
工程目录

web.xml
<?xml version="1.0" encoding="UTF-8"?>
<web-app xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns="http://java.sun.com/xml/ns/javaee" xmlns:web="http://java.sun.com/xml/ns/javaee/web-app_2_5.xsd"
xsi:schemaLocation="http://java.sun.com/xml/ns/javaee http://java.sun.com/xml/ns/javaee/web-app_2_5.xsd"
id="WebApp_ID" version="2.5">
<display-name>android</display-name>
<welcome-file-list>
<welcome-file>index.html</welcome-file>
<welcome-file>index.htm</welcome-file>
<welcome-file>index.jsp</welcome-file>
<welcome-file>default.html</welcome-file>
<welcome-file>default.htm</welcome-file>
<welcome-file>default.jsp</welcome-file>
</welcome-file-list>
<!-- 第一 这个过滤器与Struts的核心过滤器协同工作,以便更容易与sitemesh整合 -->
<filter>
<filter-name>struts-cleanup</filter-name>
<filter-class>org.apache.struts2.dispatcher.ActionContextCleanUp</filter-class>
</filter>
<!-- 第二 sitemesh的过滤器,同时也整合了Freemarker -->
<filter>
<filter-name>sitemesh</filter-name>
<filter-class>org.apache.struts2.sitemesh.FreeMarkerPageFilter</filter-class>
</filter>
<!-- 第三 struts2过滤器 -->
<filter>
<filter-name>struts2Filter</filter-name>
<filter-class>org.apache.struts2.dispatcher.ng.filter.StrutsPrepareAndExecuteFilter</filter-class>
</filter>
<filter-mapping>
<filter-name>struts-cleanup</filter-name>
<url-pattern>/*</url-pattern>
</filter-mapping>
<filter-mapping>
<filter-name>sitemesh</filter-name>
<url-pattern>/*</url-pattern>
</filter-mapping>
<filter-mapping>
<filter-name>struts2Filter</filter-name>
<url-pattern>/*</url-pattern>
</filter-mapping>
<!--
使FreeMarker模块能够使用strut2标签,使用方式:<#assign
s=JspTaglibs["/WEB-INF/struts-tags.tld"] />
-->
<servlet>
<servlet-name>JspSupportservlet</servlet-name>
<servlet-class>org.apache.struts2.views.JspSupportServlet</servlet-class>
<load-on-startup>1</load-on-startup>
</servlet>
<servlet>
<servlet-name>sitemesh-freemarker</servlet-name>
<servlet-class>com.opensymphony.module.sitemesh.freemarker.FreemarkerDecoratorServlet</servlet-class>
<init-param>
<param-name>TemplatePath</param-name>
<param-value>/</param-value>
</init-param>
<init-param>
<param-name>default_encoding</param-name>
<param-value>UTF-8</param-value>
</init-param>
<load-on-startup>1</load-on-startup>
</servlet>
<servlet-mapping>
<servlet-name>sitemesh-freemarker</servlet-name>
<url-pattern>/*</url-pattern>
</servlet-mapping>
</web-app>
struts.xml
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE struts PUBLIC "-//Apache Software Foundation//DTD Struts Configuration 2.1//EN"
"http://struts.apache.org/dtds/struts-2.1.dtd">
<struts>
<constant name="struts.convention.default.parent.package" value="crud-default" />
<constant name="struts.convention.package.locators" value="action" />
<constant name="struts.convention.package.locators.basePackage" value="org.david.android" />
<constant name="struts.convention.result.path" value="/WEB-INF/web" />
<!-- 用于CRUD Action的parent package -->
<package name="crud-default" extends="convention-default">
<!-- 基于paramsPrepareParamsStack,
增加store interceptor保证actionMessage在redirect后不会丢失 -->
<interceptors>
<interceptor-stack name="crudStack">
<interceptor-ref name="store">
<param name="operationMode">AUTOMATIC</param>
</interceptor-ref>
<interceptor-ref name="paramsPrepareParamsStack" />
</interceptor-stack>
</interceptors>
<default-interceptor-ref name="crudStack" />
</package>
<!--
使用Convention插件,实现约定大于配置的零配置文件风格.
特殊的Result路径在Action类中使用@Result设定.
-->
</struts>
decorators.xml
<?xml version="1.0" encoding="UTF-8"?>
<decorators defaultdir="/WEB-INF/decorators">
<decorator name="main" page="main.ftl">
<pattern>/*</pattern>
</decorator>
</decorators>
HelloWorldAction.java
package org.david.android.action.user;
public class HelloWorldAction {
private String message;
public String getMessage() {
return message;
}
public void setMessage(String message) {
this.message = message;
}
public String execute(){
this.message = "ITdavid";
return "success";
}
}
main.ftl
<html xmlns="http://www.w3.org/1999/xhtml">
<head>
<meta http-equiv="Content-Type" content="text/html; charset=UTF-8" />
<title>${title}</title>
</head>
<body>
<div>
hello
${body}
</body>
</html>
hello-world.ftl
<html>
<head>
<meta http-equiv="Content-Type" content="text/html; charset=UTF-8">
<meta name="layout" content="main"/>
<title>Insert title here</title>
</head>
<body>
Hello ${message!}
</body>
</html>
posted @
2009-11-29 17:05 大卫 阅读(3290) |
评论 (4) |
编辑 收藏<?xml version="1.0" encoding="UTF-8"?>
<web-app xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns="http://java.sun.com/xml/ns/javaee"
xmlns:web="http://java.sun.com/xml/ns/javaee/web-app_2_5.xsd" xsi:schemaLocation="http://java.sun.com/xml/ns/javaee http://java.sun.com/xml/ns/javaee/web-app_2_5.xsd"
id="WebApp_ID" version="2.5">
<display-name>fmtest</display-name>
<welcome-file-list>
<welcome-file>index.html</welcome-file>
<welcome-file>index.htm</welcome-file>
<welcome-file>index.jsp</welcome-file>
<welcome-file>default.html</welcome-file>
<welcome-file>default.htm</welcome-file>
<welcome-file>default.jsp</welcome-file>
</welcome-file-list>
<context-param>
<param-name>contextConfigLocation</param-name>
<param-value>/WEB-INF/config/service-context.xml</param-value>
</context-param>
<listener>
<listener-class>org.springframework.web.context.ContextLoaderListener</listener-class>
</listener>
<filter>
<display-name>Stripes Filter</display-name>
<filter-name>StripesFilter</filter-name>
<filter-class>net.sourceforge.stripes.controller.StripesFilter</filter-class>
<init-param>
<param-name>ActionResolver.Packages</param-name>
<param-value>net.sourceforge.stripes.examples</param-value>
</init-param>
<init-param>
<param-name>Interceptor.Classes</param-name>
<param-value>net.sourceforge.stripes.integration.spring.SpringInterceptor</param-value>
</init-param>
</filter>
<filter-mapping>
<filter-name>StripesFilter</filter-name>
<servlet-name>StripesDispatcher</servlet-name>
</filter-mapping>
<servlet>
<servlet-name>StripesDispatcher</servlet-name>
<servlet-class>net.sourceforge.stripes.controller.DispatcherServlet</servlet-class>
<load-on-startup>1</load-on-startup>
</servlet>
<servlet-mapping>
<servlet-name>StripesDispatcher</servlet-name>
<url-pattern>*.action</url-pattern>
</servlet-mapping>
<servlet>
<servlet-name>Freemarker</servlet-name>
<servlet-class>freemarker.ext.servlet.FreemarkerServlet</servlet-class>
<init-param>
<param-name>TemplatePath</param-name>
<param-value>/</param-value>
</init-param>
<init-param>
<param-name>template_update_delay</param-name>
<param-value>0</param-value> <!-- 0 is for dev only! Use higher value otherwise. -->
</init-param>
<init-param>
<param-name>DefaultEncoding</param-name>
<param-value>utf-8</param-value>
</init-param>
<load-on-startup>1</load-on-startup>
</servlet>
<servlet-mapping>
<servlet-name>Freemarker</servlet-name>
<url-pattern>*.ftl</url-pattern>
</servlet-mapping>
</web-app>
posted @
2009-11-25 15:45 大卫 阅读(1750) |
评论 (2) |
编辑 收藏
解决FreeMarker中文乱码问题。
在web.xml中配置如下:
<servlet>
<servlet-name>Freemarker</servlet-name>
<servlet-class>freemarker.ext.servlet.FreemarkerServlet</servlet-class>
<init-param>
<param-name>TemplatePath</param-name>
<param-value>/</param-value>
</init-param>
<init-param>
<param-name>template_update_delay</param-name>
<param-value>3600</param-value> <!-- 0 值仅用于开发环境,生产环境请设置为3600或者更大。 -->
</init-param>
<init-param>
<param-name>DefaultEncoding</param-name> <!-- 解决中文编码问题 -->
<param-value>utf-8</param-value>
</init-param>
<load-on-startup>1</load-on-startup>
</servlet>
--------------------
PES准高手
posted @
2009-11-25 15:02 大卫 阅读(5062) |
评论 (1) |
编辑 收藏
RT
太保守会影响效率,当某些代码逻辑是认为可控制时,不用保守。
posted @
2009-09-28 10:08 大卫 阅读(426) |
评论 (0) |
编辑 收藏
关于类的划分,上层应该按业务领域含义划分,下层应该按实现细节划分。
posted @
2009-09-27 12:10 大卫 阅读(412) |
评论 (0) |
编辑 收藏
其实很简单,就把标记@Id放在主键(非自增)上就OK了。
posted @
2009-02-25 14:12 大卫 阅读(2554) |
评论 (0) |
编辑 收藏
摘要: 在设计数据库表的时候,往往会设计出带有复合主键的表,即表的记录由多个字段联合标识,如:
表
CREATE TABLE TB_HOUR_DATA
(
STAT_DATE DATE &...
阅读全文
posted @
2009-02-25 14:10 大卫 阅读(3002) |
评论 (2) |
编辑 收藏如何调用执行iframe中的方法?如下:
 document.getElementById("iframeId").contentWindow.functionName();
document.getElementById("iframeId").contentWindow.functionName();posted @
2008-10-07 14:50 大卫 阅读(5356) |
评论 (5) |
编辑 收藏
http://www.nciku.com/
这个网站里面的手写输入真棒!
posted @
2008-09-19 14:15 大卫 阅读(1273) |
评论 (1) |
编辑 收藏最近用smartdraw画了一些结构图,感觉比visio之类好用,而且也包罗万象,推荐一下!
下载地址:http://soft.mumayi.net/downinfo/3393.html
posted @
2008-09-18 14:04 大卫 阅读(1853) |
评论 (2) |
编辑 收藏
 /**//* 判断是否含有GBK以外的特殊字符 */
/**//* 判断是否含有GBK以外的特殊字符 */
boolean isGBK(String s) throws UnsupportedEncodingException
 {
{
 if(s.equals(new String(s.getBytes("gbk"))))
if(s.equals(new String(s.getBytes("gbk"))))
return true;
else
return false;
 }
}posted @
2008-09-16 13:04 大卫 阅读(875) |
评论 (1) |
编辑 收藏
使用这个组合,感觉还是很方便灵活的。
1、将struts2的json插件加入web工程的lib,jsonplugin的下载地址:
http://code.google.com/p/jsonplugin/downloads/list
2、struts.xml添加专为ajax使用的package
<package name="ajax" extends="json-default">
<action name="ajaxRequest"
class="org.david.struts2.HelloWorld">
<result type="json"></result>
</action>
</package>
3、helloworld.jsp
<SCRIPT type="text/javascript" src="js/jquery-1.2.6.min.js"></script>
<SCRIPT type="text/javascript">
function clickButton()

 {
{
var url = 'ajaxRequest.action';
var params = {
name:$('#name').attr('value')
 };
};
jQuery.post(url, params, callbackFun, 'json');
}
function callbackFun(data)
{
alert(data.result);//对应HelloWorld类的message属性
//获取数据后渲染页面
}
</SCRIPT>
<input id="name" type="text">
<input type="button" value="ok" onclick="javascript:clickButton();">
4、HelloWorld.java
package org.david.struts2;
public class HelloWorld {
private String name;
private String result;
// ajax请求参数赋值
public void setName(String name) {
this.name = name;
}
// ajax返回结果
public String getResult() {
return result;
}
public String execute() {
this.result = "Hello! " + this.name + ".";
return "success";
}
}
posted @
2008-09-07 23:07 大卫 阅读(41955) |
评论 (17) |
编辑 收藏
鼠标手型代码:
this.style.cursor='pointer'
不要用hand,否则firefox无效。
posted @
2008-08-01 17:03 大卫 阅读(2338) |
评论 (1) |
编辑 收藏
word-wrap:break-word 在firefox中不会起作用,以下是解决办法:
完整的css代码为
 word-wrap:break-word; overflow:hidden;
word-wrap:break-word; overflow:hidden;
这段代码应添加到td标签的样式中。另外,应该在外层的table标签中添加样式
table-layout:fixed;
posted @
2008-07-11 13:34 大卫 阅读(2105) |
评论 (1) |
编辑 收藏(.|\s)*
posted @
2008-06-23 14:49 大卫 阅读(924) |
评论 (0) |
编辑 收藏按照下面做法,终于成功了!庆祝,纪念......
背景:某个系统的mysql数据库dnname采用默认的latin1字符集,系统升级需要将所有数据转换成utf-8格式,目标数据库为newdbname(建库时使用utf8)
方法一:
步骤一 命令行执行:mysqldump --opt -hlocalhost -uroot -p*** --default-character-set=lantin1 dbname > /usr/local/dbname.sql
步骤二 将 dbname.sql文件中的create table语句的CHARSET=latin1改为CHARSET=utf8
步骤三 在dbname.sql文件中的insert语句之前加一条'set names utf8;'
步骤四 将dbname.sql转码为utf-8格式,建议使用UltraEditor,可以直接使用该编辑器的'转换->ASCII到UTF-8(Unicode编辑)',或者将文件另存为UTF-8(无BOM)格式
步骤五 命令行执行:mysql -hlocalhost -uroot -p*** --default-character-set=utf8 new_dbname < /usr/local/dbname.sql
总结:这种方法有个致命之处就是当数据中有大量中文字符和其他特殊符号字符时,很有可能导致在[步骤五]时报错导致无法正常导入数据,如果数据库比较大可以分别对每张表执行上述步骤
方法二(推荐大家使用):
为了解决第一种方法中总结时说到的问题,在网上苦苦查找了一天资料才东拼西凑的搞出一个比较稳妥的解决方法
步骤一 将待导出的数据表的表结构导出(可以用Phpmyadmin、mysqldump等,很简单就不说了),然后将导出的create table语句的CHARSET=latin1改为CHARSET=utf8,在目标库newdbname中执行该create table语句把表结构建好,接下来开始导出-导入数据。命令:
./mysqldump -d DB_Dig > /usr/local/tmp/tables.sql
步骤二 命令行:进入mysql命令行下,mysql -hlocalhost -uroot -p*** dbname
步骤三 执行SQL select * from tbname into outfile '/usr/local/tbname.sql';
步骤四 将tbname.sql转码为utf-8格式,建议使用UltraEditor,可以直接使用该编辑器的'转换->ASCII到UTF-8(Unicode编辑)',或者将文件另存为UTF-8(无BOM)格式
步骤五 在mysql命令行下执行语句 set character_set_database=utf8; 注:设置mysql的环境变量,这样mysql在下一步读取sql文件时将以utf8的形式去解释该文件内容
步骤六 在mysql命令行下执行语句 load data infile 'tbname.sql' into table newdbname.tbname;
注意:千万不要忘了第四步
采用第二种方法,所有数据均正常导入,且格式转换成功没有乱码。
参考:http://blog.csdn.net/guoguo1980/archive/2008/01/28/2070701.aspx
--------------------
WE准高手
posted @
2008-06-11 16:54 大卫 阅读(8964) |
评论 (8) |
编辑 收藏编译:
运行junit:
java -cp ../lib/junit.jar:../lib/j2ee.jar:. junit.textui.TestRunner com.chinaren.common.ToolKitTest
posted @
2008-06-10 18:32 大卫 阅读(1194) |
评论 (0) |
编辑 收藏
build.xml
1<?xml version="1.0"?>
2<project name="anttest" default="run">
3 <property name="build.path" value="build/classes/"/>
4 <path id="compile.classpath">
5 <fileset dir="lib">
6 <include name="*.jar"/>
7 </fileset>
8 </path>
9
10 <target name="init">
11 <mkdir dir="${build.path}" />
12 <mkdir dir="dist" />
13 </target>
14 <target name="compile" depends="init">
15 <javac srcdir="src/" destdir="${build.path}" classpath="${build.path}">
16 <classpath refid="compile.classpath"/>
17 </javac>
18 <echo>compilation complete!</echo>
19 </target>
20 <target name="run" depends="compile">
21 <java classname="org.test.work.HelloWorld" classpath="${build.path}" />
22 <echo>Run complete!</echo>
23 </target>
24
25 <target name="test" depends="compile">
26 <junit printsummary="on" haltonfailure="true" showoutput="true">
27 <classpath refid="compile.classpath"/>
28 <classpath path="${build.path}"/>
29 <formatter type="xml" />
30 <test name="org.test.work.HelloWorldTest"/>
31 </junit>
32 </target>
33
34</project>
HelloWorld.java
1package org.test.work;
2
3public class HelloWorld{
4
5 public String showMessage(){
6 return "Hello world!!!";
7 }
8
9 public static void main(String[] args){
10
11 System.out.println("Hello world!!!");
12 }
13}
HelloWorldTest.java
1package org.test.work;
2
3import static org.junit.Assert.*;
4import org.junit.*;
5
6import org.test.work.HelloWorld;
7
8public class HelloWorldTest{
9
10 private static HelloWorld hw = null;
11
12 @BeforeClass
13 public static void setUp(){
14 hw = new HelloWorld();
15 }
16
17 @Test
18 public void showHelloWorld(){
19 assertEquals(hw.showMessage(),"Hello world!!!");
20 }
21
22 @AfterClass
23 public static void tearDown(){
24 hw = null;
25 }
26
27}
posted @
2008-06-09 20:24 大卫 阅读(426) |
评论 (0) |
编辑 收藏JSP+jQuery+Spring+iBatis
posted @
2008-05-29 21:06 大卫 阅读(269) |
评论 (0) |
编辑 收藏
编译:
1D:\je-3.2.76\examples\je>javac -classpath ..\..\lib\je-3.2.76.jar .\SimpleExample.java
执行:
D:\je-3.2.76\examples>java -classpath .\;..\lib\je-3.2.76.jar je.SimpleExample
posted @
2008-05-07 15:28 大卫 阅读(452) |
评论 (1) |
编辑 收藏超级简单的一段代码,通过正则表达式获取字符串中某部分的值,代码:
1/** *//**
2 * 这段代码就是要获取到字符串"2008-05-10"的月份值及日期
3 */
4
5 Pattern pattern = Pattern.compile("[0-9]{4}-([0-9]{1,2})-([0-9]{1,2})");//括号用于组获取
6 Matcher matcher = pattern.matcher("2008-05-10");
7
8 int i = 0;
9 //循环只运行了一次
10 while(matcher.find())
11 {
12 System.out.println(++i);
13 System.out.println(matcher.group(0));//组0为全部串值
14 System.out.println(matcher.group(1));//pattern模式中中间的括号中的为组1
15 System.out.println(matcher.group(2));//pattern模式中后面的括号中的为组2
16 }
posted @
2008-05-05 18:16 大卫 阅读(1076) |
评论 (0) |
编辑 收藏
执行如下批处理:
1@echo off
2echo 正在清除系统垃圾文件,请稍等
3del /f /s /q %systemdrive%\*.tmp
4del /f /s /q %systemdrive%\*._mp
5del /f /s /q %systemdrive%\*.log
6del /f /s /q %systemdrive%\*.gid
7del /f /s /q %systemdrive%\*.chk
8del /f /s /q %systemdrive%\*.old
9del /f /s /q %systemdrive%\recycled\*.*
10del /f /s /q %windir%\*.bak
11del /f /s /q %windir%\prefetch\*.*
12rd /s /q %windir%\temp & md %windir%\temp
13del /f /q %userprofile%\小甜饼s\*.*
14del /f /q %userprofile%\recent\*.*
15del /f /s /q "%userprofile%\Local Settings\Temporary Internet Files\*.*"
16del /f /s /q "%userprofile%\Local Settings\Temp\*.*"
17del /f /s /q "%userprofile%\recent\*.*"
18echo 清除系统LJ完成!
19echo. & pause
绝对安全!
--------------------
WE准高手
posted @
2008-03-30 18:22 大卫 阅读(1639) |
评论 (8) |
编辑 收藏
数据格式:
1var folders=[{'folderId':'1','folderName':'收信箱'},{'folderId':'2','folderName':'发信箱'}];
2
3//用于下拉列表的store
4var foldersJsonStore = new Ext.data.SimpleStore({
5 fields: [{name: 'folderId', mapping:'folderId'},{name: 'folderName', mapping:'folderName'}],
6 data: folders
7});
刷新数据:
1foldersJsonStore.loadData(folders);
下拉框组件:
1var combo = new Ext.form.ComboBox({
2 fieldLabel: '文件夹',
3 name: 'folderMoveTo',
4 store: foldersJsonStore,
5 displayField: 'folderName',
6 valueField: 'folderId',
7 mode: 'local',
8 typeAhead: true, //自动将第一个搜索到的选项补全输入
9 triggerAction: 'all',
10 emptyText: '全部',
11 selectOnFocus: true,
12 forceSelection: true
13})
--------------------
WE准高手
posted @
2008-03-28 15:07 大卫 阅读(5626) |
评论 (4) |
编辑 收藏
摘要: 在使用Ext与DWR框架时,我们往往会用到GridPanel组件搭配PagingToolbar组件来实现翻页数据列表。翻页的时候每一页都要从后台获取该页的数据列表信息。
在解决此问题时,花了不少时间,看过不少前人的代码,终于成功了!共享之。
关键代码如下:
Store为:
1var ds = new Ext.data.Store({
...
阅读全文
posted @
2008-03-20 13:51 大卫 阅读(6940) |
评论 (1) |
编辑 收藏
一、配置
在页面中添加:
1<script type='text/javascript' src='dwr/interface/Folder.js'>
2 </script>
3 <script type='text/javascript' src='dwr/engine.js'>
4 </script>
5 <script type='text/javascript' src='dwr/util.js'>
6 </script>
需要注意的是路径,而不是官方的:
1<script type='text/javascript' src='../interface/Folder.js'></script>
2 <script type='text/javascript' src='../engine.js'></script>
3 <script type='text/javascript' src='../util.js'></script>
二、返回的json串需要进行处理,才可以在前台javascript正确处理。
使用json-lib的JSONArray对List类型数据进行处理:
1JSONArray.fromObject(folders).toString();
返回List型的json数据为:
1[{"folderId":1,"folderName":"收信箱"},{"folderId":2,"folderName":"发信箱"},{"folderId":3,"folderName":"草稿箱"},{"folderId":4,"folderName":"回收站"},{"folderId":5,"folderName":"垃圾箱"}]
这个数据返回到前台一定要用Ext.util.JSON.decode(data)进行编码,否则javascript不能正常处理。
1//刷新文件夹列表,DWR获取数据。
2function initFolders(){
3 Folder.getFolderList(refrashFolders);}
4
5function refrashFolders(data){
6 folders = Ext.util.JSON.decode(data);//一定要用这个进行解码
7 initFolderTreeNode();}
--------------------
WE准高手
posted @
2008-03-14 10:21 大卫 阅读(2420) |
评论 (1) |
编辑 收藏
摘要: 页面代码:
1<html>
2 <head>
3 <meta http-equiv="Content-Type" content="text/html; ch...
阅读全文
posted @
2008-03-07 16:11 大卫 阅读(5090) |
评论 (1) |
编辑 收藏 1package test;
2
3import java.lang.reflect.Method;
4import java.lang.reflect.ParameterizedType;
5import java.lang.reflect.Type;
6import java.util.List;
7import java.util.Map;
8
9public class TempTest {
10
11 public static void main(String[] args) throws Exception {
12 Method[] methods = TempTest.class.getDeclaredMethods();
13 for (Method method : methods) {
14 System.out.println("method:" + method.getName());// 方法名
15
16 // //////////////方法的参数
17 System.out.println(" paramTypeType: ");
18 Type[] paramTypeList = method.getGenericParameterTypes();// 方法的参数列表
19 for (Type paramType : paramTypeList) {
20 System.out.println(" " + paramType);// 参数类型
21 if (paramType instanceof ParameterizedType)/**//* 如果是泛型类型 */{
22 Type[] types = ((ParameterizedType) paramType)
23 .getActualTypeArguments();// 泛型类型列表
24 System.out.println(" TypeArgument: ");
25 for (Type type : types) {
26 System.out.println(" " + type);
27 }
28 }
29 }
30
31 // //////////////方法的返回值
32 System.out.println(" returnType: ");
33 Type returnType = method.getGenericReturnType();// 返回类型
34 System.out.println(" " + returnType);
35 if (returnType instanceof ParameterizedType)/**//* 如果是泛型类型 */{
36 Type[] types = ((ParameterizedType) returnType)
37 .getActualTypeArguments();// 泛型类型列表
38 System.out.println(" TypeArgument: ");
39 for (Type type : types) {
40 System.out.println(" " + type);
41 }
42 }
43
44 }
45
46 }
47
48 public static String method1(List list) {
49 return null;
50 }
51
52 private static Map<String, Double> method2(Map<String, Object> map) {
53 return null;
54 }
55
56}
posted @
2008-02-28 10:29 大卫 阅读(5810) |
评论 (3) |
编辑 收藏算法程序题:
该公司笔试题就1个,要求在10分钟内作完。
题目如下:用1、2、2、3、4、5这六个数字,用java写一个main函数,打印出所有不同的排列,如:512234、412345等,要求:"4"不能在第三位,"3"与"5"不能相连。
基本思路:
1 把问题归结为图结构的遍历问题。实际上6个数字就是六个结点,把六个结点连接成无向连通图,对于每一个结点求这个图形的遍历路径,所有结点的遍历路径就是最后对这6个数字的排列组合结果集。
2 显然这个结果集还未达到题目的要求。从以下几个方面考虑:
1. 3,5不能相连:实际要求这个连通图的结点3,5之间不能连通, 可在构造图结构时就满足改条件,然后再遍历图。
2. 不能有重复: 考虑到有两个2,明显会存在重复结果,可以把结果集放在TreeSet中过滤重复结果。//TreeSet用于过滤一个集合中相同的东西还真是个挺不错的方法
3. 4不能在第三位: 仍旧在结果集中去除满足此条件的结果。
采用二维数组定义图结构,最后的代码是:
1package test;
2
3import java.util.Iterator;
4import java.util.TreeSet;
5
6public class TestQuestion {
7
8 private String[] b = new String[] { "1", "2", "2", "3", "4", "5" };
9 private int n = b.length;
10 private boolean[] visited = new boolean[n];
11 private int[][] a = new int[n][n];
12 private String result = "";
13 private TreeSet treeSet = new TreeSet();// 用于保存结果,具有过滤相同结果的作用。
14
15 public static void main(String[] args) {
16 new TestQuestion().start();
17 }
18
19 private void start() {
20 // 创建合法路径标识集合
21 for (int i = 0; i < n; i++) {
22 for (int j = 0; j < n; j++) {
23 if (i == j) {
24 a[i][j] = 0;
25 } else {
26 a[i][j] = 1;
27 }
28 }
29 }
30 a[3][5] = 0;
31 a[5][3] = 0;
32 for (int i = 0; i < n; i++) {
33 this.depthFirstSearch(i);// 深度递归遍历
34 }
35 Iterator it = treeSet.iterator();
36 while (it.hasNext()) {
37 String string = (String) it.next();
38
39 if (string.indexOf("4") != 2) {
40 System.out.println(string);
41 }
42 }
43 }
44
45 /** *//**
46 * 深度优先遍历
47 *
48 * @param startIndex
49 */
50 private void depthFirstSearch(int startIndex) {
51 // 递归的工作
52 visited[startIndex] = true;// 用于标识已经走过的节点
53 result = result + b[startIndex];// 构造结果
54 if (result.length() == n) {
55 treeSet.add(result);// 添加到TreeSet类型中,具有过滤相同结果的作用
56 }
57 // 每走到一个节点,挨个遍历下一个节点
58 for (int j = 0; j < n; j++) {
59 if (a[startIndex][j] == 1 && visited[j] == false) {
60 depthFirstSearch(j);// 深度递归遍历
61 } else {
62 continue;
63 }
64 }
65 // 递归的收尾工作
66 result = result.substring(0, result.length() - 1);
67 visited[startIndex] = false;// 取消访问标识
68 }
69}
70
--------------------
WE准高手
posted @
2008-02-27 14:30 大卫 阅读(2993) |
评论 (12) |
编辑 收藏
TreeSet类型是J2SE中唯一可实现自动排序的类型,用法如下:
MyComparator.java
1package test;
2
3import java.util.Comparator;
4
5
 public class MyComparator<T> implements Comparator<T> {
public class MyComparator<T> implements Comparator<T> {
6
7
 public int compare(T arg0, T arg1) {
public int compare(T arg0, T arg1) {
8 if (arg0.equals(arg1)) {
9 return 0;
10 }
}
11 return ((Comparable<T>) arg0).compareTo(arg1) * -1;
12 }
13
14 }
}
TreeSetTest.java
1package test;
2
3import java.util.Iterator;
4import java.util.TreeSet;
5
6public class TreeSetTest {
7
8 /** *//**
9 * @param args
10 */
11 public static void main(String[] args) {
12
13 MyComparator<String> myComparator = new MyComparator<String>();
14
15 // /////////////////////不添加自定义排序
16 TreeSet<String> treeSet1 = new TreeSet<String>();
17 treeSet1.add("c");
18 treeSet1.add("a");
19 treeSet1.add("b");
20
21 Iterator<String> iterator1 = treeSet1.iterator();
22 while (iterator1.hasNext()) {
23 System.out.println(iterator1.next());
24 }
25
26 // /////////////////////添加自定义排序
27 TreeSet<String> treeSet2 = new TreeSet<String>(myComparator);
28 treeSet2.add("c");
29 treeSet2.add("a");
30 treeSet2.add("b");
31
32 Iterator<String> iterator2 = treeSet2.iterator();
33 while (iterator2.hasNext()) {
34 System.out.println(iterator2.next());
35 }
36 }
37
38}
39
运行结果:
--------------------
WE准高手
posted @
2008-02-27 13:34 大卫 阅读(8427) |
评论 (3) |
编辑 收藏
假设要添加库文件
richfaces-ui-3.1.3.GA.jar
1、为库
richfaces-ui-3.1.3.GA.jar文件建立pom文件
richfaces-ui-3.1.3.GA.pom
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/maven-v4_0_0.xsd">
<modelVersion>
4.0.0</modelVersion>
<groupId>
org.richfaces</groupId>
<artifactId>
richfaces-ui</artifactId>
<version>
3.1.3.GA</version>
<name>RichFaces JSF components library</name>
<packaging>jar</packaging>
</project>
2、用ant为jar和pom文件分别生成校验文件.sha1
<project default="main">
<target name="main" description="Generate checksum file for jar and pom">
<checksum algorithm="SHA" fileext=".sha1">
<fileset dir="
F:/software/java/richfaces-ui-3.1.3.GA/lib" id="id">
<include name="**/*.pom" />
<include name="**/*.jar" />
<include name="**/*.xml" />
<exclude name="**/*.sh1" />
</fileset>
</checksum>
</target>
</project>
3、在.m2目录中创建该库文件的代码库目录
.m2\repository\org\richfaces\richfaces-ui\3.1.3.GA
其中,
org\richfaces为包路径,
richfaces-ui为包名,
3.1.3.GA为版本,这三项是与pom文件中的
groupId,artifactId,version分别对应的。
将
richfaces-ui-3.1.3.GA.jar,richfaces-ui-3.1.3.GA.jar.sha1,richfaces-ui-3.1.3.GA.pom,richfaces-ui-3.1.3.GA.pom.sha1拷贝到该目录下。
4、在工程的pom文件中添加依赖
<dependency>
<groupId>
org.richfaces</groupId>
<artifactId>
richfaces-ui</artifactId>
<version>
3.1.3.GA</version>
</dependency>
--------------------
WE准高手
posted @
2008-02-12 15:07 大卫 阅读(1451) |
评论 (0) |
编辑 收藏
1、mvn archetype:create -DgroupId=org.david.app -DartifactId=mywebapp -DarchetypeArtifactId=maven-archetype-webapp
2、cd mywebapp
mvn eclipse:eclipse
导入eclipse工程
(或者直接从eclipse中导入maven工程)
3、添加servlet依赖
<dependency>
<groupId>javax.servlet</groupId>
<artifactId>servlet-api</artifactId>
<version>2.5</version>
</dependency>
4、添加源代码目录src/main/java
将源代码放在该目录下。
5、添加jetty插件
<build>
<finalName>mywebapp</finalName>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<configuration>
<source>1.5</source>
<target>1.5</target>
</configuration>
</plugin>
<plugin>
<groupId>org.mortbay.jetty</groupId>
<artifactId>maven-jetty-plugin</artifactId>
</plugin>
</plugins>
</build>
6、用jetty调试(http://www.blogjava.net/alwayscy/archive/2007/06/01/118584.html)
命令行:mvn jetty:run
或者
1、先来配置一个外部工具,来运行JETTY:
选择菜单Run->External Tools->External Tools ...在左边选择Program,再点New:
配置
Location为mvn完整命令行。定位到bin下的mvn.bat
选择
Working Directory为本项目。
Arguments填写:jetty:run
再点选Enviroment页:加入MAVEN_OPTS变量,值为:
-Xdebug -Xnoagent -Djava.compiler=NONE -Xrunjdwp:transport=dt_socket,address=
8080,server=y,suspend=
y
其中,如果suspend=n 表示不调试,直接运行。address=8080为端口
然后,点APPLY,再关闭本对话框。
另外注意一点,好像external tool菜单项在java browering的perspective下才会出现。如果在java下看不见,可以切换下试试。
启动jetty
2、调试应用
点选run->debug...
选中左树中的Remote Java Application,再点New。
选择你的项目,关键是要填和之前设置外部工具时相同的端口号。
--------------------
WE准高手
posted @
2008-02-12 15:05 大卫 阅读(6506) |
评论 (1) |
编辑 收藏
tomcatPlugin(启动tomcat):http://www.sysdeo.com/eclipse/tomcatPlugin.html,2.x版本的eclipse要用3的版本,2.1版本不好用。
Lomboz(开发jsp程序,jsp动态提示,调试):http://forge.objectweb.org/project/showfiles.php?group_id=97
CSS Editor for Eclipse
http://csseditor.sourceforge.net/
FacesIDE
FacesIDE是一个用于开发JSF的Eclispe插件.它可以可视化编辑faces-config.xml文件并且提供代码编辑与校验,预览JSF的JSP文件.FacesIDE包含MyFaces来作为JSF的实现
http://amateras.sourceforge.jp/cgi-b ... iki.cgi?page=FacesIDE
Eclipse SQLExplorer plugin
一个数据库管理插件
http://sourceforge.net/projects/eclipsesql
Poperties Editor
一个在编辑完成后可以将资源文件中的中文编码格式转换为unicode编码的插件,在开发国际化应用程序的时候非常有用
http://propedit.sourceforge.jp/eclipse/updates/
eclipseME
http://eclipseme.org/updates/
Eclipse加速插件KeepResident
http://suif.stanford.edu/pub/keepresident/
MyEclipse J2EE开发插件,支持SERVLET/JSP/EJB/数据库操纵等
www.myeclipseide.com
Properties Editor 编辑java的属性文件,并可以自动存盘为Unicode格式
http://propedit.sourceforge.jp/index_en.html
http://propedit.sourceforge.jp/eclipse/updates/
Colorer Take 为上百种类型的文件按语法着色
http://colorer.sourceforge.net/
XMLBuddy 编辑xml文件
www.xmlbuddy.com
Code Folding 加入多种代码折叠功能(比eclipse自带的更多)
http://www.coffee-bytes.com/servlet/PlatformSupport
Easy Explorer 从eclipse中访问选定文件、目录所在的文件夹
http://easystruts.sourceforge.net/
Fat Jar 打包插件,可以方便的完成各种打包任务,可以包含外部的包等
http://fjep.sourceforge.net/
RegEx Test 测试正则表达式
http://brosinski.com/stephan/archives/000028.php
JasperAssistant 报表插件(强,要钱的)
http://www.jasperassistant.com/
Jigloo GUI Builder JAVA的GUI编辑插件
http://cloudgarden.com/jigloo/
Profiler 性能跟踪、测量工具,能跟踪、测量BS程序
http://sourceforge.net/projects/eclipsecolorer/
AdvanQas 提供对if/else等条件语句的提示和快捷帮助(自动更改结构等)
http://eclipsecolorer.sourceforge.net/advanqas/index.html
Log4E Log4j插件,提供各种和Log4j相关的任务,如为方法、类添加一个logger等
http://log4e.jayefem.de/index.php/Main_Page
VSSPlugin VSS插件
http://sourceforge.net/projects/vssplugin
Implementors 提供跳转到一个方法的实现类,而不是接口中的功能(实用!)
http://eclipse-tools.sourceforge.net/implementors/
Call Hierarchy 显示一个方法的调用层次(被哪些方法调,调了哪些方法)
http://eclipse-tools.sourceforge.net/call-hierarchy/index.html
EclipseTidy 检查和格式化HTML/XML文件
http://eclipsetidy.sourceforge.net/
Checkclipse 检查代码的风格、写法是否符合规范
http://www.mvmsoft.de/content/plugins/checkclipse/checkclipse.htm
Hibernate Synchronizer Hibernate插件,自动映射等
http://www.binamics.com/hibernatesync/
spring updatesite 插件
http://springide.org/updatesite/
VeloEclipse Velocity插件
http://propsorter.sourceforge.net/
EditorList 方便的列出所有打开的Editor
http://editorlist.sourceforge.net/
MemoryManager 内存占用率的监视
http://cloudgarden.com/memorymanager/
Eclipse的游戏插件
http://eclipse-games.sourceforge.net/
JBoss-IDE
http://jboss.sourceforge.net/jbosside/updates/
自动反编译class,安装后要设定class文件缺省关联到jode
http://www.technoetic.com/eclipse/update
jigloo swing/sw设计工具,里面自带的form/anchor布局很好用!
http://cloudgarden.soft-gems.net/update-site/
jinto的资源文件编辑工具,同时编辑多种语言,而且自动转换成iso8859-1编码。很好用!
http://www.guh-software.de/eclipse/
lomboz:
http://forge.objectweb.org/project/showfiles.php?group_id=97
emf:模型框架
http://download.eclipse.org/tools/emf/scripts/downloads-viewer.php?s=2.1.0/R200507070200
--------------------
WE准高手
posted @
2008-02-04 18:38 大卫 阅读(4351) |
评论 (3) |
编辑 收藏
| 发布时间:2007.11.28 04:52 来源:赛迪网 作者:baocl |
|
(1) 类名首字母应该大写。字段、方法以及对象(句柄)的首字母应小写。对于所有标识符,其中包含的所有单词都应紧靠在一起,而且大写中间单词的首字母。例如:
ThisIsAClassName
thisIsMethodOrFieldName
若在定义中出现了常数初始化字符,则大写static final基本类型标识符中的所有字母。这样便可标志出它们属于编译期的常数。
Java包(Package)属于一种特殊情况:它们全都是小写字母,即便中间的单词亦是如此。对于域名扩展名称,如com,org,net或者edu等,全部都应小写(这也是Java 1.1和Java 1.2的区别之一)。
(2) 为了常规用途而创建一个类时,请采取“经典形式”,并包含对下述元素的定义:
equals()
hashCode()
toString()
clone()(implement Cloneable)
implement Serializable
(3) 对于自己创建的每一个类,都考虑置入一个main(),其中包含了用于测试那个类的代码。为使用一个项目中的类,我们没必要删除测试代码。若进行了任何形式的改动,可方便地返回测试。这些代码也可作为如何使用类的一个示例使用。
(4) 应将方法设计成简要的、功能性单元,用它描述和实现一个不连续的类接口部分。理想情况下,方法应简明扼要。若长度很大,可考虑通过某种方式将其分割成较短的几个方法。这样做也便于类内代码的重复使用(有些时候,方法必须非常大,但它们仍应只做同样的一件事情)。
(5) 设计一个类时,请设身处地为客户程序员考虑一下(类的使用方法应该是非常明确的)。然后,再设身处地为管理代码的人考虑一下(预计有可能进行哪些形式的修改,想想用什么方法可把它们变得更简单)。
(6) 使类尽可能短小精悍,而且只解决一个特定的问题。下面是对类设计的一些建议:
■一个复杂的开关语句:考虑采用“多形”机制
■数量众多的方法涉及到类型差别极大的操作:考虑用几个类来分别实现
■许多成员变量在特征上有很大的差别:考虑使用几个类
(7) 让一切东西都尽可能地“私有”——private。可使库的某一部分“公共化”(一个方法、类或者一个字段等等),就永远不能把它拿出。若强行拿出,就可能破坏其他人现有的代码,使他们不得不重新编写和设计。若只公布自己必须公布的,就可放心大胆地改变其他任何东西。在多线程环境中,隐私是特别重要的一个因素——只有private字段才能在非同步使用的情况下受到保护。
(8) 谨惕“巨大对象综合症”。对一些习惯于顺序编程思维、且初涉OOP领域的新手,往往喜欢先写一个顺序执行的程序,再把它嵌入一个或两个巨大的对象里。根据编程原理,对象表达的应该是应用程序的概念,而非应用程序本身。
(9) 若不得已进行一些不太雅观的编程,至少应该把那些代码置于一个类的内部。
(10) 任何时候只要发现类与类之间结合得非常紧密,就需要考虑是否采用内部类,从而改善编码及维护工作(参见第14章14.1.2小节的“用内部类改进代码”)。
(11) 尽可能细致地加上注释,并用javadoc注释文档语法生成自己的程序文档。
(12) 避免使用“魔术数字”,这些数字很难与代码很好地配合。如以后需要修改它,无疑会成为一场噩梦,因为根本不知道“100”到底是指“数组大小”还是“其他全然不同的东西”。所以,我们应创建一个常数,并为其使用具有说服力的描述性名称,并在整个程序中都采用常数标识符。这样可使程序更易理解以及更易维护。
(13) 涉及构建器和异常的时候,通常希望重新丢弃在构建器中捕获的任何异常——如果它造成了那个对象的创建失败。这样一来,调用者就不会以为那个对象已正确地创建,从而盲目地继续。
(14) 当客户程序员用完对象以后,若你的类要求进行任何清除工作,可考虑将清除代码置于一个良好定义的方法里,采用类似于cleanup()这样的名字,明确表明自己的用途。除此以外,可在类内放置一个boolean(布尔)标记,指出对象是否已被清除。在类的finalize()方法里,请确定对象已被清除,并已丢弃了从RuntimeException继承的一个类(如果还没有的话),从而指出一个编程错误。在采取象这样的方案之前,请确定finalize()能够在自己的系统中工作(可能需要调用System.runFinalizersOnExit(true),从而确保这一行为)。
(15) 在一个特定的作用域内,若一个对象必须清除(非由垃圾收集机制处理),请采用下述方法:初始化对象;若成功,则立即进入一个含有finally从句的try块,开始清除工作。
(16) 若在初始化过程中需要覆盖(取消)finalize(),请记住调用super.finalize()(若Object属于我们的直接超类,则无此必要)。在对finalize()进行覆盖的过程中,对super.finalize()的调用应属于最后一个行动,而不应是第一个行动,这样可确保在需要基础类组件的时候它们依然有效。
(17) 创建大小固定的对象集合时,请将它们传输至一个数组(若准备从一个方法里返回这个集合,更应如此操作)。这样一来,我们就可享受到数组在编译期进行类型检查的好处。此外,为使用它们,数组的接收者也许并不需要将对象“造型”到数组里。
(18) 尽量使用interfaces,不要使用abstract类。若已知某样东西准备成为一个基础类,那么第一个选择应是将其变成一个interface(接口)。只有在不得不使用方法定义或者成员变量的时候,才需要将其变成一个abstract(抽象)类。接口主要描述了客户希望做什么事情,而一个类则致力于(或允许)具体的实施细节。
(19) 在构建器内部,只进行那些将对象设为正确状态所需的工作。尽可能地避免调用其他方法,因为那些方法可能被其他人覆盖或取消,从而在构建过程中产生不可预知的结果(参见第7章的详细说明)。
(20) 对象不应只是简单地容纳一些数据;它们的行为也应得到良好的定义。
(21) 在现成类的基础上创建新类时,请首先选择“新建”或“创作”。只有自己的设计要求必须继承时,才应考虑这方面的问题。若在本来允许新建的场合使用了继承,则整个设计会变得没有必要地复杂。
(22) 用继承及方法覆盖来表示行为间的差异,而用字段表示状态间的区别。一个非常极端的例子是通过对不同类的继承来表示颜色,这是绝对应该避免的:应直接使用一个“颜色”字段。
(23) 为避免编程时遇到麻烦,请保证在自己类路径指到的任何地方,每个名字都仅对应一个类。否则,编译器可能先找到同名的另一个类,并报告出错消息。若怀疑自己碰到了类路径问题,请试试在类路径的每一个起点,搜索一下同名的.class文件。
(24) 在Java 1.1 AWT中使用事件“适配器”时,特别容易碰到一个陷阱。若覆盖了某个适配器方法,同时拼写方法没有特别讲究,最后的结果就是新添加一个方法,而不是覆盖现成方法。然而,由于这样做是完全合法的,所以不会从编译器或运行期系统获得任何出错提示——只不过代码的工作就变得不正常了。
(25) 用合理的设计方案消除“伪功能”。也就是说,假若只需要创建类的一个对象,就不要提前限制自己使用应用程序,并加上一条“只生成其中一个”注释。请考虑将其封装成一个“独生子”的形式。若在主程序里有大量散乱的代码,用于创建自己的对象,请考虑采纳一种创造性的方案,将些代码封装起来。
(26) 警惕“分析瘫痪”。请记住,无论如何都要提前了解整个项目的状况,再去考察其中的细节。由于把握了全局,可快速认识自己未知的一些因素,防止在考察细节的时候陷入“死逻辑”中。
(27) 警惕“过早优化”。首先让它运行起来,再考虑变得更快——但只有在自己必须这样做、而且经证实在某部分代码中的确存在一个性能瓶颈的时候,才应进行优化。除非用专门的工具分析瓶颈,否则很有可能是在浪费自己的时间。性能提升的隐含代价是自己的代码变得难于理解,而且难于维护。
(28) 请记住,阅读代码的时间比写代码的时间多得多。思路清晰的设计可获得易于理解的程序,但注释、细致的解释以及一些示例往往具有不可估量的价值。无论对你自己,还是对后来的人,它们都是相当重要的。如对此仍有怀疑,那么请试想自己试图从联机Java文档里找出有用信息时碰到的挫折,这样或许能将你说服。
(29) 如认为自己已进行了良好的分析、设计或者实施,那么请稍微更换一下思维角度。试试邀请一些外来人士——并不一定是专家,但可以是来自本公司其他部门的人。请他们用完全新鲜的眼光考察你的工作,看看是否能找出你一度熟视无睹的问题。采取这种方式,往往能在最适合修改的阶段找出一些关键性的问题,避免产品发行后再解决问题而造成的金钱及精力方面的损失。
(30) 良好的设计能带来最大的回报。简言之,对于一个特定的问题,通常会花较长的时间才能找到一种最恰当的解决方案。但一旦找到了正确的方法,以后的工作就轻松多了,再也不用经历数小时、数天或者数月的痛苦挣扎。我们的努力工作会带来最大的回报(甚至无可估量)。而且由于自己倾注了大量心血,最终获得一个出色的设计方案,成功的快感也是令人心动的。坚持抵制草草完工的诱惑——那样做往往得不偿失。
(责任编辑:包春林)
|
文章来自:http://nolan022.javaeye.com/blog/161326
posted @
2008-02-04 15:38 大卫 阅读(3039) |
评论 (2) |
编辑 收藏
下面是用PipedInputStream,PipedOutputStream实现的输入流与输出流的链接:
PipedInputStream pis = new PipedInputStream();
PipedOutputStream pos = new PipedOutputStream();
pos.connect(pis);
用commons-io的IOUtils.copy方法也可以实现输入流、输出流的链接,但是原理是不一样的。
--------------------
WE准高手
posted @
2008-02-03 14:56 大卫 阅读(2803) |
评论 (3) |
编辑 收藏
maven上传jar的pom.xml:
<?xml version="1.0" encoding="UTF-8"?>
<project>
<modelVersion>4.0.0</modelVersion>
<groupId>com.asiainfo.mime4j</groupId><!- 存储位置 -->
<artifactId>aimime4j</artifactId><!- 工程名 -->
<name>aimime4j</name>
<version>1.0-SNAPSHOT</version>
<url>http://localhost</url><!- 服务器 -->
<!- 部署位置 -->
<distributionManagement>
<repository>
<id>aicu-repository</id>
<name>AICU Repository</name>
<url>ftp://localhost/repository/</url>
</repository>
</distributionManagement>
<dependencies>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>3.8.1</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>commons-logging</groupId>
<artifactId>commons-logging</artifactId>
<version>1.1</version>
</dependency>
<dependency>
<groupId>commons-io</groupId>
<artifactId>commons-io</artifactId>
<version>1.3.1</version>
</dependency>
</dependencies>
<!- 需要的插件 -->
<build>
<defaultGoal>install</defaultGoal>
<plugins>
<plugin>
<artifactId>maven-compiler-plugin</artifactId>
<version>2.0.2</version>
<configuration>
<source>1.5</source>
<target>1.5</target>
</configuration>
</plugin>
</plugins>
<extensions>
<extension>
<groupId>org.apache.maven.wagon</groupId>
<artifactId>wagon-ftp</artifactId>
<version>1.0-alpha-6</version>
</extension>
</extensions>
</build>
</project>
--------------------
WE准高手
posted @
2008-01-29 17:23 大卫 阅读(2660) |
评论 (0) |
编辑 收藏
如何显示如下日期格式:Fri, 11 Jan 2008 15:29:31 +0800 ?
代码如下:
1import java.io.IOException;
2import java.text.ParseException;
3import java.text.SimpleDateFormat;
4import java.util.Date;
5import java.util.Locale;
6
7/** *//**
8 *
9 * @author david
10 *
11 */
12public class Test {
13
14 public static void main(String[] args) throws NumberFormatException,
15 IOException, ParseException {
16
17 SimpleDateFormat sdfIn = new SimpleDateFormat("yyyy-MM-dd E HH:mm:ss",
18 Locale.US);/**//* 输入格式 */
19 Date date = sdfIn.parse("2008-01-11 Fri 15:29:31");/**//* 输入日期 */
20
21 SimpleDateFormat sdfOut = new SimpleDateFormat(
22 "E, dd MMM yyyy HH:mm:ss Z", Locale.US);/**//* 输出格式 */
23 System.out.println(sdfOut.format(date));/**//* 输出日期 */
24 }
25
26}
其中,MM为月份,mm为分钟,HH为24进制的小时,hh为12进制的小时。
另外,在创建SimpleDateFormat的时候,第二个参数Locale.US为指定系统编码,如果不指定的话,输出的星期会根据本地操作系统的编码而定,中文系统会是“星期五”,而不是Fri 。
--------------------
WE准高手
posted @
2008-01-25 11:27 大卫 阅读(1291) |
评论 (0) |
编辑 收藏
摘要: Java程序性能测试
1 概述
在开发中,性能测试是设计初期容易忽略的问题,开发人员会为了解决一个问题而“不择手段”,作者所参与的项目中也遇到了类似问题,字符串拼接、大量的网络调用和数据库访问等等都对系统的性能产生了影响,可是大家不会关心这些问题,“CPU速度在变快”,“内存在变大”,并且,“好像也没有那么慢吧...
阅读全文
posted @
2008-01-24 13:13 大卫 阅读(1958) |
评论 (4) |
编辑 收藏数据库设计5步骤
1.确定entities及relationships
a)设计宏观行为。你用此数据库来做什么?比如,希望管理雇员的信息。
b)确定entities。对于一系列的行为,确定所管理信息所涉及到的主题范围。这将变成table。比如,雇用员工,指定具体部门,确定技能等级。
c)确定relationships。看着行为,确定tables之间有何种关系。比如,在部门与雇员之间存在一种关系。给这种关系命名。
d)细化行为。你从宏观行为开始,现在仔细检查这些行为,看有哪些行为能转为微观行为。比如,管理雇员的信息可细化为:
● 增加新员工
● 修改存在员工信息
● 删除调走的员工
e)确定业务规则。看着你的业务规则,确定你要采取哪种。比如,可能有这样一种规则,一个部门有且只能有一个部门领导。这些规则将被设计到数据库的结构中。
范例:
ACME是一个小公司,在5个地方都设有办事处。当前,有75名员工。公司准备快速扩大规模,划分了9个部门,每个部门都有其领导。
为有助于寻求新的员工,人事部门规划了68种技能,为将来人事管理作好准备。员工被招进时,每一种技能的专业等级都被确定。
定义宏观行为
一些ACME公司的宏观行为包括:
● 招聘员工
● 解雇员工
● 管理员工个人信息
● 管理公司所需的技能信息
● 管理哪位员工有哪些技能
● 管理部门信息
● 管理办事处信息
确定entities及relationships
我们可以确定要存放信息的主题领域(表)及其关系,并创建一个基于宏观行为及描述的图表。
我们用方框来代表table,用菱形代表relationship。我们可以确定哪些relationship是一对多,一对一,及多对多。
这是一个E-R草图,以后会细化。
 细化宏观行为
细化宏观行为
以下微观行为基于上面宏观行为而形成:
● 增加或删除一个员工
● 增加或删除一个办事处
● 列出一个部门中的所有员工
● 增加一项技能
● 增加一个员工的一项技能
● 确定一个员工的技能
● 确定一个员工每项技能的等级
● 确定所有拥有相同等级的某项技能的员工
● 修改员工的技能等级
这些微观行为可用来确定需要哪些table或relationship。
确定业务规则
业务规则常用于确定一对多,一对一,及多对多关系。
相关的业务规则可能有:
● 现在有5个办事处;最多允许扩展到10个。
● 员工可以改变部门或办事处
● 每个部门有一个部门领导
● 每个办事处至多有3个电话号码
● 每个电话号码有一个或多个扩展
● 员工被招进时,每一种技能的专业等级都被确定。
● 每位员工拥有3到20个技能
● 某位员工可能被安排在一个办事处,也可能不安排办事处。
2.确定所需数据
要确定所需数据:
1. 确定支持数据
2. 列出所要跟踪的所有数据。描述table(主题)的数据回答这些问题:谁,什么,哪里,何时,以及为什么
3. 为每个table建立数据
4. 列出每个table目前看起来合适的可用数据
5. 为每个relationship设置数据
6. 如果有,为每个relationship列出适用的数据
确定支持数据
你所确定的支持数据将会成为table中的字段名。比如,下列数据将适用于表Employee,表Skill,表Expert In。

如果将这些数据画成图表,就像:

需要注意:
● 在确定支持数据时,请一定要参考你之前所确定的宏观行为,以清楚如何利用这些数据。
● 比如,如果你知道你需要所有员工的按姓氏排序的列表,确保你将支持数据分解为名字与姓氏,这比简单地提供一个名字会更好。
● 你所选择的名称最好保持一致性。这将更易于维护数据库,也更易于阅读所输出的报表。
● 比如,如果你在某些地方用了一个缩写名称Emp_status,你就不应该在另外一个地方使用全名(Empolyee_ID)。相反,这些名称应当是Emp_status及Emp_id。
● 数据是否与正确的table相对应无关紧要,你可以根据自己的喜好来定。在下节中,你会通过测试对此作出判断。
3.标准化数据
标准化是你用以消除数据冗余及确保数据与正确的table或relationship相关联的一系列测试。共有5个测试。本节中,我们将讨论经常使用的3个。
关于标准化测试的更多信息,请参考有关数据库设计的书籍。
标准化格式
标准化格式是标准化数据的常用测试方式。你的数据通过第一遍测试后,就被认为是达到第一标准化格式;通过第二遍测试,达到第二标准化格式;通过第三遍测试,达到第三标准化格式。
如何标准格式:
1. 列出数据
2. 为每个表确定至少一个键。每个表必须有一个主键。
3. 确定relationships的键。relationships的键是连接两个表的键。
4. 检查支持数据列表中的计算数据。计算数据通常不保存在数据库中。
5. 将数据放在第一遍的标准化格式中:
6. 从tables及relationships除去重复的数据。
7. 以你所除去数据创建一个或更多的tables及relationships。
8. 将数据放在第二遍的标准化格式中:
9. 用多于一个以上的键确定tables及relationships。
10. 除去只依赖于键一部分的数据。
11. 以你所除去数据创建一个或更多的tables及relationships。
12. 将数据放在第三遍的标准化格式中:
13. 除去那些依赖于tables或relationships中其他数据,并且不是键的数据。
14. 以你所除去数据创建一个或更多的tables及relationships。
数据与键
在你开始标准化(测试数据)前,简单地列出数据,并为每张表确定一个唯一的主键。这个键可以由一个字段或几个字段(连锁键)组成。
主键是一张表中唯一区分各行的一组字段。Employee表的主键是Employee ID字段。Works In relationship中的主键包括Office Code及Employee ID字段。给数据库中每一relationship给出一个键,从其所连接的每一个table中抽取其键产生。
 将数据放在第一遍的标准化格式中
将数据放在第一遍的标准化格式中
● 除去重复的组
● 要测试第一遍标准化格式,除去重复的组,并将它们放进他们各自的一张表中。
● 在下面的例子中,Phone Number可以重复。(一个工作人员可以有多于一个的电话号码。)将重复的组除去,创建一个名为Telephone的新表。在Telephone与Office创建一个名为Associated With的relationship。
将数据放在第二遍的标准化格式中
● 除去那些不依赖于整个键的数据。
● 只看那些有一个以上键的tables及relationships。要测试第二遍标准化格式,除去那些不依赖于整个键的任何数据(组成键的所有字段)。
● 在此例中,原Employee表有一个由两个字段组成的键。一些数据不依赖于整个键;例如,department name只依赖于其中一个键(Department ID)。因此,Department ID,其他Employee数据并不依赖于它,应移至一个名为Department的新表中,并为Employee及Department建立一个名为Assigned To的relationship。
 将数据放在第三遍的标准化格式中
将数据放在第三遍的标准化格式中
● 除去那些不直接依赖于键的数据。
● 要测试第三遍标准化格式,除去那些不是直接依赖于键,而是依赖于其他数据的数据。
● 在此例中,原Employee表有依赖于其键(Employee ID)的数据。然而,office location及office phone依赖于其他字段,即Office Code。它们不直接依赖于Employee ID键。将这组数据,包括Office Code,移至一个名为Office的新表中,并为Employee及Office建立一个名为Works In的relationship。
 4.考量关系
4.考量关系
当你完成标准化进程后,你的设计已经差不多完成了。你所需要做的,就是考量关系。
考量带有数据的关系
你的一些relationship可能集含有数据。这经常发生在多对多的关系中。

遇到这种情况,将relationship转化为一个table。relationship的键依旧成为table中的键。
考量没有数据的关系
要实现没有数据的关系,你需要定义外部键。外部键是含有另外一个表中主键的一个或多个字段。外部键使你能同时连接多表数据。
有一些基本原则能帮助你决定将这些键放在哪里:
一对多 在一对多关系中,“一”中的主键放在“多”中。此例中,外部键放在Employee表中。
 一对一
一对一 在一对一关系中,外部键可以放进任一表中。如果必须要放在某一边,而不能放在另一边,应该放在必须的一边。此例中,外部键(Head ID)在Department表中,因为这是必需的。
 多对多
多对多 在多对多关系中,用两个外部键来创建一个新表。已存的旧表通过这个新表来发生联系。
 5.检验设计
5.检验设计
在你完成设计之前,你需要确保它满足你的需要。检查你在一开始时所定义的行为,确认你可以获取行为所需要的所有数据:
● 你能找到一个路径来等到你所需要的所有信息吗?
● 设计是否满足了你的需要?
● 所有需要的数据都可用吗?
如果你对以上的问题都回答是,你已经差不多完成设计了。
最终设计
最终设计看起来就像这样:
 设计数据库的表属性
设计数据库的表属性
数据库设计需要确定有什么表,每张表有什么字段。此节讨论如何指定各字段的属性。
对于每一字段,你必须决定字段名,数据类型及大小,是否允许NULL值,以及你是否希望数据库限制字段中所允许的值。
选择字段名
字段名可以是字母、数字或符号的任意组合。然而,如果字段名包括了字母、数字或下划线、或并不以字母打头,或者它是个关键字(详见关键字表),那么当使用字段名称时,必须用双引号括起来。
为字段选择数据类型
SQL Anywhere支持的数据类型包括:
整数(int, integer, smallint)
小数(decimal, numeric)
浮点数(float, double)
字符型(char, varchar, long varchar)
二进制数据类型(binary, long binary)
日期/时间类型(date, time, timestamp)
用户自定义类型
关于数据类型的内容,请参见“SQL Anywhere数据类型”一节。字段的数据类型影响字段的最大尺寸。例如,如果你指定SMALLINT,此字段可以容纳32,767的整数。INTEGER可以容纳2,147,483,647的整数。对CHAR来讲,字段的最大值必须指定。
长二进制的数据类型可用来在数据库中保存例如图像(如位图)或者文字编辑文档。这些类型的信息通常被称为二进制大型对象,或者BLOBS。
关于每一数据类型的完整描述,见“SQL Anywhere数据类型”。
NULL与NOT NULL
如果一个字段值是必填的,你就将此字段定义为NOT NULL。否则,字段值可以为NULL值,即可以有空值。SQL中的默认值是允许空值;你应该显示地将字段定义为NOT NULL,除非你有好理由将其设为允许空值。
关于NULL值的完整描述,请见“NULL value”。有关其对比用法,见“Search conditions”。
选择约束
尽管字段的数据类型限制了能存在字段中的数据(例如,只能存数字或日期),你或许希望更进一步来约束其允许值。
你可以通过指定一个“CHECK”约束来限制任意字段的值。你可以使用能在WHERE子句中出现的任何有效条件来约束被允许的值,尽管大多数CHECK约束使用BETWEEN或IN条件。
更多信息
有关有效条件的更多信息,见“Search conditions”。有关如何为表及字段指定约束,见“Ensuring Data Integrity”。
例子
例子数据库中有一个名为department的表,字段是dept_id, dept_name, dept_head_id。其定义如下:

注意每一字段都被指定为“not null”。这种情况下,表中每一记录的所有字段的数据都必填。
选择主键及外部键
主键是唯一识别表中每一项记录的字段。如何你的表已经正确标准化,主键应当成为数据库设计的一部分。
外部键是包含另一表中主键值的一个或一组字段。外部键关系在数据库中建立了一对一及一对多关系。如果你的设计已经正确标准化,外部键应当成为数据库设计的一部分。
posted @
2008-01-24 10:07 大卫 阅读(88640) |
评论 (48) |
编辑 收藏要开发出用户满意的软件并不是件容易的事,软件架构师必须全面把握各种各样的需求、权衡需求之间有可能的矛盾之处,分门别类地将不同需求一一满足。本文从理解需求种类的复杂性谈起,通过具体案例的分析,展示了如何通过RUP的4+1视图方法,针对不同需求进行架构设计,从而确保重要的需求一一被满足。
呼唤架构设计的多重视图方法
灵感一闪,就想出了把大象放进冰箱的办法,这自然好。但希望每个架构设计策略都依靠灵感是不现实的--我们需要系统方法的指导。
需要架构设计的多重视图方法,从根本上来说是因为需求种类的复杂性所致。以工程领域的例子开道吧。比如设计一座跨江大桥:我们会考虑"连接南北的公路交通"这个"功能需求",从而初步设计出理想化的桥墩支撑的公路桥方案;然后还要考虑造桥要面临的"约束条件",这个约束条件可能是"不能影响万吨轮从桥下通过",于是细化设计方案,规定桥墩的高度和桥墩之间的间距;另外还要顾及"大桥的使用期质量属性",比如为了"能在湍急的江流中保持稳固",可以把大桥桥墩深深地建在岩石层之上,和大地浑然一体;其实,"建造期间的质量属性"也很值得考虑,比如在大桥的设计过程中考虑"施工方便性"的一些措施。
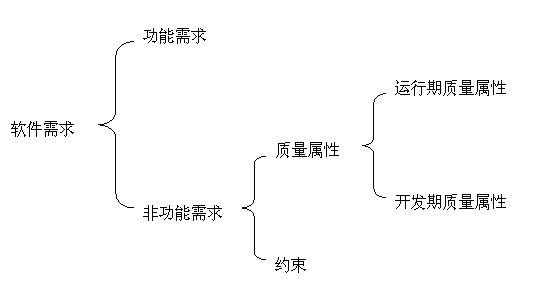
和工程领域的功能需求、约束条件、使用期质量属性、建造期间的质量属性等类似,软件系统的需求种类也相当复杂,具体分类如图1所示。
图1 软件需求分类的复杂性
超市系统案例:理解需求种类的复杂性
例子是最好的老师。为了更好地理解软件需求种类的复杂性,我们来分析一个实际的例子。在表1中,我们列举了一个典型的超市系统的需求子集,从这个例子中可以清晰地看到需求可以分为两大类:功能需求和非功能需求。
表1 超市系统案例:理解需求种类的复杂性

简单而言,功能需求就是"软件有什么用,软件需要做什么"。同时,注意把握功能需求的层次性是软件需求的最佳实践。以该超市系统为例:
* 超市老板希望通过软件来"提高收银效率"。
* 那么,你可能需要为收银员提供一系列功能来促成这个目的,比如供收银员使用的"任意商品项可单独取消"功能有利于提供收银效率(笔者曾在超市有过被迫整单取消然后一车商品重新扫描收费的痛苦经历)。
* 而具体到这个超市系统,系统分析员可能会决定要提供的具体功能为:通过收银终端的按键组合,可以使收银过程从"逐项录入状态"进入"选择取消状态",从而取消某项商品。
从上面的例子中我们还惊讶地发现,非功能需求--人们最经常忽视的一大类需求--包括的内容非常宽、并且极其重要。非功能需求又可以分为如下三类:
* 约束。要开发出用户满意的软件并不是件容易的事,而全面理解要设计的软件系统所面临的约束可以使你向成功迈进一步。约束性需求既包括企业级的商业考虑(例如"项目预算有限"),也包括最终用户级的实际情况(例如"用户的平均电脑操作水平偏低");既可能包括具体技术的明确要求(例如"要求能在Linux上运行"),又可能需要考虑开发团队的真实状况(例如"开发人员分散在不同地点")。这些约束性需求当然对架构设计影响很大,比如受到"项目预算有限"的限制,架构师就不应选择昂贵的技术或中间件等,而考虑到开发人员分散在不同地点",就更应注重软件模块职责划分的合理性、松耦合性等等。
* 运行期质量属性。这类需求主要指软件系统在运行期间表现出的质量水平。运行期质量属性非常关键,因为它们直接影响着客户对软件系统的满意度,大多数客户也不会接受运行期质量属性拙劣的软件系统。常见的运行期质量属性包括软件系统的易用性、性能、可伸缩性、持续可用性、鲁棒性、安全性等。在我们的超市系统的案例中,用户对高性能提出了具体要求(真正的性能需求应该量化,我们的表1没体现),他们不能容忍金额合计超过 2秒的延时。
* 开发期质量属性。这类非功能需求中的某些项人们倒是念念不忘,可惜很多人并没有意识到"开发期质量属性"和" 运行期质量属性"对架构设计的影响到底有何不同。开发期质量属性是开发人员最为关心的,要达到怎样的目标应根据项目的具体情况而定,而过度设计(overengineering)会花费额外的代价。
什么是软件架构视图
那么,什么是软件架构视图呢?Philippe Kruchten在其著作《Rational统一过程引论》中写道:
一个架构视图是对于从某一视角或某一点上看到的系统所做的简化描述,描述中涵盖了系统的某一特定方面,而省略了于此方面无关的实体。
也就是说,架构要涵盖的内容和决策太多了,超过了人脑"一蹴而就"的能力范围,因此采用"分而治之"的办法从不同视角分别设计;同时,也为软件架构的理解、交流和归档提供了方便。
值得特别说明的,大多数书籍中都强调多视图方法是软件架构归档的方法,其实不然。多视图方法不仅仅是架构归档技术,更是指导我们进行架构设计的思维方法。
Philippe Kruchten提出的4+1视图方法
1995年,Philippe Kruchten在《IEEE Software》上发表了题为《The 4+1 View Model of Architecture》的论文,引起了业界的极大关注,并最终被RUP采纳。如图2所示。
图2 Philippe Kruchten提出的4+1视图方法
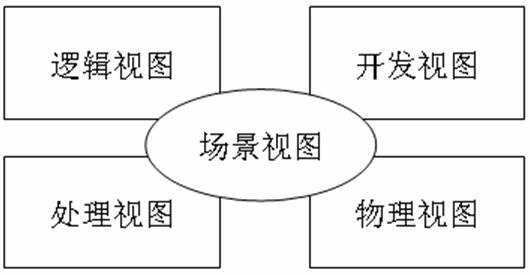
该方法的不同架构视图承载不同的架构设计决策,支持不同的目标和用途:
* 逻辑视图:当采用面向对象的设计方法时,逻辑视图即对象模型。
* 开发视图:描述软件在开发环境下的静态组织。
* 处理视图:描述系统的并发和同步方面的设计。
* 物理视图:描述软件如何映射到硬件,反映系统在分布方面的设计。
运用4+1视图方法:针对不同需求进行架构设计
如前文所述,要开发出用户满意的软件并不是件容易的事,软件架构师必须全面把握各种各样的需求、权衡需求之间有可能的矛盾之处,分门别类地将不同需求一一满足。
Philippe Kruchten提出的4+1视图方法为软件架构师"一一征服需求"提供了良好基础,如图3所示。
图3 运用4+1视图方法针对不同需求进行架构设计
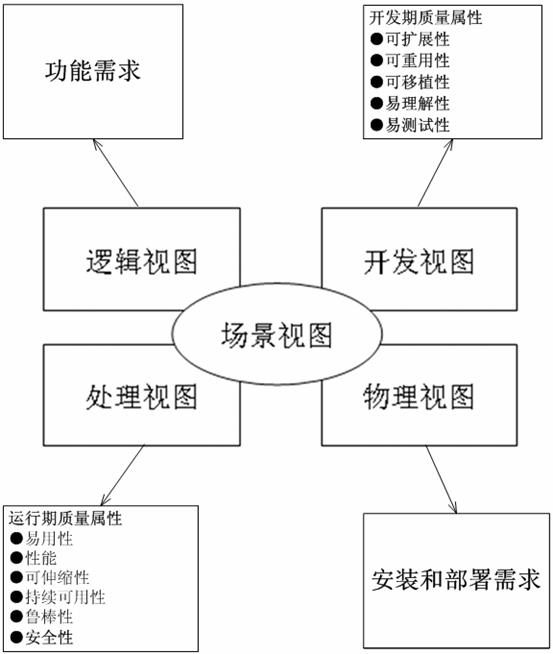
逻辑视图。逻辑视图关注功能,不仅包括用户可见的功能,还包括为实现用户功能而必须提供的"辅助功能模块";它们可能是逻辑层、功能模块等。
开发视图。开发视图关注程序包,不仅包括要编写的源程序,还包括可以直接使用的第三方SDK和现成框架、类库,以及开发的系统将运行于其上的系统软件或中间件。开发视图和逻辑视图之间可能存在一定的映射关系:比如逻辑层一般会映射到多个程序包等。
处理视图。处理视图关注进程、线程、对象等运行时概念,以及相关的并发、同步、通信等问题。处理视图和开发视图的关系:开发视图一般偏重程序包在编译时期的静态依赖关系,而这些程序运行起来之后会表现为对象、线程、进程,处理视图比较关注的正是这些运行时单元的交互问题。
物理视图。物理视图关注"目标程序及其依赖的运行库和系统软件"最终如何安装或部署到物理机器,以及如何部署机器和网络来配合软件系统的可靠性、可伸缩性等要求。物理视图和处理视图的关系:处理视图特别关注目标程序的动态执行情况,而物理视图重视目标程序的静态位置问题;物理视图是综合考虑软件系统和整个IT系统相互影响的架构视图。
设备调试系统案例概述
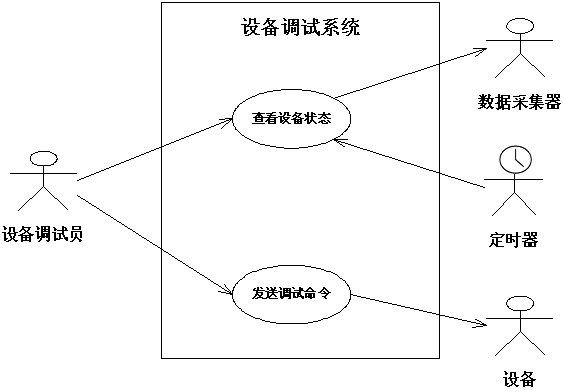
本文的以下部分,将研究一个案例:某型号设备调试系统。
设备调试员通过使用该系统,可以察看设备状态(设备的状态信息由专用的数据采集器实时采集)、发送调试命令。该系统的用例图如图4所示。
图4 设备调试系统的用例图
经过研制方和委托方的紧密配合,最终确定的需求可以总括地用表2来表示。
表2 设备调试系统的需求

下面运用RUP推荐的4+1视图方法,从不同视图进行架构设计,来分门别类地将不同需求一一满足。
逻辑视图:设计满足功能需求的架构
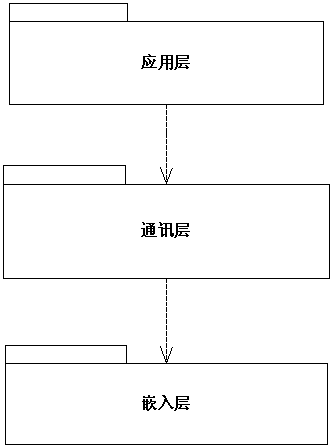
首先根据功能需求进行初步设计,进行大粒度的职责划分。如图5所示。
* 应用层负责设备状态的显示,并提供模拟控制台供用户发送调试命令。
* 应用层使用通讯层和嵌入层进行交互,但应用层不知道通讯的细节。
* 通讯层负责在RS232协议之上实现一套专用的"应用协议"。
* 当应用层发送来包含调试指令的协议包,由通讯层负责按RS232协议将之传递给嵌入层。
* 当嵌入层发送来原始数据,由通讯层将之解释成应用协议包发送给应用层。
* 嵌入层负责对调试设备的具体控制,以及高频度地从数据采集器读取设备状态数据。
* 设备控制指令的物理规格被封装在嵌入层内部,读取数采器的具体细节也被封装在嵌入层内部。
图5 设备调试系统架构的逻辑视图
开发视图:设计满足开发期质量属性的架构
软件架构的开发视图应当为开发人员提供切实的指导。任何影响全局的设计决策都应由架构设计来完成,这些决策如果"漏"到了后边,最终到了大规模并行开发阶段才发现,可能造成"程序员碰头儿临时决定"的情况大量出现,软件质量必然将下降甚至导致项目失败。
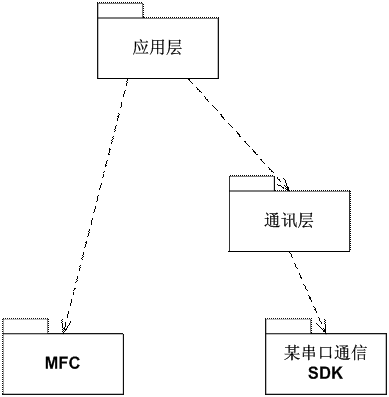
其中,采用哪些现成框架、哪些第三方SDK、乃至哪些中间件平台,都应该考虑是否由软件架构的开发视图确定下来。图6展示了设备调试系统的(一部分)软件架构开发视图:应用层将基于MFC设计实现,而通讯层采用了某串口通讯的第三方SDK。
图6 设备调试系统架构的开发视图
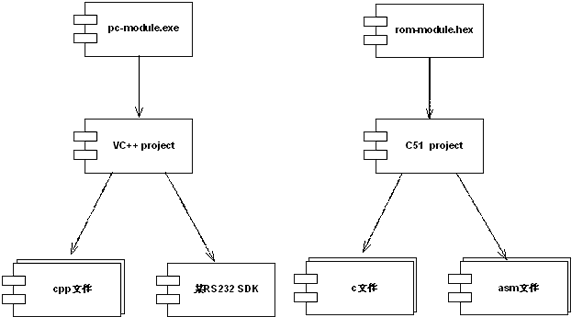
在说说约束性需求。约束应该是每个架构视图都应该关注和遵守的一些设计限制。例如,考虑到"一部分开发人员没有嵌入式开发经验"这条约束情况,架构师有必要明确说明系统的目标程序是如何编译而来的:图7展示了整个系统的桌面部分的目标程序pc-moduel.exe、以及嵌入式模块rom- module.hex是如何编译而来的。这个全局性的描述无疑对没有经验的开发人员提供了实感,利于更全面地理解系统的软件架构。
图7 设备调试系统架构的开发视图
处理视图:设计满足运行期质量属性的架构
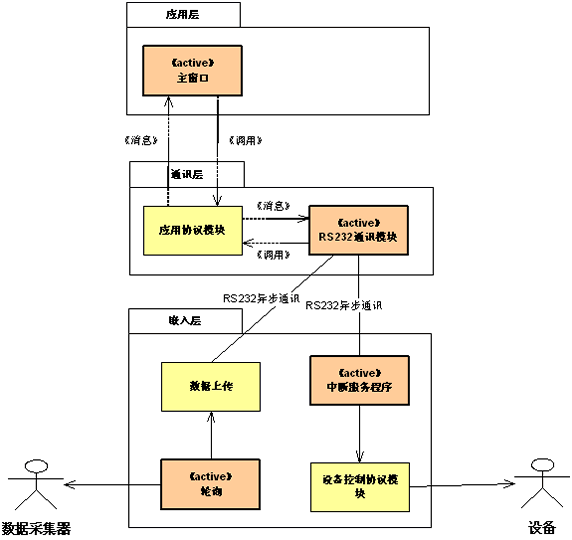
性能是软件系统运行期间所表现出的一种质量水平,一般用系统响应时间和系统吞吐量来衡量。为了达到高性能的要求,软件架构师应当针对软件的运行时情况进行分析与设计,这就是我们所谓的软件架构的处理视图的目标。处理视图关注进程、线程、对象等运行时概念,以及相关的并发、同步、通信等问题。图8展示了设备调试系统架构的处理视图。
可以看出,架构师为了满足高性能需求,采用了多线程的设计:
* 应用层中的线程代表主程序的运行,它直接利用了MFC的主窗口线程。无论是用户交互,还是串口的数据到达,均采取异步事件的方式处理,杜绝了任何"忙等待"无谓的耗时,也缩短了系统响应时间。
* 通讯层有独立的线程控制着"上上下下"的数据,并设置了数据缓冲区,使数据的接收和数据的处理相对独立,从而数据接收不会因暂时的处理忙碌而停滞,增加了系统吞吐量。
* 嵌入层的设计中,分别通过时钟中断和RS232口中断来激发相应的处理逻辑,达到轮询和收发数据的目的。
图8 设备调试系统架构的处理视图
物理视图:和部署相关的架构决策
软件最终要驻留、安装或部署到硬件才能运行,而软件架构的物理视图关注"目标程序及其依赖的运行库和系统软件"最终如何安装或部署到物理机器,以及如何部署机器和网络来配合软件系统的可靠性、可伸缩性等要求。图9所示的物理架构视图表达了设备调试系统软件和硬件的映射关系。可以看出,嵌入部分驻留在调试机中(调试机是专用单板机),而PC机上是常见的桌面可执行程序的形式。
图9 设备调试系统架构的物理视图
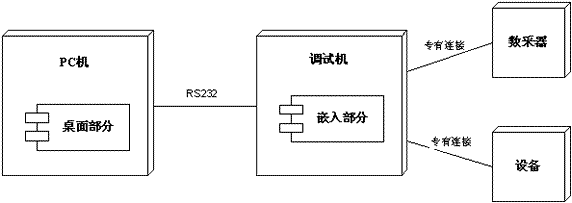
我们还可能根据具体情况的需要,通过物理架构视图更明确地表达具体目标模块及其通讯结构,如图10所示。
图10 设备调试系统架构的物理视图
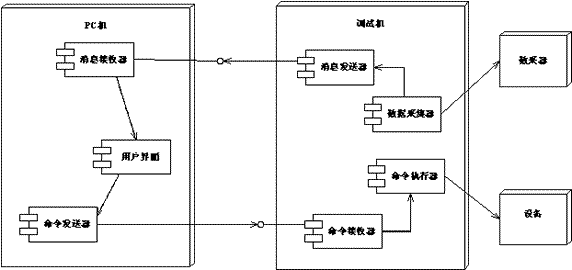
小结与说明
所谓本立道生。深入理解软件需求分类的复杂性,明确区分功能需求、约束、运行期质量属性、开发期质量属性等不同种类的需求就是"本",因为各类需求对架构设计的影响截然不同。本文通过具体案例的分析,展示了如何通过RUP的4+1视图方法,针对不同需求进行架构设计,从而确保重要的需求一一被满足。
本文重点在于方法的解说,因此省略了对架构设计中不少具体问题的说明,同时本文提供的说明架构设计方案的模型也经过了简化。请读者注意。
本文来自:http://www.uml.org.cn/SoftWareProcess/200607315.htm
posted @
2008-01-23 22:25 大卫 阅读(1828) |
评论 (0) |
编辑 收藏
1.到www.eclipse.org上下载SWT.
我这里用的是1.1.0.1,并且页面上就有推荐的Eclipse3.1.1,EMF,GEF。都下载了!
2.按照Eclipse安装插件的方法,安装SWT,EMF,GEF。
3.如果不出意外,就可以正常使用了!
这里有一个建议:最好使用纯的Eclipse,我开始用WTP版的,怎么配置也不行。
可以建立Visual Class,但是不能可视化添加控件,或者看不到控件的属性,或者Text,TextArea控件无法添加。后来按照以上方法,重新来了一次,OK了!
二打包发布SWT程序
1.因为需要SWT的jar.但是Eclipse3.1.1配合的的SWT不是通过SWT.jar发布的!是org.eclipse.swt.win32.win32.x86_3.1.0.jar。里面包括了JINI的DLL和SWT类文件。
需要下载
http://www.eclipse.org/downloads/download.php?file=/eclipse/dow ... 09290840/swt-3.1.1-win32-win32-x86.zip
这里有SWT.jar,和3个DLL,把他们解压缩出来,备用!
2.通过Eclipse的导出功能,生成一个可执行的jar,MANIFEST.MF文件选择由Eclipse生成,
并且保存到项目中。
3.上面2的步骤,只是为了得到MANIFEST.MF文件。下面修改一下这个文件。
加上 Class-Path: SWT.jar
如果还有其他的jar,用空格分开,加到后面
4.
再生成一次jar,MANIFEST.MF选择修改后的。
5.
将打包的jar,SWT.jar,3个DLL放到一个文件夹下,双击可执行的jar,程序运行!
三jar转EXE
1.打开JSmooth0.9.7。
2.选择skeleton,在skeleton properties中先把Launch java app in the exe process,Debug console选中。可以查看生成EXE文件执行过程信息。
3.选择Executable.
选择生成的EXE文件存放位置。
选择EXE文件图标
设置当前路径,选择要转换的jar文件所在文件夹
4.选择Application
设置Main Class,可执行jar中的Main Class注意写类全名
设置Application Argument,如果需要传入参数,写到这里
设置Embedded jar: 可执行的jar
设置Classpath:SWT.jar 如果有其他的继续添加
5.选择JVM Selection。默认吧。
6.JVM Configuration:
可以设置java properties,内存使用
7.点齿轮。生成!看是否有错误。
8.EXE执行需要的文件:EXE,3个DLL,SWT.jar
把他们考到其他目录,一样可以执行!
9.去掉skeleton properties中的Launch java app in the exe process,Debug console选项。
重新生成。应该OK了!
-----
看了这个,终于完成了SWT程序打包,太爽了
posted @
2008-01-23 15:13 大卫 阅读(1606) |
评论 (1) |
编辑 收藏
摘要: 来学习Java也有两个年头了,永远不敢说多么精通,但也想谈谈自己的感受,写给软件学院的同仁们,帮助大家在技术的道路上少一点弯路。说得伟大一点是希望大家为软件学院争气,其实最主要的还是大家自身的进步提升??
1. 关于动态加载机制??
学习Java比C++更容易理解OOP的思想,毕竟C++还混合了不少面向过程的成分。很多人都能背出来Java语言的特点,所谓的动态加载机制等等。当然概...
阅读全文
posted @
2008-01-23 10:41 大卫 阅读(8863) |
评论 (17) |
编辑 收藏
1、用eclipse写好带main函数的程序
要将程序能够访问到的所有目录放在工程的下一级目录下,比如有个sys文件夹,那么就将它放在<工程根目录>/下,不要放在src目录下,便于将一些需要修改的配置文件与最终生成的jar文件分开。
程序中要访问文件,那么根目录就是<工程目录>,也就是说"./"代表<工程目录>。
2、用eclipse导出jar
Export...->JAR file
仅仅选取src,并取消eclipse工程文件。指定JAR文件导出位置,设置JAR file。选中:Export all output folders for checked projects 输出所有选中的文件夹。选中:Export java source files and resources。
Next->Next
选取Main class。
Finish
3、修改jar的MANIFEST.MF文件
在最后添加
Class-Path: lib/OXmlEd1.11-nolib-bin.jar lib/dom4j-1.6.1.jar lib/commons-logging-1.0.4.jar lib/log4j-1.2.8.jar
注意:这里只能一个个添加jar,暂时不知道如何适用通配符之类的。
4、制作run.bat
java -jar ./<jar文件名>
echo 执行完毕!
pause
--------------------
WE准高手
posted @
2008-01-22 15:57 大卫 阅读(2493) |
评论 (5) |
编辑 收藏关于这个问题,下面是一些同仁的观点:
观点一:(单例)
单例模式比静态方法有很多优势:
首先,单例可以继承类,实现接口,而静态类不能(可以集成类,但不能集成实例成员);
其次,单例可以被延迟初始化,静态类一般在第一次加载是初始化;
再次,单例类可以被集成,他的方法可以被覆写;
最后,或许最重要的是,单例类可以被用于多态而无需强迫用户只假定唯一的实例。举个例子,你可能在开始时只写一个配置,但是以后你可能需要支持超过一个配置集,或者可能需要允许用户从外部从外部文件中加载一个配置对象,或者编写自己的。你的代码不需要关注全局的状态,因此你的代码会更加灵活。
观点二:(静态方法)
静态方法中产生的对象,会随着静态方法执行完毕而释放掉,而且执行类中的静态方法时,不会实例化静态方法所在的类。如果是用singleton, 产生的那一个唯一的实例,会一直在内存中,不会被GC清除的(原因是静态的属性变量不会被GC清除),除非整个JVM退出了。这个问题我之前也想几天,并且自己写代码来做了个实验。
观点三:(
Good!)
由于DAO的初始化,会比较占系统资源的,如果用静态方法来取,会不断地初始化和释放,所以我个人认为如果不存在比较复杂的事务管理,用singleton会比较好。个人意见,欢迎各位高手指正。
抛砖引玉,请不吝赐教!
--------------------
WE准高手
posted @
2008-01-22 10:46 大卫 阅读(20162) |
评论 (11) |
编辑 收藏