摘要:
阅读全文
posted @
2009-07-16 22:33 donnie 阅读(309) |
评论 (0) |
编辑 收藏posted @
2009-06-22 16:34 donnie 阅读(211) |
评论 (0) |
编辑 收藏posted @
2009-06-12 12:55 donnie 阅读(190) |
评论 (0) |
编辑 收藏
摘要:
阅读全文
posted @
2009-06-12 12:06 donnie 阅读(328) |
评论 (0) |
编辑 收藏
摘要:
阅读全文
posted @
2009-06-12 11:46 donnie 阅读(200) |
评论 (0) |
编辑 收藏
摘要:
阅读全文
posted @
2009-06-12 11:45 donnie 阅读(191) |
评论 (0) |
编辑 收藏
摘要:
阅读全文
posted @
2009-05-12 22:31 donnie 阅读(242) |
评论 (0) |
编辑 收藏
摘要:
阅读全文
posted @
2009-05-12 17:21 donnie 阅读(241) |
评论 (0) |
编辑 收藏
摘要:
阅读全文
posted @
2009-05-12 17:13 donnie 阅读(4628) |
评论 (0) |
编辑 收藏
摘要:
阅读全文
posted @
2009-05-12 16:53 donnie 阅读(202) |
评论 (0) |
编辑 收藏
摘要:
阅读全文
posted @
2009-05-12 16:49 donnie 阅读(197) |
评论 (0) |
编辑 收藏
摘要:
阅读全文
posted @
2009-05-12 16:46 donnie 阅读(179) |
评论 (0) |
编辑 收藏
摘要:
阅读全文
posted @
2009-05-08 12:06 donnie 阅读(295) |
评论 (0) |
编辑 收藏
摘要:
阅读全文
posted @
2009-05-08 12:05 donnie 阅读(3807) |
评论 (2) |
编辑 收藏
摘要:
阅读全文
posted @
2009-05-06 22:45 donnie 阅读(613) |
评论 (0) |
编辑 收藏
摘要:
阅读全文
posted @
2009-05-05 23:06 donnie 阅读(906) |
评论 (0) |
编辑 收藏
摘要:
阅读全文
posted @
2009-05-05 22:55 donnie 阅读(229) |
评论 (1) |
编辑 收藏
摘要:
阅读全文
posted @
2009-05-05 22:31 donnie 阅读(148) |
评论 (0) |
编辑 收藏
摘要:
阅读全文
posted @
2009-05-05 22:27 donnie 阅读(106) |
评论 (0) |
编辑 收藏
摘要:
阅读全文
posted @
2009-05-05 22:23 donnie 阅读(149) |
评论 (0) |
编辑 收藏
摘要:
阅读全文
posted @
2009-04-28 17:48 donnie 阅读(2788) |
评论 (0) |
编辑 收藏
摘要:
阅读全文
posted @
2009-04-28 17:03 donnie 阅读(254) |
评论 (0) |
编辑 收藏
摘要:
阅读全文
posted @
2009-04-28 15:12 donnie 阅读(348) |
评论 (0) |
编辑 收藏
摘要:
阅读全文
posted @
2009-04-28 15:09 donnie 阅读(141) |
评论 (0) |
编辑 收藏
摘要:
阅读全文
posted @
2009-04-28 14:41 donnie 阅读(365) |
评论 (0) |
编辑 收藏
摘要:
阅读全文
posted @
2009-04-28 11:48 donnie 阅读(1005) |
评论 (0) |
编辑 收藏
摘要:
阅读全文
posted @
2009-04-28 11:32 donnie 阅读(1024) |
评论 (0) |
编辑 收藏
摘要:
阅读全文
posted @
2009-04-24 21:43 donnie 阅读(240) |
评论 (0) |
编辑 收藏
摘要:
阅读全文
posted @
2009-04-24 21:43 donnie 阅读(444) |
评论 (0) |
编辑 收藏
摘要:
阅读全文
posted @
2009-04-24 11:39 donnie 阅读(289) |
评论 (0) |
编辑 收藏
摘要:
阅读全文
posted @
2009-04-24 10:54 donnie 阅读(258) |
评论 (0) |
编辑 收藏posted @
2009-04-23 11:25 donnie 阅读(143) |
评论 (0) |
编辑 收藏http://www.hadoop.org/
The Apache Hadoop project develops open-source software for reliable, scalable, distributed computing, including:
- Hadoop Core, our flagship sub-project, provides a distributed filesystem (HDFS) and support for the MapReduce distributed computing metaphor.
- HBase builds on Hadoop Core to provide a scalable, distributed database.
- Pig is a high-level data-flow language and execution framework for parallel computation. It is built on top of Hadoop Core.
- ZooKeeper is a highly available and reliable coordination system. Distributed applications use ZooKeeper to store and mediate updates for critical shared state.
- Hive is a data warehouse infrastructure built on Hadoop Core that provides data summarization, adhoc querying and analysis of datasets.
posted @
2009-04-17 15:20 donnie 阅读(142) |
评论 (0) |
编辑 收藏
摘要:
阅读全文
posted @
2009-04-17 11:02 donnie 阅读(358) |
评论 (0) |
编辑 收藏http://www.hadoop.org/
The Apache Hadoop project develops open-source software for reliable, scalable, distributed computing, including:
- Hadoop Core, our flagship sub-project, provides a distributed filesystem (HDFS) and support for the MapReduce distributed computing metaphor.
- HBase builds on Hadoop Core to provide a scalable, distributed database.
- Pig is a high-level data-flow language and execution framework for parallel computation. It is built on top of Hadoop Core.
- ZooKeeper is a highly available and reliable coordination system. Distributed applications use ZooKeeper to store and mediate updates for critical shared state.
- Hive is a data warehouse infrastructure built on Hadoop Core that provides data summarization, adhoc querying and analysis of datasets.
posted @
2009-04-17 10:32 donnie 阅读(139) |
评论 (0) |
编辑 收藏posted @
2009-04-17 10:27 donnie 阅读(174) |
评论 (0) |
编辑 收藏posted @
2009-04-17 10:26 donnie 阅读(155) |
评论 (0) |
编辑 收藏
摘要:
阅读全文
posted @
2009-04-13 21:15 donnie 阅读(134) |
评论 (0) |
编辑 收藏A SQL query walks into a bar and sees two tables. He walks up to them and says 'Can I join you?'
from: http://tkyte.blogspot.com/
posted @
2009-04-06 17:03 donnie 阅读(117) |
评论 (0) |
编辑 收藏
select to_date('Mon Jan 21 13:25:47 2008', 'dy mon dd hh24:mi:ss yyyy') from dual
Ora-01846: not a valid day of the week
出现的是中文的字符日期,如下:星期五 12月 19 13:53:15 2008
是字符集的问题,解决:
alter session set nls_date_language = 'American'
posted @
2009-04-06 16:00 donnie 阅读(1139) |
评论 (0) |
编辑 收藏
摘要:
阅读全文
posted @
2009-04-06 11:50 donnie 阅读(160) |
评论 (0) |
编辑 收藏
http://v.youku.com/v_playlist/f2076316o1p28.html
posted @
2009-04-04 18:26 donnie 阅读(116) |
评论 (0) |
编辑 收藏
目录
一、 前言... 4
二、 思路... 4
三、 vmstat脚本及步骤... 4
1. 安装statspack. 4
2. 创建stats$vmstat表... 4
3. 创建vmstat目录... 6
4. 创建get_vmstat.ksh脚本... 6
5. 创建run_vmstat.ksh脚本... 8
6. 创建crontab作业,定时执行run_vmstat.ksh脚本... 9
7. 分析数据... 9
1) 异常报告... 9
2) 每小时趋势报告... 13
3) 周趋势报告... 14
4) 长期趋势报告... 14
四、 使用Excel生成趋势图... 15
五、 参考资料... 15
posted @
2009-04-02 10:46 donnie 阅读(136) |
评论 (0) |
编辑 收藏
改用传统的pfile方式启动,具体pfile的内容可从spfile文件中copy,或者从数据库的警告日志文件中获取。
posted @
2009-03-30 22:32 donnie 阅读(224) |
评论 (0) |
编辑 收藏在oracle中,NULL与NULL既不相等,也不完全不相等。SQL Server与Sybase中,NULL等于NULL.
--REF: oracle expert....
 scott@ORCL> select * from dual where null=null;
scott@ORCL> select * from dual where null=null;
未选定行
scott@ORCL> select * from dual where null <> null;
未选定行
scott@ORCL> select * from dual where null is null;
D
-
X
posted @
2009-03-27 22:47 donnie 阅读(118) |
评论 (0) |
编辑 收藏scott@ORCL> select count(*) from t;
COUNT(*)
----------
28
scott@ORCL> begin
2 for x in (select * from t)
3 loop
4 insert into t values (x.username,x.user_id,x.created);
5 end loop;
6 end;
7 /
PL/SQL 过程已成功完成。
scott@ORCL> select count(*) from t;
COUNT(*)
----------
56
posted @
2009-03-26 23:18 donnie 阅读(122) |
评论 (0) |
编辑 收藏SET SERVEROUTPUT ON;
DECLARE
stock_price NUMBER := 9.73;
net_earnings NUMBER := 0;
pe_ratio NUMBER;
BEGIN
-- Calculation might cause division-by-zero error.
pe_ratio := stock_price / net_earnings;
dbms_output.put_line('Price/earnings ratio = ' || pe_ratio);
EXCEPTION -- exception handlers begin
-- Only one of the WHEN blocks is executed.
WHEN ZERO_DIVIDE THEN -- handles 'division by zero' error
dbms_output.put_line('Company must have had zero earnings.');
pe_ratio := null;
WHEN OTHERS THEN -- handles all other errors
dbms_output.put_line('Some other kind of error occurred.');
pe_ratio := null;
END; -- exception handlers and block end here
/
ref : http://www.sc.ehu.es/siwebso/KZCC/Oracle_10g_Documentacion/appdev.101/b10807/07_errs.htm
posted @
2009-03-25 10:52 donnie 阅读(100) |
评论 (0) |
编辑 收藏scott@ORCL> connect / as sysdba
已连接。
sys@ORCL> grant execute on dbms_flashback to scott;
授权成功。
sys@ORCL> connect scott/tiger
已连接。
scott@ORCL> variable SCN number
scott@ORCL> exec :scn := sys.dbms_flashback.get_system_change_number
PL/SQL 过程已成功完成。
scott@ORCL> print scn
SCN
----------
762534
scott@ORCL> select count(*) from emp;
COUNT(*)
----------
14
scott@ORCL> delete from emp;
已删除14行。
scott@ORCL> select count(*) from emp;
COUNT(*)
----------
0
scott@ORCL> select count(*) from emp AS OF SCN :scn;
COUNT(*)
----------
14
scott@ORCL> commit;
提交完成。
scott@ORCL> select *
2 from (select count(*) from emp),
3 (select count(*) from emp as of scn :scn)
4 /
COUNT(*) COUNT(*)
---------- ----------
0 14
scott@ORCL> select *
2 from (select count(*) from emp),
3 (select count(*) from emp as of scn :scn)
4 /
COUNT(*) COUNT(*)
---------- ----------
0 14
scott@ORCL> alter table emp enable row movement;
表已更改。
scott@ORCL> flashback table emp to scn :scn;
闪回完成。
scott@ORCL> select *
2 from (select count(*) from emp),
3 (select count(*) from emp as of scn :scn)
4 /
COUNT(*) COUNT(*)
---------- ----------
14 14
scott@ORCL>
posted @
2009-03-24 22:58 donnie 阅读(308) |
评论 (1) |
编辑 收藏scott@ORCL> drop table t;
表已删除。
scott@ORCL>
scott@ORCL> create table t
2 as
3 select *
4 from all_users;
表已创建。
scott@ORCL>
scott@ORCL> variable x refcursor
scott@ORCL>
scott@ORCL> begin
2 open :x for select * from t;
3 end;
4 /
PL/SQL 过程已成功完成。
scott@ORCL> delete from t;
已删除28行。
scott@ORCL>
scott@ORCL> commit;
提交完成。
scott@ORCL>
scott@ORCL> print x
USERNAME USER_ID CREATED
------------------------------ ---------- --------------
BI 60 13-3月 -09
PM 59 13-3月 -09
SH 58 13-3月 -09
IX 57 13-3月 -09
OE 56 13-3月 -09
HR 55 13-3月 -09
SCOTT 54 30-8月 -05
MGMT_VIEW 53 30-8月 -05
MDDATA 50 30-8月 -05
SYSMAN 51 30-8月 -05
MDSYS 46 30-8月 -05
SI_INFORMTN_SCHEMA 45 30-8月 -05
ORDPLUGINS 44 30-8月 -05
ORDSYS 43 30-8月 -05
此处 open 不复制任何数据,只是在你获取数据时它才从表中读数据。
posted @
2009-03-24 22:46 donnie 阅读(127) |
评论 (0) |
编辑 收藏
http://blogs.sun.com/chrisoliver/entry/javafx_vs_actionscript_performance
posted @
2009-03-23 15:34 donnie 阅读(156) |
评论 (0) |
编辑 收藏demo: https://openjfx.dev.java.net/
posted @
2009-03-23 11:58 donnie 阅读(129) |
评论 (0) |
编辑 收藏
sudo passwd root;
posted @
2009-03-19 23:44 donnie 阅读(101) |
评论 (0) |
编辑 收藏
This solution worked perfectly for me:
http://www.insecure.ws/2008/10/20/vm...nd-kernel-2627
add this patch:
vmware-update-2.6.27-5.5.7-2
posted @
2009-03-18 22:23 donnie 阅读(494) |
评论 (2) |
编辑 收藏
$sudo apt-get install scim scim-modules-socket scim-modules-table scim-pinyin scim-tables-zh scim-gtk2-immodule scim-qtimm
$sudo im-switch -s scim
重新启动Xwindow完成。按 Ctrl + 空格 键激活输入法。
posted @
2009-03-18 14:56 donnie 阅读(335) |
评论 (0) |
编辑 收藏
sudo apt-get install linux-restricted-modules-2.6.27-11-server
sudo apt-get install linux-headers-server
sudo apt-get install linux-image-server linux-server
--it works.
posted @
2009-03-18 14:54 donnie 阅读(189) |
评论 (0) |
编辑 收藏
sudo apt-get install pidgin
——————————————————————
pidgin是一个多协议的聊天工具,只要你有对应的帐户,就可以同时和几个帐户下的好友同时聊。
按提示添加帐户就行了。
posted @
2009-03-17 21:35 donnie 阅读(162) |
评论 (0) |
编辑 收藏
系统-系统管理-软件源,choose chinese site to get higher speed.
posted @
2009-03-17 21:14 donnie 阅读(160) |
评论 (0) |
编辑 收藏
http://msdn.microsoft.com/en-us/library/aa366778.aspx#physical_memory_limits_windows_xp
posted @
2009-03-17 16:40 donnie 阅读(7813) |
评论 (1) |
编辑 收藏
需以sysdba身份连接才能安装。
1,cd [oracle_home]\rdbms\admin;
2,run @spcreate.sql;
按提示输入必要的信息。
如果输入错误或者取消了安装,下次安装前需要先执行 spdrop.sql删除用户和已安装的视图。
--SPCPKG complete. Please check spcpkg.lis for any errors.
posted @
2009-03-16 22:47 donnie 阅读(91) |
评论 (0) |
编辑 收藏
1,cd [oracle_home]\rdbms\admin;
2, run @utlxplan;
3, create public synonym plan_table to public; --no need to run in oracle10,oracle default
4, grant all on plan_table to public;--no need to run in oracle10,oracle default, here public can be any user;
----create role plustrace and grant it to user
1, cd [oracle_home]\sqlplus\admin;
2, conn sqlplus as sysdba;
3, run @plustrce;
4, grant plustrace to public;
---test
1, conn sqlplus with user scott;
1.1, set autotrace on;
2, run : select * from dual;
3, show stat info;
--1.1 可选项: set autotrace off: 不生成报告,默认;
set autotrace on explain: 报告只显示优化器执行路径;
set autotrace on statistics: 报告只显示sql语句执行统计信息;
set autotrace on: 报告显示优化器执行路径,sql语句统计信息;
set autotrace traceonly: 报告显示优化器执行路径,sql语句统计信息,不显示查询输出;
ref:oracle 9i、10g编程艺术。
posted @
2009-03-16 22:35 donnie 阅读(106) |
评论 (0) |
编辑 收藏
ref:oracle 9i、10g编程艺术。
sqlplus允许建立一个login.sql,通过设置环境变量SQLPATH,指向文件所在目录,每次启动sqlplus都会执行这个脚本。
login.sql例子:
define _editor=notepad
set serveroutput on size 1000000
set trimspool on
set long 5000
set linesize 100
set pagesize 9999
column plan_plus_exp format a80
column global_name new_value gname
set termout off
define gname=idle
column global_name new_value gname
select lower(user) || '@' || substr( global_name, 1, decode( dot, 0,
length(global_name), dot-1) ) global_name
from (select global_name, instr(global_name,'.') dot from global_name );
set sqlprompt '&gname> '
set termout on
define _editor: sqlplus默认的编辑器;
set serveroutput on size 1000000:默认打开DBMS_OUTPUT,将缓冲区设置尽可能大;
posted @
2009-03-16 22:07 donnie 阅读(286) |
评论 (0) |
编辑 收藏
现象:
sys@ORCL> grant select on v$session to scott;
grant select on v$session to scott
*
第 1 行出现错误:
ORA-02030: 只能从固定的表/视图查询
解决:
grant select on v_$session to scott;
posted @
2009-03-16 21:59 donnie 阅读(826) |
评论 (0) |
编辑 收藏
HKEY_LOCAL_MACHINE\SOFTWARE\Macromedia\FlashPlayer\SafeVersions]
将"9.0",“10.0” 项删除,重新安装。
posted @
2009-03-16 15:31 donnie 阅读(2923) |
评论 (2) |
编辑 收藏
http://www.centospub.com/
CentOS 是 RHEL(Red Hat Enterprise Linux)源代码再编译的产物,而且在 RHEL 的基础上修正了不少已知的 Bug ,相对于其他 Linux 发行版,其稳定性值得信赖。
CentOS 4.4 的下载及安装
http://www.centospub.com/make/install.html
从镜像站点上下载ISO的镜像文件
CD 1 :
http://mirror.tini4u.net/centos/4.4/isos/i386/CentOS-4.4-i386-bin1of4.iso
CD 2 :
http://mirror.tini4u.net/centos/4.4/isos/i386/CentOS-4.4-i386-bin2of4.iso
CD 3 :
http://mirror.tini4u.net/centos/4.4/isos/i386/CentOS-4.4-i386-bin3of4.iso
CD 4 :
http://mirror.tini4u.net/centos/4.4/isos/i386/CentOS-4.4-i386-bin4of4.iso
md5校验码:
http://mirror.tini4u.net/centos/4.4/isos/i386/md5sum
将上面所有文件(包括md5校验码)下载到同一个目录(文件夹)下。(这里,选择了从CentOS的韩国镜像站上下载。根据具体位置可以选择距离近、速度快的景象站点。查找CentOS的镜像请见
官方镜像站点列表。)
posted @
2009-03-13 13:20 donnie 阅读(106) |
评论 (1) |
编辑 收藏
http://wiki.mbalib.com/wiki/%E6%AD%A3%E6%80%81%E5%88%86%E5%B8%83
正态分布
正态分布(normal distribution)
什么是正态分布
正态分布是一种概率分布。正态分布是具有两个参数μ和σ2的连续型随机变量的分布,第一参数μ是遵从正态分布的随机变量的均值,第二个参数σ2是此随机变量的方差,所以正态分布记作N(μ,σ2 )。遵从正态分布的随机变量的概率规律为取 μ邻近的值的概率大 ,而取离μ越远的值的概率越小;σ越小,分布越集中在μ附近,σ越大,分布越分散。正态分布的密度函数的特点是:关于μ对称,在μ处达到最大值,在正(负)无穷远处取值为0,在μ±σ处有拐点。它的形状是中间高两边低 ,图像是一条位于x 轴上方的钟形曲线。当μ=0,σ2 =1时,称为标准正态分布,记为N(0,1)。μ维随机向量具有类似的概率规律时,称此随机向量遵从多维正态分布。多元正态分布有很好的性质,例如,多元正态分布的边缘分布仍为正态分布,它经任何线性变换得到的随机向量仍为多维正态分布,特别它的线性组合为一元正态分布。
正态分布的发展
正态分布是最重要的一种概率分布。正态分布概念是由德国的数学家和天文学家Moivre于1733年受次提出的,但由于德国数学家Gauss率先将其应用于天文学家研究,故正态分布又叫高斯分布高斯这项工作对后世的影响极大,他使正态分布同时有了“高斯分布”的名称,后世之所以多将最小二乘法的发明权归之于他,也是出于这一工作。高斯是一个伟大的数学家,重要的贡献不胜枚举。但现今德国10马克的印有高斯头像的钞票,其上还印有正态分布的密度曲线。这传达了一种想法:在高斯的一切科学贡献中,其对人类文明影响最大者,就是这一项。在高斯刚作出这个发现之初,也许人们还只能从其理论的简化上来评价其优越性,其全部影响还不能充分看出来。这要到20世纪正态小样本理论充分发展起来以后。皮埃尔-西蒙·拉普拉斯很快得知高斯的工作,并马上将其与他发现的中心极限定理联系起来,为此,他在即将发表的一篇文章(发表于1810年)上加上了一点补充,指出如若误差可看成许多量的叠加,根据他的中心极限定理,误差理应有高斯分布。这是历史上第一次提到所谓“元误差学说”——误差是由大量的、由种种原因产生的元误差叠加而成。后来到1837年,海根(G.Hagen)在一篇论文中正式提出了这个学说。
其实,他提出的形式有相当大的局限性:海根把误差设想成个数很多的、独立同分布的“元误差” 之和,每只取两值,其概率都是1/2,由此出发,按狄莫佛的中心极限定理,立即就得出误差(近似地)服从正态分布。皮埃尔-西蒙·拉普拉斯所指出的这一点有重大的意义,在于他给误差的正态理论一个更自然合理、更令人信服的解释。因为,高斯的说法有一点循环论证的气味:由于算术平均是优良的,推出误差必须服从正态分布;反过来,由后一结论又推出算术平均及最小二乘估计的优良性,故必须认定这二者之一(算术平均的优良性,误差的正态性) 为出发点。但算术平均到底并没有自行成立的理由,以它作为理论中一个预设的出发点,终觉有其不足之处。拉普拉斯的理把这断裂的一环连接起来,使之成为一个和谐的整体,实有着极重大的意义。
正态分布的主要特征
1、集中性:正态曲线的高峰位于正中央,即均数所在的位置。
2、对称性:正态曲线以均数为中心,左右对称,曲线两端永远不与横轴相交。
3、均匀变动性:正态曲线由均数所在处开始,分别向左右两侧逐渐均匀下降。
4、正态分布有两个参数,即均数μ和标准差σ,可记作N(μ,σ):均数μ决定正态曲线的中心位置;标准差σ决定正态曲线的陡峭或扁平程度。σ越小,曲线越陡峭;σ越大,曲线越扁平。
5、u变换:为了便于描述和应用,常将正态变量作数据转换。
正态分布的应用
1.估计正态分布资料的频数分布
例1.某地1993年抽样调查了100名18岁男大学生身高(cm),其均数=172.70cm,标准差s=4.01cm,①估计该地18岁男大学生身高在168cm以下者占该地18岁男大学生总数的百分数;②分别求 、
、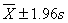 、
、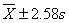 范围内18岁男大学生占该地18岁男大学生总数的实际百分数,并与理论百分数比较。
范围内18岁男大学生占该地18岁男大学生总数的实际百分数,并与理论百分数比较。
本例,μ、σ未知但样本含量n较大,按式(3.1)用样本均数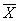 和标准差S分别代替μ和σ,求得u值,u=(168-172.70)/4.01=-1.17。查附表标准正态曲线下的面积,在表的左侧找到-1.1,表的上方找到0.07,两者相交处为0.1210=12.10%。该地18岁男大学生身高在168cm以下者,约占总数12.10%。其它计算结果见表3.1。
和标准差S分别代替μ和σ,求得u值,u=(168-172.70)/4.01=-1.17。查附表标准正态曲线下的面积,在表的左侧找到-1.1,表的上方找到0.07,两者相交处为0.1210=12.10%。该地18岁男大学生身高在168cm以下者,约占总数12.10%。其它计算结果见表3.1。
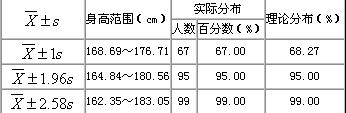
表:1100名18岁男大学生身高的实际分布与理论分布
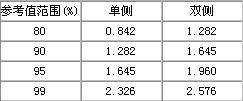
2.制定医学参考值范围:亦称医学正常值范围。它是指所谓“正常人”的解剖、生理、生化等指标的波动范围。制定正常值范围时,首先要确定一批样本含量足够大的 “正常人”,所谓“正常人”不是指“健康人”,而是指排除了影响所研究指标的疾病和有关因素的同质人群;其次需根据研究目的和使用要求选定适当的百分界值,如80%,90%,95%和99%,常用95%;根据指标的实际用途确定单侧或双侧界值,如白细胞计数过高过低皆属不正常须确定双侧界值,又如肝功中转氨酶过高属不正常须确定单侧上界,肺活量过低属不正常须确定单侧下界。另外,还要根据资料的分布特点,选用恰当的计算方法。常用方法有:
(1)正态分布法:适用于正态或近似正态分布的资料。
双侧界值: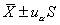 单侧上界:
单侧上界: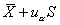 ,或单侧下界:
,或单侧下界: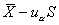
(2)对数正态分布法:适用于对数正态分布资料。
双侧界值: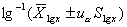 ;单侧上界:
;单侧上界: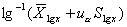 ,或单侧下界:
,或单侧下界: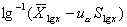 。
。
常用u值可根据要求由表3.2查出。
(3)百分位数法:常用于偏态分布资料以及资料中一端或两端无确切数值的资料。
双侧界值:P2.5和P97.5;单侧上界:P95,或单侧下界:P5。
表:常用u值表
3.正态分布是许多统计方法的理论基础:如t分布、F分布、分布都是在正态分布的基础上推导出来的,u检验也是以正态分布为基础的。此外,t分布、二项分布、Poisson分布的极限为正态分布,在一定条件下,可以按正态分布原理来处理。
如果您认为本条目还有待完善,需要补充新内容或修改错误内容,请编辑条目。
-------------------------------------------------------------------------------------
http://baike.baidu.com/view/45379.html?wtp=tt
正态分布

正态分布
normal distribution
一种概率分布。正态分布是具有两个参数μ和σ2的连续型随机变量的分布,第一参数μ是服从正态分布的随机变量的均值,第二个参数σ2是此随机变量的方差,所以正态分布记作N(μ,σ2 )。 服从正态分布的随机变量的概率规律为取与μ邻近的值的概率大 ,而取离μ越远的值的概率越小;σ越小,分布越集中在μ附近,σ越大,分布越分散。正态分布的密度函数的特点是:关于μ对称,在μ处达到最大值,在正(负)无穷远处取值为0,在μ±σ处有拐点。它的形状是中间高两边低 ,图像是一条位于x轴上方的钟形曲线。当μ=0,σ2 =1时,称为标准正态分布,记为N(0,1)。μ维随机向量具有类似的概率规律时,称此随机向量遵从多维正态分布。多元正态分布有很好的性质,例如,多元正态分布的边缘分布仍为正态分布,它经任何线性变换得到的随机向量仍为多维正态分布,特别它的线性组合为一元正态分布。
正态分布最早由A.棣莫弗在求二项分布的渐近公式中得到。C.F.高斯在研究测量误差时从另一个角度导出了它。P.S.拉普拉斯和高斯研究了它的性质。
生产与科学实验中很多随机变量的概率分布都可以近似地用正态分布来描述。例如,在生产条件不变的情况下,产品的强力、抗压强度、口径、长度等指标;同一种生物体的身长、体重等指标;同一种种子的重量;测量同一物体的误差;弹着点沿某一方向的偏差;某个地区的年降水量;以及理想气体分子的速度分量,等等。一般来说,如果一个量是由许多微小的独立随机因素影响的结果,那么就可以认为这个量具有正态分布(见中心极限定理)。从理论上看,正态分布具有很多良好的性质 ,许多概率分布可以用它来近似;还有一些常用的概率分布是由它直接导出的,例如对数正态分布、t分布、F分布等。
正态分布应用最广泛的连续概率分布,其特征是“钟”形曲线。
from http://www.5yiso.cn
(一)正态分布
1.正态分布
若 的密度函数(频率曲线)为正态函数(曲线)
(3-1)
则称 服从正态分布,记号 ~ 。其中 、 是两个不确定常数,是正态分布的参数,不同的 、不同的 对应不同的正态分布。
正态曲线呈钟型,两头低,中间高,左右对称,曲线与横轴间的面积总等于1。
2.正态分布的特征
服从正态分布的变量的频数分布由 、 完全决定。
(1) 是正态分布的位置参数,描述正态分布的集中趋势位置。正态分布以 为对称轴,左右完全对称。正态分布的均数、中位数、众数相同,均等于 。
(2) 描述正态分布资料数据分布的离散程度, 越大,数据分布越分散, 越小,数据分布越集中。 也称为是正态分布的形状参数, 越大,曲线越扁平,反之, 越小,曲线越瘦高。
(二)标准正态分布
1.标准正态分布是一种特殊的正态分布,标准正态分布的μ和σ2为0和1,通常用 (或Z)表示服从标准正态分布的变量,记为 Z~N(0,1)。
2.标准化变换:此变换有特性:若原分布服从正态分布 ,则Z=(x-μ)/σ ~ N(0,1) 就服从标准正态分布,通过查标准正态分布表就可以直接计算出原正态分布的概率值。故该变换被称为标准化变换。
3. 标准正态分布表
标准正态分布表中列出了标准正态曲线下从-∞到X(当前值)范围内的面积比例 。
(三)正态曲线下面积分布
1.实际工作中,正态曲线下横轴上一定区间的面积反映该区间的例数占总例数的百分比,或变量值落在该区间的概率(概率分布)。不同 范围内正态曲线下的面积可用公式3-2计算。
(3-2)
。
2.几个重要的面积比例
轴与正态曲线之间的面积恒等于1。正态曲线下,横轴区间(μ-σ,μ+σ)内的面积为68.27%,横轴区间(μ-1.96σ,μ+1.96σ)内的面积为95.00%,横轴区间(μ-2.58σ,μ+2.58σ)内的面积为99.00%。
(四)正态分布的应用
某些医学现象,如同质群体的身高、红细胞数、血红蛋白量,以及实验中的随机误差,呈现为正态或近似正态分布;有些指标(变量)虽服从偏态分布,但经数据转换后的新变量可服从正态或近似正态分布,可按正态分布规律处理。其中经对数转换后服从正态分布的指标,被称为服从对数正态分布。
1. 估计频数分布 一个服从正态分布的变量只要知道其均数与标准差就可根据公式(3-2)估计任意取值 范围内频数比例。
2. 制定参考值范围
(1)正态分布法 适用于服从正态(或近似正态)分布指标以及可以通过转换后服从正态分布的指标。
(2)百分位数法 常用于偏态分布的指标。表3-1中两种方法的单双侧界值都应熟练掌握。
表3-1 常用参考值范围的制定
概率
(%) 正态分布法 百分位数法
双侧 单 侧 双侧 单侧
下 限 上 限 下 限 上 限
90
95
99
3. 质量控制:为了控制实验中的测量(或实验)误差,常以 作为上、下警戒值,以 作为上、下控制值。这样做的依据是:正常情况下测量(或实验)误差服从正态分布。
4. 正态分布是许多统计方法的理论基础。 检验、方差分析、相关和回归分析等多种统计方法均要求分析的指标服从正态分布。许多统计方法虽然不要求分析指标服从正态分布,但相应的统计量在大样本时近似正态分布,因而大样本时这些统计推断方法也是以正态分布为理论基础的。
from http://www.foodmate.net/lesson/41/3-1.php
一、正态分布的概念
由表1.1的频数表资料所绘制的直方图,图3.1(1)可以看出,高峰位于中部,左右两侧大致对称。我们设想,如果观察例数逐渐增多,组段不断分细,直方图顶端的连线就会逐渐形成一条高峰位于中央(均数所在处),两侧逐渐降低且左右对称,不与横轴相交的光滑曲线图3.1(3)。这条曲线称为频数曲线或频率曲线,近似于数学上的正态分布(normal distribution)。由于频率的总和为100%或1,故该曲线下横轴上的面积为100%或1。
图3.1频数分布逐渐接近正态分布示意图
为了应用方便,常对正态分布变量X作变量变换。
(3.1)
该变换使原来的正态分布转化为标准正态分布 (standard normal distribution),亦称u分布。u被称为标准正态变量或标准正态离差(standard normal deviate)。
二、正态分布的特征:
1.正态曲线(normal curve)在横轴上方均数处最高。
2.正态分布以均数为中心,左右对称。
3.正态分布有两个参数,即均数和标准差。是位置参数,当固定不变时,越大,曲线沿横轴越向右移动;反之,越小,则曲线沿横轴越向左移动。是形状参数,当固定不变时,越大,曲线越平阔;越小,曲线越尖峭。通常用表示均数为,方差为的正态分布。用N(0,1)表示标准正态分布。
4.正态曲线下面积的分布有一定规律。
实际工作中,常需要了解正态曲线下横轴上某一区间的面积占总面积的百分数,以便估计该区间的例数占总例数的百分数(频数分布)或观察值落在该区间的概率。正态曲线下一定区间的面积可以通过附表1求得。对于正态或近似正态分布的资料,已知均数和标准差,就可对其频数分布作出概约估计。
查附表1应注意:①表中曲线下面积为-∞到u的左侧累计面积;②当已知μ、σ和X时先按式(3.1)求得u值,再查表,当μ、σ未知且样本含量n足够大时,可用样本均数和标准差S分别代替μ和σ,按式求得u值,再查表;③曲线下对称于0的区间面积相等,如区间(-∞,-1.96)与区间(1.96,∞)的面积相等,④曲线下横轴上的总面积为100%或1。
正态分布曲线下有三个区间的面积应用较多,应熟记:①标准正态分布时区间(-1,1)或正态分布时区间(μ-1σ,μ+1σ)的面积占总面积的68.27%;②标准正态分布时区间(-1.96,1.96)或正态分布区间(μ-1.96σ,μ+1.96σ)的面积占总面积的95%;③标准正态分布时区间(-2.58,2.58)或正态分布时区间(μ-2.58σ,μ+2.58σ)的面积占总面积的99%。如图3.2所示。(μ-3σ)的面积比例为99.74%,(μ-2σ)面积比例为95.44%。
图3.2 正态曲线与标准正态曲线的面积分布
posted @
2009-03-12 23:08 donnie 阅读(960) |
评论 (0) |
编辑 收藏http://baike.baidu.com/view/1052684.htm
均值
统计学术语,与“平均”(***erage)意义相同。例如: l、3、6,10、20这5个数字的均值是8。
posted @
2009-03-12 22:55 donnie 阅读(145) |
评论 (0) |
编辑 收藏
http://wiki.mbalib.com/wiki/%E6%96%B9%E5%B7%AE
方差(Variance)
什么是方差
方差和标准差是测度数据变异程度的最重要、最常用的指标。
方差是各个数据与其算术平均数的离差平方和的平均数,通常以σ2表示。方差的计量单位和量纲不便于从经济意义上进行解释,所以实际统计工作中多用方差的算术平方根——标准差来测度统计数据的差异程度。
标准差又称均方差,一般用σ表示。方差和标准差的计算也分为简单平均法和加权平均法,另外,对于总体数据和样本数据,公式略有不同。
方差的计算公式
设总体方差为σ2,对于未经分组整理的原始数据,方差的计算公式为:
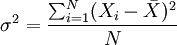
对于分组数据,方差的计算公式为:
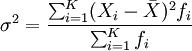
方差的平方根即为标准差,其相应的计算公式为:
未分组数据: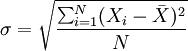
分组数据: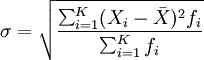
样本方差和标准差
样本方差与总体方差在计算上的区别是:总体方差是用数据个数或总频数去除离差平方和,而样本方差则是用样本数据个数或总频数减1去除离差平方和,其中样本数据个数减1即n-1称为自由度。设样本方差为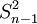 ,根据未分组数据和分组数据计算样本方差的公式分别为:
,根据未分组数据和分组数据计算样本方差的公式分别为:
未分组数据: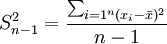
分组数据: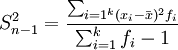
未分组数据: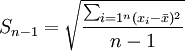
分组数据: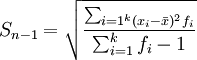
例:考察一台机器的生产能力,利用抽样程序来检验生产出来的产品质量,假设搜集的数据如下:
| 3.43 |
3.45 |
3.43 |
3.48 |
3.52 |
3.50 |
3.39 |
| 3.48 |
3.41 |
3.38 |
3.49 |
3.45 |
3.51 |
3.50 |
根据该行业通用法则:如果一个样本中的14个数据项的方差大于0.005,则该机器必须关闭待修。问此时的机器是否必须关闭?
解:根据已知数据,计算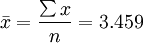
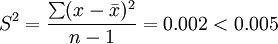
因此,该机器工作正常。
方差和标准差也是根据全部数据计算的,它反映了每个数据与其均值相比平均相差的数值,因此它能准确地反映出数据的离散程度。方差和标准差是实际中应用最广泛的离散程度测度值。
---------------------------------------------------------------------
http://zh.wikipedia.org/wiki/%E6%96%B9%E5%B7%AE
方差
维基百科,自由的百科全书
在概率论和统计学中,一个随机变量的“方差”描述的是它的离散程度,也就是该变量离其期望值的距离。 一个实随机变量的方差也称为它的二阶距,恰巧也是它的二阶culmulent。 方差的算术平方根称为该随机变量的标准差。
[编辑] 定义
设 X 为服从分布 F 的随机变量,则称 Var(X) = E(X − EX)2 为随机变量 X 或者分布 F 的方差。
如果 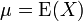 是隨機變數 X 的期望值 (平均數) , 則其變異數為:
是隨機變數 X 的期望值 (平均數) , 則其變異數為: 
[编辑] 特性
在样本空间Ω上存在有限期望和方差的随机变量构成一个希尔伯特空间: L^2(Ω, dP),不过这里的内积和长度跟方差,标准差还是不大一样。 所以,我们得把这个空间“除”常变量构成的子空间,也就是说把相差一个常数的 所有原来那个空间的随机变量做成一个等价类。这还是一个新的无穷维线性空间, 并且有一个从老空间内积诱导出来的新内积,而这个内积就是方差
[编辑] 一般化
如果X是一个向量其取值范围在Rn空间,并且其每个元素都是一个一维随机变量,我们就把X称为随机向量。随机向量的方差是一维随机变量方差的自然推广,其定义为E[(X − μ)(X − μ)T], 其中 μ = E(X) ,XT是X的转秩. 这个方差是一个非负定方阵,通常称为协方差矩阵。
如果X是一个复随机变量,那么其方差定义则为E[(X − μ)(X − μ)*], 其中X*是X的复共轭向量。根据这个定义,方差为实数。
[编辑] 历史
方差这个词首先由Ronald Fisher在论文The Correlation Between Relatives on the Supposition of Mendelian Inheritance中引入.
[编辑] 参考出处
- ^ Press, W. H., Teukolsky, S. A., Vetterling, W. T. & Flannery, B. P. (1986) Numerical recipes: The art of scientific computing. Cambridge: Cambridge University Press. (online)
posted @
2009-03-12 22:51 donnie 阅读(10891) |
评论 (0) |
编辑 收藏
工作若干年以来,荒废了太多时间,昨天上课听项目管理老师讲到计划,何不把日常学习也来计划一下呢。
于是,订计划若干,时间涵盖工作时间、晚上。 唯无人监督,看我能坚持多久,做记号。
posted @
2009-03-09 22:09 donnie 阅读(76) |
评论 (0) |
编辑 收藏
看cd学日语,大概浏览了一下, 写法并不是十分特殊,要记的基础比较多,发音要适应一下。
posted @
2009-03-09 22:05 donnie 阅读(78) |
评论 (0) |
编辑 收藏
起因:掉电。
现象:系统文件多找不到。
恢复:尝试修复文件系统,失败;
安装盘引导修复,失败;
安装盘引导,覆盖安装,失败;
安装盘引导,全新安装,成功。tips: 定制安装;手动设置分区,保留原raid设置。
posted @
2009-02-25 18:30 donnie 阅读(107) |
评论 (0) |
编辑 收藏
怀疑是采用:共享存储。其存储空间已经有的文件,不会重复上传,链接到当前用户的文件中转站,造成瞬间上传完成之假象。
已经测试过。
posted @
2009-02-24 22:42 donnie 阅读(134) |
评论 (1) |
编辑 收藏