后的结果相加。我想哪个运行的比较快就不用说了,另外多线程在图像处理,多用户通信等方面用户都很多。 可能读者会说如果我们用的是单CPU的PC那么他们就差别不大了,但是现在的事实是现在的PC基本都是多核了,所以多线程是为了我们更好的将程序移植到多核的CPU上。还有一点就是对于线程的切换,比进程的切换速度快的多,多线程更好的发挥CPU的效率。 写的不好,如果哪里错了希望大家指出。希望对你有帮助。
(转载请注明出处:[url=http://www.6rfd.com]澳门博彩[/url] [url=http://www.9gds.com]易博网[/url])
当面临一个问题,有多种实现算途径的时候,要想到java中的核心:多态。
多态的思想:
概括地讲,在运用父类引用指向子类对象的情况下,基本上就用到了多态了。
最简单的多态应该是继承: public class Tank {
public void move() {
System.out.println("I am father");
}
}
public class Tank2 extends Tank{
@Override
public void move(){
System.out.println("I am child a");
}
public class Client {public static void main(String[] args) {Tank t2 = new Tank2(); ///父类引用指向了子类对象t2.move(); ///父类中的move方法,但实际具体的实现是tank2对象对move的实现。} } 接口和抽象类的例子:
对于抽象类和接口,有许多类实现这个接口(或者继承这个抽象类)。
在调用的时候,用父类引用指向子类对象的方法。然后,调用对象的方法,编译器就会自动根据这个对象实际属于哪个实现类,
来调出这个类对于接口或者抽象类的具体实现。
例:
public class Address {
private String name;
public Address(String name){
this.name = name;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
}
定义基类(抽象类):
public abstract class Vehicle {
abstract void go(Address address);
}
Car对于基类的实现:
public class Car extends Vehicle{
@Override
public void go(Address address){
System.out.println("Car to " + address.getName());
}
}
Plane对于基类的实现:
public class Plane extends Vehicle{
@Override
void go(Address address) {
System.out.println("Plane to " + address.getName());
}
}
Driver中多态:
public void drive(Vehicle v){ ///多态,父类引用指向子类对象,实际传过来的是抽象类Vehicle的子类,或者实现类,然后编译器会根据具体实现类,来找实现方法。
v.go(new Address("杭州(abstract)")); ///此方法在具体的实现中被重写
}
Test:
public static void main(String[] args) {
Driver d = new Driver();
d.drive(new Plane()); //实际是Plane对象,则编译器就会找到Plane中,对go的实现
d.drive(new Car()); //实际是Car对象,则编译器就会找到Plane中,对go的实现
}
输出结果:
Plane to 杭州(abstract)
Car to 杭州(abstract)
事实上,这就是多态所起的作用,可以实现控制反转这在大量的J2EE轻量级框架中被用到,比如Spring的依赖注射机制。
(通过注入不同的bean,来得到不同的实现类)
接口与抽象类的区别:
有个概念,但还没有想到具体实现。
对于一些共用的,已经有实现了,可以设计成接口。
上面是抽象类,下面把它转化为接口:
IVehicle.java
public interface IVehicle {
public void go(Address address);
}
CarImpl.java
public class CarImpl implements IVehicle{
public void go(Address address) {
System.out.println("CarImpl to " +address.getName());
}
}
PlameImpl.java
public class PlaneImpl implements IVehicle{
public void go(Address address) {
System.out.println("PlaneImpl to " + address.getName());
}
}
Driver.java
////多态之接口
public void driveI(IVehicle v){
v.go(new Address("杭州(interface)"));
}
Test.java
////用接口实现
d.driveI(new PlaneImpl());
d.driveI(new PlaneImpl());
打印结果:
PlaneImpl to 杭州(interface)
PlaneImpl to 杭州(interface)
多态的三要素:1.继承 2.重写 3.父类引用指向子类对象 以上就是我目前学习中的总结,如有不足之处,还望多多赐教。
(转载请注明出处:[url=http://www.k8764.com]博彩通[/url] [url=http://www.5sfd.com]e世博[/url])
用java读取Properties文件来改变实现类的Demo:public abstract class Vehicle {public abstract void run();}public class Car extends Vehicle{public void run(){System.out.println("with Car");}}public class Broom extends Vehicle {@Overridepublic void run() {System.out.println("Broom");}}test.properties 中:VehicleType=abstractfactory.step4properties.Broom注意:该文件要放在src目录下,且等号两边不可有空格import java.util.Properties;public class Test {public static void main(String[] args) throws Exception{Properties pros = new Properties();///配置文件编译之后放在bin目录下//每个class的类,都会被当作Class对象。getClassLoader:拿到了装载这个Class的装载器///把它当作一个流读进来,默认路径是根目录。读出来之后,把它转化为一个properties对象,然后,等号左边的就是key,等号右边的就是valuepros.load(Test.class.getClassLoader().getResourceAsStream("abstractfactory/step4properties/spring.properties"));String vehicleTypeName = pros.getProperty("VehicleType");System.out.println(vehicleTypeName);///现在,得到的字符串,我们想把字符串代表的类,产生一个对象,用到反射///Class.forName把字符串所代表的表装到内存,newInstance:生成对象,得到的是个ObjectVehicle v = (Vehicle)Class.forName(vehicleTypeName).newInstance();v.run();//只要改变test.properties中的VehicleType=factory.step4Spring.Broom,即可实现改变实现类的功能。}}
(转载请注明出处:[url=http://www.k6567.com]e世博[/url][url=http://www.d9732.com]澳门博彩[/url])
用JAVA/JSP做开发很久了,也见过许多朋友做过,有很大一部分用的是MYSQL的数据库,现在MYSQL数据库版本5.0及以上的都已经被用的很广泛了,但一直有一个问题,使刚入门的朋友费劲心思.就是JSP连接MYSQL5数据库的时候的一些中文问题.于是网络上也出现了很多相关的帖子.由些大家对MYSQL5数据库的配制文件MY.INI也有了些了解.甚至一些朋友就直接问:你们的MYSQL是什么编码的?你们的TOMCAT是什么样的编码,可能不是很规范的问法,但说明了编码问题的确影响了大家的使用. 下面的讲解是在MYSQL5.0.18,TOMCAT5.0.28,驱动为mysql-connector-java-3.2.0-alpha-bin.jar及以上版本的情况下测试的 JSP连接数据库的乱码问题,分两部分来看 1 数据库中是不是乱码? 我们需要保证数据库保存的不是"?????"形式的乱码,如何保证呢? 我们在管理MYSQL数据库的时候,需要用一个客户端,无论你用MYSQL-FRONT,EMS SQL Manager for MySQL,还是MYSQL命令行,这些都是客户端,也是程序连接了数据库,我们现在用客户端EMS SQL Manager for MySQL连接数据库,连接的时候一定要设置客户端字符集为GBK或者GB2312,这样你才能知道数据库里面是不是乱码.这一编码设置很重要,不然,就算数据库里是中文,你看到的还是乱码 
这样连接后,我们看下我们做测试的表格,里面的汉字就是正常的,这个时候也可以直接在上面的记录中进入中文的修改 
若这里没有选择编码的话,一般默认的就是UTF8的了,连接后再看这个表格,就会出现乱码 
而这个时候就会出现不能插入中文的问题,若您插入中文的话,就会出现下列错误 
这个时候大家什么不要误解,不是不能插入中文,也不是你插入的字符太长, 更改下连接编码就OK了.下面是这个表格的SQL语句 CREATE TABLE `test` (
`name` varchar(100) default NULL,
`adesc` varchar(100) default NULL
) ENGINE=InnoDB DEFAULT CHARSET=gb2312; 二.程序连接数据时,也要设置好连接时候的编码,JSP连接MYSQL数据库时候,有个URL参数,jdbc:mysql://localhost:3307/sssdb?user=demoUser&password=demoPwd&useUnicode=true&characterEncoding=UTF-8,在这里需要设置成UTF-8, 下面是连接数据库的程序代码 <%@ page contentType="text/html;charset=GB2312" language="java"%>
<%@ page import="java.io.*" %>
<%@ page import="java.util.*" %>
<%@ page import="java.sql.*" %> <%
out.println("您的数据库某表格中的内容如下<br>");
try {
Class.forName("com.mysql.jdbc.Driver").newInstance();
String url ="jdbc:mysql://localhost:3307/sssdb?user=demoUser&password=demoPwd&useUnicode=true&characterEncoding=UTF-8";
//testDB为你的数据库名
Connection conn= DriverManager.getConnection(url);
Statement stmt=conn.createStatement(ResultSet.TYPE_SCROLL_SENSITIVE,ResultSet.CONCUR_UPDATABLE);
String sql="select * from test"; ResultSet rs=stmt.executeQuery(sql);
while(rs.next()) {
out.println("第一个字段内容:<font color=red>"+rs.getString(1)+"</font> 第二个字段内容:<font color=red>"+rs.getString(2)+"</font><br>");
}
out.print("数据库操作成功,恭喜你"); sql = "insert into test (name,adesc) values ('中文','汉字')";
stmt.execute(sql);
rs.close();
stmt.close();
conn.close();
}
catch(Exception e){
System.out.println("数据库连接不成功"+e.toString());
}
%>
上面的经验是经过多次尝试总结出来的,不管是MYSQL的客户端还是程序连接MYSQL数据库,在本质上都是程序连接数据库,可以自己在本地多试验下,有时候有可能是驱动太旧.
(转载请注明出处:[url=http://www.a9832.com]博彩网[/url]
[url=http://www.tswa.org]博彩通[/url])
qtp录制鼠标右键单击事件要通过模拟键盘操作来实现step 1,修改replaytype为2,一般情况默认设置是1的。(1 – 使用浏览器事件运行鼠标操作。 2 – 使用鼠标运行鼠标操作)setting.webpackage(”replaytype”) = 2step 2,鼠标右键单击事件(附:click的事件有三种 micleftbtn 0 鼠标左键。 micrightbtn 1 鼠标右键。 micmiddlebtn 2 鼠标中键)browser(”支付宝 – 网上支付 安全快速!”).page(”支付宝 – 网上支付 安全快速!”).link(”返回我要付款”).click , , micrightbtnstep 3,点击右键弹出的菜单(采用键盘事件来模拟)set wshshell = createobject(”wscript.shell”)wshshell.sendkeys “{down}” //键盘向下的箭头wshshell.sendkeys “{down}”wshshell.sendkeys “{enter}” //回车键step 4,修改replaytype为1(使用浏览器事件运行鼠标操作)setting.webpackage(”replaytype”) = 1good to go now. (转载请注明出处:[url=http://www.live588.org]淘金盈[/url][url=http://www.10086money.com]时尚资讯[/url])
摘要: $("#父窗口元素ID",window.parent.document); 对应javascript版本为window.parent.document.getElementByIdx_x("父窗口元素ID"); 取父窗口的元素方法:$(selector, window.parent.document); 那么你取父窗口的父窗口的元素就可以用:$(selector, w... 阅读全文
摘要: C#代码 using System; using System.Collections.Generic; using System.ComponentModel; using System.Data; using System.Drawin... 阅读全文
摘要: 1.可以在servlet的init方法里 String path = getServletContext().getRealPath("/"); 这将获取web项目的全路径 例如 :E:\eclipseM9\workspace\tree\ tree是我web项目的根目录 2.你也可以随时在任意的class里调用 this.getClass... 阅读全文
摘要: Maven带有超过40+个Maven模板,让开发者快速开始一个新的Java项目。这一章,演示怎样使用Maven的命令“mvn archetype:generate”生成一个新的Java Web项目。 下面是使用Maven模板生成项目的步骤。 1、mvn archetype:generate命令 定位到要生成的项目的目录下,如“D:\... 阅读全文
Spring也提供了声明式事务管理。这是通过Spring AOP实现的。 Spring 中进行事务管理的通常方式是利用AOP(面向切片编程)的方式,为普通java类封装事务控制,它是通过动态代理实现的,由于接口是延迟实例化的, spring在这段时间内通过拦截器,加载事务切片。原理就是这样,具体细节请参考jdk中有关动态代理的文档。本文主要讲解如何在spring中进行事务控制。 动态代理的一个重要特征是,它是针对接口的,所以我们的dao要通过动态代理来让spring接管事务,就必须在dao前面抽象出一个接口,当然如果没有这样的接口,那么spring会使用CGLIB来解决问题,但这不是spring推荐的方式,所以不做讨论. 大多数Spring用户选择声明式事务管理。这是最少影响应用代码的选择, 因而这是和非侵入性的轻量级容器的观念是一致的。 从考虑EJB CMT和Spring声明式事务管理的相似以及不同之处出发是很有益的。 它们的基本方法是相似的:都可以指定事务管理到单独的方法;如果需要可以在事务上 下文调用setRollbackOnly()方法。不同之处如下: 不象EJB CMT绑定在JTA上,Spring声明式事务管理可以在任何环境下使用。 只需更改配置文件,它就可以和JDBC、JDO、Hibernate或其他的事务机制一起工作 Spring可以使声明式事务管理应用到普通Java对象,不仅仅是特殊的类,如EJB Spring提供声明式回滚规则:EJB没有对应的特性, 我们将在下面讨论这个特性。回滚可以声明式控制,不仅仅是编程式的 Spring允许你通过AOP定制事务行为。例如,如果需要,你可以在事务 回滚中插入定制的行为。你也可以增加任意的通知,就象事务通知一样。使用 EJB CMT,除了使用setRollbackOnly(),你没有办法能 够影响容器的事务管理 Spring不提供高端应用服务器提供的跨越远程调用的事务上下文传播。如 果你需要这些特性,我们推荐你使用EJB。然而,不要轻易使用这些特性。通常我 们并不希望事务跨越远程调用 回滚规则的概念是很重要的:它们使得我们可以指定哪些异常应该发起自 动回滚。我们在配置文件中,而不是Java代码中,以声明的方式指定。因此,虽然我们仍 然可以编程调用TransactionStatus对象的 setRollbackOnly()方法来回滚当前事务,多数时候我们可以 指定规则,如MyApplicationException应该导致回滚。 这有显著的优点,业务对象不需要依赖事务基础设施。例如,它们通常不需要引 入任何Spring API,事务或其他任何东西。 EJB的默认行为是遇到系统异常(通常是运行时异常), EJB容器自动回滚事务。EJB CMT遇到应用程序异常 (除了java.rmi.RemoteException外的checked异常)时不 会自动回滚事务。虽然Spring声明式事务管理沿用EJB的约定(遇到unchecked 异常自动回滚事务),但是这是可以定制的。 按照我们的测试,Spring声明式事务管理的性能要胜过EJB CMT。 通常通过TransactionProxyFactoryBean设置Spring事务代理。我们需要一个目标对象包装在事务代理中。这个目标对象一般是一个普通Java对象的bean。当我们定义TransactionProxyFactoryBean时,必须提供一个相关的 PlatformTransactionManager的引用和事务属性。 事务属性含有上面描述的事务定义。 <bean id="petStore" class="org.springframework.transaction.interceptor.TransactionProxyFactoryBean"> <property name="transactionManager"><ref bean="transactionManager"/></property> <property name="target"><ref bean="petStoreTarget"/></property> <property name="transactionAttributes"> <props> <prop key="insert*">PROPAGATION_REQUIRED,-MyCheckedException</prop> <prop key="update*">PROPAGATION_REQUIRED</prop> <prop key="*">PROPAGATION_REQUIRED,readOnly</prop> </props> </property></bean> code] 事务代理会实现目标对象的接口:这里是id为petStoreTarget的bean。(使用 CGLIB也可以实现具体类的代理。只要设置proxyTargetClass属性为true就可以。如果目标对象没有实现任何接口,这将自动设置该属性为true。通常,我们希望面向接口而不是类编程。)使用proxyInterfaces属性来限定事务代理来代 理指定接口也是可以的(一般来说是个好想法)。也可以通过从 org.springframework.aop.framework.ProxyConfig继承或所有AOP代理工厂共享 的属性来定制TransactionProxyFactoryBean的行为。 这里的transactionAttributes属性定义在 org.springframework.transaction.interceptor.NameMatchTransactionAttributeSource 中的属性格式来设置。这个包括通配符的方法名称映射是很直观的。注意 insert*的映射的值包括回滚规则。添加的-MyCheckedException 指定如果方法抛出MyCheckedException或它的子类,事务将 会自动回滚。可以用逗号分隔定义多个回滚规则。-前缀强制回滚,+前缀指定提交(这允许即使抛出unchecked异常时也可以提交事务,当然你自己要明白自己 在做什么)。 TransactionProxyFactoryBean允许你通过 “preInterceptors”和“postInterceptors”属性设置“前”或“后”通知来提供额外的 拦截行为。可以设置任意数量的“前”和“后”通知,它们的类型可以是 Advisor(可以包含一个切入点), MethodInterceptor或被当前Spring配置支持的通知类型 (例如ThrowAdvice, AfterReturningtAdvice或BeforeAdvice, 这些都是默认支持的)。这些通知必须支持实例共享模式。如果你需要高级AOP特 性来使用事务,如有状态的maxin,那最好使用通用的 org.springframework.aop.framework.ProxyFactoryBean, 而不是TransactionProxyFactoryBean实用代理创建者。 也可以设置自动代理:配置AOP框架,不需要单独的代理定义类就可以生成类的 代理。 附两个spring的事务配置例子: <prop key="add"> PROPAGATION_REQUIRES_NEW, -MyException </prop> 注:上面的意思是add方法将独占一个事务,当事务处理过程中产生MyException异常或者该异常的子类将回滚该事务。 <prop key="loadAll"> PROPAGATION_SUPPORTS, ISOLATION_READ_COMMITED, Readonly </prop> 注:表示loadAll方法支持事务,而且不会读取没有提交事务的数据。它的数据为只读(这样有助于提高读取的性能) 附A Spring中的所有事务策略 PROPAGATION_MANDATORY PROPAGATION_NESTED PROPAGATION_NEVER PROPAGATION_NOT_SUPPORTED PROPAGATION_REQUIRED PROPAGATION_REQUIRED_NEW PROPAGATION_SUPPORTS 附B Spring中所有的隔离策略: ISOLATION_DEFAULT ISOLATION_READ_UNCOMMITED ISOLATION_COMMITED ISOLATION_REPEATABLE_READ ISOLATION_SERIALIZABL (转载请注明出处:[url=http://www.a9832.com]博彩网[/url] [url=http://www.tswa.org]博彩通[/url])
摘要: java反射与代理 一. 关于数据库. 当今的数据处理大致可以分成两大类:联机事务处理OLTP(on-line transaction processing)、联机分析处理OLAP(On-Line Analytical Processing)。OLTP是传统的关系型数据库的主要应用,主要是基本的、日常的事务处理,例如银行交易。OLAP是数据仓库系统的主要应用,支持复杂的分析操作... 阅读全文
众所周知,当多个消息消费者(MessageConsumer)同时监听同一个消息队列(Queue)的时候,JMS提供者会在它们之间提供一种负载均衡机制,从而达到可以同时处理多个消息的目的。图一是一个简单的示意图,当消息生产者发送多个消息时,JMS提供者会把这些消息均匀的分发到不同的消息消费者。
图一 JMS负载均衡示意图
一、WebService负载均衡
要在原来的WebService上应用负载均衡,首先应该明确一个前提,就是客户端和服务端应尽可能的不做修改。另外还需要确保可以方便的添加和删除一个Service节点,而不会影响整个应用的运行。庆幸的是WebService调用通常都是无状态的,类似于无状态会话 Bean(Stateless Session Bean)的远程调用,服务端和客户端不需要维持一个会话,也就是说同一个客户端调用多次WebService请求,每个请求可以由不同的Service 为它服务,这样就可以避免Session复制的问题,如果一个Service崩溃了,另一个Service可以继续为客户端服务。
二、将JMS负载均衡应用到WebService中
接下来就把JMS的负载均衡机制应用到WebService当中去,图二是一个整体的框架图,Proxy作为一个WebService的代理来和客户端交互, 而Listener会去掉用具体的WebService,来完成一次WebService方法的调用。
图二 整体框架图
与客户端直接交互的是Proxy,它是一个简单的Servlet,它的作用就是拦截客户端发送过来的请求,提取请求中的SOAP包的内容,然后把它封装成一个消息发送到指定的Queue中去,同时它会等待消息的回复,因为回复的消息中包含着WebService调用返回的结果,后面会详细讲到。当Proxy收到回复消息之后,读取其中的内容并把它返回给客户端,从而完成一个WebService的调用。另外需要注意的是,在这里Proxy需要区分出客户端发出的是GET请求,还是POST请求。如果是GET请求,就有可能是客户端正在获取WebService的WSDL。如果是POST请求,那么通常就是客户端在调用一个WebService方法了。下面是一个简单的Proxy实现:
1 public class ServiceProxy extends HttpServlet {
2
3 private ConnectionFactory factory;
4
5 private Connection connection;
6
7 private Queue queue;
8
9 public void init() throws ServletException {
10
11 super.init();
12
13 try {
14
15 //在这里为了简单起见,采用了ActiveMQ。在实际的J2EE应用中应通过JNDI查找相应的ConnectionFactory和Queue。|||
16
17 factory = new ActiveMQConnectionFactory("vm://localhost");
18
19 connection = factory.createConnection();
20
21 connection.start();
22
23 queue = new ActiveMQQueue("testQueue");
24
25 } catch (JMSException e) {
26
27 e.printStackTrace();
28
29 }
30
31 }
32
33 protected void doGet(HttpServletRequest req, HttpServletResponse resp) {
34
35 if (req.getQueryString().endsWith("wsdl") || req.getQueryString().endsWith("WSDL")) {
36
37 try {
38
39 Session session = connection.createSession(false, Session.AUTO_ACKNOWLEDGE);
40
41 Message message = session.createMessage();
42
43 //这个属性用来标示请求是否是WSDL请求,后面的Listener会根据它来调用具体的WebService。
44
45 message.setBooleanProperty("isWsdl", true);
46
47 message.setJMSReplyTo(session.createTemporaryQueue());
48
49 session.createProducer(queue).send(message);
50
51 //等待回复消息,它里面包含Service返回的WSDL,这里使用了一个选择器。
52
53 String selector = String.format("JMSCorrelationID=‘%s‘", message.getJMSMessageID());
54
55 MessageConsumer consumer = session.createConsumer(message.getJMSReplyTo(), selector);
56
57 TextMessage replyMessage = (TextMessage) consumer.receive();
58
59 //将WSDL返回给客户端。
60
61 resp.getWriter().write(replyMessage.getText());
62
63 } catch (Exception e) {
64
65 e.printStackTrace();
66
67 }
68
69 }
70
71 }
72
73 protected void doPost(HttpServletRequest req, HttpServletResponse resp) {
74
75 try {
76
77 //首先从客户端请求中得到SOAP请求部分。
78
79 StringBuffer payLoad = new StringBuffer();
80
81 BufferedReader reader = req.getReader();
82
83 String temp;
84
85 while ((temp = reader.readLine()) != null) {
86
87 payLoad.append(temp);
88
89 }
90
91 //将SOAP请求封装成一个消息,发送到Queue。
92
93 Session session = connection.createSession(false, Session.AUTO_ACKNOWLEDGE);
94
95 Message message = session.createTextMessage(payLoad.toString());
96
97 message.setBooleanProperty("isWsdl", false);
98
99 message.setJMSReplyTo(session.createTemporaryQueue());
100|||
101 session.createProducer(queue).send(message);
102
103 //等待回复,回复的消息中包含着服务端返回的SOAP响应。
104
105 String selector = String.format("JMSCorrelationID=‘%s‘", message.getJMSMessageID());
106
107 MessageConsumer consumer = session.createConsumer(message.getJMSReplyTo(), selector);
108
109 TextMessage replyMessage = (TextMessage) consumer.receive();
110
111 //将SOAP响应返回给客户端。
112
113 resp.getWriter().write(replyMessage.getText());
114
115 } catch (Exception e) {
116
117 e.printStackTrace();
118
119 }
120
121 }
122
123 }
接下来需要看一下Listener了。对于每一个Service都有一个Listener与之相对应,当一个Listener从Queue中取得一个消息之后,首先应该判断是否是WSDL请求。如果是WSDL请求,则向WebService发送一个GET请求,并将请求的结果,也就是WSDL封装成一个Message回复给Proxy。如果是SOAP请求,则从中取出SOAP请求部分并通过POST方法发送给Service,所得到的返回结果即为Service的SOAP响应,把它回复给Proxy,进而回复给客户端。
下面是Listener的一个简单实现,在这里我们使用了HttpClient来发送GET和POST请求。
1 public class Listener {
2
3 private ConnectionFactory factory;
4
5 private Connection connection;
6
7 private Queue queue;
8
9 private Session session;
10
11 public Listener() throws Exception {
12
13 //为了简单,还是采用了ActiveMQ。
14
15 factory = new ActiveMQConnectionFactory("vm://localhost");
16
17 connection = factory.createConnection();
18
19 connection.start();
20
21 queue = new ActiveMQQueue("testQueue");
22
23 session = connection.createSession(false, Session.AUTO_ACKNOWLEDGE);
24
25 }
26
27 public void startUp() throws Exception {
28
29 MessageConsumer consumer = session.createConsumer(queue);
30
31 consumer.setMessageListener(new MessageListener() {
32
33 public void onMessage(Message message) {
34
35 try {
36
37 String response;
38
39 //通过判断isWSDL这个属性来判断是否是WSDL请求。
40
41 if (message.getBooleanProperty("isWsdl")) {
42
43 //如果是WSDL请求,则向服务器发送一个GET请求,并等待WSDL响应结果。
44
45 HttpClient client = new HttpClient();|||
46
47 //具体Service的地址,可以使用properties文件等。
48
49 GetMethod m = new GetMethod("http://localhost:8081/hello?wsdl");
50
51 client.executeMethod(m);
52
53 response = m.getResponseBodyAsString();
54
55 } else {
56
57 //如果是SOAP请求,则将SOAP包发送给服务器,并等待SOAP响应。
58
59 HttpClient client = new HttpClient();
60
61 PostMethod m = new PostMethod("http://localhost:8081/hello");
62
63 m.setRequestBody(((TextMessage) message).getText());
64
65 client.executeMethod(m);
66
67 response = m.getResponseBodyAsString();
68
69 }
70
71 //将WSDL响应或SOAP响应封装成一个消息,回复给Proxy。
72
73 MessageProducer producer = session.createProducer(message.getJMSReplyTo());
74
75 TextMessage replyMessage = session.createTextMessage(response);
76
77 //设置JMSCorrelationID,Proxy通过它来得到该回复消息。
78
79 replyMessage.setJMSCorrelationID(message.getJMSCorrelationID());
80
81 producer.send(replyMessage);
82
83 } catch (Exception ex) {
84
85 ex.printStackTrace();
86
87 }
88
89 }
90
91 });
92
93 }
94
95 }
三、还需要考虑的
1,如果其中一个Service崩溃,我们需要停止相应的Listener,这一点可以在Listener中做到,例如当Listener访问 Service时出错,它可以等待一段时间以后再去监听Queue,同时把已经取得的消息重新发回到Queue中去,以便让其他的Listener处理。当然也可以将Listener放置到Service端,这样Service崩溃,Listener也就跟着不可用了。
2,如果某一时刻,所有的Service都不可用,Proxy也不应该无限等待下去,而应该设置一个等待回复消息的超时期限,如果这个期限内没有收到回复消息,则表明Service都不可用,同时通知客户端。
3,过期消息的处理,如同上一点,当Service不可用时,Proxy通知客户端出错,但是此时Proxy已经向Queue中发送了一条消息,当Service恢复时,这条消息会被重新处理。我们应该避免这种情况发生,因为这条消息已经过期了。可以设置消息的过期期限小于Proxy等待回复消息的期限,以确保它不会被重新处理。
4,最糟糕的情况就是,Proxy或者Queue崩溃,这样就算Service正常,客户端也会调用失败。
5,效率,既然我们选择了WebService和负载均衡,那就表示我们应该接受它效率相对低下的弱点,在这里需要说明的是JMS并不是效率的瓶颈,因为Listener只负责拿到消息并发送给Service,这时Service还是运行在多线程下的。
(转载请注明出处:[url=http://www.6rfd.com]澳门博彩[/url] [url=http://www.9gds.com]易博网[/url])
hashCode就是我们所说的散列码,使用hashCode算法可以帮助我们进行高效率的查找,例如HashMap,说hashCode之前,先来看看Object类。 我们知道,Object类是java程序中所有类的直接或间接父类,处于类层次的最高点。在Object类里定义了很多我们常见的方法,包括我们要讲的hashCode方法,如下 - public final native Class<?> getClass();
- public native int hashCode();
- public boolean equals(Object obj) {
- return (this == obj);
- }
- public String toString() {
- return getClass().getName() + "@" + Integer.toHexString(hashCode());
- }
注意到hashCode方法前面有个native的修饰符,这表示hashCode方法是由非java语言实现的,具体的方法实现在外部,返回内存对象的地址。
在java的很多类中都会重写equals和hashCode方法,这是为什么呢?最常见的String类,比如我定义两个字符相同的字符串,那么对它们进行比较时,我想要的结果应该是相等的,如果你不重写equals和hashCode方法,他们肯定是不会相等的,因为两个对象的内存地址不一样。
String类的重写的hashCode方法 - public int hashCode() {
- int h = hash;
- if (h == 0) {
- int off = offset;
- char val[] = value;
- int len = count;
-
- for (int i = 0; i < len; i++) {
- h = 31*h + val[off++];
- }
- hash = h;
- }
- return h;
- }
1、这段代码究竟是什么意思? 其实这段代码是这个数学表达式的实现 - s[0]*31^(n-1) + s[1]*31^(n-2) + ... + s[n-1]
s[i]是string的第i个字符,n是String的长度。那为什么这里用31,而不是其它数呢?《Effective Java》是这样说的:之所以选择31,是因为它是个奇素数,如果乘数是偶数,并且乘法溢出的话,信息就会丢失,因为与2相乘等价于移位运算。使用素数的好处并不是很明显,但是习惯上都使用素数来计算散列结果。31有个很好的特性,就是用移位和减法来代替乘法,可以得到更好的性能:31*i==(i<<5)-i。现在的VM可以自动完成这种优化。
2、它返回的hashCode有什么特点呢? 可以看到,String类是用它的value值作为参数来计算hashCode的,也就是说,相同的value就一定会有相同的hashCode值。这点也很容易理解,因为value值相同,那么用equals比较也是相等的,equals方法比较相等,则hashCode一定相等。反过来不一定成立。它不保证相同的hashCode一定有相同的对象。
一个好的hash函数应该是这样的:为不相同的对象产生不相等的hashCode。 在理想情况下,hash函数应该把集合中不相等的实例均匀分布到所有可能的hashCode上,要想达到这种理想情形是非常困难的,至少java没有达到。因为我们可以看到,hashCode是非随机生成的,它有一定的规律,就是上面的数学等式,我们可以构造一些具有相同hashCode但value值不一样的,比如说:Aa和BB的hashCode是一样的。
说到这里,你可能会想,原来构造hash冲突那么简单啊,那我是不是可以对HashMap函数构造很多<key,value>不都一样,但具有相同的hashCode,这样的话可以把HashMap函数变成一条单向链表,运行时间由线性变为平方级呢?虽然HashMap重写的hashCode方法比String类的要复杂些,但理论上说是可以这么做的。这也是最近比较热门的Hash Collision DoS事件。 HashMap里重写的hashCode方法 - public final int hashCode() {
- return (key==null ? 0 : key.hashCode()) ^
- (value==null ? 0 : value.hashCode());
- }
(转载请注明出处:[url=http://www.k8764.com]博彩通[/url]
[url=http://www.5sfd.com]e世博[/url])
由于工作需要,要在JS端将JSON对象转化为字符串,并写到用户的COOKIE中,用来保存用户的一些个人操作习惯。便在网上搜寻了一遍,发现方法有很多,有些代码不清晰,看得乱,有些考虑不周全,生成的字符串有问题,便整合了一些好的写法,自己改进了一下。可能还是考虑得不周全,但是感觉常用的类型都考虑了,望大家多多拍砖指点! JSON.stringify(jsonobj),本来是最简便的方法,可是存在浏览器兼容问题(仅适用于IE8+,Chrome 1+,FF 3+)。 var O2String = function (O) {
//return JSON.stringify(jsonobj);
var S = [];
var J = "";
if (Object.prototype.toString.apply(O) === '[object Array]') {
for (var i = 0; i < O.length; i++)
S.push(O2String(O[i]));
J = '[' + S.join(',') + ']';
}
else if (Object.prototype.toString.apply(O) === '[object Date]') {
J = "new Date(" + O.getTime() + ")";
}
else if (Object.prototype.toString.apply(O) === '[object RegExp]' || Object.prototype.toString.apply(O) === '[object Function]') {
J = O.toString();
}
else if (Object.prototype.toString.apply(O) === '[object Object]') {
for (var i in O) {
O[i] = typeof (O[i]) == 'string' ? '"' + O[i] + '"' : (typeof (O[i]) === 'object' ? O2String(O[i]) : O[i]);
S.push(i + ':' + O[i]);
}
J = '{' + S.join(',') + '}';
}
return J;
};
/*-----------------------以下是测试代码-----------------------*/
var jsonStr = O2String(
[
{
"Page": "plan",
"Custom":
[
{
"ItemName": "CustomLabel1",
"ItemContent": 1,
"IsItem": true,
"ItemDate": new Date(1320774905467),
"ItemReg": /[\w]*?/gi,
"ItemFunc": function () { alert("ItemFunc"); }
},
{
"ItemName": "CustomLabel1",
"ItemContent": 1,
"IsItem": true,
"ItemDate": new Date(1320774905467),
"ItemReg": /[\w]*?/gi,
"ItemFunc": function () { alert("ItemFunc"); }
}
]
},
{
"Page": "project",
"Custom":
[
{
"ItemName": "CustomLabel2",
"ItemContent": 2,
"IsItem": false,
"ItemDate": new Date(1320774905467),
"ItemReg": /[\w]*?/gi,
"ItemFunc": function () { alert("ItemFunc"); }
},
{
"ItemName": "CustomLabel2",
"ItemContent": 2,
"IsItem": false,
"ItemDate": new Date(1320774905467),
"ItemReg": /[\w]*?/gi,
"ItemFunc": function () { alert("ItemFunc"); }
}
]
}
]
);
alert(jsonStr);
var jsonObj = eval("(" + jsonStr + ")");
alert(jsonObj.length);
(转载请注明出处:[url=http://www.tdtf.org]易博网
[/url] [url=http://www.k5048.com]博彩网[/url])
现象:
系统突然报连接数过高,基本的现象就是有什么东西被锁了,导致后续的连接都在等待,那么到底是那个会话导致了阻塞那?
可以查看视图v$session ,关注以下几个字段
sid-------------------------被阻塞的进程id
status--------------------被阻塞的进程状态
COMMAND--------------被阻塞的进程执行的命令
ROW_WAIT_FILE#----被阻塞的进程对应的rowid所在的数据文件id
row_wait_block#-----row_wait_row#对应的rowid所在的表的object id
row_wait_obj#-------row_wait_row#对应的rowid所在的表的object id
row_wait_row#-----Current row being locked. This column is valid only if the session is currently waiting for another transaction to commit and the value of ROW_WAIT_OBJ# is not -1.但是准确的说是对应的于rowid的rownum,并非是单纯的rownum
blocking_session -----阻塞进程id
STATE-------------------被阻塞进程的状态
EVENT#----------------被阻塞进程等待的事件号
EVENT------------------被阻塞进程等待的事件
-----注意create_time是程序自动添加的select t.sid,t.status,t.COMMAND,t.ROW_WAIT_FILE#,t.row_wait_block#,t.row_wait_obj#,t.row_wait_row#,t.blocking_session ,t.STATE,t.EVENT#,t.EVENT from temp_session t where t.BLOCKING_SESSION_STATUS='VALID' and t.create_time=to_date('2012/3/20 18:47:16','yyyy/mm/dd hh24:mi:ss'); SID STATUS COMMAND ROW_WAIT_FILE# ROW_WAIT_BLOCK# ROW_WAIT_OBJ# ROW_WAIT_ROW# BLOCKING_SESSION STATE EVENT# EVENT175 620 ACTIVE 3 8 571147 77418 17 885 WAITING 239 enq: TX - row lock contention174 616 ACTIVE 3 8 571147 77418 17 885 WAITING 239 enq: TX - row lock contention173 615 ACTIVE 3 8 571147 77418 17 885 WAITING 239 enq: TX - row lock contention333 1050 ACTIVE 3 8 571147 77418 17 885 WAITING 239 enq: TX - row lock contention179 632 ACTIVE 3 8 571147 77418 17 885 WAITING 239 enq: TX - row lock contention178 629 ACTIVE 3 8 571147 77418 17 885 WAITING 239 enq: TX - row lock contention332 1049 ACTIVE 3 8 571147 77418 17 885 WAITING 239 enq: TX - row lock contention171 610 ACTIVE 3 8 571147 77418 17 885 WAITING 239 enq: TX - row lock contention166 592 ACTIVE 3 8 571147 77418 17 885 WAITING 239 enq: TX - row lock contention165 591 ACTIVE 3 8 571147 77418 17 885 WAITING 239 enq: TX - row lock contention164 589 ACTIVE 3 8 571147 77418 17 885 WAITING 239 enq: TX - row lock contention现在可以看到885进程阻塞了好多进程,那么要获得到底是那条记录被锁定了那?想要知道某一个表具体被锁定的是哪一行,可以利用上面这几个值,查找出被锁定行的rowid。使用dbms_rowidb包的一个子过程(Subprograms)rowid_createDBMS_ROWID.ROWID_CREATE (rowid_type IN NUMBER,object_number IN NUMBER,relative_fno IN NUMBER,block_number IN NUMBER,row_number IN NUMBER)RETURN ROWID;其中rowid_type的取值为 0 表示生成一个restricted ROWID(pre-oracle8 format); 取值为1 表示生成一个extended ROWID.object_number取值是dba_objects视图中的data_object_id,并不是object_id,也就是说不能用row_wait_obj#.relative_fno取值是Relative文件号,在dba_data_files里可以查到block_number取值是数据文件的块号,也就是v$session中的row_wait_block#的值row_number通过rowid对应出来的rownum,也就是row_wait_row#的值。
接下来找到这些数据rowid_type=1(11g)
object_number
selectdata_object_id from dba_objects where object_id='77418'
OBJECT_IDTT_BIGINT NOT NULLDictionary object number of the object.DATA_OBJECT_IDTT_BIGINTIs ignored.----这是11g的文档说明,可以看出,使用object_id就可以relative_fno=8
block_number=row_wait_block#
row_number =row_wait_row#
select * from table_name t where rowid=(select DBMS_ROWID.ROWID_CREATE(1,77418,8,571147,17) from dual);---得到被锁定的记录;此时查看885进程在做神马?kill之就可以 (转载请注明出处:[url=http://www.k6567.com]e世博[/url] [url=http://www.d9732.com]澳门博彩[/url])
#include <windows.h>
#include <stdio.h> LRESULT CALLBACK WinSunProc(//名字可以更改。参数类型不能变
HWND hwnd, // handle to window 窗口句柄
UINT uMsg, // message identifier
WPARAM wParam, // first message parameter 消息参数
LPARAM lParam // second message parameter
);
/*
int WINAPI WinMain(
HINSTANCE hInstance, // handle to current instance
HINSTANCE hPrevInstance, // handle to previous instance
LPSTR lpCmdLine, // pointer to command line
int nCmdShow // show state of window
); */
int WINAPI WinMain(//Windows程序的入口函数
HINSTANCE hInstance, // handle to current instance 当前实例句柄
HINSTANCE hPrevInstance, // handle to previous instance 前次实例句柄
LPSTR lpCmdLine, // command line 命令行参数
int nCmdShow // show state 显示方式
)
{
/*
创建一个完整的窗口需要经过下面四个操作步骤:
1、设计一个窗口类;
2、注册窗口类;
3、创建窗口;
4、显示及更新窗口。 typedef struct _WNDCLASS {
UINT style; //类的类型
WNDPROClpfnWndProc; //longpointfunction函数指针
int cbClsExtra; //类的附加内存
int cbWndExtra; //窗口附加内存
HANDLE hInstance; //实例号(句柄)
HICON hIcon; //图标句柄
HCURSOR hCursor; //光标句柄
HBRUSH hbrBackground; //画刷句柄
LPCTSTR lpszMenuName; //菜单的名字
LPCTSTR lpszClassName; //类的名字
} WNDCLASS;
*/
//1、设计一个窗口类;
WNDCLASS wndcls;//窗口类
wndcls.style=CS_HREDRAW | CS_VREDRAW;//重画垂直方向、水平方向
wndcls.lpfnWndProc=WinSunProc;//函数地址
wndcls.cbClsExtra=0;//类的附加内存
wndcls.cbWndExtra=0;//窗口的附加内存
wndcls.hInstance=hInstance;//实例号
wndcls.hIcon=LoadIcon(NULL,IDI_ERROR);//图标 设置
wndcls.hCursor=LoadCursor(NULL,IDC_CROSS);//光标 设置
wndcls.hbrBackground=(HBRUSH)GetStockObject(WHITE_BRUSH);//画刷的句柄
wndcls.lpszMenuName=NULL;//(菜单名字)
wndcls.lpszClassName="VCXTU";//注册类名(longpoint命令行参数)
//2、注册窗口类;
RegisterClass(&wndcls);//注册类 /*
HWND CreateWindow(
LPCTSTR lpClassName, // pointer to registered class name
LPCTSTR lpWindowName, // pointer to window name
DWORD dwStyle, // window style
int x, // horizontal position of window
int y, // vertical position of window
int nWidth, // window width
int nHeight, // window height
HWND hWndParent, // handle to parent or owner window
HMENU hMenu, // handle to menu or child-window identifier
HANDLE hInstance, // handle to application instance
LPVOID lpParam // pointer to window-creation data
);
*/
//3、创建窗口;
HWND hwnd;//窗口句柄
hwnd=CreateWindow(
"VCXTU",//注册类名(lpszClassName)
"湖南省湘潭市湘潭大学",//窗口名字
/*
WS_OVERLAPPEDWINDOW:
窗口风格
WS_OVERLAPPED 层叠的 具有标题栏和边框
WS_CAPTION 有标题栏
WS_SYSMENU 带有系统菜单
WS_THICKFRAME 具有可调边框
WS_MINIMIZEBOX 具有最小化按钮
WS_MAXIMIZEBOX) 具有最大化按钮
*/
WS_OVERLAPPEDWINDOW,//窗口风格
CW_USEDEFAULT,//窗口水平坐标(缺省的)
CW_USEDEFAULT,//窗口垂直坐标(缺省的)
600,//窗口宽度
400,//窗口高度
NULL,// 父窗口句柄(hWndParent/handle to parent or owner window)
NULL,// 菜单句柄(handle to menu or child-window identifier)
hInstance,//句柄(handle to application instance)
NULL//窗口参数(pointer to window-creation data)
); /*
BOOL ShowWindow(
HWND hWnd, // handle to window
int nCmdShow // show state of window
);
*/
//4、显示及更新窗口。
ShowWindow(
hwnd,//窗口句柄
SW_SHOWNORMAL//显示状态 show state of window
);
UpdateWindow(hwnd);//可有可无 /*
操作系统将每个事件都包装成一个称为消息的结构体MSG来传递给应用程序
MSG结构定义如下:
typedef struct tagMSG {
HWND hwnd;
UINT message;
WPARAM wParam;
LPARAM lParam;
DWORD time;
POINT pt;
} MSG;
*/
//消息循环
MSG msg;
/*
BOOL GetMessage(
LPMSG lpMsg, // address of structure with message
HWND hWnd, // handle of window
UINT wMsgFilterMin, // first message
UINT wMsgFilterMax // last message
);
*/
while(
GetMessage(
&msg,
NULL,
0,//设成0。表示对所有消息都有兴趣
0
)
)
{
/*
转换消息。可以将WM_KEYUP/WM_KEYDOWN转换为WM_CHAR消息、产生新消息并放到队列中
BOOL TranslateMessage(
CONST MSG *lpMsg // address of structure with message
);
*/
TranslateMessage(&msg);
/*
将收到的消息传到窗口的回调函数:wndcls.lpfnWndProc=WinSunProc;回调函数:WinSunProc
LONG DispatchMessage(
CONST MSG *lpmsg // pointer to structure with message
);
*/
DispatchMessage(&msg);
}
return 0;
} LRESULT CALLBACK WinSunProc(
HWND hwnd, // handle to window
UINT uMsg, // message identifier
WPARAM wParam, // first message parameter
LPARAM lParam // second message parameter
)
{
switch(uMsg)
{
case WM_CHAR://表示按下了某个字符按键
char szChar[20];
sprintf(szChar,"char is %d",wParam);//格式化消息。WM_CHAR中的wParam参数
/*
int MessageBox(
HWND hWnd, //拥有消息的父窗口 handle of owner window
LPCTSTR lpText, //文本 address of text in message box
LPCTSTR lpCaption, //标题 address of title of message box
UINT uType //消息框的风格 style of message box
);
*/
MessageBox(
hwnd,
szChar,
"湘潭大学",//标题
MB_OKCANCEL//MB_YESNO//消息框的风格
);
break;
case WM_LBUTTONDOWN:
MessageBox(hwnd,"鼠标左键点击了","湘潭大学",MB_OKCANCEL);
HDC hdc;//句柄 handle to device context
/*
HDC GetDC(
HWND hWnd // handle to a window
);
*/
hdc=GetDC(hwnd);
/*
BOOL TextOut(
HDC hdc, // handle to device context
int nXStart, // x-coordinate of starting position
int nYStart, // y-coordinate of starting position
LPCTSTR lpString, // pointer to string
int cbString // number of characters in string
);
*/
TextOut(hdc,0,50,"湖南省湘潭市湘潭大学1",strlen("湖南省湘潭市湘潭大学1"));
ReleaseDC(hwnd,hdc);//释放DC
break;
case WM_PAINT://窗口重绘
HDC hDC;
PAINTSTRUCT ps;
/*
HDC BeginPaint(
HWND hwnd, // handle to window
LPPAINTSTRUCT lpPaint
// pointer to structure for paint information
);
*/
hDC=BeginPaint(hwnd,&ps);//只能在WM_PAINT里面使用
TextOut(hDC,0,0,"湖南省湘潭市湘潭大学hDC",strlen("湖南省湘潭市湘潭大学hDC"));
EndPaint(hwnd,&ps);//只能在WM_PAINT里面使用
break;
case WM_CLOSE://关闭窗口时响应
if(IDYES==MessageBox(hwnd,"是否真的结束?","湘潭大学",MB_YESNO))
{
DestroyWindow(hwnd);//销掉hwnd窗口 还会发送 WM_DESTROY、WM_NCDESTROY 消息
}
break;
case WM_DESTROY:
PostQuitMessage(0);//退出程序
break;
default:
return DefWindowProc(hwnd,uMsg,wParam,lParam);
}
return 0;
}
(转载请注明出处:[url=http://www.live588.org]淘金盈[/url] [url=http://www.10086money.com]时尚资讯[/url])
1、查询v$sql视图
selectsql_id, sql_text, bind_data,HASH_VALUE from v$sql where sql_text Like '%select * from test where id1%';
它的记录频率受_cursor_bind_capture_interval 隐含参数控制,默认值900,表示每900秒记录一次绑定值,可以通过alter system set "_cursor_bind_capture_interval"=10;
此时查询到的data值得形式是这样的:BEDA0B2002004F8482D10065FFFF0F00000000000000000000C0021602C102C0021602C102F0018003691532303132303431313032504F443834363135313635F0018003691532303132303431313032504F443834363135313730F0018003691532303132303431313032504F443834363135313731F0018003691532303132303431313032504F443834363135313734F0018003691532303132303431313032504F443834363135313735F0018003691532303132303431313032504F443834363135313739F0018003691532303132303431313032504F443834363135313830F0018003691532303132303431313032504F443834363135313833F0018003691532303132303431313032504F443834363135313834F0018003691532303132303431313032504F443834363135313838F0018003691532303132303431313032504F443834363135313839F0018003691532303132303431313032504F443834363135313933F0018003691532303132303431313032504F443834363135313934F0018003691532303132303431313032504F443834363135313937F0018003691532303132303431313032504F443834363135313938F0018003691532303132303431313032504F443834363135323033F0018003691532303132303431313032504F443834363135323034F0018003691532303132303431313032504F443834363135323037
这样肯定是没法看懂的
需哟进行转换
select dbms_sqltune.extract_binds(bind_data) bind from v$sql WHERE SQL_TEXT LIKE '%FROM TEST11%';
2、查询SELECT VALUE_STRING FROM V$SQL_BIND_CAPTURE WHERE SQL_ID='abhf6n1xqgrr0';
通过v$sql_bind_capture视图,可以查看绑定变量,但是这个视图不太给力,只能捕获最后一次记录的绑定变量值。
而且两次捕获的间隔有一个隐含参数控制。默认是900秒,才会重新开始捕获。在900内,绑定变量值的改变不会反应在这个视图中。 10G以后可以通过如下方法查看AWR报告里记录的SQL的绑定变量值。 select snap_id, name, position, value_string,last_captured,WAS_CAPTUREDfrom dba_hist_sqlbind where sql_id = '576c1s91gua19' and snap_id='20433'; ----------SNAP_ID就是AWR报告的快照ID。 ----------name,绑定变量的名称 ----------position,绑定值在SQL语句中的位置,以1,2,3进行标注 ---------value_string,就是绑定变量值 ---------,last_captured,最后捕获到的时间 ---------WAS_CAPTURED,是否绑定被捕获,where子句前面的绑定不进行捕获。 dba_hist_sqlbind视图强大的地方在于,它记录了每个AWR报告里的SQL的绑定变量值,当然这个绑定变量值也是AWR生成的时候从v$sql_bind_capture采样获得的。 通过这个视图,我们能够获得比较多的绑定变量值,对于我们排查问题,这些值一般足够了。 还有一个需要注意的地方是,这两个视图中记录的绑定变量只对where条件后面的绑定进行捕获,这点需要使用的时候注意。 3、查询dba_hist_sqlbind VALUE_STRING列
DBA_HIST_SQLBIND是视图V$SQL_BIND_CAPTURE历史快照 4、查询wrh$_sqlstat
select dbms_sqltune.extract_bind(bind_data, 1).value_stringfrom wrh$_sqlstatwhere sql_id = '88dz0k2qvg876'----根据绑定变量的多少增加dbms_sqltune.extract_bind(bind_data, 2).value_string等 (转载请注明出处:[url=http://www.6rfd.com]澳门博彩[/url] [url=http://www.9gds.com]易博网[/url])
在SQL语句的执行计划中,包含很多字段项和很多模块,其不同字段代表了不同的含义且在不同的情形下某些字段、模块显示或不显示,下面的描述给出了执行计划中各字段的含义以及各模块的描述。有关执行计划中各字段模块的描述请参考: 执行计划中各字段各模块描述有关由SQL语句来获取执行计划请参考:使用EXPLAIN PLAN获取SQL语句执行计划有关使用autotrace来获取执行计划请参考:启用AUTOTRACE功能有关display_cursor函数的使用请参考:http://www.2cto.com/database/201202/120814.html一、执行计划中各字段的描述1、基本字段(总是可用的)Id 执行计划中每一个操作(行)的标识符。如果数字前面带有星号,意味着将在随后提供这行包含的谓词信息Operation 对应执行的操作。也叫行源操作Name 操作的对象名称2、查询优化器评估信息Rows(E-Rows) 预估操作返回的记录条数Bytes(E-Bytes) 预估操作返回的记录字节数TempSpc 预估操作使用临时表空间的大小Cost(%CPU) 预估操作所需的开销。在括号中列出了CPU开销的百分比。注意这些值是通过执行计划计算出来的。换句话说,父操作的开销包含子操作的开销Time 预估执行操作所需要的时间(HH:MM:SS)3、分区(仅当访问分区表时下列字段可见)Pstart 访问的第一个分区。如果解析时不知道是哪个分区就设为KEY,KEY(I),KEY(MC),KEY(OR),KEY(SQ)Pstop 访问的最后一个分区。如果解析时不知道是哪个分区就设为KEY,KEY(I),KEY(MC),KEY(OR),KEY(SQ)4、并行和分布式处理(仅当使用并行或分布式操作时下列字段可见)Inst 在分布式操作中,指操作使用的数据库链接的名字TQ 在并行操作中,用于从属线程间通信的表队列IN-OUT 并行或分布式操作间的关系PQ Distrib 在并行操作中,生产者为发送数据给消费者进行的分配5、运行时统计(当设定参数statistics_level为all或使用gather_plan_statistics提示时,下列字段可见)Starts 指定操作执行的次数A-Rows 操作返回的真实记录数A-Time 操作执行的真实时间(HH:MM:SS.FF)6、I/O 统计(当设定参数statistics_level为all或使用gather_plan_statistics提示时,下列字段可见)Buffers 执行期间进行的逻辑读操作数量Reads 执行期间进行的物理读操作数量Writes 执行期间进行的物理写操作数量7、内存使用统计OMem 最优执行所需内存的预估值1Mem 一次通过(one-pass)执行所需内存的预估值0/1/M 最优/一次通过/多次通过(multipass)模式操作执行的次数Used-Mem 最后一次执行时操作使用的内存量Used-Tmp 最后一次执行时操作使用的临时空间大小。这个字段必须扩大1024倍才能和其他衡量内存的字段一致(比如,32k意味着32MB)Max-Tmp 操作使用的最大临时空间大小。这个字段必须扩大1024倍才能和其他衡量内存的字段一致(比如,32k意味着32MB)二、执行计划中各模块的描述与举例1、预估的执行计划中的各字段与模块SQL> explain plan for2 select * from emp e,dept d3 where e.deptno=d.deptno4 and e.ename='SMITH';Explained./**************************************************//* Author: Robinson Cheng *//* Blog: http://blog.csdn.net/robinson_0612 *//* MSN: robinson_0612@hotmail.com *//* QQ: 645746311 *//**************************************************/ SQL> set linesize 180SQL> set pagesize 0 SQL> select * from table(dbms_xplan.display(null,null,'advanced')); --使用dbms_xplan.display函数获得语句的执行计划Plan hash value: 351108634 --SQL语句的哈希植---------------------------------------------------------------------------------------- /*执行计划部分*/| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |----------------------------------------------------------------------------------------| 0 | SELECT STATEMENT | | 1 | 117 | 4 (0)| 00:00:01 || 1 | NESTED LOOPS | | 1 | 117 | 4 (0)| 00:00:01 ||* 2 | TABLE ACCESS FULL | EMP | 1 | 87 | 3 (0)| 00:00:01 || 3 | TABLE ACCESS BY INDEX ROWID| DEPT | 1 | 30 | 1 (0)| 00:00:01 ||* 4 | INDEX UNIQUE SCAN | PK_DEPT | 1 | | 0 (0)| 00:00:01 |----------------------------------------------------------------------------------------Query Block Name / Object Alias (identified by operation id): --这部分显示的为查询块名和对象别名-------------------------------------------------------------1 - SEL$1 --SEL$为select 的缩写,位于块1,相应的还有DEL$,INS$,UPD$等2 - SEL$1 / E@SEL$1 --E@SEL$1,对应到执行计划中的操作ID为2上,即在表E上的查询,E为别名,下面类同3 - SEL$1 / D@SEL$1 4 - SEL$1 / D@SEL$1Outline Data --提纲部分,这部分将执行计划中的图形化方式以文本形式来呈现,即转换为提示符方式-------------/*+BEGIN_OUTLINE_DATA USE_NL(@"SEL$1" "D"@"SEL$1") --使用USE_NL提示,即嵌套循环LEADING(@"SEL$1" "E"@"SEL$1" "D"@"SEL$1") --指明前导表INDEX_RS_ASC(@"SEL$1" "D"@"SEL$1" ("DEPT"."DEPTNO")) --指明对于D上的访问方式为使用索引FULL(@"SEL$1" "E"@"SEL$1") --指明对于E上的访问方式为全表扫描 OUTLINE_LEAF(@"SEL$1")ALL_ROWS OPTIMIZER_FEATURES_ENABLE('10.2.0.3')IGNORE_OPTIM_EMBEDDED_HINTSEND_OUTLINE_DATA*/Predicate Information (identified by operation id): --谓词信息部分,在执行计划中ID带有星号的每一行均对应到下面中的一行--------------------------------------------------- 2 - filter("E"."ENAME"='SMITH') 4 - access("E"."DEPTNO"="D"."DEPTNO")Column Projection Information (identified by operation id): --执行时每一步骤所返回的列,下面的不同步骤返回了不同的列-----------------------------------------------------------1 - (#keys=0) "E"."EMPNO"[NUMBER,22], "E"."ENAME"[VARCHAR2,10],"E"."JOB"[VARCHAR2,9], "E"."MGR"[NUMBER,22], "E"."HIREDATE"[DATE,7],"E"."SAL"[NUMBER,22], "E"."COMM"[NUMBER,22], "E"."DEPTNO"[NUMBER,22],"D"."DEPTNO"[NUMBER,22], "D"."DNAME"[VARCHAR2,14], "D"."LOC"[VARCHAR2,13]2 - "E"."EMPNO"[NUMBER,22], "E"."ENAME"[VARCHAR2,10], "E"."JOB"[VARCHAR2,9],"E"."MGR"[NUMBER,22], "E"."HIREDATE"[DATE,7], "E"."SAL"[NUMBER,22],"E"."COMM"[NUMBER,22], "E"."DEPTNO"[NUMBER,22]3 - "D"."DEPTNO"[NUMBER,22], "D"."DNAME"[VARCHAR2,14], "D"."LOC"[VARCHAR2,13]4 - "D".ROWID[ROWID,10], "D"."DEPTNO"[NUMBER,22]Note --注释与描述部分,下面的描述中给出了本次SQL语句使用了动态采样功能----- - dynamic sampling used for this statement58 rows selected.2、实际执行计划中的各字段与模块SQL> select /*+ gather_plan_statistics */ * --注意此处增加了提示gather_plan_statistics并且该语句被执行2 from emp e,dept d3 where e.deptno=d.deptno4 and e.ename='SMITH'; 7369 SMITH CLERK 7902 17-DEC-80 800 20 20 RESEARCH DALLASSQL> select * from table(dbms_xplan.display_cursor(null,null,'iostats last')); --使用display_cursor获取实际的执行计划SQL_ID fpx7zw59f405d, child number 0 --这部分给出了SQL语句的SQL_ID,子游标号以及原始的SQL语句-------------------------------------select /*+ gather_plan_statistics */ * from emp e,dept d where e.deptno=d.deptno ande.ename='SMITH'Plan hash value: 351108634 --SQL 语句的哈希值--SQL语句的执行计划,可以看到下面显示的字段一部分不同于预估执行计划中的字段-----------------------------------------------------------------------------------------------------------| Id | Operation | Name | Starts | E-Rows | A-Rows | A-Time | Buffers | Reads | -----------------------------------------------------------------------------------------------------------| 1 | NESTED LOOPS | | 1 | 1 | 1 |00:00:00.01 | 10 | 1 ||* 2 | TABLE ACCESS FULL | EMP | 1 | 1 | 1 |00:00:00.01 | 8 | 0 || 3 | TABLE ACCESS BY INDEX ROWID| DEPT | 1 | 1 | 1 |00:00:00.01 | 2 | 1 ||* 4 | INDEX UNIQUE SCAN | PK_DEPT | 1 | 1 | 1 |00:00:00.01 | 1 | 1 |-----------------------------------------------------------------------------------------------------------Predicate Information (identified by operation id):--------------------------------------------------- 2 - filter("E"."ENAME"='SMITH') 4 - access("E"."DEPTNO"="D"."DEPTNO")Note----- - dynamic sampling used for this statement26 rows selected.三、总结由上可知,在不同的情形下可以获得执行计划的不同信息,而不同信息则展现了SQL语句对应的不同情况,因此应根据具体的情形具体分析。 (转载请注明出处:[url=http://www.k8764.com]博彩通[/url] [url=http://www.5sfd.com]e世博[/url])
摘要: DBMS_XPLAN包中display_cursor函数不同于display函数,display_cursor用于显示SQL语句的真实的执行计划,在大多数情况下,显示真实的执行计划有助于更好的分析SQL语句的全过程,尤其是运行此SQL语句实时的I/O开销。通过对比预估的I/O与真实的I/O开销来判断SQL语句所存在问题,如缺少统计信息,SQL语句执行的次数,根据实际中间结果集的大小来选择合适的连接... 阅读全文
首先,上一道开胃菜:怎么判断两个单链表是否相交?
我们假设两个单链表分别是A(有m个结点)和B(有n个结点),当然,最容易想到的肯定是两层循环,遍历A中的元素,然后分别与B中的元素进行比较,但是这样做的时间复杂度达到了O(m*n),那么有没有更简单的办法呢?肯定有!
我们来看看单链表的性质:每个结点只通过一个指针指向后继结点。那么是不是意味着两个单链表如若相交,它们就只能是Y形相交,而不可能是X形相交,亦即从第一个相同的结点开始,后面的结点全部一样。如果能想到这个,后面的就简单明了了:只要A链表和B链表的最后一个结点值相等,则证明A链表和B链表相交。该算法的时间复杂度也下降到O(m+n)。
我们进一步来思考:怎么找到第一个相交的元素呢?
这里就当然不能像刚才那样,但是出发点还是一样,我们同样可以保证只要两次遍历。我们假设m > n,那么如果我们将两个链表的末尾对齐,是不是从最后一个往前看(当然单链表不能往前遍历,我们先这样看)的时候,A链表会比B链表多m-n个元素,而A链表中的前m-n个元素可以忽略,直接从第m-n个元素开始和B链表一起向前遍历,比较A链表上第m-n+i个元素和B链表第i个元素(i<n)即可。第一个相同的元素即为所求。参看下图可以帮助理解: 实现代码如下: - /**
- * 寻找两个单链表第一个相同的元素。
- * @param A 第一个单链表
- * @param B 第二个单链表
- * @return 若存在相同元素,则返回其值;否则返回-1并打印消息
- */
- public static int findSame(FLinkedList A, FLinkedList B){
- int m = A.length();
- int n = B.length();
- FLinkedNode aHead = A.getElem(0);
- FLinkedNode bHead = B.getElem(0);
- if(m >= n){
- int s = m - n;
- for(int i = 0; i < s; i ++){
- aHead = aHead.getNext();
- } // end for
- while(aHead.getNext() != null){
- if(aHead.getValue() == bHead.getValue()){
- return aHead.getValue();
- }else{
- aHead = aHead.getNext();
- bHead = bHead.getNext();
- } // end if-else
- } // end while
- }else{
- int s = n - m;
- for(int i = 0; i < s; i ++){
- bHead = bHead.getNext();
- } // end for
- while(aHead.getNext() != null){
- if(aHead.getValue() == bHead.getValue()){
- return bHead.getValue();
- }else{
- aHead = aHead.getNext();
- bHead = bHead.getNext();
- } // end if-else
- } // end while
- } // end if-else
- System.out.println("没有找到相同的元素!!");
- return -1;
- } // end findSame
下面来看看其它的几个单链表相关的典型问题(贴代码太占空间,这里就只谈谈思路,大家可以动手试试):
单链表的反转
如题,怎么实现一个单链表A(有m个元素)的反转呢?
方案一:如果不能破坏原单链表,我们需要重新新建一个链表C,然后遍历原来的A链表,对C链表实行头插法建表(头插法即将新加入的结点作为链表的头结点,对应的还有尾插法,即直接在链表末尾添加元素);
方案二:如果可以破坏原单链表呢?暴力一点的办法是不断地交换相邻的两个元素,即首先将第一个元素通过m-1次交换使其变成链表的最后一个元素,然后又是同样的方法将现任的第一个元素通过m-2次交换使其成为链表的倒数第二个元素,以此类推。
单链表的排序
就排序原理而言,个人觉得其实不用过多考虑存储结构的问题,即不管是顺序存储还是链式存储,都不影响排序的基本原理,只是不同的存储结构会影响不同排序方法的效率而已。因为我们完全可以夸张地将顺序存储也想象为不连续的存储只是它们相邻两者的间隙极端的小。即我们将货物分别存在美国和中国的仓库里和都存放在一个仓库里是一样的,只是运费问题而已。
明白了这一点,那么单链表的排序就和普通的数组排序没有什么太大的区别。我们现在要做的事就是针对性地选择一个时间性能相对较好的排序算法。
我们知道的排序方法有很多:插入排序、冒泡排序、快速排序、归并排序、堆排序以及基数排序等等,那么这其中哪些对顺序结构和链式结构不那么感冒呢?熟悉这些排序的童鞋肯定知道,是插入排序和冒泡排序。其他的几种常见排序方法就比较偏袒顺序存储结构了。所以,如果要对链表进行排序,我会选择插入排序或者冒泡排序。(不太清楚这些基本排序原理的click here:http://wlh0706-163-com.iteye.com/blog/1465570)
删除单链表中的最小元素
我能想到的办法就是遍历两次:第一次找到单链表中最小的元素,第二次遍历删除该元素。第一次遍历的时候需要借助两个变量,一个保存当前的最小元素的值,另一个保存当前最小值的位序。第二次遍历的时候当然就是删除第一次遍历得到的最小元素的位序上的元素了。
删除所有重复结点
这个一般得借助其他的数据结构了。基本思路应该是:遍历链表,用一个数据结构保存当前已经遍历的元素,若下一个访问的链表里的元素已经存在于已经访问的元素集合中,则删除单链表中的该元素,否则继续,直至到达链表的末尾。保存已经访问过的元素可以用数组,也可以用其他的。
判断一个链表是否包含另一个链表
这个问题其实和开篇的问题一样,只是换了一种说法而已。因此只要找到第一个相同的元素就可以了。
找出单链表中的倒数第K个元素
我们首先要确保的就是单链表的元素个数大于K。
这里的实现思路也很巧妙:我们定义两个指针a和b,全部指向链表的头结点,然后a指针开始向后遍历,但a遍历到第K个元素的时候,b指针也开始从头开始遍历,接下来的事你应该知道了,当a指针到达链表的末尾时,b指针恰好指着链表的倒数第K个元素。这样的时间复杂度是O(n)。
推广一下:怎么找单链表中间的那个元素呢?Ok, u let me know!
PS:这些问题肯定还有更好地解法和方案,希望您不吝赐教。 (转载请注明出处:[url=http://www.k6567.com]e世博[/url] [url=http://www.d9732.com]澳门博彩[/url])
为方便讨论,例子中dll只导出了一个计算两个参数和的方法。 ------------------------- 注: java调用dll一般来说都是要根据头文件再去实现一下dll(c++,fortran等),有的童鞋可能会问:我只有一个dll文件,我想调用里面的方法,能不能直接用?这个据偶的水平没法解决,可能有高手会~~ ------------------------- 第一步:生成编写dll文件所需的C语言头文件 首先建立dllTest工程,在src目录下建包com.lxw; 建立java文件DllTest.java: package com.lxw; import java.lang.System; public class DllTest { static{ System.loadLibrary("DllTest"); //载入dll,不用后缀 } public native static int getSum(int i,int j);//函数声明 } cmd进入dos下,进入D:\workspace\dllTest\src\com\lxw目录; 使用命令javac DllTest.java,编译文件,在lxw目录下生成DllTest.class文件; 使用命令cd..两次进入src目录; 使用命令javah -jni com.lxw.DllTest即可在src目录下生成com_lxw_DllTest.h的头文件,内容如下: /* DO NOT EDIT THIS FILE - it is machine generated */ #include <jni.h> /* Header for class com_lxw_DllTest */ #ifndef _Included_com_lxw_DllTest #define _Included_com_lxw_DllTest #ifdef __cplusplus extern "C" { #endif /* * Class: com_lxw_DllTest * Method: getSum * Signature: (II)I */ JNIEXPORT jint JNICALL Java_com_lxw_DllTest_getSum (JNIEnv *, jclass, jint, jint); #ifdef __cplusplus } #endif #endif 注意生成的头文件导出的函数名字为Java_com_lxw_DllTest_getSum; ------------------------- 第二步:编写dll文件 打开vc选择新建工程DllTest,类型选择dll,可以将export symbols参数选上,帮你生成一些基本文件;也可不选;将com_lxw_DllTest.h文件拷贝到工程目录下,我这里为:D:\vs2010projects\DllTest\DllTest; 将jawt_md.h,jni.h,jni_md.h文件(jdk的include目录和include\win32目录)拷贝到vc目录:C:\Program Files\Microsoft Visual Studio 10.0\VC\include; 这时工程并不包含拷贝进去的头文件,所以在工程的Header Files下右键导入com_lxw_DllTest.h文件;导入后同级的头文件还有stdafx.h和targetver.h文件,自动生成的DllTest.h可以删掉; 在Source Files下有三个文件dllmain.cpp,DllTest.cpp,stdafx.cpp,其中dllmain是dll必须的,自动生成,stdafx也是系统自动生成的,不用管,dllmain的内容如下: // dllmain.cpp : Defines the entry point for the DLL application. #include "stdafx.h" BOOL APIENTRY DllMain( HMODULE hModule, DWORD ul_reason_for_call, LPVOID lpReserved ) { switch (ul_reason_for_call) { case DLL_PROCESS_ATTACH: case DLL_THREAD_ATTACH: case DLL_THREAD_DETACH: case DLL_PROCESS_DETACH: break; } return TRUE; } 这个就是dll的入口函数,和main winmain类似,主要处理dll的四种状态,不详谈了,有兴趣可以自己去了解; DllTest.cpp文件可能会自动生成一些内容,vs2010的会实现一个int,class以及一个函数,这里将他们全部删除,编辑内容如下: // DllTest.cpp : Defines the exported functions for the DLL application. // #include "stdafx.h" #include "com_lxw_DllTest.h" JNIEXPORT jint JNICALL Java_com_lxw_DllTest_getSum
(JNIEnv *, jclass, jint a, jint b){ return a+b; } 注意包含头文件,导出函数的格式可以从com_lxw_DllTest.h拷贝,不过多了参数a,b; OK,编译工程,会在debug或者release目录下生成DllTest.dll文件; 我们可以看一下此文件导出的内容: 在dll所在目录下使用命令dumpbin -exports DllTest.dll >1.txt,打开1.txt,其中里面有内容: ordinal hint RVA name 1 0 00001010 _Java_com_lxw_DllTest_getSum@16 = _Java_com_lxw_DllTest_getSum@16 我们可以看到这个dll导出了一个函数,名字为_Java_com_lxw_DllTest_getSum;但是我们在后面的java文件中调用的时候使用getSum名字就可以; ------------------------- 第三步:java中调用DllTest.dll 首先必须将DllTest.dll文件拷贝到java可以识别的路径,这里我拷贝到jdk的bin目录; 在刚才的java工程中新建java文件: package com.lxw; public class DllMain { public static void main(String[] args) { System.out.println(DllTest.getSum(10, 11)); } } 注意:这里直接使用getSum函数即可;而这里的DllTest.java文件就起到类似C语言中的头文件的作用; ---------------- 应该没什么遗忘的了~~~ 这里写的很详细了~~~ 希望可以帮到大家~~~ (转载请注明出处:[url=http://www.a9832.com]博彩网[/url] [url=http://www.tswa.org]博彩通[/url])
摘要: 面试的时候,经常会遇到这样的考题:给你两个类的代码,它们之间是继承的关系,每个类里只有构造器方法和一些变量,构造器里可能还有一段代码对变量值进行了某种运算,另外还有一些将变量值输出到控制台的代码,然后让我们判断输出的结果。这实际上是在考查我们对于继承情况下类的初始化顺序的了解。 我们大家都知道,对于静态变量、静态初始化块、变量、初始化块、构造器,它们的初始化顺序以此是(静态变量、静态初始... 阅读全文
摘要: 花了大概两天的时间,终于把Android的Socket编程给整明白了。抽空和大家分享一下: Socket Programming on Android Socket 编程基础知识: 主要分服务器端编程和客户端编程。 服务器端编程步骤: 1: 创建服务器端套接字并绑定到一个端口上(0-1023是系统预留的,最好大约1024) 2: 套接字设... 阅读全文
“软件编程中最重要的操作之一在于判断俩个变量是不是相同” - 来自Nicholas Zakas的书JavaScript for Web Developers. 换句话说,可能在你的编程中,你可能用过这些代码片段吧: if (x == y) {
// do something here
}或者你使用最佳实践方式: if (x === y) {
// do something here
}以上代码片段中不同的地方在于第二个例子使用了“===”操作符,也叫“严格等于”或者“绝对等于”。 对于Javascript新手来说呢,什么时候使用双等于号,或者什么时候使用三等于号确实有点儿迷糊。这里今天这篇文章我们将帮助大家了解这背后的故事。 有没有区别? 使用双等于号操作符的话,如果两者相等的话,结果会返回true。但是大家要注意:如果是不同类型的变量比较的话,变量强制变换就会发生。当然,这也是javascript语法的特点之一。 每 一个javascript的变量都属于一个指定的类型。例如,数字,boolean,功能和对象。如果你比较一个字符串和数字,浏览器就会在比较之前将字 符串强制的转化为数字。同样,如果你将true或者false和数字比较的话。true和false会被强制转化为数字1或者0。 这将会带来不可预知的结果,如下: console.log(99 == "99"); // true
console.log(0 == false); // true 当然,以上例子非常不错,因为浏览器将帮助你自动转化,省了你不少劲儿。但是这有可能出错,如下: console.log(' \n\n\n' == 0); // true
console.log(' ' == 0); // true
因为如上原因,javascript的高手都推荐你使用“===”来执行等于操作。永远不要使用“==”。 “===”永远不执行类型转化。因为你使用它来执行等于操作非常安全。 以下例子将都产生正确的结果: console.log(99 === "99"); // false
console.log(0 === false); // false
console.log(' \n\n\n' === 0); // false
console.log(' ' === 0); // false
不等于如何操作呢? 类似,只不过这里我们使用“!==”来执行。如下: console.log(99 !== "99"); // true
console.log(0 !== false); // true
console.log(' \n\n\n' !== 0); // true
console.log(' ' !== 0); // true
(转载请注明出处:[url=http://www.k8764.com]博彩通[/url]
[url=http://www.5sfd.com]e世博[/url])
摘要: 我想标题可能会引进部分人的不满,抑或作者带着强烈的个人色彩,但是如果你能认真读完全文,我想你会有新的收获。 永远也不要使用(非包装类型)的String、long、int,那些原始类型没有语义,这样的变量类型很难理解、维护麻烦、而且不易扩展,接下来看一个简单的例子-----关于电影票的服务 在看这个例子之前要说的话:如果你在评论中告诉我,你坚决反对我的... 阅读全文
最近的机器内存又爆满了,除了新增机器内存外,还应该好好review一下我们的代码,有很多代码编写过于随意化,这些不好的习惯或对程序语言的不了解是应该好好打压打压了。 下面是参考网络资源总结的一些在Java编程中尽可能要做到的一些地方。 1. 尽量在合适的场合使用单例 使用单例可以减轻加载的负担,缩短加载的时间,提高加载的效率,但并不是所有地方都适用于单例,简单来说,单例主要适用于以下三个方面: 第一,控制资源的使用,通过线程同步来控制资源的并发访问; 第二,控制实例的产生,以达到节约资源的目的; 第三,控制数据共享,在不建立直接关联的条件下,让多个不相关的进程或线程之间实现通信。 2. 尽量避免随意使用静态变量 要知道,当某个对象被定义为stataic变量所引用,那么gc通常是不会回收这个对象所占有的内存,如 public class A{ static B b = new B(); } 此时静态变量b的生命周期与A类同步,如果A类不会卸载,那么b对象会常驻内存,直到程序终止。 3. 尽量避免过多过常的创建Java对象 尽量避免在经常调用的方法,循环中new对象,由于系统不仅要花费时间来创建对象,而且还要花时间对这些对象进行垃圾回收和处理,在我们可以控制的范围内,最大限度的重用对象,最好能用基本的数据类型或数组来替代对象。 4. 尽量使用final修饰符 带有final修饰符的类是不可派生的。在Java核心API中,有许多应用final的例子,例如java.lang.String。为String类指定final防止了使用者覆盖length()方法。另外,如果一个类是final的,则该类所有方法都是final的。Java编译器会寻找机会内联(inline)所有的final方法(这和具体的编译器实现有关)。此举能够使性能平均提高50%。 5. 尽量使用局部变量 调用方法时传递的参数以及在调用中创建的临时变量都保存在栈(Stack)中,速度较快。其他变量,如静态变量、实例变量等,都在堆(Heap)中创建,速度较慢。 6. 尽量处理好包装类型和基本类型两者的使用场所 虽然包装类型和基本类型在使用过程中是可以相互转换,但它们两者所产生的内存区域是完全不同的,基本类型数据产生和处理都在栈中处理,包装类型是对象,是在堆中产生实例。 在集合类对象,有对象方面需要的处理适用包装类型,其他的处理提倡使用基本类型。 7. 慎用synchronized,尽量减小synchronize的方法 都知道,实现同步是要很大的系统开销作为代价的,甚至可能造成死锁,所以尽量避免无谓的同步控制。synchronize方法被调用时,直接会把当前对象锁 了,在方法执行完之前其他线程无法调用当前对象的其他方法。所以synchronize的方法尽量小,并且应尽量使用方法同步代替代码块同步。 8. 尽量使用StringBuilder和StringBuffer进行字符串连接 这个就不多讲了。 9. 尽量不要使用finalize方法 实际上,将资源清理放在finalize方法中完成是非常不好的选择,由于GC的工作量很大,尤其是回收Young代内存时,大都会引起应用程序暂停,所以再选择使用finalize方法进行资源清理,会导致GC负担更大,程序运行效率更差。 10. 尽量使用基本数据类型代替对象 String str = "hello"; 上面这种方式会创建一个“hello”字符串,而且JVM的字符缓存池还会缓存这个字符串; String str = new String("hello"); 此时程序除创建字符串外,str所引用的String对象底层还包含一个char[]数组,这个char[]数组依次存放了h,e,l,l,o 11. 单线程应尽量使用HashMap、ArrayList HashTable、Vector等使用了同步机制,降低了性能。 12. 尽量合理的创建HashMap 当你要创建一个比较大的hashMap时,充分利用另一个构造函数 public HashMap(int initialCapacity, float loadFactor) 避免HashMap多次进行了hash重构,扩容是一件很耗费性能的事,在默认中initialCapacity只有16,而loadFactor是 0.75,需要多大的容量,你最好能准确的估计你所需要的最佳大小,同样的Hashtable,Vectors也是一样的道理。13. 尽量减少对变量的重复计算 如 for(int i=0;i<list.size();i++) 应该改为 for(int i=0,len=list.size();i<len;i++) 并且在循环中应该避免使用复杂的表达式,在循环中,循环条件会被反复计算,如果不使用复杂表达式,而使循环条件值不变的话,程序将会运行的更快。 14. 尽量避免不必要的创建 如 A a = new A(); if(i==1){list.add(a);} 应该改为 if(i==1){ A a = new A(); list.add(a);} 15. 尽量在finally块中释放资源 程序中使用到的资源应当被释放,以避免资源泄漏。这最好在finally块中去做。不管程序执行的结果如何,finally块总是会执行的,以确保资源的正确关闭。 16. 尽量使用移位来代替'a/b'的操作 "/"是一个代价很高的操作,使用移位的操作将会更快和更有效 如 int num = a / 4; int num = a / 8; 应该改为 int num = a >> 2; int num = a >> 3; 但注意的是使用移位应添加注释,因为移位操作不直观,比较难理解 17.尽量使用移位来代替'a*b'的操作 同样的,对于'*'操作,使用移位的操作将会更快和更有效 如 int num = a * 4; int num = a * 8; 应该改为 int num = a << 2; int num = a << 3; 18. 尽量确定StringBuffer的容量 StringBuffer 的构造器会创建一个默认大小(通常是16)的字符数组。在使用中,如果超出这个大小,就会重新分配内存,创建一个更大的数组,并将原先的数组复制过来,再 丢弃旧的数组。在大多数情况下,你可以在创建 StringBuffer的时候指定大小,这样就避免了在容量不够的时候自动增长,以提高性能。 如: StringBuffer buffer = new StringBuffer(1000); 19. 尽量早释放无用对象的引用 大部分时,方法局部引用变量所引用的对象 会随着方法结束而变成垃圾,因此,大部分时候程序无需将局部,引用变量显式设为null。 例如: Public void test(){ Object obj = new Object(); …… Obj=null; } 上面这个就没必要了,随着方法test()的执行完成,程序中obj引用变量的作用域就结束了。但是如果是改成下面: Public void test(){ Object obj = new Object(); …… Obj=null; //执行耗时,耗内存操作;或调用耗时,耗内存的方法 …… } 这时候就有必要将obj赋值为null,可以尽早的释放对Object对象的引用。 20. 尽量避免使用二维数组 二维数据占用的内存空间比一维数组多得多,大概10倍以上。 21. 尽量避免使用split 除非是必须的,否则应该避免使用split,split由于支持正则表达式,所以效率比较低,如果是频繁的几十,几百万的调用将会耗费大量资源,如果确实需 要频繁的调用split,可以考虑使用apache的StringUtils.split(string,char),频繁split的可以缓存结果。 22. ArrayList & LinkedList 一 个是线性表,一个是链表,一句话,随机查询尽量使用ArrayList,ArrayList优于LinkedList,LinkedList还要移动指 针,添加删除的操作LinkedList优于ArrayList,ArrayList还要移动数据,不过这是理论性分析,事实未必如此,重要的是理解好2 者得数据结构,对症下药。 23. 尽量使用System.arraycopy ()代替通过来循环复制数组 System.arraycopy() 要比通过循环来复制数组快的多 24. 尽量缓存经常使用的对象 尽可能将经常使用的对象进行缓存,可以使用数组,或HashMap的容器来进行缓存,但这种方式可能导致系统占用过多的缓存,性能下降,推荐可以使用一些第三方的开源工具,如EhCache,Oscache进行缓存,他们基本都实现了FIFO/FLU等缓存算法。 25. 尽量避免非常大的内存分配 有时候问题不是由当时的堆状态造成的,而是因为分配失败造成的。分配的内存块都必须是连续的,而随着堆越来越满,找到较大的连续块越来越困难。 26. 慎用异常 当创建一个异常时,需要收集一个栈跟踪(stack track),这个栈跟踪用于描述异常是在何处创建的。构建这些栈跟踪时需要为运行时栈做一份快照,正是这一部分开销很大。当需要创建一个 Exception 时,JVM 不得不说:先别动,我想就您现在的样子存一份快照,所以暂时停止入栈和出栈操作。栈跟踪不只包含运行时栈中的一两个元素,而是包含这个栈中的每一个元素。 如 果您创建一个 Exception ,就得付出代价。好在捕获异常开销不大,因此可以使用 try-catch 将核心内容包起来。从技术上讲,您甚至可以随意地抛出异常,而不用花费很大的代价。招致性能损失的并不是 throw 操作——尽管在没有预先创建异常的情况下就抛出异常是有点不寻常。真正要花代价的是创建异常。幸运的是,好的编程习惯已教会我们,不应该不管三七二十一就 抛出异常。异常是为异常的情况而设计的,使用时也应该牢记这一原则。 (转载请注明出处:[url=http://www.k6567.com]e世博[/url] [url=http://www.d9732.com]澳门博彩[/url])
1. 创建一个嵌套的过滤器.filter(":not(:has(.selected))") //去掉所有不包含class为.selected的元素 2. 重用你的元素查询var allItems = $("div.item"); var keepList = $("div#container1 div.item"); <div>class names: $(formToLookAt + " input:checked").each(function() { keepListkeepList = keepList.filter("." + $(this).attr("name")); }); </div> 3. 使用has()来判断一个元素是否包含特定的class或者元素//jQuery 1.4.* includes support for the has method. This method will find //if a an element contains a certain other element class or whatever it is //you are looking for and do anything you want to them. $("input").has(".email").addClass("email_icon"); 4. 使用jQuery切换样式//Look for the media-type you wish to switch then set the href to your new style sheet $('link[media='screen']').attr('href', 'Alternative.css'); 5. 限制选择的区域//Where possible, pre-fix your class names with a tag name //so that jQuery doesn't have to spend more time searching //for the element you're after. Also remember that anything //you can do to be more specific about where the element is //on your page will cut down on execution/search times var in_stock = $('#shopping_cart_items input.is_in_stock'); <ul id="shopping_cart_items"> <li> <input value="Item-X" name="item" class="is_in_stock" type="radio"> Item X</li> <li> <input value="Item-Y" name="item" class="3-5_days" type="radio"> Item Y</li> <li> <input value="Item-Z" name="item" class="unknown" type="radio"> Item Z</li> </ul> 6. 如何正确使用ToggleClass//Toggle class allows you to add or remove a class //from an element depending on the presence of that //class. Where some developers would use: a.hasClass('blueButton') ? a.removeClass('blueButton') : a.addClass('blueButton'); //toggleClass allows you to easily do this using a.toggleClass('blueButton'); 7. 设置IE指定的功能if ($.browser.msie) { // Internet Explorer is a sadist. } 8. 使用jQuery来替换一个元素$('#thatdiv').replaceWith('fnuh'); 9. 验证一个元素是否为空if ($('#keks').html()) { //Nothing found ;} 10. 在无序的set中查找一个元素的索引$("ul > li").click(function () { var index = $(this).prevAll().length; }); 11. 绑定一个函数到一个事件$('#foo').bind('click', function() { alert('User clicked on "foo."'); }); 12. 添加HTML到一个元素$('#lal').append('sometext'); 13. 创建元素时使用对象来定义属性var e = $("", { href: "#", class: "a-class another-class", title: "..." }); 14. 使用过滤器过滤多属性//This precision-based approached can be useful when you use //lots of similar input elements which have different types var elements = $('#someid input[type=sometype][value=somevalue]').get(); 15. 使用jQuery预加载图片jQuery.preloadImages = function() { for(var i = 0; i').attr('src', arguments[i]); } }; // Usage $.preloadImages('image1.gif', '/path/to/image2.png', 'some/image3.jpg'); 16. 设置任何匹配一个选择器的事件处理程序$('button.someClass').live('click', someFunction); //Note that in jQuery 1.4.2, the delegate and undelegate options have been //introduced to replace live as they offer better support for context //For example, in terms of a table where before you would use.. // .live() $("table").each(function(){ $("td", this).live("hover", function(){ $(this).toggleClass("hover"); }); }); //Now use.. $("table").delegate("td", "hover", function(){ $(this).toggleClass("hover"); }); 17. 找到被选择到的选项(option)元素$('#someElement').find('option:selected'); 18. 隐藏包含特定值的元素$("p.value:contains('thetextvalue')").hide(); 19. 自动的滚动到页面特定区域jQuery.fn.autoscroll = function(selector) { $('html,body').animate( {scrollTop: $(selector).offset().top}, 500 ); } //Then to scroll to the class/area you wish to get to like this: $('.area_name').autoscroll(); 20. 检测各种浏览器Detect Safari (if( $.browser.safari)), Detect IE6 and over (if ($.browser.msie && $.browser.version > 6 )), Detect IE6 and below (if ($.browser.msie && $.browser.version <= 6 )), Detect FireFox 2 and above (if ($.browser.mozilla && $.browser.version >= '1.8' )) 21. 替换字符串中的单词var el = $('#id'); el.html(el.html().replace(/word/ig, '')); 22. 关闭右键的菜单$(document).bind('contextmenu',function(e){ return false; }); 23. 定义一个定制的选择器$.expr[':'].mycustomselector = function(element, index, meta, stack){ // element- is a DOM element // index - the current loop index in stack // meta - meta data about your selector // stack - stack of all elements to loop // Return true to include current element // Return false to explude current element }; // Custom Selector usage: $('.someClasses:test').doSomething(); 24. 判断一个元素是否存在if ($('#someDiv').length) {//hooray!!! it exists...} 25. 使用jQuery判断鼠标的左右键点击$("#someelement").live('click', function(e) { if( (!$.browser.msie && e.button == 0) || ($.browser.msie && e.button == 1) ) { alert("Left Mouse Button Clicked"); } else if(e.button == 2) alert("Right Mouse Button Clicked"); });
(转载请出处:[url=http://www.a9832.com]博彩网[/url]
[url=http://www.tswa.org]博彩通[/url])
项目经理的“势能”培养 我很早之前就听说过,做为一个项目经理,至少要在公司工作两年以上,且年龄不小于三十岁。我当时还年轻,对这两点很不屑。而现在,我却很理解。在公司工作时间短,对人员不熟悉,将很难横向协调资源;年纪过轻则不够沉稳、练达,难以实现快速沟通。 作为IT企业,很多项目经理都是由基层做起的,技术好、经验丰富、熟悉行业知识。作为项目经理本人,也觉得自己对团队的领导能力勿庸置疑。并不会认为自己沟通上会有问题。在这里,我也不想讲什么大道理,只举例子、讲故事。 举一个例子。去财务报帐,出纳说票贴的不对,公司财务制度上要求餐费与交通费分开贴,退回来重贴。贴完让出纳整好单子,找老总签字,老总出去了,没办法,只好到明天。而到明天,老总回来,自己却要出差了。 好不容易等老总签了字,拿到财务室,出纳说,财务上没有钱,票先放这里,等两天吧。一拖好几天,票压一堆报不了,项目中各项开销还得支出,严重影响工作情绪。这里要说明一下,财务上没有现金是很正常的,当然也不是完全没有,还是要留一些费用应对日常开销的,至于给不给你,就看财务的心情了。 如果换一个场景。 发票拿到财务室,出纳一看不合格,直接开涮:“你怎么搞的呀,刚公布的财务制度都没看吗,整天忙啥哩?算了,算了,放这吧,反正老总不在,等会儿还是我整一下吧,指望你干这活也没指望。你该干啥干啥去吧,下一回再这样我就给你扔出去。” 过两天,财务电话过来:“你的钱还要不要呀?公司有回款了,要拿钱的赶紧啦。”然后项目经理直接到财务签字拿钱,发票老总已经签过字,整个流程出纳都帮做了。 一个空降的项目经理与一个老员工项目经理,在协调资源时,差别是很明显的。 为什么空降的项目经理不能很好的协调资源。因为他跟同事不熟悉,他的团队会很支持他,其它人员则不一定。人家只给你照章办事,或许不会影响你工作,但同样不会推动你的工作。 而老员工项目经理,与各部门人员都很熟悉,老总也很信任他。这样处理工作就比较顺利,例如前面说的,出纳帮助你贴票,然后替你拿到老总那里,老总出于对项目经理与出纳的信任,就直接把字签了。项目经理出差回来签字就能领钱,效率高多了。 再举一个例子。项目临近结束,各个功能都差不多要做完了,项目完成进度也被标到90%。而项目经理心里很清楚,后面的修修补补,测试、调整会占用大量时间。公司项目管理不够完善,很多隐性的东西都无法显现出来。而客户此时又提出了一些新的要求,急切要完成。 如果告诉老总说,现在还需增加三个月的工作时间,老总肯定不同意,因为既然都完成90%了,剩下的工作还不加把劲在两星期内搞定,竟然还要增加三个月,挨批是难免的。如果给客户说,实在没有精力做新功能,客户要挟说,不做就不验收。 项目经理谁也不敢得罪,心里明白问题关键,却不知道该如何说服别人。只有硬着头皮往下做。结果项目延期,质量下降,勉强验收了,还有一大堆问题。最主要是因为工作强度加大,加班加点,透支团队成员工作激情,项目最终结束后,大批成员离职。 而如果项目经理换种思路。首先向团队成员灌输“行百里者半九十”,越到后面,繁杂琐事越多,越不能放松冲刺。要尽可能保持成员的工作积极性。一方面,向公司说明情况,通过项目管理的知识来讲解问题的具体原因,尤其是项目收尾管理,并不是代码写完就是项目结束,还有很多事情要做。总之,摆事实讲道理,积极向公司申请资源,尤其是宽限项目时间(此时单独强调增加开发人手并不明智)。 再一方面,与客户方负责人沟通,甚至私人宴请以促进感情。尽可能把一些新功能放到项目运营维护中来实现,或是项目二期中实现。如果客户仍然坚持,则最好说服他降低质量要求,在验收时放自己一马。向其承诺,在运维中提升质量。 整个情况要向团队成员说明,争取成员的理解与支持。也要向公司说明情况,尽可能多申请些额外福利。 从这个例子中可以看出,项目经理所做的工作,都不是“高科技”的,非技术的却又是重要的。针对不同对象,例如团队成员、公司高层、客户方负责人等,分析利害与关注点,权衡利益,各个击破。 一个年轻的项目经理与一个老成的项目经理,在处理这些事情时,风格会大不相同。就像上个例子,客户方负责人一般也不会太年轻,三十来岁才会担当个负责人,如果项目经理太年轻,阅历浅薄,则不太容易与对方平等交流。即便他明白道理,也很难影响他人支持自己工作。 讲一个故事很多年前,我还年少的时候,喜欢下象棋,在学校里基本上我能下赢的,我总能下赢,我下不赢的,总也下不赢。不得其解,也慢慢懒得操练了。 后来有次学校搞业余活动,有个老师是省象棋协会的,组织了一节棋课。我去晚了,只听了半节。大致意思是讲,下棋要讲全局观,要有战略,例如中局五种策略,中局成杀、不成杀则优、不占优占先、不占先则多子、不多子则求和。还有什么炮破士、马破相、残局炮归家等等。却没有讲如何下棋,课堂上也没有摆个象棋,或是什么棋谱。 我并没有把这些当回事儿,之后也很少下棋。 又过多年,毕业后同学聚一起,闲来无事,与一个同学下了两盘。刚开始,他问我这两年有没有下棋,我说没有。他调侃我,“那你以前下不赢我,今天你也难赢了”。我也笑着认同,反正只是玩玩,何必认真。 可是一开局,他就傻眼了,一直处在下风,且每局必输。他很吃惊,我也很吃惊。之后我认真思考了这件事,觉得是那节棋课影响了我,人的思考能力、计算能力都差不多,而思维方式不同,结果也会有很大不同。他看到的是“棋”,我看到的是“局”。决定胜败的不是棋艺。 又过了几年,我已经不再年少,但还算年轻吧。有一次找一个朋友玩,正好他的一个朋友也在,吃完饭没事儿做,恰巧有副象棋,就与他的朋友下了几局。他们都比我年龄大,已经三十多岁了。不过我也没有放在眼里,自以为水平相当可以,三局我两胜,颇为自得。 等他走后,我朋友问我:“他水平怎么样呀?”我带着些“谦虚”,洋洋自得:“他水平挺可以的,我差点就输了,还好我三局两胜,略胜那么一点点。” 我朋友听完哈哈大笑:“你知道他是干吗的吗?他是卖保险的。卖保险的吗,任何人都可能是他的潜在客户,他自然不会去赢你,不光让你赢,还要让你赢得有面子,这才是高手。他原来是在象棋协会的,论象棋,那叫牛×死了。” 我听完之后,惭愧至极。我关注的是“棋局”,人家所关注的,则超脱棋局之外。眼界不一样,看到的也不一样,操控点也不一样,输赢已经不重要,重要的是输与赢,哪个更有利于自己,然后才是“如何去输”与“如何去赢”。棋局只是一个棋子。决定成败的不是棋艺。 我讲这个故事,是想说明,一个项目经理,对自己操作的项目要有全局观;而且,视角不能仅限于项目本身。明确自身定位,了解外部环境,才能最大成度影响到整个“局”中的各个元素,而这个影响力,就叫“势”。可以这么说,你明确的势力范围,可以只是你的团队,但你的影响力却不能仅限于团队本身。 做到这些,容易吗?当然不容易。如文章开头所说,“做为一个项目经理,至少要在公司工作两年以上,且年龄不小于三十岁。”这样,才有可能会做得好一些。
(转载请注明出处:[url=http://www.a9832.com]博彩网[/url]
[url=http://www.tswa.org]博彩通[/url])
网站通常都是由很多非专业网站运营专员在管理和打理,由于他们的专业知识和综合技能都不合格,所以导致没有科学的网站运营管理。 下面就列出网站运营专员的网站运营管理七宗罪(看名字感觉是陈腔滥调但是我想内容还是非常具有意义的,要不然我也不会写出来作为自己以后巩固和回忆的博文了): 第一,使用开源程序和第三方插件,导致网站出现诸多安全漏洞,由于专业知识不够,并不能察觉和防范这些网站存在的安全漏洞,可能当网站比较有商业价值的时候,你的竞争对手或者无聊的黑客们就把你网站当成了练手靶子。 第二,服务器的组件长期不升级更新,如PHP、MYSQL、第三方组件。 第三,服务器密码和数据库密码、网站后台密码过于简单,或者很少更改新的密码,网站密码备份在网络里或者主机的电脑里面,网络密码涉及到自己的生日电话号码等容易被猜测到的数字或者字母,网站用户名和密码和网络上自己经常使用的用户名和密码是一致的,这些都是影响网站安全的因素,如果你还有支付宝、网银等涉及到主机人身财产等帐号和密码都要善于管理和维护更新,不可偷懒。 第四,程序的代码不够严谨,造成诸多的网站漏洞或者执行超时引起用户反感。所以作为一个网站运营人员可以不要求任何语言的代码都要懂,但是开发逻辑和安全方面都要有一定的了解。主要漏洞是在用户提交信息,如注册和上传文件、上传图片等。 第五,数据库安全管理方便不够完善,在开发的过程中没有考虑到数据库安全,如数据库名称和密码没有经过加密,数据库没有独立的控制权,如虚拟空间的数据库,其代理商和管理员都可以随便查看你的数据库资料,如果公司网站涉及到很多客户资料等信息是非常不安全的。其实是程序开发是否防SQL注入,这些都是最基本的技术了。 第六,服务器密码知道的人太多了,防火墙阻碍最好不要关闭。然后就是阻止其他不相关人员访问服务器上面的资源。加强服务器的管理和维护,时常查看服务器的登录日志,让你了解服务器最近的状况和应该怎么修复或者维护。 第七,从不记录服务器管理日志,导致服务器出现问题不知道该从何查起。老莫觉得其实无论是维护服务器还是网站开发、网站维护都需要记录操作步骤和过程,当网站或者服务器出现问题的时候,我们就能够好的排查和检测,对具体问题进行修改。 所以对于网站运营管理要求也是非常的高,这就要求网站运营专员要有足够强的网站运营管理知识。
(转载请注明出处:[url=http://www.live588.org]淘金盈[/url] [url=http://www.10086money.com]时尚资讯[/url])
“谁也无法改变现状,唯有无数程序员血洒大地,才能使项目重建天日。”这一点也不夸张,软件项目做烂了就是个坑,参与者也不过是填坑的。就像是在魔兽世界战场遇到国家队一样,你赢也赢不了,出也出不去。 一 坑有多深? 当我们进入一个项目时,通过不断观察我们可以发现我们的项目到底是不是一个坑。造坑的项目,往往具有某些“臭味”,以下是我的一些认识,这些“臭味”即是项目健康状态不佳的明显标志: - 编码规范形同废纸,代码质量低下 每个项目都有编码规范,但真正严格实施却是另一回事。太多的项目把编码规范作为形式的存在,没人在乎让开发人员写出“人能读懂的程序”,注释和命名也成了开发人员的随心所欲。project上永远只有开发任务,而几乎找不到单元测试的时间和代码审查的时间。在高压进度之下的项目,显得如此山寨。当我们还在抱怨自己工资低的时候,就先看看我们的程序还能称作OOP吗。
- 缺乏文档或文档质量低下 前期文档很重要,不论是框架的API使用手册,还是需求或设计文档,以及各种既定流程的规范,不同种类的模板及核对表,等等这些文档,对于项目来说都是非常重要的资源。而往往有些项目,这类文档就是交由非软件行业的人员来编写,或者前期根本不打算在文档上浪费时间。这就导致了,缺少相关文档或文档质量低下,在软件构建过程中,开发者和团队,不得不为这种“表面工程”的产物而纠结。甚至会退回到前期准备工作,完成所需的文档。有些文档可以在后期补,但有些必须在前期进行准备,以保住团队降低风险,减少缺陷引人的几率并提高编码质量,如果前期这类文档没有做好,那么就会像考前不复习一样,自食恶果。
- 无尽的需求变更,永远追不上的进度 这是最常见也是最可怕的,因为无论怎样,我们都无法完成它。客户可能认为改个程序,就像改个Excel一样简单省事,甚至会使用可动用的一切权利和资源来推行变更。好吧,我承认这样的客户我遇到过很多。当我向客户解释过变更的代价并提供备选方案后,也就只能等待客户的选择了,这多少有些运数的成分,但也是无奈之举。
- 仅仅靠加班应对进度落后 进度落后并不可怕,可怕的是仅靠加班来追赶进度。这是问题的关键,长时间的赶工仍然无法赶上进度,这只意味着项目有某种更深层次的问题,已经不是单开赶工可以解决的了。留意那些长时间加班的项目,他们往往在管理上存在很大问题,发现这些问题,在你成为PM时,不要犯类似错误。
- 沟通无门 如果你在一个“叫天天不应,叫地地不灵”的项目里,那你最好省心吧。项目中沟通很重要,但总有些项目,领导的工作太忙,人就是找不到,发出去的邮件就是没人回,遇到问题就是自己扛。在这样的项目里也有一些好处,比如锻炼自己的自学能力,以及磨练意志与根性。不过这些,也都是我的自嘲。低效的沟通将导致不必要的返工,这才是我所痛恨之处。我最为恼火的一段经历是,甲方要进行变更,开了一周的会没人通知我,我的小组在这一周里完成了原计划的数个需求并进入到测试阶段, 但这些需求均被砍掉 。本来只有甲方告知是可以调整进度开发其它模块的,但最终演变为资源的浪费。可见,沟通是多么的重要。
- 没人关心质量 因为软件构建属于专业领域,客户并不具备相应领域的知识,由于这种信息不对称,助长了软件的质量低下。我们开发的软件可以是“低等级高质量”的,但不能够是“高等级低质量”的。但是,太多的项目不在注重编码质量,这与软件构建的复杂度有关,也与整个行业的风气有关。但不管何种原因,提高代码质量仍然应该作为团队的努力方向。团队应该奖励那些,编写高质量代码的程序员。如果你的团队奖励的是那些,“BUG杀手”(每天修改上百个BUG),而冷落那些缺陷检出数量很低的程序员,那么,你的PM是个不懂技术的,至少我本人认为,任何有技术背景的PM都应该奖励那些正在保持职业操守,认真对待需求,保证代码质量的程序员。他们为项目付出了更多,更多的异常处理, 更多的测试调试,更多的检查,更多的重构,虽然他们的进度并不快,但他们引人的缺陷数量很少。每个做过开发的人都会在质量和进度上做出取舍,而我敬佩那些选择质量程序员,因为他们才是真正拿开发当事业的人。在此,向所有努力提高代码质量的程序员致敬!
- 没人为缺陷买单 没人为自己的成果负责。需求产出了低质量的文档,设计没有进行充分的迭代,开发可以怎么简单怎么写,测试可以随意测测,没人为自己的成果中的缺陷买单,除了项目经理,他为项目承担唯一责任。当项目组所有人员都在混时,就是在给自己挖坑。这种缺陷的堆积,会像放射性元素在食物链中的堆积一样,早晚项目会因此而崩溃。
- 过高的离职率 这个是最明显的“臭味”,这说明我们的同行已经在这里无法忍受了。它所带来的恶略影响不光体现在可用资源的减少,还体现在对成员士气的极大影响。如果不及时改善,这将是一个非常恶性的循环,当往一个进度落后的项目中添加资源只会使进度进一步落后,而非正离职导致必须补充新的资源,资源从入职到培训都会对对团队产生震荡,并降低现行团队的生产力。一个频繁处于形成阶段的团队,很难要求其有什么凝聚力,团队问题将会凸显,尤其是在沟通上,在项目忙的时候很少能照顾到新人。花费在对新人进行培训,和与其沟通上的时间,很可能得不偿失。
- 团队中的不良情绪 不同团队开始扎堆并相互敌视,例如开发组认为设计组是一帮搞业务的白痴,根本不懂编程;测试组认为开发组的人就是垃圾,BUG提交了多少便还是无法关闭;PM开始抱怨,自己的成员不配合;成员开始抱怨,PM是个纯管理没资格指挥内行做事。等等,诸如此类的怨念会在团队中积累,并以某个导火索为契机爆发。面对现实吧,至少,我远没有自己想象的那样高尚。我承认我曾经会和别的程序员说:“你看XX他们写的代码...什么呀...”,这样的话。在过去我也吐槽过别人代码,这种做法是错误的,我为此表示歉意。现在,如果有必要,我会说代码有缺陷,但绝不会说他的代码不好。我希望,我们能彼此尊重。对于技术人来说,不尊重他的成果就是不尊重他的人,所以我还是建议PM在管理工作中,多用“缺陷”,少用“不行”、“不对”。但是,项目中也总是有些人,靠鄙视别人的成果来彰显自己的实力。这些人,有,但很少。至少我遇到的很少,遇到过几个,让他们的话语成为你学习的动力吧。我曾经被人讽刺UI做的太丑,之后我学会了SL和FLEX;被人鄙视基础太差,之后开始阅读《CLR Via C#》;我朋友被人嘲笑过数据库设计,现在人家也开始买书深造。团队中就是这样,我们无法管住别人的嘴,但我们可以管住自己的。少说多听,一鸣惊人,乃上上之策。不要受情绪的影响,保持一个平静的心。
- 没有项目或阶段的后评价 不对项目的阶段进行后评价,也意味着没人在乎你到底干了些什么,所有人都只是进度是否完成,而没有对完成的好坏进行评价。这也意味了,仅靠做好你的工作,你是无法得到领导的重视的。最终只有那些加班时间最长的程序员被领导认可。而能力强,口碑好的成员也只能在团队和客户中间留下传说。
二 谁在造坑? 软件项目涉众众多,造坑的多为项目实施团队内部,而究其原因也是多方面的,但是始终离不了项目的四个维度——时间、范围、成本、质量。很多时候客户并不具备软件项目的实施经验,而实施团队为了迎合客户意愿,也会多多少少的在这四了维度上做文章。资源、时间不足,轻质量重功能,往往成为造坑的契机。所以,不用怀疑,造坑的往往是我们自己。很难理解,真正挖出大坑的人,最后也是填坑的人。一个人很容易被外部事务所左右,就如“同假的多了,真的到成假的了一样”,多数人不愿意在一个新环境中表现得特立独行。但也有老的程序员对我说过:“当别人做错了,你就不要跟着去做!”所以,我认为工作就是工作,不需要我们在其中融合多少兴趣,也不要求我们有过多的付出,但对于工作的成果则要求我们认真的对待。俗话说:“拿多少钱,办多少事!”如果多少有些团队意识,能够对自己的工作负责,那至少在意识上,我们能给自己少造些坑。 三 如何免坑? (一) 清除盲区 以下观点,仅是我对软件项目中一些错误认识的归纳: - 写出能用的程序就行啦! 我们应该首先清楚我们做的是什么,一个成熟的团队产出的可交付成果应该包括软件编程产品,相关文档,项目实施过程中的经验教训已经其它一些非形式的成果(培训)。这里,我们必须清楚的认识到,我们所开发是是编程产品,而不是我们个人的技术实践或大学的毕设。对于编程产品,我们必须认识到,其是产品级别的,必须保证质量,必须提高用户体验,必须考虑系统的诸多特性或维度。这一过程远比我们自己写个程序要复杂的多。设计需要不断地进行迭代;开发人员需要遵守严苛的规范,编写大量的注释和大量的异常处理;测试人员需要不断地进行各种重复测试,但是正是这种全局的规范,全体团队的不懈努力,才保证了我们的编程产物可以称之为产品。所以,一定要明确,我们要完成的是一个产品,而不是一个毕业设计,它不是一个人的技术实践,而是整个团队倾注精力去完成的最佳成果。我们可以轻松的实现客户的某些需求,但需求背后的某些东西,需要我们认真对待,比如安全性和性能等。实现功能的程序谁都会写,而写出高质量的程序的才是真正的艺术。
- 尽快开始编码吧 ! 软件构件是一个精心设计的过程,其前期准备十分重要。在后期修复缺陷的成本要远远高于前期。因此,在项目执行前,前期的规化十分必要。在前期每发现一个缺陷,都会为后期节省大量的成本。
- 需求怎么变了! 没有不变的需求。
- 进度落后了就招人呗! 这是种典型的错误认识,《人月神话》中已经说明的很清楚了——往一个进度落后的项目中注入资源,只会使进度进一步落后。虽然,这本著作成为PM必读之作,其思想也被业界所广泛认可,但是,还是会有很多管理者单纯的认为,通过注入资源能解决问题。对于这些人,只能让实践来检验真理了。
- 软件质量保证是测试的工作!这是一种逃避责任的说辞。如果把代码质量比喻为减肥,那么测试无疑是一个磅秤,减肥工作还是要有开发人员来完成。所以,不要将代码质量都寄希望于测试工作上。即使是大规模的用户测试,其错误检出率也不足五成。而真正挑起代码质量重担的是代码审查。
- 程序员你8小时就写了这么点代码? 让开发人员将全部时间都花在编码上是不可能的。开发人员需要时间预读文档,需要与相关干系人进行沟通,需要花时间来搜索资源。此外,可能还需要编写文档,参加会议,培训以及处理个人事务等等。这些时间都会无情的夺走编码的时间。程序员大约有近似20%的时间甚至更多会用在与编码无关的事情上(不算上班或聊QQ),所以不要错误的以为每个程序员每天能写8小时的程序。
- 你今天写了这么多行代码真有效率! 编码不是在扫地,比谁扫的面积大。不能单纯用行数来评价开发人员的工作量。评判的标准应该结合模块的复杂度,编码的缺陷检出量以及最终交付时可用代码的比例(实践表明,我们报废了大量的无用代码)。
- 他今天把自己100多个BUG都改了,我们得在组里表扬下他! 在我看来这样的领导不跟也罢,这就是让人相当无语的行为。好的开发者在提交测试前,觉得会对自己的代码进行走查和调试,甚至使用单元测试工具,因此其代码的缺陷检出量很小。这样的程序员,才值得被表扬。而那个一天改了自己100多个BUG的人,作为管理者应该想想,流程哪里错了,需要进行改进。
- 设计我来定,开发你闭嘴! 这样的例子也不少,这种做法有一种听起来非常合理的理由——保证项目架构的概念完整性。其解释为,如果将设计人员从开发人员剥离,那么就可以将架构的概念完整性统一,因为设计人员的数量比开发人员是数量要少的多,更容易统一认识。而这样做的项目组,也默认地认为设计组的技术实力要明显高于开发组。他们往往从开发组中选择优秀的设计人员到设计组,但也会有走眼的时候。其一,硬手没有被提拔。这时候多半是硬手对设计不满,并对团队管理层产生质疑,并想法设法进行沟通。如果处理的好,可能硬手会被重视,如果沟通无门,那之后,可能会充斥着抱怨和不满,以及人际关系的恶化。有些强硬些的可能会选择拒绝不合理的设计或更为极端的是离职。走眼的另一种情况是,挑的人干不了设计。这样往往就是让他锻炼,而不是撤换(彼得原理——每个人都会被晋升到他不适合的岗位)。这就郁闷到极点了,设计者将会与相应的数名开发人员进行一场旷日持久的暗战。其中,已经不只是个人的抱怨,甚至会演变成成员集体的士气低落,并最终促成小组的重组。我认为,有必要将开发人员纳入设计活动。应该参考开发人员的意见,其原因有三:其一,开发人员对实现相当熟悉,往往发现设计中的不足;其二,通过授权开发者参与设计,能让其感受到认同感,提升其参与项目的欲望,和责任心;其三,让开发参与设计,可以对设计人员进行储备,在需要时作为备选资源使用。
- 客户(领导)说必须完成,我也没办法! 这就是“领导一句话,劳动人民跑断腿!”这是非常典型的加班借口。软件构建过程如同耕种,你每次只处理它的一小部分,一点一点的加到整个系统,使系统一点一点的“生长”。这也暗示了,工作应该按部就班,正如春种秋收一样,各个环节有强硬的逻辑存在。所以,我们必须学会对不合理的要求说“不”。这里并不是说要拒绝客户的需求,而是指应该向客户说明情况并提出相应的备选方案以供参考。例如通过通过削减范围来达到按时完工的目的。PM需要向客户说明情况,并向其提供几套可行的解决方案,以促成项目向良性发展。
- 我是领导我来排进度! 工作进度的安排不能是领导的单方决策,而应该参考做了解这项工作的人的意见。
- 系统上线了,项目就算结束了! 只有当可交付成果成功移交,项目进行的相应的收尾工作,项目的经验教训文档被总结和归纳,一个项目才算真正意义上的完成。
(二) 参考建议 - 做好前期准备 前期准备很重要,如果在开始构建之前认真的地进行适当的准备活动,那么项目会运作的良好。充足的准备防止我们制造一个错误的产品。前期工作的好坏,多少会为这个项目的成功和失败打下基础。即使进入构建阶段,如果我们发现前期工作做的不好,也完全有理由退回去。前期准备工作和核心目标就是降低风险——一个好的项目规划者能够尽可能早地将主要的风险清除掉,以使项目的大部分工作能够尽可平稳地进行。目前,对后期影响最严重的风险是糟糕的需求分析和项目规划,因此准备工作就倾向于集中改进需求分析和项目规划。
- 预先行其事,必先利其器 用软件武装团队提高生产效率,例如:版本控制,错误跟踪,信息发布,自动发布,CASE工具,调试工具,测试工具,文档管理,代码生成工具等等。
- 分析项目类型,在管理和构建之间找寻平衡 商业系统、使命攸关的系统、性命攸关的系统在整个项目阶段具备不同的控制粒度。需要根据项目的具体类型来确定管理的严谨程度,避免“过度控制”或“控制不足”。
- 需求必须被冻结 需求必须被冻结,如果需求不能冻结,那么谁来了都没有用。再强的团队也无法完成一个无尽的任务。
- 变更必须走流程 正确应对变更,变更并不可怕,可怕的是失控的变更。以下建议希望对读者有所帮助:
在构建期间处理需求变更 - 核对需求,评估质量:如果需求不够好,停下来,把它做好再开始。
- 确保每一个人都知道需求变更的代价:让客户知道需求办更并不像在Excel上进行几个修改那样容易,“进度”和“成本”是你最有力的武器。
- 建立一套变更控制程序:固定的变更控制程序让你知道在什么时候处理变更,让客户知道你会处理他们的提议。
- 使用能适应变更的开发方法:迭代与增量。
- 放弃这个项目:如果以上提议没有一条奏效,需求变更极其频繁,那么,评估你的项目,考虑放弃它吧,继续下去你只会越陷越深。
- 注意项目的商业案例:性价比,没必要满足超出项目成本的需求。
- 关于加班 做IT的加班是很正常的,但加班要加的有意义,而且不应该长期加班。必须针对关键路径上的工作进行赶工,而不是做些无法加快整体进度的工作。而且,应当安排调休,而不是支付加班费。其主要原因也是我不赞成加班的原因——疲劳更容易引人缺陷。加班无疑会使人疲劳,每个人都想尽快结束手上的工作后回家休息。在长期疲惫的情况下,人员的工作效率会下降,士气会低落,非正常离职率增加,最重要的是疲惫的团队很难保证软件的质量,缺陷在不知不觉中引人,在后期无疑会为此付出代价。项目的总成本和周期,都会随着引人缺陷的数量的增加而倍增,而且发现的越晚越严重。
- 做好版本控制和配置管理 版本控制和配置管理是必须有的,即便是再小的项目也不能忽视,必须加以重视,一旦版本混乱,多多少少会对构活动造成影响。所以,平时不要偷懒,管理好每个基线。
- 授权的好处 授权好处多多,包括:一,减少管理者工作量;二,对人员有意识地进行锻炼,培养储备人才;三,提高人员对项目的参与度,从而提高士气。
- 乐观管理与悲观管理 乐观与悲观完全取决于人的性格,一般来讲多数倾向于乐观,应该清楚这两种性格在项目中的优势与劣势。我本人倾向于悲观,可能是性格使然,但悲观的管理至少不会误事。乐观管理的优势在于,很容易营造气氛,擅长给客户或领导描绘一个美好的未来。这种作风,前期很舒服,但后期可能要吃苦了。乐观管理容易出现的问题是对风险的预计不足,不能预留充足的缓冲时间,没有准备足够的预防措施。其表现就是,在进行进度计划时,总是认为今天的问题今天可以解决,已经修复的BUG将不会再次出现,用户需求是最后一次变更,等等诸如此类的乐观想法会使管理者蒙蔽双眼,而没有做足风险应对,其结果就是不管怎么加班就是赶不上进度,因为进度计划被设计为最顺利的情形,而不是现实场景。悲观管理的好处是,为潜在风险做足了准备。但悲观管理有一个非常大的缺陷,就是“过度控制”,可以比喻为“疑心病”(小心的都有些病态了)。其表现是为:按照之前的措施,发现遗漏了一个问题,那么悲观管理者会在之前措施基础上增加新的保障措施,然后又发现遗漏了一个问题,之后会继续追加保障措施。乍看之下没啥问题,因为是在不断地进行过程改进,但问题出在保障措施的增长速度过于惊人,称其为“疑心病”一点也不为过,悲观管理者容易在很小的地方施加过多的控制,造成人日的浪费,而忽略掉本应该关注的更为重要的问题。不管那种性格的管理,清楚自己的弱点总是好的。
- 有效的沟通,不要踢皮球 软件项目因为其本身的复杂度和涉众众多,所以更加需要沟通。沟通问题是所有大型项目都共用的问题,在大多数团队中往往也不认为沟通是个问题。但我还是想请读者认真对待沟通,比如邮件。邮件可以回复的慢,但请回复邮件。当我在一个连发出的邮件都没人回复的团队中工作时,除了无法解决问题,让我感受到的只有无奈以及冷漠。
- 客户是我们的朋友 把你的客户当成朋友,客户是我们做重要的资源之一。在每个客户背后往往隐藏着更多潜在的客户。我们必须清楚,客户作为非专业人士,其可能并不理解我们的工作,在项目执行阶段产生摩擦是难免的。但是,这些都不能成为我们迁怒客户或故意在工作中放水的借口。即便是为了项目能成功收尾,我们也必须维护好与客户的关系。
- 不要超前设计,不要项目镀金 超前设计和项目镀金都是不可取的,因为他是在浪费资源。满足需求以外的东西,不会对你的项目有任何好处,但是却可能引人缺陷。
- 总结经验教训 必须对阶段进行经验教训总结,没有什么比这些收获更有价值。这样文档就是组织的资产,是以后类似项目的参考和依据,并在持续优化方面发挥更为重要的作用。
- 不要让会议和文档拖了团队的后腿 “当船快要沉的时候,我们需要的是一个发号施令的领袖,而不是开会。”软件项目的核心问题是降低复杂度,越是复杂的项目就越需要沟通,但别让开会拖了我们的后腿。没有必要的会尽量少开或不开,要常开会,开小会,每次会议就几个相关干系人碰头沟通下就可以了,没有必要扩大为全员参与。冗长的讨论应该适时的终止,毕竟会议室上只能做出决策,而解决问题还得在会下。所以我认为应该精简那些冗长的会议,别然开会成为我们的工作。此外,要时刻谨记客户最终需要的是可以良好运行的软件产品而不是华丽的文档。所以,文档要恰到好处,写的再漂亮的文档没有完备的系统也不过是废纸一堆,别丢了西瓜捡芝麻,可以正常工作的软件才是我们的工作重心。
- 核对表的你的好助手 就像飞机工程师在检查飞机时使用核对表一样,软件项目也可以大量使用核对表。核对表可以帮助检验文档的质量,降低缺陷数量,以及改进项目管理。好的核对表,是你工作中的好助手。
- 小范围的受控好过大范围的失控 要注意控制的粒度,事无巨细。根据项目规模,人员构成,要采用不同的控制粒度。评估可控范围,并不是控制越广越好,控制不了就是失控。 对无暇顾及的地方授权别人管理是个可行的做法。 即便是小范围是受控,也好过大范围的失控。一个失控的项目,谁也不知道其会走向何方。
(转载请注明出处:[url=http://www.6rfd.com]澳门博彩[/url][url=http://www.9gds.com]易博网[/url])
摘要: 一年前写过一个百万级别数据库数据生成配置xml文件的程序,程序目的是用来把数据库里面的数据生成xml文件.程序可以配置多少文件生成到一个文件中去. 程序刚开始设计的时候说的是最多百万级别数据,最多50W数据生成到一个xml文件里面去,所以在做测试的时候自己也只是造了100W的数据并... 阅读全文
Javascript没有任何内建的格式化函数,这里我们通过Google收集了5个javascript的数字格式化函数,希望对于大家的web开发能够带来方便。
十进制四舍五入 这两段代码帮助你做到四舍五入,对于你显示价格或者订单比较有用: 代码1: function CurrencyFormatted(amount) {
var i = parseFloat(amount);
if(isNaN(i)) { i = 0.00; }
var minus = '';
if(i < 0) { minus = '-'; }
i = Math.abs(i);
i = parseInt((i + .005) * 100);
i = i / 100;
s = new String(i);
if(s.indexOf('.') < 0) { s += '.00'; }
if(s.indexOf('.') == (s.length - 2)) { s += '0'; }
s = minus + s;
return s;
}
/**
* Usage: CurrencyFormatted(12345.678);
* result: 12345.68
**/代码2: function format_number(pnumber,decimals){
if (isNaN(pnumber)) { return 0};
if (pnumber=='') { return 0};
var snum = new String(pnumber);
var sec = snum.split('.');
var whole = parseFloat(sec[0]);
var result = '';
if(sec.length > 1){
var dec = new String(sec[1]);
dec = String(parseFloat(sec[1])/Math.pow(10,(dec.length - decimals)));
dec = String(whole + Math.round(parseFloat(dec))/Math.pow(10,decimals));
var dot = dec.indexOf('.');
if(dot == -1){
dec += '.';
dot = dec.indexOf('.');
}
while(dec.length <= dot + decimals) { dec += '0'; }
result = dec;
} else{
var dot;
var dec = new String(whole);
dec += '.';
dot = dec.indexOf('.');
while(dec.length <= dot + decimals) { dec += '0'; }
result = dec;
}
return result;
}
/**
* Usage: format_number(12345.678, 2);
* result: 12345.68
**/添加逗号这俩段代码帮助你添加逗号到每三位数字中,这让大的数字比较容易查看。 代码1: function CommaFormatted(amount) {
var delimiter = ","; // replace comma if desired
amount = new String(amount);
var a = amount.split('.',2)
var d = a[1];
var i = parseInt(a[0]);
if(isNaN(i)) { return ''; }
var minus = '';
if(i < 0) { minus = '-'; }
i = Math.abs(i);
var n = new String(i);
var a = [];
while(n.length > 3)
{
var nn = n.substr(n.length-3);
a.unshift(nn);
n = n.substr(0,n.length-3);
}
if(n.length > 0) { a.unshift(n); }
n = a.join(delimiter);
if(d.length < 1) { amount = n; }
else { amount = n + '.' + d; }
amount = minus + amount;
return amount;
}
/**
* Usage: CommaFormatted(12345678);
* result: 12,345,678
**/ 代码2: function addCommas(nStr) {
nStr += '';
var x = nStr.split('.');
var x1 = x[0];
var x2 = x.length >; 1 ? '.' + x[1] : '';
var rgx = /(d+)(d{3})/;
while (rgx.test(x1)) {
x1 = x1.replace(rgx, '$1' + ',' + '$2');
}
return x1 + x2;
}
/**
* Usage: addCommas(12345678);
* result: 12,345,678
**/数字格式化,来自PHP 这段javascript代码功能设计来自PHP的nubmer_format功能。能够四舍五入并且加入逗号分隔。而且可以自定义10进制分隔。 function number_format (number, decimals, dec_point, thousands_sep) {
number = (number + '').replace(/[^0-9+-Ee.]/g, '');
var n = !isFinite(+number) ? 0 : +number,
prec = !isFinite(+decimals) ? 0 : Math.abs(decimals),
sep = (typeof thousands_sep === 'undefined') ? ',' : thousands_sep,
dec = (typeof dec_point === 'undefined') ? '.' : dec_point,
s = '',
toFixedFix = function (n, prec) {
var k = Math.pow(10, prec);
return '' + Math.round(n * k) / k;
};
// Fix for IE parseFloat(0.55).toFixed(0) = 0;
s = (prec ? toFixedFix(n, prec) : '' + Math.round(n)).split('.');
if (s[0].length > 3) {
s[0] = s[0].replace(/B(?=(?:d{3})+(?!d))/g, sep);
}
if ((s[1] || '').length < prec) {
s[1] = s[1] || '';
s[1] += new Array(prec - s[1].length + 1).join('0');
}
return s.join(dec);
}
/**
* Usage: number_format(123456.789, 2, '.', ',');
* result: 123,456.79
**/添加一个英文的排序后缀
Number.prototype.toOrdinal = function() {
var n = this % 100;
var suffix = ['th', 'st', 'nd', 'rd', 'th'];
var ord = n < 21 ? (n < 4 ? suffix[n] : suffix[0]) : (n % 10 > 4 ? suffix[0] : suffix[n % 10]);
return this + ord;
}
/*
* Usage:
* var myNumOld = 23
* var myNumNew = myNumOld.toOrdinal()
* Result: 23rd
*/ 除去非数字的字符function stripNonNumeric( str )
{
str += '';
var rgx = /^d|.|-$/;
var out = '';
for( var i = 0; i < str.length; i++ )
{
if( rgx.test( str.charAt(i) ) ){
if( !( ( str.charAt(i) == '.' && out.indexOf( '.' ) != -1 ) ||
( str.charAt(i) == '-' && out.length != 0 ) ) ){
out += str.charAt(i);
}
}
}
return out;
}
/*
* Usage: stripNonNumeric('123et45dhs6.789');
* Result: 123456.789
*/ 希望对大家有帮助!
(转载请注明出处:[url=http://www.tdtf.org]易博网[/url] [url=http://www.k5048.com]博彩网[/url] )
我们在做网页开发时候,相信使用ajax请求对页面进行局部刷新的技术,大家应该都很熟悉了吧。
有时候我们需要动态的请求服务器,这时服务器如果发过一段带有
<script>
//there are some codes here.
</script>
这样的脚本,我们如何让他客户端生效呢?
好吧,我承认我是用的jquery,需且很实现起来很简单,很多人也都是用一些js库实现的吧。如果我需要写js的源码呢?昨天同事碰到了这个问题,我就去深入地了解了一下,结果收获了一些以前不太明确的,不知道的知识。
一开始不能使脚本生效的方法:
在服务器端请求得到了带有<script>code...<script>的html的片段,然后直接使用document.getElementById("target_div").innerHTML = responseText,很好,得到的html内容都进来了,而且页面显示也正确。可以在触发刚请求到<script></script>中功能的时候,发现这里的代码失效了,无论如何也执行不了。于是我就去找使script生效的方法。
后来,想到我看看jquery是怎么实现的不就行了吗?jqury的代码如下:
- // Evalulates a script in a global context
- globalEval: function( data ) {
- if ( data && /\S/.test(data) ) {
- // Inspired by code by Andrea Giammarchi
- // http://webreflection.blogspot.com/2007/08/global-scope-evaluation-and-dom.html
- var head = document.getElementsByTagName("head")[0] || document.documentElement,
- script = document.createElement("script");
-
- script.type = "text/javascript";
- if ( jQuery.support.scriptEval )
- script.appendChild( document.createTextNode( data ) );
- else
- script.text = data;
-
- // Use insertBefore instead of appendChild to circumvent an IE6 bug.
- // This arises when a base node is used (#2709).
- head.insertBefore( script, head.firstChild );
- head.removeChild( script );
- }
- }
这个函数就是实现动态加载执行script的关键,函数中的参数data指的就是<script>data</script>这里的data,函数代码很简单,意思就是在<head>这个节点中的第一个位置插入<script>data</script>,这时候data就会被浏览器执行。最后再把这个节点给删了。
刚看到这个代码的时候,我就想,难道把<script>data</script>插入到<head>的第一个位置就会生效吗?而我放到自已的target_div里就不会生效,一直就搞不明白这个问题。因为没有听过哪本书,或哪个资料上这么说过啊。笨笨的我想了一下午,晚上回家的时候突然想明白了,jquery这里的插入script,和我写的插入script是不一样的,jquery是先创建一个script节点(这里是关键),然后将插入到html页面中。再看看我的插入,是直接用的innerHTML进行赋值。然而这是为什么呢?大家应该知道script的执行顺序吧,script在html文档加载的时候会执行一次。这里区别就在于,虽然是ajax请求来的script,jquery的实现方法是属于文档加载,另一个却只是文本的插入。浏览器会区分出这两种方式,所以只有jquery的方法才是正确的。
那么我们还看到为什么非要插入到head的第一个元素位置呢,这里面应该有点学问吧,我还不知道这里有什么原因。希望哪位高手可以帮我解惑。
最后删掉这个结点,是因为我们已经把script代码插入到target_div了,为了不让我们觉得莫名其秒,所以从外表的html代码中是看不到任何端倪的。
如果你已经看到这段文字,我想你应该交学费了,哈哈。当然,我也学别人东西也不交学费的。这样就算了。不过欢迎大家一起讨论、交流,能有新的想法,新的问题。
(转载请注明出处:
[url=http://www.d9732.com]澳门博彩[/url])
Flex与Javascript互相通信。
(1):在Flex中有这么一个类:ExternalInterface.在这个类中它给我们:call和addCallback Flex中As调用Js的方法是:
1、导入包 (import flash.external.ExternalInterface;)
2、使用ExternalInterface.call("Js函数名称",参数)进行调用,其返回的值就是Js函数所返回的值
Js调用As的方法是:
1、导入包 (import flash.external.ExternalInterface;)
2、在initApp中使用ExternalInterface.addCallback("用于Js调用的函数名",As中的函数名)进行注册下
3、js中 就可以用document.getElementById("Flas在Html中的ID").注册时设置的函数名(参数)进行调用. (2):实例演习:
[1]:flex调用javascript中的函数:
mxml:
<mx:Script>
<![CDATA[
import mx.controls.Alert;
internal function jspHello():void {
var taStr:String = this.ta.text;
var s:String = ExternalInterface.call("hello", taStr);
Alert.show(s);
}
]]>
</mx:Script> <mx:Button x="480" y="84" label="flex call javascript" click="jspHello()"/>
<mx:TextArea id="ta" x="265" y="85" height="80" width="199"/> javascript中的函数:
js:
<script type="text/javascript">
function hello(param) {
return "Hello: + param;
}
</script> 打印出来是:Hello: *****.
[2]:javascript调用Flex中的函数
mxml:
<mx:Application xmlns:mx="http://www.adobe.com/2006/mxml" layout="absolute" initialize="initApp();">
<mx:Script>
<![CDATA[
import mx.controls.TextArea;
internal function initApp():void {
ExternalInterface.addCallback("callBackFlex", testJavascript);
}
public function testJavascript():String {
var taStr:String = "中俄实弹演习成功!";
return taStr;
}
]]>
</mx:Script>
</mx:Application> js: <script type="text/javascript">
function callApp() {
var str = testJavascriptCallFlex.callBackFlex();
alert("javascript调用flex成功 : + str);
}
</script>
打印出来:javascript调用flex成功:中俄实弹演习成功。
(转载请注明出处:[url=http://www.k6567.com]e世博[/url])
前阵子,公司项目开发的时候,有个xxx.mxml编译后的swf始终加载不出来。开发环境是MyEclipse,后来仔细一看。原来是因为对xxx.mxml使用了flex applications 和 flex modules两种编译方式,导致mxml编译冲突,而无法编译成正确的swf文件。 正确做法:每个项目只用一个flex application,然后各个业务项里的mxml文件做成modules加入进来即可。
(转载请注明出处:[url=http://www.tswa.org]博彩通[/url])
软件开发人员是一个日新月异的领域—–IT中的大师,今天的编程方式与明天的编程或许截然不同,技术在不断地革新,新语言、新平台的如雨后春笋般出现、更好的解决方案的冒出,因此我们需要跟得上节奏,我们别无选择,唯有努力提高自己。 下面的几点建议或许能帮助你成为一个优秀的开发者。 你是否听说过Kaizen这个词呢?简单地说就是“改良”的意思。当然它不仅仅是一个单词,同时代表着一种哲学,一个不断完善自我的理念。它需要客观的监督和改善。更多的细节可以从这里了解。 
当然下面的建议是没有先后顺序的。 0. 阅读代码: 经常认真阅读他人的代码。寻找大家公认的优秀软件作品,学习其背后的运作原理,领悟他人解决问题的方法,有时候你也会遇到同样的问题,试着对比其技术和解决方案。 1. 编写代码: 在一个你还从未解决过的问题上多花点时间,尝试着培养自己的思考方法以及思维模式,你会因此而获得很多的乐趣。其实这样做并不难,而且它还是很好的问题反馈源。对于每个问题几乎任何时候都有不同的解决方法,学着用不同的方法解决问题,对比它们之间的优点和弊端,使用诸如模块化和系统集成的方式编程,因为那样写代码非常的简洁、清晰。 2. 跟上技术潮流: 在twitter和facebook、weibo等社交网络关注技术大牛,订阅你的RRS。及时了解新语言,对技术要有深入研究而不是仅仅停留在只会调用API的层面上。技术是要靠实力说话的,光忽悠没用,所以尽可能早的去深入了解。 3. 从不同的角度思考问题: 没错,你就是一个开发者,但是你会把自己的作品当做普普通通的产品吗?商业价值怎么样?写出来的软件能给你带来什么样的价值?需要用到哪些资源?有比软件带来更多价值还重要的事情吗?软件所表达的思想是什么?用户在使用过程中软件能扮演什么样的角色?这些问题看似很老套或者微不足道,其实不然,我们应该不断地去回答这些问题,开始不同角度思考问题。 4. 测试是开发者的工作: 未测试的代码就像一个未知的承诺,不去测试代码,编程技巧很难得到提高。作为用户,你会因为一个得不到保证的承诺而把钱交给一个完全陌生的人吗?用测试单元做功能和集成测试,证明你的代码可以正确执行,使他人放心地使用。把代码放到GitHub资源库上去。记住:扩大代码测试覆盖范围,减少代码的复杂度、去除代码的异味,不断调整、提高。 5. 在社区和开发者交流 向他人学习,和他人探讨问题。通过阅读他人代码提高自己的水平,同时尽可能去帮助他人,用一种开放地思维接受和分析他人的解决方案以及思想。 6. 每天交付可使用的部分 学会把大项目分解成为更小的,变成可交付使用的部分。做里程碑、做测试证明、做进度规划。分析和总结是必不可少的,此刻就把它记录下来,注意前后细节的变化,长期的积累将使你更加自信,外人对你会刮目相看,做一个快乐的程序员。 7. 忙里偷闲: 参加娱乐、体育活动、接触大自然。你的身体和大脑需要休息,经常站起来活动活动,切忌一直坐着盯着屏幕。
(转载请注明出处:[url=http://www.a9832.com]博彩网[/url])
|