- 先下载适合自己系统的即时客户端,可通过下面的地址下载。
http://www.oracle.com/technetwork/database/features/instant-client/index-097480.html
- 直接解压到你想要存放的目录中,如:D:\Java\instantclient_10_2
- 编辑环境变量:
TNS_ADMIN 设置为 D:\Java\instantclient_10_2
ORACLE_HOME 设置为 D:\Java\instantclient_10_2
- 编辑连接配置文件 tnsnames.ora,该文件需要自行在即时客户端目录(C:\instantclient_11_2)中创建。在该文件内输入如下内容:
MYDB =
(DESCRIPTION =
(ADDRESS_LIST =
(ADDRESS = (PROTOCOL = TCP)(HOST = 192.168.3.250)(PORT = 1521))
)
(CONNECT_DATA =
(SERVER = DEDICATED)
(SERVICE_NAME = MYDB)
)
)
MYDB:是数据库实例名
192.168.3.259:是数据库的 IP 地址
1521:是数据库的端口
- 然后你就可以使用 PLSQL Developer 和 TOAD 这类软件来管理 Oracle 数据库了。
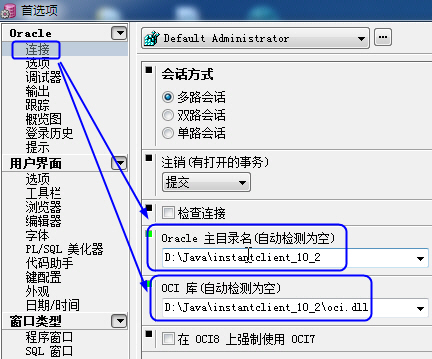
下面根据自己的实际情况配置PL/SQL:在首选项(perference)里面设置Oracle主目录名(Oracle_home)和OIC库(OCI Library),我的设置是Oracle_home=D:\Java\instantclient_10_2,OCI Library=D:\Java\instantclient_10_2\oci.dll。
posted @
2010-08-26 17:01 CoderDream 阅读(734) |
评论 (0) |
编辑 收藏
摘要: 视频名称:
[A218]JAVA反射机制与动态代理.exe
[A219]JAVA反射机制与动态代理续一.exe
[A220]JAVA反射机制与动态代理续二.exe
主讲教师:风中叶
Java 语言的反射机制
在Java运行时环境中,对于任意一个类,可以知道这个类有哪些属性和方法。对于任意一个对象,可以调用它的任意一个方法。
这种动态获取类的信息以及动态调用对象的方法的功能...
阅读全文
posted @
2010-08-25 16:12 CoderDream 阅读(2281) |
评论 (0) |
编辑 收藏有时候我们会碰到需要设置代理,然后通过svn获取源代码,下面我们来看一下如何设置;
1、找到 C:\Documents and Settings\your userName\Application Data\Subversion 这个目录下的servers文件,用任意一个文本编辑器打开,找到类似于如下的文字:
[global]
# http-proxy-exceptions = *.exception.com, www.internal-site.org
#http-proxy-host = proxy2.some-domain-name.com
#http-proxy-port = 9000
# http-proxy-username = defaultusername
将
#http-proxy-host
#http-proxy-port
这两行前面的#号去掉,并将=号右边的值分别改为你的代理服务器地址和端口号即可。
2、设置Eclipse/MyEclipse,确认SVN的客户端是SVNKit:

这样,就可以在Eclipse/MyEclipse中通过代理使用SVN了。
![]()
posted @
2010-03-05 15:29 CoderDream 阅读(3805) |
评论 (2) |
编辑 收藏
我们在软件开发中,经常需要以表格的方式展现批量数据,如统计分析等等。
这里介绍一个Flash的表格生成工具--FusionCharts,它是一个收费软件,不过如果不是用于商业用途,只是用于,可以到网上下载破解版,csdn上面就有,如果想商业,购买应该也不贵。
下面我们来看一个最简单的例子:
这个软件生成表格的模式是:数据(XML文件或文件流)+模板。
1、XML数据:
<chart caption='Monthly Sales Summary' subcaption='For the year 2006' xAxisName='Month' yAxisName='Sales' numberPrefix='$'>
<set label='January' value='17400' />
<set label='February' value='19800' />
<set label='March' value='21800' />
<set label='April' value='23800' />
<set label='May' value='29600' />
<set label='June' value='27600' />
<set label='July' value='31800' />
<set label='August' value='39700' />
<set label='September' value='37800' />
<set label='October' value='21900' />
<set label='November' value='32900' />
<set label='December' value='39800' />
</chart>
2、将所有需要用到的模板拷贝到固定的位置。
3、在html中指定数据位置和模板名称:
<html>
<head>
<title>My First FusionCharts</title>
</head>
<body bgcolor="#ffffff">
<object classid="clsid:d27cdb6e-ae6d-11cf-96b8-444553540000" codebase="http://fpdownload.macromedia.com/pub/shockwave/cabs/flash/swflash.cab#version=8,0,0,0" width="900" height="300" id="Column3D" >
<param name="movie" value="../FusionCharts/Column3D.swf" />
<param name="FlashVars" value="&dataURL=Data.xml">
<param name="quality" value="high" />
<embed src="../FusionCharts/Column3D.swf" flashVars="&dataURL=Data.xml" quality="high" width="900" height="300" name="Column3D" type="application/x-shockwave-flash" pluginspage="http://www.macromedia.com/go/getflashplayer" />
</object>
</body>
</html>
4、运行结果:

posted @
2010-02-03 11:16 CoderDream 阅读(1085) |
评论 (0) |
编辑 收藏
1、FCKeditor源代码分析(一 )----------fckeditor.js的中文注释分析(原创)
http://blog.csdn.net/nileader/archive/2009/10/21/4710559.aspx
2、
Developers GuideJavaScript
http://docs.cksource.com/FCKeditor_2.x/Developers_Guide/Integration/JavaScript
3、网络营销实战密码——策略.技巧.案例
http://product.dangdang.com/product.aspx?product_id=20449076
posted @
2009-10-23 16:00 CoderDream 阅读(405) |
评论 (0) |
编辑 收藏1、安装
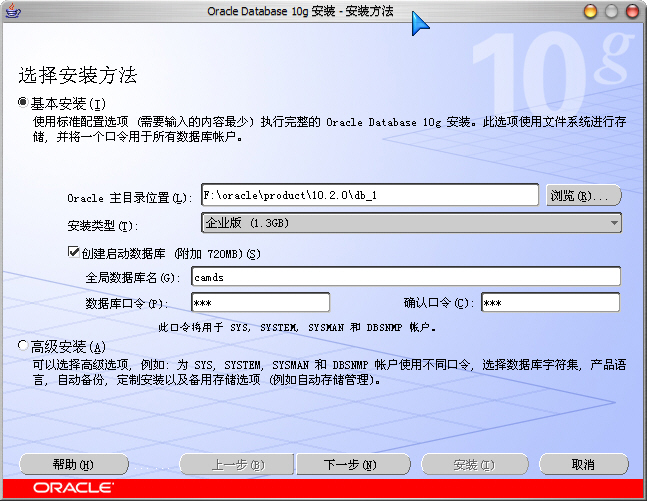
Oracle 版本:Oracle Database 10g Release 2 (10.2.0.1)
下载地址:
http://www.oracle.com/technology/software/products/database/oracle10g/htdocs/10201winsoft.html
安装设置:
1)这里的全局数据库名即为你创建的数据库名,以后在访问数据,创建“本地Net服务名”时用到;
2)数据库口令在登录和创建“本地Net服务名”等地方会用到。
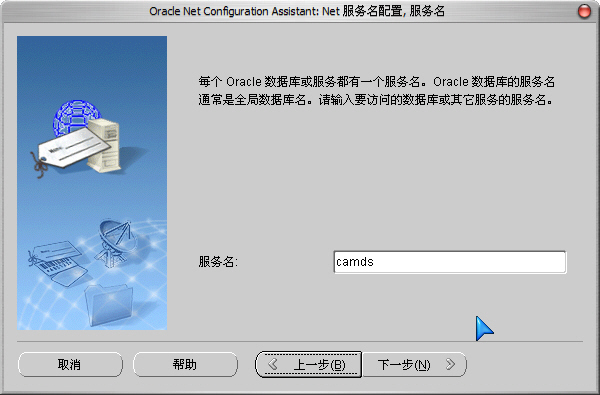
2、创建“本地Net服务名”
1)通过【程序】-》【Oracle - OraDb10g_home1】-》【配置和移植工具】-》【Net Configuration Assistant】,运行“网络配置助手”工具:

2)选择“本地 Net 服务名配置”:
3)这里的“Net 服务名”我们输入安装数据库时的“全局数据库名”:
4)主机名我们输入本机的IP地址:
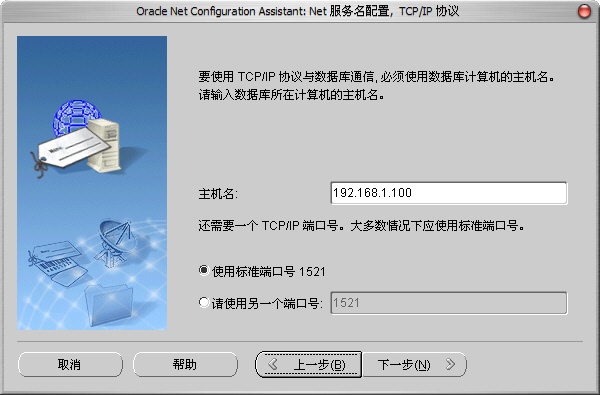
5)测试数据库连接,用户名/密码为:System/数据库口令(安装时输入的“数据库口令”):
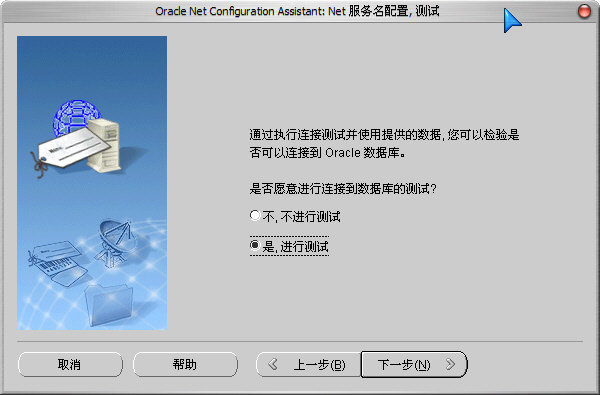
默认的用户名/密码错误:

更改登录,输入正确的用户名/密码:

测试成功:

3、PLSQL Developer 连接测试
输入正确的用户名/口令:

成功登陆:

4、创建表空间
打开sqlplus工具:
sqlplus /nolog
连接数据库:
conn /as sysdba
创建表空间:
create tablespace camds datafile 'D:\oracle\product\10.2.0\oradata\camds\camds.dbf' size 200m autoextend on next 10m maxsize unlimited;
5、创建新用户
运行“P/L SQL Developer”工具,以DBA(用户名:System)的身份登录:
1)新建“User(用户):

2)设置用户名、口令、默认表空间(使用上面新建的表空间)和临时表空间:

3)设置角色权限:

4)设置”系统权限“:

5)点击应用后,【应用】按钮变灰,新用户创建成功:

6)新用户登录测试:
输入新用户的“用户名/口令”:

新用户“testcamds”成功登陆:

6、导入导出数据库
先运行cmd命令,进入命令行模式,转到下面的目录:D:"oracle"product"10.2.0"db_1"BIN【该目录下有exp.exe文件】
1)导入
命令语法:
imp userid / pwd @sid file = path / file fromuser = testcamds touser = userid
命令实例:
imp testcamds / 123 @camds file = c:"testcamds fromuser = testcamds touser = testcamds
导入结果:

2)导出:
命令语法:
exp userid / pwd @sid file = path / file owner = userid
命令实例:
exp testcamds / 123 @camdsora file = c:"testcamds owner = testcamds
导入结果:

posted @
2009-10-18 20:13 CoderDream 阅读(20343) |
评论 (1) |
编辑 收藏
1
、Java通过XML Schema校验XML
http://lavasoft.blog.51cto.com/62575/97597
posted @
2009-08-27 09:50 CoderDream 阅读(383) |
评论 (0) |
编辑 收藏
1、实例不能启动!
症状:“计算机管理”-》“服务和应用程序”-》“服务”-》“OracleOraDb10g_camdsTNSListener”的启动类型为“自动”,但是状态为空(已停止),手工启动,状态变为“已启动”,1~5秒后状态变回“已停止”,数据库不能正常使用;
解决方法:【开始】-》【程序】-》【Oracle - OraDb10g_camds】-》【Configuration and Migration Tools】-》【Net Configuration Assistant】,重新配置一下刚才的【监听程序配置】,然后刷新服务就可以看到服务正常“自动”启动了。
posted @
2009-06-25 09:15 CoderDream 阅读(513) |
评论 (0) |
编辑 收藏
由于Spring AOP实现了AOP联盟约定的接口,而Spring框架并不提供该接口的源代码,我在网上搜索了一下相关资料,整理如下:
1、官方网站:
http://sourceforge.net/projects/aopalliance/
2、源代码:
http://coderdream.javaeye.com/topics/download/322bb187-64b3-3f4f-9ac2-fdc0ef4d0033
3、在线文档:
http://aopalliance.sourceforge.net/doc/index.html
posted @
2009-04-04 22:31 CoderDream 阅读(3450) |
评论 (0) |
编辑 收藏
最近,myeclipse 发布了最新的7.1版,其中blue版提供了对RAD 6.X的支持:
本版本的最引人注目之处莫过于对WSAD5.1、RAD 6.X和7.X项目的加强支持, 包括促进WSAD/RAD用户在MyEclipse Blue 和RAD环境下提高项目质量, . 全面有效执行任务的特性。此外,那些希望能将自己的项目完全移植到 MyEclipse Blue 版本的朋友们,可以通过使用MyEclipse Blue 7.1中的简单向导来实现了。 同时,新项目也能够完全支持已有的开发和服务器工具。
下载地址为:
A:普通版:
http://downloads.myeclipseide.com/downloads/products/eworkbench/7.0/myeclipse-7.1-win32.exe
B:Blue版
http://downloads4.myeclipseide.com/downloads/products/eworkbench/7.0-Blue/myeclipse-blue-7.1-win32.exe
其中普通版可以直接用迅雷下载,但是blue却连不上。
尝试了多种方式,终于找到了下载方法,不过速度很慢,而且很不稳定:
使用的软件
1、OperaTor-2.5
这是一个附带代理的浏览器软件;
2、eMule V1.1.3
常用的电驴软件;
下面我们来看看如何下载:
【步骤1】:打开OperaTor,程序打开后,会发现托盘区有一个蓝色图标,上面有一个字母“P";
【步骤2】:将鼠标移到该图标,点击右键,依次选择【Edit】-》【Main configuration】

【步骤3】:在打开的config.txt文件中,我们可以看到,本地代理的端口为:9050,

【步骤4】:设置电驴的代理服务器,这里的服务器类型选”Socks 4a“:

【步骤5】:最后,点击电驴的”新建“按钮,将”blue版“的地址拷贝过来就可以下载了:

不过通过代理方式下载的速度很慢,有时候还会断线,这时候只需要重新打开上面软件就可以了。
posted @
2009-03-16 22:04 CoderDream 阅读(2676) |
评论 (0) |
编辑 收藏启动服务:
1、首先建立一个新的“服务器”
在“Servers”面板空白处点击右键,依次选择【New】-》【Server】:

2、选择新服务器的类型
服务器主机名默认为:localhost,类型为:Oracle WebLogic Server v10.3:

3、选择域的文件路径:
这里选择WebLogic安装路径下的base_domain
注:我们安装WebLogic后有两个domain,分别为:base_domain和test_domain,其实还可以自己创建自定义的domain,点击面板中链接进入新建向导。

4、启动服务器
选择新建的服务器,点击右键,选中【Start】即可,通过控制台(Console)面板即可看到启动信息:

5、出现错误警告
提示:
The domain edit lock is owned by another session - this
deployment operation requires exclusive access to the edit lock and
hence cannot proceed.
You can release the lock in Administration Console by first disabling
"Automatically Acquire Lock and Activate Changes" in Preference,
then clicking the Release Configuration button.

解决方法:
1、进入WebLogic控制台:
链接:http://localhost:7001/console/

2、进入参数(Preferences)面板:

3、将自动锁定和激活勾选去掉:

4、点击页面左上角的【Release Configuration】,使刚才的设置生效:

posted @
2009-03-10 14:58 CoderDream 阅读(1633) |
评论 (0) |
编辑 收藏
01、
Java中的易混问题收集
02、
Java程序的加密和反加密
03、
JAVA JSP
servlet取路径问题总结....
04、
[转载]社会生存的75条忠告----胜读十年书(转载)
05、
【转载}08年Java开发者最迫切的五个期望
06、
【转载】给研究起步者的忠告 !
07、
[转载]Glassfish介绍
08、
民间偏方大全(总有你需要的时候)(转载)
09、
【转载】25条人生建议
10、
【转载】让你的生活和人生有所改变的45个方法
11、
【转载】Java程序员面试宝典
12、
【转载】sql 面试中的问题
13、
【转载】面试进行曲之技术面试(项目经验)
14、
【转载】一家公司的面试题
15、
【转载】面试杂谈
16、
[转载]一条sql 数据库去除重复记录
17、
【转载】如何快速面试筛选,找到合适的人
18、
【原创】动态生成日历
19、
[原创]日期时间处理实用类
20、
[原创]八皇后回溯版
21、
[原创]java.util.Comparator使用示例
22、
【转载】一个IT强人的奋斗历程
23、
【转载】Javeline的八年之期,走出象牙塔的纸象
24、
【转载】职业生涯几句话
25、
【整理】八皇后回溯版
26、
【转载】2007年值得去思考的N大软件技术
27、
【转载】2008年值得学习的五种Java技术
28、
【转载】实战 JDK 6.0 自带web service
29、
【转载】Linux学习系列之J2EE(JAVA EE)配置指南
30、
【转载】招聘的吹牛体系
31、
【转载】经典论坛回复收集
32、
【转帖】什么是MIS
33、
【转载】如何去做你讨厌做的事情?
34、
【转载】在windowsXP系统中卸载oracle9i
35、
【原创】泛型动态数组类
36、
【原创】数目字计数器,可多次添加整形数,累计0-9各个数字出现了多少次
37、
【原创】输出一万以内(1-9999)整数的中文大写形式
38、
【原创】求两字符串的公共子串
posted @
2008-10-27 19:57 CoderDream 阅读(298) |
评论 (0) |
编辑 收藏
1、
SQL注入攻击及其防范浅谈
posted @
2008-10-14 16:35 CoderDream 阅读(276) |
评论 (0) |
编辑 收藏<META HTTP-EQUIV='pragma' CONTENT='no-cache'>
<META HTTP-EQUIV='Cache-Control' CONTENT='no-cache, must-revalidate'>
<META HTTP-EQUIV='expires' CONTENT='0'>
posted @
2008-09-09 17:55 CoderDream 阅读(853) |
评论 (0) |
编辑 收藏
摘要: 需求:
对XML中的特定内容进行排序:
原始XML:
<?xml version="1.0" encoding="UTF-8"?>
<hostgateway>
<header>
&nb...
阅读全文
posted @
2008-08-20 15:14 CoderDream 阅读(958) |
评论 (0) |
编辑 收藏
Comparable & Comparator 都是用来实现集合中的排序的,只是 Comparable 是在集合内部定义的方法实现的排序,Comparator 是在集合外部实现的排序,所以,如想实现排序,就需要在集合外定义 Comparator 接口的方法或在集合内实现 Comparable 接口的方法。
一、Comparator
强行对某个对象collection进行整体排序的比较函数,可以将Comparator传递给Collections.sort或Arrays.sort。
接口方法:
/**
* @return o1小于、等于或大于o2,分别返回负整数、零或正整数。
*/
int compare(Object o1, Object o2);
二、Comparable
强行对实现它的每个类的对象进行整体排序,实现此接口的对象列表(和数组)可以通过Collections.sort或Arrays.sort进行自动排序。
接口方法:
/**
* @return 该对象小于、等于或大于指定对象o,分别返回负整数、零或正整数。
*/
int compareTo(Object o);
三、Comparator和Comparable的区别
一个类实现了Camparable接口则表明这个类的对象之间是可以相互比较的,这个类对象组成的集合就可以直接使用sort方法排序。
Comparator可以看成一种算法的实现,将算法和数据分离,Comparator也可以在下面两种环境下使用:
1、类的设计师没有考虑到比较问题而没有实现Comparable,可以通过Comparator来实现排序而不必改变对象本身
2、可以使用多种排序标准,比如升序、降序等。
完整代码:
import java.util.ArrayList;
import java.util.Collections;
import java.util.Comparator;
import java.util.List;
public class SortObject {
public static void main(String[] args) {
sortByComparable();
sortByComparator();
}
/**
* 通过Comparable排序
*/
public static void sortByComparable() {
List list = new ArrayList();
list.add(new Person("Coder", 1));
list.add(new Person("King", 3));
list.add(new Person("Dream", 2));
list.add(new Person("Baby", 4));
System.out.println("--- Sort Before ---");
printPerson(list);
Collections.sort(list);
System.out.println("--- After Sorted ---");
printPerson(list);
}
/**
* 通过Comparator排序
*/
public static void sortByComparator() {
List list = new ArrayList();
list.add(new Person("Coder", 1));
list.add(new Person("King", 3));
list.add(new Person("Dream", 2));
list.add(new Person("Baby", 4));
System.out.println("--- Sort Before ---");
printPerson(list);
Collections.sort(list, new PersonComparator());
System.out.println("--- After Sorted ---");
printPerson(list);
}
/**
* 打印List
*
* @param list
*/
public static void printPerson(List list) {
int size = list.size();
Person p = null;
for (int i = 0; i < size; i++) {
p = (Person) list.get(i);
System.out.println(p.getName() + ":" + p.getId());
}
}
}
class Person implements Comparable {
public String name;
public int id;
public Person() {
}
public Person(String name, int id) {
this.name = name;
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getId() {
return id;
}
public void setId(int id) {
this.id = id;
}
public int compareTo(Object o) {
Person p = (Person) o;
return this.getName().compareTo(p.getName());
}
}
class PersonComparator implements Comparator {
public int compare(Object o1, Object o2) {
Person p1 = (Person) o1;
Person p2 = (Person) o2;
return p1.name.compareTo(p2.name);
}
}
输出结果:
--- Sort Before ---
Coder:1
King:3
Dream:2
Baby:4
--- After Sorted ---
Baby:4
Coder:1
Dream:2
King:3
--- Sort Before ---
Coder:1
King:3
Dream:2
Baby:4
--- After Sorted ---
Baby:4
Coder:1
Dream:2
King:3
参考:
1、
Comparator和Comparable在排序中的应用
2、
java中对于复杂对象排序的模型及其实现 [转]
posted @
2008-08-20 11:37 CoderDream 阅读(354) |
评论 (0) |
编辑 收藏
|
 WebSphere V6 专题 WebSphere V6 专题 |
作为 WebSphere 软件平台的基础,WebSphere® Application Server V6.0 是业内首选的基于 Java 的应用程序平台,集成了动态电子商务世界的企业数据和事务。每个可用配置都提供了丰富的应用程序部署环境和应用程序服务,这些服务提供了增强的事务管理性能,同时还具备 WebSphere 产品家族的共同特性,包括安全性、性能、可用性、连接性和可伸缩性。
>>更多产品信息
posted @
2008-06-19 10:04 CoderDream 阅读(343) |
评论 (0) |
编辑 收藏
目标:将形如(tppabs="js_3.htm#window 窗口对象")之类的问题替换成新的文字。
规则:以(tppabs=")开头,(")结尾,中间有任意个字符
Java:^tppabs=".*"$
EditPlus(替换时注意选择"正则表达式"):^tppabs=".*" 如果末尾加美元符号($),则不行!

Eclipse的正则表达式插件:Regular Expression Tester
Eclipse Regular Expression Tester

Features
- Test and search for regular expression
- Matches are colorized, for an easy visual clue
- Support for pattern flags (e.g. Pattern.DOTALL)
- LiveEval evaluates your regular expression while you are typing it, gives feedback on possible errors and shows any matches automatically
- LiveEval is supported for changes of the regular expression, the search text and the pattern flags
- 4 distinct match modes:
- Find a sequence of characters
- Match a complete text
- Split text
- Replace every occurence of the regex with a different string
Replacing supports back references ($1,$2,...)
- LiveEval for match mode changes
- Context sensitive "Regular Expression Assist"
- Selective evaluation of expressions
- Bracket Matching
- Generation of string literals based on the regexp, e.g. "\(x\)" becomes "\\(x\\)"
- De-escape patterns in your code, e.g. \\(x\\) becomes \(x\)
- Improved "Clear Menu", choose which parts of the view you would like to get cleared every time you press the clear button
- Easy movement through matches: Choose "Previous Match" or "Next Match" and cycle through all matches found.
- Polished and accessible user interface, everything is reachable via keyboard
Download the plugin
- Unzip it to ECLIPSE_HOME
- Restart Eclipse
- In Eclipse, choose Window > Show View > Other > RegEx Tester
- Configure it in Window > Preferences > RegEx Tester
If you like RegEx Tester, please rate it at
eclipse-plugins.info.
The plugin requires a 1.4 JRE/JDK and Eclipse 3.0 or later.
There is an old (sorry) user guide which can
also be found here.
posted @
2008-06-18 15:08 CoderDream 阅读(504) |
评论 (0) |
编辑 收藏
左边链接(包括锚点)、右边显示
文件清单1:
<!-- ------------------------------ -->
<!-- 文件范例:index.html -->
<!-- 文件说明:框架集 -->
<!-- ------------------------------ -->
<HTML>
<HEAD>
<META HTTP-EQUIV="CONTENT-TYPE" CONTENT="TEXT/HTML;CHARSET=UTF-8">
<TITLE>框架集</TITLE>
</HEAD>
<FRAMESET COLS="30%,70%">
<FRAME SRC=menu.html Scrolling="No">
<FRAME SRC=1.html Name="right">
</FRAMESET>
</HTML>
说明:
1、<meta>标签放在<title>之前可以让IE自动选择字符集,如UTF-8;
2、第二个frame的name为“right”,这个值会在menu.html中用到;
文件清单2:
<!-- ------------------------------ -->
<!-- 文件范例:menu.html -->
<!-- 文件说明:左侧框架 -->
<!-- ------------------------------ -->
<HTML>
<HEAD>
<META HTTP-EQUIV="CONTENT-TYPE" CONTENT="TEXT/HTML;CHARSET=UTF-8">
<TITLE>左侧框架</TITLE>
</HEAD>
<BODY>
<A href="1.HTML" Target="right">《商业周刊》:iPhone2.0带来的鲶鱼效应</A><P>
1、<A href="1.HTML#a1" Target="right">无线运营商的日子更不好过</A><P>
2、<A href="1.HTML#a2" Target="right">手机制造厂商们将更烦恼</A><P>
3、<A href="1.HTML#a3" Target="right">iPhone带来的冲击会持续多久?</A><P>
<A href="2.HTML" Target="right">Fireworks MX</A><P>
<A href="3.HTML" Target="right">Flash MX</A><P>
</BODY>
</HTML>
说明:
1、注意,这里<A>标签的target都为index.html中定义的"right"
文件清单3:
<!-- ------------------------------ -->
<!-- 文件范例:1.html -->
<!-- 文件说明:右侧框架一 -->
<!-- ------------------------------ -->
<HTML>
<HEAD>
<META HTTP-EQUIV="CONTENT-TYPE" CONTENT="TEXT/HTML;CHARSET=UTF-8">
<TITLE>右侧框架一</TITLE>
<Style Type="text/css">
<!--
.abc {
font-weight: bold;
font-size: 18px;
}
-->
</Style>
</HEAD>
<BODY>
<H1><A name=aTitle>《商业周刊》:iPhone2.0带来的鲶鱼效应</A></H1>
ugmbbc发布于 2008-06-17 08:26:20|2998 次阅读 字体:大 小 打印预览<BR><BR>
北京时间6月16日,《商业周刊》发表评论文章分析了iPhone2.0对无线运营商和手机制造商们带来的冲击,以下为其全文:
当苹果准备凭着3G版iPhone再次吹响战斗号角的时候,也是手机制造商和无线运营商们更加头疼的时候.苹果在手机市场中可谓旗开得胜,在iPhone 入市的第一年,苹果就从竞争对手RIM公司中抢过不少市场份额,而AT&T作为 iPhone唯一授权的运营商,也从其竞争对手Alltel和T-Mobile中吸引了不少用户.可以想象,一个更便宜、速度更快、功能更全的 iPhone将带来什么样的冲击.<BR><BR>
将在7月面市的新版iPhone,不仅售价不到200美元、升级到更快的网络,而且新增了很多吸引普通消费者以及商业用户的功能.
<A name=a1><p class=abc> 无线运营商的日子更不好过</p></A>
据业内人士说,为了对付iPhone带来的冲击,无线服务运营商们不得不提高对手机的补贴、提高营销预算并降低一些服务的价格,所有这一切意味着利润空间的缩减.面对iPhone的冲击,本来就已经处在政府监管日益增加以及直面Google竞争的无线运营商们的日子更不好过了.<BR><BR>
在过去的一年里,美国的无线运营商们已经在手机津贴上展开激烈竞争,通过增加对手机的补贴来获得长期无线服务合同.但现在AT&T以 iPhone为诱惑来吸引用户,对别的运营商来说,必须采取相应的措施来吸引用户,他们可能引进类iPhone的手机.但"大多数人要的是iPhone,就像他们喜欢iPod而不是其他MP3播放器一样",东北大学营销系教授Gloria Barczak说到,"人们要的是真正的iPhone".因此,要想让用户被吸引,必须得有别的优势,比如价格优势等.<BR><BR>
为了留住高端用户,运营商们需要加大业务推广的力度.据广告顾问公司TNS媒体情报的数据,运营商Verizon无线今年第一季度的广告支出增加了30%.<BR><BR>
Sprint Nextel同期的广告开支下降20%,主要是由于自身的财务问题,当看到用户不断流失的时候,Sprint Nextel应该会加大广告的投入."他们必须拿出能对抗iPhone诱惑的方案来,尽量发挥自己的长处",顾问公司TMNG的CEO Rich Nespola说到.<BR><BR>
另一种留住用户的方式是降低服务的价格.事实上,这是一个有效对付AT&T的办法.AT&T对提供iPhone的用户增加了服务的价格,以弥补高额的津贴费用."AT&T的对手们将在今年下半年继续加强价格优势,可能会有30%到40%的下降.当人们因为高油价开支增多的情况下,每月在无线服务上节省50美元也是很有吸引力的",Pali研究所的分析师Walter Piecyk说到,"因此,无线运营商的利润将从目前的40%下滑到30%".
<p class=abc><A name=a2> 手机制造厂商们将更烦恼</A></p>
手机制造厂商们也正在因为iPhone而大伤脑筋,尽管现在他们正受益于两位数增长的智能手机市场.当运营商们因iPhone而必须提高补贴的时候,他们会将压力转加到手机制造厂商头上,进而压低手机价格.何况,如果iPhone真像分析师们预期那样大卖的话,其他手机厂商的市场份额也会受到很大侵蚀.很久没推出拳头产品的摩托罗拉可能受创最重,三星、LG甚至诺基亚也会遭受冲击,NPD集团的主任分析师Ross Rubin说到,"高端、时尚机型将受冲击最大".<BR><BR>
还有,为了赶上iPhone的技术水平和图形表现能力,手机制造厂商们将不得不提高他们的软件研发成本.去年售出300万台触摸手机的 HTC,已经开发了一种特殊的3D菜单,该菜单表现力强劲,把通讯录做得就像在实际的纸制通讯录中翻找一样."我们希望能把用户的触摸体验提升到一个新的水平",HTC 首席营销官的John Wang说到.<BR><BR>
作为世界上最大手机制造商的诺基亚,在Ovi上投了大量资金,希望为它的智能手机建立一个集地图、游戏和照片共享于一身的Web服务平台,这次在iPhone的刺激下也在加紧推出新服务."我们将继续推出新服务",诺基亚美洲区副总裁Bill Plummer说到.
<p class=abc><A name=a3> iPhone带来的冲击会持续多久?</A></p>
iPhone带来的冲击将会持续多久?这个很难说.一个重量级手机的销售要达到顶峰需要几年的时间.摩托罗拉传奇的RAZR系列手机在2004年推出,直到2007年一季度才达到销售的顶峰,据NPD的数据,当时RAZR系列手机销售占全美手机销售的12%.<BR><BR>
虽然不好说那些别的智能手机和类iPhone的手机将会如何发展,但是"毕竟,重要的是,它们不是iPhone",Jupiter研究所分析师Neil Strother说到,"这不是在苹果堆里挑苹果".<BR><BR>
</BODY>
</HTML>
文件清单4:
<!-- ------------------------------ -->
<!-- 文件范例:2.html -->
<!-- 文件说明:右侧框架二 -->
<!-- ------------------------------ -->
<HTML>
<HEAD>
<TITLE>右侧框架二</TITLE>
<META HTTP-EQUIV="CONTENT-TYPE" CONTENT="TEXT/HTML;CHARSET=UTF-8">
</HEAD>
<BODY>
<H1>Fireworks MX</H1>
Fireworks MX作为网页图像设计软件的代表,在继承了前期版本图形绘制、页面特效功能的同时,大大地发展了位图图像方面的处理功能,这无疑使这个软件有了向Photoshop挑战的更多资本,而其在网页设计方面的诸多应用,又无任何软件可与之媲美。与Dreamweaver MX的整合使其在专业网站图像设计过程中,扮演着不可或缺的角色。
</BODY>
</HTML>
文件清单5:
<!-- ------------------------------ -->
<!-- 文件范例:3.html -->
<!-- 文件说明:右侧框架三 -->
<!-- ------------------------------ -->
<HTML>
<HEAD>
<TITLE>右侧框架三</TITLE>
<META HTTP-EQUIV="CONTENT-TYPE" CONTENT="TEXT/HTML;CHARSET=UTF-8">
</HEAD>
<BODY>
<H1>Flash MX</H1>
Flash MX作为网页矢量交互动画软件的代表,提供了图形绘制、动画制作和交互三大功能。掌握了这个软件的核心,也就有能力在网上冲浪的同时,充当一把闪客的角色。越来越多的个人、商业网站采用Flash技术制作广告Banner、动画片头、MTV、交互游戏,其广泛的应用为Flash的学习者提供了广阔的发展平台,学习Flash MX软件更是一个具有诱惑力的过程。
</BODY>
</HTML>
源代码
posted @
2008-06-18 11:47 CoderDream 阅读(810) |
评论 (3) |
编辑 收藏
大家好,网页设计思考栏目今天继续第八讲。我们上次讨论了首页设计的版面布局 和色彩的搭配,今天我们来谈谈字体。
●字体(Font)的设置是网页制作新手遇到的第一个难点。如何控制字体大小,如何取消 超链接字体的下划线是网友来信问得最多的。好,我们来彻底研究一下字体的各个方面:
○字符集的设定。
在查看html文件原代码时,我们经常可以在文件头<head>和</head>之间看到这么一句代码:
<meta http-equiv="Content-Type" content="text/html; charset=gb2312">
这段代码的作用是什么呢?是否可以删除呢?
其实这是meta标签的设定语句,是给浏览器看的。它的作用就是告诉浏览器:这个HTML 文件是采用gb2312字符集制作的。当浏览器读到这一代码,便以gb2312字符集来解释和翻译 网页原代码,然后我们就可以看到正确的网页。所以这个meta语句是非常重要的,尽量不要 删除。
gb2312就是我们最熟悉的GB简体码,英文是iso-8859-1字符集。其它还有BIG5,UTF-8, Shift-JIS,EUC,KOI8-2等字符集,分别用于不同的字体显示。
○字体的使用。
在网页里,字体的定义语句是:<font face="Arial">显示文字</font> 其中Arial就是一种字体的名称。 默认的浏览器定义的标准字体是中文宋体和英文times new Roma字体。也就是说, 如果你没有设置任何字体,网页将以这两种标准字体显示。同时,着两种字体也可以在任 何操作系统和浏览器里正确显示。
windows另外自带了40多种英文字体和5种中文字体。这些字体,你也可以在网页里自由 使用和设置。凡是使用windows操作系统的浏览器都可以正确显示这些字体,但在其它操作 系统里,如unix 则不能完全正确显示。
如果你需要用一种特殊的字体来体现你的风格,那么如何让大家可以真正看到你的设计 页面呢?解决的办法是:用图片。
将需要用这种字体的地方用图片代替,以保证所有人看到的页面是同一效果。
○字体的样式(style)。
字体的样式有四种:正常体(regular),斜体(Italic),粗体(Bold),粗斜体(Bold Italic)。 设置方法很简单,阿捷就不多罗嗦了。
○字体的效果。
这里指通过html语言设定可以直接显示的效果,在html里的语句设定为: <span style="text-decoration: overline">显示文字</span>
其中,overline是指上划线效果。其它常用的效果还有:underline(下划线), uppercase(大写)等等。
○字体大小的控制。
字体大小的控制是本节的重点。
一般字体默认的大小是12pt(镑).用<font size="+1">语句可以将文字增大2pt。这种方法我们都已经掌握了。而现在网络上最流行的小中文字体大小为9pt,是如何设定的呢?有三种方法:
1.用"<span style="font-size:9pt">显示文字</span>"语句来设定。
显然这种方法非常麻烦,你必须为每段文字都设定大小。
2.用CSS层叠样式表。
CSS是DHTML的一个组成部分,它可以定义整个页面的字体显示风格和大小。是较为简便的方法。比如,这里需要设定整个页面文字大小为9 pt,只要将下面这段代码加入html代码的<head>和</head>之间:
<style type="text/css">
<--
body {FONT-SIZE: 9pt}
th {FONT-SIZE: 9pt}
td {FONT-SIZE: 9pt}
-->
</style>
其中FONT-SIZE:9pt指字体的大小为9镑
3.第二种方法已经简化了许多步骤,但是仍然不是最理想的方法,因为你必须在每个页面的head区都放置这么一段代码,扩大了文件的字节。另外这样的做法还有一个重大缺点,就是如果我需要修改整个站点的字体大小,就必须一页一页的改!
所以推荐给你最终也是目前最好的方法---外部摸板文件调用法。
“外部摸板调用”就是说你将css的设定作成一个单独的文件,在每个页面里都调用它。一旦你需要修改字体大小,只要修改一个.cs s文件,几百个页面就同时修改了。(这种方法类似子程序调用编写过程序的网友很容易理解
调用的具体方法如下:
(1)将上面的css代码copy成一个mycss.txt文件,然后修改后缀名为mycss.css
(2)在html文件的<head></head>之间插入<LINK href="mycss.css" rel=stylesheet type=text/css>, 语句调用mycss.css(注意有关路径的设置正确)OK!
○字体超链接样式的设定。
通常在网页的<body>中设置连接的颜色,如<body link="#FF00FF" vlink="#FF0000" alink="#008080"> 其中:
link -- Hyperlink(连接)的颜色
vlink-- visited Hyperlink(已访问过的连接)颜色
alink-- active Hyperlink (当前活动的连接)颜色 颜色用rgb的16进制码表示如红色是#FF0000。
同样用CSS可以更简便的设定网页超连接的样式,看下面这段代码:
<style type="text/css"> A:link {TEXT-DECORATION: none;COLOR: #0000FF} A:visited {TEXT-DECORATION: none;COLOR: #000000} A:active {TEXT-DECORATION: none;COLOR: #FF0000} A:hover {COLOR: #FF0000} </style>
将它插入html文件的head区就可以了。其中link设定的是有超链接的颜色;visited是访问过的超 链接颜色;active是鼠标移上去的颜色;hover是鼠标点击时的颜色。而"text-decoration:none"是指 取消超链接的下划线显示。
关于CSS的设定还有更多的用法和技巧,比如在同一页中设定不同的字体大小和超链接颜色,请学习有关CSS的专门知识(可以到阿捷的主页h ttp://pageone.yeah.net查阅)在这里我们不在冗述。
●上面已经介绍了字体在技术上的各个方面。有关字体的设计使用,目前还没有一个成熟的理论, 下面是几条网页设计中字体的使用原则,仅供参考:
1.不要使用超过3种以上的字体。字体太多则显得杂乱,没有主题。
2.不要用太大的字。因为版面是宝贵,有限的,粗陋的大字体不能带给访问者更多信息。
3.不要使用不停闪烁的文字。想让浏览者多停留一会儿的话,就不要使用闪烁的文字。
4.原则上标题的字体较正文大,颜色也应有所区别。
posted @
2008-06-18 09:42 CoderDream 阅读(384) |
评论 (0) |
编辑 收藏在windows操作系统上使用IE作为浏览器时。常常会发生这样的问题:在浏览使用UTF-8编码的网页时,浏览器无法自动侦测(即没有设定“自动选择”编码格式时)该页面所用的编码。即使网页已经声明过编码格式:
<meta http-equiv="Content-Type" content="text/html; charset=UTF-8" />
由此造成某些含有中文UTF-8编码的页面产生空白输出。
如果使用的是Mozilla、Mozilla 浏览器、Sarafi的浏览器这不会造成这个问题。这是由于IE解析网页编码时以HTML内的标签优先,而后才是HTTP header内的讯息;而mozilla系列的浏览器则刚刚相反。
由于UTF-8为3个字节表示一个汉字,而普通的GB2312或BIG5是两个。页面输出时,由于上述原因,使浏览器解析、输出<title></title>的内容时,如果在</title>前有奇数个全角字符时,IE把UTF-8当作两个字节解析时出现半个汉字的情况,这时该半个汉字会和</title>的<结合成一个乱码字,导致IE无法读完<title>部分,使整个页面为空百输出。而这个时候如果察看源文件的话,会发现实际上整个叶面全部已经输出了。
因此最简单的解决办法是在网页文件的<head></head>标签中一定要把字符定义
<meta http-equiv="Content-Type" content="text/html; charset=UTF-8" />
放在<title></title>之前。
posted @
2008-06-18 09:30 CoderDream 阅读(413) |
评论 (0) |
编辑 收藏
1、
如何使用Log4j?
2、
http://supportweb.cs.bham.ac.uk/documentation/tutorials/docsystem/build/tutorials/log4j/log4j.html
3、
Log4j
http://my.so-net.net.tw/idealist/Java/Log4j.html
posted @
2008-06-13 17:56 CoderDream 阅读(404) |
评论 (0) |
编辑 收藏
摘要: 14.1 什么是JavaScript
14.1.1 JavaScript概念
JavaScript是一种基于对象和事件驱动并具有安全性能的脚本语言。
14.1.2 JavaScript特点
是一种脚本编写语言;
基于对象的语言;
简单性;
安全性;
动态性;
跨平台性
14.2 编写第一个JavaScript脚本
文件范例:1401.html
<!-- --...
阅读全文
posted @
2008-06-04 09:29 CoderDream 阅读(422) |
评论 (0) |
编辑 收藏
我们在开发的过程中,调试的时候经常要进入某些包,如果没有将这些包与对应的源文件文件夹或zip包对应,就会提示“Source not found”,但是现在很多jar文件都会有相应的源文件,如Struts、Spring等等。而且JavaEE的很多源文件可以通过Tomcat的源文件找到,我们把它打成zip包,注意要和jar文件夹对应,然后设置一下,以后新建Web Project的时候,就可以很方便的查看servlet文件夹下面的源代码了。
这是javaee.jar的设置画面,其他Struts等等设置类似。

posted @
2008-05-29 14:57 CoderDream 阅读(3156) |
评论 (0) |
编辑 收藏
有时候如果看到某个包里面的文件夹没有SVN的标志,直接用“Ctrl+Delete”手工删除,然后“清理”,最后“更新”或“提交”。
网络摘抄1:
错误信息
Malformed file
svn: E:\svn\repository\conf\svnserve.conf:12: Option expected
原因:
配置文件12行开头有空格
错误信息
Attempted to lock an already-locked dir
svn: Working copy 'E:\integration\com.svn.practise' locked
原因:
需要用svn cleanup上次关闭时的锁定
网络摘抄2:
在eclipse里提交和更新文件是抱错。
Attempted to lock an already-locked dir
svn: Working copy 'F:\workspace\WebFrame\WebRoot\attach\prodrelation' locked
执行“清除”操作后,问题解决了。
很多操作,例如中断提交,都会进入这种工作拷贝的锁定状态。
网络摘抄3:
因为这两天频出这个现象,现在基本不怕这个问题了
我是这样解决的:
1 三令五申项目的组员必须先同步,合并,再提交
2 操作后经常地在父目录使用clean up命令
3 解决了locked问题后,还出现不能更新的现象时,就删除目录下的所有文件,包括.svn,再重新check out服务器同目录一次
4 总之,操作要规范,要强调组员每天开工时,先在ECLIPSE里同步,下班时,要提交(提交前,先在文件夹的右菜单中,选择小组>清除),保证每个人的机子里在开工前都是最新版本
老实讲,因为版本冲突,提交冲突,更新失败等等问题,耽误了好些时间,但我知道主要还是自身操作不熟练不规范的问题。我相信,只要坚持,大家包括我的组员一定都会喜欢上这个小海龟的
posted @
2008-05-27 09:51 CoderDream 阅读(108655) |
评论 (14) |
编辑 收藏
效果:
文件清单:
| 序号 |
文件名 |
| 1 |
ChangeLocaleAction.java |
| 2 |
ChangeLocaleForm.java |
| 3 |
struts-config.xml |
| 4 |
index.jsp |
| 5 |
application_en_US.properties |
| 6 |
application_zh_CN.properties |
| 7 |
application_zh_TW.properties |
清单1:
package com.coderdream.struts.action;
import java.util.Locale;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
import org.apache.struts.Globals;
import org.apache.struts.action.Action;
import org.apache.struts.action.ActionForm;
import org.apache.struts.action.ActionForward;
import org.apache.struts.action.ActionMapping;
import com.coderdream.struts.form.ChangeLocaleForm;
public class ChangeLocaleAction extends Action {
public ActionForward execute(ActionMapping mapping, ActionForm form,
HttpServletRequest request, HttpServletResponse response) {
ChangeLocaleForm clForm = (ChangeLocaleForm)form;
String language = clForm.getLanguage();
if (language != null) {
Locale locale;
if (language.equalsIgnoreCase("en")) {
locale = Locale.US;
request.getSession().setAttribute(
Globals.LOCALE_KEY, locale);
} else if (language.equalsIgnoreCase("tw")) {
locale = Locale.TAIWAN;
request.getSession().setAttribute(
Globals.LOCALE_KEY, locale);
} else {
locale = Locale.CHINA;
request.getSession().setAttribute(
Globals.LOCALE_KEY, locale);
}
}
return mapping.findForward("success");
}
}
清单2:
package com.coderdream.struts.form;
import org.apache.struts.action.ActionForm;
/**
*
* description:
*
* @author
*
*/
public class ChangeLocaleForm extends ActionForm{
public ChangeLocaleForm() {
super();
}
private String language;
public String getLanguage() {
return language;
}
public void setLanguage(String language) {
this.language = language;
}
}
清单3:
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE struts-config PUBLIC "-//Apache Software Foundation//DTD Struts Configuration 1.2//EN" "http://struts.apache.org/dtds/struts-config_1_2.dtd">
<struts-config>
<data-sources />
<form-beans>
<form-bean name="ChangeLocaleForm"
type="com.coderdream.struts.form.ChangeLocaleForm" />
</form-beans>
<action-mappings>
<action name="ChangeLocaleForm" path="/ChangeLocale"
scope="request"
type="com.coderdream.struts.action.ChangeLocaleAction"
validate="false">
<forward name="success" path="/index.jsp" />
</action>
</action-mappings>
<message-resources key="application"
parameter="com.coderdream.struts.resources.application" />
</struts-config>
清单4:
<%@ page contentType="text/html; charset=UTF-8"%>
<%@page import="org.apache.struts.Globals"%>
<%@ taglib uri="/WEB-INF/struts-bean.tld" prefix="bean"%>
<%@ taglib uri="/WEB-INF/struts-html.tld" prefix="html"%>
<%@ taglib uri="/WEB-INF/struts-logic.tld" prefix="logic"%>
<html:html>
<head>
<title>多语言测试</title>
<meta http-equiv="pragma" content="no-cache">
<meta http-equiv="cache-control" content="no-cache">
<meta http-equiv="expires" content="0">
<meta http-equiv="keywords" content="keyword1,keyword2,keyword3">
<meta http-equiv="description" content="This is my page">
</head>
<script language="javascript">
function onLanguage(){
var language = document.getElementsByName("language")[0].value;
if(language!=null&&language!=""){
document.forms[0].submit();
}
}
</script>
<body>
<html:form action="ChangeLocale.do">
<html:select property="language" styleId="height:18"
onchange="onLanguage();">
<option value="" title="">
--
<bean:message bundle="application" key="global.select.language" />
--
</option>
<option value="en" title="English">
English
</option>
<option value="cn" title="简体中文">
简体中文
</option>
<option value="tw" title="繁體中文">
繁體中文
</option>
</html:select>
</html:form>
<br>
<br>
<br>
<bean:message bundle="application" key="global.select.test" />
<%=request.getSession().getAttribute(Globals.LOCALE_KEY)%>
</body>
</html:html>
清单5:
#Generated by ResourceBundle Editor (http://eclipse-rbe.sourceforge.net)
global.select.language = Language
global.select.test = Test
清单6:
#Generated by ResourceBundle Editor (http://eclipse-rbe.sourceforge.net)
#BizException
global.select.language = \u8BED\u8A00
global.select.test = \u6D4B\u8BD5
清单7:
#Generated by ResourceBundle Editor (http://eclipse-rbe.sourceforge.net)
global.select.language = \u8A9E\u8A00
global.select.test = \u6E2C\u8A66
此功能的关键是在Action里面将页面传过来的language信息得到,然后根据信息设置Locale,然后将新的Locale放到Session中。
源代码:
点击下载
posted @
2008-05-14 18:20 CoderDream 阅读(1016) |
评论 (0) |
编辑 收藏
原始画面:

由于原来的程序使用的是AWT中的Panel,而这个控件我们没有设置titleBorder的方法。
现在将更新为Swing中的JPanel面板,代码分别为:
旧代码:
Panel pRoboCtrl=new Panel();
pRoboCtrl.setLayout(new GridLayout(5, 1, 2, 5));
// Robot控制面板的第一排,面板的标题
Panel pR1=new Panel();
pR1.setLayout(new GridLayout(1, 1, 2, 3));
//Row One
pR1.add(new Label("Robot Control",Label.CENTER));
新代码:
JPanel pRoboCtrl=new JPanel();
pRoboCtrl.setLayout(new GridLayout(4, 1, 2, 5));
Border titleBorder1=BorderFactory.createTitledBorder("Robot Control");
pRoboCtrl.setBorder(titleBorder1);
原来的处理方式是将一个Label放到Panel中,然后将这个Panel放到外层的Panel中,新方式是将外层Panel定义成JPanel,然后设置Border的值为BorderFactory产生的一个实例。

解决这个问题后,新问题又来了,两个JPanel中的内容不一样,上面多,下面少,但是现在面板却是一样大,要改成面板高度自动适应。
其实这只需要修改一行代码就可以了,代码如下:
旧代码:
 CP.setLayout(new GridLayout(3, 1, 2, 5));
CP.setLayout(new GridLayout(3, 1, 2, 5));
新代码:
CP.setLayout(new BoxLayout(CP, BoxLayout.Y_AXIS)); // 沿垂直方向布置组件
旧代码的处理方式是网格布局,新代码的方式是用BoxLayout布局管理器,它会按要求垂直或水平分布。

以下代码创建了一个JPanel容器,它采用垂直 BoxLayout,在这个容器中包含两个Button,这两个Button沿垂直方向分布,并且保持像素为 5 的固定垂直间隔。
JPanel panel = new JPanel();
panel.setLayout(new BoxLayout(panel, BoxLayout.Y_AXIS));// 沿垂直方向布置组件
panel.add(new JButton("Button1"));
panel.add(Box.createVerticalStrut(5));
panel.add(new JButton("Button2"));
源代码:
下载
posted @
2008-04-29 16:16 CoderDream 阅读(15612) |
评论 (2) |
编辑 收藏
1、下载
http://www.opensymphony.com/quartz/download.action
https://quartz.dev.java.net/files/documents/1267/43545/quartz-1.6.0.zip
2、
详细讲解Quartz如何从入门到精通
3、
用 Quartz 进行作业调度
posted @
2008-04-15 17:46 CoderDream 阅读(736) |
评论 (0) |
编辑 收藏
数据库和表
create table USERS
(
USERNAME VARCHAR2(20) not null,
PASSWORD VARCHAR2(20)
)
alter table USERS
add constraint U_PK primary key (USERNAME)
/**
* JdbcExample.java
*
* Provider: CoderDream's Studio
*
* History
* Date(DD/MM/YYYY) Author Description
* ----------------------------------------------------------------------------
* Apr 14, 2008 CoderDream Created
*/
package com.coderdream.jdbc.oracle;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
import java.sql.SQLException;
import java.sql.Statement;
/**
* @author XL
*
*/
public class JdbcExample {
private static Connection getConn() {
String driver = "oracle.jdbc.driver.OracleDriver";
String url = "jdbc:oracle:thin:@10.5.15.117:1521:csi";
String username = "scott";
String password = "tiger";
Connection conn = null;
try {
Class.forName(driver);
// new oracle.jdbc.driver.OracleDriver();
conn = DriverManager.getConnection(url, username, password);
}
catch (ClassNotFoundException e) {
e.printStackTrace();
}
catch (SQLException e) {
e.printStackTrace();
}
return conn;
}
private static int insert(String username, String password) {
Connection conn = getConn();
int i = 0;
String sql = "insert into users (username,password) values(?,?)";
PreparedStatement pstmt;
try {
pstmt = conn.prepareStatement(sql);
// Statement stat = conn.createStatement();
pstmt.setString(1, username);
pstmt.setString(2, password);
i = pstmt.executeUpdate();
System.out.println("resutl: " + i);
pstmt.close();
conn.close();
}
catch (SQLException e) {
e.printStackTrace();
}
return i;
}
private static void query() {
Connection conn = getConn();
String sql = "select * from users";
PreparedStatement pstmt;
try {
pstmt = conn.prepareStatement(sql);
ResultSet rs = pstmt.executeQuery();
while (rs.next()) {
System.out.println("name: " + rs.getString("username")
+ " \tpassword: " + rs.getString("password"));
}
rs.close();
pstmt.close();
conn.close();
}
catch (SQLException e) {
e.printStackTrace();
}
}
private static int update(String oldName, String newPass) {
Connection conn = getConn();
int i = 0;
String sql = "update users set password='" + newPass
+ "' where username='" + oldName + "'";
PreparedStatement pstmt;
try {
pstmt = conn.prepareStatement(sql);
i = pstmt.executeUpdate();
System.out.println("resutl: " + i);
pstmt.close();
conn.close();
}
catch (SQLException e) {
e.printStackTrace();
}
return i;
}
private static int delete(String username) {
Connection conn = getConn();
int i = 0;
String sql = "delete users where username='" + username + "'";
PreparedStatement pstmt;
try {
pstmt = conn.prepareStatement(sql);
i = pstmt.executeUpdate();
System.out.println("resutl: " + i);
pstmt.close();
conn.close();
}
catch (SQLException e) {
e.printStackTrace();
}
return i;
}
/**
* @param args
*/
public static void main(String[] args) {
insert("CDE", "123");
insert("CoderDream", "456");
query();
update("CoderDream", "456");
query();
delete("CoderDream");
query();
}
}
posted @
2008-04-14 17:55 CoderDream 阅读(7048) |
评论 (0) |
编辑 收藏
1、首先下载eclipse的Tomcat插件,文件名为:tomcatPluginV321.zip
下载:
地址
2、安装Tomcat插件,即将zip档解压,放入eclipse目录下的 plugins 文件夹中。
3、在项目上点右键,设置properties,在'Tomcat'下面设置'export to war settings'输入要导出的war文件路径和文件名,确定,返回项目。

4、在项目上点右键,选择tomcat project->Export to the war file sets in project properties

5、 进入C盘,可以看到csi.war文件正在生成,成功后会有提示框。这样就可以通过Tomcat插件导出WAR档了。
posted @
2008-04-08 13:43 CoderDream 阅读(3735) |
评论 (1) |
编辑 收藏有关CVS权限设置参考
个人建议:如果各个项目独立,我还是建议每个项目一个库!
你的整体思路是正确的,步骤很清晰。
不过要注意cvs chacl -R default:n 的使用,此命令会把该模块的全部权限都去掉的。
另外建议 如果admini,pm 是管理员用户,可以在CVSROOT下建立超级用户admin文件,将这两个用户加入。
=====================================================================
那就按找你的思想设计权限
假设目录结构如下
project
|
|……pro1
| |_pro
| |_aa
|
|……Pro2
| |_pro
| |_bb
|
|_CVSROOT
权限要求
1.用户admini,pm 对project 整个目录有rcw的权限
2.用户h,y,w 对pro1\pro 整个目录有rcw的权限
3.用户y 对pro1\aa 整个目录有rcw的权限
4.用户h 对pro2 整个目录有rcw的权限
=====================================================================
权限设置步骤如下:
首先,建立一个组包含3个用户h,y,w。 group1:h,y,w
一.用户admini,pm 对project 目录有rcw的权限
选中模块roject设置权限:
cvs chacl -R default:n
cvs chacl -R admini:rcw
cvs chacl -R pm:rcw
cvs lsacl
二.用户h,y,w 对pro1\pro目录有rcw的权限
选中模块pro设置权限:
cvs chacl -R group1:rcw
cvs lsacl
三.用户y 对pro1\aa目录有rcw的权限
选中模块aa设置权限:
cvs chacl -R y:rcw
cvs lsacl
四.用户h 对pro2目录有rcw的权限
选中模块pro2:
cvs chacl -R h:rcw
cvs lsacl
结束!
C应该是check out/in
R:READ-只读权限;用户不能对文件进行修改操作;
A:ADD/RENAME/DELETE-用户可以对文件进行添加、删除和更名的操作;其中删除的操作支持从视图中删除文件连接,并没有彻底删除文件,配置库中依然保存文件及其日志信息;
C:CHECK IN/CHECK OUT-文件修改权限:用户可以将文件进行签出进行修改,并可以将修改后的文件签入到配置库中;
D:DESTROY-彻底删除权限;
1、
VSS和CVS的比较
2、
CVS使用手册
3、
一篇CVS权限管理手册
4、
CVS资料集中营
5、
CVS权限设置
posted @
2008-04-07 16:32 CoderDream 阅读(529) |
评论 (0) |
编辑 收藏
摘要: Struts连接数据库一般有直接JDBC和数据源两种方式,
1、JDBC:
在MySQL中创建数据库:
drop database if exists login;
create database login;
use login;
create table user(...
阅读全文
posted @
2008-03-26 13:47 CoderDream 阅读(3869) |
评论 (5) |
编辑 收藏4.1 Web应用的发布描述文件
包含以下信息:
- 初始化参数
- Session配置
- Servlet声明
- Servlet映射
- 应用生命周期的监听类
- 过滤器定义和映射
- MIME类型映射
- 欢迎文件列表
- 出错处理页面
- 标签库映射
- JNDI引用
4.1.1 Web应用发布描述文件的文档类型定义(DTD)
包含元素,属性,实体
<web-app>元素是web.xml的根元素,其他元素必须嵌入在<web-app>元素以内。
<servlet>必须在<servlet-mapping>之前;
<servlet-mapping>必须在<taglib>之前;
4.2 为Struts 应用配置 web.xml 文件
4.2.1 配置 Struts 的 ActionServlet
<!-- Standard Action Servlet Configuration (with debugging) -->
<servlet>
<servlet-name>action</servlet-name>
<servlet-class>
org.apache.struts.action.ActionServlet
</servlet-class>
<init-param>
<param-name>config</param-name>
<param-value>
/WEB-INF/conf/struts-config.xml
</param-value>
</init-param>
<init-param>
<param-name>config/bank</param-name>
<param-value>
/WEB-INF/conf/struts-config-bank.xml
</param-value>
</init-param>
<init-param>
<param-name>config/card</param-name>
<param-value>
/WEB-INF/conf/struts-config-card.xml
</param-value>
</init-param>
<init-param>
<param-name>config/publicarea</param-name>
<param-value>
/WEB-INF/conf/struts-config-publicarea.xml
</param-value>
</init-param>
<init-param>
<param-name>config/maintenance</param-name>
<param-value>
/WEB-INF/conf/struts-config-maintenance.xml
</param-value>
</init-param>
<init-param>
<param-name>config/report</param-name>
<param-value>
/WEB-INF/conf/struts-config-report.xml
</param-value>
</init-param>
<init-param>
<param-name>debug</param-name>
<param-value>2</param-value>
</init-param>
<init-param>
<param-name>detail</param-name>
<param-value>2</param-value>
</init-param>
<load-on-startup>2</load-on-startup>
</servlet>
<servlet-mapping>
<!-- Standard Action Servlet Mapping -->
<servlet-mapping>
<servlet-name>action</servlet-name>
<url-pattern>*.do</url-pattern>
</servlet-mapping>
说明:
1、一个项目可以配置多个<servlet>,且其中一个名为action;
2、在action的<servlet>中,可配置多个config,第一个为config,其他以“config/”开头,如:config/bank;
3、在全局<forward>元素中的例子:
<global-forwards>
<forward name="toBank" path="/bank/login.do" />
</global-forwards>
4、使用<action>元素中的局部<forward>元素,例如:
<action-mappings>

<action>
<forward> name="success" path="/bank/index.do" />
</action>
</action-mappings>
5、<url-pattern>属性为“*.do”,表明ActionServlet负责处理所有以“.do”扩展名结尾的URL。
4.2.2、 声明 ActionServlet 的初始化参数
<init-param>子元素用于声明 Servlet 初始化参数。见4.2.1的代码清单。
4.2.3、配置欢迎文件清单
<!-- The Usual Welcome File List -->
<welcome-file-list>
<welcome-file>index.jsp</welcome-file>
</welcome-file-list>
从第一个文件依次往后面找,如果没有找到,抛出404错误。
在欢迎文件中不能配置Servlet映射,可通过变通的方式处理。
1、在 Struts 配置文件中为被调用的 Action 创建一个全局的( global) 转发项,例如:
<global-forwards>
<forward name="welcome" path="HelloWordl.do" />
</global-forwards>
2、创建一个welcome.jsp文件:
<%@ tablib uri="/WEB-INF/struts-logic.tld" prefix="logic" %>
<html>
<body>
<logic:forward name="welcome" />
</body>
</html>
3、最后配置欢迎页面为welcome.jsp即可。
4.2.4 配置错误处理
1、避免用户看到原始的错误信息
<error-page>
<error-code>404</error-code>
<location>/common/404.jsp</location>
</error-page>
<error-page>
<error-code>500</error-code>
<location>/common/500.jsp</location>
</error-page>
2、也可为Web 容器捕获 Java 异常配置 <error-page>元素,这是需要设置<exception-type>子元素,它用于指定Java异常类。可捕获如下异常:
A、RuntimeException 或 Error
B、ServletException 或它的子类
C、IOException 或它的子类
例如:
<!-- The default error page -->
<error-page>
<exception-type>java.lang.IOException</exception-type>
<location>/common/IOError.jsp</location>
</error-page>
4.2.5 配置 Struts 标签库
<!-- Struts Tag Library Descriptors -->
<taglib>
<taglib-uri>/tags/struts-bean</taglib-uri>
<taglib-location>/WEB-INF/struts-bean.tld</taglib-location>
</taglib>
<taglib>
<taglib-uri>/tags/struts-html</taglib-uri>
<taglib-location>/WEB-INF/struts-html.tld</taglib-location>
</taglib>
<taglib>
<taglib-uri>/tags/struts-logic</taglib-uri>
<taglib-location>/WEB-INF/struts-logic.tld</taglib-location>
</taglib>
<taglib>
<taglib-uri>/tags/struts-nested</taglib-uri>
<taglib-location>/WEB-INF/struts-nested.tld</taglib-location>
</taglib>
<taglib>
<taglib-uri>/tags/struts-tiles</taglib-uri>
<taglib-location>/WEB-INF/struts-tiles.tld</taglib-location>
</taglib>
用户自定义的客户化标签库和标准的类似。
posted @
2008-03-21 11:51 CoderDream 阅读(402) |
评论 (0) |
编辑 收藏1、
<html:form action="getImporterDonneesTypeList.do">
<div class="finFormulaire1" onClick="document.forms[1].submit();" STYLE="position:relative;right:10%;">
<div class="bouton" onclick="">
<span class="bold">
<rcd:label key="boutonNouveau"/>
</span>
<img src="<%= "/resources/"+ userMarque + "/img/common/btn/right.gif" %>" alt="" style="vertical-align:middle"/>
</div>
</div>
</html:form>
2
function goBack(){
document.forms[0].action="/initCommerentitesSearchAction.do";
document.forms[0].method="post";
document.forms[0].encoding="multipart/form-data";
document.forms[0].submit();
}
<div class="finFormulaire" align="center">
<div class="bouton" onClick="goBack();"><span class="bold"><rcd:label key="boutonRetour"/></span><img src="<%= "/resources/"+ userMarque + "/img/common/btn/right.gif" %>" alt="" style="vertical-align:middle"/></div>
</div>
posted @
2008-03-14 13:15 CoderDream 阅读(430) |
评论 (0) |
编辑 收藏1、RCD-499:某个<html:text/>不能修改。
style="color:#BCBCBC;">
posted @
2008-03-12 10:23 CoderDream 阅读(274) |
评论 (0) |
编辑 收藏
1、日志类型:Metaweblog API;
2、日志的远程发布URL:
http://www.blogjava.net/用户名/services/metaweblog.aspx
我的:http://www.blogjava.net/coderdream/services/metaweblog.aspx
参考地址:http://www.cnblogs.com/dudu/articles/495718.html
posted @
2008-03-11 11:54 CoderDream 阅读(222) |
评论 (0) |
编辑 收藏使用下面的命令就可以了:
db2cmd
然后:
db2set db2codepage=1252
后面的数字是安装DB2时数据库的CodePage。
DB2 CODEPAGE --代码页查询列表
http://www.itdata.cn/bbs/dispbbs.asp?boardid=6&id=928
--------------------------------------------------
Conversion between any of the following codepages is provided.
37 (=x0025) EBCDIC US English
273 (=x0111) EBCDIC German
277 (=x0115) EBCDIC Danish/Norwegian
278 (=x0116) EBCDIC Finnish/Swedish
280 (=x0118) EBCDIC Italian
284 (=x011C) EBCDIC Spanish
285 (=x011D) EBCDIC UK English
297 (=x0129) EBCDIC French
300 (=x012C) EBCDIC Japanese DBCS
301 (=x012D) Japanese PC DBCS
420 (=x01A4) EBCDIC Arabic
424 (=x01A8) EBCDIC Arabic
437 (=x01B5) PC-ASCII US
500 (=x01F4) EBCDIC International
803 (=x0323) Hebrew Set A
813 (=x032D) ISO8859-7 Greek
819 (=x0333) ISO8859-1 Western European
833 (=x0341) IBM-833: Korean
834 (=x0342) IBM-834: Korean Host DBCS
835 (=x0343) EBCDIC Traditional Chinese DBCS
836 (=x0344) EBCDIC Simplified Chinese SBCS
838 (=x0346) EBCDIC Thai SBCS
850 (=x0352) ISO8859-1 Western European
852 (=x0354) PC-ASCII Eastern European
855 (=x0357) PC-ASCII Cyrillic
856 (=x0358) PC-ASCII Hebrew
857 (=x0359) PC-ASCII Turkish
858 (=x035A) PC-ASCII Western European with Euro
860 (=x035C) PC-ASCII Portuguese
861 (=x035D) PC-ASCII Icelandic
862 (=x035E) PC-ASCII Hebrew
863 (=x035F) PC-ASCII Canadian French
864 (=x0360) PC-ASCII Arabic
865 (=x0361) PC-ASCII Scandinavian
866 (=x0362) PC-ASCII Cyrillic #2
868 (=x0364) PC-ASCII Urdu
869 (=x0365) PC-ASCII Greek
870 (=x0366) EBCDIC Eastern Europe
871 (=x0367) EBCDIC Icelandic
872 (=x0368) PC-ASCII Cyrillic with Euro
874 (=x036A) PC-ASCII Thai SBCS
875 (=x036B) EBCDIC Greek
880 (=x0370) EBCDIC Cyrillic
891 (=x037B) IBM-891: Korean
897 (=x0381) PC-ASCII Japan Data SBCS
903 (=x0387) PC Simplified Chinese SBCS
904 (=x0388) PC Traditional Chinese Data - SBCS
912 (=x0390) ISO8859-2 Eastern European
915 (=x0393) ISO8859-5 Cyrillic
916 (=x0394) ISO8859-8 Hebrew
918 (=x0396) EBCDIC Urdu
920 (=x0398) ISO8859-9 Turkish
921 (=x0399) ISO Baltic
922 (=x039A) ISO Estonian
923 (=x039B) ISO8859-15 Western Europe with euro (Latin 9)
924 (=x039C) EBCDIC Western Europe with euro
927 (=x039F) PC Traditional Chinese DBCS
928 (=x03A0) PC Simplified Chinese DBCS
930 (=x03A2) EBCDIC Japanese Katakana/Kanji mixed
932 (=x03A4) Japanese OS/2
933 (=x03A5) EBCDIC Korean Mixed
935 (=x03A7) EBCDIC Simplified Chinese Mixed
937 (=x03A9) EBCDIC Traditional Chinese Mixed
939 (=x03AB) EBCDIC Japanese Latin/Kanji mixed
941 (=x03AD) Japanese PC DBCS - for open systems
942 (=x03AE) Japanese PC Data Mixed - extended SBCS
943 (=x03AF) Japanese PC Mixed - for open systems
944 (=x03BO) Korean PC data Mixed - extended SBCS
946 (=x03B2) Simplified Chinese PC data Mixed - extended SBCS
947 (=x03B3) PC Traditional Chinese DBCS
948 (=x03B4) PC Traditional Chinese Mixed - extended SBCS
949 (=x03B5) PC Korean Mixed - KS code
950 (=x03B6) PC Traditional Chinese Mixed - big5
951 (=x03B7) PC Korean DBCS - KS code
970 (=x03CA) euc Korean
1004 (=x03EC) PC Data Latin1
1006 (=x03EE) ISO Urdu
1008 (=x03F0) ASCII Arabic 8-bit ISO
1025 (=x0401) EBCDIC Cyrillic
1026 (=x0402) EBCDIC Turkish
1027 (=x0403) EBCDIC Japanese Latin
1040 (=x0410) IBM-1040: Korean
1041 (=x0411) Japanese PC - extended SBCS
1042 (=x0412) PC Simplified Chinese - extended SBCS
1043 (=x0413) PC Traditional Chinese - extended SBCS
1046 (=x0416) PC-ASCII Arabic
1047 (=x0417) IBM-1047: Western European
1051 (=x041B) ASCII roman8 for HP Western European
1088 (=x0440) PC Korean SBCS - KS code
1089 (=x0441) ISO8859-6 Arabic
1097 (=x0449) EBCDIC Farsi
1098 (=x044A) PC-ASCII Farsi
1112 (=x0458) EBCDIC Baltic (Latvian/Lithuanian)
1114 (=x045A) PC Traditional Chinese - big 5 SBCS
1115 (=x045B) PC Simplified Chinese SBCS
1122 (=x0462) EBCDIC Estonian
1123 (=x0463) EBCDIC Ukrainian
1124 (=x0464) UNIX-ASCII Ukrainian
1131 (=x046B) PC-ASCII Belarus
1140 (=x0474) EBCDIC USA, with euro (like 037)
1141 (=x0475) EBCDIC Austria, Germany, with euro (like 273)
1142 (=x0476) EBCDIC Denmark, Norway, with euro (like 277)
1143 (=x0477) EBCDIC Finland, Sweden, with euro (like 278)
1144 (=x0478) EBCDIC Italy, with euro (like 280)
1145 (=x0479) EBCDIC Spain, with euro (like 284)
1146 (=x047A) EBCDIC UK, with euro (like 285)
1147 (=x047B) EBCDIC France, with euro (like 297)
1148 (=x047C) EBCDIC International, with euro (like 500)
1149 (=x047D) EBCDIC Iceland, with euro (like 871)
1200 (=x04B0) Unicode - UCS-2
1208 (=x04B8) Unicode - UTF-8
1250 (=x04E2) Windows - Eastern European
1251 (=x04E3) Windows - Cyrillic
1252 (=x04E4) Windows - Western European
1253 (=x04E5) Windows - Greek
1254 (=x04E6) Windows - Turkish
1255 (=x04E7) Windows - Hebrew
1256 (=x04E8) Windows - Arabic
1257 (=x04E9) Windows - Baltic Rim
1275 (=x04FB) Apple - Western European
1280 (=x0500) Apple - Greek
1281 (=x0501) Apple - Turkish
1282 (=x0502) Apple - Eastern European
1283 (=x0503) Apple - Cyrillic
1284 (=x0504) IBM-504: Eastern European
1285 (=x0505) IBM-505: Eastern European
1363 (=x0553) Windows Korean PC Mixed including 11,172 full hangul
1364 (=x0554) Korean Host Mixed extended including 11,172 full hangul
1380 (=x0564) PC Simplified Chinese DBCS
1381 (=x0565) PC Simplified Chinese Mixed
1383 (=x0567) euc Simplified Chinese Mixed
1386 (=x056A) PC Simplified Chinese Data GBK Mixed
1388 (=x056C) DBCS Host Simplified Chinese Data GBK Mixed
5346 (=x14E2) Windows-Eastern European with Euro (like 1250)
5347 (=x14E3) Windows - Cyrillic with Euro (like 1251)
5348 (=x14E4) Windows-Western European with Euro (like 1252)
5349 (=x14E5) Windows-Windows - Greek with Euro (like 1253)
5350 (=x14E6) Windows - Turkish with Euro (like 1254)
5351 (=x14E7) Windows - Hebrew with Euro (like 1255)
5352 (=x14E8) Windows - Arabic with Euro (like 1256)
5353 (=x14E9) Windows - Baltic Rim with Euro (like 1257)
5354 (=x14EA) 'Windows - Vietnamese with Euro (like 1258)
posted @
2008-03-07 18:02 CoderDream 阅读(1900) |
评论 (0) |
编辑 收藏
1、先将数据库中该字段全部转为大写,然后用Upper()函数将条件转为大写:
select * from code_table_data t where Upper(t.DETAIL_DESC)=Upper('tr');
2、 模糊查询:在Java中将条件转为大写,然后将该变量放入百分号(%)之间!
select * from code_table_data t where Upper(t.DETAIL_DESC) like '%T%';
posted @
2008-03-05 18:06 CoderDream 阅读(8361) |
评论 (6) |
编辑 收藏1、进入出错页面,找到该页面的链接:
这里链接地址为:http://localhost:8082/getSideBar.do?id=481

2、在Project文档中找到记录相关信息的Excel文件:

3、打开该文件,找到对应信息:


4、在struts-config.xml中找到相关信息:
注意:项目中有很多struts-config.xml,一定要找RCDWeb->WebContent->WEB-INF下面的struts-config.xml和conf下面的tiles-def.xml。

先通过<forward>标签,找到相应的Action.do:

然后通过该信息,找到具体的Action的详细信息:

从上图可以找到相关的Java类的信息,type对应的值就是。
5、查找相关的Jsp:
通过上图的<forward name="success" ...>,可以通过查找tiles-def.xml文件找到相应的Jsp页面。

PS:这两个星期被安排到一个新项目改Bug,这个项目是一个法国项目,架构都是法国人自己写的。看来还有很多东西要学习,不然发现问题了也不知如何下手。
posted @
2008-03-05 15:45 CoderDream 阅读(317) |
评论 (0) |
编辑 收藏
CVS馆不仅能管理源代码,同时也可以用来管理文档。
一般,我们用eclipse来取文档,用wincvs客户端来取文档。
1、本地环境(繁体中文)与CVS馆的环境(简体中文)不一致
这里我们要用到微软提供的一个软件:Microsoft AppLocale,下载地址:
http://download.pchome.net/download-17721.html
软件详细信息
中文程序乱码消除器,消除中文程序接口上的乱码。如果您在繁体中文 Windows 上执行一个简体字版本的程序,那么这个程序的外观可能会变成许多中文乱码,让您无法辨识。此时便可试试本程序,且看他是否能为您化腐朽为神奇。
步骤:
A、选择将要设置的exe文件;

B、选择要运行的环境语言(如:简体中文)。这样启动的wincvs的字符环境就是简体中文了。

C、然后建立快捷方式放到桌面方便以后使用:

2、登录取文档:
A、配置好服务器地址和文件目录,登录界面如下:

输入密码,登录成功:
CVSROOT: ***@10.5.6.32:/psacvs (password authentication)
TCL or Python are not available, shell is disabled
cvs -d :pserver:***@10.5.6.32:/psacvs login
Logging in to :pserver:***@10.5.6.32:2401:/psacvs
***** CVS exited normally with code 0 *****
B、然后在本地建立一个文件夹,如:psa,在wincvs中点击文件夹psa右键,选择“Checkout settings”:

C、通过“Module name and path on the server:”的下拉选单我们可以选择要Checkout的文档工程,如果没有,可以直接输入,如:“003627W-ARCAD”:

D、如果输入没有错误,就会正常取出文档,而且简体中文文件名不会显示乱码:

PS:不过如果还有法文的文件名,那乱码就不可避免了!
posted @
2008-03-04 10:27 CoderDream 阅读(655) |
评论 (0) |
编辑 收藏Java程序员:一刻钟精通正则表达式
想必很多人都对正则表达式都头疼。今天,我以我的认识,加上网上一些文章,希望用常人都可以理解的表达方式来和大家分享学习经验。
开篇,还是得说说 ^ 和 $ 他们是分别用来匹配字符串的开始和结束,以下分别举例说明:
"^The": 开头一定要有"The"字符串;
"of despair$": 结尾一定要有"of despair" 的字符串;
那么,
"^abc$": 就是要求以abc开头和以abc结尾的字符串,实际上是只有abc匹配。
"notice": 匹配包含notice的字符串。
你可以看见如果你没有用我们提到的两个字符(最后一个例子),就是说 模式(正则表达式) 可以出现在被检验字符串的任何地方,你没有把他锁定到两边。
接着,说说 '*', '+',和 '?',
他们用来表示一个字符可以出现的次数或者顺序。 他们分别表示:
"zero or more"相当于{0,},
"one or more"相当于{1,},
"zero or one."相当于{0,1}, 这里是一些例子:
"ab*": 和ab{0,}同义,匹配以a开头,后面可以接0个或者N个b组成的字符串("a", "ab", "abbb", 等);
"ab+": 和ab{1,}同义,同上条一样,但最少要有一个b存在 ("ab", "abbb", 等。);
"ab?":和ab{0,1}同义,可以没有或者只有一个b;
"a?b+$": 匹配以一个或者0个a再加上一个以上的b结尾的字符串。
要点, '*', '+',和 '?'只管它前面那个字符。
你也可以在大括号里面限制字符出现的个数,比如
"ab{2}": 要求a后面一定要跟两个b(一个也不能少)("abb");
"ab{2,}": 要求a后面一定要有两个或者两个以上b(如"abb", "abbbb", 等。);
"ab{3,5}": 要求a后面可以有2-5个b("abbb", "abbbb", or "abbbbb")。
现在我们把一定几个字符放到小括号里,比如:
"a(bc)*": 匹配 a 后面跟0个或者一个"bc";
"a(bc){1,5}": 一个到5个 "bc."
还有一个字符 '│', 相当于OR 操作:
"hi│hello": 匹配含有"hi" 或者 "hello" 的 字符串;
"(b│cd)ef": 匹配含有 "bef" 或者 "cdef"的字符串;
"(a│b)*c": 匹配含有这样多个(包括0个)a或b,后面跟一个c的字符串;
一个点('.')可以代表所有的单一字符,不包括"\n"
如果,要匹配包括"\n"在内的所有单个字符,怎么办?
对了,用'[\n.]'这种模式。
"a.[0-9]": 一个a加一个字符再加一个0到9的数字
"^.{3}$": 三个任意字符结尾 .
中括号括住的内容只匹配一个单一的字符
"[ab]": 匹配单个的 a 或者 b ( 和 "a│b" 一样);
"[a-d]": 匹配'a' 到'd'的单个字符 (和"a│b│c│d" 还有 "[abcd]"效果一样); 一般我们都用[a-zA-Z]来指定字符为一个大小写英文
"^[a-zA-Z]": 匹配以大小写字母开头的字符串
"[0-9]%": 匹配含有 形如 x% 的字符串
",[a-zA-Z0-9]$": 匹配以逗号再加一个数字或字母结尾的字符串
你也可以把你不想要得字符列在中括号里,你只需要在总括号里面使用'^' 作为开头 "%[^a-zA-Z]%" 匹配含有两个百分号里面有一个非字母的字符串。
要点:^用在中括号开头的时候,就表示排除括号里的字符。为了PHP能够解释,你必须在这些字符面前后加'',并且将一些字符转义。
不要忘记在中括号里面的字符是这条规路的例外?在中括号里面, 所有的特殊字符,包括(''), 都将失去他们的特殊性质 "[*\+?{}.]"匹配含有这些字符的字符串。
还有,正如regx的手册告诉我们: "如果列表里含有 ']', 最好把它作为列表里的第一个字符(可能跟在'^'后面)。 如果含有'-', 最好把它放在最前面或者最后面, or 或者一个范围的第二个结束点[a-d-0-9]中间的‘-’将有效。
看了上面的例子,你对{n,m}应该理解了吧。要注意的是,n和m都不能为负整数,而且n总是小于m. 这样,才能 最少匹配n次且最多匹配m次。 如"p{1,5}"将匹配 "pvpppppp"中的前五个p.
下面说说以\开头的
\b 书上说他是用来匹配一个单词边界,就是……比如've\b',可以匹配love里的ve而不匹配very里有ve
\B 正好和上面的\b相反。例子我就不举了
……突然想起来……可以到http://www.phpv.net/article.php/251 看看其它用\ 开头的语法
好,我们来做个应用:
如何构建一个模式来匹配 货币数量 的输入
构建一个匹配模式去检查输入的信息是否为一个表示money的数字。我们认为一个表示money的数量有四种方式: "10000.00" 和 "10,000.00",或者没有小数部分, "10000" and "10,000". 现在让我们开始构建这个匹配模式:
^[1-9][0-9]*$
这是所变量必须以非0的数字开头。但这也意味着 单一的 "0" 也不能通过测试。 以下是解决的方法:
^(0│[1-9][0-9]*)$
"只有0和不以0开头的数字与之匹配",我们也可以允许一个负号在数字之前:
^(0│-?[1-9][0-9]*)$
这就是: "0 或者 一个以0开头 且可能 有一个负号在前面的数字。" 好了,现在让我们别那么严谨,允许以0开头。现在让我们放弃 负号 , 因为我们在表示钱币的时候并不需要用到。 我们现在指定 模式 用来匹配小数部分:
^[0-9]+(\.[0-9]+)?$
这暗示匹配的字符串必须最少以一个阿拉伯数字开头。 但是注意,在上面模式中 "10." 是不匹配的, 只有 "10" 和 "10.2" 才可以。 (你知道为什么吗)
^[0-9]+(\.[0-9]{2})?$
我们上面指定小数点后面必须有两位小数。如果你认为这样太苛刻,你可以改成:
^[0-9]+(\.[0-9]{1,2})?$
这将允许小数点后面有一到两个字符。 现在我们加上用来增加可读性的逗号(每隔三位), 我们可以这样表示:
^[0-9]{1,3}(,[0-9]{3})*(\.[0-9]{1,2})?$
不要忘记 '+' 可以被 '*' 替代 如果你想允许空白字符串被输入话 (为什么?)。 也不要忘记反斜杆 ‘\’ 在php字符串中可能会出现错误 (很普遍的错误)。
现在,我们已经可以确认字符串了, 我们现在把所有逗号都去掉 str_replace(",", "", $money) 然后在把类型看成 double然后我们就可以通过他做数学计算了。
再来一个:
构造检查email的正则表达式
在一个完整的email地址中有三个部分:
1. 用户名 (在 '@' 左边的一切),
2.'@',
3. 服务器名(就是剩下那部分)。
用户名可以含有大小写字母阿拉伯数字,句号 ('.'), 减号('-'), and 下划线 ('_')。 服务器名字也是符合这个规则,当然下划线除外。
现在, 用户名的开始和结束都不能是句点。 服务器也是这样。 还有你不能有两个连续的句点他们之间至少存在一个字符,好现在我们来看一下怎么为用户名写一个匹配模式:
^[_a-zA-Z0-9-]+$
现在还不能允许句号的存在。 我们把它加上:
^[_a-zA-Z0-9-]+(\.[_a-zA-Z0-9-]+)*$
上面的意思就是说: "以至少一个规范字符(除了。)开头,后面跟着0个或者多个以点开始的字符串。"
简单化一点, 我们可以用 eregi()取代 ereg()。eregi()对大小写不敏感, 我们就不需要指定两个范围 "a-z" 和 "A-Z" ? 只需要指定一个就可以了:
^[_a-z0-9-]+(\.[_a-z0-9-]+)*$
后面的服务器名字也是一样,但要去掉下划线:
^[a-z0-9-]+(\.[a-z0-9-]+)*$
好。 现在只需要用“@”把两部分连接:
^[_a-z0-9-]+(\.[_a-z0-9-]+)*@[a-z0-9-]+(\.[a-z0-9-]+)*$
这就是完整的email认证匹配模式了,只需要调用
eregi(‘^[_a-z0-9-]+(\.[_a-z0-9-]+)*@[a-z0-9-]+(\.[a-z0-9-]+)*$ ’,$eamil)
就可以得到是否为email了。
正则表达式的其他用法
提取字符串
ereg() and eregi() 有一个特性是允许用户通过正则表达式去提取字符串的一部分(具体用法你可以阅读手册)。 比如说,我们想从 path/URL 提取文件名 ? 下面的代码就是你需要:
ereg("([^\\/]*)$", $pathOrUrl, $regs);
echo $regs[1];
高级的代换
ereg_replace() 和 eregi_replace()也是非常有用的: 假如我们想把所有的间隔负号都替换成逗号:
ereg_replace("[ \n\r\t]+", ",", trim($str));
最后,我把另一串检查EMAIL的正则表达式让看文章的你来分析一下。
"^[-!#$%&\'*+\\./0-9=?A-Z^_`a-z{|}~]+'.'@'.'[-!#$%&\'*+\\/0-9=?A-Z^_`a-z{|}~]+\.'.'[-!#$%&\'*+\\./0-9=?A-Z^_`a-z{|}~]+$"
如果能方便的读懂,那这篇文章的目的就达到了。
原文地址:http://java.chinaitlab.com/base/732793.html
posted @
2008-02-29 09:49 CoderDream 阅读(961) |
评论 (0) |
编辑 收藏
1、
揭开正则表达式的神秘面纱
2、
正则表达式话题
3、
如何使用Java自带的正则表达式
4、
处理正则表达式的java包:regexp
5、
Java正则表达式技巧总结
6、
学点Java正则表达式
7、
在JAVA中使用正则表达式
8、
Java正则表达式(1)
9、
java正则表达式; regular expression(2)
10、
JAVA正则表达式(2)
posted @
2008-02-29 09:47 CoderDream 阅读(323) |
评论 (0) |
编辑 收藏§1黑暗岁月
有一个String,如何查询其中是否有y和f字符?最黑暗的办法就是:
程序1:我知道if、for语句和charAt()啊。
class Test{
public static void main(String args[]) {
String str="For my money, the important thing "+
"about the meeting was bridge-building";
char x='y';
char y='f';
boolean result=false;
for(int i=0;i<str.length();i++){
char z=str.charAt(i); //System.out.println(z);
if(x==z||y==z) {
result=true;
break;
}
else result=false;
}
System.out.println(result);
}
}
好像很直观,但这种方式难以应付复杂的工作。如查询一段文字中,是否有is?是否有thing或ting等。这是一个讨厌的工作。
§2 Java的java.util.regex包
按照面向对象的思路,把希望查询的字符串如is、thing或ting封装成一个对象,以这个对象作为模板去匹配一段文字,就更加自然了。作为模板的那个东西就是下面要讨论的正则表达式。先不考虑那么复杂,看一个例子:
程序2:不懂。先看看可以吧?
import java.util.regex.*;
class Regex1{
public static void main(String args[]) {
String str="For my money, the important thing "+
"about the meeting was bridge-building";
String regEx="a|f"; //表示a或f
Pattern p=Pattern.compile(regEx);
Matcher m=p.matcher(str);
boolean result=m.find();
System.out.println(result);
}
}
如果str匹配regEx,那么result为true,否则为flase。如果想在查找时忽略大小写,则可以写成:
Pattern p=Pattern.compile(regEx,Pattern.CASE_INSENSITIVE);
虽然暂时不知道Pattern(模板、模式)和Matcher(匹配器)的细节,程序的感觉就比较爽,如果先查询is、后来又要查询thing或ting,我们只需要修改一下模板Pattern,而不是考虑if语句和for语句,或者通过charAt()。
1、写一个特殊的字符串??正则表达式如a|f。
2、将正则表达式编译成一个模板:p
3、用模板p去匹配字符串str。
思路清楚了,现在看Java是如何处理的(Java程序员直到JDK1.4才能使用这些类。
§3 Pattern类与查找
①public final class java.util.regex.Pattern是正则表达式编译后的表达法。下面的语句将创建一个Pattern对象并赋值给句柄p:Pattern p=Pattern.compile(regEx);
有趣的是,Pattern类是final类,而且它的构造器是private。也许有人告诉你一些设计模式的东西,或者你自己查有关资料。这里的结论是:Pattern类不能被继承,我们不能通过new创建Pattern类的对象。
因此在Pattern类中,提供了2个重载的静态方法,其返回值是Pattern对象(的引用)。如:
public static Pattern compile(String regex) {
return new Pattern(regex, 0);
}
当然,我们可以声明Pattern类的句柄,如Pattern p=null;
②p.matcher(str)表示以用模板p去生成一个字符串str的匹配器,它的返回值是一个Matcher类的引用,为什么要这个东西呢?按照自然的想法,返回一个boolean值不行吗?
我们可以简单的使用如下方法:
boolean result=Pattern.compile(regEx).matcher(str).find();
呵呵,其实是三个语句合并的无句柄方式。无句柄常常不是好方式。后面再学习Matcher类吧。先看看regEx??这个怪咚咚。
§4 正则表达式之限定符
正则表达式(Regular Expression)是一种生成字符串的字符串。晕吧。比如说,String regEx="me+";这里字符串me+能够生成的字符串是:me、mee、meee、meeeeeeeeee等等,一个正则表达式可能生成无穷的字符串,所以我们不可能(有必要吗?)输出正则表达式产生的所有东西。
反过来考虑,对于字符串:me、mee、meee、meeeeeeeeee等等,我们能否有一种语言去描述它们呢?显然,正则表达式语言是这种语言,它是一些字符串的模式??简洁而深刻的描述。
我们使用正则表达式,用于字符串查找、匹配、指定字符串替换、字符串分割等等目的。
生成字符串的字符串??正则表达式,真有些复杂,因为我们希望由普通字符(例如字符 a 到 z)以及特殊字符(称为元字符)描述任意的字符串,而且要准确。
先搞几个正则表达式例子:
程序3:我们总用这个程序测试正则表达式。
import java.util.regex.*;
class Regex1{
public static void main(String args[]) {
String str="For my money, the important thing ";
String regEx="ab*";
boolean result=Pattern.compile(regEx).matcher(str).find();
System.out.println(result);
}
}//ture
①"ab*"??能匹配a、ab、abb、abbb……。所以,*表示前面字符可以有零次或多次。如果仅仅考虑查找,直接用"a"也一样。但想想替换的情况。 问题regEx="abb*"结果如何?
②"ab+"??能匹配ab、abb、abbb……。等价于"abb*"。问题regEx="or+"结果如何?
③"or?"??能匹配o和or。? 表示前面字符可以有零次或一次。
这些限定符*、+、?方便地表示了其前面字符(子串)出现的次数(我们用{}来描述):
x* 零次或多次 ≡{0,}
x+ 一次或多次 ≡{1,}
x? 零次或一次 ≡{0,1}
x{n} n次(n>0)
x{n,m} 最少n次至最多m次(0<n<m)
x{n,} 最少n次,
现在我们知道了连续字符串的查找、匹配。下面的是一些练习题:
①查找粗体字符串(不要求精确或要求精确匹配),写出其正则表达式:
str regEX(不要求精确) regEX(要求精确) 试一试
abcffd b或bcff或bcf*或bc*或bc+ bcff或bcf{2} bc{3}
gooooogle o{1,}、o+ o{5}
banana (an)+ (an){2}a、a(na) {2}
②正则表达式匹配字符串,输出是什么?
§5替换(删除)、Matcher类
现在我们可能厌烦了true/false,我们看看替换。如把book,google替换成bak(这个文件后缀名,在EditPlus中还行)、look或goooogle。
程序4:字符串的替换。
import java.util.regex.*;
class Regex1{
public static void main(String args[]) {
String regEx="a+";//表示一个或多个a
String str="abbbaaa an banana hhaana";
Pattern p=Pattern.compile(regEx);
Matcher m=p.matcher(str);
String s=m.replaceAll("⊙⊙"); // ("") 删除
System.out.println(s);
}
}
这个程序与前面的程序的区别,在于使用了m.replaceAll(String)方法。看来Matcher类还有点用处。
① Matcher是一个匹配器。可以把他看成一个人,一手拿着模子(Pattern类的对象),一手拿着一个字符序列(CharSequence),通过解释该模子而对字符序列进行匹配操作(match operations)。常常我们这样编程:“喂,模子p,你和字符串str一起创建一个匹配器对象”。即Matcher m=p.matcher(str);
② m可以进行一些操作,如public String replaceAll(String replacement),它以replacement替换所有匹配的字符串。
§6正则表达式之特殊字符
我们熟悉这样一个字符串"\n" 如:System.out.print(s+"\nbbb");这是Java中常用的转移字符之一。其实转移字符就是一种正则表达式,它使用了特殊字符 \ 。
下面是正则表达式中常用的特殊字符:
匹配次数符号 * + ? {n}、{n,}、{n,m}
“或”符号 | 程序2已经使用过了
句点符号 . 句点符号匹配所有字符(一个),包括空格、Tab字符甚至换行符。
方括号 [ ] 仅仅匹配方括号其中的字符)
圆括号 () 分组,圆括号中的字符视为一个整体。
连字符 - 表示一个范围。
“否”符号 ^ 表示不希望被匹配的字符(排除)
我们一下子学不了太多的东西,这不是正则表达式的全部内容和用法。但已经够我们忙活的了。我们用程序4 验证。(⊙⊙表示替换的字符)
① regEx为下列字符串时,能够表示什么?
regEx 匹配 测试用str
(a|b){2} aa、ab、bb、ba aabbfooaabfooabfoob
a[abc]b aab、abb、acb 3dfacb5ooyfo6abbfooaab
. all string 3dfac
a. aa、ax……等等 3dfacgg
d[^j]a daa、d9a等等,除dja 3dfacggdjad5a
[d-g][ac]c dac、ecc、gac等 3dfacggggccad5c
[d-g].{2}c d⊙⊙c…… 3dfacggggccad5c
g{1,10} g、ggg…… 3dfacggggccad5c
[a|c][^a] 3dfacggggccad5c
② 下列字符串如何用regEx表示?
测试用str 匹配 regEx
aabbfoaoabfooafobob a⊙⊙b a..b
aabbfoaaobfooafbob a⊙b、除aab a[^a]b、
gooooooogle oooo……变成oo o{2,20}
一本书中的“tan”、“ten”、“tin”和“ton” t.n、t[aeio]n
abcaccbcbaacabccaa 删除ac、ca (ca)|(ac)
abccbcbaabca 再删除ab、ba 结果ccbcca(如何与上面的合并)
注:
1、String str="一本书中的tan、ten、tin和ton";
输出: 一本书中的⊙⊙、⊙⊙、⊙⊙和⊙⊙
2、String str=" abcaccbcbaacabccaa "; 输出:ccbcca
程序5:if、for语句和charAt(),886。
import java.util.regex.*;
class Regex1{
public static void main(String args[]) {
String str="abcaccbcbaacabccaa";
String regEx="(ac)|(ca)";
Pattern p=Pattern.compile(regEx);
Matcher m=p.matcher(str);
String s=m.replaceAll("");//⊙⊙
regEx="(ab)|(ba)";
p=Pattern.compile(regEx);
s=p.matcher(s).replaceAll("");
System.out.print(s+"\n");
}
}
§7 开始
好像我们知道了一些正则表达式与 Java的知识,事实上,我们才刚刚开始。这里列出我们知道的东西,也说一点我们不知道的东西。
① Java在JDK1.4引入了(java.util.regex包)以支持正则表达式,包中有两个类,分别是Pattern和Matcher。它们都有很多的方法,我们还不知道。String类中的split、matches方法等等也使用到了正则表达式。StringTokenizer是否没有用处了?
② 正则表达式是一门语言。有许多正则表达式语法、选项和特殊字符,在Pattern.java源文件中大家可以查看。可能比想象中的要复杂。系统学习正则表达式的历史、语法、全部特殊字符(相当于Java中的关键字的地位),组合逻辑是下一步的事情。
③ 正则表达式是文本处理的重要技术,在Perl、PHP、Python、JavaScript、Java、C#中被广泛支持。被列为“保证你现在和未来不失业的十种关键技术”,呵呵,信不信由你
posted @
2008-02-28 14:35 CoderDream 阅读(450) |
评论 (0) |
编辑 收藏
JAVA 正则表达式4种常用的功能
正则表达式在字符串处理上有着强大的功能,sun在jdk1.4加入了对它的支持
下面简单的说下它的4种常用功能:
查询:
以下是代码片段:
String str="abc efg ABC";
String regEx="a|f"; //表示a或f
Pattern p=Pattern.compile(regEx);
Matcher m=p.matcher(str);
boolean rs=m.find();
如果str中有regEx,那么rs为true,否则为flase。如果想在查找时忽略大小写,则可以写成Pattern p=Pattern.compile(regEx,Pattern.CASE_INSENSITIVE);
提取:
以下是代码片段:
String regEx=".+\(.+)$";
String str="c:\dir1\dir2\name.txt";
Pattern p=Pattern.compile(regEx);
Matcher m=p.matcher(str);
boolean rs=m.find();
for(int i=1;i<=m.groupCount();i++){
System.out.println(m.group(i));
}
以上的执行结果为name.txt,提取的字符串储存在m.group(i)中,其中i最大值为m.groupCount();
分割:
以下是代码片段:
String regEx="::";
Pattern p=Pattern.compile(regEx);
String[] r=p.split("xd::abc::cde");
执行后,r就是{"xd","abc","cde"},其实分割时还有跟简单的方法:
String str="xd::abc::cde";
String[] r=str.split("::");
替换(删除):
以下是代码片段:
String regEx="a+"; //表示一个或多个a
Pattern p=Pattern.compile(regEx);
Matcher m=p.matcher("aaabbced a ccdeaa");
String s=m.replaceAll("A");
结果为"Abbced A ccdeA"
如果写成空串,既可达到删除的功能,比如:
String s=m.replaceAll("");
结果为"bbced ccde"
附:
\D 等於 [^0-9] 非数字
\s 等於 [ \t\n\x0B\f ] 空白字元
\S 等於 [^ \t\n\x0B\f ] 非空白字元
\w 等於 [a-zA-Z_0-9] 数字或是英文字
\W 等於 [^a-zA-Z_0-9] 非数字与英文字
^ 表示每行的开头
$ 表示每行的结尾
原文地址:
http://java.chinaitlab.com/advance/350770.html
posted @
2008-02-28 13:41 CoderDream 阅读(325) |
评论 (0) |
编辑 收藏如果你曾经用过Perl或任何其他内建正则表达式支持的语言,你一定知道用正则表达式处理文本和匹配模式是多么简单。如果你不熟悉这个术语,那么“正则表达式”(Regular Expression)就是一个字符构成的串,它定义了一个用来搜索匹配字符串的模式。
许多语言,包括Perl、PHP、Python、JavaScript和JScript,都支持用正则表达式处理文本,一些文本编辑器用正则表达式实现高级“搜索-替换”功能。那么Java又怎样呢?本文写作时,一个包含了用正则表达式进行文本处理的Java规范需求(Specification Request)已经得到认可,你可以期待在JDK的下一版本中看到它。
然而,如果现在就需要使用正则表达式,又该怎么办呢?你可以从Apache.org下载源代码开放的Jakarta-ORO库。本文接下来的内容先简要地介绍正则表达式的入门知识,然后以Jakarta-ORO API为例介绍如何使用正则表达式。
一、正则表达式基础知识
我们先从简单的开始。假设你要搜索一个包含字符“cat”的字符串,搜索用的正则表达式就是“cat”。如果搜索对大小写不敏感,单词“catalog”、“Catherine”、“sophisticated”都可以匹配。也就是说:

1.1 句点符号
假设你在玩英文拼字游戏,想要找出三个字母的单词,而且这些单词必须以“t”字母开头,以“n”字母结束。另外,假设有一本英文字典,你可以用正则表达式搜索它的全部内容。要构造出这个正则表达式,你可以使用一个通配符——句点符号“.”。这样,完整的表达式就是“t.n”,它匹配“tan”、“ten”、“tin”和“ton”,还匹配“t#n”、“tpn”甚至“t n”,还有其他许多无意义的组合。这是因为句点符号匹配所有字符,包括空格、Tab字符甚至换行符:

1.2 方括号符号
为了解决句点符号匹配范围过于广泛这一问题,你可以在方括号(“[]”)里面指定看来有意义的字符。此时,只有方括号里面指定的字符才参与匹配。也就是说,正则表达式“t[aeio]n”只匹配“tan”、“Ten”、“tin”和“ton”。但“Toon”不匹配,因为在方括号之内你只能匹配单个字符:

1.3 “或”符号
如果除了上面匹配的所有单词之外,你还想要匹配“toon”,那么,你可以使用“|”操作符。“|”操作符的基本意义就是“或”运算。要匹配“toon”,使用“t(a|e|i|o|oo)n”正则表达式。这里不能使用方扩号,因为方括号只允许匹配单个字符;这里必须使用圆括号“()”。圆括号还可以用来分组,具体请参见后面介绍。

1.4 表示匹配次数的符号
表一显示了表示匹配次数的符号,这些符号用来确定紧靠该符号左边的符号出现的次数:

假设我们要在文本文件中搜索美国的社会安全号码。这个号码的格式是999-99-9999。用来匹配它的正则表达式如图一所示。在正则表达式中,连字符(“-”)有着特殊的意义,它表示一个范围,比如从0到9。因此,匹配社会安全号码中的连字符号时,它的前面要加上一个转义字符“\”。

图一:匹配所有123-12-1234形式的社会安全号码
假设进行搜索的时候,你希望连字符号可以出现,也可以不出现——即,999-99-9999和999999999都属于正确的格式。这时,你可以在连字符号后面加上“?”数量限定符号,如图二所示:

图二:匹配所有123-12-1234和123121234形式的社会安全号码
下面我们再来看另外一个例子。美国汽车牌照的一种格式是四个数字加上二个字母。它的正则表达式前面是数字部分“[0-9]{4}”,再加上字母部分“[A-Z]{2}”。图三显示了完整的正则表达式。

图三:匹配典型的美国汽车牌照号码,如8836KV
1.5 “否”符号
“^”符号称为“否”符号。如果用在方括号内,“^”表示不想要匹配的字符。例如,图四的正则表达式匹配所有单词,但以“X”字母开头的单词除外。

图四:匹配所有单词,但“X”开头的除外
1.6 圆括号和空白符号
假设要从格式为“June 26, 1951”的生日日期中提取出月份部分,用来匹配该日期的正则表达式可以如图五所示:

图五:匹配所有Moth DD,YYYY格式的日期
新出现的“\s”符号是空白符号,匹配所有的空白字符,包括Tab字符。如果字符串正确匹配,接下来如何提取出月份部分呢?只需在月份周围加上一个圆括号创建一个组,然后用ORO API(本文后面详细讨论)提取出它的值。修改后的正则表达式如图六所示:

图六:匹配所有Month DD,YYYY格式的日期,定义月份值为第一个组
1.7 其它符号
为简便起见,你可以使用一些为常见正则表达式创建的快捷符号。如表二所示:
表二:常用符号

例如,在前面社会安全号码的例子中,所有出现“[0-9]”的地方我们都可以使用“\d”。修改后的正则表达式如图七所示:

图七:匹配所有123-12-1234格式的社会安全号码
二、Jakarta-ORO库
有许多源代码开放的正则表达式库可供Java程序员使用,而且它们中的许多支持Perl 5兼容的正则表达式语法。我在这里选用的是Jakarta-ORO正则表达式库,它是最全面的正则表达式API之一,而且它与Perl 5正则表达式完全兼容。另外,它也是优化得最好的API之一。
Jakarta-ORO库以前叫做OROMatcher,Daniel Savarese大方地把它赠送给了Jakarta Project。你可以按照本文最后参考资源的说明下载它。
我首先将简要介绍使用Jakarta-ORO库时你必须创建和访问的对象,然后介绍如何使用Jakarta-ORO API。
▲ PatternCompiler对象
首先,创建一个Perl5Compiler类的实例,并把它赋值给PatternCompiler接口对象。Perl5Compiler是PatternCompiler接口的一个实现,允许你把正则表达式编译成用来匹配的Pattern对象。

▲ Pattern对象
要把正则表达式编译成Pattern对象,调用compiler对象的compile()方法,并在调用参数中指定正则表达式。例如,你可以按照下面这种方式编译正则表达式“t[aeio]n”:

默认情况下,编译器创建一个大小写敏感的模式(pattern)。因此,上面代码编译得到的模式只匹配“tin”、“tan”、 “ten”和“ton”,但不匹配“Tin”和“taN”。要创建一个大小写不敏感的模式,你应该在调用编译器的时候指定一个额外的参数:

创建好Pattern对象之后,你就可以通过PatternMatcher类用该Pattern对象进行模式匹配。
▲ PatternMatcher对象
PatternMatcher对象根据Pattern对象和字符串进行匹配检查。你要实例化一个Perl5Matcher类并把结果赋值给PatternMatcher接口。Perl5Matcher类是PatternMatcher接口的一个实现,它根据Perl 5正则表达式语法进行模式匹配:

使用PatternMatcher对象,你可以用多个方法进行匹配操作,这些方法的第一个参数都是需要根据正则表达式进行匹配的字符串:
· boolean matches(String input, Pattern pattern):当输入字符串和正则表达式要精确匹配时使用。换句话说,正则表达式必须完整地描述输入字符串。
· boolean matchesPrefix(String input, Pattern pattern):当正则表达式匹配输入字符串起始部分时使用。
· boolean contains(String input, Pattern pattern):当正则表达式要匹配输入字符串的一部分时使用(即,它必须是一个子串)。
另外,在上面三个方法调用中,你还可以用PatternMatcherInput对象作为参数替代String对象;这时,你可以从字符串中最后一次匹配的位置开始继续进行匹配。当字符串可能有多个子串匹配给定的正则表达式时,用PatternMatcherInput对象作为参数就很有用了。用PatternMatcherInput对象作为参数替代String时,上述三个方法的语法如下:
· boolean matches(PatternMatcherInput input, Pattern pattern)
· boolean matchesPrefix(PatternMatcherInput input, Pattern pattern)
· boolean contains(PatternMatcherInput input, Pattern pattern)
三、应用实例
下面我们来看看Jakarta-ORO库的一些应用实例。
3.1 日志文件处理
任务:分析一个Web服务器日志文件,确定每一个用户花在网站上的时间。在典型的BEA WebLogic日志文件中,日志记录的格式如下:

分析这个日志记录,可以发现,要从这个日志文件提取的内容有两项:IP地址和页面访问时间。你可以用分组符号(圆括号)从日志记录提取出IP地址和时间标记。
首先我们来看看IP地址。IP地址有4个字节构成,每一个字节的值在0到255之间,各个字节通过一个句点分隔。因此,IP地址中的每一个字节有至少一个、最多三个数字。图八显示了为IP地址编写的正则表达式:

图八:匹配IP地址
IP地址中的句点字符必须进行转义处理(前面加上“\”),因为IP地址中的句点具有它本来的含义,而不是采用正则表达式语法中的特殊含义。句点在正则表达式中的特殊含义本文前面已经介绍。
日志记录的时间部分由一对方括号包围。你可以按照如下思路提取出方括号里面的所有内容:首先搜索起始方括号字符(“[”),提取出所有不超过结束方括号字符(“]”)的内容,向前寻找直至找到结束方括号字符。图九显示了这部分的正则表达式。

图九:匹配至少一个字符,直至找到“]”
现在,把上述两个正则表达式加上分组符号(圆括号)后合并成单个表达式,这样就可以从日志记录提取出IP地址和时间。注意,为了匹配“- -”(但不提取它),正则表达式中间加入了“\s-\s-\s”。完整的正则表达式如图十所示。

图十:匹配IP地址和时间标记
现在正则表达式已经编写完毕,接下来可以编写使用正则表达式库的Java代码了。
为使用Jakarta-ORO库,首先创建正则表达式字符串和待分析的日志记录字符串:

这里使用的正则表达式与图十的正则表达式差不多完全相同,但有一点例外:在Java中,你必须对每一个向前的斜杠(“\”)进行转义处理。图十不是Java的表示形式,所以我们要在每个“\”前面加上一个“\”以免出现编译错误。遗憾的是,转义处理过程很容易出现错误,所以应该小心谨慎。你可以首先输入未经转义处理的正则表达式,然后从左到右依次把每一个“\”替换成“\\”。如果要复检,你可以试着把它输出到屏幕上。
初始化字符串之后,实例化PatternCompiler对象,用PatternCompiler编译正则表达式创建一个Pattern对象:

现在,创建PatternMatcher对象,调用PatternMatcher接口的contain()方法检查匹配情况:

接下来,利用PatternMatcher接口返回的MatchResult对象,输出匹配的组。由于logEntry字符串包含匹配的内容,你可以看到类如下面的输出:

3.2 HTML处理实例一
下面一个任务是分析HTML页面内FONT标记的所有属性。HTML页面内典型的FONT标记如下所示:

程序将按照如下形式,输出每一个FONT标记的属性:

在这种情况下,我建议你使用两个正则表达式。第一个如图十一所示,它从字体标记提取出“"face="Arial, Serif" size="+2" color="red"”。

图十一:匹配FONT标记的所有属性
第二个正则表达式如图十二所示,它把各个属性分割成名字-值对。

图十二:匹配单个属性,并把它分割成名字-值对
分割结果为:

现在我们来看看完成这个任务的Java代码。首先创建两个正则表达式字符串,用Perl5Compiler把它们编译成Pattern对象。编译正则表达式的时候,指定Perl5Compiler.CASE_INSENSITIVE_MASK选项,使得匹配操作不区分大小写。
接下来,创建一个执行匹配操作的Perl5Matcher对象。

假设有一个String类型的变量html,它代表了HTML文件中的一行内容。如果html字符串包含FONT标记,匹配器将返回true。此时,你可以用匹配器对象返回的MatchResult对象获得第一个组,它包含了FONT的所有属性:

接下来创建一个PatternMatcherInput对象。这个对象允许你从最后一次匹配的位置开始继续进行匹配操作,因此,它很适合于提取FONT标记内属性的名字-值对。创建PatternMatcherInput对象,以参数形式传入待匹配的字符串。然后,用匹配器实例提取出每一个FONT的属性。这通过指定PatternMatcherInput对象(而不是字符串对象)为参数,反复地调用PatternMatcher对象的contains()方法完成。PatternMatcherInput对象之中的每一次迭代将把它内部的指针向前移动,下一次检测将从前一次匹配位置的后面开始。
本例的输出结果如下:

3.3 HTML处理实例二
下面我们来看看另一个处理HTML的例子。这一次,我们假定Web服务器从widgets.acme.com移到了newserver.acme.com。现在你要修改一些页面中的链接:

执行这个搜索的正则表达式如图十三所示:

图十三:匹配修改前的链接
如果能够匹配这个正则表达式,你可以用下面的内容替换图十三的链接:

注意#字符的后面加上了$1。Perl正则表达式语法用$1、$2等表示已经匹配且提取出来的组。图十三的表达式把所有作为一个组匹配和提取出来的内容附加到链接的后面。
现在,返回Java。就象前面我们所做的那样,你必须创建测试字符串,创建把正则表达式编译到Pattern对象所必需的对象,以及创建一个PatternMatcher对象:

接下来,用com.oroinc.text.regex包Util类的substitute()静态方法进行替换,输出结果字符串:

Util.substitute()方法的语法如下:

这个调用的前两个参数是以前创建的PatternMatcher和Pattern对象。第三个参数是一个Substiution对象,它决定了替换操作如何进行。本例使用的是Perl5Substitution对象,它能够进行Perl5风格的替换。第四个参数是想要进行替换操作的字符串,最后一个参数允许指定是否替换模式的所有匹配子串(Util.SUBSTITUTE_ALL),或只替换指定的次数。
【结束语】在这篇文章中,我为你介绍了正则表达式的强大功能。只要正确运用,正则表达式能够在字符串提取和文本修改中起到很大的作用。另外,我还介绍了如何在Java程序中通过Jakarta-ORO库利用正则表达式。至于最终采用老式的字符串处理方式(使用StringTokenizer,charAt,和substring),还是采用正则表达式,这就有待你自己决定了
原文地址:
http://www.ccw.com.cn/htm/app/aprog/01_7_31_4.asp
posted @
2008-02-28 13:35 CoderDream 阅读(664) |
评论 (0) |
编辑 收藏如果我们问那些UNIX系统的爱好者他们最喜欢什么,答案除了稳定的系统和可以远程启动之外,十有八九的人会提到正则表达式;如果我们再问他们最头痛的是什么,可能除了复杂的进程控制和安装过程之外,还会是正则表达式。那么正则表达式到底是什么?如何才能真正的掌握正则表达式并正确的加以灵活运用?本文将就此展开介绍,希望能够对那些渴望了解和掌握正则表达式的读者有所助益。
入门简介
简单的说,正则表达式是一种可以用于模式匹配和替换的强有力的工具。我们可以在几乎所有的基于UNIX系统的工具中找到正则表达式的身影,例如,vi编辑器,Perl或PHP脚本语言,以及awk或sed shell程序等。此外,象JavaScript这种客户端的脚本语言也提供了对正则表达式的支持。由此可见,正则表达式已经超出了某种语言或某个系统的局限,成为人们广为接受的概念和功能。
正则表达式可以让用户通过使用一系列的特殊字符构建匹配模式,然后把匹配模式与数据文件、程序输入以及WEB页面的表单输入等目标对象进行比较,根据比较对象中是否包含匹配模式,执行相应的程序。
举例来说,正则表达式的一个最为普遍的应用就是用于验证用户在线输入的邮件地址的格式是否正确。如果通过正则表达式验证用户邮件地址的格式正确,用户所填写的表单信息将会被正常处理;反之,如果用户输入的邮件地址与正则表达的模式不匹配,将会弹出提示信息,要求用户重新输入正确的邮件地址。由此可见正则表达式在WEB应用的逻辑判断中具有举足轻重的作用。
基本语法
在对正则表达式的功能和作用有了初步的了解之后,我们就来具体看一下正则表达式的语法格式。
正则表达式的形式一般如下:
/love/
其中位于“/”定界符之间的部分就是将要在目标对象中进行匹配的模式。用户只要把希望查找匹配对象的模式内容放入“/”定界符之间即可。为了能够使用户更加灵活的定制模式内容,正则表达式提供了专门的“元字符”。所谓元字符就是指那些在正则表达式中具有特殊意义的专用字符,可以用来规定其前导字符(即位于元字符前面的字符)在目标对象中的出现模式。
较为常用的元字符包括: “+”, “*”,以及 “?”。其中,“+”元字符规定其前导字符必须在目标对象? 续出现一次或多次,“*”元字符规定其前导字符必须在目标对象中出现零次或连续多次,而“?”元字符规定其前导对象必须在目标对象中连续出现零次或一次。
下面,就让我们来看一下正则表达式元字符的具体应用。
/fo+/
因为上述正则表达式中包含“+”元字符,表示可以与目标对象中的 “fool”, “fo”, 或者 “football”等在字母f后面连续出现一个或多个字母o的字符串相匹配。
/eg*/
因为上述正则表达式中包含“*”元字符,表示可以与目标对象中的 “easy”, “ego”, 或者 “egg”等在字母e后面连续出现零个或多个字母g的字符串相匹配。
/Wil?/
因为上述正则表达式中包含“?”元字符,表示可以与目标对象中的 “Win”, 或者 “Wilson”,等在字母i后面连续出现零个或一个字母l的字符串相匹配。
除了元字符之外,用户还可以精确指定模式在匹配对象中出现的频率。例如,
/jim{2,6}/
上述正则表达式规定字符m可以在匹配对象中连续出现2-6次,因此,上述正则表达式可以同jimmy或jimmmmmy等字符串相匹配。
在对如何使用正则表达式有了初步了解之后,我们来看一下其它几个重要的元字符的使用方式。
\s:用于匹配单个空格符,包括tab键和换行符;
\S:用于匹配除单个空格符之外的所有字符;
\d:用于匹配从0到9的数字;
\w:用于匹配字母,数字或下划线字符;
\W:用于匹配所有与\w不匹配的字符;
. :用于匹配除换行符之外的所有字符。
(说明:我们可以把\s和\S以及\w和\W看作互为逆运算)
下面,我们就通过实例看一下如何在正则表达式中使用上述元字符。
/\s+/
上述正则表达式可以用于匹配目标对象中的一个或多个空格字符。
/\d000/
如果我们手中有一份复杂的财务报表,那么我们可以通过上述正则表达式轻而易举的查找到所有总额达千元的款项。
除了我们以上所介绍的元字符之外,正则表达式中还具有另外一种较为独特的专用字符,即定位符。定位符用于规定匹配模式在目标对象中的出现位置。
较为常用的定位符包括: “^”, “$”, “\b” 以及 “\B”。其中,“^”定位符规定匹配模式必须出现在目标字符串的开头,“$”定位符规定匹配模式必须出现在目标对象的结尾,\b定位符规定匹配模式必须出现在目标字符串的开头或结尾的两个边界之一,而“\B”定位符则规定匹配对象必须位于目标字符串的开头和结尾两个边界之内,即匹配对象既不能作为目标字符串的开头,也不能作为目标字符串的结尾。同样,我们也可以把“^”和“$”以及“\b”和“\B”看作是互为逆运算的两组定位符。举例来说:
/^hell/
因为上述正则表达式中包含“^”定位符,所以可以与目标对象中以 “hell”, “hello”或 “hellhound”开头的字符串相匹配。
/ar$/
因为上述正则表达式中包含“$”定位符,所以可以与目标对象中以 “car”, “bar”或 “ar” 结尾的字符串相匹配。
/\bbom/
因为上述正则表达式模式以“\b”定位符开头,所以可以与目标对象中以 “bomb”, 或 “bom”开头的字符串相匹配。
/man\b/
因为上述正则表达式模式以“\b”定位符结尾,所以可以与目标对象中以 “human”, “woman”或 “man”结尾的字符串相匹配。
为了能够方便用户更加灵活的设定匹配模式,正则表达式允许使用者在匹配模式中指定某一个范围而不局限于具体的字符。例如:
/[A-Z]/
上述正则表达式将会与从A到Z范围内任何一个大写字母相匹配。
/[a-z]/
上述正则表达式将会与从a到z范围内任何一个小写字母相匹配。
/[0-9]/
上述正则表达式将会与从0到9范围内任何一个数字相匹配。
/([a-z][A-Z][0-9])+/
上述正则表达式将会与任何由字母和数字组成的字符串,如 “aB0” 等相匹配。这里需要提醒用户注意的一点就是可以在正则表达式中使用 “()” 把字符串组合在一起。“()”符号包含的内容必须同时出现在目标对象中。因此,上述正则表达式将无法与诸如 “abc”等的字符串匹配,因为“abc”中的最后一个字符为字母而非数字。
如果我们希望在正则表达式中实现类似编程逻辑中的“或”运算,在多个不同的模式中任选一个进行匹配的话,可以使用管道符 “|”。例如:
/to|too|2/
上述正则表达式将会与目标对象中的 “to”, “too”, 或 “2” 相匹配。
正则表达式中还有一个较为常用的运算符,即否定符 “[^]”。与我们前文所介绍的定位符 “^” 不同,否定符 “[^]”规定目标对象中不能存在模式中所规定的字符串。例如:
/[^A-C]/
上述字符串将会与目标对象中除A,B,和C之外的任何字符相匹配。一般来说,当“^”出现在 “[]”内时就被视做否定运算符;而当“^”位于“[]”之外,或没有“[]”时,则应当被视做定位符。
最后,当用户需要在正则表达式的模式中加入元字符,并查找其匹配对象时,可以使用转义符“\”。例如:
/Th\*/
上述正则表达式将会与目标对象中的“Th*”而非“The”等相匹配。
原文链接:
http://www.yesky.com/181/51681.shtml
posted @
2008-02-28 11:49 CoderDream 阅读(664) |
评论 (0) |
编辑 收藏
在String类中,有四个特殊的方法:
public String[] split(String regex)
- 根据给定的正则表达式的匹配来拆分此字符串。
该方法的作用就像是使用给定的表达式和限制参数 0 来调用两参数 split 方法。因此,结果数组中不包括结尾空字符串。
例如,字符串 "boo:and:foo" 产生带有下面这些表达式的结果:
| Regex |
结果 |
| : |
{ "boo", "and", "foo" } |
| o |
{ "b", "", ":and:f" } |
-
- 参数:
regex - 定界正则表达式
- 返回: 字符串数组,根据给定正则表达式的匹配来拆分此字符串,从而生成此数组。
- 抛出:
PatternSyntaxException - 如果正则表达式的语法无效
public String[] split(String regex, int limit)
- 根据匹配给定的正则表达式来拆分此字符串。
此方法返回的数组包含此字符串的每个子字符串,这些子字符串由另一个匹配给定的表达式的子字符串终止或由字符串结束来终止。数组中的子字符串按它们在此字符串中的顺序排列。如果表达式不匹配输入的任何部分,则结果数组只具有一个元素,即此字符串。
limit 参数控制模式应用的次数,因此影响结果数组的长度。如果该限制 n 大于 0,则模式将被最多应用 n - 1 次,数组的长度将不会大于 n,而且数组的最后项将包含超出最后匹配的定界符的所有输入。如果 n 为非正,则模式将被应用尽可能多的次数,而且数组可以是任意长度。如果 n 为零,则模式将被应用尽可能多的次数,数组可有任何长度,并且结尾空字符串将被丢弃。
例如,字符串 "boo:and:foo" 使用这些参数可生成下列结果:
| Regex |
Limit |
结果 |
| : |
2 |
{ "boo", "and:foo" } |
| : |
5 |
{ "boo", "and", "foo" } |
| : |
-2 |
{ "boo", "and", "foo" } |
| o |
5 |
{ "b", "", ":and:f", "", "" } |
| o |
-2 |
{ "b", "", ":and:f", "", "" } |
| o |
0 |
{ "b", "", ":and:f" } |
这种形式的方法调用 str.split(regex, n) 产生与以下表达式完全相同的结果:
Pattern.compile(regex).split(str, n)
参数: regex - 定界正则表达式 ;limit - 结果阈值,如上所述
- 返回: 字符串数组,根据给定正则表达式的匹配来拆分此字符串,从而生成此数组
public String replaceAll(String regex, String replacement)
- 使用给定的 replacement 字符串替换此字符串匹配给定的正则表达式的每个子字符串。
此方法调用的 str.replaceAll(regex, repl) 形式产生与以下表达式完全相同的结果:
Pattern.compile(regex).matcher(str).replaceAll(repl)
参数: regex - 用来匹配此字符串的正则表达式
- 返回: 得到的 String
public String replaceFirst(String regex, String replacement)
- 使用给定的 replacement 字符串替换此字符串匹配给定的正则表达式的第一个子字符串。
此方法调用的 str.replaceFirst(regex, repl) 形式产生与以下表达式完全相同的结果:
Pattern.compile(regex).matcher(str).replaceFirst(repl)
参数:regex - 用来匹配此字符串的正则表达式
- 返回: 得到的 String
这四个方法中都有一个参数为正则表达式(Regular Expression),而不是普通的字符串。
在正则表达式中具有特殊含义的字符
|
特殊字符
|
描述
|
| . |
表示任意一个字符 |
| [abc] |
表示a、b或c中的任意一个字符 |
| [^abc] |
除a、b和c以外的任意一个字符 |
| [a-zA-z] |
介于a到z,或A到Z中的任意一个字符 |
| \s |
空白符(空格、tab、换行、换页、回车) |
| \S |
非空白符 |
| \d |
任意一个数字[0-9] |
| \D |
任意一个非数字[^0-9] |
| \w |
词字符[a-zA-Z_0-9] |
| \W |
非词字符 |
表示字符出现次数的符号
|
表示次数的符号
|
描述
|
| * |
0 次或者多次 |
| + |
1 次或者多次 |
| ? |
0 次或者 1 次 |
| {n} |
恰好 n 次 |
| {n, m} |
至少 n 次,不多于 m 次 |
public class RegDemo2 {
/**
* @param args
*/
public static void main(String[] args) {
// 例如,字符串 "boo:and:foo" 产生带有下面这些表达式的结果: Regex 结果
// : { "boo", "and", "foo" }
// o { "b", "", ":and:f" }
String tempStr = "boo:and:foo";
String[] a = tempStr.split(":");
pringStringArray(a);
String[] b = tempStr.split("o");
pringStringArray(b);
System.out.println("--------------------------");
// Regex Limit 结果
// : 2 { "boo", "and:foo" }
// : 5 { "boo", "and", "foo" }
// : -2 { "boo", "and", "foo" }
// o 5 { "b", "", ":and:f", "", "" }
// o -2 { "b", "", ":and:f", "", "" }
// o 0 { "b", "", ":and:f" }
pringStringArray(tempStr.split(":", 2));
pringStringArray(tempStr.split(":", 5));
pringStringArray(tempStr.split(":", -2));
pringStringArray(tempStr.split("o", 5));
pringStringArray(tempStr.split("o", -2));
pringStringArray(tempStr.split("o", 0));
// 字符串 "boo:and:foo"中的所有“:”都被替换为“XX”,输出:booXXandXXfoo
System.out.println(tempStr.replaceAll(":", "XX"));
// 字符串 "boo:and:foo"中的第一个“:”都被替换为“XX”,输出: booXXand:foo
System.out.println(tempStr.replaceFirst(":", "XX"));
}
public static void pringStringArray(String[] s) {
int index = s.length;
for (int i = 0; i < index; i++) {
System.err.println(i + ": " + s[i]);
}
}
}
下面的程序演示了正则表达式的用法:
/**
* discription:
*
* @author CoderDream
*
*/
public class RegularExTester {
/**
* @param args
*/
public static void main(String[] args) {
// 把字符串中的“aaa”全部替換為“z”,打印:zbzcz
System.out.println("aaabaaacaaa".replaceAll("a{3}", "z"));
// 把字符串中的“aaa”、“aa”或者“a”全部替換為“*”,打印:*b*c*
System.out.println("aaabaaca".replaceAll("a{1,3}", "\\*"));
// 把字符串中的數字全部替換為“z”,打印:zzzazzbzzcc
System.out.println("123a44b35cc".replaceAll("\\d", "z"));
// 把字符串中的非數字全部替換為“0”,打印:1234000435000
System.out.println("1234abc435def".replaceAll("\\D", "0"));
// 把字符串中的“.”全部替換為“\”,打印:com\abc\dollapp\Doll
System.out.println("com.abc.dollapp.Doll".replaceAll("\\.", "\\\\"));
// 把字符串中的“a.b”全部替換為“_”,
// “a.b”表示長度為3的字符串,以“a”開頭,以“b”結尾
// 打印:-hello-all
System.out.println("azbhelloahball".replaceAll("a.b", "-"));
// 把字符串中的所有詞字符替換為“#”
// 正則表達式“[a-zA-z_0-9]”等價于“\w”
// 打印:#.#.#.#.#.#
System.out.println("a.b.c.1.2.3.4".replaceAll("[a-zA-z_0-9]", "#"));
System.out.println("a.b.c.1.2.3.4".replaceAll("\\w", "#"));
}
}
值得注意的是,由于“.”、“?”和“*”等在正则表达式中具有特殊的含义,如果要表示字面上的这些字符,必须以“\\”开头。例如为了把字符串“com.abc.dollapp.Doll”中的“.”替换为“\”,应该调用replaceAll("\\.",
\\\\)方法。
Java中的正则表达式类
public interface MatchResult
匹配操作的结果。
此接口包含用于确定与正则表达式匹配结果的查询方法。通过 MatchResult 可以查看匹配边界、组和组边界,但是不能修改
public final class Matcher
-
- extends Object
- implements MatchResult
通过解释 Pattern 对
通过调用模式的 matcher 方法从模式创建匹配器。创建匹配器后,可以使用它执行三种不同的匹配操作:
每个方法都返回一个表示成功或失败的布尔值。通过查询匹配器的状态可以获取关于成功匹配的更多信息。
public final class Pattern
-
- extends Object
- implements Serializable
正则表达式的编译表示形式。
指定为字符串的正则表达式必须首先被编译为此类的实例。然后,可将得到的模式用于创建 Matcher 对象,依照正则表达式,该对象可以与任意
因此,典型的调用顺序是
Pattern p = Pattern.compile("a*b");
Matcher m = p.matcher("aaaaab");
boolean b = m.matches();
在仅使用一次正则表达式时,可以方便地通过此类定义 matches 方法。此方法编译表达式并在单个调用中将输入序列与其匹配。语句
boolean b = Pattern.matches("a*b", "aaaaab");
等效于上面的三个语句,尽管对于重复的匹配而言它效率不高,因为它不允许重用已编译的模式。
此类的实例是不可变的,可供多个并发线程安全使用。Matcher 类的实例用于此目的则不安全。
测试代码:
/**
* discription:Java中正则表达式类的使用
*
* @author CoderDream
*
*/
public class RegDemo {
/**
* @param args
*/
public static void main(String[] args) {
// 檢查字符串中是否含有“aaa”,有返回:true,無返回:false
System.out.println(isHaveBeenSetting("a{3}", "aaabaaacaaa"));
System.out.println(isHaveBeenSetting("a{3}", "aab"));
// 把字符串“abbaaacbaaaab”中的“aaa”全部替換為“z”,打印:abbzbza
System.out.println(replaceStr("a{3}", "abbaaabaaaa", "z"));
}
/**
*
* @param regEx
* 设定的正则表达式
* @param tempStr
* 系统参数中的设定的字符串
* @return 是否系统参数中的设定的字符串含有设定的正则表达式 如果有的则返回true
*/
public static boolean isHaveBeenSetting(String regEx, String tempStr) {
boolean result = false;
try {
Pattern p = Pattern.compile(regEx);
Matcher m = p.matcher(tempStr);
result = m.find();
} catch (Exception e) {
e.printStackTrace();
}
return result;
}
/**
* 将字符串含有的regEx表达式替换为replaceRegEx
*
* @param regEx
* 需要被替换的正则表达式
* @param tempStr
* 替换的字符串
* @param replaceRegEx
* 替换的正则表达式
* @return 替換好后的字符串
*/
public static String replaceStr(String regEx, String tempStr,
String replaceRegEx) {
Pattern p = Pattern.compile(regEx);
Matcher m = p.matcher(tempStr);
tempStr = m.replaceAll(replaceRegEx);
return tempStr;
}
}
posted @
2008-02-28 11:40 CoderDream 阅读(2343) |
评论 (0) |
编辑 收藏import java.awt.Point;
class PassByValue {
public static void modifyPoint(Point pt, int j) {
pt.setLocation(5, 5); // 1
j = 15;
System.out.println("During modifyPoint " + "pt = " + pt + " and j = " + j);
}
public static void main(String args[]) {
Point p = new Point(0, 0); // 2
int i = 10;
System.out.println("Before modifyPoint " + "p = " + p + " and i = " + i);
modifyPoint(p, i); // 3
System.out.println("After modifyPoint " + "p = " + p + " and i = " + i);
}
}
这段代码在//2处建立了一个Point对象并设初值为(0,0),接着将其值赋予object reference 变量p。然后对基本类型int i赋值10。//3调用static modifyPoint(),传入p和i。modifyPoint()对第一个参数pt调用了setLocation(),将其左边改为(5,5)。然后将第二个参数j赋值为15.当modifyPoint()返回的时候,main()打印出p和i的值。
程序输出如下:
Before modifyPoint p = java.awt.Point[x=0,y=0] and i = 10
During modifyPoint pt = java.awt.Point[x=5,y=5] and j = 15
After modifyPoint p = java.awt.Point[x=5,y=5] and i = 10
这显示modifyPoint()改变了//2 所建立的Point对象,却没有改变int i。在main()之中,i被赋值10.由于参数通过by value方式传递,所以modifyPoint()收到i的一个副本,然后它将这个副本改为15并返回。main()内的原值i并没有受到影响。
对比之下,事实上modifyPoint() 是在与“Point 对象的 reference 的复件”打交道,而不是与“Point对象的复件”打交道。当p从main()被传入modifyPoint()时,传递的是p(也就是一个reference)的复件。所以modifyPoint()是在与同一个对象打交道,只不过通过别名pt罢了。在进入modifyPoint()之后和执行 //1 之前,这个对象看起来是这样:

所以//1 执行以后,这个Point对象已经改变为(5,5)。
Java 关键字 final 用来表示常量数据。例如:
public class Test {
static final int someInt = 10;
//
}
这段代码声明了一个 static 类变量,命名为 someInt,并设其初值为10。
任何试图修改 someInt 的代码都将无法通过编译。例如:
//
someInt = 9; // Error
//
关键字 final 可防止 classes 内的 instance 数据遭到无意间的修改。如果我们想要一个常量对象,又该如何呢?例如:
class Circle {
private double rad;
public Circle(double r) {
rad = r;
}
public void setRadius(double r) {
rad = r;
}
public double radius() {
return rad;
}
}
public class FinalTest {
private static final Circle wheel = new Circle(5.0);
public static void main(String args[]) {
System.out.println("Radius of wheel is " + wheel.radius());
wheel.setRadius(7.4);
System.out.println("Radius of wheel is now " + wheel.radius());
}
}
这段代码的输出是:
Radius of wheel is 5.0
Radius of wheel is now 7.4
在上述第一个示例中,我们企图改变final 数据值时,编译器会侦测出错误。
在第二个示例中,虽然代码改变了 instance变量wheel的值,编译器还是让它通过了。我们已经明确声明wheel为final,它怎么还能被改变呢?
不,我们确实没有改变 wheel 的值,我们改变的是wheel 所指对象的值。wheel 并无变化,仍然指向(代表)同一个对象。变量wheel是一个 object reference,它指向对象所在的heap位置。有鉴如此,下面的代码会怎样?
public class FinalTest {
private static final Circle wheel = new Circle(5.0);
public static void main(String args[]) {
System.out.println("Radius of wheel is " + wheel.radius());
wheel = new Circle(7.4); // 1
System.out.println("Radius of wheel is now " + wheel.radius());
}
}
编译代码,// 1 处出错。由于我们企图改变 final 型变量 wheel 的值,所以这个示例将产生编译错误。换言之,代码企图令wheel指向其他对象。变量wheel是final,因此也是不可变的。它必须永远指向同一个对象。然而wheel所指向的对象并不受关键字final的影响,因此是可变的。
关键字 final 只能防止变量值的改变。如果被声明为 final 的变量是个 object reference,那么该reference不能被改变,必须永远指向同一个对象,但被指的那个对象可以随意改变内部的属性值。
关键字final 在Java中有多重用途,即可被用于instance变量、static变量,也可用于classes或methods,用于类,表示该类不能有子类;用于方法,表示该方法不允许被子类覆盖。
array和Vector的比较
|
|
支持基本类型
|
支持对象
|
自动改变大小
|
速度快
|
|
array
|
Yes
|
Yes
|
No
|
Yes
|
|
Vector
|
No(1.5以上支持)
|
Yes
|
Yes
|
No
|
代码1:instanceof方式
interface Employee {
public int salary();
}
class Manager implements Employee {
private static final int mgrSal = 40000;
public int salary() {
return mgrSal;
}
}
class Programmer implements Employee {
private static final int prgSal = 50000;
private static final int prgBonus = 10000;
public int salary() {
return prgSal;
}
public int bonus() {
return prgBonus;
}
}
class Payroll {
public int calcPayroll(Employee emp) {
int money = emp.salary();
if (emp instanceof Programmer)
money += ((Programmer) emp).bonus(); // Calculate the bonus
return money;
}
public static void main(String args[]) {
Payroll pr = new Payroll();
Programmer prg = new Programmer();
Manager mgr = new Manager();
System.out.println("Payroll for Programmer is " + pr.calcPayroll(prg));
System.out.println("payroll for Manager is " + pr.calcPayroll(mgr));
}
}
依据这个设计,calcPayroll()必须使用instanceof操作符才能计算出正确结果。因为它使用了Employee接口,所以它必须断定Employee对象究竟实际属于哪个class。程序员有奖金而经理没有,所以你必须确定Employee对象的运行时类型。
代码2:多态方式
interface Employee {
public int salary();
public int bonus();
}
class Manager implements Employee {
private static final int mgrSal = 40000;
private static final int mgrBonus = 0;
public int salary() {
return mgrSal;
}
public int bonus() {
return mgrBonus;
}
}
class Programmer implements Employee {
private static final int prgSal = 50000;
private static final int prgBonus = 10000;
public int salary() {
return prgSal;
}
public int bonus() {
return prgBonus;
}
}
class Payroll {
public int calcPayroll(Employee emp) {
// Calculate the bonus. No instanceof check needed.
return emp.salary() + emp.bonus();
}
public static void main(String args[]) {
Payroll pr = new Payroll();
Programmer prg = new Programmer();
Manager mgr = new Manager();
System.out.println("Payroll for Programmer is " + pr.calcPayroll(prg));
System.out.println("Payroll for Manager is " + pr.calcPayroll(mgr));
}
}
在这个设计中,我们为Employee接口增加了 bonus(),从而消除了instanceof的必要性。实现Employee接口的两个 classes:Programmer和Manager,都必须实现salary()和bonus()。这些修改显著简化了calcPayroll()。
import java.util.Vector;
class Shape {
}
class Circle extends Shape {
public double radius() {
return 5.7;
}
//
}
class Triangle extends Shape {
public boolean isRightTriangle() {
// Code to determine if triangle is right
return true;
}
//
}
class StoreShapes {
public static void main(String args[]) {
Vector shapeVector = new Vector(10);
shapeVector.add(new Triangle());
shapeVector.add(new Triangle());
shapeVector.add(new Circle());
//
// Assume many Triangles and Circles are added and removed
//
int size = shapeVector.size();
for (int i = 0; i < size; i++) {
Object o = shapeVector.get(i);
if (o instanceof Triangle) {
if (((Triangle) o).isRightTriangle()) {
//
}
} else if (o instanceof Circle) {
double rad = ((Circle) o).radius();
//
}
}
}
}
这段代码表明在 这种场合下 instanceof 操作符是必需的。当程序从Vector 取回对象,它们属于java.lang.Object。利用instanceof确定对象实际属于哪个class后,我们才能正确执行向下转型,而不至于在运行期抛出异常。
posted @
2008-02-26 17:56 CoderDream 阅读(300) |
评论 (0) |
编辑 收藏9.1 Java异常处理机制概述
主要考虑的两个问题:(1)如何表示异常情况?(2)如何控制处理异常的流程?
9.1.1 Java异常处理机制的优点
Java语言按照面向对象的思想来处理异常,使得程序具有更好的可维护性。
Java异常处理机制具有以下优点:
- 把各种不同类型的异常情况进行分类,用Java类来表示异常情况,发挥类的可扩展性和可重用性。
- 异常流程的代码和正常流程的代码分离,提供了程序的可读性,简化了程序的结构。
- 可以灵活地处理异常,如果当前方法有能力处理异常,就捕获并处理它,否则只需要抛出异常,由方法调用者来处理它。
9.1.2 Java虚拟机的方法调用栈
如果方法中的代码块可能抛出异常,有如下两种处理方法:
(1)在当前方法中通过try...catch语句捕获并处理异常;
(2)在方法的声明处通过throws语句声明抛出异常。
当Java虚拟机追溯到调用栈的底部的方法时,如果仍然没有找到处理该异常的代码,将按以下步骤处理:
(1)调用异常对象的printStachTrace()方法,打印来自方法调用栈的异常信息。
(2)如果该线程不是主线程,那么终止这个线程,其它线程继续正常运行。如果该线程是主线程,那么整个应用程序被终止。
9.1.3 异常处理对性能的影响
一般来说,影响很小,除非方法嵌套调用很深。
9.2 运用Java异常处理机制
9.2.1 try...catch语句:捕获异常
9.2.2 finally语句:任何情况下都必须执行的代码
主要用于关闭某些流和数据库连接。
9.2.3 thorws子句:声明可能会出现的异常
9.2.4 throw语句:抛出异常
9.2.5 异常处理语句的语法规则
(1)try代码块不能脱离catch代码块或finally代码块而单独存在。try代码块后面至少有一个catch代码块或finally代码块。
(2)try代码块后面可以有零个或多个catch代码块,还可以有零个或至多一个finally代码块。
(3)try代码块后面可以只跟finally代码块。
(4)在try代码块中定义的变量的作用域为try代码块,在catch代码块和finally代码块中不能访问该变量。
(5)当try代码块后面有多个catch代码块时,Java虚拟机会把实际抛出的异常类对象依次和各个catch代码块声明的异常类型匹配,如果异常对象为某个异常类型或其子类的实例,就执行这个catch代码块,而不会再执行其他的catch代码块。
(6)如果一个方法可能出现受检查异常,要么用try...catch语句捕获,要么用throws子句声明将它抛出,否则会导致编译错误。
9.2.6 异常流程的运行过程
(1)finally语句不被执行的唯一情况是先执行了用于终止程序的System.exit()方法。
(2)return语句用于退出本方法。
(3)finally代码块虽然在return语句之前被执行,但finally代码块不能通过重新给变量赋值来改变return语句的返回值。
(4)建议不要在finally代码块中使用return语句,因为它会导致以下两种潜在的错误
A:覆盖try或catch代码块的return语句
public class SpecialException extends Exception {
public SpecialException() {
}
public SpecialException(String msg) {
super(msg);
}
}
public class FinallyReturn {
/**
* @param args
*/
public static void main(String[] args) {
FinallyReturn fr = new FinallyReturn();
System.out.println(fr.methodB(1));// 打印100
System.out.println(fr.methodB(2));// 打印100
}
public int methodA(int money) throws SpecialException {
if (--money <= 0) {
throw new SpecialException("Out of money");
}
return money;
}
@SuppressWarnings("finally")
public int methodB(int money) {
try {
return methodA(money);// 可能抛出异常
} catch (SpecialException e) {
return -100;
} finally {
return 100;// 会覆盖try和catch代码块的return语句
}
}
}
B:丢失异常
public class ExLoss {
/**
* @param args
*/
public static void main(String[] args) {
try {
System.out.println(new ExLoss().methodB(1));// 打印100
System.out.println("No Exception");
} catch (Exception e) {
System.out.println(e.getMessage());
}
}
public int methodA(int money) throws SpecialException {
if (--money <= 0) {
throw new SpecialException("Out of money");
}
return money;
}
@SuppressWarnings("finally")
public int methodB(int money) {
try {
return methodA(money);// 可能抛出异常
} catch (SpecialException e) {
throw new Exception("Wrong");
} finally {
return 100;// 会丢失catch代码块中的异常
}
}
}
9.3 Java异常类
所有异常类的祖先类为java.lang.Throwable类,它的实例表示具体的异常对象,可以通过throw语句抛出。
Throwable类提供了访问异常信息的一些方法,常用的方法包括:
- getMessage() --返回String类型的异常信息。
- printStachTrace()--打印跟踪方法调用栈而获得的详细异常信息。在程序调试阶段,此方法可用于跟踪错误。
public class ExTrace {
/**
* @param args
*/
public static void main(String[] args) {
try {
new ExTrace().methodB(1);
} catch (Exception e) {
System.out.println("--- Output of main() ---");
e.printStackTrace();
}
}
public void methodA(int money) throws SpecialException {
if (--money <= 0) {
throw new SpecialException("Out of money");
}
}
public void methodB(int money) throws Exception {
try {
methodA(money);
} catch (SpecialException e) {
System.out.println("--- Output of methodB() ---");
System.out.println(e.getMessage());
throw new Exception("Wrong");
}
}
}
打印结果:
--- Output of methodB() ---
Out of money
--- Output of main() ---
java.lang.Exception: Wrong
at chapter09.d0903.ExTrace.methodB(ExTrace.java:45)
at chapter09.d0903.ExTrace.main(ExTrace.java:26)
Throwable类有两个直接子类:
- Error类--表示仅靠程序本身无法恢复的严重错误,如内存不足等。
- Exception类--表示程序本身可以处理的异常。
9.3.1 运行时异常
RuntimeException类及其子类都被称为运行时异常,这种异常的特点是Java编译器不会检查它,会编译通过,但运行时如果条件成立就会出现异常。
例如当以下divided()方法的参数b为0,执行“a/b”操作时会出现ArrithmeticException异常,它属于运行时异常,Java编译器不会检查它。
public int divide2(int a, int b) {
return a / b;// 当参数为0,抛出ArrithmeticException
}
下面的程序中的IllegalArgumentException也是运行时异常,divided()方法即没有捕获它,也没有声明抛出它。
public class WithRuntimeEx {
/**
* @param args
*/
public static void main(String[] args) {
new WithRuntimeEx().divide(1, 0);
System.out.println("End");
}
public int divide(int a, int b) {
if (b == 0) {
throw new IllegalArgumentException("除數不能為0");
}
return a / b;
}
}
由于程序代码不会处理运行时异常,因此当程序在运行时出现了这种异常时,就会导致程序异常终止。以上程序的打印结果为:
Exception in thread "main" java.lang.IllegalArgumentException: 除數不能為0
at chapter09.d0903.WithRuntimeEx.divide(WithRuntimeEx.java:29)
at chapter09.d0903.WithRuntimeEx.main(WithRuntimeEx.java:23)
9.3.2 受检查异常
除了RuntimeException及其子类以外,其他的Exception类及其子类都属于受检查异常(Checked Exception)。这种异常要么catch语句捕获,要么throws子句声明抛出,否则编译出错。
9.3.3 区分运行时异常和受检查异常
受检查异常表示程序可以处理的异常。
运行时异常表示无法让程序恢复运行的异常,导致这种异常的原因通常是由于执行了错误操作。一旦出现了错误操作,建议终止程序,因此Java编译器不检查这种异常。
9.3.4 区分运行时异常和错误
Error类及其子类表示程序本身无法修复的错误,它和运行时异常的相同之处是:Java编译器都不会检查它们,当程序运行时出现它们,都会终止程序。
两者的不同之处是:Error类及其子类表示的错误通常是由Java虚拟机抛出。
而RuntimeException类表示程序代码中的错误,它是可扩展的,用户可以根据特定的问题领域来创建相关的运行时异常类。
9.4 用户定义异常
9.4.1 异常转译和异常链
public class BaseException extends Exception {
protected Throwable cause = null;
public BaseException() {
}
public BaseException(String msg) {
super(msg);
}
public BaseException(Throwable cause) {
this.cause = cause;
}
public BaseException(String msg, Throwable cause) {
super(msg);
this.cause = cause;
}
public Throwable initCause(Throwable cause) {
this.cause = cause;
return this;
}
public Throwable getCause() {
return cause;
}
public void printStackTrace() {
printStackTrace(System.err);
}
public void printStackTrace(PrintStream outStream) {
printStackTrace(new PrintStream(outStream));
}
public void printStackTrace(PrintWriter writer) {
super.printStackTrace(writer);
if (getCause() != null) {
getCause().printStackTrace(writer);
}
writer.flush();
}
}
9.4.2 处理多样化异常
public class MultiBaseException extends Exception {
protected Throwable cause = null;
private List<Throwable> exceptions = new ArrayList<Throwable>();
public MultiBaseException() {
}
public MultiBaseException(Throwable cause) {
this.cause = cause;
}
public MultiBaseException(String msg, Throwable cause) {
super(msg);
this.cause = cause;
}
public List getException() {
return exceptions;
}
public void addException(MultiBaseException ex) {
exceptions.add(ex);
}
public Throwable initCause(Throwable cause) {
this.cause = cause;
return this;
}
public Throwable getCause() {
return cause;
}
public void printStackTrace() {
printStackTrace(System.err);
}
public void printStackTrace(PrintStream outStream) {
printStackTrace(new PrintStream(outStream));
}
public void printStackTrace(PrintWriter writer) {
super.printStackTrace(writer);
if (getCause() != null) {
getCause().printStackTrace(writer);
}
writer.flush();
}
}
9.5 异常处理原则
9.5.1 异常只能用于非正常情况
9.5.2 为异常提供说明文档
9.5.3 尽可能地避免异常
9.5.4 保持异常的原子性
9.5.5 避免过于庞大的try代码块
9.5.6 在catch子句中指定具体的异常类型
9.5.7 不要在catch代码块中忽略被捕获的异常,可以处理异常、重新抛出异常、进行异常转译
posted @
2008-02-22 17:50 CoderDream 阅读(884) |
评论 (0) |
编辑 收藏8.1 接口的概念和基本特征
(1)、接口中的成员变量默认都是public、static、final类型的,必须被显式初始化;
(2)、接口中的方法默认都是public、abstract类型的;
(3)、接口中只能包含public、static、final类型的成员变量和public、abstract类型的成员方法;
(4)、接口没有构造方法,不能被实例化;
(5)、一个接口不能实现另一个接口,但可以继承多个其他接口;
(6)、接口必须通过类来实现它的抽象方法。类实现接口的关键字是implements;
(7)、与子类继承抽象父类相似,当类实现了某个接口时,它必须实现接口中所有的抽象方法,否则这个类必须被定义为抽象类;
(8)、不允许创建接口类型的实例,但允许定义接口类型的引用变量,该变量引用实现了这个接口的类的实例;
(9)、一个类只能继承一个直接的父类,但能实现多个接口。
8.2 比较抽象类与接口
相同点:
- 代表系统的抽象层
- 都不能被实例化
- 都能包含抽象方法
两大区别:
- 在抽象类中可以为部分方法提供默认的实现,从而避免在子类中重复实现它们,提高代码的可重用性,这是抽象类的优势所在;而接口中只能包含抽象方法;
- 一个类只能继承一个直接的父类,这个父类有可能是抽象类;但一个类可以实现多个接口,这是接口的优势所在。
使用接口和抽象类的原则:
- 用接口作为系统与外界交互的窗口;
- 由于外界使用者依赖系统的接口,并且系统内部会实现接口,因此接口本身必须十分稳定,接口一旦制订,就不允许随意修改,否则会对外界使用者及系统内部都造成影响。
- 用抽象类来定制系统中的扩展点。
8.3 与接口相关的设计模式
8.3.1 定制服务模式
如何设计接口?定制服务模式提出了设计精粒度的接口的原则。
8.3.2 适配器模式
当两个系统之间接口不匹配时,如果处理?适配器模式提供了接口转换方案。
包括继承实现方式和组合实现方式。优先考虑用组合关系来实现适配器。
8.3.3 默认适配器模式
为了简化编程,JDK为MouseListener提供了一个默认适配器MouseAdapter,它实现了MouseListener接口,为所有的方法提供了空的方法体。用户自定义的MyMouseLIstener监听器可以继承MouseAdapter类,在MyMouseListener类中,只需要覆盖特定的方法,而不必实现所有的方法。使用默认适配器可以简化编程,但缺点是该类不能在继承其他的类。
8.3.4 代理模式
下面以房屋出租人的代理为例,介绍代理模式的运用。在下图中,出租人Renter和代理Deputy都具有RenterIFC接口。Tenant类代表租赁人,HouseMarket类代表整个房产市场,它记录了所有房产代理人的信息,出租人从房产市场找到房产代理人。

为了简化起见,假定一个代理人只会为一个出租人做代理,租赁人租房屋rentHouse()的大致过程如下:
- 从房产市场上找到一个房产代理人,即调用HouseMarket对象的findRenter()方法;
- 报出期望的租金价格,征求代理人的意见,即调用Deputy对象的isAgree()方法;
- 代理人的处理方式为:如果租赁人的报价低于出租人的租金价格底线,就立即做出拒绝答复;否则征求出租人的意见,即调用Renter对象的isAgree()方法。
- 出租人的处理方式为:如果租赁人的报价比租金价格底线多100元,就同意出租
- 如果租赁人得到代理人同意的答复,就从存款中取出租金,通知代理人领取租金,即调用Deputy对象的fetchRent()方法
- 代理人通知出租人领取租金,即调用Renter对象的fecthRent()方法。

房屋租赁交易顺利执行的时序图
源代码:
/**
* RetnerIFC 接口,它定义了出租人的两个行为,即决定是否同意按租赁人提出的价格出租房屋,以及收房租
*
* @author XL
*
*/
public interface RenterIFC {
/**
* 是否同意按租赁人提出的价格出租房屋
*
* @param expectedRent
* @return
*/
public boolean isAgree(double expectedRent);
/**
* 收房租
*
* @param rent
*/
public void fetchRent(double rent);
}
/**
* 房屋出租人
*
* @author XL
*
*/
public class Renter implements RenterIFC {
/**
* 房屋租金最低价格
*/
private double rentDeadLine;
/**
* 存款
*/
private double money;
/**
* @param rentDeadLine
* @param money
*/
public Renter(double rentDeadLine, double money) {
super();
System.out.println("New Renter, rentDeadLine: " + rentDeadLine
+ ", saveMoney: " + money);
this.rentDeadLine = rentDeadLine;
this.money = money;
}
/*
* (non-Javadoc)
*
* @see chapter08.d0800.RenterIFC#fetchRent(double)
*/
public void fetchRent(double rent) {
System.out.println("OK, you can use the house.");
money += rent;
}
/*
* (non-Javadoc) 如果租赁人的期望价格比房屋租金最低价格多100元,则同意出租
*
* @see chapter08.d0800.RenterIFC#isAgree(double)
*/
public boolean isAgree(double expectedRent) {
System.out.println("If the money less 100 than the rentDeadLine.");
return expectedRent - this.rentDeadLine > 100;
}
/**
* @return
*/
public double getRentDeadLine() {
return rentDeadLine;
}
}
/**
* 房产代理人
*
* @author XL
*
*/
public class Deputy implements RenterIFC {
private Renter renter;
/**
* 接受代理
*
* @param renter
*/
public void registerRenter(Renter renter) {
System.out.println("OK, I have some business.");
this.renter = renter;
}
public void fetchRent(double rent) {
System.out.println("Get the monty: " + rent);
renter.fetchRent(rent);
}
/*
* (non-Javadoc) 如果租赁人的期望价格低于房屋租金最低价格,则不同意出租 否则请示出租人的意见
*
* @see chapter08.d0800.RenterIFC#isAgree(double)
*/
public boolean isAgree(double expectedRent) {
//
if (expectedRent < renter.getRentDeadLine()) {
System.out.println("Sorry, you can't rent the house.");
return false;
} else {
System.out.println("Let me ask the renter.");
return renter.isAgree(expectedRent);
}
}
}
import java.util.HashSet;
import java.util.Set;
/**
* @author XL
*
*/
public class HouseMarket {
private static Set<RenterIFC> renters = new HashSet<RenterIFC>();
public static void registerRenter(RenterIFC deputy) {
System.out.println("A new man has registered!");
renters.add(deputy);
}
public static RenterIFC findRenter() {
System.out.println("Let's find something!");
return (RenterIFC) renters.iterator().next();
}
}
/**
* 房屋租赁人
*
* @author XL
*
*/
public class Tenant {
private double money;
public Tenant(double money) {
//
System.out.println("New Tenant!");
System.out.println("I have " + money);
this.money = money;
}
public boolean rentHouse(double expectedRent) {
// 从房地产市场找到一个房产代理人
RenterIFC renter = HouseMarket.findRenter();
System.out.println("I can offer " + expectedRent);
// 如果代理人不同意预期的租金价格,就拉倒,否则继续执行
if (!renter.isAgree(expectedRent)) {
System.out.println("I can't offer any more!");
return false;
}
// 从存款中取出预付租金
money -= expectedRent;
System.out.println("OK, get the money, " + expectedRent);
// 把租金交给房产代理人
renter.fetchRent(expectedRent);
return true;
}
}
/**
* @author XL
*
*/
public class AppMain {
/**
* @param args
*/
public static void main(String[] args) {
// 创建一个房屋出租人,房屋租金最低价格为2000元,存款1万元
Renter renter = new Renter(2000, 10000);
// 创建一个房产代理人
Deputy deputy = new Deputy();
// 房产代理人到房产市场登记
HouseMarket.registerRenter(deputy);
// 建立房屋出租人和房产代理人的委托关系
deputy.registerRenter(renter);
// 创建一个房屋租赁人,存款为2万元
Tenant tenant = new Tenant(20000);
// 房屋租赁人试图租赁期望租金为1800元的房屋,遭到房产代理人拒绝
tenant.rentHouse(1800);
// 房屋租赁人试图租赁期望租金为2300元的房屋,租房成功
tenant.rentHouse(2300);
}
}
输出结果:
New Renter, rentDeadLine: 2000.0, saveMoney: 10000.0
A new man has registered!
OK, I have some business.
New Tenant!
I have 20000.0
Let's find something!
I can offer 1800.0
Sorry, you can't rent the house.
I can't offer any more!
Let's find something!
I can offer 2300.0
Let me ask the renter.
If the money less 100 than the rentDeadLine.
OK, get the money, 2300.0
Get the monty: 2300.0
OK, you can use the house.
8.3.5 标识类型模式
标识类型接口没有任何方法,仅代表一种抽象类型。
在JDK中,有如下两个典型的标识类型接口:
- java.io.Serializable接口:实现该接口的类可以被序列化。
- java.io.Remote接口:实现该接口的类的实例可以作为远程对象。
8.3.6 常量接口模式
posted @
2008-02-19 18:03 CoderDream 阅读(399) |
评论 (0) |
编辑 收藏
摘要: 教程:CSS修饰表格
代码:
<html>
<head>
<title>用css美化表格边框</title>
...
阅读全文
posted @
2008-02-03 15:09 CoderDream 阅读(5939) |
评论 (0) |
编辑 收藏<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.0 Transitional//EN">
<HTML>
<HEAD>
<TITLE> New Document </TITLE>
<META NAME="Generator" CONTENT="EditPlus">
<META NAME="Author" CONTENT="">
<META NAME="Keywords" CONTENT="">
<META NAME="Description" CONTENT="">
</HEAD>
<BODY>
<div>
<table style="border:blue solid;border-width:2 1 1 2" width="800" cellspacing="0" cellpadding="0" border="0" class="table4">
<tr >
<td style="border:blue solid;border-width:0 1 1 0 " width="40"><CENTER><B>序号</B></CENTER></td>
<td style="border:blue solid;border-width:0 1 1 0 " width="700"><CENTER><B>标题</B></CENTER></td>
<td style="border:blue solid;border-width:0 1 1 0 " width="60"><CENTER><B>地址</B></CENTER></td>
</tr>
<tr>
<td style="border:blue solid;border-width:0 1 1 0 "><CENTER>01</CENTER></td>
<td style="border:blue solid;border-width:0 1 1 0 "> </td>
<td style="border:blue solid;border-width:0 1 1 0 "><CENTER>地址</CENTER></td>
</tr>
<tr>
<td style="border:blue solid;border-width:0 1 1 0 "><CENTER>02</CENTER></td>
<td style="border:blue solid;border-width:0 1 1 0 "> </td>
<td style="border:blue solid;border-width:0 1 1 0 "><CENTER>地址</CENTER></td>
</tr>
<tr>
<td style="border:blue solid;border-width:0 1 1 0 "><CENTER>03</CENTER></td>
<td style="border:blue solid;border-width:0 1 1 0 "> </td>
<td style="border:blue solid;border-width:0 1 1 0 "><CENTER>地址</CENTER></td>
</tr>
</table>
</div>
</BODY>
</HTML>
效果:
|
序号 |
标题 |
地址 |
|
01 |
|
地址 |
|
02 |
|
地址 |
|
03 |
|
地址 |
posted @
2008-02-03 15:05 CoderDream 阅读(3216) |
评论 (0) |
编辑 收藏
|
序号 |
标题 |
地址 |
|
01 |
CSS修饰表格 |
地址 |
|
02 |
制作强制固定表格大小的效果 |
地址 |
|
03 |
html语言教程 |
地址 |
|
04 |
CSS教程 |
地址 |
posted @
2008-02-03 15:03 CoderDream 阅读(348) |
评论 (0) |
编辑 收藏
要求:根据Reinsurance_Level和ReCompanyCode进行汇总:
select t.reinsurance_Level,t.re_Company_Code,sum(t.ceded_Amount)
from Claimnotice_Insurance_Detail t
where 1=1
-- 此处加条件
group by t.reinsurance_Level,t.re_Company_Code;
结果:
| REINSURANCE_LEVEL |
RE_COMPANY_CODE |
3 |
| 1 |
1 |
2621000 |
| 1 |
2 |
1534000 |
| 1 |
3 |
375000 |
| Q |
2 |
302000 |
| Q |
4 |
302000 |
posted @
2008-01-21 11:33 CoderDream 阅读(678) |
评论 (0) |
编辑 收藏http://blog.csdn.net/goody9807/archive/2007/09/11/1780717.aspx
[Tree命令作用]
以图形显示驱动器或路径的文件夹结构。很多时候,这是一个非常有用的命令!
[Tree命令格式]
可以在命令行窗口敲tree /?看帮助。
TREE [drive:][path] [/F] [/A]
/F 显示每个文件夹中文件的名称。
/A 使用 ASCII 字符,而不使用扩展字符。
使用/F参数时显示所有目录及目录下的所有文件,省略时,只显示目录,不显示目录下的文件;
选用>PRN参数时,则把所列目录及目录中文件名打印输出
tree c:\ | more
出现由 tree 命令产生的第一个输出命令提示符窗口,后面跟着 -- More -- 提示。输出暂停,直到用户按键盘上的任意键为止(Pause除外)。
空格:显示一整页
按下:Ctrl+Break退出
[Tree命令范例]
[例一]
tree d: > d:\dTree.txt
或者
tree d:\ > d:\dTree.txt
作用:把D盘下的所有目录结构以树状结构导出,以文本文件dTree.txt保存在文件夹d:\下。
[例二]
tree d: /f > d:\dF.txt
或者
tree d:\ /f > d:\dF.txt
作用:把D盘下的所有目录及文件结构以树状结构导出,以文本文件dF.txt保存在文件夹d:\下。
[例三]
tree C:\WINDOWS\system32 /f > C:\s32f.txt
作用:把C:\WINDOWS\system32 /f > C:\s32f.txt下的所有目录及文件结构以树状结构导出,以文本文件s32f.txt保存在文件夹c:\下。
[例四]
tree E:\BitComet\Downloads /f > f:\download\tree\dl.txt
作用:把E:\BitComet\Downloads下的所有目录及文件以树状结构导出,以文本文件dl.txt保存在文件夹f:\download\tree\下。
[Tree命令注意事项]
[注意1] TREE命令中涉及的文件夹名称中不得有空格
例如,类似下面的命令发挥不了作用:
tree C:\Documents and Settings\Administrator /f > c:\administrator.txt
若要提取诸如E盘My doc文件夹下的文件结构,可以先进入这个目录(先e:回车,再cd My doc回车),再用tree命令提取:
tree /f>mydoc.txt
[注意2]了解DOS的对当前提示符的一些默认
例如,在提示符 E:\My doc> 下,可以用下面的简洁命令
tree /f>mydoc.txt
把E:\My doc>下的所有目录及文件结构以树状结构导出,以文本文件mydoc.txt保存在文件夹E:\My doc下。
注意这个TREE命令后没有盘符及路径,缺省时,默认值就是当前提示符所在路径。导出符“>”后也同此默认。
[注意3]关于路径后面的反斜杠
(1)在提示符 C:\Documents and Settings\Administrator> 下,如果要导出C盘的所有文件结构,必须使用类似下列命令:
tree c:\ > c:\ct.txt
而不能是诸如此类之命令:
tree c: > c:\ct.txt
因为此命令导出的不是整个C盘的内容,而是提示符所在路径C:\Documents and Settings\Administrator>下的内容。
(2)但在一般情况下,路径后面不能有反斜杠
例如若需导出D:\ghost下的结构,不能用诸如此类的命令:
tree D:\ghost\ /f > d:\ghost.txt
而只能是:
tree D:\ghost /f > d:\ghost.txt
[注意4]导出符前后空格均可省略,但参数\F等前面的空格不可以。
此命令有效:tree D:\ghost /F>d:\ghost.txt
而此命令无效:tree D:\ghost/F > d:\ghost.txt
posted @
2008-01-18 22:29 CoderDream 阅读(17693) |
评论 (2) |
编辑 收藏 有两个表,文章表中TypeId字段记录栏目Id,栏目表中的字段是栏目Id和栏目名,现在要达到的效果就是读取文章列表的时候显示栏目名称。
以前没用过inner join外联操作,所以就束手无策了。其实有些功能是仅仅靠SQL语句就可以实现的,inner join能够组合两个表中的记录,只要在公共字段之中有相符的值。
所以要显示栏目名称,只要用如下SQL语句:
Select [Article].id,[Article].content,[栏目表].[栏目名称] FROM [Article] inner join [栏目表] on [栏目表].id=[Article].ArType orDER BY [ArId] DESC
------------------------------------------------------------------------------
附相关文章:
多表联接建立记录集是十分有用的,因为某些情况下,我们需要把数字数据类型显示为相应的文本名称,这就遇到了多表联接建立记录集的问题。比如作一个会员注册系统,共有五个表,会员信息数据表member、会员身份表MemberIdentity、会员权限表 MemberLevel、会员类别表MemberSort和会员婚姻状况表Wedlock。如果想把会员注册信息全部显示出来,肯定要将这四个表连起来,否则大家看到的某些会员信息可能只是数据编号。
以会员类别表来说,在其数据表中,1代表普通会员,2代表高级会员,3代表终身会员,在显示时,如果不将会员类别表与会员详细数据表相关联,那么假如我们现在看到的是一名普通会员的注册信息,我们只能看到其类别为1,而谁又会知道1代表的是普通会员呢?所以要将会员类别表与会员详细数据表相关联,关联后,1就显示为普通会员,2就显示为高级会员,3就显示为终身会员,这样多好?同理,其它两个表也要与会员详细数据表相关联才能把数据编号显示为相应的名称。
前天制作网站后台时遇到此问题,在面包论坛、狂迷俱乐部、蓝色理想、和5D多媒体论坛发了贴子求救,都没有获得答案,只好自己研究,花了两天时间终于成功,现将其写成教程供大家分享,希望大家少走弯路。
本教程是把五个表联在一起,如果愿意,您可以将更多的表联在一起,方法大同小异啦~
步骤一:用Access软件建立一个名为Member的数据库,在其中建五个表,分别为:会员信息数据表member、会员身份表MemberIdentity、会员权限表MemberLevel、会员类别表MemberSort和会员婚姻状况表Wedlock。
●会员信息数据表member:
MemberID:自动编号,主键(ID号)
MemberSort:数字(会员类别)
MemberName:文本,会员姓名
Password:文本(会员密码)
MemberLevel:数字(会员权限)
MemberIdentity:数字(会员身份)
Wedlock:数字(婚姻状况)
MemberQQ:文本(QQ号码)
MemberEmail:文本(会员邮箱)
MemberDate:日期/时间(会员注册日期)
●会员身份表MemberIdentity:
MemberIdentity:自动编号,主键(ID号)
IdentityName:文本(会员身份名称)
●会员权限表MemberLevel:
MemberLevel:自动编号,主键(ID号)
LevelName:文本(会员权限名称)
●会员类别表MemberSort:
MemberSort:自动编号,主键(ID号)
SortName:文本(会员类别名称)
●会员婚姻状况表Wedlock
Wedlock:自动编号,主键(ID号)
WedlockName:文本(会员婚姻状况类别)
说明:五个表建好后,您可以自行设置您想要的类别,如会员权限,您可以设置两个类别--“未付费会员”和“已付费会员”,编号分别为“1”、“2”,如您设置了三个选项,那么第三个选项的编号当然就是“3”了。
下面我们所要作的工作就是把“1”、“2”之类的编号显示为“未付费会员”和“已付费会员”,否则,大家谁会知道“1”代表的是“未付费会员”,“2”代表的是“已付费会员”?
步骤二:建DSN数据源,建记录集
●运行Dreamweaver MX软件,在会员注册信息显示页面建一个名为ConnMember(您也可以起其它的名称)的DSN数据源。
●点击服务器行为面板中的“绑定”,建一个名为MemberShow的数据集,“连接”选择ConnMember,“表格”选择Member,“列”全选,“排序”选择MemberDate,降序。点击“高级”按钮,修改SQL框中自动生成的代码:
原代码为:
Select *
FROM Member
orDER BY MemberDate DESC
将代码修改为:
Select *
FROM (((Member INNER JOIN MemberSort ON Member.MemberSort=MemberSort.MemberSort) INNER JOIN MemberLevel ON Member.MemberLevel=MemberLevel.MemberLevel) INNER JOIN MemberIdentity ON Member.MemberIdentity=MemberIdentity.MemberIdentity) INNER JOIN Wedlock ON Member.Wedlock=Wedlock.Wedlock
orDER BY MemberDate DESC
修改完代码后,点击“确定”,大功告成!
现在,您可以打开记录集看一下,五个表中的字段全部集成在MemberShow记录集中,您只要将相应的字段绑定在该字段想显示的单元格中即可。这下好了,所有的数字编号全部变成了相应的名称,如会员权限,不再是“1”和“2”的数字形式了,而是变成了相应的名称“未付费会员”和“已付费会员”。其它的数字编号也变成了显示的文本名称,是不是很开心呢?
注意事项:
●在输入字母过程中,一定要用英文半角标点符号,单词之间留一半角空格;
●在建立数据表时,如果一个表与多个表联接,那么这一个表中的字段必须是“数字”数据类型,而多个表中的相同字段必须是主键,而且是“自动编号”数据类型。否则,很难联接成功。
● 代码嵌套快速方法:如,想连接五个表,则只要在连接四个表的代码上加一个前后括号(前括号加在FROM的后面,后括号加在代码的末尾即可),然后在后括号后面继续添加“INNER JOIN 表名X ON 表1.字段号=表X.字段号”代码即可,这样就可以无限联接数据表了:)
语法格式:
其实 INNER JOIN ……ON的语法格式可以概括为:
FROM (((表1 INNER JOIN 表2 ON 表1.字段号=表2.字段号) INNER JOIN 表3 ON 表1.字段号=表3.字段号) INNER JOIN 表4 ON Member.字段号=表4.字段号) INNER JOIN 表X ON Member.字段号=表X.字段号
您只要套用该格式就可以了。
现成格式范例:
虽然我说得已经比较明白了,但为照顾初学者,我还是以本会员注册系统为例,提供一些现成的语法格式范例,大家只要修改其中的数据表名称和字段名称即可。
连接两个数据表的用法:
FROM Member INNER JOIN MemberSort ON Member.MemberSort=MemberSort.MemberSort
语法格式可以概括为:
FROM 表1 INNER JOIN 表2 ON 表1.字段号=表2.字段号
连接三个数据表的用法:
FROM (Member INNER JOIN MemberSort ON Member.MemberSort=MemberSort.MemberSort) INNER JOIN MemberLevel ON Member.MemberLevel=MemberLevel.MemberLevel
语法格式可以概括为:
FROM (表1 INNER JOIN 表2 ON 表1.字段号=表2.字段号) INNER JOIN 表3 ON 表1.字段号=表3.字段号
连接四个数据表的用法:
FROM ((Member INNER JOIN MemberSort ON Member.MemberSort=MemberSort.MemberSort) INNER JOIN MemberLevel ON Member.MemberLevel=MemberLevel.MemberLevel) INNER JOIN MemberIdentity ON Member.MemberIdentity=MemberIdentity.MemberIdentity
语法格式可以概括为:
FROM ((表1 INNER JOIN 表2 ON 表1.字段号=表2.字段号) INNER JOIN 表3 ON 表1.字段号=表3.字段号) INNER JOIN 表4 ON Member.字段号=表4.字段号
连接五个数据表的用法:
FROM (((Member INNER JOIN MemberSort ON Member.MemberSort=MemberSort.MemberSort) INNER JOIN MemberLevel ON Member.MemberLevel=MemberLevel.MemberLevel) INNER JOIN MemberIdentity ON Member.MemberIdentity=MemberIdentity.MemberIdentity) INNER JOIN Wedlock ON Member.Wedlock=Wedlock.Wedlock
语法格式可以概括为:
FROM (((表1 INNER JOIN 表2 ON 表1.字段号=表2.字段号) INNER JOIN 表3 ON 表1.字段号=表3.字段号) INNER JOIN 表4 ON Member.字段号=表4.字段号) INNER JOIN 表5 ON Member.字段号=表5.字段号
------------------------------------------------------------------------------
INNER JOIN 运算
组合两个表中的记录,只要在公共字段之中有相符的值。
语法
FROM table1 INNER JOIN table2 ON table1.field1 compopr table2.field2
INNER JOIN 运算可分为以下几个部分:
部分 说明
table1, table2 记录被组合的表的名称。
field1, field2 被联接的字段的名称。若它们不是由数字构成的,则这些字段必须为相同的数据类型并包含同类数据,但它们无须具有相同的名称。
compopr 任何的关系比较运算子:"=," "<," ">," "<=," ">=," 或 "<>."
说明
可以在 FROM 子句中使用INNER JOIN运算。.这是最普通的联接类型。只要在这两个表的公共字段之中有相符值,内部联接将组合两个表中的记录。
可以使用 INNER JOIN 与部门表及员工表选择每一个部门中的全部员工。反之,可以使用 LEFT JOIN或 RIGHT JOIN运算创建 outer join,从而选择所有部门(即使有些并没有员工)或所有员工(即使有些尚未分配到部门)。
若试图联接包含 Memo或 OLE Object数据的字段,会导致错误。
可以联接任何两个相同类型的数值字段。例如,可以联接 AutoNumber和 Long字段,因为它们类型相似。但不能联接 Single 和 Double 类型的字段。
下列示例显示如何在类标识符字段联接类表及产品表:
Select CategoryName, ProductName
FROM Categories INNER JOIN Products
ON Categories.CategoryID = Products.CategoryID;
在上面的示例中,类标识符是已被联接的字段,但是它并不包含在查询输出中,因它并非被包含在 Select 语句之中。在这个示例中,若要包含联接字段,将字段名包含在 Select 语句中, Categories.CategoryID.
也可以使用下列语法,在一个 JOIN 语句中链接多个 ON 子句:
Select fields
FROM table1 INNER JOIN table2
ON table1.field1 compopr table2.field1 AND
ON table1.field2 compopr table2.field2) or
ON table1.field3 compopr table2.field3)];
也可以使用下列语法,嵌套 JOIN 语句:
Select fields
FROM table1 INNER JOIN
(table2 INNER JOIN [( ]table3
[INNER JOIN [( ]tablex [INNER JOIN ...)]
ON table3.field3 compopr tablex.fieldx)]
ON table2.field2 compopr table3.field3)
ON table1.field1 compopr table2.field2;
在一个 INNER JOIN 之中,可以嵌套 LEFT JOIN 或 RIGHT JOIN,但是在 LEFT JOIN 或 RIGHT JOIN 中不能嵌套 INNER JOIN。
原文链接:
http://www.and8.net/article.asp?id=194
posted @
2008-01-17 15:48 CoderDream 阅读(520) |
评论 (0) |
编辑 收藏著名的Java图表软件jfreechart的作者模仿Google chart api的风格(样式和URL)开发出了一套Servlet--EastWood。让Google chart可以脱离Google和在线服务了。该项目的图表效果和Google chart api的效果相差无几,鉴于Google chart api是第三方在线服务而存在一些风险和不便,在实际开发当中您可以选择使用“伊士活”来作为Google chart的代替品,来一个google chart in house。
前些时候Google推出了一款报表API“Google chart api”。该API让开发者可以通过URL来动态生成图表,图表的样式有流行的线状图、柱形图、饼图等。下面是一个使用实例:在你的浏览器输入下面的地址:http://chart.apis.google.com/chart?cht=p3&chd=s:hW&chs=250x100&chl=Hello|World 然后回车或确定,你将看到下面这一幅图片。

还有更多样式,更复杂的图表Google chart api也能胜任,本文不打算重复参考文档里的内容了。有兴趣的同学可以自己去研究一番。
也就是说,Google为你提供远程的图表生成服务,但是这个服务并非没有限制的,Google限定了,每个用户访问图表的数量不能大于50,000次, 说实在的,普通的应用的用户要达到这个数本来就很难,所以这倒不是最大的限制。另外,如果你的项目是在企业内部部署,用户不能直接访问外网,那 Google chart api就哑火了。你可能会说“真可惜了,Google chart api如此强大,我都已经掌握了它的全部用法了,如今却因为这种原因使用不了”。使用第三方的在线服务,还有一个潜在的问题就是,你不知道他们什么时候会 把这个服务撤掉。
现在你不需要为这件事而发愁了,有一个好东西一定会让苦恼的你兴奋不已。著名的Java报表引擎Jfreechart的作者模仿Google chart api的URL风格开发出了一套Servlet--Eastwood, 这个项目是基于Jfreechart的,它可以让你使用Google chart api的方式生成与Google生成的几乎百分之百一样的图表,这味道着,如果你用Google chart api开发了一套图表,那么你需要Google chart inside的话,只需要把eastwood作为一个Servlet配置起来,然后替换一下URL的Host就搞定了。
来看看Google和EastWood生成的图表之间的差异:

更多的比较看这里。要进行最全面的比较,下载一份Eastwood的发行版,部署,打开Test.html就见到效果了。很赞。Jfreechart的作者怎么在之前没有想到以这样的方式来提供报表生成的功能呢?呵。看了下EastWood的代码量很少,只是将Jfreechart做一下封装就完了。
posted @
2008-01-17 09:14 CoderDream 阅读(2005) |
评论 (0) |
编辑 收藏
1、
XML 2007
2、
XML 2007中文版
3、
Ten predictions for XML in 2007
4、
2007 年 XML 的十大预测
posted @
2008-01-16 14:27 CoderDream 阅读(257) |
评论 (0) |
编辑 收藏問題一
季帳單的金額欄位, 請四捨五入到”元 “, 不要帶出小數位數字
之前季帳單沒有這樣的問題存在, 為什麼交付的新程式會出現這個問題呢?

我们先查询第一笔记录:
| 再保項目 |
弱體等級 |
資料別 |
被保人性別 |
金額 |
| Rein. premium |
標準體 |
新件 |
|
1901.5949 |
看看数据库中的情况是怎样的,因为金额“1901.5949”
是加总后的结果。
通过下面的SQL语句查询结果:
条件:1、2006年第二季度,即会计年月为:200604、200605、200606;
2、再保公司为CRC,即为“01”;
3、年度为“2006”,即PREM_YEAR为:2006;
4、资料别为新件,即MONTHLY_FLAG为:N、NC;
5、报表险种群为ICE,即再保类别为“12”
6、弱体等级为标准体,即BODY_FLAG为“1”
SELECT mt.Q_PREMIUM
FROM RIS.MONTHLY_TEMP mt
WHERE 1=1
AND mt.ACCOUNT_YM_DATE in ('200604','200605','200606')
AND mt.RE_COMPANY_CODE='01'
AND mt.PREM_YEAR=2006
AND mt.MONTHLY_FLAG in ('N','NC')
AND mt.REINSURANCE_CLASS='12'
AND mt.BODY_FLAG='1'
;
然后我们将得到的记录拷贝到Excel档中,

通过结果下面的SQL同样可以得到结果:1901.5949
SELECT sum(mt.Q_PREMIUM) Q_PREMIUM
FROM RIS.MONTHLY_TEMP mt
WHERE 1=1
AND mt.ACCOUNT_YM_DATE in ('200604','200605','200606')
AND mt.RE_COMPANY_CODE='01'
AND mt.PREM_YEAR=2006
AND mt.MONTHLY_FLAG in ('N','NC')
AND mt.REINSURANCE_CLASS='12'
AND mt.BODY_FLAG='1'
GROUP BY mt.PREM_YEAR
;
从Excel档可以看到数据的小数部分没有处理,而我们的记录都放在一个Map中,Map的键为对象的Id,即SeasonAccountDetailAmountId,而值为SeasonAccountDetailAmount,我们要处理的属性金额在Map的值中。我们只需遍历Map,然后处理(四舍五入)值中对象的某个属性,然后将这个“键值对”放到Map中,它会自动覆盖以前的同Key的记录。
/**
* 將Map中SeasonAccountDetailAmount對象的amount的值四舍五入
*
* @author XuLin
*
* 2008.01.15
*
* @param detailMap
*/
private void roundingMap(Map detailMap) {// TODO
Map map = (FastHashMap) detailMap;
Iterator it = map.entrySet().iterator();
SeasonAccountDetailAmountId sadaId = null;
SeasonAccountDetailAmount sada = null;
while (it.hasNext()) {
Map.Entry entry = (Map.Entry) it.next();
sadaId = (SeasonAccountDetailAmountId) entry.getKey();
sada = (SeasonAccountDetailAmount) entry.getValue();
if (sada.getAmount() != null) {
sada.setAmount(Common.roundingBigDecimal(sada.getAmount(),
Constant.MONEY_SCALE));//四舍五入到整數位
seasonAccontDetailCache.put(sadaId, sada);
}
}
}
問題二
新增的季帳單(CRC-2006-384)再保項目-Return Rein. Commission Last Year 一筆金額100,000
為何反應在季帳單PDF上會有兩筆記錄??
Return Rein. Commission Last Year-2006 NTS 空白??
Return Rein. Commission Last Year-2005 NTS 100,000

處理方法:
交給第三方處理,我們的報表做法是我們生成文本格式的txtFile,然后由第三方處理。
出現問題的原因是該“再保險種”的值為,應該不顯示在PDF上,他應該多加一層判斷。
posted @
2008-01-16 11:34 CoderDream 阅读(321) |
评论 (0) |
编辑 收藏查询条件与查询结果:

查询条件:险种、年期、版次、投保年龄、吸烟别、被保人性别、体位别、保单年度、眷属序号、生效日期,
涉及的表有两个再保险种设定档(表1)和安泰险种危险保额设定档(表2) :
其中险种和版次在两张表中都有,而“体位别”这个条件不是用来查询,而是用来计算“危险保额”的。
操作步骤:
1、先通过传入的条件查询表1,得到ReinsuranceItemData对象:
ReinsuranceItemData reinsuranceItemData = reinsuranceItemDataDao
.getItemPropertyValue(
Constant.COMPANY_FLAG_ANTAI,
lraVO.getItemCode(),
lraVO.getItemVrsn(),
lraVO.getRelNo(),
lraVO.getBoundDate(),
DetailCodeConstant.ITEM_PROPERTY_REINSURANCE_CLASS);
2、如果返回结果为null,则抛出异常信息:查詢不到險種的再保類別
3、计算危险保额(计算危险保额时会用到责任准备金,查询表2可以得到)。
posted @
2007-12-29 16:02 CoderDream 阅读(384) |
评论 (0) |
编辑 收藏 有家就是幸福!
不需要太大的地方,也不需要装璜的怎么富丽堂皇,但必须是在你的精心打理和细心呵护下充满温馨和爱意的家,无论外面的世界多精彩,外面的风景都美好,都留不住你回家的脚步,家是你心中最美的一道风景线,谁也代替不了:当你不开心的时候,你会想到家;当你外出的时候,你最想的是家;当你每天下班,迫不及待想回的是家;你最留恋的还是家……家是温馨的港湾;家是女人心灵的栖息地;家有着期盼等待你的亲人。即使有时出现波浪,但是都不能阻止你义无返顾地奔向它的怀抱。
有个守候的丈夫就是幸福。
人们都说:女人最大的幸福是嫁一个好男人。好男人的标准很广泛,有人说好男人就应该是财富名利、事业辉煌双收的男人,又有人说好男人一定是英俊潇洒,浪漫多情。让我告诉你。那种男人是极品男人,但不一定是好男人,我们不能要求他尽善尽美,只要生活中用心去体会,你会感受到男人的好,也许他既不多金又不英俊,但他确实实在在的守候在你的身边,渴了会给你递上一杯热茶;困了会搂着你入睡;累了会为你放好洗澡水,轻轻为你揉揉肩、敲敲背;病了他会一刻不离的守候在你的身边,轻轻扶摸着你的脸;用充满爱怜的目光看着你,病在你身上,痛却在他心上;饿了会给你端来可口的饭菜;天凉了他会提醒你加衣;下雨了他会叮咛你小心;你想浪漫一下的时候,他会递上一朵玫瑰;薄雾的晨曦中,黄昏的街道上他会的牵着你的手一起散步。夕阳下相拥着与你一起慢慢变老。你不觉得这就是一种幸福吗?
有孩子就是幸福。
孩子是自己生命的延续,十月怀胎,诞生了自己和爱人爱情的结晶,此时女人是最幸福的人。之后,在孩子的蹒跚学步中,在孩子咿呀学语时,当孩子用稚嫩的声音叫出第一声妈妈时候;当他用胖乎乎的小手捧着你的脸很幼稚的对说:妈妈你笑起来好漂亮好漂亮的时候;这种幸福的感觉会从心底布满全身渗透进你每一个细胞中。看着孩子在你身边一天天健康成长,他的每一个经历每一个精彩表现都给你的生活增添了无数的快乐。当你需要仰着头才能看清那长满青春痘的脸时候,他还会依偎在你身边用已不太稚嫩的声音叫着可爱的妈妈,看你的眼神还是充满了依恋和崇拜,妈妈在孩子的眼中永远是最美丽的。孩子在妈妈的眼中永远是最优秀的。你能说这不是一种幸福吗?
有工作就是幸福。
现在社会上的竞争异常的激烈,就业形势也越来越严峻.我们女人,谁不在期盼自己能找到一个适合自己的好工作,通过自己的努力拼搏付出了大量的心血后,换来了一份相对稳定的工作,这不是一种幸福吗?尽管在工作中你会付出很多辛劳,承担许多压力,但它却让你的生活丰富多彩,让你的人生活的充实,最起码能让你衣食无忧,做一个经济独立,人格独立的女人。你会加倍珍惜拥有的这个"饭碗"-----上班努力工作,下班回家和丈夫孩子还有老人一起共渡美好时光,多惬意!
有朋友就是幸福。
你的快乐有他们分享,你的伤痛有他们安抚,你的烦恼有他们聆听,他们是你晦暗心情时的一缕阳光,因为有了他们,你的世界不会孤单寂寞;因为有他们,你的人生才那么丰富多彩。朋友的魅力在于聆听!当你最需要倾诉的时候,往往只有朋友的耳朵里能装进你的酸甜苦辣,给你安慰和你一起分享生活,让彼此触动, 让你心绪重新聚合重新沸腾,让彼此情感世界里多一份细腻温馨的味道.不管在身边还是在远方,有那么几个人老惦记着自己,是自己最忠实的听众难道不是一种幸福吗?
其实,只要你用心去感受去体会,幸福就是那么简简单单!幸福可能就象空气一样弥漫在你生活的点点滴滴、琐琐碎碎之中。如同一杯白开水,表面清清淡淡,却是你生命之泉;如同一杯淡淡的西湖龙井茶,表面简简单单,细细品味那一丝丝,一点点的清香渗透进你的心底......如同一杯苦咖,虽然有点苦,回味却是香甜的,还能让你精神振奋;如同一杯蜂蜜茶,香香甜甜一种又健康又美容的饮品。那如意的工作,那优厚的经济收入,那称心的家庭,只是我们获得幸福的载体,如果我们不懂得去感受幸福体会幸福,那么再好的日子也不会让你感觉到幸福.记住:幸福就在我们手中,它需要我们去创造;幸福就在我们心中,它需要我们去感受;幸福就在我们眼中,它需要我们去发现。让我们在幸福的长河中,在幸福的阳光下,好好的去感受生活中的点点幸福,能感受幸福的人,是快乐的人,是永远年轻的人。
本文转载自『左岸读书_blog!』
http://dhlmtzx.edudh.net/oblog/
更多精彩内容,欢迎访问左岸读书_blog!
posted @
2007-12-26 11:48 CoderDream 阅读(306) |
评论 (0) |
编辑 收藏怎样移动富士山?
这个问题是比尔·盖茨对那些渴望应聘微软公司的大学毕业生提出的一道面试题。而对此,比尔·盖茨的解释是:它没有固定的正确答案,我只想了解这些年轻人有没有按照正确的思维方式去思考问题。
最明智的选择
If you don’t like something, change it. If you can’t change it ,change your
attitude. Don’t complain
一个年轻人,觉得自己怀才不遇,有位老人听了他的遭遇,随即把一粒沙子扔在沙滩上,说:“请把它找回来”,“这怎么可能”年轻人说道,接着老人又把一颗珍珠扔到沙滩上,“那现在呢?”他说。
——如果你只是沙滩中的一粒沙,那你不能苛求别人注意你,认可你。如果要别人认可你,那你就想办法先让自己变成一颗珍珠。
“无论你想做什么,现在就做。”著名画家柯罗,为一位年轻画家指出了这位年轻人作品需要改进的地方,“谢谢您,”年轻画家说,“明天我就将它全部修改。”柯罗激动的说:“为什么是明天,要是你今晚就死了呢?”
——你也许会滞留原地,但时间绝对不会。
(You may delay, but time will not)
——富兰克林
你必须用你手中的牌玩下去,就好比人生,发牌的是上帝,不管是怎样的牌,你都必须拿着,你所做的就是尽你全力,求得最好的结果。(注:这句话和电影《阿甘正传》中阿甘的母亲说的关于巧克力的那段很相似,但那句话却只说了前半句:你永远不知道下一颗巧克力是什么味道,对于怎么去处理这个事实却没有提及,而个人觉得阿甘的处事风格更倾向于随遇而安,不管有多少困难,既来之则安之,去面对他,但又不强求,不反抗,我想很多人不会接受这样的态度,因为要达到阿甘这样的境界还是需要些运气的,呵呵,不过我喜欢阿甘的原因是他对生活下去的信念,即时老天对儿时的他并不公平,他对爱和未来的执著态度,坚持下去,不放弃的精神我想是感动了上帝吧,呵呵,说多了,其实就是本电影,被导演戏弄了一会。)
有一只小狮子问母亲:“妈妈,幸福在哪里?”母亲说:“幸福就在你的尾巴上啊。”于是,小狮子转起了圈,追着自己的尾巴。母狮子笑着说:“孩子,幸福不是那样得到的,只要你昂首向前走,幸福就会一直跟着你。”
当肖邦已经是非常知名的演奏家时,他遇到十年前一起在街头演奏的伙伴,发现他仍在他们当年一起占到的那块最赚钱的地方演奏。伙伴遇到肖邦非常高兴,问他现在在哪里演奏,肖邦回答了一个很有名的音乐厅,伙伴惊讶的说:“怎么?那里门口也很好赚钱吗?”“最赚钱的好地盘”同样是一个“风平浪静的小港湾”,那位伙伴停留在那里,甚至有些沾沾自喜,却没有意识到自己的才华,潜力,前程全都被这块“最赚钱的好地盘”葬送了。(注:过于安逸的生活的确会使一个人失去激情和斗志。)
知道自己想要什么的一半是知道自己在得到它之前必须先舍弃什么。
某家报社举办这样一次有奖智力竞赛,如果卢浮宫不幸失火,你只有时间救出一幅画,你会选择救哪幅?答案最多的是《蒙娜丽莎》,但是得奖的答案却是:救那幅离出口最近的。
——We must do the best we can with what we have.
有位大师,潜心修炼了多年,终于练成了“移山大法”。有人向他请教,他说:“要移山其实很简单,如果山不过来,我们就过去”。
——人类可以通过改变自己的态度去改变自己的生活,这是属于每一代人的最伟大的发现。
很显然,问题的答案已经揭晓了,从事帆船运动的朋友说:“当一个人在大海中航行时,他当然不可能改变海面的风向,但他却可以通过不断调整船上的风帆,让自己一直向目的地驶去” 比尔·盖茨说过:“生活是公平的,你要去适应他”
所以,怎样移动富士山? 答案很简单,那就是如果富士山不过来,我们就过去!
[PPT]如何移动富士山点击下载此文件 [简]
本文转载自『左岸读书_blog!』
http://dhlmtzx.edudh.net/oblog/
更多精彩内容,欢迎访问左岸读书_blog!
posted @
2007-12-26 11:47 CoderDream 阅读(361) |
评论 (0) |
编辑 收藏WinCVS与CVSNT简明使用手则
(作者:Jackey,整理:CoderDream)
1 前言:
CVS是版本控制的利器,目前在Linux和Windows下都有不同版本;但是国内大多数应用介绍都是基于Linux等开放源代码的开放性软件组织,而且讲解的也不系统,让人摸不着头脑;Windows下的CVS使用介绍更是了了无几。
本文是针对Windows的LAN环境下使用CVS的经验介绍,一步一步的向您介绍如何配置和使用CVS的服务器端和客户端。同时,本文只使用到了CVS当中最基本的东西,还有很多更为高级的东西,本文暂不涉及。
完整版CHM:点击下载
posted @
2007-12-25 16:57 CoderDream 阅读(286) |
评论 (0) |
编辑 收藏
1、
prototype.js 1.4版开发者手册(强烈推荐)
posted @
2007-12-25 09:54 CoderDream 阅读(248) |
评论 (0) |
编辑 收藏你的工作是不是总也做不完?是不是经常加班?
你是不是在互联网上很贪婪,感觉总是乐此不疲?
有时候这一切很可能是由坏习惯造成的……
1、 QQ、MSN、Gtalk,一个都不少。
由于聊天对象与聊天内容的不可控制性,使用即时通讯软件是降低工作效率的罪魁祸首。有调查显示,使用即时通讯软件,工作效率会降低20%。(对策:离开他们一段时间,试着专门做你手头上的工作。)
2、“总想多看一点点”——忘记上网的目的。
本想查找工作资料,结果在网页上发现《哈利波特7》出来了;再点进去,又在网页底端看到自己喜欢的明星跟某某又传出了绯闻……点着点着,就忘记自己要上网做什么了。(对策:千万别把工作和娱乐放在一起,工作就好好工作,娱乐才能尽情地挥洒,控制对互联网新奇的诱惑吧。)
3、长期不擦拭电脑屏幕和鼠标。
电脑屏幕已经糊了厚厚的一层灰尘,每次都要瞪大眼睛去看,费力去猜屏幕污点下面的字是什么;鼠标点起来已经非常费力了,反应也迟钝得像八十岁的老汉。这些都间接地影响了工作效率。(对策:保持干净的电脑桌面包括电脑桌面不能放置过多的图标,鼠标一定要好用,不然累死你的手。)
4、长期不清理电脑系统。
防火墙的防御力是有限的。长期不清理电脑系统的后果就是,内存被一些潜藏的垃圾程序给占用了,直接影响了电脑的运行速度。电脑运行慢了,也就降低了工作效率。 (对策:对系统垃圾即时清理,可以请一些系统垃圾清理软件来帮忙。比如:一键清理系统垃圾文件)
5、长期不整理办公桌和文件。
办公桌和文件杂乱的后果就是,想找东西的时候却找不到。以前,有调查公司专门对美国200家大公司职员做了调查,发现公司职员每年都要把6周时间浪费在寻找乱放的东西上面。(对策:养成东西归位的好习惯,现在就开始整理你的桌面的文件档案吧!)
6、长期不整理电子邮件和通讯录。
想给客户发个邮件,却记不得E-mail地址,于是在电子邮箱中一通乱找,却发现自己的邮箱早已被垃圾邮件搞得汪洋一片。想搜什么都变得很困难。再返回一堆堆名片中去找,就又陷入了第5个坏习惯。(对策:平时花些时间把电子邮件分类,设置好邮件的过滤功能。)
7、不适时保存文件。
尽管现在电脑的性能越来越高,死机现象越来越少,可是,意外地碰掉电脑插头、程序操作不当从而造成电脑关机、死机,总是不可避免的,如果不适时保存文件,那么文件就很可能会丢失,前功尽弃。(对策:关键时刻保存一下,免得一回儿痛心疾首。)
8、“不磨刀误了砍柴工”。
工作之前,不做充分的计划、准备。行动之后,才发现要么是工具准备得不充分,只得停下工作再去找文件、资料;要么工作做到一半,才发现偏离了预定的方向,只得重新开始,前功尽弃。(对策:还是习惯问题!)
9、梦想电脑有“三头六臂”。
在同一时间,一个网页打不开,一个程序在等待,为了节约时间,就只好再打开其他网页。结果同一时间,十几个窗口同时打开着,电脑就变得“老态龙钟”,一动不动。什么都干不成。(对策:做重要事情的时候,只做一件,不然过多的程序会让你分心,我理解你的心境,PC都已经双核了,不榨干真是浪费!这心态不好。)
10、不会充分利用等待时间。
打开一个软件,电脑迟迟没有反应,于是坐在电脑旁干等;打开一个网页,迟迟显示不出来,又打开新的网页,又是一阵干等;要打印文件,发现打印机里排着队的文件有好多,只好继续等待……一天的工作中,光是耗在电脑上的等待时间就很可观,如果不充分利用这些等待间隙的话,那自己的工作时间只好额外延长了。 (对策:等不能解决问题,因为程序卡在那里了,动手检查一下吧。)
11、“耻于下问”。
现在,电脑出现的病症越来越离奇。不是每个人都是电脑高手。身为IT中人,似乎像别人请教就显得自己太不专业了。于是就上网查找解决方案。结果,在垃圾信息的汪洋大海中奋力拼搏,折腾半天,才化解问题,浪费了工作的宝贵时间。如果问问身边人,可能几秒钟就解决问题了。(对策:我就常常被问,我发现我身边的同事是太会问,因为他们不是IT中人, 他们遇到问题就问我,这也一个“累”字啊。)
12、过分崇拜科技。
IT人很容易就会陷入科技崇拜。如果有新软件、新系统发布,IT人一定是最早尝试的。不管自己的电脑能不能撑起Vista,一定要给电脑装上。电脑负荷不了,只好不断罢工。工作也会因之延误。(对策:呵呵,这是很多的通病,总认为新出的一定更好,功能更大,其实软件适用才是根本,别再喜新厌旧了。)
13、长期端坐于电脑前面。
一坐就是半天。工作并不会因为你的马不停蹄而加速。相反,如果总是沉浸在工作中,不适时休息,容易造成大脑的疲倦,反而降低了工作效率 。(对策:马上关闭电脑,去休息。)
本文转载自『左岸读书_blog!』
http://dhlmtzx.edudh.net/oblog/
更多精彩内容,欢迎访问左岸读书_blog!
posted @
2007-12-20 14:08 CoderDream 阅读(414) |
评论 (1) |
编辑 收藏■ 1、起床先叠被 人体本身也是一个污染源。一夜睡眠,人体皮肤会排出大量水蒸气,使被子不同程度地受潮。人的呼吸和分布全身的毛孔排出的化学物质有145种,从汗液中蒸发的化学物质有151种。被子吸收或吸附水分和气体,如起床就立即叠被,不让其散发出去,易使被子受潮及受化学物质污染。
■ 2、不吃早餐 不吃早餐的人通常饮食无规律,容易感到疲倦,头晕无力,天长日久会造成营养不良、贫血、抵抗力降低,并会产生胰、胆结石。
■ 3、饭后松裤带 可使腹腔内压下降,消化器官的活动与韧带的负荷量增加,从而促使肠子蠕动加剧,易发生肠扭转,使人腹胀、腹痛、呕吐,还容易患胃下垂等病。
■ 4、饭后即睡 会使大脑的血液流向胃部,由于血压降低,大脑的供氧量也随之减少,造成饭后极度疲倦,易引起心口灼热及消化不良,还会发胖。如果血液原已有供应不足的情况,饭后倒下便睡,这种静止不动的状态,极易招致中风。
■ 5、饱食 容易引起记忆力下降,思维迟钝,注意力不集中,应变能力减弱。经常饱食,尤其是过饱的晚餐,因热量摄入太多,会使体内脂肪过剩,血脂增高,导致脑动脉粥样硬化。还会引起一种叫“纤维芽细胞生长因子”的物质,在大脑中数以万倍增长,这是一种促使动脉硬化的蛋白质。脑动脉硬化的结果会导致大脑缺氧和缺乏营养,影响脑细胞的新陈代谢。经常饱食,还会诱发胆结石、胆囊炎、糖尿病等疾病,使人未老先衰,寿命缩短。
■ 6、空腹吃糖 越来越多的证据表明,空腹吃糖的嗜好时间越长,对各种蛋白质吸收的损伤程度越重。由于蛋白质是生命活动的基础,因而长期空腹吃糖,会影响人体各种正常机能,使人体变得衰弱以致缩短寿命。
■ 7、留胡子 胡子吸附有害物质。当人吸气时,被吸附在胡子上的有害物质就可能被吸入呼吸道。通过对留有胡子的人吸入空气成分进行的定量分析,发现吸进的空气中含有几十种有害物质,包括酚、甲苯、丙酮、异戊丙二烯等多种致癌物,留胡子的人吸入的空气污染指数是普通空气的4.2倍。如果下巴有胡子,又留八字胡,污染指数可高达7.2倍。加上抽烟等因素,污染指数将高达普通空气的50倍。
■ 8、跷二郎腿 会使腿部血流不畅,影响健康。如果是静脉瘤、关节炎、神经痛、静脉血栓患者,跷腿会使病情更加严重。尤其是腿长的人或孕妇,容易得静脉血栓。
■ 9、伏案午睡 一般人在伏案午睡后会出现暂时性的视力模糊,原因就是眼球受到压迫,引起角膜变形、弧度改变造成的。倘若每天都压迫眼球,会造成眼压过高,长此下去视力就会受到损害。
■ 10、睡前不刷牙 睡前刷牙比起床后刷牙更重要。这是因为遗留在口腔中和牙齿上的细菌、残留物等,在夜间对牙齿、牙龈有较强的腐蚀作用。
■ 11、睡懒觉 使大脑皮层抑制时间过长,天长日久,可引起一定程度的大脑功能障碍,导致理解力和记忆力减退,还会使免疫功能下降,扰乱肌体的生物节律,使人懒散,产生惰性,同时对肌肉、关节和泌尿系统也不利。另外,血液循环不畅,全身的营养输送不及时,还会影响新陈代谢。
■ 12、热水沐浴时间过长 在自来水中,氯仿和三氯化烯是水中容易挥发的有害物质,由于在沐浴时水滴有更多的氯和空气接触,从而使这两种有害物质释放很多。资料显示,若用热水盆浴,只有25%的氯仿和40%的三氯化烯释放到空气中;而用热水沐浴,释放到空气中的氯仿就要达到50%,三氯化烯高达80%。
本文转载自『左岸读书_blog!』
http://dhlmtzx.edudh.net/oblog/
更多精彩内容,欢迎访问左岸读书_blog!
posted @
2007-12-20 09:11 CoderDream 阅读(328) |
评论 (0) |
编辑 收藏
摘要: 在项目开发中,经常会遇到一些排序的问题。
现在有一个操作VO(Member),它有三个属性,分别为:id(String)、name(String)和age(int)。
情景一:
初始页面,Member对象会以id排序,现在name中保存的是英文名,需对name进行排序;
首先我们来看我们要用到的Java API中的一个接口Comp...
阅读全文
posted @
2007-12-19 16:07 CoderDream 阅读(1696) |
评论 (0) |
编辑 收藏1、[原创]Java 正则表达式的总结和一些小例子
2、[原创]Dom4j下载及使用Dom4j读写XML简介
3、[原创]HashMap和Hashtable的实验比较结果
4、[整理]使用dom4j在xml文件中指定编码从而输入中文
posted @
2007-12-18 13:50 CoderDream 阅读(280) |
评论 (0) |
编辑 收藏
感觉使用沙堆模型来形容知识的广度和深度,以及两者之间的关系比较恰当。沙堆能够堆多高代表知识的深度,沙堆底面占的面积则代表知识的广度。
术业有专攻,真正能够代表核心竞争力和创造效益的是沙堆的高度即知识的深度。因此当我们要准备达到一个高度,首先要准备够一个知识的广度或者说沙堆的底面的基础。在一定的沙堆底面积下,沙堆堆积到一定高度后就很难再堆高了,这个时候必须首先要把沙堆的底面积扩大,即进一步拓展知识的广度,当广度扩大后才能够在广度的基础上进一步朝高度发展。
有了广度后,即沙堆底面积累到一定面积后,就需要有意识的将这种广度朝深度转换,因为转换为深度才能够提高个人核心竞争力和创造效益。如果一味的追求广度将无法将价值最大化。
在学校学习阶段或未工作之前,重点是积累基础知识,铺开沙堆的底面积为广度做准备。因此学习积累的知识越多,视野越宽在工作后更容易比别人的沙堆堆的更高。在工作后,如果不再关注广度的积累,则走到一定高度就很难再向前迈进,这个时候必须回过头来拓展知识的广度。深度是目标,广度是基础,两者的关系必须要兼顾好。
posted @
2007-12-12 10:25 CoderDream 阅读(394) |
评论 (0) |
编辑 收藏
原文地址:
http://blog.sina.com.cn/s/blog_49b7e6a101000dab.html
Lomboz是Eclipse的一个主要的开源插件(open-source plug-in),Lomboz插件能够使Java开发者更好的使用Eclipse去创建,调试和部署一个100%基于J2EE的Java应用服务器。
Lomboz插件的使用,使得Eclipse将多种J2EE的元素、Web应用的开发和最流行的应用服务器车结合为一体。
Lomboz的主要功能有:
1、 使用HTML pages, servlets, JavaServer" Page (JSP) files等方式建立Web应用程序
2、 JSP的编辑带有高亮显示和编码助手
3、 JSP语法检查
4、 利用Wizard创建Web应用和EJB应用
5、 利用Wizard创建EJB客户端测试程序
6、 支持部署J2EE Web应用档案(EAR),Web模块文件(WAR)和EJB档案文件(JAR)
7、 利用Xdoclet开发符合EJB1.1和2。0的应用
8、 能够实现端口对端口的本地和远程的测试应用服务
9、 能够支持所有的有可扩展定义的Java应用服务
10、能够利用强大的Java调试器调试正在运行的服务器端代码(JSP&EJB)
11、通过使用Wizard和代码生成器提高开发效率
12、创建Web服务客户端的WSDL形式的文件
Lomboz适用的服务器有:
Apache Tomcat, JBOSS, JOnAS, Resin, Orion, JRun, Oracle IAS, BEA WebLogic Server andIBM WebSphere
在安装Lomboz插件得时候,要安装emf-sdo-runtime-2.0.0插件,要不然,你得Eclipse虽然加载了Lomboz插件,但是在你得视图里面还是不会出现Lomboz选项。
装完这些,再按照一般文档里面得步骤。就没有问题了。
posted @
2007-12-10 17:39 CoderDream 阅读(400) |
评论 (0) |
编辑 收藏
配置环境
WINDOWS XP SP2
JDK 1.6
TOMCAT 6.0
ECLIPSE 3.3
LOMBOZ 3.3
一. JDK(JDK1.6)的安装与配置
(1) 在JAVA官方网站下载JDK工具包(JDK1.6)
http://java.sun.com/javase...



(2) 执行安装文件,如图



(3) 配置JAVA运行环境:
【开始】-【控制面板】-【性能和维护】-【系统】-【高级】或者右键单击【我的电脑】-【属性】-【高级】

进入【环境变量】界面,选择【系统变量】中的【Path】选项

在【变量值】项的初始端输入您的JDK安装目录(%JAVA_HOME%\bin,%JAVA_HOME%为JAVA安装目录)至bin目录,注意:不要忘记分号。

(4) 测试
【开始】-【运行】-【cmd】-【java -version】可以查看您当前的JDK版本


在C盘根目录中创建一文本文档,键入以下语句(如图),并保存为JAVA文件,注意:CLASS类名与保存的文档名必须一致,且大小写敏感。

在命令行模式中测试刚刚编写的JAVA文件(如图),运行成功则显示Hello World!

二. Tomcat6.0的安
(1) 下载Tomcat安装包
http://tomcat.apache.org/d...

(2) 执行安装文件,如图






(3) 测试(测试结束后关闭Tomcat服务器)
在%TOMCAT_HOME%\bin目录下执行tomcat6w.exe(%TOMCAT_HOME%为Tomcat安装目录),点击Start启动Tomcat服务器。

打开浏览器,在地址栏中输入:http://localhost:8080 运行成功则出现如下画面

PS:示例中的Tomcat为Windows Service Installer(.exe)程序,安装成功后无需再进行额外配置。
三. Eclipse(Eclipse3.3)与Lomboz(Lomboz3.3)的安装
(1) 下载Eclipse与Lomboz合包(Eclipse与Lomboz版本号必须匹配,否则会引发错误)
http://forge.objectweb.org...


(2) 执行程序(解压后直接使用,无需安装),如图

注意:Lomboz3.1版本以上在Eclipse首选项界面中均不会再有【Lomboz】选项

四. Tomcat插件的安装与配置
(1) 下载TomcatPluginV321.zip,鉴于官网无法访问,可以去百度、谷歌搜索,以下地址仅供参考
http://d.download.csdn.net...(需要先注册)
(2) 将TomcatPluginV321.zip解压缩到eclipse安装目录中的plugins文件夹下
(3) 在命令行模式中重新启动Eclipse(以-clean模式启动)

(4) 配置Tomcat version与Tomcat home(参照自身的安装路径)
打开Eclipse,选择【Window】-【Preferences】-【Tomcat】

五. 集成环境测试(JSP程序)
创建一个新项目
打开Eclipse,选择【File】-【New】-【Project】-【Web】

输入项目名Test,点击Finish

创建服务器,选择【File】-【New】-【Other】-【Server】





创建JSP文件,选择【File】-【New】-【Other】-【Web】

输入文件名


编辑JSP文件,如图

打开服务器,右击选择Start


运行服务器,选择【Run】-【Run As】-【Run on Server】

打开浏览器,在地址栏中输入 http://localhost:8080/Test/Test.jsp 运行成功则显示以下画面
posted @
2007-12-10 17:35 CoderDream 阅读(1910) |
评论 (1) |
编辑 收藏
eclispe想必大家都很熟悉了,一般来说,eclipse插件都是安装在plugins目录下。不过这样一来,当安装了许多插件之后,eclipse变的很大,最主要的是不便于更新和管理众多插件。用links方式安装eclipse插件,可以解决这个问题。
当前配置XP SP1,eclipse3.0.1
现在假设我的eclipse安装目录是D:\eclipse,待安装插件目录是D:\plug-in ,我将要安装LanguagePackFeature(语言包)、emf-sdo-xsd-SDK、GEF-SDK、Lomboz这四个插件。
先把这四个插件程序全部放在D:\plug-in目录里,分别解压。如Lomboz3.0.1.zip解压成Lomboz3.0.1目录,这个目录包含一个plugins目录,要先在Lomboz3.0.1目录中新建一个子目录eclipse,然后把plugins目录移动到刚建立的eclipse目录中,即目录结构要是这样的:D:\plug-in\Lomboz3.0.1\eclipse\plugins
Eclipse 将会到指定的目录下去查找 eclipse\features 目录和eclipse\plugins 目录,看是否有合法的功能部件和(或)插件。也就是说,目标目录必须包含一个 \eclipse 目录。如果找到,附加的功能部件和插件在运行期配置是将是可用的,如果链接文件是在工作区创建之后添加的,附加的功能部件和插件会作为新的配置变更来处理。
其它压缩文件解压后若已经包含eclipse\plugins目录,则不需要建立eclipse目录。
然后在 eclipse安装目录D:\eclipse目录中建立一个子目录links,在links目录中建立一个link文件,比如 LanguagePackFeature.link,改文件内容为 path=D:/plug-in/LanguagePackFeature 即这个link文件要对应一个刚解压后的插件目录。
说明:
1. 插件可以分别安装在多个自定义的目录中。
2. 一个自定义目录可以安装多个插件。
3. link文件的文件名及扩展名可以取任意名称,比如ddd.txt,myplugin都可以。
4. link文件中path=插件目录的path路径分隔要用\\或是/
5. 在links目录也可以有多个link文件,每个link文件中的path参数都将生效。
6. 插件目录可以使用相对路径。
7. 可以在links目录中建立一个子目录,转移暂时不用的插件到此子目录中,加快eclipse启动。
8. 如果安装后看不到插件,把eclipse 目录下的configuration目录删除,重启即可。

注意:关于用links方式安装Lomboz插件,在编辑EJB时可能会产生问题,这个将会在有关Lomboz插件的文章中探讨。
posted @
2007-12-10 17:29 CoderDream 阅读(288) |
评论 (0) |
编辑 收藏
1、
Anatomy of an Android Application(中文翻译)
2、
在android平台上测试C/C++程序及库
3、
http://www.forwind.cn/category/linux/android/
4、
http://www.1android.cn/Default.asp
5、
Android开发者论坛
6、
Android中文网
7、
Android中文文档
posted @
2007-12-10 17:18 CoderDream 阅读(348) |
评论 (0) |
编辑 收藏
1、
推荐一个很棒的JS绘图库Flot
2、
DroidDraw - Android的界面设计器
3、
AppFuse 2.0.1发布
4、
MySQL InnoDB数据恢复工具
5、
用 AjaxTags 简化 Ajax 开发
6、
Java SE 6 Update N Early Access Program
7、
JSFUnit - JSF的测试工具
posted @
2007-12-06 14:27 CoderDream 阅读(267) |
评论 (0) |
编辑 收藏
1、
正则表达式30分钟入门教程
posted @
2007-11-29 11:06 CoderDream 阅读(310) |
评论 (1) |
编辑 收藏
1、
《EJB3.0实例教程》官方网
2、
将 EJB 部署到 WebSphere 应用服务器
3、
Enterprise JavaBeans 入门
posted @
2007-11-28 13:50 CoderDream 阅读(254) |
评论 (0) |
编辑 收藏1、安装Weblogic:
使用的EJB服务是BEA的weblogic8.1,下载BEA的weblogic8.1,然后安装。安装步骤省略。
2、定义EJB远程接口(Remote Interface):
任何一个EJB都是通过Remote Interface被调用,EJB开发者首先要在Remote Interface中定义这个EJB可以被外界调用的所有方法。执行Remote Interface的类由EJB生成工具生成。
以下是HelloBean的Remote Inteface程序:
package com.leo;
import java.rmi.RemoteException;
import java.rmi.Remote;
import javax.ejb.*;
public interface Hello extends EJBObject, Remote {
//this method just get "Hello EJB" from HelloEJB.
public String getHello() throws RemoteException;
}
3、定义Home Interface
EJB容器通过EJB的Home Interface来创建EJB实例,和Remote Interface一样,执行Home Interface的类由EJB生成工具生成。以下是HelloEJB 的Home Interface程序:
package com.leo;
import javax.ejb.*;
import java.rmi.Remote;
import java.rmi.RemoteException;
import java.util.*;
/**
* This interface is extremely simple it declares only
* one create method.
*/
public interface HelloHome extends EJBHome {
public Hello create() throws CreateException,
RemoteException;
}
4、写EJB类
在EJB类中,编程者必须给出在Remote Interface中定义的远程方法的具体实现。EJB类中还包括一些 EJB规范中定义的必须实现的方法,这些方法都有比较统一的实现模版,编程者只需花费精力在具体业务方法的实现上。
以下是HelloEJB的代码:
package com.leo;
import javax.ejb.*;
public class HelloEJB implements SessionBean{
public void ejbCreate(){}
public void ejbRemove(){}
public void ejbActivate(){}
public void ejbPassivate(){}
public void setSessionContext(SessionContext ctx){}
public String getHello() {
return new String("Hello,EJB");
}
}
5、创建ejb-jar.xml文件
ejb-jar.xml文件是EJB的部署描述文件,包含EJB的各种配置信息,如是有状态Bean(Stateful Bean) 还是无状态Bean(Stateless Bean),交易类型等。ejb-jar.xml文件的详细信息请参阅EJB规范。以下是HelloBean的配置文件:
<?xml version="1.0"?>
<!DOCTYPE ejb-jar PUBLIC "-//Sun Microsystems Inc.//DTD Enterprise JavaBeans 1.2//EN" "http://java.sun.com/j2ee/dtds/ejb-jar_1_2.dtd">
<ejb-jar>
<enterprise-beans>
<session>
<ejb-name>Hello</ejb-name>
<home>com.leo.HelloHome</home>
<remote>com.leo.Hello</remote>
<ejb-class>com.leo.HelloEJB</ejb-class>
<session-type>Stateless</session-type>
<transaction-type>Container</transaction-type>
</session>
</enterprise-beans>
</ejb-jar>
6、创建weblogic-ejb-jar.xml
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE weblogic-ejb-jar PUBLIC "-//BEA Systems, Inc.//DTD WebLogic 8.1.0 EJB//EN" "http://www.bea.com/servers/wls810/dtd/weblogic-ejb-jar.dtd">
<weblogic-ejb-jar>
<description><![CDATA[Generated by XDoclet]]></description>
<weblogic-enterprise-bean>
<ejb-name>Hello</ejb-name>
<stateless-session-descriptor>
</stateless-session-descriptor>
<reference-descriptor>
</reference-descriptor>
<jndi-name>Hello</jndi-name>
<local-jndi-name>HelloLocal</local-jndi-name>
</weblogic-enterprise-bean>
</weblogic-ejb-jar>
7、部署和编译
EJB的jar包是由class文件和描述文件组成,对于weblogic服务器来说还要增加weblogic-ejb-jar.xml描述文件。编译Java源文并将编译后class和ejb-jar.xml、weblogic-ejb-jar.xml打包到Hello.jar
7.1:创建目录build。
7.2:在build下新建目录META-INF,把文件ejb-jar.xml、weblogic-ejb-jar.xml拷到META-INF下。
7.3:把编译好的class文件拷到build目录下(此时为com/leo/Hello.class,HelloEJB.class,HelloHome.class)。
7.4:打包成jar文件: jar -cvf hello.jar *.* 。
7.5:再将hello.jar文件部署到weblogic服务器中。
8、写客户端调用程序
您可以从Java Client,JSP,Servlet或别的EJB调用HelloBean。
调用EJB有以下几个步骤:
通过JNDI(Java Naming Directory Interface)得到EJB Home Interface
通过EJB Home Interface 创建EJB对象,并得到其Remote Interface
通过Remote Interface调用EJB方法
以下是一个从Java Client中调用HelloBean的例子:
package ejb.hello;
import javax.naming.Context;
import javax.naming.InitialContext;
import java.util.Hashtable;
import javax.ejb.*;
import java.rmi.RmoteException;
/**
* @author Copyright (c) 2000 by Apusic, Inc. All Rights Reserved.
*/
public class HelloClient {
public static void main(String args[]){
String url = "rmi://localhost:7100";
Context initCtx = null;
HelloHome hellohome = null;
try {
Hashtable env = new Hashtable();
env.put(Context.INITIAL_CONTEXT_FACTORY,"com.apusic.jndi.InitialContextFactory");
env.put(Context.PROVIDER_URL, url);
initCtx = new InitialContext(env);
} catch(Exception e){
System.out.println("Cannot get initial context: " + e.getMessage());
System.exit(1);
}
try {
Object obj=ctx.lookup("Hello");
HelloHome home=(HelloHome)PortableRemoteObject.narrow(obj,HelloHome.class);
Hello hello = hellohome.create();
String s = hello.getHello();
System.out.println(s);
}catch(Exception e){
System.out.println(e.getMessage());
System.exit(1);
}
}
}
运行HelloClient,可得到以下输出:
Hello EJB
posted @
2007-11-28 13:44 CoderDream 阅读(2172) |
评论 (0) |
编辑 收藏ejb3.0开发环境配置
运行环境配置
1、工具下载与安装
1>下载安装JDK5.0(
www.java.sun.com)
2>下载安装eclipse3.2.x(
www.eclipse.org)(如果你下载了JBOSS IDE2.0(内含eclipse3.2.x,这个可以不要)
3>下载和安装jboss-4.0.5.GA 服务器(记住一定要下载安装版,内含EJB3.0Container,地址:
http://sourceforge.net/project/d ... mp;use_mirror=jaist)
4>下载插件JBOSS IDE 2.0(
http://sourceforge.net/project/d ... amp;use_mirror=nchc)
安装JBOSS是要注意几点:
1>议不要安装在Program Files 目录,否则一些应用会导致莫名的错。
2>选择带集群功能的安装选项“ejb3-clustered”
3>在输入配置名称时,输入“all”
4>在配置JMX时,把所有选择荐都勾上,并输入jmx-console的用户名和密码!
5》运行JBOSS,进行JBOSS安装目录下,进入BIN目录下,运行 run -c all,如果直接运行run,会报错!(因为你run.bat不知道你运行的是那种配置all,default,还是min)
2、设置环境变量
JAVA_HOME=JAVA安装目录
JBOSS_HOME=JBOSS安装目录
3、认识JBOSS目录用途
目录 描述
bin 启 动 和关闭JBoss的脚本
client 客户端与JBoss通信所需的Java 库(JARs)
docs 配置的样本文件(数据库配置等)
docs/dtd 在JBoss中使用的各种XML文件的DTD。
lib 一些JAR,JBoss启动时加载,且被所有JBoss配置共享。(不要把你的库放在这里)
server 各种JBoss配置。每个配置必须放在不同的子目录。子目录的名字表示配置的名字。JBoss
包含3 个默认的配置:minimial,default和all,在你安装时可以进行选择
server/all JBoss的完全配置,启动所有服务,包括集群和IIOP。(本教程就采用此配置)
server/default JBoss 的默认配置。在没有在JBoss 命令航中指定配置名称时使用。(本教程没有安装此
配置,如果不指定配置名称,启动将会出错)
server/all/conf JBoss的配置文件。
server/all/data JBoss的数据库文件。比如,嵌入的数据库,或者JBossMQ。
server/all/deploy JBoss的热部署目录。放到这里的任何文件或目录会被JBoss自动部署。
EJB、WAR、EAR,甚至服务。
server/all/lib 一些JAR,JBoss在启动特定配置时加载他们。(default和minimial配置也包含这个和下面两个目录。)
server/all/log JBoss的日志文件
server/all/tmp JBoss的临时文件
4、
EJB部署
JBoss中的部署过程非常的简单、直接。在每一个配置中,JBoss不断的扫描一个特殊目录的变化:
[jboss安装目录]/server/config-name/deploy。
posted @
2007-11-28 11:49 CoderDream 阅读(676) |
评论 (0) |
编辑 收藏
大多数人学英语只知整天死背词汇表,或昏昏欲睡地听老师絮叨语法。尽管老师常会夸张运用脸部肌肉演示发音,然而仅仅一天之后,所学一切就开始在你脑海中逐渐褪色。这便导致了一个无奈的结果:就算你会读会写,可当你真正面对一个外国人进行电话会议或演讲陈述的实战练习时,你还是傻眼了。
现在EF中国区总裁Peter Winn告诉你:只需掌握了五个基本秘诀,即可轻松掌握单词、词组,真正实现“无痛”学英语。
1.确定目标,适时褒奖。大多数人把学英语的目的简单地定义为“对未来有益”,其实精准的目标设定更有助于集中精力达成最终结果,其关键在于确定成绩测试方式及时间范围。你需要对自身英语水平做出客观评估,并制定渐进提高的详细步骤。须谨记:衡量学习成果,定要始终使用同一衡量标准,这样才能清楚看见进步空间。另外,设立长远目标倒也无妨,如同“说一口流利的、不带丝毫口音的英语”等等,就是不少人正在使用着的目标。不过,以阶段性目标作为发端容易敲开成功之门,“我希望能与同事进行基本商务对话”,就是一个不错的例子。最后,千万不要忘记,哪怕你获得最微小的进步,也应适时奖励自己,如此可以保证长期的学习激情。
2.快乐学习,轻松记忆。学习英语,可以脱离教室。研究表明,当人们处于快乐的心境下,记忆力更突出、自信心更富裕。把英语学习同兴趣爱好结合起来。喜欢打网球,就参加英语交流的网球俱乐部;喜欢烹饪,就报名采用英语教学的烹饪培训班;喜欢唱歌,不妨试试在卡拉OK演唱英语歌曲……用眼睛盯着屏幕,用耳朵捕捉一遍遍重复的歌词,辅以熟悉流畅的旋律,这一切让单词记忆变得越发简单。可能最初有点难,但是这会强迫你使用英语。尤其是你正做着自己热爱的事情,学习英语的痛苦也就一扫而光了。
3. 融入环境,异化自己。建立英语学习自信心的关键无非:实践实践再实践!缺少实践机会和语言环境是目前中国学生面临的最大挑战。当年我学习中文的时候,我和身边朋友定下默契,尽量强迫自己用中文互相交流,即便中文不是我们其中任何一个人的母语。我们大家约定不到万不得已之时,必须一直说英语,甚至对违反默认规则的人实行惩罚措施!虽然刚开始可能会犯很多错误,但随着对英语对话模式的逐渐熟悉,所犯错误也将越来越少。令自己处于一个天然外语环境同样重要,这个环境可以是办公室、俱乐部、健身馆、酒吧、餐厅,诸如此类的场所越多越好。尽量挑选“主动”语言环境,比如俱乐部或派对,在那里你会更有说话的欲望。而像电影院之类的“被动”语言环境,收效往往并不出色。不要害怕犯错——走出门去,找外国人交流。
4. 寻求帮助,制订规划。学习英语的一个关键步骤,是接受高质量学习指导或参加高端语言培训项目。据我了解,很多学生宁愿选择自学,以及与外国友人实战练习。最终,这些学生的确能够建立充分信心,敢于流利表达自己,但词汇量却相当有限。这就等于缺少了最基本的砖块,无法建起坚实的语言基础。我认识一个女孩,她说话速度很快,却从不注意用词,因此总是表达不够清晰。另外一个学生经常和外国友人一起泡吧,于是连他自己都没有意识到,他的口头英语里夹杂许多酒吧用语,甚至包括hey dude、yeah man 、that rocks!这些粗俗的脏话,就好像他长年在酒吧工作一样。扮演不同的社会角色,必然有完全迥异的英语表达方式,你能想象与国外客户高层管理人员开电话会议时突然冒出hey dude、that rocks这些词句吗?而这些区别只能由一个专业老师指导。一个称职老师会详细分析学生的优势和不足,找到需要辅导的不足所在,强化本身具备的优势,由此制定一个切实可行的学习规划。 学习语言不仅需要流利,更加需要得体!
5. 承诺自己,态度积极。从来没有确切证据表明,某种特质的某些人更易于或更难于熟练掌握一门语言。相信我,任何人无论年龄、基础,只要具备正确学习态度,都足以学好英语。那些失败过的学生,并不是因为他们不够聪明,而是因为他们没有把学英语当作一种对自己的承诺。你越早制定明确目标和学习计划,就能越快克服重重障碍。当然,最初要让舌头适应陌生的声音和句式,确实有些困难。这并不该让你退却。失败原因永远只有一个,那就是你自己向这些困难投降了。
遵循这5个简单步骤,你很快会发现词汇量和造句能力迅速提高,而对英语学习信心逐渐增强,与老外对话时逐渐懂得镇定心思。曾经有位老师教育我要“操控”语言,而不是让语言“操控”你。 不知不觉,你会爱上英语,学习也不再感觉痛苦。
posted @
2007-11-27 17:27 CoderDream 阅读(350) |
评论 (0) |
编辑 收藏
可能是有些自负的因素吧,我常常觉得《程序员》杂志上的很多观点和我不谋而合。我一般喜欢看的是人物介绍、产品的底层实现方法等文章;对其它的新名词倒不是很感兴趣;最不喜欢的栏目反而是几个人不断的在说各家产品的有什么新技术、新趋势的文章。
在接触《程序员》杂志的这七年,也是我从迷茫走向成熟的七年,至少我能明白我现在在做什么,也能够承担因此而引起的后果,不论是苦还是甜。
这几年来,我也发生了很大的变化,各种生活也逐渐定型,虽然开发不是一个很好的工作,但对我个人来说,技术(特别是开发)仍然是能最发挥我的特点的一个职业。随着年龄的增长,我也能坦然接受自己对这个工作的喜爱,并感受到其中的一点乐趣。
粗粗算来,已经工作快十八年了,接触计算机也有二十年的时间,其中用于编程的时间大概也有十年,在这里将我的几点体会和大家分享一下。如果您是一个程序员、或者打算做一个程序员,或者打算开一个公司从事软件开发方面的工作,希望这些观点能够对您有所帮助。
1、开发规模问题
对于目前业内的一些观点,我并不认同。例如在各种报刊杂志上,经常有专家教授唠唠叨叨在说现在的软件开发已经进入工业化时代,要多少多少人团队开发,才能如何如何。但是,基于国内的实际情况,其实许多1000万元以下的项目完全是几个人的小团队开发模式,即使大到规模上市的软件公司,具体到每个定制开发的项目,实际项目组的开发人员,也经常只有不到十个人的规模,三、五个人的情况更是多如牛毛。
再看看国际上,我们所使用的一些著名的产品,如unix系统、C语言、notes系统、java语言、甚至最早的windows、dos很多都是几个人的小组所完成的开发。
至于这些产品的推广完善,所需要的巨大人力资源和开发之初的人力投入完全是两回事。在开发阶段,人多不一定就是好事,甚至肯定要坏事。
这就像生小孩一样,只要一男一女两个人就完全足够,但是,将这个孩子养大成人,除了他的父母,整个家庭、学校、社会等其它各色人等也直接或间接付出了很多。但这个孩子仍然只是他父母开发出来的,其它人只是起一个推波助澜的作用。
2、技术与思想问题
综合分析目前国内的软件开发方法(甚至包括其它IT技术),不难发现,我们总是热衷于技术,而不注重标准。从Basic、C、C++、一直到java、 C#等语言,再到.Net、J2EE等架构,多少技术在我们眼前晃来晃去,有些人也以掌握这些技术为目的,甚至洋洋得意。
其实,冷静下来分析一下其中的核心技术内容,现在的Web开发和早期的CGI方式的Web开发,只有方法上的不同,没有实质上的区别,所遵循的数据标准也没有任何变化。
整天只沉迷于片面的技术,使我们离核心技术越来越远,根本谈不上什么创造性。现在国内很多电子政务的项目在投标时均要求必须基于J2EE或.Net技术,完全拒绝LAMP和其它技术,估计很多美国公司老板做梦都要笑出声来。
重要的是思想而不是工具,就象毛泽东打败蒋介石是依靠思想而不是武器一样,技术并不起决定作用。
3、技术沉淀的重要性
由于不注重核心技术(其实那怕是一个小小的strcpy都是核心技术的一部分),很多公司没有任何技术积累,也没有可重复使用的底层开发库,更谈不上编程方法和思想上的积累。
因为工作的关系,我曾经接触过不少项目,这些项目都是号称采用了何等先进的技术云云,但实际上很多项目即使一个简单的按钮修改都需要在每个JSP文件中逐个修改。看了这样的代码,你真的不能不相信,语言是一个项目中最不重要的技术。
4、面向对象的是与非
我始终认为翻译“面向对象”的那个人是一个典型的老光棍,整天想着找对象,所以就想当然的这么翻译,其实我觉得“面向对象”应该是“面向目的”才对。所谓面向目的,说白了就是黑猫白猫的一句话。
其实“面向目的”(而不是“面向对象”)更多的是一种思想,而不是一个所谓的编程方法。所谓的抽象,固然有其必要性,但到处都是对象的说法,往往只是一些外行说出的内行话。难怪Torvalds对C++批的一无是处。
真正的“面向目的”,就是对一个项目的各个部分采用最适合的方法以达成目的。
5、大道至简
我越来越相信“大道至简”这个哲学观点,从设计产品、系统分析、模块划分,一直到做饭洗菜、吃饭睡觉,甚至到人际交往,这个道理都是相通的。从程序的角度也是如此,一段好的代码大多都是一个简洁的代码。
就像做人一样,简单做人,自己不辛苦,别人也不辛苦。同样一种开发语言、一种技术、一种开发工具、一种框架平台也是如此。
我个人认为C语言几十年不倒的主要原因,主要就是因为其结构简单,扩充方便。n年前玩音响的时候,很多发烧友也一致认为,在价格相当的情况下,一个旋钮最少的音响基本上就是最好的音响,也是同样的道理。
6、责任心和细节
其实大家都知道这一点,但是实际操作起来往往又根本不在乎。做项目需求时,有些人往往只是考虑实现客户要求的功能,而不是从客户要求的内容去思考和分析,甚至因为工作量的关系,故意避开一些问题。但是这些问题仍然存在,最后仍然会逐渐暴露出来,反而自讨苦吃。
其实,对客户而言,能有更好更完善的方案一般都会乐意接受,如果能本着对客户负责的精神,客户才能真正信任你;你和客户谈起价格时也才能有理有据。
很多时候只要负起责任,就会有助于发现所有的问题,并提出一个妥善的解决方法,注意到每一个细小的问题。其实大到卫星上天,小到刷锅洗碗,最根本的关键不是什么技术,而是在高度责任心的基础上对细节的把握。
我曾经在跳蚤市场买过一个七十年代的收音机,是春雷703,一个很古老的上海牌子,其信噪比和灵敏度比现在的集成电路的高出很多,原因无它,每一件细小的功能都做到最好而已。其实看一个程序员只要看他对程序跳格的处理,就可以决定90%的情况。
7、坚持熬下去
前几天看一个关于抗战的记录片,老毛对抗战相持阶段的说法是熬下去,当然是积极的熬法。其实不仅是做程序,做其它事情又何尝不是这样。
如果一天写100行代码,10年下来就是30多万行,记得好像unix最早的代码也不到40万行,30多万行代码,可以做多少事情呀。
有一天和一个朋友谈起代码量,他说最近在招人,要求曾经独立写过1万行代码,我后来仔细算了我开发的MCIS中间件系统,在代码最多时也才5万多行,后来不断调整优化,现在只有4万行不到。再统计一下数据库接口部分,每个数据库接口只有可怜的400行代码不到,但就这简单的400行已经可以完成一个数据库接口应具备的完整功能。
这几天刚好赶上亚洲杯,中国队0-3负于乌兹别克斯坦,又一次在打平即可出线的时候情况下完蛋。看看中国足球队的窝囊,其实就是没有认真对待场上的每一分钟,姑且不论技术和意识,只要场上每个人都能坚持90分钟不停的奔跑拦截,估计在亚洲也可以独立独行。最根本而又最简单的没有做到,又何谈胜利。
总想写一些东西,但因时间的关系,一直拖了下来,这几天刚好朋友约稿,就写一点自己的想法。从职业的角度而言,每个职业都有不同的酸甜苦辣,相比而言,选择一个自己比较喜欢的职业,也确实是一个不错的选择。可能是年龄的关系,我反而觉得生活才是最重要的,当然最好能在工作中保持乐趣,在生活中享受乐趣。在《程序员》杂志7年之际,写下这点东西,希望《程序员》杂志能够成为更多程序员的朋友。
posted @
2007-11-27 15:15 CoderDream 阅读(512) |
评论 (0) |
编辑 收藏
在反射机制中,Class.forName(className).newInstance();
如果你想通过反射机制得到当前包的某个类的实例,传入类名的同时必须传入包名。
例如在包com.coderdream下有两个类Shape,ShapeFactory,如果你想在ShapeFactory中的某个方法中用反射的方法生成Shape类,那么如果直接使用:
Class.forName("Shape").newInstance();
会抛出找不到类的异常,因为确实没有Shape类,而只有com.coderdream.Shape类。
但是我们传参数时一般只会传不带包的类名,那么我们可以这样处理:
String packageName = new ShapeFactory().getClass().getPackage().getName();
return (Shape) Class.forName(packageName + "." + className).newInstance();
其中 new ShapeFactory().getClass().getPackage().getName() 会得到包名“com.coderdream”,我们只要加上“.”和类名就没有问题了。
posted @
2007-11-23 15:34 CoderDream 阅读(6352) |
评论 (2) |
编辑 收藏第一篇:过去将来时(思想准备篇)
有人会问:你为什么要把它背下来呢?我觉的学一学就蛮好的吗?
故事的起因一个真实的小故事:(2002年的夏天在新东方听到)
新东方有个学员现在在Duke大学,他从高一开始背《新概念英语》第三册,背到高三就背完了。高考考进了北大,进北大后,他本来不想再背了。但当他背给同学听的时候,其他同学都露出了羡慕的眼光,于是,为了这种虚荣心,他就坚持背第四册,把第三、四册都背得滚瓜烂熟,他熟到什么地步呢,有人把其中任何一句说出来,把能把上一句和下一句连接下去,而且语音非常标准,因为他是模仿着磁带来背的。后来他去了美国Duke大学,他给新东方的教师写信,老师不敢回,因为老师对他的英文有畏惧感,他的英文学得太好,只能给他回中文信,并告诉他不是不会写英文,而是想让他温习温习中文,不要忘记祖国的语言。
这位学员到美国第一个星期写文章,教授把他叫过去说他的文章是剽窃的,因为他的文章写得太好了,教授说:"我20年教书没有教出这么漂亮的文章来。"这个学员说,我没有办法证明我能写出这么优秀的文章,但我告诉你,我能背108篇文章,而且背得非常熟练,你想不想听。结果,他没有背完两篇,教授就哭了起来,为什么?因为这个教授想一想自己教了20年了,居然一篇文章也没有背过,被中国学生背掉了,所以很难过……
从那个时候起我就有一种冲动,有一天我相信我也能将这108篇文章全背下来,看来我是做到了。
我相信也会有人问:你在背诵的过程中最大的困难是什么?我的回答就是:“坚持”。其实我能够坚持下来也是原于一个我在《读者》上看到的一个小故事:
古希腊哲学家苏格拉底在给学生上第一节课的时候,要求他的学生在每天上课之前都向上挥一下手。过了一个星期,他发现已经有一半的学生不在挥手了;过了一个月,他发现只剩下三分之一在挥手;过了半年,他再看,发现最后只剩下一个人在挥手,那个人就是柏拉图。柏拉图后来成为伟大的思想家和哲学家。
其实任何一件事到最后都是“简单的重复和机械的劳动”。只要你做到了,ok,你就有可能在一个领域做到很前列,甚至是Number One。
第二篇:现在进行时(背诵具体策略篇)
无论我们学习什么,都可能给自己做一个计划或者是有一个步奏。
在很早以前就听说过王国维的三种境界:
昨夜西风凋碧树,独上高楼望尽天涯路。
衣带渐宽终不悔,为伊消得人憔悴。
众里寻她前百度,慕然回首那人却在灯火阑珊处。
这些话是不是让你在做事情上有一定的启发呢?
我很喜欢《毛主席诗词》,所以我也有了用《毛主席诗词》串联起来我的做事三境界。
雄关漫道真如铁,而今迈步从头跃。(此乃第一境界)
一万年太久,只征朝夕。(此乃第二境界)
待到山花烂漫时,“我”在丛中笑。(此乃终极目标)
三个月的正式背诵,每天基本上是狂背10-12小时,对我来说既是一种痛苦又是一种快乐。痛苦,是因为太累了,有时一看到《新概念》我都恶心的想吐;快乐,看着自己一天天一篇篇把这些文章背掉,那种愉悦的心情是不言而喻的。也许这就叫作“痛,并快乐着”吧。
在这个“痛,并快乐着”中我也经历了几个过程:
1。从小我背课文就拿者一本书在我自己的小屋里低着头边走边背(出声背)。在一开始背《新概念》的时候我也是这样,结果一天下来弄得我简直是精疲力尽,而且效率不高,这种方法很快就被淘汰。
2。我发现坐在自己的床上背诵(出声音背)效率大大的提高,这样一天下来,感觉除了嗓子有点累还是蛮轻松的。就这样我在4月30日把第三册背完了。想想第三册有60课我仅用了一个多月(哦,我的背诵是从2003年3月20日开始)就搞定,那么第四册才48课估计一个月搞定应该没什么问题。但是事实超出了我的预料。
3。五月一日正式开始背诵第四册,当背到第10课(silicon vallay)的是时候我的嗓子已经受不了了,只要我一背就咳嗽,而且咳的很厉害,背诵被迫终止了5天。后来我只能不出声音的背(就是默背),结果奇迹出现了,我不再咳嗽了,而且我的效率提高了一倍。(也许“默背”是很多人的背诵习惯,可是对我来说就意味着要改变从“儿时”养成的背诵习惯,还是挺不容易的。)事情到此,可能也就没有什么可讲的了。但是,在我快要把第四册背完的时候(背到第39课what every writer wants),我遇到了一个大困难,那就是“噪音”。因为我家是住在(天津人叫做)“大杂院”。时值夏日,人们都出来乘凉,这种生活噪音成了我的最大敌人。背诵的速度被迫降了下来。就这样原定第四册最迟在6月10日拿下,结果直到6月21日才全部搞定。
所以,对我而言(是否适用其他人我不敢说)背诵的最快的方法是:1。坐在一个地方 2。默背 3。尽量找噪音小的地方背。
第三篇:现在完成时(背诵过后的感觉)
《新概念英语》30年不衰说明她的确是一本好书。
1。第三册大部分文章都会让你觉的:这篇文章真好玩,这个故事有意思。第三册的文章可以说都是作者象做一个精品一样来把这个文章弄出来。如果你能背下三册的前40篇文章,那么你的写作功力一定会大增。如果你说我背下来三册前40篇了,我还是不会写作文,那不是你问题,就是我有问题,要不就是《新概念》有问题。
2。第四册难了。但是她究竟难在什么地方呢?她比第三册究竟难在哪里呢?实际上我的感觉就是第四册基本上都是“说明文”而第三册可以说都是“记叙文”。所以第四册难在她的文体上,她没有什么情节,而且她有自己的Ideas。所以,像第44课patterns of culture 这课简直就是超超难,她没有什么情节,背诵的难度非常的大。
posted @
2007-11-21 17:21 CoderDream 阅读(438) |
评论 (2) |
编辑 收藏
1、未知异常
Security Manage系统中新增功能时报“未知异常”,后来在本地测试看Log信息知道是“空指针异常”,然后定位到抛出异常的位置:
iFuncNo = iFuncNo + 1;
然后单步调试,发现iFuncNo为Null,所以操作时会报空指针异常,这是iFuncNo的赋值语句:
List list = functionDao.selectByParentId(functionVo.getParentId());
if (list != null && list.size() > 0) {
Functiontb functb = (Functiontb) list.get(0);
iFuncNo = functb.getFunctionNo();
从中可以看出,iFuncNo是一个Functiontb的属性,而且可能为空,如果不加判断直接用操作符对它进行操作,会报“空指针异常”。
iFuncNo用于菜单的排序,因为菜单是动态生成的,根据权限不同,看到的菜单也不同,而且应该可以根据客户的要求对菜单排序,所以增加了这个字段,但是由于这个字段是后来新增的,所以数据库中的某些记录该字段的值为空。在程序中先判断一下就可以了,如果为空,就置为0;
List list = functionDao.selectByParentId(functionVo.getParentId());
if (list != null && list.size() > 0) {
Functiontb functb = (Functiontb) list.get(0);
iFuncNo = functb.getFunctionNo();
if (null == iFuncNo) {// 如果資料庫中該欄位的值為null,則先置為0
iFuncNo = 0;
}
iFuncNo = iFuncNo + 1;
}
这样就OK了。
2、季帐单的团体险及意外险部分的数据在生成的PDF报表中看不到。
原因:手工输入数据时,弱体等级(标准体、次标准体)栏位不是必填的,也就是说值可以为空,但是我生成报表时是按照这两种弱体等级来生成报表的,所以没有在报表中。就好像一个公共厕所,上面写着“男”和“女”,这时候来了一个性别为“空”的人,我肯定不好让“他/她”进其中的任何一个地方了。
今天要客户确认一下怎么处理!
posted @
2007-11-20 09:18 CoderDream 阅读(334) |
评论 (0) |
编辑 收藏