|
|
2008年7月7日
谨以此文庆祝清华建校108周年,及5字班本科毕业20周年 作者: Canonical 众所周知,计算机科学得以存在的基石是两个基本理论:图灵于1936年提出的图灵机理论和丘奇同年早期发表的Lambda演算理论。这两个理论奠定了所谓通用计算(Universal Computation)的概念基础,描绘了具有相同计算能力(图灵完备),但形式上却南辕北辙、大相径庭的两条技术路线。如果把这两种理论看作是上帝所展示的世界本源面貌的两个极端,那么是否存在一条更加中庸灵活的到达通用计算彼岸的中间路径? 自1936年以来,软件作为计算机科学的核心应用,一直处在不间断的概念变革过程中,各类程序语言/系统架构/设计模式/方法论层出不穷,但是究其软件构造的基本原理,仍然没有脱出两个基本理论最初所设定的范围。如果定义一种新的软件构造理论,它所引入的新概念本质上能有什么特异之处?能够解决什么棘手的问题? 本文中笔者提出在图灵机和lambda演算的基础上可以很自然的引入一个新的核心概念--可逆性,从而形成一个新的软件构造理论--可逆计算(Reversible Computation)。可逆计算提供了区别于目前业内主流方法的更高层次的抽象手段,可以大幅降低软件内在的复杂性,为粗粒度软件复用扫除了理论障碍。 可逆计算的思想来源不是计算机科学本身,而是理论物理学,它将软件看作是处于不断演化过程中的抽象实体, 在不同的复杂性层次上由不同的运算规则所描述,它所关注的是演化过程中产生的微小差量如何在系统内有序的传播并发生相互作用。 本文第一节将介绍可逆计算理论的基本原理与核心公式,第二节分析可逆计算理论与组件和模型驱动等传统软件构造理论的区别和联系,并介绍可逆计算理论在软件复用领域的应用,第三节从可逆计算角度解构Docker、React等创新技术实践。 一. 可逆计算的基本原理可逆计算可以看作是在真实的信息有限的世界中,应用图灵计算和lambda演算对世界建模的一种必然结果,我们可以通过以下简单的物理图像来理解这一点。 首先,图灵机是一种结构固化的机器,它具有可枚举的有限的状态集合,只能执行有限的几条操作指令,但是可以从无限长的纸带上读取和保存数据。例如我们日常使用的电脑,它在出厂的时候硬件功能就已经确定了,但是通过安装不同的软件,传入不同的数据文件,最终它可以自动产生任意复杂的目标输出。图灵机的计算过程在形式上可以写成 
与图灵机相反的是,lambda演算的核心概念是函数,一个函数就是一台小型的计算机器,函数的复合仍然是函数,也就是说可以通过机器和机器的递归组合来产生更加复杂的机器。lambda演算的计算能力与图灵机等价,这意味着如果允许我们不断创建更加复杂的机器,即使输入一个常数0,我们也可以得到任意复杂的目标输出。lambda演算的计算过程在形式上可以写成 
可以看出,以上两种计算过程都可以被表达为Y=F(X) 这样一种抽象的形式。如果我们把Y=F(X)理解为一种建模过程,即我们试图理解输入的结构以及输入和输出之间的映射关系,采用最经济的方式重建输出,则我们会发现图灵机和lambda演算都假定了现实世界中无法满足的条件。在真实的物理世界中,人类的认知总是有限的,所有的量都需要区分已知的部分和未知的部分,因此我们需要进行如下分解: 
重新整理一下符号,我们就得到了一个适应范围更加广泛的计算模式 
除了函数运算F(X)之外,这里出现了一个新的结构运算符⊕,它表示两个元素之间的合成运算,并不是普通数值意义上的加法,同时引出了一个新的概念:差量△。△的特异之处在于,它必然包含某种负元素,F(X)与△合并在一起之后的结果并不一定是“增加”了输出,而完全可能是“减少”。 在物理学中,差量△存在的必然性以及△包含逆元这一事实完全是不言而喻的,因为物理学的建模必须要考虑到两个基本事实: - 世界是“测不准”的,噪声永远存在
- 模型的复杂度要和问题内在的复杂度相匹配,它捕获的是问题内核中稳定不变的趋势及规律。
例如,对以下的数据 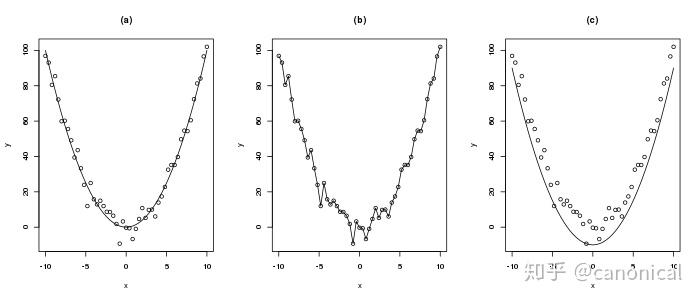 我们所建立的模型只能是类似图(a)中的简单曲线,图(b)中的模型试图精确拟合每一个数据点在数学上称之为过拟合,它难以描述新的数据,而图(c)中限制差量只能为正值则会极大的限制模型的描述精度。 以上是对Y=F(X)⊕△这一抽象计算模式的一个启发式说明,下面我们将介绍在软件构造领域落实这一计算模式的一种具体技术实现方案,笔者将其命名为可逆计算。 所谓可逆计算,是指系统化的应用如下公式指导软件构造的一种技术路线 
App : 所需要构建的目标应用程序
DSL: 领域特定语言(Domain Specific Language),针对特定业务领域定制的业务逻辑描述语言,也是所谓领域模型的文本表示形式
Generator : 根据领域模型提供的信息,反复应用生成规则可以推导产生大量的衍生代码。实现方式包括独立的代码生成工具,以及基于元编程(Metaprogramming)的编译期模板展开
Biz : 根据已知模型推导生成的逻辑与目标应用程序逻辑之间的差异被识别出来,并收集在一起,构成独立的差量描述
aop_extends: 差量描述与模型生成部分通过类似面向切面编程(Aspect Oriented Programming)的技术结合在一起,这其中涉及到对模型生成部分的增加、修改、替换、删除等一系列操作 DSL是对关键性领域信息的一种高密度的表达,它直接指导Generator生成代码,这一点类似于图灵计算通过输入数据驱动机器执行内置指令。而如果把Generator看作是文本符号的替换生成,则它的执行和复合规则完全就是lambda演算的翻版。差量合并在某种意义上是一种很新奇的操作,因为它要求我们具有一种细致入微、无所不达的变化收集能力,能够把散布系统各处的同阶小量分离出来并合并在一起,这样差量才具有独立存在的意义和价值。同时,系统中必须明确建立逆元和逆运算的概念,在这样的概念体系下差量作为“存在”与“不存在”的混合体才可能得到表达。 现有的软件基础架构如果不经过彻底的改造,是无法有效的实施可逆计算的。正如图灵机模型孕育了C语言,Lambda演算促生了Lisp语言一样,为了有效支持可逆计算,笔者提出了一种新的程序语言X语言,它内置了差量定义、生成、合并、拆分等关键特性,可以快速建立领域模型,并在领域模型的基础上实现可逆计算。 为了实施可逆计算,我们必须要建立差量的概念。变化产生差量,差量有正有负,而且应该满足下面三条要求: - 差量独立存在
- 差量相互作用
- 差量具有结构
在第三节中笔者将会以Docker为实例说明这三条要求的重要性。 可逆计算的核心是“可逆”,这一概念与物理学中熵的概念息息相关,它的重要性其实远远超出了程序构造本身,在可逆计算的方法论来源一文中,笔者会对它有更详细的阐述。 正如复数的出现扩充了代数方程的求解空间,可逆计算为现有的软件构造技术体系补充了“可逆的差量合并”这一关键性技术手段,从而极大扩充了软件复用的可行范围,使得系统级的粗粒度软件复用成为可能。同时在新的视角下,很多原先难以解决的模型抽象问题可以找到更加简单的解决方案,从而大幅降低了软件构造的内在复杂性。在第二节中笔者将会对此进行详细阐述。 软件开发虽然号称是知识密集性的工作,但到目前为止,众多一线程序员的日常中仍然包含着大量代码拷贝/粘贴/修改的机械化手工操作内容,而在可逆计算理论中,代码结构的修改被抽象为可自动执行的差量合并规则,因此通过可逆计算,我们可以为软件自身的自动化生产创造基础条件。笔者在可逆计算理论的基础上,提出了一个新的软件工业化生产模式NOP(Nop is nOt Programming),以非编程的方式批量生产软件。NOP不是编程,但也不是不编程,它强调的是将业务人员可以直观理解的逻辑与纯技术实现层面的逻辑相分离,分别使用合适的语言和工具去设计,然后再把它们无缝的粘接在一起。笔者将在另一篇文章中对NOP进行详细介绍。 可逆计算与可逆计算机有着同样的物理学思想来源,虽然具体的技术内涵并不一致,但它们目标却是统一的。正如云计算试图实现计算的云化一样,可逆计算和可逆计算机试图实现的都是计算的可逆化。 二. 可逆计算对传统理论的继承和发展软件的诞生源于数学家研究希尔伯特第十问题时的副产品,早期软件的主要用途也是数学物理计算,那时软件中的概念无疑是抽象的、数学化的。随着软件的普及,越来越多应用软件的研发催生了面向对象和组件化的方法论,它试图弱化抽象思维,转而贴近人类的常识,从人们的日常经验中汲取知识,把业务领域中人们可以直观感知的概念映射为软件中的对象,仿照物质世界的生产制造过程从无到有、从小到大,逐步拼接组装实现最终软件产品的构造。 像框架、组件、设计模式、架构视图等软件开发领域中耳熟能详的概念,均直接来自于建筑业的生产经验。组件理论继承了面向对象思想的精华,借助可复用的预制构件这一概念,创造了庞大的第三方组件市场,获得了空前的技术和商业成功,即使到今天仍然是最主流的软件开发指导思想。但是,组件理论内部存在着一个本质性的缺陷,阻碍了它把自己的成功继续推进到一个新的高度。 我们知道,所谓复用就是对已有的制成品的重复使用。为了实现组件复用,我们需要找到两个软件中的公共部分,把它分离出来并按照组件规范整理成标准形式。但是,A和B的公共部分的粒度是比A和B都要小的,大量软件的公共部分是比它们中任何一个的粒度都要小得多的。这一限制直接导致越大粒度的软件功能模块越难以被直接复用,组件复用存在理论上的极限。可以通过组件组装复用60%-70%的工作量,但是很少有人能超过80%,更不用说实现复用度90%以上的系统级整体复用了。 为了克服组件理论的局限,我们需要重新认识软件的抽象本质。软件是在抽象的逻辑世界中存在的一种信息产品,信息并不是物质。抽象世界的构造和生产规律与物质世界是有着本质不同的。物质产品的生产总是有成本的,而复制软件的边际成本却可以是0。将桌子从房间中移走在物质世界中必须要经过门或窗,但在抽象的信息空间中却只需要将桌子的坐标从x改为-x而已。抽象元素之间的运算关系并不受众多物理约束的限制,因此信息空间中最有效的生产方式不是组装,而是掌握和制定运算规则。 如果从数学的角度重新去解读面向对象和组件技术,我们会发现可逆计算可以被看作是组件理论的一个自然扩展。 - 面向对象 : 不等式 A > B
- 组件 : 加法 A = B + C
- 可逆计算 : 差量 Y = X + △Y
面向对象中的一个核心概念是继承:派生类从基类继承,自动具有基类的一切功能。例如老虎是动物的一种派生类,在数学上,我们可以说老虎(A)这个概念所包含的内容比动物(B)这个概念更多,老虎>动物(即A>B)。据此我们可以知道,动物这个概念所满足的命题,老虎自然满足, 例如动物会奔跑,老虎必然也会奔跑( P(B) -> P(A) )。程序中所有用到动物这一概念的地方都可以被替换为老虎(Liscov代换原则)。这样通过继承就将自动推理关系引入到软件领域中来,在数学上这对应于不等式,也就是一种偏序关系。 面向对象的理论困境在于不等式的表达能力有限。对于不等式A > B,我们知道A比B多,但是具体多什么,我们并没有办法明确的表达出来。而对于 A > B, D > E这样的情况,即使多出来的部分一模一样,我们也无法实现这部分内容的重用。组件技术明确指出"组合优于继承",这相当于引入了加法 
这样就可以抽象出组件C进行重用。 沿着上述方向推演下去,我们很容易确定下一步的发展是引入“减法”,这样才可以把 A = B + C看作是一个真正的方程,通过方程左右移项求解出 
通过减法引入的“负组件”是一个全新的概念,它为软件复用打开了一扇新的大门。 假设我们已经构建好了系统 X = D + E + F, 现在需要构建 Y = D + E + G。如果遵循组件的解决方案,则需要将X拆解为多个组件,然后更换组件F为G后重新组装。而如果遵循可逆计算的技术路线,通过引入逆元 -F, 我们立刻得到 
在不拆解X的情况下,通过直接追加一个差量△Y,即可将系统X转化为系统Y。 组件的复用条件是“相同方可复用”,但在存在逆元的情况下,具有最大颗粒度的完整系统X在完全不改的情况下直接就可以被复用,软件复用的范围被拓展为“相关即可复用”,软件复用的粒度不再有任何限制。组件之间的关系也发生了深刻的变化,不再是单调的构成关系,而成为更加丰富多变的转化关系。 Y = X + △Y 这一物理图像对于复杂软件产品的研发具有非常现实的意义。X可以是我们所研发的软件产品的基础版本或者说主版本,在不同的客户处部署实施时,大量的定制化需求被隔离到独立的差量△Y中,这些定制的差量描述单独存放,通过编译技术与主版本代码再合并到一起。主版本的架构设计和代码实现只需要考虑业务领域内稳定的核心需求,不会受到特定客户处偶然性需求的冲击,从而有效的避免架构腐化。主版本研发和多个项目的实施可以并行进行,不同的实施版本对应不同的△Y,互不影响,同时主版本的代码与所有定制代码相互独立,能够随时进行整体升级。 模型驱动架构(MDA)是由对象管理组织(Object Management Group,OMG)在2001年提出的软件架构设计和开发方法,它被看作是软件开发模式从以代码为中心向以模型为中心转变的里程碑,目前大部分所谓软件开发平台的理论基础都与MDA有关。 MDA试图提升软件开发的抽象层次,直接使用建模语言(例如Executable UML)作为编程语言,然后通过使用类似编译器的技术将高层模型翻译为底层的可执行代码。在MDA中,明确区分应用架构和系统架构,并分别用平台无关模型PIM(Platform Independent Model)和平台相关模型PSM(Platform Specific Model)来描述它们。PIM反映了应用系统的功能模型,它独立于具体的实现技术和运行框架,而PSM则关注于使用特定技术(例如J2EE或者dotNet)实现PIM所描述的功能,为PIM提供运行环境。 使用MDA的理想场景是,开发人员使用可视化工具设计PIM,然后选择目标运行平台,由工具自动执行针对特定平台和实现语言的映射规则,将PIM转换为对应的PSM,并最终生成可执行的应用程序代码。基于MDA的程序构造可以表述为如下公式 
MDA的愿景是像C语言取代汇编那样最终彻底消灭传统编程语言。但经历了这么多年发展之后,它仍未能够在广泛的应用领域中展现出相对于传统编程压倒性的竞争优势。 事实上,目前基于MDA的开发工具在面对多变的业务领域时,总是难掩其内在的不适应性。根据本文第一节的分析,我们知道建模必须要考虑差量。而在MDA的构造公式中,左侧的App代表了各种未知需求,而右侧的Transformer和PIM的设计器实际上都主要由开发工具厂商提供,未知=已知这样一个方程是无法持久保持平衡的。 目前,工具厂商的主要做法是提供大而全的模型集合,试图事先预测用户所有可能的业务场景。但是,我们知道“天下没有免费的午餐”,模型的价值在于体现了业务领域中的本质性约束,没有任何一个模型是所有场景下都最优的。预测需求会导致出现一种悖论: 模型内置假定过少,则无法根据用户输入的少量信息自动生成大量有用的工作,也无法防止用户出现误操作,模型的价值不明显,而如果反之,模型假定很多,则它就会固化到某个特定业务场景,难以适应新的情况。 打开一个MDA工具的设计器,我们最经常的感受是大部分选项都不需要,也不知道是干什么用的,需要的选项却到处找也找不到。 可逆计算对MDA的扩展体现为两点: - 可逆计算中Generator和DSL都是鼓励用户扩充和调整的,这一点类似于面向语言编程(Language-oriented programming)。
- 存在一个额外的差量定制机会,可以对整体生成结果进行精确的局部修正。
在笔者提出的NOP生产模式中,必须要包含一个新的关键组件:设计器的设计器。普通的程序员可以利用设计器的设计器快速设计开发自己的领域特定语言(DSL)及其可视化设计器,同时可以通过设计器的设计器对系统中的任意设计器进行定制调整,自由的增加或者删除元素。 面向切面(AOP)是与面向对象(OOP)互补的一种编程范式,它可以实现对那些横跨多个对象的所谓横切关注点(cross-cutting concern)的封装。例如,需求规格中可能规定所有的业务操作都要记录日志,所有的数据库修改操作都要开启事务。如果按照面向对象的传统实现方式,需求中的一句话将会导致众多对象类中陡然膨胀出现大量的冗余代码,而通过AOP, 这些公共的“修饰性”的操作就可以被剥离到独立的切面描述中。这就是所谓纵向分解和横向分解的正交性。 
AOP本质上是两个能力的组合: - 在程序结构空间中定位到目标切点(Pointcut)
- 对局部程序结构进行修改,将扩展逻辑(Advice)编织(Weave)到指定位置。
定位依赖于存在良好定义的整体结构坐标系(没有坐标怎么定位?),而修改依赖于存在良好定义的局部程序语义结构。目前主流的AOP技术的局限性在于,它们都是在面向对象的语境下表达的,而领域结构与对象实现结构并不总是一致的,或者说用对象体系的坐标去表达领域语义是不充分的。例如,申请人和审批人在领域模型中是需要明确区分的不同的概念,但是在对象层面却可能都对应于同样的Person类,使用AOP的很多时候并不能直接将领域描述转换为切点定义和Advice实现。这种限制反映到应用层面,结果就是除了日志、事务、延迟加载、缓存等少数与特定业务领域无关的“经典”应用之外,我们找不到AOP的用武之地。 可逆计算需要类似AOP的定位和结构修正能力,但是它是在领域模型空间中定义这些能力的,因而大大扩充了AOP的应用范围。特别是,可逆计算中领域模型自我演化产生的结构差量△能够以类似AOP切面的形式得到表达。 我们知道,组件可以标识出程序中反复出现的“相同性”,而可逆计算可以捕获程序结构的“相似性”。相同很罕见,需要敏锐的甄别,但是在任何系统中,有一种相似性都是唾手可得的,即动力学演化过程中系统与自身历史快照之间的相似性。这种相似性在此前的技术体系中并没有专门的技术表达形式。 通过纵向和横向分解,我们所建立的概念之网存在于一个设计平面当中,当设计平面沿着时间轴演化时,很自然的会产生一个“三维”映射关系:后一时刻的设计平面可以看作是从前一时刻的平面增加一个差量映射(定制)而得到,而差量是定义在平面的每一个点上的。这一图像类似于范畴论(Category Theory)中的函子(Functor)概念,可逆计算中的差量合并扮演了函子映射的角色。因此,可逆计算相当于扩展了原有的设计空间,为演化这一概念找到了具体的一种技术表现形式。 软件产品线理论源于一个洞察,即在一个业务领域中,很少有软件系统是完全独特的,大量的软件产品之间存在着形式和功能的相似性,可以归结为一个产品家族,把一个产品家族中的所有产品(已存在的和尚未存在的)作为一个整体来研究、开发、演进,通过科学的方法提取它们的共性,结合有效的可变性管理,就有可能实现规模化、系统化的软件复用,进而实现软件产品的工业化生产。 软件产品线工程采用两阶段生命周期模型,区分领域工程和应用工程。所谓领域工程,是指分析业务领域内软件产品的共性,建立领域模型及公共的软件产品线架构,形成可复用的核心资产的过程,即面向复用的开发(development for reuse)。而应用工程,其实质是使用复用来开发( development with reuse),也就是利用已经存在的体系架构、需求、测试、文档等核心资产来制造具体应用产品的生产活动。 卡耐基梅隆大学软件工程研究所(CMU-SEI)的研究人员在2008年的报告中宣称软件产品线可以带来如下好处: - 提升10倍以上生产率
- 提升10倍以上产品质量
- 缩减60%以上成本
- 缩减87%以上人力需求
- 缩减98%以上产品上市时间
- 进入新市场的时间以月计,而不是年
软件产品线描绘的理想非常美好:复用度90%以上的产品级复用、随需而变的敏捷定制、无视技术变迁影响的领域架构、优异可观的经济效益等等。它所存在的唯一问题就是如何才能做到?尽管软件产品线工程试图通过综合利用所有管理的和技术的手段,在组织级别策略性的复用一切技术资产(包括文档、代码、规范、工具等等),但在目前主流的技术体制下,发展成功的软件产品线仍然面临着重重困难。 可逆计算的理念与软件产品线理论高度契合,它的技术方案为软件产品线的核心技术困难---可变性管理带来了新的解决思路。在软件产品线工程中,传统的可变性管理主要是适配、替换和扩展这三种方式: 
这三种方式都可以看作是向核心架构补充功能。但是可复用性的障碍不仅仅是来自于无法追加新的功能,很多时候也在于无法屏蔽原先已经存在的功能。传统的适配技术等要求接口一致匹配,是一种刚性的对接要求,一旦失配必将导致不断向上传导应力,最终只能通过整体更换组件来解决问题。可逆计算通过差量合并为可变性管理补充了“消除”这一关键性机制,可以按需在领域模型空间中构建出柔性适配接口,从而有效的控制变化点影响范围。 可逆计算中的差量虽然也可以被解释为对基础模型的一种扩展,但是它与插件扩展技术之间还是存在着明显的区别。在平台-插件这样的结构中,平台是最核心的主体,插件依附于平台而存在,更像是一种补丁机制,在概念层面上是相对次要的部分。而在可逆计算中,通过一些形式上的变换,我们可以得到一个对称性更高的公式: 
如果把G看作是一种相对不变的背景知识,则形式上我们可以把它隐藏起来,定义一个更加高级的“括号”运算符,它类似于数学中的“内积”。在这种形式下,B和D是对偶的,B是对D的补充,而D也是对B的补充。同时,我们注意到G(D)是模型驱动架构的体现,模型驱动之所以有价值就在于模型D中发生的微小变化,可以被G放大为系统各处大量衍生的变化,因此G(D)是一种非线性变换,而B是系统中去除D所对应的非线性因素之后剩余的部分。当所有复杂的非线性影响因素都被剥离出去之后,最后剩下的部分B就有可能是简单的,甚至能够形成一种新的可独立理解的领域模型结构(可以类比声波与空气的关系,声波是空气的扰动,但是不用研究空气本体,我们就可以直接用正弦波模型来描述声波)。 A = (B,D)的形式可以直接推广到存在更多领域模型的情况 
因为B、D、E等概念都是某种DSL所描述的领域模型,因此它们可以被解释为A投影到特定领域模型子空间所产生的分量,也就是说,应用A可以被表示为一个“特征向量”(Feature Vector), 例如 
与软件产品线中常用的面向特征编程(Feature Oriented Programming)相比,可逆计算的特征分解方案强调领域特定描述,特征边界更加明确,特征合成时产生的概念冲突更容易处理。 特征向量本身构成更高维度的领域模型,它可以被进一步分解下去,从而形成一个模型级列,例如定义 ![D' \equiv [B,D]\ G'(D')\equiv B\oplus G(D)\\](https://www.zhihu.com/equation?tex=D%27+%5Cequiv+%5BB%EF%BC%8CD%5D%5C+G%27%28D%27%29%5Cequiv+B%5Coplus+G%28D%29%5C%5C)
, 并且假设D'可以继续分解 
,则可以得到 ![\begin{align} A &= B ⊕ G(D) \\ &= G'(D') \\ &= G'(M'(U'))\\ &= G'(M'([V,U])) \\ \end{align} \\](https://www.zhihu.com/equation?tex=%5Cbegin%7Balign%7D+A+%26%3D+B+%E2%8A%95+G%28D%29+%5C%5C+++%26%3D+G%27%28D%27%29+%5C%5C++%26%3D+G%27%28M%27%28U%27%29%29%5C%5C++%26%3D+G%27%28M%27%28%5BV%2CU%5D%29%29+%5C%5C++%5Cend%7Balign%7D+%5C%5C)
最终我们可以通过领域特征向量U'来描述D’,然后再通过领域特征向量D‘来描述原有的模型A。 可逆计算的这一构造策略类似于深度神经网络,它不再局限于具有极多可调参数的单一模型,而是建立抽象层级不同、复杂性层级不同的一系列模型,通过逐步求精的方式构造出最终的应用。 在可逆计算的视角下,应用工程的工作内容变成了使用特征向量来描述软件需求,而领域工程则负责根据特征向量描述来生成最终的软件。 三. 初露端倪的差量革命(一)DockerDocker是2013年由创业公司dotCloud开源的应用容器引擎,它可以将任何应用及其依赖的环境打包成一个轻量级、可移植、自包含的容器(Container),并据此以容器为标准化单元创造了一种新型的软件开发、部署和交付形式。 Docker一出世就秒杀了Google的亲儿子lmctfy (Let Me Contain That For You)容器技术,同时也把Google的另一个亲儿子Go语言迅速捧成了网红,之后Docker的发展 更是一发而不可收拾。2014年开始一场Docker风暴席卷全球,以前所未有的力度推动了操作系统内核的变革,在众多巨头的跟风造势下瞬间引爆容器云市场,真正从根本上改变了企业应用从开发、构建到部署、运行整个生命周期的技术形态。  Docker技术的成功源于它对软件运行时复杂性的本质性降低,而它的技术方案可以看作是可逆计算理论的一种特例。Docker的核心技术模式可以用如下公式进行概括 
Dockerfile是构建容器镜像的一种领域特定语言,例如 FROM ubuntu:16.04
RUN useradd --user-group --create-home --shell /bin/bash work
RUN apt-get update -y && apt-get install -y python3-dev
COPY . /app RUN make /app
ENV PYTHONPATH /FrameworkBenchmarks
CMD python /app/app.py
EXPOSE 8088
通过Dockerfile可以快速准确的描述容器所依赖的基础镜像,具体的构建步骤,运行时环境变量和系统配置等信息。 Docker应用程序扮演了可逆计算中Generator的角色,负责解释Dockerfile,执行对应的指令来生成容器镜像。 创造性的使用联合文件系统(Union FS),是Docker的一个特别的创新之处。这种文件系统采用分层的构造方式,每一层构建完毕后就不会再发生改变,在后一层上进行的任何修改都只会记录在自己这一层。例如,修改前一层的文件时会通过Copy-On-Write的方式复制一份到当前层,而删除前一层的文件并不会真的执行删除操作,而是仅在当前层标记该文件已删除。Docker利用联合文件系统来实现将多个容器镜像合成为一个完整的应用,这一技术的本质正是可逆计算中的aop_extends操作。 Docker的英文是码头搬运工人的意思,它所搬运的容器也经常被人拿来和集装箱做对比:标准的容器和集装箱类似,使得我们可以自由的对它们进行传输/组合,而不用考虑容器中的具体内容。但是这种比较是肤浅的,甚至是误导性的。集装箱是静态的、简单的、没有对外接口的,而容器则是动态的、复杂的、和外部存在着大量信息交互的。这种动态的复杂结构想和普通的静态物件一样封装成所谓标准容器,其难度不可同日而语。如果没有引入支持差量的文件系统,是无法构建出一种柔性边界,实现逻辑分离的。 Docker所做的标准封装其实虚拟机也能做到,甚至差量存储机制在虚拟机中也早早的被用于实现增量备份,Docker与虚拟机的本质性不同到底在什么地方?回顾第一节中可逆计算对差量三个基本要求,我们可以清晰的发现Docker的独特之处。 - 差量独立存在:Docker最重要的价值就在于通过容器封装,抛弃了作为背景存在(必不可少,但一般情况下不需要了解),占据了99%的体积和复杂度的操作系统层。应用容器成为了可以独立存储、独立操作的第一性的实体。轻装上阵的容器在性能、资源占用、可管理性等方面完全超越了虚胖的虚拟机。
- 差量相互作用:Docker容器之间通过精确受控的方式发生相互作用,可通过操作系统的namespace机制选择性的实现资源隔离或者共享。而虚拟机的差量切片之间是没有任何隔离机制的。
- 差量具有结构:虚拟机虽然支持增量备份,但是人们却没有合适的手段去主动构造一个指定的差量切片出来。归根结底,是因为虚拟机的差量定义在二进制字节空间中,而这个空间非常贫瘠,几乎没有什么用户可以控制的构造模式。而Docker的差量是定义在差量文件系统空间中,这个空间继承了Linux社区最丰富的历史资源。每一条shell指令的执行结果最终反映到文件系统中都是增加/删除/修改了某些文件,所以每一条shell指令都可以被看作是某个差量的定义。差量构成了一个异常丰富的结构空间,差量既是这个空间中的变换算符(shell指令),又是变换算符的运算结果。差量与差量相遇产生新的差量,这种生生不息才是Docker的生命力所在。
(二)React2013年,也就是Docker发布的同一年,Facebook公司开源了一个革命性的Web前端框架React。React的技术思想非常独特,它以函数式编程思想为基础,结合一个看似异想天开的虚拟DOM(Virtual DOM)概念,引入了一整套新的设计模式,开启了前端开发的新大航海时代。 class HelloMessage extends React.Component {
constructor(props) {
super(props);
this.state = { count: 0 };
this.action = this.action.bind(this);
}
action(){
this.setState(state => ({
count: state.count + 1
}));
},
render() {
return (
<button onClick={this.action}>
Hello {this.props.name}:{this.state.count}
</button>
);
}
}
ReactDOM.render(
<HelloMessage name="Taylor" />,
mountNode
);
React组件的核心是render函数,它的设计参考了后端常见的模板渲染技术,主要区别在于后端模板输出的是HTML文本,而React组件的Render函数使用类似XML模板的JSX语法,通过编译转换在运行时输出的是虚拟DOM节点对象。例如上面HelloMessage组件的render函数被翻译后的结果类似于 render(){
return new VNode("button", {onClick: this.action,
content: "Hello "+ this.props.name + ":" + this.state.count });
} 可以用以下公式来描述React组件: VDom = render(state) 当状态发生变化以后,只要重新执行render函数就会生成新的虚拟DOM节点,虚拟DOM节点可以被翻译成真实的HTML DOM对象,从而实现界面更新。这种根据状态重新生成完整视图的渲染策略极大简化了前端界面开发。例如对于一个列表界面,传统编程需要编写新增行/更新行/删除行等多个不同的DOM操作函数,而在React中只要更改state后重新执行唯一的render函数即可。 每次重新生成DOM视图的唯一问题是性能很低,特别是当前端交互操作众多、状态变化频繁的时候。React的神来之笔是提出了基于虚拟DOM的diff算法,可以自动的计算两个虚拟DOM树之间的差量,状态变化时只要执行虚拟Dom差量对应的DOM修改操作即可(更新真实DOM时会触发样式计算和布局计算,导致性能很低,而在JavaScript中操作虚拟DOM 的速度是非常快的)。整体策略可以表示为如下公式 
显然,这一策略也是可逆计算的一种特例。 只要稍微留意一下就会发现,最近几年merge/diff/residual/delta等表达差量运算的概念越来越多的出现在软件设计领域中。比如大数据领域的流计算引擎中,流与表之间的关系可以表示为 
对表的增删改查操作可以被编码为事件流,而将表示数据变化的事件累积到一起就形成了数据表。 现代科学发端于微积分的发明,而微分的本质就是自动计算无穷小差量,而积分则是微分的逆运算,自动对无穷小量进行汇总合并。19世纪70年代,经济学经历了一场边际革命,将微积分的思想引入经济分析,在边际这一概念之上重建了整个经济学大厦。软件构造理论发展到今天,已经进入一个瓶颈,也到了应该重新认识差量的时候。 四. 结语笔者的专业背景是理论物理学,可逆计算源于笔者将物理学和数学的思想引入软件领域的一种尝试,它最早由笔者在2007年左右提出。一直以来,软件领域对于自然规律的应用一般情况下都只限于"模拟"范畴,例如流体动力学模拟软件,虽然它内置了人类所认知的最深刻的一些世界规律,但这些规律并没有被用于指导和定义软件世界自身的构造和演化,它们的指向范围是软件世界之外,而不是软件世界自身。在笔者看来,在软件世界中,我们完全可以站在“上帝的视角”,规划和定义一系列的结构构造规律,辅助我们完成软件世界的构建。而为了完成这一点,我们首先需要建立程序世界中的“微积分”。 类似于微积分,可逆计算理论的核心是将“差量”提升为第一性的概念,将全量看作是差量的一种特例(全量=单位元+全量)。传统的程序世界中我们所表达的都只是“有”,而且是“所有”,差量只能通过全量之间的运算间接得到,它的表述和操纵都需要特殊处理,而基于可逆计算理论,我们首先应该定义所有差量概念的表达形式,然后再围绕这些概念去建立整个领域概念体系。为了保证差量所在数学空间的完备性(差量之间的运算结果仍然需要是合法的差量),差量所表达的不能仅仅是“有”,而必须是“有”和“没有”的一种混合体。也就是说差量必须是“可逆的”。可逆性具有非常深刻的物理学内涵,在基本的概念体系中内置这一概念可以解决很多非常棘手的软件构造问题。 为了处理分布式问题,现代软件开发体系已经接受了不可变数据的概念,而为了解决大粒度软件复用问题,我们还需要接受不可变逻辑的概念(复用可以看作是保持原有逻辑不变,然后增加差量描述)。目前,业内已经逐步出现了一些富有创造性的主动应用差量概念的实践,它们都可以在可逆计算的理论框架下得到统一的诠释。笔者提出了一种新的程序语言X语言,它可以极大简化可逆计算的技术实现。目前笔者已经基于X语言设计并实现了一系列软件框架和生产工具,并基于它们提出了一种新的软件生产范式(NOP)。
浏览器前端编程的面貌自2005年以来已经发生了深刻的变化,这并不简单的意味着出现了大量功能丰富的基础库,使得我们可以更加方便的编写业务代码,更重要的是我们看待前端技术的观念发生了重大转变,明确意识到了如何以前端特有的方式释放程序员的生产力。本文将结合jQuery源码的实现原理,对javascript中涌现出的编程范式和常用技巧作一简单介绍。
1. AJAX: 状态驻留,异步更新
首先来看一点历史。
A. 1995年Netscape公司的Brendan Eich开发了javacript语言,这是一种动态(dynamic)、弱类型(weakly typed)、基于原型(prototype-based)的脚本语言。
B. 1999年微软IE5发布,其中包含了XMLHTTP ActiveX控件。
C. 2001年微软IE6发布,部分支持DOM level 1和CSS 2标准。
D. 2002年Douglas Crockford发明JSON格式。
至此,可以说Web2.0所依赖的技术元素已经基本成形,但是并没有立刻在整个业界产生重大的影响。尽管一些“页面异步局部刷新”的技巧在程序员中间秘密的流传,甚至催生了bindows这样庞大臃肿的类库,但总的来说,前端被看作是贫瘠而又肮脏的沼泽地,只有后台技术才是王道。到底还缺少些什么呢?
当我们站在今天的角度去回顾2005年之前的js代码,包括那些当时的牛人所写的代码,可以明显的感受到它们在程序控制力上的孱弱。并不是说2005年之前的js技术本身存在问题,只是它们在概念层面上是一盘散沙,缺乏统一的观念,或者说缺少自己独特的风格, 自己的灵魂。当时大多数的人,大多数的技术都试图在模拟传统的面向对象语言,利用传统的面向对象技术,去实现传统的GUI模型的仿制品。
2005年是变革的一年,也是创造概念的一年。伴随着Google一系列让人耳目一新的交互式应用的发布,Jesse James Garrett的一篇文章《Ajax: A New Approach to Web Applications》被广为传播。Ajax这一前端特有的概念迅速将众多分散的实践统一在同一口号之下,引发了Web编程范式的转换。所谓名不正则言不顺,这下无名群众可找到组织了。在未有Ajax之前,人们早已认识到了B/S架构的本质特征在于浏览器和服务器的状态空间是分离的,但是一般的解决方案都是隐藏这一区分,将前台状态同步到后台,由后台统一进行逻辑处理,例如ASP.NET。因为缺乏成熟的设计模式支持前台状态驻留,在换页的时候,已经装载的js对象将被迫被丢弃,这样谁还能指望它去完成什么复杂的工作吗?
Ajax明确提出界面是局部刷新的,前台驻留了状态,这就促成了一种需要:需要js对象在前台存在更长的时间。这也就意味着需要将这些对象和功能有效的管理起来,意味着更复杂的代码组织技术,意味着对模块化,对公共代码基的渴求。
jQuery现有的代码中真正与Ajax相关(使用XMLHTTP控件异步访问后台返回数据)的部分其实很少,但是如果没有Ajax, jQuery作为公共代码基也就缺乏存在的理由。
2. 模块化:管理名字空间
当大量的代码产生出来以后,我们所需要的最基础的概念就是模块化,也就是对工作进行分解和复用。工作得以分解的关键在于各人独立工作的成果可以集成在一起。这意味着各个模块必须基于一致的底层概念,可以实现交互,也就是说应该基于一套公共代码基,屏蔽底层浏览器的不一致性,并实现统一的抽象层,例如统一的事件管理机制等。比统一代码基更重要的是,各个模块之间必须没有名字冲突。否则,即使两个模块之间没有任何交互,也无法共同工作。
jQuery目前鼓吹的主要卖点之一就是对名字空间的良好控制。这甚至比提供更多更完善的功能点都重要的多。良好的模块化允许我们复用任何来源的代码,所有人的工作得以积累叠加。而功能实现仅仅是一时的工作量的问题。jQuery使用module pattern的一个变种来减少对全局名字空间的影响,仅仅在window对象上增加了一个jQuery对象(也就是$函数)。
所谓的module pattern代码如下,它的关键是利用匿名函数限制临时变量的作用域。
var feature =(function() {
// 私有变量和函数
var privateThing = 'secret',
publicThing = 'not secret',
changePrivateThing = function() {
privateThing = 'super secret';
},
sayPrivateThing = function() {
console.log(privateThing);
changePrivateThing();
};
// 返回对外公开的API
return {
publicThing : publicThing,
sayPrivateThing : sayPrivateThing
}
})();
js本身缺乏包结构,不过经过多年的尝试之后业内已经逐渐统一了对包加载的认识,形成了RequireJs库这样得到一定共识的解决方案。jQuery可以与RequireJS库良好的集成在一起, 实现更完善的模块依赖管理。http://requirejs.org/docs/jquery.html
require(["jquery", "jquery.my"], function() {
//当jquery.js和jquery.my.js都成功装载之后执行
$(function(){
$('#my').myFunc();
});
});
通过以下函数调用来定义模块my/shirt, 它依赖于my/cart和my/inventory模块,
require.def("my/shirt",
["my/cart", "my/inventory"],
function(cart, inventory) {
// 这里使用module pattern来返回my/shirt模块对外暴露的API
return {
color: "blue",
size: "large"
addToCart: function() {
// decrement是my/inventory对外暴露的API
inventory.decrement(this);
cart.add(this);
}
}
}
);
3. 神奇的$:对象提升
当你第一眼看到$函数的时候,你想到了什么?传统的编程理论总是告诉我们函数命名应该准确,应该清晰无误的表达作者的意图,甚至声称长名字要优于短名字,因为减少了出现歧义的可能性。但是,$是什么?乱码?它所传递的信息实在是太隐晦,太暧昧了。$是由prototype.js库发明的,它真的是一个神奇的函数,因为它可以将一个原始的DOM节点提升(enhance)为一个具有复杂行为的对象。在prototype.js最初的实现中,$函数的定义为
var $ = function (id) {
return "string" == typeof id ? document.getElementById(id) : id;
};
这基本对应于如下公式
e = $(id)
这绝不仅仅是提供了一个聪明的函数名称缩写,更重要的是在概念层面上建立了文本id与DOM element之间的一一对应。在未有$之前,id与对应的element之间的距离十分遥远,一般要将element缓存到变量中,例如
var ea = docuement.getElementById('a');
var eb = docuement.getElementById('b');
ea.style....
但是使用$之后,却随处可见如下的写法
$('header_'+id).style...
$('body_'+id)....
id与element之间的距离似乎被消除了,可以非常紧密的交织在一起。
prototype.js后来扩展了$的含义,
function $() {
var elements = new Array();
for (var i = 0; i < arguments.length; i++) {
var element = arguments[i];
if (typeof element == 'string')
element = document.getElementById(element);
if (arguments.length == 1)
return element;
elements.push(element);
}
return elements;
}
这对应于公式
[e,e] = $(id,id)
很遗憾,这一步prototype.js走偏了,这一做法很少有实用的价值。
真正将$发扬光大的是jQuery, 它的$对应于公式
[o] = $(selector)
这里有三个增强
A. selector不再是单一的节点定位符,而是复杂的集合选择符
B. 返回的元素不是原始的DOM节点,而是经过jQuery进一步增强的具有丰富行为的对象,可以启动复杂的函数调用链。
C. $返回的包装对象被造型为数组形式,将集合操作自然的整合到调用链中。
当然,以上仅仅是对神奇的$的一个过分简化的描述,它的实际功能要复杂得多. 特别是有一个非常常用的直接构造功能.
$("<table><tbody><tr><td>...</td></tr></tbody></table>")....
jQuery将根据传入的html文本直接构造出一系列的DOM节点,并将其包装为jQuery对象. 这在某种程度上可以看作是对selector的扩展: html内容描述本身就是一种唯一指定.
$(function{})这一功能就实在是让人有些无语了, 它表示当document.ready的时候调用此回调函数。真的,$是一个神奇的函数, 有任何问题,请$一下。
总结起来, $是从普通的DOM和文本描述世界到具有丰富对象行为的jQuery世界的跃迁通道。跨过了这道门,就来到了理想国。
4. 无定形的参数:专注表达而不是约束
弱类型语言既然头上顶着个"弱"字, 总难免让人有些先天不足的感觉. 在程序中缺乏类型约束, 是否真的是一种重大的缺憾? 在传统的强类型语言中, 函数参数的类型,个数等都是由编译器负责检查的约束条件, 但这些约束仍然是远远不够的. 一般应用程序中为了加强约束, 总会增加大量防御性代码, 例如在C++中我们常用ASSERT, 而在java中也经常需要判断参数值的范围
if (index < 0 || index >= size)
throw new IndexOutOfBoundsException(
"Index: "+index+", Size: "+size);
很显然, 这些代码将导致程序中存在大量无功能的执行路径, 即我们做了大量判断, 代码执行到某个点, 系统抛出异常, 大喊此路不通. 如果我们换一个思路, 既然已经做了某种判断,能否利用这些判断的结果来做些什么呢? javascript是一种弱类型的语言,它是无法自动约束参数类型的, 那如果顺势而行,进一步弱化参数的形态, 将"弱"推进到一种极致, 在弱无可弱的时候, weak会不会成为标志性的特点?
看一下jQuery中的事件绑定函数bind,
A. 一次绑定一个事件 $("#my").bind("mouseover", function(){});
B. 一次绑定多个事件 $("#my").bind("mouseover mouseout",function(){})
C. 换一个形式, 同样绑定多个事件
$("#my").bind({mouseover:function(){}, mouseout:function(){});
D. 想给事件监听器传点参数
$('#my').bind('click', {foo: "xxxx"}, function(event) { event.data.foo..})
E. 想给事件监听器分个组
$("#my").bind("click.myGroup″, function(){});
F. 这个函数为什么还没有疯掉???
就算是类型不确定, 在固定位置上的参数的意义总要是确定的吧? 退一万步来说, 就算是参数位置不重要了,函数本身的意义应该是确定的吧? 但这是什么?
取值 value = o.val(), 设置值 o.val(3)
一个函数怎么可以这样过分, 怎么能根据传入参数的类型和个数不同而行为不同呢? 看不顺眼是不是? 可这就是俺们的价值观. 既然不能防止, 那就故意允许. 虽然形式多变, 却无一句废话. 缺少约束, 不妨碍表达(我不是出来吓人的).
5. 链式操作: 线性化的逐步细化
jQuery早期最主要的卖点就是所谓的链式操作(chain).
$('#content') // 找到content元素
.find('h3') // 选择所有后代h3节点
.eq(2) // 过滤集合, 保留第三个元素
.html('改变第三个h3的文本')
.end() // 返回上一级的h3集合
.eq(0)
.html('改变第一个h3的文本');
在一般的命令式语言中, 我们总需要在重重嵌套循环中过滤数据, 实际操作数据的代码与定位数据的代码纠缠在一起. 而jQuery采用先构造集合然后再应用函数于集合的方式实现两种逻辑的解耦, 实现嵌套结构的线性化. 实际上, 我们并不需要借助过程化的思想就可以很直观的理解一个集合, 例如 $('div.my input:checked')可以看作是一种直接的描述,而不是对过程行为的跟踪.
循环意味着我们的思维处于一种反复回绕的状态, 而线性化之后则沿着一个方向直线前进, 极大减轻了思维负担, 提高了代码的可组合性. 为了减少调用链的中断, jQuery发明了一个绝妙的主意: jQuery包装对象本身类似数组(集合). 集合可以映射到新的集合, 集合可以限制到自己的子集合,调用的发起者是集合,返回结果也是集合,集合可以发生结构上的某种变化但它还是集合, 集合是某种概念上的不动点,这是从函数式语言中吸取的设计思想。集合操作是太常见的操作, 在java中我们很容易发现大量所谓的封装函数其实就是在封装一些集合遍历操作, 而在jQuery中集合操作因为太直白而不需要封装.
链式调用意味着我们始终拥有一个“当前”对象,所有的操作都是针对这一当前对象进行。这对应于如下公式
x += dx
调用链的每一步都是对当前对象的增量描述,是针对最终目标的逐步细化过程。Witrix平台中对这一思想也有着广泛的应用。特别是为了实现平台机制与业务代码的融合,平台会提供对象(容器)的缺省内容,而业务代码可以在此基础上进行逐步细化的修正,包括取消缺省的设置等。
话说回来, 虽然表面上jQuery的链式调用很简单, 内部实现的时候却必须自己多写一层循环, 因为编译器并不知道"自动应用于集合中每个元素"这回事.
$.fn['someFunc'] = function(){
return this.each(function(){
jQuery.someFunc(this,...);
}
}
6. data: 统一数据管理
作为一个js库,它必须解决的一个大问题就是js对象与DOM节点之间的状态关联与协同管理问题。有些js库选择以js对象为主,在js对象的成员变量中保存DOM节点指针,访问时总是以js对象为入口点,通过js函数间接操作DOM对象。在这种封装下,DOM节点其实只是作为界面展现的一种底层“汇编”而已。jQuery的选择与Witrix平台类似,都是以HTML自身结构为基础,通过js增强(enhance)DOM节点的功能,将它提升为一个具有复杂行为的扩展对象。这里的思想是非侵入式设计(non-intrusive)和优雅退化机制(graceful degradation)。语义结构在基础的HTML层面是完整的,js的作用是增强了交互行为,控制了展现形式。
如果每次我们都通过$('#my')的方式来访问相应的包装对象,那么一些需要长期保持的状态变量保存在什么地方呢?jQuery提供了一个统一的全局数据管理机制。
获取数据 $('#my').data('myAttr') 设置数据 $('#my').data('myAttr',3);
这一机制自然融合了对HTML5的data属性的处理
<input id="my" data-my-attr="4" ... />
通过 $('#my').data('myAttr')将可以读取到HTML中设置的数据。
第一次访问data时,jQuery将为DOM节点分配一个唯一的uuid, 然后设置在DOM节点的一个特定的expando属性上, jQuery保证这个uuid在本页面中不重复。
elem.nodeType ? jQuery.cache[ elem[jQuery.expando] ] : elem[ jQuery.expando ];
以上代码可以同时处理DOM节点和纯js对象的情况。如果是js对象,则data直接放置在js对象自身中,而如果是DOM节点,则通过cache统一管理。
因为所有的数据都是通过data机制统一管理的,特别是包括所有事件监听函数(data.events),因此jQuery可以安全的实现资源管理。在clone节点的时候,可以自动clone其相关的事件监听函数。而当DOM节点的内容被替换或者DOM节点被销毁的时候,jQuery也可以自动解除事件监听函数, 并安全的释放相关的js数据。
7. event:统一事件模型
"事件沿着对象树传播"这一图景是面向对象界面编程模型的精髓所在。对象的复合构成对界面结构的一个稳定的描述,事件不断在对象树的某个节点发生,并通过冒泡机制向上传播。对象树很自然的成为一个控制结构,我们可以在父节点上监听所有子节点上的事件,而不用明确与每一个子节点建立关联。
jQuery除了为不同浏览器的事件模型建立了统一抽象之外,主要做了如下增强:
A. 增加了自定制事件(custom)机制. 事件的传播机制与事件内容本身原则上是无关的, 因此自定制事件完全可以和浏览器内置事件通过同一条处理路径, 采用同样的监听方式. 使用自定制事件可以增强代码的内聚性, 减少代码耦合. 例如如果没有自定制事件, 关联代码往往需要直接操作相关的对象
$('.switch, .clapper').click(function() {
var $light = $(this).parent().find('.lightbulb');
if ($light.hasClass('on')) {
$light.removeClass('on').addClass('off');
} else {
$light.removeClass('off').addClass('on');
}
});
而如果使用自定制事件,则表达的语义更加内敛明确,
$('.switch, .clapper').click(function() {
$(this).parent().find('.lightbulb').trigger('changeState');
});
B. 增加了对动态创建节点的事件监听. bind函数只能将监听函数注册到已经存在的DOM节点上. 例如
$('li.trigger').bind('click',function(){}}
如果调用bind之后,新建了另一个li节点,则该节点的click事件不会被监听.
jQuery的delegate机制可以将监听函数注册到父节点上, 子节点上触发的事件会根据selector被自动派发到相应的handlerFn上. 这样一来现在注册就可以监听未来创建的节点.
$('#myList').delegate('li.trigger', 'click', handlerFn);
最近jQuery1.7中统一了bind, live和delegate机制, 天下一统, 只有on/off.
$('li.trigger’).on('click', handlerFn); // 相当于bind
$('#myList’).on('click', 'li.trigger', handlerFn); // 相当于delegate
8. 动画队列:全局时钟协调
抛开jQuery的实现不谈, 先考虑一下如果我们要实现界面上的动画效果, 到底需要做些什么? 比如我们希望将一个div的宽度在1秒钟之内从100px增加到200px. 很容易想见, 在一段时间内我们需要不时的去调整一下div的宽度, [同时]我们还需要执行其他代码. 与一般的函数调用不同的是, 发出动画指令之后, 我们不能期待立刻得到想要的结果, 而且我们不能原地等待结果的到来. 动画的复杂性就在于:一次性表达之后要在一段时间内执行,而且有多条逻辑上的执行路径要同时展开, 如何协调?
伟大的艾萨克.牛顿爵士在《自然哲学的数学原理》中写道:"绝对的、真正的和数学的时间自身在流逝着". 所有的事件可以在时间轴上对齐, 这就是它们内在的协调性. 因此为了从步骤A1执行到A5, 同时将步骤B1执行到B5, 我们只需要在t1时刻执行[A1, B1], 在t2时刻执行[A2,B2], 依此类推.
t1 | t2 | t3 | t4 | t5 ...
A1 | A2 | A3 | A4 | A5 ...
B1 | B2 | B3 | B4 | B5 ...
具体的一种实现形式可以是
A. 对每个动画, 将其分装为一个Animation对象, 内部分成多个步骤.
animation = new Animation(div,"width",100,200,1000,
负责步骤切分的插值函数,动画执行完毕时的回调函数);
B. 在全局管理器中注册动画对象
timerFuncs.add(animation);
C. 在全局时钟的每一个触发时刻, 将每个注册的执行序列推进一步, 如果已经结束, 则从全局管理器中删除.
for each animation in timerFuncs
if(!animation.doOneStep())
timerFuncs.remove(animation)
解决了原理问题,再来看看表达问题, 怎样设计接口函数才能够以最紧凑形式表达我们的意图? 我们经常需要面临的实际问题:
A. 有多个元素要执行类似的动画
B. 每个元素有多个属性要同时变化
C. 执行完一个动画之后开始另一个动画
jQuery对这些问题的解答可以说是榨尽了js语法表达力的最后一点剩余价值.
$('input')
.animate({left:'+=200px',top:'300'},2000)
.animate({left:'-=200px',top:20},1000)
.queue(function(){
// 这里dequeue将首先执行队列中的后一个函数,因此alert("y")
$(this).dequeue();
alert('x');
})
.queue(function(){
alert("y");
// 如果不主动dequeue, 队列执行就中断了,不会自动继续下去.
$(this).dequeue();
});
A. 利用jQuery内置的selector机制自然表达对一个集合的处理.
B. 使用Map表达多个属性变化
C. 利用微格式表达领域特定的差量概念. '+=200px'表示在现有值的基础上增加200px
D. 利用函数调用的顺序自动定义animation执行的顺序: 在后面追加到执行队列中的动画自然要等前面的动画完全执行完毕之后再启动.
jQuery动画队列的实现细节大概如下所示,
A. animate函数实际是调用queue(function(){执行结束时需要调用dequeue,否则不会驱动下一个方法})
queue函数执行时, 如果是fx队列, 并且当前没有正在运行动画(如果连续调用两次animate,第二次的执行函数将在队列中等待),则会自动触发dequeue操作, 驱动队列运行.
如果是fx队列, dequeue的时候会自动在队列顶端加入"inprogress"字符串,表示将要执行的是动画.
B. 针对每一个属性,创建一个jQuery.fx对象。然后调用fx.custom函数(相当于start)来启动动画。
C. custom函数中将fx.step函数注册到全局的timerFuncs中,然后试图启动一个全局的timer.
timerId = setInterval( fx.tick, fx.interval );
D. 静态的tick函数中将依次调用各个fx的step函数。step函数中通过easing计算属性的当前值,然后调用fx的update来更新属性。
E. fx的step函数中判断如果所有属性变化都已完成,则调用dequeue来驱动下一个方法。
很有意思的是, jQuery的实现代码中明显有很多是接力触发代码: 如果需要执行下一个动画就取出执行, 如果需要启动timer就启动timer等. 这是因为js程序是单线程的,真正的执行路径只有一条,为了保证执行线索不中断, 函数们不得不互相帮助一下. 可以想见, 如果程序内部具有多个执行引擎, 甚至无限多的执行引擎, 那么程序的面貌就会发生本质性的改变. 而在这种情形下, 递归相对于循环而言会成为更自然的描述.
9. promise模式:因果关系的识别
现实中,总有那么多时间线在独立的演化着, 人与物在时空中交错,却没有发生因果. 软件中, 函数们在源代码中排着队, 难免会产生一些疑问, 凭什么排在前面的要先执行? 难道没有它就没有我? 让全宇宙喊着1,2,3齐步前进, 从上帝的角度看,大概是管理难度过大了, 于是便有了相对论. 如果相互之间没有交换信息, 没有产生相互依赖, 那么在某个坐标系中顺序发生的事件, 在另外一个坐标系中看来, 就可能是颠倒顺序的. 程序员依葫芦画瓢, 便发明了promise模式.
promise与future模式基本上是一回事,我们先来看一下java中熟悉的future模式.
futureResult = doSomething();
...
realResult = futureResult.get();
发出函数调用仅仅意味着一件事情发生过, 并不必然意味着调用者需要了解事情最终的结果. 函数立刻返回的只是一个将在未来兑现的承诺(Future类型), 实际上也就是某种句柄. 句柄被传来传去, 中间转手的代码对实际结果是什么,是否已经返回漠不关心. 直到一段代码需要依赖调用返回的结果, 因此它打开future, 查看了一下. 如果实际结果已经返回, 则future.get()立刻返回实际结果, 否则将会阻塞当前的执行路径, 直到结果返回为止. 此后再调用future.get()总是立刻返回, 因为因果关系已经被建立, [结果返回]这一事件必然在此之前发生, 不会再发生变化.
future模式一般是外部对象主动查看future的返回值, 而promise模式则是由外部对象在promise上注册回调函数.
function getData(){
return $.get('/foo/').done(function(){
console.log('Fires after the AJAX request succeeds');
}).fail(function(){
console.log('Fires after the AJAX request fails');
});
}
function showDiv(){
var dfd = $.Deferred();
$('#foo').fadeIn( 1000, dfd.resolve );
return dfd.promise();
}
$.when( getData(), showDiv() )
.then(function( ajaxResult, ignoreResultFromShowDiv ){
console.log('Fires after BOTH showDiv() AND the AJAX request succeed!');
// 'ajaxResult' is the server’s response
});
jQuery引入Deferred结构, 根据promise模式对ajax, queue, document.ready等进行了重构, 统一了异步执行机制. then(onDone, onFail)将向promise中追加回调函数, 如果调用成功完成(resolve), 则回调函数onDone将被执行, 而如果调用失败(reject), 则onFail将被执行. when可以等待在多个promise对象上. promise巧妙的地方是异步执行已经开始之后甚至已经结束之后,仍然可以注册回调函数
someObj.done(callback).sendRequest() vs. someObj.sendRequest().done(callback)
callback函数在发出异步调用之前注册或者在发出异步调用之后注册是完全等价的, 这揭示出程序表达永远不是完全精确的, 总存在着内在的变化维度. 如果能有效利用这一内在的可变性, 则可以极大提升并发程序的性能.
promise模式的具体实现很简单. jQuery._Deferred定义了一个函数队列,它的作用有以下几点:
A. 保存回调函数。
B. 在resolve或者reject的时刻把保存着的函数全部执行掉。
C. 已经执行之后, 再增加的函数会被立刻执行。
一些专门面向分布式计算或者并行计算的语言会在语言级别内置promise模式, 比如E语言.
def carPromise := carMaker <- produce("Mercedes");
def temperaturePromise := carPromise <- getEngineTemperature()
...
when (temperaturePromise) -> done(temperature) {
println(`The temperature of the car engine is: $temperature`)
} catch e {
println(`Could not get engine temperature, error: $e`)
}
在E语言中, <-是eventually运算符, 表示最终会执行, 但不一定是现在. 而普通的car.moveTo(2,3)表示立刻执行得到结果. 编译器负责识别所有的promise依赖, 并自动实现调度.
10. extend: 继承不是必须的
js是基于原型的语言, 并没有内置的继承机制, 这一直让很多深受传统面向对象教育的同学们耿耿于怀. 但继承一定是必须的吗? 它到底能够给我们带来什么? 最纯朴的回答是: 代码重用. 那么, 我们首先来分析一下继承作为代码重用手段的潜力.
曾经有个概念叫做"多重继承", 它是继承概念的超级赛亚人版, 很遗憾后来被诊断为存在着先天缺陷, 以致于出现了一种对于继承概念的解读: 继承就是"is a"关系, 一个派生对象"is a"很多基类, 必然会出现精神分裂, 所以多重继承是不好的.
class A{ public: void f(){ f in A } }
class B{ public: void f(){ f in B } }
class D: public A, B{}
如果D类从A,B两个基类继承, 而A和B类中都实现了同一个函数f, 那么D类中的f到底是A中的f还是B中的f, 抑或是A中的f+B中的f呢? 这一困境的出现实际上源于D的基类A和B是并列关系, 它们满足交换律和结合律, 毕竟,在概念层面上我们可能难以认可两个任意概念之间会出现从属关系. 但如果我们放松一些概念层面的要求, 更多的从操作层面考虑一下代码重用问题, 可以简单的认为B在A的基础上进行操作, 那么就可以得到一个线性化的结果. 也就是说, 放弃A和B之间的交换律只保留结合律, extends A, B 与 extends B,A 会是两个不同的结果, 不再存在诠释上的二义性. scala语言中的所谓trait(特性)机制实际上采用的就是这一策略.
面向对象技术发明很久之后, 出现了所谓的面向方面编程(AOP), 它与OOP不同, 是代码结构空间中的定位与修改技术. AOP的眼中只有类与方法, 不知道什么叫做意义. AOP也提供了一种类似多重继承的代码重用手段, 那就是mixin. 对象被看作是可以被打开,然后任意修改的Map, 一组成员变量与方法就被直接注射到对象体内, 直接改变了它的行为.
prototype.js库引入了extend函数,
Object.extend = function(destination, source) {
for (var property in source) {
destination[property] = source[property];
}
return destination;
}
就是Map之间的一个覆盖运算, 但很管用, 在jQuery库中也得到了延用. 这个操作类似于mixin, 在jQuery中是代码重用的主要技术手段---没有继承也没什么大不了的.
11. 名称映射: 一切都是数据
代码好不好, 循环判断必须少. 循环和判断语句是程序的基本组成部分, 但是优良的代码库中却往往找不到它们的踪影, 因为这些语句的交织会模糊系统的逻辑主线, 使我们的思想迷失在疲于奔命的代码追踪中. jQuery本身通过each, extend等函数已经极大减少了对循环语句的需求, 对于判断语句, 则主要是通过映射表来处理. 例如, jQuery的val()函数需要针对不同标签进行不同的处理, 因此定义一个以tagName为key的函数映射表
valHooks: { option: {get:function(){}}}
这样在程序中就不需要到处写
if(elm.tagName == 'OPTION'){
return ...;
}else if(elm.tagName == 'TEXTAREA'){
return ...;
}
可以统一处理
(valHooks[elm.tagName.toLowerCase()] || defaultHandler).get(elm);
映射表将函数作为普通数据来管理, 在动态语言中有着广泛的应用. 特别是, 对象本身就是函数和变量的容器, 可以被看作是映射表. jQuery中大量使用的一个技巧就是利用名称映射来动态生成代码, 形成一种类似模板的机制. 例如为了实现myWidth和myHeight两个非常类似的函数, 我们不需要
jQuery.fn.myWidth = function(){
return parseInt(this.style.width,10) + 10;
}
jQuery.fn.myHeight = function(){
return parseInt(this.style.height,10) + 10;
}
而可以选择动态生成
jQuery.each(['Width','Height'],function(name){
jQuery.fn['my'+name] = function(){
return parseInt(this.style[name.toLowerCase()],10) + 10;
}
});
12. 插件机制:其实我很简单
jQuery所谓的插件其实就是$.fn上增加的函数, 那这个fn是什么东西?
(function(window,undefined){
// 内部又有一个包装
var jQuery = (function() {
var jQuery = function( selector, context ) {
return new jQuery.fn.init( selector, context, rootjQuery );
}
....
// fn实际就是prototype的简写
jQuery.fn = jQuery.prototype = {
constructor: jQuery,
init: function( selector, context, rootjQuery ) {... }
}
// 调用jQuery()就是相当于new init(), 而init的prototype就是jQuery的prototype
jQuery.fn.init.prototype = jQuery.fn;
// 这里返回的jQuery对象只具备最基本的功能, 下面就是一系列的extend
return jQuery;
})();
...
// 将jQuery暴露为全局对象
window.jQuery = window.$ = jQuery;
})(window);
显然, $.fn其实就是jQuery.prototype的简写.
无状态的插件仅仅就是一个函数, 非常简单.
// 定义插件
(function($){
$.fn.hoverClass = function(c) {
return this.hover(
function() { $(this).toggleClass(c); }
);
};
})(jQuery);
// 使用插件
$('li').hoverClass('hover');
对于比较复杂的插件开发, jQuery UI提供了一个widget工厂机制,
$.widget("ui.dialog", {
options: {
autoOpen: true,...
},
_create: function(){ ... },
_init: function() {
if ( this.options.autoOpen ) {
this.open();
}
},
_setOption: function(key, value){ ... }
destroy: function(){ ... }
});
调用 $('#dlg').dialog(options)时, 实际执行的代码基本如下所示:
this.each(function() {
var instance = $.data( this, "dialog" );
if ( instance ) {
instance.option( options || {} )._init();
} else {
$.data( this, "dialog", new $.ui.dialog( options, this ) );
}
}
可以看出, 第一次调用$('#dlg').dialog()函数时会创建窗口对象实例,并保存在data中, 此时会调用_create()和_init()函数, 而如果不是第一次调用, 则是在已经存在的对象实例上调用_init()方法. 多次调用$('#dlg').dialog()并不会创建多个实例.
13. browser sniffer vs. feature detection
浏览器嗅探(browser sniffer)曾经是很流行的技术, 比如早期的jQuery中
jQuery.browser = {
version:(userAgent.match(/.+(?:rv|it|ra|ie)[/: ]([d.]+)/) || [0,'0'])[1],
safari:/webkit/.test(userAgent),
opera:/opera/.test(userAgent),
msie:/msie/.test(userAgent) && !/opera/.test(userAgent),
mozilla:/mozilla/.test(userAgent) && !/(compatible|webkit)/.test(userAgent)
};
在具体代码中可以针对不同的浏览器作出不同的处理
if($.browser.msie) {
// do something
} else if($.browser.opera) {
// ...
}
但是随着浏览器市场的竞争升级, 竞争对手之间的互相模仿和伪装导致userAgent一片混乱, 加上Chrome的诞生, Safari的崛起, IE也开始加速向标准靠拢, sniffer已经起不到积极的作用. 特性检测(feature detection)作为更细粒度, 更具体的检测手段, 逐渐成为处理浏览器兼容性的主流方式.
jQuery.support = {
// IE strips leading whitespace when .innerHTML is used
leadingWhitespace: ( div.firstChild.nodeType === 3 ),
...
}
只基于实际看见的,而不是曾经知道的, 这样更容易做到兼容未来.
14. Prototype vs. jQuery
prototype.js是一个立意高远的库, 它的目标是提供一种新的使用体验,参照Ruby从语言级别对javascript进行改造,并最终真的极大改变了js的面貌。$, extends, each, bind...这些耳熟能详的概念都是prototype.js引入到js领域的. 它肆无忌惮的在window全局名字空间中增加各种概念, 大有谁先占坑谁有理, 舍我其谁的气势. 而jQuery则扣扣索索, 抱着比较实用化的理念, 目标仅仅是write less, do more而已.
不过等待激进的理想主义者的命运往往都是壮志未酬身先死. 当prototype.js标志性的bind函数等被吸收到ECMAScript标准中时, 便注定了它的没落. 到处修改原生对象的prototype, 这是prototype.js的独门秘技, 也是它的死穴. 特别是当它试图模仿jQuery, 通过Element.extend(element)返回增强对象的时候, 算是彻底被jQuery给带到沟里去了. prototype.js与jQuery不同, 它总是直接修改原生对象的prototype, 而浏览器却是充满bug, 谎言, 历史包袱并夹杂着商业阴谋的领域, 在原生对象层面解决问题注定是一场悲剧. 性能问题, 名字冲突, 兼容性问题等等都是一个帮助库的能力所无法解决的. Prototype.js的2.0版本据说要做大的变革, 不知是要与历史决裂, 放弃兼容性, 还是继续挣扎, 在夹缝中求生.
1. C语言抽象出了软件所在的领域(domain): 由变量v1,v2,...和函数f1,f2,...组成的空间
2. 面向对象(OOP)指出,在这一领域上可以建立分组(group)结构:一组相关的变量和函数构成一个集合,我们称之为对象(Object)。同时在分组结构上可以定义一个运算(推理)关系: D > B, 派生类D从基类B继承(inheritance),相应的派生对象符合基类对象所满足的所有约束。推理是有价值的,因为根据 D > B, B > A 可以自动推导出 D > A,所有针对A的断言在理论上对D都成立(这也就是我们常说的“派生对象 is a 基类对象”)。编译器也能有点智能了。
一个有趣的地方是,D > B意味着在D和B之间存在着某种差异,但是我们却无法把它显式的表达出来!也就是说在代码层面上我们无法明确表达 D - B是什么。为了把更多的信息不断的导入到原有系统中,面向对象内置提供的方法是建立不断扩展的类型树,类型树每增长一层,就可以多容纳一些新的信息。这是一种金字塔式的结构,只不过是一种倒立的金字塔,最终基点会被不断增长的结构压力所压垮。
3. 组件技术(Component)本质上是在提倡面向接口(interface),然后通过接口之间的组合(Composition)而不是对象之间的继承(inheritance)来构造系统。基于组合的观念相当于是定义了运算关系:D = B + C。终于,我们勉强可以在概念层面上做加法了。
组件允许我们随意的组合,按照由简单到复杂的方向构造系统,但是组件构成的成品之间仍然无法自由的建立关系。这意味着组件组装得到的成品只是某种孤立的,偶然的产物。
F = A + B + C ? G = A + D + C。
4. 在数学上,配备了加法运算的集合构成半群,如果要成为群(Group),则必须定义相应的逆运算:减法。 群结构使得大粒度的结构变换成为可能。
F = A + B + C = A + D - D + B + C = (A + D + C) - D + B = G - D + B
在不破坏原有代码的情况下,对原有系统功能进行增删,这就是面向切面(AOP)技术的全部价值。
业务架构平台的设计与实现要比普通业务系统困难很多。一个核心难点在于如何建立普遍有效的应用程序模型,如何控制各种偶然性的业务需求对系统整体架构的冲击。大多数现有的业务架构平台都是提供了一个庞大的万能性产品,它预料到了所有可能在业务系统开发中出现的可能性,并提供了相应的处理手段。业务系统开发人员的能力被限定在业务架构平台所允许的范围之内。如果业务架构平台的复杂度为A+,则我们最多只能用它来开发复杂度为A的业务系统。一个典型的特征就是使用业务架构平台的功能配置非常简单,但是要开发相应的功能特性则非常困难,而且必须采用与业务系统开发完全不同的技术手段和开发方式。
采用业务架构平台来开发业务系统,即使看似开发工作量小,最终产生的各类配置代码量也可能会大大超过普通手工编程产生的代码量,这意味着平台封装了业务内在的复杂性,还是意味着平台引入了不必要的复杂性?很多业务架构平台的卖点都是零代码的应用开发,低水平的开发人员也可以主导的开发,但是为什么高水平的程序员不能借助于这些开发平台极大的提高生产率?
一般的业务架构平台无法回答以下问题:
1) 业务系统可以通过使用设计工具来重用业务架构平台已经实现的功能,但是业务系统内部大量相似的模型配置如何才能够被重用?
2) 特定的业务领域中存在着大量特殊的业务规则,例如“审批串行进行,每一步都允许回退到上一步,而且允许选择跳转到任意后一步”。这些规则如何才能够被引入设计工具,简化配置过程?
3) 已经开发好的业务系统作为产品来销售的时候,如何应对具体客户的定制化?如果按照客户要求修改配置,则以后业务系统自身是否还能够实现版本升级?
Witrix平台提供的基本开发模型为
App = Biz aop-extends Generator<DSL>
在这一图景下,我们就可以回答以上三个问题:
1) 业务模型通过领域特定语言(DSL)来表达,因此可以使用语言中通用的继承或者组件抽象机制来实现模型重用。
2) 推理机对于所有推理规则一视同仁,特殊的业务规则与通用的业务规则一样都可以参与推理过程,并且一般情况下特殊的业务规则更能够大幅简化系统实现结构。
3) 相对于原始模型的修改被独立出来,然后应用面向切面(AOP)技术将这些特定代码织入到原始模型中。原始模型与差异修改相互分离,因此原始模型可以随时升级。
Witrix平台所强调的不是强大的功能,而是一切表象之后的数学规律。Witrix平台通过少数基本原理的反复应用来构造软件系统,它本身就是采用平台技术构造的产物。我们用复杂度为A的工具制造复杂度为A+的产品,然后进一步以这个复杂度为A+的产品为工具来构造复杂度为A++的产品。
一种技术思想如果确实能够简化编程,有效降低系统构造的复杂性,那么它必然具有某种内在的数学解释。反之,无论一种技术机制显得如何华丽高深,如果它没有
清晰的数学图象,那么就很难证明自身存在的价值。对于模型驱动架构(MDA),我长期以来一直都持有一种批判态度。(Physical Model
Driven http://canonical.javaeye.com/blog/29412
)。原因就在于“由工具自动实现从平台无关模型(PIM)向平台相关模型(PSM)的转换”这一图景似乎只是想把系统从实现的泥沼中拯救出来,遮蔽特定语
言,特定平台中的偶然的限制条件,并没有触及到系统复杂性这一核心问题。而所谓的可视化建模充其量不过是说明人类超强的视觉模式识别能力使得我们可以迅速
识别系统全景图中隐含的整体结构,更快的实现对系统结构的理解,并没有证明系统复杂性有任何本质性的降低。不过如果我们换一个视角,
不把模型局限为某种可视化的结构图,而将它定义为某种高度浓缩的领域描述,
则模型驱动基本上等价于根据领域描述自动推导得到最终的应用程序。沿着这一思路,Witrix平台中的很多设计实际上可以被解释为模型定义,模型推导以及
模型嵌入等方面的探索。这些具体技术的背后需要的是比一般MDA思想更加精致的设计原理作为支撑。我们可以进行如下抽象分析。(Witrix架构分析 http://canonical.javaeye.com/blog/126467
)
1. 问题复杂?线性切分是削减问题规模(从而降低问题复杂性)的通用手段,例如模块(Module)。(软件中的分析学 http://canonical.javaeye.com/blog/33885
)
App = M1 + M2 + M3 + 
2. 分块过多?同态映射是系统约化的一般化策略,例如多态(polymorphism)。(同构与同态:认识同一性 http://canonical.javaeye.com/admin/blogs/340704
)
(abc,abb,ade,) -> [a], (bbb, bcd,bab,) -> [b]
3. 递归使用以上两种方法,将分分合合的游戏进行到底,推向极致。
4. 以少控多的终极形态?如果存在,则构成输入与输出之间的非线性变换(输入中局部微小变化将导致输出中大范围明显的变化)。
App = F(M)
5.
变换函数F可以被诠释为解释器(Interpreter)或者翻译机,例如工作流引擎将工作流描述信息翻译为一步步的具体操作,工作流描述可以看作是由底
层引擎支撑的,在更高的抽象层面上运行的领域模型。但是在这种观点下,变换函数F似乎是针对某种特定模型构造的,引擎内部信息传导的途径是确定的,关注的
重点始终在模型上,那么解释器自身应该如何被构造出来呢?
App ~ M
6.
另外一种更加开放的观点是将变换函数F看作是生成器(Generator)或者推理机。F将根据输入的信息,结合其他知识,推理生成一系列新的命题和断
言。模型的力量源于推导。变换函数F本身在系统构造过程中处于核心地位,M仅仅是触发其推理过程的信息源而已。F将榨干M的最后一点剩余价值,所有根据M
能够确定的事实将被自动实现,而大量单靠M自身的信息无法判定的命题也可以结合F内在的知识作出判断。生成器自身的构造过程非常简单--只要不断向推理系
统中增加新的推理规则即可。语言内置的模板机制(template)及元编程技术(meta
programming),或者跨越语言边界的代码生成工具都可以看作是生成器的具体实例。(关于代码生成和DSL http://canonical.javaeye.com/blog/275015
)
App = G<M>
7. 生成器G之所以可以被独立实现,是因为我们可以实现相对知识与绝对知识的分离, 这也正是面向对象技术的本质所在。(面向对象之形式系统 http://canonical.javaeye.com/blog/37064
)
G<M> ==> G = {m => m.x(a,b,c);m.y(); }
8.
现实世界的不完美,就在于现实决不按照我们为其指定的理想路线前进。具体场景中总是存在着大量我们无法预知的“噪声”,它们使得任何在“过去”确立的方程
都无法在“未来”保持持久的平衡。传统模型驱动架构的困境就在于此。我们可以选择将模型M和生成器G不断复杂化,容纳越来越多的偶然性,直至失去对模型整
体结构的控制力。另外一种选择是模型在不断膨胀,不断提高覆盖能力的过程中,不断的空洞化,产生大量可插入(plugin)的接入点,最终丧失模型的推理
能力,退化成为一种编码规范。Witrix平台中采用的是第三种选择:模型嵌入--模型中的多余信息被不断清洗掉,模型通过精炼化来突出自身存在的合理
性,成为更广泛的运行环境中的支撑骨架。(结构的自足性 http://canonical.javaeye.com/blog/482620
)
App != G0<M0> , App != G0<M1>, App = G1<M1>
9.
现在的问题是:如何基于一个已经被完美解决的重大问题,来更有效率的搞定不断出现但又不是重复出现的小问题。现在我们所需要的不是沿着某个维度进行均匀的
切分,而必须是某种有效的降维手段。如果我们可以定义一种投影算子P,
将待解决的问题投射到已经被解决的问题域中,则剩下的补集往往可以被简化。(主从分解而不是正交分解 http://canonical.javaeye.com/blog/196826
)
dA = App - P[App] = App - G0<M0>
10. 要实现以上微扰分析策略,前提条件是可以定义逆元,并且需要定义一种精细的粘结操作,可以将分散的扰动量极为精确的应用到基础系统的各处。Witrix平台的具体实现类似于某种AOP(面向切面编程)技术。(逆元:不存在的真实存在 http://canonical.javaeye.com/blog/325051
)
App = A + D + B = (A + B + C) - C + D = App0 + (-C + D) = G0<M0> + dA
11. 模型驱动并不意味着一个应用只能由唯一的一个模型来驱动,但是如果引入多个不同形式的模型,则必须为如下推理提供具体的技术路径:
A. 将多个模型变换到共同的描述域
B. 实现多个模型的加和
C. 处理模型之间的冲突并填补模型之间的空白
在Witrix平台中模型嵌入/组合主要依赖于文本化及编译期运行等机制。(文本化 http://canonical.javaeye.com/blog/309395
)
App = Ga<Ma> + Gb<Mb> + dA
12.
系统的开发时刻t0和实施时刻t1一般是明确分离的,因此如果我们要建立一个包含开发与实施时刻信息的模型,则这一模型必须是含时的,多阶段的。关于时
间,我们所知道的最重要的事实之一是“未来是不可预知的”。在t0时刻建立的模型如果要涵盖t1时刻的所有变化,则必须做出大量猜测,而且t1时刻距离
t0时刻越远,猜测的量越大,“猜测有效”这一集合的测度越小,直至为0。延迟选择是实现含时系统控制的不二法门。
在Witrix平台中,所有功能特性的实现都包含某种元数据描述或者定制模板,因此结合配置机制以及动态编译技术既可实现多阶段模型。例如对于一个在未来
才能确定的常量数组,我们可以定义一个Excel文件来允许实施人员录入具体的值,然后通过动态编译技术在编译期解析Excel文件,并完成一系列数值映
射运算,最终将其转化为编译期存在的一个常量。这一过程不会引入任何额外的运行成本,也不要求任何特定的缓存机制,最终的运行结构与在未来当所有信息都在
位之后再手写代码没有任何区别。(D语言与tpl之编译期动作 http://canonical.javaeye.com/blog/57244
)
App(t1) = G(t0,t1)<M(t0,t1)> + dA(t0,t1)
13. 级列理论提供了一个演化框架,它指出孤立的模型必须被放在模型级列中被定义,被解释。(关于级列设计理论 http://canonical.javaeye.com/blog/33824
)
M[n] = G<M[n-1]> + dMn
14.
推理的链条会因为任何局部反例的出现而中断。在任意时空点上,我们能够断言的事实有哪些?信息越少,我们能够确定的事实越少,能够做出的推论也就越少。现
在流行的很多设计实质上是在破坏系统的对称性,破坏系统大范围的结构。比如明明ORM容器已经实现所有数据对象的统一管理,非要将其拆分为每个业务表一个
的DAO接口。很多对灵活性的追求完全没有搞清楚信息是对不确定性的消除,而不确定性的减少意味着限制的增加,约束的增加。(From Local To
Global http://canonical.javaeye.com/blog/42874
)
组件/构件技术的宣言是生产即组装,但是组装有成本,有后遗症(例如需要额外的胶水或者螺钉)。软件的本质并不是物质,而是信息,而信息的本质是抽象的规
律。在抽象世界中最有效的生产方式是抽象的运算,运算即生产。组件式开发意味着服从现有规律,熟练应用,而原理性生产则意味着不断创造新的规律。功能模
块越多,维护的成本越高,是负担,而推理机制越多,生产的成本越低,是财富。只有恢复软件的抽象性,明确把握软件构造过程内在的数学原理,才能真正释放软
件研发的生产力。(从编写代码到制造代码 http://canonical.javaeye.com/blog/333167
)
注解1:很多设计原则其实是在强调软件由人构造由人理解,软件开发本质上是人类工程学,需要关注人类的理解力与协作能力。例如共同的建模语言减少交互成本,基于模型减少设计与实现的分离,易读的代码比高性能的代码更重要,做一件事只有唯一的一种方式等。
注解2:生成系统的演绎远比我们想象的要深刻与复杂得多。例如生命的成长可以被看作是在外界反馈下不断调整的生成过程。
注解3:领域描述是更紧致但却未必是更本质的表达。人类的DNA如果表达为ATGC序列完全可以拷贝到U盘中带走,只要对DNA做少量增删,就可以实现老
鼠到人类的变换(人类和老鼠都有大约30000条基因,其中约有80%的基因是“完全一样的”,大约共享有99%的类似基因),但是很难认为人类所有智慧
的本质都体现在DNA中,DNA看起来更像是某种序列化保存形式而已。
注解4:模型转换这一提法似乎是在强调模型之间的同构对应,转换似乎总是可以双向进行的,仅仅是实现难度限制了反向转换而已。但是大量有用的模型变换却是单向的,变换过程要求不断补充新的信息。
注解5:模型驱动在很多人看来就是数据库模型或者对象模型驱动系统界面运行,但实际上模型可以意指任意抽象知识。虽然在目前业内广泛流行的对象范式下,所
有知识都可以表达为对象之间的关联,但是对象关系(名词之间的关联关系)对运算结构的揭示是远远不够充分的。很多时候所谓的领域模型仅仅是表明概念之间具
有相关性,但是如果不补充一大段文字说明,我们对于系统如何运作仍然一知半解。数学分析其实是将领域内在的意义抽空,仅余下通用的形式化符号。
html主要通过内置的<script>,<link>, <img>等标签引入外部的资源文件,一般的Web框架并没有对这些资源文件进行抽象,因此在实现组件封装时存在一些难以克服的困难。例如一个使用传统JSP Tag机制实现的Web组件中可能用到js1.js, js2.js和css1.css等文件,当在界面上存在多个同样的组件的时候,可能会生成多个重复的<script>和<link>标签调用,这将对页面性能造成严重的负面影响。资源管理应该是一个Web框架的内置组成部分之一。在Witrix平台中,我们主要借助于tpl模板引擎来输出html文本, 因此可以通过自定义标签机制重新实现资源相关的html标签, 由此来提供如下增强处理功能:
1. 识别contextPath
tpl模板中的所有资源相关标签都会自动拼接Web应用的contextPath, 例如当contextPath=myApp时
<script src="/a.js"></script> 将最终输出 <script src="/myApp/a.js" ...>
2. 识别重复装载
<script src="a.js" tpl:once="true"></script>
tpl:once属性将保证在页面中script标签实际只会出现一次.
3. 识别组件内相对路径
开发Web组件时,我们希望所有资源文件都应该相对组件目录进行定位,但是直接输出的<script>等标签都是相对于最终的调用链接进行相对路径定位的. 例如在page1.jsp中调用了组件A, 在组件A的实现中, 输出了<script src="my_control.js"></script>
我们的意图一般是相对于组件A的实现文件进行定位, 而不是相对于page1.jsp进行定位. tpl模板引擎的相对路径解析规则为永远相对于当前文件进行定位. 例如
<c:include src="sub.tpl" />
在sub.tpl中的所有相对路径都相对于sub.tpl文件进行定位.
4. 编译期文件有效性检查
在编译期, tpl引擎会检查所有引入的资源文件的有效性. 如果发现资源文件丢失, 将直接抛出异常. 这样就不用等到上线后才发现文件命名已修改等问题.
5. 缓存控制
浏览器缺省会缓存css, js等文件, 因此系统上线后如果修改资源文件可能会造成与客户端缓存不一致的情况. 一个简单的处理方式是每次生成资源链接的时候都拼接文件的修改日期或者版本号, 这样既可利用客户端缓存, 又可以保证总是使用最新版本. 例如
<script src="a.js"></script>将会输出 <script src="/myApp/myModule/a.js?344566" ...>
6. 字符集选择
为了简化国际化处理, 一般提倡的最佳实践方式是坚持使用UTF-8编码. 但是很多情况下可能使用系统内置的GBK编码会更加方便一些, 另外集成一些既有代码时也存在着不同字符集的问题. 在Witrix平台中, 所有输出的资源标签都会标明对应的字符集, 如果没有明确设置就取系统参数中的缺省字符集.
例如 <script src="a.js"></script> 将会输出 <script ... charset="GBK"></script>
7. 缺省theme支持
为了支持多种页面风格, 往往不是简单的替换css文件即可实现的, 它可能意味着整个组件的实现代码的更换. Witrix平台中通过一系列缺省判断来简化这一过程. 例如如下代码表明如果设置了ui_theme系统参数, 并且对应的特殊实现存在, 则使用特殊实现, 否则系统缺省实现.
<c:include src="${cp:ui_theme()}/ctl_my_ctl.tpl" >
<c:include src="default/ctl_my_ctl.tpl" />
</c:include>
AOP(Aspect Oriented Programming)早已不是什么新鲜的概念,但有趣的是,除了事务(transaction), 日志(Log)等寥寥几个样板应用之外,我们似乎找不到它的用武之地。http://canonical.javaeye.com/blog/34941
很多人的疑惑是我直接改代码就行了,干吗要用AOP呢?AOP的定义和实现那么复杂,能够提供什么特异的价值呢?
Witrix平台依赖于AOP概念来完成领域模型抽象与模型变换,但是在具体的实现方式上,却与常见的AOP软件包有着很大差异。http://canonical.javaeye.com/blog/542622
AOP的具体技术内容包括定位和组装两个部分。简化切点定位方式和重新规划组装空间,是Witrix中有效使用AOP技术的前提。
在Witrix平台中,对于AOP技术的一种具体应用是支持产品的二次开发。在产品的实施过程中,经常需要根据客户的特定需求,修改某些函数的实现。我们
可以选择在主版本代码中不断追加相互纠缠的if-else语句,试图去包容所有已知和未知的应用场景。我们也可以选择主版本代码和定制代码独立开发的方
式,主版本代码实现逻辑框架,定制代码通过AOP机制与主版本代码融合,根据具体场景要求对主版本功能进行修正。AOP的这种应用与所谓的横切概念是有所
区别的。典型的,一个横切的切点会涉及到很多类的很多方法,而函数定制则往往要求准确定位到某个业务对象的某个特定的业务方法上。传统AOP技术的切点定
义方式并不适合这种精确的单点定位。在Witrix平台中,我们通过直接的名称映射来定义切点。例如,修正spring中注册的MyObject对象的
myFunc方法,可以在app.aop.xml文件中增加如下标签
<myObject.myFunc>
在原函数执行之前执行
<aop:Proceed/> <!-- 执行原函数内容 -->
在原函数执行之后执行
</myObject.myFunc>
[spring对象名.方法名]这种映射方法比基于正则字符串匹配的方式要简单明确的多。spring容器本身已经实现了对象的全局管理功能,spring对象名称必然是唯一的,公开发布的,相互之间不冲突的,没有必要再通过匹配运算重新发现出它的唯一性。
对于一些确实存在的横切需求,我们可以通过Annotation机制来实现切点坐标标定,将复杂的切点匹配问题重新划归为[对象名.方法名]。
@AopClass({"myObject","otherObject"})
class SomeClass{
@AopMethod({"myFunc","otherFunc"})
void someFunc(){}
}
针对以上对象,在app.aop.xml文件中可以定义
<I-myObject.I-myFunc>
.
</I-myObject.I-myFunc>
结构的稳定性,直观的理解起来,就是结构在存在外部扰动的情况下长时间保持某种形式不变性的能力。稳定意味着小的扰动造成的后果也是“小”的。在数学中,Taylor级数为我们描绘了变化传播的基本图景。
F(x0 + dx) = F(x0) + F'(x0)*dx + 0.5*F''(x0)*dx^2 +
扰动dx可能在系统F中引发非常复杂的作用过程,在系统各处产生一个个局部变化结果。表面上看起来,似乎这些变化结果存在着无穷多种可能的分组方式,例如 (F'(x0)-2)*dx + 2*dx^2, 但是基于微分分析,我们却很容易了解到Taylor级数的每一级都对应着独立的物理解释,它们构成自然的分组标准。某一量级下的所有变化汇总归并到一起,并对应一个明确的整体描述。在抽象的数理空间中,我们具有一种无所不达的变化搜集能力。变化项可以从基础结构中分离出来,经过汇总后可以对其进行独立的研究。变化本身并不会直接导致基础结构的崩溃。
在软件建模领域,模型的稳定性面临的却是另一番场景。一个软件模型一旦被实现之后,种种局部需求变更就都会形成对原有基础结构的冲击。一些局部的需求变化可能造成大片原有实现失效,我们将被迫为类似的需求重新编写类似的代码。此时,软件开发并不像是一种纯粹的信息创造,而是宛若某种物质产品的生产(参见从编写代码到制造代码 http://canonical.javaeye.com/blog/333167 )。显然,我们需要一种能力,将局部变化从基础结构中剥离出来,经过汇总归并之后再进行综合分析和处理。这正是AOP(Aspect Oriented Programming)技术的价值所在。
M1 = (G0+dG0)<M0+dM0> ==> M1 = G0<M0> + dM
AOP本质上是软件结构空间的自由修正机制。只有结合AOP技术之后,软件模型才能够重新恢复抽象的本质,在时间之河中逃离随机变化的侵蚀,保持实现层面的稳定性。在这一背景下,建模的目的将不是为了能够跟踪最终需求的变动,而是要在某个独立的层面上能够自圆其说,能够具有某种独立存在的完满性,成为思维上可以把握的某个稳定的基点。模型的真实性将因为自身结构的完备性而得到证明,与外部世界的契合程度不再是价值判断的唯一标准。 http://canonical.javaeye.com/blog/482620
说到软件建模,一个常见的论调是模型应该符合实际需求,反映问题的本质。但是何谓本质,却是没有先验定义的。在成功的建立一个模型之前,无论在内涵上还是在外延上我们都很难说清楚一个问题的本质是什么。如果将模型看作是对领域结构的一种显式描述和表达,我们可以首先考察一下一个“合适”的结构应该具备哪些特征。
按照结构主义哲学的观点,结构具有三个要素:整体性,具有转换规律或法则(转换性),自身调整性(自律性)。整体性意味着结构不能被简单的切分,其构成要素通过内在的关系运算实现大范围的关联与转换,整体之所以成为整体正是以转换/运算的第一性为保证的。这种转换可以是共时的(同时存在的各元素),也可以是历时的(历史的转换构造过程),这意味着结构总要求一个内在的构造过程,在独立于外部环境的情况下结构具有某种自给自足的特性,不依赖于外部条件即可独立的存在并保持内在的活动。自律性意味着结构内在的转换总是维持着某种封闭性和守恒性,确保新的成分在无限地构成而结构边界却保持稳定。注意到这里对结构的评判并不是来自外在规范和约束,而是基于结构内在的规律性,所强调的不是结构对外部条件的适应性,而是自身概念体系的完备性。实际上,一个无法直接对应于当前实际环境的结构仍然可能具有重要的价值,并在解决问题的过程中扮演不可或缺的角色。在合理性这个视角下,我们所关注的不仅仅是当前的现实世界,而是所有可能的世界。一个“合理”的结构的价值必能在它所适应的世界中凸现出来。
在信息系统中,我们可能经常会问这个模型是否是对业务的准确描述,是否可以适应需求的变更,是否允许未来的各种扩展等等。但是如果换一个思维方向,我们会发现这些问题都是针对最终确立的模型而发问的,而在模型构建的过程中,那些可被利用的已存在的或者可以存在的模型又是哪些呢。每一个信息模型都对应着某种自动推理机,可以接收信息并做一定的推导综合工作。一个可行的问题是,如何才能更有效的利用已有的信息进行推导,如何消除冗余并减少各种转换成本。我们经常可以观察到,某一信息组织方式更充分的发掘了信息之间的内在关联(一个表象是它对信息的使用不是简单的局域化的,而是在多处呈现为互相纠缠的方式,难以被分解),这种内在关联足够丰富,以至于我们不依赖于外部因素就可以独立的理解。这种纠缠在一起的信息块自然会成为我们建模的对象。
如果模型的“覆盖能力”不再是我们关注的重点,那么建模的思维图式将会发生如下的转化
最终的模型可以由一系列微模型交织构成。模型的递进构造过程并不同于组件(Component)的实物组装接口,也不是CAD图纸堆叠式的架构概念所能容纳的。在Witrix平台中,模型分解和构造表达为如下形式 http://canonical.javaeye.com/blog/333167
Biz[n] = Biz[n+1] aop-extends CodeGenerator<DSLx, DSLy>。
在软件发展的早期,所有的程序都是特殊构造的,其必然的假设是【在此情况下】,重用不在考虑范围之内,开发可以说是一个盲目试错的过程。随着我们逐步积累了一些经验,开始自觉的应用理论分析手段,【在所有情况下】都成立的一些普适的原理被揭示出来,它们成为我们在广阔的未知世界中跋涉时的向导。当我们的足迹渐渐接近领域的边界,对领域的全貌有一个总体的认知之后,一种对自身成熟性的自信很自然的将我们导向更加领域特定的分析。很多时候,我们会发现一个特化假设可以大大提高信息的利用率,推导出众多未被显式设定的知识。我们需要那些【在某些情况下】有效的规则来构成一个完备的模型库。这就如同有大量备选的数学定理,面对不同的物理现象,我们会从一系列的数学工具中选择一个进行使用一样。
软件开发技术的技术本质在于对代码结构的有效控制. 我们需要能够有效的分解/重组代码片断, 凸显设计意图. 面向对象是目前最常见的代码组织技术. 典型的, 它可以处理如下模式
A1 --> B2, A2 --> B2, A3 --> B3 ...
我们观察到A1和A2之间, B2和B2之间具有某种概念关联性, 同时存在某种抽象结构 [A] --> [B].
对于这种情况, 我们可以定义对象 [A], [B], 它们分别是 A1和A2的聚合, B1和B2的聚合等. 举例来说, 对于如下表格描述, <ui:Col>所提供的信息在映射为html实现的时候将在多处被应用.
<ui:Table data="${data}">
<ui:Col name="fieldA" label="labelA" width="20" />
<ui:Col name="fieldB" label="labelB" width="10" />
</ui:Table>
这里<ui:Col>提供的信息对应三个部分的内容: 1. 列标题 2. 列样式(宽度等) 3. 列数据
面向对象的常见做法是抽象出 UiCol对象, 它作为UiTable对象的属性存在, 在生成表头, 表列样式和表格数据内容时将被使用. 但是我们注意到面向对象要求多个方法通过this指针形成状态耦合
,在某种意义上它意味着所有的成员方法在任一时刻都是同时存在着的。它们所代表着的存在的代价必须被接受(存储空间等)。即使并不同时被使用,我们仍然需要同时持有所有成员函数指针及
共享的this指针。实际上, 我们并不一定需要A1和A2同时在场. 在这种情况下, 编译期技术可以提供另一种不同的行为聚合方式.
<table>
<thead>
<sys:CompileTagBody cp:part="thead" />
</thead>
<cols>
<sys:CompileTagBody cp:part="cols" />
</cols>
<tbody>
<sys:CompileTagBody cp:part="tbody" />
</tbody>
</table>
只要<ui:Col>标签的实现中针对编译期的cp:part变量进行分别处理, 即可实现信息的部分析取.
html最早的设计目标只是作为某种多媒体文档展现技术,其设计者显然无法预料到今天Web应用的蓬勃发展,一些设计缺陷也就难以避免。特别是html规范中缺乏对于复杂交互式组件模型的支持,直接导致企业应用的前台开发困难重重。AJAX技术可以看作是对这种困境的一种改良性响应,它试图通过javascript语言在应用层创建并维护一系列复杂的交互机制。很多完善的ajax框架走得相当遥远,最终基本将html作为一种底层“汇编”语言来使用。例如,一个很整齐美观的类Excel表格可能是由一个个div拼接而成,与html原生的table元素已经没有任何关系。
Witrix平台中对于前台html模型也作了一定的增强,但基本的设计思想是尽量利用原生控件,并尽量保持原生控件内在的数据关系,而不是重新构建一个完整的底层支撑环境。采用这种设计的原因大致有如下几点:
1. 前台技术目前竞争非常激烈,我们优先选择的方式是集成第三方组件,尽量保持原生环境有利于降低集成成本。
2. 通过javascript构造的控件可能存在性能瓶颈和其他浏览器内在的限制。例如一般Ajax框架提供的Grid控件都无法支撑大量单元格的显示。
3. Witrix平台的tpl模板技术可以非常方便的生成html文本,并提供强大的控件抽象能力,因此在前台动态创建并组织界面元素在Witrix平台中是一种不经济的做法。
4. Witrix平台提供的分解机制非常细致,存储于不同地方的不同来源的代码会在不同的时刻织入到最终的页面中,基于原生环境有利于降低平台快速演进过程中的设计风险。
Witrix平台中对于html模型的增强主要关注于以最少的代码实现界面控件与业务逻辑的自然结合。基本结构包括:
1. 通过ControlManager对象在前台建立一种container结构,统一管理控件的注册和获取。js.makeControl(elmOrId)返回特殊注册的控件对象或者根据原生html元素生成一个包装对象。
2. 通过js.getWxValue(elm)和js.setWxValue(elm,value)这两个函数统一对控件的值的存取过程。
3. 通过js.regListener(elm,listenerFunc)统一管理控件之间的相关触发,实现控件之间的相互监听。当js.setWxValue(elm,value)被调用时,注册在ControlManager中的listenerFunc将被调用。
4. stdPage.setFieldValue(fieldName,value)和stdPage.getFieldValue(fieldName,value)统一针对业务字段的值的存取过程,这里fieldName对应于实体上的业务字段名。
5. 通过ajax.addForm(frmId)等函数统一前台提交参数的提取过程,通过stdPage.buildAjax()等函数统一后台服务的调用方式。
6. 通过stdPage对象统一封装业务场景中的"常识"。
基于以上一些基础机制,Witrix平台即可提供一些复杂的业务组件封装。例如<input name="productCode" onkeypress="stdPage.keyPressToLoadRefByCode({objectName:'SomeProduct',queryField:'productCode'})" .../>通过简单的调用一个js函数即可实现如下功能:
a. 在文本框中输入回车的时候自动提交到后台查找对应产品代码的产品,并更新前台多个相关字段的值
b. 如果没有查找到相应产品,则弹出对话框根据界面上已有的部分字段信息提示客户添加新的产品信息。
c. 如果找到多个对应产品,则弹出列表允许客户选择其一。
d. 具体的处理过程可以通过函数参数进行精细的控制。
在meta文件中,结合上下文环境中的元数据信息,我们在缺省情况下可以直接使用 <ds:LoadRefByCodeInputor objectName="SomeProduct" />标签,不需要任何其他附加参数。
Witrix平台中一般利用原生控件来保存数据值,而不是将数据保存在分离的js对象中。例如对于一个选择控件,经常要求选择得到的是实体的id,而显示在界面上的是某个其他字段的值。Witrix平台中一般的实现结构是
<input type="hidden" name="${fieldName}" value="${entity[dsMeta.idField]}" id="${id}" textId="text_${id}" />
<input type="text" value="${entity[dsMeta.nameField]}" id="text_${id}" />
通过textId等扩展属性即可明确定义控件多个部分之间的关联关系,同时保证控件的实现完全与html规范相兼容。
Witrix平台中目前使用的"标准化"的扩展属性有textId(对应文本显示控件的id), showName(某些无文字显示的选择控件需要保留显示字段值), op(字段作为查询条件提交时的比较算符),validator(字段值对应的检验函数),setWxValue/getWxValue(重定义控件值的存取行为),serializer(特殊处理前台控件的提交参数)等。扩展属性不仅可以引入说明信息,还可以引入丰富的控件行为。
分层是最常见的软件架构方式之一。分层之后可以区分出横纵两个维度,纵向往往表现出一种隔离性。出于有意无意的各种原因,层次之间传递信息很容易出现模糊甚至丢失的现象。B/S多层体系架构下的程序因为浏览器和服务器之间的状态空间相互独立,相对于共享全局状态空间的C/S程序,更容易出现信息传递不畅的问题。实际上,我们经常可以观察到B/S程序中存在着大量的"接力"代码,即在交界处,总是存在着大量用于读取变量,拼接变量,转换变量等与主体业务无关但却又不可或缺的代码。在多层架构程序中,信道构建应该是一个需要给予足够重视的问题。
在系统规划中,多层结构应该内置与具体语义无关的通用信道,它跨越多个层次,允许信息透明的通过,并以未预期的方式在不同的层面激发各种相关的行为。在Witrix平台中,平台代码与特定应用中的业务代码处于高度交织的状态,一个特定业务功能的实现往往需要多处业务代码相互协同,平台必须成为某种透明的背景。例如,假设我们编制了一个通用的列表选择控件,它封装的逻辑是从一个实体列表中进行选择
<app:SelectOne objectName="MyEntity" />
如果现在要求选择时只列出某个类型的实体,则调用形式为
<app:SelectOne objectName="MyEntity" extArgs="$bizId=select&$type=1" />
在调用入口处补充必要的信息之后会推动系统在遥远的状态空间中应用一个特定的过滤条件。这里$bizId负责指示平台应用特定的元数据配置,而其他的参数则由元数据中的逻辑负责处理。平台与特定业务代码各取所需,相互配合,将尽可能多的逻辑剥离为通用机制。
现代数学是建立在等价类这一概念的基础之上的。同构是对等价关系的一种刻划。简单的可以把它理解为两个系统之间的一种“保持”运算规则的一一对应关系。在
数学中一个符号所代表的是所有能够互相同构的对象。例如整数3可以看作是与某个元素个数为3的集合可以建立一一对应关系的所有的集合所构成的整体。所以在
数学中,如果我们解决某个特定的问题,它同时也就意味着我们解决了一系列相互等价的问题。
同构关系对于认知可以起到本质上的简化作用。如果通过一个推理链条,确认了A == B == C == D,则可以直接从概念上推导出 A
== D,
这一关系有可能被直观理解,而不需要理会中间的推理步骤。(注意到以上元素两两建立同构关系的时候可能要采用不同的对应手段,因此上面的等式并不是平凡
的。)另一方面,我们可以确定一个模型元素M, 将系统简化为 A == M, B == M, C == M, D ==
M。只要理解了元素M就理解了等价的其他元素。
Witrix平台中PDM定义作为基础的结构模型,它同时映射成为数据库表,以及hbm, java,
meta等多个代码文件,此外还对应于约定的WebObject名称和BizFlow文件名称,相应的报表文件目录等。我们只要理解了pdm模型,即可通
过推理自然的掌握各个层面上对应的结构。这意味着只要知道实体名称,就知道如何通过Web访问这个对象,知道数据在数据库中对应的数据库表,而不需要知道
后台是如何读取前台提交的参数以及如何执行保存数据指令的。不仅仅是在模型驱动领域,在系统设计的各个方面,我们都应该尽量充分的利用当前的信息通过推理
得到系统其他部分的结构,而不是通过手工关联或者判断在程序中动态维持这种对应关系。例如在flow-cp机制中,biz的id,
action的id等都根据step配置的id推导得到,这样在工作列表跳转的时候就可以根据规则推导出跳转页面对应的链接,而不需要手工编写页面重定向
代码。

同态(homomorphism)关系相对于同构关系,只强调单向映射的可行性,它是一个舍弃属性的过程。同态作为最基础的认知手段之一,它不仅仅是用一
个符号来置换一组元素,而是同时保留了某种全局的运算关系,因此同态映像可以构成某种独立的完整的研究对象。通过同态映射,我们可以在不同的抽象层面上研
究原系统的一个简化版本。例如meta中的layout是一种典型的领域特定语言(DSL)。
userName userTitle
emailAddress
每一个字段表示了一个可能任意复杂的inputor或者viewer,
字段之间的前后关系描述了最终显示页面上显示内容的相对关系。当viewer根据需求发生改变的时候,并不影响到layout层面上的关系,因此
layout可以保持不变。如果我们在系统中把问题分解为多个抽象层面上,多个观察视角上的同态模型,则可能实现更高的软件复用程度。
在Witrix平台的设计中,很多细粒度的标签都定义为tpl文本段,这样平台只要理解某一层面上的交互关系,实际应用中可能出现的细节在标签内部进行局
部处理,不会突破原始设计的形式边界,不会影响到原先设定的主体系统结构。例如BizFlow中的tpls段,action的source段等。
上世纪50年代以前,生物学家做梦也想象不到具有无限复杂性的生物遗传过程,竟然可以被抽象为ATGC四个抽象符号的串联。生命竟然不理会各种已知的或是
未知的物理化学作用,被抽象的三联码所驱动。一种抽象的本质似乎成了生命世界的本原。在软件的世界中,可以被识别的抽象元素绝不只是语言本身所提供的那些
机制。
有一个心理学实验,要求被试者将青草,公鸡,牛三个东西分
成两组,结果多数中国儿童将青草和牛分成一组,而多数美国儿童将公鸡和牛分成一组。中国人的思想中青草和牛之间存在现实的关系,牛吃草,而西方人的典型逻
辑是公鸡和牛都属于动物这一范畴。通过分类将物体类型化,这是西方人从小就接受的训练。据说美国婴儿学习名词的速度要快于动词,而中国的婴儿则相反,这并不是偶然的。
中国人的传统哲学认为世界是普遍联系的,事物之间存在着祸福相依的辩证转化关系。而古希腊人强调个体意识,以两分法看待世界,他们将世界看成是孤立的物体组成(原子论)构成,然后选择一个孤立物体(脱离背景),开始研究它的各项属性,接着将属性泛化,构成分类的基础。西方语言中大量抽象概念都是从作为属性的形容词直接转化而来,例如
white
-->
whiteness
。而中文中很少有精确的类型定义,而多半是富有表现力的,隐喻性的词语,例如我们不谈论抽象的白,而只说雪白,没有抽象的
size
,而只说具体的大小。
亚里士多德认为铁球在空气中下落是因为它具有“重性”,而木块在水中漂浮是因为木块具有“轻性”。这种将一切原因归结为事物内在属性的传统在一定程度上妨碍了西方人认识到背景的存在和作用,但使得他们可以把问题简化。
古希腊人对于类型的热衷源于他们对于永恒的迷恋。静态的亘古不变的世界才是他们的思想栖息的场所。具体的物体是易逝的,多变的,只有抽象的类型才是永恒的存在,也只有抽象概念之间的关系才是永真的联系。而具体实例之间的关联在某种程度上被认为是不重要的,甚至是不可靠的。

将具有某一属性的所有物体定义为一个集合,这一做法在上世纪初被发现会引起逻辑悖论,动摇了整个数学的基础,它绝不像表面上看起来那么单纯。但确定无疑的是,通过类型来把握不变的事实是一种非常重要且有效的认识策略。面向对象语言强调名词概
念,从引入类定义以及类之间的继承关系开始,这符合西方一贯的作风。而
Ruby
这种强调实例间关系的动态语言首先由日本人发明,可能也不是偶然的。虽然现在大家都在玩高科技了,可实际贩卖给你的多半仍然是包治百病的祖传秘方。文化可能造成认知上的一种偏执,在技术领域这一现象并没有被清楚的意识到。
软件开发作为一种工程技术,它所研究的一个重点就是如何才能有效降低软件产品的研发成本。在这一方向上,组件技术取得了空前的成功。它所提供的基本图景是
像搭积木一样从无到有的组装出最终的产品。在某种意义上,这是对现代建筑工业的模仿和致敬。新材料,预制件,框架结构,这些建筑学的进展在软件领域被一一
复制,建筑工地上的民工自然也成为了程序员们学习的楷模。毕竟,在组件的世界中码代码,基本上也是一种“搬砖”的行为。
值得庆幸的是,软件开发作为一种智力活动,它天生具有一种“去民工化”的倾向。信息产品有着与物质世界产品完全不同的抽象本质。在物理空间中,建造100
栋房屋,必须付出100倍的努力,老老实实的干上100遍。而在概念空间中建造100栋房屋,我们却可以说其他房屋与第一栋一模一样,加点平移旋转变换即
可。一块砖填了地基就不能用来盖屋顶,而一段写好的代码却可以在任何可用的场合无损耗的被使用。一栋建好的房屋发现水管漏水要大动干戈,而在完成的软件中
补个局部bug却是小菜一碟。在抽象的世界中有效的进行生产,所依赖的不应该是大干,苦干的堆砌,而应该是发现某种可用于推导的原理,基于这些原理,输入
信息可以立刻转换为最终的结果,而不需要一个逐步构造的过程。即我们有可能超越组装性生产,实现某种类似于数学的原理性生产。http://canonical.javaeye.com/blog/325051
代码复用是目前软件业中鼓吹降低生产成本的主要口号之一。但是在组件技术的指向下,一般所复用的只是用于构建的砖块,而并不是某种构造原理。即使在所有信
息已经确定的情况下,我们仍然不可能从需求立刻得到可执行的产品。很多代码即使我们在想象中已经历历在目,却仍然需要一行行把它们誊写下来。当我们发现系
统中已经没有任何组件值得抽象的时候,仍然留下来众多的工作需要机械化的执行。代码复用的理想国距离我们仍然非常的遥远。
子例程(subroutine)是最早的代码重用机制。这就像是将昨天已经完成的工作录制下来,在需要的时候重新播放。函数(function)相对于子
例程更加强大。很多代码看起来并不一样,但是如果把其中的差异部分看作是变量,那么它们的结构就可以统一了。再加上一些判断和循环,很多面目迥异的东西其
实是存在着大量共享信息的。面向对象技术是一次飞跃性的发展。众多相关信息被打包到一个名称(类型)中,复用的粒度和复杂度都大大提升。派生类从基类继
承,可以通过重载实现对原有代码的细致调整。不过,这种方式仍然无法满足日益增长的复用需求。很多时候,一个名称并不足以标定我们最终需要的代码结构,在
实际使用的时候还需要补充更多的信息。类型参数化,即泛型技术,从事后的角度看其实是一种明显的解决方案。根据参数动态的生成基类自然可以吸纳更多的变
化。经历了所谓Modern
C++的发展之后,我们现在已经非常明确,泛型并非仅仅能够实现类型共变,而是可以从类型参数中引入更丰富的结构信息,它的本质是一种代码生成的过程。http://canonical.javaeye.com/blog/57244
认清了这一点,它的扩展就非常明显了
BaseClass<ArgClass> --> CodeGenerator<DSL>
DSL(或者某种模型对象)相对于普通的类型(Class),信息密度要大很多,它可以提供更丰富也更完整的输入信息。而CodeGenerator也不必拘泥于基础语言本身提供的各种编译机制,而是可以灵活应用各种文本生成技术。http://canonical.javaeye.com/blog/309395
CodeGenerator在这里所提供的正是根据输入模型推导出完整实现代码的构造原理。
现在很多人热衷于开发自己的简易代码生成工具,这些工具也许可以在简单的情形下减轻一些体力工作,但是生成的代码一般不能直接满足需求,仍然需要手工执行
大量的删改工作。当代码生成之后,它成为一种固化的物质产品,不再能够随着代码生成工具的改进而同步改进,在长期的系统演化过程中,这些工具并不一定能够
减少累积的工作量。
修正过程 ==> CodeGenerator<DSL>
为了改进以上代码生产过程,一些人试图在CodeGenerator中引入越来越多的可配置性,将各种变化的可能内置在构造原理中。显然这会造成CodeGenerator的不正常的肿胀。当更多的偶然性被包含在原理中的时候,必然会破坏原理的简单性和普适性。
输入信息 + 一段用于推导的原理 + 修正补充 = 真实模型
必须存在[修正补充]这一项才能维持以上方程的持久平衡。
为了摆脱人工修正过程,将模型调整纳入到概念世界中,我们需要超越继承机制的,更加强大的,新的技术手段。其实在当前的技术背景下,这一技术已经是呼之欲出了。这就是AOP, Aspect Oriented Programming。http://canonical.javaeye.com/blog/34941
Biz ==[AOP extends]==> CodeGenerator<DSL>
继承仅仅能够实现同名方法之间的简单覆盖,而AOP所代表的技术原理却是在代码结构空间中进行任意复杂的删改操作,它潜在的能力等价于人工调整。
为了实现上述生产模式,需要对编程语言,组件模型,框架设计等方面进行一系列改造。目前通用的AOP实现和元编程技术其实并不足以支持以上模式。http://canonical.javaeye.com/blog/275015
这一生产模式将会如何演化,也是一个有趣的问题。按照级列理论,我们立刻可以得到如下发展方向:
Context0 + DSL1 + EXT0 = DSL0
Context1 + DSL2 + EXT1 = DSL1
http://canonical.javaeye.com/blog/33824
Witrix平台中BizFlow可以看作是对DaoWebAction的修正模型,但是它本身具有完整的意义,可以直观的被理解。在BizFlow的基础上可以逐步建立SeqFlow,StateFlow等模型。http://canonical.javaeye.com/blog/126467
现在有些人试图深挖函数式语言,利用模式匹配之类的概念,做符号空间的全局优化。但是我们需要认识到通用的机制是很少的,能够在通用语言背景下被明确提出
的问题更是很少的。只有在特定领域中,在掌握更多局部信息的情况下,我们才能提出丰富的问题,并作出一定背景下的解答。DSL的世界中待做的和可做的工作
很多。http://canonical.javaeye.com/blog/147065
对于程序员而言,未来将变得越来越丰富而复杂,它将持续拷问我们的洞察力。我们不是一行行的编写代码,把需求一条条的翻译到某种实现上,而是不断发明局部的生产原理,依靠自己制定的规则在抽象的空间中不断的创造新的表象。
负数没有直接的几何意义,因此它被认为是对应于不存在的事物。而按照古希腊的逻辑,不存在的事物是不可能存在的,因而也就是无法被理解的,更不可能参与到
推理过程中,因此是无意义的,无法被定义的,
因此它是不存在的。中国人注重的是运算的合理性,而不是数的真理性,大概在公元前400年左右就创造了负数和零的概念。而在西方直到公元7世纪(唐代)的
一本印度人的著作中才出现负数,它被用来表示负债。西方人没有能够创造负数,他们对负数的接受更迟至15世纪左右。这件事实在一定程度上说明了存在某种深
刻的困难阻碍我们理解负数概念。
在引入负数之前,3x^2 + 8 = 4x 和 3x^2 + 4x + 8 = 0
这两个方程的结构是完全不同的,它们需要不同的求解技术,因此也就不可能利用符号抽象出 a x^2 + b x + c =
0。引入负数才使得我们能够以统一的方式提出问题,并研究通用的求解技术。
群论(Group Theory)是对结构进行抽象研究的数学分支。群的定义包括四条规则
1. 元素之间的运算满足结合律 (a * b) * c = a * (b * c)
2. 元素之间的运算封闭,即 a * b 仍然属于该群
3. 存在单位元,即对所有a, a * e = e*a = a
4. 每个元素存在对应的逆元,a * a^-1= e
逆运算是非常重要的结构要求,逆元是对负数的一种抽象推广。如果没有逆元,则只能构成半群(semi-group),它的性质要少很多。
目前软件设计中所有的原则都指向组装过程,从无到有,层层累进。构件组装的隐喻中所包含的图像是操纵实际可见的积木,是缺少逆元概念的。
考察一个简单的例子,假设需要的产品是三角形内部挖去一个五边形的剩余部分。有三种生产策略:
1. 对最终需要的产品形态进行三角剖分,使用8个小三角形拼接出来。这种方式比较繁琐,而且最后粘接工序的可靠性和精确性值得怀疑。
2. 拿到一个真实的三角形,然后用刀在内部挖出一个五边形的洞。这种方式需要消耗一定的人工,而且也很难保证五边形的精确性,即使我们曾经精确的生产过其他五角形和三角形。实际上一般情况下我们是逐步锉出一个五边形的,并没有充分利用到五边形的对称性。
3. 在概念空间中做一个抽象计算 (-五边形) + (三角形) = 所需产品
如果我们能够生产一种负的五边形和一种正的三角形,则可以立刻得到最终的产品。

在软件开发的实践中,我们目前多数采用的是两种方式:
1. 采用可视化设计工具通过拖拽操作开发出完整的界面和后台
2. 拷贝一些已有的代码,删除掉不需要的部分,增加一些新的实现,也可能对已有实现做一些不兼容的修正。
在第二种方式中
新结构的构造 = 已有结构 + 软件之外的由人执行的一个剪裁过程
这个剪裁过程表现为一个时间序列。如果我们对原有结构进行了调整,则需要重新关联一个时间序列,而此时间序列并不会自动重播。为了压缩以时间为度量单位的
生产成本,我们必须减少对时间序列的依赖。在时间序列中展开的一个构造过程可以被转化为一个高维设计空间中的一种更加丰富的构造原理,我们最终的观测可以
看作是设计空间向物理空间的一个投影(想象一束光打下来)。这种方式更容易保证程序的正确性。
时间序列 --[原理转化]--> 空间关系
这样我们就可以使用第三种生产策略:利用构造原理进行抽象计算。如果我们只盯着产品的最终形态看,只是想着怎么把它像搭积木一样搭建出来,就不可能识别出
系统结构本身所蕴含的对称性。如果我们发现了系统内蕴的结构特征,但是却只能通过构造过程中的行动序列来追随它,同样无法实现有效的工作复用。同时因为这
个行动序列一般处于系统规则约束之外,完全由人的自觉来保障,因此很难保证它的正确性。现实世界的规范要求并不是模型本身所必须满足的,只要我们能够创造
新的结构原理,在概念空间中我们就可以拥有更多的自由。现在业内鼓吹的软件构造原理多半是参照物理世界中生产具体物质产品的生产工序,却没有真正把握信息的抽象本质。掌握规则,制订规则,才是信息空间中的游戏规则。
物理学中最重要的分析学思想之一是微扰论(Perturbation).
针对一个复杂的物理现象,首先建立一个全局的规范的模型,然后考虑各种微扰条件对原有模型的影响。在小扰动情况下,模型的变化部分往往可以被线性化,被局
域化,因而问题得到简化。微扰分析得到的解依赖于全局模型的解而存在,因而这是一种主从关系的分解方式。但是如果主体模型是我们已经熟知的物理现象,则我
们关注的重点可以全部放在扰动解上,认为所有特定的物理规律都体现在扰动解中。如果微扰分析得到的物理元素足够丰富,则微扰模型本身可以成为独立的研究对
象,在其中我们同样可以发现某种普适的结构规律。
考察如下的构造过程
X = a + b + c
Y = a + b + d = (a + b + c) - c + d = X - c + d
对于数学而言,上述的推导是等价的,但是对于物理学而言,Y = a + b + d 和 Y = X - c +
d是有着本质不同的。第一种方式要求打破原先X的构造,而重新的组装其实是有成本的,特别是在X本身非常复杂的情况下。典型的,如果X是经过测试的功能,
重新组装后原先由测试保障的概念边界被打破。
我们可以从Y = X + dX抽象出扰动模型 dX = - c + d
主从分解模式自然的导出逆元概念。
如果没有逆元,我们必然需要分解。但是如果发掘了背景这一概念,在逆元运算下,对背景不是分解让其成为可见的部分,而是采用追加的,增删的方法对背景结构
进行修正,则我们有可能在没有完整背景知识的情况下,独立的理解局部变化的结构。即背景是透明的,知识成为局部的。在Witrix平台中,BizFlow
+ DaoWebAction + StdPage
才构成完整的程序模型,BizFlow其实是对标准模型的差异描述,但是它可以被单独的理解。如果我们从接触程序开始就接受BizFlow,
就可能完全不需要了解数据库访问和前台界面渲染的知识。我们并不是通过在DaoWebAction中设定各种可预见的调用形式,而是在BizFlow中通
过类似AOP的操作方式直接对标准模型进行修正。这种修正中一个很重要的部分就是删除标准模型中缺省提供的功能。
WebMVC之前世今生 http://canonical.javaeye.com/blog/163196
Witrix架构分析 http://canonical.javaeye.com/blog/126467
变化的部分构成独立于原始模型的新的模型,它的结构关系是完备的,可以独立的理解。在原始模型崩溃的情况下,它仍然可能保持有效性。
从物理学的角度看,我们所观测到的一切物理现象,都是某种物理作用的结果,也就是物质结构相对于背景状况的一种偏离。我们只可能观测到变化的部分,因此我们对世界的认识其实只是世界的扰动模型而已,世界的本体不属于科学研究的范畴。
软件技术的发展是一个结构化不断加深的过程,我们逐渐拥有了越来越丰富的结构识别, 表达和处理手段。在这一方向上,
组件技术最终取得了巨大的商业成功。但是区分同时也就意味着隔阂。面向对象技术最基础的概念在于 O = C(O),
对象的复合(Composition)仍然是对象. 然而在越来越复杂的软件生态环境中,这一图景实现的可能性被大大的压缩.
面对层层封装造成的形态各异的表达方式, 不同来源, 不同目标, 不同运行环境下的信息的交互变得越来越困难。我们逐渐丧失了概念上的简洁性,
也丧失了数学世界中的那种穿透一切的统一的力量. 所谓SOA(Serivce Oriented
Architecture)技术试图通过补充更多的环境信息,放弃状态关联,暴露元知识等方式来突破现有的困境。 http://canonical.javaeye.com/blog/33803
这其中一项关键的技术抉择是基于文本格式进行信息表达。
在过去10年中Web技术取得了空前的成功,它造就了互联网这一世界上最大的分布式集成应用。SOA从某种程度上说是对这一事实在技术层面上的反思。基于
文本传递的web技术所表现出来的开放性,可理解性和可观测性,与封闭的,难以直接解读的,必须拥有大量相关知识才能正确操作的二进制结构相比,这本身就
是革命性的创新。不需要特殊的工具就可以非常轻易的察看到网页程序的输入输出,所有交互过程都处在完全透明的检查下,各种不曾事先规划的文本处理手段都可
以参与到web创建的过程中。随着速度,存储不再是我们考虑的首要问题,文本化作为一种技术趋势逐渐变得明确起来。但是任何一种技术思想的成功或失败都不
可能是因为某种单一的原因所造成的,因此有必要对文本化的技术价值做更加细致的剖析。
1.
文本化是一定程度上的去结构化,但是通过这种方式我们获得了对程序结构的更强的控制力。无论我们所关心的文本片断层层嵌套在大段文本的哪个部分,我们都可
以通过text.indexOf(subStr)来实现定位,通过text.replace(oldStr,newStr)实现变换。而在组件系统中,我
们只有通过某种预定的遍历方式逐步递归才有可能访问到组件内部的组成对象。如果某个组件不按照规范实现或者规范中缺少明确的设定,则这一信息关联链条将会
断裂。在一些组件系统中,甚至没有规定一种统一的遍历方式,则我们根本无法定义出通用的大范围的结构定位/变换手段。即使是在设计精良的组件框架中,受限
制于组件的封装性要求,我们也不可能访问到全部的信息。当我们以组件设计者意料之外的方式使用这些组件的时候,就会遇到重重障碍。即使所需的只是微小的局
部调整,因为无法触及到需要修改的部分,我们也可能被迫放弃整个组件。
2.
文本是普适的信道。各种操作系统,各种程序语言所具有的最基本的能力就是文本处理能力,对于文本格式的约定是最容易达成共识的。虽然对于机器而言,理解基
于地址定位的二进制数字可能更加直接,但是所有的应用程序都是由人来负责编制,调试,部署,维护的,如果人可以不借助特殊的工具就可以明确了解到系统内发
生的过程,则系统的构建和维护成本就会大幅下降。
3.
文本表述形式上的冗余性增强了系统的概念稳定性和局部可理解性。在二进制格式中,经常出现的是根据相对地址定位,这要求我们完整理解整个二进制结构,才能
够逐步定位到局部数据块。同时,二进制格式中也经常使用一些外部的信息,例如某个位置处的数据为整型,占用四个字节等。这样的信息可能只能在文档说明里查
到,而在数据体中没有任何的体现,这限制了独立的理解可能性。与此相反,文本格式经常是自说明式的,例如width:3.5px,
这提高了系统的可理解性,特别是局部可理解性。即使我们对系统只具有很少的知识,一般也能根据数据周围的相关信息进行局部操作。一般很容易就能够定位到特
殊的局部数据区,安全的跳过众多未知的或者不被关心的结构. 一个程序新手也可以在很短时间内靠着连蒙带猜,
实现xml格式的word文件中的书签替换功能,而要搞清楚word的二进制格式,并独立编制出正确的替换功能,显然就不是一两周的工作量可以解决的了.
这其中, 可理解性的差异是存在着数量级上的鸿沟的.
4. xml这种半结构化的文本格式规范的兴起, 以通用的方式为文本描述引入了基本的形式约束, 实现了结构表达的均一性.
C语言中的宏(Macro)本质上就是一种文本替换技术,它的威力在于没有预定义的语义, 因此可以超越其他语法成分, 破除现有语法无法跨越的限制.
但是它的危险性在于缺乏与其能力相适应的形式约束, 难以控制. 而在xml格式规范下, 不同语义,
不同抽象层面的节点可以共存在同一个形式体系中, 可以用通用的方式进行定位,校验, 转换等. Witrix平台在动态xml方面发展了一系列技术,
为文本处理引入了更多应用相关的规则, 增强了文本描述的抽象能力和表达能力.
5. 文本作为描述(description)而不是执行指令(execution). C语言的源代码与机器码基本上是一一对应的,
即源代码本身所表达的就是指令的执行过程. 而在Web应用领域, HTML语言仅仅是声明界面上需要展现什么,
但是如何去实现是由通用的解析引擎负责,它并不是我们关注的重点. 描述需要结合诠释(解释)才能够产生实际的运行效果,
才能对现实的物理世界产生影响.这在某种程度上实际上是延迟了执行过程. 一种描述可以对应多种诠释,
例如同样的元数据在前台可以用来生成界面,在后台可以用于生成数据库, 进行数据有效性校验等. 在特定的应用领域中,执行引擎可以是通用的,
可以独立于描述本身不断演化, 因此一种领域特定的描述,它所承载的内容并不是固化的, 而是可以随着执行引擎的升级不断增强的. 例如,
在Witrix平台中, FlowDSL本身所做出的流程描述是稳定的,
但是随着流程引擎不断改进,不断引入新的功能,所有使用DSL的已实现的应用都同步得到升级. http://canonical.javaeye.com/blog/275015
6. Text = Process(Text) 这个不动点在Unix系统中得到了充分的应用: 多个小程序通过管道(Pipe)组合在一起,
可以完成相当复杂的功能. 一个更加丰富的处理模型是 XML = Process(XML). 文本描述很自然的支持多趟处理,
它使得我们可以充分利用全局知识(后续的处理过程可以使用前次处理过程收集的全局信息), 可以同时支持多个抽象层面(例如DSL的不断动态展开).
Witrix平台中的编译期运行技术实际上就对应于如下简单规则: 编译期运行产生文本输出, 对输出文本再次进行编译. 通过这一递归模式,
可以简单的实现动态解析与静态描述之间的平衡. 模板(Template)技术是具有关键性作用的文本生成技术.
out.write("<div>");out.write(value);out.write("</div>");这种
API拼接方式显然不如<div>${value}</div>这种模板生成方式直观且易于使用.
在Witrix平台的tpl模板语言中, xml的规范性使得在多趟编译过程中我们一直可以维持某种形式约束.
7. 不是所有的情况下都应该使用文本. 普元EOS中所鼓吹的XML总线之类的技术是我所极力反对的. http://canonical.javaeye.com/blog/33794
代码生成(Code Generation)本身是一个非常宏大的概念。从某种意义上说,当我们明确了计算的意义之后,所做的一切都只是一系列代码生成的过程,最终的目标是生成某种可执行的机器码。对web程序员来说,代码生成是最熟悉不过的了,每天我们所做的工作就是JSP=>Servlet=>HTML。不过,现在多数人脑海中的代码生成,指的一般只是根据配置输出一个或多个程序文本的过程,最常见的是根据数据库模型生成增删改查相关代码。这种技术其实很少在小型以上的项目中起到积极的作用.因为一般的生成工具都没有实现追加功能,无法适应模型的增量修改。此外一般生成的代码相比于手工书写的代码要更加冗长,需要被直接理解的代码总量不降反升.为图一时之快,所要付出的是长期的维护成本。
在应用开发中,有些领域是非常适合于使用代码生成技术的。例如根据领域模型生成ORM(对象-关系映射)描述,或者根据接口描述生成远程调用代理/存根 (Proxy/Stub)等。因为它们实际上只是对同一信息的不同技术形式或者不同技术层面的同义反复而已。这种生成最理想的方式是动态进行,可以随时保持模型的有效性。RoR(RubyOnRails)框架中ActiveRecord技术便是一个成功的范例,它甚至提供了动态生成的DAO函数,减少了一系列的包装调用过程。
代码生成更加深刻的应用是完成高层模型向低层模型的转化,这一过程往往是非平凡(non-trivial)的。在Witrix平台中通过代码生成来支持领域抽象,可以用非常低的成本跨越结构障碍,将自定义的领域模型嵌入到现有的技术体系中。这其中我们的主要工作是解决了生成代码与手工书写代码之间的有效隔离及动态融合问题,确保代码生成可以反复的以增量的方式进行,同时支持最细粒度处对生成的代码进行定制调整。
举一个简单的例子,假设现在需要开发一个三步审批的流程,每一步的操作人可以录入意见,可以选择通过或者回退,可以选择下一步操作的具体操作人,系统自动记录操作时间,每个操作人可以查看自己的操作历史等。虽然在现有技术体系中实现这一功能需要不少代码,但是在业务层面上描述这一功能并不需要很多文字,实际需要提供的信息量很小。显然,建立领域模型是比较适合的做法,可以定义一种DSL(Domain Specific Language)来描述这一模型。
<flow_cp:SeqFlow>
<step id="draft" userField="draferId" dateField="draftTime" waitStatus="drafted" />
<step id="check" userField="checkerId" dateField="checkTime" opinionField="checkOpinion"
waitStatus="sent" />
<step id="approve" userField="approverId" dateField="approveTime"
opinionField="approveOpinion" waitStatus="checked" passStatus="approved" />
</flow_cp:SeqFlow>
以上功能涉及到多个操作场景,实现的时候需要补充大量具体信息,其中很大一部分信息来自于背景知识,例如显示样式,界面布局,前后台通信方式等。以上模型可以进一步抽象为如下标签
<flow_cp:StepFlow3/>
在不同应用中复用以上流程逻辑的时候可能需要局部修正,例如
<flow_cp:StepFlow3>
<step id="check" userField="checker" />
</flow_cp:StepFlow3>
更加复杂的情形是DSL本身提供的抽象无法满足全部需求,而需要在局部补充更多模型之外的信息,例如物品接收单审批通过后自动导入库存等。
在Witrix中,代码生成不是直接产生最终的输出,而是在编译期生成基础模型,它与补充描述通过extends算子进行融合运算之后产生最终输出, 这种融合可以实现基础功能的新增,更改或者删除。典型的调用形式为
<biz-flow>
<extends>
<flow_cp:StepFlow3>
<step id="check" userField="checker" />
</flow_cp:StepFlow3>
</extends>
<action id="pass_approve">
.
</action>
</biz-flow>
这里的操作过程可以看作是BizFlow extends SeqFlow<FlowConfig extends StepFlow3Config>,与泛型技术非常类似,只是需要更强的局部结构控制能力。
按照级列理论 http://canonical.javaeye.com/blog/33824 ,我们可以定义一个DSL的级列,整个抽象过程为
Context0 + DSL1 + EXT0 = DSL0
Context1 + DSL2 + EXT1 = DSL1
在目前一些通用语言中,也有一些所谓内嵌DSL的方案,可以提供比较简洁的业务描述。但是仅仅建立DSL描述是不充分的,从级列理论的观点看,我们必须提供一种DSL的补充手段,能够在细节处补充DSL模型之外的信息,实现两者的自然融合。同时我们应该可以在不同的抽象层面上独立的进行操作,例如在 DSL1和DSL2的层面上都可以通过类似继承的操作实现局部调整,这同时也包括在不同的抽象层面上都能对模型进行合法性校验。
软件系统的构建之所以与建筑工程不同,无法达到建筑工程的精确性和可控性,其中一个很重要的原因在于建筑的产物是一个静态的结构,建筑的过程主要是采用各种预制件填充某个规划好的建筑空间,而软件是一种动态运行的产品,它的各个组成部分之间的关系不是可以静态描述的,而是存在着复杂的交互关系,而且软件在运行的过程中还需要根据需求的变化进行动态的调整,这种动态性使得软件开发中很难抽象出固定的预制件,很难像建筑工程那样实现标准件的组装。现在所谓构件技术的构件插拔图景其实是具有误导性的。
但是从另外一方面说,软件内在的动态性使得它可以具备更强的适应能力,如果所编制的软件把握住了业务机制的核心内容,则在运行过程中只需要进行少量调整就可以应对大量类似情况。100栋类似的建筑需要花费100倍的建造费用,而100个近似的软件需求的满足可能只需要花费2至3倍的开发费用。现代软件企业在研发过程中都在不断的追求自身产品的平台化,其目的正在于以不断提高的适应性来应对不断变化的客户需求。我们所面对的要求不仅仅是精确把握需求,而是要深刻把握需求背后所对应的业务机制。
AOP(Apsect Oriented Programming)概念的正式出现也有一些时日了,但是它在程序构造过程中似乎仍未找到合适的切入点,一般系统的设计实现很少将AOP作为必要的技术元素。AOP作为一种普适的技术思想,它所代表的是程序结构空间中的定位和组装技术。 http://canonical.javaeye.com/blog/34941 AOP使我们可以通过非侵入性的方式动态修改“任意”已经构建好的程序,而不需要事前有大量的设计准备。原则上说,这种技术思想是可以在任何程序语言基础上进行表达的,并不是只有java, C#这样的面向对象语言才允许AOP操作. Witrix平台中所应用的部分技术与AOP有些类似,只是大量的结构调整表现为xml生成和xml变换,在具体的使用方式上也有一些微妙的差异。 http://canonical.javaeye.com/blog/126467
相对于通用程序语言,xml语言其实是AOP技术的一个更加合适的形式载体。
1. xml格式特殊的规范性确保了在最细的逻辑粒度上,程序结构也是可识别的,可操纵的(在这一点上非常类似于函数式语言)。而所有的命令式语言(imperative language)中,函数内部的结构都是很难采用统一方式进行描述和定位的。
<ns1:loop>
<rpt:Row/>
</ns1:loop>
2. xml节点的坐标可以采用xpath或者css选择符等通用方式进行描述,而一般程序结构无法达到xml格式这样的均一性,其中的坐标定位方式要复杂得多。
3. xml节点上可以增加任意属性,不同的属性可以属于不同的命名空间(namespace),这些属性可以辅助AOP的定位机制。而一般程序语言中如果没有Annotation机制, 则定位只能依赖于函数名和类名(函数参数只有类型没有名称),而类名和函数名随时可能因为业务变化而调整(不是专为定位而存在), 由此构建的切点描述符是不稳定的。
<ui:PageTable pager="${pager}" cache:timeout="1000" />
4. xml节点的增删改查显然要比字节码生成技术要简单和直观得多。
AOP技术难以找到应用的一个重要原因在于很多人机械式的将它定位为一种横切技术,认为它的价值完全在于某个确定的切面可以插入到多个不同的切点,实现系统的横向分解。而在实际应用中,业务层面上很少具有可抽象的固定的共同性,我们所迫切需要的一般是对已有程序结构进行动态扩展的一种能力。横切是AOP的一种特殊的应用,但不是它的全部。相对于继承(inheritance)等依赖于概念诠释的结构扩展机制,AOP所代表正是对程序结构空间进行任意操纵的一种能力。AOP可以为基础结构增加功能,改变原有功能实现,也可以取消原有功能实现,它不需要把所有的扩展逻辑按照树形结构进行组织,不要求在基础结构中为扩展编写特殊的代码。这种自由的结构扩展能力在Witrix平台中被发展为“实现业务代码与平台基础架构之间的动态融合”。
在Witrix平台的实际应用中,AOP的切点匹配能力并不是十分重要。一般情况下我们主要通过整体结构规划来确保控制点意义明确且相对集中,因此不需要额外通过切点匹配进行业务功能的再组织,不需要再次从杂乱的程序逻辑中重新发现特殊的控制点。例如在Witrix平台的Jsplet框架中所有后台事件响应都通过objectName和objectEvent参数触发,在触发后台事件响应函数之前都会调用bizflow文件中的beforeAction段。
在bizflow文件中,aop操作是明确指定到具体函数的,使用模糊匹配在一般情况下只会使问题变得不必要的复杂化。例如扩展actQuery函数
<action id="aop-Query-default">
<source>
通过自定义标签抽象出多个Action之间的共用代码
<app:DoWorkA/>
</source>
</action>
在Witrix平台中结构组装主要是通过自定义标签库和extends算子来实现,它们都依赖于xml格式的规范性。
1. 通过在custom目录下实现同名的自定义标签,即可覆盖Witrix平台所提供的缺省标签实现,这里所依赖的并不是复杂的匹配过程,而是自然直观的映射过程。 http://canonical.javaeye.com/blog/196826
2. 所有的xml配置文件支持extends操作,它允许定制两个具有业务含义的xml节点之间的结构融合规则。例如<biz-flow extends="docflow">。
实际使用中, AOP技术的一个应用难点在于状态空间的管理问题。一般interceptor中所能访问的变量局限为this指针所携带的成员变量,以及函数调用时传入的调用参数。interceptor很难在状态空间中创建新的变量,也很难读取在其他地方所产生的状态变量。例如对于如下扩展 A(arg1); B(arg2); C(arg3); =〉 Ax(arg1); B(arg2); Cx(arg3); 因为原有的调用序列中没有传递额外的参数,因此A和C的扩展函数之间很难实现共享内部变量x。在TPL模板语言中,tpl本身是无状态的,状态变量通过外部的$thisContext对象统一管理。通过这种行为与状态的分离,结合灵活的变量作用域控制机制,可以以比较简单的方式实现扩展函数之间的信息共享。
|