==========================================================
概述
JDBC类库使得Java程序可以访问多个数据源,但在大多数情况下,这个数据源是关系数据库,并且通过SQL访问。然而,实现JDBC技术的驱动也可以基于其它的数据源,包括遗留文件系统和面向对象的系统。JDBC类库的一个主要目的就是提供一个应用程序访问多种数据源的标准接口。
这一章介绍JDBC类库的一些关键概念,并描述JDBC应用的两个通用环境及其中的功能实现。两层和三层模型都是能被实现在多个物理配置上的逻辑模型。
=================================================
4.1 创建连接
JDBC类库中的Connection接口代表了底层数据源的一个连接。
在典型场景中,JDBC应用程序使用两种机制连接到数据源:
1.DriverManager --- 这个类在JDBC 1.0中引入,它使用硬编码的URL来加载驱动。
2.DataSource --- 这个接口在JDBC 2.0可选包中引入。它优于DriverManager方式,因为它隐藏了数据源的详细信息。我们通过设置DataSource的属性来标明它代表的数据源。当getConnection方法被调用时,DataSource对象会返回一个对应的连接。我们可以通过改变DataSource的属性来使它指向另一个数据源,而不是改变程序代码。而且,即使DataSource的实现改变了,使用它的应用程序代码也不需要改变。
JDBC类库定义了两个DataSource的扩展来支持企业级应用,如下:
1.ConnectionPoolDataSource --- 支持物理连接的缓存和重用,这样可以提高应用的性能和可伸缩性。
2.XADataSource --- 提供可以使用在分布式事务中的连接。
=========================================================
4.2 执行SQL语句和操纵结果
连接建立后,我们可以使用JDBC类库对目标数据源进行查询和更新。JDBC类库提供了对大多数SQL2003通用特性的支持。由于各个厂商可能要支持不同的特性,JDBC类库提供了一个DatabaseMetadata接口。应用可以通过这个接口了解数据源是否支持某个特性。JDBC类库也定义了转义语义来支持特定厂商非标准的特性。转义语义使得我们可以访问与本地程序相同的SQL特性集,同时保持应用的可移植性。
应用通过使用Connection接口来设置事务属性和创建Statement, PreparedStatement和CallableStatement. 这些statement被用来执行SQL语句和检索结果。ResultSet接口封装了SQL查询的结果。语句也可以批处理,这样应用可以通过一次单元执行提交对数据源的多次更新。
RowSet接口扩展了ResultSet接口。它提供了一个比标准结果集功能更多的表数据容器。RowSet对象是Java Beans组件,它可以在中断数据库连接的情况下操纵数据。例如,一个RowSet实现可以被序列化从而传送到网络上,这对于吞吐量小的客户端尤为有用,因为这可以省去加载JDBC驱动和建立JDBC连接的开销。RowSet还可以使用定制的阅读器(Reader)来访问表格数据(不仅仅是关系数据库的数据)。甚者,RowSet对象可以在中断数据库连接的情况下更新数据,并在连接正常时通过一个定制的书写器(Writer)将更新写入数据源。
4.2.1 对SQL高级数据类型的支持
JDBC类库定义了SQL数据类型到JDBC数据类型的标准映射。映射也包含了对SQL2003高级数据类型如BLOB,CLOB,ARRAY,REF,STRUCT和DISTINCT的支持。JDBC驱动也可以实现多个用户自定义类型(UDTs,user-defined types)的映射,在这里,每个UDT映射到Java中的一个类。
JDBC类库也提供对外部数据的支持,例如数据源外部的一个文件。
========================================
4.3 两层模型
两层模型将功能分配到客户端和服务器端,如图4-1.
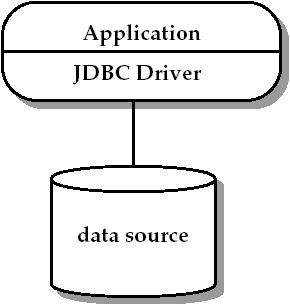
FIGURE 4-1 两层模型
客户端包含了应用和一个或多个JDBC驱动,这些应用负责下列内容:
* 表示逻辑
* 业务逻辑
* 对多语句事务(multiple-statement transactions)或分布式事务的管理
* 资源管理
在这个模型中,应用直接跟JDBC驱动打交道,包括建立和管理物理连接,以及处理底层数据源的相关细节。应用可以通过对数据源实现的了解来使用它的非标准特性或者提升性能。
模型的缺点:
* 将表示逻辑、业务逻辑和基础设施、系统级别的功能混淆在一起,不利于维护。
* 由于被绑定到特定的数据库,应用很难被移植。需要连接到多个数据库的应用要注意各个厂商实现的区别。
* 缺少可伸缩性。典型地,应用将从始至终占有一个或多个物理连接,缺少对并发应用的支持。在这个模型中,性能、可伸缩性和可靠性问题都是由JDBC驱动和底层数据源处理的。如果应用要跟多个驱动打交道,它需要注意每个驱动/数据源对是怎么处理这些问题的。
======================================================
4.4 三层模型
三层模型引入了中间层服务器来管理业务逻辑和基础结构,如图4-2.
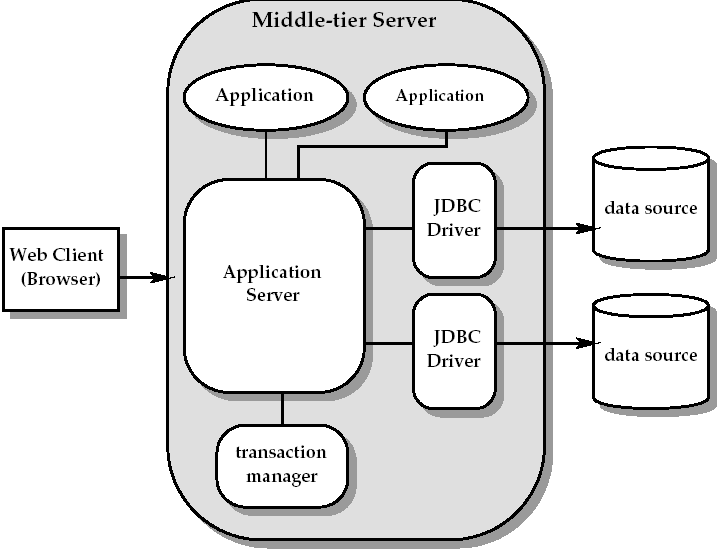
FIGURE 4-2 三层模型
这个架构为企业级应用提供了更好的性能、可伸缩性和可靠性。功能划分如下:
1.客户端 --- 只负责表示逻辑,处理人机交互。Java应用程序、网页浏览器和PDA等都是典型的客户端。客户端与中间层应用交互,它不需要了解底层的基础结构和数据源实现。
2.中间层服务器 --- 中间层包含:
* 一些应用程序。这些应用负责跟客户端打交道和实现业务逻辑。如果应用包含与数据源的交互,它应该使用高层抽象,例如DataSource对象和逻辑连接,而不是底层的驱动程序类库。
* 一个应用服务器。提供支持大部分应用的基础结构。这可能包含管理和池化物理连接、管理事务和掩盖不同JDBC驱动的细节。最后一点使得应用更容易被移植。应用服务器可以使用J2EE服务器。它应该直接和JDBC驱动交互和提供高层应用使用的功能抽象。
* 一个或多个JDBC驱动。提供与底层数据源的连接,每个驱动使用底层数据源支持的特性来实现标准JDBC类库。驱动层需要掩盖SQL2003标准和底层数据源语言的不同。如果数据源不是一个关系型数据库管理系统(DBMS),那么驱动要实现应用服务器使用的关系层。
3.底层数据源 --- 存放数据的层。包含关系型数据库管理系统(relational DBMS),遗留文件系统,面向对象的DBMS,数据仓库,报表或者其他包装和表示数据的方式,只要有对应的支持JDBC类库的驱动。
===================================================
4.5 J2EE平台中的JDBC
J2EE组件,例如JSP,Servlets和EJB,经常需要利用JDBC类库访问关系型数据。当在J2EE组件里使用JDBC类库时,容器可能帮你管理事务和数据源(译者注:Container Managed Persistence,容器管理持久性)。这样,J2EE组件开发者就不直接使用JDBC类库的事务和数据源管理功能。详情请见J2EE平台规范。