
2013年8月19日
一、准备
正式开始前,编译环境gcc、g++等开发库需要提前安装。
nginx依赖以下模块:
gzip模块需要 zlib 库
rewrite模块需要 pcre 库
ssl 功能需要openssl库
源码目录为:/usr/local/src
1、安装make
yum -y install gcc automake autoconf libtool make
2、安装g++
yum install gcc gcc-c++
3、安装PCRE库
cd /usr/local/src
wget ftp://ftp.csx.cam.ac.uk/pub/software/programming/pcre/pcre-8.42.tar.gz
tar -zxvf pcre-8.42.tar.gz
cd pcre-8.42/
./configure
make && make install
出现如下报错:
make[2]: *** [install-libLTLIBRARIES] Error 1
make[2]: Leaving directory `/usr/local/src/pcre-8.42'
make[1]: *** [install-am] Error 2
make[1]: Leaving directory `/usr/local/src/pcre-8.42'
make: *** [install] Error 2
权限不够,切换到root,重新make install即可。
4、安装zlib库
cd /usr/local/src
wget http://zlib.net/zlib-1.2.11.tar.gz
tar -zxvf zlib-1.2.11.tar.gz
cd zlib-1.2.11/
./configure
make && make install
5、安装OpenSSL库
cd /usr/local/src
wget http://www.openssl.org/source/openssl-1.1.0h.tar.gz
tar -zxvf openssl-fips-2.0.16.tar.gz
cd openssl-fips-2.0.16/
./config
make && make install
编译安装 Openssl 1.1.1 支持国密标准
https://blog.51cto.com/1012682/2380553
6、创建用户及用户组
一般为了服务器安全,会指定一个普通用户权限的账号做为Nginx的运行角色,这里使用www用户做为Nginx工作进程的用户。后续安装的PHP也以www用户作为工作进程用户。
groupadd -r www
useradd -r -g www www
二、NGINX
1、下载
cd /usr/local/src
wget http://nginx.org/download/nginx-1.14.0.tar.gz
tar –zxvf nginx-1.14.0.tar.gz
cd nginx-1.14.0
2、配置
./configure --prefix=/usr/local/nginx --sbin-path=/usr/local/nginx/sbin/nginx --conf-path=/usr/local/nginx/conf/nginx.conf --error-log-path=/var/log/nginx/error.log --http-log-path=/var/log/nginx/access.log --pid-path=/var/run/nginx/nginx.pid --lock-path=/var/lock/nginx.lock --user=www --group=www --with-http_ssl_module --with-http_stub_status_module --with-http_gzip_static_module --with-http_flv_module --with-http_mp4_module --http-client-body-temp-path=/var/tmp/nginx/client/ --http-proxy-temp-path=/var/tmp/nginx/proxy/ --http-fastcgi-temp-path=/var/tmp/nginx/fcgi/ --http-uwsgi-temp-path=/var/tmp/nginx/uwsgi --http-scgi-temp-path=/var/tmp/nginx/scgi
make && make install
nginx编译选项说明:
--prefix表示nginx要安装到哪个路径下,这里指定刚才新建好的/alidata/server目录下的nginx-1.12.2;
--sbin-path表示nginx的可执行文件存放路径
--conf-path表示nginx的主配置文件存放路径,nginx允许使用不同的配置文件启动,通过命令行中的-c选项
--pid-path表示nginx.pid文件的存放路径,将存储的主进程的进程号。安装完成后,可以随时改变的文件名 , 在nginx.conf配置文件中使用 PID指令。默认情况下,文件名 为prefix/logs/nginx.pid
--error-log-path表示nginx的主错误、警告、和诊断文件存放路径
--http-log-path表示nginx的主请求的HTTP服务器的日志文件的存放路径
--user表示nginx工作进程的用户
--group表示nginx工作进程的用户组
--with-select_module或--without-select_module表示启用或禁用构建一个模块来允许服务器使用select()方法
--with-poll_module或--without-poll_module表示启用或禁用构建一个模块来允许服务器使用poll()方法
--with-http_ssl_module表示使用https协议模块。默认情况下,该模块没有被构建。建立并运行此模块的OpenSSL库是必需的
--with-pcre表示pcre的源码路径,因为解压后的pcre是放在root目录下的,所以是/root/pcre-8.41;
--with-zlib表示zlib的源码路径,这里因为解压后的zlib是放在root目录下的,所以是/root/zlib-1.2.11
--with-openssl表示openssl库的源码路径
配置OK:
Configuration summary
+ using PCRE library: /usr/local/src/pcre-8.42
+ using OpenSSL library: /usr/local/src/openssl-1.1.0h
+ using zlib library: /usr/local/src/zlib-1.2.11
nginx path prefix: "/usr/local/nginx"
nginx binary file: "/usr/local/nginx/sbin/nginx"
nginx modules path: "/usr/local/nginx/modules"
nginx configuration prefix: "/usr/local/nginx"
nginx configuration file: "/usr/local/nginx/nginx.conf"
nginx pid file: "/usr/local/nginx/nginx.pid"
nginx error log file: "/usr/local/nginx/logs/error.log"
nginx http access log file: "/usr/local/nginx/logs/access.log"
nginx http client request body temporary files: "/var/tmp/nginx/client/"
nginx http proxy temporary files: "/var/tmp/nginx/proxy/"
nginx http fastcgi temporary files: "/var/tmp/nginx/fcgi/"
nginx http uwsgi temporary files: "/var/tmp/nginx/uwsgi"
nginx http scgi temporary files: "/var/tmp/nginx/scgi"
3、安装
make && make install
4、启动
/usr/local/nginx/sbin/nginx
启动时报错:
nginx: [emerg] mkdir() "/var/tmp/nginx/client/" failed (2: No such file or directory)
手动创建该目录即可:mkdir -p /var/tmp/nginx/client
再次启动,打开浏览器访问此机器的IP,浏览器出现Welcome to nginx! 则表示 Nginx 已经安装并运行成功。
5、设置软连接
ln -sf /usr/local/nginx/sbin/nginx /usr/sbin
这样就可以直接执行nginx来启动了。
6、检测nginx
nginx -t
显示:
nginx: the configuration file /usr/local/nginx/nginx.conf syntax is ok
nginx: configuration file /usr/local/nginx/nginx.conf test is successful
三、PHP
1、安装PHP需要的常用库
yum -y install libmcrypt-devel mhash-devel libxslt-devel libjpeg libjpeg-devel libpng libpng-devel freetype freetype-devel libxml2 libxml2-devel zlib zlib-devel glibc glibc-devel glib2 glib2-devel bzip2 bzip2-devel ncurses ncurses-devel curl curl-devel e2fsprogs e2fsprogs-devel krb5 krb5-devel libidn libidn-devel openssl openssl-devel
2、下载
cd /usr/local/src
wget http://cn2.php.net/downloads.php/php-7.2.5.tar.gz
tar -zxvf php-7.2.5.tar.gz
3、配置
./configure --prefix=/usr/local/php \
--with-mysql=mysqlnd \
--enable-mysqlnd \
--with-gd \
--enable-gd-jis-conv \
--enable-fpm
4、安装
make && make install
安装信息如下:
Installing shared extensions: /usr/local/php/lib/php/extensions/no-debug-non-zts-20170718/
Installing PHP CLI binary: /usr/local/php/bin/
Installing PHP CLI man page: /usr/local/php/php/man/man1/
Installing PHP FPM binary: /usr/local/php/sbin/
Installing PHP FPM defconfig: /usr/local/php/etc/
Installing PHP FPM man page: /usr/local/php/php/man/man8/
Installing PHP FPM status page: /usr/local/php/php/php/fpm/
Installing phpdbg binary: /usr/local/php/bin/
Installing phpdbg man page: /usr/local/php/php/man/man1/
Installing PHP CGI binary: /usr/local/php/bin/
Installing PHP CGI man page: /usr/local/php/php/man/man1/
Installing build environment: /usr/local/php/lib/php/build/
Installing header files: /usr/local/php/include/php/
Installing helper programs: /usr/local/php/bin/
program: phpize
program: php-config
Installing man pages: /usr/local/php/php/man/man1/
page: phpize.1
page: php-config.1
Installing PEAR environment: /usr/local/php/lib/php/
[PEAR] Archive_Tar: upgrade to a newer version (1.4.3 is not newer than 1.4.3)
[PEAR] Console_Getopt: upgrade to a newer version (1.4.1 is not newer than 1.4.1)
[PEAR] Structures_Graph: upgrade to a newer version (1.1.1 is not newer than 1.1.1)
[PEAR] XML_Util: upgrade to a newer version (1.4.2 is not newer than 1.4.2)
[PEAR] PEAR: upgrade to a newer version (1.10.5 is not newer than 1.10.5)
/usr/local/src/php-7.2.5/build/shtool install -c ext/phar/phar.phar /usr/local/php/bin
ln -s -f phar.phar /usr/local/php/bin/phar
Installing PDO headers: /usr/local/php/include/php/ext/pdo/
5、添加环境变量
vim /etc/profile
在末尾加入
export PHP_HOME=/usr/local/php
export PATH=/bin:/usr/bin:/usr/sbin:/sbin:$PATH:PHP_HOME/bin:$PHP_HOME/sbin
保存修改后,使用source命令重新加载配置文件:
source /etc/profile
查看环境变量:
echo $PATH
6、配置php-fpm
cd /usr/local/php/etc
cp php-fpm.conf.default php-fpm.conf
cd php-fpm.d/
cp www.conf.default www.conf
使用vim命令对php-fpm.conf的内容进行如下修改:
pid = /usr/local/php/var/run/php-fpm.pid
使用vim命令对php-fpm.conf的内容进行如下修改:
user = www
group = www
其他配置可根据需求进行修改,比如pm.max_children(php-fpm 能启动的子进程的最大数量)、pm.start_servers(php启动时,开启的子进程的数量)、pm.min_spare_servers(动态方式空闲状态下的最小php-fpm进程数量)、pm.max_spare_servers(动态方式空闲状态下的最大php-fpm进程数量)等。
7、启动php-fpm
/usr/local/php/sbin/php-fpm
可以通过ps aux | grep php查看php进程。
https://www.cnblogs.com/sunshineliulu/p/8991957.html
三、MySQL
https://blog.csdn.net/weixin_33859844/article/details/90948191
https://www.cnblogs.com/yangchunlong/p/8477743.html
posted @
2019-08-13 17:37 Alpha 阅读(381) |
评论 (0) |
编辑 收藏一、安装git服务器所需软件
打开终端输入以下命令:
ubuntu:~$ sudo apt-get install git-core openssh-server openssh-client
git-core是git版本控制核心软件
安装openssh-server和openssh-client是由于git需要通过ssh协议来在服务器与客户端之间传输文件
然后中间有个确认操作,输入Y后等待系统自动从镜像服务器中下载软件安装,安装完后会回到用户当前目录。如果
安装提示失败,可能是因为系统软件库的索引文件太旧了,先更新一下就可以了,更新命令如下:
ubuntu:~$ sudo apt-get update
更新完软件库索引后继续执行上面的安装命令即可。
安装python的setuptools和gitosis,由于gitosis的安装需要依赖于python的一些工具,所以我们需要先安装python
的setuptools。
执行下面的命令:
ubuntu:~$ sudo apt-get install python-setuptools
这个工具比较小,安装也比较快,接下来准备安装gitosis,安装gitosis之前需要初始化一下服务器的git用户信息,这个随便填。
ubuntu:~$ git config --global user.name "myname"
ubuntu:~$ git config --global user.email "******@gmail.com"
初始化服务器用户信息后,就可以安装gitosis了,gitosis主要是用于给用户授权,设置权限也算是很方便的。
可以通过以下命令获取gitosis版本文件
ubuntu:~$ git clone https://github.com/res0nat0r/gitosis.git
注意:中间有两个是数字零
获取gitosis文件后,进入到文件目录下面
ubuntu:/tmp$ cd gitosis/
接着使用python命令安装目录下的setup.py的python脚本进行安装
ubuntu:/tmp/gitosis$ sudo python setup.py install
到这里,整个安装步骤就完成了,下面就开始对git进行一些基本的配置。
二、创建git管理员账户、配置git
创建一个账户(git)作为git服务器的管理员,可以管理其他用户的项目权限。
ubuntu:/tmp/gitosis$ sudo useradd -m git
ubuntu:/tmp/gitosis$ sudo passwd git
然后再/home目录下创建一个项目仓库存储点,并设置只有git用户拥有所有权限,其他用户没有任何权限。
ubuntu:/tmp/gitosis$ sudo mkdir /home/gitrepository
ubuntu:/tmp/gitosis$ sudo chown git:git /home/gitrepository/
ubuntu:/tmp/gitosis$ sudo chmod 700 /home/gitrepository/
由于gitosis默认状态下会将仓库放在用户的repositories目录下,例如git用户的仓库地址默认在/home/git/repositories/目录下,这里我们需要创建一个链接映射。让他指向我们前面创建的专门用于存放项目的仓库目录/home/gitrepository。
ubuntu:/tmp/gitosis$ sudo ln -s /home/gitrepository /home/git/repositories
这里我将在服务器端生成ssh公钥,如果想在其他机器上管理也可以在其他机器上生成一个ssh的公钥。
ubuntu:/home/git$ ssh-keygen -t rsa
这里会提示输入密码,我们不输入直接回车即可。
然后用刚生成公钥id_rsa.pub来对gitosis进行初始化。
向gitosis添加公钥并初始化:
$ cp ~/.ssh/id_rsa.pub /tmp
$ sudo -H -u gitadmin gitosis-init < /tmp/id_rsa.pub

出现如上信息说明gitosis已经初始化成功。
gitosis主要是通过gitosis-admin.git仓库来管理一些配置文件的,如用户权限的管理。这里我们需要对其中的一个post-update文件添加可执行的权限。
ubuntu:/home/git$ sudo chmod 755 /home/gitrepository/gitosis-admin.git/hooks/post-update
三、服务器上创建项目仓库
使用git账户在服务器上创建一个目录(mytestproject.git)并初始化成git项目仓库。
ubuntu:/home/git$ su git
$ cd /home/gitrepository
$ mkdir mytestproject.git
$ git init --bare mytestproject.git
$ exit
如果出现以下信息就说明已经成功创建了一个名为mytestproject.git的项目仓库了,新建的这个仓库暂时还是空的,不能被客户端clone,还需要对gitosis进行一些配置操作。
四、使用gitosis管理用户操作项目的权限
首先需要在前面生成ssh公钥(用来初始化gitosis)的机器上将gitosis-admin.git的仓库clone下来。
在客户端机器上新建一个目录用于存放gitosis-admin.git仓库
ubuntu:~$ mkdir gitadmin
ubuntu:~$ cd gitadmin/
ubuntu:~/gitadmin$ git clone git@192.168.1.106:gitosis-admin.git
clone正确会显示以下信息

clone下来会有一个gitosis.conf的配置文件和一个keydir的目录。gitosis.conf用于配置用户的权限信息,keydir主要用户存放ssh公钥文件(一般以“用户名.pub”命名,gitosis.conf配置文件中需使用相同用户名),用于认证请求的客户端机器。
现在让需要授权的用户使用前面的方式各自在其自己的机器上生成相应的ssh公钥文件,管理员把他们分别按用户名命名好,复制到keydir目录下。
ubuntu:~$ cp /home/aaaaa/Desktop/zhangsan.pub /home/aaaaa/gitadmin/gitosis-admin/keydir/
ubuntu:~$ cp /home/aaaaa/Desktop/lisi.pub /home/aaaaa/gitadmin/gitosis-admin/keydir/
继续编辑gitosis.conf文件
[gitosis]
[group gitosis-admin]
####管理员组
members = charn@ubuntu
####管理员用户名,需要在keydir目录下找到相应的.pub文件,多个可用空格隔开(下同)
writable = gitosis-admin####可写的项目仓库名,多个可用空格隔开(下同)
[group testwrite]
####可写权限组
members = zhangsan####组用户
writable = mytestproject####可写的项目仓库名
[group
testread] ####只读权限组
members =lisi####组用户
readonly= mytestproject####只读项目仓库名
因为这些配置的修改只是在本地修改的,还需要推送到服务器中才能生效。
ubuntu:~/gitadmin/gitosis-admin$ git add .
ubuntu:~/gitadmin/gitosis-admin$ git commit -am "add a user permission"
ubuntu:~/gitadmin/gitosis-admin$ git push origin master
推送成功会显示下面提示信息

又是后新增的用户不能立即生效,这时候需要重新启动一下sshd服务
ubuntu:~/gitadmin/gitosis-admin$ sudo /etc/init.d/ssh restart
现在,服务端的git就已经安装和配置完成了,接下来就需要有权限的组成员在各自的机器上clone服务器上的相应
项目仓库进行相应的工作了。
五、客户端(windows)使用git
下载安装windows版本的git客户端软件,下载地址:http://msysgit.github.io/
安装完成后右键菜单会出现几个git相关的菜单选项,我们主要使用其中的git
bash通过命令行来进行操作。
在本地新建一个目录,使用git初始化这个目录,然后再里面新建一个文本文件用于测试,最后关联到git服务器仓库
中的相关项目,最后上传本地版本到服务器。
$ mkdir testgit
$ cd testgit
$ git init
$ echo "this is a test text file,will push to server" > hello.txt
$ git add .
$ git commit -am "init a base version,add a first file for push to server"
$ git remote add origin git@serverip:mytestproject.git
$ git push origin master
这样服务端就创建好了一个mytestproject.git的仓库的基础版本了,现在其他组员只要从服务端进行clone就可以了。
window下面进入到需要克隆的本地目录下面右键选择git bash选项,输入
$ git clone git@serverip:mytestproject.git
就可以把项目clone到本地仓库了。
下面进行简单的修改和提交操作
$ cd mytestproject
$ echo "this is another text file created by other" >another.txt
$ git add .
$ git commit -am "add a another file by other"
$ git push origin master
最后推送到服务器成功会显示如下信息

gitolite搭建git仓库(服务端+客户端)
http://blog.csdn.net/ChiChengIT/article/details/49863383
posted @
2018-03-13 15:35 Alpha 阅读(1178) |
评论 (0) |
编辑 收藏
摘要: Git 教程http://www.runoob.com/git/git-tutorial.htmlGit本地服务器搭建及使用Git是一款免费、开源的分布式版本控制系统。众所周知的Github便是基于Git的开源代码库以及版本控制系统,由于其远程托管服务仅对开源免费,所以搭建本地Git服务器也是个较好的选择,本文将对此进行详细讲解。(推荐一家提供私有源代码免费托管的网站:Bitbucket,目前支持...
阅读全文
posted @
2018-03-08 10:44 Alpha 阅读(3229) |
评论 (0) |
编辑 收藏1.查看内存 free
2.查看cpu cat cpuinfo
3.查看磁盘 fdisk -l
4.查看带宽 iptraf-ng
5.查看负载 top
6.查看请求数 netstat -anp | wc -l
7.查看请求详情 netstat -anp
8.查看某个程序请求数 netstat -anp | grep php |wc -l
9.查看磁盘使用情况 df -h
10.查看系统日志 dmesg
11.查看进程数量 ps aux | wc -l
12.查看运行网络程序 ps auxww | more
13.查看php运行程序 ps auxww | grep php
14.查看php运行程序数量 ps auxww | grep php | wc -l
15.查看init.d运行 ls -al /etc/init.d/
16.查找文件路径 find / -name php.ini
17.查看mysql端口 netstat -anp | grep 3306
18.查看本机ip地址 ip add
19.查找某个字符串在文件中出现的 grep 127.0.0.1:9000 *.conf
20.
posted @
2017-12-25 10:16 Alpha 阅读(616) |
评论 (0) |
编辑 收藏一、背景
系统管理员,最谨慎的linux就是rm命令了,一不小心数据就没干掉,最恐怖的是数据没有备份,没法还原了,此类事情发生的太多了,针对于此,我们经过多次尝试演练,终于成功的把大部分删除的数据找回来了,下面我把演练过程给大家介绍一下。
二、安装恢复软件
extundelete,该工具官方给出的是可以恢复ext3或者ext4文件系统被删除的文件。
1:通过命令安装
#yum install extundelete -y
2:通过源码编译安装
#yum -y install e2fsprogs-devel e2fsprogs #wget http://zy-res.oss-cn-hangzhou.aliyuncs.com/server/extundelete-0.2.4.tar.bz2 #tar -xvjf extundelete-0.2.4.tar.bz2 #cd extundelete-0.2.4 #./configure #make &&make install
三、删除数据查找
首先,我们先删除一个文件,如图:
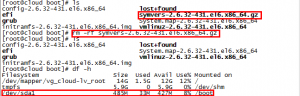
如上图,我们刚才在/boot目录下删除了个symvers-2.6.32-431.el6.x86_64.gz文件,/boot是落到/dev/sda1下
在Linux下可以通过“ls -id”命令来查看某个文件或者目录的inode值,例如查看根目录的inode值,可以输入:
[root@cloud boot]# ls -id /boot 2 /boot
注:根目录的inode一般为2
然后我们开始查找被删除的文件,需要根据分区inode查找,命令如下:
#extundelete /dev/sda1 --inode 2
结果如下图:
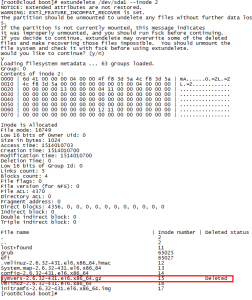
我们就可以看到标识为Deleted的被删除数据了。
四、数据恢复
我们就开始恢复,命令如下:
#extundelete /dev/sda1 --restore-file symvers-2.6.32-431.el6.x86_64.gz
如图:
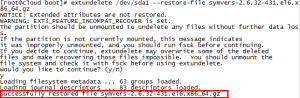

还原成功
当然,还有可能删除整个文件夹,我们也举个例子,如下:
#extundelete /dev/sda1 --restore-directory test
恢复全部删除数据,如下:
#extundelete /dev/sdb1 --restore-all
也可以通过时间段恢复,这里就不说了,参数如下:
--version, -[vV],显示软件版本号。 --help,显示软件帮助信息。 --superblock,显示超级块信息。 --journal,显示日志信息。 --after dtime,时间参数,表示在某段时间之后被删的文件或目录。 --before dtime,时间参数,表示在某段时间之前被删的文件或目录。 动作(action)有: --inode ino,显示节点“ino”的信息。 --block blk,显示数据块“blk”的信息。 --restore-inode ino[,ino,...],恢复命令参数,表示恢复节点“ino”的文件,恢复的文件会自动放在当前目录下的RESTORED_FILES文件夹中,使用节点编号作为扩展名。 --restore-file 'path',恢复命令参数,表示将恢复指定路径的文件,并把恢复的文件放在当前目录下的RECOVERED_FILES目录中。 --restore-files 'path',恢复命令参数,表示将恢复在路径中已列出的所有文件。 --restore-all,恢复命令参数,表示将尝试恢复所有目录和文件。 -j journal,表示从已经命名的文件中读取扩展日志。 -b blocknumber,表示使用之前备份的超级块来打开文件系统,一般用于查看现有超级块是不是当前所要的文件。 -B blocksize,通过指定数据块大小来打开文件系统,一般用于查看已经知道大小的文件。
五、总结
数据恢复,不一定能全部将数据恢复回来,还是一句话,操作要谨慎。万一操作失误,也不要慌,将损失减少到最小,首先停止所有操作,其次让专业人员去处理。

posted @
2017-12-23 16:11 Alpha 阅读(1992) |
评论 (0) |
编辑 收藏
- 安裝 nginx
CentOS 7 沒有內建的 nginx,所以先到 nginx 官網 http://nginx.org/en/linux_packages.html#stable ,找到 CentOS 7 的 nginx-release package 檔案連結,然後如下安裝
rpm -Uvh http://nginx.org/packages/centos/7/noarch/RPMS/nginx-release-centos-7-0.el7.ngx.noarch.rpm
安裝後,會自動產生 yum 的 repository 設定(在 /etc/yum.repos.d/nginx.repo),
接下來便可以使用 yum 指令安裝 nginx
yum install nginx
- 啟動 nginx
以前用 chkconfig 管理服務,CentOS 7 改用 systemctl 管理系統服務
立即啟動
systemctl start nginx
查看目前運作狀態
systemctl status nginx
查看 nginx 服務目前的啟動設定
systemctl list-unit-files | grep nginx
若是 disabled,可以改成開機自動啟動
systemctl enable nginx
若有設定防火牆,查看防火牆運行狀態,看是否有開啟 nginx 使用的 port
firewall-cmd --state
永久開放開啟防火牆的 http 服務
firewall-cmd --permanent --zone=public --add-service=http
firewall-cmd --reload
列出防火牆 public 的設定
firewall-cmd --list-all --zone=public
經過以上設定,應該就可以使用瀏覽器訪問 nginx 的預設頁面。
- 安裝 PHP-FPM
使用 yum 安裝 php、php-fpm、php-mysql
yum install php php-fpm php-mysql
查看 php-fpm 服務目前的啟動設定
systemctl list-unit-files | grep php-fpm
改成開機自動啟動
systemctl enable php-fpm
立即啟動
systemctl start php-fpm
查看目前運作狀態
systemctl status php-fpm
- 修改 PHP-FPM listen 的方式
若想將 PHP-FPM listen 的方式,改成 unix socket,可以編輯 /etc/php-fpm.d/www.conf
將
listen = 127.0.0.1:9000
改成
listen = /var/run/php-fpm/php-fpm.sock
然後重新啟動 php-fpm
systemctl restart php-fpm
註:不要改成 listen = /tmp/php-fcgi.sock (將 php-fcgi.sock 設定在 /tmp 底下), 因為系統產生 php-fcgi.sock 時,會放在 /tmp/systemd-private-*/tmp/php-fpm.sock 隨機私有目錄下, 除非把 /usr/lib/systemd/system/ 裡面的 PrivateTmp=true 設定改成 PrivateTmp=false, 但還是會產生其他問題,所以還是換個位置最方便
删除之前的版本
# yum remove php*
rpm 安装 Php7 相应的 yum源
CentOS/RHEL 7.x:
# rpm -Uvh https://dl.fedoraproject.org/pub/epel/epel-release-latest-7.noarch.rpm # rpm -Uvh https://mirror.webtatic.com/yum/el7/webtatic-release.rpm
CentOS/RHEL 6.x:
# rpm -Uvh https://mirror.webtatic.com/yum/el6/latest.rpm
yum安装php7
yum install php70w php70w-opcache
安装其他插件(选装)
注:如果安装pear,需要安装php70w-devel
php70w
php70w-bcmath
php70w-cli
php70w-common
php70w-dba
php70w-devel
php70w-embedded
php70w-enchant
php70w-fpm
php70w-gd
php70w-imap
php70w-interbase
php70w-intl
php70w-ldap
php70w-mbstring
php70w-mcrypt
php70w-mysql
php70w-mysqlnd
php70w-odbc
php70w-opcache
php70w-pdo
php70w-pdo_dblib
php70w-pear
php70w-pecl-apcu
php70w-pecl-imagick
php70w-pecl-xdebug
php70w-pgsql
php70w-phpdbg
php70w-process
php70w-pspell
php70w-recode
php70w-snmp
php70w-soap
php70w-tidy
php70w-xml
php70w-xmlrp
编译安装php7
配置(configure)、编译(make)、安装(make install)
使用configure --help
编译安装一定要指定定prefix,这是安装目录,会把所有文件限制在这个目录,卸载时只需要删除那个目录就可以,如果不指定会安装到很多地方,后边删除不方便。
Configuration: --cache-file=FILE cache test results in FILE --help print this message --no-create do not create output files --quiet, --silent do not print `checking...' messages --version print the version of autoconf that created configure Directory and file names: --prefix=PREFIX install architecture-independent files in PREFIX [/usr/local] --exec-prefix=EPREFIX install architecture-dependent files in EPREFIX
注意
内存小于1G安装往往会出错,在编译参数后面加上一行内容--disable-fileinfo
其他配置参数
--exec-prefix=EXEC-PREFIX
可以把体系相关的文件安装到一个不同的位置,而不是PREFIX设置的地方.这样做可以比较方便地在不同主机之间共享体系相关的文件
--bindir=DIRECTORY
为可执行程序声明目录,缺省是 EXEC-PREFIX/bin
--datadir=DIRECTORY
设置所安装的程序需要的只读文件的目录.缺省是 PREFIX/share
--sysconfdir=DIRECTORY
用于各种各样配置文件的目录,缺省为 PREFIX/etc
--libdir=DIRECTORY
库文件和动态装载模块的目录.缺省是 EXEC-PREFIX/lib
--includedir=DIRECTORY
C 和 C++ 头文件的目录.缺省是 PREFIX/include
--docdir=DIRECTORY
文档文件,(除 “man(手册页)”以外, 将被安装到这个目录.缺省是 PREFIX/doc
--mandir=DIRECTORY
随着程序一起带的手册页 将安装到这个目录.在它们相应的manx子目录里. 缺省是PREFIX/man
注意: 为了减少对共享安装位置(比如 /usr/local/include) 的污染,configure 自动在 datadir, sysconfdir,includedir, 和 docdir 上附加一个 “/postgresql” 字串, 除非完全展开以后的目录名字已经包含字串 “postgres” 或者 “pgsql”.比如,如果你选择 /usr/local 做前缀,那么 C 的头文件将安装到 /usr/local/include/postgresql, 但是如果前缀是 /opt/postgres,那么它们将 被放进 /opt/postgres/include
--with-includes=DIRECTORIES
DIRECTORIES 是一系列冒号分隔的目录,这些目录将被加入编译器的头文件 搜索列表中.如果你有一些可选的包(比如 GNU Readline)安装在 非标准位置,你就必须使用这个选项,以及可能还有相应的 --with-libraries 选项.
--with-libraries=DIRECTORIES
DIRECTORIES 是一系列冒号分隔的目录,这些目录是用于查找库文件的. 如果你有一些包安装在非标准位置,你可能就需要使用这个选项 (以及对应的--with-includes选项)
--enable-XXX
打开XXX支持
--with-XXX
制作XXX模块
- PHP FPM設定參考
[global]
pid = /usr/local/php/var/run/php-fpm.pid
error_log = /usr/local/php/var/log/php-fpm.log
[www]
listen = /var/run/php-fpm/php-fpm.sock
user = www
group = www
pm = dynamic
pm.max_children = 800
pm.start_servers = 200
pm.min_spare_servers = 100
pm.max_spare_servers = 800
pm.max_requests = 4000
rlimit_files = 51200
listen.backlog = 65536
;設 65536 的原因是-1 可能不是unlimited
;說明 http://php.net/manual/en/install.fpm.configuration.php
slowlog = /usr/local/php/var/log/slow.log
request_slowlog_timeout = 10
- nginx.conf 設定參考
user nginx;
worker_processes 8;
error_log /var/log/nginx/error.log warn;
pid /var/run/nginx.pid;
events {
use epoll;
worker_connections 65535;
}
worker_rlimit_nofile 65535;
http {
include /etc/nginx/mime.types;
default_type application/octet-stream;
log_format main '$remote_addr - $remote_user [$time_local] "$request" '
'$status $body_bytes_sent "$http_referer" '
'"$http_user_agent" "$http_x_forwarded_for"';
access_log /var/log/nginx/access.log main;
sendfile on;
tcp_nopush on;
keepalive_timeout 65;
server_names_hash_bucket_size 128;
client_header_buffer_size 32k;
large_client_header_buffers 4 32k;
client_max_body_size 8m;
server_tokens off;
client_body_buffer_size 512k;
fastcgi_connect_timeout 300;
fastcgi_send_timeout 300;
fastcgi_read_timeout 300;
fastcgi_buffer_size 64k;
fastcgi_buffers 4 64k;
fastcgi_busy_buffers_size 128k;
fastcgi_temp_file_write_size 128k;
fastcgi_intercept_errors on;
gzip off;
gzip_min_length 1k;
gzip_buffers 32 4k;
gzip_http_version 1.0;
gzip_comp_level 2;
gzip_types text/css text/xml application/javascript application/atom+xml application/rss+xml text/plain application/json;
gzip_vary on;
include /etc/nginx/conf.d
若出現出現錯誤:setrlimit(RLIMIT_NOFILE, 65535) failed (1: Operation not permitted)
先查看目前系統的設定值
ulimit -n
若設定值太小,修改 /etc/security/limits.conf
vi /etc/security/limits.conf
加上或修改以下兩行設定
* soft nofile 65535
* hard nofile 65535
posted @
2016-08-10 13:44 Alpha 阅读(6014) |
评论 (0) |
编辑 收藏1.关于Tomcat的session数目
这个可以直接从Tomcat的web管理界面去查看即可
或者借助于第三方工具Lambda Probe来查看,它相对于Tomcat自带的管理稍微多了点功能,但也不多
2.监视Tomcat的内存使用情况
使用JDK自带的jconsole可以比较明了的看到内存的使用情况,线程的状态,当前加载的类的总量等
JDK自带的jvisualvm可以下载插件(如GC等),可以查看更丰富的信息。如果是分析本地的Tomcat的话,还可以进行内存抽样等,检查每个类的使用情况
3.打印类的加载情况及对象的回收情况
这个可以通过配置JVM的启动参数,打印这些信息(到屏幕(默认也会到catalina.log中)或者文件),具体参数如下:
-XX:+PrintGC:输出形式:[GC 118250K->113543K(130112K), 0.0094143 secs] [Full GC 121376K->10414K(130112K), 0.0650971 secs]
-XX:+PrintGCDetails:输出形式:[GC [DefNew: 8614K->781K(9088K), 0.0123035 secs] 118250K->113543K(130112K), 0.0124633 secs] [GC [DefNew: 8614K->8614K(9088K), 0.0000665 secs][Tenured: 112761K->10414K(121024K), 0.0433488 secs] 121376K->10414K(130112K), 0.0436268 secs]
-XX:+PrintGCTimeStamps -XX:+PrintGC:PrintGCTimeStamps可与上面两个混合使用,输出形式:11.851: [GC 98328K->93620K(130112K), 0.0082960 secs]
-XX:+PrintGCApplicationConcurrentTime:打印每次垃圾回收前,程序未中断的执行时间。可与上面混合使用。输出形式:Application time: 0.5291524 seconds
-XX:+PrintGCApplicationStoppedTime:打印垃圾回收期间程序暂停的时间。可与上面混合使用。输出形式:Total time for which application threads were stopped: 0.0468229 seconds
-XX:PrintHeapAtGC: 打印GC前后的详细堆栈信息
-Xloggc:filename:与上面几个配合使用,把相关日志信息记录到文件以便分析
-verbose:class 监视加载的类的情况
-verbose:gc 在虚拟机发生内存回收时在输出设备显示信息
-verbose:jni 输出native方法调用的相关情况,一般用于诊断jni调用错误信息
4.添加JMS远程监控
对于部署在局域网内其它机器上的Tomcat,可以打开JMX监控端口,局域网其它机器就可以通过这个端口查看一些常用的参数(但一些比较复杂的功能不支持),同样是在JVM启动参数中配置即可,配置如下:
-Dcom.sun.management.jmxremote.ssl=false -Dcom.sun.management.jmxremote.authenticate=false
-Djava.rmi.server.hostname=192.168.71.38 设置JVM的JMS监控监听的IP地址,主要是为了防止错误的监听成127.0.0.1这个内网地址
-Dcom.sun.management.jmxremote.port=1090 设置JVM的JMS监控的端口
-Dcom.sun.management.jmxremote.ssl=false 设置JVM的JMS监控不实用SSL
-Dcom.sun.management.jmxremote.authenticate=false 设置JVM的JMS监控不需要认证
5.专业点的分析工具有
IBM ISA,JProfiler等,具体监控及分析方式去网上搜索即可。
集群方案
单个Tomcat的处理性能是有限的,当并发量较大的时候,就需要有部署多套来进行负载均衡了。
集群的关键点有以下几点:
1.引入负载端
软负载可以使用nginx或者apache来进行,主要是使用一个分发的功能
参考:
http://ajita.iteye.com/blog/1715312(nginx负载)
http://ajita.iteye.com/blog/1717121(apache负载)
2.共享session处理
目前的处理方式有如下几种:
1).使用Tomcat本身的Session复制功能
参考http://ajita.iteye.com/blog/1715312(Session复制的配置)
方案的有点是配置简单,缺点是当集群数量较多时,Session复制的时间会比较长,影响响应的效率
2).使用第三方来存放共享Session
目前用的较多的是使用memcached来管理共享Session,借助于memcached-sesson-manager来进行Tomcat的Session管理
参考http://ajita.iteye.com/blog/1716320(使用MSM管理Tomcat集群session)
3).使用黏性session的策略
对于会话要求不太强(不涉及到计费,失败了允许重新请求下等)的场合,同一个用户的session可以由nginx或者apache交给同一个Tomcat来处理,这就是所谓的session sticky策略,目前应用也比较多
参考:http://ajita.iteye.com/blog/1848665(tomcat session sticky)
nginx默认不包含session sticky模块,需要重新编译才行(windows下我也不知道怎么重新编译)
优点是处理效率高多了,缺点是强会话要求的场合不合适
3.小结
以上是实现集群的要点,其中1和2可以组合使用,具体场景具体分析吧~
JVM优化
Tomcat本身还是运行在JVM上的,通过对JVM参数的调整我们可以使Tomcat拥有更好的性能。针对JVM的优化目前主要在两个方面:
1.内存调优
内存方式的设置是在catalina.sh中,调整一下JAVA_OPTS变量即可,因为后面的启动参数会把JAVA_OPTS作为JVM的启动参数来处理。
具体设置如下:
JAVA_OPTS="$JAVA_OPTS -Xmx3550m -Xms3550m -Xss128k -XX:NewRatio=4 -XX:SurvivorRatio=4"
其各项参数如下:
-Xmx3550m:设置JVM最大可用内存为3550M。
-Xms3550m:设置JVM促使内存为3550m。此值可以设置与-Xmx相同,以避免每次垃圾回收完成后JVM重新分配内存。
-Xmn2g:设置年轻代大小为2G。整个堆大小=年轻代大小 + 年老代大小 + 持久代大小。持久代一般固定大小为64m,所以增大年轻代后,将会减小年老代大小。此值对系统性能影响较大,Sun官方推荐配置为整个堆的3/8。
-Xss128k:设置每个线程的堆栈大小。JDK5.0以后每个线程堆栈大小为1M,以前每个线程堆栈大小为256K。更具应用的线程所需内存大小进行调整。在相同物理内存下,减小这个值能生成更多的线程。但是操作系统对一个进程内的线程数还是有限制的,不能无限生成,经验值在3000~5000左右。
-XX:NewRatio=4:设置年轻代(包括Eden和两个Survivor区)与年老代的比值(除去持久代)。设置为4,则年轻代与年老代所占比值为1:4,年轻代占整个堆栈的1/5
-XX:SurvivorRatio=4:设置年轻代中Eden区与Survivor区的大小比值。设置为4,则两个Survivor区与一个Eden区的比值为2:4,一个Survivor区占整个年轻代的1/6
-XX:MaxPermSize=16m:设置持久代大小为16m。
-XX:MaxTenuringThreshold=0:设置垃圾最大年龄。如果设置为0的话,则年轻代对象不经过Survivor区,直接进入年老代。对于年老代比较多的应用,可以提高效率。如果将此值设置为一个较大值,则年轻代对象会在Survivor区进行多次复制,这样可以增加对象再年轻代的存活时间,增加在年轻代即被回收的概论。
2.垃圾回收策略调优
垃圾回收的设置也是在catalina.sh中,调整JAVA_OPTS变量。
具体设置如下:
JAVA_OPTS="$JAVA_OPTS -Xmx3550m -Xms3550m -Xss128k -XX:+UseParallelGC -XX:MaxGCPauseMillis=100"
具体的垃圾回收策略及相应策略的各项参数如下:
串行收集器(JDK1.5以前主要的回收方式)
-XX:+UseSerialGC:设置串行收集器
并行收集器(吞吐量优先)
示例:
java -Xmx3550m -Xms3550m -Xmn2g -Xss128k -XX:+UseParallelGC -XX:MaxGCPauseMillis=100
-XX:+UseParallelGC:选择垃圾收集器为并行收集器。此配置仅对年轻代有效。即上述配置下,年轻代使用并发收集,而年老代仍旧使用串行收集。
-XX:ParallelGCThreads=20:配置并行收集器的线程数,即:同时多少个线程一起进行垃圾回收。此值最好配置与处理器数目相等。
-XX:+UseParallelOldGC:配置年老代垃圾收集方式为并行收集。JDK6.0支持对年老代并行收集
-XX:MaxGCPauseMillis=100:设置每次年轻代垃圾回收的最长时间,如果无法满足此时间,JVM会自动调整年轻代大小,以满足此值。
-XX:+UseAdaptiveSizePolicy:设置此选项后,并行收集器会自动选择年轻代区大小和相应的Survivor区比例,以达到目标系统规定的最低相应时间或者收集频率等,此值建议使用并行收集器时,一直打开。
并发收集器(响应时间优先)
示例:java -Xmx3550m -Xms3550m -Xmn2g -Xss128k -XX:+UseConcMarkSweepGC
-XX:+UseConcMarkSweepGC:设置年老代为并发收集。测试中配置这个以后,-XX:NewRatio=4的配置失效了,原因不明。所以,此时年轻代大小最好用-Xmn设置。
-XX:+UseParNewGC: 设置年轻代为并行收集。可与CMS收集同时使用。JDK5.0以上,JVM会根据系统配置自行设置,所以无需再设置此值。
-XX:CMSFullGCsBeforeCompaction:由于并发收集器不对内存空间进行压缩、整理,所以运行一段时间以后会产生“碎片”,使得运行效率降低。此值设置运行多少次GC以后对内存空间进行压缩、整理。
-XX:+UseCMSCompactAtFullCollection:打开对年老代的压缩。可能会影响性能,但是可以消除碎片
3.小结
在内存设置中需要做一下权衡
1)内存越大,一般情况下处理的效率也越高,但同时在做垃圾回收的时候所需要的时间也就越长,在这段时间内的处理效率是必然要受影响的。
2)在大多数的网络文章中都推荐 Xmx和Xms设置为一致,说是避免频繁的回收,这个在测试的时候没有看到明显的效果,内存的占用情况基本都是锯齿状的效果,所以这个还要根据实际情况来定。
Server.xml的Connection优化
Tomcat的Connector是Tomcat接收HTTP请求的关键模块,我们可以配置它来指定IO模式,以及处理通过这个Connector接受到的请求的处理线程数以及其它一些常用的HTTP策略。其主要配置参数如下:
1.指定使用NIO模型来接受HTTP请求
protocol="org.apache.coyote.http11.Http11NioProtocol" 指定使用NIO模型来接受HTTP请求。默认是BlockingIO,配置为protocol="HTTP/1.1"
acceptorThreadCount="2" 使用NIO模型时接收线程的数目
2.指定使用线程池来处理HTTP请求
首先要配置一个线程池来处理请求(与Connector是平级的,多个Connector可以使用同一个线程池来处理请求)
<Executor name="tomcatThreadPool" namePrefix="catalina-exec-"
maxThreads="1000" minSpareThreads="50" maxIdleTime="600000"/>
<Connector port="8080"
executor="tomcatThreadPool" 指定使用的线程池
3.指定BlockingIO模式下的处理线程数目
maxThreads="150"//Tomcat使用线程来处理接收的每个请求。这个值表示Tomcat可创建的最大的线程数。默认值200。可以根据机器的时期性能和内存大小调整,一般可以在400-500。最大可以在800左右。
minSpareThreads="25"---Tomcat初始化时创建的线程数。默认值4。如果当前没有空闲线程,且没有超过maxThreads,一次性创建的空闲线程数量。Tomcat初始化时创建的线程数量也由此值设置。
maxSpareThreads="75"--一旦创建的线程超过这个值,Tomcat就会关闭不再需要的socket线程。默认值50。一旦创建的线程超过此数值,Tomcat会关闭不再需要的线程。线程数可以大致上用 “同时在线人数*每秒用户操作次数*系统平均操作时间” 来计算。
acceptCount="100"----指定当所有可以使用的处理请求的线程数都被使用时,可以放到处理队列中的请求数,超过这个数的请求将不予处理。默认值10。如果当前可用线程数为0,则将请求放入处理队列中。这个值限定了请求队列的大小,超过这个数值的请求将不予处理。
connectionTimeout="20000" --网络连接超时,默认值20000,单位:毫秒。设置为0表示永不超时,这样设置有隐患的。通常可设置为30000毫秒。
4.其它常用设置
maxHttpHeaderSize="8192" http请求头信息的最大程度,超过此长度的部分不予处理。一般8K。
URIEncoding="UTF-8" 指定Tomcat容器的URL编码格式。
disableUploadTimeout="true" 上传时是否使用超时机制
enableLookups="false"--是否反查域名,默认值为true。为了提高处理能力,应设置为false
compression="on" 打开压缩功能
compressionMinSize="10240" 启用压缩的输出内容大小,默认为2KB
noCompressionUserAgents="gozilla, traviata" 对于以下的浏览器,不启用压缩
compressableMimeType="text/html,text/xml,text/javascript,text/css,text/plain" 哪些资源类型需要压缩
5.小结
关于Tomcat的Nio和ThreadPool,本身的引入就提高了处理的复杂性,所以对于效率的提高有多少,需要实际验证一下。
6.配置示例
<Connector port="8080"
redirectPort="8443"
maxThreads="150"
minSpareThreads="25"
maxSpareThreads="75"
acceptCount="100"
connectionTimeout="20000"
protocol="HTTP/1.1"
maxHttpHeaderSize="8192"
URIEncoding="UTF-8"
disableUploadTimeout="true"
enableLookups="false"
compression="on"
compressionMinSize="10240"
noCompressionUserAgents="gozilla, traviata"
compressableMimeType="text/html,text/xml,text/javascript,text/css,text/plain">
...
</Connector>
管理AJP端口
AJP是为 Tomcat 与 HTTP 服务器之间通信而定制的协议,能提供较高的通信速度和效率。如果tomcat前端放的是apache的时候,会使用到AJP这个连接器。由于我们公司前端是由nginx做的反向代理,因此不使用此连接器,因此需要注销掉该连接器。
<!-- <Connector port="8009" protocol="AJP/1.3" redirectPort="8443" /> -->
默认 Tomcat 是开启了对war包的热部署的。为了防止被植入木马等恶意程序,因此我们要关闭自动部署。
修改实例:
<Host name="localhost" appBase="" unpackWARs="false" autoDeploy="false">
posted @
2016-04-29 11:59 Alpha 阅读(2490) |
评论 (2) |
编辑 收藏
摘要: 最新的版本可以在这里获取,目前下载的最新版本是5.08,更新于2016-02-03。在这里可以找到更多的说明。
下载好后,server端分为两个部分,一个是tracker,一个是storage。顾名思义,前者调度管理,负载均衡,后者则是实际的存储节点。两个都能做成集群,以防止单点故障。以前的4.x版本依赖libevent,现在不需要了,只需要libfastcommon。安装方法如下:
1....
阅读全文
posted @
2016-04-07 13:58 Alpha 阅读(2825) |
评论 (2) |
编辑 收藏
摘要: 1.第一步需要安装PPTP,以用来提供VPN服务.
?
1
sudo apt-get install pptpd
...
阅读全文
posted @
2016-03-07 12:30 Alpha 阅读(534) |
评论 (0) |
编辑 收藏1.# rpm -Uvh http://poptop.sourceforge.net/yum/stable/rhel6/pptp-release-current.noarch.rpm
3.配置pptp.首先我们要编辑/etc/pptpd.conf文件:
#vim /etc/pptpd.conf
找到”locapip”和”remoteip”这两个配置项,将前面的”;”注释符去掉,更改为你期望的IP段值.localip表示服务器的IP,remoteip表示分配给客户端的IP地址,可以设置为区间.这里我们使用pptp默认的配置:
localip 192.168.0.1
remoteip 192.168.0.234-238,192.168.0.245
注意,这里的IP段设置,将直接影响后面的iptables规则添加命令.请注意匹配的正确性,如果你嫌麻烦,建议就用本文的配置,就可以一直复制命令和文本使用了.
4.接下来我们再编辑/etc/ppp/options.pptpd文件,为VPN添加Google DNS:
#vim /etc/ppp/options.pptpd
在末尾添加下面两行:
ms-dns 8.8.8.8
ms-dns 8.8.4.4
5、设置pptp VPN账号密码.我们需要编辑/etc/ppp/chap-secrets这个文件:
#vim /etc/ppp/chap-secrets
在这个文件里面,按照”用户名 pptpd 密码 *”的形式编写,一行一个账号和密码.比如添加用户名为test,密码为1234的用户,则编辑如下内容:
test pptpd 1234 *
6、修改内核设置,使其支持转发.编辑/etc/sysctl.conf文件:
#vim /etc/sysctl.conf
将”net.ipv4.ip_forward”改为1,变成下面的形式.
net.ipv4.ip_forward=1
保存退出,并执行下面的命令来生效它:
#sysctl -p
7、添加iptables转发规则.经过前面的6个步骤,我们的VPN已经可以拨号了,但是还不能访问任何网页.最后一步就是添加iptables转发规则了,输入下面的指令:
#iptables -t nat -A POSTROUTING -s 192.168.0.0/24 -o eth0 -j MASQUERADE
需要注意的是,这个指令中的”192.168.0.0/24″是根据之前的配置文件中的”localip”网段来改变的,比如你设置的”10.0.0.1″网段,则应该改为”10.0.0.0/24″.此外还有一点需要注意的是eth0,如果你的外网网卡不是eth0,而是eth1(比如SoftLayer的服务器就是这样的情况),那么请记得将eth0也更改为对应的网卡编号,不然是上不了网的.
然后我们输入下面的指令让iptables保存我们刚才的转发规则,以便重启系统后不需要再次添加:
#/etc/init.d/iptables save
然后我们重启iptables:
#/etc/init.d/iptables restart
8、重启pptp服务.输入下面的指令重启pptp:
#/etc/init.d/pptpd restart
现在你已经可以连接自己的VPN并浏览网页了.不过我们还需要做最后的一步.
9、设置开机自动运行服务.我们最后一步是将pptp和iptables设置为开机自动运行,这样就不需要每次重启服务器后手动启动服务了,当然你不需要自动启动服务的话可以忽略这一步,输入指令:
#chkconfig pptpd on
#chkconfig iptables on
这样就大功告成了,赶快到Windows下建立一个VPN连接,IP填写自己的服务器IP,用户名和密码填写自己设置好的用户名和密码,点击”连接”,成功后就可以使用服务器去浏览网页啦.
备注:
多ip服务器转发指定规则
iptables -t nat -A POSTROUTING -s 192.168.8.0/24 -j SNAT --to-source 192.168.8.1
or
iptables -t nat -A POSTROUTING -s 192.168.8.0/24 -j SNAT --to-source 服务器外网ip
如果iphone之类的设备能连上,访问网页或者youtube特别慢,需要做如下修改:
vi /etc/ppp/ip-up
增加一行
/sbin/ifconfig $1 mtu 1400
或者修改iptables规则
iptables -A FORWARD -p tcp --syn -s 192.168.8.0/24 -j TCPMSS --set-mss 1356
1356的值可能需要自己调整,调节到能保证网络正常使用情况下的最大值
posted @
2016-02-25 22:31 Alpha 阅读(504) |
评论 (0) |
编辑 收藏
摘要: 关于IP Tables在初始化设置系统后,为了让系统更安全,Ubuntu把Iptabls作为发行版的默认防火墙。起初,尽管Ubuntu防火墙已经被配置了,但是它设置为通过一个虚拟主机允许所有的进入与流出流量。要打开服务器上某些更强的保护功能,我们需要在IP Table山增加一些基础的规则。IP Table 规则来自于一系列可以组合起来创建各自的特定的处理方法的选项。每一个通过防火墙的包被所有的规则...
阅读全文
posted @
2015-10-31 15:51 Alpha 阅读(2562) |
评论 (0) |
编辑 收藏我有一个
阿里云推荐码,分享给大家免费使用,购买云服务器ECS或云数据库RDS可享受原价优惠,拿走不谢。
马上可享受优惠,购买阿里云主机马上给你省钱!

我有几张
阿里云幸运券分享给你,用券购买或者升级阿里云相应产品会有
特惠惊喜哦!把想要买的产品的幸运券都领走吧!快下手,马上就要抢光了。
posted @
2015-10-28 14:25 Alpha 阅读(699) |
评论 (0) |
编辑 收藏安装 MySQL 5 数据库
安装 MySQL 运行命令:
sudo
apt-get install mysql-server mysql-client
将mysql的datadir从默认的/var/lib/mysql 移到/app/data/mysql下,操作如下:
1.修改了/etc/mysql/my.cnf,改为:datadir = /app/data/mysql
2.cp -a /var/lib/mysql /app/data/
3./etc/init.d/mysql start
如果出现系统报错,无法启动mysql,日志显示为:Can't find file: "./mysql/plugin.frm'(errno:13)
[ERROR] Can't open the mysql.plugin table. Please run mysql_upgrade to create it.
修改系统的chroot,需要修改/etc/apparmor.d下的相关文件,这里以mysql为例,需要修改:usr.sbin.mysqld和abstractions/mysql两个文件。
1.修改usr.sbin.mysqld里面的两行内容:/var/lib/mysql/ r,改为:/app/data/mysql/ r,/var/lib/mysql/** rwk,改为:/app/data/mysql/** rwk,
2.修改abstractions/mysql中一行:/var/lib/mysql/mysql.sock rw,改为:/app/data/mysql/mysql.sock rw,
3.重新加载apparmor服务:/etc/init.d/apparmor reload
安装 Nginx
在安装 Nginx 之前,如果你已经安装 Apache2 先删除在安装 nginx:
service apache2 stop
update-rc.d -f apache2 remove
sudo apt-get remove apache2
sudo
apt-get install nginx
安装 PHP5
我们必须通过 PHP-FPM 才能让PHP5正常工作,安装命令:
sudo
apt-get install php5-fpm
php-fpm是一个守护进程。
安装mysql和GD扩展
sudo apt-get install php5-gd libapache2-mod-auth-mysql php5-mysql openssl libssl-dev
sudo apt-get install curl libcurl3 libcurl3-dev php5-curl
安装 JDK8
可以通过访问Oracle官网下载,或者直接通过命令行下载。
lxh@ubuntu:~$ wget -c http://download.oracle.com/otn-pub/java/jdk/8u11-b12/jdk-8u25-linux-x64.tar.gz
解压安装
lxh@ubuntu:~$ mkdir -p /usr/lib/jvm
lxh@ubuntu:~$ sudo mv jdk-8u25-linux-x64.tar.gz /usr/lib/jvm
lxh@ubuntu:~$ cd /usr/lib/jvm
lxh@ubuntu:~$ sudo tar xzvf jdk-8u25-linux-x64.tar.gz
在系统中添加环境变量,主要是PATH、CLASSPATH和JAVA_HOME。
lxh@ubuntu:~$ sudo vim ~/.profile
在文件最后加入
export JAVA_HOME=/usr/lib/jvm/jdk1.8.0_25/
export JRE_HOME=/usr/lib/jvm/jdk1.8.0_25/jre
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar:$JAVA_HOME/lib:$JRE_HOME/lib:$CLASSPATH
export PATH=$JAVA_HOME/bin:$PATH
保存退出,并通过命令使脚本生效:
lxh@ubuntu:~$ $source ~/.profile
配置默认JDK版本
在有的系统中会预装OpenJDK,系统默认使用的是这个,而不是刚才装的。所以这一步是通知系统使用Oracle的JDK,非OpenJDK。
sudo update-alternatives --install /usr/bin/java java /usr/lib/jvm/jdk1.8.0_25/bin/java 300
sudo update-alternatives --install /usr/bin/javac javac /usr/lib/jvm/jdk1.8.0_25/bin/javac 300
sudo update-alternatives --config java
因为我是在虚拟机中安装的Ubuntu 14.04,默认不安装OpenJDK,所以没有需要选择的JDK版本。如果是在物理机上安装的Ubuntu版本,会出现几个候选项,可用于替换 java (提供 /usr/bin/java)。
====================================
编译安装nginx
1. 下载最新版nginx
2.解压
3. 安装
$ ./configure #检查编译前置条件
$ make #编译
$ sudo make install #使用sudo权限进行安装
安装后路径在 /usr/local/
启动nginx
/usr/local/nginx/sbin/nginx
1)使用在 /etc/init.d/ 目录下创建名为 nginx 文件,注意没有后缀名,将以下内容复制到该文件中(感谢提供脚本的兄弟)。
1 #! /bin/sh
2 #用来将Nginx注册为系统服务的脚本
3 #Author CplusHua
4 #http://www.219.me
5 #chkconfig: - 85 15
6 set -e
7 PATH=/usr/local/sbin:/usr/local/bin:/sbin:/bin:/usr/sbin:/usr/bin
8 DESC="Nginx Daemon"
9 NAME=nginx
10 DAEMON=/usr/local/nginx/sbin/$NAME
11 SCRIPTNAME=/etc/init.d/$NAME
12 #守护进程不存在就退出
13 test -x $DAEMON ||exit 0
14 d_start(){
15 $DAEMON ||echo -n "aready running"
16 }
17 d_stop(){
18 $DAEMON -s quit || echo -n "not running"
19 }
20 d_reload(){
21 $DAEMON -s reload || echo -n "could not reload"
22 }
23 case "$1" in
24 start)
25 echo -n "Starting $DESC: $NAME"
26 d_start
27 echo "."
28 ;;
29 stop)
30 echo -n "Stopping $DESC: $NAME"
31 d_stop
32 echo "."
33 ;;
34 reload)
35 echo -n "Reloading $DESC: configurationg .."
.."
36 d_reload
37 echo "reloaded."
38 ;;
39 restart)
40 echo -n "Restarting $DESC: $NAME"
41 d_stop
42 sleep 3
43 d_start
44 echo "."
45 ;;
46 *)
47 echo "Usage: $SCRIPTNAME {start|stop|restart|reload}" >&2
48 exit 3
49 ;;
50 esac
51
52 exit 0
2)添加权限
$ sudo chmod +x nginx
3)服务方式启动 如果配置服务前已启动,执行以下命令停止Nginx。
$ sudo service nginx stop
4)启动Nginx
$ sudo service nginx start
pastingnginx出现connect() to unix:/var/run/php5-fpm.sock failed (13: Permission denied)的错误
处理方式是:编辑/etc/php5/fpm/pool.d/www.conf文件,
将以下的注释去掉:
listen.owner = www-data
listen.group = www-data
listen.mode = 0660
然后重启php5-fpm
$ sudo service php5-fpm restart
Ubuntu 14.04快速搭建SVN服务器及日常使用
SVN相关命令了解
svn:命令行客户端
svnadmin:用来创建、调整或修复版本库的工具
svnserve:svn服务程序
svndumpfilter:过滤svn版本库转储数据流的工具
svnsync:svn数据同步工具,实现另外存一份相同的
svnlook:用来查看办本科中不同的修订版和事务
直接安装
# apt-get install subversion
创建版本库
# sudo mkdir /app/svn
# sudo svnadmin create /app/svn/prj
配置版本库
# sudo vi svnserve.conf #将以下参数去掉注释
[general]
anon-access = none #匿名访问权限,默认read,none为不允许访问
auth-access = write #认证用户权限
password-db = passwd #用户信息存放文件,默认在版本库/conf下面,也可以绝对路径指定文件位置
authz-db = authz
# sudo vi passwd #格式是用户名=密码,采用明文密码
[users]
xiaoming = 123
zhangsan = 123
lisi = 123
# sudo vi authz
[groups] #定义组的用户
manager = xiaoming
core_dev = zhangsan,lisi
[repos:/] #以根目录起始的repos版本库manager组为读写权限
@manager = rw
[repos:/media] #core_dev对repos版本库下media目录为读写权限
@core_dev = rw
启动svn服务
# sudo svnserve -d -r /app/svn
# 查看是否启动成功,可看的监听3690端口
# sudo netstat -antp |grep svnserve
tcp 0 0 0.0.0.0:3690 0.0.0.0:* LISTEN 28967/svnserve
# 如果想关闭服务,可使用pkill svnserve
访问svn
# 访问repos版本库地址
svn://192.168.1.100/prj
备份与恢复
svnadmin dump备份
# 完整备份
svnadmin dump /app/svn/prj > YYmmdd_fully_backup.svn
# 完整压缩备份
svnadmin dump /app/svn/prj | gzip > YYmmdd_fully_backup.gz
# 备份恢复
svnadmin load /app/svn/prj < YYmmdd_fully_backup.svn
zcat YYmmdd_fully_backup.gz | svnadmin load repos
### 增量备份 ###
# 先完整备份
svnadmin dump /app/svn/prj -r 0:100 > YYmmdd_incremental_backup.svn
# 再增量备份
svnadmin dump /app/svn/prj -r 101:200 --incremental > YYmmdd_incremental_backup.svn
svnadmin hotcopy备份
# 备份
svnadmin hotcopy /app/svn/prj YYmmdd_fully_backup --clean-logs
# 恢复
svnadmin hotcopy YYmmdd_fully_backup /app/svn/prj
Tomcat 内存优化
Linux下修改JVM内存大小
要添加在tomcat 的bin 下catalina.sh 里,位置cygwin=false前 。注意引号要带上,红色的为新添加的.
# OS specific support. $var _must_ be set to either true or false.
JAVA_OPTS="-server -Xms512M -Xmx512M -Xss256K -Djava.awt.headless=true -Dfile.encoding=utf-8 -XX:PermSize=64M -XX:MaxPermSize=128m"
cygwin=false
posted @
2015-10-07 15:28 Alpha 阅读(982) |
评论 (0) |
编辑 收藏当然一定有人接私活接的很好,只是别人的成功很难複制,但别人的失败可以避免,如果你能避掉我以上所说的陷阱也无法保证你能成功,因为这也只是冰山一角,我已经离开接私活的状态很久,很多事忘了也不想去想,只是希望你在决定接私活前,仔细想一下,你真的只有接私活这个选项吗 ? 如果可以,我会建议你应该要开发自己的产品及服务。
来自:電子豹博客
posted @
2015-06-10 14:28 Alpha 阅读(2226) |
评论 (0) |
编辑 收藏fn:contains 判断字符串是否包含另外一个字符串 <c:if test="${fn:contains(name, searchString)}">
fn:containsIgnoreCase 判断字符串是否包含另外一个字符串(大小写无关) <c:if test="${fn:containsIgnoreCase(name, searchString)}">
fn:endsWith 判断字符串是否以另外字符串结束 <c:if test="${fn:endsWith(filename, ".txt")}">
fn:escapeXml 把一些字符转成XML表示,例如 <字符应该转为< ${fn:escapeXml(param:info)}
fn:indexOf 子字符串在母字符串中出现的位置 ${fn:indexOf(name, "-")}
fn:join 将数组中的数据联合成一个新字符串,并使用指定字符格开 ${fn:join(array, ";")}
fn:length 获取字符串的长度,或者数组的大小 ${fn:length(shoppingCart.products)}
fn:replace 替换字符串中指定的字符 ${fn:replace(text, "-", "?")}
fn:split 把字符串按照指定字符切分 ${fn:split(customerNames, ";")}
fn:startsWith 判断字符串是否以某个子串开始 <c:if test="${fn:startsWith(product.id, "100-")}">
fn:substring 获取子串 ${fn:substring(zip, 6, -1)}
fn:substringAfter 获取从某个字符所在位置开始的子串 ${fn:substringAfter(zip, "-")}
fn:substringBefore 获取从开始到某个字符所在位置的子串 ${fn:substringBefore(zip, "-")}
fn:toLowerCase 转为小写 ${fn.toLowerCase(product.name)}
fn:toUpperCase 转为大写字符 ${fn.UpperCase(product.name)}
fn:trim 去除字符串前后的空格 ${fn.trim(name)}
函数
描述
fn:contains(string, substring)
如果参数string中包含参数substring,返回true
fn:containsIgnoreCase(string, substring)
如果参数string中包含参数substring(忽略大小写),返回true
fn:endsWith(string, suffix)
如果参数 string 以参数suffix结尾,返回true
fn:escapeXml(string)
将有特殊意义的XML (和HTML)转换为对应的XML character entity code,并返回
fn:indexOf(string, substring)
返回参数substring在参数string中第一次出现的位置
fn:join(array, separator)
将一个给定的数组array用给定的间隔符separator串在一起,组成一个新的字符串并返回。
fn:length(item)
返回参数item中包含元素的数量。参数Item类型是数组、collection或者String。如果是String类型,返回值是String中的字符数。
fn:replace(string, before, after)
返回一个String对象。用参数after字符串替换参数string中所有出现参数before字符串的地方,并返回替换后的结果
fn:split(string, separator)
返回一个数组,以参数separator 为分割符分割参数string,分割后的每一部分就是数组的一个元素
fn:startsWith(string, prefix)
如果参数string以参数prefix开头,返回true
fn:substring(string, begin, end)
返回参数string部分字符串, 从参数begin开始到参数end位置,包括end位置的字符
fn:substringAfter(string, substring)
返回参数substring在参数string中后面的那一部分字符串??
fn:substringBefore(string, substring)
返回参数substring在参数string中前面的那一部分字符串
fn:toLowerCase(string)
将参数string所有的字符变为小写,并将其返回
fn:toUpperCase(string)
将参数string所有的字符变为大写,并将其返回
fn:trim(string)
在jsp中 使用EL表达式时,不可以使用java提供的功能,比如indexOf()等。
<c:if test="${Boolean.valueOf(requestScope.addresult)==false}">
报错
The function valueOf must be used with a prefix when a default namespace is not specified
posted @
2014-08-05 15:24 Alpha 阅读(15567) |
评论 (0) |
编辑 收藏
公司发布的SEO专员招聘有一段时间了,一直没有找到合适的人选, 一方面专门从事这块职业的人员比较少,另一方面对这个职位有一定了解的人也比较少.那么我们所说的
seo专员是什么样的一个职位呢? 今天我们来探讨一下,在网上搜索了一个相关资料,找到这么一篇文章:
http://seo.aizhan.com/qa/542.html,我们看看文章里面的表述:
其实seo专员的主要职责就是执行完成SEO主管制定的SEO策略和优化目标任务,通常需要做大量的内容编辑、软文发布和外链建设等各种体力活。现在也有很多公司在发布招聘的时候也有专门招聘SEO外链专员这样的职位,有一定规模的网站也会分为SEO网站优化、SEO网站编辑、SEO外链专员等这样的细分岗位,每个岗位根据SEO优化工作的侧重点不同,执行完成的工作重点也是不一样的。那么今天我们要讲的SEO专员的具体工作是什么?做好这个职位需要具备什么样的素质?
SEO专员的具体工作,说到底核心工作就是研究搜索引擎,完成网站内容建设,丰富网站的内容,到各大网站平台发布定量合适的外链,交换友情链接,帮助网站获得关键词排名,并做好数据分析与跟踪。
在这篇文章里讲述了什么是SEO专员, SEO专员的具体工作,说到底核心工作就是研究搜索引擎,完成网站内容建设,丰富网站的内容,到各大网站平台发布定量合适的外链,交换友情链接,帮助网站获得关键词排名,并做好数据分析与跟踪。 但是要找到一名有耐心,有良好的沟通能力,超强的执行力,有比较强的心里承受能力,受得了寂寞的SEO专员却是一件不容易的事情。
发布一则
房民网SEO专员招聘要求:
任职要求:
1、男女不限,大专以上学历,年龄在20-35岁之间;
2、对互联网有浓厚的兴趣,熟悉网站的运作和推广的各种方式,能够根据公司的需求独立策划网站推广方案并执行;会熟练打字操作常用办公软件;
3、有一定的分析判断能力,能根据推广效果提出调整建议,具有敏锐的思维和创新能力,思维开阔;
4、工作认真、细致、敬业,有较强的沟通能力和团队合作精神;
5、1年以上相关工作经历或精通网站编辑及平面设计者或有一定的文字写作能力者优先。
岗位职责:
1、负责完成网站内容建设,友链外链建设,关键字优化,提高网站排名、搜索引擎收录量;
2、执行在线推广活动,收集推广反馈数据,不断改进推广效果;
3、及时提出网络推广改进建议,给出实际可行的改进方案。
快来加入吧:)
posted @
2013-11-24 10:04 Alpha 阅读(1547) |
评论 (2) |
编辑 收藏
一直从事于开发与运维相关技术的研究实践,最近在做几个房产网分站的SEO优化技术储备, 缘于
长沙房产网的百度快照阴情不定让人很蛋疼,于是对此进行了深入的研究,发现SEO网站优化也是一门相当有技术含量的技术活,涉及的知识点和技术面都要广才能掌握大局,同时也要调动团队各环节,从网站的最初版面功能策划到页面的视觉设计和代码编写,再到程序开发时的架构设计,最后做内容时的内容编排等一系列的问题都得考虑到,且都要执行到位,否则任何一个环节没做好都有可能影响到整个SEO优化的效果.因此,今天开辟一个新版块,专门从事SEO优化技术的研究与实践.
目前在拿房产网的四个分站进行实战研究,希望能从中找到一些答案,这四个站的主关键词也是相当有竞争难度,比如
东莞房产网这个关键词的收录量有250多万,但是http://dg.fmw.cn/这个域名的百度收入占有量却只有两位数,而比东莞房产网迟了一个多月上线的
昆明房产网,这个站域名是
http://km.fmw.cn/,它收录量都上三位数了,远远超过了东莞房产网的收入量,这让人更是摸不着头脑.表现最满意的是
佛山房产网,它同样比东莞房产网上线迟了一个多月,但是收入量等各方面指数上升很明显.同样的网站架构,同样每天都有坚持在做内容,但是却有不一样的表现,这是一个值得研究的课题.
SEO既Search Engine Optimization,翻译为搜索引擎优化,是一种利用技术手段提升网站在搜索引擎之中的排名的方式,让搜索引擎更为信任网站,通过排在搜索引擎的前页从而获得更多的流量。
希望在接下来的SEO优化研究和实践工作中能找到这一系列的答案,届时
房民网与大家一起来分享.
posted @
2013-10-09 00:12 Alpha 阅读(1423) |
评论 (0) |
编辑 收藏给大家推荐一处php主机-wopus主机,专业的wordpress主机!还可以省钱购买php主机,永久免费使用.
购买可以用wopus主机优惠码:alpha, 提交订单时手动输入 alpha
或者通过>>wopus主机优惠码<<链接进入直接购买就可获得优惠,可以省钱哟. http://idc.wopus.org/?f=alpha
(wopus主机推介优惠码:alpha 永久有效)!打算买php主机的朋友请看以下介绍!
他们自己是这样介绍他们的产品的:
专业博客主机服务商
WopusIDC一直致力于为广大独立博客用户提供优质实惠的专业博客主机服务,现已积累有超过四年的专业博客主机服务经验,成为众多独立博客们的主机首选。
国内、国外主机任选
从国外主机到国内主机,WopusIDC给用户带来多种主机选择,打破访问速度的瓶颈,给广大独立博客用户带来更佳的主机体验。
快速搭建个性化博客
依托于Wopus平台上发布的数量众多的主题、插件以及文章教程,WopusIDC用户可以简单快速的搭建属于自己的个性化博客。
买php主机用 wopus主机优惠码:alpha , 提交订单时手动输入 alpha ,永久免费使用,长期有效.
或 点击 http://idc.wopus.org/?f=alpha 购买主机立即省钱!
posted @
2013-08-19 01:04 Alpha 阅读(1832) |
评论 (1) |
编辑 收藏