2007年7月24日
您想做 Google 的中国地图吗?
您是否曾震撼于 Google 地图(maps.google.com)的绚丽表现和强大技术?您是不是想让中国也拥有这样好的地图服务?你是否想开发吸引三亿眼球的手机地图?请加入我们!
我们是 Mapabc.com 的地图技术和搜索技术开发团队,负责为 Google(bendi.google.com)、新浪(bendi.iask.com)和中国移动提供地图服务和技术支持。我们需要有能力、经验和理想抱负的杰出青年加入我们的队伍,我们期待着您。
北京图盟科技有限公司(Mapabc.com),是中国领先的地图和导航服务提供商,专业从事互联网、手机地图及相关的位置服务。Mapabc 的用户遍及各个领域。在互联网行业,Mapabc为搜索引擎(Eg:Google、中国搜索...)、门户网站(Eg:新浪...)和行业网站(Eg:搜房...)等用户提供的地图技术和地理位置检索服务;在移动增值领域,Mapabc为中国移动用户提供的手机地图和位置搜索服务(LBS);在行业应用领域,Mapabc帮助政府和行业用户构建高效的无线定位、监控和办公自动化系统(Eg:城管通...)。
我们目前招聘以下方面的人才,待遇面谈:
基本要求:
计算机软件相关专业本科及以上学历,本科要求有1年以上开发经验;
具有团队合作精神和独立工作能力,具备钻研和开拓精神,责任心强,能够承受工作压力;
本科生必须全职,硕士研究生可全职或实习。
岗位:
图形算法高级工程师(3人)
高级测试经理(2人)
导航开发高级工程师(2人)
GIS研发高级工程师(3人)
GIS及导航产品经理(2人)
算法开发工程师(5人)
三维开发工程师(3人)
嵌入式开发工程师(2人)
Kjava开发工程师(1人)
Java开发工程师(3人)
三维美工(兼职)
岗位详细描述:
(1) 图形算法高级工程师(3人)
职位描述: 核心图形引擎相关算法的设计、研发
学历要求:本科及以上专业毕业;
职位要求:
1、精通算法设计/数据结构者, 熟悉操作系统原理
2、能熟练阅读英文资料
3、精通C/C++语言编程
4、三年以上二/三维图形图像底层开发经验, 有GIS行业相关工作经验者优先
5、具备较强的系统设计能力和代码开发能力,沟通能力较强,思路清晰,性格稳定,有较强合作意识
(2) 高级测试经理(2人)
职位描述: 根据开发项目、产品开发计划和测试需求,编制测试方案,制定测试计划,分配测试资源和测试任务,组织设计并搭建测试环境,组织、计划、实施测试,控制测试进度,调整测试计划。
学历要求:本科及以上专业毕业;
职位要求:
1、精通测试相关知识,熟悉CMMI相关知识
2、能熟练阅读英文资料
3、熟练使用相关工具软件
4、二年以上测试管理职位工作经验,四年以上测试工作经验
5、有较强的组织协调能力、沟通能力、分析决策能力、影响力、计划与执行能力及寻根究底的探索精神,具有驾驶经验,思路清晰,性格稳定,有较强合作意识。
(3) 导航开发高级工程师(2人)
职位描述:手机导航或车载导航软件方向的研发和产品化
学历要求:本科及以上专业毕业;
职位要求:
1、精通算法设计/数据结构者, 熟悉操作系统原理
2、能熟练阅读英文资料
3、精通C/C++语言编程
4、一年以上导航软件及相关软件的设计开发经验,熟悉整个导航流程过程
5、具备较强的系统设计能力和代码开发能力,具有驾驶经验,具有良好沟通能力,思路清晰,性格稳定,有较强合作意识。
(4) GIS研发高级工程师(3人)
职位描述: GIS引擎相关空间算法的设计、研发,GIS引擎相关模块的系统设计、研发
学历要求:本科及以上专业毕业
职位要求:
1、精通算法设计/数据结构者, 熟悉操作系统原理
2、能熟练阅读英文资料
3、精通C/C++语言编程
4、三年以上GIS算法或二/三维图形图像底层开发经验
5、具备较强的系统设计能力和代码开发能力,沟通能力较强,思路清晰,性格稳定,有较强合作意识。
(5) GIS及导航产品经理(2人)
职位描述:GIS平台产品或导航产品的负责GIS平台产品或导航产品的发展、规划和设计;撰写和整理相关文档
学历要求:本科及以上专业毕业
职位要求:
1、具有GIS或导航相关行业知识
2、能熟练阅读英文资料
3、能够使用项目管理及产品流程制定等相关软件,熟悉C++编程
4、至少三年的GIS从业经历,具有代码开发、市场运作、运营管理和项目管理经历者优先,具有GIS或导航产品评测、测试和质量控制的经验。
5、深厚的文字功底,良好的沟通能力,对GIS或导航行业发展深有研究,有独到的见解;具有良好的技术功底和专业知识
6、具有驾驶经验
7、思路清晰,性格稳定,有较强合作意识。
(6) 算法开发工程师(5人)
职位描述: 实时交通,导航以及图像处理的基础服务研发
学历要求:本科及以上专业毕业
职位要求:
1、有较深的算法基础和较广泛的算法知识,对开发相关算法程序抱有较大的热情和兴趣
2、英语4级
3、熟练使用C++或Java语言,2年以上工作经验
4、有GIS行业开发经验者优先
5、有路径规划、地图匹配、图像处理等相关经验者优先
6、责任心强、较强的语言和文字表达能力,创新、为人坦诚,积极
(7) 三维开发工程师(3人)
职位描述: 三维的GIS底层研发
学历要求:本科及以上专业毕业
职位要求:
1、精通计算机图形图像技术与算法实现
2、英语四级以上,能熟练阅读英文文献
3、精通c/c++技术, 掌握VC开发技巧,2年以上工作经验
4、精通Directx或OpenGL开发,深刻理解Directx或OpenGL渲染流程,掌握Shader相关技术
5、有三维应用或游戏开发经验者优先,GIS开发经验者优先
6、责任心强、较强的语言和文字表达能力,创新、为人坦诚,积极
(8) 嵌入式开发工程师(2人)
职位描述:客户端底层平台研发
学历要求:本科及以上专业毕业
职位要求:
1、精通算法设计/数据结构
2、能熟练阅读英文资料
3、精通C++程序开发,了解STL
4、两年以上嵌入式系统开发经验,熟悉EVC4或者Windows Mobile5.0
5、具备较强的系统设计能力和代码开发能力,思维活跃,积极上进,可以独立开展工作,为人坦诚、积极、责任心强,可承受较大工作压力
(9) Kjava开发工程师(1人)
职务描述:客户端以及服务端的地图基础服务研发
学历要求:专科及以上专业毕业;
职位要求:
1、精通java底层以及算法
2、能熟练阅读英文资料
3、具有团队合作精神和独立工作能力,具备钻研和开拓精神,责任心强,能够承受工作压力
4、精通 Java 语言、J2EE技术,熟练掌握java底层和算法
5、一年以上的kjava游戏开发经验
6、具备较强的系统设计能力和代码开发能力,具有良好的团队精神和人际沟通能力,以及工作的创新能力和稳定性,思路清晰,性格稳定,有较强合作意识
(10) Java开发工程师(3人)
职位描述: 地图服务以及新技术应用开发
学历要求:
职位要求:
1、精通java底层以及算法
2、能熟练阅读英文资料
3、至少2年java开发工作
4、具有团队合作精神和独立工作能力,具备钻研和开拓精神,责任心强,能够承受工作压力
5、精通 Java 语言、J2EE技术,熟练掌握java底层和算法
6、熟悉javascript开发经验者优先,有大型项目的开发经验经验者优先
7、熟悉 Jsp、Servlet、JavaBean、XML、Struts、Hibernate等WEB动态服务开发技术
8、有GIS相关工作经验者优先
9、具备较强的系统设计能力和代码开发能力,具有良好的团队精神和人际沟通能力,以及工作的创新能力和稳定性,思路清晰,性格稳定,有较强合作意识
(11) 三维美工(兼职)
职位描述:三维美工(兼职)
学历要求:
职位要求:
1、熟练掌握3DMAX,PHOTOSHOP
2、发简历时,请注明要应聘的职位,并提供作品
3、负责3D建模贴图,特效绘制等相关美术工作。
4、美术或相关专业、有游戏美术开发相关工作经验者优先。
5、具备一年以上相关工作经验;
6、熟练使用3dMAX等相关美工软件;
7、具有良好的团队合作精神。
有意加入我们团队的朋友,请联系我们:
E_mail:basemanager@mapabc.com
请将您的简历通过E_mail发给我们,在简历里请详细描述您的工作经历和技术专长。
“12年前没有我,就没有今天的新浪”
理财周报记者 李冰心/文
你可能有段时间没关注过唐骏了,那个走出微软光环后,成为中国最高身价职业经理人的唐骏。
上周,在上海的一个创业投资论坛上,身为盛大网络总裁的唐骏忽然心血来潮道出了一段12年前的尘封往事,他对理财周报记者说,“如果没有我,就没有今天的新浪。”
应该感谢我
否则新浪还在做Rich Win
“这是一个非常真实的故事,没有一个人知道,包括王志东在内。”在唐骏说起这番话的时候,新浪创始人王志东刚刚走下演讲台落座,谁也没有想到,唐骏要说的往事是跟微软和王志东息息相关。
1995年,王志东带着自己研发的中文平台RichWin去美国与微软洽谈合作。
唐骏说,那时候他刚进微软两个月,作为一名普通软件工程师和王志东开会。“你在会上跟我们讲述了你的RichWin是多么伟大,微软需要RichWin,没有RichWin微软在中国很难推广,因为微软做不到中文系统和英文系统同时进行。我很佩服,RichWin的技术上伟大得令微软人深感佩服。”王志东的这句话深深刺激了微软工程师唐骏。
“你看不起微软,所以我就下狠心要改变这样的局面,因为那个时候我代表的是微软。”从此以后,唐骏在微软日夜工作,提出了Windows Linux的开发模式,使各种语言系统的开发模式变得全面统一,从此才有了今天的Windows2000、XP和vista,中文、英文、日文等所有的操作系统在全球统一发布。
“因为微软使用了我们当时提出的操作系统国际版本的开发模式。你应该感谢我,当时如果我不提出这个开发模式,你还在享受着你的RichWin给你带来的巨大利润。你应该感谢我,如果没有我唐骏,也没有今天的新浪,因为你还会做你的RichWin。”回忆往事,唐骏情不自禁地问,“你们没有觉得唐骏做人真的是很低调吗?”
卡拉OK记分系统发明专利
唐骏卖了8万美元
很难想象,一向在公众面前温文尔雅的唐骏回首往事会意兴难平。不过,仅认为是王志东的高傲激发了唐骏的斗志,显然有失公允。因为在加盟微软之前,他已经进行了多次创业尝试。
“1992年的时候我在美国,没有王志东那样的伟大梦想,我就是为了生存,我只是觉得做一般的普通员工给我带来的生存价值并不是很大,所以我创业。”唐骏说,如今街头随处可见的大头贴就是他当年在美国花两天时间想出来的创意,后来转让给了一家日本公司,连带其他交易共获利50万美元,而那间日本公司如今已是上市公司。
唐骏自豪地说,卡拉OK的记分系统也是他发明的,虽然已经过了15年,现在别人还是做不出来——这个技术专利唐骏卖了8万美元。“实际上那就是唐骏标准,很多人说不准,是因为你唱得距离唐骏太远了,也有很多人分数高,因为咱们是一条线上的。”唐骏用顽童般得意的口气调侃着自己的发明,他说,那时创业就是为了追求新鲜,追求满足感。
唐骏在美国还曾创办了一家律师事务所,虽然那时他并没有律师执照。更像一家皮包公司的律师事务所,却取了一个响亮的名字:美国第一律师事务所。后来他还帮助国内一些演艺界明星到美国走穴。
我对创业充满激情
我喜欢改变生活
唐骏在公众眼中,被视为职业经理人的杰出代表,但他的职业生涯中也经历了草根式、外援式、温室型三个创业阶段:“其实我很幸运,我没有像创业者一样追求什么东西,我只是希望我的人生精彩。”
当唐骏觉得自己对创业已经失去新鲜刺激感之后,他幸运的加入了微软。三年之后,唐骏在微软公司内部得到了一次创业机会, 创立上海徐家汇微软全球技术中心。
“微软派我一个人到上海来,无非给了我资金、政策,除了微软的大力支持,其他的都等同创业。”1997年唐骏只身来到上海,从选址到装修都是他一个人操作,而当他离开的时候,这个技术中心的员工已经达到500多人。
此后,唐骏说服了上海联投和微软公司各出资两百万美金,令他完成了一次外援式创业——创办上海微创软件公司。同样是他一个人再次开创了一条成功的商业模式。“在微软的大温室环境下,给我很多资源,让我去创建微软全球技术中心,更重要的是我也通过资本运作的方式让我拥有了微创软件创始人、CEO的角色。所以我觉得我的创业人生非常完美,我对创业还是充满激情,我喜欢做一些改变生活的东西。”
50万的日薪成为
中国身价最高的职业经理人
2003年底在上海的一个软件外包会议上,唐骏与盛大网络创始人陈天桥不期而遇,陈天桥“网上迪斯尼”的构想令他再次准备迎接新一轮挑战。
2004年,唐骏离开微软正式加盟盛大网络,以日薪高达50万元成为中国身价最高的职业经理人。
近日,盛大宣布收购网游公司成都锦天科技,收购涉及金额超过人民币1亿元,年仅23岁的加拿大籍青年彭海涛一夜之间成为亿万富翁。
谈及最终促成这桩收购的原因,唐骏说,网游在当今的互联网商业模式当中被华尔街认为是中国最成功的一种商业模式,而彭海涛纯粹靠自己打拼,能够在网游界占有一席位置实属不易。
对创业的激情令唐骏更多关注对创业者投入,他透露,盛大有一个专门的收购团队在不断寻找合适的并购对象。唐骏的理论则是,“首先你要选对商业模式,当然你还需要核心竞争力,最重要的是一个创业者的基本素质,这种创业的精神,这种执着。
为了桌面Java的未来发展,许多的重大改进正在进行中,对此做了很大的努力
就语言方面来说,出现了JavaFX script 项目。JavaFX是很灵巧的,它提供了一个高级的脚本接口,运行在Java 2D的API上。从用户的角度来看,他们不需要编写Java代码,不需要深入理解复杂的线程,Java 2D,Swing类的层次结构,定时框架结构(timing framework)等等。相反,他们只是编写脚本语言和描绘出所需要的GUI,包括活波的音响效果,图形效果,比如说梯度或者音乐,和数据绑定等等,这些都建立在一个基础API上。
这里有许多的工具帮助你学习syntax语言,相关资源这个从这个网站获得;JavaFX研发小组的目标就是提供syntax语言,和一些关于JavaFX的用户体验,这些用户包括美术设计员和那些对应用程序可视界面美观感兴趣的民众。当前,JavaFX某种程度上作为第四步产生的语言在运行,因为首先是解释器将FX脚本创建成为Java代码,然后再调用适当的Java 2D API。该小组长期的目标是将FX脚本直接编译成字节码。
JavaFX添加到桌面Java是一件非常好的事情,但是,这得取决于是否有这样的一种JRE的存在,它能运行JavaFX生成的代码。有些人认为FX已经进军到RIA(rich Internet application)领域,和Adobe公司的 Flex一较高下。但是,目前还是有一些难题需要解决,举个例子,如何才能让桌面Java的安装体验和运行时间性能比得上其它的RIA框架。还好,这种问题正在被其他的项目解决,这个项目名称就是Java kernel。
Java kernel主动承认这么一个事情,即大多数的Java应用程序都是只有JRE的部分大小,如Limewire(一个文件共享的桌面应用程序),它只有JRE的三分之一大小。Kernel将会对JRE重新打包,使得只下载应用程序所需要的部分JRE。每个程序所需要的基本部分将会被下载,作为JRE启动所需要的最小部分,其他的部分根据需要下载,或者根据ClassNotFound异常信息,下载缺失的类。这将是一个巨大的好消息帮助桌面Java应用程序瘦身,同时还能使得桌面Java应用程序执行的更为有效。除了解决如何下载的问题外,kernel还非常关注Java程序的启动性能。
在先前的kernel几个版本,热启动时间(warm start times)减少了很多,但是,在应用程序调用main(String[])前,冷启动JRE仍然需要延误许多秒的时间。Java kernel正在尝试有效的处理冷启动,将冷启动转变为热启动,通过一些相关的技术,如预加载(pre-loading)JRE,从硬盘读入到内存,还有一个操作系统服务,这个服务的功能就是监视可分配的内存来加载JRE,使得用户获得最佳的性能。出了这些,kernel还提供了一个新的浏览器插件,提供给Web 开发者更多的关于桌面运行信息,可获得的JRE水平等等。
对于桌面Java来说,Java kernel 和Java FX两大好消息。说Kernel是一个非常好的技术,是因为它承认了Swing已经到了一个非常成熟的阶段,并且帮助开发这如何将他们的Java应用程序更为快速,更为有效的搬到用户桌面上。说FX是两外一个非常好的消息,是因为它为Java开发者打开了新篇章,特别是那些愿意使用脚本语言和做一些高级的,活波的,图形效果的开发者,他们只需要写简单几行代码就可以完成。我相信这两项技术将会使得更多的应用程序用Java语言编写,运行在用户的机器上,同时,对于用户和开发者来说,应用程序变得更快,更简单。
7月18日下午,年仅26岁的华为员工张锐,在深圳梅林某小区的楼道内自缢身亡。
进入华为只有60多天的他,生前曾多次向亲人表示工作压力太大,并两度想要辞职,为此父亲两度来深看望劝说。
在父亲第二次来到深圳时,张锐选择了以这种方式与亲人告别,没留下一句话,身后只有因上大学欠下的5万多元债务。
对于父母来说,张锐是上天给他们迟来的“礼物”——张锐出生的那一年,父亲已经37岁,母亲29岁。他离开的时候,父母都已经白发苍苍。
毕业后换了4份工作
据其父母提供的材料显示,张锐,今年26岁,2000年考上武汉大学电子科学与技术系,2004年毕业。这对这个贫困的家庭来说是非常艰难的事情。在武汉一家工厂工作的父亲早已下岗,每月只有几百元的下岗费,而母亲没有工作。4年大学下来,家中债务高达近5万元。
毕业后,张锐在湖北当地一家企业工作了一年多,随后来到了深圳,在两家企业工作了一段时间。
今年4月份,张锐应聘华为并被录取。5月14日,张锐与华为签订了为期一年的劳动合同。对此,他很高兴,还打电话告诉了父母。
两度要辞职父亲两次赴深
但张锐的兴奋并没有持续多长时间,和他住在一起的表弟首先感觉到了这种变化。表弟告诉记者,几天之后张锐就有些不高兴,晚上经常失眠。他问张锐是否工作压力比较大,张锐说表现不好就会被主管批评,还要经常加班。
1个多月后,父母接到了儿子的电话。张锐表示,因为工作压力比较大,他想不干了,并征求父母的意见。对此母亲明确表示不同意。由于惦记着儿子,母亲催促父亲去深圳劝说孩子不要放弃这份工作。7月1日,张锐父亲买了张站票,带了个小板凳坐车到了深圳。在父亲的劝说下,张锐逐渐恢复平静,同意继续工作。3天之后,父亲回到了武汉老家。
但几天之后,张锐再次打电话回家表示准备辞职,老父只好第二次来到了深圳。
未留一句遗言他自缢身亡
7月17日,进入公司60多天从没请过假的张锐向主管请了一天假。晚上,他与父亲一起到小区附近散步。7月18日,张锐又请了一天假。下午2时,他告诉父亲要出去,从此再也没有回去。
当晚上11时左右,正在武汉的张锐母亲突然听到敲门声,当地民警告诉她,下午深圳警方在梅林地区某小区的楼道内发现了一个自缢身亡的人,其身份证显示是她的儿子张锐。
母亲一时无法相信这个事实,因为孩子父亲还正在深圳。而此时张锐父亲也正在深圳四处搜寻儿子。他去网吧找了几次没找到,手机也关了。随后他打电话回家,才得知孩子已经出事。
对于父母,张锐没有留下一句遗言。当父亲赶到小区时,尸体已经被运走。事后他得知,这里是儿子刚来深圳时,与同学们一起住过的地方,距离他在华为坂田基地旁边的出租屋约有4公里路程。
华为愿付1万元“安抚费”
昨日下午,张锐父母与华为公司进行了第三次协商。张锐父母提出,希望公司能做出补偿。但华为人事部副部长张志刚表示,根据公司规定只能给予1万元的安抚费。他说,张锐是自杀而且发生在公司外,其死亡并不在公司的员工伤亡补贴制度之内,这1万元也是公司对家属的慰问。
对于家属认为的压力过大问题,张志刚承认华为公司的员工的确都有压力,但对于张锐来说,压力实际上远没到把他击垮的程度。他说,张锐进入华为只有60多天,没有转正,也不能独立承担项目。
而且对于新进员工,公司都会配备思想导师,从各方面给予指导。此外,张锐性格比较内向,“外人很难进入他的内心世界”。
“张锐选择了这条路,将痛苦留给你们,也给公司造成了负面影响,这是一种不负责任的行为。”张志刚对张锐父母说。
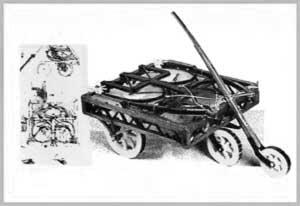
达·芬奇设计的第一辆汽车草图与模型图。
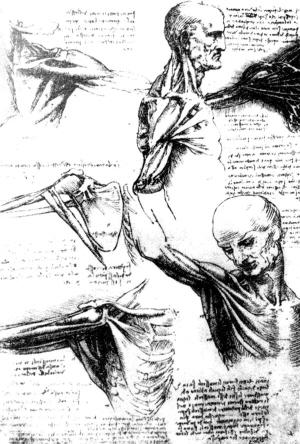
达·芬奇亲自解剖了几十具尸体,对人体骨骼、肌肉、关节以及内脏器官进行了精确了解和绘制。他甚至还设计了心脏复原手术。
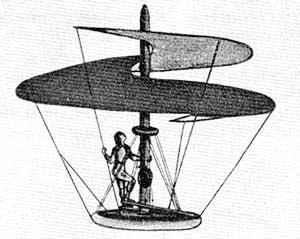
达·芬奇设计世界上第一款直升机。
造汽车,造飞机,造机器人,杰出画家竟是百科全书式科学巨匠
蒙娜丽莎的微笑,迷人而神秘,直到今天还有人在破解其中之谜。只是破解这个谜谈何容易,要知道制造这个谜的人,曾经自己就破解了许多自然科学之谜。他就是达·芬奇。近日,达·芬奇发明的自行车来到北京,一个科学天才与他当年的设想再次让我们仰望了一下。
事实上,达·芬奇在天马行空中,一直将奇思妙想写在手稿上,直到去世也没有发表。然而,“科学家达·芬奇”的称号对达·芬奇来说是当之无愧的,有人甚至评价为世界十大科学家之首。
达·芬奇科学成就:
● 天文学
达·芬奇对传统的“地球中心说”持否定的观点。他认为地球不是太阳系的中心,更不是宇宙的中心,而只是一颗绕太阳运转的行星,太阳本身是不运动的。达·芬奇还认为月亮自身并不发光,它只是反射太阳的光辉。他的这些观点的提出早于哥白尼“太阳中心说”。甚至在当时,达·芬奇就幻想利用太阳能了。
● 物理学
达·芬奇重新发现了液体压力的概念,提出了连通器原理。他指出:在连通器内,同一液体的液面高度是相同的,不同液体的液面高度不同,液体的高度与密度成反比。他发现了惯性原理,后来为伽利略的实验所证明。他认为一个抛射体最初是沿倾斜的直线上升,在引力和冲力的混合作用下作曲线位移,最后冲力耗尽,在引力的作用下作垂直下落运动。他的这一发现使亚里士多德的落体学说产生了动摇。他发展了杠杆原理,除推导出作用力与臂长关系外,还算出了速度与臂长的关系。他指出了“永动机”作为能源的不可能性。
● 建筑
在建筑方面,达·芬奇表现出卓越的才华。他设计过桥梁、教堂、圆屋顶建筑和城市下水道。在城市街道设计中,他将车马道和人行道分开;设计城市建筑时,具体规定了房屋的高度和街道的宽度。米兰的护城河就是他设计和建造的。
● 水利工程
达·芬奇对水利学的研究比意大利的学者克斯铁列早一个世纪。为了排除泥沙,他作了疏通亚诺河的施工计划。他设计并亲自主持修建了米兰至帕维亚的运河灌溉工程。由他经手建造的一些水库、水闸、拦水坝便利了农田灌溉,推动了农业生产的发展。有些水利设施至今仍在发挥作用。
● 军事和机械
发明了飞行机械、直升机、降落伞、机关枪、手榴弹、坦克车、潜水艇、双层船、壳战舰、起重机等等。
● 地质学
达·芬奇根据高山上有海中动物化石的事实推断出地壳有过变动,指出地球上洪水的痕迹是海陆变迁的证明,这个思想与300年后赫顿在地质学方面的发现颇为近似。并且在麦哲伦环球航行之前,他就计算出地球的直径为7000余英里。
他是直升机之祖
这位文艺复兴时期的天才早在莱特兄弟之前就有可能开创人类飞行的历史。
“如果他当初发表了他的著作的话,科学一定会一下就跳到一百年以后的局面。猜测这种情况对人类的学术与社会的进步,当然是毫无用处的,但是我们可以万无一失地说,如果真有这种情况发生的话,人类的学术和社会的演变一定都会大不相同,”科学史家丹皮尔津津乐道的这位科学巨人正是达·芬奇。
事实上,达·芬奇时代的人们也与前人一样,有着飞行的梦想。在佛罗伦萨呆了一段时间后, 达·芬奇又来到米兰。1483至1486年期间,达·芬奇绘制了一幅飞行器草图。
在达·芬奇的设想中,这是一种依靠飞行员自身提供动力来驱动的飞行器。这位天才称自己的设计为“扑翼飞机”,达·芬奇让自己的飞机同时具备了推动力和提升力。
让我们姑且根据达·芬奇画的草图来还原出这架飞机。飞机的外形由木头、帆布等当时的材料制成,在飞行器两侧是一双膜状的翅膀,结构和形状酷似蝙蝠或翼龙,这双翅膀展翼可以达到11米。飞行员背负着这个巨大的飞行器,通过不停地踩动一个动力滑轮来驱动,而这个推动力又通过手摇曲轴得到放大,同时向提升装置提供动力。
设计出这款飞机时,达·芬奇心中一直有个理念:只要力量足够就可以飞行。看来,这位文艺复兴时期的天才早在莱特兄弟之前就有可能开创人类飞行的历史。事实上,这个最早的飞行器的机械设计十分完美,但是,由于人自身所提供的动力和飞行器本身的自重相比不成比例,是无法实际应用的。事实上,达·芬奇称自己的发明也是提供一个直升动力,而不是真正能工作的飞机。直到今天,人们还将达·芬奇的设计视为直升机的先祖。
他设计出初级机器人
更为奇妙的是,达·芬奇还设计了一套方法以做心脏修复手术。
达·芬奇曾自称自己没有受过书本教育,大自然才是他真正的老师。而认识自然,认识自己。这位文艺复兴时期的天才不遗余力地履行着。为了认识人类自身,达·芬奇亲自解剖了几十具尸体,对人体骨骼、肌肉、关节以及内脏器官进行了精确了解和绘制。
在多次解剖后,达·芬奇发现了血液对人体所起到的新陈代谢作用,血液把营养带到身体的各个部分,又把废物从各部分带走。在具体的解剖观察中,达·芬奇发现了心脏由4个腔组成并画出了心脏瓣膜图。
事实上,当年达·芬奇连人体循环系统工作机理的一点概念都没有。更为神奇的是,2005年,一名英国外科医生还利用达·芬奇设计的方法做心脏修复手术。不过,解剖学的研究在当时并没有给达·芬奇带来声誉,而是遭到了无数的诽谤。
不过,就是对人体的这种深入了解,达·芬奇在手稿中甚至绘制了西方文明世界的第一款人形机器人。
达·芬奇赋予了这个机器人以木头、皮革和金属的外壳。而如何让机器人动起来,才是让达·芬奇大伤脑筋的。在达·芬奇的构想中,他想到了用下部的齿轮作为驱动装置。由此通过两个机械杆的齿轮再与胸部的一个圆盘齿轮咬合,机器人的胳膊就可以挥舞,坐或者站立。更绝的是,再通过一个传动杆与头部相连,头部就可以转动甚至可以开合下颌。而一旦配备了自动鼓装置后,这个机器人甚至还可以发出声音。
原来,500多年前,就已经有了机器人的雏形。
他本可让文明提前一百年
点燃现代汽车发明灵感之火的正是这辆“达·芬奇汽车”。
最酷的事实是达·芬奇长达7000多页的手稿(现存约5000多页)至今仍在影响科学研究,他就是一位现代世界的预言家,而他的手稿页被称为一部15世纪科学技术的真正百科全书。
很早,达·芬奇就对当时的四轮马车不满。在他的科学世界中,早就有了汽车的影子。事实上,点燃现代汽车发明灵感之火的正是这辆“达·芬奇汽车”。
既然是汽车就要考虑动力问题,达·芬奇在汽车中部安装了两根弹簧以解决这个问题。人力转动车的后轮使得各个齿轮相互咬合,弹簧绷紧就产生了力,再通过杠杆作用将力传递到轮子上。
那么怎么控制车速呢?达·芬奇也想到了。他在车身上安装了一个圆盘装置,圆盘表面设置了很多方形的木块,和每个轮子连接的铁杆另一端与圆盘相接,这就是用于控制车速的装置。圆盘扇放置的木块数量越多,与铁杆之间的摩擦就会越大,阻力也越大,轮子的运转速度越慢,行驶的距离越长。
当然,达·芬奇也想到了刹车装置。位于齿轮之间有一个木块,拉动绳索将木块卡在齿轮之间,车就可以停止。不过,这辆汽车不能载人,因为仅靠弹簧的动力根本无法行驶很长的距离。
同时,达·芬奇还将弹簧巧妙地运用在了钟表设计上。后来大型钟表采用的原理,就是出自达·芬奇的设想。只是在这个设想中,弹簧的弹力被物体的重力所代替,物体向下的重力通过众多齿轮咬合作用被均匀传递,钟表便得以保持匀速运动。
此外,挖河机、潜水机、起重机、照相机、加热机、温度计……达·芬奇曾有过无数的发明设计。而这些发明足足可以让我们的世界科学文明进程提前100年。
对机械世界痴迷不已
水下呼吸装置、发条传动装置,滚珠装置、反向螺旋、纺织物扩张器……
水下呼吸装置、拉动装置,发条传动装置、滚珠装置、反向螺旋、差动螺旋、纺织物扩张器……达·芬奇将他无数的奇思妙想呈现在世人面前。故事的开头不得不说起达·芬奇初到佛罗伦萨学画的经历。事实上,这段经历开启了艺术家达·芬奇的大门,也开启了科学家达·芬奇的大门。
1460年,达·芬奇随父亲来到佛罗伦萨,开始了他的学徒生涯,同时开始学画。学画的达·芬奇参与安装佛罗伦萨圣母玛丽亚大教堂穹顶灯塔上巨型铜球,由此接触并感受到了各式各样机械系统的神奇。
佛罗伦萨圣母玛丽亚大教堂是文艺复兴建筑的开端。达·芬奇在安装穹顶灯塔上巨型铜球时,亲眼目睹了三速提升机等机械装置的效率,深感其中的神奇。由此,布鲁内莱斯基的机械系统设计理念对达·芬奇产生了很大影响。当时一批“锡耶纳工程师”对达·芬奇的科学世界也产生了重要影响。
而锡耶纳的工程师们设计的一种外形像船的河道淤泥挖掘机,用来清除浅水狂口的沙砾和淤泥,还有一种能够提高装载量又加快行驶速度的桨叶船,这些锡耶纳工程师的发明,让达·芬奇对机械的魔力产生了巨大的兴趣。
从此,达·芬奇对机械世界痴迷不已
摘要: 先按照文档,做一次:
1,建立WEB.XML:
<?xml version="1.0" encoding="UTF-8"?> <web-app> <display-name>Struts Blank</dis... 阅读全文
摘要: [导读]本文通过实例,介绍在做验证码的时候为了给用户很好的体验,需要在原有验证方式基础之上增加一段js,通过xmlhttp来获取返回值,以此来验证是否有效。同时,本例还特别适合检验用户名是否有效。 1、我们在做验证码的时候往往由于要反作弊,验证有时故意加入多的干扰因素,这时验证码显示不很清楚,用户经常输入错误。这样不但要重新刷新页面,导致用户没有看清楚验证码而重填而不是修改,... 阅读全文
为了方便放到自己的blog里好查,呵呵
1. document.form.item 问题
(1)现有问题:
现有代码中存在许多 document.formName.item("itemName") 这样的语句,不能在 MF 下运行
(2)解决方法:
改用 document.formName.elements["elementName"]
(3)其它
参见 2
2. 集合类对象问题
(1)现有问题:
现有代码中许多集合类对象取用时使用 (),IE 能接受,MF 不能。
(2)解决方法:
改用 [] 作为下标运算。如:document.forms("formName") 改为 document.forms["formName"]。
又如:document.getElementsByName("inputName")(1) 改为 document.getElementsByName("inputName")[1]
(3)其它
3. window.event
(1)现有问题:
使用 window.event 无法在 MF 上运行
(2)解决方法:
MF 的 event 只能在事件发生的现场使用,此问题暂无法解决。可以这样变通:
原代码(可在IE中运行):
<input type="button" name="someButton" value="提交" onclick="javascript:gotoSubmit()"/>
...
<script language="javascript">
function gotoSubmit() {
...
alert(window.event); // use window.event
...
}
</script>
新代码(可在IE和MF中运行):
<input type="button" name="someButton" value="提交" onclick="javascript:gotoSubmit(event)"/>
...
<script language="javascript">
function gotoSubmit(evt) {
evt = evt ? evt : (window.event ? window.event : null);
...
alert(evt); // use evt
...
}
</script>
此外,如果新代码中第一行不改,与老代码一样的话(即 gotoSubmit 调用没有给参数),则仍然只能在IE中运行,但不会出错。所以,这种方案 tpl 部分仍与老代码兼容。
4. HTML 对象的 id 作为对象名的问题
(1)现有问题
在 IE 中,HTML 对象的 ID 可以作为 document 的下属对象变量名直接使用。在 MF 中不能。
(2)解决方法
用 getElementById("idName") 代替 idName 作为对象变量使用。
5. 用idName字符串取得对象的问题
(1)现有问题
在IE中,利用 eval(idName) 可以取得 id 为 idName 的 HTML 对象,在MF 中不能。
(2)解决方法
用 getElementById(idName) 代替 eval(idName)。
6. 变量名与某 HTML 对象 id 相同的问题
(1)现有问题
在 MF 中,因为对象 id 不作为 HTML 对象的名称,所以可以使用与 HTML 对象 id 相同的变量名,IE 中不能。
(2)解决方法
在声明变量时,一律加上 var ,以避免歧义,这样在 IE 中亦可正常运行。
此外,最好不要取与 HTML 对象 id 相同的变量名,以减少错误。
(3)其它
参见 问题4
7. event.x 与 event.y 问题
(1)现有问题
在IE 中,event 对象有 x, y 属性,MF中没有。
(2)解决方法
在MF中,与event.x 等效的是 event.pageX。但event.pageX IE中没有。
故采用 event.clientX 代替 event.x。在IE 中也有这个变量。
event.clientX 与 event.pageX 有微妙的差别(当整个页面有滚动条的时候),不过大多数时候是等效的。
如果要完全一样,可以稍麻烦些:
mX = event.x ? event.x : event.pageX;
然后用 mX 代替 event.x
(3)其它
event.layerX 在 IE 与 MF 中都有,具体意义有无差别尚未试验。
8. 关于frame
(1)现有问题
在 IE中 可以用window.testFrame取得该frame,mf中不行
(2)解决方法
在frame的使用方面mf和ie的最主要的区别是:
如果在frame标签中书写了以下属性:
<frame src="xx.htm" id="frameId" name="frameName" />
那么ie可以通过id或者name访问这个frame对应的window对象
而mf只可以通过name来访问这个frame对应的window对象
例如如果上述frame标签写在最上层的window里面的htm里面,那么可以这样访问
ie: window.top.frameId或者window.top.frameName来访问这个window对象
mf: 只能这样window.top.frameName来访问这个window对象
另外,在mf和ie中都可以使用window.top.document.getElementById("frameId")来访问frame标签
并且可以通过window.top.document.getElementById("testFrame").src = 'xx.htm'来切换frame的内容
也都可以通过window.top.frameName.location = 'xx.htm'来切换frame的内容
关于frame和window的描述可以参见bbs的‘window与frame’文章
以及/test/js/test_frame/目录下面的测试
9. 在mf中,自己定义的属性必须getAttribute()取得
10.在mf中没有 parentElement parement.children 而用
parentNode parentNode.childNodes
childNodes的下标的含义在IE和MF中不同,MF使用DOM规范,childNodes中会插入空白文本节点。
一般可以通过node.getElementsByTagName()来回避这个问题。
当html中节点缺失时,IE和MF对parentNode的解释不同,例如
<form>
<table>
<input/>
</table>
</form>
MF中input.parentNode的值为form, 而IE中input.parentNode的值为空节点
MF中节点没有removeNode方法,必须使用如下方法 node.parentNode.removeChild(node)
11.const 问题
(1)现有问题:
在 IE 中不能使用 const 关键字。如 const constVar = 32; 在IE中这是语法错误。
(2)解决方法:
不使用 const ,以 var 代替。
12. body 对象
MF的body在body标签没有被浏览器完全读入之前就存在,而IE则必须在body完全被读入之后才存在
13. url encoding
在js中如果书写url就直接写&不要写&例如var url = 'xx.jsp?objectName=xx&objectEvent=xxx';
frm.action = url那么很有可能url不会被正常显示以至于参数没有正确的传到服务器
一般会服务器报错参数没有找到
当然如果是在tpl中例外,因为tpl中符合xml规范,要求&书写为&
一般MF无法识别js中的&
14. nodeName 和 tagName 问题
(1)现有问题:
在MF中,所有节点均有 nodeName 值,但 textNode 没有 tagName 值。在 IE 中,nodeName 的使用好象
有问题(具体情况没有测试,但我的IE已经死了好几次)。
(2)解决方法:
使用 tagName,但应检测其是否为空。
15. 元素属性
IE下 input.type属性为只读,但是MF下可以修改
16. document.getElementsByName() 和 document.all[name] 的问题
(1)现有问题:
在 IE 中,getElementsByName()、document.all[name] 均不能用来取得 div 元素。
用java写桌面程序的时候,总是抱怨Swing的页面太难看,而很多的Look and Feel 都是收费的。 今天发现一个好东东,全是免费的,效果还不错呀,感兴趣的话赶紧去下吧! 下载地址: http://www.javootoo.com/ 上有一个free look and feel 栏目
摘要: 优化RandomAccessFile类后完整版代码
1.BufferedRandomAccessFile.java类
1 package kbps.io; 2 3 import java.io.RandomAccessFile; 4 imp... 阅读全文
通过扩展RandomAccessFile类使之具备Buffer改善I/O性能

JAVA的文件随机存取类(RandomAccessFile)的I/O效率较低。通过分析其中原因,提出解决方案。逐步展示如何创建具备缓存读写能力的文件随机存取类,并进行了优化。通过与其它文件访问类的性能对比,证明了其实用价值。
主体:
开发人员使用RandomAccessFile类时。其I/O性能较之其它常用开发语言的同类性能差距甚远,严重影响程序的运行效率。开发人员迫切需要提高效率,下面分析RandomAccessFile等文件类的源代码,找出其中的症结所在,并加以改进优化,创建一个"性/价比"俱佳的随机文件访问类BufferedRandomAccessFile。
在改进之前先做一个基本测试:逐字节COPY一个12兆的文件(这里牵涉到读和写)。
| 读 |
写 |
耗用时间(秒) |
| RandomAccessFile |
RandomAccessFile |
95.848 |
| BufferedInputStream + DataInputStream |
BufferedOutputStream + DataOutputStream |
2.935 |
我们可以看到两者差距约32倍,RandomAccessFile也太慢了。先看看两者关键部分的源代码,对比分析,找出原因。
1.1.[RandomAccessFile]
public class RandomAccessFile implements DataOutput, DataInput {
public final byte readByte() throws IOException {
int ch = this.read();
if (ch < 0)
throw new EOFException();
return (byte)(ch);
}
public native int read() throws IOException;
public final void writeByte(int v) throws IOException {
write(v);
}
public native void write(int b) throws IOException;
}
|
可见,RandomAccessFile每读/写一个字节就需对磁盘进行一次I/O操作。
1.2.[BufferedInputStream]
public class BufferedInputStream extends FilterInputStream {
private static int defaultBufferSize = 2048;
protected byte buf[]; // 建立读缓存区
public BufferedInputStream(InputStream in, int size) {
super(in);
if (size <= 0) {
throw new IllegalArgumentException("Buffer size <= 0");
}
buf = new byte[size];
}
public synchronized int read() throws IOException {
ensureOpen();
if (pos >= count) {
fill();
if (pos >= count)
return -1;
}
return buf[pos++] & 0xff; // 直接从BUF[]中读取
}
private void fill() throws IOException {
if (markpos < 0)
pos = 0; /* no mark: throw away the buffer */
else if (pos >= buf.length) /* no room left in buffer */
if (markpos > 0) { /* can throw away early part of the buffer */
int sz = pos - markpos;
System.arraycopy(buf, markpos, buf, 0, sz);
pos = sz;
markpos = 0;
} else if (buf.length >= marklimit) {
markpos = -1; /* buffer got too big, invalidate mark */
pos = 0; /* drop buffer contents */
} else { /* grow buffer */
int nsz = pos * 2;
if (nsz > marklimit)
nsz = marklimit;
byte nbuf[] = new byte[nsz];
System.arraycopy(buf, 0, nbuf, 0, pos);
buf = nbuf;
}
count = pos;
int n = in.read(buf, pos, buf.length - pos);
if (n > 0)
count = n + pos;
}
}
|
1.3.[BufferedOutputStream]
public class BufferedOutputStream extends FilterOutputStream {
protected byte buf[]; // 建立写缓存区
public BufferedOutputStream(OutputStream out, int size) {
super(out);
if (size <= 0) {
throw new IllegalArgumentException("Buffer size <= 0");
}
buf = new byte[size];
}
public synchronized void write(int b) throws IOException {
if (count >= buf.length) {
flushBuffer();
}
buf[count++] = (byte)b; // 直接从BUF[]中读取
}
private void flushBuffer() throws IOException {
if (count > 0) {
out.write(buf, 0, count);
count = 0;
}
}
}
|
可见,Buffered I/O putStream每读/写一个字节,若要操作的数据在BUF中,就直接对内存的buf[]进行读/写操作;否则从磁盘相应位置填充buf[],再直接对内存的buf[]进行读/写操作,绝大部分的读/写操作是对内存buf[]的操作。
1.3.小结
内存存取时间单位是纳秒级(10E-9),磁盘存取时间单位是毫秒级(10E-3),同样操作一次的开销,内存比磁盘快了百万倍。理论上可以预见,即使对内存操作上万次,花费的时间也远少对于磁盘一次I/O的开销。显然后者是通过增加位于内存的BUF存取,减少磁盘I/O的开销,提高存取效率的,当然这样也增加了BUF控制部分的开销。从实际应用来看,存取效率提高了32倍。
根据1.3得出的结论,现试着对RandomAccessFile类也加上缓冲读写机制。
随机访问类与顺序类不同,前者是通过实现DataInput/DataOutput接口创建的,而后者是扩展FilterInputStream/FilterOutputStream创建的,不能直接照搬。
2.1.开辟缓冲区BUF[默认:1024字节],用作读/写的共用缓冲区。
2.2.先实现读缓冲。
读缓冲逻辑的基本原理:
A 欲读文件POS位置的一个字节。
B 查BUF中是否存在?若有,直接从BUF中读取,并返回该字符BYTE。
C 若没有,则BUF重新定位到该POS所在的位置并把该位置附近的BUFSIZE的字节的文件内容填充BUFFER,返回B。
以下给出关键部分代码及其说明:
public class BufferedRandomAccessFile extends RandomAccessFile {
// byte read(long pos):读取当前文件POS位置所在的字节
// bufstartpos、bufendpos代表BUF映射在当前文件的首/尾偏移地址。
// curpos指当前类文件指针的偏移地址。
public byte read(long pos) throws IOException {
if (pos < this.bufstartpos || pos > this.bufendpos ) {
this.flushbuf();
this.seek(pos);
if ((pos < this.bufstartpos) || (pos > this.bufendpos))
throw new IOException();
}
this.curpos = pos;
return this.buf[(int)(pos - this.bufstartpos)];
}
// void flushbuf():bufdirty为真,把buf[]中尚未写入磁盘的数据,写入磁盘。
private void flushbuf() throws IOException {
if (this.bufdirty == true) {
if (super.getFilePointer() != this.bufstartpos) {
super.seek(this.bufstartpos);
}
super.write(this.buf, 0, this.bufusedsize);
this.bufdirty = false;
}
}
// void seek(long pos):移动文件指针到pos位置,并把buf[]映射填充至POS
所在的文件块。
public void seek(long pos) throws IOException {
if ((pos < this.bufstartpos) || (pos > this.bufendpos)) { // seek pos not in buf
this.flushbuf();
if ((pos >= 0) && (pos <= this.fileendpos) && (this.fileendpos != 0))
{ // seek pos in file (file length > 0)
this.bufstartpos = pos * bufbitlen / bufbitlen;
this.bufusedsize = this.fillbuf();
} else if (((pos == 0) && (this.fileendpos == 0))
|| (pos == this.fileendpos + 1))
{ // seek pos is append pos
this.bufstartpos = pos;
this.bufusedsize = 0;
}
this.bufendpos = this.bufstartpos + this.bufsize - 1;
}
this.curpos = pos;
}
// int fillbuf():根据bufstartpos,填充buf[]。
private int fillbuf() throws IOException {
super.seek(this.bufstartpos);
this.bufdirty = false;
return super.read(this.buf);
}
}
|
至此缓冲读基本实现,逐字节COPY一个12兆的文件(这里牵涉到读和写,用BufferedRandomAccessFile试一下读的速度):
| 读 |
写 |
耗用时间(秒) |
| RandomAccessFile |
RandomAccessFile |
95.848 |
| BufferedRandomAccessFile |
BufferedOutputStream + DataOutputStream |
2.813 |
| BufferedInputStream + DataInputStream |
BufferedOutputStream + DataOutputStream |
2.935 |
可见速度显著提高,与BufferedInputStream+DataInputStream不相上下。
2.3.实现写缓冲。
写缓冲逻辑的基本原理:
A欲写文件POS位置的一个字节。
B 查BUF中是否有该映射?若有,直接向BUF中写入,并返回true。
C若没有,则BUF重新定位到该POS所在的位置,并把该位置附近的 BUFSIZE字节的文件内容填充BUFFER,返回B。
下面给出关键部分代码及其说明:
// boolean write(byte bw, long pos):向当前文件POS位置写入字节BW。
// 根据POS的不同及BUF的位置:存在修改、追加、BUF中、BUF外等情
况。在逻辑判断时,把最可能出现的情况,最先判断,这样可提高速度。
// fileendpos:指示当前文件的尾偏移地址,主要考虑到追加因素
public boolean write(byte bw, long pos) throws IOException {
if ((pos >= this.bufstartpos) && (pos <= this.bufendpos)) {
// write pos in buf
this.buf[(int)(pos - this.bufstartpos)] = bw;
this.bufdirty = true;
if (pos == this.fileendpos + 1) { // write pos is append pos
this.fileendpos++;
this.bufusedsize++;
}
} else { // write pos not in buf
this.seek(pos);
if ((pos >= 0) && (pos <= this.fileendpos) && (this.fileendpos != 0))
{ // write pos is modify file
this.buf[(int)(pos - this.bufstartpos)] = bw;
} else if (((pos == 0) && (this.fileendpos == 0))
|| (pos == this.fileendpos + 1)) { // write pos is append pos
this.buf[0] = bw;
this.fileendpos++;
this.bufusedsize = 1;
} else {
throw new IndexOutOfBoundsException();
}
this.bufdirty = true;
}
this.curpos = pos;
return true;
}
|
至此缓冲写基本实现,逐字节COPY一个12兆的文件,(这里牵涉到读和写,结合缓冲读,用BufferedRandomAccessFile试一下读/写的速度):
| 读 |
写 |
耗用时间(秒) |
| RandomAccessFile |
RandomAccessFile |
95.848 |
| BufferedInputStream + DataInputStream |
BufferedOutputStream + DataOutputStream |
2.935 |
| BufferedRandomAccessFile |
BufferedOutputStream + DataOutputStream |
2.813 |
| BufferedRandomAccessFile |
BufferedRandomAccessFile |
2.453 |
可见综合读/写速度已超越BufferedInput/OutputStream+DataInput/OutputStream。
优化BufferedRandomAccessFile。
优化原则:
- 调用频繁的语句最需要优化,且优化的效果最明显。
- 多重嵌套逻辑判断时,最可能出现的判断,应放在最外层。
- 减少不必要的NEW。
这里举一典型的例子:
public void seek(long pos) throws IOException {
...
this.bufstartpos = pos * bufbitlen / bufbitlen;
// bufbitlen指buf[]的位长,例:若bufsize=1024,则bufbitlen=10。
...
}
|
seek函数使用在各函数中,调用非常频繁,上面加重的这行语句根据pos和bufsize确定buf[]对应当前文件的映射位置,用"*"、"/"确定,显然不是一个好方法。
优化一:this.bufstartpos = (pos << bufbitlen) >> bufbitlen;
优化二:this.bufstartpos = pos & bufmask; // this.bufmask = ~((long)this.bufsize - 1);
两者效率都比原来好,但后者显然更好,因为前者需要两次移位运算、后者只需一次逻辑与运算(bufmask可以预先得出)。
至此优化基本实现,逐字节COPY一个12兆的文件,(这里牵涉到读和写,结合缓冲读,用优化后BufferedRandomAccessFile试一下读/写的速度):
| 读 |
写 |
耗用时间(秒) |
| RandomAccessFile |
RandomAccessFile |
95.848 |
| BufferedInputStream + DataInputStream |
BufferedOutputStream + DataOutputStream |
2.935 |
| BufferedRandomAccessFile |
BufferedOutputStream + DataOutputStream |
2.813 |
| BufferedRandomAccessFile |
BufferedRandomAccessFile |
2.453 |
| BufferedRandomAccessFile优 |
BufferedRandomAccessFile优 |
2.197 |
可见优化尽管不明显,还是比未优化前快了一些,也许这种效果在老式机上会更明显。
以上比较的是顺序存取,即使是随机存取,在绝大多数情况下也不止一个BYTE,所以缓冲机制依然有效。而一般的顺序存取类要实现随机存取就不怎么容易了。
需要完善的地方
提供文件追加功能:
public boolean append(byte bw) throws IOException {
return this.write(bw, this.fileendpos + 1);
}
|
提供文件当前位置修改功能:
public boolean write(byte bw) throws IOException {
return this.write(bw, this.curpos);
}
|
返回文件长度(由于BUF读写的原因,与原来的RandomAccessFile类有所不同):
public long length() throws IOException {
return this.max(this.fileendpos + 1, this.initfilelen);
}
|
返回文件当前指针(由于是通过BUF读写的原因,与原来的RandomAccessFile类有所不同):
public long getFilePointer() throws IOException {
return this.curpos;
}
|
提供对当前位置的多个字节的缓冲写功能:
public void write(byte b[], int off, int len) throws IOException {
long writeendpos = this.curpos + len - 1;
if (writeendpos <= this.bufendpos) { // b[] in cur buf
System.arraycopy(b, off, this.buf, (int)(this.curpos - this.bufstartpos),
len);
this.bufdirty = true;
this.bufusedsize = (int)(writeendpos - this.bufstartpos + 1);
} else { // b[] not in cur buf
super.seek(this.curpos);
super.write(b, off, len);
}
if (writeendpos > this.fileendpos)
this.fileendpos = writeendpos;
this.seek(writeendpos+1);
}
public void write(byte b[]) throws IOException {
this.write(b, 0, b.length);
}
|
提供对当前位置的多个字节的缓冲读功能:
public int read(byte b[], int off, int len) throws IOException {
long readendpos = this.curpos + len - 1;
if (readendpos <= this.bufendpos && readendpos <= this.fileendpos ) {
// read in buf
System.arraycopy(this.buf, (int)(this.curpos - this.bufstartpos),
b, off, len);
} else { // read b[] size > buf[]
if (readendpos > this.fileendpos) { // read b[] part in file
len = (int)(this.length() - this.curpos + 1);
}
super.seek(this.curpos);
len = super.read(b, off, len);
readendpos = this.curpos + len - 1;
}
this.seek(readendpos + 1);
return len;
}
public int read(byte b[]) throws IOException {
return this.read(b, 0, b.length);
}
public void setLength(long newLength) throws IOException {
if (newLength > 0) {
this.fileendpos = newLength - 1;
} else {
this.fileendpos = 0;
}
super.setLength(newLength);
}
public void close() throws IOException {
this.flushbuf();
super.close();
}
|
至此完善工作基本完成,试一下新增的多字节读/写功能,通过同时读/写1024个字节,来COPY一个12兆的文件,(这里牵涉到读和写,用完善后BufferedRandomAccessFile试一下读/写的速度):
| 读 |
写 |
耗用时间(秒) |
| RandomAccessFile |
RandomAccessFile |
95.848 |
| BufferedInputStream + DataInputStream |
BufferedOutputStream + DataOutputStream |
2.935 |
| BufferedRandomAccessFile |
BufferedOutputStream + DataOutputStream |
2.813 |
| BufferedRandomAccessFile |
BufferedRandomAccessFile |
2.453 |
| BufferedRandomAccessFile优 |
BufferedRandomAccessFile优 |
2.197 |
| BufferedRandomAccessFile完 |
BufferedRandomAccessFile完 |
0.401 |
与JDK1.4类MappedByteBuffer+RandomAccessFile的对比?
JDK1.4提供了NIO类 ,其中MappedByteBuffer类用于映射缓冲,也可以映射随机文件访问,可见JAVA设计者也看到了RandomAccessFile的问题,并加以改进。怎么通过MappedByteBuffer+RandomAccessFile拷贝文件呢?下面就是测试程序的主要部分:
RandomAccessFile rafi = new RandomAccessFile(SrcFile, "r");
RandomAccessFile rafo = new RandomAccessFile(DesFile, "rw");
FileChannel fci = rafi.getChannel();
FileChannel fco = rafo.getChannel();
long size = fci.size();
MappedByteBuffer mbbi = fci.map(FileChannel.MapMode.READ_ONLY, 0, size);
MappedByteBuffer mbbo = fco.map(FileChannel.MapMode.READ_WRITE, 0, size);
long start = System.currentTimeMillis();
for (int i = 0; i < size; i++) {
byte b = mbbi.get(i);
mbbo.put(i, b);
}
fcin.close();
fcout.close();
rafi.close();
rafo.close();
System.out.println("Spend: "+(double)(System.currentTimeMillis()-start) / 1000 + "s");
|
试一下JDK1.4的映射缓冲读/写功能,逐字节COPY一个12兆的文件,(这里牵涉到读和写):
| 读 |
写 |
耗用时间(秒) |
| RandomAccessFile |
RandomAccessFile |
95.848 |
| BufferedInputStream + DataInputStream |
BufferedOutputStream + DataOutputStream |
2.935 |
| BufferedRandomAccessFile |
BufferedOutputStream + DataOutputStream |
2.813 |
| BufferedRandomAccessFile |
BufferedRandomAccessFile |
2.453 |
| BufferedRandomAccessFile优 |
BufferedRandomAccessFile优 |
2.197 |
| BufferedRandomAccessFile完 |
BufferedRandomAccessFile完 |
0.401 |
| MappedByteBuffer+ RandomAccessFile |
MappedByteBuffer+ RandomAccessFile |
1.209 |
确实不错,如果以后采用1.4版本开发软件时,需要对文件进行随机访问,建议采用MappedByteBuffer+RandomAccessFile的方式。但鉴于目前采用JDK1.3及以前的版本开发的程序占绝大多数的实际情况,如果您开发的JAVA程序使用了RandomAccessFile类来随机访问文件,并因其性能不佳,而担心遭用户诟病,请试用本文所提供的BufferedRandomAccessFile类,不必推翻重写,只需IMPORT 本类,把所有的RandomAccessFile改为BufferedRandomAccessFile,您的程序的性能将得到极大的提升,您所要做的就这么简单。
未来的考虑
读者可在此基础上建立多页缓存及缓存淘汰机制,以应付对随机访问强度大的应用。
(完整代码见下篇)
我爸和我后母结婚的时候,我读初二。我后母比我爸小了整整十五岁……最初是我爸的下属,死不要脸地追我爸,我爸的确是比较有魅力的那种男人,但是她也是特别地不要脸,知道别人是有妇之夫还要追……后来我爸妈离婚,她就跟我爸结了婚……一句话,她就是一个不折不扣的二奶,不过比二奶还要无耻一点,是晋级了的二奶……自从他们结了婚,我的生活里除了上学,主要的事情就是对付我后妈……她让我妈不好过,这些年我也没让她太爽……我的脑子有一半的力气都花在恶作剧上了……
恶作剧一
偷偷用洗碗的铁丝球划她的丝袜,而且还是专门挑收在衣橱里丝袜抽屉的划,因为那些丝袜都是贵的几百块一双的那种。每次就划开两三条丝,刚开始,她都不知道是我划坏的。
恶作剧二
用针和剪刀把她的衣服拆线。特别是上衣的腋部和长裤的裆部。而且都是拆里面的那层隐线,穿的时候根本看不出来,但是一穿,一走动,线马上就开了。哈哈,看见那个无耻的婊 子穿着露内裤的长裤去跟客户谈判,我心里爽的要死!我还在她内衣上动过手脚,让她一整天背后都垂着一条bra带在公司里跑来跑去!我不只一次看见她因为衣服脱线而气急败坏,还曾经拿着衣服去商店投诉过。
后来有一次,她买了一件贵的大衣,将近八千多,我在屋里听到她和同事电话说起这件衣服,就留心想:这件衣服我一定要把它弄坏弄到补都不能补。我把那件纯白色毛料的大衣的背部放在煤气上烧……烧出了一个大洞。当时我就知道这么一来她肯定就知道以前的事情也是我干的了,但是还是义无反顾地做了,做的时候心理很有一种悲壮的感觉,觉得自己在给我妈出气。那种视死如归的感觉到现在都还记得。
这件事把我后母几乎气得抓狂,告诉我爸,我爸把我痛揍了一顿……那天晚上我整晚上都没睡觉,在卧室里把门反锁着,趴在窗户前面大声哭……还用书卷了个喇叭对着哭……哭声把半个小区的人都惊动了……后来我每次惹了我后母,她骂我一句,我一声不坑就地跑到窗户边哭……后来我和小区的几个同龄女孩子混熟了,经常在花坛边跳皮筋,大家都知道了我有个后妈,而且这个后妈还是“当狐狸精”抢别人的老公来的,小女孩子们回家都跟父母说,小区的人都很同情我……特别是那些老太太,有时候我放学回来看见了,在门口买菜的中年妇女看见了就要议论一句“这孩子学习还特别好呢,可惜了……”当然,我后妈的名声因此在小区变得特别臭,连开电梯的阿姨都鄙视她……
恶作剧三
在她的香水里偷偷加盐或者味精或者雪碧其它什么东西……反正加了看不大出来的那种乱七八糟的东西……我有次上化学实验还让男生偷偷给我弄了点高锰酸钾,就是做氧气那个……后来也没敢放,因为胆子还小,怕放了中毒什么的我就惨了……我还想过往她香水里倒点尿之类的,后来自己觉得怪恶心,就也没有付诸实施……
恶作剧四
自从跟了我后妈,我的衣服和鞋子都变得特别容易破……尤其是球鞋和袜子,经常是前面一个大破洞……我们上机房都是要换鞋的,每次我换鞋的时候就露出破破烂烂的袜子……我的同学缘很好,每次我同学他们就非常气愤,诅咒“那个死女人”(好朋友们都这么称呼我后妈)不得好死……我爸看了很气,就经常拿钱给我去买鞋买衣服……然后他当然也不知道物品的价钱,每次都胡乱给了不少钱……我攒上两三次多半就能攒个六七百,然后去商场买东西孝敬我妈或者我奶奶……我奶奶问我哪里来的钱,我就说我爸给我买鞋子的……我奶奶看看我的穿戴,就觉得我特别孝顺懂事,然后就大骂一通我后妈是狐狸精,然后会带着我去商店给我买衣服买鞋……反正我是赚回来了……
我后妈和我爸后来就经常吵架,因为我奶奶很厌恶她,而且如果亲家母遇到了,我奶奶对她妈也很不客气……当然这里面很大的功劳都归功于我在中间用各种方式煽风点火……让我奶奶总觉得我在家特别受虐待……不过我后母对我本来就不好……
恶作剧五
中学的时候住家里,我经常把家里的设施故意弄坏……比如往下水道倒剩菜,用过的卫生巾直接扔到抽水马桶里,开了冰箱就不关(当然要赶在父母下班前关上),夏天里把空调开到二十四五度,然后裹着棉被睡觉(为了把空调往死里用,用坏最好),吃饭的时候,我后妈炒完菜,我经常失手打翻……我后妈骂我,我就说:“我又不知道……我又不是故意的……你干吗这么挑剔……”我后妈如果说:“你有这么笨吗?一个盘子都拿不住吗?”我就说:“我就是笨啊,女儿都遗传爸爸的,你问我爸去啊?”她如果说:“我上次不是说了吗?剩菜不能倒在下水道里!你就是故意的。”我就说:“我不记得了啊!顺手就倒了!随便你啊,你看我不顺眼,当然觉得我是故意的罗!”每次都把她噎得半死。但是有客人在家,我就会特别老实……我后妈让做什么就做什么,而且经常用眼睛瞟她,装得很怕她的样子……我现在想起来觉得我真是天生当演员的料……那么小的年纪就知道做虚弄假……所以我们家亲戚朋友都觉得我很乖……我估计如果我后妈跟人说我在家里怎么怎么使坏,他们肯定会想“怪不得人家说后妈的孩子可怜,怪不得她那么怕你呢……”
恶作剧六
我初三的时候参加市里的新概念作文,得了一等奖,里面写的是我妈,里面就写了家庭变故,就是第三者插足,后来父母离婚,那个第三者嫁给了我爸等等,那作文写得很煽情……我在班上念,我们班同学听得热泪盈眶的说,要是放在现在,也算是篇悲情小说了……期中考试我考了年级第一,家长会上先是前三名家长介绍经验,我爸和别的家长满面春风地介绍了一通……然后是学生的成果展和节目表演……我的节目就是念我那篇获奖作文……我在上面念,下面众目睽睽地听,念到后面,家长们都在下面窃窃私语,我爸和我后妈在下面听得脸一阵红一阵白……当时很痛快,代价就是我回家又被我爸痛揍一顿……
恶作剧七
我现在想起来,那时候很有点肆无忌惮的意思,我爸虽然有时候痛揍我,不过因为他就我一个女儿(我后妈怕影响体形,不肯生孩子),所以心里还是很疼我的说,而且我学习一向很好,年年被评市三好,初中和高中的时候还被评过省三好……后来又保送上了一个好大学……所以总的来说还是比较纵容我的……我的要求基本是有求必应……我小时候很尊敬我爸,但是都是因为他和我妈的事情,我的心里一直有疙瘩……有时候我是很想原谅他,但是人的心理是这样的,理智有的时候真的很难控制感情……我妈后来一直没有结婚,一个人住着一套旧房子,每次我想起我妈,我对我爸就根本爱不起来。
-我上大学的时候,花钱很厉害……因为我觉得不花白不花,我爸的钱我不花那个女人也要花……我毕业以后才知道隔壁班的同学称我每次都是“**(专业)班的那个头号富婆”……那时候我每个月生活费经常七八千都打不住……还不算作平时过生日出去旅游之类的花销……我放假回家,一家人出去吃饭,我后妈讽刺我说:“你读书怎么每个月花那么多钱?都快赶上我工资了”我就顶嘴说:“我花钱关你屁事,你嫁我爸不就是看上他的钱“,一点都不顾忌。我后妈骂我没家教,我就说我再没家教也不去泡别人的老公。把边上的服务小姐听得一愣一愣的,特别解恨。我在家给我妈打电话,每次都故意当着他们的面说将来我结了婚出国什么什么的肯定把她带着,以后要让我妈过好日子,以后过得比谁都舒服。反正是什么话刺激他们就专挑什么话。
我在家的时候,就什么都对着她干……比如我自己有自己的化妆品……但是每次都狠用她的……尤其是香水精华油之类……后来我每次回家,她就得把自己得化妆品收回卧室……每次出门还得把卧室锁着……晚上她睡觉前要跑步,我看看时间差不多了就赶快上跑步机,边看电视边跑……结果每年放假回家都要瘦一圈……因为我存心霸占跑步机……她总不能把我硬赶下来……后来我一回家,她就只好去健身房办卡,虽然家里有跑步机这。我bf是学医的,我还想过不少回弄点激素什么的涂在她的维生素丸或者花粉里……让她怎么保持都会象猪一样胖起来。不过我还算仁慈了,没有付诸实施……我后母当然每次都跟我骂骂咧咧,不过我就当没听见好了……反正我又不能掉块肉,可是自己解气,我算是狠赚的,我连我爸的巴掌都不怕,怕她个鸟。
刚上大学的时候,我忘记从哪里看到的一个狠办法,如果把我爸和后妈床头柜里的套套戳几个洞……但是我找到他们用的套套才发现套套是有包装袋的,如果我拆开了戳洞他们肯定会发现……结果不了了之……那个想法有点太弱智了……不知道哪个混蛋想出来的……无耻的二奶,不要脸的第三者,我恨她!
历史上最愚蠢的八大事件
1.1971年,一位亚利桑那人开枪打伤了自己。这倒没有什么可大惊小怪的,这种事情时有发生。可是为了提高呼救声的分贝,这位受伤的人又开了一枪,打中了另外一条腿。
2.一位在竞选活动的民意调查中落后的日本政客,为了获得同情的支持选票,制造出被人暗杀的假象。为了使暗杀看上去确有其事,这位政客用刀在自己腿上砍了一刀。没想到砍断了动脉,血流如注。在发表最后的竞选演说之前,他就一命呜呼。
3.17世纪的西班牙国王菲利普三世因发烧而去世,他的高烧是由于长时间坐在炉火旁而引起的。 既然他知道温度高,可为什么不从炉火那里移开呢?原因是:那不是他作为国王的工作。宫廷里负责照看炉火的佣人没有上班这名佣人的工作就是把国王的座椅往后拉。
4.一个法国人1998年尝试一次复杂的自杀。他站在一个高高的悬崖上,在脖子上套上一个索套,把绳索固定在一块巨大的岩石上。然后他喝下了毒药,并开始自杀悬崖上跳下去的时候,他又朝着自己的脑袋开了一枪。 结果是:子弹没有打中目标,反而打穿了绳索,因此他掉到了海里而没能吊死。冰冷的海水扑灭了他衣服上的火焰,而且这种冲击力使他把毒药呕吐出来。 一位渔民把他从水里拖了起来,送到医院,结果他由于体温过低而死亡。
5.1932年洛杉矶奥运会。当法国的朱利?内尔打破了铁饼的奥运会纪录时,他那获胜的一掷被判无效并非他违反了任何比赛规则,而是因为所有本应该注视着铁饼比赛的裁判员都转过头去观看撑杆跳高了。
6.在投篮秒表出现之前,伊利诺伊州有过这样一场比赛:比赛开始不久,乔治城队罚球得了一分,接着他们就把球藏起来了,霍马队的队员毫无办法,只好在球场上席地而坐,而裁判则在看报纸。当比赛时间结束时,乔治城队开始庆祝他们1:0的胜利。
7.一位乌克兰商人给他的50名员工每人买了一个传呼机作为礼物。在他返回的路上,这50个传呼机同时叫了起来,他由于受惊过度以至于把车撞到电线杆上。 检查完伤势之后,他开始查看传呼机上的信息。只见这50个传呼机上出现了同一句话:“感谢购买本机!”
8.1968年,底特律的一个窃贼带着他的爱犬入室行窃。当警察发现时,窃贼仓皇逃走,却把爱犬留在后面。警察非常容易地就抓住了窃贼,因为他们只是对狗说了句:“回家,宝贝!”
listner.log如果达到2G,数据库将无法建立连接。
解决办法有两个:
1) 用script定期切换日志
2) 设置log_status
现给出第二种方法:
1) 以oracle身份进入linux
2) lsnrctl
3) set log_status off
4) save_config
完成,listner.log不会再涨了。
以oracle 用户登陆,允许sqlplus "sys/oracle as sysdba"
1.shutdown abort
2.startup nomount pfile=/home/oracle/admin/shlbs/pfile/initshlbs.ora
3.如果startup nomount正常则
重做控制文件
CREATE CONTROLFILE REUSE DATABASE "SHLBS" NORESETLOGS ARCHIVELOG MAXLOGFILES 16 MAXLOGMEMBERS 3 MAXDATAFILES 100 MAXINSTANCES 8 MAXLOGHISTORY 454 LOGFILE GROUP 1 '/home/oracle/oradata/shlbs/redo01.log' SIZE 100M,GROUP 2 '/home/oracle/oradata/shlbs/redo02.log' SIZE 100M,GROUP 3 '/home/oracle/oradata/shlbs/redo03.log' SIZE 100M DATAFILE '/home/oracle/oradata/shlbs/CITYMGR.dbf','/home/oracle/oradata/shlbs/cwmlite01.dbf','/home/oracle/oradata/shlbs/drsys01.dbf','/home/oracle/oradata/shlbs/example01.dbf','/home/oracle/oradata/shlbs/indx01.dbf','/home/oracle/oradata/shlbs/LBS.dbf','/home/oracle/oradata/shlbs/odm01.dbf','/home/oracle/oradata/shlbs/system01.dbf','/home/oracle/oradata/shlbs/tools01.dbf','/home/oracle/oradata/shlbs/undotbs01.dbf','/home/oracle/oradata/shlbs/users01.dbf','/home/oracle/oradata/shlbs/xdb01.dbf' CHARACTER SET ZHS16GBK
4.如果需要,重做口令文件
orapwd file=口令文件路径和文件名 password=test entries=2
5.如果重做控制文件成功,则恢复数据库
recover database;
以上操作具体参数可能和具体数据相关,请修改。
linux联盟原创www.xxlinux.com www.linuxunion.org转贴请标明出处 作者上上智
看了这么久的blog,我自写一点配置哈
现在有很多想学习linux的人, 就是因为不能配置上网,所以不想学习现在我从adsl配置到nat全过程如下:
1)安装rp-pppoe-3.5-2包
在安装系统时,对新用户一般选择全部安装的,那就安装了,以后rpm, 或者tarball了,这很方便,对初学者:
eg:
rpm -ivh rp-pppoe-3.5-2.rpm
tarball 安装:
tar zxvf rp-pppoe-3.5-2.tar.gz
cd rp-pppoe-3.5-2
./configure
make
make install
2)rp-pppoe-3.5-2配置
步骤:
a) adsl-setup
出现:
Welcome to the ADSL client setup. First, I will run some checks on
your system to make sure the PPPoE client is installed properly...
The following DSL config was found on your system:
Device: Name:
ppp0
Please enter the device if you want to configure the present DSL config
(default ppp0) or enter 'n' if you want to create a new one:
//这是我已经安装过了,主要是写文档:选择默认按回车
LOGIN NAME
Enter your Login Name (default lanlgn409ldj@zgcnc):
//这是我已经安装过了,:没有安装是输入adsl用户名
INTERFACE
Enter the Ethernet interface connected to the ADSL modem
For Solaris, this is likely to be something like /dev/hme0.
For Linux, it will be ethX, where 'X' is a number.
(default eth0):
//选择默认按回车
Do you want the link to come up on demand, or stay up continuously?
If you want it to come up on demand, enter the idle time in seconds
after which the link should be dropped. If you want the link to
stay up permanently, enter 'no' (two letters, lower-case.)
NOTE: Demand-activated links do not interact well with dynamic IP
addresses. You may have some problems with demand-activated links.
Enter the demand value (default no):
//选择默认按回车
DNS
Please enter the IP address of your ISP's primary DNS server.
If your ISP claims that 'the server will provide dynamic DNS addresses',
enter 'server' (all lower-case) here.
If you just press enter, I will assume you know what you are
doing and not modify your DNS setup.
Enter the DNS information here:
// 输入server自动得到dns,server的ip
PASSWORD
Please enter your Password:
USERCTRL
Please enter 'yes' (two letters, lower-case.) if you want to allow
normal user to start or stop DSL connection (default yes):
//选择默认按回车问你是否连接
Please choose the firewall rules to use. Note that these rules are
very basic. You are strongly encouraged to use a more sophisticated
firewall setup; however, these will provide basic security. If you
are running any servers on your machine, you must choose 'NONE' and
set up firewalling yourself. Otherwise, the firewall rules will deny
access to all standard servers like Web, e-mail, ftp, etc. If you
are using SSH, the rules will block outgoing SSH connections which
allocate a privileged source port.
The firewall choices are:
0 - NONE: This script will not set any firewall rules. You are responsible
for ensuring the security of your machine. You are STRONGLY
recommended to use some kind of firewall rules.
1 - STANDALONE: Appropriate for a basic stand-alone web-surfing workstation
2 - MASQUERADE: Appropriate for a machine acting as an Internet gateway
for a LAN
Choose a type of firewall (0-2):
//是否设置firwall
Do you want to start this connection at boot time?
Please enter no or yes (default no):
//启动时是否连接
Do you want to start this connection at boot time?
Please enter no or yes (default no):
** Summary of what you entered **
Ethernet Interface: eth0
User name: lanlgn409ldj@zgcnc
Activate-on-demand: No
DNS: Do not adjust
Firewalling: NONE
User Control: yes
Accept these settings and adjust configuration files (y/n)?
//是否写入配置文件里 选择 y
3)假如你是用别人的mac连接
1 redhat9.0改mac:
ifconfig eth0 down
ifconfig eth0 hw ether 5254ab323d51
ifconfig eth0 up
ifup ppp0
2 fedora 4.0改mac:
ifdown eth0
ifconfig eth0 hw ether 5254ab323d51
ifup eth0
ifup ppp0 & adsl-start
4)测试一下
ping www.baidu.com
5)做nat
echo "1" > /proc/sys/net/ipv4/ip_forward //这很重要,路由转发
modprobe ip_tables
modprobe ip_nat_ftp
modprobe ip_nat_irc
modprobe ip_conntrack
modprobe ip_conntrack_ftp
modprobe ip_conntrack_irc
/sbin/iptables -F
/sbin/iptables -X
/sbin/iptables -Z
/sbin/iptables -F -t nat
/sbin/iptables -X -t nat
/sbin/iptables -Z -t nat
/sbin/iptables -P INPUT ACCEPT
/sbin/iptables -P OUTPUT ACCEPT
/sbin/iptables -P FORWARD ACCEPT
/sbin/iptables -t nat -P PREROUTING ACCEPT
/sbin/iptables -t nat -P POSTROUTING ACCEPT
/sbin/iptables -t nat -P OUTPUT ACCEPT
/sbin/iptables -t nat -A POSTROUTING -o ppp0 -s 192.168.0.0/24 -j MASQUERADE//不是adsl也可以把ppp0改成eth0 ,
1一般网卡nat:
[root@test root]# vi /etc/sysconfig/network-scripts/ifcfg-eth0
DEVICE=eth0
BOOTPROTO=dhcp
BROADCAST=192.168.0.255
IPADDR=192.168.0.1
NETMASK=255.255.255.0
NETWORK=192.168.0.0
ONBOOT=yes
[root@test root]# vi /etc/sysconfig/network-scripts/ifcfg-eth0:0
DEVICE=eth0:0
BOOTPROTO=static
BROADCAST=192.168..255
IPADDR=192.168.1.2
NETMASK=255.255.255.0
NETWORK=192.168..0
ONBOOT=yes
2 两块网卡nat:
只是那個 eth0:0 改成了 eth1 而已啦,其它都是一样的设置
6)dns 设置
在里面/etc/resolv.conf
把你的ip写入里面去
nameserver 192.168.0.1
然后重启要不然,客户机不能上网
问题引发: 服务器每天产生大量的系统日志,查询日志,目前日志这块没有人专门拿出来做分析,处理这些日志.随着时间以及服务器访问量的与日俱增,不小心就会出现硬盘被日志文件占满的现象.如果删除这些日志,以后日志分析也许要用到.不删现有服务会受到影响.以后可能会专门有一台服务器来处理这些日志,分析日志,估算出性能瓶颈,以及得出相应的有价值的商业信息.所以只能临时处理一下. 看了一下linux的压缩格式好多种,忽然一看有些晕,发一篇关于linux压缩文件的详细文章,摘自:Unix爱好者家园unix-cd.com ,以下是原文 对于刚刚接触 Linux 的人来说,一定会给 Linux 下一大堆各式各样的文件名给搞晕。别个不说,单单就压缩文件为例,我们知道在 Windows 下最常见的压缩文件就只有两种,一是 .zip,另一个是 .rar。可是 Linux 就不同了,它有.gz、.tar.gz、tgz、bz2、.Z、.tar 等众多的压缩文件名,此外 windows 下的 .zip 和 .rar 也可以在 Linux 下使用,不过在 Linux 使用 .zip 和 .rar 的人就太少了。 在具体总结各类压缩文件之前呢,首先要弄清两个概念:打包和压缩。打包是指将一大堆文件或目录什么的变成一个总的文件,压缩则是将一个大的文件通过一些压缩算法变成一个小文件。为什么要区分这两个概念呢?其实这源于 Linux 中的很多压缩程序只能针对一个文件进行压缩,这样当你想要压缩一大堆文件时,你就得先借助另它的工具将这一大堆文件先打成一个包,然后再就原来的压缩程序进行压缩。 Linux下最常用的打包程序就是 tar 了,使用 tar 程序打出来的包我们常称为 tar 包,tar 包文件的命令通常都是以 .tar 结尾的。生成 tar 包后,就可以用其它的程序来进行压缩了,所以我们先了解一下 tar 命令的基本用法: tar 命令的选项有很多(用man tar可以查看到),但我们通常需要的就是那么几个: # tar -cf all.tar *.jpg 这条命令是将所有 .jpg 的文件打成一个名为 all.tar 的包。-c 是表示产生新的包,-f 指定包的文件名。 # tar -rf all.tar *.gif 这条命令是将所有.gif的文件增加到 all.tar 的包里面去。-r 是表示增加文件的意思。 # tar -uf all.tar logo.gif 这条命令是更新原来 tar 包 all.tar 中 logo.gif 文件,-u是表示更新文件的意思。 # tar -tf all.tar 这条命令是列出 all.tar 包中所有文件,-t 是列出文件的意思 # tar -xf all.tar 这条命令是解出 all.tar 包中所有文件,-t 是解开的意思 以上就是 tar 的最基本的用法。为了方便用户在打包解包的同时可以压缩或解压文件,tar 提供了一种特殊的功能。这就是 tar 可以在打包或解包的同时调用其它的压缩程序,比如调用 gzip、bzip2 等。 (一)、 tar 调用 gzip gzip 是 GNU 组织开发的一个压缩程序,.gz 结尾的文件就是 gzip 压缩的结果。与 gzip 相对的解压程序是 gunzip。tar 中使用 -z 这个参数来调用 gzip。下面来举例说明一下: # tar -czf all.tar.gz *.jpg 这条命令是将所有 .jpg 的文件打成一个 tar 包,并且将其用 gzip 压缩,生成一个 gzip 压缩过的包,包名为 all.tar.gz。 # tar -xzf all.tar.gz 这条命令是将上面产生的包解开。 (二)、 tar 调用 bzip2 bzip2 是一个压缩能力更强的压缩程序,.bz2 结尾的文件就是 bzip2 压缩的结果。与 bzip2 相对的解压程序是 bunzip2。tar 中使用-j这个参数来调用 gzip。下面来举例说明一下: # tar -cjf all.tar.bz2 *.jpg 这条命令是将所有 .jpg 的文件打成一个 tar 包,并且将其用 bzip2 压缩,生成一个 bzip2 压缩过的包,包名为 all.tar.bz2。 # tar -xjf all.tar.bz2 这条命令是将上面产生的包解开。 (三)、 tar 调用 compress compress 也是一个压缩程序,但是好象使用 compress 的人不如 gzip 和 bzip2 的人多。.Z 结尾的文件就是 bzip2 压缩的结果。与 compres s相对的解压程序是 uncompress。tar 中使用 -Z 这个参数来调用 gzip。下面来举例说明一下: # tar -cZf all.tar.Z *.jpg 这条命令是将所有 .jpg 的文件打成一个 tar 包,并且将其用 compress 压缩,生成一个 uncompress 压缩过的包,包名为 all.tar.Z # tar -xZf all.tar.Z 这条命令是将上面产生的包解开 有了上面的知识,你应该可以解开多种压缩文件了,下面对于 tar 系列的压缩文件作一个小结: (一)、对于 .tar 结尾的文件 tar -xf all.tar (二)、对于 .gz 结尾的文件 gzip -d all.gz gunzip all.gz (三)、对于 .tgz 或 .tar.gz 结尾的文件 tar -xzf all.tar.gz tar -xzf all.tgz (四)、对于 .bz2 结尾的文件 bzip2 -d all.bz2 bunzip2 all.bz2 (五)、对于 tar.bz2 结尾的文件 tar -xjf all.tar.bz2 (六)、对于 .Z 结尾的文件 uncompress all.Z (七)、对于.tar.Z结尾的文件 tar -xZf all.tar.z 另外对于 Window 下的常见压缩文件 .zip 和 .rar,Linux 也有相应的方法来解压它们: (1)对于 .zip linux 下提供了 zip 和 unzip 程序,zip 是压缩程序,unzip 是解压程序。它们的参数选项很多,这里只做简单介绍,依旧举例说明一下其用法: # zip all.zip *.jpg 这条命令是将所有 .jpg 的文件压缩成一个 zip 包 # unzip all.zip 这条命令是将 all.zip 中的所有文件解压出来 (2)对于 .rar 要在 linux 下处理 .rar 文件,需要安装 RAR for Linux,可以从网上下载,但要记住,RAR for Linux 不是免费的;可从 http://www.rarsoft.com/download.htm 下载 RAR for Linux 3.2.0,然后安装: # tar -xzpvf rarlinux-3.2.0.tar.gz # cd rar # make 这样就安装好了,安装后就有了 rar 和 unrar 这两个程序,rar 是压缩程序,unrar 是解压程序。它们的参数选项很多,这里只做简单介绍,依旧举例说明一下其用法: # rar a all *.jpg 这条命令是将所有 .jpg 的文件压缩成一个 rar 包,名为 all.rar,该程序会将 .rar 扩展名将自动附加到包名后。 # unrar e all.rar 这条命令是将 all.rar 中的所有文件解压出来 到此为至,我们已经介绍过 linux 下的 tar、gzip、gunzip、bzip2、bunzip2、compress、uncompress、zip、unzip、rar、unrar 等程式,你应该已经能够使用它们对 .tar、.gz、.tar.gz、.tgz、.bz2、.tar.bz2、.Z、.tar.Z、.zip、.rar 这 10 种压缩文件进行解压了,以后应该不需要为下载了一个软件而不知道如何在 Linux 下解开而烦恼了。而且以上方法对于 Unix 也基本有效。 本文介绍了 linux 下的压缩程式 tar、gzip、gunzip、bzip2、bunzip2、compress、uncompress、zip、unzip、rar、unrar 等程式,以及如何使用它们对 .tar、.gz、.tar.gz、.tgz、.bz2、.tar.bz2、.Z、.tar.Z、.zip、.rar 这 10 种压缩文件进行操作。
3.2 VSFTP 安全与效能兼备的ftp 服务器
3.2.1 VSFTP 概述
FTP,file transfer protocol,这是档案传输的通讯协议,也是一般最常用来传送档案的方式。读者在使用RedHat9 的时候,可能会感受到ftp server 有一些改变:第一,就是ftp server 只剩下vsftp,原有的wuftp 等都没放入 第二,就是vsftp 从XINETD 中独立出来,并将设定档从/etc/vsftpd.conf 之中移到/etc/vsftpd/vsftpd.conf。
为什么做这样的改变?可以想见的是vsftp 已有独立运作的能力,不需要XINETD 来做更进一步的管控,并且类似sendmail、httpd、ssh、samba 等,将设定文件的放入/etc 下独立的目录。
FTP 分为两类,一种为PORT FTP,也就是一般的FTP 另一类是PASVFTP,分述如下:
PORT FTP
这是一般形式的FTP,首先会建立控制频道,默认值是port 21,也就是跟port 21 建立联机,并透过此联机下达指令。第二,由FTP server 端会建立数据传输频道,默认值为20,也就是跟port 20 建立联机,并透过port 20 作数据的传输。
PASV FTP
跟PORT FTP 类似,首先会建立控制频道,默认值是port 21,也就是跟port 21 建立联机,并透过此联机下达指令。第二,会由client 端做出数据传输的请求,包括数据传输port 的数字。
这两者的差异为何?PORT FTP 当中的数据传输port 是由FTP server 指定,而PASV FTP 的数据传输port 是由FTP client 决定。通常我们使用PASV FTP,是在有防火墙的环境之下,透过client 与server 的沟通,决定数据传输的port。
3.2.2 范例
3.2.1. 直接启动VSFTP 服务
这个范例是套用RedHat 的预设范例,直接启动vsftp。
[root@relay vsftpd]# /sbin/service vsftpd start
Starting vsftpd for vsftpd: OK ]
3.2.2. 更换port 提供服务:将预设的port 21 更换为2121
为了安全,或是以port 来区隔不同的ftp 服务,我们可能会将ftp port 改为21 之外的port,那么,可参考以下步骤。
Step1. 修改/etc/vsftpd/vsftpd.conf
新增底下一行
listen_port=2121
Step2. 重新启动vsftpd
[root@home vsftpd]# /sbin/service vsftpd restart
Shutting down vsftpd: OK ]
Starting vsftpd for vsftpd: OK ]
3.2.3. 特定使用者peter、john 不得变更目录
使用者的预设目录为/home/username,若是我们不希望使用者在ftp 时能够
切换到上一层目录/home,则可参考以下步骤。
Step1. 修改/etc/vsftpd/vsftpd.conf
将底下三行
#chroot_list_enable=YES
# (default follows)
#chroot_list_file=/etc/vsftpd.chroot_list
改为
chroot_list_enable=YES
# (default follows)
chroot_list_file=/etc/vsftpd/chroot_list
Step2. 新增一个档案: /etc/vsftpd/chroot_list
内容增加两行:
peter
john
Step3. 重新启动vsftpd
[root@home vsftpd]# /sbin/service vsftpd restart
Shutting down vsftpd: OK ]
Starting vsftpd for vsftpd: OK ]
若是peter 欲切换到根目录以外的目录,则会出现以下警告:
ftp> cd /home
550 Failed to change directory.
3.2.4. 取消anonymous 登入
若是读者的主机不希望使用者匿名登入,则可参考以下步骤。
Step1. 修改/etc/vsftpd/vsftpd.conf
将
anonymous_enable=YES
改为
anonymous_enable=NO
Step2. 重新启动vsftpd
[root@home vsftpd]# /sbin/service vsftpd restart
Shutting down vsftpd: OK ]
Starting vsftpd for vsftpd: OK ]
3.2.5. 安排欢迎话语
若是我们希望使用者在登入时,能够看到欢迎话语,可能包括对该主机的说明,或是目录的介绍,可参考以下步骤。
首先确定在/etc/vsftpd/vsftpd.conf 当中是否有底下这一行
dirmessage_enable=YES
RedHat9 的默认值是有上面这行的。
接着,在各目录之中,新增名为.message 的档案,再这边假设有一个使用者test1,且此使用者的根目录下有个目录名为abc,那首先我们在/home/test1
之下新增.message,内容如下:
Hello~ Welcome to the home directory
This is for test only...
接着,在/home/test1/abc 的目录下新增.message,内容如下:
Welcome to abc's directory
This is subdir...
那么,当使用者test1 登入时,会看到以下讯息:
230- Hello~ Welcome to the home directory
230-
230- This is for test only...
230-
若是切换到abc 的目录,则会出现以下讯息:
250- Welcome to abc's directory
250-
250- This is subdir ...
3.2.6. 对于每一个联机,以独立的process 来运作
一般启动vsftp 时,我们只会看到一个名为vsftpd 的process 在运作,但若是读者希望每一个联机,都能以独立的process 来呈现,则可执行以下步骤。
Step1. 修改/etc/vsftpd/vsftpd.conf
新增底下一行
setproctitle_enable=YES
Step2. 重新启动vsftpd
[root@home vsftpd]# /sbin/service vsftpd restart
Shutting down vsftpd: OK ]
Starting vsftpd for vsftpd: OK ]
使用ps -ef 的指令,可以看告不同使用者联机的情形,如下图所示:
[root@home vsftpd]# ps -ef|grep ftp
root 2090 1 0 16:41 pts/0 00:00:00 vsftpd: LISTENER
nobody 2120 2090 0 17:18 ? 00:00:00 vsftpd: 192.168.10.244:
connected
test1 2122 2120 0 17:18 ? 00:00:00 vsftpd: 192.168.10.244/test1:
IDLE
nobody 2124 2090 0 17:19 ? 00:00:00 vsftpd: 192.168.10.244:
connected
test2 2126 2124 0 17:19 ? 00:00:00 vsftpd: 192.168.10.244/test2:
IDLE
root 2129 1343 0 17:20 pts/0 00:00:00 grep ftp
[root@home vsftpd]#
3.2.7. 限制传输档案的速度:
本机的使用者最高速度为200KBytes/s,匿名登入者所能使用的最高速度为50KBytes/s
Step1. 修改/etc/vsftpd/vsftpd.conf
新增底下两行
anon_max_rate=50000
local_max_rate=200000
Step2. 重新启动vsftpd
[root@home vsftpd]# /sbin/service vsftpd restart
Shutting down vsftpd: OK ]
Starting vsftpd for vsftpd: OK ]
在这边速度的单位为Bytes/s,其中anon_max_rate 所限制的是匿名登入的
使用者,而local_max_rate 所限制的是本机的使用者。VSFTPD 对于速度的限
制,范围大概在80%到120%之间,也就是我们限制最高速度为100KBytes/s,
但实际的速度可能在80KBytes/s 到120KBytes/s 之间,当然,若是频宽不足
时,数值会低于此限制。
3.2.8. 针对不同的使用者限制不同的速度:
假设test1 所能使用的最高速度为250KBytes/s,test2 所能使用的最高速度为500KBytes/s。
Step1. 修改/etc/vsftpd/vsftpd.conf
新增底下一行
user_config_dir=/etc/vsftpd/userconf
Step2. 新增一个目录:/etc/vsftpd/userconf
mkdir /etc/vsftpd/userconf
Step3. 在/etc/vsftpd/userconf 之下新增一个名为test1 的档案
内容增加一行:
local_max_rate=250000
Step4. 在/etc/vsftpd/userconf 之下新增一个名为test2 的档案
内容增加一行:
local_max_rate=500000
Step5. 重新启动vsftpd
[root@home vsftpd]# /sbin/service vsftpd restart
Shutting down vsftpd: OK ]
Starting vsftpd for vsftpd: OK ]
3.2.9-1. 建置一个防火墙下的ftp server,使用PORT FTP mode:
预设的ftp port:21 以及ftp data port:20
启动VSFTPD 之后执行以下两行指令,只允许port 21 以及port 20 开放,其它关闭。
iptables -A INPUT -p tcp -m multiport --dport 21,20 -j ACCEPT
iptables -A INPUT -p tcp -j REJECT --reject-with tcp-reset
3.2.9-2. 建置一个防火墙下的ftp server,使用PORT FTP mode:
ftp port:2121 以及ftp data port:2020
Step1. 执行以下两行指令,只允许port 2121 以及port 2020 开放,其它关闭。
iptables -A INPUT -p tcp -m multiport --dport 2121,2020 -j ACCEPT
iptables -A INPUT -p tcp -j REJECT --reject-with tcp-reset
Step2. 修改/etc/vsftpd/vsftpd.conf
新增底下两行
listen_port=2121
ftp_data_port=2020
Step3. 重新启动vsftpd
[root@home vsftpd]# /sbin/service vsftpd restart
Shutting down vsftpd: OK ]
Starting vsftpd for vsftpd: OK ]
在这边要注意,8、9 两个例子中,ftp client(如cuteftp)的联机方式不能够选择passive mode,否则无法建立数据的联机。也就是读者可以连上ftp
server,但是执行ls、get 等等的指令时,便无法运作。
3.2.10. 建置一个防火墙下的ftp server,使用PASS FTP mode:
ftp port:2121 以及ftp data port 从9981 到9986。
Step1. 执行以下两行指令,只允许port 2121 以及port 9981-9990 开放,其它关闭。
iptables -A INPUT -p tcp -m multiport --dport
2121,9981,9982,9983,9984,9985,9986,9987,9988,9989,9990 -j ACCEPT
iptables -A INPUT -p tcp -j REJECT --reject-with tcp-reset
Step2. 修改/etc/vsftpd/vsftpd.conf
新增底下四行
listen_port=2121
pasv_enable=YES
pasv_min_port=9981
pasv_max_port=9986
Step3. 重新启动vsftpd
[root@home vsftpd]# /sbin/service vsftpd restart
Shutting down vsftpd: OK ]
Starting vsftpd for vsftpd: OK ]
在这边要注意,在10 这个例子中,ftp client(如cuteftp)的联机方式必须选择passive mode,否则无法建立数据的联机。也就是读者可以连上ftp server,但是执行ls,get 等等的指令时,便无法运作。
3.2.11. 将vsftpd 与TCP_wrapper 结合
若是读者希望直接在/etc/hosts.allow 之中定义允许或是拒绝的来源地址,可执行以下步骤。这是简易的防火墙设定。
Step1. 确定/etc/vsftpd/vsftpd.conf 之中tcp_wrappers 的设定为YES,如下图所
示:
tcp_wrappers=YES
这是RedHat9 的默认值,基本上不需修改。
Step2. 重新启动vsftpd
[root@home vsftpd]# /sbin/service vsftpd restart
Shutting down vsftpd: OK ]
Starting vsftpd for vsftpd: OK ]
Step3. 设定/etc/hosts.allow,譬如提供111.22.33.4 以及10.1.1.1 到10.1.1.254 连
线,则可做下图之设定:
vsftpd : 111.22.33.4 10.1.1. : allow
ALL : ALL : DENY
3.2.12. 将vsftpd 并入XINETD
若是读者希望将vsftpd 并入XINETD 之中,也就是7.x 版的预设设定,那
么读者可以执行以下步骤。
Step1. 修改/etc/vsftpd/vsftpd.conf
将
listen=YES
改为
listen=NO
Step2. 新增一个档案: /etc/xinetd.d/vsftpd
内容如下:
service vsftpd
{
disable = no
socket_type = stream
wait = no
user = root
server = /usr/sbin/vsftpd
port = 21
log_on_success += PID HOST DURATION
log_on_failure += HOST
}
Step3. 重新启动xinetd
[root@home vsftpd]# /sbin/service xinetd restart
Stopping xinetd: OK ]
Starting xinetd: OK ]
3.2.3 设定档说明
在范例中,有些省略的设定可以在这边找到,譬如联机的总数、同一个位址的联机数、显示档案拥有者的名称等等,希望读者细读后,可以做出最适合自己的设定。
格式
vsftpd.conf 的内容非常单纯,每一行即为一项设定。若是空白行或是开头为#的一行,将会被忽略。内容的格式只有一种,如下所示
option=value
要注意的是,等号两边不能加空白,不然是不正确的设定。
===ascii 设定=====================
ascii_download_enable
管控是否可用ASCII 模式下载。默认值为NO。
ascii_upload_enable
管控是否可用ASCII 模式上传。默认值为NO。
===个别使用者设定===================
chroot_list_enable
如果启动这项功能,则所有的本机使用者登入均可进到根目录之外的数据夹,除了列
在/etc/vsftpd.chroot_list 之中的使用者之外。默认值为NO。
userlist_enable
用法:YES/NO
若是启动此功能,则会读取/etc/vsftpd.user_list 当中的使用者名称。此项功能可以在询问密码前就出现失败讯息,而不需要检验密码的程序。默认值为关闭。
userlist_deny
用法:YES/NO
这个选项只有在userlist_enable 启动时才会被检验。如果将这个选项设为YES,则在/etc/vsftpd.user_list 中的使用者将无法登入 若设为NO , 则只有在
/etc/vsftpd.user_list 中的使用者才能登入。而且此项功能可以在询问密码前就出现错误讯息,而不需要检验密码的程序。
user_config_dir
定义个别使用者设定文件所在的目录,例如定义user_config_dir=/etc/vsftpd/userconf,且主机上有使用者test1,test2,那我们可以在user_config_dir 的目录新增文件名为test1 以及test2。若是test1 登入,则会读取user_config_dir 下的test1 这个档案内的设定。默认值为无。
===欢迎语设定=====================
dirmessage_enable
如果启动这个选项,使用者第一次进入一个目录时,会检查该目录下是否有.message这个档案,若是有,则会出现此档案的内容,通常这个档案会放置欢迎话语,或是对该目录的说明。默认值为开启。
banner_file
当使用者登入时,会显示此设定所在的档案内容,通常为欢迎话语或是说明。默认值为无。
ftpd_banner
这边可定义欢迎话语的字符串,相较于banner_file 是档案的形式,而ftpd_banner 是字串的格式。预设为无。
===特殊安全设定====================
chroot_local_user
如果设定为YES,那么所有的本机的使用者都可以切换到根目录以外的数据夹。预设值为NO。
hide_ids
如果启动这项功能,所有档案的拥有者与群组都为ftp,也就是使用者登入使用ls -al之类的指令,所看到的档案拥有者跟群组均为ftp。默认值为关闭。
ls_recurse_enable
若是启动此功能,则允许登入者使用ls -R 这个指令。默认值为NO。
write_enable
用法:YES/NO
这个选项可以控制FTP 的指令是否允许更改file system,譬如STOR、DELE、
RNFR、RNTO、MKD、RMD、APPE 以及SITE。预设是关闭。
setproctitle_enable
用法:YES/NO
启动这项功能,vsftpd 会将所有联机的状况已不同的process 呈现出来,换句话说,使用ps -ef 这类的指令就可以看到联机的状态。默认值为关闭。
tcp_wrappers
用法:YES/NO
如果启动,则会将vsftpd 与tcp wrapper 结合,也就是可以在/etc/hosts.allow 与/etc/hosts.deny 中定义可联机或是拒绝的来源地址。
pam_service_name
这边定义PAM 所使用的名称,预设为vsftpd。
secure_chroot_dir
这个选项必须指定一个空的数据夹且任何登入者都不能有写入的权限,当vsftpd 不需要file system 的权限时,就会将使用者限制在此数据夹中。默认值为/usr/share/empty
===纪录文件设定=====================
xferlog_enable
用法:YES/NO
如果启动,上传与下载的信息将被完整纪录在底下xferlog_file 所定义的档案中。预设为开启。
xferlog_file
这个选项可设定纪录文件所在的位置,默认值为/var/log/vsftpd.log。
xferlog_std_format
如果启动,则纪录文件将会写为xferlog 的标准格式,如同wu-ftpd 一般。默认值为关闭。
===逾时设定======================
accept_timeout
接受建立联机的逾时设定,单位为秒。默认值为60。
connect_timeout
响应PORT 方式的数据联机的逾时设定,单位为秒。默认值为60。
data_connection_timeout
建立数据联机的逾时设定。默认值为300 秒。
idle_session_timeout
发呆的逾时设定,若是超出这时间没有数据的传送或是指令的输入,则会强迫断线,单位为秒。默认值为300。
===速率限制======================
anon_max_rate
匿名登入所能使用的最大传输速度,单位为每秒多少bytes,0 表示不限速度。默认值为0。
local_max_rate
本机使用者所能使用的最大传输速度,单位为每秒多少bytes,0 表示不限速度。预设值为0。
===新增档案权限设定==================
anon_umask
匿名登入者新增档案时的umask 数值。默认值为077。
file_open_mode
上传档案的权限,与chmod 所使用的数值相同。默认值为0666。
local_umask
本机登入者新增档案时的umask 数值。默认值为077。
===port 设定======================
connect_from_port_20
用法:YES/NO
若设为YES,则强迫ftp-data 的数据传送使用port 20。默认值为YES。
ftp_data_port
设定ftp 数据联机所使用的port。默认值为20。
listen_port
FTP server 所使用的port。默认值为21。
pasv_max_port
建立资料联机所可以使用port 范围的上界,0 表示任意。默认值为0。
pasv_min_port
建立资料联机所可以使用port 范围的下界,0 表示任意。默认值为0。
===其它========================
anon_root
使用匿名登入时,所登入的目录。默认值为无。
local_enable
用法:YES/NO
启动此功能则允许本机使用者登入。默认值为YES。
local_root
本机使用者登入时,将被更换到定义的目录下。默认值为无。
text_userdb_names
用法:YES/NO
当使用者登入后使用ls -al 之类的指令查询该档案的管理权时,预设会出现拥有者的UID,而不是该档案拥有者的名称。若是希望出现拥有者的名称,则将此功能开启。默认值为NO。
pasv_enable
若是设为NO,则不允许使用PASV 的模式建立数据的联机。默认值为开启。
===更换档案所有权===================
chown_uploads
用法:YES/NO
若是启动,所有匿名上传数据的拥有者将被更换为chown_username 当中所设定的使用者。这样的选项对于安全及管理,是很有用的。默认值为NO。
chown_username
这里可以定义当匿名登入者上传档案时,该档案的拥有者将被置换的使用者名称。预设值为root。
===guest 设定=====================
guest_enable
用法:YES/NO
若是启动这项功能,所有的非匿名登入者都视为guest。默认值为关闭。
guest_username
这里将定义guest 的使用者名称。默认值为ftp。
===anonymous 设定==================
anonymous_enable
用法:YES/NO
管控使否允许匿名登入,YES 为允许匿名登入,NO 为不允许。默认值为YES。
no_anon_password
若是启动这项功能,则使用匿名登入时,不会询问密码。默认值为NO。
anon_mkdir_write_enable
用法:YES/NO
如果设为YES,匿名登入者会被允许新增目录,当然,匿名使用者必须要有对上层目录的写入权。默认值为NO。
anon_other_write_enable
用法:YES/NO
如果设为YES,匿名登入者会被允许更多于上传与建立目录之外的权限,譬如删除或是更名。默认值为NO。
anon_upload_enable
用法:YES/NO
如果设为YES,匿名登入者会被允许上传目录的权限,当然,匿名使用者必须要有对上层目录的写入权。默认值为NO。
anon_world_readable_only
用法:YES/NO
如果设为YES,匿名登入者会被允许下载可阅读的档案。默认值为YES。
ftp_username
定义匿名登入的使用者名称。默认值为ftp。
deny_email_enable
若是启动这项功能,则必须提供一个档案/etc/vsftpd.banner_emails,内容为email
address。若是使用匿名登入,则会要求输入email address,若输入的email address 在此档案内,则不允许联机。默认值为NO。
===Standalone 选项==================
listen
用法:YES/NO
若是启动,则vsftpd 将会以独立运作的方式执行,若是vsftpd 独立执行,如RedHat9的默认值,则必须启动 若是vsftpd 包含在xinetd 之中,则必须关闭此功能,如RedHat8。在RedHat9 的默认值为YES。
listen_address
若是vsftpd 使用standalone 的模式,可使用这个参数定义使用哪个IP address 提供这项服务,若是主机上只有定义一个IP address,则此选项不需使用,若是有多个IP address,可定义在哪个IP address 上提供ftp 服务。若是不设定,则所有的IP address均会提供此服务。默认值为无。
max_clients
若是vsftpd 使用standalone 的模式,可使用这个参数定义最大的总联机数。超过这个数目将会拒绝联机,0 表示不限。默认值为0。
max_per_ip
若是vsftpd 使用standalone 的模式,可使用这个参数定义每个ip address 所可以联机的数目。超过这个数目将会拒绝联机,0 表示不限。默认值为0。
=============================
3.2.4 FTP 数字代码的意义
110 重新启动标记应答。
120 服务在多久时间内ready。
125 数据链路埠开启,准备传送。
150 文件状态正常,开启数据连接端口。
200 命令执行成功。
202 命令执行失败。
211 系统状态或是系统求助响应。
212 目录的状态。
213 文件的状态。
214 求助的讯息。
215 名称系统类型。
220 新的联机服务ready。
221 服务的控制连接埠关闭,可以注销。
225 数据连结开启,但无传输动作。
226 关闭数据连接端口,请求的文件操作成功。
227 进入passive mode。
230 使用者登入。
250 请求的文件操作完成。
257 显示目前的路径名称。
331 用户名称正确,需要密码。
332 登入时需要账号信息。
350 请求的操作需要进一部的命令。
421 无法提供服务,关闭控制连结。
425 无法开启数据链路。
426 关闭联机,终止传输。
450 请求的操作未执行。
451 命令终止:有本地的错误。
452 未执行命令:磁盘空间不足。
500 格式错误,无法识别命令。
501 参数语法错误。
502 命令执行失败。
503 命令顺序错误。
504 命令所接的参数不正确。
530 未登入。
532 储存文件需要账户登入。
550 未执行请求的操作。
551 请求的命令终止,类型未知。
552 请求的文件终止,储存位溢出。
553 未执行请求的的命令,名称不正确。
1. 什么是grub
grub 是一个多重启动管理器。grub是GRand Unified Bootloader的缩写,它可以在多个操作系统共存时选择引导哪个系统。它可以引导的操作系包括linux,FreeBSD,Solaris,NetBSD,BeOSi,OS/2,Windows95/98,Windows NT,Windows2000。它可以载入操作系统的内核和初始化操作系统(如Linux,FreeBSD),或者把引导权交给操作系统(如Windows 98)来完成引导。
2. grub的特点
grub可以代替lilo来完成对Linux的引导,特别适用于linux与其它操作系统共存情况,与lilo相比,它有以下特点:
支持大硬盘
现在大多数Linux发行版本的lilo都有同样的一个问题:根分区(/boot分区)不能分在超过1024柱面的地方,一般是在8.4G左右的地方,否则lilo不能安装,或者安装后不能正确引导系统。而grub就不会出现这种情况,只要安装时你的大硬盘是在LBA模式下,grub就可以引导根分区在8G以外的操作系统。
支持开机画面
grub支持在引导开机的同时显示一个开机画面。对于玩家来说,这样可以制作自己的个性化开机画面;对于PC厂商,这样可以在开机时显示电脑的一些信息和厂商的标志等。grub支持640x480,800x600,1024x768各种模式的开机画面,而且可以自动侦测选择最佳模式,与Windows那320x400的开机画面不可同日而语。
两种执行模式
grub不但可以通过配置文件进行例行的引导,还可以在选择引导前动态改变引导时的参数,还可以动态加载各种设备。例如你在Linux下编译了一个新的核心,但不能确定它能不能工作,你就可以在引导时动态改变grub的参数,尝试装载这个新的核心进行使用。Grub的命令行有非常强大的功能,而且支持如bash或doskey一样的历史功能,你可以用上下键来寻找以前的命令。
菜单式选择
在lilo下,你需要手工输入操作系统的名字来引导不同的操作系统。而grub使用一个菜单来选择不同的系统进行引导。你还可以自己配置各种参数,如延迟时间,默认操作系统等。
分区位置改变后不必重新配置
lilo是通过读取硬盘上的绝对扇区来装入操作系统,因此每次分区改变都必须重新配置lilo,例如你用PQ magic调整了分区的大小,那lilo在你重新配置好之前就不能引导这个分区的操作系统了。而grub是通过文件系统直接把核心读取到内存,因此只要操作系统核心的路径没有改变,grub就可以引导系统。 除此之外,Grub还有许多非常强大的功能。例如支持多种外部设备,动态装载操作系统内核,甚至可以通过网络装载操作系统核心。Grub支持多种文件系统,支持多种可执行文件格式,支持自动解压,可以引导不支持多重引导的操作系统等。
3. grub的使用
安装grub
如果已经安装了蓝点Linux2.0则grub是默认安装的。要把grub重新安装到主引导扇区上,只需要简单打入makebootable命令就可以了。
制作grub启动盘
首先确定grub已经安装,然后进入grub的目录,键入:
#cd /boot/grub
放入一张软盘,然后敲入命令:
#dd if=stage1 of=/dev/fd0 bs=512 count=1
#dd if=/stage2 of=/dev/fd0 bs512 seek=1
这样就可以做好一张启动盘了。
开机
安装了grub开机后会出现一个菜单,列出所有的启动选项。如果设置了启动画面则会显示启动画面,按Esc键则可以取消启动画面显示菜单选项。蓝点Linux所带的grub的命令提示是全中文的,在菜单下面详细列出如按e是编辑启动命令,按c是使用命令行等。用上下键可以选择菜单项,按回车启动所选项。按e键可以编辑所选项的启动命令,你可以用这个功能临时改变你的系统的启动参数,参见配置grub一节。按c键则进入命令行模式。
在命令行模式下可以打入命令直接执行,例如你可以敲入poweroff关闭计算机。按Tab键可以列出所有支持的命令。蓝点Linux已经把grub汉化了,其中一部分命令敲入名字后会给出中文提示,显示命令的用法和参数。
4. 配置grub
grub启动时会在/boot/grub/中寻找一个名字为menu.lst的配置文件,如果找不到此文件则不进入菜单模式而直接进入命令行模式。
menu.lst 是一个文本文件,你可以用任何一个文本编辑器来打开它。每一行代表一个配置命令,如果一行的第一个字符为井号"#"则这一行为注释,你可以简单地用增加或减少注释行来改变配置。
编辑menu.lst,一般会有以下各行
timeout second
设定在second秒之后引导默认的操作系统。
蓝点Linux默认是timeout 5,就是5秒没有其他指令就引导系统,如果设成-1,则grub会一直等待直到用户选择一个选项为止。
default num
默认启动第num+1行选项,也就说default=0则默认启动菜单第一行的操作系统,default=1则启动第2行的系统,如此类推。
splash pathname/filename
指出开机画面的文件所存放的路径和文件名,如 splash /boot/logo/800x600x8.img 是指用在/boot/logo路径下的800x600.img文件作为开机画面
title OSname title
后面的字符就是你在菜单项上所看见的选项,你可以写上操作系统的名字和描述,如用
title BluePoint Linux, Single Mode 代表这一选项是引导蓝点Linux的单用户模式。
下面结合两个系统引导描述来解释几个引导选项的意义
title BluePoint Linux, Default Mode
root (hd0,1)
kernel /boot/vmlinuz vga=auto root=/dev/hda2
hd0是指第一个硬盘(主硬盘) (hd0,1)是指第一个硬盘的第二个分区。 kernel /boot/vmlinuz 是指出Linux核心的路径在/boot/vmlinuz中。vga=auto 是设定显示模式,root=/dev/hda2是指把第一个硬盘的第二个分区作为根挂载点("/")。
title Microsoft Windows
root (hd1,0)
chainloader (hd1,0)+1 root (hd1,0)这是指第二个硬盘(从硬盘)上第一个分区
chainloader (hd1,0)+1 装入一个扇区的数据然后把引导权交给它。
5. 从软盘启动grub
制作启动盘后可以用软盘启动引导硬盘上的操作系统 插入制作好的启动软盘,进入BIOS设定软盘启动。软盘启动成功后就会进入grub的命令行模式
grub>
要启动一个操作系统,首先指定引导哪个分区上的系统,例如要引导指第一个硬盘上的第一个分区的操作系统,先键入
grub>root (hd0,0)
接着如果要启动的是Windows系统,键入 grub>chainloader (hd0,0)+1
注意(hd0,0)要随着硬盘和分区的不同而改变数字。 如果要引导Linux或其他系统,应键入
grub>kernel (hd0,0)/boot/vmlinuz root=/dev/hda1
注意hda1参数也要随着硬盘和分区的不同而改变,如从第二个硬盘的第一个分区引导则用hdb1。 最后敲入boot就可以启动系统了。
在任何时候不能确定命令或者命令的参数都可以按Tab获得相关的帮助。用上下键可以获得命令的历史记录。 其实这些命令就是menu.lst的启动描述,您也可以根据那些描述来自己键入启动命令,最后敲入boot就可以引导系统了。
一、什么是init
init是Linux系统操作中不可缺少的程序之一。 是一个由内核启动的用户级进程。
内核启动(已经被载入内存,开始运行,并已初始化所有的设备驱动程序和数据结构等)之后,就通过启动一个用户级程序init的方式来启动其他用户级的进程或服务。所以,init始终是第一个进程(其PID始终为1)。
内核会在过去曾使用过init的几个地方查找它,它的正确位置(对Linux系统来说)是/sbin/init。如果内核找不到init,它就会试着运行/bin/sh,如果运行失败,系统的启动也会失败。
二、运行级别
运行级就是操作系统当前正在运行的功能级别。这个级别从1到6,具有不同的功能。其功能级别如下:
# 0 - 停机(千万不能把initdefault 设置为0 )
# 1 - 单用户模式
# 2 - 多用户,没有 NFS
# 3 - 完全多用户模式(标准的运行级)
# 4 - 没有用到
# 5 - X11 (xwindow)
# 6 - 重新启动 (千万不要把initdefault 设置为6——把被你黑掉的linux的initdefault设置为0或6也算是拒绝服务攻击噢!)
除此之外还有ABC三个运行级别,但在RHLinux中都没有意义。
这些级别在/etc/inittab 文件里指定。这个文件是init 程序寻找的主要文件,最先运行的服务是放在/etc/rc.d 目录下的文件。在大多数的Linux 发行版本中,启动脚本都是位于 /etc/rc.d/init.d中的。这些脚本被用ln 命令连接到 /etc/rc.d/rcn.d 目录。(这里的n 就是运行级0-6)
三、运行级别的配置
运行级别的配置是在/etc/inittab行内进行的,如下所示:
12 : 2 : wait : / etc / init.d / rc 2
各字段解释如下:
id:runlevels:action:process
id:是一个任意指定的四个字符以内的序列标号,在本文件内必须唯一;使用老版本的libc5(低于5.2.18)或a.out库编译出来的 sysvinit限制为2字符。注意:像getty之类的登陆进程必须使id字段与tty编号一致,如tty1需要id=1,许多老版本的登陆进程都遵循这种规则。
runlevels:表示这一行适用于运行那个/些级别(这里是2,可以有多个,表示在相应的运行级均需要运行);另外sysinit、boot、bootwait这三个进程会忽略这个设置值。
action:表示进入对应的runlevels时,init应该运行process字段的命令的方式,常用的字段值及解释在附录内。例子中的wait表示需要运行这个进程一次并等待其结束。
process:具体应该执行的命令。例子中的/etc/init.d/rc命令启动运行级别2中应该运行的进程/命令,并负责在退出运行级时将其终止(当然在进入的runlevel中仍要运行的程序除外。)
当运行级别改变,并且正在运行的程序并没有在新的运行级别中指定需要运行,那么init会先发送一个SIGTERM 信号终止,然后是SIGKILL。
有效的action值如下:
respawn:表示init应该监视这个进程,即使其结束后也应该被重新启动。
wait: init应该运行这个进程一次,并等待其结束后再进行下一步操作。
once: init需要运行这个进程一次。
boot: 随系统启动运行,所以runlevel值对其无效。
bootwait:随系统启动运行,并且init应该等待其结束。
off: 没有任何意义。
initdefault:系统启动后的默认运行级别;由于进入相应的运行级别会激活对应级别的进程,所以对其指定process字段没有任何意义。如果inittab文件内不存在这一条记录,系统启动时在控制台上询问进入的运行级。
sysinit: 系统启动时准备运行的命令。比如说,这个命令将清除/tmp。可以查看/etc/rc.d/rc.sysinit脚本了解其运行了那些操作。
powerwait:允许init在电源被切断时,关闭系统。当然前提是有U P S和监视U P S并通知init电源已被切断的软件。RH linux默认没有列出该选项。
powerfail: 同powerwait,但init不会等待正在运行的进程结束。RH linux默认没有列出该选项。
powerokwait:当电源监视软件报告“电源恢复”时,init要执行的操作。
powerfailnow:检测到ups电源即将耗尽时,init要执行的操作,和powerwait/powerfail不同的哟。
ctrlaltdel:允许init在用户于控制台键盘上按下C t r l + A l t + D e l组合键时,重新启动系统。注意,如果该系统放在一个公共场所,系统管理员可将C t r l + A l t + D e l组合键配置为别的行为,比如忽略等。我是设置成打印一句骂人的话了^o^。
kbrequest:监视到特定的键盘组合键被按下时采取的动作,现在还不完善。
ondemand:A process marked with an ondemand runlevel will be executed whenever the specified ondemand runlevel is called. However, no runlevel change will occur (ondemand runlevels are ‘a’, ‘b’,and ‘c’),(英语太菜,那个however不知道该怎么翻译才好。惭愧!)
补充:
1、关于进入单用户模式,一般都是采用设置initdefault为1或者在grub/lilo中指定一个“single”或“emergency” 命令行参数来实现。其实另外还有一个更干净的方法,编辑:
kernel /vmlinuz-2.6.9-22.EL ro root=/bin/sh,这样init就直接启动一个shell,其他任何进程都没有启动哦,够干净吧!
2、系统正在运行时,telinit命令可更改运行级别。运行级别发生变化时, init 就会从/etc/inittab运行相应的命令。
DHCP是动态主机配置协议.这个协议用于向计算机自动提供IP地址,子网掩码和路由信息。网络管理员通常会分配某个范围的 IP 地址来分发给局域网上的客户机。当设备接入这个局域网时,它们会向 DHCP 服务器请求一个 IP 地址。然后 DHCP 服务器为每个请求的设备分配一个地址,直到分配完该范围内的所有 IP 地址为止。已经分配的 IP 地址必须定时地延长借用期。这个延期的过程称作 leasing,确保了当客户机设备在正常地释放 IP 地址之前突然从网络断开时被分配的地址可以归还给服务器。本文以Redhat Linux 9.0为例,介绍如何建立一个完整和安全的DHCP服务器。
一、建立DHCP服务器配置文件
可以使用Redhat Linux 9.0自身携带rpm包安装。安装结束后, DHCP 端口监督程序 dhcpd 配置文件是 /etc 目录中的名为 dhcpd.conf 的文件。下面手工建立/etc/dhcpd.conf文件。/etc/dhcpd.conf通常包括三部分:parameters、declarations 、option。
1. DHCP配置文件中的parameters(参数):表明如何执行任务,是否要执行任务,或将哪些网络配置选项发送给客户。主要内容见表1:
参数 解释
ddns-update-style 配置DHCP-DNS 互动更新模式。
default-lease-time 指定确省租赁时间的长度,单位是秒。
max-lease-time 指定最大租赁时间长度,单位是秒。
hardware 指定网卡接口类型和MAC地址。
server-name 通知DHCP客户服务器名称。
get-lease-hostnames flag 检查客户端使用的IP地址。
fixed-address ip 分配给客户端一个固定的地址。
authritative 拒绝不正确的IP地址的要求。
2. DHCP配置文件中的declarations (声明):用来描述网络布局、提供客户的IP地址等。主要内容见表2:
声明 解释
shared-network 用来告知是否一些子网络分享相同网络。
subnet 描述一个IP地址是否属于该子网。
range 起始IP 终止IP 提供动态分配IP 的范围。
host 主机名称 参考特别的主机。
group 为一组参数提供声明。
allow unknown-clients ﹔deny unknown-client 是否动态分配IP给未知的使用者。
allow bootp;deny bootp 是否响应激活查询。
allow booting﹔deny booting 是否响应使用者查询。
filename 开始启动文件的名称,应用于无盘工作站。
next-server 设置服务器从引导文件中装如主机名,应用于无盘工作站。
3. DHCP配置文件中的option(选项):用来配置DHCP可选参数,全部用option关键字作为开始,主要内容包括见表3:
选项 解释
subnet-mask 为客户端设定子网掩码。
domain-name 为客户端指明DNS名字。
domain-name-servers 为客户端指明DNS服务器IP地址。
host-name 为客户端指定主机名称。
routers 为客户端设定默认网关。
broadcast-address 为客户端设定广播地址。
ntp-server 为客户端设定网络时间服务器IP地址。
time-offset 为客户端设定和格林威治时间的偏移时间,单位是秒。
注意:如果客户端使用的是视窗操作系统,不要选择“host-name”选项,即不要为其指定主机名称。
下面是一个笔者使用的DHCP配置文件,这是一个C类网络,共126个IP地址可以分配的例子。读者可以复制后使用,注意红色部分是必须要修改的。
ddns-update-style interim;
ignore client-updates;
subnet 192.168.1.0 netmask 255.255.255.0 {
option routers 192.168.1.254;
option subnet-mask 255.255.255.0;
option broadcast-address 192.168.1.255;
option domain-name-servers 192.168.1.3;
option domain-name "www.cao.com"; #DNS名称#
option domain-name-servers 192.168.1.3;
option time-offset -18000;
range dynamic-bootp 192.168.1.128 192.168.1.255;
default-lease-time 21600;
max-lease-time 43200;
host ns {
hardware ethernet 52:54:AB:34:5B:09;#运行DHCP的网络接口的MAC地址#
fixed-address 192.168.1.9;
}
}
二、建立客户租约文件
运行DHCP服务器还需要一个名为 dhcpd.leases 的文件,保持所有已经分发出去的 IP 地址。在Redhat Linux 发行版本中,该文件位于 /var/lib/dhcp/ 目录中。如果您通过 RPM 安装 ISC DHCP,那么该目录应该已经存在。dhcpd.leases的文件格式为:
Leases address {statement}
一个典型的文件内容如下:
lease 192.168.1.255 { #DHCP服务器分配的IP地址#
starts 1 2005/05/02 03:02:26; # lease 开始租约时间#
ends 1 2005/05/02 09:02:26; # lease 结束租约时间#
binding state active;
next binding state free;
hardware ethernet 00:00:e8:a0:25:86; #客户机网卡MAC地址#
uid "\001\000\000\350\240%\206"; #用来验证客户机的UID标示#
client-hostname "cjh1"; #客户机名称#
}
注意lease 开始租约时间和lease 结束租约时间是格林威治标准时间(GMT),不是本地时间。
第一次运行DHCP服务器时dhcpd.leases是一个空文件,也不用手工建立。如果不是通过 RPM 安装 ISC DHCP,或者 dhcpd 已经安装,那么您应该试着确定 dhcpd 将其 lease 文件写到何处,并确保该文件存在。也可以手工建立一个空文件:
#touch /var/lib/dhcp/dhcpd.leases
三、启动和检查DHCP服务器
使用命令启动DHCP服务器:
#service dhcpd start
使用ps命令检查dhcpd进程:
#ps -ef | grep dhcpd
root 2402 1 0 14:25 ? 00:00:00 /usr/sbin/dhcpd
root 2764 2725 0 14:29 pts/2 00:00:00 grep dhcpd
使用检查dhcpd运行的端口:
# netstat -nutap | grep dhcpd
udp 0 0 0.0.0.0:67 0.0.0.0:* 2402/dhcpd
四、配置DHCP客户端
通常网管员使用选择手工配置 DHCP 客户,需要修改 /etc/sysconfig/network 文件来启用联网;并修改 /etc/sysconfig/network-scripts 目录中每个网络设备的配置文件。在该目录中,每个设备都有一个叫做 ifcfg-eth? 的配置文件,eth?是网络设备的名称。 如eth0等。如果你想在引导时启动联网,NETWORKING 变量必须 被设为 yes。 除了此处之外/etc/sysconfig/network 文件应该包含以下行:
NETWORKING=yes
DEVICE=eth0
BOOTPROTO=dhcp
ONBOOT=yes
五、DHCP配置常见错误排除
通常配置DHCP 服务器很容易,不过,在这里有一些技巧可以帮助您避免出现问题。对服务器而言,要确保网卡正常工作,并具备广播功能。对客户机而言,还要确保客户机的网卡正常工作。最后,要考虑网络的拓扑,并考虑客户机向 DHCP 服务器发出的广播消息是否会受到阻碍。另外如果dhcpd进程没有启动,那么可以浏览 syslog 消息文件来确定是哪里出了问题。这个消息文件通常是 /var/log/messages。
典型故障:
1.DHCP服务器配置完成,没有语法错误。但是网络中的客户机却没办法取得IP地址。
通常是Linux DHCP服务器沒有办法接收來自255.255.255.255 的 DHCP 客户机的Request 封包造成的。一般是Linux DHCP服务器的网卡没有设置具有MULTICAST功能。为了让dhcpd(dhcp程序的守护进程)能够正常的和DHCP客户机沟通,dhcpd必须传送封包到255.255.255.255这个IP地址,但是有些Linux系统里255.255.255.255这个IP地址被用来做为监听区域子网域(local subnet)广播的 IP地址,所以需要在路由表(routing table)里加入255.255.255.255以激活MULTICAST功能;
使用命令:
route add -host 255.255.255.255 dev eth0
如果报告错误消息:255.255.255.255:Unkown host
那么请先修改/etc/hosts加入一行:
255.255.255.255 dhcp
2. DHCP客户端程序和DHCP服务器不兼容
由于Linux有许多发现版本,不同版本使用DHCP客户端程序和DHCP服务器也不相同。Linux提供了四种DHCP客户端程序:pump, dhclient, dhcpxd, 和dhcpcd。了解不同Linux发行版本的服务器端和客户端程序对于常见错误排除是必要的。笔者曾经遇到过使用SuSE Linux 9.1 DHCP服务器和使用Mandrake Linux 9.0客户机不兼容的情况。此时就必须更换客户端程序。方法是先停止客户机的网络服务,卸载原程序,安装和服务器端兼容程序。附表:主要Linux发行版使用的DHCP客户端。
发行版本
缺省 DHCP客户端 可选 DHCP 客户端 DHCP客户端启动
脚本 附加配置文件
Red Hat Linux 9.0 dhclient 无 /sbin/ifup /etc/sysconfig/network,
/etc/sysconfig/network-scripts/ifcfg-eth0
Debian Linux 3.0 dhclient 无 /sbin/ifup /etc/network/interfaces,
/etc/dhclient.conf
Mandrake Linux 9.1 dhclient dhcpcd, dhcpxd, pump /sbin/ifup /etc/sysconfig/network,
/etc/sysconfig/network-scripts/ifcfg-eth0,
/etc/dhclient-eth0.conf
SuSE Linux 9.1 dhcpcd dhclient /sbin/ifup-dhcp /etc/sysconfig/network/dhcp,
/etc/sysconfig/network/ifcfg-eth0
六、DHCP服务器的安全
1. 在指定网络接口启动DHCP服务器
如果你的Linux系统连接了不止一个网络界面,但是你只想让 DHCP 服务器启动其中之一,你可以配置 DHCP 服务器只在那个设备上启动。在 /etc/sysconfig/dhcpd 中,把界面的名称添加到 DHCPDARGS 的列表中:
DHCPDARGS=eth0
或者直接使用命令:
Echo “DHCPDARGS=eth0”>> /etc/ sysconfig/dhcpd
这样对于带有两个网卡的防火墙机器,更加安全:一个网卡可以被配置成 DHCP 客户来从互联网上检索 IP 地址;另一个网卡可以被用作防火墙之后的内部网络的 DHCP 服务器。仅指定连接到内部网络的网卡使系统更加安全,因为用户无法通过互联网来连接它的守护进程。
2. 让DHCP服务器在监牢中运行
所谓“监牢”就是指通过chroot机制来更改某个软件运行时所能看到的根目录,即将某软件运行限制在指定目录中,保证该软件只能对该目录及其子目录的文件有所动作,从而保证整个服务器的安全。这样即使出现被破壞或被侵入,所受的損傷也较小。
将软件chroot化的一个问题是该软件运行时需要的所有程序、配置文件和库文件都必须事先安装到chroot目录中,通常称这个目录为chroot jail(chroot“监牢”)。如果要在“监牢”中运行dhcpd,而事实上根本看不到文件系统中那个真正的目录。因此需要事先创建目录,并将dhcpd复制到其中。同时dhcpd需要几个库文件,可以使用ldd(library Dependency Display缩写)命令,ldd作用是显示一个可执行程序必须使用的共享库。
ldd dhcpd
libc.so.6 => /lib/tls/libc.so.6 (0x42000000)
/lib/ld-linux.so.2 => /lib/ld-linux.so.2 (0x40000000)
这意味着还需要在“监牢”中创建lib目录,并将库文件复制到其中。手工完成这一工作是非常麻烦的,此时可以用jail软件包来帮助简化chroot“监牢”建立的过程。
(1)Jail软件的编译和安装
Jail官方网站是:http://www.jmcresearch.com/ ,最新版本:1.9a。
#Wget http://www.jmcresearch.com/static/dwn/projects/jail/jail_1.9a.tar.gz
#tar xzvf jail.tar.gz ;cd jail/src
#make; make install
(2)用jail创建监牢
jail软件包提供了几个Perl脚本作为其核心命令,包括mkjailenv、addjailuser和addjailsw。
mkjailenv:创建chroot“监牢”目录,并且从真实文件系统中拷贝基本的软件环境。addjailsw:从真实文件系统中拷贝二进制可执行文件及其相关的其它文件(包括库文件、辅助性文件和设备文件)到该“监牢”中。addjailuser:创建新的chroot“监牢”用户。
首先停止目前dhcpd服务,然后建立chroot目录:
#/sbin/service dhcpd start
#mkjailenv /chroot/
mkjailenv
A component of Jail (version 1.9 for linux)
http://www.gsyc.inf.uc3m.es/~assman/jail/
Juan M. Casillas
Making chrooted environment into /chroot
Doing preinstall()
Doing special_devices()
Doing gen_template_password()
Doing postinstall()
Done.
下面的例子展示为“监牢”添加dhcpd程序的过程
# addjailsw /chroot/ -P /usr/sbin/dhcpd
addjailsw
A component of Jail (version 1.9 for linux)
http://www.gsyc.inf.uc3m.es/~assman/jail/
Juan M. Casillas
Guessing dhcpd args(0)
Warning: file /chroot//lib/tls/libc.so.6 exists. Overwritting it
Warning: file /chroot//lib/ld-linux.so.2 exists. Overwritting it
………
Done.
不用在意那些警告信息,因为jail会调用ldd检查dhcpd用到的库文件。而几乎所有基于共享库的二进制可执行文件都需要上述的几个库文件。接下来将dhcpd的相关文件拷贝到“监牢”中:
# mkdir -p /chroot/dhcp/etc
# cp /etc/dhcpd.conf /chroot/dhcp/etc/
# mkdir -p /chroot/dhcp/var/state/dhcp
# touch /chroot/dhcp/var/state/dhcp/dhcp.leases
此时的“监牢”目录结构见图1。
图1 “监牢”目录结构
重新启动dhcpd:
[root@www root]# /chroot/usr/sbin/dhcpd
使用ps命令检查dhcpd进程:
#ps -ef | grep dhcpd
root 2402 1 0 14:25 ? 00:00:00 /chroot/usr/sbin/dhcpd
root 2764 2725 0 14:29 pts/2 00:00:00 grep dhcpd
注意此时进程名称已经改变,使用检查dhcpd运行的端口:
# netstat -nutap | grep dhcpd
udp 0 0 0.0.0.0:67 0.0.0.0:* 2402/dhcpd
端口号没有改变。现在dhcpd已经成功运行在“监牢”中。
到此为止一个这样,一个完整和安全的 DHCP服务器就完成了。
Apache服务器的最新稳定发布版本是httpd-2.2..0,官方下载地址是: http://httpd.apache.org/download.cgi。我们通过下面的步骤来快速的搭建一个web服务器。 1、 下载源码文件httpd-2.2.0.tar.gz 到linux服务器的某个目录。 2、 解压文件 # tar zxvf httpd-2.2.0.tar.gz . 3、 配置 # ./configure –refix=/usr/local/apache //指定安装目录,以后要删除安装就只需删除这个目录。 4、 编译和安装。 # make ; make install . 5、 编写启动脚本,把它放到目录 /etc/rc.d/init.d/里,这里取名为httpd,其内容如下: #!/bin/bash #description:http server #chkconfig: 235 98 98 case "$1" in start) echo "Starting Apache daemon..." /usr/local/apache2/bin/apachectl -k start ;; stop) echo "Stopping Apache daemon..." /usr/local/apache2/bin/apachectl -k stop ;; restart) echo "Restarting Apache daemon..." /usr/local/apache2/bin/apachectl -k restart ;; status) statusproc /usr/local/apache2/bin/httpd ;; *) echo "Usage: $0 {start|stop|restart|status}" exit 1 ;; Esac 注意:#description:http server 这一行必须加上,否则在执行命令 # chkconfig –add httpd 时会出现“service apache does not support chkconfig”的错误报告。#chkconfig: 2345 98 98 表示在执行命令 # chkconfig –add httpd 时会在目录 /etc/rc2.d/ 、/etc/rc3.d/ /etc/rc5.d 分别生成文件 S98httpd和 K98httpd。这个数字可以是别的。 6、 执行命令 # chkconfig –add httpd ,进入目录/etc/rc3.d/检查是否生成文件 S98httpd及K98httpd. 7、 启动服务 # service httpd start .
花了几天才编译成功kernel2.6.7,其过程真可谓艰辛.古语有云:"苦尽甘来!"现在终于可以乐上一阵了.由于许多朋友对操作的顺序及某些重要的配置知之甚少或知之不详,往往病急乱投医.加之网上的信息多且烦杂,使得编译内核成功率不高,甚至造成原来的系统崩溃的也不在少数.我就是其中一个。 其实,编译内核并不是一件难事.如果能按照正确的方法来操作,最多花上一个半小时就能搞定.是不是很受鼓舞呀! 废话少说,现在我们马上开始.我原来的系统是redhat9.0,内核2.4.20-8,编译的内核2.6.7,仅供参考. 共分为四部分:编译前准备->编译配置->编译过程->运行内核的常见问题 一 编译前准备 1)下载一份内核源代码,我下的是linux-2.6.7.tar.bz2,你可在如下地址下载它或者是更新的版本. http://kernel.org/pub/linux/kernel/v2.6/ 2) 下载最新版本的module-init-tools( "module-init-tools-3.0.tar.gz" and "modutils-2.4.21-23.src.rpm") http://www.kernel.org/pub/linux/kernel/people/rusty/modules/module-init-tools-3.0.tar.gz http://www.kernel.org/pub/linux/kernel/people/rusty/modules/modutils-2.4.21-23.src.rpm 3)安装module-init-tools. 它会替代depmod [/sbin/depmod]和其他工具. tar -zxvf module-init-tools-3.0.tar.gz cd module-init-tools-3.0 ./configure --prefix=/sbin make make install ./generate-modprobe.conf /etc/modprobe.conf 4)安装modutils-2.4.21-23.src.rpm. 你可能会看到"user rusty and group rusty not existing"的警告. 没关系,你只需强制安装就是了.如果你不对Redhat 9和Redhat 8做这几步, 你将会在"make modules_install"这一步时出现问题. rpm -i modutils-2.4.21-23.src.rpm rpmbuild -bb /usr/src/redhat/SPECS/modutils.spec rpm -Fi /usr/src/redhat/RPMS/i386/modutils-2.4.21-23.i386.rpm 5)解压缩内核源代码.把下载的源代码包放到目录/usr/src下,然后 cd /usr/src tar xvfj linux-2.6.7.tar.bz2 cd linux-2.6.7 二 编译配置 在这一部分涉及几个重要模块的配置请,特别注意.一般用"make menuconfig"命令来配置内核. 输入以上命令后出现一个菜单界面,用户可以对需要的模块.下面着重讲几个重要的配置 1)文件系统 请务必要选中ext3文件系统, File systems---> • Ext3 journalling file system support • Ext3 Security Labels • JBD (ext3) debugging support 以上三项一定要选上,而且要内建(即标*). 这个非常重要,在配置完后一定要检查一下.config文件有没有"CONFIG_EXT3_FS=y"这一项. 如果不是"CONFIG_EXT3_FS=y"而是"CONFIG_EXT3_FS=m",你在运行内核时就会遇上以下错误: pivotroot: pivot_root(/sysroot,/sysroot/initrd) failed 2)网卡驱动 请务必把自己网卡对应的驱动编译进内核,比较普遍的网卡是realtek 8139,以下就是这种网卡的配置,以供参考 Device Drivers---> Networking support---> Ethernet (10 or 100Mbit) ---> <*> RealTek RTL-8139 C+ PCI Fast Ethernet Adapter support (EXPERIMENTAL) <*> RealTek RTL-8139 PCI Fast Ethernet Adapter support 3)声卡驱动 也要选择自己声卡对应的驱动编译进内核,比较普遍的声卡是i810_audio,以下就是这种声卡的配置,以供参考 Device Drivers ---> Sound ---> <*> Sound card support Advanced Linux Sound Architecture ---> <*> Advanced Linux Sound Architecture <*> Sequencer support < > Sequencer dummy client <*> OSS Mixer API <*> OSS PCM (digital audio) API • OSS Sequencer API <*> RTC Timer support PCI devices ---> <*> Intel i8x0/MX440, SiS 7012; Ali 5455; NForce Audio; AMD768/8111 Open Sound System ---> < > Open Sound System (DEPRECATED) 以上三项配置关系到新内核能否正常运行,请备加注意.其他的配置如果不是很了解,大可以按默认的选择. 三 编译 按如下命令编译,大概需要一个多小时,大可以好好放松一下 make bzImage make modules make modules_install make install 运行新内核之前,请检查一下/boot/grub/grub.conf的内容,下面的配置可作参考 # grub.conf generated by anaconda # # Note that you do not have to rerun grub after making changes to this file # NOTICE: You have a /boot partition. This means that # all kernel and initrd paths are relative to /boot/, eg. # root (hd0,0) # kernel /vmlinuz-version ro root=/dev/hdc3 # initrd /initrd-version.img #boot=/dev/hdc default=1 timeout=10 splashimage=(hd0,0)/grub/splash.xpm.gz title Red Hat Linux (2.6.7) root (hd0,0) kernel /vmlinuz-2.6.7 ro root=LABEL=/ initrd /initrd-2.6.7.img title Red Hat Linux root (hd0,0) kernel /vmlinuz-2.4.20-8 ro root=LABEL=/ initrd /initrd-2.4.20-8.img 四 运行内核的常见问题 1)RPM问题 进入编译好的内核后,与RPM相关的命令有些不能使用,并出现下列错误: rpmdb: unable to join the environment error: db4 error(11) from dbenv->open: Resource temporarily unavailable error: cannot open Packages index using db3 - Resource temporarily unavailable (11) error: cannot open Packages database in /var/lib/rpm no packages 解决方法是执行“export LD_ASSUME_KERNEL =2.2.25”命令,也可以将其写入/etc/bashrc。 2)Sound问题 声音部分的模块名也改变了。我的笔记本原来的声卡驱动是i810_audio,现在已改为snd-intel8x0。因此需要把下面的内容添加到/etc/modprobe.conf中: alias char-major-14 soundcore alias sound snd-intel8x0 alias sound-slot-0 snd-intel8x0 alias snd-card-0 snd-intel8x0 alias sound-service-0-0 snd-mixer-oss alias sound-service-0-1 snd-seq-oss alias sound-service-0-3 snd-pcm-oss alias sound-service-0-8 snd-seq-oss alias sound-service-0-12 snd-pcm-oss install snd-intel8x0 /sbin/modprobe --ignore-install sound-slot-0 && { /bin/aumix-minimal -f /etc/.aumixrc -L >/dev/null 2>&1; /bin/true; } remove snd-intel8x0 { /bin/aumix-minimal -f /etc/.aumixrc -S >/dev/null 2>&1; /bin/true; }; /sbin/modprobe -r --ignore-remove sound-slot-0 然后执行“modprobe sound”加载声音模块,并使用下列命令检验声卡驱动: #cat /proc/asound/cards 显示结果如下: 0 [SI7012]: ICH - SiS SI7012 SiS SI7012 at 0xdc00, irq 11 3)VMware问题 解决方法是: ◆ 将/usr/bin/vmware-config.pl中所有的“/proc/ksyms”替换为“/proc/kallsyms”。使用“sed”命令可以达到这个目的。 ◆ 重新运行该脚本,使用内核头文件编译新的内核模块。在编译过程中如发生错误,应该进入/usr/lib/vmware/modules/source,使用下面的命令将vmnet.tar解包: #tar xvf vmnet.tar ◆ 进入vmnet-only目录修改bridge.c文件。将“atomic_add(skb->truesize, &sk->wmem_alloc);”修改为“atomic_add(skb->truesize, &sk->sk_wmem_alloc);”,并用类似的方式将“protinfo”改为“sk_protinfo”。 ◆ 再次把vmnet-only目录用下面的命令重新打包为vmmon.tar: #tar cvf vmmon.tar v
集群系统(Cluster)主要解决下面几个问题: 高可靠性(HA)。利用集群管理软件,当主服务器故障时,备份服务器能够自动接管主服务器的工作,并及时切换过去,以实现对用户的不间断服务。 高性能计算(HP)。即充分利用集群中的每一台计算机的资源,实现复杂运算的并行处理,通常用于科学计算领域,比如基因分析,化学分析等。 负载平衡。即把负载压力根据某种算法合理分配到集群中的每一台计算机上,以减轻主服务器的压力,降低对主服务器的硬件和软件要求。 在实际应用中,最常见的情况是利用集群解决负载平衡问题,比如用于提供WWW服务。在这里主要展示如何使用LVS(Linux Virtial Server)来实现实用的WWW负载平衡集群系统。 LVS简介 LVS是章文嵩博士发起和领导的优秀的集群解决方案,许多商业的集群产品,比如RedHat的Piranha,TurboLinux公司的Turbo Cluster等,都是基于LVS的核心代码的。在现实的应用中,LVS得到了大量的部署,请参考http: //www.linuxvirtualserver.org/deployment.html 关于Linux LVS的工作原理和更详细的信息,请参考 http://www.linuxvirtualserver.org。 LVS配置实例 通过Linux LVS,实现WWW,Telnet服务的负载平衡。这里实现Telnet集群服务仅为了测试上的方便。 LVS有三种负载平衡方式,NAT(Network Address Translation),DR(Direct Routing),IP Tunneling。其中,最为常用的是DR方式,因此这里只说明DR(Direct Routing)方式的LVS负载平衡。 1、网络拓扑结构。 如图1所示,为测试方便,4台机器处于同一网段内,通过一交换机或者集线器相连。实际的应用中,最好能够将虚拟服务器vs1和真实服务器rs1, rs2置于于不同的网段上,即提高了性能,也加强了整个集群系统的安全性。 2、服务器的软硬件配置 首先说明,虽然本文的测试环境中用的是3台相同配置的服务器,但LVS并不要求集群中的服务器规格划一,相反,可以根据服务器的不同配置和负载情况,调整负载分配策略,充分利用集群环境中的每一台服务器。 这3台服务器中,vs1作为虚拟服务器(即负载平衡服务器),负责将用户的访问请求转发到集群内部的rs1,rs2,然后由rs1,rs2分别处理。 client为客户端测试机器,可以为任意操作系统。 4台服务器的操作系统和网络配置分别为: vs1: RedHat 6.2, Kernel 2.2.19 vs1: eth0 192.168.0.1 vs1: eth0:101 192.168.0.101 rs1: RedHat 6.2, Kernel 2.2.14 rs1: eth0 192.168.0.3 rs1: dummy0 192.168.0.101 rs2: RedHat 6.2, Kernel 2.2.14 rs2: eth0 192.168.0.4 rs2: dummy0 192.168.0.101 client: Windows 2000 client: eth0 192.168.0.200 其中,192.168.0.101是允许用户访问的IP。 虚拟服务器的集群配置 大部分的集群配置工作都在虚拟服务器vs1上面,需要下面的几个步骤: 重新编译内核。 首先,下载最新的Linux内核,版本号为2.2.19,下载地址为: http://www.kernel.org/,解压缩后置于/usr/src/linux目录下。 其次需要下载LVS的内核补丁,地址为: http://www.linuxvirtualserver.org/software/ipvs- 1.0.6-2.2.19.tar.gz。这里注意,如果你用的Linux内核不是2.2.19版本的,请下载相应版本的LVS内核补丁。将ipvs- 1.0.6-2.2.19.tar.gz解压缩后置于/usr/src/linux目录下。 然后,对内核打补丁,如下操作: [root@vs2 /root]# cd /usr/src/linux [root@vs2 linux]# patch -p1 < ipvs-1.0.6-2.2.19/ipvs-1.0.6-2.2.19.patch 下面就是重新配置和编译Linux的内核。特别注意以下选项: 1 Code maturity level options---> * [*]Prompt for development and/or incomplete code/drivers 2 Networking部分: [*] Kernel/User netlink socket [*] Routing messages <*> Netlink device emulation * [*] Network firewalls [*] Socket Filtering <*> Unix domain sockets * [*] TCP/IP networking [*] IP: multicasting [*] IP: advanced router [ ] IP: policy routing [ ] IP: equal cost multipath [ ] IP: use TOS value as routing key [ ] IP: verbose route monitoring [ ] IP: large routing tables [ ] IP: kernel level autoconfiguration * [*] IP: firewalling [ ] IP: firewall packet netlink device * [*] IP: transparent proxy support * [*] IP: masquerading --- Protocol-specific masquerading support will be built as modules. * [*] IP: ICMP masquerading --- Protocol-specific masquerading support will be built as modules. * [*] IP: masquerading special modules support * IP: ipautofw masq support (EXPERIMENTAL)(NEW) * IP: ipportfw masq support (EXPERIMENTAL)(NEW) * IP: ip fwmark masq-forwarding support (EXPERIMENTAL)(NEW) * [*] IP: masquerading virtual server support (EXPERIMENTAL)(NEW) [*] IP Virtual Server debugging (NEW) <--最好选择此项,以便观察LVS的调试信息 * (12) IP masquerading VS table size (the Nth power of 2) (NEW) * IPVS: round-robin scheduling (NEW) * IPVS: weighted round-robin scheduling (NEW) * IPVS: least-connection scheduling (NEW) * IPVS: weighted least-connection scheduling (NEW) * IPVS: locality-based least-connection scheduling (NEW) * IPVS: locality-based least-connection with replication scheduling (NEW) * [*] IP: optimize as router not host * IP: tunneling IP: GRE tunnels over IP [*] IP: broadcast GRE over IP [*] IP: multicast routing [*] IP: PIM-SM version 1 support [*] IP: PIM-SM version 2 support * [*] IP: aliasing support [ ] IP: ARP daemon support (EXPERIMENTAL) * [*] IP: TCP syncookie support (not enabled per default) --- (it is safe to leave these untouched) < > IP: Reverse ARP [*] IP: Allow large windows (not recommended if <16Mb of memory) < > The IPv6 protocol (EXPERIMENTAL) 上面,带*号的为必选项。 然后就是常规的编译内核过程,不再赘述,请参考编译 Linux 教程 在这里要注意一点:如果你使用的是RedHat自带的内核或者从RedHat下载的内核版本,已经预先打好了LVS的补丁。这可以通过查看/usr/src/linux/net/目录下有没有几个ipvs开头的文件来判断:如果有,则说明已经打过补丁。 编写LVS配置文件,实例中的配置文件如下: #lvs_dr.conf (C) Joseph Mack mack@ncifcrf.govLVS_TYPE=VS_DR INITIAL_STATE=on VIP=eth0:101 192.168.0.101 255.255.255.0 192.168.0.0 DIRECTOR_INSIDEIP=eth0 192.168.0.1 192.168.0.0 255.255.255.0 192.168.0.255 SERVICE=t telnet rr rs1:telnet rs2:telnet SERVICE=t www rr rs1:www rs2:www SERVER_VIP_DEVICE=dummy0 SERVER_NET_DEVICE=eth0 #----------end lvs_dr.conf------------------------------------ 将该文件置于/etc/lvs目录下。 使用LVS的配置脚本产生lvs.conf文件。该配置脚本可以从http: //www.linuxvirtualserver.org/Joseph.Mack/configure-lvs_0.8.tar.gz 单独下载,在ipvs-1.0.6-2.2.19.tar.gz包中也有包含。 脚本configure的使用方法: [root@vs2 lvs]# configure lvs.conf 这样会产生几个配置文件,这里我们只使用其中的rc.lvs_dr文件。 修改/etc/rc.d/init.d/rc.local,增加如下几行: echo 1 > /proc/sys/net/ipv4/ip_forward echo 1 > /proc/sys/net/ipv4/ip_always_defrag # 显示最多调试信息 echo 10 > /proc/sys/net/ipv4/vs/debug_level 配置NFS服务。这一步仅仅是为了方便管理,不是必须的步骤。假设配置文件lvs.conf文件放在/etc/lvs目录下,则/etc/exports文件的内容为: /etc/lvs ro(rs1,rs2) 然后使用exportfs命令输出这个目录: [root@vs2 lvs]# exportfs 如果遇到什么麻烦,可以尝试: [root@vs2 lvs]# /etc/rc.d/init.d/nfs restart [root@vs2 lvs]# exportfs 这样,各个real server可以通过NFS获得rc.lvs_dr文件,方便了集群的配置:你每次修改lvs.conf中的配置选项,都可以即可反映在rs1,rs2的相应目录里。 修改/etc/syslogd.conf,增加如下一行: kern.* /var/log/kernel_log 这样,LVS的一些调试信息就会写入/var/log/kernel_log文件中. real server的配置 real server的配置相对简单,主要是是以下几点: 配置telnet和WWW服务。telnet服务没有需要特别注意的事项,但是对于www服务,需要修改httpd.conf文件,使得apache在虚拟服务器的ip地址上监听,如下所示: Listen 192.168.0.101:80 关闭real server上dummy0的arp请求响应能力。这是必须的,具体原因请参见ARP problem in LVS/TUN and LVS/DR( http://www.linuxvirtualserver.org/arp.html)。关闭dummy0的arp响应的方式有多种,比较简单地方法是,修改/etc/rc.d/rc.local文件,增加如下几行: echo 1 > /proc/sys/net/ipv4/conf/all/hidden ifconfig dummy0 up ifconfig dummy0 192.168.0.101 netmask 255.255.255.0 broadcast 192.168.0.0 up echo 1 > /proc/sys/net/ipv4/conf/dummy0/hidden 再次修改/etc/rc.d/rc.local,增加如下一行:(可以和步骤2合并) echo 1 > /proc/sys/net/ipv4/ip_forward LVS的测试 好了,经过了上面的配置步骤,现在可以测试LVS了,步骤如下: 分别在vs1,rs1,rs2上运行/etc/lvs/rc.lvs_dr。注意,rs1,rs2上面的/etc/lvs目录是vs2输出的。如果您的 NFS配置没有成功,也可以把vs1上的/etc/lvs/rc.lvs_dr复制到rs1,rs2上,然后分别运行。 确保rs1,rs2上面的apache已经启动并且允许telnet。 然后从client运行telnet 192.168.0.101,如果登录后看到如下输出就说明集群已经开始工作了:(假设以guest用户身份登录) [guest@rs1 guest]$-----------说明已经登录到服务器rs1上。 再开启一个telnet窗口,登录后会发现系统提示变为: [guest@rs2 guest]$-----------说明已经登录到服务器rs2上。 然后在vs2上运行如下命令: [root@vs2 /root]ipvsadm 运行结果应该为: IP Virtual Server version 1.0.6 (size=4096) Prot LocalAddress:Port Scheduler Flags -> RemoteAddress:Port Forward Weight ActiveConn InActConn TCP 192.168.0.101:telnet rr -> rs2:telnet Route 1 1 0 -> rs1:telnet Route 1 1 0 TCP 192.168.0.101:www rr -> rs2:wwwRoute 1 0 0 -> rs1:wwwRoute 1 0 0 至此已经验证telnet的LVS正常。 然后测试一下WWW是否正常:用你的浏览器查看 http://192.168.0.101/是否有什么变化?为了更明确的区别响应来自那个real server,可以在rs1,rs2上面分别放置如下的测试页面(test.html): 我是real server #1 or #2 然后刷新几次页面( http://192.168.0.101/test.html),如果你看到“我是real server #1”和“我是real server #2”交替出现,说明www的LVS系统已经正常工作了。 但是由于Internet Explore 或者Netscape本身的缓存机制,你也许总是只能看到其中的一个。不过通过ipvsadm还是可以看出,页面请求已经分配到两个real server上了,如下所示: IP Virtual Server version 1.0.6 (size=4096) Prot LocalAddress:Port Scheduler Flags -> RemoteAddress:Port Forward Weight ActiveConn InActConn TCP 192.168.0.101:telnet rr -> rs2:telnet Route 1 0 0 -> rs1:telnet Route 1 0 0 TCP 192.168.0.101:www rr -> rs2:wwwRoute 1 0 5 -> rs1:wwwRoute 1 0 4 或者,可以采用linux的lynx作为测试客户端,效果更好一些。如下运行命令: [root@client /root]while true; do lynx -dump http://10.64.1.56/test.html; sleep 1; done 这样,每隔1秒钟“我是realserver #1”和“我是realserver #2”就交替出现一次,清楚地表明响应分别来自两个不同的real server。 调试技巧 如果您的运气不好,在配置LVS的过程中也许会遇到一些困难,下面的技巧或许有帮助: 首先确定网络硬件没有问题,尤其是网线,ping工具就足够了。 使用netstat查看端口的活动情况。 使用tcpdump查看数据包的流动情况。 查看/var/log/kernel_log文件。
1、引言 基于Web技术的Internet/Intranet近年来已经得到了广泛的应用,Intranet是以TCP/IP协议为基础、以Web为核心的企业内部网,用户通过低成本、简单易用的客户浏览器就能随时随地到企业的Web站点上查阅自己所需的数据。浏览器客户端操作界面的一致性避免了C/S模式客户端程序的多样性,而服务器端的开放和基于标准的连接方案使企业很方便地通过Internet同外界联系;同时,Web信息动态的、交互式的发布方式从根本上改变了企业的服务质量,增加了企业的商业机会。 在许多用户看来,一个Web网站的成败主要在于它所提供的内容和功能,而支持这些内容和功能的Web服务器起着非常重要的作用。 2、Tomcat容器 Tomcat是一个免费的开源的Serlvet容器,它是Apache基金会的Jakarta项目中的一个核心项目,由Apache,Sun和其它一些公司及个人共同开发而成。由于有了Sun的参与和支持,最新的Servlet和Jsp规范总能在Tomcat中得到体现。 Tomcat是稳固的独立的Web服务器与Servlet Container,不过,其Web服务器的功能则不如许多更健全的Web服务器完整,如Apache Web服务器(举例来说,Tomcat没有大量的选择性模块)。不过,Tomcat是自由的开源软件,而且有许多高手致力于其发展。 2.1 Linux下安装Tomcat 在安装Tomcat之前需要安装j2sdk(Java 2 Software Development Kit),安装j2sdk的步骤如下: 1)到 http://www.java.sun.com下载j2sdk ,如j2sdk-1_4_2_04-linux-i586-rpm.bin。 2)在终端中转到j2sdk-1_4_2_04-linux-i586-rpm.bin所在的目录,输入命令chmod +x j2sdk-1_4_2_04-linux-i586-rpm.bin,添加执行的权限。 3)执行命令./j2sdk-1_4_2_04-linux-i586-rpm.bin,生成j2sdk-1_4_2_04-linux-i586.rpm的文件。 4)执行命令chmod +x j2sdk-1_4_2_04-linux-i586.rpm,给j2sdk-1_4_2_04-linux-i586.rpm添加执行的权限。 5)执行命令 rpm –ivh j2sdk-1_4_2_04-linux-i586.rpm ,安装j2sdk。 6)安装界面会出现授权协议,按Enter键接受,把j2sd安装在/usr/java/j2sdk1.4.2_04。 7)设置环境变量,在 /etc/profile.d/目录下建立文件java.sh,文件的内容如下: #set java environment export JAVA_HOME=/usr/java/j2sdk1.4.2_04 export CLASSPATH=.:$JAVA_HOME/lib:$JAVA_HOME/jre/lib:/usr/java/jdbc export PATH=$JAVA_HOME/bin:$JAVA_HOME/jre/bin:$PATH 8)执行命令chmod 755 /etc/profile.d/java.sh,给java.sh分配权限。 9)在终端中分别执行命令javac –help和java –version,如果看到有关的信息,则表示j2sdk已成功安装。 接下来安装tomcat,安装tomcat的步骤如下: 1)访问 http://jakarta.apache.org/tomcat/index.html,下载二进制版的tomcat,如jakarta-tomcat-5.5.10.tar.gz,解压到/usr/local目录: cd /usr/local gzip –zxvf jakarta-tomcat-5.5.10.tar.gz 2)修改$tomcat/bin/startup.sh和shutdown.sh文件, export JAVA_HOME=/usr/java/j2sdk1.4.2_04 export CATALINA_HOME=/usr/local/tomcat-5.5.10 export CLASSPATH=.:$JAVA_HOME/lib:$JAVA_HOME/jre/lib:/usr/java/jdbc export PATH=$JAVA_HOME/bin:$JAVA_HOME/jre/bin:$PATH 3)执行startup.sh即可在 http://localhost:8080/ 访问到tomcat的缺省面页. 2.2单独运行Tomcat的优点 1)容易架设。下载Tomcat,设定一些配置,就完成了。不需要花费时间将Web服务器的连接器整合至其它的Web服务器中。 2)不需要担心连接器。永远不需要排除在其它Web服务器与Tomcat之间的任何性能或联机方面的问题。 3)有较佳的安全防护。相对于其它以C、C++所编写的Web服务器,Tomcat比较能忍受远程缓冲区溢位的攻击。因为Tomcat的Java虚拟机是位于网络及操作系统之间,它可以防止几乎所有类型的缓冲区溢位攻击。使用Tomcat的安全防护领域,可以指定对各个资源的访问。 4)容易移植。可以将Tomcat服务器(以及应用程序)移植到不同的服务器、操作系统甚至架构上。因为Tomcat是以Java编写的,因此可以将其整个目录结构的内容复制到其它计算机上运行,而完全不需要任何改变,甚至于新的计算机的架构与原来的不同也一样。 2.3单独运行Tomcat的缺点 1)Tomcat的支持软件比较少。Tomcat内建Web服务器的支持软件比Apache httpd Web服务器少。 2)Tomcat的Web服务器功能少。相对于Tomcat Web服务器,Apache httpd服务器有更完整的功能。 3)虽然Tomcat运行速度快,但还没有Apache httpd快。Tomcat服务器比Apache httpd慢,不过,它还在改进中,而且仍然非常快,快到足以运行今日大多数的企业网站,只是在提供静态页面内容上没有Apache快。 3、Apache Web服务器 Apache是根据NCSA的服务器发展而来的,NCSA是最早出现的Web服务器程序之一,由伊利诺斯大学Urbana-Champaign分校的美国国家超级计算应用中心开发。在发展初期,Apache主要是一个基于UNIX系统的服务器,它的宗旨就是建成一个基于UNIX系统的、功能更强、效率更高并且速度更快的WWW服务器,这就决定了它是从其他的服务器演变而来的,并且添加了大量补丁来增强它在某一方面的性能,所以它就被命名为“APA+CHy Server(一个补丁组成的服务器)”。发展到今天,Apache已经被移植到很多平台上了。 Apache的开发遵循GPL协议,由全球的志愿者一起开发和维护。在保持强大的功能及不断更新的同时,它仍然是免费的,并且公开源代码。 3.1 安装Apache服务器 可以通过以下三种方法安装Apache服务器。 1)如果安装的Linux版本中带用Apache的话,就在选择所要安装的服务器的时候,将httpd这个服务选上,Linux安装程序将自动完成Apache的安装工作,并做好基本的配置。 2)使用可执行文件软件包,这比较适合那些对编译工作不是太熟悉的初级用户,因为它相对比较简单。下载软件包apache_1.2.4.e.tar.gz ,执行命令tar xvzf apache_1.2.4.e.tar.gz 完成安装工作。如果使用的是RedHat Linux的话,也可以下载apache_1.2.4.rpm软件安装包,然后使用rpm –ivh apache_1.2.4.rpm命令安装。 3)如果想把Apache服务器充分利用起来的话,就一定要自己编译Apache 定制其功能。 下载包含Apache源代码的软件包apache_1.2.4.tar.gz;然后用tar命令将它解开;将当前目录改变为Apache源代码发行版的src目录;将配置样本文件(Configuration.tmpl)复制为Configuration文件;编辑Configuration文件中的配置选项: Makefile配置选项:一些编译选项: . “CC=”一行指定用什么编译软件编译,一般为“CC=gcc”;如果需要将额外的标志(参数)指定给C编译软件,可以使用: EXTRA_CFLAGS= EXTRA_LFLAGS= 如果系统需要特殊的库和包含文件,可以在这里指定它们: EXTRA_LIBS= EXTRA_INCLUDES= 如果要改变代码优化设置的话,须将下面一句去掉注释,然后改成所需要的值: #OPTIM=-O2 Rule配置选项:用来决定需要什么功能,一般情况下无需改变。 模块配置:模块是Apache的组成部分,它为Apache内核增加新功能。通过使用模块配置,可以自定义在Apache服务器中需要什么功能,这个部分也是Apache灵活性的表现。模块配置行如下所示: AddModule modules/standard/mod_env.o 如果需要Apache服务器具备什么功能,就将那个模块用AddModule语句加到配置文件Configuration中去。 下面列出了Apache的模块功能: 模块名 功能 缺省 mod_access 提供基于主机的访问控制命令 y mod_actions 能够运行基于MIME类型的CGI脚本或HTTP请求方法 y mod_alias 能执行URL重定向服务 y mod_asis 使文档能在没有HTTP头标的情况下被发送到客户端 y mod_auth 支持使用存储在文本文件中的用户名、口令实现认证 y mod_auth_dbm 支持使用DBM文件存储基本HTTP认证 n mod_auth_mysql 支持使用MySQL数据库实现基本HTTP认证 n mod_auth_anon 允许以匿名方式访问需要认证的区域 y mod_auth_external 支持使用第三方认证 n mod_autoindex 当缺少索引文件时,自动生成动态目录列表 y mod_cern_meta 提供对元信息的支持 n mod_cgi 支持CGI y mod_dir 能够重定向任何对不包括尾部斜杠字符命令的请求 y mod_env 使你能够将环境变量传递给CGI或SSI脚本 n mod_expires 让你确定Apache在服务器响应请求时如何处理Expires y mod_headers 能够操作HTTP应答头标 y mod_imap 提供图形映射支持 n mod_include 使支持SSI n mod_info 对服务器配置提供了全面的描述 y mod_log_agent 允许在单独的日志文件中存储用户代理的信息 n mod_log_config 支持记录日志 y mod_log_referer 提供了将请求中的Referer头标写入日志的功能 n mod_mime 用来向客户端提供有关文档的元信息 y mod_negotiation 提供了对内容协商的支持 y mod_setenvif 使你能够创建定制环境变量 y mod_speling 使你能够处理含有拼写错误或大小写错误的URL请求 n mod_status 允许管理员通过WEB管理Apache y mod_unique_id 为每个请求提供在非常特殊的条件下保证是唯一的标识 n 在src目录下执行:“. /configure”; 编译Apache:执行命令“make”; 将编译好的可执行文件httpd复制到/etc/httpd/bin目录下;将Apache发行版的配置文件:access.conf、httpd.conf、mime.types、srm.conf文件复制到/etc/httpd/conf目录下。到此为止,安装完成。 3.1单独运行Apache httpd的优点 1)Apache httpd比Tomcat内建的Web服务器快。 2)较多的软件支持。Apache httpd有庞大的支持软件链接库。 3)启动与停止快。一般来说,Apache httpd的启动与停止时间都比Tomcat短。 3.2单独运行Apache httpd的缺点 1)架设比较困难。比起单独运行Tomcat,安装Apache Web服务器并让它与Tomcat协同运行要复杂很多。 2)会拖慢动态网页内容的服务。 3)安全漏洞。Apache httpd比较容易受到缓冲区溢位的攻击。 4)升级比较复杂。 4、Tomcat与Apache的整合 有几种将Tomcat整合到Apache httpd Web服务器的方法: 1)架使用不同的端口号分担负载。 该方法是最容易实现的,只需要在现成的网页目录中假如URL以连接到在同一台Web服务器机器上的Tomcat Web服务器端口(如8080)。实际上还是执行两个完整的Web服务器程序,彼此之间并没有真正的整合。 2)从Apache将请求发送至Tomcat的代理服务器。 该方法会在主服务器中使用HTTP的代理机制。代理机制常会用来将来自网关上运行的Web服务器的Web信息流重新路由至外部因特网上的网站。不过,也可以用来将网站区域或目录的信息流重导至Tomcat Web服务器。 3)使用mod_jk2连接器。 该方法使用运行于现有的Apache httpd Web服务器之内的连接器模块(如mod_jk),并经由特定的协议快速地将请求转送至Tomcat。这是将Tomcat连接至Apache httpd的标准方式。 4)单一进程中执行两个程序。 该方法通过让JVM在Apache httpd的进程空间中运行的方式,可以提供“完全整合”的功能。这是最有效的办法,但也是最依赖于服务器的实现。
十种领带的打法:






双交叉结
这样的领结很容易让人有种高雅且隆重的感觉,适合正式之活动场合选用该领结应多运用在素色且丝质领带上,若搭配大翻领的衬衫不但适合且有种尊贵感。

双环结
能营造时尚感,适合年轻的上班族选用该领结完成的特色就是第一圈会稍露出于第二圈之外,可别刻意给盖住了啰。

交叉结
这是对于单色素雅质料且较薄领带适合选用的领结对于喜欢展现流行感的男士不妨多加使用。

平结
平结为最多男士选用的领结打法之一,几乎适用于各种材质的领带。
要诀:领结下方所形成的凹洞需让两边均匀且对称。

第一阶段
此阶段主要是能熟练地使用某种语言。这就相当于练武中的套路和架式这些表面的东西。
第二阶段
此阶段能精通基于某种平台的接口(例如我们现在常用的Win 32的API函数)以及所对应语言的自身的库函数。到达这个阶段后,也就相当于可以进行真实散打对练了,可以真正地在实践中做些应用。
第三阶段
此阶段能深入地了解某个平台系统的底层,已经具有了初级的内功的能力,也就是“手中有剑,心中无剑”。
第四阶级
此阶段能直接在平台上进行比较深层次的开发。基本上,能达到这个层次就可以说是进入了高层次。这时进入了高级内功的修炼。比如能进行VxD或操作系统的内核的修改。
这时已经不再有语言的束缚,语言只是一种工具,即使要用自己不会的语言进行开发,也只是简单地熟悉一下,就手到擒来,完全不像是第一阶段的时候学习语言的那种情况。一般来说,从第三阶段过渡到第四阶段是比较困难的。为什么会难呢?这就是因为很多人的思想变不过来。
第五阶级
此阶段就已经不再局限于简单的技术上的问题了,而是能从全局上把握和设计一个比较大的系统体系结构,从内核到外层界面。可以说是“手中无剑,心中有剑”。到了这个阶段以后,能对市面上的任何软件进行剖析,并能按自己的要求进行设计,就算是MS Word这样的大型软件,只要有充足的时间,也一定会设计出来。
第六阶级
此阶段也是最高的境界,达到“无招胜有招”。这时候,任何问题就纯粹变成了一个思路的问题,不是用什么代码就能表示的。也就是“手中无剑,心中也无剑”。
此时,对于练功的人来说,他已不用再去学什么少林拳,只是在旁看一下少林拳的对战,就能把此拳拿来就用。这就是真正的大师级的人物。这时,Win 32或Linux在你眼里是没有什么差别的。
每一个阶段再向上发展时都要按一定的方法。第一、第二个阶段通过自学就可以完成,只要多用心去研究,耐心地去学习。
要想从第二个阶段过渡到第三个阶段,就要有一个好的学习环境。例如有一个高手带领或公司里有一个好的练手环境。经过二、三年的积累就能达到第三个阶段。但是,有些人到达第三个阶段后,常常就很难有境界上的突破了。他们这时会产生一种观念,认为软件无非如此,认为自己已无所不能。其实,这时如果遇到大的或难些的软件,他们往往还是无从下手。
现在我们国家大部分程序员都是在第二、三级之间。他们大多都是通过自学成才的,不过这样的程序员一般在软件公司也能独当一面,完成一些软件的模块。
但是,也还有一大堆处在第一阶段的程序员,他们一般就能玩玩VB,做程序时,去找一堆控件集成一个软件.
1、对自己所在公司或部门的产品具有起码的好奇心是极为重要的一点。你必须亲自使用该产品。对于身处计算机行业的人来说,这一点怎么强调都不为过。当然,这一点同样适用于其他知识密集型领域,因为在这些领域内技术与应用发展更新极快,对其技术的掌握很难做到一劳永逸。如果你对这些产品没什么兴趣,你将很快落伍,并被淘汰出局。
2、在与客户交谈如何使用产品时,需要以极大的兴趣和传道士般的热情和执着打动客户,了解他们欣赏什么,不喜欢什么。同时必须清醒地知道本公司的产品有哪些不足,或哪里可以改进。
3、了解了客户的需求后,必须乐于思考如何让产品更贴近并帮助客户。
4、作为一个独立的员工,必须与公司制定的长期计划保持步调一致。员工需要关注其终身的努力方向,如提高自身及同事的能力。
5、在对于周遭事物具有高度洞察力的同时,必须掌握某种专业知识和技能。特别是一些大公司,他们要求员工迅速掌握专业技术。没有人能保证他目前拥有的技能仍适用于将来的工作,所以,好学精神是非常关键的。
6、非常灵活地利用那些有利于发展的机会。在微软,我们通过一系列方法为每一个人提供许多不同的工作机会。任何热衷参与微软管理的员工,都将被鼓励在不同客户服务部门工作。
7、一个好的员工会尽量去学习了解公司业务运作的经济原理,为什么公司的业务会这样运作?公司的业务模式是什么?如何才能盈利?员工必须了解导致本行业中企业盈利或亏损的原因,才能对自己所从事的工作的价值有更深入的理解。
8、关注竞争对手的动态。我非常欣赏那些随时注意整个市场动态的员工,他们会分析我们的竞争对手的可借鉴之处,并注意总结,避免重返竞争对手的错误。
9、好的员工善于动脑子。分析问题,但并不局限于分析。他们知道如何寻找潜在的平衡点,如何寻找最佳的行动时机。思考还要与实践相结合。好的员工会合理、高效地利用时间,并会为其他部门清楚地提出建议。
10、不要忽略了一些必须具备的美德,如诚实、有道德和刻苦,这些都是很重要的,在此无需赘言。
Lucene是apache组织的一个用java实现全文搜索引擎的开源项目。其功能非常的强大,但api其实很简单的,它最主要就是做两件事:建立索引和进行搜索。 1. 建立索引时最重要的几个术语 * Document:一个要进行索引的单元,相当于数据库的一行纪录,任何想要被索引的数据,都必须转化为Document对象存放。 * Field:Document中的一个字段,相当于数据库中的Column ,Field是lucene比较多概念一个术语,详细见后。 * IndexWriter:负责将Document写入索引文件。通常情况下,IndexWriter的构造函数包括了以下3个参数:索引存放的路径,分析 器和是否重新创建索引。特别注意的一点,当IndexWriter执行完addDocument方法后,一定要记得调用自身的close方法来关闭它。只 有在调用了close方法后,索引器才会将存放在内在中的所有内容写入磁盘并关闭输出流。 * Analyzer:分析器,主要用于文本分词。常用的有StandardAnalyzer分析器,StopAnalyzer分析器,WhitespaceAnalyzer分析器等。 * Directory:索引存放的位置。lucene提供了两种索引存放的位置,一种是磁盘,一种是内存。一般情况将索引放在磁盘上;相应地lucene提供了FSDirectory和RAMDirectory两个类。 * 段:Segment,是Lucene索引文件的最基本的一个单位。Lucene说到底就是不断加入新的Segment,然后按一定的规则算法合并不同的Segment以合成新的Segment。 lucene建立索引的过程就是将待索引的对象转化为Lucene的Document对象,使用IndexWriter将其写入lucene 自定义格式的索引文件中。
待索引的对象可以来自文件、数据库等任意途径,用户自行编码遍历目录读取文件或者查询数据库表取得ResultSet,Lucene的API只负责和字符串打交道。
1.1 Field 的解释
从源代码中,可以看出Field 构造函数如下:
Field(String name, byte[] value, Field.Store store)
Field(String name, Reader reader)
Field(String name, Reader reader, Field.TermVector termVector)
Field(String name, String value, Field.Store store, Field.Index index)
Field(String name, String value, Field.Store store, Field.Index index, Field.TermVector termVector)
在Field当中有三个内部类:Field.Index,Field.Store,Field.termVector。其中
* Field.Index有四个属性,分别是:
Field.Index.TOKENIZED:分词索引
Field.Index.UN_TOKENIZED:分词进行索引,如作者名,日期等,Rod Johnson本身为一单词,不再需要分词。
Field.Index:不进行索引,存放不能被搜索的内容如文档的一些附加属性如文档类型, URL等。
Field.Index.NO_NORMS:;
* Field.Store也有三个属性,分别是:
Field.Store.YES:索引文件本来只存储索引数据, 此设计将原文内容直接也存储在索引文件中,如文档的标题。
Field.Store.NO:原文不存储在索引文件中,搜索结果命中后,再根据其他附加属性如文件的Path,数据库的主键等,重新连接打开原文,适合原文内容较大的情况。
Field.Store.COMPRESS 压缩存储;
* termVector是Lucene 1.4.3新增的它提供一种向量机制来进行模糊查询,很少用。
上面所说的Field属性与lucene1.4.3版本的有比较大的不同,在旧版的1.4.3里lucene是通过Field.Keyword (...),FieldUnIndexed(...),FieldUnstored(...)和Field.Text(...)来设置不同字段的类型以达 到不同的用途,而当前版本由Field.Index和Field.Store两个字段的不同组合来达到上述效果。
还有一点说明,其中的两个构造函数其默认的值为Field.Store.NO和Field.Index.TOKENIZED。:
Field(String name, Reader reader)
Field(String name, Reader reader, Field.TermVector termVector)
* 限制Field的长度:
IndexWriter类提供了一个setMaxFieldLength的方法来对Field的长度进行限制,看一下源代码就知道其默认值为10000; 我们可以在使用时重新设置此参数。如果使用默认值,那么Lucene就仅仅对文档的前面的10000个term进行索引,超过这一个数的文档就不会被建立 索引。
1.2 索引的合并、删除、优化
* IndexWriter中的addIndexes方法将索引进行合并;当在不同的地方创建了索引后,如果需要将索引合并,这时候使用addIndexes方法就显得很有意义。
* 可以通过IndexReader类从索引中进行文档的删除。IndexReader是很特别的一个类,看源代码就知道它主要是通过自身的静态方法来完成构造的。示例:
IndexReader reader = IndexReader.open("C:\\springside");
reader.deleteDocument(X); //这里的X是一个int的常数;不推荐这一种删除方法
reader.deleteDocument(new Term("name","springside"));//这是另一种删除索引的方法,按字段来删除,推荐使用这一种做法
reader.close();
* 优化索引:可以使用IndexWriter类的optimize方法来进行优先,它会将多个Segment进行合并,组成一个新的Segment,可以加 快建立索引后搜索的速度。另外需要注意的一点,optimize方法会降低建立索引的速度,而且要求的磁盘空间会增加。
2. 进行搜索时最常用的几个术语
* IndexSearcher:是lucene中最基本的检索工具,所有的检索都会用到IndexSearcher工具。初始化IndexSearcher需要设置索引存放的路径,让查询器能定位索引而进行搜索。
* Query:查询,lucene中支持模糊查询,语义查询,短语查询,组合查询等等,如有TermQuery,BooleanQuery,RangeQuery,WildcardQuery等一些类。
* QueryParser: 是一个解析用户输入的工具,可以通过扫描用户输入的字符串,生成Query对象。
* Hits:在搜索完成之后,需要把搜索结果返回并显示给用户,只有这样才算是完成搜索的目的。在lucene中,搜索的结果的集合是用Hits类的实例来表示的。Hits对象中主要方法有:
length(): 返回搜索结果的总数,下面简单的用法中有用到Hit的这一个方法
doc(int n): 返回第n个文档
iterator(): 返回一个迭代器
这里再提一下Hits,这也是Lucene比较精彩的地方,熟悉hibernate的朋友都知道hibernate有一个延迟加载的属性,同样, Lucene也有。Hits对象也是采用延迟加载的方式返回结果的,当要访问某个文档时,Hits对象就在内部对Lucene的索引又进行一次检索,最后 才将结果返回到页面显示。
3. 一个简单的实例:
首先把lucene的包放在classpath路径中去,写下面一个简单的类:
public class FSDirectoryTest {
//建立索引的路径
public static final String path = "c:\\index2";
public static void main(String[] args) throws Exception {
Document doc1 = new Document();
doc1.add( new Field("name", "lighter springside com",Field.Store.YES,Field.Index.TOKENIZED));
Document doc2 = new Document();
doc2.add(new Field("name", "lighter blog",Field.Store.YES,Field.Index.TOKENIZED));
IndexWriter writer = new IndexWriter(FSDirectory.getDirectory(path, true), new StandardAnalyzer(), true);
writer.addDocument(doc1);
writer.addDocument(doc2);
writer.close();
IndexSearcher searcher = new IndexSearcher(path);
Hits hits = null;
Query query = null;
QueryParser qp = new QueryParser("name",new StandardAnalyzer());
query = qp.parse("lighter");
hits = searcher.search(query);
System.out.println("查找\"lighter\" 共" + hits.length() + "个结果");
query = qp.parse("springside");
hits = searcher.search(query);
System.out.println("查找\"springside\" 共" + hits.length() + "个结果");
}
}
执行的结果:
查找"lighter" 共2个结果
查找"springside" 共1个结果
4. 一个复杂一点的实例
* 在windows系统下的的C盘,建一个名叫s的文件夹,在该文件夹里面随便建三个txt文件,随便起名啦,就叫"1.txt","2.txt"和"3.txt"啦
其中1.txt的内容如下:
springside社区
更大进步,吸引更多用户,更多贡献
2007年
而"2.txt"和"3.txt"的内容也可以随便写几写,这里懒写,就复制一个和1.txt文件的内容一样吧
* 下载lucene包,放在classpath路径中,然后建立索引:
/**
* author lighter date 2006-8-7
*/
public class LuceneExample {
public static void main(String[] args) throws Exception {
File fileDir = new File("c:\\s"); // 指明要索引文件夹的位置,这里是C盘的S文件夹下
File indexDir = new File("c:\\index"); // 这里放索引文件的位置
File[] textFiles = fileDir.listFiles();
Analyzer luceneAnalyzer = new StandardAnalyzer();
IndexWriter indexWriter = new IndexWriter(indexDir,luceneAnalyzer,true);
indexFile(luceneAnalyzer,indexWriter, textFiles);
indexWriter.optimize();//optimize()方法是对索引进行优化
indexWriter.close();
}
public static void indexFile(Analyzer luceneAnalyzer,IndexWriter indexWriter,File[] textFiles) throws Exception
{
//增加document到索引去
for (int i = 0; i < textFiles.length; i++) {
if (textFiles[i].isFile() && textFiles[i].getName().endsWith(".txt")) {
String temp = FileReaderAll(textFiles[i].getCanonicalPath(),"GBK");
Document document = new Document();
Field FieldBody = new Field("body", temp, Field.Store.YES,Field.Index.TOKENIZED);
document.add(FieldBody);
indexWriter.addDocument(document);
}
}
}
public static String FileReaderAll(String FileName, String charset)throws IOException {
BufferedReader reader = new BufferedReader(new InputStreamReader(
new FileInputStream(FileName), charset));
String line = "";
String temp = "";
while ((line = reader.readLine()) != null) {
temp += line;
}
reader.close();
return temp;
}
}
* 执行查询:
public class TestQuery {
public static void main(String[] args) throws IOException, ParseException {
Hits hits = null;
String queryString = "社区";
Query query = null;
IndexSearcher searcher = new IndexSearcher("c:\\index");
Analyzer analyzer = new StandardAnalyzer();
try {
QueryParser qp = new QueryParser("body", analyzer);
query = qp.parse(queryString);
} catch (ParseException e) {
}
if (searcher != null) {
hits = searcher.search(query);
if (hits.length() > 0) {
System.out.println("找到:" + hits.length() + " 个结果!");
}
}
}
}
* 执行结果:
找到:3 个结果!
其实很早以前就使用过FCKeditor,那是在做一个新闻发布系统中,当时使用jsp + struts来开发,FCKeditor在jsp下的配置在网上有很多相关的文章,这里就不多说了。现在使用Velocity开发tycho时,也用到了FCKeditor,其实配置和jsp一样,只是思维需要转换一下,即,网上所介绍的jsp下使用FCKeditor一般都是在jsp页面上生成实例,而Velocity并不能完成这一需求,那么我们将FCKeditor的实例放在后台bean中生成,并放入request,然后在Velocity中对其进行设置。后台bean中写法如下:
FCKeditor fckEditor = new FCKeditor(super.getRequest());
request.setAttribute("fckEditor", fckEditor);
Velocity页在中取到这个实例并对其进行设置:
$!{fckEditor.setHeight("190")}
$!{fckEditor.setWidth("420")}
$!{fckEditor.setBasePath("fckeditor/")}
$!{fckEditor.setToolbarSet("Basic")}
$!{fckEditor.setInstanceName("comment")}
$!{fckEditor.create()}
非常简单,比用jsp实现要容易多了。至少不用设置page。
利用Javascript取和设FCKeditor值也是非常容易的,如下:
// 获取编辑器中HTML内容
function getEditorHTMLContents(EditorName) {
var oEditor = FCKeditorAPI.GetInstance(EditorName);
return(oEditor.GetXHTML(true));
}
// 获取编辑器中文字内容
function getEditorTextContents(EditorName) {
var oEditor = FCKeditorAPI.GetInstance(EditorName);
return(oEditor.EditorDocument.body.innerText);
}
// 设置编辑器中内容
function SetEditorContents(EditorName, ContentStr) {
var oEditor = FCKeditorAPI.GetInstance(EditorName) ;
oEditor.SetHTML(ContentStr) ;
}
FCKeditorAPI是FCKeditor加载后注册的一个全局对象,利用它我们就可以完成对编辑器的各种操作。
在当前页获得 FCK 编辑器实例:
var Editor = FCKeditorAPI.GetInstance('InstanceName');
从 FCK 编辑器的弹出窗口中获得 FCK 编辑器实例:
var Editor = window.parent.InnerDialogLoaded().FCK;
从框架页面的子框架中获得其它子框架的 FCK 编辑器实例:
var Editor = window.FrameName.FCKeditorAPI.GetInstance('InstanceName');
从页面弹出窗口中获得父窗口的 FCK 编辑器实例:
var Editor = opener.FCKeditorAPI.GetInstance('InstanceName');
获得 FCK 编辑器的内容:
oEditor.GetXHTML(formatted); // formatted 为:true|false,表示是否按HTML格式取出
也可用:
oEditor.GetXHTML();
设置 FCK 编辑器的内容:
oEditor.SetHTML("content", false); // 第二个参数为:true|false,是否以所见即所得方式设置其内容。此方法常用于"设置初始值"或"表单重置"哦作。
插入内容到 FCK 编辑器:
oEditor.InsertHtml("html"); // "html"为HTML文本
检查 FCK 编辑器内容是否发生变化:
oEditor.IsDirty();
在 FCK 编辑器之外调用 FCK 编辑器工具条命令:
命令列表如下:
DocProps, Templates, Link, Unlink, Anchor, BulletedList, NumberedList, About, Find, Replace, Image, Flash, SpecialChar, Smiley, Table, TableProp, TableCellProp, UniversalKey, Style, FontName, FontSize, FontFormat, Source, Preview, Save, NewPage, PageBreak, TextColor, BGColor, PasteText, PasteWord, TableInsertRow, TableDeleteRows, TableInsertColumn, TableDeleteColumns, TableInsertCell, TableDeleteCells, TableMergeCells, TableSplitCell, TableDelete, Form, Checkbox, Radio, TextField, Textarea, HiddenField, Button, Select, ImageButton, SpellCheck, FitWindow, Undo, Redo
使用方法如下:
oEditor.Commands.GetCommand('FitWindow').Execute();
FCKeditor目录精简说明:
1. 根目录下的文件只留下fckconfig.js, fckeditor.js, fckstyles.xml, fcktemplates.xml四个文件
2. 删除所有的以_开头的文件和文件夹
3. 删除FCKeditor\editor\filemanager\upload目录下的所有文件
4. 删除FCKeditor\editor\filemanager\browser\default\connectors目录下的所有文件
5. 删除FCKeditor\editor\_source目录
以下部分为引用,觉得挺实用,做个备份。
上传文件部分的定制,适用于高级用户。
第一部分,装自己定制的插件,实现模板标签(开源的东西就有这点好处,随心所欲地修改),打开fckconfig.js文件找到
FCKConfig.PluginsPath = FCKConfig.BasePath + 'plugins/' ;
// FCKConfig.Plugins.Add( 'placeholder', 'en,it' ) ;
去掉//后,就相当于把placeholder这个插件功能加上了,fckeditor的插件文件都在/editor/plugins/文件夹下分类按文件夹放置的,对于fckeditor2.0来说,里面有两个文件夹,也就是有两个官方插件,placeholder这个文件夹就是我们刚才加上去的,主要用于多参数或单参数自定义标签的匹配,这个在制作编辑模板时非常管用,要想看具体实例的话,大家可以去下载acms这个系统查看学习,另一个文件夹tablecommands就是编辑器里的表格编辑用到的了。当然,如果你想制作自己其它用途的插件,那就只要按照fckeidtor插件的制作规则制作完放置在/editor/plugins/下就行,然后再在fckeidtor.js里再添加FCKConfig.Plugins.Add('Plugin Name',',lang,lang');就可以了。
第二部分 ,如何让编辑器一打开的时候,编辑工具条不出现,等点“展开工具栏”时才出现?Easy,FCKeditor本身提供了这个功能啦,打开fckconfig.js,找到
FCKConfig.ToolbarStartExpanded = true ;
改成
FCKConfig.ToolbarStartExpanded = false ;
就可以啦!
第三部分,使用自己的表情图标,同样打开fckcofnig.js到最底部那一段
FCKConfig.SmileyPath = FCKConfig.BasePath + 'images/smiley/msn/' ;
FCKConfig.SmileyImages = ['regular_smile.gif','sad_smile.gif','wink_smile.gif'] ;
FCKConfig.SmileyColumns = 8 ;
FCKConfig.SmileyWindowWidth = 320 ;
FCKConfig.SmileyWindowHeight = 240 ;
上面这段已经是我修改过的了,为了我发表此文的版面不会被撑得太开,我把FCKConfig.SmileyImages那一行改得只有三个表情图了。
第一行,当然是表情图标路径的设置,第二行是相关表情图标文件名的一个List,第三行是指弹出的表情添加窗口最每行的表情数,下面两个参数是弹出的模态窗口的宽和高喽。
第四部分,文件上传管理部分
此部分可能是大家最为关心的,上一篇文章简单的讲了如何修改来上传文件以及使用fckeidtor2.0才提供的快速上传功能。再我们继续再深层次的讲解上传功能
FCKConfig.LinkBrowser = true ;
FCKConfig.ImageBrowser = true ;
FCKConfig.FlashBrowser = true ;在fckconfig.js找到这三句,这三句不是连着的哦,只是我把他们集中到这儿来了,设置为true的意思就是允许使用fckeditor来浏览服务器端的文件图像以及flash等,这个功能是你插入图片时弹出的窗口上那个“浏览服务器”按钮可以体现出来,如果你的编辑器只用来自己用或是只在后台管理用,这个功能无疑很好用,因为他让你很直观地对服务器的文件进行上传操作。但是如果你的系统要面向前台用户或是像blog这样的系统要用的话,这个安全隐患可就大了哦。于是我们把其一律设置为false;如下
FCKConfig.LinkBrowser = false ;
FCKConfig.ImageBrowser = false ;
FCKConfig.FlashBrowser = false ;
这样一来,我们就只有快速上传可用了啊,好!接下来就来修改,同样以asp为范例进行,进入/editor/filemanager/upload/asp/打开config.asp,修改
ConfigUserFilesPath = "/UserFiles/"这个设置是上传文件的总目录,我这里就不动了,你想改自己改了
好,再打开此目录下的upload.asp文件,找到下面这一段
Dim resourceType
If ( Request.QueryString("Type") <> "" ) Then
resourceType = Request.QueryString("Type")
Else
resourceType = "File"
End If
然后再在其后面添加
ConfigUserFilesPath = ConfigUserFilesPath & resourceType &"/"& Year(Date()) &"/"& Month(Date()) &"/"
这样的话,上传的文件就进入“/userfiles/文件类型(如image或file或flash)/年/月/”这样的文件夹下了,这个设置对单用户来用已经足够了,如果你想给多用户系统用,那就这样来改
ConfigUserFilesPath = ConfigUserFilesPath & Session("username") & resourceType &"/"& Year(Date()) &"/"& Month(Date()) &"/"
这样上传的文件就进入“/userfiles/用户目录/文件类型/年/月/”下了,当然如果你不想这么安排也可以修改成别的,比如说用户目录再深一层等,这里的Session("username")请根据自己的需要进行修改或换掉。
上传的目录设置完了,但是上传程序还不会自己创建这些文件夹,如果不存在的话,上传不会成功的,那么我们就得根据上面的上传路径的要求进行递归来生成目录了。
找到这一段
Dim sServerDir
sServerDir = Server.MapPath( ConfigUserFilesPath )
If ( Right( sServerDir, 1 ) <> "\" ) Then
sServerDir = sServerDir & "\"
End If
把它下面的这两行
Dim oFSO
Set oFSO = Server.CreateObject( "Scripting.FileSystemObject" )
用下面这一段代码来替换
dim arrPath,strTmpPath,intRow
strTmpPath = ""
arrPath = Split(sServerDir, "\")
Dim oFSO
Set oFSO = Server.CreateObject( "Scripting.FileSystemObject" )
for intRow = 0 to Ubound(arrPath)
strTmpPath = strTmpPath & arrPath(intRow) & "\"
if oFSO.folderExists(strTmpPath)=false then
oFSO.CreateFolder(strTmpPath)
end if
next
用这段代码就可以生成你想要的文件夹了,在上传的时候自动生成。
好了,上传文件的修改到现在可以暂时告一段落了,但是,对于中文用户还存在这么个问题,就是fckeditor的文件上传默认是不改名的,同时还不支持中文文件名,这样一来是上传的文件会变成“.jpg”这样的无法读的文件,再就是会有重名文件,当然重名这点倒没什么,因为fckeditor会自动改名,会在文件名后加(1)这样来进行标识。但是,我们通常的习惯是让程序自动生成不重复的文件名
在刚才那一段代码的下面紧接着就是
' Get the uploaded file name.
sFileName = oUploader.File( "NewFile" ).Name
看清楚了,这个就是文件名啦,我们来把它改掉,当然得有个生成文件名的函数才行,改成下面这样
'//取得一个不重复的序号
Public Function GetNewID()
dim ranNum
dim dtNow
randomize
dtNow=Now()
ranNum=int(90000*rnd)+10000
GetNewID=year(dtNow) & right("0" & month(dtNow),2) & right("0" & day(dtNow),2) & right("0" & hour(dtNow),2) & right("0" & minute(dtNow),2) & right("0" & second(dtNow),2) & ranNum
End Function
' Get the uploaded file name.
sFileName = GetNewID() &"."& split(oUploader.File( "NewFile" ).Name,".")(1)
这样一来,上传的文件就自动改名生成如20050802122536365.jpg这样的文件名了,是由年月日时分秒以及三位随机数组成的文件名了。
试用了一下FCKeditor,感觉不错(http://www.fckeditor.net)
稍稍整理了一下,过程如下:
1.下载
FCKeditor.java 2.3 (FCKeditot for java)
FCKeditor 2.2 (FCKeditor基本文件)
2.建立项目:tomcat/webapps/FCKeditor
3.FCKeditor.java 2.3解压后,把其中的web目录下的WEB-INF目录copy到FCKeditor下(里面有commons-fileupload.jar,FCKeditor-2.3.jar,web.xml等几个文件), 把其中的src目录下的FCKeditor.tld文件copy到FCKeitor/WEB-INF/下
4.修改web.xml:
把SimpleUploader中的配置属性enabled定义为true(开启文件上传功能)
添加标签定义:
<taglib>
<taglib-uri>/FCKeditor</taglib-uri>
<taglib-location>/WEB-INF/FCKeditor.tld</taglib-location>
</taglib>
5.解压FCKeditor2.2后,把目录/editor和fckconfig.js, fckeditor.js, fckstyles.xml, fcktemplates.xml四个文件copy到/FCKeditor下
删除目录/editor/_source,
删除/editor/filemanager/browser/default/connectors/下的所有文件
删除/editor/filemanager/upload/下的所有文件
删除/editor/lang/下的除了fcklanguagemanager.js, en.js, zh.js, zh-cn.js四个文件的所有文件
6.打开/FCKeditor/fckconfig.js
修改 FCKConfig.DefaultLanguage = 'zh-cn' ;
把FCKConfig.LinkBrowserURL等的值替换成以下内容:
FCKConfig.LinkBrowserURL = FCKConfig.BasePath + "filemanager/browser/default/browser.html?Connector=connectors/jsp/connector" ;
FCKConfig.ImageBrowserURL = FCKConfig.BasePath + "filemanager/browser/default/browser.html?Type=Image&Connector=connectors/jsp/connector" ;
FCKConfig.FlashBrowserURL = FCKConfig.BasePath + "filemanager/browser/default/browser.html?Type=Flash&Connector=connectors/jsp/connector" ;
FCKConfig.LinkUploadURL = FCKConfig.BasePath + 'filemanager/upload/simpleuploader?Type=File' ;
FCKConfig.FlashUploadURL = FCKConfig.BasePath + 'filemanager/upload/simpleuploader?Type=Flash' ;
FCKConfig.ImageUploadURL = FCKConfig.BasePath + 'filemanager/upload/simpleuploader?Type=Image' ;
7.添加文件 /FCKeditor/test.jsp:
<%@ page language="java" import="com.fredck.FCKeditor.*" %>
<%@ taglib uri="/FCKeditor" prefix="FCK" %>
<script type="text/javascript" src="/FCKeditor/fckeditor.js"></script>
<%--
三种方法调用FCKeditor
1.FCKeditor自定义标签 (必须加头文件 <%@ taglib uri="/FCKeditor" prefix="FCK" %> )
2.script脚本语言调用 (必须引用 脚本文件 <script type="text/javascript" src="/FCKeditor/fckeditor.js"></script> )
3.FCKeditor API 调用 (必须加头文件 <%@ page language="java" import="com.fredck.FCKeditor.*" %> )
--%>
<%--
<form action="show.jsp" method="post" target="_blank">
<FCK:editor id="content" basePath="/FCKeditor/"
width="700"
height="500"
skinPath="/FCKeditor/editor/skins/silver/"
toolbarSet = "Default"
>
input
</FCK:editor>
<input type="submit" value="Submit">
</form>
--%>
<form action="show.jsp" method="post" target="_blank">
<table border="0" width="700"><tr><td>
<textarea id="content" name="content" style="WIDTH: 100%; HEIGHT: 400px">input</textarea>
<script type="text/javascript">
var oFCKeditor = new FCKeditor('content') ;
oFCKeditor.BasePath = "/FCKeditor/" ;
oFCKeditor.Height = 400;
oFCKeditor.ToolbarSet = "Default" ;
oFCKeditor.ReplaceTextarea();
</script>
<input type="submit" value="Submit">
</td></tr></table>
</form>
<%--
<form action="show.jsp" method="post" target="_blank">
<%
FCKeditor oFCKeditor ;
oFCKeditor = new FCKeditor( request, "content" ) ;
oFCKeditor.setBasePath( "/FCKeditor/" ) ;
oFCKeditor.setValue( "input" );
out.println( oFCKeditor.create() ) ;
%>
<br>
<input type="submit" value="Submit">
</form>
--%>
添加文件/FCKeditor/show.jsp:
<%
String content = request.getParameter("content");
out.print(content);
%>
8.浏览http://localhost:8080/FCKeditor/test.jsp
ok!
9.上传遇到错误: internal server error 500,
直接引用servlet(com.fredck.FCKeditor.connector.ConnectorServlet)也遇到错误: "Provider org.apache.xalan.processor.TransformerFactoryImpl not found",
拷贝xalan.jar到lib目录就可以了
新免覆盖注册
更新说明:不使用覆盖安装法,直接输入注册码即可。
下面把 5.5 GA 版本的“注册信息”“注册码”“破解”给大家:
Subscriber: www.1cn.biz
Subscriber Code: jLR7ZL-655355-5450755330522962
时间:20090520
|
|
|
| | 日 | 一 | 二 | 三 | 四 | 五 | 六 |
|---|
| 24 | 25 | 26 | 27 | 28 | 29 | 30 | | 1 | 2 | 3 | 4 | 5 | 6 | 7 | | 8 | 9 | 10 | 11 | 12 | 13 | 14 | | 15 | 16 | 17 | 18 | 19 | 20 | 21 | | 22 | 23 | 24 | 25 | 26 | 27 | 28 | | 29 | 30 | 31 | 1 | 2 | 3 | 4 |
|
导航
统计
常用链接
留言簿(1)
随笔分类(32)
随笔档案(33)
搜索
最新评论

阅读排行榜
评论排行榜
|
|