
2007年1月5日
摘要: 做为程序员,从感性角度讲评一下7年里我使用过的9款机械键盘,确实更有特色,这种特殊的触听体验非常美妙!
阅读全文
posted @
2021-03-30 15:45 我爱佳娃 阅读(393) |
评论 (0) |
编辑 收藏
搬了个家,想通过A410点播imac上下载的电影,通过系统自带共享samba怎么都不成功。
想到是13年买的A410,应该升级一下,可官网都没了,最后搜索到这个16年的最新固件:
https://drivers.softpedia.com/get/DVD-BluRay-Media-Players/Cloud-Media/Cloud-Media-Popcorn-Hour-A-410-Media-Player-Firmware-050816061625POP425802.shtml通过USB顺利更新了一把。
再查看mac可以开nfs,方法如下:
sudo vi /etc/exports
加入:
/ -sec=sys
/Users /Users/popeye /Users/popeye/movies -ro -mapall=popeye:staff -alldirs
检查配置:
sudo nfsd checkexports
重启:
sudo nfsd restart
这里要注意movies目录是我重新建立的755权限,不要用系统原来的目录,不然总是访问不了。
再到A410里网络浏览里就能找到了。
posted @
2020-01-19 21:43 我爱佳娃 阅读(696) |
评论 (0) |
编辑 收藏
http://mathias-kettner.de/checkmk_livestatus.html下载并解压最新的包:
check_mk-1.2.1i3.tar.gz
再解压其中的到livestatus目录:
livestatus.tar.gz
进入:livestatus/src
再:make clean livestatus.o
会发现一堆错误,根据编译NDO的选项:
ndoutils-1.4b7/src:
make clean ndomod-3x.o
gcc -fno-common -g -O2 -DHAVE_CONFIG_H -D BUILD_NAGIOS_3X -o ndomod-3x.o ndomod.c io.o utils.o -bundle -flat_namespace -undefined suppress -lz
在最后的编译选项里添上:
-flat_namespace -undefined suppress -lz
就可以编译出:
livestatus.o
--------------------------
livecheck编不过,报找不到n_short:
ip_icmp.h:92: error: expected specifier-qualifier-list before ‘n_short’
vi ./check_icmp.c
把这个调整到INCLUDE序列的最后即可:
#include "/usr/include/netinet/ip_icmp.h"
posted @
2012-12-21 07:00 我爱佳娃 阅读(1550) |
评论 (0) |
编辑 收藏
摘要:
场景
想要用到的场景:用户访问WEB服务,WEB访问非WEB服务1,服务1又再访问2、3,合并计算后,把数据返回给WEB及前端用户。想让访问链上的所有服务都能得到认证和鉴权,认为本次请求确实是来自用户的。所以想到用CAS,让用户在一点登录,所有服务都到此处认证和鉴权。
阅读全文
posted @
2012-12-01 10:43 我爱佳娃 阅读(9798) |
评论 (3) |
编辑 收藏This tutorial will walk you through how to configure SSL (https://localhost:8443 access) on Tomcat in 5 minutes.

For this tutorial you will need:
- Java SDK (used version 6 for this tutorial)
- Tomcat (used version 7 for this tutorial)
The set up consists in 3 basic steps:
- Create a keystore file using Java
- Configure Tomcat to use the keystore
- Test it
- (Bonus ) Configure your app to work with SSL (access through https://localhost:8443/yourApp)
1 – Creating a Keystore file using Java
Fisrt, open the terminal on your computer and type:
Windows:
cd %JAVA_HOME%/bin
Linux or Mac OS:
cd $JAVA_HOME/bin
The $JAVA_HOME on Mac is located on “/System/Library/Frameworks/JavaVM.framework/Versions/{your java version}/Home/”
You will change the current directory to the directory Java is installed on your computer. Inside the Java Home directory, cd to the bin folder. Inside the bin folder there is a file named keytool. This guy is responsible for generating the keystore file for us.
Next, type on the terminal:
keytool -genkey -alias tomcat -keyalg RSA
When you type the command above, it will ask you some questions. First, it will ask you to create a password (My password is “password“):
loiane:bin loiane$ keytool -genkey -alias tomcat -keyalg RSA Enter keystore password: password Re-enter new password: password What is your first and last name? [Unknown]: Loiane Groner What is the name of your organizational unit? [Unknown]: home What is the name of your organization? [Unknown]: home What is the name of your City or Locality? [Unknown]: Sao Paulo What is the name of your State or Province? [Unknown]: SP What is the two-letter country code for this unit? [Unknown]: BR Is CN=Loiane Groner, OU=home, O=home, L=Sao Paulo, ST=SP, C=BR correct? [no]: yes Enter key password for (RETURN if same as keystore password): password Re-enter new password: password
It will create a .keystore file on your user home directory. On Windows, it will be on: C:\Documents and Settings\[username]; on Mac it will be on /Users/[username] and on Linux will be on /home/[username].
2 – Configuring Tomcat for using the keystore file – SSL config
Open your Tomcat installation directory and open the conf folder. Inside this folder, you will find the server.xml file. Open it.
Find the following declaration:
<!-- <Connector port="8443" protocol="HTTP/1.1" SSLEnabled="true" maxThreads="150" scheme="https" secure="true" clientAuth="false" sslProtocol="TLS" /> -->
Uncomment it and modify it to look like the following:
Connector SSLEnabled="true" acceptCount="100" clientAuth="false" disableUploadTimeout="true" enableLookups="false" maxThreads="25" port="8443" keystoreFile="/Users/loiane/.keystore" keystorePass="password" protocol="org.apache.coyote.http11.Http11NioProtocol" scheme="https" secure="true" sslProtocol="TLS" />
Note we add the keystoreFile, keystorePass and changed the protocol declarations.
3 – Let’s test it!
Start tomcat service and try to access https://localhost:8443. You will see Tomcat’s local home page.
Note if you try to access the default 8080 port it will be working too: http://localhost:8080
4 – BONUS - Configuring your app to work with SSL (access through https://localhost:8443/yourApp)
To force your web application to work with SSL, you simply need to add the following code to your web.xml file (before web-app tag ends):
<security-constraint> <web-resource-collection> <web-resource-name>securedapp</web-resource-name> <url-pattern>/*</url-pattern> </web-resource-collection> <user-data-constraint> <transport-guarantee>CONFIDENTIAL</transport-guarantee> </user-data-constraint> </security-constraint>
The url pattern is set to /* so any page/resource from your application is secure (it can be only accessed with https). The transport-guarantee tag is set to CONFIDENTIAL to make sure your app will work on SSL.
If you want to turn off the SSL, you don’t need to delete the code above from web.xml, simply changeCONFIDENTIAL to NONE.
Reference: http://tomcat.apache.org/tomcat-7.0-doc/ssl-howto.html (this tutorial is a little confusing, that is why I decided to write another one my own).
Happy Coding!
posted @
2012-11-12 23:17 我爱佳娃 阅读(3174) |
评论 (0) |
编辑 收藏
EXTJS和D3都很强大,不解释了,把D3绘的图直接放到一个EXT的TAB里,直接上图上代码:

代码中的D3例子来自:
https://github.com/mbostock/d3/wiki/Force-Layout
可用于绘制拓扑结构图.
Ext.define('EB.view.content.SingleView', {
extend : 'Ext.panel.Panel',
alias : 'widget.singleview',
layout : 'fit',
title : 'single view',
initComponent : function() {
this.callParent(arguments);
},
onRender : function() {
var me = this;
me.doc = Ext.getDoc();
me.callParent(arguments);
me.drawMap();
},
drawMap : function() {
var width = 960, height = 500
var target = d3.select("#" + this.id+"-body");
var svg = target.append("svg").attr("width", width).attr("height",
height);
var force = d3.layout.force().gravity(.05).distance(100).charge(-100)
.size([width, height]);
// get from: https://github.com/mbostock/d3/wiki/Force-Layout
// example: force-directed images and labels
d3.json("graph.json", function(json) {
force.nodes(json.nodes).links(json.links).start();
var link = svg.selectAll(".link").data(json.links).enter()
.append("line").attr("class", "link");
var node = svg.selectAll(".node").data(json.nodes).enter()
.append("g").attr("class", "node").call(force.drag);
node.append("image").attr("xlink:href",
"https://github.com/favicon.ico").attr("x", -8).attr("y",
-8).attr("width", 16).attr("height", 16);
node.append("text").attr("dx", 12).attr("dy", ".35em").text(
function(d) {
return d.name
});
force.on("tick", function() {
link.attr("x1", function(d) {
return d.source.x;
}).attr("y1", function(d) {
return d.source.y;
}).attr("x2", function(d) {
return d.target.x;
}).attr("y2", function(d) {
return d.target.y;
});
node.attr("transform", function(d) {
return "translate(" + d.x + "," + d.y + ")";
});
});
});
}
});
posted @
2012-09-27 07:38 我爱佳娃 阅读(4471) |
评论 (0) |
编辑 收藏
到这里下载最新PKG:
http://www.mysql.com/downloads/
下来后先装:mysql-5.5.27-osx10.6-x86_64.pkg
它是装到/usr/local/mysql,到此目录运行下:
./scripts/mysql_install_db --user mysql
通过这个启动:
./bin/mysqld_safe
排错:
看下上面的LOG提示.
Can't find file: './mysql/host.frm' :一般是没权限,把DATA目录删除,再用上面命令建一次
unknow option:把/etc/my.cnf删除掉,里面有新版本不认识的上一版本遗留配置
说mysql.sock找不到,这个版本是在/tmp/目录下哦!
再把剩下两个包装了,就可以通过配置面板启动了:
MySQL.prefPane
MySQLStartupItem.pkg
下次升级可能要给下/usr/local/mysql/data目录的权限posted @
2012-08-05 16:43 我爱佳娃 阅读(2634) |
评论 (0) |
编辑 收藏
摘要: 非常浅显易懂的PERL编码说明.
一目了然PERL编码,注意是转的
阅读全文
posted @
2011-10-09 08:04 我爱佳娃 阅读(3218) |
评论 (0) |
编辑 收藏下面以MAC为例,如果是LINUX需要把DYLD发为LD
把下面代码加到代码开头,它就可以自启动了,不需要再EXPORT或者-I
BEGIN {
#需要加到LOADPATH的路径
my $need = '/usr/local/nagios/pkg/ebase/';
push @INC, $need;
if ( $^O !~ /MSWin32/ ) {
my $ld = $ENV{DYLD_LIBRARY_PATH};
if ( !$ld ) {
$ENV{DYLD_LIBRARY_PATH} = $need;
}
elsif ( $ld !~ m#(^|:)\Q$need\E(:|$)# ) {
$ENV{DYLD_LIBRARY_PATH} .= ':' . $need;
}
else {
$need = "";
}
if ($need) {
exec 'env', $^X, $0, @ARGV;
}
}
}
@import url(http://www.blogjava.net/CuteSoft_Client/CuteEditor/Load.ashx?type=style&file=SyntaxHighlighter.css);@import url(/css/cuteeditor.css);
posted @
2011-10-03 21:37 我爱佳娃 阅读(1760) |
评论 (0) |
编辑 收藏限制用户在自己目录下载文件:
建立nagiosdnld
指向软链接:/usr/local/nagios/dnld -> /Users/nagiosdnld/dnld
编辑/etc/sshd_config
Match User nagiosdnld
X11Forwarding no
AllowTcpForwarding no
ForceCommand internal-sftp
ChrootDirectory /Users/nagiosdnld
重启下服务:
launchctl stop org.openbsd.ssh-agent
launchctl start org.openbsd.ssh-agent
@import url(http://www.blogjava.net/CuteSoft_Client/CuteEditor/Load.ashx?type=style&file=SyntaxHighlighter.css);@import url(/css/cuteeditor.css);
posted @
2011-10-03 03:15 我爱佳娃 阅读(1805) |
评论 (0) |
编辑 收藏
摘要: iostat 输出解析
1. /proc/partitions
对于kernel 2.4, iostat 的数据的主要来源是 /proc/partitions,而对于kernel 2.6, 数据主要来自/proc/diskstats或者/sys/block/[block-device-name]/stat。
先看看 /proc/partitions 中有些什么。
# cat /proc/partitions
major minor #blocks name rio rmerge rsect ruse wio wmerge wsect wuse running use aveq
阅读全文
posted @
2011-09-17 11:37 我爱佳娃 阅读(1643) |
评论 (0) |
编辑 收藏
@import url(http://www.blogjava.net/CuteSoft_Client/CuteEditor/Load.ashx?type=style&file=SyntaxHighlighter.css);@import url(/css/cuteeditor.css);
@import url(http://www.blogjava.net/CuteSoft_Client/CuteEditor/Load.ashx?type=style&file=SyntaxHighlighter.css);@import url(/css/cuteeditor.css);
编译:
修改Makefile.PL:
$archname="universal64-macosx";
去除生成的makefile中所有-arch i386 -Werror
make all
最后把所有可执行文件拷到同一目录,再用
export DYLD_LIBRARY_PATH=/tmp/test
即可直接运行:
eb:tmp$ ls ./test/
Sigar.bundle cpu_info.pl
Sigar.pm libsigar-universal64-macosx.dylib
eb:tmp popeyecai$ perl -I./test ./test/cpu_info.pl
2 total CPUs..
Vendor........Intel
Model.........Macmini4,1
Mhz...........2660
Cache size....3072
Vendor........Intel
Model.........Macmini4,1
Mhz...........2660
Cache size....3072
posted @
2011-09-10 10:45 我爱佳娃 阅读(850) |
评论 (0) |
编辑 收藏
摘要: Stl 删除元素注意事项 STL中的容器按存储方式分为两类,一类是按以数组形式存储的容器(如:vector 、deque);另一类是以不连续的节点形式存储的容器(如:list、set、map)。在使用erase方法来删除元素时,需要注意一些问题。 在使用 list、set 或 m...
阅读全文
posted @
2011-07-18 17:02 我爱佳娃 阅读(1484) |
评论 (0) |
编辑 收藏目的:
限制用户在特定目录(不能看到上级或者根目录)
只能执行scp或者sftp拷贝特别目录下的文件
不能SSH登陆,其它命令不能执行
机制:
SSH登陆成功后,scponly会接管SHELL,并CHROOT到特别目录,让用户“以为”这个目录就是根目录
它只会响应SFTP和SCP命令
只影响配置SHELL为SCPONLY的用户,其它用户不受影响
MAC下安装:
LINUX下安装SCPONLY非常简单,不多说,特说下MAC的
GOOGLE一下scponly,下载解压后编译安装:
./configure --enable-chrooted-binary --enable-rsync-compat --enable-scp-compat --enable-sftp-logging-compat --with-sftp-server=/usr/libexec/sftp-server
make clean all
sudo make install
会安装好:/usr/local/sbin/scponlyc
用workgroup manager建立下载用户,比方说是dnld,并配置其login shell到上述路径
因为CHROOT后执行的命令都以用户目录/Users/dnld做为根目录,所以要把scponly用到的scp和sftp-server两个可执行文件和信赖库拷到其下。以ROOT用户登录,且CD至/Users/dnld,执行以下脚本就会把这件事做好:
perl ./printlib.pl /usr/bin/scp
perl ./printlib.pl /usr/libexec/sftp-server
我写的脚本源码,自动搜索信赖关系,并在当前目录建立目录结构:
#!/bin/perl
%result=();
$result{$ARGV[0]}=1;
sub addlib{
@a = `otool -L \"$_[0]\"`;
#print @a;
for $i (@a){
if ($i =~/\s*([a-z|A-Z|\.|0-9|\/|\+|\-]*)\s*/){
#print "$1\n";
$result{$1}=1;
}
}
}
$before = 1;
$after = 0;
while ($before != $after){
$before = scalar keys %result;
for $i (keys %result){
addlib($i);
}
$after = scalar keys %result;
print "before $before, after $after\n";
}
for $i (keys %result){
#print "$i\n";
if ($i =~ /(.*)\/([~\/]*)/){
system ("mkdir -p \.$1");
system ("cp $i \.$1/");
}
}
调试:
加大LOG级别:
cat 7 /usr/local/scponly/etc/scponly/debuglevel
从其它机器或者本机用dnld用户来拷贝文件,看登陆LOG:
tail -f /var/log/*
dstruss类似strace来看进程在做什么
直接到SCPONLY里加LOG,这个最直接了。
posted @
2011-07-13 02:25 我爱佳娃 阅读(784) |
评论 (0) |
编辑 收藏
brew install openssl安装完SSL库后,
Update the configure file for Mac OS X compatibility
- vim ./configure
- on line 6673 change the text to read
- if test -f “$dir/libssl.dylib”; then
这个是用BREW装的SSL,貌似MAC下是64位的,这个还用不了:
./configure --enable-command-args --with-ssl-inc=/usr/local/Cellar/openssl/0.9.8r/include --with-ssl-lib=/usr/local/Cellar/openssl/0.9.8r/lib
只能用MAC自带的成功了:
./configure --enable-command-args --with-ssl-inc=/Developer/SDKs/MacOSX10.6.sdk/usr/inclue/openssl --with-ssl-lib=/Developer/SDKs/MacOSX10.6.sdk/usr/lib
posted @
2011-06-03 21:29 我爱佳娃 阅读(387) |
评论 (0) |
编辑 收藏创建如下文件和内容:/etc/yum.repos.d/dag.repo
运行:yum install rrdtool
[dag]
name=Dag RPM Repository for Red Hat Enterprise Linux
baseurl=http://apt.sw.be/redhat/el$releasever/en/$basearch/dag
gpgcheck=1
gpgkey=http://dag.wieers.com/rpm/packages/RPM-GPG-KEY.dag.txt
enabled=1
posted @
2011-02-03 21:38 我爱佳娃 阅读(1615) |
评论 (2) |
编辑 收藏要SSH和系统两边都配置对才行,其实也很简单:
用命令:
dpkg-reconfigure locales
进去后只选择zh_CN.UTF-8,并设置成默认字符集。
再到/root/.bashrc里加上:
export LC_ALL=zh_CN.UTF-8
SSH客户端使用UTF-8字符集,如SECURECRT就在SESSION
OPTIONS->APPERANCE->CHARACTER ENCODING里选择UTF-8
posted @
2010-05-08 09:58 我爱佳娃 阅读(1462) |
评论 (0) |
编辑 收藏
一、设置YUM源
cd /etc/yum.repos.d/
wget http://centos.ustc.edu.cn/CentOS-Base.repo.5
mv CentOS-Base.repo.5 CentOS-Base.repo
因为默认的配置文件中服务器地址用的版本号是变量$releasever,所以需要将其替换为实际的版本号,否则是无法连接到服务器的,当前CentOS
最新版是5.3,所以我们修改CentOS-Base.repo
vi CentOS-Base.repo
在vi编辑器中进行全文件替换
:%s/$releasever/5.3/
二、安装
1:安装apache
yum install httpd httpd-devel
2:安装mysql
yum install mysql mysql-server mysql-devel
3:安装php
yum install php php-mysql php-common php-gd php-mbstring php-mcrypt php-devel php-xml
4:启动apache
测试php
建立以下文件/var/www/html/test.php
编辑其内容
// test.php
<?php
phpinfo();
?>
5:测试
在浏览器中输入:http://IP/test.php
看是否显示PHP的信息
6:设置开机启动
chkconfig httpd on
posted @
2010-04-20 09:56 我爱佳娃 阅读(2244) |
评论 (0) |
编辑 收藏
安装SAMBA后,配置下面SHARE:
[popeye]
path = /
valid users = root
read only = no
public = yes
writable = yes
发现可以浏览目录,但不可写,查了下是SELINUX在作怪,把它禁用即可:
先实时停止它:
setenforce 0
改配置:
vi /etc/sysconfig/selinux
修改成:
SELINUX=disabled
posted @
2010-04-07 14:36 我爱佳娃 阅读(2302) |
评论 (0) |
编辑 收藏
摘要: 经过一段时间知识积累后,你可能想在自己的网站建立一个WIKI。WIKI有专用的格式和标记,习惯了用M$的WORD,在它们之间转换会相当痛苦。
这里介绍了从各种格式文档向WIKI转化的办法:点这里。
阅读全文
posted @
2010-03-27 12:15 我爱佳娃 阅读(5209) |
评论 (2) |
编辑 收藏
摘要: 讲了SED的用法,特别是换行c\命令,以及多行替换。
阅读全文
posted @
2009-09-01 10:12 我爱佳娃 阅读(3969) |
评论 (1) |
编辑 收藏有个帖子论证HIBERNATE在批量插入时性能下降,以及一些解决方式。
其核心在于批量插入时,积攒一定量后就写库,并清除SESSION里的第一级缓存,以免后续插入操作受缓存查找而影响效率:
if ( j % batchNum2 == 0 ) {//执行物理批量插入
session.flush();
session.clear();
}
基于JPA的事务操作,SESSION不可见,此时,需要直接调用EntityManager的flush和clear。
但EntityManager也是被封装入JpaDaoSupport,实际的EntityManager对象也不容易取得。
此时可以用其JpaTemplate成员的execute方法来实现这两个操作:
getJpaTemplate().execute(new JpaCallback() {
public Object doInJpa(EntityManager em) throws PersistenceException {
em.flush();
em.clear();
return null;
}
}, true);
在我这里测试结果:
没有定期调用以上方法时,插入50个记录要2秒,并且随着记录增多,时间越来越长。
每插入50个调用以上方法后,插入50个记录小于300毫秒,且不随记录个数线性增长。
posted @
2009-07-16 21:20 我爱佳娃 阅读(6709) |
评论 (0) |
编辑 收藏
Linux 运行的时候,是如何管理共享库(*.so)的?在 Linux 下面,共享库的寻找和加载是由 /lib/ld.so 实现的。 ld.so 在标准路经(/lib, /usr/lib) 中寻找应用程序用到的共享库。
但是,如果需要用到的共享库在非标准路经,ld.so 怎么找到它呢?
目前,Linux 通用的做法是将非标准路经加入 /etc/ld.so.conf,然后运行 ldconfig 生成 /etc/ld.so.cache。 ld.so 加载共享库的时候,会从 ld.so.cache 查找。
传统上, Linux 的先辈 Unix 还有一个环境变量 -
LD_LIBRARY_PATH 来处理非标准路经的共享库。ld.so 加载共享库的时候,也会查找这个变量所设置的路经。但是,有不少声音主张要避免使用
LD_LIBRARY_PATH 变量,尤其是作为全局变量。这些声音是:
*
LD_LIBRARY_PATH is not the answer -
http://prefetch.net/articles/linkers.badldlibrary.html
* Why
LD_LIBRARY_PATH is bad -
http://xahlee.org/UnixResource_dir/_/ldpath.html
*
LD_LIBRARY_PATH - just say no -
http://blogs.sun.com/rie/date/20040710
解决这一问题的另一方法是在编译的时候通过 -R<path> 选项指定 run-time path。
posted @
2009-06-11 09:52 我爱佳娃 阅读(831) |
评论 (0) |
编辑 收藏
摘要: 今天搞了一天,JAVA调用一个PERL程序,得不得就退不出,千试万试,LOG精细到逐行,知道在哪停住了,但打死不知道为什么。
后来吃个饭都放弃了,居然又找到答案,要没看到它,那真以为里面有鬼了。
阅读全文
posted @
2009-05-15 21:04 我爱佳娃 阅读(14239) |
评论 (4) |
编辑 收藏
如需要,设置PROXY:
export http_proxy=http://127.0.0.1:3128
启动,然后设置MIRROR,直接安装:
perl -MCPAN -e shell
cpan> o conf urllist set http://www.perl87.cn/CPAN/
cpan> install JSON
posted @
2009-05-12 16:31 我爱佳娃 阅读(1196) |
评论 (0) |
编辑 收藏方法1:采用String的split,验证代码如下:
import java.util.Arrays;
public class TestSplit {
public static void main(String[] args) {
String orignString = new String("5,8,7,4,3,9,1");
String[] testString = orignString.split(",");
int[] test = { 0, 0, 0, 0, 0, 0, 0 };
//String to int
for (int i = 0; i < testString.length; i++) {
test[i] = Integer.parseInt(testString[i]);
}
//sort
Arrays.sort(test);
//asc sort
for (int j = 0; j < test.length; j++) {
System.out.println(test[j]);
}
System.out.println("next ");
// desc
for (int i = (test.length - 1); i >= 0; i--) {
System.out.println(test[i]);
}
}
}
方法2:采用StringTokenizer
import java.util.Arrays;
import java.util.StringTokenizer;
public class SplitStringTest {
public static void main(String[] args) {
String s = new String("5,8,7,4,3,9,1");
int length = s.length();
//split s with ","
StringTokenizer commaToker = new StringTokenizer(s, ",");
String[] result = new String[commaToker.countTokens()];
int k = 0;
while (commaToker.hasMoreTokens()) {
result[k] = commaToker.nextToken();
k++;
}
int[] a = new int[result.length];
for (int i = 0; i < result.length; i++) {
a[i] = Integer.parseInt(result[i]);
}
//sort
Arrays.sort(a);
//asc sort
for (int j = 0; j < result.length; j++) {
System.out.println(a[j]);
}
}
}
posted @
2009-04-24 13:07 我爱佳娃 阅读(487) |
评论 (0) |
编辑 收藏
摘要: mysqldump 是采用SQL级别的备份机制,它将数据表导成 SQL 脚本文件,在不同的 MySQL 版本之间升级时相对比较合适,这也是最常用的备份方法。
阅读全文
posted @
2009-03-29 17:02 我爱佳娃 阅读(2524) |
评论 (0) |
编辑 收藏
摘要: 在EXT里如果定义类和扩展类
阅读全文
posted @
2009-03-03 15:57 我爱佳娃 阅读(1077) |
评论 (1) |
编辑 收藏
update user set password = password ('xxxx') where user = "root";
grant all privileges on *.* to root@'%' identified by 'xxxx';
其它参数的例子:
grant select,insert,update,delete,create,drop on vtdc.employee to joe@10.163.225.87 identified by '123';
给来自10.163.225.87的用户joe分配可对数据库vtdc的employee表进行select,insert,update,delete,create,drop等操作的权限,并设定口令为123。
要重启一次MYSQL才能使本地用户密码生效:
/usr/local/mysql/support-files/mysql.server restart
posted @
2009-02-12 14:31 我爱佳娃 阅读(1654) |
评论 (0) |
编辑 收藏
由于EXTJS是用XMLHTTP来LOAD的,所以在本地会看到一直LOADING的画面。应该把它放到一个WEB服务器上,以HTTPD为例:
编辑文件:
/etc/httpd/conf.d/extjs.conf
内容如下:
Alias /extjs "/point/to/real/dir/ext/"
<Directory "/point/to/real/dir/ext/">
Options Indexes
AllowOverride AuthConfig Options
Order allow,deny
Allow from all
</Directory>
重启httpd:
service httpd restart
这样访问http://hostip/extjs/docs/index.html就能在本地看EXTJS的文档了。
注,经下面同学回复,有不用架设服务器的办法,我搜了一下,供大家参考,本人未尝试:
http://www.blogjava.net/mengyuan760/archive/2008/04/21/194510.html
posted @
2009-02-05 11:52 我爱佳娃 阅读(2446) |
评论 (2) |
编辑 收藏
继这篇动物机搭建起来后:
自己DIY了一个低功耗基于ADSL的JAVA J2EE服务器
又有新功能加入:
摘要: 以前家里动物机长开着只是下载电影,公司封了淘宝和MSN,现在又可以用它从公司上网了。
可以使用如下模式上网:
APP <=> HTTP TUNNEL <=> SERVER
HTTP TUNNEL有一个客户端,它可以起一个SOCKS本地代理来接收APP数据,然后打包发送到运行在家里的HTTP TUNNEL服务端,由这个服务端程序通过ADSL出到公网即可。
阅读全文
posted @
2008-12-03 17:55 我爱佳娃 阅读(1820) |
评论 (0) |
编辑 收藏
摘要: 摘要:
本文从介绍基础概念入手,探讨了在C/C++中对日期和时间操作所用到的数据结构和函数,并对计时、时间的获取、时间的计算和显示格式等方面进行了阐述。本文还通过大量的实例向你展示了time.h头文件中声明的各种函数和数据结构的详细使用方法。
关键字:UTC(世界标准时间),Calendar Time(日历时间),epoch(时间点),clock tick(时钟计时单元)
阅读全文
posted @
2008-11-28 09:57 我爱佳娃 阅读(15629) |
评论 (0) |
编辑 收藏
摘要: 当ManyToMany或者ManyToOne定义时,JoinTable中referencedColumnName指向的是非主键(non PK columns),将 报ClassCastException。这里有个简单解决办法。
阅读全文
posted @
2008-10-27 17:30 我爱佳娃 阅读(4013) |
评论 (1) |
编辑 收藏
摘要: RRD插入值的计算方式
阅读全文
posted @
2008-09-17 21:15 我爱佳娃 阅读(762) |
评论 (0) |
编辑 收藏
摘要: linux通过ntlm上网/vmware的image管理/yum更新系统
阅读全文
posted @
2008-09-08 09:57 我爱佳娃 阅读(1600) |
评论 (0) |
编辑 收藏
Ways to include code/library from another file (eval, do, require
and use)
1) do $file is like eval `cat $file`, except the former:
1.1: searches @INC.
1.2: bequeaths an *unrelated* lexical scope on the eval'ed code.
2) require $file is like do $file, except the former:
2.1: checks for redundant loading, slipping already loaded files.
2.2: raises an exception on failure to find, compile, or execute $file.
3) require Module is like require "Module.pm", except the former:
3.1: translates each "::" into your system's directory separator.
3.2: primes the parser to disambiguate class Module as an indirect object.
4) use Module is like require Module, except the former:
4.1: loads the module at compile time, not run-time.
4.2: imports symbols and semantics from that package to the current one.
eval除了可以形成动态CODE外,还可以做异常捕捉:
eval {
...
};
if ($@) {
errorHandler($@);
}
$@在无异常时是NULL,否则是异常原因
posted @
2008-08-12 10:42 我爱佳娃 阅读(445) |
评论 (0) |
编辑 收藏
摘要: PERL开源打包程序PAR和PP(类似于商业程序的perl2exe/perlapp)
阅读全文
posted @
2008-08-11 21:13 我爱佳娃 阅读(598) |
评论 (0) |
编辑 收藏
摘要: 在多至上万台主机的系统中,集中定义配置,然后自动应用到所有主机。
阅读全文
posted @
2008-07-28 11:12 我爱佳娃 阅读(561) |
评论 (0) |
编辑 收藏如下图所示位置设置不扫描迅雷网络通信即可:
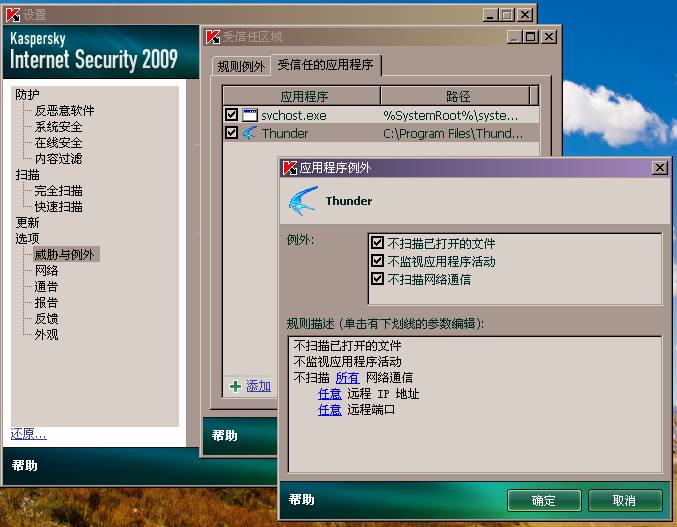
posted @
2008-06-28 08:11 我爱佳娃 阅读(3046) |
评论 (6) |
编辑 收藏
摘要: 相信很多人都有过这样的经验,改一个东西可能就几分钟,但找到在哪改、会影响到什么地方,却要花半小时。有了这个工具,让我们在非常大的项目里,在文件和代码的海洋里能马上找到所要关注的部分。有的人说,我有CTRL+SHIFT+T,可是你能记住几年前一个项目里的类名吗?而查阅文字描述的任务却要容易得多。
Mylyn的项目领队这样说道:这个新名字是向“髓磷脂”物质致敬,该物质通过使神经元更有效的传导电流来促进你的思考。我们已经听到使用者声称,Mylyn工具将他们的效率提高到了他们觉得正在以思考的速度编码的地步。减少阻碍我们生产力的UI摩擦就是Mylyn项目全部的内容。
此文是我之Mylyn初体验,不搞大而全,而只把我觉得这个工具最爽、最KILLER的功能介绍出来。
阅读全文
posted @
2008-06-15 13:02 我爱佳娃 阅读(45461) |
评论 (7) |
编辑 收藏
摘要: # Select location bar: Ctrl/Cmd+L or Alt+D
# Select search bar: Ctrl/Cmd+K
阅读全文
posted @
2008-06-02 12:56 我爱佳娃 阅读(1975) |
评论 (0) |
编辑 收藏
摘要: ECLIPSE的快捷键非常多,如果只挑3个,我就选择它们:
1
Alt + /
自动完成
2
Ctrl + O
Quick Outline:函数列表,可以定制这个窗口
3
Ctrl+K (加SHIFT是向上)
向下查找选中的字符串
阅读全文
posted @
2008-06-01 16:31 我爱佳娃 阅读(1475) |
评论 (0) |
编辑 收藏
摘要: FF是深受广大程序员喜爱,不是因为它的快,而是因为FIREBUG1.2版本(点这里)这个宇宙无敌插件,调试JS程序变成了一片小蛋糕。
最后,要说一下FF的几个小技巧
阅读全文
posted @
2008-05-30 13:43 我爱佳娃 阅读(3871) |
评论 (2) |
编辑 收藏
摘要: ASSERT是在调试与测试环境,让程序员和测试者及时发现运行时错误的极简极佳之方法。
它的语法因为简单所以美丽。
有的文章攻击ASSERT(点这里),是混淆了其使用目的的结果。
阅读全文
posted @
2008-05-30 11:54 我爱佳娃 阅读(2080) |
评论 (3) |
编辑 收藏命令行:
C:\Program Files\Rational\ClearCase\bin>clearfsimport -recurse -nsetevent d:\temp\cli D:\prj\pcrf\PCFFACN\web\
SNAPVIEW时,要把需加入的文件放到一临时目录,不能直接在SNAPVIEW对应的目录加入。
另外,要把需要加入的目录先行加入到CC,如上面的cli目录
posted @
2008-05-26 18:10 我爱佳娃 阅读(553) |
评论 (0) |
编辑 收藏
摘要: 回调函数是相当有用,它的意义不仅可以让调用者控制调用函数的执行,还可以有效的将“算法”与“数据”分离,将涉及数据的部分放入回调接口(inner class)中,算法就会相对独立。下面是一个示例。
阅读全文
posted @
2008-05-16 19:19 我爱佳娃 阅读(2644) |
评论 (3) |
编辑 收藏
摘要: 平时编程中经常遇到将多项内容放入字串,然后再一一解析出来的情况,常常是这样的字串操作不胜其烦。
我们可以使用JSON这一标准格式来组织内容到字符串,然后现成的类库来进行解析,准确而清晰。
阅读全文
posted @
2008-05-10 12:15 我爱佳娃 阅读(7108) |
评论 (4) |
编辑 收藏
摘要: 描述在WEB浏览器端的代码架构,主要讲得是有哪些功能点,JS代码结构如何划分。
阅读全文
posted @
2008-03-09 16:52 我爱佳娃 阅读(1607) |
评论 (0) |
编辑 收藏
摘要: 当我们写好SERVICE层的MANAGER方法后,就已经完成业务逻辑,可以用DWR从BROWSER直接调用,不必要再写一个“缓冲层”,这样的好处是避免了今后对SERVICE层的多处同时改动。
阅读全文
posted @
2008-03-03 20:59 我爱佳娃 阅读(4772) |
评论 (1) |
编辑 收藏
摘要: 有时候,在SPRING中两个类互相含有对方的声明,一般情况这是不允许并且极可能是有错误的。
但有时候这正是我们想要的,考虑这种情况:
阅读全文
posted @
2008-02-24 10:13 我爱佳娃 阅读(38406) |
评论 (11) |
编辑 收藏
摘要: ACTIVEPERL在LINUX下的安装以及PERL2EXE的使用
阅读全文
posted @
2008-02-20 12:40 我爱佳娃 阅读(3127) |
评论 (0) |
编辑 收藏
摘要:
阅读全文
posted @
2008-02-03 15:06 我爱佳娃 阅读(530) |
评论 (0) |
编辑 收藏
摘要: JPA标准+HIBERNATE实现+SPINRG揉和
搭建MAVEN2的内网服务器:设置一个目录在WEB服务上可以访问
MYSQL可以被外部机器连接
cannot connect to VM错误
阅读全文
posted @
2008-01-28 23:08 我爱佳娃 阅读(6414) |
评论 (1) |
编辑 收藏
摘要: “编程的核心是数据结构,而不是算法”,“编程的本质是控制复杂度”,“过早的优化是万恶之源”,“宁花机器一分,不花程序员一秒”。这些UNIX的设计哲学,非常值得体味。
阅读全文
posted @
2007-12-05 17:52 我爱佳娃 阅读(3991) |
评论 (12) |
编辑 收藏
摘要: 用PERL编写SOAP服务是相当方便的,但是如果用其它语言来访问它,却不容易,下面介绍一种不需要WSDL描述就能访问它的方法。
阅读全文
posted @
2007-12-05 12:00 我爱佳娃 阅读(3094) |
评论 (0) |
编辑 收藏
摘要: 设计不在乎一开始就非常完备,并且考虑到所有情况和变化;设计的精髓在于当某种变化来临时,能够重新审视,甚至是调整全部的设计,让它能够兼容之后的“同种类”变化,从而使今后再有这样的变化时,带来最少量改动。为此目的,哪怕是推翻重来也在所不惜......
阅读全文
posted @
2007-12-02 17:35 我爱佳娃 阅读(2237) |
评论 (9) |
编辑 收藏
摘要: 事情开始想的简单,可开始做发现没那么容易。本文描述配置LINGO+SPRING+ACTIVEMQ的曲折过程,希望看过的人不要再犯相同错误。
阅读全文
posted @
2007-11-24 15:29 我爱佳娃 阅读(4034) |
评论 (0) |
编辑 收藏
摘要: 目前网络上大多是PHP或者ASP的空间,如果自己想搭建一个基于JAVA的WEB服务器或者自己调试J2EE的服务都不方便。另一方面,大家现在基本上家里都是包月的ADSL,它的上行带宽有512K,足够搭建一个自己WEB服务器了。不妨参考下我最近DIY的一台功耗不足40W的动物机:BT,电驴,路由器,防火墙,WEB服务器,SUBVERSION代码服务器,APACHE,MYSQL一个都不少!全部配下来RMB1100。
阅读全文
posted @
2007-11-19 21:47 我爱佳娃 阅读(4200) |
评论 (8) |
编辑 收藏(转)
设我们有一台计算机,有两块网卡,eth0连外网,ip为1.2.3.4;eth1连内网,ip为192.168.0.1.现在需要把发往地址1.2.3.4的81端口的ip包转发到ip地址192.168.0.2的8180端口,设置如下:
1. iptables -t nat -A PREROUTING -d 1.2.3.4 -p tcp -m tcp --dport 81 -j DNAT --to-destination192.168.0.2:8180
2. iptables -t nat -A POSTROUTING -s 192.168.0.0/255.255.0.0 -d 192.168.0.2 -p tcp -m tcp --dport 8180 -j SNAT --to-source 192.168.0.1
真实的传输过程如下所示:
假设某客户机的ip地址为6.7.8.9,它使用本机的1080端口连接1.2.3.4的81端口,发出的ip包源地址为6.7.8.9,源端口为1080,目的地址为1.2.3.4,目的端口为81.
主机1.2.3.4接收到这个包后,根据nat表的第一条规则,将该ip包的目的地址更该为192.168.0.2,目的端口更该为8180,同时在连接跟踪表中创建一个条目,(可从/proc/net/ip_conntrack文件中看到),然后发送到路由模块,通过查路由表,确定该ip包应发送到eth1接口.在向eth1接口发送该ip包之前,根据nat表的第二条规则,如果该ip包来自同一子网,则将该ip包的源地址更该为192.168.0.1,同时更新该连接跟踪表中的相应条目,然后送到eth1接口发出.
此时连接跟踪表中有一项:
连接进入: src=6.7.8.9 dst=1.2.3.4 sport=1080 dport=81
连接返回: src=192.168.0.2 dst=6.7.8.9 sport=8180 dport=1080
是否使用: use=1
而从192.168.0.2发回的ip包,源端口为8180,目的地址为6.7.8.9,目的端口为1080,主机1.2.3.4的TCP/IP栈接收到该ip包后,由核心查找连接跟踪表中的连接返回栏目中是否有同样源和目的地址和端口的匹配项,找到后,根据条目中的记录将ip包的源地址由192.168.0.2更该为1.2.3.4, 源端口由8180更该为81,保持目的端口号1080不变.这样服务器的返回包就可以正确的返回发起连接的客户机,通讯就这样开始.
还有一点, 在filter表中还应该允许从eth0连接192.168.0.2地址的8180端口:
iptables -A INPUT -d 192.168.0.2 -p tcp -m tcp --dport 8180 -i eth0 -j ACCEPT
posted @
2007-11-18 18:54 我爱佳娃 阅读(7446) |
评论 (0) |
编辑 收藏
摘要:
阅读全文
posted @
2007-11-18 12:20 我爱佳娃 阅读(1203) |
评论 (0) |
编辑 收藏
摘要:
阅读全文
posted @
2007-11-18 12:19 我爱佳娃 阅读(2936) |
评论 (1) |
编辑 收藏udev是devfs的替代品,可以动态管理/dev下的设备,主要作用是根据硬件的信息(match条件),将它建立到分配(assign语句)到/dev相应的名字下。
这篇文章相当不错,易懂:
http://www.reactivated.net/writing_udev_rules.html
posted @
2007-11-14 14:45 我爱佳娃 阅读(911) |
评论 (0) |
编辑 收藏
摘要: 网上材料大多比较复杂,本文是简洁明了的快餐式文章。分安装部分和使用部分。
安装部分对SUBVERSION做为SSL访问方式配置做了详细说明,使用部分对实际使用时最常用的模式做了说明。
阅读全文
posted @
2007-11-13 13:04 我爱佳娃 阅读(1876) |
评论 (0) |
编辑 收藏<bean id="nodeSvcImpl" class="com.exchangebit.nms.magic.NodeSvcImpl">
<property name="notifyClient" ref="notifyClient"/>
</bean>
<jaxws:endpoint
id="nodeSvc"
implementor="#nodeSvcImpl"
address="/NodeSvc">
</jaxws:endpoint>
posted @
2007-11-01 17:38 我爱佳娃 阅读(4992) |
评论 (0) |
编辑 收藏
摘要: Reverse Ajax主要是在BS架构中,从服务器端向多个浏览器主动推数据的一种技术。应用范围广泛。
本文就DWR使用中,代码组织、声明做了说明。并解决了在非DWR线程中,WebContextFactory.get()返回空的问题。
阅读全文
posted @
2007-11-01 17:35 我爱佳娃 阅读(5224) |
评论 (3) |
编辑 收藏今天在WINDOWS下用SOCKET时发现如下错误:(LINUX下正常)
Your vendor has not defined Fcntl macro F_GETFL, used at :/Perl/site/lib/IO/Multiplex.pm line 932.
只需要替换Multiplex.pm line 932处函数nonblock:
sub nonblock
{
my $fh = shift;
my $flags = fcntl($fh, F_GETFL, 0)
or die "fcntl F_GETFL: $!\n"
fcntl($fh, F_SETFL, $flags | O_NONBLOCK)
or die "fcntl F_SETFL $!\n"
}
替换为:
use constant WIN32 => $^O =~ /win32/i;
sub nonblock {
my $sock = shift;
if (WIN32) {
my $set_it = "1"
ioctl( $sock, 0x80000000 | (4 << 16) | (ord('f') << 8) | 126, $set_it) || return 0;
} else {
fcntl($sock, F_SETFL, fcntl($sock, F_GETFL, 0) | O_NONBLOCK) || return 0;
}
}
即可。
posted @
2007-10-31 20:40 我爱佳娃 阅读(1183) |
评论 (0) |
编辑 收藏
摘要: SOAP中不支持HashMap,但可以通过定义XmlAdapter适配器将数组转换成HashMap的方式来支持。本文通过完整例子来说明。
有了转换器这个工具,我们可以在SOAP的JAXB绑定里支持各种JAVA的COLLECTION类型,以及自定义类型,打破了SOAP原始支持类型的限制。
阅读全文
posted @
2007-10-29 16:41 我爱佳娃 阅读(7223) |
评论 (5) |
编辑 收藏我一个JSP页面,在IE6下死活分隔条没有响应,在FF下没问题,左找右找,才发现是开头的一句:
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01//EN" "http://www.w3.org/TR/html4/strict.dtd">
把我害惨了!
posted @
2007-10-26 22:16 我爱佳娃 阅读(888) |
评论 (0) |
编辑 收藏
在Eclipse的Software Updates/Find and Install…中点New Remote Site…填入:
http://download.macromedia.com/pub/labs/jseclipse/autoinstall/
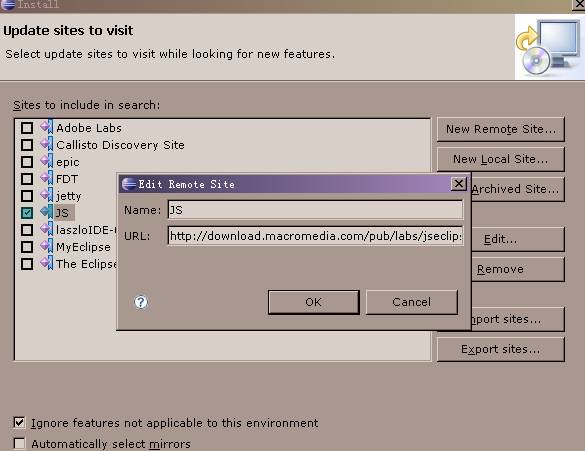
安装JSEclipse完成后。
如果你用EXT库的话,再把完整的库,点这里
拷贝到这里,注意user_library需要自己创建,另外,是不要带解压目录,而是所有的XML文件直接拷入:
E:\myeclipse\workspace\.metadata\.plugins\com.interaktonline.jseclipse\user_library
posted @
2007-09-13 21:14 我爱佳娃 阅读(11335) |
评论 (6) |
编辑 收藏
摘要: 之前文章提到过用MAVEN2启动JETTY,这里介绍一种直接从ECLIPSE中启动的办法。
适用于6.1.3以上,包括6.1.5的JETTY。
它主要是利用了JDK的代码自动更换性能(code hot replace),可以不用重启JETTY就调试、更换资源文件。注意:一定是DEBUG方式运行才有这项功能。
所以应该说这篇文章的方法更好:
在Run->Debug中,N...
阅读全文
posted @
2007-09-13 21:04 我爱佳娃 阅读(19648) |
评论 (8) |
编辑 收藏
摘要: 本文说明了 Linux 系统的配置文件,在多用户、多任务环境中,配置文件控制用户权限、系统应用程序、守护进程、服务和其它管理任务。这些任务包括管理用户帐号、分配磁盘配额、管理电子邮件和新闻组,以及配置内核参数。本文还根据配置文件的使用和其所影响的服务的情况对目前 Red Hat Linux 系统中的配置文件进行了分类。
阅读全文
posted @
2007-09-10 18:24 我爱佳娃 阅读(439) |
评论 (0) |
编辑 收藏

posted @
2007-09-10 17:54 我爱佳娃 阅读(507) |
评论 (0) |
编辑 收藏今天被SWFObject困扰一天,发现:
- SWFObject通过本地HTML用不成功,必须通过WEB在线方式取。
- 直接用ADOBE的OBJECT标签都可以。但是如果一旦加入EXT-YUI的使用,在IE下不行,FF可以。所以还是用SWFObject稳妥些。
- 就算是在线取,如果在嵌套IE的浏览工具里(如TT)也会不成功,FF没有问题。
- 用SWFObject时还要注意,如果要访问FLASH的函数,输出完FLASH后,并不能马上取得指针使用,而要在其它函数中使用,比如:通过某个按钮事件激发。
也就是,把这部分放在初始化中:
var so = new SWFObject(format_path ("swf/hehe.swf"), "mytopo", "800", "600", "8", "#FFFFFFFF");
so.write("flashcontent");
this._topo = thisMovie("mytopo");
使用的语句放在另一处:
_topo.setBK(format_path ("images/pic3.jpg"));
归根结底,FLASH函数调用的调试,目前实验成功的:一是要用SWF,二是要在线调试。
posted @
2007-09-08 22:02 我爱佳娃 阅读(888) |
评论 (0) |
编辑 收藏
在
上一篇文章中的问题,今天又再试了下,居然解决了,看来把遇到问题放一放是有好处的。
第一,是要用对CXF的库,在一行代码未变的情况下,只要使用最新的库。看来在最新库里解决了数组问题:
2.1-incubator-SNAPSHOT
就没问题,如果是用:
2.0-incubator
就会出现上篇文章的情况。我使用MAVEN2,就写成:
 <!--for cxf-->
<!--for cxf-->
<dependency>
<groupId>org.apache.cxf</groupId>
<artifactId>cxf-rt-frontend-jaxws</artifactId>
<version>2.1-incubator-SNAPSHOT</version>
<!-- version>2.0-incubator</version-->
</dependency>
<dependency>
<groupId>org.apache.cxf</groupId>
<artifactId>cxf-rt-transports-http</artifactId>
<version>2.1-incubator-SNAPSHOT</version>
</dependency>
<dependency>
<groupId>org.apache.cxf</groupId>
<artifactId>cxf-rt-databinding-aegis</artifactId>
<version>2.1-incubator-SNAPSHOT</version>
</dependency>第二,对SOAP::Lite的改变,SOAP::Lite不支持doc/literal,但通过阅读
"NET-based Web Service Using the SOAP::Lite Perl Library".
我的上篇文章有链接,我写的PERL程序在某些情况下依然不行。
这次再加了两处改动后就可以了:(注意:CXF里不要使用aegisDatabinding,用默认的即可)
my $soap = SOAP::Lite
-> uri('http://magic.nms.exchangebit.com/')
-> on_action( sub{ join '/', 'http://www.alfredbr.com', $_[1] })
-> proxy('http://127.0.0.1:8080/ebnms/NotifyService')
->autotype(0);
其中的autotype(0)非常重要。另外一处改动是,程序中的根变量名改成"arg0",即与WSDL中定义一致。
实验发现,带不带attr中的xmlns都可以。完整代码如下:
use SOAP::Lite ( +trace => all, maptype => {} );
my $soap = SOAP::Lite
-> uri('http://magic.nms.exchangebit.com/')
-> on_action( sub{ join '/', 'http://www.alfredbr.com', $_[1] })
-> proxy('http://127.0.0.1:8080/ebnms/NotifyService')
->autotype(0);
#$soap->sendAlarmString ("good");
#$soap->sendAlarm (SOAP::Data->name(arg0=>{devName=>"hehe", devIp=>"ip1"}));
{# call send alarm
my @params = (
# $header,
SOAP::Data->name(arg0 => goodhehe)
);
my $method = SOAP::Data->name('ns1:sendAlarmString')
->attr({"xmlns:ns1" => 'http://magic.nms.exchangebit.com/'});
my $result = $soap->call($method => @params);
print "\nsend string alarm result:\n";
if ($result->fault)
{
print $result->faultstring;
}
else
{
print $result->result;
}
print "\nn";
}
{# call send dev alarm
my @params = (SOAP::Data->name(arg0=>{devName=>"hehe", devIp=>"ip1"}));
my $method = SOAP::Data->name('sendAlarm');
# ->attr({"xmlns:ns1" => 'http://magic.nms.exchangebit.com/'});
my $result = $soap->call($method => @params);
print "\nsend string alarm result:\n";
if ($result->fault)
{
print $result->faultstring;
}
else
{
print $result->result;
}
print "\n\n";
}
{# call send arr alarm
my @params = (
SOAP::Data->name(arg0 => [
{devName=>"hehe1", devIp=>"ip1"},
{devName=>"hehe1", devIp=>"ip1"},
{devName=>"hehe1", devIp=>"ip1"},
{devName=>"hehe1", devIp=>"ip1"},
{devName=>"hehe1", devIp=>"ip1"},
{devName=>"hehe1", devIp=>"ip1"},
{devName=>"hehe1", devIp=>"ip1"},
{devName=>"hehe1", devIp=>"ip1"},
{devName=>"hehe1", devIp=>"ip1"},
{devName=>"hehe1", devIp=>"ip1"},
{devName=>"hehe2", devIp=>"ip2"}])
);
my $method = SOAP::Data->name('sendAlarmArr');
my $result = $soap->call($method => @params);
print "\nsend string alarm result:\n";
if ($result->fault)
{
print $result->faultstring;
}
else
{
my @a = @{$result->result->{item}};
foreach $i (@a) {
print "ele: $i->{devName}, $i->{devIp}\n";
}
}
print "\n\n";
}
posted @
2007-08-23 14:13 我爱佳娃 阅读(1436) |
评论 (1) |
编辑 收藏
摘要: 最近需要一个能根据请求数变化的线程池,JAVA有这样的东西,可是C++下好像一般只是固定大小的线程池。所以就基于ACE写了个,只做了初步测试。
主要思想是:1. 重载ACE_Task,这相当于是个固定线程池,用一个信号量(ACE_Thread_Semaphore)来记数空闲线程数。2. 初始化时根据用户的输入,确定最少线程数minnum和最大线程数maxnum,当多个请求到来,并且无空闲线程(信...
阅读全文
posted @
2007-08-14 17:56 我爱佳娃 阅读(6080) |
评论 (4) |
编辑 收藏编译指南:
http://support.hyperic.com/confluence/display/DOCSHQ30/Build+Instructions
直接按照这个走,设置一些变量:
JBOSS_HOME=C:\Program Files\server-3.1.0\hq-engine
JAVA_HOME = %SDKS_HOME%\jdk1.5.0_04
JAVA_OPTS = "-ea"
ANT_HOME = %TOOLS_HOME%\apache-ant-1.6.5
ANT_OPTS = -Xmx256M -XX:MaxPermSize=128m
发现SERVER起不来,后来不用自己下载的JBOSS,而是直接下载个可以直接解压的HQ安装包,然后把JBOSS_HOME改到安装目录(如上)。然后再运行ant deploy就安过去了。
AGENT没有发现问题,编译出来的直接运行就好了,在build/agent目录下。
posted @
2007-08-12 15:59 我爱佳娃 阅读(493) |
评论 (0) |
编辑 收藏
摘要: 最近因为用HYPERIC产品,装了一下Postgres数据库,下面简说下在WINDOWS下安装的情况。
下载那个直接解压版,解压
在"$PG"目录下创建一个rootpass.txt文件,内容为数据库的超级用户密码。可以填个“p”,方便后面登陆。准备工作到此结束,下面的步骤以管理员身份执行。
移动DLL文件[8.1.5及以上版本不需要这一步骤]:
cd...
阅读全文
posted @
2007-08-12 15:56 我爱佳娃 阅读(5769) |
评论 (0) |
编辑 收藏
最近想用PERL通过SOAP与JAVA通信,想到了XFIRE,现在叫CXF提供的服务。但总是差一点成功。
第一步,
由于用了SPRING,所以最先看了这篇文章:
Writing a service with Spring 服务是建成功了,PERL和JAVA是可以正常通信了,详见
上篇文章可是CXF自己的CLIENT生成代码却访问“自定义结构数组”的函数不成功:
public List<DeviceValue> sendAlarmArr (List<DeviceValue> arr);
第二步,
左试右试不成功,甚至去试了Axis2,但那个生成的WSDL把上面的结构变成AnyType,估计不对。
又回来,看了
Aegis绑定,我还找到将它用到SPRING里的方法:
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:jaxws="http://cxf.apache.org/jaxws"
xsi:schemaLocation="
http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd
http://cxf.apache.org/jaxws http://cxf.apache.org/schemas/jaxws.xsd">
<import resource="classpath:META-INF/cxf/cxf.xml" />
<import resource="classpath:META-INF/cxf/cxf-extension-soap.xml" />
<import resource="classpath:META-INF/cxf/cxf-servlet.xml" />
<bean id="serviceClass" class="com.exchangebit.nms.magic.NotifyServiceImpl"/>
<bean id="aegisDatabinding" class="org.apache.cxf.aegis.databinding.AegisDatabinding"/>
<bean id="serviceFactory" class="org.apache.cxf.jaxws.support.JaxWsServiceFactoryBean">
<property name="dataBinding" ref="aegisDatabinding"/>
</bean>
<bean id="serverBeanFactory" class="org.apache.cxf.frontend.ServerFactoryBean" init-method="create">
<property name="address" value="/NotifyService"/>
<property name="bindingId" value="http://schemas.xmlsoap.org/soap/"/>
<property name="serviceBean" ref="serviceClass"/>
<property name="serviceFactory" ref="serviceFactory"/>
</bean>
<jaxws:endpoint
id="notifyService"
implementor="com.exchangebit.nms.magic.NotifyServiceImpl"
address="/NotifyService">
<!--jaxws:serviceFactory>
<ref bean="serviceFactory"/>
</jaxws:serviceFactory-->
</jaxws:endpoint>
</beans>
其实,跟前一种JAX-WS的方式转换非常简单,把其中的注释去掉就是Aegis绑定,注释掉就是JAX-WS。
客户端没有在SPRING里试成功,但写代码也相当简单,Aegis真好:
getBean ("notifyClient");
ClientProxyFactoryBean factory = new ClientProxyFactoryBean();
factory.setServiceClass(NotifyService.class);
factory.setAddress("http://127.0.0.1:8080/ebnms/NotifyService");
factory.getServiceFactory().setDataBinding(new AegisDatabinding());
NotifyService client = (NotifyService) factory.create();
DoTest (client);
这次,到是CXF的SERVER和CLIENT都可以正常通信了。但我不说也知道啦,PERL又出问题了!
第三步,
又进一步搜,才知道Document, Literal, RPC, Encoding对SOAP消息的影响,
这篇文章(
中文的)相当好!
大义是RPC/Encoding将方法名称放入了operation节中,并且消息里含有类型信息,不方便检验。
而Document/Literal通过增加WSDL复杂度,将方法名、参数类型全部放入了types一节,方便了处理。
而SOAP::Lite只支持RPC/Encoding的方式,但也有办法让它形成Doc/Lit的消息:
点这里。
但,这种方法只支持JAX-WS的服务,Aegis的PERL就会出错了。
所以,不管用哪种要么JAVA的CLIENT和SERVER通信有问题,不然就是把PERL拒之门外。我怀疑是不是CXF的JAX-WS的数组处理有问题,不然Aegis为何不出错?另外,Aegis对PERL的消息不够宽容,本已是Doc/Lit格式,只是带有TYPE信息也会出错。
不知如何解,先记在此,以后回过头来再研究了。
posted @
2007-08-07 21:39 我爱佳娃 阅读(2919) |
评论 (1) |
编辑 收藏
摘要: SOAP::Lite的Lite是说其好用,其实它的实现并不“轻量”,功能也非常强大,所以我们要用好它。
在调用服务时,有时遇到有复杂结构或者数组时,还是有点小麻烦,下面以调用以下三个函数为例分别写出SOAP::Lite如何组合它们的参数,其它情况也应该能迎刃而解。
public class DeviceValue {
&nbs...
阅读全文
posted @
2007-08-03 22:37 我爱佳娃 阅读(2878) |
评论 (0) |
编辑 收藏一般bat只能运行一个程序,有时需要在电脑启动或者自己有多个程序要启动时,编辑一个bat实现一组程序的启动。可以使用start语句。
它不支持带空格的目录名,可以先CD到程序目录,再start,举例如下:
cd "C:\Program Files\Tor\"
start tor.exe
cd "C:\Program Files\Privoxy\"
start privoxy.exe
cd "C:\Program Files\Mozilla Firefox\"
start firefox.exe
posted @
2007-07-29 10:36 我爱佳娃 阅读(4536) |
评论 (0) |
编辑 收藏以下文字摘自:JOIN, JOIN2, HQL, Fetch
Join用法:
主要有Inner Join 及 Outer Join:
最常用的(默认是Inner):
Select <要选择的字段> From <主要资料表>
<Join 方式> <次要资料表> [On <Join 规则>]
Inner Join 的主要精神就是 exclusive , 叫它做排他性吧! 就是讲 Join 规则不相符的资料就会被排除掉, 譬如讲在 Product 中有一项产品的供货商代码 (SupplierId), 没有出现在 Suppliers 资料表中, 那么这笔记录便会被排除掉
Outer Join:
Select <要查询的字段> From <Left 资料表>
<Left | Right> [Outer] Join <Right 资料表> On <Join 规则>
语法中的 Outer 是可以省略的, 例如你可以用 Left Join 或是 Right Join, 在本质上, Outer Join 是 inclusive, 叫它做包容性吧! 不同于 Inner Join 的排他性, 因此在 Left Outer Join 的查询结果会包含所有 Left 资料表的资料, 颠倒过来讲, Right Outer Join 的查询就会包含所有 Right 资料表的资料
另外,还有全外联:
FULL JOIN 或 FULL OUTER JOIN
完整外部联接返回左表和右表中的所有行。当某行在另一个表中没有匹配行时,则另一个表的选择列表列包含空值。如果表之间有匹配行,则整个结果集行包含基表的数据值。
以及,
交叉联接
交叉联接返回左表中的所有行,左表中的每一行与右表中的所有行组合。交叉联接也称作笛卡尔积。
没有 WHERE 子句的交叉联接将产生联接所涉及的表的笛卡尔积。第一个表的行数乘以第二个表的行数等于笛卡尔积结果集的大小。也就是说在没有 WHERE 子句的情况下,若表 A 有 3 行记录,表 B 有 6 行记录 : :
SELECT A.*,B.* FROM 表A CROSS JOIN 表B
那以上语句会返回 18 行记录。
Fetch:
在我们查询Parent对象的时候,默认只有Parent的内容,并不包含childs的信息,如果在Parent.hbm.xml里设置lazy="false"的话才同时取出关联的所有childs内容.
问题是我既想要hibernate默认的性能又想要临时的灵活性该怎么办? 这就是fetch的功能。我们可以把fetch与lazy="true"的关系类比为事务当中的编程式事务与声明式事务,不太准确,但是大概是这个意思。
总值,fetch就是在代码这一层给你一个主动抓取得机会.
Parent parent = (Parent)hibernateTemplate.execute(new HibernateCallback() {
public Object doInHibernate(Session session) throws HibernateException, SQLException {
Query q = session.createQuery(
"from Parent as parent "+
" left outer join fetch parent.childs " +
" where parent.id = :id"
);
q.setParameter("id",new Long(15));
return (Parent)q.uniqueResult();
}
});
Assert.assertTrue(parent.getChilds().size() > 0);
你可以在lazy="true"的情况下把fetch去掉,就会报异常. 当然,如果lazy="false"就不需要fetch了
HQL一些特色方法:
in and between may be used as follows:
from DomesticCat cat where cat.name between 'A' and 'B'
from DomesticCat cat where cat.name in ( 'Foo', 'Bar', 'Baz' )
and the negated forms may be written
from DomesticCat cat where cat.name not between 'A' and 'B'
from DomesticCat cat where cat.name not in ( 'Foo', 'Bar', 'Baz' )
Likewise, is null and is not null may be used to test for null values.
Booleans may be easily used in expressions by declaring HQL query substitutions in Hibernate configuration:
<property name="hibernate.query.substitutions">true 1, false 0</property>
This will replace the keywords true and false with the literals 1 and 0 in the translated SQL from this HQL:
from Cat cat where cat.alive = true
You may test the size of a collection with the special property size, or the special size() function.
from Cat cat where cat.kittens.size > 0
from Cat cat where size(cat.kittens) > 0
For indexed collections, you may refer to the minimum and maximum indices using minindex and maxindex functions. Similarly, you may refer to the minimum and maximum elements of a collection of basic type using the minelement and maxelement functions.
from Calendar cal where maxelement(cal.holidays) > current_date
from Order order where maxindex(order.items) > 100
from Order order where minelement(order.items) > 10000
The SQL functions any, some, all, exists, in are supported when passed the element or index set of a collection (elements and indices functions) or the result of a subquery (see below).
select mother from Cat as mother, Cat as kit
where kit in elements(foo.kittens)
select p from NameList list, Person p
where p.name = some elements(list.names)
from Cat cat where exists elements(cat.kittens)
from Player p where 3 > all elements(p.scores)
from Show show where 'fizard' in indices(show.acts)
Note that these constructs - size, elements, indices, minindex, maxindex, minelement, maxelement - may only be used in the where clause in Hibernate3.
Elements of indexed collections (arrays, lists, maps) may be referred to by index (in a where clause only):
from Order order where order.items[0].id = 1234
select person from Person person, Calendar calendar
where calendar.holidays['national day'] = person.birthDay
and person.nationality.calendar = calendarselect item from Item item, Order order
where order.items[ order.deliveredItemIndices[0] ] = item and order.id = 11
select item from Item item, Order order
where order.items[ maxindex(order.items) ] = item and order.id = 11
The expression inside [] may even be an arithmetic expression.
select item from Item item, Order order
where order.items[ size(order.items) - 1 ] = item
HQL also provides the built-in index() function, for elements of a one-to-many association or collection of values.
select item, index(item) from Order order
join order.items item
where index(item) < 5
Scalar SQL functions supported by the underlying database may be used
from DomesticCat cat where upper(cat.name) like 'FRI%'
posted @
2007-07-26 16:44 我爱佳娃 阅读(33585) |
评论 (1) |
编辑 收藏这几个学习材料非常短小精悍,可清晰快捷的掌握以下几个概念,方便更深入学习。建议象我一样没接触过或者有疑惑的同学看一下。每个项目10至20分钟就可以看完、看懂:
XML tutorial:
http://www.w3schools.com/xml/default.asp
SOAP tutorial:
http://www.w3schools.com/soap/default.asp
WSDL tutorial:
http://www.w3schools.com/wsdl/default.asp
WEB Service tutorial:
http://www.w3schools.com/webservices/default.asp
posted @
2007-07-10 10:25 我爱佳娃 阅读(1684) |
评论 (1) |
编辑 收藏DWR2.0的推技术:这里有介绍
comet的实现介绍:这里
其中的原理在于维护HTTP长连接,这里有介绍
摘录一部分,说明其原理:
Pushlet基于HTTP流,这种技术常常用在多媒体视频、通讯应用中,比如QuickTime。与装载HTTP页面之后马上关闭HTTP连接的做法相反,Pushlet采用HTTP流方式将新数据源源不断地推送到client,再此期间HTTP连接一直保持打开。有关如何在Java中实现这种Keep-alive的长连接请参看Sun提供的《HTTP Persistent Connection》和W3C的《HTTP1.1规范》。
示例1
我们利用HTTP流开发一个JSP页面(因为它易于部署,而且它在web server中也是作为servlet对待的),此页面在一个定时器循环中不断地发送新的HTML内容给client:
<%
int i = 1;
try {
while (true) {
out.print("<h1>"+(i++)+"</h1>");
out.flush();
try {
Thread.sleep(3000);
} catch (InterruptedException e) {
out.print("<h1>"+e+"</h1>");
}
}
} catch (Exception e) {
out.print("<h1>"+e+"</h1>");
}
%>
在Pushlet源代码中提供了此页面(examples/basics/push-html-stream.jsp)。上面的页面并不是十分有用,因为在我们刷新页面时,新内容机械地、持续不断地被添加到页面中,而不是server端更新的内容。
示例2 现在让我们步入Pushlet工作机理中一探究竟。通过运行Pushlet的示例源代码(examples/basics/ push-js-stream.html),我们会看到这个每3秒刷新一次的页面。那么它是如何实现的呢?
此示例中包含了三个文件:push-js-stream.html、push-js-stream-pusher.jsp、push-js-stream-display.html。
其中push-js-stream.html是主框架文件,它以HTML Frame的形式包含其它两个页面。
push-js-stream-pusher.jsp是一个JSP,它执行在server端,此文件内容如下:
7: <%
8: /** Start a line of JavaScript with a function call to parent frame. */
9: String jsFunPre = "<script language=JavaScript >parent.push('";
10:
11: /** End the line of JavaScript */
12: String jsFunPost = "')</script> ";
13:
14: int i = 1;
15: try {
16:
17: // Every three seconds a line of JavaScript is pushed to the client
18: while (true) {
19:
20: // Push a line of JavaScript to the client
21: out.print(jsFunPre+"Page "+(i++)+jsFunPost);
22: out.flush();
23:
24: // Sleep three secs
25: try {
26: Thread.sleep(3000);
27: } catch (InterruptedException e) {
28: // Let client display exception
29: out.print(jsFunPre+"InterruptedException: "+e+jsFunPost);
30: }
31: }
32: } catch (Exception e) {
33: // Let client display exception
34: out.print(jsFunPre+"Exception: "+e+jsFunPost);
35: }
36: %>
注意在示例1和示例2中使用JSP时都存在一个问题:一些servlet引擎在某个client离开时会“吃掉”IOException,以至于JSP页面将永不抛出此异常。所以在这种情况下,页面循环将会永远执行下去。而这正是Pushlet实现采用servlet的原因之一:可以捕获到IOException。 在上面代码的第21行中可以看到在一个定时器循环(3秒/周期)中打印了一些HTML并将它们输出到client浏览器。请注意,这里推送的并非HTML而是Javascript!这样做的意义何在?
它把类似“<script language=JavaScript >parent.push('Page 4')</script>”的一行代码推送到浏览器;而具有JavaScript引擎的浏览器可以直接执行收到的每一行代码,并调用parent.push()函数。而代码中的Parent便是浏览器页面中所在Frame的Parent,也就是push-js-stream.html。让我们看看都发生了什么?
<script LANGUAGE="JavaScript">
var pageStart="<HTML><HEAD></HEAD><BODY BGCOLOR=blue TEXT=white><H2>Server pushes: <para>";
var pageEnd="</H2></BODY></HTML>";
// Callback function with message from server.
// This function is called from within the hidden JSP pushlet frame
function push(content) {
// Refresh the display frame with the content received
window.frames['displayFrame'].document.writeln(pageStart+content+pageEnd);
window.frames['displayFrame'].document.close();
}
</script>
<!-- frame to display the content pushed by the pushlet -->
<!-- Hidden frame with the pushlet that pushes lines of JavaScript-->
</FRAMESET>
可以看到push-js-stream.html中的push()函数被名为pushletFrame的JSP Frame调用:把传入的参数值写入到displayFrame(此Frame为push-js-stream-display.html)。这是动态HTML的一个小技巧:使用document对象的writeln方法刷新某个Frame或者Window的内容。
于是displayFrame成为了用于显示内容的、真正的视图。displayFrame初始化为黑色背景并显示“wait…”直到来自server的内容被推送过来:
<H1>WAIT...</H1>
这便是Pushlet的基本做法:我们从servlet(或者从示例中的JSP)把JavaScript代码作为HTTP流推送到浏览器。这些代码被浏览器的JavaScript引擎解释并完成一些有趣的工作。于是便轻松地完成了从server端的Java到浏览器中的JavaScript的回调。
上面的示例展示了Pushlet原理,但这里存在一些等待解决的问题和需要增添的特性。于是我建立了一个小型的server端Pushlet框架(其类结构图表将会展示在下面),添加了一些用在client中的JavaScript库。由于client需要依赖更多的DHTML特性(比如Layers),我们将首先粗略地温习一些
DHTML知识。示例代码见examples/dhtml。
posted @
2007-07-03 18:10 我爱佳娃 阅读(2324) |
评论 (0) |
编辑 收藏什么叫北向或者南向接口:
A northbound interface is an interface that conceptualizes lower level details. It interfaces to higher level layers and is normally drawn at the top of an architectural overview.
A southbound interface decomposes concepts in the technical details, mostly specific to a single component of the architecture. Southbound interfaces are drawn at the bottom of an architectural overview.
Northbound interfaces normally talk to southbound interfaces of higher level components and vice versa.
These terms are generic in the sense that they are uniformly used over all layers of an application, i.e. independent of the fact that the system is about hardware, GUI, middle-ware etc.
A northbound interface is typically an output-only interface (as opposed to one that accepts user input) found in carrier-grade network and telecommunications network elements. The languages or protocols commonly used include SNMP and TL1. For example, a device that is capable of sending out syslog messages but is not configurable by the user is said to implement a northbound interface.
B-NT: Broadband-Network Termination. A specific type of Broadband CPE used in DSL networks.
CPE: Customer Premises Equipment; 用户预置设备。it refers to any TR-069-compliant devices and therefore covers both Internet Gateway Devices and LAN-side end devices.
CWMP: CPE WAN Management Protocol (the subject of TR069 standard).
Managed Object (MO): A managed object is a software object that encapsulates the manageable characteristics and behaviors of a particular Network Resource.
posted @
2007-07-02 11:30 我爱佳娃 阅读(1036) |
评论 (0) |
编辑 收藏dojo提供了不错的树控件,但上下文菜单比较简单,不能动态改变:比如我想根据不同节点显示不同的上下文菜单就比较困难,根据多种实验和查阅下面提供一种实现方式。在此过程中也学到不少东西。先把解决方案说一下,再把发现过程说一下:
DOJO提供了AOP的方式来“注入”代码,我们就把修改menu的代码注入到TreeContextMenuV3里就可以了:
在open事件前注入我们的代码:
dojo.event.connect("before", dojo.widget.byId("contextMenu1"), "open", this, "onContextMenuOpen");
注意before是表示在menu打开之前调用,其它关键字还可以是after,around。强,赞一个!
在onContextMenuOpen函数中,做改变菜单的事情:

 this.onContextMenuOpen = function (evt)
this.onContextMenuOpen = function (evt)  {
{
 dojo.log.info ("before context open");
dojo.log.info ("before context open");
dojo.log.info (evt);
var m = dojo.widget.byId("contextMenu1");
dojo.log.info (m);
m.removeChild (dojo.widget.byId("treeContextMenuEdit"));
m.removeChild (dojo.widget.byId("treeContextMenuDown"));
m.removeChild (dojo.widget.byId("treeContextMenuCreate"));
m.removeChild (dojo.widget.byId("treeContextMenuCreate2"));

 if (null == this.context_menu["MenuItem2"]) {
if (null == this.context_menu["MenuItem2"]) {
var id = dojo.widget.createWidget("MenuItem2", {caption: "Page Info"});
dojo.log.info (id);
this.context_menu["MenuItem2"] = id;
m.addChild(id);
 }
}
//m.destroyChildren ();
dojo.log.info (m);
//w.destory ();
 };
};
在这里可以根据节点来增删菜单项了,context_menu成员是用来记录加入过的菜单项,以免重复加入。
另外,removeChild没有destory掉菜单项,应该可以重复使用。所以,我设想的实现是,在程序开头将所有可能的菜单项动态创建好,存在一个MAP中,然后,在这里来动态加删它们。
下面是寻找解决方法的过程:
刚开始时,我想是改变整个树的菜单,确实也找到了可以编程改变它的方法:
var ctxMenu = dojo.widget.byId("contextMenu");
var tree = dojo.widget.byId("phyTree");
dojo.log.info (ctxMenu);
ctxMenu.listenTree(tree);
ctxMenu.bindDomNode(tree.domNode);
关键是一句:bindDomNode。
这样虽然可以动态“加载”菜单了,可是没有“时机”来加载新菜单,无法达到根据节点变化来做改变。
随后,我又想到重载,去创造这个“时机”:
dojo.require ("dojo.widget.TreeContextMenuV3");
dojo.provide("mywidgets.MyTreeContextMenu");
dojo.widget.defineWidget(
// widget name and class
"mywidgets.MyTreeContextMenu",
// superclass
[dojo.widget.TreeContextMenuV3],
function() {
dojo.log.info ("my context menu create1");
},
// properties and methods
{
open: function() {
var result = dojo.widget.PopupMenu2.prototype.open.apply(this, arguments);
dojo.log.info ("my context menu create");
for(var i=0; i< this.children.length; i++) {
/**//* notify children */
if (this.children[i].menuOpen) {
this.children[i].menuOpen(this.getTreeNode());
}
}
return result;
}
}
);
这也是我第一次重载DOJO,发现其实很简单,关键要注意它的namespace:
dojo.require()语句的寻找方法是:
dojo.xxx => dojo/src/xxx.js
dojo.xxx.yyy => dojo/src/xxx/yyy.js
dojo.xxx.yyy.zzz => dojo/src/xxx/yyy/zzz.js
如果遇到不是dojo开头时,它的寻找方法是:
example.xxx => dojo/../example/xxx.js
example.xxx.yyy => dojo/../example/xxx/yyy.js
example.xxx.yyy.zzz => dojo/../example/xxx/yyy/zzz.js
所以要把自己的代码放到跟dojo同级就可以了。
这个办法我没往下试,因为重载的是contextmenu,在它里面把它“整个自己”换成别的menu,我觉得是不可行的。而看半天代码也没找着在哪重载右键点击这个事件。不过启发我可以更换子item来解决。
于是有了开头的解决方案。
posted @
2007-07-01 11:15 我爱佳娃 阅读(2610) |
评论 (3) |
编辑 收藏我使用MSN博客两年,几乎是在它推出,并刚为中国用户所知时,就使用了。两年来发表了很多游记、照片、感想、评论。
但是,最近它被无情删除了,多次发送邮件给微软技术支持,都石沉大海。所以,我要以最强烈和最负责任的态度在这里呼吁和告诫每一位博客使用者:
请象远离毒品一样,远离MSN博客!
(天下虽无免费的蛋糕,但就算施舍给乞丐的蛋糕也没有微软这种做法的。)
posted @
2007-06-21 18:03 我爱佳娃 阅读(353) |
评论 (0) |
编辑 收藏spring包装了rmi后,使我们得到几点便利:
不用调用rmic编译stub和skeleton
不用直接实现remote接口
不需要启动命名服务rmiregistry
但,却不支持原来rmi的回调功能。查阅许多网页也不得其解。
今天,想到一招,共享出来,如果大家有好办法欢迎回贴共享。
正常做法是:
回调一般是用在一群client端需要server来通知的情况,一般server就用Vector来保存client对象。
server端需要提供一个方法,client把对象传过来后,保存到Vector中,以后就可以通知client们了:
register (ClientObject obj);
在spring里,基本做法是一样的,唯一不同是,在这个方法里,client不能传对象,我们就传一个client提供出来的rmi对象的url:
register(String url);
在client端,就如正常使用先获得server对象,再调用这个方法,注意组成url的代码:
NodeService service = (NodeService) factory.getAPIObject("nodeServiceProxy");
String name = null;
try {
name = "rmi://" + InetAddress.getLocalHost().getHostName() + "/NodeNotifyService";
} catch (Exception ue) {}
int result = service.registerFlower (name);
logger.info ("result="+result);
在server端registerFlower处理里,根据url动态创建这个对象,代码如下:
public class NodeServiceImpl implements NodeService {
public static final Logger logger = LoggerFactory.getLogger(NodeServiceImpl.class);
public NodeNotifyService service = null;
public int registerFlower (String url) {
logger.info (url);
RmiProxyFactoryBean rmiProxyFactoryBean = new RmiProxyFactoryBean();
rmiProxyFactoryBean.setServiceInterface(NodeNotifyService.class);
logger.info ("begin set url");
rmiProxyFactoryBean.setServiceUrl(url);
try {
logger.info ("begin set");
rmiProxyFactoryBean.afterPropertiesSet();
} catch (Exception ex) {
logger.info ("exception");
}
if (rmiProxyFactoryBean.getObject() instanceof NodeNotifyService) {
service = (NodeNotifyService) rmiProxyFactoryBean.getObject();
}
return 0;
}
}
这样就从url转换成client对象了,当然了,还是需要在client和server各自配置文件里配置RmiServiceExporter,这一步很简单,和正常的spring的rmi是一样的了。
做到这步后,我还想把所有接口文件放到一个JAR里,client和server的实现,以及各自逻辑放到各自的JAR中,这样各自改实现就不需要两边更新包。改接口的话,就更新接口所在JAR。不知道这样安排是否合理?
posted @
2007-06-21 15:46 我爱佳娃 阅读(3275) |
评论 (4) |
编辑 收藏1、谁创建线程?
即使您从未显式地创建一个新线程,您仍可能会发现自己在使用线程。线程被从各种来源中引入到我们的程序中。
有许多工具可以为您创建线程,如果要使用这些工具,应该了解线程如何交互,以及如何防止线程互相干扰。
2、AWT 和 Swing
任何使用 AWT 或 Swing 的程序都必须处理线程。AWT 工具箱创建单个线程,用于处理 UI 事件,任何由 AWT 事件调用的事件侦听器都在 AWT 事件线程中执行。
您不仅必须关心同步对事件侦听器和其它线程之间共享的数据项的访问,而且还必须找到一种方法,让由事件侦听器触发的长时间运行任务(如在大文档中检查拼写或在文件系统中搜索一个文件) 在后台线程中运行,这样当该任务运行时,UI 就不会停滞了(这可能还会阻止用户取消操作)。这样做的一个好的框架示例是 SwingWorker 类
AWT 事件线程并不是守护程序线程;这就是通常使用 System.exit() 结束 AWT 和 Swing 应用程序的原因。
3、使用 TimerTask
JDK 1.3 中,TimerTask 工具被引入到 Java 语言。这个便利的工具让您可以稍后在某个时间执行任务(例如,即从现在起十秒后运行一次任务),或者定期执行任务(即,每隔十秒运行任务)。
实现 Timer 类非常简单:它创建一个计时器线程,并且构建一个按执行时间排序的等待事件队列。
TimerTask 线程被标记成守护程序线程,这样它就不会阻止程序退出。
因为计时器事件是在计时器线程中执行,所以必须确保正确同步了针对计时器任务中使用的任何数据项的访问。
在 CalculatePrimes 示例中,并没有让主线程休眠,我们可以使用 TimerTask,方法如下:
public static void main(String[] args) {
Timer timer = new Timer();
final CalculatePrimes calculator = new CalculatePrimes();
calculator.start();
timer.schedule(
new TimerTask() {
public void run()
{
calculator.finished = true;
}
}, TEN_SECONDS);
}
4、servlet 和 JavaServer Pages 技术
servlet 容器创建多个线程,在这些线程中执行 servlet 请求。作为 servlet 编写者,您不知道(也不应该知道)您的请求会在什么线程中执行;如果同时有多个对相同 URL 的请求入站,那么同一个 servlet 可能会同时在多个线程中是活动的。
当编写 servlet 或 JavaServer Pages (JSP) 文件时,必须始终假设可以在多个线程中并发地执行同一个 servlet 或 JSP 文件。必须适当同步 servlet 或 JSP 文件访问的任何共享数据;这包括 servlet 对象本身的字段。
5、实现 RMI 对象
RMI 工具可以让您调用对在其它 JVM 中运行的对象进行的操作。当调用远程方法时,RMI 编译器创建的 RMI 存根会打包方法参数,并通过网络将它们发送到远程系统,然后远程系统会将它们解包并调用远程方法。
假设您创建了一个 RMI 对象,并将它注册到 RMI 注册表或者 Java 命名和目录接口(Java Naming and Directory Interface (JNDI))名称空间。当远程客户机调用其中的一个方法时,该方法会在什么线程中执行呢?
实现 RMI 对象的常用方法是继承 UnicastRemoteObject。在构造 UnicastRemoteObject 时,会初始化用于分派远程方法调用的基础结构。这包括用于接收远程调用请求的套接字侦听器,和一个或多个执行远程请求的线程。
所以,当接收到执行 RMI 方法的请求时,这些方法将在 RMI 管理的线程中执行。
6、小结
线程通过几种机制进入 Java 程序。除了用 Thread 构造器中显式创建线程之外,还可以用许多其它机制创建线程:
AWT 和 Swing
RMI
java.util.TimerTask 工具
servlet 和 JSP 技术
共享变量
1、 共享变量
要使多个线程在一个程序中有用,它们必须有某种方法可以互相通信或共享它们的结果。
让线程共享其结果的最简单方法是使用共享变量。它们还应该使用同步来确保值从一个线程正确传播到另一个线程,以及防止当一个线程正在更新一些相关数据项时,另一个线程看到不一致的中间结果。
线程基础中计算素数的示例使用了一个共享布尔变量,用于表示指定的时间段已经过去了。这说明了在线程间共享数据最简单的形式是:轮询共享变量以查看另一个线程是否已经完成执行某项任务。
2、存在于同一个内存空间中的所有线程
正如前面讨论过的,线程与进程有许多共同点,不同的是线程与同一进程中的其它线程共享相同的进程上下文,包括内存。这非常便利,但也有重大责任。只要访问共享变量(静态或实例字段),线程就可以方便地互相交换数据,但线程还必须确保它们以受控的方式访问共享变量,以免它们互相干扰对方的更改。
任何线程可以访问所有其作用域内的变量,就象主线程可以访问该变量一样。素数示例使用了一个公用实例字段,叫做 finished,用于表示已经过了指定的时间。当计时器过期时,一个线程会写这个字段;另一个线程会定期读取这个字段,以检查它是否应该停止。注:这个字段被声明成 volatile,这对于这个程序的正确运行非常重要。在本章的后面,我们将看到原因。
3、受控访问的同步
为了确保可以在线程之间以受控方式共享数据,Java 语言提供了两个关键字:synchronized 和 volatile。
Synchronized 有两个重要含义:它确保了一次只有一个线程可以执行代码的受保护部分(互斥,mutual exclusion 或者说 mutex),而且它确保了一个线程更改的数据对于其它线程是可见的(更改的可见性)。
如果没有同步,数据很容易就处于不一致状态。例如,如果一个线程正在更新两个相关值(比如,粒子的位置和速率),而另一个线程正在读取这两个值,有可能在第一个线程只写了一个值,还没有写另一个值的时候,调度第二个线程运行,这样它就会看到一个旧值和一个新值。同步让我们可以定义必须原子地运行的代码块,这样对于其他线程而言,它们要么都执行,要么都不执行。
同步的原子执行或互斥方面类似于其它操作环境中的临界段的概念。
4、确保共享数据更改的可见性
同步可以让我们确保线程看到一致的内存视图。
处理器可以使用高速缓存加速对内存的访问(或者编译器可以将值存储到寄存器中以便进行更快的访问)。在一些多处理器体系结构上,如果在一个处理器的高速缓存中修改了内存位置,没有必要让其它处理器看到这一修改,直到刷新了写入器的高速缓存并且使读取器的高速缓存无效。
这表示在这样的系统上,对于同一变量,在两个不同处理器上执行的两个线程可能会看到两个不同的值!这听起来很吓人,但它却很常见。它只是表示在访问其它线程使用或修改的数据时,必须遵循某些规则。
Volatile 比同步更简单,只适合于控制对基本变量(整数、布尔变量等)的单个实例的访问。当一个变量被声明成 volatile,任何对该变量的写操作都会绕过高速缓存,直接写入主内存,而任何对该变量的读取也都绕过高速缓存,直接取自主内存。这表示所有线程在任何时候看到的 volatile 变量值都相同。
如果没有正确的同步,线程可能会看到旧的变量值,或者引起其它形式的数据损坏。
5、用锁保护的原子代码块
Volatile 对于确保每个线程看到最新的变量值非常有用,但有时我们需要保护比较大的代码片段,如涉及更新多个变量的片段。
同步使用监控器(monitor)或锁的概念,以协调对特定代码块的访问。
每个 Java 对象都有一个相关的锁。同一时间只能有一个线程持有 Java 锁。当线程进入 synchronized 代码块时,线程会阻塞并等待,直到锁可用,当它可用时,就会获得这个锁,然后执行代码块。当控制退出受保护的代码块时,即到达了代码块末尾或者抛出了没有在 synchronized 块中捕获的异常时,它就会释放该锁。
这样,每次只有一个线程可以执行受给定监控器保护的代码块。从其它线程的角度看,该代码块可以看作是原子的,它要么全部执行,要么根本不执行。
6、简单的同步示例
使用 synchronized 块可以让您将一组相关更新作为一个集合来执行,而不必担心其它线程中断或看到计算的中间结果。以下示例代码将打印“1 0”或“0 1”。如果没有同步,它还会打印“1 1”(或“0 0”,随便您信不信)。
public class SyncExample {
private static lockObject = new Object();
private static class Thread1 extends Thread {
public void run() {
synchronized (lockObject) {
x = y = 0;
System.out.println(x);
}
}
}
private static class Thread2 extends Thread {
public void run() {
synchronized (lockObject) {
x = y = 1;
System.out.println(y);
}
}
}
public static void main(String[] args) {
new Thread1().run();
new Thread2().run();
}
}
在这两个线程中都必须使用同步,以便使这个程序正确工作。
7、Java 锁定
Java 锁定合并了一种互斥形式。每次只有一个线程可以持有锁。锁用于保护代码块或整个方法,必须记住是锁的身份保护了代码块,而不是代码块本身,这一点很重要。一个锁可以保护许多代码块或方法。
反之,仅仅因为代码块由锁保护并不表示两个线程不能同时执行该代码块。它只表示如果两个线程正在等待相同的锁,则它们不能同时执行该代码。
在以下示例中,两个线程可以同时不受限制地执行 setLastAccess() 中的 synchronized 块,因为每个线程有一个不同的 thingie 值。因此,synchronized 代码块受到两个正在执行的线程中不同锁的保护。
public class SyncExample {
public static class Thingie {
private Date lastAccess;
public synchronized void setLastAccess(Date date) {
this.lastAccess = date;
}
}
public static class MyThread extends Thread {
private Thingie thingie;
public MyThread(Thingie thingie) {
this.thingie = thingie;
}
public void run() {
thingie.setLastAccess(new Date());
}
}
public static void main() {
Thingie thingie1 = new Thingie(),
thingie2 = new Thingie();
new MyThread(thingie1).start();
new MyThread(thingie2).start();
}
}
8、同步的方法
创建 synchronized 块的最简单方法是将方法声明成 synchronized。这表示在进入方法主体之前,调用者必须获得锁:
public class Point {
public synchronized void setXY(int x, int y) {
this.x = x;
this.y = y;
}
}
对于普通的 synchronized方法,这个锁是一个对象,将针对它调用方法。对于静态 synchronized 方法,这个锁是与 Class 对象相关的监控器,在该对象中声明了方法。
仅仅因为 setXY() 被声明成 synchronized 并不表示两个不同的线程不能同时执行 setXY(),只要它们调用不同的 Point 实例的 setXY() 就可同时执行。对于一个 Point 实例,一次只能有一个线程执行 setXY(),或 Point 的任何其它 synchronized 方法。
9、同步的块
synchronized 块的语法比 synchronized 方法稍微复杂一点,因为还需要显式地指定锁要保护哪个块。Point 的以下版本等价于前一页中显示的版本:
public class Point {
public void setXY(int x, int y) {
synchronized (this) {
this.x = x;
this.y = y;
}
}
}
使用 this 引用作为锁很常见,但这并不是必需的。这表示该代码块将与这个类中的 synchronized 方法使用同一个锁。
由于同步防止了多个线程同时执行一个代码块,因此性能上就有问题,即使是在单处理器系统上。最好在尽可能最小的需要保护的代码块上使用同步。
访问局部(基于堆栈的)变量从来不需要受到保护,因为它们只能被自己所属的线程访问。
10、大多数类并没有同步
因为同步会带来小小的性能损失,大多数通用类,如 java.util 中的 Collection 类,不在内部使用同步。这表示在没有附加同步的情况下,不能在多个线程中使用诸如 HashMap 这样的类。
posted @
2007-06-17 12:26 我爱佳娃 阅读(682) |
评论 (0) |
编辑 收藏
典型的三层结构
三层结构估计大家都很熟悉了。就是表示(presentation)层, 领域(domain)层, 以及基础架构(infrastructure)层。
表示层逻辑主要处理用户和软件的交互。现在最流行的莫过于视窗图形界面(wimp)和基于html的界面了。表示层的主要职责就是为用户提供信息,以及把用户的指令翻译。传送给业务层和基础架构层。 基础架构层逻辑包括处理和其他系统的通信,代表系统执行任务。例如数据库系统交互,和其他应用系统的交互等。大多数的信息系统,这个层的最大的逻辑就是存储持久数据。
还有一个就是领域层逻辑,有时也被叫做业务逻辑。它包括输入和存储数据的计算。验证表示层来的数据,根据表示层的指令指派一个基础架构层逻辑。
领域逻辑中,人们总是搞不清楚什么事领域逻辑,什么是其它逻辑。例如,一个销售系统中有这样一个逻辑:如果本月销售量比上个月增长10%,就要用红色标记。要实现这个功能,你可能会把逻辑放在表示层中,比较两个月的数字,如果超出10%,就标记为红色。
这样做,你就把领域逻辑放到了表示层中了。要分离这两个层,你应该现在领域层中提供一个方法,用来比较销售数字的增长。这个方法比较两个月的数字,并返回boolean类型。表示层则简单的调用该方法,如果返回true,则标记为红色。
————————————————
| 客户端层 | 用户交互,UI实现
| Browser,WirelessDevice,WebService | Http, Soap 协议(SOP体系)
————————————————
————————————————
| 表现层 | 集中登录,会话管理
| Struts,Jsf,Webwork,Tapstry, Velocity | 内容创建,格式,传送
————————————————
————————————————
| 业务服务层 | 业务逻辑,事务,数据,服务
| SessionEJB,Spring,Jdoframework) | SessionEjb,POJO Service
————————————————
————————————————
| 集中层 | 资源适配器,遗留/外部系统
|Jms,Jdbc,Connnector,External Service | 规则引擎,工作流
————————————————
(持久化EntityBean,Hibernate,iBatis,Jdo,Dao,TopLink etc.)
————————————————
| 资源层 | 资源,数据库,外部服务
| DataBase,Resource,External Service | (大型主机,B2B集中系统)
————————————————
原文摘录如下:
Part 1 层
层(layer)这个概念在计算机领域是非常了不得的一个概念。计算机本身就体现了一种层的概念:系统调用层、设备驱动层、操作系统层、CPU指令集。每个层都负责自己的职责。网络同样也是层的概念,最著名的OSI的七层协议。
层到了软件领域也一样好用。为什么呢?我们看看使用层技术有什么好处:
● 你使用层,但是不需要去了解层的实现细节。
● 可以使用另一种技术来改变基础的层,而不会影响上面的层的应用。
● 可以减少不同层之间的依赖。
● 容易制定出层标准。
● 底下的层可以用来建立顶上的层的多项服务。 当然,层也有弱点:
● 层不可能封装所有的功能,一旦有功能变动,势必要波及所有的层。
● 效率降低。
当然,层最难的一个问题还是各个层都有些什么,以及要承担何种责任。
典型的三层结构
三层结构估计大家都很熟悉了。就是表示(presentation)层, 领域(domain)层, 以及基础架构(infrastructure)层。
表示层逻辑主要处理用户和软件的交互。现在最流行的莫过于视窗图形界面(wimp)和基于html的界面了。表示层的主要职责就是为用户提供信息,以及把用户的指令翻译。传送给业务层和基础架构层。 基础架构层逻辑包括处理和其他系统的通信,代表系统执行任务。例如数据库系统交互,和其他应用系统的交互等。大多数的信息系统,这个层的最大的逻辑就是存储持久数据。
还有一个就是领域层逻辑,有时也被叫做业务逻辑。它包括输入和存储数据的计算。验证表示层来的数据,根据表示层的指令指派一个基础架构层逻辑。
领域逻辑中,人们总是搞不清楚什么事领域逻辑,什么是其它逻辑。例如,一个销售系统中有这样一个逻辑:如果本月销售量比上个月增长10%,就要用红色标记。要实现这个功能,你可能会把逻辑放在表示层中,比较两个月的数字,如果超出10%,就标记为红色。
这样做,你就把领域逻辑放到了表示层中了。要分离这两个层,你应该现在领域层中提供一个方法,用来比较销售数字的增长。这个方法比较两个月的数字,并返回boolean类型。表示层则简单的调用该方法,如果返回true,则标记为红色。
例子
层技术不存在说永恒的技巧。如何使用都要看具体的情况才能够决定,下面我就列出了三个例子:
例子1:一个电子商务系统。要求能够同时处理大量用户的请求,用户的范围遍及全球,而且数字还在不断增长。但是领域逻辑很简单,无非是订单的处理,以 及和库存系统的连接部分。这就要求我们1、表示层要友好,能够适应最广泛的用户,因此采用html技术;2、支持分布式的处理,以胜任同时几千的访问; 3、考虑未来的升级。
例子2:一个租借系统。系统的用户少的多,但是领域逻辑很复杂。这就要求我们制作一个领域逻辑非常复杂的系统,另外,还要给他们的用户提供一个方便的输入界面。这样,wimp是一个不错的选择。
例子3:简单的系统。非常简单,用户少、逻辑少。但是也不是没有问题,简单意味着要快速交付,并且还要充分考虑日后的升级。因为需求在不断的增加之中。
何时分层
这样的三个例子,就要求我们不能够一概而论的解决问题,而是应该针对问题的具体情况制定具体的解决方法。这三个例子比较典型。
第二个例子中,可能需要严格的分成三个层次,而且可能还要加上另外的中介(mediating)层。例3则不需要,如果你要做的仅是查看数据,那仅需要几个server页面来放置所有的逻辑就可以了。
我一般会把表示层和领域层/基础架构层分开。除非领域层/基础架构层非常的简单,而我又可以使用工具来轻易的绑定这些层。这种两层架构的最好的例子就 是在VB、PB的环境中,很容易就可以构建出一个基于SQL数据库的windows界面的系统。这样的表示层和基础架构层非常的一致,但是一旦验证和计算 变得复杂起来,这种方式就存在先天缺陷了。
很多时候,领域层和基础架构层看起来非常类似,这时候,其实是可以把它们放在一起的。可是,当领域层的业务逻辑和基础架构层的组织方式开始不同的时候,你就需要分开二者。
更多的层模式
三层的架构是最为通用的,尤其是对IS系统。其它的架构也有,但是并不适用于任何情况。
第一种是Brown model [Brown et al]。它有五个层:表示层(Presentation),控制/中介层(Controller/Mediator),领域层(Domain), 数据映射层(Data Mapping), 和数据源层(Data Source)。它其实就是在三层架构种增加了两个中间层。控制/中介层位于表示层和领域层之间,数据映射层位于领域层和基础架构层之间。
表示层和领域层的中介层,我们通常称之为表示-领域中介层,是一个常用的分层方法,通常针对一些非可视的控件。例如为特定的表示层组织信息格式,在不 同的窗口间导航,处理交易边界,提供Server的facade接口(具体实现原理见设计模式)。最大的危险就是,一些领域逻辑被放到这个层里,影响到其 它的表示层。
我常常发现把行为分配给表示层是有好处的。这可以简化问题。但表示层模型会比较复杂,所以,把这些行为放到非可视化的对象中,并提取出一个表示-领域中介层还是值得的。
Brown ISA
表示层 表示层
控制/中介层 表示-领域中介层
领域层 领域层
数据映射层 数据库交互模式中的Database Mapper
数据源层 基础架构层
领域层和基础架构层之间的中介层属于本书中提到的Database Mapper模式,是三种领域层到数据连接的办法之一。和表示-领域中介层一眼,有时候有用,但不是所有时候都有用。
还有一个好的分层架构是J2EE的架构,这方面的讨论可以见『J2EE核心模式』一书。他的分层是客户层(Client),表示层(Presentation),业务层(Business ),整合层(Integration),资源层(Resource)。差别如下图:
J2EE核心 ISA
客户层 运行在客户机上的表示层
表示层 运行在服务器上的表示层
业务层 领域层
整合层 基础架构层
资源层 基础架构层通信的外部数据
微软的DNA架构定义了三个层:表示层(presentation),业务层(business),和数据存储层(data access),这和我的架构相似,但是在数据的传递方式上还有很大的不同。在微软的DNA中,各层的操作都基于数据存储层传出的SQL查询结果集。这样的话,实际上是增加了表示层和业务层同数据存储层之间的耦合度。 DNA的记录集在层之间的动作类似于Data Transfer Object。
Part 2 组织领域逻辑
要组织基于层的系统,首要的是如何组织领域逻辑。领域逻辑的组织有好几种模式。但其中最重要的莫过于两种方法:Transation Script和Domain Model。选定了其中的一种,其它的都容易决定。不过,这两者之间并没有一条明显的分界线。所以如何选取也是门大学问。一般来说,我们认为领域逻辑比较复杂的系统可以采用Domain Model。
Transation Script就是对表示层用户输入的处理程序。包括验证和计算,存储,调用其它系统的操作,把数据回传给表示层。用户的一个动作表示一个程序,这个程序可 以是script,也可以是transation,也可以是几个子程序。在例子1中,检验,在购物车中增加一本书,显示递送状态,都可以是一个 Transation Script。
Domain Model是要建立对应领域名词的模型,例如例1中的书、购物车等。检验、计算等处理都放到领域模型中。
Transation Script属于结构性思维,Domain Model属于OO思维。Domain Model比较难使用,一旦习惯,你能够组织更复杂的逻辑,你的思想会更OO。到时候,即使是小的系统,你也会自然的使用Domain Model了。
但如何抉择呢?如果逻辑复杂,那肯定用Domain Model:如果只需要存取数据库,那Transation Script会好一些。但是需求是在不断进化的,你很难保证以后的需求还会如此简单。如果你的团队不善于使用Domain Model,那你需要权衡一下投入产出比。另外,即使是Transation Script,也可以做到把逻辑和基础架构分开,你可以使用Gateway。
对例2,毫无疑问要使用Domain Model。对例1就需要权衡了。而对于例3,你很难说它将来会不会像例2那样,你现在可以使用Transation Script,但未来你可能要使用Domain Model。所以说,架构的决策是至关紧要的。
除了这两种模式,还有其它中庸的模式。Use Case Controller就是处于两者之间。只有和单个的用例相关的业务逻辑才放到对象中。所以大致上他们还是在使用Transation Script,而Domain Model只是Database Gateway的一组集合而已。我不太用这种模式。
Table Module是另一个中庸模式。很多的GUI环境依托于SQL查询的返回结果。你可以建立内存中的对象,来把GUI和数据库分开来。为每个表写一个模块,因此每一行都需要关键字变量来识别每一个实例。
Table Module适用于很多的组件构建于一个通用关系型数据库之上,而且领域逻辑不太复杂的情况。Microsoft COM 环境,以及它的带ADO.NET的.NET环境都适合使用这种模式。而对于Java,就不太适用了。
领域逻辑的一个问题是领域对象非常的臃肿。因为对象的行为太多了,类也就太大了。它必须是一个超集。这就要考虑哪些行为是通用的,哪些不是,可以由其它的类来处理,可能是Use Case Controller,也可能是表示层。
还有一个问题,复制。他会导致复杂和不一致。这比臃肿的危害更大。所以,宁可臃肿,也不要复制。等到臃肿为害时再处理它吧。
选择一个地方运行领域逻辑
我们的精力集中在逻辑层上。领域逻辑要么运行在Client上,要么运行在Server上。
比较简单的做法是全部集中在Server上。这样你需要使用html的前端以及web server。这样做的好处是升级和维护都非常的简单,你也不用考虑桌面平台和Server的同步问题,也不用考虑桌面平台的其它软件的兼容问题。
运行在Client适合于要求快速反应和没有联网的情况。在Server端的逻辑,用户的一个再小的请求,也需要信息从Client到Server绕一圈。反应的速度必然慢。再说,网络的覆盖程度也不是说达到了100%。
对于各个层来说,又是怎么样的呢?
基础架构层:一般都是在Server啦,不过有时候也会把数据复制到合适的高性能桌面机,但这是就要考虑同步的问题了。
表示层在何处运行取决于用户界面的设计。一个Windows界面只能在Client运行。而一个Web界面就是在Server运行。也有特别的例子,在桌面机上运行web server的,例如X Server。但这种情况少的多。
在例1中,没有更多的选择了,只能选在Server端。因此你的每一个bit都会绕一个大圈子。为了提高效率,尽量使用一些纯html脚本。
人们选用Windows界面的原因主要就是需要执行一些非常复杂的任务,需要一个合适的应用程序,而web GUI则无法胜任。这就是例2的做法。不过,人们应该会渐渐适应web GUI,而web GUI的功能也会越来越强大。
剩下的是领域逻辑。你可以全部放在Server,也可以全部放在Client,或是两边都放。
如果是在Client端,你可以考虑全部逻辑都放在Client端,这样至少保证所有的逻辑都在一个地方。而把web server移至Client,是可以解决没有联网的问题,但对反应时间不会有多大的帮助。你还是可以把逻辑和表示层分离开来。当然,你需要额外的升级和维护的工作。
在Client和Server端都具有逻辑并不是一个好的处理办法。但是对于那些仅有一些领域逻辑的情况是适用的。有一个小窍门,把那些和系统的其它部分没有联系的逻辑封装起来。 领域逻辑的接口
你的Server上有一些领域逻辑,要和Client通信,你应该有什么样的接口呢?要么是一个http接口,要么是一个OO接口。
http接口适用于web browser,就是说你要选择一个html的表示层。最近的新技术就是web service,通过基于http、特别是XML进行通信。XML有几个好处:通信量大,结构好,仅需一次的回路。这样远程调用的的开销就小了。同时,XML还是一个标准,支持平台异构。XML又是基于文本的,能够通过防火墙。
虽然XML有那么多的好处,不过一个OO的接口还是有它的价值的。hhtp的接口不明显,不容易看清楚数据是如何处理的。而OO的接口的方法带有变量和名字,容易看出处理的过程。当然,它无法通过防火墙,但可以提供安全和事务之类的控制。
最好的还是取二者所长。OO接口在下,http接口在上。但这样做就会使得实现机制非常的复杂。
Part 3 组织web Server
很多使用html方式的人,并不能真正理解这种方式的优点。我们有各种各样好用的工具,但是却搞到让程序难以维护。
在web server上组织程序的方式大致可以分为两种:脚本和server page。
脚本方式就是一个程序,用函数和方法来处理http调用。例如CGI脚本和java servlet。它和普通的程序并没有什么两样。它从web页面上获得html string形态的数据,有时候还要做一些表达式匹配,这正是perl能够成为CGI脚本的常用语言的原因。而java servelet则是把这种分析留给程序员,但它允许程序员通过关键字接口来访问信息,这样就会少一些表达式的判断。这种格式的web server输出是另一种html string,称为response,可以通过流数据来操作。
糟糕的是流数据是非常麻烦的,因此就导致了server page的产生,例如PHP,ASP,JSP。
server page的方式适合回应(response)的处理比较简单的情况。例如“显示歌曲的明细”,但是你的决策取决于输入的时候,就会比较杂乱。例如“通俗和摇滚的显示格式不同”。
脚步擅长于处理用户交互,server page擅长于处理格式化回应信息。所以很自然的就会采用脚本处理请求的交互,使用server page处理回应的格式化。这其实就是著名的MVC(Model View Controller)模式中的view/controller的处理。
应用Model View Controller模式首要的一点就是模型要和web服务完全分离开来。使用Transaction Script或Domain Model模式来封装处理流程。
接下来,我们就把剩余的模式归入两类模式中:属于Controller的模式,以及属于View的模式。
View模式
View这边有三种模式:Transform View,Template View和Two Step View。Transform View和Template View的处理只有一步,将领域数据转换为html。Two Step View要经过两步的处理,第一步把领域数据转换为逻辑表示形式,第二步把逻辑表示转换为html。
两步处理的好处是可以将逻辑集中于一处,如果只有一步,变化发生时,你就需要修改每一个屏幕。但这需要你有一个很好的逻辑屏幕结构。如果一个web应用有很多的前端用户时,两步处理就特别的好用。例如航空订票系统。使用不同的第二步处理,就可以获得不同的逻辑屏幕。
使用单步方法有两个可选的模式:Template View,Transform View。Template View其时就是把代码嵌入到html页面中,就像现在的server page技术,如ASP,PHP,JSP。这种模式灵活,强大,但显得杂乱无章。如果你能够把逻辑程序逻辑在页面结构之外进行很好的组织,这种模式还是有它的优点的。
Transform View使用翻译方式。例如XSLT。如果你的领域数据是用XML处理的,那这种模式就特别的好用。
Controller模式
Controller有两种模式。一般我们会根据动作来决定一项控制。动作可能是一个按钮或链接。所这种模式就是Action Controller模式。
Front Controller更进一步,它把http请求的处理和处理逻辑分离开来。一般是只有一个web handle来处理所有的请求。你的所有的http请求的处理都由一个对象来负责。你改变动作结构的影响就会降到最小。
posted @
2007-06-08 19:32 我爱佳娃 阅读(1191) |
评论 (1) |
编辑 收藏
文章在这里
可参考:
http://www-900.ibm.com/developerWorks/cn/xml/x-injava/index.shtml
http://www-900.ibm.com/developerWorks/cn/xml/x-injava2/index.shtml
结论是:DOM4J是这场测试的获胜者,目前许多开源项目中大量采用 DOM4J
其实我认为归根结底就是两种技术:DOM和SAX
DOM是一次性把XML读进内存,构造Document对象,然后可以以任何规则来解析文件,也可以做响应修改,处理比较灵活。但是DOM比较消耗内存,不能处理太大的文件。主流的DOM有JDOM,DOM4J;
SAX是一个事件驱动的解析器,是逐句读文件,触发事件,执行操作。但是它只能解析,不能对XML文件修改。
posted @
2007-06-08 18:55 我爱佳娃 阅读(774) |
评论 (0) |
编辑 收藏
完整文章在这里
文章写得比较易懂清晰,最后倾向于用HTTP Invoker,是轻量级的易于安装而灵活的方案,但它只在通信两边都是SPRING时适用。
要点如下:
每一种远程技术都有其优点与不足,表格1对它们进行了简单的对比。
按框架 优点 缺点分述如下:
RMI
全面支持Java对象串行化。因此,你能够通过网络发送复杂数据类型。
RMI仅是一种Java到Java型远程方案。如果你拥有任何非Java客户端的话,那么你无法使用它。另外,你还无法通过HTTP协议存取对象,除非你有专门的“通道”实现RMI通讯。注意,它需要一个RMI编译器(为了生成代理和框架)和一个外部注册表(用于查询服务)。
Hessian/Burlap
跨防火墙工作良好
它们使用一种专利对象串行化机制。其中,Burlap仅支持Java客户端。它们能够串行化Hibernate对象,但是对集合对象执行“惰式”加载。
HTTP Invoker
基于HTTP的Java到Java Remoting;通过HTTP实现Java串行化;容易建立。
服务器和客户端应用程序都需要使用Spring。
仅是一种Java方案。
EJB
支持Remoting J2EE服务,应用程序安全以及事务处理
EJB是一种重量级技术。它要求使用一个J2EE容器。
Web服务
平台和语言独立
要付出SOAP操作所带来的开销,并且要求使用一个Web服务引擎。
表格1:各种Spring Remoting技术优缺点比较
如你所见,每一种Spring Remoting技术都有各自的优缺点,但是大多数实际的应用程序都会要求使用一种轻量级Remoting技术。当实现远程服务时,使用例如EJB这样的重量级远程组件模型需要其它额外的开销。通常情况下,使用一种支持对象串行化能力的HTTP服务就足够了。
posted @
2007-06-08 18:53 我爱佳娃 阅读(846) |
评论 (0) |
编辑 收藏被强制更新了ie7,英文字体非常不心惯,可以通过以下方法恢复:
关闭cleartype的效果:
工具-internat选项-高级-多媒体-总是将cleartype应用于html,把钩去掉。
posted @
2007-06-05 17:27 我爱佳娃 阅读(576) |
评论 (0) |
编辑 收藏最近通过搜索发现建立TreeV3时候,方便的加载图标方法:在这里
但是有个问题,想在程序里动态修改它却没有函数,经过研究代码发现可以用如下简单方法实现:
取得之前定义的TreeDocIconExtension的引用:
var treeicons = dojo.widget.manager.getWidgetById("phyTreedocIcons");
改变TreeNodeV3的TYPE值为CSS文件定义过的项目:
node.nodeDocType = 3;
最关键是要去刷新iconNode的innerHTML,调用如下:
treeicons.setnodeDocTypeClass (node);
已经实验通过。这样就可以方便的根据后台数据刷新节点状态,而不必重建树节点。
posted @
2007-06-02 12:06 我爱佳娃 阅读(1304) |
评论 (0) |
编辑 收藏转录自:这里
并实验通过。
TreeV3支持节点图标, 因为和老版本的使用方式大相径庭, 而且没有文档, 所以给升级到V3的developer造成一定的困扰. 我利用google, 并分析了源代码后找到了方法.
在TreeV3中加入图标的方法如下:
首先定义一个widget:
<div dojoType="TreeDocIconExtension" widgetId="docIcons"></div>
并给tree加入一个名为"docIcons"的listener:
<div dojoType="TreeV3" listeners="link;selector;docIcons;treeController;menu">
在定义节点时需要加入一个属性"nodeDocType", 如:
<div dojoType="TreeNodeV3" title="nodetitle" nodeDocType="nodetype1" ></div>
最后给每一个nodedoctype定义一个名为".TreeIconXXXX"的style, 这里的XXXX就是给节点定义的nodeDoctype的名字:
<style>
.TreeIconnodetype1{
background-image: url('icon.gif');
}
</style>
posted @
2007-06-01 17:37 我爱佳娃 阅读(1720) |
评论 (1) |
编辑 收藏$self->{net_server}就是Multiplex,为了能够实现多态调用(在父类中调用实现子类的方法,PERL中使用SUPER实现),又定义了:
Net::Server::Multiplex::MUX
每有一个新连接,会NEW一个这样的对象进行管理。
而封装的IO::Multiplex对象是存在:$self->{net_server}->{mux}中。
posted @
2007-05-29 11:11 我爱佳娃 阅读(334) |
评论 (0) |
编辑 收藏Jetty启动后,如果修改javascript文件,将不能保存,使调试很麻烦。这是因为使用了CACHE,JETTY说是WINDOWS下的一个限制。可以通过如下方法修正:
解压出jetty.jar中的org/mortbay/jetty/webapp/webdefault.xml文件,将这一选项由true改为false,另存到src/main/resources目录,或者其它自选目录。
<init-param> <param-name>useFileMappedBuffer</param-name> <param-value>true</param-value> <!-- change to false --> </init-param>
在pom.xml中加入对这个文件的指向:
<plugin>
<groupId>org.mortbay.jetty</groupId>
<artifactId>maven-jetty-plugin</artifactId>
<configuration>
<webDefaultXml>src/main/resources/webdefault.xml</webDefaultXml>
</configuration>
</plugin>
本人已经验证通过。
问题描述,点这里。
posted @
2007-05-27 16:50 我爱佳娃 阅读(5620) |
评论 (0) |
编辑 收藏
随着AJAX的普遍应用,客户端的开发也要走向面向对象,面向模式的开发范畴。
看到一篇文章(附文链接见后),着重归纳一种开发模式:
一页就是一个“应用程序”,一个系统可能有好几个这样的应用程序;
用JSF或者STRUTS形成各“应用程序”的第一页;
其中,每一页含有:
controller.js负责:(这是CONTROLLER)
接来自页面的调用,通过AJAX封装包(如JSON-RPC或者DWR)调用系统服务;
因为要异步响应,需要安排CALLBACK;
在CALLBACK中,调用VIEW及MODEL的维护
datacopy.js负责:(这是MODEL)
保存数据模型,并由CONTROLLER来更新
render.js负责:(这是VIEW)
听从CONTROLLER调用,通过取MODEL的数据,建立widgets,刷新页面
原文来自,
这里。
另外,有关JS的面向对象编程<<javascript权威指南>>一书讲的相当不错,我简单的与C++比较了一下,
请点这里。
posted @
2007-05-26 10:56 我爱佳娃 阅读(1362) |
评论 (0) |
编辑 收藏多行注释:
perl没有多行注释,可以用下面代替:
=pod
代码行;
.
.
.
代码行;
=cut
关于ref函数:
ref EXPR
ref Returns a non-empty string if EXPR is a reference, the empty
string otherwise. If EXPR is not specified, $_ will be used. The
value returned depends on the type of thing the reference is a
reference to. Builtin types include:
SCALAR
ARRAY
HASH
CODE
REF
GLOB
LVALUE
If the referenced object has been blessed into a package, then
that package name is returned instead. You can think of "ref" as
a "typeof" operator.
讲类的段落,比较明了:
Object Construction
All objects are references, but not all references are objects. A reference won't work as an object unless its referent is specially marked to tell Perl what package it belongs to. The act of marking a referent with a package name--and therefore, its class, since a class is just a package--is known as blessing. You can think of the blessing as turning a reference into an object, although it's more accurate to say that it turns the reference into an object reference.
The bless function takes either one or two arguments. The first argument is a reference and the second is the package to bless the referent into. If the second argument is omitted, the current package is used.
$obj = { }; # Get reference to anonymous hash.
bless($obj); # Bless hash into current package.
bless($obj, "Critter"); # Bless hash into class Critter.
Here we've used a reference to an anonymous hash, which is what people usually use as the data structure for their objects. Hashes are extremely flexible, after all. But allow us to emphasize that you can bless a reference to anything you can make a reference to in Perl, including scalars, arrays, subroutines, and typeglobs. You can even bless a reference to a package's symbol table hash if you can think of a good reason to. (Or even if you can't.) Object orientation in Perl is completely orthogonal to data structure.
Once the referent has been blessed, calling the built-in ref function on its reference returns the name of the blessed class instead of the built-in type, such as HASH. If you want the built-in type, use the reftype function from the attributes module. See use attributes in Chapter 31, "Pragmatic Modules".
And that's how to make an object. Just take a reference to something, give it a class by blessing it into a package, and you're done. That's all there is to it if you're designing a minimal class. If you're using a class, there's even less to it, because the author of a class will have hidden the bless inside a method called a constructor, which creates and returns instances of the class. Because bless returns its first argument, a typical constructor can be as simple as this:
package Critter;
sub spawn { bless {}; }
Or, spelled out slightly more explicitly:
package Critter;
sub spawn {
my $self = {}; # Reference to an empty anonymous hash
bless $self, "Critter"; # Make that hash a Critter object
return $self; # Return the freshly generated Critter
}
With that definition in hand, here's how one might create a Critter object:
$pet = Critter->spawn;
12.4.1. Inheritable Constructors
Like all methods, a constructor is just a subroutine, but we don't call it as a subroutine. We always invoke it as a method--a class method, in this particular case, because the invocant is a package name. Method invocations differ from regular subroutine calls in two ways. First, they get the extra argument we discussed earlier. Second, they obey inheritance, allowing one class to use another's methods.
We'll describe the underlying mechanics of inheritance more rigorously in the next section, but for now, some simple examples of its effects should help you design your constructors. For instance, suppose we have a Spider class that inherits methods from the Critter class. In particular, suppose the Spider class doesn't have its own spawn method. The following correspondences apply:
Method Call Resulting Subroutine Call
Critter->spawn() Critter::spawn("Critter")
Spider->spawn() Critter::spawn("Spider")
The subroutine called is the same in both cases, but the argument differs. Note that our spawn constructor above completely ignored its argument, which means our Spider object was incorrectly blessed into class Critter. A better constructor would provide the package name (passed in as the first argument) to bless:
sub spawn {
my $class = shift; # Store the package name
my $self = { };
bless($self, $class); # Bless the reference into that package
return $self;
}
Now you could use the same subroutine for both these cases:
$vermin = Critter->spawn;
$shelob = Spider->spawn;
And each object would be of the proper class. This even works indirectly, as in:
$type = "Spider";
$shelob = $type->spawn; # same as "Spider"->spawn
That's still a class method, not an instance method, because its invocant holds a string and not a reference.
If $type were an object instead of a class name, the previous constructor definition wouldn't have worked, because bless needs a class name. But for many classes, it makes sense to use an existing object as the template from which to create another. In these cases, you can design your constructors so that they work with either objects or class names:
sub spawn {
my $invocant = shift;
my $class = ref($invocant) || $invocant; # Object or class name
my $self = { };
bless($self, $class);
return $self;
}
12.4.2. Initializers
Most objects maintain internal information that is indirectly manipulated by the object's methods. All our constructors so far have created empty hashes, but there's no reason to leave them empty. For instance, we could have the constructor accept extra arguments to store into the hash as key/value pairs. The OO literature often refers to such data as properties, attributes, accessors, member data, instance data, or instance variables. The section "Instance Variables" later in this chapter discusses attributes in more detail.
Imagine a Horse class with instance attributes like "name" and "color":
$steed = Horse->new(name => "Shadowfax", color => "white");
If the object is implemented as a hash reference, the key/value pairs can be interpolated directly into the hash once the invocant is removed from the argument list:
sub new {
my $invocant = shift;
my $class = ref($invocant) || $invocant;
my $self = { @_ }; # Remaining args become attributes
bless($self, $class); # Bestow objecthood
return $self;
}
This time we used a method named new for the class's constructor, which just might lull C++ programmers into thinking they know what's going on. But Perl doesn't consider "new" to be anything special; you may name your constructors whatever you like. Any method that happens to create and return an object is a de facto constructor. In general, we recommend that you name your constructors whatever makes sense in the context of the problem you're solving. For example, constructors in the Tk module are named after the widgets they create. In the DBI module, a constructor named connect returns a database handle object, and another constructor named prepare is invoked as an instance method and returns a statement handle object. But if there is no suitable context-specific constructor name, new is perhaps not a terrible choice. Then again, maybe it's not such a bad thing to pick a random name to force people to read the interface contract (meaning the class documentation) before they use its constructors.
Elaborating further, you can set up your constructor with default key/value pairs, which the user could later override by supplying them as arguments:
sub new {
my $invocant = shift;
my $class = ref($invocant) || $invocant;
my $self = {
color => "bay",
legs => 4,
owner => undef,
@_, # Override previous attributes
};
return bless $self, $class;
}
$ed = Horse->new; # A 4-legged bay horse
$stallion = Horse->new(color => "black"); # A 4-legged black horse
This Horse constructor ignores its invocant's existing attributes when used as an instance method. You could create a second constructor designed to be called as an instance method, and if designed properly, you could use the values from the invoking object as defaults for the new one:
$steed = Horse->new(color => "dun");
$foal = $steed->clone(owner => "EquuGen Guild, Ltd.");
sub clone {
my $model = shift;
my $self = $model->new(%$model, @_);
return $self; # Previously blessed by ->new
}
posted @
2007-05-24 15:31 我爱佳娃 阅读(8318) |
评论 (2) |
编辑 收藏Maven2代比1代改进很多,其中主要强调的是--它不仅仅是个依赖包管理器!
开始先要推荐一个专讲Maven2的电子书给大家,对MAVEN学习相当有助益:Better Builds with Maven
下面就专门介绍下Maven2对WEBAPP在管理和调试方面的支持。
1.创建项目
mvn archetype:create -DgroupId=com.mycompany.app -DartifactId=my-webapp -DarchetypeArtifactId=maven-archetype-webapp
也可参看这里
创建要注意遵循MAVEN的目录结构,尤其要注意源文件要放在main/java下:

2. POM文件的配置
这里要特别注意对resource一节的配置,因为我的SPRING以及WEB相关的XML是放在WEB-INF目录,为了在unit test的时候也能用,加入了对这些配置文件的引用。相当于加了一个classpath。
这里还有个插曲:不知为何MAVEN2里没有JTA的包,自动下载时会有提示教你如何手工通过命令加入,非常简单。
JETTY的plugin是为后面用它来调试做准备。
DWR也是目前WEB开发一个热选。
另外,为使用JAVA5代来编译,加入了maven-compiler-plugin一节。
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/maven-v4_0_0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.exchangebit.nms</groupId>
<artifactId>ebnms</artifactId>
<packaging>war</packaging>
<version>1.0-SNAPSHOT</version>
<name>ebnms Maven Webapp</name>
<url>http://maven.apache.org</url>
<build>
<finalName>ebnms</finalName>
<resources>
<resource>
<directory>src/main/java</directory>
<includes>
<include>**/*.xml</include>
</includes>
</resource>
<resource>
<directory>src/main/webapp/WEB-INF</directory>
<includes>
<include>**/*.xml</include>
<include>**/log4j.properties</include>
</includes>
</resource>
</resources>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<configuration>
<source>1.5</source>
<target>1.5</target>
</configuration>
</plugin>
<plugin>
<groupId>org.mortbay.jetty</groupId>
<artifactId>maven-jetty-plugin</artifactId>
</plugin>
</plugins>
</build>
<dependencies>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>3.8.1</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.hibernate</groupId>
<artifactId>hibernate</artifactId>
<version>3.1</version>
</dependency>
<dependency>
<groupId>log4j</groupId>
<artifactId>log4j</artifactId>
<version>1.2.11</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>3.1.11</version>
<scope>runtime</scope>
</dependency>
<dependency>
<groupId>javax.servlet</groupId>
<artifactId>servlet-api</artifactId>
<version>2.4</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>javax.servlet</groupId>
<artifactId>jstl</artifactId>
<version>1.1.2</version>
<scope>runtime</scope>
</dependency>
<dependency>
<groupId>taglibs</groupId>
<artifactId>standard</artifactId>
<version>1.1.2</version>
<scope>runtime</scope>
</dependency>
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring</artifactId>
<version>1.2.6</version>
</dependency>
<dependency>
<groupId>dwr</groupId>
<artifactId>dwr</artifactId>
<version>1.1.3</version>
</dependency>
</dependencies>
</project>
代码放入/main/java后,可以在项目目录下执行:
mvn compile来做编译尝试,
也可以用mvn war直接生成打包文件,
当然最后可以用 mvn jetty:run来运行你的WEBAPP!
3. 在Eclipse中配置jetty进行调试
要把之前的项目导入Eclipse首先让maven为我们生成Eclipse工程文件,执行:
mvn eclipse:eclipse
再把M2_REPO加入到Eclipse的classpath中,有两种方法,其中的b)方法是有效的:
a) mvn -Declipse.workspace=<path-to-eclipse-workspace> eclipse:add-maven-repo
b) Window > Preferences. Select the Java > Build Path > Classpath Variables page
之后,就可以通过Eclipse的File->Import功能将工程导入。
有人为了使用WEBAPP开发功能,而装象MYECLIPSE这样的巨物。有了JETTY,通过轻松配置就可以实现比TOMCAT更快更便捷的容器,所以在调试时强力推荐这个东东。下面就来看下如何配置。
先下配置一个外部工具,来运行JETTY:
选择菜单Run->External Tools->External Tools ...在左边选择Program,再点New:
配置Location为mvn完整命令行。
选择Working Directory为本项目。
Arguments填写:jetty:run
再点选Enviroment页:加入MAVEN_OPTS变量,值为:
-Xdebug -Xnoagent -Djava.compiler=NONE -Xrunjdwp:transport=dt_socket,address=4000,server=y,suspend=y
其中,如果suspend=n 表示不调试,直接运行。
然后,点APPLY,再关闭本对话框。
另外注意一点,好像external tool菜单项在java browering的perspective下才会出现。如果在java下看不见,可以切换下试试。
下面新建运行配置:
点选run->debug...
选中左树中的Remote Java Application,再点New。
选择你的项目,关键是要填和之前设置外部工具时相同的端口号。
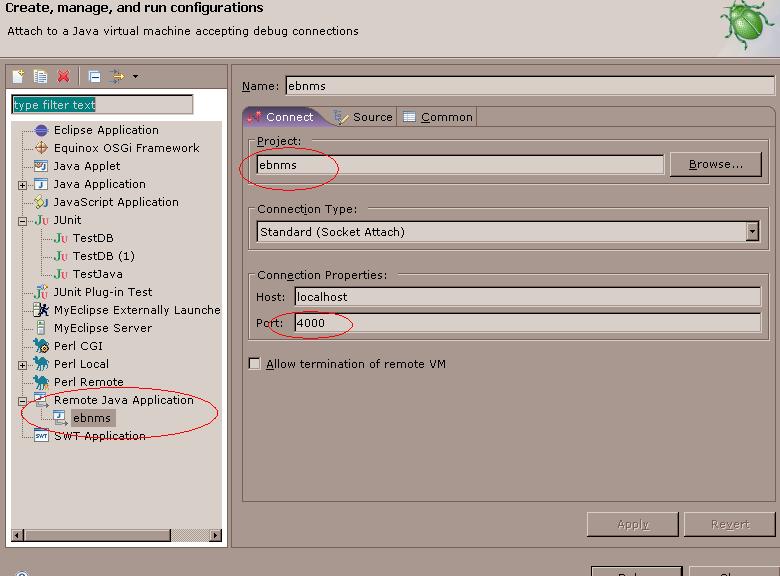
配置就完成了,正面开始调试运行:
首先要把JETTY运行起来(有点象TOMCAT里的运行APPSERVER),从Run->External Tools中选择之前配置的外部工具运行,这时LOG里会显示:
listening at port 4000字样,
再选择Run->Debug选择我们刚建的运行配置,这时程序就RUN起来了,可以通过WEB进行访问,设置断点调试了。
后记:
在ECLIPSE中,有更方便高效的调试方式,
点这里
posted @
2007-05-19 23:08 我爱佳娃 阅读(25813) |
评论 (4) |
编辑 收藏STEP 3:配置
打开/conf/目录,打开svnserve.conf找到一下两句:
# [general]
# password-db = passwd
去之每行开头的#,其中第二行是指定身份验证的文件名,即passwd文件
同样打开passwd文件,将
# [users]
# harry = harryssecret
# sally = sallyssecret
这几行的开头#字符去掉,这是设置用户,一行一个,存储格式为“用户名 = 密码”,如可插入一行:admin = admin888,即为系统添加一个用户名为admin,密码为admin888的用户
create it:
sc create svnservice binpath= "\"c:\program files\Subversion\bin\svnserve.exe\" --service -r D:\svn" displayname= "SVNService" depend= Tcpip
delete it:
sc delete svnservice
mysql:
C:\>
mysqld-nt --install C:\>
NET START MySql
C:\>
NET STOP MySql C:\>
mysqld-nt --remove
posted @
2007-05-16 22:38 我爱佳娃 阅读(614) |
评论 (0) |
编辑 收藏用C++和JS的类来类比如下:
C++ JS
类 一个function(也是一个对象,即名称-属性集合),因为它实际定义了一个类,所以又叫constructor
成员函数 constructor的属性prototype对象里定义,这样用constructor来new的对象都会继承它
成员 在constructor中用this.xxx赋值的一般属性
静态成员 直接function的名字"."赋值
多重继承 constructor.prototype = new SuperClass (),这样新定义的constructor的prototype继承了SuperClass的prototype,但要用constructor.prototype.constructor = constructor,把构造函数赋成新的constructor
所以说白了,JS的类就是一个函数对象。JS自动为它创建了属性prototype,可以被new出来的对象继承。
posted @
2007-05-13 18:01 我爱佳娃 阅读(631) |
评论 (0) |
编辑 收藏
例如:表示主机HOST含有多个磁盘DISK关系:
在PD的OOM中双击一条关系连线,设置Navigate,这样才会在各自hbm.xml中生成many-to-one及one-to-many关系。
另外,根据“附文”的效率说明还需要设置:由多方DISK维护关系,并且当HOST更新时,也要更新DISK。

生成的HBM.XML如下:
HOST的:
<joined-subclass name="Host" table="host" dynamic-update="false" dynamic-insert="false" select-before-update="false" lazy="true" abstract="false">
<key on-delete="noaction" unique="true">
<column name="dev_id" sql-type="int" not-null="true" length="0"/>
</key>
<array name="nic" optimistic-lock="true">
<key on-delete="noaction" unique="true">
<column name="dev_id" sql-type="int" not-null="false" length="0"/>
</key>
<list-index column="IndexColumnB"/>
<one-to-many class="eb.nms.db.Nic"/>
</array>
<set name="disk" outer-join="false"
inverse="true" lazy="true" optimistic-lock="true"
cascade="save-update">
<key on-delete="noaction" unique="true">
<column name="dev_id" sql-type="int" not-null="false" length="0"/>
</key>
<one-to-many class="eb.nms.db.Disk"/>
</set>
</joined-subclass>
DISK的:
<class name="Disk" table="disk" mutable="true" lazy="true" abstract="false">
<id name="diskId">
<column name="disk_id" sql-type="int" not-null="true"/>
<generator class="native">
</generator>
</id>
<property name="diskName" insert="true" update="true" optimistic-lock="true">
<column name="disk_name" sql-type="varchar(254)" length="254"/>
</property>
<many-to-one name="host" class="Host" outer-join="false" update="true" insert="true">
<column name="dev_id" sql-type="int" not-null="false" length="0"/>
</many-to-one>
</class>
附文:
|
在 多對一 、一對多 中都是單向關聯,也就是其中一方關聯到另一方,而另一方不知道自己被關聯。
如果讓雙方都意識到另一方的存在,這就形成了雙向關聯,在多對一、一對多的例子可以改寫一下,重新設計User類別如下:
package onlyfun.caterpillar;
public class User {
private Integer id;
private String name;
private Room room;
public User() {}
public Integer getId() {
return id;
}
public void setId(Integer id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public Room getRoom() {
return room;
}
public void setRoom(Room room) {
this.room = room;
}
}
Room類別如下:
package onlyfun.caterpillar;
import java.util.Set;
public class Room {
private Integer id;
private String address;
private Set users;
public Room() {}
public Integer getId() {
return id;
}
public void setId(Integer id) {
this.id = id;
}
public String getAddress() {
return address;
}
public void setAddress(String address) {
this.address = address;
}
public Set getUsers() {
return users;
}
public void setUsers(Set users) {
this.users = users;
}
public void addUser(User user) {
users.add(user);
}
public void removeUser(User user) {
users.remove(user);
}
}
如此,User實例可參考至Room實例而維持多對一關係,而Room實例記得User實例而維持一對多關係。
在映射文件方面,可以如下撰寫:
<?xml version="1.0" encoding="utf-8"?>
<!DOCTYPE hibernate-mapping
PUBLIC "-//Hibernate/Hibernate Mapping DTD 3.0//EN"
"http://hibernate.sourceforge.net/hibernate-mapping-3.0.dtd">
<hibernate-mapping>
<class name="onlyfun.caterpillar.User" table="user">
<id name="id" column="id" type="java.lang.Integer">
<generator class="native"/>
</id>
<property name="name" column="name" type="java.lang.String"/>
<many-to-one name="room"
column="room_id"
class="onlyfun.caterpillar.Room"
cascade="save-update"
outer-join="true"/>
</class>
</hibernate-mapping>
<?xml version="1.0" encoding="utf-8"?>
<!DOCTYPE hibernate-mapping
PUBLIC "-//Hibernate/Hibernate Mapping DTD 3.0//EN"
"http://hibernate.sourceforge.net/hibernate-mapping-3.0.dtd">
<hibernate-mapping>
<class name="onlyfun.caterpillar.Room" table="room">
<id name="id" column="id">
<generator class="native"/>
</id>
<property name="address"
column="address"
type="java.lang.String"/>
<set name="users" table="user" cascade="save-update">
<key column="room_id"/>
<one-to-many class="onlyfun.caterpillar.User"/>
</set>
</class>
</hibernate-mapping>
映射文件雙方都設定了cascade為save-update,所以您可以用多對一的方式來維持關聯:
User user1 = new User();
user1.setName("bush");
User user2 = new User();
user2.setName("caterpillar");
Room room1 = new Room();
room1.setAddress("NTU-M8-419");
user1.setRoom(room1);
user2.setRoom(room1);
Session session = sessionFactory.openSession();
Transaction tx = session.beginTransaction();
session.save(user1);
session.save(user2);
tx.commit();
session.close();
或是反過來由一對多的方式來維持關聯:
User user1 = new User();
user1.setName("bush");
User user2 = new User();
user2.setName("caterpillar");
Room room1 = new Room();
room1.setUsers(new HashSet());
room1.setAddress("NTU-M8-419");
room1.addUser(user1);
room1.addUser(user2);
Session session = sessionFactory.openSession();
Transaction tx = session.beginTransaction();
session.save(room1);
tx.commit();
session.close();
這邊有個效率議題可以探討,上面的程式片段Hibernate將使用以下的SQL進行儲存:
Hibernate: insert into room (address) values (?)
Hibernate: insert into user (name, room_id) values (?, ?)
Hibernate: insert into user (name, room_id) values (?, ?)
Hibernate: update user set room_id=? where id=?
Hibernate: update user set room_id=? where id=?
上面的程式寫法表示關聯由Room單方面維持,而主控方也是Room,User不知道Room的room_id是多少,所以必須分別儲存Room與 User之後,再更新user的room_id。
在一對多、多對一形成雙向關聯的情況下,可以將關聯維持的控制權交給多的一方,這樣會比較有效率,理由不難理解,就像是在公司中,老闆要記住多個員工的姓名快,還是每一個員工都記得老闆的姓名快。
所以在一對多、多對一形成雙向關聯的情況下,可以在「一」的一方設定控制權反轉,也就是當儲存「一」的一方時,將關聯維持的控制權交給「多」的一方,以上面的例子來說,可以設定Room.hbm.xml如下:
<?xml version="1.0" encoding="utf-8"?>
<!DOCTYPE hibernate-mapping
PUBLIC "-//Hibernate/Hibernate Mapping DTD 3.0//EN"
"http://hibernate.sourceforge.net/hibernate-mapping-3.0.dtd">
<hibernate-mapping>
<class name="onlyfun.caterpillar.Room" table="room">
<id name="id" column="id">
<generator class="native"/>
</id>
<property name="address"
column="address"
type="java.lang.String"/>
<set name="users" table="user" cascade="save-update" inverse="true">
<key column="room_id"/>
<one-to-many class="onlyfun.caterpillar.User"/>
</set>
</class>
</hibernate-mapping>
由於關聯的控制權交給「多」的一方了,所以直接儲存「一」方前,「多」的一方必須意識到「一」的存在,所以程式片段必須改為如下:
User user1 = new User();
user1.setName("bush");
User user2 = new User();
user2.setName("caterpillar");
Room room1 = new Room();
room1.setUsers(new HashSet());
room1.setAddress("NTU-M8-419");
room1.addUser(user1);
room1.addUser(user2);
// 多方必須意識到單方的存在
user1.setRoom(room1);
user2.setRoom(room1);
Session session = sessionFactory.openSession();
Transaction tx = session.beginTransaction();
session.save(room1);
tx.commit();
session.close();
上面的程式片段Hibernate將使用以下的SQL:
Hibernate: insert into room (address) values (?)
Hibernate: insert into user (name, room_id) values (?, ?)
Hibernate: insert into user (name, room_id) values (?, ?)
如果控制權交給另一方了,而另一方沒有意識到對方的存在的話會如何?試著將上面的程式片段中user1.setRoom(room1);與 user2.setRoom(room1);移去,執行之後,您會發現資料庫中room_id會出現null值,這種結果就好比在 多對一 中,您沒有分配給User一個Room,理所當然的,room_id會出現null。
|
posted @
2007-04-15 17:17 我爱佳娃 阅读(6450) |
评论 (0) |
编辑 收藏
http://macrochen.blogdriver.com/macrochen/687759.html
posted @
2007-04-15 15:06 我爱佳娃 阅读(891) |
评论 (0) |
编辑 收藏执行:New->Conceptual Data Model
编译完概念模型后,再通过CDM生成PDM和OOM,注意要先生成OOM,再生成PDM。
在3种模型都具备时,生成JAVA CODE时才会有*.hbm.xml文件:
执行:Tools->Generate Object-Oriented Model
在对话框中,选择Detail,勾选O/R Mapping,点击Enable Transformations,在多出来的选项卡Extended Model Definitions中的O/R Mapping页中选择Hibernate。
执行:Tools->Generate Physical Data Model
在对话框中,选择Detail,勾选O/R Mapping,点击Enable Transformations,在多出来的选项卡Extended Model Definitions中的O/R Mapping页中选择Hibernate。
再执行:Language->Generate Java Code
就会看见生成的JAVA代码和映射HBM.XML文件
这里只是刚刚摸索的一些步骤,如果有实际用过,或者有详细资料的XDJM,请回复出来共享下。多谢。
PD的帮助让人摸不着头脑。
这是最后结果:

posted @
2007-04-07 15:25 我爱佳娃 阅读(9880) |
评论 (11) |
编辑 收藏解决方案:针对windows xp
1. 运行gpedit.msc到组策略管理界面下,计算机配置--->Winsows设置----->安全设置--->本地策略--->用户权利指派,看看右边有一行:"拒绝从网络访问这台计算机 "看它的属性里有没有guest一项,若有,则删除.
2. 若还不行,在我的电脑窗口里 工具--->文件夹选项---->查看----->高级选项里有"使用简单文件共享" 打勾去掉,确定下去,.然后再访问.
3. 启用 Guest、修改安全策略允许Guest从网络访问、禁用3里面的安全策略或者给Guest
加个密码。
http://hi.baidu.com/zhangqiguang123/blog/item/00882ff440c6d3ee7609d7f3.html
posted @
2007-04-07 11:09 我爱佳娃 阅读(352) |
评论 (0) |
编辑 收藏
regex_t rt1_;
int cflags = RE_SYNTAX_AWK;
cflags &= ~REG_NOSUB;
if (regcomp (&rt1_, // match: Interesting ports on 10.45.8.12:
"([0-9]{1,2}|1[0-9][0-9]|2[0-4][0-9]|25[0-5])\\.([0-9]{1,2}|1[0-9][0-9]|2[0-4][0-9]|25[0-5])\\.([0-9]{1,2}|1[0-9][0-9]|2[0-4][0-9]|25[0-5])\\.([0-9]{1,2}|1[0-9][0-9]|2[0-4][0-9]|25[0-5])",
cflags) != 0)
{
ulogEx(ULOG_LL_WARNING, MESW_DEV_NM,MON_ULOG_MID,MON_ULOG_EC_TRACE,
"%s: reg comp error!\n\n", __func__);
}
static char ip [32];
regmatch_t rm [1];
memset (&rm, 0, sizeof rm);
if (0 == regexec (&rt1_, pline, 1, rm, 0))
{
strncpy (ip, &pline[rm[0].rm_so], rm[0].rm_eo-rm[0].rm_so+1);
ip [rm[0].rm_eo-rm[0].rm_so] = '\0';
return ip;
}
else
return NULL;
regfree (&rt1_);
posted @
2007-04-04 16:47 我爱佳娃 阅读(2703) |
评论 (0) |
编辑 收藏
摘要: 为了大家能更好使用象ECLIPSE这种“巨无霸”(且不断在增长)。网上看的可以优化XP的文章,并自己写了一个脚本文件来停止服务,避免大家一个个去改麻烦。我试了可以,大概停了10多个服务。但有问题别找我呀!俺也不懂的说。
停止不用的服务bat命令
Code highlighting produced by Actip...
阅读全文
posted @
2007-04-01 14:00 我爱佳娃 阅读(11667) |
评论 (2) |
编辑 收藏
摘要: http://blog.csdn.net/sunjavaduke/archive/2007/03/15/1530069.aspx
<target name="sh" depends="compile"> <exec command="sh ./runsvr.sh" failonerror="false"/> </target>...
阅读全文
posted @
2007-03-22 09:43 我爱佳娃 阅读(3286) |
评论 (0) |
编辑 收藏归纳一些网上取JAVA路径的方法:
注明:如果从ANT启动程序,this.getClass().getResource("")取出来的比较怪,直接用JAVA命令行调试就可成功。
得到classpath和当前类的绝对路径的一些方法
获得CLASSPATH之外路径的方法:
URL base = this.getClass().getResource(""); //先获得本类的所在位置,如/home/popeye/testjava/build/classes/net/
String path = new File(base.getFile(), "../../../"+name).getCanonicalPath(); //就可以得到/home/popeye/testjava/name
下面是一些得到classpath和当前类的绝对路径的一些方法。你可能需要使用其中的一些方法来得到你需要的资源的绝对路径。
1.FileTest.class.getResource("")
得到的是当前类FileTest.class文件的URI目录。不包括自己!
如:file:/D:/java/eclipse32/workspace/jbpmtest3/bin/com/test/
2.FileTest.class.getResource("/")
得到的是当前的classpath的绝对URI路径。
如:file:/D:/java/eclipse32/workspace/jbpmtest3/bin/
3.Thread.currentThread().getContextClassLoader().getResource("")
得到的也是当前ClassPath的绝对URI路径。
如:file:/D:/java/eclipse32/workspace/jbpmtest3/bin/
4.FileTest.class.getClassLoader().getResource("")
得到的也是当前ClassPath的绝对URI路径。
如:file:/D:/java/eclipse32/workspace/jbpmtest3/bin/
5.ClassLoader.getSystemResource("")
得到的也是当前ClassPath的绝对URI路径。
如:file:/D:/java/eclipse32/workspace/jbpmtest3/bin/
我推荐使用Thread.currentThread().getContextClassLoader().getResource("")来得到当前的classpath的绝对路径的URI表示法。
在Web应用程序中,我们一般通过ServletContext.getRealPath("/")方法得到Web应用程序的根目录的绝对路径。这样,我们只需要提供相对于Web应用程序根目录的路径,就可以构建出定位资源的绝对路径。
注意点:
1.尽量不要使用相对于System.getProperty("user.dir")当前用户目录的相对路径。这是一颗定时炸弹,随时可能要你的命。
2.尽量使用URI形式
的绝对路径资源。它可以很容易的转变为URI,URL,File对象。
3.尽量使用相对classpath的相对路径。不要使用绝对路径。使用上面ClassLoaderUtil类的public static URL getExtendResource(String relativePath)方法已经能够使用相对于classpath的相对路径定位所有位置的资源。
4.绝对不要使用硬编码的绝对路径。因为,我们完全可以使用ClassLoader类的getResource("")方法得到当前classpath的绝对路径。
使用硬编码的绝对路径是完全没有必要的!它一定会让你死的很难看!程序将无法移植!
如果你一定要指定一个绝对路径,那么使用配置文件,也比硬编码要好得多!
当然,我还是推荐你使用程序得到classpath的绝对路径来拼资源的绝对路径
posted @
2007-03-21 11:43 我爱佳娃 阅读(4757) |
评论 (2) |
编辑 收藏inverse,表示两个表的关系由谁维护。值为false的一方将维护这种关系。如下面多对多关系中,由HOST来维护它们之间的关系表hostalarmrule。
cascade,表示更新本表时,是否附带更新与其相关的其它表。如下面,更新HOST表,由于值为save-update,也会将rules增加或者更新到ALARMRULE表;但,删除HOST时,不会删除ALARMRULE表中数据。除非,其值为all。
<class name="db.Host" table="host" catalog="rw">
<set name="rules" inverse="false" table="hostalarmrule" cascade="save-update">
<key column="host_id"/>
<many-to-many class="db.Alarmrule" column="alarmrule_id"/>
</set>
</class>
<class name="db.Alarmrule" table="alarmrule" catalog="rw">
<set name="hosts" table="hostalarmrule" inverse="true">
<key column="alarmrule_id"/>
<many-to-many class="db.Host" column="host_id"/>
</set>
</class>
posted @
2007-03-13 21:17 我爱佳娃 阅读(470) |
评论 (0) |
编辑 收藏Dev-C++下基本数据类型学习小结
环境: Dev-C++ 4.9.6.0 (gcc/mingw32), 使用-Wall编译选项
基本类型包括字节型(char)、整型(int)和浮点型(float/double)。
定义基本类型变量时,可以使用符号属性signed、unsigned(对于char、int),和长度属性short、long(对
于int、double)对变量的取值区间和精度进行说明。
下面列举了Dev-C++下基本类型所占位数和取值范围:
符号属性 长度属性 基本型 所占位数 取值范围 输入符举例 输出符举例
-- -- char 8 -2^7 ~ 2^7-1 %c %c、%d、%u
signed -- char 8 -2^7 ~ 2^7-1 %c %c、%d、%u
unsigned -- char 8 0 ~ 2^8-1 %c %c、%d、%u
[signed] short [int] 16 -2^15 ~ 2^15-1 %hd
unsigned short [int] 16 0 ~ 2^16-1 %hu、%ho、%hx
[signed] -- int 32 -2^31 ~ 2^31-1 %d
unsigned -- [int] 32 0 ~ 2^32-1 %u、%o、%x
[signed] long [int] 32 -2^31 ~ 2^31-1 %ld
unsigned long [int] 32 0 ~ 2^32-1 %lu、%lo、%lx
[signed] long long [int] 64 -2^63 ~ 2^63-1 %I64d
unsigned long long [int] 64 0 ~ 2^64-1 %I64u、%I64o、%I64x
-- -- float 32 +/- 3.40282e+038 %f、%e、%g
-- -- double 64 +/- 1.79769e+308 %lf、%le、%lg %f、%e、%g
-- long double 96 +/- 1.79769e+308 %Lf、%Le、%Lg
几点说明:
1. 注意! 表中的每一行,代表一种基本类型。“[]”代表可省略。
例如:char、signed char、unsigned char是三种互不相同的类型;
int、short、long也是三种互不相同的类型。
可以使用C++的函数重载特性进行验证,如:
void Func(char ch) {}
void Func(signed char ch) {}
void Func(unsigned char ch) {}
是三个不同的函数。
2. char/signed char/unsigned char型数据长度为1字节;
char为有符号型,但与signed char是不同的类型。
注意! 并不是所有编译器都这样处理,char型数据长度不一定为1字节,char也不一定为有符号型。
3. 将char/signed char转换为int时,会对最高符号位1进行扩展,从而造成运算问题。
所以,如果要处理的数据中存在字节值大于127的情况,使用unsigned char较为妥当。
程序中若涉及位运算,也应该使用unsigned型变量。
4. char/signed char/unsigned char输出时,使用格式符%c(按字符方式);
或使用%d、%u、%x/%X、%o,按整数方式输出;
输入时,应使用%c,若使用整数方式,Dev-C++会给出警告,不建议这样使用。
5. int的长度,是16位还是32位,与编译器字长有关。
16位编译器(如TC使用的编译器)下,int为16位;32位编译器(如VC使用的编译器cl.exe)下,int为32
位。
6. 整型数据可以使用%d(有符号10进制)、%o(无符号8进制)或%x/%X(无符号16进制)方式输入输出。
而格式符%u,表示unsigned,即无符号10进制方式。
7. 整型前缀h表示short,l表示long。
输入输出short/unsigned short时,不建议直接使用int的格式符%d/%u等,要加前缀h。
这个习惯性错误,来源于TC。TC下,int的长度和默认符号属性,都与short一致,
于是就把这两种类型当成是相同的,都用int方式进行输入输出。
8. 关于long long类型的输入输出:
"%lld"和"%llu"是linux下gcc/g++用于long long int类型(64 bits)输入输出的格式符。
而"%I64d"和"%I64u"则是Microsoft VC++库里用于输入输出__int64类型的格式说明。
Dev-C++使用的编译器是Mingw32,Mingw32是x86-win32 gcc子项目之一,编译器核心还是linux下的gcc。
进行函数参数类型检查的是在编译阶段,gcc编译器对格式字符串进行检查,显然它不认得"%I64d",
所以将给出警告“unknown conversion type character `I' in format”。对于"%lld"和"%llu",gcc理
所当然地接受了。
Mingw32在编译期间使用gcc的规则检查语法,在连接和运行时使用的却是Microsoft库。
这个库里的printf和scanf函数当然不认识linux gcc下"%lld"和"%llu",但对"%I64d"和"%I64u",它则是
乐意接受,并能正常工作的。
9. 浮点型数据输入时可使用%f、%e/%E或%g/%G,scanf会根据输入数据形式,自动处理。
输出时可使用%f(普通方式)、%e/%E(指数方式)或%g/%G(自动选择)。
10. 浮点参数压栈的规则:float(4 字节)类型扩展成double(8 字节)入栈。
所以在输入时,需要区分float(%f)与double(%lf),而在输出时,用%f即可。
printf函数将按照double型的规则对压入堆栈的float(已扩展成double)和double型数据进行输出。
如果在输出时指定%lf格式符,gcc/mingw32编译器将给出一个警告。
11. Dev-C++(gcc/mingw32)可以选择float的长度,是否与double一致。
12. 前缀L表示long(double)。
虽然long double比double长4个字节,但是表示的数值范围却是一样的。
long double类型的长度、精度及表示范围与所使用的编译器、操作系统等有关。
posted @
2007-01-23 14:29 我爱佳娃 阅读(3319) |
评论 (2) |
编辑 收藏
看了几篇中英文的AJAX库/框架比较文章,为方便选择使用,特归纳如下:
首先,要在两个类别中选择,一个是编译类,一个是非编译类别。
Echo2/GWT是将JAVA代码编译成JAVASCRIPT,乍看很方便,不用掌握JS也能做出炫目界面。但这只适于不会或者不想了解JS的情况,对于还是想完全控制和定制界面的项目就不适合。
另外,有一种观点认为JAVA->JS转换是一种低级语言向高级语言转换,本身没有意义。有点像去学汇编,然后再找个工具把汇编语言代码转换成C代码来用。我虽然没完全想通这个观点,不过,我一直用C/C++,这几年才逐渐发现JAVA确实是一种进化。没准别人说的是对的呢?
在Echo2和GWT中,GWT大部分工作是在客户端,尽量少跟SERVER打交道,适合大型网站运用;ECHO2信奉“用到才加载”的信条,所以会有大量向SERVER的访问,适合企业应用。另外,个人觉得ECHO2是个更全面的的一站式框架,界面也非常炫。但它的开发工具要收费。
再谈非编译类别,它们包括DOJO、PROTOTYPE、JQEURY,下面一一介绍:
先说PROTOTYPE,它比较轻量极,能让你的代码更加简化。最经典莫过于“美圆函数”:
document.getElementById(’elementid’) 变成$(’elementid’)
它加强了JS语言的可开发性,降低了学习JS的门槛。
DOJO最吸引人的是它的事件系统和丰富的可定制组件。它可以用形如下面的语句为各种HTML元素加入事件:
dojo.event.connect(someNode, "onclick", doStuff);
正由于DOJO提供了强大功能,它分成了许多包,可以分别包含使用。
JQUERY也提供了美圆函数,它的插件系统也提供象DOJO的组件,但它没有PROTOTYPE那样简洁,也没有DOJO这么多的组件供使用,但它兼收两家优点,并且个头不大,文档也算完整,所以说它介乎于前述两者之间。
所以,如果你需要非常完整的工具组件请用DOJO,如果你想优化你的JS代码,提高书写技巧请用PROTOTYPE,如果你想两者兼顾就用JQUERY。
posted @
2007-01-05 17:24 我爱佳娃 阅读(10930) |
评论 (6) |
编辑 收藏