CentOS 是 RHEL(Red Hat Enterprise Linux)源代码再编译的产物,而且在 RHEL 的基础上修正了不少已知的 Bug ,相对于其他 Linux 发行版,其稳定性值得信赖。
将上面所有文件(包括md5校验码)下载到同一个目录(文件夹)下。(这里,选择了从CentOS的韩国镜像站上下载。根据具体位置可以选择距离近、速度快的景象站点。查找CentOS的镜像请见
正态分布(normal distribution)
什么是正态分布
正态分布是一种概率分布。正态分布是具有两个参数μ和σ2的连续型随机变量的分布,第一参数μ是遵从正态分布的随机变量的均值,第二个参数σ2是此随机变量的方差,所以正态分布记作N(μ,σ2 )。遵从正态分布的随机变量的概率规律为取 μ邻近的值的概率大 ,而取离μ越远的值的概率越小;σ越小,分布越集中在μ附近,σ越大,分布越分散。正态分布的密度函数的特点是:关于μ对称,在μ处达到最大值,在正(负)无穷远处取值为0,在μ±σ处有拐点。它的形状是中间高两边低 ,图像是一条位于x 轴上方的钟形曲线。当μ=0,σ2 =1时,称为标准正态分布,记为N(0,1)。μ维随机向量具有类似的概率规律时,称此随机向量遵从多维正态分布。多元正态分布有很好的性质,例如,多元正态分布的边缘分布仍为正态分布,它经任何线性变换得到的随机向量仍为多维正态分布,特别它的线性组合为一元正态分布。
正态分布的发展
正态分布是最重要的一种概率分布。正态分布概念是由德国的数学家和天文学家Moivre于1733年受次提出的,但由于德国数学家Gauss率先将其应用于天文学家研究,故正态分布又叫高斯分布高斯这项工作对后世的影响极大,他使正态分布同时有了“高斯分布”的名称,后世之所以多将最小二乘法的发明权归之于他,也是出于这一工作。高斯是一个伟大的数学家,重要的贡献不胜枚举。但现今德国10马克的印有高斯头像的钞票,其上还印有正态分布的密度曲线。这传达了一种想法:在高斯的一切科学贡献中,其对人类文明影响最大者,就是这一项。在高斯刚作出这个发现之初,也许人们还只能从其理论的简化上来评价其优越性,其全部影响还不能充分看出来。这要到20世纪正态小样本理论充分发展起来以后。皮埃尔-西蒙·拉普拉斯很快得知高斯的工作,并马上将其与他发现的中心极限定理联系起来,为此,他在即将发表的一篇文章(发表于1810年)上加上了一点补充,指出如若误差可看成许多量的叠加,根据他的中心极限定理,误差理应有高斯分布。这是历史上第一次提到所谓“元误差学说”——误差是由大量的、由种种原因产生的元误差叠加而成。后来到1837年,海根(G.Hagen)在一篇论文中正式提出了这个学说。
其实,他提出的形式有相当大的局限性:海根把误差设想成个数很多的、独立同分布的“元误差” 之和,每只取两值,其概率都是1/2,由此出发,按狄莫佛的中心极限定理,立即就得出误差(近似地)服从正态分布。皮埃尔-西蒙·拉普拉斯所指出的这一点有重大的意义,在于他给误差的正态理论一个更自然合理、更令人信服的解释。因为,高斯的说法有一点循环论证的气味:由于算术平均是优良的,推出误差必须服从正态分布;反过来,由后一结论又推出算术平均及最小二乘估计的优良性,故必须认定这二者之一(算术平均的优良性,误差的正态性) 为出发点。但算术平均到底并没有自行成立的理由,以它作为理论中一个预设的出发点,终觉有其不足之处。拉普拉斯的理把这断裂的一环连接起来,使之成为一个和谐的整体,实有着极重大的意义。
正态分布的主要特征
1、集中性:正态曲线的高峰位于正中央,即均数所在的位置。
2、对称性:正态曲线以均数为中心,左右对称,曲线两端永远不与横轴相交。
3、均匀变动性:正态曲线由均数所在处开始,分别向左右两侧逐渐均匀下降。
4、正态分布有两个参数,即均数μ和标准差σ,可记作N(μ,σ):均数μ决定正态曲线的中心位置;标准差σ决定正态曲线的陡峭或扁平程度。σ越小,曲线越陡峭;σ越大,曲线越扁平。
5、u变换:为了便于描述和应用,常将正态变量作数据转换。
正态分布的应用
1.估计正态分布资料的频数分布
例1.某地1993年抽样调查了100名18岁男大学生身高(cm),其均数=172.70cm,标准差s=4.01cm,①估计该地18岁男大学生身高在168cm以下者占该地18岁男大学生总数的百分数;②分别求 、
、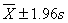 、
、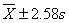 范围内18岁男大学生占该地18岁男大学生总数的实际百分数,并与理论百分数比较。
范围内18岁男大学生占该地18岁男大学生总数的实际百分数,并与理论百分数比较。
本例,μ、σ未知但样本含量n较大,按式(3.1)用样本均数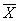 和标准差S分别代替μ和σ,求得u值,u=(168-172.70)/4.01=-1.17。查附表标准正态曲线下的面积,在表的左侧找到-1.1,表的上方找到0.07,两者相交处为0.1210=12.10%。该地18岁男大学生身高在168cm以下者,约占总数12.10%。其它计算结果见表3.1。
和标准差S分别代替μ和σ,求得u值,u=(168-172.70)/4.01=-1.17。查附表标准正态曲线下的面积,在表的左侧找到-1.1,表的上方找到0.07,两者相交处为0.1210=12.10%。该地18岁男大学生身高在168cm以下者,约占总数12.10%。其它计算结果见表3.1。
表:1100名18岁男大学生身高的实际分布与理论分布
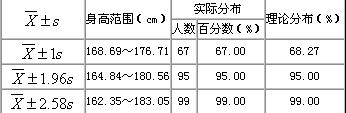
2.制定医学参考值范围:亦称医学正常值范围。它是指所谓“正常人”的解剖、生理、生化等指标的波动范围。制定正常值范围时,首先要确定一批样本含量足够大的 “正常人”,所谓“正常人”不是指“健康人”,而是指排除了影响所研究指标的疾病和有关因素的同质人群;其次需根据研究目的和使用要求选定适当的百分界值,如80%,90%,95%和99%,常用95%;根据指标的实际用途确定单侧或双侧界值,如白细胞计数过高过低皆属不正常须确定双侧界值,又如肝功中转氨酶过高属不正常须确定单侧上界,肺活量过低属不正常须确定单侧下界。另外,还要根据资料的分布特点,选用恰当的计算方法。常用方法有:
(1)正态分布法:适用于正态或近似正态分布的资料。
双侧界值: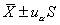 单侧上界:
单侧上界: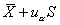 ,或单侧下界:
,或单侧下界: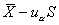
(2)对数正态分布法:适用于对数正态分布资料。
双侧界值: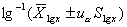 ;单侧上界:
;单侧上界: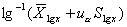 ,或单侧下界:
,或单侧下界: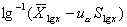 。
。
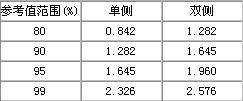
常用u值可根据要求由表3.2查出。
(3)百分位数法:常用于偏态分布资料以及资料中一端或两端无确切数值的资料。
双侧界值:P2.5和P97.5;单侧上界:P95,或单侧下界:P5。
表:常用u值表
3.正态分布是许多统计方法的理论基础:如t分布、F分布、分布都是在正态分布的基础上推导出来的,u检验也是以正态分布为基础的。此外,t分布、二项分布、Poisson分布的极限为正态分布,在一定条件下,可以按正态分布原理来处理。
如果您认为本条目还有待完善,需要补充新内容或修改错误内容,请编辑条目。
-------------------------------------------------------------------------------------
http://baike.baidu.com/view/45379.html?wtp=tt
正态分布

正态分布
normal distribution
一种概率分布。正态分布是具有两个参数μ和σ2的连续型随机变量的分布,第一参数μ是服从正态分布的随机变量的均值,第二个参数σ2是此随机变量的方差,所以正态分布记作N(μ,σ2 )。 服从正态分布的随机变量的概率规律为取与μ邻近的值的概率大 ,而取离μ越远的值的概率越小;σ越小,分布越集中在μ附近,σ越大,分布越分散。正态分布的密度函数的特点是:关于μ对称,在μ处达到最大值,在正(负)无穷远处取值为0,在μ±σ处有拐点。它的形状是中间高两边低 ,图像是一条位于x轴上方的钟形曲线。当μ=0,σ2 =1时,称为标准正态分布,记为N(0,1)。μ维随机向量具有类似的概率规律时,称此随机向量遵从多维正态分布。多元正态分布有很好的性质,例如,多元正态分布的边缘分布仍为正态分布,它经任何线性变换得到的随机向量仍为多维正态分布,特别它的线性组合为一元正态分布。
正态分布最早由A.棣莫弗在求二项分布的渐近公式中得到。C.F.高斯在研究测量误差时从另一个角度导出了它。P.S.拉普拉斯和高斯研究了它的性质。
生产与科学实验中很多随机变量的概率分布都可以近似地用正态分布来描述。例如,在生产条件不变的情况下,产品的强力、抗压强度、口径、长度等指标;同一种生物体的身长、体重等指标;同一种种子的重量;测量同一物体的误差;弹着点沿某一方向的偏差;某个地区的年降水量;以及理想气体分子的速度分量,等等。一般来说,如果一个量是由许多微小的独立随机因素影响的结果,那么就可以认为这个量具有正态分布(见中心极限定理)。从理论上看,正态分布具有很多良好的性质 ,许多概率分布可以用它来近似;还有一些常用的概率分布是由它直接导出的,例如对数正态分布、t分布、F分布等。
正态分布应用最广泛的连续概率分布,其特征是“钟”形曲线。
from http://www.5yiso.cn
(一)正态分布
1.正态分布
若 的密度函数(频率曲线)为正态函数(曲线)
(3-1)
则称 服从正态分布,记号 ~ 。其中 、 是两个不确定常数,是正态分布的参数,不同的 、不同的 对应不同的正态分布。
正态曲线呈钟型,两头低,中间高,左右对称,曲线与横轴间的面积总等于1。
2.正态分布的特征
服从正态分布的变量的频数分布由 、 完全决定。
(1) 是正态分布的位置参数,描述正态分布的集中趋势位置。正态分布以 为对称轴,左右完全对称。正态分布的均数、中位数、众数相同,均等于 。
(2) 描述正态分布资料数据分布的离散程度, 越大,数据分布越分散, 越小,数据分布越集中。 也称为是正态分布的形状参数, 越大,曲线越扁平,反之, 越小,曲线越瘦高。
(二)标准正态分布
1.标准正态分布是一种特殊的正态分布,标准正态分布的μ和σ2为0和1,通常用 (或Z)表示服从标准正态分布的变量,记为 Z~N(0,1)。
2.标准化变换:此变换有特性:若原分布服从正态分布 ,则Z=(x-μ)/σ ~ N(0,1) 就服从标准正态分布,通过查标准正态分布表就可以直接计算出原正态分布的概率值。故该变换被称为标准化变换。
3. 标准正态分布表
标准正态分布表中列出了标准正态曲线下从-∞到X(当前值)范围内的面积比例 。
(三)正态曲线下面积分布
1.实际工作中,正态曲线下横轴上一定区间的面积反映该区间的例数占总例数的百分比,或变量值落在该区间的概率(概率分布)。不同 范围内正态曲线下的面积可用公式3-2计算。
(3-2)
。
2.几个重要的面积比例
轴与正态曲线之间的面积恒等于1。正态曲线下,横轴区间(μ-σ,μ+σ)内的面积为68.27%,横轴区间(μ-1.96σ,μ+1.96σ)内的面积为95.00%,横轴区间(μ-2.58σ,μ+2.58σ)内的面积为99.00%。
(四)正态分布的应用
某些医学现象,如同质群体的身高、红细胞数、血红蛋白量,以及实验中的随机误差,呈现为正态或近似正态分布;有些指标(变量)虽服从偏态分布,但经数据转换后的新变量可服从正态或近似正态分布,可按正态分布规律处理。其中经对数转换后服从正态分布的指标,被称为服从对数正态分布。
1. 估计频数分布 一个服从正态分布的变量只要知道其均数与标准差就可根据公式(3-2)估计任意取值 范围内频数比例。
2. 制定参考值范围
(1)正态分布法 适用于服从正态(或近似正态)分布指标以及可以通过转换后服从正态分布的指标。
(2)百分位数法 常用于偏态分布的指标。表3-1中两种方法的单双侧界值都应熟练掌握。
表3-1 常用参考值范围的制定
概率
(%) 正态分布法 百分位数法
双侧 单 侧 双侧 单侧
下 限 上 限 下 限 上 限
90
95
99
3. 质量控制:为了控制实验中的测量(或实验)误差,常以 作为上、下警戒值,以 作为上、下控制值。这样做的依据是:正常情况下测量(或实验)误差服从正态分布。
4. 正态分布是许多统计方法的理论基础。 检验、方差分析、相关和回归分析等多种统计方法均要求分析的指标服从正态分布。许多统计方法虽然不要求分析指标服从正态分布,但相应的统计量在大样本时近似正态分布,因而大样本时这些统计推断方法也是以正态分布为理论基础的。
from http://www.foodmate.net/lesson/41/3-1.php
一、正态分布的概念
由表1.1的频数表资料所绘制的直方图,图3.1(1)可以看出,高峰位于中部,左右两侧大致对称。我们设想,如果观察例数逐渐增多,组段不断分细,直方图顶端的连线就会逐渐形成一条高峰位于中央(均数所在处),两侧逐渐降低且左右对称,不与横轴相交的光滑曲线图3.1(3)。这条曲线称为频数曲线或频率曲线,近似于数学上的正态分布(normal distribution)。由于频率的总和为100%或1,故该曲线下横轴上的面积为100%或1。
图3.1频数分布逐渐接近正态分布示意图
为了应用方便,常对正态分布变量X作变量变换。
(3.1)
该变换使原来的正态分布转化为标准正态分布 (standard normal distribution),亦称u分布。u被称为标准正态变量或标准正态离差(standard normal deviate)。
二、正态分布的特征:
1.正态曲线(normal curve)在横轴上方均数处最高。
2.正态分布以均数为中心,左右对称。
3.正态分布有两个参数,即均数和标准差。是位置参数,当固定不变时,越大,曲线沿横轴越向右移动;反之,越小,则曲线沿横轴越向左移动。是形状参数,当固定不变时,越大,曲线越平阔;越小,曲线越尖峭。通常用表示均数为,方差为的正态分布。用N(0,1)表示标准正态分布。
4.正态曲线下面积的分布有一定规律。
实际工作中,常需要了解正态曲线下横轴上某一区间的面积占总面积的百分数,以便估计该区间的例数占总例数的百分数(频数分布)或观察值落在该区间的概率。正态曲线下一定区间的面积可以通过附表1求得。对于正态或近似正态分布的资料,已知均数和标准差,就可对其频数分布作出概约估计。
查附表1应注意:①表中曲线下面积为-∞到u的左侧累计面积;②当已知μ、σ和X时先按式(3.1)求得u值,再查表,当μ、σ未知且样本含量n足够大时,可用样本均数和标准差S分别代替μ和σ,按式求得u值,再查表;③曲线下对称于0的区间面积相等,如区间(-∞,-1.96)与区间(1.96,∞)的面积相等,④曲线下横轴上的总面积为100%或1。
正态分布曲线下有三个区间的面积应用较多,应熟记:①标准正态分布时区间(-1,1)或正态分布时区间(μ-1σ,μ+1σ)的面积占总面积的68.27%;②标准正态分布时区间(-1.96,1.96)或正态分布区间(μ-1.96σ,μ+1.96σ)的面积占总面积的95%;③标准正态分布时区间(-2.58,2.58)或正态分布时区间(μ-2.58σ,μ+2.58σ)的面积占总面积的99%。如图3.2所示。(μ-3σ)的面积比例为99.74%,(μ-2σ)面积比例为95.44%。
图3.2 正态曲线与标准正态曲线的面积分布
统计学术语,与“平均”(***erage)意义相同。例如: l、3、6,10、20这5个数字的均值是8。
样本方差与总体方差在计算上的区别是:总体方差是用数据个数或总频数去除离差平方和,而样本方差则是用样本数据个数或总频数减1去除离差平方和,其中样本数据个数减1即n-1称为自由度。设样本方差为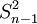 ,根据未分组数据和分组数据计算样本方差的公式分别为:
,根据未分组数据和分组数据计算样本方差的公式分别为:
维基百科,自由的百科全书
在概率论和统计学中,一个随机变量的“方差”描述的是它的离散程度,也就是该变量离其期望值的距离。 一个实随机变量的方差也称为它的二阶距,恰巧也是它的二阶culmulent。 方差的算术平方根称为该随机变量的标准差。
[编辑] 定义
设 X 为服从分布 F 的随机变量,则称 Var(X) = E(X − EX)2 为随机变量 X 或者分布 F 的方差。
如果 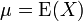 是隨機變數 X 的期望值 (平均數) , 則其變異數為:
是隨機變數 X 的期望值 (平均數) , 則其變異數為: 
[编辑] 特性
在样本空间Ω上存在有限期望和方差的随机变量构成一个希尔伯特空间: L^2(Ω, dP),不过这里的内积和长度跟方差,标准差还是不大一样。 所以,我们得把这个空间“除”常变量构成的子空间,也就是说把相差一个常数的 所有原来那个空间的随机变量做成一个等价类。这还是一个新的无穷维线性空间, 并且有一个从老空间内积诱导出来的新内积,而这个内积就是方差
[编辑] 一般化
如果X是一个向量其取值范围在Rn空间,并且其每个元素都是一个一维随机变量,我们就把X称为随机向量。随机向量的方差是一维随机变量方差的自然推广,其定义为E[(X − μ)(X − μ)T], 其中 μ = E(X) ,XT是X的转秩. 这个方差是一个非负定方阵,通常称为协方差矩阵。
如果X是一个复随机变量,那么其方差定义则为E[(X − μ)(X − μ)*], 其中X*是X的复共轭向量。根据这个定义,方差为实数。
[编辑] 历史
方差这个词首先由Ronald Fisher在论文The Correlation Between Relatives on the Supposition of Mendelian Inheritance中引入.
[编辑] 参考出处
- ^ Press, W. H., Teukolsky, S. A., Vetterling, W. T. & Flannery, B. P. (1986) Numerical recipes: The art of scientific computing. Cambridge: Cambridge University Press. (online)