 2008年8月28日
2008年8月28日
通过本教程,您将了解到什么是Mondiran,及如何将mondrian支持添加到您的Java Web项目中。
在阅读本教程之前,您可能需要掌握以下概念:
OLAP(联机分析处理On-Line Analytical Processing),您可以通过阅读ROLAP的概念.pptx来了解OLAP
MDX多维表达式,您可以通过阅读MDX的基本语法及概念.pptx来了解MDX
1. Mondrian是什么?
Mondrian是一个开源项目。一个用Java写成的OLAP引擎。它用MDX语言实现查询,从关系数据库(RDBMS)中读取数据。然后经过Java API以多维的方式对结果进行展示。
Mondrian的使用方式同JDBC驱动类似。可以非常方便的与现有的Web项目集成
1.1 Mondrian的体系结构(Architecture)
Mondrian OLAP 系统由四个层组成; 从最终用户到数据中心, 顺序为:
1.1.1 表现层(the presentation layer)
1.1.2 维度层(the dimensional layer)
1.1.3 集合层(the star layer)
1.1.4 存储层(the storage layer)
结构图如下:

1.1.1 表现层(the presentation layer)
表现层决定了最终用户将在他们的显示器上看到什么, 及他们如何同系统产生交互。
有许多方法可以用来向用户显示多维数据集, 有 pivot 表 (一种交互式的表), pie, line 和图表(bar charts)。它们可以用Swing 或 JSP来实现。
表现层以多维"文法(grammar)(维、度量、单元)”的形式发出查询,然后OLAP服务器返回结果。
1.1.1.1 Jpivot表现层
JPivot 是Mondrian的表现层TagLib,一直保持着良好的开发进度。
您可以通过访问jpivot的官方网站http://jpivot.sourceforge.net/以获得更多的帮助及支持
jpivot使用XML/ XSLT渲染OLAP报表:
JPivot 使用 WCF (Web Component Framework) ,基于XML/XSLT来渲染Web UI组件。这使它显得十分另类。不过,OLAP报表这种非常复杂但又有规律可循的东西,最适合使用XSLT来渲染。
jpivot完全基于JSP+TagLib:
JPivot另外一个可能使人不惯的地方是它完全基于taglib而不是大家熟悉的MVC模式。
但它可以很方便的将多维数据展示给最终用户,如下表格:

jpivot其实是一个自定义jsp的标签库。它基于XML/XSLT配置来生成相应的html。所幸的是,我们并不需要了解太多关于这方面的内容,我们只要掌握相应jsp标签的使用即可。
在本教程的实例中,我们将会对一些常用到的jpivot标签进行讲解。
您还可以通过汉化WEB-INF/jpivot下的xml文件来完成对jpivot的汉化工作
1.1.2 维度层(the dimensional layer)
维度层用来解析、验证和执行MDX查询要求。
一个MDX查询要通过几个阶段来完成:首先是计算坐标轴(axes),再者计算坐标轴axes 中cell的值。
为了提高效率,维度层把要求查询的单元成批发送到集合层,查询转换器接受操作现有查询的请求,而不是对每个请求都建立一个MDX 声明。
1.1.3 集合层(the star layer)
集合层负责维护和创建集合缓存,一个集合是在内存中缓存一组单元值, 这些单元值由一组维的值来确定。
维度层对这些单元发出查询请求,如果所查询的单元值不在缓存中,则集合管理器(aggregation manager)会向存储层发出查询请求
1.1.4 存储层(the storage layer)
存储层是一个关系型数据库(RDBMS)。它负责创建集合的单元数据,和提供维表的成员。
1.2 API
Mondrian 为客户端提供一个用于查询的API
因为到目前为止,并没有一个通用的用于OLAP查询的API,因此Mondrian提供了它私有的API.
尽管如此,一个常使用JDBC的人将同样发现它很熟悉.不同之处仅在于它使用的是MDX查询语言,而非SQL
下面的java片段展示了如何连接到Mondrian,然后执行一个查询,最后打印结果.
- import mondrian.olap.*;
- import java.io.PrintWriter;
- Connection connection = DriverManager.getConnection("Provider=mondrian;"
- +"Jdbc=jdbc:odbc:MondrianFoodMart;"
- +"Catalog=/WEB-INF/FoodMart.xml;",null,false);
- Query query = connection.parseQuery("SELECT {[Measures].[Unit Sales], [Measures].[Store Sales]} on columns,"
- +" {[Product].children} on rows "
- +"FROM [Sales] " +"WHERE ([Time].[1997].[Q1], [Store].[CA].[San Francisco])");
- Result result = connection.execute(query);
- result.print(new PrintWriter(System.out));
与JDBC类似,一个Connection由DriverManager创建,Query 对象类似于JDBC 的Statement,它通过传递一个MDX语句来创建.Result对象类似于JDBC的ResultSet,只不过它里面保存的是多维数据
您可以通过查看Mondrian帮助文档里的javadoc来获取更多关于Mondrian API的资料
通过上面的介绍,您应该对mondrian的体系有一个基本的了解。
下面我们将通过一个简单的例子来加深您的理解。
2. 一个简单的Mondrian例子
现在让我们用一个简单的例子来说明将Mondrian支持添加到您java web的具体步骤。
2.1 准备开发工具及环境
本测试需要的环境:
操作系统:Windows 2000;
Web服务器:tomcat6.0;
关系数据库:sql server 2000;
开发工具:eclipse + myeclipse;
JDBC驱动:jtds-1.2.2;
您可以在http://tomcat.apache.org/上下载到tomcat的最新版本及帮助;
您可以在http://www.myeclipseide.com/上下载到myeclipse的最新版本及相应的eclipse开发平台版本
2.2 准备Mondrian资源:
从http://sourceforge.net/projects/mondrian/下载Mondrian的最新版本(目前版本为3.0,大约有50M+大小)。

2.3 创建项目
启动eclipse。
在eclipse中新创建一个web项目,名为Tezz。注意需要加入JSTL支持。
具体步骤如下:
2.3.1 打开新建web项目对话框



一个新项目Tezz的文件结构如下:

2.4 添加必须的文件
将下载的压缩包进行解压。完成后,进入文件夹可以看到如下目录结构。双击进入lib文件夹。

Lib文件夹有如下内容:注意到这里的mondrian.war文件是一个可直接布署的项目,我们需要将它解压,然后从中取出我们所需要的文件。(建议将其扩展名改成zip,然后直接右键解压)

进入解压后的文件夹,选中jpivot、wcf二个文件夹及busy.jsp、error.jsp、testpage.jsp三个文件,我们需要将这些资源复制到我们测试项目的WebRoot文件夹中。按ctrl+C键复制。

注:jpivot、wcf这两个文件夹包含mondrian使用的图像和css文件。Busy.jsp显示等待页面、error.jsp显示出错页面、testpage.jsp这文件的用处将在后面介绍。
切换到eclipse界面,在我们的Tezz项目的WebRoot文件夹处右击鼠标,在弹出的菜单中选择Paste(粘贴)即可

粘贴完成后的项目结构如下

注意:因为我们还未将所有资料复制到项目中,因此eclipse会显示错误图标
最后进入WEB-INF文件夹(在上面步骤中解压的项目文件mondrian.war里),选中jpivot、lib、wcf这三个文件夹,同样需要复制它们到测试项目的WEB-INF文件夹中。

Jpivot、wcf这两个文件夹包含jpivot和wcf用于生成用户界面的配置文件(*.xml、*.xsl)及标签文件(*.tld)的定义。Lib文件夹包含的是mondrian所要用的java包。
切换到eclipse界面,在我们的Tezz项目的WebRoot文件夹处右击鼠标,在弹出的菜单中选择Paste(粘贴)

至此Mondrian的支持添加完毕,下面我们将配置web.xml,让我们的项目能够使用到mondrian的功能。
2.5 配置web.xml
用eclipse打开我们在上面解压的布署项目的WEB-INF/web.xml文件

过滤器(filter)
复制如下所示的xml代码到我们测试项目Tezz的web.xml文件中。
作用:这个过滤器在访问/testpage.jsp前被调用。它被设计成jpivot的前端控制器,用于判断并将用户的请求发送到某个页面。
注:在实际项目中可以使用您自己定义的servlet或使用其他技术来替代它以提供更多的功能
- <filter>
- <filter-name>JPivotController</filter-name>
- <filter-class>com.tonbeller.wcf.controller.RequestFilter</filter-class>
- <init-param>
- <param-name>indexJSP</param-name>
- <param-value>/index.html</param-value>
- <description>如果这是一个新的会话,则转到此页面</description>
- </init-param>
- <init-param>
- <param-name>errorJSP</param-name>
- <param-value>/error.jsp</param-value>
- <description>出错时显示的页面</description>
- </init-param>
- <init-param>
- <param-name>busyJSP</param-name>
- <param-value>/busy.jsp</param-value>
- <description>这个页面用于当用户点击一个查询时,在这个查询还未将结果还回给用户时所显示的界面</description>
- </init-param>
- </filter>
-
- <filter-mapping>
- <filter-name>JPivotController</filter-name>
- <url-pattern>/testpage.jsp</url-pattern>
- </filter-mapping>
复制下面的listener到我们的web.xml文件中(用于初始化一些资源)
- <listener>
- <listener-class>mondrian.web.taglib.Listener</listener-class>
- </listener>
-
- <!– 资源初始化-->
- <listener>
- <listener-class>com.tonbeller.tbutils.res.ResourcesFactoryContextListener</listener-class>
- </listener>
Print servlet,该servlet用于将数据生成Excel文件或pdf文件并返回给用户,如果您需要用到该功能,则需要将其copy到您项目的web.xml文件中
- <servlet>
- <servlet-name>Print</servlet-name>
- <display-name>Print</display-name>
- <description>Default configuration created for servlet.</description>
- <servlet-class>com.tonbeller.jpivot.print.PrintServlet</servlet-class>
- </servlet>
- <servlet-mapping>
- <servlet-name>Print</servlet-name>
- <url-pattern>/Print</url-pattern>
- </servlet-mapping>
MDXQueryServlet用于接受并执行一个MDX查询,然后将该查询以Html表格的形式返回。其中的参数connectString用于指定连接到数据库的字符串,例如使用jtds驱动连接到sql server 2000的字符串如下:
Provider=mondrian;Jdbc=jdbc:jtds:sqlserver://localhost/Tezz;user=sa;password=123456;Catalog=/WEB-INF/queries/tezz.xml;JdbcDrivers=net.sourceforge.jtds.jdbc.Driver;
如果您需要用到该功能,则需要将其copy到您项目的web.xml文件中。
- <servlet>
- <servlet-name>MDXQueryServlet</servlet-name>
- <servlet-class>mondrian.web.servlet.MDXQueryServlet</servlet-class>
- <init-param>
- <param-name>connectString</param-name>
- <param-value>@mondrian.webapp.connectString@</param-value>
- </init-param>
- </servlet>
- <servlet-mapping>
- <servlet-name>MDXQueryServlet</servlet-name>
- <url-pattern>/mdxquery</url-pattern>
- </servlet-mapping>
DisplayChart 和GetChart 这两个Servlet 用于生成图表和将其显示给最终用户,如果您需要用到该功能,则需要将其copy到您项目的web.xml文件中。
- <!-- jfreechart provided servlet -->
- <servlet>
- <servlet-name>DisplayChart</servlet-name>
- <servlet-class>org.jfree.chart.servlet.DisplayChart</servlet-class>
- </servlet>
- <!-- jfreechart provided servlet -->
- <servlet>
- <servlet-name>GetChart</servlet-name>
- <display-name>GetChart</display-name>
- <description>Default configuration created for servlet.</description>
- <servlet-class>com.tonbeller.jpivot.chart.GetChart</servlet-class>
- </servlet>
- <servlet-mapping>
- <servlet-name>DisplayChart</servlet-name>
- <url-pattern>/DisplayChart</url-pattern>
- </servlet-mapping>
- <servlet-mapping>
- <servlet-name>GetChart</servlet-name>
- <url-pattern>/GetChart</url-pattern>
- </servlet-mapping>
它们用于向用户生成和显示如下所示的各种图表:

最后添加以下标签库到我们的web.xml项目中即可
- <taglib>
- <taglib-uri>http://www.tonbeller.com/wcf</taglib-uri>
- <taglib-location>/WEB-INF/wcf/wcf-tags.tld</taglib-location>
- </taglib>
-
- <taglib>
- <taglib-uri>http://www.tonbeller.com/jpivot</taglib-uri>
- <taglib-location>/WEB-INF/jpivot/jpivot-tags.tld</taglib-location>
- </taglib>
到这里,您应该对mondrian在web.xml的配置有一定的了解,并可按需要添加相应的功能。
接下来我们将要创建本例子所要用到的表格及数据。
2.6 准备测试用表
本例使用的表结构如下所示:

Sale是事实表,它有两个维:客户(customer)维和由两个表组成的产品(Product)维。
表格的创建很简单,您只需要将下面的sql语句导入数据库即可
2.6.1 使用以下sql语句创建表
- /**销售表*/
- create table Sale (
- saleId int not null,
- proId int null,
- cusId int null,
- unitPrice float null, --单价
- number int null, --数量
- constraint PK_SALE primary key (saleId)
- )
- /**用户表*/
- create table Customer (
- cusId int not null,
- gender char(1) null, --性别
- constraint PK_CUSTOMER primary key (cusId)
- )
- /**产品表*/
- create table Product (
- proId int not null,
- proTypeId int null,
- proName varchar(32) null,
- constraint PK_PRODUCT primary key (proId)
- )
- /**产品类别表*/
- create table ProductType (
- proTypeId int not null,
- proTypeName varchar(32) null,
- constraint PK_PRODUCTTYPE primary key (proTypeId)
- )
2.6.2 使用以下sql语句导入数据
- insert into Customer(cusId,gender) values(1,'F')
- insert into Customer(cusId,gender) values(2,'M')
- insert into Customer(cusId,gender) values(3,'M')
- insert into Customer(cusId,gender) values(4,'F')
- insert into producttype(proTypeId,proTypeName) values(1,'电器')
- insert into producttype(proTypeId,proTypeName) values(2,'数码')
- insert into producttype(proTypeId,proTypeName) values(3,'家具')
- insert into product(proId,proTypeId,proName) values(1,1,'洗衣机')
- insert into product(proId,proTypeId,proName) values(2,1,'电视机')
- insert into product(proId,proTypeId,proName) values(3,2,'mp3')
- insert into product(proId,proTypeId,proName) values(4,2,'mp4')
- insert into product(proId,proTypeId,proName) values(5,2,'数码相机')
- insert into product(proId,proTypeId,proName) values(6,3,'椅子')
- insert into product(proId,proTypeId,proName) values(7,3,'桌子')
- insert into sale(saleId,proId,cusId,unitPrice,number) values(1,1,1,340.34,2)
- insert into sale(saleId,proId,cusId,unitPrice,number) values(2,1,2,140.34,1)
- insert into sale(saleId,proId,cusId,unitPrice,number) values(3,2,3,240.34,3)
- insert into sale(saleId,proId,cusId,unitPrice,number) values(4,3,4,540.34,4)
- insert into sale(saleId,proId,cusId,unitPrice,number) values(5,4,1,80.34,5)
- insert into sale(saleId,proId,cusId,unitPrice,number) values(6,5,2,90.34,26)
- insert into sale(saleId,proId,cusId,unitPrice,number) values(7,6,3,140.34,7)
- insert into sale(saleId,proId,cusId,unitPrice,number) values(8,7,4,640.34,28)
- insert into sale(saleId,proId,cusId,unitPrice,number) values(9,6,1,140.34,29)
- insert into sale(saleId,proId,cusId,unitPrice,number) values(10,7,2,740.34,29)
- insert into sale(saleId,proId,cusId,unitPrice,number) values(11,5,3,30.34,28)
- insert into sale(saleId,proId,cusId,unitPrice,number) values(12,4,4,1240.34,72)
- insert into sale(saleId,proId,cusId,unitPrice,number) values(13,3,1,314.34,27)
- insert into sale(saleId,proId,cusId,unitPrice,number) values(14,3,2,45.34,27)
2.7 建立模式(schema)文件
一个模式定义了一个多维数据库. 它包含一个逻辑模型(logical model)、一组数据立方(consisting of cubes)、层次(hierarchies)、和成员(members), 并映射到物理模型(关系数据库)上。
简单的说,配置一个模式就是配置一个关系数据结构到多维数据结构的映射。
注:关于mondrian的模式及模式的配置,您可以通过阅读mondrian的基本模式.pptx来了解。这里我们只对其进行了简单介绍。
2.7.1 创建模式文件:
模式文件的创建很简单。首先在WEB-INF下新建一个queries的文件夹,然后在该文件夹下创建一个名为tezz.xml的文件。再按下面的步骤将xml元素添加入即可。

2.7.2 配置模式文件:
2.7.2.1 添加数据立方Sales:

2.7.2.2 添加数据立方Sales的维:

添加产品维(因为产品维由两个表连接而成,因此比客户维复杂些):

添加度量(共有三个度量:数量、平均单价和总销售额):

最后生成的tezz.xml文件内容如下:
- <?xml version="1.0" encoding="UTF-8"?>
- <Schema name="tezz">
- <Cube name="Sales">
- <!-- 事实表(fact table) -->
- <Table name="sale" />
- <!-- 客户维 -->
- <Dimension name="客户性别" foreignKey="cusId">
- <Hierarchy hasAll="true" allMemberName="所有性别" primaryKey="cusId">
- <Table name="Customer"></Table>
- <Level name="gender" column="gender"></Level>
- </Hierarchy>
- </Dimension>
- <!-- 产品类别维 -->
- <Dimension name="产品类别" foreignKey="proId">
- <Hierarchy hasAll="true" allMemberName="所有产品" primaryKey="proId" primaryKeyTable="product">
- <join leftKey="proTypeId" rightKey="proTypeId">
- <Table name="product" />
- <Table name="producttype"></Table>
- </join>
- <Level name="proTypeId" column="proTypeId"
- nameColumn="proTypeName" uniqueMembers="true" table="producttype" />
- <Level name="proId" column="proId" nameColumn="proName"
- uniqueMembers="true" table="product" />
- </Hierarchy>
- </Dimension>
- <Measure name="数量" column="number" aggregator="sum" datatype="Numeric" />
- <Measure name="总销售额" aggregator="sum" formatString="¥#,##0.00">
- <!-- unitPrice*number所得值的列 -->
- <MeasureExpression>
- <SQL dialect="generic">(unitPrice*number)</SQL>
- </MeasureExpression>
- </Measure>
- <CalculatedMember name="平均单价" dimension="Measures">
- <Formula>[Measures].[总销售额] / [Measures].[数量]</Formula>
- <CalculatedMemberProperty name="FORMAT_STRING" value="¥#,##0.00" />
- </CalculatedMember>
- </Cube>
- </Schema>
2.8 编写MDX查询语句
在模式文件定义完成之后,我们就可以根据它来编写相应MDX查询语句了。
本例所用的MDX语句如下:

2.9 创建查询文件
现在我们将创建一个jsp文件,该jsp使用jpivot的mondrianQuery标签来完成查询。
该文件最后将被testpage.jsp使用。
在/WEB-INF/queries文件夹下面创建一名为tezz的jsp文件。该jsp包含如下内容:

2.10 布署项目
至此我们已经全部配置完成,文件结构如下:

布署项目,启动Tomcat,在浏览器上输入http://localhost:8080/Tezz/testpage.jsp?query=tezz即可看到如下结果:

注:testpage.jsp?query=tezz,这里的tezz即刚我们创建的用于查询jsp文件名称
3. testpage.jsp的流程
testpage.jsp文件用于发出查询及将结果转换成html格式。它使用一组jsp标签来完成这些复杂的工作。
在本教程的最后一章里,我们对testpage.jsp的流程及用到的主要标签进行简单介绍。
3.1 wcf:include标签:

3.2 jp:table标签:
<jp:table id="table01" query="#{query01}"/>
jp:table根据query01中保存的结果(领域数据)准备显示OLAP表格所需的数据(显示数据)
<wcf:render ref="table01" xslUri="/WEB-INF/jpivot/table/mdxtable.xsl"/>
根据table01的结果,使用mdxtable.xsl中的配置,渲染出OLAP表格。
3.3 其他jp、wcf标签
同样,其他jp标签,如<jp:chart id=“chart01“ ---/>等标签准备待渲染的数据,再由相应的<wcf:render ref=“chart01” ---/>标签将它们渲染成html格式。
这样,用户将在浏览器上看到最终的结果。
至此,一个完整的mondrian查询结束。
http://blog.csdn.net/ozwarld/article/details/7735915
IBM MQ 6.0中设置两个队列,(远程队列、通道之类都不设置)。
队列管理器是XIR_QM_1502
队列名称是ESBREQ
IP地址是10.23.117.134(远程的一台电脑,跟我的电脑不在一个局域网内)
端口1414
CCSID 1208
MQ配置可以参考这个,有配图http://wenku.baidu.com/view/06d108d0360cba1aa811daa3.html
程序如下,发送线程两个,接收线程一个。接收完毕后就结束。
运行结果如下:
进入线程Sender2
进入线程Sender
Sender2 Connecting to queue manager: XIR_QM_1502
Sender Connecting to queue manager: XIR_QM_1502
Sender2 Accessing queue: ESBREQ
Sender2 Sending a message...
Sender Accessing queue: ESBREQ
Sender Sending a message...
Sender2 putting the message... 1
Sender putting the message... 1
Sender2 putting the message... 2
Sender putting the message... 2
Sender2 putting the message... 3
Sender putting the message... 3
Sender2 putting the message... 4
Sender putting the message... 4
Sender2 Done!
==========
Sender Done!
==========
进入线程Receiver
Receiver Connecting to queue manager: XIR_QM_1502
Receiver Accessing queue: ESBREQ
... Receiver getting the message back again
ID: MSGID Num: 1 Type: 1 Flag: 0
The message is: Salemetsizbe Yerasel 1
ID: MSGID Num: 1 Type: 1 Flag: 0
The message is: Salemetsizbe Yerasel 1
ID: MSGID Num: 1 Type: 1 Flag: 0
The message is: Salemetsizbe Yerasel 2
ID: MSGID Num: 1 Type: 1 Flag: 0
The message is: Salemetsizbe Yerasel 2
ID: MSGID Num: 1 Type: 1 Flag: 0
The message is: Salemetsizbe Yerasel 3
ID: MSGID Num: 1 Type: 1 Flag: 0
The message is: Salemetsizbe Yerasel 3
ID: MSGID Num: 1 Type: 1 Flag: 0
The message is: Salemetsizbe Yerasel 4
ID: MSGID Num: 1 Type: 1 Flag: 0
The message is: Salemetsizbe Yerasel 4
Receiver Closing the queue
Receiver Disconnecting from the Queue Manager
Receiver Done!
2013 年 3 月 11 日 – 09:41 | 2,420 views |  收藏
收藏 PDO_MYSQL以下操作都在Linux 系统下操作
1、下载 文件 或者 进入 在PHP源码包中进入ext/pdo_mysql
http://pecl.php.net/get/PDO_MYSQL-1.0.2.tgz
2、解压文件
tar zxvf PDO_MYSQL-1.0.2.tgz
3、配置和编译文件
#cd PDO_MYSQL-1.0.2
#/usr/local/php5/bin/phpize
#./configure –with-php-config=/usr/local/php5/bin/php-config –with-pdo-mysql=/usr/local/mysql
#make
#make install
注: 我的PHP安装在 : /usr/local/php5/ mysql 安装在 : /usr/local/mysql 编译的时候注意你自己的安装目录在哪里
3、安装到PHP配置下
把这个记住,然后打开 php.ini文件,
并添加一行
extension=pdo_mysql.so
并将上面编译产生的so复制到 php.ini文件中extension_dir指定的目录中
重新启动!
说明:
操作系统:CentOS 5.x 64位
已安装php版本:php-5.4.4
已安装php路径:/usr/local/php
实现目的:
在不影响网站访问的情况下,重新编译php,增加对mcrypt扩展的支持
具体操作:
一、下载软件包
1、下载php(版本要与系统安装的一致)
http://museum.php.net/php5/php-5.4.4.tar.gz
2、下载libmcrypt(安装mcrypt需要此软件包)
http://nchc.dl.sourceforge.net/project/mcrypt/Libmcrypt/2.5.8/libmcrypt-2.5.8.tar.gz
3、下载mhash(安装mcrypt需要此软件包)
https://acelnmp.googlecode.com/files/mhash-0.9.9.9.tar.gz
4、下载mcrypt
https://lcmp.googlecode.com/files/mcrypt-2.6.8.tar.gz
以上软件包下载之后,上传到/usr/local/src目录
二、安装软件包
1、安装libmcrypt
cd /usr/local/src #进入软件包存放目录
tar zxvf libmcrypt-2.5.8.tar.gz #解压
cd libmcrypt-2.5.8 #进入安装目录
./configure #配置
make #编译
make install #安装
2、安装mhash
cd /usr/local/src
tar zxvf mhash-0.9.9.9.tar.gz
cd mhash-0.9.9.9
./configure
make
make install
3、安装mcrypt
cd /usr/local/src
tar zxvf mcrypt-2.6.8.tar.gz
cd mcrypt-2.6.8
ln -s /usr/local/bin/libmcrypt_config /usr/bin/libmcrypt_config #添加软连接
export LD_LIBRARY_PATH=/usr/local/lib:$LD_LIBRARY_PATH #添加环境变量
./configure
make
make install
三、重新编译php
1、查看系统之前安装的php编译参数
系统运维 www.osyunwei.com 温馨提醒:qihang01原创内容 版权所有,转载请注明出处及原文链接
/usr/local/php/bin/php -i |grep configure #查看php编译参数,记录下编译参数,后面会用到
2、安装php
cd /usr/local/src
tar zxvf php-5.4.4.tar.gz
cd php-5.4.4
'./configure' '--prefix=/usr/local/php' '--enable-mbstring=all' '--with-config-file-path=/usr/local/php/etc' '--with-zlib' '--with-mysql=/usr/local/mysql-5.1.38/' '--with-gd' '--with-mysqli=/usr/local/mysql-5.1.38/bin/mysql_config' '--with-jpeg-dir=/usr' '--with-png-dir=/usr' '--enable-fpm' '--enable-soap' '--with-freetype-dir=/usr/lib64' '--with-iconv=/usr/local' '--with-curl' '--with-mcrypt'
#在之前的编译参数后面增加'--with-mcrypt' 回车
make #编译
make install #安装
/usr/local/src/php-5.4.4/sapi/fpm/init.d.php-fpm reload #重新加载php-fpm
四、测试mcrypt扩展是否已安装成功
在网站目录下新建一个info.php测试页面,写上下面代码,保存
<?php
phpinfo();
?>
在浏览器中打开info.php 会看到如下的信息


说明mcrypt扩展已经安装成功
至此,Linux下php安装mcrypt扩展完成。
注册表中查看outlook临时目录
HK_CURRENT_USER\software\microsoft\Office\11.0\Outlook\Security\OutlookSecureTempFolder
查看键值 OutlookSecureTempFolder
C:\Documents and Settings\li.shi\Local Settings\Temporary Internet Files\OLK11\
删除临时目录下文件即可
RedHat Linux6.0安装Oracle 11g单机
Ø 第一步配置YUM仓库
1、 挂载光盘
mount /dev/cdrom /media
2、 复制光盘里头的rpm包到rpm包源目录
cp –rf /media/Packages /mnt (也可以直接通过桌面COPY)
(这里可以取消挂在了 umount /dev/cdrom,顺便删除media目录 rm –rf /media)
3、 进入你自己创建的YUM仓库,并安装createrepo工具
cd /mnt/Packages
rpm –ivh createrepo-0.4.11-3.e15.noarch.rpm(可以在桌面手动双击安装)
4、 重建仓库信息配置文件
createrepo /mnt (这个配置文件在 /mnt/repodata/下)
5、 创建YUM配置文件
cd /etc/yum.repos.d/
touch yumredhat.repo
vim yumredhat.repo
添加如下信息:
[rhel6]
name=Red Hat Enterprise Linux6
baseurl=file:///mnt
enabled=1
gpgcheck=0
gpgfile=file:///etc/pki/rpm-gpg/RPM-GPG-KEY-redhat-release
6、测试
yum list
yum clear all
Ø 第二步Oracle安装前系统参数的配置以及包的安装
(安装Oracle必须关闭掉防火墙以及selinux)
service iptables stop
vim /etc/selinux/config
SELINUX=disabled
========================
想办法把下面2个文件传进 Linux 操作系统里面去
linux_11gR2_database_1of2.zip
linux_11gR2_database_2of2.zip
要借助一个软件 FileZilla_3.3.3_win32-setup.exe
上传完毕后, 使用 unzip 命令解压刚才上传的2个文件, 命令格式如下:
unzip 文件名
======================================
检查相关的开发工具和一些包
检查命令格式如下:
rpm -qa | grep 名字
binutils-2.17.50.0.6
compat-libstdc++-33-3.2.3
elfutils-libelf-0.125
elfutils-libelf-devel-0.125
#elfutils-libelf-devel-static-0.125 (RedHat Linux6.0中无此包,CentOS中有)
gcc-4.1.2
gcc-c++-4.1.2
glibc-2.5-24
glibc-common-2.5
glibc-devel-2.5
glibc-headers-2.5
kernel-headers-2.6.18
ksh-20060214
libaio-0.3.106
libaio-devel-0.3.106
libgcc-4.1.2
libgomp-4.1.2
libstdc++-4.1.2
libstdc++-devel-4.1.2
make-3.81
numactl-devel-0.9.8.i386
sysstat-7.0.2
unixODBC-2.2.11
unixODBC-devel-2.2.11
======================================
利用配置好的YUM仓库安装包
yum install (包名).rpm
创建用户以及修改配置参数
groupadd oinstall
groupadd dba
mkdir -p /u01/oracle //路径可修改,看实际的生产环节
添加一个oracle用户, 根目录是 /u01/oracle, 主的组是 oinstall 副的组是dba
useradd -g oinstall -G dba -d /u01/oracle oracle
cp /etc/skel/.bash_profile /u01/oracle
cp /etc/skel/.bashrc /u01/oracle
cp /etc/skel/.bash_logout /u01/oracle
为oracle用户设置密码 123456 /111111
passwd oracle
/]#ls -l
/]#chown -R oracle:oinstall u01
/]#ls -l
检查 nobody 是否存在 , id nobody
缺省存在的。如果不存在 # /usr/sbin/useradd -g nobody
========================================
vi /etc/sysctl.conf
fs.aio-max-nr = 1048576
fs.file-max = 6815744
kernel.shmall = 2097152
kernel.shmmax = 536870912
kernel.shmmni = 4096
kernel.sem = 250 32000 100 128
net.ipv4.ip_local_port_range = 9000 65500
net.core.rmem_default = 262144
net.core.rmem_max = 4194304
net.core.wmem_default = 262144
net.core.wmem_max = 1048586
-------------
vi /etc/security/limits.conf
oracle soft nproc 2047
oracle hard nproc 16384
oracle soft nofile 1024
oracle hard nofile 65536
------------
vi /etc/pam.d/login
session required pam_limits.so
=================================================
设置oracle 用户环境变量
su - oracle
pwd
ls -la
---------------
vi .bash_profile
ORACLE_BASE=/u01
ORACLE_HOME=$ORACLE_BASE/oracle
ORACLE_SID=ORCLTEST
PATH=$ORACLE_HOME/bin:$PATH:$HOME/bin
export ORACLE_BASE ORACLE_HOME ORACLE_SID PATH
===================================
mv database /u01/
cd /u01
ls -l
chown -R oracle:oinstall database/
===========
Ø 第三步正式开始安装.Oracle.11g.r2(图形界面安装)
使用oracle账号 登陆图形界面 进行安装
运行终端 Terminal
cd /u01/database
./runInstaller
运行./runInstaller【INS-06101】IP address of localhost could not be determined
Are you sure you want to continue?
这里需要指定一个IP与localhost
Vi /etc/hosts
#127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
10.110.12.132 ORCLDEV ORCLDEV.ELLINGTON
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
运行./runInstaller出现中文汉字为方框
在运行runinstaller之前,
export LANG=C
export LC_ALL=C
Installation Optiong
install database software only
Grid Options
Single instance database installation
Product Languages
English
Database Edition
Enterprise Edition (3.95)
Installation Location
Oracle Base: /u01
Software Loacation: /u01/oracle
提示: yes
Create Inventory
mkdir /oraInventory
chown -R oracle:oinstall oraInventory
Operating System Groups
Next
Prerequis ite Checks
Ignore All
Summary
Finish
Install Product
安装完毕, 提示执行 2个脚本
//root用户执行
/oraInventory/orainstRoot.sh
/u01/oracle/root.sh
直接按回车, 缺省值就可以
Finish
The installation of Oracle Database was successful
====================================
上面只是安装了软件, 数据库没有创建, 还有配置 监听器 Listener
netca
一直默认下一步 , 呵呵, 最后 Finish
ps -ef 可以查看Listener是否配置成功
-----------
dbca
一直 Next, Global Database Name 和 SID 都是输入 wilson
选择 User the Same.....All Accounts
密码: 123456
选择 Sample Schemas
Memory 内存分配,默认就可以了
Character Sets 选择 中文GBK Use Unicode(AL32UTF8)
然后一直 Next , 到最后 Finish
弹出一个 Confirmation , 点击 OK 就可以了, 然后自动进行安装
安装到目录 /u01/oradata/wilson
/u01/等等。。。 会发现多了很多文件。
[oracle@localhost ~]$ sqlplus /nolog
//中文字符显示?号解决方法
编辑并运行.bash_profile
export NLS_LANG=AMERICAN_AMERICA.UTF8
(如果是GBK
export NLS_LANG=american_america.ZHS16GBK)
export NLS_LANG=AMERICAN_AMERICA.ZHS16GBK
注销后生效
这样再重新进入sqlplus
已经不会是乱码。
SQL*Plus: Release 11.2.0.1.0 Production on Fri Jun 25 15:05:54 2010
Copyright (c) 1982, 2009, Oracle. All rights reserved.
SQL> conn / as sysdba
Connected to an idle instance.
出现错误
SQL> startup
查看当前用户的表名
SQL> select table_name from user_tables;
SQL> create table testUser( id integer,name char(10));
Table created.
SQL> insert into testUser values(0,'Jack');
1 row created.
SQL> commit;
Commit complete.
SQL> select * from testUser;
ID NAME
---------- ----------
0 Jack
关闭数据库
SQL> shutdown immediate
SQL> quit
SELECT TOP 10
[Total Cost] = ROUND(avg_total_user_cost * avg_user_impact * (user_seeks + user_scans),0)
, avg_user_impact
, TableName = statement
, [EqualityUsage] = equality_columns
, [InequalityUsage] = inequality_columns
, [Include Cloumns] = included_columns
FROM sys.dm_db_missing_index_groups g
INNER JOIN sys.dm_db_missing_index_group_stats s
ON s.group_handle = g.index_group_handle
INNER JOIN sys.dm_db_missing_index_details d
ON d.index_handle = g.index_handle
ORDER BY [Total Cost] DESC;
================================
CREATE NONCLUSTERED INDEX IX_Kq_RecordQk_QKRMan
ON Kq_RecordQk ([QKRMan])
include([COMP_CODE], [QKREMPID], [ApStatus])
http://www.itokit.com/2012/1018/74794.html
MySQL的max_connections参数用来设置最大连接(用户)数。每个连接
MySQL的用户均算作一个连接,max_connections的默认值为100。本文将讲解此参数的详细作用与性能影响。
max_connections配置参数的相关的特性
1、MySQL无论如何都会保留一个用于管理员(SUPER)登陆的连接,用于管理员连接数据库进行维护操作,即使当前连接数已经达到了max_connections。因此MySQL的实际最大可连接数为max_connections+1;
2、这个参数实际起作用的最大值(实际最大可连接数)为16384,即该参数最大值不能超过16384,即使超过也以16384为准;
3、增加max_connections参数的值,不会占用太多系统资源。系统资源(CPU、内存)的占用主要取决于查询的密度、效率等;
4、该参数设置过小的最明显特征是出现“Too many connections”错误;
如何去调整max_connections参数的值(有以下三个方法可调整)
调整此参数的方法有几种,既可以在编译的时候设置,也可以在MySQL配置文件 my.cnf 中设置,也可以直接使用命令调整并立即生效。
1、在编译的时候设置默认最大连接数
打开MySQL的源码,进入sql目录,修改mysqld.cc文件:
C/C++ Code复制内容到剪贴板
- {“max_connections”, OPT_MAX_CONNECTIONS,
- “The number of simultaneous clients allowed.”, (gptr*) &max_connections,
- (gptr*) &max_connections, 0, GET_ULONG, REQUIRED_ARG, 100, 1, 16384, 0, 1,
- 0},
红色的“100”即为该参数的默认值,修改为想要的数值,存盘退出。然后执行
C/C++ Code复制内容到剪贴板
- ./configure;make;make install
重新编译安装MySQL;注意,由于编译安装且修改了MySQL源码,此操作最好在安装MySQL之前进行;
2、在配置文件my.cnf中设置max_connections的值
打开MySQL配置文件my.cnf
- [root@www ~]# vi /etc/my.cnf
找到max_connections一行,修改为(如果没有,则自己添加),
max_connections = 1000
上面的1000即该参数的值。
3、实时(临时)修改此参数的值
首先登陆mysql,执行如下命令:
C/C++ Code复制内容到剪贴板
- [root@www ~]# mysql -uroot -p
然后输入MySQL Root的密码。
查看当前的Max_connections参数值:
- mysql> SELECT @@MAX_CONNECTIONS AS 'Max Connections';
设置该参数的值:
- mysql> set GLOBAL max_connections=1000;
(注意上面命令的大小写)
修改完成后实时生效,无需重启MySQL。
mysql的max_connections的总结
总体来说,该参数在服务器资源够用的情况下应该尽量设置大,以满足多个客户端同时连接的需求。否则将会出现类似“Too many connections”的错误。
SPComm的一点小诀窍 spcomm的问题导致数据丢失
2010-01-08 09:50:51| 分类: 串口 |字号 订阅
最近几天完成了BiasDAC的程序编写。调试的过程还算比较顺利,除了几个有点bt的小问题。其中一个困扰了我两三天的时间,今天上午终于将其解决。
由于BiasDAC是用RS232 Serial Port通信的,延用之前的程序,使用了Delphi的SPComm控件。在之前的使用中,SPComm控件一直工作正常,使用的是一般的string进行消息的传递。
而BiasDAC由于通信协议的限制,消息的发送使用的是hex方式,会用到从0x00到0xFF所有的这些字符。在调试中发现,发送0x11和0x13之后,SPComm的工作就会不正常。
首先是0x11发送之后,返回的0x11消息会被忽略;其次0x13发送之后,只能返回很有限的消息,而且似乎Serial Port就此关闭,如果再发送消息,就会造成Serial Port失去响应,只能通过重新启动计算机才能恢复。
后来上网上查询,原来不能正常处理0x11和0x13的问题早就存在,原因是SPComm空间中两个属性的存在。
OutX_XonXOffFlow/InX_XonXoffFlow:这个属性是指进行发送/接收时的软件握手标志,两个握手信号之间的数据被认为是通讯数据,收到握手信号后,通讯就中止了。
FOutx_XonXoffFlow := True;
FInx_XonXoffFlow := True;
默认的初始化中,这两个属性是默认开启的。
XOffChar/XOnChar:这是指握手的字节,默认的初始中,有
FXonChar := chr($11);
FXoffChar := chr($13);
至此,真相大白。0x11,0x13被占用为通讯握手信号,自然不会得到正确的处理。
问题找到了,解决也很容易。只需要在Comm的初始化中,自己定义
Comm.Inx_XonXoffFlow:=False;
Comm.Outx_XonXoffFlow:=False;
关闭软件握手功能即可。在一般通讯中,硬件已经具备了握手功能,所以也不会影响到正常的Comm通讯。
在通达OA2009中,“数据选择控件”目前只有自带的三种类型数据。
现增加第三方的数据来源,以增强其功能。
一、
MYOA\webroot\general\system\workflow\flow_form\cool_form\data\config.php在Config.php 增加
'TX_USERS' => array("NAME" => "同享系统用户" , "CONTENT" => array("EMP_NAME" => "工号姓名",
"DEPT_NAME" => "部门","ZHIWEI" => "职位","ZHIWU" => "职务","ZHIJI" => "职级"))
二、
MYOA\webroot\general\workflow\list\input_form
增加连接MSSQL-SERVER的输出
if ($dataSrc == 'TX_USERS') {
if($act=="count")
$query = "select count(*) from OA_Employee_View where 1=1";
else
$query = "select top 10 $dataField from OA_Employee_View where 1=1";
if(strstr($dataQuery,"1,"))
{
$array1 = explode(",",$dataQuery);
$array2 = explode(",",$dataField);
$array3 = explode(",",$dataFieldName);
foreach($array1 as $k => $v)
{
if($v==1)
{
$name = $array2[$k];
$value = $$name;
if($value!="")
$query .= " and $name like '%$value%'";
}
}
}
$txconn=mssql_connect($MSSQL_TX_SERVER,$MSSQL_TX_USER,$MSSQL_TX_PASS);
mssql_select_db($MSSQL_TX_DB,$txconn);
if($act=="count")
{
$cursor = mssql_query($query);
if($ROW=mssql_fetch_array($cursor))
$COUNT=$ROW[0];
echo $COUNT;
exit;
}
$cursor = mssql_query($query);
$COUNT=0;
$dataField_arr = explode(",",$dataField);
$dataFieldName_arr = explode(",",$dataFieldName);
while($ROW=mssql_fetch_array($cursor))
{
$COUNT++;
if($COUNT%2==1)
$TableLine="TableLine1";
else
$TableLine="TableLine2";
foreach($dataField_arr as $k=> $v)
{
if($v=="") continue;
if($COUNT==1)
{
if($k==0)
$thead.='<table class="TableList" align="center" width="90%"><tr class="TableHeader">';
$thead.='<td nowrap align="center">'.$dataFieldName_arr[$k].'</td>';
}
if($k==0)
$tbody.='<tr class="'.$TableLine.'">';
$tbody.='<td nowrap align="center">'.$ROW[$v].'</td>';
}
if($COUNT==1) $thead.='<td nowrap align="center">操作</td></tr>';
$tbody.='<td nowrap align="center"> <a href="#" class="orgAdd" onclick="addData(this)">添加</a></td></tr>';
}
$tbody.="</table>";
echo $thead.$tbody;
一、增加流程定义时可以选择项目
MYOA\webroot\general\system\workflow\flow_type\flow_design\view_list\edit.php
794行
<option value="11" <? if($AUTO_TYPE=="11")echo "selected";?>>按表单字段选择的直属上司</option>
\\10.110.2.210\d$\MYOA\webroot\general\workflow\list\turn\condition.php
765行处增加
}elseif($AUTO_TYPE==11) //根据表单字段的主属上司来处理
{
if(is_numeric($AUTO_USER))
{
$query3 = "SELECT ITEM_DATA from FLOW_RUN_DATA where RUN_ID='$RUN_ID' AND ITEM_ID='$AUTO_USER'";
$cursor3= exequery($connection,$query3);
if($ROW=mysql_fetch_array($cursor3))
$ITEM_DATA = $ROW["ITEM_DATA"];
$APPLY_USER_ID = substr($ITEM_DATA,strpos($ITEM_DATA,"_")-1);
//根据前一节点的直属上司
$query = "select EMP_MANAGECODE from user where user_id ='$APPLY_USER_ID'";
$cursor= exequery($connection,$query);
if($ROW=mysql_fetch_array($cursor))
{
$USER_ID=$ROW["EMP_MANAGECODE"];
$query1 = "SELECT * from USER where USER_ID='$USER_ID'";
$cursor1= exequery($connection,$query1);
if($ROW=mysql_fetch_array($cursor1))
{
$PRCS_NEW_USER_ID=$USER_ID;
$PRCS_NEW_USER_NAME=$ROW["USER_NAME"];
$PRCS_NEW_DEPT_ID=$ROW["DEPT_ID"];
$PRCS_NEW_USER_PRIV=$ROW["USER_PRIV"];
$PRCS_NEW_USER_PRIV_OTHER=$ROW["USER_PRIV_OTHER"];
}
}
$PRCS_OP_USER=$PRCS_NEW_USER_ID;
$PRCS_OP_USER_NAME=$PRCS_NEW_USER_NAME;
$PRCS_USER_AUTO=$PRCS_NEW_USER_ID.",";
$PRCS_USER_NAME=$PRCS_NEW_USER_NAME.",";
/*//检查该发起人是否有经办权限
if($PRCS_DEPT=="ALL_DEPT"||find_id($PRCS_USER,$PRCS_NEW_USER_ID)||find_id($PRCS_DEPT,$PRCS_NEW_DEPT_ID)||find_id($PRCS_PRIV,$PRCS_NEW_USER_PRIV)||priv_other($PRCS_PRIV,$PRCS_NEW_USER_PRIV_OTHER))
{
$PRCS_OP_USER=$PRCS_NEW_USER_ID;
$PRCS_OP_USER_NAME=$PRCS_NEW_USER_NAME;
$PRCS_USER_AUTO=$PRCS_NEW_USER_ID.",";
$PRCS_USER_NAME=$PRCS_NEW_USER_NAME.",";
}*/
}
}
3.在流程定义处保存的地方也要修改
MYOA\webroot\general\system\workflow\flow_type\flow_design\view_list\update.php
的66修改成:
if($AUTO_TYPE==7 || $AUTO_TYPE==11)
select * from sysprocesses
where dbid in (select dbid from sysdatabases where name='overtime')
and program_name ='PHP 5'
USE master
DECLARE @spid int
DECLARE CUR CURSOR
FOR SELECT spid FROM sysprocesses WHERE dbid = 11 and program_name ='PHP 5'
OPEN CUR
FETCH NEXT FROM CUR INTO @spid
WHILE @@FETCH_STATUS = 0
BEGIN
EXEC ('KILL ' + @spid )
FETCH NEXT FROM CUR INTO @spid
END
CLOSE CUR
DEALLOCATE CUR
1)interactive_timeout:
参数含义:服务器关闭交互式连接前等待活动的秒数。交互式客户端定义为在mysql_real_connect()中使用CLIENT_INTERACTIVE选项的客户端。
参数默认值:28800秒(8小时)
(2)wait_timeout:
参数含义:服务器关闭非交互连接之前等待活动的秒数。
在线程启动时,根据全局wait_timeout值或全局interactive_timeout值初始化会话wait_timeout值,取决于客户端类型(由mysql_real_connect()的连接选项CLIENT_INTERACTIVE定义)。
参数默认值:28800秒(8小时)
MySQL服务器所支持的最大连接数是有上限的,因为每个连接的建立都会消耗内存,因此我们希望客户端在连接到MySQL Server处理完相应的操作后,应该断开连接并释放占用的内存。如果你的MySQL Server有大量的闲置连接,他们不仅会白白消耗内存,而且如果连接一直在累加而不断开,最终肯定会达到MySQL Server的连接上限数,这会报'too many connections'的错误。对于wait_timeout的值设定,应该根据系统的运行情况来判断。在系统运行一段时间后,可以通过show processlist命令查看当前系统的连接状态,如果发现有大量的sleep状态的连接进程,则说明该参数设置的过大,可以进行适当的调整小些。
问题:
如果在配置文件my.cnf中只设置参数wait_timeout=100,则重启服务器后进入,执行:
Mysql> show variables like “%timeout%”;
会发现参数设置并未生效,仍然为28800(即默认的8个小时)。
查询资料后,要同时设置interactive_timeout和wait_timeout才会生效。
【mysqld】
wait_timeout=100
interactive_timeout=100
重启MySQL Server进入后,查看设置已经生效。
问题1:这里为什么要同时设置interactive_timeout,wait_timeout的设置才会生效?
问题2:interactive的值如果设置的和wait_timeout不同,为什么Interactive_timeout会覆盖wait_timeout?
问题3:在进行MySQL优化时,因为interactive_timeout决定的是交互连接的时间长短,而wait_timeout决定的是非交互连接的时间长短。如果在进行连接配置时mysql_real_connect()最后一个参数client_flag不设置为CLIENT_INTERACTIVE,是不是interactive_timeout的值不会覆盖wait_timeout?
问题4:为了减少长连接的数量,在设置优化时是不是可以将interactive_timeout的值设置的大些,而wait_timeout的值设置的小些?但是问题2的描述好像又不允许这样。。。
1、查询oracle被锁对象及其语句
SELECT a_s.owner,
a_s.object_name,
a_s.object_type,
VN.SID,
VN.SERIAL#,
VS.SPID "OS_PID",
VN.PROCESS "CLIENT_PID",
VN.USERNAME,
VN.OSUSER,
VN.MACHINE "HOSTNAME" ,
VN.TERMINAL,
VN.PROGRAM,
TO_CHAR(VN.LOGON_TIME,'YYYY-MM-DD HH24:MI:SS')"LOGIN_TIME",
'alter system kill session '''||vn.sid||','||vn.serial#||''';' "ORACKE_KILL",
'kill -9 '|| VS.SPID "OS_KILL"
FROM ALL_OBJECTS A_S,
V$LOCKED_OBJECT V_T,
V$SESSION VN,
V$PROCESS VS
WHERE A_S.OBJECT_ID=V_T.OBJECT_ID
AND V_T.SESSION_ID =VN.SID
AND VS.ADDR=VN.PADDR
AND VN.USERNAME NOT IN('SYSMAN','SYS');
|
2、查询该sid的sql语句
select * from v$sql vl,v$session vn
where vl.ADDRESS= decode(vn.SQL_ADDRESS,null,vn.PREV_SQL_ADDR,VN.SQL_ADDRESS)
and vn.sid=&sid;
|
3、解锁
alter system kill session 'sid,serial#';
|
4、查询被锁对象增强版
SELECT DDL.OWNER AS 用户,
DDL.NAME AS 对象,
DDL.type AS 类型,
VS.OSUSER AS OS_USER,
VS.MACHINE,
VS.STATUS,
VS.PROGRAM,
VS.LOGON_TIME AS "LOGIN_TIME",
VP.SPID,
'kill -9 ' || VP.SPID AS OS_KILL,
vs.sid,
vs.SERIAL#,
'alter system kill session ''' || vs.sid || ',' || vs.serial# ||
''';' "ORACKE_KILL"
FROM DBA_DDL_LOCKS DDL, V$SESSION VS, V$PROCESS VP
WHERE DDL.SESSION_ID = VS.SID
AND VS.PADDR = VP.ADDR;
|
在日常的sql server开发中,经常会用到Identity类型的标识列作为一个表结构的自增长编号。比如文章编号、记录序号等等。自增长的标识列的引用很大程度上方便了数据库程序的开发,但有时这个固执的字段类型也会带来一些麻烦。
一、修改标识列字段值:
有时,为了实现某种功能,需要修改类型为Identity自增长类型的字段的值,但由于标识列的类型所限,这种操作默认是不允许的。比如目前数据库有5条正常添加的数据,此时删除2条,那么如果再添加数据时,自增长的标识列会自动赋值为6,可这时如果想在插入数据时给赋值3呢,默认是不允许的。如果您特别想改变这个字段的值,完全由自己控制该标识字段值的插入,方法还是有的,哈哈。
SET IDENTITY_INSERT [TABLE] [ON|OFF]
使用上述语句,可以方便的控制某个表的某个自增长标识列是否自动增长,也就是说是否允许你在insert一条记录时手动指定标识列字段的值。如果指定为on,则可以insert时指定标识列字段的值,该值不自动增长赋值。当然,如果使用完毕,还需使用这个语句将开关关闭到默认状态off,不然下次insert数据时该字段还是不会自动增长赋值的,有始有终嘛。
如:
SET IDENTITY_INSERT [TABLE_NAME] ON
----------- INSERT SEG--------
SET IDENTITY_INSERT [TABLE_NAME] OFF
二、重置标识列字段值:
当数据记录被删除一部分后,后面再添加的新数据记录,标识列数值会有很大的空闲间隔,看上去是不是很不爽呢。即使你删除表中全部记录,identity标识列的值还是会无休止的自动增加变大,而不是从头开始增长。通过下面这条语句可以重置自增长字段的种子值:
DBCC CHECKIDENT(TABLE, [RESEED|NORESEED], 200)上述语句将把指定表的种子值强制重设为1。然而,如果你不想将种子重设为1,你可以用你想用的种子值替代第三个参数。如果你想知道当前的种子,而不是想重设标识种子,这时你就要用NORESEED,而不用再去设置第三个参数。
如 DBCC CHECKIDENT(Product, RESEED, 210)
测试人:QQ -- 35629400 子夜时分,如有错误,请指出。
环境:Win7+Phpnow+V57_UTF8_SP1(2013-6-7版本)
一、系统设置
1.【后台管理】--》【系统】--》【核心设置】,红色区域设置成“是”

2.【后台管理】--》【核心】--》【网站栏目管理】--》选择一个顶级栏目进行修改。
在【高级选项】中“启用”【多站点支持】
在【绑定域名】中输入所要的域名,如:http://webbase.chugui.com

二、Apache中设置
打开Apache的虚拟主机配置文件。
如我的文件在:D:\Phpnow\Apache-22\conf\extra\httpd-vhosts.conf
<Directory ../vhosts>
AllowOverride All
Order allow,deny
Allow from all
</Directory>
NameVirtualHost * #这个必须有
<VirtualHost *>
DocumentRoot ../htdocs
ServerName default:80
ErrorLog logs/default-error_log
</VirtualHost>
<VirtualHost *>
<Directory "D:/Phpnow/htdocs/dedecms">
Options -Indexes FollowSymLinks
Allow from all
AllowOverride All
</Directory>
ServerAdmin admin@ww2.chugui.com
DocumentRoot "D:/Phpnow/htdocs/dedecms"
ServerName ww2.chugui.com:80
ServerAlias *.ww2.chugui.com
ErrorLog logs/ww2.chugui.com-error_log
php_admin_value open_basedir "D:\Phpnow\htdocs\dedecms;C:\Windows\Temp;"
</VirtualHost>
<VirtualHost *>
<Directory "D:/Phpnow/htdocs/dedecms/html/webbase">
Options -Indexes FollowSymLinks
Allow from all
AllowOverride All
</Directory>
ServerAdmin admin@webbase.chugui.com
DocumentRoot "D:/Phpnow/htdocs/dedecms/html/webbase"
ServerName webbase.chugui.com:80 #二级域名指定处
ErrorLog logs/webbase.chugui.com-error_log
php_admin_value open_basedir "D:\Phpnow\htdocs\dedecms\html\webbase;C:\Windows\Temp;"
</VirtualHost>
三、如果公网上做以上两步就行了,为了在本地测试,需要修改host文件。
在文件中加入以下几行:(目的告诉浏览器以下地址不用去公网上解析)
127.0.0.1 ww2.chugui.com
127.0.0.1 chugui.com
127.0.0.1 webbase.chugui.com
四、针对网上有些人说要修改channelunit.help.php里面的内容,否则会现部门分js,css有引用的问题,我没有修改,貌似也没有发现错。这个有待后期考证。
//是否强制使用绝对网址
if($GLOBALS['cfg_multi_site']=='Y')
{
if($siteurl=='')
{
$siteurl = $GLOBALS['cfg_basehost'];
}
if($moresite==1)
{
$articleUrl = preg_replace("#^".$sitepath."#", '', $articleUrl);
}
if(!preg_match("/http:/", $articleUrl))
{
$articleUrl = $siteurl.$articleUrl;
}
}
五、至此查看结果如下:


六、
广州白马档口出租
番禺大石空调维修中心
重启dbmail
EXEC msdb.dbo.sysmail_stop_sp
EXEC msdb.dbo.sysmail_start_sp
http://social.msdn.microsoft.com/Forums/en-US/sqldatabaseengine/thread/fabfecfe-f493-4628-a355-79a4322ca7e1/
广州白马档口出租
番禺大石空调维修中心
package com.ellington.test;
import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.InputStream;
import java.io.OutputStream;
import java.util.Date;
import java.util.Properties;
import javax.mail.BodyPart;
import javax.mail.Message;
import javax.mail.MessagingException;
import javax.mail.Multipart;
import javax.mail.Session;
import javax.mail.Transport;
import javax.mail.internet.InternetAddress;
import javax.mail.internet.MimeBodyPart;
import javax.mail.internet.MimeMessage;
import javax.mail.internet.MimeMultipart;
import sun.misc.BASE64Decoder;
import sun.misc.BASE64Encoder;
public class Mailer {
private String host;
private String auth;
private String username;
private String domainUser;
private String password;
public boolean send(String[] to, String[] cc, String[] bcc, String subject, String content) throws MessagingException {
Properties props = new Properties();
props.put("mail.smtp.host", host);
props.put("mail.smtp.auth", auth);
Session s = Session.getInstance(props);
// s.setDebug(true);
MimeMessage message = new MimeMessage(s);
InternetAddress from = new InternetAddress(username);
message.setFrom(from);
InternetAddress[] Toaddress = new InternetAddress[to.length];
for (int i = 0; i < to.length; i++)
Toaddress[i] = new InternetAddress(to[i]);
message.setRecipients(Message.RecipientType.TO, Toaddress);
if (cc != null) {
InternetAddress[] Ccaddress = new InternetAddress[cc.length];
for (int i = 0; i < cc.length; i++)
Ccaddress[i] = new InternetAddress(cc[i]);
message.setRecipients(Message.RecipientType.CC, Ccaddress);
}
if (bcc != null) {
InternetAddress[] Bccaddress = new InternetAddress[bcc.length];
for (int i = 0; i < bcc.length; i++)
Bccaddress[i] = new InternetAddress(bcc[i]);
message.setRecipients(Message.RecipientType.BCC, Bccaddress);
}
message.setSubject(subject);
message.setSentDate(new Date());
BodyPart mdp = new MimeBodyPart();
mdp.setContent(content, "text/html;charset=utf-8");
Multipart mm = new MimeMultipart();
mm.addBodyPart(mdp);
message.setContent(mm);
message.saveChanges();
Transport transport = s.getTransport("smtp");
transport.connect(host, (null == domainUser) ? username : domainUser, password);
transport.sendMessage(message, message.getAllRecipients());
transport.close();
return true;
}
public Mailer(String host, String auth, String domainUser, String username, String password) {
super();
this.host = host;
this.auth = auth;
this.domainUser = domainUser;
this.username = username;
this.password = password;
}
/**
* @param args
* @throws MessagingException
*/
public static void main(String[] args) throws MessagingException {
// TODO Auto-generated method stub
System.out.println(GetImageStr());
new Mailer("10.110.4.4", "false", "abc\\sysadmin", "sysadmin@abc.com", "sysadmin").send(new String[] { "G@abc.com","F@abc.com" }, null, null, "邮件中发送文字与图片", "<h3>hello html5</h3><img src=\"data:image/png;base64,"+GetImageStr()+"\">" );
}
public static String GetImageStr()
{//将图片文件转化为字节数组字符串,并对其进行Base64编码处理
String imgFile = "d:\\111.jpg";//待处理的图片
InputStream in = null;
byte[] data = null;
//读取图片字节数组
try
{
in = new FileInputStream(imgFile);
data = new byte[in.available()];
in.read(data);
in.close();
}
catch (IOException e)
{
e.printStackTrace();
}
//对字节数组Base64编码
BASE64Encoder encoder = new BASE64Encoder();
return encoder.encode(data);//返回Base64编码过的字节数组字符串
}
public static boolean GenerateImage(String imgStr)
{//对字节数组字符串进行Base64解码并生成图片
if (imgStr == null) //图像数据为空
return false;
BASE64Decoder decoder = new BASE64Decoder();
try
{
//Base64解码
byte[] b = decoder.decodeBuffer(imgStr);
for(int i=0;i<b.length;++i)
{
if(b[i]<0)
{//调整异常数据
b[i]+=256;
}
}
//生成jpeg图片
String imgFilePath = "d:\\222.jpg";//新生成的图片
OutputStream out = new FileOutputStream(imgFilePath);
out.write(b);
out.flush();
out.close();
return true;
}
catch (Exception e)
{
return false;
}
}
}
广州白马档口出租
番禺大石空调维修中心
1.查看系统当前时间
>date
2.修改正确的时间
>date 04180819 ==4月18号8点19分
>确认当前时间:
>clock -w
广州白马档口出租
番禺大石空调维修中心
http://www.centos.bz/2011/03/auto-run-task-crontab/
1.进行编辑
>crontab -e
*/10 * * * * /usr/bin/wget -q -O /usr/local/oataskrun.log http://10.110.8.41:81/task/pe_geber_remind.php
每10钟执行一次任务。
>service crond restart 重启服务使其生效。
crontab简介
crontab命令常见于Unix和类Unix的操作系统之中,用于设置周期性被执行的指令。该命令从标准输入设备读取指令,并将其存放于 “crontab”文件中,以供之后读取和执行。该词来源于希腊语 chronos(χρόνος),原意是时间。 通常,crontab储存的指令被守护进程激活, crond常常在后台运行,每一分钟检查是否有预定的作业需要执行。这类作业一般称为cron jobs。
crontab用法
crontab的格式如下面:
f1 f2 f3 f4 f5 program
其中 f1 是表示分钟,f2 表示小时,f3 表示一个月份中的第几日,f4 表示月份,f5 表示一个星期中的第几天。program 表示要执行程式的路径。
- 当 f1 为 * 时表示每分钟都要执行 program,f2 为 * 时表示每小时都要执行程式,其余类推
- 当 f1 为 a-b 时表示从第 a 分钟到第 b 分钟这段时间内要执行,f2 为 a-b 时表示从第 a 到第 b 小时都要执行,其余类推
- 当 f1 为 */n 时表示每 n 分钟个时间间隔执行一次,f2 为 */n 表示每 n 小时个时间间隔执行一次,其余类推
- 当 f1 为 a, b, c,… 时表示第 a, b, c,… 分钟要执行,f2 为 a, b, c,… 时表示第 a, b, c…个小时要执行,其余类推
管理员登录SSH,输入命令crontab -e编辑crontab文件,根据上面的格式输入并保存。
crontab例子
每月每天每小时的第 0 分钟执行一次 /bin/ls :
在 12 月内, 每天的早上 6 点到 12 点中,每隔 20 分钟执行一次 /usr/bin/backup :
- */20 6-12 * 12 * /usr/bin/backup
周一到周五每天下午 5:00 寄一封信给 alex@domain.name :
- 0 17 * * 1-5 mail -s "hi" alex@domain.name < /tmp/maildata
每月每天的午夜 0 点 20 分, 2 点 20 分, 4 点 20 分….执行 echo “haha”
- 20 0-23/2 * * * echo "haha"
晚上11点到早上8点之间每两个小时,早上8点
在hp unix,中,每20分钟执行一次,表示为:0,20,40 * * * * 而不能采用*/n方式,否则出现语法错误
crontab用法其实很容易掌握,懂得使用crontab,对网站和服务器维护起到很大的帮助,比如定时备份,定时优化服务器
前一段时间修改了主机的hostname,重启oracle是提示错误ORA-00119: invalid specification for system parameter LOCAL_LISTENER。
分析原因可能在于hostname进行了修改。
解决方法:
首先仍然是了解错误信息:oerr ora 00119
00119, 00000, "invalid specification for system parameter %s"
// *Cause: The syntax for the specified parameter is incorrect.
// *Action: Refer to the Oracle Reference Manual for the correct syntax.
既然参数出现错误,那么需要调整参数LOCAL_LISTENER
1、创建pfile:SQL>create pfile from spfile
2、修改pfile,pfile的命名方式为init$ORACLE_SID.ora,存储位置为$ORACLE_HOME/dbs,检查LOCAL_LISTENER这个参数,如果没有,则在最后一行添加:
*.local_listener='(ADDRESS_LIST=(ADDRESS=(PROTOCOL=TCP)(HOST=ip)))',此处的ip就是oracle数据库所在服务器的ip
3、修改完成后,保存退出
4、SQL>startup pfile='$ORACLE_HOME/dbs/init$ORACLE_SID.ora';
可以看到,数据库启动成功
5、重新创建spfile SQL>create spfile from pfile
--打开高级设置
EXEC sp_configure 'show advanced options', 1
RECONFIGURE
--打开xp_cmdshell扩展存储过程
EXEC sp_configure 'xp_cmdshell', 1
RECONFIGURE
exec master..xp_cmdshell 'net use I: \\10.110.2.192\e\sqlbackup
A /User:
B\
C'A:密码
B:域或工作组
C:登录名
--以上设定一次即可
把以下命令放到定时任务器中。
BACKUP DATABASE [MyDB] TO DISK = N'I:\MyDB.bak' WITH RETAINDAYS = 2, NOFORMAT, NOINIT, NAME = N'MyDBTest', SKIP, REWIND, NOUNLOAD, COMPRESSION, STATS = 10
---以下不用的时候删除所建的盘
--删除映射
exec master..xp_cmdshell 'net use I: /delete'
--关闭xp_cmdshell扩展存储过程、高级设置
EXEC sp_configure 'xp_cmdshell', 0
RECONFIGURE
EXEC sp_configure 'show advanced options', 0
RECONFIGURE
广州白马档口出租
番禺大石空调维修中心
http://www.cnblogs.com/sopost/archive/2011/10/22/2221498.htmlexec dbms_workload_repository.modify_snapshot_settings(interval=>0) ;//60分中为一小时,0是自动关闭
1.查看当前的AWR保存策略
select * from dba_hist_wr_control;
DBID,SNAP_INTERVAL,RETENTION,TOPNSQL
860524039,+00 01:00:00.000000,+07 00:00:00.000000,DEFAULT
以上结果表示,每小时产生一个SNAPSHOT,保留7天
2.调整AWR配置
AWR配置都是通过dbms_workload_repository包进行配置
2.1调整AWR产生snapshot的频率和保留策略,如:如将收集间隔时间改为30 分钟一次。并且保留5天时间(注:单位都是为分钟):
exec dbms_workload_repository.modify_snapshot_settings(interval=>30, retention=>5*24*60);
2.2关闭AWR,把interval设为0则关闭自动捕捉快照
2.3手工创建一个快照
exec DBMS_WORKLOAD_REPOSITORY.CREATE_SNAPSHOT ();
2.4 查看快照
select * from sys.wrh$_active_session_history
2.5手工删除指定范围的快照
exec WORKLOAD_REPOSITORY.DROP_SNAPSHOT_RANGE(low_snap_id => 22, high_snap_id => 32, dbid => 3310949047);
2.6创建baseline
exec dbms_workload_repository.create_baseline (56,59,'apply_interest_1')
2.7删除baseline
exec DBMS_WORKLOAD_REPOSITORY.DROP_BASELINE(baseline_name => ' apply_interest_1', cascade => FALSE);
3.生产AWR报告
$ORACLE_HOME/rdbms/admin/awrrpt.sql
4.1 Snapshots( 快照)
前面操作报表生成时,snap这个关键字已经出现过多次了,想必你对它充满了疑惑,这个东西是哪来的咋来的谁让它来的呢?事实上,Snap是Snapshot的简写,这正是AWR在自动性方面的体现,虽然你没有创建,但是AWR自动帮你创建了(当然也可以手动创建snapshot),并且是定时(每小时)创建,定期清除(保留最近7天)。
Snapshots 是一组某个时间点时历史数据的集合,这些数据就可被ADDM(Automatic Database Diagnostic Monitor)用来做性能对比。默认情况下,AWR能够自动以每小时一次的频率生成Snapshots性能数据,并保留7天,,如果需要的话,DBA可以通过DBMS_WORKLOAD_REPOSITORY过程手动创建、删除或修改snapshots。
提示:调用DBMS_WORKLOAD_REPOSITORY包需要拥有DBA权限。
4.1.1 手动创建Snapshots
手动创建Snapshots,通过DBMS_WORKLOAD_REPOSITORY.CREATE_SNAPSHOT过程,例如:
SQL> exec dbms_workload_repository.create_snapshot();
PL/SQL procedure successfully completed.
然后可以通过DBA_HIST_SNAPSHOT 视图查看刚刚创建的Snapshots信息。
4.1.2 手动删除Snapshots
删除Snapshots是使用DBMS_WORKLOAD_REPOSITORY包的另一个过程:DROP_SNAPSHOT_RANGE,该过程在执行时可以通过指定snap_id的范围的方式一次删除多个Snapshots,例如:
SQL> select count(0) from dba_hist_snapshot where snap_id between 7509 and 7518;
COUNT(0)
----------
10
SQL> begin
2 dbms_workload_repository.drop_snapshot_range(
3 low_snap_id => 7509,
4 high_snap_id => 7518,
5 dbid => 3812548755);
6 end;
7 /
PL/SQL procedure successfully completed.
SQL> select count(0) from dba_hist_snapshot where snap_id between 7509 and 7518;
COUNT(0)
----------
注意当snapshots被删除的话,与其关联的ASH记录也会级联删除。
4.1.3 修改Snapshots设置
通过MODIFY_SNAPSHOT_SETTINGS过程,DBA可以调整包括快照收集频率、快照保存时间、以及捕获的SQL数量三个方面的设置。分别对应MODIFY_SNAPSHOT_SETTINGS的三个参数:
- Retention :设置快照保存的时间,单位是分钟。可设置的值最小为1天,最大为100年。设置该参数值为0的话,就表示永久保留收集的快照信息。
- Interval :设置快照收集的频率,以分钟为单位。可设置的值最小为10分钟,最大为1年。如果设置该参数值为0,就表示禁用AWR特性。
- Topnsql :指定收集的比较占用资源的SQL数量,可设置的值最小为30,最大不超过100000000。
查看当前快照收集的相关设置,可以通过DBA_HIST_WR_CONTROL视图查看,例如:
SQL> select * from dba_hist_wr_control;
DBID SNAP_INTERVAL RETENTION TOPNSQL
---------- ------------------------ -------------------- ----------
3812548755 +00000 01:00:00.0 +00007 00:00:00.0 DEFAULT
又比如通过MODIFY_SNAPSHOT_SETTTINGS过程修改snap_intrval的设置:
SQL> exec dbms_workload_repository.modify_snapshot_settings(interval=>120);
PL/SQL procedure successfully completed.
SQL> select * from dba_hist_wr_control;
DBID SNAP_INTERVAL RETENTION TOPNSQL
---------- ------------------------ -------------------- ----------
3812548755 +00000 02:00:00.0 +00007 00:00:00.0 DEFAULT
4.2 Baselines( 基线)
Baseline ,直译的话叫做基线,顾名思义的方式理解,就是用于比较的基本线。因为Baseline中包含指定时间点时的性能数据,因此就可以用来与其它时间点时的状态数据做对比,以分析性能问题。
创建Baseline时,Snapshots是做为其中的一个组成部分存在,因此一般来说当AWR自动维护快照时,如果定义过baseline,与baseline相关的快照不会被删除,即使是过期的快照,这样就相当于手动保留了一份统计数据的历史信息,DBA可以在适当的时间将其与现有的快照进行对比,以生成相关的统计报表。
用户可以通过DBMS_WORKLOAD_REPOSITORY包中的相关过程,手动的创建或删除Baseline。
4.2.1 创建Baseline
创建Baseline使用CREATE_BASELINE过程,执行该过程时分别指定开始和结果的snap_id,然后为该baseline定义一个名称即可,例如:
SQL> BEGIN
2 DBMS_WORKLOAD_REPOSITORY.CREATE_BASELINE(start_snap_id => 7550,
3 end_snap_id => 7660,
4 baseline_name => ¨am_baseline¨);
5 END;
6 /
PL/SQL procedure successfully completed.
SQL> select dbid,baseline_name,start_snap_id,end_snap_id from dba_hist_baseline;
DBID BASELINE_NAME START_SNAP_ID END_SNAP_ID
---------- -------------------- ------------- -----------
3812548755 am_baseline 7550 7660
4.2.2 删除Baseline
删除Baseline使用DROP_BASELINE过程,删除时可以通过cascade参数选择是否将其关联的Snapshots级别进行删除,例如:
SQL> BEGIN
2 DBMS_WORKLOAD_REPOSITORY.DROP_BASELINE(baseline_name => ¨am_baseline¨,
3 cascade => true);
4 END;
5 /
PL/SQL procedure successfully completed.
SQL> select * from dba_hist_baseline;
no rows selected
SQL> select * from dba_hist_snapshot where snap_id between 7550 and 7660;
如上例中所示,删除时指定了cascade参数值为true,对应的snap也被级联删除了。
不管是EM也好,或是前面演示中使用的awr*.sql脚本也好,实质都是访问ORACLE中的部分相关视图来生成统计数据,因此如果DBA对自己的理解能力有足够的自信,也可以直接查询动态性能视图(或相关数据字典)的方式来获取自己想要的那部分性能数据。ORACLE将这部分性能统计数据保存在DBA_HIST开头的数据字典中,要查询当前实例所有能够访问的DBA_HIST字典,可以通过下列语句:
SQL> select * from dict where table_name like ¨DBA_HIST%¨;
TABLE_NAME COMMENTS
------------------------------ --------------------------------------------------------------------------------
DBA_HIST_DATABASE_INSTANCE Database Instance Information
DBA_HIST_SNAPSHOT Snapshot Information
DBA_HIST_SNAP_ERROR Snapshot Error Information
DBA_HIST_BASELINE Baseline Metadata Information
DBA_HIST_WR_CONTROL Workload Repository Control Information
DBA_HIST_DATAFILE Names of Datafiles
DBA_HIST_FILESTATXS Datafile Historical Statistics Information
DBA_HIST_TEMPFILE Names of Temporary Datafiles
DBA_HIST_TEMPSTATXS Temporary Datafile Historical Statistics Information
DBA_HIST_COMP_IOSTAT I/O stats aggregated on component level
DBA_HIST_SQLSTAT SQL Historical Statistics Information
DBA_HIST_SQLTEXT SQL Text
......................
ORACLE 数据库中以DBA_HIST命名的视图非常多,下面简单介绍几个,比如说:
该视图由ASH自动维护,以每秒一次的频率收集当前系统中活动session的信息。虽然说是记录SESSION的历史记录,不过该视图与V$SESSION还是有差异的。
SQL> desc v$active_session_history;
Name Type Nullable Default Comments
------------------------- ------------ -------- ------- --------
SAMPLE_ID NUMBER Y
SAMPLE_TIME TIMESTAMP(3) Y
SESSION_ID NUMBER Y
SESSION_SERIAL# NUMBER Y
USER_ID NUMBER Y
SQL_ID VARCHAR2(13) Y
SQL_CHILD_NUMBER NUMBER Y
SQL_PLAN_HASH_VALUE NUMBER Y
FORCE_MATCHING_SIGNATURE NUMBER Y
SQL_OPCODE NUMBER Y
PLSQL_ENTRY_OBJECT_ID NUMBER Y
PLSQL_ENTRY_SUBPROGRAM_ID NUMBER Y
PLSQL_OBJECT_ID NUMBER Y
PLSQL_SUBPROGRAM_ID NUMBER Y
SERVICE_HASH NUMBER Y
SESSION_TYPE VARCHAR2(10) Y
SESSION_STATE VARCHAR2(7) Y
QC_SESSION_ID NUMBER Y
QC_INSTANCE_ID NUMBER Y
BLOCKING_SESSION NUMBER Y
BLOCKING_SESSION_STATUS VARCHAR2(11) Y
BLOCKING_SESSION_SERIAL# NUMBER Y
EVENT VARCHAR2(64) Y
EVENT_ID NUMBER Y
EVENT# NUMBER Y
SEQ# NUMBER Y
P1TEXT VARCHAR2(64) Y
P1 NUMBER Y
P2TEXT VARCHAR2(64) Y
P2 NUMBER Y
P3TEXT VARCHAR2(64) Y
P3 NUMBER Y
WAIT_CLASS VARCHAR2(64) Y
WAIT_CLASS_ID NUMBER Y
WAIT_TIME NUMBER Y
TIME_WAITED NUMBER Y
XID RAW(8) Y
CURRENT_OBJ# NUMBER Y
CURRENT_FILE# NUMBER Y
CURRENT_BLOCK# NUMBER Y
PROGRAM VARCHAR2(48) Y
MODULE VARCHAR2(48) Y
ACTION VARCHAR2(32) Y
v$session 中与操作相关的列均被收集,除此之外还冗余了部分列,这是为了方便DBA查询V$ACTIVE_SESSION_HISTORY时能够快速获取到自己需要的数据。
-
DBA_HIST_ACTIVE_SESS_HISTORY
该视图与V$ACTIVE_SESSION_HISTORY的结构灰常灰常灰常的想像,功能也灰常灰常灰常的类似,都是记录活动session的操作记录,所不同点在于,V$ACTIVE_SESSION_HISTORY是ORACLE自动在内存中维护的,受制于其可用内存区限制,并非所有记录都能保存,而DBA_HIST_ACTIVE_SESS_HISTORY视图则是维护到磁盘中的。简单理解的话,就是说通常情况下,DBA_HIST_ACTIVE_SESS_HISTORY视图的数据量要比V$ACTIVE_SESSION_HISTORY的多。
提示:上述结构并不绝对,因为默认情况下DBA_HIST_ACTIVE_SESS_HISTORY字典的数据每10秒收集一次,而V$ACTIVE_SESSION_HISTORY中则是每秒一次,因此也有可能V$ACTIVE_SESSION_HISTORY中记录量更大。不过相对来说,DBA_HIST字典中保存的数据更长久。
-
DBA_HIST_DATABASE_INSTANCE
该视图用来显示数据库和实例的信息,比如DBID,实例名,数据库版本等等信息,生成报表中第一行表格,就是由该视图生成的。如图:

如果你去分析awrrpt.sql脚本的话,会发现其中有如下脚本,上述表格中显示的内容信息,正是来自于下列脚本:
select distinct
(case when cd.dbid = wr.dbid and
cd.name = wr.db_name and
ci.instance_number = wr.instance_number and
ci.instance_name = wr.instance_name
then ¨* ¨
else ¨ ¨
end) || wr.dbid dbbid
, wr.instance_number instt_num
, wr.db_name dbb_name
, wr.instance_name instt_name
, wr.host_name host
from dba_hist_database_instance wr, v$database cd, v$instance ci;
该视图用来记录当前数据库收集到的快照信息。相信朋友应该还记得之前使用脚本生成报表时,输入完快照区间后显示的一堆列表,没错,那正是DBA_HIST_SNAPSHOT记录的内容,该段功能对应的代码如下:
select to_char(s.startup_time,¨dd Mon "at" HH24:mi:ss¨) instart_fmt
, di.instance_name inst_name
, di.db_name db_name
, s.snap_id snap_id
, to_char(s.end_interval_time,¨dd Mon YYYY HH24:mi¨) snapdat
, s.snap_level lvl
from dba_hist_snapshot s
, dba_hist_database_instance di
where s.dbid = :dbid
and di.dbid = :dbid
and s.instance_number = :inst_num
and di.instance_number = :inst_num
and di.dbid = s.dbid
and di.instance_number = s.instance_number
and di.startup_time = s.startup_time
and s.end_interval_time >= decode( &num_days
, 0 , to_date(¨31-JAN-9999¨,¨DD-MON-YYYY¨)
, 3.14, s.end_interval_time
, to_date(:max_snap_time,¨dd/mm/yyyy¨) - (&num_days-1))
order by db_name, instance_name, snap_id;
http://www.doc88.com/p-692153078075.html
参考:http://www.cnblogs.com/xiaochaohuashengmi/archive/2011/07/29/2121347.html
http://www.soitway.com/woaibiancheng/19.html
记得重启一下office_anywhere
另:mssql.secure_connection = Off 要设置为 off
在td_config.php(webroot\inc目录下)增加变量。
//-- OT 数据库配置
$MSSQL_OT_SERVER="192.168.1.1";
$MSSQL_OT_USER="sa";
$MSSQL_OT_DB="DBName";
$MSSQL_OT_PASS="XXXX";
function OpenOTConnection()
{
global $otconnection,$MSSQL_OT_SERVER,$MSSQL_OT_USER,$MSSQL_OT_DB,$MSSQL_OT_PASS;
if(!$otconnection)
{
if(!function_exists("mssql_pconnect"))
{
echo "PHP配置有误,不能调用Mssql函数库,请检查有关配置";
exit;
}
$C=@mssql_pconnect($MSSQL_OT_SERVER,$MSSQL_OT_USER,$MSSQL_OT_PASS);
//$C=@mssql_connect($MSSQL_OT_SERVER,$MSSQL_OT_USER,$MSSQL_OT_PASS);
}
else
$C=$otconnection;
$result=mssql_select_db($MSSQL_OT_DB,$C);
if(!$result)
{
PrintError("数据库 ".$MSSQL_OT_DB."不存在");
//exit;
}
return $C;
}
function exemsqlquery($C,$Q)
{
$cursor = mssql_query($Q,$C);
if(!$cursor)
{
PrintError("<b>SQL语句:</b> ".$Q);
//exit;
}
return $cursor;
}
function send_webmail_ext($USER_STR, $CC_STR,$SUBJECT,$CONTENT)
{
global $connection,$LOGIN_USER_ID,$LOGIN_USER_NAME,$RUN_ID;
$query = "SELECT * from WEBMAIL where USER_ID='admin'";
$cursor= exequery($connection,$query);
if($ROW=mysql_fetch_array($cursor))
{
$EMAIL=$ROW["EMAIL"];
$SMTP_SERVER=$ROW["SMTP_SERVER"];
$LOGIN_TYPE=$ROW["LOGIN_TYPE"];
$SMTP_PASS=$ROW["SMTP_PASS"];
$SMTP_PORT=$ROW["SMTP_PORT"];
$SMTP_SSL=$ROW["SMTP_SSL"]=="1" ? "ssl":"";
$EMAIL_PASS=$ROW["EMAIL_PASS"];
$EMAIL_PASS=decrypt_str($EMAIL_PASS,"webmail");
if($LOGIN_TYPE=="1")
$SMTP_USER = substr($EMAIL,0,strpos($EMAIL,"@")); // SMTP username
else
$SMTP_USER =$EMAIL;
if($SMTP_PASS=="yes")
$SMTP_PASS = $EMAIL_PASS; // SMTP password
else
$SMTP_PASS = "";
$USER_ARRAY=explode(",",$USER_STR);
//接收人
$query = "select USER_ID,EMAIL from USER WHERE find_in_set(USER_ID,'$USER_STR')";
echo $query;
$cursor = exequery($connection,$query);
while($ROW=mysql_fetch_array($cursor))
{
$USER_ID=$ROW["USER_ID"];
/*if($USER_ID==$LOGIN_USER_ID)
continue;*/
$TO_EMAIL=$ROW["EMAIL"];
/*if($TO_EMAIL=="")
{
$query1 = "select EMAIL from WEBMAIL WHERE USER_ID='$USER_ID' limit 1";
$cursor1 = exequery($connection,$query1);
if($ROW1=mysql_fetch_array($cursor))
$TO_EMAIL=$ROW["EMAIL"];
}
if($TO_EMAIL != "") */
$TO_WEBMAIL.=$TO_EMAIL.",";
}
//抄送
$query = "select USER_ID,EMAIL from USER WHERE (EMAIL IS NOT NULL AND EMAIL<>'') AND find_in_set(USER_ID,'$CC_STR')";
$cursor = exequery($connection,$query);
while($ROW=mysql_fetch_array($cursor))
{
$USER_ID=$ROW["USER_ID"];
/*if($USER_ID==$LOGIN_USER_ID)//本人
continue;*/
$CC_EMAIL=$ROW["EMAIL"];
/*if($TO_EMAIL=="")
{
$query1 = "select EMAIL from WEBMAIL WHERE USER_ID='$USER_ID' limit 1";
$cursor1 = exequery($connection,$query1);
if($ROW1=mysql_fetch_array($cursor))
$TO_EMAIL=$ROW["EMAIL"];
}*/
$CC_WEBMAIL.=$CC_EMAIL.",";
}
$result=send_mail($EMAIL,$TO_WEBMAIL,$SUBJECT,$CONTENT,$SMTP_SERVER,$SMTP_USER,$SMTP_PASS,true,$LOGIN_USER_NAME,'',$CC_WEBMAIL,'','',true,$SMTP_PORT,$SMTP_SSL);
if($result===true)
{
Message("提示","外部邮件发送成功");
}
else
{
Message("外部邮件发送失败",$result);
}
}
}
--工作流中表单控件中返回“工号_姓名”格式,目前只返回“姓名”。
1.在 selected.php中(webroot\module\user_select目录下)的12行"USERNAME"修改为
concat(USER_ID,'_',USER_NAME)USER_NAME
2.在 query.php中(webroot\module\user_select目录下)41行,修改同上
3.同理,将这个目录下所有查询 from USER中字段的 USERNAME修改同上。
4.修改这里会造成以下问题:
如果流程走向是根据表单内容来选择的,比哪"A1974_徐进海",就不会自动匹配人员
要修改 condition.php 的657行加入以下(webroot\general\workflow\list\turn 目录下)
$ITEM_DATA = preg_replace('/([x80-xff])/',"",$ITEM_DATA);//将非中文去掉 GBK模式下
$ITEM_DATA = str_replace("_","",$ITEM_DATA);
--增加超时邮件自动提醒功能
要求:定时启动任务当发生超时将邮件发给任务启动者,任务主办者,主办者直属上司(部门负责人),HR相关人员
1.在user表中增加 EMP_MANAGECODE varchar(20)
2.修改user_edit.php(webroot\general\system\user目录下),用以填写直属上司工号。
修改update.php(webroot\general\system\user目录下),用以保存直属上司工号。
3.增加workflow_timeout_remind.php(webroot\task\目录下)
4.以管理员进入“系统管理”,增加定时任务调度。
执行如下命令编辑文件/etc/exports:
# vi /etc/exports
在该文件里添加如下内容:
/home/work 192.168.0.*(rw,sync,no_root_squash)
然后保存退出。
添加的内容表示:允许ip 地址范围在192.168.0.*的计算机以读写的权限来访问/home/work 目录。
/home/work 也称为服务器输出共享目录。
括号内的参数意义描述如下:
rw:读/写权限,只读权限的参数为ro;
sync:数据同步写入内存和硬盘,也可以使用async,此时数据会先暂存于内存中,而不立即写入硬盘。
no_root_squash:NFS 服务器共享目录用户的属性,如果用户是 root,那么对于这个共享目录来说就具有 root 的权限。
接着执行如下命令,启动端口映射:
# /etc/rc.d/init.d/portmap start
最后执行如下命令启动NFS 服务,此时NFS 会激活守护进程,然后就开始监听 Client 端的请求:
--# /etc/rc.d/init.d/NFS start
# service nfs start
在客户端:
mount -t nfs 10.110.2.29:/mnt/d /home/oracle/backup
一、准备工作
查看是否处在归档模式
SQL> archive log list;
Database log mode No Archive Mode
Automatic archival Disabled
Archive destination USE_DB_RECOVERY_FILE_DEST
Oldest online log sequence 28
Current log sequence 30
如果是"No Archive Mode"
修改为归档模式
首先要关闭数据库,启动到mount状态。
SQL> shutdown immediate;
SQL> startup mount;
修改为归档模式
SQL>alter database archivelog;
验证修改结果
SQL> select log_mode from v$database;
LOG_MODE
------------
ARCHIVELOG
打开数据库
SQL> alter database open;
二、RMAN Catalog 配置
创建 RMAN Calalog表空间
SQL>create tablespace RMAN_TS datafile '/opt/oracle/oradata/orcl/RMAN_TS01.dbf' size 500M;
--创建用户rman/rman 默认表空间味RMAN_TS允许自由使用
SQL> create user rman identified by rman default tablespace RMAN_TS quota unlimited on RMAN_TS;
用户授权
SQL>grant connect, resource,recovery_catalog_owner to rman;
创建恢复目录
在命令终端
[oracle@localhost ~]$rman catalog rman/rman
RMAN> CREATE CATALOG;
连接,注册目标数据库,同步catalog和控制文件
[oracle@localhost ~]$rman target sys/wxbwer catalog rman/rman
连接成功出现下面的信息
connected to target database: ORCL (DBID=1325399111)
connected to recovery catalog database
RMAN> REGISTER DATABASE;
RMAN> RESYNC CATALOG;
下面是否有注册信息即可
RMAN>LIST INCARNATION;
List of Database Incarnations
DB Key Inc Key DB Name DB ID STATUS Reset SCN Reset Time
------- ------- -------- ---------------- --- ---------- ----------
2 36 ORCL 1325399111 PARENT 1 13-AUG-09
2 4 ORCL 1325399111 CURRENT 754488 25-OCT-12
三、创建RMAN备份脚本
来自:http://blog.csdn.net/robinson_0612/article/details/8029245
##===========================================================
## db_bak_rman.sh
## created by Robinson
## 2011/11/07
## usage: db_bak_rman.sh <$ORACLE_SID> <$BACKUP_LEVEL>
## BACKUP_LEVEL:
## F: full backup
## 0: level 0
## 1: level 1
##============================================================
#!/bin/bash
# User specific environment and startup programs
if [ -f ~/.bash_profile ];
then
. ~/.bash_profile
fi
ORACLE_SID=${1}; export ORACLE_SID
RMAN_LEVEL=${2}; export RMAN_LEVEL
TIMESTAMP=`date +%Y%m%d%H%M`; export TIMESTAMP
DATE=`date +%Y%m%d`; export DATE
#RMAN_DIR=/u02/database/${ORACLE_SID}/backup/rman; export RMAN_DIR
#RMAN_DATA=${RMAN_DIR}/${DATE}; export RMAN_DATA
#RMAN_LOG=/u02/database/${ORACLE_SID}/backup/rman/log export RMAN_LOG
RMAN_DIR=/opt/oracle/oradata/backup/rman; export RMAN_DIR
RMAN_DATA=${RMAN_DIR}/${DATE}; export RMAN_DATA
RMAN_LOG=${RMAN_DIR}/log export RMAN_LOG
# Check rman level
#======================================================================
if [ "$RMAN_LEVEL" == "F" ];
then unset INCR_LVL
BACKUP_TYPE=full
else
INCR_LVL="INCREMENTAL LEVEL ${RMAN_LEVEL}"
BACKUP_TYPE=lev${RMAN_LEVEL}
fi
RMAN_FILE=${RMAN_DATA}/${ORACLE_SID}_${BACKUP_TYPE}_${TIMESTAMP}; export RMAN_FILE
SSH_LOG=${RMAN_LOG}/${ORACLE_SID}_${BACKUP_TYPE}_${TIMESTAMP}.log; export SSH_LOG
MAXPIECESIZE=4G; export MAXPIECESIZE
#Check RMAN Backup Path
#=========================================================================
if ! test -d ${RMAN_DATA}
then
mkdir -p ${RMAN_DATA}
fi
echo "---------------------------------" >>${SSH_LOG}
echo " " >>${SSH_LOG}
echo "Rman Begin to Working ........." >>${SSH_LOG}
echo "Begin time at:" `date` --`date +%Y%m%d%H%M` >>${SSH_LOG}
#Startup rman to backup
#=============================================================================
$ORACLE_HOME/bin/rman log=${RMAN_FILE}.log <<EOF
connect target /
connect catalog rman/rman
run {
CONFIGURE RETENTION POLICY TO RECOVERY WINDOW OF 3 DAYS;
CONFIGURE BACKUP OPTIMIZATION ON;
CONFIGURE CONTROLFILE AUTOBACKUP ON;
CONFIGURE CONTROLFILE AUTOBACKUP FORMAT FOR DEVICE TYPE DISK TO '${RMAN_FILE}_%F';
ALLOCATE CHANNEL 'ch1' TYPE DISK maxpiecesize=${MAXPIECESIZE};
ALLOCATE CHANNEL 'ch2' TYPE DISK maxpiecesize=${MAXPIECESIZE};
set limit channel ch1 readrate=10240;
set limit channel ch1 kbytes=4096000;
set limit channel ch2 readrate=10240;
set limit channel ch2 kbytes=4096000;
CROSSCHECK ARCHIVELOG ALL;
DELETE NOPROMPT EXPIRED ARCHIVELOG ALL;
BACKUP
#AS COMPRESSED BACKUPSET
${INCR_LVL}
DATABASE FORMAT '${RMAN_FILE}_%U' TAG '${ORACLE_SID}_${BACKUP_TYPE}_${TIMESTAMP}';
SQL 'ALTER SYSTEM ARCHIVE LOG CURRENT';
BACKUP ARCHIVELOG ALL FORMAT '${RMAN_FILE}_arc_%U' TAG '${ORACLE_SID}_arc_${TIMESTAMP}'
DELETE INPUT;
DELETE NOPROMPT OBSOLETE;
RELEASE CHANNEL ch1;
RELEASE CHANNEL ch2;
}
sql "alter database backup controlfile to ''${RMAN_DATA}/cntl_${BACKUP_TYPE}.bak''";
exit;
EOF
RC=$?
cat ${RMAN_FILE}.log >>${SSH_LOG}
echo "Rman Stop working @ time:"`date` `date +%Y%m%d%H%M` >>${SSH_LOG}
echo >>${SSH_LOG}
echo "------------------------" >>${SSH_LOG}
echo "------ Disk Space ------" >>${SSH_LOG}
df -h >>${SSH_LOG}
echo >>${SSH_LOG}
if [ $RC -ne "0" ]; then
echo "------ error ------" >>${SSH_LOG}
else
echo "------ no error found during RMAN backup peroid------" >>${SSH_LOG}
rm -rf ${RMAN_FILE}.log
fi
#Remove old backup than 3 days
#============================================================================
RMDIR=${RMAN_DIR}/`/bin/date +%Y%m%d -d "3 days ago"`; export RMDIR
echo >>${SSH_LOG}
echo -e "------Remove old backup than 3 days ------\n" >>${SSH_LOG}
if test -d ${RMDIR}
then
rm -rf ${RMDIR}
RC=$?
fi
echo >>${SSH_LOG}
if [ $RC -ne "0" ]; then
echo -e "------ Remove old backup exception------ \n" >>${SSH_LOG}
else
echo -e "------ no error found during remove old backup set peroid------ \n" >>${SSH_LOG}
fi
exit
[oracle@localhost backup]$ pwd
/opt/oracle/oradata/backup
[oracle@localhost backup]$vi db_bak_rman.sh
将上面脚本复制进去,并保存,且设置权限
[oracle@localhost backup]$ chmod 755 db_bak_rman.sh
测试脚本
orcl 为 SID
0: 代表0级备份
[oracle@localhost backup]$ ./db_bak_rman.sh orcl 0
四、crontab 定时任务 以 oralce用户登录
[oracle@localhost backup]$crontab -e
45 23 * * 0 /opt/oracle/oradata/backup/db_bak_rman.sh orcl 0
45 23 * * 1-3 /opt/oracle/oradata/backup/db_bak_rman.sh orcl 2
45 23 * * 4 /opt/oracle/oradata/backup/db_bak_rman.sh orcl 1
45 23 * * 5-6 /opt/oracle/oradata/backup/db_bak_rman.sh orcl 2
以root用户登录
[root@localhost backup]$/etc/init.d/crond restart
Stopping crond: [ OK ]
Starting crond: [ OK ]
脚本的增量备份策略: 周日0级备份,周四1级备份,其他2级备份
差异备份有3个级别:
0级:相当于全备,不同的是0级可用于增量备份,全备不行。
1级:备份自上次0级备份以来的数据
2级:备份自上次备份依赖的数据
logminer的安装配置使用
安装
环境:linux AS5,oracle 11gR2
2.添加补充日志
如果数据库需要使用logminer,就应该添加,只有添加这个日志之后的才能捕获DML
ALTER DATABASE ADD SUPPLEMENTAL LOG DATA (PRIMARY KEY, UNIQUE INDEX) COLUMNS;
3.开启归档(对logminer来说不是必须)
alter system set log_Archive_dest_1='/opt/oracle/flash_recovery_area' scope=both;
shutdown immediate
startup mount
alter database archivelog;
alter database open;
创建DBMS_LOGMNR包
SQL>@?/rdbms/admin/dbmslm.sql
创建相关数据字典
SQL>@?/rdbms/admin/dbmslmd.sql
修改初始化参数UTL_FILE_DIR,指定分析数据的存放处
SQL>alter system set UTL_FILE_DIR='/opt/oracle/oradata/logminer' scope=spfile;
重启数据库
SQL>shutdown immediate
SQL>startup
SQL> show parameter utl;
NAME TYPE VALUE
------------------------------------ ----------- ------------------------------
create_stored_outlines string
utl_file_dir string /opt/oracle/oradata/logminer
生成字典信息文件:
SQL> execute dbms_logmnr_d.build(dictionary_filename=>'/opt/oracle/oradata/logminer/sqltrace.ora',dictionary_location=>'/opt/oracle/oradata/logminer');
PL/SQL 过程已成功完成。
查当前日志组
SQL>select Group#, Status from v$log;
GROUP# STATUS
---------- ----------------
1 INACTIVE
2 CURRENT
3 INACTIVE
SQL>select Group#, MEMBER from v$logfile;
GROUP# MEMBER
---------- ----------------------------------------
3 /opt/oracle/oradata/orcl/redo03.log
2 /opt/oracle/oradata/orcl/redo02.log
1 /opt/oracle/oradata/orcl/redo01.log
添加需要分析的日志文件(在线日志)
SQL> execute dbms_logmnr.add_logfile(options=>dbms_logmnr.new,logfilename=>'/opt/oracle/oradata/orcl/redo02.log');
#归档日志
execute dbms_logmnr.add_logfile(options=>dbms_logmnr.new,logfilename=>'/opt/oracle/oradata/logminer/1_6356_704818301.dbf');
PL/SQL 过程已成功完成。
SQL> execute dbms_logmnr.add_logfile(options=>dbms_logmnr.addfile,logfilename=>'opt/oracle/oradata/orcl/redo03.log');
PL/SQL 过程已成功完成。
options选项有三个参数可选:
NEW - 表示创建一个新的日志文件列表
ADDFILE - 表示向这个列表中添加日志文件
REMOVEFILE - 和addfile相反。
开始分析
SQL> execute dbms_logmnr.start_logmnr(dictfilename=>'/opt/oracle/oradata/logminer/sqltrace.ora');
#设置 STARTTIME / ENDTIME
SQL>execute dbms_logmnr.start_logmnr(dictfilename=>'/u01/app/oracle/logminer/sqltrace.ora',starttime => to_date('2012/11/01-08:00:00','yyyy/mm/dd-hh24:mi:ss'),endtime => to_date('2012/11/02-12:30:00','yyyy/mm/dd-hh24:mi:ss'));
#也可以设置不用数据字典,只是看不到解释过来,没有意义了。
begin
dbms_logmnr.start_logmnr(starttime => to_date('2012/09/29-08:55:00','yyyy/mm/dd-hh24:mi:ss'),
endtime => to_date('2012/09/29-15:30:00','yyyy/mm/dd-hh24:mi:ss')
);
PL/SQL 过程已成功完成。
dbms_logmnr.start_logmnr()过程还有其它几个用于定义分析日志时间/SCN窗口的参数,它们分别是:
STARTSCN / ENDSCN - 定义分析的起始/结束SCN号,
STARTTIME / ENDTIME - 定义分析的起始/结束时间。
查询分析的日志文件包含的scn范围和日期范围。
SQL> select low_time,high_time,low_scn,next_scn from v$logmnr_logs;
LOW_TIME HIGH_TIME LOW_SCN NEXT_SCN
-------------- -------------- ---------- ----------
08-8月 -07 08-8月 -07 626540 637998
08-8月 -07 01-1月 -88 637998 2.8147E+14
SQL> create table ELLINGTON.log_content NOLOGGING Tablespace Users as select timestamp,sql_redo,sql_undo,USERNAME,OS_USERNAME,MACHINE_NAME from v$logmnr_contents;
将内容复制到一张表中查询并指定存储表空间,desc v$logmnr_contents
结束分析
SQL> execute dbms_logmnr.end_logmnr;
结束后视图v$logmnr_contents中的分析结果也不再存在,关闭sqlplus自动结束。
注意:1. LogMiner必须使用被分析数据库实例产生的字典文件,而不是安装LogMiner的数据库产生的字典文件,另外必须保证安装LogMiner数据库的字符集和被分析数据库的字符集相同。
2. 被分析数据库平台必须和当前LogMiner所在数据库平台一样,也就是说如果我们要分析的文件是由运行在UNIX平台上的Oracle 8i产生的,那么也必须在一个运行在UNIX平台上的Oracle实例上运行LogMiner,而不能在其他如Microsoft NT上运行LogMiner。当然两者的硬件条件不一定要求完全一样。
3. 生产库的归档日志拿到测试机上来分析,虽然可以分析,但是由于db_id不同,不能使用数据字典,也就看不到翻译过的语句(16进制的东西)
一。查出原系统有多少表空间:
select a.tablespace_name,total,free,round(free/total*100,2) free_precent,total-free used from
( select tablespace_name,sum(bytes)/1024/1024 total from dba_data_files
group by tablespace_name) a,
( select tablespace_name,sum(bytes)/1024/1024 free from dba_free_space
group by tablespace_name) b
where a.tablespace_name=b.tablespace_name
order by tablespace_name;
TABLESPACE_NAME TOTAL FREE FREE_PRECENT USED
------------------------------ ---------- ---------- ------------ ----------
AUDTOOL 5120 959.9375 18.75 4160.0625
DBA01_2001 500 499.9375 99.99 0.0625
DBA01_2002 500 499.9375 99.99 0.0625
DBA01_2003 500 499.9375 99.99 0.0625
DBA01_2004 500 499.9375 99.99 0.0625
DBA01_2005 1024 1023.9375 99.99 0.0625
DBA01_2006 1024 1023.9375 99.99 0.0625
DBA01_2007 1024 1023.9375 99.99 0.0625
DBA01_2008 1024 1023.9375 99.99 0.0625
DBA01_2009 1024 1023.9375 99.99 0.0625
DBA01_2010 1024 1023.9375 99.99 0.0625
DBA01_2011 1024 1023.9375 99.99 0.0625
INDX 98816 19484.3125 19.72 79331.6875
SYSAUX 27080.9375 1126.6875 4.16 25954.25
SYSTEM 2788 1626.3125 58.33 1161.6875
UNDOTBS2 3524 3299 93.62 225
USERS 92160 54093.875 58.7 38066.125
二。查出各表空间数据文件大小
SQL> SELECT TABLESPACE_NAME ,FILE_NAME, BYTES/1024/1024 SIZE_M from dba_data_files WHERE TABLESPACE_NAME = 'USERS';
TABLESPACE FILE_NAME SIZE_M
---------- ------------------------------ ----------
USERS /u02/oradata/orcl/users01.dbf 30720
USERS /u02/oradata/orcl/users02.dbf 30720
USERS /u02/oradata/orcl/users03.dbf 30720
SQL>SELECT TABLESPACE_NAME ,FILE_NAME, BYTES/1024/1024 SIZE_M from dba_data_files WHERE TABLESPACE_NAME = 'DBA01_2001';
TABLESPACE FILE_NAME SIZE_M
---------- ---------------------------------------- ----------
DBA01_2001 /u02/oradata/orcl/users_2001.dbf 500
SQL> SELECT TABLESPACE_NAME ,FILE_NAME, BYTES/1024/1024 SIZE_M from dba_data_files WHERE TABLESPACE_NAME = 'DBA01_2002';
TABLESPACE FILE_NAME SIZE_M
---------- ---------------------------------------- ----------
DBA01_2002 /u02/oradata/orcl/users_2002.dbf 500
SQL> SELECT TABLESPACE_NAME ,FILE_NAME, BYTES/1024/1024 SIZE_M from dba_data_files WHERE TABLESPACE_NAME = 'DBA01_2003';
TABLESPACE FILE_NAME SIZE_M
---------- ---------------------------------------- ----------
DBA01_2003 /u02/oradata/orcl/users_2003.dbf 500
SQL> SELECT TABLESPACE_NAME ,FILE_NAME, BYTES/1024/1024 SIZE_M from dba_data_files WHERE TABLESPACE_NAME = 'DBA01_2004';
TABLESPACE FILE_NAME SIZE_M
---------- ---------------------------------------- ----------
DBA01_2004 /u02/oradata/orcl/users_2004.dbf 500
SQL> SELECT TABLESPACE_NAME ,FILE_NAME, BYTES/1024/1024 SIZE_M from dba_data_files WHERE TABLESPACE_NAME = 'DBA01_2005';
TABLESPACE FILE_NAME SIZE_M
---------- ---------------------------------------- ----------
DBA01_2005 /u02/oradata/orcl/users_2005.dbf 1024
SQL> SELECT TABLESPACE_NAME ,FILE_NAME, BYTES/1024/1024 SIZE_M from dba_data_files WHERE TABLESPACE_NAME = 'DBA01_2006';
TABLESPACE FILE_NAME SIZE_M
---------- ---------------------------------------- ----------
DBA01_2006 /u02/oradata/orcl/users_2006.dbf 1024
SQL> SELECT TABLESPACE_NAME ,FILE_NAME, BYTES/1024/1024 SIZE_M from dba_data_files WHERE TABLESPACE_NAME = 'DBA01_2007';
TABLESPACE FILE_NAME SIZE_M
---------- ---------------------------------------- ----------
DBA01_2007 /u02/oradata/orcl/users_2007.dbf 1024
SQL> SELECT TABLESPACE_NAME ,FILE_NAME, BYTES/1024/1024 SIZE_M from dba_data_files WHERE TABLESPACE_NAME = 'DBA01_2008';
TABLESPACE FILE_NAME SIZE_M
---------- ---------------------------------------- ----------
DBA01_2008 /u02/oradata/orcl/users_2008.dbf 1024
SQL> SELECT TABLESPACE_NAME ,FILE_NAME, BYTES/1024/1024 SIZE_M from dba_data_files WHERE TABLESPACE_NAME = 'DBA01_2009';
TABLESPACE FILE_NAME SIZE_M
---------- ---------------------------------------- ----------
DBA01_2009 /u02/oradata/orcl/users_2009.dbf 1024
SQL> SELECT TABLESPACE_NAME ,FILE_NAME, BYTES/1024/1024 SIZE_M from dba_data_files WHERE TABLESPACE_NAME = 'DBA01_2010';
TABLESPACE FILE_NAME SIZE_M
---------- ---------------------------------------- ----------
DBA01_2010 /u02/oradata/orcl/users_2010.dbf 1024
SQL> SELECT TABLESPACE_NAME ,FILE_NAME, BYTES/1024/1024 SIZE_M from dba_data_files WHERE TABLESPACE_NAME = 'DBA01_2011';
TABLESPACE FILE_NAME SIZE_M
---------- ---------------------------------------- ----------
DBA01_2011 /u02/oradata/orcl/users_2011.dbf 1024
SQL> SELECT TABLESPACE_NAME ,FILE_NAME, BYTES/1024/1024 SIZE_M from dba_data_files WHERE TABLESPACE_NAME = 'INDX';
TABLESPACE FILE_NAME SIZE_M
---------- ---------------------------------------- ----------
INDX /u02/oradata/orcl/indx01.dbf 10240
INDX /u02/oradata/orcl/indx02.dbf 20480
INDX /u02/oradata/orcl/indx03.dbf 23808
INDX /u02/oradata/orcl/indx04.dbf 23808
INDX /u02/oradata/orcl/indx05.dbf 20480
SQL> SELECT TABLESPACE_NAME ,FILE_NAME, BYTES/1024/1024 SIZE_M from dba_data_files WHERE TABLESPACE_NAME = 'USERS';
TABLESPACE FILE_NAME SIZE_M
---------- ---------------------------------------- ----------
USERS /u02/oradata/orcl/users01.dbf 30720
USERS /u02/oradata/orcl/users02.dbf 30720
USERS /u02/oradata/orcl/users03.dbf 30720
SQL> SELECT TABLESPACE_NAME ,FILE_NAME, BYTES/1024/1024 SIZE_M from dba_data_files WHERE TABLESPACE_NAME = 'SYSAUX';
TABLESPACE FILE_NAME SIZE_M
---------- ---------------------------------------- ----------
SYSAUX /u02/oradata/orcl/sysaux01.dbf 27080.9375
三.根据以上文件分别建立表空间
1.先扩大本身的user01.dbf的空间
SQL>alter database datafile '/opt/oracle/oradata/orcl/users01.dbf' resize 30G;
2.再增加数据文件
SQL>alter tablespace users add datafile '/opt/oracle/oradata/orcl/users02.dbf' size 30G;
SQL>alter tablespace users add datafile '/opt/oracle/oradata/orcl/users03.dbf' size 30G;
3.创建索引表空间
SQL>create tablespace INDX datafile '/opt/oracle/oradata/orcl/indx01.dbf' size 30G;
SQL>alter tablespace INDX add datafile '/opt/oracle/oradata/orcl/indx02.dbf' size 30G;
SQL>alter tablespace INDX add datafile '/opt/oracle/oradata/orcl/indx03.dbf' size 30G;
其它表空间
create tablespace DBA01_2001 datafile '/opt/oracle/oradata/orcl/users_2001.dbf' size 500M;
create tablespace DBA01_2002 datafile '/opt/oracle/oradata/orcl/users_2002.dbf' size 500M;
create tablespace DBA01_2003 datafile '/opt/oracle/oradata/orcl/users_2003.dbf' size 500M;
create tablespace DBA01_2004 datafile '/opt/oracle/oradata/orcl/users_2004.dbf' size 500M;
create tablespace DBA01_2005 datafile '/opt/oracle/oradata/orcl/users_2005.dbf' size 500M;
create tablespace DBA01_2006 datafile '/opt/oracle/oradata/orcl/users_2006.dbf' size 500M;
create tablespace DBA01_2007 datafile '/opt/oracle/oradata/orcl/users_2007.dbf' size 500M;
create tablespace DBA01_2008 datafile '/opt/oracle/oradata/orcl/users_2008.dbf' size 500M;
create tablespace DBA01_2009 datafile '/opt/oracle/oradata/orcl/users_2009.dbf' size 500M;
create tablespace DBA01_2010 datafile '/opt/oracle/oradata/orcl/users_2010.dbf' size 500M;
create tablespace DBA01_2011 datafile '/opt/oracle/oradata/orcl/users_2011.dbf' size 500M;
建立目录:以SYS管理登录
sql> create directory expdir as '/opt/oracle/oradata/orcl';
一。授权用户
sql> grant EXP_FULL_DATABASE to orauser
sql> grant IMP_FULL_DATABASE to orauser
注意:
针对大数据库导入时,遇到了 由于db_recovery_file_dest_size=4G (太小),导致不能写日志,导入过程停在那里了。
通过
SQL> alter system set db_recovery_file_dest_size =50G scope=both来设置。--调大
在linux命令窗口以 oracle用户登录
导入
# impdp orauser/password directory=expdir dumpfile=data.dmp logfile=exp.log full=y
#单张表。如果表已经存在则要先删除
impdp 用户名/密码 TABLES= DIRECTORY=expdir DUMPFILE=data.dmp
导出:
# expdp orauser/password directory=expdir compression=ALL dumpfile=data.dmp full=y logfile=exp.log
建立目录:以SYS管理登录
sql> create directory expdir as '/opt/oracle/oradata/orcl';
一。授权用户
sql> grant EXP_FULL_DATABASE to orauser
sql> grant IMP_FULL_DATABASE to orauser
在linux命令窗口以 oracle用户登录
导出:
# expdp orauser/password directory=expdir compression=ALL dumpfile=data.dmp full=y logfile=exp.log
导入(整个数据库):
# impdp orauser/password directory=expdir dumpfile=data.dmp logfile=exp.log
full=y
导入(指定用户):
# impdp orauser/password directory=expdir dumpfile=data.dmp logfile=exp.log schemas=xxx
注意:
针对大数据库导入时,遇到了 由于db_recovery_file_dest_size=4G (太小),导致不能写日志,导入过程停在那里了。
通过
SQL> alter system set db_recovery_file_dest_size =50G scope=both来设置。
http://zxf261.blog.51cto.com/701797/762048
Oracle 11g缺省安装数据库启动了audit功能,导致oracle不断累积sys.aud$表及相关索引数据量增加;
如果导致表空间满了,在alert日志中将会报ORA-1654: unable to extend index SYS....错误。
如果不用到审计功能,建议关闭审计。
处理过程:
1、用oracle用户登录到数据库服务器,执行:
sqlplus / as sysdba
2、取消audit,将初始化参数audit_trail设置为NONE
alter system set audit_trail=none scope=spfile;
3、然后重启数据库.
shutdown immediate;
sqlplus / as sysdba
startup;
4、删除签权数据,oracle用户登录到数据库服务器:
sqlplus / as sysdba
truncate table SYS.AUD$;
Oracle 在Linux X86上使用超过2G的SGA
转自(http://cnhtm.itpub.net/post/39970/496153)
有空测试一下!
=================================================
在Linux X86上,SGA最大使用2G内存,如果设置超过2G的SGA,会报如下错误
| ORA-27123: unable to attach to shared memory segment |
可以通过使用shared memory file的方式使用超过2G的sga。
下面演示其过程(RedHat as 4+Oracle 10.2.0.1)
1、SGA过大的错误演示
SQL> alter system set sga_target=3G scope=spfile;
System altered.
SQL> startup force
ORA-27123: unable to attach to shared memory segment
SQL> exit
Disconnected from Oracle Database 10g Enterprise Edition Release 10.2.0.1.0 - Production
With the Partitioning, OLAP and Data Mining options |
2、Mount ramfs 文件系统,并保证可以被oracle用户访问
以下下过程用root用户操作
[root@linux32 ~]# umount /dev/shm
[root@linux32 ~]# mount -t ramfs ramfs /dev/shm
[root@linux32 ~]# chown oracle:dba /dev/shm |
然后将上面的三个命令加入到/etc/rc.local文件最后,修改后的文件如下所示
[root@linux32 ~]# cat /etc/rc.local
#!/bin/sh
#
# This script will be executed *after* all the other init scripts.
# You can put your own initialization stuff in here if you don't
# want to do the full Sys V style init stuff.
touch /var/lock/subsys/local
umount /dev/shm
mount -t ramfs ramfs /dev/shm
chown oracle:dba /dev/shm |
3、设置shared pool可以使用的内存
编辑/etc/security/limits.conf文件,加入标记为红色的两行
最后数字的计算公式为(假设要使用1g的shared pool,计算公式为 1×1024×1024=1048576),
[root@linux32 ~]# cat /etc/security/limits.conf
# /etc/security/limits.conf
#
......
#@student - maxlogins 4
# End of file
oracle soft nproc 2047
oracle hard nproc 16384
oracle soft nofile 1024
oracle hard nofile 65536
oracle soft memlock 1048576
oracle hard memlock 1048576 |
可以在另一个终端中重新用oracle用户登录,查看设置是否生效
[oracle@linux32 ~]$ ulimit -l
1048576 |
4、设置SHMMAX参数值
编辑/etc/sysctl.conf文件,按照如下规则设置如下3行
kernel.shmmax = 2147483648 #Linux主机内存的一半,单位为byte,但最大最不能超过4294967295
kernel.shmmni = 4096 #一般固定为4094
kernel.shmall = 2097152 #应该>或= kernel.shmmax/kernel.shmmni |
使用sysctl -p命令使设置生效
| [root@linux32 ~]# sysctl -p |
5、修改oracle的pfile文件
以下操作使用oracle用户操作
使用spfile生产pfile文件
| [oracle@linux32 dbs]$ strings spfileorcl.ora > init.ora.bak |
编辑init.ora.bak文件,增加标记为红色的三行
*.db_block_size=8192
......
*.use_indirect_data_buffers=true
*.db_block_buffers = 393216
*.shared_pool_size = 452984832 |
db_block_buffers表示db_block_size的大小,如欲使用3g的db_block_size,则公司为:(3×1024×1024/8=393216)(8代表db_block_size为8k)
shared_pool_size表示shared pool的大小,单位为byte,不能超过步骤3设置的内存大小,否则启动时会报告如下错误:
ORA-27102: out of memory
Linux Error: 28: No space left on device |
然后将*.sga_max_size和*.sga_target行删掉
6、使用修改好的pfile文件启动
[oracle@linux32 dbs]$ sqlplus / as sysdba
SQL*Plus: Release 10.2.0.1.0 - Production on Wed Jan 20 21:52:40 2010
Copyright (c) 1982, 2005, Oracle. All rights reserved.
Connected to an idle instance.
SQL> startup pfile='?/dbs/init.ora.bak'
ORACLE instance started.
Total System Global Area 3724541952 bytes
Fixed Size 1218076 bytes
Variable Size 486541796 bytes
Database Buffers 3221225472 bytes
Redo Buffers 15556608 bytes
Database mounted.
Database opened. |
生成spfile
SQL> create spfile from pfile='?/dbs/init.ora.bak';
File created. |
使用spfile启动
SQL> startup force;
ORACLE instance started.
Total System Global Area 3724541952 bytes
Fixed Size 1218076 bytes
Variable Size 486541796 bytes
Database Buffers 3221225472 bytes
Redo Buffers 15556608 bytes
Database mounted.
Database opened. |
显示sga情况
SQL> show sga
Total System Global Area 3724541952 bytes
Fixed Size 1218076 bytes
Variable Size 486541796 bytes
Database Buffers 3221225472 bytes
Redo Buffers 15556608 bytes
SQL> show parameter sga
NAME TYPE VALUE
------------------------------------ ----------- ------------------------------
lock_sga boolean FALSE
pre_page_sga boolean FALSE
sga_max_size big integer 3552M
sga_target big integer 0 |
--end--
删除过期归档日志
1. 进入rman
2. connect target /
3. crosscheck archivelog all;
4.delete expired archivelog all;==>没有rman备份的情况下不适用。
5.delete archivelog all completed before 'SYSDATE-30'; 删除一个月前的日志。
--1:无ORDER BY排序的写法。(效率最高) --(经过测试,此方法成本最低,只嵌套一层,速度最快!即使查询的数据量再大,也几乎不受影响,速度依然!) SELECT * FROM (Select ROWNUM AS ROWNO, T.* from k_task T where Flight_date between to_date('20060501', 'yyyymmdd') and to_date('20060731', 'yyyymmdd') AND ROWNUM <= 20) TABLE_ALIAS WHERE TABLE_ALIAS.ROWNO >= 10; --2:有ORDER BY排序的写法。(效率最高) --(经过测试,此方法随着查询范围的扩大,速度也会越来越慢哦!) SELECT * FROM (SELECT TT.*, ROWNUM AS ROWNO FROM (Select t.* from k_task T where flight_date between to_date('20060501', 'yyyymmdd') and to_date('20060531', 'yyyymmdd') ORDER BY FACT_UP_TIME, flight_no) TT WHERE ROWNUM <= 20) TABLE_ALIAS where TABLE_ALIAS.rowno >= 10; --3:无ORDER BY排序的写法。(建议使用方法1代替) --(此方法随着查询数据量的扩张,速度会越来越慢哦!) SELECT * FROM (Select ROWNUM AS ROWNO, T.* from k_task T where Flight_date between to_date('20060501', 'yyyymmdd') and to_date('20060731', 'yyyymmdd')) TABLE_ALIAS WHERE TABLE_ALIAS.ROWNO <= 20 AND TABLE_ALIAS.ROWNO >= 10; --TABLE_ALIAS.ROWNO between 10 and 100; --4:有ORDER BY排序的写法.(建议使用方法2代替) --(此方法随着查询范围的扩大,速度会越来越慢哦!) SELECT * FROM (SELECT TT.*, ROWNUM AS ROWNO FROM (Select * from k_task T where flight_date between to_date('20060501', 'yyyymmdd') and to_date('20060531', 'yyyymmdd') ORDER BY FACT_UP_TIME, flight_no) TT) TABLE_ALIAS where TABLE_ALIAS.rowno BETWEEN 10 AND 20; --5另类语法。(有ORDER BY写法) --(语法风格与传统的SQL语法不同,不方便阅读与理解,为规范与统一标准,不推荐使用。) With partdata as( SELECT ROWNUM AS ROWNO, TT.* FROM (Select * from k_task T where flight_date between to_date('20060501', 'yyyymmdd') and to_date('20060531', 'yyyymmdd') ORDER BY FACT_UP_TIME, flight_no) TT WHERE ROWNUM <= 20) Select * from partdata where rowno >= 10; --6另类语法 。(无ORDER BY写法) With partdata as( Select ROWNUM AS ROWNO, T.* From K_task T where Flight_date between to_date('20060501', 'yyyymmdd') and To_date('20060531', 'yyyymmdd') AND ROWNUM <= 20) Select * from partdata where Rowno >= 10;
http://www.blogjava.net/pitey/archive/2008/03/05/183932.html
applicationContext.xml里面设置
<bean id="dataSource" class="org.springframework.jndi.JndiObjectFactoryBean" lazy-init="default" autowire="default" dependency-check="default">
<property name="jndiName">
<value>JDBC/TEST</value>
</property>
</bean> 或者
<bean id="dataSource" class="org.apache.commons.dbcp.BasicDataSource" destroy-method="close">
<property name="driverClassName" value="oracle.jdbc.driver.OracleDriver"></property>
<property name="url" value="jdbc:oracle:thin:@127.0.0.1:1521:ora"></property>
<property name="username" value="test"></property>
<property name="password" value="123456"></property>
</bean>
通过DataSourceUtils.getConnection(DataSource);就能获取到设置的DataSource 然后获得connection
public static Connection getConnection()
throws SQLException
{
return DataSourceUtils.getConnection((DataSource)ServiceLocator.getBean("dataSource"));
}
在currentuser目录下.m2文件夹中,新增一个setting.xml文件
<settings>
<proxies>
<proxy>
<active>true</active>
<protocol>http</protocol>
<host>10.110.1.238</host> =>代理服务器地址
<port>3128</port>
<username>proxyuser</username>
<password>somepassword</password>
<nonProxyHosts>www.google.com|*.somewhere.com</nonProxyHosts>
</proxy>
</proxies>
</settings>
单击Eclipse菜单“Run”中的“Run Configurations”。
2、在弹出的对话框中的左侧树中找“到Maven Build”,在其上点击右键并单击“New”。
3、在右侧的“Name”一栏填入自定义的名称。单击在“Main”选项卡的“Browse Workspace”按钮,选择目标项目,选择后在“Base directory”一栏中会出现形如“${workspace_loc:/project_a}”的内容(project_a是前文所述应用项目A,它 会根据你所选的目标项目而改变)。
4、在“Goals”一栏中填入“tomcat:run”。
5、在“Maven Runtime”选择你需要的Maven环境(注意:必须是2.0.8以上的版本)。
6、单击“Apply”,配置完成。
经过测试,通过以上配置,在eclipse自身的Run(“右箭头”)和Debug(“小虫子”)按钮下都会找到以你先前配置中“Name”值为名 的条目(条目最前端也会有“m2”标识),单击之后即可启动基于Tomcat之上的相应项目的运行操作或调试操作。至于是运行项目还是调试项目,只取决于 你单击的条目是在“右箭头”按钮下还是在“小虫子”按钮下。从这方面来看,他们还是很智能化的。

http://blog.csdn.net/dangerous_fire/article/details/6278435
最近要配置tomcat集群,在网上搜了很多文章,但照着步骤一步一步做到最后却无法成功,着使我费了两天的劲查看了apache 和 tomcat的大量文档,才将问题一一解决。为方便自己和新手配置tomcat集群,我将整理好的过程晒一晒,希望可以帮到后来人少走一些弯路。
==================
目标:
使用 apache 和 tomcat 配置一个可以应用的 web 网站,要达到以下要求:
1、 Apache 做为 HttpServer ,后面连接多个 tomcat 应用实例,并进行负载均衡。
2、 为系统设定 Session 超时时间,包括 Apache 和 tomcat
3、 为系统屏蔽文件列表,包括 Apache 和 tomcat
注:本例程以一台机器为例子,即同一台机器上装一个apache和2个Tomcat。
一、前期准备工作:安装用的程序(前提保证已安装了JDK1.5以上的版本)
APAHCE 2.2.8下载:apache_2.2.8-win32-x86-no_ssl.msi
TOMCAT6.0.14下载:apache-tomcat-6.0.14.zip直接解压。
二、安装过程
APAHCE安装目录:D:/Apache。
两个TOMCAT目录:自行解压到(D:/TomcatCluster/)下。
分别为 tomcat6-a,tomcat6-b
三、配置
1、Apache配置
1.1 httpd.conf配置
修改APACHE的配置文件D:/Apache/conf/httpd.conf
这里并没有使用mod_jk.so进行apache和tomcat的链接,从2.X以后apache自身已集成了mod_jk.so的功能。只需简单的把下面几行去掉注释,就相当于以前用mod_jk.so比较繁琐的配置了。
这里主要采用了代理的方法,就这么简单。
将以下Module的注释去掉
LoadModule proxy_module modules/mod_proxy.so
LoadModule proxy_connect_module modules/mod_proxy_connect.so
LoadModule proxy_ftp_module modules/mod_proxy_ftp.so
LoadModule proxy_http_module modules/mod_proxy_http.so
LoadModule proxy_ajp_module modules/mod_proxy_ajp.so
LoadModule proxy_balancer_module modules/mod_proxy_balancer.so
再找到
<IfModule dir_module>
DirectoryIndex index.html
</IfModule>
加上index.jsp修改成
<IfModule dir_module>
DirectoryIndex index.html index.jsp
</IfModule>
此处添加index.jsp 主要为了配置完成以后利用index.jsp输出测试信息!
在 httpd.conf 最后面加入
ProxyRequests Off
<proxy balancer://cluster>
BalancerMember ajp://127.0.0.1:8009 loadfactor=1 route=jvm1
BalancerMember ajp://127.0.0.1:9009 loadfactor=1 route=jvm2
</proxy>
上面的两个BalancerMember成员是我们配置的tomcat集群。
1.2 httpd-vhosts.conf设置
接下来进行虚拟主机的设置。
APACHE的虚拟主机设置如下:
首先要修改 conf/httpd.conf
找到
# Virtual hosts
#Include conf/extra/httpd-vhosts.conf
把Include语句注释去掉。改成
# Virtual hosts
Include conf/extra/httpd-vhosts.conf
在文件(extra/httpd-vhosts.conf)最下面加入
<VirtualHost *:80>
ServerAdmin adminname
ServerName localhost
ServerAlias localhost
ProxyPass / balancer://cluster/ stickysession=jsessionid nofailover=On lbmethod=bytraffic
ProxyPassReverse / balancer://cluster/
</VirtualHost>
其中的域名和路径根据你自己情况设置
负载均衡有三种方式,可以通过设置 lbmethod 选择自己需要的方式,详细可查看apache文档
proxy是位于客户端与实际的服务器之间的服务器,一般称为facade server,负责将外部的请求分流,也负责对内部的响应做一些必要的处理。
如果结合mod_cache,则可提高访问速度,适当的减轻网络流量压力。
闲话少说,直接拿个例子来:
设本站地址为 www.test.com
ProxyPass /images/ !
ProxyPass /js/ !
ProxyPass /css/ !
ProxyPass /example http://www.example.com/
ProxyPassReverse /example http://www.example.com/
ProxyPass / ajp://127.0.0.1:8009/
ProxyPassReverse / ajp://127.0.0.1:8009/
还是上一篇的例子,ProxyPass易理解,就是转发url上的请求,而其中的配置顺序也是需要遵守。
要禁止转发的url需要放在一般的请求之前。
对于
http://www.test.com/images/
http://www.test.com/js/
http://www.test.com/css/
的请求是不予转发的,对于http://www.test.com/example/的请求,会转发到http://www.example.com。
值得注意的就是ProxyPassReverse的配置了,这是反向代理。
为什么要在这里加上这样的配置?我们来看个例子:
在没有加这样的反向代理设置的情况下,访问http://www.test.com/example/a,
如果www.example.com对请求进行了redirect至http://www.example.com/b,
那么,客户端就会绕过反向代理,进而访问http://www.test.com/example/b。
如果设置了反向代理,则会在转交HTTP重定向应答到客户端之前调整它为http://www.test.com/example/a/b
即是在原请求之后追加上了redirect的路径。
更多更详细的关于mod_proxy的描述可以参见手册:
http://lamp.linux.gov.cn/Apache/ApacheMenu/mod/mod_proxy.html
2 配置 tomcat
2.1 配置 server 的关闭
我们需要在一台机器上跑两个不同的 tomcat ,需要修改不同的 tomcat 的关闭口,避免出现端口被占用的情况。
其中tomcat6-a用默认值,不修改。
tomcat6-b修改。在tomcat6-b/conf下的 server.xml 中找到 server, 将:
<Server port="8005" shutdown="SHUTDOWN">
改为
<Server port="9005" shutdown="SHUTDOWN">
2.2 配置 Engine
把原来的配置注释掉,把下面一句去掉注释。并标明jvmRoute="jvm2"
<Engine name="Standalone" defaultHost="localhost" jvmRoute="jvm2">
以下是原来的配置。
<Engine name="Catalina" defaultHost="localhost">
2.3. 配置 Connector
原来的默认配置。
<Connector port="8080" protocol="HTTP/1.1"
connectionTimeout="20000"
redirectPort="8443" />
<!-- Define an AJP 1.3 Connector on port 8009 -->
<Connector port="8009" protocol="AJP/1.3" redirectPort="8443" />
将tomcal6-b 中的 protocol="HTTP/1.1" 的 Connector 端口改为 8081 避免冲突。tomcat6-a 中的保持不变。
protocol="AJP/1.3" 的 Connector 是apache和tomcat链接的关键,前台apache就是通过AJP协议与tomcat进行通信的,以完成负载均衡的作用。
也可以用HTTP协议。大家注意它们是如何连接通信的,(port="8009")就是连接的接口了。
把tomcat6-b的<Connector port="8009" protocol="AJP/1.3" redirectPort="8443" /> 中的port改成 9009
<proxy balancer://cluster>
#与 tomcat6-a 对应,route与<Engine jvmRoute="jvm1">对应。
BalancerMember ajp://127.0.0.1:8009 loadfactor=1 route=jvm1
#与 tomcat6-b 对应,route与<Engine jvmRoute="jvm2">对应。
BalancerMember ajp://127.0.0.1:9009 loadfactor=1 route=jvm2
</proxy>
中的端口对应,
tomcat6-a 的ajp端口port:8009
tomcat6-b 的ajp端口port:9009
一定要与上面的一致。
2.5.配置Cluster(两个tomcat中都要修改)
原来的配置。
<Cluster className="org.apache.catalina.ha.tcp.SimpleTcpCluster"/>
修改为以下的代码:<Receiver port=”XX”/>port也要保证唯一性。
<Cluster className="org.apache.catalina.ha.tcp.SimpleTcpCluster"? channelSendOptions="6">
<Manager className="org.apache.catalina.ha.session.BackupManager"
expireSessionsOnShutdown="false"
notifyListenersOnReplication="true"
mapSendOptions="6"/>
<!--
<Manager className="org.apache.catalina.ha.session.DeltaManager"
expireSessionsOnShutdown="false"
notifyListenersOnReplication="true"/>
-->
<Channel className="org.apache.catalina.tribes.group.GroupChannel">
<Membership className="org.apache.catalina.tribes.membership.McastService"
address="228.0.0.4"
port="45564"
frequency="500"
dropTime="3000"/>
<Receiver className="org.apache.catalina.tribes.transport.nio.NioReceiver"
address="auto"
port="5001"
selectorTimeout="100"
maxThreads="6"/>
<Sender className="org.apache.catalina.tribes.transport.ReplicationTransmitter">
<Transport className="org.apache.catalina.tribes.transport.nio.PooledParallelSender"/>
</Sender>
<Interceptor className="org.apache.catalina.tribes.group.interceptors.TcpFailureDetector"/>
<Interceptor className="org.apache.catalina.tribes.group.interceptors.MessageDispatch15Interceptor"/>
<Interceptor className="org.apache.catalina.tribes.group.interceptors.ThroughputInterceptor"/>
</Channel>
<Valve className="org.apache.catalina.ha.tcp.ReplicationValve"
filter=".*/.gif;.*/.js;.*/.jpg;.*/.png;.*/.htm;.*/.html;.*/.css;.*/.txt;"/>
<Deployer className="org.apache.catalina.ha.deploy.FarmWarDeployer"
tempDir="/tmp/war-temp/"
deployDir="/tmp/war-deploy/"
watchDir="/tmp/war-listen/"
watchEnabled="false"/>
<ClusterListener className="org.apache.catalina.ha.session.ClusterSessionListener"/>
</Cluster>
这个设置是主要用以tomcat的集群。
tomcat集群各节点通过建立tcp链接来完成Session的拷贝,拷贝有同步和异步两种模式。
在同步模式下,对客户端的响应必须在Session拷贝到其他节点完成后进行;异步模式无需等待Session拷贝完成就可响应。
异步模式更高效,但是同步模式可靠性更高。同步异步模式由channelSendOptions参数控制,默认值是8,为异步模式,4是同步模式。
在异步模式下,可以通过加上拷贝确认(Acknowledge)来提高可靠性,此时channelSendOptions设为10。
Manager用来在节点间拷贝Session,默认使用DeltaManager,DeltaManager采用的一种all-to-all的工作方式,
即集群中的节点会把Session数据向所有其他节点拷贝,而不管其他节点是否部署了当前应用。
当集群中的节点数量很多并且部署着不同应用时,可以使用BackupManager,BackManager仅向部署了当前应用的节点拷贝Session。
但是到目前为止BackupManager并未经过大规模测试,可靠性不及DeltaManager。
四、启动服务,测试tomcat自带的例子
1、测试apache和tomcat协作。
先在每个tomcat中的/webapps/ROOT下的index.jsp下面加上以下的测试代码部分:
(X代表不同的tomcat的输出不同的信息),把index.html删除,以免影响测试效果。
在最后面的加上.即</table></body>之间。
<%
System.out.println("tomcat6 A|B deal with request");
%>
然后再通过http://127.0.0.1来访问一下,就会出现大家熟悉的猫猫。
然后再通过分别访问
http://127.0.0.1:8080
http://127.0.0.1:8081
它们访问的内容和上面的http:// 127.0.0.1是一样的。
这样就说明apache和TOMCAT整合成功!
2、测试均衡器
如果在 extra/httpd-vhosts.conf 中配置 没有设置 lbmethod=bytraffic,将使用默认的 byrequests ,控制分配的一共有三种方式,还有一种是 bybusyness 。
通过http://127.0.0.1多次访问,
如 果使用的是 byrequests 的分配方式,要想看到真正的效果,必须用一些压力测试工具,可用微软Microsoft Web Application Stress Tool进行简单压力测试,不然你靠不停刷新是体现不出来的,你只会在一个tomcat的控制台有输出结果。
只用用压力测试工具模拟大量用户同时访问,你会发现四个tomcat控制台均有打出控制信息,说明均衡器工作正常。
而如果配置为 bytraffic 并且tomcat6-a 和 tomcat6-b 设置了 loadfactor=1,则请求会均匀的分配给不同的tomcat,很容易测试出来。
如果想对此感兴趣,请查看apache 的文档并尝试修改
httpd.conf
----------------------
ProxyRequests Off
<proxy balancer://cluster>
BalancerMember ajp://127.0.0.1:8009 loadfactor=1 route=jvm1
BalancerMember ajp://127.0.0.1:9009 loadfactor=1 route=jvm2
</proxy>
----------------------
中的 loadfactor 参数和
extra/httpd-vhosts.conf
----------------------
<VirtualHost *:80>
ServerAdmin adminname
ServerName localhost
ServerAlias localhost
ProxyPass / balancer://cluster/ stickysession=jsessionid nofailover=On lbmethod=bytraffic
ProxyPassReverse / balancer://cluster/
</VirtualHost>
----------------------
中的 lbmethod 参数
注意:如果apache 中出现如下错误
Encountered too many errors accepting client connections. Possible causes: dynamic address renewal, or incompatible VPN or firewall software. Try using the Win32DisableAcceptEx directive.
编辑httpd.conf 加入
Win32DisableAcceptEx ##加入这行
重启apache就解决了。
如果修改后还是不行,任然有错误记录,
cmd下
netsh winsock reset
因为这个错误可能与winsock有关,有网友也出现了这个问题,他认为是金山毒霸或者升级精灵修改了WINSOCK导致的。我没有安装但是系统经常自动更新,别的软件也有,可能会有冲突。
使用此条命令恢复Winsock后,重启电脑后这个问题就会解决了。
http://www.cnblogs.com/shiyangxt/archive/2009/02/26/1398902.html
开学以后,连续几天休息不好,总是犯困,也许这就是“春困秋乏”的症状吧。最近老师提出了负载均衡功能的需求,以减轻
网站的高峰期的服务器负担,现在学校的硬件设施还是蛮好的,有三,四台服务器可以提供使用,也很大程度的上方便了我做一些测试。
因为这个子项目,假期三个同学已经基本完工,所以我也只能出点微薄之力,把这个负载均衡搞定,具体用不用我不管,起码是我的一个
小功能。
其实无论是分布式,数据缓存,还是负载均衡,无非就是改善网站的性能瓶颈,在网站源码不做优化的情况下,负载均衡可以说
是最直接的手段了。其实抛开这个名词,放开了说,就是希望用户能够分流,也就是说把所有用户的访问压力分散到多台服务器上,也可以
分散到多个tomcat里,如果一台服务器装多个tomcat,那么即使是负载均衡,性能也提高不了太多,不过可以提高稳定性,即容错性。
当其中一个主tomcat当掉,其他的tomcat也可以补上,因为tomcat之间实现了Session共享。待tomcat服务器修复后再次启动,就会
自动拷贝所有session数据,然后加入集群。这样就可以不间断的提供服务。如果要真正从本质上提升性能,必须要分布到多台服务器。
同样tomcat也可以做到。网上相关资料比较多,可以很方便的查到,但是质量不算高。我希望可以通过这篇随笔,系统的总结。本文的
例子是同一台服务器上运行两个tomcat,做两个tomcat之间的负载均衡。其实多台服务器各配置一个tomcat也可以,而且那样的话,可以使用
安装版的tomcat,而不用是下文中的免安装的tomcat,而且tomcat端口配置也就不用修改了。下文也会提到。
tomcat的负载均衡需要apache服务器的加入来实现。在进行配置之前请先卸载调已安装的tomcat,然后检查apache的版本。
我这次配置使用的是apache-tomcat-6.0.18免安装版本,我亲自测试后推断安装版的tomcat在同一台机子上会不能启动两个以上,可能是
因为安装版的tomcat侵入了系统,导致即使在server.xml里修改了配置,还是会引起冲突。所以我使用tomcat免安装版。
apache使用的是apache_2.2.11-win32-x86-no_ssl.msi。如果版本低于2.2负载均衡的配置要有所不同,因为这个2.2.11和2.2.8版本
集成了jk2等负载均衡工具,所以配置要简单许多。别的版本我没有具体测试,有待考究。这两个软件可以到官方网站下载。
把Apache安装为运行在80端口的Windows服务,安装成功后在系统服务列表中可以看到Apache2.2服务。服务启动后在浏览器中
输入http://localhost进行测试,如果能看到一个"It works!"的页面就代表Apache已经正常工作了。把tomcat解压到任意目录,赋值一个另命名。
起名和路径对配置没有影响。但要保证端口不要冲突,如果装有Oracle或IIS的用户需要修改或关闭相关接口的服务。当然jdk的配置也是
必须的,这个不再过多叙述。
首先,在Apache安装目录下找到conf/httpd.conf文件,去掉以下文本前的注释符(#)以便让Apache在启动时自动加载代理(proxy)
模块。
LoadModule proxy_module modules/mod_proxy.so
LoadModule proxy_ajp_module modules/mod_proxy_ajp.so
LoadModule proxy_balancer_module modules/mod_proxy_balancer.so
LoadModule proxy_connect_module modules/mod_proxy_connect.so
LoadModule proxy_ftp_module modules/mod_proxy_ftp.so
LoadModule proxy_http_module modules/mod_proxy_http.so
向下拉动文档找到<IfModule dir_module>节点,在DirectoryIndex index.html后加上index.jsp,这一步只是为了待会配置完tomcat后能看到小
猫首页,可以不做。继续下拉文档找到Include conf/extra/httpd-vhosts.conf,去掉前面的注释符。
然后打开conf/extra/httpd-vhosts.conf,配置虚拟站点,在最下面加上
<VirtualHost *:80>
ServerAdmin 管理员邮箱
ServerName localhost
ServerAlias localhost
ProxyPass / balancer://sy/ stickysession=jsessionid nofailover=On
ProxyPassReverse / balancer://sy/
ErrorLog "logs/sy-error.log"
CustomLog "logs/sy-access.log" common
</VirtualHost>
然后回到httpd.conf,在文档最下面加上
ProxyRequests Off
<proxy balancer://sy>
BalancerMember ajp://127.0.0.1:8009 loadfactor=1 route=jvm1
BalancerMember ajp://127.0.0.1:9009 loadfactor=1 route=jvm2
</proxy>
ProxyRequests Off 是告诉Apache需要使用反向代理,ip地址和端口唯一确定了tomcat节点和配置的ajp接受端口。loadfactor是负载因子,
Apache会按负载因子的比例向后端tomcat节点转发请求,负载因子越大,对应的tomcat服务器就会处理越多的请求,如两个tomcat都
是1,Apache就按1:1的比例转发,如果是2和1就按2:1的比例转发。这样就可以使配置更灵活,例如可以给性能好的服务器增加处理
工作的比例,如果采取多台服务器,只需要修改ip地址和端口就可以了。route参数对应后续tomcat配置中的引擎路径(jvmRoute)。
如果仅仅为了配置一个可用的集群,Tomcat的配置将会非常简单。分别打开两个tomcat的server.xml配置文件,其中一台可以采用默认
的设置,只需要修改两个地方,而另一个要有较大改动以避免与前一台冲突。如果两台不在同一台服务器上运行,对于端口就不需做改动。首先是
配置关闭端口,找到<Server port="8005" shutdown="SHUTDOWN">,第一台不变,把第二台改为9005。
下面配置Connector的端口,找到non-SSL HTTP/1.1 Connector,即tomcat单独工作时的默认Connector,保留第一台默认配置,在8080端
口侦听,而把第二台设置为在9080端口侦听。往下找到AJP 1.3 Connector,<Connector port="8009" protocol="AJP/1.3" redirectPort="8443" />,这是
tomcat接收从Apache过来的ajp连接请求时使用的端口,保留第一台默认设置,把第二台端口改为9009。第一台tomcat的server.xml中找到
<Engine name="Catalina" defaultHost="localhost">,去掉这段或改为注释,把上方紧挨的<Engine name="Catalina" defaultHost="localhost" jvmRoute="jvm1">
注释符去掉,对于第二台,去掉注释符并把jvm1改为jvm2。
向下找到<Cluster className="org.apache.catalina.ha.tcp.SimpleTcpCluster"/>,去掉注释,这里的配置是为了可以在集群中的所有tomcat节点
间共享会话(Session)。如果仅仅为了获得一个可用的tomcat集群,Cluster只需要这么配置就可以了。
只需要简单的几步就配置完成,然后可以测试一下是否配置成功。引用网上的一个测试方法,就是在webapps目录下新建test目录,在test目
录下新建test.jsp文件,代码我稍作改动如下:
<%@ page contentType="text/html; charset=GBK" %>
<%@ page import="java.util.*" %>
<html><head><title>shiyang</title></head>
<body>
服务信息:
<%
out.println(request.getLocalAddr() + " : " + request.getLocalPort()+"<br/>");%>
<%
out.println("<br> ID " + session.getId()+"<br/>");
String dataName = request.getParameter("dataName");
if (dataName != null && dataName.length() > 0) {
String dataValue = request.getParameter("dataValue");
session.setAttribute(dataName, dataValue);
}
out.print("<b>Session 列表</b><br/>");
Enumeration e = session.getAttributeNames();
while (e.hasMoreElements()) {
String name = (String)e.nextElement();
String value = session.getAttribute(name).toString();
out.println( name + " = " + value+"<br/>");
System.out.println( name + " = " + value);
}
%>
<form action="test.jsp" method="POST">
名称:<input type=text size=20 name="dataName">
<br/>
值:<input type=text size=20 name="dataValue">
<br/>
<input type=submit value="提交">
</form>
</body>
</html>
在test目录下继续新建WEB-INF目录和web.xml,在<web-app>节点下加入<distributable />,这一步非常重要,是为了通知tomcat服务器,
当前应用需要在集群中的所有节点间实现Session共享。如果tomcat中的所有应用都需要Session共享,也可以把conf/context.xml中的
<Context>改为<Context distributable="true">,这样就不需对所有应用的web.xml再进行单独配置。测试代码完成!
先启动Apache服务,在先后启动两台tomcat,分别点startup.bat批处理。如果一切顺利的话,就会启动成功。再次访问http://localhost,
可以看到小猫页面。访问http://localhost/test/test.jsp。可以看到包括服务器地址,端口,session等信息在内的页面。
然后你可以测试一下容错功能,关闭一个tomcat,看看服务是否正常,然后重启tomcat,关掉另一台tomcat,看看
是否也可以继续提供服务。当然你也可以配置多台tomcat,但是原理都一样。
OK,讲到这里。
http://www.ibm.com/developerworks/cn/java/j-ap/
http://books.zkoss.org/wiki/Small_Talks/2012/May/Perform_stress_test_on_ZK_using_JMeter-take_Shopping_Cart_as_an_example
Preface
Dennis Chen has shared a small talk illustrating how you can execute a loading test with ZK applications using JMeter. Now, in this small talk we will take a real application as an example to demonstrate in detail how you can actually apply the ideas illustrated in Dennis’ article to perform a stress test.
Test plan
We will be using the "shopping cart" example from ZK Essentials as the template application to perform the stress test.
Setup
- ZK 5.0.11
- zk testing demo ( a demo based on the shopping cart sample)
- Jmeter 2.5.1
Test Scenario
- User enters his user name and password for authentication
- Login successfully to the shopping site, redirect to index.zul
- User selects an item and drag to the shopping cart
- User checks out
Since this is a stress test, we can apply 50, 100, 150,... concurrent users to perform the test scenario simultaneously. In our example we have created a max of 300 accounts, which allows you to perform the test with as many as 300 concurrent users.
Before we start
As mentioned above we will be using the "shopping cart" example from ZK Essentials as the template application. However there is only one set of login/password in the current shopping cart implementation which is not sufficient for multiple users. To support multiple users, we have modified the shopping cart example to generate multiple accounts, so that each user will be logged in using a different account. This is done as follows, and it will be triggered as you click "createUserBtn" in login.zul:
1. prepare a CSV file that includes a list of user names and passwords:

2. Add the following code to LoginViewCtrl.java
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 | public void onClick$createUserBtn() {
Map map = userinfo();
Session session = StoreHibernateUtil.openSession();
Transaction t = session.beginTransaction();
Iterator entries = map.entrySet().iterator();
int i = 0;
while (entries.hasNext()) {
i ++;
Map.Entry entry = (Map.Entry) entries.next();
String name = (String)entry.getKey();
String pwd = (String)entry.getValue();
User user = new User(i, name, pwd, "user");
session.save(user);
if (i % 20 == 0) {
session.flush();
session.clear();
}
}
t.commit();
session.close();
}
|
Configuring ZK
As illustrated in Dennis’ small talk, you need to define IdGenerator to fix the desktop IDs and component IDs so that we can record and play the testing script. The IdGenerator is implemented as follows:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 | public class MyIdgenerator implements IdGenerator {
private static ThreadLocal<HttpServletResponse> response = new ThreadLocal<HttpServletResponse>();
private static AtomicInteger ai = new AtomicInteger();
public String nextComponentUuid(Desktop desktop, Component comp) {
String number;
if ((number = (String) desktop.getAttribute("Id_Num")) == null) {
number = "0";
desktop.setAttribute("Id_Num", number);
}
int i = Integer.parseInt(number);
i++;// Start from 1
desktop.setAttribute("Id_Num", String.valueOf(i));
return "t_" + i;
}
public String nextDesktopId(Desktop desktop) {
HttpServletRequest req = (HttpServletRequest)Executions.getCurrent().getNativeRequest();
String dtid = req.getParameter("tdtid");
if(dtid!=null){
}
return dtid==null?null:dtid;
}
public String nextPageUuid(Page page) {
return null;
}
}
|
- Define your IdGenerator in zk.xml
Then, define your IdGenerator in zk.xml, for example,
1 2 3 | <system-config>
<id-generator-class>foo.MyIdgenerator</id-generator-class>
</system-config>
|
Preparing Testing Scripts
Now we are ready to record the scripts. We will be recording 6 HTTP requests as illustrated in the image below. What we need to do is to configure the parameters of these 6 requests based on the application that we wish to test.

Load CSV file as the variable of the user name and password
- Add a CSV Data Set Config
First we need to add a CSV Data Set Config here. The element will iterate the csv data set to simulate muti-users login into the application. Please specify a fully qualified name to the Filename field (ex: C:\mycsv\users.csv ), and specify the variable name to the Variable Names field for later use.

Then we need to ask jmeter to generate the accounts and passwords automatically based on our CSV file. What we need to do is to add a BSF PostProcessor element, set the language to beanshell, and define:
var username = vars.get("username");
var password = vars.get("password");
vars.put("user","{\"value\":\""+username+"\",\"start\":2}");
vars.put("pwd","{\"value\":\""+password+"\",\"start\":2}");
This script will get the username and password variables generated by CSV Data Set Config element, and combine the result and some text as a parameter which will be used as user names and passwords later.

Set account & password as variables
With these settings ready, we can now set the parameter dtid as ${dtid} and use EL to replace a fixed account and password in the first ajax request (i.e. the login request). For example if we send zk/zk as user name and password, then we will be seeing
data_3: {"value":"zk","start":2} //for username
data_4: {"value":"zk","start":2} //for password
in the recorded jmeter’s request. Then, we use ${user} and ${pwd} to replace {"value":"zk","start":2} for handling the accounts and passwords dynamically.

Generate new desktop ID for redirecting to a new page
After an user logged into the system, he will be redirected to index.zul. Since the URL is changed, the desktop and it’s id will also be changed, we need to retrieve the desktop id again using ${__intSum(${dtid},1,dtid)}.
Specify parameter
The last 3 http requests are for adding products to the shopping cart, check out, and close the browser tab. What we need to do is just to modify their tdtid to ${__intSum(${dtid},1,dtid).

Add the listeners for creating reports
There are many different elements that allows you to generate different kinds of reports, such as Aggregate Report and Graph Results. You can add these listeners to Thread Group or HTTP request depending on the report you wish to generate.

Now we have completed all the settings and have saved these configurations as test.jmx.
Running the test
Now we are ready to start the application and to run the test.
- Generate accounts
Start your web server, and access login.zul. Click createUserBtn for creating multiple accounts.

- Run the testing script
- Open jmeter’s menu, File > Open , and load test.jmx.
- Specify your IP and port, for example we use localhost/8080 as ip and port number

- In Thread Group ( the root element), set the number of concurrent users to test.

- Perform Run > Start to run the test.
You can then observe the average response time, 90% line response time, median response time and other results by accessing the Aggregate Report .

Trouble-shooting & Tips
- Tips: Performing repeating tests
If you have finished a round of test (for example 0~50) you should restart your server before performing another round of test. This is because after you finish a round of test, there will be an extra item listed in each user’s page because they all ordered an item. This extra item is displayed at the bottom of the page (see the image on the right). As there is a DOM change due to this extra item, components’ IDs and orders are also changed thus different from the script you recorded earlier. To solve this problem, just restart your server before performing another round of test.


- Trouble-shooting: Erred response

If you encounter the Response data error shown as the image above, it is most likely that you did not implement IdGenerator correctly. Please refer to Configuring ZK section to implement UUID.
- Trouble-shooting: Timeout error

Timeout errors occur when the desktop id in the Ajax request is no longer available at the server side. This normally happens when the URL is changed. If this happens, you need to retrieve desktop ID again. Please refer to Testing Scripts section to implement Desktop ID.
Timeout may also relate to the max allowed desktops. In ZK there is a setting called “max-desktops-per-session” which defines the max concurrent desktops for each session. The more browser tabs an user opens the more desktops will be saved on the session. If the number exceeds the max allowed desktops then some desktops will be dropped with the timeout error.
By default the number is 15 which means an user can open as many as 15 tabs in a same browser at the same time. If you have configured it to a smaller number for saving the memory, and in your use case the users will be opening up multiple tabs then you should double check whether this is the reason causing the timeout error. To change this setting, use:
1 2 3 | <session-config>
<max-desktops-per-session>1</max-desktops-per-session>
</session-config>
|
- Tips: close browser tab for saving memory
ZK stores desktops in sessions, when user closes the browser tab ZK will send the rmDesktop command to remove the desktop. We can simulate this behavior to save memory when performing a stress test. This is done in the last http request defined in test.jmx. You can refer to the image below:

Downloads
users.csv - users.csv (Please place the csv file under C:/mycsv/)
zk testing demo – the modified shopping cart application used in this small talk
jmeter 2.5.1 – http://jmeter.apache.org/download_jmeter.cgi
test.jmx – test.jmx
http://blog.csdn.net/jinjazz/article/details/5495955
最近一个项目中需要监测SQLServer数据库中某些表的数据更新情况,于是做了一番POC测试和简单性能的评估.这里使用的是 SQLServer2008的更改跟踪.因为需求原因,没有考虑使用进一步的变更数据捕获.
POC过程如下:
这里我们建立一个测试环境,模拟数据在 Insert , Update 和 Delete 情况下的跟踪效果。
1 、测试脚本的准备,下面脚本建立一个新的数据库环境,并作相应的跟踪配置后向表中添加删除更改数据。
Use master
go
/***
1 、建立测试环境:生成一个带主键的测试表 T_Trace
*/
if ( DB_ID ( 'db_Trace_test' ) is not null ) drop database db_Trace_test
go
Create DataBase db_Trace_test
go
use db_Trace_test
go
Create Table T_Trace ( id int not null , name varchar ( 100 )
CONSTRAINT [ PK_T_Trace ] PRIMARY KEY CLUSTERED ( [ id ] ASC )
)
go
/***
2 、配置数据库和表的更改跟踪参数
*/
ALTER DATABASE db_Trace_test SET
CHANGE_TRACKING = ON (
AUTO_CLEANUP = ON , -- 打开自动清理选项
CHANGE_RETENTION = 1 HOURS -- 数据保存期为时
);
ALTER TABLE dbo . T_Trace ENABLE CHANGE_TRACKING
go
/***
3 、向表中增加修改删除数据
*/
insert into T_Trace values ( 1 , ' 上海 ' ),( 2 , ' 北京 ' ),( 3 , ' 广州 ' )
delete from T_Trace where id = 3
update T_Trace set name = ' 天津 ' where id = 1
2 、跟踪分析,测试脚本和效果如下
/***
4 、获取更改过的数据
*/
SELECT
CHG . Sys_Change_Version as 序 列 , id as 主键 , Sys_change_Operation as 操 作
FROM CHANGETABLE ( CHANGES dbo . T_Trace , 0 ) CHG
order by CHG . Sys_Change_Version
/*
其中,测试脚本中函数 CHANGETABLE 的第二个参数 0 代表查询开始的事物操作序列,这三条数据分别表示两个插入( I )和一个删除( D )操作并且用主键 ID 标识出来。
* 这里主键为 1 的数据标志为插入,是因为 Insert 和 Update 是在同一个跟踪事务中查询出来的。
3 、调整跟踪范围参数,我们从序列为 2 的操作开始跟踪,这样可以跟踪到测试数据的 Update 语句:
SELECT
CHG . Sys_Change_Version as 序列 , id as 主键 , Sys_change_Operation as 操作
FROM CHANGETABLE ( CHANGES dbo . T_Trace , 2) CHG
order by CHG . Sys_Change_Version 这个结果则表示,主键为 1 的数据数据执行过更新操作 (U)
1、硬件测试环境:

2 、软件测试环境:
Windows 2008Server , SQLServer2008
3 、样本数据:
/--**--/
4 、测试结果:其中判断和提取更新表示查询时间,包含了返回到 SQLServer 客户端的传输时间。
| 序列 | 源表数据 | 操作 | 判断更新 | 提取更新 |
| 1 | 1000 条 | Delete 语句删除 1000 条 | 0 秒 | 无 |
| 2 | 0 条 | Insert 语句插入 100 条 | 0 秒 | 0 秒 |
| 3 | 100 条 | Insert 语句插入 1000 条 | 0 秒 | 0 秒 |
| 4 | 1100 条 | Insert 语句插入 10000 条 | 0 秒 | 0 秒 |
| 5 | 11100 条 | Insert 语句插入 100000 条 | 3 秒 | 4 秒 |
| 6 | 111100 条 | Insert 语句插入 100000 条 | 6 秒 | 7 秒 |
| 7 | 211100 条 | Insert 语句插入 100000 条 | 7 秒 | 11 秒 |
| 8 | 311100 条 | Delete 语句删除 100 条 | 0 秒 | 无 |
| 9 | 311100 条 | Update 语句更新 100 条 | 0 秒 | 0 秒 |
| 10 | 311100 条 | Update 语句更新 1000 条 | 0 秒 | 0 秒 |
| 11 | 311100 条 | Update 语句更新 10000 条 | 0 秒 | 0 秒 |
5 、测试评估:
在变更数据量万级的情况下,可以很快地响应跟踪结果并提取出所需要的数据。
DECLARE
/**
* Please change this one to any client id you want to delete
**/
v_Client_ID NUMBER := 1000014;
v_SQL1 VARCHAR2(1024);
CURSOR Cur_Contraints IS
select table_name,constraint_name
from user_constraints
where status='ENABLED' AND constraint_type='R' ;
CURSOR Cur_Contraints2 IS
select table_name,constraint_name
from user_constraints
where status='DISABLED' AND constraint_type='R';
CURSOR Cur_Triggers IS
select TRIGGER_NAME
from user_triggers
where status='ENABLED';
CURSOR Cur_RemoveData IS
select 'delete from '|| TABLENAME ||' where AD_Client_ID=' || v_Client_ID
AS v_SQL
from AD_Table a where a.ISVIEW='N'
AND exists ( select AD_Column_ID from AD_Column c where
a.AD_Table_ID=c.AD_Table_ID
and upper(c.COLUMNNAME)= upper('AD_Client_ID') );
BEGIN
DBMS_OUTPUT.PUT_LINE(' Delete Client Where AD_Client_ID=' || v_Client_ID);
/****************************************************************
* Disable all the constraints one by one
****************************************************************/
DBMS_OUTPUT.PUT_LINE(' Disable the contraints ');
FOR p IN Cur_Contraints LOOP
BEGIN
v_SQL1 := 'alter table '|| p.table_name ||' disable constraint '|| p.constraint_name;
EXECUTE IMMEDIATE v_SQL1;
END;
END LOOP; -- Disable contraints
DBMS_OUTPUT.PUT_LINE(' Disable the triggers ');
FOR p IN Cur_Triggers LOOP
v_SQL1 := 'alter trigger '|| p.TRIGGER_NAME ||' disable ';
EXECUTE IMMEDIATE v_SQL1;
END LOOP; -- Disable contraints
/****************************************************************
* Remove all the records belongs to that client
****************************************************************/
FOR p IN Cur_RemoveData LOOP
v_SQL1 := p.v_SQL;
EXECUTE IMMEDIATE v_SQL1;
END LOOP; -- Remove data
/****************************************************************
* Disable all the constraints one by one
****************************************************************/
DBMS_OUTPUT.PUT_LINE(' Enable the contraints ');
FOR p IN Cur_Contraints2 LOOP
BEGIN
v_SQL1 := 'alter table '|| p.table_name ||' enable constraint '|| p.constraint_name;
EXECUTE IMMEDIATE v_SQL1;
END;
END LOOP; -- Enable contraints
DBMS_OUTPUT.PUT_LINE(' Enable the triggers ');
FOR p IN Cur_Triggers LOOP
v_SQL1 := 'alter trigger '|| p.TRIGGER_NAME ||' enabled ';
EXECUTE IMMEDIATE v_SQL1;
END LOOP; -- Enable contraints
COMMIT;
END;


http://www.sqlstudy.com/sql_article.php?id=2008072403
SQL Server:在 SQL Server 2005 中配置数据库邮件,发送邮件
[作/译者]:鹏城万里 [日期]:2008-07-24 [来源]:本站原创 [查看]: 6343
【鹏城万里】 发表于 www.sqlstudy.com
SQL Server:在 SQL Server 2005 中配置数据库邮件。
对于真正的 DBA 来说,数据库邮件是必不可少的。 例如,数据库发生了警报(alert), DBA 希望得到邮件通知,以便即时排除故障。 或者是监控数据库作业(SQL Server Job)的运行状况,当检查到失败的作业时, 就发送数据库邮件报告给 DBA。
在 SQL Server 2000 中 配置 “SQL Mail”,需要安装 Outlook,配置过程比较麻烦。 在 SQL Server 2005 中配置 “Database Mail” 就相对容易多了。 主要是理清思路。
SQL Server 并没有内置邮件服务器(Mail Server), 它跟我们发送邮件一样,需要用户名和密码通过 SMTP(Simple Message Transfer Protocol) 去连接邮件服务器。我们想让 SQL Server 来发送邮件,首先要告诉它用户名称,密码, 服务器地址,网络传送协议,邮件服务器的端口。。。等信息。这是通过 SQL Server 系统 存储过程 sysmail_add_account_sp 来实现的。
exec sysmail_add_account_sp
这样,在 SQL Server 2005 中就添加了一个发送邮件的帐户。 道理上讲,有了这个邮件帐户,SQL Server 就可以发送邮件了。 如:
sp_send_dbmail @account_name = 'mail_account'
但是,SQL Server 考虑的更周全。试想:如果这个邮件帐户发生故障 (比如:用户密码过期,或者邮件服务器宕机)那岂不是发送不了邮件了? 为了应对这种情况,SQL Server 2005 引入了 mail profile 这个东东。 一个 profile 中可以包含多个 account (邮件帐户),这样,SQL Server 发邮件的时候会依次尝试 profile 中的多个邮件帐户,如果发送成功,则退出, 否则,利用下一个邮件帐户发送邮件。其中,添加 profile 和 在 account 和 profile 建立映射是通过下面两个系统存储过程实现的:
sysmail_add_profile_sp sysmail_add_profileaccount_sp
这时候,SQL Server 发送邮件,就采用下面的方法了:
sp_send_dbmail @profile_name = 'profile_name'
下面是具体的配置邮件步骤
在 sa 系统帐户下运行。
1. 启用 SQL Server 2005 邮件功能。
use master go exec sp_configure 'show advanced options',1 go reconfigure go exec sp_configure 'Database mail XPs',1 go reconfigure go
2. 在 SQL Server 2005 中添加邮件帐户(account)
exec msdb..sysmail_add_account_sp @account_name = 'p.c.w.l' -- 邮件帐户名称(SQL Server 使用) ,@email_address = 'webmaster@sqlstudy.com' -- 发件人邮件地址 ,@display_name = null -- 发件人姓名 ,@replyto_address = null ,@description = null ,@mailserver_name = '58.215.64.159' -- 邮件服务器地址 ,@mailserver_type = 'SMTP' -- 邮件协议(SQL 2005 只支持 SMTP) ,@port = 25 -- 邮件服务器端口 ,@username = 'webmaster@sqlstudy.com' -- 用户名 ,@password = 'xxxxxxxxx' -- 密码 ,@use_default_credentials = 0 ,@enable_ssl = 0 ,@account_id = null
3. 在 SQL Server 2005 中添加 profile
exec msdb..sysmail_add_profile_sp @profile_name = 'dba_profile' -- profile 名称 ,@description = 'dba mail profile' -- profile 描述 ,@profile_id = null
4. 在 SQL Server 2005 中映射 account 和 profile
exec msdb..sysmail_add_profileaccount_sp @profile_name = 'dba_profile' -- profile 名称 ,@account_name = 'p.c.w.l' -- account 名称 ,@sequence_number = 1 -- account 在 profile 中顺序
5. 利用 SQL Server 2005 Database Mail 功能发送邮件。
exec msdb..sp_send_dbmail @profile_name = 'dba_profile' -- profile 名称 ,@recipients = 'sqlstudy@163.com' -- 收件人邮箱 ,@subject = 'SQL Server 2005 Mail Test' -- 邮件标题 ,@body = 'Hello Mail!' -- 邮件内容 ,@body_format = 'TEXT' -- 邮件格式
6. 查看邮件发送情况:
use msdb go select * from sysmail_allitems select * from sysmail_mailitems select * from sysmail_event_log
如果不是以 sa 帐户发送邮件,则可能会出现错误:
Msg 229, Level 14, State 5, Procedure sp_send_dbmail, Line 1 EXECUTE permission denied on object 'sp_send_dbmail', database 'msdb', schema 'dbo'.
这是因为,当前 SQL Server 登陆帐户(login),在 msdb 数据库中没有发送数据库邮件的权限, 需要加入 msdb 数据库用户,并通过加入 sp_addrolemember 角色赋予权限。假设该SQL Server 登陆帐户 名字为 “dba”
use msdb go create user dba for login dba go exec dbo.sp_addrolemember @rolename = 'DatabaseMailUserRole', @membername = 'dba' go
此时,再次发送数据库邮件,仍可能有错误:
Msg 14607, Level 16, State 1, Procedure sp_send_dbmail, Line 119 profile name is not valid
虽然,数据库用户 “dba” 已经在 msdb 中拥有发送邮件的权限了, 但这还不够,他还需要有使用 profile:“dba_profile” 的权限。
use msdb go exec sysmail_add_principalprofile_sp @principal_name = 'dba' ,@profile_name = 'dba_profile' ,@is_default = 1
从上面的参数 @is_default=1 可以看出,一个数据库用户可以在多个 mail profile 拥有发送权限。
现在,可以利用 SQL Server 2005 发送数据库邮件了吧。如仍有问题,请留言。
以前使用官方Subversion搭建SVN版本控制环境,感觉很繁琐,需要手动该文件,很麻烦,今天在网上看到了VisualSVN搭建版本控制环境的方法,写出来和大家分享一下。欢迎提出问题O(∩_∩)O~
1、下载安装文件(服务器端和客户端)
服务器端采用VisualSVN,一个可用的下载地址是:http://idc218b.newhua.com/down/VisualSVN-Server-2.1.2.zip,如果链接失效,从百度谷歌搜索就可以了,很多下载地址。
客户端采用大家熟悉的Tortoisesvn,没错,就是那个小乌龟,官方下载地址是:http://tortoisesvn.net/
服务器端用来存放提交的文件,客户端用来连接服务器端,提交和下载服务器端的文件,(这个不用我多说了吧,下一话题^_^)
2、安装服务器端,解压缩下载的文件VisualSVN-Server-2.1.2.zip,双击VisualSVN-Server-2.1.2.msi进行安装
安装过程中有一个界面是选择安装的组件,选择第一个“VisualSVN Server and Management Console”就可以了。如图
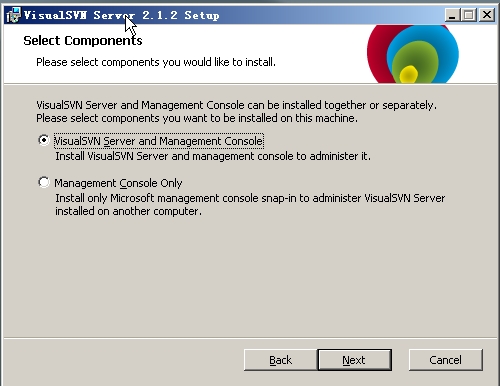
下一个界面的设置如图:
可以更改目录,也可以更改端口,注意,端口不要和已经使用的端口冲突,去掉“use secure connnection https://”的选项
这里的C:/Repositories是服务器文档目录,也就是我们提交到SVN里的文档的存放目录,这个目录大家可以更改
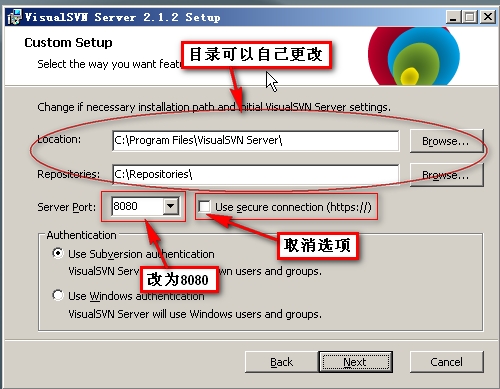
点击下一步,默认安装完成即可。
3、安装客户端软件TortoiseSVN-1.5.3.13783-win32-svn-1.5.2.msi,双击默认安装就可以了,安装完成可能要重启,重启即可。
4、配置服务器端
点击开始-->程序->VisualSVN-->VisuaSVN Server Manager启动服务器管理器,右键选择VisualSVN Server(Local),选择Properties,在弹出窗口中选择NetWork标签,在ServerName处输入本机的IP地址,我的地址为 192.168.158.129,端口我选择8080.,确定保存,再点击VisualSVN Server可以看到右面的界面,我们的访问地址就是Sever URL http://192.168.158.129:8080/svn/
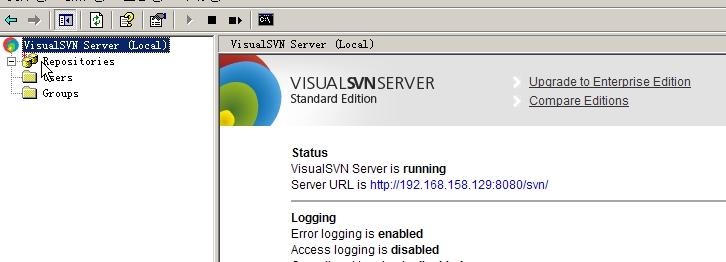
现在我们新建两个目录,右键选择Repositories,选择Create new Repository,输入名字document,保存
新建用户,右键选择 Users,选择Create User,输入用户密码test,test,这个口令将在客户端连接SVN服务器时使用
为刚才创建的document Repository添加用户,右键选择document,选择Properties,点击Add按钮,选择刚才添加的用户,保存,如图
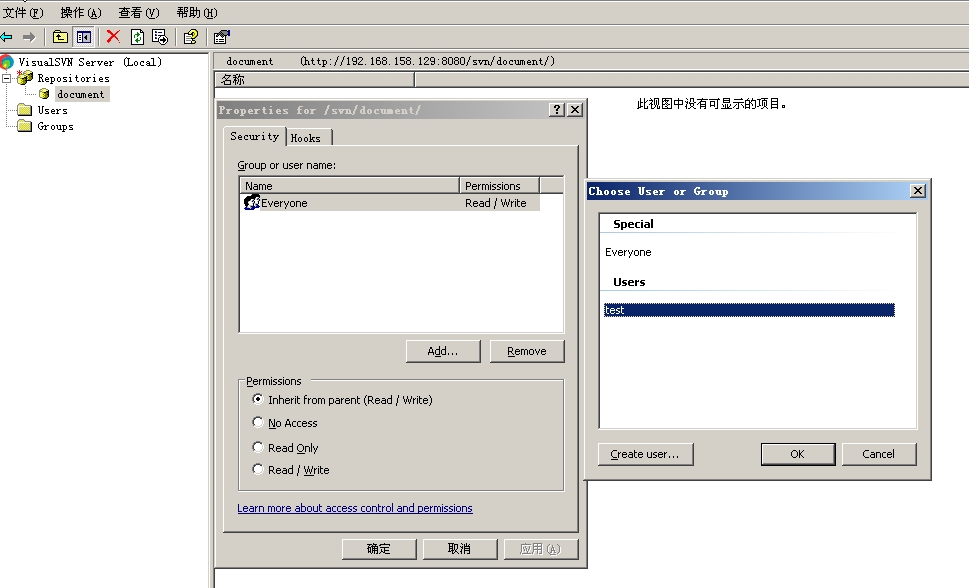
这样,服务器端就配置好了,回到客户端
因为已经安装了客户端软件Tortoisesvn,在D盘下,新建文件夹testsvn,打开文件夹,右键选择check out(检出),
在弹出窗口的版本库URL处输入,http://192.168.158.129:8080/svn/document
如图

确定,保存。注意上面的检出至目录是D:/testsvn,
在testsvn中新建一个文本文档,新建文本文档.txt,在testsvn空白处,点击右键,选择提交,(commit),则文件会被传到文档服务器,其他人就可以下载了。
subversion程序,和mysql很类似,是c/s结构的,有客户端和服务器端。服务器端和客户端都是通过命令行方式启动和执行的。本文只会使用到客户端的命令。
第三方提供了各种图形界面的客户端工具,比如eclipse插件subclipse,windows图形界面工具tortoiseSVN。这些后面会提到它们的基本使用。
subversion资源
安装subversion
有关subversion和subclise的安装暂略,因为目前提供的虚拟机开发环境已经安装和配置。
tortoiseSVN,可到官方网站上下载最新版本的windows安装包,默认安装,不需要做其他设置,安装后需要重启计算机。能在资源管理器中鼠标右键菜单看到如下图所示条目,就说明安装成功。

使用subversion
日常工作中使用subversion仅仅是几个命令或者操作,并不复杂。但是它内部的一些机制需要逐渐去理解。
检出代码
在刚开始进入一个开发队伍的时候,已经有版本控制和软件项目,使用的第一个命令往往是检出(checkout)代码。或者当使用和研究开源软件的时候,也是第一个要用到这个命令。这个命令的作用是把项目的源代码下载到用户本地,并且带有版本控制信息。
比如,执行以下命令获取一个项目的源代码:
svn co http://easymorse.googlecode.com/svn/trunk/vfs.demo/
这个命令将在本地当前目录建vfs.demo目录并将该服务器目录下的所有文件下载到本地,并且,会生成隐藏文件.SVN目录,用于记录版本控制信息。
tortoiseSVN有图形界面的检出操作,但是命令行方便快捷,建议使用命令行。
如果使用eclipse并安装了subclipse插件,可以通过插件导入项目。

然后,

选择或者新建资源库位置,

选择资源库中的项目目录。

然后,就可以完成(finish)了。

初始导入
何时使用初始导入,比如,对于java开发人员来说,在eclipse中编写了一个项目,并决定把项目共享到版本控制器上,这时就需要初始导入操作了。
以下以subclipse为例说明初始导入的步骤。
第一步,选择share project,共享你的项目:

选择通过svn共享项目:

填写svn提交的url:

这个url,需要subversion的管理员告知你,还有用户名和密码。如果想练习一下,google提供了免费的svn,你可以通过:http://code.google.com 申请项目,这样就会有类似我上面的url和权限。
然后可以直接点击finish,完成初始提交。选择next,可以做定制模块名和初始提交的信息,一般不需要。
如果你的svn服务器使用了https协议,需要接受一个数字证书,一般选择永久接受。

之后,会要求输入用户名和密码。建议勾选保存密码,否则会很麻烦。

这样,再看项目,会发现条目上多了问号,这时需要选择哪些目录和文件需要提交,哪些需要忽略,比如生成的class文件等。

选择需要忽略的文件或者目录,这时需要切换到导航视图下才能看到所有文件和目录:

从导航视图看到的情况:

选中需要忽略的目录和文件,操作svn:

然后提交整个项目即可。有关提交的操作见下文。
更新项目
项目在提交前,应该先做更新项目操作。比如有一个文件a.txt,已经提交到svn中,这样,可能有其他用户提交了新的改动到a.txt,你现在又 修改了a.txt,准备提交你的改动。先操作更新a.txt,这样如果该文件在svn服务器已经改动,会将改动加入到当前本地的a.txt中。
在subclipse中的操作:

提交代码
提交代码,一般会级联当前目录下所有改动的内容。

删除代码
对于不再使用的代码,可以直接删除掉,比如通过windows删除文件,通过ubuntu的rm命令或者通过eclipse的delete功能,然后提交项目,subclipse会知道哪个文件被删除了,并将这个变化通知给svn服务器。
还原代码
如果代码做了改动,可以是多个文件,也可以删除了文件或者新增了文件,但是没有提交到svn服务器,可以通过还原功能恢复到改动前的样子。

版本的分支与合并
版本的分支和合并,是版本控制的核心功能。
比如,软件通过版本的分支,将项目分配给多人做分工开发,通过版本合并,将这些分工实现的代码合并到新的版本中;或者,修改代码bug的时候,可以 先打出一个版本分支,保留出现bug的版本,比如分支版本名称为pre_fix_bug_2201,这里2201表示bug的代号,然后针对这个分支做修 改fix这个bug,再将修改后的内容提交到一个新的分支版本,比如post_fix_bug_2201,再到适当时候将这个分支合并到代码主干中去。
以上说了一下版本分支与合并的用途,这里简单说一下svn版本分支合并的基本原理。
首先是版本分支,实际上是将当前版本“copy”到分支上,非常类似windows下,将某个目录的快捷方式复制到其他路径。这种copy,可以说 是轻量级copy或者叫廉价copy,不是复制版本内容,而是做一个内部的引用。这样的copy很快,对服务器也没有空间上的开销。
版本的合并,是svn开发中的难点,当做版本合并的时候,服务器会试图智能的合并同一个文件的不同版本,可能会带来版本冲突,这需要操作者做手工的处理,消除版本冲突。合理分工的项目应该可以通过管理手段尽量避免这种情况。
以下是通过subclipse演示版本分支的操作。首先,项目文档应该已经全部提交,然后,选择

然后,填写url,一般是在tags/目录下:

然后默认选项,next即可,然后选择finish按钮。在svn的相应路径下就会有一个同名的项目。

打分支,实际上就是建立了一个项目的轻量级copy。
如何从版本的一个分支切换到另外一个分支,这也是很重要的,它能帮助你轻松在不同的项目版本中自动切换,而不必在eclipse里维持多个项目。

选择要切换的项目版本路径,或者直接输入亦可。

然后点击ok后,项目即可切换到该版本下。
在分支上做了改动,并且已经提交(一般tags目录下的项目约定是只读的,不建议改动,这里是为了举例方便),那么,可以将这个版本合并到trunk(主干)代码中,让主干也拥有最新的代码。

选择需要合并的源,比如从tags上面一个版本,合并到主干(trunk)代码中。

之后,需要设置一些合并的特性,这里默认配置即可。

执行完毕后,会有一个合并报告,可见没有出现冲突情况。

这时候看源代码,可以发现有改动,这些改动就是合并过来的代码。

改动如果没有问题,就可以提交,这样就完成了一次版本的合并工作。
“还原”已经提交的改动
如果文档没有提交,还原是很容易的,只需执行还原(revert)就可以了。有时候,已经提交了代码,结果发现了问题,需要回退到之前提交的版本,就不是很容易了。
这时候的还原,其实是将以前的某个修订本(revision)覆盖当前的本地工作拷贝。然后再提交这些改动,成为新的修订本。
下面演示一下。
首先提交了一个版本的改动,这是以后需要还原回来,这里,为了以后还原方便,要在提交的消息中说明改动了什么。(这一步在开发中是必须的,是纪律)

下面,再修改一下项目,然后提交一次,这里故意增加一个文件。

提交以后,后悔了,想恢复到前一个修订版。虽然可以通过版本号进行覆盖还原,但是一般人是无法记忆这个版本号的,另外就是实际情况往往更复杂,不会像示例中那样是相邻的两个修订版。
所以提交修订版时的注解消息就显得特别重要。
这时可以通过svn的日志功能查看到这些版本和它们的注释消息。

看到历次版本的消息内容。

这样,根据注释,我们很容易找到需要还原到以前的那个修订版。如果不放心,我们还可以根据上下文菜单,对比两个修订版的区别。

看比较结果。可以看出,增加了一个文件,另外一个文件中有一处差异。

那么,可以确定是从125修订版恢复(还原)。

更改后的项目,相当于用125修订版还原了126修订版。

可以看到126版本添加的文件不见了,另外VfsDemo.java文件也还原到125版本的内容。这时提交将成为127版本,这个版本其实就是125版本。算是还原了主干(trunk)上的代码。

刷新历史,可以看到修订版已经生效。

参考:
http://blog.ofriend.cn/post/95.html
Windows下安装SVN(Subversion)独立服务器步骤:
安装之前需要准备的软件:
1、Setup-Subversion-1.7.0.msi
2、TortoiseSVN-1.7.0.22068-win32-svn-1.7.0.msi
3、LanguagePack_1.7.0.22068-win32-zh_CN.msi
下载地址:
1、http://sourceforge.net/projects/win32svn/files/
2、http://sourceforge.net/projects/tortoisesvn/files/
安装步骤及简要配置:
1、安装Setup-Subversion-1.7.0.msi
2、安装TortoiseSVN-1.7.0.22068-win32-svn-1.7.0.msi
3、安装LanguagePack_1.7.0.22068-win32-zh_CN.msi
4、添加subversion环境变量:c:\program files\subversion\bin
5、创建版本库:
a、svnadmin create c:\svn\repository
b、创建空目录repository->右键->TortoiseSVN->Create Repository here...
6、配置用户和认证:
Svnserve.conf:核心配置文件:
# password-db = passwd >password-db = passwd
# authz-db = authz >authz-db = authz
Authz:配置用户权限的文件
Passwd:新加用户名和密码的文件
启动subversion:
在dos命令下,输入:> svnserve exe -d -r d:\svn_repo(这行自己加的)
7、运行Subversion:c:\svn\repository>svnserve --daemon
或者:c:\svn\repository>svnserve --daemon --root c:\svn
注:运行的时候不能关闭命令行窗口,关闭服务就退出了!因此可以添加到系统服务项随机启动即可!
8、添加系统服务,随系统启动:
sc create svnservice binpath= "c:\program files\subversion\bin\svnserve.exe --service --root c:\svn" displayname= "Subversion" depend= tcpip start= auto
9、删除服务:
sc delete svnservice
注:在Windows XP SP3下测试通过!其他平台暂未测试!
http://www.vogella.com/articles/OSGi/article.html#OSGi_firstbundle
http://www.vogella.com/articles/OSGi/article.html#exportbundle
http://wiki.eclipse.org/Gemini/Web
值得说明一点:
网页的目录不会放在webapps(tomcat)目录下的,是根据MANIFEST.MF 的
Web-ContextPath: /osgi-web-app的属性来访问的,如http://domain:port/osgi-web-app
Install file: plugins/myplugins.jar
Osgi> start xx
让你的plugin自安装
在C:\adempiere\configuration\org.eclipse.equinox.simpleconfigurator 目录下的bundles.info
最后一行增加
osgi.web.app,0.0.1,plugins/osgi.web.app.war,4,false(名字,版本号,路径,启动优先级)
有些情况下,bundle没有能自启动,状态不是active,要在
要在config.ini设置bundle @start,就可以了
==
另如果自己写了一个plugin,想通过buckminster来自动打包,要在cspec文件中增加,仿wstore样式。
http://www.globalqss.com/wiki/index.php/IDempiere
http://kenai.com/projects/hengsin/pages/Building
下载Eclipse 3.6以上版本
Eclipse IDE for Java EE Developers 3.6+
我这这里下的是3.7
安装Mecurial插件
(1.)打开Mercurial Eclipse Plugin 1.6+
(2.)复制红色方框中的地址

(3.)在Eclipse的Help->Install New Software

(4.)如果你不懂怎么安装插件,请看这里
http://download.eclipse.org/tools/buckminster/updates-3.7
安装Mercurial 2.1.1客户端
Mercurial Client
http://mercurial.selenic.com/downloads/
因我的操作系统是XP的,所以下载X86, 如果是win7 就要下载X64的。
安装完成后,下载原代码:
cd D:\idempiere\
hg clone https://bitbucket.org/idempiere/idempiere
1. 从 adempiere的根目录 下面搜索一下 Test.sql
2. 在 adempiere的根目录 下面新建 utils\oracle\ 文件夹。
3. 将搜索到的Test.sql放到 utils\oracle\ 文件夹下就可以。
启动server/client 参考:
http://www.adempiere.com/OSGI_HengSin
exec sp_addlinkedserver 'PA_EHR','','SQLOLEDB','10.110.8.41'
exec sp_addlinkedsrvlogin 'PA_EHR','false',null,'sa','123456'
exec sp_dropserver 'PA_EHR' 如果删除不了,去企业管理器中删除。
select * from PA_EHR.tongxehr.dbo.AdvQueryProject
摘要: Hibernate Tools 简介: Hibernate Tools是由JBoss推出的一个Eclipse综合开发工具插件,该插件可以简化ORM框架Hibernate,以及JBoss Seam,EJB3等的开发工作。Hibernate Tools可以以Ant Task以及Eclipse插件的形式运行。 Mapping Editor(映射文件编辑器):...
阅读全文
1、DB的存储层次(在其他文章中已经介绍过了,这里只是简述)
1)blocks:是data file I/O的最小单位,也是空间分配的最小单位。一个Oracle block是由一个或多个连续的OS blocks组成。
2)extents:是由多个连续的data blocks组成的拥有存储空间分配的逻辑单位。一个或多个extents组成了一个segment。当在一个segment中的所有空间都被用完时,Oracle server会给segment分配新的extent。
3)segments:一个segment是一个extents的集合,存放了tablespace中具体的逻辑存储结构的所有数据。例如,每个 table,Oracle server会分配一个或多个extents用于组成该table的data segments。对于indexes,Oracle server分配一个或多个extents用于组成index segment。
2、extents的分配:为了尽可能降低动态分配extent的弊端,应该如下:
* 使用本地管理表空间的方法。
* 适当的评估segments的大小:确定object的最大size;创建object时,选择恰当的存储参数用于分配足够的空间给相应的data。
* 监控segments的动态extend的情况。
select owner, table_name, blocks, empty_blocks from dba_tables where empty_blocks/(blocks+empty_blocks)<.1;
alter table hr.employees allocate extent;
①创建本地管理extents的tablespace,其实自9i以来,系统默认的表空间都是本地管理的表空间。
create tablespace tsp_name datafile ‘/path/datafile.dbf’ size nM
extent management local uniform size mM;
本地管理表空间在其datafile内部创建一个位图用于记录每个block的使用状态。当extent被分配或释放重用,bitmap的相应值会被修 改,用于显示其中blocks的新状态。这些修改不会产生rollback information,因为没有修改data dictionary。
②大extents的优点:DBA应该分配适当的size给segments和extents,一般原则是大extents优于小extents,主要表现在:
* large extents在一定程度上降低了segments动态的分配extents的可能性
* large extents可以稍微的提高I/O的性能,因为Oracle server从磁盘读取一个连续的large extent的多个blocks应该比从几个small extents不连续的blocks的速度快。为了避免分离的multiblock的读取,可以考虑将extents设置为 5*DB_FILE_MULTIBLOCK_READ_COUNT。但是对于不经常进行全表扫描的table,这种设置不会有太大的性能改观。
* 对于非常large的tables,OS在文件大小上的限制可能使DBA不得不将object分配到multiple extents。
* 使用index查找的性能不会受到index是否在一个或多个extents中的影响。
* Extent maps存放了某个segment中所有extents的信息。如果MAXEXTENTS设置为UNLIMITED,这些maps可以存放在多个 blocks中,从性能角度讲,应该尽可能在一次I/O中读取该extent map。此外多个extents也会降低dictionary的性能,因为每个extent都会占用dictionary cache的少量空间。
附注:①在ASSM表空间中,每个segment的 segment header都有一个extent map,记录着segment所属的所有extents的第一个块的位置和区的大小,如果segment header中容纳不下所有的extents信息,oracle会另外添加专门的extents map块,保存segment中extents的位置大小信息。全表扫描时oracle会根据extents map中所记录的信息,扫描高水标记之下的所有extents的所有blocks.每个extents map block都有一个指向下一个extents map block的地址,segment header中的extents map信息也有指向第一个extents map block的地址.也就是说所有的extents map block构成了一个链表.全表扫描时就依据这个链表中所记录的block的位置信息进行扫描.extents map的主要作用是用于全表扫描.
②FLM段(Free List Managed Segment),其段头存放着段中Extent的信息,包括Extent的起始地址,Extent的长度。如果由于segment扩展过 多,segment header不能容下所有EXTENT的信息,则会用新的称之为EXTENT MAP BLOCK的块来专门存放EXTENT的信息。段头与各Extent Map Block之间用链表形式连接起来。它与ASSM中的extent map链表作用不同。
③large extents的缺点:因为需要更多连续的blocks,Oracle server可能很难找到足够的连接的空间用于对其的分配。
3、高水位线(High-Water Mark)
在空间分配中,有两类空闲blocks:曾经被占用过,但相应的数据被删除了,这些blocks将被记录到相应的free list中,当有insert操作时进程reuse,在high-water mark以下;另一类是自分配给相应的segment后,从来没有被使用过的,所以在high-water mark之上。
①high-water mark:被记录在segment header block中;在segment被创建时设置:当插入rows时,每次增加five-block;truncate tables会重置high-water mark,但delete不会。
②在table level,可以将high-water 玛瑞咖之上的空间收回:
alter table t_name deallocate unused …
全表扫描中,Oracle server会读取high-water mark以下的所有blocks,high-water mark以上的空闲blocks不会影响性能。
③在cluster中,空间是为所有的cluster keys分配的,无论其是否含有data。分配的空间依靠cluster在创建时参数size指定的大小和cluster的类型:
* 在hash cluster中,因为hash keys的数量在cluster被创建是已经被确定了,所以每个hash key所占用的空间都在high-water mark之下。
* 在index cluster中,空间被分配给每个cluster index。
4、table statistics
可以使用analyze语句或是dbms_stats对table的当前状况进行统计并保存在数据字典中,随后通过查看dba_tables获得相关信息。
eg:
analyze table t_name compute statistics;
select num_rows, blocks, empty_blocks as empty, avg_space, chain_cnt, avg_row_len from dba_tables where table_name=’T_NAME’;
其中dba_tables中不同的字段具体含义如下:
Num_Rows – Number of rows in the table
Blocks – Number of blocks below the high-water mark of the table
Empty_blocks – Number of blocks above the high-water mark of the table
Avg_space – Average free space in bytes in the blocks below the highwater mark
Avg_row_len – Average row length, including row overhead
Chain_cnt – Number of chained, or migrated, rows in the table
Avg_space_freelist_blocks – The average freespace of all blocks on a freelist
Num_freelist_blocks – The number of blocks on the freelist
5、DBMS_SPACE包:可用于获得segments中的space的状态信息,常用的有以下两个procedures:
* UNUSED_SPACE:用于获得分配给object未使用的space。
* FREE_BLOCKS:用于获得object的空闲的space。在运行时,必须提供相应的FREELIST_GROUP_ID,一般使用1,除非你使用的是Oracle Parallel server。
该DBMS_SPACE包是由dbmsutil.sql创建的。
6、恢复表空间:
1)对于在high-water mark以下的空间:
方法一:export the table;drop or truncate the table;import the table
在选择是drop还是truncate的时候,要考虑:drop将table在data dictionary中的所有information删除,并且space被收回;而truncate没有,并保留了相应已经分配的space等待 reused;如果使用的是data dictionary管理tablespace,则影响空间收回与分配的时间开销的主要因素是extents的数量(而不是size);如果使用的是 drop方法,则考虑在import时使用compress选项,因为整个空间的分配可能不是在一个连续的大空间上。
方法二:alter table t_name move;此方法执行之后,所有相关的indexes都为unusable状态,必须rebuild。
2)对于在high-water mark之上的unused block可使用:alter table t_name deallocate unused语句进行收回。
7、DB的block size设置
1)减少访问block的数量,这是DB tuning的一个目标。DBA对此调节的方法主要有:增大block size;尽可能紧凑的将rows放在block中,避免row的迁移现象。
2)database block size是在DB创建时由参数DB_BLOCK_SIZE指定的,是I/O读取datafile的最小单元。当前有些OS允许block size达到64KB,可以查看相应的OS,从而调整DB的block size。block size一旦设置就不能改变,除非对DB重建或是duplicate,在9i中已经进行了相应的改进,可以使用多中block sizes,但是对于base data size仍不可变。DB的block size应该是OS的整数倍。如果application中有大量的全表扫描,可以考虑增大block size,但不要超过OS的I/O size。
3)小block size的优劣:
* 优:降低了block 的冲突;有利于small rows;有利于随机访问,因为可以在一定程度上提高buffer cache的利用率,特别是在内存资源不足的情况下。
* 劣:small blocks管理所用的空间开销大;每个block存放的row较少,也会加大I/O的开销;可能造成更多的index blocks被读入。
在OLTP环境中,经常存在large object的随机访问时,small blocks相对更好。
4)large block size的优劣:
* 优:所用的管理空间开销小,更多的空间可用于存放具体的data;有利于顺序的读取;有利于large rows;改善了index读取的性能,因为大的block可以降低index的level数量,从而减少I/O的次数。
* 劣:在OLTP环境中不利于index blocks,可能会引起index leaf blocks的争用冲突;如果存在大量随机访问可能会造成buffer cache的浪费。
在DSS环境中,连续读取大量数据操作较多,使用large block更好。
8、PCTREE和PCTUSED(具体内容在其他文章中介绍过了,这里不累述了)
只有两类DML语句可以影响free blocks和used blocks的数量:delete和update。
释放的空间在一个block中很可能不是连续的,Oracle server只在下面情况同时出现时进行free space的合并:insert或update操作试图向一个有足够空间的block中插入数据;free space存在碎片,以至于row piece无法被写入。
具体设置:
①PCTFREE:默认情况下是10;如果不存在update操作,可以使用0;PCTFREE = 100 * UPD / (Average row length)
②PCTUSED:默认是40;PCTUSED = 100 – PCTFREE – 100 * Rows * ( average row length) / block size
其中:
UPD = update操作平均增加的bytes数量。
average row length和rows都可以在analyze之后从dba_tables表中获得。
当对一个已经存在的表进行这两个参数的修改,不会有马上的影响,只是在后续的DML操作中才发生作用。
9、migration和chaining(具体原因也在其他的文章中介绍过了)
①migration和chaining对性能的影响:一方面,引起这两种现象的insert和update本身性能比较差;另一方面,在查询此类记录的操作会因为额外的I/O造成性能较差。
migration现象过的,主要是由于PCTFREE参数设置过低引起的,对此可以考虑增大该值。
②对两者的检测,主要是通过analyze相应的表,随后从dba_tables表中观察其chain_cnt字段。此外可以从v$sysstat视图或 是statspack report中的“instance activity stats for DB”获得“table fetch continued row”的值。
还可以收集每个表中发生了migration和chaining的具体的rows:首先执行utlchain.sql脚本创建chained_rows统计表,随后执行语句:
analyze table t_name list chained rows;
③消除migration rows:
* export/import
* alter table t_name move
* 执行迁移脚本,具体见Oracle 9i Performance Tuning SG的P398
• Find migrated rows using ANALYZE.
• Copy migrated rows to new table.
• Delete migrated rows from original table.
• Copy rows from new table to original table.
此方法执行时,必须注意与original table相关的外键约束,应将其disable。
10、索引的重组
在经常发生DML的table上,indexes往往是带来性能问题的原因。
在data blocks中,Oracle server会将delete row释放的空间重新分配给insert rows,但是对于index blocks,Oracle server的应用时连续的。即使一个index block中只有一个index,也要维护该block。如果删除了block中的所有index,该block才会被送入free list。因此,必要时需要进行index的rebuild。
①对index space的监控:
* analyze index i_name validate structure;
* select name, (del_lf_rows_len / lf_rows_len) * 100 as wastage from index_stats;
在index_stats视图中,各字段含义如下:
• Lf_rows – Number of values currently in the index
• Lf_rows_len – Sum of all the length of values, in bytes
• Del_lf_rows – Number of values deleted from the index
• Del_lf_rows_len – Length of all deleted values
note:index_stats视图只保存最近一次analyze的结果,并且当前session只能看到当前session的分析结果。
* alter index emp_name_ix rebuild;
* alter index emp_name_ix coalesce;
如果如果已删除的index 记录超过20%,则应该选用rebuild。
rebuild会以原有的index作为基础,重建索引,可以重新指定STORAGE, TABLESPACE, INITRANS参数,同时可以用下面的参数加快重建的效率:
* PARALLEL/NOPARALLEL(NOPARALLEL是默认值)
* RECOVERABLE/UNRECOVERABLE ( RECOVERABLE是默认的):当使用unrecoverable时速度将更快,因为它不产生redo log,只在index创建是起作用,而不是设置参数,不记录到dictionary中。它使用隐含式的logging参数,意味着在index创建结束 后插入index项时,仍然会记录redo log。
* LOGGING/NOLOGGING:如果设置为NOLOGGING,该参数表明在index运行使用期间,将不产生任何redo log。它将记录到dictionary中。可以用alter index 进行修改。
注意:unrecoverable和logging是不兼容的。
alter index rebuild要快于index的drop后re-create,因为它使用了full scan的方法。
②监控index的使用情况
* EXECUTE DBMS_STATS.GATHER_INDEX_STATS(‘SECHMA_NAME’, ‘T_NAME’);
* create index … compute statistics;
* alter index .. rebuild compute statistics;
③此外,还可以用下面的方法查看没有使用的index:
从9i开始,对index的使用情况可以被收集到视图v$object_usage中。辅助DBA删除未使用的index,提高性能:
* 打开监控:alter index i_name monitoring usage;
* 停止监控:alter index i_name nomonioring usage;
随后查看v$object_usage:select index_name, used from v$object_usage;
在v$object_usage中各个字段的意义:
• index_name – The index name
• table_name – The corresponding table
• monitoring – Indicates whether monitoring is “ON or OFF”
• used – Indicates (YES or NO) the index has been used during the monitoring time
• start_monitoring – Time at which monitoring began on index
• stop_monitoring – Time at which monitoring stopped on index
1、Overview:
Oracle shared server主要用于允许多user进程能够共享有限数量的servers。
在dedicated server环境中,每个user 进程都会分配到一个server进程,但如果这些server进程不能完全被利用,常处于idle状态,就会造成内存和cpu的浪费。
当使用shared server模式,user进程是动态的被分配到可以被任何user进程共享的server进程上的。当dispatcher进程获得一个user 进程请求后会将其放入请求队列,以便server进程可以处理该请求并将结果返回给dispatcher的response队列。随后 dispatcher进程会将response队列中的结果返回给user进程。
Oracle Shared Server主要用于下面的情况:当dedicated Server的系统对于system开销相对较大;在访问的资源上存在限制。
2、对dispatchers的监控:
1)可以通过v$MTS视图获得关于连接和session的会话以及当前使用的使用的数据信息。如果sessions的设置低于实际的dispatcher的设置,MAXIMUM_CONNECTIONS的默认值是参数SESSIONS的值。
2)V$DISPATCHER视图查询dispatcher的繁忙率:
select network “protocol”, status “status”, sum(owned) “clients”, sum(busy) * 100/(sum(busy)+sum(idle)) “busy rate” from v$dispatche group by network;
note:在选择dispatcher数量的时候,应该考虑客户端的数量对于dispatcher的繁忙比率。如果一个dispatcher的繁忙比率 超过50%,就需要考虑增加dispatcher的数量。如果发现部分dispatcher经常处于idle的状态,应该考虑减少dispatcher的 数量。
可用下面的SQL查看users sessions是否在等待dispatchers:
select decode(sum(totalq), 0, ‘no responses’, sum(wait)/sum(totalq)) “average wait time” from v$queue q, v$dispatcher d where q.type = ‘DISPATCHER’ AND q.paddr = d.paddr;
如果观察到大量的等待比率并不断增长,需要考虑增加dispatcher的数量。
增加或减少dispatcher使用:
alter system set mts_dispatchers = ‘protocol, number’;
执行上述语句后只有新的连接建立才会使用new增加的dispatcher。
2)此外,可以使用视图V$DISPATCHER_RATE视图来分析冲突。它分组显示了cur、avg、max的统计信息。如果使用shared Server的性能不理想,则cur的值将接近max的值,对此应该考虑增加dispatcher的数量。如果发现shared Server性能良好,cur值远远低于max的值,可以考虑降低dispatcher的个数。
3、对Shared Server的监控:
当PMON后台进程发现当前存在的shared Servers都处在忙碌状态,Oracle shared Server进程就会被是动态创建的创建。当然此时MAX_SHARED_SERVERS的值必须大于实际的servers值。当然,如果PMON检测到 当前有shared servers存在idle状态的,则会减少相应的shared servers的数量,直到数量达到SHARED_SERVERS的值。所以不必太多的考虑shared servers的状态。但是有时需要调整SHARED_SERVERS和MAX_SHARED_SERVERS的参数的大小。
对此,可以使用视图V$SHARED_SERVER视图获得shared servers的当前信息。
select name, requests, busy*100/(busy+idle) “busy %”, status from v$shared_server where status != ’QUIT’;
此外,可以查看每个请求的平均等待时间:
select decode(totalq, 0, ‘No Requests’, wait/totalq ||’ hundredths of seconds’ )”Average Wait Time Per Requests” from v$queue where type = ‘COMMON’;
4、监控进程的作用:查看共享连接。如果觉得user程序有问题或是某个进程似乎做了很多操作,可能需要查看当前user的共享连接。对此可以使用 v$session视图查看应用的状态和使用的连接类型,可以使用v$circuit获得相应的server、session和dispatcher的 addresses。
5、shared server和memory 使用:之前有说过,当使用shared server模式时,部分称为UGA(user global area)的数据将被存放在shared pool中,同时session的data Components被存放在large pool中。如果没有设置large pool,将存放在shared pool中。
从总体将使用shared server模式,内存的开支减少了。
shared servers使用UGA用于sorts,此模式下,应该设置SORT_AREA_RETAINED_SIZE相对小于SORT_AREA_SIZE,以便可以快速释放内存给其他user。
6、troubleshooting:常见问题有:
1)所有共享连接都失败时,查看Oracle net listener在running。
2)查看是否在建立shared connection时存在Oracle net配置的错误”TNS_”
3)不要轻易在OS层kill掉user的server进程,建议使用alter system kill session。如果使用dispatcher连接的,kill掉dispatcher进程会更糟,会影响其他user。
4)dispatchers和servers都是后台进程,所以在设置PROCESSES时要考虑相应的数量。
5)如果参数INSTANCE_NAME, SERVICE_NAMES 或 DB_DOMAIN 没有被设置,或是设置不正确,则其不能进行自动instance注册。
• V$CIRCUIT: Contains information about user connections to the database
• V$DISPATCHER: Provides information on the dispatcher processes
• V$DISPATCHER_RATE: Provides rate statistics for the dispatcher processes
• V$QUEUE: Contains information on the multithread message queues
• V$MTS: Contains information for tuning the Oracle shared server
• V$SESSION: Lists session information for each current session
• V$SHARED_SERVER: Contains information about the shared server processes
eg:
SELECT d.network network, d.name disp, s.username oracle_user,
s.sid sid,s.serial# serial#, p.username os_user,
p.terminal terminal, s.program program
FROM v$dispatcher d, v$circuit c, v$session s, v$process p
WHERE d.paddr = c.dispatcher(+)
AND c.saddr = s.saddr(+)
AND s.paddr = p.addr (+)
order by d.network, d.name, s.username
1、选择适当的物理结构:为了达到读写尽可能快的目的,必须考虑下面的问题:
1)如果application对rows的访问是按照groups进行的,则需要考虑使用clusters的方式才存储,但clusters对于大量的DML操作会影响性能,所以要考虑application中DML和select操作的数量。
2)对于较大规模的表,使用单独的表空间。对于一个partitioned表,考虑使用多个表空间,从而平均分配磁盘的使用。
3)对于9i中可以允许在同一个DB中有多block size,因此,row size较大的可以有较大的block size。如果设置较大的block size,有助于全表扫描的应用的性能提高。
4)对于小的small transaction占用undo space的回滚信息少,大transaction占用的undo space多,所以所需的free undo space多。
5)对于较大的查询,可以考虑使用多server 进程进程并发查询。
2、数据的访问方法:为了提高性能,可以使用下面的数据访问方法:clusters;indexes:b-tree(普通和翻转关键字)、位图、Function based;索引组织表;固化视图。
1)Clusters:是将一组一个或多个因为有共享columns所以有相同数据块的表放在一起的方法。这些数据块会经常被同时访问或join。这种方法可以使DBA对数据库非规范化,而对user和programmer是透明的。
它在一定程度上降低了磁盘I/O,使用clustered table可以很好的改善join的效率。每个cluster关键字对于多行且值相同的情况下,只会存储一次,所以占用存储空间较小。
但是对于全表扫描,clustered表比nonclustered 表慢很多。
cluster的类型有:
①index cluster:它使用一个被称作cluster index的索引维持cluster中的数据。在index cluster中,对数据的维护、访问、存储cluster index必须是可用的。cluster index用于指向包含给定关键字值的rows的block位置。与普通index不同的是cluster indexes会存储null 值。对于每个cluster index中的关键字,只有一条记录。所以一个cluster index会比普通index的占用空间小。
②hash clusters:它使用hash算法(也已user定义,也可系统指定)计算row的位置。用于查询和DML操作。对于等值查找clusters key,hash cluster的性能要比index cluster的好。
不应使用clusters的情况:经常执行全表扫描的情况;如果对于所有rows的cluster key的数据超出了一到两个Oracle blocks,这样,为了访问在clustered key table中的一条row,Oracle server需要读取有相同值的所有blocks。
不应使用hash clusters的情况:如果表不断增长,并且重建新的、更大的hash cluster不可能的情况下,不应使用hash cluster;如果application经常使用full scans,并且要考虑为table的增大所必须预留的空间。
2)B-Tree indexes:
①使用B-Tree index的情况:当经常访问表中的记录占全表的不足5%时,应该考虑创建B-Tree index;如果在查询时,indexes可以包含所有要访问的字段,这个百分比可以更高些;或是对可以用于进行表的join时,也应考虑建立B- Tree index。
②indexes的增长方式:index总是平衡的,总是自下而上的增长。当rows被增加时,会添加到叶子节点的block上,如果叶子节点的 block被填满,Oracle server会将该block split成两个叶子blocks,每个保存50%的数据。因为新block的添加,叶子节点的父节点也需要添加相应的blocks索引值。如果父节点的 block被填满,父节点也会被split成两个节点,类似与刚才的子节点的split。这个过程会循环进行,直到b-tree保持平衡。index的层 次越多,其效率越低。此外,对于delete操作,会降低index的效率,特别是当有15%的rows被删除,应该考虑rebuilding index。
③为了提高b-tree index的性能,应该定期对index进行rebuild。自9i,可以online创建、rebuild indexes,并且可以并行化进行。当index被rebuild时,相关的table仍然可以被访问和进程DML操作。
ALTER INDEX i_name REBUILD ONLINE;
–ONLINE关键字表示在rebuild时,DML仍可进行。但是不允许并发的DML操作。
④压缩索引:
在创建索引时使用下面的方法可以对index进程压缩:
create index i_name on t_name(col1, col2) compress;
重建索引时可以使用:
alter index i_name rebuild compress;
压缩索引不会多次存储重复出现的关键字从而减少了存储空间的需求。
对于非唯一索引的压缩:Oracle存储重复的关键字作为前缀在index block中,唯一的row id作为后缀存储。
对于唯一索引的压缩:也是类似的,将一致的前缀只保存一次,用于区分唯一性的部分会作为后缀存储。但是这只适用于有多个字段组成的唯一索引,如果只有一个column的唯一索引没有用于share的部分。
3)位图(bitmap)索引:主要适用于distinct的values很少的字段,在其上建立索引。例如性别、工种等字段。但是对于有大量DML操作的表,bitmap index的性能不好,此情况应慎用。
① 适用bitmap index的情况:对于基数较低(low-cardinality)的column创建的索引;如果查询语句中使用多个where条件,Oracle server可以使用逻辑的bit-and或bit-or操作来合并不同columns的bitmaps。
②性能的考虑:bitmap index占用空间较小,每个distinct key的存储时以压缩的方式,bitmap被分成不同的bitmap segments;对于low-cardinality字段非常快;很适合与规模大的只读系统,如决策支持系统(DSS);但是对于DML操作性能比较 慢,不适用于OLTP应用,locking是加载在bitmap-segment上的,不是在记录上的;bitmap index是存储null值的,但b-tree不存储;并发查询、并发DML和并发的CREATE语句在bitmap indexes上是有效的。
③bitmap indexes的创建及管理:
create bitmap index i_name on t_name(col1) storage ( initial 200k next 200k pctincrease 0 maxextents 50) tablespace tsp_name;
对于每个DML操作之后,会对bitmap indexes进行相应的维护,所以对于每个DML操作,每个bitmap segment只会更新一次,既是该bitmap segment中不只一行更新数据。
4)反转关键字索引(reverse key index):在创建索引时会将索引字段按bytes进行反转(reverse)随后将结果作为索引关键字。
①对于一个不断增长的关键字,如由sequence产生的id,可以通过使用reverse key index避免索引的不断split。但是对于常使用范围查找的应用,只能使用全表扫描。
②创建reverse key index:
create index i_name on t_name(col1) reverse pctfree 30 storage( intial 200k next 200k pctincrease 0 maxextents 50) tablespace i_tspname;
或者
create index i_name on t_name(col1);
alter index i_name rebuild reverse;
5)组织索引表(IOT——index-organized table):类似与mysql中的innodb的存储结构,具体结构如下图:
适用于频繁通过primary key或primary key的前缀访问数据的情况。但是必须要求有primary key的限制。它加快了通过key查找数据的速度,并且从table和index整体上节省空间。
①在IOT中,没有常规表中的那种物理上的row id的概念,而是引入了逻辑row id的概念,它是以变长的方式存储的,其size要依靠primary key的值。
对于IOT中数据的访问有两种方法:
i)物理猜测guess,访问时间等同于物理rowid的访问时间
ii)当guess失败,则通过primary key访问IOT中的数据
(guess就是基于row所在的文件和block访问,block的地址在表建立时是精确的,但是如果leaf block进行了拆分split是,就发生了改变。如果guess失败,则通过primary key进行访问。)这里没太搞懂啊:(
②创建
CREATE TABLE countries
( country_id CHAR(2) CONSTRAINT country_id_nn NOT NULL,
country_name VARCHAR2(40),
currency_name VARCHAR2(25),
currency_symbol VARCHAR2(3),
map BLOB,
flag BLOB,
CONSTRAINT country_c_id_pk PRIMARY KEY (country_id))
ORGANIZATION INDEX
PCTTHRESHOLD 20
OVERFLOW TABLESPACE USERS;
影响IOT的行溢出的三个主要因素有:
** pctthreshold:此子句指明了在index block中容纳一行数据可使用块空间的百分比。如果one row数据超过基于此值计算的大小,所有的在including子句之后的字段将被移入overflow segment。如果overflow没有被定义,则这种row溢出转移将被拒绝。PCTTHRESHOLD默认值是50必须在0到50之间。
** including:后跟一个字段,如果数据行的长度超过了PCTTHRESHOLD指定的可用空间,从这个字段之后将数据行分为两段,后面的部分放入溢出段中;
** overflow TABLESPACE :指明当index-organized表数据超出pctthreshold时,将部分columns放入data segment。
③IOT的字典视图:
④使用mapping table
create table countries
( country_id char(2) constaint country_id_nn not null,
country_name varchar2(40),
currency_name varchar2(25),
currency_symbol varchar2(3),
constraint country_c_id_pk primary key (country_id))
organization index mapping table tablespace users;
当在索引组织表上创建位图索引同heap table上创建bitmap是类似的,只是在组织索引表中的rowid对应的不是基础表,而是相应的映射表(mapping table)。mapping table主要是维护一个逻辑row id(访问组织索引表所需的)到physical row id(访问位图索引所需的)的映射。每个组织索引表会有一个mapping table,用于全表的映射。在heap organized base table中,用key访问数据时,如果找到相应的key,bitmap记录返回的是物理row id,可以用于基础表的访问。在组织索引表中,位图索引也是用key进行搜索,当找到相应的key,bitmap返回的依然是物理row id,通过查询mapping table,获得相应的逻辑row id,再用于进入guess data block address或是用primary key访问组织索引表
组织索引表中的row发生移动,不会使其上的bitmap indexes不可用,只是使mapping table中的相应逻辑row id不可用,但仍可通过primary key对其进行访问。
对于mapping table的维护:
** 通过对IOT表进行analyze获得mapping table的统计信息
** 查询DBA_INDEXES视图得知当前mapping table的精确度
SELECT INDEX_NAME, PCT_DIRECT_ACCESS FROM DBA_INDEXES WHERE PCT_DIRECT_ACCESS IS NOT NULL;
** 如果需要,使用alter table重建mapping table
alter table t_name mapping table update block references;
6)物化视图(Materialized views)
物化视图既存储视图的定义,又存储视图创建语句的查询结果。可以将物化视图定义的结果会产生一个实际的表,可以对其做类似normal table的定义,将其指派的某个表空间,对其添加索引,进行分区等。如果通过固化视图就可以满足的查询,server会将查询转换为对物化视图的查询, 而不是对基础表的查询。这样,部分代价昂贵的如join或统计的查询就不必重复执行。
①创建:
create materialized view depart_sal_sum
tablespace data parallel (degree 4)
build immediate|deferred refresh fast
enable|disable query rewrite
as
select d.departmet_name, sum(e.salary) from departments d, employees e
where d.departmant_id=e.department_id group by d.department_name;
②refresh 物化视图:具体有两类:
i)完全的refresh:主要是通过truncate 当前的data,通过执行物化视图的创建语句重新插入数据。
ii)fast refresh方法:它只会更新自上次refresh之后发生变化的数据。具体又有两种:
** 使用materialized view logs:此方法中,所有关于视图的基础表的变化都会被捕获并记录到一个log中,将这些log data用于materialized view即可。
** 使用row id范围:此方法需要一个直接装在日志。记录了需要被重新load的row id相关信息。materialized view就利用这些row id进行直接路径的load。
一个视图的定义使用force的refresh类型时,会尽可能的使用fast refresh方法,不得已才会使用complete refresh。默认情况是使用force refresh类型。如果使用never选项,则会抑制所有materialized view的refresh。
③自动refresh可以通过下面方法设置:
** 如果为materialized view设置oncommit选项,视图会在base table每次commit操作后进行refresh。因为操作时异步的,所以不会让user察觉到性能的降低。
** 在具体的时间点:可以使用START WITH和NEXT子句定义每次refresh的具体时间。为了实现此方法,必须将参数JOB_QUEUE_PROCESSES设置为大于0的值。
④可以用DBMS_MVIEW包进行手动的refresh。
** 对具体的某个materialized view进行refresh
DBMS_MVIEW.REFRESH(…)
** 对依赖某个基础表的所有物化视图进行refresh
DBMS_MVIEW.REFRESH_DEPENDENT(…)
** 对所有的materialized view进行refresh
DBMS_MVIEW.REFRESH_ALL_MVIEWS;
为了执行手动refresh job,必须为其设置适当的JOB_QUEUE_PROCESSES和JOB_QUEUE_INTERVAL参数。
⑤物化视图的查询重写(query rewrite):这一过程是通过优化器(optimizer)完成的,对于应用而言是透明的。可以加速对基础表的部分访问。user不需要被明确的赋予 materialized view的权限,只要其有base table的权限,则其发出的相关查询就可以被重写为对物化视图的访问。materialized view也可设置为enable和disable。
进行query rewrite,必须使QUERY_REWRITE_ENABLED设置为true。对于使用query rewrite的user必须有GLOBAL QUERY REWRITE或QUERY REWRITE的权限。后者只允许user对自己schema下面的materialized view进行query rewrite,前者除此还可对其他有权限的schema进行query rewrite。
⑥物化视图在带来效率的同时也会增加占用的额外空间,并且需要refresh的开支。对此在DBMS_OLAP包的sumary advisor可以用于对代价与收益的比较从而辅助觉得materialized view的创建。
vii)对query rewrit的控制分为三个层次:
** 在初始化参数级别上:
OPTIMIZER_MODE:查询重写只有在cost-based优化模式下才能进行。可在session级别动态设置;
QUERY_REWRITE_ENABLED:可设置为true或是false,可在session级别动态设置;
QUERY_REWRITE_INTEGRITY:可设置为ENFORCED(默认值,只有server能确保一致性时——物化视图是最新的并且 query rewrite使用了有效的验证约束的情况下才进行query rewrite)、TRUSTED(物化视图是最新的,此外相信RELY的约束, 就算这个约束没有Enabled和Validated)、 STALE_TOLERATED(query rewrite允许使用没有及时refresh的物化视图)。此参数也是可以在session级别上动态设置的。
** 在sql中使用hints——REWRITE和NOREWRITE,它可以覆盖在创建或alter物化视图是设置的enable query rewrite子句。
** dimensions(这个也没太懂~~~~(>_<)~~~~ )
viii)可以使用dbms_mview包中的EXPLAIN_MVIEW和explain_rewrite对materialized view和query rewrite进行解释。
3、OLTP系统:
主要特点是:集中的insert和update操作,数据不断增长,多事务并发进行。要求高可用性、高速、高度并发、降低恢复时间。
1)空间分配:避免动态的空间分配,应该为tables、cluster、indexes明确指明占用的tablespace。此外通过观察数据增长的规律,设计extent每次分配的大小。
2)indexes:在DB中indexes的创建和维护都是占用一定开支的,所以,索引的创建必须严谨,每个索引的存在必须是实际需要的;在外键上建立 索引有助于在子表数据被修改时不会locking父表中的数据;b-tree索引在OLTP中优于位图索引,因为locking对DML的影响(当DML 操作发生时b-tree索引中只是锁某些rows,但bitmap索引,会locking整个有相同key的rows);可以考虑使用reverse index来解决b-tree中sequence columns的问题;应该定期对indexes进行rebuild。
3)hash clustering:使用hash clusters可以提高等值查询的访问速度。但是对于下面的情况则不适用它:
** 大量insert操作
** 存在大量用更大的columns values对表进行update的操作,因为会引起数据的迁移。
如果表不断增长,可能在hash key上存在大量冲突,从而是部分数据存放在overflow blocks中,为了避免这种情况,正确的评估hashkeys的值。给hash key更大的number,有助于解决冲突。
4)OLTP Application Issues:
* 对于完整性约束,应该使用DB中声明的constraints代替application中code的逻辑限制。这里主要考虑的是参照完整性和约束的check。
* 应该考虑使用Oracle中的共享code对象,如packages、procedures和Functions。
* 应该尽可能使用绑定变量
* 定义恰当的cursor_sharing参数,有助于user共享解析代码。可设置的值有:
EXACT:默认值,只在精确匹配的情况下共享cursors
SIMILAR:如果SQL语句是字面量,则只有当已有的执行计划是最佳时才使用它,如果已有执行计划不是最佳则重新对这个SQL语句进行分析来制定最佳执行计划。
FORCE:如果SQL语句是字面量,则迫使Optimizer始终使用已有的执行计划,无论已有的执行计划是不是最佳的。
4、决策支持系统(DSS/Data Warehouses)
DSS的特点是该application会提取相应的有用数组成容易理解的报表。将OLTP中的数据进行提取、整合、汇总。使用大量的全表扫描。决策者根 据相关的结果做下一步的决策。它需要有快速的响应时间,并且数据应该确保精确。并发查询的特点就是为了data warehouse环境设计的。
1)存储的分配:
* 谨慎的考虑block size和DB_FILE_MULTIBLOCK_READ_COUNT参数的设置。可以考虑适当增大block_size、DB_FILE_MULTIBLOCK_READ_COUNT。
* 确保extent的size是block_size的整数倍。
* 定期执行analyze或是dbms_stats进行表的statistics。
2)indexing:因为大量的查询是通过全表扫描完成的,所以应尽量减少index占用的空间和对其维护带来的开销。
* 可以的话,可以考虑不使用索引,只保留那些需要用于进行筛选查询的index;
* 定期的用不一致的分布数据产生直方图。
* 考虑使用bitmap indexes
* 对于需要快速用关键字查询的data可将相应的表建为IOT。
* 考虑使用index和hash cluster,特别是hash cluster。但不要在定期批量增长的表上建立cluster。
3)application issues:
在data warehouse中,sql的解析时间并不重要,所以可以适当的减小library cache的大小。应该更关注执行计划:尽量使用并发查询。Symmetric multiprocessors (SMP), clustered, or massively parallel processing (MPP)将能很好的提高性能。SQL的调节优化很重要。
有时可以弃用绑定变量,因为:当analyze后产生直方图,可以用于一定的查询优化,但是这种优化只使用在不使用绑定变量的情况。如果使用绑定变量,则optimizer就不会使用直方图了。对此要小心设置cursor_sharing参数的值。
5、混合系统(Hybrid System)
1、对于闩(Latches)的概览
Latches是为了保护SGA中的共享数据结构而创建的简单的底层的序列化机制,是轻量级的锁。server或后台进程为了操作或是查看共享数据结构必 须先申请Latches,当操作结束,需要释放Latches。Latches的争用是不用tuning的,它是不合理使用SGA资源的征兆,需要 tuning内部的争用。仅仅是观察v$LATCH是不足的,但可以将其看做是诊断工具,查找SGA资源争用的位置。
1)Latches的目的:
* 控制序列化访问:保护SGA中的数据结构;保护共享内存的分配。
* 序列化执行某些操作:避免同时执行某些关键的临界code;避免corruptions。
2)等待Latch
尽管latch的实现根据不同的OS和平台而不同,但是其都是内存中的一块地址空间,当latch空闲时是0,已经被申请了时为非0值。
在单cpu中,当进程p1申请的latch被占用,p1将释放cpu,sleep一小段时间,等待latch被释放。
在多cpu中,如果进程p1申请的latch被p2占用,很可能p2在其他的cpu上,则p1不会释放cpu,而是spin计数,重试,spin计数,重试,直到重试次数达到设置数,仍未成功,才会释放cpu,但这种可能比较小。
3)Latch的请求类型:
latch的请求方式有两类:willing-to-wait和immediate。
willing-to-wait:当进程申请一个latch时,如果当前latch已经被占用,该进程会等待片刻再重试,等待-重试,直到获得latch,这是一般普遍的latch申请方式。
immediate:如果进程申请的latch不能获得,该进程会继续执行后续的指令。
4)latch 冲突:latch的申请释放都是Oracle自动实现的,所以速度比较快。latch的资源是有限的。
在诊断latch时,可利用视图v$latch,该视图中主要columns的意义:
• gets: Number of successful willing-to-wait requests for a latch
• misses: Number of times an initial willing-to-wait request was unsuccessful
• sleeps: Number of times a process waited after an initial willing-to-wait request
• wait_time: Number of milliseconds waited after willing-to-wait request
• cwait_time: A measure of the cumulative wait time including the time spent spinning and sleeping, the overhead of context switches due to OS time slicing and page faults and interrupts
• spin_gets: Gets that missed first try but succeeded after spinning
• immediate_gets: Number of successful immediate requests for each latch.
• immediate_misses: Number of unsuccessful immediate requests for each latch.
在使用statspack是,可先查看其report的top 5 wait events部分,是否有latch free事件,如果有再进行后续的分析。
2、降低Latches的冲突
一般,DBA不应该调节latches的数目,自9i以来,Oracle已经可以自己进行latches数量的调节了,这主要是根据DB在建立时设置的初始参数和OS的环境。
latches的冲突是性能问题的表现。最好的解决latches冲突问题的方法是修改application行为。此外,如果观察到是buffer或shared poolsize的问题,也需要进行适当的修改。
3、对DBA而言,几个重要的latches
1)shared pool latch和library cache latch:如果冲突出现在这两类latch上,则表示sql或是pl/sql命令没有被有效重用,可能是没有有效的使用绑定变量,或是cursor cache不足。如果是Oracle Shared server模式,如果没有设置large pool,也可能导致Shared pool Latch的冲突,则需要考虑设置large pool。
2)cache buffer lru chain latch:当dirty blocks被写入disk或server进程查找blocks用于写入操作时会request此latch。如果它存在较大冲突,则表示buffer cache任务繁重,可能存在较多的cache-based sorts、低效的SQL(使用了不正确的迭代索引)或是较多的全表扫描。此外,也可能是由于DBWn的写速度跟不上data blocks的变化速度。使得访问进程不得不为了找到buffer中的free blocks等待。对这个latch的冲突,应该从buffer cache或DBWn的调节入手。
3)cache buffers chains latch:当user进程试图分配buffer cache中的data blocks时,需要申请此latch。它的冲突反映了某些热块被重复访问的情况。
4、共享池和library cache latch冲突:如上所述,此类冲突的一个主要原因是不必要的解析。其调节方法已经在之前介绍过了。
1)辨识因为拼写方式而造成的多次解析:
select sql_text from v$sqlarea where executions=1 order by upper(sql_text);
2)查看是否有不必要的重复解析。
select sql_text, parse_calls, executions from v$sqlarea order by parse_calls;
1、rollback segments的作用:事务的rollback;transaction recovery(当事务尚未提交或rollback时instance fail,startup时会用rollback segment进行回滚恢复);读一致性也需要rollback segment进行数据的还原。在新的版本中(我记得是从10g中)flashback技术也使用了rollback segment。这里先不介绍了,碰到时在说。
2、rollback segment的activity:
1)transaction以顺序循环的方式使用rollback segment中的extents。一个transaction在rollback segment的当前位置写入记录,并将指针移动写入记录的大小的步长。写入rollback segment的请求需要相应的undo data在database buffer cache中是可用的。这就要求有较大的buffer cache。
2)注意:多个transaction可以对一个rollback segment中的同一个extent进行写操作。每个rollback segment block只会包含一个transaction的数据信息。
3)rollback segment header中包含了不同transaction各自的记录:Oracle server在每个rollback segment header中保存一个transaction tables,从而控制改变rollback segments中data block的操作。
因为需要不断修改,所以rollback segment header block被长期保存在data block buffer cache。而不断的访问rollback segment header block会增加命中率。这种影响对于某些有大量小型事务的OLTP的application影响较大。每个transaction都需要修改 transaction tables,所以必须有足够大的rollback segment从而避免对transaction tables的冲突。低估rollback segment的需求,可能引起性能问题或errors。高估会浪费空间。可以使用自动undo表空间管理的方法管理undo segments。
4)rollback segments的增长:
当当前extent写满后,指针或是rollback segment的头回移动到下一个extent。当最后一个extent作为当前写入的extent,被写满后,如果此时第一个extent是free 的,则指针将指向第一个extent的开始。指针式不能跳过(skip over)extent,移动到后面的extent上的。所以如果第一个extent仍被使用,将会为此rollback segment分配一个新的extent。这被称作extend。
在正常的运行期间,rollback segments不应该被extend。所以在之前应该分配足够的rollback segment空间。应该尽量避免动态空间的管理。
2、调节手动管理的rollback segments
1)调节rollback segment的目标:
* 尽量使transaction不会为访问rollback segment而等待:这需要有足够的rollback segment
* 在运行期间,应避免rollback segment的extend:
需要每个segment有适当数量的extents
extents的四则应该正确
适当数量的rollback segment
尽量减少应用中对rollback的应用
* 应该没有transaction把rollback space占用完:对此应该将较大transaction用多个transaction替代
* 数据查询user应该总是能获得读一致的数据:这需要考虑设置适当数量的segments和适当的segments size。
2)诊断工具:常用的监控视图有:
* V$ROLLNAME:显示了在线rollback segments的名字和数量
* V$ROLLSTAT:显示了每个在线rollback segment的统计信息。等待header transaction tables的数量,transaction写数据的卷标等信息。
* V$WAITSTAT:显示等待header blocks和rollback segments的blocks累计数量。undo header和undo block两条记录。
* V$SYSSTAT:显示
select name, value from v$sysstat where name like ‘%undo%’;
* V$TRANSACTION:显示当前transaction使用的rollback segment和require的空间的卷标。
在查询时需要用视图中的USN作为连接字段。
3)对手动管理的rollback segment header冲突的诊断
查看:v$rollstat中的waits字段;v$waitstat中的undo header行;
select event, total_waits, time_waited from v$system_event where event like ‘%undo%’;
select class, count from v$waitstat where class like ‘%undo%’;
select sum(value) from v$sysstat where name in (‘db block gets’, ‘consistent gets’);
select sum(waits)*100/sum(gets) “ratio”, sum(waits) “waits”, sum(gets) “gets” from v$rollstat;
当等待的比率大于1%,则考虑创建更多的rollback segment。
4)对于手动管理的rollback segment的数量的考虑
* 对于OLTP application,其特点是有大量的小transaction并发,每个transaction只修改很少的数据量。对此可以设置small rollback segments。一般的设定规律是,并发的transaction中,每4个设置一个rollback segment。
* 如果对于存在较大的批量transaction时,如果rollback segment较小,就可能会发生extend。允许rollback segment可以无限自行extend。
* 如果想要给long transaction分配large rollback segment,可以使用下面的语法:
SET TRANSACTION USE ROLLBACK SEGMENT large_rbs; –必须是事务的第一句
或
execute dbms_transaction.use_rollback_segment(‘large_rbs’);
5)Sizing 手动管理的rollback segment的大小
设置适当的rollback segment size一方面可以避免动态的extend,另一方面当undo blocks被请求时增大了它在cache的可能性。
* 对于small transactions设置segments的initial参数为8KB、16KB、32KB或64KB,对于larger transaction设置为128KB、256KB、512KB、1MB、2MB、4MB等。该值应该设置的足够大,以免出现wrapping现象(当 一个rollback entry在当前使用的空间中找不到足够的空间时,被写入下一个extent)。
* 使用与initial相等的数值做next的参数值。因为PCTINCREASE设置为0,所以后续所有的extents都将是next大小。
* 将DB中的所有rollback segment都设置为相同的size。如果暂时不需要large rollback segment,可以先将其offline。
* 将minextents参数设置为20 。这大致可以避免extend的现象。
* 对于表空间的size设置,我以为书中没有介绍太多的方法,需要在实际应用中查看产生的undo entries的数量进行设置。此外,可以为其保留一个专门用于large-than-usual transaction的segment。
3、transaction rollback data的sizing
1)不同的sql操作所产生的rollback data的大小有下面而定:
* delete操作对rollback segment的开销很大,会存储实际row的数据。如果使用truncate,则会对性能有所改变,但是因为没有写rollback entries,所以不能再恢复。
* insert 使用的rollback space很少,只会记录row id。
* update操作占用的空间要依靠修改的字段数量而定。
* indexed 值将会产生较多rollback。因为server在修改index的同时需要修改tables中row,对于对index字段的update操作,需要 记录old data value、old index value和new index value。
note:lob数据类型的回滚数据不使用rollback segment space,而是占用其自己的segment中由参数pctversion定义的大小的空间。
可以通过下面的sql查看当前事务产生的rollback data
select s.username, t.user_ublk, t.start_time from v$transaction t, v$session s where t.addr, s.taddr;
2)另一种衡量方法是,实际执行相应的操作,从而观察rollback segment的变化
* 在执行操作前运行:select usn, writes from v$rollstat;
* 执行测试的事务操作
* 再次查看rollback segment的统计数据:select usn, writes from v$rollstat;
4、使用产生少量rollback data 的语句:
* user应该尽可能有规律的commit,避免其transaction锁住外部的rollback segment extents。
* 开发人员应该在code时不使用long transaction。
* import操作时,指定commit=y,使得每插入一定数据后就进行commit;用buffer_size关键字设置rows集合的大小。
* export操作时:设置参数consistent=n,避免该是我被设置为只读,那将占用更多的rollback segment space。consistent=y时,确保了导出的数据在一个时间点上是一致的。
* sql*loader:在执行时也应用rows关键字设置commit interval。
note:对于小rollback segments可能带来的问题有:
* interested transaction list(ITL)被存放在block的header。每个ITL entry都包含了发起此处变更的transaction id、undo block的位置、标识位、空闲空间credit和SCN。row lock byte包含了ITL实体number,就相当于该transaction拥有该row的锁。
如果transaction很大,可能会由于rollback segment达到其最大的extents,或是表空间中已经没有可用于extend的空间给rollback segment了,而导致transaction的失败。
* 在查询操作遇到ORA-01555: snapshot too old (rollback segment too small)的错误时,说明此操作需要为了保持一致读的镜像数据块被其他transaction覆盖了。对此的修复只有增大rollback segments。
5、自动管理undo表空间模式
从9i开始,也已通过将UNDO_MANAGEMENT设置为auto将DB设置为自动管理undo表空间的模式(AUM),如果设置为manual则仍 使用手工的管理(RBU)。当在一个transaction中,第一个DML操作被执行,transaction将被分配到当前undo tablespace中的一个rollback segment上。可以通过参数UNDO_RETENTION设置存放在AUM中的undo信息的数量。
1)AUM的tablespace:
具体创建undo tablespace的方法:create database是使用undo tablespace子句,此时会创建一个名为SYS_UNDOTBS的undo tablespace,在$ORACLE_HOME/dbs下将会生成DBU1<SID>.dbf的文件,并且autoextend=on; 另外可以使用create undo tablespace创建。
2)对于AUM的表空间,可做下面的操作:
alter tablespace tspname
• ADD DATAFILE
• RENAME
• DATAFILE [ONLINE|OFFLINE]
• BEGIN BACKUP
• ENDBACKUP
DBA仍可切换当前使用的undo tablespace,只有一个undo tablespace可以设置为active。
eg:ALTER SYSTEM SET UNDO_TABLESPACE=UNDOTBS2;
当该指令发出,所有新的transaction将被指向新的undo tablespace,当前正在运行的transaction将继续沿用旧的undo tablespace,直到结束。
DBA只能通过drop tablespace命令删除当前非active的undo tablespace,并且其不包含任何未提交的transaction的rollback data。
3)对于自动管理undo tablespace的参数设置:
* UNDO_MANAGEMENT:指明是AUTO或MANUAL
* UNDO_TABLESPACE:指明当前active的undo tablespace。如果在创建是没有undo tablespace可用,则会使用system表空间作为rollback segment的分配空间。
* UNDO_SUPPRESS_ERRORS:此参数主要用于使用SET TRANSACTION USE ROLLBACK命令下
* UNDO_RETENTION:设置存放在AUM中的undo信息的数量。其单位是秒,默认值是900
关于undo retention所需的空间的计算:
undo space = (UNDO_RETENTION * (undo blocks per second*db_block_size) ) + DB_BLOCK_SIZE
可以使用下面的sql进行计算,并设置undo tablespace的大小:
SELECT (RD*(UPS*OVERHEAD) + OVERHEAD) AS “bytes”
FROM (SELECT value AS RD FROM v$parameter where name = ‘undo_retention’),
(SELECT (SUM(UNDOBLKS)/SUM(((end_time-begin_time)*86400))) as UPS FORM v$undostat),
(SELECT value AS Overhead FROM v$parameter where name=’db_block_size’);
4)对自动管理undo tablespace的监控:
通过查看V$UNDOSTAT视图可以完成监控的任务。字段UNDOBLKS显示了undo blocks的分配数量。
1、Locking机制
1)Oracle Server中是自动管理锁的。默认会使用最低的锁级别对数据进行一致性的保护,从而满足最大的并发度。
note:默认的锁机制可以通过ROW_LOCKING改变。默认该值是ALWAYS,它将在DML语句中使用最低级别的锁。另一个可能的值是 INTENT,它将使用更高级别的限制(table level),除了select for update语句,它将使用行级锁。
2)quiesced database:如果Oracle被设置为只有DBA可以访问的状态时,就是quiesced database。
3)锁的种类:
** DML locks:
①表级锁(TM):当修改table data时,被设置,如:INSERT, UPDATE, DELETE, SELECT … FOR UPDATE或LOCK TABLE。此时table将被加锁,避免其他DDL的操作引起transaction之间的冲突。
## 在TM中又可分为两种锁,是由server根据当前其他表锁的加载情况而自动为DML选择加上的。这两种锁具体是:row exclusive(RX),运行其他transaction中的insert、update、delete或其他加行级锁的并发操作在当前同一 table上,但不允许其他手动加载的排他读/写锁;row share(RS),运行SELECT … FOR UPDATE命令时加载的表锁,这只会对避免其他事务手动的对当前table加载锁用于排他的写操作。
## 表锁模式:
(i)手动加载表锁模式使用语句LOCK TABLE table_name IN mode_name MODE; –一般不使用这种明确加锁的方法,只有application要求,才会不得不加较高级别的锁。
(ii)Share(S)锁模式:此类表锁只允许其他transaction发出select … from update的请求,不允许任何对table的修改。隐含式的获得share lock的sql语句中,会包含相应的完整性约束。在9i中,不会申请子表中外键字段的索引约束。
(iii)Share Row Exclusive(SRX):它是比S模式更高的锁模式。它不允许任何其他的DML语句和手动加载的共享锁模式。相应的SQL语句会隐式的获得相应的完整性约束的SRX锁。
(iv)Exclusive(X)锁:这是最高的锁模式,只允许其他对该表的查询请求,拒绝一切对表的任何DML操作和手动锁。
②行级锁(TX):当发出命令INSERT, UPDATE, DELETE, SELECT … FOR UPDATE命令时,会自动为所操作的row对象加TX,从而确保没有其他user同时对同一行进行才操作。
一个DML事务,会同时获得两个锁:共享表级锁和排他行级锁。获得行级锁的每行都返回
③在blocks中的DML锁:加锁的信息只有在transaction被commit或是rollback后才会被清除。而不是在当前事务的下一个请求语句发起时被释放。在blocks header中,Oracle server为每个当前active的transaction保存了一个标识符。在每条row中,会有一个lock byte存储了包含当前transaction的slot的标识符。
** DDL locks:避免对schema对象的定义时,有其他相关的DDL操作进行。
Oracle是通过入队的方式对锁进行维护的,入队机制会记录下面的信息:user等待的locks被其他user占用;users请求的locks的具体类型;users请求的locks的顺序。
可以通过改变参数DML_LOCKS和ENQUEUE_RESOURCES参数来增加可被request的locks。这在Parallel server中是必须的设置。DDL锁的分类有:
①Exclusive DDL Locks:某些DDL语句,如CREATE, ALTER, DROP,必须获得其操作object的排他锁。如果其他user获得了其他任何级别的lock,当前user都不能得到其DDL的排他锁。
②Shared DDL locks:当发起GRANT和CREATE PACKAGE操作时,需要获得相应object的共享DDL lock。该类locks不会阻止类似的DDL语句或是任何DML语句,但会防止其他user对当前引用的object被修改或删除。
③Breakable Parse Locks:保存在library cache中的statement和PL/SQL对象保存了其引用的每个object的breakable parse Lock,直到该statement过期。它用于检验library cache中的相应内容是否因为object的改变而可用。
2、可能引起Locks冲突的原因:
1)使用了不必要的high-level锁
2)长期运行的transaction的存在
3)user没有及时的commit对database的修改
4)使用Oracle instance的application使用了higher locks
3、监控并诊断当前加锁情况的工具
1)如上图所示,其中视图DBA_WAITERS和DBA_BLOCKERS用于进一步查看当前获得或是等待不同table的locks的信息。对此,需要用$ORACLE_HOME/rdbms/admin中的catblock.sql脚本创建。
2)对于v$lock视图来说,当lock tpye为TX时,id1中显示的回滚段的number和slot number;当lock tpye为TM时,id1中显示的是被修改表的object ID。
SELECT owner, object_id, object_name, object_type, v$lock.type FROM dba_objects, v$lock WHERE object_id=v$lock.id1 and object_name=table_name;
3)V$LOCKED_OBJECT视图
XIDUSN:Rollback segment number
OBJECT_ID:ID of the object being modified
SESSION_ID:ID of the session locking the object
ORACLE_USERNAME
LOCKED_MODE
在此视图中,当XIDUSN为0时,则表示当前session正在等他其他已经获得该lock的session释放。
4)关于脚本utllockt.sql
可以使用$ORACLE_HOME/rdbms/admin/utllockt.sql脚本显示当前等待lock的进程继承关系。但使用之前必须用catblock.sql脚本创建视图dba_locks和dba_blockers。
5)如果想要得知哪一行造成了lock冲突,可以查看v$session中的row_wait_block#, row_wait_row#, row_wait_file#, row_wait_obj#四个字的的值。
4、解决locks的冲突方法有:一方面可以请相应的user做commit/rollback;在万不得已的时候,可以kill掉某些user session,从而回滚相应的transaction并释放locks。具体方法如下:
select sid, serial#, username from v$session where type=’USER’;
alter system kill session ’sid,serial#’;
5、死锁:对于Oracle,当其检测到死锁的存在,会rolling back那个检测到死锁的语句,当不是整个transaction的rollback。必要时,需要DBA完成剩下的rollback工作。明确的指明语 句中使用的锁,从而覆盖默认的锁机制,可能容易引起deadlock。
当发生死锁后,server会将deadlock的情况记录到USER_DUMP_DEST目录下的跟踪文件。在分布式transaction中,本地的 deadlock是通过等待关系图(waits for graph)来判断的,全局死锁是通过time-out来判断的。
Oracle进程与files
1、performance guidelines
1)对于吞吐量较大的OLTP应用中,当使用dictionary管理表空间的方法时,由于所有的extent分配时都会要访问dictionary,从而造成了冲突。而使用本地管理表空间的方法避免了这类冲突,从而提高了并发性。
2)在本地管理表空间中,使用自动空间管理方法,用位图记录不同blocks的使用情况。也提高了相应的速度。
3)当创建一个user后,就会分配一块所需的磁盘排序所需临时表空间。这些排序区应该从其他database object中分离开,如果没有给user分配临时表空间,则其所需的排序区域将从system表空间分配。
4)tables和indexes应该被分开存储在不同表空间中。因为indexes和tables经常被同时读写。
5)对于含有LONG或LOB数据类型的tables,应该被分配在不同的表空间中。
6)适当创建多个临时表空间。
2、distributing files across devices:
1)应该将redo log和data file存放在不同的磁盘上,从而在一定程度上降低i/o的压力。
2)对于规模较大的表,如果分不同的区域并发访问也可以提高性能partition。
3)尽可能排除非Oracle Server进程对database file的I/O操作。对此可以使用v$filestat动态的观察。
4)了解应用程序主要的I/O操作,合理安排disk布局,从而提高性能。
3、表空间的作用:其中system表空间主要是用于存放sys创建的data dictionary objects。其他users不可使用该表空间。需要明确的是,packages和database triggers对象等都是data dictionary的一部分。rollback segments应该排他使用其rollback segment。undo segments可以只能存在在undo tablespace中。
4、监控I/O状态的工具
1)v$filestat视图。
select phyrds, phywrts, d.name from v$datafile d, v$filestat f where d.file# = f.file# order by d.name;
2)statspack
5、file striping
1)对OS的striping,通过使用硬件或是软件层次上的striping,可以将同一个文件的不同blocks放在不同的devices上,例如raid技术。提供一定的冗余的同时增大I/O性能的。
此外,设置适当的DB_FILE_MULTIBLOCK_READ参数。
2)手工的striping:可以在多个不同的disk创建tablespace。随后将不同的tables、indexes分配到不同的 tablespace中。此外,可以创建对象时使用MINEXTENTS句柄其值大于1,这样每个extents都将略小于striped data files。也可直接给extents进行分配定位(但我认为这会给管理带来麻烦):alter table tablename allocate extent ( datafile ‘filename’ size 10M);
对于这块争用的问题,使用手动的striping还是比较有效的。
6、对全表扫描的tuning:当对某个disk有较高的读写操作时,多是由于没有适当调节sql的原因。
查看全表扫描的次数:
select name, value form v$sysstat where name like ‘%table scans%‘;
获得的结果中’table scans ( long tables)’的值如果较大,则需要考虑调节sql或是增加适当的indexes。
long tables (长表)指多于4个块的表, short table(短表)指等于或小于4个块的表。
初始化参数DB_FILE_MULTIBLOCK_READ_COUNT决定了在全表扫描时,一次I/O操作中读入的最大的database blocks。它可以改变全表扫描时需要的I/O的次数。该参数的设置应该受到OS限制的I/O的上限的约束。此外此参数还可以在session级别进行 调节。对它的调节可以先查看完成每个表的全表扫描扫描多少blocks。从而从整体上得到较好的设置。要注意的是,对cost-based 优化将会使用该参数评估使用全表扫描的代价,从而判断是否使用全表扫描。
对于全表扫描,Oracle提供了视图v$session_longops来进行监控。
select sid, serial#, opname, to_char(start_time,’HH24:MI:SS’) as starttime, (sofar/totalwork)*100 as percent_complete from v$session_longops;
7、checkpoints
什么是checkpoint?
checkpoint是一个数据库事件,它将已修改的数据从高速缓存刷新到磁盘,并更新控制文件和数据文件。
什么时候发生checkpoint?
我们知道了checkpoint会刷新脏数据,但什么时候会发生checkpoint呢?以下几种情况会触发checkpoint。
1.当发生日志组切换的时候
2.当符合LOG_CHECKPOINT_TIMEOUT,LOG_CHECKPOINT_INTERVAL,fast_start_io_target,fast_start_mttr_target参数设置的时候
3.当运行ALTER SYSTEM SWITCH LOGFILE的时候
4.当运行ALTER SYSTEM CHECKPOINT的时候
5.当运行alter tablespace XXX begin backup,end backup的时候
6.当运行alter tablespace ,datafile offline的时候;
1)它可以引起DBWn的I/O操作,同时会更新datafile header和control file中的scn等信息。
频繁的进行checkpoint可以缩短instance恢复的时间,但是会降低Oracle运行的性能。
在LGWR写redo log文件时,当一个group 被写满时,需要进行log switch是,会先发起一个checkpoint,这就意味着:DBWn会先将所有的与该redo log有关的dirty data blocks写入datafile,随后CKPT会修改datafile header和控制文件。
checkpoint并不会影响其他工作。如果DBWn进程尚未完成checkpoint一个file,此时LGWR需要在此需要这个file时,LGWR不得不等待。
2)对checkpoint性能的监控与调节:
** checkpoint的监控主要是查看alert.log文件。可以将LOG_CHECKPOINT_TO_ALERT参数设置true,从而记录checkpoint的开始结束时间。
** 通过调节online redo log files的大小来降低因日志切换引起的checkpoint;
** 增多redo log 的groups,从而延长LGWR覆盖写的时间,从而避免引起不必要的LGWR等待。
** 具体可调节的参数有:
– FAST_START_IO_TARGET
– LOG_CHECKPOINT_INTERVAL
– LOG_CHECKPOINT_TIMEOUT
– DB_BLOCK_MAX_DIRTY_TARGET
– FAST_START_MTTR_TARGET
如果在OLTP系统中,SGA设置过大,同时checkpoint稀少,可能引起disk冲突。所以也要适当增加checkpoint的频率。
貌似我的理解是除了user发起的alter database checkpoint命令外,主要两类checkpoint,时间间隔型和fast-start类型的。
通过查看v$instance_recovery视图,查看参数设置对DB recovery时间的影响,其中:
RECOVERY_ESTIMATED_IOS:显示了基于fast-start的设置,在recovery时,需要处理的data blocks。
ACTUAL_REDO_BLKS:显示了当前要进行recovery时所需的redo blocks。
TARGET_REDO_BLKS:在recovery时,最大的需要处理的redo blocks。是下面四个指标的最小值。
LOG_FILE_SIZE_REDO_BLKS:在recovery时,为了确保log switch不会等待checkpoint,要处理的redo blocks数量。
LOG_CHKPT_TIMEOUT_REDO_BLKS:在recovery时满足log_checkpoint_timeout,需要处理的redo blocks的数量。
LOG_CHKPT_INTERVAL_REDO_BLKS:在recovery时为了满足log_checkpoint_interval,需要处理的redo blocks的数量。
FAST_START_IO_TARGET_REDO_BLKS:在recovery时为了满足fast_start_io_target,需要处理的redo blocks的数量。
对checkpoint的设置主要围绕的中心就是recovery用时,和它引起的I/O是否会造成性能的问题。
8、redo log的groups和members的设计
一般会把同一组的不同成员放置在不同的disk上,如果在归档模式下,则要考虑将归档日志放到不同的磁盘上。为redo log选择适当的size。同时在一定程度上增加log file的groups,从而避免不必要的等待。
对redo log的监控视图主要有:V$LOGFILE, V$LOG, V$LOG_HISTORY,此外还可结合v$system_event获得的结果。
9、归档日志的设置
当开启归档模式时,可以考虑将不同的groups放在不同的disks上(当然不一定是每个group一个磁盘),同时与归档文件的存放也分离,这样使LGWR进程写的disk和ARCn进程读的disk不在一个上。
可以从视图V$ARCHIVED_LOG上获得动态的归档log文件的信息。V$ARCHIVE_DEST当前归档进程的destinations的状态信息。(由参数log_archive_dest_n设置的destination)
监控诊断ARCn的工具主要是使用视图:V$ARCHIVED_LOG, V$ARCHIVE_PROCESSES, V$ARCHIVE_DEST。
对归档的调节,可以使用LOG_ARCHIVE_MAX_PROCESSES参数指定最大可以创建的归档进程。
如果预计归档工作量较大,可以通过定期运行下面语句来获得其他进程来分担。
alter system archive log all to ‘directory_name’;
注意:9i中,当DBWR_IO_SLAVES参数的设置大于0,Oracle会自动将ARCn的进程数设置为4。(但是我的11g貌似DBWR_IO_SLAVES=0,而ARCn也是4个多啊,大概是设了其他的参数)
设置适当的fast_start_io_target,
1、排序进程:
1)如果排序请求使用的memory不大于参数SORT_AREA_SIZE的设置值,则sort操作在内存中进程。反之,如果超过该值:
①数据将被分隔成更小的pieces,被称作sort runs;每个sorted先被分别的sort。
②server进程会将pieces写入临时表空间segment中;这些segments用于存储中间的sort data。
③sorted pieces被合并从而产生最终结果。如果SORT_AREA_SIZE大小不足以一次merge所有sorted runs,sorted runs的子集会经历几次merge过程。
2)sort area的大小是由SORT_AREA_SIZE设置的,它可动态设置(alter session、alter system deferred),其默认值根据OS的不同而不同。其默认值可以满足一般的OLTP需求,对于DSS应用、批量jobs或是较大操作需要适当的条件。
3)另一个相关的参数是SORT_AREA_RETAINED_SIZE。当sorting操作结束,sort area仍保存了部分等待取出的sorted rows,sort area可以shrink到最小为SORT_AREA_RETAINED_SIZE的大小。该部分memory仍然是被释放到UGA中。其默认值等于 SORT_AREA_SIZE。
4)关于位图索引的初始化参数:
CREATE_BITMAP_AREA_SIZE:此参数是静态的,指明了用于创建位图索引可以分配的memory,默认值是8MB(较大的memory设置会加快bitmap的创建速度,如果位图索引的基数比较小,所需的memory也相对小)
BITMAP_MERGE_AREA_SIZE:该参数也是静态的。默认值是1MB。oracle为索引位图段建立一张位图。在进行位图索引扫描时,需要将扫描到的位图索引排序后与位图合并(Merge
),Oracle会在PGA中开辟一片区域用于排序和合并。它就指定了这片区域的大小。
5)sort Area的新参数:
PGA_AGGREGATE_TARGET:指明了连接instance的所有进程的PGA的总区域大小,大小可从10MB到4000GB。设置时,应该先考虑system总的memory,以及分配给SGA的memory大小,将剩余的部分分配给该参数。它指明了自动sort area管理。
WORKAREA_SIZE_POLICY:该参数可设置为(i)AUTO:只有定义了PGA_AGGREGATE_TARGET参数后才可被设置为 AUTO;(ii)MANUAL:对work areas的Sizing是手动的,是基于*_AREA_SIZE参数设置的值来分配的。如果设置为MANUAL,可能会降低PGA内存的利用率。
6)一般SORT_AREA_SIZE和SORT_AREA_RETAINED_SIZE应该设为相同的大小,除非system memory不足或使用的是Oracle shared server模式。
7)内存的需求:
在single server process中:一个执行计划可能会包含多个排序。例如,一个用sort-merge方式join两个tables并使用order 不用子句的sql,包含了三个sort。对此,在运行order by时,一个SORT_AREA_SIZE大小的memory用于当前的sort;两个SORT_AREA_RETAINED_SIZE大小的 memory用于join sorts。
在parallel query 进程中:假设有2个server,则会使用(SORT_AREA_SIZE*2*并发度)大小的memory,此外如果需要,还要使用 (SORT_AREA_RETAINED_SIZE*并发度*事先做的排序次数)的memory。实验表明分配更大的memory不会对性能有更好的提 高。
2、Tuning sorts
需要注意的问题有:
* 如果数据已经使用索引进行了排序,尽量避免再次排序
* 如果sort操作本身并不大,但是设定的sort area过小使得其不得不进行页面的交换。
* 此外使用大的内存chunks用sort也会造成paging核swapping,从而降低系统性能。
* 避免在频繁分配和收回磁盘上的临时表空间操作
所以应该:尽可能的避免排序操作;尽量使sort操作在内存中完成,减少swapping和paging的操作;尽可能的减少对临时空间的请求。
1)临时表空间的优化:
明确指明sort操作使用的临时表空间,可以有效的避免在分配与收回sort空间时的序列化操作。在临时表空间中,不能包含任何永久的object,在 Oracle Parallel Server中,对于每个instance,会有一个单独的临时表空间。临时表空间的datafile在备份时时不需要备份的。
对于临时sort segment:
* 在第一次需要申请临时表空间的sort操作申请时,sort segment才被创建;
* 在DB被关闭时才被drop,可以用命令行对其进行扩容
* 它也是由extents组成的,可以用于不同的sort 操作
* 在SGA中存在一个叫sort extents pool(SEP)的数据结构,用于管理临时表空间。当进程需要申请sort space时,会先在SEP中查找临时表空间中空闲的extents。
2)需要进行排序的命令请求有:
* 索引的创建:在建立b-tree之前,必须先将索引列进行排序操作;
* order by和group by子句:必须先对该子句使用的字段进行排序;
* distinct关键字:必须为消除重复行先进行排序;
* UNION、INTERSECT或MINUS操作符:server需要为了消除重复rows先对表进行sort。
* 两表之间的sort-merge连接:如果没有相应的索引用于两表的连接,对于等值连接,如果使用此方法join,则先需要对两表进行全表扫描,并分别进行排序,再合并两表。
对于server的排序操作的监控,可以从v$sysstat中查看:
select name, value from v$sysstat where name = ’sorts (rows)’;
可以使用analyze或是dbms_utility.analyze_*等方法对tables、indexes或是cluster进程统计,从而更好的指导CBO,从而产生更好的执行计划。
3)避免使用sort:在任何可能的地方尽量避免使用sort
* 使用nosort关键字创建索引:
默认情况下,在表中创建索引的时候,会对表中的记录进行排序,排序成功后再创建索引。但是当记录比较多的是,这个排序作业会占用比较多的时间,这也就增加了索引建立的时间(排序作业是在索引创建作业中完成)。有时候,我们导入数据的时候,如采用insert into 语句插入数据过程中同时采用Order by子句对索引字段进行了排序。此时如果在索引创建过程中再进行排序的话,就有点脱裤子放屁,多此一举了。为此在重新创建索引时,如果表中的数据已经排好序了(按索引字段排序),那么在创建索引时就不需要为此重新排序。此时在创建索引时,数据库管理员就可以使用NOSORT可选项,告诉数据库系统不需要对 表中当记录进行重新排序了。
采用了这个选项之后,如果表中的记录已经按顺序排列,那么在重新创建索引的时候,就不会重新排序,可以提高索引创建的时间,节省内存中的排序缓存空 间。相反,如果表中的记录是不按索引关键字排序的话,那么此时采用NOSORT关键字的话,系统就会提示错误信息,并拒绝创建索引。所以在使用 NOSORT可选项的时候,数据库管理员尽管放心大胆的使用。因为其实在不能够使用这个选项的时候,数据库也会明确的告知。为此其副作用就比较少,数据库管理员只需要把这个可选项去掉然后重新执行一次即可。不过这里需要注意的是,如果表中的记录比较少的话,那么使用NOSORT选项的效果并不是很明显。
* 使用UNION ALL代替UNION:因为UNION ALL不会消除重复的rows,所以也无需进行sort操作。
* 使用Nested loop join代替sort-merge join
* 在经常使用order by子句的列上创建索引。
* 使用analyze时,只统计所需字段的数据:
ANALYZE … FOR COLUMNS或ANALYZE … FOR ALL INDEXED COLUMNS
* 对于ANALYZE COMPUTE,其统计结果更精确,但是需要进行一定的sort,对此,可以使用ESTIMATE子句来替代大表或cluster中的ANALYZE。
4)诊断工具:
* 在视图v$sysstat中显示的信息中有:
sorts (memory):完全在内存中进行的排序的次数
sorts (disk):请求临时segments的I/O进行sorts的次数
sorts (rows):当前已经进行过的sort的rows的数量
* 在statspack输出的report中也存在上述信息,并计算了部分平均值
* 视图v$sort_segment和v$sort_usage显示了当前临时segment中的使用情况,以及那些user占用了这些临时segment。
@@ 在具体诊断时,可计算磁盘sort和memory sort的比率,它应该小于5%。否则,如果此比率显示了较大的磁盘排序,则需要考虑是否可以增大SORT_AREA_SIZE的设置。
@@ 注意的是:如果增大了sort area,则每个需要sort的进程所占用的memory可能都会增加,在一定程度上影响了OS的memory分配及paging和swapping。所 以当增加了sort_area_size后,考虑是否可以适当减小SORT_RESERVED_AREA_SIZE的值,不过此值的减小,在一定程度上减 少了内存的使用,但也可能附加着造成了I/O的可能性。
6) 监控临时表空间:主要是查看V$SORT_SEGMENT视图:
select tablespace_name, current_users, total_extents, used_extents, extent_hits, max_used_blocks, max_sort_blocks from v$sort_segment;
具体字段的意义如下:
CURRENT_USERS:Number of active users
TOTAL_EXTENTS :Total number of extents
USED_EXTENTS :Extents currently allocated to sorts
EXTENT_HITS: Number of times an unused extent was found in the pool
MAX_USED_BLOCKS: Maximum number of used blocks
MAX_SORT_BLOCKS :Maximum number of blocks used by an individual sort
7)临时表空间的设置:
默认临时表空间的存储参数对于sort segment都是适用的,只是它们有无限的extents。
设置临时表空间的参数时,先要考虑sort_area_size的值。temporary tablespace的initial和next参数应该是sort_area_size的整数倍,并要考虑额外的segment header的空间。将PCTINCREASE设置为0 。
可以为users指定不同的temporary tablespace,并且可以将temp tablespace放在不同的磁盘上,对于查看使用情况,可以看v$sort_usage
select username, tablespace, contents, extents, blocks from v$sort_usage;
此外,还可查看V$TEMPFILE和DBA_TEMP_FILES可以获得temporary tablespace的相关信息。
1、redo log buffer:
当时常遇到较大的事务时,增大log buffer可以减少不必要的log file I/O操作。commit操作将会flush log buffer,频繁的commit可以考虑较小的buffer size。log_buffer最小为64K。
①对redo log buffer的诊断:
** 查看动态视图:v$session_wait查看当前是否正有对log buffer的请求等待。
select sid, event, seconds_in_wait, state from v$session_wait where event = ‘log buffer space%’;
** 计算redo buffer allocation的重试的出现概率,此值应该尽量接近0,不应该大于1%,如果该值不断增加,说明大量对redo log buffer的等待。
select name, value from v$sysstat where name = ‘redo buffer allocation retries’; –显示了user 进程等待log buffer中的space所重试的次数。
select name, value from v$sysstat where name = ‘redo log space requests’;
引起等待的原因可能是由于log buffer过小,或是checkpoint,或是log switching所致。
对此,可以尝试:增大log_buffer的值;或是改善checkpoint或归档进程。
** SECONDS_IN_WAIT值显示的是除了由于log swith以外造成的log buffer等待的时间。它表明redo buffer被写满的速度要大于LGWR写logfile的速度。也可能反映在redo logfile上的I/O存在冲突。
如果怀疑是LGWR的问题,可以继续查看:
@@ 是否存在I/O冲突,是否redo log file存放在分开的快速存储设备上。
@@ 查看日志切换的次数,考虑是否是切换太频繁,是否需要增大log file 的size。
select event, total_waits, time_waited, average_wait from v$system_event where event like ‘log file switch completion%’;
@@ 如果DBWn在尚未完成checkpointing file时,LGWR在此需要相应的文件时,会引起LGWR的等待。对此可以从alert.log文件中查看到相关信息。查看当前是否有未完成的checkpoint事件:
select event, total_waits, time_waited, average_wait from v$system_event where event like ‘log file switch (check%’;
查看参数LOG_CHECKPOINT_INTERVAL和LOG_CHECKPOINT_TIMEOUT是否恰当;并查看redo log file的size和group数。
@@ 如果归档进程不能及时的将redo logfile,也可能会引起LGWR的写入等待。
对此,先确认归档目录没有满,适当增加redo log 的groups。下面的SQL显示了由于归档问题引起的log file switch等待统计。
select event, total_waits, time_waited, average_wait from v$system_evnet where event like ‘log file switch (arch%’;
可以适当增大参数LOG_ARCHIVE_MAX_PROCESSES从而在大负荷量时增多归档进程。
@@ 如果将DB_BLOCK_CHECKSUM设置为true,会因此增加性能上的开支。
此外,尽可能减少redo的操作:
** 直接路径的loading在非归档模式下,是不记录redo log的
** 在归档模式下,直接路径的loading可以使用nologging mode
** 直接insert也可使用nologging mode
** 部分sql可以使用nologging mode
但要明确,即使对table、index、tablespace使用nologging模式,但对于部分操作仍然会产生redo log。如create table … as select; create index … ; alter index … rebuild;
此外,nologging属性对update, delete, 常规路径的insert和各种DDL语句是不会起作用的。(这里貌似对insert添加hint也可以使其nologging)
2、监控Java池内存:select * from v$sgastat where pool = ‘java pool’;
1)用于限制Java session占用的内存的初始参数:
①JAVA_SOFT_SESSIONSPACE_LIMIT:当user session的java命令占用的内存超过该设置,将会发出warning,在跟踪文件做一定的记录,默认为1M。
②JAVA_MAX_SESSIONSPACE_SIZE:当user session的java命令占用内存超过该值,该session将被kill掉,默认为4G。
2)为Java Sizing SGA
①每装载一个class,java引擎会使用8KB shared pool的内存,当装载并处理大的jar files时,可占用50MBshared pool的内存。
②java pool是SGA中的一个组成部分,用于所有存在java code或是在EJE中存在数据的session中。instance startup时,会分配JAVA_POOL_SIZE指定大小的内存。一般会设置为50MB左右,默认是20MB。
3、multiple I/O slave:
4、multiple DBWR 进程
1) 多DBWn进程可以使用DB_WRITER_PROCESSES参数控制。它对于多cpu的SMP系统较有效。但是multiple DBWR与multiple I/O slave是不能同时使用的。
2)对其的调节:
select event, total_waits, time_waited from v$system_event where event=’free buffer waits’;
如果发现上述的SQL的total_waits是较大,可以考虑将增加DBWn进程的数量。
1、Shared Pool的组成
** library cache:存储共享的SQL和PL/SQL代码(解析和编译后的SQL和pl/sql blocks——procedures,Functions,packages,triggers和匿名的pl/sql块)使用最近最少使用算法管理 (LRU),避免语句的重复解析。
** data dictionary cache:保存字典对象的信息
** user global area(UGA):用于在没有设置large pool时存放共享的server connection的信息。保存在Shared模式下session的信息。
当缺少data dictionary cache或library cache的代价比缺少database buffer cache的代价更高,所以对Shared pool的tuning有更高的优先权。在tuning Shared pool时主要关心library cache提高其hit ratio又更重要些。
当Shared pool过小,server为了管理有限的空间,需要消耗更多的cpu,从而引起争用。
Shared pool从整体上可以通过参数shared_pool_size来调节。
2、library cache
在server查找是否有被缓冲的sql时,会先把statement转换为ASCII文本,再进行hash函数的计算。
1)尽可能减少重复解析的次数:尽可能使code扁平化,使用bind variables;可以适当增大library cache的大小,从而减少由于cache不足造成的已经被解析的SQL被换出而引起重新解析的可能;如果在cache中保存的被解析的SQL相关联的 schema object被修改,则该cache中的内容将不可用,所以要尽量避免这样的事件发生。
2)避免library cache的碎片产生:为较大的内存需求保留一定的内存,主要通过shared_pool_reserved_size参数设置;将常用的较大的SQL和 PL/SQL对象pinning到内存中,避免其被换出;为Oracle Shared server设置large pool;尽量少使用较大的匿名blocks,用小的PL/SQL包的方法代替;在Oracle Shared Server中测量共享进程所用的session内存。
3)在v$librarycache中保存了每类数据保存在library cache中的统计信息。其中,三个字段较为重要:gets,显示了相应item总的请求数量;pins,显示了执行的次数;reloads显示了被换出后重载的次数
4)调节library cache的诊断工具:
** v$sgastat
** v$librarycache
eg:sql> select namespace, gethitratio from v$librarycache; –获得命中率,在OLTP中应该高于90%,如果没有达到可以考虑以下方法:
a)提高应用程序代码效率(通过绑定变量,避免SQL的硬解析)
b)增加共享池的大小(增加之前先通过v$sgastat查询是free memory是否足够大,有无增加共享池必要)
** v$sqltext:full SQL text
eg:sql> select sql_text, users_executing, executions, loads from v$sqlarea;
sql> select * from v$sqltext where sql_text like ’select %’;
** v$db_object_cache:缓冲的DB object,包括packages、tables或是SQL中参照的别名
** v$sqlarea:统计了所有的共享cursor和相应的sql的前1000个字符
** 如果重载的比率大于1%,需要考虑增大shared_pool_size。
sql> select sum(pins) “executions”, sum(reloads) “cache misses”, sum(reloads)/sum(pins) from v$librarycache;
在statspack report中,library cache activity (Instance state activity)的内容也显示了此信息:parse count(total、hard、failure)
5)还需要明确的是多次的修改对象,也可能使library cache的内容被标记为invalid,从而造成reload-to-pins值增大。在v$librarycache中的invalidations 字段显示了标记为invalid的次数。注意:analyze语句可用使标记为invalid。
sql>select namespace, pins, reloads, invalidations from v$librarycache;
可以查询v$shared_pool_advice查看oracle建议使用共享内存,也可以通过oracle 的OEM查看共享内存图。
6)与缓冲的执行计划的相关的view:
** 动态性能视图v$sql_plan可用于查看缓冲了的cursor的的执行计划信息,它比plan_table表还多7个字段,两者中的相同字段的值是一 致的。此外在v$sql视图中添加了一个字段plan_hash_value,它为一个hash值,用于匹配执行计划。与v$sqltext、 v$sql_plan、v$sqlarea中的hash_value字段对应。
7)测试applications:对应已经存在的application,先分配一个较大的shared_pool_size,开启应用,计算当前使用的共享内存:
select sum(sharable_mem)
from v$db_object_cache
where type=’PACKAGE’ or type=’PACKAGE BODY’
type = ‘FUNCTION’ or type = ‘PROCEDURE’;
对于相关的SQL语句,需要通过v$SQLAREA查询:
select sum(sharable_mem) from v$sqlarea where executions>5;
此外,也可以假设在每个user每打开一个cursor将增加250 bytes。这可以测试application在高峰期的shared pool的占用:
select sum(250* users_opening) from v$sqlarea;
在测试环境中,可以根据user的多少来估算打开的cursors数量。
select 250 * value bytest_per_user
from v$sesstat s, v$statname n
where s.statistic# = n.statistic# and n.name = ‘opened cursors current’ and s.sid=15;
这样,在理想情况下,application中将占用的library cache大约是上述的总和加上少量的动态SQL。
8)large memory的存在必要性在于满足较大的连续内存的需求,可以通过large_pool_size和 shared_pool_reservered_size来设置。一般会建议将其设置为shared_pool_size 的10%,如果设置为50%或以上,系统将报错。
通过视图v$shared_pool_reserved可以帮助tuning其大小。其中最好的目标是设置使request_misses(由于 large mem不足,通过LRU实现的flush)的长期统计结果接近0。还有一个procedure工具 dbms_shared_pool.aborted_request_threshold,用于限制shared pool在出现ORA-4031之前被flush
对于其调节:如果v$shared_pool_reserved中的request_misses值不为0并且不断增加,需要考虑增加 shared_pool_reserved_size;如果request_misses为0,并且free_memory=>50%,考虑减少 shared_pool_reserved_size;v$shared_pool_reserved中的request_failures(显示了没有 memory用于满足请求)>0并不断增加,可以适当考虑减小shared_pool_reserved_size或增大 shared_pool_size。
9)将large object保存在内存中。
通过下面的语句可以查看在内存中已经cache了那些对象:
select * from v$db_object_cache
where sharable_mem > 10000 and (type=’PACKAGE’ or type = ‘PACKAGE BODY’ or
type = ‘FUNCTION’ or type = ‘PROCEDURE’) and kept = ‘NO’;
需要被pin入内存中的对象主要有:常用的较大的存储对象,如standard、diutil包;编译的常用的triggers;sequences。最 好在开机时就将其pin入内存中(我以为这里可以编写适当的开机trigger)。这样,既是使用命令alter system flush shared_pool时,也不会讲这些object flush掉。
具体pin对象到内存的方法可以使用DBMS_SHARED_POOL.keep存储过程。可以用unkeep方法解除其pin状态。
10)对于匿名pl/sql块:可以先在视图v$sqlarea中找到相应的sql_text,并将其适当的改为packaged Functions来执行。
select sql_text from v$sqlarea where command_type = 47 and length(sql_text) > 500;
此外,可以适当的将这些匿名的PL/SQL blocks pin入内存,如下:
declare /* KEEP_ME */ x number;
begin x := 5;
end;
select address, hash_value from v$sqlarea where command_type = 47 and sql_text like ‘%KEEP_ME%’;
execute dbms_shared_pool.keep(‘address, hash_value’);
11)其他影响library pool的参数
** open_cursors:此参数定义了user进程可分配到的私有SQL area中可以引用的cursor的数量。这些私有SQL area将一直存在,直到cursor被关闭。所以应用中应该及时关闭不用的cursor。
** cursor_space_for_time:其为Boolean值,默认为false,如果设置为true,则共享 SQL areas中将不会把其标识为过期,直到其被关闭。不要将其设置为true,除非v$librarycache中的reload始终保持0时再考虑。当应 用中使用了form或大量的动态SQL,应设置为false。
** session_cached_cursors:此参数用于同一个user会经常解析同一个sql的情况。这会经常出现在form的应用中。当设置了该值,会将关闭的游标的解析仍然cache在内存中,用于后面的软解析。
为了验证设置是否恰当,可以查证v$sesstat中的”session cursor cache hits”和”parse count”的值,如果parses 结果的hits比较小,则考虑增加该值,但是,其增加的开支来自于memory。
3、data dictionary cache及其术语、tuning:
1)了解一些术语:
gets:对某object请求的总次数;
getmisses:显示了data请求造成cache misses的次数
当instance被刚刚startup时,dictionary cache中是空的,所以任何sql都会引起getmisses的增加,但是随着大量data被读入cache,getmisses也会减少。最终,将达到一个稳定的平衡状态。
对data dictionary的调节只能通过间接的调节shared_pool_size。
诊断data dictionary的工具有:
** 视图v$rowcache:主要需要关注的字段是parameter、gets和getmisses
** 在statspack的report中,有相关的内容,其中每个数据字典项的misses的百分比大多数应该< 2%,整个Dictionary Cache应该< 15%。report中的cache usage是cache的实体被使用的次数。
sql>select 1-sum(getmisses)/sum(gets) "dta dic hitration" from v$rowcache;
pct SGA是用于data dictionary cache的SGA的比率。
查看getmisses比gets的总比率的方法:
select parameter, gets, getmisses from v$rowcache where parameter=’dc_objects’ or parameter=’dc_synonyms’;
应尽量将该比率降低到<15%的情况。否则,考虑增加shared_pool_size。
4、UGA和Oracle shared Server
在不同的Oracle Server模式下,UGA的位置也不同,具体如下图:
如果使用的Oracle Shared Server模式,并且没有设置large pool,则user的session data和cursor state将存储在shared pool中,而非dedicated Server模式中的PGA中。sort area和private SQL area包含在session data中。在这种模式的Server中应增加shared_pool_size,PGA将变小。
相关的查询:
select sum(value) || ‘ bytes’ “total session memory” from v$mystat, v$statname
where v$statname.name=’session uga memory’ and v$mystat.statistic#=v$statname.statistic#;
select sum(value) || ‘ bytes’ “total session memory” from v$sesstat, v$statname
where v$statname.name=’session uga memory’ and v$sesstat.statistic#=v$statname.statistic#;
select sum(value) || ‘ bytes’ “total session memory” from v$mystat, v$statname
where v$statname.name=’session uga memory max’ and v$mystat.statistic#=v$statname.statistic#;
5、Large Pool
它是在shared_pool_size之外被分配的,设置它的主要好处在于:
1.它可以用于给I/O服务器进程(dbwr_io_salves,操作系统不支持异步IO,用它来模拟异步)
2.backup、resort进程提供所需的较大的内存,
3.共享服务器的会话内存
4.并行查询消息处理
从而降低shared pool产生碎片的可能及其带来的开支。
它的大小由参数large_pool_size决定。
sql>show parameter large_pool_size
它的使用情况:
sql>select * from v$sgastat where pool='large pool'
1、overview
buffer cache中缓冲了数据文件中的data blocks,是SGA的一部分,可以被所有的进程共享。为了提高性能,Server 进程一次读入多data blocks,DBWn一次写入多个data blocks到data file。
相关的初始化参数有:
DB_CACHE_SIZE:指定默认的buffer pool的size,以bytes为单位。
DB_KEEP_CACHE_SIZE:以bytes为单位,指明keep buffer pool的大小。
DB_RECYCLE_CACHE_SIZE:以bytes为单位,指明recycle buffer pool的大小。
在Oracle8i中,有以下特点:
** buffer cache的大小事由DB_BLOCK_BUFFERS * DB_BLOCK_SIZE决定的;
** 在某个时间点,buffer cache中可能存在同一个data block的多个copies。只有一个是当前实际的block。但是Server为了时间读一致性,结合使用rollback信息,满足不同的查询。
** buffer cache中的blocks通过两个lists进行管理:①LRU list;②dirty list
** buffer cache中的blocks可能有三种状态:①free buffers:其在disk和memory中是一致的,可以被重用;②dirty blocks:disk和memory中的数据不同,只有这些blocks被写入disk,才可被重用;③pinned blocks:当前正在被访问的blocks
2、buffer cache Sizing的参数(9i中)
** 支持多种大小的block,system的block大小仍用db_block_size设置(后面称其为primary block size),但其他tablespace可以有自己不同的block size。
** 默认的与primary block size相关的buffer pool通过db_cache_size设置。DB_KEEP_CACHE_SIZE和DB_RECYCLE_CACHE_SIZE与DB_CACHE_SIZE是独立的。
** 从9i开始对SGA的infrastructure修改变为动态的,可以不必shutdown在startup。
注:由于动态SGA的分配,也引入的新的分配单元granule。可以通过v$buffer_pool监控到buffer cache中granule的分配与回收
1)granule:在9i中,SGA组件分配回收的单位是granule。是一段连续的虚拟内存分配单位。其大小要依赖于对总SGA的估计:如果估计 SGA不足128MB,则设置为4MB,否则设置为16MB。当instance startup时,Server分配granule实体,组成SGA_MAX_SIZE的大小,并分配个SGA的不同组件。最小的SGA中要有3个 granules,分别拥有redo buffer、data buffer cache和shared pool。dba可以通过alter system动态的增加SGA的某个组件的memory大小,但是必须确保有足够的free granules方可成功;memory granules不会被自动释放从而满足其他组件memory增加的需求,可以减小某些组件的memory granules,但是缩减granules必须确保是未使用的,方可成功。在动态添加组件memory时,必须注意:新的cache sizes必须是granule size的整数倍;总的SGA size不可超过MAX_SGA_SIZE;DB_CACHE_SIZE不能设置为0(注意这是9i中,而我现在安装的是11g,情况有所不同啊)
2)动态buffer cache的advisory parameter:通过设置db_cache_advice参数为on,可以提供buffer cache size的合并和预测统计数据,从而辅助DBA调节buffer cache。db_cache_advice的可以设置为:off关闭advisory,并收回相应的memory;ready,关闭advisory, 但保留其memory;on,打开advisory,从而引起一定的cpu和memory开销。为了避免从off过渡到on时引起的ORA-4031 err,需要现将其设置为ready。
3)buffer cache advisory收集的数据信息主要可以通过v$db_cache_advice视图显示
select size_for_estimate, buffers_for_estimate, estd_physical_read_factor,estd_physical_reads
from v$db_cache_advice where name=’DEFAULT’
and block_size = (select value from v$parameter where name = ‘db_block_size’)
and advice_status = ‘ON’;
4)管理database buffer cache
①服务器进程和database buffer cache:当server需要申请一个block时,需要一些步骤:
i)server通过hash函数检查被请求的block是否已经在buffer cache中了。如果被找到了,则将其从LRU list中移动到尾部。这将是逻辑读。如果没被找到,server 进程需要将block从data file中读入。
ii)在从data file中读入时,server 进程将先查找LRU list,找到一个free block。
iii)当查找LRU list时,server 进程同时会将相应的dirty block移动到dirty list中。
iv)如果dirty list超过了其threshold size,server将给DBWn发信号,让其flush在dirty list中的 dirty blocks到data file中。如果server在查找的threshold范围内找不到空闲的block时,DBWn也会受到类似信号,直接将LRU list中的block写入data file。
v)当空闲块被找到之后,server将相应的block读入空闲块。并将其放入LRU list的尾部。
vi)如果block不一致,server将通过当前block和rollback segments重建一个早期版本。
vii)此外,对于DWRn进程,每过3秒,会先将LRU list中的dirty blocks移动到dirty list中,随后将dirty list中的blocks写入data file。
viii)当LGWR进程发起checkpoint signals时,DWRn也会先将LRU list中的dirty blocks移动到dirty list中,随后将dirty list中的blocks写入data file。
ix)当发出命令alter tablespace offline或是进行在线备份时,DBWn也会先将LRU list中的dirty blocks移动到dirty list中,随后将dirty list中的blocks写入data file。
x)在删除object时,DBWn会先将与该object有关的dirty blocks写入磁盘。
xi)在正常的normal、immediate、transactional shutdown时,也会flush data buffer。
2、data buffer size的调节
1)调节的目标是提高data cache中的命中率,从而减少实际的物理I/O。
2)诊断的工具主要是观察cache的命中率(使用v$sysstat和utlbstat.sql与utlestat.sql等)和v$db_cache_advice
select name,value from v$sysstat
where name in (’session logical reads’, ‘physical reads’,
‘physical reads direct’,'physical reads direct (lob)’);
• physical reads: Number of blocks read from disk
• physical reads direct: Number of direct reads, does not require the cache
• physical reads direct (lob): Number of direct reads of large binary objects
• session logical reads: Number of logical read requests
命中率 = 1- (physical reads – physical reads direct – physical reads direct (lob)) / session logical reads
由于v$sysstat中的数据是自instance startup后的累计数据,所以在startup不久就进行此查询获得的结果是没有太大意义的。
v$buffer_pool描述了multiple buffer pools的情况,v$buffer_pool_statistics显示了各个pool的统计情况
select name, physical_reads, db_block_gets,consistent_gets from v$buffer_pool_statistics;
v$bh:描述了保存在cache中的数据blocks
3)tuning:
改变cache的命中率,DBA可以:
①当出现下面的情况时,可以考虑增加buffer cache size:
* cache的命中率不足90%
* 有足够的memory,不会引起额外的缺页现象
* 之前对cache的增加有较好的收效
②如果是由于data的访问特点造成了较低的命中率,可以考虑为不同的blocks使用多buffer pools,并适当的将table配置缓冲到cache中
③此外,对于sorting和parallel reads,如果可以的话,避免其读入cache。
需要注意的是:还需考虑OS的caching的影响。
4)对于命中率主要受到数据访问方式的影响
* 全表扫描
* data和application的设计
* large table的随机访问
* cache的不均匀分布
5)对于cache命中率的评估:
* 如果上一次对data buffer cache的增加没有活动较好的收效,就不要继续对其增加。
* 当查看命中率时,要明确:在全表扫描时遇到的blocks并没有放入到LRU的head部分,所以重复扫描不会造成blocks的缓冲
* 由于设计和应用层造成的重复扫描某个大表时,将会造成性能问题。所以建议尽量在一次读取数据,并适当建立索引。
6)使用multiple buffer pools:当使用multiple buffer pools方法时,objects被分配到那个pool要依靠其访问的方式。有三类buffer pools(我记得在11g中更灵活,不止三类了):
* keep:此类pool用于存放可能被reused的对象。
* recycle:该pool被用于存放reused可能性较小的blocks。
* default:同single buffer cache中的cache是一致的。
主要是通过DB_CACHE_SIZE, DB_KEEP_CACHE_SIZE和DB_RECYCLE_CACHE_SIZE参数设置的。它们都是动态的。在9i中其latches是自动分配 的。在8i中需要用db_block_lru_latches分配,一般是至少每50个blocks分配一个latch。
在使用multiple buffer pools时,可以使用如下sql语句:
CREATE INDEX cust_idx .. STORAGE (BUFFER_POOL KEEP);
ALTER TABLE customer STORAGE (BUFFER_POOL RECYCLE);
ALTER INDEX cust_name_idx STORAGE (BUFFER_POOL KEEP);
当发出alter命令来修改buffer pool时,之前的blocks仍保存在原有的buffer中,新load的才会被cache到新buffer pool中。
因为buffer pool是以segment为单位分配的,有多个segments组成对象就可能被缓冲到不同的buffer pools中。
7)keep buffer pool的使用:在确定keep pool大小时,可以在设计时考虑要把那些object放入该buffer,然后求和即可。具体可以如下:
analyze table hr.countries estimate statistics;
select table_name, blocks from dba_table where owner = ‘HR’ and table_name = ‘COUNTRIES’;
具体可以编写脚本先后对DBA_TABLES, DBA_TAB_PARTITIONS, DBA_INDEXES和DBA_CLUSTERS进行analyze。并根据访问的特性,将部分对象分对象所需要的blocks加总计算。
8)对recycle pool的设置,不要设置过小,以免在事务或SQL还没有被执行完,就已经被换出了。
对其进行监控、并确定其size的工具可以使用v$sysstat中的物理读(physical reads)的统计信息,此外可以使用v$cache视图,它需要在sys下运行catparr.sql脚本进行创建。
v$cache视图从object的角度对buffer pool的blocks的占用进行了统计。其实v$cache是为了Oracle parallel server(OPS)而发布的,在执行catparr.sql时,还创建了其他只在OPS中才有用的视图。它还映射了DB object在datafile中的 extents。当创建了新的object后,需要重新运行该脚本。
在决定recycle pool大小时,可先令recycle pool disable;运行catparr.sql;在DB使用高峰期,运行下述语句计算每个object占用了多少blocks:
select owner#, name, count(*) blocks from v$cache group by owner#, name;
根据不同对象的访问特点,确定哪些应该被放入recycle pool并加总这些对象所占用的blocks,这里我用rcb来表示这个数。分配rcb/4大小的recycle pool。
9)跟踪物理读的方法有很多:用调节工具如Oracle trace manager、sqlplus autotrace或是tkprof运行sql都可以跟踪其执行时的物理读。此外可以查看视图v$sess_io。例如:
select s.username, io.block_gets, io.consistent_gets, io.physical_reads
from v$sess_io io, v$session s where io.sid = s.sid;
10)计算multiple pools下的命中率,可以使用视图v$buffer_pool_statistics
select name, 1-(physical_reads/(db_block_gets+consistent_gets)) “hit_ratio”
from v$buffer_pool_statistics where db_block_gets + consistent_gets > 0;
11)在考虑不同的object使用何种pool时,可从下面的观点出发:
** 对于keep pool:blocks将被频繁使用;segments的大小应该小于default buffer pool大小的10%
** recycle pool:在所属的transaction之外将很少被reused;segment的大小是default buffer pool两倍之多
12)将table caching:如果server通过全表扫描获得数据,blocks将被放到LRUlist的尾部,并可能会很快因缺少free blocks被换出。对此可以选择将整个表cache到list的最近经常使用的部分。具体可以在create table时使用cache关键字,或alter table使用cache,或使用cache的暗示。但是如果将太多的table放入LRU list的most recently used端,可能会使buffer cache非常拥挤。
13)其他cache performance indicators
①select name, value from v$sysstat where name = ‘free buffer inspected’;
如果此获得的等待统计很大,并不断增加需要考虑增加buffer pool。其表示了在查找free buffer是skipped的buffer。之所以skipped,是由于dirty或pinned。
②select event, total_waits from v$system_event where event in (‘free buffer waits’, ‘buffer busy waits’);
除了v$system_event,也可从v$session_wait视图。buffer busy wait表示有多个进程尝试同时访问buffer cache中的部分buffers。通过v$waitstat视图可以查看所有不同buffer被等待统计数据。buffer busy wait中包含的类型有data block、segment header、undo header和undo block。如果在v$waitstat视图中:
* data block(tables或indexes的contention)较大:查看sql是否正确使用了索引;查看是否存在right-hand- indexes的情况(例如索引上的数据是由sequence产生);考虑是否使用segment-space管理或是增加free lists避免多个进程同时向一个block中insert。
* undo header:显示了在回滚段header上冲突:对此如果不使用自动的undo管理,则尝试增加更多的rollback segments。
* undo block:显示了在rollback segment block的冲突:如果不使用自动undo的管理,考虑增大rollback segment的sizes。
* free buffer waits:表示server进程不能找到free buffer了,signal DWRn写入dirty blocks,这个过程引起的等待。对此,可以尝试提升DBWR的效率,另一方面可以考虑是不是buffer cache设置过小了。
引起DBWR高效工作的原因可能是:i/o系统慢;i/o可能在等待某些资源,如latches;buffer cache太小了,造成DBWR需要不断写入脏数据;buffer cache太大了,一个DBWR进程迅速的无法释放足够的buffer。对此,可以进一步查看等待DBWR的session,获知具体的问题。
14)free list:它为每个对象维护一个blocks list用于数据的insert,free lists的数量是可以动态设置的。但是对于单核cpu的系统,使用多free lists的好处不大。调节free list的目的是可以减少insert时对free lists的争用冲突。当使用automatic free space management时,Oracle使用bitmap存储free-list的信息,在数据库上降低了冲突,free lists就可以不用使用了。
** 诊断free list的冲突的存在:
如上,通过v$session_wait获得等待时间具体在等待哪一个block,通过v$waitstat中class为segment header显示了等待freelist的数据,v$system_event视图中event字段为’buffer busy waits’的记录显示freelist的等待的整体信息。我们可以通过dba_segments表查看是那些segments需要增加 freelist。具体的查询语句如下:
select s.segment_name, s.segment_type, s.freelists,
w.wait_time, w.seconds_in_wait, w.state
from dba_segments s, v$session_wait w
where w.event=’buffer busy waits’
and w.p1 = s.header_files and w.p2 = s.header_block;
对freel ist的修改可以使用alter table语句进行动态修改,但是对于自动segment空间管理的模式下是不能对freelist的数量进行修改的。
对于降低buffer busy waits可采取的措施有:
** 对于data blocks:适当改变pctfree或pctused;查看是否有right-hand index;增大initrans的值,降低每个block中存放的记录的数量。
** 对于segment header:使用free lists或增加free lists的数量,使用free list groups。
** 对free list blocks:增加更多的free lists。(在Oracle Parallel Server中,应该确保每个instance有自己的free list group)
15)自动管理空闲空间。从9i开始,可以使用位图对空闲和使用的blocks使用自动空间管理,与free list相比,性能更好。它只能在创建tablespace时指明,此后,建立在该表空间上的所有segment都将以自动空间管理方式管理。
create tablespace tsp datafile ‘/path/datafile.dbf’ size nM
extent management local segment space management auto;
1、alert log file:DBA必须定期查看alert log文件,主要关注的信息主要有:内部的errors(ORA-600)和block corruption errors(ORA-1578或ORA-1498);DB的操作信息,如create database、startup、shutdown、archive log、recover等;对非默认参数的设置。它所记录的checkpoint start和end时间、未完成的checkpoint、归档时间crash的恢复时间是对调优很重要的。
注:alert_sid.log文件的路径由参数background_dump_dest决定;只有在参数log_checkpoints_to_alert被设置为true时,才会将checkpoint动作记录其中。
2、后台进程的trace files:Oracle会将后台进程检测出的errors信息写入trace files,主要用于诊断和查找故障原因,不包含tuning信息。
3、user trace files:它可以通过user或DBA的server processes请求产生,分为instance-level-tracing(通过set sql_trace=true/false设置)和session-level-tracing(通过 dbms_system.set_sql_trace_in_session设置指定session的tracing,或用alter session set sql_trace=true设置当前session的tracing)。user trace files包含了对tracing session的sql的信息。此外,还可用于alter database backup controlfile to trace和alter system set events(这个看到后面再说,现在不同了解)
4、views、utilities和tools:
①v$xxx视图显示了当前system的动态统计信息特别是v$sysstat。但是这些信息时往往是自实例启动以来的一个累计数据。所以有时会比较unhelpful。DBA_xxx视图记录了数据的存储统计信息。
②utlbstat和utlestat工具脚本:主要收集某段时间内的性能指标。
③statspack:其本质与utlbstat和utlestat是一致的,收集性能指标,优点在于它可以把统计信息保存在DB中从而进行不同阶段的比较。
④等待事件wait events:在troubleshooting时需要关注那些进程在等待,并在等待什么资源。
⑤此外还有其他的GUI工具用于DB的诊断。
5、dictionary和特殊的views:
当想要获得数据存储的细节信息时,需要先使用analyze语句对数据进行分析统计,再查看相关的DBA_xxx和特定的views。但这些统计信息是静 态的,只有再次运行analyze才会发生改变,而且对于较大data,用时较大。analyze获得的数据主要在下面的视图中:
DBA_TABLES/DBA_TAB_COLUMNS/DBA_CLUSTERS/DBA_INDEXES/INDEX_STATS/DBA_TAB_HISTOGRAMS/INDEX_HISTOGRAM
这个将会在后面详细讲述。
6、动态troubleshooting和性能视图:
①v$ views:是建立在想x$ tables的基础上,存储在内存结构中,保留instance的信息,所以只要在instance处于nomount的情况即可查询了。它们被罗列在v$fixed_table中,只有sys user可用。
②x$ tables:是动态的,数据随时变化,并且在shutdown时被清除,在startup时重新组装。当设置timed_statistics为true时,它们将保存时间信息。
③ systemwide statistics的收集
所有systemwide statistics的指标类型存放在v$statname中。所有指标的统计值存储在v$sysstat中。例如:select name, class, value from v$sysstat;
一般systemwide statistics的类型为:
• Class 1 refers to general instance activity.
• Class 2 refers to redo log buffer activity.
• Class 4 refers to locking.
• Class 8 refers to database buffer cache activity.
• Class 16 refers to OS activity.
• Class 32 refers to parallelization.
• Class 64 refers to tables access.
• Class 128 refers to debugging purposes.
④SGA全局统计,可以通过查看v$SGASTAT获得。
⑤等待事件的统计:所有可能引起等待的事件类型都存放在v$event_name中。
I) 所有的sessions的累计统计存放在v$system_event,显示了自instance startup后所有等待事件的统计数据。
II) 在troubleshooting时,往往需要知道某些进程在等待什么资源,对此,需要查找与session相关的视图。session的数据是从连接建立开始计算的。视图v$mystat显示了当前连接创建的session的统计信息。 eg. select sid, username, server from v$session where type=’USER’;
v$sesstat中显示了所有session的每个v$sysname的统计信息。如上图。
eg. 下面查询pga使用大约30000 bytes的session
select username,name,value
from v$statname a, v$session b, v$sesstat c
where a.statistic# = c.statistic#
and b.sid = c.sid
and b.type = ‘USER’
and a.name = ’session pga memory’
and c.value > 30000;
III) session等待事件的统计:v$session_event显示了自instance startup后,每个session的所有不同等待统计。v$session_wait显示了active的session正在等待的事件或资源。
7、statspack 这个我在其他文章中介绍了,嘻嘻这里只是提一下。sg中说,可以设置dbms_job,从而每周监控DB一定时间段的性能状态,进行对比从而定期进行tuning。
8、Oracle的等待事件:前面已经叙述了很多了,在这里要指出的是,v$session_wait中的p1text字段和 v$event_name中的parameter1字段是相对应。p2text和p3text也是一样的。此外,动态的初始化参数 timed_statistics设置为true时,将可以取wait_time字段的value。
此外,Oracle还提供了performance manager和Oracle enterprise两个可选包,用于性能的检测和管理。另外,DBA还应该根据自己的需要,创建自己的脚本用于统计,例如查看不同数据文件的使用状况的脚本。
转自:http://blog.chinaunix.net/u2/66903/showart_2004210.html
通过查看v$librarycache视图,可以监控library cache的活动情况,进一步衡量share pool设置是否合理。其中RELOADS列,表示对象被重新加载的次数,在一个设置合理的系统里,这个数值应该接近于0,另外,INVALIDATIONS列表示对象失效的次数,对象失效后,这意味着sql必须要被重新解析。
下述sql查询librarycache的性能状况:
log_checkpoints_to_alert
SELECT NAMESPACE, PINS, PINHITS, RELOADS, INVALIDATIONS
FROM V$LIBRARYCACHE
ORDER BY NAMESPACE;
输出如下:
NAMESPACE PINS PINHITS RELOADS INVALIDATIONS
--------------- ---------- ---------- ---------- -------------
BODY 8870 8819 0 0
CLUSTER 393 380 0 0
INDEX 29 0 0 0
OBJECT 0 0 0 0
PIPE 55265 55263 0 0
SQL AREA 21536413 21520516 11204 2
TABLE/PROCEDURE 10775684 10774401 0 0
TRIGGER 18521844 0 0 0
通过上述查询,可以算出library cache的命中率:
Library Cache Hit Ratio = sum(pinhits) / sum(pins)SUM(PINHITS)/SUM(PINS)
----------------------
.999466248
另外,对于上述的查询,解释如下:
1.对于SQL AREA来说,共执行了21536413次。
2.其中11,204次执行导致了library cache miss。这就需要对这些sql进行重新解析,因为它们已经被age out。
3.sql有2次失效,这同时导致了library cache miss。
4.命中率为99.94%,这意味着只有0.06%的sql需要重复解析。、
另外一个问题,在什么情况下需要调整share pool的大小?
根据performance tuning上的解释,综合我自己的看法,结论如下:
(1)当V$LIBRARYCACHE.RELOADS的值较大,且应用程序已经很好的使用了绑定变量时,可以考虑调大share pool的值。
(2)当V$LIBRARYCACHE.RELOADS的值很小,且share pool里的free值较大,可以考虑减少share pool的值。通过以下查询,获取share pool的free情况:
SELECT * FROM V$SGASTAT
WHERE NAME = 'free memory'
AND POOL = 'shared pool';
POOL NAME BYTES
----------- -------------------------- ----------
shared pool free memory 4928280
另参考:
http://www.itpub.net/thread-269800-1-1.html
--查询跟踪文件位置和文件名脚本
SELECT a.VALUE || b.symbol || c.instance_name || '_ora_' || d.spid || '.trc' trace_file
FROM (SELECT VALUE FROM v$parameter WHERE NAME = 'user_dump_dest') a,
(SELECT SUBSTR (VALUE, -6, 1) symbol FROM v$parameter
WHERE NAME = 'user_dump_dest') b,
(SELECT instance_name FROM v$instance) c,
(SELECT spid FROM v$session s, v$process p, v$mystat m
WHERE s.paddr = p.addr AND s.SID = m.SID AND m.statistic# = 0) d
/
另一种方式:
其实也可以使用控制文件tracefile_identifier 参数来确定跟踪文件的名称,例如:
参数tracefile_identifie可以用来控制生成在user_dump_dest 目录下的trace文件名称
SQL> alter session set sql_trace=true ;
Session altered.
SQL> alter session set tracefile_identifier ='DEBUG';
Session altered.
在user_dump_dest 目录下的trace文件名称定义为:
INSTANCE_PID_ora_TRACEID.trc , 其中INSTANCE为ORACLE的实例名,PID为操作系统的进程ID(V$PROCESS.OSPID),TRACEID就是设置的tracefile_identifie值。
--读取当前session设置的参数(10g以前)www.6zhang.com
set feedback off
set serveroutput on
declare
event_level number;
begin
for event_number in 10000..10999 loop
sys.dbms_system.read_ev(event_number,event_level);
if (event_level > 0) then
sys.dbms_output.put_line('Event '||to_char(event_number)||
'is set at level '||to_char(event_level));
end if ;
end loop;
end;
/
转: http://hi.baidu.com/windy8848/blog/item/3844fef25e7a8114b07ec51e.html
1.监控事例的等待:
select event,sum(decode(wait_time,0,0,1)) prev, sum(decode(wait_time,0,1,0)) curr,count(*)
from v$session_wait
group by event order by 4;
2.回滚段的争用情况:
select name,waits,gets,waits/gets ratio from v$rollstat a,v$rollname b where a.usn=b.usn;
3.监控表空间的I/O比例:
col name format a10
col file format a50
select df.tablespace_name name,df.file_name "file",f.phyrds pyr,f.phyblkrd pbr,f.phywrts pyw,
f.phyblkwrt pbw
from v$filestat f,dba_data_files df
where f.file#=df.file_id
4.监控文件系统的I/O比例:
select substr(a.file#,1,2) "#",substr(a.name,1,30) "name",a.status,a.bytes,
b.phyrds,b.phywrts
from v$datafile a,v$filestat b
where a.file#=b.file#
5.在某个用户下找所有的索引:
select user_indexes.table_name, user_indexes.index_name,uniqueness, column_name
from user_ind_columns, user_indexes
where user_ind_columns.index_name = user_indexes.index_name
and user_ind_columns.table_name = user_indexes.table_name
order by user_indexes.table_type, user_indexes.table_name,
user_indexes.index_name, column_position;
6. 监控 SGA 的Buffer Cache 中的命中率
/*select a.value + b.value "logical_reads", c.value "phys_reads",
round(100 * ((a.value+b.value)-c.value) / (a.value+b.value)) "BUFFER HIT RATIO"
from v$sysstat a, v$sysstat b, v$sysstat c
where a.statistic# = 38 and b.statistic# = 39
and c.statistic# = 40;
*/
select 1-((a.value-b.value-c.value)/d.value)
from v$sysstat a,v$sysstat b,v$sysstat c,v$sysstat d
where a.name='physical reads' and
b.name='physical reads direct' and
c.name='physical reads direct (lob)' and
d.name='session logical reads';
7. 监控 SGA 中字典缓冲区的命中率
select parameter, gets,Getmisses , getmisses/(gets+getmisses)*100 "miss ratio",
(1-(sum(getmisses)/ (sum(gets)+sum(getmisses))))*100 "Hit ratio"
from v$rowcache
where gets+getmisses <>0
group by parameter, gets, getmisses;
8. 监控 SGA 中共享缓存区的命中率,应该小于1%
select sum(pins) "Total Pins", sum(reloads) "Total Reloads",
sum(reloads)/sum(pins) *100 libcache
from v$librarycache;
#I f the reloads-to-pins ratio is greater than 1%,increase the value of the SHARED_POOL_SIZE parameter.
来自OCP9i教材
select sum(pinhits-reloads)/sum(pins) "hit radio",sum(reloads)/sum(pins) "reload percent"
from v$librarycache;
9. 显示所有数据库对象的类别和大小
select count(name) num_instances ,type ,sum(source_size) source_size ,
sum(parsed_size) parsed_size ,sum(code_size) code_size ,sum(error_size) error_size,
sum(source_size) +sum(parsed_size) +sum(code_size) +sum(error_size) size_required
from dba_object_size
group by type order by 2;
10. 监控 SGA 中重做日志缓存区的命中率,应该小于1%
SELECT name, gets, misses, immediate_gets, immediate_misses,
Decode(gets,0,0,misses/gets*100) ratio1,
Decode(immediate_gets+immediate_misses,0,0,
immediate_misses/(immediate_gets+immediate_misses)*100) ratio2
FROM v$latch WHERE name IN (''redo allocation'', ''redo copy'');
11. 监控内存和硬盘的排序比率,最好使它小于 .10,增加 sort_area_size
SELECT name, value FROM v$sysstat WHERE name IN (''sorts (memory)'', ''sorts (disk)'');
12. 监控当前数据库谁在运行什么SQL语句
SELECT osuser, username, sql_text from v$session a, v$sqltext b
where a.sql_address =b.address order by address, piece;
13. 监控字典缓冲区
SELECT (SUM(PINS - RELOADS)) / SUM(PINS) "LIB CACHE" FROM V$LIBRARYCACHE;
SELECT (SUM(GETS - GETMISSES - USAGE - FIXED)) / SUM(GETS) "ROW CACHE" FROM V$ROWCACHE;
SELECT SUM(PINS) "EXECUTIONS", SUM(RELOADS) "CACHE MISSES WHILE EXECUTING" FROM V$LIBRARYCACHE;
后者除以前者,此比率小于1%,接近0%为好。
SELECT SUM(GETS) "DICTIONARY GETS",SUM(GETMISSES) "DICTIONARY CACHE GET MISSES"
FROM V$ROWCACHE
14. 找ORACLE字符集
select * from sys.props$ where name=''NLS_CHARACTERSET'';
15. 监控 MTS
select busy/(busy+idle) "shared servers busy" from v$dispatcher;
此值大于0.5时,参数需加大
select sum(wait)/sum(totalq) "dispatcher waits" from v$queue where type=''dispatcher'';
select count(*) from v$dispatcher;
select servers_highwater from v$mts;
servers_highwater接近mts_max_servers时,参数需加大
16. 碎片程度
select tablespace_name,count(tablespace_name) from dba_free_space group by tablespace_name
having count(tablespace_name)>10;
alter tablespace name coalesce;
alter table name deallocate unused;
create or replace view ts_blocks_v as
select tablespace_name,block_id,bytes,blocks,''free space'' segment_name from dba_free_space
union all
select tablespace_name,block_id,bytes,blocks,segment_name from dba_extents;
select * from ts_blocks_v;
select tablespace_name,sum(bytes),max(bytes),count(block_id) from dba_free_space
group by tablespace_name;
查看碎片程度高的表
SELECT segment_name table_name , COUNT(*) extents
FROM dba_segments WHERE owner NOT IN (''SYS'', ''SYSTEM'') GROUP BY segment_name
HAVING COUNT(*) = (SELECT MAX( COUNT(*) ) FROM dba_segments GROUP BY segment_name);
17. 表、索引的存储情况检查
select segment_name,sum(bytes),count(*) ext_quan from dba_extents where
tablespace_name=''&tablespace_name'' and segment_type=''TABLE'' group by tablespace_name,segment_name;
select segment_name,count(*) from dba_extents where segment_type=''INDEX'' and owner=''&owner''
group by segment_name;
18、找使用CPU多的用户session
12是cpu used by this session
select a.sid,spid,status,substr(a.program,1,40) prog,a.terminal,osuser,value/60/100 value
from v$session a,v$process b,v$sesstat c
where c.statistic#=12 and c.sid=a.sid and a.paddr=b.addr order by value desc;
20.监控log_buffer的使用情况:(值最好小于1%,否则增加log_buffer 的大小)
select rbar.name,rbar.value,re.name,re.value,(rbar.value*100)/re.value||''%'' "radio"
from v$sysstat rbar,v$sysstat re
where rbar.name=''redo buffer allocation retries''
and re.name=''redo entries'';
21、查看运行过的SQL语句:
SELECT SQL_TEXT
FROM V$SQL
22.
oracle等待事件检测
使用ORACLE的等待事件检测性能瓶颈
案例分析:以sys用户登录
1.首先从整个系统考虑,找到从系统启动以来最主要的等待事件是什么?
SQL>@syssum.sql
2.更为重要的是,在应用执行的时候,最主要的等待事件是什么?
SQL>@cr_base.sql
SQL>@in_base.sql
执行用户应用操作一段时间后
SQL>@re_base.sql
3. 查询产生等待事件最多的哪些会话??(以等待事件log file parallel write为例)
SQL>@seswt.sql log
4.查找哪些语句引起的等待,按照最消耗资源的顺序排列显示
SQL>@sqls1.sql 1000 1000
--以最消耗资源会话13为例
SQL>@sqlst.sql 13
查找出相关sql语句的地址比如:2168CBB8
SQL>@sqls2.sql 2168CBB8
附录:脚本
--syssum.sql
set linesize 200
col "Wait Event" for a45
select EVENT "Wait Event",TIME_WAITED "Time Waited",
TIME_WAITED/(SELECT SUM(TIME_WAITED) FROM v$system_event) "%Time waited",
TOTAL_WAITS "Waits",
TOTAL_WAITS/(SELECT SUM(TOTAL_WAITS) FROM V$system_event) "%Waited"
from v$system_event
order by 3 desc;
--cr_base.sql
create table sys_b(
event varchar2(64),
time_waited number,
total_waits number);
create table sys_e(
event varchar2(64),
time_waited number,
total_waits number);
--in_base.sql
insert into sys_b
select event,time_waited,total_waits
from v$system_event;
--re_base.sql
insert into sys_e
select event,time_waited,total_waits
from v$system_event;
create table sys_dif
as
select e.event ,e.time_waited-b.time_waited TIME_WAITED,
e.total_waits-b.total_waits TOTAL_WAITS
from sys_b b,sys_e e
where b.event=e.event;
select event "Wait Event",time_waited "Time Waited",
time_waited/(select sum(time_waited) from sys_dif) "%Time waited",
total_waits "Waits",
total_waits /(select sum(total_waits) from sys_dif) "%Waited"
from sys_dif
order by 3 desc;
drop table sys_dif;
drop table sys_b;
drop table sys_e;
等待事件的等待次数
--seswa.sql
select event "Wait Event",
count(seconds_in_wait) "Waited So Far(sec)",
count(sid) "Num Sess Waiting"
from v$session_wait
group by event;
--seswt.sql
select sid,event "Wait Event",state "Wait Stat",
wait_time "W'd So Far(secs)", seconds_in_wait "Time W'd (secs)"
from v$session_wait
where event like '&a'
order by 5;
--sqls1.sql
select * from
(select address "Stmt Addr",
disk_reads "Disk RDS",
buffer_gets "Buff Gets",
sorts "Sorts",
executions "Runs",
loads "Body Loads"
from v$sqlarea where disk_reads > &A
order by disk_reads )
where rownum < &B;
--sqlst.sql
select cpu.sid "SID",cpu.username "USER Name",cpu.value "CPU(sec)",
reads.value "IO Read(k)",writes.value "IO Write(k)"
from
(select a.sid sid,a.username username,b.name,c.value value, a.serial# serial#
from v$session a,v$statname b,v$sesstat c
where a.sid=c.sid and b.statistic#=c.statistic# and b.name='CPU used by this session') cpu,
(select a.sid,a.username,b.name,c.value value from v$session a,v$statname b ,v$sesstat c
where a.sid=c.sid and b.statistic#=c.statistic# and b.name='physical reads') reads,
(select a.sid,a.username,b.name,c.value value from v$session a,v$statname b ,v$sesstat c
where a.sid=c.sid and b.statistic#=c.statistic# and b.name='physical writes') writes
where cpu.sid=reads.sid and reads.sid=writes.sid and cpu.username is not null;
--sqls2.sql
select sql_text "SQL Statement Text"
from v$sqlarea
where ADDRESS='&a';
转:http://blog.csdn.net/biti_rainy/archive/2004/06/30/30974.aspx
关于 show sga 结果的描述
Total System Global Area AAAAA bytes
Fixed Size BBBBB bytes
Variable Size CCCCC bytes
Database Buffers DDDDD bytes
Redo Buffers EEEEE bytes
fixes size : oracle 的不同平台和不同版本下可能不一样,但对于确定环境是一个固定的值,里面存储了 SGA 各部分 组件 的信息,可以看作 引导 建立 SGA 的区域
Variable Size : 包括 shared pool ,java pool ,large pool, 管理DB_BLOCK_BUFFERS 的内存,管理控制文件信息的内存,等等其他管理和控制 oracle 内部结构的内存
redo buffer
分
1: 设置参数
SQL> show parameters log_buffer
NAME TYPE VALUE
------------------------------------ ------- ------------------------------
log_buffer integer 524288
2:日志内存大小
SQL> select * from v$sgastat where name like '%log%';
POOL NAME BYTES
----------- -------------------------- ----------
log_buffer 656384
3 : 为了保护日志内存,而增加了辅助的内存,也就是保护页
SQL> show sga
Total System Global Area 496049552 bytes
Fixed Size 454032 bytes
Variable Size 109051904 bytes
Database Buffers 385875968 bytes
Redo Buffers 667648 bytes
SQL>
对于数据库来说,在不同 的平台下
log_buffer 是离散的 一组值,假设是集合 R,并且不是按照 os blockck 或者 db block 为步长增加的,(比如可能是 65k,128k,512k ,641k....这样的值) 当设置参数为某个值的时候,数据库选择的实际大小是 大于等于 该值 的 min(R) ,根据这组值,比如你设置了 log_buffer = 600k ,则实际选择的是641 k
然后,在实际分配内存的时候,为了 给 log buffer 做一些保护,还另外分配了一小部分空间,通常是 11 k 大小。则有641+11 = 652 k ,这才是 最后真正的 内存大小 ,也就是 show SGA 时候显示大小
本文来自CSDN博客,转载请标明出处:http://blog.csdn.net/biti_rainy/archive/2004/06/30/30974.aspx
转:
http://carson.ycool.com/post.1264755.html
- oracle 采用 latch、enqueue、distribute lock 、global lock等来进行‘锁’的管理
- Latches are low level serialization mechanisms used to protect shared data structures in the SGA. A latch is a type of a lock that can be very quickly acquired and freed
- Enqueue 是另外一种锁,An enqueue is a more sophisticated mechanism which permits several concurrent processes to have varying degree of sharing of "known" resources. Any object which can be concurrently used, can be protected with enqueues. 它于 latch的不同之处在于,它是OS级别的,由OS的lock manger 来进行管理,并且严格遵守FIFO,而latch 确不然,很有可能是先申请latch的进程,却最后得到latch
- A process acquires a latch when working with a structure in the SGA (System Global Area). 在process 工作的过程中持有,在工作结束的时候释放,在process 意外结束的时候,由PMON 来收拾残局
- Latch 有两种,一个是willing-to-wait,一个是no wait
- 如果一个process 申请latch 没有申请的到,就开始spin,spin的次数有_spin_count参数来决定,当达到_spin_count的值时,就开始休眠,休眠时间为0.01秒
- 主要相关视图:v$latch,v$latch_misses,v$latch_name,
主要的Latch
- Cache buffers chains latch: 产生:在data buffer 有block 被access的时候产生; 解决: 减少这个latch 竞争就是要减少sql 的逻辑IO
- Cache buffers LRU chain latch: 产生: 1、当一个新的block 被读到data buffer 的时候 2、data 从databuffer 写到disk 3、对Data buffer 进行scan 以获得那些block是dirty 时候; 解决: 1、加大data buffer,但是这对于FTS 比较多的系统并不中用 2、设置Multiple buffer pools 3、加大DB_BLOCK_LRU_LATCHES 参数的值 4、always ensure DB_BLOCK_LRU_STATISTICS is set to FALSE
- Redo allocation latch: 产生:在log buffer中分配空间的时候获得,一个instance 只有一个Redo allocation latch ; 解决:1、加大log buffer 2、设置 nologging 选项
- Redo copy latch: 产生:当系统将redo records 写到log buffer 的时候产生;
- Library cache latch: 产生:The library cache latches 保护cached 的sql 语句,以及cached 的object 的定义,它是当将新的解析的sql 语句 插入到library cache 的时候产生,该值过大,表示hard parse 过多; 解决: 1、绑定变量 2、 适当加大shared pool 3、加大_KGL_LATCH_COUNT 参数
- Library cache pin latch: 产生: 当cached sql 语句再次被执行的时候产生,这个latch 的严重丢失表明sql 被严重的多次执行; 解决: 几乎没有办法来解决该问题,一个效果不大的办法是书写:a.b 类似的sql
- Shared pool latch: the shared pool latchis used to protect critical operations when allocating and freeing memory in the shared pool. 解决: 1、绑定变量 2、避免hard parse 3、尽量一次解析多次执行 4、适当的shared_pool 5、MTS
- Row cache objects latch: 产生: 当用户进程读取数据字典定义的时候 解决: 加大shared_pool
如果一个系统中的CPU 很繁忙,就应该减少_SPIN_COUNT 的值,反之,就应该增加
确认实例并删除数据库:
$ more /etc/oratab
$ . /usr/local/bin/oraenv
$ dbca (xmanager里,执行删除)
删除oracle软件:
$ export ORACLE_HOME=/u01/app/oracle/product/1020/db_1
$ $ORACLE_HOME/bin/emctl stop dbconsole
$ ps -ef | grep dbconsole | grep -v grep (检查)
$ $ORACLE_HOME/bin/lsnrctl stop
$ ps -ef | grep tnslsnr | grep -v grep (检查)
$ $ORACLE_HOME/bin/isqlplusctl stop
$ ps -ef | grep isqlplus | grep -v grep (检查)
$ $ORACLE_HOME/bin/searchctl stop
$ ps -ef | grep ultrasearch | grep -v grep (检查)
$ $ORACLE_HOME/oui/bin/runInstaller (xmanager里,执行删除操作)
=================================================================================
1.$ORACLE_BASE/product & oraInventory
2./etc/oratab
3./tmp/ora相关
4./opt/orcl*
5./usr/local/bin/下的几个文件可以不删除,但注意下次跑root.sh时,提示覆盖文件时选择y
/usr/local/bin下的3个受影响的文件是
dbhome
oraenv
coraenv
下次安装跑root.sh时,注意选择覆盖
================================================================================
1.用oracle用户登录
如果要再次安装, 最好先做一些备份工作。
包括用户的登录脚本,数据库自动启动关闭的脚本,和Listener自动启动的脚本。
要是有可能连创建数据库的脚本也保存下来
2.使用SQL*PLUS停止数据库
[oracle@ora920 oracle]$ sqlplus /nolog
SQL> connect / as sysdba
SQL> shutdown [immediate]
SQL> exit
3.停止Listener
[oracle@ora920 oracle]$ lsnrctl stop
4.停止HTTP服务
[oracle@ora920 oracle]$ $ORACLE_HOME/Apache/Apache/bin/apachectl stop
5.用su或者重新登录到root(如想重新安装可以保留oracle用户,省得输入环境变量了)
6.将安装目录删除
[root@ora920 /root]# rm -rf /opt/oracle/
7.将/usr/bin下的文件删除
[root@ora920 /root]# rm /usr/bin/dbhome
[root@ora920 /root]# rm /usr/bin/oraenv
[root@ora920 /root]# rm /usr/bin/coraenv
8.将/etc/oratab删除
[root@ora920 /root]# rm /etc/oratab
9.将/etc/oraInst.loc删除
[root@ora920 /root]# rm /etc/oraInst.loc
10.将oracle用户删除(若要重新安装,可以不删除)
[root@ora920 /root]# userdel –r oracle
11.将用户组删除(若要重新安装,可以不删除)
[root@ora920 /root]# groupdel oinstall
[root@ora920 /root]# groupdel dba
12.将启动服务删除
[root@ora920 /root]# chkconfig --del dbora
rem run rman
rman target / cmdfile=G:\oracle\ msglog= e:/orabackup/full_rmanlog%date:~4,10%.log
run{
allocate channel c1 type disk;
backup
incremental level=0
format 'G:\inc0_%u_%T'
tag sun_inc0
database
plus archivelog delete input;
release channel c1;
}
run{
allocate channel c1 type disk;
backup
incremental level=2
format 'G:\inc2_%u_%T'
tag mon_inc2
database
plus archivelog delete input;
release channel c1;
}
run{
allocate channel c1 type disk;
backup
incremental level=2
format 'G:\inc2_%u_%T'
tag tue_inc2
database
plus archivelog delete input;
release channel c1;
}
run{
allocate channel c1 type disk;
backup
incremental level=1
format 'G:\inc1_%u_%T'
tag wed_inc1
database
plus archivelog delete input;
release channel c1;
}
run{
allocate channel c1 type disk;
backup
incremental level=2
format 'G:\inc2_%u_%T'
tag thu_inc2
database
plus archivelog delete input;
release channel c1;
}
run{
allocate channel c1 type disk;
backup
incremental level=2
format 'G:\inc2_%u_%T'
tag fri_inc2
database
plus archivelog delete input;
release channel c1;
}
run{
allocate channel c1 type disk;
backup
incremental level=2
format 'G:\inc2_%u_%T'
tag sat_inc2
database
plus archivelog delete input;
release channel c1;
}
run {
set archivelog destination to 'g:\';
restore archivelog sequence 16;
}
startup mount;
--如果是控制文件丢失
sql>startup nomount;
sql>
DECLARE
DEVTYPE VARCHAR2(256);
DONE BOOLEAN;
BEGIN
DEVTYPE:=DBMS_BACKUP_RESTORE.DEVICEALLOCATE(NULL);
DBMS_BACKUP_RESTORE.RESTORESETDATAFILE;
DBMS_BACKUP_RESTORE.RESTORECONTROLFILETO('G:\oracle\oradata\orcl\CONTROL01.CTL');
DBMS_BACKUP_RESTORE.RESTOREBACKUPPIECE('G:\CTRL_C-1231731297-20091202-03',DONE=>done);
DBMS_BACKUP_RESTORE.RESTORESETDATAFILE; DBMS_BACKUP_RESTORE.RESTORECONTROLFILETO('G:\oracle\oradata\orcl\CONTROL02.CTL');
DBMS_BACKUP_RESTORE.RESTOREBACKUPPIECE('G:\CTRL_C-1231731297-20091202-03',DONE=>done);
DBMS_BACKUP_RESTORE.RESTORESETDATAFILE; DBMS_BACKUP_RESTORE.RESTORECONTROLFILETO('G:\oracle\oradata\orcl\CONTROL03.CTL');
DBMS_BACKUP_RESTORE.RESTOREBACKUPPIECE('G:\CTRL_C-1231731297-20091202-03',DONE=>done);
DBMS_BACKUP_RESTORE.DEVICEDEALLOCATE(NULL);
END;
/
sql>alter database mount;
restore database;
近期研究备份和恢复卓有成效,正好对日志恢复有些生疏,看到EYGLE里有篇好文,先借过用用。
http://space.itpub.net/8334342/viewspace-523080
当数据库出现问题,但不需要restore只需recover时,发现要用到的archivelog已经备份并删除了,因为我们备份archivelog一般是采用delete input的,
4z9k�V C�@ s2t0这时先需要restore archivelog,然后才能做recover,下面介绍一下restore archivelog的用法:
restore archivelog后面可以跟的参数有"all, from, high, like, logseq, low, scn, sequence, time, until"
$d"~2o�|�A g�z3\0现在举一列子说明:ITPUB个人空间�K�x�v#D'^�D�N
1.列出已经备份的archivelog
�I'@ `�{�t�}0list backup of archivelog all;
:k�B�P3g�U(].y�B02.预览恢复出程,但不真正恢复
�@5X�t�p4z0可以在你执行恢复前先看看恢复过程,也可以验证一下你的语法是否写对
8d6k5{�@�\)h�Y B0restore archivelog all preview; 即在你要执行的restore archivelog命令后加previewITPUB个人空间�m8U P C�f;K/h
restore archivelog sequence 18 preview;ITPUB个人空间2i9W�_%C:c
3.恢复指定时间范围的archivelog
�`�o#C�m e M�k.Z03.1 显示2008-08-13 10:00:00到2008-08-13 11:00:00之间的archivelogITPUB个人空间�s�q�P8I�G
list backup of archivelog time between "to_date('2008-08-13 10:00:00','yyyy-mm-dd hh24:mi:ss')" and "to_date('2008-08-13 11:00:00','yyyy-mm-dd hh24:mi:ss')";ITPUB个人空间�w7V�I�K Z�v�j,n1q o*O
3.2 预览恢复2008-08-13 10:00:00到2008-08-13 11:00:00之间的archivelogITPUB个人空间3e�P"q n,}4G8Z�D3g
restore archivelog time between "to_date('2008-08-13 10:00:00','yyyy-mm-dd hh24:mi:ss')" and "to_date('2008-08-13 11::00','yyyy-mm-dd hh24:mi:ss')" preview;ITPUB个人空间#Q�@6r'O y�W.S
3.3 真正恢复2008-08-13 10:00:00到2008-08-13 11:00:00之间的archivelogITPUB个人空间�Q9v+F�s�]�d�}�E�Y�i;E5T
restore archivelog time between "to_date('2008-08-13 10:00:00','yyyy-mm-dd hh24:mi:ss')" and "to_date('2008-08-13 11::00','yyyy-mm-dd hh24:mi:ss')"ITPUB个人空间*x�J�[�m2m�U%m
4.恢复指定的archivelog
/c Z#W.ci \�A�s1g6r ~�N Z0restore archivelog sequence 18; 恢复sequence为18的archivelog
*N�L�O:A�U3k0y�Q5Y05.restore archivelog like恢复模糊查询出来的archivelog,这个只能用于通过catalog的备份,用nocatalog的会报错
6H A `�l�{4s4W6M�i0restore archivelog like '%18%';
C o3j*f K�O2d/B�[6k;O06.恢复指定sequence范围的archivelog
:D�Z5L5K+N�{0restore archivelog from sequence 18 until sequence 20;
7I�r,V�s P x�c0或restore archivelog low sequence 18 high sequence 20;ITPUB个人空间�m } ~*I�b%X5m�z
或restore archivelog low logseq 18 high logseq 20;
3y�@*n�P�P2y�k07.指定archivelog的恢复目的地,如你想把archivelog恢复到一个临时目录时有用,但这个必须包含在run{}里面才能用ITPUB个人空间#~2D4f5P a�w�r
set archivelog destination to 'e:\temp';
以上基本上可以解决你恢复archivelog的需求,我是在10.2.0.4版本中测试通过的,欢迎大家补充,转载请说明出处.
---------------------------------------------ITPUB个人空间+|,S�D�L.br�F
以下部分是在本人正式环境中遇到的实际情况,非转载:
�}%|�Q$G3w�[�c0备份日志中有以下内容:
�A z�Z�Y�i�\0通道 t1: 正在指定备份集中的存档日志
#m�f l�j j�[ l�L�g0i�_0输入存档日志线程 =1 序列 =18070 记录 ID=35794 时间戳=671966051
�e�g/s&[#J9X�T�A0输入存档日志线程 =1 序列 =18071 记录 ID=35796 时间戳=671966351ITPUB个人空间3K xs(E y5Z4n?
输入存档日志线程 =1 序列 =18072 记录 ID=35798 时间戳=671966652ITPUB个人空间$w�`�S$T`2D @�Z1e'r
输入存档日志线程 =1 序列 =18073 记录 ID=35800 时间戳=671966952
4Z�~/_*T�X�l0输入存档日志线程 =1 序列 =18074 记录 ID=35802 时间戳=671967249
*R1t:\!A�N n�r�h0输入存档日志线程 =1 序列 =18075 记录 ID=35804 时间戳=671967550
8p�~�].O�C9P�d0输入存档日志线程 =1 序列 =18076 记录 ID=35806 时间戳=671967850
�{;] a�?�M*R6j�j�X C0输入存档日志线程 =1 序列 =18077 记录 ID=35808 时间戳=671968151ITPUB个人空间�g;BE�G2c:j
输入存档日志线程 =1 序列 =18078 记录 ID=35810 时间戳=671968451ITPUB个人空间�`.X�D�t6S @)c6a
5h*G�I5i+W+u:R6g0单独恢复18071 到18076ITPUB个人空间'J N1g+C x�H�w l4`3q
rman> run
n*G j�V2~ g0{ allocate channel t1 type 'sbt_tape' parms 'ENV=(tdpo_optfile=/usr/tivoli/tsm/client/oracle/bin64/tdpo.opt)';ITPUB个人空间�w�k�u�w�|-B�\
restore archivelog from logseq 18071 until logseq 18076 ;
,Y�m"i�p�\9C�Q4M*n0release channel t1;
�^(T�s�t B-C�s0}
ITPUB个人空间5^�J v*m�Y�M'|�j�K3O+g+?
ITPUB个人空间�y9d�n8O2|#V.w(M,y�I
经过在线环境的实地测试,以上脚本可行
在归档模式下的Rman全恢复
cmd
$>rman target nocatelog
RMAN> run{allocate channel c1 type disk;
CONFIGURE CONTROLFILE AUTOBACKUP ON; #备份
CONFIGURE CONTROLFILE AUTOBACKUP FORMAT FOR DEVICE TYPE DISK TO 'G:\ctrl_%F';
backup database format 'G:\orcl_%U';
sql 'alter system archive log current';
release channel c1;}
==
修改数据
sql>shutdown immediate
==
$>rman target nocatelog
rman>startup mount; --必须启动到mount
rman>restore database;
rman>recover database;
rman>run {sql'alter database open';} 如果在非归档的模式下:
run {sql'alter database open resetlogs';} 并且修改的数据找不回来。
在归档模式下的基于时间点的不完全恢复
sql>shutdown immediate
==
对数据进行全备份 full backup database
==
sql> startup
==
修改数据
update test2 set.. 10:44:01
drop table test1 10:45:05 ==>错误操作
==
sql>shutdown immediate
==
备份事故现场
注意:
在实际生产环境中,在做恢复的之前,一定要全备份目前的数据库,即:保存现场
因为在恢复的过程不一定是一次可以恢复到我想得到状态。
==
restore datafile
现将之前全备份的所有数据文件(*.dbf)Copy回,不要恢复control file, redo logs等
==
sql>startup mount
sql>recover database until time '2009-11-27:10:45:01'
Media recovery complete.
sql>alter database open resetlogs;
Database altered
sql>conn test/test
sql>select table_name from user_tables;
TABLE_NAME
----------
TEST
TEST1
TEST2
==
这里发现之前drop 掉的table test1没有被删除了。
接下来又要对整个数据进行一次全备份,因为以前的归档日志和数据都没有用了。
==
在归档模式下的基于Cancel的不完全恢复,当前在线日志损坏
sql>shutdown immediate
==
对数据进行全备份 full backup database
==
sql> startup
==
当前状态
==
sql> select table_name from user_tables
TABLE_NAME
----------
TEST
sql> select * from v$log;
GROUP# THREAD# SEQUENCE# BYTES MEMBERS ARC STATUS FIRS
---------- ---------- ---------- ---------- ---------- --- ---------------- ----
1 1 0 104857600 1 YES UNUSED
2 1 0 104857600 1 YES UNUSED
3 1 1 104857600 1 NO CURRENT 26-N
sql> alter system switch logfile;
sql> select * from v$log;
GROUP# THREAD# SEQUENCE# BYTES MEMBERS ARC STATUS FIRS
---------- ---------- ---------- ---------- ---------- --- ---------------- ----
1 1 2 104857600 1 NO CURRENT 27-N
2 1 0 104857600 1 YES UNUSED
3 1 1 104857600 1 YES ACTIVE 26-N
sql> create table test2 as select * from test;
sql> select table_name from user_tables
TABLE_NAME
----------
TEST
TEST2
sql> alter system switch logfile;
sql> select * from v$log;
GROUP# THREAD# SEQUENCE# BYTES MEMBERS ARC STATUS FIRS
---------- ---------- ---------- ---------- ---------- --- ---------------- ----
1 1 2 104857600 1 YES ACTIVE 27-N
2 1 3 104857600 1 NO CURRENT 27-N
3 1 1 104857600 1 YES INACTIVE 26-N
sql> create table test3 as select * from test;
sql> select table_name from user_tables;
TABLE_NAME
-----------
TEST
TEST2
TEST3
sql> alter system switch logfile;
sql> select * from v$log; ==>日志正好走完一个循环
GROUP# THREAD# SEQUENCE# BYTES MEMBERS ARC STATUS FIRS
---------- ---------- ---------- ---------- ---------- --- ---------------- ----
1 1 2 104857600 1 YES INACTIVE 27-N
2 1 3 104857600 1 YES ACTIVE 27-N
3 1 4 104857600 1 NO CURRENT 27-N
sql> create table test4 as select * from test;
sql> select table_name from user_tables;
TABLE_NAME
-----------
TEST
TEST2
TEST3
TEST4
==
修改数据
==
sql>shutdown immediate
==
备份事故现场
注意:
在实际生产环境中,在做恢复的之前,一定要全备份目前的数据库,即:保存现场
因为在恢复的过程不一定是一次可以恢复到我想得到状态。
==
restore datafile
现将之前全备份的所有数据文件(*.dbf)Copy回,不要恢复control file, redo logs等
并模拟当前日志文件丢失,可以直接删除
==
sql>startup mount
sql>recover database until cancel
ORA-00279: change 220847 generated at 11/27/2009 08:28:25
ORA-00289: suggestion : G:\ORACLE\ARC\ORCL_1_1.ARC
ORA-00280: change 220847 for thread 1 is in sequence #1
Specify log: {<RET>=suggested | filename | AUTO | CANCEL}
输入:auto
ORA-00279: change 221514 generated at 11/27/2009 13:29:04 needed for thread 1
ORA-00289: suggestion : G:\ORACLE\ARC\ORCL_1_2.ARC
ORA-00280: change 221514 for thread 1 is in sequence #2
ORA-00278: log file 'G:\ORACLE\ARC\ORCL_1_1.ARC' no longer needed for this
recovery
ORA-00279: change 222100 generated at 11/27/2009 13:32:35 needed for thread 1
ORA-00289: suggestion : G:\ORACLE\ARC\ORCL_1_3.ARC
ORA-00280: change 222100 for thread 1 is in sequence #3
ORA-00278: log file 'G:\ORACLE\ARC\ORCL_1_2.ARC' no longer needed for this
recovery
ORA-00279: change 222367 generated at 11/27/2009 13:34:18 needed for thread 1
ORA-00289: suggestion : G:\ORACLE\ARC\ORCL_1_4.ARC
ORA-00280: change 222367 for thread 1 is in sequence #4
ORA-00278: log file 'G:\ORACLE\ARC\ORCL_1_3.ARC' no longer needed for this
recovery
ORA-00308: cannot open archived log 'G:\ORACLE\ARC\ORCL_1_4.ARC'
ORA-27041: unable to open file
OSD-04002: unable to open file
O/S-Error: (OS 2) 靠靠靠靠靠
SQL> recover database until cancel #再次输入
ORA-00279: change 222367 generated at 11/27/2009 13:34:18 needed for thread 1
ORA-00289: suggestion : G:\ORACLE\ARC\ORCL_1_4.ARC
ORA-00280: change 222367 for thread 1 is in sequence #4
Specify log: {<RET>=suggested | filename | AUTO | CANCEL}
cancel #选Cancel因为此处ORCL_1_4.ARC没有归档
Media recovery cancelled.
SQL> alter database open resetlogs; #一定要 open resetlogs 重新生成log文件
Database altered.
sql>conn test/test
sql>select table_name from user_tables;
TABLE_NAME
----------
TEST
TEST1
TEST2
TEST3
==
这里发现在恢复前当前日志的操作没有办法救回。TEST4没有办法找回了。
接下来又要对整个数据进行一次全备份,因为以前的归档日志和数据都没有用了。
==
数据库今天宕机了,数据文件和控制文件在一个磁盘,全部损坏,redo文件和
归档日志在两外一个磁盘,完好无损,只有两天前的rman全备份。经过30分钟的奋战,数据全部恢复。
模拟环境,具体恢复如下:
1:首先用rman全备份数据库数据(模拟两天前的rman全备份)
[oracle@www oracle]$ rman target /
Recovery Manager: Release 9.2.0.8.0 - Production
Copyright (c) 1995, 2002, Oracle Corporation. All rights reserved.
connected to target database: EXITGOGO (DBID=267967027)
RMAN> backup database;
Starting backup at 23-11月-06
using target database controlfile instead of recovery catalog
allocated channel: ORA_DISK_1
channel ORA_DISK_1: sid=11 devtype=DISK
channel ORA_DISK_1: starting full datafile backupset
channel ORA_DISK_1: specifying datafile(s) in backupset
input datafile fno=00001 name=/free/oracle/oradata/exitgogo/system01.dbf
input datafile fno=00002 name=/free/oracle/oradata/exitgogo/undotbs01.dbf
input datafile fno=00003 name=/free/oracle/oradata/exitgogo/users01.dbf
input datafile fno=00006 name=/free/oracle/oradata/exitgogo/pub.dbf
input datafile fno=00004 name=/free/oracle/oradata/exitgogo/tools01.dbf
input datafile fno=00005 name=/free/oracle/oradata/exitgogo/indx01.dbf
channel ORA_DISK_1: starting piece 1 at 23-11月-06
channel ORA_DISK_1: finished piece 1 at 23-11月-06
piece handle=/free/oracle/product/9.2.0.8/dbs/03i34pja_1_1 comment=NONE
channel ORA_DISK_1: backup set complete, elapsed time: 00:01:06
Finished backup at 23-11月-06
Starting Control File Autobackup at 23-11月-06
piece handle=/free/oracle/orabak/c-267967027-20061123-01 comment=NONE
Finished Control File Autobackup at 23-11月-06
RMAN> show all;
RMAN configuration parameters are:
CONFIGURE RETENTION POLICY TO REDUNDANCY 2;
CONFIGURE BACKUP OPTIMIZATION ON;
CONFIGURE DEFAULT DEVICE TYPE TO DISK; # default
CONFIGURE CONTROLFILE AUTOBACKUP ON;
CONFIGURE CONTROLFILE AUTOBACKUP FORMAT FOR DEVICE TYPE DISK TO '/free/oracle/orabak/%F';
CONFIGURE DEVICE TYPE DISK PARALLELISM 1;
CONFIGURE DATAFILE BACKUP COPIES FOR DEVICE TYPE DISK TO 1; # default
CONFIGURE ARCHIVELOG BACKUP COPIES FOR DEVICE TYPE DISK TO 1; # default
RMAN configuration has no stored or default parameters
CONFIGURE MAXSETSIZE TO UNLIMITED; # default
CONFIGURE SNAPSHOT CONTROLFILE NAME TO '/free/oracle/product/9.2.0.8/dbs/snapcf_exitgogo.f'; # default
RMAN>quit
2:创建一个新的表空间,然后添加测试数据(模拟两天之间数据库的变化)
创建了一个新的表空间pub,然后创建了用户pub。
[oracle@www oracle]$ sqlplus pub/pub
SQL*Plus: Release 9.2.0.8.0 - Production on 星期四 11月 23 17:37:28 2006
Copyright (c) 1982, 2002, Oracle Corporation. All rights reserved.
Connected to:
Oracle9i Enterprise Edition Release 9.2.0.8.0 - Production
With the Partitioning and Oracle Data Mining options
JServer Release 9.2.0.8.0 – Production
添加一点测试数据:
SQL> create table gaojf1 as select * from all_objects;
Table created.
SQL> insert into gaojf1 select * from gaojf1;
5884 rows created.
SQL> /
11768 rows created.
SQL> /
。。。。。。。。。。。
188288 rows created.
SQL> /
376576 rows created.
SQL> commit;
Commit complete.
SQL> quit
Disconnected from Oracle9i Enterprise Edition Release 9.2.0.8.0 - Production
With the Partitioning and Oracle Data Mining options
JServer Release 9.2.0.8.0 - Production
3:删除所有数据文件和控制文件(模拟数据库宕机)
[oracle@www exitgogo]$ls -sh
total 886M
3.5M control01.ctl 33M indx01.dbf 51M redo02.log 136K temp01.dbf 129M users01.dbf 3.5M control02.ctl 101M pub.dbf 51M redo03.log 65M tools01.dbf 3.5M control03.ctl 51M redo01.log 201M system01.dbf 201M undotbs01.dbf
[oracle@www exitgogo]$ rm -rf ./*.dbf ./*.ctl
[oracle@www exitgogo]$ ls
redo01.log redo02.log redo03.log
4:恢复开始:
[oracle@www exitgogo]$ rman target /
Recovery Manager: Release 9.2.0.8.0 - Production
Copyright (c) 1995, 2002, Oracle Corporation. All rights reserved.
connected to target database (not started)
RMAN> startup nomount
Oracle instance started
Total System Global Area 235999648 bytes
Fixed Size 450976 bytes
Variable Size 201326592 bytes
Database Buffers 33554432 bytes
Redo Buffers 667648 bytes
首先从原来的全备份中恢复控制文件
RMAN>
restore controlfile from '/free/oracle/orabak/c-267967027-20061123-01';
Starting restore at 23-11月-06
using target database controlfile instead of recovery catalog
allocated channel: ORA_DISK_1
channel ORA_DISK_1: sid=13 devtype=DISK
channel ORA_DISK_1: restoring controlfile
channel ORA_DISK_1: restore complete
replicating controlfile
input filename=/free/oracle/oradata/exitgogo/control01.ctl
output filename=/free/oracle/oradata/exitgogo/control02.ctl
output filename=/free/oracle/oradata/exitgogo/control03.ctl
Finished restore at 23-11月-06
RMAN> alter database mount;
database mounted
RMAN> list backup;
List of Backup Sets
===================
BS Key Type LV Size Device Type Elapsed Time Completion Time
------- ---- -- ---------- ----------- ------------ ---------------
1 Full 3M DISK 00:00:00 23-11月-06
BP Key: 1 Status: AVAILABLE Tag:
Piece Name: /free/oracle/orabak/c-267967027-20061123-01
Controlfile Included: Ckp SCN: 73561 Ckp time: 23-11月-06
BS Key Type LV Size Device Type Elapsed Time Completion Time
------- ---- -- ---------- ----------- ------------ ---------------
2 Full 223M DISK 00:00:57 23-11月-06
BP Key: 2 Status: AVAILABLE Tag: TAG20061123T173423
Piece Name: /free/oracle/product/9.2.0.8/dbs/03i34p90_1_1
List of Datafiles in backup set 2
File LV Type Ckp SCN Ckp Time Name
---- -- ---- ---------- ---------- ----
1 Full 73688 23-11月-06 /free/oracle/oradata/exitgogo/system01.dbf
2 Full 73688 23-11月-06 /free/oracle/oradata/exitgogo/undotbs01.dbf
3 Full 73688 23-11月-06 /free/oracle/oradata/exitgogo/users01.dbf
4 Full 73688 23-11月-06 /free/oracle/oradata/exitgogo/tools01.dbf
5 Full 73688 23-11月-06 /free/oracle/oradata/exitgogo/indx01.dbf
还原数据文件
RMAN> restore database;
Starting restore at 23-11月-06
using channel ORA_DISK_1
channel ORA_DISK_1: starting datafile backupset restore
channel ORA_DISK_1: specifying datafile(s) to restore from backup set
restoring datafile 00001 to /free/oracle/oradata/exitgogo/system01.dbf
restoring datafile 00002 to /free/oracle/oradata/exitgogo/undotbs01.dbf
restoring datafile 00003 to /free/oracle/oradata/exitgogo/users01.dbf
restoring datafile 00004 to /free/oracle/oradata/exitgogo/tools01.dbf
restoring datafile 00005 to /free/oracle/oradata/exitgogo/indx01.dbf
channel ORA_DISK_1: restored backup piece 1
piece handle=/free/oracle/product/9.2.0.8/dbs/03i34p90_1_1 tag=TAG20061123T173423 params=NULL
channel ORA_DISK_1: restore complete
Finished restore at 23-11月-06
RMAN> quit
下面进入sqlplus进行不完全恢复
[oracle@www exitgogo]$ sqlplus "/as sysdba"
SQL*Plus: Release 9.2.0.8.0 - Production on 星期四 11月 23 17:51:07 2006
Copyright (c) 1982, 2002, Oracle Corporation. All rights reserved.
Connected to:
Oracle9i Enterprise Edition Release 9.2.0.8.0 - Production
With the Partitioning and Oracle Data Mining options
JServer Release 9.2.0.8.0 - Production
SQL> select name from v$datafile;
NAME
------------------------------------------------------------------------------
/free/oracle/oradata/exitgogo/system01.dbf
/free/oracle/oradata/exitgogo/undotbs01.dbf
/free/oracle/oradata/exitgogo/users01.dbf
/free/oracle/oradata/exitgogo/tools01.dbf
/free/oracle/oradata/exitgogo/indx01.dbf
可以看到,由于rman的全备份早于创建pub表空间,因此restore恢复中没有记录pub表空间的信息,但是由于redo file中还记录了pub表空间创建的信息,因此,先recover试试!
SQL> recover database using backup controlfile;
ORA-00279: change 73688 generated at 11/23/2006 17:34:24 needed for thread 1
ORA-00289: suggestion :
/free/oracle/product/9.2.0.8/dbs/archexitgogo/T0001S0000000008.ARC
ORA-00280: change 73688 for thread 1 is in sequence #8
Specify log: {<RET>=suggested | filename | AUTO | CANCEL}
auto
ORA-00283: recovery session canceled due to errors
ORA-01244: unnamed datafile(s) added to controlfile by media recovery
ORA-01110: data file 6: '/free/oracle/oradata/exitgogo/pub.dbf'
ORA-01112: media recovery not started
可以看到,在恢复了一个归档日志以后,oracle认出了pub表空间,同时提示了ORA-01244 错误,继续往下看:
SQL> select name from v$datafile;
NAME
------------------------------------------------------------------------------
/free/oracle/oradata/exitgogo/system01.dbf
/free/oracle/oradata/exitgogo/undotbs01.dbf
/free/oracle/oradata/exitgogo/users01.dbf
/free/oracle/oradata/exitgogo/tools01.dbf
/free/oracle/oradata/exitgogo/indx01.dbf
/free/oracle/product/9.2.0.8/dbs/UNNAMED00006
6 rows selected.
可以看到,oracle中莫名的多出了一个文件UNNAMED00006,
IXDBA.NET社区论坛
出现这个文件的原因是由于redo file中记录了pub的信息,在通过recover恢复后,系统也认到了有pub这个表空间的存在,但是由于控制文件中没有记录这个文件的信息,所以oracle抛了一个错误,说发现一个没有命名的文件,然后oracle系统本身给这个文件做了一个命名。
可以通过下面的方式把pub表空间数据文件移动到合适的位置。
SQL>
alter database create datafile 6 as '/free/oracle/oradata/exitgogo/pub.dbf';
Database altered.
SQL> col name format a40
SQL> select file#,name from v$datafile;
FILE# NAME
---------- ----------------------------------------
1 /free/oracle/oradata/exitgogo/system01.d bf
2 /free/oracle/oradata/exitgogo/undotbs01.dbf
3 /free/oracle/oradata/exitgogo/users01.dbf
4 /free/oracle/oradata/exitgogo/tools01.dbf
FILE# NAME
---------- ----------------------------------------
5 /free/oracle/oradata/exitgogo/indx01.dbf
6 /free/oracle/oradata/exitgogo/pub.dbf
6 rows selected.
继续恢复:
SQL> recover database using backup controlfile;
ORA-00279: change 73805 generated at 11/23/2006 17:37:18 needed for thread 1
ORA-00289: suggestion :
/free/oracle/product/9.2.0.8/dbs/archexitgogo/T0001S0000000008.ARC
ORA-00280: change 73805 for thread 1 is in sequence #8
Specify log: {<RET>=suggested | filename | AUTO | CANCEL}
auto
ORA-00279: change 74363 generated at 11/23/2006 17:38:51 needed for thread 1
ORA-00289: suggestion :
/free/oracle/product/9.2.0.8/dbs/archexitgogo/T0001S0000000009.ARC
ORA-00280: change 74363 for thread 1 is in sequence #9
ORA-00278: log file
'/free/oracle/product/9.2.0.8/dbs/archexitgogo/T0001S0000000008.ARC' no longer
needed for this recovery
ORA-00308: cannot open archived log
'/free/oracle/product/9.2.0.8/dbs/archexitgogo/T0001S0000000009.ARC'
ORA-27037: unable to obtain file status
Linux Error: 2: No such file or directory
Additional information: 3
由于我的归档没有T0001S0000000009了,所以可能需要redo file了
SQL> recover database using backup controlfile;
ORA-00279: change 74363 generated at 11/23/2006 17:38:51 needed for thread 1
ORA-00289: suggestion :
/free/oracle/product/9.2.0.8/dbs/archexitgogo/T0001S0000000009.ARC
ORA-00280: change 74363 for thread 1 is in sequence #9
Specify log: {<RET>=suggested | filename | AUTO | CANCEL}
/free/oracle/oradata/exitgogo/redo01.log
ORA-00310: archived log contains sequence 7; sequence 9 required
ORA-00334: archived log: '/free/oracle/oradata/exitgogo/redo01.log'
SQL> recover database using backup controlfile;
ORA-00279: change 74363 generated at 11/23/2006 17:38:51 needed for thread 1
ORA-00289: suggestion :
/free/oracle/product/9.2.0.8/dbs/archexitgogo/T0001S0000000009.ARC
ORA-00280: change 74363 for thread 1 is in sequence #9
Specify log: {<RET>=suggested | filename | AUTO | CANCEL}
/free/oracle/oradata/exitgogo/redo02.log
ORA-00310: archived log contains sequence 8; sequence 9 required
ORA-00334: archived log: '/free/oracle/oradata/exitgogo/redo02.log'
SQL> recover database using backup controlfile;
ORA-00279: change 74363 generated at 11/23/2006 17:38:51 needed for thread 1
ORA-00289: suggestion :
/free/oracle/product/9.2.0.8/dbs/archexitgogo/T0001S0000000009.ARC
ORA-00280: change 74363 for thread 1 is in sequence #9
Specify log: {<RET>=suggested | filename | AUTO | CANCEL}
/free/oracle/oradata/exitgogo/redo03.log
Log applied.
Media recovery complete.
可以看到,新建的pub表空间的数据信息在redo03.log中存在,这是因为我的测试数据量很小的原因。如果从rman全备份后到系统宕机这段时间数据量很大的话,可能有很多的归档信息需要恢复,同时redo file也是不可少的。
SQL> alter database open resetlogs;
alter database open resetlogs
*
ERROR at line 1:
ORA-01153: an incompatible media recovery is active
SQL> quit
Disconnected from Oracle9i Enterprise Edition Release 9.2.0.8.0 - Production
With the Partitioning and Oracle Data Mining options
JServer Release 9.2.0.8.0 - Production
[oracle@www exitgogo]$ sqlplus "/as sysdba"
SQL*Plus: Release 9.2.0.8.0 - Production on 星期四 11月 23 18:02:00 2006
Copyright (c) 1982, 2002, Oracle Corporation. All rights reserved.
Connected to:
Oracle9i Enterprise Edition Release 9.2.0.8.0 - Production
With the Partitioning and Oracle Data Mining options
JServer Release 9.2.0.8.0 - Production
SQL> alter database open resetlogs;
Database altered.
SQL> conn pub/pub
Connected.
SQL> select count(*) from gaojf1;
COUNT(*)
----------
753152
SQL>
可以看到,数据完全恢复,
这样恢复完成后,马上又做了一个全库的rman备份。
9i和10g上rman全备的一点差别
http://space.itpub.net/231499/viewspace-63823
我们知道,9i和10g下,用rman做全库备份时,rman会把数据文件、控制文件、参数文件等都备份,但是它们还有有差别的,先看看两者的备份日志:
--9i的rman全备日志
E:oracleora92�in>rman target /
恢复管理器: 版本9.2.0.1.0 - Production
Copyright (c) 1995, 2002, Oracle Corporation. All rights reserved.
连接到目标数据库: SUK (DBID=1788145367)
RMAN> run{
2> allocate channel c1 type disk;
3> backup database format 'f:�ackupsuk_%U';
4> sql 'alter system archive log current';
5> release channel c1;
6> }
分配的通道: c1
通道 c1: sid=17 devtype=DISK
启动 backup 于 22-6月 -07
通道 c1: 正在启动 full 数据文件备份集
通道 c1: 正在指定备份集中的数据文件
在备份集中包含当前的 SPFILE --备份参数文件
备份集中包括当前控制文件 --备份控制文件
输入数据文件 fno=00014 name=E:ORACLEORADATASUKHEBEI01.DBF
输入数据文件 fno=00001 name=E:ORACLEORADATASUKSYSTEM01.DBF
输入数据文件 fno=00002 name=E:ORACLEORADATASUKUNDOTBS01.DBF
输入数据文件 fno=00006 name=E:ORACLEORADATASUKSUK01.DBF
输入数据文件 fno=00007 name=E:ORACLEORADATASUKSUK02.DBF
输入数据文件 fno=00008 name=E:ORACLEORADATASUKSUK03.DBF
输入数据文件 fno=00003 name=E:ORACLEORADATASUKINDX01.DBF
输入数据文件 fno=00005 name=E:ORACLEORADATASUKUSERS01.DBF
输入数据文件 fno=00004 name=E:ORACLEORADATASUKTOOLS01.DBF
输入数据文件 fno=00009 name=E:ORACLEORADATASUKIND01.DBF
输入数据文件 fno=00010 name=E:ORACLEORADATASUKIND02.DBF
输入数据文件 fno=00011 name=E:ORACLEORADATASUKIND03.DBF
输入数据文件 fno=00012 name=E:ORACLEORADATASUKNEWUNDO01.DBF
输入数据文件 fno=00013 name=E:ORACLEORADATASUKNEWUNDO02.DBF
通道 c1: 正在启动段 1 于 22-6月 -07
通道 c1: 已完成段 1 于 22-6月 -07
段 handle=F:BACKUPSUK_07IKTQ6C_1_1 comment=NONE
通道 c1: 备份集已完成, 经过时间:00:02:27
完成 backup 于 22-6月 -07
sql 语句: alter system archive log current
释放的通道: c1
--可以看到,9i下,rman全备时是先备份参数文件、控制文件,再备份数据文件。
由于备份信息是放在控制文件中的,所以当次备份的控制文件是不包含当次的备份信息的(用include current controlfile也一样).
在恢复时如果用备份的控制文件恢复,很可能遇到错误:
RMAN> restore database;
启动 restore 于 22-6月 -07
使用通道 ORA_DISK_1
RMAN-00571: ===========================================================
RMAN-00569: =============== ERROR MESSAGE STACK FOLLOWS ===============
RMAN-00571: ===========================================================
RMAN-03002: failure of restore command at 06/22/2007 13:27:03
RMAN-06026: some targets not found - aborting restore
RMAN-06023: no backup or copy of datafile 14 found to restore
RMAN-06023: no backup or copy of datafile 13 found to restore
RMAN-06023: no backup or copy of datafile 12 found to restore
RMAN-06023: no backup or copy of datafile 11 found to restore
RMAN-06023: no backup or copy of datafile 10 found to restore
RMAN-06023: no backup or copy of datafile 9 found to restore
RMAN-06023: no backup or copy of datafile 8 found to restore
RMAN-06023: no backup or copy of datafile 7 found to restore
RMAN-06023: no backup or copy of datafile 6 found to restore
RMAN-06023: no backup or copy of datafile 5 found to restore
RMAN-06023: no backup or copy of datafile 4 found to restore
RMAN-06023: no backup or copy of datafile 3 found to restore
RMAN-06023: no backup or copy of datafile 2 found to restore
RMAN-06023: no backup or copy of datafile 1 found to restore
--10g的rman全备日志
C:>rman target /
恢复管理器: Release 10.2.0.1.0 - Production on 星期二 6月 19 10:50:18 2007
Copyright (c) 1982, 2005, Oracle. All rights reserved.
连接到目标数据库: ORA10G (DBID=3939087858)
RMAN> run{
2> allocate channel c1 type disk;
3> backup database format 'f:�ackupsuk_%U';
4> sql 'alter system archive log current';
5> release channel c1;
6> }
分配的通道: c1
通道 c1: sid=145 devtype=DISK
启动 backup 于 22-6月 -07
通道 c1: 启动全部数据文件备份集
通道 c1: 正在指定备份集中的数据文件
输入数据文件 fno=00006 name=E:ORACLEORADATAORA10GHEBEI01.DBF
输入数据文件 fno=00005 name=E:ORACLEORADATAORA10GSUK01.DBF
输入数据文件 fno=00001 name=E:ORACLEORADATAORA10GSYSTEM01.DBF
输入数据文件 fno=00003 name=E:ORACLEORADATAORA10GSYSAUX01.DBF
输入数据文件 fno=00002 name=E:ORACLEORADATAORA10GUNDOTBS01.DBF
输入数据文件 fno=00004 name=E:ORACLEORADATAORA10GUSERS01.DBF
通道 c1: 正在启动段 1 于 22-6月 -07
通道 c1: 已完成段 1 于 22-6月 -07
段句柄=F:BACKUPSUK_05IKTQ08_1_1 标记=TAG20070622T125639 注释=NONE
通道 c1: 备份集已完成, 经过时间:00:01:26
通道 c1: 启动全部数据文件备份集
通道 c1: 正在指定备份集中的数据文件
备份集中包括当前控制文件
在备份集中包含当前的 SPFILE
通道 c1: 正在启动段 1 于 22-6月 -07
通道 c1: 已完成段 1 于 22-6月 -07
段句柄=F:BACKUPSUK_06IKTQ2U_1_1 标记=TAG20070622T125639 注释=NONE
通道 c1: 备份集已完成, 经过时间:00:00:05
完成 backup 于 22-6月 -07
sql 语句: alter system archive log current
释放的通道: c1
可以看出,10g下全库备份的备份顺序与9i是相反的,它先备份数据文件,再备份控制文件、参数文件。
oracle已经意识到9i的这个不足,在10g中修复了。
在9i中,应该设置控制文件字段备份来避免上述问题。
E:oracleora92�in>rman target /
恢复管理器: 版本9.2.0.1.0 - Production
Copyright (c) 1995, 2002, Oracle Corporation. All rights reserved.
连接到目标数据库: SUK (DBID=1788145367)
RMAN> run{
2> allocate channel c1 type disk;
3> CONFIGURE CONTROLFILE AUTOBACKUP ON;
4> CONFIGURE CONTROLFILE AUTOBACKUP FORMAT FOR DEVICE TYPE DISK TO 'f:�ackupc
n_%F';
5> backup database format 'f:�ackupsuk_%U';
6> sql 'alter system archive log current';
7> release channel c1;
8> }
正在使用目标数据库控制文件替代恢复目录
分配的通道: c1
通道 c1: sid=12 devtype=DISK
新的 RMAN 配置参数:
CONFIGURE CONTROLFILE AUTOBACKUP ON;
已成功存储新的 RMAN 配置参数
新的 RMAN 配置参数:
CONFIGURE CONTROLFILE AUTOBACKUP FORMAT FOR DEVICE TYPE DISK TO 'f:�ackupcn_%F
';
已成功存储新的 RMAN 配置参数
启动 backup 于 22-6月 -07
通道 c1: 正在启动 full 数据文件备份集
通道 c1: 正在指定备份集中的数据文件
输入数据文件 fno=00014 name=E:ORACLEORADATASUKHEBEI01.DBF
输入数据文件 fno=00001 name=E:ORACLEORADATASUKSYSTEM01.DBF
输入数据文件 fno=00002 name=E:ORACLEORADATASUKUNDOTBS01.DBF
输入数据文件 fno=00006 name=E:ORACLEORADATASUKSUK01.DBF
输入数据文件 fno=00007 name=E:ORACLEORADATASUKSUK02.DBF
输入数据文件 fno=00008 name=E:ORACLEORADATASUKSUK03.DBF
输入数据文件 fno=00003 name=E:ORACLEORADATASUKINDX01.DBF
输入数据文件 fno=00005 name=E:ORACLEORADATASUKUSERS01.DBF
输入数据文件 fno=00004 name=E:ORACLEORADATASUKTOOLS01.DBF
输入数据文件 fno=00009 name=E:ORACLEORADATASUKIND01.DBF
输入数据文件 fno=00010 name=E:ORACLEORADATASUKIND02.DBF
输入数据文件 fno=00011 name=E:ORACLEORADATASUKIND03.DBF
输入数据文件 fno=00012 name=E:ORACLEORADATASUKNEWUNDO01.DBF
输入数据文件 fno=00013 name=E:ORACLEORADATASUKNEWUNDO02.DBF
通道 c1: 正在启动段 1 于 22-6月 -07
通道 c1: 已完成段 1 于 22-6月 -07
段 handle=F:BACKUPSUK_01IKTVM1_1_1 comment=NONE
通道 c1: 备份集已完成, 经过时间:00:01:55
完成 backup 于 22-6月 -07
启动 Control File and SPFILE Autobackup 于 22-6月 -07
段 handle=F:BACKUPCN_C-1788145367-20070622-00 comment=NONE
完成 Control File and SPFILE Autobackup 于 22-6月 -07
sql 语句: alter system archive log current
释放的通道: c1
http://blog.chinaunix.net/u1/50863/showart_400578.html
问题:用户查询一个表时,报数据文件有坏块
目标:用户可以接受丢失这些坏块的数据,但该数据文件其它的好块应该可以查询数据。
下面是具体的步骤:
1.询问用户徐工出错的表名,收集出错信息
出错表名:
fsgazhjf.fsgazhjf_tac_20061018
trace文件中的出错信息:
***
Corrupt block relative dba: 0xb8428b33 (file 737, block 166707)
Fractured block found during user buffer read
Data in bad block -
type: 6 format: 2 rdba: 0xb8428b33
last change scn: 0x0000.0a66398d seq: 0x1 flg: 0x00
consistency value in tail: 0xbddc0601
check value in block header: 0x0, block checksum disabled
spare1: 0x0, spare2: 0x0, spare3: 0x0
***
2.根据出错块id,查询出该块对应的物理表,跟第一步收集的比对
select * from dba_extents
where file_id=737 and block_id <= 166707 and (block_id + blocks - 1) >= 166707;
FSGAZHJF FSGAZHJF_TAC_20061018 TABLE FSGAZHJF_GSM_10 1201 737 166665 1048576 128 737
结果:的确是该表:FSGAZHJF_TAC_20061018,用户FSGAZHJF,表空间FSGAZHJF_GSM_10
3.查询该表,看报错信息是否和第一步一致
select count(1) from fsgazhjf.fsgazhjf_tac_20061018;
结果:果然报错
4.收集该表的所有索引
select * from dba_indexes where owner='FSGAZHJF' and lower(table_name)='fsgazhjf_tac_20061018';
no rows
结果:无索引
5.用dbv工具来check bad block
SQL> select file_id||' '||file_name from dba_data_files where file_id=737;
FILE_ID||''||FILE_NAME
------------------------------------------------------------------------------
--------------------
737 K:ORADATAORA8FSGAZHJF_GSM_10_50.DBF
C:>dbv file='K:ORADATAORA8FSGAZHJF_GSM_10_50.DBF' blocksize=8192 logfile='h:dbv.log'
DBVERIFY: Release 8.1.7.4.1 - Production on 星期四 11月 9 10:57:13 2006
(c) Copyright 2000 Oracle Corporation. All rights reserved.
DBVERIFY: Release 8.1.7.4.1 - Production on 星期四 11月 9 10:57:13 2006
(c) Copyright 2000 Oracle Corporation. All rights reserved.
DBVERIFY - 检验开始:FILE = K:ORADATAORA8FSGAZHJF_GSM_10_50.DBF
标记为损坏的页面166708
***
Corrupt block relative dba: 0xb8428b34 (file 0, block 166708)
Bad header found during dbv:
Data in bad block -
type: 6 format: 2 rdba: 0xcf012b08
last change scn: 0x0000.0a91bf69 seq: 0x1 flg: 0x00
consistency value in tail: 0x0ccc0601
check value in block header: 0x0, block checksum disabled
spare1: 0x0, spare2: 0x0, spare3: 0x0
***
标记为损坏的页面166709
***
Corrupt block relative dba: 0xb8428b35 (file 0, block 166709)
Bad header found during dbv:
Data in bad block -
type: 6 format: 2 rdba: 0xce00e7e9
last change scn: 0x0000.0a910ce8 seq: 0x1 flg: 0x00
consistency value in tail: 0x0ce80601
check value in block header: 0x0, block checksum disabled
spare1: 0x0, spare2: 0x0, spare3: 0x0
***
标记为损坏的页面166710
***
Corrupt block relative dba: 0xb8428b36 (file 0, block 166710)
Bad header found during dbv:
Data in bad block -
type: 6 format: 2 rdba: 0xce00e7ea
last change scn: 0x0000.0a910ce8 seq: 0x1 flg: 0x00
consistency value in tail: 0x0ce80601
check value in block header: 0x0, block checksum disabled
spare1: 0x0, spare2: 0x0, spare3: 0x0
***
标记为损坏的页面166711
***
Corrupt block relative dba: 0xb8428b37 (file 0, block 166711)
Bad header found during dbv:
Data in bad block -
type: 6 format: 2 rdba: 0xce00e7eb
last change scn: 0x0000.0a910ce8 seq: 0x1 flg: 0x00
consistency value in tail: 0x39910601
check value in block header: 0x0, block checksum disabled
spare1: 0x0, spare2: 0x0, spare3: 0x0
***
DBVERIFY - 完成检验
检查的页面总数 :262144
处理的页面总数(数据):262010
失败的页面总数(数据):0
处理的页面总数(索引):0
失败的页面总数(索引):0
处理的页面总数(其它):9
空的页面总数 :120
标记损坏的页面总数:4
汇集的页面总数 :0
检查结果:4个坏块,块号是166708 ~ 166711 ,经查询,发现都在一个extent里,属于同一张表
6.开始打标记
具体过程:
C:>sqlplus sys/change_on_install
SQL*Plus: Release 8.1.7.0.0 - Production on 星期四 11月 9 12:18:08 2006
(c) Copyright 2000 Oracle Corporation. All rights reserved.
连接到:
Oracle8i Enterprise Edition Release 8.1.7.4.1 - Production
With the Partitioning option
JServer Release 8.1.7.4.1 - Production
SQL>exec dbms_repair.admin_tables('REPAIR_TABLE',1,1,'USERS');
PL/SQL 过程已成功完成。
SQL>exec dbms_repair.admin_tables('ORPHAN_TABLE',2,1,'USERS');
PL/SQL 过程已成功完成。
SQL> declare
2 cc number;
3 begin
4 dbms_repair.check_object(schema_name => 'FSGAZHJF',object_name => 'FSGAZHJF_TAC_20061018',corrupt_count => cc);
5 dbms_output.put_line(a => to_char(cc));
6 end;
7 /
PL/SQL 过程已成功完成。
SQL>
SQL> select count(1) from repair_table;
COUNT(1)
----------
5
***这里发现5个坏快,dbv发现的是4个
SQL>
***具体信息参考repair_table.xls
发现marked_corrupt列 已经为true,可能不需执行
exec dbms_repair.skip_corrupt_blocks(schema_name => 'FSGAZHJF',object_name => 'FSGAZHJF_TAC_20061018',flags => 1);
了,通过下面的查询,确认不需要执行了
SQL> select count(1) from FSGAZHJF.FSGAZHJF_TAC_20061018;
COUNT(1)
----------
18804767
7.为该表建立两个索引
建立成功
证明可以对该表进行全表扫描了,问题解决,但丢失5个块的数据
http://blog.chinaunix.net/u1/50863/showart_400576.html
试验的目的:
1.查找含坏块的数据的所有的rowid,从而得到损坏的数据量
2.查找损坏表的现在可用的数据量
3.根据1和2得到该表的本来的总的数据量
试验步骤:
1)参照 数据文件出现坏块时之五(如何利用dbms_repair来标记和跳过坏块)的第一步和第二部
建了表空间block,用户test1107,表test,初始化了数据4512行,模拟了数据坏块,
并用dbv得到所有的坏块ID(34~52,68~87)
2)参照 数据文件出现坏快时之三(如何查找坏块所含的数据表名称和数据的rowid)的步骤,查找出所有的坏块包含的rowid
select /*+ index(test1107, i_test)*/ rowid
from test1107.test
where dbms_rowid.rowid_to_absolute_fno(rowid,'TEST1107','TEST')=13
and (dbms_rowid.rowid_block_number(rowid) between 34 and 52 or
dbms_rowid.rowid_block_number(rowid) between 68 and 87);
结果返回了1598行坏记录
3)参照 数据文件出现坏块时之六(设置内部事件使exp跳过坏块)
先exp报错,后来设置了events事件,然后exp出来,显示有 2914行,抓屏幕如下:
C:\Documents and Settings\liguohua>exp test1107/aaaa tables=test file=d:\work\temp\test.dmp
即将导出指定的表通过常规路径 ...
. . 正在导出表 TEST
EXP-00056: 遇到 ORACLE 错误 1578
ORA-01578: ORACLE 数据块损坏(文件号13,块号34)
ORA-01110: 数据文件 13: 'D:\ORACLE\ORADATA\BLOCK.DBF'
导出成功终止,但出现警告。
C:\Documents and Settings\liguohua>alter system set events='10231 trace name context forever,level 10';
C:\Documents and Settings\liguohua>exp test1107/aaaa tables=test file=d:\work\temp\test.dmp
即将导出指定的表通过常规路径 ...
. . 正在导出表 TEST 2914 行被导出
在没有警告的情况下成功终止导出。
结果表示有2914行记录可用
另外一种方法,其实可以用
select count(1) from test1107.test where rowid not in
(
select /*+ index(test1107, i_test)*/ rowid
from test1107.test
where dbms_rowid.rowid_to_absolute_fno(rowid,'TEST1107','TEST')=13
and (dbms_rowid.rowid_block_number(rowid) between 34 and 52 or
dbms_rowid.rowid_block_number(rowid) between 68 and 87)
);
来查询可用的记录数,这样比较简单
4)1598 + 2914 = 4512,正好和原表总记录数吻合!
5)恢复events参数
alter system set events='10231 trace name context off';
http://blog.chinaunix.net/u1/50863/showart_400575.html
和数据文件出现坏块时之五中提到的前几步一样,先模拟出坏块,然后用dbv检查,此时,不用dbms_repair,而用下面的方法:
1.先exp该表试验一下
在这种情况下,如果有备份,需要从备份中恢复
如果没有备份,那么坏块部分的数据肯定要丢失了
在这个时候导出是不允许的:
E:\>exp eygle/eygle file=t.dmp tables=t
Export: Release 9.2.0.4.0 - Production on 星期一 3月 8 20:54:15 2004
Copyright (c) 1982, 2002, Oracle Corporation. All rights reserved.
连接到: Oracle9i Enterprise Edition Release 9.2.0.4.0 - Production
With the Partitioning, OLAP and Oracle Data Mining options
JServer Release 9.2.0.4.0 - Production
已导出 ZHS16GBK 字符集和 AL16UTF16 NCHAR 字符集
即将导出指定的表通过常规路径 ...
. . 正在导出表 T
EXP-00056: 遇到 ORACLE 错误 1578
ORA-01578: ORACLE 数据块损坏(文件号4,块号35)
ORA-01110: 数据文件 4: 'E:\ORACLE\ORADATA\EYGLE\BLOCK.DBF'
导出成功终止,但出现警告。
2.当然,对于不同的情况需要区别对待 ,如果损失不是数据而是重要的oracle内部信息,则不能用set event
首先你需要检查损坏的对象,使用以下SQL:
--------------------------------------------------------------------------------
SQL> SELECT tablespace_name, segment_type, owner, segment_name
2 FROM dba_extents
3 WHERE file_id = 4
4 and 35 between block_id AND block_id + blocks - 1
5 ;
TABLESPACE_NAME SEGMENT_TYPE OWNER
------------------------------ ------------------ -------------------------
SEGMENT_NAME
---------------------------------------------------------------------------
BLOCK TABLE 'EYGLE'
'T'
--------------------------------------------------------------------------------
3.如果损失的是数据,ok,可以设置内部事件,使exp跳过这些损坏的block
10231事件指定数据库在进行全表扫描时跳过损坏的块
ALTER SYSTEM SET EVENTS='10231 trace name context forever,level 10' ;
SQL> ALTER SYSTEM SET EVENTS='10231 trace name context forever,level 10' ;
系统已更改。
然后我们可以导出未损坏的数据
SQL> host
Microsoft Windows XP [版本 5.1.2600]
(C) 版权所有 1985-2001 Microsoft Corp.
E:\
E:\>exp eygle/eygle file=t.dmp tables=t
Export: Release 9.2.0.4.0 - Production on 星期一 3月 8 20:57:13 2004
Copyright (c) 1982, 2002, Oracle Corporation. All rights reserved.
连接到: Oracle9i Enterprise Edition Release 9.2.0.4.0 - Production
With the Partitioning, OLAP and Oracle Data Mining options
JServer Release 9.2.0.4.0 - Production
已导出 ZHS16GBK 字符集和 AL16UTF16 NCHAR 字符集
即将导出指定的表通过常规路径 ...
. . 正在导出表 T 8036 行被导出
在没有警告的情况下成功终止导出。
这时候数据成功导出.
然后我们可以drop table,recreate,然后导入数据
本例中
我们损失了
8192 - 8036 = 156 行数据
4.重建表,再导入
SQL> connect eygle/eygle
已连接。
SQL> drop table t;
表已丢弃。
SQL> host
Microsoft Windows XP [版本 5.1.2600]
(C) 版权所有 1985-2001 Microsoft Corp.
E:\Oracle\ora92\bin>cd \
E:\>imp eygle/eygle file=t.dmp tables=t
Import: Release 9.2.0.4.0 - Production on 星期一 3月 8 21:12:38 2004
Copyright (c) 1982, 2002, Oracle Corporation. All rights reserved.
连接到: Oracle9i Enterprise Edition Release 9.2.0.4.0 - Production
With the Partitioning, OLAP and Oracle Data Mining options
JServer Release 9.2.0.4.0 - Production
经由常规路径导出由EXPORT:V09.02.00创建的文件
已经完成ZHS16GBK字符集和AL16UTF16 NCHAR 字符集中的导入
. 正在将EYGLE的对象导入到 EYGLE
. . 正在导入表 "T" 8036行被导入
成功终止导入,但出现警告。
E:\>exit
SQL> select count(*) from t;
COUNT(*)
----------
8036
完成数据恢复
最后如果要取消events设置,做以下操作:
如果你在初始化参数中设置的
注释之
如果在命令行设置的
alter system set events='10231 trace name context off';
http://blog.chinaunix.net/u1/50863/showart_400574.html
第一步:准备试验环境(建表空间,用户,表,初始化一些数据,然后破坏对应的数据文件)
E:\Oracle\ora92\bin>sqlplus "/ as sysdba"
SQL*Plus: Release 9.2.0.4.0 - Production on 星期一 3月 8 20:27:15 2004
Copyright (c) 1982, 2002, Oracle Corporation. All rights reserved.
连接到:
Oracle9i Enterprise Edition Release 9.2.0.4.0 - Production
With the Partitioning, OLAP and Oracle Data Mining options
JServer Release 9.2.0.4.0 - Production
SQL> select name from v$datafile;
NAME
--------------------------------------------------------------------------------
E:\ORACLE\ORADATA\oracle92\SYSTEM01.DBF
E:\ORACLE\ORADATA\oracle92\UNDOTBS01.DBF
E:\ORACLE\ORADATA\oracle92\app01.DBF
grant dba to test1107;
SQL> create tablespace block datafile 'd:\oracle\oradata\block.dbf' size 2M;
表空间已创建。
SQL> create user test1107 identified by aaaa default tablespace block;
用户已创建
SQL> conn test1107/aaaa;
已连接。
SQL> create table test tablespace block as select * from all_tables;
表已创建。
SQL> insert into test select * from test;
已创建8行。
SQL> /
已创建16行。
SQL> /
已创建32行。
SQL> /
已创建64行。
SQL> /
已创建128行。
SQL> /
已创建256行。
SQL> /
已创建512行。
SQL> /
已创建1024行。
SQL> /
已创建2048行。
SQL> /
已创建4096行。
SQL> /
insert into test select * from test
*
ERROR 位于第 1 行:
ORA-01653: 表test1107.TEST无法通过8(在表空间BLOCK中)扩展
SQL> create index i_test on test(table_name);
Index created
SQL> alter system checkpoint;
System altered
SQL> connect sys/sys as sysdba
已连接。
SQL> shutdown immediate
数据库已经关闭。
已经卸载数据库。
ORACLE 例程已经关闭。
--使用UltraEdit编辑block.dbf,修改几个字符
SQL> startup
ORACLE 例程已经启动。
Total System Global Area 72424008 bytes
Fixed Size 453192 bytes
Variable Size 46137344 bytes
Database Buffers 25165824 bytes
Redo Buffers 667648 bytes
数据库装载完毕。
数据库已经打开。
QL> select count(*) from test1107.test;
select count(*) from test1107.test
ORA-01578: ORACLE 数据块损坏(文件号13,块号9)
ORA-01110: 数据文件 13: 'D:\ORACLE\ORADATA\BLOCK.DBF'
第二步:利用dbv检查数据文件
dbv file='d:\oracle\ora92\block.dbf' blocksize=8192 logfile='d:\work\temp\dbv.log'
日志:
DBVERIFY - 验证完成
检查的页总数 :256
处理的页总数(数据):112
失败的页总数(数据):0
处理的页总数(索引):17
失败的页总数(索引):0
处理的页总数(其它):10
处理的总页数 (段) : 0
失败的总页数 (段) : 0
空的页总数 :102
标记为损坏的总页数:15
汇入的页总数 :0
第三步:利用dbms_repair包进行处理
1.创建管理表:
SQL> connect sys/sys as sysdba
Connected to Oracle9i Enterprise Edition Release 9.2.0.1.0
Connected as SYS
SQL> exec DBMS_REPAIR.ADMIN_TABLES('REPAIR_TABLE',1,1,'USERS');
PL/SQL procedure successfully completed
SQL> exec DBMS_REPAIR.ADMIN_TABLES('ORPHAN_TABLE',2,1,'USERS');
PL/SQL procedure successfully completed
2.检查坏块:
declare
cc number;
begin
dbms_repair.check_object(schema_name => 'TEST1107',object_name => 'TEST',corrupt_count => cc);
dbms_output.put_line(a => to_char(cc));
end;
15
PL/SQL 过程已成功完成。
看到这里用dbms_repair.check,检查的结果corrupt_count=15,有15个块损坏,和dbv的结果一致。
check完之后,在我们刚在创建的REPAIR_TABLE中查看块损坏信息:
SQL> SELECT * from repair_table
在这个table中,可以看到损坏的block的信息,这里的信息和我们用dbv得到的一致。
我这个实验是在9i下模拟的,注意看MARKED_CORRUPT的值,这里经过check_object后,已经标识为TRUE了。
所以可以直接进行第四步了。按照oracle文档上的说法,在8i下,check_object只会检查坏块,MARKED_CORRUPT为false需要使用第3步,fix_corrupt_blocks定位 ,修改MARKED_CORRUPT为true,同时更新CHECK_TIMESTAMP。
这里我们经过实验,确认在9i下跳过第3步,是完全可行的。那么8i是否需要执行第三步,我没有实验过,但推测应该是不可以跳过的。
3.定位坏块:
dbms_repair.fix_corrupt_blocks
只有将坏块信息写入定义的REPAIR_TABLE后,才能定位坏块。
declare
cc number;
begin
dbms_repair.fix_corrupt_blocks(schema_name => 'TEST1107',object_name => 'TEST',fix_count => cc);
dbms_output.put_line(a => to_char(cc));
end;
4.跳过坏块:
我们前面虽然定位了坏块,但是,如果我们访问table还是会得到错误信息。
这里需要用skip_corrupt_blocks来跳过坏块:
SQL> exec dbms_repair.skip_corrupt_blocks(schema_name => 'TEST1107',object_name => 'TEST',flags => 1);
PL/SQL procedure successfully completed
SQL> select count(*) from test1107.test;
COUNT(*)
----------
4490
5.处理index上的无效键值;
SQL> declare
2 cc number;
3 begin
4 dbms_repair.dump_orphan_keys(schema_name => 'TEST1107',object_name => 'I_TEST',object_type => 2,
5 repair_table_name => 'REPAIR_TABLE',orphan_table_name => 'ORPHAN_TABLE',key_count => CC);
6 end;
7 /
PL/SQL procedure successfully completed
SQL> SELECT * FROM ORPHAN_TABLE;
22 rows selected
表示损失了22行数据
我们根据这个结果来考虑是否需要rebuild index.
6.重建freelist:rebuild_freelists
SQL> exec dbms_repair.rebuild_freelists(schema_name => 'TEST1107',object_name => 'TEST');
PL/SQL procedure successfully completed
1.define constraints as immediate or deferred
sql> alter session set constraint[s] = immediate/deferred/default;
set constraint[s] constraint_name/all immediate/deferred;
sql> alter table add constraint ck_sales_1 initially immediate/deferred/default;
alter table modify constraint ck_sales_1 initially
immediate/deferred/default;
2. sql> drop table table_name cascade constraints
sql> drop tablespace tablespace_name including contents cascade constraints
3. define constraints while create a table
sql> create table xay(id number(7) constraint xay_id primary key deferrable
sql> using index storage(initial 100k next 100k) tablespace indx);
primary key/unique/references table(column)/check
4.enable constraints
sql> alter table xay enable novalidate constraint xay_id; #enable novalidate 新
数据应用规则,旧数据不管
5.enable constraints
sql> alter table xay enable validate constraint xay_id; #enable validate 新数据
应用规则,旧数据也要检查
同样还有:disable novalidate, disable validate
6.disable constraints
sql> alter table sales disable constraint fk_1
sql> truncate table sales
7.using the exceptions table
#生效约束时将不符合约束条件的记录写入到exceptions table,反复检查,直至没有错误
sql> start d:\xxx\utlexcpt.sql
sql> desc exceptions
sql> alter table sales add constraint ch_sales_1(qty>15)
enable validate exceptions into exceptions
8.obtaining constraint information
dba_constraints dba_cons_columns
sql> select constraint_name, constraint_type. deferrable,deferred, validated
from dba_constraints where owner='HR' and table_name ='employee'
sql> select c.constraint_name, c.constraint_type,cc.column_name
from dba_constraints c, dba_cons_columns cc
where c.owner ='HR' and c.table_name = 'employee'
and c.owner = cc.owner and c.constraint_name = cc.constraint_name
order by cc.position;
1.system privileges: view => system_privilege_map ,dba_sys_privs,session_privs
2.grant system privilege
sql> grant create session,create table to managers;
sql> grant create session to scott with admin option;
with admin option can grant or revoke privilege from any user or role;
3.sysdba and sysoper privileges:
sysoper: startup,shutdown,alter database open|mount,alter database backup controlfile,
alter tablespace begin/end backup,recover database
alter database archivelog,restricted session
sysdba: sysoper privileges with admin option,create database,recover database until
4.password file members: view:=> v$pwfile_users
5.O7_dictionary_accessibility =true restriction access to view or tables in other schema
6.revoke system privilege
sql> revoke create table from karen;
sql> revoke create session from scott;
7.grant object privilege
sql> grant execute on dbms_pipe to public;
sql> grant update(first_name,salary) on employee to karen with grant option;
8.display object privilege : view => dba_tab_privs, dba_col_privs
9.revoke object privilege
sql> revoke execute on dbms_pipe from scott [cascade constraints];
10.audit record view :=> sys.aud$
11. protecting the audit trail
sql> audit delete on sys.aud$ by access;
12.statement auditing
sql> audit user;
13.privilege auditing
sql> audit select any table by summit by access;
14.schema object auditing
sql> audit lock on summit.employee by access whenever successful;
15.view audit option : view=> all_def_audit_opts,dba_stmt_audit_opts,dba_priv_audit_opts,
dba_obj_audit_opts
16.view audit result: view=> dba_audit_trail,dba_audit_exists,dba_audit_object,
dba_audit_session,dba_audit_statement
Managing users
1.create a user: database authentication
sql> create user juncky identified by oracle default tablespace users
temporary tablespace temp quota 10m on data
password expire
[account lock|unlock]
[profile profilename|default];
2.change user quota on tablespace
sql> alter user juncky quota 0 on users;
#0 代表以后不能再新增对像,之前已经建好的还将保留
3.drop a user
sql> drop user juncky [cascade];
#[cascade],删除与用户相关的所有对像,如table, index,trriger
#如果当前用户正连接在oracle上,是不能够被删除的。
4. monitor user
view: dba_users , dba_ts_quotas
一、目的:
Oracle系统中的profile可以用来对用户所能使用的数据库资源进行限制,使用
Create
Profile命令创建一个Profile,用它来实现对数据库资源的限制使用,如果把该profile分配给用户,则该用户所能使用的数据库资源都在该
profile的限制之内。
二、条件:
创建profile必须要有CREATE PROFILE的系统权限。
为用户指定资源限制,必须:
1.动态地使用alter system或使用初始化参数resource_limit使资源限制生效。该改变对密码资源无效,密码资源总是可用。
SQL> show parameter resource_limit
NAME TYPE VALUE
———————————— ———– ——————————
resource_limit boolean FALSE
SQL> alter system set resource_limit=true;
系统已更改。
SQL> show parameter resource_limit;
NAME TYPE VALUE
———————————— ———– ——————————
resource_limit boolean TRUE
SQL>
2.使用create profile创建一个定义对数据库资源进行限制的profile。
3.使用create user 或alter user命令把profile分配给用户。
三、语法:
CREATE PROFILE profile
LIMIT { resource_parameters
| password_parameters
}
[ resource_parameters
| password_parameters
]... ;
<resource_parameters>
{ { SESSIONS_PER_USER
| CPU_PER_SESSION
| CPU_PER_CALL
| CONNECT_TIME
| IDLE_TIME
| LOGICAL_READS_PER_SESSION
| LOGICAL_READS_PER_CALL
| COMPOSITE_LIMIT
}
{ integer | UNLIMITED | DEFAULT }
| PRIVATE_SGA
{ integer [ K | M ] | UNLIMITED | DEFAULT }
}
< password_parameters >
{ { FAILED_LOGIN_ATTEMPTS
| PASSWORD_LIFE_TIME
| PASSWORD_REUSE_TIME
| PASSWORD_REUSE_MAX
| PASSWORD_LOCK_TIME
| PASSWORD_GRACE_TIME
}
{ expr | UNLIMITED | DEFAULT }
| PASSWORD_VERIFY_FUNCTION
{ function | NULL | DEFAULT }
}
四、语法解释:
profile:配置文件的名称。Oracle数据库以以下方式强迫资源限制:
1.如果用户超过了connect_time或idle_time的会话资源限制,数据库就回滚当前事务,并结束会话。用户再次执行命令,数据库则返回一个错误,
2.如果用户试图执行超过其他的会话资源限制的操作,数据库放弃操作,回滚当前事务并立即返回错误。用户之后可以提交或回滚当前事务,必须结束会话。
提示:可以将一条分成多个段,如1小时(1/24天)来限制时间,可以为用户指定资源限制,但是数据库只有在参数生效后才会执行限制。
Unlimited:分配该profile的用户对资源使用无限制,当使用密码参数时,unlimited意味着没有对参数加限制。
Default:指定为default意味着忽略对profile中的一些资源限制,Default profile初始定义对资源不限制,可以通过alter profile命令来改变。
Resource_parameter部分
Session_per_user:指定限制用户的并发会话的数目。
Cpu_per_session:指定会话的CPU时间限制,单位为百分之一秒。
Cpu_per_call:指定一次调用(解析、执行和提取)的CPU时间限制,单位为百分之一秒。
Connect_time:指定会话的总的连接时间,以分钟为单位。
Idle_time:指定会话允许连续不活动的总的时间,以分钟为单位,超过该时间,会话将断开。但是长时间运行查询和其他操作的不受此限制。
Logical_reads_per_session:指定一个会话允许读的数据块的数目,包括从内存和磁盘读的所有数据块。
Logical_read_per_call:指定一次执行SQL(解析、执行和提取)调用所允许读的数据块的最大数目。
Private_sga:指定一个会话可以在共享池(SGA)中所允许分配的最大空间,以字节为单位。(该限制只在使用共享服务器结构时才有效,会话在SGA中的私有空间包括私有的SQL和PL/SQL,但不包括共享的SQL和PL/SQL)。
Composite_limit:指定一个会话的总的资源消耗,以service
units单位表示。Oracle数据库以有利的方式计算
cpu_per_session,connect_time,logical_reads_per_session和private-sga总的
service units
Password_parameter部分:
Failed_login_attempts:指定在帐户被锁定之前所允许尝试登陆的的最大次数。
Password_life_time:指定同一密码所允许使用的天数。如果同时指定了
password_grace_time参数,如果在grace
period内没有改变密码,则密码会失效,连接数据库被拒绝。如果没有设置password_grace_time参数,默认值unlimited将引
发一个数据库警告,但是允许用户继续连接。
Password_reuse_time和password_reuse_max:这两个参数必须互相关联设置,password_reuse_time指定了密码不能重用前的天数,而password_reuse_max则指定了当前密码被重用之前密码改变的次数。两个参数都必须被设置为整数。
1.如果为这两个参数指定了整数,则用户不能重用密码直到密码被改变了password_reuse_max指定的次数以后在password_reuse_time指定的时间内。
如:password_reuse_time=30,password_reuse_max=10,用户可以在30天以后重用该密码,要求密码必须被改变超过10次。
2.如果指定了其中的一个为整数,而另一个为unlimited,则用户永远不能重用一个密码。
3.如果指定了其中的一个为default,Oracle数据库使用定义在profile中的默认值,默认情况下,所有的参数在profile中都被设置为unlimited,如果没有改变profile默认值,数据库对该值总是默认为unlimited。
4.如果两个参数都设置为unlimited,则数据库忽略他们。
Password_lock_time:指定登陆尝试失败次数到达后帐户的缩定时间,以天为单位。
Password_grace_time:指定宽限天数,数据库发出警告到登陆失效前的天数。如果数据库密码在这中间没有被修改,则过期会失效。
Password_verify_function:该字段允许将复杂的PL/SQL密码验证脚本做为参
数传递到create profile语句。Oracle数据库提供了一个默认的脚本,但是自己可以创建自己的验证规则或使用第三方软件验证。
对Function名称,指定的是密码验证规则的名称,指定为Null则意味着不使用密码验证功能。如果为密码参数指定表达式,则该表达式可以是任意格
式,除了数据库标量子查询。
五、举例:
1.创建一个profile:
create profile new_profile
limit password_reuse_max 10
password_reuse_time 30;
2.设置profile资源限制:
create profile app_user limit
sessions_per_user unlimited
cpu_per_session unlimited
cpu_per_call 3000
connect_time 45
logical_reads_per_session default
logical_reads_per_call 1000
private_sga 15k
composite_limit 5000000;
总的resource cost不超过五百万service units。计算总的resource cost的公式由alter resource cost语句来指定。
3.设置密码限制profile:
create profile app_users2 limit
failed_login_attempts 5
password_life_time 60
password_reuse_time 60
password_reuse_max 5
password_verify_function verify_function
password_lock_time 1/24
password_grace_time 10;
4.将配置文件分配给用户:
SQL> alter user dinya profile app_user;
用户已更改。
SQL> alter user dinya profile default;
用户已更改。
第八章: managing password security and resources
1.controlling account lock and password
sql> alter user juncky identified by oracle account unlock;
2.user_provided password function
sql> function_name(userid in varchar2(30),password in varchar2(30),
old_password in varchar2(30)) return boolean
3.create a profile : password setting
sql> create profile grace_5 limit failed_login_attempts 3
sql> password_lock_time unlimited password_life_time 30
sql>password_reuse_time 30 password_verify_function verify_function
sql> password_grace_time 5;
4.altering a profile
sql> alter profile default failed_login_attempts 3
sql> password_life_time 60 password_grace_time 10;
5.drop a profile
sql> drop profile grace_5 [cascade];
6.create a profile : resource limit
sql> create profile developer_prof limit sessions_per_user 2
sql> cpu_per_session 10000 idle_time 60 connect_time 480;
7. view => resource_cost : alter resource cost
dba_Users,dba_profiles
8. enable resource limits
sql> alter system set resource_limit=true;
9.设置指定用户应用profile
sql> alter user test profile profile_user;
第四章:索引
1.creating function-based indexes
sql> create index summit.item_quantity on summit.item(quantity-
quantity_shipped);
2.create a B-tree index #oracle 默认是这种索引,此种索引适用于唯一性高的列
sql> create [unique] index index_name on table_name(column,.. asc/desc)
tablespace
sql> tablespace_name [pctfree integer] [initrans integer] [maxtrans integer] #不能指定pctused参数
sql> [logging | nologging] [nosort] storage(initial 200k next 200k pctincrease 0
sql> maxextents 50);
3.pctfree(index)=(maximum number of rows-initial number of rows)*100/maximum
number of rows
4.creating reverse key indexes
sql> create unique index xay_id on xay(a) reverse pctfree 30 storage(initial
200k
next 200k pctincrease 0 maxextents 50) tablespace indx;
5.create bitmap index #此种索引适用于唯一性低的列,如性别列,只有"男","女"两种
情况,也就是说,很多行会重复。
sql> create bitmap index xay_id on xay(a) pctfree 30 storage( initial 200k next
200k
sql> pctincrease 0 maxextents 50) tablespace indx;
6.change storage parameter of index
sql> alter index xay_id storage (next 400k maxextents 100);
7.allocating index space
sql> alter index xay_id allocate extent(size 200k datafile
'c:/oracle/index.dbf');
8.deallocating index space
sql> alter index xay_id deallocate unused;
9.rebuilding indexes
sql> alter index testindex3 rebuild tablespace indx;#移到指定tablespace
sql> alter index testindex3 rebuild reverse;#转换成反转索引
10.online rebuild of indexes
sql> alter index testindex3 rebuild online #不锁定表,原有索引的基础上建
11.coalescing indexes 碎片整理
sql> alter index testindex3 coalesce;
12.checking index validity 校验索引
sql> analyze index testindex validate structrue;
13.dropping indexes
sql> drop index testindex;
14.identifying unused indexes
sql> alter index testindex monitoring useage; #开始监视
sql> alter index testindex nomonitoring useage; #取消监视
15. obtaining index information
dba_indexes, dba_ind_columns, dba_ind_expressions,v$object_usage
16.oracle B-tree和bitmap索引区别
1、都是树型结构,叶子节点存储内容不一样。
2、列的取值范围较大(适合常规b—tree索引),取值范围较小(适合位图索引);
3、由于bitmap索引的特点,他不是unique型的,也不涉及unique概念。
4、bitmap通常where如果有or连接效率比较高。
5、b-tree适合oltp,bitmap适合数据仓库。
16.索引占用空间使用情况
sql>analyze index ***.***_subscriber_groupid_indx validate structure;
Index analyzed.
column name format a15
column blocks heading "ALLOCATED|BLOCKS"
column lf_blks heading "LEAF|BLOCKS"
column br_blks heading "BRANCH|BLOCKS"
column Empty heading "UNUSED|BLOCKS"
SQL> list
1 select name,
2 blocks,
3 lf_blks,
4 br_blks,
5 blocks-(lf_blks+br_blks) empty
6* from index_stats
SQL> /
ALLOCATED LEAF BRANCH UNUSED
NAME BLOCKS BLOCKS BLOCKS BLOCKS
————— ———- ———- ———- ———-
***_SUBSCRIBER 640 577 3 60
_GROUPID_INDX
也可通过如下的查询来确定该索引在BTREE空间内使用情况
SQL> list
1 select name,
2 btree_space,
3 used_space,
4 pct_used
5* from index_stats
SQL> /
NAME BTREE_SPACE USED_SPACE PCT_USED
—————————— ———– ———- ———-
AGCF_SUBSCRIBER_GROUPID_INDX 4637776 3027283 66
Temp Table 的特点:
(1) 多用户操作的独立性:对于使用同一张临时表的不同用户,ORACLE都会分配一个独立的 Temp Segment,这样就避免了多个用户在对同一张临时表操作时发生交叉,从而保证了多个用户操作的并发性和独立性;
(2) 数据的临时性:既然是临时表,顾名思义,存放在该表中的数据是临时性的。ORACLE根据你创建临时表时指定的参数(On Commit Delete Rows / On Commit Preserve Rows),自动将数据TRUNCATE掉。
Temp Table 数据的时效性:
(1)On Commit Delete Rows: 数据在 Transaction 期间有效,一旦COMMIT后,数据就被自动 TRUNCATE 掉了;
SQL> CREATE GLOBAL TEMPORARY TABLE QCUI_Temp_Trans
2 ON COMMIT DELETE ROWS
3 AS
4 SELECT * FROM t_Department;
表已创建。
SQL> INSERT INTO QCUI_Temp_Trans
2 SELECT * FROM t_Dept;
已创建4行。
SQL> SELECT * FROM QCUI_Temp_Trans;
DEPTID DEPTNAME
---------- --------------------
101 销售部
201 财务部
301 货运部
401 采购部
SQL> commit;
提交完成。
SQL> SELECT * FROM QCUI_Temp_Trans;
未选定行
(2)On Commit Preserve Rows :数据在 Session 期间有效,一旦关闭了Session 或 Log Off 后,数据就被 ORACLE 自动 Truncate 掉。
SQL> CREATE GLOBAL TEMPORARY TABLE QCUI_Temp_Sess
2 ON COMMIT PRESERVE ROWS
3 AS
4 SELECT * FROM t_Department;
表已创建。
SQL> Select * from QCUI_Temp_Sess;
DEPTID DEPTNAME
---------- --------------------
101 销售部
301 货运部
401 采购部
201 财务部
SQL> exit
C:\Documents and Settings\QCUI>sqlplus sqltrainer@ibm
SQL> SELECT * FROM QCUI_Temp_Sess;
未选定行
注:这里要说明的是,ORACLE Truncate 掉的数据仅仅是分配给不同 Session 或 Transaction的 Temp Segment 上的数据,而不是将整张表数据 TRUNCATE 掉。
Temp Table 的应用:
Temp Table 就我理解而言,主要有两方面应用。
对于一个电子商务类网站,不同消费者在网站上购物,就是一个独立的 SESSION,选购商品放进购物车中,最后将购物车中的商品进行结算。也就是说,必须在整个SESSION期间保存购物车中的信息。同时,还存在有些消费者,往往最终结账时放弃购买商品。如果,直接将消费者选购信息存放在最终表(PERMANENT)中,必然对最终表造成非常大的压力。
因此,对于这种案例,就可以采用创建临时表( ON COMMIT PRESERVE ROWS )的方法来解决。数据只在 SESSION 期间有效,对于结算成功的有效数据,转移到最终表中后,ORACLE自动TRUNCATE 临时数据;对于放弃结算的数据,ORACLE 同样自动进行 TRUNCATE ,而无须编码控制,并且最终表只处理有效订单,减轻了频繁的DML的压力。
注:这里似乎说得不对,对于B/S应用,虽然SESSION是一个,但此session并不是数据库连接的session,每次页面请求都是使用新的连接(或从连接池中获取的),对于数据库而言是新的session,这种情况下,临时表内的数据是不是不能共享呀??
wallimn 2009-11-11
Temp Table 的另一个应用,就是存放数据分析的中间数据。
Temp Table 存放在哪儿?
Temp Table 并非存放在用户的表空间中,而是存放在 Schema 所指定的临时表空间中。
SQL> Select Table_Name, Tablespace_Name
2 From User_Tables
3 Where Table_Name Like 'QCUI%';
TABLE_NAME TABLESPACE_NAME
------------------------------ ------------------------------
QCUI_TEMP_SESS
QCUI_TEMP_TRANS
可见这两张临时表并未存放在用户的表空间中。
用户 SQLTRAINER 的临时表空间是 TEMP , 用户创建的临时表是存放在TEMP表空间中的。下面来证明
SQL> SELECT UserName, Default_Tablespace def_ts, Temporary_Tablespace temp_ts
2 FROM User_Users;
USERNAME DEF_TS TEMP_TS
----------------------------- ------------------ ----------
SQLTRAINER ts_ORASQLTraining TEMP
SQL> connect system/manager@ibm
已连接。
SQL> alter tablespace temp offline;
表空间已更改。
SQL> connect sqltrainer/sqltrainer@ibm
已连接。
SQL> INSERT INTO QCUI_Temp_Sess
2 SELECT * FROM t_Department;
INSERT INTO QCUI_Temp_Sess
*
ERROR 位于第 1 行:
ORA-01542: 表空间'TEMP'脱机,无法在其中分配空间
对 Temp Table 的 DML 操作是否不产生 Redo Log ?
尽管对临时表的DML操作速度比较快,但同样也是要产生 Redo Log 的,只是同样的DML语句,比对 PERMANENT 的DML 产生的Redo Log 少。
SQL> Set AutoTrace On
SQL> CREATE GLOBAL TEMPORARY TABLE QCUI_Temp_Sess_AllObj
2 ON COMMIT PRESERVE ROWS
3 AS
4 SELECT * FROM All_Objects;
表已创建。
SQL> INSERT INTO QCUI_Temp_Sess_AllObj
2 SELECT * FROM All_Objects;
已创建21839行。
Statistics
---------------------------------------------------------
……
168772 redo size
……
SQL> CREATE TABLE QCUI_ALL_OBJECTS
2 AS
3 SELECT * FROM All_Objects
4 WHERE 1 = 0;
表已创建。
SQL> INSERT INTO QCUI_All_Objects
2 SELECT * FROM ALL_Objects;
已创建21839行。
Statistics
----------------------------------------------------------
……
2439044 redo size
……
第三章:表
1.create a table
sql> create table table_name (column datatype,column datatype]....)
sql> tablespace tablespace_name [pctfree integer] [pctused integer]
sql> [initrans integer] [maxtrans integer]
sql> storage(initial 200k next 200k pctincrease 0 maxextents 50)
sql> [logging|nologging] [cache|nocache]
2.copy an existing table
sql> create table table_name [logging|nologging] as subquery
3.create temporary table
sql> create global temporary table xay_temp as select * from xay;
on commit preserve rows/on commit delete rows #具体可见oracle临时表的应用
4.pctfree = (average row size - initial row size) *100 /average row size
pctused = 100-pctfree- (average row size*100/available data space)
5.change storage and block utilization parameter
sql> alter table table_name pctfree=30 pctused=50 storage(next 500k
sql> minextents 2 maxextents 100);
6.manually allocating extents
sql> alter table table_name allocate extent(size 500k datafile 'c:/oracle/data.dbf');
7.move tablespace
sql> alter table employee move tablespace users;
#此操作会造成索引不可用,需要重建索引,但权限之类的不受影响
sql> alter index index_name rebuild;
8.deallocate of unused space
sql> alter table table_name deallocate unused [keep integer]
9.truncate a table
sql> truncate table table_name;
10.drop a table
sql> drop table table_name [cascade constraints];
11.drop a column
sql> alter table table_name drop column comments cascade constraints checkpoint 1000;
alter table table_name drop columns continue;
12.mark a column as unused
sql> alter table table_name set unused column comments cascade constraints;
alter table table_name drop unused columns checkpoint 1000;
alter table orders drop columns continue checkpoint 1000
13.obtaining table information
data_dictionary : dba_unused_col_tabs
dba_tables
dba_objects
sql> select * from dba_tables where owner = 'ET';
sql> select * from dba_objectswhere owner = 'ET';
14.truncate,delete,drop的异同点
之前看到的:“在删除一个表中的全部数据时,须使用TRUNCATE TABLE 表名;因为用DROP TABLE,DELETE * FROM 表名时,TABLESPACE表空间该表的占用空间并未释放,反复几次
DROP,DELETE操作后,该TABLESPACE上百兆的空间就被耗光了”
之前看到的:“在删除一个表中的全部数据时,须使用TRUNCATE TABLE 表名;因为用DROP TABLE,DELETE * FROM 表名时,TABLESPACE表空间该表的占用空间并未释放,反复几次
DROP,DELETE操作后,该TABLESPACE上百兆的空间就被耗光了”后来查了点资料,感觉有一定道理,因为Oracle 10g开始,当我执行Drop Table是,Oracle也会把被删除的表放到
数据库回收站(Database Recyclebin)里。这样我们就可以用flashback table命令恢复被删除的表,语法:
Flashback table 表名 to before drop;
但没有资料说,可以恢复truncate的内容。当然,他说的也不完全,因为我们删除表时想要的效果不同。其实这三个指令之前我从来没有怎么注意,只是知道我想保住表结构,但
不想要里头内容时,我会用truncate,如果删除的内容不太确定,就是用delete,因为它可以回退,有点像垃圾筒的概念,如果这整张表我都不想要了,我就drop掉它。今天在网
上查了点资料,有一篇写得挺好,感觉比较全面:
truncate,delete,drop的异同点
注意:这里说的delete是指不带where子句的delete语句
相同点:truncate和不带where子句的delete, 以及drop都会删除表内的数据
不同点:
1. truncate和 delete只删除数据不删除表的结构(定义)
drop语句将删除表的结构被依赖的约束(constrain),触发器(trigger),索引(index); 依赖于该表的存储过程/函数将保留,但是变为invalid状态.
2.delete语句是dml,这个操作会放到rollback segement中,事务提交之后才生效;如果有相应的trigger,执行的时候将被触发.
truncate,drop是ddl, 操作立即生效,原数据不放到rollback segment中,不能回滚. 操作不触发trigger.
3.delete语句不影响表所占用的extent, 高水线(high watermark)保持原位置不动
显然drop语句将表所占用的空间全部释放
truncate 语句缺省情况下将空间释放到 minextents个 extent,除非使用reuse storage; truncate会将高水线复位(回到最开始).
4.速度,一般来说: drop> truncate > delete
5.安全性:小心使用drop 和truncate,尤其没有备份的时候.否则哭都来不及
使用上,想删除部分数据行用delete,注意带上where子句. 回滚段要足够大.
想删除表,当然用drop
想保留表而将所有数据删除. 如果和事务无关,用truncate即可. 如果和事务有关,或者想触发trigger,还是用delete.
如果是整理表内部的碎片,可以用truncate跟上reuse stroage,再重新导入/插入数据
1.forcing log switches
sql> alter system switch logfile;
2.forcing checkpoints
sql> alter system checkpoint;
3.adding online redo log groups
sql> alter database add logfile [group 4] ('/disk3/log4a.rdo','/disk4/log4b.rdo') size 1m;
4.adding online redo log members
sql> alter database add logfile member '/disk3/log1b.rdo' to group 1, '/disk4/log2b.rdo' to group 2;
5.changes the name of the online redo logfile
sql> alter database rename file 'c:/oracle/oradata/oradb/redo01.log' to 'c:/oracle/oradata/redo01.log';
6.drop online redo log groups
sql> alter database drop logfile group 3;
7.drop online redo log members
sql> alter database drop logfile member 'c:/oracle/oradata/redo01.log';
8.clearing online redo log files
sql> alter database clear [unarchived] logfile 'c:/oracle/log2a.rdo';
9.using logminer analyzing redo logfiles #这个可能是8i的日志分析,10g的请看另一篇日志挖掘。
a. in the init.ora specify utl_file_dir = ' '
b. sql> execute dbms_logmnr_d.build('oradb.ora','c:"oracle"oradb"log');
c. sql> execute dbms_logmnr_add_logfile('c:"oracle"oradata"oradb"redo01.log', dbms_logmnr.new);
d. sql> execute dbms_logmnr.add_logfile('c:"oracle"oradata"oradb"redo02.log', dbms_logmnr.addfile);
e. sql> execute dbms_logmnr.start_logmnr(dictfilename=>'c:"oracle"oradb"log"oradb.ora');
f. sql> select * from v$logmnr_contents(v$logmnr_dictionary,v$logmnr_parameters v$logmnr_logs);
g. sql> execute dbms_logmnr.end_logmnr;
10.查看系统日志文件信息及大小
sql>select a.group#, a.sequence#,a.bytes/1024/1024 tsize , a.members,a.status,b.member,b.type from v$log a , v$logfile b where a.group#=b.group#;
oracle数据库通过控制文件保持数据库的完整性,一旦控制文件被破坏数据库将无法启动,因此建议采用多路控制文件或者备份控制文件的方法。
控制文件是数据库建立的时候自动生成的二进制文件,只能通过实例进行修改,如果手动修改的话会造成控制文件与物理信息不符合,从而导致数据库不能正常工作。
控制文件主要包括下面内容:
1.控制文件所属数据库的名字,一个控制文件只能属一个数据库
2.数据库创建时间
3.数据文件的名称,位置,联机,脱机状态信息
4.所有表空间信息
5.当前日志序列号
6.最近检查点信息
其中,数据库名称,标识和创建时间在数据库创建时写入;数据文件和重做日志名称和位置在增加,重命名或者删除的时候更新;表空间信息在增加或者删除表空间的时候进行更新。
在初始化参数文件中control_files参数主要来描述控制文件的文件名跟物理路径,如下所示:
control_files=("d:\oracle\oradata\oradb\control01.ctl")
该参数只设置一个,也可以设置多个,如下所示:
control_files=('d:\oracle\oradata\oradb\control01.ctl',
'd:\oracle\oradata\oradb\control02.ctl',
'd:oracle\oradata\oradb\control03.ctl')
这个方法叫做多路控制文件,oracle可以利用这个方法恢复被破坏的控制文件,oracle最多允许设置8个多路控制文件。
必须所有的多路控制文件都完整正确数据库才能正常启动,只要丢失一个或者一个内容不正确数据库就不能顺利启动。
对控制文件的管理原则:
1.明确控制文件的名称和存储路径
参数设置错误将无法打开数据库,数据库打开以后,实例将同时写入所有的控制文件但是只会读取第一个控制文件的内容。
2.为数据库创建多路控制文件
a.多路控制文件内容必须完全一样,oracle实例同时将内容写入到control_files变量所设置的控制文件中。
b.初始化参数control_files中列出的第一个文件是数据库运行期间唯一可读取的控制文件。
c.创建,恢复和备份控制文件必须在数据库关闭的状态下运行,这样才能保证操作过程中控制文件不被修改。
d.数据库运行期间如果一个控制文件变为不可用,那么实例将不再运行,应该终止这个实例,并对破坏的控制文件进行修复。
3.将多路控制文件放在不同的硬盘上
4.采用操作系统镜像方式备份控制文件
5.手工方式备份控制文件
应该及时备份特别是发生了如下的操作的时候:
添加删除重命名数据文件
添加删除表空间,改变表空间读写状态
添加删除重做日志文件
如果手工备份不及时的话,就会产生备份的控制文件与正在使用的控制文件不一致,那么利用备份的控制文件启动数据库时会破坏数据库的一致性完整性,甚至不能启动数据库,因此手工备份控制文件要注意及时备份。
创建多路控制文件
利用spfile文件创建多路控制文件
(spfile以二进制文本形式存在,不能用vi等编辑器对其中参数进行修改。文件格式为spfileSID.ora。如果要对spfile文件进行修改,可以采用SQL语言)
1.利用SYS帐号登陆SQL*PLUS,查询一下控制文件信息视图
SQL>select name from v$controlfile;
结果显示为:
NAME
----------------------------------
d:\oracle\oradata\oradb\control01.ctl
d:\oracle\oradata\oradb\control02.ctl
d:\oracle\oradata\oradb\control03.ctl
这里列出了控制文件的名称以及位置
2.更改spfile中控制文件的信息:(增加了一个新的控制文件)
SQL>alter system set control_files=
'd:\oracle\oradata\oradb\control01.ctl',
'd:\oracle\oradata\oradb\control02.ctl',
'd:\oracle\oradata\oradb\control03.ctl',
'd:\oracle\oradata\oradb\control04.ctl'
scope=spfile
结果显示为:
系统已经更改。
(第二步的操作需要注意的是:进行这些操作,必须是在DB启动的时候,否则会弹出“ORACLE not available”错误。)
3.关闭数据库
4.在操作系统中将已有的控制文件复制,修改名称保存到刚才增加控制文件的指定位置。(这步必须做的,否则数据库无法启动)
5.重新启动控制文件,使控制文件改变生效。
6.还可以使用pfile的方法来修改控制文件,使用create pfile from spfile;来生成pfile,然后使用vi等编辑器编译pfile,先手工拷贝控制文件修改相应的名称,然后把新的控制文件的路径增加到pfile中,使用pfile启动数据库,然后使用pfile创建spfile即可.
管理控制文件
备份控制文件
SQL> alter database backup controlfile to ‘d:\20080326.ctl’
SQL> alter database backup controlfile to trace;(备份创建控制文件的脚本)
# 具体文件名请看<background_dump_dest>/alert_<SID>.log文件里有详细说明。例如在/opt/app/oracle/diag/rdbms/orcl/orcl/trace/目录下。
alter database backup controlfile to trace
Mon Nov 23 10:27:56 2009
ALTER DATABASE BACKUP CONTROLFILE TO TRACE
Backup controlfile written to trace file /opt/app/oracle/diag/rdbms/orcl/orcl/trace/orcl_ora_4169.trc
数据库已更改。
然后从这个备份的位置直接把文件拷贝回之前的目录覆盖就好了。
删除控制文件(删除某一路的控制文件)
spfile文件
1.利用SYS帐号登陆SQL*PLUS,查询一下控制文件信息视图
SQL>select name from v$controlfile;
结果显示为:
NAME
----------------------------------
d:oracle\oradata\oradb\control01.ctl
d:oracle\oradata\oradb\control02.ctl
d:oracle\oradata\oradb\control03.ctl
d:oracle\oradata\oradb\control04.ctl
这里列出了控制文件的名称以及位置
2.更改spfile中控制文件的信息,删除一个新的控制文件
SQL>alter system set control_files=
'd:oracle\oradata\oradb\control01.ctl',
'd:oracle\oradata\oradb\control02.ctl',
'd:oracle\oradata\oradb\control03.ctl',
scope=spfile
结果显示为:
系统已经更改。
3.关闭数据库
4.在操作系统中删除控制文件
5.重新启动数据库,使控制文件生效
Oracle 10g可以使用LOGMNR在线分析和挖掘日志,使用当前在线的数据字典,非常方便。
查看包是否已经安装
SQL>desc dbms_logmnr
首先执行一些DDL或DML操作:
SQL> connect eygle/eygle
Connected.
SQL> alter system switch logfile;
System altered.
SQL> create table eygle as select * from dba_users;
Table created.
SQL> set autotrace on
SQL> select count(*) from eygle;
COUNT(*)
----------
19
Execution Plan
----------------------------------------------------------
Plan hash value: 3602634261
--------------------------------------------------------------------
| Id | Operation | Name | Rows | Cost (%CPU)| Time |
--------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 3 (0)| 00:00:01 |
| 1 | SORT AGGREGATE | | 1 | | |
| 2 | TABLE ACCESS FULL| EYGLE | 19 | 3 (0)| 00:00:01 |
--------------------------------------------------------------------
Note
-----
- dynamic sampling used for this statement
Statistics
----------------------------------------------------------
5 recursive calls
0 db block gets
7 consistent gets
5 physical reads
0 redo size
411 bytes sent via SQL*Net to client
400 bytes received via SQL*Net from client
2 SQL*Net roundtrips to/from client
0 sorts (memory)
0 sorts (disk)
1 rows processed
然后可以执行LOGMNR解析工作:
SQL> connect / as sysdba
Connected.
SQL> select * from v$log where status='CURRENT';
GROUP# THREAD# SEQUENCE# BYTES MEMBERS ARC STATUS FIRST_CHANGE# FIRST_TIME
---------- ---------- ---------- ---------- ---------- --- ---------------- ------------- ------------
2 1 100 52428800 1 NO CURRENT 12729697 01-JUL-09
SQL> SELECT MEMBER from v$logfile where group#=2;
MEMBER
------------------------------------------------------------------------------------------------------------------------
/opt/oracle/oradata/mmstest/redo02.log
SQL> exec dbms_logmnr.add_logfile('/opt/oracle/oradata/mmstest/redo02.log',dbms_logmnr.new);
PL/SQL procedure successfully completed.
SQL> exec dbms_logmnr.start_logmnr(options=>dbms_logmnr.dict_from_online_catalog); # 这里可以指定参数:STARTTIME与ENDTIME
PL/SQL procedure successfully completed.
SQL> select count(*) from v$logmnr_contents;
COUNT(*)
----------
136
SQL> select sql_redo from v$logmnr_contents; #同样这里可以执行命令 select sql_undo from v$logmnr_contents;
SQL_REDO
------------------------------------------------------------------------------------------------------------------------
set transaction read write;
insert into "SYS"."OBJ$"("OBJ#","DATAOBJ#","OWNER#","NAME","NAMESPACE","SUBNAME","TYPE#","CTIME","MTIME","STIME","STATUS
","REMOTEOWNER","**NAME","FLAGS","OID$","SPARE1","SPARE2","SPARE3","SPARE4","SPARE5","SPARE6") values ('25847','25847'
,'31','EYGLE','1',NULL,'2',TO_DATE('01-JUL-09', 'DD-MON-RR'),TO_DATE('01-JUL-09', 'DD-MON-RR'),TO_DATE('01-JUL-09', 'DD-
MON-RR'),'1',NULL,NULL,'0',NULL,'6','1',NULL,NULL,NULL,NULL);
set transaction read write;
update "SYS"."CON$" set "CON#" = '10823' where "CON#" = '10822' and ROWID = 'AAAAAcAABAAAACqAAM';
commit;
set transaction read write;
SQL_REDO
------------------------------------------------------------------------------------------------------------------------
update "SYS"."CON$" set "CON#" = '10824' where "CON#" = '10823' and ROWID = 'AAAAAcAABAAAACqAAM';
commit;
set transaction read write;
update "SYS"."CON$" set "CON#" = '10825' where "CON#" = '10824' and ROWID = 'AAAAAcAABAAAACqAAM';
commit;
set transaction read write;
update "SYS"."CON$" set "CON#" = '10826' where "CON#" = '10825' and ROWID = 'AAAAAcAABAAAACqAAM';
commit;
set transaction read write;
update "SYS"."CON$" set "CON#" = '10827' where "CON#" = '10826' and ROWID = 'AAAAAcAABAAAACqAAM';
commit;
set transaction read write;
update "SYS"."CON$" set "CON#" = '10828' where "CON#" = '10827' and ROWID = 'AAAAAcAABAAAACqAAM';
commit;
set transaction read write;
update "SYS"."CON$" set "CON#" = '10829' where "CON#" = '10828' and ROWID = 'AAAAAcAABAAAACqAAM';
commit;
create table eygle as select * from dba_users;
set transaction read write;
Unsupported
update "SYS"."TSQ$" set "TS#" = '0', "GRANTOR#" = '43080', "BLOCKS" = '0', "MAXBLOCKS" = '0', "PRIV1" = '0', "PRIV2" = '
0' where "TS#" = '0' and "GRANTOR#" = '43072' and "BLOCKS" = '0' and "MAXBLOCKS" = '0' and "PRIV1" = '0' and "PRIV2" = '
0' and ROWID = 'AAAAAKAABAAAABbAAF';
commit;
set transaction read write;
SQL> exec dbms_logmnr.end_logmnr
注:在Oracle安装过程中,如果数据库是自动创建的,那么该数据库最初的存档模式是由操作系统指定的。通常情况下,归档日志在Oracle数据库安装结束后需要手工创建。
环境:Oracle 10g 10.2.0.1.0/Windows 2003 Server SP1
数据字典视图:v$archived_log,v$log,v$archive_dest,v$database,v$archive_processes,
v$backup_redolog,v$log_histroy,v$recovery_file_dest.
一、关闭归档
1、启动SQL*PLUS以管理身份登录Oracle数据库:
SQL> connect / as sysdba
2、关闭数据库实例
SQL> shutdown immediate
3、备份数据库:在对数据库做出任何重要的改变之前,建议备份数据库以免出现任何问题。
4、启动一个新的实例并装载数据库,但不打开数据库:
SQL> startup mount
5、禁止自动存档
SQL> alter system archive log stop;
6、禁止存档联机重做日志:转换数据库的存档模式。
SQL> alter database noarchivelog ;
7、打开数据库:
SQL> alter database open ;
8、察看已连接实例的存档信息:
SQL> archive log list ;
数据库日志模式 非存档模式
自动存档 禁用
存档终点 E:\oracle\arc
最早的联机日志序列 50
当前日志序列 52
二、启用类Oracle9i的归档
1、启动SQL*PLUS以管理身份登录Oracle数据库:
SQL> connect / as sysdba
2、关闭数据库实例
SQL> shutdown immediate
3、备份数据库:在对数据库做出任何重要的改变之前,建议备份数据库以免出现任何问题。
4、启动一个新的实例并装载数据库,但不打开数据库:
SQL> startup mount
5、转换数据库的存档模式为归档方式:
SQL> alter database archivelog ;
6、打开数据库:
SQL> alter database open ;
7、在数据库实例启动后允许自动存档方式:
SQL> alter system set log_archive_start=true scope=spfile;
8、指定归档日志文件的存放位置并记录到SPFILE:
SQL> alter system set log_archive_dest_1='location=E:\oracle\arc' scope=spfile;
9、指定归档日志文件名命名格式:使用%s来包含日志序号作为文件名的一部份,并且使用%t来包含线程号,使用大写字母(%S和%T)来以0填补文件名左边的空处。
The following variables can be used in the format:
%s log sequence number
%S log sequence number, zero filled
%t thread number
%T thread number, zero filled
SQL> alter system set log_archive_format='BE%S_%R_%T.arc' scope=spfile;
三、在Oracle 10g里启动自动归档模式
$ sqlplus "/ as sysdba"
SQL> archive log list;
Database log mode No Archive Mode
Automatic archival Disabled
Archive destination USE_DB_RECOVERY_FILE_DEST
Oldest online log sequence 25
Current log sequence 27
SQL> show parameter log_archive_start
NAME TYPE VALUE
------------------------------------ ----------- ------------------------------
log_archive_start boolean FALSE
SQL> shutdown immediate;
Database closed.
Database dismounted.
ORACLE instance shut down.
SQL> startup mount;
ORACLE instance started.
Total System Global Area 3204448256 bytes
Fixed Size 1304912 bytes
Variable Size 651957936 bytes
Database Buffers 2550136832 bytes
Redo Buffers 1048576 bytes
Database mounted.
SQL> alter database archivelog;
Database altered.
SQL> alter database open;
Database altered.
SQL> archive log list;
Database log mode Archive Mode
Automatic archival Enabled
Archive destination USE_DB_RECOVERY_FILE_DEST
Oldest online log sequence 25
Next log sequence to archive 27
Current log sequence 27
SQL>
查看表空间有多大
select t.tablespace_name, round(sum(bytes/(1024*1024)),0) ts_size
from dba_tablespaces t, dba_data_files d
where t.tablespace_name = d.tablespace_name
group by t.tablespace_name;
查看表空间及其数据文件
select tablespace_name, file_id, file_name,
round(bytes/(1024*1024),0) total_space
from dba_data_files
order by tablespace_name;
查看表空间总大小,已使用,剩下多少
select a.tablespace_name,total,free,round(free/total*100,2) free_precent,total-free used from
( select tablespace_name,sum(bytes)/1024/1024 total from dba_data_files
group by tablespace_name) a,
( select tablespace_name,sum(bytes)/1024/1024 free from dba_free_space
group by tablespace_name) b
where a.tablespace_name=b.tablespace_name;
1.create tablespaces
sql> create tablespace tablespace_name datafile 'c:"oracle"oradata"file1.dbf' size 100m,
sql> 'c:"oracle"oradata"file2.dbf' size 100m minimum extent 550k [logging/nologging]
sql> default storage (initial 500k next 500k maxextents 500 pctinccease 0)
sql> [online/offline] [permanent/temporary] [extent_management_clause]
2.locally managed tablespace
sql> create tablespace user_data datafile 'c:"oracle"oradata"user_data01.dbf'
sql> size 500m extent management local uniform size 10m;
3.temporary tablespace
sql> create temporary tablespace temp tempfile 'c:"oracle"oradata"temp01.dbf'
sql> size 500m extent management local uniform size 10m;
4.change the storage setting
sql> alter tablespace app_data minimum extent 2m;
sql> alter tablespace app_data default storage(initial 2m next 2m maxextents 999);
5.taking tablespace offline or online
sql> alter tablespace app_data offline;
sql> alter tablespace app_data online;
6.read_only tablespace
sql> alter tablespace app_data read only|write;
7.droping tablespace
sql> drop tablespace app_data including contents;
8.enableing automatic extension of data files
sql> alter tablespace app_data add datafile 'c:"oracle"oradata"app_data01.dbf'size 200m
sql> autoextend on next 10m maxsize 500m;
9.change the size fo data files manually
sql> alter database datafile 'c:\oracle\oradata\app_data.dbf' resize 200m;
9.1改变表空间大小有三种方法:
a)sql>alter database datafile 'c:\oracle\oradata\app_data.dbf' autoextend on .. 自动扩大
b)sql>alter database datafile 'c:\oracle\oradata\app_data.dbf' resize 200m; #同9一样
c) alter tablesapce users add datafile 'c:\oracle\oradata\app_data01.dbf' size 10M #为表空间,手动新增一个datafile
10.Moving data files: alter tablespace
sql> alter tablespace app_data rename datafile 'c:\oracle\oradata\app_data.dbf' to 'c:\oracle\app_data.dbf';
11.moving data files:alter database
sql> alter database rename file 'c:\oracle\oradata\app_data.dbf' to 'c:\oracle\app_data.dbf';
12.OMF管理表空间
设置参数:db_create_file_dest
sql>alter system set db_create_file_dest = 'c:\oradata';
sql>create tablespace usertb; #默认100M,并存放于db_create_file_dest 目录下
sql>drop tablespace usertb; #相应的物理文件也自动删除
13.表空间的一些数据字典与动态性能表
dba_tablespaces v$tablespace v$datafile dba_data_files,
14.查询系统回滚段
sql>select * from dba_rollback_segs
15.限制用户使用表空间大小
sql>alter user eton quota 10M on users(表空间名 )
16.何为临时表空间
由于Oracle工作时经常需要一些临时的磁盘空间,这些空间主要用作查询时带有排序(Group by,Order by等)等算法所用,当用完后就立即释放,对记录在磁盘区的信息不再使用,因此叫临时表空间。一般安装之后只有一个TEMP临时表空间。
摘要: 1.查看 tablespace存放哪些数据表
select table_name from all_tables where tablespace_name = 'Example'
2.查看 表属于哪个用户
select owne...
阅读全文
安装tomcat后,在客户端输入地址
http://serverAddress:8080,发现默认端口8080不能访问。
由于Linux防火墙默认是关闭8080端口。因此,若要能够访问8080端口,可以用两种方式,一个是关闭防火墙,另一个就是让防火墙开放8080端口。
开放8080端口的解决步骤如下:
1、修改/etc/sysconfig/iptables文件,增加如下一行:
-A RH-Firewall-1-INPUT -m state --state NEW -m tcp -p tcp --dport 8080 -j ACCEPT
重启 iptables
service iptables restart
2、重启防火墙,这里有两种方式重启防火墙
a) 重启后生效
开启: chkconfig iptables on
关闭: chkconfig iptables off
b) 即时生效,重启后失效
开启: service iptables start
关闭: service iptables stop
再次从客户端访问,成功!
一个回滚段可以存放多个事务的回滚信息。
回滚段的作用
1。事务回滚:当事务修改表中数据的时候,该数据修改前的值(即前影像)会存放在
回滚段中,当用户回滚事务(ROLLBACK)时,ORACLE 将会利用回滚段中的数据前影像
来将修改的数据恢复到原来的值。
2。事务恢复:当事务正在处理的时候,例程失败,回滚段的信息保存在重做日志文件
中,ORACLE 将在下次打开数据库时利用回滚来恢复未提交的数据。
3。读一致性:当一个会话正在修改数据时,其他的会话将看不到该会话未提交的修改。
而且,当一个语句正在执行时,该语句将看不到从该语句开始执行后的未提交的修改(语句
级读一致性)。当ORACLE 执行SELECT 语句时,ORACLE 依照当前的系统改变号(SYSTEM
CHANGE NUMBER-SCN)来保证任何前于当前SCN 的未提交的改变不被该语句处理。可
以想象:当一个长时间的查询正在执行时,若其他会话改变了该查询要查询的某个数据块,
ORACLE 将利用回滚段的数据前影像来构造一个读一致性视图。
事务级的读一致性
ORACLE 一般提供SQL 语句级(SQL STATEMENT LEVEL)的读一致性,可以用以下
语句来实现事务级的读一致性。
SET TRANSACTION READ ONLY;
或:
SET TANNSACTION SERIALIZABLE;
以上两个语句都将在事务开始后提供读一致性。需要注意的是,使用第二个语句对数据
库的并发性和性能将带来影响。
回滚段的种类
1。系统回滚段:当数据库创建后,将自动创建一个系统回滚段,该回滚段只用于存放
系统表空间中对象的前影像。
2。非系统回滚段:拥有多个表空间的数据库至少应该有一个非系统回滚段,用于存放
非系统表空间中对象的数据前影像。非系统回滚段又分为私有回滚段和公有回滚段,私有回
滚段应在参数文件的ROLLBACK SEGMENTS 参数中列出,以便例程启动时自动使其在线
(ONLINE)。公有回滚段一般在OPS(ORACLE 并行服务器)中出现,将在例程启动时自
动在线。
3。DEFERED 回滚段:该回滚段在表空间离线(OFFLINE)时由系统自动创建,当表
空间再次在线(ONLINE)时由系统自动删除,用于存放表空间离线时产生的回滚信息。
回滚段的使用
分配回滚段:当事务开始时,ORACLE 将为该事务分配回滚段,并将拥有最少事务的
回滚段分配给该事务。事务可以用以下语句申请指定的回滚段:
SET TRANSTRACTION USE ROLLBACK SEGMENT rollback_segment
事务将以顺序,循环的方式使用回滚段的区(EXTENTS),当当前区用满后移到下一个
区。几个事务可以写在回滚段的同一个区,但每个回滚段的块只能包含一个事务的信息。
例如(两个事务使用同一个回滚段,该回滚段有四个区):
1、事务在进行中,它们正在使用回滚段的第三个区;
2、当两个事务产生更多的回滚信息,它们将继续使用第三个区;
3、当第三个区满后,事务将写到第四个区,当事务开始写到一个新的区时,称为翻转
(WRAP);
4、当第四个区用满时,如果第一个区是空闲或非活动(使用该区的所有事务完成而没
有活动的事务)的,事务将接着使用第一个区。
回滚段的扩张(EXTEND)
当当前回滚段区的所有块用完而事务还需要更多的回滚空间时,回滚段的指针将移到下
一个区。当最后一个区用完,指针将移到第一个区的前面。回滚段指针移到下一个区的前提
是下一个区没有活动的事务,同时指针不能跨区。当下一个区正在使用时,事务将为回滚段
分配一个新的区,这种分配称为回滚段的扩展。回滚段将一直扩展到该回滚段区的个数到达
回滚段的参数MAXEXTENTS 的值时为止。
回滚段的回收和OPTIMAL 参数
OPTIMAL 参数指明回滚段空闲时收缩到的位置,指明回滚段的OPTIMAL 参数可以减
少回滚段空间的浪费。
V$ROLLSTAT 中的常用列
USN:回滚段标识
RSSIZE:回滚段默认大小
XACTS:活动事务数
在一段时间内增量用到的列
WRITES:回滚段写入数(单位:bytes)
SHRINKS:回滚段收缩次数
EXTENDS:回滚段扩展次数
WRAPS:回滚段翻转(wrap)次数
GETS:获取回滚段头次数
WAITS:回滚段头等待次数
V$ROLLSTAT 中的连接列
Column View Joined Column(s)
-------------- ----------------------- ------------------------
USN V$ROLLNAME USN
注意:
通过花费时间除以翻转次数,你可以得到一次回滚段翻转(wrap)的平均用时。此方法常
用于在长查询中指定合适的回滚段大小以避免'Snapshot Too Old'错误。同时,通过查看
extends 和shrinks 列可以看出optimal 是否需要增加。
示例:
1.查询回滚段的信息。所用数据字典:DBA_ROLLBACK_SEGS,可以查询的信息:回滚段
的标识(SEGMENT_ID)、名称(SEGMENT_NAME)、所在表空间(TABLESPACE_NAME)、类
型(OWNER)、状态(STATUS)。
select * from DBA_ROLLBACK_SEGS
查看回滚段的统计信息:
SELECT n.name, s.extents, s.rssize, s.optsize, s.hwmsize, s.xacts,
s.status
FROM v$rollname n, v$rollstat s
WHERE n.usn = s.usn;
3.查看回滚段的使用情况,哪个用户正在使用回滚段的资源:
select s.username, u.name
from v$transaction t, v$rollstat r, v$rollname u, v$session s
where s.taddr = t.addr
and t.xidusn = r.usn
and r.usn = u.usn
order by s.username;
学习动态性能表
第16 篇--V$ROWCACHE 2007.6.12
本视图显示数据字典缓存(也叫rowcache)的各项统计。每一条记录包含不同类型的数据
字典缓存数据统计,注意数据字典缓存有层次差别,因此同样的缓存名称可能不止一次出现。
V$ROWCACHE 常用列
PARAMETER:缓存名
COUNT:缓存项总数
USAGE:包含有效数据的缓存项数
GETS:请求总数
GETMISSES:请求失败数
SCANS:扫描请求数
SCANMISSES:扫描请求失败次数
MODIFICATIONS:添加、修改、删除操作数
DLM_REQUESTS:DLM 请求数
DLM_CONFLICTS:DLM 冲突数
DLM_RELEASES:DLM 释放数
使用 V$ROWCACHE 数据
1>.确认数据字典缓存是否拥有适当的大小。如果shared pool 过小,那数据字典缓存就
不足以拥有合适的大小以缓存请求信息。
2>.确认应用是否有效访问缓存。如果应用设计未能有效使用数据字典缓存(比如,大数
据字典缓存并不有助于解决性能问题)。例如,DC_USERS 缓存在过去某段时期内出现
大量GETS,看起来像是数据库中创建了大量的不同用户,并且应用记录下用户频繁登
陆和注销。通过检查logon 比率以及系统用户数可以验证上述数据。同时解析比率也会
很高,如果这是一个大型的OLTP 系统的中间层,它可能在中间层更有效的管理个别帐
户,允许中间层以单用户登陆成为应用所有者。通过保持活动连接来减少logon/logoff
比率也同样有效。
3>. 确认是否发生动态空间分配。DC_SEGMENTS, DC_USED_EXTENTS, 以及
DC_FREE_EXTENTS 大量的类似大小修改将指出存在大量动态空间分配。可行的解决
方案包括指定下一个区大小或者使用本地管理表空间。如果发生空间分配的是临时的表
空间,则可以为其指定真正的临时表空间(If the space allocation is occurring on the temp
tablespace, then use a true temporary tablespace for the temp. )。
4>.dc_sequences 值的变化指出是否大量sequence 号正在产生。
5>.搜集硬解析的证据。硬解析常表现为大量向DC_COLUMNS, DC_VIEWS 以及
DC_OBJECTS caches 的gets。
示例:
1.分组统计数据字典统计项
SELECT parameter,sum("COUNT"),sum(usage),sum(gets),sum(getmisses),
sum(scans),sum(scanmisses),sum(modifications),
sum(dlm_requests),sum(dlm_conflicts),sum(dlm_releases)
FROM V$ROWCACHE
GROUP BY parameter;
2.检查数据字典的命中率
select 1 - sum(getmisses) / sum(gets) "data dictionary hitratio" from
v$rowcache;
学习动态性能表
第17 篇-(1)-V$SEGSTAT 2007.6.13
本视图实时监控段级(segment-level)统计项,支持oracle9ir2 及更高版本
V$SEGSTAT 中的常用列
TS#:表空间标识
OBJ#:字典对象标识
DATAOBJ#:数据对象标识
STATISTIC_NAME:统计项名称
STATISTIC#:统计项标识
VALUE:统计项值
V$SEGSTAT 中的连接列
Column View Joined Column(s)
-------------- ----------------------- ------------------------
TS# V$TABLESPACE TS#
OBJ# ALL_OBJECTS OBJECT_ID
示例:
9. 查询指定对象的统计
select * from v$segstat where ts# = 11
and obj# = (select object_id from user_objects
where object_name = 'TMPTABLE1' and owner = 'JSS')
第 17 篇-(2)-V$SEGMENT_STATISTICS 2007.6.13
这是一个友好的视图,支持Oracle9ir2 及更高版本。实时监测段级(segment-level)统计项,
可用于鉴定性能问题源于表或索引
V$SEGMENT_STATISTICS 中的列
OWNER:对象所有者
OBJECT_NAME:对象名称
SUBOBJECT_NAME:子对象名称
TABLESPACE_NAME:对象所在表空间
TS#:表空间标识
OBJ#:字典对象标识
DATAOBJ#:数据对象标识
OBJECT_TYPE:对象类型
STATISTIC_NAME:统计项名称
STATISTIC#:统计项标识
VALUE:统计项值
基本与上相同,只是信息更加详细,不再赘述。
学习动态性能表
第18 篇--V$SYSTEM_EVENT 2007.6.13
本视图概括了实例各项事件的等待信息。v$session_wait 显示了系统的当前等待项,
v$system_event 则提供了自实例启动后各个等待事件的概括。常用于获取系统等待信息的历
史影象。而通过两个snapshot 获取等待项增量,则可以确定这段时间内系统的等待项。
V$SYSTEM_EVENT 中的常用列
1. EVENT:等待事件名称
2. TOTAL_WAITS:此项事件总等待次数
3. TIME_WAITED:此项事件的总等待时间(单位:百分之一秒)
4. AVERAGE_WAIT : 此项事件的平均等待用时( 单位: 百分之一
秒)(time_waited/total_waits)
5. TOTAL_TIMEOUTS:此项事情总等待超时次数
示例:
1.查看系统的各项等待,按总耗时排序
SELECT event,total_waits waits,total_timeouts timeouts,
time_waited total_time,average_wait avg
FROM V$SYSTEM_EVENT
ORDER BY 4 DESC;
比如,通过checkpoint completed、log file switch(checkpoint incomplete)可以查看检查点进
程的性能。通过log file parallel write、log file switch completed 可以查看联机重做日志文件的
性能。通过log file switch(archiving needed)事件可以检查归档进程的性能。
找出瓶颈:
1。通过Statspack 列出空闲事件。
2。检查不同事件的等待时间开销。
3。检查每条等待记录的平均用时,因为某些等待事件(比较log file switch completion)可能周
期性地发生,但发生时却造成了严重的性能损耗。
学习动态性能表
第19 篇--V$UNDOSTAT 2007.6.14
本视图监控当前实例中undo 空间以及事务如何运行。并统计undo 空间开销,事务开销
以及实例可用的查询长度。
V$UNDOSTAT 中的常用列
Endtime:以10 分钟为间隔的结束时间
UndoBlocksUsed:使用的undo 块总数
TxnConcurrency:事务并发执行的最大数
TxnTotal:在时间段内事务执行总数
QueryLength:查询长度的最大值
ExtentsStolen:在时间段内undo 区必须从一个undo 段转到另一个的次数
SSTooOldError:在时间段内'Snapshot Too Old'错误发生的次数
UNDOTSN:这段时间内最后活动的undo 表空间ID
视图的第一行显示了当前时间段的统计,其它的每一条记录分别以每10 分钟一个区间。
24 小时循环,一天最多144 条记录。
示例:
1.本例显示undo 空间从16:27 到之前24 小时内的各项统计。
SQL>select * from v$undostat;
End-Time UndoBlocks TxnConcrcy TxnTotal QueryLen ExtentsStolen SSTooOldError
-------- ---------- ---------- -------- -------- ------------- -------------
16:07 252 15 1511 25 2 0
16:00 752 16 1467 150 0 0
15:50 873 21 1954 45 4 0
15:40 1187 45 3210 633 20 1
15:30 1120 28 2498 1202 5 0
15:20 882 22 2002 55 0 0
在统计项收集过程中,undo 消耗最高发生在15:30-15:40 这个时间段。10 分钟内有1187 个
undo 块被占用(基本上每秒钟2 个块)。同时,最高事务并发也是在相同的时间段,45 个事
务被并发执行。执行的最长查询(1202 秒)是在15:20-15:30 之间,需要注意的是查询实际上
是15:00-15:10 段即开始并直到15:20 这个时间段。
学习动态性能表
第20 篇--V$WAITSTAT 2007.6.15
本视图保持自实例启动所有的等待事件统计信息。常用于当你发现系统存在大量的
"buffer busy waits"时据此做出适当调整。
V$WAITSTAT 中的常用列
CLASS:块类别
WAITS:本类块的等待次数
TIME:本类块的总等待时间
等待发生的原因:
1.undo 段头部:没有足够的回滚段
2.数据段头部/数据段空闲列:空闲列争夺
3.数据块冲突
4.缓存存在大量的CR 复制
5.range 检索时,索引列存在大量不连续
6.全表检索的表有大量被删除记录
7.高并发的读写块
本视图列出session打开的所有cursors,很多时候都将被用到,比如:你可以通过它查看各个session打开的cursor数。
当诊断系统资源占用时,它常被用于联接v$sqlarea和v$sql查询出特定SQL(高逻辑或物理I/O)。然后,下一步就是找出源头。在应用环境,基本都是同一类用户登陆到数据库(在V$SQLAREA中拥有相同的PARSING_USER_ID),而通过这个就可以找出它们的不同。V$SQLAREA中的统计项在语句完全执行后被更新(并且从V$SESSION.SQL_HASH_VALUE中消失)。因此,你不能直接找到session除非语句被再次执行。不过如果session的cursor仍然打开着,你可以通过v$open_cursor找出执行这个语句的session。
V$OPEN_CURSOR中的连接列
Column View Joined Column(s)
----------------------------- ---------------------------------------- -----------------------------
HASH_VALUE, ADDRESS V$SQLAREA, V$SQL, V$SQLTEXT HASH_VALUE, ADDRESS
SID V$SESSION SID
示例:
1.找出执行某语句的session:
SELECT hash_value, buffer_gets, disk_reads
FROM V$SQLAREA
WHERE disk_reads > 1000000
ORDER BY buffer_gets DESC;
HASH_VALUE BUFFER_GETS DISK_READS
---------- ----------- ----------
1514306888 177649108 3897402
478652562 63168944 2532721
360282550 14158750 2482065
3 rows selected.
SQL> SELECT sid FROM V$SESSION WHERE sql_hash_value = 1514306888 ;
no rows selected
--直接通过hash_value查找v$session,没有记录
SQL> SELECT sid FROM V$OPEN_CURSOR WHERE hash_Value = 1514306888 ;
SID
-----
1125
233
935
1693
531
5 rows selected.
--通过hash_value在v$open_cursor中查找sid(只有在session的cursor仍然打开的情况下才有可能找到)
2.列出拥有超过400个cursor的sessionID
SQL> SELECT sid, count(0) ct FROM v$open_cursor
GROUP BY sid HAVING COUNT(0) > 400 ORDER BY ct desc;
事实上,v$open_cursor是一个相当常用的视图,特别是web开发应用的时候。仅通过它一个视图你就能分析出当前的连接情况,主要执行语句等。
这两个视图列出的各参数项名称以及参数值。V$PARAMETER显示执行查询的session的参数值。V$SYSTEM_PARAMETER视图则列出实例的参数值。
例如,下列查询显示执行查询的session的SORT_AREA_SIZE参数值:
SELECT value
FROM V$PARAMETER
WHERE name = 'sort_area_size';
呵呵,可能有朋友还是不明白v$parameter和v$system_parameter的区别,我再举个例子,相信你马上就明白了。
SQL>select value from v$parameter where name = 'global_names';
VALUE
------------------------------------------------------------------------------------------------
TRUE
1 row selected.
SQL> alter session set global_names = false;
Session altered.
SQL> select value from v$parameter where name = 'global_names';
VALUE
------------------------------------------------------------------------------------------------
FALSE
1 row selected.
SQL> select value from v$system_parameter where name = 'global_names';
VALUE
------------------------------------------------------------------------------------------------
TRUE
1 row selected.
V$PARAMETER中的常用列:
l NAME:参名
l VALUE:参值(session或实例)
l ISDEFAULT:参值是否默认值
l ISSES_MODIFIABLE:此参数是否session级可修改
l ISSYS_MODIFIABLE:此参数在实例启动后是否可由实例修改
l ISMODIFIED:自实例启动起,参值是否被修改,如果被修改,session级或是实例(系统)级修改(如果执行一条alter session,则值将被MODIFIED,如果执行的是alter system,则值为SYS_MODIFIED)
l ISADJUSTED:
l DESCRIPTION:参数简要描述
l UPDATE_COMMENT:由dba提供的参数说明
使用v$parameter以及v$system_parameter数据:
在调优期间通过查询v$parameter以确认当前参数设置。例如,如果buffer cache hit ratio较低,那么通过查询DB_BLOCK_BUFFERS(或DB_CACHE_SIZE)可以明确当前的buffer cache大小。
SELECT name, value, isdefault, isses_modifiable, issys_modifiable, ismodified
FROM V$PARAMETER
WHERE name = 'sort_area_size';
NAME VALUE ISDEF ISSES ISSYS_MOD ISMODIFIED
-------------------- ---------- ----- ----- --------- ----------
sort_area_size 1048576 TRUE TRUE DEFERRED MODIFIED
前例显示了SORT_AREA_SIZE初始参数在实例启动时并非初始值,不过被session修改回了初始值。
注意:当查询v$parameter时要注意,如果你想查看实例参数,要查询v$system_parameter。
Oracle Rdbms应用了各种不同类型的锁定机制,latch即是其中的一种。Latch是用于保护SGA区中共享数据结构的一种串行化锁定机制。Latch的实现是与操作系统相关的,尤其和一个进程是否需要等待一个latch、需要等待多长时间有关。Latch是一种能够极快地被获取和释放的锁,它通常用于保护描述buffer cache中block的数据结构。与每个latch相联系的还有一个清除过程,当持有latch的进程成为死进程时,该清除过程就会被调用。Latch还具有相关级别,用于防止死锁,一旦一个进程在某个级别上得到一个latch,它就不可能再获得等同或低于该级别的latch。
本视图保存自实例启动各类栓锁的统计信息。常用于当v$session_wait中发现栓锁竞争时鉴别SGA区中问题所在区域。
v$latch表的每一行包括了对不同类型latch的统计,每一列反映了不同类型的latch请求的活动情况。不同类型的latch请求之间的区别在于,当latch不可立即获得时,请求进程是否继续进行。按此分类,latch请求的类型可分为两类:willing-to-wait和immediate。
l Willing-to-wait:是指如果所请求的latch不能立即得到,请求进程将等待一很短的时间后再次发出请求。进程一直重复此过程直到得到latch。
l Immediate:是指如果所请求的latch不能立即得到,请求进程就不再等待,而是继续执行下去。
V$LATCH中的常用列:
l NAME:latch名称
l IMMEDIATE_GETS:以Immediate模式latch请求数
l IMMEDIATE_MISSES:请求失败数
l GETS:以Willing to wait请求模式latch的请求数
l MISSES:初次尝试请求不成功次数
l SPIN_GETS:第一次尝试失败,但在以后的轮次中成功
l SLEEP[x]:成功获取前sleeping次数
l WAIT_TIME:花费在等待latch的时间
V$LATCH中的连接列
Column View Joined Column(s)
--------------------- ------------------------------ ------------------------
NAME/LATCH# V$LATCH_CHILDREN NAME/LATCH#
NAME V$LATCHHOLDER NAME
NAME/LATCH# V$LATCHNAME NAME/LATCH#
NAME V$LATCH_MISSES PARENT_NAME
示例:
下列的示例中,创建一个表存储查询自v$latch的数据:
CREATE TABLE snap_latch as SELECT 0 snap_id, sysdate snap_date, a.* FROM V$LATCH a;
ALTER TABLE snap_latch add (constraint snap_filestat primary key (snap_id, name));
最初,snap_id被置为0,稍后,snap_latch表的snap_id列被更新为1:
INSERT INTO snap_latch SELECT 1, sysdate, a.* FROM V$LATCH a;
注意你通过sql语句插入记录时必须增加snap_id的值。
在你连续插入记录之后,使用下列的select语句列出统计。注意0不能成为被除数。
SELECT SUBSTR(a.name,1,20) NAME, (a.gets-b.gets)/1000 "Gets(K)",
(a.gets-b.gets)/(86400*(a.snap_date-b.snap_date)) "Get/s",
DECODE ((a.gets-b.gets), 0, 0, (100*(a.misses-b.misses)/(a.gets-b.gets))) MISS,
DECODE ((a.misses-b.misses), 0, 0,
(100*(a.spin_gets-b.spin_gets)/(a.misses-b.misses))) SPIN,
(a.immediate_gets-b.immediate_gets)/1000 "Iget(K)",
(a.immediate_gets-b.immediate_gets)/ (86400*(a.snap_date-b.snap_date)) "IGet/s",
DECODE ((a.immediate_gets-b.immediate_gets), 0, 0,
(100*(a.immediate_misses-b.immediate_misses)/ (a.immediate_gets-b.immediate_gets)))
IMISS
FROM snap_latch a, snap_latch b
WHERE a.name = b.name
AND a.snap_id = b.snap_id + 1
AND ( (a.misses-b.misses) > 0.001*(a.gets-b.gets)
or (a.immediate_misses-b.immediate_misses) >
0.001*(a.immediate_gets-b.immediate_gets))
ORDER BY 2 DESC;
下例列出latch统计项,miss列小于0.1%的记录已经被过滤。
NAME Gets(K) Get/s MISS SPIN IGets(K) IGet/s IMISS
------------------ -------- ------- ----- ------ -------- ------- -----
cache buffers chai 255,272 69,938 0.4 99.9 3,902 1,069 0.0
library cache 229,405 62,851 9.1 96.9 51,653 14,151 3.7
shared pool 24,206 6,632 14.1 72.1 0 0 0.0
latch wait list 1,828 501 0.4 99.9 1,836 503 0.5
row cache objects 1,703 467 0.7 98.9 1,509 413 0.2
redo allocation 984 270 0.2 99.7 0 0 0.0
messages 116 32 0.2 100.0 0 0 0.0
cache buffers lru 91 25 0.3 99.0 7,214 1,976 0.3
modify parameter v 2 0 0.1 100.0 0 0 0.0
redo copy 0 0 92.3 99.3 1,460 400 0.0
什么时候需要检查latch统计呢?看下列项:
l misses/gets的比率是多少
l 获自spinning的misses的百分比是多少
l latch请求了多少次
l latch休眠了多少次
Redo copy latch看起来有很高的的失误率,高达92.3%。不过,我们再仔细看的话,Redo copy latches是获自immediate模式。immediate模式的数值看起来还不错,并且immediate模式只有个别数大于willing to wait模式。所以Redo copy latch其实并不存在竞争。不过,看起来shared pool和library cache latches可能存在竞争。考虑执行一条查询检查latches的sleeps以确认是否确实存在问题。
latch有40余种,但作为DBA关心的主要应有以下几种:
l Cache buffers chains latch:当用户进程搜索SGA寻找database cache buffers时需要使用此latch。
l Cache buffers LRU chain latch:当用户进程要搜索buffer cache中包括所有 dirty blocks的LRU (least recently used) 链时使用该种latch。
l Redo log buffer latch:这种latch控制redo log buffer中每条redo entries的空间分配。
l Row cache objects latch:当用户进程访问缓存的数据字典数值时,将使用Row cache objects latch。
Latches调优
不要调整latches。如果你发现latch存在竞争,它可能是部分SGA资源使用反常的征兆。要修正问题所在,你更多的是去检查那部分SGA资源使用的竞争情况。仅仅从v$latch是无法定位问题所在的。
关于latches的更多信息可以浏览Oracle Database Concepts。
第十一篇-(2)-V$LATCH_CHILDREN 2007.6.6
数据库中有些类别的latches拥有多个。V$LATCH中提供了每个类别的总计信息。如果想看到单个latch,你可以通过查询本视图。
例如:
select name,count(*) ct from v$Latch_children group by name order by ct desc;
与v$latch相比,除多child#列外,其余列与之同,不详述~~
本视图提供对象在library cache(shared pool)中对象统计,提供比v$librarycache更多的细节,并且常用于找出shared pool中的活动对象。
v$db_object_cache中的常用列:
l OWNER:对象拥有者
l NAME:对象名称
l TYPE:对象类型(如,sequence,procedure,function,package,package body,trigger)
l KEPT:告知是否对象常驻shared pool(yes/no),有赖于这个对象是否已经利用PL/SQL 过程DBMS_SHARED_POOL.KEEP“保持”(永久固定在内存中)
l SHARABLE_MEM:共享内存占用
l PINS:当前执行对象的session数
l LOCKS:当前锁定对象的session数
瞬间状态列:
下列列保持对象自初次加载起的统计信息:
l LOADS:对象被加载次数。
示例:
1.shared pool执行以及内存使用总计
下列查询显示出shared pool内存对不同类别的对象
同时也显示是否有对象通过DBMS_SHARED_POOL.KEEP()过程常驻shared pool。
SELECT type, kept, COUNT(*), SUM(sharable_mem)
FROM V$DB_OBJECT_CACHE
GROUP BY type, kept;
2.通过载入次数找出对象
SELECT owner, name sharable_mem, kept, loads
FROM V$DB_OBJECT_CACHE
WHERE loads > 1 ORDER BY loads DESC;
3.找出使用的内存超过10M并且不在常驻内存的对象。
SELECT owner, name, sharable_mem, kept
FROM V$DB_OBJECT_CACHE
WHERE sharable_mem > 102400 AND kept = 'NO'
ORDER BY sharable_mem DESC;
本视图记录各文件物理I/O信息。如果瓶颈与I/O相关,可用于分析发生的活动I/O事件。V$FILESTAT显示出数据库I/O的下列信息(不包括日志文件):
l 物理读写数
l 块读写数
l I/O读写总耗时
以上数值自实例启动即开始记录。如果获取了两个快照,那么二者之间的差异即是这一时间段内活动I/O统计。
V$FILESTAT中的常用列:
l FILE#:文件序号;
l PHYRDS:已完成的物理读次数;
l PHYBLKRD:块读取数;
l PHYWRTS:DBWR完成的物理写次数;
l PHYBLKWRT:写入磁盘的块数;
V$FILESTAT注意项:
l 因为multiblock读调用,物理读数和数据块读数有可能不同;
l 因为进程直写,物理写和数据块写也可能不一致;
l Sum(physical blocks read) 近似于v$sysstat中的physical reads;
l Sum(physical blocks written) 近似于v$sysstat中的physical writes;
l 数据读(由缓存读比直读好)由服务进程处理。从buffer cache写只能由DBWR进行,直写由服务进程处理。
V$FILESTAT中的连接列
Column View Joined Column(s)
----------- ------------------------- -------------------------
FILE# DBA_DATA_FILES FILE_ID
FILE# V$DATAFILE FILE#
示例:
1.获得数据文件物理读写和数据块读写信息:
select df.tablespace_name name,
df.file_name "file",
f.phyrds pyr,
f.phyblkrd pbr,
f.phywrts pyw,
f.phyblkwrt pbw
from v$filestat f, dba_data_files df where f.file# = df.file_id
order by df.tablespace_name;
注意:尽管oracle记录的读写次数非常精确,但如果数据库运行在Unix文件系统(UFS)有可能不能表现真实的磁盘读写,例如,读次数可能并非真实的磁盘读,而是UFS缓存。不过裸设备的读写次数应该是比较精准的。
本视图显示运行超过6秒的操作的状态。包括备份,恢复,统计信息收集,查询等等。
要监控查询执行进展状况,你必须使用cost-based优化方式,并且:
l 设置TIMED_STATISTICS或SQL_TRACE参数值为true。
l 通过ANALYZE或DBMS_STATS数据包收集对象统计信息。
你可以通过DBMS_APPLICATION_INFO.SET_SESSION_LONGOPS过程添加application-specific长运行操作信息到本视图。关于DBMS_APPLICATION_INFO.SET_SESSION_LONGOPS的更多信息可以浏览:Oracle Supplied PL/SQL Packages and Types Reference。
V$SESSION_LONGOPS列说明
l SID:Session标识
l SERIAL#:Session串号
l OPNAME:操作简要说明
l TARGET:操作运行所在的对象
l TARGET_DESC:目标对象说明
l SOFAR:至今为止完成的工作量
l TOTALWORK:总工作量
l UNITS:工作量单位
l START_TIME:操作开始时间
l LAST_UPDATE_TIME:统计项最后更新时间
l TIME_REMAINING:预计完成操作的剩余时间(秒)
l ELAPSED_SECONDS:从操作开始总花费时间(秒)
l CONTEXT:前后关系
l MESSAGE:统计项的完整描述
l USERNAME:执行操作的用户ID
l SQL_ADDRESS:用于连接查询的列
l SQL_HASH_VALUE:用于连接查询的列
l QCSID:
示例:
找一较大表,确认该表查询将超过6秒,哎呀让它快咱没把握,让它慢这可是我的强项啊~~
SQL> set timing on
SQL> create table ttt as select level lv,rownum rn from dual connect by level<10000000; --创建一个临时表
Table created
Executed in 19.5 seconds
SQL> commit;
Commit complete
Executed in 0 seconds
SQL> select * from (select * from ttt order by lv desc) where rownum<2; --执行一个费时的查询
LV RN
---------- ----------
9999999 9999999
Executed in 9.766 seconds --哈哈,成功超过6秒
SQL> select sid,opname,sofar,totalwork,units,sql_hash_value from v$session_longops; ----看看v$session_longops中是不是已经有记录了
SID OPNAME SOFAR TOTALWORK UNITS SQL_HASH_VALUE
---------- ---------------------------------------------------------------- ---------- ---------- -------------------------------- --------------
10 Table Scan 47276 47276 Blocks 2583310173
Executed in 0.047 seconds
SQL> select a.sql_text from v$sqlarea a,v$session_longops b where a.HASH_VALUE=b.SQL_HASH_VALUE; --通过hash_value联系查询出刚执行的查询语句。
SQL_TEXT
--------------------------------------------------------------------------------
select * from (select * from ttt order by lv desc) where rownum<2
Executed in 0.063 seconds
摘要:
这个视图列出Oracle 服务器当前拥有的锁以及未完成的锁或栓锁请求。如果你觉着session在等待等待事件队列那你应该检查本视图。如果你发现session在等待一个锁。那么按如下先后顺序:
1. 使用V$LOCK找出session持有的锁。
2. ...
阅读全文
摘要:
本视图包含当前系统oracle运行的所有进程信息。常被用于将oracle或服务进程的操作系统进程ID与数据库session之间建立联系。在某些情况下非常有用:
1. 如果数据库瓶颈是系统资源(如:cpu,内存),并且占用资源最多的用户总是停留在某几个服务进程,那么进行如...
阅读全文
摘要:
这是一个寻找性能瓶颈的关键视图。它提供了任何情况下session在数据库中当前正在等待什么(如果session当前什么也没在做,则显示它最后的等待事件)。当系统存在性能问题时,本视图可以做为一个起点指明探寻问题的方向。
V$SESSION_WAIT中,每一个连接到实例的session都对应一条记录。
V$SESSION_WAIT中的常用列
...
阅读全文
在本视图中,每一个连接到数据库实例中的session都拥有一条记录。包括用户session及后台进程如DBWR,LGWR,arcchiver等等。
V$SESSION中的常用列
V$SESSION是基础信息视图,用于找寻用户SID或SADDR。不过,它也有一些列会动态的变化,可用于检查用户。如例:
SQL_HASH_VALUE,SQL_ADDRESS:这两列用于鉴别默认被session执行的SQL语句。如果为null或0,那就说明这个session没有执行任何SQL语句。PREV_HASH_VALUE和PREV_ADDRESS两列用来鉴别被session执行的上一条语句。
注意:当使用SQL*Plus进行选择时,确认你重定义的列宽不小于11以便看到完整的数值。
STATUS:这列用来判断session状态是:
l Achtive:正执行SQL语句(waiting for/using a resource)
l Inactive:等待操作(即等待需要执行的SQL语句)
l Killed:被标注为删除
下列各列提供session的信息,可被用于当一个或多个combination未知时找到session。
Session信息
l SID:SESSION标识,常用于连接其它列
l SERIAL#:如果某个SID又被其它的session使用的话则此数值自增加(当一个 SESSION结束,另一个SESSION开始并使用了同一个SID)。
l AUDSID:审查session ID唯一性,确认它通常也用于当寻找并行查询模式
l USERNAME:当前session在oracle中的用户名。
Client信息
数据库session被一个运行在数据库服务器上或从中间服务器甚至桌面通过SQL*Net连接到数据库的客户端进程启动,下列各列提供这个客户端的信息
l OSUSER:客户端操作系统用户名
l MACHINE:客户端执行的机器
l TERMINAL:客户端运行的终端
l PROCESS:客户端进程的ID
l PROGRAM:客户端执行的客户端程序
要显示用户所连接PC的 TERMINAL、OSUSER,需在该PC的ORACLE.INI或Windows中设置关键字TERMINAL,USERNAME。
Application信息
调用DBMS_APPLICATION_INFO包以设置一些信息区分用户。这将显示下列各列。
l CLIENT_INFO:DBMS_APPLICATION_INFO中设置
l ACTION:DBMS_APPLICATION_INFO中设置
l MODULE:DBMS_APPLICATION_INFO中设置
下列V$SESSION列同样可能会被用到:
l ROW_WAIT_OBJ#
l ROW_WAIT_FILE#
l ROW_WAIT_BLOCK#
l ROW_WAIT_ROW#
V$SESSION中的连接列
Column View Joined Column(s)
SID V$SESSION_WAIT,,V$SESSTAT,,V$LOCK,V$SESSION_EVENT,V$OPEN_CURSOR SID
(SQL_HASH_VALUE, SQL_ADDRESS) V$SQLTEXT, V$SQLAREA, V$SQL (HASH_VALUE, ADDRESS)
(PREV_HASH_VALUE, PREV_SQL_ADDRESS) V$SQLTEXT, V$SQLAREA, V$SQL (HASH_VALUE, ADDRESS)
TADDR V$TRANSACTION ADDR
PADDR V$PROCESS ADDR
示例:
1.查找你的session信息
SELECT SID, OSUSER, USERNAME, MACHINE, PROCESS
FROM V$SESSION WHERE audsid = userenv('SESSIONID');
2.当machine已知的情况下查找session
SELECT SID, OSUSER, USERNAME, MACHINE, TERMINAL
FROM V$SESSION
WHERE terminal = 'pts/tl' AND machine = 'rgmdbs1';
3.查找当前被某个指定session正在运行的sql语句。假设sessionID为100
select b.sql_text
from v$session a,v$sqlarea b
where a.sql_hash_value=b.hash_value and a.sid=100
寻找被指定session执行的SQL语句是一个公共需求,如果session是瓶颈的主要原因,那根据其当前在执行的语句可以查看session在做些什么。
本视图包括Shared pool中SQL语句的完整文本,一条SQL语句可能分成多个块被保存于多个记录内。
注:V$SQLAREA只包括头1000个字符。
V$SQLTEXT中的常用列
l HASH_VALUE:SQL语句的Hash值
l ADDRESS:sql语句在SGA中的地址
l SQL_TEXT:SQL文本。
l PIECE:SQL语句块的序号
V$SQLTEXT中的连接列
Column View Joined Column(s)
HASH_VALUE, ADDRESS V$SQL, V$SESSION HASH_VALUE, ADDRESS
HASH_VALUE. ADDRESS V$SESSION SQL_HASH_VALUE, SQL_ADDRESS
示例:已知hash_value:3111103299,查询sql语句:
select * from v$sqltext
where hash_value='3111103299'
order by piece
第四篇-(2)-V$SQLAREA 2007.5.29
本视图持续跟踪所有shared pool中的共享cursor,在shared pool中的每一条SQL语句都对应一列。本视图在分析SQL语句资源使用方面非常重要。
V$SQLAREA中的信息列
l HASH_VALUE:SQL语句的Hash值。
l ADDRESS:SQL语句在SGA中的地址。
这两列被用于鉴别SQL语句,有时,两条不同的语句可能hash值相同。这时候,必须连同ADDRESS一同使用来确认SQL语句。
l PARSING_USER_ID:为语句解析第一条CURSOR的用户
l VERSION_COUNT:语句cursor的数量
l KEPT_VERSIONS:
l SHARABLE_MEMORY:cursor使用的共享内存总数
l PERSISTENT_MEMORY:cursor使用的常驻内存总数
l RUNTIME_MEMORY:cursor使用的运行时内存总数。
l SQL_TEXT:SQL语句的文本(最大只能保存该语句的前1000个字符)。
l MODULE,ACTION:使用了DBMS_APPLICATION_INFO时session解析第一条cursor时的信息
V$SQLAREA中的其它常用列
l SORTS: 语句的排序数
l CPU_TIME: 语句被解析和执行的CPU时间
l ELAPSED_TIME: 语句被解析和执行的共用时间
l PARSE_CALLS: 语句的解析调用(软、硬)次数
l EXECUTIONS: 语句的执行次数
l INVALIDATIONS: 语句的cursor失效次数
l LOADS: 语句载入(载出)数量
l ROWS_PROCESSED: 语句返回的列总数
V$SQLAREA中的连接列
Column View Joined Column(s)
HASH_VALUE, ADDRESS V$SESSION SQL_HASH_VALUE, SQL_ADDRESS
HASH_VALUE, ADDRESS V$SQLTEXT, V$SQL, V$OPEN_CURSOR HASH_VALUE, ADDRESS
SQL_TEXT V$DB_OBJECT_CACHE NAME
示例:
1.查看消耗资源最多的SQL:
SELECT hash_value, executions, buffer_gets, disk_reads, parse_calls
FROM V$SQLAREA
WHERE buffer_gets > 10000000 OR disk_reads > 1000000
ORDER BY buffer_gets + 100 * disk_reads DESC;
2.查看某条SQL语句的资源消耗:
SELECT hash_value, buffer_gets, disk_reads, executions, parse_calls
FROM V$SQLAREA
WHERE hash_Value = 228801498 AND address = hextoraw('CBD8E4B0');
摘要:
V$SQL中存储具体的SQL语句。
一条语句可以映射多个cursor,因为对象所指的cursor可以有不同用户(如例1)。如果有多个cursor(子游标)存在,在V$SQLAREA为所有cursor提供集合信息。
例1:
这里介绍以下child cursor
user A: select * from tbl
user B: select * ...
阅读全文
按照OracleOnlineBook中的描述,v$sesstat存储session从login到logout的详细资源使用统计。
类似于v$sysstat,该视图存储下列类别的统计:
l 事件发生次数的统计,如用户提交数。
l 数据产生,存取或者操作的total列(如:redo size)
l 执行操作所花费的时间累积,例如session CPU占用(如果TIMED_STATISTICS值为true)
注意:
如果初始参数STATISTICS_LEVEL被设置为TYPICAL或ALL,时间统计被数据库自动收集如果STATISTICS_LEVEL被设置为BASIC,你必须设置TIMED_STATISTICS值为TRUE以打开收集功能。
如果你已设置了DB_CACHE_ADVICE,TIMED_STATISTICS或TIMED_OS_STATISTICS,或在初始参数文件或使用ALTER_SYSTEM或ALTER SESSION,那么你所设定的值的值将覆盖STATISTICS_LEVEL的值。
v$sysstat和v$sesstat差别如下:
n v$sesstat只保存session数据,而v$sysstat则保存所有sessions的累积值。
n v$sesstat只是暂存数据,session退出后数据即清空。v$sysstat则是累积的,只有当实例被shutdown才会清空。
n v$sesstat不包括统计项名称,如果要获得统计项名称则必须与v$sysstat或v$statname连接查询获得。
v$sesstat可被用于找出如下类型session:
n 高资源占用
n 高平均资源占用比(登陆后资源使用率)
n 默认资源占用比(两快照之间)
在V$SESSTAT中使用统计
多数v$sesstat中的统计参考是v$sysstat描述的子集,包括session logical reads, CPU used by this session, db block changes, redo size, physical writes, parse count (hard), parse count (total), sorts (memory), and sorts (disk).
V$SESSTAT常用列说明
n SID:session唯一ID
n STATISTIC#:资源唯一ID
n VALUE:资源使用
示例1:下列找出当前session中最高的logical和Physical I/O比率.
下列SQL语句显示了所有连接到数据库的session逻辑、物理读比率(每秒)。logical和physical I/O比率是通过自登陆后的时间消耗计算得出。对于sessions连接到数据库这种长周期操作而言也许不够精确,不过做个示例却足够了。
先获得session逻辑读和物理读统计项的STATISTIC#值:
SELECT name, statistic#
FROM V$STATNAME
WHERE name IN ('session logical reads','physical reads') ;
NAME STATISTIC#
------------------------------ ----------
session logical reads 9
physical reads 40
通过上面获得的STATISTIC#值执行下列语句:
SELECT ses.sid
, DECODE(ses.action,NULL,'online','batch') "User"
, MAX(DECODE(sta.statistic#,9,sta.value,0))
/greatest(3600*24*(sysdate-ses.logon_time),1) "Log IO/s"
, MAX(DECODE(sta.statistic#,40,sta.value,0))
/greatest(3600*24*(sysdate-ses.logon_time),1) "Phy IO/s"
, 60*24*(sysdate-ses.logon_time) "Minutes"
FROM V$SESSION ses
, V$SESSTAT sta
WHERE ses.status = 'ACTIVE'
AND sta.sid = ses.sid
AND sta.statistic# IN (9,40)
GROUP BY ses.sid, ses.action, ses.logon_time
ORDER BY
SUM( DECODE(sta.statistic#,40,100*sta.value,sta.value) )
/ greatest(3600*24*(sysdate-ses.logon_time),1) DESC;
SID User Log IO/s Phy IO/s Minutes
----- ------ -------- -------- -------
1951 batch 291 257.3 1
470 online 6,161 62.9 0
730 batch 7,568 43.2 197
2153 online 1,482 98.9 10
2386 batch 7,620 35.6 35
1815 batch 7,503 35.5 26
1965 online 4,879 42.9 19
1668 online 4,318 44.5 1
1142 online 955 69.2 35
1855 batch 573 70.5 8
1971 online 1,138 56.6 1
1323 online 3,263 32.4 5
1479 batch 2,857 35.1 3
421 online 1,322 46.8 15
2405 online 258 50.4 8
示例2:又例如通过v$sesstat和v$statname连接查询某个SID各项信息。
select a.*,b.name
from v$sesstat a,v$statname b
where a.sid=10 and a.statistic#=b.statistic#;
转自网络
按照OracleDocument中的描述,v$sysstat存储自数据库实例运行那刻起就开始累计全实例(instance-wide)的资源使用情况。
类似于v$sesstat,该视图存储下列的统计信息:
1>.事件发生次数的统计(如:user commits)
2>.数据产生,存取或者操作的total列(如:redo size)
3>.如果TIMED_STATISTICS值为true,则统计花费在执行操作上的总时间(如:CPU used by this session)
v$sysstat视图常用列介绍:
l STATISTIC#: 标识
l NAME: 统计项名称
l VALUE: 资源使用量
该视图还有一列class-统计类别但极少会被使用,各类信息如下:
1 代表事例活动
2 代表Redo buffer活动
4 代表锁
8 代表数据缓冲活动
16 代表OS活动
32 代表并行活动
64 代表表访问
128 代表调试信息
注意:Statistic#的值在不同版本中各不相同,使用时要用Name做为查询条件而不要以statistic#的值做为条件。
使用v$sysstat中的数据
该视图中数据常被用于监控系统性能。如buffer cache命中率、软解析率等都可从该视图数据计算得出。
该视图中的数据也被用于监控系统资源使用情况,以及系统资源利用率的变化。正因如此多的性能数据,检查某区间内系统资源使用情况可以这样做,在一个时间段开始时创建一个视图数据快照,结束时再创建一个,二者之间各统计项值的不同(end value - begin value)即是这一时间段内的资源消耗情况。这是oracle工具的常用方法,诸如Statspack以及BSTAT/ESTAT都是如此。
为了对比某个区间段的数据,源数据可以被格式化(每次事务,每次执行,每秒钟或每次登陆),格式化后数据更容易从两者中鉴别出差异。这类的对比在升级前,升级后或仅仅想看看一段时间内用户数量增长或数据增加如何影响资源使用方面更加实用。
你也可以使用v$sysstat数据通过查询v$system_event视图来检查资源消耗和资源回收。
V$SYSSTAT中的常用统计
V$SYSSTAT中包含多个统计项,这部分介绍了一些关键的v$sysstat统计项,在调优方面相当有用。下列按字母先后排序:
数据库使用状态的一些关键指标:
l CPU used by this session:所有session的cpu占用量,不包括后台进程。这项统计的单位是百分之x秒.完全调用一次不超过10ms
l db block changes:那部分造成SGA中数据块变化的insert,update或delete操作数 这项统计可以大概看出整体数据库状态。在各项事务级别,这项统计指出脏缓存比率。
l execute count:执行的sql语句数量(包括递归sql)
l logons current:当前连接到实例的Sessions。如果当前有两个快照则取平均值。
l logons cumulative:自实例启动后的总登陆次数。
l parse count (hard):在shared pool中解析调用的未命中次数。当sql语句执行并且该语句不在shared pool或虽然在shared pool但因为两者存在部分差异而不能被使用时产生硬解析。如果一条sql语句原文与当前存在的相同,但查询表不同则认为它们是两条不同语句,则硬解析即会发生。硬解析会带来cpu和资源使用的高昂开销,因为它需要oracle在shared pool中重新分配内存,然后再确定执行计划,最终语句才会被执行。
l parse count (total):解析调用总数,包括软解析和硬解析。当session执行了一条sql语句,该语句已经存在于shared pool并且可以被使用则产生软解析。当语句被使用(即共享) 所有数据相关的现有sql语句(如最优化的执行计划)必须同样适用于当前的声明。这两项统计可被用于计算软解析命中率。
l parse time cpu:总cpu解析时间(单位:10ms)。包括硬解析和软解析。
l parse time elapsed:完成解析调用的总时间花费。
l physical reads:OS blocks read数。包括插入到SGA缓存区的物理读以及PGA中的直读这项统计并非i/o请求数。
l physical writes:从SGA缓存区被DBWR写到磁盘的数据块以及PGA进程直写的数据块数量。
l redo log space requests:在redo logs中服务进程的等待空间,表示需要更长时间的log switch。
l redo size:redo发生的总次数(以及因此写入log buffer),以byte为单位。这项统计显示出update活跃性。
l session logical reads:逻辑读请求数。
l sorts (memory) and sorts (disk):sorts(memory)是适于在SORT_AREA_SIZE(因此不需要在磁盘进行排序)的排序操作的数量。sorts(disk)则是由于排序所需空间太大,SORT_AREA_SIZE不能满足而不得不在磁盘进行排序操作的数量。这两项统计通常用于计算in-memory sort ratio。
l sorts (rows): 列排序总数。这项统计可被'sorts (total)'统计项除尽以确定每次排序的列。该项可指出数据卷和应用特征。
l table fetch by rowid:使用ROWID返回的总列数(由于索引访问或sql语句中使用了'where rowid=&rowid'而产生)
l table scans (rows gotten):全表扫描中读取的总列数
l table scans (blocks gotten):全表扫描中读取的总块数,不包括那些split的列。
l user commits + user rollbacks:系统事务起用次数。当需要计算其它统计中每项事务比率时该项可以被做为除数。例如,计算事务中逻辑读,可以使用下列公式:session logical reads / (user commits + user rollbacks)。
注:SQL语句的解析有软解析soft parse与硬解析hard parse之说,以下是5个步骤:
1:语法是否合法(sql写法)
2:语义是否合法(权限,对象是否存在)
3:检查该sql是否在公享池中存在
-- 如果存在,直接跳过4和5,运行sql. 此时算soft parse
4:选择执行计划
5:产生执行计划
-- 如果5个步骤全做,这就叫hard parse.
注意物理I/O
oracle报告物理读也许并未导致实际物理磁盘I/O操作。这完全有可能因为多数操作系统都有缓存文件,可能是那些块在被读取。块也可能存于磁盘或控制级缓存以再次避免实际I/O。Oracle报告有物理读也许仅仅表示被请求的块并不在缓存中。
由V$SYSSTAT得出实例效率比(Instance Efficiency Ratios)
下列是些典型的instance efficiency ratios 由v$sysstat数据计算得来,每项比率值应该尽可能接近1:
l Buffer cache hit ratio:该项显示buffer cache大小是否合适。
公式:1-((physical reads-physical reads direct-physical reads direct (lob)) / session logical reads)
执行:
select1-((a.value-b.value-c.value)/d.value)
from v$sysstat a,v$sysstat b,v$sysstat c,v$sysstat d
where a.name='physical reads'and
b.name='physical reads direct'and
c.name='physical reads direct (lob)'and
d.name='session logical reads';
l Soft parse ratio:这项将显示系统是否有太多硬解析。该值将会与原始统计数据对比以确保精确。例如,软解析率仅为0.2则表示硬解析率太高。不过,如果总解析量(parse count total)偏低,这项值可以被忽略。
公式:1 - ( parse count (hard) / parse count (total) )
执行:
select1-(a.value/b.value)
from v$sysstat a,v$sysstat b
Wherea.name='parse count (hard)'and b.name='parse count (total)';
l In-memory sort ratio:该项显示内存中完成的排序所占比例。最理想状态下,在OLTP系统中,大部分排序不仅小并且能够完全在内存里完成排序。
公式:sorts (memory) / ( sorts (memory) + sorts (disk) )
执行:
select a.value/(b.value+c.value)
from v$sysstat a,v$sysstat b,v$sysstat c
wherea.name='sorts (memory)'and
b.name='sorts (memory)'andc.name='sorts (disk)';
l Parse to execute ratio:在生产环境,最理想状态是一条sql语句一次解析多数运行。
公式:1 - (parse count/execute count)
执行:
select1-(a.value/b.value)
from v$sysstat a,v$sysstat b
where a.name='parse count (total)'and b.name='execute count';
l Parse CPU to total CPU ratio:该项显示总的CPU花费在执行及解析上的比率。如果这项比率较低,说明系统执行了太多的解析。
公式:1 - (parse time cpu / CPU used by this session)
执行:
select1-(a.value/b.value)
from v$sysstat a,v$sysstat b
where a.name='parse time cpu'and
b.name='CPU used by this session';
l Parse time CPU to parse time elapsed:通常,该项显示锁竞争比率。这项比率计算
是否时间花费在解析分配给CPU进行周期运算(即生产工作)。解析时间花费不在CPU周期运算通常表示由于锁竞争导致了时间花费
公式:parse time cpu / parse time elapsed
执行:
select a.value/b.value
from v$sysstat a,v$sysstat b
where a.name='parse time cpu'and b.name='parse time elapsed';
从V$SYSSTAT获取负载间档(Load Profile)数据
负载间档是监控系统吞吐量和负载变化的重要部分,该部分提供如下每秒和每个事务的统计信息:logons cumulative, parse count (total), parse count (hard), executes, physical reads, physical writes, block changes, and redo size.
被格式化的数据可检查'rates'是否过高,或用于对比其它基线数据设置为识别system profile在期间如何变化。例如,计算每个事务中block changes可用如下公式:
db block changes / ( user commits + user rollbacks )
执行:
select a.value/(b.value+c.value)
from v$sysstat a,v$sysstat b,v$sysstat c
where a.name='db block changes'and
b.name='user commits'andc.name='user rollbacks';
其它计算统计以衡量负载方式,如下:
l Blocks changed for each read:这项显示出block changes在block reads中的比例。它将指出是否系统主要用于只读访问或是主要进行诸多数据操作(如:inserts/updates/deletes)
公式:db block changes / session logical reads
执行:
select a.value/b.value
from v$sysstat a,v$sysstat b
where a.name='db block changes'and
b.name='session logical reads' ;
l Rows for each sort:
公式:sorts (rows) / ( sorts (memory) + sorts (disk) )
执行:
select a.value/(b.value+c.value)
from v$sysstat a,v$sysstat b,v$sysstat c
where a.name='sorts (rows)'and
b.name='sorts (memory)'andc.name='sorts (disk)';
ORACLE中SQL TRACE和TKPROF的使用
SQL TRACE 和 tkprof sql语句分析工具
一 SQL TRACE 使用方法:
1.初始化sql trace
参数:
timed_statistics=true 允许sql trace 和其他的一些动态性能视图收集与时间有关的参数、
SQL>alter session set titimed_statistics=true
max_dump_file_size=500 指定跟踪文件的大小
SQL> alter system set max_dump_file_size=500;
user_dump_dest 指定跟踪文件的路径
SQL> alter system set user_dump_dest=/oracle/oracle/diag/rdbms/orcl/orcl/trace;
2.为一个session 启动sql trace
2.1命令方式
alter session set sql_trace=true
2.2 通过存储过程启动sqltrace
select sid,serial#,osuser from v$session;
SID SERIAL# OSUSER
168 1 oracle
execute rdbms_system.set_sql_trace_in_session (168 ,1,true);
3.停止一个sql trace 会话
3.1 命令方式
alter session set sql_trace=false
3.2 储存过程的方式
execute rdbms_system.set_sql_trace_in_session (168 ,1,false);
4. 为整个实例启动SQL trace (一般消耗系统性能较高,不会用)
alter system set sql_trace=true scope=spfile
从新启动数据库
5. 停止一个实例的sql trace
alter system set sql_trace=flase scope=spfile
启动sql trace 之后收集的信息包括
1.解析、执行、返回数据的次数
2.cpu和执行命令的时间
3.物理读和逻辑读的次数
4.系统处理的记录数
5.库缓冲区错误
二 TKPROF的使用
tkprof 的目的是将sql trace 生成的跟踪文件转换成用户可以理解的格式
1. 格式
tkprof inputfile outputfile [optional | parameters ]
参数和选项:
explain=user/password 执行explain命令将结果放在SQL trace的输出文件中
table=schema.table 指定tkprof处理sql trace文件时临时表的模式名和表名
insert=scriptfile 创建一个文件名为scriptfile的文件,包含了tkprof存放的输出sql语句
sys=[yes/no] 确定系统是否列出由sys用户产生或重调的sql语句
print=number 将仅生成排序后的第一条sql语句的输出结果
record=recordfile 这个选项创建一个名为recorderfile的文件,包含了所有重调用的sql语句
sort=sort_option 按照指定的方法对sql trace的输出文件进行降序排序
sort_option 选项
prscnt 按解析次数排序
prscpu 按解析所花cpu时间排序
prsela 按解析所经历的时间排序
prsdsk 按解析时物理的读操作的次数排序
prsqry 按解析时以一致模式读取数据块的次数排序
prscu 按解析时以当前读取数据块的次数进行排序
execnt 按执行次数排序
execpu 按执行时花的cpu时间排序
exeela 按执行所经历的时间排序
exedsk 按执行时物理读操作的次数排序
exeqry 按执行时以一致模式读取数据块的次数排序
execu 按执行时以当前模式读取数据块的次数排序
exerow 按执行时处理的记录的次数进行排序
exemis 按执行时库缓冲区的错误排序
fchcnt 按返回数据的次数进行排序
fchcpu 按返回数据cpu所花时间排序
fchela 按返回数据所经历的时间排序
fchdsk 按返回数据时的物理读操作的次数排序
fchqry 按返回数据时一致模式读取数据块的次数排序
fchcu 按返回数据时当前模式读取数据块的次数排序
fchrow 按返回数据时处理的数据数量排序
三 sql trace 的输出结果
count:提供OCI过程的执行次数
CPU: 提供执行CPU所花的时间单位是秒
Elapsed:提供了执行时所花的时间。单位是秒。这个参数值等于用户响应时间
Disk:提供缓存区从磁盘读取的次数
Query:以一致性模式从缓存区获得数据的次数
Current:以当前模式从缓存区获得数据的次数
ROWs: 返回调用或执行调用时,处理的数据行的数量。
在report.txt文件头有各个数据的解释,根据以下一些指标可以分析一下SQL的执行性能: query+current/rows 平均每行所需的block数,太大的话(超过20)SQL语句效率太低
Parse count/Execute count parse count应尽量接近1,如果太高的话,SQL会进行不必要的reparse。要检查Pro*C程序的MAXOPENCURSORS是不是太低了,或不适当的使用的RELEASE_CURSOR选项
rows Fetch/Fetch Fetch Array的大小,太小的话就没有充分利用批量Fetch的功能,增加了数据在客户端和服务器之间的往返次数。在Pro*C中可以用prefetch=NN,Java/JDBC中可调用SETROWPREFETCH,在PL/SQL中可以用BULK COLLECT,SQLPLUS中的arraysize(缺省是15)
disk/query+current 磁盘IO所占逻辑IO的比例,太大的话有可能是db_buffer_size过小(也跟SQL的具体特性有关)
elapsed/cpu 太大表示执行过程中花费了大量的时间等待某种资源
cpu OR elapsed 太大表示执行时间过长,或消耗了大量的CPU时间,应该考虑优化
执行计划中的Rows 表示在该处理阶段所访问的行数,要尽量减少
四:举例:
sql>alter session set sql_trace=true
SQL>select * from dba_users;
SQL>show parameter user_dump_dest
user_dump_dest string /oracle/oracle/diag/rdbms/orcl/orcl/trace
SQL>exit
cd /oracle/oracle/diag/rdbms/orcl/orcl/trace
tkprof orcl_ora_11066.trc /oracle/oracle/trace1.out sys=yes
vi trace.out
1. query+current/rows 平均每行所需的block数,太大的话(超过20)SQL语句效率太低
2. Parse count/Execute count parse count应尽量接近1,如果太高的话,SQL会进行不必要的reparse。
要检查Pro*C程序的MAXOPENCURSORS是不是太低了,或不适当的使用的RELEASE_CURSOR选项
3. rows Fetch/Fetch Fetch Array的大小,太小的话就没有充分利用批量Fetch的功能,
增加了数据在客户端和服务器之间的往返次数。在Pro*C中可以用prefetch=NN,Java/JDBC中可调用SETROWPREFETCH,
在PL/SQL中可以用BULK COLLECT,SQLPLUS中的arraysize(缺省是15)
4. disk/query+current 磁盘IO所占逻辑IO的比例,太大的话有可能是db_buffer_size过小(也跟SQL的具体特性有关)
5. elapsed/cpu 太大表示执行过程中花费了大量的时间等待某种资源
6. cpu OR elapsed 太大表示执行时间过长,或消耗了大量的CPU时间,应该考虑优化
7. 执行计划中的Rows 表示在该处理阶段所访问的行数,要尽量
http://www.knowsky.com/388420.html
最近在做一个客户关系治理系统,项目做的到不是非常成功,可还是学到了不少的知识,由于数据量很大,没有专门的
Oracle数据库人员支持,对数据库优化治理等也只有我这个约懂一点的人上了。在对数据库优化上有一点点心得写出来希望能同大家一起学习和交流。
数据库大表的优化:采用蔟表(clustered tables)及蔟索引(Clustered Index)
蔟表和蔟索引是
oracle所提供的一种技术,其基本思想是将几张具有相同数据项、
并且经常性一起使用的表通过共享数据块(data block)的模式存放在一起。各表间的共同字段作为蔟键值(cluster
key),数据库在访问数据时,首先找到蔟键值,以此同时获得若干张表的相关数据。蔟表所能带来的好处是可以减少I/O和减少存储空间,其中我更看重前
者。采用表分区(partition)
表分区技术是在超大型数据库(VLDB)中将大表及其索引通过分区(patition)的形式分割为若干较小、可治理的小块,并且每一分区可
进一步划分为更小的子分区(sub partition)。而这种分区对于应用来说是透明的。通过对表进行分区,可以获得以下的好处:
1)减少数据损坏的可能性。
2)各分区可以独立备份和恢复,增强了数据库的可治理性。
3)可以控制分区在硬盘上的分布,以均衡IO,改善了数据库的性能。
蔟表与表分区技术的侧重点各有不同,前者侧重于改进关联表间查询的效率,而表分区侧重于大表的可治理性及局部查询的性能。而这两项对于我的系统来说都是极为重要。由于本人技术限制,目前尚不确定两者是否可以同时实现,有那位在这方面有经验的给点指导将不胜感激。
在两者无法同时实现的情况下,应依照需实现的功能有所取舍。综合两种模式的优缺点,我认为采用表分区技术较为适用于我们的应用。
Oracle的表分区有以下几种类型:
1)范围分区:将表按某一字段或若干个字段的取值范围分区。
2)hash分区:将表按某一字段的值均匀地分布到若干个指定的分区。
3)复合分区:结合了前面两种分区类型的优点,首先通过值范围将表进行分区,然后以hash模式将数据进一步均匀分配至物理存储位置。
综合考虑各项因素,以第三种类型最为优越。(本人实在技术有限仅采用了第1种范围分区,因为比较简单,便于治理)
优化的具体步骤:
1.确定需要优化分区的表:
经过对系统数据库表结构和字段,应用程序的分析,现在确定那些大表需要进行分区:
如帐户交易明细表acct_detail.
2.确定表分区的方法和分区键:
分区类型:采用范围分区。
分 区 键:
按trans_date(交易时间)字段进行范围分区.
3.确定分区键的分区范围,及打算分多少分区:
如:帐户交易明细表acct_detail.
根据字段(trans_date)分成一下分区:
1).分区1:09/01/2003
2).分区2:10/01/2003
3).分区3:11/01/2003
4).分区4:12/01/2003
5).分区5:01/01/2004
6).分区6:02/01/2004
该表明显需要在以后增加分区。
4.建立分区表空间和分区索引空间
1).建立表的各个分区的表空间:
1.分区1:crm_detail_200309
CREATE TABLESPACE crm_detail_200309 DATAFILE
‘/u1/oradata/orcl/crm_detail_20030901.dbf’
SIZE 2000M EXTENT MANAGEMENT LOCAL UNIFORM size 16M;
其它月份以后同以上(我在此采用
oracle的表空间本地治理的方法)。
2). 建立分区索引表空间
1.分区1:index_detail_200309
CREATE TABLESPACE index_detail_200309 DATAFILE
‘/u3/oradata/orcl/index_detail_20030901.dbf’
SIZE 2000M EXTENT MANAGEMENT LOCAL UNIFORM size 16M;
5.建立基于分区的表:
create table table name
(
........
)
enable row movment --此语句是能修改行分区键值,也就是如不添加该 句不能修改记录的分区键值,不能使记录分区迁移
PARTITION BY RANGE (TRANS_DATE)
(
PARTITION crm_detail_200309 VALUES LESS THAN
(TO_DATE (‘09/01/2003’,’mm/dd/yyyy’ ) )
TABLESPACE crm_detail_200309,
其他分区.....
);
6.建立基于分区的索引:
create index index_name on table_name (分区键+…)
global --这里是全局分区索引,也可以建本地索引
PARTITION BY RANGE (TRANS_DATE)
(
PARTITION index_detail_200309 VALUES LESS THAN
(TO_DATE ('09/01/2003','mm/dd/yyyy' ))
TABLESPACE index_detail_200309,
其他索引分区...
);
对表的分区就这样完成了,第一次主要确定表分区的分区策约是最重要的,可我觉得对表分区难在以后对表分区的治理上面,因为随着数据量的增加,表分
区必然存在删除,扩容,增加等。在这些过程中还牵涉到全局等索引,因为对分区表进行ddl操作为破坏全局索引,故全局索引必须在ddl后要重
rebuild.
以上写的很乱也很差,希望大家多多谅解和指点。
http://m77m78.itpub.net/post/125/280787
在ORACLE里如果遇到特别大的表,可以使用分区的表来改变其应用程序的性能。
同事的分区表总结,转载一下。
1.1分区表PARTITION table
在ORACLE里如果遇到特别大的表,可以使用分区的表来改变其应用程序的性能。
1.1.1分区表的建立:
某公司的每年产生巨大的销售记录,DBA向公司建议每季度的数据放在一个分区内,以下示范的是该公司1999年的数据(假设每月产生30M的数据),操作如下:
范围分区表:
CREATE TABLE sales
(invoice_no NUMBER,
...
sale_date DATE NOT NULL )
PARTITION BY RANGE (sale_date)
(PARTITION sales1999_q1
VALUES LESS THAN (TO_DATE(‘1999-04-01’,’YYYY-MM-DD’)
TABLESPACE ts_sale1999q1,
PARTITION sales1999_q2
VALUES LESS THAN (TO_DATE(‘1999-07-01’,’YYYY-MM-DD’)
TABLESPACE ts_sale1999q2,
PARTITION sales1999_q3
VALUES LESS THAN (TO_DATE(‘1999-10-01’,’YYYY-MM-DD’)
TABLESPACE ts_sale1999q3,
PARTITION sales1999_q4
VALUES LESS THAN (TO_DATE(‘2000-01-01’,’YYYY-MM-DD’)
TABLESPACE ts_sale1999q4 );
--values less than (maxvalue)
列表分区表:
create table emp (
empno number(4),
ename varchar2(30),
location varchar2(30))
partition by list (location)
(partition p1 values ('北京'),
partition p2 values ('上海','天津','重庆'),
partition p3 values ('广东','福建')
partition p0 values (default)
);
哈希分区:
create table emp (
empno number(4),
ename varchar2(30),
sal number)
partition by hash (empno)
partitions 8
store in (emp1,emp2,emp3,emp4,emp5,emp6,emp7,emp8);
组合分区:
范围哈希组合分区:
create table emp (
empno number(4),
ename varchar2(30),
hiredate date)
partition by range (hiredate)
subpartition by hash (empno)
subpartitions 2
(partition e1 values less than (to_date('20020501','YYYYMMDD')),
partition e2 values less than (to_date('20021001','YYYYMMDD')),
partition e3 values less than (maxvalue));
范围列表组合分区:
CREATE TABLE customers_part (
customer_id NUMBER(6),
cust_first_name VARCHAR2(20),
cust_last_name VARCHAR2(20),
nls_territory VARCHAR2(30),
credit_limit NUMBER(9,2))
PARTITION BY RANGE (credit_limit)
SUBPARTITION BY LIST (nls_territory)
SUBPARTITION TEMPLATE
(SUBPARTITION east VALUES ('CHINA', 'JAPAN', 'INDIA', 'THAILAND'),
SUBPARTITION west VALUES ('AMERICA', 'GERMANY', 'ITALY', 'SWITZERLAND'),
SUBPARTITION other VALUES (DEFAULT))
(PARTITION p1 VALUES LESS THAN (1000),
PARTITION p2 VALUES LESS THAN (2500),
PARTITION p3 VALUES LESS THAN (MAXVALUE));
create table t1 (id1 number,id2 number)
partition by range (id1) subpartition by list (id2)
(partition p11 values less than (11)
(subpartition subp1 values (1))
);
索引分区:
CREATE INDEX month_ix ON sales(sales_month)
GLOBAL PARTITION BY RANGE(sales_month)
(PARTITION pm1_ix VALUES LESS THAN (2)
PARTITION pm12_ix VALUES LESS THAN (MAXVALUE));
1.1.2分区表的维护:
增加分区:
ALTER TABLE sales ADD PARTITION sales2000_q1
VALUES LESS THAN (TO_DATE(‘2000-04-01’,’YYYY-MM-DD’)
TABLESPACE ts_sale2000q1;
如果已有maxvalue分区,不能增加分区,可以采取分裂分区的办法增加分区!
删除分区:
ALTER TABLE salesDROP PARTION sales1999_q1;
截短分区:
alter table sales truncate partiton sales1999_q2;
合并分区:
alter table sales merge partitons sales1999_q2, sales1999_q3 into sales1999_q23;
alter index ind_t2 rebuild partition p123 parallel 2;
分裂分区:
ALTER TABLE sales
SPLIT PARTITON sales1999_q4
AT TO_DATE (‘1999-11-01’,’YYYY-MM-DD’)
INTO (partition sales1999_q4_p1, partition sales1999_q4_p2) ;
alter table t2 split partition p123 values (1,2) into (partition p12,partition p3);
交换分区:
alter table x exchange partition p0 with table bsvcbusrundatald ;
访问指定分区:
select * from sales partition(sales1999_q2)
EXPORT指定分区:
exp sales/sales_password tables=sales:sales1999_q1
file=sales1999_q1.dmp
IMPORT指定分区:
imp sales/sales_password FILE =sales1999_q1.dmp
TABLES = (sales:sales1999_q1) IGNORE=y
查看分区信息:
user_tab_partitions, user_segments
注:若分区表跨不同表空间,做导出、导入时目标数据库必须预建这些表空间。分表区各区所在表空间在做导入时目标数据库一定要预建这些表空间!这些表空间不一定是用户的默认表空间,只要存在即可。如果有一个不存在,就会报错!
默
认时,对分区表的许多表维护操作会使全局索引不可用,标记成UNUSABLE。 那么就必须重建整个全局索引或其全部分区。如果已被分区,Oracle
允许在用于维护操作的ALTER TABLE 语句中指定UPDATE GLOBAL INDEXES
来重载这个默认特性,指定这个子句也就告诉Oracle 当它执行维护操作的DDL 语句时更新全局索引,这提供了如下好处:
1.在操作基础表的同时更新全局索引这就不需要后来单独地重建全局索引;
2.因为没有被标记成UNUSABLE, 所以全局索引的可用性更高了,甚至正在执行分区的DDL 语句时仍然可用索引来访问表中的其他分区,避免了查询所有失效的全局索引的名字以便重建它们;
另外在指定UPDATE GLOBAL INDEXES 之前还要考虑如下性能因素:
1.因为要更新事先被标记成UNUSABLE 的索引,所以分区的DDL 语句要执行更长时间,当然这要与先不更新索引而执行DDL 然后再重建索引所花的时间做个比较,一个适用的规则是如果分区的大小小于表的大小的5% ,则更新索引更快一点;
2.DROP TRUNCATE 和EXCHANGE 操作也不那么快了,同样这必须与先执行DDL 然后再重建所有全局索引所花的时间做个比较;
3.要登记对索引的更新并产生重做记录和撤消记录,重建整个索引时可选择NOLOGGING;
4.重建整个索引产生一个更有效的索引,因为这更利于使用空间,再者重建索引时允许修改存储选项。
注意分区索引结构表不支持UPDATE GLOBAL INDEXES 子句。
1.1.3普通表变为分区表
将已存在数据的普通表转变为分区表,没有办法通过修改属性的方式直接转化为分区表,必须通过重建的方式进行转变,一般可以有三种方法,视不同场景使用:
用例:
方法一:利用原表重建分区表。
CREATE TABLE T (ID NUMBER PRIMARY KEY, TIME DATE);
INSERT INTO T
SELECT ROWNUM, SYSDATE - ROWNUM FROM DBA_OBJECTS WHERE ROWNUM <= 5000;
COMMIT;
CREATE TABLE T_NEW (ID, TIME) PARTITION BY RANGE (TIME)
(PARTITION P1 VALUES LESS THAN (TO_DATE('2000-1-1', 'YYYY-MM-DD')),
PARTITION P2 VALUES LESS THAN (TO_DATE('2002-1-1', 'YYYY-MM-DD')),
PARTITION P3 VALUES LESS THAN (TO_DATE('2005-1-1', 'YYYY-MM-DD')),
PARTITION P4 VALUES LESS THAN (MAXVALUE))
AS SELECT ID, TIME FROM T;
RENAME T TO T_OLD;
RENAME T_NEW TO T;
SELECT COUNT(*) FROM T;
COUNT(*)
----------
5000
SELECT COUNT(*) FROM T PARTITION (P1);
COUNT(*)
----------
2946
SELECT COUNT(*) FROM T PARTITION (P2);
COUNT(*)
----------
731
SELECT COUNT(*) FROM T PARTITION (P3);
COUNT(*)
----------
1096
优点:方法简单易用,由于采用DDL语句,不会产生UNDO,且只产生少量REDO,效率相对较高,而且建表完成后数据已经在分布到各个分区中了。
不足:对于数据的一致性方面还需要额外的考虑。由于几乎没有办法通过手工锁定T表的方式保证一致性,在执行CREATE TABLE语句和RENAME T_NEW TO T语句直接的修改可能会丢失,如果要保证一致性,需要在执行完语句后对数据进行检查,而这个代价是比较大的。另外在执行两个RENAME语句之间执行的对T的访问会失败。
适用于修改不频繁的表,在闲时进行操作,表的数据量不宜太大。
方法二:使用交换分区的方法。
Drop table t;
CREATE TABLE T (ID NUMBER PRIMARY KEY, TIME DATE);
INSERT INTO T
SELECT ROWNUM, SYSDATE - ROWNUM FROM DBA_OBJECTS WHERE ROWNUM <= 5000;
COMMIT;
CREATE TABLE T_NEW (ID NUMBER PRIMARY KEY, TIME DATE) PARTITION BY RANGE (TIME)
(PARTITION P1 VALUES LESS THAN (TO_DATE('2005-9-1', 'YYYY-MM-DD')),
PARTITION P2 VALUES LESS THAN (MAXVALUE));
ALTER TABLE T_NEW EXCHANGE PARTITION P1 WITH TABLE T;
RENAME T TO T_OLD;
RENAME T_NEW TO T;
优点:只是对数据字典中分区和表的定义进行了修改,没有数据的修改或复制,效率最高。如果对数据在分区中的分布没有进一步要求的话,实现比较简单。在执行完RENAME操作后,可以检查T_OLD中是否存在数据,如果存在的话,直接将这些数据插入到T中,可以保证对T插入的操作不会丢失。
不足:仍然存在一致性问题,交换分区之后RENAME T_NEW TO T之前,查询、更新和删除会出现错误或访问不到数据。如果要求数据分布到多个分区中,则需要进行分区的SPLIT操作,会增加操作的复杂度,效率也会降低。
适用于包含大数据量的表转到分区表中的一个分区的操作。应尽量在闲时进行操作。
方法三:Oracle9i以上版本,利用在线重定义功能
Drop table t;
CREATE TABLE T (ID NUMBER PRIMARY KEY, TIME DATE);
INSERT INTO T
SELECT ROWNUM, SYSDATE - ROWNUM FROM DBA_OBJECTS WHERE ROWNUM <= 5000;
COMMIT;
EXEC DBMS_REDEFINITION.CAN_REDEF_TABLE(USER, 'T');
PL/SQL 过程已成功完成。
CREATE TABLE T_NEW (ID NUMBER PRIMARY KEY, TIME DATE) PARTITION BY RANGE (TIME)
(PARTITION P1 VALUES LESS THAN (TO_DATE('2004-7-1', 'YYYY-MM-DD')),
PARTITION P2 VALUES LESS THAN (TO_DATE('2005-1-1', 'YYYY-MM-DD')),
PARTITION P3 VALUES LESS THAN (TO_DATE('2005-7-1', 'YYYY-MM-DD')),
PARTITION P4 VALUES LESS THAN (MAXVALUE));
表已创建。
EXEC DBMS_REDEFINITION.START_REDEF_TABLE(USER, 'T', 'T_NEW');
PL/SQL 过程已成功完成。
EXEC DBMS_REDEFINITION.FINISH_REDEF_TABLE(USER, 'T', 'T_NEW');
PL/SQL 过程已成功完成。
SELECT COUNT(*) FROM T;
COUNT(*)
----------
5000
SELECT COUNT(*) FROM T PARTITION (P3);
COUNT(*)
----------
1096
优点:保证数据的一致性,在大部分时间内,表T都可以正常进行DML操作。只在切换的瞬间锁表,具有很高的可用性。这种方法具有很强的灵活性,对各种不同的需要都能满足。而且,可以在切换前进行相应的授权并建立各种约束,可以做到切换完成后不再需要任何额外的管理操作。
不足:实现上比上面两种略显复杂。
适用于各种情况。
这里只给出了在线重定义表的一个最简单的例子,详细的描述和例子可以参考下面两篇文章。
Oracle的在线重定义表功能:http://blog.itpub.net/post/468/12855
Oracle的在线重定义表功能(二):http://blog.itpub.net/post/468/12962
XSB:
把一个已存在数据的大表改成分区表:
第一种(表不是太大):
1.把原表改名:
rename xsb1 to xsb2;
2.创建分区表:
CREATE TABLE xsb1
PARTITION BY LIST (c_test)
(PARTITION xsb1_p1 VALUES (1),
PARTITION xsb1_p2 VALUES (2),
PARTITION xsb1_p0 VALUES (default))
nologging AS SELECT * FROM xsb2;
3.将原表上的触发器、主键、索引等应用到分区表上;
4.删除原表:
drop table xsb2;
第二种(表很大):
1.创建分区表:
CREATE TABLE x PARTITION BY LIST (c_test) [range ()]
(PARTITION p0 VALUES [less than ](1) tablespace tbs1,
PARTITION p2 VALUES (2) tablespace tbs1,
PARTITION xsb1_p0 VALUES ([maxvalue]default))
AS SELECT * FROM xsb2 [where 1=2];
2.交换分区 alter table x exchange partition p0 with table bsvcbusrundatald ;
3.原表改名alter table bsvcbusrundatald rename to x0;
4.新表改名alter table x rename to bsvcbusrundatald ;
5.删除原表drop table x0;
6.创建新表触发器和索引create index ind_busrundata_lp on bsvcbusrundatald(。。。) local tablespace tbs_brd_ind ;
或者:
1.规划原大表中数据分区的界限,原则上将原表中近期少量数据复制至另一表;
2.暂停原大表中的相关触发器;
3.删除原大表中近期数据;
4.改名原大表名称;
5.创建分区表;
6.交换分区;
7.重建相关索引及触发器(先删除之再重建).
参考脚本:
select count(*) from t1 where recdate>sysdate-2
create table x2 nologging as select * from t1 where recdate>trunc(sysdate-2)
alter triger trg_t1 disable
delete t1 where recdate>sysdate-2
commit
rename t1 to x1
create table t1 [nologging] partition by range(recdate)
(partition pbefore values less than (trunc(sysdate-2)),
partition pmax values less than (maxvalue))
as select * from x1 where 1=2
alter table t1 exchange partition pbefore with table x1
alter table t1 exchange partition pmax with table x2
drop table x2
[重建触发器]
drop table x1
1.1.4参考材料:
如果表中预期的数据量较大,通常都需要考虑使用分区表,确定使用分区表后,还要确定什么类型的分区(range partition、hash partition、list partition等)、分区区间大小等。分区的创建最好与程序有某种默契,偶曾经创建分区表,按自然月份定义分区的,但程序却在查询时默认的开始时间与结束时间是:当前日期-30至当前日期,比如当天是9.18号,那查询条件被产生为8.18-9.18,结果分区后并不没有大幅提高性能,后来对程序的查询日期做了调整,按自然月查询,系统的负载小了很多。
从Oracle8.0开始支持表分区(MSSQL2005开始支持表分区)。
Oracle9i 分区能够提高许多应用程序的可管理性、性能与可用性。分区可以将表、索引及索引编排表进一步划分,从而可以更精细地对这些数据库对象进行管理和访问。Oracle 提供了种类繁多的分区方案以满足所有的业务需要。另外,由于在 SQL 语句中是完全透明的,所以分区可以用于几乎所有的应用程序。
分区表允许将数据分成被称为分区甚至子分区的更小的更好管理的块。索引也可以这么分区。每个分区可以被单独管理,可以不依赖于其他分区而单独发挥作用,因此提供了一个更有利于可用性和性能的结构。
分
区可以提高可管理性、性能与可用性,从而给各种各样的应用程序带来极大的好处。通常,分区可以使某些查询以及维护操作的性能大大提高。此外,分区还能够在
很大程度上简化日常管理任务。分区还使数据库设计人员和管理员能够解决尖端应用程序带来的最难的问题。分区是建立上亿万字节数据系统或需要极高可用性系统
的关键工具。
在多CPU配置环境下,如果打算使用并行执行,则分区提供了另一种并行的方法。通过给表或索引的不同分区分配不同的并行执行服务器,就可以并行执行对分区表和分区索引的操作。
表或索引的分区和子分区都共享相同的逻辑属性。例如表的所有分区或子分区共享相同的列和约束定义,一个索引的分区或子分区共享相同的索引选项。然而它们可以具有不同的物理属性如表空间。
尽管不需要将表或索引的每个分区或子分区放在不同的表空间,但这样做更好。将分区存储到不同的表空间能够
l减少数据在多个分区中冲突的可能性
l可以单独备份和恢复每个分区
l控制分区与磁盘驱动器之间的映射对平衡I/O 负载是重要的
l改善可管理性可用性和性能
分区操作对现存的应用和运行在分区表上的标准DML 语句来说是透明的。但是可以通过在DML 中使用分区扩展表或索引的名字来对应用编程,使其利用分区的优点。
可以使用SQL*Loader、Import 和Export 工具来装载或卸载分区表中的数据。这些工具都是支持分区和子分区的。
分区的方法
Oracle9i 提供了如下5种分区方法:
l范围分区Range
l散列分区Hash
l列表分区List
l组合范围-散列分区Range-Hash
l组合范围-列表分区Range-List
可对索引和表分区。全局索引只能按范围分区,但可以将其定义在任何类型的分区或非分区表上。通常全局索引比局部索引需要更多的维护。
一般组建局部索引,以便反映其基础表的结构。它与基础表是等同分区的,即它与基础
表在同样的列上分区,创建同样数量的分区或子分区,设置与基础表相对应的同样的分区边界。对局部索引而言,当维护活动影响分区时,会自动维护索引分区。这保证了索引与基础表之间的等同分区。
关于范围分区Range:
要想将行映射到基于列值范围的分区,就使用范围分区方法。当数据可以被划分成逻辑范围时如年度中的月份,这种类型的分区就有用了。当数据在整个范围中能被均等地划分时性能最好。如果靠范围的分区会由于不均等的划分而导致分区在大小上明显不同时,就需要考虑其他的分区方法。
关于散列分区Hash:
如果数据不那么容易进行范围分区,但为了性能和管理的原因又想分区时,就使用散列分区方法。散列分区提供了一种在指定数量的分区中均等地划分数据的方法。基于分区键的散列值将行映射到分区中。创建和使用散列分区会给你提供了一种很灵活的放置数据的方法,因为你可以通过在I/O 驱动器之间播撒(摘掉)这些均等定量的分区,来影响可用性和性能。
关于列表分区List:
当
你需要明确地控制如何将行映射到分区时,就使用列表分区方法。可以在每个分区的描述中为该分区列指定一列离散值,这不同于范围分区,在那里一个范围与一个
分区相关,这也不同于散列分区,在那里用户不能控制如何将行映射到分区。列表分区方法是特意为遵从离散值的模块化数据划分而设计的。范围分区或散列分区不
那么容易做到这一点。进一步说列表分区可以非常自然地将无序的和不相关的数据集进行分组和组织到一起。
与范围分区和散列分区所不同,列表分区不支持多列分区。如果要将表按列分区,那么分区键就只能由表的一个单独的列组成,然而可以用范围分区或散列分区方法进行分区的所有的列,都可以用列表分区方法进行分区。
关于组合范围-散列分区:
范围和散列技术的组合,首先对表进行范围分区,然后用散列技术对每个范围分区再次分区。给定的范围分区的所有子分区加在一起表示数据的逻辑子集。
关于组合范围-列表分区:
范围和列表技术的组合,首先对表进行范围分区,然后用列表技术对每个范围分区再次分区。与组合范围-散列分区不同的是,每个子分区的所有内容表示数据的逻辑子集,由适当的范围和列表分区设置来描述。
创建或更改分区表时可以指定行移动子句,即ENABLE ROW MOVEMENT 或者DISABLE ROW MOVEMENT ,当其键被更改时,该子句启用或停用将行迁移到一个新的分区。默认值为DISABLE ROW MOVEMENT。本产品(项目)使用ENABLE ROW MOVEMENT子句。
分区技术能够提高数据库的可管理性:
使用分区技术,维护操作可集中于表的特定部分。例如,数据库管理员可以只对表的一部分做备份,而不必对整个表做备份。对整个数据库对象的维护操作,可以在每个分区的基础上进行,从而将维护工作分解成更容易管理的小块。
分区技术提高可管理性的一个典型用法是支持数据仓库中的‘滚动视窗’加
载进程。假设数据库管理员每周向表中加载新数据。该表可以是范围分区,以便每个分区包含一周的数据。加载进程只是简单地添加新的分区。添加一个新分区的操
作比修改整个表效率高很多,因为数据库管理员不需要修改任何其他分区。从分区后的表中去除数据也是一样。你只要用一个很简便快捷的数据字典操作删掉一个分
区,而不必发出使用大量资源和调动所有要删除的数据的 ‘DELETE’ 命令。
分区技术能够提高数据库的性能:
由于减少了所检查或操作的数据数量,同时允许并行执行,Oracle9i 的分区功能提供了性能上的优势。这些性能包括:
l分
区修整:分区修整是用分区技术提高性能的最简单最有价值的手段。分区修整常常能够将查询性能提高几个数量级。例如,假定应用程序中有包含定单历史记录的定
单表,该表用周进行了分区。查询一周的定单只需访问该定单表的一个分区。如果该定单表包含两年的历史记录,这个查询只需要访问一个而不是一百零四个分区。
该查询的执行速度因为分区修整而有可能快一百倍。分区修整能与所有其他 Oracle 性能特性协作。Oracle 公司将把分区修整技术与索引技术、连结技术和并行访问方法一起联合使用。
l分
区智能联接:分区功能可以通过称为分区智能联接的技术提高多表联接的性能。当两个表要联接在一起,而且每个表都用联接关键字来分区时,就可以使用分区智能
联接。分区智能联接将大型联接分解成较小的发生在各个分区间的联接,从而用较少的时间完成全部联接。这就给串行和并行的执行都能带来显著的性能改善。
l更新和删除的并行执行:分区功能能够无限地并行执行 UPDATE、DELETE 与 MERGE 语句。当访问分区或未分区的数据库对象时Oracle 将并行处理 SELECT 与 INSERT 语句。当不使用位图索引时,也可以对分区或未分区的数据库对象并行处理 UPDATE、DELETE 和 MERGE 语句。为了对有位图索引的对象并行处理那些操作,目标表必须先分区。这些 SQL 语句的并行执行可以大大提高性能,特别是提高 UPDATE 与 DELETE 或 MERGE 操作涉及大量数据时的性能。
分区技术提高可用性:
分
区的数据库对象具有分区独立性。该分区独立性特点可能是高可用性战略的一个重要部分,例如,如果分区表的分区不能用,但该表的所有其他分区仍然保持在线并
可用。那么这个应用程序可以继续针对该分区表执行查询和事务处理,只要不是访问那个不可用的分区,数据库操作仍然能够成功运行。 数据库管理员可以指定各分区存放在不同的表空间里,从而让管理员独立于其它表分区针对每个分区进行备份与恢复操作。 还有,分区功能可以减少计划停机时间。性能由于分区功能得到了改善,使数据库管理员在相对较小的批处理窗口完成大型数据库对象的维护工作。
摘要: http://www.cnblogs.com/sumh/archive/2008/03/27/1123903.html
一、在vs中创建表单模板把数据存到数据库中。
新建infopath表单模板:
打开vs2008,新建Project,在Project Types 区中选择 Visual C#àOffice-à2007--àInfoPathFormTempl...
阅读全文
摘要: 关于Can't connect to local MySQL server through socket '/tmp/mysql.sock' (2)的问题
转自:http://www.blogjava.net/asenyifei/articles/82575.html
阅读全文
http://hl13571.cnblogs.com/archive/2006/02/08/326997.aspx
注:本文来源与互联网,时间很久了也不知道是哪的了。另外,本文针对的是sqlserver2000,在2005中数据同步好像有更好的解决方案
复制的概念
复制是将一组数据从一个数据源拷贝到多个数据源的技术,是将一份数据发布到多个存储站点上的有效方式。使用复制技术,用户可以将一份数据发布到多台服务
器上,从而使不同的服务器用户都可以在权限的许可的范围内共享这份数据。复制技术可以确保分布在不同地点的数据自动同步更新,从而保证数据的一致性。
SQL复制的基本元素包括
出版服务器、订阅服务器、分发服务器、出版物、文章
SQL复制的工作原理
SQL SERVER
主要采用出版物、订阅的方式来处理复制。源数据所在的服务器是出版服务器,负责发表数据。出版服务器把要发表的数据的所有改变情况的拷贝复制到分发服务
器,分发服务器包含有一个分发数据库,可接收数据的所有改变,并保存这些改变,再把这些改变分发给订阅服务器
SQL SERVER复制技术类型
SQL SERVER提供了三种复制技术,分别是:
1、快照复制(呆会我们就使用这个)
2、事务复制
3、合并复制
【快照复制step by step 】
只要把上面这些概念弄清楚了那么对复制也就有了一定的理解。接下来我们就一步一步来实现复制的步骤。
第一先来配置出版服务器
(1)选中指定[服务器]节点
(2)从[工具]下拉菜单的[复制]子菜单中选择[发布、订阅服务器和分发]命令
(3)系统弹出一个对话框点[下一步]然后看着提示一直操作到完成。
(4)当完成了出版服务器的设置以后系统会为该服务器的树形结构中添加一个复制监视器。同时也生成一个分发数据库(distribution)
第二创建出版物
(1)选中指定的服务器
(2)从[工具]菜单的[复制]子菜单中选择[创建和管理发布]命令。此时系统会弹出一个对话框
(3)选择要创建出版物的数据库,然后单击[创建发布]
(4)在[创建发布向导]的提示对话框中单击[下一步]系统就会弹出一个对话框。对话框上的内容是复制的三个类型。我们现在选第一个也就是默认的快照发布(其他两个大家可以去看看帮助)
(5)单击[下一步]系统要求指定可以订阅该发布的数据库服务器类型,SQLSERVER允许在不同的数据库如 ORACLE或ACCESS之间进行数据复制。但是在这里我们选择运行"SQL SERVER 2000"的数据库服务器
(6)单击[下一步]系统就弹出一个定义文章的对话框也就是选择要出版的表
(7)然后[下一步]直到操作完成。当完成出版物的创建后创建出版物的数据库也就变成了一个共享数据库。
第三设计订阅
(1)选中指定的订阅服务器
(2)从[工具]下拉菜单中选择[复制]子菜单的[请求订阅]
(3)按照单击[下一步]操作直到系统会提示检查SQL SERVER代理服务的运行状态,执行复制操作的前提条件是SQL SERVER代理服务必须已经启动。
(4)单击[完成]。完成订阅操作。
完成上面的步骤其实复制也就是成功了。但是如何来知道复制是否成功了呢?这里可以通过这种方法来快速看是否成功。展开出版服务器下面的复制——发布内容
——右键发布内容——属性——击活——状态然后点立即运行代理程序接着点代理程序属性击活调度把调度设置为每一天发生,每一分钟,在0:00:00和
23:59:59之间。接下来就是判断复制是否成功了打开C:\Program Files\Microsoft SQL
Server\MSSQL\REPLDATA\unc\XIAOWANGZI_database_database下面看是不是有一些以时间做为文件名的
文件夹差不多一分中就产生一个。要是你还不信的话就打开你的数据库看在订阅的服务器的指定订阅数据库下看是不是看到了你刚才所发布的表—
【手工作业调度同步方案(sql)】
--定时同步服务器上的数据(通过作业对同步处理存储过程的调度)
--例子:
--测试环境,SQL Server2000,远程服务器名:xz,用户名为:sa,无密码,测试数据库:test
--服务器上的表(查询分析器连接到服务器上创建)
create table [user](id int primary key,number varchar(4),name varchar(10))
go
--以下在局域网(本机操作)
--本机的表,state说明:null 表示新增记录,1 表示修改过的记录,0 表示无变化的记录
if exists (select * from dbo.sysobjects where id = object_id(N'[user]') and OBJECTPROPERTY(id, N'IsUserTable') = 1)
drop table [user]
GO
create table [user](id int identity(1,1),number varchar(4),name varchar(10),state bit)
go
--创建触发器,维护state字段的值
create trigger t_state on [user]
after update
as
update [user] set state=1
from [user] a join inserted b on a.id=b.id
where a.state is not null
go
--为了方便同步处理,创建链接服务器到要同步的服务器
--这里的远程服务器名为:xz,用户名为:sa,无密码
if exists(select 1 from master..sysservers where srvname='srv_lnk')
exec sp_dropserver 'srv_lnk','droplogins'
go
exec sp_addlinkedserver 'srv_lnk','','SQLOLEDB','xz'
exec sp_addlinkedsrvlogin 'srv_lnk','false',null,'sa'
go
--创建同步处理的存储过程
if exists (select * from dbo.sysobjects where id = object_id(N'[dbo].[p_synchro]') and OBJECTPROPERTY(id, N'IsProcedure') = 1)
drop procedure [dbo].[p_synchro]
GO
create proc p_synchro
as
--set XACT_ABORT on
--启动远程服务器的MSDTC服务
--exec master..xp_cmdshell 'isql /S"xz" /U"sa" /P"" /q"exec master..xp_cmdshell ''net start msdtc'',no_output"',no_output
--启动本机的MSDTC服务
--exec master..xp_cmdshell 'net start msdtc',no_output
--进行分布事务处理,如果表用标识列做主键,用下面的方法
--BEGIN DISTRIBUTED TRANSACTION
--同步删除的数据
delete from srv_lnk.test.dbo.[user]
where id not in(select id from [user])
--同步新增的数据
insert into srv_lnk.test.dbo.[user]
select id,number,name from [user] where state is null
--同步修改的数据
update srv_lnk.test.dbo.[user] set
number=b.number,name=b.name
from srv_lnk.test.dbo.[user] a
join [user] b on a.id=b.id
where b.state=1
--同步后更新本机的标志
update [user] set state=0 where isnull(state,1)=1
--COMMIT TRAN
go
--创建作业,定时执行数据同步的存储过程
if exists(SELECT 1 from msdb..sysjobs where name='数据处理')
EXECUTE msdb.dbo.sp_delete_job @job_name='数据处理'
exec msdb..sp_add_job @job_name='数据处理'
--创建作业步骤
declare @sql varchar(800),@dbname varchar(250)
select @sql='exec p_synchro' --数据处理的命令
,@dbname=db_name() --执行数据处理的数据库名
exec msdb..sp_add_jobstep @job_name='数据处理',
@step_name = '数据同步',
@subsystem = 'TSQL',
@database_name=@dbname,
@command = @sql,
@retry_attempts = 5, --重试次数
@retry_interval = 5 --重试间隔
--创建调度
EXEC msdb..sp_add_jobschedule @job_name = '数据处理',
@name = '时间安排',
@freq_type = 4, --每天
@freq_interval = 1, --每天执行一次
@active_start_time = 00000 --0点执行
go
摘要: Tomcat5.5配置-多域名绑定和虚拟目录
阅读全文