转载自:
http://www.knowsky.com/2991.html
XML轻松学习手册(1)XML快速入门
文章类别:XML教程 发表日期:2003-6-3 星期二
--------------------------------------------------------------------------------
转自:动态网制作指南 www.knowsky.com
前言
XML越来越热,关于XML的基础教程网络上也随处可见。可是一大堆的概念和术语往往让人望而生畏,很多朋友问我:XML到底有什么用,我们是否需要学习它?我想就我个人学习过程的心得和经验,写一篇比较全面的介绍文章。首先有两点是需要肯定的:
第一:XML肯定是未来的发展趋势,不论是网页设计师还是网络程序员,都应该及时学习和了解,等待只会让你失去机会;
第二:新知识肯定会有很多新概念,尝试理解和接受,您才可能提高。不要害怕和逃避,毕竟我们还年轻。
提纲
本文共分五大部分。分别是XML快速入门,XML的概念,XML的术语,XML的实现,XML的实例分析。最后附录介绍了XML的相关资源。作者站在普通网页设计人员的角度,用平实生动的语言,向您讲述XML的方方面面,帮助你拨开XML的神秘面纱,快速步入XML的新领域。
第一章:XML快速入门
一. 什么是XML?
二. XML是新概念吗?
三. 使用XML有什么好处?
四. XML很难学吗?
五. XML和HTML的区别
六. XML的严格格式
七. 关于XML的更多
一. 什么是XML?
这往往是第一个问题,也往往在第一个问题上你就会搞不明白,因为大多的教材上这样回答:
XML是Extensible Markup Language的简写,一种扩展性标识语言。 这是标准的定义。那么什么是标志语言,为什么叫扩展性?已经让人有些糊涂。我想我们这样来理解会好一些:
对HTML你已经非常熟悉了吧,它就是一种标记语言,记得它的全称吗:"Hypertext Markup Language" 超文本标记语言。明白了?同时,HTML里面有很多标签,类似,等,都是在HTML
4.0里规范和定义,而XML里允许你自己创建这样的标签,所以叫做可扩展性。
这里有几个容易混淆的概念要提醒大家:
1.XML并不是标记语言。它只是用来创造标记语言(比如HTML)的元语言。天,又糊涂了!不要紧,你只要知道这一点:XML和HTML是不一样的,它的用处途比HTML广泛得多,我们将在后面仔细介绍。
2.XML并不是HTML的替代产品。XML不是HTML的升级,它只是HTML的补充,为HTML扩展更多功能。我们仍将在较长的一段时间里继续使用HTML。(但值得注意的是HTML的升级版本XHTML的确正在向适应XML靠拢。)
3.不能用XML来直接写网页。即便是包含了XML数据,依然要转换成HTML格式才能在浏览器上显示。
下面就是一段XML示例文档(例1),用来表示本文的信息:
<myfile>
<title>XML Quick Start</title>
<author>ajie</author>
<email>ajie@aolhoo.com</email>
<date>20010115</date>
</myfile>
注意:
1.这段代码仅仅是代码,让你初步感性认识一下XML,并不能实现什么具体应用;
2.其中类似< title>,< author>的语句就是自己创建的标记(tags),它们和HTML标记不一样,例如这里的< title>是文章标题的意思,HTML里的< title>是页面标题。
二. XML是新概念吗?
不是。XML来源于SGML,一种比HTML更早的标志语言标准。
关于SGML,我们来简单了解一下,你只需要有个大致概念就可以。
SGML全称是"Standard Generalized Markup Language"(通用标识语言标准)。看名称就知道:它是标志语言的标准,也就是说所有标志语言都是依照SGML制定的,当然包括HTML。SGML的覆盖面很广,凡是有一定格式的文件都属于SGML,比如报告,乐谱等等,HTML是SGML在网络上最常见的文件格式。因此,人们戏称SGML是HTML的"妈妈"。
而XML就是SGML的简化版,只不过省略了其中复杂和不常用的部分。(哦,明白了!是HTML第二个"mother",难怪比HTML功能强大呢。),和SGML一样,XML也可以应用在金融,科研等各个领域,我们这里讲的,只是XML在web方面的运用而已。
到这里,你应该有点明白了:XML是用来创建定义类似HTML的标记语言,然后再用这个标记语言来显示信息。 三. 使用XML有什么好处?
有了HTML,为什么还需要用XML?
因为现在网络应用越来越广泛,仅仅靠HTML单一文件类型来处理千变万化的文档和数据已经力不丛心,而且HTML本身语法十分不严密,严重影响网络信息传送和共享。(想想浏览器兼容的问题伤透多少设计师的脑细胞啊。)人们早已经开始探讨用什么方法来满足网络上各种应用的需要。使用SGML是可以的,但SGML太庞大,编程复杂,于是最终选择了"减肥"的SGML---XML作为下一代web运用的数据传输和交互的工具。
使用XML有什么好处?来看w3c组织(XML标准制定者)的说明:
XML使得在网络上使用SGML语言更加"简单和直接": 简化了定义文件类型的过程,简化了编程和处理SGML文件的过程,简化了在Web上的传送和共享。
1.XML可以广泛的运用于web的任何地方;
2.XML可以满足网络应用的需求;
3.使用XML将使编程更加简单;
4.XML便于学习和创建;
5.XML代码将清晰和便于阅读理解;
还是抽象了些。让我们在后面的实例教程中慢满体会XML的强大优势吧!
四. XML很难学吗?
如果你有兴趣学习XML,不禁会问:XML难吗?学习XML需要什么样的基础?
XML非常简单,学习容易。如果你熟悉HTML,你会发现它的文档和HTML非常相似,看同样的示例文档(例1):
?xml version="1.0"?>
<myfile>
<title>XML Quick Start</title>
<author>ajie</author>
<email>ajie@aolhoo.com</email>
<date>20010115</date>
</myfile>
第一行是一个XML声明,表示文档遵循的是XML的1.0 版的规范。
第二行定义了文档里面的第一个元素(element),也称为根元素: < myfile>。这个就类似HTML里的< HTML>开头标记。注意,这个名称是自己随便定义的。
再下面定义了四个子元素:title,author,email,和date。分别说明文章的标题,作者,邮箱和日期。当然,你可以用中文来定义这些标签,看上去更便于理解:
<?xml version="1.0" encoding="GB2312"?>
<文章>
<标题>XML轻松学习手册</标题>
<作者>ajie</作者>
<信箱>ajie@aolhoo.com</信箱>
<日期>20010115</日期>
</文章>
这就是XML的文档,任何掌握HTML的网友都可以直接写出这样简单的XML文档。
另外,学习XML还必须掌握一种页面脚本语言,常见的就是javascript和VB script。因为XML数据是使用script实现HTML中调用和交互的。我们看一个最简单的例子(例2):
1.将下面代码存为myfile.htm
<html>
<head>
<script language="javascript" for="window" event="onload">
var xmlDoc = new ActiveXObject("Microsoft.XMLDOM");
xmlDoc.async="false";
xmlDoc.load("myfile.xml");
nodes = xmlDoc.documentElement.childNodes;
title.innerText = nodesitem(0).text;
author.innerText = nodes.item(1).text;
email.innerText = nodes.item(2).text;
date.innerText = nodes.item(3).text;
</script>
<title>在HTML中调用XML数据</title>
</head>
<body bgcolor="#FFFFFF">
<b>标题: </b>
<span id="title"> </span>
<b>作者: </b>>
<span id="author"></span>
<b>信箱: </b>
<span id="email"></span>
<b>日期:</b>
<span id="date"></span>
</body>
</html>
2.将下面代码存为myfile.xml
<?xml version="1.0" encoding="GB2312"?>
<myfile>
<title>XML轻松学习手册</title>
<author>ajie</author>
<email>ajie@aolhoo.com</email>
<date>20010115</date>
</myfile>
3.将它们放在同一个目录下,用IE5以上版本浏览器打开,可以看到效果。 学习并掌握一种script,你将真正了解到XML无比的强大的功能。
五. XML和HTML的区别
XML和HTML都来自于SGML,它们都含有标记,有着相似的语法,HTML和XML的最大区别在于:HTML是一个定型的标记语言,它用固有的标记来描述,显示网页内容。比如< H1>表示首行标题,有固定的尺寸。相对的,XML则没有固定的标记,XML不能描述网页具体的外观,内容,它只是描述内容的数据形式和结构。
这是一个质的区别:网页将数据和显示混在一起,而XML则将数据和显示分开来。
我们看上面的例子,在myfile.htm中,我们只关心页面的显示方式,我们可以设计不同的界面,用不同的方式来排版页面,但数据是储存在myfile.xml中,不需要任何改变。
(如果你是程序员,你会惊讶的发现,这与模块化面向对象编程的思想极其相似!其实网页何尝不是一种程序呢?)
正是这种区别使得XML在网络应用和信息共享上方便,高效,可扩展。所以我们相信,XML做为一种先进的数据处理方法,将使网络跨越到一个新的境界。
六. XML的严格格式
吸取HTML松散格式带来的经验教训,XML一开始就坚持实行"良好的格式"。
我们先看HTML的一些语句,这些语句在HTML中随处可见:
1.
sample
2.< b>< i>sample< /b>< /i>
3.< td>sample< /TD>
4.< font color=red>samplar< /font>
在XML文档中,上述几种语句的语法都是错误的。因为:
1.所有的标记都必须要有一个相应的结束标记;
2.所有的XML标记都必须合理嵌套;
3.所有XML标记都区分大小写;
4.所有标记的属性必须用""括起来;
所以上列语句在XML中正确的写法是
1.
sample
2.< b>< i>sample< /i>< /b>
3.< td>sample< /td>
4.< font color="red">samplar< /font>
另外,XML标记必须遵循下面的命名规则:
1.名字中可以包含字母、数字以及其它字母;
2.名字不能以数字或"_" (下划线) 开头;
3.名字不能以字母 xml (或 XML 或 Xml ..) 开头;
4.名字中不能包含空格。
在XML文档中任何的差错,都会得到同一个结果:网页不能被显示。各浏览器开发商已经达成协议,对XML实行严格而挑剔的解析,任何细小的错误都会被报告。你可以将上面的myfile.xml修改一下,比如将< email>改为< Email>,然后用IE5直接打开myfile.xml,会得到一个出错信息页面:
<?xml version="1.0" encoding="GB2312"?>
<myfile>
<title>XML轻松学习手册</title>
<author>ajie</author>
<Email>ajie@aolhoo.com</email>
<date>20010115</date>
</myfile>
七. 关于XML的更多
好了,到现在你已经知道:
1.什么是XML;
2.XML,HTML,SGML之间的关系和区别;
3.XML的简单应用。
恭喜你!你已经不再对XML一无所知,并且已经走在了网络技术的前沿。整个学习过程好象并不很难哦:)
如果你对XML有更多的兴趣,希望进一步了解XML的详细资料和其它的实际运用技术,欢迎继续浏览我们的下一章:XML的概念。
XML轻松学习手册(2)XML概念
第二章 XML概念
导言
经过第一章的快速入门学习,你已经知道了XML是一种能够让你自己创造标识的语言,它可以将数据与格式从网页中分开,它可以储存数据和共享数据的特性使得XML无所不能。如果你希望深入学习XML,系统掌握XML的来龙去脉,那么我们首先还是要回到XML概念的问题上来。XML(Extensible Markup Language),一种扩展性标识语言。"扩展性""标识""语言"。每一个词都明确的点明了XML的重要特点和功能。我们来仔细分析:
一. 扩展性
二. 标识
三. 语言
四. 结构化
五. Meta数据
六. 显示
七. DOM
一.扩展性---使用XML,你可以为你的文档建立自己的标记(tags)。
XML的第一个词是"扩展性",这正是XML强大的功能和弹性的原因。
在HTML里,有许多固定的标记,我们必须记住然后使用它们,你不能使用HTML规范里没有的标记。而在XML中,你能建立任何你需要的标记。你可以充分发挥你的想象力,给你的文档起一些好记的标记名称。比如,你的文档里包含一些游戏的攻略,你可以建立一个名为<game>的标记,然后在<game>下再根据游戏类别建立<RPG>,<SLG>等标记。只要清晰,易于理解你可以建立任何数量的标记。
一开始你也许会不适应,因为我们在学习HTML时,有固定的标记可以直接学习和使用;(很多人包括我自己都是边分析别人的代码和标识,边建立自己的网页),而XML却没有任何标记可以学,也很少有文档的标记是一模一样的。我们怎么办?呵呵,没有就自己创建呀。一旦你真正开始写XML文档,你会发现随心所欲的创造新标记也是一份很有趣的事。你可以建立有自己特色的标记,甚至建立你自己的HTML语言。
扩展性使你有更多的选择和强大的能力,但同时也产生一个问题就是你必须学会规划。你自己要理解自己的文档,知道它由哪几部分组成,相互之间的关系和如何识别它们。
关于建立标识还需要说明一点,标识是描述数据的类型或特性,比如<width>,年龄<age>,姓名<name>等,而不是数据的内容,比如:<10pxl>,<18>,<张三>,这些都是无用的标记。如果你学过数据库,你可以这样理解,标识就是一种字段名。
二.标识---使用XML你可以识别文档中的元素。
XML的第二个词是"标识",这表明了XML的目的是标识文档中的元素。
不论你是HTML,还是XML,标识的本质在于便于理解,如果没有标识,你的文档在计算机看来只是一个很长的字符串,每个字看起来都一样,没有重点之分。
通过标识,你的文档才便于阅读和理解,你可以划分段落,列明标题。XML中,你更可以利用其扩展性 来为文档建立更合适的标识。
不过,有一点要提醒大家注意:标识仅仅是用来识别信息,它本身并不传达信息。例如这样的HTML代码:
<b>frist step<b>
这里<b>表示粗体,只用来说明是用粗体来显示"frist step"字符,<b>本身并不包含任何实际的信息,在页面上你看不到<b>,真正传达信息的是"frist step "。
三.语言---使用XML你要遵循特定的语法来标识你的文档。
XML第三个词是"语言"。这表明了作为一种语言XML必须遵循一定的规则。虽然XML的扩展性允许你创建新标识,但它仍然必须遵循特定的结构,语法和明确的定义。
在计算机领域,语言常常表示一?quot;程序语言",用来编程实现一些功能和应用,但不是所有的"语言"都是用来编程的,XML就只是一种用来定义标识和描述信息的语言。
下面我们来深入了解一下XML应用的其本原理,可能会很枯燥,但是对于整体的理解很重要,你可以先快速过一遍,心里有一个模糊的概念,具体精髓则需要在实践中慢慢领会。
四.结构化---XML促使文档结构化,所有的信息按某种关系排列。
"结构化"听起来太抽象了,我们这样理解,结构化就是为你的文档建立一个框架,就象写文章先写一个提纲。结构化使你的文档看起来不会杂乱无章,每一部分都紧密联系,形成一个整体。
结构化有两个原则:
1.每一部分(每一个元素)都和其他元素有关联。关联的级数就形成了结构。
2.标识本身的含义与它描述的信息相分离。
我们来看一个简单的例子帮助理解:
<?xml version="1.0" encoding="GB2312"?>
<myfile>
<title>XML轻松学习手册</title>
<chapter>XML快速入门
<para>什么是XML</para>
<para>使用XML的好处</para>
</chapter>
<chapter>XML的概念
<para>扩展性</para>
<para>标识</para>
</chapter>
</myfile>
这是本文的XML描述文档,可以看到标识分三级关联,非常清晰:
<myfile>
<chapter>
<para>
...
</para>
</chapter>
</myfile>
上面这样的文档结构,我们又称之为"文档树",主干是父元素,如<myfile>,分支和页是子元素,如<chapter>和<para>。
五.Meta数据(Metadata)---专业的XML使用者会使用meta数据来工作。
在HTML中我们知道可以使用meta标识来定义网页的关键字,简介等,这些标识不会显示在网页中,但可以被搜索引擎搜索到,并影响搜索结果的排列顺序。
XML对这一原理进行了深化和扩展,用XML,你可以描述你的信息在哪里,你可以通过meta来验证信息,执行搜索,强制显示,或者处理其他的数据。
下面是一些XML metadata在实际应用中的用途:
1.可以验证数字签名,使在线商务的提交动作(submission)有效。
2.可以被方便的建立索引和进行更有效搜索。
3.可以在不同语言之间传输数据。
W3C组织正在研究一种名为RDF(Resource Description Framework)的metadata处理方法,可以自动交换信息,W3C宣称,使用RDF配合数字签名,将使网络中存在"真实可信"的电子商务。
六.显示
单独用XMl不能显示页面,我们使用格式化技术,比如CSS或者XSL,才能显示XML标记创建的文档。
我们在前面第一章讲到XML是将数据和格式分离的。XML文档本身不知道如何来显示,必须有辅助文件来帮助实现。(XML取消了所有标识,包括font,color,p等风格样式定义标识,因此XML全部是采用类似DHTML中CSS的方法来定义文档风格样式。),XML中用来设定显示风格样式的文件类型有:
1.XSL
XSL全称是Extensible Stylesheet Language(可扩展样式语言), 是将来设计XML文档显示样式的主要文件类型。它本身也是基于XML语言的。使用XSL,你可以灵活的设置文档显示样式,文档将自动适应任何浏览器和PDA(掌上电脑)。
XSL也可以将XML转化为HTML,那样,老的浏览器也可以浏览XML文档了。
2.CSS
CSS大家很熟悉了,全称是Cascading Style Sheets(层叠样式表),是目前用来在浏览器上显示XML文档的主要方法。
3.Behaviors
Behaviors现在还没有成为标准。它是微软的IE浏览器特有的功能,用它可以对XML标识设定一些有趣动作。
七.DOM
DOM全称是document object model(文档对象模型),DOM是用来干什么的呢?假设把你的文档看成一个单独的对象,DOM就是如何用HTML或者XML对这个对象进行操作和控制的标准。
面向对象的思想方法已经非常流行了,在编程语言(例如java,js)中,都运用面向对象的编程思想。在XML中,就是要将网页也作为一个对象来操作和控制,我们可以建立自己的对象和模板。与对象进行交流,如何命令对象,就要用到API。API全称Application Programming Interface,它是访问和操作对象的规则。而DOM就是一种详细描述HTML/XML文档对象规则的API。它规定了HTML/XML文档对象的命名协定,程序模型,沟通规则等。在XML文档中,我们可以将每一个标识元素看作一个对象---它有自己的名称和属性。
XML创建了标识,而DOM的作用就是告诉script如何在浏览器窗口中操作和显示这些标识
上面我们已经简要的讲述了一些XML的基本原理,我们来看看它们之间的关联以及它们是如何工作的,先看这里一张图:
 此主题相关图片如下:
此主题相关图片如下:
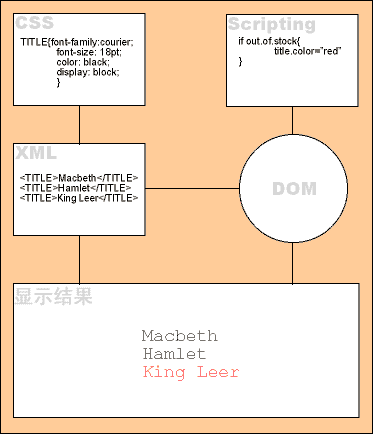
1.XML描述数据类型。例如:"King lear"是一个标题元素;
2.CSS储存并控制元素的显示样式。例如:标题将被以18pt字体显示
3.script脚本控制元素如何动作。例如:当一个title元素"out of stock",将被用红色显示。
4.DOM则为脚本和对象的交流提供一个公共平台,并将结果显示在浏览器窗口。
如果任何一个部分发生错误,都不会得到正确结果。
好了,看到这里,我们已经对XML是如何工作的有一个整体的大致的概念。通过这一章的学习,我们可能感觉到XML似乎更偏向数据处理,更方便程序员学习。实际情况也是这样的,XML设计的目的就是用来方便的共享和交互数据的。下一章,我们将系统的了解关于XML的各种术语。欢迎您继续浏览。
XML轻松学习手册(3)XML的术语
第三章 XML的术语
提纲:
导言
一.XML文档的有关术语
二.DTD的有关术语
导言
初学XML最令人头疼的就是有一大堆新的术语概念要理解。由于XML本身也是一个崭新的技术,正在不断发展和变化,各组织和各大网络公司(微软,IBM,SUN等)都在不断推出自己的见解和标准,因此新概念漫天飞就不足为奇了。而国内又缺乏权威的机构或组织来对这些术语正式定名,你所看见的有关XML的中文教材大部分是靠作者本身的理解翻译过来的,有些是正确的,有些是错误的,更加妨碍了我们对这些概念的理解和学习。
你下面将要看到的关于XML术语的解释,也是作者本身的理解和翻译。阿捷是以W3C组织发布的XML1.0标准规范和相关的正式说明文档为根据来讲述。可以确保这些理解是基本正确的,至少不是错误的。你如果想进一步阅读和了解,我在本文的最后部分列明了相关资源的出处和链接,你可以直接访问。好,我们转入正题:
一.XML文档的有关术语
什么是XML文档?知道HTML原代码文件吧,XML文档就是用XML标识写的XML原代码文件。XML文档也是ASCII的纯文本文件,你可以用Notepad创建和修改。XML文档的后缀名为.XML,例如myfile.xml。用IE5.0以上浏览器也可以直接打开.xml文件,但你看到的就是"XML原代码",而不会显示页面内容。你可以将下面代码存为myfile.xml试试:
<?xml version="1.0" encoding="GB2312"?>
<myfile>
<title>XML轻松学习手册</title>
<author>ajie</author>
<email>ajie@aolhoo.com</email>
<date>20010115</date>
</myfile>
XML文档包含三个部分:
1. 一个XML文档声明;
2. 一个关于文档类型的定义;
3. 用XML标识创建的内容。
举例说明:
<?xml version="1.0"?>
<!DOCTYPE filelist SYSTEM "filelist.dtd">
<filelist>
<myfile>
<title>QUICK START OF XML</title>
<author>ajie</author>
</myfile>
......
</filelist>
其中第一行<?xml version="1.0"?>就是一个XML文档的声明,第二行说明这个文档是用filelist.dtd来定义文档类型的,第三行以下就是内容主体部分。
我们来了解XML文档中有关的术语:
1.Element(元素):
元素在HTML我们已经有所了解,它是组成HTML文档的最小单位,在XML中也一样。一个元素由一个标识来定义,包括开始和结束标识以及其中的内容,就象这样:<author>ajie</author>
唯一不同的就是:在HTML中,标识是固定的,而在XML中,标识需要你自己创建。
2.Tag(标识)
标识是用来定义元素的。在XML中,标识必须成对出现,将数据包围在中间。标识的名称和元素的名称是一样的。例如这样一个元素:
<author>ajie</author>
其中<author>就是标识。
3.Attribute(属性):
什么是属性?看这段HTML代码:<font color="red">word</font>。其中color就是font的属性之一。
属性是对标识进一步的描述和说明,一个标识可以有多个属性,例如font的属性还有size。XML中的属性与HTML中的属性是一样的,每个属性都有它自己的名字和数值,属性是标识的一部分。举例:
<author sex="female">ajie</author>
XML中属性也是自己定义的,我们建议你尽量不使用属性,而将属性改成子元素,例如上面的代码可以改成这样:
<author>ajie
<sex>female</sex>
</author>
原因是属性不易扩充和被程序操作。
4.Declaration(声明)
在所有XML文档的第一行都有一个XML声明。这个声明表示这个文档是一个XML文档,它遵循的是哪个XML版本的规范。一个XML的声明语句就象这样:
<?xml version="1.0"?>
5.DTD(文件类型定义)
DTD是用来定义XML文档中元素,属性以及元素之间关系的。
通过DTD文件可以检测XML文档的结构是否正确。但建立XML文档并不一定需要DTD文件。关于DTD文件的详细说明我们将在下面单独列项。
6.Well-formed XML(良好格式的XML)
一个遵守XML语法规则,并遵守XML规范的文档称之为"良好格式"。如果你所有的标识都严格遵守XML规范,那么你的XML文档就不一定需要DTD文件来定义它。
良好格式的文档必须以一个XML声明开始,例如:
<?xml version="1.0" standalone="yes" encoding="UTF-8"?>
其中你必须说明文档遵守的XML版本,目前是1.0;其次说明文档是"独立的",它不需要DTD文件来验证其中的标识是否有效;第三,要说明文档所使用的语言编码。默认的是UTF-8,如果使用中文,你需要设置为GB2312。
良好格式的XML文档必须有一个根元素,就是紧接着声明后面建立的第一个元素,其它元素都是这个根元素的子元素,属于根元素一组。
良好格式的XML文档的内容书写时必须遵守XML语法。(有关XML语法我们将在下一章仔细讲解)
7.Valid XML(有效的XML)
一个遵守XML语法规则,并遵守相应DTD文件规范的XML文档称为有效的XML文档。注意我们比较"Well-formed XML"和"Valid
XML",它们最大的差别在于一个完全遵守XML规范,一个则有自己的"文件类型定义(DTD)"。
将XML文档和它的DTD文件进行比较分析,看是否符合DTD规则的过程叫validation(确认)。这样的过程通常我们是通过一个名为parser的软件来处理的。
有效的XML文档也必须以一个XML声明开始,例如:
<?xml version="1.0" standalone="no" encode="UTF-8"?>
和上面例子不同的,在standalone(独立)属性中,这里设置的是"no",因为它必须和相应的DTD一起使用,DTD文件的定义方法如下:
<!DOCTYPE type-of-doc SYSTEM/PUBLIC "dtd-name">
其中:
"!DOCTYPE"是指你要定义一个DOCTYPE;
"type-of-doc"是文档类型的名称,由你自己定义,通常于DTD文件名相同;
"SYSTEM/PUBLIC"这两个参数只用其一。SYSTEM是指文档使用的私有DTD文件的网址,而PUBLIC则指文档调用一个公用的DTD文件的网址。
"dtd-name" 就是DTD文件的网址和名称。所有DTD文件的后缀名为".dtd"。
我们还是用上面的例子,应该写成这样:
<?xml version="1.0" standalone="no" encode="UTF-8"?>
<!DOCTYPE filelist SYSTEM "filelist.dtd">
二.DTD的有关术语
什么是DTD,我们上面已经简略提到。DTD是一种保证XML文档格式正确的有效方法,可以比较XML文档和DTD文件来看文档是否符合规范,元素和标签使用是否正确。一个DTD文档包含:元素的定义规则,元素间关系的定义规则,元素可使用的属性,可使用的实体或符号规则。
DTD文件也是一个ASCII的文本文件,后缀名为.dtd。例如:myfile.dtd。
为什么要用DTD文件呢?我的理解是它满足了网络共享和数据交互,使用DTD最大的好处在于DTD文件的共享。(就是上文DTD说明语句中的PUBLIC属性)。比如,两个相同行业不同地区的人使用同一个DTD文件来作为文档创建规范,那么他们的数据就很容易交换和共享。网上有其他人想补充数据,也只需要根据公用的DTD规范来建立文档,就立刻可以加入。
目前,已经有数量众多的写好的DTD文件可以利用。针对不同的行业和应用,这些DTD文件已经建立了通用的元素和标签规则。你不需要自己重新创建,只要在他们的基础上加入你需要的新标识。
当然,如果愿意,你可以创建自己的DTD,它可能和你的文档配合的更加完美。建立自己的DTD也是很简单的一件事,一般只需要定义4-5个元素就可以了。
调用DTD文件的方法有两种:
1.直接包含在XML文档内的DTD
你只要在DOCTYPE声明中插入一些特别的说明就可以了,象这样:
我们有一个XML文档:
<?xml version="1.0" encoding="GB2312"?>
<myfile>
<title>XML轻松学习手册</title>
<author>ajie</author>
</myfile>
我们在第一行后面插入下面代码就可以:
<!DOCTYPE myfile [
<!ELEMENT title (#PCDATA)>
<!ELEMENT author (#PCDATA)>
<!ENTITY copyright "Copyright 2001, Ajie.">
]>
2.调用独立的DTD文件
将DTD文档存为.dtd的文件,然后在DOCTYPE声明行中调用,例如,将下面的代码存为myfile.dtd
<!ELEMENT myfile (title, author)>
<!ELEMENT title (#PCDATA)>
<!ELEMENT author (#PCDATA)>
然后在XML文档中调用,在第一行后插入:
<!DOCTYPE myfile SYSTEM "myfile.dtd">
我们可以看到DTD文档和HTML中js的调用是差不多的,关于DTD文档具体如何写,我们将在下一章和XML文档的语法一起介绍。
下面我们来了解DTD有关的术语:
1.Schema(规划)
schema是数据规则的描述。schema做两件事:
a.它定义元素数据类型和元素之间的关系;
b.它定义元素所能包含的内容类型。
DTD就是关于XML文档的一个schema。
2.Document Tree(文档树)
"文档树"在前面第二章我们已经提到过,它是文档元素分级结构的形象表示。一个文档结构树包含根元素,根元素是最顶级的元素,(就是紧接着XML声明语句后的第一个元素)。看例子:
<?xml version="1.0"?>
<filelist>
<myfile>
<title>...</title>
<author>...</author>
</myfile>
</filelist>
上面的例子分三级结构排列成"树"状,其中的<filelist>就是根元素。在XML和DTD文件中,第一个定义的都是根元素。
3.Parent Element(父元素)/Child Element(子元素)
父元素是指包含有其它元素的元素,被包含的元素称为它的子元素。看上面的"结构树",其中<myfile>是父元素,<title>,<author>是它的子元素,而<myfile>又是<filelist>的子元素。象<title>这样没有包含任何子元素的最后一级元素我们也称之为"页元素"。
4.Parser(解析软件)
Parser是一种检查XML文档是否遵循DTD规范的工具软件。
XML的parser发展为两类:一种是"非确认类paeser",只检测文档是否遵守XML语法规则,是否用元素标识建立了文档树。另一种是"确认类paeser",它不但检测文档语法,结构树,而且比较解析你使用的元素标识是否遵守了相应DTD文件的规范。
Parser能独立使用,也可以成为编辑软件或浏览器的一部分。在后面的相关资源列表里,我列出了当前比较流行的一些parsers。
好了,通过第三章的学习,我们已经了解了一些XML和DTD的基本术语,但是我们还不知道怎样来写这些文件,需要遵循什么样的语法,在下一章,将重点介绍有关撰写XML和DTD文档的语法。请继续浏览,谢谢!
XML轻松学习手册(4)XML语法
第四章 XML语法
提纲:
一.XML语法规则
二.元素的语法
三.注释的语法
四.CDATA的语法
五.Namespaces的语法
六.entity的语法
七.DTD的语法
通过前面三章的学习,我们已经对什么是XML,它的实现原理以及相关的术语有所了解。接下来我们就开始学习XML的语法规范,动手写自己的XML文档。
一.XML语法规则
XML的文档和HTML的原代码类似,也是用标识来标识内容。创建XML文档必须遵守下列重要规则:
规则1:必须有XML声明语句
这一点我们在上一章学习时已经提到过。声明是XML文档的第一句,其格式如下:
<?xml version="1.0" standalone="yes/no" encoding="UTF-8"?>
声明的作用是告诉浏览器或者其它处理程序:这个文档是XML文档。声明语句中的version表示文档遵守的XML规范的版本;standalone表示文档是否附带DTD文件,如果有,参数为no;encoding表示文档所用的语言编码,默认是UTF-8。
规则2:是否有DTD文件
如果文档是一个"有效的XML文档"(见上一章),那么文档一定要有相应DTD文件,并且严格遵守DTD文件制定的规范。DTD文件的声明语句紧跟在XML声明语句后面,格式如下:
<!DOCTYPE type-of-doc SYSTEM/PUBLIC "dtd-name">
其中:
"!DOCTYPE"是指你要定义一个DOCTYPE;
"type-of-doc"是文档类型的名称,由你自己定义,通常于DTD文件名相同;
"SYSTEM/PUBLIC"这两个参数只用其一。SYSTEM是指文档使用的私有DTD文件的网址,而PUBLIC则指文档调用一个公用的DTD文件的网址。
"dtd-name" 就是DTD文件的网址和名称。所有DTD文件的后缀名为".dtd"。
我们还是用上面的例子,应该写成这样:
<?xml version="1.0" standalone="no" encode="UTF-8"?>
<!DOCTYPE filelist SYSTEM "filelist.dtd">
规则3:注意你的大小写
在XML文档中,大小写是有区别的。<P>和<p>是不同的标识。注意在写元素时,前后标识大小写要保持一样。例如:<Author>ajie</Author>,写成<Author>ajie</author>是错误的。
你最好养成一种习惯,或者全部大写,或者全部小写,或者大写第一个字母。这样可以减少因为大小写不匹配产生的文档错误。
规则4:给属性值加引号
在HTML代码里面,属性值可以加引号,也可以不加。例如:<font color=red>word</font>和<font color="red">word</font>都可以被浏览器正确解释。
但是在XML中则规定,所有属性值必须加引号(可以是单引号,也可以是双引号),否则将被视为错误。
规则5:所有的标识必须有相应的结束标识
在HTML中,标识可能不是成对出现的,比?lt;br>。而在XML中规定,所有标识必须成对出现,有一个开始标识,就必须有一个结束标识。否则将被视为错误。
规则6:所有的空标识也必须被关闭
空标识就是标识对之间没有内容的标识。比如
,<img>等标识。在XML中,规定所有的标识必须有结束标识,针对这样的空标识,XML中处理的方法是在原标识最后加/,就可以了。例如:
应写为<br />;
<META name="keywords" content="XML, SGML, HTML">应写为<META name="keywords" content="XML, SGML, HTML" />;
<IMG src= "cool.gif">应写为<IMG src= "cool.gif" />
第四章 XML语法
二.元素的语法
元素由一对标识以及其中的内容组成。就象这样:ajie。元素的名称和标识的名称是一样的。标识可以用属性来进一步描述。
在XML中,没有任何保留字,所以你可以随心所欲的用任何词语来作为元素名称。但是也必须遵守下列规范:
1.名称中可以包含字母、数字以及其它字母;
2.名称不能以数字或"_" (下划线)开头;
3.名称不能以字母 xml(或 XML 或 Xml ..)开头
4.名称中不能包含空格
5.名称中间不能包含":"(冒号)
为了使元素更容易阅读理解和操作,我们还有一些建议:
1.名称中不要使用"."。因为在很多程序语言中,"."是作为对象的属性,例如:font.color。同样的原因"-"也最好不要用,必须使用的,以"_"代替;
2.名称尽量简短。
3.名称的大小写尽量采用同一标准。
4.名称可以使用非英文字符,比如用中文。但是有些软件可能不支持。(IE5目前是支持中文元素的。)
另外,补充一点关于属性的说明。在HTML中,属性可以用来定义元素的显示格式,比如:<font color="red">word</font>将把word显示为红色。而在XML中,属性只是对标识的描述,与元素内容的显示无关。例如同样一句:<font color="red">word</font>,并不会将word显示为红色。(那么,有网友会问:如何在XML中将文字显示为红色呢?这就需要使用CSS或者XSL,我们在下面详细讲述。)
三.注释的语法
注释是为了便于阅读和理解,在XML文档添加的附加信息,将不会被程序解释或则浏览器显示。
注释的语法如下:
<!-- 这里是注释信息 -->
可以看到,它和HTML中的注释语法是一样的,非常容易。养成良好的注释习惯将使你的文档更加便于维护,共享,看起来也更专业。
四.CDATA的语法
CDATA全称character data,翻译为字符数据。我们在写XML文档时,有时需要显示字母,数字和其它的符号本身,比如"<",而在XML中,这些字符已经有特殊的含义,我们怎么办呢?这就需要用到CDATA语法。语法格式如下:
<![CDATA[这里放置需要显示的字符]]>
例如:
<![CDATA[<AUTHOR sex="female">ajie</AUTHOR>]]>
在页面上显示的内容将是"<AUTHOR sex="female">ajie</AUTHOR>"
第四章 XML语法
五.Namespaces的语法
Namespaces翻译为名字空间。名字空间有什么作用呢?当我们在一个XML文档中使用他人的或者多个DTD文件,就会出现这样的矛盾:因为XML中标识都是自己创建的,在不同的DTD文件中,标识名可能相同但表示的含义不同,这就可能引起数据混乱。
比如在一个文档<table>wood table</table>中<table>表示桌子,
而在另一个文档<table>namelist</table>中<table>表示表格。如果我需要同时处理这两个文档,就会发生名字冲突。
了解决这个问题,我们引进了namespaces这个概念。namespaces通过给标识名称加一个网址(URL)定位的方法来区别这些名称相同的标识。
Namespaces同样需要在XML文档的开头部分声明,声明的语法如下:
<document xmlns:yourname='URL'>
其中yourname是由你定义的namespaces的名称,URL就是名字空间的网址。
假设上面的"桌子<table>"文档来自http://www.zhuozi.com,我们就可以声明为
<document xmlns:zhuozi='http://www.zhuozi.com'>
然后在后面的标识中使用定义好的名字空间:
<zhuozi:table>wood table</table>
这样就将这两个<table>区分开来。注意的是:设置URL并不是说这个标识真的要到那个网址去读取,仅仅作为一种区别的标志而已。
六.entity的语法
entity翻译为"实体"。它的作用类似word中的"宏",也可以理解为DW中的摸板,你可以预先定义一个entity,然后在一个文档中多次调用,或者在多个文档中调用同一个entity。
entity可以包含字符,文字等等,使用entity的好处在于:1.它可以减少差错,文档中多个相同的部分只需要输入一遍就可以了。2.它提高维护效率。比如你有40个文档都包含copyright的entity,如果需要修改这个copyright,不需要所有的文件都修改,只要改最初定义的entity语句就可以了。
XML定义了两种类型的entity。一种是我们这里说的普通entity,在XML文档中使用;另一种是参数entity,在DTD文件中使用。
entity的定义语法为:
<!DOCTYPE filename [
<!ENTITY entity-name "entity-content"
]
>
例如我要定义一段版权信息:
<!DOCTYPE copyright [
<!ENTITY copyright "Copyright 2001, Ajie. All rights reserved"
]
>
如果我的版权信息内容和他人共享一个XML文件,也可以使用外部调用的方法,语法象这样:
<!DOCTYPE copyright [
<!ENTITY copyright SYSTEM "http://www.sample.com/copyright.xml">
]
>
定义好的entity在文档中的引用语法为:&entity-name;
例如,上面定义的版权信息,调用时写作?copyright;
完整的例子如下,你可以copy下来存为copyright.xml观看实例:
<?xml version="1.0" encoding="GB2312"?>
<!DOCTYPE copyright [
<!ENTITY copyright "Copyright 2001, Ajie. All rights reserved">
]>
<myfile>
<title>XML</title>
<author>ajie</author>
<email>ajie@aolhoo.com</email>
<date>20010115</date>
©right;
</myfile>
第四章 XML语法
七.DTD的语法
DTD是"有效XML文档"的必须文件,我们通过DTD文件来定义文档中元素和标识的规则及相互关系。如何建立一个DTD文件呢?让我们一起来学习:
1.设置元素
元素是XML文档的基本组成部分。你要在DTD中定义一个元素,然后在XML文档中使用。元素的定义语法为:<!ELEMENT DESCRIPTION (#PCDATA, DEFINITION)*>
说明:
"<!ELEMENT" 是元素的声明,说明你要定义的是一个元素;
声明后面的"DESCRIPTION",是元素的名称;
"(#PCDATA, DEFINITION)*>"则是该元素的使用规则。规则定义了元素可以包含的内容以及相互的关系。下面的表格概要列出了元素的规则:
2.元素规则表:
此主题相关图片如下:

另外,我们还可以为元素定义属性,因为我们不推荐使用属性,在这里就不详细展开了。
最后,我们来总结一些前四章学习的内容,写一个包含DTD,XML,以及Script的简单实例,便于读者理解:
1.将下面文件存为myfile.dtd
<!ELEMENT myfile (title, author)>
<!ELEMENT title (#PCDATA)>
<!ELEMENT author (#PCDATA)>
2.然后建立XML文档myfile.xml:
<?xml version="1.0" encoding="GB2312"?>
<!DOCTYPE myfile SYSTEM "myfile.dtd">
<myfile>
<title>XML轻松学习手册</title>
<author>ajie</author>
</myfile>
3.建立HTML文档myfile.html
<html>
<head>
<script language="javascript" for="window" event="onload">
var xmlDoc = new ActiveXObject("Microsoft.XMLDOM");
xmlDoc.async="false";
xmlDoc.load("myfile.xml");
nodes = xmlDoc.documentElement.childNodes;
title.innerText = nodes.item(0).text;
author.innerText = nodes.item(1).text;
</script>
<title>在HTML中调用XML数据</title>
</head>
<body bgcolor="#FFFFFF">
<b>标题: </b>
<span id="title"></span><br>
<b>作者: </b>
<span id="author"></span><br>
</body>
</html>
4.用IE5.0以上浏览器打开myfile.html就可以看到效果了。
XML轻松学习手册(5)XML实例解析
第五章:XML实例解析
提纲:
一:实例效果
二:实例解析
1.定义新标识。
2.建立XML文档。
3.建立相应的HTML文件。
XML在不同领域有着广泛的应用,比如在科技领域的MathML,无线通信应用的WML,在网络图象方面的SVG等等,我们这里侧重讨论XML在web上的应用。XML在web上应用主要是利用其强大的数据操作能力。一般用XML配合javascript和asp等服务器端程序,可以实现网络上几乎所有的应用需求。
考虑讲解方便,我们在下面介绍一个简单的实例,不包含服务器端程序。目的在于让您对XML的数据操作能力有一个感性的认识。
好,我们首先[ 点击这里 ]来看实例的效果。(请用IE5.0以上版本浏览器打开)
这是一个简单的CD唱片数据检索功能。你通过点击"上一张","下一张"可以看到单张CD的有关信息。这样的效果我们原来用两种方法可以实现:
1.利用DHTML,将数据隐藏在不同的层中,通过鼠标事件依次显示;
2.利用后台程序(如ASP,CGI,PHP,JSP等),调用服务器端的数据。
但是在这个实例中,我们打开页面原代码可以看到,其中没有用DHTML的DIV,也没有表单的action,它完全是用XML来实现的。下面我们来分析它的制作过程:
第一步:定义新标识。
根据实际的CD数据,首先新建一个名为<CD>的标识;其次建立它相关的数据标识,分别是:CD名称<Title>,演唱者<Artist>,出版年代<Year>,国家<Country>,发行公司<Company>和价格<Price>;最后还要建立一个名为目录<CATALOG>的标识。为什么要再建立一个<CATALOG>标识呢?因为在XML文档中规定,必须且只能有一个根元素(标识),我们有多个CD数据,这些数据是并列的关系,所以需要为这些并列的元素建立一个根元素。
以上元素的定义和关系都完全符合XML标准,不需要特别的DTD文件来定义,所以可以省略DTD定义。如果我们想使用DTD来定义,以上过程可以表示为:
<!ELEMENT CATALOG (CD)*>
<!ELEMENT CD (Title,Artist,Year,Country,Company,Price)>
<!ELEMENT Title (#PCDATA)>
<!ELEMENT Artist (#PCDATA)>
<!ELEMENT Year (#PCDATA)>
<!ELEMENT Country (#PCDATA)>
<!ELEMENT Company (#PCDATA)>
<!ELEMENT Price (#PCDATA)>
这段代码表示:元素CATALOG包含多个CD子元素,而子元素CD又依次包含Title, Artist, Year, Country, Company, Price 六个子元素,它们的内容都定义为文本(字符,数字,文本)。(注:具体的语法说明可以看上一章关于DTD的介绍)
第二步:建立XML文档。
<?xml version="1.0"?>
<CATALOG>
<CD>
<TITLE>Empire Burlesque</TITLE>
<ARTIST>Bob Dylan</ARTIST>
<COUNTRY>USA</COUNTRY>
<COMPANY>Columbia</COMPANY>
<PRICE>10.90</PRICE>
<YEAR>1985</YEAR>
</CD>
<CD>
<TITLE>Hide your heart</TITLE>
<ARTIST>Bonnie Tylor</ARTIST>
<COUNTRY>UK</COUNTRY>
<COMPANY>CBS Records</COMPANY>
<PRICE>9.90</PRICE>
<YEAR>1988</YEAR>
</CD>
<CD>
<TITLE>Greatest Hits</TITLE>
<ARTIST>Dolly Parton</ARTIST>
<COUNTRY>USA</COUNTRY>
<COMPANY>RCA</COMPANY>
<PRICE>9.90</PRICE>
<YEAR>1982</YEAR>
</CD>
<CD>
<TITLE>Still got the blues</TITLE>
<ARTIST>Gary More</ARTIST>
<COUNTRY>UK</COUNTRY>
<COMPANY>Virgin redords</COMPANY>
<PRICE>10.20</PRICE>
<YEAR>1990</YEAR>
</CD>
<CD>
<TITLE>Eros</TITLE>
<ARTIST>Eros Ramazzotti</ARTIST>
<COUNTRY>EU</COUNTRY>
<COMPANY>BMG</COMPANY>
<PRICE>9.90</PRICE>
<YEAR>1997</YEAR>
</CD>
</CATALOG>
上面代码首先用<?xml version="1.0"?>声明语句表明这是一个XML文档,它的格式遵守XML 1.0标准规范。然后是文档内容,结构树非常清晰:
<CATALOG>
<CD>
......
</CD>
<CD>
......
</CD>
</CATALOG>
一共定义了5组数据。我们将上面的代码存为cd.xml文件,以备调用。
第三步:建立相应的HTML文件。
1.导入XML数据。
我们知道,目前流行的浏览器中,暂时只有微软的IE5.0以上版本浏览器支持XML。IE是通过在HTML中的object物件来支持插入XML,并通过js的XMLDocument.load()方法来导入数据。我们看代码: <object WIDTH="0" HEIGHT="0"
CLASSID="clsid:550dda30-0541-11d2-9ca9-0060b0ec3d39" ID="xmldso">
</object>
定义一个object,ID名为xmldso。然后在head区用js引入xml数据:
<script for="window" event="onload">
xmldso.XMLDocument.load("cd.xml");
</script>
2.捆绑数据。
然后将用<SPAN>标识来将XML数据绑定在表格中。其中ID,DATASRC,DTATFLD都是<SPAN>的属性。代码如下:
<table>
<tr><td>Title:</td><td><SPAN ID="title" DATASRC=#xmldso DATAFLD="TITLE"></SPAN></td></tr>
<tr><td>Artist:</td><td><SPAN ID="artist" DATASRC=#xmldso DATAFLD="ARTIST"></SPAN></td></tr>
<tr><td>Year:</td><td><SPAN ID="year" DATASRC=#xmldso DATAFLD="YEAR"></SPAN></td></tr>
<tr><td>Country:</td><td><SPAN ID="country" DATASRC=#xmldso DATAFLD="COUNTRY"></SPAN></td></tr>
<tr><td>Company:</td><td><SPAN ID="company" DATASRC=#xmldso DATAFLD="COMPANY"></SPAN></td></tr>
<tr><td>Price:</td><td><SPAN ID="price" DATASRC=#xmldso DATAFLD="PRICE"></SPAN></td></tr>
</table>
3.动作操作。
最后,为数据提供浏览按钮:
<INPUT TYPE=button value="上一张CD" onCLICK="moveprevious()">
<INPUT TYPE=button value="下一张CD" onCLICK="movenext()">
并利用js来完成两个鼠标点击功能:movenext()和moveprevious()。在head区加入如下代码:
<script language="javascript">
function movenext()
{
if (xmldso.recordset.absoluteposition < xmldso.recordset.recordcount)
{
xmldso.recordset.movenext();
}
}
function moveprevious()
{
if (xmldso.recordset.absoluteposition > 1)
{
xmldso.recordset.moveprevious();
}
}
</script>
好,我们先看HTML文件的全部原代码:
<html>
<head>
<script for="window" event="onload">
xmldso.XMLDocument.load("cd.xml");
</script>
<script language="javascript">
function movenext()
{
if (xmldso.recordset.absoluteposition < xmldso.recordset.recordcount)
{
xmldso.recordset.movenext();
}
}
function moveprevious()
{
if (xmldso.recordset.absoluteposition > 1)
{
xmldso.recordset.moveprevious();
}
}
</script>
<TITLE>CD Navigate</TITLE>
</head>
<body>
<p>
<object WIDTH="0" HEIGHT="0"
CLASSID="clsid:550dda30-0541-11d2-9ca9-0060b0ec3d39" ID="xmldso">
</object>
<table>
<tr><td>Title:</td><td><SPAN ID="title" DATASRC=#xmldso DATAFLD="TITLE"></SPAN></td></tr>
<tr><td>Artist:</td><td><SPAN ID="artist" DATASRC=#xmldso DATAFLD="ARTIST"></SPAN></td></tr>
<tr><td>Year:</td><td><SPAN ID="year" DATASRC=#xmldso DATAFLD="YEAR"></SPAN></td></tr>
<tr><td>Country:</td><td><SPAN ID="country" DATASRC=#xmldso DATAFLD="COUNTRY"></SPAN></td></tr>
<tr><td>Company:</td><td><SPAN ID="company" DATASRC=#xmldso DATAFLD="COMPANY"></SPAN></td></tr>
<tr><td>Price:</td><td><SPAN ID="price" DATASRC=#xmldso DATAFLD="PRICE"></SPAN></td></tr>
</table>
<p>
<INPUT TYPE=button value="上一张CD" onCLICK="moveprevious()">
<INPUT TYPE=button value="下一张CD" onCLICK="movenext()">
</p>
</body>
</html>
将以上代码存为cd.htm文件,于第二步的cd.xml文件放在一起。打开cd.htm文件,你就看见和上面实例一样的效果了。
好,到今天为止,我们已经学习了关于XML的不少知识,我们来总结一下前面五个章节,分别是XML快速入门,XML的概念原理,XML的术语,XML的语法和本章的实例解析。到这里,教程部分就结束了。在写作过程中,阿捷尽最大努力将有关XML概念讲得通俗易懂,尽量把自己的理解告诉给大家,但因为本人学习XML时间也不长,对整个XML的技术把握还不够系统和深入,所以难免有疏漏的地方,请大家指正和谅解,谢谢!
<完>