
2009年6月26日
Microsoft SQL Server 2008 基本安装说明
安装SQL2008的过程与SQL2005的程序基本一样,只不过在安装的过程中部分选项有所改变,当然如果只熟悉SQL2000安装的同志来说则是一个革命性的变动,
一、安装前的准备
1. 需要.Net Framework 3.5,若在Vista或更高的OS上需要3.5 SP1的支持(在SQL2008安装的前会自动更新安装)
2. 需要Widnows PowerShell的支持,WPS是一个功能非常强大的Shell应用,命令与DOX/UNIX兼容并支持直接调用.NET模块做行命令编辑,是非常值得深入研究的工具(在SQL2008安装时会自动更新安装)
3. 需要确保Windows Installer的成功启动,需要4.5以上版本(需要检查服务启动状态service.msc)
4. 需要MDAC2.8 sp1的支持(XP以上系统中已集成)
5. 若机器上已经安装Visual studio 2008则需要VS 2008 sp1以上版本的支持(需要自己从MS的网站上下载安装http://www.microsoft.com/downloads/details.aspx?familyid=FBEE1648-7106-44A7-9649-6D9F6D58056E&displaylang=en)
二、安装配置过程
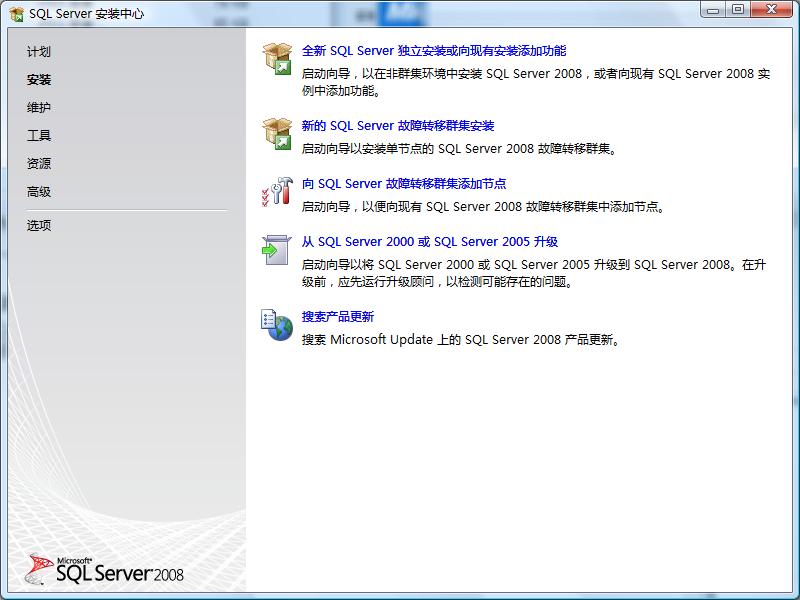
1.进行SQL Server安装中心,选择"安装"选项,在新的电脑上安装SQL2008可以直接选择“全新SQL Server独立安装或向现有安装功能",将会安装一个默认SQL实列,如下图
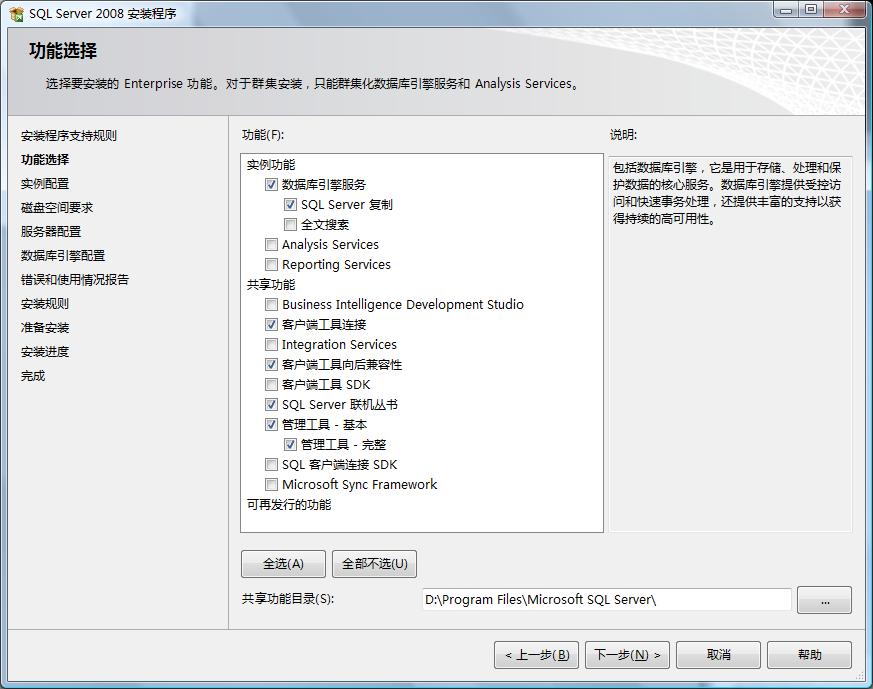
2.功能选择,对于只安装数据库服务器来说,功能的选择上可以按实际工作需要来制定,本人一般选择:数据库引擎服务、客户端工具连接、SQL Server 联机丛书、管理工具-基本、管理工具-完整
其中数据库引擎服务是SQL数据库的核心服务,Analysis及Reporting服务可按部署要求安装,这两个服务可能需要IIS的支持。如下图
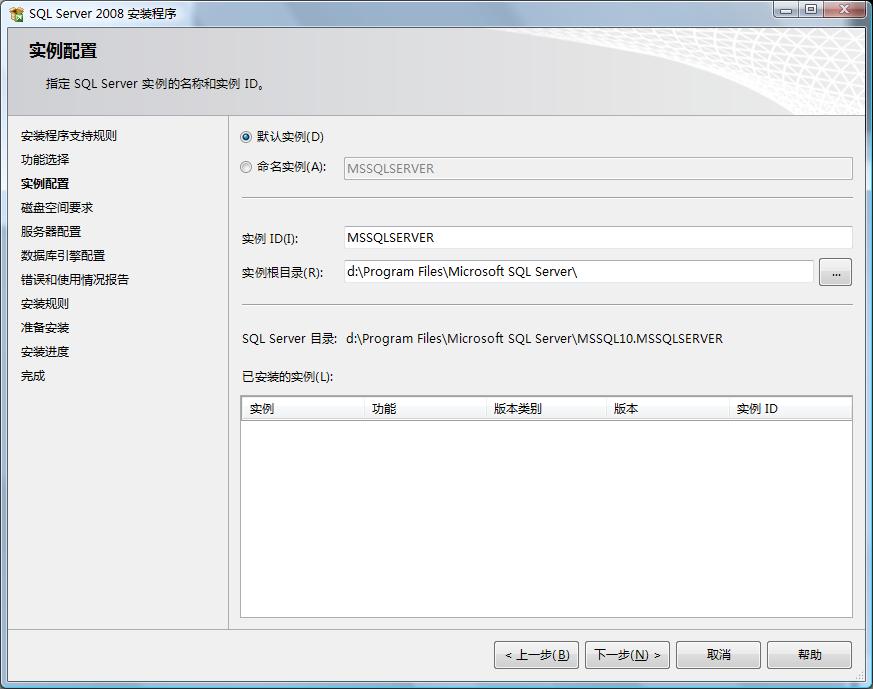
3.实列设置,可直接选择默认实例进行安装,或则若同一台服务器中有多个数据服务实列可按不同实列名进行安装。如图
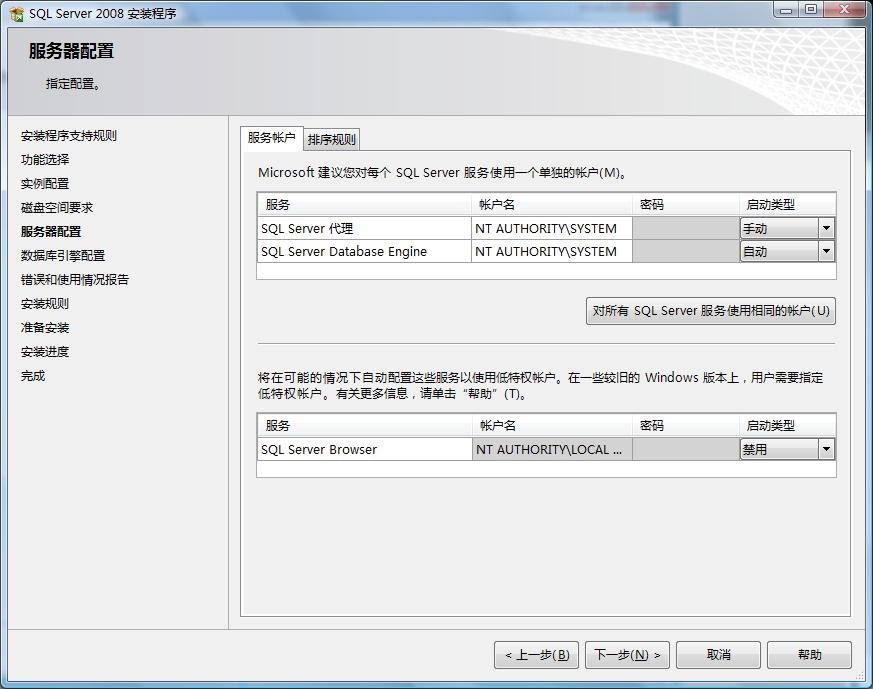
4.服务器配置,服务器配置主要是服务启动帐户的配置,服务的帐户名推荐使用NT AUTHORITY\SYSTEM的系统帐户,并指定当前选择服务的启动类型,如图
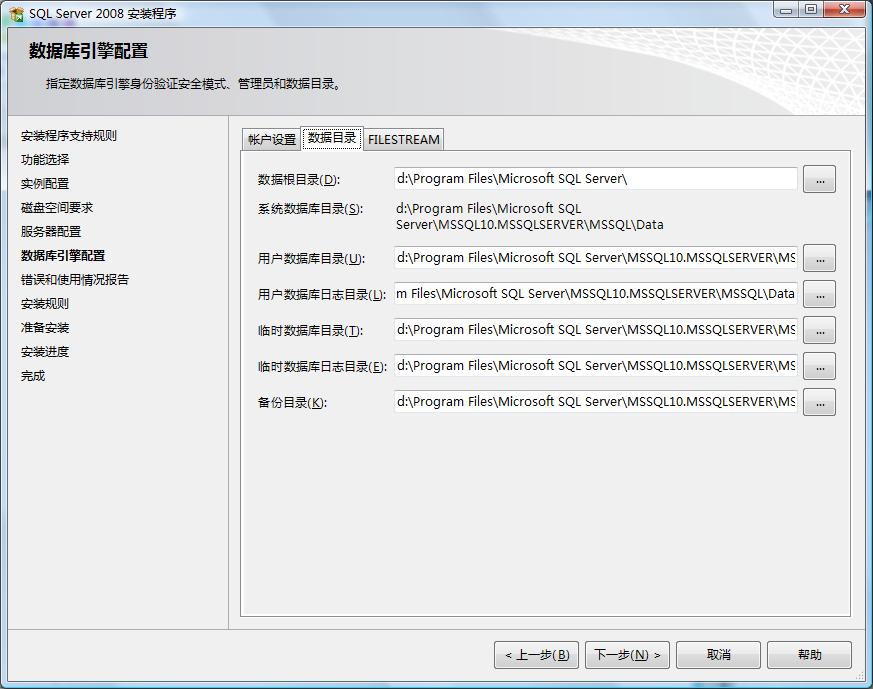
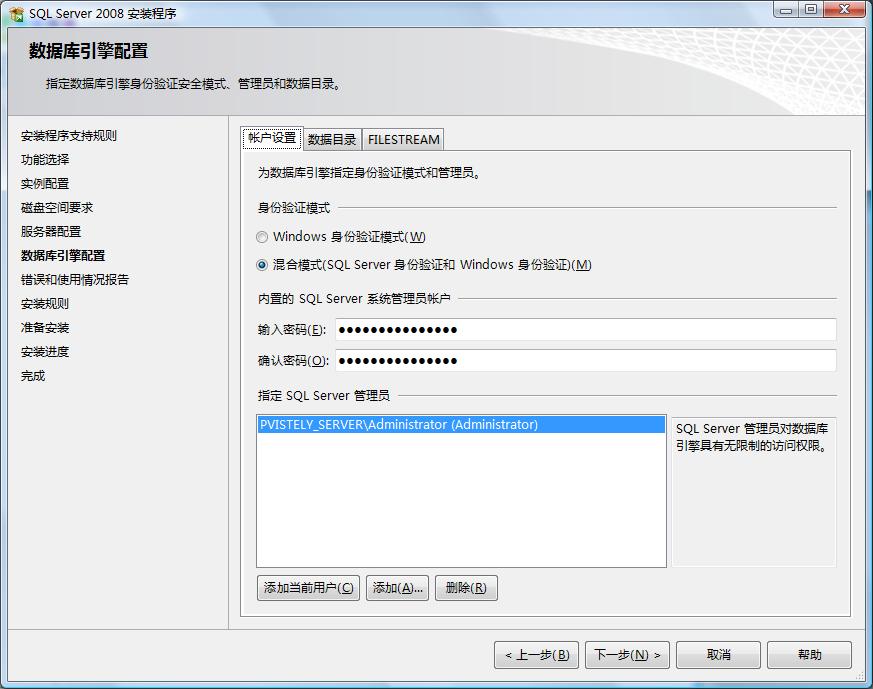
5.数据库引擎配置,在当前配置中主要设置SQL登录验证模式及账户密码,与SQL的数据存储目录,身份验证模式推荐使用混合模式进行验证,在安装过程中内置的SQL Server系统管理员帐户(sa)的密码比较特殊,SQL2008对SA的密码强度要求相对比较高,需要有大小写字母、数字及符号组成,否则将不允许你继续安装。在"指定Sql Server管理员"中最好指定本机的系统管理员administrator。如图
posted @
2013-09-27 13:27 RoyPayne 阅读(234) |
评论 (0) |
编辑 收藏
依次点击设置--高级选项--内容设置--cookies--选择“显示cookies和其他网站数据按钮就可以看到了
firefox:
依次点开FF浏览器工具选项: 工具》选项》隐私》在历史选项框中选择“使用自定义历史记录设置” 进入后,再选择“显示Cookies”.出来一个对话框,里面就是FF记录的所有Cookie。其值你也可以很方便查看到。
posted @
2013-01-28 06:54 RoyPayne 阅读(2913) |
评论 (1) |
编辑 收藏 死锁是一个经典的多线程问题,因为不同的线程都在等待那些根本不可能被释放的锁,
从而导致所有的工作都无法完成。假设有两个线程,分别代表两个饥饿的人,他们必须共享刀叉并轮流吃饭。
他们都需要获得两个锁:共享刀和共享叉的锁。假如线程 "A" 获得了刀,而线程 "B" 获得了叉。
线程 A 就会进入阻塞状态来等待获得叉,而线程 B 则阻塞来等待 A 所拥有的刀。
让所有的线程按照同样的顺序获得一组锁。这种方法消除了 X 和 Y 的拥有者分别等待对方的资源的问题。
将多个锁组成一组并放到同一个锁下。前面死锁的例子中,可以创建一个银器对象的锁。于是在获得刀或叉之前都必须获得这个银器的锁。
将那些不会阻塞的可获得资源用变量标志出来。当某个线程获得银器对象的锁时,就可以通过检查变量来判断是否整个银器集合中的对象锁都可获得。如果是,它就可以获得相关的锁,否则,就要释放掉银器这个锁并稍后再尝试。
最重要的是,在编写代码前认真仔细地设计整个系统。多线程是困难的,在开始编程之前详细设计系统能够帮助你避免难以发现死锁的问题。
posted @
2012-12-10 10:54 RoyPayne 阅读(339) |
评论 (0) |
编辑 收藏<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN" "http://www.w3.org/TR/html4/loose.dtd">
<html>
<head>
<title> New Document </title>
<meta name="Generator" content="EditPlus">
<meta name="Author" content="">
<meta name="Keywords" content="">
<meta name="Description" content="">
</head>
<script type="text/javascript" src="jquery.js"></script>
<script type="text/javascript">
function go() {
var str="";
$("input[name='checkbox']:checkbox").each(function(){
if($(this).attr("checked")){
str += $(this).val()+","
}
})
//alert(str);
str.split(",");
alert(str[0]);
}
</script>
<body>
<div>
<input type="text" id="content" value="111"/>
<input type="checkbox" name="checkbox" value="1"/>
<input type="checkbox" name="checkbox" value="2"/>
<input type="checkbox" name="checkbox" value="3"/>
<input type="checkbox" name="checkbox" value="4"/>
<input type="checkbox" name="checkbox" value="5"/>
<input type="button" id="test" onclick="go();"/>
</div>
</body>
</html>
posted @
2012-03-02 09:40 RoyPayne 阅读(88783) |
评论 (21) |
编辑 收藏posted @
2012-02-01 14:50 RoyPayne 阅读(351) |
评论 (0) |
编辑 收藏
摘要: oracle脚本:drop table t_student cascade constraints;Code highlighting produced by Actipro CodeHighlighter (freeware)http://www.CodeHighlighter.com/-->/*==================================================...
阅读全文
posted @
2012-01-31 13:25 RoyPayne 阅读(2243) |
评论 (2) |
编辑 收藏在Session的缓存中存放的是相互关联的对象图。默认情况下,当Hibernate从数据库中加载Customer对象时,会同时加载所有关联的 Order对象。以Customer和Order类为例,假定ORDERS表的CUSTOMER_ID外键允许为null
以下Session的find()方法用于到数据库中检索所有的Customer对象:
List customerLists=session.find("from Customer as c");
运行以上find()方法时,Hibernate将先查询CUSTOMERS表中所有的记录,然后根据每条记录的ID,到ORDERS表中查询有参照关系的记录,Hibernate将依次执行以下select语句:
select * from CUSTOMERS;
select * from ORDERS where CUSTOMER_ID=1;
select * from ORDERS where CUSTOMER_ID=2;
select * from ORDERS where CUSTOMER_ID=3;
select * from ORDERS where CUSTOMER_ID=4;
通过以上5条select语句,Hibernate最后加载了4个Customer对象和5个Order对象,在内存中形成了一幅关联的对象图.
Hibernate在检索与Customer关联的Order对象时,使用了默认的立即检索策略。这种检索策略存在两大不足:
(1) select语句的数目太多,需要频繁的访问数据库,会影响检索性能。如果需要查询n个Customer对象,那么必须执行n+1次select查询语 句。这就是经典的n+1次select查询问题。这种检索策略没有利用SQL的连接查询功能,例如以上5条select语句完全可以通过以下1条 select语句来完成:
select * from CUSTOMERS left outer join ORDERS
on CUSTOMERS.ID=ORDERS.CUSTOMER_ID
以上select语句使用了SQL的左外连接查询功能,能够在一条select语句中查询出CUSTOMERS表的所有记录,以及匹配的ORDERS表的记录。
(2)在应用逻辑只需要访问Customer对象,而不需要访问Order对象的场合,加载Order对象完全是多余的操作,这些多余的Order对象白白浪费了许多内存空间。
为了解决以上问题,Hibernate提供了其他两种检索策略:延迟检索策略和迫切左外连接检索策略。延迟检索策略能避免多余加载应用程序不需要访问的关联对象,迫切左外连接检索策略则充分利用了SQL的外连接查询功能,能够减少select语句的数目。
对数据库访问还是必须考虑性能问题的, 在设定了1 对多这种关系之后, 查询就会出现传说中的n +1 问题。
1 )1 对多,在1 方,查找得到了n 个对象, 那么又需要将n 个对象关联的集合取出,于是本来的一条sql查询变成了n +1 条
2)多对1 ,在多方,查询得到了m个对象,那么也会将m个对象对应的1 方的对象取出, 也变成了m+1
怎么解决n +1 问题?
1 )lazy=true, hibernate3开始已经默认是lazy=true了;lazy=true时不会立刻查询关联对象,只有当需要关联对象(访问其属性,非id字段)时才会发生查询动作。
2)二级缓存, 在对象更新,删除,添加相对于查询要少得多时, 二级缓存的应用将不怕n +1 问题,因为即使第一次查询很慢,之后直接缓存命中也是很快的。
不同解决方法,不同的思路,第二条却刚好又利用了n +1 。
3) 当然你也可以设定fetch=join(annotation : @ManyToOne() @Fetch(FetchMode.JOIN))
posted @
2012-01-30 14:20 RoyPayne 阅读(10902) |
评论 (1) |
编辑 收藏<!-- Spring security Filter -->
<filter>
<filter-name>springSecurityFilterChain</filter-name>
<filter-class>org.springframework.web.filter.DelegatingFilterProxy</filter-class>
</filter>
<filter-mapping>
<filter-name>springSecurityFilterChain</filter-name>
<url-pattern>/*</url-pattern>
</filter-mapping>
这个Filter会拦截所有的URL请求,并且对这些URL请求进行Spring Security的验证。
注意,springSecurityFilterChain这个名称是由命名空间默认创建的用于处理web安全的一个内部的bean的id。所以你在你的Spring配置文件中,不应该再使用这个id作为你的bean。
与Acegi的配置不同,Acegi需要自行声明一个Spring的bean来作为Filter的实现,而使用Spring Security后,无需再额外定义bean,而是使用<http>元素进行配置。
通过扩展Spring Security的默认实现来进行用户和权限的管理 事实上,Spring Security提供了2个认证的接口,分别用于模拟用户和权限,以及读取用户和权限的操作方法。这两个接口分别是:UserDetails和UserDetailsService。
public interface UserDetails extends Serializable {
GrantedAuthority[] getAuthorities();
String getPassword();
String getUsername();
boolean isAccountNonExpired();
boolean isAccountNonLocked();
boolean isCredentialsNonExpired();
boolean isEnabled();
}
public interface UserDetailsService {
UserDetails loadUserByUsername(String username)
throws UsernameNotFoundException, DataAccessException;
}
非常清楚,一个接口用于模拟用户,另外一个用于模拟读取用户的过程。所以我们可以通过实现这两个接口,来完成使用数据库对用户和权限进行管理的需求。在这里,我将给出一个使用Hibernate来定义用户和权限之间关系的示例。
posted @
2012-01-20 10:41 RoyPayne 阅读(1711) |
评论 (1) |
编辑 收藏
摘要: Quartz是一个强大的企业级任务调度框架,Spring中继承并简化了Quartz,下面就看看在Spring中怎样配置Quartz:
阅读全文
posted @
2012-01-19 14:53 RoyPayne 阅读(311) |
评论 (0) |
编辑 收藏
1.自定义拦截器继承AbstractInterceptor,重写public String intercept(ActionInvocation invocation)方法。
intercept方法有ActionInvocation对象,可以获取当前的Action请求。
public class AuthorityInterceptor extends AbstractInterceptor {
private static final long serialVersionUID = 1L;
private Logger LOG = Logger.getLogger(AuthorityInterceptor.class.getName());
private AuthorityUtil authorityUtil;
public String intercept(ActionInvocation invocation) throws Exception {
if (authorityUtil == null) {
authorityUtil = new AuthorityUtil();
}
//获取当前用户所有的权限
List<OperatorPurviewDO> operatorPurviews = getCurrentOperatorPurviews();
//获取当前操作的url
String currentUrl = getCurrentUrl();
//如果是超级管理员或有当前url的权限,那么直接返回。
if (OperatorUtil.getIsSuperAdmin() ||(OperatorUtil.getLoginName()!=null&&authorityUtil.checkUrl(operatorPurviews, currentUrl))){
return invocation.invoke();
}
if (!OperatorUtil.getIsSuperAdmin()&&operatorPurviews.size()==0) {
LOG.info("此用户:" + OperatorUtil.getLoginName() + " 没有任何角色,没有权限执行任何功能");
return "loginErr";
}
return "authorityErr";
}
2.struts2.xml 配置interceptor
2.1 定义自定义拦截器
<interceptor name="authorityInterceptor" class="com.wasu.eis.authority.AuthorityInterceptor" />
2.2 加上struts2默认拦截器,形成拦截器栈
<interceptor-stack name="eisManagerBasicStack">
<interceptor-ref name="exception"/>
<interceptor-ref name="alias"/>
<interceptor-ref name="servletConfig"/>
<interceptor-ref name="prepare"/>
<interceptor-ref name="i18n"/>
<interceptor-ref name="chain"/>
<interceptor-ref name="debugging"/>
<interceptor-ref name="profiling"/>
<interceptor-ref name="scopedModelDriven"/>
<interceptor-ref name="modelDriven"/>
<interceptor-ref name="checkbox"/>
<interceptor-ref name="staticParams"/>
<interceptor-ref name ="fileUploadStack" />
<interceptor-ref name="params">
<param name="excludeParams">dojo\..*</param>
</interceptor-ref>
<interceptor-ref name="conversionError"/>
<interceptor-ref name="validation">
<param name="excludeMethods">input,back,cancel,browse</param>
</interceptor-ref>
<interceptor-ref name="workflow">
<param name="excludeMethods">input,back,cancel,browse</param>
</interceptor-ref>
</interceptor-stack>
<interceptor-stack name="authorityInterceptorStack">
<interceptor-ref name="authorityInterceptor" />
<interceptor-ref name="eisManagerBasicStack" />
</interceptor-stack>
3.设置为缺省的拦截器
<default-interceptor-ref name="authorityInterceptorStack"/>
posted @
2012-01-17 16:35 RoyPayne 阅读(2752) |
评论 (0) |
编辑 收藏
摘要: 分页显示一直是web开发中一大烦琐的难题,传统的网页设计只在一个JSP或者ASP页面中书写所有关于数据库操作的代码,那样做分页可能简单一点,但当把网站分层开发后,分页就比较困难了,下面是我做Spring+Hibernate+Struts2项目时设计的分页代码,与大家分享交流。
阅读全文
posted @
2012-01-17 13:56 RoyPayne 阅读(654) |
评论 (1) |
编辑 收藏1.第一个例子:
<s:select list="{'aa','bb','cc'}" theme="simple" headerKey="00" headerValue="00"></s:select>
2.第二个例子:
<s:select list="#{1:'aa',2:'bb',3:'cc'}" label="abc" listKey="key" listValue="value" headerKey="0" headerValue="aabb">
3.第三个例子:
<%
java.util.HashMap map = new java.util.LinkedHashMap();
map.put(1,"aaa");
map.put(2,"bbb");
map.put(3,"ccc");
request.setAttribute("map",map);
request.setAttribute("aa","2");
%>
<s:select list="#request.map" label="abc" listKey="key" listValue="value"
value="#request.aa" headerKey="0" headerValue="aabb"></
s:select
>
headerKey headerValue 为设置缺省值
4.第四个例子
public class Program implements Serializable {
/** serialVersionUID */
private static final long serialVersionUID = 1L;
private int programid;
private String programName;
public int getProgramid() {
return programid;
}
public void setProgramid(int programid) {
this.programid = programid;
}
public String getProgramName() {
return programName;
}
public void setProgramName(String programName) {
this.programName = programName;
}
}
在 xxx extends extends ActionSupport {
private List<Program> programs ;
public List<Program> getPrograms() {
return programs;
}
public void setPrograms(List<Program> programs) {
this.programs = programs;
}
}
在jsp页面
<s:select list="programs " listValue="programName " listKey="programid " name="program" id="program"
headerKey="0l" headerValue=" " value="bean.programid "
></s:select>
红色部分为在action里面的list,黄色为<option value="xxx">value</option>对应bean里面的字段programName
绿色为<option value="xxx",对应bean里面的字段programid
紫色为设定select被选中的值,s:select 会自动在 bean选中 key对应的值
posted @
2012-01-12 15:10 RoyPayne 阅读(245) |
评论 (0) |
编辑 收藏工作中碰到个ConcurrentModificationException。代码如下:
List list = ...;
for(Iterator iter = list.iterator(); iter.hasNext();) {
Object obj = iter.next();
...
if(***) {
list.remove(obj);
}
}
在执行了remove方法之后,再去执行循环,iter.next()的时候,报java.util.ConcurrentModificationException(当然,如果remove的是最后一条,就不会再去执行next()操作了)
下面来看一下源码
public interface Iterator<E> {
boolean hasNext();
E next();
void remove();
}
public interface Collection<E> extends Iterable<E> {
...
Iterator<E> iterator();
boolean add(E o);
boolean remove(Object o);
...
}
这里有两个remove方法
接下来来看看AbstractList
public abstract class AbstractList<E> extends AbstractCollection<E> implements List<E> {
//AbstractCollection和List都继承了Collection
protected transient int modCount = 0;
private class Itr implements Iterator<E> { //内部类Itr
int cursor = 0;
int lastRet = -1;
int expectedModCount = modCount;
public boolean hasNext() {
return cursor != size();
}
public E next() {
checkForComodification(); //特别注意这个方法
try {
E next = get(cursor);
lastRet = cursor++;
return next;
} catch(IndexOutOfBoundsException e) {
checkForComodification();
throw new NoSuchElementException();
}
}
public void remove() {
if (lastRet == -1)
throw new IllegalStateException();
checkForComodification();
try {
AbstractList.this.remove(lastRet); //执行remove对象的操作
if (lastRet < cursor)
cursor--;
lastRet = -1;
expectedModCount = modCount; //重新设置了expectedModCount的值,避免了ConcurrentModificationException的产生
} catch(IndexOutOfBoundsException e) {
throw new ConcurrentModificationException();
}
}
final void checkForComodification() {
if (modCount != expectedModCount) //当expectedModCount和modCount不相等时,就抛出ConcurrentModificationException
throw new ConcurrentModificationException();
}
}
}
remove(Object o)在ArrayList中实现如下:
public boolean remove(Object o) {
if (o == null) {
for (int index = 0; index < size; index++)
if (elementData[index] == null) {
fastRemove(index);
return true;
}
} else {
for (int index = 0; index < size; index++)
if (o.equals(elementData[index])) {
fastRemove(index);
return true;
}
}
return false;
}
private void fastRemove(int index) {
modCount++; //只增加了modCount
....
}
所以,产生ConcurrentModificationException的原因就是:
执行remove(Object o)方法之后,modCount和expectedModCount不相等了。然后当代码执行到next()方法时,判断了checkForComodification(),发现两个数值不等,就抛出了该Exception。
要避免这个Exception,就应该使用remove()方法。
这里我们就不看add(Object o)方法了,也是同样的原因,但没有对应的add()方法。一般嘛,就另建一个List了
下面是网上的其他解释,更能从本质上解释原因:
Iterator 是工作在一个独立的线程中,并且拥有一个 mutex 锁。 Iterator 被创建之后会建立一个指向原来对象的单链索引表,当原来的对象数量发生变化时,这个索引表的内容不会同步改变,所以当索引指针往后移动的时候就找不到要迭代的对象,所以按照 fail-fast 原则 Iterator 会马上抛出 java.util.ConcurrentModificationException 异常。
所以 Iterator 在工作的时候是不允许被迭代的对象被改变的。但你可以使用 Iterator 本身的方法 remove() 来删除对象, Iterator.remove() 方法会在删除当前迭代对象的同时维护索引的一致性。
posted @
2012-01-06 17:14 RoyPayne 阅读(203) |
评论 (0) |
编辑 收藏import java.util.concurrent.ArrayBlockingQueue;
import java.util.concurrent.BlockingQueue;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
/**
本例介绍一个特殊的队列:BlockingQueue,如果BlockQueue是空的,从BlockingQueue取东西的操作将会被阻断进入等待状态,直到BlockingQueue进了东西才会被唤醒.同样,如果BlockingQueue是满的,任何试图往里存东西的操作也会被阻断进入等待状态,直到BlockingQueue里有空间才会被唤醒继续操作.
本例再次实现11.4线程----条件Condition中介绍的篮子程序,不过这个篮子中最多能放的苹果数不是1,可以随意指定.当篮子满时,生产者进入等待状态,当篮子空时,消费者等待.
*/
/**
使用BlockingQueue的关键技术点如下:
1.BlockingQueue定义的常用方法如下:
1)add(anObject):把anObject加到BlockingQueue里,即如果BlockingQueue可以容纳,则返回true,否则招聘异常
2)offer(anObject):表示如果可能的话,将anObject加到BlockingQueue里,即如果BlockingQueue可以容纳,则返回true,否则返回false.
3)put(anObject):把anObject加到BlockingQueue里,如果BlockQueue没有空间,则调用此方法的线程被阻断直到BlockingQueue里面有空间再继续.
4)poll(time):取走BlockingQueue里排在首位的对象,若不能立即取出,则可以等time参数规定的时间,取不到时返回null
5)take():取走BlockingQueue里排在首位的对象,若BlockingQueue为空,阻断进入等待状态直到Blocking有新的对象被加入为止
2.BlockingQueue有四个具体的实现类,根据不同需求,选择不同的实现类
1)ArrayBlockingQueue:规定大小的BlockingQueue,其构造函数必须带一个int参数来指明其大小.其所含的对象是以FIFO(先入先出)顺序排序的.
2)LinkedBlockingQueue:大小不定的BlockingQueue,若其构造函数带一个规定大小的参数,生成的BlockingQueue有大小限制,若不带大小参数,所生成的BlockingQueue的大小由Integer.MAX_VALUE来决定.其所含的对象是以FIFO(先入先出)顺序排序的
3)PriorityBlockingQueue:类似于LinkedBlockQueue,但其所含对象的排序不是FIFO,而是依据对象的自然排序顺序或者是构造函数的Comparator决定的顺序.
4)SynchronousQueue:特殊的BlockingQueue,对其的操作必须是放和取交替完成的.
3.LinkedBlockingQueue和ArrayBlockingQueue比较起来,它们背后所用的数据结构不一样,导致LinkedBlockingQueue的数据吞吐量要大于ArrayBlockingQueue,但在线程数量很大时其性能的可预见性低于ArrayBlockingQueue.
*/
public class BlockingQueueTest {
/**定义装苹果的篮子*/
public static class Basket{
//篮子,能够容纳3个苹果
BlockingQueue<String> basket = new ArrayBlockingQueue<String>(3);
//生产苹果,放入篮子
public void produce() throws InterruptedException{
//put方法放入一个苹果,若basket满了,等到basket有位置
basket.put("An apple");
}
//消费苹果,从篮子中取走
public String consume() throws InterruptedException{
//take方法取出一个苹果,若basket为空,等到basket有苹果为止
return basket.take();
}
}
//测试方法
public static void testBasket(){
final Basket basket = new Basket();//建立一个装苹果的篮子
//定义苹果生产者
class Producer implements Runnable{
public void run(){
try{
while(true){
//生产苹果
System.out.println("生产者准备生产苹果: " + System.currentTimeMillis());
basket.produce();
System.out.println("生产者生产苹果完毕: " + System.currentTimeMillis());
//休眠300ms
Thread.sleep(300);
}
}catch(InterruptedException ex){
}
}
}
//定义苹果消费者
class Consumer implements Runnable{
public void run(){
try{
while(true){
//消费苹果
System.out.println("消费者准备消费苹果: " + System.currentTimeMillis());
basket.consume();
System.out.println("消费者消费苹果完毕: " + System.currentTimeMillis());
//休眠1000ms
Thread.sleep(1000);
}
}catch(InterruptedException ex){
}
}
}
ExecutorService service = Executors.newCachedThreadPool();
Producer producer = new Producer();
Consumer consumer = new Consumer();
service.submit(producer);
service.submit(consumer);
//程序运行5s后,所有任务停止
try{
Thread.sleep(5000);
}catch(InterruptedException ex){
}
service.shutdownNow();
}
public static void main(String[] args){
BlockingQueueTest.testBasket();
}
}
posted @
2012-01-06 16:32 RoyPayne 阅读(231) |
评论 (0) |
编辑 收藏 Java? 语言包含两种内在的同步机制:同步块(或方法)和 volatile 变量。这两种机制的提出都是为了实现代码线程的安全性。其中 Volatile 变量的同步性较差(但有时它更简单并且开销更低),而且其使用也更容易出错。在这期的 Java 理论与实践中,Brian Goetz 将介绍几种正确使用 volatile 变量的模式,并针对其适用性限制提出一些建议。 Java 语言中的 volatile 变量可以被看作是一种 “程度较轻的 synchronized”;与 synchronized 块相比,volatile 变量所需的编码较少,并且运行时开销也较少,但是它所能实现的功能也仅是 synchronized 的一部分。本文介绍了几种有效使用 volatile 变量的模式,并强调了几种不适合使用 volatile 变量的情形。 锁提供了两种主要特性:互斥(mutual exclusion)和可见性(visibility)。互斥即一次只允许一个线程持有某个特定的锁,因此可使用该特性实现对共享数据的协调访问协议,这样,一次就只有一个线程能够使用该共享数据。可见性要更加复杂一些,它必须确保释放锁之前对共享数据做出的更改对于随后获得该锁的另一个线程是可见的 —— 如果没有同步机制提供的这种可见性保证,线程看到的共享变量可能是修改前的值或不一致的值,这将引发许多严重问题。Volatile 变量
Volatile 变量具有 synchronized 的可见性特性,但是不具备原子特性。这就是说线程能够自动发现 volatile 变量的最新值。Volatile 变量可用于提供线程安全,但是只能应用于非常有限的一组用例:多个变量之间或者某个变量的当前值与修改后值之间没有约束。因此,单独使用 volatile 还不足以实现计数器、互斥锁或任何具有与多个变量相关的不变式(Invariants)的类(例如 “start <=end”)。 出于简易性或可伸缩性的考虑,您可能倾向于使用 volatile 变量而不是锁。当使用 volatile 变量而非锁时,某些习惯用法(idiom)更加易于编码和阅读。此外,volatile 变量不会像锁那样造成线程阻塞,因此也很少造成可伸缩性问题。在某些情况下,如果读操作远远大于写操作,volatile 变量还可以提供优于锁的性能优势。正确使用 volatile 变量的条件
您只能在有限的一些情形下使用 volatile 变量替代锁。要使 volatile 变量提供理想的线程安全,必须同时满足下面两个条件: ● 对变量的写操作不依赖于当前值。 ● 该变量没有包含在具有其他变量的不变式中。 实际上,这些条件表明,可以被写入 volatile 变量的这些有效值独立于任何程序的状态,包括变量的当前状态。 第一个条件的限制使 volatile 变量不能用作线程安全计数器。虽然增量操作(x++)看上去类似一个单独操作,实际上它是一个由读取-修改-写入操作序列组成的组合操作,必须以原子方式执行,而 volatile 不能提供必须的原子特性。实现正确的操作需要使 x 的值在操作期间保持不变,而 volatile 变量无法实现这点。(然而,如果将值调整为只从单个线程写入,那么可以忽略第一个条件。) 大多数编程情形都会与这两个条件的其中之一冲突,使得 volatile 变量不能像 synchronized 那样普遍适用于实现线程安全。清单 1 显示了一个非线程安全的数值范围类。它包含了一个不变式 —— 下界总是小于或等于上界。
清单 1. 非线程安全的数值范围类
@NotThreadSafe
public class NumberRange {
private int lower, upper;
public int getLower() {
return lower; }
public int getUpper() {
return upper; }
public void setLower(
int value) {
if (value > upper)
throw new IllegalArgumentException(

);
lower = value;
}
public void setUpper(
int value) {
if (value < lower)
throw new IllegalArgumentException(
);
upper = value;
}
}
这种方式限制了范围的状态变量,因此将 lower 和 upper 字段定义为 volatile 类型不能够充分实现类的线程安全;从而仍然需要使用同步。否则,如果凑巧两个线程在同一时间使用不一致的值执行 setLower 和 setUpper 的话,则会使范围处于不一致的状态。例如,如果初始状态是 (0, 5),同一时间内,线程 A 调用 setLower(4) 并且线程 B 调用 setUpper(3),显然这两个操作交叉存入的值是不符合条件的,那么两个线程都会通过用于保护不变式的检查,使得最后的范围值是 (4, 3) —— 一个无效值。至于针对范围的其他操作,我们需要使 setLower() 和 setUpper() 操作原子化 —— 而将字段定义为 volatile 类型是无法实现这一目的的。
性能考虑
使用 volatile 变量的主要原因是其简易性:在某些情形下,使用 volatile 变量要比使用相应的锁简单得多。使用 volatile 变量次要原因是其性能:某些情况下,volatile 变量同步机制的性能要优于锁。 很难做出准确、全面的评价,例如 “X 总是比 Y 快”,尤其是对 JVM 内在的操作而言。(例如,某些情况下 VM 也许能够完全删除锁机制,这使得我们难以抽象地比较 volatile和 synchronized 的开销。)就是说,在目前大多数的处理器架构上,volatile 读操作开销非常低 —— 几乎和非 volatile 读操作一样。而 volatile 写操作的开销要比非 volatile 写操作多很多,因为要保证可见性需要实现内存界定(Memory Fence),即便如此,volatile 的总开销仍然要比锁获取低。 volatile 操作不会像锁一样造成阻塞,因此,在能够安全使用 volatile 的情况下,volatile 可以提供一些优于锁的可伸缩特性。如果读操作的次数要远远超过写操作,与锁相比,volatile 变量通常能够减少同步的性能开销。正确使用 volatile 的模式
很多并发性专家事实上往往引导用户远离 volatile 变量,因为使用它们要比使用锁更加容易出错。然而,如果谨慎地遵循一些良好定义的模式,就能够在很多场合内安全地使用 volatile 变量。要始终牢记使用 volatile 的限制 —— 只有在状态真正独立于程序内其他内容时才能使用 volatile —— 这条规则能够避免将这些模式扩展到不安全的用例。 模式 #1:状态标志 也许实现 volatile 变量的规范使用仅仅是使用一个布尔状态标志,用于指示发生了一个重要的一次性事件,例如完成初始化或请求停机。 很多应用程序包含了一种控制结构,形式为 “在还没有准备好停止程序时再执行一些工作”,如清单 2 所示: 清单 2. 将 volatile 变量作为状态标志使用
volatile boolean shutdownRequested;
public void shutdown() { shutdownRequested =
true; }
public void doWork() {
while (!shutdownRequested) {
// do stuff
}
}
很可能会从循环外部调用 shutdown() 方法 —— 即在另一个线程中 —— 因此,需要执行某种同步来确保正确实现 shutdownRequested 变量的可见性。(可能会从 JMX 侦听程序、GUI 事件线程中的操作侦听程序、通过 RMI 、通过一个 Web 服务等调用)。然而,使用 synchronized 块编写循环要比使用清单 2 所示的 volatile 状态标志编写麻烦很多。由于 volatile 简化了编码,并且状态标志并不依赖于程序内任何其他状态,因此此处非常适合使用 volatile。 这种类型的状态标记的一个公共特性是:通常只有一种状态转换;shutdownRequested 标志从 false 转换为 true,然后程序停止。这种模式可以扩展到来回转换的状态标志,但是只有在转换周期不被察觉的情况下才能扩展(从 false 到 true,再转换到 false)。此外,还需要某些原子状态转换机制,例如原子变量。 模式 #2:一次性安全发布(one-time safe publication) 缺乏同步会导致无法实现可见性,这使得确定何时写入对象引用而不是原语值变得更加困难。在缺乏同步的情况下,可能会遇到某个对象引用的更新值(由另一个线程写入)和该对象状态的旧值同时存在。(这就是造成著名的双重检查锁定(double-checked-locking)问题的根源,其中对象引用在没有同步的情况下进行读操作,产生的问题是您可能会看到一个更新的引用,但是仍然会通过该引用看到不完全构造的对象)。 实现安全发布对象的一种技术就是将对象引用定义为 volatile 类型。清单 3 展示了一个示例,其中后台线程在启动阶段从数据库加载一些数据。其他代码在能够利用这些数据时,在使用之前将检查这些数据是否曾经发布过。 清单 3. 将 volatile 变量用于一次性安全发布
public class BackgroundFloobleLoader {
public volatile Flooble theFlooble;
public void initInBackground() {
// do lots of stuff
theFlooble =
new Flooble();
// this is the only write to theFlooble
}
}
public class SomeOtherClass {
public void doWork() {
while (
true) {
// do some stuff
// use the Flooble, but only if it is ready
if (floobleLoader.theFlooble !=
null)
doSomething(floobleLoader.theFlooble);
}
}
}
如果 theFlooble 引用不是 volatile 类型,doWork() 中的代码在解除对 theFlooble 的引用时,将会得到一个不完全构造的 Flooble。 该模式的一个必要条件是:被发布的对象必须是线程安全的,或者是有效的不可变对象(有效不可变意味着对象的状态在发布之后永远不会被修改)。volatile 类型的引用可以确保对象的发布形式的可见性,但是如果对象的状态在发布后将发生更改,那么就需要额外的同步。 模式 #3:独立观察(independent observation) 安全使用 volatile 的另一种简单模式是:定期 “发布” 观察结果供程序内部使用。例如,假设有一种环境传感器能够感觉环境温度。一个后台线程可能会每隔几秒读取一次该传感器,并更新包含当前文档的 volatile 变量。然后,其他线程可以读取这个变量,从而随时能够看到最新的温度值。 使用该模式的另一种应用程序就是收集程序的统计信息。清单 4 展示了身份验证机制如何记忆最近一次登录的用户的名字。将反复使用 lastUser 引用来发布值,以供程序的其他部分使用。 清单 4. 将 volatile 变量用于多个独立观察结果的发布 public class UserManager {
public volatile String lastUser;
public boolean authenticate(String user, String password) {
boolean valid = passwordIsValid(user, password);
if (valid) {
User u = new User();
activeUsers.add(u);
lastUser = user;
}
return valid;
}
}
该模式是前面模式的扩展;将某个值发布以在程序内的其他地方使用,但是与一次性事件的发布不同,这是一系列独立事件。这个模式要求被发布的值是有效不可变的 —— 即值的状态在发布后不会更改。使用该值的代码需要清楚该值可能随时发生变化。 模式 #4:“volatile bean” 模式 volatile bean 模式适用于将 JavaBeans 作为“荣誉结构”使用的框架。在 volatile bean 模式中,JavaBean 被用作一组具有 getter 和/或 setter 方法 的独立属性的容器。volatile bean 模式的基本原理是:很多框架为易变数据的持有者(例如 HttpSession)提供了容器,但是放入这些容器中的对象必须是线程安全的。 在 volatile bean 模式中,JavaBean 的所有数据成员都是 volatile 类型的,并且 getter 和 setter 方法必须非常普通 —— 除了获取或设置相应的属性外,不能包含任何逻辑。此外,对于对象引用的数据成员,引用的对象必须是有效不可变的。(这将禁止具有数组值的属性,因为当数组引用被声明为 volatile 时,只有引用而不是数组本身具有 volatile 语义)。对于任何 volatile 变量,不变式或约束都不能包含 JavaBean 属性。清单 5 中的示例展示了遵守 volatile bean 模式的 JavaBean: 清单 5. 遵守 volatile bean 模式的 Person 对象
@ThreadSafe
public class Person {
private volatile String firstName;
private volatile String lastName;
private volatile int age;
public String getFirstName() { return firstName; }
public String getLastName() { return lastName; }
public int getAge() { return age; }
public void setFirstName(String firstName) {
this.firstName = firstName;
}
public void setLastName(String lastName) {
this.lastName = lastName;
}
public void setAge(int age) {
this.age = age;
}
}
volatile 的高级模式 前面几节介绍的模式涵盖了大部分的基本用例,在这些模式中使用 volatile 非常有用并且简单。这一节将介绍一种更加高级的模式,在该模式中,volatile 将提供性能或可伸缩性优势。 volatile 应用的的高级模式非常脆弱。因此,必须对假设的条件仔细证明,并且这些模式被严格地封装了起来,因为即使非常小的更改也会损坏您的代码!同样,使用更高级的 volatile 用例的原因是它能够提升性能,确保在开始应用高级模式之前,真正确定需要实现这种性能获益。需要对这些模式进行权衡,放弃可读性或可维护性来换取可能的性能收益 —— 如果您不需要提升性能(或者不能够通过一个严格的测试程序证明您需要它),那么这很可能是一次糟糕的交易,因为您很可能会得不偿失,换来的东西要比放弃的东西价值更低。 模式 #5:开销较低的读-写锁策略 目前为止,您应该了解了 volatile 的功能还不足以实现计数器。因为 ++x 实际上是三种操作(读、添加、存储)的简单组合,如果多个线程凑巧试图同时对 volatile 计数器执行增量操作,那么它的更新值有可能会丢失。 然而,如果读操作远远超过写操作,您可以结合使用内部锁和 volatile 变量来减少公共代码路径的开销。清单 6 中显示的线程安全的计数器使用 synchronized 确保增量操作是原子的,并使用 volatile 保证当前结果的可见性。如果更新不频繁的话,该方法可实现更好的性能,因为读路径的开销仅仅涉及 volatile 读操作,这通常要优于一个无竞争的锁获取的开销。 清单 6. 结合使用 volatile 和 synchronized 实现 “开销较低的读-写锁” @ThreadSafe
public class CheesyCounter {
// Employs the cheap read-write lock trick
// All mutative operations MUST be done with the 'this' lock held
@GuardedBy("this") private volatileint value;
public int getValue() { return value; }
public synchronizedint increment() {
return value++;
}
}
之所以将这种技术称之为 “开销较低的读-写锁” 是因为您使用了不同的同步机制进行读写操作。因为本例中的写操作违反了使用 volatile 的第一个条件,因此不能使用 volatile 安全地实现计数器 —— 您必须使用锁。然而,您可以在读操作中使用 volatile 确保当前值的可见性,因此可以使用锁进行所有变化的操作,使用 volatile 进行只读操作。其中,锁一次只允许一个线程访问值,volatile 允许多个线程执行读操作,因此当使用 volatile 保证读代码路径时,要比使用锁执行全部代码路径获得更高的共享度 —— 就像读-写操作一样。然而,要随时牢记这种模式的弱点:如果超越了该模式的最基本应用,结合这两个竞争的同步机制将变得非常困难。 结束语 与锁相比,Volatile 变量是一种非常简单但同时又非常脆弱的同步机制,它在某些情况下将提供优于锁的性能和伸缩性。如果严格遵循 volatile 的使用条件 —— 即变量真正独立于其他变量和自己以前的值 —— 在某些情况下可以使用 volatile 代替 synchronized 来简化代码。然而,使用 volatile 的代码往往比使用锁的代码更加容易出错。本文介绍的模式涵盖了可以使用 volatile 代替 synchronized 的最常见的一些用例。遵循这些模式(注意使用时不要超过各自的限制)可以帮助您安全地实现大多数用例,使用 volatile 变量获得更佳性能。
posted @
2012-01-06 10:44 RoyPayne 阅读(296) |
评论 (1) |
编辑 收藏
摘要: JSP内置对象:我们在使用JSP进行页面编程时可以直接使用而不需自己创建的一些Web容器已为用户创建好的JSP内置对象。如request,session,response,out等。下面就JSP2.0给出的9个内置对象: 内置对象类型作用域requestjavax.servlet.http.HttpServletRequestrequestresponsejavax.servlet.ht...
阅读全文
posted @
2012-01-05 16:36 RoyPayne 阅读(18586) |
评论 (1) |
编辑 收藏一、Propagation (事务的传播属性)
Propagation : key属性确定代理应该给哪个方法增加事务行为。这样的属性最重要的部份是传播行为。有以下选项可供使用:PROPAGATION_REQUIRED--支持当前事务,如果当前没有事务,就新建一个事务。这是最常见的选择。
PROPAGATION_SUPPORTS--支持当前事务,如果当前没有事务,就以非事务方式执行。
PROPAGATION_MANDATORY--支持当前事务,如果当前没有事务,就抛出异常。
PROPAGATION_REQUIRES_NEW--新建事务,如果当前存在事务,把当前事务挂起。
PROPAGATION_NOT_SUPPORTED--以非事务方式执行操作,如果当前存在事务,就把当前事务挂起。
PROPAGATION_NEVER--以非事务方式执行,如果当前存在事务,则抛出异常。
1: PROPAGATION_REQUIRED
加入当前正要执行的事务不在另外一个事务里,那么就起一个新的事务
比如说,ServiceB.methodB的事务级别定义为PROPAGATION_REQUIRED, 那么由于执行ServiceA.methodA的时候,
ServiceA.methodA已经起了事务,这时调用ServiceB.methodB,ServiceB.methodB看到自己已经运行在ServiceA.methodA
的事务内部,就不再起新的事务。而假如ServiceA.methodA运行的时候发现自己没有在事务中,他就会为自己分配一个事务。
这样,在ServiceA.methodA或者在ServiceB.methodB内的任何地方出现异常,事务都会被回滚。即使ServiceB.methodB的事务已经被
提交,但是ServiceA.methodA在接下来fail要回滚,ServiceB.methodB也要回滚
2: PROPAGATION_SUPPORTS
如果当前在事务中,即以事务的形式运行,如果当前不再一个事务中,那么就以非事务的形式运行
3: PROPAGATION_MANDATORY
必须在一个事务中运行。也就是说,他只能被一个父事务调用。否则,他就要抛出异常
4: PROPAGATION_REQUIRES_NEW
这个就比较绕口了。 比如我们设计ServiceA.methodA的事务级别为PROPAGATION_REQUIRED,ServiceB.methodB的事务级别为PROPAGATION_REQUIRES_NEW,
那么当执行到ServiceB.methodB的时候,ServiceA.methodA所在的事务就会挂起,ServiceB.methodB会起一个新的事务,等待ServiceB.methodB的事务完成以后,
他才继续执行。他与PROPAGATION_REQUIRED 的事务区别在于事务的回滚程度了。因为ServiceB.methodB是新起一个事务,那么就是存在
两个不同的事务。如果ServiceB.methodB已经提交,那么ServiceA.methodA失败回滚,ServiceB.methodB是不会回滚的。如果ServiceB.methodB失败回滚,
如果他抛出的异常被ServiceA.methodA捕获,ServiceA.methodA事务仍然可能提交。
5: PROPAGATION_NOT_SUPPORTED
当前不支持事务。比如ServiceA.methodA的事务级别是PROPAGATION_REQUIRED ,而ServiceB.methodB的事务级别是PROPAGATION_NOT_SUPPORTED ,
那么当执行到ServiceB.methodB时,ServiceA.methodA的事务挂起,而他以非事务的状态运行完,再继续ServiceA.methodA的事务。
6: PROPAGATION_NEVER
不能在事务中运行。假设ServiceA.methodA的事务级别是PROPAGATION_REQUIRED, 而ServiceB.methodB的事务级别是PROPAGATION_NEVER ,
那么ServiceB.methodB就要抛出异常了。
7: PROPAGATION_NESTED
理解Nested的关键是savepoint。他与PROPAGATION_REQUIRES_NEW的区别是,PROPAGATION_REQUIRES_NEW另起一个事务,将会与他的父事务相互独立,
而Nested的事务和他的父事务是相依的,他的提交是要等和他的父事务一块提交的。也就是说,如果父事务最后回滚,他也要回滚的。
而Nested事务的好处是他有一个savepoint。
*****************************************
ServiceA {
/**
* 事务属性配置为 PROPAGATION_REQUIRED
*/
void methodA() {
try {
//savepoint
ServiceB.methodB(); //PROPAGATION_NESTED 级别
} catch (SomeException) {
// 执行其他业务, 如 ServiceC.methodC();
}
}
}
********************************************
也就是说ServiceB.methodB失败回滚,那么ServiceA.methodA也会回滚到savepoint点上,ServiceA.methodA可以选择另外一个分支,比如
ServiceC.methodC,继续执行,来尝试完成自己的事务。
但是这个事务并没有在EJB标准中定义。
Spring事务的隔离级别
1. ISOLATION_DEFAULT: 这是一个PlatfromTransactionManager默认的隔离级别,使用数据库默认的事务隔离级别.
另外四个与JDBC的隔离级别相对应
2. ISOLATION_READ_UNCOMMITTED: 这是事务最低的隔离级别,它充许令外一个事务可以看到这个事务未提交的数据。
这种隔离级别会产生脏读,不可重复读和幻像读。
3. ISOLATION_READ_COMMITTED: 保证一个事务修改的数据提交后才能被另外一个事务读取。另外一个事务不能读取该事务未提交的数据
4. ISOLATION_REPEATABLE_READ: 这种事务隔离级别可以防止脏读,不可重复读。但是可能出现幻像读。
它除了保证一个事务不能读取另一个事务未提交的数据外,还保证了避免下面的情况产生(不可重复读)。
5. ISOLATION_SERIALIZABLE 这是花费最高代价但是最可靠的事务隔离级别。事务被处理为顺序执行。
除了防止脏读,不可重复读外,还避免了幻像读。
什么是脏数据,脏读,不可重复读,幻觉读?
脏读: 指当一个事务正在访问数据,并且对数据进行了修改,而这种修改还没有提交到数据库中,这时,
另外一个事务也访问这个数据,然后使用了这个数据。因为这个数据是还没有提交的数据, 那么另外一
个事务读到的这个数据是脏数据,依据脏数据所做的操作可能是不正确的。
不可重复读: 指在一个事务内,多次读同一数据。在这个事务还没有结束时,另外一个事务也访问该同一数据。
那么,在第一个事务中的两次读数据之间,由于第二个事务的修改,那么第一个事务两次读到的数据
可能是不一样的。这样就发生了在一个事务内两次读到的数据是不一样的,因此称为是不可重复读。
幻觉读: 指当事务不是独立执行时发生的一种现象,例如第一个事务对一个表中的数据进行了修改,这种修改涉及
到表中的全部数据行。同时,第二个事务也修改这个表中的数据,这种修改是向表中插入一行新数据。那么,
以后就会发生操作第一个事务的用户发现表中还有没有修改的数据行,就好象发生了幻觉一样。
posted @
2012-01-05 15:25 RoyPayne 阅读(388) |
评论 (0) |
编辑 收藏两者的区别有:
1、最主要是sleep方法没有释放锁,而wait方法释放了锁,使得其他线程可以使用同步控制块或者方法。 2、这两个方法来自不同的类分别是Thread和Object
3、wait,notify和notifyAll只能在同步控制方法或者同步控制块里面使用,而sleep可以在
任何地方使用
synchronized(x){
x.notify()
//或者wait()
}
4、sleep必须捕获异常,而wait,notify和notifyAll不需要捕获异常
posted @
2012-01-05 14:32 RoyPayne 阅读(459) |
评论 (0) |
编辑 收藏
public class CeilAndFloor {
public static void main(String[] args) {
/*
这两个宝贝函数的主要任务是截掉小数以后的位数.
区别是: floor总是把数字变得越来越小,而ceil总是把数字变大。
其实名字可以理解floor是地板,ceil是天花板。
*/
System.out.println("==============Math.floor()==============");
System.out.println("Math.floor(99.1) = " + Math.floor(99.1));
System.out.println("Math.floor(-99.1) = " + Math.floor(-99.1));
System.out.println("Math.floor(99.9) = " + Math.floor(99.9));
System.out.println("Math.floor(99.9) = " + Math.floor(-99.9));
System.out.println("\n\n==============Math.ceil()==============");
System.out.println("Math.ceil(99.1) = " + Math.ceil(99.1));
System.out.println("Math.ceil(-99.1) = " + Math.ceil(-99.1));
System.out.println("Math.ceil(99.9) = " + Math.ceil(99.9));
System.out.println("Math.ceil(99.9) = " + Math.ceil(-99.9));
}
}
结果
==============Math.floor()==============
Math.floor(99.1) = 99.0
Math.floor(-99.1) = -100.0
Math.floor(99.9) = 99.0
Math.floor(99.9) = -100.0
==============Math.ceil()==============
Math.ceil(99.1) = 100.0
Math.ceil(-99.1) = -99.0
Math.ceil(99.9) = 100.0
Math.ceil(99.9) = -99.0
posted @
2012-01-05 09:20 RoyPayne 阅读(363) |
评论 (0) |
编辑 收藏 首先编写一个MonitorInfoBean类,用来装载监控的一些信息,包括物理内存、剩余的物理内存、已使用的物理内存、内存使用率等字段,该类的代码如下:
package com.amigo.performance;
/**
* 监视信息的JavaBean类.
* @author <a href="mailto:xiexingxing1121@126.com">AmigoXie</a>
* @version 1.0
* Creation date: 2008-4-25 - 上午10:37:00
*/
public class MonitorInfoBean {
/** 可使用内存. */
private long totalMemory;
/** 剩余内存. */
private long freeMemory;
/** 最大可使用内存. */
private long maxMemory;
/** 操作系统. */
private String osName;
/** 总的物理内存. */
private long totalMemorySize;
/** 剩余的物理内存. */
private long freePhysicalMemorySize;
/** 已使用的物理内存. */
private long usedMemory;
/** 线程总数. */
private int totalThread;
/** cpu使用率. */
private double cpuRatio;
public long getFreeMemory() {
return freeMemory;
}
public void setFreeMemory(long freeMemory) {
this.freeMemory = freeMemory;
}
public long getFreePhysicalMemorySize() {
return freePhysicalMemorySize;
}
public void setFreePhysicalMemorySize(long freePhysicalMemorySize) {
this.freePhysicalMemorySize = freePhysicalMemorySize;
}
public long getMaxMemory() {
return maxMemory;
}
public void setMaxMemory(long maxMemory) {
this.maxMemory = maxMemory;
}
public String getOsName() {
return osName;
}
public void setOsName(String osName) {
this.osName = osName;
}
public long getTotalMemory() {
return totalMemory;
}
public void setTotalMemory(long totalMemory) {
this.totalMemory = totalMemory;
}
public long getTotalMemorySize() {
return totalMemorySize;
}
public void setTotalMemorySize(long totalMemorySize) {
this.totalMemorySize = totalMemorySize;
}
public int getTotalThread() {
return totalThread;
}
public void setTotalThread(int totalThread) {
this.totalThread = totalThread;
}
public long getUsedMemory() {
return usedMemory;
}
public void setUsedMemory(long usedMemory) {
this.usedMemory = usedMemory;
}
public double getCpuRatio() {
return cpuRatio;
}
public void setCpuRatio(double cpuRatio) {
this.cpuRatio = cpuRatio;
}
}
接着编写一个获得当前的监控信息的接口,该类的代码如下所示:
package com.amigo.performance;
/**
* 获取系统信息的业务逻辑类接口.
* @author <a href="mailto:xiexingxing1121@126.com">AmigoXie</a>
* @version 1.0
* Creation date: 2008-3-11 - 上午10:06:06
*/
public interface IMonitorService {
/**
* 获得当前的监控对象.
* @return 返回构造好的监控对象
* @throws Exception
* @author <a href="mailto:xiexingxing1121@126.com">AmigoXie</a>
* Creation date: 2008-4-25 - 上午10:45:08
*/
public MonitorInfoBean getMonitorInfoBean() throws Exception;
}
该类的实现类MonitorServiceImpl如下所示:
package com.amigo.performance;
import java.io.InputStreamReader;
import java.io.LineNumberReader;
import sun.management.ManagementFactory;
import com.sun.management.OperatingSystemMXBean;
/**
* 获取系统信息的业务逻辑实现类.
* @author <a href="mailto:xiexingxing1121@126.com">AmigoXie</a>
* @version 1.0 Creation date: 2008-3-11 - 上午10:06:06
*/
public class MonitorServiceImpl implements IMonitorService {
private static final int CPUTIME = 30;
private static final int PERCENT = 100;
private static final int FAULTLENGTH = 10;
/**
* 获得当前的监控对象.
* @return 返回构造好的监控对象
* @throws Exception
* @author <a href="mailto:xiexingxing1121@126.com">AmigoXie</a>
* Creation date: 2008-4-25 - 上午10:45:08
*/
public MonitorInfoBean getMonitorInfoBean() throws Exception {
int kb = 1024;
// 可使用内存
long totalMemory = Runtime.getRuntime().totalMemory() / kb;
// 剩余内存
long freeMemory = Runtime.getRuntime().freeMemory() / kb;
// 最大可使用内存
long maxMemory = Runtime.getRuntime().maxMemory() / kb;
OperatingSystemMXBean osmxb = (OperatingSystemMXBean) ManagementFactory
.getOperatingSystemMXBean();
// 操作系统
String osName = System.getProperty("os.name");
// 总的物理内存
long totalMemorySize = osmxb.getTotalPhysicalMemorySize() / kb;
// 剩余的物理内存
long freePhysicalMemorySize = osmxb.getFreePhysicalMemorySize() / kb;
// 已使用的物理内存
long usedMemory = (osmxb.getTotalPhysicalMemorySize() - osmxb
.getFreePhysicalMemorySize())
/ kb;
// 获得线程总数
ThreadGroup parentThread;
for (parentThread = Thread.currentThread().getThreadGroup(); parentThread
.getParent() != null; parentThread = parentThread.getParent())
;
int totalThread = parentThread.activeCount();
double cpuRatio = 0;
if (osName.toLowerCase().startsWith("windows")) {
cpuRatio = this.getCpuRatioForWindows();
}
// 构造返回对象
MonitorInfoBean infoBean = new MonitorInfoBean();
infoBean.setFreeMemory(freeMemory);
infoBean.setFreePhysicalMemorySize(freePhysicalMemorySize);
infoBean.setMaxMemory(maxMemory);
infoBean.setOsName(osName);
infoBean.setTotalMemory(totalMemory);
infoBean.setTotalMemorySize(totalMemorySize);
infoBean.setTotalThread(totalThread);
infoBean.setUsedMemory(usedMemory);
infoBean.setCpuRatio(cpuRatio);
return infoBean;
}
/**
* 获得CPU使用率.
* @return 返回cpu使用率
* @author <a href="mailto:xiexingxing1121@126.com">AmigoXie</a>
* Creation date: 2008-4-25 - 下午06:05:11
*/
private double getCpuRatioForWindows() {
try {
String procCmd = System.getenv("windir")
+ "\\system32\\wbem\\wmic.exe process get Caption,CommandLine,"
+ "KernelModeTime,ReadOperationCount,ThreadCount,UserModeTime,WriteOperationCount";
// 取进程信息
long[] c0 = readCpu(Runtime.getRuntime().exec(procCmd));
Thread.sleep(CPUTIME);
long[] c1 = readCpu(Runtime.getRuntime().exec(procCmd));
if (c0 != null && c1 != null) {
long idletime = c1[0] - c0[0];
long busytime = c1[1] - c0[1];
return Double.valueOf(
PERCENT * (busytime) / (busytime + idletime))
.doubleValue();
} else {
return 0.0;
}
} catch (Exception ex) {
ex.printStackTrace();
return 0.0;
}
}
/**
* 读取CPU信息.
* @param proc
* @return
* @author <a href="mailto:xiexingxing1121@126.com">AmigoXie</a>
* Creation date: 2008-4-25 - 下午06:10:14
*/
private long[] readCpu(final Process proc) {
long[] retn = new long[2];
try {
proc.getOutputStream().close();
InputStreamReader ir = new InputStreamReader(proc.getInputStream());
LineNumberReader input = new LineNumberReader(ir);
String line = input.readLine();
if (line == null || line.length() < FAULTLENGTH) {
return null;
}
int capidx = line.indexOf("Caption");
int cmdidx = line.indexOf("CommandLine");
int rocidx = line.indexOf("ReadOperationCount");
int umtidx = line.indexOf("UserModeTime");
int kmtidx = line.indexOf("KernelModeTime");
int wocidx = line.indexOf("WriteOperationCount");
long idletime = 0;
long kneltime = 0;
long usertime = 0;
while ((line = input.readLine()) != null) {
if (line.length() < wocidx) {
continue;
}
// 字段出现顺序:Caption,CommandLine,KernelModeTime,ReadOperationCount,
// ThreadCount,UserModeTime,WriteOperation
String caption = Bytes.substring(line, capidx, cmdidx - 1)
.trim();
String cmd = Bytes.substring(line, cmdidx, kmtidx - 1).trim();
if (cmd.indexOf("wmic.exe") >= 0) {
continue;
}
// log.info("line="+line);
if (caption.equals("System Idle Process")
|| caption.equals("System")) {
idletime += Long.valueOf(
Bytes.substring(line, kmtidx, rocidx - 1).trim())
.longValue();
idletime += Long.valueOf(
Bytes.substring(line, umtidx, wocidx - 1).trim())
.longValue();
continue;
}
kneltime += Long.valueOf(
Bytes.substring(line, kmtidx, rocidx - 1).trim())
.longValue();
usertime += Long.valueOf(
Bytes.substring(line, umtidx, wocidx - 1).trim())
.longValue();
}
retn[0] = idletime;
retn[1] = kneltime + usertime;
return retn;
} catch (Exception ex) {
ex.printStackTrace();
} finally {
try {
proc.getInputStream().close();
} catch (Exception e) {
e.printStackTrace();
}
}
return null;
}
/**
* 测试方法.
* @param args
* @throws Exception
* @author <a href="mailto:xiexingxing1121@126.com">AmigoXie</a>
* Creation date: 2008-4-30 - 下午04:47:29
*/
public static void main(String[] args) throws Exception {
IMonitorService service = new MonitorServiceImpl();
MonitorInfoBean monitorInfo = service.getMonitorInfoBean();
System.out.println("cpu占有率=" + monitorInfo.getCpuRatio());
System.out.println("可使用内存=" + monitorInfo.getTotalMemory());
System.out.println("剩余内存=" + monitorInfo.getFreeMemory());
System.out.println("最大可使用内存=" + monitorInfo.getMaxMemory());
System.out.println("操作系统=" + monitorInfo.getOsName());
System.out.println("总的物理内存=" + monitorInfo.getTotalMemorySize() + "kb");
System.out.println("剩余的物理内存=" + monitorInfo.getFreeMemory() + "kb");
System.out.println("已使用的物理内存=" + monitorInfo.getUsedMemory() + "kb");
System.out.println("线程总数=" + monitorInfo.getTotalThread() + "kb");
}
}
该实现类中需要用到一个自己编写byte的工具类,该类的代码如下所示:
package com.amigo.performance;
/**
* byte操作类.
* @author <a href="mailto:xiexingxing1121@126.com">AmigoXie</a>
* @version 1.0
* Creation date: 2008-4-30 - 下午04:57:23
*/
public class Bytes {
/**
* 由于String.subString对汉字处理存在问题(把一个汉字视为一个字节),因此在
* 包含汉字的字符串时存在隐患,现调整如下:
* @param src 要截取的字符串
* @param start_idx 开始坐标(包括该坐标)
* @param end_idx 截止坐标(包括该坐标)
* @return
*/
public static String substring(String src, int start_idx, int end_idx){
byte[] b = src.getBytes();
String tgt = "";
for(int i=start_idx; i<=end_idx; i++){
tgt +=(char)b[i];
}
return tgt;
}
}
运行下MonitorBeanImpl类,读者将会看到当前的内存、cpu利用率等信息。
posted @
2012-01-04 14:54 RoyPayne 阅读(1992) |
评论 (1) |
编辑 收藏
摘要: 1.java的System.getProperty()方法可以获取的值java.versionJava 运行时环境版本java.vendorJava 运行时环境供应商java.vendor.urlJava 供应商的 URLjava.homeJava 安装目录java.vm.specification.versionJava 虚拟机规范版本java....
阅读全文
posted @
2012-01-04 14:37 RoyPayne 阅读(8334) |
评论 (0) |
编辑 收藏 ListResourceBundle 是 ResourceBundle 的一个抽象类,用于管理方便而又易于使用的列表中的语言环境资源。有关资源包的常规信息,请参阅 ResourceBundle。
子类必须重写
getContents 并提供一个数组,其中数组中的每个项都是一个对象对。每对的第一个元素是键,该键必须是一个
String,并且第二个元素是和该键相关联的值。
下面的示例显示了具有基本名称 "MyResources" 的资源包系列的两个成员。"MyResources" 是资源包系列的默认成员,"MyResources_fr" 是 French 成员。这些成员是基于ListResourceBundle(一个相关的示例显示了如何把一个资源包添加到基于属性文件的此系列)。此示例中的键形式为 "s1" 等。实际的键完全取决于您的选择,只要它们和程序中用于从资源包中获取对象的键相同。键区分大小写。
public class MyResources extends ListResourceBundle {
protected Object[][] getContents() {
return new Object[][] = {
// LOCALIZE THIS
{"s1", "The disk \"{1}\" contains {0}."}, // MessageFormat pattern
{"s2", "1"}, // location of {0} in pattern
{"s3", "My Disk"}, // sample disk name
{"s4", "no files"}, // first ChoiceFormat choice
{"s5", "one file"}, // second ChoiceFormat choice
{"s6", "{0,number} files"}, // third ChoiceFormat choice
{"s7", "3 Mar 96"}, // sample date
{"s8", new Dimension(1,5)} // real object, not just string
// END OF MATERIAL TO LOCALIZE
};
}
}
public class MyResources_fr extends ListResourceBundle {
protected Object[][] getContents() {
return new Object[][] = {
// LOCALIZE THIS
{"s1", "Le disque \"{1}\" {0}."}, // MessageFormat pattern
{"s2", "1"}, // location of {0} in pattern
{"s3", "Mon disque"}, // sample disk name
{"s4", "ne contient pas de fichiers"}, // first ChoiceFormat choice
{"s5", "contient un fichier"}, // second ChoiceFormat choice
{"s6", "contient {0,number} fichiers"}, // third ChoiceFormat choice
{"s7", "3 mars 1996"}, // sample date
{"s8", new Dimension(1,3)} // real object, not just string
// END OF MATERIAL TO LOCALIZE
};
}
}
posted @
2012-01-04 14:29 RoyPayne 阅读(308) |
评论 (0) |
编辑 收藏ORACLE日期时间函数大全
TO_DATE格式(以时间:2007-11-02 13:45:25为例)
Year:
yy two digits 两位年 显示值:07
yyy three digits 三位年 显示值:007
yyyy four digits 四位年 显示值:2007
Month:
mm number 两位月 显示值:11
mon abbreviated 字符集表示 显示值:11月,若是英文版,显示nov
month spelled out 字符集表示 显示值:11月,若是英文版,显示november
Day:
dd number 当月第几天 显示值:02
ddd number 当年第几天 显示值:02
dy abbreviated 当周第几天简写 显示值:星期五,若是英文版,显示fri
day spelled out 当周第几天全写 显示值:星期五,若是英文版,显示friday
ddspth spelled out, ordinal twelfth
Hour:
hh two digits 12小时进制 显示值:01
hh24 two digits 24小时进制 显示值:13
Minute:
mi two digits 60进制 显示值:45
Second:
ss two digits 60进制 显示值:25
其它
Q digit 季度 显示值:4
WW digit 当年第几周 显示值:44
W digit 当月第几周 显示值:1
24小时格式下时间范围为: 0:00:00 - 23:59:59....
12小时格式下时间范围为: 1:00:00 - 12:59:59 ....
1. 日期和字符转换函数用法(to_date,to_char)
select to_char(sysdate,'yyyy-mm-dd hh24:mi:ss') as nowTime from dual; //日期转化为字符串
select to_char(sysdate,'yyyy') as nowYear from dual; //获取时间的年
select to_char(sysdate,'mm') as nowMonth from dual; //获取时间的月
select to_char(sysdate,'dd') as nowDay from dual; //获取时间的日
select to_char(sysdate,'hh24') as nowHour from dual; //获取时间的时
select to_char(sysdate,'mi') as nowMinute from dual; //获取时间的分
select to_char(sysdate,'ss') as nowSecond from dual; //获取时间的秒
select to_date('2004-05-07 13:23:44','yyyy-mm-dd hh24:mi:ss') from dual//
2.
select to_char( to_date(222,'J'),'Jsp') from dual
显示Two Hundred Twenty-Two
3.求某天是星期几
select to_char(to_date('2002-08-26','yyyy-mm-dd'),'day') from dual;
星期一
select to_char(to_date('2002-08-26','yyyy-mm-dd'),'day','NLS_DATE_LANGUAGE = American') from dual;
monday
设置日期语言
ALTER SESSION SET NLS_DATE_LANGUAGE='AMERICAN';
也可以这样
TO_DATE ('2002-08-26', 'YYYY-mm-dd', 'NLS_DATE_LANGUAGE = American')
4. 两个日期间的天数
select floor(sysdate - to_date('20020405','yyyymmdd')) from dual;
5. 时间为null的用法
select id, active_date from table1
UNION
select 1, TO_DATE(null) from dual;
注意要用TO_DATE(null)
6.月份差
a_date between to_date('20011201','yyyymmdd') and to_date('20011231','yyyymmdd')
那么12月31号中午12点之后和12月1号的12点之前是不包含在这个范围之内的。
所以,当时间需要精确的时候,觉得to_char还是必要的
7. 日期格式冲突问题
输入的格式要看你安装的ORACLE字符集的类型, 比如: US7ASCII, date格式的类型就是: '01-Jan-01'
alter system set NLS_DATE_LANGUAGE = American
alter session set NLS_DATE_LANGUAGE = American
或者在to_date中写
select to_char(to_date('2002-08-26','yyyy-mm-dd'),'day','NLS_DATE_LANGUAGE = American') from dual;
注意我这只是举了NLS_DATE_LANGUAGE,当然还有很多,
可查看
select * from nls_session_parameters
select * from V$NLS_PARAMETERS
8.
select count(*)
from ( select rownum-1 rnum
from all_objects
where rownum <= to_date('2002-02-28','yyyy-mm-dd') - to_date('2002-
02-01','yyyy-mm-dd')+1
)
where to_char( to_date('2002-02-01','yyyy-mm-dd')+rnum-1, 'D' )
not in ( '1', '7' )
查找2002-02-28至2002-02-01间除星期一和七的天数
在前后分别调用DBMS_UTILITY.GET_TIME, 让后将结果相减(得到的是1/100秒, 而不是毫秒).
9. 查找月份
select months_between(to_date('01-31-1999','MM-DD-YYYY'),to_date('12-31-1998','MM-DD-YYYY')) "MONTHS" FROM DUAL;
1
select months_between(to_date('02-01-1999','MM-DD-YYYY'),to_date('12-31-1998','MM-DD-YYYY')) "MONTHS" FROM DUAL;
1.03225806451613
10. Next_day的用法
Next_day(date, day)
Monday-Sunday, for format code DAY
Mon-Sun, for format code DY
1-7, for format code D
11
select to_char(sysdate,'hh:mi:ss') TIME from all_objects
注意:第一条记录的TIME 与最后一行是一样的
可以建立一个函数来处理这个问题
create or replace function sys_date return date is
begin
return sysdate;
end;
select to_char(sys_date,'hh:mi:ss') from all_objects;
12.获得小时数
extract()找出日期或间隔值的字段值
SELECT EXTRACT(HOUR FROM TIMESTAMP '2001-02-16 2:38:40') from offer
SQL> select sysdate ,to_char(sysdate,'hh') from dual;
SYSDATE TO_CHAR(SYSDATE,'HH')
-------------------- ---------------------
2003-10-13 19:35:21 07
SQL> select sysdate ,to_char(sysdate,'hh24') from dual;
SYSDATE TO_CHAR(SYSDATE,'HH24')
-------------------- -----------------------
2003-10-13 19:35:21 19
13.年月日的处理
select older_date,
newer_date,
years,
months,
abs(
trunc(
newer_date-
add_months( older_date,years*12+months )
)
) days
from ( select
trunc(months_between( newer_date, older_date )/12) YEARS,
mod(trunc(months_between( newer_date, older_date )),12 ) MONTHS,
newer_date,
older_date
from (
select hiredate older_date, add_months(hiredate,rownum)+rownum newer_date
from emp
)
)
14.处理月份天数不定的办法
select to_char(add_months(last_day(sysdate) +1, -2), 'yyyymmdd'),last_day(sysdate) from dual
16.找出今年的天数
select add_months(trunc(sysdate,'year'), 12) - trunc(sysdate,'year') from dual
闰年的处理方法
to_char( last_day( to_date('02' | | :year,'mmyyyy') ), 'dd' )
如果是28就不是闰年
17.yyyy与rrrr的区别
'YYYY99 TO_C
------- ----
yyyy 99 0099
rrrr 99 1999
yyyy 01 0001
rrrr 01 2001
18.不同时区的处理
select to_char( NEW_TIME( sysdate, 'GMT','EST'), 'dd/mm/yyyy hh:mi:ss') ,sysdate
from dual;
19.5秒钟一个间隔
Select TO_DATE(FLOOR(TO_CHAR(sysdate,'SSSSS')/300) * 300,'SSSSS') ,TO_CHAR(sysdate,'SSSSS')
from dual
2002-11-1 9:55:00 35786
SSSSS表示5位秒数
20.一年的第几天
select TO_CHAR(SYSDATE,'DDD'),sysdate from dual
310 2002-11-6 10:03:51
21.计算小时,分,秒,毫秒
select
Days,
A,
TRUNC(A*24) Hours,
TRUNC(A*24*60 - 60*TRUNC(A*24)) Minutes,
TRUNC(A*24*60*60 - 60*TRUNC(A*24*60)) Seconds,
TRUNC(A*24*60*60*100 - 100*TRUNC(A*24*60*60)) mSeconds
from
(
select
trunc(sysdate) Days,
sysdate - trunc(sysdate) A
from dual
)
select * from tabname
order by decode(mode,'FIFO',1,-1)*to_char(rq,'yyyymmddhh24miss');
//
floor((date2-date1) /365) 作为年
floor((date2-date1, 365) /30) 作为月
d(mod(date2-date1, 365), 30)作为日.
23.next_day函数 返回下个星期的日期,day为1-7或星期日-星期六,1表示星期日
next_day(sysdate,6)是从当前开始下一个星期五。后面的数字是从星期日开始算起。
1 2 3 4 5 6 7
日 一 二 三 四 五 六
---------------------------------------------------------------
select (sysdate-to_date('2003-12-03 12:55:45','yyyy-mm-dd hh24:mi:ss'))*24*60*60 from ddual
日期 返回的是天 然后 转换为ss
24,round[舍入到最接近的日期](day:舍入到最接近的星期日)
select sysdate S1,
round(sysdate) S2 ,
round(sysdate,'year') YEAR,
round(sysdate,'month') MONTH ,
round(sysdate,'day') DAY from dual
25,trunc[截断到最接近的日期,单位为天] ,返回的是日期类型
select sysdate S1,
trunc(sysdate) S2, //返回当前日期,无时分秒
trunc(sysdate,'year') YEAR, //返回当前年的1月1日,无时分秒
trunc(sysdate,'month') MONTH , //返回当前月的1日,无时分秒
trunc(sysdate,'day') DAY //返回当前星期的星期天,无时分秒
from dual
26,返回日期列表中最晚日期
select greatest('01-1月-04','04-1月-04','10-2月-04') from dual
27.计算时间差
注:oracle时间差是以天数为单位,所以换算成年月,日
select floor(to_number(sysdate-to_date('2007-11-02 15:55:03','yyyy-mm-dd hh24:mi:ss'))/365) as spanYears from dual //时间差-年
select ceil(moths_between(sysdate-to_date('2007-11-02 15:55:03','yyyy-mm-dd hh24:mi:ss'))) as spanMonths from dual //时间差-月
select floor(to_number(sysdate-to_date('2007-11-02 15:55:03','yyyy-mm-dd hh24:mi:ss'))) as spanDays from dual //时间差-天
select floor(to_number(sysdate-to_date('2007-11-02 15:55:03','yyyy-mm-dd hh24:mi:ss'))*24) as spanHours from dual //时间差-时
select floor(to_number(sysdate-to_date('2007-11-02 15:55:03','yyyy-mm-dd hh24:mi:ss'))*24*60) as spanMinutes from dual //时间差-分
select floor(to_number(sysdate-to_date('2007-11-02 15:55:03','yyyy-mm-dd hh24:mi:ss'))*24*60*60) as spanSeconds from dual //时间差-秒
28.更新时间
注:oracle时间加减是以天数为单位,设改变量为n,所以换算成年月,日
select to_char(sysdate,'yyyy-mm-dd hh24:mi:ss'),to_char(sysdate+n*365,'yyyy-mm-dd hh24:mi:ss') as newTime from dual //改变时间-年
select to_char(sysdate,'yyyy-mm-dd hh24:mi:ss'),add_months(sysdate,n) as newTime from dual //改变时间-月
select to_char(sysdate,'yyyy-mm-dd hh24:mi:ss'),to_char(sysdate+n,'yyyy-mm-dd hh24:mi:ss') as newTime from dual //改变时间-日
select to_char(sysdate,'yyyy-mm-dd hh24:mi:ss'),to_char(sysdate+n/24,'yyyy-mm-dd hh24:mi:ss') as newTime from dual //改变时间-时
select to_char(sysdate,'yyyy-mm-dd hh24:mi:ss'),to_char(sysdate+n/24/60,'yyyy-mm-dd hh24:mi:ss') as newTime from dual //改变时间-分
select to_char(sysdate,'yyyy-mm-dd hh24:mi:ss'),to_char(sysdate+n/24/60/60,'yyyy-mm-dd hh24:mi:ss') as newTime from dual //改变时间-秒
29.查找月的第一天,最后一天
SELECT Trunc(Trunc(SYSDATE, 'MONTH') - 1, 'MONTH') First_Day_Last_Month,
Trunc(SYSDATE, 'MONTH') - 1 / 86400 Last_Day_Last_Month,
Trunc(SYSDATE, 'MONTH') First_Day_Cur_Month,
LAST_DAY(Trunc(SYSDATE, 'MONTH')) + 1 - 1 / 86400 Last_Day_Cur_Month
FROM dual;
三. 字符函数(可用于字面字符或数据库列)
1,字符串截取
select substr('abcdef',1,3) from dual
2,查找子串位置
select instr('abcfdgfdhd','fd') from dual
3,字符串连接
select 'HELLO'||'hello world' from dual;
4, 1)去掉字符串中的空格
select ltrim(' abc') s1,
rtrim('zhang ') s2,
trim(' zhang ') s3 from dual
2)去掉前导和后缀
select trim(leading 9 from 9998767999) s1,
trim(trailing 9 from 9998767999) s2,
trim(9 from 9998767999) s3 from dual;
5,返回字符串首字母的Ascii值
select ascii('a') from dual
6,返回ascii值对应的字母
select chr(97) from dual
7,计算字符串长度
select length('abcdef') from dual
8,initcap(首字母变大写) ,lower(变小写),upper(变大写)
select lower('ABC') s1,
upper('def') s2,
initcap('efg') s3
from dual;
9,Replace
select replace('abc','b','xy') from dual;
10,translate
select translate('abc','b','xx') from dual; -- x是1位
11,lpad [左添充] rpad [右填充](用于控制输出格式)
select lpad('func',15,'=') s1, rpad('func',15,'-') s2 from dual;
select lpad(dname,14,'=') from dept;
12, decode[实现if ..then 逻辑] 注:第一个是表达式,最后一个是不满足任何一个条件的值
select deptno,decode(deptno,10,'1',20,'2',30,'3','其他') from dept;
例:
select seed,account_name,decode(seed,111,1000,200,2000,0) from t_userInfo//如果seed为111,则取1000;为200,取2000;其它取0
select seed,account_name,decode(sign(seed-111),1,'big seed',-1,'little seed','equal seed') from t_userInfo//如果seed>111,则显示大;为200,则显示小;其它则显
示相等
13 case[实现switch ..case 逻辑]
SELECT CASE X-FIELD
WHEN X-FIELD < 40 THEN 'X-FIELD 小于 40'
WHEN X-FIELD < 50 THEN 'X-FIELD 小于 50'
WHEN X-FIELD < 60 THEN 'X-FIELD 小于 60'
ELSE 'UNBEKNOWN'
END
FROM DUAL
注:CASE语句在处理类似问题就显得非常灵活。当只是需要匹配少量数值时,用Decode更为简洁。
四.数字函数
1,取整函数(ceil 向上取整,floor 向下取整)
select ceil(66.6) N1,floor(66.6) N2 from dual;
2, 取幂(power) 和 求平方根(sqrt)
select power(3,2) N1,sqrt(9) N2 from dual;
3,求余
select mod(9,5) from dual;
4,返回固定小数位数 (round:四舍五入,trunc:直接截断)
select round(66.667,2) N1,trunc(66.667,2) N2 from dual;
5,返回值的符号(正数返回为1,负数为-1)
select sign(-32),sign(293) from dual;
五.转换函数
1,to_char()[将日期和数字类型转换成字符类型]
1) select to_char(sysdate) s1,
to_char(sysdate,'yyyy-mm-dd') s2,
to_char(sysdate,'yyyy') s3,
to_char(sysdate,'yyyy-mm-dd hh12:mi:ss') s4,
to_char(sysdate, 'hh24:mi:ss') s5,
to_char(sysdate,'DAY') s6
from dual;
2) select sal,to_char(sal,'$99999') n1,to_char(sal,'$99,999') n2 from emp
2, to_date()[将字符类型转换为日期类型]
insert into emp(empno,hiredate) values(8000,to_date('2004-10-10','yyyy-mm-dd'));
3, to_number() 转换为数字类型
select to_number(to_char(sysdate,'hh12')) from dual; //以数字显示的小时数
六.其他函数
1.user:
返回登录的用户名称
select user from dual;
2.vsize:
返回表达式所需的字节数
select vsize('HELLO') from dual;
3.nvl(ex1,ex2):
ex1值为空则返回ex2,否则返回该值本身ex1(常用)
例:如果雇员没有佣金,将显示0,否则显示佣金
select comm,nvl(comm,0) from emp;
4.nullif(ex1,ex2):
值相等返空,否则返回第一个值
例:如果工资和佣金相等,则显示空,否则显示工资
select nullif(sal,comm),sal,comm from emp;
5.coalesce:
返回列表中第一个非空表达式
select comm,sal,coalesce(comm,sal,sal*10) from emp;
6.nvl2(ex1,ex2,ex3) :
如果ex1不为空,显示ex2,否则显示ex3
如:查看有佣金的雇员姓名以及他们的佣金
select nvl2(comm,ename,') as HaveCommName,comm from emp;
七.分组函数
max min avg count sum
1,整个结果集是一个组
1) 求部门30 的最高工资,最低工资,平均工资,总人数,有工作的人数,工种数量及工资总和
select max(ename),max(sal),
min(ename),min(sal),
avg(sal),
count(*) ,count(job),count(distinct(job)) ,
sum(sal) from emp where deptno=30;
2, 带group by 和 having 的分组
1)按部门分组求最高工资,最低工资,总人数,有工作的人数,工种数量及工资总和
select deptno, max(ename),max(sal),
min(ename),min(sal),
avg(sal),
count(*) ,count(job),count(distinct(job)) ,
sum(sal) from emp group by deptno;
2)部门30的最高工资,最低工资,总人数,有工作的人数,工种数量及工资总和
select deptno, max(ename),max(sal),
min(ename),min(sal),
avg(sal),
count(*) ,count(job),count(distinct(job)) ,
sum(sal) from emp group by deptno having deptno=30;
3, stddev 返回一组值的标准偏差
select deptno,stddev(sal) from emp group by deptno;
variance 返回一组值的方差差
select deptno,variance(sal) from emp group by deptno;
4, 带有rollup和cube操作符的Group By
rollup 按分组的第一个列进行统计和最后的小计
cube 按分组的所有列的进行统计和最后的小计
select deptno,job ,sum(sal) from emp group by deptno,job;
select deptno,job ,sum(sal) from emp group by rollup(deptno,job);
cube 产生组内所有列的统计和最后的小计
select deptno,job ,sum(sal) from emp group by cube(deptno,job);
八、临时表
只在会话期间或在事务处理期间存在的表.
临时表在插入数据时,动态分配空间
create global temporary table temp_dept
(dno number,
dname varchar2(10))
on commit delete rows;
insert into temp_dept values(10,'ABC');
commit;
select * from temp_dept; --无数据显示,数据自动清除
on commit preserve rows:在会话期间表一直可以存在(保留数据)
on commit delete rows:事务结束清除数据(在事务结束时自动删除表的数据)
posted @
2011-12-31 13:59 RoyPayne 阅读(255) |
评论 (0) |
编辑 收藏What is ClassLoader?
与普通程序不同的是,Java程序(class文件)并不是本地的可执行程序。当运行Java程序时,首先运行JVM(Java虚拟机),然后再把Java class加载到JVM里头运行,负责加载Java class的这部分就叫做Class Loader。
JVM本身包含了一个ClassLoader称为Bootstrap ClassLoader,和JVM一样,BootstrapClassLoader是用本地代码实现的,它负责加载核心JavaClass(即所有java.*开头的类)。另外JVM还会提供两个ClassLoader,它们都是用Java语言编写的,由BootstrapClassLoader加载;其中Extension ClassLoader负责加载扩展的Javaclass(例如所有javax.*开头的类和存放在JRE的ext目录下的类),ApplicationClassLoader负责加载应用程序自身的类。 当运行一个程序的时候,JVM启动,运行bootstrapclassloader,该ClassLoader加载java核心API(ExtClassLoader和AppClassLoader也在此时被加载),然后调用ExtClassLoader加载扩展API,最后AppClassLoader加载CLASSPATH目录下定义的Class,这就是一个程序最基本的加载流程。 注: 学ClassLoader看OSGI When to load the class?
什么时候JVM会使用ClassLoader加载一个类呢?当你使用java去执行一个类,JVM使用ApplicationClassLoader加载这个类;然后如果类A引用了类B,不管是直接引用还是用Class.forName()引用,JVM就会找到加载类A的ClassLoader,并用这个ClassLoader来加载类B。JVM按照运行时的有效执行语句,来决定是否需要装载新类,从而装载尽可能少的类,这一点和编译类是不相同的。 Why use your own ClassLoader? 似乎JVM自身的ClassLoader已经足够了,为什么我们还需要创建自己的ClassLoader呢? 因为JVM自带的ClassLoader只是懂得从本地文件系统加载标准的java class文件,如果编写你自己的ClassLoader,你可以做到: 1)在执行非置信代码之前,自动验证数字签名 2)动态地创建符合用户特定需要的定制化构建类 3)从特定的场所取得java class,例如数据库中 4) 等等 事实上当使用Applet的时候,就用到了特定的ClassLoader,因为这时需要从网络上加载java class,并且要检查相关的安全信息。 目前的应用服务器大都使用了ClassLoader技术,即使你不需要创建自己的ClassLoader,了解其原理也有助于更好地部署自己的应用。
ClassLoader Tree & Delegation Model
当你决定创建你自己的ClassLoader时,需要继承java.lang.ClassLoader或者它的子类。在实例化每个ClassLoader对象时,需要指定一个父对象;如果没有指定的话,系统自动指定ClassLoader.getSystemClassLoader()为父对象。 所以当创建自己的Class Loader时,只需要重载findClass()这个方法。
Unloading? Reloading?
当一个javaclass被加载到JVM之后,它有没有可能被卸载呢?我们知道Win32有FreeLibrary()函数,Posix有dlclose()函数可以被调用来卸载指定的动态连接库,但是Java并没有提供一个UnloadClass()的方法来卸载指定的类。 在Java中,java class的卸载仅仅是一种对系统的优化,有助于减少应用对内存的占用。既然是一种优化方法,那么就完全是JVM自行决定如何实现,对Java开发人员来说是完全透明的。 在什么时候一个java class/interface会被卸载呢?Sun公司的原话是这么说的:"class or interfacemay be unloaded if and only if its class loader is unreachable. Classesloaded by the bootstrap loader may not be unloaded." 事实上我们关心的不是如何卸载类的,我们关心的是如何更新已经被加载了的类从而更新应用的功能。JSP则是一个非常典型的例子,如果一个JSP文件被更改了,应用服务器则需要把更改后的JSP重新编译,然后加载新生成的类来响应后继的请求。 其实一个已经加载的类是无法被更新的,如果你试图用同一个ClassLoader再次加载同一个类,就会得到异常(java.lang.LinkageError: duplicate classdefinition),我们只能够重新创建一个新的ClassLoader实例来再次加载新类。至于原来已经加载的类,开发人员不必去管它,因为它可能还有实例正在被使用,只要相关的实例都被内存回收了,那么JVM就会在适当的时候把不会再使用的类卸载。 使用线程上下文类加载器, 可以在执行线程中, 抛弃双亲委派加载链模式, 使用线程上下文里的类加载器加载类. 典型的例子有, 通过线程上下文来加载第三方库jndi实现, 而不依赖于双亲委派. 大部分java app服务器(jboss, tomcat..)也是采用contextClassLoader来处理web服务。 当然, 好东西都有利弊. 使用线程上下文加载类, 也要注意, 保证多根需要通信的线程间的类加载器应该是同一个, 防止因为不同的类加载器, 导致类型转换异常(ClassCastException). 参考资料及图片来源——Understanding J2EE Application Server Class Loading Architectures
posted @
2011-12-30 12:07 RoyPayne 阅读(253) |
评论 (0) |
编辑 收藏1.memcached client for java客户端API:memcached client for java 网址:http://www.whalin.com/memcached 最新版本:java_memcached-release_2.0.1
操作示例:
import com.danga.MemCached.*;
import org.apache.log4j.*;
public class TestMemcached {
public static void main(String[] args) {
/*初始化SockIOPool,管理memcached的连接池*/
String[] servers = { "192.168.1.20:12111" };
SockIOPool pool = SockIOPool.getInstance();
pool.setServers(servers);
pool.setFailover(true);
pool.setInitConn(10);
pool.setMinConn(5);
pool.setMaxConn(250);
pool.setMaintSleep(30);
pool.setNagle(false);
pool.setSocketTO(3000);
pool.setAliveCheck(true);
pool.initialize();
/*建立MemcachedClient实例*/
MemCachedClient memCachedClient = new MemCachedClient();
for (int i = 0; i < 10; i++) {
/*将对象加入到memcached缓存*/
boolean success = memCachedClient.set("" + i, "Hello!");
/*从memcached缓存中按key值取对象*/
String result = (String) memCachedClient.get("" + i);
System.out.println(String.format("set( %d ): %s", i, success));
System.out.println(String.format("get( %d ): %s", i, result));
}
}
}
2.spymemcached客户端API:spymemcached client
网址:http://code.google.com/p/spymemcached/
最新版本:memcached-2.1.jar
操作示例:
用spymemcached将对象存入缓存
import java.net.InetSocketAddress;
import java.util.concurrent.Future;
import net.spy.memcached.MemcachedClient;
public class MClient {
public static void main(String[] args){
try{
/*建立MemcachedClient 实例,并指定memcached服务的IP地址和端口号*/
MemcachedClient mc = new MemcachedClient(new InetSocketAddress("192.168.1.20", 12111));
Future<Boolean> b = null;
/*将key值,过期时间(秒)和要缓存的对象set到memcached中*/
b = mc.set("neea:testDaF:ksIdno", 900, "someObject");
if(b.get().booleanValue()==true){
mc.shutdown();
}
}
catch(Exception ex){
ex.printStackTrace();
}
}
}
用spymemcached从缓存中取得对象
import java.net.InetSocketAddress;
import java.util.concurrent.Future;
import net.spy.memcached.MemcachedClient;
public class MClient {
public static void main(String[] args){
try{
/*建立MemcachedClient 实例,并指定memcached服务的IP地址和端口号*/
MemcachedClient mc = new MemcachedClient(new InetSocketAddress("192.168.1.20", 12111));
/*按照key值从memcached中查找缓存,不存在则返回null */
Object b = mc.get("neea:testDaF:ksIdno ");
mc.shutdown();
}
catch(Exception ex){
ex.printStackTrace();
}
}
}
3.两种API比较
memcached client for java:较早推出的memcached JAVA客户端API,应用广泛,运行比较稳定。
spymemcached:A simple, asynchronous, single-threaded memcached client written in java. 支持异步,单线程的memcached客户端,用到了java1.5版本的concurrent和nio,存取速度会高于前者,但是稳定性不好,测试中常报timeOut等相关异常。
由于memcached client for java发布了新版本,性能上有所提高,并且运行稳定,所以建议使用memcached client for java。
posted @
2011-12-30 09:51 RoyPayne 阅读(526) |
评论 (0) |
编辑 收藏
摘要: http://www.iteye.com/topic/834447http://www.blogjava.net/focusJ/archive/2011/11/03/367225.html1. 基本 概念IO 是主存和外部设备 ( 硬盘、终端和网络等 ) 拷贝数据的过程。 IO 是操作...
阅读全文
posted @
2011-12-29 15:59 RoyPayne 阅读(119) |
评论 (0) |
编辑 收藏
java锁机制有两种实现方式:jdk1.4 通过synchronized的方式实现,jdk1.5加入java.util.concurrent.locks包下的各种lock
1.代码层的区别。
synchronized 类似面向对象 修饰 类,方法,对象。
lock不作为修饰,类似面向过程,在方法中需要锁的时候lock,在结束的时候unlock。(一般在finally块里)
2.性能
并发高,lock有优势。低并发 synchronized 有优势。
3.实现机制
synchronized 对象加锁
posted @
2011-12-28 17:22 RoyPayne 阅读(266) |
评论 (0) |
编辑 收藏
mark下,不错,单列模式,在并发环境下,还是用勤奋初始化模式好,不要用懒惰初始化模式
posted @
2011-12-28 15:11 RoyPayne 阅读(304) |
评论 (0) |
编辑 收藏 Volatile修饰的成员变量在每次被线程访问时,都强迫从共享内存中重读该成员变量的值。而且,当成员变量发生变化时,强迫线程将变化值回写到共享内存。这样在任何时刻,两
个不同的线程总是看到某个成员变量的同一个值。 Java语言规范中指出:为了获得最佳速度,允许线程保存共享成员变量的私有拷贝,而且只当线程进入或者离开同步代码块时才与
共享成员变量的原始值对比。 这样当多个线程同时与某个对象交互时,就必须要注意到要让线程及时的得到共享成员变量的变化。 而volatile关键字就是提示VM:对于这个成员变量
不能保存它的私有拷贝,而应直接与共享成员变量交互。 使用建议:在两个或者更多的线程访问的成员变量上使用volatile。当要访问的变量已在synchronized代码块中,或者为常量
时,不必使用。 由于使用volatile屏蔽掉了VM中必要的代码优化,所以在效率上比较低,因此一定在必要时才使用此关键字。 就跟C中的一样 禁止编译器进行优化~~~~
posted @
2011-12-28 13:58 RoyPayne 阅读(215) |
评论 (0) |
编辑 收藏
4.2 执行环境及作用域
1.执行环境(execution context)
执行环境定义了变量或函数有权访问的其他数据,决定了它们各自的行为。
2.变量对象(variable object)
环境中定义的所有变量和函数都保存在这个对象中。虽然我们在编码时无法访问这个对象,但解析器在处理数据时会在后台使用它。
posted @
2011-12-21 17:00 RoyPayne 阅读(213) |
评论 (0) |
编辑 收藏
摘要: 让我们来看看该命令的参数:
pathname find命令所查找的目录路径。例如用.来表示当前目录,用/来表示系统根目录。
-print find命令将匹配的文件输出到标准输出。
-exec find命令对匹配的文件执行该参数所给出的shell命令。
-ok 和- exec的作用相同,只不过以一种更为安全的模式来执行该参数所给出的shell命令,在执行每一个命令之前,都会给出提示,让用户来确定是否执行.
阅读全文
posted @
2011-12-21 10:52 RoyPayne 阅读(221) |
评论 (0) |
编辑 收藏
摘要: 在Linux或Unix中,查看文件的方法有很多种:more,less,cat,od,head,tail等等,其中head可查看一个文件的前面的几行,tail则与之相反。这里只对tail的语法及常用的使用方法做以介绍。
相信最基本的cat、more和less你已经很熟悉了,如果有特殊的要求呢:
1. 如果你只想看文件的前5行,可以使用head命令,如:
head -5 /etc/passwd
2. 如果你想查看文件的后10行,可以使用tail命令,如:
tail -2 /etc/passwd 或 tail -n 2 /etc/passwd
tail -f /var/log/messages
参数-f使tail不停地去读最新的内容,这样有实时监视的效果,用Ctrl+c来终止!
3. 查看文件中间一段,你可以使用sed命令,如:
sed -n '5,10p' /etc/passwd
这样你就可以只查看文件的第5行到第10行。
阅读全文
posted @
2011-12-21 09:20 RoyPayne 阅读(1333) |
评论 (0) |
编辑 收藏 Xshell对于嵌入式开发来说,是个非常不错的工具。但或许都有过被中文显示为乱码的问题感觉有点不爽。解决方法其实很简单的,即把xshell编码方式改成UTF-8即可。
[文件]–>[打开]–>在打开的session中选择连接的那个,点击[属性] -> [终端], 编码选择为:Unicode(UTF-8),然后重新连接服务器即可。也可以在Xshell的工具栏里面点击“编码 ”按钮,选择Unicode(UTF-8)编码即可。
本人用的Xshell版本是:xshell3.0(build 0206) 简体中文
posted @
2011-12-21 09:07 RoyPayne 阅读(39639) |
评论 (1) |
编辑 收藏
摘要: 最近在网上查阅了不少Javascript闭包(closure)相关的资料,写的大多是非常的学术和专业。对于初学者来说别说理解闭包了,就连文字叙述都很难看懂。撰写此文的目的就是用最通俗的文字揭开Javascript闭包的真实面目。
阅读全文
posted @
2011-12-19 16:59 RoyPayne 阅读(220) |
评论 (0) |
编辑 收藏
摘要: javascript数组操作大全,数组方法总汇
1. shift:删除原数组第一项,并返回删除元素的值;如果数组为空则返回undefined
var a = [1,2,3,4,5];
var b = a.shift(); //a:[2,3,4,5] b:1
阅读全文
posted @
2011-12-16 12:09 RoyPayne 阅读(2290) |
评论 (0) |
编辑 收藏
摘要: vi编辑器是所有Unix及Linux系统下标准的编辑器,它的强大不逊色于任何最 新的文本编辑器,这里只是简单地介绍一下它的用法和一小部分指令。由于对Unix及Linux系统的任何版本,vi编辑器是完全相同的,因此您可以在其他 任何介绍vi的地方进一步了解它。Vi也是Linux中最基本的文本编辑器,学会它后,您将在Linux的世界里畅行无阻。
阅读全文
posted @
2011-12-14 10:38 RoyPayne 阅读(255) |
评论 (0) |
编辑 收藏
ζ var o={name:"张三", age:19}; //此处o是js对象 alert(o.name); ζ var str_json = '{"name":"张三", "age":19}'; //str_json是符合JSON规范的字符串 var oJSON = eval('('+str_json+')'); //把JSON字符串转化成js对象oJSON alert(oJSON.name); The JSON Object is different from String having JSON format 看来就是这个分别了 由于服务器Response一般都采取文本形式,所以eval还是必要的
posted @
2011-12-13 16:16 RoyPayne 阅读(225) |
评论 (0) |
编辑 收藏
摘要: 简介
Asynchronous JavaScript and XML (Ajax) 是驱动新一代 Web 站点(流行术语为 Web 2.0 站点)的关键技术。Ajax 允许在不干扰 Web 应用程序的显示和行为的情况下在后台进行数据检索。使用 XMLHttpRequest 函数获取数据,它是一种 API,允许客户端 JavaScript 通过 HTTP 连接到远程服务器。Ajax 也是许多 mashup 的驱动力,它可将来自多个地方的内容集成为单一 Web 应用程序。
不过,由于受到浏览器的限制,该方法不允许跨域通信。如果尝试从不同的域请求数据,会出现安全错误。如果能控制数据驻留的远程服务器并且每个请求都前往同一域,就可以避免这些安全错误。但是,如果仅停留在自己的服务器上,Web 应用程序还有什么用处呢?如果需要从多个第三方服务器收集数据时,又该怎么办?
阅读全文
posted @
2011-12-10 19:18 RoyPayne 阅读(253) |
评论 (0) |
编辑 收藏
摘要: 介绍JSONP之前,先简单的介绍一些JSON。JSON是JavaScript Object Notation的缩写,是一种轻量的、可读的基于文本的数据交换开放标准。源于JavsScript编程语言中对简单数据结构和关联数组的展示功能。它是仅含有数据对和简单括号结构的纯文本,因此可通过许多途径进行JSON消息的传递。
阅读全文
posted @
2011-12-10 19:14 RoyPayne 阅读(576) |
评论 (0) |
编辑 收藏posted @
2011-11-30 14:05 RoyPayne 阅读(257) |
评论 (0) |
编辑 收藏
1.查找缺少的数据。
取出相邻2条的数据,如果公历日期后一条减前一条大于1,就证明缺少。
2.去网上找网页,数据全的。
http://www.nongli.com/item4/index.asp
3.利用jsoup抓取网页中的相关数据。
posted @
2011-11-30 14:00 RoyPayne 阅读(304) |
评论 (0) |
编辑 收藏posted @
2011-11-25 10:07 RoyPayne 阅读(312) |
评论 (0) |
编辑 收藏
links目录下,创建link文件(文件名和后缀可以随意指定),比如findbugs.link,内容如下:
path = D:\\plugins\\spket-1.6.16
path后面跟的就是插件的地址。
需要注意的是,插件必须采用标准的目录结构eclipse |------plugins |------features
采用link的方式,不但方便插件的管理,而且当eclipse重装的时候,只要把links目录copy到新的$ECLIPSE_HOME下即可。
posted @
2011-11-25 09:57 RoyPayne 阅读(172) |
评论 (0) |
编辑 收藏1windows →Preferences→general→editors→text editors
2在 appearance color options 里选在background color
3去掉复选框的钩,设置颜色为
色调85
饱和度123
亮度205
另一种方式:
桌面鼠标右键->属性->外观-高级->窗口
设置颜色。
posted @
2011-11-23 08:58 RoyPayne 阅读(343) |
评论 (0) |
编辑 收藏1、#可以进行预编译,进行类型匹配,#变量名#? 会转化为 jdbc的?类型
?? $不进行数据类型匹配,$变量名$就直接把$name$替换为 name的内容
?? 例如:
????select * from tablename where id = #id#,假设id的值为12,其中如果数据库字段id为字符型,那么#id#表示的就是'12',如果id为整型,那么#id#就是 12
??? 会转化为jdbc的select * from tablename where id=?,把?参数设置为id的值
????select * from tablename where id = $id$,如果字段id为整型,Sql语句就不会出错,但是如果字段id为字符型,
????那么Sql语句应该写成 select * from table where id = '$id$'
????
3、#方式能够很大程度防止sql注入.
4、$方式无法方式sql注入.
5、$方式一般用于传入数据库对象.例如传入表名.
6、所以ibatis用#比$好,一般能用#的就别用$.
另外,使用##可以指定参数对应数据库的类型
如:
select * from tablename where id =#id:number#?
在做in,like 操作时候要特别注意
mysql: select * from user where user_name like concat('%',#name#,'%')oracle: select * from user where user_name like '%'||#name#||'%'sql server: select * from user where user_name like '%'+#name#+'%'
posted @
2011-11-17 22:15 RoyPayne 阅读(612) |
评论 (0) |
编辑 收藏
摘要: 一、JAR包简介
要使程序可以运行必须引入JSON-lib包,JSON-lib包同时依赖于以下的JAR包:
1.commons-lang.jar
2.commons-beanutils.jar
3.commons-collections.jar
4.commons-logging.jar
5.ezmorph.jar
6.json-lib-2.2.2-jdk15.jar
阅读全文
posted @
2011-05-02 21:25 RoyPayne 阅读(1721) |
评论 (0) |
编辑 收藏
摘要: 我是谁?我是谁?这是多人反复自诘的老问题。虽然每个人都可通过镜中的影象看到自己的容貌,尽管他清楚自己的姓名、年龄与过去,但是对于真正的“自己”,很多人未必都能真正的明白,故而仍旧要问“我是谁”?
阅读全文
posted @
2010-01-30 11:51 RoyPayne 阅读(355) |
评论 (0) |
编辑 收藏TOMCAT部署项目有3种方法:
1、直接把项目放在webapps里
2、修改conf里server.xml文件,添加一个Context,指向项目的目录
3、在Catalina/localhost目录里,新增一个xml文件,添加一个Context内容,指向项目的目录。
<Context path="/目录名" docBase="e:\example" debug="0" reloadable="true" />
优先级别为:3>2>1
第3个方法有个优点,可以定义别名。服务器端运行的项目名称为path,外部访问的URL则使用XML的文件名。这个方法很方便的隐藏了项目的名称,对一些项目名称被固定不能更换,但外部访问时又想换个路径,非常有效。
第2、3还有优点,可以定义一些个性配置,如数据源的配置等。
posted @
2009-07-01 11:19 RoyPayne 阅读(298) |
评论 (0) |
编辑 收藏
摘要: 写了好几篇关于这个方向的文章了,但连自己都感觉写的有点乱,没有总结。所以现在把所有方法整理到一起,如果以后又发现新的,我继续补充到这篇文章里。
这篇是技巧性的文章,如果要找关于GC或者调整内纯的文章,看我其他几篇文章。因为是JVM 调优总结,所以废话少说。从各方面一共收集到以下几个方法:
阅读全文
posted @
2009-06-28 10:57 RoyPayne 阅读(427) |
评论 (0) |
编辑 收藏
摘要: 延迟加载:
延迟加载机制是为了避免一些无谓的性能开销而提出来的,所谓延迟加载就是当在真正需要数据的时候,才真正执行数据加载操作。在Hibernate中提供了对实体对象的延迟加载以及对集合的延迟加载,另外在Hibernate3中还提供了对属性的延迟加载。下面我们就分别介绍这些种类的延迟加载的细节。
阅读全文
posted @
2009-06-28 08:30 RoyPayne 阅读(196) |
评论 (0) |
编辑 收藏
摘要: ClassLoader一个经常出现又让很多人望而却步的词,本文将试图以最浅显易懂的方式来讲ClassLoader,希望能对不了解该机制的朋友起到一点点作用.
要深入了解ClassLoader,首先就要知道ClassLoader是用来干什么的,顾名思义,它就是用来加载Class文件到JVM,以供程序使用的。我们知道,java程序可以动态加载类定义,而这个动态加载的机制就是通过ClassLoader来实现的,所以可想而知ClassLoader的重要性如何。
阅读全文
posted @
2009-06-26 22:38 RoyPayne 阅读(260) |
评论 (0) |
编辑 收藏