
2007年11月21日
一、准备
正式开始前,编译环境gcc、g++等开发库需要提前安装。
nginx依赖以下模块:
gzip模块需要 zlib 库
rewrite模块需要 pcre 库
ssl 功能需要openssl库
源码目录为:/usr/local/src
1、安装make
yum -y install gcc automake autoconf libtool make
2、安装g++
yum install gcc gcc-c++
3、安装PCRE库
cd /usr/local/src
wget ftp://ftp.csx.cam.ac.uk/pub/software/programming/pcre/pcre-8.42.tar.gz
tar -zxvf pcre-8.42.tar.gz
cd pcre-8.42/
./configure
make && make install
出现如下报错:
make[2]: *** [install-libLTLIBRARIES] Error 1
make[2]: Leaving directory `/usr/local/src/pcre-8.42'
make[1]: *** [install-am] Error 2
make[1]: Leaving directory `/usr/local/src/pcre-8.42'
make: *** [install] Error 2
权限不够,切换到root,重新make install即可。
4、安装zlib库
cd /usr/local/src
wget http://zlib.net/zlib-1.2.11.tar.gz
tar -zxvf zlib-1.2.11.tar.gz
cd zlib-1.2.11/
./configure
make && make install
5、安装OpenSSL库
cd /usr/local/src
wget http://www.openssl.org/source/openssl-1.1.0h.tar.gz
tar -zxvf openssl-fips-2.0.16.tar.gz
cd openssl-fips-2.0.16/
./config
make && make install
编译安装 Openssl 1.1.1 支持国密标准
https://blog.51cto.com/1012682/2380553
6、创建用户及用户组
一般为了服务器安全,会指定一个普通用户权限的账号做为Nginx的运行角色,这里使用www用户做为Nginx工作进程的用户。后续安装的PHP也以www用户作为工作进程用户。
groupadd -r www
useradd -r -g www www
二、NGINX
1、下载
cd /usr/local/src
wget http://nginx.org/download/nginx-1.14.0.tar.gz
tar –zxvf nginx-1.14.0.tar.gz
cd nginx-1.14.0
2、配置
./configure --prefix=/usr/local/nginx --sbin-path=/usr/local/nginx/sbin/nginx --conf-path=/usr/local/nginx/conf/nginx.conf --error-log-path=/var/log/nginx/error.log --http-log-path=/var/log/nginx/access.log --pid-path=/var/run/nginx/nginx.pid --lock-path=/var/lock/nginx.lock --user=www --group=www --with-http_ssl_module --with-http_stub_status_module --with-http_gzip_static_module --with-http_flv_module --with-http_mp4_module --http-client-body-temp-path=/var/tmp/nginx/client/ --http-proxy-temp-path=/var/tmp/nginx/proxy/ --http-fastcgi-temp-path=/var/tmp/nginx/fcgi/ --http-uwsgi-temp-path=/var/tmp/nginx/uwsgi --http-scgi-temp-path=/var/tmp/nginx/scgi
make && make install
nginx编译选项说明:
--prefix表示nginx要安装到哪个路径下,这里指定刚才新建好的/alidata/server目录下的nginx-1.12.2;
--sbin-path表示nginx的可执行文件存放路径
--conf-path表示nginx的主配置文件存放路径,nginx允许使用不同的配置文件启动,通过命令行中的-c选项
--pid-path表示nginx.pid文件的存放路径,将存储的主进程的进程号。安装完成后,可以随时改变的文件名 , 在nginx.conf配置文件中使用 PID指令。默认情况下,文件名 为prefix/logs/nginx.pid
--error-log-path表示nginx的主错误、警告、和诊断文件存放路径
--http-log-path表示nginx的主请求的HTTP服务器的日志文件的存放路径
--user表示nginx工作进程的用户
--group表示nginx工作进程的用户组
--with-select_module或--without-select_module表示启用或禁用构建一个模块来允许服务器使用select()方法
--with-poll_module或--without-poll_module表示启用或禁用构建一个模块来允许服务器使用poll()方法
--with-http_ssl_module表示使用https协议模块。默认情况下,该模块没有被构建。建立并运行此模块的OpenSSL库是必需的
--with-pcre表示pcre的源码路径,因为解压后的pcre是放在root目录下的,所以是/root/pcre-8.41;
--with-zlib表示zlib的源码路径,这里因为解压后的zlib是放在root目录下的,所以是/root/zlib-1.2.11
--with-openssl表示openssl库的源码路径
配置OK:
Configuration summary
+ using PCRE library: /usr/local/src/pcre-8.42
+ using OpenSSL library: /usr/local/src/openssl-1.1.0h
+ using zlib library: /usr/local/src/zlib-1.2.11
nginx path prefix: "/usr/local/nginx"
nginx binary file: "/usr/local/nginx/sbin/nginx"
nginx modules path: "/usr/local/nginx/modules"
nginx configuration prefix: "/usr/local/nginx"
nginx configuration file: "/usr/local/nginx/nginx.conf"
nginx pid file: "/usr/local/nginx/nginx.pid"
nginx error log file: "/usr/local/nginx/logs/error.log"
nginx http access log file: "/usr/local/nginx/logs/access.log"
nginx http client request body temporary files: "/var/tmp/nginx/client/"
nginx http proxy temporary files: "/var/tmp/nginx/proxy/"
nginx http fastcgi temporary files: "/var/tmp/nginx/fcgi/"
nginx http uwsgi temporary files: "/var/tmp/nginx/uwsgi"
nginx http scgi temporary files: "/var/tmp/nginx/scgi"
3、安装
make && make install
4、启动
/usr/local/nginx/sbin/nginx
启动时报错:
nginx: [emerg] mkdir() "/var/tmp/nginx/client/" failed (2: No such file or directory)
手动创建该目录即可:mkdir -p /var/tmp/nginx/client
再次启动,打开浏览器访问此机器的IP,浏览器出现Welcome to nginx! 则表示 Nginx 已经安装并运行成功。
5、设置软连接
ln -sf /usr/local/nginx/sbin/nginx /usr/sbin
这样就可以直接执行nginx来启动了。
6、检测nginx
nginx -t
显示:
nginx: the configuration file /usr/local/nginx/nginx.conf syntax is ok
nginx: configuration file /usr/local/nginx/nginx.conf test is successful
三、PHP
1、安装PHP需要的常用库
yum -y install libmcrypt-devel mhash-devel libxslt-devel libjpeg libjpeg-devel libpng libpng-devel freetype freetype-devel libxml2 libxml2-devel zlib zlib-devel glibc glibc-devel glib2 glib2-devel bzip2 bzip2-devel ncurses ncurses-devel curl curl-devel e2fsprogs e2fsprogs-devel krb5 krb5-devel libidn libidn-devel openssl openssl-devel
2、下载
cd /usr/local/src
wget http://cn2.php.net/downloads.php/php-7.2.5.tar.gz
tar -zxvf php-7.2.5.tar.gz
3、配置
./configure --prefix=/usr/local/php \
--with-mysql=mysqlnd \
--enable-mysqlnd \
--with-gd \
--enable-gd-jis-conv \
--enable-fpm
4、安装
make && make install
安装信息如下:
Installing shared extensions: /usr/local/php/lib/php/extensions/no-debug-non-zts-20170718/
Installing PHP CLI binary: /usr/local/php/bin/
Installing PHP CLI man page: /usr/local/php/php/man/man1/
Installing PHP FPM binary: /usr/local/php/sbin/
Installing PHP FPM defconfig: /usr/local/php/etc/
Installing PHP FPM man page: /usr/local/php/php/man/man8/
Installing PHP FPM status page: /usr/local/php/php/php/fpm/
Installing phpdbg binary: /usr/local/php/bin/
Installing phpdbg man page: /usr/local/php/php/man/man1/
Installing PHP CGI binary: /usr/local/php/bin/
Installing PHP CGI man page: /usr/local/php/php/man/man1/
Installing build environment: /usr/local/php/lib/php/build/
Installing header files: /usr/local/php/include/php/
Installing helper programs: /usr/local/php/bin/
program: phpize
program: php-config
Installing man pages: /usr/local/php/php/man/man1/
page: phpize.1
page: php-config.1
Installing PEAR environment: /usr/local/php/lib/php/
[PEAR] Archive_Tar: upgrade to a newer version (1.4.3 is not newer than 1.4.3)
[PEAR] Console_Getopt: upgrade to a newer version (1.4.1 is not newer than 1.4.1)
[PEAR] Structures_Graph: upgrade to a newer version (1.1.1 is not newer than 1.1.1)
[PEAR] XML_Util: upgrade to a newer version (1.4.2 is not newer than 1.4.2)
[PEAR] PEAR: upgrade to a newer version (1.10.5 is not newer than 1.10.5)
/usr/local/src/php-7.2.5/build/shtool install -c ext/phar/phar.phar /usr/local/php/bin
ln -s -f phar.phar /usr/local/php/bin/phar
Installing PDO headers: /usr/local/php/include/php/ext/pdo/
5、添加环境变量
vim /etc/profile
在末尾加入
export PHP_HOME=/usr/local/php
export PATH=/bin:/usr/bin:/usr/sbin:/sbin:$PATH:PHP_HOME/bin:$PHP_HOME/sbin
保存修改后,使用source命令重新加载配置文件:
source /etc/profile
查看环境变量:
echo $PATH
6、配置php-fpm
cd /usr/local/php/etc
cp php-fpm.conf.default php-fpm.conf
cd php-fpm.d/
cp www.conf.default www.conf
使用vim命令对php-fpm.conf的内容进行如下修改:
pid = /usr/local/php/var/run/php-fpm.pid
使用vim命令对php-fpm.conf的内容进行如下修改:
user = www
group = www
其他配置可根据需求进行修改,比如pm.max_children(php-fpm 能启动的子进程的最大数量)、pm.start_servers(php启动时,开启的子进程的数量)、pm.min_spare_servers(动态方式空闲状态下的最小php-fpm进程数量)、pm.max_spare_servers(动态方式空闲状态下的最大php-fpm进程数量)等。
7、启动php-fpm
/usr/local/php/sbin/php-fpm
可以通过ps aux | grep php查看php进程。
https://www.cnblogs.com/sunshineliulu/p/8991957.html
三、MySQL
https://blog.csdn.net/weixin_33859844/article/details/90948191
https://www.cnblogs.com/yangchunlong/p/8477743.html
posted @
2019-08-13 17:37 Alpha 阅读(394) |
评论 (0) |
编辑 收藏一、安装git服务器所需软件
打开终端输入以下命令:
ubuntu:~$ sudo apt-get install git-core openssh-server openssh-client
git-core是git版本控制核心软件
安装openssh-server和openssh-client是由于git需要通过ssh协议来在服务器与客户端之间传输文件
然后中间有个确认操作,输入Y后等待系统自动从镜像服务器中下载软件安装,安装完后会回到用户当前目录。如果
安装提示失败,可能是因为系统软件库的索引文件太旧了,先更新一下就可以了,更新命令如下:
ubuntu:~$ sudo apt-get update
更新完软件库索引后继续执行上面的安装命令即可。
安装python的setuptools和gitosis,由于gitosis的安装需要依赖于python的一些工具,所以我们需要先安装python
的setuptools。
执行下面的命令:
ubuntu:~$ sudo apt-get install python-setuptools
这个工具比较小,安装也比较快,接下来准备安装gitosis,安装gitosis之前需要初始化一下服务器的git用户信息,这个随便填。
ubuntu:~$ git config --global user.name "myname"
ubuntu:~$ git config --global user.email "******@gmail.com"
初始化服务器用户信息后,就可以安装gitosis了,gitosis主要是用于给用户授权,设置权限也算是很方便的。
可以通过以下命令获取gitosis版本文件
ubuntu:~$ git clone https://github.com/res0nat0r/gitosis.git
注意:中间有两个是数字零
获取gitosis文件后,进入到文件目录下面
ubuntu:/tmp$ cd gitosis/
接着使用python命令安装目录下的setup.py的python脚本进行安装
ubuntu:/tmp/gitosis$ sudo python setup.py install
到这里,整个安装步骤就完成了,下面就开始对git进行一些基本的配置。
二、创建git管理员账户、配置git
创建一个账户(git)作为git服务器的管理员,可以管理其他用户的项目权限。
ubuntu:/tmp/gitosis$ sudo useradd -m git
ubuntu:/tmp/gitosis$ sudo passwd git
然后再/home目录下创建一个项目仓库存储点,并设置只有git用户拥有所有权限,其他用户没有任何权限。
ubuntu:/tmp/gitosis$ sudo mkdir /home/gitrepository
ubuntu:/tmp/gitosis$ sudo chown git:git /home/gitrepository/
ubuntu:/tmp/gitosis$ sudo chmod 700 /home/gitrepository/
由于gitosis默认状态下会将仓库放在用户的repositories目录下,例如git用户的仓库地址默认在/home/git/repositories/目录下,这里我们需要创建一个链接映射。让他指向我们前面创建的专门用于存放项目的仓库目录/home/gitrepository。
ubuntu:/tmp/gitosis$ sudo ln -s /home/gitrepository /home/git/repositories
这里我将在服务器端生成ssh公钥,如果想在其他机器上管理也可以在其他机器上生成一个ssh的公钥。
ubuntu:/home/git$ ssh-keygen -t rsa
这里会提示输入密码,我们不输入直接回车即可。
然后用刚生成公钥id_rsa.pub来对gitosis进行初始化。
向gitosis添加公钥并初始化:
$ cp ~/.ssh/id_rsa.pub /tmp
$ sudo -H -u gitadmin gitosis-init < /tmp/id_rsa.pub

出现如上信息说明gitosis已经初始化成功。
gitosis主要是通过gitosis-admin.git仓库来管理一些配置文件的,如用户权限的管理。这里我们需要对其中的一个post-update文件添加可执行的权限。
ubuntu:/home/git$ sudo chmod 755 /home/gitrepository/gitosis-admin.git/hooks/post-update
三、服务器上创建项目仓库
使用git账户在服务器上创建一个目录(mytestproject.git)并初始化成git项目仓库。
ubuntu:/home/git$ su git
$ cd /home/gitrepository
$ mkdir mytestproject.git
$ git init --bare mytestproject.git
$ exit
如果出现以下信息就说明已经成功创建了一个名为mytestproject.git的项目仓库了,新建的这个仓库暂时还是空的,不能被客户端clone,还需要对gitosis进行一些配置操作。
四、使用gitosis管理用户操作项目的权限
首先需要在前面生成ssh公钥(用来初始化gitosis)的机器上将gitosis-admin.git的仓库clone下来。
在客户端机器上新建一个目录用于存放gitosis-admin.git仓库
ubuntu:~$ mkdir gitadmin
ubuntu:~$ cd gitadmin/
ubuntu:~/gitadmin$ git clone git@192.168.1.106:gitosis-admin.git
clone正确会显示以下信息

clone下来会有一个gitosis.conf的配置文件和一个keydir的目录。gitosis.conf用于配置用户的权限信息,keydir主要用户存放ssh公钥文件(一般以“用户名.pub”命名,gitosis.conf配置文件中需使用相同用户名),用于认证请求的客户端机器。
现在让需要授权的用户使用前面的方式各自在其自己的机器上生成相应的ssh公钥文件,管理员把他们分别按用户名命名好,复制到keydir目录下。
ubuntu:~$ cp /home/aaaaa/Desktop/zhangsan.pub /home/aaaaa/gitadmin/gitosis-admin/keydir/
ubuntu:~$ cp /home/aaaaa/Desktop/lisi.pub /home/aaaaa/gitadmin/gitosis-admin/keydir/
继续编辑gitosis.conf文件
[gitosis]
[group gitosis-admin]
####管理员组
members = charn@ubuntu
####管理员用户名,需要在keydir目录下找到相应的.pub文件,多个可用空格隔开(下同)
writable = gitosis-admin####可写的项目仓库名,多个可用空格隔开(下同)
[group testwrite]
####可写权限组
members = zhangsan####组用户
writable = mytestproject####可写的项目仓库名
[group
testread] ####只读权限组
members =lisi####组用户
readonly= mytestproject####只读项目仓库名
因为这些配置的修改只是在本地修改的,还需要推送到服务器中才能生效。
ubuntu:~/gitadmin/gitosis-admin$ git add .
ubuntu:~/gitadmin/gitosis-admin$ git commit -am "add a user permission"
ubuntu:~/gitadmin/gitosis-admin$ git push origin master
推送成功会显示下面提示信息

又是后新增的用户不能立即生效,这时候需要重新启动一下sshd服务
ubuntu:~/gitadmin/gitosis-admin$ sudo /etc/init.d/ssh restart
现在,服务端的git就已经安装和配置完成了,接下来就需要有权限的组成员在各自的机器上clone服务器上的相应
项目仓库进行相应的工作了。
五、客户端(windows)使用git
下载安装windows版本的git客户端软件,下载地址:http://msysgit.github.io/
安装完成后右键菜单会出现几个git相关的菜单选项,我们主要使用其中的git
bash通过命令行来进行操作。
在本地新建一个目录,使用git初始化这个目录,然后再里面新建一个文本文件用于测试,最后关联到git服务器仓库
中的相关项目,最后上传本地版本到服务器。
$ mkdir testgit
$ cd testgit
$ git init
$ echo "this is a test text file,will push to server" > hello.txt
$ git add .
$ git commit -am "init a base version,add a first file for push to server"
$ git remote add origin git@serverip:mytestproject.git
$ git push origin master
这样服务端就创建好了一个mytestproject.git的仓库的基础版本了,现在其他组员只要从服务端进行clone就可以了。
window下面进入到需要克隆的本地目录下面右键选择git bash选项,输入
$ git clone git@serverip:mytestproject.git
就可以把项目clone到本地仓库了。
下面进行简单的修改和提交操作
$ cd mytestproject
$ echo "this is another text file created by other" >another.txt
$ git add .
$ git commit -am "add a another file by other"
$ git push origin master
最后推送到服务器成功会显示如下信息

gitolite搭建git仓库(服务端+客户端)
http://blog.csdn.net/ChiChengIT/article/details/49863383
posted @
2018-03-13 15:35 Alpha 阅读(1192) |
评论 (0) |
编辑 收藏
摘要: Git 教程http://www.runoob.com/git/git-tutorial.htmlGit本地服务器搭建及使用Git是一款免费、开源的分布式版本控制系统。众所周知的Github便是基于Git的开源代码库以及版本控制系统,由于其远程托管服务仅对开源免费,所以搭建本地Git服务器也是个较好的选择,本文将对此进行详细讲解。(推荐一家提供私有源代码免费托管的网站:Bitbucket,目前支持...
阅读全文
posted @
2018-03-08 10:44 Alpha 阅读(3241) |
评论 (0) |
编辑 收藏1.查看内存 free
2.查看cpu cat cpuinfo
3.查看磁盘 fdisk -l
4.查看带宽 iptraf-ng
5.查看负载 top
6.查看请求数 netstat -anp | wc -l
7.查看请求详情 netstat -anp
8.查看某个程序请求数 netstat -anp | grep php |wc -l
9.查看磁盘使用情况 df -h
10.查看系统日志 dmesg
11.查看进程数量 ps aux | wc -l
12.查看运行网络程序 ps auxww | more
13.查看php运行程序 ps auxww | grep php
14.查看php运行程序数量 ps auxww | grep php | wc -l
15.查看init.d运行 ls -al /etc/init.d/
16.查找文件路径 find / -name php.ini
17.查看mysql端口 netstat -anp | grep 3306
18.查看本机ip地址 ip add
19.查找某个字符串在文件中出现的 grep 127.0.0.1:9000 *.conf
20.
posted @
2017-12-25 10:16 Alpha 阅读(622) |
评论 (0) |
编辑 收藏一、背景
系统管理员,最谨慎的linux就是rm命令了,一不小心数据就没干掉,最恐怖的是数据没有备份,没法还原了,此类事情发生的太多了,针对于此,我们经过多次尝试演练,终于成功的把大部分删除的数据找回来了,下面我把演练过程给大家介绍一下。
二、安装恢复软件
extundelete,该工具官方给出的是可以恢复ext3或者ext4文件系统被删除的文件。
1:通过命令安装
#yum install extundelete -y
2:通过源码编译安装
#yum -y install e2fsprogs-devel e2fsprogs #wget http://zy-res.oss-cn-hangzhou.aliyuncs.com/server/extundelete-0.2.4.tar.bz2 #tar -xvjf extundelete-0.2.4.tar.bz2 #cd extundelete-0.2.4 #./configure #make &&make install
三、删除数据查找
首先,我们先删除一个文件,如图:
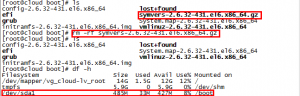
如上图,我们刚才在/boot目录下删除了个symvers-2.6.32-431.el6.x86_64.gz文件,/boot是落到/dev/sda1下
在Linux下可以通过“ls -id”命令来查看某个文件或者目录的inode值,例如查看根目录的inode值,可以输入:
[root@cloud boot]# ls -id /boot 2 /boot
注:根目录的inode一般为2
然后我们开始查找被删除的文件,需要根据分区inode查找,命令如下:
#extundelete /dev/sda1 --inode 2
结果如下图:
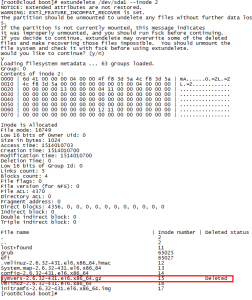
我们就可以看到标识为Deleted的被删除数据了。
四、数据恢复
我们就开始恢复,命令如下:
#extundelete /dev/sda1 --restore-file symvers-2.6.32-431.el6.x86_64.gz
如图:
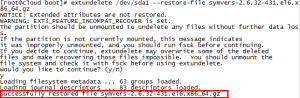

还原成功
当然,还有可能删除整个文件夹,我们也举个例子,如下:
#extundelete /dev/sda1 --restore-directory test
恢复全部删除数据,如下:
#extundelete /dev/sdb1 --restore-all
也可以通过时间段恢复,这里就不说了,参数如下:
--version, -[vV],显示软件版本号。 --help,显示软件帮助信息。 --superblock,显示超级块信息。 --journal,显示日志信息。 --after dtime,时间参数,表示在某段时间之后被删的文件或目录。 --before dtime,时间参数,表示在某段时间之前被删的文件或目录。 动作(action)有: --inode ino,显示节点“ino”的信息。 --block blk,显示数据块“blk”的信息。 --restore-inode ino[,ino,...],恢复命令参数,表示恢复节点“ino”的文件,恢复的文件会自动放在当前目录下的RESTORED_FILES文件夹中,使用节点编号作为扩展名。 --restore-file 'path',恢复命令参数,表示将恢复指定路径的文件,并把恢复的文件放在当前目录下的RECOVERED_FILES目录中。 --restore-files 'path',恢复命令参数,表示将恢复在路径中已列出的所有文件。 --restore-all,恢复命令参数,表示将尝试恢复所有目录和文件。 -j journal,表示从已经命名的文件中读取扩展日志。 -b blocknumber,表示使用之前备份的超级块来打开文件系统,一般用于查看现有超级块是不是当前所要的文件。 -B blocksize,通过指定数据块大小来打开文件系统,一般用于查看已经知道大小的文件。
五、总结
数据恢复,不一定能全部将数据恢复回来,还是一句话,操作要谨慎。万一操作失误,也不要慌,将损失减少到最小,首先停止所有操作,其次让专业人员去处理。

posted @
2017-12-23 16:11 Alpha 阅读(2002) |
评论 (0) |
编辑 收藏
- 安裝 nginx
CentOS 7 沒有內建的 nginx,所以先到 nginx 官網 http://nginx.org/en/linux_packages.html#stable ,找到 CentOS 7 的 nginx-release package 檔案連結,然後如下安裝
rpm -Uvh http://nginx.org/packages/centos/7/noarch/RPMS/nginx-release-centos-7-0.el7.ngx.noarch.rpm
安裝後,會自動產生 yum 的 repository 設定(在 /etc/yum.repos.d/nginx.repo),
接下來便可以使用 yum 指令安裝 nginx
yum install nginx
- 啟動 nginx
以前用 chkconfig 管理服務,CentOS 7 改用 systemctl 管理系統服務
立即啟動
systemctl start nginx
查看目前運作狀態
systemctl status nginx
查看 nginx 服務目前的啟動設定
systemctl list-unit-files | grep nginx
若是 disabled,可以改成開機自動啟動
systemctl enable nginx
若有設定防火牆,查看防火牆運行狀態,看是否有開啟 nginx 使用的 port
firewall-cmd --state
永久開放開啟防火牆的 http 服務
firewall-cmd --permanent --zone=public --add-service=http
firewall-cmd --reload
列出防火牆 public 的設定
firewall-cmd --list-all --zone=public
經過以上設定,應該就可以使用瀏覽器訪問 nginx 的預設頁面。
- 安裝 PHP-FPM
使用 yum 安裝 php、php-fpm、php-mysql
yum install php php-fpm php-mysql
查看 php-fpm 服務目前的啟動設定
systemctl list-unit-files | grep php-fpm
改成開機自動啟動
systemctl enable php-fpm
立即啟動
systemctl start php-fpm
查看目前運作狀態
systemctl status php-fpm
- 修改 PHP-FPM listen 的方式
若想將 PHP-FPM listen 的方式,改成 unix socket,可以編輯 /etc/php-fpm.d/www.conf
將
listen = 127.0.0.1:9000
改成
listen = /var/run/php-fpm/php-fpm.sock
然後重新啟動 php-fpm
systemctl restart php-fpm
註:不要改成 listen = /tmp/php-fcgi.sock (將 php-fcgi.sock 設定在 /tmp 底下), 因為系統產生 php-fcgi.sock 時,會放在 /tmp/systemd-private-*/tmp/php-fpm.sock 隨機私有目錄下, 除非把 /usr/lib/systemd/system/ 裡面的 PrivateTmp=true 設定改成 PrivateTmp=false, 但還是會產生其他問題,所以還是換個位置最方便
删除之前的版本
# yum remove php*
rpm 安装 Php7 相应的 yum源
CentOS/RHEL 7.x:
# rpm -Uvh https://dl.fedoraproject.org/pub/epel/epel-release-latest-7.noarch.rpm # rpm -Uvh https://mirror.webtatic.com/yum/el7/webtatic-release.rpm
CentOS/RHEL 6.x:
# rpm -Uvh https://mirror.webtatic.com/yum/el6/latest.rpm
yum安装php7
yum install php70w php70w-opcache
安装其他插件(选装)
注:如果安装pear,需要安装php70w-devel
php70w
php70w-bcmath
php70w-cli
php70w-common
php70w-dba
php70w-devel
php70w-embedded
php70w-enchant
php70w-fpm
php70w-gd
php70w-imap
php70w-interbase
php70w-intl
php70w-ldap
php70w-mbstring
php70w-mcrypt
php70w-mysql
php70w-mysqlnd
php70w-odbc
php70w-opcache
php70w-pdo
php70w-pdo_dblib
php70w-pear
php70w-pecl-apcu
php70w-pecl-imagick
php70w-pecl-xdebug
php70w-pgsql
php70w-phpdbg
php70w-process
php70w-pspell
php70w-recode
php70w-snmp
php70w-soap
php70w-tidy
php70w-xml
php70w-xmlrp
编译安装php7
配置(configure)、编译(make)、安装(make install)
使用configure --help
编译安装一定要指定定prefix,这是安装目录,会把所有文件限制在这个目录,卸载时只需要删除那个目录就可以,如果不指定会安装到很多地方,后边删除不方便。
Configuration: --cache-file=FILE cache test results in FILE --help print this message --no-create do not create output files --quiet, --silent do not print `checking...' messages --version print the version of autoconf that created configure Directory and file names: --prefix=PREFIX install architecture-independent files in PREFIX [/usr/local] --exec-prefix=EPREFIX install architecture-dependent files in EPREFIX
注意
内存小于1G安装往往会出错,在编译参数后面加上一行内容--disable-fileinfo
其他配置参数
--exec-prefix=EXEC-PREFIX
可以把体系相关的文件安装到一个不同的位置,而不是PREFIX设置的地方.这样做可以比较方便地在不同主机之间共享体系相关的文件
--bindir=DIRECTORY
为可执行程序声明目录,缺省是 EXEC-PREFIX/bin
--datadir=DIRECTORY
设置所安装的程序需要的只读文件的目录.缺省是 PREFIX/share
--sysconfdir=DIRECTORY
用于各种各样配置文件的目录,缺省为 PREFIX/etc
--libdir=DIRECTORY
库文件和动态装载模块的目录.缺省是 EXEC-PREFIX/lib
--includedir=DIRECTORY
C 和 C++ 头文件的目录.缺省是 PREFIX/include
--docdir=DIRECTORY
文档文件,(除 “man(手册页)”以外, 将被安装到这个目录.缺省是 PREFIX/doc
--mandir=DIRECTORY
随着程序一起带的手册页 将安装到这个目录.在它们相应的manx子目录里. 缺省是PREFIX/man
注意: 为了减少对共享安装位置(比如 /usr/local/include) 的污染,configure 自动在 datadir, sysconfdir,includedir, 和 docdir 上附加一个 “/postgresql” 字串, 除非完全展开以后的目录名字已经包含字串 “postgres” 或者 “pgsql”.比如,如果你选择 /usr/local 做前缀,那么 C 的头文件将安装到 /usr/local/include/postgresql, 但是如果前缀是 /opt/postgres,那么它们将 被放进 /opt/postgres/include
--with-includes=DIRECTORIES
DIRECTORIES 是一系列冒号分隔的目录,这些目录将被加入编译器的头文件 搜索列表中.如果你有一些可选的包(比如 GNU Readline)安装在 非标准位置,你就必须使用这个选项,以及可能还有相应的 --with-libraries 选项.
--with-libraries=DIRECTORIES
DIRECTORIES 是一系列冒号分隔的目录,这些目录是用于查找库文件的. 如果你有一些包安装在非标准位置,你可能就需要使用这个选项 (以及对应的--with-includes选项)
--enable-XXX
打开XXX支持
--with-XXX
制作XXX模块
- PHP FPM設定參考
[global]
pid = /usr/local/php/var/run/php-fpm.pid
error_log = /usr/local/php/var/log/php-fpm.log
[www]
listen = /var/run/php-fpm/php-fpm.sock
user = www
group = www
pm = dynamic
pm.max_children = 800
pm.start_servers = 200
pm.min_spare_servers = 100
pm.max_spare_servers = 800
pm.max_requests = 4000
rlimit_files = 51200
listen.backlog = 65536
;設 65536 的原因是-1 可能不是unlimited
;說明 http://php.net/manual/en/install.fpm.configuration.php
slowlog = /usr/local/php/var/log/slow.log
request_slowlog_timeout = 10
- nginx.conf 設定參考
user nginx;
worker_processes 8;
error_log /var/log/nginx/error.log warn;
pid /var/run/nginx.pid;
events {
use epoll;
worker_connections 65535;
}
worker_rlimit_nofile 65535;
http {
include /etc/nginx/mime.types;
default_type application/octet-stream;
log_format main '$remote_addr - $remote_user [$time_local] "$request" '
'$status $body_bytes_sent "$http_referer" '
'"$http_user_agent" "$http_x_forwarded_for"';
access_log /var/log/nginx/access.log main;
sendfile on;
tcp_nopush on;
keepalive_timeout 65;
server_names_hash_bucket_size 128;
client_header_buffer_size 32k;
large_client_header_buffers 4 32k;
client_max_body_size 8m;
server_tokens off;
client_body_buffer_size 512k;
fastcgi_connect_timeout 300;
fastcgi_send_timeout 300;
fastcgi_read_timeout 300;
fastcgi_buffer_size 64k;
fastcgi_buffers 4 64k;
fastcgi_busy_buffers_size 128k;
fastcgi_temp_file_write_size 128k;
fastcgi_intercept_errors on;
gzip off;
gzip_min_length 1k;
gzip_buffers 32 4k;
gzip_http_version 1.0;
gzip_comp_level 2;
gzip_types text/css text/xml application/javascript application/atom+xml application/rss+xml text/plain application/json;
gzip_vary on;
include /etc/nginx/conf.d
若出現出現錯誤:setrlimit(RLIMIT_NOFILE, 65535) failed (1: Operation not permitted)
先查看目前系統的設定值
ulimit -n
若設定值太小,修改 /etc/security/limits.conf
vi /etc/security/limits.conf
加上或修改以下兩行設定
* soft nofile 65535
* hard nofile 65535
posted @
2016-08-10 13:44 Alpha 阅读(6026) |
评论 (0) |
编辑 收藏1.关于Tomcat的session数目
这个可以直接从Tomcat的web管理界面去查看即可
或者借助于第三方工具Lambda Probe来查看,它相对于Tomcat自带的管理稍微多了点功能,但也不多
2.监视Tomcat的内存使用情况
使用JDK自带的jconsole可以比较明了的看到内存的使用情况,线程的状态,当前加载的类的总量等
JDK自带的jvisualvm可以下载插件(如GC等),可以查看更丰富的信息。如果是分析本地的Tomcat的话,还可以进行内存抽样等,检查每个类的使用情况
3.打印类的加载情况及对象的回收情况
这个可以通过配置JVM的启动参数,打印这些信息(到屏幕(默认也会到catalina.log中)或者文件),具体参数如下:
-XX:+PrintGC:输出形式:[GC 118250K->113543K(130112K), 0.0094143 secs] [Full GC 121376K->10414K(130112K), 0.0650971 secs]
-XX:+PrintGCDetails:输出形式:[GC [DefNew: 8614K->781K(9088K), 0.0123035 secs] 118250K->113543K(130112K), 0.0124633 secs] [GC [DefNew: 8614K->8614K(9088K), 0.0000665 secs][Tenured: 112761K->10414K(121024K), 0.0433488 secs] 121376K->10414K(130112K), 0.0436268 secs]
-XX:+PrintGCTimeStamps -XX:+PrintGC:PrintGCTimeStamps可与上面两个混合使用,输出形式:11.851: [GC 98328K->93620K(130112K), 0.0082960 secs]
-XX:+PrintGCApplicationConcurrentTime:打印每次垃圾回收前,程序未中断的执行时间。可与上面混合使用。输出形式:Application time: 0.5291524 seconds
-XX:+PrintGCApplicationStoppedTime:打印垃圾回收期间程序暂停的时间。可与上面混合使用。输出形式:Total time for which application threads were stopped: 0.0468229 seconds
-XX:PrintHeapAtGC: 打印GC前后的详细堆栈信息
-Xloggc:filename:与上面几个配合使用,把相关日志信息记录到文件以便分析
-verbose:class 监视加载的类的情况
-verbose:gc 在虚拟机发生内存回收时在输出设备显示信息
-verbose:jni 输出native方法调用的相关情况,一般用于诊断jni调用错误信息
4.添加JMS远程监控
对于部署在局域网内其它机器上的Tomcat,可以打开JMX监控端口,局域网其它机器就可以通过这个端口查看一些常用的参数(但一些比较复杂的功能不支持),同样是在JVM启动参数中配置即可,配置如下:
-Dcom.sun.management.jmxremote.ssl=false -Dcom.sun.management.jmxremote.authenticate=false
-Djava.rmi.server.hostname=192.168.71.38 设置JVM的JMS监控监听的IP地址,主要是为了防止错误的监听成127.0.0.1这个内网地址
-Dcom.sun.management.jmxremote.port=1090 设置JVM的JMS监控的端口
-Dcom.sun.management.jmxremote.ssl=false 设置JVM的JMS监控不实用SSL
-Dcom.sun.management.jmxremote.authenticate=false 设置JVM的JMS监控不需要认证
5.专业点的分析工具有
IBM ISA,JProfiler等,具体监控及分析方式去网上搜索即可。
集群方案
单个Tomcat的处理性能是有限的,当并发量较大的时候,就需要有部署多套来进行负载均衡了。
集群的关键点有以下几点:
1.引入负载端
软负载可以使用nginx或者apache来进行,主要是使用一个分发的功能
参考:
http://ajita.iteye.com/blog/1715312(nginx负载)
http://ajita.iteye.com/blog/1717121(apache负载)
2.共享session处理
目前的处理方式有如下几种:
1).使用Tomcat本身的Session复制功能
参考http://ajita.iteye.com/blog/1715312(Session复制的配置)
方案的有点是配置简单,缺点是当集群数量较多时,Session复制的时间会比较长,影响响应的效率
2).使用第三方来存放共享Session
目前用的较多的是使用memcached来管理共享Session,借助于memcached-sesson-manager来进行Tomcat的Session管理
参考http://ajita.iteye.com/blog/1716320(使用MSM管理Tomcat集群session)
3).使用黏性session的策略
对于会话要求不太强(不涉及到计费,失败了允许重新请求下等)的场合,同一个用户的session可以由nginx或者apache交给同一个Tomcat来处理,这就是所谓的session sticky策略,目前应用也比较多
参考:http://ajita.iteye.com/blog/1848665(tomcat session sticky)
nginx默认不包含session sticky模块,需要重新编译才行(windows下我也不知道怎么重新编译)
优点是处理效率高多了,缺点是强会话要求的场合不合适
3.小结
以上是实现集群的要点,其中1和2可以组合使用,具体场景具体分析吧~
JVM优化
Tomcat本身还是运行在JVM上的,通过对JVM参数的调整我们可以使Tomcat拥有更好的性能。针对JVM的优化目前主要在两个方面:
1.内存调优
内存方式的设置是在catalina.sh中,调整一下JAVA_OPTS变量即可,因为后面的启动参数会把JAVA_OPTS作为JVM的启动参数来处理。
具体设置如下:
JAVA_OPTS="$JAVA_OPTS -Xmx3550m -Xms3550m -Xss128k -XX:NewRatio=4 -XX:SurvivorRatio=4"
其各项参数如下:
-Xmx3550m:设置JVM最大可用内存为3550M。
-Xms3550m:设置JVM促使内存为3550m。此值可以设置与-Xmx相同,以避免每次垃圾回收完成后JVM重新分配内存。
-Xmn2g:设置年轻代大小为2G。整个堆大小=年轻代大小 + 年老代大小 + 持久代大小。持久代一般固定大小为64m,所以增大年轻代后,将会减小年老代大小。此值对系统性能影响较大,Sun官方推荐配置为整个堆的3/8。
-Xss128k:设置每个线程的堆栈大小。JDK5.0以后每个线程堆栈大小为1M,以前每个线程堆栈大小为256K。更具应用的线程所需内存大小进行调整。在相同物理内存下,减小这个值能生成更多的线程。但是操作系统对一个进程内的线程数还是有限制的,不能无限生成,经验值在3000~5000左右。
-XX:NewRatio=4:设置年轻代(包括Eden和两个Survivor区)与年老代的比值(除去持久代)。设置为4,则年轻代与年老代所占比值为1:4,年轻代占整个堆栈的1/5
-XX:SurvivorRatio=4:设置年轻代中Eden区与Survivor区的大小比值。设置为4,则两个Survivor区与一个Eden区的比值为2:4,一个Survivor区占整个年轻代的1/6
-XX:MaxPermSize=16m:设置持久代大小为16m。
-XX:MaxTenuringThreshold=0:设置垃圾最大年龄。如果设置为0的话,则年轻代对象不经过Survivor区,直接进入年老代。对于年老代比较多的应用,可以提高效率。如果将此值设置为一个较大值,则年轻代对象会在Survivor区进行多次复制,这样可以增加对象再年轻代的存活时间,增加在年轻代即被回收的概论。
2.垃圾回收策略调优
垃圾回收的设置也是在catalina.sh中,调整JAVA_OPTS变量。
具体设置如下:
JAVA_OPTS="$JAVA_OPTS -Xmx3550m -Xms3550m -Xss128k -XX:+UseParallelGC -XX:MaxGCPauseMillis=100"
具体的垃圾回收策略及相应策略的各项参数如下:
串行收集器(JDK1.5以前主要的回收方式)
-XX:+UseSerialGC:设置串行收集器
并行收集器(吞吐量优先)
示例:
java -Xmx3550m -Xms3550m -Xmn2g -Xss128k -XX:+UseParallelGC -XX:MaxGCPauseMillis=100
-XX:+UseParallelGC:选择垃圾收集器为并行收集器。此配置仅对年轻代有效。即上述配置下,年轻代使用并发收集,而年老代仍旧使用串行收集。
-XX:ParallelGCThreads=20:配置并行收集器的线程数,即:同时多少个线程一起进行垃圾回收。此值最好配置与处理器数目相等。
-XX:+UseParallelOldGC:配置年老代垃圾收集方式为并行收集。JDK6.0支持对年老代并行收集
-XX:MaxGCPauseMillis=100:设置每次年轻代垃圾回收的最长时间,如果无法满足此时间,JVM会自动调整年轻代大小,以满足此值。
-XX:+UseAdaptiveSizePolicy:设置此选项后,并行收集器会自动选择年轻代区大小和相应的Survivor区比例,以达到目标系统规定的最低相应时间或者收集频率等,此值建议使用并行收集器时,一直打开。
并发收集器(响应时间优先)
示例:java -Xmx3550m -Xms3550m -Xmn2g -Xss128k -XX:+UseConcMarkSweepGC
-XX:+UseConcMarkSweepGC:设置年老代为并发收集。测试中配置这个以后,-XX:NewRatio=4的配置失效了,原因不明。所以,此时年轻代大小最好用-Xmn设置。
-XX:+UseParNewGC: 设置年轻代为并行收集。可与CMS收集同时使用。JDK5.0以上,JVM会根据系统配置自行设置,所以无需再设置此值。
-XX:CMSFullGCsBeforeCompaction:由于并发收集器不对内存空间进行压缩、整理,所以运行一段时间以后会产生“碎片”,使得运行效率降低。此值设置运行多少次GC以后对内存空间进行压缩、整理。
-XX:+UseCMSCompactAtFullCollection:打开对年老代的压缩。可能会影响性能,但是可以消除碎片
3.小结
在内存设置中需要做一下权衡
1)内存越大,一般情况下处理的效率也越高,但同时在做垃圾回收的时候所需要的时间也就越长,在这段时间内的处理效率是必然要受影响的。
2)在大多数的网络文章中都推荐 Xmx和Xms设置为一致,说是避免频繁的回收,这个在测试的时候没有看到明显的效果,内存的占用情况基本都是锯齿状的效果,所以这个还要根据实际情况来定。
Server.xml的Connection优化
Tomcat的Connector是Tomcat接收HTTP请求的关键模块,我们可以配置它来指定IO模式,以及处理通过这个Connector接受到的请求的处理线程数以及其它一些常用的HTTP策略。其主要配置参数如下:
1.指定使用NIO模型来接受HTTP请求
protocol="org.apache.coyote.http11.Http11NioProtocol" 指定使用NIO模型来接受HTTP请求。默认是BlockingIO,配置为protocol="HTTP/1.1"
acceptorThreadCount="2" 使用NIO模型时接收线程的数目
2.指定使用线程池来处理HTTP请求
首先要配置一个线程池来处理请求(与Connector是平级的,多个Connector可以使用同一个线程池来处理请求)
<Executor name="tomcatThreadPool" namePrefix="catalina-exec-"
maxThreads="1000" minSpareThreads="50" maxIdleTime="600000"/>
<Connector port="8080"
executor="tomcatThreadPool" 指定使用的线程池
3.指定BlockingIO模式下的处理线程数目
maxThreads="150"//Tomcat使用线程来处理接收的每个请求。这个值表示Tomcat可创建的最大的线程数。默认值200。可以根据机器的时期性能和内存大小调整,一般可以在400-500。最大可以在800左右。
minSpareThreads="25"---Tomcat初始化时创建的线程数。默认值4。如果当前没有空闲线程,且没有超过maxThreads,一次性创建的空闲线程数量。Tomcat初始化时创建的线程数量也由此值设置。
maxSpareThreads="75"--一旦创建的线程超过这个值,Tomcat就会关闭不再需要的socket线程。默认值50。一旦创建的线程超过此数值,Tomcat会关闭不再需要的线程。线程数可以大致上用 “同时在线人数*每秒用户操作次数*系统平均操作时间” 来计算。
acceptCount="100"----指定当所有可以使用的处理请求的线程数都被使用时,可以放到处理队列中的请求数,超过这个数的请求将不予处理。默认值10。如果当前可用线程数为0,则将请求放入处理队列中。这个值限定了请求队列的大小,超过这个数值的请求将不予处理。
connectionTimeout="20000" --网络连接超时,默认值20000,单位:毫秒。设置为0表示永不超时,这样设置有隐患的。通常可设置为30000毫秒。
4.其它常用设置
maxHttpHeaderSize="8192" http请求头信息的最大程度,超过此长度的部分不予处理。一般8K。
URIEncoding="UTF-8" 指定Tomcat容器的URL编码格式。
disableUploadTimeout="true" 上传时是否使用超时机制
enableLookups="false"--是否反查域名,默认值为true。为了提高处理能力,应设置为false
compression="on" 打开压缩功能
compressionMinSize="10240" 启用压缩的输出内容大小,默认为2KB
noCompressionUserAgents="gozilla, traviata" 对于以下的浏览器,不启用压缩
compressableMimeType="text/html,text/xml,text/javascript,text/css,text/plain" 哪些资源类型需要压缩
5.小结
关于Tomcat的Nio和ThreadPool,本身的引入就提高了处理的复杂性,所以对于效率的提高有多少,需要实际验证一下。
6.配置示例
<Connector port="8080"
redirectPort="8443"
maxThreads="150"
minSpareThreads="25"
maxSpareThreads="75"
acceptCount="100"
connectionTimeout="20000"
protocol="HTTP/1.1"
maxHttpHeaderSize="8192"
URIEncoding="UTF-8"
disableUploadTimeout="true"
enableLookups="false"
compression="on"
compressionMinSize="10240"
noCompressionUserAgents="gozilla, traviata"
compressableMimeType="text/html,text/xml,text/javascript,text/css,text/plain">
...
</Connector>
管理AJP端口
AJP是为 Tomcat 与 HTTP 服务器之间通信而定制的协议,能提供较高的通信速度和效率。如果tomcat前端放的是apache的时候,会使用到AJP这个连接器。由于我们公司前端是由nginx做的反向代理,因此不使用此连接器,因此需要注销掉该连接器。
<!-- <Connector port="8009" protocol="AJP/1.3" redirectPort="8443" /> -->
默认 Tomcat 是开启了对war包的热部署的。为了防止被植入木马等恶意程序,因此我们要关闭自动部署。
修改实例:
<Host name="localhost" appBase="" unpackWARs="false" autoDeploy="false">
posted @
2016-04-29 11:59 Alpha 阅读(2501) |
评论 (2) |
编辑 收藏
摘要: 最新的版本可以在这里获取,目前下载的最新版本是5.08,更新于2016-02-03。在这里可以找到更多的说明。
下载好后,server端分为两个部分,一个是tracker,一个是storage。顾名思义,前者调度管理,负载均衡,后者则是实际的存储节点。两个都能做成集群,以防止单点故障。以前的4.x版本依赖libevent,现在不需要了,只需要libfastcommon。安装方法如下:
1....
阅读全文
posted @
2016-04-07 13:58 Alpha 阅读(2838) |
评论 (2) |
编辑 收藏
摘要: 1.第一步需要安装PPTP,以用来提供VPN服务.
?
1
sudo apt-get install pptpd
...
阅读全文
posted @
2016-03-07 12:30 Alpha 阅读(537) |
评论 (0) |
编辑 收藏1.# rpm -Uvh http://poptop.sourceforge.net/yum/stable/rhel6/pptp-release-current.noarch.rpm
3.配置pptp.首先我们要编辑/etc/pptpd.conf文件:
#vim /etc/pptpd.conf
找到”locapip”和”remoteip”这两个配置项,将前面的”;”注释符去掉,更改为你期望的IP段值.localip表示服务器的IP,remoteip表示分配给客户端的IP地址,可以设置为区间.这里我们使用pptp默认的配置:
localip 192.168.0.1
remoteip 192.168.0.234-238,192.168.0.245
注意,这里的IP段设置,将直接影响后面的iptables规则添加命令.请注意匹配的正确性,如果你嫌麻烦,建议就用本文的配置,就可以一直复制命令和文本使用了.
4.接下来我们再编辑/etc/ppp/options.pptpd文件,为VPN添加Google DNS:
#vim /etc/ppp/options.pptpd
在末尾添加下面两行:
ms-dns 8.8.8.8
ms-dns 8.8.4.4
5、设置pptp VPN账号密码.我们需要编辑/etc/ppp/chap-secrets这个文件:
#vim /etc/ppp/chap-secrets
在这个文件里面,按照”用户名 pptpd 密码 *”的形式编写,一行一个账号和密码.比如添加用户名为test,密码为1234的用户,则编辑如下内容:
test pptpd 1234 *
6、修改内核设置,使其支持转发.编辑/etc/sysctl.conf文件:
#vim /etc/sysctl.conf
将”net.ipv4.ip_forward”改为1,变成下面的形式.
net.ipv4.ip_forward=1
保存退出,并执行下面的命令来生效它:
#sysctl -p
7、添加iptables转发规则.经过前面的6个步骤,我们的VPN已经可以拨号了,但是还不能访问任何网页.最后一步就是添加iptables转发规则了,输入下面的指令:
#iptables -t nat -A POSTROUTING -s 192.168.0.0/24 -o eth0 -j MASQUERADE
需要注意的是,这个指令中的”192.168.0.0/24″是根据之前的配置文件中的”localip”网段来改变的,比如你设置的”10.0.0.1″网段,则应该改为”10.0.0.0/24″.此外还有一点需要注意的是eth0,如果你的外网网卡不是eth0,而是eth1(比如SoftLayer的服务器就是这样的情况),那么请记得将eth0也更改为对应的网卡编号,不然是上不了网的.
然后我们输入下面的指令让iptables保存我们刚才的转发规则,以便重启系统后不需要再次添加:
#/etc/init.d/iptables save
然后我们重启iptables:
#/etc/init.d/iptables restart
8、重启pptp服务.输入下面的指令重启pptp:
#/etc/init.d/pptpd restart
现在你已经可以连接自己的VPN并浏览网页了.不过我们还需要做最后的一步.
9、设置开机自动运行服务.我们最后一步是将pptp和iptables设置为开机自动运行,这样就不需要每次重启服务器后手动启动服务了,当然你不需要自动启动服务的话可以忽略这一步,输入指令:
#chkconfig pptpd on
#chkconfig iptables on
这样就大功告成了,赶快到Windows下建立一个VPN连接,IP填写自己的服务器IP,用户名和密码填写自己设置好的用户名和密码,点击”连接”,成功后就可以使用服务器去浏览网页啦.
备注:
多ip服务器转发指定规则
iptables -t nat -A POSTROUTING -s 192.168.8.0/24 -j SNAT --to-source 192.168.8.1
or
iptables -t nat -A POSTROUTING -s 192.168.8.0/24 -j SNAT --to-source 服务器外网ip
如果iphone之类的设备能连上,访问网页或者youtube特别慢,需要做如下修改:
vi /etc/ppp/ip-up
增加一行
/sbin/ifconfig $1 mtu 1400
或者修改iptables规则
iptables -A FORWARD -p tcp --syn -s 192.168.8.0/24 -j TCPMSS --set-mss 1356
1356的值可能需要自己调整,调节到能保证网络正常使用情况下的最大值
posted @
2016-02-25 22:31 Alpha 阅读(506) |
评论 (0) |
编辑 收藏
摘要: 关于IP Tables在初始化设置系统后,为了让系统更安全,Ubuntu把Iptabls作为发行版的默认防火墙。起初,尽管Ubuntu防火墙已经被配置了,但是它设置为通过一个虚拟主机允许所有的进入与流出流量。要打开服务器上某些更强的保护功能,我们需要在IP Table山增加一些基础的规则。IP Table 规则来自于一系列可以组合起来创建各自的特定的处理方法的选项。每一个通过防火墙的包被所有的规则...
阅读全文
posted @
2015-10-31 15:51 Alpha 阅读(2570) |
评论 (0) |
编辑 收藏我有一个
阿里云推荐码,分享给大家免费使用,购买云服务器ECS或云数据库RDS可享受原价优惠,拿走不谢。
马上可享受优惠,购买阿里云主机马上给你省钱!

我有几张
阿里云幸运券分享给你,用券购买或者升级阿里云相应产品会有
特惠惊喜哦!把想要买的产品的幸运券都领走吧!快下手,马上就要抢光了。
posted @
2015-10-28 14:25 Alpha 阅读(704) |
评论 (0) |
编辑 收藏安装 MySQL 5 数据库
安装 MySQL 运行命令:
sudo
apt-get install mysql-server mysql-client
将mysql的datadir从默认的/var/lib/mysql 移到/app/data/mysql下,操作如下:
1.修改了/etc/mysql/my.cnf,改为:datadir = /app/data/mysql
2.cp -a /var/lib/mysql /app/data/
3./etc/init.d/mysql start
如果出现系统报错,无法启动mysql,日志显示为:Can't find file: "./mysql/plugin.frm'(errno:13)
[ERROR] Can't open the mysql.plugin table. Please run mysql_upgrade to create it.
修改系统的chroot,需要修改/etc/apparmor.d下的相关文件,这里以mysql为例,需要修改:usr.sbin.mysqld和abstractions/mysql两个文件。
1.修改usr.sbin.mysqld里面的两行内容:/var/lib/mysql/ r,改为:/app/data/mysql/ r,/var/lib/mysql/** rwk,改为:/app/data/mysql/** rwk,
2.修改abstractions/mysql中一行:/var/lib/mysql/mysql.sock rw,改为:/app/data/mysql/mysql.sock rw,
3.重新加载apparmor服务:/etc/init.d/apparmor reload
安装 Nginx
在安装 Nginx 之前,如果你已经安装 Apache2 先删除在安装 nginx:
service apache2 stop
update-rc.d -f apache2 remove
sudo apt-get remove apache2
sudo
apt-get install nginx
安装 PHP5
我们必须通过 PHP-FPM 才能让PHP5正常工作,安装命令:
sudo
apt-get install php5-fpm
php-fpm是一个守护进程。
安装mysql和GD扩展
sudo apt-get install php5-gd libapache2-mod-auth-mysql php5-mysql openssl libssl-dev
sudo apt-get install curl libcurl3 libcurl3-dev php5-curl
安装 JDK8
可以通过访问Oracle官网下载,或者直接通过命令行下载。
lxh@ubuntu:~$ wget -c http://download.oracle.com/otn-pub/java/jdk/8u11-b12/jdk-8u25-linux-x64.tar.gz
解压安装
lxh@ubuntu:~$ mkdir -p /usr/lib/jvm
lxh@ubuntu:~$ sudo mv jdk-8u25-linux-x64.tar.gz /usr/lib/jvm
lxh@ubuntu:~$ cd /usr/lib/jvm
lxh@ubuntu:~$ sudo tar xzvf jdk-8u25-linux-x64.tar.gz
在系统中添加环境变量,主要是PATH、CLASSPATH和JAVA_HOME。
lxh@ubuntu:~$ sudo vim ~/.profile
在文件最后加入
export JAVA_HOME=/usr/lib/jvm/jdk1.8.0_25/
export JRE_HOME=/usr/lib/jvm/jdk1.8.0_25/jre
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar:$JAVA_HOME/lib:$JRE_HOME/lib:$CLASSPATH
export PATH=$JAVA_HOME/bin:$PATH
保存退出,并通过命令使脚本生效:
lxh@ubuntu:~$ $source ~/.profile
配置默认JDK版本
在有的系统中会预装OpenJDK,系统默认使用的是这个,而不是刚才装的。所以这一步是通知系统使用Oracle的JDK,非OpenJDK。
sudo update-alternatives --install /usr/bin/java java /usr/lib/jvm/jdk1.8.0_25/bin/java 300
sudo update-alternatives --install /usr/bin/javac javac /usr/lib/jvm/jdk1.8.0_25/bin/javac 300
sudo update-alternatives --config java
因为我是在虚拟机中安装的Ubuntu 14.04,默认不安装OpenJDK,所以没有需要选择的JDK版本。如果是在物理机上安装的Ubuntu版本,会出现几个候选项,可用于替换 java (提供 /usr/bin/java)。
====================================
编译安装nginx
1. 下载最新版nginx
2.解压
3. 安装
$ ./configure #检查编译前置条件
$ make #编译
$ sudo make install #使用sudo权限进行安装
安装后路径在 /usr/local/
启动nginx
/usr/local/nginx/sbin/nginx
1)使用在 /etc/init.d/ 目录下创建名为 nginx 文件,注意没有后缀名,将以下内容复制到该文件中(感谢提供脚本的兄弟)。
1 #! /bin/sh
2 #用来将Nginx注册为系统服务的脚本
3 #Author CplusHua
4 #http://www.219.me
5 #chkconfig: - 85 15
6 set -e
7 PATH=/usr/local/sbin:/usr/local/bin:/sbin:/bin:/usr/sbin:/usr/bin
8 DESC="Nginx Daemon"
9 NAME=nginx
10 DAEMON=/usr/local/nginx/sbin/$NAME
11 SCRIPTNAME=/etc/init.d/$NAME
12 #守护进程不存在就退出
13 test -x $DAEMON ||exit 0
14 d_start(){
15 $DAEMON ||echo -n "aready running"
16 }
17 d_stop(){
18 $DAEMON -s quit || echo -n "not running"
19 }
20 d_reload(){
21 $DAEMON -s reload || echo -n "could not reload"
22 }
23 case "$1" in
24 start)
25 echo -n "Starting $DESC: $NAME"
26 d_start
27 echo "."
28 ;;
29 stop)
30 echo -n "Stopping $DESC: $NAME"
31 d_stop
32 echo "."
33 ;;
34 reload)
35 echo -n "Reloading $DESC: configurationg .."
.."
36 d_reload
37 echo "reloaded."
38 ;;
39 restart)
40 echo -n "Restarting $DESC: $NAME"
41 d_stop
42 sleep 3
43 d_start
44 echo "."
45 ;;
46 *)
47 echo "Usage: $SCRIPTNAME {start|stop|restart|reload}" >&2
48 exit 3
49 ;;
50 esac
51
52 exit 0
2)添加权限
$ sudo chmod +x nginx
3)服务方式启动 如果配置服务前已启动,执行以下命令停止Nginx。
$ sudo service nginx stop
4)启动Nginx
$ sudo service nginx start
pastingnginx出现connect() to unix:/var/run/php5-fpm.sock failed (13: Permission denied)的错误
处理方式是:编辑/etc/php5/fpm/pool.d/www.conf文件,
将以下的注释去掉:
listen.owner = www-data
listen.group = www-data
listen.mode = 0660
然后重启php5-fpm
$ sudo service php5-fpm restart
Ubuntu 14.04快速搭建SVN服务器及日常使用
SVN相关命令了解
svn:命令行客户端
svnadmin:用来创建、调整或修复版本库的工具
svnserve:svn服务程序
svndumpfilter:过滤svn版本库转储数据流的工具
svnsync:svn数据同步工具,实现另外存一份相同的
svnlook:用来查看办本科中不同的修订版和事务
直接安装
# apt-get install subversion
创建版本库
# sudo mkdir /app/svn
# sudo svnadmin create /app/svn/prj
配置版本库
# sudo vi svnserve.conf #将以下参数去掉注释
[general]
anon-access = none #匿名访问权限,默认read,none为不允许访问
auth-access = write #认证用户权限
password-db = passwd #用户信息存放文件,默认在版本库/conf下面,也可以绝对路径指定文件位置
authz-db = authz
# sudo vi passwd #格式是用户名=密码,采用明文密码
[users]
xiaoming = 123
zhangsan = 123
lisi = 123
# sudo vi authz
[groups] #定义组的用户
manager = xiaoming
core_dev = zhangsan,lisi
[repos:/] #以根目录起始的repos版本库manager组为读写权限
@manager = rw
[repos:/media] #core_dev对repos版本库下media目录为读写权限
@core_dev = rw
启动svn服务
# sudo svnserve -d -r /app/svn
# 查看是否启动成功,可看的监听3690端口
# sudo netstat -antp |grep svnserve
tcp 0 0 0.0.0.0:3690 0.0.0.0:* LISTEN 28967/svnserve
# 如果想关闭服务,可使用pkill svnserve
访问svn
# 访问repos版本库地址
svn://192.168.1.100/prj
备份与恢复
svnadmin dump备份
# 完整备份
svnadmin dump /app/svn/prj > YYmmdd_fully_backup.svn
# 完整压缩备份
svnadmin dump /app/svn/prj | gzip > YYmmdd_fully_backup.gz
# 备份恢复
svnadmin load /app/svn/prj < YYmmdd_fully_backup.svn
zcat YYmmdd_fully_backup.gz | svnadmin load repos
### 增量备份 ###
# 先完整备份
svnadmin dump /app/svn/prj -r 0:100 > YYmmdd_incremental_backup.svn
# 再增量备份
svnadmin dump /app/svn/prj -r 101:200 --incremental > YYmmdd_incremental_backup.svn
svnadmin hotcopy备份
# 备份
svnadmin hotcopy /app/svn/prj YYmmdd_fully_backup --clean-logs
# 恢复
svnadmin hotcopy YYmmdd_fully_backup /app/svn/prj
Tomcat 内存优化
Linux下修改JVM内存大小
要添加在tomcat 的bin 下catalina.sh 里,位置cygwin=false前 。注意引号要带上,红色的为新添加的.
# OS specific support. $var _must_ be set to either true or false.
JAVA_OPTS="-server -Xms512M -Xmx512M -Xss256K -Djava.awt.headless=true -Dfile.encoding=utf-8 -XX:PermSize=64M -XX:MaxPermSize=128m"
cygwin=false
posted @
2015-10-07 15:28 Alpha 阅读(992) |
评论 (0) |
编辑 收藏当然一定有人接私活接的很好,只是别人的成功很难複制,但别人的失败可以避免,如果你能避掉我以上所说的陷阱也无法保证你能成功,因为这也只是冰山一角,我已经离开接私活的状态很久,很多事忘了也不想去想,只是希望你在决定接私活前,仔细想一下,你真的只有接私活这个选项吗 ? 如果可以,我会建议你应该要开发自己的产品及服务。
来自:電子豹博客
posted @
2015-06-10 14:28 Alpha 阅读(2231) |
评论 (0) |
编辑 收藏fn:contains 判断字符串是否包含另外一个字符串 <c:if test="${fn:contains(name, searchString)}">
fn:containsIgnoreCase 判断字符串是否包含另外一个字符串(大小写无关) <c:if test="${fn:containsIgnoreCase(name, searchString)}">
fn:endsWith 判断字符串是否以另外字符串结束 <c:if test="${fn:endsWith(filename, ".txt")}">
fn:escapeXml 把一些字符转成XML表示,例如 <字符应该转为< ${fn:escapeXml(param:info)}
fn:indexOf 子字符串在母字符串中出现的位置 ${fn:indexOf(name, "-")}
fn:join 将数组中的数据联合成一个新字符串,并使用指定字符格开 ${fn:join(array, ";")}
fn:length 获取字符串的长度,或者数组的大小 ${fn:length(shoppingCart.products)}
fn:replace 替换字符串中指定的字符 ${fn:replace(text, "-", "?")}
fn:split 把字符串按照指定字符切分 ${fn:split(customerNames, ";")}
fn:startsWith 判断字符串是否以某个子串开始 <c:if test="${fn:startsWith(product.id, "100-")}">
fn:substring 获取子串 ${fn:substring(zip, 6, -1)}
fn:substringAfter 获取从某个字符所在位置开始的子串 ${fn:substringAfter(zip, "-")}
fn:substringBefore 获取从开始到某个字符所在位置的子串 ${fn:substringBefore(zip, "-")}
fn:toLowerCase 转为小写 ${fn.toLowerCase(product.name)}
fn:toUpperCase 转为大写字符 ${fn.UpperCase(product.name)}
fn:trim 去除字符串前后的空格 ${fn.trim(name)}
函数
描述
fn:contains(string, substring)
如果参数string中包含参数substring,返回true
fn:containsIgnoreCase(string, substring)
如果参数string中包含参数substring(忽略大小写),返回true
fn:endsWith(string, suffix)
如果参数 string 以参数suffix结尾,返回true
fn:escapeXml(string)
将有特殊意义的XML (和HTML)转换为对应的XML character entity code,并返回
fn:indexOf(string, substring)
返回参数substring在参数string中第一次出现的位置
fn:join(array, separator)
将一个给定的数组array用给定的间隔符separator串在一起,组成一个新的字符串并返回。
fn:length(item)
返回参数item中包含元素的数量。参数Item类型是数组、collection或者String。如果是String类型,返回值是String中的字符数。
fn:replace(string, before, after)
返回一个String对象。用参数after字符串替换参数string中所有出现参数before字符串的地方,并返回替换后的结果
fn:split(string, separator)
返回一个数组,以参数separator 为分割符分割参数string,分割后的每一部分就是数组的一个元素
fn:startsWith(string, prefix)
如果参数string以参数prefix开头,返回true
fn:substring(string, begin, end)
返回参数string部分字符串, 从参数begin开始到参数end位置,包括end位置的字符
fn:substringAfter(string, substring)
返回参数substring在参数string中后面的那一部分字符串??
fn:substringBefore(string, substring)
返回参数substring在参数string中前面的那一部分字符串
fn:toLowerCase(string)
将参数string所有的字符变为小写,并将其返回
fn:toUpperCase(string)
将参数string所有的字符变为大写,并将其返回
fn:trim(string)
在jsp中 使用EL表达式时,不可以使用java提供的功能,比如indexOf()等。
<c:if test="${Boolean.valueOf(requestScope.addresult)==false}">
报错
The function valueOf must be used with a prefix when a default namespace is not specified
posted @
2014-08-05 15:24 Alpha 阅读(15582) |
评论 (0) |
编辑 收藏
公司发布的SEO专员招聘有一段时间了,一直没有找到合适的人选, 一方面专门从事这块职业的人员比较少,另一方面对这个职位有一定了解的人也比较少.那么我们所说的
seo专员是什么样的一个职位呢? 今天我们来探讨一下,在网上搜索了一个相关资料,找到这么一篇文章:
http://seo.aizhan.com/qa/542.html,我们看看文章里面的表述:
其实seo专员的主要职责就是执行完成SEO主管制定的SEO策略和优化目标任务,通常需要做大量的内容编辑、软文发布和外链建设等各种体力活。现在也有很多公司在发布招聘的时候也有专门招聘SEO外链专员这样的职位,有一定规模的网站也会分为SEO网站优化、SEO网站编辑、SEO外链专员等这样的细分岗位,每个岗位根据SEO优化工作的侧重点不同,执行完成的工作重点也是不一样的。那么今天我们要讲的SEO专员的具体工作是什么?做好这个职位需要具备什么样的素质?
SEO专员的具体工作,说到底核心工作就是研究搜索引擎,完成网站内容建设,丰富网站的内容,到各大网站平台发布定量合适的外链,交换友情链接,帮助网站获得关键词排名,并做好数据分析与跟踪。
在这篇文章里讲述了什么是SEO专员, SEO专员的具体工作,说到底核心工作就是研究搜索引擎,完成网站内容建设,丰富网站的内容,到各大网站平台发布定量合适的外链,交换友情链接,帮助网站获得关键词排名,并做好数据分析与跟踪。 但是要找到一名有耐心,有良好的沟通能力,超强的执行力,有比较强的心里承受能力,受得了寂寞的SEO专员却是一件不容易的事情。
发布一则
房民网SEO专员招聘要求:
任职要求:
1、男女不限,大专以上学历,年龄在20-35岁之间;
2、对互联网有浓厚的兴趣,熟悉网站的运作和推广的各种方式,能够根据公司的需求独立策划网站推广方案并执行;会熟练打字操作常用办公软件;
3、有一定的分析判断能力,能根据推广效果提出调整建议,具有敏锐的思维和创新能力,思维开阔;
4、工作认真、细致、敬业,有较强的沟通能力和团队合作精神;
5、1年以上相关工作经历或精通网站编辑及平面设计者或有一定的文字写作能力者优先。
岗位职责:
1、负责完成网站内容建设,友链外链建设,关键字优化,提高网站排名、搜索引擎收录量;
2、执行在线推广活动,收集推广反馈数据,不断改进推广效果;
3、及时提出网络推广改进建议,给出实际可行的改进方案。
快来加入吧:)
posted @
2013-11-24 10:04 Alpha 阅读(1553) |
评论 (2) |
编辑 收藏
一直从事于开发与运维相关技术的研究实践,最近在做几个房产网分站的SEO优化技术储备, 缘于
长沙房产网的百度快照阴情不定让人很蛋疼,于是对此进行了深入的研究,发现SEO网站优化也是一门相当有技术含量的技术活,涉及的知识点和技术面都要广才能掌握大局,同时也要调动团队各环节,从网站的最初版面功能策划到页面的视觉设计和代码编写,再到程序开发时的架构设计,最后做内容时的内容编排等一系列的问题都得考虑到,且都要执行到位,否则任何一个环节没做好都有可能影响到整个SEO优化的效果.因此,今天开辟一个新版块,专门从事SEO优化技术的研究与实践.
目前在拿房产网的四个分站进行实战研究,希望能从中找到一些答案,这四个站的主关键词也是相当有竞争难度,比如
东莞房产网这个关键词的收录量有250多万,但是http://dg.fmw.cn/这个域名的百度收入占有量却只有两位数,而比东莞房产网迟了一个多月上线的
昆明房产网,这个站域名是
http://km.fmw.cn/,它收录量都上三位数了,远远超过了东莞房产网的收入量,这让人更是摸不着头脑.表现最满意的是
佛山房产网,它同样比东莞房产网上线迟了一个多月,但是收入量等各方面指数上升很明显.同样的网站架构,同样每天都有坚持在做内容,但是却有不一样的表现,这是一个值得研究的课题.
SEO既Search Engine Optimization,翻译为搜索引擎优化,是一种利用技术手段提升网站在搜索引擎之中的排名的方式,让搜索引擎更为信任网站,通过排在搜索引擎的前页从而获得更多的流量。
希望在接下来的SEO优化研究和实践工作中能找到这一系列的答案,届时
房民网与大家一起来分享.
posted @
2013-10-09 00:12 Alpha 阅读(1426) |
评论 (0) |
编辑 收藏给大家推荐一处php主机-wopus主机,专业的wordpress主机!还可以省钱购买php主机,永久免费使用.
购买可以用wopus主机优惠码:alpha, 提交订单时手动输入 alpha
或者通过>>wopus主机优惠码<<链接进入直接购买就可获得优惠,可以省钱哟. http://idc.wopus.org/?f=alpha
(wopus主机推介优惠码:alpha 永久有效)!打算买php主机的朋友请看以下介绍!
他们自己是这样介绍他们的产品的:
专业博客主机服务商
WopusIDC一直致力于为广大独立博客用户提供优质实惠的专业博客主机服务,现已积累有超过四年的专业博客主机服务经验,成为众多独立博客们的主机首选。
国内、国外主机任选
从国外主机到国内主机,WopusIDC给用户带来多种主机选择,打破访问速度的瓶颈,给广大独立博客用户带来更佳的主机体验。
快速搭建个性化博客
依托于Wopus平台上发布的数量众多的主题、插件以及文章教程,WopusIDC用户可以简单快速的搭建属于自己的个性化博客。
买php主机用 wopus主机优惠码:alpha , 提交订单时手动输入 alpha ,永久免费使用,长期有效.
或 点击 http://idc.wopus.org/?f=alpha 购买主机立即省钱!
posted @
2013-08-19 01:04 Alpha 阅读(1834) |
评论 (1) |
编辑 收藏1.首先确认服务器出于安全的状态,也就是没有人能够任意地连接MySQL数据库。
因为在重新设置MySQL的root密码的期间,MySQL数据库完全出于没有密码保护的
状态下,其他的用户也可以任意地登录和修改MySQL的信息。可以采用将MySQL对
外的端口封闭,并且停止Apache以及所有的用户进程的方法实现服务器的准安全
状态。最安全的状态是到服务器的Console上面操作,并且拔掉网线。
2.修改MySQL的登录设置:
# vi /etc/my.cnf
在[mysqld]的段中加上一句:skip-grant-tables
例如:
[mysqld]
datadir=/var/lib/mysql
socket=/var/lib/mysql/mysql.sock
skip-grant-tables
保存并且退出vi。
3.重新启动mysqld
# /etc/init.d/mysqld restart
Stopping MySQL: [ OK ]
Starting MySQL: [ OK ]
4.登录并修改MySQL的root密码
# /usr/bin/mysql
Welcome to the MySQL monitor. Commands end with ; or \g.
Your MySQL connection id is 3 to server version: 3.23.56
Type 'help;' or '\h' for help. Type '\c' to clear the buffer.
mysql> USE mysql ;
Reading table information for completion of table and column names
You can turn off this feature to get a quicker startup with -A
Database changed
mysql> UPDATE user SET Password = password ( 'new-password' ) WHERE User = 'root' ;
Query OK, 0 rows affected (0.00 sec)
Rows matched: 2 Changed: 0 Warnings: 0
mysql> flush privileges ;
Query OK, 0 rows affected (0.01 sec)
mysql> quit
Bye
5.将MySQL的登录设置修改回来
# vi /etc/my.cnf
将刚才在[mysqld]的段中加上的skip-grant-tables删除
保存并且退出vi。
6.重新启动mysqld
# /etc/init.d/mysqld restart
Stopping MySQL: [ OK ]
Starting MySQL: [ OK ]
posted @
2013-04-19 11:39 Alpha 阅读(1724) |
评论 (0) |
编辑 收藏
经常使用CentOS的朋友,可能会遇到和我一样的问题。开启了防火墙导致80端口无法访问,刚开始学习centos的朋友可以参考下。
经常使用CentOS的朋友,可能会遇到和我一样的问题。最近在Linux CentOS防火墙下安装配置 ORACLE
数据库的时候,总显示因为网络端口而导致的EM安装失败,遂打算先关闭一下CentOS防火墙。偶然看到CentOS防火墙的配置操作说明,感觉不错。执
行”setup”命令启动文字模式配置实用程序,在”选择一种工具”中选择”防火墙配置”,然后选择”运行工具”按钮,出现CentOS防火墙配置界面,
将”安全级别”设为”禁用”,然后选择”确定”即可.
这样重启计算机后,CentOS防火墙默认已经开放了80和22端口
简介:CentOS是Linux家族的一个分支。
CentOS防火墙在虚拟机的CENTOS装好APACHE不能用,郁闷,解决方法如下
/sbin/iptables -I INPUT -p tcp --dport 80 -j ACCEPT
/sbin/iptables -I INPUT -p tcp --dport 22 -j ACCEPT
然后保存:
/etc/rc.d/init.d/iptables save
centos 5.3,5.4以上的版本需要用
service iptables save
来实现保存到配置文件。
这样重启计算机后,CentOS防火墙默认已经开放了80和22端口。
这里应该也可以不重启计算机:
/etc/init.d/iptables restart
CentOS防火墙的关闭,关闭其服务即可:
查看CentOS防火墙信息:/etc/init.d/iptables status
关闭CentOS防火墙服务:/etc/init.d/iptables stop
永久关闭?不知道怎么个永久法:
chkconfig –level 35 iptables off
上面的内容是针对老版本的centos,下面的内容是基于新版本。
iptables -P INPUT DROP
这样就拒绝所有访问 CentOS 5.3 本系统数据,除了 Chain RH-Firewall-1-INPUT (2 references) 的规则外 , 呵呵。
用命令配置了 iptables 一定还要 service iptables save 才能保存到配置文件。
cat /etc/sysconfig/iptables 可以查看 防火墙 iptables 配置文件内容
# Generated by iptables-save v1.3.5 on Sat Apr 14 07:51:07 2001
*filter
:INPUT DROP [0:0]
:FORWARD ACCEPT [0:0]
:OUTPUT ACCEPT [1513:149055]
:RH-Firewall-1-INPUT - [0:0]
-A INPUT -j RH-Firewall-1-INPUT
-A FORWARD -j RH-Firewall-1-INPUT
-A RH-Firewall-1-INPUT -i lo -j ACCEPT
-A RH-Firewall-1-INPUT -p icmp -m icmp --icmp-type any -j ACCEPT
-A RH-Firewall-1-INPUT -p esp -j ACCEPT
-A RH-Firewall-1-INPUT -p ah -j ACCEPT
-A RH-Firewall-1-INPUT -d 224.0.0.251 -p udp -m udp --dport 5353 -j ACCEPT
-A RH-Firewall-1-INPUT -p udp -m udp --dport 631 -j ACCEPT
-A RH-Firewall-1-INPUT -p tcp -m tcp --dport 631 -j ACCEPT
-A RH-Firewall-1-INPUT -m state --state RELATED,ESTABLISHED -j ACCEPT
-A RH-Firewall-1-INPUT -p tcp -m state --state NEW -m tcp --dport 22 -j ACCEPT
-A RH-Firewall-1-INPUT -j REJECT --reject-with icmp-host-prohibited
COMMIT
# Completed on Sat Apr 14 07:51:07 2001
另外补充:
CentOS 防火墙配置 80端口
看了好几个页面内容都有错,下面是正确方法:
#/sbin/iptables -I INPUT -p tcp --dport 80 -j ACCEPT
#/sbin/iptables -I INPUT -p tcp --dport 22 -j ACCEPT
然后保存:
#/etc/rc.d/init.d/iptables save
再查看是否已经有了:
[root@vcentos ~]# /etc/init.d/iptables status
Table: filter
Chain INPUT (policy ACCEPT)
num target prot opt source destination
1 ACCEPT udp -- 0.0.0.0/0 0.0.0.0/0 udp dpt:80
2 ACCEPT tcp -- 0.0.0.0/0 0.0.0.0/0 tcp dpt:80
3 RH-Firewall-1-INPUT all -- 0.0.0.0/0 0.0.0.0/0
Chain FORWARD (policy ACCEPT)
num target prot opt source destination
1 RH-Firewall-1-INPUT all -- 0.0.0.0/0 0.0.0.0/0
* 设置iptables为自动启动
chkconfig --level 2345 iptables on
可能因为大家使用的版本不一,所有使用方法也略有不同。
如果需要远程管理mysql,则使用以下指令临时打开,用完后关闭
* 打开指令
iptables -A INPUT -p tcp -s xxx.xxx.xxx.xxx --dport 3306 -j ACCEPT
* 关闭指令
iptables -D INPUT -p tcp -s xxx.xxx.xxx.xxx --dport 3306 -j ACCEPT
nginx 80 端口访问不了?
添加一个本地回路
iptables -A INPUT -i lo -j ACCEPT
posted @
2012-09-17 23:59 Alpha 阅读(32152) |
评论 (0) |
编辑 收藏系统连接状态篇:
1.查看TCP连接状态
netstat -nat |awk '{print $6}'|sort|uniq -c|sort -rn
netstat -n | awk '/^tcp/ {++S[$NF]};END {for(a in S) print a, S[a]}' 或
netstat -n | awk '/^tcp/ {++state[$NF]}; END {for(key in state) print key,"t",state[key]}'
netstat -n | awk '/^tcp/ {++arr[$NF]};END {for(k in arr) print k,"t",arr[k]}'
netstat -n |awk '/^tcp/ {print $NF}'|sort|uniq -c|sort -rn
netstat -ant | awk '{print $NF}' | grep -v '[a-z]' | sort | uniq -c
2.查找请求数请20个IP(常用于查找攻来源):
netstat -anlp|grep 80|grep tcp|awk '{print $5}'|awk -F: '{print $1}'|sort|uniq -c|sort -nr|head -n20
netstat -ant |awk '/:80/{split($5,ip,":");++A[ip[1]]}END{for(i in A) print A[i],i}' |sort -rn|head -n20
3.用tcpdump嗅探80端口的访问看看谁最高
tcpdump -i eth0 -tnn dst port 80 -c 1000 | awk -F"." '{print $1"."$2"."$3"."$4}' | sort | uniq -c | sort -nr |head -20
4.查找较多time_wait连接
netstat -n|grep TIME_WAIT|awk '{print $5}'|sort|uniq -c|sort -rn|head -n20
5.找查较多的SYN连接
netstat -an | grep SYN | awk '{print $5}' | awk -F: '{print $1}' | sort | uniq -c | sort -nr | more
6.根据端口列进程
netstat -ntlp | grep 80 | awk '{print $7}' | cut -d/ -f1
网站日志分析篇1(Apache):
1.获得访问前10位的ip地址
cat access.log|awk '{print $1}'|sort|uniq -c|sort -nr|head -10
cat access.log|awk '{counts[$(11)]+=1}; END {for(url in counts) print counts[url], url}'
2.访问次数最多的文件或页面,取前20
cat access.log|awk '{print $11}'|sort|uniq -c|sort -nr|head -20
3.列出传输最大的几个exe文件(分析下载站的时候常用)
cat access.log |awk '($7~/.exe/){print $10 " " $1 " " $4 " " $7}'|sort -nr|head -20
4.列出输出大于200000byte(约200kb)的exe文件以及对应文件发生次数
cat access.log |awk '($10 > 200000 && $7~/.exe/){print $7}'|sort -n|uniq -c|sort -nr|head -100
5.如果日志最后一列记录的是页面文件传输时间,则有列出到客户端最耗时的页面
cat access.log |awk '($7~/.php/){print $NF " " $1 " " $4 " " $7}'|sort -nr|head -100
6.列出最最耗时的页面(超过60秒的)的以及对应页面发生次数
cat access.log |awk '($NF > 60 && $7~/.php/){print $7}'|sort -n|uniq -c|sort -nr|head -100
7.列出传输时间超过 30 秒的文件
cat access.log |awk '($NF > 30){print $7}'|sort -n|uniq -c|sort -nr|head -20
8.统计网站流量(G)
cat access.log |awk '{sum+=$10} END {print sum/1024/1024/1024}'
9.统计404的连接
awk '($9 ~/404/)' access.log | awk '{print $9,$7}' | sort
10. 统计http status
cat access.log |awk '{counts[$(9)]+=1}; END {for(code in counts) print code, counts[code]}'
cat access.log |awk '{print $9}'|sort|uniq -c|sort -rn
10.蜘蛛分析,查看是哪些蜘蛛在抓取内容。
/usr/sbin/tcpdump -i eth0 -l -s 0 -w - dst port 80 | strings | grep -i user-agent | grep -i -E 'bot|crawler|slurp|spider'
网站日分析2(Squid篇)按域统计流量
zcat squid_access.log.tar.gz| awk '{print $10,$7}' |awk 'BEGIN{FS="[ /]"}{trfc[$4]+=$1}END{for(domain in trfc){printf "%st%dn",domain,trfc[domain]}}'
数据库篇
1.查看数据库执行的sql
/usr/sbin/tcpdump -i eth0 -s 0 -l -w - dst port 3306 | strings | egrep -i 'SELECT|UPDATE|DELETE|INSERT|SET|COMMIT|ROLLBACK|CREATE|DROP|ALTER|CALL'
系统Debug分析篇
1.调试命令
strace -p pid
2.跟踪指定进程的PID
gdb -p pid
awk '{ip[$1]+=1} END{for(i in ip){print i," "ip[i]}}' access.log |wc -l
其中access.log就是apache的访问日志。这个就可以统计独立ip数据
1、把IP数量直接输出显示:
cat access_log_2011_06_26.log |awk '{print $1}'|uniq -c|wc -l
永久链接 : http://www.ha97.com/4392.html
posted @
2012-09-13 17:47 Alpha 阅读(1298) |
评论 (0) |
编辑 收藏经常使用CentOS的朋友,可能会遇到和我一样的问题。开启了防火墙导致80端口无法访问,刚开始学习centos的朋友可以参考下。
经常使用CentOS的朋友,可能会遇到和我一样的问题。最近在Linux CentOS防火墙下安装配置 ORACLE 数据库的时候,总显示因为网络端口而导致的EM安装失败,遂打算先关闭一下CentOS防火墙。偶然看到CentOS防火墙的配置操作说明,感觉不错。执 行”setup”命令启动文字模式配置实用程序,在”选择一种工具”中选择”防火墙配置”,然后选择”运行工具”按钮,出现CentOS防火墙配置界面, 将”安全级别”设为”禁用”,然后选择”确定”即可.
这样重启计算机后,CentOS防火墙默认已经开放了80和22端口
简介:CentOS是Linux家族的一个分支。
CentOS防火墙在虚拟机的CENTOS装好APACHE不能用,郁闷,解决方法如下
/sbin/iptables -I INPUT -p tcp --dport 80 -j ACCEPT
/sbin/iptables -I INPUT -p tcp --dport 22 -j ACCEPT
然后保存:
/etc/rc.d/init.d/iptables save
centos 5.3,5.4以上的版本需要用
service iptables save
来实现保存到配置文件。
这样重启计算机后,CentOS防火墙默认已经开放了80和22端口。
这里应该也可以不重启计算机:
/etc/init.d/iptables restart
CentOS防火墙的关闭,关闭其服务即可:
查看CentOS防火墙信息:/etc/init.d/iptables status
关闭CentOS防火墙服务:/etc/init.d/iptables stop
永久关闭?不知道怎么个永久法:
chkconfig –level 35 iptables off
上面的内容是针对老版本的centos,下面的内容是基于新版本。
iptables -P INPUT DROP
这样就拒绝所有访问 CentOS 5.3 本系统数据,除了 Chain RH-Firewall-1-INPUT (2 references) 的规则外 , 呵呵。
用命令配置了 iptables 一定还要 service iptables save 才能保存到配置文件。
cat /etc/sysconfig/iptables 可以查看 防火墙 iptables 配置文件内容
# Generated by iptables-save v1.3.5 on Sat Apr 14 07:51:07 2001
*filter
:INPUT DROP [0:0]
:FORWARD ACCEPT [0:0]
:OUTPUT ACCEPT [1513:149055]
:RH-Firewall-1-INPUT - [0:0]
-A INPUT -j RH-Firewall-1-INPUT
-A FORWARD -j RH-Firewall-1-INPUT
-A RH-Firewall-1-INPUT -i lo -j ACCEPT
-A RH-Firewall-1-INPUT -p icmp -m icmp --icmp-type any -j ACCEPT
-A RH-Firewall-1-INPUT -p esp -j ACCEPT
-A RH-Firewall-1-INPUT -p ah -j ACCEPT
-A RH-Firewall-1-INPUT -d 224.0.0.251 -p udp -m udp --dport 5353 -j ACCEPT
-A RH-Firewall-1-INPUT -p udp -m udp --dport 631 -j ACCEPT
-A RH-Firewall-1-INPUT -p tcp -m tcp --dport 631 -j ACCEPT
-A RH-Firewall-1-INPUT -m state --state RELATED,ESTABLISHED -j ACCEPT
-A RH-Firewall-1-INPUT -p tcp -m state --state NEW -m tcp --dport 22 -j ACCEPT
-A RH-Firewall-1-INPUT -j REJECT --reject-with icmp-host-prohibited
COMMIT
# Completed on Sat Apr 14 07:51:07 2001
另外补充:
CentOS 防火墙配置 80端口
看了好几个页面内容都有错,下面是正确方法:
#/sbin/iptables -I INPUT -p tcp --dport 80 -j ACCEPT
#/sbin/iptables -I INPUT -p tcp --dport 22 -j ACCEPT
然后保存:
#/etc/rc.d/init.d/iptables save
再查看是否已经有了:
[root@vcentos ~]# /etc/init.d/iptables status
Table: filter
Chain INPUT (policy ACCEPT)
num target prot opt source destination
1 ACCEPT udp -- 0.0.0.0/0 0.0.0.0/0 udp dpt:80
2 ACCEPT tcp -- 0.0.0.0/0 0.0.0.0/0 tcp dpt:80
3 RH-Firewall-1-INPUT all -- 0.0.0.0/0 0.0.0.0/0
Chain FORWARD (policy ACCEPT)
num target prot opt source destination
1 RH-Firewall-1-INPUT all -- 0.0.0.0/0 0.0.0.0/0
* 设置iptables为自动启动
chkconfig --level 2345 iptables on
可能因为大家使用的版本不一,所有使用方法也略有不同。
posted @
2012-09-13 15:06 Alpha 阅读(14542) |
评论 (0) |
编辑 收藏1.关闭防火墙
[root@CentOS ~]# chkconfig iptables off
2.关闭selinux
vi /etc/sysconfig/selinux
//将SELINUX=enforcing修改为disabled然后重启生效
3、配置CentOS 6.0 第三方yum源(CentOS默认的标准源里没有nginx软件包)
[root@CentOS ~]# yum install wget
//下载wget工具
[root@CentOS ~]# wget http://www.atomicorp.com/installers/atomic
//下载atomic yum源
[root@CentOS ~]# sh ./atomic
//安装提示输入时输yes
[root@CentOS ~]# yum check-update
//更新yum软件包
4.安装开发包和库文件
[root@CentOS ~]# yum -y install ntp make openssl openssl-devel pcre pcre-devel libpng
libpng-devel libjpeg-6b libjpeg-devel-6b freetype freetype-devel gd gd-devel zlib zlib-devel
gcc gcc-c++ libXpm libXpm-devel ncurses ncurses-devel libmcrypt libmcrypt-devel libxml2
libxml2-devel imake autoconf automake screen sysstat compat-libstdc++-33 curl curl-devel
5.卸载已安装的apache、mysql、php
[root@CentOS ~]# yum remove httpd
[root@CentOS ~]# yum remove mysql
[root@CentOS ~]# yum remove php
6.安装nginx
[root@CentOS ~]# yum install nginx
[root@CentOS ~]# service nginx start
[root@CentOS ~]# chkconfig --levels 235 nginx on
//设2、3、5级别开机启动
7.安装mysql
[root@CentOS ~]# yum install mysql mysql-server mysql-devel
[root@CentOS ~]# service mysqld start
[root@CentOS ~]# chkconfig --levels 235 mysqld on
[root@CentOS ~]# mysqladmin -u root password "123456"
//为root用户设置密码
[root@CentOS ~]# service mysqld restart
//重启mysql
8.安装php
[root@CentOS ~]# yum install php lighttpd-fastcgi php-cli php-mysql php-gd php-imap php-ldap
php-odbc php-pear php-xml php-xmlrpc php-mbstring php-mcrypt php-mssql php-snmp php-soap
php-tidy php-common php-devel php-fpm
//安装php和所需组件使PHP支持MySQL、FastCGI模式
[root@CentOS ~]# service php-fpm start
[root@CentOS ~]# chkconfig --levels 235 php-fpm on
9.配置nginx支持php
[root@CentOS ~]# mv /etc/nginx/nginx.conf /etc/nginx/nginx.confbak
//将配置文件改为备份文件
[root@CentOS ~]# cp /etc/nginx/nginx.conf.default /etc/nginx/nginx.conf
//由于原配置文件要自己去写因此可以使用默认的配置文件作为配置文件
//修改nginx配置文件,添加fastcgi支持
[root@CentOS ~]# vi /etc/nginx/nginx.conf
index index.php index.html index.htm;
//加入index.php
location ~ \.php$ {
root /usr/share/nginx/html;
fastcgi_pass 127.0.0.1:9000;
fastcgi_index index.php;
fastcgi_param SCRIPT_FILENAME /usr/share/nginx/html$fastcgi_script_name;
include fastcgi_params;
}
//将以上代码注释去掉,并修改成nginx默认路径
10.配置php
//编辑文件php.ini,在文件末尾添加cgi.fix_pathinfo = 1
[root@CentOS ~]# vi /etc/php.ini
11.重启nginx php-fpm
[root@CentOS ~]# service nginx restart
[root@CentOS ~]# service php-fpm restart
12.建立info.php文件
[root@CentOS ~]# vi /usr/share/nginx/html/info.php
<?php
phpinfo();
?>
13.测试nginx是否解析php
输入:192.168.1.105/info.php
显示php界面说明解析成功
posted @
2012-09-12 18:39 Alpha 阅读(5436) |
评论 (1) |
编辑 收藏本文主要讲述如何使用Linux系统中的日志子系统及其命令,来更好地保护系统安全。
Linux系统中的日志子系统对于系统安全来说非常重要,它记录了系统每天发生的各种各 样的事情,包括那些用户曾经或者正在使用系统,可以通过日志来检查错误发生的原因,更重要的是在系统受到黑客攻击后,日志可以记录下攻击者留下的痕迹,通 过查看这些痕迹,系统管理员可以发现黑客攻击的某些手段以及特点,从而能够进行处理工作,为抵御下一次攻击做好准备。
在Linux系统中,有三类主要的日志子系统:
● 连接时间日志: 由多个程序执行,把记录写入到/var/log/wtmp和/var/run/utmp,login等程序会更新wtmp和utmp文件,使系统管理员能够跟踪谁在何时登录到系统。
● 进程统计: 由系统内核执行,当一个进程终止时,为每个进程往进程统计文件(pacct或acct)中写一个记录。进程统计的目的是为系统中的基本服务提供命令使用统计。
● 错误日志: 由syslogd(8)守护程序执行,各种系统守护进程、用户程序和内核通过syslogd(3)守护程序向文件/var/log/messages报告 值得注意的事件。另外有许多Unix程序创建日志。像HTTP和FTP这样提供网络服务的服务器也保持详细的日志。
Linux下日志的使用
1.基本日志命令的使用
utmp、wtmp日志文件是多数Linux日志子系统的关键,它保存了用户登录进入和 退出的记录。有关当前登录用户的信息记录在文件utmp中; 登录进入和退出记录在文件wtmp中; 数据交换、关机以及重启的机器信息也都记录在wtmp文件中。所有的记录都包含时间戳。时间戳对于日志来说非常重要,因为很多攻击行为分析都是与时间有极 大关系的。这些文件在具有大量用户的系统中增长十分迅速。例如wtmp文件可以无限增长,除非定期截取。许多系统以一天或者一周为单位把wtmp配置成循 环使用。它通常由cron运行的脚本来修改,这些脚本重新命名并循环使用wtmp文件。
utmp文件被各种命令文件使用,包括who、w、users和finger。而 wtmp文件被程序last 和ac使用。但它们都是二进制文件,不能被诸如tail命令剪贴或合并(使用cat命令)。用户需要使用who、w、users、last和ac来使用这 两个文件包含的信息。具体用法如下:
who命令: who命令查询utmp文件并报告当前登录的每个用户。Who的缺省输出包括用户名、终端类型、登录日期及远程主机。使用该命令,系统管理员可以查看当前系统存在哪些不法用户,从而对其进行审计和处理。例如: 运行who命令显示如下:
[root@working]# who
root pts/0 May 9 21:11 (10.0.2.128)
root pts/1 May 9 21:16 (10.0.2.129)
lhwen pts/7 May 9 22:03 (10.0.2.27)
如果指明了wtmp文件名,则who命令查询所有以前的记录。例如命令who /var/log/wtmp将报告自从wtmp文件创建或删改以来的每一次登录。
日志使用注意事项
系统管理人员应该提高警惕,随时注意各种可疑状况,并且按时和随机地检查各种系统日志文件,包括一般信息日志、网络连接日志、文件传输日志以及用户登录日志等。在检查这些日志时,要注意是否有不合常理的时间记载。例如:
■ 用户在非常规的时间登录;
■ 不正常的日志记录,比如日志的残缺不全或者是诸如wtmp这样的日志文件无故地缺少了中间的记录文件;
■ 用户登录系统的IP地址和以往的不一样;
■ 用户登录失败的日志记录,尤其是那些一再连续尝试进入失败的日志记录;
■ 非法使用或不正当使用超级用户权限su的指令;
■ 无故或者非法重新启动各项网络服务的记录。
另外, 尤其提醒管理人员注意的是: 日志并不是完全可靠的。高明的黑客在入侵系统后,经常会打扫现场。所以需要综合运用以上的系统命令,全面、综合地进行审查和检测,切忌断章取义,否则很难发现入侵或者做出错误的判断。
users命令: users用单独的一行打印出当前登录的用户,每个显示的用户名对应一个登录会话。如果一个用户有不止一个登录会话,那他的用户名将显示相同的次数。运行该命令将如下所示:
[root@working]# users
root root //只登录了一个Root权限的用户
last命令: last命令往回搜索wtmp来显示自从文件第一次创建以来登录过的用户。系统管理员可以周期性地对这些用户的登录情况进行审计和考核,从而发现其中存在的问题,确定不法用户,并进行处理。运行该命令,如下所示:
[root@working]# last
devin pts/1 10.0.2.221 Mon Jul 21 15:08-down (8+17:46)
devin pts/1 10.0.2.221 Mon Jul 21 14:42 - 14:53 (00:11)
changyi pts/2 10.0.2.141 Mon Jul 21 14:12 - 14:12 (00:00)
devin pts/1 10.0.2.221 Mon Jul 21 12:51 - 14:40 (01:49)
reboot system boot 2.4.18 Fri Jul 18 15:42 (11+17:13)
reboot system boot 2.4.18 Fri Jul 18 15:34 (00:04)
reboot system boot 2.4.18 Fri Jul 18 15:02 (00:36)
读者可以看到,使用上述命令显示的信息太多,区分度很小。所以,可以通过指明用户来显示其登录信息即可。例如: 使用last devin来显示devin的历史登录信息,则如下所示:
[root@working]# last devin
devin pts/1 10.0.2.221 Mon Jul 21 15:08 - down (8+17:46)
devin pts/1 10.0.2.221 Mon Jul 21 14:42 - 14:53 (00:11)
ac命令:ac命令根据当前的/var/log/wtmp文件中的登录进入和退出来报告用户连接的时间(小时),如果不使用标志,则报告总的时间。另外,可以加一些参数,例如,last -t 7表示显示上一周的报告。
lastlog命令 lastlog文件在每次有用户登录时被查询。可以使用lastlog命令检查某特定用户上次登录的时间,并格式化输出上次登录日志 /var/log/lastlog的内容。它根据UID排序显示登录名、端口号(tty)和上次登录时间。如果一个用户从未登录过,lastlog显示 “**Never logged**”。注意需要以root身份运行该命令。运行该命令如下所示:
[root@working]# lastlog
Username Port From Latest
root pts/1 10.0.2.129 二 5月 10 10:13:26 +0800 2005
opal pts/1 10.0.2.129 二 5月 10 10:13:26 +0800 2005
2.使用Syslog设备
Syslog已被许多日志函数采纳,被用在许多保护措施中,任何程序都可以通过syslog 记录事件。Syslog可以记录系统事件,可以写到一个文件或设备中,或给用户发送一个信息。它能记录本地事件或通过网络记录另一个主机上的事件。
Syslog设备核心包括一个守护进程(/etc/syslogd守护进程)和一个配置 文件(/etc/syslog.conf配置文件)。通常情况下,多数syslog信息被写到/var/adm或/var/log目录下的信息文件中 (messages.*)。一个典型的syslog记录包括生成程序的名字和一个文本信息。它还包括一个设备和一个优先级范围。
系统管理员通过使用syslog.conf文件,可以对生成的日志的位置及其相关信息进行灵活配置,满足应用的需要。例如,如果想把所有邮件消息记录到一个文件中,则做如下操作:
#Log all the mail messages in one place
mail.* /var/log/maillog
其他设备也有自己的日志。UUCP和news设备能产生许多外部消息。它把这些消息存到自己的日志(/var/log/spooler)中并把级别限为\"err\"或更高。例如:
# Save news errors of level crit and higher in a special file.
uucp,news.crit /var/log/spooler
当一个紧急消息到来时,可能想让所有的用户都得到。也可能想让自己的日志接收并保存。
#Everybody gets emergency messages, plus log them on anther machine
*.emerg *
*.emerg @linuxaid.com.cn
用户可以在一行中指明所有的设备。下面的例子把info或更高级别的消息送到/var/log/messages,除了mail以外。级别\"none\"禁止一个设备:
#Log anything(except mail)of level info or higher
#Don\'t log private authentication messages!
*.info:mail.none;autHPriv.none /var/log/messages
在有些情况下,可以把日志送到打印机,这样网络入侵者怎么修改日志都不能清除入侵的痕迹。因此,syslog设备是一个攻击者的显著目标,破坏了它将会使用户很难发现入侵以及入侵的痕迹,因此要特别注意保护其守护进程以及配置文件。
3.程序日志的使用
许多程序通过维护日志来反映系统的安全状态。su命令允许用户获得另一个用户的权限,所 以它的安全很重要,它的文件为sulog,同样的还有sudolog。另外,诸如Apache等Http的服务器都有两个日志: access_log(客户端访问日志)以及error_log(服务出错日志)。 FTP服务的日志记录在xferlog文件当中,Linux下邮件传送服务(sendmail)的日志一般存放在maillog文件当中。
程序日志的创建和使用在很大程度上依赖于用户的良好编程习惯。对于一个优秀的程序员来 说,任何与系统安全或者网络安全相关的程序的编写,都应该包含日志功能,这样不但便于程序的调试和纠错,而且更重要的是能够给程序的使用方提供日志的分析 功能,从而使系统管理员能够较好地掌握程序乃至系统的运行状况和用户的行为,及时采取行动,排除和阻断意外以及恶意的入侵行为。
posted @
2012-03-22 14:12 Alpha 阅读(1020) |
评论 (0) |
编辑 收藏CentOS 5.5下FTP安装及配置
一、FTP的安装
1、检测是否安装了FTP :
[root@localhost ~]# rpm -q vsftpd
vsftpd-2.0.5-16.el5_5.1
否则显示:[root@localhost ~]# package vsftpd is not installed
查看ftp运行状态
service vsftpd status
2、如果没安装FTP,运行yum install vsftpd命令进行安装
如果无法下载,需要设置好yum 如下
cd /etc/yum.repos.d
mv CentOS-Base.repo CentOS-Base.repo.save
wget http://centos.ustc.edu.cn/CentOS-Base.repo
3、完成ftp安装后,将 /etc/vsftpd/user_list文件和/etc/vsftpd/ftpusers文件中的root这一行注释掉
# root
4、执行 setsebool -P ftpd_disable_trans=1 修改SELinux 状态
[root@localhost vsftpd]# setsebool -P ftpd_disable_trans=1
setsebool: SELinux is disabled.
5、修改/etc/vsftpd/vsftpd.conf,在最后一行处添加local_root=/
6、重启ftp进程 #service vsftpd restart
注:每次修改过ftp相关的配置文件,都需要重启ftp进程来生效。
安装完成
+++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
vsftpd 文件布局
/etc/vsftpd/vsftpd.conf 主配置文件
/usr/sbin/vsftpd 主程序
/etc/rc.d/init.d/vsftpd 启动脚本
/etc/pam.d/vsftpd PAM认证文件
/etc/vsftpd.ftpusers 禁止使用vsftpd的用户列表文件
/etc/vsftpd.user_list 禁止或允许使用vsftpd用户列表文件
/var/ftp 匿名用户主目录
/var/ftp/pub 匿名用户下载目录
/etc/logrotate.d/vsftpd.log 日志文件
++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
二.系统帐户
1.建立Vsftpd服务的宿主用户:
[root@localhost]# adduser -d /data guest -s /sbin/nologin
默认的Vsftpd的服务宿主用户是root,但是这不符合安全性的需要。www.linuxidc.com这里建立名字为vsftpd的用户,用他来作为支持Vsftpd的
建立Vsftpd虚拟宿主用户:
[root@linuxidc.com nowhere]# useradd virtusers -s /sbin/nologin
++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
三 、vsftpd的配置
#anonymous_enable=YES
anonymous_enable=NO 设定不允许匿名访问
local_enable=YES 设定本地用户可以访问。注意:如果该项目设定为NO那么所有虚拟用户将无法访问。
write_enable=YES 设定可以进行写操作。
local_umask=022 设定上传后文件的权限掩码。
anon_upload_enable=NO 禁止匿名用户上传。
anon_mkdir_write_enable=NO 禁止匿名用户建立目录。
dirmessage_enable=YES 设定开启目录标语功能。
xferlog_enable=YES 设定开启日志记录功能。
connect_from_port_20=YES 设定端口20进行数据连接。
chown_uploads=NO 设定禁止上传文件更改宿主。
chroot_local_user=YES 设定登陆后.只可以访问自己的属主目录.不可访问上一层目录文件
xferlog_file=/var/log/vsftpd.log 设定Vsftpd的服务日志保存路径。注意,该文件默认不存在。必须要手动touch出来,并且由于这里更改了Vsftpd的服务宿主
用户为手动建立的Vsftpd。必须注意给与该用户对日志的写入权限,否则服务将启动失败。
xferlog_std_format=YES 设定日志使用标准的记录格式
idle_session_timeout=600 设定空闲连接超时时间,这里使用默认。
data_connection_timeout=120 设定单次最大连续传输时间,这里使用默认
nopriv_user=vsftpd 设定支撑Vsftpd服务的宿主用户为手动建立的Vsftpd用户。注意,一旦做出更改宿主用户后,必须注意一起与该服务相关的读写文件的读写赋权问题
比如日志文件就必须给与该用户写入权限等。
async_abor_enable=YES 设定支持异步传输功能。
ascii_upload_enable=YES
ascii_download_enable=YES 设定支持ASCII模式的上传和下载功能。
ftpd_banner=Welcome to blah FTP service ^_^ 设定Vsftpd的登陆标语。
chroot_list_enable=NO 禁止用户登出自己的FTP主目录。
ls_recurse_enable=NO 禁止用户登陆FTP后使用"ls -R"的命令。该命令会对服务器性能造成巨大开销。如果该项被允许,那么挡多用户同时使用该命
令时将会对该服务器造成威胁。
listen=YES 设定该Vsftpd服务工作在StandAlone模式下。
pam_service_name=vsftpd 设定PAM服务下Vsftpd的验证配置文件名。
userlist_enable=YES 设定userlist_file中的用户将不得使用FTP。
tcp_wrappers=YES 服务器使用tcp_wrappers作为主机的访问控制方式。
以下这些是关于Vsftpd虚拟用户支持的重要配置项目。默认Vsftpd.conf中不包含这些设定项目,需要自己手动添加配置。
guest_enable=YES 设定启用虚拟用户功能。
guest_username=virtusers 指定虚拟用户的宿主用户。
virtual_use_local_privs=YES 设定虚拟用户的权限符合他们的宿主用户。
user_config_dir=/etc/vsftpd/vconf 设定虚拟用户个人Vsftp的配置文件存放路径。也就是说,这个被指定的目录里,将存放每个Vsftp虚拟用户个性的配置文件,
一个需要注意的地方就是这些配置文件名必须和虚拟用户名相同。保存退出。
max_clients= 99 服务器的最大并发数
max_per_ip=5 用户最大线程数
anon_max_rate=1000000 设置本底账号最大传输率为1Mbps
禁止某些IP段得主机匿名访问服务器
tcp_wrappers=YES
编辑 /etc/hosts.allow
增加
vsftpd:192.168.110.11:DENY
查看ftp日志
xferlog_enable=YES 上传和下载日志文件记录 /var/log/vsftpd.log
xferlog_std_format=YES 传输日志文件将以标准xferlog的格式书写 /var/log/xferlog
xferlog_file= /var/log/xferlog
dual_log_enable=YES
vsftpd_log_file=/var/log/vsftpd.log
通过本底数据文件实现虚拟用户访问
安装db4-utils
yum install db4-utils
创建本地映射用户,修改本底映射用户目录权限
useradd -d /data/ftp/temp -s /sbin/nologin game
chmod o=rwx /data/ftp/temp
修改 /etc/vsftpd/vsftpd.conf
guest_enable=YES
guest_username=zqgamexw
生成虚拟用户文件
/etc/vsftpd/vsftpuser.txt
test001 虚拟user
123456 虚拟passwd
生成虚拟用户数据文件
db_load -T -t hash -f /etc/vsftpd/vsftpuser.txt /etc/vsftpd/vsftpuser.db
修改生成的用户数据文件权限
chmod 600 /etc/vsftpd/vsftpuser.db
修改PAM 认证文件 /etc/pam.d/vsftpd 注销原有内容后添加
auth required /lib/security/pam_userdb.so db=/etc/vsftpd/vsftpuser
account required /lib/security/pam_userdb.so db=/etc/vsftpd/vsftpuse
建立Vsftpd的日志文件,并更该属主为Vsftpd的服务宿主用户:
[root@localhost]# touch /var/log/vsftpd.log
[root@localhost]# chown vsftpd.vsftpd /var/log/vsftpd.log
建立虚拟用户配置文件存放路径:
[root@localhost]# mkdir /etc/vsftpd/vconf/
制作虚拟用户数据库文件
先建立虚拟用户名单文件:
[root@localhost]# touch /etc/vsftpd/virtusers
建立了一个虚拟用户名单文件,这个文件就是来记录vsftpd虚拟用户的用户名和口令的数据文件,
这里给它命名为virtusers。为了避免文件的混乱,我把这个名单文件就放置在/etc/vsftpd/下。
编辑虚拟用户名单文件:
[root@localhost]# vi /etc/vsftpd/virtusers
----------------------------
ftp001
123456
ftp002
123456
ftp003
123456
----------------------------
编辑这个虚拟用户名单文件,在其中加入用户的用户名和口令信息。格式很简单:“一行用户名,一行口令”。3.生成虚拟用
户数据文件:
[root@localhost]# db_load -T -t hash -f /etc/vsftpd/virtusers /etc/vsftpd/virtusers.db
4.察看生成的虚拟用户数据文件
[root@localhost]# ll /etc/vsftpd/virtusers.db
-rw-r--r-- 1 root root 12288 Sep 16 03:51 /etc/vsftpd/virtusers.db
需要特别注意的是,以后再要添加虚拟用户的时候,只需要按照“一行用户名,一行口令”的格式将新用户名和口令添加进虚
拟用户名单文件。但是光这样做还不够,不会生效的哦!还要再执行一遍“ db_load -T -t hash -f 虚拟用户名单文件虚拟
用户数据库文件.db ”的命令使其生效才可以!
设定PAM验证文件,并指定虚拟用户数据库文件进行读取
1.察看原来的Vsftp的PAM验证配置文件:
[root@localhost]# cat /etc/pam.d/vsftpd
----------------------------------------------------------------
#%PAM-1.0
session optional pam_keyinit.so force revoke
auth required pam_listfile.so item=user sense=deny file=/etc/vsftpd/ftpusers onerr=succeed
auth required pam_shells.so
auth include system-auth
account include system-auth
session include system-auth
session required pam_loginuid.so
----------------------------------------------------------------
2.在编辑前做好备份:
[root@localhost]# cp /etc/pam.d/vsftpd /etc/pam.d/vsftpd.backup
3.编辑Vsftpd的PAM验证配置文件
[root@localhost]# vi /etc/pam.d/vsftpd
----------------------------------------------------------------
#%PAM-1.0
auth required /lib/security/pam_userdb.so db=/etc/vsftpd/virtusers
account required /lib/security/pam_userdb.so db=/etc/vsftpd/virtusers
以上两条是手动添加的,上面的全部加#注释了.内容是对虚拟用户的安全和帐户权限进行验证。
!!!!!!!这里有个要注意说明的:如果系统是64位系统在这里的所有lib后面要加入64!!!!!!
!!!!!!!如下这样才可以:
#%PAM-1.0
auth required /lib64/security/pam_userdb.so db=/etc/vsftpd/virtusers
account required /lib64/security/pam_userdb.so db=/etc/vsftpd/virtusers
五.虚拟用户的配置
1.规划好虚拟用户的主路径:
[root@localhost]# mkdir /opt/vsftp/
2.建立测试用户的FTP用户目录:
[root@localhost]# mkdir /opt/vsftp/ftp001 /opt/vsftp/ftp002 /opt/vsftp/ftp003
3.建立虚拟用户配置文件模版:
[root@localhost]# cp /etc/vsftpd/vsftpd.conf.backup /etc/vsftpd/vconf/vconf.tMP4.定制虚拟用户模版配置文件:
[root@localhost]# vi /etc/vsftpd/vconf/vconf.tmp
--------------------------------
local_root=/opt/vsftp/virtuser
virtuser 这个就是以后要指定虚拟的具体主路径。
anonymous_enable=NO
设定不允许匿名用户访问。
write_enable=YES
设定允许写操作。
local_umask=022
设定上传文件权限掩码。
anon_upload_enable=NO
设定不允许匿名用户上传。
anon_mkdir_write_enable=NO
设定不允许匿名用户建立目录。
idle_session_timeout=600 (根据用户要求.可选)
设定空闲连接超时时间。
data_connection_timeout=120
设定单次连续传输最大时间。
max_clients=10 (根据用户要求.可选)
设定并发客户端访问个数。
max_per_ip=5 (根据用户要求.可选)
设定单个客户端的最大线程数,这个配置主要来照顾Flashget、迅雷等多线程下载软件。
local_max_rate=50000 (根据用户要求.可选)
设定该用户的最大传输速率,单位b/s。
pam_service_name=vsftpd
chroot_local_user=YES
--------------------------------
这里将原vsftpd.conf配置文件经过简化后保存作为虚拟用户配置文件的模版。这里将并不需要指定太多的配置内容,主要的
框架和限制交由Vsftpd的主配置文件vsftpd.conf来定义,即虚拟用户配置文件当中没有提到的配置项目将参考主配置文件中
的设定。而在这里作为虚拟用户的配置文件模版只需要留一些和用户流量控制,访问方式控制的配置项目就可以了。这里的关
键项是local_root这个配置,用来指定这个虚拟用户的FTP主路径。5.更改虚拟用户的主目录的属主为虚拟宿主用户:
[root@localhost]# chown -R virtusers.virtusers /opt/vsftp/
6.检查权限:
[root@localhost]# ll /opt/vsftp/
total 24
drwxr-xr-x 2 overlord overlord 4096 Sep 16 05:14 ftp001
drwxr-xr-x 2 overlord overlord 4096 Sep 16 05:00 ftp002
drwxr-xr-x 2 overlord overlord 4096 Sep 16 05:00 ftp003
.给测试用户定制:
1.从虚拟用户模版配置文件复制:
[root@localhost]# cp /etc/vsftpd/vconf/vconf.tmp /etc/vsftpd/vconf/ftp001
2.针对具体用户进行定制:
[root@localhost]# vi /etc/vsftpd/vconf/ftp001
---------------------------------
local_root=/opt/vsftp/ftp001 (FTP用户ftp001 的登陆目录文件)
anonymous_enable=NO
write_enable=YES
local_umask=022
anon_upload_enable=NO
anon_mkdir_write_enable=NO
idle_session_timeout=300
data_connection_timeout=90
max_clients=1
max_per_ip=1
local_max_rate=25000
pam_service_name=vsftpd
chroot_local_user=YES
---------------------------------
七.启动服务:
[root@localhost]# service vsftpd start
Starting vsftpd for vsftpd: [ OK ]
八.测试:
1.在虚拟用户目录中预先放入文件:
[root@localhost]# touch /opt/vsftp/ftp001/test.txt
2.从其他机器作为客户端登陆FTP:
可以IE或FTP客户端软直接访问
ie里输入 ftp://127.0.0.1 (服务器IP)
弹出对话框后.输入FTP用户名和密码
---------------------------------------------
注意:
在/etc/vsftpd/vsftpd.conf中,local_enable的选项必须打开为Yes,使得虚拟用户的访问成为可能,否则会出现以下现象:
----------------------------------
[root@localhost]# ftp
ftp> open 192.168.1.22
Connected to 192.168.1.22.
500 OOPS: vsftpd: both local and anonymous access disabled!
----------------------------------
原因:虚拟用户再丰富,其实也是基于它们的宿主用户virtusers的,如果virtusers这个虚拟用户的宿主被限制住了,那么虚
拟用户也将受到限制。
补充:
1.要查看服务器自带的防火墙有无挡住FTP 21端口 导致不能访问
2.查看 SELinux 禁用没有.要禁用
3.500 OOPS:错误 有可能是你的vsftpd.con配置文件中有不能被实别的命令,还有一种可能是命令的YES 或 NO 后面有空格。
4.要仔细查看各个用到的文件夹权限,及用户属主权限等
1 如何新加FTP用户
打开密码文件里加入(一行是用户.一是密码.依次类推)
#vi /etc/vsftpd/virtusers
加入用户后 保存退出
#db_load -T -t hash -f /etc/vsftpd/virtusers /etc/vsftpd/virtusers.db (然后生成新的虚拟用数据文件)
#cp /etc/vsftpd/vconf/vconf.tmp d (新建d用户,用虚拟用户模板vconf.tmp文件生成d虚拟用户文件)
#vi /etc/vsftpd/vconf/d (打开D虚拟用户文件.在第一行最后加入该用户对应的FTP目录)
#mkdir /opt/vsftp/WWW (新建WWW目录为d FTP用户登陆目录)
#service vsftpd restart
-------------------------------------------------------
2 如何修改FTP 用户登陆密码
打开密码文件里加入(第一行是用户.第二是密码.依次类推,只要改对应用户下面的密码即可)
#vi /etc/vsftpd/virtusers
#db_load -T -t hash -f /etc/vsftpd/virtusers /etc/vsftpd/virtusers.db (然后生成新的虚拟用数据文件)
#service vsftpd restart
posted @
2012-02-02 16:49 Alpha 阅读(5285) |
评论 (0) |
编辑 收藏 MySQL + PHP的模式在大并发压力下经常会导致MySQL中存在大量僵死进程,导致服务挂死。为了自动干掉这些进程,弄了个脚本,放在服务器后台通过crontab自动执行。发现这样做了以后,的确很好的缓解了这个问题。把这个脚本发出来和大家Share。
根据自己的实际需要,做了一些修改:
SHELL脚本:mysqld_kill_sleep.sh
#!/bin/sh
mysql_pwd="root的密码"
mysqladmin_exec="/usr/local/bin/mysqladmin"
mysql_exec="/usr/local/bin/mysql"
"/tmp"
mysql_timeout_log="$mysql_timeout_dir/mysql_timeout.log"
mysql_kill_timeout_sh="$mysql_timeout_dir/mysql_kill_timeout.sh"
"$mysql_timeout_dir/mysql_kill_timeout.log"
$mysqladmin_exec -uroot -p"$mysql_pwd" processlist | awk '{ print $12 , $2 ,$4}' | grep -v Time | grep -v '|' | sort -rn > $mysql_timeout_log
awk '{if($1>30 && $3!="root") print "'""$mysql_exec""' -e " "/"" "kill",$2 "/"" " -uroot " "-p""/"""'""$mysql_pwd""'""/"" ";" }' $mysql_timeout_log > $mysql_kill_timeout_sh
echo "check start ." >> $mysql_kill_timeout_log
echo `date` >> $mysql_kill_timeout_log
cat $mysql_kill_timeout_sh 把这个写到mysqld_kill_sleep.sh。然后chmod 0 mysqld_kill_sleep.sh,chmod u+rx mysqld_kill_sleep.sh,然后用root账户到cron里面运行即可,时间自己调整。执行之后显示:
www# ./mysqld_kill_sleep.sh
/usr/local/bin/mysql -e "kill 27549" -uroot -p"mysql root的密码";
/usr/local/bin/mysql -e "kill 27750" -uroot -p"mysql root的密码";
/usr/local/bin/mysql -e "kill 27840" -uroot -p"mysql root的密码";
/usr/local/bin/mysql -e "kill 27867" -uroot -p"mysql root的密码";
/usr/local/bin/mysql -e "kill 27899" -uroot -p"mysql root的密码";
/usr/local/bin/mysql -e "kill 27901" -uroot -p"mysql root的密码";
/usr/local/bin/mysql -e "kill 27758" -uroot -p"mysql root的密码";
/usr/local/bin/mysql -e "kill 27875" -uroot -p"mysql root的密码";
/usr/local/bin/mysql -e "kill 27697" -uroot -p"mysql root的密码";
"kill 27888" -uroot -p"mysql root的密码";
/usr/local/bin/mysql -e "kill 27861" -uroot -p"mysql root的密码";
如果确认没有问题了,把最后的cat修改为sh即可。本人改写了下上面的脚本:
#!/bin/bash
mysql_pwd="密码"
mysql_exec="/usr/local/mysql/bin/mysql"
mysql_timeout_dir="/tmp"
mysql_kill_timeout_sh="$mysql_timeout_dir/mysql_kill_timeout.sh"
"$mysql_timeout_dir/mysql_kill_timeout.log"
$mysql_exec -uroot -p$mysql_pwd -e "show processlist" | grep -i "Locked" >> $mysql_kill_timeout_log
for line in `$mysql_kill_timeout_log | awk '{print $1}'`
do
echo "$mysql_exec -uroot -p$mysql_pwd -e /"kill $line/"" >> $mysql_kill_timeout_sh
done
cat $mysql_kill_timeout_sh
很多时候!一不小心就锁表!这里讲解决锁表终极方法!
案例一
mysql>showprocesslist;
参看sql语句,一般少的话
mysql>killthread_id;
就可以解决了,kill掉第一个锁表的进程, 依然没有改善.既然不改善,咱们就想办法将所有锁表的进程kill掉吧,简单的脚本如下:
#!/bin/bash
mysql-uroot-e"show processlist"|grep-i"Locked">>locked_log.txt
forlinein`cat locked_log.txt | awk '{print$1}'`
do
echo"kill$line;">>kill_thread_id.sql
done
现在kill_thread_id.sql的内容像这个样子
kill66402982;
kill66402983;
kill66402986;
kill66402991;
.....
好了,我们在mysql的shell中执行,就可以把所有锁表的进程杀死了。
mysql>sourcekill_thread_id.sql
当然了,也可以一行搞定。
foridin`mysqladmin processlist | grep -i locked | awk '{print$1}'`
do
mysqladminkill${id}
done
案例二
如果大批量的操作能够通过一系列的select语句产生,那么理论上就能对这些结果批量处理。但是mysql并没用提供eval这样的对结果集进行分析操作的功能。所以只能现将select结果保存到临时文件中,然后再执行临时文件中的指令。具体过程如下:
mysql> SELECT concat('KILL ',id,';') FROM information_schema.processlist WHERE user='root';
+------------------------+
| concat('KILL ',id,';')
+------------------------+
| KILL 3101;
| KILL 2946;
+------------------------+
2 rows IN SET (0.00 sec)
mysql> SELECT concat('KILL ',id,';') FROM information_schema.processlist WHERE user='root' INTO OUTFILE '/tmp/a.txt';
Query OK, 2 rows affected (0.00 sec)
mysql> source /tmp/a.txt;
Query OK, 0 rows affected (0.00 sec)
案例三
MySQL + PHP的模式在大并发压力下经常会导致MySQL中存在大量僵死进程,导致服务挂死。为了自动干掉这些进程,弄了个脚本,放在服务器后台通过crontab自动执行。发现这样做了以后,的确很好的缓解了这个问题。把这个脚本发出来和大家Share。根据自己的实际需要,做了一些修改:
SHELL脚本:mysqld_kill_sleep.sh
#!/bin/sh
mysql_pwd="root的密码"
mysqladmin_exec="/usr/local/bin/mysqladmin"
mysql_exec="/usr/local/bin/mysql"
mysql_timeout_dir="/tmp"
mysql_timeout_log="$mysql_timeout_dir/mysql_timeout.log"
mysql_kill_timeout_sh="$mysql_timeout_dir/mysql_kill_timeout.sh"
mysql_kill_timeout_log="$mysql_timeout_dir/mysql_kill_timeout.log"
$mysqladmin_exec -uroot -p"$mysql_pwd" processlist | awk '{ print $12 , $2 ,$4}' | grep -v Time | grep -v '|' | sort -rn > $mysql_timeout_log
awk '{if($1>30 && $3!="root") print "'""$mysql_exec""' -e " "\"" "kill",$2 "\"" " -uroot " "-p""\"""'""$mysql_pwd""'""\"" ";" }' $mysql_timeout_log > $mysql_kill_timeout_sh
echo "check start ...." >> $mysql_kill_timeout_log
echo `date` >> $mysql_kill_timeout_log
cat $mysql_kill_timeout_sh
把这个写到mysqld_kill_sleep.sh。然后chmod 0 mysqld_kill_sleep.sh,chmod u+rx mysqld_kill_sleep.sh,然后用root账户到cron里面运行即可,时间自己调整。执行之后显示:
www# ./mysqld_kill_sleep.sh
/usr/local/bin/mysql -e "kill 27549" -uroot -p"mysql root的密码";
/usr/local/bin/mysql -e "kill 27750" -uroot -p"mysql root的密码";
/usr/local/bin/mysql -e "kill 27840" -uroot -p"mysql root的密码";
/usr/local/bin/mysql -e "kill 27867" -uroot -p"mysql root的密码";
/usr/local/bin/mysql -e "kill 27899" -uroot -p"mysql root的密码";
/usr/local/bin/mysql -e "kill 27901" -uroot -p"mysql root的密码";
/usr/local/bin/mysql -e "kill 27758" -uroot -p"mysql root的密码";
/usr/local/bin/mysql -e "kill 27875" -uroot -p"mysql root的密码";
/usr/local/bin/mysql -e "kill 27697" -uroot -p"mysql root的密码";
/usr/local/bin/mysql -e "kill 27888" -uroot -p"mysql root的密码";
/usr/local/bin/mysql -e "kill 27861" -uroot -p"mysql root的密码";
如果确认没有问题了,把最后的cat修改为sh即可。本人改写了下上面的脚本:
#!/bin/bash
mysql_pwd="密码"
mysql_exec="/usr/local/mysql/bin/mysql"
mysql_timeout_dir="/tmp"
mysql_kill_timeout_sh="$mysql_timeout_dir/mysql_kill_timeout.sh"
mysql_kill_timeout_log="$mysql_timeout_dir/mysql_kill_timeout.log"
$mysql_exec -uroot -p$mysql_pwd -e "show processlist" | grep -i "Locked" >> $mysql_kill_timeout_log
chmod 777 $mysql_kill_timeout_log
for line in `$mysql_kill_timeout_log | awk '{print $1}'`
do
echo "$mysql_exec -uroot -p$mysql_pwd -e \"kill $line\"" >> $mysql_kill_timeout_sh
done
chmod 777 $mysql_kill_timeout_sh
cat $mysql_kill_timeout_sh
是不是很方便呢!processlist命令的输出结果显示了有哪些线程在运行,可以帮助识别出有问题的查询语句,两种方式使用这个命令。
1、进入mysql/bin目录下输入mysqladmin processlist;
2、启动mysql,输入show processlist;
如果有SUPER权限,则可以看到全部的线程,否则,只能看到自己发起的线程(这是指,当前对应的MySQL帐户运行的线程)。得到数据形式如下(只截取了三条):
mysql> show processlist;
+-----+-------------+--------------------+-------+---------+-------+----------------------------------+----------
| Id | User | Host | db | Command | Time| State | Info
+-----+-------------+--------------------+-------+---------+-------+----------------------------------+----------
|207|root |192.168.0.20:51718 |mytest | Sleep | 5 | | NULL
|208|root |192.168.0.20:51719 |mytest | Sleep | 5 | | NULL
|220|root |192.168.0.20:51731 |mytest |Query | 84 | Locked |
select bookname,culture,value,type from book where id=001
先简单说一下各列的含义和用途,第一列,id,不用说了吧,一个标识,你要kill一个语句的时候很有用。user列,显示单前用户,如果不是root,这个命令就只显示你权限范围内的sql语句。host列,显示这个语句是从哪个ip的哪个端口上发出的。呵呵,可以用来追踪出问题语句的用户。db列,显示这个进程目前连接的是哪个数据库。command列,显示当前连接的执行的命令,一般就是休眠(sleep),查询(query),连接(connect)。time列,此这个状态持续的时间,单位是秒。state列,显示使用当前连接的sql语句的状态,很重要的列,后续会有所有的状态的描述,请注意,state只是语句执行中的某一个状态,一个sql语句,已查询为例,可能需要经过copying to tmp table,Sorting result,Sending data等状态才可以完成,info列,显示这个sql语句,因为长度有限,所以长的sql语句就显示不全,但是一个判断问题语句的重要依据。
这个命令中最关键的就是state列,mysql列出的状态主要有以下几种:
Checking table
正在检查数据表(这是自动的)。
Closing tables
正在将表中修改的数据刷新到磁盘中,同时正在关闭已经用完的表。这是一个很快的操作,如果不是这样的话,就应该确认磁盘空间是否已经满了或者磁盘是否正处于重负中。
Connect Out
复制从服务器正在连接主服务器。
Copying to tmp table on disk
由于临时结果集大于tmp_table_size,正在将临时表从内存存储转为磁盘存储以此节省内存。
Creating tmp table
正在创建临时表以存放部分查询结果。
deleting from main table
服务器正在执行多表删除中的第一部分,刚删除第一个表。
deleting from reference tables
服务器正在执行多表删除中的第二部分,正在删除其他表的记录。
Flushing tables
正在执行FLUSH TABLES,等待其他线程关闭数据表。
Killed
发送了一个kill请求给某线程,那么这个线程将会检查kill标志位,同时会放弃下一个kill请求。MySQL会在每次的主循环中检查kill标志位,不过有些情况下该线程可能会过一小段才能死掉。如果该线程程被其他线程锁住了,那么kill请求会在锁释放时马上生效。
Locked
被其他查询锁住了。
Sending data
正在处理Select查询的记录,同时正在把结果发送给客户端。
Sorting for group
正在为GROUP BY做排序。
Sorting for order
正在为ORDER BY做排序。
Opening tables
这个过程应该会很快,除非受到其他因素的干扰。例如,在执Alter TABLE或LOCK TABLE语句行完以前,数据表无法被其他线程打开。正尝试打开一个表。
Removing duplicates
正在执行一个Select DISTINCT方式的查询,但是MySQL无法在前一个阶段优化掉那些重复的记录。因此,MySQL需要再次去掉重复的记录,然后再把结果发送给客户端。
Reopen table
获得了对一个表的锁,但是必须在表结构修改之后才能获得这个锁。已经释放锁,关闭数据表,正尝试重新打开数据表。
Repair by sorting
修复指令正在排序以创建索引。
Repair with keycache
修复指令正在利用索引缓存一个一个地创建新索引。它会比Repair by sorting慢些。
Searching rows for update
正在讲符合条件的记录找出来以备更新。它必须在Update要修改相关的记录之前就完成了。
Sleeping
正在等待客户端发送新请求.
System lock
正在等待取得一个外部的系统锁。如果当前没有运行多个mysqld服务器同时请求同一个表,那么可以通过增加--skip-external-locking参数来禁止外部系统锁。
Upgrading lock
Insert DELAYED正在尝试取得一个锁表以插入新记录。
Updating
正在搜索匹配的记录,并且修改它们。
User Lock
正在等待GET_LOCK()。
Waiting for tables
该线程得到通知,数据表结构已经被修改了,需要重新打开数据表以取得新的结构。然后,为了能的重新打开数据表,必须等到所有其他线程关闭这个表。以下几种情况下会产生这个通知:
FLUSH TABLES tbl_name, Alter TABLE, RENAME TABLE, REPAIR TABLE, ANALYZE TABLE,或OPTIMIZE TABLE。
waiting for handler insert
Insert DELAYED已经处理完了所有待处理的插入操作,正在等待新的请求。大部分状态对应很快的操作,只要有一个线程保持同一个状态好几秒钟,那么可能是有问题发生了,需要检查一下。
还有其他的状态没在上面中列出来,不过它们大部分只是在查看服务器是否有存在错误是才用得着。
posted @
2012-01-19 14:20 Alpha 阅读(1938) |
评论 (0) |
编辑 收藏MySql中添加用户,新建数据库,用户授权,删除用户,修改密码
1.新建用户。
//登录MYSQL
@>mysql -u root -p
@>密码
//创建用户
mysql> mysql> insert into mysql.user(Host,User,Password,ssl_cipher,x509_issuer,x509_sub
ject) values("localhost","pppadmin",password("passwd"),'','','');
这样就创建了一个名为:phplamp 密码为:1234 的用户。
然后登录一下。
mysql>exit;
@>mysql -u phplamp -p
@>输入密码
mysql>登录成功
2.为用户授权。
//登录MYSQL(有ROOT权限)。我里我以ROOT身份登录.
@>mysql -u root -p
@>密码
//首先为用户创建一个数据库(phplampDB)
mysql>create database phplampDB;
//授权phplamp用户拥有phplamp数据库的所有权限。
>grant all privileges on phplampDB.* to phplamp@localhost identified by '1234';
//刷新系统权限表
mysql>flush privileges;
mysql>其它操作
/*
如果想指定部分权限给一用户,可以这样来写:
mysql>grant select,update on phplampDB.* to phplamp@localhost identified by '1234';
//刷新系统权限表。
mysql>flush privileges;
*/
3.删除用户。
@>mysql -u root -p
@>密码
mysql>Delete FROM user Where User="phplamp" and Host="localhost";
mysql>flush privileges;
//删除用户的数据库
mysql>drop database phplampDB;
4.修改指定用户密码。
@>mysql -u root -p
@>密码
mysql>update mysql.user set password=password('新密码') where User="phplamp" and Host="localhost";
mysql>flush privileges;
5.列出所有数据库
mysql>show database;
6.切换数据库
mysql>use '数据库名';
7.列出所有表
mysql>show tables;
8.显示数据表结构
mysql>describe 表名;
9.删除数据库和数据表
mysql>drop database 数据库名;
mysql>drop table 数据表名;
posted @
2011-12-27 17:30 Alpha 阅读(9837) |
评论 (0) |
编辑 收藏
搭建SVN服务,有效的管理代码,以下三步可以快速搞定。
1、安装
#yum install subversion
判断是否安装成功
#subversion -v
svnserve, version 1.6.11 (r934486)出现上面的提示,说明安装成功。
有了SVN软件后还需要建立SVN库。
#mkdir /opt/svn/repos
#svnadmin create /opt/svn/repos
执行上面的命令后,自动在repos下建立多个文件, 分别是conf, db,format,hooks, locks, README.txt。
2、配置 上面的操作很简单,几个命令就搞定, 下面的操作也不难。
进入上面生成的文件夹conf下,进行配置, 有以下几个文件authz, passwd, svnserve.conf
其中authz 是权限控制,可以设置哪些用户可以访问哪些目录, passwd是设置用户和密码的, svnserve是设置svn相关的操作。
2.1先设置passwd
[users]
# harry = harryssecret
# sally = sallyssecret
hello=123
用户名=密码
这样我们就建立了hello用户, 123密码
2.2 再设置权限authz
[/]
hello= rw
意思是hello用户对所有的目录有读写权限,当然也可以限定。
如果是自己用,就直接是读写吧。
2.3最后设定snvserv.conf
anon-access = none # 使非授权用户无法访问
auth-access = write # 使授权用户有写权限
password-db = password
authz-db = authz # 访问控制文件
realm = /opt/svn/repos # 认证命名空间,subversion会在认证提示里显示,并且作为凭证缓存的关键字。
采用默认配置. 以上语句都必须顶格写, 左侧不能留空格, 否则会出错.
好了,通过以上配置,你的svn就可以了。
3、连接
启动svn: svnserve -d -r /opt/svn/repos
svn默认端口是3690
如果已经有svn在运行,可以换一个端口运行
svnserve -d -r /opt/svn/repos --listen-port 3391
这样同一台服务器可以运行多个svnserver
好了,启动成功后,就可以使用了。
建议采用TortoiseSVN, 连接地址为: svn://your server address (如果指定端口需要添加端口 :端口号)
连接后可以上传本地的文件,有效的管理你的代码。
svn 端口和常用命令
有效选项:
-d [--daemon] : 后台模式
--listen-port 参数 : 监听端口(后台模式)
--listen-host 参数 : 监听主机名或IP地址(后台模式)
--foreground : 在前台运行(调试时有用)
-h [--help] : 显示这个帮助
--version : 显示程序版本信息
-i [--inetd] : inetd 模式
-r [--root] 参数 : 服务根目录
-R [--read-only] : 强制只读成;优先于仓库配置文件
-t [--tunnel] : 隧道模式
--tunnel-user 参数 : 隧道用户名(模式是当前用户UID的名字)
-X [--listen-once] : 监听一次(调试时有用)
--pid-file 参数 : 将服务进程ID写入文件ARG中
--service : 作为windows服务运行(仅SCM)[/quote]
你可以用--listen-port 指定端口
在httpd.conf中,查找Listen 80,将80修改为你想要的端口,svn默认端口是3690
为svnserve 加上--listen-port参数,比如svnserve -d -r d:\svn --listen-port 81
你可以采用svn+apache组合搭建,既可以设置你想要的端口,还可以以WEB形式访问代码库
通过以上三步,可以快速的搭建起svn
SVN数据库迁移方法
版本库数据的移植:svnadmin dump、svnadmin load 导出:
$svnadmin dump repos > dumpfile //将指定的版本库导出成文件dumpfile
新建:
$svnadmin create newrepos
导入:
$svnadmin load newrepos < dumpfile
posted @
2011-12-19 11:44 Alpha 阅读(3900) |
评论 (0) |
编辑 收藏DNS是域名系统(Domain Name System)的缩写,它的作用是将主机名解析成IP(正向解析),从IP地址查询其主机名(反向解析)。
DNS的工作原理
(1)客户机发出查询请求
当被询问到有关本域中的主机名称的时候,DNS服务器会直接做出回答。如果所查询的主机名称属于其它域的话,则会检查缓存中有没有相关资料,如果没有发现则会转向root服务器查询,然后root服务器会将该域名的授权(authoritative)服务器(可能会超过一台)的地址告知本地服务器,然后会向其中的一台服务器查询,并将这些服务器名单存到缓存中以备将来之需(省去再向root查询的步骤)。
(2)远方服务器回应查询
将查询结果回应给客户,并同时将结果存储一个备份在自己的缓存里面,如果在存放时间尚未过时之前再接到相同的查询,则以存放于缓存里面的资料来做回应。
DNS服务器分类
1.主域名服务器(master)
主域名服务器是一个域或区域的管理权威。这个服务器的主要责任就是解析域或区域内的所有主机的名称。可以使用一个或多个辅域名服务器作为主域名服务器的备份。
2.辅域名服务器(slave)
辅域名服务器是备份服务器。它们不是域区源数据存放的地方,但它们也授权响应域名的查询。辅域名服务器通常从域的主域名服务器获得域区数据。辅服务器也被称为从属服务器。
3.唯高速缓存服务器(hint)
缓存服务器负责临时存储主域名服务器己解析过域名记录。
打算用两个vps,一个做主域名服务器,一个做辅助域名服务器。系统用的是CentOS5.6(32bit)。
Linux上常用的是bind,包括以下软件包:
bind bind-libs bind-utils bind-chroot caching-nameserver
bind是DNS服务器软件
bind-libs是bind使用的库
bind-utils是bind查询工具
caching-nameserver唯高速缓存服务器
一、安装DNS服务器
1.开始安装DNS服务器:
yum install bind bind-libs bind-utils bind-chroot
这里更新源上的版本是bind 9.3.6-16.P1.el5,DNS的配置文件放在/var/named/chroot目录下。
2.复制配置规范文件:
cp /usr/share/doc/bind-9.3.6/sample/etc/* /var/named/chroot/etc
cp -a /usr/share/doc/bind-9.3.6/sample/var/named/* /var/named/chroot/var/named
相关配置文件说明:
主配置文件:/var/named/chroot/etc/named.conf 设置一般的named参数,指向该服务器使用的域数据库的信息源。
根域名服务器指向文件:/var/named/chroot/var/named/named.root 指向根域名服务器,用于唯高速缓存服务器的初始配置。
正向解析文件:/var/named/chroot/var/named/localhost.zone localhost区文件,用于将名字localhost转换为本地回送IP地址(127.0.0.1),正向解析。
反向解析文件:/var/named/chroot/var/named/named.local localhost区文件,用于将本地回送IP地址(127.0.0.1)转换成名字localhost,反向解析。
3.尝试启动DNS服务器:
service named restart
显示:
Stopping named: [ OK ]
Starting named: [FAILED]
查看系统日志:
cat /var/log/messages |grep named
发现错误:
my named[1384]: /etc/named.conf:100 configuring key ‘ddns_key’: bad base64 encoding
是没有ddns_key造成的,执行/usr/sbin/dns-keygen来生成TSIG keys。然后替换named.conf中
secret “use /usr/sbin/dns-keygen to generate TSIG keys”;引号内的内容。
/usr/sbin/dns-keygen
5L6JQccNVZ53CHA3iW4VnPgDZXdcX3U3pnhL2txKUsaPqwBRddE58LpA7uiI
编辑/var/named/chroot/etc/named.conf文件,添加ddns_key:
vim /var/named/chroot/etc/named.conf
修改如下:
key ddns_key
{
algorithm hmac-md5;
secret “5L6JQccNVZ53CHA3iW4VnPgDZXdcX3U3pnhL2txKUsaPqwBRddE58LpA7uiI”;
};
添加好ddns_key后,重启named服务成功,但是DNS服务器还不能使用,需要进行其他配置。
4.我们看到在named.conf文件中有这样几个区块:
options //设置data相关文件,对data/目录要有写的权限
logging //debug log
view “localhost_resolver” //本地解析,caching only nameserver
view “internal” //限定同一个局域网的内部用户使用
key ddns_key //设置ddns key
view “external” //限制外部用户请求这个DNS服务器
5.首先设置/var/named/chroot/var/named/data目录的用户和组为named:named:
cd /var/named/chroot/var/named
chown named:named data
6.为/var/named/chroot/var/named目录添加写权限:
cd /var/named/chroot/var
chmod g+w named
如果这个目录没有写权限的话,named服务可以启动,但是系统日志里会有,”the working directory is not writable”错误。
7.修改name.conf中view “external”区域内设置:
vim /var/named/chroot/etc/named.conf
recursion yes; //打开递归
allow-query-cache { any; }; //允许查询缓存
8.再重启DNS服务器:
service named restart
Stopping named: [ OK ]
Starting named: [ OK ]
启动成功。
此时查看日志:
tail -30 /var/log/messages |grep named
没有报错即可。
9.设置开机自启动:
chkconfig –level named 345 on
此时这个DNS服务器就可以使用了。
windows系统下修改网络连接里的DNS服务器地址用ping、nslookup命令测试。
linux系统修改/etc/resolv.conf里的nameserver地址,使用host、dig、nslookup命令测试。
二、配置区域主域名服务器
以test.com域为例子:
www.test.com 192.168.1.100 //web服务
ns.test.com 192.168.1.101 //域名服务
work.test.com 192.168.1.100
mail.test.com 192.168.1.103 //邮件服务
ftp.test.com 192.168.1.104 //文件服务
1.编辑/var/named/chroot/etc/named.rfc1912.zones文件:
vim /var/named/chroot/etc/named.rfc1912.zones
在最后添加正向解析区域test.com:
zone “test.com” IN {
type master;
file “test.com.zone”;
allow-update { none; };
};
然后添加反向解析区域1.168.192.in-addr.arpa:
zone “1.168.192.in-addr.arpa” IN {
type master;
file “test.com.resv”;
allow-update { none; };
};
2.创建正向解析数据文件/var/named/chroot/var/named/test.com.zone:
cd /var/named/chroot/var/named
cp localhost.zone test.com.zone
3.编辑test.com.zone文件:
vim test.com.zone
修改如下
$TTL 86400
@ IN SOA @ root (
42 ; serial (d. adams)
3H ; refresh
15M ; retry
1W ; expiry
1D ) ; minimum
IN NS ns.test.com.
www IN A 192.168.1.100
ns IN A 192.168.1.101
work IN CNAME www
mail IN A 192.168.1.103
@ IN MX 10 mail.test.com.
ftp IN A 192.168.1.104
4.创建反向解析数据文件/var/named/chroot/var/named/test.com.resv:
cp named.local test.com.resv
5.编辑test.com.resv文件:
vim test.com.resv
修改如下
$TTL 86400
@ IN SOA localhost. root.localhost. (
1997022700 ; Serial
28800 ; Refresh
14400 ; Retry
3600000 ; Expire
86400 ) ; Minimum
IN NS ns.test.com.
100 IN PTR www.test.com.
101 IN PTR ns.test.com.
103 IN PTR mail.test.com.
104 IN PTR ftp.test.com.
6.编辑named.conf,将test.com区域加入到view “external”中:
vim /var/named/chroot/etc/named.conf
由于zone “test.com”是写在named.rfc1912.zones文件中的,在view “external”中添加:
include “/etc/named.rfc1912.zones”;
7.重启服务:
service named restart
此时客户端请求解析test.com域会直接使用设置的参数,不会向根去询问。
三、配置辅域名服务器
配置辅域名服务器相对来说简单不少,只要主配置文件中加入一个区域,然后指定可以更新信息的主域名服务器就可以了,无需配置区域数据库文件。
1.编辑/var/named/chroot/etc/named.rfc1912.zones文件:
vim /var/named/chroot/etc/named.rfc1912.zones
在最后添加正向解析区域test.com:
zone “test.com” IN {
type slave;
file “slaves/test.com.hosts”;
masters { 1.1.1.1; }; //这里填主DNS服务器IP
};
然后添加反向解析区域1.168.192.in-addr.arpa:
zone “1.168.192.in-addr.arpa” IN {
type slave;
file “slaves/test.com.resv”;
masters { 1.1.1.1; }; //这里填主DNS服务器IP
};
2.编辑named.conf,将named.rfc1912.zones文件加入到view “external”中:
vim /var/named/chroot/etc/named.conf
在view “external”中添加:
include “/etc/named.rfc1912.zones”;
3.设置/var/named/chroot/var/named/slaves目录用户和组为root:named:
cd /var/named/chroot/var/named
chown root:named slaves
为/var/named/chroot/var/named/slaves添加写权限:
chmod g+w slaves
named用户对slaves目录没有写权限会同步不了主域名服务器上的解析数据文件。
4.重启DNS服务:
service named restart
5.查看/var/named/chroot/var/named/slaves目录:
产生test.com.hosts test.com.resv文件,说明更新成功。
需要注意:
1)主从服务器中正/反向zone名称必须一致。
2)从服务器中file可指定相对路径,也可指定绝对路径。
3)需将辅助DNS服务器的首选DNS服务器指向为主DNS服务器。
参考资料:
http://www.cnblogs.com/cabin/archive/2010/10/18/1848168.html
http://www.linux.gov.cn/netweb/
http://blog.iuhux.com/2011/08/11/%E5%9C%A8centos%E7%9A%84vps%E4%B8%8A%E5%AE%89%E8%A3%85dns%E6%9C%8D%E5%8A%A1%E5%99%A8/
posted @
2011-11-21 16:25 Alpha 阅读(3633) |
评论 (1) |
编辑 收藏posted @
2011-11-18 10:51 Alpha 阅读(449) |
评论 (0) |
编辑 收藏
[root@Hammer home]# rpm -qa |grep rsync #检查系统是否安装了rsync软件包
rsync-2.6.8-3.1
[root@Hammer CentOS]# rpm -ivh rsync-2.6.8-3.1.i386.rpm # 如果没有安装则手动安装
[root@test rsync-3.0.4]# vim /etc/xinetd.d/rsync
1 配置rsync servervi /etc/xinetd.d/rsync
将disable=yes改为no
service rsync
{
disable = no
socket_type = stream
wait = no
user = root
server = /usr/bin/rsync
server_args = --daemon
log_on_failure += USERID
}
2 配置rsync自动启动
[root@test etc]# chkconfig rsync on
[root@test etc]# chkconfig rsync --list
rsync on
3 配置rsyncd.conf
[root@test etc]# vim rsyncd.conf
uid = root
gid = root
use chroot = no
max connections = 4
strict modes = yes
port = 873
pid file = /var/run/rsyncd.pid
lock file = /var/run/rsync.lock
log file = /var/log/rsyncd.log
[backup]
path = /srv
comment = This is test
auth users = scihoo
uid = root
gid = root
secrets file = /home/rsync.ps
read only = no
list = no
4 确保etc/services中rsync端口号正确
[root@test etc]# vim /etc/services
rsync 873/tcp # rsync
rsync 873/udp # rsync
5 配置rsync密码(在上边的配置文件中已经写好路径)/home/rsync.ps(名字随便写,只要和上边配置文件里的一致即可),格式(一行一个用户)
[root@test etc]# vi /home/rsync.ps
scihoo:scihoo
6 配置rsync密码文件权限
[root@test home]# chown root.root rsync.ps
[root@test home]# chmod 400 rsync.ps
7 启动配置
[root@test home]# /etc/init.d/xinetd restart
Stopping xinetd: [ OK ]
Starting xinetd: [ OK ]
8 如果xinetd没有的话,需要安装一下
[root@test home]# yum -y install xinetd
启动rsync server
RSYNC服务端启动的两种方法
9、启动rsync服务端(独立启动)
[root@test home]# /usr/bin/rsync --daemon
10、启动rsync服务端 (有xinetd超级进程启动)
[root@test home]# /etc/init.d/xinetd reload
11 加入rc.local
在各种操作系统中,rc文件存放位置不尽相同,可以修改使系统启动时把rsync --daemon加载进去。
[root@test home]# vi /etc/rc.local
/usr/local/rsync –daemon #加入一行
12 检查rsync是否启动
[root@test home]# lsof -i :873
COMMAND PID USER FD TYPE DEVICE SIZE NODE NAME
xinetd 4396 root 5u IPv4 633387 TCP *:rsync (LISTEN)
客户端配置
1 配置三个过程就可以了
1.1 设定密码文件
1.2 测试rsync执行指令
1.3 将rsync指令放入工作排程(crontab)
[root@aj1 home]# vi /etc/xinetd.d/rsync
# default: off
# description: The rsync server is a good addition to an ftp server, as it \
# allows crc checksumming etc.
service rsync
{
disable = yes
socket_type = stream
wait = no
user = root
server = /usr/bin/rsync
server_args = --daemon
log_on_failure += USERID
}
1.1 配置密码文件 (注:为了安全,设定密码档案的属性为:600。rsync.ps的密码一定要和Rsync Server密码设定案里的密码一样)
[root@aj1 home]# vi rsync.ps
sciooo
[root@aj1 home]# chown root.root .rsync.ps # 注意必须给权限
[root@aj1 home]# chmod 600 .rsync.ps # 必须修改权限
1.2 从服务器上下载文件
[root@aj1 rsync-3.0.4]# rsync -avz --password-file=/home/rsync.ps scihoo@192.168.0.206::backup /home/
从本地上传到服务器上去
[root@aj1 rsync-3.0.4]# rsync -avz --password-file=/home/rsync.ps /home scihoo@192.168.0.206::backup
http://www.linuxsir.org/main/?q=node/256#5.1
http://os.51cto.com/art/201101/243374.htm
posted @
2011-06-30 15:04 Alpha 阅读(15686) |
评论 (3) |
编辑 收藏前些时间在VMware上安装了Gentoo Linux,用了当前最新版的Gentoo,安装过程记录下来了,但一直没有整理到blog上。今天重新整理一下,写出来与大家分享和备用。接触Gentoo不久,对这个版本还不是很熟。
与其他Linux发行版相比,Gentoo确实有其优势的地方,如内核基于源代码编译,可以自动优化与定制,升级方便等!
关于Gentoo发行版的介绍请看:全球最受欢迎的十大Linux发行版(图)
Host机环境:Win2008 + VMware 7.1
下载安装包
下载安装 CD 和 stage3 包:
http://www.gentoo.org/main/en/where.xml
我用的是 x86平台的:
http://distfiles.gentoo.org/releases/x86/autobuilds/current-iso/
wget -c http://distfiles.gentoo.org/releases/x86/autobuilds/current-iso/install-x86-minimal-20100216.iso
wget -c http://distfiles.gentoo.org/releases/x86/autobuilds/current-iso/stage3-i686-20100216.tar.bz2
wget -c http://distfiles.gentoo.org/snapshots/portage-20100617.tar.bz2
最新的stage3包在这里:http://distfiles.gentoo.org/releases/x86/autobuilds/current-stage3/
开始安装
将安装 CD 插入虚拟机,默认引导进入终端。
先配置好网络,之后的操作可以全部通过 ssh 连接来操作。
ifconfig eth0 192.168.80.133(我这里VM已经自动分配了这个内网IP了。)
echo nameserver 8.8.8.8 > /etc/resolv.conf
echo nameserver 8.8.4.4 > /etc/resolv.conf

设置 root 用户密码:
passwd root
启动 sshd 服务:
/etc/init.d/sshd start
在windows上用SecureCRT或PuTTY连接虚拟机操作。
磁盘分区
先分区,建议使用cfdisk,先查看分区情况:
cfdisk /dev/sda
我的分区表(/boot分区我单独分出来),/dev/sda2是/根分区,/dev/sda3是swap分区:

格式化分区:
mkfs.ext3 /dev/sda1
mkfs.ext3 /dev/sda2
mkswap /dev/sda3

激活swap交换分区:
swapon /dev/sda3
将分区信息写入fstab配置文件:(注:gentoo-minimal没带vi编辑器,只带有nano编辑器。)
nano -w /etc/fstab
写入下面的分区信息:
/dev/sda1 /boot ext3 noauto,noatime 1 2
/dev/sda2 / ext3 noatime 0 1
/dev/sda3 none swap sw 0 0
解压 stage3 和 portage
创建基本目录结构:
mount /dev/sda2 /mnt/gentoo
mkdir /mnt/gentoo/boot
mount /dev/sda1 /mnt/gentoo/boot
cd /mnt/gentoo
使用WinSCP或CuteFTP 上传 stage3 软件包到 /mnt/gentoo下,然后解压:

(注:上面标签的地址之前没改过来,实际地址是192.168.80.133)
tar jxvf stage3-i686-20100608.tar.bz2
rm -f stage3-i686-20100608.tar.bz2
上传 portage 包到 /mnt/gentoo/usr,然后解压:
tar jxvf portage-20100617.tar.bz2
rm -f portage-20100617.tar.bz2
切换系统
cd /
mount -t proc proc /mnt/gentoo/proc
mount -o bind /dev /mnt/gentoo/dev
cp -L /etc/resolv.conf /mnt/gentoo/etc/
chroot /mnt/gentoo /bin/bash
env-update && source /etc/profile
主机域名设置
cd /etc
echo “127.0.0.1 gentoo.at.home gentoo localhost” > hosts
sed -i -e ’s/HOSTNAME.*/HOSTNAME=”gentoo”/’ conf.d/hostname
hostname gentoo
编译安装内核
lsmod
找到网卡驱动模块:
floppy 55736 0
rtc 7960 0
tg3 103228 0
libphy 24952 1 tg3
e1000 114636 0
fuse 59344 0
jfs 153104 0
raid10 20648 0
下载源码,配置内核:
emerge –sync
emerge gentoo-sources
cd /usr/src/linux
make menuconfig

在配置界面输入/e1000,搜索 e1000,找到驱动所在位置:

| Symbol: E1000 [=y]
| Prompt: Intel(R) PRO/1000 Gigabit Ethernet support
| Defined at drivers/net/Kconfig:2020
| Depends on: NETDEVICES && NETDEV_1000 && PCI
| Location:
| -> Device Drivers
| -> Network device support (NETDEVICES [=y])
| -> Ethernet (1000 Mbit) (NETDEV_1000 [=y])
(这里一定要注意,选对内核的网卡驱动!)
虚拟机的硬盘使用的 SCSI 适配器为 LSI Logic。
需要增加对 Fusion MPT base driver 的支持(见 dmesg 日志):

Device Drivers —>
— Fusion MPT device support
<*> Fusion MPT ScsiHost drivers for SPI
<*> Fusion MPT ScsiHost drivers for FC
<*> Fusion MPT ScsiHost drivers for SAS
(128) Maximum number of scatter gather entries (16 – 128)
<*> Fusion MPT misc device (ioctl) driver
必须添加这个驱动,否则系统启动时可能出现类似以下错误:
VFS: Unable to mount root fs via NFS, trying floppy.
VFS: Cannot open root device “sda2”or unknown-block(2,0)
Please append a correct “root=” boot option; here are the available partitions:
0b00 1048575 sr0 driver: sr
Kernel panic – not syncing: VFS: Unable to mount root fs on unknown-block(2,0)
增加对 ext4文件系统的支持:
File systems —>
<*> Second extended fs support
[*] Ext4 extended attributes
[*] Ext4 POSIX Access Control Lists
[*] Ext4 Security Labels
[*] Ext4 debugging support
开始编译内核:
make -j2
make modules_install
cp arch/x86/boot/bzImage /boot/kernel

安装配置 grub
emerge grub
grub
> root (hd0,0)
> setup (hd0)
> quit
编辑启动配置文件grub.conf:
nano -w /boot/grub/grub.conf
grub.conf 内容如下:
default 0
timeout 9
title Gentoo
root (hd0,0)
kernel /boot/kernel root=/dev/sda2
系统配置
文件系统挂载点:
nano -w /etc/fstab
/dev/sda1 /boot ext3 noauto,noatime 1 2
/dev/sda2 / ext3 noatime 0 1
/dev/sda3 none swap sw 0 0
网络设置:
echo ‘config_eth0=( “192.168.80.133″ )’ >> /etc/conf.d/net
echo ‘routes_eth0=( “default via 192.168.80.2″ )’ >> /etc/conf.d/net
SSH服务设置:
rc-update add sshd default
时区设置:
cp /usr/share/zoneinfo/Asia/Shanghai /etc/localtime
nano -w /etc/conf.d/clock
设置 root 密码:
passwd root
重启,完成安装
exit
umount /mnt/gentoo/dev /mnt/gentoo/proc /mnt/gentoo/boot /mnt/gentoo
reboot
如图,Gentoo启动成功:

OK,完成!
附 make.conf
 CFLAGS="-march=native -O2 -pipe -fomit-frame-pointer -mmmx -msse -msse2"
CFLAGS="-march=native -O2 -pipe -fomit-frame-pointer -mmmx -msse -msse2"
CXXFLAGS="${CFLAGS}"
MAKEOPTS="-j5"
CHOST="x86_64-pc-linux-gnu"
USE="jpeg ssl nls unicode cjk zh nptl nptlonly mmx sse sse2 -X -gtk -gnome \
sasl maildir imap libwww mysql xml sockets vhosts snmp \
-lvm -lvm1 -kde -qt -cups -alsa -apache"
ACCEPT_KEYWORDS="~amd64"
LINGUAS="zh_CN"
SYNC="rsync://rsync.asia.gentoo.org/gentoo-portage"
GENTOO_MIRRORS="http://mirrors.163.com/gentoo ftp://gg3.net/pub/linux/gentoo"
VIDEO_CARDS="vesa"
ALSA_CARDS=""
ALSA_PCM_PLUGINS=""
APACHE2_MODULES=""
QEMU_SOFTMMU_TARGETS="i386 x86_64"
QEMU_USER_TARGETS="i386 x86_64"
参考文档
http://www.gentoo.org/doc/zh_cn/handbook/handbook-amd64.xml
参考:http://www.ha97.com/
posted @
2011-06-28 16:03 Alpha 阅读(3982) |
评论 (1) |
编辑 收藏在页面中使用gzip可以有效的减低页面的大小,加快网页的下载速度。在lighttpd中对php页面进行压缩,需要两个步骤:
1. 编辑 lighttpd.conf
将 “mod_compress” 设为启用
接著找到
## compress module
在下面加入
compress.cache-dir = “/var/tmp/lighttpd/cache/”
compress.filetype = (”text/plain”, “text/html”, “text/css”, “text/javascript”)
做完上面的动作后,
基本上 .txt .html .css .js 的文件都会被Gzip压缩了。但php此时还没有压缩
对于动态的php文件,还需要在php.ini中做相关设置,否则.php页面还是不使用压缩模式
2. 编辑 php.ini
修改
zlib.output_compression = On
zlib.output_handler = On
重新启动Lighttpd。
这样php也压缩了
posted @
2011-06-22 23:25 Alpha 阅读(799) |
评论 (0) |
编辑 收藏Lighttpd 作为新一代的web server,以小巧(不到1M的大小)、快速而著称,因为服务器上安装了rails、java,并以lighttpd为前端代理服务器,不想再部署apache了,所以直接使用lighttpd来部署,顺便看一下性能如何。
本文主要介绍在CentOS下,配置一套用lighttp作为web server的php环境
· 安装Lighttpd
从http://www.lighttpd.net/download/下载源码
安装前先检查pcre是否安装,需要pcre和pcre-devel两个包。 用yum search pcre\*检查,如果都是installed就是都安装了。否则安装缺少的包。
yum
install pcre-devel
tar xzvf lighttpd-1.4.23.tar.gz
cd lighttpd-1.4.23
./configure –prefix=/usr/local/lighttpd
configure完毕以后,会给出一个激活的模块和没有激活模块的清单,可以检查一下,是否自己需要的模块都已经激活,在enable的模块中一定要有“mod_rewrite”这一项,否则重新检查pcre是否安装。然后编译安装:
make && make install
编译后配置:
cp doc/sysconfig.lighttpd /etc/sysconfig/lighttpd
mkdir /etc/lighttpd
cp doc/lighttpd.conf /etc/lighttpd/lighttpd.conf
如果你的Linux是RedHat/CentOS,那么:
cp doc/rc.lighttpd.redhat /etc/init.d/lighttpd
如果你的Linux是SuSE,那么:
cp doc/rc.lighttpd /etc/init.d/lighttpd
其他Linux发行版本可以自行参考该文件内容进行修改。然后修改/etc/init.d/lighttpd,把
lighttpd="/usr/sbin/lighttpd"
改为
lighttpd="/usr/local/lighttpd/sbin/lighttpd"
此脚本用来控制lighttpd的启动关闭和重起:
/etc/init.d/lighttpd start
/etc/init.d/lighttpd stop
/etc/init.d/lighttpd restart
如果你希望服务器启动的时候就启动lighttpd,那么:
chkconfig lighttpd on
这样lighttpd就安装好了,接下来需要配置lighttpd。
配置Lighttpd
修改/etc/lighttpd/lighttpd.conf
1)server.modules
取消需要用到模块的注释,mod_rewrite,mod_access,mod_fastcgi,mod_simple_vhost,mod_cgi,mod_compress,mod_accesslog是一般需要用到的。
2)server.document-root, server.error-log,accesslog.filename需要指定相应的目录
3)用什么权限来运行lighttpd
server.username = “nobody”
server.groupname = “nobody”
从安全角度来说,不建议用root权限运行web server,可以自行指定普通用户权限。
4)静态文件压缩
compress.cache-dir = “/tmp/lighttpd/cache/compress”
compress.filetype = (“text/plain”, “text/html”,”text/javascript”,”text/css”)
可以指定某些静态资源类型使用压缩方式传输,节省带宽,对于大量AJAX应用来说,可以极大提高页面加载速度。
5)配置ruby on rails
最简单的配置如下:
$HTTP["host"] == "www.xxx.com" {
server.document-root = "/yourrails/public"
server.error-handler-404 = "/dispatch.fcgi"
fastcgi.server = (".fcgi" =>
("localhost" =>
("min-procs" => 10,
"max-procs" => 10,
"socket" => "/tmp/lighttpd/socket/rails.socket",
"bin-path" => "/yourrails/public/dispatch.fcgi",
"bin-environment" => ("RAILS_ENV" => "production")
)
)
)
}
即由lighttpd启动10个FCGI进程,lighttpd和FCGI之间使用本机Unix Socket通信。
如果想指定www.abc.com以及所有二级域名,则需要把第一行改为
$HTTP[”host”] =~ “(^|\.)abc\.com” {
…
}
如果要设置代理,比如lighttpd和tomcat整合,tomcat放在lighttpd后面,则需要通过代理访问tomcat
$HTTP["host"] =~ “www.domain.cn” {
proxy.server = ( “” => ( “localhost” => ( “host”=> “127.0.0.1″, “port”=> 8080 ) ) )
}
则www.domain.cn为主机的网址都交给tomcat处理,tomcat的端口号为8080. 在tomcat的虚拟主机中,需要捕获www.domain.cn这个主机名,设置这个虚拟主机。这里的host都是跟tomcat里面的虚拟主机对应的。
· 安装支持fastcgi的PHP
安装PHP所需的相关类库
curl
wget http://curl.cs.pu.edu.tw/download/curl
-7.19.5.
tar.bz2
tar xvjf curl-7.19.5.tar.bz2
cd curl-7.19.5
./configure –prefix=/usr/local/curl
make
make install
gettext
wget ftp://ftp.ntu.edu.tw/pub/gnu/gnu/gettext/gettext-0.17.tar.gz
tar xvzf gettext-0.17.tar.gz
cd gettext-0.17
./configure –prefix=/usr/local/gettext
make
make install
zlib
wget http://kent.dl.sourceforge.net/sourceforge/libpng/zlib-1.2.3.tar.gz
tar xvzf zlib-1.2.3.tar.gz
cd zlib-1.2.3
./configure –prefix=/usr/local/zlib
make && make install
libpng
wget http://www.mirrorservice.org/sites/download.sourceforge.net/pub/sourceforge/l/li/libpng/libpng-1.2.9.tar.gz
tar xvzf libpng-1.2.9.tar.gz
cd libpng-1.2.9
./configure –prefix=/usr/local/libpng
make && make install
jpeg
wget http://www.ijg.org/files/jpegsrc.v6b.
tar.gz
tar xvzf jpegsrc.v6b.
tar.gz
cd jpeg-6b/
./configure –
prefix=/usr/
local/jpeg6
make
mkdir /usr/local/jpeg6/bin
mkdir -p /usr/local/jpeg6/bin
mkdir -p /usr/local/jpeg6/man/man1
mkdir -p /usr/local/jpeg6/lib
mkdir -p /usr/local/jpeg6/include
make install-lib
make install
freetype
wget http://download.savannah.gnu.org/releases/freetype/freetype-2.3.9.tar.gz
tar xvzf freetype-2.3.9.tar.gz
cd freetype-2.3.9
./configure –prefix=/usr/local/freetype2
make
make install
gd
wget http://www.libgd.org/releases/gd-2.0.35.tar.gz
tar xvzf gd-2.0.35.tar.gz
cd gd-2.0.35
./configure –prefix=/usr/local/gd2 –with-zlib=/usr/local/zlib/ –with-png=/usr/local/libpng/ –with-jpeg=/usr/local/jpeg6/ –with-freetype=/usr/local/freetype2/
make
如果第一次make出错,试着再make一次,我就是这样,第二次就对了。
make install
PHP
tar xvzf php
-5.2.10.
tar.gz
cd php
-5.2.10
./configure –
prefix=/usr/
local/php –with-
mysql=/usr/
local/mysql –with-pdo-
mysql=/usr/
local/mysql –with-jpeg-
dir=/usr/
local/jpeg6/ –with-png-
dir=/usr/
local/libpng/ –with-
gd=/usr/
local/gd2/ –with-freetype-
dir=/usr/
local/freetype2/ –with-zlib-
dir=/usr/
local/zlib –with-
curl=/usr/
local/curl –with-
gettext=/usr/
local/
gettext –enable-fastcgi –enable-zend-multibyte –with-config-file-
path=/etc –enable-discard-path –enable-force-cgi-redirect
make
make install
cp php.ini-dist /etc/php.ini
可以使用php -m查看你安装的模块
eAccelerator
eAccelerator是一个开源的PHP加速器
wget http://bart.eaccelerator.net/source/0.9.5.3/eaccelerator-0.9.5.3.tar.bz2
tar xjvf eaccelerator-0.9.5.3.tar.bz2
cd eaccelerator-0.9.5.3
export PHP_PREFIX="/usr/local/php"
$PHP_PREFIX/bin/phpize
./configure –enable-eaccelerator=shared –with-php-config=$PHP_PREFIX/bin/php-config
make
make install
执行好后,会提示安装到的路径,下面会用到,如我的被安装到这里
/usr/local/php/lib/php/extensions/no-debug-non-zts-20060613
编辑php.ini中的内容
vim /etc/php.ini
cgi.fix_pathinfo =
1
zend_extension="/usr/local/php/lib/php/extensions/no-debug-non-zts-20060613/eaccelerator.so"
eaccelerator.shm_size="16"
eaccelerator.cache_dir="/tmp/eaccelerator"
eaccelerator.enable="1"
eaccelerator.optimizer="1"
eaccelerator.check_mtime="1"
eaccelerator.debug="0"
eaccelerator.filter=""
eaccelerator.shm_max="0"
eaccelerator.shm_ttl="0"
eaccelerator.shm_prune_period="0"
eaccelerator.shm_only="0"
eaccelerator.compress="1"
eaccelerator.compress_level="9"
如果一切顺利,你可以通过下面命令来验证是否安装成功
$ php -v
PHP 5.2.10 (cli) (built: Jun 20 2009 23:32:09)
Copyright (c) 1997-2009 The PHP Group
Zend Engine v2.2.0, Copyright (c) 1998-2009 Zend Technologies
with eAccelerator v0.9.5.3, Copyright (c) 2004-2006 eAccelerator, by eAccelerator
修改/etc/lighttpd/lighttpd.conf文件,添加下面的配置
vim /etc/lighttpd/lighttpd.conf
fastcgi.server = ( ".php" =>
( "localhost" =>
(
"socket" => "/tmp/php-fastcgi.socket",
"bin-path" => "/usr/local/php/bin/php-cgi"
)
)
)
重启lighttpd
/etc/init.d/lighttpd restart
写一个php测试文件在lighttpd的网站目录里,测试php是否安装成功
http://blog.prosight.me/
posted @
2011-06-22 23:24 Alpha 阅读(1784) |
评论 (0) |
编辑 收藏使用proxy可以使lighttpd成为一个代理服务器。例如将java的请求全都转向给jboss来处理
mod_proxy有三个标签:
proxy.debug,0或者1. 表示是否启动调试模式。 1表示启动
proxy.balance,使用负载均衡的模式。可以使“hash”,“round-robin”,”fair”三种模式之一。
’round-robin’ 交替轮训, ‘hash’ 根据请求的url产生一个 hash值,来确保同样的请求的url都访问同样的主机
‘fair’ is the normal load-based, passive balancing.
语法结构
( <extension> =>
( [ <name> => ]
( "host" => <string> ,
"port" => <integer> ),
( "host" => <string> ,
"port" => <integer> )
),
<extension> => …
)
* : 表示请求url的文件扩展名或者文件前缀 (如果以”/”开始); 可以是空 (“”) 表示所有的请求
* : 可选名称
* “host”: 被代理的服务器的ip
* “port”: 被代理服务器的端口,默认是80
如:
proxy.server = ( ".jsp" =>
( (
"host" => "10.0.0.242",
"port" => 8080
) )
)
再如:
$HTTP["host"] == "www.domain.me" {
proxy.server = ( "" =>
( (
"host" => "127.0.0.1",
"port"=>"8080"
) )
)
}
负载均衡的例子,例如有8个squid缓存,需要用lighttpd做负载均衡
$HTTP["host"] == "www.example.org" {
proxy.balance = "hash"
proxy.server = ( "" => ( ( "host" => "10.0.0.10" ),
( "host" => "10.0.0.11" ),
( "host" => "10.0.0.12" ),
( "host" => "10.0.0.13" ),
( "host" => "10.0.0.14" ),
( "host" => "10.0.0.15" ),
( "host" => "10.0.0.16" ),
( "host" => "10.0.0.17" ) ) )
}
当一个服务器宕机后,它上面的请求将被转移给其他设备server
posted @
2011-06-22 23:20 Alpha 阅读(2323) |
评论 (0) |
编辑 收藏
摘要: 花了一个上午的时间研究nginx+tomcat的负载均衡测试,集群环境搭建比较顺利,但是session同步的问题折腾了几个小时才搞定,现把我的过程贴上来,以备用。
软件及环境是:
虚拟机上装centos 5.5
IP为:192.168.0.51 装上nginx和tomcat 6.0.32 命名为 Tomcat1
一台win7上装tomcat 6.0.32 ...
阅读全文
posted @
2011-06-21 15:38 Alpha 阅读(20431) |
评论 (5) |
编辑 收藏
CATALINA_BASE D:\tomcat
CATALINA_HOME D:\tomcat
CLASSPATH .;D:\Java\jdk1.6.0_24\lib;D:\Java\jdk1.6.0_24\lib\dt.jar;D:\Java\jdk1.6.0_24\lib\tools.jar;D:\tomcat\lib\servlet-api.jar
JAVA_HOME D:\Java\jdk1.6.0_24
Path ;D:\Java\jdk1.6.0_24\bin
TOMCAT_HOME D:\tomcat
posted @
2011-05-09 16:29 Alpha 阅读(583) |
评论 (0) |
编辑 收藏数据的唯一性是所有应用程序非常基本的要求,由开发者或者用户来维护这种唯一性存在着较大的风险,因此,由系统自动产生唯一标识是一种常见的做法。OpenJPA 中支持四种不同的实体标识自动生成策略:
- 容器自动生成的实体标识;
- 使用数据库的自动增长字段生成实体标识;
- 根据数据库序列号(Sequence)技术生成实体标识;
- 使用数据库表的字段生成实体标识;
这四种方式各有优缺点,开发者可以根据实际情况进行选择。
可选择的注释
要让容器和数据库结合管理实体标识的自动生成,根据实际情况的不同,开发者可以选择 javax.persistence.*包下面的 GeneratedValue、SequenceGenerator、TableGenerator三个注释来描述实体的标识字段。
@javax.persistence.GeneratedValue
每一个需要自动生成实体标识的实体都需要为它的实体标识字段提供 GeneratedValue注释和相应的参数,OpenJPA 框架会根据注释和参数来处理实体标识的自动生成。
使用 GeneratedValue注释自动生成的实体标识可以是数值类型字段如 byte、short、int、long等,或者它们对应的包装器类型 Byte、Short、Integer、Long等,也可以是字符串类型。
GeneratedValue注释可以支持两个属性 strategy和 generator。
strategy
strategy是 GenerationType类型的枚举值,它的内容将指定 OpenJPA 容器自动生成实体标识的方式。strategy属性可以是下列枚举值:
GeneratorType.AUTO
表示实体标识由 OpenJPA 容器自动生成,这也是 Strategy 属性的默认值。
GenerationType.IDENTITY
OpenJPA 容器将使用数据库的自增长字段为新增加的实体对象赋唯一值,作为实体的标识。这种情况下需要数据库提供对自增长字段的支持,常用的数据库中,HSQL、SQL Server、MySQL、DB2、Derby 等数据库都能够提供这种支持。
GenerationType.SEQUENCE
表示使用数据库的序列号为新增加的实体对象赋唯一值,作为实体的标识。这种情况下需要数据库提供对序列号的支持,常用的数据库中,Oracle、PostgreSQL 等数据库都能够提供这种支持。
GenerationType.TABLE
表示使用数据库中指定表的某个字段记录实体对象的标识,通过该字段的增长为新增加的实体对象赋唯一值,作为实体的标识。
String generator
generator属性中定义实体标识生成器的名称。如果实体的标识自动生成策略不是 GenerationType.AUTO或者 GenerationType.IDENTITY,就需要提供相应的 SequenceGenerator或者 TableGenerator注释,然后将 generator属性值设置为注释的 name属性值。
@javax.persistence.SequenceGenerator
如果实体标识的自动生策略是 GenerationType.SEQUENCE,开发者需要为实体标识字段提供 SequenceGenerator注释,它的参数描述了使用序列号生成实体标识的具体细节。该注释支持以下四个属性:
表 1. SequenceGenerator 注释属性说明
| 属性 |
说明 |
name |
该属性是必须设置的属性,它表示了 SequenceGenerator注释在 OpenJPA 容器中的唯一名称,将会被 GeneratedValue注释的 generator属性使用。将实体标识的自动生成委托给数据库的序列号特性时,实体标识字段的 GeneratedValue注释的 generator属性的值必须和某个 SequenceGenerator注释的 name属性值保持一致。 |
sequenceName |
实体标识所使用的数据库序列号的名称。该属性是可选的,如果我们没有为该属性设置值,OpenJPA 框架将自动创建名为 OPENJPA_SEQUENCE的序列号。如果一个 OpenJPA 容器中管理的多个实体都选择使用序列号机制生成实体标识,而且实体类中都没有指定标识字段的 sequenceName属性,那么这些实体将会共享系统提供的默认名为 OPENJPA_SEQUENCE的序列号。这可能引起实体类编号的不连续。我们可以用下面的这个简单例子说明这种情况:假设 OpenJPA 容器中存在两个实体类 Dog 和 Fish,它们的实体标识字段都是数值型,并且都选择使用序列号生成实体标识,但是实体类中并没有提供 sequenceName属性值。当我们首先持久化一个 Dog 对象时,它的实体标识将会是 1,紧接着我们持久化一个 Fish 对象,它的实体标识就是 2,依次类推。 |
initialValue |
该属性设置所使用序列号的起始值。 |
allocationSize |
一些数据库的序列化机制允许预先分配序列号,比如 Oracle,这种预先分配机制可以一次性生成多个序列号,然后放在 cache 中,数据库用户获取的序列号是从序列号 cache 中获取的,这样就避免了在每一次数据库用户获取序列号的时候都要重新生成序列号。allocationSize属性设置的就是一次预先分配序列号的数目,默认情况下 allocationSize属性的值是 50。 |
@javax.persistence.TableGenerator
如果实体标识的自动生策略是 GenerationType.TABLE,开发者需要为实体标识字段提供 TableGenerator 注释,它的参数描述了使用数据库表生成实体标识的具体细节。该注释支持下列属性:
表 2. TableGenerator 注释属性说明
| 属性 |
说明 |
name |
该属性是必须设置的属性,它表示了 TableGenerator注释在 OpenJPA 容器中的唯一名称,将会被 GeneratedValue注释的 generator属性所使用。将实体标识的自动生成委托给数据库表时,实体标识字段的 GeneratedValue注释的 generator属性的值必须和某个 TableGenerator注释的 name属性值保持一致。 |
table |
该属性设置的是生成序列号的表的名称。该属性并不是必须设置的属性,如果开发者没有为该属性设置值,OpenJPA 容器将会使用默认的表名 OPENJPA_SEQUENCES_TABLE。 |
schema |
该属性设置的是生成序列号的表的 schema。该属性并不是必须设置的属性,如果开发者没有为该属性设置值,OpenJPA 容器将会默认使用当前数据库用户对应的 schema。 |
catalog |
该属性设置的是生成序列号的表的 catalog。该属性并不是必须设置的属性,如果开发者没有为该属性设置值,OpenJPA 容器将会使用默认当前数据库用户对应的 catalog。 |
pkColumnName |
该属性设置的是生成序列号的表中的主键字段的名称,该字段将保存代表每个实体对应的标识值对应的特征字符串。该属性并不是必须设置的属性,如果开发者没有为该属性设置值,OpenJPA 容器将会使用默认值 ID。 |
valueColumnName |
该属性设置的是生成序列号的表中记录实体对应标识最大值的字段的名称。该属性并不是必须设置的属性,如果开发者没有为该 属性设置值,OpenJPA 容器将会使用默认值 SEQUENCE_VALUE。 |
pkColumnValue |
该属性设置的是生成序列号的表中的主键字段的特征字符串值 ( 比如 customID ),该字段将保存代表每个实体对应的标识值对应的特征字符串。该属性并不是必须设置的属性,如果开发者没有为该属性设置值,OpenJPA 容器将会使用默认值 DEFAULT。可以为多个实体设置相同的 pkColumnValue属性值,这些实体标识的生成将通过同一列的值的递增来实现。 |
initialValue |
该属性设置的是生成序列号的表实体标识的初始值。该属性并不是必须设置的属性,如果开发者没有为该属性设置值,OpenJPA 容器将会使用默认值 0 。 |
allocationSize |
为了降低标识生成时频繁操作数据库造成 的性能上的影响,实体标识生成的时候会一次性的获取多个实体标识,该属性设置的就是一次性获取实体标识的数目。该属性并不是必须设置的属性,如果开发者没有为该属性设置值,OpenJPA 容器将会使用默认值 50 。 |
回页首
实体标识自动生成
在上面的小节中,我们了解了和实体标识自动生成相关的注释,接下来我们将结合一个简单的例子讲述如何分别使用这些实体标识自动生成策略实现实体标识的自动生成。
我们首先假设有一个 Animal实体需要被持久化,它包括 ID和 NAME属性,其中 ID是它的主键字段。Animal实体的标识需要自动生成,我们将分析在这四种不用的情况下,如何使用 OpenJPA 提供的注释,结合具体数据库支持的特性,如自增长字段、序列号等来实现实体标识的自动生成。
容器自动生成
OpenJPA 容器默认的实体标识自动生成策略是由容器管理实体标识的自动生成,容器管理的实体标识可以支持数值型和字符型两种。当容器管理的实体标识是数字型时,OpenJPA 容器自动创建一个数据库表 OPENJPA_SEQUENCE_TABLE,用其中的 SEQUENCE_VALUE字段来记录实体的实体标识的增长。
当容器管理的实体标识是字符串类型时,OpenJPA 支持使用 uuid-string 和 uuid-hex 两种方式生成相应的实体标识。如果我们选择使用 uuid-string 方式生成实体标识时,OpenJPA 框架会自动为实体生成一个 128 位的 UUID,并且将这个 UUID 转化为使用 16 位字符表示的字符串。如果我们选择使用 uuid-hex 方式生成实体标识时,OpenJPA 框架会自动为实体生成一个 128 位的 UUID,并且将这个 UUID 转化为使用 32 位字符表示的 16 进制的字符串。
数值标识
容器管理的实体标识可以是数值型的,OpenJPA 框架管理的实体标识借助于数据库的表来实现,在运行时 OpenJPA 框架会自动在数据库中创建表 OPENJPA_SEQUENCE_TABLE。它有两个字段:ID和 SEQUENCE_VALUE,这两个字段都是数值类型,其中 ID是表的主键字段,它的内容是查询当前实体标识时所使用的关键词,默认值是 0。而 SEQUENCE_VALUE记录了当前 OpenJPA 框架中当前实体标识的历史数据,内容是已经被获取实体标识的最大数值加 1。
我们要使用注释描述 Animal实体的标识由容器自动生成,只需要为它的标识字段提供 GeneratedValue注释,并且把它的 strategy属性设置为 GenerationType.AUTO, Animal实体类的代码片断如下:
清单 1. 标识由容器自动生成的 Animal 实体类
1. import javax.persistence.Entity;
2. import javax.persistence.GeneratedValue;
3. import javax.persistence.GenerationType;
4. import javax.persistence.Id;
5.
6. @Entity
7. public class Animal {
8. @Id
9. @GeneratedValue(strategy=GenerationType.AUTO)
10. private long id;
11. private String name;
12.
13. …
14.
15. }
|
保存 Animal实体的第一个实例时,OpenJPA 框架自动调用 SQL 语句 SELECT SEQUENCE_VALUE FROM OPENJPA_SEQUENCE_TABLE WHERE ID=0,从默认保存实体标识的 OPENJPA_SEQUENCE_TABLE表中获取实体的标识,如果不存在 ID为 0 的记录,OpenJPA 框架自动将实体的标识设置为 1。
容器管理实体标识的情况下,为了获得实体标识,应用程序将不得不频繁地和数据库交互,这会影响应用程序的运行效率。OpenJPA 中使用实体标识缓存机制解决这个问题。默认情况下,当应用程序第一次获取实体标识时,OpenJPA 框架从数据库中一次性获取 50 个连续的实体标识缓存起来,当下一次应用程序需要获取实体标识时,OpenJPA 将首先检测缓存中是否存在实体标识,如果存在,OpenJPA 将直接使用缓存中的实体标识,如果不存在,OpenJPA 框架将会从数据库中再次获取 50 个连续的实体标识缓存起来,如此类推。这样的处理方式可以大大减少由于获取实体标识而产生的数据库交互,提升应用程序的运行效率。
当实体标识成功获取之后,OpenJPA 框架会把当前实体标识的最大值 +1 后持久化到数据库中。由于实体标识缓存的原因,当我们第一次获取实体标识后,OpenJPA 会将 OPENJPA_SEQUENCE_TABLE表的 SEQUENCE_VALUE的值设置为 51,当 OpenJPA 多次从数据库中获取实体标识后,SEQUENCE_VALUE的值会以 50 为单位递增,变为 101、151、201 …。
OpenJPA 缓存的实体标识不是永久存在的,只能在同一个 EntityManagerFactory管理范围内起作用,也就是说,当获取实体标识的 EntityManagerFactory对象被关闭后,这些被获取的实体标识中没有用掉的那一部分标识就丢失了,这会造成实体标识的不连续。由同一个 EntityManagerFactory对象创建的 EntityManager上下文之间则能够共享 OpenJPA 框架获取的实体标识,这意味着,我们可以使用同一个 EntityManagerFactory对象创建多个 EntityManager对象,用它来持久化实体,然后关闭它,在持久化过程中所需要的实体表示将会使用同一个实体标识的缓存区,因此不会引起实体标识的丢失。
容器管理的实体标识还有一个非常重要的特性:所有被容器管理的实体标识都是共享的。不管 OpenJPA 容器中存在多少个不同的被容器管理的实体标识,它们都会从同一个实体标识缓存中获取实体标识。我们可以用下面的例子说明这种情况:假设 OpenJPA 容器中存在两个实体类 Dog和 Fish,它们的实体标识字段都是数值型,并且都由 OpenJPA 管理。当我们首先持久化一个 Dog对象时,它的实体标识将会是 1,紧接着我们持久化一个 Fish对象,它的实体标识就是 2,依次类推。
uuid-string
要使用 uuid-string 机制自动生成实体标识,我们需要将实体主键字段的 GeneratedValue注释的 strategy属性设置为 GenarationType.AUTO,然后将 GeneratedValue注释的 generator属性设置为 uuid-string。以 Animal 实体类为例,我们只需要将 Animal 实体修改为如下内容:
清单 2. 使用 uuid-string 机制自动生成实体标识
1. import javax.persistence.Entity;
2. import javax.persistence.GeneratedValue;
3. import javax.persistence.GenerationType;
4. import javax.persistence.Id;
5.
6. @Entity
7. public class Animal {
8. @Id
9. @GeneratedValue(strategy=GenerationType.AUTO, generator = "uuid-string")
10. private String id;
11. private String name;
12.
13. …
14.
15. }
|
uuid-hex
要使用 uuid-hex 机制自动生成实体标识,我们必须将实体主键字段的 GeneratedValue注释的 strategy属性设置为 GenarationType.AUTO,然后将 GeneratedValue注释的 generator属性设置为 uuid-hex。以 Animal 实体类为例,我们只需要将 Animal 实体修改为如下内容:
清单 3. 使用 uuid-hex 机制自动生成实体标识
1. import javax.persistence.Entity;
2. import javax.persistence.GeneratedValue;
3. import javax.persistence.GenerationType;
4. import javax.persistence.Id;
5.
6. @Entity
7. public class Animal {
8. @Id
9. @GeneratedValue(strategy=GenerationType.AUTO, generator = "uuid-hex")
10. private String id;
11. private String name;
12.
13. …
14.
15. }
|
自增长字段
自增长字段是 HSQL、SQL Server、MySQL、DB2、Derby 等数据库提供的一种特性,用于为数据库的记录提供自动增长的编号,应用程序的设计者通常期望将实体标识的自动生成委托给数据库的这种特性,OpenJPA 框架中的实体标识能够满足应用程序设计者的要求,使用数据库的自增长字段为实体自动生成标识。
要将实体标识的自动生成委托给数据库的自增长字段特性,需要数据库和实体定义的双方配合才能够达到:首先,必须将实体标识字段对应的数据库列修改为自动增长列,另外还需要将实体类中实体标识字段的 GeneratedValue注释的 stragety属性的值设置为 GenerationType.IDENTITY。
我们以 Animal 实体在 HSQL 数据库中的持久化来说明如何使用自增长字段自动生成实体标识所需要采取的步骤:
首先,我们使用下面的 SQL 语句创建 Animal 表,把它的 ID字段设置为自动增长类型:
清单 4. 将 ID 字段设置为自动增长类型的 SQL 语句
CREATE TEXT TABLE ANIMAL (
ID INTEGER GENERATED BY DEFAULT AS IDENTITY(START WITH 0) NOT NULL PRIMARY KEY,
NAME VARCHAR(255) NOT NULL
)
|
在数据库部分将表的主键字段设置为自动增长字段后,在实体 Animal的定义中,我们需要将 id字段 GeneratedValue注释的 stragety属性的值设置为 GenerationType.IDENTITY。Animal 实体类修改后的代码片段如下。
清单 5. 标识由自增长字段生成的 Animal 实体类
1. import javax.persistence.Entity;
2. import javax.persistence.GeneratedValue;
3. import javax.persistence.GenerationType;
4. import javax.persistence.Id;
5.
6. @Entity
7. public class Animal {
8. @Id
9. @GeneratedValue(strategy=GenerationType.IDENTITY)
10. private long id;
11. private String name;
12.
13. …
14.
15. }
|
序列号(Sequence)
序列号是 Oracle、PostgreSQL 等数据库提供的一种特性,用于为数据库的记录提供自动增长的编号,使用 Oracle、PostgreSQL 等数据库应用程序的设计者通常期望将实体标识的自动生成委托给数据库的这种特性,OpenJPA 框架中的实体标识能够满足应用程序设计者的要求,使用数据库的序列号为实体自动生成标识。
要将实体标识的自动生成委托给数据库的序列号特性,需要数据库和实体定义的双方配合才能够达到:首先,必须在数据库中创建合适的序列号,另外还需要为实体标识字段提供 SequenceGenerator注释,设置它的参数,为实体类提供关于序列号的信息,同时将实体类中实体标识字段的 GeneratedValue注释的 stragety属性的值设置为 GenerationType.SEQUENCE,将 generator属性的值设置为 SequenceGenerator注释的 name属性的值。
我们以 Animal 实体在 Oracle 数据库中的持久化来说明如何使用自增长字段自动生成实体标识所需要采取的步骤:
首先,在 Oracle 数据库中运行下面的 SQL 语句创建名为 HelloWorldSequence的序列号,序列号支持 cache,大小为 50:
清单 6. 创建序列号的 SQL 语句
CREATE SEQUENCE HELLOWORLDSEQUENCE
START WITH 0
INCREMENT BY 1
MINVALUE 1
CACHE 50
NOCYCLE
NOORDER
|
然后,在 Oracle 数据库中,我们使用下面的 SQL 语句创建 ANIMAL表:
清单 7. 创建 ANIMAL 表
CREATE TABLE EOS52.ANIMAL
(
ID CHAR(10),
NAME VARCHAR2(100) NOT NULL,
CONSTRAINT PK_ANIMAL PRIMARY KEY (ID )
)
|
在数据库部分创建合适的序列号和相应的数据库表后,在实体 Animal的定义中,我们需要将 id字段 GeneratedValue注释的 stragety属性的值设置为 GenerationType.SEQUENCE,设置它的 generator属性的值为 SeqGenerator。我们还需要为 id字段提供另外一个相关的注释 SequenceGenerator,设置它的 name属性为 SeqGenerator,设置它 sequenceName属性为 HelloWorldSequence。Animal 实体类修改后的代码片段如下。
清单 8. 标识由序列号生成的 Animal 实体类
1. import javax.persistence.Entity;
2. import javax.persistence.GeneratedValue;
3. import javax.persistence.GenerationType;
4. import javax.persistence.Id;
5.
6. @Entity
7. public class Animal {
8. @Id
9. @GeneratedValue(strategy = GenerationType.SEQUENCE,
generator = "SeqGenerator")
10. @SequenceGenerator(name = "SeqGenerator",
sequenceName = " HelloWorldSequence")
11. private long id;
12. private String name;
13.
14. …
15.
16. }
|
数据库表
除了使用容器生成的实体标识,或者借助于数据库的自增长字段或者序列号等方式生成实体标识之外,我们还可以选择借助数据库表来自动生成实体标识。原理是我们提供一个独立的数据库表,该表的主键列 ( 假设列名 ID) 记录实体编号的特征字符串 ( 假设存在一条记录的 ID为 customID),另外一列 ( 假设列名为 SEQUENCE_VALUE) 记录该特征字符串对应实体标识的最大值。编写实体代码时,我们指定实体标识由数据库表中指定的特征字符串 ( 如 customID) 对应的列 SEQUENCE_VALUE处理,当有新的实体被持久化时,容器将获取行 customID、列 SEQUENCE_VALUE对应的数值 +1 后作为新实体的标识,同时将该列的值也自动 +1。
要将实体标识的自动生成委托给数据库表,需要数据库和实体定义的双方配合才能够达到:首先,必须在数据库中创建合适的保存实体标识的表,另外还需要为实体标识字段提供 TableGenerator注释,设置它的参数,为实体类提供关于数据库表、字段的信息,同时将实体类中实体标识字段的 GeneratedValue注释的 stragety属性的值设置为 GenerationType.Table,将 generator属性的值设置为 SequenceGenerator注释的 name属性的值。
我们以 Animal 实体类来说明使用数据库表自动生成实体标识所需要采取的步骤:我们假设存在这样的场景,Animal 实体的标识由应用程序中自定义的数据库表 MY_KEYS自动生成,MY_KEYS表中有两列,一列是 KEYID,它保存实体标识的特征值,一列是 KEYVALUE,它保存实体当前的最大编号,除此之外,我们还决定使用 ANIMALID作为 Animal 实体标识的特征字符串。
首先,在数据库中使用下面的 SQL 语句创建名为 MY_KEYS的数据库表。在 OpenJPA 容器中,如果我们没有创建 MY_KEYS表,OpenJPA 容器将帮我们自动生成对应的表结构。
清单 9. 创建数据库表 MY_KEYS
CREATE TABLE MY_KEYS (
KEYID VARCHAR(255) NOT NULL,
KEYVALUE BIGINT,
PRIMARY KEY (KEYID)
)
|
在数据库部分创建合适的数据库表后,在实体 Animal 的定义中,我们需要将 id字段 GeneratedValue注释的 stragety属性的值设置为 GenerationType.TABLE,设置它的 generator属性的值为 TableGenerator。我们还需要为 id字段提供另外一个注释 TableGenerator,设置它的 name属性为 TableGenerator,设置它的 table属性为 MYKEYS、pkColumnName属性为 KEYID、valueColumnName属性为 KEYVALUE、 ANIMALID属性为 ANIMALID。Animal 实体类修改后的代码片段如下。
清单 10. 标识由数据库表生成的 Animal 实体类
1. import javax.persistence.Entity;
2. import javax.persistence.GeneratedValue;
3. import javax.persistence.GenerationType;
4. import javax.persistence.Id;
5.
6. @Entity
7. public class Animal {
8. @Id
9. @GeneratedValue(strategy = GenerationType.TABLE,
generator = " TableGenerator ")
10. @TableGenerator(name = " TableGenerator", table = "MY_KEYS",
pkColumnName = "KEYID", valueColumnName = "KEYVALUE",
pkColumnValue = "ANIMALID")
11. private long id;
12. private String name;
13.
14. …
15.
16. }
|
回页首
调用代码
上面的章节中我们学习了分别使用四种方式来自动生成实体的标识,由于这四种情况下,Animal 实体的标识都由 OpenJPA 和数据库协作后自动生成,对于开发者而言,这个过程是透明的,因此我们可以使用相同的方式来创建这些实体:创建新的 Animal 实例的时候不再需要为主键字段提供属性值,只需要设置 Animal 实例的非标识字段 name的值即可。下面的代码演示了 Animal 实例的持久化代码,请注意代码中并没有调用 Animal 实例的 setId 方法。
清单 11. Animal 实例的持久化代码
1. EntityManagerFactory factory = Persistence.
2. createEntityManagerFactory(
3. "jpa-unit", System.getProperties());
4. EntityManager em = factory.createEntityManager();
5. em.getTransaction().begin();
6.
7. Animal animal = new Animal();
8. // 此处不需要调用 animal 的 setId 方法
9. animal.setName("ba guai!");
10. em.persist(animal);
11.
12. em.getTransaction().commit();
13. em.close();
14. em2.close();
15. factory.close();
|
回页首
总结
本文介绍了开发者使用 OpenJPA 实现实体标识自动生成时可选择使用的注释,并且结合简单的例子,分别介绍了 OpenJPA 中实现容器管理的实体标识自动生成、结合数据库自增长字段、序列号、数据库表等特性实现实体标识自动生成时注释的具体用法和操作步骤。
http://www.ibm.com/developerworks/cn/java/j-lo-openjpa5/
posted @
2011-05-03 23:06 Alpha 阅读(12994) |
评论 (0) |
编辑 收藏1,oracle中实例的创建:oracle中实例创建即SID的创建,通常在安装完oracle后,启动 配置和移植工具中的(数据库配置向导)
database configuration assistant ,按照向导去创建SID,当日利用database configuration assistant 还可以 创建数据库、配置数据选件、删除数据库、管理模板、配置自动存储管理。
2,oracle中服务的创建:在oracle实例创建完后,就可以创建服务名了。注意:连接一个实例可以有多个服务名。启动 配置和移植工具中的net manager(网络配置),按照向导开始配置 网络服务名==》TCP/IP协议==》主机名(服务端的IP地址)==》oracle8i或更高版本 服务名(即SID实例名称)==》测试 ==》完成。
3,框架中db.properties的配置:
datasource.driverClassName=oracle.jdbc.OracleDriver
datasource.url=jdbc:oracle:thin:@//127.0.0.1:1521/ORCL (注意,这个orcl就是指第二项 oracle中服务的创建)
datasource.username=card
datasource.password=1111
c3p0.minPoolSize=1
c3p0.maxPoolSize=30
hibernate.dialect=org.hibernate.dialect.Oracle10gDialect
hibernate.jdbc.batch_size=25
hibernate.jdbc.fetch_size=50
hibernate.show_sql=true
posted @
2011-05-03 22:19 Alpha 阅读(1502) |
评论 (0) |
编辑 收藏
access add all alter and any as asc audit between by char check cluster column comment
compress connect create current date decimal default delete desc distinct drop else exclusive
exists file float for from grant group having identified immediate in increment index initial
insert integer intersect into is level like lock long maxextents minus mlslabel mode modify
noaudit nocompress not nowait null number of offline on online option or order pctfree prior
privileges public raw rename resource revoke row rowid rownum rows select session set
share size smallint start successful synonym sysdate table then to trigger uid union unique
update user validate values varchar varchar2 view whenever where with
posted @
2011-05-03 22:19 Alpha 阅读(825) |
评论 (0) |
编辑 收藏posted @
2011-05-03 09:05 Alpha 阅读(453) |
评论 (0) |
编辑 收藏http://blog.s135.com/nginx_php_v6/
http://www.mike.org.cn
posted @
2011-04-27 11:29 Alpha 阅读(446) |
评论 (0) |
编辑 收藏
完善api-doc,用eclipse生成javadoc的时候发生“编码 GBK 的不可映射字符 ”其实是字符编码问题。
打开eclipse,project -> Generate javadoc 一项一项的选你要输出javadoc的项目,最后一步中VM设置行中加入以下代码
-encoding utf-8 -charset utf-8
-encoding utf-8 -charset utf-8 -J-Xmx256m
这次操作,输出的html代码不会发生“编码 GBK 的不可映射字符 ”问题,而且html字符编码都设为了UTF-8,问题彻底解决
posted @
2011-04-26 11:15 Alpha 阅读(1184) |
评论 (0) |
编辑 收藏一、简介:
BeanUtils提供对 Java反射和自省API的包装。其主要目的是利用反射机制对JavaBean的属性进行处理。我们知道,一个JavaBean通常包含了大量的属性,很多情况下,对JavaBean的处理导致大量get/set代码堆积,增加了代码长度和阅读代码的难度。
二、用法:
BeanUtils是这个包里比较常用的一个工具类,这里只介绍它的copyProperties()方法。该方法定义如下:
- public static void copyProperties(java.lang.Object dest,java.lang.Object orig)
- throws java.lang.IllegalAccessException,
- java.lang.reflect.InvocationTargetException
public static void copyProperties(java.lang.Object dest,java.lang.Object orig)
throws java.lang.IllegalAccessException,
java.lang.reflect.InvocationTargetException
如果你有两个具有很多相同属性的JavaBean,一个很常见的情况就是Struts里的PO对象(持久对象)和对应的ActionForm,例如 Teacher和TeacherForm。我们一般会在Action里从ActionForm构造一个PO对象,传统的方式是使用类似下面的语句对属性逐个赋值:
-
- TeacherForm teacherForm=(TeacherForm)form;
-
- Teacher teacher=new Teacher();
-
- teacher.setName(teacherForm.getName());
- teacher.setAge(teacherForm.getAge());
- teacher.setGender(teacherForm.getGender());
- teacher.setMajor(teacherForm.getMajor());
- teacher.setDepartment(teacherForm.getDepartment());
-
-
- HibernateDAO=;
- HibernateDAO.save(teacher);
-
-
- 而使用BeanUtils后,代码就大大改观了,如下所示:
-
- TeacherForm teacherForm=(TeacherForm)form;
-
- Teacher teacher=new Teacher();
-
- BeanUtils.copyProperties(teacher,teacherForm);
-
- HibernateDAO=;
- HibernateDAO.save(teacher);
//得到TeacherForm
TeacherForm teacherForm=(TeacherForm)form;
//构造Teacher对象
Teacher teacher=new Teacher();
//赋值
teacher.setName(teacherForm.getName());
teacher.setAge(teacherForm.getAge());
teacher.setGender(teacherForm.getGender());
teacher.setMajor(teacherForm.getMajor());
teacher.setDepartment(teacherForm.getDepartment());
//持久化Teacher对象到数据库
HibernateDAO=;
HibernateDAO.save(teacher);
而使用BeanUtils后,代码就大大改观了,如下所示:
//得到TeacherForm
TeacherForm teacherForm=(TeacherForm)form;
//构造Teacher对象
Teacher teacher=new Teacher();
//赋值
BeanUtils.copyProperties(teacher,teacherForm);
//持久化Teacher对象到数据库
HibernateDAO=;
HibernateDAO.save(teacher);
如果Teacher和TeacherForm间存在名称不相同的属性,则BeanUtils不对这些属性进行处理,需要程序员手动处理。例如 Teacher包含modifyDate(该属性记录最后修改日期,不需要用户在界面中输入)属性而TeacherForm无此属性,那么在上面代码的 copyProperties()后还要加上一句:
- teacher.setModifyDate(new Date());
teacher.setModifyDate(new Date());
怎么样,很方便吧!除BeanUtils外还有一个名为PropertyUtils的工具类,它也提供copyProperties()方法,作用与 BeanUtils的同名方法十分相似,主要的区别在于后者提供类型转换功能,即发现两个JavaBean的同名属性为不同类型时,在支持的数据类型范围内进行转换,而前者不支持这个功能,但是速度会更快一些。BeanUtils支持的转换类型如下:
* java.lang.BigDecimal
* java.lang.BigInteger
* boolean and java.lang.Boolean
* byte and java.lang.Byte
* char and java.lang.Character
* java.lang.Class
* double and java.lang.Double
* float and java.lang.Float
* int and java.lang.Integer
* long and java.lang.Long
* short and java.lang.Short
* java.lang.String
* java.sql.Date
* java.sql.Time
* java.sql.Timestamp
这里要注意一点,java.util.Date是不被支持的,而它的子类java.sql.Date是被支持的。因此如果对象包含时间类型的属性,且希望被转换的时候,一定要使用java.sql.Date类型。否则在转换时会提示argument mistype异常。
三、优缺点:
Apache Jakarta Commons项目非常有用。我曾在许多不同的项目上或直接或间接地使用各种流行的commons组件。其中的一个强大的组件就是BeanUtils。我将说明如何使用BeanUtils将local实体bean转换为对应的value 对象:
- BeanUtils.copyProperties(aValue, aLocal);
BeanUtils.copyProperties(aValue, aLocal);
上面的代码从aLocal对象复制属性到aValue对象。它相当简单!它不管local(或对应的value)对象有多少个属性,只管进行复制。我们假设local对象有100个属性。上面的代码使我们可以无需键入至少100行的冗长、容易出错和反复的get和set方法调用。这太棒了!太强大了!太有用了!
BeanUtils.copyProperties 与 PropertyUtils.copyProperties 都是拷贝对象属性的方法,BeanUtils 支持类型转换,而 PropertyUtils 不支持。但是 BeanUtils 不允许对象的属性值为 null,PropertyUtils 可以拷贝属性值 null 的对象。
如果对象属性值为 null,BeanUtils.copyProperties 方法会报 commons.beanutils.ConversionException: No value specified 错误。
现在,还有一个坏消息:使用BeanUtils的成本惊人地昂贵!我做了一个简单的测试,BeanUtils所花费的时间要超过取数据、将其复制到对应的 value对象(通过手动调用get和set方法),以及通过串行化将其返回到远程的客户机的时间总和。所以要小心使用这种威力!
MethodUtils类使用方法:
- package rong.propertyUtils;
-
- import java.util.Map;
- import org.apache.commons.beanutils.MethodUtils;
- import org.apache.commons.beanutils.PropertyUtils;
-
- public class TestPropertyUtils {
-
- public static void main(String[] args) throws Exception{
-
- Entity entity = new Entity();
-
-
- Integer id = (Integer)PropertyUtils.getProperty(entity, "id");
- String name = (String)PropertyUtils.getProperty(entity, "name");
- System.out.println("id = " + id + " name = " + name);
-
-
- PropertyUtils.setProperty(entity, "name", "心梦帆影");
- System.out.println("name = " + entity.getName());
-
-
- Map map = PropertyUtils.describe(entity);
- System.out.println("id = " + map.get("id") + " name = " + map.get("name"));
-
-
- System.out.println( MethodUtils.invokeMethod(entity, "haha", null) );
-
-
- MethodUtils.invokeMethod(entity, "sayHelle", "心梦帆影");
-
-
- Object[] params = new Object[]{new Integer(10),new Integer(12)};
- String msg = (String)MethodUtils.invokeMethod(entity, "countAges", params);
- System.out.println(msg);
-
- }
-
- }
posted @
2010-05-10 14:07 Alpha 阅读(3273) |
评论 (1) |
编辑 收藏
本人经常用到的命令,在这里做下记录。
.tar.bz2
解压:tar jxvf FileName.tar.bz2 压缩:tar jcvf FileName.tar.bz2 DirName
.gz
解压1:gunzip FileName.gz 解压2:gzip -d FileName.gz 压缩:gzip FileName
.tar.gz 和 .tgz
解压:tar zxvf FileName.tar.gz 压缩:tar zcvf FileName.tar.gz DirName
.rpm
解包:rpm2cpio FileName.rpm | cpio -div
.deb
解包:ar p FileName.deb data.tar.gz | tar zxf -
从远程scp到本地:
scp root@192.168.2.100:/opt/test/* /opt/test ,输入远程机器密码后完成
scp -P 3588 root@192.168.2.100:/opt/test/* /opt/test 走特殊端口号
从本地scp到远程:
scp /opt/test/* root@192.168.2.100:/opt/test ,输入远程机器密码后完成
使用方式 : chmod [-cfvR] [--help] [--version] mode file...
使用方式 :chown jessie:users file1.txt
Mysql 初始化:chkconfig –add mysqld
正在使用的端口:netstat -ant
挂载USB: mount /dev/sdc /mnt/usb
Rpm 安装: rpm –ivh filename
www服务配置:/etc/httpd/conf/httpd.conf
网络测试:curl -I http://www.job5156.com
改IP地址:ifconfig eth0 192.168.2.29 netmask 255.255.255.0
改网关:route add default gw 192.168.2.254 查看:route –n
改DNS:nano -w /etc/resolv.conf
导出表结构:mysqldump -u root -p -d --add-drop-table dbName tableName > /opt/name.sql
导入表结构:mysql dbName < name.sql
修复Mysql表: mysqlrepair --auto-repair -F -r dbName tableName
给mysql用户加账号权限: grant all on dbName.* to user@'%' identified by 'pwd'; FLUSH PRIVILEGES;
加字段:ALTER TABLE table_name ADD field_name field_type;
删字段:alter table t2 drop column c;
字段重命名:alter table t1 change a b integer;
表重命名:alter table t1 rename t2;
加索引:alter table tablename add index 索引名 (字段名1[,字段名2 …]);
删索引:alter table tablename drop index emp_name;
posted @
2010-04-16 15:17 Alpha 阅读(1243) |
评论 (0) |
编辑 收藏最近在寻找这方面的资料:
1,查看apache进程:
ps aux | grep httpd | grep -v grep | wc -l
2,查看80端口的tcp连接:
netstat -tan | grep "ESTABLISHED" | grep ":80" | wc -l
3,通过日志查看当天ip连接数,过滤重复:
cat access_log | grep "24/Jul/2007" | awk '{print $2}' | sort | uniq -c | sort -nr
4,当天ip连接数最高的ip都在干些什么(原来是蜘蛛):
cat access_log | grep "24/Jul/2007:00" | grep "61.135.166.230" | awk '{print $8}' | sort | uniq -c | sort -nr | head -n 10
5,当天访问页面排前10的url:
cat access_log | grep "24/Jul/2007:00" | awk '{print $8}' | sort | uniq -c | sort -nr | head -n 10
6,用tcpdump嗅探80端口的访问看看谁最高
tcpdump -i eth0 -tnn dst port 80 -c 1000 | awk -F"." '{print $1"."$2"."$3"."$4}' | sort | uniq -c | sort -nr
接着从日志里查看该ip在干嘛:
cat access_log | grep 220.181.38.183| awk '{print $1"\t"$8}' | sort | uniq -c | sort -nr | less
7,查看某一时间段的ip连接数:
grep "2006:0[7-8]" www20060723.log | awk '{print $2}' | sort | uniq -c| sort -nr | wc -l
posted @
2010-03-31 16:55 Alpha 阅读(1928) |
评论 (0) |
编辑 收藏当你在客户端用view source看JSP生成的代码时,会发现有很多空行,他们是由< %...% >后的回车换行而生成的,也就是说每一行由< %...% >包含的JSP代码到客户端都变成一个空行,虽然不影响浏览,但还是希望能把他们删掉。这里将为大家介绍如何删除JSP编译后的空行。
- <%@ page trimDirectiveWhitespaces="true" %>
在 Tomcat 6.0.14下测试JSP编译成功
2. 支持servlet 2.5+, 即 web.xml的 XSD版本为2.5,在web.xml中加入如下代码
- <jsp-config>
- <jsp-property-group>
- <url-pattern>*.jsp</url-pattern>
- <trim-directive-whitespaces>true</trim-directive-whitespaces>
- </jsp-property-group>
- </jsp-config>
在tomcat 6.0.14下测试JSP编译成功
3. Tomcat 5.5.x+,在Tomcat安装目录/conf/web.xml中找到名叫"jsp"的servlet,添加下面一段代码:
- <init-param>
- <param-name>trimSpaces</param-name>
- <param-value>true</param-value>
- </init-param>
本人测过
trimSpaces Should white spaces in template text between actions or directives be trimmed? [false]
在实际操作中我加入了5.5的配置到页面中并反复启动了几次tomcat但是还是没有成功,后来才想到JSP已经编译成servlet了所以没有能改变,进入到tomcat中的work目录把已经进行JSP编译的class全部删除,哇哈哈,整个世界清净了,成功删除空行
posted @
2010-03-25 10:12 Alpha 阅读(1484) |
评论 (0) |
编辑 收藏
摘要: 优化是一项复杂的任务,因为它最终需要对整个系统的理解。当用你的系统/应用的小知识做一些局部优化是可能的时候,你越想让你的系统更优化,你必须知道它也越多。
阅读全文
posted @
2009-09-22 16:55 Alpha 阅读(6394) |
评论 (20) |
编辑 收藏
现今存在的开源协议很多,而经过Open Source Initiative组织通过批准的开源协议目前有58种(
http://www.opensource.org/licenses/alphabetical)。我们在常见的开源协议如BSD, GPL, LGPL,MIT等都是OSI批准的协议。如果要开源自己的代码,最好也是选择这些被批准的开源协议。
这里我们来看四种最常用的开源协议及它们的适用范围,供那些准备开源或者使用开源产品的开发人员/厂家参考。
BSD开源协议(original BSD license、FreeBSD license、Original BSD license)
BSD开源协议是一个给于使用者很大自由的协议。基本上使用者可以"为所欲为",可以自由的使用,修改源代码,也可以将修改后的代码作为开源或者专有软件再发布。
但"为所欲为"的前提当你发布使用了BSD协议的代码,或则以BSD协议代码为基础做二次开发自己的产品时,需要满足三个条件:
Ruby代码
1.如果再发布的产品中包含源代码,则在源代码中必须带有原来代码中的BSD协议。
2.如果再发布的只是二进制类库/软件,则需要在类库/软件的文档和版权声明中包含原来代码中的BSD协议。
3.不可以用开源代码的作者/机构名字和原来产品的名字做市场推广。
如果再发布的产品中包含源代码,则在源代码中必须带有原来代码中的BSD协议。
如果再发布的只是二进制类库/软件,则需要在类库/软件的文档和版权声明中包含原来代码中的BSD协议。
不可以用开源代码的作者/机构名字和原来产品的名字做市场推广。
BSD 代码鼓励代码共享,但需要尊重代码作者的著作权。BSD由于允许使用者修改和重新发布代码,也允许使用或在BSD代码上开发商业软件发布和销售,因此是对 商业集成很友好的协议。而很多的公司企业在选用开源产品的时候都首选BSD协议,因为可以完全控制这些第三方的代码,在必要的时候可以修改或者二次开发。
Apache Licence 2.0(Apache License, Version 2.0、Apache License, Version 1.1、Apache License, Version 1.0)
Apache Licence是著名的非盈利开源组织Apache采用的协议。该协议和BSD类似,同样鼓励代码共享和尊重原作者的著作权,同样允许代码修改,再发布(作为开源或商业软件)。需要满足的条件也和BSD类似:
Ruby代码
1.需要给代码的用户一份Apache Licence
2.如果你修改了代码,需要再被修改的文件中说明。
3.在延伸的代码中(修改和有源代码衍生的代码中)需要带有原来代码中的协议,商标,专利声明和其他原来作者规定需要包含的说明。
4.如果再发布的产品中包含一个Notice文件,则在Notice文件中需要带有Apache Licence。你可以在Notice中增加自己的许可,但不可以表现为对Apache Licence构成更改。
需要给代码的用户一份Apache Licence
如果你修改了代码,需要再被修改的文件中说明。
在延伸的代码中(修改和有源代码衍生的代码中)需要带有原来代码中的协议,商标,专利声明和其他原来作者规定需要包含的说明。
如果再发布的产品中包含一个Notice文件,则在Notice文件中需要带有Apache Licence。你可以在Notice中增加自己的许可,但不可以表现为对Apache Licence构成更改。
Apache Licence也是对商业应用友好的许可。使用者也可以在需要的时候修改代码来满足需要并作为开源或商业产品发布/销售。
GPL(GNU General Public License)
我们很熟悉的Linux就是采用了 GPL。GPL协议和BSD, Apache Licence等鼓励代码重用的许可很不一样。GPL的出发点是代码的开源/免费使用和引用/修改/衍生代码的开源/免费使用,但不允许修改后和衍生的代 码做为闭源的商业软件发布和销售。这也就是为什么我们能用免费的各种linux,包括商业公司的linux和linux上各种各样的由个人,组织,以及商 业软件公司开发的免费软件了。
GPL协议的主要内容是只要在一个软件中使用("使用"指类库引用,修改后的代码或者衍生代码)GPL 协议的产品,则该软件产品必须也采用GPL协议,既必须也是开源和免费。这就是所谓的"传染性"。GPL协议的产品作为一个单独的产品使用没有任何问题, 还可以享受免费的优势。
由于GPL严格要求使用了GPL类库的软件产品必须使用GPL协议,对于使用GPL协议的开源代码,商业软件或者对代码有保密要求的部门就不适合集成/采用作为类库和二次开发的基础。
其它细节如再发布的时候需要伴随GPL协议等和BSD/Apache等类似。
LGPL(GNU Lesser General Public License)
LGPL是GPL的一个为主要为类库使用设计的开源协议。和GPL要求任何使用/修改/衍生之GPL类库的的软件必须采用GPL协议不同。LGPL允许商 业软件通过类库引用(link)方式使用LGPL类库而不需要开源商业软件的代码。这使得采用LGPL协议的开源代码可以被商业软件作为类库引用并发布和 销售。
但是如果修改LGPL协议的代码或者衍生,则所有修改的代码,涉及修改部分的额外代码和衍生的代码都必须采用LGPL协议。因此LGPL协议的开源代码很 适合作为第三方类库被商业软件引用,但不适合希望以LGPL协议代码为基础,通过修改和衍生的方式做二次开发的商业软件采用。
GPL/LGPL都保障原作者的知识产权,避免有人利用开源代码复制并开发类似的产品。
MIT(MIT)
MIT是和BSD一样宽范的许可协议,作者只想保留版权,而无任何其他了限制.也就是说,你必须在你的发行版里包含原许可协议的声明,无论你是以二进制发布的还是以源代码发布的。
posted @
2009-08-05 15:59 Alpha 阅读(953) |
评论 (0) |
编辑 收藏
摘要: Flex中As调用Js的方法是:
1、导入包 (import flash.external.ExternalInterface;)
2、使用ExternalInterface.call("Js函数名称",参数)进行调用,其返回的值就是Js函数所返回的值
Js调用As的方法是:
1、导入包 (import flash.external.ExternalInterface;)
2、在initApp中使用ExternalInterface.addCallback("用于Js调用的函数名",As中的函数名)进行注册下
3、js中 就可以用document.getElementById("Flas在Html中的ID").注册时设置的函数名(参数)进行调用
阅读全文
posted @
2009-06-27 10:32 Alpha 阅读(26663) |
评论 (4) |
编辑 收藏
摘要: 在低版本的Spring中,你必须通过JSTL或
将表单对象绑定到HTML表单页面中,对于习惯了Struts表单标签的开发者来说,Spring MVC的这一表现确实让人失望。不过这一情况已经一去不复返了,从Spring 2.0开始,Spring MVC开始全面支持表单标签,通过Spring MVC表单标签,我们可以很容易地将控制器相关的表单对象绑定到HTML表单元素中。
在上一篇文章《Spring MVC的表单控制器》中(http://tech.it168.com/j/2007-07-26/200707261434046.shtml)我们已经使用到了部分的Spring MVC表单标签,在本文中我们将对Spring MVC表单标签进行全面的介绍,让我们首先从标签开始吧。 阅读全文
posted @
2009-06-26 11:01 Alpha 阅读(23978) |
评论 (4) |
编辑 收藏1
PermGen space的全称是Permanent Generation space,是指内存的永久保存区域OutOfMemoryError: PermGen space从表面上看就是内存益出,解决方法也一定是加大内存说说为什么会内存益出:这一部分用于存放Class和Meta的信息,Class在被 Load的时候被放入PermGen space区域,它和和存放Instance的Heap区域不同,GC(Garbage Collection)不会在主程序运行期对PermGen space进行清理,所以如果你的APP会LOAD很多CLASS的话,就很可能出现PermGen space错误这种错误常见在web服务器对JSP进行pre compile的时候
改正方法:-Xms256m -Xmx256m -XX:MaxNewSize=256m -XX:MaxPermSize=256m
2
在tomcat中redeploy时出现outofmemory的错误.
可以有以下几个方面的原因:
1,使用了proxool,因为proxool内部包含了一个老版本的cglib.
2, log4j,最好不用,只用common-logging
3, 老版本的cglib,快点更新到最新版
4,更新到最新的hibernate3.2
3
这里以tomcat环境为例,其它WEB服务器如jboss,weblogic等是同一个道理
一java.lang.OutOfMemoryError: PermGen space
PermGen space的全称是Permanent Generation space,是指内存的永久保存区域,
这块内存主要是被JVM存放Class和Meta信息的,Class在被Loader时就会被放到PermGen space中,
它和存放类实例(Instance)的Heap区域不同,GC(Garbage Collection)不会在主程序运行期对
PermGen space进行清理,所以如果你的应用中有很多CLASS的话,就很可能出现PermGen space错误,
这种错误常见在web服务器对JSP进行pre compile的时候如果你的WEB APP下都用了大量的第三方jar, 其大小
超过了jvm默认的大小(4M)那么就会产生此错误信息了
解决方法: 手动设置MaxPermSize大小
修改TOMCAT_HOME/bin/catalina.sh
在echo "Using CATALINA_BASE: $CATALINA_BASE"上面加入以下行:
JAVA_OPTS="-server -XX:PermSize=64M -XX:MaxPermSize=128m
建议:将相同的第三方jar文件移置到tomcat/shared/lib目录下,这样可以达到减少jar 文档重复占用内存的目的
二java.lang.OutOfMemoryError: Java heap space
Heap size 设置
JVM堆的设置是指java程序运行过程中JVM可以调配使用的内存空间的设置.JVM在启动的时候会自动设置Heap size的值,
其初始空间(即-Xms)是物理内存的1/64,最大空间(-Xmx)是物理内存的1/4可以利用JVM提供的-Xmn -Xms -Xmx等选项可
进行设置Heap size 的大小是Young Generation 和Tenured Generaion 之和
提示:在JVM中如果98%的时间是用于GC且可用的Heap size 不足2%的时候将抛出此异常信息
提示:Heap Size 最大不要超过可用物理内存的80%,一般的要将-Xms和-Xmx选项设置为相同,而-Xmn为1/4的-Xmx值
解决方法:手动设置Heap size
修改TOMCAT_HOME/bin/catalina.sh
在echo "Using CATALINA_BASE: $CATALINA_BASE"上面加入以下行:
JAVA_OPTS="-server -Xms800m -Xmx800m -XX:MaxNewSize=256m"
三实例,以下给出1G内存环境下java jvm 的参数设置参考:
JAVA_OPTS="-server -Xms800m -Xmx800m -XX:PermSize=64M -XX:MaxNewSize=256m -XX:MaxPermSize=128m -Djava.awt.headless=true "
三相关资料
题外话:经常看到网友抱怨tomcat的性能不如...,不稳定等,其实根据笔者几年的经验,从"互联星空到现在的房产门户网,我们
均使用tomcat作为WEB服务器,每天访问量百万多,tomcat仍然运行良好建议大家有问题多从自己程序入手,多看看java的DOC文档
并详细了解JVM的知识这样开发的程序才会健壮
posted @
2009-06-19 16:04 Alpha 阅读(896) |
评论 (0) |
编辑 收藏posted @
2009-06-03 14:59 Alpha 阅读(6488) |
评论 (2) |
编辑 收藏前一段时间,一直被mysql的字符集困扰,今天就这方面的知识总结一下.
MySQL的字符集支持(Character Set Support)有两个方面:
字符集(Character set)和排序方式(Collation)。
对于字符集的支持细化到四个层次:
服务器(server),数据库(database),数据表(table)和连接(connection)。
1.MySQL默认字符集
MySQL对于字符集的指定可以细化到一个数据库,一张表,一列,应该用什么字符集。
但是,传统的程序在创建数据库和数据表时并没有使用那么复杂的配置,它们用的是默认的配置,那么,默认的配置从何而来呢?
(1)编译MySQL 时,指定了一个默认的字符集,这个字符集是 latin1;
(2)安装MySQL 时,可以在配置文件 (my.ini) 中指定一个默认的的字符集,如果没指定,这个值继承自编译时指定的;
(3)启动mysqld 时,可以在命令行参数中指定一个默认的的字符集,如果没指定,这个值继承自配置文件中的配置,此时
character_set_server 被设定为这个默认的字符集;
(4)当创建一个新的数据库时,除非明确指定,这个数据库的字符集被缺省设定为
character_set_server;
(5)当选定了一个数据库时,
character_set_database 被设定为这个数据库默认的字符集;
(6)在这个数据库里创建一张表时,表默认的字符集被设定为
character_set_database,也就是这个数据库默认的字符集;
(7)当在表内设置一栏时,除非明确指定,否则此栏缺省的字符集就是表默认的字符集;
简单的总结一下,如果什么地方都不修改,那么所有的数据库的所有表的所有栏位的都用 latin1 存储,不过我们如果安装 MySQL,一般都会选择多语言支持,也就是说,安装程序会自动在配置文件中把 default_character_set 设置为 UTF-8,这保证了缺省情况下,所有的数据库的所有表的所有栏位的都用 UTF-8 存储。
2.查看默认字符集(默认情况下,mysql的字符集是latin1(ISO_8859_1)
通常,查看系统的字符集和排序方式的设定可以通过下面的两条命令:
mysql> SHOW VARIABLES LIKE 'character%';
+--------------------------+---------------------------------+
| Variable_name | Value |
+--------------------------+---------------------------------+
| character_set_client | latin1 |
| character_set_connection | latin1 |
| character_set_database | latin1 |
| character_set_filesystem | binary |
| character_set_results | latin1 |
| character_set_server | latin1 |
| character_set_system | utf8 |
| character_sets_dir | D:"mysql-5.0.37"share"charsets" |
+--------------------------+---------------------------------+
mysql> SHOW VARIABLES LIKE 'collation_%';
+----------------------+-----------------+
| Variable_name | Value |
+----------------------+-----------------+
| collation_connection | utf8_general_ci |
| collation_database | utf8_general_ci |
| collation_server | utf8_general_ci |
+----------------------+-----------------+
3.修改默认字符集
(1) 最简单的修改方法,就是修改mysql的my.ini文件中的字符集键值,
如 default-character-set = utf8
character_set_server = utf8
修改完后,重启mysql的服务,service mysql restart
使用 mysql> SHOW VARIABLES LIKE 'character%';查看,发现数据库编码均已改成utf8
+--------------------------+---------------------------------+
| Variable_name | Value |
+--------------------------+---------------------------------+
| character_set_client | utf8 |
| character_set_connection | utf8 |
| character_set_database | utf8 |
| character_set_filesystem | binary |
| character_set_results | utf8 |
| character_set_server | utf8 |
| character_set_system | utf8 |
| character_sets_dir | D:"mysql-5.0.37"share"charsets" |
+--------------------------+---------------------------------+
(2) 还有一种修改字符集的方法,就是使用mysql的命令
mysql> SET character_set_client = utf8 ;
mysql> SET character_set_connection = utf8 ;
mysql> SET character_set_database = utf8 ;
mysql> SET character_set_results = utf8 ;
mysql> SET character_set_server = utf8 ;
mysql> SET collation_connection = utf8 ;
mysql> SET collation_database = utf8 ;
mysql> SET collation_server = utf8 ;
一般就算设置了表的默认字符集为utf8并且通过UTF-8编码发送查询,你会发现存入数据库的仍然是乱码。问题就出在这个connection连接层上。解决方法是在发送查询前执行一下下面这句:
SET NAMES 'utf8';
它相当于下面的三句指令:
SET character_set_client = utf8;
SET character_set_results = utf8;
SET character_set_connection = utf8;
总结:
因此,使用什么数据库版本,不管是3.x,还是4.0.x还是4.1.x,其实对我们来说不重要,重要的有二:
1) 正确的设定数据库编码.MySQL4.0以下版本的字符集总是默认ISO8859-1,MySQL4.1在安装的时候会让你选择。如果你准备使用UTF- 8,那么在创建数据库的时候就要指定好UTF-8(创建好以后也可以改,4.1以上版本还可以单独指定表的字符集)
2) 正确的设定数据库connection编码.设置好数据库的编码后,在连接数据库时候,应该指定connection的编码,比如使用jdbc连接时,指定连接为utf8方式.
参考 "关中刀客" 的 <Mysql编码问题>,原文地址http://lixiang.cn/?q=node/98
posted @
2009-04-11 10:29 Alpha 阅读(976) |
评论 (2) |
编辑 收藏
<c3p0-config>
<default-config>
<!--当连接池中的连接耗尽的时候c3p0一次同时获取的连接数。Default: 3 -->
<property name="acquireIncrement">3</property>
<!--定义在从数据库获取新连接失败后重复尝试的次数。Default: 30 -->
<property name="acquireRetryAttempts">30</property>
<!--两次连接中间隔时间,单位毫秒。Default: 1000 -->
<property name="acquireRetryDelay">1000</property>
<!--连接关闭时默认将所有未提交的操作回滚。Default: false -->
<property name="autoCommitOnClose">false</property>
<!--c3p0将建一张名为Test的空表,并使用其自带的查询语句进行测试。如果定义了这个参数那么
属性preferredTestQuery将被忽略。你不能在这张Test表上进行任何操作,它将只供c3p0测试
使用。Default: null-->
<property name="automaticTestTable">Test</property>
<!--获取连接失败将会引起所有等待连接池来获取连接的线程抛出异常。但是数据源仍有效
保留,并在下次调用getConnection()的时候继续尝试获取连接。如果设为true,那么在尝试
获取连接失败后该数据源将申明已断开并永久关闭。Default: false-->
<property name="breakAfterAcquireFailure
">false</property>
<!--当连接池用完时客户端调用getConnection()后等待获取新连接的时间,超时后将抛出
SQLException,如设为0则无限期等待。单位毫秒。Default: 0 -->
<property name="checkoutTimeout">100</property>
<!--通过实现ConnectionTester或QueryConnectionTester的类来测试连接。类名需制定全路径。
Default: com.mchange.v2.c3p0.impl.DefaultConnectionTester-->
<property name="connectionTesterClassName"></property>
<!--指定c3p0 libraries的路径,如果(通常都是这样)在本地即可获得那么无需设置,默认null即可
Default: null-->
<property name="factoryClassLocation">null</property>
<!--Strongly disrecommended. Setting this to true may lead to subtle and bizarre bugs.
(文档原文)作者强烈建议不使用的一个属性-->
<property name="forceIgnoreUnresolvedTransactions">false</property>
<!--每60秒检查所有连接池中的空闲连接。Default: 0 -->
<property name="idleConnectionTestPeriod">60</property>
<!--初始化时获取三个连接,取值应在minPoolSize与maxPoolSize之间。Default: 3 -->
<property name="initialPoolSize">3</property>
<!--最大空闲时间,60秒内未使用则连接被丢弃。若为0则永不丢弃。Default: 0 -->
<property name="maxIdleTime">60</property>
<!--连接池中保留的最大连接数。Default: 15 -->
<property name="maxPoolSize">15</property>
<!--JDBC的标准参数,用以控制数据源内加载的PreparedStatements数量。但由于预缓存的statements
属于单个connection而不是整个连接池。所以设置这个参数需要考虑到多方面的因素。
如果maxStatements与maxStatementsPerConnection均为0,则缓存被关闭。Default: 0-->
<property name="maxStatements">100</property>
<!--maxStatementsPerConnection定义了连接池内单个连接所拥有的最大缓存statements数。Default: 0 -->
<property name="maxStatementsPerConnection"></property>
<!--c3p0是异步操作的,缓慢的JDBC操作通过帮助进程完成。扩展这些操作可以有效的提升性能
通过多线程实现多个操作同时被执行。Default: 3-->
<property name="numHelperThreads">3</property>
<!--当用户调用getConnection()时使root用户成为去获取连接的用户。主要用于连接池连接非c3p0
的数据源时。Default: null-->
<property name="overrideDefaultUser">root</property>
<!--与overrideDefaultUser参数对应使用的一个参数。Default: null-->
<property name="overrideDefaultPassword">password</property>
<!--密码。Default: null-->
<property name="password"></property>
<!--定义所有连接测试都执行的测试语句。在使用连接测试的情况下这个一显著提高测试速度。注意:
测试的表必须在初始数据源的时候就存在。Default: null-->
<property name="preferredTestQuery">select id from test where id=1</property>
<!--用户修改系统配置参数执行前最多等待300秒。Default: 300 -->
<property name="propertyCycle">300</property>
<!--因性能消耗大请只在需要的时候使用它。如果设为true那么在每个connection提交的
时候都将校验其有效性。建议使用idleConnectionTestPeriod或automaticTestTable
等方法来提升连接测试的性能。Default: false -->
<property name="testConnectionOnCheckout">false</property>
<!--如果设为true那么在取得连接的同时将校验连接的有效性。Default: false -->
<property name="testConnectionOnCheckin">true</property>
<!--用户名。Default: null-->
<property name="user">root</property>
<!--早期的c3p0版本对JDBC接口采用动态反射代理。在早期版本用途广泛的情况下这个参数
允许用户恢复到动态反射代理以解决不稳定的故障。最新的非反射代理更快并且已经开始
广泛的被使用,所以这个参数未必有用。现在原先的动态反射与新的非反射代理同时受到
支持,但今后可能的版本可能不支持动态反射代理。Default: false-->
<property name="usesTraditionalReflectiveProxies">false</property>
<property name="automaticTestTable">con_test</property>
<property name="checkoutTimeout">30000</property>
<property name="idleConnectionTestPeriod">30</property>
<property name="initialPoolSize">10</property>
<property name="maxIdleTime">30</property>
<property name="maxPoolSize">25</property>
<property name="minPoolSize">10</property>
<property name="maxStatements">0</property>
<user-overrides user="swaldman">
</user-overrides>
</default-config>
<named-config name="dumbTestConfig">
<property name="maxStatements">200</property>
<user-overrides user="poop">
<property name="maxStatements">300</property>
</user-overrides>
</named-config>
</c3p0-config>
转:http://www.wujianrong.com/archives/2007/08/c3p0.html解决MYSQL 8小时问题
最近的一个项目在Hibernate使用C3P0的连接池,数据库为Mysql。开发测试没有问题,在运行中每个一段长的空闲时间就出现异常:
java 代码
- org.hibernate.exception.JDBCConnectionException: could not execute query
- at org.hibernate.exception.SQLStateConverter.convert(SQLStateConverter.java:74)
- at org.hibernate.exception.JDBCExceptionHelper.convert(JDBCExceptionHelper.java:43)
- .......
- Caused by: com.mysql.jdbc.exceptions.MySQLNonTransientConnectionException: No operations allowed after connection closed.Connection was implicitly closed due to underlying exception/error:
- ** BEGIN NESTED EXCEPTION **
- com.mysql.jdbc.CommunicationsException
- MESSAGE: Communications link failure due to underlying exception:
- ** BEGIN NESTED EXCEPTION **
- java.net.SocketException
- MESSAGE: Broken pipe
- STACKTRACE:
- java.net.SocketException: Broken pipe
- at java.net.SocketOutputStream.socketWrite0(Native Method)
- ......
- ** END NESTED EXCEPTION **
查看了Mysql的文档,以及Connector/J的文档以及在线说明发现,出现这种异常的原因是:
Mysql服务器默认的“wait_timeout”是8小时,也就是说一个connection空闲超过8个小时,Mysql将自动断开该 connection。这就是问题的所在,在C3P0 pools中的connections如果空闲超过8小时,Mysql将其断开,而C3P0并不知道该connection已经失效,如果这时有 Client请求connection,C3P0将该失效的Connection提供给Client,将会造成上面的异常。
解决的方法有3种:
- 增加wait_timeout的时间。
- 减少Connection pools中connection的lifetime。
- 测试Connection pools中connection的有效性。
当然最好的办法是同时综合使用上述3种方法,下面就DBCP和C3P0分别做一说明,假设wait_timeout为默认的8小时
DBCP增加以下配置信息:
-
- validationQuery = "SELECT 1"
-
- testWhileIdle = "true"
-
- timeBetweenEvictionRunsMillis = 3600000
-
- minEvictableIdleTimeMillis = 18000000
-
- testOnBorrow = "true"
C3P0增加以下配置信息:
-
- testConnectionOnCheckin = true
- //自动测试的table名称
- automaticTestTable=C3P0TestTable
-
- idleConnectionTestPeriod = 18000
-
- maxIdleTime = 25000
-
- testConnectionOnCheckout = true
更多的配置信息大家可以查看C3P0文档,Connector/J文档,以及DBCP的文档。
转: http://www.javaeye.com/article/38506
我自己的配置:
jdbc.driverClass=com.mysql.jdbc.Driver
jdbc.jdbcUrl = jdbc:mysql://localhost:3306/test
jdbc.user = root
jdbc.password = 12345
jdbc.miniPoolSize = 1
jdbc.maxPoolSize = 20
jdbc.initialPoolSize = 1
jdbc.maxIdleTime = 25000
jdbc.acquireIncrement = 1
jdbc.acquireRetryAttempts = 30
jdbc.acquireRetryDelay = 1000
jdbc.testConnectionOnCheckin = true
jdbc.automaticTestTable = c3p0TestTable
jdbc.idleConnectionTestPeriod = 18000
jdbc.checkoutTimeout=3000
<bean id="dataSource" class="com.mchange.v2.c3p0.ComboPooledDataSource" destroy-method="close">
<property name="driverClass" value="${jdbc.driverClass}" />
<property name="jdbcUrl" value="${jdbc.jdbcUrl}" />
<property name="user" value="${jdbc.user}" />
<property name="password" value="${jdbc.password}" />
<property name="minPoolSize" value="${jdbc.miniPoolSize}" />
<property name="maxPoolSize" value="${jdbc.maxPoolSize}"/>
<property name="initialPoolSize" value="${jdbc.initialPoolSize}"/>
<property name="maxIdleTime" value="${jdbc.maxIdleTime}"/>
<property name="acquireIncrement" value="${jdbc.acquireIncrement}"/>
<property name="acquireRetryAttempts" value="${jdbc.acquireRetryAttempts}"/>
<property name="acquireRetryDelay" value="${jdbc.acquireRetryDelay}"/>
<property name="testConnectionOnCheckin" value="${jdbc.testConnectionOnCheckin}"/>
<property name="automaticTestTable" value="${jdbc.automaticTestTable}"/>
<property name="idleConnectionTestPeriod" value="${jdbc.idleConnectionTestPeriod}"/>
<property name="checkoutTimeout" value="${jdbc.checkoutTimeout}"/>
</bean>
posted @
2009-03-29 23:31 Alpha 阅读(91817) |
评论 (26) |
编辑 收藏JDK中Jconsole的使用
2008-04-03 14:16
JAVA应用程序打成jar包的部署方式:
一、Local方式
1、cmd进入dos下,进入到应用程序所在目录,执行语句如下:
java -Dcom.sun.management.jmxremote -jar 程序名.jar
(java -Dcom.sun.management.jmxremote -jar Java2Demo.jar)(测试例子Java2Demo.jar在C:\Program Files\Java\jdk1.6.0_02\demo\jfc\Java2D\)
还出不来的话 直接 在dos里 jconsole 进程号
2、启动jdk_home\bin目录下的Jconsole.exe就可以看到有一个
本地的连接在里面。点击连接就可以进入相应的监视界面了。
二、JMX方式(远程连接):
1、cmd进入dos下,进入到应用程序所在目录,执行语句如下:
java -Dcom.sun.management.jmxremote.port=8903 -
Dcom.sun.management.jmxremote.ssl=false -
Dcom.sun.management.jmxremote.authenticate=false
-Djava.rmi.server.hostname=192.168.***.***
2、启动jdk_home\bin目录下的Jconsole.exe点高级。在JMX
URL:中输入语句如下:
service:jmx:rmi:///jndi/rmi://192.168.***.***:8903/jmxr
mi
点连接就可以进行远程监控了
web应用程序在tomcat中部署JMX(示例:tomcat-6.0.14)
1、启动tomcat\bin目录下的tomcat6w.exe,在JAVA_OPTS里设
置如下:
-Dcom.sun.management.jmxremote.port=8903
-Dcom.sun.management.jmxremote.ssl=false
-Dcom.sun.management.jmxremote.authenticate=false
-Djava.rmi.server.hostname=192.168.***.***
注意:不能有空格,不然tomcat不能启动。
2、tomcat启动成功后,就可以在另一台机器上启动
jdk_home\bin目录下的Jconsole.exe点高级。在JMX URL:中输
入语句如下:
service:jmx:rmi:///jndi/rmi://192.168.***.***:8903/jmxr
mi
点连接就可以进行远程监控了
以上是JMX基本部署,没有涉及到验证方面,如果使用的话,可
能会有漏洞,因为SSL和authenticate设置为false的话,那么
8903端口就有可能有暴露的危险。
如果想进行密码验证话,可以在网上找资料,自己进行调试。
我自己的应用:
1.修改Linux下tomcat的bin目录下的catalina.sh文件
添加
JAVA_OPTS=-Dcom.sun.management.jmxremote.authenticate=false -Dcom.sun.management.jmxremote.ssl=false
-Dcom.sun.management.jmxremote.port=7080
-Dcom.sun.management.jmxremote
2.修改/etc/hosts文件下的localhost对应的IP(127.0.0.1)地址,改为linux自身的IP如10.0.0.157.
3.打开jconsole远程输入 10.0.0.157:7080
三
Eden Space (heap): 内存最初从这个线程池分配给大部分对象。
Survivor Space (heap):用于保存在eden space内存池中经过垃圾回收后没有被回收的对象。
Tenured Generation (heap):用于保持已经在 survivor space内存池中存在了一段时间的对象。
Permanent Generation (non-heap): 保存虚拟机自己的静态(refective)数据,例如类(class)和方法(method)对象。Java虚拟机共享这些类数据。这个区域被分割为只读的和只写的,
Code Cache (non-heap):HotSpot Java虚拟机包括一个用于编译和保存本地代码(native code)的内存,叫做“代码缓存区”(code cache)
================================================
使用 jconsole 监控 tomcat6
在
catalina.bat
找到
set DEBUG_OPTS=
set JPDA=
在下面添加
set JAVA_OPTS=%JAVA_OPTS% -Dcom.sun.management.jmxremote.port=1090 -Dcom.sun.management.jmxremote.ssl=false -Dcom.sun.management.jmxremote.authenticate=false
保存
通过startup。bat启动 tomcat
启动jconsole (jdk1.6.0_02\lib):输入
localhost:1090
用户名 口令 为空
进入 即可 查看
posted @
2008-11-20 15:00 Alpha 阅读(6217) |
评论 (0) |
编辑 收藏
有的女人就像UNIX 她条件很好,然而不是谁都能玩的起。
有的女人就像C# 长的很漂亮,但是家务活不行。
有的女人就像C++,她会默默的为你做很多的事情。
有的女人就像JAVA,只需一点付出她就会为你到处服务。
有的女人就像JAVA script,虽然对她处处小心但最终还是没有结果。
有的女人就像汇编 虽然很麻烦,但是有的时候还得求它。
有的女人就像 SQL,她会为你的发展带来莫大的帮助。
爱情就是死循环,一旦执行就陷进去了。
爱上一个人,就是内存泄露,你永远释放不了。
真正爱上一个人的时候,那就是常量限定,永远不会改变。
女朋友就是私有变量,只有我这个类才能调用。
情人就是指针用的时候一定要注意,要不然就带来巨大的灾难
posted @
2008-10-12 21:29 Alpha 阅读(748) |
评论 (1) |
编辑 收藏
.tar
解包:tar xvf FileName.tar
打包:tar cvf FileName.tar DirName
(注:tar是打包,不是压缩!)
---------------------------------------------
.gz
解压1:gunzip FileName.gz
解压2:gzip -d FileName.gz
压缩:gzip FileName
.tar.gz 和 .tgz
解压:tar zxvf FileName.tar.gz
压缩:tar zcvf FileName.tar.gz DirName
---------------------------------------------
.bz2
解压1:bzip2 -d FileName.bz2
解压2:bunzip2 FileName.bz2
压缩: bzip2 -z FileName
.tar.bz2
解压:tar jxvf FileName.tar.bz2
压缩:tar jcvf FileName.tar.bz2 DirName
---------------------------------------------
.bz
解压1:bzip2 -d FileName.bz
解压2:bunzip2 FileName.bz
压缩:未知
.tar.bz
解压:tar jxvf FileName.tar.bz
压缩:未知
---------------------------------------------
.Z
解压:uncompress FileName.Z
压缩:compress FileName
.tar.Z
解压:tar Zxvf FileName.tar.Z
压缩:tar Zcvf FileName.tar.Z DirName
---------------------------------------------
.zip
解压:unzip FileName.zip
压缩:zip FileName.zip DirName
---------------------------------------------
.rar
解压:rar x FileName.rar
压缩:rar a FileName.rar DirName
rar请到:http://www.rarsoft.com/download.htm 下载!
解压后请将rar_static拷贝到/usr/bin目录(其他由$PATH环境变量指定的目录也可以):
[root@www2 tmp]# cp rar_static /usr/bin/rar
---------------------------------------------
.lha
解压:lha -e FileName.lha
压缩:lha -a FileName.lha FileName
lha请到:http://www.infor.kanazawa-it.ac.jp/~ishii/lhaunix/下载!
>解压后请将lha拷贝到/usr/bin目录(其他由$PATH环境变量指定的目录也可以):
[root@www2 tmp]# cp lha /usr/bin/
---------------------------------------------
.rpm
解包:rpm2cpio FileName.rpm | cpio -div
---------------------------------------------
.deb
解包:ar p FileName.deb data.tar.gz | tar zxf -
---------------------------------------------
.tar .tgz .tar.gz .tar.Z .tar.bz .tar.bz2 .zip .cpio .rpm .deb .slp .arj .rar .ace .lha .lzh .lzx .lzs .arc .sda .sfx .lnx .zoo .cab .kar .cpt .pit .sit .sea
解压:sEx x FileName.*
压缩:sEx a FileName.* FileName
posted @
2008-07-02 09:31 Alpha 阅读(1820) |
评论 (1) |
编辑 收藏
<!--MySql 驱动程序 eg. mysql-connector-java-5.0.4-bin.jar-->
<property name="dialect">org.hibernate.dialect.MySQLDialect</property>
<property name="connection.driver_class">com.mysql.jdbc.Driver</property>
<!-- JDBC URL -->
<property name="connection.url">jdbc:mysql://localhost/dbname?characterEncoding=gb2312</property>
<!-- 数据库用户名-->
<property name="connection.username">root</property>
<!-- 数据库密码-->
<property name="connection.password">root</property>
<!--Sql Server 驱动程序 eg. jtds-1.2.jar-->
<property name="dialect">org.hibernate.dialect.SQLServerDialect</property>
<property name="connection.driver_class">net.sourceforge.jtds.jdbc.Driver</property>
<!-- JDBC URL -->
<property name="connection.url">jdbc:jtds:sqlserver://localhost:1433;DatabaseName=dbname</property>
<!-- 数据库用户名-->
<property name="connection.username">sa</property>
<!-- 数据库密码-->
<property name="connection.password"></property>
<!--Oracle 驱动程序 ojdbc14.jar-->
<property name="dialect">org.hibernate.dialect.OracleDialect</property>
<property name="connection.driver_class">oracle.jdbc.driver.OracleDriver</property>
<!-- JDBC URL -->
<property name="connection.url">jdbc:oracle:thin:@localhost:1521:dbname</property>
<!-- 数据库用户名-->
<property name="connection.username">test</property>
<!-- 数据库密码-->
<property name="connection.password">test</property>
如果出现如下错误,则可能是Hibernate SQL方言 (hibernate.dialect)设置不正确。
Caused by: java.sql.SQLException: [Microsoft][SQLServer 2000 Driver for JDBC][SQLServer]'last_insert_id' 不是可以识别的 函数名。
| RDBMS
| 方言
|
| DB2
|
org.hibernate.dialect.DB2Dialect
|
| DB2 AS/400
|
org.hibernate.dialect.DB2400Dialect
|
| DB2 OS390
|
org.hibernate.dialect.DB2390Dialect
|
| PostgreSQL
|
org.hibernate.dialect.PostgreSQLDialect
|
| MySQL
|
org.hibernate.dialect.MySQLDialect
|
| MySQL with InnoDB
|
org.hibernate.dialect.MySQLInnoDBDialect
|
| MySQL with MyISAM
|
org.hibernate.dialect.MySQLMyISAMDialect
|
| Oracle (any version)
|
org.hibernate.dialect.OracleDialect
|
| Oracle 9i/10g
|
org.hibernate.dialect.Oracle9Dialect
|
| Sybase
|
org.hibernate.dialect.SybaseDialect
|
| Sybase Anywhere
|
org.hibernate.dialect.SybaseAnywhereDialect
|
| Microsoft SQL Server
|
org.hibernate.dialect.SQLServerDialect
|
| SAP DB
|
org.hibernate.dialect.SAPDBDialect
|
| Informix
|
org.hibernate.dialect.InformixDialect
|
| HypersonicSQL
|
org.hibernate.dialect.HSQLDialect
|
| Ingres
|
org.hibernate.dialect.IngresDialect
|
| Progress
|
org.hibernate.dialect.ProgressDialect
|
| Mckoi SQL
|
org.hibernate.dialect.MckoiDialect
|
| Interbase
|
org.hibernate.dialect.InterbaseDialect
|
| Pointbase
|
org.hibernate.dialect.PointbaseDialect
|
| FrontBase
|
org.hibernate.dialect.FrontbaseDialect
|
| Firebird
|
org.hibernate.dialect.FirebirdDialect |
posted @
2008-04-15 14:06 Alpha 阅读(50277) |
评论 (0) |
编辑 收藏
(给使用电脑的朋友)告诉你们一种保护眼睛的好方法:
桌面->右键->属性->外观->高级->项目选择(窗口)、颜色1(L)选择(其它)将色调改为:85。饱和度:123。亮度:205->添加到自定义颜色->在自定义颜色选定点确定->确定
这样所有的文档都不再是刺眼的白底黑字,而是非常柔和的豆沙绿色,这个色调是眼科专家配置的,长时间使用会很有效的缓解眼睛疲劳保护眼睛
posted @
2008-03-31 23:17 Alpha 阅读(1192) |
评论 (4) |
编辑 收藏posted @
2008-03-01 14:02 Alpha 阅读(1269) |
评论 (0) |
编辑 收藏posted @
2007-11-21 10:29 Alpha 阅读(6446) |
评论 (2) |
编辑 收藏