2005年5月12日
Adobe Kuler是一个在线颜色配色方案管理工具,位于http://kuler.adobe.com/。

它也可通过AIR运行在桌面,下载地址:Download the Kuler desktop
其主界面应该是一个 Flex应用:
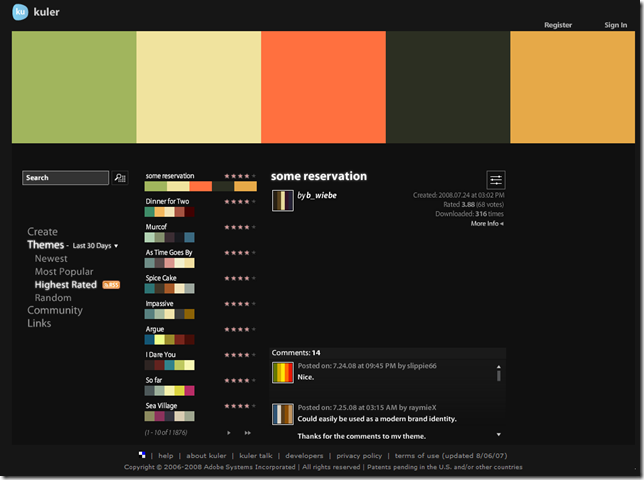
在其中你可以查询下载别人创建的配色,并进行评价。或者创建自己的配色方案。
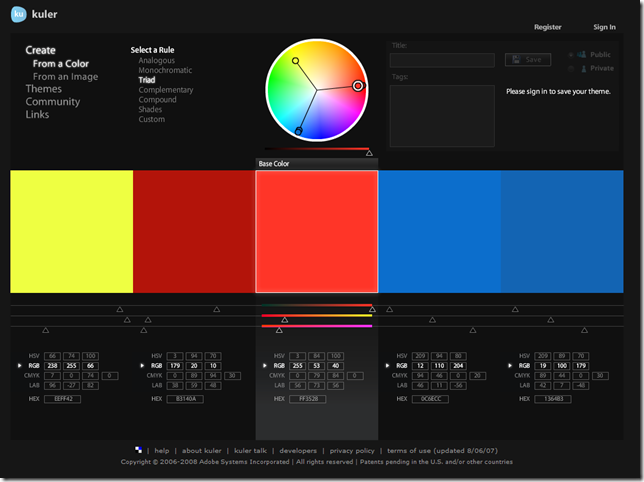
创建新的配色界面:
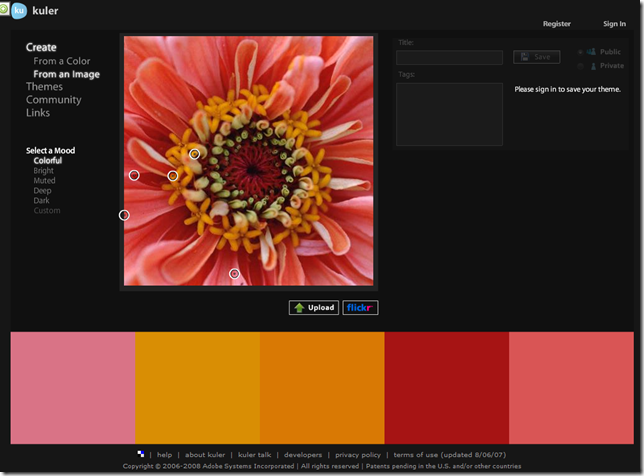
可以根据颜色空间创建,也可以根据现有的图像创建。并且可选择预设的风格或者定制自己的风格。
根据图像创建
 version 1.0
version 1.0
Class Hierarchy

奥运会场馆规则出台,其中明文规定“禁止裸奔”。呵呵,觉得非常之好,非常有必要!!
在火炬传递的时候,我给一个担任开道车任务的公安朋友说,我要去裸奔。他说,得了吧,就你那点东西,别丢人现眼了。人家老外还可以拿出来亮亮相。
我哈哈大笑说,也是,大大有道理。我放弃....
其实,现在社会,有许许多多就恰似“裸奔”的现象和行为,人们就当没看见。比如,薪水只有千多元的公务员,每天抽的都是中华之类的,再比如.....
算了,懒得说
OLPC基金会的廉价电脑随着全球性物价上涨的浪潮,可谓路途多艰。意大利一家命名为V12 Design的公司设计的双屏笔记本则非常之Cool。其实看起来,液晶或者其他显示介质的发展,键盘已经成为完全可以虚拟的东西。当然,这样更加依赖于软件和系统了。IPhone和HTC的Diamond都非常的Cool。
这款笔记本也非常的惹人流口水:
")
")
对于看大量电子书的我,这样看起来多安逸阿,尤其是可以在上面乱写乱画,就像在纸张上一样。
")
Web 2 时代的Meshup 应用有两种极端,简约模式 和 丰富模式。前者 遵循简洁的界面更个和简单的UI体验,所谓 显式设计,业务上遵循独特简单的模型。 后者则是RIA宣扬的丰富如桌面的Web应用,并且开始用Web占领桌面,如AIR,SilverLight之类。
地图和位置则是一个很好的调味剂,凡位置相关者应用均可混入。公共Map应用不多,主要有:
Google Map
Yahoo Map
MS Map
国内还是51ditu (灵图)做的较好,国内地图比较详细,但不能提供卫星地图。
使用条款
google
就使用条款来说,Google地图的主要条款有几条值得注意:
““服务”只能用于一般情况下无需收费即可访问的服务。”这个一般情况下是什么意思?
诸如合法性、知识产权的部分无需多说,不得将“服务”用于:(a) 用作或与实时路线指南一起使用(包括但不限于线路规划指南和其他可通过传感器接受的路线指导),或 (b) 用作或与任何系统或功能一起使用来实施对自动或自主驾驶行为的控制。
还有一个限制就是流量问题,地址解析请求。每天每个地图 API Key 可发出最多 5 万个地址解析请求。相当于大约每 5.76 秒发送一个。如果当天超过这个限制,您可能暂时无法使用地图 API 地址解析。如果继续违反此限制,可能会造成此后您对地图 API 地址解析的访问被永久拦截。
大体来看,还是比较宽松的。
Yahoo
而yahoo地图几乎是明文限制商业使用的。而且中国的地图数据几乎没什么用。至于Yahoo中国搞的地图,好像是Map2China提供的,也基本上没更新。
MS
Ms的地图属于Live系列,引擎为Wirtual earth. 英文为 map.live.com,支持3D。中文为 ditu.live.com,2D地图。地图还算比较详细,即时性不够。
live Map的API 称为 interactive SDK,开发中心位于 http://dev.live.com/virtualearth/。看来 是live 平台的一部分。
51ditu
除了地图比较详尽即时外,还提供应用API。但速度不太快。API提供免费服务,也提供商业服务,根据流量收费。详见http://api.51ditu.com/special/vip/index.html。
Oracle公司的网站现在基本上出于打不开的状态,都持续数月了。真不知道是怎么回事,难道是收购BEA了之后还在重组中,不过这种现象好像是在收购事件发生之前哦。
1 驱动程序:
微软官方驱动:
http://www.microsoft.com/downloads/details.aspx?FamilyID=6d483869-816a-44cb-9787-a866235efc7c&DisplayLang=en
2 连接
设置 SQL Service的服务引擎和客户端均开启TCP/IP连接,通常TCP端口为1433默认。注意IP All的端口设置也须设置为1433,否则会出现 Connection Refused错误。
3 设置认证方式。
SQL EXPRESS Management Studio中好像无法修改认证方式,可以直接修改注册表
HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\Mi crosoft SQL Server\MSSQL.1\MSSQLServer LoginMode
1 为Windows Only
2 Mixed
否则,如果为1,出现user not associated with a trusted sql server connection
从偶然架构到一个全球规模的统一的集成基础设施可能是像一个使人畏缩的任务。 把一切都准备就绪,然后再象扳动一下开关那样将所有的应用都一下子转移到新的基础设施之上是不现实的。这已经是组织为什么老是要不断添加偶然架构方案作为权益解决之计的一个主要的理由,甚至他们确实知道这样使相关的问题永垂不朽也是如此。
ESB 提供了能力来帮助减轻所介绍的痛苦。 第 9 章将通过一个案例来介绍如何远离一个完全建立在 FTP 和每夜批处理作业之上的早以存在的集成解决方案。
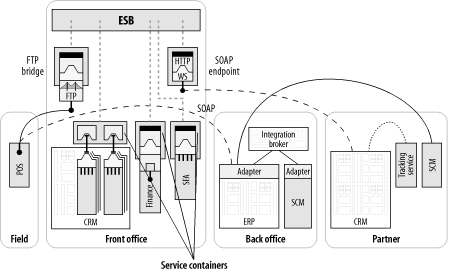
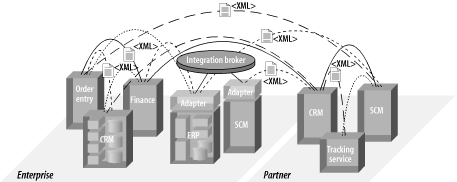
让我们现在重新回到对偶然架构的讨论。 在图 2-6中,实线、虚线、点划线代表用于集成的不同类型的连接技术和通信协议。注意其中有一个用集成Broker表达的已存在的 “集成孤岛”,以及POS应用和财务应用之间的连接是使用FTP 文件传输。在POS应用和ERP应用之间先前已经升级来使用HTTP 之上的SOAP协议,正如销售自动化应用 (SFA) 和客户关系管理 (CRM) 之间的联结。
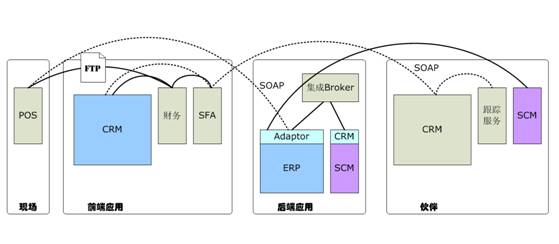
图表 2‑6 使用SOAP通信、 FTP 、手工插座(Socket)、而且包括一个集成Broker的代表性的偶然架构
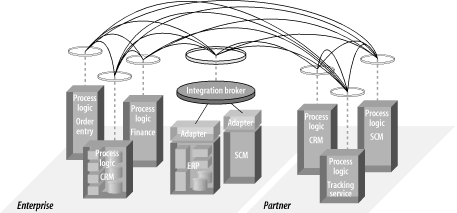
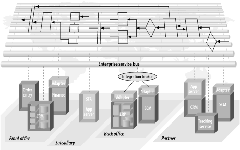
ESB 可以在一个部门级的层次或在一个项目的基础上被引入。 在项目层次采用 ESB 允许你能够习惯于使用 ESB 服务容器进行基于标准的集成,并且完全可以坚信该项目能够集成到一个更大的集成网络之中,并且与企业级的公司的集成策略目标相一致。
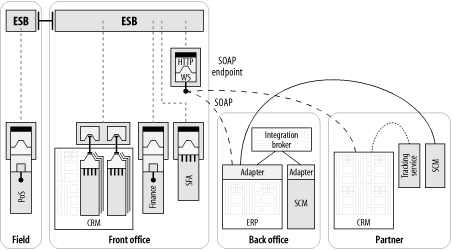
我们采用ESB的例子中的第一个步骤是要集成前端应用(FrontOffice)。在图 2-7 中,前端的CRM、财务和SFA 通过“服务容器”连接到ESB 之中。这些容器是 ESB 架构的主要组件,我们将在第 6 章详细解释。 经过 ESB 服务容器进行的集成的特性可能会不同。 容器和应用之间的接口可以通过使用第三方的应用适配器来完成;容器可以暴露使用WSDL描述的XML数据;或者它可能被实现为完全用户定制的代码。
图表 2‑7 ESB 可以在不打破原有点对点路径的前提下,在单个项目基础上采用
但是也许更有趣的不是那些已经集成到ESB 之内的东西,而是还没有集成进去的东西。图 2-7 表示了已有的 FTP 和SOAP协议之间的通信线,原来是连接到前端应用的,现在直接连接到那些特别配制来使用那些协议进行通信的ESB组件。应用仍然处于总线“之外”,Pos应用和伙伴CRM应用可以与集成到ESB总线“之内”的前端应用进行通信而不需要做任何修改,对他们如何参与ESB基础设施也不需要知道任何东西。注意,现在POS应用是连接到ESB 上的一个 FTP 桥接器,而且伙伴CRM应用则是连接到配置为总线的一部分的Web Services端点。
ESB 已经被引入了,但是对这些配备了ESB能力的应用以前所连接的点对点通信组合区没有产生任何影响。被插入总线的应用如今转而使用连接到ESB 集成容器的一个单一接口, 而且已经省却了对它们先前所有其他类型的通信连接的管理和维护。
我们将会在第 9 章中看到,即使是总线域中最新集成的应用也可以就地将他们转移到完全的ESB方式,并且与它们各自的项目开发时间线相一致。
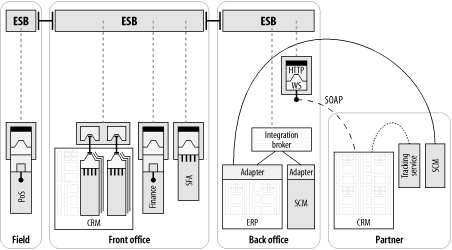
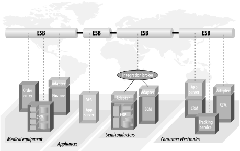
在我们的ESB采用的例子得下一阶段中,POS应用将在每一个远端实现ESB能力,并且去除对不可靠的 FTP 联结上的依赖。 这可能会简单如在每一个远端安装一个ESB容器,并且插入到总部的ESB之中,或者涉及到在每一个远端的多个应用之间的一个“迷你”的集成环境。那么二个 ESB节点就可以通过一个基于可靠消息的安全连接进行通信(图 2-8)
图表 2‑8 在各个地点分立安装的ESB可以安全和可靠地连接在一起
此外,远端位置仍然可以在他们自己的分离集成环境里面运行,并且可以按照需要有选择地共享数据。例如,远端位置可以独立地拥有并且运作一个属于集体特许经营的零售店铺。它们没有必须共享关于它们的日常运作的信息,但是的确需要共享诸如价格更新和库存信息之类的数据。远程ESB 节点可以连接到位于总部的 ESB 网络,有选择地暴露消息通道以共享价格变动之类的数据。
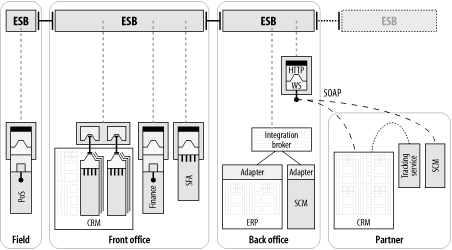
我们的ESB 采用示例项目的第三阶段涉及到桥接进进一个已经部分地与一个集线器-和-插头 EAI Broker集成在一起的部门。我们先前提醒过,采用 ESB 不是一个全有或全无的概念。如图 2-9 所示, ESB 允许IT部门通过将一个已存在的 EAI Broker桥接到ESB之内来保护它里面的IT资产。
图表 2‑9 “保留-和-分层”方式允许将ESB桥接到EAI Broker安装之内
桥接 EAI Broker可以一多种方式进行。比如,它可以通过使用一个Web Services接口来完成,或者绑定到下层的消息通道。依赖于ESB和 EAI Broker 的实现,ESB 更加可以建立在EAI Broker下面的消息队列基础设施之上,因此部分地替换EAI Broker的功能仍然可以保留较低层的、消息通道。
我们的 ESB 采用示例项目的最后步骤是解决和业务伙伴集成的问题。如图 2-10 所示,这可能包括原样保留SOAP联结,以及在每个伙伴端安装一个 ESB 节点。决定采用哪一种方法完全依赖于你的组织和伙伴之间的关系,以及业务伙伴是否允许你在其地点安装软件,或者他们已经有能够连接到你的ESB之上的ESB。
图表 2‑10 ESB 可以个别地管理与业务伙伴的SOAP联结, 或者可以连接到另一个地点的ESB节点
插入到一个 ESB 扩展的分层的服务能够管理对伙伴的连接的后勤保障。例如,一个特殊的伙伴经理者服务可以在每一个伙伴的基础上管理与伙伴之间的正在进行的协作的细节。这些细节可能包括正在使用哪一个更高层次的业务协议(比如, ebXML、RosettaNet 等)、以及对话的状态,比如消息交换的当前状态、是否收到一个期望的应答消息、以及从业务伙伴接收到一个业务响应所能够接受多长的时延。
本章包含下列主题:
- 对更广泛的、更通用的集成基础设施的需要的各种驱动因素
- 偶然架构是今天所使用的主要集成设计。 在这种系统中,当前的企业完全没有很好地联通的。
- 只有 10% 的应用被联接。
- 而这些之中,只有 15%的使用了某种类型中间件。
- 到目前为止,分布式计算技术加重了,而不是解决了,偶然架构的问题。
- 集线器-和- 插头EAI Broker已经有了一定程度的成功。然而,它们:
- 大部分是专有技术
- 没有为组织提供一个标准化的、可以在企业内通用使用的集成平台。
- ESB 借鉴了在 EAI Broker技术方面学习的经验的价值。
- 集成作为是一个部门层面和公司文化的问题,和它作为一个技术上问题同样重要。
- ESB 允许逐渐增加的采用,以符合各个部门单独的开发时间表。
因为RFID要产生和辐射电磁波,所以法律上将其归为无线电通信系统(radio systems)。 无线电服务必须在不被RFID 系统所干扰和影响的前提之下。为了确保RFID 系统不会干扰邻近的广播和电视,移动无线服务(警用,安全,工业),航海和海空无线通信服务和移动电话服务,这一点很重要。
所以必须仔细的规划适用于RFID系统所用的频率范围。(基于此,通常只可能使用保留工业、科学和医疗用途的频段。这些频段称为是ISM 频段,可以用作RFID 应用。
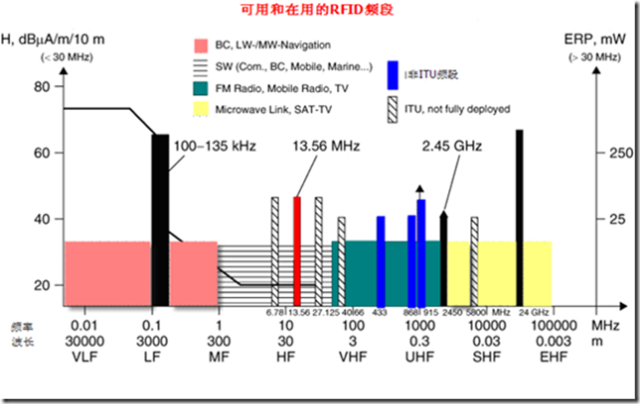
图表 6‑1 RFID 系统使用的频段
除了ISM 频率,整个低于135 kHz (在北美、南美和日本为<400 kHz)也是可以使用的,因为这些频率可以工作于高磁场强度,特别是针对感应耦合式RFID 系统。
因此, RFID 最重要的频段是0–135 kHz, 以及ISM频段中围绕6.78M(在德国已经不适合),13.56 MHz,27.125 MHz,40.68 MHz,433.92 MHz,869.0 MHz,915.0 MHz (非欧洲地区),2.45 GHz, 5.8 GHz 和24.125 GHz的频段。
RFID 在各个频段总体分布如下图:
图表 6‑2 估计的RFID在各频段的全球总体分布图(百万单位)

图表 6‑3 全球RFID频率使用分布图
低于135 kHz 的频率被各种无线服务大量使用,因为他们没有保留作ISM 频段。这个长波频段的传播特性可以使得在低技术成本下达到连续传播超过1000 km 半径的范围。通常这个范围的服务服务是用作航空和航海的导航服务 (LORAN C, OMEGA, DECCA),授时服务,标准频率服务以及军方的无线电服务。因此,位于中欧Mainflingen的授时发射机DCF 77 使用的就是77.5 kHz的频率。因此RFID 系统在此频率运行可能会影响到reader周围数百米范围内的无线接收的时钟失效。
为了防止这种冲突,欧洲对感应式无线电系统的管制法案 220 ZV 122,将定义一个从70 到119 kHz的保护区,这个区域将不再分配给RFID 系统。
频率6.765–6.795 MHz 属于短波频段。其传播条件可以是你能够在白天的传播达到100 km。而在夜间,横贯大陆的传播都是可能的。这个范围主要云南关于宽范围的无线电服务,例如广播,天气和航空无线电服务以及新闻社。
这个频段在德国还没有被通过为ISM 频段,但是已经被ITU指定为ISM 波段,并且已经在法国用作RFID系统。而CEPT/ERC和 ETSI 则在CEPT/ERC 70-03准则中将起指定为协调波段。
频段13.553–13.567 MHz 位于短波波段的中间。其传输特性使得其可以整天都可以达到横贯大陆的传播。这个范围一般用于范围要求非常广的无线电服务,比如新闻社和电信点对点服务(PTP)。
这个范围内的其他ISM 应用,除RFID之外,主要还有远程控制系统,远程控制模型,试验无限设备和寻呼系统。
频段26.565–27.405MHz分配给美国、加拿大和欧洲的CB 广播。无须注册和免费的无线电系统,功率小于4 Watts 的私人无线电爱好者可以使用,传输可超过30 km。
这个频段的ISM 应用除RFID之外,还有电疗器械(医用设备)、高频焊接设备(工业应用)、远程控制模型和寻呼系统。
当安装27 MHz RFID 系统时,必须特别注意附近的高频工业焊接设备。HF 焊接设备可产生很高的场强,可以干扰附近的RFID 系统的运行。当为医院规划27 MHz RFID 系统时,也要考虑电疗设备的因素。
范围40.660–40.700 MHz 位于VHF 频段的低端。其传输特性仅限于地面波,所以由于建筑物和其他障碍所产生的衰减很明显。这个频段邻近的其他ISM 范围主要由移动商业无线电系统(森林,高速公路管理等) 以及电视广播的(VHF 频段 I)。
这个频段主要的ISM 应用包括遥感和远程控制应用。这个范围目前很少用作RFID 系统。 这个频段所能达到的有效范围要远远低于更低的频段所能达到的范围,因为这个频段的7.5 m 波长不适合构造小巧和便宜的backscatter transponders。
这个频段430.000–440.000 MHz 主要分配给全球的业务无线电爱好者。无线电爱好者使用这个频段来进行声音和数据的传输以及通过中继广播站和卫星的通信。
UHF 频段的传输特性近似于光。当遇到建筑物和其他障碍时将会出现衰减和反射。依赖于操作方法和发射功率,无线电爱好者使用的系统可能达到的范围在30 到300 km之间。使用卫星也可以达到全球连接。
ISM 范围433.050–434.790 MHz 主要位于业务爱好者使用频段的中部,并且被各种各样的应用所占据。包括,内部通话器,遥感发射器,无绳电话,短距离对讲机,车库自动进入发射器等等。所幸的是,这个频段的干扰倒是很少见。
频段868–870 MHz 在欧洲主要用作短距离设备(SRD) ,因此在 CEPT的43个成员国中都可以用作RFID系统。
亚太地区的国家也正在考虑通过这个频率为SRD频率。.
这个频段在欧洲未作为ISM 应用。欧洲之外(美国和澳洲) 频段888–889 MHz 和902–928 MHz 是可用作后向散射式RFID系统的。
其邻近频段主要由D-net 电话和CT1+ 和 CT2 标准的无绳电话所占据。
ISM 频段2.400–2.4835 GHz 部分和业余无线电爱好者使用的频率和电波探测服务是用的频率相重叠。这一段的UHF 频率和更高的SHF 频率的传播特性几乎相当于光。建筑物和其他障碍将是很好的反射体,并且产生非常强的衰减。
除了backscatter RFID 系统之外,主要的ISM 应用包括遥感发射器和PC WLAN 系统。
ISM 频段5.725–5.875 GHz 部分和无线电爱好者使用频率和电波探测服务的频率相重叠。
这一频段的主要服务包括运动传感器(用作防盗等),非接触式卫生间干手器,以及RFID系统。
ISM 频段24.00–24.25 GHz 部分和业务爱好者使用频率,电波探测服务和卫星地球资源服务的频率重叠。
目前还没有RFID系统运行于此频段。
新的CEPT 协调文档'ERC Recommendation 70-03 relating to the use of short range devices (SRD)' (ERC, 2002) 开始作为CEPT 44个成员国的国家法令。旧的协调文档则被新的欧洲协调文档代替2002版的REC 70-03 也包括在CEPT成员国中对特殊应用和频率的国家限制的综合注解 (REC 70-03, Appendix 3-National Restrictions)。
REC 70-03 定义了频段、功率等级和短波设备的发射期间。在使用R&TTE Directive 1999/5/EC)的CEPT 成员国中,那些符合第12条 (CE 标识) 和第 7.2条 的设备将不用重新申请执照。
REC 70-03 主要处理总共13 中不同的不同频段的短距离设备,具体在各自的附录中描述,包括:

REC 70-03 也引用了ETSI 标准(如EN 300 330),后者包含测量和测试指南。
此标准是由ETSI (European Telecommunications Standards Institute) 负责,主要向国家电信当局提供无线电和电信管理的基本规则的制定。
ETSI EN 300 330 标准形成了European licensing regulations for inductive radio system 的基础:
ETSI EN 300 330: 'Electromagnetic compatibility and Radio spectrum Matters (ERM); Short Range Devices (SRD); Radio equipment in the frequency range 9 kHz to 25 MHz and inductive loop systems in the frequency range 9 kHz to 30 MHz'.
Part 1: 'Technical characteristics and test methods'
Part 2: 'Harmonized EN under article 3.2 of the R&TTE Directive'
除了感应式无线电系统之外, EN 300330 还涉及了Electronic Article Surveillance (商店用), 报警系统,遥感发射器,短距离遥控系统等。
除了CEPT 成员国之外,这个规则还被亚洲和美洲的一些国家用作RFID 系统能够许可证的管理。
标准 EN 300 220, 题为'Radio Equipment and Systems (RES); Short range devices, Technical characteristics and test methods for radio equipment to be used in the 25 MHz to 1000 MHz frequency range with power levels ranging up to 500 mW', 提供了关于低功率无线电系统的许可法规基础,它有两部分组成: EN 300 220-1 针对发射器和其功率特性, EN 300 220-2定义接受器的特性。
EN 300 220 将设备分为4类— 从Class I到Class IV 。这个标准包括ISM 波段和整个频段的低功率设备。
RFID 系统在本标准中并没有明确提及。
EN 300 440 标准,'Radio Equipment and Systems (RES); Short range devices, technical characteristics and test methods for radio equipment to be used in the 1 GHz to 25 GHz frequency range with power levels ranging up to 500 mW,' 则形成了低功率无线电系统的欧洲国家法规的基础。EN 300 440 将设备分类为3种,— classes I 到 III。
使用backscatter transponders 的RFID 系统被分为class II系统。进一步的细节则由CEPT recommendation T/R 60-01 文本:'Low power radiolocation equipment for detecting movement and for alert' (EAS) 和T/R 22-04文本 'Harmonisation of frequency bands for Road Transport Information Systems (RTI)' (toll systems, freight identification)进行管理。
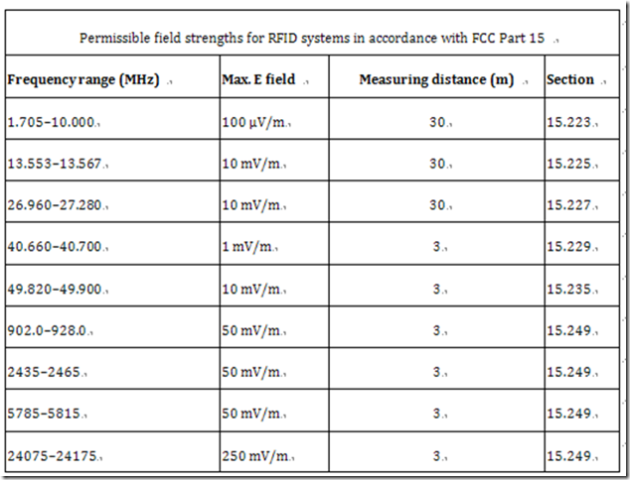
在美国,RFID 系统必须根据'FCC Part l5'取得许可证。这个法规涉及了频率范围从9 kHz 到大于64 GHz 和由低和中等功率发射器故意产生的电磁场和由广播和电视接收机以及计算机等设备非故意产生的电磁波。低功率发射器的目录包括了各种各样的应用,例如无绳电话,遥感发射器,校园广播站,玩具遥控设备和车门遥控设备等。感应耦合或者后向散射式RFID 系统在FCC法规中并没有明确提及,但因其频段和低功率特性,自然包含在法规管制之下。
下表 列出了对RFID 系统很重要的频段。其他频段中适用于RFID系统的许可限制值则在接下的表中。 应该注意到,和欧洲的ETS 300 330不同,Reader的最大许可场强值主要是通过电场强度E 定义的。
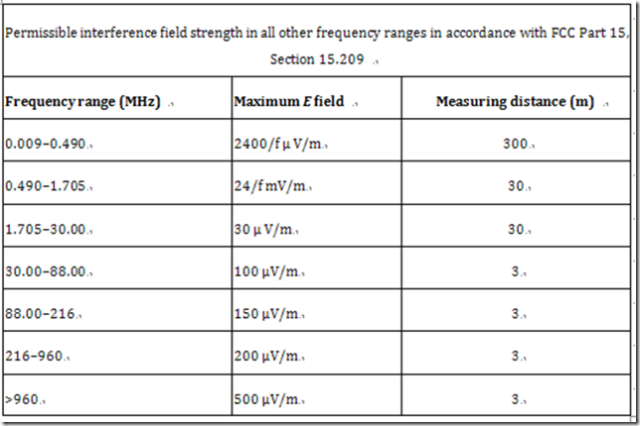
6.4 中国对RFID的无线电频率管理
实际上RFID技术在中国已经存在很多年,123K赫兹和23.5兆赫兹频率的应用在我国已经得到了广泛的应用。这些主要是常规的非接触式IC卡的应用范围。
对于目前最受关注的主要用于物流和跟踪的UHF频段,即800M-900MHz频段,目前正在积极研究中。在这个频段,美国是902M-928MHz,日本是两个一个在952-954MHz,今后会发展到950-956MHz,中国香港地区是865-868MHz,以及825-828MHz。
由于在800M-900MHz频段上,每个国家使用和分布的情况不一样,功率限制和频谱框架图也不一样。因为各个国家和 地区都是根据各自的无线电业务使用情况,制定出相关的频率规划和标准的。中国还没有正式发布应用于RFID的频段规划,其原是是因为中国在800M-900MHz频段都有了频率规划,而且非常拥挤,包括公共通讯、数据通讯、点对点通讯、立体声广播传输、无线电定位和航空无线电导航等等业务。基本上没有空闲的频率给RFID使用。如果要在此频段,则必须正在使用的无线电业务中调整出几兆赫兹带宽的赫兹给RFID使用。
从2004年下半年开始,信息产业部无线电管理局就组织相关人员对这个频段RFID频率规划问题进行研究,完成了大量的理论分析、仿真试验工作,今年我们还在继续组织完善相关的理论分析、仿真实验和实际的电子兼容实验。据估计,可能会在860赫兹以下的频段。
(对于国内的RIFD频率部分的资料可能比较老了,读者可去查询最新进展。)
被动标签必须在某个地方有无线电发射器来对其进行供电,而它自己则必须有接收这些发射的接收器。甚至就连主动标签一般还是需要与连接到网络的某种形式的发射器连络。在 RFID 领域中,这一发射器/ 网络端点通常被称为阅读器(Reader)。阅读器通常位于一个 RFID 系统的标签和事件过滤器之间。知道如何与标签通信,如何从读取动作中创建底层事件,以及如何发送这些事件给一个事件过滤器,这就是阅读器的职责。
我们可以从二个视角来描述阅读器。首先是阅读器的物理组件: 你可以在电路板上找到的东西。其次则是阅读器的逻辑部份。
我们还会继续说明RFID 打印机和用具。
|因为阅读器与标签使用射频进行通信,所以任何 RFID 都必须有一个或多个天线。并且因为阅读器必须要与某些其他的设备或者服务器通信,所以它必须有某种类型的网络接口。通常的网络接口的例子为 10 BaseT 或 100 BaseT 以太网接口,或者 RS 232 或 RS 485 串行接口。一些阅读器甚至有 Bluetooth 或无线以太网接口。最后,为了实现通信协议和控制发射器,每个阅读器必须有微控制器或者微型处理器。下图展示了RFID 阅读器的实际成份。
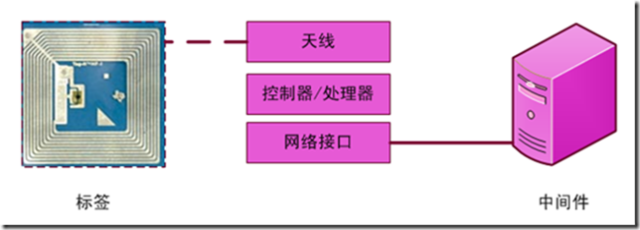
图表 5‑1 READER的物理组件
虽然天线自己在概念上很简单,但是工程师一直在努力使其能够在低能量的情况下获得更好的接收性能,以及使天线工作在一些特殊的环境中。一些阅读器只有一个或者二个天线,并且和阅读器自己封装在一起;其他一些阅读器则可能在远程位置安装许多外接天线。阅读器所能控制的天线的数量的主要限制在于连接阅读器的发射器和接收器与天线之间的电缆的信号损失。 大多数安装都把天线安装在离阅读器2米左右的距离,当然更远些也是可以的。
一些阅读器使用一个天线来传输和另一个用来接收。在这种配置结构中,标签针对阅读器的场的运动方向特别重要。如果发射天线位于接收天线的“靠前些”,接收天线将会花更长的时间来接收来自标签的信号。如果天线布置与此相反,标签将会花更少的事件来激励,并且位于接收天线的范围之内。下图表示了两个具有标签的包装盒在一条传送带上依次经过第一个传输 (TX) 天线和一个接收 (RX) 天线。
箭头指出了传送带上的运动方向。当它经过 TX 天线的时候,每个盒子上的标签便被激励,然后它们开始广播响应。因为RX要稍微远离传送带一些,因此RX 天线将要比其应该的时间更长些来接收到响应,如果二个天线颠倒,则意谓有标签将会有更多的被读取的机会。
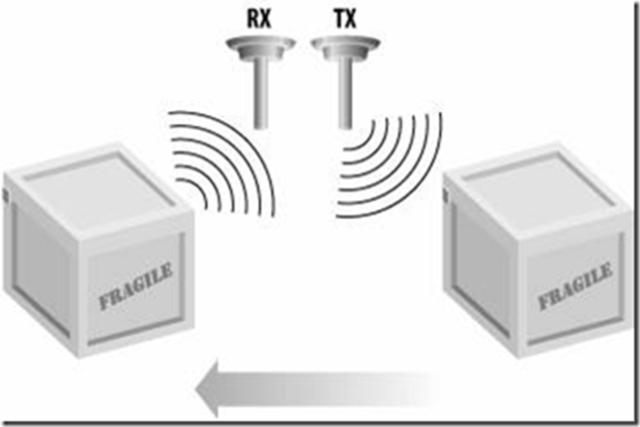
图表 5‑2 接收和发射天线的最佳布置
控制一个阅读器的计算装置的复杂程度可能从单芯片的处理器到能够运行网络操作系统和允许存储大量数据在硬盘上的完整的微型计算机。前者可以嵌入到一些移动设备之中。控制器负责控制阅读器一端的标签协议,以及构成一个事件的标签读取信息何时被传送到网络中。阅读器控制器也负责管理阅读器协议中的阅读器一侧的相关处理。
如果阅读器不告诉任何人相关的事件信息,读取标签并且识别事件并没有多少用处。阅读器通过多种网络接口与其他装置进行通信。过去,大多数的 RFID 阅读器都具有串行接口RS 232 或 RS 422(点对点,双绞线) 或 RS 485 (可寻址的,双绞线)。最近,越来越多的阅读器支持Ethernet,甚至有些已经开始支持内建的无线以太网络, Bluetooth 和ZigBee 了。
图表 5‑3 Symbol的X480阅读器,具有以太网、USB以及串行接口。左边是天线接口
在 RFID 阅读器的控制器中,我们可以想像有四个处理不同职责的单独的子系统。下图就展示了阅读器的逻辑组件图,供参考。
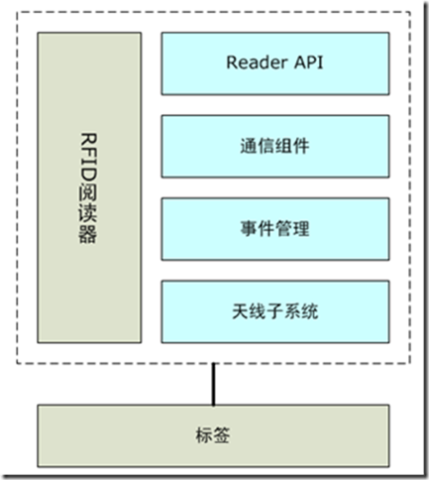
图表 5‑4 READER的逻辑组件
每个阅读器都会呈现一个允许其他应用来请求标签数据、监控阅读器状态或者控制诸如电源水平和当前之建设定之类的应用编程接口。这个组件最关心的是创建发送到RFID中间件的消息以及解析来自于RFID中间件的消息。API可以是同步的,也可以是非同步的。
通信子系统主要处理阅读器可以用来与中间件通信的传输协议之上的通信细节。这也是具体实现诸如Bluetooth、Ethernet、或者专用鞋以来传输组成API的消息的组件。
当一个阅读器感知到一个标签的时候,我们称其为一个“发现”。一个不同于先前发现的另一次发现被称为一个“事件”。将这些事件进行清理称为是“事件过滤”。事件管理子系统就是定义什么类型的发现被视为事件,而哪些事件被认为足够有意义而必须立即报告到在网络上的外部应用。随着阅读器越来越智能,它们将会能够在这一级应用更复杂的处理,以减少网络流量。
天线子系统由使 RFID 阅读器能够质询 RFID 标签且控制实际的天线的接口和逻辑所组成。 这些组件要实现标签协议中的一些部分,并且与阅读器中的某些电路一起实现与标签的空中接口协议。
大多数常用的应用场合都使用智能标签(Label)。我们前面说过,智能标签就是在纸质标签的夹层中插入RFID 电子标签。这个种标签的主要好处是,对于用户,除了编码RFID 标签的身份之外,还能在纸张标签上面打印条形码和/或人可读的本文。
RFID 打印机就是能够打印可读信息同时也能够编码RFID标签的设备。记住,一个阅读器也能够 “写”一个可写的标签,因此一个 RFID 阅读器和一台 RFID 打印机之间的主要不同与对编码标签的能力无关;不同之处在于后者同时还是一台激光或者喷墨打印机。
对于小规模的应用,一个操作员可以手动应用智能标签,但是大规模的应用需要所谓的“打印-使用”的自动装置。这些特殊的装置包含一个RFID 阅读器,一台打印机,以及一个能够将标签自动粘贴到经过的物品( 通常是盒子)的自动化系统。 方法可能是使用一种空气臂将打印和编码好的标签粘贴到盒子上。因为编码标签可能会失败必须被丢弃然后重新更换,因此这些装置通常都会成对或者更多地在一起安装。目前,一般这样的设备或者系统可以在一分钟编码和粘贴30 到 60个标签。然而,在第2代(Gen2)标签开始使用的时候,这个速度可成倍上升。
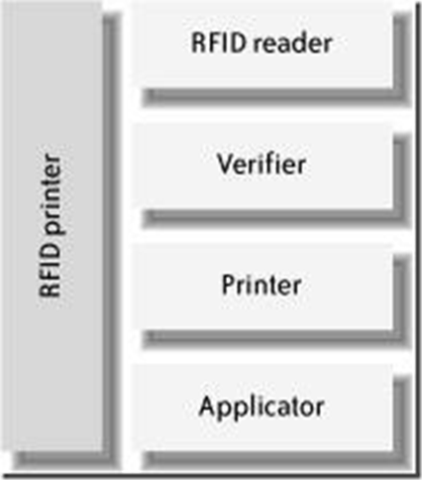
图表 5‑5 PRINT-AND-APPLY 设备的部件

图表 5‑6 Zebra公司的RFID标签打印机
RFID 即打即贴设备的厂商几乎都不是RFID Reader的厂商,因此一般来说,它们都会和通常的Reader场上进行合作。即打即贴设备通常将Reader API封装到自己的API中,然后提供一种方式来访问Reader API。
虽然即打即贴 RFID 设备上的打印机与其他条形码打印机并无什么本质不同,但和办公室用的打印机相比还是不同的。这些打印机通常都是用成卷的标签,以便能够打印一个面,然后将另一面用作粘贴之用。所有的这些打印机都能够按照描述适当的标签布局的型板来打印标签。 比如,某个模板会让整个两英寸宽的条形码占据标签的下部,而顶部则打印一个公司标记。它也可能设定人可读的零配件号码,序列号和公司名字字段的位置。
即打即用设备通常包含一个RFID验证步骤和一个条形码验证步骤。 典型地, RFID 校验是通过编码该标签的同一个Reader进行,而条形码校验则是通过打印机旁边的光学扫描器运行。
这类设备一般使用某种方式将打印和编码好的,并且经过较严的标签粘贴到被标记的物品之上。但过程中需要注意静电防护的问题。
阅读器,像标签一样,也有不同的方式,并且没有一个Reader能够适合和满足所有的场合。Reader可能具有许多不同的形状和大小,支持不同的协议,并且通常必须遵照管制的要求,即意谓着一个特定的Reader可能是用于某个地区,而不适合于另一个地区。
Readers 的大小从一个英寸到一台老式台式计算机那么大都有。Reader也可以嵌入到一些手持设备甚至移动电话之中。它们也可以被固定到一个防爆机架上(固定式)。通过与天线布置的设计和安排方案,可以形成不同的Reader系统。
5.4.2 标准和协议
Reader通常遵循与他们所读取的标签相同的标准和规范。但是有些reader支持不止一种协议。有些则只针对专门厂商的标签。
5.4.3 区域差别
每个地区都有不同的无线电管制规定,包括发射功率、频率范围等等。比如, EPC UHF reader在美国是阅读915 MHz 的标签,在欧洲则是869 MHz 。因此,必须仔细了解该地区的频率管制的详细规定,以选择或者配置可用的Reader。
5.5 阅读器、天线和阅读器系统
阅读器和天线必须被安装好之后才能使用。因为通过RFID,我们试图感应现实物理世纪的特质,特定物品在物理世界中的出现或者缺席全在于安装的实际情况。因为这一个原因,每个感应器的安装是不同的。可能的变化是无穷的,但是讨论RFID 的一些原型应用则能帮助你理解各种安装情形。这些种类可能包括门户系统,隧道,手持式,堆高机阅读器和智能货架。
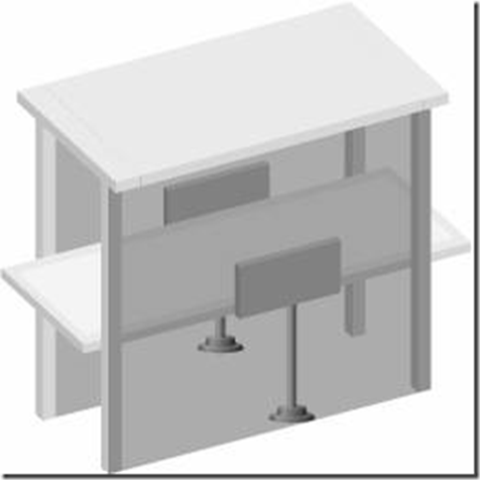
这里,词语“Portal”意味着门口或者入口,而 RFID 门闸则是天线的一种安排方式。通过这种设计,阅读器能够识别通过(进入或者离开)一个门闸的被标记的物品。这是仓库的一种通常的装备,一般安装在物品进入或者离开的装卸台的地方。它也用来识别物品在一个工厂的不同区域之间的移动。门闸系统也可以是能够移动的装置;在这种应用环境下,阅读器和天线被内置到一个具有轮子的框架上,可以被推着沿轨道或者通道移动。这一般用作装卸识别,或者材料跟踪。下图是一个典型的门闸系统。

图表 5‑7 RFID PORTAL
隧道是一个包围型的装置,通常围着一条传送带,天线 ( 有时甚至阅读器)都可能被安装在其中。隧道类似于小型的门闸,但其好处是能够形成RF的屏蔽效应,不至于干扰附近的阅读器和天线的运作。这可以用在集配线或者包装传送带上,阅读器识别每个通过该隧道的被标识物品。下图是一个传送装置上的典型隧道示意。
图表 5‑8 TUNNEL
整合了天线、控制器和通信组件的手持式阅读器能够允许操作员以方便与被标识物品的场合或者位置对其进行扫描识别。手持式 RFID 阅读器的使用与手持式条形码阅读器的使用非常相似的。并不令人惊讶,大部份这些 RFID 手持式阅读器的厂商同时也生产条形码扫描器。它们可能通过无线以太网络、射频调制解调器沟通与网络进行沟通。实际上大多数手持设备,是一个具有足够处理能力的计算机。下图是Symbol提供的一个手持式阅读设备。

图表 5‑9 带阅读器的手持设备
5.5.4 叉车阅读器
叉车(堆高机)也可以携带 RFID 阅读器,就象一个携带一个手持式阅读器的相同情形。叉车制造商开始提供 RFID 阅读器作为他们产品的可选择部件,正如他们过去已经提供的条形码阅读器或者操作员终端什么的。在叉车上添加这种阅读器设备的缺点是可靠性,以及在此类设备上加装阅读器的管制。下图 展示了一个叉车如何加装一个阅读器。
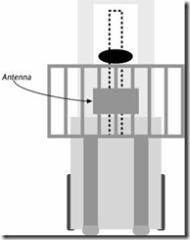
图表 5‑10 带阅读器的叉车示意图
在我们继续前进并且牺牲我们的先前努力,丢掉前面的每个技术,并且向失败举起我们的双手之前,还有一条路能够让我们能够利用从学来的宝贵经验,并且仍然远离偶然架构—那就是采用ESB。 集成的最佳实践,已经经过对集成Broker的经验被精炼,如今还可以结合建立于XML、Web Services、可靠的异步消息、以及分布式的ESB集成组件之上的基于标准的架构来一起使用。 他们一起形成一个高度分布的、松散耦合的集成架构,以提供集成Broker的所有主要功能,却没有其所有的障壁。
远离偶然架构并且使用 ESB重构到的一个统一的和一致的集成骨干,涉及到下面小结描述的步骤。
虽然ESB 确实能够传送许多类型的数据格式,但是采用XML作为应用间交换数据的手段 (图 2-2),如同已经被用在一些传统的 EAI 方式中一样,可以由很多好处。我们将会在第 4 章中看到,使用XML可以一劳永逸地隔绝全局的数据格式和接口的变更和偶然架构本身。ESB可以进一步通过检查XML消息的内容,并且控制其向何处提交,有时候还可以改变提交路径来包括可能会修改和增加数据的附加服务,一次来促进业务处理。
图表 2‑2 ESB 使用XML来作为应用间共享数据的方式
2.3.2 采用Web ervices并实现 SOA
以 SOA 的方式来思考和规划在向 ESB重构的一个基本步骤。如图 2-3 所示,服务级接口的引入在提供了一个公共抽象层来创建接口和实现之间的分离。这样就通过使用一种通用的接口定义机制,比如Web Services描述语言(WSDL),来减轻了由细粒度服务接口组成的复合业务流程定义的构造的难度。
图表 2‑3 Web 服务和 SOA 提供了一个隔离接口和实现的通用抽象层
虽然服务级接口的抽象是正确方向上的一步,结果仍然是一个路由逻辑密合于应用之内的硬连接 ( 注意在图 2-3 中,“流程逻辑”仍然黏附于应用)。Web Services中的传统智慧已经模仿了客户/服务器模式。甚至在一个Web Services分布式网络中,一个应用总是另一个 “客户”。范例用法仍然需要抽象层也包括胶水代码,比如说“调用服务X上的方法a,然后调用服务Y上的方法 b()….”诸如此类。。
Web Services实现中所确实的东西是将流程路由逻辑从接口定义和应用逻辑中分离出来观念。如图 2-4所示,ESB 就提供了那种隔离,并且仍然完全利用SOA。
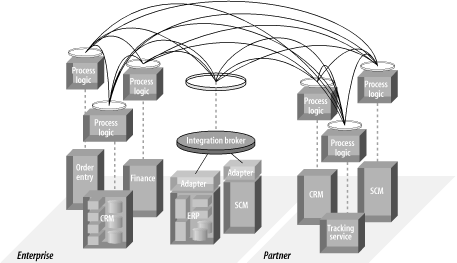
图表 2‑4 ESB 将业务流程的路由逻辑从接口定义和应用实现中分离出来
通过分离接口定义和流程路由逻辑,我们已经开始看到ESB 形式的总线层(图 2-5)。通过将流程业务路由逻辑和接口定义放入总线层之内,应用能够继续自己集中于实现逻辑。 我们在第 1 章中看到过,ESB 被实际上区分为多个功能层。它为应用间的可靠的、异步的、基于消息的通信提供了一种坚固的底板。也是在这里,流程路由通过基于检查消息中的XML内容来附加的条件决策点,从而变得具具智能。这个智能路由是被可管理地定义的、可以被修改、并且可以加上增值服务,比如补充数据变换功能。ESB 提供了一个可扩展的集成服务网络,并且可以无限伸展,同时仍然可以以逐渐增加的方式进行构建
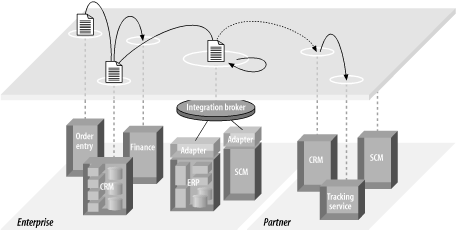
图表 2‑5 ESB 可靠地连接和协调SOA 的服务之间的交互
如果我们根据transponder 提供的信息和数据处理范围,以及数据内存的大小对RFID 系统进行分类,则又可以的得到另一个分类体系。这种方式的端点分别称为低端和高端系统。
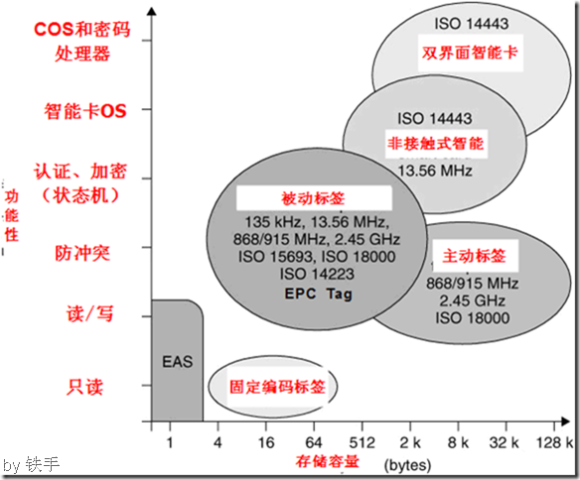
图表 4‑12 RFID 系统分为中端、低端和高端系统
4.3.1 低端系统(Low-end system)
EAS 系统(Electronic Article Surveillance systems) 使用了最低端的low-end 系统。这些系统仅仅使用最简单的物理效应通过检测单元的reader来检查transponder 的可能出现。
带芯片的只读transponder 也归入低端系统。这些transponder都常具有一个永久编码的表示多个字节组成的唯一序列号的数据。如果一个只读transponder被放入一个reader的HF 场中, transponder 就会连续的广播其自身的序列号。对reader 来说是不能够寻址只读transponder的 — 这里只有从transponder 到reader的单向数据流。在实际运行的只读系统中,也有必要确保仅有一个transponder 处在reader的质询区,否则如果有多个transponders 同时发射其数据,将造成冲突。reader 将不能够监测到transponder。尽管有此限制,只读transponders 非常适合于那些只需要读取一个唯一编号的应用场合。因为只读transponder的功能简单,芯片面积可以最小化,因此可以达到低功耗和低成本。
只读系统可以运行于所有适用于RFID系统的频率。由于芯片的低功耗有效范围通常可以达到很远的距离。
只读系统通常可以用于之需要很少的数据读取或者替代条形码系统的场合。例如,生产流程的控制,货盘的标识,容器和气瓶的标识(ISO 18000),以及动物的标识 (ISO 11785)。
4.3.2 中端系统
中端系统是各种具有科协数据存储体的系统,这意味着这个区域具有最多的变体。内存容量从几bytes 到超过100 Kbyte 的EEPROM (被动transponder) 或 SRAM (主动transponder)。这些transponder能够处理简单的reader 命令来在永久编码的状态机中有选择的读取或者写入数据。通常, transponders 也支持防冲突手段(anticollision procedure),以便 多个位于reader质询区的transponders 可以同时存在而不会干扰对方,并且reader也可以对他们进行有选择的寻址。
密码学过程,比如transponder 和reader之间的认证,以及数据流加密也常用在这些系统中。这些系统也通常可以工作在所有RFID 频段。
4.3.3 高端系统
高端系统(high-end system)由具有微处理器和职能卡操作系统的系统组成。微处理器的使用使得这些系统可以采用比固化的状态机的复杂逻辑更加高级的加密和认证算法。这个领域之高端的就是现代双接口智能卡(dual interface smart cards ),它还具有一个专门用作安全的密码学协处理器。协处理器的使用减少了大量的计算时间,使得其可以使用在对数据传输加密具有高安全要求的场合,比如电子钱包,公交票务等。
高端系统几乎都运行在13.56 MHz频率。transponder 和reader之间的数据传输描述在ISO 14443。
4.4 RFID 系统的选择原则
近年来RFID的应用高潮迭现,从公交卡中的非接触式IC卡的大规模使用到零售系统使用的低端系统和物流系统中使用的终端系统。并且各种可能的应用领域还在不断的开发。
市场上有各种不同的RFID 系统。各种不同的系统,其技术参数可能根据不同的应用需要进行优化。但是这些应用领域的技术要求会出现交叠,这样选择适合的系统并不是一件简单的事情。但是根据不同的应用要求,需要考虑的4个主要因素和要求就是:
这一节将详细讨论,今天各个企业应用怎样进行集成、或者怎样没有集成。还包括对今天很多组织中很流行的集成方式:偶然架构的讨论。
在过去二十年以来,无数分布式计算模型一一登场:包括 DCE、CORBA、DCOM、MOM、 EAI Broker、J2EE、Web Services、.NET。 然而,迹象表明,不管采用何种技术,只有很少数企业的应用时很好连通的。按照来自 Gartner 公司的一个研究报告[1],这个数字少于10%。
关于应用的连通性,其他的统计数结果更令人吃惊,— 只有 15% 的应用的集成采用了正式的集成中间件。其余则使用 ETL 和批量文件传输技术,其主要以手工编写的脚本和其他定制方案为基础。关于 ETL 和批量文件传输的更多信息,以及他们相关的问题,我们在第9章讨论。
Gartner 15% 统计值提供一个关于当今的集成状态的一个令人深思的数据。那么其他85% 的应用是如何连接的呢? 一种在今天的企业中普遍存在的情形,我将其称为是“偶然架构”。所谓偶然架构就是没有人公开宣布创造的;相反,是多年积累的一种“就事论事”的解决方案。在一个偶然架构中,公司的应用被永远锁定在一个不灵活的刚性基础架构之上。然后他们又被视为是信息“地牢”,因为集成基础设施不能适应新的业务需求。 (图 2-1)
大多数集成尝试都从某个深思熟虑的设计开始,但是经过一段时间后,其他的部分好像都各就各位地“集成”了,但是手工编写的代码却早已飘移出原来的内容之外。经过逐渐进行的螺栓和补丁,所谓整合的系统已经失去了其原来的设计完整性,尤其是如果系统是被很多的人来维护的,而他们对最初的设计意图可能没有很好地沟通。事实上,这种“就事论事”的方法将完全失去集成的一致性,因为工程师总将是“只是做一点点修改”作为解决问题的权益之计。最后甚至对找出那些地方做了修改都变得非常困难,更不要说要理解这些结果导致了那些方面的副作用影响。在一个部署系统中,这可能会对你的业务造成损失惨重的悲惨结果。
对集成遵守标准能够为你创建一个针对所期望功能的基线来遵从。如果基础设施是专有的, 不基于标准的,那么随时间变化保持计划的设计和指导原则就变成棘手问题。虽然也可以构造专有的平台并且变通规则,但是这通常又导致更加“多样性”的后果,结果更加锁定于其上。然而,你应该记住的是简单地遵守标准并不必然地阻止你构建一个偶然架构。
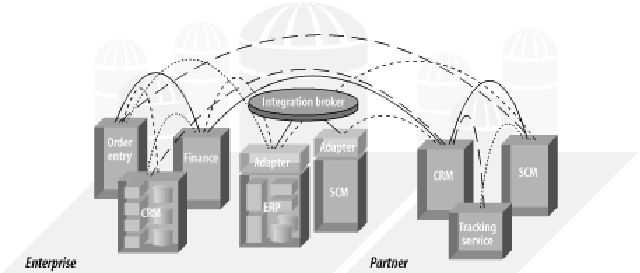
图表 2‑1 偶然架构将永远使公司的应用成为“信息发射井”
在偶然架构背后的技术是各不相同的。图 2-1中的实线、虚线和点划线表示了连接应用的不同技术。这些技术可能包括 FTP 文件传输、直接的socket连接 、专有的MOM、以及有时是 CORBA 或其他类型的远程过程调用(RPC) 机制。某些定向的点对点解决方案可能已经使用了XML信封定义,或者基于SOAP或者其他什么机制的技术,来为集成的应用之间承载数据。
图中间的集成Broker表示了在部门级的层次连接应用的一个岛屿。然而这并不意味着它能够连接任何事物。集成Broker通常只是结交给基础设施中的某一块,因此资金丰富的项目可能会取得适度的成功,但是它们再也不能与其它所承诺的部分进行很好的集成。
偶见架构表现为得到一个刚性的,不能对集成提供一致的、持久的基础设施。它不能如其应该达到的效果那样很好地解决你的组织性的问题。要改变偶然架构一直以来就是个挑战,因为点对点的解决方案的数量不断在增长。这通常也意谓着应用之间的互相依赖性是紧密耦合的。使应用中的数据的表现的修改意谓着你还必须修改共享该数据的其他所有应用。这就限制你快速地改变你的业务流程,以适应变化了的或者新的业务机会。这些紧密耦合的、硬连接的接口不仅仅是偶然架构的问题。因为控制流、业务应用之间的通信的编排被硬编码进应用本身之中,这进一步导致了复杂化。这些都增加了系统之间的紧密耦合和脆弱性,使变更业务流程更加困难,并且导致了厂商所定。
偶然架构的先天技术不足队组织中的人力协调问题具有推波助澜的作用。不管问题是紧密耦合的接口还是硬编码的流程编排,要想回头或者对其进行较大的翻新改造简直是一件恐怖的事情。这经常需要安排大量的会议,和属于不同项目的不同的开发组的人们开会,就紧紧对要做什么以及何时做这类的问题达成一致。如果应用,以及他们分属的开发项目组,分别处于不同的地理位置和时间区,应用改变所需的协调问题则会变得更加困难。
有时某些应用程序被视为“遗留”系统,对他们你是不愿意或不能够对其进行多少修改,因为它们已经进入维护模式。我们通常说,“遗留系统”的一个定义就是那些你昨天刚安装的系统。即使你对自己开发的应用具有完全的访问和源代码的控制权,当开发人员继续进行其他项目或离开公司的时候,对其进行修改也是非常困难的。我们将会在第 4 章中看到, ESB 大大地减少了随时间变化,修改数据模式和格式所带来的影响。
即使你已经对跟踪和修改应用数据及其接口建立了良好的公司实践,偶然架构仍然还有其他缺点。使用不同的连接技术意谓着安全模型可能是混杂的,所以没有确定的方式来建立和执行公司级的安全策略。 对插入新的应用没有一致的 API可以依赖,而且没有基础来在棋上构建公司关于集成的最佳实践。最近与一些领导的专家进行了交流,总结了偶然架构的下列各项问题:
应用之间的通信或许能得益于异步的消息的可靠性。如果一个大型业务流程中的某两个应用之间的通信连接失败,整个业务流程可能会事务性地返回或者重启。我们将会在第5章学到更多有关松散耦合的、异步的可靠消息的更多内容。
不管你是否你已经有了一个预先的性能规划并且试图分析一个现有的性能问题,由于偶然架构的许许多多的子系统和他们各自的运行特征,这个工作是极其困难的。通常的做法是采用混杂的、“投入资源到其中,直到它能正确运行”式的解决方法,这将造成磁盘、处理器、内存等上面的过度开支。
没有哪个单一方法能够提供充分的诊断和报告能力。 意外架构需要很多具有很高能力的维护人员围着所有有缺陷得生产系统转,这将导致整体拥有成本 (TCO)的急剧上升。各部分实现的方式差异越大,在其失效时需要用来解决它们的问题的专家经验就越宽。另外,建立一个基线来描述期望的正确行为也是一个挑战。
没有任何方式能够保证这个泥潭中的所有组建都能够满足你的关于可接受的冗余、弹性和容错度的定义。这意谓着要为依赖于后段系统的新功能定义可达到的服务级别协议 (SLAs) 是很困难的。
如果你的系统携带又能够收费的帐单数据 ( 比如电信),那么账单数据的利息就可以被丢失在偶然架构之中。因此,你可能会损失收入并且还一点都不知道。
没有一致的方法来监控和管理一个偶然架构。假定你的整合应用系统必须运行 24/7 ,而且你的职员负责关注运行监控工具,并且做出纠正。这些工具将不会以相同的方式工作,那么在无数不同的小方案的基础上进行培训 ( 和再培训) 将是非常昂贵的事情。简单地安装企业级的运行管理工具并不能自动地将自省能力提供给集成基础设施,并且偶然架构通常并不能提供所有可能需要的控制点。
总而言之,偶然架构表现为一种刚性的、高成本的基础设施,并且不能满足你的组织变更的需要,还要承受以下缺点的痛苦:
- 紧密耦合的、易碎的、对变更不灵活的
- 因为多个点对点解决方案导致的昂贵的维护负担
- 修改一个应用程序可能影响其他很多应用
- 路由逻辑是硬编码到应用程序之中的
- 没有通用的安全模型;安全是混杂的
- 没有通用的 API(通常)
- 没有通用的通信协议
- 没有建立和构建最佳实践的通用基础
- 难以支持异步处理
- 不可靠
- 没有对应用和集成组件的健康监控和部署管理
如你所知,偶然架构的创建已经有些年头了,要替换和解决它并不是一蹴而就的事情。随着继承项目的需求的增加,解决方案应该更加柔性的、简单、以及运行便宜,而不是其他什么东西。偶然架构给了你的那些敏捷的竞争者得到好处,而你却不能够在一个合理的时间范围内实现新的业务机会。
你需要一个内聚的架构,面向实践、标准来解决着大量的问题。ESB 提供了架构和基础设施,并且使你能够逐个项目的基础上采用它。采用 ESB 并不是全有或全无,推倒重来式的方式。而是,你可以渐进式地采用它,同时还能利用你的现有资产-包括偶然架构和集成Broker,以一种“留下而分层”的方式。
2.2.3 ETL,批量传输,和 FTP
提取、转换、和载入 (ETL) 技术,比如 FTP 文件传输和每夜批处理式的集成在今天仍然是最流行的方法。
这通常涉及到将位于各个应用中的数据打包然后上传这样的操作。问题是有很大的可能在应用间的数据失去同步。一个失败的打包上传的处理程序可能要花上一天的时间。在京及和业务全球化的情况下,系统以24/7 的方式运行,再也没有了“夜晚”的概念,那你得批处理又该在何时执行呢?
其他问题也可能与每夜的批处理相关。因为批处理的反应期问题,在分析关键业务数据的时候,最好的情形是24 小时轮转时间。这一延迟可能严重地阻碍你对随时变化的业务事件进行反应的能力。
有时,一次跨越多个面向批处理系统的端对端处理处理甚至会花费一整个星期才能完成。处理从源头到目标的数据的总体潜伏反应期完全阻止了收集具有意义的,反应目前业务情形的数据的洞察力。比如,在供应链的场景中,这将导致你永远不知道你的库存的真实状态。
第 9 章将会呈现一个通过FTP进行成批传输的技术和业务意义的案例研究,并且会研究ESB如何能帮助你逃脱偶然架构的困境。
2.2.4 集成Broker
集线器-和-插头的集成Broker,或者EAI Broker,提供了偶然架构的替代。集成Broker是从上世纪90年代出现在,现在已经被植入到MOM主干或应用服务器平台之中。
集成Broker市场的一些公司包括:
- SeeBeyond
- IBM
- webMethods
- TIBCO
- Ascential (Mercator)
- BEA (more recently)
- Vitria
集成Broker能够使用一个集线器-和-插头架构帮助偶然架构提供应用之间的集中路由。此外,他们还允许使用业务程序管理 (BPM) 软件将业务流程从下层的集成代码中分离出来。到此为止,所有的都是好消息。
然而,对集成Broker方式也有缺点。一个集线器-和- 插头拓扑不允许对局部集成域之上进行局部控制。构建在一个集线器-和-插头拓扑之上的BPM 不能够建立跨越部门和业务单位的业务流程极其编排。 集成Broker也可能受限于下面的MOM不能越过物理的LAN网段和防火墙的能力限制。
有许多公司已经在其集成策略中采用了集线器-和-插头的集成Broker解决方案。 这些技术具有较高的成本,并且成功也值得怀疑。1990 年代后期的昂贵集成Broker项目已经取得了名义上的成功,但是将组织置于专有的集成域的井中。一项Forrester在2001 年十二月发布的研究报告[2] 展示了下列各项统计:
- 集成项目平均 20+ 个月才完成
- 少于 35% 的项目能够准时和在预算内完成
- 35% 的软件维护预算被花费在维护点对点应用连接之上
- 在 2003 年, 全球 3500 家企业平均期望花费六百四十万美元到集成项目上
这项研究还是在EAI 在它的最尖峰的时候进行的,而且几乎没有迹象表明这一数字在那时候起之后得到了改善。注意一年六百四十万美元是公司会在集成项目上花费的平均数的一个预测。当于这些公司的领导们交流这些问题的时候,我进行了一个一般性的求证。
照今天的预算标准来看,EAI Broker项目是很昂贵的。集成软件费用很贵的,通常单独对于软件许可费用,每个项目的价格范围就在从 $250,000 到一百万美元不等。这还不算一起的咨询服务组件,而这个组件的价格往往是软件许可费用的5到12倍。
集成Broker高昂的启动成本又被另一事实所进一步恶化,即从一个项目中学到的知识不能很好地转移到下一个项目。由于传统的 EAI Broker技术的专有特性,通常具有很陡峭的学习曲线,对于每个项目来说,有时候实6个月。要试图弥补这个负担的通常方式是聘请事前对专有技术经过培训的特别的顾问。当然,高特殊性=高价格。这是高昂咨询费用的一个重要组成部分( 另一个大的组成是技术安装、配置、部署、和管理的复杂性)。并且一旦项目完成,顾问就不见了。
集成项目的实现时间普遍是在 6-18 月之间。这意谓着。根据事前针对短期设定的标准、以及项目资金,实施时间吃掉了项目原本想要利用的策略性窗囗。
集成Broker的专有性质,以及高昂的咨询费用通常导致供应商锁定和重启后续项目的巨大成本。这意谓即便对于成功的项目,增长和伸展也是令人恐惧的。而且在你对你的供应商或者实现心生不满的时候,你也得面对到底是就目前的情况继续走下去,还是选择完全重新开始,雇用更多的咨询顾问或者投入另一个新的学习曲线之间左右为难。因为所有这些,一些IT组织通常留下了一些难以再集成到其他项目的“集成孤岛”。总而言之,集成Broker已经证明是偶然架构里面的老套技术,而并非它的解决方案。
当我们更详细地讨论集成Broker的时候,我们将看到导致这里所列的问题的技术屏障。另外,许许多多的非技术因素也导致了对采用ESB的需求的增长。
[1] [2]来自 Gartner 公司的统计,"集成Broker,应用服务器和 APSs,"10/2002.
[2] [3]来自 Forrester 研究的统计学,"减少集成费用,"12/2001.
最常见的构成形式称为是disk (coin), 即transponder位于一个圆形的ABS注塑的腔中,至今从几毫米到10 cm 左右。中间通常有一个紧固螺钉孔。材料上除了ABS注塑之外,还包括polystyrol 或者环氧树脂等已达到更大的温度适应范围。

图表 4‑1 盘状transponder的不同构造。
玻璃transponders 可用于将其植入动物皮下一边进行识别和定位等。

图表 4‑2 玻璃体glass 的transponder,用于动物识别等。
长度大约为12-32 mm 的玻璃管包含一个安装在PCB载体上的微芯片和一个平滑电源电流的芯片电容。而transponder 则围绕在一个铁酸盐芯棒之上,厚度大约为0.03 mm 。这些内部足见嵌在一个软的粘合剂上以达到较强的机械稳定性。
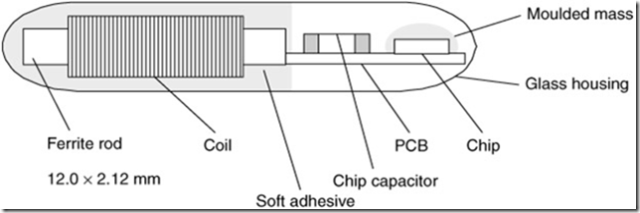
图表 4‑3 玻璃体transponder 的结构
塑料包装主要用于那些特别需要高度机械需要的场合。这种容器可以很容易的集成到其他产品中,比如 汽车防盗系统的车钥匙之中。 (图3-5)

图表 4‑4 塑料封装的Transponder
对于安装到金属表面的transponder 需要特殊构造。transponder coil 被绕在一个铁酸盐芯棒之上。transponder 芯片则安装在芯棒的反面并和transponder coil相接处。
为了取得充足的机械强度,抗震动和耐热性, transponder 芯片和芯棒都要使用环氧树脂铸入一个PPS 外壳中。用于工具的transponder 的外部尺寸和装配面积由ISO 69873 进行标准化。而用于气瓶的transponder 则需要不同的设计。展示了一个安装在金属表面的transponder 的机械轮廓。

图表 4‑5 采用ISO 69873标准格式的Transponder,用于工业自动化场合。
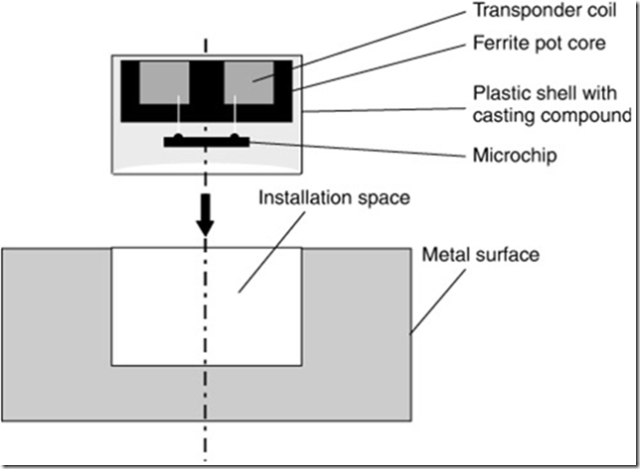
图表 4‑6 安装与金属表面的Transponder的机械轮廓图
Transponder 也可以集成到车辆防盗或者高安全门禁所需的机械钥匙之中。它们通常基于塑料封装的transponder并注入一个钥匙体中。
钥匙化的transponder设计被证明是一种门禁和物理安全访问的流行做法。

图表 4‑7 钥匙状的RFID访问控制系统
ID-1 格式在信用卡和电话卡中最为常见 (85.72 mm x 54.03 mm x 0.76 mm ± tolerances),也逐渐成为RFID系统中的非接触智能卡的常见形式。(Figure 2.11)。这种格式的主要优点是比较大的线圈区域,这样也增大了智能卡的适用范围。

图表 4‑8 非接触IC卡的轮廓
非接触智能卡在transponder 上叠片覆盖了四层PVC膜。每一层膜都使用100°C度以上的高温和高压进行烘烤以产生永久的结合。ID-1 格式的非接触智能卡还适合于进行广告传播和艺术装饰。
但是并不总是一定能够保证ISO 7810中为ID-1卡所规定的0.8 mm 的厚度。特殊需要的微波transponders 就要求更厚一些的设计,因为这种设计通常将transponder 插入两个PVC 外壳之中或者使用ABS注塑的方式进行封装。

图表 4‑9 塑料封套内的微波transponder
术语smart label 指的是象纸张一张薄的transponder 格式。在这种格式的transponder中, transponder coil 被用于使用丝网印刷或者蚀刻的仅0.1 mm 厚的塑料薄膜上。这样 foil通常被层压在纸张上并且表面涂上一层粘合剂。transponders 通常以卷状的不干胶的形式提供,以便可以适用于行李、包裹或者其他货物的形式。(Figures 2.14, 2.15)。因为不干胶标签可以很容易的重印,因此还可以很简单的将所存储的数据和标签表面的条形码项联系。

图表 4‑10 智能标签(Smart Label)
4.1.9 芯片上线圈
前面所述的构成格式中, transponder都是由一个充当天线的transponder coil 和一个transponder 芯片所组成。而transponder coil 则通过常规的方式绑定到transponder chip。

图表 4‑11 一种由安装在很薄的塑料薄片上的transponder线圈和transponder 芯片构成的智能标签
除了这些主要的设计,还存在一些应用特定的设计形式。比如用作比赛计时的“比赛信鸽transponder”。Transponder 还可以根据客户的需要进行定制。最好的形式可能是玻璃或者PP transponder。
RFID 系统的最重要的区分准则就是reader的工作频率,物理的耦合方法和系统范围。RFID 系统工作与很宽的不同的频段,从135 kHz 的长波到5.8 GHz 的微波。并使用电、磁以及电磁场作为物理耦合方法。最后,有效范围则从几mm到15 m。
对于很小的有效范围,通常小于1 cm的RFID系统,一般称为紧密耦合系统。为了运行, transponder 必须要插入reader 中或者接触其表面。紧密耦合系统一般使用电和磁场进行耦合,理论上可以工作于任何需要的频段,从DC 到30 MHz,因为transponder 的工作不依赖于场的辐射。紧密耦合可以得到充足的电源供应,所以即使微波和没有经过功耗优化的微处理器也可以工作。紧密耦合系统主要用于那些有严格安全需求,但是不需要太大范围的场合。比如电子门禁系统和非接触智能卡支付系统。紧密耦合系统采用ID-1 格式的非接触智能卡体系(ISO 10536)。但是,在市场中,其重要性正逐渐降低。
系统读写范围达到1 m 的RFID系统称为是远耦合系统。几乎所有远耦合系统都是基于磁感应耦合方式。 这些系统也被称为是inductive radio systems。 另外也有一些远耦合系统采用的是电容耦合方式。如今销售的RFID中至少90% 的是感应耦合系统。因此,市场中也有非常多种的这种系统存在。因此,也有一系列标准来规定用于各种应用的transponder 和reader 的技术参数,比如非接触smart card, 动物识别和工业自动化领域。它们还包括接近耦合(proximity coupling )(ISO 14443, contactless smart card) 和邻近耦合 (vicinity coupling system) (ISO 15693, smart label 和 contactless smart cards)。大多使用低于 135 kHz 或者 13.56 MHz 的频率作为发射频率。一些特殊的应用 (如 Eurobalise) 也运行在27.125 MHz上。
有效范围远大于1m的RFID系统称为远距离系统(long-range system)。所有远距离系统都在UHF 和 微波波段使用电磁波。绝大多数这种系统由于其物理原理都使用后向散射系统。也有一些在微波波段使用表面声波transponders 。所有这些系统都工作在UHF 频段的 868 MHz (Europe) 和915 MHz (USA) 以及微波频段2.5 GHz 和5.8 GHz。通常3 m 的范围可以使用被动(无电池)的后向散射式(backscatter) transponder达到,而15 m 或者更大的范围则可以使用主动(内置电池)的后向散射式transponder达到。但是,主动transponder的电池并不用来作为在transponder和reader之间的数据传输提供电力,而是为微芯片和所存储的数据的保持提供电源。至于两者之间的数据传输所需的电力则主要是由从reader 接受的电磁场的能源提供。
各种因素,包括技术和业务层面的,导致对新的集成方式的需要。有许多新的业务驱动因素,比如经济条件的改变、新的革命性的硬件技术比如射频识别标签 (RFID)的出现、法规管制的遵从,都预示着从业务视图来看,应用集成和数据共享都要发生重大变革。这些驱动好像与企业中目前的集成状态不一致子,并不象你所想的那样超前。当我们在这一章中详细研究的时候,大多数应该只是简单集成的项目不能很好集成,主要是由于缺乏能够广泛采用的一致的继承策略所致。
下面是影像着对更大规模的集成解决方案的需要的各种需要:
这些已经改变了IT花费的形式。经济因素导致IT部门主要集中于使事情能够与他们当前已经有的应用一起工作。
调查结果表明集成继续处于CIO的优先序列的最顶层。
Sarbanes-Oxley法案、PATRIOT法案、以及 FCC 法规都强迫公司建立一个必须的内部基础设施来比以前一样更加详细地跟踪、路由、监控、和获取业务数据。
STP 的目标是消除业务流程的无效率,比如数据的人工再输入、传真、纸面邮件、或者不必要的数据批量处理。在行业中,比如金融服务,这可以帮助达到几乎零反应期的交易处理。
被视为下一代条形码的革新, RFID 可能会产生大量的新型数据,然后这些数据需要被路由、变换、聚集,和处理。
不幸的是,公司的集成环境的目前状态在这些领域几乎没有取得什么进展。这又使得业界领袖不得不重新寻找更广泛的集成解决方案。而有关集成的目前状态的问题包括:
这阻碍了企业向自动化业务流程进步,然后由阻碍了其对不断变化的业务需求的快速反应。
偶然架构是一种一直使用的事实上的集成方式,其结果是没有连贯一致的公司级的集成策略。这表现为老是要留下点对点的集成、每一个都有其自己的连接和集成风格。偶然架构表现为不连贯的脆弱和刚性架构、并且不能经受集成环境的新的附加条件和变化。
使用FTP文件传输和每夜批处理的方式进行提取、变换和载入 (ETL) 的技术仍然是今天“集成”最流行的方法。 这些处理涉及到每夜对各种应用之上的数据进行打包上载的操作。由于这种做法的潜伏反应期和错误率,组织从来不会不真正拥有对它们的关键数据的好的快照。
上世纪90 年代后期,昂贵的集成Broker项目看似成功,但是给组织留下了大量专有的集成领域难以消化。
这章将会详细讨论这些因素。除此之外,它将会解释通过逐渐采用重构到ESB的好处,同时使用学习自集成Broker技术的最佳实践。
经济因素导致IT部门主要集中于使事情能够与他们当前已经有的应用一起工作。在Y2K之前,大多数公司都把它们的主要花费集中在准备应付 Y2K之上,包括购买打包的没有Y2K问题的应用。
后来的经济低迷时期,不管是否归结于后Y2K时代、Internet泡沫破灭时代、9/11、或者战争的不确定性,都已经导致了IT花费的急剧变化。这已经有对集成造成了特殊的冲击,不管是正面的还是负面的。IT预算和前 Y2K时代相比已经今非昔比。再也不会出现IT经理手中握着对集成Broker软件和服务的数百万美元预算,并且还要花费18-24个月的时间来等待项目结果这样的事情了。IT花费现在变得都要通过执行层,每一个项目都要经过仔细审查。只有对业务生存能力至关重要的项目才能得到资金。公司在每一个项目的基础上要求在3-6个月的时间片内得到切实的效果和投资回报,虽然他们仍然维持着改良整体运行效率的策略目标。
新的节俭时代并没有减少对业务流程的改进和对集成的需要。 业务层面的驱动仍然存在;减少业务周转时间需要,减少存货水平的需要,消除重复IT服务的需要,如此等等。
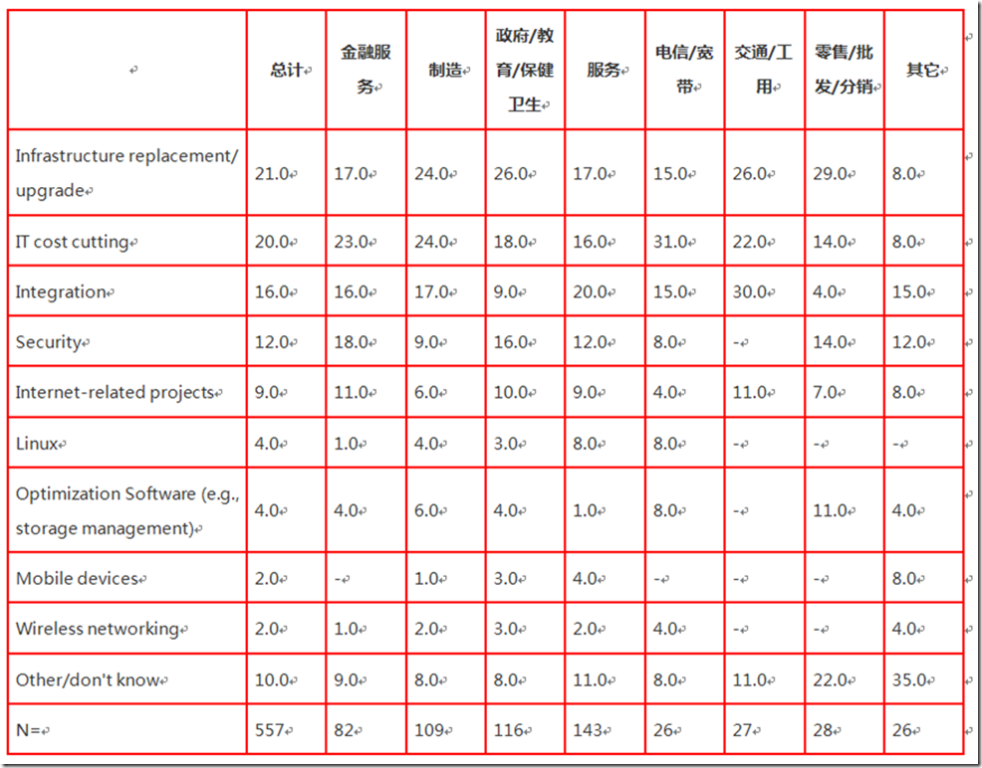
IDC的一分报告指出[1] 他们调查了557个CIO关于他们2004年事情的优先级。关于集成报告中这样说:
在2003年6月举行的IT和执行层交流会上,关于什么可以被称为“市场推动”趋势的问题,集成已经成为2004年IT规划中比安全具有更高优先级的事情。
报告同时指出,集成和安全分别占第三和第四位,在最高的CIO优先级的列表中,仅仅排在“基础设施替换/升级”和“IT费用削减”之后。
总体百分比则受到了有 21% 的“中间市场”公司将集成的重要性排在前面的影响,甚至超过了“减低成本”和“基础设施替换/ 升级”。表 2-1 战士了这个问题的答案:“ 下列各项问题,你认为在 2004 年终期待有最高的优先级吗? 选择一个。”
[1] IDC,应用开发中的集成标准趋势: 着全赖于“开放”的真正含义,2003 年11月 (文件 #30365) , http:// www.idc.com 。
有时候,对集成的需要在强加于你的,不管你是否喜欢它。 甚至在困难时期,当预算紧张时,为了集成目的而对基础设施进行修补也一定要遵从政府的法规管制。 如大部分它人们会证明,不有而有很多的仅仅继续尝试维持状态.为新的集成策略担忧。 然而,没有像有者监牢时间和强烈的罚款视野得到资深的管理注意。
由于范规管制的问题,一些行业的公司必须向竞争者提供信息,并且对信息访问进行审计。比如,在电信业中,负有职责的电信营运商(ILECs) 应该提供信息给竞争的 LECs 。能源公用事业也应该提供账单信息给竞争者。保健机构和隐私法律需要跟踪客户记录访问以供审计之目的。这需要你的分离的数据能够以标准的协议和以标准的格式轻易被访问。
下面是一些领域,在其中法规遵从是个驱动力。
一个 FCC 法规要求所有的电讯提供商和地方性的向地方性的营运商暴露他们的客户数据的某些部分。 一主修电讯供给者正在有强烈的罚款欺骗它为不遵从这一个需求。很明显,甚至一家主要公司也不能够负担得起继续基础上支付那么多的钱。与法律要求的共享信息相关的许多问题和高额成本,并且过滤掉那些法律不要求的部分。因此,一个过分单纯的方法不能同时满足法律要求又能保护敏感的公司数据。你需要又细粒度的过滤器和有选择的数据变换来只提供必需的数据 (也许只有在最后的一分钟) 来最小化你的竞争者可能访问所导致的对你的数据的利用。所有这些都需要有对业务流程的细粒度的访问和控制。
电信提供商需要一个基于标准的、能够伸展到小的电信提供商的集成解决方案,使用较小的电信商也能够采用来作为集成策略的各种协议。为了满足这个需要,公司最终采用 ESB 。
2002年颁布的Sarbanes- Oxley 法案旨在通过改善公司信息披露的准确性和可靠性来保护投资者,它强制了新的报告需求,并且对公司的决策者和他们的企业引入了更高的问责性。 遵从Sarbanes- Oxley 法案需要面临一些真正的挑战。包括费用考虑,后勤复杂性,数据收集和管理问题,以及正确的数据的及时报告,不管数据存在于哪一个企业之中。
美国联邦政府已经设定一个目标 在2003 之前变成无纸化。在2003年一月的美国政府CIO高峰会上,Brand Niemann,CIO理事会XML Web Services工作组的主席,对美国政府的集成中采用XML的驱动力是这样说的:
1998年的政府文书工作消除法案,要求联邦政府机构在2003年10月前,如果可行,允许与政府打交道的个人或者实体能够有选择地向政府机构电子化地提交信息和进行交易处理,或者如果可行,允许维持电子记录。
法规遵守产生了巨大驱动能量,并且集中于跨越整个政府机构集成后端应用和数据源。当我们在第 11 章讨论门户环境中的ESB 的时候,ESB能够在门户服务器和多个后端应用之间扮演媒介中介而提供重要的价值。
2.1.3.4 直通处理 (STP)
直通处理 (STP)意味着对于跨越整个系统和组织的业务流程的事务性数据只需要输入一次。在其他行业中, STP 可能被称为“流通供给”、“无纸采集”、“lights-out”或者“hands-free”处理。
达成 STP 的目标要消除业务流程的无效率,比如数据的手工重新输入、传真、纸面邮件、或数据的不必要的批处理。今天阻碍 STP 的事物的例子包括将采购订单重新输入到信用卡验证系统,或者周期性处理的数据分批。
在金融服务、电信和公用事业中,STP 是一个主要驱动。在金融服务中,“T+1”的目标是将交易数据沉淀一天。自动化程序运行可以帮助公司在整个订单和贸易的生命周期中减少成本,更快捷地服务客户,以及更有效地管理业务风险。
2.1.3.5 射频识别标签 (RFID)
射频识别标签(RFID) 正在改变企业跟踪其整个供应链中各处的货物和供应的方式。RFID标签还承诺能够通过消除人们打开外包板条箱和托盘扫描条形码内容的需要从而自动化供应链。装备有RFID标签的货物通过安装在仓库或者装货码头的阅读器时,会差生大量的消息,而这些数据又将会产生大量的需要被捕捉、路由、变换和输入到其他队业务有意义的应用之中的数据。
零售卖场中装备有RFID阅读器的“智能货架”能够自动跟踪货架上的货物数量,并且在货架存量低于标准的时候自动产生补货的订货命令。这些货架阅读器也会知道,消费者从货架上拿起一件商品平,然后可能又因为另一种商品而将它放回货架。这种类型的数据对于那件重新放回货架的商品的制造商来说也是很有价值的。
领导零售商,比如Wal- Mart和 Tesco、和美国防卫部,已经对齐大型供应商强制要求在大外包装级别装备RFID标签了。其最终目标是要驱动标签本身的价格下降,使得最终对每一但见商品,比如一把牙刷或者一罐苏打,进行RFID标签识别变得可行。这样将大大增加在一个托盘经过阅读器是所产生的消息数量。这种数据量在人工扫描外包装上的条码的时候是不会产生的。当一个托盘经过阅读器的时候,ESB能够作为因为而缠身的爆发性数据的缓冲以便能够准确捕获这些数据。那些没有针对这种数据量进行设计的应用可以得到ESB 的消息层的保护,它能够将工作量分配到多个后端系统,或者进入消息队列排队,直到其能够被处理。
因为个体物品级RFID标签而导致的消息的粒度更细,对那些没有针对处理超过大包装级别粒度的数据的应用也是个问题。ESB 能提供殊的缓存、聚集和变换服务,以便能够将收集更细粒度的数据,并将其聚集为大包装级别的数据,以便那些应用能够读取。
EPCglobal 组织正在促使 RFID 标签、阅读器、以及将阅读器整合到应用的软件的标准化。为了要广泛地共享 RFID 数据,需要对整个供应链中的相关应用和阅读器网络定义集成规则。而为了避免网络中的RFID 数据洪水,过滤和聚集规则应该尽可能地分布到最靠近RFID 事件的产生点。ESB 是一个很好的管理和配置那些控制数据流得规则的理想远程集成平台。
RFID 系统存在着无数的变体,也存在许多开发和制造商。如果想要对RFID系统有一个整体的了解,必须首先知道如何区分这些不同类型的RFID 系统。
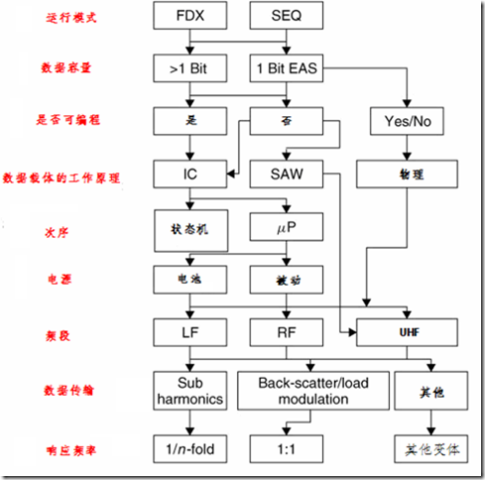
图3.1是一个RFID体系分类的示意图。
图表 3‑4 各种不同的RFID系统
RFID系统的运行基于两种模式:全双工(FDX)/半双工(HDX)模式和顺序模式 (SEQ)。
在全双工和半双工模式下,收发器的响应在阅读器的RF域打开的时候是按广播方式运作的。因为从收发器到阅读器天线的信号和阅读器自身信号相比是非常微弱的,所以必须采取适当的传输方式来将收发器的信号和来自于其他阅读器的信号相区分。实践中,从收发器到阅读器的数据传输采用负载调制(load modulation)的方式,它使用副载波,以及阅读器传输频率的分谐波。
对此对应,顺序方式使用在阅读器RF域按规则的间隔关闭的场合。这个间隔将被收发器识别,然后被用来从收发器向阅读器传输数据。这种方式的缺点是,如果传输终端则收发器将失去电力,所以必不采取其他备用供电方式或者电池以保证收发器的供电的平滑性。
RFID 收发器的数据容量通常从数byte 到数K byte。所以1-bit 收发器则是这种规则的例外。实际只有1-bit的数据量已经足够用来向阅读器标识两种状态了: 即“收发器在域中”或者“收发器不在域中”。当然,这对于满足简单的监控或者信号发送功能已经足够。因为1-bit transponder 不需要电子芯片,这些transponders 便可以非常便宜的制造,甚至几分之一美分的价格。基于此原因,所以在Electronic Article Surveillance (EAS)系统中使用了大规模的1-bit transponder以保护货物在商店和交易中的状况。 如果某人试图将为付款的商品带离商店,那么装载出口的阅读器将识别到'transponder in the field'的状态,并采取必要的反应。而在正常收费后,1-bit transponder 将被去除或者予以禁止。
能否将数据写到transponder 中向我们提供了另一种分类RFID 系统的方式。在简单系统中, transponder的数据记录通常是简单的序列编码,并且可以是在芯片制造时写入的,而且在随后不能修改。用来存储数据的主要的方式是:在感应耦合的RFID 系统中,EEPROM占了统治地位。但是其缺点是在写操作时功耗很高,以及有限的写入周期寿命限制 (通常是100 000 到1 000 000)。FRAM最近也被用在隔离的场所。FRAM的读取功耗是EEPROM的100 分之1,而写入功耗则比后者低1000 倍。但是其制造比较困难,因此限制了市场的广泛使用。
特别是在微波系统中,则普遍使用 SRAM来作为数据存储媒介。其优点是极快的数据读写速度,而缺点则是必须要使用辅助电力供应以便保持数据的持久性。
在可编程系统中,对存储器的读写访问和其他读写授权必须由数据载体的内部逻辑进行控制。在最简单的场合中,这些功能可以通过状态机来实现。状态机也可以是下复杂的逻辑顺序。但是状态机方式则不够灵活,因为以编程状态的变更必须要随之进行芯片电路的变更。实际应用中将导致芯片重新布局,并产生额外的费用。
微处理器的使用可以改善这种状况。在处理器制造时,将使用掩模的方式采用一个操作系统来管理数据。因此变更可以更加便宜的实现,并且软件可以重新编程以适应不同的应用。
对于非接触式智能卡来说,使用状态机的数据载体一般存储卡(memory card),而与之对应的则是处理器卡(processor card)。
这里还应该提及那些使用物理效应来存储数据的transponder。包括只读表面声波transponder 和通常可以禁止(设置为0)但是不能重新激活(设置为1)的1-bit transponder。
RFID 系统的一个重要特征是transponder的供电。被动transponder 自身没有电源,因此操作被动 transponder 所需的所有电力必须来自于reader的电/磁场。相反,主动transponders 自己有辅助供电措施,如电池,可提供其自身运行所需的部分或者全部电力。
RFID 系统的主要特征之一是系统的运行频率和有效范围。RFID 系统的运行频率是reader 所发射的频率。而transponder 的发射频率则不重要。在大多数情况下,它和reader的发射频率是相等。但是, transponder的发射功率通常设置为比reader的发射功率还要低10的几次方。
将不同的发射频率分为3个主要频段:LF (低频, 30–300 kHz), HF (高频)/RF 射频 (3–30 MHz) 和UHF (甚高频, 300 MHz–3 GHz)/微波(>3 GHz)。 根据有效范围的进一步区分还可以将RFID 系统区分为紧密耦合(0–1 cm), 远耦合(0–1 m), 和长距离耦合(>1 m) 系统。
从transponder 发送数据到reader的方式可分为3类:
- 使用反射或反向散射(即对应于reader发射频率的反射波的频率→ 频率比1:1)
- load modulation (reader的场受到transponder的影响 → 频率比 1:1),
- 在transponder中使用分谐波(1/n fold) 和谐波的产生(n-fold) 。
将标签附加到被标识的物品有多种方法。通常手工方式是最明显和最有效的方法。在条形码的使用场合,经常使用一种打印机来打印好标签然后通过某种方式在物品通过装配线上的某点的时候粘贴到物品上,对于Smart Label类型的RFID标签,也有类似的方式。这些Smart Label类型的设备同时编码RFID标签和在纸张上打印条形码以及人可读的其它标记。
- 采用何种方式来附加标签到物品考虑的因素包括:
- 使用自动化设备和系统的成本;
- 成卷的Smart Label可能存在的有缺陷的标签;
- 附加过程中可能因为敏感性会损坏标签;
另外,对于不同的形状、尺寸和本身特性的物体,标签的位置和附加方式需要考虑的问题和原则不尽相同,才能得到最大的可靠性和可读取性。详细信息参见DoD的标签附加注意事项。
3.2.2.1 跟踪物品的移动
附加了标签的物品被运输时,对于发送放和接受方来说都是有益的,因为他们都可以跟踪该物品的移动。对于整个业务流程来说,参与供应链的各方都应该能够跟踪其移动,或者共享相关的跟踪信息。以使得任何业务都能够对整个供应链得到一个实时的“数据快照”,从而驱动更加有效的业务流程处理。
对被标签物品的跟踪是通过该物品出现在各种关键控制点而得到的数据,这些控制点可能根据:
等进行联合的多层次的位置和领域标识。
3.2.2.2 在业务应用中使用RFID数据
在写入的时候,RFID系统所作的大部分工作主要集中在标签和阅读器的物理部分。因此确保选择正确的标签、阅读器和天线,并且对其进行正确的配置和设置以达到要求的读取率是非常重要的。但是,只有在将RFID各组件的跟踪信息集成到你的业务应用系统之中才能意识到RFID技术的真正好处。很有可能,使用RFID信息需要将其集成到你的现有业务应用之中,或者还需要对其进行某些修改。将RFID信息与企业业务系统进行集成与集成其它数据源没什么不同。因此,企业集成所需的架构方法、技术和产品也可以用在RFID信息的集成场合。
3.2.2.3 在B2B应用间共享RFID数据
一旦公司在内部集成了RFID数据,并且使其业务过程利用这些数据,便会逐渐发现RFID数据在逻辑上可以促进业务数据的共享从而改善B2B的业务集成。比如在使用了RFID技术的药品行业。某个药剂师甚至可以将某个配置了RFID标签的药品包装靠近RFID阅读器终端,就可以马上获得有关该药物的信息,比如政府药品管理部门的警告或其它用药信息。药房的POS系统可以根据该标签代码请求由药品供应商或者政府卫生管理部门提供的Web Services服务。药品公司也可以或者跟踪其所生产的具体每一件产品的信息,包括分销、运输以及使用等等。
所有这些应用情形都假定这些相关的各个公司会共享其信息。当然,驱动这样的B2B具有“一次性”的解决方案,但是长期来说,这并不使最节省成本的、最有效率的、最灵活的、以及最快捷的共享信息的方式。跨越企业边界共享信息和工作流并非新的概念。对于整个业界来说,需要某种标准化的共享信息的方式。
3.2.2.4 智能设备的自组织
目前最明显的趋势是越来越多的设备连接到Internet,如何提供、配置、监控和管理他们越发成为最大的挑战。一个连锁零售机构可能有数十台服务器连接着其数百个POS终端。但是,当该机构添置了具有RFID能力的智能货架或者POS终端的时候,又会有成百上千的天线和阅读器连接到上述基础设施架构中。RFID 中间件标准,比如应用层事件将会有助于将企业应用和阅读器或者天线之类的边缘设备分隔开来,但是要正确配置这些边缘产品将是一个非常消耗时间的工作。诸如Jini和网状网络(mesh networks)之类的技术,以及老些的SMTP技术都提供了动态配置和自愈特征,RFID中间件可以使用它们来改变阅读器和其它感应器的物理配置。
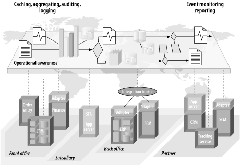
下图展示了一个RFID系统的主要部件。我们以一个零售系统为例来说明。图的左下方是代表了被标记的商品的一系列标签。商店也有一系列的阅读器布置在货架和结账通道上。这些阅读器每分钟可以读取数百个甚至数千个标签。阅读器必须要仔细配置和进行管理,以便知道如何一些协同工作以覆盖到某个阅读器失效时出现的盲区。RFID中间件就代表着一个或者多个负责处理这些问题的软件模块。边缘应用代表着任何运行在商店之内的企业应用,比如POS系统。而RFID信息服务则代表着存储在边缘发生的RFID事件和相关数据的机制。同样,在企业数据中心或者其业务伙伴的数据中心也可以有相似的信息服务。这是因为RFID 信息是被存储在基础架构中的各个地方:比如边缘、数据中心之内或者业务伙伴处。
3.3.1 RFID 系统组件
企业数据中心中的两个主要部分是企业应用和企业服务总线。企业服务总线是一种基于分布式消息机制和SOA的集成基础架构。已经有很多这些基于标准的产品。而企业应用则是解决企业实际业务问题的各种应用,将要集成并且消费RFID数据。
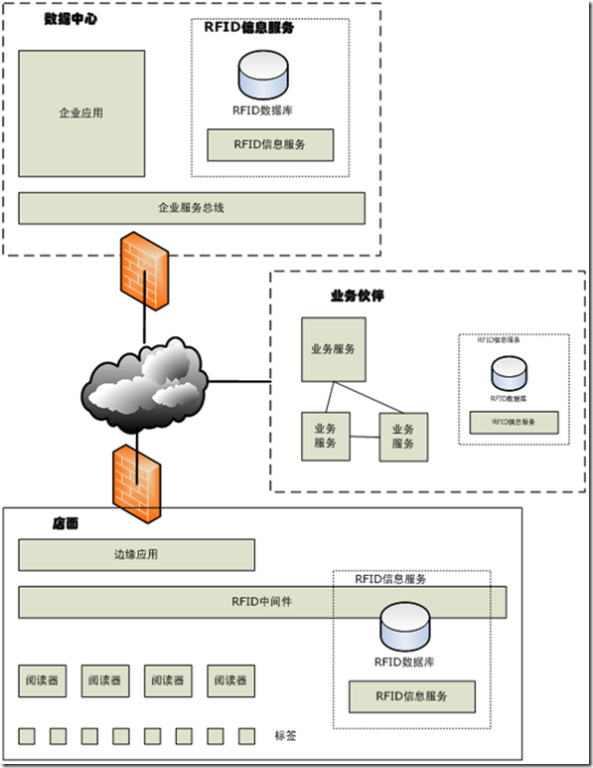
企业数据中心中的两个主要部分是企业应用和企业服务总线。企业服务总线是一种基于分布式消息机制和SOA的集成基础架构。已经有很多这些基于标准的产品。而企业应用则是解决企业实际业务问题的各种应用,将要集成并且消费RFID数据。
3.3.2 标签(Tags)
RFID系统的本质能力是基站(阅读器)能够通过无线的通信机制,包括微波,但不包括红外和可见光,来识别另一个电子设备(标签)。因为阅读器能够识别某个特定的标签,因此系统便可以声称能够识别该标签所附着的对象。标签可以被封装在一些诸如塑料钮扣、玻璃腔体、纸质标签、甚至金属盒之内。它们可以被粘贴到包装上、嵌入到人体或者动物体内、夹在衣服上、或者隐藏在钥匙的头部。
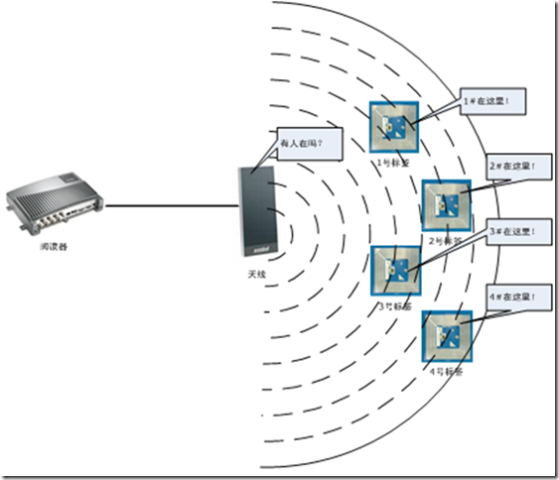
对RFID标签的识别是通过RFID相应阅读器的询问,像阅读器通知其到场,并且标明他自己的身份(编码)。如下图所示,RFID 阅读器首先以一定的时间间隔(通常每秒数百次)发射一个预定频率的无线电信号。任何处于月底起的发射范围的标签都可以收到该发射信号,因为每一个标签都有一个能够在某个预定频率上监听这种信号的天线。标签使用接收自阅读器的能领来向阅读器响应相应的信号。标签可以在这些信号上调制信息,比如发送ID编号。
3.3.2.1 RFID标签和阅读器之间的通信
不同种类的标签和阅读器使用与不同的应用需要和环境。要决定使用哪种标签或阅读器涉及到许多因素。其中主要的因素之一是成本原因,因为标签的成本决定整个系统和运行的成本。阅读器本身也有许多需哟考虑的价格因素和特征。
RFID标签的重要特征包括:
标签可以封装在PVC、玻璃、纸张、金属甚至塑料卡片之中。也可以镶嵌在珠宝上、悬挂在钥匙链上、或者嵌入到钥匙体之中。DIN/ISO 69873 标准就定义了一中可以插入到构造在机床工具的孔中的一种标签。有些用于汽车组装线的标签必须要承受油漆烘干室的高热环境。总而言之,封装标签的方式由多种多样的。比如,下图中就包含了两种不同的标签,一种在卡中,一种在钥匙中。
耦合意思是阅读器和标签之间通信的手段。不同的耦合方式各有优缺点。选择耦合方式的主要因素包括通信的有效范围、标签的价格、以及可能造成干扰的条件。
大部分的标签都使用被动系统,从阅读器发射的电磁场或者无线电波中获取能量。也有一部分主动标签,由内置电池供应为芯片和其它感应器以电力。然而,主动标签一般还是使用来自阅读器的能量进行通信。还有一种标签是“双向标签”,不通过阅读器就可以在两个标签之间进行通信。
标签都提供一定容量的信息存储能力。只读标签是在工厂预设了特定的值。还有一次读入和可多次写入的标签。有些标签还可以收集新的信息,比如温度和压力的感应值。标签的存储能力可能从1-bit 标签到数K字节。
不同的国家、地区和组织各种不同的RFID标准,有些是通用标准,有些则针对不同的应用场合。这些标准可能涉及到标签乃至系统的物理、电气、系统、软件、协议、运行、维护管理等等方面。
3.3.2..2 选择标签
在选择标签式可能涉及到许多因素,包括:
主动标签一般长于被动标签。
不同的材料具有不同的射频特性。液体可能会完全阻断无线电波。
根据不同的应用需要选择不同的形状尺寸。某些形式可能是标准界定的。
选择不同的标准意味着决定整个RFID系统的工作环境,从数据编码、工作频率到阅读器等等。
单个RFID标签的成本对于整个系统和项目设施具有非常重大的作用。
3.3.3阅读器
RFID 阅读器,也称质询器(interrogators),用来识别它附近到场的RFID标签。RFID将通过一个或者多个天线发射RF能量,并且形成一个质询区。质询区内的标签通过其天线的感应将其转换成能量,然后供应它的工作甚至它与阅读器之间的通信。标签然后通过变换天线的阻抗来以类似莫尔斯代码的方式向阅读器发送器身份编码。这仅是其中一种方式,不同的标签可能工作方式不同。
阅读器也可以由多种方式,由固定的、移动的、也有手持的。阅读器连接到网络中的方式也有多种,这取决于其所持的网络连接的能力。下图所示是阅读器的组成。
3.3.3.1 阅读器的组成部件
一个阅读器通常典型地由四个子系统构成:
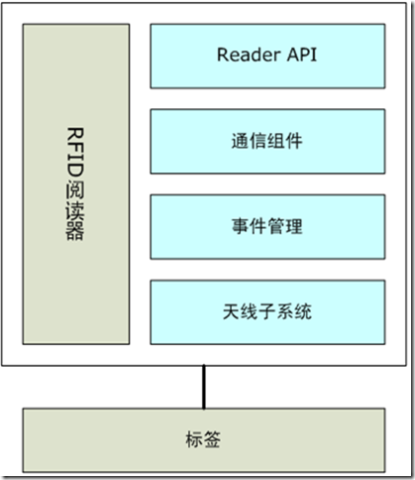
Reader API 是阅读器的应用编程接口,允许程序员注册和捕获RFID阅读事件。它也提供配置、监控和其它管理阅读器的能力。
阅读器是边缘设备,和其他RFID设备一样,需要连接到整个边缘网络和企业主干之中。通信组件就是处理网络连接功能,可能支持以太网、工业总线、高速串行接口、无线网络等等,也支持多种不同的网络协议。
当阅读器读取到一个标签时,我们称之为一次发现。一次不同于上一次发现的发现就成为一次事件。对发现的分析也称事件过滤。事件管理就是定义那些类型的发现可以被视为事件,那些事件足够具有价值和兴趣,值得马上送到网络中的外部应用之中。
天线子系统又一个或者多个天线组成。它支持使阅读器能够质询标签的接口和逻辑,并且完成无线电波的发射和接收。
3.3.4 RFID 中间件
选择了正确的标签和阅读器,以及决定怎样布置天线只是构造RFID系统的第一步,因为识别到物品只是管理它们的第一个步骤。物品在供应连上移动时阅读数以百万的标签,以及将标签编码和有意义的信息联系在一起会产生的大量的具有复杂相互关系的数据。使用RFID中间件的好处之一就是提供一种标准化的方式来处理小小的标签所产生的大量的数据。除了事件过滤之外,你还需要有一种方式来封装应用接口,以便使它们不必知道整个基础架构,比如物理层面的阅读器以及其它设备。理想情况是,你需要一个RFID基础设施的基于标准的、应用层的接口,以便你的应用可以用来请求有意义的RFID发现。
下图所示是RFID中间件的主要部件。
3.3.4.1 RFID middleware的主要部件

使用RFID中间件的主要动机是:
- 提供对阅读器的连接
- 处理来自于阅读器的初步的发现信息,以供应用之用
- 提供应用层接口来管理阅读器和捕获RFID事件
市场上有多种不同的RFID readers,每一种都有其专有的接口。要使得开发人员都能够了解不同的reader接口是不现实的。Reader接口、以及数据的访问和管理能力是各不相同的,所以应该使用中间件来屏蔽具体的Reader接口。reader adapter层就是将专有的reader 接口封装成通用的抽象接口提供给应用开发人员。
对于一个完整的、具有RFID能力的大型企业的供应链系统中,可能具有成百上千个阅读器,或者每分钟同时有数百个阅读器在进行扫描。大部分发现都太过于细粒度,从而对应用来说没多大实际意义,所以需要对阅读器接口进行封装以隔离大部分原始数据的洪流。企业所以需要在其IT基础设施的边缘部署一些特殊目的的RFID中间件。
Readers 对接近它们的标签的读取准确率并不是100%的准确。假定100个物品出现在阅读器附近,该阅读器被设置为每分钟读取数百次。那么阅读器每次扫描到这些物品的机会是80%到99%。例如,对于2#物品来说,在多个扫描周期内有80%的机会被阅读器感应到则认为其到场。但是,这种RFID阅读方式产生的数据被认为是“原始数据”,需要进一步处理成为有意义的业务事件。
RFID 事件管理器(event manager)汇聚来自不同数据源(比如阅读器)的读取数据,并且基于预先配置的应用层时间过滤器进行调整和过滤。然后将经过过滤的数据送到后端系统。
我们来看事件管理器处理智能货架的情形。假定对于一个特定的应用,每个阅读器都会每分钟扫描货架10次。每次扫描都会返回一组发现,每个发现都会类似于下面的格式(包含这些信息):
Reader Observation
timestamp,
reader code,
antenna code,
RF tag id,
signal strength
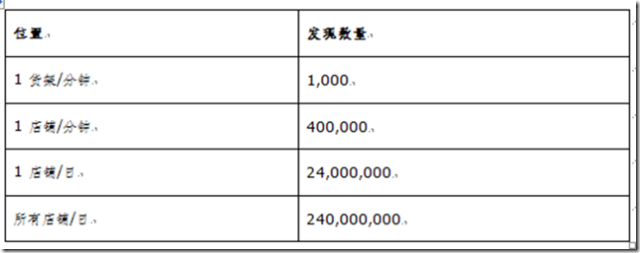
假定一个电子零售商ABC公司要实现一个智能货架系统。平均每个货架四层,每层货架平均放置25个货物,则平均每行货架100个货物。该公司共有10个店铺,每个店铺平均有20个货架岛,每个岛平均20个货架(每侧各10个)。则整个公司共有400 个货架,因为这平均存活为40,000 个商品。下表是一个总计:
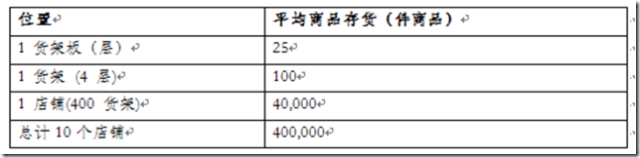
在此基础上产生的RFID数据量为:
l 每次扫描会产生包含目标货架上所有能够识别的商品的相关信息的发现
l 25 个商品/层 x 4 层/货架x 10 次扫描/分钟= 1,000 个发现/分钟.货架
l 1,000 个商品/分钟x 400 货架 = 400,000 发现/分钟
l 400,000 商品/分钟 x 60 分钟/小时= 2,400,000 发现/小时
l 假设商店每日营业10 小时。10 小时 x 2,400,000 i商品/小时 = 24,000,000 发现/日.店铺
l 10 店铺 = 240,000,000 发现。
所以数据量总结于下表:
这是多么巨大的数据量,这还不包括来自于收银台的RFID数据。处理这些数据需要严格的规划。如果将这些数据直接交给后端业务应用来处理,不但会加重后端系统的负担,而且会严重堵塞网络传输,消耗大量的带宽。并且,下游应用却认为绝大部分发现不是它们所感兴趣的。例如,一个客户取了一张DVD影碟,然后由在一段时间后将其放到货架上这样的事件。对于订单管理系统来说,这样的事件没什么意义,因为存货并没有改变。实施上,即使顾客买了那张DVD,对订单管理系统也没关系,只要存货还在安全范围上,这时,存货管理系统就有关系了。
所以需要有一种机制来汇聚各个阅读器不断产生的发现数据。以及对这些数据进行过滤、调整、和变换。这种机制就是位于边缘和企业数据中心之间的RFID中间件的职能。通过中间件,只有对应用具有重要意义的数据才传送给它,否则被中间件过滤掉。
那么,什么样的数据必须要被过滤掉?首先,因为天线之间是十分接近的(每个架两个),则它们的都区范围会有所重叠。因此,来自于它们的发现数据便会需要被过滤来消除数据重复。另外,因为每一次单独的扫描都不会100%准确,所以这些发现将会被载多个读取周期之上汇聚在一起一边是数据更加平滑。(不准确的原因有多个因素,包括射频发射的因素、RFID标签布置的因素、障碍、以及环境因素等。) 也许一个顾客从走道上经过,也许他的手中或者购物车中就有某些商品,那么邻近的读写器也可能会读到这些商品。我们肯定应该过滤到这些虚假的发现以防止向存货系统发送大量的不准确的数据洪流。下图就表示了一个针对零售商店典型场景的数据过滤和平滑系统。
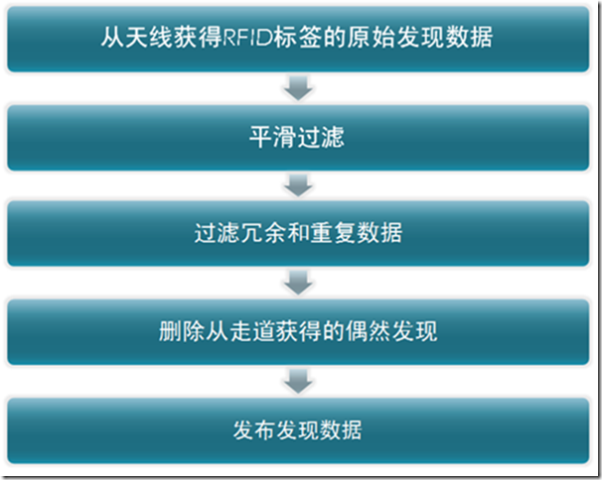
上图中的每个流程解释如下:
阅读器将获得原始事件数据(发现)。
当前的读写器在单次扫描的时候基本上都不可能达到100%的准确,所以我们将根据分析多次扫描的发现数据的平均来得到实际的发现数据。例如,如果,如果70%的发现都告诉我们某个商品在某个地方,我们便会接受这个数据。当然这个阀值是可以调整的。
重复数据是因为不止一个天线读取到了同一个物品,因此这种数据应该被删除重复部分。
来自于从走道上经过的商品的发现通常具有较低的信号强度并且是暂时的。它们也应该被过滤掉。
经过了必要的过滤之后,我们的数据才可以提交给下游客户使用。
RFID 阅读器已经提供了一些过滤能力,并且随着reader 越来越聪明,它们自己将承担更过的过滤任务。那么还需要在中间间进行进一步的过滤吗?我们可以想到,一些过滤要求对来自多个阅读器、其他感应器、或者甚至其他系统(比如存货系统,在比较库存级别的情况下)的信息。这些更高阶的过滤需要发生在高于阅读器之上的事件层面的系统中进行。
3.3.4.3 应用层接口(ALI)
应用层接口在RFID中间件栈的顶层。其主要目的在于提供一个标准机制来使应用注册和接受来自于一组阅读器的经过过滤的事件。除此之外,ALI还提供标准的API来配置、监控和管理RFID 中间件以及它所控制的阅读器和感应器。许多RFID中间件供应商提供针对这些目的设计的专用接口。最近,EPCglobal 发布了一个应用层事件(ALE)规范来标准化RFID功能的事件管理部分。
最后,RFID 中间件具有不同的形态和规模。我们所述的仅仅是中间件的一个逻辑分解。实践中,你总可以找到能够针对特定应用类型部署在特定阅读器类型上的模块。
3.3.4.4 关的RFID标准
对于RFID中间件来说,应该有一些相关的标准。比如,对于EPCglobal 标准来说,就包括两种:
对于象标签阅读器或者打印机、编码器之类的边缘RFID设备,由于有不同的厂商提供这些产品,因此需要有一种标准来对其进行界定。比如,EPCglobal就制定了相关的阅读器标准,包括Reader协议等等。这样FID middleware 产商才能据此兼容不同的Reader。
ALE 是事件处于应用领域而非边缘领域,提供业务层面的标准接口来对经过边缘过滤的数据再进行处理。ALE 标准一般支持同步的请求响应模式或者异步的发布订阅模式,这主要取决于下层的通信基础,比如MOM或者服务户操作性框架,比如ESB。
3.3.5 RFID 服务总线
企业服务总线(ESB)是一个针对解决应用连接性、数据变换、有保证的事务、以及消息传递的分布式集成平台。而RFID 服务总线则是一个典型的用于集成使用RFID数据的集成中间件软件。一般来说,ESB产品典型地会提供web services、消息传递、业务流程编排、数据变换等功能。不同的厂商可能稍微有些不同。但是,同的来说, ESB能够通过可靠的消息机制来继承跨越企业边界的业务流程,而这些业务流程使用抽象端点表示的Web Services,必要时通过数据变换将数据统一到规范的数据标准之上。
RFID系统在企业架构中不能单独存在,因此它总是要和其它应用发生联系才能使数据具有真正的业务含义。比如企业仓库管理系统 (WMS),企业资源计划 (ERP) 系统,企业资产管理系统(EAM)、或者POS系统。这些系统的数据统统都可以升级到能够驱动RFID数据的可能,然后将RFID的所有有点带入到企业业务流程之中。因此扩展现有应用来支持RFID将是非常重要的事情。
现在的集成领域,越来越多地采用ESB 架构的集成,使得在分布式的环境下实现统一的集成和写作,促进整个企业的数据交换和共享。最低限度,它可以集成各种采用不同技术开发的分散应用。它提供适配器来解析从其他系统的数据输入,然后将其转换为一种规范的通用格式 (通常是XML),然后提供给同样具有适配器的数据消费者。一般来说,ESB服务还有业务流程编排的能力,通过定义的业务流程,连接不同的服务和数据,可以在一个引擎中执行。在RFID中间件系统中,一般通过事件管理起来提供类似的能力或者用标准服务中间件提供。
RFID 服务总线的主要目的在于将事件服务器捕获的应用层事件集成到企业边缘发生的工作流中。不同的厂商可能不同,但是RFID 服务总线基本上是一个运行边缘工作流并且提供与边远模块比如、POS、WMS集成能力的一种服务器。RFID服务总线也要集成到企业ESB中,以提供可配置的特定事件和发现来将RFID数据最终集成到企业应用中。因为典型的ESB产品可能很复杂,如果业务和应用简单,也可以使用基于应用服务器的定制实现来完成这部分功能。
3.3.5.1 RFID 信息服务
一般来说,不管是EPC还是其他什么标准化组织或者特定的系统,都只是提供一种物品识别系统的唯一性表示机制,而不是有关具体产品的。EPCglobal 设想了一种野心勃勃的业务和服务,设置一个EPC 信息服务(EPCIS)网络,来提供与EPC编码相关的信息的存储库和相关服务。EPCIS 服务器提供的信息可能包括携带EPC标签的物品的最后发现的位置 (基于RF reader 发现),以及价格信息、产品手册、警告和参考信息等等。当然实现这个网络好需要很多的努力,包括技术和政策以及经济环境、贸易环境等因素,但是可以表现实现一个中介数据库来将RFID数据映射到与业务相关的信息上面。
EPCglobal 实际上是可以用现有的数据系统和数据源来进行RFID信息服务。例如,序列化全球贸易商品编号 (SGTIN) 就被EPC 用作消费产品和零售行业的标识符编码。
3.3.5.2 RFID 信息网路
因为RFID标签标记的产品可以在整个供应连中移动,那么该链条中的所有参与者都需要一种标准化的方式来供向它们的跟踪信息,并且基于EPC ID相关的来获得相关的参考信息。EPCglobal 设想的网状网的B2B EPCIS 系统就旨在提供一个与EPC相关的综合信息服务。EPCglobal Network 是想要通过不断推出的一系列标准来提供产品数据和信息交换的标准化网络和机制。通过结合RFID 技术和现有的Internet基础架构和软件集成技术,EPCglobal Network 将提供更好的产品在整个供应链中的跟踪的准确性和效率。
许多新生技术都经受过试图找到问题来解决以获得采用的痛苦经历。另一方面,ESB的概念是由业界领袖的架构师和技术社区中的领导厂商一起和定义和构建的,因此,ESB从诞生之时便得到采用。ESB正在或已经被用在多种行业,包括金融服务、保险、制造业、零售、电信、能源、食品分销和政府。下面是一些例子。
- 一个领先的Subprime借贷公司实现了 ESB,减少了60% 的业务处理费用。这是通过在eCredit 系统、第三方信用机构、以及他们自己的后端系统之上建立一个统一的客户数据视图来达到的。
- 领先的银行已经使用ESB实现了金融交易的直通处理,很客官地节省了手工处理成本。
- 一个派生的贸易系统依靠ESB每天为1,200用户处理超过100,000 笔交易,记录超过数十亿美元的帐务。
- 世界最大的寿命和健康再保险公司,年收入二百亿美元,将ESB作为理清在总部和销售及管理其政策的保险代理商之间的后端交易数据的交换的解决方案,产生了可观的费用节省。
- 一个橱柜台面和地板制造商通过使用ESB实现了一个一体化管理的存货系统和“可用性承诺”查询系统,提高了供应链的预见能力,减少了最低库存报警的条件。在部署的第一阶段, ESB被用来连接该制造商和其60个分销商之间的供应链网络。
ESB 的部署模型允许制造商在分销商的地点部署ESB 服务容器。这是在每个远程地点部署一个集成Broker方案的另一选择。
- 一个主要的照明、电视和医学成像的制造商正在使用 ESB 创建一个统一的集成主干来连接其遍布全球的业务单位,并且为全球的客户创建一个统一的产品和订单视图。
- 使用一个基于标准的,集中的管理框架,一个全家的影像零售连锁店正在采用ESB 基础设施来通过一个中央管理和配置控制台动态地配置和管理 1,800个远程店铺,
- 世界最大的邮购公司 (收入一百二十亿美元)依靠 ESB 来从其许许多多的供应商订购产品。
- 一个电话营运商的Web门户网站依靠ESB来对用户点击进行分析跟踪 (二小时的响应对 30 天的响应时间), 并且每天处理一千六百万个消息。
- 美国第二大的电信营运商,收入四百三十亿美元,使用 ESB来从内部的系统向竞争者提供信息。
- 一家一百亿美元的电力公司可靠地实现了 ESB,用来连接内部系统和政府强制的应用。 对帐务、系统管理、运行报告、以及法规强制的与竞争者的信息共享,提供了实时数据。
- 一个主要的欧洲食品分销网 ( 一个十二亿美元的分公司)在八个星期内实现了 ESB,并且节省了使用一个集中的集线器-插头 Broker的集成方式所需的三百万美元。ESB 通过管理供应链中的买、卖和物流协调,从肉类产品的配送到饲养家畜的饲料的生产,从而自动化了整个分销网络。
- 在这个食物分销网络中, ESB 集成了跨越三个不同的运行公司和许多第三方伙伴的应用,导致运行效率增加、可观的费用节省、以及更容易的集成新系统的方法。
n 一个美国政府机构正在使用ESB 来整合多个政府系统,以满足USA PATRIOT法案。USA PATRIOT法案允许政府跟踪金融交易,以防止恐怖份子得到资金。该项目包括使用 ESB 来集成门户服务器和各种政府机构中的后端系统,以提供一个统一的数据视图。
概括起来, ESB 具有下列各项特性:
ESB 可以采用来适应各种集成情形下的各种通用目的集成项目的需要。它能够构建跨越整个企业和其业务伙伴的集成项目。
松散耦合的集成组件可以在总线上以广泛分布的地理拓扑进行部署,并且在总线中可以随处作为共享服务进行访问。
适配器、分布式的数据变换服务、基于内容的路由服务都可以在需要时有选择地部署,并且可以独立地伸缩。
通过总线进行通信的所有组件能得益于可靠消息、事务完整性、以及安全的认证通信机制。
ESB 允许数据流过插入到总线中的任何应用, 不管是本地还是远程。
ESB 支持部门和业务单元级别的本地自治,并且仍然能够在较大的受管的集成环境中整合。
每个个别的项目能进入一个更大的集成网络,它们可以从总线上的任何地方进行远程管理。
ESB 可以充分利用XML作为“原生”数据类型的好处。
ESB 提供了对及时业务数据的实时洞察能力。BAM能力已经被构建到ESB 框架之内。
你现在应该有了关于 ESB的足够的信息来满足你的好奇欲了。 接下来,在更详细的章节中,你将会学到更多有关其底层技术方面的内容。下几章将会讨论 ESB 的进化、目前的集成状态,采用XML来作为一个通用的数据交换架构以在不同的数据表示之间协调的好处,以及异步消息和MOM。
编码RFID标签分为两个步骤。
首先是选择唯一跟踪所需识别的物品的身份识别方案。其次是将这个身份识别附加到RFID标签之上。
3.2.1.1 决定身份编码方案
身份识别是一个鉴别某个对象或者物品的身份的动作过程。但是什么是身份(identity)? 在 RFID中,身份是一串附加到物品你上的字母或者数字编码,允许人工或者自动化设备能够识别到该物品的类型甚至其唯一性。这正如你在图书馆查询图书时,书籍是使用杜威十进制分类法或者通用十进制分类法来标识的。但是目前的图书分类法只能标识到书籍的类型而不能标识到
考虑到有时候需要进行实体的唯一性识别,比如产品、集装箱、物理资产、动物甚至人类本身。对一个大型企业来说,在企供应链上同时可能有数以百万的物品在流动。可以使用某种编号系统来对这些物品进行标识,但是如果在公司之外没有人,或者系统能够理解它们,其价值就大打折扣。所以需要行业的或者通用的标准方案。
1999年,美国的MIT、英国的剑桥、澳大利亚的Adelaide 、日本的Keio、中国的复旦以及新西兰的St. Gallen大学与行业伙伴如Sun Microsystems 和 Gillette组成了Auto-ID 中心。它们希望能够开发一个通用标准来减少单个标签的成本。因为该成本也是采用RFID应用的一个主要组成部分,而标准可以促进业务伙伴之间的信息共享程度从而减少单位成本。2003年8月, EPCglobal公司接管了该标准的管理,而该研究中心继续进行单独的研究工作。EPCglobal是欧洲物品编码国际组织(European Article Number International,即EAN International,现在是GS1),统一代码协会(Uniform Code Council,即UCC,现在是GS1 US),以及想要在RFID领域重塑条形码的EAN.UCC标准的成功的一些业界伙伴的合资企业。EPCglobal正在开发的标准的各个组件将构成一个所谓的“EPCglobal Network”。其理念是这个网络将兼容构建在整个供应链之上的标签、阅读器、以及信息系统,制造商、分销商、物流商以及零售商。EPCglobal 的编码方案被称之为电子产品代码(Electronic Product Code :EPC)。
在现今的物品跟踪领域,主要使用的是EAN.UCC 条形码,为什么还要在RFID系统中使用同样的类似系统呢?事实上,我们可以在RFID标签中使用现有的成熟的条形码编码方案。但这些系统基本上是设计来跟踪物品的分类而不是单个物品的,但是如果加上序列号,光学代码和二维条码也可以用来跟踪到个体。那么物品级别的跟踪和RFID本身就是趋于一致的。比如,EPCglobal的版本1.1的标签数据标准,就定义了一个通用的身份类型:通用标识符(General Identifier:GID)。同时还定义了衍生自EAN.UCC 产品代码的五种特定的身份类型。这些特定的身份类型是在现有的EAN.UCC标识符,诸如连续全球贸易物品编号(SGTIN)或者连续运输集装箱代码(SSCC)之上添加一个额外的资产引用编号或者序列号而得来。
比如使用统一资源标识符(URI)可以标识一个GID为:
urn:epc:id:gid:GeneralManagerNumber.ObjectClass.SerialNumber
那么,一个具体的GID可能会是这样:
urn:epc:id:gid:00012345.054322.4208
GID中的urn:epc:id:gid 部分是静态的,作为标识符的一个头部(header),指出标识符的类型,以及基于EPC规范还会出现哪些字段域。该header后跟值字段域,其长度和编号是由header决定的。这三个段分别表示了GID的通用管理者编号(General Manager Number)、对象类(Object Class), 以及序列号(Serial Number )。
General Manager Number 标识了负责分配接下来的两个字段域的编号的组织(通常为一个公司或者贸易集团) 。Object Class 标识了产品的类型或者族。最后, Serial Number 被标签标识的对象类的一个特定实例。这种将一个特定范围的编号委托给某个通用管理者的方式,在允许组织管理其自身的产品编号而不用提交到中心当局,同时又确保了不与其他组织的产品相混淆,这就提供了一种灵活性。
3.2.1.2 将编码身份编码到RFID标签
选定编码方案或者方法之后,必须考虑到如何将这个身份标识编码(物理的)到RFID标签之中。所谓编码(Encoding)是将认可度的消息转换为机器可读的代码所必须遵循的规则。每种识别标签的类型,从条形码到光学散射代码到磁条再到RFID标签,都各自有一zhogbiaoshi期身份的特定的编码规则。
理论上讲,一旦对某个物品建立了一个身份标识,我们只需要将其简单地写到标签(Label)并将其贴到物品上即可。其它人就可以毫无困难地识别出它。但是,一个自动化的系统却要困难得多。以某种特定的字体打印下来可能对机器识别来说要容易得多,但是如果该身份之需要能够被自动系统阅读,为什么还要花费精力来研究如何更好地打印。
今天到处使用的条形码就是这种推理的结果。在条形码中,特定宽度的线条代表了特定的字母或者数字。条形码有不同的类型,每一种都有其特定的规则来描述其如何形成一个特定类型的身份。决定我们如何将数字和字母转换成特定的线条,以及我们可以添加什么特定的数字和字母来构成有效的标签的规则称为是标签编码规则,或者简称编码。因此,条形码可能会包含物品的身份,即一个指示所用的是何种条形码的编号,以及在许多情况下的一个标识分配该身份的组织的编号。下图是一个ISBM的条形码编号。
在上图中,标注A, B, 和 C 分别指示了条形码的不同部分。A部分包含数字636,即一个指示图书行业的编码。B 部分指示ISBN 编号本身。C部分是一个校验码,用于阅读器验证是否误读了该编码。中间的ISBM编码部分是根据ISBM规则的身份,而A和C则是根据条形码的要求所加。
为了选择适当的编码将身份写入到RFID标签中,你必须知道你将要写入的身份的类型和所用的标签的类型和存储容量。在EPC规范中,GID是一个纯粹身份(pure identity),它不能在没有通过某种形式的编码的情况下写入到任何类型的标签中。例如,假入我们想要将其写入到一个96-bit Class I EPC标签中,即一个可以保存96bit的ID,并且符合EPC标准的可写入标签。首先,我们需要将GID的各部分按照标签的要求正确排序,留下那些不是标签编码的部分。幸运的是,仅包含相关字段的GID对EPC来说已经是正确的顺序了。接下来可以添加必要的附加信息已产生一个阅读器和事件器都能够理解的URN 表示。对于一个GID在9bit标签中的URN表示是:
urn:epc:tag:gid-96:FilterValue.GeneralManagerNumber.ObjectClass.SerialNumber
那么一个具体的例子可能是:
urn:epc:tag:gid-96:0.00012345.054322.4208
如果应用直接和阅读器通信,你可能需要产生这些标签特定的URN。如果你的应用是通过某种形式的RFID中间件通信,或者某种具有数据管理能力的智能阅读器通信,你便可以使用某种纯粹的URN 身份表示。反之亦然:阅读器可以给你一个标签特定的URN,而中间件则可以给你一个独立于标签的纯粹身份。
由于试图快速进入成长中的 ESB 范畴的厂商的慌乱,以及大量行业分析师和记者在分析报告中分别展示他们各自的观点,可以理解,这其中对于ESB 到底是什么还具有很多混淆。这一节将概略说明 ESB 的主要特性。
如第 1 章所示, ESB 能形成普遍的网格的核心。它能够跨越和超过扩展企业,并且横跨部门组织、业务单位和贸易伙伴形成全局的范围。ESB 也能很好地适合于局部的集成项目,并且对促进它们采用任何类型的集成环境提供柔性的支撑。
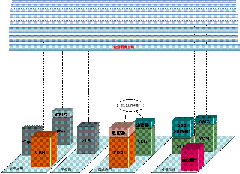
图表 1‑2 ESB 形成一个能跨越了一个全球企业网络的普遍网格
应用可以按需插入总线,并且具有可视性,以及能够与其它已经插入到总线中的任何其他应用和服务共享数据。虽然Web Services是 ESB 架构的一个有机组成部份,但是所有的应用并不是一定要被修改成为真正的Web Services才能参与到 ESB。连接性是通过多种协议、客户端API 技术、遗留消息环境、以及第三方应用适配器来达到的。
基于标准的集成是 ESB 的基本概念。对于连接性,ESB 可以使用J2EE组件,比如使用Java Message Service (JMS)来进行MOM连接,使用J2EE 连接器结构 (JCA 或 J2CA) 来连接应用适配器。ESB 也能够非常漂亮地与使用.Net、COM、C#、C/C++构建的应用进行集成。除此之外,ESB 也能集成支持SOAP和Web Services API的任何组件,这其中包括事实上的标准Web Services工具箱的实现,比如Apache Axis。为了处理数据操纵, ESB 可以使用XML标准,比如XSLT、XPath 和 XQuery 来提供数据变换、智能路由、以及在数据流过总线的时候提供“空中”查询。为了处理 SOA 和业务流程路由, ESB 可以使用 Web Services描述语言 (WSDL) 来描述抽象的服务接口,使用针对Web Services的业务流程运行语言(BPEL4WS)、WS- Choreography或者一些其他基于XML的词汇表,如 ebXML BPSS,来描述抽象的业务流程。
如果你还不懂这些深奥的词汇的含义,也不要担心。虽然本书并不想作为是这些各个技术的详细参考或个别指导,我们也会在他们如何与 ESB 有关的语境中足够详细地解释它们。
这些基于标准的接口和组件被整合到一个意义非凡的包含开放端点的可插入架构之中。ESB提供了一种基础设置来同时支持基于工业标准接口集成组件和使用标准化接口来实现的专有元素。下图展示了一个使用JMS和JCA集成一个 J2EE 应用、使用JCA应用适配器集成第三方打包软件、使用C#客户端程序集成一个.NET应用、使用Web Services集成两个外部应用的案例的高阶视图。
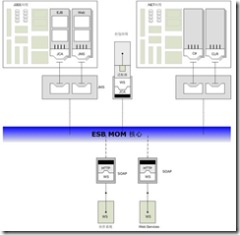
图表 1‑3 ESB 整合多种不同的技术
ESB 在其中借鉴了传统EAI Broker的许多功能,比如从它提供集成服务 , 像是业务流程编排、数据路由、数据变换、以及应用适配器。然而,集成中介者通常是高度集中和单一的形态。ESB 将这些集成能力提供为独立的服务,能够以一种高度分布的形态一起工作,并且能够彼此间独立伸缩。在第 6 章中,你将会学习更多有关 ESB“服务容器”,ESB 的一项核心概念的内容,它允许对集成服务进行选择部署。
任何集成策略的一个关键部分就是能够轻易地在应用之间转换数据格式的能力。许多应用对描述相似的数据并不共享相同的数据格式。
数据变换是一个 ESB部署的一个固有部份。变换服务特别针对那些被插入总线的个别应用能够在总线的任何地方被定位和访问的需要。因为数据变换是ESB 本身的一个有机组成部份,解决应用之间的阻抗失配问题便可以想到ESB。
ESB 能够为你提供本质上针对任何集成项目所必需的核心能力,并且可以通过使用分层的服务来处理特定的用途来增加。例如,特殊的能力,比如业务流程管理 (BPM) 软件能处理工作流相关的业务流程,而协作服务器能够提供对伙伴业务流程管理的特殊服务。专门的第三方翻译器能够将外部数据,比如EDI,转换到能进入目标企业资源规划 (ERP) 系统之内的格式,或者在通用总线之上的规范XML表现。
在 ESB驱动的、事件驱动的 SOA中,应用和服务被当做抽象服务端点,能够轻易地对异步事件做出响应。SOA 对其底层的连接性和管线细节提供了一个抽象的方式。服务的实现不需要理解协议。服务也不需要了解消息是如何路由到其它服务的。他们只是简单地将接收自 ESB 的一个消息作为一个事件,然后处理该消息。ESB 可以把消息发送到它想要去的其他任何地方。
在 ESB SOA 中,用户定制服务可以被创建、扩展,并且被重用为ESB 功能。被暴露为服务的应用端点,可以同特殊的集成功能一起构造成复合业务服务和业务流程,并且它们可以根据不同目的重新组合,其目标是在一个即时企业中提供自动化的业务功能。
第 7 章将会更详细地讨论 ESB 中的 SOA 。
ESB的处理流从简单的优先步骤序列到使用条件分支和联合来并行执行的综合业务流程编排。这些特征可以使用简单的消息元数据或者通过使用诸如BPEL4WS 之类的业务编排语言来控制。
ESB 的处理流能力使得定义属于某个部门或者业务单位局部的,或者共存于一个较大的集成网络中的业务流程成为可能。这点却是一个集线器-插头中介者或一个 BPM 工具自己所不能很好地自己解决的问题。第 7 章将会详细讨论分布式的流程能力,它能提供高度分布的流程编排能力而不需要中心化的流程和规则引擎。
ESB的业务流能力也涉及到基于内容的消息的智能路由的特殊集成服务。
因为ESB 的业务流能力构建于分布式的SOA之上,它也能够跨越高度分布的物理部署拓扑(甚至扩越大洋)而不用痛苦地忍受总线上各种应用和服务之间的物理边界和多协议的鸿沟。
图表 1‑4 跨越物理和逻辑边界之上的部署拓扑的编排和业务流
在 ESB 上的节点之间的连结是具有防火墙能力的。应用和 ESB之间的安全性,甚至在 ESB 节点自身之间的安全性,能够建立和维护最高强度的认证、凭证管理、和访问控制。
可靠性是通过处于ESB核心的企业级MOM来达到的。MOM核心提供异步通信能力、业务数据的可靠传输、以及事务的完整性。你们将在第 5 章中学到,这已经不是十年以前的传统MOM技术了。需求从那时以后开始进展,并且已经成熟,而 作为ESB 的核心的MOM必须符合今天的需求。
传统的集线器-插头中介者方式往往具有组织性的边界问题,这主要是因为EAI Broker对跨越防火墙和网络域的无能的实际限制所引起。更重要的是,即使一个集线器-插头架构能够被伸展而跨过组织的交界,它仍然不允许各个业务单位彼此半独立地运行所需要的局部自治。与不断扩展的集成范围延伸超过部门层次所相关的最大问题之一是自治和集中控制之间的问题。
作为大多数大型公司环境的业务文化的一部分,每个部门或业务单位需要彼此独立地运作。 然而,他们仍然依赖于共享资源,以及输入到通用业务功能之中的报告和帐户信息。
在这样一个环境中,需要所有的消息流量都流过位于总部的一个集中的消息Broker的集成策略是不合理的。 这不只是一个技术上的障碍;它也是公司文化的问题。在一个松散耦合的业务单元环境中,诸如本地应用之间的业务流程,或者安全域,被一个集中化的公司IT功能管理简直没有一点道理。组织中的松散耦合业务单元需要彼此独立地运作。他们每一个都应该有其自己的IT功能,而不必须路由所有的消息流量,或代表它的业务规则和安全域的控制, 经过一个集中的集成经纪人在一个位置或另一个(第 1 章)。

图表 1‑5 如果使用一个集中的集线器,分开业务单位缺乏必需的自治-和-了集成经纪人
本地业务单位和部门需要有对他们自己的局部IT资源的控制,比如在其站点运行的应用。集成基础设施应该支持部署拓扑来支持具有实用性的业务模型。ESB 也提供这种部署模型, 允许本地流量、集成组件以及适配器能够被本地安装、配置、加固和管理,并且仍然能够以一种集成的安全模型一起将本地集成域插入到一个更大的联邦集成网络之中。
图表 1‑6 自治的而且公布联邦制,ESB 允许横过组织的交界对合作地同盟的运算组织
ESB 的分布式特征是通过从实际的部署细节和底层的连接协议中抽象出来的将端点定义,以及在那些端点之间的数据的编排和路由来达到的。联邦特征则是通过 ESB 能够隔离和选择地横过应用域和安全边界的能力来达到的。
在一些业务模型中,在每一个远程地点都安排有本地的IT职员是不大可能的,虽然仍然需要松散耦合的、自治的联邦的集成网络。举例来说明这一个点,我们来想象一下部署在零售行业中的ESB 的案例。一个视频租借链可能有数百或数千个包含相同应用的地点,所有以相同的形态运行的操作涉及到目录管理、会计和报表等。
图表 1‑7 和数以千计遥远的储存一个视像零售链,所有的包含应用程序的相同组
使用 ESB,可以建立一个集成蓝图来处理远程店铺中的局部应用之间的通信。这包括店内应用的接口定义、消息流量的路由、消息通道的管理、以及安全许可。它还可能包括集成组件,比如应用适配器、协议适配器或者数据变换器。这个集成蓝图,或称模板,可以在所有地点进行部署和定制,并且独立地扮演所有其他店铺。
图表 1‑8 ESB 配置蓝图在每个遥远的位置和很远地展开配置而且处理
这个远程部署蓝图的能力并不单针对零售行业,它也可以扩展到所有其他行业的应用。联邦的集成域的远程管理对于在一个高度分布的环境中的任何ESB的成功部署都是非常关键的。
安全、可靠的消息联结
除了在每个店铺的本地应用之间共享数据之外,这些远程店铺还需要同总部共享信息以便进行帐务处理和报表、信用管理以及职员数据的追踪。远程店铺还需要彼此之间共享信息。举例来说,一个大型的音像连锁店可能会提供这样的服务,顾客可以选择从离家近的店租赁影碟,然后在离办公室近的另一个店归还。因此,在同一个地理区域内的店铺之间可能会需要以近乎实时的状态共享有关租赁的数据。因为在远程店铺和总部之间的卫星网络通信连接存在较大的反应期和弹性,要在总部维护一个有关所有租赁信息的实时集中访问点是不现实的。那些有关你只是在两个小时之租借的数据需要共享,或者通过远程店铺之间的一个集成的数据共享连接来进行访问。
因为总部和远程店铺之间的连接是通过可靠的消息来达到的,因此由于不可靠的卫星电路所造成的网络服务终端可以从消息层得到补偿。也应该注意到,对于远程店铺之间来说,通过Internet来建立一个安全和可靠的消息通道也是可以的。
当数据通过ESB 在应用之间流动的时候,XML是一个表现它们的理想基础。被应用程序的一个巨大的行列生产而且耗尽的数据能以多种的格式存在和包装方案。有大量的应用产生和消费的数据,可以以各种格式或者打包的Schema存在。对ESB来说虽然的确可以依你喜欢的打包形式或者封装方案来承载数据,但将途中数据表现为XML具有莫大的好处,包括使用能够结合来自于不同的源数据以创建一个新的数据视图的产生数据的特殊 ESB 服务, 以及针对应用间高级数据共享的浓缩和重定目标。第 4 章将会探究使用XML功能本好处—将避免一个组织的应用间同步升级的需要—并且更详细地讨论分布式XML变换之后的基本原理。
ESB通过为途中数据在总线之上的应用间传输的时候提供实时吞吐消除了潜伏反应问题。目前,最流行的集成方法之一是每夜进行批处理。 然而,打包的成批处理集成策略,不管是每夜还是其它,都具有较高的边际错误率,并且造成信息获取的延迟。其结果是高反应期产生获取了过时数据将使代价高昂的。第 9 章将详细讨论这个问题,并且研究 ESB 可以如何用来将你的业务数据从每夜批处理模式重构为实时吞吐模式。
运行感知意思是业务分析师能够获得对业务运行的状态和健康情况的洞察能力。 一个允许对数据在其以某个业务流程中的某个消息形式在组织中流动时进行实时跟踪和报告的基础设施,对于帮助建立运行感知是一个无价的工具。一个称为是业务活动监控 (BAM)的产品门类已经出现来解决运行感知的这些问题。
使用XML作为ESB的原生数据格式的好处之一就是消息没有被处理为不透明的数据块。如果应用和服务之间的所有数据都被格式化为XML文档,ESB提供的基础支撑便允许你在ESB之上再构建一层高级能力,以获得对流过你的企业的业务数据的实时洞察能力。这些能力,不管是否是ESB的固有组成部分,还是有一个扩展来驱动,都表现为包括了路由、处理流、以及下层的管线,并且不需要再在其上锁定一个第三方的BAM产品的一个通用基础设施的一个有机组成部分。
作为ESB的一个基础部分的审计和跟踪能力允许对在SOA中的所有流动的业务流程和消息流的健康状况进行监控和跟踪。诸如数据缓存、数据收集和聚集、以及XML数据的可视化表现之类的增值服务,可以用来创建一个基础服务,该基础服务可以在数据在企业中流动时,产生对业务流程的状况洞察的警告、提醒和报表能力。
图表 1‑9 增值型服务促成操作的觉察提供对活的业务数据的即时洞察
对ESB中的数据的根踪和报表是通过在业务流中定义审计点来达到的,然后再对从业务消息中收集的重要内容在ESB中流动时提供插入点。可追踪数据例子是业务消息自身,以及指示某业务消息是否通过了某个特定的业务处理步骤的业务事件。
高级的增值服务可以提供数据收集服务、查询机制以及报表能力,它们能够讲所有数据进行收集、进而表现为各种具有意义的形式。XML持久性服务可以提供缓存和聚集点,这样可以收集将要转换的数据从而向其他应用提供数据输入,或进入到可以被业务分析师使用的人可读的报表机制之内。这意味着流经ESB的数据可以进行实时分析,以提供有关你的业务状态的实时信息—比如,可以随时提供有关你的供应链中的存货的状态快照。
区别是否真正是 ESB 的一个主要方面是看其是否具有逐渐采用的能力,相对于另一个“全有-或-全无”的论断。在 Y2K 之后的开支削减中,数百万美元预算的项目数目已经今非昔比。有一些迹象表明,预算资金筹备正在开始释放以解决短期的战术性集成需要,但是预算仍然谨慎地处于一个执行层面。,然而,同时仍然有一些期望实现较大的公司范围集成策略计划—这些计划严重依赖于集成和现有IT资产的重用。
图1-10说明了 ESB 可以如何用于小项目中,然后它们都可以进入到一个更大的集成网络之内。 当我们深入阅读本书的时候,我们会详细研究这是如何实现的。

图表 1‑10 ESB 支持逐渐采用的集成,同时向着一个策略目标工作
ESB 的联邦/自治能力也对一次一个项目采用 ESB的能力有助益。ESB 集成项目渐进式的分布部署能够在朝着一个更广的企业层面的计划目标的前提下得到立即价值。
逐渐采用的观念将进一步通过桥接到一个已有的集成Broker集线机器和遗留系统Broker来得到进一步支持。集成Broker集线器和他们的特点将在第 2 章中详细研究。
一版来说,架构是指将系统分解为各个单独的组件,以表示它们之间如何一起协同工作来满足整个系统的需求和目的。随着技术的融合,RFID系统提供的一些主要功能已经对使用它的系统架构带来明显的影响。我们本部分将研究RFID加入到系统架构中的组件,以及这些组件如何影响系统的相关特性,比如:系统的非功能性需求,如性能、安全、可伸缩性、可管理性等等。并且对使用RFID的系统提出架构指南。.
RFID 可能在跟踪技术和传感器网络技术方面具有很强的相关性和可融和性,在很多领域的技术发展和进步也体现了这一征兆。
根据摩尔定律,RFID 会越来越便宜,并且可能会集成更高的存储和处理能力,并且在市场可以接受大规模使用的场景。
半导体技术的进步并不仅仅是使得RFID的成本变得越来越便宜,而且也随着网络和痛惜年技术的发展出现了许多智能设备,比如移动电话、PDA、数字媒体设备等,也包括RFID阅读器的传感器。智能设备和无处不在的网络连接和带宽会导致许多基于移动和边缘的应用。RFID 就是物联网(Network of Things)之随处连接以提供超出企业和组织数据中心和内部网络边界的自动化的理念的一种实现。智能家居、智能汽车、甚至智能衣服和消费品都是需要这些边缘处理能力的应用。比如当前的智能家居概念和实现就利用了大量各种具有IP能力的家用设备连接到住宅网关,然后由它在连接到互联网络。下图就描述了一个连接到Internet的智能设备的概念示意图,可称为网络化生活:
图表 3‑1 网络化智能生活
越来越普遍的宽带数据网络和超越连线和物理限制的无线通信,以及更加能够接受的强大的服务器,使得应用的架构越来越偏向于分布,即将业务的处理移到业务发生的地方,凡是保证中心的管理和统一的安全。这意味着在一个整体框架之下,可以部属各种企业应用组件到边缘位置,比如仓库和店面。
所谓边缘处理能力就是企业系统中由于强大但低廉的个人计算机、以及企业部属在边缘的服务器、以及到企业数据中心安全和可靠的宽带连接给企业带来的在边缘处理业务的计算能力。RFID 系统就将大量的计算、数据管理和带宽需求放到这些边缘。这并不是偶然的单独现象而是一个总体趋势。所谓边缘,就是分布于企业数据中心或者总部之外的地点,而大都是实际业务发生的所在地,比如仓库、店面、生产线甚至物流运输途中。
企业中成功采用RFID技术的关键在于如何将RFID数据集成到企业业务应用骨干中。RFID阅读器会产生大量的数据。如果它们不加过滤地传递到下游应用,可能会使其崩溃。为了避免后端关键业务应用遭受数据洪水,以及将重复、无效或者无用的数据隔离在物理设备,如阅读器和天线之外,可以使用专门的RFID中间件,比如事件管理器。SOA允许我们开发和部署松散耦合的应用组件,这些组件件使用简单但强大的服务接口来进行通信。目前许多RFID 中间件都基于Web Services标准,RFID中间件的总体架构也符合在企业业务系统中日益被接受和采用的SOA架构。
图表 3‑2 企业边缘
RFID系统具有多重可能的不同用法,这自然会影响到其架构的差别。例如,通常由制造商实现的用于标签和物流跟踪的应用的实现通常关注于产品的自动化标签以及在物流过程中的特定的阅读器能够以一种高于最小可接受准确率来读取。总而言之,这些系统都主要集中于实现的物理方面,而不是产生诸如提前装船通知之类的简单报表。这样的话,它们趋向于具有最小的数据管理和交换要求。但另一方面,一家药品公司可能会想要根据其药品从工厂到分销商再到零售药店,这就需要具有实时的信息,包括某件在流程的某个点上某件商品位于何处之类的详细信息,以及它们是被如何以及在何处生产的,以及到过什么地方。很多可能,零售商和制造商都需要这些跟踪信息的某些部分。因此,这种系统将要求不但具有单个物品级的跟踪能力,还需要具有某种程度的B2B信息交换能力。
下图所示是RFID的5种基本能力和相关不同应用对这些能力的需求映射。
可以想见, RFID 系统将不断演进以满足更广的应用需要,因此也要求不同的架构方式。但是我们可以定义通用的,失和于所有RFID用法的RFID 系统架构或者实现。但是,几乎对每个RFID系统来说可能都需要某些特定的能力。

图表 3‑3 不同的RFID应用系统需要的能力
总的来说,一个RFID 系统必须能够提供下述特征或者能力中的全部或者部分::
- 编码RFID标签的能力
- 附加经过编码的RFID标签到被标识物品上的能力
- 跟踪被标签的物品的移动的能力
- 将RFID信息集成到业务应用的能力
- 产生能够在业务之间共享的信息的能力
- 开发自组织智能设备的能力
哈哈,下午再来,变成366天啦:
射频识别标签(RFID)技术是一种综合了自动识别技术(Auto-ID)和无线电射频通信技术的新技术。它可望在网络、生活、经济、文化、道德和伦理、法律、军事等等诸多方面带来彻底的变革,成为继Internet和无线和移动通信之后又一个决定性的社会变革力量。并最终可能和Internet(IPV6)、移动通信网络、无线传感器网络、生物识别技术、GPS技术等融合。
RFID 的出现可追溯至上世纪30年代,当然其基本技术无线电射频技术还可以追溯至1897年Guglielmo Marconi 发明无线电的时候。RFID 采用与无线电广播相同的物理原理来发射和接收数据。
RFID的基本前端系统一般由3个部分组成:
- 标签(tag)或者雷达收发器(transponder);
- 接收器(receiver)或者阅读器(reader);
- 天线。
而这些部件则有许多变体,基于不同的功率、发射范围和距离、天线设计、工作频率、数据容量、管理和操作软件、数据编码格式、空中接口和通信协议等等。这样,便出现了许多不同类型的系统,具有不同的特点和针对的应用范畴。
这些应用中涉及和影响到当今社会、生活、经济、军事、法律和文化的方方面面。而目前最热烈和最受关注的莫过于廉价标签在商品(货物)流通生命周期过程中的识别应用。
RFID技术很早就和军事联系在一起。在上世纪30年代,美国陆军和海军都面临着在陆地、海上和空中对目标的识别的问题。1937年,美国海军研究试验室(U.S. Naval Research Laboratory (NRL))开发了敌我识别系统(Identification Friend-or-Foe (IFF) system),来将盟军的飞机和敌方的飞机区别开来。这种技术后来在50年代成为现代空中交通管制的基础。并且是早期RFID技术的萌芽,而优先地应用在军事、实验室等。
早期系统组件昂贵而庞大,但随着集成电路、可编程存储器、微处理器、以及软件技术和编程语言的发展,创造了RFID技术推广和部署的基础。
60年代后期和70年代早期,有些公司(如Sensormatic 和Checkpoint Systems)开始推广稍微不那么复杂的RFID系统的商用,主要用于电子物品监控(electronic article surveillance (EAS)),即保证仓库、图书馆等等的物品安全和监视。这种早期的商业RFID 系统,称为1-bit 标签系统,相对容易构建、部署和维护。但是这种1比特系统只能检测被表示的目标是否在场,不能有更大的数据容量,甚至不能区分被标识目标之间的差别。
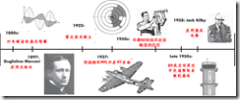
图表 2‑1 早期的RFID发展里程碑
因此早期的1bit系统只能作为简单的检测用途。
在70年代,制造、运输、仓储等行业都试图研究和开发基于IC的RFID 系统的应用。比如、工业自动化、动物识别、车辆跟踪等等。在此期间,基于IC的标签体现出了可读写存储器、更快的速度、更远的距离等优点。但这些早期的系统仍然是专有的设计、没有相关标准、也没有功率和频率的管理。
在80年代早期,更加完善的RFID 技术和应用出现,比如铁路车辆的识别、农场动物和农产品的跟踪。
90年代,道路电子收费系统在大西洋沿岸得到广泛应用,从意大利、法国、西班牙、葡萄牙、挪威,到美国的达拉斯、纽约和新泽西。这些系统提供了更完善的访问控制特征,因为它们集成了支付功能,也成为综合性的集成RFID应用的开始。
从90年代开始,多个区域和公司开始注意这些系统之间的互操作性,即运行频率和通信协议的标准化问题。只有标准化,才能将RFID的自动识别技术得到更广泛的应用。比如,这时期美国出现的E-ZPass 系统。
同时,作为访问控制和物理安全的手段, RFID 卡钥匙开始流行起来,试图取代传统的访问控制机制。这种称为非接触式的IC智能卡具有较强的数据存储和处理能力,能够针对持有人进行个性化处理,也能够更灵活地实现访问控制策略。
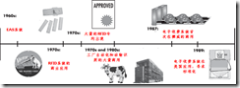
图表 2‑2 唯一性识别的应用
在上世纪末期,大量的RFID 应用指数般地试图扩展到全球范围。
在美国,Texas Instruments 则是这方面的推动先锋。TI从1991年开始建立德州仪器注册和识别系统(Texas Instruments Registration and Identification Systems (TIRIS))。该系统如今叫TI-RFid (Texas Instruments Radio Frequency Identification System),已经是一个主要的RFID应用开发平台。
在欧洲,EM Microelectronic-Marin 从1971年开始研究超低功率的集成电路。1982年,Mikron Integrated Microelectronics 开始了ASIC技术,并在1987年由其奥地利分公司开始开发识别和智能卡芯片。1995年,Philips Semiconductors 收购了Mikron Graz。如今EM Microelectronic 和Philips Semiconductors 是欧洲的主要RFID 厂商。
从技术上看,数年前,所部署的RFID应用基本上都是低频(LF) 和高频 (HF) 的被动式RFID技术。LF 和HF 系统都具有优先的数据传输速度和有效距离。因此,有效距离限制了可部署性。数据传输速度则限制了其可伸缩性。因此,90年代后期,开始出现甚高频(UHF)的主动式标签技术,提供更远的传输距离,更快的传输速度。基于此,重载的企业应用才开始使用这种技术,比如供应链管理中的托盘和包装跟踪、存货和仓库管理、集装箱管理、物流管理等等。并且逐渐试图成为合成的企业应用(包括ERP、SCM、CRM、EAM、B2B等等)的数据和语义基础。
从90年代末期到现在,零售巨头如Wal-Mart,Target,Metro Group 以及一些政府机构,如美国国防部 (DoD),都开始推进RFID应用,并要求他们的供应商也采用此技术。同时,标准化的纷争出现了多个全球性的RFID标准和技术联盟,主要有EPCglobal、AIM Global、ISO/IEC、UID、IP-X 等。这些组织主要在标签技术、频率、数据标准、传输和接口协议、网络运营和管理、行业应用等方面试图达成全球统一的平台。

图表 2‑3 整合应用开始
一个RFID 系统 通常有两个组件组成: (Figure 1.7):
- 收发器(transponder)或者标签(Tag),位于或者通过某种物理手段附加于被识别的对象之上;
- 讯问器(interrogator)或者阅读器(reader),取决于设计和所采用的技术,可以是阅读或者读写设备。
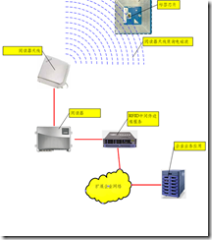
图表 2‑4 RFID系统的主要构成
阅读器通常包含一个射频模块(发射器和接收器),一个控制单元和一个与收发器的耦合单元。另外,某些阅读器还包含其他数据接口系统(RS 232, RS 485,TCP/IP等),以便将数据转发到其他系统 (PC, 机器人控制系统等)。
雷达收发器,表示RFID系统的实际数据载体,通常有一个耦合单元和一个电子芯片组成。(Figure 1.9)。雷达收发器通常不具备自身电源供应,当它不在质询器的质询范围时,整体呈被动状态。它只有在质询器的质询范围之内才被激活。激活雷达收发器的电力通过耦合单元传输给收发器,所需的数据和时钟脉冲也是如此。

图表 2‑5 RFID 数据承载设备的主要布局。上面是一个UHF标签,下面是一个HF标签。
本系列编译自 O'Reilly的《Enterprise Service Bus》,将陆续发布上来。
1 企业服务总线简介
在一个事件驱动型企业中,影响业务流程的正常进程的业务事件可以以任何顺序随时发生。那些以自动化的业务处理方式交换数据的应用需要使用事件驱动的 SOA 来彼此通信,以便能够对不断变化的业务需求具有敏捷的反应。SOA 向业务分析师和集成架构师提供了处理高阶服务的关于应用和集成组件的宽泛的抽象视图。而在 ESB,应用和事件驱动的服务彼此以一种松散耦合的紧密地与流行的 SOA 维系在一起,这允许它们彼此能够独立运行,并且仍然能够提供较宽广的业务功能价值。
在 SOA 的王国,事件被表现为一种开放的XML格式文件,以及经过一个对验证开放的,可以协调的透明管线中的流(Flow)
—John Udell, InfoWorld
SOA 的服务组件暴露的是一种粗粒度的接口,其目的是使应用之间能够异步地共享数据。而使用 ESB,一种集成架构将应用程序和分离的集成组件拉在一起,以产生服务装配组合从而形成复合的业务流程,进而自动化一个即时企业中的业务功能。
ESB 为SOA提供实现骨架。那就是说,它通过一个跨越多种协议的消息总线来提供一个有关命名路由目的地的高度分布的世界来提供松散耦合的,事件驱动的 SOA。ESB 中的应用程序 (和集成组件) 在理论上是彼此解耦的,而且通过总线彼此连接为暴露为事件驱动服务的逻辑端点。
通过分布式的部署配置基础设施, ESB 能有效率地提供对在扩展企业中分布的服务的中心配置、部署和管理。一种普遍集成的新方式应用诸如SOA、EAI、B2B 和Web服务之类的技术的通常目标主要是创建一个集成架构,且能够深入并且跨越整个扩展企业。对于一个集成基础设施到达到这种普遍性,它必须具有下列各项特性:
- 它必须能够适应多种集成情形项目的通常目的需要,不管是大型的还是小型的。适应性包括提供一个能够经受协议、接口技术、甚至流程模型的变化趋势的持久架构。
- 它必须以一种单一和统一的方式,以及一个通用的基础设施来连接扩越扩展企业的各种应用。
- 它必须能够扩展超出单一公司IT中心的边界。并且自动化伙伴关系,比如在B2B 和供应链的情况下。
- 它必须具有设计的简单性和较低的进入门坎,使得日常的IT专业人员也能够成为自我修练的集成架构师。
- 它必须提供一个跨越普遍集成的 SOA,它能使集成架构师能够对公司的应用资产和自动化业务流程有一个广泛的、抽象的视图。
- 它需要有能够反应和符合不断变更的业务需求和竞争的压力需要的灵活性和能力。
在 ESB中,应用和事件驱动服务以一种松散耦合的方式紧密地联系在SOA 中。 这使得它们能够彼此独立运行,并且仍然能够提供广泛的业务功能价值。
ESB 架构解决了这些需要,并且正在被各种通用的集成项目所采用。它也能够在企业应用层面普遍地伸展,不管是物理位置还是技术平台。任何应用都可以通过大量的连接选择插入到一个 ESB 网络中,并且可以立即参与到与那些通过总线暴露为共享服务的应用之间的数据共享之中。这是 ESB 为什么经常被称为集成网络(integration network)或集成构造(fabric)的缘故。
ESB 提供为集成提供了一种高度分布式的架构,并且具有能够让独立的部门和业务单元能够以一种逐渐增加的、可消化的分块来构建它们的集成项目的独特能力。使用 ESB,部门和业务单元仍然能够继续在独立的集成项目中维护它们自己的本地控制和自治,并且仍然能够将它们的集成计划连接到一个更大的、更全局的的集成网络或网格之中。
Web 服务已经通过为应用间的互操作性提供一种基于标准的方式为面向服务架构找到了新的重要性。Web服务的主要目的是提供了一种服务抽象,它允许应用之间的互操作性使用不同的平台和环境来构建。这一个目标的实现将能够提供一个应用之间的普遍集成的更容易的路径。
由于ESB的出现,现在有了一种方式能够将Web Services和SOA合并到一个意义非凡的架构中,以将应用和服务以一种高度伸缩的状态集成到一个扩越扩展企业的骨架之中。ESB使用今天已经成熟的技术立刻使得Web Services、XML、以及其他集成技术更加有用。
SOA 的核心原则对于普遍集成项目的成功至关重要,并且已经在 ESB 中被彻底实现。 Web Services标准正在有朝着正确的方向前进,但是在提供企业级能力方面还未完成,比如安全性、可靠性、事务管理和业务流程编排。ESB 以这些领域中今天已经确定的标准为基础,而且已经有实际实现部署在各种领域和行业中。ESB完全有能力跟上Web Services相关能力的革新进展步伐。第 12 章提供了更详细的关于这一个主题的讨论。
ESB 通过从EAI中介者(Broker)那里学来的概念和技术将Web Services和其他补充标准结合在一起。然而,ESB 并不仅仅是在同一个老式的EAI 集线器之上的简单的Web Services外衣。
传统的形式化的集成方法都有其优缺点。第 1 章就展示了有关集成的一些高阶的显著特色, 范围从左下方最不令人想要的,到右上方象限中的最令人想要的。
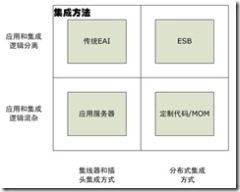
图表 1‑1 传统的 EAI 中介器,应用服务器,MOM和 ESB 的特性
传统的 EAI 中介器,包括那些已经构建在应用服务器之上的,使用一种集线器和插头(hub-and-spoke)架构。集线器和插头有一些中心化功能的好处,比如路由逻辑和业务规则的管理,但是不能很好地伸展扩越部门和业务单位的边界。第 2 章将讨论使用集线器在集成中的早期尝试的巨大代价,以及它们的初步成功。
应用服务器可以通过标准协议进行互操作,然而它们是以一种紧密耦合的方式进行连接的,并且集成逻辑和应用程序逻辑纠缠在一起。
EAI 中介器通过将应用逻辑从集成和流程路由逻辑中分离出来提供了增加价值,然而你仍旧要忍受集线器-插头架构的痛苦。
面向消息中间件 (MOM) 提供了以松散耦合和异步的方式连接应用的能力。然而,MOM自身需要在应用中进行低级的编码。使用传统的MOM,以及定制的编程技术,比可以在分布式的集成解决方案上走得更远。然而,没有对路由逻辑的高阶抽象,这种方式仍然要忍受集成逻辑难以连接,并且也和应用逻辑纠缠在一起的痛苦。依赖于MOM的使用,即使是分布式特征也会受到限制,因为一些传统的MOM基础设施对实际的网络边界的跨越也不是做得很好。
最后,在 ESB 中,服务可以被配置而不是编码。处理流程和服务能够透明地跨越整个服务总线。ESB 提供了能够很好地扩越集线器-插头架构范围的高度分布式集成环境,并且清晰地分离了应用逻辑和路由数据变换之类的集成逻辑。一个 ESB 架构形成了一个消息集线器和集成服务的互连接性网格,具有一个彻底分布的集成网络的功能性和智能性。
第 6 章更进一步描述在使用应用服务器集成和使用ESB集成之间的对比。MOM的概念在第 5 章讨论。第 2 章的 “附属架构”继续讨论业务流程路由逻辑和业务逻辑之间的分离。
ESB 的一个关键特性就是要为支持分布式的、松散耦合的业务单位和伙伴,比如自动化供应链,提供支撑基础。ESB 的这些能力是其固有的必要特征,并且是中间件厂商与那些想要创建大规模集成架构的业界专家共同工作的结果。这些业界专家包括了大公司IT架构师、以及电子市集贸易社区中想要基于共享服务、消息、XML何其他众多的连接选择来建立B2B集成骨架的改革者,并且要坚持遵守工业标准。第 3 章将会讨论对 ESB 概念的创造有助益的许多催化剂。
同时,仍然必须解决的最大需要在于如何还没有的最大需要被定址包括该如何有效地提供集成能力、比如应用适配器、数据变换、以及能够用于通用的集成项目,跨越多种集成情性的智能路由。并且需要超越于个别战术性的集成项目之上的,更加通用的技术和更加架构性的方式。
IT专家已经对以前的一些技术趋势失望,比如CORBA、或者EAI什么的。CORBA 有着与SOA 一样的正确理念,但是其与生俱来就太复杂而难以维护,因为它依赖于应用和服务之间的紧密耦合接口。EAI 也痛苦于对单个项目上的陡峭的学习曲线和昂贵的进入负担 (下一章将详细讨论这个内容)。真正需要的是SOA的简单方式,以及可以被采用来适应任何集成工作,大型或者小型,的一种架构。此外,那就是需要一个能够经受协议、接口、甚至业务建模趋势的变革的持久架构。ESB的概念就是创建来解决这些需要的。
自从ESB 概念在 2002 年被首次引入,ESB 的集成方式已经被中间件、集成和Web服务市场中的很多重要的厂商采用。其接受度正在稳定持续地增长。
从2002年早期开始,分析公司,比如 Gartner 公司、IDC、ZapThink等,就已经开始跟踪和编写有关 ESB 的技术趋势。在Gartner 公司于2002年发布的一份报告(DF-18-7304)中,分析师 Roy Schulte 这样写道:
一种新型的 企业服务总线架构- 结合了面向消息中间件(MOM)、Web Services、数据变换和智能路由的基础设施—将会 2005 之前在很多的企业中运行。
这些高功能、低成本的ESB能够被很好地适应作为面向服务架构和企业神经系统的主干。
那四个支柱—MOM、Web Services、数据变换和路由智能 — 表现了任何优秀的ESB 的基础。当我们探究 ESB 的时候,本书将会集中于其中每一个基础和其他必须的组件的角色。我们还要讨论将会讨论 ESB 究竟能为企业做些什么、以及它的基本组件所扮演的角色。我们还要讨论一些高阶主题,包括横越多种行业之上的实践性使用的架构性概述。
有许多中间件和集成厂商已经,或者正在构建,符合ESB描述的某些产品。并且这个名单还在不断增加。附录中列出所有的已知厂商。一些厂商已经声称他们已经开始提供 ESB了 ;而有些则正在计划构建;有些则只是在市场宣传材料中使用这一技术术语而实际上背后还没有实质性的东西。当超过 25个厂商正在为相同的技术空间竞争的时候,这一个技术范畴注定要变成像上世纪90年代的应用服务器一样的炙手可热。
这个清单中有个别厂商应该特别提及。Sonic软件最先倡导了这个概念,此后不久许多其他的较小厂商业进入此领域,声称他们也正在提供 ESB 或是正在开发之中。一但那些著名的集成公司,比如webMethods、SeeBeyond 和 IBM 最终搭上这趟巴士(“BUS”),并且想要开始建立他们的ESB,ESB 术语才真的开始广泛引起业界注意,是一个强大的不断发展技术范畴。
在本书写作的时候,微软公司还没有对其Indigo项目和有关ESB发布任何公开的说明。然而,一些记者和分析师在Indigo项目宣布的时候还是将二者联系起来。2003 年11月 30 日, ComputerWorld 的文章说,“开发人员的兴趣被微软的技术伤害了”,Gartner 公司的 Roy Schulte关于Indigo项目提出。
Roy Schulte,是Gartner 公司在斯坦福的一个分析师,注意到Indigo项目其实是微软消息队列(MSMQ)、公司的COM、COM+、.Net Remoting、以及Web Services技术的超集。“把它想成代表微软公司的通信中间件计划的简化和统一,”他说,并说他认为Indigo是一个非常好的企业服务总线(ESB)。
Indigo以消息为基础,并且打算结合MSMQ 和Web Services。可以提供一个消息总线的基础。然而,其集成能力的其余部分则被锁定到BizTalk 之内,而它是一个集线器-插头风格的集成服务器。为了成为真正的ESB,分布式消息总线和分布式集成能力都要具备。
如果Indigo项目完成,构建于微软平台之上的应用和服务将能够更加吸引人地作为端点连接到ESB之上。将Indigo包含到微软平台和开发环境之内将更加能够使得应用具有松散耦合和消息感知能力。
这个系列会陆续编写有关RFID的基础知识和产业及应用分析。
1.1 RFID领域和市场概述
近年来,自动识别系统 (Auto-ID) 在很多服务领域、商务和分销、物流、工业和制造以及材料流等领域变得越老越流行。在这些领域中,自动识别过程提供关于人员、动物、货物、材料和产品等在传输过程中的信息。
普遍使用的条形码标签在很久前出发了一场识别系统的革命,但是现在随着急剧增长的编号数量已经发现越来越不适用了。条形码可以十分便宜,但是其致命缺陷是其低存储容量和不能重新编程的特点。
技术上讲,更好的方案是在硅芯片之上存储数据。我们日常生活中在用的最常见的电子数据设备是接触式IC卡(电话卡,银行卡等)。然是机械接触的IC卡却限制了其适用性。在数据承载设备和阅读器之间的非接触式数据传输可以带来更大的灵活性。在理想情况下,用于操作数据承载设备所需的电力也可以通过非接触方式从阅读器进行传输。因为用于传输数据和电力的方式,非接触ID 系统也称为是RFID系统(射频识别)。
活跃在RFID系统领域中进行开发和销售的公司的数量说明了这是一个应该认真对待的市场。在2000年,RFID系统在美国的销售额大约是9亿美元,并可望在2005年达到26.5亿美元,在2008年达到42亿美元左右。RFID 市场因此成为射频技术领域 (还包括移动电话和无绳电话)增长最快的领域。
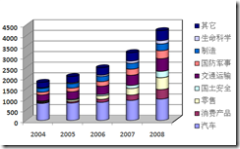
图表 1‑1 RFID的应用市场细分及增长
并且,近年来,非接触识别已经发展成一本独立的交叉学科,它整合了多种完全不同的领域:高频技术和EMC,半导体技术,数据保护和加密,通信,制造科学和其他相关领域的技术。
标准方面,目前RFID尚未形成统一的全球化标准,市场呈现多种标准并存的局面。从全球范围来看,美国已经在RFID标准建立、软硬件技术开发、应用等方 面走在世界前列。欧洲RFID标准追随美国主导的EPC global标准,在封闭系统应用方面与美国基本处于同一阶段。日本提出了UID标准,但支持者主要是本国厂商。韩国政府对RFID给予了高度重视,但至今韩国在RFID标准上仍模糊不清。在我国,科技部、信息产业部正联合14个部委制订《中国RFID发展策略白皮书》,预计2006年上半年可以发布。但 使用频率没有完全开放、产业整体发展水平滞后和实际应用匮乏,仍在很大程度上制约着我国RFID标准的制订与实施。
市场规模方面,截至到2005年底,全世界已经安装了约5000个RFID系统,实际年销售额约9.64亿美元。在零售巨头沃尔玛、麦德龙的推动下, RFID在零售业也取得了一定进展,但整体规模仍十分有限。随着Gen2标准的完善和实施成本的逐渐下降,我们预计,2006年全球RFID产业将取得实 质性突破。2007年,全球RFID将全面启动,进入快速增长阶段,增长率超过50%。这一过程将至少持续到2009年,之后会保持平稳增长态势。在我 国,2005年RFID市场规模达到了16亿元人民币,与2004年同比增长25%。详细情况如下图所示:
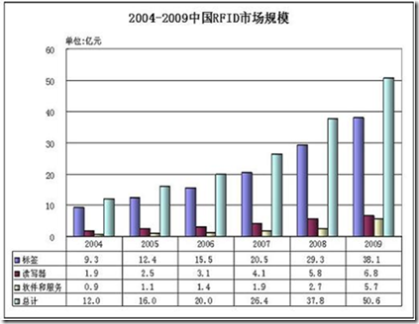
图表 1‑2 2004-2009中国RFID市场规模
应用领域方面,我国RFID主要应用于物流、医疗、货物和危险品追踪管理监控、民航行李和包裹管理、强制性检验产品、证件防伪、不停车收费、电子门票等领域。另外,在汽车防盗物品跟踪等各方面也在不断开拓新的应用。详细分布如下图所示:

图表 1‑3 中国RFID主要应用领域
从产业链的角度来看,RFID产业链包括:芯片、标签、天线、读写器、中间件、系统集成以及实施咨询等环节。其中RFID芯片全球范围内仍然由飞利浦、西门子、ST、德仪等传统半导体厂商所垄断。荷兰皇家飞利浦电子是该领域的龙头老大,其RFID标签累计出货量已经超过了10亿只。国内的复旦微电子、大唐微电子等半导体厂商虽然也已进军这一领域,但目前仅局限于第二代身份证、智能卡等业务。标签、天线、读写器等环节,总体而言也是Alien、 Intermec、Symbol等国外厂商的天下,国内只有为数不多的几家厂商在进行相关研究。中间件、系统集成方面,IBM、HP、微软、SAP、 Sybase、Sun等国际巨头已经抢占了有利位置,国内像用友之类的ERP企业也开始涉足这一领域,但研发进程和投资力度显然与上述几家国外厂商无法同 日而语。总之,中国RFID目前还没有形成完善的产业链,市场上绝大部分产品都是代理国外的。虽然目前开展RFID业务的企业已经超过了100家,但总体 而言仍受核心技术缺失的困扰,真正具有较强自主研发实力的企业并不多,而且大都集中于低端产品,同质竞争比较严重,拥有政府背景的企业更易占据有利竞争位置。
2006年,中国RFID市场仍会以产业链壮大与市场培育为主。标准的出台会对中国RFID产业产生积极的促进,预计会有越来越多的企业加入到这个行 业的竞争中,但只有像深圳远望谷、实华开这样有深厚背景和技术积累的企业才具有利用本地化优势与国外厂商一决高下的实力。不过,中国未来巨大的潜在市场规 模,无疑为国内各类RFID厂商提供了广阔的生存空间。
1.2 自动识别系统(Automatic Identification Systems)
图表 1‑4 主要的自动识别技术
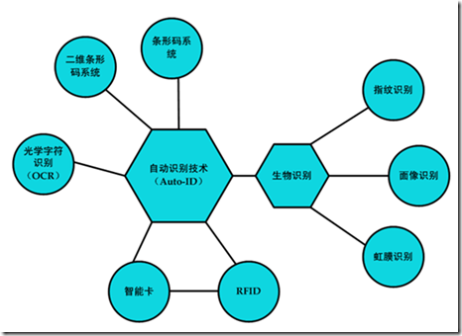
条形码系统(Bar Code System)在过去20年历牢牢的统治着识别系统领域。 据专家估计,在上世界90年代早期,条形码系统在西欧的总容量曾达到30亿德国马克。
条形码是由平行排列的线条和间隔所组成的二进制编码。它们根据预定的模式进行排列并且表达相应记号系统的数据项。宽窄不同的线条和间隔的排列次序可以解释成数字或者字母。它可以进行光学扫描阅读,即根据黑色线条和白色间隔对激光的不同反射来识别。但是尽管其物理原理相似,目前在用的大约有10数种不同的编码和布局方案。
最流行的条形码方案是EAN 编码 (欧洲物品编码),它在1976年设计,本来针对杂货店。EAN 编码是美国UPC (通用产品编码)的发展。今天, UPC表达为EAN 编码的子集,并且可以兼容之。
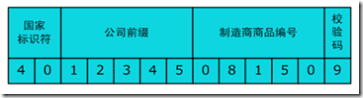
EAN 编码由13位数字组成:国家标识符,公司标识符,制造商的物品标识符和校验位。如图3:
图表 1‑5 EAN编码的条形码实例
除了EAN 之外,下列条形码在各种领域也很流行:
n Code Codabar: 医学和临床应用,以及高安全需求的领域
n Code 2/5 interleaved: 自动化工业,货物存储,货盘,集装箱和重工业。
n Code 39: 流程工业,物流,大学和图书馆。

图表 1‑6 ISBN统一书号代码
由于一维条码的信息容量很小,如商品上的条码仅能容纳几位或者几十位阿拉伯数字或字母,商品的详细描述只能依赖数据库提供,离开了预先建立的数据库,一维条码的使用就受到了局限。基于这个原因,人们迫切希望发明一种新的码制,除具备一维条码的优点外,同时还有信息容量大、可靠性高、保密防伪性强等优点。为了满足人们的这种需求,美国Symbol公司经过几年的努力,于1991年正式推出名为PDF417的二维条码,简称为PDF417条码(见下图1),即 “便携式数据文件”。

图表 1‑7 二维条码PDF417
PDF417条码是一种高密度、高信息含量的便携式数据文件,是实现证件及卡片等大容量、高可靠性信息自动存储、携带并可用机器自动识读的理想手段。PDF417条码具有如下特点:
n 信息容量大
根据不同的条空比例每平方英寸可以容纳250到1100个字符。在国际标准的证卡有效面积上(相当于信用卡面积的2/3,约为76mm*25mm), PDF417条码可以容纳1848个字母字符或2729个数字字符,约500个汉字信息。这种二维条码比普通条码信息容量高几十倍。
n 编码范围广
PDF417条码可以将照片、指纹、掌纹、签字、声音、文字等凡可数字化的信息进行编码。
n 保密、防伪性能较好
PDF417条码具有多重防伪特性,它可以采用密码防伪、软件加密及利用所包含的信息如指纹、照片等进行防伪,因此具有极强的保密防伪性能。
n 译码可靠性高
普通条码的译码错误率约为百万分之二左右,而PDF417条码的误码率不超过千万分之一,译码可靠性极高。
n 修正错误能力强
PDF417条码采用了世界上最先进的数学纠错理论,如果破损面积不超过50%,条码由于沾污、破损等所丢失的信息,可以照常破译出丢失的信息。
n 容易制作且成本低
利用现有的点阵、激光、喷墨、热敏/热转印、制卡机等打印技术,即可在纸张、卡片、PVC、甚至金属表面上印出PDF417二维条码。由此所增加的费用仅是油墨的成本,因此人们又称PDF417是“零成本”技术。
n 条码符号的形状可变
同样的信息量,PDF417条码的形状可以根据载体面积及美工设计等进行自我调整。
在我国,中国物品编码中心介绍了二维条码国家标准《四一七条码》,即GB/T17172-1997。
光学字符识别(Optical character recognition (OCR))最早在上世纪60年代开始应用。人们开发了一些特殊的字体,以便能够使人和机器都能够阅读。OCR 系统最大的优点是信息的高密度性以及在紧急情况下人可以介入进行可视阅读。
今天, OCR已经被用在生产,服务和管理领域,并且在银行用作支票的注册。
但是, OCR系统没有成为通用手段的原因是其高昂的价格和与其他识别方式相比更加复杂的阅读器。
生物特征识别(Biometrics) 是基于人类人体自身所带的某种身体或者行为特征进行模版化后对个体进行识别。因此,该方式具有其他方式所不具备的特征,即识别特征是天然的不可重复的(理论上)。对于方式来说,主要有指纹、掌纹、声音、语音、虹膜、视网膜、步态、面容等等。其中指纹方式是最流行和普遍的。
关于生物特征识别的详细内容,请参见公司编写的《生物特征识别系统》和《生物特征识别和信息安全》两篇白皮书。
智能卡(smart card)是一个数据存储系统,也可以提供附加的计算能力,并且对数据存储提供内置的防篡改支持。第一个智能卡是1984年发行的预付费电话卡。智能卡被放入阅读器中,这样,就与只能卡的触角之间形成了电流通路。阅读器向智能卡提供电源和和时钟脉冲。两者之间的数据传输使用双向串行接口的(I/O port)的方式。基于内部功能的不同,智能卡的基本类型分为两种:内存卡和处理器卡。
智能卡的一个主要优势是存储在其上的数据可以防止非授权的访问和修改。因此,智能卡克易失得与这些信息相关的服务完成简单、便宜和安全的服务事务。因此在安全访问,认证、金融和电信领域使之成为微电子领域增站最快的一块。
RFID 和上述的智能卡系统非常紧密相关。和智能卡类似,数据被存储在一个电子数据承载设备——收发器(transponder)之上。但是,和智能卡不同,数据承载设备和阅读器之间的电源供应和数据传输不是基于接触的电流方式,而是基于磁场或电磁场的方式。其基本的依赖技术包括射频和雷达工程技术。RFID 的缩写代表radio frequency identification,即是说,信息是通过无线电波承载的。因为RFID 系统和其他识别系统相比有很多优点,RFID 系统开始大规模的占领市场。一个主要的应用领域就是非接触式智能卡在短程公共交通中的应用。
上述各种不同的识别系统之间的比较如表 1.1)所示。并且在接触式智能卡和RFID 系统之间有着紧密地联系。从某一方面说,后者弥补了前者的几乎所有缺点。

图表 1‑8 不同识别技术的比较
这两本书其实两个月前就出来了,可惜一直没时间再关注它。有一些网友也在问,可以访问
http://www.turingbook.com/Books/ListBook.aspx?BookCatalogID=83去看相关信息。
一本是关于JSF一本是Struts的。


如果读者对这两本书有什么问题,可以直接在这里提出来。我可能也将这里作为这两本书的勘误之处。
另外有一本Ajax的也在编辑之中了。具体日期我也不知道.....
好久不来这里了,好像是因为忙,也好像是因为这里写作不方便。今天偶然看到这个工具。试一下。
图片?

原以为放假了会有多些时间,可以上这里来多写一点东西,可是终于发现比去上课的时候更忙,也不知道为什么。
另外,发现使用Office 2007 beta可以从Word中直接publish Blog到MSN的Spaces(如今live)中,非常方便。对于大多数时候使用Word工作的同志真是非常的方便呀。相比而言,要打开浏览器,并且登录到这些来写,终究还是要便捷的多。有给自己找了个借口。不过真希望能够直接发布到这里阿。
发现有同学对RFID感兴趣,来信询问,所以最近写一些相应的东西。
目前所定义
RFID
产品的工作频率有低频(
LF
)、高频
(HF)
和甚高频
(UHF)
的频率范围内的,并且符合不同标准的不同的产品。不同频段的
RFID
产品和系统会有不同的特性。所以基于本应用我们对各频段进行分析。
低频
(
从
125KHz
到
134KHz)
RFID
技术首先是在低频得到广泛的应用和推广。该频率主要是通过电感耦合的方式进行工作
,
也就是在读写器线圈和感应器线圈间存在着变压器耦合作用。通过读写器交变场的作用在感应器天线中感应的电压被整流
,
可作供电电源供标签使用。磁场区域能够很好的被定义,但是场强下降得太快。
所以读写距离受到影响。
低频
RFID
的特性有:
1.
工作在低频的感应器的一般工作频率从
120KHz
到
134KHz
。该频段的波长大约为
2500m
.
2.
除了金属材料影响外,一般低频能够穿过任意材料的物品而不降低它的读取距离。
因此传输特性较好。
3.
工作在低频的读写器在全球没有任何特殊的无线电许可限制。
4.
低频产品有不同的封装形式。好的封装形式虽然价格昂贵,但是具有
10
年以上的使用寿命或者能够工作在恶劣的环境中。
5.
虽然该频率的磁场区域下降很快,但是能够产生相对均匀的读写区域。
6.
相对于其他频段的
RFID
产品,该频段数据传输速率比较慢。
7.
低频感应器的价格相对与其他频段来说要贵。
基于以上特点,
LF RFID
的主要应用领域是:
1.
畜牧业的管理和动物标识系统
2.
汽车防盗和无钥匙开门系统的应用
3.
体育比赛计时系统的应用
4.
自动停车场收费和车辆管理系统
5.
自动加油系统的应用
6.
酒店门锁系统的应用
7.
门禁和安全管理系统
主要符合的国际标准有:
-
ISO 11784 RFID
畜牧业的应用-编码结构
-
ISO 11785 RFID
畜牧业的应用-技术理论
-
ISO 14223-1 RFID
畜牧业的应用-空中接口
-
ISO 14223-2 RFID
畜牧业的应用-协议定义
-
ISO 18000-2
定义低频的物理层、防冲撞和通讯协议
-
DIN 30745
主要是欧洲对垃圾管理应用定义的标准
-
高频
(
工作频率为
13.56MHz)
在该频率工作的感应器不再需要线圈进行绕制,可以通过腐蚀印刷的方式制作天线。感应器一般通过负载调制的方式
的方式进行工作。也就是通过感应器上的负载电阻的接通和断开促使读写器天线上的电压发生变化,实现用远距离感应器对天线电压进行振幅调制。如果人们通过数据控制负载电压的接通和断开,那么这些数据就能够从感应器传输到读写器。
高频
RFID
的主要特性:
1.
工作频率为
13.56MHz
,该频率的波长大概为
22m
。
2.
除了金属材料外,该频率的波长可以穿过大多数的材料,但是往往会降低读取距离。感应器需要离开金属一段距离。
3.
该频段在全球都得到认可并没有特殊的许可限制。
4.
感应器一般以电子标签的形式存在,方便使用。
5.
虽然该频率的磁场区域下降很快,但是能够产生相对均匀的读写区域。
6.
该系统具有防冲撞特性,可以同时读取多个电子标签。
7.
可以把某些数据信息写入标签中。
8.
数据传输速率比低频要快,价格不是很贵。
基于以上特性,高频主要应用有:
1
.
图书管理系统的应用
2
.
瓦斯钢瓶的管理应用
3
.
服装生产线和物流系统的管理和应用
4
.
三表预收费系统
5
.
酒店门锁的管理和应用
6
.
大型会议人员通道系统
7
.
固定资产的管理系统
8
.
医药物流系统的管理和应用
9
.
智能货架的管理
符合的国际标准:
-
ISO/IEC 14443
近耦合
IC
卡,最大的读取距离为
10cm
.
-
ISO/IEC 15693
疏耦合
IC
卡,最大的读取距离为
1m
.
-
ISO/IEC 18000-3
该标准定义了
13.56MHz
系统的物理层,防冲撞算法和通讯协议。
-
13.56MHz ISM Band Class 1
定义
13.56MHz
符合
EPC
的接口定义。
甚高频
(
工作频率为
860MHz
到
960MHz
之间
)
甚高频系统通过电场来传输能量。电场的能量下降的不是很快,但是读取的区域不是很好进行定义。该频段读取距离比较远,无源可达
10m
左右。主要是通过电容耦合的方式进行实现。
因此该频段的
RFID
具有以下特性:
1.
在该频段,全球的定义不是很相同-欧洲和部分亚洲定义的频率为
868MHz
,北美定义的频段为
902
到
905MHz
之间,在日本建议的频段为
950
到
956
之间。该频段的波长大概为
30cm
左右。
目前国内的频段没有明确的划分,相关国家标准还未出台。其中还包括对发射功率和其他相关指标,数据和传输接口等的定义。
2.
甚高频频段的电波不能通过许多材料,特别是水,灰尘,雾等悬浮颗粒物资。相对于高频的电子标签来说,该频段的电子标签不需要和金属分开来。
3.
电子标签的天线一般是长条和标签状。天线有线性和圆极化两种设计,满足不同应用的需求。
5
.
该频段有好的读取距离,但是对读取区域很难进行定义。
需要对天线布置进行配合。
6
.
有很高的数据传输速率,在很短的时间可以读取大量的电子标签。
基于以上特性,本频段的主要应用有:
-
供应链上的管理和应用
-
生产线自动化的管理和应用
-
航空包裹的管理和应用
-
集装箱的管理和应用
-
铁路包裹的管理和应用
-
后勤管理系统的应用
符合的国际标准:
a) ISO/IEC 18000-6
定义了甚高频的物理层和通讯协议;空气接口定义了
Type A
和
Type B
两部分;支持可读和可写操作。
b) EPCglobal
定义了电子物品编码的结构和甚高频的空气接口以及通讯的协议。例如:
Class 0, Class 1, UHF Gen2
。
c) Ubiquitous ID
日本的组织,定义了
UID
编码结构和通信管理协议。
好久不来写blog了,没时间。总算本期课程结束了好几门,才有时间来写上两句,相信这个假期会多些时间过来。
前不久,大牌第三方组件厂商Infragistics终于宣布了其JSF组件,这也是除了标准组件、大厂实现(SUN JSF Web UI、IBM JSF extension以及Oracle ADF Faces)、以及开源项目(典型的Apache Myfaces)之外的第一个比较大型的第三方组件。虽然这之前也有一些小型的项目,但是被这种比较牛的组件厂商进入此领域,还是第一次。当然,这个项目还是收购自Otrix,但是凭借Infragistics在ASP组件上的成功,相信不久就会有一套非常好的组件问世。目前所推出的仅仅包括:Tab、Grid、Navigator、table、Tree、menu、Editor几个组件。JSF组件同样归入其NetAdvantage产品线中,由此可见其目标之一斑。
另,《JSF in Action》一书,终于要由人民邮件出版了。请大家再等一段时间。
传了很久的Jboss收购案终于被划上了句号,4月10日签署了被RedHat的收购协议,详见此处。
收购的金额没什么重要,这仅仅是个交易而已,但是,Jboss最终并没有投向Oracle的怀抱,而是戴上了红帽子(in redhat, right?)。这对于JBoss阵营说明了什么?
从RH来说,我记得以前RH有几个很好的应用层的项目,比如CCM和Portal,愿自于著名名的ArcDigi,后来成了RH的CMS和portal项目。其中另外一支随着ArcDigi演变成OpenAcs,也是一个极其优秀的基于Tcl/tk的CMS。不知后来为何RH放弃了CCM,被流放到ObjectWeb之下,名字为ByLine .好像只是搬了个家,从那时候,2004年底起就没什么动作。
其实这是一个非常好的基于XML/XSL的 CMS, 英国的地方政府内容管理标准化开源项目就是采用它,不过名称又变为了APLAWS了。
据JBoss的Blog和TSS上的新闻说,RH有心转向SOA。但是,JBOSS也是最近才转向SOA的,其实也不是他的强项,都是收购Drool 和JBPM之后,想要打造所谓的JBoss Enterprise Middleware Suite (JEMS)。
不过JBoss.org下面还孵化着很多项目呢,有Messaging, ESB, Remoting,EJB3,WebServices等等。实际上,App server的热潮之后,JBoss已经显得有些落寞。不在其他地方拓展,光靠App Server加上 Hibernate之类的工具性东西,也实在没什么前途。
据说SUN为RH开发了官方的RPM格式的JVM,RH却瞧不起。这下,有了一直和SUN对这干的JBOSS的帮助,还不翻天了?RH从此进入应用层面的基础设施行列,具体策略如何,我们拭目以待。
倒是Oracle失落吗?也未必。Oralce目前是唯一能够和IBM抗衡的应用级的全线提供者,少了开发工具系列,或者说产品生命周期管理PLM。而且,Oralce对开源和其他技术的宽容性要比任何一个大厂商都要好,照顾到PHP,Python,以及.NET等等。Oracle 真应该收购BEA,好像一直价格谈不拢,据说是34亿美元左右。我倒是觉得值得。否则,Oralce永远会活在自己的DB的阴影之下。
本文是MULE ESB的起步体验.
PDF格式,3个分卷。
下载1
下载2
下载3
Playboy居然做了Opensource的镜像,据他们说,是因为Eclipse够Sexy。他们的技术人员称自己为“Playboy "tech nerds"”,不知道是为什么。是不是不如那些性感明星来得安逸风光?不知道,呵呵。
他们还镜像了Apache, FreeBSD等等。地址是: http://mirrors.playboy.com/,也可以通过ftp访问。目前速度很快。
另,MM的 Flex终于改姓Adobe了,如今叫Adobe Flex 2.0, 发布了Beta版本。可以在http://www.macromedia.com/cfusion/entitlement/index.cfm?sdid=czce&e=labs 这里下载。在我看来,Flex也是非常的Sexy。
Martin的EIP之概论:使用模式解决集成问题:
ESB是企业服务总线:Enterprise Services Bus,其最早概念来自于 Predicts 2004: Enterprise Service Buses Are Taking Off 。
我们来看一下Bitpipe.com的定义:An enterprise integration architecture that allows incremental integration driven by business requirements, not technology limitations. Also called: Enterprise Service Bus and Enterprise Services Bus。
而 O'reiley的Enterprise Services Bus一书中说:
在 ESB中,应用和事件驱动服务以一种松散耦合的方式紧密地联系在SOA 中。 这使得它们能够彼此独立运行,并且仍然能够提供广泛的业务功能价值。
其核心特征是:
1. Web Services
2. 数据变换
3. 智能路由
4. MOM
两个主要特点:一是分布式集成,二是松散耦合的应用和集成逻辑的分离
Oracle 去年将ADF Faces免费之后,目前又将其捐献出来,给了Apache的Myfaces项目。前些天看到过一些风声,现在TSS也公布了这一消息。
这简直是一条很好的消息,这下JSF世界终于可以有丰富的控件使用了。Myfaces本来就非常优秀,整合了Smile之后,如今再得到ADF Faces的Code base,已经兵强马壮,个人认为可以勘作企业应用了。
Untitled Document
Struts1.2.4
新特征
主要修改:
不赞成特征
Struts1.1中已经有很多构造不再赞成使用。许多已经被删除了。所以在升级到1.2.4时,请clean-compile 你的应用,并且使deprecation warnings 被打开。在升级到1.2.4之前强烈建议解决所有decprecated 的用法。最可能应用开发人员的用法是:
- org.apache.struts.Action statics: 如今使用org.apache.struts.Global statics
- Action.perform: 如今使用Action.execute
虽然没有被删除也没有被标明为不赞成使用,最好还是将ActionErrors 替换为ActionMessages 以确保正确的操作。
TagUtils 和ModuleUtils
许多以前在org.apache.struts.utils.RequestUtils中找到的工具方法如今移动到了org.apache.struts.taglibs.TagUtils 或org.apache.struts.utils.ModuleUtils包中。
GenericDataSource / GenericConnection 实现被删除
datasources manager 仍然支持,但是我们自己的datasource implementationis 并不被支持。很欢迎你插入自己的DataSource 实现,但是我们没有资源来维护我们自己的实现。如果你的容器不支持DataSource实现,推荐使用Jakarta Commons的 DBCP package。
Validator 增强
- ValidWhen
Struts Validator 如今支持ValidWhen 规则,以便一个验证可以依赖于另一个验证。
- IntRange 现在可以检测select-one 和radio 字段。比如:这使得我们可以使用一些有效的选项加上一个具有诸如"Choose one" 标题并且值为"-1"的附加选项来组装一个组合框。那么当用户试图提交一个表单时,你可以检测值是否为-1,从而决定是否没有选择选项。
- 你现在可以强制进行客户端Javascript 验证来检测所有约束,而不是停留在第一个错误之处。方法是设置Validator PlugIn上的一个新的属性stopOnFirstError为false。
- "required" 验证现在可以检测checkboxes, radio,select-one, 和 select-multiple 字段类型。参见修改后的Validator 示例来看如何使用这些新的特征。
- 一个标准的validateUrl 规则可以让你能够检测某一个属性是否包含一个格式正确的URL。
DigestingPlugIn
一个新的标准PlugIn 可以帮助你在application范围内创建你自己的对象图(object graph)。这是创建供Action调用的业务对象的快捷方式。请参见最新的MailReader 示例来看如何使用DigestingPlugin。
ModuleConfigVerifier
虽然不是全新的,一个标准类,用来验证模块配置,位于PlugIn 包。ModuleConfigVerifier 主要确认Struts对象图的各中组件被载入。但是,开发人员可扩展此类来检查确保Struts 配置文件的内部一致性。
提供了支持Maven的项目文件.
新的配置DTD
推荐使用struts-config_1_2.dtd。新的DTD 添加了两个新的元素<display-name> 和 <description> 到struts-config 元素中。这些元素可用于struts配置文件工具和文档产生工具。在Struts 1.2.x 中,已有的Struts 配置文件可以使用两个版本的DTD 都可载入。
新的Taglib URIs
标签库的URI已经被修改已反映Struts从Jakarta 移到了Apache 的顶级项目。为了兼容,使用旧的URI的TLD仍然有效,但是鼓励使用新的URI。
Struts-Chain
试验性的,这个新的"contrib" package 使用了Jakarta Sandbox中的Responsibilty package 的Chainin 来创建一个新的RequestProcessor的Breed。未来版本可能会成为默认实现。.
MappingDispatchAction
一个新的标准Action,将控制转发到ActionMapping 参数命名的一个方法。
Cancel handlers
DispatchAction, LookupDispatchAction, 和 MappingDispatchAction ,如今提供了默认的可以覆写的cancel handler。也可以指定默认的handler name。
Session-scoped ActionMessages
现在你可以将ActionMessages 保存在session 中and have them cleaned up after the first use。现在除了Action.saveMessages() 将消息保存在session中还有了另外一种选择。在消息已经被访问过一次之后ActionMessages.isAccessed() 返回true。RequestProcessor.processCachedMessages() 查询isAccessed() 已决定是否应该将消息从session中删除。
JA Mailreader
Struts Mailreader Example 应用现在包含Japanese 资源文件。
Tiles EL
Tiles tags 如今可以通过Struts EL taglib使用EL,后者基于JSTL。
Wildcard Mappings
现在可以在actiponMapping中使用通配符。详细信息参见Struts Mailreader Example application。
Action attributes
html img tag 添加了Action 属性,以匹配html link tag。
Module attribute
Forward元素以及多个核心标签中新增一个"module" 属性。这个属性允许你通过名称(或者前缀)指定另一个模块来创建模块间的直接链接。新的module 属性优于contextRelative属性,并且可以常用于"SwitchAction"中。
Struts 1.2.7
主要修改
依赖性
Struts 对下列组件的依赖性发生了改变:
依赖性 |
新的版本 |
Commons BeanUtils |
Version 1.7.0 |
Commons Digester |
Version 1.6 |
Commons Validator |
Version 1.1.4 |
Commons Collections |
removed |
Commons Lang |
removed |
Core Struts
Saving Messages in the Session
在action也新增了一个方法[saveErrors(HttpSession, ActionMessages)]来将errors 保存在Session 中,并且在其第一次被访问之后被自动从Session中删除。这是等同于1.2.4 中message上新增的功能。
Re-directing ActionForward
ActionRedirect 是ActionForward 的一个子类,其设计来用于重定向请求,支持在运行时添加参数。
Download Action
DownloadAction 是一个提供了下载文件的具体细节的抽象Action。
Dispatch Helper
ActionDispatcher 是一个提供DispatchAction 类型的行为但是不必继承自DispatchAction。
Lazy Validator Form
DynaBean 风格的ActionForm,它不需要其属性被定义,并提供Lazy List 和Lazy Map 行为。
jars 中的配置文件
配置文件(如. Struts config, Validator config 和 Tiles 配置文件)现在可以被保存在jars。Struts 会像以前一样检查servlet context,但是如果没找到, Struts 会尝试classloader 去查找。
Tag Library 改变
Highlighting Errors
Struts现在可以使用HTML Input Tags上的 errorKey, errorStyle, errorStyleClass 和 errorStyleId 属性自动高亮错误字段。
Readonly / Disabled Forms
现在可以使用<html:form> tag的readonly 和disabled属性来禁止或者使全部的字段只读。
N.B. readonly 属性只影响<html:text>, <html:textarea> 和 <html:password> as per the HTML 4 specification。
HTML Tag Refactoring
许多HTML标签都被重构了,以便更易使用。
- 添加了prepareOtherAttributes() 方法- 刚好在关闭元素之前调用,提供一个地方来渲染额外的属性。
- name 属性渲染如今在prepareName() 方法中,以便更易提供定制行为。
- value 属性如今在prepareValue() 方法中以便更易提供定制行为。
- 当渲染一个属性时,这些标签现在使用属性的getter 而不是直接使用实际的属性,这意味着如果你想,比如覆盖TextTag的 styleClass ,那么一个选择是覆盖getStyleClass()方法。
- 属性的渲染现在使用一个简单的 prepareAttribute() 方法来产生name="attribute" 格式,使多数属性渲染一个一行语句。
Bundle Attribute
bundle 属性被添加到了下列标签:ButtonTag, CancelTag, CheckboxTag, FileTag, FrameTag, HiddenTag, LinkTag, MultiboxTag, PasswordTag, RadioTag, ResetTag, SelectTag, SubmitTag, TextTag, TextareaTag。
ErrorTag
现在新增了header, footer, prefix, suffix属性。
Validator
Resource Bundle Support
Validator 配置文件中(e.g. validation.xml)的<msg> 和 <arg> 元素的bundle 属性现在随同<msg> 的resource 属性一起得到支持。
struts-examples webapp 中添加了新的页面来展示对Resource Bundle 的支持。
Struts1.2.8
主要改变
Struts 1.2.8 的主要改变是修正了Cross Site Scripting (XSS) 弱点。
最近在编写Struts教程的时候,把Struts1.1到1.2的个版本变化总结了一下,希望能够从整体上把握它的变迁脉络,在开发和维护的时候也可以参考参考。
Struts1.1的修改
新特征
引入新的配置DTD
Struts 1.0 的配置DTD 已经不赞成使用,引入了新的struts-config_1_1.dtd。在Struts 1.1 中,已有的Struts 配置文件可以使用这两个版本的DTD载入。
新的Commons 包依赖性
在Struts中使用了多个Apache Jarkarta commons的组件,而Commons组件并不仅仅可以用来构建Struts应用。在Struts1.1中,所使用的Commons组件已经重构来外部依赖于Jarkarta Commons项目,而不是1.0中的内部版本。
下面的Commons包包括了对相应的Struts 1.0 中的类的替代:
- BeanUtils [org.apache.commons.beanutils]:
- org.apache.struts.utils.BeanUtils
- org.apache.struts.utils.ConvertUtils
- org.apache.struts.utils.PropertyUtils.
- Collections [org.apache.commons.collections]
- org.apache.struts.util.ArrayStack
- org.apache.struts.util.FastArrayList
- org.apache.struts.util.FastHashMap
- org.apache.struts.util.FastTreeMap.
- Digester [org.apache.commons.digester]
- org.apache.struts.digester.*.
下面这几个包现在仍然被Struts框架的各种组件使用:
- FileUpload [org.apache.commons.fileupload]
- Logging [org.apache.commons.logging]
- Validator [org.apache.commons.validator]
XML解析器
另外,Struts 1.1 需要符合JAXP/1.1 (而不是JAXP/1.0) API的XML解析器,比如JAXP/1.1 参考实现和Xerces 1.3.1+。
源代码
如果需要从源代码开始构建Struts,请使用Ant 1.4 以上版本。
集成Struts Validator
一个新的Commons Validator组件被集成到Struts 1.1中,包含在新的Validator包中。
Tiles
引入了一个新的JSP模板组装机制Tiles,通过标签库提供集成。
Nested
Nested taglib 绑定到了Struts1.1中,增强了现有Struts标签的功能。
新的示例应用
Struts1.1发布包中包括了针对Validator 和Tiles的新的示例。
新的可选组件
CVS源代码库中新增了一个目录contrib,包含了很有用的,但是没有集成到标准代码基中的扩展。
- Scaffold – 一个对Commons Scaffold 工具包扩展,旨在提供可重用的构建Web应用的类
- Struts-EL – 可选的Struts-EL taglib 使得在Struts 中使用JSTL更加容易。(需要Servlet 2.3 +容器支持)
Action 包的增加
基本的控制器框架 [org.apache.struts.action]新增了一下特征:
- ActionServlet 现在提供了对模块化应用的支持,并且新增了多个扩展点。
- 新增了一个ActionMessages 类,支持ActionErrors功能的一个超集,可以用于通用的消息收集传递,不仅仅针对errors。
Upload 包
文件上传类[org.apache.struts.upload]新增了一下特征:
- CommonsMultipartRequestHandler:这个新类使用Jakarta Commons FileUpload 包实现了文件上传。这也是Struts的默认文件上传实现。
Util 包
工具(utility)类 [org.apache.struts.util]新增了以下特征:
- LocalStrings: 修正了与可替换参数相关的消息,以便它不会添加一个外来的无关的字符。
- LabelValueBean: 一个新类,定义了一个名值对的集合,可以用在<html:options> 和<html:optionsCollection>标签,或者其它地方。
- MessageResources: 转移包含在特定消息字符串中的单引号。
- computeParameters: 允许事务令牌是唯一的参数。
- RequestUtils: 在构建一个查询字符串时,修改来编码一个&号。
Bean Taglib
struts-bean 标签库[org.apache.struts.taglib.bean]中新增了以下特征:
- <bean:write>:加入了format, locale 和 bundle 属性以支持根据用户当前场所进行格式化的功能,格式化来自属性或者来自字符串资源的字符串。
- <bean:cookie>, <bean:header>, 或<bean:parameter>:纠正了在标签使用"multiple"属性时,所产生的脚本变量类型。
- <bean:message>:加入了name, property, 和scope 属性,以便消息资源key 可以动态地从一个bean 或者bean 属性获得。
HTML Taglib
struts-html [org.apache.struts.taglib.html]加入了如下新特征:
- <html:link>: 添加了'action' 属性
- <html:options>: 如果'property' 属性制定的属性(property)返回null,现在标签将抛出一个错误消息指名实际问题而不是造成NPE。
- <html:option> 和 <html:options>:添加了'style' 和'styleClass' 属性。
- <html:optionsCollection>:新标签。提供了一个更清晰的方式来从集合组装HTML options。
- <bean:message>:添加了'name', 'property' 和'scope' 属性,以便消息资源key 可以动态地从bean获得。
- <html:messages>:新标签。可以通过新的ActionMessages 类中的一个消息集合进行迭代。
- ActionForm:现在,此标签在它初始化ActionForm Bean的时候会调用reset() 方法。它也要求被标签所实例化的bean 是ActionForm 的一个子类。
- <html:image>:添加了'align' attribute。
- <html:img>:添加了mouse 事件属性('onclick', 'ondblclick', 'onmousedown', 'onmouseup', 'onmouseover', 'onmousemove', 'onmouseout')。
- SubmitTag, SelectTag, LinkTag.java, CheckboxTag, ButtonTag, ImageTag, RadioTag, 和TextArea 标签: 添加了indexed 属性。
Logic Taglib
struts-logic 标签库[org.apache.struts.taglib.logic]加入了如下新特征:
- <logic:empty> 和<logic:notEmpty>:新标签。类似于<logic:present> 和<logic:notPresent>,但对空字符串的处理不同。
Template Taglib
无变化,但无赞成使用。推荐使用Tiles.
运性层面的改变
加入了Config Package
- ControllerConfig:添加了inputForward 属性以指示ActionMapping.input是一个forward 而不是URI。
- ControllerConfig:添加了forwardPattern 和inputPattern 到help 应用面模块的管理页面目录
- 添加了一个新的包以提供更多的灵活性来支持控制器配置和多模块应用的支持。
Action 包
基本框架(org.apache.struts.action)进行了如下修改或者修正:
- Action 类中的所有常数:不赞成使用。提取到新的Globals类中。
- ActionMapping:如果模块的ControllerConfig bean [org.apache.struts.config.ControllerConfig]的inputForward 设置为true,input 属性将引用一个ActionForward 而不是模块相对的路径。
- ActionServlet:添加了convertNull 参数以在组装Form时仿真Struts 1.0 行为。如果设置为true,数值numeric Java wrapper 类类型 (如java.lang.Integer) 将默认为null (而不是0)。
- ActionServlet:添加了"config/$foo" 参数,不赞成使用包中的其他参数。
- ActionForms 和相关类:为了保存资源,现在在响应toString请求的时候使用一个StringBuffer。
- LookupDispatchAction:添加的新的标准Action,以帮助在国际化的按钮之间进行选择。
- ActionForm 类:修改来使用ActionServletWrapper 而不是暴露ActionServlet。
- ActionServletWrapper 类:添加的新类,用于ActionForm,以防止ActionServlet 的公开字符串属性被通过查询字符串改写。
- Action.MAPPING_KEY的 request 属性: 如果没有指定form bean,无条件地将选择的mapping 传递为请求属性("org.apache.struts.action.mapping.instance")。
- ActionServlet:避免了在初始化Servlet失败的时候导致的NullPointerException。
- ActionForm 类:现在是真正的serializable,因为两个非serializable 的实例变量(servlet 和multipartRequestHandler) 已经成为transient。但是,如果你的确需要序列化和解序列化这个实例,你要自己负责重设这两个属性。
- ActionMessages 和ActionErrors:The initial order a property/key is added in is now retained.
- processActionForward(): 不赞成,推荐使用processForwardConfig
Upload包
文件上传 (package org.apache.struts.upload) [ Upload 应用的一部分]作了如下修改和修正:
- CommonsMultipartRequestHandler:基于Jakarta Commons FileUpload 包的文件上传的新实现。这个新实现如今是默认实现。
- BufferedMultipartInputStream:解决了丢失字节的问题。
- ArrayIndexOutOfBoundsException:解决了已知的错误。
- Multipart requests:Better reporting for premature closing of input streams while reading multipart requests.
- 新行字符(New line characters):解决了上传和新换行字符时导致的文件损坏问题。
Utility包
utilities (package org.apache.struts.util)发生如下修改和修正:
- RequestUtils:添加了对ControllerConfig 的forwardPattern, pagePattern, 和inputForward 属性的支持。
- GenericDataSource:不赞成。修改为作为[org.apache.commons.dbpc.BasicDataSource]的一个薄的Wrapper。建议直接使用BasicDataSource 或其它兼容组件。
- RequestUtils 类:修改为使用ActionServletWrapper而不是暴露 ActionServlet。
- 为getActionErrors 和 getActionMessages 方法添加了错误消息。
- getActionErrors 和 getActionMessages:添加了根据基于传入的消息关键字从Request范围获取的对象来产生正确的相应对象的方法。
- ActionErrors 或 ActionMessages:创建一个这种对象的逻辑被移到了RequestUtils中的一个工具方法。.
- JspException 消息:现在在RequestUtils中生成。
- ConvertUtils.convertCharacter():现在将检测空字符串并返回默认值。
Bean Taglib包
struts-bean c标签库 [org.apache.struts.taglib.bean]发生了如下修改和修正:
- <html:errors>:当指定了属性标签时,如果指定的属性没有发生错误,则不会输出错误。而前面的错误将总是会被输出。未来的增强版本将包括额外的属性来关闭header 或 footer。
- 将helper 方法从"private"改为 "protected" 。
HTML Taglib 包
struts-html 标签库(package org.apache.struts.taglib.html)发生了如下修改和修正:
- FormTag:修正为,当指定了action mapping的名称时,要排除查询字符串。
- ImgTag:如果只有一个参数,能正确地URLEncode 查询字符串参数。
- MultiboxTag.doAfterBody()::修正为返回SKIP_BODY 而不是SKIP_PAGE。
- Errortag:不赞成使用defaultLocale方法。
Documentation 示例应用
Struts Documentation 应用(对应Struts 网站的内容)发生了如下修改:
- 重新组织了资源到单独的页面中。
- 在Tag Developers Guide中,添加了更详细的文件上传要求。
- 在Building View Components,澄清了额外的i18n 支持可以由浏览器提供,并且超出了框架的范围。
- 在Building Controller Components一节,文档 'validating' init-param,添加了各种参数的默认值,澄清了某些web.xml 设置不是Struts特定的。
- Tag library 文档:移到User's Guide下。
MailReader 示例应用
Struts MailReader Example Application 发生如下修改和修正:
- 添加了应用资源的 Russian 和Japanese 翻译,并且设置JSP的字符集为"UTF-8"以便其可以显示English 或Japanese。
- 在Struts配置文件中交换了Edit mappings的"attribute" 属性的"name" 。
- 删除了对"tour"文档中的保存的数据库数据的引用,因为这个功能已经被删除。
Exercise Taglib 示例应用
Struts Exercise Taglib Example Application 发生了如下修改和修正:
- 添加了针对使用了"action"属性的<html:link> 的test case 。
- 添加了针对基于保存在page上下文中的集合使用<html:options> 和 <html:optionsCollection>的<html:select> 的test case。
不同之处
这里列出1.0到1.1中新增的类和已经不赞成使用的类:
1.0中不赞成使用,1.1中已经删除的类。
- 删除:org.apache.struts.utils.BeanUtils, org.apache.struts.utils.ConvertUtils, and org.apache.struts.utils.PropertyUtils – 替换为org.apache.commons.beanutils
- 删除:org.apache.struts.util.ArrayStack, org.apache.struts.util.FastArrayList, org.apache.struts.util.FastHashMap, org.apache.struts.util.FastTreeMap – 替换为org.apache.commons.collections
- 删除: org.apache.struts.digester.* - 替换为org.apache.commons.digester
- 删除:struts-config.dtd – 替换为struts-config_1_1.dtd.
- 删除:omnibus "struts" taglib 和其相应的TLD – 替换为bean, logic, 和html taglib。
- 删除:"form" taglib 和其相应的TLD – 替换为html taglib.
Struts 1.1新增的包
- config
- taglib.nested
- taglib.nested.bean
- taglib.nested.html
- taglib.nested.logic
- validator
Struts 1.1新增的类
action
- ActionMessage
- ActionMessages
- DynaActionForm
- DynaActionFormClass
- ExceptionHandler
- RequestProcessor
actions
- LookupDispatchAction
taglib.html
- FrameTag
- JavascriptValidatorTag
- MessagesTag
- OptionsCollectionTag
taglib.logic
- EmptTag
- MessagesNotPresentTag
- MessagesPresentTag
- NotEmptyTag
upload
- CommonsMultipartRequestHandler
util
- LabelValueBean
Struts 1.1中新增的类成员
action.Action
- ACTION_SERVLET_KEY
- APPLICATION_KEY
- MESSAGE_KEY
- PLUG_INS_KEY
- REQUEST_PROCESSOR_KEY
- execute
- getResources(javax.servlet.http.HttpServletRequest)
- saveMessages
action.ActionServlet
- configDigester
- convertHack
- log
- processor
- getInternal
- destroyApplications
- destroyConfigDigester
- getApplicationConfig
- getRequestProcessor
- initApplicationConfig
- initApplicationDataSources
- initApplicationPlugIns
- initApplicationMessageResources
- initConfigDigester
- methods created for backward-compatiblity only
- defaultControllerConfig
- defaultFormBeansConfig
- defaultForwardsConfig
- defaultMappingsConfig
- defaultMessageResourcesConfig
taglib.html.BaseHandlerTag
- indexed
- setIndexed
- getIndexed
Struts 1.0 到Struts 1.1不赞成的类
action
- ActionException
- ActionFormBeans
- ActionForwards
- ActionMappings
Struts 1.0 不赞成的类成员
action.Action
- FORM_BEANS_KEY
- FORWARDS_KEY
- MAPPINGS_KEY
- getResources()
- perform
ActionServlet
- findDataSource
- findFormBean
- findForward
- findMapping
- initDataSources
- methods created for backward-compatiblity only
- defaultControllerConfig
- defaultFormBeansConfig
- defaultForwardsConfig
- defaultMappingsConfig
- defaultMessageResourcesConfig
Untitled Document
由于集成的RFID系统实际上是一个计算机网络应用系统,因此安全问题类似病相关于网络和计算机安全。而安全的主要目的则是保证存储数据和在各子系
统/模块之间传输的数据的安全。但是
RFID系统的安全仍然有两个特殊的特点:首先,RFDI标签和后端系统之间的通信是非接触和无线的,使它们很易受到窃听;其次,标签本身的计算能力和可
编程性,直接受到成本要求的限制。更准确地说,标签越便宜,则其计算能力越弱,而更难以实现对安全威胁的防护。
我们将分析RFID系统的主要脆弱性,以及相关的安全风险评估和建议的解决方案。
RFID 组件的安全脆弱性
在RFID系统中,受到非授权攻击的数据可能保存在标签中、阅读器中、或者后端计算机中,或者当数据在各个组件之间传输的时候。我们将分别说明:
标签中数据的脆弱性
通常每个标签包含一个IC,本质上说是一个具有存储器的微芯片。在其中的数据受到的威胁类似于计算机中保存的数据。非授权地通过阅读器或者其他手段读取标签中的数据将使其丧失安全性;在可读写的标签情况下,甚至可能非授权地改写或者也删除标签中的数据。
标签和阅读器之间的通信脆弱性
当标签传输数据给阅读器,或者阅读器质询标签的时候,数据通过无线电波进行传输。在这种交换中,数据安全是脆弱的。利用这种脆弱性的攻击手段包括:
- 非授权的阅读器截取数据;
- 第3方阻塞或者欺骗数据通信;
- 非法标签发送数据;
阅读器中的数据的脆弱性
当数据从标签出收集到阅读器中之后,在发送到后端系统之前,阅读器一般要进行一些初步处理。在这种处理中,数据则受到和其他任何计算机安全脆弱性相
似的问题。而且,有两点特别需要注意,一些移动式阅读器需要特别关注;其次,阅读器多是专有的设备,很难具有公共接口进行安全加固。
后端系统的脆弱性
数据进入后端系统之后,则属于传统的网络安全、应用安全的范畴。在这一领域具有比较强的安全基础,有很多手段来保证这一范畴的安全。
值得注意的是,基于应用层的安全(XML消息一级)正在不断发展和完善中,而基于RFID的中间件基础将大量采用基于XML的技术。
评估RFDI系统的风险
不同类型的系统由于其特点可能面临不同的安全风险。我们将RFID应用系统分为两种类型,消费者RFID应用和企业RFID应用。
消费者应用的风险
消费者RFID应用主要是指收集和管理有关消费者数据的应用。主要包括访问控制、电子收费系统、或者零售POS系统等等。这些系统由于将消费者数据和RFID数据发生了关联,其安全风险也包括两个方面:
- 对后端业务系统的损害;
- 对消费者隐私的损害;
- 对消费者经济的直接和间接损害。
企业应用的风险
企业RFID应用时企业内部相关的业务系统使用RFID技术驱动。典型地包含企业供应链管理,以及相关的集成,如ERP、工业自动化等等。企业应用
的风险主要体现在对机构的直接和间接经济损害,以及对该机构的产品、服务设计到的客户的损害。而且这还体现在由于集成化程度和数据共享程度越高,受到的安
全风险越大、损害的范围越大(比如可能损害到企业的伙伴)。
另一方面,如果系统与消费者相关联,则存在于上述消费者应用类似的风险。
国防和军事领域的RFID应用的安全风险类似于企业应用,但是它则完全涉及到国家的安全。
保护RFID数据的安全
由于保存于阅读器或者后端系统中的数据属于传统信息安全的范畴,我们主要提及标签中的数据安全和标签与阅读器通信安全的解决方案。如下表:
1 保护RFID数据安全的解决方案
|
错弱性 |
方案 |
标签数据访问 |
标签和阅读器通信 |
安全许可 |
√ |
|
使用只读标签 |
√ |
|
限制通信范围 |
|
√ |
实现专有协议 |
√ |
√ |
屏蔽 |
√ |
√ |
Using the Kill Command Feature |
√ |
|
物理损坏标签 |
√ |
|
认证和加密 |
√ |
√ |
选择性锁定 |
√ |
√ |
安全许可
对于某些不需要经常移动的被标签目标,可以通过常规的物理安全手段限制对标签的访问。不幸的是,被标签的目标一般都需要移动。
使用只读标签
这种方式消除了数据被篡改和删除的风险,但是仍然具有被非法阅读的风险。
限制标签和阅读器之间的通信距离
采用不同的工作频率、天线设计、标签技术和阅读器技术可以限制两者之间的通信距离,降低非法接近和阅读标签的风险,但是这仍然不能解决数据传输的风险还以损害可部署性为代价。
实现专有的通信协议
在高度安全敏感和互操作性不高的情况下,实现专有通信协议是有效的。它涉及到实现一套非公有的通信协议和加解密方案。基于完善的通信协议和编码方
案,可实现较高等级的安全。但是这样便丧失了与采用工业标准的系统之间的RFID数据共享能力。当然,还可以通过专用的数据网关来进行处理。.
屏蔽
当然,屏蔽掉标签之后,也同时丧失了RF特征。但是在不需要阅读和通信的时候,这也是一个主要的保护手段。特别是包含有金融价值和敏感数据的标签(高端标签,如智能卡)的场合。可以在需要通信的时候接触屏蔽。
使用杀死命令(Kill Command)
Kill命令是用来在需要的时候是标签失效的命令。接收到这个命令之后,标签便终止其功能,无法再发射和接收数据。屏蔽和杀死都可以使标签失效,但后者是永久的。
特别是在零售场合,基于保护消费者隐私的目的,必须在离开卖场的时候杀死标签。
这种方式的最大缺点是影响到反向跟踪,比如退货、维修和服务。因为标签已经无效,相应的信息系统将不能再识别该数据。
物理损坏
物理损坏是指使用物理手段彻底销毁标签,并且不必象杀死命令一样担心是否标签的确失效。但是对一些嵌入的,难以接触的标签则难以做到。
认证和加密
可使用各种认证和加密手段来确保标签和阅读器之间的数据安全。比如,直至阅读器发送一个密码来解锁数据之前,标签的数据一直处于锁定状态。更严格的
还可能同时包括认证和加密方案。但是标签的成本直接影响到其计算能力以及采用的算法的强度。因此,一般来说,在高端RFID系统(智能卡)和高价值的被标
签物品场合,可以采用这种方式。
选择性锁定
这种方法使用一个特殊的称为锁定者(Blocker)的RFID标签来模拟无穷的标签的一个子集。这一方法可以把阻止非授权的阅读器读取某个标签的子集。
这一方法克复或者平衡了以上方法的缺点,也消除了加密和认证方案带来的高成本性。这一方法在安全性和成本之间取得了较好的平衡。需要的时候,Blocker标签可以防止其他阅读器读取和跟踪其附近的标签,而在需要的时候,则可以取消这种阻止,使标签得以重新生效。
推荐安全策略
没有任何一个单一的手段可以彻底保证RFID应用的安全。在很多时候,都需要采用综合性的解决方案。对于采用某些标准的RFID应用,比如ISO 或者EPCglobal,标准体系对安全有其自己的考虑和解决。
不管如何,在实施和部署RFID应用系统之前,必须进行充分的业务安全评估和风险分析,考虑综合的解决方案、考虑成本和收益之间的关系。
很多时候需要专门的安全机构进行咨询和服务。
因为RFID要产生和辐射电磁波,所以法律上将其归为无线通信系统(radio systems)。 无线电服务必须在不被RFID 系统所干扰和影响的前提之下。为了确保RFID 系统不会干扰邻近的广播和电视,移动无线服务(警用,安全,工业),航海和海空无线通信服务和移动电话服务,这一点很重要。
所以必须仔细的规划适用于RFID系统所用的频率范围。(基于此,通常只可能使用保留工业、科学和医疗用途的频段。这些频段称为是ISM 频段,可以用作RFID 应用。

图表 1 RFID 系统使用的频段
除了ISM 频率,整个低于135 kHz (在北美、南美和日本为<400 kHz)也是可以使用的,因为这些频率可以工作于高磁场强度,特别是针对感应耦合式RFID 系统。
因此, RFID 最重要的频段是0–135 kHz, 以及ISM频段中围绕6.78M(在德国已经不适合),13.56 MHz,27.125 MHz,40.68 MHz,433.92 MHz,869.0 MHz,915.0 MHz (非欧洲地区),2.45 GHz, 5.8 GHz 和24.125 GHz的频段。
RFID 在各个频段总体分布如下图:

图表 4‑2 估计的RFID在各频段的全球总体分布图(百万单位)
低于135 kHz 的频率被各种无线服务大量使用,因为他们没有保留作ISM 频段。这个长波频段的传播特性可以使得在低技术成本下达到连续传播超过1000 km 半径的范围。通常这个范围的服务服务是用作航空和航海的导航服务 (LORAN C, OMEGA, DECCA),授时服务,标准频率服务以及军方的无线电服务。因此,位于中欧Mainflingen的授时发射机DCF 77 使用的就是77.5 kHz的频率。因此RFID 系统在此频率运行可能会影响到reader周围数百米范围内的无线接收的时钟失效。
为了防止这种冲突,欧洲对感应式无线电系统的管制法案 220 ZV 122,将定义一个从70 到119 kHz的保护区,这个区域将不再分配给RFID 系统。
频率6.765–6.795 MHz 属于短波频段。其传播条件可以是你能够在白天的传播达到100 km。而在夜间,横贯大陆的传播都是可能的。这个范围主要云南关于宽范围的无线电服务,例如广播,天气和航空无线电服务以及新闻社。
这个频段在德国还没有被通过为ISM 频段,但是已经被ITU指定为ISM 波段,并且已经在法国用作RFID系统。而CEPT/ERC和 ETSI 则在CEPT/ERC 70-03准则中将起指定为协调波段。
频段13.553–13.567 MHz 位于短波波段的中间。其传输特性使得其可以整天都可以达到横贯大陆的传播。这个范围一般用于范围要求非常广的无线电服务,比如新闻社和电信点对点服务(PTP)。
这个范围内的其他ISM 应用,除RFID之外,主要还有远程控制系统,远程控制模型,试验无限设备和寻呼系统。
频段26.565–27.405MHz分配给美国、加拿大和欧洲的CB 广播。无须注册和免费的无线电系统,功率小于4 Watts 的私人无线电爱好者可以使用,传输可超过30 km。
这个频段的ISM 应用除RFID之外,还有电疗器械(医用设备)、高频焊接设备(工业应用)、远程控制模型和寻呼系统。
当安装27 MHz RFID 系统时,必须特别注意附近的高频工业焊接设备。HF 焊接设备可产生很高的场强,可以干扰附近的RFID 系统的运行。当为医院规划27 MHz RFID 系统时,也要考虑电疗设备的因素。
范围40.660–40.700 MHz 位于VHF 频段的低端。其传输特性仅限于地面波,所以由于建筑物和其他障碍所产生的衰减很明显。这个频段邻近的其他ISM 范围主要由移动商业无线电系统(森林,高速公路管理等) 以及电视广播的(VHF 频段 I)。
这个频段主要的ISM 应用包括遥感和远程控制应用。这个范围目前很少用作RFID 系统。 这个频段所能达到的有效范围要远远低于更低的频段所能达到的范围,因为这个频段的7.5 m 波长不适合构造小巧和便宜的backscatter transponders。
这个频段430.000–440.000 MHz 主要分配给全球的业务无线电爱好者。无线电爱好者使用这个频段来进行声音和数据的传输以及通过中继广播站和卫星的通信。
UHF 频段的传输特性近似于光。当遇到建筑物和其他障碍时将会出现衰减和反射。依赖于操作方法和发射功率,无线电爱好者使用的系统可能达到的范围在30 到300 km之间。使用卫星也可以达到全球连接。
ISM 范围433.050–434.790 MHz 主要位于业务爱好者使用频段的中部,并且被各种各样的应用所占据。包括,内部通话器,遥感发射器,无绳电话,短距离对讲机,车库自动进入发射器等等。所幸的是,这个频段的干扰倒是很少见。
频段868–870 MHz 在欧洲主要用作短距离设备(SRD) ,因此在 CEPT的43个成员国中都可以用作RFID系统。
亚太地区的国家也正在考虑通过这个频率为SRD频率。.
这个频段在欧洲未作为ISM 应用。欧洲之外(美国和澳洲) 频段888–889 MHz 和902–928 MHz 是可用作后向散射式RFID系统的。
其邻近频段主要由D-net 电话和CT1+ 和 CT2 标准的无绳电话所占据。
ISM 频段2.400–2.4835 GHz 部分和业余无线电爱好者使用的频率和电波探测服务是用的频率相重叠。这一段的UHF 频率和更高的SHF 频率的传播特性几乎相当于光。建筑物和其他障碍将是很好的反射体,并且产生非常强的衰减。
除了backscatter RFID 系统之外,主要的ISM 应用包括遥感发射器和PC WLAN 系统。
ISM 频段5.725–5.875 GHz 部分和无线电爱好者使用频率和电波探测服务的频率相重叠。
这一频段的主要服务包括运动传感器(用作防盗等),非接触式卫生间干手器,以及RFID系统。
ISM 频段24.00–24.25 GHz 部分和业务爱好者使用频率,电波探测服务和卫星地球资源服务的频率重叠。
目前还没有RFID系统运行于此频段。
中国国内的800-900M UHF频段,由于中国的GSM移动通信这个全球最大的网络以及其他一些应用占用了大量的频宽,显得非常拥挤。在11月初召开的RFID全球论坛上,国家无委会透露说,他们已经对此频段进行了大量的测试,并且有了一些调整方案。估计在960M以下。这也可能和该次会议上成立的标准工作组的进展相关。
近年来,自动识别系统 (Auto-ID) 在很多服务领域、商务和分销、物流、工业和制造以及材料流等领域变得越老越流行。在这些领域中,自动识别过程提供关于人员、动物、货物、材料和产品等在传输过程中的信息。
普遍使用的条形码标签在很久前出发了一场识别系统的革命,但是现在随着急剧增长的编号数量已经发现越来越不适用了。条形码可以十分便宜,但是其致命缺陷是其低存储容量和不能重新编程的特点。
技术上讲更好的方案是在硅芯片之上存储数据。我们日常生活中在用的最常见的电子数据设备是接触式IC卡(电话卡,银行卡等)。然是机械接触的IC卡却限制了其适用性。在数据承载设备和阅读器之间的非接触式数据传输可以带来更大的灵活性。在理想情况下,用于操作数据承载设备所需的电力也可以通过非接触方式从阅读器进行传输。因为用于传输数据和电力的方式,非接触ID 系统也称为是RFID 系统(射频识别)。
活跃在RFID系统领域中进行开发和销售的公司的数量说明了这是一个应该认真对待的市场。在2000年,RFID系统在美国的销售额大约是9亿美元,并可望在2005年达到26.5亿美元。RFID 市场因此成为射频技术领域 (还包括移动电话和无绳电话)增长最快的领域。

图 1 RFID的应用市场增长
并且,近年来,非接触识别已经发展成一本独立的交叉学科,它整合了多种完全不同的领域:高频技术和EMC,半导体技术,数据保护和加密,通信,制造科学和其他相关领域的技术。

图2 主要的自动识别技术
条形码系统(Bar Code System)在过去20年历牢牢的统治着识别系统领域。 据专家估计,在上世界90年代早期,条形码系统在西欧的总容量曾达到30亿德国马克。
条形码是由平行排列的线条和间隔所组成的二进制编码。它们根据预定的模式进行排列并且表达相应记号系统的数据项。宽窄不同的线条和间隔的排列次序可以解释成数字或者字母。它可以进行光学扫描阅读,即根据黑色线条和白色间隔对激光的不同反射来识别。但是尽管其物理原理相似,目前在用的大约有10数种不同的编码和布局方案。
最流行的条形码方案是EAN 编码 (欧洲物体编码),它在1976年设计,本来针对杂货店。EAN 编码是美国UPC (通用产品编码)的发展。今天, UPC表达为EAN 编码的子集,并且可以兼容之。
EAN 编码由13位数字组成:国家标识符,公司标识符,制造商的物品标识符和校验位。如图3:

图表 3 EAN编码的条形码实例
除了EAN 之外,下列条形码在各种领域也很流行:
- Code Codabar: 医学和临床应用, 以及高安全需求的领域
- Code 2/5 interleaved: 自动化工业, 货物存储, 货盘, 装船容器和重工业。
- Code 39: 流程工业, 物流, 大学和图书馆。

图4 ISBN统一书号代码
由于一维条码的信息容量很小,如商品上的条码仅能容纳几位或者几十位阿拉伯数字或字母,商品的详细描述只能依赖数据库提供,离开了预先建立的数据库,一维条码的使用就受到了局限。基于这个原因,人们迫切希望发明一种新的码制,除具备一维条码的优点外,同时还有信息容量大、可靠性高、保密防伪性强等优点。为了满足人们的这种需求,美国Symbol公司经过几年的努力,于1991年正式推出名为PDF417的二维条码,简称为PDF417条码(见下图),即 “便携式数据文件”。

图表5 二维条码PDF417
PDF417条码是一种高密度、高信息含量的便携式数据文件,是实现证件及卡片等大容量、高可靠性信息自动存储、携带并可用机器自动识读的理想手段。PDF417条码具有如下特点:
根据不同的条空比例每平方英寸可以容纳250到1100个字符。在国际标准的证卡有效面积上(相当于信用卡面积的2/3,约为76mm*25mm), PDF417条码可以容纳1848个字母字符或2729个数字字符,约500个汉字信息。这种二维条码比普通条码信息容量高几十倍。
PDF417条码可以将照片、指纹、掌纹、签字、声音、文字等凡可数字化的信息进行编码。
PDF417条码具有多重防伪特性,它可以采用密码防伪、软件加密及利用所包含的信息如指纹、照片等进行防伪,因此具有极强的保密防伪性能。
普通条码的译码错误率约为百万分之二左右,而PDF417条码的误码率不超过千万分之一,译码可靠性极高。
PDF417条码采用了世界上最先进的数学纠错理论,如果破损面积不超过50%,条码由于沾污、破损等所丢失的信息,可以照常破译出丢失的信息。
利用现有的点阵、激光、喷墨、热敏/热转印、制卡机等打印技术,即可在纸张、卡片、PVC、甚至金属表面上印出PDF417二维条码。由此所增加的费用仅是油墨的成本,因此人们又称PDF417是“零成本”技术。
同样的信息量,PDF417条码的形状可以根据载体面积及美工设计等进行自我调整。
在我国,中国物品编码中心介绍了二维条码国家标准《四一七条码》,即GB/T17172-1997。
光学字符识别(Optical character recognition (OCR))最早在上世纪60年代开始应用。人们开发了一些特殊的字体,以便能够使人和机器都能够阅读。OCR 系统最大的优点是信息的高密度性以及在紧急情况下人可以介入进行可视阅读。
今天, OCR已经被用在生产,服务和管理领域,并且在银行用作支票的注册。
但是, OCR系统没有成为通用手段的原因是其高昂的价格和与其他识别方式相比更加复杂的阅读器。
生物特征识别(Biometrics) 是基于人类人体自身所带的某种身体或者行为特征进行模版化后对个体进行识别。因此,该方式具有其他方式所不具备的特征,即识别特征是天然的不可重复的(理论上)。对于方式来说,主要有指纹、掌纹、声音、语音、虹膜、视网膜、步态、面容等等。其中指纹方式是最流行和普遍的。
关于生物特征识别的详细内容,请参见我编写的《生物特征识别系统》和《生物特征识别和信息安全》两篇白皮书。
智能卡(smart card)是一个数据存储系统,也可以提供附加的计算能力,并且对数据存储提供内置的防篡改支持。第一个智能卡是1984年发行的预付费电话卡。智能卡被放入阅读器中,这样,就与只能卡的触角之间形成了电流通路。阅读器向智能卡提供电源和和时钟脉冲。两者之间的数据传输使用双向串行接口的(I/O port)的方式。基于内部功能的不同,智能卡的基本类型分为两种:内存卡和处理器卡。
智能卡的一个主要优势是存储在其上的数据可以防止非授权的访问和修改。因此,智能卡克易失得与这些信息相关的服务完成简单、便宜和安全的服务事务。因此在安全访问,认证、金融和电信领域使之成为微电子领域增站最快的一块。
RFID 和上述的智能卡系统非常紧密相关。和智能卡类似,数据被存储在一个电子数据承载设备——收发器(transponder)之上。但是,和智能卡不同,数据承载设备和阅读器之间的电源供应和数据传输不是基于接触的电流方式,而是基于磁场或电磁场的方式。其基本的依赖技术包括射频和雷达工程技术。RFID 的缩写代表radio frequency identification,即是说,信息是通过无线电波承载的。因为RFID 系统和其他识别系统相比有很多优点,RFID 系统开始大规模的占领市场。一个主要的应用领域就是非接触式智能卡在短程公共交通中的应用。
上述各种不同的识别系统之间的比较如下表所示。并且在接触式智能卡和RFID 系统之间有着紧密地联系。从某一方面说,后者弥补了前者的几乎所有缺点。
系统参数 |
条形码 |
OCR |
生物识别 |
智能卡 |
RFID |
|
典型的数据量 (bytes) |
1–100 |
1–100 |
— |
16–64 k |
16–64 k |
|
数据密度 |
低 |
低 |
高 |
很高 |
很高 |
|
机器可读性 |
好 |
好 |
昂贵 |
好 |
好 |
|
人可读 |
有限 |
简单 |
简单 |
不可 |
不可 |
|
污渍和潮湿的影响 |
很高 |
很高 |
-(根据具体技术) |
可能(接触式) |
不影响 |
|
遮盖的影响 |
完全失效 |
完全失效 |
—根据具体技术) |
— |
不影响 |
|
方向和位置的影响 |
低 |
低 |
— |
双向 |
不影响 |
|
退化和磨损 |
有限 |
有限 |
— |
有(接触) |
不影响 |
|
购买成本 |
很低 |
中 |
很高 |
低 |
中 |
|
运行成本 |
低 |
低 |
无 |
中(接触式) |
无 |
|
安全 |
轻微 |
轻微 |
可能 |
高 |
高 |
|
阅读速度 |
低
~4s |
低
~3s |
较低 |
较低
~4s |
很快
~0.5 s |
|
阅读器和载体之间的最大距离 |
0–50 cm |
<1 cm Scanner |
0–50 cm |
直接接触 |
0–5-m, microwave |
图表6 不同识别技术的比较
射频识别标签(RFID)技术是一种综合了自动识别技术(Auto-ID)和无线电射频通信技术的新技术。它可望在网络、生活、经济、文化、道德和伦理、法律、军事等等诸多方面带来彻底的变革,成为继Internet和无线和移动通信之后又一个决定性的社会变革力量。并最终可能和Internet(IPV6)、移动通信网络、无线传感器网络、生物识别技术、GPS技术等融合。
RFID 的出现可追溯至上世纪30年代,当然其基本技术无线电射频技术还可以追溯至1897年Guglielmo Marconi 发明无线电的时候。RFID 采用与无线电广播相同的物理原理来发射和接收数据。
RFID的基本前端系统一般由3个部分组成:
- 标签(tag)或者雷达收发器(transponder);
- 接收器(receiver)或者阅读器(reader);
- 天线。
而这些部件则有许多变体,基于不同的功率、发射范围和距离、天线设计、工作频率、数据容量、管理和操作软件、数据编码格式、空中接口和通信协议等等。这样,便出现了许多不同类型的系统,具有不同的特点和针对的应用范畴。
这些应用中涉及和影响到当今社会、生活、经济、军事、法律和文化的方方面面。而目前最热烈和最受关注的莫过于廉价标签在商品(货物)流通生命周期过程中的识别应用。
RFID技术很早就和军事联系在一起。在上世纪30年代,美国陆军和海军都面临着在陆地、海上和空中对目标的识别的问题。1937年,美国海军研究试验室(U.S. Naval Research Laboratory (NRL))开发了敌我识别系统(Identification Friend-or-Foe (IFF) system),来将盟军的飞机和敌方的飞机区别开来。这种技术后来在50年代成为现代空中交通管制的基础。并且是早期RFID技术的萌芽,而优先地应用在军事、实验室等。
早期系统组件昂贵而庞大,但随着集成电路、可编程存储器、微处理器、以及软件技术和编程语言的发展,创造了RFID技术推广和部署的基础。
60年代后期和70年代早期,有些公司(如Sensormatic 和Checkpoint Systems)开始推广稍微不那么复杂的RFID系统的商用,主要用于电子物品监控(electronic article surveillance (EAS)),即保证仓库、图书馆等等的物品安全和监视。这种早期的商业RFID 系统,称为1-bit 标签系统,相对容易构建、部署和维护。但是这种1比特系统只能检测被表示的目标是否在场,不能有更大的数据容量,甚至不能区分被标识目标之间的差别。

图1 早期的RFID发展里程碑
因此早期的1bit系统只能作为简单的检测用途。
在70年代,制造、运输、仓储等行业都试图研究和开发基于IC的RFID 系统的应用。比如、工业自动化、动物识别、车辆跟踪等等。在此期间,基于IC的标签体现出了可读写存储器、更快的速度、更远的距离等优点。但这些早期的系统仍然是专有的设计、没有相关标准、也没有功率和频率的管理。
在80年代早期,更加完善的RFID 技术和应用出现,比如铁路车辆的识别、农场动物和农产品的跟踪。
90年代,道路电子收费系统在大西洋沿岸得到广泛应用,从意大利、法国、西班牙、葡萄牙、挪威,到美国的达拉斯、纽约和新泽西。这些系统提供了更完善的访问控制特征,因为它们集成了支付功能,也成为综合性的集成RFID应用的开始。
从90年代开始,多个区域和公司开始注意这些系统之间的互操作性,即运行频率和通信协议的标准化问题。只有标准化,才能将RFID的自动识别技术得到更广泛的应用。比如,这时期美国出现的E-ZPass 系统。
同时,作为访问控制和物理安全的手段, RFID 卡钥匙开始流行起来,试图取代传统的访问控制机制。这种称为非接触式的IC智能卡具有较强的数据存储和处理能力,能够针对持有人进行个性化处理,也能够更灵活地实现访问控制策略。

图2 唯一性识别的应用
RFID的热潮和整合性应用
在上世纪末期,大量的RFID 应用指数般地试图扩展到全球范围。
在美国,Texas Instruments 则是这方面的推动先锋。TI从1991年开始建立德州仪器注册和识别系统(Texas Instruments Registration and Identification Systems (TIRIS))。该系统如今叫TI-RFid (Texas Instruments Radio Frequency Identification System),已经是一个主要的RFID应用开发平台。
在欧洲,EM Microelectronic-Marin 从1971年开始研究超低功率的集成电路。1982年,Mikron Integrated Microelectronics 开始了ASIC技术,并在1987年由其奥地利分公司开始开发识别和智能卡芯片。1995年,Philips Semiconductors 收购了Mikron Graz。如今EM Microelectronic 和Philips Semiconductors 是欧洲的主要RFID 厂商。
从技术上看,数年前,所部署的RFID应用基本上都是低频(LF) 和高频 (HF) 的被动式RFID技术。LF 和HF 系统都具有优先的数据传输速度和有效距离。因此,有效距离限制了可部署性。数据传输速度则限制了其可伸缩性。因此,90年代后期,开始出现甚高频(UHF)的主动式标签技术,提供更远的传输距离,更快的传输速度。基于此,重载的企业应用才开始使用这种技术,比如供应链管理中的托盘和包装跟踪、存货和仓库管理、集装箱管理、物流管理等等。并且逐渐试图成为合成的企业应用(包括ERP、SCM、CRM、EAM、B2B等等)的数据和语义基础。
从90年代末期到现在,零售巨头如Wal-Mart,Target,Metro Group 以及一些政府机构,如美国国防部 (DoD),都开始推进RFID应用,并要求他们的供应商也采用此技术。同时,标准化的纷争出现了多个全球性的RFID标准和技术联盟,主要有EPCglobal、AIM Global、ISO/IEC、UID、IP-X 等。这些组织主要在标签技术、频率、数据标准、传输和接口协议、网络运营和管理、行业应用等方面试图达成全球统一的平台。

图3 整合应用开始
一个RFID 系统 通常有两个组件组成: (Figure 1.7):
- 收发器(transponder), 位于被识别的对象;
- 讯问器(interrogator)或者阅读器(reader),取决于设计和所采用的技术,可以是阅读或者读写设备。

图4 RFID系统的主要构成
阅读器通常包含一个射频模块(发射器和接收器),一个控制单元和一个与收发器的耦合单元。另外,某些阅读器还包含其他数据接口系统(RS 232, RS 485,TCP/IP等),以便将数据转发到其他系统I (PC, 机器人控制系统等)。
雷达收发器,表示RFID系统的实际数据载体,通常有一个耦合单元和一个电子芯片组成。(Figure 1.9)。雷达收发器通常不具备自身电源供应,当它不在质询器的质询范围时,整体呈被动状态。它只有在质询器的质询范围之内才被激活。激活雷达收发器的电力通过耦合单元传输给收发器,所需的数据和时钟脉冲也是如此。

图表 5 RFID 数据承载设备的主要布局,左边是具有天线线圈的感应耦合transponder;右边是具有偶极天线的微波Tag/transponder
近两天WW并入Struts的事情也可算是比较激烈的一件事情了。从TSS上的讨论来说,90%以上的人还是认为是好事情的。
其实,不久前,Struts规划的路线中,1.2.8可能是最后一个Classic的版本了,并且改版本比1.2.7之前的变化还分出了Struts
Core和扩展, 象 EL, Tag, Tiles, Validation等等几乎都已经是独立模块了。
至于下一代的走向,原来规划的是2个方向 , Action Framework和Shale. 其中Shale相对独立,即以JSF为中心,补充和完善JSF框架之不足,我看倒是有些与ADF Faces在有些地方相似,当然是指前端。
只是,ActionFramework的核心原来是 COR 模式为基础,并且可能还未决断。如今,WW带着Xwork加入,可算是解决了这个问题。从Struts Wiki中,这两个项目还是分开的,从Ted的邮件和WW的消息看来,新项目已经决定是Struts Ti了, 可能会合并成Action Framework,成一个东西。是啊,搞那么多干吗?
说到Struts Ti,我才想起来,原来有一个项目是Struts Ti,是从BaseBean的BasicPortals发展起来的,今天再去看看,那个项目已经不能访问了,Sf上的BasciPortal也不能下载了。纳闷!我还没研究这个这个Ti有什么关系。
直接影响我的一个问题是,我一本以Struts 1.2.X为基础的书是继续写还是不写?下一版变化太大了。
日前IBM发布了免费的Websphere应用服务器,Websphere Community Edtion(Websphere CE)。该App server基于Apache的Geronimo,并且附带了Glucode的管理平台Bundle。Gluecode是IBM之前收购的一家商业开源厂商。
并且它还可以与Tomcat和IBM的Java 内存数据库Cloudscape集成。
这活脱脱是 Tomcat + JBOSS + HSQL的翻版,或者针锋相对的举动?
IBM这家大佬将PC这些边缘产业甩给联想这后,潜心发展软件和服务,已经基本可以说是全球第一大软件厂商了。不过,如今Java开源领域的更加繁荣,轻量级技术、方法和框架的流行,确是不争的事实。不管如何,这些巨头都想在这方面染指,插上一腿。
比如,首先,除了Oracle之外,几个重要的Java IDE纷纷转向eclispe平台。然后,BEA宣布支持Spring,hibernate等轻量技术; SUN 开放了Saloris 和 Openoffice, 松动了原来的许可证策略,培育了Java.net这个不断壮大的社区。
而JBOSS确是吸收了JBPM以及开发了portal之后,潜心打造 JEMS(Jboss Enterprise Middleware Sysytem),已经初具形象。另一家强大的开源老大ObjectWeb,虽然产品线很长,但是剑走偏锋,远远不得Jboss风光。
详细信息,可以访问 Websphere CE的站点。
 RFID的领域应用
RFID的领域应用
RFID是一种自动识别技术。从本质上讲,它对其所标记的物品本身并不带来任何附加价值,甚至增加成本。但是,它却能够驱动与物品相关的背后应用带来巨大的价值,而这些则根据不同的应用体现而不同。这其中还有一个至关重要的驱动力,那就是以Internet、网络技术、通信技术、软件技术为代表的现代信息和通信技术(ICT)。只有在此基础上,RFID本身才能成为体系,自动标记和识别的数据才能得以广泛地传输和共享,从而连接随时随地的业务。即,企业和组织能够在前所未有的集成之基础上,自动地进行通信、协作、教育、销售、配送、采购、服务,以及企业内部的业务流程。
RFID 的本质是对物体或者人进行识别。其最大优点是自动化,不要求有人为干预,被标记的对象一旦处于阅读器的质询区域便能够被自动读取,而相关信息则实时传送到后段进行处理。被传递到业务系统的相关的数据主要包括: 标签编码(tag ID),阅读器编码(reader ID)以及读取时的时间片。所有的应用都是基于这些基本数据。
资产跟踪(Asset Tracking)
很自然,资产跟踪是RFID的最通用的应用。公司和组织可以将RFID标签置于那些流动的、分散的、易于丢失或者被盗的、难以定位和查找的物品之上。几乎每一种RFID系统都能够被用于资产跟踪。比如总部位于美国Secaucus, N.J.的一个第3方物流产商,NYK Logistics就使用RFID来跟踪其位于Long Beach, Calif.的集散中心的集装箱。它使用一种基于阅读器和主动标签的实时定位系统,可以将集装箱定位在10英尺之内。对于安全管理来说,一些敏感的信息设备,特别是移动设备(如笔记本电脑等),就可以使用RFID来跟踪管理。
加拿大航空公司使用RFID来跟踪用于世界各地机场的食品车,每年可以节约数百万美元。这样,不但因为使用了更少的食品车以及减少了保持库存的时间和费用,并且对世界各地移动的食品车的妥善管理也增进了效率和客户服务。
其它应用案例还包括,El Paso County使用915 MHz被动式标签来跟踪计算机和办公设备。一家法律公司Fish & Richardson P.C.甚至使用13.56 MHz标签来跟踪重要文件。而一家新加坡公司使用13.56 MHz 技术来跟踪必须经过检测的建筑混凝土以保证建筑安全。
制造(Manufacturing)
RFID 应用在制造商其实已经很多年了。它可以对生产制造过程中的零件进行标识,甚至与工艺、制造参数、生产过程等相关。特别对自动化柔性生产线有巨大帮助。
波音公司就在其Wichita, Kansas的工厂中使用了一个915 MHz 的系统来跟踪零件的达到。而过去则是使用条形码来进行跟踪的,但条形码必须经过人工扫描,并且还必须经过特殊的化学处理。如果人工扫描环节出了差错,则会失去对零件的跟踪。而如今这些都是自动化的,并且减少了错误和需要的人手。
美国汽车通用公司(AM General )也在其位于Mishawaka 的悍马汽车制造厂内使用了以一种主动式RFID 系统来跟踪零件。而 Club Car 则甚至将RFID作为其新的高尔夫球车装配线上的一个主要部件,将每辆车的生产时间从88分钟减少到46 分钟。
供应链管理(Supply Chain Management)
RFID 技术过去已用于企业内部控制之用的供应链闭环控制。宝洁公司(Procter & Gamble)在西班牙的配送中心使用了13.56 MHz 系统来增加吞吐量、减少了差错和成本。
Paramount Farms公司,它加工大约整个美国60% 的pistachio 作物,并且出口到20多个国家,便使用了RFID来帮助自动化处理收购自越来越多的种植伙伴的产品。
随着标准的出现,比如EPC等,使得不仅在企业内部进行供应链跟踪,借助于基于标准的编码和数据交换,以及Internet的网络支持,可以扩展到与企业相关的业务伙伴,从上游的供应商到下游的分销商。整个供应链在全球范围内形成,包括间接的第3方物流、运输商、以及零售商。并且,也在前所谓有的基础上提供了对生产(EPR)、零售(POS)、服务(CRM)的集成。
一家加拿大的护肤产品制造商Canus就使用了RFID 来减少其到零售客户的运输的检测成本,并且还使用基于RFID 的温度感应器来监控运输过程中的条件。
零售(Retailing)
零售商们,如Best Buy, Metro, Target, Tesco 和 Wal-Mart 等,都是采用RFID技术的先驱。这些零售商都希望RFID能够整合供应链、有效管理库存和配送、以及有效的货架管理,以便减小成本和提高服务。
Wal-Mart已经有严格的时间表,已经要求他的前100家供应商提供RFID标记的产品,然后是前200家,500家直至全部供应商。与美国国防部DoD成为推动RFID的最大力量。
电子支付(Payment Systems)
RFID 不仅在供应链中很火热,电子支付系统也很得到关注。包括不停车收费系统、泊车收费系统、公交车票务等等。
由于其中涉及到价值存储和转移,这里主要是高端RFID 系统,特别是智能卡。在世界很多城市、包括中国的很多城市,都采用非接触式的智能卡来进行公交系统:巴士、地铁、轻轨、电车甚至出租车。
另外一个重要的方面就是银行支付,MasterCard 和Visa 都在计划将传统的磁卡转换成智能卡,增加安全性和解决其他很多问题。
安全和访问控制(Security and Access Control)
RFID 已经用于物理安全的访问控制很久了。以前一般使用低频的RFID标签。最近,供应商大都推介如今采用高频的13.56 MHz系统,提供更远的读取距离。

RFID 还用于保护重要财产。许多最新型号的汽车都使用这种技术来防盗。即在方向盘部位有一个内置的RFID reader,只有当读取到封装与钥匙中的标签发出的正确的识别号码时,才能够启动汽车。
主动式标签可以结合移动传感器来对极端敏感和高价值的东西,比如武器和珠宝进行监控,一旦检测到则会自动报警。RFID 标签也可以用于难以管理的移动计算和存储设备如笔记本电脑和USB存储设备等。
其他应用
随着技术和领域的发展,会出现层出不穷的革新应用。比如,用于大型主题公园的儿童跟踪和识别,监狱犯人的识别和监控,钞票和票据的保安、病人和孤寡老人的监控等等。
无线传感器网络是下一代自主网络,它将无数的集成温度感应、移动感应、放射传感等等感应器的主动或者被动式RFID,并且具有自主的网络功能。美国军方已经研究出能够在实物中发现病原体的RFID传感器原型。这可以用于对通过食物感染疾病的恐怖袭击的检测和保护。
比如NASA的Jet Propulsion Laboratory 就在研究新一代的无线传感器网络。在其早期的实验中,可以用于检测土壤和空气的温度、湿度,以及光线、水流方向等等。
IBM AlphaWorks有一个RFID Device
Development Kit,由一些基于OSGi(Open Service Gateway Initiative)的基础架构,工具和示例,这些一起来构成IBM的RFID 网络边缘解决方案。它可以与IBM Workplace Client Technology ME,进行集成,这时,用户可以在一个完整的开发平台上进行开发,使用其基础架构和所包含的技术、API来对新设备进行支持。其中还包括仿真器和教程。用户可以扩展基础架构从而支持特定模型的业务应用需求。
该技术是属于IBM的Emerging Technologies Toolkit (ETTK)的一个组件。
它所提供的 API和协议规范被映射到XML,可以用来产生和开发设备的Java接口。最高层的接口提供了设备,比如RFID阅读器,的通用Java模型。工具包中的指南将指导用户构建与IBM的Sensors 和
Actuators中间件新的代理类。这允许用户将RFID支持插入到现有的应用中,并且为应用开发者提供一个新的设备模型。
详细信息可访问:http://www.alphaworks.ibm.com/tech/rfiddevice?open&S_TACT=105AGX59&S_CMP=GR&ca=dgr-jw01awrfiddevice
今天看到一个网站,slashdotcn.org,嘿,风格、系统、内容设置基本上都和Slashdot.org类似,还以为是slashdot的中文
版。仔细研究了半天,好像与slashdot没什么关系。不过也是一种不错的新闻站点方式,因为它的国外榜样是大大的有名。
看到它是因为在O'Reilley看到了一片关于Web 2.0的文章,从该文的讨论中进来的。其作者是O'Reilly Media的掌门Tim O'Reilly
,旨在为 Web 2.0 正本清源: 以及讨论了软件的下一代设计模式及商业模式。非常值得一看,详细内容参见:What Is Web 2.0。
我一直喜欢的M7 Nitrox终于被BEA收购了。这下,不久的将来Nitrox就可以成为eclipse-based的Workshop的一部分。
Nitrox算是eclipse插件中可视化做的非常好的工具了,而workshop则在Java控件、Web Services、Portal等方面的功能非常强大而直观。二者结合在一起,应该效果不错。
一直认为憾事的BEA Workshop对JSF的支持,这下也有了。
前些日子,BEA还推出了对Spring 的支持包,这下,Weblogic 9和eclipse 的Workshop非常值得期待。
分卷压缩后,终于上传完了。
下载地址分别是:
Part1
Part2
Part3
Part4
Part5
Part6
下载是正常的,如果不能请检查你的网络。解压时需要全部下载完成后进行。
Struts in Action 终于整理完了。并且我根据这里的朋友们提供的意见和指出的错误进行了修改,也根据原书的勘误作了修改。
我将原来的分章节的文章删除了,准备上传完整版。可是文件太大,而且系统将Size限制在2M.又是一阵忙活,压缩了,减小PDF文件的大小了....最后的压缩包到1.8M左右。可是网络太慢,还是上传不成功。郁闷!
只好等网络不忙的时候再上传,分开打包总不太好。
昨天到学校报到了。拿到课表,居然本学期每周居然1-4晚上,周六全天上课,又郁闷!那里忙得过来!看来得好好盘算一下怎么办了?
而且,以后可能到这里的时间少了,我准备的一些文档的推出速度则更加慢了。
最近简直没有时间,可能笔误和错误颇多。请在这里指出来,一并在完整版中改正。谢谢!
这里下载。
不知为什么提交后连接地址的上下文根会变。如果上面连接不行,请直接使用这个地址:
http://www.blogjava.net/Files/SteelHand/StrutsInAction_Chinese(15).rar
基于生物特征识别的公开密钥基础设施
Biometrics-Based Public Key Infrastructure
摘要:
本文针对PKI体系所存在的难题和脆弱性,结合生物特征识别技术在网络安全中的应用提出了解决方案,并分析了相应的特点。
关键字:生物特征识别 PKI 网络安全数字证书密钥管理智能卡
前言
PKI代表着基于公开密钥密码术对数字证书进行管理、分发、存储和撤销的过程以及相关的基础架构。迄今为止被认为是最有效地解决了安全服务(包括鉴别、认证、授权、完整性、机密性和不可否认性)的基础架构。并且,由于Internet等公开网络基础的飞速发展,它也成为在公开网络上实现安全的最好方式。
PKI
PKI概述
Internet是一个强大的、支持各种通信方式和电子事务的场所。它几乎无处不在,并且涉及到不计其数的服务器、交换机、路由器和应用系统。所有的网络设备和网络服务都不是某一组织所能控制,因此它不能视为一个可信网络。消息和事务在从一端传递到另一端时需要经过无法控制的无法预知的许多设备,每一个环节都存在潜在的巨大风险。因此,重要的是需要端对端(End to End)的安全。
另外,对于网络上发生的通信和事务,双方并不能看到、听到甚至知道对方,也无法判断接受到的信息是否是原始信息。因此需要用一定的方法来确保身份认证和通过非可信网络(包括Internet和超过用户控制范围的网络)发送的消息和事务的完整性。PKI 能够提供这些方法,并且能够应用于各中场合,特别是Internet。
PKI的弱点?
但是是否所有的数据传输都需要PKI呢?不是的。首先,并不是每一个人都需要如此级别的安全。许多用户以及用户使用的服务使用ISP或者公共终端(比如桌面计算机和浏览器、电子邮件程序等)提供的默认安全级别就已经足够。只有在涉及到隐私、机密、数据安全等商业和法定领域在非可信网络上,才需要这种高强度的安全。
整个PKI体系中最显著的问题是密钥的管理。因为不管对哪一方来说,也不管对密钥采用什么样的存储和管理方式,私钥是其中最重要的关键之处。也可以说,私钥的管理关系到整个PKI的安全。这也成为整个体系中最脆弱的部分。
如果私钥是保存在硬盘、软盘,或者其它非可信媒介之上的,则私钥本身存在失窃的严重风险,从而误用私钥,威胁PKI的安全。
为了密钥安全,目前的流行形式是双因素的认证。即将证书(私钥)保存在可信的硬件载体(Smart Card或者USB Key 设备等)之中。但即便这样,也可能存在着被偷窃、丢失、抢夺等风险。通常私钥都是通过一个PIN来保护的,而PIN只是一些简单的字符组合。这样就会遇到口令管理的怪圈:如果密码太过简单,则对暴力和猜测破解的方式抵御甚弱;如果密码太过复杂,则用户可能会在某处记录下来,这又是巨大的泄密风险。因此,如果PIN失密,并且因此而可以使用私钥,则整个PKI则毫无安全可言。其提供的安全服务越全面,受到的损害越大。
因此,密钥管理和密码安全成为PKI最大的脆弱之处。
生物识别技术(Biometrics)
生物识别(Biometrics)是一种基于个体的身体和行为特征对个体进行识别的自动化方法。比较通用的方法有指纹(fingerprint),面容(face),虹膜(iris),手型(hand geometry),语音(voice)和签名(dynamic signature)等。这些方法和技术,具有不同的特点,目前处在不同的技术和应用发展水平。而关于“最好”的生物识别方法类型则根据不同的应用需要而异。
生物识别系统对生物特征进行取样,提取其唯一的特征并且转化成数字代码,并进一步将这些代码组成特征模板,人们同识别系统交互进行身份认证时,识别系统获取其特征并与数据可中的特征模板进行比对,以确定是否匹配。
几乎所有的安全服务的基础都是基于用户鉴别和认证。只有合法的用户才能授予访问的权限。为了知道用户是否是合法,必须告诉计算机一个身份声明,以及相应的认证方法。最常见的方法是通过提供用户名称或者标识ID。通常可能有多种形式:用户姓名、序列号码、甚至x.500 的全限定名称。而用户的身份认证方式则根据采取的不同认证方法而不同。
身份认证的主要方式有三种:
- 你所知道的(Something you know),比如密码;
- 你所拥有的(Something you have),比如令牌;
- 你本来是(Something you are),可以测量的自身特点。
这通常称为是认证的三个基础。他们可以单独使用,也可以结合使用以提供更高强度的认证。
基于生物特征识别的认证
个体本身所具有的独特的身体和行为特征可以用来标识某个个体,这就可以用来进行认证。这种认证方式称为是生物认证。这就是一种“你本来是”类型的认证。
生物识别可以用来进行鉴别(identification)。这种情况是指用户并未声称自己的身份。生物识别系统试图通过比对采集的个体特征和事先存储的特征进行比对来进行相似性匹配。通常称为是1:N匹配。这种能够方式一般用于法律强制的环境中,比如刑事侦查和法院查证。这种方式一般返回的是一个最相似的集合结果。最后的决定结果一般需要人工参与。
生物识别也可以用于认证。如果某个用户声明了他/她的身份,就可以使用生物手段来进行认证。生物比对则试图在预先存储的特征签名数据库中查找,然后比对看时否提交的生物特征和登记的特征相匹配。如果匹配,则认证为合法用户。这通常称为是1:1匹配。这种匹配的返回结果很简单,那就是身份验证是,还是否。
基于生物特征的多因素认证运行模式
由于加入了生物识别特征,其运行是需要实时采集的模版和预先登记存储的参考模版进行比对,以此来决定用户的身份。因此,登记的参考模版的存储地点和验证时的比对操作的进行就显得比较灵活。
对于一个完整的基于生物特征识别的认证系统,可能的环节包括:

因此在这个链条中,模版的存储和比对的地点就存在多种组合,对应不同等额运行模式。如下表所示:
|
比对存储 |
服务器 |
客户机 |
采集设备 |
智能卡 |
|
服务器 |
A |
- |
- |
B |
|
客户机 |
- |
C |
- |
D |
|
采集设备 |
- |
- |
E |
F |
|
智能卡 |
- |
- |
- |
G |
其中某些组合可在操作性,安全性等方面具有较大缺陷,因此一般情况下不予采用。比如,因为参考模版是一种非常敏感的数据,因此尽可能存放在比较安全的地方。而且在比对过程中最好在一个受控的安全环境内进行。模版最好不离开相对安全的环境。
在上述四种信任链中,一般来说智能卡和服务器是相对比较安全的环境。并且基于安全的原则,敏感的数据尽量减少网络的传输环节。因此,如果模版是存储在服务器中,一般情况下比对最好在服务器中进行,这样可以让它处在一个受控的环境之中,并且减小传输的攻击威胁。
表中标注字母的组合是目前可以运行的组合方式,具有不同的特点和优缺点,可以分别适用于不同的需要。我们对其进行了列表对比:
基于生物特征识别的网络安全运行模式比较
|
运行模式 |
优点 |
缺点 |
主要应用 |
|
A .服务器存储/服务器比对 |
管理员可以全部控制用户的生物凭证模版; |
可能会涉及到个人隐私;
需要对原有架构作出更改;
敏感的数据在网络中传输,需要额外的安全连接; |
网络安全
国土安全 |
|
B.卡内存储/服务器比对 |
|
可能会涉及到个人隐私;
需要对原有架构作出更改;
敏感的数据在网络中传输,需要额外的安全连接; |
网络安全 |
|
C.PC存储/PC比对 |
用户可以控制其自身的模版; |
PC客户端本身是一个不安全的场合;
不能扩展到整个网络环境; |
终端安全
计算机安全 |
|
D.卡内存储/PC比对 |
用户可以携带其自身的模版;
可以漫游; |
在比对时,暴露了模版数据,可能会被窃取;
|
在线安全 |
|
E.设备存储/设备比对 |
用户可以携带其自身的模版;
用户敏感的模版不会暴露; |
不能漫游; |
物理控制 |
|
F.卡内存储/设备比对 |
模版可以被多种设备访问;
用户可以控制其自身的模版; |
对于PKI应用是由一个安全漏洞,因为保护证书的密码/PIN存储在卡中,会被发送到设备中进行比对。 |
网络安全
物理控制 |
|
G.卡内存储/卡内比对 |
智能卡可以个人化;
卡内数据在没有匹配是不能被访问;
敏感的模版永不出卡;
用户可以控制其自身的模版,没有隐私侵犯问题;
与PKI架构整合时不需要对原有架构进行更改; |
|
网络安全
智能身份ID |
从以上的运行模式比较中我们可以看出,有两种方式特别适合于应用于网络安全,即卡内存储/卡内与和卡内存储,服务器对比方式。
卡内存储/卡内比对方是是一种非常具有灵活性的模式,它能具有很好的隐私性、安全性、可伸缩性、互操作性和容易集成性。
而服务器为中心的方式则是一种强控制的方式,管理员可以控制所有相关的用户的生物凭证以及与之相关的安全策略,具有很好的适应性和应用范围。
关于卡内比对的运行方式,目前可以运行在主要的智能卡操作系统(COS)之上,比如PreciseBiometrics公司基于JavaCard系统的PRECISE MATCH™技术和G&D的STARCOS SPK方案。
基于生物特征识别的PKI
公开秘钥架构(PKI)是至今最为安全的提供认证和数字签名的方法。该方法基于非对称加密的基础,而且依赖于公开和私有的密钥对必须对应于相应的人。通常公钥要进行公开分发,而私钥则由拥有人妥善保管。
而公钥的保证一般是通过证书的方式来保证,证书由双方信任的机构来进行颁发。有多种不同的证书技术,常见的X.509 v3。某个证书包含一些描述与该公私密钥对相联系的人的身份信息。而且数字是自签名的,由一个权威机构完成,以保证证书的准确性和权威性。
数字签名则是由私钥所加密的文档的单向 Hash编码。通过对应的公钥或者证书就能验证该文档的有效性和完整性。一旦某人使用私钥进行了签名,那么任何获得了该对应公钥的人都可以使用该公钥来验证该签名的有效性。
数字签名的一个重要要求是不可否认性。然而,整个PKI架构中关键的因素是签名者的私钥,那么私钥管理的安全性就直接影响到签名的不可否认性。
所以,密码管理问题是传统PKI架构的主要问题。因此导致了非常复杂的密码管理和分发机制。首先必须部署基于软件的密码管理容器到签名的机器上。这些容器当然能保护不受非法的访问,但是,这种保护同样还是基于口令密码的机制,所以口令本身的安全问题同样存在。
基于中心的策略
某些组织找到了一种相对简化的PKI部署方式,这就使以服务器为中心的PKI架构。这种方式以一种中心服务器的方式来管理私钥,因此可以很快速的完成密钥的重新生成和验证。
这种方式现在为许多公司所用,包括大型的支付和金融公司,如Visa。它们通过网络来产生对应的私钥和签名以及证书。
这种方式实际上仅仅解决了布署的成本和复杂度,却没有解决安全的真正问题,私钥的安全性依然存在。
解决这种问题的一种方式是在服务器为中心的PKI的架构中引入生物特征识别技术。这样,有两个无与伦比的优点:
- 生物认证将签名直接对应到相应的个体而不是对应的证书/公钥;
- 生物认证的高强度消除了非对称加密中私钥管理的难题。
其结构如图所示:

其工作原理是,客户端采集生物特征信息,并传送到认证服务器进行认证。认证服务器能够决定用户的凭证是否有效,并自签一个认证信息给私钥保护器。私钥保护器然后根据文档信息计算数字摘要并向客户端返回一个数字签名。这样就在所有应用和服务间建立了完全信任的关系。
这实际上使用了我们前述的服务器存储/服务器比对的方式。
然后私钥保护器会和CA进行交互,以获得CA签发的公钥和证书。理想情况下,由于私钥和生物特征的重要性,因此,可以使用基于硬件的安全模块来进行管理,这样私钥永远不会暴露。
这种方式的优点是:
- 生物特征识别方式减小了否认的风险
- 服务器为中心的密钥管理架构减小了部署成本和复杂度;
- 强大的可伸缩性,可以使用与大规模的认证场合,并且密钥的产生非常快速;
- 基于服务器的机构有利于进行痕迹审计;
- 基于策略的认证方法,可以和其他原有的认证设施集成在一起;
- 管理员对整个安全策略、密码体系和生物特征模板都具有控制权。
基于端点的策略
还有一种相对安全的保护私钥的方式是使用硬件令牌,比如智能卡和USB令牌。对智能卡来说,密钥对可以在卡中产生,而公钥输出作为验证,私钥在卡中受到保护。
这种方式的缺点是,卡可能会被窃取和丢失,而且通常这种方式产生的随机密钥对都有一定的有效期限,一旦失效必须在卡中重新生成。并且,对卡来说,同样也是通过用户名和口令(PIN)的方式来保护私钥的安全性。这样,口令威胁问题又会出现。
这种弱点也可以通过使用生物特征识别技术来进行解决。
根据以上的分析,非服务器比对方式中最安全的就是卡内存储/卡内比对的模式。这种模式下,模版的存储和比都在高度安全的卡内进行,而且敏感信息和秘密信息永不出卡。由于只有通过生物认证的情况下才可以使用卡中存储的数字证书,因此实际上可以免除PIN或者口令(当然也可以使用)。
除了基于生物特征识别的基于中心的策略所具有的优点之外,这种方式最大的优点是部署灵活和简单。它几乎不需要对原有基础实施进行改动,能够非常容易的融合到原有的PKI或者其它基于证书的安全基础架构之中。因为,所参与安全交互的只是经过生物认证后才使用的公钥(证书)。
同时,用户自身的生物特征在其自己拥有的卡(或其他设备)之中,用户能够具有控制权,消除了一些隐私的敏感性。
基于生物特征识别PKI的特点
基于生物特征的PKI主要有以下特点:
1.具体化。
虽然生物特征本身并不直接参与到网络安全和基础体系中,但是通过生物特征识别,能够将虚拟空间和显示空间联系起来。特别是对于认证和签名,可以追溯到具体的个体而不是抽象的二进制(用户名或者证书)。
2. 安全性
生物特征本身作为鉴别是目前最为安全的技术,特别是如虹膜识别等技术;
3. 自我管理
生物特征本身属于一种“我本来是”的特点,拥有人自我管理,减少了丢失、偷窃的可能(特别是活体识别技术);减少了分发管理的负担;同时拥有人对其具有控制权。
4. 不可撤销性
生物特征识别技术不象数字方式的识别,一旦丧失安全性可以撤销重新颁发;生物特征本身是不可再生,不可重新发放的。因此,必须在使用过程中主要保护原始的生物特征信息(不是提取后的模板),比如使用轮流使用手指指纹,或者加入基于图像的扰动等。
5. 非绝对性
生物特征不管如何精确,却和数字手段不同,它是采用相似性来进行匹配的,而不是通过相等性来匹配的。所以,它不能直接应用在安全体系的密码体系之中。只能作为辅助的安全手段。
结论
传统的PKI技术面临着密钥管理和分发的难题,从而影响到PKI架构的广泛使用。
基于生物特征的识别能够解决这两个问题:首先,通过生物特征识别技术,可以将原有的私钥的管理难题和脆弱性得到解决,并且可以通过中心化策略和客户端策略来进行。前者能够在最大控制基础上,解决安全的密码分发和管理问题。而后者则更加灵活,与现有PKI架构无缝集成。
生物特征本身是个体自有特征,并且从逻辑上将认证和否认性追溯到具体的个体而不是抽象的数字代码。由于其天生性,也基本没有分发的管理负担。
基于生物特征识别的PKI,从逻辑上和技术上都加强了PKI。一方面有利于PKI的广泛应用,另一方面安全强度大大提高,对政府、军队和其它敏感行业尤其重要。
参考文献:
- 公钥基础设施(PKI):实现和管理电子安全 [美] Andrew Nash 等著,张玉清等译,清华大学出版社,2002年12月第1版。
- 数字签名 Nohan Atreya 等著,贺军等译,清华大学出版社 2003年1月第1版。
TOP 10 Web应用脆弱性之一:未经验证的输入
描述
Web 应用使用HTTP 请求(也许还有文件,也是一种特殊请求) 来进行输入,并决定如何进行响应。攻击者可以篡改HTTP 请求的任何部分,包括url,查询字符串(querystring), headers, cookies, 表单字段(包括隐藏字段),试图绕过服务器的安全机制。常见的通用输入篡改攻击包括:
o 强迫浏览(forced browsing);
o 命令注入(command insertion);
o 交叉站点脚本(cross site scripting);
o 缓冲区溢出(buffer overflows);
o 格式字符串攻击(format string attacks);
o SQL注入(SQL injection);
o 有毒饼干(cookie poisoning);
o 隐藏字段操作(hidden field manipulation),等等。
某些站点试图通过过滤恶意输入来保护自己。但问题是编码信息的方式无穷无尽。这些编码方式看起来并不是加密的,所以似乎也用不着解码。但是,开发人员仍然经常忘记将所有的参数在使用之前解码为最简单的形式。参数应该在其被校验之前转换为最简单的形式,否则,恶意输入就可能掩饰自己从而流过过滤器。简化这些编码的过程称为是“规格化(canonicalization)”。因为几乎所有的HTTP 输入都可以编码为多种格式,这种技术便可以打乱各种旨在利用和攻击上述弱点的攻击行为。这使得过滤非常困难。
有非常之多的web 应用仅使用客户端校验来验证输入。客户端校验机制是非常容易绕过的,这样就使得Web应用几乎对恶意参数的攻击毫无保护。攻击者可以使用攻击甚至telnet来产生他们自己的HTTP 请求。他们才不关心开发人员预定想要在客户端发生的时候事情呢。注意,客户端校验仅仅在提高性能和可用性方面有益,但是它毫无安全可言。因此,对于恶意参数攻击,服务器端校验是必须的。
这种攻击的数量在不断上升,因为有大量的支持参数的“模糊化”(“fuzzing”)、腐朽(corruption)、以及野蛮强制增长的工具出现。不应该低估了这些使用非校验输入进行攻击的影响。实际上如果开发人员能够在使用参数之前对其进行验证,就可抵挡大部分的攻击。因此,最好使用一个中心化的、强大的验证机制来对所有HTTP 请求的输入都进行验证,这样利用此弱点进行攻击的数量就会大减。
环境影响
所有web servers, application servers, 以及应用环境都容易受到这种参数篡改的攻击。
如何决定你的应用是否脆弱
一个Web应用所用的未经验证的HTTP请求的任何和部分都称为是“脏” 参数。找出脏参数的最简单的方式是进行最详细的代码评审,找出所有从HTTP请求提取信息的方法调用。比如,在J2EE应用中,这些包括HttpServletRequest 类(以及其子类)中的方法。然后你就可以循着代码查看参数变量是在哪里使用的。如果变量在使用之前未作验证,这可能就是一个潜在的问题。在Perl中,你因该考虑使用 “taint” (-T) 选项。
你也可以通过一些工具来找出脏参数,比如OWASP的 WebScarab。它们可以查看和评审通过HTTP/HTTPS的所有数据,并进行分析。
如何保护
保护很简单,那就是确保任何参数在被使用之前都进行了验证。最好的办法是使用一个中心化的组件库,比如Java中的Jarkarta Commons Validator.每个参数都演进行严格检查。涉及到过滤脏数据的“负面”方法或者依赖于签名的方法都不可能很有效率,并且难以维护。
参数应该进行“正向”规格的检查,正向规格( “positive” specification )的定义可包括:
- 数据类型(string, integer, real, 等)
- 允许的字符集
- 最大最小长度
- 是否允许null
- 是否必需
- 是否允许重复
- 数值范围
- 特定的法定值 (枚举)
- 特定模式(正则表达式)
* 本系列整理自 OWASP(Opensource Web Applicaiton Security Project )
EXADEL Studio的3.0发布了,我个人认为这是eclipse平台的轻量IDE中比较好的了。M7的Nitrox不错,但是很贵哦。而且............加密做的不错,很难找到CRACK的。
从2.5版本开始,他就分为了标准版和Pro版,前者是免费的,后者收费。3.0Pro版本同样为$99,可以说非常便宜了。而Nitrox同时支持JSF和Struts的版本居然是$699。
关于其新特征,可以查看:Pro版:http://www.exadel.com/products_exadelstudiopro.htm 标准版:http://www.exadel.com/products_exadelstudio.htm。
有几个特征值得一提:
导航图:
 Tree视图编辑器:
Tree视图编辑器:

特别是支持表达式的帮助:

这点非常不错,看好!
对Struts的支持,除了常规的导航流图,配置编辑,可视化验证,之类,还直支持TILES的可视化,这点有很大进步,但是和Nitrox比还是有些差距,后者能够支持JSP编辑器中的TILES WYSWYG效果。
还有个有趣的特征是Struts配置文件的Debug, 直接在图形上就可以设置断点。
另外的改进就是支持JSP 的WYSWYG编辑。
PRO版与标准版的支持在于对Hibernate 和Spring 的支持,以及JSP的可视化编辑。其中Hibernate 支持可视化MAP编辑。Spring 则是有Spring IDE提供,无新意。
哈哈,我决定在我后面的Spring 和struts的书中,以它作为演示工具。
Borland 最近宣布了将要升级JBuilder IDE的相关信息。基于Eclipse平台,Borland JBuilder 2006 将提供端对端的开发人员协作功能,以提高对标准的支持和生产力增强。但是这恐怕不是令大家关注的地方,大家感兴趣的还是Eclipse平台。
BEA公司也意图将其IDE Workshop的未来版本转向Eclipse平台,在加上IBM Websphere Studio(现在叫Rational Software Architect和Rational Application Developer),似乎eclipse的势力在妄图一统天下。著名的Java IDE只剩下Oracle 的JDeveloper和IDEA了。但是实际上Java IDE 却是阴云密布,不容乐观。
基于Eclipse的 JBuilder,代号为Peloton。大约会在明年中期发布。它将会包含 JBuilder的可用性和协作特征,加上应用生命周期管理。
近两年Eclipse社区不断发展壮大,以致在Eclipse3发布的时候,疯狂下载造成服务器几乎瘫痪。因此,在Java IDE市场上, Eclipse估计占到20-30%的市场分额。.
因此,这种增长令商业的专用IDE厂商非常不安,前不久 Oracle终于宣布其JDeveloper向开发人员免费,仅对支持收费。就是一种无可奈何的反应。它们认为,Eclipse (包括商业和开源平台)的开发工具已经占据了50%的半壁江山,Oracle在J2EE方面一直不太理想,还不如让JDeveloper免费,也好做为Oracle Java的形象大使,赚回些关注。
但是实际上,Eclipse提供的是一个骨架平台,当然Eclipse本身也提供一些开源的Plugins,也有其他一些厂商在提供商业的插件支持,比如MyEclipse, Lomboz, Exadel等等。还有其它一些开源的专用插件,层出不穷。
因此,Eclipse-Based IDE实际上成为两种派系:OS和商业的。就商业来说,IBM是最嬉笑颜开的,Eclipse本身就是它鼎力支持的,从WSAD到RAD和RSA,IBM成功地将Rational 品牌产品和Websphere进行了整合,Rational体系如今专注软件开发生产和测试,而RAD和RSA则提供了业界最高标准的,包含基本IDE支持,标准支持,协作,软件生命周期(甚至集成了RUP),MDA等功能为一体的开发平台。
当然,基于Eclipse的商业IDE和开源IDE会否共存?答案当然是肯定的。最简单的原因就是,Java虽然是标准,但是厂商自有独门功夫,因此,IDE商业平台自然带有一定的专有性。如果是大型的企业应用,需要优化等等,则非商业IDE莫属。
另外一个就是Java本身的未来,轻量架构和方法的发展,比如如火如荼的IoC,MetaFramework等等,则又大大促进了开源IDE的发展。
因此,一定时期内,这两种肯定会共存。IDE的较量,背后还是AS和基础平台的较量。
Borland的未来核心是构建一个 Borland Core Software Delivery Platform (SDP), 也都基于Eclipse。JB只是其中一个组件。
SUN的IDE则有些尴尬,NetBeans 一直没什么人感兴趣。现在,SUN的另一个IDE, Java Creator则让人摸不清到底是何意思。Creator的意图是想借JSF的组件架构,构造一个轻量的开发环境,并且还苦心构造了一个轻量的后台的数据支持。这明显和SUN的J2EE架构矛盾,真是搞不懂。不过,Creator对快速开发(RAD)倒是颇有点像VS.NET的那么点样子,可惜是SUN在经营,恐怕也不会对MS造成什么威胁。
另外一个IDEA则也有一大帮拥甭。IDEA有些地方却有独到之处。其它倒是不说,不过IDEA的下一版(恐怕不妥)fabrique倒是非常有意思,它在常规的IDE之上构建了一个专门的应用框架,并且在IDE(应该说是RAD开发平台)提供了业务对象框架,Web应用框架,以及通用的服务(称为Active Libraries)(Forum,Email,...)的支持。非常具有特色。我个人十分欣赏。这点恐怕只是Oracle ADF可以与之一比。
呵呵,先说这么多。
有一个免费的Java在线教程,看样子是一个SUN的专家掌控的,名字 sang.shin ,中国人?韩国人?
其中有很多非常好的材料,有详细的课程表,还包括PPT材料,讲课录音,实验材料等等。我觉得非常有价值。
你还可以注册到一个相关的yahoo群组参与到课程中。初学者不妨试试。虽然是英文的,不过也不要怕,还可以学习英文,岂不更好?
地址是:http://www.javapassion.com
Roger Kitain ( JavaServer Faces co-specification lead )在其blog宣布了开源的 "Open JavaServer Faces" ,并且在基于OSI-approved CDDL许可之下。
原来SUN JSF RI 是基于 Sun Java Research License [Sun, JRL]对”开放开发”发布。基本上,这意味着你可以免费获得它的代码和源代码,并且你可以修改和分发它,只要你不是用作商业目的, 或者用作内部非生产之用。如果你修改了二进制代码和源代码用作商业用途或者内部生产之用,你必须使用商业许可证并且通过 JSF 技术兼容包 (TCK)的测试。你也可以提交补丁给 JSF RI 代码基。
并且在Java.net社区也launch了一个专门的项目Javaserver Faces,地址是:https://javaserverfaces.dev.java.net/
Ed Burns 也在其BLog中公布了 JavaServer Faces 1.2 和 JavaServer Pages 2.1 Proposed Final Draft Specification的一些细节:
将JSP,JSTL和Faces EL统一起来,并且类似于 OGNL 的使用方式。这将极度方便表现层之间的整合,和MVC之间的简化。
- 针对JSP/JSF应用的新的Tree 创建和内容交织模型(Content Interweaving Model)。
虽然可以不用JSP而使用Faces,但是因为技术、技能和各种生产开发环境的支持,JSP/JSF应用确实最现实和富有效率的。当然,这里还有一些集成问题,比如OnJava中的 Hans Bergsten 的这篇文章所述。 所以规范中将修改针对JSP的Faces ViewHandler 的实现,以及所有Faces组件标签所用的JSP定制标签句柄的基类的实现来解决这些问题。
有一个问题是JSTL不支持PostBack,所以使用 JSTL的 <c:forEach> 包含Faces 输入组件会出现问题。所以需要在JSTL中引入类似于PostBack的新概念,将在下一个版本中发布,并且更好地支持所有Faces组件。
- Back Button 问题和多 Frame 或Multi Window Faces 应用。
因为在Multi Frame 或者 Multi Window 应用中使用Facesa在State Management API方面会出问题,即浏览器的Back按钮会造成状态错误。这个问题已经解决。
- 将消息与页面中的某个特定的组件相关联。
- AJAX support
- 暴露一个application 层面的 ResourceBundle 给 EL.
添加了一个新的 <resource-bundle>到 faces-config 中,列出应该暴露给使用ELResolver 链的EL的资源束。这样可以优化性能。
原文见:http://weblogs.java.net/blog/edburns/archive/2005/08/javaserver_face_3.html
前些日子说要整理一下Java中文字编码的处理的文章,今天早上发现一篇比较好的材料,从各个角度都讨论了有关编码处理的问题。其实其基础和我想的一样,尽量在各个环节都统一成Unicode,而不是到处进行修修补补的转码。
作者说将不时更新,而且其中有些示例不时基于最广泛的Tomcat,不过基本上都差不多,涉及到这些环节。
他强调不要Copy文章,可以Link,以便获得最新的Update,所以,我们就link一下,地址是:
http://tomi.panula-ont.to/i18n/
前面有个朋友说看书总是希望要看4 Star以上的(Amazon Reviewed),一直想拟一个Book List,不过一直没有付诸行动。不过大家可以先看看这些数据排名:
1 TOP Java Books:
(Head First系列非常之好,可是也很难以搞到。不知为什么一直没有引进中文的计划。) |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
2 TOP Selling J2EE Book
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
3 8月TOP Selling:
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
JavaOne 2005大会上的书店有一个临时排行榜。以在此看到这些书的情况,
http://jroller.com/resources/h/habuma/j1sia.jpg列出这些书由什么意义?我也不知道。不过找得到的话,可以看看。好不好,你自己说了算。
David Geary (何许人也?Core JSF的作者之一)有一篇BLog,建议新项目都最好采用JSF而不是Struts,并且列出了10大理由,分别是:
Components
组件组件,JAVA一直希望有.NET和Delphi的RAD和拖放式开发,虽然现在和那两种还有差距,但毕竟已经是开始了。第3方组件厂商也开始出现萌芽的态势。另外一个值得注意的趋势就是,Apple,这个艺术与技术的完美缔造者,其WebObject,作为Web的组建式框架的祖宗,也准备开放了。而且,按照Apple也转向Intel平台的介绍来看,也许不久的一天,它就可以完美地运行在WinTel架构下了。
Render Kits
支持渲染包可以是一个非常重要的特征,这样可以支持不同的显示技术。移植性很好。针对XML, PDF, VML等等。不需要改动其它的东西。
Renderers
Value Binding Expressions
其实比较特色的是Method Binding,这点在其他EL或者类似的技术上还没有。
Event Model
Extensibility
Managed Beans (Dependency Injection)
只有Spring 才IoC吗?不是的,其实现在IoC无处不在。
POJO Action Methods
JSF is the standard Java-based web app framework
There's only one Struts
Struts是一个产品,而JSF是一个标准。二者层面不一样。有很多优秀的实现会出现的。
甚以为是,故摘录于此。原文见:http://jroller.com/page/dgeary?entry=top_ten_reasons_to_prefer
其实,JSF的学习曲线非常之低,呵呵。
Liferay这帮家伙干的真漂亮,自从使用了Spring之后,事情好像变得容易多了似的。16日又放出了一个小升级,新的特征支持包括:
Portlet拖放;
声明性事务(Spring Based);
Layout热部署;
虽然这不是实质性的改变,但是对Portal的可用性倒是很有帮助的。
看它们的Roadmap,下一版本的Release会增强安全方面的问题,以及支持JSR170 CMS。我一直期待的Workflow要到明年才能出来。
另外,BEA居然收购了Plumtree,看得出BEA在这方面的决心。Plumtree原来提供非常优秀的中立性的Portal解决方案,这下BEA花费2亿美元其实很划算的。
都知道BEA的portal虽然比起IBM的Portal轻便,但是这是因为它在Portal中的应用方面非常的薄弱,一直赖于定制或者第3方提供应用支持。IBM WAS6之后,将Client和Portal整合Workplace之上,更显得BEA在这方面的差距之大。而且IBM的下一代WTTK平台已经在AlphaWorks中跃跃欲出,显示出无比的霸王之气,欲将Portal与client融合,只有取代Desktop之意。
收购Plumtree之后,BEA会在协作、CMS方面充实其Portal产品,估计将作为Weblogic 9的平台发布出来。但是,就在这一步上说,它还比IBM差的地方,就是wireless部分,不知道用什么来补。
JSR 244,
the umbrella spec that defines what other specs and capabilities will
be included as part of Java EE 5 (formerly J2EE 1.5), has had it's
public review spec approved by the JCP EC. The theme of the release is
ease of development, focused on redefining the platform in light of
annotations and pojo-driven development, with major additions including
the Java Persistence API 1.0 (EJB 3 entities), JSF, JSTL, and
more.
The specific API's mandated for Java EE 5 are:
Enterprise JavaBeans (EJB) 3.0
Servlet 2.4
JavaServer Pages (JSP) 2.1
Java Message Service (JMS) 1.1
Java Transaction API (JTA) 1.0
JavaMail 1.3
JavaBeans Activation Framework 1.1
J2EE Connector Architecture 1.5
Web Services for J2EE 1.1
Java API for XML-based RPC (JAX-RPC) 1.1
Java API for XML Web Services (JAX-WS) 2.0
Java Architecture for XML Binding (JAXB) 2.0
SOAP with Attachments API for Java (SAAJ) 1.3
Java API for XML Registries (JAXR) 1.0
Java 2 Platform, Enterprise Edition Management API 1.0
Java 2 Platform, Enterprise Edition Deployment API 1.1
Java Authorization Service Provider Contract for Containers 1.0
Debugging Support for Other Languages (JSR-45)
Standard Tag Library for JavaServer Pages (JSTL) 1.1
Web Services Metadata for the Java Platform 1.0
JavaServer Faces 1.2 Requirements
Common Annotations for the Java Platform 1.0
Streaming API for XML (StAX) 1.0
Java Persistence API 1.0
恐
怕其中最引入注目的就是EJB3了。 这期间一直争论不休。而且这里还增加了一个新的Java Persistence API 1.0
,可能是需要将EJB以前的广受BS的CMP与JDO结合起来还是怎么?而且,对于EJB3,由于Oracle的加入,可能会偏向TopLink,再加上
Hibernate学来的一些内容好了。
另外就是,JSF仍然需要加强,还没与看过规范,这其间和JSP之间的融合会怎样。总之,JSF是基于Servlet的,JSP是主要表现技术,这核心还是要看Servlet有何实质性的改变。
Java EE5,听起来还是不习惯,还没叫习惯嘛,估计很快就会适应的。到底它是让开发简单了吗?简单在哪里?
Debu Panda有篇小文章倒是可以看看,也可以参与到其中讨论一下: Is Java EE 5.0 really simplifying development?
也可以看一下TSS的讨论:http://www.theserverside.com/news/thread.tss?thread_id=35945。
不过,趋势总是这样,现在是一个纷乱的时代,一方面重型技术往完全精确的工业化目标MDA发展,另一方面却层出不穷的个人英雄式的轻量方法。但是不管哪一个,单方面都不时软件工业的救星。
简单是美,壮观也是美。当然,对于应用来说,简单地解决复杂问题那才是美。
最近忙于修订《Javaserver Faces in Action》,都没有时间来修改这个文档了。我发现校对文稿真的是一个非常辛苦的事情,比起写来,要麻烦得多。何况我又不是一个细致的人。真是有些痛苦。今天抽点时间来继续将这部分发点出来。
很多人都问,Struts中用什么处理模型和数据。
我以前总说,这和Struts有什么关系?
从实际上来说,这的确和他没什么关系,因为他是M中立的。你可以使用你自己喜欢的任何M实现。但是正因如此,其实也还是和她有关系的,那就是它本质上的MVC的分层设计。
对Struts本身来说,作为最成功的一个MVC框架,实际上其最成功之处和精彩之处就是其中的C,即它是一个比较好的Front
Controller 模式的实现。 很多地方,特别是其它利用了它的大型框架,都利用了他的这个优点。比如Oracle 的ADF。
但是对小型应用来说,很多人在争论,Action到底是M还是C。其实这并不重要,如果应用小型,你尽管可以在其中实现你的Biz Logic。这样的话,它就是M。否则,稍大型一些的应用,最好还是作为一个C来使用,至少是C的一个helper。
那么,具体的M怎么办呢?常规的做法是委托给POJO或者EJB。但是基于分层的目的,这中间通常是需要一个缓冲,那就是Facade。SUN的
官方Facade实现原来推荐的是Session
EJB,这感情好,如果你能搞定它,业务和实体也可以尽管使用EJB。如果你不能负担EJB之痛,你可以使用POJO
Facade来访问你的POJO实现的逻辑。
那么你的POJO生长在哪里?目前的Spring 等IoC容器正是一个好地方。实际上我想将Spring 成为是“框架之框架”。
OK,那么数据层又如何?嘿嘿,实际上离Struts太远啦,严格说起来他不想知道,也不用知道。你可以使用任何需要的持久实现,关键是作为DTO传递给C和V的结果,以及它们之间的转换。
本书中的ProcessBean是早期的一个POJO Facade,非常不错。但是不知为和这个包一直在Apache Commons的沙坑中跳不出来。而且如今有些陈旧了。
不过,本章其中的RSS和Lucene的讲述倒是不错。值得参考。
这里下载。
一直以为,国际化是个问题,本地化不是问题。
但是,老是有人层出不穷地问中文的问题,真是生生被他们气死。
有时间的时候准备写一篇文档,彻彻底底的描述一下Java的文字处理问题。不过这里先说几点最重要的:
1 先要搞清除字符集(CharacterSet)和编码方案(Encoding Schema)的意思;
2 Java系统内置Unicode的问题处理方式,这点是最基本的前提,不要忘了;
3 操作系统的代码页(CodePage)和字符集的关系;
4 JSP中,注意page指令的charset不是字符集的意思,实际上是一中Java内置的字符集和编码方案结合的编码;
5 不知道为什么总有人喜欢GB2312,记住:早过时了;
6 解决编码问题的方法就是尽量统一到Java系统的编码上;
7 只有国际化才能彻底解决中文化的问题。尽量不要强行转码,如果每一个字符都转码,效率如何不用说了吧?
8 学会使用Local
好了,先说这么多。
下载这一章。
据Struts声称, Validator是从Struts0.5就开始使用了。从Struts1.1开始,Validator就成为Jarkarta Commons的一个组件。从而成为一个非常有用的通用工具。
关于Commons Validator的地址,可以访问:http://jakarta.apache.org/commons/validator/ 。Struts发行包中带有这个包,也可以单独在此处进行下载。
Validator应用的Struts官方指南参见:http://struts.apache.org/userGuide/dev_validator.html 其中也有几个相关资源。
使用中要注意的有几点:
- 注意DynaValidator的使用与常规ActionForm的校验
- 注意mapping中validate的配置
- 注意action中validate方法与validator的关系
Validator是一个同用框架,你可以使用在很多地方,包括最近流行的Spring 之中。
本章下载。
Liferay Portal 3.5发布了。仍然是Pro版和Enterprise版。
比上一版本相比,增加了几个显著的特色是:
- 支持JSF,Myface的Portlet
- 对Portlet URL进行了优化
- 动态热部署的theme
其实我最喜欢的是他能够内建一个WorkFlow引擎,这样就非常完美了。
它的Pro版从3.0开始就该成Struts + Spring的架构,企业版中似乎也紧紧是使用了Session Bean作为Facede.那么在Pro版本中Spring 是如何使用的,倒要仔细研究。J2EE官方模式已近在提 POJO Facede的概念了(见J2EE Core Pattern, 2nd Ed.)。这里是否就是这种用法。因为,其后端业务部分几乎不用修改的。
这是其登录后的主页面:

我没注意到,页面上部右边有个下拉列表框,支持多个工作区的选择,这是否是上一个版本就有的功能。这个倒是非常不错。
它的CMS做得基础还可以,但是做得不是很友好。需要比较麻烦的定义。如果支持分类学(Taxonomy)
就好了。一种以为,CMS不支持MetaDate和Taxnomy根本算不上content Management。这点,还不如PHP的Drupal做得好。最近SpringFramework网站的改版就是使用了Drupal框架。我觉得,就PHP阵营来说,Drupal比Mambo还要好些。不过后者似乎运作的很好,连国内也有很多FANS。
他的HOT THEME的功能,发行包中带了四个Theme,Liferay网站上一个很COOL的并没有随之发行,需要另外下载。而且原来的很多配色方案,也只有几种了。
另外就是,原来支持认为他的i18n中中文做得不好,有很多奇怪的翻译,而据说他们的核心团队还有中国人的。这次我选择中文Local,居然没反应,仍然是英文界面。不是是何原因?我使用的是Pro版本,不知Ent是否有此问题。
这是一个theme:

我一直认为tiles应该从Struts中独立出来,成为一个单独的项目。至少也应该放入Commons之中。不过,到Struts1.2版本中仍然没有动静。Shale对此也没有明确的说法。
两大主要的布局工具,相比而言,我还是觉得Tiles要好用一些,而且方式优雅。对此,Struts分发包所带的例子tiles-Document就是一个非常有用的学习例子。(很多人来消息说,想要通过例子学习Struts,那么朋友,你可曾研究过Struts的自带例子?如果没有,那就好好看一看吧。关于Struts中的示例程序,大家可以参考我前面所写的“Struts秘籍”中的一篇。)。Tiles不仅是对布局,而且本身还自带对菜单的支持。而且,著名的开源门户项目 liferay 就是使用的Tiles作为布局工具,实现了portlet的表现,甚是了得。(另一个很好的portal ExoPlatform则是使用了JSF。)
当然,Sitemesh也非常不错,而且由于使用了装饰器模式和Servlet Filter,灵活性更高。你可以用它做你爱做的事情,做你想做的事情。不过,似乎因为Sitemesh是 opensymphony 的项目,好像大家就以为它只能与WebWork配对使用,或者心存这种假设。其实不然,呵呵,这种假设不成立。它们两个都是中立的。完全可以根据你的需要选择使用。SiteMesh也完全可以用于Struts项目。
还有一个项目是Struts-Layout,这个项目则主要偏重于细微的表现,比如树型,面板之类的。较少用于总体布局。不过这些对JSF来说都是小Case了。
IBM WSAD本身支持一种模板的布局处理方式,大家可以参考。它实际上是一套可以由IDE管理的代码复制和重用机制。对整体布局和网站基础,比如导航、菜单、面包屑、SiteMap等支持也非常不错。大家也可以研究一下。
开发工具来说,最好的Struts开发工具还是M7的Nitrox,对Tiles的支持也非常之棒。可惜不是免费的。也鲜见破解版本。另外就是Exadel Studio,也非常不错,这方面好像是在学习M7。而且它前些时候刚推出免费版本。
当然,各个商业IDE还是对其支持的不错。
这一章感觉并为把Tiles讲解够深。至于Tiles的高级应用,在Tiles-Document示例应用中,可以找到一个相关的链接。
在这里下载这一章。
Struts 标签库很多人都说难用。既然难用,干脆就用JSTL代替好了。一般来说,JSTL至少可以完成95%的Struts Tag的功能。 而且JSTL还有很多Struts Tag所不能的标签。
当然,我们建议,除非JSTL不能解决的问题使用Struts Tag,大多数情况还是推荐使用JSTL为好。
第10章没有涉及Struts EL,其实这也没什么关系。大多数时候你还是不需要用它。毕竟,对于EL来说,我们推荐JSTL的EL也最好转到JSP EL上面。毕竟,这是标准。JSP 2.0可以直接支持JSP EL,对于以前的版本,比如1.3, 可以使用一个指令打开它。
好了,第10章在这里下载。
继续发布,这一章内容较多。大家注意,本章介绍了很多Apache Scafold包对Struts的扩展,目前这个包已经成为Apache Jakarta的 Commons项目的一个组件,但是发生了变化。如果需要参考,可以去Sourceforge下载原来的版本。
第8章 文档在这里下载。
第7章已经完成。可以在此处下载。
查看了一下下载统计,发现了很有趣的现象。如下图:

为什么第4章这么少?下载两这么不平衡?奇怪?!!
第6章也完成了。本章内容较少,但是ActionForward仍旧很重要,不过好多人在Struts中都没好好用它来组织URI,大多直接请求到Action。这样也没什么不好,它毕竟提供了一种包装和组织手段。
这里下载。
好多天没来这里,Mule的1.1Rc1已经发布啦。比上一版增加了对Quartz provider, FTP provider, RMI provider, VM xa transactions 的支持。
感兴趣的可以到http://mule.codehaus.org/Release+Notes去看看阿。
一支关注这个Project。原来有两个很好的FrameWork, Keel 和 1060。前者不错,但好久没有更新发展啦,后者非常之优美,但是技术却有点独特。这个骡子倒是不错。一定要抽时间来仔细研究。
改天要专门搞个文档,也让大家支持支持。
这一章终于修改完毕,这一章的毛病比较多,错别字也多。看得我眼花。
再次说明,如果发现错误,一定让我知道。谢谢。
这里下载。
 OnJava上看到一篇文章,贴在这里,做上笔记。
OnJava上看到一篇文章,贴在这里,做上笔记。
Albert Einstein once said, "Everything should be made as simple as possible, but not simpler." (哈哈,相对论再简单,也会令不知多少感到头痛,包括我。 )Indeed, the pursuit of scientific truth has been all about simplifying a theory's underlying assumptions so that we can deal with the issues that really matter. The same can be said for enterprise software development.
)Indeed, the pursuit of scientific truth has been all about simplifying a theory's underlying assumptions so that we can deal with the issues that really matter. The same can be said for enterprise software development.
A key to simplifying enterprise software development is to provide an application framework that hides complexities (such as transaction, security, and persistence) away from the developers. A well-designed framework promotes code reuse, enhances developer productivity, and results in better software quality. However, the current EJB 2.1 framework in J2EE 1.4 is widely considered poorly designed and over-complicated(复杂是对的,设计倒未必差。). Unsatisfied with the EJB 2.1 framework, Java developers have experimented with a variety of other approaches for middleware services delivery. Most noticeably, the following two frameworks have generated a lot of developer interest and positive feedback. They are posed to become the frameworks of choice for future enterprise Java applications.
- The Spring framework is a popular but non-standard open source framework. It is primarily developed by and controlled by Interface21 Inc. The architecture of the Spring framework is based upon the Dependency Injection (DI) design pattern. Spring can work standalone or with existing application servers and makes heavy use of XML configuration files. (为什么就让Springg赶上春天了?其实DI在很多地方都用到了,其实,应该是说Spring 用DI来解决Factory的依赖性问题,这点占得先机。)
- The EJB 3.0 framework is a standard framework defined by the Java Community Process (JCP) and supported by all major J2EE vendors. Open source and commercial implementations of pre-release EJB 3.0 specifications are already available from JBoss and Oracle. EJB 3.0 makes heavy use of Java annotations.(要是抢标准,Jboss显然不是Oracle的对手,这不JavaOne之后,Oracle在这上面领先了。这下,Oracle连同它独步天下的DB,加上这么一个持久层东西,很是了得。这样,Oralce今后,会不会形成JSF(ADF Faces)+EJB3的格局,在J2EE上来那么一个令人吃惊呢?IBM帕不怕?不知道,它和BEA搞的SDO也提到了JCP,不过不知前景如何?哪天,抽时间仔细看看。)
These two frameworks share a common core design philosophy: they both aim to deliver middleware services to loosely coupled plain old Java objects (POJOs). (POJO是个奇怪的名字,其中第一个O字母,就令人奇怪。呵呵,谁说老树不能开新花?这下要是搞的风水轮流转,就有好戏看啦。 )The framework "wires" application services to the POJOs by intercepting the execution context or injecting service objects to the POJO at runtime. The POJOs themselves are not concerned about the "wiring" and have little dependency upon the framework. As a result, developers can focus on the business logic, and unit test their POJOs without the framework. In addition, since POJOs do not need to inherit from framework classes or implement framework interfaces, the developers have a high degree of flexibility to build inheritance structures and construct applications.(有点包办婚姻的感觉,容易就是这些POJO的父母。总是要等到最后,才知道和自己有关系的东西是谁。是谁的悲哀?没有,但愿皆大欢喜。)
)The framework "wires" application services to the POJOs by intercepting the execution context or injecting service objects to the POJO at runtime. The POJOs themselves are not concerned about the "wiring" and have little dependency upon the framework. As a result, developers can focus on the business logic, and unit test their POJOs without the framework. In addition, since POJOs do not need to inherit from framework classes or implement framework interfaces, the developers have a high degree of flexibility to build inheritance structures and construct applications.(有点包办婚姻的感觉,容易就是这些POJO的父母。总是要等到最后,才知道和自己有关系的东西是谁。是谁的悲哀?没有,但愿皆大欢喜。)
其实,轻量架构和敏捷方法的火爆主要来源于几个主要的原因:1,程序员自身的武侠主义者,呵呵,也可说英雄主义。总想什么都会,认为武功天下第一,就是懂得更多的语言,从需求、分析、设计、测试到部署,无所不通,多多益善。当然这也是生存压力的后果。
2 SUN曾经设想,J2EE是一个重量的团队协作的开发方式,可是大大出人意料,这种方式要求很高的软件工程水平,同时支撑它的同样要重量的过程模型,比如RUP什么的。但是大型的分布式应用毕竟是少数,中小企业的信息化应用才是主流。而且,MS的解决方案,从过程MSF到, .Net和开发环境VS,无一不在生产力方面占得先机。老大!要记住,用户数量最所的才是市场。
3 出于开发成本考虑,老板总是希望工程师无所不会,这样才能减少成本嘛?!才会出现很多招聘广告上这样写道“精通A,B,C,D,E。。。。,工作经验2年”薪水却只开到2K。这样的事天天发生。是觉得可笑吗?还是觉得悲哀。是觉得人事部门的问题,还是该公司的技术管理着根本就不懂。或者就是老板的问题。不,这是市场的问题。同一个软件,规模和功能几乎一样,在国内卖个10万,很高了,在英国却卖到60万英镑。呵呵,这就是市场。市场就绝对正确吗?可是房价天天涨,现在毕业的程序员,看着房价怎的不愁?NND.
hehe, 跑题了。。。。。。。。。。。。。。
However, while sharing an overall philosophy, the two frameworks use very different approaches to deliver POJO services. While numerous books and articles have been published to compare either Spring or EJB 3.0 to the old EJB 2.1, no serious study has been done to compare Spring to EJB 3.0. In this article, I will examine some key differences behind the Spring and EJB 3.0 frameworks, and discuss their pros and cons. The topics covered in this article also apply to other lesser-known enterprise middleware frameworks, as they all converge on the "loosely coupled POJO" design. I hope this article will help you choose the best framework for your needs.
Vendor Independence
One of the most compelling reasons for developers to choose the Java platform is its vendor independence. EJB 3.0 is an open standard designed for vendor independence. The EJB 3.0 specification is developed and supported by all major open source and commercial vendors in the enterprise Java community. The EJB 3.0 framework insulates developers from application server implementations. For instance, while JBoss's EJB 3.0 implementation is based on Hibernate, and Oracle's is based on TopLink, developers need to learn neither Hibernate- nor TopLink-specific APIs to get their applications running on JBoss and Oracle. Vendor independence differentiates the EJB 3.0 framework from any other POJO middleware frameworks available today.(其实这点也是见仁见智了,总之走着瞧。)
However, as many EJB 3.0 critics are quick to point out, the EJB 3.0 specification has not yet reached the final release at the time of this writing. It will likely be another one to two years before EJB 3.0 is widely adopted by all major J2EE vendors. But even if your application server does not yet support EJB 3.0 natively, you can still run EJB 3.0 applications in the server by downloading and installing an "embeddable" EJB 3.0 product. For instance, the JBoss embeddable EJB 3.0 product is open source and runs in any J2SE-5.0-compatible environment (i.e., in any Java application server). It is currently under beta testing. Other vendors may also soon release their own embeddable EJB 3.0 products, especially for the "data persistence" part of the specification.(恐怕还是不好吧?一锅烩?前些天看Walmart迁移到Java5,真够大胆的。)
On the other hand, Spring has always been a non-standard technology and will remain that way in the foreseeable future. Although you can use the Spring framework with any application server, Spring applications are locked into both Spring itself and the specific services you choose to integrate in Spring.(其实,标准不标准,不是JCP说了算的。是大家多了算的。)
- While the Spring framework is an open source project, Spring has a proprietary XML format for configuration files and a proprietary programming interface. Of course, this type of lock-in happens to any non-standard product; it is not specific to Spring. But still, the long-term viability of your Spring application depends on the health of the Spring project itself (or Interface21 Inc., which hires most of Spring's core developers). In addition, if you use any of the Spring-specific services, such as the Spring transaction manager or Spring MVC, you are locked into those APIs as well.
- Spring applications are not agnostic to back-end service providers, either. For instance, for data persistence services, the Spring framework comes with different DAO and template helper classes for JDBC, Hibernate, iBatis, and JDO. So if you need to switch the persistence service provider (e.g., change from JDBC to Hibernate) for a Spring application, you will need to refactor your application code to use the new helper classes.(这点就是我的最爱,Spring对谁都很友好,也许也包括这里的EJB3。)
Service Integration
From a very high level, the Spring framework sits above application servers and service libraries. The service integration code (e.g., data access templates and helper classes) resides in the framework and is exposed to the application developers. In contrast, the EJB 3.0 framework is tightly integrated into the application server and the service integration code is encapsulated behind a standard interface.
As a result, EJB 3.0 vendors can aggressively optimize the overall performance and developer experience. For instance, in JBoss's EJB 3.0 implementation, when you persist an Entity Bean POJO using the EntityManager, the underlying Hibernate session transaction is automatically tied to the calling method's JTA transaction, and it commits when the JTA transaction commits. Using a simple @PersistenceContext annotation (see later in this article for an example), you can even tie the EntityManager and its underlying Hibernate transaction to an application transaction in a stateful session bean. The application transaction spans across multiple threads in a session and it is very useful in transactional web applications, such as multi-page shopping carts. The above simple and integrated programming interface is made possible due to the tight integration between the EJB 3.0 framework, Hibernate, and Tomcat inside of JBoss. A similar level of integration is also archived between Oracle's EJB 3.0 framework and its underlying Toplink persistence service.
Another good example of integrated services in EJB 3.0 is clustering support. If you deploy an EJB 3.0 application in a server cluster, all of the fail-over, load-balancing, distributed cache, and state replication services are automatically available to the application.(这恐怕不是EJB3的原因吧?) The underlying clustering services are hidden behind the EJB 3.0 programming interface and they are completely transparent to EJB 3.0 developers.
In Spring, it is more difficult to optimize the interaction between the framework and the services. For instance, in order to use Spring's declarative transaction service to manage Hibernate transactions, you have to explicitly configure the Spring TransactionManager and Hibernate SessionFactory objects in the XML configuration file. Spring application developers must explicitly manage transactions that span across several HTTP requests. In addition, there is no simple way to leverage clustering services in a Spring application.
(其实,通过annotation 扩展了语义,而Spring 确实用常规手段。这点出发点都不一样。)
Flexibility in Service Assembly
Since the service integration code in Spring is exposed as part of the programming interface, application developers have the flexibility to assemble services as needed. This feature enables you to assemble your own "lightweight" application servers. A common usage of Spring is to glue Tomcat together with Hibernate to support simple database-driven web applications. In this case, Spring itself provides transaction services and Hibernate provides persistence services--this setup creates a mini application server (这个观点倒是新鲜)in itself.
EJB 3.0 application servers typically do not give you that kind of flexibility in picking and choosing on the services you need. Most of the time, you get a set of prepackaged features, some of which you might not need. However, if the application server features a modular internal design, as JBoss does, you might be able to take it apart and strip out the unnecessary features. In any case, it is not a trivial exercise to customize a full-blown application server.
Of course, if the application scales beyond a single node, you would need to wire in services (such as resource pooling, message queuing, and clustering) from regular application servers. The Spring solution would be just as "heavyweight" as any EJB 3.0 solution, in terms of the overall resource consumption.
(当然,SPring 本身就不是针对分布式的应用需求,也不支持。所以,没必要这么比。关键是看针对那些应用。)
In Spring, the flexible service assembly also makes it easy to wire mock objects, (For Testing)instead of real service objects, into the application for out-of-the-container unit testing. In EJB 3.0 applications, most components are simple POJOs, and they can be easily tested outside of the container. But for tests that involve container service objects (e.g., the persistence EntityManager), in-container tests are recommended, as they are easier, more robust, and more accurate than the mock objects approach.(当然,脱不脱离容器的测试其实对大家并不重要,关键是要简单,快速!)
XML Versus Annotation
From the application developer's point view, Spring's programming interface is primarily based upon XML configuration files while EJB 3.0 makes extensive use Java annotations. XML files can express complex relationships, but they are also very verbose and less robust. Annotations are simple and concise, but it is hard to express complex or hierarchical structures in annotations.(所以需要简化Spring 的XML语法,尽管我已经觉得很简单了。比起Struts之类的已经简单不少了。)
Spring and EJB 3.0's choices of XML or annotation depend upon the architecture behind the two frameworks: since annotations can only hold a fairly small amount of configuration information, only a pre-integrated framework (i.e., most of plumbing has been done in the framework) can make extensive use of annotations as its configuration option. As we discussed, EJB 3.0 meets this requirement, while Spring, being a generic DI framework, does not.(谁知道,以后Spring 会不会也Anotation一下?我觉得很可能会。)
Of course, as both EJB 3.0 and Spring evolve to learn from each other's best features, they both support XML and annotations to some degree. For instance, XML configuration files are available in EJB 3.0 as an optional overriding mechanism to change the default behavior of annotations. Annotations are also available to configure some Spring services.
The best way to learn the differences between the XML and annotation approaches is through examples. In the next several sections, let's examine how Spring and EJB 3.0 provide key services to applications.
Declarative Services
Spring and EJB 3.0 wire runtime services (such as transaction, security, logging, messaging, and profiling services) to applications. Since those services are not directly related to the application's business logic, they are not managed by the application itself. Instead, the services are transparently applied by the service container (i.e., Spring or EJB 3.0) to the application at runtime. The developer (or administrator) configures the container and tells it exactly how/when to apply services.(AOP的天下)
EJB 3.0 configures declarative services using Java annotations, while Spring uses XML configuration files. In most cases, the EJB 3.0 annotation approach is the simpler and more elegant way for this type of services. Here is an example of applying transaction services to a POJO method in EJB 3.0.
public class Foo {
@TransactionAttribute(TransactionAttributeType.REQUIRED)
public bar () {
// do something ...
}
}
You can also declare multiple attributes for a code segment and apply multiple services. This is an example of applying both transaction and security services to a POJO in EJB 3.0.
@SecurityDomain("other")
public class Foo {
@RolesAllowed({"managers"})
@TransactionAttribute(TransactionAttributeType.REQUIRED)
public bar () {
// do something ...
}
}
Using XML to specify code attributes and configure declarative services could lead to verbose and unstable configuration files. Below is an example of XML elements used to apply a very simple Hibernate transaction to the Foo.bar() method in a Spring application.
<!-- Setup the transaction interceptor -->
<bean id="foo"
class="org.springframework.transaction
.interceptor.TransactionProxyFactoryBean">
<property name="target">
<bean class="Foo"/>
</property>
<property name="transactionManager">
<ref bean="transactionManager"/>
</property>
<property name="transactionAttributeSource">
<ref bean="attributeSource"/>
</property>
</bean>
<!-- Setup the transaction manager for Hibernate -->
<bean id="transactionManager"
class="org.springframework.orm
.hibernate.HibernateTransactionManager">
<property name="sessionFactory">
<!-- you need to setup the sessionFactory bean in
yet another XML element -- omitted here -->
<ref bean="sessionFactory"/>
</property>
</bean>
<!-- Specify which methods to apply transaction -->
<bean id="transactionAttributeSource"
class="org.springframework.transaction
.interceptor.NameMatchTransactionAttributeSource">
<property name="properties">
<props>
<prop key="bar">
</props>
</property>
</bean>
(EJB的方式的确简单,可是如果复杂度上升,恐怕优势也不怎么明显了。)
The XML complexity would grow geometrically if you added more interceptors (e.g., security interceptors) to the same POJO. Realizing the limitations of XML-only configuration files, Spring supports using Apache Commons metadata to specify transaction attributes in the Java source code. In the latest Spring 1.2, JDK-1.5-style annotations are also supported. (对啦,也许今后是个方向,学习是很重要的!)To use the transaction metadata, you need to change the above transactionAttributeSource bean to an AttributesTransactionAttributeSource instance and add additional wirings for the metadata interceptors.
(Spring的一个问题是各种名称都不肯缩写,弄的老长。当然,意思更加清楚明了。)
<bean id="autoproxy"
class="org.springframework.aop.framework.autoproxy
.DefaultAdvisorAutoProxyCreator"/>
<bean id="transactionAttributeSource"
class="org.springframework.transaction.interceptor
.AttributesTransactionAttributeSource"
autowire="constructor"/>
<bean id="transactionInterceptor"
class="org.springframework.transaction.interceptor
.TransactionInterceptor"
autowire="byType"/>
<bean id="transactionAdvisor"
class="org.springframework.transaction.interceptor
.TransactionAttributeSourceAdvisor"
autowire="constructor"/>
<bean id="attributes"
class="org.springframework.metadata.commons
.CommonsAttributes"/>
The Spring metadata simplifies the transactionAttributeSource element when you have many transactional methods. But it does not solve the fundamental problems with XML configuration files--the verbose and fragile transaction interceptor, transactionManager, and transactionAttributeSource are all still needed.
Dependency Injection
(这年头松散耦合这么流行,就像男女关系之间,一夜情好生流行似的。我们先前说的婚姻,恐怕也片面了些。各种滋味和含义,大家自己体会吧。)
A key benefit of middleware containers is that they enable developers to build loosely coupled applications. The service client only needs to know the service interface. The container instantiates service objects from concrete implementations and make them available to clients. This allows the container to switch between alternative service implementations without changing the interface or the client-side code.
The Dependency Injection pattern is one of best ways to implement loosely coupled applications. It is much easier to use and more elegant than older approaches, such as dependency lookup via JNDI or container callbacks. Using DI, the framework acts as an object factory to build service objects and injects those service objects to application POJOs based on runtime configuration. From the application developer's point of view, the client POJO automatically obtains the correct service object when you need to use it.
Both Spring and EJB 3.0 provide extensive support for the DI pattern. But they also have some profound differences. Spring supports a general-purpose, but complex, DI API based upon XML configuration files; EJB 3.0 supports injecting most common service objects (e.g., EJBs and context objects) and any JNDI objects via simple annotations.
The EJB 3.0 DI annotations are extremely concise and easy to use. The @Resource tag injects most common service objects and JNDI objects. The following example shows how to inject the server's default DataSource object from the JNDI into a field variable in a POJO. DefaultDS is the JNDI name for the DataSource. The myDb variable is automatically assigned the correct value before its first use.
(JNDI仍然可以玩,只不过lookup也由容器代劳了。精彩!!这对移植更加方便了)
public class FooDao {
@Resource (name="DefaultDS")
DataSource myDb;
// Use myDb to get JDBC connection to the database
}
In addition to direct field variable injection, the @Resource annotation in EJB 3.0 can also be used to inject objects via a setter method. For instance, the following example injects a session context object. The application never explicitly calls the setter method--it is invoked by the container before any other methods are called.
@Resource
public void setSessionContext (SessionContext ctx) {
sessionCtx = ctx;
}
For more complex service objects, special injection annotations are defined. For instance, the @EJB annotation is used to inject EJB stubs and the @PersistenceContext annotation is used to inject EntityManager objects, which handle database access for EJB 3.0 entity beans. The following example shows how to inject an EntityManager object into a stateful session bean. The @PersistenceContext annotation's type attribute specifies that the injected EntityManager has an extended transaction context--it does not automatically commit with the JTA transaction manager, and hence it can be used in an application transaction that spans across multiple threads in a session.
(这里才是EJB的关键。)
@Stateful
public class FooBean implements Foo, Serializable {
@PersistenceContext(
type=PersistenceContextType.EXTENDED
)
protected EntityManager em;
public Foo getFoo (Integer id) {
return (Foo) em.find(Foo.class, id);
}
}
The EJB 3.0 specification defines server resources that can be injected via annotations. But it does not support user-defined application POJOs to be injected into each other.
In Spring, you first need to define a setter method (or constructor with arguments) for the service object in your POJO. The following example shows that the POJO needs a reference to the Hibernate session factory.
public class FooDao {
HibernateTemplate hibernateTemplate;
public void setHibernateTemplate (HibernateTemplate ht) {
hibernateTemplate = ht;
}
// Use hibernateTemplate to access data via Hibernate
public Foo getFoo (Integer id) {
return (Foo) hibernateTemplate.load (Foo.class, id);
}
}
Then, you can specify how the container gets the service object and wire it to the POJO at runtime through a chain of XML elements. The following example shows the XML element that wires a data source to a Hibernate session factory, the session factory to a Hibernate template object, and finally, the template object to the application POJO. Part of the reason for the complexity of the Spring code is the fact that we need to inject the underlying Hibernate plumbing objects manually, where the EJB 3.0 EntityManager is automatically managed and configured by the server. But that just brings us back to the argument that Spring is not as tightly integrated with services as EJB 3.0 is.
<bean id="dataSource"
class="org.springframework
.jndi.JndiObjectFactoryBean">
<property name="jndiname">
<value>java:comp/env/jdbc/MyDataSource</value>
</property>
</bean>
<bean id="sessionFactory"
class="org.springframework.orm
.hibernate.LocalSessionFactoryBean">
<property name="dataSource">
<ref bean="dataSource"/>
</property>
</bean>
<bean id="hibernateTemplate"
class="org.springframework.orm
.hibernate.HibernateTemplate">
<property name="sessionFactory">
<ref bean="sessionFactory"/>
</property>
</bean>
<bean id="fooDao" class="FooDao">
<property name="hibernateTemplate">
<ref bean="hibernateTemplate"/>
</property>
</bean>
<!-- The hibernateTemplate can be injected
into more DAO objects -->
Although the XML-based Dependency Injection syntax in Spring is complex, it is very powerful. (正因如此,才和其它框架和遗恨好的集成,这样,架构就有更多选择。)You can inject any POJO, including the ones defined in your applications, to another POJO. If you really want to use Spring's DI capabilities in EJB 3.0 applications, you can inject a Spring bean factory into an EJB via the JNDI. (这样INDI也是老树新花。当然JNDI的用处大了,JavaEE不可能丢了他。)In some EJB 3.0 application servers, the vendor might define extra non-standard APIs to inject arbitrary POJOs. A good example is the JBoss MicroContainer, which is even more generic than Spring, as it handles Aspect-Oriented Programming (AOP) dependencies.
Conclusions
Although Spring and EJB 3.0 both aim to provide enterprise services to loosely coupled POJOs, they use very different approaches to archive this goal. Dependency Injection is a heavily used pattern in both frameworks.
With EJB 3.0, the standards-based approach, wide use of annotations, and tight integration with the application server all result in greater vendor independence and developer productivity. With Spring, the consistent use of dependency injection and the centralized XML configuration file allow developers to construct more flexible applications and work with several application service providers at a time.
(各有所长。EJB还是针对高端,Spring针对低端,中间一部分重合,大家两全其美。
这篇文章在OnJava一篇骂声,还是开源的同志们比较多阿。)
Acknowledgments
The author would like to thank Stephen Chambers, Bill Burke, and Andy Oliver for valuable comments.
老规矩,欢迎找出错误哈。
另外,请不要要求我单独发送。
在这里下载。
另外,本书又根据原书的勘误表,进行了仔细的校对和更新。修改了一些细微的错误。
修改之后,我会同时修改此处的下载源,请仔细检查所下载文档修订日期。
本书已经出版了,但是不是我的版本。那本书如果有问题,我不负责的哦。
经过修改后,现在发布陆续发布。会将全书都发布在这里。如果还有错别字或者其他错误指出,请大家指出来。在这里留言也行,邮件亦可。我没那么多时间在仔细校对了。非常感谢。!
第1章的下载地址是:
http://www.blogjava.net/Files/SteelHand/StrutsInAction_Chinese(1).rar
JavaOne Day4的内容之一是Web框架之间的交锋,Struts的 下一代Shale出人意料的拔得头筹,下面是具体的情况:
遗憾的是SpringMVC, ROR没有参与。
摘自:TSS
Web Frameworks Shootout
Editor’s Note: This is contributed content, and doesn’t always reflect TSS’ neutrality in such matters. TSS is made up of human editors, of course, and as such, we have biases, but we’d not express them quite this way, nor are we willing to say exactly what those biases are – and no, they’re not often what you might suspect. Let’s leave it at “each framework has its strengths and weaknesses, and each is appropriate for various uses. Thus, we’d be unwilling to stand behind any one framework over another, without detailed and specific requirements for a given implementation.
One of the more interesting talks at Wednesday's JavaONE was the Web Frameworks Shootout hosted on the Esplande level of the Moscone center. We’ll begin our coverage of this event with an overview of the shoot-out contenders and format. We will then provide a brief description of the distinguishing points of each framework, followed by a collection of the top quotes and one-liners from the shoot-out. Finally, we’ll conclude by presenting you with TheServerside.com's own scorecard of how each of the web frameworks faired in the shootout, proclaiming our winners for "Best Business Case" and "Best Technical Case".
The Shoot-Out Contenders:
Frameworks Present:
JavaServer Faces, championed by Ed Burns
Webwork, championed by Jason Carreira
Shale, championed by David Geary
Tapestry, championed by Howard Lewis Ship
Wicket, championed by Eelco Hillenius
Frameworks Conspicuously Absent:
Struts 1.x
SpringMVC
Ruby on Rails
The Shoot-Out Format:
Round 1: Each contender gets 3 minutes to introduce their framework.
Round 2: Questions from the moderator.
Round 3: Questions from the audience.
The Fight Bell: The moderator, Kevin Osborn, controls a fight-bell. The fight-bell is rung for any “hits below the belt ” or when a contender has used their allowed amount of time.
Our Commentary:
One of the major trends we noticed during this shootout was the intense focus on components. Each framework introduced its own flavor of how a web component should work. The message to the audience is that reusable web components are all the rage… the major point of contention now is what these components should look like. We couldn’t help notice, however, that Struts was conspicuously missing. Still, even while Struts wasn’t formally represented, it was clear all represented frameworks were struggling to free themselves from Struts’ shadow, highlighting how they were “different” and “better”. While web-framework technology may be advancing and leaving Struts behind, Struts is still the present incumbent as the tried and true framework with thousands of successful projects under its belt. We couldn’t help noticing that Struts doesn’t include this idea of a web component, so for developers looking for reasons to consider these other frameworks, understanding the idea of a web component is a good place to start.
Framework Overviews (Round 1)
JavaServer Faces (JSF)
- Technical Features
- First class UI component and event model (其实算起来大家还要感谢Apple的了
 )
)
- POJO Dependency Injection (aka Inversion of Control) (最近流行,有什么办法呢?就像SARS一样
 )
)
- Client device independence
- Use with or without tools
- Externalized Navigation (similar to Struts Navigation)
- Massively Extensible (witness Shale)
- Completely Integratable (witness JSF integrated with Spring)
- Localizable and accessible
- Market/Business Distinctions
- Widespread Adoption, including Sun, Oracle, IBM, BEA, Apache, EDS (大腕支持是好,可是代价也不小阿。OS的爱好者们不喜欢)
- Part of J2EE 5.0 (正宗!标准)
- Large 3rd party component market (iLog, Business Objects, Oracle, Sun, IBM) (希望看到和.net组件一样火爆的场面)
- Industry leading tools (Sun Java Studio, Oracle JDeveloper, IBM WSAD, NitroX plugin for Eclipse, Exadel Studio)
- Many Books Available
- 3 pages of JSF jobs on Monster (Author’s Note: Compare this to the dozens of pages of Struts jobs on Monster)
Webwork
- Core Values
- Testability (管这两条就值得,如今TDD也流行,没办法,他们总希望程序员能搞定一切!
 )
)
- Maintainability
- Extensibility
- View Technology agnostic, supporting JSP, Velocity, and other view technologies (这和Spring有的一拼)
- Maps HTTP request to a logical (interceptable) action (所以也可以不仅仅针对HTTP了,Command而已嘛)
- Simple components via the hierarchical MVC and template mechanisms
Shale
- A framework built on JSF technology and Jakarta (更上一层楼了,JSF虽好,但我吸取了Struts和Jarkarta项目的多年功力,你也没办法)
- A proposal for Struts 2.0 (TSS Editor’s Note: Last we checked, there is quite a bit of uncertainty as to whether Shale will actually become Struts 2.0.) (Shale原本计划成为Struts2德,可是....,她和JSF而且两者都是同一个人打造的了)
- A Struts sub-project (还在孵化培育中,所以..........看上去很美)
- No direct connection with Struts Classic (ie Struts 1.x) (和Struts不是一回事哦)
- Described as JSF++: “JSF 1.0 didn’t include everything we wanted to add due to time. So Shale attempts to add it. Features like client-side validation, AJAX, etc… are slated for JSF 2.0. Meanwhile, Shale is a proving ground for those ideas.” (JSF++有意思,那么下一版本的JSF又该如何?
 )
)
- Shale Features:
- Web Flow
- Ajax
- Spring and Tiles Integration (Tiles应该很快会独立了)
- Client and Server-side Validation (使用Commons Validator?)
- Tapestry-like views and parameterized Subtree (互相学习阿)
- Utilities: Back-Button abuse, (令人头痛的同步问题)file-uploads, JNDI API
- Shale’s Extension Points
- ShalePropertyResolver
- ShaleVariableResolver
- DialogNavigationHandler
- ShaleViewHandler
- TilesViewHandler
- “If you know nothing about JSF itself, JSF is very, very extensible.”
Tapestry
- Core Values:
- Simplicity - web applications shouldn't be rocket science!
- Consistency - what works in pages should work in components. What works in small applications should work in large applications. Different developers should find similar solutions to similar problems. (组件,又是组件。有人问,什么是组件??我也不知道,但是在软件开发中,组件无处不在!呵呵)
- Efficiency - applications should be performant and scalable
- Feedback - when things go wrong, the framework should not get in the way; in fact, it should provide useful diagnostics
- Tools:
- Does not require the use of tools
- Let you use the design tools you already know.
- New Features in Tapestry 4.0 (subset):
- Annotations Support (也是很Fancy的东西)
- Really excellent integration
- Much more flexibility in terms of how you manage serverside state. Very efficient about what it stores in the session, if anything at all.
- Portlets Support
- Extensibility:
- Over 180 extension points (老大,是不是多了点
 )
)
- Built around Component Object Model with many layers
- Terrific ability to override, change, and customize
- Great support for component libraries which are open source and available. (这个库由你一家操办,力量小了吧)
- "Tapestry is a predecessor, almost a research project, for some of the other frameworks"
Wicket
- Wicket is the new kid on the block.
- "Wicket is Easy, Wicket is Elegant", Wicket is Powerful." (怎么听都象“今年我家不收礼............”)
- Easy to Use:
- Simple, Consistent, Obvious
- Reusable Component (都想这样)
- Non-Intrusive (这点很重要,集成嘛。。。)
- Safe
- Efficient/Scalable
Noteworthy Quotes:
Editors Note: The Q&A rounds were a bit like a peanut gallery where it was often difficult to tell which contender said which cheap-shot. Furthermore, there was as much smack talk as there was bonafide technical commentary. Short of who said what, what was most telling during this round was the overall interplay. In an effort to capture this interplay without making our contenders feel their comments were misattributed, we’ve included a collection of quotes overheard during the round without necessarily attributing them to their origin.
- "Everybody is knows that JSF is much better than Struts. Meanwhile JSF is Neck and Neck with Tapestry"
- "Struts is old school, so get over it." (培养了很多人,也培养了很多框架哦,而且用户数量也还在急剧增长,基数也大)
- "If you need a tool like that, your framework is probably too complex."
- "You can talk about tools, but you can't make people use them."
- "If you want to save your Struts code-base, then JSF is the way to go." (的确二者集成比较容易)
- “It's the fact you can extend your framework in a standard way and create an artifact that can extend this piece of functionality. You can't really do that in Struts or Webwork.” To which someone replied that you don’t need a fancy event model to obtain reuse in a web app.(扩展性,)
Our Scorecard
TSS did its best to keep score during the shoot-out. We decided to score each of the frameworks in a 5-point scale in two separate categories:
- Technical Features
- Business Case
|
Technical Features |
|
Framework |
Score |
Rational |
|
JavaServer Faces (JSF) |
4.8 |
JSF win’s major points for it’s 1 st class support for true web components. Our analyst felt allegations of JSFs lack of simplicity and elegance to be unmerited. JSF is simple to use, powerful, and revolutionary. And the existence of Shale and Spring -JSF are a testament to the true extensibility of Faces.
(大腕们的支持,当然不同了。就如同少林武当的功夫) |
|
Webwork |
4.2 |
Webwork’s hierarchical MVC model was revolutionary in it’s time and served as a fore-runner to many of the web-component models we are now witnessing. However, we feel Webwork’s HMVC and template facilities are eclipsed by JSFs refinement of these ideas into JSFs truly 1 st class component model. |
|
Shale |
4.95 |
If Shale stands taller than the other frameworks, it’s because it stands on the shoulders of giants. (一个蓝图)By extending JSF to include advanced web-flow, AJAX support, tiles integration, and client-side validation, our judge felt that Shale represents the future of where web-frameworks need to move technically. |
|
Tapestry |
4.75 |
Tapestry pioneered the idea of a web-component and set the bar. The claim during the debate that “Tapestry and JSF are neck-and-neck” isn’t too far off. However, JSF’s standardized extension points and first-class support for portlet development is a truly compelling technical case against which Tapestry can’t yet compete. We’ll be watching this race closely. We’d love to see Tapestry support some of the JSF standard interfaces to support interoperability… specifically we’d love to be able to write JSF components using Tapestry and to use Tapestry components as JSF components. We’ll be eagerly watching what Howard includes in the next release. |
|
Wicket |
Not-Rated |
Wicket is the new kid on the block, only having reached 1.0 a few weeks prior to JavaONE. Our judge didn’t feel it was fair to score Wicket without knowing a little more about it. However, if Wicket is truly as simple as it claims to be we’ll certainly be keeping our eye on it. We’d also like to extend to Wicket the same interoperability challenge we just extended to Tapestry. |
|
Struts |
4.2 |
While Struts wasn’t formally included in the shootout, as the incumbent Struts is the framework by which all other web frameworks are judged. When Struts was released it revolutionized the web world with it’s inclusion of data-bound controls, action event handlers, and externalized navigation. Since then, Struts has expanded to include tiles, the Struts validator, and extensibility through dynabeans. However, Struts has also been a victim of its own success, lacking a formal component model chiefly due to the necessity for backwards compatibility trump ing its ability continue to pioneer new ground. This is why Craig McClanahan, the original creator of Struts, started Shale, in hopes that Shale may one day become the new defacto standard. (*Sorry, .tag files don’t count as web components, since they’re output-only reuse.) |
|
Business Case |
|
Framework |
Score |
Rational |
|
JavaServer Faces (JSF) |
3.9 |
JSF is now an official Java Standard and will be an integral part of J2EE 5.0. With endorsements from Sun, IBM, BEA, Oracle, and dozens of other companies, JSF shows a lot of promise. However, we cannot ignore the limited numbers of deployments currently using JSF. If JSF wants to win the heart of IT managers away from Struts, it’s going to need a plethora of success stories behind its belt. Simply naming a few big names, such as FedEx, who have used JSF on a few select projects just doesn’t cut it here. As strong as JSF is, we’ll be waiting to see those success stories come pouring in before we bet the business on it. Yet, in comparison to the other frameworks presented at the shootout (remember, Struts was absent) JSF still came in first place with a score of 3.9. |
|
Webwork |
3.1 |
When our judge stood up during the audience questions round and asked each framework for an order-of-magnitude estimate of the number of projects currently deployed using it’s framework, all the frameworks, including JSF hemmed and hawed and dodged the question. But we simply LOVED Webwork’s answer “ Do I get to count each of Google’s server’s as its own deployment”… if GOOGLE is willing to bet the business on Webwork, that lends a huge vote of confidence. |
|
Shale |
1.3 |
While Shale builds on top of JSF and is in many ways technically superior, it is still unproven. From a business risk management standpoint, it’s just too new and its is future too uncertain. Sure, the claim to fame that Shale is a proposal for Struts 2.0 sounds impressive, but that’s just it, it is just one proposal far from being adopted. Quite frankly there are a large number of barriers which must be overcome before it’s accepted by the Struts community at large. |
|
Tapestry |
2.8 |
Like Webwork, Tapestry is a framework that has been around the block quite a few times and is a robust, proven framework. (It’s used to power TheServerside.com.) Tapestry 4.0 offers a whole new set of exciting features. Yet we feel Tapestry creator Howard Lewis Ship said it best when he described Tapestry as a “research project” for the other web frameworks. For small elite development teams who want all the latest innovations, Tapestry is great. For large IT shops looking for wide industry adoption, a large community of experienced developers to choose from, and hundreds of successful deployments to point to, we just don’t feel Tapestry fits the bill (yet). Our challenge to make Tapestry play nice with JSF still stands… standards compatibility may be just what Tapestry needs to ease the minds of risk-averse IT managers. |
|
Wicket |
0.7 |
As strong as the case for Wicket’s simplicity may be, there are still less than 5 projects using Wicket, all of which belong to Wicket’s author s. As the new kid on the block, Wicket’s innovations are warmly welcomed. However Wicket still has a long way to go to prove itself. |
|
Struts |
4.6 |
With literally thousands of deployed projects using Struts, Struts has been adopted as the framework of choice by IT organizations large and small and won’t be leaving anytime soon. Struts stuffers slightly from not being an official standard, but it’s status as a “defacto-standard” is nearly as good. Almost every major vendor now includes Struts support in their products. A risk-averse IT manager can’t go wrong adopting Struts. |
从TSS看到,JBOSS启动了一个新的 JBoss TrailBlazer 计划,推动EJB3.0。
这真是一个好消息,想起以前JBOSS的资料真是难得,不过从JBOSS4之后,这种情况大有改观。如今他又更进一步了,变得也友好多了。毕竟,用户才是First Place! 而且从公司,特别是开源公司来说,服务的内容不仅仅是文档。试看Web框架的世界,有好多比Struts优秀的框架,因为资料和文档的缺乏,自然造成用户群上不去,比如,Webwork和Tapstry,以及SOFIA。
再者,JAVAONE之后,Oracle也成了EJB3的领导者,JBOSS是不是也心急的呢?
毕竟,对用户来说是好事情。
在JavaOne 2005大会上,Oracle的资深副总裁Thomas Kurian进行了一次主题演讲,展示了Oracle在构建和维护面向服务架构(SOA)方面的观点和解决方案。
Kurian表示,Oracle的“新应用蓝图”将采用JSF实现用户界面,用BPEL(业务流程执行语言)描述业务流程,用EJB 3.0开发业务逻辑。该计划还将借助web service和Java业务整合规范来整合遗留系统。
Kurian表示在这个应用蓝图中,JSF和EJB 3.0(主要用于对象持久化)将扮演非常重要的角色。
全文请看:http://www.javaworld.com/javaworld/jw-06-2005/jw-0629-iw-oracle_p.html
希望ADF Faces早些正式发表。不过JD免费之后,希望Oracle再将ADF的许可搞得友好一些。
第3.10式. 过滤文本输入
问题
你想要渲染包含HTML标记的数据,并且希望该数据被浏览器当作HTML标记解释和处理。
动作要
很简单,可以使用:
<bean:write name="myForm" property="freeText" filtered="false"/>
在使用JSTL时,你也可以使用未过滤的值:
<c:out value="${myForm.freeText}" escapeXml="false"/>
动作变化
在你使用Struts bean:write标签来产生文本时,默认情况下任何对HTML处理敏感的字符都要被它们的对等实体代替。例如,大于号字符(>) 将被替代为>字符实体。这种特征称为是响应过滤( response filtering),默认情况下是激活的。在大多数情况下,过滤正是希望的行为,因为未经过滤的文本可能被浏览器误解释。Table 3-4 列出了被bean:write标签过滤的字符和它们的对应实体。
Table 3-4. 被过滤的字符 |
|
字符名称 |
字符值 |
替代实体 |
|
大于 |
< |
< |
|
小于 |
> |
> |
|
&符号 |
& |
& |
|
双引号 |
" |
" |
|
反斜杠 |
\ |
' |
但是有时候,你希望被渲染的文本中包括HTML 标签。假设你有一个在线日志应用,允许用户输入将要显示在一个页面中的文本。允许使用HTML 标签将使得用户可以那些可以格式化文本的标记。文本中可能包含超链接,不同的字体,以及图像等等。在其他情形下,你的应用可能可能还会从其他来源,比如另一个URL,一个XML文件,一个Web Service或者数据库中,获得HTML模板文本。
通过将bean:write标签的filtered属性设置为false,你就可以告诉Struts标签不要使用相应的实体替换 tag not to 特殊字符。首先,我们来看一下过滤是如何工作的。假设一个用户在表单中输入了下面的文本:
Apache
Struts Web Framework <b>rocks</b>!
现在这个文本将被bean:write标签来渲染显示。当filtered 属性设施为true时,特殊字符将被其对等物替换,这样文本看起来就会是:
Apache
Struts Web Framework <b>rocks</b>!
这很有可能不是用户所想要的。他想要的是"Apache Struts Web Framework rocks!"。但是,因为意图是想要允许用户输入装饰文本的HTML标签,那么将filtered属性设置为false 就会得到正确的渲染:
Apache
Struts Web Framework <b>rocks</b>!
浏览器将认识这个标签,并且按其所愿正确的应用HTML 标记。
这在渲染一个Web页面时式一个有用的机制。但是,在使用这个方法时必须足够小心。如果数据是没有过滤的,那么就可能会危及渲染后的 HTML页面的布局,整个页面可能会看起来遭到破坏。例如,假定下面的文本被输入:
Apache
Struts Web Framework <b>rocks<b>!
咋看起来,这没什么问题。但是,注意到b元素的后面一个关闭标签的斜杠缺失了。这个错误很容易发生,而且这可能会使得页面中后面的所有文本都是粗体。
不幸的是,要避免这类错误是很困难的。最好还是试图确保输入的数据都是正确有效的HTML。还有个选择就是通过XML 解析器来处理输出。它会检测诸如标记不匹配之类的问题。你还可以通过一些能够试图纠正问题的解析器来完成,比如Jtidy。最后,如果数据是来自于非受控的来源,你可以选择完全不允许HTML。如果你还想使用一些文本装饰功能的话,还可以考虑使用WikiText 或者UBB Code之类的格式表示来替代。
相关动作
JTidy 提供了一个命令行接口和Java API 来解析和整理HTML。关于JTidy 的细节请访问http://jtidy.sourceforge.net。
UBBCode 是PHP本身支持的一种标记格式。也可以在Java中处理UBBCode。一个解析UBBCode 的PHP函数,有人在Java中重写了,地址可见:http://www.firegemsoftware.com/other/tutorials/ubb.php.
本书翻译工作已经完成,正在修订和联系出版事宜。
样章可以在这里下载。
请大家在这里留下意见。也欢迎发送给您的朋友。
摘要: 最近忙,好久没来这里写东西了。今天抽点时间继续。上周去北京,坐火车去,在火车上阅读《Core J2EE Patern》,想起再上一次去北京,也是坐火车,也是阅读这本书,不过那次是第1版。还有巧的是,去时铺位是16车16号,来时居然又买到16车16号,不过是上铺。真是有点意思。
Recipe 3.9. 产生动态选择列表项目
问题
你想要基于同一个表单中的另一个字... 阅读全文
摘要: 第3.8式. 使用JavaScript动态改变选择项
问题
你希望使用JavaScript 来根据从应用模型中获得的数据来动态设置显示在一个HTML select元素中的条目。
动作要领
使用Struts logic:iterate标签来为不同的选项集创建JavaScript 数组。然后使用JavaScript 的onchange事件句柄来在运行时修改options集。Example 3-... 阅读全文
第3.7式. 动态产生JavaScript
问题
你想要根据从应用模型获得的数据动态产生JavaScript。
动作要领
使用Struts 标签在你想要包含在HTML中的JavaScript 代码中渲染数据:

 <script language="JavaScript">
<script language="JavaScript">

 function showMessage( ) {
function showMessage( ) {
 alert( "Hello, <bean:write name='myForm' property='name'/>!" );
alert( "Hello, <bean:write name='myForm' property='name'/>!" );
 }
}
 </script>
</script>
动作变化
上述方案产生了一个JavaScript 函数,弹出一个消息框,消息文本为"Hello, name!" name的值是使用bean:write标签产生的。此方案展示了使用Struts 标签创建JavaScript 和它们创建HTML一样的容易。
JSTL也可以按这种方式使用。
虽然这种方法很明显,但是很奇怪很多人都在问这个问题。通常问题还可能是:"我如何才能从Struts中调用HTML中的JavaScript 函数?" 技术上讲,你并不能从Struts调用一个HTML页面中的JavaScript 函数。Struts 和JSP 技术都运行在服务器端。相反,JavaScript确是在客户端的浏览器中处理的。但是,通过这里所述的动态产生JS的能力,基本上还是相当于所需的这个行为。
这个方法的一个重要基础是JSP的转换过程。JSP 页面由JSP 声明,标准JSP 标签 (比如jsp:useBean), 定制JSP 标签(比如Struts 和JSTP 标签), 运行是表达式,以及脚本小程序(scriptlets)组成。除此之外的其他东西都是模板文本(template text)。模板文本可以是任何不会被JSP转换处理的内容。人们通常会认为模板文本就是HTML 标记,但是它其实是JavaScript 或者其他非JSP 处理的文本。JSP 翻译器并不关心模板文本采用何种形式。因此,你可以象在HTML元素中产生文本一样容易地在JavaScript 函数中产生文本。
如果你使用JSP 来产生良构的(well-formed)XHTML, 那么动态JavaScript 模版文本必须使用jsp:text元素和CDATA section的方式结合来指定。具体信息参见Hans Bergsten的ONJava 文章:http://www.onjava.com/pub/a/onjava/2004/04/21/JSP2part3.html。
这里的例子仅仅列出了很简单的使用场景。如果要访问的模型数据需要使用复杂的JavaScript数据结构,比如,数组,你可以使用迭代标签,比如logic:iterate和c:forEach来组装这些结构。
相关动作
下一动3.8或会使用迭代标签来产生客户端的JavaScript 数组。
看到JavaLobby上面有篇比较JSF和ASP的文章:
Is JSF ready to take on ASP.Net?
总体来看 JSF逐渐在使Java开发向着更加RAD的方向发展,JB, Oracle Jdeveloper, IBM WSAD/RAD, SUN JSF Creator等等都作的不错,提供了一定的visual可视化组件开发的能力和数据帮定能力。但是距离MS的可用性还是相差甚远。
尤其是VS.NET 2005一出之后,这个差距更大更需要努力了。
JSF预计出现的第3方组件市场并没有出现蓬勃发展,是因为JSF本身没有起来,还是IDE不够标准。可能两者都有,特别是后者,规范中并没有界定组件需要IDE支持,必须提供的元数据集合,那么到底是针对oracle呢,还是IBM?或者自行其是。
Struts继续占据着前端框架的霸主地位,WebWork和Tapstry艰难求生。连Spring也将触角伸到前端。JSF还是困难啊。
Matte Railbe的BLog中有一个关于框架的发展现状:
去年闹着玩的《Struts in Action》译本,想不到网上流传的还是比较广泛了。不过去年草稿发出后,再也没有修改过了。前
几天翻出来看,倒是有不少错误,包括错别字和翻译错误。
觉得这样很不好,搞不好误人子弟。于是决定近日将其重新修改整理,发一个完整半出来。
感兴趣的,可以关注我这里的相关信息。我将在这里提供下载链接。
JDJ上面有一篇 Duncan Mills 的文章,论述了框架技术的下一个发展,那就是Java世界需要一个元框架(Meta-Framework)。原文地址见:
http://java.sys-con.com/read/49198.htm
他认为,.NET之所以也很成功并且吸引很多人,总体来说,.net的技术成本要低的多(当然商业成本不低),这是因为.Net环境下有一个集成的统一框架,而java世界,则疲于整合各种JSR,各种技术,各种实现和各种框架。从Struts,WebWork, Tapstry, Hibernate, Spring, Keel....框架层出不穷。我们比较、学习、整合.....累啊。
因此,一个元框架的出现,应该符合以下的特征:
- 范围广阔(Broad Scope) 框架应该涵盖从UI,到页面流控制器,到与多个底层服务 provider的集成,包括EJB, Web services, POJO...。
- 并存(Coexistence) - 框架不能实现所有需要的功能,但是能够提供可插入的集成点。
- 抽象(Abstraction) -足够抽象,并且你可以选择。以便能够对某些组件的具体实现进行替换。
- 呵呵, 还有长寿(Longevity
- 工具支持(Tooling)
这其中最流行的是什么?POJO,IoC/DIP?想想, 重量级的EJB3.0能否重整雄风?而轻量的Spring已经繁花似锦。另外, JSF整合了JSP, JSTL和Portel API之后,能否成为前端的标准?毕竟标准的事件模型还是令人鼓舞的,而且,浏览器的兼容问题也好解决一些。这些都有可能成为metaFramework的候选。
Oracle的ADF已经从ADF UIX迁移到JSF,这下厉害了。ADF(JSF+bizmodule)+TOPLINK, 是否有能够和 SPring + Hibernate有的一拼呢?
另外,Keel是否显得比较乱?
而 NetKernel 呢?
看到XML.com一篇关于XForms引擎的评述,
地址是:
http://www.xml.com/pub/a/2005/02/09/xforms.html
-
Chibacon Chiba
-
DENG by way of UGO
-
x-port formsPlayer
-
Mozilla/Firefox
-
Novell Engines
-
OpenOffice and StarOffice
-
Oracle Engine
-
Orbeon Presentation Server (OIS)
-
Zen Interactif xslt2xforms
-
University of Helsinki X-Smiles
-
Honorable Mention: Ripcord Technology nForms
第3.6式. 从图像提交表单
问题
你想要使用户能够通过点击一个不在HTML表单标签中的图像来提交表单。
动作要领
适应一个对JavaScript URL 的链接来提交表单:
<html:link href="javascript:document.myform.submit( )">
<html:img page="/submit-form.gif"
alt="Submit" border="0"/>
</html:link>
动作变化
Web 应用经常使用可点击的图像来提交表单而不是仅仅通过表单按钮。Struts 的html:image标签可以用来产生一个显示图像的HTML input type="image" 标签。但是,对于复杂的 HTML 布局,并不总是能够将图像嵌入在表单<form> . . . </form>标签之中。有些时候,一个 HTML 页面可能在页面的某一段可能有多个表单,而提交页面的图像则在页面的另一个区域。比如,工具条风格的图像按钮。
上面的方法可以用于从表单之外的图像提交表单。所显示的图像嵌套在html:link标签中。该链接通过执行一行JavaScript来提交表单。在上面的代码中,JavaScript 将提交名为MyForm 的表单。表单名称必须匹配struts-config.xml文件中所配置的action元素的name属性。下面是这种方法产生的HTML 代码:
<a href="javascript:document.myform.submit( )">
<img src="/myapp/struts-power.gif"
border="0" alt="Submit">
</a>
虽然你可以直接使用上述HTML标记而不是Struts html标签,如果那样的话你将失去那些标签所提供的特征。通过使用Struts tag,你就不是必须要指定context 名称,并且你可以使图像名称和替换文本来自于资源束 (如果你需要的话)。
另一个办法是使用html:img 标签的onclick属性:
<html:img page="/submit-form.gif"
onclick="document.MyForm.submit( );"
alt="Submit" border="0"/>
这种方式的缺点是,有些浏览器并不提供图像是可以点击的一些可视提示线索。因为图像嵌入到一个链接中,大多数浏览器都会在改变鼠标指针以提示该图像是可以点击的。
|
如果你想要你的应用在浏览器禁止JavaScript的情况下也能够进行,还应该在表单中的某处提供一个常规的提交按钮。 |
相关招式
第3.9式会描述如何在表单的action属性中指定的地方将表单提交到另外一个URL。
摘要:
第3.4式. 在表单中使用索引属性
问题
你想要在表单中创建对应于一个Bean中的索引属性的一套输入字段。
动作要领
在Struts html标签库的标签中使用indexed属性来产生属性值:
<html:form action="TestOneAction"><p> <logic:iter... 阅读全文
很多新手来问一些很基本的问题,希望他们先从这些基本的信息开始熟悉。这个资源会不断更新中.....
The Lasted Updated :2005/05/30
http://struts.apache.org
1. SF上的一个Apache Struts 示例应用集
http://struts.sourceforge.net/
其中包括一些很著名和很有用的项目。主要有:
n AppFuse – 一个非常著名的,优秀的基线示例应用,并扩展到使用多种框架。 其官方网站是:https://appfuse.dev.java.net/ 作者Matt Raible网站是:http://raibledesigns.com/wiki/Wiki.jsp?page=Main 他是Spring Live的作者,也是Apache Struts Web Framework Resume和StrutsMenu的作者
n Polls – 一个在线调查管理的Apache Struts Web Framework 应用。
n Struts k Action Invocation Framework (SAIF) – 为Apache Struts 添加动作拦截器和IoC特征。
n Struts BSF – 一个使用BSF 兼容脚本语言的 Apache Struts Action 实现。
n Struts Cocoon – 集成Apache Struts 和Cocoon,使用Cocoon 作为表现层。
n Struts Flow – 将Cocoon的控制流带入Apache Struts 中
n Struts Resume – Appfuse作者的一个例子,使用AppFuse 作为基础。参见:http://raibledesigns.com/wiki/Wiki.jsp?page=StrutsResume
n Struts Spring – 集成Apache Struts 和Spring 框架的集成库。
n StrutsDoc – 一个用于 Struts或者 Struts 相关配置文件的JavaDoc风格的文档工具。
n AjaxTags – 添加了AJAX功能的 Struts HTML taglib 的修改版本。
该项目的下载列表中还包括其他一些有用的东西,主要有:
n artimus Struts in action作者编写,并在书中分析提及的一个应用。
n Struts in Aciton 书籍的源代码
n Struts CookBook
2 Apache Struts Web Framework Menu 也是Matt Raible 的作品,http://sourceforge.net/projects/struts-menu/
3 XPlanner 一个基于Web的项目计划跟踪工具。JSP+Struts+Velocity+Mysql+Tomcat. http://www.xplanner.org/
4 STXX Apache Struts Web Framework中通过XSL进行XML变换 http://stxx.sourceforge.net/
5 Liferay 著名的开源Java门户系统, 使用Apache Struts Web Framework作为前端 http://www.liferay.com
6
开发工具
1. Borland JBuilder
2. IBM Rational Application Developer
3. Oracle Jdeveloper
4. BEA Weblogic Workshop
5. Myeclipse
6. M7 Nitrox Apache Struts Web Framework IDE
7. Easy Apache Struts Web Framework, For Eclipse and JB
8. Apache Struts Web Framework Console
9. Exadel Studio
其他资源
1. Strust in Action的作者的资料 http://www.husted.com/struts/ 。其实有这个网站,我这个列表也显得多余。那就增加一些中文的内容好了。本网站还包括很多Java相关的资源链接。
2. Apache Struts Web Framework官方资源站点 http://wiki.apache.org/struts/StrutsResources
3. 国内主要的Apache Struts Web Framework技术论坛
n http://www.chinajavaworld.com/
n http://www.cjsdn.net
n http://www.matrix.com
n http://forum.javaeye.com/
书籍(其中红色部分有中文版)
- Jakarta Apache Struts Web Framework Cookbook Bill Siggelkow (February 2005)
- Jakarta Apache Struts Web Framework Pocket Reference by Chuck Cavaness, Brian Keeton (June 2003)
- Programming Jakarta Apache Struts Web Framework by Chuck Cavaness (November 2002)
- Professional Jakarta Apache Struts Web Framework by James Goodwill, Richard Hightower (September 2003)
- Apache Struts Web Framework Survival Guide: Basics to Best Practices by Srikanth Shenoy, Nithin Mallya (February 2004) 下载该书的电子版 点击这里
- Apache Struts Web Framework In Action by Ted Husted, Cedric Dumoulin, George Franciscus, and David Winterfeldt; Foreword by Craig R. McClanahan (November 2002) 网上可以搜索到我翻译的中文版电子书。
- Apache Struts Web Framework Kick Start by James Turner, Kevin Bedell (December 2002)
- Mastering Jakarta Apache Struts Web Framework by James Goodwill (September 2002)
- Apache Struts Web Framework: The complete reference by James Holmes (April 2004)
- Professional Apache Struts Web Framework Applications: Building Web Sites with Apache Struts Web Framework, Object Relational Bridge, Lucene, and Velocity by John Carnell, Jeff Linwood (March 2003)
- The Apache Struts Web Framework Framework: Practical Guide for Java Programmers by Sue Spielman (October 2002)
- Pro Jakarta Apache Struts Web Framework, Second Edition by John Carnell, Rob Harrop (March 2004)
- Struts Recipes by George Franciscus, Danilo Gurovick (July 2004)
- Apache Struts Web Framework Fast Track: J2EE/JSP Framework: Practical Application with Database Access and Apache Struts Web Framework Extension] by Vic Cekvenich - Sept. 2001 (1st Apache Struts Web Framework Book)
- Apache Struts Web Framework by James Turner, Kevin Bedell (June 2003)
以下是Ted Neward的一个blog,旨在陈清多年来一直可能混淆的概念,即“Web Services”是一个东西吗?
他认为,其实人们可能都混淆了,Web代表的是互操作性,而Services则是代表一种设计理念,即独立的、自治的、无耦合的组件模型。而“Web Service”仅是其中的一种结合方案而已。
颇有见地。
下面是摘录的原文,其中精彩之处予以标出:原文可访问 http://www.neward.net/ted/weblog/index.jsp?date=20050525#1117011754831
Web + Services
A lot has been written recently about Service-Orientation and Web services
and REST and the massive amounts of confusion that seem to be surrounding the
whole subject. After much navel-contemplation, I'm convinced that the root of
the problem is that there's two entirely orthogonal concepts that are being
tangled up together, and that we need to tease them apart if we're to make any
sense whatsoever out of the whole mess. (And it's necessary, I think, to make
sense out of it, or else we're going to find ourselves making a LOT of bad decisions that will come to haunt us over the
next five to ten years.)
The gist of the idea is simple: that in the term "Web services",
there are two basic concepts we keep mixing up and confusing. "Web",
meaning interoperability across languages, tools and platforms, and
"services", meaning a design philosophy seeking to correct for the
flaws we've discovered with distributed objects and components. These two
ideas, while definitely complementary, stand alone, and a quick examination of
each reveals this.
Interoperability, as an idea, only requires that programs be written with
an eye towards doing things that don't exclude any one platform, tool or
technology from playing on the playground with the other kids. For
example, interoperability is easy if we use text-based
protocols, since everybody knows how to read and write text;
hence, HTTP and SMTP and POP3 are highly-interoperable protocols, but DCOM's
MEOW or Java's JRMP protocols aren't, since each relies on sending binary
little-endian or big-endian-encoded data. Interoperability isn't necessarily a
hard thing to achieve, but it requires an attention to low-level detail that
most developers want to avoid. (This desire to avoid low-level details isn't a
criticism--it's our ability to avoid that kind of detail that allows us to
write larger- and larger-scale systems in the first place.)
This "seeking to avoid exclusion"
requirement for interoperability is why we like using XML so much. Not only is
it rooted in plain-text encoding, which makes it relatively easy to pass around
multiple platforms, but its ubiquity makes it something that we can reasonably
expect to be easily consumed in any given language or platform. Coupled with
recent additions to build higher-order constructs on top of XML, we have a
pretty good way of representing data elements in a way that lots of platforms
can consume. Does interoperability require XML to work? Of course not.
We've managed for the better part of forty years to interoperate without XML,
and we probably could have kept on doing quite well without it; XML makes things easier, nothing more.
Services, on the other hand, is a design philosophy
that seeks to correct for the major failures in distributed object and
distributed component design. It's an attempt to create
"things" that are more reliable to outages, more secure, and more
easily versioned and evolvable, things that objects/components never really
addressed or solved.
For example, building services to be autonomous (as per the "Second
Tenet of Service-Orientation", as coined by Mr. Box) means that the
service has to recognize that it stands alone,
and minimize its dependencies on other
"things" where possible. Too much dependency in distributed object
systems meant that if any one cog in the machine were to go out for some
reason, the entire thing came grinding to a halt, a particularly wasteful
exercise when over three-quarters of the rest of the code really had nothing to
do with the cog that failed. But, because everything was synchronous RPC
client/server calls, one piece down somewhere on the back-end meant the whole
e-commerce front-end system comes to a shuddering, screeching pause while we
figure out why the logging system can't write any more log messages to disk.
Or, as another example, the First Tenet states that "Boundaries are
explicit"; this is a well-recognized flaw with any distributed system, as
documented back in 1993 by Wolrath and Waldo in their paper "A Note on
Distributed Computing". Thanks to the fact that traversing across the
network is an expensive and potentially error-prone action, past attempts to
abstract away the details of the network ("Just pretend it's a local
call") eventually result in nothing but abject failure. Performance
failure, scalability failure, data failure, you name it, they're all
consequences of treating distributed communication as local. It's enough to
draw the conclusion "well-designed distributed objects are just a
contradiction in terms".
There's obviously more that can be said of both the "Web" angle
as well as the "Services" angle, but hopefully enough is here to recognize
the distinction between the two. We have a long ways to go with both ideas, by
the way. Interoperability isn't finished just because we have XML, and clearly
questions still loom with respect to services, such as the appropriate
granularity of a service, and so on. Work remains. Moreover, the larger
question still looms: if there is distinction between them, why bring them
together into the same space? And the short answer is, "Because
individually, each are interesting; collectively, they represent a powerful
means for designing future systems." By combining interoperability with
services, we create "things" that can effectively stand alone for the
forseeable future.
And in the end, isn't that what we're supposed to be doing?
第3.3式. 显示索引属性
问题
在一个JSP 页面中,你需要访问一个对象中的索引的属性。
动作要领
使用bean.property[index]来访问索引的值,如Example 3-1所示。
Example 3-1. 访问索引属性
<@taglib uri=http://jakarta.apache.org/struts/tags-bean" prefix="bean"%>
<ul>
<li><bean:write name="foo" property="bar.baz[0]"/></li>
<li><bean:write name="foo" property="bar.baz[1]"/></li>
<li><bean:write name="foo" property="bar.baz[2]"/></li>
</ul>
JSTL 也支持对索引属性的访问,如Example 3-2 所示。
Example 3-2. 访问索引属性(JSTL)
<@taglib uri="http://java.sun.com/jstl/core" prefix="c"%>
<ul>
<li><c:out value="${foo.bar.baz[0]}"/></li>
<li><c:out value="${foo.bar.baz[1]}"/></li>
<li><c:out value="${foo.bar.baz[1]}"/></li>
</ul>
动作变化
索引的属性是Struts标签中最容易误解的一个部分。一个索引属性是表达一组值的JavaBean 属性,而不是一个单独的标量值。索引属性通过下面格式的getter 方法进行访问:
public Foo getSomeProperty (int index) { }
同时,索引属性则通过下面格式的setter 方法进行设置:
public void setFoo(int index, Foo someProperty) { }
我们来考虑一个表示日历的JavaBean。CalendarHolder类的代码如Example 3-3 所示,它有一个名为monthSet的嵌套属性,表达日历中的月份。
Example 3-3. Calendar JavaBean
package com.oreilly.strutsckbk;
public class CalendarHolder {
private MonthSet monthSet;
public CalendarHolder( ) {
monthSet = new MonthSet( );
 }
}
public MonthSet getMonthSet( ) {
return monthSet;
}
}
MonthSet类的代码则如Example 3-4 所示,它是一个具有索引属性的类,该属性表达月份的名称("January," "February," 等等)。
Example 3-4. 具有索引属性的类
package com.oreilly.strutsckbk;
public class MonthSet {
static String[] months = new String[] {
"January", "February", "March", "April",
"May", "June", "July", "August",
"September", "October", "November", "December"
};
public String[] getMonths( ) {
return months;
}
public String getMonth(int index) {
return months[index];
}
public void setMonth(int index, String value) {
months[index] = value;
}
}
我们的目标是访问在JSP页面中访问CalendarHolder实例的monthSet属性的索引属性month,代码片断如下所示:
<jsp:useBean id="calendar" class="com.oreilly.strutsckbk.CalendarHolder"/>
<ul>
<li><bean:write name="calendar" property="monthSet.months[0]"/></li>
<li><bean:write name="calendar" property="monthSet.months[1]"/></li>
<li><bean:write name="calendar" property="monthSet.months[2]"/></li>
</ul>
如果显示的索引属性要动态才能决定它是什么,那么使用的索引要使用JSP 脚本变量来进行设置。你可以使用scriptlet 来产生属性值,如下所示:
You have selected month number <bean:write name="monthIndex"/>:
<bean:write name="calendar"
property='<%= "monthSet.month[" + monthIndex + "]" %>'
但是使用scriptlet 会导致极端难以阅读和维护的JSP 页面。如果使用JSTL,事情会变得更清爽一些:
You have selected month number <c:out value="${monthIndex}"/>:
<c:out value="${calendar.monthSet.month[monthIndex]}"/>
通常,索引属性是在一个循环内动态访问的。假设你想要使用Struts logic:iterate标签显示月份的列表。这个标签将在整个Collection 或者数组之上进行迭代。下面是你可以如何以一个排序列表显示所有月份的例子:
<ol>
<logic:iterate id="monthName" name="calendar" property="monthSet.months">
<li><bean:write name="monthName"/></li>
</logic:iterate>
</ol>
重申一下, JSTL 也是一个替代选择。JSTL c:forEach标签将比Struts logic:iterate标签要容易使用一些。下面是如何使用JSTL来产生上面的同一个排序列表的代码:
<ol>
<c:forEach var="monthName" items="${calendar.monthSet.months}">
<li><c:out name="${monthName}"/></li>
</c:forEach>
</ol>
相关动作
第3.4式在JSTL循环中使用索引属性。
第3.5式则提供了一个更加详细的关于在JSTL循环中使用索引属性的说明。
IBM Websphere 中国开发站点有几篇新的Websphere V6中构建ESB的文章,目前已发表3篇:
分别是 :
使用 WebSphere Application Server V6 构建企业服务总线 ——
第1 部分 WebSphere V6 消息传递资源入门
第2 部分: 业务需求以及总线
第3部分: 简单的 JMS 消息传递实例
跟踪中.....
第3.2式. 使用Struts-EL 标签
问题
你希望在将JSTL 表达式用作Struts标签的属性值。
动作要领
使用Struts 分发保提供的EL标签库,位于contrib/struts-el/lib目录。你需要将所有JAR 和 TLD 文件拷贝到应用的WEB-INF/lib目录。在需要时用该标签的地方使用下面的taglib指令:
<%@ taglib uri="http://jakarta.apache.org/struts/tags-html-el" prefix="html-el" %>
表列出了Struts-EL 标签库和对应的taglib URI。
动作变化
JSTL风格的表达式,比如${foo.bar[4].baz},并不能够被基本的 Apache Struts Web Framework 标签支持。例如,如果你能够使用下面的方式来格式化一个标签就好了:
<html:text value="${sessionScope.foo.bar[3]}"/>
相反,这些标签需要运行时表达式,它们只是Java 代码(JS表达式):
<html:text value="<%=session.((Foo)getAttribute("foo")).getBar(3)%>"/>
将Java 代码从 JSP 页面中剔除会使得你的页面更少脆弱性和更容易维护。认识到了这种对EL 支持的缺乏后,因而创建了Apache Struts Web Framework-EL 标签库。这些库扩展了html, bean, and logic Apache Struts Web Framework 标签库,以添加对EL 表达式的支持。如果一个Struts 标签的属性支持一个运行时表达式,对应的Struts-EL 标签便会支持JSTL 表达式。可以在应用中混合使用常规的Struts 标签和Struts-EL 标签,即使在同一个页面中也可以。仅仅是需要保证在页面的taglib指令中为每一个标签库定义一个不同的前缀。
然而,Struts-EL 标签不是JSTL的替代。Struts-EL 标签仅提供仅仅针对Struts的标签。如果Struts 标签可以被一个JSTL 标签所替代,该标签就不会在Struts-EL 标签库中实现。
关于JSP 2.0
如果你使用支持JSP 2.0的容器,比如Tomcat 5,那么你便可以直接在基本Struts 标签中使用JSTL表达式。这就是说,不再需要使用Struts-EL 标签了。JSP 2.0 支持EL 表达式在页面中的直接使用。这些表达式可以用来渲染动态文本,就像原来常规HTML 标记和定制JSP标签中的动态属性值中的文本一样。表达式的值就像是你使用JSTL c:out标签输出的一样:
<p>Hello, ${user.firstName}<br /><html:text value="${sessionScope.foo.bar[3]}"/>
为了使用这个强大的特征,你必须是用两种方式之一来激活EL 。如果你使用Servlet 2.4 规范, EL 则默认是支持的。你可以通过你的应用的web.xml文件来区别是不是2.4版本的servlet规范。该文件的开头应该是这样:
<web-app xmlns="http://java.sun.com/xml/ns/j2ee"xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://java.sun.com/xml/ns/j2ee http://java.sun.com/xml/ns/j2ee/web-app_2_4.xsd"version="2.4">
如果你使用Version 2.3 或者更早的规范,你将需要在JSP页面的开头使用下面的JSP 指令进行设置:
<%@page isELIgnored="false"%>
如果你使用2.4 DTD,那么你不需要设置这个指令;EL 语法将不会被忽略。如果你不确定,尽管可以设置它,这不会发生什么错误问题。 |
相关招式
第3.1式详细描述了如何配置JSTL的使用。
第3.1式. 使用JSTL
问题
你需要在Struts应用中使用JSTL标签苦的标签。
动作要领
从http://jakarta.apache.org/taglibs下载Jakarta Taglibs JSTL 的参考实现。将jstl.jar和standard.jar文件拷贝到应用程序的WEB-INF/lib文件夹。然后将c.tld, fmt.tld, sql.tld, 和x.tld文件复制到WEB-INF/lib目录。
在需要时用JSTL的地方使用适当的taglib指令:
<%@ taglib uri="http://java.sun.com/jstl/core" prefix="c" %>
Table 3-1列出了JSTL 标签库和对应的URI。
动作变化
JSTL 是一个强大的标签库集,完全应该作为Struts 开发者的工具箱之一。JSTL 包含有支持JavaBean 属性、循环、条件逻辑、以及URL 格式化的标签。也有格式化和解析日期和数值的标签。XML 标签库可以用来在页面中解析和处理XML。SQL 标签库则可以和关系数据库交互。Functions 标签库提供了一些有功的函数,可用于表达始中,特别是字符串处理。
这其中最重要的就是Core 标签库。这个库包含了很多可以取代Struts beanlogic标签的标签。那为什么要使用这个标签而不是用Struts 标签呢?答案是,这些标签要比Struts 标签要更强大而更易于使用。但是别搞错,Struts 项目并不和它是抵触的。恰恰相反,JSTL 允许Struts 集中于它最擅长的:为强壮的JSP Web应用提供控制器。
我们来看看如何分别使用JSTL 标签和Struts 标签来实现循环和显示输出。首先,下面是Struts 版本:
<ul>
<logic:iterate id="cust" name="branch" property="customers">
<li>
<bean:write name="cust" property="lastName"/>,
<bean:write name="cust" property="firstName"/>
</li>
</logic:iterate>
</ul>
使用JSTL,则变得简单一些:
<ul>
<c:forEach var="cust" items="${branch.customers}">
<li>
<c:out value="${cust.lastName}, ${cust.firstName}"/>
</li>
</c:forEach>
</ul>
后者最酷的地方在于你并不是一定要一个个的进行选择。JSTL 可以在你便干边学中使用它。JSP 表达式语言(EL) 使得访问各种范围之中的ActionForms 和对象中的数据更加容易。最困难的决策不是你到底用不用JSTL,而是使用哪一个版本的JSTL。如果你使用JSP 2.0/Servlet 2.4 容器,比如Tomcat 5, 你最好使用JSTL 1.1。否则,目前你只能使用JSTL 1.0。
对于Struts应用来说,我们还是推荐使用JSTL 标签。
相关动作
第3.2式会展示如何在Struts标签中使用EL 表达式。
<JavaServer Pages> [Hans Bergsten 著(O'Reilly),机械工业出版中文版]就详细涉及了JSTL,值得参考。
Sun 提供了一个JSTL 教程,地址是http://java.sun.com/tutorials/jstl.
下面地址也有一个快速参考:http://www.jadecove.com/jstl-quick-reference.pdf.
Manning 的 JSTL in Action也是一本很好的书:http://www.manning.com
Java.net上有很好的Java相关资源,可以随时跟踪一些相关的技术、组件、项目、框架等等。
其地址是:
http://wiki.java.net/bin/view/Javapedia
其中包括:
相关技术:
- AspectOrientedProgramming,
- ContentManagementSystem,
- FileSystems,
- Glossary,
- Internationalization,
- JNLP,
- JavaAudio,
- JavaBeans,
- JavaScripting,
- Jsr175,
- JavaWebStart,
- LayoutManager,
- LinuxRpm,
- MetaData,
- MobileCode,
- Portal,
- RegularExpressions,
- XmlParsing,
- XsltTransformation,
- ATCT
最佳实践
- AgileProgramming,
- AspectOrientedProgramming,
- Certification,
- ClassPath,
- CodingGuidelines,
- ContinuousIntegration,
- DeploymentDescriptorHell,
- InstanceBasedSecurity,
- JavaDeployment,
- Misconceptions,
- Patterns,
- Refactoring,
- Security, Telecom,
- Testing,
- WarStories?
人物、公司、组织
第2段. 用户接口
介绍
有一个现实:你尽管可以架构最纯粹、最优雅和最强壮的Web应用,但是如果用户不喜欢其接口的样子,你便注定要失败。有些Java 开发人员考虑到这些问题,并使用普通的HTML 和JavaScript技术来解决这些问题。不管你是否喜欢,这些技术,特别是HTML的知识会使得一切在涉及表现和可用性的时候变得完全不同。如果你不知道如何使用它们,你的应用便面临如何被用户去接受的风险和挑战。
这一部分将介绍一些有用的技巧和招数来解决大多数应用表现的难题。这里并不是说就不需要优秀的图形设计和用户接口设计人员。然而,通过Struts的动态能力来利用HTML的优势毕竟还有一大段距离。另外,这一部分将提供一种基于补充技术的解决方案,比如使用JSTL。
一些情形,比如使用HTML表单也非常麻烦。比如,Checkboxes 因为其对unchecked 控件状态的处理让人无休止的头疼。这部分就包括了一个专门处理这个问题的技术。表单处理中另一个通用的问题就是如何处理日期字段。有很多方式,但都有其优缺点。本部分也包含有一个对这些方式的比较。
其中保包括如何设置表单中的tab 次序,产生用于JavaScript中的URL,以及使用框架帧(frame)。总之,如果你对Struts的UI有问题,这里就是解决他们的一个好地方。
Java 平台持久性机制的比较
访问持久性数据是所有应用都需要考虑的一个重要方面。Java 语言严格的遵循了持久性数据和暂态性数据的分离,将持久性管理留给了应用或者分层机制。SUN使用一种严格的比较机制测试和比较了Java平台上的各种革新的持久性机制。
通过选择,选出了一个有代表意义的几个系统来进行评价和比较。这些机制都通过OO7J的基准测试进行量化分析。
所有的测试环境都具有足够的内存,使得测试数据库完全可以在内存中驻留,排除磁盘访问等硬件的影响,也是今天主要服务环境的通用内存容量配置。OO7J的虚拟机变体设置性能基线,每一种机制都和它进行比较。OPJ的PJama实现得到了总体最高分。它只需要最小的源代码修改,甚至对OO7J的主体基本不需要,虽然它仅是一个原型实现,却取得了最好的性能。但是它的确需要一个定制的虚拟机。
EJB 框架看起来最糟,需要最多的源代码修改和最坏的性能和可伸缩性。
JOS 和 JBP,虽然因为它们缺乏增量访问从而使得在读写数据的时候性能也很糟糕,但是,他也仅需要很少的代码修改并能在数据在内存中的情况下全速运行。
JDBC 对源代码修改也有较大影响,但是性能却是在JVM和数据库的边缘交叉处的大量交互体现的很好。两个JDO 的变体则展现出JDO模型对不同外部数据存储的多能性。特别是JDO-TP 和其事务对象模型对关系数据库工作的很好,同时允许源代码对基线保持最小的变更。并且, JDO 的性能也排在前列,一旦数据在内存中,这是合情合理的,比JDBC 和 EJB而言也是如此。
虽然EJB CMP 的性能要优于EJB BMP,其性能也差于JDO-TP很多。EJB性能差的原因还不清楚,也应该注意到,一些应用服务企业有很差的性能,可能是容器实现的原因。
作为结论,很显然,持久性对应用代码的影响是很宽的,也对结果系统的性能影响很大。. 如果在虚拟机一级得到支持,OPJ可望提供最有竞争力的性能。在另一个极端,EJB似乎很难达到可接受的性能水平,除非应用对象模型发生戏剧性的变化,从而避免在映射到EJB时产生的细粒度对象。虽然这些方法已经反映在标准的EJB设计模式中了,但是其暗示着在应用程序的各个方面均要附加更多额外的努力。相反,JDO 试图在对应用设计的影响最小的情况下达到合理的性能,同时保持对外部数据源的中立。因此,当前,JDO 似乎能够提供面向对象应用所需的最佳的总体持久性机制。但是,目前,SUN建议了一个最新的实体Bean持久性规范 [Sun04],提交给 EJB3.0,它可能更加接近于JDO 模型。
报告的原文可以在以下地址下载:http://research.sun.com/techrep/2004/smli_tr-2004-136.pdf
同时,这也是SUN首次公开披露EJB的性能问题。这也解释了为什么EJB一直得不到很好的广泛使用的原因,淡然还有它的复杂性和部署的高成本性(需要昂贵的EJB容器)。作为J2EE规范中的一个重要的核心组件,SUN的赌注押在了EJB3.0上面。EJB3.0相关的持久性机制(JSR220)吸收了JDO和oracle的TopLink的优点,并且可望提供向后兼容性和迁移API。
虽然,EJB从其规范和目标来说看上去很美。但是EJB3.0至少要今年晚些时候才能出场,目前我们能够使用什么呢?考察目前市面上的持久性框架,结合你的应用要求,也不难得出选择。毕竟,应用来说,性能并不是第一位的。
对于持久性框架的选择,从应用和功能上讲,主要考虑以下方面:
- 对O-R mapping框架的使用经验。
- 数据源(Data Source),必须支持不同的数据源,包括关系数据库和JCA体系。
- 最好提供图形化的映射工具来进行对象和数据库表之间的映射,自动生成XML配置文件。
- 数据库支持,可以利用数据库的优势,如存储过程,触发器,支持高级数据类型和数据库安全。
- 查询支持,应该支持通过Java代码或者OO查询机制,如EJB QL,按例查询,标准SQL 来编写自己的查询。
- 锁定。必须支持不同应用访问同一数据库时候的锁定机制。
- 缓存。提供有效的缓存基址,减少网络和查询的开销。 并支持不同节点的集群。
- 支持到EJB 3.0的迁移。
目前,JBOSS已经在AS 4.0中提供了EJB3.0的早期实现。可以参考。http://www.jboss.org/products/ejb3
如果你不怕在Oracle数据库平台上锁定,你打可使用Toplink,这也是目前性能最好的POJO的持久性框架。Oracle也是EJB3.0的专家组,将来肯定会提供迁移的手段。 你可以阅读这篇文章:Preparing for EJB3.0. 地址:http://www.oracle.com/technology/tech/java/newsletter/articles/toplink/preparing_for_ejb_3.html
注:
JOS
JOS,称为Java对象序列化,是JDK 1.1 引入的 [Sun99],它是一种支持几乎所有对象到流的编码和从流解码的机制。他不是基于属性表的编码,而是基于文本的,对象序列使用标准的二进制编码格式。JOS 是Java平台默认的持久性机制,也被用来作为 JAVA远程方法调用RMI的参数编组协议。在最低层次上,JOS 构成了对基础类型的编码和解码的平台支持。但是,序列化遇到了类演化的严重问题,这也使得在Java1.4中引入了“JavaBean的长期持久化”的新系统。
JDBC
JDK 1.1 也引入了Java数据库连接(JDBC) API [FEB03]作为使用标准的SQL语言在Java和关系数据库之间的通信机制。JDBC为Java 向关系数据库提供了一个强有力的跳板,并且被平台上的很多API实现证明很成功。设计者很成功地将Java 编程语言和SQL进行了嫁接,而且JDBC 对直接的数据库访问非常容易使用。然而,如果应用需要底层数据的对象视图的时候,比如,将主键转换成相等的对象间的引用关系,程序将便得非常复杂和容易出错。为了解决这个问题,有许多系统开发出来试图自动化这个流程,这通常称为是对象关系映射(O-R Mapping)。大多数开发环境都提供对这一机制的不同程度的支持。 JDBC API 也在发展,近来支持直接将Java语言中的一个类映射到SQL的面向对象扩展中的相等类型。
JDO
在JDBC 开发的同时,对象数据库管理组 (ODMG)定义了一个它们的对象模型到Java语言的绑定[Ced96],而许多对象数据库厂商则提供了这种绑定的实现。因为对象数据库并不像关系数据库那样部署普遍,因此反映在这个绑定上面也是不怎么成功。Java社区流程(JCP)出现后,这一努力被一个更广泛的建议所替代,即Java数据对象 (JDO) [JR03]。JDO 的目标是针对各种各样的底层数据存储,包括关系数据库,并向开发人员呈现一个类似于LJS所定义的对象模型,但附加限制更少。而许多对象数据库厂商也支持JDO。
OPJ
综合这些努力,SUN和 Glasgow 大学合作,提出了一个Java平台的正交持久化机制 (OPJ) [JA00]。这一方法以极高的透明性支持变成语言的各个方面。从本质上讲,OPJ 添加了对JVM稳定内存的支持,也意味着这一对JVM 实现的要求根本上限制了其可接受性。
第2.8式. 有选择地禁止Action
问题
你想要是使用一个定制属性来禁止(disable)一个,并且该属性能够在struts-config.xml文件的action元素中进行设置;转发到该disabled action 的任何请求都会得到"under construction" 页面。
动作要领
创建一个定制的ActionMapping扩展(如Example 2-16) ,它可以提供一个boolean 类型的属性来指示action 是否被禁止。
Example 2-16. 定制ActionMapping
import org.apache.struts.action.ActionMapping;
public class DisablingActionMapping extends ActionMapping {
private String disabled;
private boolean actionDisabled = false;
public String getDisabled( ) {
return disabled;
}
public void setDisabled(String disabled) {
this.disabled = disabled;
actionDisabled = new Boolean(disabled).booleanValue( );
}
public boolean isActionDisabled( ) {
return actionDisabled;
}
}
这个action mapping 就可以在struts-config.xml文件中指定。如果你想要一个action被禁止,你可以设置disabled属性为True :
<action-mappings type="com.oreilly.strutsckbk.DisablingActionMapping">
<!-- Edit mail subscription -->
<action path="/editSubscription"
type="org.apache.struts.webapp.example.EditSubscriptionAction"
attribute="subscriptionForm"
scope="request"
validate="false">
<set-property property="disabled" value="true"/>
<forward name="failure" path="/mainMenu.jsp"/>
<forward name="success" path="/subscription.jsp"/>
</action>
然后创建一个定制的RequestProcessor,比如Example 2-17中的那个,它可以处理DisablingActionMapping.
Example 2-17. 处理对被禁止的actions的请求
import java.io.IOException;
import javax.servlet.ServletException;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
import org.apache.struts.action.Action;
import org.apache.struts.action.ActionForm;
import org.apache.struts.action.ActionForward;
import org.apache.struts.action.ActionMapping;
import org.apache.struts.action.RequestProcessor;
public class CustomRequestProcessor extends RequestProcessor {
protected ActionForward processActionPerform(HttpServletRequest request,
HttpServletResponse response, Action action,ActionForm form,
ActionMapping mapping) throws IOException, ServletException {
ActionForward forward = null;
if (!(mapping instanceof DisablingActionMapping)) {
forward = super.processActionPerform( request, response,
action, form, mapping);
}
else {
DisablingActionMapping customMapping =
(DisablingActionMapping) mapping;
if (customMapping.isActionDisabled( )) {
forward = customMapping.findForward("underConstruction");
}
else {
forward = super.processActionPerform( request, response,
action, form, mapping);
}
}
return forward;
}
}
动作变化
Struts 通过两种机制来对action提供定制属性的能力。
首先,每个Struts action 都可以通过一个通用参数parameter值来传递:
<action path="/editRegistration"
type="org.apache.struts.webapp.example.EditRegistrationAction"
attribute="registrationForm"
scope="request"
validate="false"
parameter="disabled">
<forward name="success" path="/registration.jsp"/>
</action>
其次,在Action的实现中,parameter的值可以通过下面的代码来访问:
String parameterValue = mapping.getParameter( );
然而,某些Struts所提供的子类,比如DispatchAction 已经使用了parameter属性。因为你只可以指定一个parameter属性,所以,如果你使用这些预定义的Action子类,便不能再将parameter用作定制属性值。
对于完整的扩展,你可以扩展ActionMapping类,可选地为你所选择的定制属性提供accessor 和 mutator :
package com.oreilly.strutsckbk;
import org.apache.struts.ActionMapping
public class MyCustomActionMapping extends ActionMapping {
private String customValue;
public String getCustomValue( ) { return customValue; }
public String setCustomValue(String s) { customValue = s; }
}
你可以在struts-config.xml文件中引用这个扩展。如果定制action mapping 将被用于所有action,请将action-mappings元素的type属性设置为定制扩展的全限定类名:
<action-mappings type="com.oreilly.strutsckbk.MyCustomActionMapping">
否则,为定制action mapping所需的action元素设置className属性。这两种情况下,set-property元素都可以用来针对特定的action元素为定制扩展中的JavaBean 属性设置值:
<action path="/someAction"
type="com.oreilly.strutsckbk.SomeAction"
className="com.oreilly.strutsckbk.MyCustomActionMapping">
<set-property property="customValue" value="some value"/>
</action>
这种方案使用一个定制的RequestProcessor来处理定制ActionMapping的disabled 属性。如果你对特定的action使用定制的ActionMapping,你可以在Action.execute()访法中直接访问定值ActionMapping的属性:
boolean disabled = ((DisablingActionMapping) mapping).isActionDisabled( );
if (disabled) return mapping.findForward("underConstruction");
相关招式
你也可以使用授权(authorization) servlet 过滤器来解决这个问题。那是第11.8式的动作。
Mule 是一个基于ESB架构理念的消息平台。Mule 的核心是一个基于SEDA的服务容器,该容器管理被称为通用消息对象(Universal Message Objects /UMO)的服务对象,而这些对象都是POJO。所有UMO和其他应用之间的通信都是通过消息端点(message endpoint)来进行的。这些端点为众多的分立的技术,比如Jms, Smtp, Jdbc, Tcp, Http, Xmpp, file等等,提供了简单和一致的接口。
Mule 应用通常是由网络中的许多Mule 实例组成。每一个实例都是一个驻留一个或者多个UMO组件的轻量级容器。每一个UMO 组件都有一个或者多个通过它(们)发送和接收事件的端点。

容器通过UMO组件提供各种各样的服务,比如事务管理、事件转换,路由,事件关联、日志、审计和管理等等。Mule将对象构造从管理手段中分离出来,通常流行框架和IoC/DI 容器,如Spring, PicoContainer 或者 Plexus 可用这种管理手段来构建你的UMO 组件。
很多人认为, "Mule是一个Jms 实现"。实际上,Mule 不是一个Jms server,但是可以配置来使用任何你觉得非常漂亮的Jms server。Mule 的理念是,如果已经有了稳定和广泛接受的实现,就不会直接实现任何传输。例如,Mule 就重用了Axis 和 GLUE 的SOAP栈而不是重新实现一个。Mule 提供了一个一致的服务集来管理任何类型的连接的事件流、关联、事务、安全和审计。
下面是Mule Server 组件的简单图示:


Mule Manager是Mule server 实例的中心(也称为一个节点户或者Mule Node)。其主要的角色是管理各种对象,比如Mule实例的连接器、端点和转换器。这些对象然后被用来控制进出你的服务组件的消息流,并且为Model和它所管理的组件提供服务。
Model
model 是管理和执行组件的容器。它控制进出组件的消息流,管理线程、生命周期和缓充池。默认的MuleModel是基于SEDA的,它使用一个有效的基于事件的队列模型来获取的最大的性能和直通性。
UMO Components
UMO代表Universal Message Object;它是一个可以接收来自于任何地方的消息的对象。UMO 组件就是你的业务对象。它们是执行引入的事件之上的具体业务逻辑的组件。这些组件是标准的JavaBean,组件中并没有任何Mule特定的代码。Mule 基于你的组件的配置处理所有进出组件的事件的路由和转换。
Endpoints
Endpoint是Mule的通信能力的基础。一个Endpoint定义了两个或者多个组建应用或者存储库之间的通信渠道。并且提供了一个强大的机制来允许你的对象在一个统一的方式上再多种协议之上进行交谈。端点可以通过消息过滤器、安全拦截器和事务信息进行配置来控制什么消息,在何时,以及怎样通过端点进行发送和接收。
External Applications
外部应用可以使任何应用,从应用服务器到遗留的传统应用,主机程序,或者C/S系统。基本上是任何可以产生和操纵数据的应用。因为Mule通过endpoints执行所有通信,UMO 组件并不打算在其中包含应用产生数据,以及应用主流,以及使用传输协议的部分。
关键特性
- 基于J2EE 1.4的企业消息总线( Enterprise Service Bus (ESB))和消息代理(broker)
- 可插入性连接,比如Jms (1.0.2b 和 1.1), vm (嵌入), jdbc, tcp, udp, multicast, http, servlet, smtp, pop3, file, xmpp等
- 支持任何传输之上的异步,同步和请求响应事件处理机制
- 支持Axis或者Glue的Web Service.
- 灵活的部署结构[Topologies]包括Client/Server, P2P, ESB 和Enterprise Service Network.
- 支持声明性和编程性事务,包括XA 支持
- 对事件的路由、传输和转换的断到端支持
- Spring 框架集成。可用作ESB 容器,而Mule c也可以很容易的嵌入到Spring 应用中。
- 使用基于SEDA处理模型的高度可伸缩的企业服务器
- 支持REST API 来提供技术独立和语言中立的基于web的对Mule 事件的访问
- 强大的基于EIP模式的事件路由机制
- 动态、声明性的,基于内容和基于规则的路由选项
- 非入侵式的方式。任何对象都可以通过ESB 容器管理
- 强大的应用集成框架
- 完整的可扩展的开发模式
何时使用
一般在这些情形下使用Mule -
- 集成两个或者多个需要互相通信的或者多个现有的系统.
- 需要完全和周围环境去耦合的应用,或者需要在系统中伸缩不止一个组件的系统
- 开发人员不知道未来是否会将其应用分发或者伸缩需求的单VM 应用。
项目地址:http://mule.codehaus.org/
第2.7式. 访问来自于数据库中的消息资源
问题
你想要将所有标注、消息和其他静态文本都保存在数据库中而不知一个属性文件中,并且仍然可以通过bean:message标签来进行访问。
动作要领
- 下载OJBMessageResources分发包,地址是:http://prdownloads.sourceforge.net/struts/ojb-message-resources.zip?download.
- 将ZIP 文件解包到一个本地目录;
- 将ojb-msg-res.jar文件从ojb-message-resources/dist文件夹拷贝到你的应用的WEB-INF/lib文件夹。
- 将属性文件、XML 和DTD 文件从ojb-message-resources/config文件夹拷贝到你的应用的src文件夹。当你build 你的应用的时候是,这些文件必须被拷贝到WEB-INF/classes文件夹中。
- 创建数据库表来保存对象关系桥(OJB) 的元数据。OJB 使用表来保持内部的映射关系。Example 2-12 列出了在MYSQL中创建这些表的SQL。对于其他数据库的语句,包含在OJB 分发包中。
Example 2-12. OJB 元数据DDL (MySQL)
CREATE TABLE ojb_dlist (
ID int NOT NULL default '0',
SIZE_ int default NULL,
PRIMARY KEY (ID)
) TYPE=MyISAM;
CREATE TABLE ojb_dlist_entries (
ID int NOT NULL default '0',
DLIST_ID int NOT NULL default '0',
POSITION_ int default NULL,
OID_ longblob,
PRIMARY KEY (ID)
) TYPE=MyISAM;
CREATE TABLE ojb_dmap (
ID int NOT NULL default '0',
SIZE_ int default NULL,
PRIMARY KEY (ID)
) TYPE=MyISAM;
CREATE TABLE ojb_dmap_entries (
ID int NOT NULL default '0',
DMAP_ID int NOT NULL default '0',
KEY_OID longblob,
VALUE_OID longblob,
PRIMARY KEY (ID)
) TYPE=MyISAM;
CREATE TABLE ojb_dset (
ID int NOT NULL default '0',
SIZE_ int default NULL,
PRIMARY KEY (ID)
) TYPE=MyISAM;
CREATE TABLE ojb_dset_entries (
ID int NOT NULL default '0',
DLIST_ID int NOT NULL default '0',
POSITION_ int default NULL,
OID_ longblob,
PRIMARY KEY (ID)
) TYPE=MyISAM;
CREATE TABLE ojb_hl_seq (
TABLENAME varchar(175) NOT NULL default '',
FIELDNAME varchar(70) NOT NULL default '',
MAX_KEY int default NULL,
GRAB_SIZE int default NULL,
PRIMARY KEY (TABLENAME,FIELDNAME)
) TYPE=MyISAM;
CREATE TABLE ojb_lockentry (
OID_ varchar(250) NOT NULL default '',
TX_ID varchar(50) NOT NULL default '',
TIMESTAMP_ decimal(10,0) default NULL,
ISOLATIONLEVEL int default NULL,
LOCKTYPE int default NULL,
PRIMARY KEY (OID_,TX_ID)
) TYPE=MyISAM;
CREATE TABLE ojb_nrm (
NAME varchar(250) NOT NULL default '',
OID_ longblob,
PRIMARY KEY (NAME)
) TYPE=MyISAM;
CREATE TABLE ojb_seq (
TABLENAME varchar(175) NOT NULL default '',
FIELDNAME varchar(70) NOT NULL default '',
LAST_NUM int default NULL,
PRIMARY KEY (TABLENAME,FIELDNAME)
) TYPE=MyISAM;
6. 使用Example 2-13中的SQL DDL来创建保存消息资源数据的表。
Example 2-13. MessageResources DDL
create table application_resources (
subApp varchar(100) not null,
bundleKey varchar(100) not null,
locale varchar(10) not null,
msgKey varchar(255) not null,
val varchar(255),
Primary Key(
subApp,
bundleKey,
locale,
msgKey
)
);
- 将消息资源装入数据库表格中。Example 2-14 展示了一个如何使用SQL语句组装表格数据的简便方法。
Example 2-14. SQL to load message resources table
insert into application_resources (
subApp, bundleKey, locale, msgKey, val )
values ('', '', '', 'label.index.title',
'Struts Cookbook');
insert into application_resources (
subApp, bundleKey, locale, msgKey, val )
values ('', '', 'fr', 'label.index.title',
'Struts Livre de Cuisine');
修改Struts 配置文件来使用OJBMessageResourcesfactory。
<message-resources
factory="org.apache.struts.util.OJBMessageResourcesFactory"
parameter="."/>
修改WEB-INF/classes文件夹中的repository.xml (第4步中拷贝的) 来使用专门针对你的数据库的数据库连接属性。Example 2-15展示了针对MySQL 数据库的配置信息。
Example 2-15. 针对MySQL的OJB 连接描述
<jdbc-connection-descriptor
platform="MySQL"
jdbc-level="2.0"
driver="com.mysql.jdbc.Driver"
protocol="jdbc"
subprotocol="mysql"
dbalias="//localhost:3306/test"
username="user"
password="pass"
/>
动作变化
Struts MessageResources工具管理着诸如错误消息、字段标注、表格头部以及窗口标题等静态文本。通过这个工具,文本被保存在成为资源束的一个或者多个.properties文件的名值对中;名称是一个逻辑关键字而值则是要显示文本的值。如果你的应用需要针对某个特定国家和语言进行本地化,你将创建一个(套)新的属性文件。你可以使用对属性文件名称添加一个由国家代码和语言代码组成的后缀来将一个文件关联到一个特定的场所。比如,针对加拿大法语的MessageResources.properties文件可能是MessageResources_fr_CA.properties。本地化文件中的属性包含有专门针对该场所的值。这种本地化的方式实际上是Java自身决定的。
这个工具对大多数中型和小型的应用工作的很不错。但是,你可能想要使用一种更加具有可管理性的持久性手段,比如数据库来保存它。虽然Struts 本身并不支持这种方式,但是可以通过其他扩展来支持。在幕后, Struts 使用MessageResourcesFactory的实现来创建在运行时保存在servlet context中的MessageResources对象。你可以提供定制的Struts MessageResourcesFactory实现,并且在Struts 配置文件中声明你的实现:
<message-resources
factory="com.foo.CustomMessageResourcesFactory"
parameter="moduleName.bundleKey"/>
parameter 属性指定消息资源工厂要针对创建的Struts module 名称和bundle 关键字(bundle 名称) 。
所以,你可以创建你自己的从数据库中读取资源的消息资源工厂。幸运的是,这个麻烦的工作已经有人做了。James Mitchell, 一个长期的Struts 志愿者,创建了一个OJBMessageResources实现。这些类利用了对象关系映射框架OJB来提供易用的数据库驱动的MessageResources实现。
如果你不熟悉OJB,也不会阻止你练习这一招技术。你不需要完全了解OJB来能使用OJBMessageResources。OJB 中仅涉及到将关系数据映射到对象数据的部分内容。如果你使用本方案中指定的table schema ,对于映射数据不需要再作其他修改。然而,如果你想要使用一个不同的schema,你就需要对 OJB 基于XML的配置文件中的映射配置进行修改易适合你的需要。你不需要对实现MessageResourcesFactory的具体Java代码做任何修改。OJBMessageResources的文档也不错,并且有一个逐步的安装和配置指导的README文件。上面的动作要领就来自于这些指导。
为了最有效的使用OJBMessageResources ,理解数据库schema 如何映射到对象数据是很有帮助的。首先,schema 金需要创建一个表格来保存消息资源(第6步)。使用一个表简化了数据映射。Table 2-2 表述了组成该表的列,以及它们如何在Struts中使用。
|
Table 2-2. OJBMessageResources schema |
|
列 |
对应的Struts 概念 |
注释和示例 |
|
subApp |
模块前缀 |
非null。
使用一个空字符串("") 来标识默认模块 |
|
bundleKey |
在使用多个资源集时,定位某一个消息资源集的关键字。这个值必须匹配Struts配置文件中的message-resources元素的key属性的值。这个值也对应于Struts标签中的bundle 属性的值 (如, bean:message bundle="labels") |
非null。使用空字符串来表示默认关键字。否则,名称是一个逻辑值,比如"labels," "headers," 和"errors." |
|
Locale |
标识消息场所的场所代码。此值是两个字母的语言代码和两个字母的国家代码的组合。 |
非null。
使用空字符串来表示默认(服务器的)场所。比如"en_US" 标识美国英语,"fr"标识法语。 |
|
msgKey |
用于查找消息的消息的名称。此值对所有场所都是一样。这个值也是属性文件中名值对中左边的部分。此列的值对应于从MessageResources中获取值的Struts标签的key属性的值。 |
非null, 并且应该永不为空。一个关键字可能看起来如: "title.hello.world". |
|
val |
对应于msgKey的值。是对应于属性文件中名值对右边部分的本地化值。这也是将由Struts标签返回和显示的值。 |
可以为null。这是将在页面中显示的文本。比如, "Hello, World!" |
记住,虽然OJBMessageResources 使用一个单表来保存消息资源,每一个资源集都仍然必须在struts-config.xml中通过message-resources元素进行配置。换句话说,对由bundleKey 和 subApp区分的每一个消息资源集都将需要一个message-resource元素。关于多个消息资源,参见第2.6式。
相关招式
第2.6式描述了如何配置Struts 来使用多个消息资源束。第13段的动作中会描述如何进行Struts 应用的国际化。
OJB 是Apache 大伞之下的一个项目。详细信息清访问呢:http://db.apache.org/ojb.
有人正在努力将Struts 消息资源重构到一些更加通用的类中。这就是Commons Resources 项目,可以访问http://jakarta.apache.org/commons/sandbox/resources/获取相关信息。它可以提供属性文件支持的消息资源机制,或者其他持久性机制支持的消息资源机制,比如OBJ, Hibernate, Torque, 和直接JDBC。也许将来的Struts将使用这个通用的消息资源机制。
第2.6式. 使用多个资源束
问题
你可能想要将你的应用资源分解到多个文件中,以改善应用的组织和维护性,特别是在团队开发的环境中。
动作要领
创建单独的属性文件并且在struts-config.xml中为每一个文件声明一个message-resources元素。
<message-resources
parameter="com.oreilly.strutsckbk.MessageResources"/>
<message-resources
parameter="com.oreilly.strutsckbk.LabelResources"
key="labels">
</message-resources>
<message-resources
parameter="com.oreilly.strutsckbk.HeaderResources"
key="headers">
</message-resources>
动作变化
Struts 使用消息资源来提供对错误消息、字段标注、以及其他静态文本的存储机制。对于默认的Struts 实现,你可以将消息存储为属性文件(.properties文件)中的名称(关键字)/值对。消息资源集基本上相当于Java ResourceBundle(资源束)。
你可以将你的消息资源束性文件通过message-resources元素来配置。元素的parameter属性指示了属性文件的相对于classpath的名称。你可以通过将文件路径中的分隔符替换为点号,以及删除文件名中的.properties扩展名来产生这个属性的值。比如,如果你的属性文件位于/WEB-INF/classes/com/oreilly/strutsckbk/MessageResources.properties,你可以将消息资源元素设置为:
<message-resources
parameter="com.oreilly.strutsckbk.MessageResources"/>
在应用启动时, Struts将创建消息资源的运行时表达(一个对象实例),然后将其保存在servlet context中。
你并不限于只使用一个消息资源。然而,和使用多Struts配置文件不同,如果你使用多个消息资源文件,它们并不时合并成一个文件。相反,你需要定义消息资源的不同的集合。每一个集合使用一个key属性指定的唯一的值来标识。如果这个属性没被使用,那么该消息资源就会被设置为默认的消息集。只有一个默认消息集存在。同时,只有一个消息资源集对应于同一模块中的每一个唯一关键字。如果你使用同一关键字定义了多个消息资源束,则最后一个指定的将被使用。
key属性的值是作为servlet context 属性的名称,从属性文件创建的消息资源束就保存在它之下。key值被用在Struts标签之中,比如bean:message,来标识消息资源集,并引用到来自于属性文件的资源束。下面是你可以如何从labels消息资源来访问一个消息的方法:
<bean:message bundle="labels" key="label.url"/>
bundle属性的值对应于struts-config.xml文件中的message-resources元素的key属性。bean:message标签也有一个key属性,但它和message-resources元素的key属性的含义完全不同。它指定一个特定的属性来访问消息资源中的消息。
Struts 并不关心你如何分解你的消息资源属性文件。一种办法是按照消息类型分解。比如,你可以将你的消息资源分解为下面的几组:
虽然这样分解消息资源是合乎逻辑和合理的,但在团队环境中则倾向于按照功能进行分解。比如,考虑一个人力资源应用,它有薪酬、福利和管理功能区。你可以为每一个功能区创建一个消息资源属性文件。每一个属性文件都包含该功能区域所特定的错误消息、提示消息、字段标注和其他信息。如果你的开发团队是按照这些业务功能区进行分组的,按照相同的分组原则对消息资源进行分组则更加合理。相同的方法和原则也适用于Struts 配置文件的分解。
如果你熟悉Struts module,上述的每一个功能区都是一个很好的Struts module的候选。如果你使用module,那么你在struts-config文件中为某一个模块所定义的消息资源就仅适用于该模块。事实上,你可以在不同的模块中定义具有相同key属性的message-resource元素。回想一下, Struts 是使用key值将MessageResources保存在servlet context中。更准确地说,实际的值将用于模块名称(通常引用为模块的前缀),以及消息资源的key属性值的串联。
相关招式
第2.4式提供了关于分解应用组件的技术。Struts 用户指南提供了定义消息资源的文档,其地址为:http://jakarta.apache.org/struts/userGuide/configuration.html#resources_config.
Struts MessageResources的JavaDoc API可以在http://jakarta.apache.org/struts/api/org/apache/struts/util/MessageResources.html处找到。
Struts 文档中关于bean:message标签的文档可以在http://jakarta.apache.org/struts/userGuide/struts-bean.html#message处找到。