Spark简介
Spark是整个BDAS的核心组件,是一个大数据分布式编程框架,不仅实现了MapReduce的算子map 函数和reduce函数及计算模型,还提供更为丰富的算子,如filter、join、groupByKey等。是一个用来实现快速而同用的集群计算的平台。
Spark将分布式数据抽象为弹性分布式数据集(RDD),实现了应用任务调度、RPC、序列化和压缩,并为运行在其上的上层组件提供API。其底层采用Scala这种函数式语言书写而成,并且所提供的API深度借鉴Scala函数式的编程思想,提供与Scala类似的编程接口
Sparkon Yarn
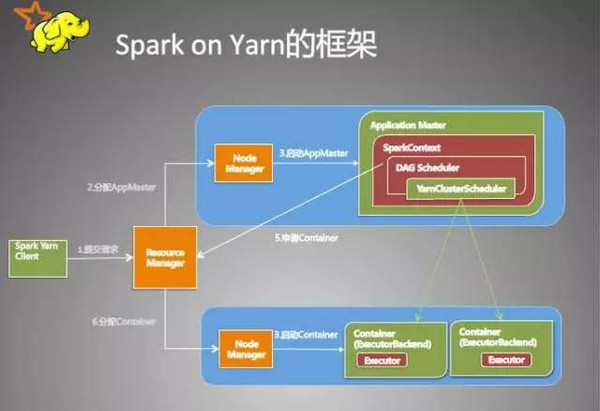
从用户提交作业到作业运行结束整个运行期间的过程分析。
一、客户端进行操作
根据yarnConf来初始化yarnClient,并启动yarnClient
创建客户端Application,并获取Application的ID,进一步判断集群中的资源是否满足executor和ApplicationMaster申请的资源,如果不满足则抛出IllegalArgumentException;
设置资源、环境变量:其中包括了设置Application的Staging目录、准备本地资源(jar文件、log4j.properties)、设置Application其中的环境变量、创建Container启动的Context等;
设置Application提交的Context,包括设置应用的名字、队列、AM的申请的Container、标记该作业的类型为Spark;
申请Memory,并最终通过yarnClient.submitApplication向ResourceManager提交该Application。
当作业提交到YARN上之后,客户端就没事了,甚至在终端关掉那个进程也没事,因为整个作业运行在YARN集群上进行,运行的结果将会保存到HDFS或者日志中。
二、提交到YARN集群,YARN操作
运行ApplicationMaster的run方法;
设置好相关的环境变量。
创建amClient,并启动;
在Spark UI启动之前设置Spark UI的AmIpFilter;
在startUserClass函数专门启动了一个线程(名称为Driver的线程)来启动用户提交的Application,也就是启动了Driver。在Driver中将会初始化SparkContext;
等待SparkContext初始化完成,最多等待spark.yarn.applicationMaster.waitTries次数(默认为10),如果等待了的次数超过了配置的,程序将会退出;否则用SparkContext初始化yarnAllocator;
当SparkContext、Driver初始化完成的时候,通过amClient向ResourceManager注册ApplicationMaster
分配并启动Executeors。在启动Executeors之前,先要通过yarnAllocator获取到numExecutors个Container,然后在Container中启动Executeors。
那么这个Application将失败,将Application Status标明为FAILED,并将关闭SparkContext。其实,启动Executeors是通过ExecutorRunnable实现的,而ExecutorRunnable内部是启动CoarseGrainedExecutorBackend的。
最后,Task将在CoarseGrainedExecutorBackend里面运行,然后运行状况会通过Akka通知CoarseGrainedScheduler,直到作业运行完成。
Spark节点的概念
一、Spark驱动器是执行程序中的main()方法的进程。它执行用户编写的用来创建SparkContext(初始化)、创建RDD,以及运行RDD的转化操作和行动操作的代码。
驱动器节点driver的职责:
把用户程序转为任务task(driver)
Spark驱动器程序负责把用户程序转化为多个物理执行单元,这些单元也被称之为任务task(详解见备注)
为执行器节点调度任务(executor)
有了物理计划之后,Spark驱动器在各个执行器节点进程间协调任务的调度。Spark驱动器程序会根据当前的执行器节点,把所有任务基于数据所在位置分配给合适的执行器进程。当执行任务时,执行器进程会把缓存的数据存储起来,而驱动器进程同样会跟踪这些缓存数据的位置,并利用这些位置信息来调度以后的任务,以尽量减少数据的网络传输。(就是所谓的移动计算,而不移动数据)。
二、执行器节点
作用:
负责运行组成Spark应用的任务,并将结果返回给驱动器进程;
通过自身的块管理器(blockManager)为用户程序中要求缓存的RDD提供内存式存储。RDD是直接缓存在执行器进程内的,因此任务可以在运行时充分利用缓存数据加快运算。
驱动器的职责:
所有的Spark程序都遵循同样的结构:程序从输入数据创建一系列RDD,再使用转化操作派生成新的RDD,最后使用行动操作手机或存储结果RDD,Spark程序其实是隐式地创建出了一个由操作组成的逻辑上的有向无环图DAG。当驱动器程序执行时,它会把这个逻辑图转为物理执行计划。
这样 Spark就把逻辑计划转为一系列步骤(stage),而每个步骤又由多个任务组成。这些任务会被打包送到集群中。
Spark初始化
每个Spark应用都由一个驱动器程序来发起集群上的各种并行操作。驱动器程序包含应用的main函数,并且定义了集群上的分布式数据集,以及对该分布式数据集应用了相关操作。
驱动器程序通过一个SparkContext对象来访问spark,这个对象代表对计算集群的一个连接。(比如在sparkshell启动时已经自动创建了一个SparkContext对象,是一个叫做SC的变量。(下图,查看变量sc)

一旦创建了sparkContext,就可以用它来创建RDD。比如调用sc.textFile()来创建一个代表文本中各行文本的RDD。(比如vallinesRDD = sc.textFile(“yangsy.text”),val spark = linesRDD.filter(line=>line.contains(“spark”),spark.count())
执行这些操作,驱动器程序一般要管理多个执行器,就是我们所说的executor节点。
在初始化SparkContext的同时,加载sparkConf对象来加载集群的配置,从而创建sparkContext对象。
从源码中可以看到,在启动thriftserver时,调用了spark- daemon.sh文件,该文件源码如左图,加载spark_home下的conf中的文件。
(在执行后台代码时,需要首先创建conf对象,加载相应参数, val sparkConf = newSparkConf().setMaster("local").setAppName("cocapp").set("spark.executor.memory","1g"), val sc: SparkContext = new SparkContext(sparkConf))
RDD工作原理:
RDD(Resilient DistributedDatasets)[1] ,弹性分布式数据集,是分布式内存的一个抽象概念,RDD提供了一种高度受限的共享内存模型,即RDD是只读的记录分区的集合,只能通过在其他RDD执行确定的转换操作(如map、join和group by)而创建,然而这些限制使得实现容错的开销很低。对开发者而言,RDD可以看作是Spark的一个对象,它本身运行于内存中,如读文件是一个RDD,对文件计算是一个RDD,结果集也是一个RDD ,不同的分片、数据之间的依赖、key-value类型的map数据都可以看做RDD。
主要分为三部分:创建RDD对象,DAG调度器创建执行计划,Task调度器分配任务并调度Worker开始运行。
SparkContext(RDD相关操作)→通过(提交作业)→(遍历RDD拆分stage→生成作业)DAGScheduler→通过(提交任务集)→任务调度管理(TaskScheduler)→通过(按照资源获取任务)→任务调度管理(TaskSetManager)
Transformation返回值还是一个RDD。它使用了链式调用的设计模式,对一个RDD进行计算后,变换成另外一个RDD,然后这个RDD又可以进行另外一次转换。这个过程是分布式的。
Action返回值不是一个RDD。它要么是一个Scala的普通集合,要么是一个值,要么是空,最终或返回到Driver程序,或把RDD写入到文件系统中
转换(Transformations)(如:map, filter, groupBy, join等),Transformations操作是Lazy的,也就是说从一个RDD转换生成另一个RDD的操作不是马上执行,Spark在遇到Transformations操作时只会记录需要这样的操作,并不会去执行,需要等到有Actions操作的时候才会真正启动计算过程进行计算。
操作(Actions)(如:count, collect, save等),Actions操作会返回结果或把RDD数据写到存储系统中。Actions是触发Spark启动计算的动因。
它们本质区别是:Transformation返回值还是一个RDD。它使用了链式调用的设计模式,对一个RDD进行计算后,变换成另外一个RDD,然后这个RDD又可以进行另外一次转换。这个过程是分布式的。Action返回值不是一个RDD。它要么是一个Scala的普通集合,要么是一个值,要么是空,最终或返回到Driver程序,或把RDD写入到文件系统中。关于这两个动作,在Spark开发指南中会有就进一步的详细介绍,它们是基于Spark开发的核心。
RDD基础
Spark中的RDD就是一个不可变的分布式对象集合。每个RDD都被分为多个分区,这些分区运行在集群的不同节点上。创建RDD的方法有两种:一种是读取一个外部数据集;一种是在群东程序里分发驱动器程序中的对象集合,不如刚才的示例,读取文本文件作为一个字符串的RDD的示例。
创建出来后,RDD支持两种类型的操作:转化操作和行动操作
转化操作会由一个RDD生成一个新的RDD。(比如刚才的根据谓词筛选)
行动操作会对RDD计算出一个结果,并把结果返回到驱动器程序中,或把结果存储到外部存储系统(比如HDFS)中。比如first()操作就是一个行动操作,会返回RDD的第一个元素。
注:转化操作与行动操作的区别在于Spark计算RDD的方式不同。虽然你可以在任何时候定义一个新的RDD,但Spark只会惰性计算这些RDD。它们只有第一个在一个行动操作中用到时,才会真正的计算。之所以这样设计,是因为比如刚才调用sc.textFile(...)时就把文件中的所有行都读取并存储起来,就会消耗很多存储空间,而我们马上又要筛选掉其中的很多数据。
这里还需要注意的一点是,spark会在你每次对它们进行行动操作时重新计算。如果想在多个行动操作中重用同一个RDD,那么可以使用RDD.persist()或RDD.collect()让Spark把这个RDD缓存下来。(可以是内存,也可以是磁盘)
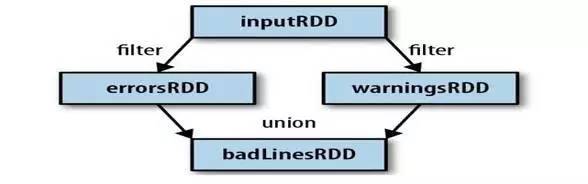
Spark会使用谱系图来记录这些不同RDD之间的依赖关系,Spark需要用这些信息来按需计算每个RDD,也可以依靠谱系图在持久化的RDD丢失部分数据时用来恢复所丢失的数据。(如下图,过滤errorsRDD与warningsRDD,最终调用union()函数)
RDD计算方式
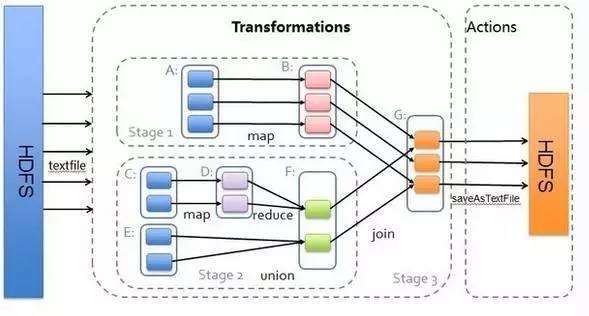
RDD的宽窄依赖

窄依赖 (narrowdependencies) 和宽依赖 (widedependencies) 。窄依赖是指 父 RDD 的每个分区都只被子 RDD 的一个分区所使用 。相应的,那么宽依赖就是指父 RDD 的分区被多个子 RDD 的分区所依赖。例如, map 就是一种窄依赖,而 join 则会导致宽依赖
这种划分有两个用处。首先,窄依赖支持在一个结点上管道化执行。例如基于一对一的关系,可以在 filter 之后执行 map 。其次,窄依赖支持更高效的故障还原。因为对于窄依赖,只有丢失的父 RDD 的分区需要重新计算。而对于宽依赖,一个结点的故障可能导致来自所有父 RDD 的分区丢失,因此就需要完全重新执行。因此对于宽依赖,Spark 会在持有各个父分区的结点上,将中间数据持久化来简化故障还原,就像 MapReduce 会持久化 map 的输出一样。
SparkExample
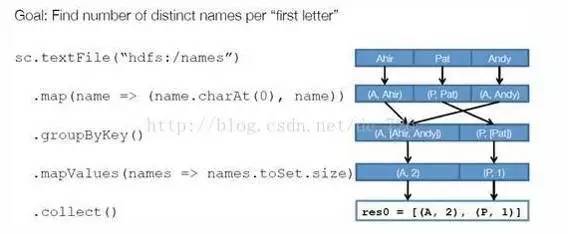
步骤 1 :创建 RDD 。上面的例子除去最后一个 collect 是个动作,不会创建 RDD 之外,前面四个转换都会创建出新的 RDD 。因此第一步就是创建好所有 RDD( 内部的五项信息 ) 。
步骤 2 :创建执行计划。Spark 会尽可能地管道化,并基于是否要重新组织数据来划分 阶段 (stage) ,例如本例中的 groupBy() 转换就会将整个执行计划划分成两阶段执行。最终会产生一个 DAG(directedacyclic graph ,有向无环图 ) 作为逻辑执行计划。
步骤 3 :调度任务。 将各阶段划分成不同的 任务 (task) ,每个任务都是数据和计算的合体。在进行下一阶段前,当前阶段的所有任务都要执行完成。因为下一阶段的第一个转换一定是重新组织数据的,所以必须等当前阶段所有结果数据都计算出来了才能继续。
假设本例中的 hdfs://names 下有四个文件块,那么 HadoopRDD 中 partitions 就会有四个分区对应这四个块数据,同时 preferedLocations 会指明这四个块的最佳位置。现在,就可以创建出四个任务,并调度到合适的集群结点上。
Spark数据分区
Spark的特性是对数据集在节点间的分区进行控制。在分布式系统中,通讯的代价是巨大的,控制数据分布以获得最少的网络传输可以极大地提升整体性能。Spark程序可以通过控制RDD分区方式来减少通讯的开销。
Spark中所有的键值对RDD都可以进行分区。确保同一组的键出现在同一个节点上。比如,使用哈希分区将一个RDD分成了100个分区,此时键的哈希值对100取模的结果相同的记录会被放在一个节点上。
(可使用partitionBy(newHashPartitioner(100)).persist()来构造100个分区)
Spark中的许多操作都引入了将数据根据键跨界点进行混洗的过程。(比如:join(),leftOuterJoin(),groupByKey(),reducebyKey()等)对于像reduceByKey()这样只作用于单个RDD的操作,运行在未分区的RDD上的时候会导致每个键的所有对应值都在每台机器上进行本地计算。
SparkSQL的shuffle过程
Spark SQL的核心是把已有的RDD,带上Schema信息,然后注册成类似sql里的”Table”,对其进行sql查询。这里面主要分两部分,一是生成SchemaRD,二是执行查询。
如果是spark-hive项目,那么读取metadata信息作为Schema、读取hdfs上数据的过程交给Hive完成,然后根据这俩部分生成SchemaRDD,在HiveContext下进行hql()查询。
SparkSQL结构化数据
首先说一下ApacheHive,Hive可以在HDFS内或者在其他存储系统上存储多种格式的表。SparkSQL可以读取Hive支持的任何表。要把Spark SQL连接已有的hive上,需要提供Hive的配置文件。hive-site.xml文件复制到spark的conf文件夹下。再创建出HiveContext对象(sparksql的入口),然后就可以使用HQL来对表进行查询,并以由行足证的RDD的形式拿到返回的数据。
创建Hivecontext并查询数据
importorg.apache.spark.sql.hive.HiveContext
valhiveCtx = new org.apache.spark.sql.hive.HiveContext(sc)
valrows = hiveCtx.sql(“SELECT name,age FROM users”)
valfitstRow – rows.first()
println(fitstRow.getSgtring(0)) //字段0是name字段
通过jdbc连接外部数据源更新与加载
Class.forName("com.mysql.jdbc.Driver")
val conn =DriverManager.getConnection(mySQLUrl)
val stat1 =conn.createStatement()
stat1.execute("UPDATE CI_LABEL_INFO set DATA_STATUS_ID = 2 , DATA_DATE ='" + dataDate +"' where LABEL_ID in ("+allCreatedLabels.mkString(",")+")")
stat1.close()
//加载外部数据源数据到内存
valDIM_COC_INDEX_MODEL_TABLE_CONF =sqlContext.jdbc(mySQLUrl,"DIM_COC_INDEX_MODEL_TABLE_CONF").cache()
val targets =DIM_COC_INDEX_MODEL_TABLE_CONF.filter("TABLE_DATA_CYCLE ="+TABLE_DATA_CYCLE).collect
SparkSQL解析
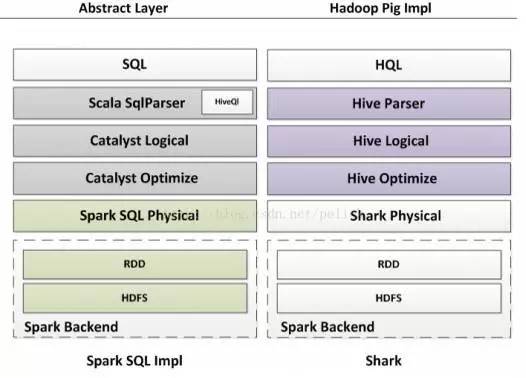
首先说下传统数据库的解析,传统数据库的解析过程是按Rusult、Data Source、Operation的次序来解析的。传统数据库先将读入的SQL语句进行解析,分辨出SQL语句中哪些词是关键字(如select,from,where),哪些是表达式,哪些是Projection,哪些是Data Source等等。进一步判断SQL语句是否规范,不规范就报错,规范则按照下一步过程绑定(Bind)。过程绑定是将SQL语句和数据库的数据字典(列,表,视图等)进行绑定,如果相关的Projection、Data Source等都存在,就表示这个SQL语句是可以执行的。在执行过程中,有时候甚至不需要读取物理表就可以返回结果,比如重新运行刚运行过的SQL语句,直接从数据库的缓冲池中获取返回结果。在数据库解析的过程中SQL语句时,将会把SQL语句转化成一个树形结构来进行处理,会形成一个或含有多个节点(TreeNode)的Tree,然后再后续的处理政对该Tree进行一系列的操作。
Spark SQL对SQL语句的处理和关系数据库对SQL语句的解析采用了类似的方法,首先会将SQL语句进行解析,然后形成一个Tree,后续如绑定、优化等处理过程都是对Tree的操作,而操作方法是采用Rule,通过模式匹配,对不同类型的节点采用不同的操作。SparkSQL有两个分支,sqlContext和hiveContext。sqlContext现在只支持SQL语法解析器(Catalyst),hiveContext支持SQL语法和HiveContext语法解析器。
原文地址:http://mt.sohu.com/20160522/n450849016.shtml