apache修改最大连接并用ab网站压力测试
apache 2.2,使用默认配置,默认最大连接数是150
1.首先在httpd.conf中加载httpd-mpm.conf配置(去掉前面的注释):
# Server-pool management (MPM
specific)
Include conf/extra/httpd-mpm.conf
2.可见的MPM配置在/usr/local/apache/conf/extra/httpd-mpm.conf,但里面根据httpd的工作模式分了很多块,哪一部才是当前httpd的工作模式呢?可通过执行
apachectl -l 来查看:
[root@zh888 extra]# /usr/local/apache/bin/apachectl
-l//因为采用静态编译
Compiled in
modules:
core.c
mod_authn_file.c
mod_authn_default.c
mod_authz_host.c
mod_authz_groupfile.c
mod_authz_user.c
mod_authz_default.c
mod_auth_basic.c
mod_cache.c
mod_disk_cache.c
mod_mem_cache.c
mod_include.c
mod_filter.c
mod_deflate.c
mod_log_config.c
mod_env.c
mod_expires.c
mod_headers.c
mod_setenvif.c
mod_version.c
mod_proxy.c
mod_proxy_connect.c
mod_proxy_ftp.c
mod_proxy_http.c
mod_proxy_scgi.c
mod_proxy_ajp.c
mod_proxy_balancer.c
prefork.c//才用prefork所以在httpd-mpm.conf中找到mpm_prefork_module
http_core.c
mod_mime.c
mod_status.c
mod_autoindex.c
mod_asis.c
mod_cgi.c
mod_negotiation.c
mod_dir.c
mod_actions.c
mod_userdir.c
mod_alias.c
mod_rewrite.c
mod_so.c
所以修改连接数就在/usr/local/apache/conf/extra/httpd-mpm.conf这个文件了,打开它就找到prefork模式的默认配置是:
StartServers
5
MinSpareServers 5
MaxSpareServers 10
MaxClients
150
MaxRequestsPerChild 0
prefork
控制进程在最初建立“StartServers”个子进程后,为了满足MinSpareServers设置的需要创建一个进程,等待一秒钟,继续创建两个,再等待一秒钟,继续创建四个……如此按指数级增加创建的进程数,最多达到每秒32个,直到满足MinSpareServers设置的值为止。
这种模式可以不必在请求到来时再产生新的进程,从而减小了系统开销以增加性能。MaxSpareServers设置了最大的空闲进程数,如果空闲进程数大于这个值,Apache会自动kill掉一些多余进程。这个值不要设得过大,但如果设的值比MinSpareServers小,Apache会自动把其调整为
MinSpareServers+1。如果站点负载较大,可考虑同时加大MinSpareServers和MaxSpareServers。
MaxRequestsPerChild设置的是每个子进程可处理的请求数。每个子进程在处理了“MaxRequestsPerChild”个请求后将自动销毁。0意味着无限,即子进程永不销毁。
虽然缺省设为0可以使每个子进程处理更多的请求,但如果设成非零值也有两点重要的好处:
1、可防止意外的内存泄漏。
2、在服务器负载下降的时侯会自动减少子进程数。因此,可根据服务器的负载来调整这个值。MaxClients是这些指令中最为重要的一个,设定的是
Apache可以同时处理的请求,是对Apache性能影响最大的参数。其缺省值150是远远不够的,如果请求总数已达到这个值(可通过ps -ef|grep
httpd|wc
-l来确认),那么后面的请求就要排队,直到某个已处理请求完毕。这就是系统资源还剩下很多而HTTP访问却很慢的主要原因。虽然理论上这个值越大,可以处理的请求就越多,但Apache默认的限制不能大于256。ServerLimit指令无须重编译Apache就可以加大MaxClients。
注意,虽然通过设置ServerLimit,我们可以把MaxClients加得很大,但是往往会适得其反,系统耗光所有内存。以我手头的一台服务器为例:内存2G,每个apache进程消耗大约0.5%(可通过ps
aux来确认)的内存,也就是10M,这样,理论上这台服务器最多跑200个apache进程就会耗光系统所有内存,所以,设置MaxClients要慎重。
3.要加到多少?
连接数理论上当然是支持越大越好,但要在服务器的能力范围内,这跟服务器的CPU、内存、带宽等都有关系。
查看当前的连接数可以用:
ps aux | grep httpd | wc -l
计算httpd占用内存的平均数:
ps
aux|grep -v grep|awk '/httpd/{sum+=$6;n++};'
由于基本都是静态页面,CPU消耗很低,每进程占用内存也不算多,大约200K。
假如服务器内存有2G,除去常规启动的服务大约需要500M(保守估计),还剩1.5G可用,那么理论上可以支持1.5*1024*1024*1024/
= 8053.
约8K个进程,支持2W人同时访问应该是没有问题的(能保证其中8K的人访问很快,其他的可能需要等待1、2秒才能连上,而一旦连上就会很流畅)
控制最大连接数的MaxClients ,因此可以尝试配置为:
StartServers 5
MinSpareServers
5
MaxSpareServers 10
ServerLimit 5500
MaxClients
5000
MaxRequestsPerChild 100
注意,MaxClients默认最大为250,若要超过这个值就要显式设置ServerLimit,且ServerLimit要放在MaxClients之前,值要不小于MaxClients,不然重启httpd时会有提示。
重启httpd后,通过反复执行pgrep httpd|wc -l
来观察连接数,可以看到连接数在达到MaxClients的设值后不再增加,但此时访问网站也很流畅,那就不用贪心再设置更高的值了,不然以后如果网站访问突增不小心就会耗光服务器内存,可根据以后访问压力趋势及内存的占用变化再逐渐调整,直到找到一个最优的设置值。
(MaxRequestsPerChild不能设置为0,可能会因内存泄露导致服务器崩溃)
更佳最大值计算的公式:
apache_max_process_with_good_perfermance < (total_hardware_memory /
apache_memory_per_process ) * 2
apache_max_process =
apache_max_process_with_good_perfermance * 1.5
4.用/usr/local/apache/bin/ab来测试压力不过还有一个工具叫webbench也可以测试。
[root@zh888 bin]# /usr/local/apache/bin/ab -n 100 -c
100http://192.168.100.1:8000/index.php//参数很多一般我们用 -c 和 -n
参数就可以了这个表示同时处理100个请求并运行100次index.php文件.
This is ApacheBench Version 2.3
Copyright 1996 Adam Twiss Zeus Technology
Ltd
Licensed to The Apache Software Foundation
Benchmarking 192.168.100.1 (be patient).....done
Server Software: Apache/2.2.19//平台apache 版本2.0.54
Server Hostname: 192.168.100.1//服务器主机名
Server Port: 8000//端口
Document Path: /index.php//测试的页面文档
Document Length: bytes//文档大小
Concurrency Level: 100//并发数
Time taken for tests: 4.482 seconds//整个测试持续的时间
Complete requests: 100//完成的请求数量
Failed requests: 0//失败的请求数量
Write errors: 0
Total transferred: bytes//整个场景中的网络传输量
HTML transferred: bytes
Requests per second: 22.31 [#/sec]
(mean)//大家最关心的指标之一,相当于 LR 中的 每秒事务数 ,后面括号中的 mean 表示这是一个平均值
Time per request: 4481.929 [ms] (mean)//大家最关心的指标之二,相当于 LR 中的 平均事务响应时间 ,后面括号中的
mean 表示这是一个平均值
Time per request: 44.819 [ms] (mean across all concurrent
requests)//每个请求实际运行时间的平均值
Transfer rate: 793.68 [Kbytes/sec]
received//平均每秒网络上的流量,可以帮助排除是否存在网络流量过大导致响应时间延长的问题
Connection Times (ms)//网络上消耗的时间的分解。
min mean[+/-sd] median max
Connect: 0 73 24.5 79 96
Processing: 252
2542 1291.7 2590 4386
Waiting: 252 2541 1292.5 2590 4384
Total: 253 2615
1311.0 2671 4482
Percentage of the requests served within a certain time
(ms)//整个场景中所有请求的响应情况。在场景中每个请求都有一个响应时间,其中50%的用户响应时间小于1093 毫秒,60% 的用户响应时间小于1247
毫秒,最大的响应时间小于7785
毫秒
由于对于并发请求,cpu实际上并不是同时处理的,而是按照每个请求获得的时间片逐个轮转处理的,所以基本上第一个Time per
request时间约等于第二个Time per request时间乘以并发请求数
50% 2671
66% 3351
75% 3923
80% 4095
90% 4358
95%
4441
98% 4472
99% 4482
100% 4482 (longest request)
4.是在使用Apache2.2的ab进行测试时遇到的问题:
使用ab测试的时候当-c并发数超过1024就会出错:
windows下提示:apr_pollset_create
failed: Invalid argument (22)
linux下提示:socket: Too
many open files (24)
解决办法:
linux下:ulimit -n
(设置系统允许同时打开的文件数,系统默认是1024),可以用ulimit -a查看open files项,# lsof |wc -l
可以查看系统所有进程的文件打开数。
ulimit:显示(或设置)用户可以使用的资源限制
ulimit -a 显示用户可以使用的资源限制
ulimit unlimited
不限制用户可以使用的资源,但本设置对可打开的最大文件数(max open files)
和可同时运行的最大进程数(max user
processes)无效
ulimit -n 设置用户可以同时打开的最大文件数(max open files)
例如:ulimit -n 8192
如果本参数设置过小,对于并发访问量大的网站,可能会出现too many open files的错误
ulimit -u
设置用户可以同时运行的最大进程数(max user processes)
例如:ulimit -u 1024
5最后补充一下apache的知识:
简介
Apache
HTTP服务器被设计为一个强大的、灵活的能够在多种平台以及不同环境下工作的服务器。不同的平台和不同的环境经常产生不同的需求,或是为了达到同样的最佳效果而采用不同的方法。Apache凭借它的模块化设计很好的适应了大量不同的环境。这一设计使得网站管理员能够在编译时和运行时凭借载入不同的模块来决定服务器的不同附加功能。
Apache2.0将这种模块化的设计延伸到了web服务器的基础功能上。这个版本带有多路处理模块(MPM)的选择以处理网络端口绑定、接受请求并指派钟进程来处理这些请求。
将模块化设计延伸到这一层次主要有以下两大好处:
*
Apache可以更简洁、更有效地支持各种操作系统。尤其是在mpm_winnt中使用本地网络特性代替Apache1.3中使用的POSIX模拟层后,Windows版本的Apache现在具有更好的性能。这个优势借助特定的MPM同样延伸到了其他各种操作系统。
*
服务器可以为某些特定的站点进行定制。比如,需要更好伸缩性的站点可以选择象worker或event这样线程化的MPM,而需要更好的稳定性和兼容性以适应一些旧的软件的站点可以用prefork
。
从用户角度来看,MPM更像其他的Apache模块。主要的不同在于:不论何时,必须有且仅有一个MPM被载入到服务器中。现有的MPM列表可以在模块索引中找到。
选择一个MPM
MPM必须在编译配置时进行选择,并静态编译到服务器中。如果编译器能够确定线程功能被启用,它将会负责优化大量功能。因为一些MPM在Unix上使用了线程,而另外一些没有使用,所以如果在编译配置时选择MPM并静态编译进Apache,Apache将会有更好的表现。
你可以在使用configure脚本时用 --with-mpm=NAME 选项指定MPM,NAME就是你想使用的MPM的名称。
一旦服务器编译完成,就可以用 ./httpd -l
命令来查看使用了哪个MPM。这个命令将列出所有已经被编译到服务器中的模块,包括MPM。
我们主要阐述prefork和worker这两种和性能关系最大的产品级MPM。
Apache MPM prefork
一个非线程型的、预派生的MPM
概述
这个多路处理模块(MPM)实现了一个非线程型的、预派生的web服务器,它的工作方式类似于Apache
1.3。它适合于没有线程安全库,需要避免线程兼容性问题的系统。它是要求将每个请求相互独立的情况下最好的MPM,这样若一个请求出现问题就不会影响到其他请求。
这个MPM具有很强的自我调节能力,只需要很少的配置指令调整。最重要的是将MaxClients设置为一个足够大的数值以处理潜在的请求高峰,同时又不能太大,以致需要使用的内存超出物理内存的大小。
工作方式
一个单独的控制进程(父进程)负责产生子进程,这些子进程用于监听请求并作出应答。Apache总是试图保持一些备用的(spare)或者是空闲的子进程用于迎接即将到来的请求。这样客户端就不需要在得到服务前等候子进程的产生。
StartServers MinSpareServers MaxSpareServers
MaxClients指令用于调节父进程如何产生子进程。通常情况下Apache具有很强的自我调节能力,所以一般的网站不需要调整这些指令的默认值。可能需要处理最大超过256个并发请求的服务器可能需要增加MaxClients的值。内存比较小的机器则需要减少MaxClients的值以保证服务器不会崩溃。更多关于调整进程产生的问题请参见性能方面的提示。
在Unix系统中,父进程通常以root身份运行以便邦定80端口,而Apache产生的子进程通常以一个低特权的用户运行。User和Group指令用于设置子进程的低特权用户。运行子进程的用户必须要对它所服务的内容有读取的权限,但是对服务内容之外的其他资源必须拥有尽可能少的权限。
MaxRequestsPerChild指令控制服务器杀死旧进程产生新进程的频率。
Apache MPM worker
支持混合的多线程多进程的多路处理模块
概述
此多路处理模块(MPM)使网络服务器支持混合的多线程多进程。由于使用线程来处理请求,所以可以处理海量请求,而系统资源的开销小于基于进程的MPM。但是,它也使用了多进程,每个进程又有多个线程,以获得基于进程的MPM的稳定性。
控制这个MPM的最重要的指令是,控制每个子进程允许建立的线程数的ThreadsPerChild指令,和控制允许建立的总线程数的MaxClients指令。
工作方式
每个进程可以拥有的线程数量是固定的。服务器会根据负载情况增加或减少进程数量。一个单独的控制进程(父进程)负责子进程的建立。每个子进程可以建立ThreadsPerChild数量的服务线程和一个监听线程,该监听线程监听接入请求并将其传递给服务线程处理和应答。
Apache总是试图维持一个备用(spare)或是空闲的服务线程池。这样,客户端无须等待新线程或新进程的建立即可得到处理。初始化时建立的进程数量由StartServers指令决定。随后父进程检测所有子进程中空闲线程的总数,并新建或结束子进程使空闲线程的总数维持在MinSpareThreads和MaxSpareThreads所指定的范围内。由于这个过程是自动调整的,几乎没有必要修改这些指令的缺省值。可以并行处理的客户端的最大数量取决于MaxClients指令。活动子进程的最大数量取决于MaxClients除以ThreadsPerChild的值。
有两个指令设置了活动子进程数量和每个子进程中线程数量的硬限制。要想改变这个硬限制必须完全停止服务器然后再启动服务器(直接重启是不行的),ServerLimit是活动子进程数量的硬限制,它必须大于或等于MaxClients除以ThreadsPerChild的值。ThreadLimit是所有服务线程总数的硬限制,它必须大于或等于ThreadsPerChild指令。这两个指令必须出现在其他workerMPM指令的前面。
在设置的活动子进程数量之外,还可能有额外的子进程处于"正在中止"的状态但是其中至少有一个服务线程仍然在处理客户端请求,直到到达MaxClients以致结束进程,虽然实际数量会很小。这个行为能够通过以下禁止特别的子进程中止的方法来避免:
* 将MaxRequestsPerChild设为"0"
* 将MaxSpareThreads和MaxClients设为相同的值
一个典型的针对workerMPM的配置如下:
ServerLimit 16
StartServers 2
MaxClients
150
MinSpareThreads 25
MaxSpareThreads 75
ThreadsPerChild
25
在Unix中,为了能够绑定80端口,父进程一般都是以root身份启动,随后,Apache以较低权限的用户建立子进程和线程。User和Group指令用于设置Apache子进程的权限。虽然子进程必须对其提供的内容拥有读权限,但应该尽可能给予它较少的特权。另外,除非使用了suexec
,否则,这些指令设置的权限将被CGI脚本所继承。
MaxRequestsPerChild指令用于控制服务器建立新进程和结束旧进程的频率。
常用指令:
StartServers
指令
StartServers指令设置了服务器启动时建立的子进程数量。因为子进程数量动态的取决于负载的轻重,所有一般没有必要调整这个参数。
MinSpareServers
指令
MinSpareServers指令设置空闲子进程的最小数量。所谓空闲子进程是指没有正在处理请求的子进程。如果当前空闲子进程数少于MinSpareServers
,那么Apache将以最大每秒一个的速度产生新的子进程。
只有在非常繁忙机器上才需要调整这个参数。将此参数设的太大通常是一个坏主意。
MaxSpareServers
指令
MaxSpareServers指令设置空闲子进程的最大数量。所谓空闲子进程是指没有正在处理请求的子进程。如果当前有超过MaxSpareServers数量的空闲子进程,那么父进程将杀死多余的子进程。
只有在非常繁忙机器上才需要调整这个参数。将此参数设的太大通常是一个坏主意。如果你将该指令的值设置为比MinSpareServers小,Apache将会自动将其修改成"MinSpareServers+1"。
MaxClients
指令
MaxClients指令设置了允许同时伺服的最大接入请求数量。任何超过MaxClients限制的请求都将进入等候队列,直到达到ListenBacklog指令限制的最大值为止。一旦一个链接被释放,队列中的请求将得到服务。
对于非线程型的MPM(也就是prefork),MaxClients表示可以用于伺服客户端请求的最大子进程数量,默认值是256。要增大这个值,你必须同时增大ServerLimit
。
对于线程型或者混合型的MPM(也就是beos或worker),MaxClients表示可以用于伺服客户端请求的最大线程数量。线程型的beos的默认值是50。对于混合型的MPM默认值是16(ServerLimit)乘以25(ThreadsPerChild)的结果。因此要将MaxClients增加到超过16个进程才能提供的时候,你必须同时增加ServerLimit的值。
MaxRequestsPerChild
指令
MaxRequestsPerChild指令设置每个子进程在其生存期内允许伺服的最大请求数量。到达MaxRequestsPerChild的限制后,子进程将会结束。如果MaxRequestsPerChild为"0",子进程将永远不会结束。
不同的默认值
在mpm_netware和mpm_winnt上的默认值是"0"。
将MaxRequestsPerChild设置成非零值有两个好处:
*
可以防止(偶然的)内存泄漏无限进行,从而耗尽内存。
*
给进程一个有限兽命,从而有助于当服务器负载减轻的时候减少活动进程的数量。
注意:
对于KeepAlive链接,只有第一个请求会被计数。事实上,它改变了每个子进程限制最大链接数量的行为。
ThreadsPerChild
指令
这个指令设置了每个子进程建立的线程数。子进程在启动时建立这些线程后就不再建立新的线程了。如果使用一个类似于mpm_winnt只有一个子进程的MPM,这个数值要足够大,以便可以处理可能的请求高峰。如果使用一个类似于worker有多个子进程的MPM,每个子进程所拥有的所有线程的总数要足够大,以便可以处理可能的请求高峰。
对于mpm_winnt,ThreadsPerChild的默认值是64;对于其他MPM是25。
ThreadLimit
指令
这个指令设置了每个子进程可配置的线程数ThreadsPerChild上限。任何在重启期间对这个指令的改变都将被忽略,但对ThreadsPerChild的修改却会生效。
使用这个指令时要特别当心。如果将ThreadLimit设置成一个高出ThreadsPerChild实际需要很多的值,将会有过多的共享内存被分配。如果将ThreadLimit和ThreadsPerChild设置成超过系统的处理能力,Apache可能无法启动,或者系统将变得不稳定。该指令的值应当和ThreadsPerChild可能达到的最大值保持一致。
对于mpm_winnt,ThreadLimit的默认值是1920;对于其他MPM这个值是64。
注意:
Apache在编译时内部有一个硬性的限制"ThreadLimit
"(对于mpm_winnt是"ThreadLimit "),你不能超越这个限制。
ServerLimit
指令
对于preforkMPM,这个指令设置了MaxClients最大允许配置的数值。对于workerMPM,这个指令和ThreadLimit结合使用设置了MaxClients最大允许配置的数值。任何在重启期间对这个指令的改变都将被忽略,但对MaxClients的修改却会生效。
使用这个指令时要特别当心。如果将ServerLimit设置成一个高出实际需要许多的值,将会有过多的共享内存被分配。如果将ServerLimit和MaxClients设置成超过系统的处理能力,Apache可能无法启动,或者系统将变得不稳定。
对于preforkMPM,只有在你需要将MaxClients设置成高于默认值256的时候才需要使用这个指令。要将此指令的值保持和MaxClients一样。
对于workerMPM,只有在你需要将MaxClients和ThreadsPerChild设置成需要超过默认值16个子进程的时候才需要使用这个指令。不要将该指令的值设置的比MaxClients
和ThreadsPerChild需要的子进程数量高。
注意:
Apache在编译时内部有一个硬限制"ServerLimit
"(对于preforkMPM为"ServerLimit ")。你不能超越这个限制。
配置apache使用workerMPM:
cd httpd-2.0.55
make clean
vi server/mpm/worker/worker.c
修改define
DEFAULT_THREAD_LIMIT 64 为100
即=你要设置的ThreadsPerChild的值(修改默认ThreadsPerChild
)
修改define
DEFAULT_SERVER_LIMIT 16 为 25
即=你要设置的ServerLimit值(修改默认ServerLimit值)
:wq
./configure
--prefix=/usr/local/apache --with-mpm=worker
make
make install
cd
/usr/local/apache/conf
vi httpd.conf
修改
StartServers
2
MaxClients 150
MinSpareThreads 25
MaxSpareThreads
75
ThreadsPerChild 25
MaxRequestsPerChild 0
内容为
StartServers
3
MaxClients 2000
ServerLimit 25
MinSpareThreads 50
MaxSpareThreads
200
ThreadLimit 200
ThreadsPerChild 100
MaxRequestsPerChild 0
修改
serveradmin servername等信息为正确配置
:wq
/usr/local/apache/bin/apachectl
start
vi /etc/rc.loacl
添加 /usr/local/apache/bin/apachectl
start
PS:
用netstat -an|grep ESTABLISHED|grep 202.100.85.249:80 |wc -l
看连接数,使用worker模式后,httpd进程数变少不能反映tcp连接数
虚拟机上的linux访问本机Windows共享文件设置方法
1.安装VMtools for linux:
选择vmware
workstation程序菜单中VM > install VMware tools...
2. 进入linux
挂载vmtools 安装文件:
mount /dev/cdrom
/mnt/cdrom(vmtools的安装文件放在vmware虚拟的cdrom中,首先要mount上这个光驱才能找到安装文件)
进入/mnt/cdrom 目录,把安装文件解压到/tmp :
cd /mnt/cdrom
tar -zxvf
VMwareTools-5.0.0-12124.i386.tar.gz -C /tmp(把安装文件解压到/tmp)
执行vwware的安装脚本:
cd
/tmp/vmware-tools-distrib
./vmware-install.pl
在这里,安装程序会询问安装文件存放位置和设置分辨率等一系列问题,在大多数情况下,安装默认配置vmware
tools就可以正常工作,因此,这里对每一个问题按回车键选择默认配置。
安装完以后,vmware会添加一个vmhgfs的模块到内核中,可以使用lsmod查看.
3.设置共享文件夹:
选择vmware
workstation程序菜单中VM>Settings>Options>Shared Folders
>Properties
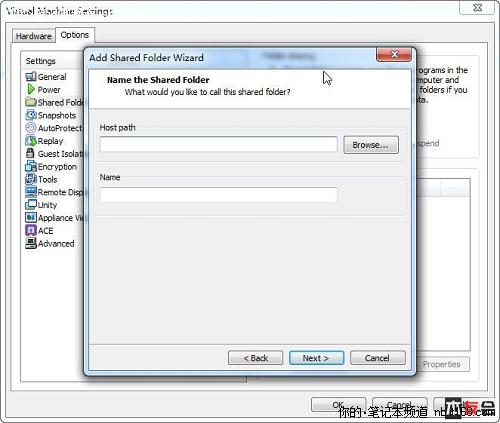
点击对话框右下的“add”按钮,点击“下一步”
在文本框“name”中输入共享目录的名字(这里填写的目录名以后VM的linux系统中将显示出同样的目录名),比如:win_linux_share
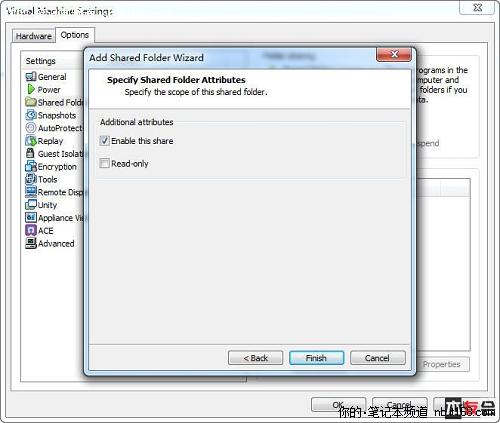
下一个对话框是选择共享的方式:Enable
this share是指这个共享长期有效,目录可读写;Read-only方式是指这个共享长期有效,目录只读;Disable after this
session方式是指下次ghost computer被关闭或挂起后,共享将会失效。一般情况下选择Enable this share然后点击“完成”
shared folder设置完毕
4.在VM的linux查看shared
folder目录的使用
cd /mnt/hgfs
/mnt/hgfs/目录下就同步了windows中的win_linux_share文件夹
[root@localhost network-scripts]# cd
/mnt/hgfs
[root@localhost hgfs]# ls
win_linux_share
[root@localhost
hgfs]# cd win_linux_share/
[root@localhost win_linux_share]#
ls
sunzhaoyao.txt
环境:
OS:Red Hat Linux As 5
1.服务器上创建共享目录
mkdir
doc_share
2.编辑exports文件
vim /etc/exports
写入
/doc_share
192.168.2.131/255.255.255.0(rw,sync)
格式是:
要共享的目录
共享的IP及掩码或者域名(权限,同步更新)
3.启动服务
/etc/init.d/portmap restart
/etc/init.d/nfs restart
chkconfig nfs
on
chkconfig portmap on
然后关闭防火墙以及更改Selinux关于NIS的选项
/etc/init.d/iptables stop (防护墙服务关闭)
chkconfig iptables off
system-config-selinux (设置selinux)
查看共享的东西
[root@rac1
/]# exportfs -rv
exporting
192.168.2.131/255.255.255.0:/doc_share
试着在本机看能否加载
mount
192.168.2.131:/doc_share /mnt
[root@rac1 doc_share]# echo
aa>aa.txt
[root@rac1 doc_share]# ls
aa.txt
[root@rac1 /]# cd
/mnt
[root@rac1 mnt]# ls
aa.txt
4.客户端
手工mount:
mount -o nolock 192.168.2.131:/doc_share
/mnt
这个时候可以看到在节点1上内容了.
[root@rac2
mnt]# cd /mnt
[root@rac2 mnt]# ls
aa.txt
自动mount:
编辑fstab文件,实现开机自动挂载
mount -t nfs IP:/目录 挂载到的目录
(此为临时挂载)
如:mount -t nfs
192.168.0.9:/doce /doc
vim /etc/fstab 添加如下内容
192.168.2.131:/doc_share /mnt nfs
defaults 0 0
相关的一些命令:
showmout命令对于NFS的操作和查错有很大的帮助.
showmout
-a:这个参数是一般在NFS SERVER上使用,是用来显示已经mount上本机nfs目录的cline机器.
-e:显示指定的NFS
SERVER上export出来的目录.
例如:
showmount -e 192.168.0.30
Export list for localhost:
/tmp *
/home/linux *.linux.org
/home/public (everyone)
/home/test 192.168.0.100
exportfs命令:
如果我们在启动了NFS之后又修改了/etc/exports,是不是还要重新启动nfs呢?这个时候我们就可以用exportfs命令来使改动立刻生效,该命令格式如下:
exportfs
[-aruv]
-a :全部mount或者unmount /etc/exports中的内容
-r :重新mount
/etc/exports中分享出来的目录
-u :umount 目录
-v :在 export
的时候,将详细的信息输出到屏幕上.
具体例子:
[root @test root]# exportfs
-rv <==全部重新 export 一次!
exporting
192.168.0.100:/home/test
exporting 192.168.0.*:/home/public
exporting
*.the9.com:/home/linux
exporting *:/home/public
exporting *:/tmp
reexporting 192.168.0.100:/home/test to kernel
exportfs -au
<==全部都卸载了
-------------------------------------------------------------------------------
今天在机器上配置NFS文件系统,在/etc/exports中加入以下信息:
/testfs 10.0.0.0/8(rw)
重启NFS服务以后,在客户机通过mount -o rw -t nfs 10.214.54.29:/testfs /rd1命令将网络文件mount到本地。执行完成之后,目录是可以访问了,但无法写入。感觉有点奇怪,明明在命令中指定可以写入了。于是到网上搜索资料,发现exports目录权限中,有这么一个参数no_root_squash。其作用是:登入 NFS 主机使用分享目录的使用者,如果是 root 的话,那么对于这个分享的目录来说,他就具有 root 的权限!。默认情况使用的是相反参数 root_squash:在登入 NFS 主机使用分享之目录的使用者如果是 root 时,那么这个使用者的权限将被压缩成为匿名使用者,通常他的 UID 与 GID 都会变成 nobody 那个身份。
因为我的客户端是使用root登录的,自然权限被压缩为nobody了,难怪无法写入。将配置信息改为:
/testfs 10.0.0.0/8(rw,no_root_squash)
据说有点不安全,但问题是解决了。
另外,在测试NFS文件系统时,会经常mount和umount文件,但有时会出现device is busy的错误提示。你肯定感到很奇怪,我明明没有使用啊,看看你当前所在的目录,是不是在mount的文件目录中?回退到上层目录重新umount,是不是OK了?
linux中,weblogic上传的文件或者创建的目录,默认只有自己读或者组员读,但web访问目录时,通常需要执行权限,所以需要在weblogic启动脚本配置,找到startWeblogic.sh,vi它,增加umask 027,则组员和自己都有r+x权限了。
ichartjs是一款基于HTML5的图形库。使用纯javascript语言,利用HTML5的canvas标签绘制各式图形。ichartjs可以为web应用提供简单、直观、可交互的体验级图表组件。是web图表方面的解决方案。最近正好在学HTML5,顺便就用ichartjs来练习。ichartjs目前支持饼图、折线图、区域图、柱形图、条形图。ichartjs是基于Apache License 2.0 协议的开源项目。今天介绍的是如何在android手机上动态实现3D柱形图。若想详细了解ichartjs,可以访问ichartjs官网:http://www.ichartjs.cn/index.html
实现主要原理是所需实现的数据打包成json格式,因为ichartjs规定的数据源统一采用json对象方式。数据源分为单一数据源与集合多值数据源,单一数据源的值为单一的数值,而集合多值数据源为数值集合。3D柱形图使用的单一的数据源。废话不多说了,直接上代码。
首先编写的是封装数据的实体类Contact:
- package com.chinasofti.html;
-
- public class Contact {
- private String name;
- private double value;
- private String color;
-
-
-
-
-
-
-
- public Contact(String name, double value, String color) {
- this.name = name;
- this.value = value;
- this.color = color;
- }
-
-
- public String getName() {
- return name;
- }
- public void setName(String name) {
- this.name = name;
- }
- public double getValue() {
- return value;
- }
- public void setValue(double value) {
- this.value = value;
- }
- public String getColor() {
- return color;
- }
- public void setColor(String color) {
- this.color = color;
- }
-
- }
package com.chinasofti.html;
public class Contact {
private String name; // 浏览器的名称
private double value; // 浏览器对应的所占市场份额值
private String color; // 在柱形图中所显示的颜色
/**
* 构造函数
* @param name 浏览器的名称
* @param value 浏览器对应的所占市场份额值
* @param color 在柱形图中所显示的颜色
*/
public Contact(String name, double value, String color) {
this.name = name;
this.value = value;
this.color = color;
}
// 下面是三个实例变量的getters and setters
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public double getValue() {
return value;
}
public void setValue(double value) {
this.value = value;
}
public String getColor() {
return color;
}
public void setColor(String color) {
this.color = color;
}
}
接着创建一个list将所需要的contact对象添加到list中:
- import java.util.ArrayList;
- import java.util.List;
-
- import com.chinasofti.html.Contact;
-
- public class ContactService {
-
- public List<Contact> getContacts() {
- List<Contact> contacts = new ArrayList<Contact>();
- contacts.add(new Contact("IE", 32.85, "#a5c2d5"));
- contacts.add(new Contact("Chrome", 33.59, "#cbab4f"));
- contacts.add(new Contact("Firefox", 22.85, "#76a871"));
- contacts.add(new Contact("Safari", 7.39, "#9f7961"));
- contacts.add(new Contact("Opera", 1.63, "#a56f8f"));
- contacts.add(new Contact("Other", 1.69, "#6f83a5"));
- return contacts;
- }
- }
import java.util.ArrayList;
import java.util.List;
import com.chinasofti.html.Contact;
public class ContactService {
public List<Contact> getContacts() {
List<Contact> contacts = new ArrayList<Contact>();
contacts.add(new Contact("IE", 32.85, "#a5c2d5"));
contacts.add(new Contact("Chrome", 33.59, "#cbab4f"));
contacts.add(new Contact("Firefox", 22.85, "#76a871"));
contacts.add(new Contact("Safari", 7.39, "#9f7961"));
contacts.add(new Contact("Opera", 1.63, "#a56f8f"));
contacts.add(new Contact("Other", 1.69, "#6f83a5"));
return contacts;
}
}然后编写android主界面代码,实现list转换成json格式字符串,并实现和html文件的交互:
- import java.util.List;
-
- import org.json.JSONArray;
- import org.json.JSONException;
- import org.json.JSONObject;
-
- import android.app.Activity;
- import android.os.Bundle;
- import android.util.Log;
- import android.webkit.WebView;
-
- public class MainActivity extends Activity {
- private static final String TAG = "MainActivity";
- private ContactService contactService;
- private WebView webView;
-
- @Override
- public void onCreate(Bundle savedInstanceState) {
- super.onCreate(savedInstanceState);
- setContentView(R.layout.main);
-
- contactService = new ContactService();
- webView = (WebView) this.findViewById(R.id.webView);
- webView.getSettings().setJavaScriptEnabled(true);
- webView.getSettings().setBuiltInZoomControls(true);
-
- webView.addJavascriptInterface(this,TAG);
- webView.loadUrl("file:///android_asset/3dchart.html");
- }
-
-
-
-
-
- public String getContacts() {
- List<Contact> contacts = contactService.getContacts();
- String json = null;
- try {
- JSONArray array = new JSONArray();
- for (Contact contact : contacts) {
-
- JSONObject item = new JSONObject();
- item.put("name", contact.getName());
- item.put("value", contact.getValue());
- item.put("color", contact.getColor());
- array.put(item);
- }
- json = array.toString();
- Log.i(TAG, json);
-
- } catch (JSONException e) {
- e.printStackTrace();
- }
- return json;
- }
- }
import java.util.List;
import org.json.JSONArray;
import org.json.JSONException;
import org.json.JSONObject;
import android.app.Activity;
import android.os.Bundle;
import android.util.Log;
import android.webkit.WebView;
public class MainActivity extends Activity {
private static final String TAG = "MainActivity";
private ContactService contactService; // 构建list的类
private WebView webView;
@Override
public void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
setContentView(R.layout.main);
contactService = new ContactService();
webView = (WebView) this.findViewById(R.id.webView);
webView.getSettings().setJavaScriptEnabled(true); // 允许使用javascript脚本语言
webView.getSettings().setBuiltInZoomControls(true); // 设置可以缩放
// 设置javaScript可用于操作MainActivity类
webView.addJavascriptInterface(this,TAG);
webView.loadUrl("file:///android_asset/3dchart.html");
}
/**
* 实现将list转换成json格式字符串
* @return json格式的字符串
*/
public String getContacts() {
List<Contact> contacts = contactService.getContacts();
String json = null;
try {
JSONArray array = new JSONArray();
for (Contact contact : contacts) {
JSONObject item = new JSONObject();
item.put("name", contact.getName());
item.put("value", contact.getValue());
item.put("color", contact.getColor());
array.put(item);
}
json = array.toString();
Log.i(TAG, json);
// webView.loadUrl("javascript:show('" + json + "')");
} catch (JSONException e) {
e.printStackTrace();
}
return json;
}
}最后是编辑html文件。要实现ichartjs表图,首先要保证在assets目录下已导入了ichart - 1.0.js。然后对html文件进行编辑:
- <!DOCTYPE html>
- <html>
- <head>
- <meta charset="UTF-8" />
- <title>Hello World</title>
- <meta name="Description" content="" />
- <meta name="Keywords" content="" />
- <script type="text/javascript" src="ichart-1.0.js"></script>
- <script type="text/javascript">
- var data = new Array();
- var contact = window.MainActivity.getContacts(); //得到MainActivity中转换出的json字符串
- eval('data='+contact); //得到json数据
-
- $(function(){
- new iChart.Column3D({
- render : 'canvasDiv', //渲染的Dom目标,canvasDiv为Dom的ID
- data: data, //绑定数据
- title : 'Top 5 Browsers in August 2012', //设置标题
- showpercent:true, //显示百分比
- decimalsnum:2,
- width : 800, //设置宽度,默认单位为px
- height : 400, //设置高度,默认单位为px
- align:'left',
- offsetx:50,
- legend : {
- enable : true
- },
- coordinate:{ //配置自定义坐标轴
- scale:[{ //配置自定义值轴
- width:600,
- position:'left', //配置左值轴
- start_scale:0, //设置开始刻度为0
- end_scale:40, //设置结束刻度为40
- scale_space:8, //设置刻度间距为8
- listeners:{ //配置事件
- parseText:function(t,x,y){ //设置解析值轴文本
- return {text:t+"%"}
- }
- }
- }]
- }
- }).draw(); //调用绘图方法开始绘图
- });
- </script>
- </head>
- <body>
- <div id='canvasDiv'></div>
- </body>
- </html>
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8" />
<title>Hello World</title>
<meta name="Description" content="" />
<meta name="Keywords" content="" />
<script type="text/javascript" src="ichart-1.0.js"></script>
<script type="text/javascript">
var data = new Array();
var contact = window.MainActivity.getContacts(); //得到MainActivity中转换出的json字符串
eval('data='+contact); //得到json数据
$(function(){
new iChart.Column3D({
render : 'canvasDiv', //渲染的Dom目标,canvasDiv为Dom的ID
data: data, //绑定数据
title : 'Top 5 Browsers in August 2012', //设置标题
showpercent:true, //显示百分比
decimalsnum:2,
width : 800, //设置宽度,默认单位为px
height : 400, //设置高度,默认单位为px
align:'left',
offsetx:50,
legend : {
enable : true
},
coordinate:{ //配置自定义坐标轴
scale:[{ //配置自定义值轴
width:600,
position:'left', //配置左值轴
start_scale:0, //设置开始刻度为0
end_scale:40, //设置结束刻度为40
scale_space:8, //设置刻度间距为8
listeners:{ //配置事件
parseText:function(t,x,y){ //设置解析值轴文本
return {text:t+"%"}
}
}
}]
}
}).draw(); //调用绘图方法开始绘图
});
</script>
</head>
<body>
<div id='canvasDiv'></div>
</body>
</html>最后得到效果为:

函数trunc是一个Oracle内置的函数,可以对date类型数据进行“度身裁剪”,来适应不同类型的数据需求。
在前篇《Oracle日期类型操作几个问题》中,我们已经了解到date类型的基本知识。date类型是一种包括年、月、日、时、分和秒的数据类型,可以表示相对精确的时间信息。内部存储上,date类型是类似于数字类型的,可以通过加减操作实现对日期的推进和后退。
但是,日期格式的精确常常给我们带来一些困扰,特别是其中的时分秒信息。很多时候,我们对这部分信息是不需要的。比如指定日期查询、只显示天信息等等。借助To_char虽然可以实现一部分这种需要,但是这样做格式上比较复杂,而且进行了数据类型的转换。是否存在不变化数据类型的方法,对日期型数据进行处理。答案就是trunc函数。
trunc(date)
截断函数trunc的作用就是将日期类型数据按照指定格式截断,返回一个日期变量数据。例如:
SQL> select to_char(sysdate,'yyyy-mm-dd hh24:mi:ss') from dual;
TO_CHAR(SYSDATE,'YYYY-MM-DDHH2
------------------------------
2010-12-10 20:39:58
SQL> select trunc(sysdate) from dual;
TRUNC(SYSDATE)
--------------
2010-12-10
SQL> select to_char(trunc(sysdate),'yyyy-mm-dd hh24:mi:ss') from dual;
TO_CHAR(TRUNC(SYSDATE),'YYYY-M
------------------------------
2010-12-10 00:00:00
默认情况下,sysdate函数返回的日期类型数据包括当前的具体时间。通过trunc(date)的处理,直接截取到天信息,返回指定天的零时。
trunc函数还支持一个重载参数,格式字符串:trunc(date,‘format’),用于指定截断的位置。如下:
//截断到年
SQL> select trunc(sysdate,'yyyy') from dual;
TRUNC(SYSDATE,'YYYY')
---------------------
2010-1-1
//截断到月
SQL> select trunc(sysdate,'mm') from dual;
TRUNC(SYSDATE,'MM')
-------------------
2010-12-1
//截断到日
SQL> select trunc(sysdate,'dd') from dual;
TRUNC(SYSDATE,'DD')
-------------------
2010-12-10
//截断到小时
SQL> select trunc(sysdate,'hh24') from dual;
TRUNC(SYSDATE,'HH24')
---------------------
2010-12-10 20:00:00
//截断到分钟
SQL> select trunc(sysdate,'mi') from dual;
TRUNC(SYSDATE,'MI')
-------------------
2010-12-10 20:52:00
使用不同的格式标志,可以指示不同的截断位置,获取各种零刻时间。
|
|
格式字符串 |
说明 |
|
年 |
yyyy或者year |
年度第一天(一月一日零时) |
|
月 |
mm或者month |
月份第一天(一日零时) |
|
日 |
dd或者day |
日期零时(00:00:00) |
|
小时 |
hh或者hh24 |
几时整(XX:00:00) |
|
分 |
mi |
几分整(XX:XX:00) |
借助trunc函数和日期类型加减处理,我们可以实现一些特殊日期的设置,实现日期功能,使用在例如Job调度方面。
//明天零点
SQL> select to_char(trunc(sysdate)+1,'yyyy-mm-dd hh24:mi:ss') from dual;
TO_CHAR(TRUNC(SYSDATE)+1,'YYYY
------------------------------
2010-12-11 00:00:00
//当天早上十点
SQL> select to_char(trunc(sysdate)+10/24,'yyyy-mm-dd hh24:mi:ss') from dual;
TO_CHAR(TRUNC(SYSDATE)+10/24,'
------------------------------
2010-12-10 10:00:00
//当月三号,上午10点半
SQL> select to_char(trunc(sysdate,'mm')+2+10/24+1/48, 'yyyy-mm-dd hh24:mi:ss') from dual;
注:trunc(sysdate,'mm')将时间取到当前月的1号零时零分零秒,那么加上2就表示当前月的3好零时零分零秒,再加上'10/24'('10/24'本身表示10个小时)就是表示当月3号的十点零分零秒,再加上'1/48'('1/48'本身表示30分钟)就表示当月3号十点三十分零秒
TO_CHAR(TRUNC(SYSDATE,'MM')+2+
------------------------------
2010-12-03 10:30:00
较复杂的to_char,trunc更加可以发挥日期类型数值本身的特色和优势,无论是代码整洁度还是处理效率都是值得关注的。
额外多说一句,trunc本身还具有处理数字截断功能,用于截断指定位数的数字类型。
//默认截断到整数,不进行四舍五入;
SQL> select trunc(15.743) from dual;
TRUNC(15.743)
-------------
15
//截断到小数点后一位;
SQL> select trunc(15.793,1) from dual;
TRUNC(15.793,1)
---------------
15.7
//截断到小数点前一位;
SQL> select trunc(15.793,-1) from dual;
TRUNC(15.793,-1)
----------------
10
trunc对数字和日期类型处理,也折射出日期类型数据和数字之间的间接关系。
原文地址:http://space.itpub.net/17203031/viewspace-681548
trunc不仅可以用来处理日期,还可以用来处理数字
TRUNC(i1,i2)截取i1的i2位而不四舍五入,如果i2是正就截取小数点右边第几位,如果是i2是负就是截取小数点左边第几位。
例如:
- select TRUNC(0.10005767,1) from dual;
-
- TRUNC(0.10005767,1) 1 0.1
而如果trunc函数没有指定参i2,那么其作用为取整,且取整的时候不会四舍五入
例如:
- select TRUNC(2.60005767) from dual;
-
TRUNC(2.60005767)
round函数和trunc函数的区别:
ROUND(i1,i2)四舍五入,i1四舍五入,如果i2是正保留小数点后i2位。如果是i2是负数,表示保留小数点前面(左边第几位)
TRUNC(i1,i2)截取i1的i2位而不四舍五入,如果i2是正就截取小数点右边第几位,如果是i2是负就是截取小数点左边第几位。
Quartz2.1与1.X有了部分变化,写下配置过程供同好者参考!
1、下载quartz
http://www.terracotta.org/download/reflector.jsp?b=tcdistributions&i=quartz-2.1.5.tar.gz将slf4j-log4j12-1.6.1.jar
slf4j-api-1.6.1.jar
quartz-all-2.1.5.jar
放入WEB-INF\lib下
2、编写自己的job
3、编写配置文件
quartz.properties:
quartz_job.xml:
web.xml:加入一个servlet,主要quartz.properties文件的位置,我是跟我的quartz_job.xml文件放在一起
4、启动应用服务器,一切ok
5、关于触发器的时间控制说明:
先说干货:quartz_job.xml中的
<trigger>
<cron>
<name>report-trigger</name>
<group>Report_Group</group>
<job-name>ReportControlScheduler</job-name>
<job-group>Report</job-group>
<cron-expression>0 0/3 * * * ?</cron-expression>
</cron>
</trigger>
就是对触发时间的描述,我这里采用的是CronTrigger的方式。下边详细描述了时间的控制。
Trigger是一个抽象类,它有三个子类:SimpleTrigger,CronTrigger和NthIncludedDayTrigger。前两个比较常用。
1。SimpleTrigger:这是一个非常简单的类,我们可以定义作业的触发时间,并选择性的设定重复间隔和重复次数。
2。CronTrigger:这个触发器的功能比较强大,而且非常灵活,但是你需要掌握有关Cron表达式的知识。如果你是一个Unix系统爱好者,你很可能已经具备这种知识,但是如果你不了解Cron表达式,请看下面的Cron详解:
Cron表达式由6或7个由空格分隔的时间字段组成,如表1所示: 表1 Cron表达式时间字段
|
位置 |
时间域名 |
允许值 |
允许的特殊字符 |
|
1 |
秒 |
0-59 |
, - * / |
|
2 |
分钟 |
0-59 |
, - * / |
|
3 |
小时 |
0-23 |
, - * / |
|
4 |
日期 |
1-31 |
, - * ? / L W C |
|
5 |
月份 |
1-12 |
, - * / |
|
6 |
星期 |
1-7 |
, - * ? / L C # |
|
7 |
年(可选) |
空值1970-2099 |
, - * / |
Cron表达式的时间字段除允许设置数值外,还可使用一些特殊的字符,提供列表、范围、通配符等功能,细说如下:
●星号(*):可用在所有字段中,表示对应时间域的每一个时刻,例如,*在分钟字段时,表示“每分钟”;
●问号(?):该字符只在日期和星期字段中使用,它通常指定为“无意义的值”,相当于点位符;
●减号(-):表达一个范围,如在小时字段中使用“10-12”,则表示从10到12点,即10,11,12;
●逗号(,):表达一个列表值,如在星期字段中使用“MON,WED,FRI”,则表示星期一,星期三和星期五;
●斜杠(/):x/y表达一个等步长序列,x为起始值,y为增量步长值。如在分钟字段中使用0/15,则表示为0,15,30和45秒,而5/15在分钟字段中表示5,20,35,50,你也可以使用*/y,它等同于0/y;
●L:该字符只在日期和星期字段中使用,代表“Last”的意思,但它在两个字段中意思不同。L在日期字段中,表示这个月份的最后一天,如一月的31号,非闰年二月的28号;如果L用在星期中,则表示星期六,等同于7。但是,如果L出现在星期字段里,而且在前面有一个数值X,则表示“这个月的最后X天”,例如,6L表示该月的最后星期五;
●W:该字符只能出现在日期字段里,是对前导日期的修饰,表示离该日期最近的工作日。例如15W表示离该月15号最近的工作日,如果该月15号是星期六,则匹配14号星期五;如果15日是星期日,则匹配16号星期一;如果15号是星期二,那结果就是15号星期二。但必须注意关联的匹配日期不能够跨月,如你指定1W,如果1号是星期六,结果匹配的是3号星期一,而非上个月最后的那天。W字符串只能指定单一日期,而不能指定日期范围;
●LW组合:在日期字段可以组合使用LW,它的意思是当月的最后一个工作日;
●井号(#):该字符只能在星期字段中使用,表示当月某个工作日。如6#3表示当月的第三个星期五(6表示星期五,#3表示当前的第三个),而4#5表示当月的第五个星期三,假设当月没有第五个星期三,忽略不触发;
● C:该字符只在日期和星期字段中使用,代表“Calendar”的意思。它的意思是计划所关联的日期,如果日期没有被关联,则相当于日历中所有日期。例如5C在日期字段中就相当于日历5日以后的第一天。1C在星期字段中相当于星期日后的第一天。Cron表达式对特殊字符的大小写不敏感,对代表星期的缩写英文大小写也不敏感。表2下面给出一些完整的Cron表示式的实例:
表2 Cron表示式示例
|
表示式 |
说明 |
|
"0 0 12 * * ? " |
每天12点运行 |
|
"0 15 10 ? * *" |
每天10:15运行 |
|
"0 15 10 * * ?" |
每天10:15运行 |
|
"0 15 10 * * ? *" |
每天10:15运行 |
|
"0 15 10 * * ? 2008" |
在2008年的每天10:15运行 |
|
"0 * 14 * * ?" |
每天14点到15点之间每分钟运行一次,开始于14:00,结束于14:59。 |
|
"0 0/5 14 * * ?" |
每天14点到15点每5分钟运行一次,开始于14:00,结束于14:55。 |
|
"0 0/5 14,18 * * ?" |
每天14点到15点每5分钟运行一次,此外每天18点到19点每5钟也运行一次。 |
|
"0 0-5 14 * * ?" |
每天14:00点到14:05,每分钟运行一次。 |
|
"0 10,44 14 ? 3 WED" |
3月每周三的14:10分到14:44,每分钟运行一次。 |
|
"0 15 10 ? * MON-FRI" |
每周一,二,三,四,五的10:15分运行。 |
|
"0 15 10 15 * ?" |
每月15日10:15分运行。 |
|
"0 15 10 L * ?" |
每月最后一天10:15分运行。 |
|
"0 15 10 ? * 6L" |
每月最后一个星期五10:15分运行。 |
|
"0 15 10 ? * 6L 2007-2009" |
在2007,2008,2009年每个月的最后一个星期五的10:15分运行。 |
|
"0 15 10 ? * 6#3" |
每月第三个星期五的10:15分运行。 |
LoginAny 使用笔记
想实现在家办公,当公司有急事的时候,可以在家就处理掉;不必在家里和公司之间copy文件,免去劳苦奔波之苦。于是开始用远程软件。
1. VNN. 免费,主要面向游戏平台。
申请2个用户,互相加为密友,能够2台机器互访,但是只有vnnc302201-winall.zip版本能用(密友功能),且不能升级,一旦升级之后,将没有了密友功能。
用了一段时间,很不错。但不久之后,本地域内3389端口封了。理解,因为远程桌面的3389是个不安全的端口。
其实,把被控机器的Terminal Service 3389端口改掉, 理论上也是可行的,但是还是比较麻烦。
2. Hamachi, 很好用的的软件。推荐,IP局域网穿透。 3389端口还是不能连接,道理同上。
3. 改用LoginAny. 免费版每月只能远程桌面20分钟,文件传输3次。速度超快。 远程桌面是LoginAny开发的,所以不再用3389端口。
自己研究下能否逆向工程下…
———先看文件传输功能———–
打开eXeScope分析资源,首先查看文字:"文件传输已经达到最大使用次数!",String Id: 484
得知Dialog: 1218是提示对话框, Dialog: 1219是文件传输Form.
打开OllyICE,反编译后,
- 搜索4C2(1218), 找提示对话框的代码,自己标注附近的代码,这是一个功能函数。
搜索4C3(1219), 找文件传输Form相关代码。
搜索1E4(484), 找"文件传输已经达到最大使用次数!"的相关代码。
004938D0 /$ 55 push ebp
004938D1 |. 8BEC mov ebp, esp
004938D3 |. 6A FF push -1
004938D5 |. 68 87C25B00 push 005BC287 ; SE 处理程序安装
004938DA |. 64:A1 0000000>mov eax, dword ptr fs:[0]
004938E0 |. 50 push eax
004938E1 |. 64:8925 00000>mov dword ptr fs:[0], esp
004938E8 |. 81EC BC000000 sub esp, 0BC
004938EE |. A1 BCEB6200 mov eax, dword ptr [62EBBC]
004938F3 |. 33C5 xor eax, ebp
004938F5 |. 8945 EC mov dword ptr [ebp-14], eax
004938F8 |. 898D 40FFFFFF mov dword ptr [ebp-C0], ecx
004938FE |. C785 4CFFFFFF>mov dword ptr [ebp-B4], 1
00493908 |. 6A 01 push 1
0049390A |. 8B85 4CFFFFFF mov eax, dword ptr [ebp-B4]
00493910 |. 50 push eax
00493911 |. 8B8D 40FFFFFF mov ecx, dword ptr [ebp-C0]
00493917 |. E8 D4EFFFFF call 004928F0 ; 关键Call !!!!
0049391C |. 85C0 test eax, eax
0049391E |. 75 05 jnz short 00493925
00493920 |. E9 F8000000 jmp 00493A1D
00493925 |> C785 48FFFFFF>mov dword ptr [ebp-B8], 0
0049392F |. 8D4D F0 lea ecx, dword ptr [ebp-10]
00493932 |. FF15 28B95C00 call dword ptr [<&MFC71.#310_ATL::CStringT<char,StrTrai>; MFC71.7C173199
00493938 |. C745 FC 00000>mov dword ptr [ebp-4], 0
0049393F |. 6A 00 push 0
00493941 |. 8D8D 54FFFFFF lea ecx, dword ptr [ebp-AC]
00493947 |. E8 64D30800 call 00520CB0
0049394C |. C645 FC 01 mov byte ptr [ebp-4], 1
00493950 |. 8B8D 4CFFFFFF mov ecx, dword ptr [ebp-B4]
00493956 |. 51 push ecx
00493957 |. 68 DD000000 push 0DD
0049395C |. 8D55 F0 lea edx, dword ptr [ebp-10]
0049395F |. 52 push edx
00493960 |. 8D85 54FFFFFF lea eax, dword ptr [ebp-AC]
00493966 |. 50 push eax
00493967 |. 8D8D 48FFFFFF lea ecx, dword ptr [ebp-B8]
0049396D |. 51 push ecx
0049396E |. 8B8D 40FFFFFF mov ecx, dword ptr [ebp-C0]
00493974 |. E8 A7190000 call 00495320 ; MessageBox ….
00493979 |. 85C0 test eax, eax
0049397B |. 75 21 jnz short 0049399E
0049397D |. C645 FC 00 mov byte ptr [ebp-4], 0
00493981 |. 8D8D 54FFFFFF lea ecx, dword ptr [ebp-AC]
00493987 |. E8 24D40800 call 00520DB0
0049398C |. C745 FC FFFFF>mov dword ptr [ebp-4], -1
00493993 |. 8D4D F0 lea ecx, dword ptr [ebp-10]
00493996 |. FF15 68B95C00 call dword ptr [<&MFC71.#578_ATL::CStringT<char,StrTrai>; MFC71.7C1771B1
0049399C |. EB 7F jmp short 00493A1D
0049399E |> 8B95 48FFFFFF mov edx, dword ptr [ebp-B8]
004939A4 |. 52 push edx
004939A5 |. 68 2CF16200 push 0062F12C
004939AA |. 51 push ecx
004939AB |. 8BCC mov ecx, esp
004939AD |. 89A5 44FFFFFF mov dword ptr [ebp-BC], esp
004939B3 |. 8D45 F0 lea eax, dword ptr [ebp-10]
004939B6 |. 50 push eax
004939B7 |. FF15 38B95C00 call dword ptr [<&MFC71.#297_ATL::CStringT<char,StrTrai>; MFC71.7C14E575
004939BD |. 8985 3CFFFFFF mov dword ptr [ebp-C4], eax
004939C3 |. 8D8D 54FFFFFF lea ecx, dword ptr [ebp-AC]
004939C9 |. 51 push ecx
004939CA |. B9 E4F26200 mov ecx, 0062F2E4
004939CF |. E8 ECDAFCFF call 004614C0 ; 调用打开文件传输Form
004939D4 |. 8985 38FFFFFF mov dword ptr [ebp-C8], eax
004939DA |. 8B95 38FFFFFF mov edx, dword ptr [ebp-C8]
004939E0 |. 8995 50FFFFFF mov dword ptr [ebp-B0], edx
004939E6 |. 6A 05 push 5
004939E8 |. 8B8D 50FFFFFF mov ecx, dword ptr [ebp-B0]
004939EE |. E8 6DCC1100 call <jmp.&MFC71.#6090_CWnd::ShowWindow>
004939F3 |. 8B8D 50FFFFFF mov ecx, dword ptr [ebp-B0]
004939F9 |. E8 12D8FAFF call 00441210
004939FE |. C645 FC 00 mov byte ptr [ebp-4], 0
00493A02 |. 8D8D 54FFFFFF lea ecx, dword ptr [ebp-AC]
00493A08 |. E8 A3D30800 call 00520DB0
00493A0D |. C745 FC FFFFF>mov dword ptr [ebp-4], -1
00493A14 |. 8D4D F0 lea ecx, dword ptr [ebp-10]
00493A17 |. FF15 68B95C00 call dword ptr [<&MFC71.#578_ATL::CStringT<char,StrTrai>; MFC71.7C1771B1
00493A1D |> 8B4D F4 mov ecx, dword ptr [ebp-C]
00493A20 |. 64:890D 00000>mov dword ptr fs:[0], ecx
00493A27 |. 8B4D EC mov ecx, dword ptr [ebp-14]
00493A2A |. 33CD xor ecx, ebp
00493A2C |. E8 5ADE1100 call 005B188B
00493A31 |. 8BE5 mov esp, ebp
00493A33 |. 5D pop ebp
00493A34 \. C3 retn
在0049 3917发现关键Call.
决定修改其后的跳转,
00493920 |. E9 F8000000 jmp 00493A1D 这一行是跳过调用打开文件传输Form的代码。
把它改为:
00493920 |. 90 90909090 Nop 什么也不做
经试验,文件传输功能可以超过3次的使用了。
———远程桌面的功能———-
远程桌面的功能只能连接20分钟。 解决办法还是老一套:
打开eXeScope分析资源,找到对话框:远程桌面,ID=1306.
打开OllyICE,搜索常量1306,很快定位下面代码:
00493670 /$ 55 push ebp
00493671 |. 8BEC mov ebp, esp
00493673 |. 6A FF push -1
00493675 |. 68 69C25B00 push 005BC269 ; SE 处理程序安装
0049367A |. 64:A1 0000000>mov eax, dword ptr fs:[0]
00493680 |. 50 push eax
00493681 |. 64:8925 00000>mov dword ptr fs:[0], esp
00493688 |. 81EC D4000000 sub esp, 0D4
0049368E |. A1 BCEB6200 mov eax, dword ptr [62EBBC]
00493693 |. 33C5 xor eax, ebp
00493695 |. 8945 EC mov dword ptr [ebp-14], eax
00493698 |. 898D 30FFFFFF mov dword ptr [ebp-D0], ecx
0049369E |. C785 50FFFFFF>mov dword ptr [ebp-B0], 0
004936A8 |. 6A 01 push 1
004936AA |. 8B85 50FFFFFF mov eax, dword ptr [ebp-B0]
004936B0 |. 50 push eax
004936B1 |. 8B8D 30FFFFFF mov ecx, dword ptr [ebp-D0]
004936B7 |. E8 34F2FFFF call 004928F0 ; 关键Call–remote desk.
004936BC |. 85C0 test eax, eax
004936BE |. 75 05 jnz short 004936C5
004936C0 |. E9 F0010000 jmp 004938B5
004936C5 |> C785 4CFFFFFF>mov dword ptr [ebp-B4], 0
004936CF |. 6A 00 push 0
004936D1 |. 8D8D 54FFFFFF lea ecx, dword ptr [ebp-AC]
004936D7 |. E8 D4D50800 call 00520CB0
004936DC |. C745 FC 00000>mov dword ptr [ebp-4], 0
004936E3 |. 8D4D F0 lea ecx, dword ptr [ebp-10]
004936E6 |. FF15 28B95C00 call dword ptr [<&MFC71.#310_ATL::CStringT<char,StrTrai>; MFC71.7C173199
004936EC |. C645 FC 01 mov byte ptr [ebp-4], 1
004936F0 |. 8B8D 50FFFFFF mov ecx, dword ptr [ebp-B0]
004936F6 |. 51 push ecx
004936F7 |. 68 19010000 push 119
004936FC |. 8D55 F0 lea edx, dword ptr [ebp-10]
004936FF |. 52 push edx
00493700 |. 8D85 54FFFFFF lea eax, dword ptr [ebp-AC]
00493706 |. 50 push eax
00493707 |. 8D8D 4CFFFFFF lea ecx, dword ptr [ebp-B4]
0049370D |. 51 push ecx
0049370E |. 8B8D 30FFFFFF mov ecx, dword ptr [ebp-D0]
00493714 |. E8 071C0000 call 00495320 ; 消息处理
00493719 |. 85C0 test eax, eax
0049371B |. 75 24 jnz short 00493741
0049371D |. C645 FC 00 mov byte ptr [ebp-4], 0
00493721 |. 8D4D F0 lea ecx, dword ptr [ebp-10]
00493724 |. FF15 68B95C00 call dword ptr [<&MFC71.#578_ATL::CStringT<char,StrTrai>; MFC71.7C1771B1
0049372A |. C745 FC FFFFF>mov dword ptr [ebp-4], -1
00493731 |. 8D8D 54FFFFFF lea ecx, dword ptr [ebp-AC]
00493737 |. E8 74D60800 call 00520DB0 ; 字符处理
0049373C |. E9 74010000 jmp 004938B5
00493741 |> 817D A4 01030>cmp dword ptr [ebp-5C], 90301
00493748 |. 0F83 E8000000 jnb 00493836
0049374E |. 8B95 4CFFFFFF mov edx, dword ptr [ebp-B4]
00493754 |. 52 push edx
00493755 |. 6A 00 push 0
00493757 |. 51 push ecx
00493758 |. 8BCC mov ecx, esp
0049375A |. 89A5 38FFFFFF mov dword ptr [ebp-C8], esp
00493760 |. 8D45 F0 lea eax, dword ptr [ebp-10]
00493763 |. 50 push eax
00493764 |. FF15 38B95C00 call dword ptr [<&MFC71.#297_ATL::CStringT<char,StrTrai>; MFC71.7C14E575
0049376A |. 8985 2CFFFFFF mov dword ptr [ebp-D4], eax
00493770 |. 8D8D 54FFFFFF lea ecx, dword ptr [ebp-AC]
00493776 |. 51 push ecx
00493777 |. B9 E4F26200 mov ecx, 0062F2E4
0049377C |. E8 BFD7FCFF call 00460F40 ; ???? XX new opeator
00493781 |. 8985 28FFFFFF mov dword ptr [ebp-D8], eax
00493787 |. 8B95 28FFFFFF mov edx, dword ptr [ebp-D8]
0049378D |. 8995 48FFFFFF mov dword ptr [ebp-B8], edx
00493793 |. 83BD 48FFFFFF>cmp dword ptr [ebp-B8], 0
0049379A |. 0F85 94000000 jnz 00493834
004937A0 |. 8D8D 40FFFFFF lea ecx, dword ptr [ebp-C0]
004937A6 |. FF15 28B95C00 call dword ptr [<&MFC71.#310_ATL::CStringT<char,StrTrai>; MFC71.7C173199
004937AC |. C645 FC 02 mov byte ptr [ebp-4], 2
004937B0 |. 8D8D 44FFFFFF lea ecx, dword ptr [ebp-BC]
004937B6 |. FF15 28B95C00 call dword ptr [<&MFC71.#310_ATL::CStringT<char,StrTrai>; MFC71.7C173199
004937BC |. C645 FC 03 mov byte ptr [ebp-4], 3
004937C0 |. FF15 90AA5C00 call dword ptr [<&KERNEL32.GetLastError>] ; [GetLastError
004937C6 |. 50 push eax
004937C7 |. 68 42010000 push 142
004937CC |. 8D85 44FFFFFF lea eax, dword ptr [ebp-BC]
004937D2 |. 50 push eax
004937D3 |. FF15 3CB95C00 call dword ptr [<&MFC71.#2321_ATL::CStringT<char,StrTra>; MFC71.7C18B260
004937D9 |. 83C4 0C add esp, 0C
004937DC |. 68 00E00000 push 0E000
004937E1 |. 8D8D 40FFFFFF lea ecx, dword ptr [ebp-C0]
004937E7 |. FF15 2CB95C00 call dword ptr [<&MFC71.#4035_ATL::CStringT<char,StrTra>; MFC71.7C153789
004937ED |. 6A 40 push 40
004937EF |. 8D8D 40FFFFFF lea ecx, dword ptr [ebp-C0]
004937F5 |. FF15 30B95C00 call dword ptr [<&MFC71.#876_ATL::CSimpleStringT<char,1>; MFC71.7C158BCD
004937FB |. 50 push eax
004937FC |. 8D8D 44FFFFFF lea ecx, dword ptr [ebp-BC]
00493802 |. FF15 30B95C00 call dword ptr [<&MFC71.#876_ATL::CSimpleStringT<char,1>; MFC71.7C158BCD
00493808 |. 50 push eax
00493809 |. 8B8D 30FFFFFF mov ecx, dword ptr [ebp-D0]
0049380F |. E8 5ECE1100 call <jmp.&MFC71.#4104_CWnd::MessageBoxA>
00493814 |. C645 FC 02 mov byte ptr [ebp-4], 2
00493818 |. 8D8D 44FFFFFF lea ecx, dword ptr [ebp-BC]
0049381E |. FF15 68B95C00 call dword ptr [<&MFC71.#578_ATL::CStringT<char,StrTrai>; MFC71.7C1771B1
00493824 |. C645 FC 01 mov byte ptr [ebp-4], 1
00493828 |. 8D8D 40FFFFFF lea ecx, dword ptr [ebp-C0]
0049382E |. FF15 68B95C00 call dword ptr [<&MFC71.#578_ATL::CStringT<char,StrTrai>; MFC71.7C1771B1
00493834 |> EB 60 jmp short 00493896 ; !!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
00493836 |> 8B8D 4CFFFFFF mov ecx, dword ptr [ebp-B4]
0049383C |. 51 push ecx
0049383D |. 68 2CF16200 push 0062F12C
00493842 |. 51 push ecx
00493843 |. 8BCC mov ecx, esp
00493845 |. 89A5 34FFFFFF mov dword ptr [ebp-CC], esp
0049384B |. 8D55 F0 lea edx, dword ptr [ebp-10]
0049384E |. 52 push edx
0049384F |. FF15 38B95C00 call dword ptr [<&MFC71.#297_ATL::CStringT<char,StrTrai>; MFC71.7C14E575
00493855 |. 8985 24FFFFFF mov dword ptr [ebp-DC], eax
0049385B |. 8D85 54FFFFFF lea eax, dword ptr [ebp-AC]
00493861 |. 50 push eax
00493862 |. B9 E4F26200 mov ecx, 0062F2E4
00493867 |. E8 74D9FCFF call 004611E0 ; 调用1:远程桌面的Form
0049386C |. 8985 20FFFFFF mov dword ptr [ebp-E0], eax
00493872 |. 8B8D 20FFFFFF mov ecx, dword ptr [ebp-E0]
00493878 |. 898D 3CFFFFFF mov dword ptr [ebp-C4], ecx
0049387E |. 6A 05 push 5
00493880 |. 8B8D 3CFFFFFF mov ecx, dword ptr [ebp-C4]
00493886 |. E8 D5CD1100 call <jmp.&MFC71.#6090_CWnd::ShowWindow>
0049388B |. 8B8D 3CFFFFFF mov ecx, dword ptr [ebp-C4]
00493891 |. E8 1A72F9FF call 0042AAB0
00493896 |> C645 FC 00 mov byte ptr [ebp-4], 0
0049389A |. 8D4D F0 lea ecx, dword ptr [ebp-10]
0049389D |. FF15 68B95C00 call dword ptr [<&MFC71.#578_ATL::CStringT<char,StrTrai>; MFC71.7C1771B1
004938A3 |. C745 FC FFFFF>mov dword ptr [ebp-4], -1
004938AA |. 8D8D 54FFFFFF lea ecx, dword ptr [ebp-AC]
004938B0 |. E8 FBD40800 call 00520DB0
004938B5 |> 8B4D F4 mov ecx, dword ptr [ebp-C]
004938B8 |. 64:890D 00000>mov dword ptr fs:[0], ecx
004938BF |. 8B4D EC mov ecx, dword ptr [ebp-14]
004938C2 |. 33CD xor ecx, ebp
004938C4 |. E8 C2DF1100 call 005B188B
004938C9 |. 8BE5 mov esp, ebp
004938CB |. 5D pop ebp
004938CC \. C3 retn
找到关键Call.
004936B7 |. E8 34F2FFFF call 004928F0 ; 关键Call–remote desk.
修改关键call之后的跳转:
004936C0 |. E9 F0010000 jmp 004938B5
修改为什么都不作。免得它影响后面的代码。
用9090909090 填充。
经试验,远程桌面功能可以超过20分钟的使用了。
实际摸索中还是走了不少弯路,总结经验为:在OllyDbg中,看过的弄明白的函数,要自己加上注释。 在看其他相关的代码的时候,极有可能就碰到了自己曾经注释过的代码,这样一下子就全通了。
Eclipse MyEclipse 没有响应 JVM terminated. Exit code=1073807364 错误 卡住 等怪问题怪现象[解决办法]
问题描述:
Eclipse的WTP和MyEclipse都会的怪毛病
在WTP或者MyEclipse下 在JSP页面中<% 和 %>之间写代码(即写:scriptlet代码)
只要输入.号 整个IDE就卡住了 比如: out. 这个后面要出来要卡好一会
强行关闭出现以下提示:
JVM terminated. Exit code=1073807364
c:\WINDOWS\system32\javaw.exe
-Xms40m
-Xmx256m
-jar F:\eclipse\startup.jar
-os win32
-ws win32
-arch x86
-launcher F:\eclipse\eclipse.exe
-name Eclipse
-showsplash 600
-exitdata f24_7c
-vm c:\WINDOWS\system32\javaw.exe
-vmargs
-Xms40m
-Xmx256m
-jar F:\eclipse\startup.jar
这个问题 让我郁闷了好几天 虽然在JSP中scriptlet的脚本是禁忌 但是有时候为了方便测试代码效果 还是会偶尔用用
经过这次 总结了一下
解决办法: (感谢Matrix论坛几位朋友的帮助)
1: ①:
在Eclipse——Window——Preferences——Java——Installed JREs下
添加你机子上的1.5+的JDK路径 添加好后把旧版本的Remove 这样下次新建工程就不用改了 一劳永逸!
或者:
②:
请将新建WEB工程的JRE 1.42的包remove掉,自己新建一个你机子上的1.5+的JDK目录下的jre的包
要导入的jre路径包括:
D:\Program Files\Java\jdk1.5.0_06\jre\lib下的 *.jar;以及
D:\Program Files\Java\jdk1.5.0_06\jre\lib\ext下的*.jar.
(这个问题其实只这一步就能解决了,谢谢yiqingxiao的提醒)
2: 在eclipse的安装目录下用EditPlus编辑eclipse.ini文件,将其中的参数改成:
-vm=D:\Program Files\Java\jdk1.5.0_06\bin\javaw.exe #这个看你自己JDK路径而定
-vmargs #下面参数视大家内存大小 自己选择合适的大小
-Xms128m
-Xmx512m
-XX:PermSize=64M
-XX:MaxPermSize=128M
3: 装过orcale的人 最好把环境变量重新设置一下:set path=D:\Program Files\Java\jdk1.5.0_06\bin
4: eclipse是3.3的,单独运行没什么问题,装上myeclipse6之后编写jsp代码时联想输入的时候就会出现eclipse无响应的情况,大概1分钟左右才能恢复,搜了半天也没有个好答案。自己琢磨,用了下面这个办法,好了,不知为什么。菜单-->myeclipse-->myeclipse-->files and editors-->html-->visual designer
取消mozilla/firefox和sarari还有show warning......(Linux only)这三个选项。就好了,你们实验看看。 |
1- java.sql.SQLException: ソケットから読み込むデータはこれ以上ありません(java.sql.SQLException: No more data to read from socket)
Driver Version: 9i.* or 10g.*
该异常通常是因为使用了连接池,当从连接池取得的connection失效或者超时的时候,使用这个连接来进行数据库操作就会抛出以上异常。
解决方法就是让数据库连接池在给你返回connection之前,检查该connnection是否超时或者失效,如果是,则evict这个connection,并返回一个可用的connection。
以DBCP为例,做如下配置即可解决问题:
<bean id="dataSource" class="org.apache.commons.dbcp.BasicDataSource" destroy-method="close">
<property name="url">
<value>${jdbc.url}</value>
</property>
<property name="driverClassName">
<value>${jdbc.driver}</value>
</property>
<property name="username">
<value>${jdbc.username}</value>
</property>
<property name="password">
<value>${jdbc.password}</value>
</property>
<property name="testOnBorrow">
<value>true</value>
</property>
<property name="testOnReturn">
<value>true</value>
</property>
<property name="testWhileIdle">
<value>true</value>
</property>
<property name="minEvictableIdleTimeMillis">
<value>180000</value>
</property>
<property name="timeBetweenEvictionRunsMillis">
<value>360000</value>
</property>
<property name="validationQuery">
<value>SELECT 1 FROM SYS.DUAL</value>
</property>
<property name="maxActive">
<value>100</value>
</property>
</bean>
另外,你也可以参考这里:http://www.websina.com/bugzero/errors/oracle-SQLException.html
转贴: Oracle SQLException: No more data to read from socket
java.sql.SQLException: No more data to read from socket at oracle.jdbc.dbaccess.DBError.throwSqlException(DBError.java:134)
at oracle.jdbc.dbaccess.DBError.throwSqlException(DBError.java:179)
at oracle.jdbc.dbaccess.DBError.check_error(DBError.java:1160)
at oracle.jdbc.ttc7.MAREngine.unmarshalUB1(MAREngine.java:963)
at oracle.jdbc.ttc7.MAREngine.unmarshalSB1(MAREngine.java:893)
at oracle.jdbc.ttc7.Oall7.receive(Oall7.java:375)
at oracle.jdbc.ttc7.TTC7Protocol.doOall7(TTC7Protocol.java:1894)
at oracle.jdbc.ttc7.TTC7Protocol.parseExecuteFetch(TTC7Protocol.java:1094)
at oracle.jdbc.driver.OracleStatement.executeNonQuery(OracleStatement.java:2132)
at oracle.jdbc.driver.OracleStatement.doExecuteOther(OracleStatement.java:2015)
at oracle.jdbc.driver.OracleStatement.doExecuteWithTimeout(OracleStatement.java:2877)
at oracle.jdbc.driver.OraclePreparedStatement.executeUpdate(OraclePreparedStatement.java:608)
This error most likely occurs in applications that use a database connections pool. When the application checked out a connection that has been timed out or has been staled, and used it to connect to the database, this error occurs.
You may need start your Oracle database server as well as your Java application. In a better designed system, however, the staled connection should be cleared out and a new connection should be establised automatically.
--------------------------------------------------
2-ORA-17004: Invalid column type (java.sql.SQLException: 列の型が無効です。) Driver Version: 9i.*
该异常初次出现在使用spring+iBatis的程序中,后来通过检查出现错误的字段和SQLMAP的参考文档,才发现问题之所在。
如果你使用iBatis,那从他的SqlMap参考文档中应该找到以下文字,当你看到他们的时候,你就发现了通向成功之门的钥匙,呵呵
Note! Most drivers only need the type specified for nullable columns. Therefore, for such drivers you only
need to specify the type for the columns that are nullable.
Note! When using an Oracle driver, you will get an “Invalid column type” error if you attempt to set a null
value to a column without specifying its type.
也就是说,当某个column允许为空,而你传的参数对应该column的值也为null的时候,对于oracle的驱动来说,这个异常是铁定的了。
解决方法,可以通过iBatis的parameterMap,指定parameter元素的jdbcType和nullValue来解决;如果你没有使用iBatis,那你可以通过检查参数,如果他对应的列为可以为空,而当前值恰好就是空的时候,为他设置一个不是空的值即可。
--------------------------------------------------
3-java.sql.SQLException: OALL8矛盾した状態にあります;(java.sql.SQLException: OALL8 is in an inconsistent state.)
该异常在我们的程序中通常是在第一个异常出现之后出现,但也不尽然,该异常搜遍网上也找不到合理的解释,只有以下信息可能会有用一些(from http://forums.oracle.com/forums/thread.jspa?messageID=1275383):
This is known to occur under when you are using too big an array size. How big your array can be depends on the length of each record and the Driver/Database combination. If you exceed the maximum size you will get the "OALL8" SQLException and your connection object may become unusable.
This message is also created if you are using the following:
9.0.1 Database
10.1.0 JDBC Driver
Generated Code that passes in an ARRAY or VARRAY of VARCHAR2 as a Parameter
或者(from http://opensource.atlassian.com/projects/spring/browse/SPR-1545?decorator=none&view=rss):
[SPR-1545] Oracle error 17447 should result in a DataAccessResourceFailureException
Oracle error 17447 is currently an unmapped exception but it should be a DataAccessResourceFailureException. This error occurs when a JDBC connection has become corrupted, usually because of failure to properly close a connection before returning the connection to the connection pool. Here is the error message:
SQL state [null]; error code [17447]; OALL8 is in an inconsistent state; nested exception is java.sql.SQLException: OALL8 is in an inconsistent state
java.sql.SQLException: OALL8 is in an inconsistent state
This is a kind of "oh crap, something bad happened and it's not really your fault" exception in Oracle. A few causes of this message are suggested in my searches on Google, including (see http://forums.oracle.com/forums/thread.jspa?threadID=274018&tstart=0):
- use of Oracle 10g JDBC drivers to connect to Oracle 9 databases
- using too big an array size (9.0.1 Database, 10.1.0 JDBC Driver and Generated Code that passes in an ARRAY or VARRAY of VARCHAR2 as a Parameter )
In any case, after this exception is thrown the connection is corrupted and unusable, hence why I advocate this exception be mapped to a DataAccessResourceFailureException
解决方法,我也不知道,呵呵,反正调整了第一个问题之后,这个异常再没有在我们的程序中出现。
说明:这是转载自远景论坛
ycjcn 的帖子,大家可以点这查看原文
无需刻录DMG光盘,教你在VMWare下安装MAC OS X Snow Leopard 10.6
补充:1、本文内容已经在Windows Vista + VMware Workstation 7.0 + MAC OS X Snow Leopard 10.6 环境下安装成功!
2、当你在虚拟机里浏览镜像文件时看不到DMG文件,需要点Browse,将文件类型CD-ROM images(*.iso)改为All files (*.*)。
3、请仔细阅读文中由粗体字标出的部分,忽略这些部分将导致安装失败。
在PC机上安装MAC OS X系统有两种方法,一是在硬盘上分区,专门安装MAC OS X;二是在现有Windows系统上使用VMWare等虚拟机软件安装。两种安装方法在网上都有介绍,但第二种方法一般都需要将苹果系统的DMG光盘镜像文件刻录到D9光盘上,不仅让没有刻录条件的同学为难,连我有刻录条件的人也觉的麻烦。今天我就在这里补充介绍一下使用VMWare安装MAC OS X时,无需刻录D9光盘,无转换成ISO格式,直接使用MAC OS X的DMG镜像文件进行安装的方法。
安装必备:
硬件:一台拥有支持虚拟技术的64位双核处理器和2GB以上内存的PC。
软件:
VMWare Workstation 7.0
DMG光盘镜像文件:
苹果操作系统 - 雪豹 10.6
darwin300
 darwin300.rar (52 K) 下载次数:29142
darwin300.rar (52 K) 下载次数:29142 或者Rebel EFI
Rebel EFI.rar (55 K) 下载次数:19897 引导光盘ISO镜像文件
首先安装好VMWare Workstation 7.0。使用File->New->Virtual Machine创建一个虚拟机,在选择操作系统时选择Other->FreeBSD 64-bit。

CPU设置1核可以,2核也可以,如果你是双核CPU,建议你分配1个核;内存建议设置为1024MB,如果你的物理内存够大也可以多给些;硬盘最少分配15GB,太小则无法进行安装,如果你还想多装些软件,建议多分配一些。最后一步可以在Customize Hardware选项里把软驱删除,因为这个用不上。
创建好之后,需要你在刚建立的虚拟机目录下找到一个扩展名为.vmx的文件,用记事本打开,找到guestOS = "freebsd-64"一行,将引号里的freebsd-64改为darwin10,改完是guestOS = "darwin10",保存修改后的文件。
做了这一步,在这个虚拟机的Options->General选项下就可以看到操作系统版本显示为:MAC OS X Server 10.6,如下图所示。仍显示为FreeBSD 64-bit的需要重启一下VMWare。

如果运行不了后面介绍的MAC OS X安装程序,很可能是忽略了这步或者修改错了。
接下来我们就要开始安装了。安装的第一步是用Darwin.iso或者Rebel EFI.iso镜像进行引导。先装载镜像文件:在刚才建立的虚拟机Settings->Hardware中,选择CD/DVD(IDE)设备,选择右侧的Use ISO image file,点Browse加载Darwin.iso或者Rebel EFI.iso。

装载完镜像文件后,现在启动虚拟机。
先演示使用Rebel EFI镜像启动,引导完成后就能看到如下图的界面:

按照屏幕提示等待10秒或者按'1'键,选择当前光盘驱动器。此时会出现如下图所示的界面:

这里提示请插入MAC OS X的DVD光盘。
此时我们再次打开这个虚拟机的Settings->Hardware,找到CD/DVD(IDE)设备(你可以双击VMWare窗口右下角的光盘图标来快速打开,如图: ),将刚才的Rebel EFI镜像替换为苹果系统的DMG镜像;点Browse,将文件类型CD-ROM images(*.iso)改为All files (*.*)就能浏览到DMG文件了。
这里有一个关键地方:选择DMG镜像文件后,将下图所示Device status里的Connected前打上勾(否则不能进入安装界面),然后确定。

此时,我们便进入了MAC OS X的安装程序准备阶段。

有的同学使用Rebel EFI引导可能会出现禁止符号,无法安装,如下图所示:

遇到这个问题可以使用Darwin镜像替换Rebel EFI,并重新启动虚拟机。在出现下图所示界面后,在CD/DVD(IDE)设备里将Darwin镜像改为苹果的DMG镜像即可,同样记得给“Connected”选项打勾。

经过一阵准备阶段就进入了苹果系统的安装过程,如下图所示:

在这里特别提一下,有的同学在进行到选择安装盘的步骤时看不到硬盘选项,不要着急,在屏幕上方的菜单中找到“实用工具”->“磁盘工具”,如图所示:

对你的虚拟硬盘执行“抹掉”操作,如图所示:
![]() =700) window.open('http://images.weiphone.com/attachments/Day_091117/102_35614_dd83da0369b2aa5.png');" border=0 src="http://images.weiphone.com/attachments/Day_091117/102_35614_dd83da0369b2aa5.png" width=700 onload="if(this.width>'700')this.width='700';if(this.height>'700')this.height='700';">
=700) window.open('http://images.weiphone.com/attachments/Day_091117/102_35614_dd83da0369b2aa5.png');" border=0 src="http://images.weiphone.com/attachments/Day_091117/102_35614_dd83da0369b2aa5.png" width=700 onload="if(this.width>'700')this.width='700';if(this.height>'700')this.height='700';">
操作完成后关闭“磁盘工具”窗口就OK了,如图所示:

根据你的电脑配置不同,大概进行几十分钟的安装,你就可以用上苹果操作系统了。

看到下图的界面,表示你的系统已经安装完成,需要重新启动。

重新启动前你要特别注意,先要去掉安装时在CD/DVD(IDE)设备上加载的苹果DMG镜像,换上Darwin或者Rebel EFI引导镜像,否则你将不能成功引导安装好的MAC OS X系统。
如果使用一种引导失败,可以试着使用其他的引导镜像。
还有需要在VMWare里的MAC系统上安装声卡、显卡等驱动的同学,可以在网上寻找相关文章和驱动,或参考
《号外!折腾无限!VMware Workstation 7.0 虚拟机安装雪豹snow leopard 10.6》
我终于知道怎么安装了,开始我也是找不到这个东西,后来在网上看到张图片,才找到的。
其实它就在MAC启动用的 drawin300.iso 里。
在MAC运行的时候用虚拟机把光盘插进去,MAC桌面上就会出来个光盘的图标,安装程序就在里面
第八步:安装VMware Tools
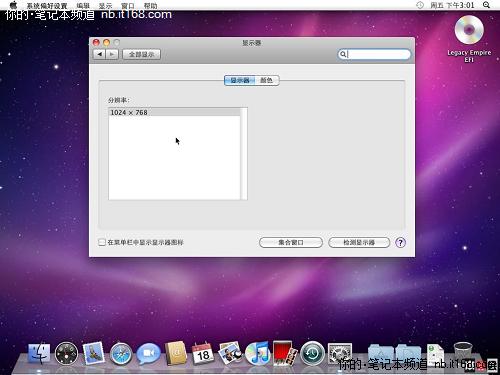
安装VMware Tools后,可以设定屏幕分辨率,可以主机共享文件等功能。
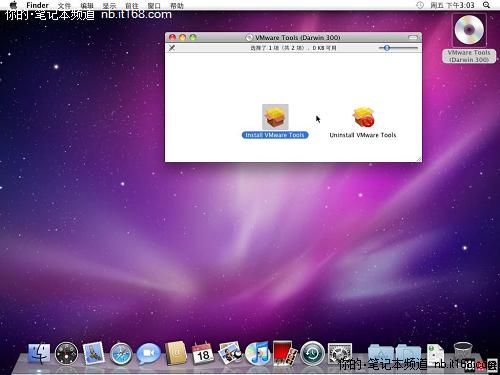
加载darwin.ISO后,进行安装
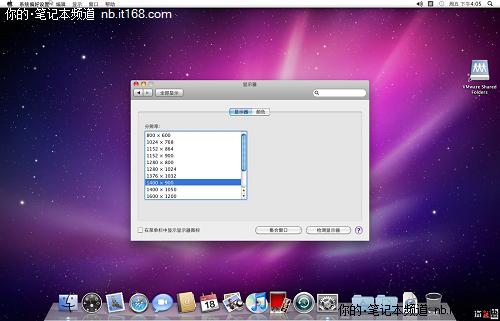
安装后,有多个分辨率选择,而且可以使用主机共享
第九步:与主机共享文件并安装声卡驱动
为了让主机和虚拟苹果文件共享,请进行下面的设置。
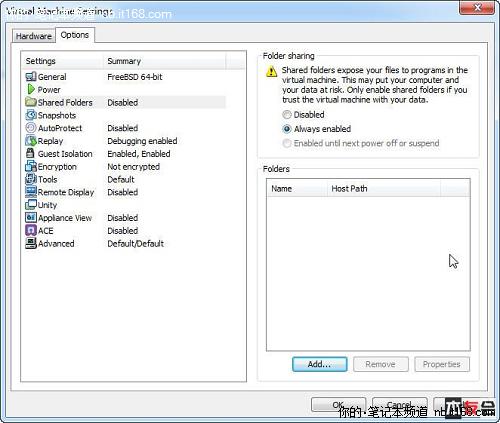
添加主机与虚拟系统共享目录
共享文件夹路径与名称
确定安装共享设置

这里要注意下:VMWare 插这个iso光盘的时候要把 直接连接 复选框选中,然后再点确定。
进入系统后,会在桌面上显示这个共享文件夹为一个新磁盘。
将EnsoniqAudioPCI 2.mpkg.RAR(声卡驱动)在主机上解压放到共享文件夹目录中。
并在Mac系统中安装后,就有声音了。
RIA(Rich Internet Applications)富互联网应用,具有高度互动性、丰富用户体验以及功能强大的客户端。
RIA的优势
特点
RIA 具有的桌面应用程序的特点包括:在消息确认和格式编排方面提供互动用户界面;在无刷新页面之下提供快捷的界面响应时间;提供通用的用户界面特性如拖放式(drag and drop)以及在线和离线操作能力。RIA具有的Web应用程序的特点包括如:立即部署、跨平台、采用逐步下载来检索内容和数据以及可以充分利用被广泛采纳的互联网标准。RIA具有通信的特点则包括实时互动的声音和图像。
客户机在RIA中的作用不仅是展示页面,它可以在幕后与用户请求异步地进行计算、传送和检索数据、显示集成的用户界面和综合使用声音和图像,这一切都可以在不依靠客户机连接的服务器或后端的情况下进行。
部署RIA的好处
对于企业来说,部署RIA的好处在于:
1)RIA可以继续使用现有的应用程序模型(包括
J2EE和
.NET),因而无需大规模替换现有的
Web应用程序。通过
Rich Client技术,可以轻松构建更为直观、易于使用、反应更迅速并且可以脱机使用的应用程序。
2)RIA可以帮助企业提供多元化的重要业务效益,包括提高销量、提高品牌忠诚度、延长网站逗留时间、较频繁的重复访问、减少带宽成本、减少支持求助以及增强客户关系等。
发展态势
在过去的两到三年中,Web开发人员一直是想构建一种比传统
HTML更丰富的客户端:这是一个用户接口,它比用HTML能实现的接口更加健壮、反应更加灵敏和更具有令人感兴趣的可视化特性。
RIA技术的出现允许我们在因特网上以一种像使用Web一样简单的方式来部署
富客户端程序。无论将来RIA是否能够如人们所猜测的那样完全代替HTML应用系统,对于那些采用C/S架构的胖客户端技术运行复杂应用系统的机构和采用基于B/S架构的瘦客户端技术部署Web应用系统地机构来说,RIA确实提供了一种廉价的选择。下面介绍一下目前出现的几种比较有实力或者有特点的RIA客户端开发技术:
1) Adobe Flash/Flex
Flash 从6.0开始Flash就逐步具备建立窗体风格的应用程序的功能。据Adobe称已经有98%以上的桌面系统的浏览器都安装了 Adobe Flash Player。这使得以Adobe Flash Player为客户端的RIA可以支持种类广泛的平台和设备。
Flex是为满足希望开发 RIA的企业级程序员的需求而推出的表示服务器和应用程序框架,它可以运行于J2EE和.NET平台。Flex表示服务器提供基于标准的、声明性的编程方法和流程,并提供运行时服务,用于开发和部署丰富客户端应用程序的表示层。Flex开发者使用直观的基于XML的MXML来定义丰富的用户界面。该语言由 Flex服务器翻译成SWF格式的客户端应用程序,在Flash Player中运行。
2) Laszlo
Laszlo 是一个开源的RIA开发环境。使用
Laszlo平台时,开发者只需编写名为LZX的描述语言(其中整合了XML和Javascript),运行在J2EE 应用服务器上的Laszlo平台会将其编译成SWF格式的文件并传输给客户端展示。从这点上来说,Laszlo的本质和Flex是一样的。Flash是任何浏览器都支持的展示形式,从而一举解决了浏览器之间的移植问题。而且,在未来的计划中,Laszlo还可以将LZX编译成Java或.NET本地代码,从而大大提高运行效率。
3) Avalon
Microsoft的Avalon是下一版本的 Windows(代号"Longhorn")的一部分,是一个图形和展示引擎,主要由新加到.NET框架中的一组类集合而成。Avalon定义了一个在 Longhorn中使用的新标记语言,其代号为"XAML"(可扩展应用程序标记语言)。可以使用XAML来定义文本、图像和控件的布局,程序代码可以直接嵌入到XAML中,也可以将它保留在一个单独的文件内。这与Flex中的MXML或者Laszlo中的LZX非常相似。不同的是:基于 Avalon的应用程序必须运行在Longhorn环境中,而Flex和Laszlo是不依赖于平台的,仅仅需要装有
Flash播放器的浏览器即可。
4) Java SWT
Java 已经出现几年了,并且完全支持创建基于窗体的用户界面。除了
Java基础类(JFC/Swing)中的用户界面组件之外,开发人员还可以使用来自于 Eclipse Project的SWT工具箱和许多第三方工具箱进行开发。对于图形来说,可以采用Java 2D API:一个非常完整且非常复杂的图形API。你可以通过一个Web浏览器使用Java插件软件,或使用Java运行时环境中较新的Java Web Start技术来部署应用程序。使用Java建立Rich Client的主要缺陷是它的复杂性(即使对简单的窗体和图形也要求编写非常烦琐的代码)和Java浏览器插件的低市场占有率。
5) XUL
XUL (念作"zool")是一种基于XML的用户界面语言,它来自于Mozilla的开放源码项目。它可用于建立窗体应用程序,这些应用程序不但可以在 Mozilla浏览器上运行,而且也可以运行在其他描述引擎上,如Zulu(一个Flash MX组件)和Thinleys(一个Java实现)。XUL描述引擎都非常小(100K以下),它可以使用XML数据也可以生成XML数据。XUL的一个主要缺点在于它目前还没有获得一个主要商业实体的支持。XUL最大的优点在于它与Gecko引擎的集成(打开了通向大量Web标准的大门),以及与大多数其它XML用户界面描述语言相比它是一种非常具有表达力和简洁的语言。
6) Bindows
Bindow 是用Javascript和DHTML开发的Web窗体框架。Javascript用于客户端界面的显示和处理,
XML HTTP用于客户端与服务器的信息传输。Javascript在客户端的表现力不容置疑,利用Javascript几乎可以实现
Windows应用程序所能干的大部分事情,XMLHTTP 一直以来常被用于实现"无刷新"的Web页面,它和
Javascript配合,可以完成数据从服务器和客户端的传输。Bindows的一个主要的缺点是它采用一次全部载入的方式来实现脚本库,在窗口的加载期,需要一个漫长的等待过程,甚至浏览器的进程会产生无响应的情况。这点Bindows根本没有遵循"用多少去多少"的准则。另外,内部大量利用了IE6 的技术,没有考虑到非IE的浏览器,限制了Bindows的流行。
7)JavaFX
2008年12月05日 Sun微系统公司今天正式发布了基于Java语言的平台JavaFX 1。0,这个平台建立在其广泛应用的Java编程语言的基础上,旨在建立大量可在电脑和手机上运行的网络程序。 Java一直以来就是编程语言,但是随着JavaFX的发布,Sun公司开始允许将编程内容创新这一任务转移到以设计艺术为重点而非编程科学为重点的设计人员身上。
“我们的目标群体是叫做创造者的人群”,Sun公司Java平台组的高级副主任 OctavianTanase对 说,“随着1.0版的发布,我们将目标锁定在网页开发人员,这群可能拓展Java界面体验的人。到2011年,主要的目标是大量使用诸如Adobe系统等设计工具的设计人员”。
当然,通向这个以设计为导向的工具还需要一些时间。Sun公司最后打算提供自己的程序给设计人员来建立RIAS,但是直到如今,这些设计人员还得使用程序员所使用的Netbeans或Eclipse集成开发环境(IDE)。新工具将在来年夏天面市。
8)Curl
Curl诞生于1995年的美国,Curl是由美国国防部高级研究项目代理资助,马萨诸塞州科技学院的David A. Kranz开发的Web开发语言, HTML语言的创建者Tim Berners-Lee也参与其中,并扮演了重要的角色。
该语言的目标是用一种统一的面向对象的语言代替HTML、Cascading Style Sheets、JavaScript等;仅使用Curl便可开发出Web应用的各种软件;Curl程序在浏览器中运行,并且因为它以类似JRE的形式提供了客户端运行环境Surge RTE,能够轻松开发出日益流行的Rich Client应用程序。
Curl是为了实现富客户端(rich client)应运而生的Web开发语言, 仅仅从其外观的丰富性上就能体现其富客户端理念。
为了实现真正有益的富客户端,它能有效地实现各种复杂处理,具备提供高信赖、高扩展性、高维护性的应用程序所应拥有的各种编码能力。其拥有在Web环境上便利的分配、管理以及低廉的维护费以及在C/S环境上的用户便利性、迅速的应答,华丽的图像显示等重多优点于一身。
Curl语言于2002年在美国正式开始商业化,在美国和日本拥有重多的客户和合作伙伴,现已进军北美及韩国市场,发展势头迅猛。
9)SilverLight
微软在Mix07上发布一些重大通告,其中最值得关注的就是SilverLight的发布,SilverLight的前身就是WPF/E技术。
这是一种新的Web 呈现技术的名称,创建该技术的目的是使其能够在各种平台上运行。该技术支持创建丰富的、具有绚丽视觉效果的交互式体验,并且可以随处实现:无论是在浏览器内、在多个设备上还是在桌面操作系统(如 Apple Macintosh)中。可扩展应用程序标记语言 (XAML) 遵循 Windows 演示基础 (WPF),前者是”WPF/E”呈现功能的基础。XAML 是 Microsoft .NET Framework 3.0(Windows 编程基础结构)中的呈现技术。
RIA未来的发展预测
就目前RIA的使用情况来说,离"RIA时代"还有很远的一段距离。今后几年时间内传统的Web应用程序和RIA将会共存。笔者认为真正具有实力担当起普及丰富客户端应用重任的只有基于Flash Player的Flash/Flex应用程序和Microsoft的基于Avalon的应用程序。短期时间内(估计2-3年时间)可能是 Flash/Flex应用程序在新兴的网络应用程序市场上占有主导地位。
目前Microsoft还在推广一种叫做Smart Client(智能客户端)的客户端程序技术,Microsoft称Smart Client是比Rich Client更优秀的客户端,因而采用Smart Client的应用程序算不算RIA目前我个人还无法作答。这里我们之所以提及Smart Client,是因为Smart Client的特性跟我们谈的Rich Client有太多的相似之处。Smart Client拥有自动更新、离线状态下的数据处理和可以使用本地资源等特征,其中的可使用本地资源这一项无疑是一大卖点,因为浏览器中的 Flash/Flex应用程序目前还无法操作本地的一些资源,比如Flash/
Flex应用程序无法将网上的文件保存到本地或者修改本地文件。虽然
Macromedia的Central1.5已经可以对本地文件进行简单的操作,并且flex1.5开发的RIA也能够运行于Central上,但是如何使Central能够得到大范围推广还是个问题。相对于轻量级的Rich Client,Smart Client更接近
C/S架构中的客户端程序。Rich Client和Smart Client的定位还是有所区别的:Rich Client更适合作为轻量级的基于浏览器的网络应用程序客户端;Smart Client更适合作为Windows桌面应用程序的智能客户端。
不管我们今天称之为的RIA今后会不会成为主流应用程序,人们对开发具有高度互动性、丰富用户体验以及功能强大的客户端的追求是不变的。有理由相信,拥有成熟技术和极高市场占有率的Flash客户端将会在RIA道路上越走越远。Microsoft未来的重量级武器:Avalon和Smart Client能否后来者居上让我们拭目以待。
RIA
放射免疫测定/放射免疫分析(Radio immunoassay,RIA)
基本原理:
在放射免疫分析的实验中,加入超量的标记抗原*Ag与未标记抗原Ag(即:
待测抗原)与较少量的抗体(Ab)竞争性结合。
如果实验结果所计量到的结合物(*Ag-Ab)放射活性较高,表示待测物的浓度较低。
如果所计量到的结合物放射活性较低,则表示待测物的浓度较高。 藉由标准 曲线图的分析,可以推算出待测物的浓度。
相信大家在启动MyEclipse的时候都很慢,很烦有没有让他更快更舒服些呢?
现在就介绍一些优化方法,很管用,对电脑配置较低的朋友相信有很大的帮助,希望大家能仔细的看完,并按以下每步设置。
1、去除不需要加载的模块
一个系统20%的功能往往能够满足80%的需求,MyEclipse也不例外,我们在大多数时候只需要20%的系统功能,所以可以将一些不使用的模块禁止 加载启动。通过Windows - Preferences打开配置窗口,依次选择左侧的General - Startup and Shutdown,这个时候在右侧就显示出了Eclipse启动时加载的模块,可以根据自己的实际情况去除一些模块。
windows–>perferences–>general–>startup and shutdown
关掉没用的启动项:
WTP :一个跟myeclipse差不多的东西,主要差别是 WTP 是免费的,如果使用myeclipse,这个可以取消
Mylyn:组队任务管理工具,类似于 CVS ,以任务为单位管理项目进度,没用到的可以取消
Derby:一种保存成 jar 形式的数据库,我没用到,取消
一大排以 MyEclipse EASIE 打头的启动项:myeclipse 支持的服务器,只选自己用的,其他取消,比如我只选了tomcat6.x
2、取消MyEclipse在启动时自动验证项目配置文件
默认情况下MyEclipse在启动的时候会自动验证每个项目的配置文件,这是一个非常耗时的过程,
可以在Preferences窗口依次选择 MyEclipse Enterprise Workbench - Validation,然后在右侧的Validator列表中只保留 Manual 项就可以了(Manual全部勾选,Bulid项只留下第一项)。
如果需要验证的时候只需要选中文件,然后右键选择 MyEclipse - Run Validation就可以了。
windows–>perferences–>myeclipse–>validation
把 除了manual 下面的全部点掉,build下只留 classpath dependency Validator
手工验证方法:
在要验证的文件上,单击鼠标右键–>myeclipse–>run validation
3、去掉拼写检查(如果你觉的有用可以不去)
拼写检查会给我们带来不少的麻烦,我们的方法命名都会是单词的缩写,他也会提示有错,所以最好去掉,没有多大的用处:
windows–>perferences–>general–>validation->editors->Text Editors->spelling
myeclipse 打开 jsp 的默认编辑器不好,会同时打开预览
windows–>perferences–>general–>editors->file associations,
把默认改成 MyEclipse JSP Editor()
原默认的jsp编辑器是 MyEclipse Visual JSP Designer,顾名思义,此编译器是jsp可视化编辑器,对于初学者有很多的帮助,
但修改此项的默认编辑器其实可以提高启动速度)
4、关闭自动更新
如果是myeclipse7.0以上版本:
(1)关掉maven自动更新:
window-preferences-MyEclipse Enterprise Workbench-Maven4MyEclipse-Maven,
关闭所有Download和Update开头的选项,共四项(去掉前面的勾)
(2)关闭更新调度:window –> preferences –> General –> Startup and Shutdown –> Automatic Updates Scheduler(去掉前面的勾)
(3)window –> preferences –>Myeclipse Dashboard,关闭Show……on start
5、加大JVM的非堆内存
打开 myeclipse.ini
-startup
../Common\plugins\org.eclipse.equinox.launcher_1.0.101.R34x_v20081125.jar
--launcher.library
../Common\plugins\org.eclipse.equinox.launcher.win32.win32.x86_1.0.101.R34x_v20080731
-clean
-configuration
configuration
-vm
C:\Users\lenovo\AppData\Local\Genuitec\Common\binary\com.sun.java.jdk.win32.x86_1.6.0.013\jre\bin\client\jvm.dll
-vmargs
-Xmx384m
-XX:MaxPermSize=384m
-XX:ReservedCodeCacheSize=96m
以上是我的myeclipse.ini,需要修改是-Xmx,-XX:MaxPermSize,-XX:ReservedCodeCacheSize,
将这三项的值调大,但并不是越大越好,曾经在相同的条件下做过测试(内存2GB),-Xmx,-XX:MaxPermSize的值为384m时比512m时要快(视具体的计算机而定),
-Xmx,-XX:MaxPermSize的值设为同样大小且两者之和不能超出你的计算机本身的内存大小
6、window-preferences-MyEclipse Enterprise Workbench-Maven4MyEclipse-Maven,将Maven JDK改为电脑上安装的JDK,即不使用myeclipse提高的JDK
登记add按钮,选择你的电脑上的JDK即可(注意:不是JRE,我的值为:Java6.014)
7、window-preferences-MyEclipse Enterprise Workbench-Matisse4Myeclipse/Swing,将Design-time information(dt.jar) location 改用电脑安装的JDK的dt.jar
(即不使用myeclipse提供的dt.jar,我的值为:C:\Java6.014\lib\dt.jar)
经过以上的优化,myeclipse的启动时间可以减少2/3,Tomcat的启动速度可以减少1/2(视具体情况而定)。
项目验收会在项目整个生命周期内是一个非常重要的里程碑。一般来说,客户同意召开验收会,就是对项目已基本认可,需要召集项目相关各方及专家来达成共识。因此,验收会不仅对乙方,而且对甲方来说都非常重要,双方都希望看到一个准备充分,进展顺利的验收会。为了准备好这个会议,项目组需要提前准备很多工作,具体说来,主要包括以下几个方面。
一.文档准备
验收之前,项目组要准备好以下几类文档:
1.开发总结文档
2.需求文档:包括需求规格说明书,需求变更文档等
3.设计文档:包括概要设计,详细设计,数据库设计等
4.测试文档:包括测试方案,内部测试报告,第三方测试报告等
5.实施文档:包括实施,部署方案,用户手册,维护手册等
6.过程文档:包括项目周报,会议纪要等
以上文档可以参考国家标准或行业标准进行准备,需要说明的是,1-5项可以在后期补,第6项在后期补就比较麻烦,因此在项目开发过程中要注意整理这类文档。另外,还要仔细阅读合同及相关采购文件,看其中是否还提到需要其它文档。
这些文档可以装订在一起,为了给客户及专家一个很好的印象,有以下几个装订技巧:
1.如果文档总页数太少,就单面打印,反之可以双面打印,总之要给人一种很厚,很充实的感觉。
2.设计一个漂亮的,彩色封面,彩打出来。
3.做一个总目录,列明这份材料包括以上哪些部分。例如:第1/7部分 项目开发报告 第2/7部分 项目需求规格说明书
4.每个部分之间用硬皮纸或突出的标签分开,如果用突出标签,在标签上注明那部分的标题
5.最好在书脊上印上标题
6.开会前问客户要装订多少份
项目验收会前,还要提前发给客户以下几份材料:
1.我方参加验收会的名单,便于客户宣读
2.验收意见
3.会议议程
另外,在验收会上,还需要带上项目过程中签署的文档备查,例如合同原件,盖单的用户需求规格说明书原件等等。
二.ppt准备
验收时的ppt一般包括以下几个部分:
1.项目背景和简介
2.合同执行情况汇报
3.开发过程:记录项目开发过程中的一些重要事件
4.系统功能
5.建设或应用成果
6.系统演示(在ppt上列明要演示哪些内容,然后一个一个对照演示)
在做系统演示时,注意要以业务流程为演示重点,用流程将功能点串起来。
三.系统准备
开会时需要对系统进行演示,因此开会前要保证系统的稳定和速度。注意事项如下:
1.尽量安装多一套系统在笔记本上,以防不测。
2.根据网络情况看是否需要带无线上网卡等设备。
2.设计好几个演示流程,一般不可能演示系统的全部功能,因此通过这几个典型流程可以全面反映系统的功能。准备这几个流程时要准备好脚本和数据,务必保证演示过程中数据完整,出现的界面没有硬伤,例如出错,图片丢失等等。
3.演示完这几个流程后,再挑一些系统的亮点进行演示。注意这个顺序,不要一上来就演示基础信息管理,客户更关心的是这个系统的核心业务。
4.把这几个流程和亮点写在ppt上,让大家可以看到你正在演示什么内容。
四.演示前准备
1.开会前一天把ppt准备好,自己试讲至少两遍,也可以邀请同事试听并给意见。
2.把系统准备好,重要功能复查几次,确保不出错
3.开会时提前一个小时到开会地点,布置会场及准备演示环境。
4.看情况是否需要带数码相机,移动硬盘,交换机,网线等物品。
5.指定同事做会议记录。
按以上要求准备验收会议,验收成功就离你不远了。验收成功后,高兴之余,不要忘了做以下几件事:
1.带回用户验收意见
2.将打印版和电子版的验收文档拿回公司归档
3.写会议纪要,把后续要继续跟进事项记录好,如果有图片,也一起发上吧
1:检查系统
sar -u 5 5
2: 看谁在用CPU
topas
ps -ef |grep ora #检查第四列,C的大小(unit,100 per cpu)
3:检查CPU数量
/usr/sbin/bindprocessor -q
lsattr El proc0
4:两种可能:
1: A Background (instance) process
2: An oracle (user) process #此种可能最大。
5: 如果是用户进程:那么高CPU的主要原因有:
Large Queries, Procedure compilation or execution,
Space management and Sorting
5.1 查看每个Session的CPU利用情况:
select ss.sid,se.command,ss.value CPU ,se.username,se.program
from v$sesstat ss, v$session se
where ss.statistic# in
(select statistic#
from v$statname
where name = 'CPU used by this session')
and se.sid=ss.sid
and ss.sid>6
order by ss.sid
5.2: 比较上述Session
比较一下哪个session的CPU使用时间最多,然后查看该Session的具体情况:
select s.sid, event, wait_time, w.seq#, q.sql_text
from v$session_wait w, v$session s, v$process p, v$sqlarea q
where s.paddr=p.addr and
s.sid=&p and
s.sql_address=q.address;
5.3:查看
得到上述信息后,查看相应操作是否有hash joins 和 full table scans。如果有hash joins 和 full table scans那么必须创建相应的Index或者检查Index是否有效。
另外必须检查是否有并行的查询存在和同一时刻有多个用户在执行相同的SQL语句,如果有必须关闭并行的查询和任何类型的并行提示(hints);如果查询使用intermedia数据,那么为了减少总的Index大小,必须限制使用Intermedia的Worldlist。(try restricting the wordlist that intermedia uses to help reduce the total indexsize)。
6:注意事项
上述方案只能根据已经运行完成的操作,对于正在执行的长时间操作只能等操作完成后才能检测得到。因此我们可以通过另外一个很好的工具来检测正在运行的长时间操作语句。v$session_longops,这个视图显示那些操作正在被运行,或者已经完成。每个process完成后会刷新本视图的信息。
7:怎样寻找集中使用CPU的Process:
很多时候会发现有N个Process在平均分享着CPU的利用率,这种情况唯一的可能性就是这些Process在执行着相同的Package或者Query.
这种情况:建议通过statspack,在CPU高利用率额时候运行几个快照,然后根据这些快照检查Statspack报告,检查报告中最TOP的Query。然后使用 sql_trace and tkprof 工具去跟踪一下。
同时检查buffer cache 的命中率是否大雨95%。
同时在报告中还需要检查一下table scans (long tables),看是否在报告生成期间有存在全表扫描。
8:参数
另外还有一些不是特别重要的,但是也必须关心检查的参数可能消耗CPU。
parallel query 并行查询:
并行查询最好用于数据仓库的环境下,那种情况任何时候只有几个用户在同时使用。在一个联机事务处理环境中,当同时许多用户去并行查询一个数据库的巨大表时候,会导致CPU的爆满。所以最好在数据库的级别关闭并行查询:设置参数如下:
parallel_min_server = 0 parallel_max_server = 0
parallel_automatic_tuning = false;
在配置上述参数后,如果SQL语句中使用的并行的提示,那么还是有可能会出现并行查询的情况,所以还需要继续监视相关的SQL语句,如果有可以直接去除提示。
今天在修改一些网页代码时用资源管理器搜索包含文字时,明明有文件里包含了这些文字,但XP就是找不到,后来经过摸索找到以下解决方法。
资源管理器的搜索功能,搜索包含某个字符的文件时,为“提高效率”,取消了对所有文件类型中字符的搜索支持,只有部分文件类型中的字符可以被搜索。
解决办法:
运行regedit,编辑注册表
HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Control\ContentIndex
右侧FilterFilesWithUnknownExtensions子键(REG_DEWORD类型)
的键值改为1。
以redhat as4和oracle 10g为例。单机在安装过程依照oracle官方的文档一步步下来,只要设置好 参数、安装好必要的包,一般不会出什么问题。安装好了以后系统重启,oracle重启服务,网上很多人建议自己写脚本(其实脚本也很简单),这里讲的是用 oracle本身的脚本实现,当然不可避免最后还要写一点点的。
1、配置dbstart和dbshut
在$ORACLE_HOME/bin 中,有dbstart和dbshut这两个脚本,more dbstart看一下可以看到:
#
# $Id: dbstart.sh.pp 11-may-2005.18:18:07 vikrkuma Exp $
# Copyright (c) 1991, 2005, Oracle. All rights reserved.
#
###################################
#
# usage: dbstart
#
# This script. is used to start ORACLE from /etc/rc(.local).
# It should ONLY be executed as part of the system boot procedure.
#
# This script. will start all databases listed in the oratab file
# whose third field is a "Y". If the third field is set to "Y" and
# there is no ORACLE_SID for an entry (the first field is a *),
# then this script. will ignore that entry.
#
# This script. requires that ASM ORACLE_SID's start with a +, and
# that non-ASM instance ORACLE_SID's do not start with a +.
#
# If ASM instances are to be started with this script, it cannot
# be used inside an rc*.d directory, and should be invoked from
# rc.local only. Otherwise, the CSS service may not be available
# yet, and this script. will block init from completing the boot
# cycle.
#
# Note:
# Use ORACLE_TRACE=T for tracing this script.
#
# The progress log for each instance bringup plus Error and Warning message[s]
# are logged in file $ORACLE_HOME/startup.log. The error messages related to
# instance bringup are also logged to syslog (system log module).
# The Listener log is located at $ORACLE_HOME_LISTNER/listener.log
......
可以看出这个脚本是用来启动oracle服务的,包括listener、instance、asm instances,并且可以放到/etc/rc(.local).,同样dbshut也是起到关闭服务的作用。
配置系统使这个脚本起作 用:
1)、以root编辑/etc/oratab,类似 orcl:/u01/product/10.2.0/db_1:N 这种格式,其中orcl是你的ORACLE_SID,/u01/product/10.2.0/db_1是ORACLE_HOME,这里需要把N改为Y, 即orcl:/u01/product/10.2.0/db_1:Y这样。
2)、以oracle编辑$ORACLE_HOME/bin /dbstart,找到其中第78行:ORACLE_HOME_LISTNER=改为你自己的路径,或者可以改成 ORACLE_HOME_LISTNER=$ORACLE_HOME
保存脚本,以oracle用户运行dbshut和dbstart看是 否能关闭、启动数据库。如 果不能,一般是参数设置,根据报错找到对应位置更改。
2、 把dbstart和dbshut加到redhat启动服务中
经过上一步的配置,可以直接用 dbstart命令启动数据listener、instance、asm instances,但是还没有启动oracle10g的EM,ORACLE利用web页 面管理数据库相当方便,也 是10g的一个特色,所以应该一并启动起该服务来。
$ORACLE_HOME/bin/emctl start dbconsole
因此我们可以用rc.local或者redhat服务都可以实现要求的开机启动。下面分别说一下:
1)、利用 rc.local。直接把dbstart加到rc.local中,实现开机自动启动。这里需要注意的是必须以oracle启动该脚本。
用 root编辑/etc/rc.local,添加下面一行:
su - oracle -c "/u01/product/10.2.0/db_1/bin/dbstart"
su - oracle -c "/u01/product/10.2.0/db_1/bin/emctl start dbconsole"
这里/u01/product/10.2.0/db_1需要替换成实际的ORACLE_HOME
保存并退出后,reboot服务器测试一下,可以看到,当系统启动以后oracle监听、实例 和em都已经起来了
2)、如果我们不用rc.local,也可以加到redhat服务中。在/etc/rc.d /init.d中添加如下脚本文件,命名为oracle:
#!/bin/sh
#chkconfig: 2345 99 01
#description: ORACLE 10g Server
ORACLE_HOME=/u01/product/10.2.0/db_1
if [ ! -f $ORACLE_HOME/bin/dbstart ]
then
echo "ORACLE cannot start"
exit
fi
case "$1" in
'start')
echo "Starting Oracle Database..."
su - oracle -c "$ORACLE_HOME/bin/dbstart"
su - oracle -c "$ORACLE_HOME/bin/emctl start dbconsole"
;;
'stop')
echo "Stoping Oracle Database"
su - oracle -c "$ORACLE_HOME/bin/emctl stop dbconsole"
su - oracle -c "$ORACLE_HOME/bin/dbshut"
;;
esac
注意其中两行注释,网上很多脚本因为少了这两行不能使服务自启动:
#chkconfig: 2345 99 01
#description: ORACLE 10g Server
其中chkconfig:2345 99 01 是指脚本将为运行级2、3、4、5启动oracle 10g服务,启动优先级为99,关闭优先级为01。
然后以root权限:
# cd /etc/rc2.d
# ln -s /etc/rc.d/init.d/oracle S99oracle
# chkconfig --list oracle
# chkconfig --level 2345 oracle on
重启系统,就可以在启动的过程中看到 Starting oracle,因为我们设置的优先级为99,一般是最后启动。[OK]以后就可以了。因为要启动emctl,可能有点慢,等待的时间要稍微长一点。
启 动以后可以以root执行oracle start或者oracle stop来启动或停止服务。
三、项目管理过程
项目管理过程组包括:
² 启动过程组:定义并批准项目或阶段
n 制定项目章程
n 制度项目范围说明书(初步)
² 规划过程组:定义和细化目标,规划最佳行动方案,以实现项目或阶段所承担的目标和范围。
n 制定项目管理计划
n 范围计划编制
n 范围定义
n 创建工作分解结构(WBS)
n 活动定义
n 活动排序
n 活动资源估算
n 活动历时估算
n 制定进度计划
n 成本估算
n 成本预算
n 质量计划编制
n 人力资源计划编制
n 组建项目团队
n 沟通计划编制
n 风险管理计划编制
n 风险识别
n 定量风险分析
n 制定风险应对计划
n 计划采购
n 编制合同
² 执行过程组:整合人员和其他资源,在项目的生命期或某个阶段执行项目管理计划。
n 指导和管理项目执行
n 执行质量保证
n 项目团队建设
n 信息发布
n 获取供方相应
n 选择供方
² 监控过程组:要求定期测量和监控进展,识别与项目管理计划的偏差,以便在必要时采取纠正措施,确保项目或阶段目标达成。
n 监督和控制项目工作
n 整体变更控制
n 范围验证
n 范围控制
n 进度控制
n 成本控制
n 执行质量控制
n 管理项目团队
n 绩效报告
n 管理项目关系人
n 风险监督和控制
n 合同管理
² 收尾过程组:正式接受产品、服务或工作成果,有序的结束项目或阶段。
n 项目收尾
n 合同收尾
同项目管理各过程有关的基本概念之一是“计划—执行—检查—行动”循环。
项目过程组和项目管理知识领域映射关系:
|
项目管理过程组
知识领域
|
启动管理过程组
|
计划过程组
|
执行过程组
|
监督和控制过程组
|
收尾过程组
|
|
项目整体管理
|
制定项目章程
制度项目范围说明书(初步)
|
项目管理规划
|
指导管理项目执行
|
监控和控制项目工作
整体变更控制
|
项目收尾
|
|
项目范围管理
|
|
范围规划
范围定义
建立WBS
|
|
范围验证
范围控制
|
|
|
项目时间管理
|
|
活动定义
活动排序
活动资源估算
活动历时估算
制定进度计划
|
|
进度控制
|
|
|
项目成本管理
|
|
成本估算
成本预算
|
|
成本控制
|
|
|
项目质量管理
|
|
质量规划
|
执行质量保证
|
执行质量控制
|
|
|
项目人力资源管理
|
|
人力资源计划编制
团队组建
|
团队建设
|
团队管理
|
|
|
项目沟通管理
|
|
沟通计划编制
|
信息发布
|
绩效报告
干系人管理
|
|
|
项目风险管理
|
|
风险管理计划编制
风险识别
定性风险分析
定量风险风险
风险响应规划
|
|
风险监控
|
|
|
项目采购管理
|
|
采购规划
计划签约
|
请求卖方回应
买房选择
|
合同管理
|
合同执行
|
项目管理学习笔记(二、项目生命期和组织)
二、项目生命期和组织
本章重点:项目生命期、项目关系人和组织的影响
信息系统项目的生命期模型
1、 瀑布模型:
一般将软件开发可以分为:可行性分析(计划)、需求分析、软件设计(概要、详细设计)、编码(含单元测试)、测试、运行维护等一个阶段。(阴影部分可看成定义阶段、开发阶段和维护阶段)
特点:
² 从上一项开发活动接受该项活动的工作对象作为输入
² 利用这一输入,实施该项活动应完成的工作内容
² 给出该项活动的工作成果,做为输出传给下一项开发活动
² 对该项活动的实施工作成果进行评审。若其工作成果得到确认,则继续下一项活动;否则返回前一项,甚至更前。
2、 迭代模型:
初始阶段:系统地阐述项目的范围,选择可行的系统架构,计划和准备业务案例
细化阶段:细化构想,细化过程和基础设施,细化构架并选择构件
构造阶段:资源管理、控制和过程最优化,完成构件的开发并依评价标准进行测试,依构想的验收标准评估产品的发布。
移交阶段:同步并使并发的构造增量集成到一致的实施基线中,与实施有关的工程活动(商业包装和生产、人员培训等),根据完整的构想和需求的验收标准评估实施基线。

3、 螺旋模型:
是一个演化过程模型,将原型实现的迭代特征与线性顺序(瀑布)模型中控制的和系统化的方面结合起来。使得软件的增量版本的快速开发成为可能。在螺旋模型中软件开发是一系列的增量发布。

4个象限分别标志每个周期所划分的四个阶段:制定计划、风险分析、实施工程和客户评估。螺旋模型强调了风险分析。
项目干系人(Project Stakeholder):也称利害相关者,是积极参与项目、或其利益因项目的实施或完成而受到积极或消极影响的个人和组织,他们还会对项目的目标和结果施加影响。
每个项目都包括如下的项目关键干系人:
² 项目经理(Project Manager)
² 顾客、客户(Customer/User)
² 执行组织(Performing Organization)
² 项目团队成员(Project Team Members)
² 项目管理团队(Project Management Team)
² 出资人(Sponsor)
² 有影响力的人(Influencers)
² 项目管理办公室(PMO)
组织的结构:
|
组织类型
项目特点
|
职能型组织
|
矩阵型组织
|
项目型组织
|
|
弱矩阵型组织
|
平衡矩阵型组织
|
强矩阵型组织
|
|
项目经理的权利
|
很小和没有
|
有限
|
小~中等
|
中等~大
|
大~全权
|
|
组织中全职参与项目工作的职员比例
|
没有
|
0%~25%
|
15%~60%
|
50%~95%
|
85%~100%
|
|
项目经理的职位
|
部分时间
|
部分时间
|
全时
|
全时
|
全时
|
|
项目经理的一般头衔
|
项目协调员/项目主管
|
项目协调员/项目主管
|
项目经理/项目主管
|
项目经理/计划经理
|
项目经理/计划经理
|
|
项目管理行政人员
|
部分时间
|
部分时间
|
部分时间
|
全时
|
全时
|
项目管理系统:指用于管理项目的工具、技术、方法、资源和规程。
项目管理学习笔记
本文为本人学习项目管理时所整理笔记将会持续更新,有兴趣的人可以无限制复制----gf7
一、项目管理绪论
项目:提供某项独特的产品、服务或成果所进行的临时的一次性努力。是用有限的资源、有限的时间为特定客户完成特定目标的一次性工作。
项目的特点:临时性、独特性和渐进性。
信息系统项目的特点:
² 目标不明确
² 需求变化频繁
² 智力密集型
² 设计队伍庞大
² 设计人员高度专业化
² 涉及的承包商多
² 各级承包商分布在各地,互相联系复杂
² 系统集成项目中需研制开发大量的软硬件系统
² 项目生命期通常较短
² 通常要采用大量的新技术
² 使用与维护的要求非常复杂
项目管理的知识领域:
² 项目管理知识体系
² 应用领域知识、标准和规定
² 项目环境知识
² 通用的管理知识和技能
² 软技能(处理人际关系技能)
国际项目管理协会(IMPA)的项目管理专业人员资质认证分为4级:
A级(Level A):认证的高级项目经理(Certificated Projects Director CPD),有能力指导一个公司(或一个分支机构),包括有诸多项目的负责规划,有能力管理该组织的所有项目,或者管理一项国际合作的复杂项目。
B级:认证的项目经理(Certificated Projects Manager CPM),可以管理一般复杂的项目。
C级:认证的项目管理专家(Certificated Projects Management Professional,PMP)能够管理一般的非复杂项目。
D级:认证的项目管理专业人员(Certificated Projects Management Practitioner,PMF)具有项目管理的基本知识,并可以将他们应用于某些领域。
项目管理的知识体系(Project Management Body of Knowledge,PMBOK),把项目管理划分为9个知识领域: 范围管理、时间管理、成本管理、质量管理、人力资源管理、沟通管理、采购管理、风险管理和整体管理。
对项目经理的一般要求:
² 广博的知识
² 丰富的经营
² 良好的协调能力
² 良好的职业道德
² 良好的沟通与表达能力
² 良好的领导能力
怎样做个好的项目经理:
² 真正理解项目经理的角色
² 重视项目团队的管理,奖罚分明
² 计划、计划、再计划
² 真正理解“一把手工程”
² 切记注重用户参与
英文缩写:
PMO(项目管理办公室)
WBS(Work Breakdown Structure 工作分解结构)
CPM(Critical Path Method,关键路径法)
PERT(Program Evaluation And Review Technique,计划评审技术)
EV(Earned Value 挣值)
IPMA (International Public Management Association 国际项目管理协会)
ICB(IMPA Competence Baseline 国际项目管理资质标准)
IPMP(International Project Management Professional 国际项目管理专业资质认证)
一位朋友说他们正在做EAI的项目,对于EAI,没有接触太深,以前项目中有这一块,却没怎么参与。于是问了一句,"EAI究竟是服务于什么目的"?提起这个名词,在我脑海中蹦出的关键词是诸如实时、总线、消息等,然而,这些似乎只是它的技术特征。
类似的名词包括EII和ETL,ETL是BI项目中必有的部分,也是目前每个项目戏份最重的环节。ETL有一种定义,如"抽取、转换和装载,为了分析的目的,将数据从多种数据源抽取,经过转换、清洗,装载到另一个数据库的过程,包括数据集市和数据仓库,或者是另一个操作型系统",我不知道这是谁的定义,恐怕也恐怕很难有权威的定义。在这个定义中,ETL是广义的,它是数据流动的过程,没有说它究竟是批量的或是实时的。因此,按照这个定义,EAI也就像是ETL。
EAI,全名为企业应用集成,这提升到一个比较高的层面,相比之下,"数据"显得太微观,太底层了。不错,现实的情况是企业的IT环境中,大量不同的系统同时并存,缺乏总体规划。在这种情况下,提出应用集成也是形势所逼。比如联通的经营分析和客户维系挽留系统,缺乏规划的时候,他们就有功能重叠的地方,各自的厂商为了自己的利益,不可能顾及"应该"如何,只是将自己的蛋糕划分得大一些才好。因此,诸如"客户价值模型"这样得东西就会抢来抢去。可能这种交叉应用的存在,才导致人们对应用集成的愿望,他们希望能够统一地看这些不同的应用,就像一个完整的大系统在运行一样。
但显然,如果达到这样的程度,理想的程度,并非一种技术就能搞定。所以,EAI的定义显得比ETL定义更加"虚头八脑",而在实际项目中看来,EAI的主要功能就是数据的集成,在多个应用之间共享数据,联通里面一般管这叫做"交互性"。技术实现上,它更像是CDC(变化数据捕获)+ETL。
至于EII,名称上意思为"企业信息集成",按照数据、信息到知识这个从低到高的层次,EII听起来又比ETL高级一些。然而对它,更加没有深入了解。也不明白它为什么会蹦出这个名词,是和ETL、EAI并列还是有取代他们的意思。从它的定义来看,EII是建立了一个虚拟的数据库,用户向这个虚拟库提交查询,而EII将这种查询物理地分布到各个不同的数据源中,然而返回数据,对于用户来说,他没有意识到这批数据是来自不同应用、不同数据库的。
喔,很酷,不过难度不小,因为这不是技术问题。假设理想的情况下,能够为数据源建立详尽的、一致的元数据,能够有一个引擎实现这种分布式查询,当然可以EII。然而我们不是生活在理想国,为不同的数据源建立一致的元数据几乎是不可能,这涉及到各个系统厂商的管理、系统设计以及维护能力,无法仅仅通过技术手段保证的。所以,EII,我只能暂且将它看作是未来理想。
在建立数据仓库时,
ETL通常都采用批处理的方式,一般来说是每天的夜间进行跑批。
随着数据仓库技术的逐步成熟,企业对数据仓库的时间延迟有了更高的要求,也就出现了目前常说的实时ETL(Real-Time ETL)。实时ETL是数据仓库领域里比较新的一部分内容。
在构建实时ETL架构的数据仓库时,有几种技术可供选择。
1.微批处理(microbatch ETL,MB-ETL)
微批处理的方式和我们通常的ETL处理方式很相似,但是处理的时间间隔要短,例如间隔一个小时处理一次。
2.企业应用集成(Enterprise Application Integration,EAI)
EAI也称为功能整合,通常由中间件来完成数据的交互。而通常的ETL称为数据整合。
对实时性要求非常高的系统,可以考虑使用EAI作为ETL的一个工具,可以提供快捷的数据交互。不过在数据量大时采用EAI工具效率比较差,而且实现起来相对复杂。
3.CTF(Capture, Transform and Flow)
CTF是一类比较新的数据整合工具。它采用的是直接的数据库对数据库的连接方式,可以提供秒级的数据。CTF的缺点是只能进行轻量级的数据整合。通常的处理方式是建立数据准备区,采用CTF工具在源数据库和数据准备区的数据库之间相连接。数据进入数据准备区后再经过其他处理后迁移入数据仓库。
4.EII(Enterprise Information Integration)
EII是另一类比较新的数据整合软件,可以给企业提供实时报表。EII的处理方式和CTF很相似,但是它不将数据迁移入数据准备区或者数据仓库,而是在抽取转换后直接加载到报表中。
在实际建立实时ETL架构的数据仓库时,可以在MB-ETL, EAI, CTF, EII及通常的ETL中作出选择或者进行组合。
Oracle数据库提供了几种不同的数据库启动和关闭方式,本文将详细介绍这些启动和关闭方式之间的区别以及它们各自不同的功能。
一、启动和关闭Oracle数据库
对于大多数Oracle DBA来说,启动和关闭Oracle数据库最常用的方式就是在命令行方式下的Server Manager。从Oracle 8i以后,系统将Server Manager的所有功能都集中到了SQL*Plus中,也就是说从8i以后对于数据库的启动和关闭可以直接通过SQL*Plus来完成,而不再另外需要Server Manager,但系统为了保持向下兼容,依旧保留了Server Manager工具。另外也可通过图形用户工具(GUI)的Oracle Enterprise Manager来完成系统的启动和关闭,图形用户界面Instance Manager非常简单,这里不再详述。
要启动和关闭数据库,必须要以具有Oracle 管理员权限的用户登陆,通常也就是以具有SYSDBA权限的用户登陆。一般我们常用INTERNAL用户来启动和关闭数据库(INTERNAL用户实际上是SYS用户以SYSDBA连接的同义词)。Oracle数据库的新版本将逐步淘汰INTERNAL这个内部用户,所以我们最好还是设置DBA用户具有SYSDBA权限。
二、数据库的启动(STARTUP)
启动一个数据库需要三个步骤:
1、 创建一个Oracle实例(非安装阶段)
2、 由实例安装数据库(安装阶段)
3、 打开数据库(打开阶段)
在Startup命令中,可以通过不同的选项来控制数据库的不同启动步骤。
1、STARTUP NOMOUNT
NONOUNT选项仅仅创建一个Oracle实例。读取init.ora初始化参数文件、启动后台进程、初始化系统全局区(SGA)。Init.ora文件定义了实例的配置,包括内存结构的大小和启动后台进程的数量和类型等。实例名根据Oracle_SID设置,不一定要与打开的数据库名称相同。当实例打开后,系统将显示一个SGA内存结构和大小的列表,如下所示:
SQL> startup nomount
ORACLE 例程已经启动。
Total System Global Area 35431692 bytes
Fixed Size 70924 bytes
Variable Size 18505728 bytes
Database Buffers 16777216 bytes
Redo Buffers 77824 bytes
2、STARTUP MOUNT
该命令创建实例并且安装数据库,但没有打开数据库。Oracle系统读取控制文件中关于数据文件和重作日志文件的内容,但并不打开该文件。这种打开方式常在数据库维护操作中使用,如对数据文件的更名、改变重作日志以及打开归档方式等。在这种打开方式下,除了可以看到SGA系统列表以外,系统还会给出"数据库装载完毕"的提示。
3、STARTUP
该命令完成创建实例、安装实例和打开数据库的所有三个步骤。此时数据库使数据文件和重作日志文件在线,通常还会请求一个或者是多个回滚段。这时系统除了可以看到前面Startup Mount方式下的所有提示外,还会给出一个"数据库已经打开"的提示。此时,数据库系统处于正常工作状态,可以接受用户请求。
如果采用STARTUP NOMOUNT或者是STARTUP MOUNT的数据库打开命令方式,必须采用ALTER DATABASE命令来执行打开数据库的操作。例如,如果你以STARTUP NOMOUNT方式打开数据库,也就是说实例已经创建,但是数据库没有安装和打开。这是必须运行下面的两条命令,数据库才能正确启动。
ALTER DATABASE MOUNT;
ALTER DATABASE OPEN;
而如果以STARTUP MOUNT方式启动数据库,只需要运行下面一条命令即可以打开数据库:
ALTER DATABASE OPEN.
4、其他打开方式
除了前面介绍的三种数据库打开方式选项外,还有另外其他的一些选项。
(1) STARTUP RESTRICT
这种方式下,数据库将被成功打开,但仅仅允许一些特权用户(具有DBA角色的用户)才可以使用数据库。这种方式常用来对数据库进行维护,如数据的导入/导出操作时不希望有其他用户连接到数据库操作数据。
(2) STARTUP FORCE
该命令其实是强行关闭数据库(shutdown abort)和启动数据库(startup)两条命令的一个综合。该命令仅在关闭数据库遇到问题不能关闭数据库时采用。
(3) ALTER DATABASE OPEN READ ONLY;
该命令在创建实例以及安装数据库后,以只读方式打开数据库。对于那些仅仅提供查询功能的产品数据库可以采用这种方式打开。
三、数据库的关闭(SHUTDOWN)
对于数据库的关闭,有四种不同的关闭选项,下面对其进行一一介绍。
1、SHUTDOWN NORMAL
这是数据库关闭SHUTDOWN命令的确省选项。也就是说如果你发出SHUTDOWN这样的命令,也即是SHUTDOWN NORNAL的意思。
发出该命令后,任何新的连接都将再不允许连接到数据库。在数据库关闭之前,Oracle将等待目前连接的所有用户都从数据库中退出后才开始关闭数据库。采用这种方式关闭数据库,在下一次启动时不需要进行任何的实例恢复。但需要注意一点的是,采用这种方式,也许关闭一个数据库需要几天时间,也许更长。
2、SHUTDOWN IMMEDIATE
这是我们常用的一种关闭数据库的方式,想很快地关闭数据库,但又想让数据库干净的关闭,常采用这种方式。
当前正在被Oracle处理的SQL语句立即中断,系统中任何没有提交的事务全部回滚。如果系统中存在一个很长的未提交的事务,采用这种方式关闭数据库也需要一段时间(该事务回滚时间)。系统不等待连接到数据库的所有用户退出系统,强行回滚当前所有的活动事务,然后断开所有的连接用户。
3、SHUTDOWN TRANSACTIONAL
该选项仅在Oracle 8i后才可以使用。该命令常用来计划关闭数据库,它使当前连接到系统且正在活动的事务执行完毕,运行该命令后,任何新的连接和事务都是不允许的。在所有活动的事务完成后,数据库将和SHUTDOWN IMMEDIATE同样的方式关闭数据库。
4、SHUTDOWN ABORT
这是关闭数据库的最后一招,也是在没有任何办法关闭数据库的情况下才不得不采用的方式,一般不要采用。如果下列情况出现时可以考虑采用这种方式关闭数据库。
1、 数据库处于一种非正常工作状态,不能用shutdown normal或者shutdown immediate这样的命令关闭数据库;
2、 需要立即关闭数据库;
3、 在启动数据库实例时遇到问题;
所有正在运行的SQL语句都将立即中止。所有未提交的事务将不回滚。Oracle也不等待目前连接到数据库的用户退出系统。下一次启动数据库时需要实例恢复,因此,下一次启动可能比平时需要更多的时间。
表1可以清楚地看到上述四种不同关闭数据库的区别和联系。
表1 Shutdown数据库不同方式对比表
| 关闭方式 |
A |
I |
T |
N |
| 允许新的连接 |
× |
× |
× |
× |
| 等待直到当前会话中止 |
× |
× |
× |
√ |
| 等待直到当前事务中止 |
× |
× |
√ |
√ |
| 强制CheckPoint,关闭所有文件 |
× |
√ |
√ |
√ |
其中:A-Abort I-Immediate T-Transaction N-Nornal
一 JSP2.0与JSP1.2比较
JSP 2.0是对JSP 1.2的升级,新增功能:
1. Expression Language (我平常都叫EL表达式的)
2. 新增Simple Tag和Tag File
3.web.xml新增<jsp:config>元素
- 特别说明:<jsp-config> 元素主要用来设定JSP相关配置,<jsp-config> 包括<taglib>和<jsp-property-group>子元素。
-
- (1)其中<taglib>以前的Jsp1.2中就有的,taglib主要作用是作为页面taglib标签中的uri和tld文件的一个映射关系
-
- (2)其中<jsp-property-group>是JSP2.0种新增的元素。
- <jsp-property-group> 主要包括8个子元素,它们分别是:
-
- <jsp-property-group>
-
- <description>
- 设定的说明
- </description>
-
- <display-name>设定名称</display-name>
-
- <url-pattern>设定值所影响的范围</url-pattern>
-
- <el-ignored>若为true则不支持EL语法</el-ignored>
-
- <page-encoding>ISO-8859-1</page-encoding>
-
- <scripting-invalid> 若为true则不支持<% scripting%> 语法</scripting-invalid>
-
- <include-prelude>设置JSP网页的抬头,扩展名为.jspf </include-prelude>
-
- <include-coda>设置JSP网页的结尾,扩展名为.jspf</include-coda>
-
- </jsp-property-group>
-
- 例如: 其中抬头程序:
- prelude.jspf
- <br>
- <center>
- 文本内容
- </center>
- <hr>
-
- 结尾程序:
- coda.jspf
- <br>
- <center>
- 文本内容
- </center>
- <hr>
二、Servlet个版本比较
servlet 2.3 新增功能:
2000年10月份出来
Servlet API 2.3中最重大的改变是增加了filters(过滤器)
servlet 2.4 新增功能:
2003年11月份出来
1、web.xml DTD改用了XML Schema;
Servlet 2.3之前的版本使用DTD作为部署描述文件的定义,其web.xml的格式为如下所示:
xml 代码
- <?xml version="1.0" encoding="IS0-8859-1"?>
- <!DOCTYPE web-app
- PUBLIC "-//sunMicrosystems,Inc.//DTD WebApplication 2.3f//EN"
- "http://java.sun.com/j2ee/dtds/web-app_2.3.dtd">
- <web-app>
- .......
- </web-app>
Servlet 2.4版首次使用XML Schema定义作为部署描述文件,这样Web容器更容易校验web.xml语法。同时XML Schema提供了更好的扩充性,其web.xml中的格式如下所示:
xml 代码
- <?xml version="1.0" encoding="UTF-8"?>
- <web-app version="2.4" xmlns="http://java.sun.com/xml/ns/j2ee"
- xmlns:workflow="http://www.workflow.com"
- xmins:xsi="http://www.w3.org/2001/XMLSchema-instance"
- xsi:schemaLocation="http://java.sun.com/xml/ns/j2ee
- http://java.sun.com/xml/ns/j2ee/web-app_2_4.xsd">
- .........
- </web-app>
注意: 改为Schema后主要加强了两项功能:
(1) 元素不依照顺序设定
(2) 更强大的验证机制
主要体现在:
a.检查元素的值是否为合法的值
b.检查元素的值是否为合法的文字字符或者数字字符
c.检查Servlet,Filter,EJB-ref等等元素的名称是否唯一
2.新增Filter四种设定:REQUEST、FORWARD、INCLUDE和ERROR。
3.新增Request Listener、Event和Request Attribute Listener、Enent。
4.取消SingleThreadModel接口。当Servlet实现SingleThreadModel接口时,它能确保同时间内,只能有一个thread执行此Servlet。
5.<welcome-file-list>可以为Servlet。
6.ServletRequest接口新增一些方法。
public String getLocalName()
public String getLocalAddr()
public int getLocalPort()
public int getRemotePort()
Servlet 2.5的新特征
2005年9月发布Servlet 2.5
Servlet2.5一些变化的介绍:
1) 基于最新的J2SE 5.0开发的。
2) 支持annotations 。
3) web.xml中的几处配置更加方便。
4) 去除了少数的限制。
5) 优化了一些实例
servlet的各个版本对监听器的变化有:
(1)servlet2.2和jsp1.1
新增Listener:HttpSessionBindingListener
新增Event: HttpSessionBindingEvent
(2)servlet2.3和jsp1.2
新增Listener:ServletContextListener,ServletContextAttributeListener
,HttpSessionListener,HttpSessionActivationListener,HttpSessionAttributeListener
新增Event: ServletContextEvent,ServletContextAttributeEvent,HttpSessionEvent
(3)servlet2.4和jsp2.0
新增Listener:ServletRequestListener,ServletRequestAttribureListener
新增Event: ServletRequestEvent,ServletRequestAttributeEvent
三、J2EE规范版本比较
1.J2EE的发展
1997年Servlet技术的产生以及紧接着JSP的产生,为Java对抗PHP,ASP等等服务器端语言带来了筹码。1998年,Sun发布了EJB1.0标准,至此J2EE平台的三个核心技术都已经出现。于是,1999年,Sun正式发布了J2EE的第一个版本。并与1999年底发布了J2EE1.2,在2001年发布了J2EE1.3,2003年发布了J2EE1.4。
2.J2EE1.3
J2EE1.3的架构,其中主要包含了Applet容器,Application Client容器,Web容器和EJB容器,并且包含了Web Component,EJB Component,Application Client Component,以JMS,JAAS,JAXP,JDBC,JAF,JavaMail,JTA等等技术做为基础。
1.3中引入了几个值得注意的功能:Java消息服务(定义了JMS的一组API),J2EE连接器技术(定义了扩展J2EE服务到非J2EE应用程序的标准),XML解析器的一组Java API,Servlet2.3,JSP1.2也都进行了性能扩展与优化,全新的CMP组件模型和MDB(消息Bean)。
3.J2EE1.4
J2EE1.4大体上的框架和J2EE1.3是一致的,1.4增加了对Web服务的支持,主要是Web Service,JAX-RPC,SAAJ,JAXR,还对EJB的消息传递机制进行了完善(EJB2.1),部署与管理工具的增强(JMX),以及新版本的Servlet2.4和JSP2.0使得Web应用更加容易。
四、Tomcat版本比较
Tomcat 3.x
servlet2.2和jsp1.1标准
Tomcat 4.x
Servlet 2.3 和 JSP 1.2 版本
Tomcat 5.x
Servlet 2.4或2.5 和 JSP 2.0 版本
五、JDK版本比较
已发行的版本:
版本号 名称 中文名 发布日期
JDK 1.1.4 Sparkler 宝石 1997-09-12
JDK 1.1.5 Pumpkin 南瓜 1997-12-13
JDK 1.1.6 Abigail 阿比盖尔--女子名 1998-04-24
JDK 1.1.7 Brutus 布鲁图--古罗马政治家和将军 1998-09-28
JDK 1.1.8 Chelsea 切尔西--城市名 1999-04-08
J2SE 1.2 Playground 运动场 1998-12-04
J2SE 1.2.1 none 无 1999-03-30
J2SE 1.2.2 Cricket 蟋蟀 1999-07-08
J2SE 1.3 Kestrel 美洲红隼 2000-05-08
J2SE 1.3.1 Ladybird 瓢虫 2001-05-17
J2SE 1.4.0 Merlin 灰背隼 2002-02-13
J2SE 1.4.1 grasshopper 蚱蜢 2002-09-16
J2SE 1.4.2 Mantis 螳螂 2003-06-26
将发行的版本:
J2SE 5.0 (1.5.0) Tiger 老虎 已发布了Beta版本
J2SE 5.1 (1.5.1) Dragonfly 蜻蜓 未发布
J2SE 6.0 (1.6.0) Mustang 野马 未发布
一些网友在Xp下安装了Windows 7(适用于Vista/WS2008)双系统,试用一段时间之后,新鲜过了,就准备卸载掉Windows 7。下面我把我在xp-windows 7双系统中卸载windows 7的方法写下来与大家分享!其中第1-5步网上很多,恕不详述,本文重点讲述第6步,即xp-windows 7(适用于Vista/WS2008)双系统在卸载windows 7后删除xp系统主引导分区的残留文件的详细步骤(注:本方法也即取得对系统文件完全控制的方法)
启动电脑进入Xp系统后按以下步骤操作,
1.插入刻好的 Windows 7 安装光盘(或者用虚拟光驱加载Windows 7镜像)。
2.依次单击“开始”按钮 、“所有程序”、“附件”,右键单击“命令提示符”,然后单击“用管理员帐户运行”。
3.键入 X:"boot"bootsect.exe /nt52 all /force,然后按 Enter。注:X:"代表你的光驱盘符,或者虚拟光驱盘符。
例如,如果 DVD 驱动器号是 F,则键入 F:"boot"bootsect.exe /nt52 ALL /force。
4.弹出 Windows Vista 安装光盘。
5.重新启动计算机。
计算机将使用已安装的以前版本的 Windows 启动。Windows 7系统的启动项不见了,Early Version windows也不见了,只剩下Windows xp的启动项了,基本成功。
6、删除在启动盘中的:
*Boot 文件夹
*Boot.BAK
*bootmgr
*BOOTSECT.BAK
7、格式化windows 7所在的分区,或者修改权限后删除Vista的文件夹。
下面详述第6步即取得对系统文件(夹)完全控制权限的方法:
新的Vista/WS2008/Win 7系统启动与XP等之前系统已经有了很大改变,用一个启动引导程序代替了以前单一的boot.ini文件。删除系统之后,在C盘XP系统分区留下了Boot 文件夹、Boot.BAK、bootmgr和BOOTSECT.BAK一个文件夹,三个文件。其中boot.bak和bootsect.bak很容易删除,剩下的boot文件夹和bootmgr文件删除时,却会提示出错信息。查看了文件和文件夹权限,发现已经被锁定,所以,思路就是通过修改文件夹权限使得当前用户可以正常删除文件。以下即为详细操作步骤:
(1)、首先请用管理员帐户登录XP系统。
(2)、进入我的电脑--工具--文件夹选项--查看,把“使用简单文件共享(推荐)”前面的勾去掉。这样,你才能进入属性里的“安全”选项卡,修改文件和文件夹权限。
删除boot文件夹:
(3)、右键点击boot文件夹--属性--安全--高级。此时,你所有的权限都无法编辑。
(4)、在“所有者”选项卡中,先将文件夹的所有者移交给“Administrators”组,记得选择下面的“替换子容器及对象的所有者”。
(5)、再打开“审核”选项卡,将“用在此显示的那些可以应用到子对象的项目替代所有子对象的审核项目”。点击“添加”按钮,在文本框内输入“administrators”,再点击右侧的“检查名称”,“确定”,进入审核项目权限设置,选择成功和失败都是“完全控制”,“应用”,退出boot文件夹属性。可能会有提示让你配置本地计算机策略,不用管它。
(6)、再次进入boot文件夹属性--安全,你会发现对于当前管理员帐户,你已经可以选择对该文件夹的控制权限了,当然选择允许“完全控制”。另外,你在“组或用户名称”这里还会发现类似S-1-5-80-956008885-3418522649-1831038044-1853292631-2271478464这样的用户,这应该就是原来的vista/ws2008/win7的用户。
(7)、还没完,你还需要再次进入高级--权限选项卡,对于“Administrators”用户组,将下面的两个选项都勾上,目的是将对boot文件夹的权限设置,被所有子文件和文件夹所继承(原来其子文件夹和文件并没有完全继承)。确定,退出。
好了,这回,你终于可以把boot文件夹删除了!
由于操作过程中没想到贴图,只有全部操作完成之后,boot文件夹权限相关信息:
图1 Boot文件夹属性

图2 Boot文件夹权限选项卡

图3 Boot文件夹审核选项卡

图4 Boot文件夹所有者选项卡
删除bootmgr文件:
只需要做删除boot文件夹的(3)、(4)、(5)、(6)步即可,而且由于只有单个文件,简单很多,不再赘述。
总结:其实对于多分区中安装多系统来说,经常会遇到这样的情况。我在以前的本本上装XP和WS2003双系统,WS2003想要查看XP分区music中的音乐文件,也需要夺权,只是没有现在这么麻烦罢了。Anyway,简单来说,就那么几步:添加当前XP管理员用户至审核组以获得审核权限-->夺取文件所有者权限-->删除原所有者-->完全控制,并应用到子文件和文件夹-->删除!
构建一个企业级的应用系统,往往数据库成为最终的一个负载瓶颈,在我们优化完sql语句、优化完应用程序之后,数据库的调优必不可少,下面就基于sql查询的命中率的oracle调优做一个简单的说明。
1.先检验数据库的查询命中率,请执行下面的2组sql语句,并且分别记录修改之前的数值。
第一组sql语句如下:
select 100- (j.value-( a.value+b.value )) /(u.value+v.value-a.value-b.value)*100 as 命中率 from
(select value from v$sysstat where name ='physical reads direct' ) a,
(select value from v$sysstat where name ='physical reads direct (lob)' ) b,
(select value from v$sysstat where name ='physical reads') j,
(select value from v$sysstat where name ='consistent gets') u,
(select value from v$sysstat where name = 'db block gets') v ;
第二组sql语句如下:
select sum(gets) "请求存取数",sum(getmisses) "不命中数" , (1-sum(getmisses)/sum(gets) )*100 "命中率"
from v$rowcache;
2.如果第一组sql语句执行的结果是<90%,则说明需要调整oracle数据库的内存(SGA的大小),第二组sql语句作为一个参照。
一般经验:在 1G 的内存的服务器上,我们能分配给SGA的内存大约为400—500M 。若是2G的内存,大约可以分到1G的内存给 SGA,8G 的内存可以分到5G的内存给SGA。
考虑到数据库服务器的机器内存大小为2G, 可以按照以下脚本执行修改:
【注:请用具有dba权限的用户登录“login as sysdba”登录,可以用pl/sql工具】
--修改前备份一下sqfile
create pfile='d:\oracle\ora9init.ora' from spfile;
--修改共享池大小
alter system set shared_pool_size =256M scope=spfile;
--修改缓冲池大小
alter system set db_cache_size=896M scope=spfile;
--大缓冲池
alter system set large_pool_size=100m scope=spfile;
--修改链接进程数
alter system set processes=1500 scope=spfile;
--会话数
alter system set sessions=900 scope=spfile;
--事务数
alter system set transactions=900 scope=spfile;
--打开游标数
alter system set open_cursors =1000 scope=spfile;
3.用pl/sql工具修改了这些参数之后,需要重启oracle服务。当重启之后再查执行开始的2组sql语句,对比数值的差异。
前言
近来公司技术,研发都在问我关于内存参数如何设置可以优化oracle的性能,所以抽时间整理了这篇文档,以做参考.
目的
希望通过整理此文档,使大家对oracle内存结构有一个全面的了解,并在实际的工作中灵活应用,使oracle的内存性能达到最优配置,提升应用程序反应速度,并进行合理的内存使用.
内容
实例结构
oracle实例=内存结构+进程结构
oracle实例启动的过程,其实就是oracle内存参数设置的值加载到内存中,并启动相应的后台进程进行相关的服务过程。
进程结构
oracle进程=服务器进程+用户进程
几个重要的后台进程:
DBWR:数据写入进程.
LGWR:日志写入进程.
ARCH:归档进程.
CKPT:检查点进程(日志切换;上一个检查点之后,又超过了指定的时间;预定义的日志块写入磁盘;例程关闭,DBA强制产生,表空间offline)
LCKn(0-9):封锁进程.
Dnnn:调度进程.
内存结构(我们重点讲解的)
内存结构=SGA(系统全局区)+PGA(程序全局区)
SGA:是用于存储数据库信息的内存区,该信息为数据库进程所共享。它包含Oracle 服务器的数据和控制信息,它是在Oracle服务器所驻留的计算机的实际内存中得以分配,如果实际内存不够再往虚拟内存中写
我们重点就是设置SGA,理论上SGA可占OS系统物理内存的1/2——1/3
原则:SGA+PGA+OS使用内存<总物理RAM
SGA=((db_block_buffers*blocksize)+(shared_pool_size+large_pool_size+java_pool_size+log_buffers)+1MB
1、SGA系统全局区.(包括以下五个区)
A、数据缓冲区:(db_block_buffers)存储由磁盘数据文件读入的数据。
大小: db_block_buffers*db_block_size
Oracle9i设置数据缓冲区为:Db_cache_size
原则:SGA中主要设置对象,一般为可用内存40%。
B、共享池:(shared_pool_size):数据字典,sql缓冲,pl/sql语法分析.加大可提速度。
原则:SGA中主要设置对象,一般为可用内存10%
C、日志缓冲区:(log_buffer)存储数据库的修改信息.
原则:128K ---- 1M 之间,不应该太大
D 、JAVA池(Java_pool_size)主要用于JAVA语言的开发.
原则:若不使用java,原则上不能小于20M,给30M通常就够了
E、 大池(Large_pool_size) 如果不设置MTS,主要用于数据库备份恢复管理器RMAN。
原则:若不使用MTS,5---- 10M 之间,不应该太大
SGA=. db_block_buffers*db_block_size+ shared_pool_size+ log_buffer+Java_pool+size+large_pool_size
原则: 达到可用内存的55-58%就可以了.
2、PGA程序全局区
PGA:包含单个服务器进程或单个后台进程的数据和控制信息,与几个进程共享的SGA 正相反PGA 是只被一个进程使用的区域,PGA 在创建进程时分配在终止进程时回收.
A、Sort_area_size 用于排序所占内存
B、Hash_area_size 用于散列联接,位图索引
这两个参数在非MTS下都是属于PGA ,不属于SGA,是为每个session单独分配的,在我们的服务器上除了OS + SGA,一定要考虑这两部分
原则:OS 使用内存+SGA+并发执行进程数*(sort_area_size+hash_ara_size+2M) < 0.7*总内存
实例配置
一:物理内存多大
二:操作系统估计需要使用多少内存
三:数据库是使用文件系统还是裸设备
四:有多少并发连接
五:应用是OLTP 类型还是OLAP 类型
基本掌握的原则是, db_block_buffer 通常可以尽可能的大,shared_pool_size 要适度,log_buffer 通常大到几百K到1M就差不多了
A、如果512M RAM 单个CPU db_block_size 是8192 bytes
SGA=0.55*512M=280M左右
建议 shared_pool_size = 50M, db_block_buffer* db_block_size = 200M
具体: shared_pool_size =52428800 #50M
db_block_buffer=25600 #200M
log_buffer = 131072 # 128k (128K*CPU个数)
large_pool_size=7864320 #7.5M
java_pool_size = 20971520 # 20 M
sort_area_size = 524288 # 512k (65k--2M)
sort_area_retained_size = 524288 # MTS 时 sort_area_retained_size = sort_area_size
B、如果1G RAM 单个CPU db_block_size 是8192 bytes
SGA=0.55*1024M=563M左右
建议 shared_pool_size = 100M , db_block_buffer* db_block_size = 400M
具体: shared_pool_size=104857600 #100M
db_block_buffer=51200 #400M
log_buffer = 131072 # 128k (128K*CPU个数)
large_pool_size=15728640 #15M
java_pool_size = 20971520 # 20 M
sort_area_size = 524288 # 512k (65k--2M)
sort_area_retained_size = 524288 # MTS 时 sort_area_retained_size = sort_area_size
C、如果2G 单个CPU db_block_size 是8192 bytes
SGA=0.55*2048M=1126.4M左右
建议 shared_pool_size = 200M , db_block_buffer *db_block_size = 800M
具体: shared_pool_size=209715200 #200M
db_block_buffer=103192 #800M
log_buffer = 131072 # 128k (128K*CPU个数)
large_pool_size= 31457280 #30M
java_pool_size = 20971520 # 20 M
sort_area_size = 524288 # 512k (65k--2M)
sort_area_retained_size = 524288 # MTS 时 sort_area_retained_size = sort_area_size
假定64 bit ORACLE
内存4G
shared_pool_size = 200M , data buffer = 2.5G
内存8G
shared_pool_size = 300M , data buffer = 5G
内存 12G
shared_pool_size = 300M-----800M , data buffer = 8G
参数更改方式
oracle8i:
主要都是通过修改oracle启动参数文件进行相关的配置
参数文件位置:
d:\oracle\admin\DB_Name\pfile\init.ora
按以上修改以上参数值即可。
Oracle9i:
两种方式:第一种是修改oracle启动参数文件后,通过此参数文件再创建服务器参数文件
第二种是直接运行oracle修改命令进行修改。
SQL>alter system set db_cache_size=200M scope=spfile;
SQL>alter system set shared_pool_size=50M scope=spfile;
在Windows系统中的文件压缩工具winrar功能强大,虽然我们都习惯于用gui的winrar,但是
它也能在命令行方式下面使用,这尤其在企图让winrar批量自动压缩解压缩的时候有用。
它自带的帮助也非常的全面,现在从中择出来一些比较常用的总结一下,以免再找的时候比
较头晕
1,最简单的压缩命令:
winrar a asdf.txt.rar asdf.txt
a的意思是进行压缩动作,后面第一个参数是被压缩后的文件名,后缀当然是rar了,最后面
的参数就是要被压缩的文件名
2,最简单的解压缩命令:
winrar e asdf.txt.rar
e的意思是执行解压缩,解压缩的文件是后面这唯一的参数,但是这个e解压缩是把解出来的
文件释放到当前目录下面,与asdf.txt.rar文件并列了,因此,更加实用的是下面的带路径
解压缩。
3,带路径的解压缩命令:
winrar x asdf.rar
x的意思是执行带绝对路径解压动作,这会在当前文件夹下创建一个文件夹asdf,把压缩包
里的文件、文件夹不改动结构释放到文件asdf里面,就像我们在winrar的图形界面下看到的
一样。
4,指定压缩级别压缩:
winrar a -m5 asdf.tr.rar asdf.tr
要被压缩的不再是一个txt文本,而是一个文本格式的十几M的仿真数据文件,希望能够最大
程度的压缩。使用压缩参数-m5。在winrar中,执行操作是不带前导-符号的参数,比如“a
”或“x”,而修饰这种动作的参数,使用带前导符号“-”的参数,比如-m5。其中-m就是
指定压缩级别的参数,压缩级别有如下五级:
-m0 存储 添加到压缩文件时不压缩文件。
-m1 最快 使用最快方式(低压缩)
-m2 较快 使用快速压缩方式
-m3 标准 使用标准(默认)压缩方式
-m4 较好 使用较好压缩方式(较好压缩,但是慢)
-m5 最好 使用最大压缩方式(最好的压缩,但是最慢)
默认的是-m3级别,级别不同,对于大数据量的文本文件压缩后的文件大小有很大的差异
5,指定压缩后删除原文件:
winrar a -m5 -df asdf.tr.rar asdf.tr
用参数-df指定压缩为asdf.tr.rar压缩文件后,删除原文件asdf.tr,也可以是:
winrar m -m5 asdf.tr.rar asdf.tr
这个m的意思是把文件asdf.tr移动入压缩文件asdf.tr.rar中
6,创建自解压文件:
winrar s asdf.tr.rar
在gui界面中,创建自解压文件是有个选项可以直接选择的。而在命令行中,是分为两个步
骤的,第一步是用压缩命令进行压缩:
winrar a -m5 -df asdf.tr.rar asdf.tr
第二步是用s命令把这个压缩文件转化为自解压文件:
winrar s asdf.tr.rar
转化后,生成了自解压文件:asdf.tr.exe
基本上,日常使用这六条就够了
摘要: 第一章 绪论
1.1 论文的选题背景
以往的基于数理统计方法的应用大多都是通过专用程序来实现的,我们知道,大多数的统计分析技术是基于严格的数学理论和高超的应用技巧的,这使得一般的用户很难从容地掌握它。数据挖掘技术是数理统计分析应用的延伸和发展,假如人们利用数据库的方式从被动地查询变成了主动发现知识的话,那么概率论和数理统计可以为我们从数...
阅读全文
什么是云计算(cloud computing)呢?云计算是一种基于因特网的超级计算模式,在远程的数据中心里,成千上万台电脑和服务器连接成一片电脑云。因此,云计算甚至可以让你体验每秒10万亿次的运算能力,拥有这么强大的计算能力可以模拟核爆炸、预测气候变化和市场发展趋势。用户通过电脑、笔记本、手机等方式接入数据中心,按自己的需求进行运算。
那么,it精英们如何看待云计算的呢?IBM的创立者托马斯·沃森曾表示,全世界只需要5台电脑就足够了。比尔·盖茨则在一次演讲中称,个人用户的内存只需640K足矣。李开复打了一个很形象的比喻:钱庄。最早人们只是把钱放在枕头底下,后来有了钱庄,很安全,不过兑现起来比较麻烦。现在发展到银行可以到任何一个网点取钱,甚至通过ATM,或者国外的渠道。就像用电不需要家家装备发电机,直接从电力公司购买一样。云计算就是这样一种变革——由谷歌、IBM这样的专业网络公司来搭建计算机存储、运算中心,用户通过一根网线借助浏览器就可以很方便的访问,把“云”做为资料存储以及应用服务的中心。
狭义云计算是指IT基础设施的交付和使用模式,指通过网络以按需、易扩展的方式获得所需的资源(硬件、平台、软件)。提供资源的网络被称为“云”。“云”中的资源在使用者看来是可以无限扩展的,并且可以随时获取,按需使用,随时扩展,按使用付费。这种特性经常被称为像水电一样使用IT基础设施。
广义云计算是指服务的交付和使用模式,指通过网络以按需、易扩展的方式获得所需的服务。这种服务可以是IT和软件、互联网相关的,也可以是任意其他的服务。
(一)原理:
云计算(Cloud Computing)是分布式处理(Distributed Computing)、并行处理(Parallel Computing)和网格计算(Grid Computing)的发展,或者说是这些计算机科学概念的商业实现。

云计算的基本原理是,通过使计算分布在大量的分布式计算机上,而非本地计算机或远程服务器中,企业数据中心的运行将更与互联网相似。这使得企业能够将资源切换到需要的应用上,根据需求访问计算机和存储系统。
这可是一种革命性的举措,打个比方,这就好比是从古老的单台发电机模式转向了电厂集中供电的模式。它意味着计算能力也可以作为一种商品进行流通,就像煤气、水电一样,取用方便,费用低廉。最大的不同在于,它是通过互联网进行传输的。
云计算的蓝图已经呼之欲出:在未来,只需要一台笔记本或者一个手机,就可以通过网络服务来实现我们需要的一切,甚至包括超级计算这样的任务。从这个角度而言,最终用户才是云计算的真正拥有者。
云计算的应用包含这样的一种思想,把力量联合起来,给其中的每一个成员使用。
(二)云计算有哪些好处?
1、安全,云计算提供了最可靠、最安全的数据存储中心,用户不用再担心数据丢失、病毒入侵等麻烦。
2、方便,它对用户端的设备要求最低,使用起来很方便。
3、数据共享,它可以轻松实现不同设备间的数据与应用共享。
4、无限可能,它为我们使用网络提供了几乎无限多的可能。
(三)云计算最有利于中小企业?
云计算技术将使得中小企业的成本大大降低。如果说“云”给大型企业的IT部门带来了实惠,那么对于中小型企业而言,它可算得上是上天的恩赐了。过去,小公司人力资源不足,IT预算吃紧,那种动辄数百万美元的IT设备所带来的生产力对它们而言真是如梦一般遥远,而如今,“云”为它们送来了大企业级的技术,并且先期成本极低,升级也很方便。
这一新兴趋势的重要性毋庸置疑,不过,它还仅仅是一系列变革的起步阶段而已。云计算不但抹平了企业规模所导致的优劣差距,而且极有可能让优劣之势易主。简单地说,当今世上最强大最具革新意义的技术已不再为大型企业所独有。“云”让每个普通人都能以极低的成本接触到顶尖的IT技术。
(四)“云”时代
目前,PC依然是我们日常工作生活中的核心工具——我们用PC处理文档、存储资料,通过电子邮件或U盘与他人分享信息。如果PC硬盘坏了,我们会因为资料丢失而束手无策。
而在“云计算”时代,“云”会替我们做存储和计算的工作。“云”就是计算机群,每一群包括了几十万台、甚至上百万台计算机。“云”的好处还在于,其中的计算机可以随时更新,保证“云”长生不老。Google就有好几个这样的“云”,其他IT巨头,如微软、雅虎、亚马逊(Amazon)也有或正在建设这样的“云”。
届时,我们只需要一台能上网的电脑,不需关心存储或计算发生在哪朵“云”上,但一旦有需要,我们可以在任何地点用任何设备,如电脑、手机等,快速地计算和找到这些资料。我们再也不用担心资料丢失。
(五)云计算的几大形式
1.SAAS(软件即服务)
这种类型的云计算通过浏览器把程序传给成千上万的用户。在用户眼中看来,这样会省去在服务器和软件授权上的开支;从供应商角度来看,这样只需要维持一个程序就够了,这样能够减少成本。Salesforce.com是迄今为止这类服务最为出名的公司。SAAS在人力资源管理程序和ERP中比较常用。 Google Apps和Zoho Office也是类似的服务
2.实用计算(Utility Computing)
这个主意很早就有了,但是知道最近才在Amazon.com、Sun、IBM和其它提供存储服务和虚拟服务器的公司中新生。这种云计算是为IT行业创造虚拟的数据中心使得其能够把内存、I/O设备、存储和计算能力集中起来成为一个虚拟的资源池来为整个网络提供服务。
3.网络服务
同SAAS关系密切,网络服务提供者们能够提供API让开发者能够开发更多基于互联网的应用,而不是提供单机程序。
4.平台即服务
另一种SAAS,这种形式的云计算把开发环境作为一种服务来提供。你可以使用中间商的设备来开发自己的程序并通过互联网和其服务器传到用户手中。
5.MSP(管理服务提供商)
最古老的云计算运用之一。这种应用更多的是面向IT行业而不是终端用户,常用于邮件病毒扫描、程序监控等等。
6.商业服务平台(如:中国云计算网 www.cloudcomputing-china.cn )
SAAS和MSP的混合应用,该类云计算为用户和提供商之间的互动提供了一个平台。比如用户个人开支管理系统,能够根据用户的设置来管理其开支并协调其订购的各种服务。
7.互联网整合
将互联网上提供类似服务的公司整合起来,以便用户能够更方便的比较和选择自己的服务供应商。
说了半天相信很多人还没搞清怎么回事,因为单“云计算”这三个字就已经够云里雾里的了。云计算到底有多强大,仍有待时代的检阅!
工具网上的资料改了refhost.xml文件 添加了
<!--Microsoft Windows 7-->
<OPERATING_SYSTEM>
<VERSION VALUE="6.1"/>
</OPERATING_SYSTEM>
后来用xp sp3 兼容模式,管理员运行安装,
刚装完 Oracle 10g,然后,进行em后,界面出来了,但报了一个错:
java.lang.Exception: Exception in sending Request :: null
很多功能不能用,提示重新登录
解决方案:找到下面的文件
$ORACLE_HOME\db_1\$HOSTNAME\sysman\config\emd.properties
其中的agentTZRegion缺省是GMT,改为你所在的时区即可,例如:
agentTZRegion=Asia/Harbin
关于时区的列表参考:10.2.0\db_1\sysman\admin\supportedtzs.lst
然后先停止 dbconsole 使时区设置生效并重启OracleDBConsole:
然后先停止dbconsole 在重启dbconsole :
set ORACLE_SID=orcl
emctl stop dbconsole
emctl start dbconsole
1、开始->设置->控制面板->管理工具->服务 停止所有Oracle服务。
2、 开始->程序->Oracle - OraHome81->Oracle Installation Products-> Universal Installer 卸装所有Oracle产品,但Universal Installer本身不能被删除
5、 运行regedit,选择HKEY_LOCAL_MACHINE\SOFTWARE\ORACLE,按del键删除这个入口。
6、 运行regedit,选择HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Services,滚动 这个列表,删除所有Oracle入口。
7、 运行refedit, HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Services\Eventlog\Application, 删除所有Oracle入口。
8、 开始->设置->控制面板->系统->高级->环境变量 删除环境变量CLASSPATH和PATH中有关Oracle的设定
9、 从桌面上、STARTUP(启动)组、程序菜单中,删除所有有关Oracle的组和图标
10、 删除\Program Files\Oracle目录
11、 重新启动计算机,重起后才能完全删除Oracle所在目录(到这基本可以安装 )
12、 删除与Oracle有关的文件,选择Oracle所在的缺省目录C:\Oracle,删除这个入 口目录及所有子目录,并从Windows 2000目录(一般为C:\WINNT)下删除以下文 件ORACLE.INI、oradim73.INI、oradim80.INI、oraodbc.ini等等。
13、 WIN.INI文件中若有[ORACLE]的标记段,删除该段
14、 如有必要,删除所有Oracle相关的ODBC的DSN
15、 到事件查看器中,删除Oracle相关的日志 说明: 如果有个别DLL文件无法删除的情况,则不用理会,重新启动,开始新的安装, 安装时,选择一个新的目录,则,安装完毕并重新启动后,老的目录及文件就可以删除掉了。
1.水晶报表 美国BO公司出品http://www.businessobjects.com , 传统条带状报表工具的代表。水晶报表是最早进入中国市场的,有大量的用户。由于其采用模型的局限性,不支持多数据源,不能做复杂的中国报表. 价格拾万圆左右. 没有加密狗.
2.Fine Report 南京帆软软件,美资公司,http://www.fine report.com ,从设计角度,选择多项支持的态度,即Fine Report在一个产品中同时集成三种模型:条带状模型,多点扩散模型,电子表格模型,把选择权交给用户。能够制作复杂的报表,支持多数据源,操作比较简单,适合中国式报表设计的需求。价格壹万圆左右. 没有加密狗.
3.如意报表 深圳明宇公司出品 http://www.soft2web.com, 基于俄罗斯的免费开源的fastreport控件, 功能类似水晶报表, delphi写的使用广泛,基于fastreport控件采用的是西式条带式报表模型,不仅画起来极为费劲,稍复杂一些的报表都要编程才能实现不支持多数据源, 不能制作复杂的中国报表.实际上更适合C/S应用。价格壹万圆左右, 有加密狗.
4.数巨报表 上海炎鼎软件公司出品, 完全本土公司, http://www.maxrpt.com , 和如意报表一样, 也是基于俄罗斯的免费开源的fastreport控件, 功能类似水晶报表, delphi写的使用广泛, 不支持多数据源, 不能制作复杂的中国报表。不过,与如意报表不同的,数巨报表不是一个孤立的产品,而是作为数巨商业智能系统(Max@X Analyser)的一个部分而存在。价格壹万圆左右, 有加密狗.
5.快逸报表 北京润乾公司出品, 完全本土公司, http://www.quiee.com , 06年才出来的, 润乾报表普及版的改头换面产品。使用不多, 纯java,不支持多数据源, 不能做复杂的中国报表, 仅能设计格式最简单的报表,稍复杂的报表就需要通过编写程序来实现。价格壹万圆左右, 有加密狗.
6.润乾报表 http://www.runqian.com,北京润乾软件公司,和快逸报表不同的是 支持多数据源,非线性报表模型, 即可以设计复杂的中国式报表。企业版价格贰拾伍万圆左右. 有加密狗.
安装介绍
对于扩展 Eclipse 的功能,首先当然就是去下载对应的 plugin,BIRT 也不能例外。BIRT 的下载地址:http://download.eclipse.org/birt/downloads/,当前版本是2.0。BIRT 依赖于 Eclipse 的其它几个 plugin(GEF 和 EMF),由于我使用的是 Eclipse WTP(这是 Eclipse 的 WEB 开发工具),在这个工具中那些 plugin 都已预装,因此直接下载 birt-report-framework-2_0_0.zip 就好了。如果没有这些 plugin,请下载。
下载之后,安装非常简单:只需解压然后将对应的features和plugins目录中的内容复制到Eclipse对应的目录下即可。且慢,这只是完成了对于BIRT的基本安装。下一步就是去下载BIRT需要的第三方软件包:
| |
需要的jar文件 |
复制位置(都在plugins目录下) |
| Apache Axis |
axis.jar
axis-ant.jar
commons-discovery-0.2.jar
jaxrpc.jar
saaj.jar
wsdl4j-1.5.1.jar
|
org.eclipse.birt.report.viewer_version/birt/WEB-INF/Lib |
| iText 1.3 |
itext-1.3.jar |
org.eclipse.birt.report.engine.emitter.pdf_version/lib |
| prototype.js v1.4.0 |
prototype.js v1.4.0 |
org.eclipse.birt.report.viewer_version/birt/ajax/lib |
自此,BIRT的安装大功告成。启动Eclipse,在"project wizard"中会出现一个BIRT的项目类型。
典型使用
在使用之前,了解一些关于BIRT的基本概念,将会对使用非常有益:
- 数据源:数据的来源,或提供者。如xml数据源、jdbc数据源等。
- 数据集:数据集合,它必须与数据源关联,可以理解为查询的结果。
- 报表以及报表项,报表可视为是针对一组数据集的表现形式,而报表项这是这个表现形式的某个具体的单元。它们之间的关系,与窗体和控件的关系非常类似。报表、数据集、数据源三者间的关系:数据源 --- 数据集 --- 报表。
- 报表参数:查询参数的表现形式,使用它可以构建更灵活的报表。
- 模板和库:主要用于复用报表设计,提高报表开发的效率。
本文中的例子都采用jdbc数据源,这是最常见的使用情形,其中涉及的数据关系是一个典型的多对多关系:

1. 简单报表
首先,让我们来看看一个"Hello World"级别的应用:"列出所有用户",以便可以快速的了解BIRT。为了完成这一任务,我们需要:
A. 通过项目向导,创建BIRT工程。工程创建完毕之后,显示BIRT的"报表设计"视图。由于此时没有报表,其它几个视图,如"数据资源管理器",不可用。

B. 在项目上点鼠标右键,选择:"new -> 报表"。在报表类型中,选择"空白报表"。
C. 创建新报表后,数据视图可用。在"数据资源管理器"中创建报表所需要的jdbc数据源。根据向导,可以方便的添加jdbc驱动、数据库url、用户名和密码。
D. 在指定的数据源上,创建数据集,这一步完成产生数据集的查询。在BIRT中支持2种数据集:基于查询语句和基于存储过程。在本例中使用前者,对应的查询语句是:select user.userid, user.username, user.addr from user。
E. 选择刚刚创建的数据集,将它拖至空白报表页上。BIRT会自动为其创建一个报表项,此处是"表"。如下图:

F. 选择预览,就可以看到报表运行的实际结果了。或在报表上点击鼠标右键,选择:"报表 -> 运行报表"。
非常简单,一个显示所有用户信息的报表就完成了。在此基础之上,让我们再来完成一些其它具有挑战性的任务:
1.格式化:这是一个内容广泛的主题,常见的需求:
| 需求 |
解决办法(以上为例) |
| 显示报表列头为中文 |
如:将userid显示为"用户标识"。
选择"userid",输入"用户标识"。 |
| 设置报表外观 |
选择对应的报表项,通过"属性编辑器"调整。 |
| 对于报表数据列进行处理 |
如:将userid和username,显示成:userid:username。双击row["userid"],出现"表达式生成器",输入: row["userid"]+":"+ row["username"] |
| 分页 |
选择"表":在"属性编辑器"中,选择"分页符",在"分页符间隔"中输入分页大小。 |
| 页眉和页脚 |
在报表设计页,选择"主页",在其中设置页眉和页脚。 |
2.排序:一种变通的做法是:将数据集排序之后,如在对应的SQL语句中使用order by,再显示。除此之外,也可以在报表设计时来完成:
A. 选择表,此时属性编辑器下方会出现与表相关的选择页。

B. 选择"排序",在对应的页面中选择"添加"按钮之后,出现:

C. 选择需要进行排序的列,以及排序方式。
3.计算列:通过"数据集编辑器"来完成。进入"数据集编辑器后",选择"计算列":输入对应的"列名称"、"数据类型"和"表达式"。
4.报表参数:它为报表的产生带来了极大的灵活性。报表参数一定是与含参数的查询对应的,否则失去了意义。现在,将以上需求改为列出"用户标识大于某一输入的所有用户":
A. 编辑数据集,修改SQL:select user.userid,user.username,user.addr from user where user.userid>?。
B. 在数据集编辑窗体内选择"参数",然后输入对应的"名称"、"数据类型"、"方向"和"默认值"(必须给出默认值)。其中"方向"表示"输入"或"输出"。对于参数,一般选"输入"。完毕之后:

C. 在"数据资源管理器"视图,创建报表参数:"用户标识"。
D. 选择"表",在"属性编辑器"中选择"绑定"。此时,会出现刚才在数据集中定义的参数"id"。在"值"列,选择报表参数"用户标识":

E. 运行报表时,此时会出现报表参数的输入框,填写值后即出现报表结果。
本例虽然只定义了一个报表参数,但是BIRT并没有这样的限制。我们可以创建多个参数,做法很简单:首先,查询有多个参数;定义数据集的参数时,按照查询中参数出现的顺序定义;最后,添加需要的报表参数。
5.分组:以上为例:将用户按地址分组。
A. 选择"表",点击鼠标右键,选择"插入组"。这里有两个选择:"在上面"和"在下面"。
B. 选择任意一种,弹出分组资料窗体。填写其中的:"名称"和"分组依据"。在本例中,"分组依据"是addr列。
C. 选择预览,或运行报表,查看结果。
2. 子报表
子报表是另一种最常见的报表,以上为例:列出所有用户,并列出每个用户所购买的项目,以及项目数。为了完成这种父子关系的报表,需要:
A. 创建新报表和数据源。
B. 创建数据集user,使用SQL:select user.userid,user.username,user.addr from user。
C. 创建数据集items,使用SQL:
select item.itemid,item.itemdesc,item.price,user_item.count from item,user_item
where item.itemid= user_item.itemid
and user_item.userid= ?
|
同时在数据集items上创建参数user,它对应SQL中的参数。
D. 从"Palette"视图拖入"列表"到报表中,在"属性编辑器"的"绑定"页中,选择数据集为user。它用来显示主表的信息,在本例中是用户信息。
E. 从"Palette"视图拖入"网格"到"列表"的"明细数据"中,设置网格为1行2列,它用来存放"用户姓名"和"用户地址"。在"数据资源管理器"视图,选择数据集user,将username和addr分别拖入网格的2列中。
F. 在"数据资源管理器"视图,选择数据集items,将它拖入"列表"的"明细数据"中,位于刚刚插入的网格下方。此时,BIRT会生成数据集items对应的"表"。
G. 选择刚刚生成的"表",在"属性编辑器"的"绑定"页中,会出现在items中定义的参数。修改它的值:row["userid"]。于是,父子报表就发生了联系。
H. 选择预览,或运行报表,就可以看到结果了。
很遗憾,到目前为止,另一种最常见的报表"交叉表"还不被BIRT支持。但是,BIRT的官方网站已明确表示,将在未来的版本中支持它。
3. 统计图表
俗话说,"一图顶千言"。没有图的报表是枯燥,且缺乏表现力的。在本例中,我们将使用图表来表示:每个用户的消费总数。
A. 创建新报表和数据源。
B. 创建数据集chart,使用SQL:
select user.username,round(sum(item.price*user_item.count),2)
from item, user_item, user
where item.itemid= user_item.itemid
and user.userid= user_item.userid
group by user.username
|
C. 从"Palette"视图拖入"图表"到报表中,此时会弹出"编辑图表"窗体。
D. 在"选择图表类型"页,选择图表类型为"条形图"。在"选择数据"页,使用数据集chart,同时选中username列,将其拖入"类别x系列"。对于统计列,同样将其拖入"类别y系列"。在"图表格式"页,分别为x和y系列,填写相应的显示名称。
E. 选择预览,或运行报表,即可看到统计图表。
4. 使用脚本
可以使用脚本,是BIRT的一大特色。在BIRT中,数据源、数据集和报表项,都可以书写脚本。具体做法:选择数据源、数据集和报表项任意一种对象,然后选择"脚本"页面。如选择数据源user后,对应的脚本输入页面:

选择对应的事件,然后在下方的脚本输入框中输入脚本即可。如对于第一个例子,我们需要统计用户地址是"No.5 St."的用户数:
A. 选择数据集,然后选择"脚本",进入数据集的脚本编辑窗口。
B. 选择事件"afterOpen",在脚本窗口内输入:count=0;
C. 选择事件"onFetch",在脚本窗口内输入:if( row["addr"]== "No.5 St.") count++;
D. 选择报表,在脚本窗口选择事件"onRender",输入:this.caption=count;
E. 预览,或运行报表后,会在报表的标题输出count的数值。
另外,BIRT也支持使用java来作为报表项的事件处理程序。具体做法,请参见BIRT的帮助文档。
5. 库和模板
除了脚本使开发者可以自定义报表的行为外,BIRT还提供了库和模板机制来重用设计,加快报表的开发。在TheServerSide上有一篇相当详细的文档:Using Eclipse BIRT Report Libraries and Templates。
应用集成
BIRT与现有应用的集成非常简单,由于BIRT主要是web应用,本节以web应用为例进行说明。
1. 从Eclipse BIRT官方网站下载birt-runtime-2_0_0.zip。
2. 解压之后,只需要其中的web view example目录下的内容。
3. 复制以下第三方软件包到web view example目录:
| |
需要的jar文件 |
复制位置 |
| Apache Axis |
axis.jar
axis-ant.jar
commons-discovery-0.2.jar
jaxrpc.jar
saaj.jar
wsdl4j-1.5.1.jar
|
WEB-INF/Lib |
| iText 1.3 |
itext-1.3.jar |
Plugins/org.eclipse.birt.report.engine.emitter.pdf/lib |
| prototype.js v1.4.0 |
prototype.js v1.4.0 |
ajax/lib |
4. 将web view example目录发布到web容器中,如tomcat,改名:birtApp。
5. 启动tomcat,并访问birtApp。在首页中选择"View Example",如果成功发布,系统将提示成功。
6. 发布设计完成的报表文件,在birtApp中创建reports目录,用于存放报表设计文件。
7. 在应用中通过:http://localhost:8080/birtApp/frameset?__report=报表文件路径,就可以访问报表了。
这个web应用支持2个动作:
- frameset,以frameset的形式显示报表。这个界面包含一些frame,如页面导航,报表主体在其中的一个frame中显示;使用形式:
http://localhost:8080/birtApp/frameset?__report=报表文件路径&参数=........
- run,报表以一个单独的html页面或pdf显示,由于这种形式没有frmaeset,因此使用者必须自己提供相应的参数,如报表参数,页号等。使用形式:
http://localhost:8080/birtApp/run?__report=报表文件路径&参数=........
对于以上2个动作,以下列出可用的参数:
| 选项 |
说明 |
| __format |
报表输出格式:html或pdf,缺省是html。对于frameset不起作用。 |
| __isnull |
指明一个参数是null,常用于字符串类型。如果提供参数且值为空: - 对于日期和数字类型,BIRT会将它们当作null处理。 - 对于字符串,BIRT会将它作为空字符串。因此,为了说明某个字符串是null,通常写为:__isnull=参数。 |
| __locale |
本地化选项,缺省是jvm的locale。 |
| __report |
报表设计文件路径。 |
| 报表参数 |
报表参数参数值对,形式:参数名=参数值。对于frameset,直接在地址栏中输入参数名=参数值后回车,不会影响报表结果。虽然,此时选择"运行报表"时,弹出的参数值已经改变。 |
虽然本节所说的是针对web应用的集成,但是这种方法同样也可与非web应用集成。此时,我们可以采取一种变通的方法:在非web应用中使用内嵌的web容器,如jetty,也可达到同样的效果。这种做法和Eclipse的做法类似。还记得在报表设计时使用"报表 -> 运行报表"吗?那个弹出的窗体,实际就是一个web页面。
结论
与一些老牌报表软件相比,BIRT可能仍显稚嫩。然而,它也不乏其独到之处,如脚本控制、库和模板。加之有世界领先的报表厂商Actuate支持,实际上BIRT的ROM(Report Object Model)就是Actuate捐献的,我们有充分的理由对BIRT的前景表示乐观。
参考资料
几种ESB(企业服务总线)介绍
ESB(Enterprise Service Bus,即企业服务总线)是传统中间件技术与XML、Web服务等技术结合的产物。ESB提供了网络中最基本的连接中枢,是构筑企业神经系统的必要元素。
企业服务总线ESB就是一种可以提供可靠的、有保证的消息技术的最新方法。ESB中间件产品利用的是Web服务标准和与公认的可靠消息MOM协议接口(例如 IBM的WebSphere MQ、Tibco的Rendezvous和Sonic Software的SoniCMQ)。ESB产品的共有特性包括:连接异构的MOM、利用Web服务描述语言接口封装MOM协议,以及在MOM传输层上传送简单对象应用协议(SOAP)传输流的能力。大多数ESB产品支持在分布式应用之间通过中间层如集成代理实现直接对等沟通。
企业服务总线(Enterprise Service Bus,ESB)的概念是从面向服务体系架构(Service -Oriented Architecture, SOA)发展而来的。SOA描述了一种IT基础设施的应用集成模型,其中的软构件集是以一种定义清晰的层次化结构相互耦合,其中,一个ESB是一个预先组装的SOA实现,它包含了实现SOA分层目标所必需的基础功能部件。
一、ESB的出现改变了传统的软件架构
ESB 是传统中间件技术与XML、Web服务等技术相互结合的产物,ESB的出现改变了传统的软件架构,可以提供比传统中间件产品更为廉价的解决方案,同时它还可以消除不同应用之间的技术差异,让不同的应用服务器协调运作,实现了不同服务之间的通信与整合。从功能上看,ESB提供了事件驱动和文档导向的处理模式,以及分布式的运行管理机制,它支持基于内容的路由和过滤,具备了复杂数据的传输能力,并可以提供一系列的标准接口。
二、企业服务总线(ESB)的用处
ESB 不是万能的,他不是一个应用程序框架,也不是一个企业应用的解决方案.它只是一个基于消息的调用企业服务的通信模块!你可以把它嵌入到你的应用程序框架中,例如嵌入到spring容器里面,或者嵌入到工作流系统中.它的作用是对企业里面的SOA服务的调用提供一个框架和简便的方法.
三、企业服务总线(ESB)的应用特征
大规模分布式的企业应用需要相对简单而实用的中间件技术来简化和统一越来越复杂、繁琐的企业级信息系统平台。面向服务体系架构(SOA)是能够将应用程序的不同功能单元通过服务之间定义良好的接口和契约联系起来。SOA使用户可以不受限制地重复使用软件、把各种资源互连起来,只要IT人员选用标准接口包装旧的应用程序、把新的应用程序构建成服务,那么其他应用系统就可以很方便的使用这些功能服务。
支撑SOA的关键是其消息传递架构-企业服务总线(ESB)。ESB是传统中间件技术与XML、Web服务等技术相互结合的产物,用于实现企业应用不同消息和信息的准确、高效和安全传递。ESB的出现改变了传统的软件架构,可以提供比传统中间件产品更为廉价的解决方案,同时它还可以消除不同应用之间的技术差异,让不同的应用服务协调运作,实现不同服务之间的通信与整合。ESB在不同领域具有非常广泛的用途:
电信领域:ESB能够在全方位支持电信行业OSS的应用整合概念。是理想的电信级应用软件承载平台。
电力领域:ESB能够在全方位支持电力行业EMS的数据整合概念,是理想的SCADA系统数据交换平台。
金融领域:ESB能够在全方位支持银企间业务处理平台的流程整合概念,是理想的B2B交易支撑平台。
电子政务:ESB能够在全方位支持电子政务应用软件业务基础平台、信息共享交换平台、决策分析支撑平台和政务门户的平台化实现。
四、几种ESB的结构和功能
ESB提供了一种开放的、基于标准的消息机制,通过简单的标准适配器和接口,来完成粗粒度应用(服务)和其他组件之间的互操作,能够满足大型异构企业环境的集成需求。它可以在不改变现有基础结构的情况下让几代技术实现互操作。
通过使用ESB,可以在几乎不更改代码的情况下,以一种无缝的非侵入方式使企业已有的系统具有全新的服务接口,并能够在部署环境中支持任何标准。更重要的是,充当“缓冲器”的ESB(负责在诸多服务之间转换业务逻辑和数据格式)与服务逻辑相分离,从而使得不同的应用程序可以同时使用同一服务,用不着在应用程序或者数据发生变化时,改动服务代码。
1. IBM WebSphere ESB
IBM 提供了三种 ESB 产品:IBM WebSphere ESB、IBM WebSphere Message Broker、IBM WebSphere DataPower Integration Appliance XI50。根据您的需求选择 ESB 来增强您的 SOA。WebSphere ESB 是一种基于平台的 ESB,作为集成的 SOA 平台,针对 WebSphere 应用服务器进行了优化。WebSphere Message Broker 是跨平台的 ESB,是为异构 IT 环境中的统一连接和转换而构建的。WebSphere DataPower Integration Appliance XI50 是一种基于设备的 ESB,是为简化的部署和更强的安全性而构建的。客户面临着从简单到复杂的各式各样的 ESB 需求。WebSphere ESB的结构如图一所示。

图一 WebSphere ESB
2. Microsoft ESB
微软通过其应用平台提供了全面的ESB服务,包括:Windows Server® 2003,.NET Framework, BizTalk® Server 2006 R2. 应用平台提供了一个基础架构,基于此可以灵活和安全地重复使用架构和商业服务,并具有协调原有的服务整合到新的端到端的业务流程中的能力。如图二所示。

图二 Microsoft ESB
微软通过一些列的产品Windows Server 2003, the .NET Framework 3.0, and BizTalk Server 2006作为对企业实现ESB的支撑,Microsoft ESB Guidance是基于BizTalk Server 2006一组应用,它提供以下公用的ESB组件:
l Message routing (消息路由)
l Message validation (消息验证)
l Message transformation (消息转换)
l Centralized exception management(集中的异常管理)
l Extensible adapter framework(可扩展的适配器框架)
l Service orchestration(服务的编制支持)
l Business rules engine(业务规则引擎)
l Business activity monitoring(业务活动监视)
微软 ESB 指南提供了架构指导,模式和实践,以及一套BizTalk Server 和 .NET Framework 组件来简化基于微软平台的大型或小规模的ESB解决方案的开发。它还可以帮助开发人员扩展现有的信息和集成解决方案,包括的一些服务和组件。
3. JBOSS SOA Platform
JBoss Enterprise SOA Platform提供了一个基于标准的平台,用以集成应用、SOA服务、业务事件和自动化业务流程。这一SOA平台集成了特定版本的JBoss ESB、jBPM、Drools、和已得到验证的JBoss企业应用平台,把它们组织在一起形成一个单一的企业级发布。如图三所示。

图三 JBOSS SOA Platform
JBoss Enterprise SOA Platform打包了不少流行组件如:
l JBoss ESB
l JBoss jBPM jPDL
l JBoss Rules (Drools)
l JBoss Application Server
l Hibernate
l Hibernate Entity Manager
l Hibernate Annotations
l JBoss Seam
l JBoss Web (嵌入式Tomcat 6.0)
l JBoss Cache
l JGroups
l JBoss Messaging
l JBoss Transactions
l JBoss Web Services (JBossWS)
l JBossXB
l JBoss AOP
l JBoss Remoting
l JBoss Serialization
l JacORB
4. ServiceMix对ESB的实现
ServiceMix是一个建立在JBI (JSR 208)语法规则和APIs上的开源ESB(Enterprise Service Bus:企业服务总线)项目。
ServiceMix是基于JBI的ESB。它是开源的基于JBI语义和API的ESB和SOA工具包,以Apache许可证方式发布。 它是轻量的ESB实现,易于作为嵌入式ESB使用;集成了对Spring技术的支持;可以在客户端或服务器端运行;可以作为独立的ESB提供者,也可以作为另外ESB的服务组件; 可以在JavaSE或JavaEE服务器中使用;ServiceMix同Apache Geronimo以及JBoss服务器完全集成,并且在Apache Geronimo服务器中可以直接部署JBI组件和服务。
Java Business Integration (JBI,Java业务集成)技术规范定义了SOA的服务导向集成的内核和组成架构。它对公共讯息路径架构、服务引擎与捆绑的插件程序接口,以及复合型服务描述机制等都进行了标准化,这样就将多种服务结合成为一个单一的可执行的和可审核的工作单元。 参见图四。

图4 JBI和ServiceMix关系图
JBI并不是一个为开发者设计的一个接口,更准确的说它是在JBI容器里为集成商提供相互集成的一个体系和一系列的接口。所以人们能集合他们所需要的所有部分,做出一个总体解决。例如在理论你能从BPEL引擎上,EJB容器上或者是数据传输产品上集合一个基础设施,并且能够集成的很合适。
ServiceMix 中包含完整的JBI容器,支持JBI规范的所有功能要求:
l 规范化消息服务和路由
l JBI管理Beans (MBeans)
l 组件管理和安装的Ant任务
l 对JBI部署单元的完全支持,支持JBI组件的热部署
【王程斯】IBM Message Broker笔记系列(四)
前面讲了那么多MB的原理和配置,这一篇blog开始正式讲讲我个人学MB的感受。“假如时间可以重来”,我会怎样利用手头的资源,以最快的速度入手。
体验MB
在安装完WMBT之后,会出现“欢迎”(这个也是eclipse
环境安装后都会有的东西,你也可以在“帮助”->“欢迎”里面找到),里面有不少很浅显的例子,让你对MB是如何工作的有个感性认识。强烈建议把里面的“入门”部分看完。
学习开发
看完“入门”后,重点就应该放在“样例”中。在样例库里面,有数十个基础的样例,每个样例都针对某类
节点,比如消息映射、
JMS、
数据库操作、Webservice调用,等等。那么多的例子,当然不可能一下子看完,而且对于一张白纸的新手,里面有些基础知识还不懂,我的建议是:结合之前提到的那本书《精通Websphere Message Broker》,看完一方面的内容,比如
数据库操作,你就可以打开“样例库”,将里面的数据库样例导入至WMBT,然后看看其中的ESQL代码、相关节点的设置,等等。一开始会比较枯燥,而且让这些样例跑起来也不是件容易的事情,但坚持下去就会慢慢体会到其中的乐趣了。
掌握Debug利器
一般来说,WMBT会自动帮你配置好样例
程序运行所需的环境(比如创建队列
管理器、数据库,等等),然后将样例
部署到MB的执行组中。这一切都是自动完成的,但有时候出于各种原因,试运行样例的时候不能得到预期的结果。首先排除掉打包和部署时的错误,因为样例程序的源代码通常是没有问题的,那么余下的问题就只能靠debug来
解决了。另一方面,当你看了书之后,对InputRoot、Environment、ExceptionList这些东西的结构、细节肯定会很好奇,但是书中提到的很少很零散,最好的方法就是在debug模式下,让消息流挂起在某一点,然后你再慢慢浏览其中的各类变量,很多东西都不言自明了。用
IBM工程师的话说,就是“没有debug就根本没法学会MB”。为什么?相关
资料太少了,去google有时候还不如直接问MB自己,所以也是很考验你的自学能力的。
配置debug环境
这些内容在《精通》那本书中都有讲到,只是比较粗略,我在这里补充我个人的
经验。
首先右键单击某个执行组,“属性”,在“JVM调试端口”中输入一个tcp端口号,不要和其他程序冲突就行,假设9090。再次右键执行组,“调试”->“启用调试9090”。然后,切记,重启执行组所在的
broker
重启后,把bar
文件部署到该执行组,然后进入“debug”视图,找到下图右下角的那个按钮:


如果是该按钮是红色的,说明debug守护程序没有启动;如果是绿色的,鼠标移过去,会显示“debug守护程序正在监听XX端口”,需要注意的是,这里的端口可不是之前在执行组设置的端口,刚好相反,必须和之前的9090不同。单击旁边的下拉箭头,可以启动或者更改守护程序的端口,这里改为9099,不必重启。
接下来,就和一般的eclipse调试一样了,在绿色的小昆虫按钮设置debug参数。新建一个debug,注意这里的“java调试端口”则必须与执行组的一致,你也可以“选择执行组….”,
系统会根据你选择的执行组,自动设置端口

然后,在“源”选项卡中,添加你要调试的项目。确定之后,就可以运行debug了。
What next?
debug配置成功后,就开始慢慢研究那些样例吧,按照之前我说的思路,“书本+样例”,按照每个人自己的学习习惯和项目开发的需要,将你要学习的样例,一步步调试过去,看看每条ESQL语句的结果,很快的你就知道其中的运行机理了。
小结
由于MB不能像java那样,输出东西到
控制台,只能输出到
日志文件,而且还得写一堆语句,或者配置trace节点,很麻烦,所以传统的在程序中插入输出语句的方式在这里没太大意义。很多情况下,要依靠debug来观察消息流执行过程中消息的变化,来决定bug的所在。
【王程斯】IBM Message Broker笔记系列(三)
安装配置
准备工作
MB的运行依赖于MQ,所以首先要安装MQ,MQ的具体安装过程略,并且以后假设你已经有关于MQ的基础知识,比如队列管理器、队列、通道,等等。
安装好MQ后,创建一个队列管理器(简称QM),名为TESTQM(MQ里面的对象是区分大小写的,为了避免不必要的麻烦,这里统一用大写,以下划线分隔),这个队列管理器是MB运行的基础,当你用MB的脚本创建配置管理器、代理和执行组时,都要指定QM的名字
然后创建运行时数据库,名为TESTDB,MB自带了derby,你也可以选择DB2,注意此处的数据库是指MB自身运行所需的数据库,目前6.1版本只能用derby或者DB2。创建的方法,可以用MB的脚本命令:mqsicreatedb,也可以用对应数据库自身的脚本命令或图形界面来创建。
关于MB的数据库:
配置管理器只能用derby,而代理可以用多种数据库,只是不同数据库的创建命令各自不同(包括在不同平台上也有差异,具体参考红皮书);代理的数据库可以共用,配置管理器也可以和某个代理共用一个derby数据库;使用mqsicreatedb创建数据库时,如果你已经安装了DB2,则默认创建一个DB2数据库,否则derby
以上是为MB的运行创造运行时环境,接下来开始创建MB的实例
首先当然是要安装MB了,过程挺简单的,略去不表。安装完成后,会在“开始菜单”中有个“命令控制台”,如下图:

单击它,进入MB的一个命令控制台环境,其实和普通的windows命令控制台没什么区别,主要在于它帮你设好了相关的环境变量,你就可以在里面直接输入MB的命令脚本了
前文提到过,MB的配置管理器是用来统一管理MB的各个运行时组件的,因此首先要创建一个配置管理器
mqsicreateconfigmgr –i user –a password –q TESTQM
指定用户名、密码和队列管理器,用户名密码是你登陆本地机器时输入的,必须要有足够的权限(具体权限就不清楚了,我直接用管理员帐号,深入讨论请参考MB的红皮书)
你会发现这里没有指定数据库的名称,因为配置管理器在创建时会自动新建一个derby数据库,而且只能用derby数据库,用户无法改动
配置管理器的名称也没有指定,在windows下是会创建默认名称的:ConfigMgr
然后是创建代理,名为TESTBROKER
mqsicreatebroker TESTBROKER –i user –a password –q TESTQM –n TESTDB
大部分都和创建配置管理器一样,只是多了一个选项,用于指定数据库,再次提醒,必须是derby或DB2,二选一。
最后,使用“mqsistart组件名” 来启动配置管理器和代理
配置MB toolkit
WMBT本身的安装没什么特殊要求,这里就不啰嗦了
接下来的关键是在WMBT里面连接到刚才创建的配置管理器,其作用就好像你在Eclipse中要配置好应用服务器的实例,才能把你的J2EE项目直接以图形界面的方式部署,而不必自己敲命令
如图,文件->新建->域连接

在弹出的窗口中,填入相关参数
这里只需填入队列管理器的名称、域名、端口,注意是队列管理器而不是配置管理器(其实你在创建配置管理器时也没有指定端口,因为它用的就是所在的队列管理器的端口)
此外对于SVRCONN通道名,SYSTEM.BKR.CONFIG是在你创建配置管理器时自动生成的,可以在“MQ 资源管理器”中,通过“显示系统对象”来查看,你也可以自己建一个服务器连接通道,然后在这里输入该通道的名字

一切正常的话,就能看到左下角的“域”窗口中,多了一个新的域连接,里面以树形结构显示了你刚才创建的代理(前提是你的代理基于derby数据库,如果基于DB2,则需要在域连接那里显式增加“代理引用”),现在你可以右键单击TESTBROKER,然后创建执行组。等你开发好MB项目后,打个包,拖到执行组里面,就可以部署了
【王程斯】IBM MessageBroker笔记系列(一)
前言
SOA已经在中国喊了几年,连象牙塔的大学生都知道了,但实施的案例并不多,而作为SOA
基础设施的企业服务总线ESB,在国内的应用更是稀少,主要都是银行和电信等大牌企业在使用。我算非常好彩,打工所在的公司恰好要为客户开发一个基于MB
和WAS的平台,让我有很多机会接触到MB
的应用。现在国内MB
的资料非常少,主要是IBM的红皮书,可惜全部都是英文的,看起来颇费力,效率也不高;出版物我所知的只有一本,是陈宇翔先生所著的《精通Websphere Message Broker
》【中国水利水电出版社】,也是目前手边唯一的一本参考书。因此希望将这段时间的一些使用心得记下来,作为一个从未接触过SOA
和MB
(甚至没用过websphere
产品)的菜鸟,面对这个上百万人民币的庞然大物,应该怎样下手
书评
先来说说这段时间翻阅的一些MB
的书籍,包括纸质和电子版,首先是上文说到的《精通Websphere Message Broker
》这本书。本来这种书给人的第一反应就是:一本红皮书的翻译,无非就是从IBM
的各个红皮书里面摘抄文字,翻译好之后综合一下的“大杂烩”。老实说这本书里面的确有很多翻译的内容,比如MB toolkit
中自带的一些教程,以及MB Information center
里面的部分实例,书的后半部分都是附录,包括函数库、命令库,等等。但是不可否认的是,IBM
的红皮书、InfoCenter
本身就是相当好的教程库,而这本书用到其中的内容也翻译的流畅,所以也是方便了国内读者。而且,作者本身也的确有一些MB
的使用经验,书中也有他自己的内容。所以,这本书作为入门的话,实在是比较辛苦,因为没有考虑太多初学者的难处,内容的编排也不太合理,但是作为一本参考书却是不错的选择。在如今没什么资料的情况下,最好咬牙坚持看下去。
再说说IBM
提供的电子资源,包括红皮书和网上资料,以及InfoCenter
。只要你买了MB
的产品,IBM
自然会提供一堆红皮书给你,当然你也可以慢慢从网上下载,这些红皮书很多写的不错,但是要从头看太痛苦,作参考比较好。此外如果你购买MB
的培训,那么培训机构也会给你一些pdf
材料(其实都是IBM
出品的),这些材料相对易懂,适合入门。再有就是developerWorks
,IBM
的官方技术网站,里面提供最新最全的资料,有空多去看看,也可以订阅它的邮件。最后是InfoCenter
,其实说白了是网页版的手册,可以在线看也可以下载,相对其他来说,难度介于中等,而且不像网站的资源那么零散,所以也是很好的提高阶段的学习资料。
ESB产品
如果你还不清楚ESB
的概念,和IBM
的相关产品,可以去IBM
网上查查资料,我之前也写了一篇简介http://blog.csdn.net/wangchengsi/archive/2008/02/25/2120316.aspx
作为一个菜鸟我没法全面评论当前的ESB
产品,只能记录一下自己的所见所闻(就是跟IBM
和BEA
公司打交道的时候听到的一些内容)。撇开两者的应用服务器不谈(这方面的口水战已经够多了,国内用BEA
的相对多,容易上手适合快速开发,性价比很高),SOA
和ESB
方面,IBM
无疑是走在前面的,这个可以从两者的产品线看出来。BEA
的ESB
产品只有一款AquaLogicBus
,IBM
却已经开始划分各类市场、推出不同档次的产品了(但这个也是BEA
宣传的好处之一,买一个就能到处用,见仁见智了);其二,BEA
自己的销售都对AquaLogic
不甚了解,而且在国内尚无成熟应用,这点是很多企业最关注的,没有成熟应用意味着没有好的技术支持,出了问题不知道找谁解决,甚至从没有人遇过这种问题;而IBM
这两年在SOA
的推广方面做得比较好,广告也做得多,在国内已经有一些成功案例,技术支持也更加完善,我们在广州就能直接联系到工程师,而不必等北京、上海,甚至国外的支持。
MB
在对异构环境的支持方面,做得也比AquaLogicBus
好,可以支持几十种通信协议和平台,而且天生和IBM
自家的大型机等结合的比较好,AquaLogicBus
支持的就相对比较少,主要是基于java
平台的SOA
流行协议,比如web service
,给人感觉更像是websphere ESB
的竞争对手。但是BEA
的产品向来给人的感觉是除了在IBM
的平台,其他平台上都比IBM
的同类产品性价比要高,不知道AquaLogicBus
是不是也一样表现优秀,这个就需要专业的测试了。
另外很重要的一点,就是BEA
的消息中间件做得不如IBM
的MQ
强大,而MB
又是依托于MQ
才能有如此强大的功能,这个是BEA
的销售也不得不承认的。尽管Web service
是当前SOA
的主流,但是性能方面却是不敢恭维,在企业内部实施SOA
,如果服务组件都用web service
连接,虽然更加通用、更加廉价易用,但是往往会有性能瓶颈,关键地方还得靠消息中间件。
最后呢,就是BEA
工作人员对于自家的产品,底气明显不足,一方面是不熟悉,另一方面也是国内用的少,也侧面反映了对于这类重量级产品、而且关乎整个系统性能的底层部件,人们还是倾向于选择IBM
,将来SOA
应用普及了,AquaLogicBus
肯定也会遍地开花,就像现在的weblogic一样。只是目前来看,还是选择MB
更让人放心。
还有一个不得不提到的有力竞争者是来自开源社区的JBOSS ESB
,这个产品我没了解过,但是现在Reahat
收购了JBOSS
,在JBOSS AS
和ESB
上也下了相当大力气,誓要在SOA
市场与IBM
和BEA
分一杯羹。很看好JBOSS
的潜力,只是开源产品在中国连个服务中心都没有,暂时只能供高手们自己研究着玩了。
【王程斯】IBM Message Broker笔记系列(二)
Remine的安装
1.首先下载InstantRails并解压,以下假设加压到C:\
InstantRails是一个Rails应用的集成包包括了Ruby运行时,Rails框架,PhpMyAdmin,Apache,MySql等,这样就不需要分别下载需要的东西。其中Apache是用的1.3版本,主要用于运行phpMyAdmin(MySql的管理工具),Redmine本身内置了一个Ruby写的Http服务器:WEBrick 因此并不需要Apache。
2.下载Redmine并解压缩,将解压缩后的文件夹直接复制到InstantRails目录的rails_apps目录下
3.启动InstantRails(在C:\InstantRails\下有个InstantRails.exe直接运行即可)会出现一个界面(见下图)上面可以控制Apache和MySql的停止和启动,请确保这两个都启动了。如果你的电脑上安装了IIS,可能需要在httpd.conf中修改Apache的监听端口,默认是80
4.使用phpMyAdmin在MySql中创建数据库,脚本如下:create database redmine character set utf8;
5.将C:\InstantRails\rails_apps\redmine-0.8.0\config 目录下的database.yml.example更名为database.yml
6.进入C:\InstantRails\rails_apps\redmine-0.8.0目录,在其下执行:rake db:migrat RAILS_ENV="production",用来创建数据库,完成后应该创建43个表
7.再执行:rake redmine:load_default_data RAILS_ENV="production",指明当前项目运行环境为production,中间会提示选择语言,我们选择zh。
8.最后在C:\InstantRails\rails_apps\redmine-0.8.0目录下执行ruby script/server -e production,启动Redmine
9.通过浏览器访问http://localHost:3000即可,缺省管理员用户名是admin,密码也是admin
配置Redmine为Windows服务
按照上面介绍的步骤就可以使用Redmine,但当机器重启后都需要手工启动InstantRails和执行第8步来启动Redmine,比较麻烦,下面就介绍将Redmine安装成Windows服务,只要系统启动无需登录也跟着启动。
在上述步骤中,MySql只是做为一个普通程序被InstantRails.exe启动,而Redmine又依赖于MySql,因此需要将MySql安装为Windows服务,进入到C:\InstantRails\mysql\bin目录下执行:Mysqld -Install即可将MySql安装为服务,在服务管理器中将其设为自动启动。
Ruby提供一个安装Ruby程序为服务的包:mongrel_service。安装其实很简单,在C:\InstantRails\ruby\bin目录下运行:gem install mongrel_service,此过程中会下载一些其他必须的包
然后使用mongrel_service将Redmine安装为服务:
mongrel_rails service::install -N RedMine -c C:\InstantRails\rails_apps\redmine-0.8.0 -p 3000 –e production
其中C:\InstantRails\rails_apps\redmine-0.8.0是Redmine所在目录 3000是监听端口,然后修改启动方式为自动即可。
如果想要移除Redmine服务,可执行如下命令:
mongrel_rails service::remove -N RedMine
配置邮件通知
Redmin可以为一些操作提供邮件通知如主题改变,新增问题等,这样可以让开发人员及时知道变化。在使用此功能前需要先配置邮件服务器,将C:\InstantRails\rails_apps\redmine-0.8.0\config目录下的email.yml.example更名为email.yml,然后用文本编辑器打开此文件,将内容改为如下:
# Outgoing email settings
production:
delivery_method: :smtp
smtp_settings:
address: "smtp.163.com"
port: 25
domain: "163.com"
authentication: :login
user_name: "PM@163.com"
password: "123456"
development:
delivery_method: :smtp
smtp_settings:
address: "smtp.163.com"
port: 25
domain: "163.com"
authentication: :login
user_name: "PM@163.com"
password: "123456"
这里我采用的是163的Smtp服务器来发送邮件,其中特别需要注意的是address,domain,user_name,password中的值都要加上双引号,否则会报错。
然后就可以在Redmine的界面中启用邮件通知,设置一下发件人地址和签名即可。
集成SubVersion
集成SubVersion就很简单了,在版本库页面选择Subersion,然后填写SVN仓库的url和登录Subversion的用户名,密码即可通过Redmine查看svn仓库中的文件并可比较差异。如下图:
Redmine的WIKI
Redmine的Wiki功能比较简单,使用wiki时一定要注意在标记的前后都要留有空格,否则会无效如变粗字体:*Ning* 其中第一个 * 的前面要留有一个空格,而第二个*后面也要留有一个空格,其他标记类似。
在Redmine中可以自定义工作流程,工作流程是指某一个角色针对某一类问题(如功能,缺陷和支持)的状态迁移规则,此时该类问题就被跟踪(此时该类问题也称之为Tracker),状态迁移规则决定了某类问题是否可以从一个状态迁移到另外一个状态
文章来自[SVN中文技术网]转发请保留本站地址:http://www.svn8.com/svnjs/20090209/2337.html
修改E:\InstantRails-2.0-win\rails_apps\redmine-0.8.5\vendor\rails\railties\lib\commands\servers\webrick.rb文件
require 'webrick'
require 'optparse'
require 'commands/servers/base'
OPTIONS = {
:port => 3000,
:ip => "0.0.0.0",
:environment => (ENV['RAILS_ENV'] || "development").dup,
:server_root => File.expand_path(RAILS_ROOT + "/public/"),
:server_type => WEBrick::SimpleServer,
:charset => "UTF-8",
:mime_types => WEBrick::HTTPUtils::DefaultMimeTypes,
:debugger => false
}
重启服务即可
要将 Windows XP 配置为能够搜索所有文件(无论文件类型是什么),请获取最新的 Windows XP Service Pack,然后打开“含有未知扩展名的索引文件类型”选项。
测试部分:『
如果您使用该方法,Windows XP 会在所有文件类型中搜索您指定的文本。这可能会影响搜索功能的性能。为此,请按照下列步骤操作: 1. 单击“开始”,然后单击“搜索”(或指向“搜索”,然后单击“文件或文件夹”)。
2. 单击“改变首选项”,然后单击“使用制作索引服务(使本地搜索更快)”。
3. 单击“改变制作索引服务设置(高级)”。请注意,您不必打开索引服务。
4. 在工具栏上,单击“显示/隐藏控制台树”。
5. 在左窗格中,右键单击“本机索引服务”,然后单击“属性”。
6. 在“生成”选项卡上,单击以选中“含有未知扩展名的索引文件”复选框,然后单击“确定”。
7. 关闭索引服务控制台。 』
警告:如果使用注册表编辑器或其他方法错误地修改了注册表,则可能导致严重问题。不提倡大家再网上搜到那些改变筛选等注册项的方法
环境:
服务器操作系统是windows2003(32位), 硬件配置为2C(CPU)8G(Memory)PC服务器, 用做Oracle服务器.
oracle版本为10.1.0.2, $oracle_home为d:/oracle/product, sid为orcl.
方案1:
--------------------------------------------------------------------------
因为服务器是32位的操作系统, 所以最大只能分2G内存给Oracle使用, 规划如下:
SGA:1.72G
PGA:250M
操作步骤
1. 创建pfile
SQL>create pfile from spfile
这样就在d:/oracle/product/10.1.0/db_1/database目录下面多1个文件INITorcl.ORA
或者copy d:/oracle/product/10.1.0/admin/orcl/pfile/init.ora.XXXXXXXX到上述目录, 名字改成INITorcl.ORA
init.ora.XXXX也是个pfile文件, 不妨试着用这个文件启动你的数据库
SQL>startup pfile='d:/oracle/product/10.1.0/admin/orcl/pfile/init.ora.XXXXXXXX'
特别是你改动参数导致数据库无法启动的情况下, 用这个文件恢复你的spfile将非常有用
SQL>create spfile from pfile='d:/oracle/product/10.1.0/admin/orcl/pfile/init.ora.XXXXXXXX'
2.修改pfile的内容
修改后主要内容为
sga_target=1700000000(1.7G左右)
lock_sga=true
pre_aggregate_tagert=250000000(250M左右)
workarea_size_policy=auto
pre_page_sga=true
sga_max_size=1720000000(1.72G左右)
3.根据pfile启动数据库
SQL>startup pfile='d:/oracle/product/10.1.0/db_1/database/INITorcl.ORA'
如果不能启动, 可能是某些参数的原因, 那么就修改INIToracl.ORA的配置文件, 直到能正常启动为止.
4.创建spfile
SQL>create spfile from pfile
上诉命令将覆盖d:/oracle/product/10.1.0/db_1/database/下的spfile文件"SPFILEORCL.ORA"
当然你也可以显式的指明pfile
SQL>create spfile from 'd:/oracle/product/10.1.0/db_1/database/INITorcl.ORA'
5.用spfile启动数据库并调整性能
SQL>startup
然后在oem中调整各种参数,调整后的参数将写在spfile中,但是不会写在pfile中
总结:这样下来,感觉服务器的内存并没有被充分利用, 8G服务器只有2G给了Oracle使用, 并不是非常理想,但是我们最终还是采用了这种方案
这是因为:
1:我们试过另外一种方案后感觉速度不但没有提升, 反而有下降, 可能是因为服务器调整的参数有些问题
2:但是我们不愿意冒着修改服务器参数的风险, 尤其是1个在线系统
3:还有1个重要的原因就是客户答应我们很快用64位的windows 2003操作系统
方案2:
--------------------------------------------------------------------------------------------------
我们使用AWE的方法来使得Oracle能使用大于2G的内存, 规划如下:
DB_BUFFER_SIZE:3.2G
large_pool:150M
java_pool:150M
share_pool:800M
PGA:500M
操作步骤
1. 修改服务器启动参数
修改c:/boot.ini文件, 在启动的操作系统参数后加上/3GB /PAE, 如:
multi(0)disk(0)rdisk(0)partition(1)\WINDOWS="Windows Server 2003, Enterprise" /noexecute=optout /fastdetect /3GB /PAE
2. 注册表增加1个二进制键值
路径为hkey_local_machine/software/oracle/key_Oradb10g_home1/, 键值为
AWE_WINDOW_MEMORY=20000000000
3. 创建pfile
SQL>create pfile from spfile
这样就在d:/oracle/product/10.1.0/db_1/database目录下面多1个文件INITorcl.ORA,
或者copy d:/oracle/product/10.1.0/admin/orcl/pfile/init.ora.XXXXXXXX到上述目录, 名字改成INITorcl.ORA
init.ora.XXXX也是个pfile文件,不妨试着用这个文件启动你的数据库
SQL>startup pfile='d:/oracle/product/10.1.0/admin/orcl/pfile/init.ora.XXXXXXXX'
特别是你改动参数导致数据库无法启动的情况下, 用这个文件恢复你的spfile将会非常有用
SQL>create spfile from pfile='d:/oracle/product/10.1.0/admin/orcl/pfile/init.ora.XXXXXXXX'
2.修改pfile的内容
修改后主要内容为
db_block_buffers=400000
db_block_size=8192
java_pool_size=150000000(150M)
job_queue_processes=10
large_pool_size=150000000(150M)
shared_pool_size=800000000(800M)
lock_sga=true
pre_aggregate_tagert=500000000(250M左右)
workarea_size_policy=auto
pre_page_sga=true
use_indirect_data_buffers=true
注意1:db_buffer_size=db_block_buffers*db_block_size, db_block_size为数据库默认值, 不要修改,
比如你的db_block_size为4096话, 那么你的db_block_buffers应该为80000, 使得它们的乘积为3.2G
注意2:pfile不要有SGA_TARGET这个参数, 也不要有db_cache_size这个参数, SGA_MAX_SIZE也不需要
3.根据pfile启动数据库
SQL>startup pfile='d:/oracle/product/10.1.0/db_1/database/INITorcl.ORA'
如果不能启动, 可能是某些参数的原因, 那么就修改INIToracl.ORA的配置文件, 直到能正常启动为止。
4.创建spfile
SQL>create spfile from pfile
上诉命令将覆盖d:/oracle/product/10.1.0/db_1/database/下的spfile文件"SPFILEORCL.ORA"
当然你也可以显式的指明pfile
SQL>create spfile from 'd:/oracle/product/10.1.0/db_1/database/INITorcl.ORA'
5.用spfile启动数据库并调整性能
SQL>startup
然后在oem中调整各种参数, 调整后的参数将写在spfile中, 但是不会写在pfile中
总结:这样以来, 大概有5G的内存给服务器使用, 但是执行同样的SQL并没有效率上的提高, 可能并发的时候效率有所提高, 所以这种方案最终放弃, 要想使用大内存, 建议使用64位数的操作系统代替32位的操作系统, 这样使人更放心.
是不是很难准确地分配不同的池所需的内存数?自动共享内存管理特性使得自动将内存分配到最需要的地方去成为可能。
无论您是一个刚入门的 DBA 还是一个经验丰富的 DBA,您肯定至少看到过一次类似以下的错误:
ORA-04031:unable to allocate 2216 bytes of shared memory ("shared pool"... ...
或者这种错误:
ORA-04031:unable to allocate XXXX bytes of shared memory
("large pool","unknown object","session heap","frame")
或者可能这种错误:
ORA-04031:unable to allocate bytes of shared memory ("shared pool",
"unknown object","joxlod:init h", "JOX:ioc_allocate_pal")
第一种错误的原因很明显:分配给共享池的内存不足以满足用户请求。(在某些情况下,原因可能不是池本身的大小,而是未使用绑定变量导致的过多分析造成的碎片,这是我很喜欢的一个主题;但目前让我们把重点放在手头的问题上。)其它的错误分别来自大型池和 Java 池的空间不足。
您需要解决这些错误情况,而不作任何与应用程序相关的修改。那么有哪些方案可选呢?问题是如何在Oracle 例程所需的所有池之间划分可用的内存。
馅饼怎么分?
正如您所了解的,一个 Oracle 例程的系统全局区域 (SGA) 包含几个内存区域(包括缓冲高速缓存、共享池、Java 池、大型池和重做日志缓冲)。这些池在操作系统的内存空间中占据了固定的内存数;它们的大小由 DBA 在初始化参数文件中指定。
这四个池(数据库块缓冲高速缓存、共享池、Java 池和大型池)几乎占据了 SGA 中所有的空间。(与其它区域相比,重做日志缓冲没有占据多少空间,对我们这里的讨论无关紧要。)作为 DBA,您必须确保它们各自的内存分配是充足的。
假定您决定了这些池的值分别是 2GB、1GB、1GB 和 1GB。您将设置以下初始化参数来为数据库例程规定池的大小。
db_cache_size = 2g
shared_pool_size = 1g
large_pool_size = 1g
java_pool_size = 1g
现在,仔细看一下这些参数。坦白讲,这些值是否准确?
我相信您一定会有疑虑。在实际中,没有人能够为这些池指定确切的内存数 — 它们太依赖于数据库内部的处理,而处理的特性随时在变化。
下面是一个示例场景。假定您有一个典型的、大部分属于 OLTP 的数据库,并且为缓冲高速缓存分配的专用内存比为纯 OLTP 数据库(现在已经很少见了)分配的要少。有一天,您的用户放开了一些非常大的全表扫描,以创建当天的结束报表。Oracle9i 数据库为您提供了在线修改内存分配的功能,但由于提供的总物理内存有限,您决定从大型池和 Java 池中取出一些内存:
alter system set db_cache_size = 3g scope=memory;
alter system set large_pool_size = 512m scope=memory;
alter system set java_pool_size = 512m scope=memory;
这个解决方案能够很好地工作一段时间,但是接着夜间的 RMAN 作业(它们使用大型池)开始了,大型池将立即出现内存不足。同样,您从数据库高速缓存中取出一些内存来补充大型池,以挽救这种局面。
RMAN 作业完成,然后启动一个广泛使用 Java 的批处理程序,接着您开始看到与 Java 池相关的错误。因此,您(再次)重新分配池,以满足 Java 池和数据库高速缓存上的内存需求:
alter system set db_cache_size = 2G scope=memory;
alter system set large_pool_size = 512M scope=memory;
alter system set java_pool_size = 1.5G scope=memory;
第二天早上,OLTP 作业恢复在线,这个循环又完全重复!
解决这种恶性循环的一种替代方法是永久设置每个池的最大需求。不过,这么做的话,您分配的总的 SGA 可能超出可用的内存 — 从而在为每个池分配的内存数不足时,将增加交换和分页的风险。人工重新分配的方法(虽然不实际)目前看起来很不错。
另一种替代方法是将值设为可接受的最小值。不过,当需求增长且内存不能完全满足时,性能将受到影响。
注意在所有这些示例中,分配给 SGA 的总内存保持不变,而池之间的内存分配根据即时的需求进行修改。如果 RDBMS 将自动探测来自用户的需求并相应地重新分布内存分配,那不是很好吗?
Oracle 数据库 10g 中的自动共享内存管理特性正好能够实现这一目的。您可以决定 SGA 的总大小,然后设置一个名称为 SGA_TARGET 的参数,这个参数决定 SGA 的总大小。SGA 内部的各个池将根据工作负载动态地进行配置。实现自动内存分配仅仅需要 SGA_TARGET 参数的一个非零值。
设置自动共享内存管理
让我们看看该特性是如何工作的。首先,确定 SGA 的总大小。您可以通过确定现在分配了多少内存来估计这个值。
SQL> select sum(value)/1024/1024 from v$sga;
SUM(VALUE)/1024/1024
--------------------
500
此时 SGA 的当前总大小近似为 500MB,并且这个值将变为 SGA_TARGET 的值。接下来,执行语句:
alter system set sga_target = 500M scope=both;
这种方法不需要为各个池设置不同值;因而,您将需要在参数文件中使它们的值为零或全部删除它们。
shared_pool_size = 0
large_pool_size = 0
java_pool_size = 0
db_cache_size = 0
再循环数据库,使这些值生效。
这个人工过程还可以通过 Enterprise Manager 10g 实施。从数据库主页中,选择 "Administration" 选项卡,然后选择 "Memory Parameters"。对于人工配置的内存参数,将显示标记为 "Enable" 的按钮,以及所有人工配置的池的值。单击 "Enable" 按钮,启用自动共享内存管理特性。企业管理器将完成剩下的工作。
在配置了自动内存分配之后,您可以利用以下命令检查它们的大小:
SQL> select current_size from v$buffer_pool;
CURRENT_SIZE
------------
340
SQL> select pool, sum(bytes)/1024/1024 Mbytes from v$sgastat group by pool;
POOL MBYTES
------------ ----------
java pool 4
large pool 4
shared pool 148
正如您所看到的,所有的池都从 500MB 的总目标大小中自动进行分配。(参见图 1。)缓冲高速缓存大小是 340MB,Java 池是 4MB,大型池是 4MB,共享池是 148MB。它们合起来总的大小为 (340+4+4+148=) 496MB,近似与 500MB 的目标 SGA 的大小相同。

图 1:池的初始分配
现在假定提供给 Oracle 的主机内存从 500MB 减少为 300MB,这意味着我们必须减少总 SGA 的大小。我们可以通过减小目标 SGA 大小来反映这种变化。
alter system set sga_target = 300M scope=both;
现在查看各个池,我们可以看到:
SQL> select current_size from v$buffer_pool;
CURRENT_SIZE
------------
244
SQL> select pool, sum(bytes)/1024/1024 Mbytes from v$sgastat group by pool;
POOL MBYTES
------------ ----------
java pool 4
large pool 4
shared pool 44
占用的总大小是 240+4+4+44 = 296MB,接近于目标的 300MB。注意如图 2 所示,当 SGA_TARGET 改变时,如何自动重新分配池。

图 2:在将 SGA 大小减少到 300MB 之后重新分配池
这些池的大小是动态的。池将根据工作负载扩展,以容纳需求的增长,或缩小以容纳另一个池的扩展。这种扩展或缩小自动发生,无需 DBA 的干预,这与本文开头的示例不同。让我们暂时返回到那个场景,假定在初始分配后,RMAN 作业启动,指示需要一个更大的大型池,大型池将从 4MB 扩展到 40MB,以容纳需求。这个额外的 36MB 将从数据库缓冲中划出,数据库块缓冲将缩小,如图 3 所示。

图 3:在对大型池的需求增长之后经过重新分配的池
池的大小变化基于系统上的工作负载,因此不需要为最坏的情况调整池的大小 — 它们将根据需求的增长自动调整。此外,SGA 的总大小始终在由 SGA_TARGET 指定的最大值之内,因此不存在使内存需求的增长比例失调(这将导致分页和交换)的风险。您可以动态地将 SGA_TARGET 增加至绝对最大值,这个绝对最大值是通过调整参数 SGA_MAX_SIZE 指定的。
哪些池不受影响?
SGA 中的一些池不受动态大小调整的影响,但是必须显式指定这些池。其中值得注意的是非标准块大小的缓冲池,以及 KEEP 池或 RECYCLE 池的非默认块大小。如果您的数据库有一个块大小为 8K,而您想要配置 2K、4K、16K 和 32K 块大小的池,那么您必须手动设置它们。它们的大小将保持不变;它们将不会根据负载缩小或扩展。当使用多种大小的缓冲池、KEEP 池和 RECYCLE 池时,您应当考虑这个因素。此外,日志缓冲不受内存调整的影响 — 不管工作负载如何,
有些参数不能动态修改,需要使用ALTER SYSTEM SET parameter = value SCOPE = SPFILE,然后重新启动数据库才能生效。
而ALTER SYSTEM SET parameter = value 使用的默认SCOPE = BOTH,包括同时修改spfile 和当前的设置。
摘要:通过探讨和研究Oracle服务器和Client/Server的特点和原理,阐述了提高、调整Oracle应用系统性能的一些原则和方法。
关键词:Oracle;客户/服务器;系统全程区;网络I/O;回滚段。
Oracle 数据库广泛应用在社会的各个领域,特别是在Client/Server模式的应用,但是应用开发者往往碰到整个系统的性能随着数据量的增大显著下降的问题,为了解决这个问题,从以下几个方面:数据库服务器、网络I/O、应用程序等对整个系统加以调整,充分发挥Oracle的效能,提高整个系统的性能。
1 调整数据库服务器的性能
Oracle数据库服务器是整个系统的核心,它的性能高低直接影响整个系统的性能,为了调整Oracle数据库服务器的性能,主要从以下几个方面考虑:
1.1 调整操作系统以适合Oracle数据库服务器运行
Oracle数据库服务器很大程度上依赖于运行服务器的操作系统,如果操作系统不能提供最好性能,那么无论如何调整,Oracle数据库服务器也无法发挥其应有的性能。
1.1.1 为Oracle数据库服务器规划系统资源
据已有计算机可用资源, 规划分配给Oracle服务器资源原则是:尽可能使Oracle服务器使用资源最大化,特别在Client/Server中尽量让服务器上所有资源都来运行Oracle服务。
1.1.2 调整计算机系统中的内存配置
多数操作系统都用虚存来模拟计算机上更大的内存,它实际上是硬盘上的一定的磁盘空间。当实际的内存空间不能满足应用软件的要求时,操作系统就将用这部分的磁盘空间对内存中的信息进行页面替换,这将引起大量的磁盘I/O操作,使整个服务器的性能下降。为了避免过多地使用虚存,应加大计算机的内存。
1.1.3 为Oracle数据库服务器设置操作系统进程优先级
不要在操作系统中调整Oracle进程的优先级,因为在Oracle数据库系统中,所有的后台和前台数据库服务器进程执行的是同等重要的工作,需要同等的优先级。所以在安装时,让所有的数据库服务器进程都使用缺省的优先级运行。
1.2 调整内存分配
Oracle数据库服务器保留3个基本的内存高速缓存,分别对应3种不同类型的数据:库高速缓存,字典高速缓存和缓冲区高速缓存。库高速缓存和字典高速缓存一起构成共享池,共享池再加上缓冲区高速缓存便构成了系统全程区(SGA)。SGA是对数据库数据进行快速访问的一个系统全程区,若SGA本身需要频繁地进行释放、分配,则不能达到快速访问数据的目的,因此应把SGA放在主存中,不要放在虚拟内存中。内存的调整主要是指调整组成SGA的内存结构的大小来提高系统性能,由于Oracle数据库服务器的内存结构需求与应用密切相关,所以内存结构的调整应在磁盘I/O调整之前进行。
1.2.1 库缓冲区的调整
库缓冲区中包含私用和共享SQL和PL/SQL区,通过比较库缓冲区的命中率决定它的大小。要调整库缓冲区,必须首先了解该库缓冲区的活动情况,库缓冲区的活动统计信息保留在动态性能表v$librarycache数据字典中,可通过查询该表来了解其活动情况,以决定如何调整。
Select sum(pins),sum(reloads) from v$librarycache;
|
Pins列给出SQL语句,PL/SQL块及被访问对象定义的总次数;Reloads列给出SQL 和PL/SQL块的隐式分析或对象定义重装载时在库程序缓冲区中发生的错误。如果sum(pins)/sum(reloads) ≈0,则库缓冲区的命中率合适;若sum(pins)/sum(reloads)>1, 则需调整初始化参数 shared_pool_size来重新调整分配给共享池的内存量。
1.2.2 数据字典缓冲区的调整
数据字典缓冲区包含了有关数据库的结构、用户、实体信息。数据字典的命中率,对系统性能影响极大。数据字典缓冲区的使用情况记录在动态性能表v$librarycache中,可通过查询该表来了解其活动情况,以决定如何调整。
Select sum(gets),sum(getmisses) from v$rowcache;
|
Gets列是对相应项请求次数的统计;Getmisses 列是引起缓冲区出错的数据的请求次数。对于频繁访问的数据字典缓冲区,sum(getmisses)/sum(gets)<10%~15%。若大于此百分数,则应考虑增加数据字典缓冲区的容量,即需调整初始化参数shared_pool_size来重新调整分配给共享池的内存量。
1.2.3 缓冲区高速缓存的调整
用户进程所存取的所有数据都是经过缓冲区高速缓存来存取,所以该部分的命中率,对性能至关重要。缓冲区高速缓存的使用情况记录在动态性能表v$sysstat中,可通过查询该表来了解其活动情况,以决定如何调整。
Select name,value from v$sysstat where name in
('dbblock gets','consistent gets','physical reads');
|
dbblock gets和consistent gets的值是请求数据缓冲区中读的总次数。physical reads的值是请求数据时引起从盘中读文件的次数。从缓冲区高速缓存中读的可能性的高低称为缓冲区的命中率,计算公式:
Hit Ratio=1-(physical reds/(dbblock gets+consistent gets))
如果Hit Ratio<60%~70%,则应增大db_block_buffers的参数值。db_block_buffers可以调整分配给缓冲区高速缓存的内存量,即db_block_buffers可设置分配缓冲区高速缓存的数据块的个数。缓冲区高速缓存的总字节数=db_block_buffers的值*db_block_size的值。db_block_size 的值表示数据块大小的字节数,可查询 v$parameter 表:
select name,value from v$parameter where name='db_block_size';
|
在修改了上述数据库的初始化参数以后,必须先关闭数据库,在重新启动数据库后才能使新的设置起作用。
1.3 调整磁盘 I/O
磁盘的I/O速度对整个系统性能有重要影响。解决好磁盘I/O问题,可显著提高性能。影响磁盘I/O的性能的主要原因有磁盘竞争、I/O次数过多和数据块空间的分配管理。
为Oracle数据库服务器创建新文件时,不论是表空间所用的数据文件还是数据事务登录所用的日志文件,都应仔细考虑数据库服务器上的可用磁盘资源。如果服务器上有多个磁盘,则可将文件分散存储到各个可用磁盘上,减少对数据库的数据文件及事务日志文件的竞争,从而有效地改善服务器的性能。对于不同的应用系统都有各自的数据集,应当创见不同的表空间分别存储各自应用系统的数据,并且尽可能的把表空间对应的数据文件存放在不同的磁盘上,这种从物理上把每个应用系统的表空间分散存放的方法,可以排除两个应用系统竞争磁盘的可能性。数据文件、事务日志文件分别存放在不同的磁盘上,这样事务处理执行的磁盘访问不妨碍对相应的事物日志登记的磁盘访问。如果有多个磁盘可用,将两个事物日志成员放在不同的磁盘驱动器上,就可以消除日志文件可能产生的磁盘竞争。应把一个应用的表数据和索引数据分散存放不同表空间上,并且尽量把不同类型的表空间存放在不同磁盘上,这样就消除了表数据和索引数据的磁盘竞争。
1.4 调整数据库服务器的回滚段
回滚段是一个存储区域,数据库使用该存储区域存放曾经由一个事务更新或删除的行的原始数据值。如果用户要回滚一个事务所做的改变,那么数据库就从回滚段中读回改变前的数据并使该事务影响的行改变为它们的原状态。回滚段控制着数据库处理事务的能力,因而在数据库成功中起着关键性的作用,不管数据库的其它部分设计得多好,如果它设计得不合理,将会严重影响系统的性能。建立和调整回滚段的原则如下。
1.4.1 分离回滚段
分离回滚段是指单独为回滚段创建一个以上的表空间,使回滚段与数据字典、用户数据、索引等分离开来。由于回滚段的写入与数据和索引的写入是并行进行的,因此将它分离出来可以减少I/O争用。如果回滚段与数据不分离,倘若要某个表空间脱机或撤消,那么在该表空间中的各个回滚段没有全部脱机之前,不能将这个表空间脱机或撤消。而一旦该表空间不可用,则该表空间中的所有回滚段也不能使用,这将浪费所有分配的磁盘空间。所以,独立回滚段可使数据库管理变得容易。回滚段的经常性收缩,使得表空间的自由块更容易形成碎片。分离回滚段可以减少数据库表空间的碎片产生。
1.4.2 创建不同大小的回滚段群
对于一些联机事物处理,他们一般是频繁地对少量数据进行修改,创建许多小的回滚段对之有利。每一个事物的入口项只能限于一个回滚段,回滚段应该充分大以容纳一个完整的事物处理,因此对一些较大型事物,需要较大型的回滚段。极个别脱机处理事物会产生大量的回滚信息,这时需要一个特大号的回滚段来处理。根据这些理论,在Oracle数据库服务器中针对上述3种事物处理创建三组:小事物组、较大事物组、特大事物组等大小不同的回滚段群,并且将之分散到3个不同的表空间上,群内大小相同,应能满足该组事物处理的最大要求。
1.4.3 创建数量适当的回滚段
一般回滚段数量与并发事物个数有关,以下给出由于并发事物个数而应建立回滚段的参考数:
并发事物(n) 回滚段数
n<16 4
16 ≤ n<32 8
n≥ 32 n/4
|
2 调整 Client/Server 模式下的网络 I/O
Client/Server环境中的应用处理是分布在客户应用程序和数据库服务程序之间的。在 Client/Server环境中Client与Server之间的网络I/O是整个系统性能提高的瓶颈,一个客户应用程序引起的网络I/O越少,应用及整个系统的性能越好。减少网络I/O的最重要的一条原则:将应用逻辑集中在数据库服务器中。
2.1 使用Oracle数据库的完整约束性
当为应用建表时,应当为一些有特殊要求的数据加上适当的完整性约束,这样就能实现由数据库本身而不是应用程序来约束数据符合一定的条件。数据库服务器端的完整约束的执行操作是在比SQL语句级别更低的系统机制上优化,它与客户端无关,只在服务器中运行,不需在Client 端和Server端之间传递SQL语句,有效地减轻网络I/O负担。
2.2 使用数据库触发器
完整约束性只能实现一些较简单的数据约束条件,对一些较复杂的事物处理规则就无能为力,这时最好不要在应用程序中实施复杂的程序控制,而是应当采用数据库触发器来实施复杂的事物规则。数据库触发器能实现由数据库本身,而不是应用程序,来约束数据符合复杂的事物处理规则,并且容易创建,便于管理,避免大量的网络I/O。
例如:将当前表A中成为历史的记录从A表中转储到历史表B中,表示为Lsbs。
在应用程序中实现: 用数据库触发器实现:
Beign Create trigger delete1
Update A set lsbs='T'; After update of lsbs on A
Insert into B For each row
Select * from A where lsbs='T'; Insert into B
Delete A where lsbs='T'; select * from A where :new.lsbs='T';
End; Delete A where :new.lsbs='T';
End delete1;
|
在应用程序中实现时,所有的SQL命令请求传送的数据都要通过网络在Client端和Server端进行交换,而不像数据库触发器一样,SQL本身在Server端,不需要通过网络传输数据。当进行操作的数据量相当大时,并且多个用户同时操作时,通过在应用程序中实现复杂的控制,必将增大网络I/O的负荷,使整个系统的性能降低,而用数据库触发器能完全避免这种情况发生。
2.3 使用存储过程、存储函数和包
Oracle的存储过程和存储函数是命名的能完成一定功能并且存储在Server端的PL/SQL的集合。包是一种把有关的过程和函数组织封装成一个数据库程序单元的方法。它们相对于应用程序的过程、函数而言,把SQL命令存储在Server端。使用存储过程和存储函数,应用程序不必再包含多个网络操作的SQL语句去执行数据库服务器操作,而是简单调用存储过程和存储函数,在网络上传输的只是调用过程的名字和输出结果,这样就可减少大量的网络I/O。
例如:基表A、B的定义:name char(20);detail char(10);A表100万记录,应用程序将从基表A中检索detail列符合给出条件的记录,并将之插入基表B。
Declare
Cursor cursor1 is select*from A;poin cursor1%type;
con1 number(2);res1 char(4)='abcd';
Begin Insert into B values(poin.name,poin.detail);end if;
For poin in cursor1 loop End loop;End loop;
For con1 in 1..7 loop Commit;
If substr(poin.detail ,con1,4)=res1 then End;
|
如果在Developer/2000 From中按钮触发器直接用PL/SQL实现和把它改写为一个Oracle存储过程,然后在From中调用此过程实现比较,后者性能显著提高。
在考虑使用上述3种方法时:首先考虑使用完整约束性。对于数据库触发器和存储过程,如果需要所有访问数据库的程序自动实施一定规则或检查,那么使用数据库触发器;如果只需对少数的程序实施一定的规则或检查,则可创建一个过程,让有关程序调用这个过程。
3 应用程序的调整
3.1 SQL语句的优化
SQL语句的执行速度,可以受很多因素的影响而变化。但主要的影响因素是:驱动表、执行操作的先后顺序和索引的运用。可以由很多不同的方法间接地改变这些因素,以达到最优的执行速度。这里主要探讨当对多个表进行连接查询时应遵循的优化原则:
(1) 用于连接的子句的列应被索引、在Where子句中应尽量利用索引,而不是避开索引。
(2) 连接操作应从返回较少行上驱动。
(3) 如果所连接的表A和B,A表长度远远大于B表,建议从较大的A表上驱动。
(4) 如果Where子句中含有选择性条件,Where No=20,将最具有选择性部分放在表达式最后。
(5) 如果只有一个表有索引,另一表无索引,无索引的表通常作为驱动表。如A表的No列以被索引,而B表的No 列没被索引,则应当B表作为驱动表,A表作为被驱动表。
(6) 若用于连接的列和Where子句中其他选择条件列均有索引,则按各个索引对查询的有效性和选择性分别定出级别,结合表中具体数据构成情况,从中选出优化路径,一般需要考虑:子句中哪些列可以使用索引、哪些索引具有唯一性及被查询表行数目等。
3.2 建立和使用视图、索引
利用视图可以将基表中的列或行进行裁减、隐藏一部分数据,并且能够将涉及到多个表的复杂查询以视图的方式给出,使应用程序开发简洁快速。利用索引可以提高查询性能,减少磁盘 I/O,优化对数据表的查询,加速SQL语句的执行。但任何时候建立索引都能提高性能,何时建立索引应当遵循以下原则:该表常用来在索引列上查询,该表不常更新、插入、删除等操作,查询出来的结果记录数应控制在原表的2%~4%。
3.3 使用 Oracle 的数组接口
当一个客户应用程序插入一行或用一个查询来向服务器请求某行时,不是发送具有单个行的网络包,而是采用数组处理,即把要插入的多个行或检索出的多个行缓冲在数组中,然后通过很少的几个包就可在网上传送这些数组。例如,一个给定的Select语句返回2000行数据,每行平均大小为40个字节,数据包的大小为4kB,而数组大小参数(arraysize)设置为20 ,则需从服务器发送100个数据包到客户机。如果简单地把(arraysize)设置为2000,那么同样的操作只需要传送 20个数据包。这样就减少了网络的传输量,提高了所有应用的性能。
4 总结
我们在开发应用程序时,遵循上述的方法和原则,对系统进行调整,收到了令人满意的效果。但是应当指出,由于客户机、网络、服务器这3个相互依存的组成部分都必须调整和同步才能产生最佳的性能,因此还应根据系统的具体情况,具体分析和调整。
Oracle Database 10g Release 2 (10.2.0.1.0) Enterprise/Standard Edition for Microsoft Windows (32-bit)
http://download.oracle.com/otn/nt/oracle10g/10201/10201_database_win32.zip
http://download.oracle.com/otn/nt/oracle10g/10201/10201_client_win32.zip
http://download.oracle.com/otn/nt/oracle10g/10201/10201_clusterware_win32.zip
http://download.oracle.com/otn/nt/oracle10g/10201/10201_gateways_win32.zip
Oracle Database 10g Release 2 (10.2.0.1.0) Enterprise/Standard Edition for Microsoft Windows (x64)
http://download.oracle.com/otn/nt/oracle10g/10201/102010_win64_x64_database.zip
http://download.oracle.com/otn/nt/oracle10g/10201/102010_win64_x64_client.zip
http://download.oracle.com/otn/nt/oracle10g/10201/102010_win64_x64_clusterware.zip
Oracle Database 10g Release 2 (10.2.0.1.0) Enterprise/Standard Edition for Linux x86
http://download.oracle.com/otn/linux/oracle10g/10201/10201_database_linux32.zip
http://download.oracle.com/otn/linux/oracle10g/10201/10201_client_linux32.zip
http://download.oracle.com/otn/linux/oracle10g/10201/10201_gateways_linux32.zip
Oracle Database 10g Release 2 (10.2.0.1.0) Enterprise/Standard Edition for Linux x86-64
http://download.oracle.com/otn/linux/oracle10g/10201/10201_database_linux_x86_64.cpio.gz
http://download.oracle.com/otn/linux/oracle10g/10201/10201_client_linux_x86_64.cpio.gz
http://download.oracle.com/otn/linux/oracle10g/10201/10201_clusterware_linux_x86_64.cpio.gz
http://download.oracle.com/otn/linux/oracle10g/10201/10201_gateways_linux_x86_64.cpio.gz
Oracle Database 10g Release 2 (10.2.0.1.0) Enterprise/Standard Edition for AIX5L
http://download.oracle.com/otn/aix/oracle10g/10201/10gr2_aix5l64_database.cpio.gz
http://download.oracle.com/otn/aix/oracle10g/10201/10gr2_aix5l64_client.cpio.gz
http://download.oracle.com/otn/aix/oracle10g/10201/10gr2_aix5l64_cluster.cpio.gz
http://download.oracle.com/otn/aix/oracle10g/10201/10gr2_aix5l64_gateways.cpio.gz
Oracle Database 10g Release 2 (10.2.0.2) Enterprise/Standard Edition for Solaris Operating System (x86)
http://download.oracle.com/otn/solaris/oracle10g/10202/10202_database_solx86.zip
http://download.oracle.com/otn/solaris/oracle10g/10202/10202_client_solx86.zip
http://download.oracle.com/otn/solaris/oracle10g/10202/10202_clusterware_solx86.zip
Oracle Database 10g Release 2 (10.2.0.1.0) Enterprise/Standard Edition for Solaris Operating System (x86-64)
http://download.oracle.com/otn/solaris/oracle10g/10201/x8664/10201_database_solx86_64.zip
http://download.oracle.com/otn/solaris/oracle10g/10201/x8664/10201_client_solx86_64.zip
http://download.oracle.com/otn/solaris/oracle10g/10201/x8664/10201_clusterware_solx86_64.zip
---------------------------------------------------------------------------------------------------------
更多oracle10g数据库相关下载请参考下面的官方下载网址:http://www.oracle.com/technology/global/cn/software/products/database/index.html
ORACLE10gR2下载_oracle10G官方下载_Oracle10G Release2(10.2.0.1.0)下载_Oracle10g下载_oracle下载(Authour: 王大帅 Email: dashuaiwang@126.com 个人空间:http://wds.3u.cn)
ORACLE10G 补丁_ORACLE10g PATCH下载地址:
oracle 10.2.0.2 patch:
ftp://updates.oracle.com/4547817/p4547817_10202_AIX64-5L.zip
ftp://updates.oracle.com/4547817/p4547817_10202_HP64.zip
ftp://updates.oracle.com/4547817/p4547817_10202_HPUX-IA64.zip
ftp://updates.oracle.com/4547817/p4547817_10202_LINUX.zip
ftp://updates.oracle.com/4547817/p4547817_10202_Linux-IA64.zip
ftp://updates.oracle.com/4547817/p4547817_10202_Linux-x86-64.zip
ftp://updates.oracle.com/4547817/p4547817_10202_MVS.zip
ftp://updates.oracle.com/4547817/p4547817_10202_SOLARIS.zip
ftp://updates.oracle.com/4547817/p4547817_10202_SOLARIS64.zip
ftp://updates.oracle.com/4547817/p4547817_10202_WINNT.zip
ftp://updates.oracle.com/4547817/p4547817_10202_WINNT64.zip
oracle 10.2.0.3 patch:
ftp://updates.oracle.com/5337014/p5337014_10203_WINNT.zip
ftp://updates.oracle.com/5337014/p5337014_10203_WINNT64.zip
ftp://updates.oracle.com/5337014/p5337014_10203_AIX5L.zip
ftp://updates.oracle.com/5337014/p5337014_10203_WINNT.zip
ftp://updates.oracle.com/5337014/p5337014_10203_WINNT.zip
ftp://updates.oracle.com/5337014/p5337014_10203_WINNT.zip
oracle 10.2.0.4 patch:
ftp://updates.oracle.com/6810189/p6810189_10204_AIX5L.zip
ftp://updates.oracle.com/6810189/p6810189_10204_LINUX.zip
ftp://updates.oracle.com/6810189/p6810189_10204_Linux-x86-64.zip
ftp://updates.oracle.com/6810189/p6810189_10204_Linux-x86.zip
ftp://updates.oracle.com/6810189/p6810189_10204_Win32.zip
ftp://updates.oracle.com/6810189/p6810189_10204_Win64.zip
Oracle9i
Oracle9i Database Release 2 Enterprise/Standard/Personal Edition for Windows NT/2000/XP
http://download.oracle.com/otn/nt/oracle9i/9201/92010NT_Disk1.zip
http://download.oracle.com/otn/nt/oracle9i/9201/92010NT_Disk2.zip
http://download.oracle.com/otn/nt/oracle9i/9201/92010NT_Disk3.zip
Oracle9i Database Release 2 Enterprise/Standard/Personal/Client Edition for Windows XP 2003/Windows Server 2003 (64-bit)
http://download.oracle.com/otn/nt/oracle9i/9202/92021Win64_Disk1.zip
http://download.oracle.com/otn/nt/oracle9i/9202/92021Win64_Disk2.zip
Oracle9i Database Release 2 Enterprise/Standard Edition for Intel Linux
http://download.oracle.com/otn/linux/oracle9i/9204/ship_9204_linux_disk1.cpio.gz
http://download.oracle.com/otn/linux/oracle9i/9204/ship_9204_linux_disk2.cpio.gz
http://download.oracle.com/otn/linux/oracle9i/9204/ship_9204_linux_disk3.cpio.gz
Oracle9i Database Release 2 (9.2.0.4) Enterprise/Standard Edition for Linux x86-64
http://download.oracle.com/otn/linux/oracle9i/9204/amd64_db_9204_Disk1.cpio.gz
http://download.oracle.com/otn/linux/oracle9i/9204/amd64_db_9204_Disk2.cpio.gz
http://download.oracle.com/otn/linux/oracle9i/9204/amd64_db_9204_Disk3.cpio.gz
Oracle9i Database Release 2 Enterprise/Standard Edition for AIX - Based 4.3.3 Systems (64-bit)
http://download.oracle.com/otn/aix/oracle9i/9201/server_9201_AIX64_Disk1.cpio.gz
http://download.oracle.com/otn/aix/oracle9i/9201/server_9201_AIX64_Disk2.cpio.gz
http://download.oracle.com/otn/aix/oracle9i/9201/server_9201_AIX64_Disk3.cpio.gz
http://download.oracle.com/otn/aix/oracle9i/9201/server_9201_AIX64_Disk4.cpio.gz
Oracle9i Database Release 2 Enterprise/Standard Edition for AIX- Based 5L Systems
http://download.oracle.com/otn/aix/oracle9i/9201/A99331-01.zip
http://download.oracle.com/otn/aix/oracle9i/9201/A99331-02.zip
http://download.oracle.com/otn/aix/oracle9i/9201/A99331-03.zip
http://download.oracle.com/otn/aix/oracle9i/9201/A99331-04.zip
Oracle9i Database Release 2 Enterprise/Standard Edition for Sun SPARC Solaris (32-bit)
http://download.oracle.com/otn/solaris/oracle9i/9201/92010Sol_Disk1.cpio.gz
http://download.oracle.com/otn/solaris/oracle9i/9201/92010Sol_Disk2.cpio.gz
http://download.oracle.com/otn/solaris/oracle9i/9201/92010Sol_Disk3.cpio.gz
Oracle9i Database Release 2 Enterprise/Standard Edition for Sun SPARC Solaris (64-bit)
http://download.oracle.com/otn/solaris/oracle9i64/9201/solaris64_9.2.0.1.0.Disk1.cpio.gz
http://download.oracle.com/otn/solaris/oracle9i64/9201/solaris64_9.2.0.1.0.Disk2.cpio.gz
http://download.oracle.com/otn/solaris/oracle9i64/9201/solaris64_9.2.0.1.0.Disk3.cpio.gz
http://MSTRWebURL?server={&SERVERNAME}&project={&PR OJECT}&evt
48001&ViewMode=2&documentID=[ProvideDocID]&originMe ssageID={&DOCUMENTMESSAGEID}&elementsPromptAnswers ={&[ProvideAttributeName]@GUID};{&[ProvideAttribut e Name]@ElementID}
mstrWeb?server={&SERVERNAME}&project={&PROJECT}&port=0&evt=4001&src=mstrWeb.4001&reportID={&[固定资本形成总额各年情况分析]:GUID}&originMessageID={&DOCUMENTMESSAGEID}&reportViewMode=2
package com.dbs.vote.common.test.excel;
import java.io.File;
import java.io.FileOutputStream;
import java.io.OutputStream;
import java.util.ArrayList;
import java.util.Date;
import jxl.Cell;
import jxl.CellType;
import jxl.Sheet;
import jxl.Workbook;
import jxl.WorkbookSettings;
import jxl.format.Alignment;
import jxl.format.Border;
import jxl.format.BorderLineStyle;
import jxl.format.Colour;
import jxl.format.VerticalAlignment;
import jxl.write.Formula;
import jxl.write.Label;
import jxl.write.NumberFormat;
import jxl.write.WritableCellFeatures;
import jxl.write.WritableCellFormat;
import jxl.write.WritableFont;
import jxl.write.WritableSheet;
import jxl.write.WritableWorkbook;
import jxl.write.WriteException;
public class JExcelUtils {
/**
* 生成Excel文件
* @param path 文件路径
* @param sheetName 工作表名称
* @param dataTitles 数据标题
*/
public void createExcelFile(String path,String sheetName,String[] dataTitles){
WritableWorkbook workbook;
try{
OutputStream os=new FileOutputStream(path);
workbook=Workbook.createWorkbook(os);
WritableSheet sheet = workbook.createSheet(sheetName, 0); //添加第一个工作表
initialSheetSetting(sheet);
Label label;
for (int i=0; i<dataTitles.length; i++){
//Label(列号,行号,内容,风格)
label = new Label(i, 0, dataTitles[i],getTitleCellFormat());
sheet.addCell(label);
}
//插入一行
insertRowData(sheet,1,new String[]{"200201001","张三","100","60","100","260"},getDataCellFormat(CellType.STRING_FORMULA));
//一个一个插入行
label = new Label(0, 2,"200201002",getDataCellFormat(CellType.STRING_FORMULA));
sheet.addCell(label);
label = new Label(1, 2,"李四",getDataCellFormat(CellType.STRING_FORMULA));
sheet.addCell(label);
insertOneCellData(sheet,2,2,70.5,getDataCellFormat(CellType.NUMBER));
insertOneCellData(sheet,3,2,90.523,getDataCellFormat(CellType.NUMBER));
insertOneCellData(sheet,4,2,60.5,getDataCellFormat(CellType.NUMBER));
insertFormula(sheet,5,2,"C3+D3+E3",getDataCellFormat(CellType.NUMBER_FORMULA));
//插入日期
mergeCellsAndInsertData(sheet, 0, 3, 5, 3, new Date(), getDataCellFormat(CellType.DATE));
workbook.write();
workbook.close();
}catch(Exception e){
e.printStackTrace();
}
}
/**
* 初始化表格属性
* @param sheet
*/
public void initialSheetSetting(WritableSheet sheet){
try{
//sheet.getSettings().setProtected(true); //设置xls的保护,单元格为只读的
sheet.getSettings().setDefaultColumnWidth(10); //设置列的默认宽度
//sheet.setRowView(2,false);//行高自动扩展
//setRowView(int row, int height);--行高
//setColumnView(int col,int width); --列宽
sheet.setColumnView(0,20);//设置第一列宽度
}catch(Exception e){
e.printStackTrace();
}
}
/**
* 插入公式
* @param sheet
* @param col
* @param row
* @param formula
* @param format
*/
public void insertFormula(WritableSheet sheet,Integer col,Integer row,String formula,WritableCellFormat format){
try{
Formula f = new Formula(col, row, formula, format);
sheet.addCell(f);
}catch(Exception e){
e.printStackTrace();
}
}
/**
* 插入一行数据
* @param sheet 工作表
* @param row 行号
* @param content 内容
* @param format 风格
*/
public void insertRowData(WritableSheet sheet,Integer row,String[] dataArr,WritableCellFormat format){
try{
Label label;
for(int i=0;i<dataArr.length;i++){
label = new Label(i,row,dataArr[i],format);
sheet.addCell(label);
}
}catch(Exception e){
e.printStackTrace();
}
}
/**
* 插入单元格数据
* @param sheet
* @param col
* @param row
* @param data
*/
public void insertOneCellData(WritableSheet sheet,Integer col,Integer row,Object data,WritableCellFormat format){
try{
if(data instanceof Double){
jxl.write.Number labelNF = new jxl.write.Number(col,row,(Double)data,format);
sheet.addCell(labelNF);
}else if(data instanceof Boolean){
jxl.write.Boolean labelB = new jxl.write.Boolean(col,row,(Boolean)data,format);
sheet.addCell(labelB);
}else if(data instanceof Date){
jxl.write.DateTime labelDT = new jxl.write.DateTime(col,row,(Date)data,format);
sheet.addCell(labelDT);
setCellComments(labelDT, "这是个创建表的日期说明!");
}else{
Label label = new Label(col,row,data.toString(),format);
sheet.addCell(label);
}
}catch(Exception e){
e.printStackTrace();
}
}
/**
* 合并单元格,并插入数据
* @param sheet
* @param col_start
* @param row_start
* @param col_end
* @param row_end
* @param data
* @param format
*/
public void mergeCellsAndInsertData(WritableSheet sheet,Integer col_start,Integer row_start,Integer col_end,Integer row_end,Object data, WritableCellFormat format){
try{
sheet.mergeCells(col_start,row_start,col_end,row_end);//左上角到右下角
insertOneCellData(sheet, col_start, row_start, data, format);
}catch(Exception e){
e.printStackTrace();
}
}
/**
* 给单元格加注释
* @param label
* @param comments
*/
public void setCellComments(Object label,String comments){
WritableCellFeatures cellFeatures = new WritableCellFeatures();
cellFeatures.setComment(comments);
if(label instanceof jxl.write.Number){
jxl.write.Number num = (jxl.write.Number)label;
num.setCellFeatures(cellFeatures);
}else if(label instanceof jxl.write.Boolean){
jxl.write.Boolean bool = (jxl.write.Boolean)label;
bool.setCellFeatures(cellFeatures);
}else if(label instanceof jxl.write.DateTime){
jxl.write.DateTime dt = (jxl.write.DateTime)label;
dt.setCellFeatures(cellFeatures);
}else{
Label _label = (Label)label;
_label.setCellFeatures(cellFeatures);
}
}
/**
* 读取excel
* @param inputFile
* @param inputFileSheetIndex
* @throws Exception
*/
public ArrayList<String> readDataFromExcel(File inputFile, int inputFileSheetIndex){
ArrayList<String> list = new ArrayList<String>();
Workbook book = null;
Cell cell = null;
WorkbookSettings setting = new WorkbookSettings();
java.util.Locale locale = new java.util.Locale("zh","CN");
setting.setLocale(locale);
setting.setEncoding("ISO-8859-1");
try{
book = Workbook.getWorkbook(inputFile, setting);
}catch(Exception e){
e.printStackTrace();
}
Sheet sheet = book.getSheet(inputFileSheetIndex);
for (int rowIndex = 0; rowIndex < sheet.getRows(); rowIndex++) {//行
for (int colIndex = 0; colIndex < sheet.getColumns(); colIndex++) {//列
cell = sheet.getCell(colIndex, rowIndex);
//System.out.println(cell.getContents());
list.add(cell.getContents());
}
}
book.close();
return list;
}
/**
* 得到数据表头格式
* @return
*/
public WritableCellFormat getTitleCellFormat(){
WritableCellFormat wcf = null;
try {
//字体样式
WritableFont wf = new WritableFont(WritableFont.TIMES,12, WritableFont.NO_BOLD,false);//最后一个为是否italic
wf.setColour(Colour.RED);
wcf = new WritableCellFormat(wf);
//对齐方式
wcf.setAlignment(Alignment.CENTRE);
wcf.setVerticalAlignment(VerticalAlignment.CENTRE);
//边框
wcf.setBorder(Border.ALL,BorderLineStyle.THIN);
//背景色
wcf.setBackground(Colour.GREY_25_PERCENT);
} catch (WriteException e) {
e.printStackTrace();
}
return wcf;
}
/**
* 得到数据格式
* @return
*/
public WritableCellFormat getDataCellFormat(CellType type){
WritableCellFormat wcf = null;
try {
//字体样式
if(type == CellType.NUMBER || type == CellType.NUMBER_FORMULA){//数字
NumberFormat nf = new NumberFormat("#.00");
wcf = new WritableCellFormat(nf);
}else if(type == CellType.DATE || type == CellType.DATE_FORMULA){//日期
jxl.write.DateFormat df = new jxl.write.DateFormat("yyyy-MM-dd hh:mm:ss");
wcf = new jxl.write.WritableCellFormat(df);
}else{
WritableFont wf = new WritableFont(WritableFont.TIMES,10, WritableFont.NO_BOLD,false);//最后一个为是否italic
wcf = new WritableCellFormat(wf);
}
//对齐方式
wcf.setAlignment(Alignment.CENTRE);
wcf.setVerticalAlignment(VerticalAlignment.CENTRE);
//边框
wcf.setBorder(Border.LEFT,BorderLineStyle.THIN);
wcf.setBorder(Border.BOTTOM,BorderLineStyle.THIN);
wcf.setBorder(Border.RIGHT,BorderLineStyle.THIN);
//背景色
wcf.setBackground(Colour.WHITE);
wcf.setWrap(true);//自动换行
} catch (WriteException e) {
e.printStackTrace();
}
return wcf;
}
/**
* 打开文件看看
* @param exePath
* @param filePath
*/
public void openExcel(String exePath,String filePath){
Runtime r=Runtime.getRuntime();
String cmd[]={exePath,filePath};
try{
r.exec(cmd);
}catch(Exception e){
e.printStackTrace();
}
}
public static void main(String[] args){
String[] titles = {"学号","姓名","语文","数学","英语","总分"};
JExcelUtils jxl = new JExcelUtils();
String filePath = "E:/test.xls";
jxl.createExcelFile(filePath,"成绩单",titles);
jxl.readDataFromExcel(new File(filePath),0);
jxl.openExcel("C:/Program Files/Microsoft Office/OFFICE11/EXCEL.EXE",filePath);
}
}
在Hibernate2.x里Hql支持 not is null 也支持 is not null 但是你打印出SQL语句就可以发现两者到最后生成的SQL语句都就变成了 is not null
但是在Hibernate3.x里Hql就不支持 not is null 的写法了,这是公司系统从Hibernate2.x升级到Hibernate3.x时候发现的,所以在Hibernate2.x里还是不要写成 not is null,
免得升到Hibernate3的时候麻烦
职称、软考、职称资格及三者之间的关系
软考的指导性政策。由于这个政策的解释不是很清楚,各地在执行政策时的做法也不统一,导致有关软考、职称、职称资格之间的关系问题,一直困扰着所有考生。在此,笔者做一个统一的解释。
软考
软考是全国计算机技术与软件专业技术资格(水平)考试的简称,是由国家人事部和信息产业部组织和领导的国家级考试,目的是科学、公正地对全国计算机与软件专业技术人员进行专业技术资格、职业资格认定和专业技术水平测试。
《计算机技术与软件专业技术资格(水平)考试暂行规定》第十条规定:“通过考试并获得相应级别计算机专业技术资格(水平)证书的人员,表明其已具备从事相应专业岗位工作的水平和能力,用人单位可根据《工程技术人员职务试行条例》有关规定和工作需要,从获得计算机专业技术资格(水平)证书的人员中择优聘任相应专业技术职务。取得初级资格可聘任技术员或助理工程师职务;取得中级资格可聘任工程师职务;取得高级资格,可聘任高级工程师职务”。
职称
具备某个职称资格的人,如果得到了单位的聘用,则其就拥有了相应的职称。例如,某个考生通过了程序员级别的考试(具备了初级职称资格),然后在用人单位根据某些条件聘任了专业技术职务,则其就拥有了技术员或助理工程师职称。例如,根据有关规定(各地不完全一样),对于大学本科以上毕业有初级资格者,可以聘任助理工程师;对于本科以下文化程度的初级资格者,则聘任技术员职称。
职称资格
职称资格是一种“资历”,根据我国的职称体系,可分为初级、中级和高级三类职称资格,其中高级职称资格又可分为副高和正高(高级工程师职称资格属于副高级)。某人具备某个职称资格,是指他已具备从事相应专业岗位工作的水平和能力。对于具备职称资格的人,由国家人事部门(省/市人事部门)颁发资格证书。
对于参加软考的人而言,如果通过了初级(例如程序员、网络管理员、信息处理技术员等)的考试,则其就具备了初级职称资格;如果通过了中级(例如软件设计师、网络工程师、数据库系统工程师、信息系统监理师、软件评测师等)的考试,则其就具备了中级职称资格;如果通过了高级(例如系统分析师、信息系统项目管理师等),则其就具备了副高级职称资格。
三者关联关系
也就是说,通过了软考,我们所获得的只是一种资格,是否聘任相应的职称,完全取决于各单位的实际情况,国家有关部门并没有直接的规定。事实上,通过评审方法(也就是常说的“评职称”)得到的也只是一个资格,单位既可以不聘用,也可以聘用,还可以高资格低聘用、低资格高聘用。例如,湖南大学的一个教授(既有职称资格,也聘任了相应的职称),如果他到清华大学,则只能聘为副教授或者讲师。相反,如果清华大学的一个副教授调到湖南大学,则会被聘任为教授。
就目前来看,对于通过软考的人,有些地方、有些单位是聘任相应职称的,而另外一些地方和单位却不聘任。因此,如果我们通过了软考,而当前所在单位又不聘任,可以采取下列两种方法:
(1)与单位领导据理力争。看本单位通过评审方法获得职称资格的人是否都得到了聘任,如果都得到了聘任,单位就应该聘任你。因为别人有职称资格,就能得到聘任,你也有职称资格,为什么得不到聘任呢?除非你是单位中水平和能力最差的人。
昨天老项目的客户来电话说系统有问题了,过去一看是数据库起不来了,看来一下日志。
Errors in file /opt/ora9/admin/xwoa/udump/xwoa_ora_17933.trc:
ORA-01115: 从文件 16 读取块时出现 IO 错误 (块 # 189544)
ORA-27072: skgfdisp: I/O 错误
Linux Error: 25: Inappropriate ioctl for device
Additional information: 189543
靠,数据表空间文件被删除。
好在数据库采用了归档模式。
开始恢复:
1、SQL>shutdown immediate
备份全部数据文件和控制文件和log以防恢复过程中出现问题。
2、SQL> startup mount;
3、SQL> alter database create datafile '/opt/ora9/oradata/xwoa/CHAOYANGJP.dbf' as '/opt/ora9/oradata/xwoa/CHAOYANGJP.dbf' reuse;
创建误删除的数据文件。
4、recover datafile '/opt/ora9/oradata/xwoa/CHAOYANGJP.dbf';
ORA-00279: 更改 57900012 (在 09/19/2007 10:27:05 生成) 对于线程 1 是必需的
ORA-00289: 建议: /opt/ora9/oradata/xwoa/archive/1_863.dbf
ORA-00280: 更改 57900012 对于线程 1 是按序列 # 863 进行的
指定日志: {<RET>=suggested | filename | AUTO | CANCEL}
输入:AUTO回车
开始恢复过程,这个时间比较长。
5、SQL> select d.file#,d.name,d.status,h.status from v$datafile d,v$datafile_header
h where d.file#=h.file# ;
查看一下数据文件是否online。
如果没有online,
6、SQL> ALTER DATABASE DATAFILE '/opt/ora9/oradata/xwoa/CHAOYANGJP.dbf' ONLINE;
ok!完成恢复过程。
用一个叫做虚拟软盘的软件,而且是免费的,当前版本1.5,装上软件,然后选择NTFS的启动img文件,然后重启机器,然后进入DOS,结果出现的是CIA Commander界面,逐级进入C:\windows\system32,然后找到vrv开头的所有的文件,一律F8(删除),但VRVEDP_M.EXE文件不能删除(是不是那个软件公司做的保护措施之一呢?),没关系,我重启试试。
重启进入XP,然后使用奇虎的360安全卫士找到VRVWatchServer服务,暂停,然后进入Windows的服务里面让它disable(我的是英文操作系统,我忘了中文的下面叫什么了),重启,发现这个VRVWatchServer服务已经没有启动了,然后进入cmd,执行命令:
sc delete VRVWatchServer
删除这个 VRVWatchServer服务。
重启,发现噩梦终于结束了,然后我在XP下很容易的就删除了VRVEDP_M.EXE文件,为了干掉这个软件,浪费了我4个小时,MMD!!!
另外记得要将虚拟软盘启动取消!
package net.risesoft.microstrategy;
import com.microstrategy.web.objects.WebDisplayUnit;
import com.microstrategy.web.objects.WebObjectInfo;
/**
* MSTR报表
*
* @author gf
*
*/
public class MstrReportViewMode {
public void getReportViewMode(WebDisplayUnit wdu) {
if (wdu instanceof WebObjectInfo) {
WebObjectInfo wi = (WebObjectInfo) wdu;
if (wi.getSubType() == 768) {
// 表
System.out.println("表:reportViewMode=1");
} else if (wi.getSubType() == 769) {
// 图
System.out.println("图:reportViewMode=2");
} else {
// 图表774
System.out.println("图表:reportViewMode=3");
}
}
}
}
摘要: EL(Expression Language,以下译为表达式语言)表达式语言主要有以下几大好处:
避免(MyType) request.getAttribute()和myBean.getMyProperty()之类的语句,使页面更简洁;
支持运算符(如+-*/),比普通的标志具有更高的自由度和更强的功能;
简单明了地表达代码逻辑,使用代码更可读与便于维护。
Struts 2中的表达式语言
Struts 2支持以下几种表达式语言:
OGNL(Object-Graph Navigation Language),可以方便地操作对象属性的开源表达式语言;
JSTL(JSP Standard Tag Library),JSP 2.0集成的标准的表达式语言;
Groovy,基于Java平台的动态语言,它具有时下比较流行的动态语言(如Python、Ruby和Smarttalk等)的一些起特性;
Velocity,严格来说不是表达式语言,它是一种基于Java的模板匹配引擎,具说其性能要比JSP好。
阅读全文
摘要: 1.List转换成为数组。(这里的List是实体是ArrayList)
调用ArrayList的toArray方法。
toArray
public <T> T[] toArray(T[] a)返回一个按照正确的顺序包含此列表中所有元素的数组;返回数组的运行时类型就是指定数组的运行时类型。假如列表能放入指定的数组,则返回放入此列表元素的数组。否则,将根据指定数组的运行时类型和此...
阅读全文
<style type="text/css">
img{vertical-align:bottom}
</style>
加入 <head>与 </head>就可以了。
摘要: 本文主要介绍使用kettle 来建立一个Type 2的Slowly Changing Dimension 以及其中一些细节问题
阅读全文
最近在写一个荧光图像分析软件,需要自己拟合方程。一元回归线公式的算法参考了《Java数值方法》,拟合度R^2(绝对系数)是自己写的,欢迎讨论。计算结果和Excel完全一致。
总共三个文件:
DataPoint.java
/**
* A data point for interpolation and regression.
*/
public class DataPoint
{
/** the x value */ public float x;
/** the y value */ public float y;
/**
* Constructor.
* @param x the x value
* @param y the y value
*/
public DataPoint(float x, float y)
{
this.x = x;
this.y = y;
}
}
/**
* A least-squares regression line function.
*/
import java.util.*;
import java.math.BigDecimal;
public class RegressionLine
//implements Evaluatable
{
/** sum of x */ private double sumX;
/** sum of y */ private double sumY;
/** sum of x*x */ private double sumXX;
/** sum of x*y */ private double sumXY;
/** sum of y*y */ private double sumYY;
/** sum of yi-y */ private double sumDeltaY;
/** sum of sumDeltaY^2 */ private double sumDeltaY2;
/**误差 */
private double sse;
private double sst;
private double E;
private String[] xy ;
private ArrayList listX ;
private ArrayList listY ;
private int XMin,XMax,YMin,YMax;
/** line coefficient a0 */ private float a0;
/** line coefficient a1 */ private float a1;
/** number of data points */ private int pn ;
/** true if coefficients valid */ private boolean coefsValid;
/**
* Constructor.
*/
public RegressionLine() {
XMax = 0;
YMax = 0;
pn = 0;
xy =new String[2];
listX = new ArrayList();
listY = new ArrayList();
}
/**
* Constructor.
* @param data the array of data points
*/
public RegressionLine(DataPoint data[])
{
pn = 0;
xy =new String[2];
listX = new ArrayList();
listY = new ArrayList();
for (int i = 0; i < data.length; ++i) {
addDataPoint(data[i]);
}
}
/**
* Return the current number of data points.
* @return the count
*/
public int getDataPointCount() { return pn; }
/**
* Return the coefficient a0.
* @return the value of a0
*/
public float getA0()
{
validateCoefficients();
return a0;
}
/**
* Return the coefficient a1.
* @return the value of a1
*/
public float getA1()
{
validateCoefficients();
return a1;
}
/**
* Return the sum of the x values.
* @return the sum
*/
public double getSumX() { return sumX; }
/**
* Return the sum of the y values.
* @return the sum
*/
public double getSumY() { return sumY; }
/**
* Return the sum of the x*x values.
* @return the sum
*/
public double getSumXX() { return sumXX; }
/**
* Return the sum of the x*y values.
* @return the sum
*/
public double getSumXY() { return sumXY; }
public double getSumYY() { return sumYY; }
public int getXMin() {
return XMin;
}
public int getXMax() {
return XMax;
}
public int getYMin() {
return YMin;
}
public int getYMax() {
return YMax;
}
/**
* Add a new data point: Update the sums.
* @param dataPoint the new data point
*/
public void addDataPoint(DataPoint dataPoint)
{
sumX += dataPoint.x;
sumY += dataPoint.y;
sumXX += dataPoint.x*dataPoint.x;
sumXY += dataPoint.x*dataPoint.y;
sumYY += dataPoint.y*dataPoint.y;
if(dataPoint.x > XMax){
XMax = (int)dataPoint.x;
}
if(dataPoint.y > YMax){
YMax = (int)dataPoint.y;
}
//把每个点的具体坐标存入ArrayList中,备用
xy[0] = (int)dataPoint.x+ "";
xy[1] = (int)dataPoint.y+ "";
if(dataPoint.x!=0 && dataPoint.y != 0){
System.out.print(xy[0]+",");
System.out.println(xy[1]);
try{
//System.out.println("n:"+n);
listX.add(pn,xy[0]);
listY.add(pn,xy[1]);
}
catch(Exception e){
e.printStackTrace();
}
/*
System.out.println("N:" + n);
System.out.println("ArrayList listX:"+ listX.get(n));
System.out.println("ArrayList listY:"+ listY.get(n));
*/
}
++pn;
coefsValid = false;
}
/**
* Return the value of the regression line function at x.
* (Implementation of Evaluatable.)
* @param x the value of x
* @return the value of the function at x
*/
public float at(int x)
{
if (pn < 2) return Float.NaN;
validateCoefficients();
return a0 + a1*x;
}
public float at(float x)
{
if (pn < 2) return Float.NaN;
validateCoefficients();
return a0 + a1*x;
}
/**
* Reset.
*/
public void reset()
{
pn = 0;
sumX = sumY = sumXX = sumXY = 0;
coefsValid = false;
}
/**
* Validate the coefficients.
* 计算方程系数 y=ax+b 中的a
*/
private void validateCoefficients()
{
if (coefsValid) return;
if (pn >= 2) {
float xBar = (float) sumX/pn;
float yBar = (float) sumY/pn;
a1 = (float) ((pn*sumXY - sumX*sumY)
/(pn*sumXX - sumX*sumX));
a0 = (float) (yBar - a1*xBar);
}
else {
a0 = a1 = Float.NaN;
}
coefsValid = true;
}
/**
* 返回误差
*/
public double getR(){
//遍历这个list并计算分母
for(int i = 0; i < pn -1; i++) {
float Yi= (float)Integer.parseInt(listY.get(i).toString());
float Y = at(Integer.parseInt(listX.get(i).toString()));
float deltaY = Yi - Y;
float deltaY2 = deltaY*deltaY;
/*
System.out.println("Yi:" + Yi);
System.out.println("Y:" + Y);
System.out.println("deltaY:" + deltaY);
System.out.println("deltaY2:" + deltaY2);
*/
sumDeltaY2 += deltaY2;
//System.out.println("sumDeltaY2:" + sumDeltaY2);
}
sst = sumYY - (sumY*sumY)/pn;
//System.out.println("sst:" + sst);
E =1- sumDeltaY2/sst;
return round(E,4) ;
}
//用于实现精确的四舍五入
public double round(double v,int scale){
if(scale<0){
throw new IllegalArgumentException(
"The scale must be a positive integer or zero");
}
BigDecimal b = new BigDecimal(Double.toString(v));
BigDecimal one = new BigDecimal("1");
return b.divide(one,scale,BigDecimal.ROUND_HALF_UP).doubleValue();
}
public float round(float v,int scale){
if(scale<0){
throw new IllegalArgumentException(
"The scale must be a positive integer or zero");
}
BigDecimal b = new BigDecimal(Double.toString(v));
BigDecimal one = new BigDecimal("1");
return b.divide(one,scale,BigDecimal.ROUND_HALF_UP).floatValue();
}
}
演示程序:
LinearRegression.java
/**
* <p><b>Linear Regression</b>
* <br>
* Demonstrate linear regression by constructing the regression line for a set
* of data points.
*
* <p>require DataPoint.java,RegressionLine.java
*
* <p>为了计算对于给定数据点的最小方差回线,需要计算SumX,SumY,SumXX,SumXY; (注:SumXX = Sum (X^2))
* <p><b>回归直线方程如下: f(x)=a1x+a0 </b>
* <p><b>斜率和截距的计算公式如下:</b>
* <br>n: 数据点个数
* <p>a1=(n(SumXY)-SumX*SumY)/(n*SumXX-(SumX)^2)
* <br>a0=(SumY - SumY * a1)/n
* <br>(也可表达为a0=averageY-a1*averageX)
*
* <p><b>画线的原理:两点成一直线,只要能确定两个点即可</b><br>
* 第一点:(0,a0) 再随意取一个x1值代入方程,取得y1,连结(0,a0)和(x1,y1)两点即可。
* 为了让线穿过整个图,x1可以取横坐标的最大值Xmax,即两点为(0,a0),(Xmax,Y)。如果y=a1*Xmax+a0,y大于
* 纵坐标最大值Ymax,则不用这个点。改用y取最大值Ymax,算得此时x的值,使用(X,Ymax), 即两点为(0,a0),(X,Ymax)
*
* <p><b>拟合度计算:(即Excel中的R^2)</b>
* <p> *R2 = 1 - E
* <p>误差E的计算:E = SSE/SST
* <p>SSE=sum((Yi-Y)^2) SST=sumYY - (sumY*sumY)/n;
* <p>
*/
public class LinearRegression
{
private static final int MAX_POINTS = 10;
private double E;
/**
* Main program.
*
* @param args
* the array of runtime arguments
*/
public static void main(String args[])
{
RegressionLine line = new RegressionLine();
line.addDataPoint(new DataPoint(20, 136));
line.addDataPoint(new DataPoint(40, 143));
line.addDataPoint(new DataPoint(60, 152));
line.addDataPoint(new DataPoint(80, 162));
line.addDataPoint(new DataPoint(100, 167));
printSums(line);
printLine(line);
}
/**
* Print the computed sums.
*
* @param line
* the regression line
*/
private static void printSums(RegressionLine line)
{
System.out.println("\n数据点个数 n = " + line.getDataPointCount());
System.out.println("\nSum x = " + line.getSumX());
System.out.println("Sum y = " + line.getSumY());
System.out.println("Sum xx = " + line.getSumXX());
System.out.println("Sum xy = " + line.getSumXY());
System.out.println("Sum yy = " + line.getSumYY());
}
/**
* Print the regression line function.
*
* @param line
* the regression line
*/
private static void printLine(RegressionLine line)
{
System.out.println("\n回归线公式: y = " +
line.getA1() +
"x + " + line.getA0());
System.out.println("拟合度: R^2 = " + line.getR());
}
}
MicroStrategy Web 的设计模式
MicroStrategy Web 应用的实现方式是使用类似Struts 的MVC 模式,整个应用的核心是一个servlet 作为MVC 中的Controller 。所有的请求都发送给这个servlet,按照默认的web.xml 中的定义,这个servlet 名称是 mstrWeb, mstrWeb 只接受两种参数evt=或者页面参数 pg=通过在客户自己的应用中,通过URL 就可以访问已经订制的报表、文档或者某个特定页面(例如 共享报表页面)
MicroStrategy Web 的URL 参数说明
h ttp:/ /210.82.33.248/MicroStrategy/servlet/mstrWeb?evt=4001&src=mstrWeb.4001&reportViewMode=1&reportID=D08450DF4E71E2068B9AE78845C1BA28&Port=0&Project=MicroStrategy+Tutorial&Server=FBI&Uid=xxx&Pwd=xxx
在MicroStrategy Web 中要执行一个报表、或者访问一个已知的页面的时候,需要必要的认证信息,从request 或者session 中需要提供的五个最基本认证参数如下:
Server ---- Intelligence Server 的HostName 或者IP 地址
Port –--- Interlligence Server 的监听端口,0 表示默认的端口
Project –--- 项目名称
Uid –--- MSTR 用户名
Pwd –--- MSTR 口令
在具体的应用集成中,往往要求业务用户在登陆业务系统后,在调用MicroStrategy 的时候,不需要再次输入用户信息,即单点认证。在具体实现中,MicroStrategy Web 将上面的五个认证基本参数,封装在一个内部对象中WebIServerSession。每个WebIServerSession 的实例代表一个用户的连接,其中WebIServerSession 代表在Intelligence Server 中的一个用户会话,这个会话通过sessionID进行唯一的标识。
MicroStrategy Web 对SSO 的支持—ExternalSecurity
MicroStrategy Web 提供ExternakSecurity 机制,来支持SSO。External Security 提供如下的接口,这些接口实现以后的客户自定义的ExternalSecurity 通过web.xml 的配置加入到现有的Web 应用中,供MicroStratey Web使用。在用户首次访问MicroStratey Web 的时候,或者是签退后重新访问的时候, Web应用会调用实现中的handlesAuthenticationRequest 的方法,其返回值一共三种,根据返回的参数的不同,Web 应用会调用ExternalSecurity 实现中的不同函数,参见下:
通用的实现ExternalSecurity 步骤流程
1、继承 AbstractExternalSecurity 父类,实现代码public class WithSUN_ExternalSecurity extends AbstractExternalSecurity { ... ...
2、编译的类,打成jar 放在 web-inf/lib 下,或者按照包路径放在 web-inf/classes 下
3、修改 web.xml 中的 mstrWeb Servlet 配置中的 ExternalSecurityClass 参数,注释原有的参数,使用用户定义的类,例如
<param-name>externalSecurityClass</param-name>
<!--param-value>com.microstrategy.web.app.DefaultExternalSecurity</param-value-->
<param-value>com.fbi.WithSUN_ExternalSecurity</param-value>
</init-param>
在不同的项目中,根据集成模式的不同,会有不同的集成模式。解决这个问题的核心是如何根据传入的TOKEN 或者信息获取对应的MSTR 的登录信息。
下面就几种不同的模式进行介绍:
Web Universal 作为单独的Web 应用使用
使用MicroStrategy 的登陆界面,(或者自定义的Login 页面)进行登陆。这个时候用户输入的是外部用户的业务ID,以及Password。
[解决方式] 通过定义ExternalSecurity 类,实现用户输入的用户信息和MicroStrategy 之间用户的转换。通常是基于数据库用户信息表,通过输入的信息映射到MSTR 的用户信息。使用到了数据库表来存储用户名和密码。
[需要附加的包]
SQL Server 的 JDBC 包: jtds-0.9.jar
Oracle 的JDBC 包:
模式二 用户有自己的Web 应用,需要调用MicroStrategy Web 的应用
这种模式下不会提供MSTR 的任何登录的页面,但是要求从发起调用的Web 应用,在访问MicroStrategy,需要通过Session 或者 Request 传递某个参数给MicroStrategy。
简化的实现是:在Web 应用调用handlesAuthenticationRequest 的时候返回常数COLLECT_SESSION_NOW;
然后Web 应用会调用getWebIServerSession 方法,在getWebIServerSession 中系统会传递两个参数,RequestKeys 和 ContainerServices,其中前者是对httpRequest 的封装,后者则是对httpSession 的封装。需要在这个方法中返回一个WebIServerSession 的实例。
接下来,Web应用会调用底层的API 创建相应的Session,并将session 交于SessionManager(内部对象)维护。
注意一个问题,传入的这个参数,可以考虑加密处理,可以将登录MSTR 的用户名和密码信息加密后直接传入。另外更可为的方式为传入某一个临时的Key利用 Key 从数据库,或者其他位置获得登陆MSTR 的用户名和密码。
[模式三] 与 SUN 的Identity Server 进行集成,SSO 软件进行集成,
客户化方式同模式二,特殊的是:
步骤1: 需要修改Web 的描述文件web.xml,将应用配置使用SUN SSO 认证,这样当未认证的用户访问Web Universal 的时候,会进入SUN SSO 的登录界面。
样例,具体项目需要参考SUN 的文档
- <filter>
<filter-name>Agent1</filter-name>
<filter-class>com.sun.amagent.as.filter.AgentFilter</filter-class>
</filter>
- <filter>
<filter-name>Agent2</filter-name>
<filter-class>com.sun.amagent.as.filter.AgentFilter</filter-class>
</filter>
- <filter-mapping>
<filter-name>Agent1</filter-name>
<url-pattern>/servlet/*</url-pattern>
</filter-mapping>
- <filter-mapping>
<filter-name>Agent2</filter-name>
<url-pattern>/userinfo/*</url-pattern>
</filter-mapping>
步骤2:当用户输入统一的用户身份信息后,认证成功后,进入MicroStrategy 的界面,Web Universal 会调用External Security 模块。
在handleAuthentication 或者 getWebIServerSession 中获得SUN Identity 的Token,调用SUN SSO Client 的API,需要import SUN 的包:
- import com.iplanet.sso.*;
- import com.iplanet.am.sdk.*;
- import com.sun.identity.authentication.*;
-
-
- SSOTokenManager manager = SSOTokenManager.getInstance();
- SSOToken ssoToken = manager.createSSOToken(reqKeys);
- if(manager.isValidToken(ssoToken))
- {
- AMStoreConnection dpsc = new AMStoreConnection(ssoToken);
- AMUser dpUser = dpsc.getUser(ssoToken.getPrincipal().getName());
- uid = dpUser.getStringAttribute("uid");
- cn = dpUser.getStringAttribute("cn");
- employeeNo = dpUser.getStringAttribute("employeenumber");
- alias = dpUser.getStringAttribute("iplanet-am-user-alias-list");
- mail = dpUser.getStringAttribute("mail");
- entrydn = dpUser.getStringAttribute("entrydn");
- }
通过认证源的返回的信息,如果正常,那么需要根据其他的信息获得MSTR 的登录信息。
否则,需要参见下面 [关于认证失败的处理]
[模式四] 与第三方开发的认证进行集成的样例:
样例1: 用户自己开发了portal,实现集中的认证源,那么需要在External Sercurity 类的handelAuthentication 或者getWebIServerSession 中利用下面的代码:
- URL url=new URL("http://portal.xbxs.petrochina:38081/ssoauth/SSOValidate?tokenID=" + tokenId);
- URLConnection con=url.openConnection();
- con.setUseCaches(false);
- java.io.BufferedReader br = new BufferedReader(new InputStreamReader(con.getInputStream()));
- String line= br.readLine();
- while(null != line){
- if (line.indexOf("SUCCESS")>-1) break;
通过认证源的返回的信息,如果正常,那么需要根据其他的信息获得MSTR 的登录信息。
否则,需要参见下面 [关于认证失败的处理]。
[关于认证失败的处理]
第一种方法是:在 getwebiserversession 中,用提供的credential 创建session,如果创建session 不成功,getwebiserversession 会自动return null。这时getfailureurl 方法会被call with reason =1。可以在getfailureurl 方法中指定reason=1 时出现的错误信息页面的url
第二个方法是:
1. 在handlehandlesAuthenticationRequest 中用非建立session 的方法验证credential
2. 如果验证ok,就call getWebIServerSession,create mstr session
3. 如果验证不ok,就call getCustomLoginURL, 然后在getCustomLoginURL 方法中,指定error page 的url
这两个方法那个更好,取决于如何验证mstr credential。如果credential 只能通过session是不是null 来验证,就用方法1。如果是通过其他方法验证credential,就用方法2。
RSS的历史
那么RSS究竟代表什么呢?比较普遍的有两种说法,一种是“Rich Site Summary”或“RDF Site Summary”,另一种是“Really Simple Syndication”,之所以有这些分歧,需要从RSS发展的历史说起。
最初的0.90版本RSS是由Netscape公司设计的,目的是用来建立一个整合了各主要新闻站点内容的门户,但是0.90版本的RSS规范过于复杂,而一个简化的RSS 0.91版本也随着Netscape公司对该项目的放弃而于2000年暂停。
不久,一家专门从事博客写作软件开发的公司UserLand接手了RSS 0.91版本的发展,并把它作为其博客写作软件的基础功能之一继续开发,逐步推出了0.92、0.93和0.94版本。随着网络博客的流行,RSS作为一种基本的功能也被越来越多的网站和博客软件支持。
在UserLand公司接手并不断开发RSS的同时,很多的专业人士认识到需要通过一个第三方、非商业的组织,把RSS发展成为一个通用的规范,并进一步标准化。于是2001年一个联合小组在0.90版本RSS的开发原则下,以W3C新一代的语义网技术RDF(Resource Description Framework)为基础,对RSS进行了重新定义,发布RSS1.0,并将RSS定义为“RDF Site Summary”。但是这项工作没有与UserLand公司进行有效的沟通,UserLand公司也不承认RSS 1.0的有效性,并坚持按照自己的设想进一步开发出RSS的后续版本,到2002年9月发布了最新版本RSS 2.0,UserLand公司将RSS定义为“Really Simple Syndication”。
目前RSS已经分化为RSS 0.9x/2.0和RSS 1.0两个阵营,由于分歧的存在和RSS 0.9x/2.0的广泛应用现状,RSS 1.0还没有成为标准化组织的真正标准。
什么是RSS?
RSS是一种网页内容联合格式(web content sydication format)。
它的名字是Really Simple Syndication的缩写。
RSS是XML的一种。所有的RSS文档都遵循XML 1.0规范,该规范发布在W3C网站上。
在一个RSS文档的开头是一个<rss>节点和一个规定的属性version,该属性规定了该文档将以RSS的哪个版本表示。如果该文档以这个规范来表示,那么它的version属性就必须等于2.0。
在<rss>节点的下一级是一个独立的<channel>节点,该节点包含关于channel的信息和内容。
关于本文档
该文档是在2002年秋天撰写的,当时的RSS版本为2.0.1。
它包含从RSS 0.91规范(2000年)开始的所有的修改和添加,以及包含在RSS 0.92(2000年12月)和RSS 0.94(2002年8月)中的新的特性。
必需的频道节点
下面有一份必须包含的频道(channel)节点的列表,每一个都有一个简单的描述、一个例子、应该出现的位置和更详细描述的超链接。
| 元素 |
描述 |
范例 |
| title |
频道(channel)名称。它可以告诉别人如何访问你的服务。如果你有一个与你的RSS文件内容一致的HTML网站,你的title元素值应该与你的网站的标题相同。 |
GoUpstate.com News Headings |
| link |
响应该频道的网站的URL |
http://www.goupstate.com/ |
| description |
关于该频道的描述 |
The latest news from GoUpstate.com, a Spartanburg Herald-Joural Web Site |
可选的频道元素
下面是可选的频道元素列表
| 节点 |
描述 |
范例 |
| language |
使用的语言。这允许聚合器对所有的意大利语站点分组。 |
en-us |
| copyright |
版权声明 |
Copyright 2002, Spartanburg Herald-Journal |
| managingEditor |
内容负责人的Email |
geo@herald.com (George Matesky) |
| webMaster |
技术人员的Email |
betty@herald.com (Betty Guernsey) |
| pubDate |
内容的发布时间 |
Sat, 07 Sep 2002 00:00:01 GMT |
| lastBuildDate |
最后更新时间 |
Sat, 07 Sep 2002 09:42:31 GMT |
| category |
指定该频道所属的一个或多个分类。遵循与item级category元素相同的规则。 |
<category>Newspapers</category> |
| generator |
生成该频道的程序名称 |
MightyInHouse Content System v2.3 |
| docs |
指向rss格式文档的url地址? |
http://blogs.law.harvard.edu/tech/rss |
| cloud |
允许所有进程注册一个cloud用于获得频道的更新通知,并为rss种子实现一个轻量级的发布订阅协议。 |
<cloud domain="rpc.sys.com" port="80" path="/RPC2" registerProcedure="pingMe" protocol="soap"/> |
| ttl |
ttl是Time to live的缩写。它指示cache的有效保存时间。 |
<ttl>60</ttl> |
| image |
与频道一起显示的图片地址 |
|
| rating |
该频道的统计图片地址 |
|
| textInput |
指定一个textbox与该频道一起显示 |
|
| skipHours |
告诉使用者哪些时段是可以忽略的 |
|
| skipDays |
告诉使用着哪些天是可以忽略的 |
|
<channel>子节点<image>
<image>是一个可选的<channel>子节点,该节点包含三个必需的子元素和三个可选的子元素。
<url>是GIF、JPEG或PNG图像文件的URL地址,该图像代表整个频道
<title>用于描述上面的图像,等同于HTML语言中的<img>的alt属性
<link>是要连接的站点的url,当显示频道时,图像的连接指向该站点。
<title>和<link>应该与频道的<title>和<link>有相同的值
可选的节点包括<width>和<height>,它们是数字类型,指定图像的宽度和高度,单位为像素
<description>就是link的TITLE属性中文本,它将在调用网页时显示出来。
图像宽度的最大值为144,默认值为88
图像高度的最大值为400,默认值为31
<channel>子节点<cloud>
<cloud>是一个可选的<channel>子节点。
它指定一个可以支持rssCloud接口的web服务,rssCloud接口可以用HTTP-POST,XML-RPC或SOAP1.1实现。
它的目的是允许通知注册为cloud的进程频道被更新,从而实现一个轻量级的发布订阅协议。
 <cloud domain="rpc.sys.com" port="80" path="/RPC2" registerProcedure= "myCloud.rssPleaseNotify" protocol="xml-rpc" />
<cloud domain="rpc.sys.com" port="80" path="/RPC2" registerProcedure= "myCloud.rssPleaseNotify" protocol="xml-rpc" />
在这个例子中,为了请求频道通知,你需要发送一个XML-RPC消息到rpc.sys.com的80端口,路径为/RPC2。调用的过程为myCloud.rssPleaseNotify。
<channel>子节点<ttl>
<ttl>是一个可选的<channel>子节点。
ttl是time to live的缩写。它表示频道在被刷新前应该被缓存的时间。这使得rss源可以被一个支持文件共享的网络所管理,例如Gnutella
例如:<ttl>60</ttl>
<channel>子节点<textInput>
<textInput>是<channel>的可选的子节点,<textInput>包含四个子节点。
<title>--提交按钮的标签
<description>--该文本输入区的描述
<name>--文本输入区的名称
<link>--处理文本输入的CGI脚本的URL
使用<textInput>的目的有些神秘(?)。你可以用它提供一个搜索引擎输入框,或让读者提供反馈信息。许多聚合器忽略该节点。
<item>的节点
一个频道可以包含许多项目(item)节点。一个项目可以代表一个故事——比如说一份报纸或杂志上的故事,如果是这样的话,那么项目的描述则是故事的概要,项目的链接则指向整个故事的存放位置。项目的所有节点都是可选的,但是至少要包含至少一个标题(title)和描述(description)。
| 节点 |
描述 |
范例 |
| title |
item的标题 |
Venice Film Festival Tries to Quit Sinking |
| link |
item的URL |
http://www.nytimes.com/2002/09/07/movies/07FEST.html |
| description |
item概要 |
Some of the most heated chatter at the Venice Film Festival this week was about the way that the arrival of the stars at the Palazzo del Cinema was being staged. |
| author |
作者的email地址 |
oprah@oxygen.net |
| category |
item可以包含在一个或多个分类中 |
Simpsons Characters |
| comments |
与item相关的评论的地址 |
http://www.myblog.org/cgi-local/mt/mt-comments.cgi?entry_id=290 |
| enclosure |
附加的媒体对象 |
|
| guid |
可以唯一确定item的字符串 |
http://inessential.com/2002/09/01.php#a2 |
| pubDate |
item发布的时间 |
Sun, 19 May 2002 15:21:36 GMT |
| source |
rss频道来源 |
Quotes of the Day |
<item>子节点<source>
<source>是<item>的可选节点。
它的值是item来自的rss频道的名称,从item的title衍生而来。它有一个必须包含的属性url, 该属性链接到XML序列化源。
<source url="http://static.userland.com/tomalak/links2.xml">Tomalak's Realm</source>
该节点的作用是提高连接的声望,进一步推广新闻项目的源头。它可以用在聚合器的Post命令中。当从聚合器通过webblog访问一个item时,<source>能够自动被生成。
<item>子节点<enclosure>
<enclosure>是<item>的可选节点。
它有三个必要的属性。url属性指示enclosure的位置,length指出它的字节大小,type属性指出它的标准MIME类型
url必须为一个http url。
<enclosure url="http://www.scripting.com/mp3s/weatherReportSuite.mp3" length="12216320" type="audio/mpeg" />
<item>子节点<category>
<category>是<item>的可选节点。
它有一个可选属性或域,该属性是一个用来定义分类法的字符串。
该节点的值是一个正斜杠分割的字符串,它用来在指定的分类法中识别一个分级位置(hierarchic location)。处理器可以为分类的识别建立会话。(Processors may establish conventions for the interpretation of categories)下面有两个例子:
<category>Grateful Dead</category>
<category domain="http://www.fool.com/cusips">MSFT</category>
你可以根据你的需要为不同的域(domain)包含很多category节点,并且可以在相同域的不同部分拥有一个前后参照的item。
<item>子节点<pubDate>
<pubDate>是<item>的可选节点。
它的值是item发布的日期。如果它是一个没有到达的日期,聚合器在日期到达之前可以选择不显示该item。
<pubDate>Sun, 19 May 2002 15:21:36 GMT</pubDate>
<item>子节点<guid>
<guid>是<item>的可选节点。
guid是globally unique identifier的缩写。它是一个可以唯一识别item的字符串。当item发布之后,聚合器可以选择使用该字符串判断该item是否是新的。
<guid>http://some.server.com/weblogItem3207</guid>
guid没有特定的语法规则,聚合器必须将他们看作一个字符串。生成具有唯一性的字符串guid取决于种子的源头。
如果guid节点有isPermaLink属性,并且值为真,读取器就会认为它是item的permalink。permalink是一个可在web浏览器中打开的url链接,它指向<item>节点所描述的全部item。
<guid isPermaLink="true">http://inessential.com/2002/09/01.php#a2</guid>
isPermaLink是可选属性,默认值为真。如果值为假,guid将不会被认为是一个url或指向任何对象的url。
<item>子节点<comment>
<comment>是<item>的可选节点。
如果出现,它指向该item评论的url
<comments>http://rateyourmusic.com/yaccs/commentsn/blogId=705245&itemId=271</comments>
<item>子节点<author>
<author>是<item>的可选节点。
它是item的作者的email。对于通过rss传播的报纸和杂志,作者可能是写该item所描述的文章的人。对于聚集型webblogs,作者可能不是责任编辑或站长。对于个人维护的webblog,忽略<author>节点是有意义的。
<author>lawyer@boyer.net (Lawyer Boyer)</author>
查找一个sheet中的数据是用找个语句"SELECT * from [Sheet1$]",如果sheet的名字是aaa应该写成[aaa$]。 语句应该是这样"SELECT * from [aaa$]"。
摘要: 首先简单介绍一下weka,Weka是基于java,用于数据挖掘和知识分析一个平台。来自世界各地的java爱好者们都可以把自己的算法放在这个平台上,然后从海量数据中发掘其背后 ...
阅读全文
摘要: 对于许多软件开发者来说,一提到国际化(亦称为 i18n)支持就会感到害怕。 要使编写的代码能够面向外国使用者,确实需要费一翻思量,因为在现有软件的代码中添加国际化支持可不是一件轻而易举的事。
阅读全文
设置正确的Content-Type以解决Ext的中文乱码问题
1、前后台所有文件统一用utf-8编码方式。
2、在Request Headers中设置Content-Type:application/x-www-form-urlencoded; charset=utf-8,具体方法:将Ext.lib.Ajax.defaultPostHeader += '; charset=utf-8'加在Ext.onReady块里,此方法可以解决用EXT在POST时的中文乱码问题。
3、在Response Headers中设置Content-Type:text/json;charset=utf-8,在JAVA中实现方法:response.setContentType("text/json; charset=utf-8"),此方法可以解决用EXT在显示后台中文时的乱码问题。
今天用jfreechart做图,发现生产的柱状图无法显示数值,经过一段时间摸索终于解决,现给一demo如下:
test.jsp
<%@ page contentType="text/html; charset=GBK" %>
<%@ page import="org.jfree.chart.*"%>
<%@ page import="org.jfree.chart.axis.AxisLocation"%>
<%@ page import="org.jfree.chart.plot.*"%>
<%@ page import="org.jfree.data.*"%>
<%@ page import ="java.text.DecimalFormat"%>
<%@ page import ="java.text.NumberFormat"%>
<%@ page import ="java.awt.Color"%>
<%@ page import="java.awt.Font"%>
<%@ page import="org.jfree.chart.renderer.category.*"%>
<%@ page import="org.jfree.chart.axis.*"%>
<%@ page import="org.jfree.chart.title.TextTitle"%>
<%@ page import="org.jfree.chart.labels.*"%>
<%@page import="org.jfree.data.category.*"%>
<%@page import="org.jfree.chart.plot.PlotOrientation"%>
<%@page import="org.jfree.chart.servlet.ServletUtilities"%>
<%
CategoryDataset dcd= getDataset();
JFreeChart chart= ChartFactory.createStackedBarChart3D("各部门参加培训情况", "部门", "人数", dcd, PlotOrientation.VERTICAL, true, false, false);
// 图例字体清晰
//chart.setTextAntiAlias(false);
//chart.setBackgroundPaint(Color.WHITE);
// 2 .2 主标题对象 主标题对象是 TextTitle 类型
//chart .setTitle(new TextTitle("ok", new Font("隶书", Font.BOLD, 25)));
// 2 .2.1:设置中文 // x,y轴坐标字体
Font labelFont = new Font("SansSerif", Font.TRUETYPE_FONT, 12);
// 2 .3 Plot 对象 Plot 对象是图形的绘制结构对象
CategoryPlot plot = (CategoryPlot)chart.getPlot();
ValueAxis rangeAxis = plot.getRangeAxis();
//设置最高的一个 Item 与图片顶端的距离
rangeAxis.setUpperMargin(0.15);
//设置最低的一个 Item 与图片底端的距离
rangeAxis.setLowerMargin(0.15);
plot.setRangeAxis(rangeAxis);
StackedBarRenderer3D renderer=new StackedBarRenderer3D();
//renderer.setBaseOutlinePaint(Color.BLACK);
//设置 Wall 的颜色
//renderer.setWallPaint(Color.gray);
//设置每种柱的颜色
renderer.setSeriesPaint(0, new Color(153, 153, 255));
renderer.setSeriesPaint(1, new Color(204, 255, 255));
renderer.setSeriesPaint(2, Color.GREEN);
//显示每个柱的数值,并修改该数值的字体属性
renderer.setItemLabelGenerator(new StandardCategoryItemLabelGenerator());
renderer.setItemLabelFont(new Font("黑体",Font.PLAIN,9));
renderer.setItemLabelsVisible(true);
plot.setRenderer(renderer);
String filename=ServletUtilities.saveChartAsPNG(chart,500,300,null,session);
String url=request.getContextPath()+"/servletDisplayChart?filename="+filename;
%>
<p align="center">
<img src="<%=url%>" width="500" height="300" border="0" usemap="#map0">
</p>
<%!
private static CategoryDataset getDataset()
{
DefaultCategoryDataset defaultcategorydataset = new DefaultCategoryDataset();
defaultcategorydataset.addValue(10.399999999999999D, "培训人数", "中心机关");
defaultcategorydataset.addValue(10.800000000000001D, "未培训人数", "中心机关");
defaultcategorydataset.addValue(43.200000000000003D, "培训人数", "物探部");
defaultcategorydataset.addValue(15.6D, "未培训人数", "物探部");
defaultcategorydataset.addValue(23D, "培训人数", "遥感部");
defaultcategorydataset.addValue(11.300000000000001D, "未培训人数", "遥感部");
defaultcategorydataset.addValue(13D, "培训人数", "物业部");
defaultcategorydataset.addValue(11.800000000000001D, "未培训人数", "物业部");
defaultcategorydataset.addValue(15, "培训人数", "企业部");
defaultcategorydataset.addValue(12D, "未培训人数", "企业部");
return defaultcategorydataset;
}
%>
相信大多数人对iGoogle(Google 个性化首页)都不会陌生,除了可以定制iGoogle的内容之外,iGoogle的主题外 观都是可以定制的。之前Google官方只提供几个iGoogle主题,如今Google推出 了iGoogle主题API,任何人都可以轻松地创建个性化的主题。

然而,Google给出的API文档 是相当繁复的,非常考验英文与编程能力。这里介绍3种快速创建iGoogle主 题的方法,你可以不需要看那个复杂的文档,只需鼠标轻点即可完成个性化的主 题。
1、igThemer
igThemer是一个在线的主题编辑器,提供下图所示的各种参数的定制,包括 背景颜色、背景图片、选项卡颜色等等。

制作完成后点击create即可在线生成一个xml文件,文件会存储在igThemer网 站上,方便共享。你无需上传到自己的空间。
2、Haochi's igthemer
和igThemer几乎是一样的,目前似乎还在建设中。但依然可用。或许过一段 时间后会更完善。
3、iGoogle theme API bookmarklet
这个方法我最喜欢,与前两种相比,这个方法更实时。打 开iGoogle首页,把下面的代码粘贴到地址栏:
| javascript:var s=document.createElement('script');s.id="igteid"; s.type="text/javascript";s.src= "http://igoogle-theme-editor.googlecode.com/svn/" +"trunk/iGoogleThemeEditor/dist/ige.js?lang=en&" +new Date().getTime(); document.body.appendChild(s);void(0); |
浏览器的左侧马上出现了下图所示的编辑栏。

在编辑栏里你可以轻松地定制各种参数。参数得改变会即时在浏览器里显现 。最后,点击create xml,生成iGoogle主题。和igThemer不同,你需要把这个 xml文件上传到自己的空间上方可使用。
如何使用iGoogle主题?
如果你的主题是自用的,把生成的xml文档上传到网上,然后在浏览器里输入 下面的地址即可使用:
http://www.google.com/ig?skin=主题地址
当然,你还可以将主题 提交到iGoogle目录,Google采纳后,每个人都可以直接使用。目前iGoogle目录里已经有将近50 个主题。
摘要: Sing Li (westmakaha@yahoo.com), 作家, Wrox Press
2007 年 1 月 08 日
现代软件项目不再是单个本地团队独立开发的产物。随着健壮的企业级开源组件的可用性日益提高,当今的软件项目需要项目团队间的动态协作,往往也需要混合使用在全球范围内创建和维护的组件。如今,Apache Maven 构建系统步入了第二代,它和由 Internet 带来的全球软件...
阅读全文
使用 AppFuse 的七个理由
学习 Java 开放源码工具 —— 并使用这些工具提高生产效率
 |
 |
|
级别: 初级
Matt Raible (mraible@virtuas.com), 开放源码实践先驱, Virtuas Open Source Solutions
2006 年 8 月 31 日
开始学习在 Java™ 平台上使用诸如 Spring、Hibernate 或 MySQL 之类的开放源码工具时可能非常困难。再加上 Ant 或 Maven,以及与 DWR 一起的小 Ajax,还有 Web 框架 —— 即 JSF,我们必须睁大眼睛盯着如何配置应用程序。AppFuse 减少了集成开放源码项目的痛苦。它可以把测试变成一等公民,让我们可以从数据库表生成整个 UI,并使用 XFire 来支持 Web 服务。另外,AppFuse 的社区也非常健全,这是不同 Web 框架用户可以一起融洽相处的地方之一。
AppFuse 是一个开放源码的项目和应用程序,它使用了在 Java 平台上构建的开放源码工具来帮助我们快速而高效地开发 Web 应用程序。我最初开发它是为了减少在为客户构建新 Web 应用程序时所花费的那些不必要的时间。从核心上来说,AppFuse 是一个项目骨架,类似于通过向导创建新 Web 项目时 IDE 所创建的东西。当我们使用 AppFuse 创建一个项目时,它会提示我们将使用开放源码框架,然后才创建项目。它使用 Ant 来驱动测试、代码生成、编译和部署。它提供了目录和包结构,以及开发基于 Java 语言的 Web 应用程序所需要的库。
与大部分 “new project” 向导不同,AppFuse 创建的项目从最开始就包含很多类和文件。这些文件用来实现特性,不过它们同时也会在您开发应用程序时被用作示例。通过使用 AppFuse 启动新项目,我们通常可以减少一到两周的开发时间。我们不用担心如何将开放源码框架配置在一起,因为这都已经完成了。我们的项目都已提前配置来与数据库进行交互,它会部署到应用服务器上,并对用户进行认证。我们不必实现安全特性,因为这都早已集成了。
当我最初开发 AppFuse 时,它只支持 Struts 和 Hibernate。经过几年的努力,我发现了比 Struts 更好的 Web 框架,因此我还添加了为这些 Web 框架使用的选项。现在,AppFuse 可以支持 Hibernate 或 iBATIS 作为持久性框架。对于 Web 框架来说,我们可以使用 JavaServer Faces(JSF)、Spring MVC、Struts、Tapestry 或 WebWork。
AppFuse 提供了很多应用程序需要的一些特性,包括:
- 认证和授权
- 用户管理
- Remember Me(这会保存您的登录信息,这样就不用每次都再进行登录了)
- 密码提醒
- 登记和注册
- SSL 转换
- E-mail
- URL 重写
- 皮肤
- 页面修饰
- 模板化布局
- 文件上载
这种 “开箱即用” 的功能是 AppFuse 与其他 CRUD 代 框架的区别之一(CRUD 取自创建、检索、更新 和删除 几个操作的英文首字母),包括 Ruby on Rails、Trails 和 Grails。上面提到的这些框架,以及 AppFuse,都让我们可以从数据库表或现有的模型对象中生成主页/细节页。
图 1 阐述了一个典型 AppFuse 应用程序的概念设计:
图 1. 典型的 AppFuse 应用程序

清单 1 给出了我们在创建 devworks 项目时所使用的命令行交互操作,同时还给出了所生成的结果。这个项目使用了 WebWork 作为自己的 Web 框架(请参考下面 参考资料 一节给出的链接)。
清单 1. 使用 AppFuse 创建新项目
alotta:~/dev/appfuse mraible$ ant new
Buildfile: build.xml
clean:
[echo] Cleaning build and distribution directories
init:
new:
[echo]
[echo] +-------------------------------------------------------------+
[echo] | -- Welcome to the AppFuse New Application Wizard! -- |
[echo] | |
[echo] | To create a new application, please answer the following |
[echo] | questions. |
[echo] +-------------------------------------------------------------+
[input] What would you like to name your application [myapp]?
devworks
[input] What would you like to name your database [mydb]?
devworks
[input] What package name would you like to use [org.appfuse]?
com.ibm
[input] What web framework would you like to use [webwork,tapestry,spring,js
f,struts]?
webwork
[echo] Creating new application named 'devworks'...
[copy] Copying 359 files to /Users/mraible/Work/devworks
[copy] Copying 181 files to /Users/mraible/Work/devworks/extras
[copy] Copying 1 file to /Users/mraible/Work/devworks
[copy] Copying 1 file to /Users/mraible/Work/devworks
install:
[echo] Copying WebWork JARs to ../../lib
[copy] Copying 6 files to /Users/mraible/Work/devworks/lib
[echo] Adding WebWork entries to ../../lib.properties
[echo] Adding WebWork classpath entries
[echo] Removing Struts-specific JARs
[delete] Deleting directory /Users/mraible/Work/devworks/lib/struts-1.2.9
[delete] Deleting directory /Users/mraible/Work/devworks/lib/strutstest-2.1.3
[echo] Deleting struts_form.xdt for XDoclet
[delete] Deleting directory /Users/mraible/Work/devworks/metadata/templates
[echo] Deleting Struts merge-files in metadata/web
[delete] Deleting 7 files from /Users/mraible/Work/devworks/metadata/web
[echo] Deleting unused Tag Libraries and Utilities
[delete] Deleting 2 files from /Users/mraible/Work/devworks/src/web/org/appfu
se/webapp
[echo] Modifying appgen for WebWork
[copy] Copying 12 files to /Users/mraible/Work/devworks/extras/appgen
[echo] Replacing source and test files
[delete] Deleting directory /Users/mraible/Work/devworks/src/web/org/appfuse/
webapp/form
[delete] Deleting directory /Users/mraible/Work/devworks/src/web/org/appfuse/
webapp/action
[copy] Copying 13 files to /Users/mraible/Work/devworks/src
[delete] Deleting directory /Users/mraible/Work/devworks/test/web/org/appfuse
/webapp/form
[delete] Deleting directory /Users/mraible/Work/devworks/test/web/org/appfuse
/webapp/action
[copy] Copying 5 files to /Users/mraible/Work/devworks/test
[echo] Replacing web files (images, scripts, JSPs, etc.)
[delete] Deleting 1 files from /Users/mraible/Work/devworks/web/scripts
[copy] Copying 34 files to /Users/mraible/Work/devworks/web
[delete] Deleting: /Users/mraible/Work/devworks/web/WEB-INF/validator-rules-c
ustom.xml
[echo] Modifying Eclipse .classpath file
[echo] Refactoring build.xml
[echo] ----------------------------------------------
[echo] NOTE: It's recommended you delete extras/webwork as you shouldn't ne
ed it anymore.
[echo] ----------------------------------------------
[echo] Repackaging info written to rename.log
[echo]
[echo] +-------------------------------------------------------------+
[echo] | -- Application created successfully! -- |
[echo] | |
[echo] | Now you should be able to cd to your application and run: |
[echo] | > ant setup test-all |
[echo] +-------------------------------------------------------------+
BUILD SUCCESSFUL
Total time: 15 seconds
|
|
为什么使用 WebWork?
Struts 社区最近在热情地拥抱 WebWork,这种结合导致为 Java 平台提供了一个非常优秀的新 Web 框架:Struts 2。当然,Spring MVC 是一个非常优秀的基于请求的框架,但是它不能像 Struts 2 一样支持 JSF。基于内容的框架(例如 JSF 和 Tapestry)也都很好,但是我发现 WebWork 更为直观,更容易使用(更多有关 Structs 2 和 JSF 的内容请参看 参考资料)。 |
|
在创建一个新项目之后,我们就得到了一个类似于图 2 所示的目录结构。Eclipse 和 Intellij IDEA 项目文件都是作为这个过程的一部分创建的。
图 2. 项目的目录结构

这个目录结构与 Sun 为 Java 2 Platform Enterprise Edition(J2EE)Web 应用程序推荐的目录结构非常类似。在 2.0 版本的 AppFuse 中,这个结构会变化成适合 Apache Maven 项目的标准目录结构(有关这两个目录介绍的内容,请参看 参考资料 中的链接)。AppFuse 还会从 Ant 迁移到 Maven 2 上,从而获得相关下载的能力和对生成 IDE 项目文件的支持。目前基于 Ant 的系统要求提交者维护项目文件,而 Maven 2 可以通过简单地使用项目的 pom.xml 文件生成 IDEA、Eclipse 和 NetBeans 项目文件。(这个文件位于您项目的根目录中,是使用 Maven 构建应用程序所需要的主要组件)。它与利用 Ant 所使用的 build.xml 文件非常类似。)
现在我们对 AppFuse 是什么已经有一点概念了,在本文剩下的部分中,我们将介绍使用 AppFuse 的 7 点理由。即使您选择不使用 AppFuse 来开始自己的项目,也会看到 AppFuse 可以为您提供很多样板代码,这些代码可以在基于 Java 语言的 Web 应用程序中使用。由于它是基于 Apache 许可证的,因此非常欢迎您在自己的应用程序中重用这些代码。
理由 1:测试
测试是在软件开发项目中很少被给予足够信任的一个环节。注意我并不是说在软件开发的一些刊物中没有得到足够的信任!很多文章和案例研究都给出了测试优先的开发方式和足够的测试覆盖面以提高软件的质量。然而,测试通常都被看作是一件只会延长项目开发时间的事情。实际上,如果我们使用测试优先的方法在编写代码之前就开始撰写测试用例,我相信我们可以发现这实际上会加速 开发速度。另外,测试优先也可以使维护和重用更加 容易。如果我们不编写代码来测试自己的代码,那么就需要手工对应用程序进行测试 —— 这通常效率都不高。自动化才是关键。
当我们首次开始使用 AppFuse 时,我们可能需要阅读这个项目 Web 站点上提供的快速入门指南和教程(请参看 参考资料 中的链接)。这些教程的编写就是为了您可以首先编写测试用例;它们直到编写接口和/或实现之后才能编译。如果您有些方面与我一样,就会在开始编写代码之前就已经编写好测试用例了;这是真正可以加速编写代码的惟一方式。如果您首先编写了代码的实现,通过某种方式验证它可以工作,那么您可能会对自己说,“哦,看起来不错 —— 谁需要测试呢?我还有更多的代码需要编写!”这种情况不幸的一面是您通常都会做一些事情 来测试自己的代码;您简单地跳过了可以自动化进行测试的地方。
AppFuse 的文档展示了如何测试应用程序的所有 层次。它从数据库层开始入手,使用了 DbUnit(请参看 参考资料)在运行测试之前提前使用数据来填充自己的数据库。在数据访问(DAO)层,它使用了 Spring 的 AbstractTransactionalDataSourceSpringContextTests 类(是的,这的确是一个类的名字!)来允许简单地加载 Spring 上下文文件。另外,这个类对每个 testXXX() 方法封装了一个事务,并当测试方法存在时进行回滚。这种特性使得测试 DAO 逻辑变得非常简单,并且不会对数据库中的数据造成影响。
在服务层,jMock (请参看 参考资料)用来编写那些可以消除 DAO 依赖的真正 单元测试。这允许进行验证业务逻辑正确的快速测试;我们不用担心底层的持久性逻辑。
|
HtmlUnit 支持
HtmlUnit 团队在 1.8 发行版中已经完成了相当多的工作来确保包可以与流行的 Ajax 框架(Prototype 和 Scriptaculous)很好地工作。 |
|
在 Web 层,测试会验证操作(Struts/WebWork)、控件(Spring MVC)、页面(Tapestry)和管理 bean(JSF)如我们所期望的一样进行工作。Spring 的 spring-mock.jar 可以非常有用地用来测试所有这些框架,因为它包含了一个 Servlet API 的仿真实现。如果没有这个有用的库,那么测试 AppFuse 的 Web 框架就会变得非常困难。
UI 通常是开发 Web 应用程序过程中最为困难的一部分。它也是顾客最经常抱怨的地方 —— 这既是由于它并不是非常完美,也是由于它的工作方式与我们期望的并不一样。另外,没有什么会比在客户面前作演示的过程中看到看到异常堆栈更糟糕的了!您的应用程序可能会非常可怕,但是客户可能会要求您做到十分完美。永远不要让这种事情发生。Canoo WebTest 可以对 UI 进行测试。它使用了 HtmlUnit 来遍历测试 UI,验证所有的元素都存在,并可以填充表单的域,甚至可以验证一个假想的启用 Ajax 的 UI 与我们预期的工作方式一样。(有关 WebTest 和 HTMLUnit 的链接请参看 参考资料。)
为了进一步简化 Web 的测试,Cargo(请参看 参考资料)对 Tomcat 的启动和停止(分别在运行 WebTest 测试之前和之后)进行了自动化。
理由 2:集成
正如我在本文简介中提到的一样,很多开放源码库都已经预先集成到 AppFuse 中了。它们可以分为以下几类:
- 编译、报告和代码生成:Ant、Ant Contrib Tasks、Checkstyle、EMMA、Java2Html、PMD 和 Rename Packages
- 测试框架:DbUnit、Dumbster、jMock、JUnit 和 Canoo WebTest
- 数据库驱动程序:MySQL 和 PostgreSQL
- 持久性框架:Hibernate 和 iBATIS
- IoC 框架:Spring
- Web 框架:JSF、Spring MVC、Struts、Tapestry 和 WebWork
- Web 服务:XFire
- Web 工具:Clickstream、Display Tag、DWR、JSTL、SiteMesh、Struts Menu 和 URL Rewrite Filter
- Security:Acegi Security
- JavaScript 和 CSS:Scriptaculous、Prototype 和 Mike Stenhouse 的 CSS Framework
除了这些库之外,AppFuse 还使用 Log4j 来记录日志,使用 Velocity 来构建 e-mail 和菜单模板。Tomcat 可以支持最新的开发,我们可以使用 1.4 或 5 版本的 Java 平台来编译或构建程序。我们应该可以将 AppFuse 部署到任何 J2EE 1.3 兼容的应用服务器上;这已经经过了测试,我们知道它在所有主要版本的 J2EE 服务器和所有主要的 servlet 容器上都可以很好地工作。
图 3 给出了上面创建的 devworks 项目的 lib 目录。这个目录中的 lib.properties 文件控制了每个依赖性的版本号,这意味着我们可以简单地通过把这些包的新版本放到这个目录中并执行诸如 ant test-all -Dspring.version=2.0 之类的命令来测试这些包的新版本。
图 3. 项目依赖性

预先集成这些开放源码库可以在项目之初极大地提高生产效率。尽管我们可以找到很多文档介绍如何集成这些库,但是定制工作示例并简单地使用它来开发应用程序要更加简单。
除了可以简化 Web 应用程序的开发之外,AppFuse 让我们还可以将 Web 服务简单地集成到自己的项目中。尽管 XFire 也在 AppFuse 下载中一起提供了,不过如果我们希望,也可以自己集成 Apache Axis(请参看 参考资料 中有关 Axis 集成的教程)。另外,Spring 框架和 XFire 可以一起将服务层作为 Web 服务非常简单地呈现出来,这就为我们提供了开发面向服务架构的能力。
另外,AppFuse 并不会将我们限定到任何特定的 API 上。它只是简单地对可用的最佳开放源码解决方案重新进行打包和预先集成。AppFuse 中的代码可以处理这种集成,并实现了 AppFuse 的基本安全性和可用性特性。只要可能,就会减少代码,以便向 AppFuse 的依赖框架添加一个特性。例如,AppFuse 自带的 Remember Me 和 SSL 切换特性最近就因为类似的特性而从 Acegi Security 中删除了。
理由 3:自动化
Ant 使得简化了从编译到构建再到部署的自动化过程。Ant 是 AppFuse 中的一等公民,这主要是因为我发现在命令行中执行操作比从 IDE 中更加简单。我们可以使用 Ant 实现编译、测试、部署和执行任何代码生成的任务。
尽管这种能力对于有些人来说非常重要,但是它并不适用于所有的人。很多 AppFuse 用户目前都使用 Eclipse 或 Intellij IDEA 来构建和测试自己的项目。在这些 IDE 中运行 Ant 的确可以工作,但是这样做的效率通常都不如使用 IDE 内置的 JUnit 支持来运行测试效率高。
幸运的是,AppFuse 支持在 IDE 中运行测试,不过管理这种特性对于 AppFuse 开发人员来说就变得非常困难了。最大的痛苦在于 XDoclet 用来生成 Hibernate 映射文件和 Web 框架所使用的一些工件(例如 ActionForms 和 Struts 使用的 struts-config.xml)。IDE 并不知道需要生成的代码,除非我们配置使用 Ant 来编译它们,或者安装了一些可以认识 XDoclet 的插件。
这种对知识的缺乏是 AppFuse 2.0 切换到 JDK 5 和 Maven 2 上的主要原因。JDK 5、注释和 Struts 2 将让我们可以摆脱 XDoclet。Maven 2 将使用这些生成的文件和动态类路径来生成 IDE 项目文件,这样对项目的管理就可以进行简化。目前基于 Ant 的编译系统已经为不同的层次生成了一些工件(包括 dao.jar、service.jar 和 webapp.war),因此切换到 Maven 的模型上应该是一个非常自然的调整。
除了 Ant 之外(它对于编译、测试、部署和报告具有丰富的支持),对于 CruiseControl 的支持也构建到了 AppFuse 中。CruiseControl 是一个 Continuous Integration 应用程序,让我们可以在源代码仓库中代码发生变化时自动运行所有的测试。extras/cruisecontrol 目录包含了我们为基于 AppFuse 的项目快速、简单地设置 Continuous Integration 时所需要的文件。
设置 Continuous Integration 是软件开发周期中我们首先要做的事情之一。它不但激发程序员去编写测试用例,而且还通过 “You broke the build!” 游戏促进了团队之间的合作和融合。
理由 4:安全特性和可扩展性
AppFuse 最初是作为我为 Apress 编写的书籍 Pro JSP 中示例应用程序的一部分开发的。这个示例应用程序展示了很多安全特性和用于简化 Struts 开发的特性。这个应用程序中的很多安全特性在 J2EE 的安全框图中都不存在。使用容器管理认证(CMA)的认证方法非常简单,但是 Remember Me、密码提示、SSL 切换、登记和用户管理等功能却都不存在。另外,基于角色的保护方法功能在非 EJB 环境中也是不可能的。
最初,AppFuse 使用自己的代码和用于 CMA 的解决方案完全实现了这些特性。我在 2004 年年初开始学习 Spring 时就听说过有关 Acegi Security 的知识。我对 Acegi 所需要的 XML 的行数(175)与 web.xml 中所需要的 CMA 的行数(20)进行了比较,很快就决定丢弃 Acegi 了,因为它太过复杂了。
一年半之后 —— 在为另外一本书 Spring Live 中编写了一章有关使用 Acegi Security 的内容之后 —— 我就改变了自己的想法。Acegi 的确(目前仍然)需要很多 XML,但是一旦我们理解了这一点,它实际上是相当简单的。当我们最终作出改变,使用 Acegi Security 的特性来全部取代 AppFuse 的特性之后,我们最终删除了大量的代码。类之上的类都已经没有了,“Acegi handles that now” 中消失的部分现在全部进入了 CVS 的 Attic 中了。
Acegi Security 是 J2EE 安全模型中曾经出现过的最好模型。它让我们可以实现很多有用的特性,这些特性在 Servlet API 的安全模型中都不存在:认证、授权、角色保护方法、Remember Me、密码加密、SSL 切换、用户切换和注销。它让我们还可以将用户证书存储到 XML 文件、数据库、LDAP 或单点登录系统(例如 Yale 的 Central Authentication Service (CAS) 或者 SiteMinder)中。
AppFuse 对很多与安全性相关的特性的实现从一开始都是非常优秀的。现在 AppFuse 使用了 Acegi Security,这些特性 —— 以及更多特性 —— 都非常容易实现。Acegi 有很多地方都可以进行扩充:这是它使用巨大的 XML 配置文件的原因。正如我们已经通过去年的课程对 Acegi 进行集成一样,我们已经发现对很多 bean 的定义进行定制可以更加紧密地与 AppFuse 建立联系。
Spring IoC 容器和 Acegi Security 所提供的简单开发、容易测试的代码和松耦合特性的组合是 AppFuse 是这么好的一种开发平台的主要原因。这些框架都是不可插入的,允许生成干净的可测试代码。AppFuse 集成了很多开放源码项目,依赖注入允许对应用程序层进行简单的集成。
理由 5:使用 AppGen 生成代码
有些人会将代码生成称为代码气味的散播(code smell)。在他们的观点中,如果我们需要生成代码,那么很可能就会做一些错事。我倾向于这种确定自己代码使用的模式和自动化生成代码的能力应该称为代码香味的弥漫(code perfume)。如果我们正在编写类似的 DAO、管理器、操作或控件,并且不想为它们生成代码,那么这就需要根据代码的气味来生成代码。当然,当语言可以为我们提供可以简化任务的特性时,一切都是那么美好;不过代码生成通常都是一个必需 —— 通常其生产率也非常高 —— 的任务。
AppFuse 中提供了一个基于 Ant 和 XDoclet 的代码生成工具,名叫 AppGen。默认情况下,常见的 DAO 和管理器都可以允许我们对任何普通老式 Java 对象(POJO)进行 CRUD 操作,但是在 Web 层上这样做有些困难。AppGen 有几个特性可以用来执行以下任务:
- (使用 Middlegen 和 Hibernate 工具)从数据库表中生成 POJO
- 从 POJO 生成 UI
- 为 DAO、管理器、操作/控制器和 UI 生成测试
在运行 AppGen 时,您会看到提示说 AppGen 要从数据库表或 POJO 中生成代码。如果在命令行中执行 ant install-detailed,AppGen 就会安装 POJO 特定的 DAO、管理器以及它们的测试。运行 ant install 会导致 Web 层的类重用通用的 DAO 和默认存在的管理器。
为了阐述 AppGen 是如何工作的,我们在 devworks MySQL 数据库中创建了如清单 2 所示的表:
清单 2. 创建一个名为 cat 的数据库表
create table cat (
cat_id int(8) auto_increment,
color varchar(20) not null,
name varchar(20) not null,
created_date datetime not null,
primary key (cat_id)
) type=InnoDB;
|
在 extras/appgen 目录中,运行 ant install-detailed。这个命令的输出结果对于本文来说实在太长了,不过我们在清单 3 中给出了第一部分的内容:
清单 3. 运行 AppGen 的 install-detailed 目标
$ ant install-detailed
Buildfile: build.xml
init:
[mkdir] Created dir: /Users/mraible/Work/devworks/extras/appgen/build
[echo]
[echo] +-------------------------------------------------------+
[echo] | -- Welcome to the AppGen! -- |
[echo] | |
[echo] | Use the "install" target to use the generic DAO and |
[echo] | Manager, or use "install-detailed" to general a DAO |
[echo] | and Manager specifically for your model object. |
[echo] +-------------------------------------------------------+
[input] Would you like to generate code from a table or POJO? (table,pojo)
table
[input] What is the name of your table (i.e. person)?
cat
[input] What is the name, if any, of the module for your table (i.e. organization)?
[echo] Running Middlegen to generate POJO...
|
要对 cat 表使用这个新生成的代码,我们需要修改 src/dao/com/ibm/dao/hibernate/applicationContext-hibernate.xml,来为 Hibernate 添加 Cat.hbm.xml 映射文件。清单 3 给出了我们修改后的 sessionFactory bean 的样子:
清单 4. 将 Cat.hbm.xml 添加到 sessionFactory bean 中
<bean id="sessionFactory" class="...">
<property name="dataSource" ref="dataSource"/>
<property name="mappingResources">
<list>
<value>com/ibm/model/Role.hbm.xml</value>
<value>com/ibm/model/User.hbm.xml</value>
<value>com/ibm/model/Cat.hbm.xml</value>
</list>
</property>
...
</bean>
|
在运行 ant setup deploy 之后,我们就应该可以在部署的应用程序中对 cat 表执行 CRUD 操作了:
图 4. Cat 列表

图 5. Cat 表单

我们在上面的屏幕快照中看到的记录都是作为代码生成的一部分创建的,因此现在就有测试数据了。
理由 6:文档
我们可以找到 AppFuse 各个风味的教程,并且它们都以 6 种不同的语言给出了:中文、德语、英语、韩语、葡萄牙语和西班牙语。使用风味(flavor) 一词,我的意思是不同框架的组合,例如 Spring MVC 加上 iBATIS、Spring MVC 加上 Hibernate 或 JSF 加上 Hibernate。使用这 5 种 Web 框架和两种持久框架,可以有好几种组合。有关它们的翻译,AppFuse 为自己的默认特性提供了 8 种翻译。可用语言包括中文、荷兰语、德语、英语、法语、意大利语、葡萄牙语和西班牙语。
除了核心教程之外,还添加了很多教程(请参看 参考资料) 来介绍与各种数据库、应用服务器和其他开放源码技术(包括 JasperReports、Lucene、Eclipse、Drools、Axis 和 DWR)的集成。
理由 7:社区
Apache 软件基金会对于开放源码有一个有趣的看法。它对围绕开放源码项目开发一个开放源码社区最感兴趣。它的成员相信如果社区非常强大,那么产生高质量的代码就是一个自然的过程。下面的内容引自 Apache 主页:
“我们认为自己不仅仅是一组共享服务器的项目,而且是一个开发人员和用户的社区。”
AppFuse 社区从 2003 年作为 SourceForge 上的一个项目(是 struts.sf.net 的一部分)启动以来,已经获得了极大的增长。通过在 2004 年 3 月转换到 java.net 上之后,它已经成为这里一个非常流行的项目,从 2005 年 1 月到 3 月成为访问量最多的一个项目。目前它仍然是一个非常流行的项目(有关 java.net 项目统计信息的链接,请参看 参考资料),不过在这个站点上它正在让位于 Sun 赞助的很多项目。
在 2004 年年末,Nathan Anderson 成为继我之后第一个提交者。此后有很多人都加入了进来,包括 Ben Gill、David Carter、Mika G?ckel、Sanjiv Jivan 和 Thomas Gaudin。很多现有的提交者都已经通过各种方式作出了自己的贡献,他们都帮助 AppFuse 社区成为一个迅速变化并且非常有趣的地方。
邮件列表非常友好,我们试图维护这样一条承诺 “没有问题是没有人理会的问题”。我们的邮件列表归档文件中惟一一条 “RTFM” 是从用户那里发出的,而不是从开发者那里发出的。我们绝对信奉 Apache 开放源码社区的哲学。引用我最好的朋友 Bruce Snyder 的一句话,“我们为代码而来,为人们而留下”。目前,大部分开发者都是用户,我们通常都喜欢有一段美妙的时间。另外,大部分文档都是由社区编写的;因此,这个社区的知识是非常渊博的。
结束语
我们应该尝试使用 AppFuse 进行开发,这是因为它允许我们简单地进行测试、集成、自动化,并可以安全地生成 Web 应用程序。其文档非常丰富,社区也非常友好。随着其支撑框架越来越好,AppFuse 也将不断改进。
从 AppFuse 2.0 开始,我们计划迁移到 JDK 5(仍然支持部署到 1.4)和 Maven 2 上去。这些工具可以简化使用 AppFuse 的开发、安装和升级。我们计划充分利用 Maven 2 的功能来处理相关依赖性。我们将碰到诸如 appfuse-hibernate-2.0.jar 和 appfuse-jsf-2.0.jar 之类的工件。这些工件都可以在 pom.xml 文件中进行引用,它们负责提取其他相关依赖性。除了在自己的项目中使用 AppFuse 基类之外,我们还可以像普通的框架一样在 JAR 中对这些类简单地进行扩展,这应该会大大简化它的升级过程,并鼓励更多用户将自己希望的改进提交到这个项目中。
如果没有其他问题,使用 AppFuse 可以让您始终处于 Java Web 开发的技术前沿上 —— 就像我们一样!
参考资料
学习
获得产品和技术
讨论
关于作者
|
http://downloads4.myeclipseide.com/downloads/products/eworkbench/6.5M1/MyEclipse_6.5M1.exe
注册前一定要把网络断开
Subscriber:QQ24785490
Subscription Code:DLR8ZC-855551-65657857678050018
Subscriber: administrator
Subscription Code: nLR7ZL-655342-54657656405281154
摘要: <!-- Example Server Configuration File -->
<!-- Tomcat服务器配置示例文件 -->
<!-- Note that component elements are nested corresponding to their
parent-child ...
阅读全文
import org.eclipse.swt.SWT;
import org.eclipse.swt.internal.ole.win32.COM;
import org.eclipse.swt.internal.ole.win32.DISPPARAMS;
import org.eclipse.swt.internal.ole.win32.EXCEPINFO;
import org.eclipse.swt.internal.ole.win32.GUID;
import org.eclipse.swt.internal.ole.win32.IDispatch;
import org.eclipse.swt.internal.ole.win32.ITypeInfo;
import org.eclipse.swt.internal.ole.win32.IUnknown;
import org.eclipse.swt.internal.win32.OS;
import org.eclipse.swt.ole.win32.OLE;
import org.eclipse.swt.ole.win32.Variant;
/*
* Created on 2006-7-11
*
*
* Window - Preferences - Java - Code Style - Code Templates
*/
/**
* @author hcw
*
* TODO To change the template for this generated type comment go to Window -
* Preferences - Java - Code Style - Code Templates
*/
public class CComObject {
private GUID guid = new GUID();
//private GUID IID = new GUID();
private IDispatch Autoface = null;
private ITypeInfo TypeInfo = null;
private String FMachineName = null;
private void CreateComObject() throws Exception{
dispose();
int[] ppv = new int[1];
int ret = COM.CoCreateInstance(guid, 0,
COM.CLSCTX_INPROC_SERVER | COM.CLSCTX_LOCAL_SERVER,
COM.IIDIUnknown, ppv);
if(ret!=COM.S_OK)
OLE.error(ret);
//throw new Exception("对象创建失败!");
IUnknown objIUnknown = new IUnknown(ppv[0]);
ppv = new int[1];
ret = objIUnknown.QueryInterface(COM.IIDIDispatch, ppv);
objIUnknown.Release();
if(ret!=COM.S_OK)
OLE.error(ret);
//throw new Exception("对象不支持Dispatch!");
Autoface = new IDispatch(ppv[0]);
ppv = new int[1];
ret = Autoface.GetTypeInfo(0, COM.LOCALE_USER_DEFAULT, ppv);
if (ret == OLE.S_OK) {
TypeInfo = new ITypeInfo(ppv[0]);
TypeInfo.AddRef();
}
}
private int getIDsOfNames(String name){
int[] rgdispid = new int[1];
String[] names = new String[]{name};
int ret = Autoface.GetIDsOfNames(guid, names, names.length, COM.LOCALE_USER_DEFAULT, rgdispid);
if (ret != COM.S_OK) return -1;
return rgdispid[0];
}
private void getVariantData(Variant aVar, int pData){
if (pData == 0) OLE.error(OLE.ERROR_OUT_OF_MEMORY);
COM.VariantInit(pData);
if ((aVar.getType() & COM.VT_BYREF) == COM.VT_BYREF) {
COM.MoveMemory(pData, new short[] {aVar.getType()}, 2);
COM.MoveMemory(pData + 8, new int[]{aVar.getByRef()}, 4);
return;
}
switch (aVar.getType()) {
case COM.VT_EMPTY :
break;
case COM.VT_BOOL :
COM.MoveMemory(pData, new short[] {aVar.getType()}, 2);
COM.MoveMemory(pData + 8, new int[]{(aVar.getBoolean()) ? COM.VARIANT_TRUE : COM.VARIANT_FALSE}, 2);
break;
case COM.VT_R4 :
COM.MoveMemory(pData, new short[] {aVar.getType()}, 2);
COM.MoveMemory(pData + 8, new float[]{aVar.getFloat()}, 4);
break;
case COM.VT_I4 :
COM.MoveMemory(pData, new short[] {aVar.getType()}, 2);
COM.MoveMemory(pData + 8, new int[]{aVar.getInt()}, 4);
break;
case COM.VT_DISPATCH :
aVar.getDispatch().AddRef();
COM.MoveMemory(pData, new short[] {aVar.getType()}, 2);
COM.MoveMemory(pData + 8, new int[]{aVar.getDispatch().getAddress()}, 4);
break;
case COM.VT_UNKNOWN :
aVar.getUnknown().AddRef();
COM.MoveMemory(pData, new short[] {aVar.getType()}, 2);
COM.MoveMemory(pData + 8, new int[]{aVar.getUnknown().getAddress()}, 4);
break;
case COM.VT_I2 :
COM.MoveMemory(pData, new short[] {aVar.getType()}, 2);
COM.MoveMemory(pData + 8, new short[]{aVar.getShort()}, 2);
break;
case COM.VT_BSTR :
COM.MoveMemory(pData, new short[] {aVar.getType()}, 2);
char[] data = (aVar.getString()+"\0").toCharArray();
int ptr = COM.SysAllocString(data);
COM.MoveMemory(pData + 8, new int[] {ptr}, 4);
break;
default :
OLE.error(SWT.ERROR_NOT_IMPLEMENTED);
}
}
private Variant setVariantData(int pData){
if (pData == 0) OLE.error(OLE.ERROR_INVALID_ARGUMENT);
Variant ret = null;
short[] dataType = new short[1];
COM.MoveMemory(dataType, pData, 2);
int type = dataType[0];
if ((type & COM.VT_BYREF) == COM.VT_BYREF) {
int[] newByRefPtr = new int[1];
OS.MoveMemory(newByRefPtr, pData + 8, 4);
return new Variant(newByRefPtr[0], COM.VT_BYREF);
}
switch (type) {
case COM.VT_EMPTY :
break;
case COM.VT_BOOL :
short[] newBooleanData = new short[1];
COM.MoveMemory(newBooleanData, pData + 8, 2);
ret = new Variant(newBooleanData[0]!=0);
break;
case COM.VT_R4 :
float[] newFloatData = new float[1];
COM.MoveMemory(newFloatData, pData + 8, 4);
ret = new Variant(newFloatData[0]);
break;
case COM.VT_I4 :
int[] newIntData = new int[1];
OS.MoveMemory(newIntData, pData + 8, 4);
ret = new Variant(newIntData[0]);
break;
case COM.VT_DISPATCH : {
int[] ppvObject = new int[1];
OS.MoveMemory(ppvObject, pData + 8, 4);
if (ppvObject[0] == 0) {
type = COM.VT_EMPTY;
break;
}
ret = new Variant(new IDispatch(ppvObject[0]));
break;
}
case COM.VT_UNKNOWN : {
int[] ppvObject = new int[1];
OS.MoveMemory(ppvObject, pData + 8, 4);
if (ppvObject[0] == 0) {
type = COM.VT_EMPTY;
break;
}
ret = new Variant(new IUnknown(ppvObject[0]));
break;
}
case COM.VT_I2 :
short[] newShortData = new short[1];
COM.MoveMemory(newShortData, pData + 8, 2);
ret = new Variant(newShortData[0]);
break;
case COM.VT_BSTR :
// get the address of the memory in which the string resides
int[] hMem = new int[1];
OS.MoveMemory(hMem, pData + 8, 4);
if (hMem[0] == 0) {
type = COM.VT_EMPTY;
break;
}
int size = COM.SysStringByteLen(hMem[0]);
if (size > 0){
char[] buffer = new char[(size + 1) /2]; // add one to avoid rounding errors
COM.MoveMemory(buffer, hMem[0], size);
ret = new Variant(new String(buffer));
} else {
ret = new Variant(""); //$NON-NLS-1$
}
break;
default :
int newPData = OS.GlobalAlloc(OS.GMEM_FIXED | OS.GMEM_ZEROINIT, Variant.sizeof);
if (COM.VariantChangeType(newPData, pData, (short) 0, COM.VT_R4) == COM.S_OK) {
ret = setVariantData(newPData);
} else if (COM.VariantChangeType(newPData, pData, (short) 0, COM.VT_I4) == COM.S_OK) {
setVariantData(newPData);
} else if (COM.VariantChangeType(newPData, pData, (short) 0, COM.VT_BSTR) == COM.S_OK) {
ret = setVariantData(newPData);
}
COM.VariantClear(newPData);
OS.GlobalFree(newPData);
break;
}
return ret;
}
private int invoke(int dispIdMember, int wFlags, Variant[] rgvarg, int[] rgdispidNamedArgs, Variant[] pVarResult) {
if (Autoface == null) return COM.E_FAIL;
DISPPARAMS pDispParams = new DISPPARAMS();
if (rgvarg != null && rgvarg.length > 0) {
pDispParams.cArgs = rgvarg.length;
pDispParams.rgvarg = OS.GlobalAlloc(COM.GMEM_FIXED | COM.GMEM_ZEROINIT, Variant.sizeof * rgvarg.length);
int offset = 0;
for (int i = rgvarg.length - 1; i >= 0 ; i--) {
getVariantData(rgvarg[i], pDispParams.rgvarg + offset);
offset += Variant.sizeof;
}
}
if (rgdispidNamedArgs != null && rgdispidNamedArgs.length > 0) {
pDispParams.cNamedArgs = rgdispidNamedArgs.length;
pDispParams.rgdispidNamedArgs = OS.GlobalAlloc(COM.GMEM_FIXED | COM.GMEM_ZEROINIT, 4 * rgdispidNamedArgs.length);
int offset = 0;
for (int i = rgdispidNamedArgs.length; i > 0; i--) {
COM.MoveMemory(pDispParams.rgdispidNamedArgs + offset, new int[] {rgdispidNamedArgs[i-1]}, 4);
offset += 4;
}
}
EXCEPINFO excepInfo = new EXCEPINFO();
int[] pArgErr = new int[1];
int pVarResultAddress = 0;
if (pVarResult != null)
pVarResultAddress = OS.GlobalAlloc(OS.GMEM_FIXED | OS.GMEM_ZEROINIT, Variant.sizeof);
int ret = Autoface.Invoke(dispIdMember, new GUID(), COM.LOCALE_USER_DEFAULT, wFlags, pDispParams, pVarResultAddress, excepInfo, pArgErr);
if(ret!=COM.S_OK)
return ret;
if (pVarResultAddress != 0){
pVarResult[0] = setVariantData(pVarResultAddress);
COM.VariantClear(pVarResultAddress);
OS.GlobalFree(pVarResultAddress);
}
if (pDispParams.rgdispidNamedArgs != 0){
OS.GlobalFree(pDispParams.rgdispidNamedArgs);
}
if (pDispParams.rgvarg != 0) {
int offset = 0;
for (int i = 0, length = rgvarg.length; i < length; i++){
COM.VariantClear(pDispParams.rgvarg + offset);
offset += Variant.sizeof;
}
OS.GlobalFree(pDispParams.rgvarg);
}
return ret;
}
/**
* 创建空对象在使用需调用CreateComObject或CreateComObjectProgID创建COM对象。
*
*/
public CComObject(){
}
/**
* 使用CLSID创建COM对象,建构后可以调用COM对象方法或属性。
* @param sCLSID COM对象CLSID
* @throws Exception
*/
public CComObject(String sCLSID) throws Exception{
COM.IIDFromString(sCLSID.toCharArray(), guid);
CreateComObject();
}
/**
* 使用现有自动化对象接口创建COM对象。
* @param prgDispatch
*/
public CComObject(IDispatch prgDispatch){
Autoface = prgDispatch;
Autoface.AddRef();
}
/**
* 使用CLSID创建COM对象。可用于创建新的对象(原有对象将释放)
* @param sCLSID
* @return
* @throws Exception
*/
public IDispatch CreateComObject(String sCLSID) throws Exception{
COM.IIDFromString(sCLSID.toCharArray(), guid);
CreateComObject();
return Autoface;
}
/**
* 创建远程COM对象(未实现)。
* @param MachineName
* @param sCLSID
* @return
*/
public IDispatch CreateRemoteComObject(String MachineName, String sCLSID){
COM.IIDFromString(sCLSID.toCharArray(), guid);
return Autoface;
}
/**
* 使用ProgID创建COM对象。
* @param ProgID
* @return
* @throws Exception
*/
public IDispatch CreateComObjectProgID(String ProgID) throws Exception{
COM.CLSIDFromProgID(ProgID.toCharArray(), guid);
CreateComObject();
return Autoface;
}
/**
* 调用COM对象方法,有返回值(可变参数暂不支持)。
* @param FunctionName
* @param rgvarg
* @return
* @throws Exception
*/
public Variant CallFunction(String FunctionName, Variant[] rgvarg) throws Exception{
if(Autoface==null)
throw new Exception("对象为空");
int rgdispid = getIDsOfNames(FunctionName);
if(rgdispid==-1)
throw new Exception("方法不支持!");
Variant[] pVarResult = new Variant[1];
int ret = invoke(rgdispid, COM.DISPATCH_METHOD, rgvarg, null, pVarResult);
if(ret!=COM.S_OK)
OLE.error(ret);
//throw new Exception("方法调用失败!");
return pVarResult[0];
}
/**
* 调用COM对象方法,无参数和返回值。
* @param FunctionName
* @throws Exception
*/
public void CallFunction(String FunctionName) throws Exception{
CallFunction(FunctionName, new Variant[]{});
}
/**
* 获取COM对象属性值。
* @param PropertyName
* @param rgvarg
* @return
* @throws Exception
*/
public Variant getProperty(String PropertyName, Variant[] rgvarg) throws Exception{
if(Autoface==null)
throw new Exception("对象为空");
int rgdispid = getIDsOfNames(PropertyName);
if(rgdispid==-1)
throw new Exception("属性不支持!");
Variant[] pVarResult = new Variant[1];
int ret = invoke(rgdispid, COM.DISPATCH_PROPERTYGET, rgvarg, null, pVarResult);
if(ret!=COM.S_OK)
OLE.error(ret);
//throw new Exception("属性获取失败");
return pVarResult[0];
}
/**
* 给COM对象属性赋值。
* @param PropertyName
* @param rgvarg
* @throws Exception
*/
public void setProperty(String PropertyName, Variant[] rgvarg) throws Exception{
if(Autoface==null)
throw new Exception("对象为空");
int rgdispid = getIDsOfNames(PropertyName);
if(rgdispid==-1)
throw new Exception("属性不支持!");
int[] rgdispidNamedArgs = new int[] {COM.DISPID_PROPERTYPUT};
int dwFlags = COM.DISPATCH_PROPERTYPUT;
for (int i = 0; i < rgvarg.length; i++) {
if ((rgvarg[i].getType() & COM.VT_BYREF) == COM.VT_BYREF)
dwFlags = COM.DISPATCH_PROPERTYPUTREF;
}
Variant[] pVarResult = new Variant[1];
int ret = invoke(rgdispid, dwFlags, rgvarg, rgdispidNamedArgs, pVarResult);
if(ret != COM.S_OK)
OLE.error(ret);
//throw new Exception("属性设置失败!");
}
/**
* 释放COM对象的连接。在对象不用的时候需调用此函数,以便及时释放对象。
*
*/
public void dispose(){
if(Autoface!=null)
Autoface.Release();
Autoface = null;
if(TypeInfo!=null)
TypeInfo.Release();
TypeInfo = null;
}
}
摘要: package com.bovy.officehelper;
import org.eclipse.swt.SWT;
import org.eclipse.swt.SWTException;
import org.eclipse.swt.internal.ole.win32.TYPEATTR;
import org.eclipse.sw...
阅读全文
摘要: Office (2007) Open XML 文件格式简介
发布日期: 2007-07-06 | 更新日期: 2007-07-06
Frank Rice, Microsoft Corporation
学习Office Open XML格式的优势。用户可以在Office应用程序和企业系统之间使用XML和ZIP技术来交换数据。文档是全局可以访问的。并且,您还可以减少文件损坏的风险。
适用于...
阅读全文
产品中要用到在Rcp程序中操作Excel。在网上goole了一下,发现一篇文章还不错,测试了一下通过。
Integrate Eclipse RCP with Microsoft Applications - Tutorial
Lars Vogel
<webmaster@vogella.de>
Version 0.5
Copyright © 2007 Lars Vogel
01.11.2007
Abstract
The Eclipse Rich Client Platform (RCP) is using the SWT GUI framework. SWT does allow to integrated Microsoft application via OLE (Object Linking and Embedding). This article will demonstrate how SWT can be used within an Eclipse RCP application to integrate / use Microsoft applications. Microsoft Outlook and Microsoft Excel are used as examples
This article assumes that you are already familiar with using the Eclipse IDE and with developing simple Eclipse RCP applications.
--------------------------------------------------------------------------------
Table of Contents
1. Microsoft Object Linking and Embedding
1.1. Overview
2. Microsoft Integration - Sending an email via outlook
2.1. Create Project
2.2. Add action
2.3. Program the action
3. Microsoft Integration - Use Excel in your application.
3.1. Create Project
3.2. Change View code
4. Links and Literature
1. Microsoft Object Linking and Embedding
1.1. Overview
Windows applications use OLE (Object Linking and Embedding) to allow applications to control other application objects. The following will show how to do this using a few examples.
2. Microsoft Integration - Sending an email via outlook
This example assumes you running an MS operating system and that you have a version of Outlook installed.
2.1. Create Project
Create a new project "OutlookTest" (see here how to create a new RCP project). Use the "Hello RCP " as a template.
2.2. Add action
Using extensions add action "sendEmail" (see here how to add an action). The class of this action should be "outlooktest.SendEmail". Run the application. The result should look like the following.
2.3. Program the action
Lets program the action. The following coding will create and open the email for the user. It also assumes that you have a file c:\temp\test.txt which will be attached to the email.
package outlooktest;
import java.io.File;
import org.eclipse.jface.action.IAction;
import org.eclipse.jface.dialogs.MessageDialog;
import org.eclipse.jface.viewers.ISelection;
import org.eclipse.swt.SWT;
import org.eclipse.swt.ole.win32.OLE;
import org.eclipse.swt.ole.win32.OleAutomation;
import org.eclipse.swt.ole.win32.OleClientSite;
import org.eclipse.swt.ole.win32.OleFrame;
import org.eclipse.swt.ole.win32.Variant;
import org.eclipse.swt.widgets.Display;
import org.eclipse.swt.widgets.Shell;
import org.eclipse.ui.IWorkbenchWindow;
import org.eclipse.ui.IWorkbenchWindowActionDelegate;
public class SendEmail implements IWorkbenchWindowActionDelegate {
private Shell shell;
@Override
public void dispose() {
// TODO Auto-generated method stub
}
@Override
public void init(IWorkbenchWindow window) {
shell = window.getShell();
}
@Override
public void run(IAction action) {
Display display = Display.getCurrent();
Shell shell = new Shell(display);
OleFrame frame = new OleFrame(shell, SWT.NONE);
// This should start outlook if it is not running yet
OleClientSite site = new OleClientSite(frame, SWT.NONE, "OVCtl.OVCtl");
site.doVerb(OLE.OLEIVERB_INPLACEACTIVATE);
// Now get the outlook application
OleClientSite site2 = new OleClientSite(frame, SWT.NONE,
"Outlook.Application");
OleAutomation outlook = new OleAutomation(site2);
//
OleAutomation mail = invoke(outlook, "CreateItem", 0 /* Mail item */)
.getAutomation();
setProperty(mail, "To", "test@gmail.com"); /* Empty but could also be predefined */
setProperty(mail, "Bcc", "test@gmail.com"); /* Empty but could also be predefined */
setProperty(mail, "BodyFormat", 2 /* HTML */);
setProperty(mail, "Subject", "Top News for you");
setProperty(mail, "HtmlBody",
"<html>Hello<p>, please find some infos here.</html>");
File file = new File("c:/temp/test.txt");
if (file.exists()) {
OleAutomation attachments = getProperty(mail, "Attachments");
invoke(attachments, "Add", "c:/temp/test.txt");
} else {
MessageDialog
.openInformation(shell, "Info",
"Attachment File c:/temp/test.txt not found; will send email with attachment");
}
invoke(mail, "Display" /* or "Send" */);
}
private static OleAutomation getProperty(OleAutomation auto, String name) {
Variant varResult = auto.getProperty(property(auto, name));
if (varResult != null && varResult.getType() != OLE.VT_EMPTY) {
OleAutomation result = varResult.getAutomation();
varResult.dispose();
return result;
}
return null;
}
private static Variant invoke(OleAutomation auto, String command,
String value) {
return auto.invoke(property(auto, command),
new Variant[] { new Variant(value) });
}
@Override
public void selectionChanged(IAction action, ISelection selection) {
// TODO Auto-generated method stub
}
private static Variant invoke(OleAutomation auto, String command) {
return auto.invoke(property(auto, command));
}
private static Variant invoke(OleAutomation auto, String command, int value) {
return auto.invoke(property(auto, command),
new Variant[] { new Variant(value) });
}
private static boolean setProperty(OleAutomation auto, String name,
String value) {
return auto.setProperty(property(auto, name), new Variant(value));
}
private static boolean setProperty(OleAutomation auto, String name,
int value) {
return auto.setProperty(property(auto, name), new Variant(value));
}
private static int property(OleAutomation auto, String name) {
return auto.getIDsOfNames(new String[] { name })[0];
}
}
If you now start the application and press the button an email should be prepared and shown to the user.
3. Microsoft Integration - Use Excel in your application.
This example assume that you running on Microsoft and that you have a version of Microsoft Excel installed.
3.1. Create Project
Create a new project "ExcelTest" (see here how to create a new RCP project). Use the "RCP with a view" as a template. Run it and see that is working.
3.2. Change View code
Select View.java and replace the coding with the following.
package exceltest;
import org.eclipse.swt.SWT;
import org.eclipse.swt.SWTError;
import org.eclipse.swt.ole.win32.OleClientSite;
import org.eclipse.swt.ole.win32.OleFrame;
import org.eclipse.swt.widgets.Composite;
import org.eclipse.ui.part.ViewPart;
public class View extends ViewPart {
public static final String ID = "ExcelTest.view";
private OleClientSite site;
public View() {
}
@Override
public void createPartControl(Composite parent) {
try {
OleFrame frame = new OleFrame(parent, SWT.NONE);
site = new OleClientSite(frame, SWT.NONE, "Excel.Sheet");
} catch (SWTError e) {
System.out.println("Unable to open activeX control");
return;
}
}
@Override
public void setFocus() {
// Have to set the focus see https://bugs.eclipse.org/bugs/show_bug.cgi?id=207688
site.setFocus();
}
}
Start your application and excel should be displayed.
4. Links and Literature
http://www.eclipse.org/ Eclipse Website
http://www.vogella.de/articles/Eclipse/article.html Using Eclipse as IDE - Tutorial
http://www.vogella.de/articles/RichClientPlatform/article.html Eclipse Rich Client Platform - Tutorial
http://www.vogella.de/articles/EclipseCodeAccess/article.html A guide to access the Eclipse Sources
我用的是Eclipse 3.2,操作系统是WinXP SP2。
需要把eclipse\plugins\org.eclipse.swt.win32.win32.x86_3.2.0.v3232m.jar里面的swt-win32-3232.dll解压缩出来拷贝到WINDOWS\SYSTEM32里面。
然后就OK了。
是在Eclipse里面运行Springside的ANT Task的时候,如果需要通过console输入交互信息,则会报这个错。应该是因为Eclipse的console依赖于那个本地库,而平常我们安装Eclipse不会拷贝那个库。
在服务器管理过程中,通常会遇到分区空间不够,或要调整分区的大小,如果是普通用户,大不了备份数据然后重装系统,可是,在正常运营的linux 服务器系统中,这么做是不现实的,我们必须学会动态的调整linux 的分区,linux为我们提供了一个lvm 逻辑驱动器卷的方案,除此之外,还有一个方法,本文将向你一一道来:
其实linux为我们的管理提供更方便的方法,我们知道,在linux系统中的各种状态都分别以相应的运行级来代表,比如,关机进程是run level 0 单用户管理是run level 1, 我们常用的图形用户界面在某此系统中被定义为run level 5,而重启是run level 6,关于linux中的运行级,在今后的文章中,小编会向你详细介绍,今天,小编主要向你介绍如何在运行的linux中移动tmp分区!
在正常的系统初始化的情况下,启动时会加载/etc/fstab文件来挂载文件系统,当我们正常进入系统后,进行维护性的管理时,所有的文件系统是不允许被卸掉的,那么有什么方法可以让我们卸掉文件系统呢,答案就是运行级,在运行级1中,系统进入单用户管理模式,只有root用户能够登录系统,这个时候系统完全在内存中运行,我们就可以对硬盘进行完全的操作,好,下面我们就进入运行级1
# init 1 以root用户执行此命令后,系统会关闭所有运行中的服务,并切换到单用户模式,这时只有root用户能够登录,登录后,比如,我们可以需要把/tmp移动到/var/tmp下面,我们可以使用:
# mv /tmp /var/tmp
这样,/tmp中的内容就被移动到了/var/tmp下面,接下来我们删除/tmp目录:
#rm -rf /tmp
接下来,创建一个到/var/tmp的符号链接:
ln -s /var/tmp /tmp
这时,/tmp实际就变为了指向/var/tmp的一个符号链接,然后我们按ctrl+D命令返回到图形界面,登录后,就看到/tmp目录已经被移走了。
用相同的方法也可以移动/var分区到新的硬盘,只是/var分区不比/tmp分区,系统运行的重要数据保存在这里,移动前一定要好备份并仔细检查哦。
摘要: 9月买的葫芦晒干了。于是今天取出子,在网上搜了下种植方法。已经按方法操作。不知是否可以成活。呵呵,过几天就知道了。种植方法如下:
阅读全文
摘要: 在我的项目中两个系统需要切换,应用服务器是weblogic8.1,在同一台机器上建了两个域。当从一个域访问另一个域后,再点第一个域的链接就会跳出系统转入登录界面。经过反复测试如果将第二个域部署到另一台机器则不会发生该问题。于是,我觉得seesion肯定是在访问同一机器的第二个域时被复写了。
阅读全文
Sybase IQ for Data Warehouse 培训总结(一)
*作 者: xuwedo
培训主要内容:Administering Sybase IQ for Data Warehouse (volume 1 &volume 2)
一、 本次培训涉及到以下内容:
1. Sybase IQ产品概述
2. 架构和专业述语
3. 环境变量和安装
4. 怎样创建数据库
5. 设置服务器和数据选项
6. Sybase IQ索引和数据类型
7. 创建表和索引
8. Sybase IQ内存配置
9. 从文件中加载数据
10. 用INSERT语句加载数据
11. 使用Sybase IQ
12. 用户的管理和安全
13. 事务管理和锁
14. 监控和问题解决
15. 管理DBspace 和索引
16. 备份和恢复
17. Sybase IQ的多元架构
18. 创建一个多元架构的数据库
二、 以下为各部分的详细叙述:
(一) Sybase IQ产品概述
1、 Sybase IQ是一个强大的即席查询服务器。
2、 用Sybase IQ来分离决策支持系统(DSS,Decision Support System,READER)和在线事务处理系统(OLTP,OnLine Transaction Processing,WRITER)。
3、 Sybase IQ的特点有:
(1)、垂直数据存储和压缩
(2)、优化了所有数据类型的存取方法
(3)、基于位的存储技术
(4)、即席查询优化器
(5)、标准的对外接口
(6)Sybase Central 支持
4、 Sybase IQ不适合做:
(1)、在线事务处理引擎
用Adaptive Server Enterprise代替
(2)、需要实时更新的在线应用服务器
用Adaptive Server Enterprise或Adaptive Server Anywhere代替
5、 Sybase数据库的基本原理:
(1)、列方式的存储,可以减少IO
例如:SELECT COUNT(*) FORM customer WHERE gender = “m”
(2)、基于位的索引方式
分为高基数数据(唯一值数量大于1500个)和低基数数据(唯一值数量小于1500个)。
(二) 架构和专业述语
1、 Sybase IQ平台支持的操作系统版本可以查看Sybase的官方网站,注意:必须有相关的操作系统补丁。
2、 Sybase IQ Server是在主机上运行的一个进程。
3、 一个Sybase IQ Server只支持一个Sybase IQ数据库。可以在一个Sybase IQ Server上部署多个数据库,但不推荐。
4、 Sybase IQ数据库包括:
l 三种DBSPACEE:
(1)、Catalog Store(for metadata,扩展名为:.db)
一个IQ 数据库只能有一个Catalog store DBspace,而且只能创建在一个文件系统上,不能创建在裸设备上。
Catalog Store会随着元数据、表、视图、存储过程等对象的增加动态增长。
Catalog Store包含了管理一个IQ数据库的所有信息。
Catalog Store的逻辑名为SYSTEM。
一个数据库中所有表的信息都存储在Catalog Store的系统表中。例如系统表有:SYSIQCOLUMN、SYSIQFILE、 SYSIQINDEX、 SYSIQINFO、 SYSIQTABLE等。可以用语句:
Select * from SYSIQINFO 语句来查看相关信息。
(2)、IQ Store(for data,扩展名为:.iq)
IQ Store存储了压缩的数据信息,例如索引信息、事务日志、管理分配空间的结构等。
每一个数据库只有一个IQ Store。一个IQ Store通常情况下包括多个DBspace。
IQ Store的DBspace可以建立在裸设备或文件系统上。
IQ Store的逻辑名为:IQ_SYSTEM_MAIN
注意:IQ Store的文件系统的扩展名为.iq,裸设备没有扩展名。
(3)、IQ temporary Store(for temporary data,扩展名为:.iqtmp)
IQ temporary Store是数据库的工作区间。在装入数据时在其中进行排序数据,以建立索引。
一个数据库只有一个IQ temporary Store。一个IQ temporary Store可以包含多个物理文件。
IQ temporary Store可以是文件系统或裸设备。
IQ temporary Store的逻辑名为IQ_SYSTEM_TEMP
l 三种日志文件:
(1)、IQ Message log
IQ数据库的可读日志文件,包括:插入和删除信息、错误信息、状态信息、查询计划等。
IQ Message Log只能在文件系统中,扩展名为.iqmsg。
一个数据库只能有一个IQ Message。
(2)、Catalog Store Transaction Log
Catalog Store Transaction Log是Catalog Store的事务日志。
用来作为必需时的回滚和前滚。
文件的扩展名为:.log。
随时间,此文件会越来越大。
(3)、IQ server logs
记录每次服务器启动时的信息。每启动一次就会产生一个IQ server log。
通常在$ASDIR/Logfiles目录下。
ASIQ_startup_nt.log文件中记录了服务器启动的参数。
Server_name.00n.srvlog中的n是服务器启动的次数。
其他信息发送到控制窗口中。
5、 一个DBspace是一个数据库文件的逻辑名。
6、 DBspace可以是分配给Sybase IQ的一个文件系统或裸设备。
7、 一个Sybase IQ 数据库包括多个DBspace。
8、 IQ中的表是指定义在Catalog Store的逻辑表。IQ中有三种表:基本表、本地临时表、全局临时表。
9、 IQ表的每一列最少有一种索引。每当创建新表时,系统会自动为表创建默认索引。
10、 IQ中一共有9种索引。
(三) 环境变量和安装
1. 对硬盘的空间要求:
UNIX:不少于800M。
WINDOWS:不少于375M。
IQ STORE 约点总磁盘空间的70%。IQ temporary Store大小约为IQ Store的20%。
l 对内存的要求:
虚拟内存=物理内存+磁盘交换分区大小。
推荐生产环境最小内存不小于1G的物理内存。
如果虚拟内存过小,会导致服务器失败。
l CPU要求:
颗数越多越好,速度越快越好。
l 启动IQ Server:
使用命令:start_asiq [config file] dbname [switchs]
例如:start_asiq @saiqdemo.cfg asiqdemo.db
l 停止IQ server:
(1)、使用命令:
Dbstop –c “uid=DBA; pwd=SQL; eng=server_name; dbn=db_name”
(2)、使用存储过程:
Stop_asiq
l 当安装完Sybase IQ后会自动生成一个名为“Utility”的数据库,此数据库没有数据,也没有数据文件与之关联(仅为一个util_db.ini文件)。它主要用于以下目的:
(1)、当没有实际的数据库时,用于测试连接。
(2)、用来创建和恢复数据库。
(3)、千万不能删除之。
(4)、此数据库的用户名为:DBA,密码为:SQL。
l 有七种方法可以连接到Sybase IQ:
(1)、ODBC
(2)、JDBC
(3)、OLE_DB
(4)、Sybase Open Client
(5)、用DBISQL
(6)、用Sybase Central。
(7)、用DBISQLC
Sybase IQ for Data Warehouse 培训总结(二)
*作 者: xuwedo
(一) 怎样创建数据库
1、DBspace是分配到IQ数据库的驱动空间的逻辑名
2、一个新IQ数据库最多可以有2047个DBspace。
3、Sybase的各种类型DBspace的限制:
(1)、Catalog Store最大为1TB。
(2)、IQ Store 和IQ temp Store 在裸设备上没有大小限制,在文件系统中为4TB。
4、IQ Store 和IQ temp Store可以扩大或从数据库删除。
5、创建数据库:
CREATE DATABASE full_path db_name[[TRANSACTION] {LOG ON [log_file_name][MIRROR mirror_file_name]}]
IQ PATH iq_file_anem
[IQ SIZE iq_file_size]
[IQ RESERVE sizeMb]
TEMPORARY PATH temp_file_name
[TEMPORARY SIZE temp_db_szie]
[TEMPORARY RESERVE sizeMB]
[MESSAGE PATH message_file_name]
例子1:
CREATE DATABASE ‘d:\\mydb\\mydb.db’
IQ PATH ‘d:\\iqmain\\mydb01.iq’
IQ SIZE 200
TEMPORARY PATH ‘e:\\iqtem\\mydb01.iqtmp’
TEMPORARY SIZE 200
IP PAGE SIZE 65536
6、可以用Sybase Central创建数据库(在图形环境下)。
7、可以用sp_iqstatus来查看当前数据库的详细信息。
8、删除一个DBspace
(1)、一个IQ store如果存有数据的话,则不能被删除。(可以使用Utility数据库将一个DBspace的数据移动到另一个DBspace中去,再删除)。
(2)、一个IQ temporary Store仅在为空时才可以被删除。
9、删除一个数据库的语法:
DROP DATABASE db_filename
例子:DROP DATABASE ‘d:\\mydb\\mydb.db’
10、怎样才能看到所有的DBspace的物理文件名?
用以下命令:Select * from sysqifile
(二) 设置服务器和数据选项
1、 数据库的启动参数均可以写在“.cfg”文件中。
2、 启动服务器的语法:
start_asiq server-switchs database_file
其中:“server-switchs”可以为:
-c :缓存大小,默认windows为32M,Unix为48M。
-gp:Catalog store页大小。
-gm:服务器允许的连接数。
-n:IQ server的名字。如果有两个“-n”选项,则第一个是IQ server的名字,第二个“-n”为IQ 数据库的名字。
-gc:checkpoint时间间隔。默认为20,推荐为6000。
-gr:最大的恢复时间。默认为2。
-ti:客户端超时时间。默认为4400分钟。
-tl:默认网络超时时间。默认120秒。
-iqmc:主缓存大小,单位:M。
-iqtc:临时缓存大小,单位:M。
注:主缓存:临时缓存=2:3
在默认情况下,Sybase IQ server使用2338端口。
3、 使用SET OPTION命令更变数据库的配置:
(1)、语法:
SET [TEMPORARY] OPTION
[user_id. | PUBLIC.]option_name = [option_value]
其中的“option_name”可以是:
Force_No_Scroll_Cursors=‘on’(默认为“off”)禁止缓存用户的查询结果。
Query_Temp_Space_Limit=0(默认为2000M),设置临时缓存的最大值。0表示不限制。
Public.Query_Plan=‘off’(默认为“on”)禁止将用户的查询计划打印到IQ Message File中,因为查询计划可以会使之大小迅速增加。
例子:
SET OPTION public.Force_NO_Scroll_Cursors=’no’
4、 查看数据库的所有被改动过的(即非默认值)选项,用存储过程:sp_iqcheckoptions。
(三) Sybase IQ索引和数据类型
1、Sybase IQ的9种索引类型:
(1)、FP(Fast Projection)此索引为默认的索引形式,在创建表时系统自动设置此索引。
特点:用于SELECT、LIKE ‘%sys%’、SUM(A+B)、JOIN操作等语句。
此类型索引也是唯一可用于BIT数据类型的索引。
FP索引可以优化索引,将小于255的唯一值的索引压缩到1字节中,将小于65537的唯一值索引压缩到2字节中。
(2)、LF(Low Fast)基于平衡树的结构,存储唯一值小于1500个的索引,是最快的索引类型。可以用作唯一索引。
特点:用于=、 !=、IN、NOT IN查询参数。
MIN()、MAX()、COUNT()、Group By、JOIN等。
(3)、HNG(High Nongroup)基于位的优化索引,适合于数字索引。用于范围查找和求合计算。
特点:Rangs、Between、MIN()、MAX()、SUM()、AVG()等。
(4)、HG(High Group) 基于平衡树的结构,存储唯一值大于1500个的索引,是最快的索引类型。可以用作唯一索引。
特点:同LF索引的特点。
(5)、CMP(compare)仅用于比较一个表中的两个列的比较。
特点:<、 =、 >、 <= 、>=
(6)、WD(Word),仅用于索引数据类型为WORD的列。
特点:‘CONTAINS’、LIKE操作(但没有‘%’)。
例子:
Select count(*) from Customer where address contains(‘Main’)
(7)、DATE(date)仅用于日期类型的列。
(8)、DTTM(Datetime)仅用于日期时间类型的列。
(9)、TIME(Time)仅用于时间类型的列。
例子:
Select * from sales where DATAPART(YEAR,dales_dt) = 2007
Select * from sales where sales_dt>=‘2003-01-01 08:00:00’
(四) 创建表和索引
1、创建表:
例子1:
CREATE TABLE employee(
Emp_id int NOT NULL
,lname varchar(30) NULL
,fname varchar(30) NULL
,salary money NULL)
例子2:
CREATE TABLE stores(
Store_id char(4) NOT NULL
,store_name varchar(20) NOT NULL
,store_address varchar(40) NOT NULL
,UNIQUE(store_id))
例子3:
CREATE TABLE products(
Product_code char(5) NOT NULL
,product varchar(40) NOT NULL
,price money NULL
PRIMARY KEY (products_code))
例子4:
CREATE TABLE sales(
Sales_code char(10) PRIMARY KEY
,sales_date DATE NOT NULL
,product_code char(5) NOT NULL
,FOREIGN KEY fk1(product_code) REFERENCES product (product_code))
例子5:
SELECT * INTO co_residential_customer from customer where 1=2
2、用Sybase Central 可以在图形界面下创建表。
3、删除表:DROP TABLE tablename
4、删除表中的所有内容:TRUNCATE TABLE [owner.]table_name
5、创建视图,语法:
CREATE VIEW [owner.]view_name[(column-name[,…])]
AS select-without-order-by
[WITH CHECK OPTION]
例子1:
CREATE VIEW sd_customer AS SELECT * FROM customer
WHERE sheng = ‘SD’
例子2:
CREATE VIEW emp_dept
AS SELECT emp_home,emp_fname,dept_name
From Employee,Department
WHERE Employee.dept_id = Department.dept_id
5、用Sybase Central 可以在图形界面下创建视图。
6、创建索引:
CREATE [UNIQUE] [index-type] INDEX
Index_name ON
[owner.]table_name (column_name[,…])
[{IN | ON} DBSpace_name]
[NOTIFY integer]
[DELIMITED BY ‘separators-string’]
[LIMIT maxwordsize-integer]
例子1:
CREATE HG INDEX
Cust_customer_id ON
Cutomer(customer_id)
例子2:
CREATE CMP INDEX price_compare
ON orders(purchase_price,list_cost)
7、删除索引:
DROP INDEX [[owner.]tablename.]index_name
例子:
DROP INDEX cust_customer_id
(五) Sybase IQ内存配置
1、 IQ从单一的一个内存池中分配内存。
2、 从操作系统层面来看,IQ Server的内存是由堆组成。
3、 Buffer:内存中的一块区域,它存储了写入数据库或从数据库中读取的未解压的数据。
4、 IQ Page Size:IQ Server中每一个内存页的大小。
5、 IQ Page Size/16=BLOCK SIZE
6、 在启动服务器时,可以用参数-c来指定服务器缓存的初始大小。在所有平台中,这个值最大为256M。
7、 IQ Buffer有两种类型:
(1)、主Buffer缓存:IQ Store的Buffer。(占总大小的40%)
(2)、临时Buffer:IQ temporary Buffer。(占总大小的60%)
8、 在Sybase IQ server中一个活动的用户大约占用10M内存,一个非活动用户大约占5M内存。
作 者: xuwedo
(一) 从文件中加载数据
1、有三种方法向IQ table中加入数据:
(1)、用LOAD TABLE命令,从命名管道或文件中将数据导入表中。(速度是最快的)
(2)、用INSERT FROM SELECT 命令,将其他表中的数据加入当前表中。
(3)、用INSERT VALUES命令,“手动”地向表中加入数据。
2、关于数据加载和锁:
(1)、当一个用户正在装载、插入或修改一个表中的数据时,其他用户可以对该表进行查询操作。(原理是:版本控制)
(2)、多个用户可以并发地执行DML语句,但必须针对不同的表。
(3)、如果多个用户试图修改同一个表,则第一个用户获得DML锁。
3、从文件中装入数据的例子:
LOAD TABLE customer(customer_id ‘|’
,cust_type ‘|’
,organization ‘|’
,contact_name ‘|’
,contact_phone ‘|’
,address ‘|’
,city ‘|’
,country ‘\x0a’)
FROM ‘/work/data/cutomer1.dat’
ESCAPES OFF
QUOTES OFF;
4、删除表中的数据有三种方法:
(1)、用DELETE 命令:
DELETE FROM customer
WHERE customer_id IN( SELECT cutomer_id FROM customer
WHERE postno = ‘250001’)
(2)、用DROP TABLE命令
(3)、用TRUNCATE TABLE命令
5、删除后再增加数据有两种方式:
(1)、插入到删除后留下的空隙中。
(2)、追加到现有表的最后一行后面。(速度再快一些,但要更大的存储空间)
由APPEND_LOAD=‘ON’来控制。
6、UPDATE 命令:
UPDATE employee
SET dept_id = 400
WHERE emp_id = 111
(二) 用INSERT语句加载数据
例1:
INSERT INTO dept_head(name,dept)
NOTIFY 20
SELECT emp_fname ||‘ ’||emp_lname AS name
,dept_name
FROM employee JOIN department
ON emp_id = dept_head_id;
commit
例2:
INSERT INTO lineitem(shipdate,orderkey)
LOCATION‘servername.dbname’
PACKETSIZE 512
{SELECT l_shipdate,l_orderkey FROM lineitem};
commit
(三) 使用Sybase IQ
因为本章节均为图形化操作,比较简单。略
(四) 用户的管理和安全
1. 系统预置的两个组:SYS和PUBLIC组。
想知道系统中共有多少组,用以下命令:
SELECT * FROM Sys.sysgroups
2. 系统管理员的用户名:DBA,默认密码为:SQL
3. 向系统中加入用户有三种方法:
(1)、“GRANT CONNECT”命令,
GRANT CONNECT TO userid [,…]
INDENTIFIED BY password [,…]
注:更改用户的密码也是上面的命令,这可能导致管理员无意识地改变现有用户的密码,而其目的是增加用户。此操作没有警告提示。
(2)、Sybase Central 向导,图形化操作。
(3)、sp_iqaddlogin存储过程,
4. 与系统中用户管理有关的两个系统表:
IQ_User_Login_Info_Table和IQ_System_Login_Info_Table
如果想查看该系统表中的内容,则可以用以下语句:
SELECT * FROM IQ_User_Login_Info_Table
5. 与管理用户有关的几个存储过程:
sp_iqmodifyadmin
sp_iqaddlogin
sp_iqprocess_login
sp_iqdroplogin
sp_iqlistexpiredpasswords
sp_iqlistlockedusers
sp_iqlistpasswordexpirations
sp_iqlocklogin
sp_iqmodifylogin
sp_iqpassword
(五) 事务管理和锁
1、与事务有关的几个命令:
(1)、开始一个事务:
BEGIN TRANSACTION [transaction_name]
(2)、提交一个事务:
COMMIT [work]
(3)、回滚一个事务:
ROLLBACK [work]
(4)、在当前事务中建立一个保存点:
SAVEPOINT [savepoint_name]
(5)、回滚到一个保存点:
ROLLBACK TO SAVEPOINT [savepoint_name]
(6)、将改变保存到磁盘上:
CHECKPOINT
(7)、执行完一条语句后,自动提交:
WITH CHECKPOINT ON
(六) 监控和问题解决
1、 可以在Sybase Central中监控用户
2、 存储过程:sp_iqconnection可以显示用户连接的信息。包括connection_handle,User_ID,最后的请求的时间,最后IQ命令时间等。
3、 用drop connection connection_handle可以让服务器主动断开与某用户连接。
4、 用sp_iqcontext来显示服务器上执行SQL语句的情况,包括哪个用户正在执行哪条SQL语句,是否提交等信息。
5、 将服务器执行SQL情况写入日志:
方法1:
-zr SQL ;表明要收集SQL语句信息
-zo c:\\sqllog.txt ;重定向请求级别信息到文件中
方法2:
call sa_server_option (‘request_level_logging’ , ‘SQL’);
call sa_server_option(
‘ request_level_log_file ’,’sqllog.txt’);
关闭将SQL信息写入日志文件中:
call sa_server_option (‘request_level_logging’ , ‘’);
call sa_server_option(
‘ request_level_log_file ’,NONE);
6、 用sp_iqtransaction查看系统中事务的相关信息。
7、 错误处理:
(1)、UNIX 下有一脚本:getiqinfo.sh
(2)、Windows下为getiqinfo.bat
来得到服务器的相关信息,然后将生成的报告发送给Sybase即可。
(七) 管理DBspace 和索引
1、 改变DBSPACE的模式或改变DBSPACE的大小:
ALTER DBSPACE
2、 卸载一个空的DBSPACE:
DROP DBSPACE
3、 报告DBSPACE的一般信息和模式:
Sp_iqdbspace
4、 报告DBSPACE中的OBJECTS和它们的大小信息。
Sp_dbspaceinfo
5、 将一个DBSPACE中的OBJECTS移动到另一个DBSPACE中:
Sp_iqrelocate
6、 Sp_iqrebuildindex存储过程重新建立某列的索引。
7、 管理DBspace 和索引的操作均可以在Sybase Central中操作,比较简单。
(八) 备份和恢复
1、Sybase IQ server有三种备份类型:
(1)、完全备份
(2)、增量备份
(3)、完全备份的基础上增量备份
注:增量备份和完全备份的基础上增量备份都会对Catalog Store 进行完全备份。
默认情况下为完全备份。
2、Sybase IQ server的顺序:
(1)、Catalog Store
(2)、Transaction log File
(3)、IQ Store
3、当IQ server正在备份时:
(1)、默认情况下操作员必须在现场,挂持接备份介质。
(2)、操作员可以不在场,但必须正确地估算出备份的数据量大小,并且在安装备份设备时,要选“高级”安装方可。
4、备份命令:
BACKUP DATABASE [CRC ON|OFF]
[Attended ON|OFF]
[BLOCK FACTOR integer]
[{FULL|INCREMENTAL|INCREMENTAL SINCE FULL}]
TO ‘archive_device’ [SIZE # of KB integer]
例子:
BACKUP DATABASE TO ‘dev/rmt/0n’
注:BACKUP不支持裸设备
5、系统级别的备份:
如果IQ server运行时进行系统级别的备份,则会导致服务崩溃或丢失数据。所以,必须确定IQ server是停止状态时,方可进行系统级别备份。
6、备份的恢复:
(1)、必须连接到utility_db数据库后才可以进行恢复操作,并且在恢复数据时不能有用户连接到数据库。
(2)、如果有完全恢复,Catalog Store 和Transaction Log(即.db 和.log文件)必须从目标文件夹下删除。
(3)、如果为增量恢复,Catalog Store 和Transaction Log(即.db 和.log文件)必须存在于目标文件夹中。
7、恢复的命令:
RESTORE DATABASE ‘c:\\newdir\\mydb.db’
FROM ‘c:\\asiq\\backup1’
FROM ‘c:\\asiq\\backup2’
在进行恢复时,必须注意恢复的顺序和备份时的顺序完全一致。
8、数据库备份后,配置文件和日志文件是没有被备份的,所以如果恢复时要单独对这两种文件进行恢复。配置文件可以直接拷贝即可,但日志文件是不能用原来的.log文件的。
如果恢复到原来的目录中,则不用新建.log文件。如果没有恢复到原目录,则必须用dblog工具手动生成.log文件。
9、dblog工具的命令语法:
Dblog [option] database_file
Option:
-t log-name,指定事务log文件名。
-m mirror-name,设置事务日志镜象名。
-r,停止事务日志的镜象。
-o,输出日志信息到文件。
-q,安静模式,不打印信息。
例:dblog –t demolog.log asiqdemo
(九) Sybase IQ的多元架构
(十) 创建一个多元架构的数据库
在Sybase Central中完成。略。
1.1.
内存使用对SybaseIQ而言,内存越多越好,一般要求每个服务器的CPU配置内存2GB,数据装载需要动态使用额外的内存,计算使用缓存caches;降低IO的方法是使用大buffer caches;使用超出内存会导致频繁swapping;IQ从操作系统申请内存,从操作系统级别看SybaseIQ的内存为堆内存,所有的内存分配自动进行。IQ使用内存进行以下活动:
l
从磁盘读取数据并执行查询;
l
从系统平面文件加载时缓冲磁盘数据;
l
缓冲元数据文件 (Catalog)
l
管理连接,事务,缓冲区和数据库对象。
一个安装SybaseIQ的数据库服务器的典型内存分布如图所示:包括操作系统其他应用程序内存,服务器内存,额外内存,IQ存储缓存,临时存储缓存。

 1.1.1.
1.1.1.
服务器内存SybaseIQ服务器进程使用的内存,不同的操作系统平台其使用量存在差异,一般需要30MB。
1.1.2.
额外内存元数据缓存
由数据库启动选项 –c, -cl, 和 –ch参数控制使用RAM数量,专门用来作元数据库读写缓存,当数据库对象较多时,建议调大此数据。
线程内存
线程内存在数据库启动时分配给数据库服务器,用于线程的堆栈空间,总的空间数值按照公式“stack size * IQ 线程数量”计算,数据库启动参数–iqtss确定数据库的stack size大小单位KB。启动参数-iqmt指定IQ可以使用的线程数量,最小值是2*num_conn+1,缺省值是:
60*numCPU+2*num_conn+1
“活动”用户内存
每个Sybase IQ 用户对应一个连接进程,此进程大概需要 10MB空间;活动用户是指到数据库的一个连接或执行的查询命令,连接到数据库而不活动的用户需要更少的内存。
表版本内存
表版本内存在SybaseIQ运行时分配,通常这类内存非常小(每个被跟踪的表版本1KB到3KB),通常为KB到MB,但是当系统中存在成千上万的表版本时,占用空间会比较大。
数据加载内存
SybaseIQ在进行数据加载时,分配内存提供数据加载性能,通过数据库选项LOAD_MEMORY_MB设定,缺省情况为0,表示堆内存的分配不受限制,如果数据加载时需要更多内存,可能导致数据加载耗尽虚拟内存,降低数据加载性能,一般建议设定此选项,其配置值可根据加载数据的表宽进行如下计算:
Load_Memory_MB = <表宽字节数> * 10,000 * 45 / 1024 / 1024
以下语句将数据加载内存设置成300MB:
SET OPTION PUBLIC.LOAD_MEMORY_MB = 300
数据库备份内存
数据库备份内存的大小与CPU个数、备份的IQ存储和本地存储的数据库空间个数,BLOCK的交错因子,IQ的BLOCK大小有关系。可以通过如下公式粗略估计:
y = max( 2 * cpu个数, 8 * number_of_main_or_local_dbspaces)
z = (y * 20 ) * ( block factor * block_size )
Z表示的是备份时需要的内存的虚拟估计值,假设如下情况:
dbspaces = 50
block factor = 100
number of cpus = 4
block_size = 8,192
采用上面的公式和算法,数据库备份时需要的内存总数是:
'y' is max(8, 400) è y=400
'z' is ( 400 * 20 ) * ( 100 * 8,192 ) è 6.5GB
备份内存来自操作系统,属于堆内存,当备份操作完成后,内存释放。当空间充足时,唯一可以控制备份内存使用的是块的交错因子,在前面的例子中,如果交错因子变成10, 总的备份内存需求将降低到655MB:
( 400 * 20 ) * ( 10 * 8,192 ) è 655MB
在磁盘I/O不是瓶颈的情况下,在数据库备份时降低内存将减慢备份数度。数据库备份性能与磁盘子系统I/O的读写块性能一致,为减少I/O的额外开销,备份程序一次I/O中读入连续的块,相应地按照“块交错因子”写这些块数据。
通过“块交错因子”可以减少备份内存,增加可用的内存,以此计算数据库备份时需要的总内存量。
1.1.3.
数据库缓存数据库缓存是操作系统内存中分配用来保存从数据库中读出或者准备写入数据库的数据。SybaseIQ数据库缓存包括主存储缓存和临时存储缓存。参数设置可以通过数据库选项或者数据库启动配置文件。
主存储缓存
用于缓存数据库服务器从IQ存储中读取的数据,供 IQ 数据表空间的数据缓存使用,所有用户均可使用。较大的缓存可以降低磁盘的IO以提升性能,主存储缓存在数据库启动时初始化,缺省配置是16MB,对于大多数应用来说太小,修改此参数配置需要重新启动数据库。一般将IQ服务器可以使用的内存的40%分配给SybaseIQ主存储缓存。
临时存储缓存
SybaseIQ临时存储缓存用于数据查询时的表关联,分组,排序和哈系算法。数据加载时,也需要较多的临时存储缓存,例如HG索引的管理、FP索引加载时的1个字节和2个字节的字典表等。较大的临时存储缓存可以减少内存调度。
主存储缓存在数据库启动时初始化,缺省配置是12MB,对于大多数应用来说太小,修改此参数配置需要重新启动数据库。一般将IQ服务器可以使用的内存的60%分配给SybaseIQ的临时存储缓存。
Sybase IQ 12.6 的redhat AS4安装
由于我的iq126解压出来是一个个tgz文件,执行sybinstall.sh安装后会报告复制文件失败。打开sybinstall.sh文件来看看,应该是解压缩文件这个环节出错了,那就先把文件解压出来看看再试一下:
gzip -d *.tgz
sybinstall
好了,一路畅通。
启动测试数据看看有没有什么问题.
start_asiq @asiqdemo.cfg asiqdemo.db
..
启动正常,
stop_asiq
...没有发现server,
再打开stop_asiq看看:
哦原来也是用"ps -ef|.....",有点土吧,居然没找到server,肯定是这个脚本又有错误。修改一下,呵呵,搞定.
"case "$OS_TYPE" in
Linux) if ps -m >/dev/null 2>&1
then MY_PS="ps -efwm |awk -f $AWK_CMD ps_type=long"
else MY_PS="ps -efw |awk -f $AWK_CMD ps_type=long"
fi
;;"
把第一个ps_type=long改为ps_type=short
[注]我的os为RHEL 4 patch 2
数巨报表和其它国产报表一样,有一定的客户群和口碑,基本上自主研发了两年以上,价格基本在万元左右。数巨报表和如意报表类似,都是用于拖拽式,有一定的技术代表性。数巨报表产品主要定位于中低端市场,以易用性、满足中国用户需求、价格低为目标,逐渐建立中低端市场客户满意度,毕竟这部分客户还是担心项目的风险性。
Microstrategy是国外品牌,在全球BI软件市场占用很大的份额,通过BI软件产品向中国高端市场进军。他们往往能与最终用户直接签单,能给系统集成商和软件开发商带来丰厚的利润。Microstrategy报表软件的确功能强大,提供了很多二次开发接口,能给用户解决很多实际问题,但是价格昂贵不是一般客户可以接受的。
这是本人的一点认识,不正确的地方希望得到大家的指出。
本人不是MicroStrategy的代理或原厂,仅代表个人观点。
这两个产品在我看来,不在一个层次上,应用的范围和覆盖面也不相同,是国产软件比拼国外软件。
1.价格方面:正如楼上说数巨报表价格在万元左右,而MSTR一个普通配置均在20万以上,从目前局势,MSTR厂家还一直在涨价过程中。
2.服务方面:外商只要收到钱,服务还是满周到的,包括升级、技术支持,但千万不要指望他们帮你开发什么东西(除非付钱或厂家有其他战略企图);国产软件,由于开发时间短,资金投入不足,所以BUG会多一些,厂家靠自己的工程师来维护有些项目。
3.技术方面:虽然老外挣钱比较黑,但东西还是好东西,特别是MSTR,本身就定位于高端产品,在国内银行、电信、石油等大型企业的TB级数据仓库中,经常被采纳和使用。相反对于应用可有可无的政府、街道,用用国产软件还可以拼凑着玩玩,因为这些地方有工具无工具不会对生产造成影响。
技术比拼应该以下几个方面进行
一、伸缩性
MicroStrategy的第三代ROLAP架构,在容量上很容易能达到TB级或一个数据库平台能存储的数据量,这是通过以下方式实现的:反复地在优化的基于server的平台、数据库和MicroStrategy’s Intelligence Server中执行分析。根据定义,假定BI平台能够像MicroStrategy 那样产生高度优化的基于平台的SQL,数据库技术不断扩展并且将是一个理想的场所来完成大容量数据处理。MicroStrategy中的 Intelligence Server能进行多维分析,比如能利用各种各样的OLAP函数,执行那些不能被数据库高效率处理的cube-like slice and dice fully offloading analysis。
MicroStrategy 中的Intelligence Server是一个基于组件的应用服务器,提供了高度伸缩性环境所具备的必要控制和应用系统管理,如下所述:
• 在理想平台上完成多维分析处理(通过Intelligence Server或数据库中的200多个分析库)
• 真正共享的多级别的缓存完全与Intelligence Server中的安全模式进行了集成
• 通过连接池、粒状数据和应用控制来智能地管理所有的用户对数据库的连接
• 通过排队等候和线程管理,对所有请求动态分配优先权
• 系统用法和性能调整工具
• 群集管理和负载均衡
• 通过动态资源分配进行自我调整的结构使组件满负荷工作
MicroStrategy是第一个认可主动信息传递需要的BI厂商。以1998年的Broadcaster产品为开端,还有近期新近命名的Narrowcast Server,MicroStrategy使得通过各种媒体如:email、传真、呼机、手机,主动传递高度个性化的相关信息成为可能。该功能是out of the box并且不需要任何定制代码。用户定制他们想收到的信息、条件,例如数据中的异常或者是基于事件的标准和设备类型。
结构被设计成从MicroStrategy Intelligence Server和外部信息源中接受个性化的内容。从多种来源中获得的信息可能会出现在MicroStrategy Narrowcast Server的输出结果当中。数据源的例子包括从ERP系统中获得的XML内容、从内容供给者和入口处获得的ICE内容,或者其它的非关系型的内容如:平面文件、图片等等。基于XML的结构确保了完善的内容控制和对任何当前或将来存在的设备的适应性。Out of the box,MicroStrategy Narrowcast Server使你能够以HTML、普通文本、或Excel的形式给任何一个SMTP网关传送商业智能报告。
二、安全性
MicroStrategy满足以下需求:MicroStrategy 9安全模式包含必要的广度和深度,通过internet允许BI应用系统对员工、合作伙伴、供应商和顾客进行安全部署。MicroStrategy产品是通过以下方式实现其安全性的:应用功能级别的特权的使用、报表对象级别上的访问控制列表、安全过滤器、连接映射和在数据级别上对数据库视图的支持。另外,用户级别的安全是通过MicroStrategy与NT、WIN2003、LDAP的集成实现的,传输级别的安全是通过128位的SSL传输、128位数据加密或在web服务器上无数据库连接的双防火墙配置来实现的。
MicroStrategy 基于配置文档的安全性能确保了平台和传输体系中的每一部分都是安全的,都被严格管理。另外,MicroStrategy对工业标准的安全尺度的实现确保了MicroStrategy的安全模型能与当前存在的任一安全方式进行集成。
三、部署能力(包括维护能力)
MicroStrategy提供了desktop方式和web方式的集成的全功能性的BI,完整的BI功能包括静态报表制作,报表分发,查询和报表制作,OLAP分析,集分析并且从一个集成的接口利用数据挖掘。
允许用户从一个单独的接口,通过MicroStrategy Architect, MicroStrategy Agent 和 MicroStrategy 服务器管理之间紧密的集成来进行设计、创建、维护、运行和监视分析。
四、分析能力
由于MicroStrategy具有能够以优化的方式存取TB级数据的能力,用户有权在他们的安全角色确定的适当的控制范围内使用整个数据仓库。虽然许多查询工具能够检索少量的slice级别的数据,仅有MicroStrategy能够对可用的信息进行足够深度和宽度的优化存取。
五、易用
MicroStrategy Web中的纯HTML解决方案,使得能通过任何浏览器、在任何操作系统上、穿过任何防火墙被迅速存取。MicroStrategy Web提供了像完全互动地钻取引导、递增的获取、导航、转出到Excel、ad hoc报表创建、排序/分等级、表格和图形方式、任意旋转、报表提示等功能。
MicroStrategy Web中的Page-By提供了一个类似slice and dice 功能的cube。另外,MicroStrategy的互动处理是完全透明的。
六、性能
MicroStrategy 以cube响应时间的方式提供了具有ROLAP结构的数据伸缩性。这是MicroStrategy 通过动态地在所有级别上优化性能、阻止瓶颈在BI环境中发生来实现的,如下所述:
数据库处理
MicroStrategy利用数据库平台内在的优化,通过高度优化的、能对产生的SQL类型和优化提供粒状控制的数据库版本明确的VLDB驱动程序,进行大数据量处理和进一步提高整个数据库处理的效率。
MicroStrategy自动的aggregate table generation and advanced aggregate awareness意味着任何要添加进数据库的聚合表被MicroStrategy SQL引擎自动地动态利用。其它的数据库构造自动地利用包括本地数据库函数,性能调节算法和对像,MicroStrategy中的VLDB驱动程序包含大约60个
应用处理层
虽然MicroStrategy 中的Intelligence Server提供了大量的performance tuning aspects,然而它的主要目的是作为神经中枢对所有处理资源进行有效的协调-确保组件被正确利用,在优化的平台进行的处理包括:
• 在内存中有多级缓存,自动提示
• 依靠请求类型和可用资源,在数据库或应用服务器上反复处理
• 通过动态给超载组件分配资源的自我调整的结构
• 聚类和动态的负载均衡
• 异步的处理能力保证能够在同一时间处理多个web客户端请求
数据传输
MicroStrategy的ROLAP方式保证了在网络上只传输结果集。MicroStrategy把XML作为信息传递的机制保证了只向web浏览器发送高效结果集。递增的Fetch确保了请求结果行的数量在被需要的时候,从MicroStrategy Intelligence Server发送到web浏览器。
展示/本地desktop
大多报表格式和数据操纵在瘦客户端完成。类似于cube的数据操纵如Page By等和其它的数据操纵如数据排序是在本地完成的。
The MicroStrategy Narrowcast Server subscription portal也在关系结构中缓存HTML内容,这主要是为了允许narrowcast server subscription portal用户通过portal来浏览个性化的静态服务。
Max@X Analyser 5是新一代的报表与数据分析技术产品。针对复杂应用环境下的数据Web报表展现与联机数据分析(OLAP)而设计,重点在部署与集成、复杂表样支持、特殊需求适应、数据填报、OLAP 快速实施及可用性、服务器性能等方面进行了创造性的优化。
Max@X Analyser由四部分组成:Web报表(Reports)、联机数据分析(OLAP)、服务器引擎(Server Engine)、决策门户(Analyser Portal)。
可满足任何复杂样式需求的WEB报表设计模型(Reports)
报表是数据分析的最基础形式,也是应用最为广泛的数据表现形式。Max@X Analyser包含了一套功能强大且简单易用的专业Web报表工具。除了解决传统工具已经涵盖的B/S架构报表制作、预览、打印及导出文件等方面外,Max@X Analyser更进一步,在复杂报表的设计处理、特殊样式的扩展适应、海量数据的快速响应等方面,提供了更为优越的性能表现。
可直连多数据库的联机数据分析模型(OLAP)
联机分析处理OLAP是Max@X Analyser的重要核心之一,支持动态分析操作,侧重决策支持,并提供直观易懂的查询结果。Max@X Analyser无需数据仓库建设,也无需任何第三方OLAP Server支持,用户仅仅需要懂得数据库管理知识,就可以快速建立OLAP系统,设计并部署OLAP分析模型。Max@X Analyser联机分析功能不仅能进行数据汇总/聚集,建立多维度的分析、查询和报表,同时还提供切片、切块、下钻、上卷和旋转等数据分析功能,从而使用户从更快、更易使用的交互方式中获得收益。
可集成、可独立部署的服务器引擎(Server Engine)
服务器引擎是Max@X Analyser专门提供给集成用户的服务器核心。服务器引擎的表现形式在Java下是一系列JAR文件,在VS.NET下是一个Web组件。无论是JAVA还是VS.NET版本,服务器引擎均可作为应用程序的一个组成部分与应用程序进行集成,并接受应用程序的授权等控制,与应用程序共享数据库连接池。
100%免代码的快速部署发布应用门户服务器(Analyser Portal Server)
如果说我们可以把企业看做一架飞机的话,那么决策门户服务器(Analyser Portal Server)就是这架飞机的仪表及控制平台。Analyser Portal Server无需任何代码,根据人机交互的部署配置,自动创建应用页面及控制平台,包含了信息发布、信息共享、快速决策、任务定制以及授权控制等功能前端应用,与所有Max@X Analyser产品组件紧密关联。同时,它是一个基于Web的应用平台。通过这个平台,终端用户可以方便地完成数据分析、信息发布以及信息协同等任务。
我感觉大家对于两种产品的讨论已经很充分了,也详细的讨论了两种产品的功能和优缺点。
的确,两种产品的定位不同,针对的客户群也不一样,也没有必要非要评出个孰优孰劣,应该说是各有千秋。
在技术方面:
MSTR作为BI软件的领导厂商之一,通过一组软件产品满足BI领域的五大应用,分别是:
企业级报表——报表生成器用来生成很好的格式化的静态报表,这些报表广泛的向多数人发布。
立方体分析——基于立方体的BI工具向业务经理们提供简单的切片和钻取分析能力。
任意查询和分析——关系型OLAP(ROLAP)工具供超级用户对数据库进行任意的访问,对整个数据库进行切片、钻取,从而分析到最细粒度的交易信息。
统计分析和数据挖掘——通过统计分析和数据挖掘工具,可以使用各类模型进行预测或者寻找两个变量之间的因果相关性。
报表分发和预警——基于报表分发机制,可以根据订阅、调度或者数据库中的触发事件向大量的用户群发送整个报表或者告警信息。
从软件伸缩性来讲,它支持TB级的数据和百万级的用户;
在商务智能平台方面:它支持快速的集成,丰富的业务分析手段和主动分发;
在适应互联网方面:它以纯Web界面、快速部署与简单维护、全面的安全、高可靠和高性能著称。
同样,数巨作为后起之秀,以其优惠的价格,支持复杂报表的能力而获得用户的青睐,正如maxatx仁兄所介绍的一样,作为国产软件,它非常注重国人的特殊需求,比如国内常见的异常负责的报表表头,国外通常是很少见的,而且国内企业在BI方面的应用往往是刚刚起步,对于分析的需求多数还停留在报表方面,在这种情况下选择数巨是就成为了一个性价比很高的选择。
在价格方面,根据需求的不同采购的模块不同价格差异较大,但从满足基本的报表功能方面来比较,MSTR的价格通常在几十万这个量级,而数巨通常在几万到十几万这个区间,如果单从价格方面来说,数巨当然是占有较大优势了。
在服务方面,作为国外软件,通常认为其服务难以跟上,但MSTR已经进入国内市场多年,拥有一支完备的代理商和技术服务队伍,因此从服务方面来讲还是有保障的,不过其服务价格也不菲。而数巨作为国产软件,当然发挥其本土优势,服务方面应该是没的说的。
总之,两种软件对应的是不同的客户群,对于电信、银行等大数据量,大访问量,有复杂分析需求且资金充裕的行业,可以选择MSTR来满足其特殊应用。而对于广大中小企业,并没有太多的数据量和访问量,分析需求又相对简单以报表为主,且对价格比较敏感的话,那么数巨就成为了最好的选择。
软件评分:
MSTR:技术:65;价格:5;服务:20;总分90分。
数巨:技术:55;价格:10;服务25;总分90分。
Microsoft SQL Server 2000报表服务是服务器端的完整平台,它对传统纸面报表以及可交互的基于Web的报表都可以进行建立、管理和发布。它是微软已有的商业智能与数据仓库解决方案产品——Microsoft Office、Microsoft Business Solutions与Microsoft SQL Server的有益补充。
Microsoft Office Web Component(OWC)包含在Microsoft Office 2000以后的产品中。在使用Microsoft Internet Explorer浏览包含Office Web组件的Web页时,您可以直接在Internet Explorer中处理显示的数据,如对数据进行排序和筛选,输入新的数值,展开和折叠明细数据,进行行列旋转以查看源数据的不同汇总信息等。由于Office Web组件是完全可编程的,可以在很多设计环境中使用这些组件来建立复杂的、交互的和基于Web的解决方案。这些设计环境包括Microsoft FrontPage、Microsoft Access数据访问页以及Microsoft Visual Basic。您也可以使用最小的设计设置直接在Microsoft Excel中发布这些Office Web组件。
笔者根据所参与的项目及以前的应用经验,对Microsoft SQL Server Reporting Services、OWC和Microsoft SQL Server组成的微软企业级报表解决方案与相关产品的解决方案作了一个简单比较。
与Cognos公司产品的比较
Cognos的产品简介
Cognos公司的产品Cognos Suite是由一系列的功能模块组合而成的套件,包括ImpromptU、Powerplay和Scenario等模块。
Impromptu提供查询、报表功能,针对关系型数据。可以将Powerplay的数据形成报表,这是Cognos公司的集成。Impromptu Web Reports(WR)在Web上为大量报表用户提供易于打印的管理报表。用户可以订阅已发布报表,对其进行定制来满足特定的需要。
Powerplay提供OLAP分析功能,针对多维数据PowerCube(Cognos定义的多维数据结构)。在Powerplay中可以钻取到Impromptu中。这是Cognos公司的集成。
Transformer将Impromptu及其他数据源中的数据形成PowerCube,以备Powerplay使用。Scenari是数据挖掘工具。4Thought是采用神经网络技术的建模与预测模块。
Cognos报表解决方案与Reporting Services的不同点Cognos的解决方案不是集成的产品(将查询、报表作一个工具,分析作一个工具,Cognos的理由是先分析再做表);没有类似于Designer的专门设计模块,在Impromptu模块中完成数据库的连接与catalog的定义,因此Impromptu的使用要求用户具备数据库专业知识;没有对报表的集中管理、分发和调配的功能。目前引进中国的只有Impromptu、Powerplay。
Reporting Services的特点
1)Reporting Services是集查询、报表和分析于一体的产品,只需学习一个工具的使用、在一个界面上操作,易用性强。符合查询、分析、再查询、再分析循环往复的决策思维方式; Impromptu和Powerplay所使用的数据层不同,不能共用,Powerplay使用的多维数据由其它模块生成,是静态的多维立方体,维的改变需切换到其它模块。
2)Reporting Services的几大模块在SQL Server数据库引擎的管理下形成一个统一完整的系统,具有统一的用户与资源管理,安全性高。
3)文档共享方面,Reporting Services提供输出多种格式或Email等多种方式。
4)Reporting Services是32位结构,Impromptu是16位结构。数据量大时,使用Impromptu不稳定,会出现死机等。
与SAS的比较
SAS简介
SAS以统计分析软件包起家,在统计分析方面具备很强实力。发展到现在,SAS成为一个包含许多模块与功能的庞大的软件包,有两种使用方式:一是直接使用一些应用模块对存于SAS自己数据库中的数据进行多种多样的统计分析,这些应用模块包括统计分析STAT、财务分析ETS、运筹学OR等等。利用这些模块要求用户具备较高的数学尤其是统计分析专业知识,同时要具备较高的计算机操作能力。而且如果数据存在其它数据源中,需要利用SAS进行预先转换,这需要用户具备数据库专业知识。二是用户单位的计算机人员利用SAS的若干模块编程,为最终用户提供特定的应用系统。这样做的优点是可以为最终用户提供所要求的简便界面,但对技术人员的要求很高,培训时间也很长;而且灵活性差:一旦用户需求有改变,需要重新编程。SAS对数据的处理能力很强,但需要用户长时间的培训才能应用起来。
SAS与微软的企业级报表解决方案的比较
SAS与微软的企业级报表解决方案不是同类产品。
1)易用性相差很大,从而面向的用户对象不同
SAS功能很多,提供算法很多,因此易用性差,要求用户具备很扎实的数学基础、统计分析基础和计算机基础。
2)若利用SAS开发一套系统,优势是贴切需求,但对应用需求的提出、开发、实施和相关厂商的技术支持要求很高,并且开发系统的开放性、稳定性、可移植性、灵活性上比商业软件要差,尤其国内现阶段的开发手段相对比较落后。
与Pilot产品的比较
Pilot公司的产品包含服务器端和客户端,其服务器端的产品是多维数据库。客户端产品功能与Microsoft SQL Server Reporting Services相似,有如下不同之处:
l)Microsoft SQL Server Reporting Services不但支持关系型数据,而且支持来自第三方的多维数据。而Pilot的客户端产品只支持自己格式的多维数据。因此关系型数据用户必须先将数据导入Pilot的多维数据库中。用户工作量很大,相当于重新建立多维数据库,这样不如选择其它产品构建数据仓库,以Reporting Services做前端展现。
2)Pilot的多维数据的维的改动很难,不灵活。
3)Pilot客户端产品的易用性差,需要编程,工作量大,后期维护难。
与Oracle公司产品的比较
Oracle公司的Discoverer与Reporting Services功能近似,但两者也有一些区别。
Reporting Services支持的数据源更为广泛,可以是数据仓库,也可以是大型关系数据库如 Sybase、Oracle、Informix、SQL Server、DB2,单机数据库如Access、Foxpro、dBase等,多维数据库如Essbase、Express,常用应用软件如SAP R/3、Peoplesoft或Oracle的一些常用应用软件包,数据文件如Excel、TXT文件等,只要有相应的驱动即可。
Discoverer 3是针对关系数据库的,不适用于数据仓库和多维数据库,即使对Oracle自己的多维数据库Express也不支持。
Reporting Services对Oracle、SQL Server数据库有内部直接连接,其他较为流行的大型数据库Sybase、Informix、DB2可以通过OLEDB连接。Discoverer 3只能通过ODBC与数据库连接,因此查询数据的速度相对较慢。
Discoverer 3不能在一个文件中同时用表和统计图表示数据。
Discoverer 3不能在统计图上对数据进行钻取。
Discoverer 3的安全控制弱,不能定义用户及用户组的不同描述文件,既不能对哪些用户使用哪些模块进行控制,也不能对一些敏感数据进行进一步的控制。而Reporting Services可以对整个报表运行系统进行管理,对权限及某些数据进行控制。
Reporting Services还可以对报表集中分发、管理。例如用户可以规定刷新和发送报表的时间,如每小时、每天、每周、每月等刷新发送一次,或在现定时间只发送一次。通过一些简单的属性设置,还可以发送报表到Web页面上,并定时刷新。Discoverer 3没有对报表文件的集中批处理。
Discoverer3可以将文件转为HTML格式,但不支持定时刷新。
与Seagate公司产品的比较
公司简介
希捷公司由Alan Shugart创建于1979年,最初主要生产数据存储设备,在随后的发展过程中,逐渐由硬件设备厂商扩展为“数据技术公司”。1994到1997年间,相继收购了Crystal Service(Crystal Report,Crystal Info产品的创建公司)、Holistic Systems(Holos OLAP Server产品的创建公司)等公司来扩展其软件产品系列。
解决方案
产品线:
Seagate Info——包括查询、报表和多维分析,以及安全管理,其中包含Seagate Analysis模块;支持多种关系型数据、多维数据库;
Seagate Analysis——提供查询、报表和多维分析;
Seagate Crystal Reports——报表制作工具,提供查询、报表功能和API接口,可以在开发工具中集成;
Seagate Holos——OLAP Server。
相关比较
Seagate Info没有语义层技术,无论是使用Seagate Info还是Crystal Reports,都需要让用户自己从数据库选择表,构造SQL语句,因此用户必须了解数据库技术。
Crystal Reports主要是为专业计算机人员提供的报表制作工具,有较强的二次开发能力,因此它作为报表工具组件曾被集成到多种开发工具和应用程序中,如Microsoft Visual Studio.NET。但考虑到相关的使用许可,Crystal Reports是一个相对昂贵的选择。
与MicroStrategy公司产品的比较
MicroStrategy公司由Michael J.Savior创建于1989年,最初主要是作为一家决策支持领域的咨询公司,在随后的发展过程中,于1993年推出了第一个产品包:MicroStrategy Agent,以后相继推出一系列产品:MicroStrategy Web、MicroStrategy Broadcaster、MicroStrategy Telecaster等,现新产品包称为MicroStrategy7,致力于提供面向个性化的电子商务智能解决方案。
MicroStrategy解决方案的产品线包括:
MicroStrategy Intelligence Server——整个产品中的核心产品,多层体系结构下的中间应用服务器,为各种前端应用提供中间应用层能力。
MicroStrategy Web——Web体系下的应用服务器,提供基于Web体系下的查询、电算表格和多维分析能力。
MicroStrategy Agent——数据挖掘、应用开发工具,提供API接口。
MicroStrategy InfoCenter——企业级报表、门户工具。
MicroStrategy Architect——商业对象抽象层设计工具。
MicroStrategy Desktop——MicroStrategy Agent、MicroStrategy Architect和MicroStrategy Administration Utility的集成化应用环境
MicroStrategy有较弱的语义层技术,称之为企业商业体系,但能力比较弱,无法支持复杂的语义表达。
前端工具MicroStrategy Desktop的易用性较差,Businessobjects是唯一在决策支持工具中获得Microsoft office兼容认证的产品,易用性同Office类似,同时支持Microsoft VBA二次开发技术。
前端工具MicroStrategy Desktop对灵活查询支持较弱。
MicroStrategy不具备企业级特征,对企业级报表制作、企业信息共享与分发、企业级维护与管理支持较弱,管理复杂。
MicroStrategy整个产品学习和使用较为困难,需要更多的技术支持。
Reporting Services有支持XML的designer和应用模板(Wizard),使得用户只需按照自己的需求稍做调整,就可以达到应用效果,MicroStrategy没有提供类似能力。
MicroStrategy采用了N-tier体系结构,在构架的灵活性上与微软的企业级报表解决方案相当
使用Oracle9i的新特性Flashback Query恢复误删除数据
作者:
eygle |
English Version
链接:
http://www.eygle.com/archives/2005/06/eoaoracle9iaeai.html
下午接到研发工程师的电话,说误删除了部分重要数据,并且已经提交,需要恢复。
登陆到数据库上查看,由于是Oracle9iR2,首先尝试使用flashback query闪回数据。
首先确认数据库的SCN变化:
SQL> col fscn for 9999999999999999999
SQL> col nscn for 9999999999999999999
SQL> select name,FIRST_CHANGE# fscn,NEXT_CHANGE# nscn,FIRST_TIME from v$archived_log;
...................
NAME FSCN NSCN FIRST_TIME
------------------------------ -------------------- -------------------- -------------------
/mwarch/oracle/1_52413.dbf 12929941968 12929942881 2005-06-22 14:38:28
/mwarch/oracle/1_52414.dbf 12929942881 12929943706 2005-06-22 14:38:32
/mwarch/oracle/1_52415.dbf 12929943706 12929944623 2005-06-22 14:38:35
/mwarch/oracle/1_52416.dbf 12929944623 12929945392 2005-06-22 14:38:38
/mwarch/oracle/1_52417.dbf 12929945392 12929945888 2005-06-22 14:38:41
/mwarch/oracle/1_52418.dbf 12929945888 12929945965 2005-06-22 14:38:44
/mwarch/oracle/1_52419.dbf 12929945965 12929948945 2005-06-22 14:38:45
/mwarch/oracle/1_52420.dbf 12929948945 12929949904 2005-06-22 14:46:05
/mwarch/oracle/1_52421.dbf 12929949904 12929950854 2005-06-22 14:46:08
/mwarch/oracle/1_52422.dbf 12929950854 12929951751 2005-06-22 14:46:11
/mwarch/oracle/1_52423.dbf 12929951751 12929952587 2005-06-22 14:46:14
...................
/mwarch/oracle/1_52498.dbf 12930138975 12930139212 2005-06-22 15:55:57
/mwarch/oracle/1_52499.dbf 12930139212 12930139446 2005-06-22 15:55:59
/mwarch/oracle/1_52500.dbf 12930139446 12930139682 2005-06-22 15:56:00
NAME FSCN NSCN FIRST_TIME
------------------------------ -------------------- -------------------- -------------------
/mwarch/oracle/1_52501.dbf 12930139682 12930139915 2005-06-22 15:56:02
/mwarch/oracle/1_52502.dbf 12930139915 12930140149 2005-06-22 15:56:03
/mwarch/oracle/1_52503.dbf 12930140149 12930140379 2005-06-22 15:56:05
/mwarch/oracle/1_52504.dbf 12930140379 12930140610 2005-06-22 15:56:05
/mwarch/oracle/1_52505.dbf 12930140610 12930140845 2005-06-22 15:56:07
14811 rows selected.
|
当前的SCN为:
SQL> select dbms_flashback.get_system_change_number fscn from dual;
FSCN
--------------------
12930142214
|
使用应用用户尝试闪回
SQL> connect username/password
Connected.
|
现有数据:
SQL> select count(*) from hs_passport;
COUNT(*)
----------
851998
|
创建恢复表
SQL> create table hs_passport_recov as select * from hs_passport where 1=0;
Table created.
|
选择SCN向前恢复
SQL> select count(*) from hs_passport as of scn 12929970422;
COUNT(*)
----------
861686
|
尝试多个SCN,获取最佳值(如果能得知具体时间,那么可以获得准确的数据闪回)
SQL> select count(*) from hs_passport as of scn &scn;
Enter value for scn: 12929941968
old 1: select count(*) from hs_passport as of scn &scn
new 1: select count(*) from hs_passport as of scn 12929941968
COUNT(*)
----------
861684
SQL> /
Enter value for scn: 12927633776
old 1: select count(*) from hs_passport as of scn &scn
new 1: select count(*) from hs_passport as of scn 12927633776
select count(*) from hs_passport as of scn 12927633776
*
ERROR at line 1:
ORA-01466: unable to read data - table definition has changed
SQL> /
Enter value for scn: 12929928784
old 1: select count(*) from hs_passport as of scn &scn
new 1: select count(*) from hs_passport as of scn 12929928784
COUNT(*)
----------
825110
SQL> /
Enter value for scn: 12928000000
old 1: select count(*) from hs_passport as of scn &scn
new 1: select count(*) from hs_passport as of scn 12928000000
select count(*) from hs_passport as of scn 12928000000
*
ERROR at line 1:
ORA-01466: unable to read data - table definition has changed
|
最后选择恢复到SCN为12929941968的时间点
SQL> insert into hs_passport_recov select * from hs_passport as of scn 12929941968;
861684 rows created.
SQL> commit;
Commit complete.
|
研发人员确认,已经可以满足需要,找回误删除部分数据,至此闪回恢复成功完成。
| 自定义file类型input框样式的方法 |
在WEB上传文件时,要用到上传框:
<input type="file" id="f" name="f">
这东东在IE(其他偶没经过测试)中是一个非常特殊的对象。
如果是您手动写入的或其他对象经过某些事件触发填入的值
由于安全问题,在进行提交表单时,往往会被清空,所以上传失败。
简单点说,除非你的鼠标亲自点到了上传框f上,IE才会给你上传文件!
哪怕你将 f 的onclick句柄赋给某个对象,如:
<input type="file" id="f" name="f">
<input onclick="f.click()" value="点击">
你 “点击” 后,同样会弹出文件选择对话框,可惜失望地:你照样不能上传文件!
怎么办呢?
看下这段:
<BODY onmousemove="f.style.pixelLeft=event.x-200;f.style.pixelTop=event.y-10;">
<input type="text"><input type="button" onmousemove="">
<input type="file" id="f" name="f" style="position:absolute;">
</BODY>
随便点击鼠标,看到效果了吧?
基于上面的思路,偶们就可以把它弄到一个button下面就OK了!!
<style>
input{border:1px solid green;}
</style>
<BODY>
<BR><BR><BR>
<form method="post" action="" enctype="multipart/form-data">
<input type="text" id="txt" name="txt">
<input type="button" onmousemove="f.style.pixelLeft=event.x-60;f.style.pixelTop=this.offsetTop;" value="请选择文件" size="30">
<input type="file" id="f" name="f" style="position:absolute;" size="1" onChange="txt.value=this.value"><BR>
<INPUT TYPE="submit">
</form>
</BODY>
为了达到真正模拟的效果,还得要把f给隐藏,加个不透明的alpha 滤镜即可,再加上 hidefocus 属性,隐藏f的虚线:
<style>
input{border:1px solid green;}
</style>
<BODY>
<BR><BR><BR>
<form method="post" action="" enctype="multipart/form-data">
<input type="text" id="txt" name="txt">
<input type="button" onmousemove="f.style.pixelLeft=event.x-60;f.style.pixelTop=this.offsetTop;" value="请选择文件" size="30" onclick="f.click()">
<input type="file" id="f" onchange="txt.value=this.value" name="f" style="position:absolute;filter:alpha(opacity=0);" size="1" hidefocus><BR>
<INPUT TYPE="submit">
</form>
</BODY>
可以看下opacity=0改为稍大些的效果。
OK了,现在你就可以控制它们的样式、位置了。。。
|
商业智能平台研究 (十) ETL 选型
ETL (Extract-Transform-Load的缩写,即数据抽取、转换、装载的过程)作为BI/DW(Business Intelligence)的核心和灵魂,能够按照统一的规则集成并提高数据的价值,是负责完成数据从数据源向目标数据仓库转化的过程,是实施数据仓库的重要步骤。如果说数据仓库的模型设计是一座大厦的设计蓝图,数据是砖瓦的话,那么ETL就是建设大厦的过程。在整个项目中最难部分是用户需求分析和模型设计,而ETL规则设计和实施则是工作量最大的,约占整个项目的60%~80%,这是国内外从众多实践中得到的普遍共识。
ETL工具从厂商来分为两种,一种是数据库厂商自带的ETL工具,Oracle warehouse builder 就是这种,另外一种是第三方工具提供商.开源世界也有一大票的ETL工具,功能各异,强弱不一,你可以从一下地址找到开源ETL工具的列表 http://www.manageability.org/blog/stuff/open-source-etl/view , 提醒一句,选用工具的时候要慎重,真的,千万要慎重,不管你是选用商业的ETL工具(一般比较贵),还是开源的工具,都要在你充分了解产品的特性才去选择,千万不要听某某人说什么这个工具好,就购买了那个工具,一定要自己了解产品.
开源的ETL工具的列表 (排名是乱排的)
kettle http://kettle.pentaho.org/ ,pentaho官方的ETL工具,是一个metadata-driven 的ETL工具,不需要自己写code .
talend http://www.talend.com/ talend是talend自己公司的产品,宣传的是全功能的Data Integration 解决方案,基于eclipse 平台,包括很多的模块来实现商业流程建模,数据流程建模,最后输出的是perl 和 Java code
jasperETL http://www.jaspersoft.com/ JasperETL是基于talend的平台,不太清楚有什么区别,jaspersoft开发的ETL产品.
Octopus http://www.enhydra.org/tech/octopus/index.html octopuc是enhydra 的一个ETL工具,enhydra是一个产品跨度非常大的开源站点,它有个开源的Workflow ,Shark ,pentaho就是使用的这个Workflow ,这个组织从workflow 到application server , 从ETL工具到application framework ,还有一些其他的中间件,octopus非常的原始,支持任何的JDBC数据源,用XML语言来定义的.也支持JDBC-DOBC ,和excel 和 access ,csv-files, XML files ,用Ant 和 JUnit 来创建表和测试.
CloverETL http://cloveretl.berlios.de/ CloverETL是提供给你一组API,用XML来定义ETL过程,同样支持JDBC数据源, CloverETL是开源的,但是它是没有图形界面的,它提供一个有图形界面的CloverGUI 来进行ETL的图形化开发过程,但是不是开源的,需要购买商业许可证.
KETL http://www.ketl.org/ 听说是几个前IBM员工做出来的ETL产品,
另外还有很多.不一一写介绍了,只列个表吧,
Joost http://joost.sourceforge.net/ 最近有个web2.0 网站也叫Joost,名字相同而已.
Xineo http://software.xineo.net/xil.jspx
BabelDoc http://sourceforge.net/projects/babeldoc
CB2XML http://sourceforge.net/projects/cb2xml
mec-eagle http://sourceforge.net/projects/mec-eagle/
Transmorpher http://transmorpher.inrialpes.fr/
XPipe http://xpipe.sourceforge.net/Articles/Miscellaneous/fog0000000018.html
DataSift http://www.datasift.org/
Xephyrus Flume http://www.xephyrus.com/flume/flume-intro.Prlx
Smallx https://smallx.dev.java.net/
Nux http://dsd.lbl.gov/nux/index.html
Netflux http://www.netflux.org/
OpenDigger https://opendigger.dev.java.net/
ServingXML http://servingxml.sourceforge.net/
Scriptella http://scriptella.javaforge.com/
ETL Integrator http://www.glassfishwiki.org/jbiwiki/Wiki.jsp?page=ETLSE
Jitterbit http://www.jitterbit.com/
Apatar http://www.apatar.com/
Spring Batch http://static.springframework.org/spring-batch/
大多数站点都是在sf.net上的.其中最后一个是Spring的,大名鼎鼎的Spring 也往ETL插一脚.实在是..........
根据talend官方介绍的数据,ETL工具的市场份额在2006好像是有160多亿美元.由于BI项目的成功,ETL的这一市场份额还会扩大,这也不难理解,为什么这么多的公司都在做ETL工具了.开源世界也免不了想要分一杯羹.再次废话一句,开源的东西你可以免费得到和使用,但是当你想应用到企业级开发的时候,省钱可不是唯一应该考虑的因素.还是那句话,慎重呀慎重.
下一篇介绍BI的基本概念.
开源BI系统简述
1. 概述
开源的BI项目在在2005年之前并没有太大的发展,到了2005年才开始呈现繁荣之势,并在2006年蓬勃发展。这些众多的BI项目从规模和对BI系统支撑的完善程度上来说,大体可以分为Framework、Stand-alone Tools和BI Suit三种类型。
l Framework
开源框架,这是在商业BI系统中所没有的。我们可以使用它们来构建自己的BI工具,或者增强和扩展我们的BI解决方案。
l Stand-alone Tools
独立的BI工具,这是开源项目中数量最多的一类。很多工具只侧重BI系统中的某个环节和方面,如ETL、Report、OLAP和Database等等。
l BI Suit
在统一的架构下提供了多种BI系统的特性的工具集合。就目前的情况看,不管是商业软件还是开源软件,还没有任何一个套件提供了完整的端到端的BI解决方案。这些开源的BI Suit是通过连接多个其他的组件和工具的方式形成套件的,由于BI系统涉及到的工具是非常多的,所以整合一套完整的BI解决方案是很困难的。
一个完整的BI解决方案中有多种工具来完成BI系统中各个阶段的工作。
数据抽取、转换和加载工具。优秀的ETL工具应该具有以下特性:
1、 Workflow Management, Job Execution and Scheduling Manager。能方便地定义流程并自动化执行ETL任务。
2、 Centralized Metadata Repository and Management。集中存储和管理符合业界标准的元数据。
3、 Data Profile and Validation。可以检验数据的质量。
4、 High Performance。在大负荷的任务执行中仍然有良好的性能。
5、 Scalable, Platform Independent。具有良好的弹性,支持多种操作系统和数据库系统,能操作多种异构的数据源。
6、 Open Architecture and API。具有开放的架构和易于使用的二次开发接口。
目前较为知名的开源ETL工具有:
1、 KETL,由具有IBM和KPMG背景的Kinetic Networks公司开发,现在已经有三年多的产品应用历史,成功应用于一些产品中,在点击流(ClickStream)分析应用中表现出色。KETL采用Plug-in的架构,使用Java开发。
2、 KETTLE,为一个元数据驱动的ETL工具。已经加入Pentaho。
3、 Clover ETL,为一个基于Java的ETL Framework,可以用来开发自己的ETL应用。
4、 Enhydra Octopus,为一个基于Java的ETL工具,使用JDBC来连接各种数据源,易于使用和部署。曾有人应用于电信网络资源分析系统中。
优秀的报表工具通常具有以下特性:
1、 支持多种数据源。
2、 直观的可视化设计器,简单易用的报表定制功能。
3、 方便的数据访问和格式化,丰富的数据呈现方式。
4、 符合数据呈现的通用标准,能和应用程序很好地进行结合。
5、 易于扩展和部署。
目前较为知名的开源报表工具有:
1、 JasperReports,一个优秀的Java报表工具,始于2001,现在JasperSoft公司持续开发和支持该工具。该工具类似于商业软件Crystal Report,支持PDF、HTML、XLS、CSV和XML文件输出格式,现在是Java开发者最常用的报表工具。
2、 OpenReports,提供基于web的灵活报表解决方案,通过浏览器自动生成动态PDF,XLS,HTMLCSV 和Chart报表,它是用Java开发的,使用JasperReports 作为报表引擎,利用到的开源技术有Hibernate,Veloctiy,Webwork。
3、 JFreeReport,现在是Pentaho的一部分,它是一个优秀的用来生成报表的Java类库。它为Java应用程序提供一个灵活的打印 功能并支持输出到打印机和PDF, Excel, HTML和XHTML, PlainText, XML和CSV文件中。
4、 Eclipse BIRT,是Eclipse下面的一个企业智能和报表 工具,能为J2EE的WEB应用程序创建漂亮醒目的PDF或者HTML格式的报表,它提供了核心的报表功能。
联机分析处理工具。目前开源的OLAP工具也分为MOLAP、ROLAP和HOLAP,优秀的OLAP工具通常有以下特性:
1、 良好的执行性能,能快速地进行分析处理工作。
2、 良好的适用性和可伸缩性。
3、 开放式接口和丰富的API。
目前较为知名的开源OLAP工具有:
1、 Mondrian,是Pentaho的一部分,为一个用Java开发的OLAP服务器,实现了MDX语言、XML解析和JOLAP规范,可以不写SQL就能分析存储于SQL 数据库的庞大数据集,可以封装JDBC数据源并把数据以多维的方式展现出来。
2、 JPivot,是一个JSP 自定制的标签库,可以绘制一个OLAP表格和图表。用户可以执行 典型的OLAP导航,如下钻,切片和方块。它使用Mondrian 作为其OLAP服务器。它使用WCF (Web Component Framework) ,基于XML/XSLT来渲染Web UI组件。JPivot在元数据缓存方面的过于简化的整体性初始化装载的做法将限制它只能处理很小的立方体(Cube)。
开源的数据库也有很多,大多数为关系型数据库,少数为应用于数据仓库环境做了专门的优化工作。Bizgres以PostgreSQL为基础进行了数据仓库环境下的优化,提高了分析查询性能。
下面列出相对成熟和完整,并且有借鉴意义的开源BI套件。
为GreenPlum公司主导的开源项目,和Sun公司达成合作关系。Bizgres为BI应用而对PostgreSQL做了优化,提高了大负荷的并行计算能力,在BI环境中,相对于普通的关系型数据库具有卓越的数据处理性能。Bizgres的数据库平台可以和KETL和JasperReports进行整合,从而形成一个BI套件:
1、 数据库:BI专业数据库Bizgres,或者大型应用中的高性能服务器Bizgres MPP,能比普通关系数据库快20倍
2、 ETL工具:KETL
3、 报表工具:JasperReports
是一个Java开发的Web应用,能对OLAP服务器、关系数据库和数据挖掘服务器进行分析和报表展示,非常易于使用和部署,界面美观友好,后续还将支持数据挖掘和ETL等。Openi主要包括:
1、 OLAP展示:JPivot
2、 报表工具:JFreeChart
3、 分析数据源连接器
是一个以工作流为核心的、强调面向解决方案而非工具组件的BI套件,整合了多个开源项目,目标是和商业BI相抗衡。它包括:
1、 工作流引擎:Shark and JaWE
2、 数据库:Firebird RDBMS
3、 集成管理和开发环境:Eclipse
4、 报表工具:Eclipse BIRT
5、 ETL工具:Enhydra/Kettle
6、 OLAP Server:Mondrian
7、 OLAP展示:JPivot
8、 数据挖掘组件:Weka
9、 应用服务器和Portal服务器:JBoss
10、 单点登陆服务及LDap认证:JOSSO
11、 自定义脚本支持:Mozilla Rhino Javascript脚本处理器
由上可见Pentaho是一个很完善的BI解决方案。Pentaho偏向于与业务流程相结合的BI解决方案,侧重于大中型企业应用。
SpagoBI 集成了Mondrain和JProvit,能够通过OpenLaszlo产生实时报表。SpagoBI使用java开发,不依赖于具体的操作系统,有很强的扩展能力。它主要包括:
1、 报表工具:JasperReports /Eclipse BIRT/ iReport
2、 OLAP Server:Mondrian
3、 OLAP展示:JPivot
4、 数据挖掘组件:Weka
5、 Map引擎:Geo
6、 ETL:BIE
7、 搜索引擎:Lucene
8、 Dashboard:OpenLaszlo
9、 Portal Server:JBoss/ Tomcat/ JOnAS
根据其Roadmap可以看出,SpagoBI将融入更多的BI功能,甚至BI之外的功能。
如何收缩数据文件的大小?
下面这个实验用于描述如何通过move tablespace来完成resize datafile。
HWM的概念就不在此阐述了。
测试环境为Oracle10g for Linux,其它版本的一样。
我们先创建两个表空间,分别为t_tbs和t_tbs1,分别有一个数据文件,大小都是5M
再创建一个test_user用户,给这个用户上述两个表空间的无限限额,并且设置默认表空间是t_tbs。
[zhangleyi@as zhangleyi]$ sqlplus / as sysdba
SQL*Plus: Release 10.1.0.2.0 - Production on Tue Apr 13 21:01:25 2004
Copyright (c) 1982, 2004, Oracle. All rights reserved.
Connected to:
Oracle Database 10g Enterprise Edition Release 10.1.0.2.0 - Production
With the Partitioning, OLAP and Data Mining options
SYS at orcl10>alter user test_user default tablespace t_tbs;
User altered.
SYS at orcl10>alter user test_user quota unlimited on t_tbs;
User altered.
SYS at orcl10>alter user test_user quota unlimited on t_tbs1;
User altered
用test_user登录,创建表
TEST_USER at orcl10>create table t_obj as select * from dba_objects where rownum<10000;
Table created.
TEST_USER at orcl10>insert into t_obj select * from t_obj;
9999 rows created.
TEST_USER at orcl10>/
19998 rows created.
TEST_USER at orcl10>/
insert into t_obj select * from t_obj
*
ERROR at line 1:
ORA-01653: unable to extend table TEST_USER.T_OBJ by 128 in tablespace T_TBS
TEST_USER at orcl10>commit;
Commit complete.
TEST_USER at orcl10>select sum(blocks) "Total Blocks",sum(bytes) "Total Size" from dba_extents where owner='TEST_USER' and segment_name='T_OBJ';
Total Blocks Total Size
------------ ----------
512 4194304
好,上面我们创建了一个表,并且插入了很多数据,通过dba_extents视图我们可以看到总共用的block熟和总共的大小。
下面我们用delete删除全部数据,并且插入新的9999条数据
TEST_USER at orcl10>delete from t_obj;
39996 rows deleted.
TEST_USER at orcl10>insert into t_obj select * from dba_objects where rownum<10000;
9999 rows created.
TEST_USER at orcl10>commit;
Commit complete.
TEST_USER at orcl10>select sum(blocks) "Total Blocks",sum(bytes) "Total Size" from dba_extents
2 where owner='TEST_USER' and segment_name='T_OBJ';
Total Blocks Total Size
------------ ----------
512 4194304
再次查看dba_extents视图,发现占用的空间并没有减少。
我们尝试resize这个数据文件,file#为6的是t_tbs表空间下面的数据文件
SYS at orcl10>alter database datafile 6 resize 4M;
alter database datafile 6 resize 4M
*
ERROR at line 1:
ORA-03297: file contains used data beyond requested RESIZE value
SYS at orcl10>alter database datafile 6 resize 4500000;
Database altered.
我们发现想resize到4M不可以,但是resize到4500000就可以了,因为上面查看出来的Total Size是4194304,这个值大于4M而小于4500000。
然后我们move这张表到t_tbs1表空间,这个表空间下面的数据文件file#是8
EST_USER at orcl10>alter table t_obj move tablespace t_tbs1;
Table altered.
TEST_USER at orcl10>select sum(blocks) "Total Blocks",sum(bytes) "Total Size" from dba_extents
2 where owner='TEST_USER' and segment_name='T_OBJ';
Total Blocks Total Size
------------ ----------
128 1048576
我们检查dba_extents视图,发现Total Size已经变化了,此时已经可以说明move表是会重新进行block的整理的,同时也重置了HWM。
下面我们resize这个数据文件。
SYS at orcl10>alter database datafile 8 resize 2M;
Database altered.
SYS at orcl10>host
[zhangleyi@as ORCL10]$ cd /oracle/oradata/ORCL10/datafile/
[zhangleyi@as datafile]$ ls -l
总用量 1419076
-rw-r----- 1 zhangleyi dba 20979712 4月 13 21:17 cattbs01.dbf
-rw-r----- 1 zhangleyi dba 157294592 4月 13 21:17 o1_mf_example_02p0gpoj_.dbf
-rw-r----- 1 zhangleyi dba 419438592 4月 13 21:20 o1_mf_sysaux_02p09kny_.dbf
-rw-r----- 1 zhangleyi dba 555753472 4月 13 21:17 o1_mf_system_02p09kno_.dbf
-rw-r----- 1 zhangleyi dba 20979712 4月 13 21:02 o1_mf_temp_02p0fzsd_.tmp
-rw-r----- 1 zhangleyi dba 62922752 4月 13 21:20 o1_mf_undotbs1_02p09kog_.dbf
-rw-r----- 1 zhangleyi dba 209723392 4月 13 21:17 o1_mf_users_02p09kqv_.dbf
-rw-r----- 1 zhangleyi dba 2105344 4月 13 21:21 TEST01.DBF(这是file#8)
-rw-r----- 1 zhangleyi dba 4513792 4月 13 21:20 test.dbf(这是file#6)
可以看到我们的目的已经达到了。
在真实应用中,我们可以将一个表空间中的所有object,全部move到一个新的表空间中,然后drop掉原来的表空间,再从磁盘上删除原来表空间中的数据文件。
至于如何得知HWM,我们可以通过analyze之后的数据字典得到,那么如果不进行analyze的话,我们也可以运行下面这个脚本。
这个脚本可以用于检查一个object占有的总共block数和处于HWM之上的block数,这当然也就知道了HWM是在什么位置。
DECLARE
v_total_blocks NUMBER;
v_total_bytes NUMBER;
v_unused_blocks NUMBER;
v_unused_bytes NUMBER;
v_last_used_extent_file_id NUMBER;
v_last_used_extent_block_id NUMBER;
v_last_used_block NUMBER;
BEGIN
dbms_space.unused_space('SCOTT','BIGEMP','TABLE',v_total_blocks,v_total_bytes,v_unused_blocks,v_unused_bytes,v_last_used_extent_file_id,v_last_used_extent_block_id,v_last_used_block);
dbms_output.put_line('Total Blocks: '||TO_CHAR(v_total_blocks));
dbms_output.put_line('Blocks above HWM: '||TO_CHAR(v_unused_blocks));
END;
/
Total Blocks: 256
Blocks above HWM: 0
PL/SQL procedure successfully completed
Executed in 0.01 seconds
我们都知道“瞎子摸象”的故事。不同的瞎子对大象的认识不同,因为他们只认识了自己摸到的地方。而企业如果要避免重犯这样的错误,那就离不开商务智能(BI)。专家认为,BI对于企业的重要性就像聪明才智对于个人的重要性。欧美企业的经验也证明,企业避免无知和一知半解危险的有效手段就是商务智能。商务智能旨在充分利用企业在日常经营过程中收集的大量数据和资料,并将它们转化为信息和知识来免除各种无知状态和瞎猜行为。
支持BI的开源工具数量众多,但是大多数的工具都是偏重某方面的。例如,CloverETL偏重ETL,JPivot偏重多维分析展现,Mondrian是OLAP服务器。而Bee、Pentaho和SpagoBI等项目则针对商务智能问题提供了完整的解决方案。
ETL 工具
ETL开源工具主要包括CloverETL和Octupus等。
(1)CloverETL是一个Java的ETL框架,用来转换结构化的数据,支持多种字符集之间的转换(如ASCII、UTF-8和ISO-8859-1等);支持JDBC,同时支持dBase和FoxPro数据文件;支持基于XML的转换描述。
(2)Octupus是一个基于Java的ETL工具,它也支持JDBC数据源和基于XML的转换定义。Octupus提供通用的方法进行数据转换,用户可以通过实现转换接口或者使用Jscript代码来定义转换流程。
OLAP服务器
(1)Lemur主要面向HOLAP,虽然采用C++编写,但是可以被其他语言的程序所调用。Lemur支持基本的操作,如切片、切块和旋转等基本操作。
(2)Mondrian面向ROLAP包含4层:表示层、计算层、聚集层、存储层。
● 表示层:指最终呈现在用户显示器上的以及与用户之间的交互,有许多方法来展现多维数据,包括数据透视表、饼、柱、线状图。
● 计算层:分析、验证、执行MDX查询。
● 聚集层:一个聚集指内存中一组计算值(cell),这些值通过维列来限制。计算层发送单元请求,如果请求不在缓存中,或者不能通过旋转聚集导出的话,那么聚集层向存储层发送请求。聚合层是一个数据缓冲层,从数据库来的单元数据,聚合后提供给计算层。聚合层的主要作用是提高系统的性能。
● 存储层:提供聚集单元数据和维表的成员。包括三种需要存储的数据,分别是事实数据、聚集和维。
OLAP客户端
JPivot是JSP风格的标签库,用来支持OLAP表,使用户可以执行典型的OLAP操作,如切片、切块、上钻、下钻等。JPivot使用Mondrian服务器,分析结果可以导出为Excel或PDF文件格式。
数据库管理系统
主要的开源工具包括MonetDB、MySQL、MaxDB和PostgreSQL等。这些数据库都被设计用来支持BI环境。MySQL、MaxDB和PostgreSQL均支持单向的数据复制。BizGres项目的目的在于使PostgreSQL成为数据仓库和 BI的开源标准。BizGres为BI环境构建专用的完整数据库平台。
完整的BI开源解决方案
1.Pentaho 公司的Pentaho BI 平台
它是一个以流程为中心的、面向解决方案的框架,具有商务智能组件。BI 平台是以流程为中心的,其中枢控制器是一个工作流引擎。工作流引擎使用流程定义来定义在 BI 平台上执行的商务智能流程。流程可以很容易被定制,也可以添加新的流程。BI 平台包含组件和报表,用以分析这些流程的性能。BI 平台是面向解决方案的,平台的操作是定义在流程定义和指定每个活动的 action 文档里。这些流程和操作共同定义了一个商务智能问题的解决方案。这个 BI 解决方案可以很容易地集成到平台外部的商业流程。一个解决方案的定义可以包含任意数量的流程和操作。
BI平台包括一个 BI 框架、BI 组件、一个 BI 工作台和桌面收件箱。BI 工作台是一套设计和管理工具,集成到Eclipse环境。这些工具允许商业分析人员或开发人员创建报表、仪表盘、分析模型、商业规则和 BI 流程。Pentaho BI 平台构建于服务器、引擎和组件的基础之上,包括J2EE 服务器、安全与权限控制、portal、工作流、规则引擎、图表、协作、内容管理、数据集成、多维分析和系统建模等功能。这些组件的大部分是基于标准的,可使用其他产品替换之。
2.ObjectWeb
该项目近日发布了SpagoBi 1.8版本。SpagoBi 是一款基于Mondrain+JProvit的BI方案,能够通过OpenLaszlo产生实时报表,为商务智能项目提供了一个完整开源的解决方案,它涵盖了一个BI系统所有方面的功能,包括:数据挖掘、查询、分析、报告、Dashboard仪表板等等。SpagoBI使用核心系统与功能模块集成的架构,这样在确保平台稳定性与协调性的基础上又保证了系统具有很强的扩展能力。用户无需使用SpagoBI的所有模块,而是可以只利用其中的一些模块。
SpagoBI使用了许多已有的开源软件,如Spago和Spagosi等。因此,SpagoBI集成了 Spago的特征和技术特点,使用它们管理商务智能对象,如报表、OLAP分析、仪表盘、记分卡以及数据挖掘模型等。SpagoBI支持BI系统的监控管理,包括商务智能对象的控制、校验、认证和分配流程。SpagoBI采用Portalet技术将所有的BI对象发布到终端用户,因此BI对象就可以集成到为特定的企业需求而已经选择好的Portal系统中去。
3.Bee项目
该项目是一套支持商务智能项目实施的工具套件,包括ETL工具和OLAP 服务器。Bee的ETL工具使用基于Perl的BEI,通过界面描述流程,以XML形式进行存储。用户必须对转换过程进行编码。Bee的ROLAP 服务器保证多通SQL 生成和强有力的高速缓存管理(使用MySQL数据库管理系统)。ROLAP服务器通过SOAP应用接口提供丰富的客户应用。Web Portal作为主要的用户接口,通过Web浏览器进行报表设计、展示和管理控制,分析结果可以以Excel、PDF、PNG、PowerPoint、 text和XML等多种形式导出。
Bee项目的特点在于:
● 简单快捷的数据访问;
● 支持预先定义报表和实时查询;
● 通过拖拽方式轻松实现报表定制;
● 完整报表的轻松控制;
● 以表和图进行高质量的数据展示。
/*
*标 题: Sybase IQ for Data Warehouse 培训总结(二)
*作 者: xuwedo
*文章属性: 原创
*时 间: 2007-03-11
*来 源: http://blog.csdn.net/xuwedo2003/
*链 接: http://blog.csdn.net/xuwedo2003/
* Copyright (c) 2007
* All rights reserved.
* 如有转载,请注明作者及本信息
* 文件名称:
* 文件标识:
* 摘 要: Sybase IQ, Data Warehouse
* 开始时间: 2007-03-11
*
* 当前版本: 1.0
* 作 者: xuwedo2001@sohu.com
* 相关信息:
* 完成日期: 2007年3月11日
*/
正文:
(一)
怎样创建数据库
1
、DBspace是分配到IQ数据库的驱动空间的逻辑名
2
、一个新IQ数据库最多可以有2047个DBspace。
3
、Sybase的各种类型DBspace的限制:
(1)、Catalog Store最大为1TB。
(2)、IQ Store 和IQ temp Store 在裸设备上没有大小限制,在文件系统中为4TB。
4
、IQ Store 和IQ temp Store可以扩大或从数据库删除。
5
、创建数据库:
CREATE DATABASE full_path db_name[[TRANSACTION] {LOG ON [log_file_name][MIRROR mirror_file_name]}]
IQ PATH iq_file_anem
[IQ SIZE iq_file_size]
[IQ RESERVE sizeMb]
TEMPORARY PATH temp_file_name
[TEMPORARY SIZE temp_db_szie]
[TEMPORARY RESERVE sizeMB]
[MESSAGE PATH message_file_name]
例子1:
CREATE DATABASE
‘
d:\\mydb\\mydb.db
’
IQ PATH
‘
d:\\iqmain\\mydb01.iq
’
IQ SIZE 200
TEMPORARY PATH
‘
e:\\iqtem\\mydb01.iqtmp
’
TEMPORARY SIZE 200
IP PAGE SIZE 65536
6
、可以用Sybase Central创建数据库(在图形环境下)。
7
、可以用sp_iqstatus来查看当前数据库的详细信息。
8
、删除一个DBspace
(1)、一个IQ store如果存有数据的话,则不能被删除。(可以使用Utility数据库将一个DBspace的数据移动到另一个DBspace中去,再删除)。
(2)、一个IQ temporary Store仅在为空时才可以被删除。
9
、删除一个数据库的语法:
DROP DATABASE db_filename
例子:DROP DATABASE ‘d:\\mydb\\mydb.db
’
10
、怎样才能看到所有的DBspace的物理文件名?
用以下命令:Select * from sysqifile
(二)
设置服务器和数据选项
1、
数据库的启动参数均可以写在“.cfg”文件中。
2、
启动服务器的语法:
start_asiq server-switchs database_file
其中:“server-switchs”可以为:
-c
:缓存大小,默认windows为32M,Unix为48M。
-gp:Catalog store
页大小。
-gm
:服务器允许的连接数。
-n
:IQ server的名字。如果有两个“-n”选项,则第一个是IQ server的名字,第二个“-n”为IQ 数据库的名字。
-gc
:checkpoint时间间隔。默认为20,推荐为6000。
-gr
:最大的恢复时间。默认为2。
-ti
:客户端超时时间。默认为4400分钟。
-tl
:默认网络超时时间。默认120秒。
-iqmc
:主缓存大小,单位:M。
-iqtc
:临时缓存大小,单位:M。
注:主缓存:临时缓存=2:3
在默认情况下,Sybase IQ server使用2338端口。
3、
使用SET OPTION命令更变数据库的配置:
(1)、语法:
SET [TEMPORARY] OPTION
[user_id. | PUBLIC.]option_name = [option_value]
其中的“option_name”可以是:
Force_No_Scroll_Cursors=‘on’(默认为“off”)禁止缓存用户的查询结果。
Query_Temp_Space_Limit=0(默认为2000M),设置临时缓存的最大值。0表示不限制。
Public.Query_Plan=‘off’(默认为“on”)禁止将用户的查询计划打印到IQ Message File中,因为查询计划可以会使之大小迅速增加。
例子:
SET OPTION public.Force_NO_Scroll_Cursors=
’
no
’
4、
查看数据库的所有被改动过的(即非默认值)选项,用存储过程:sp_iqcheckoptions。
(三)
Sybase IQ
索引和数据类型
1
、Sybase IQ的9种索引类型:
(1)、FP(Fast Projection)此索引为默认的索引形式,在创建表时系统自动设置此索引。
特点:用于SELECT、LIKE ‘%sys%’、SUM(A+B)、JOIN操作等语句。
此类型索引也是唯一可用于BIT数据类型的索引。
FP
索引可以优化索引,将小于255的唯一值的索引压缩到1字节中,将小于65537的唯一值索引压缩到2字节中。
(2)、LF(Low Fast)基于平衡树的结构,存储唯一值小于1500个的索引,是最快的索引类型。可以用作唯一索引。
特点:用于=、 !=、IN、NOT IN查询参数。
MIN
()、MAX()、COUNT()、Group By、JOIN等。
(3)、HNG(High Nongroup)基于位的优化索引,适合于数字索引。用于范围查找和求合计算。
特点:Rangs、Between、MIN()、MAX()、SUM()、AVG()等。
(4)、HG(High Group) 基于平衡树的结构,存储唯一值大于1500个的索引,是最快的索引类型。可以用作唯一索引。
特点:同LF索引的特点。
(5)、CMP(compare)仅用于比较一个表中的两个列的比较。
特点:<、 =、 >、 <= 、>=
(6)、WD(Word),仅用于索引数据类型为WORD的列。
特点:‘CONTAINS’、LIKE操作(但没有‘%’)。
例子:
Select count(*) from Customer where address contains(
‘Main’)
(7)、DATE(date)仅用于日期类型的列。
(8)、DTTM(Datetime)仅用于日期时间类型的列。
(9)、TIME(Time)仅用于时间类型的列。
例子:
Select * from sales where DATAPART(YEAR,dales_dt) = 2007
Select * from sales where sales_dt>=‘2003-01-01 08:00:00’
(四)
创建表和索引
1
、创建表:
例子1:
CREATE TABLE employee(
Emp_id int NOT NULL
,lname varchar(30) NULL
,fname varchar(30) NULL
,salary money NULL)
例子2:
CREATE TABLE stores(
Store_id char(4) NOT NULL
,store_name varchar(20) NOT NULL
,store_address varchar(40) NOT NULL
,UNIQUE(store_id))
例子3:
CREATE TABLE products(
Product_code char(5) NOT NULL
,product varchar(40) NOT NULL
,price money NULL
PRIMARY KEY (products_code))
例子4:
CREATE TABLE sales(
Sales_code char(10) PRIMARY KEY
,sales_date DATE NOT NULL
,product_code char(5) NOT NULL
,FOREIGN KEY fk1(product_code) REFERENCES product (product_code))
例子5:
SELECT * INTO co_residential_customer from customer where 1=2
2
、用Sybase Central 可以在图形界面下创建表。
3
、删除表:DROP TABLE tablename
4
、删除表中的所有内容:TRUNCATE TABLE [owner.]table_name
5
、创建视图,语法:
CREATE VIEW [owner.]view_name[(column-name[,
…
])]
AS select-without-order-by
[WITH CHECK OPTION]
例子1:
CREATE VIEW sd_customer AS SELECT * FROM customer
WHERE sheng =
‘
SD
’
例子2:
CREATE VIEW emp_dept
AS SELECT emp_home,emp_fname,dept_name
From Employee,Department
WHERE Employee.dept_id = Department.dept_id
5
、用Sybase Central 可以在图形界面下创建视图。
6
、创建索引:
CREATE [UNIQUE] [index-type] INDEX
Index_name ON
[owner.]table_name (column_name[,
…
])
[{IN | ON} DBSpace_name]
[NOTIFY integer]
[DELIMITED BY
‘
separators-string
’
]
[LIMIT maxwordsize-integer]
例子1:
CREATE HG INDEX
Cust_customer_id ON
Cutomer(customer_id)
例子2:
CREATE CMP INDEX price_compare
ON orders(purchase_price,list_cost)
7
、删除索引:
DROP INDEX [[owner.]tablename.]index_name
例子:
DROP INDEX cust_customer_id
(五)
Sybase IQ
内存配置
1、
IQ
从单一的一个内存池中分配内存。
2、
从操作系统层面来看,IQ Server的内存是由堆组成。
3、
Buffer
:内存中的一块区域,它存储了写入数据库或从数据库中读取的未解压的数据。
4、
IQ Page Size
:IQ Server中每一个内存页的大小。
5、
IQ Page Size/16=BLOCK SIZE
6、
在启动服务器时,可以用参数-c来指定服务器缓存的初始大小。在所有平台中,这个值最大为256M。
7、
IQ Buffer
有两种类型:
(1)、主Buffer缓存:IQ Store的Buffer。(占总大小的40%)
(2)、临时Buffer:IQ temporary Buffer。(占总大小的60%)
8、
在Sybase IQ server中一个活动的用户大约占用10M内存,一个非活动用户大约占5M内存。
使用sys,以sysdba权限登录:
c:\sqlplus /nolog
SQL>conn / as sysdba
SQL> show parameter processes;
NAME TYPE VALUE
------------------------------------ ----------- ------------------------------
aq_tm_processes integer 1
db_writer_processes integer 1
job_queue_processes integer 10
log_archive_max_processes integer 1
processes integer 150
SQL> alter system set processes=300 scope = spfile;
系统已更改。
SQL> show parameter processes;
NAME TYPE VALUE
------------------------------------ ----------- ------------------------------
aq_tm_processes integer 1
db_writer_processes integer 1
job_queue_processes integer 10
log_archive_max_processes integer 1
processes integer 150
SQL> create pfile from spfile;
文件已创建。
重启数据库,OK!
因为前些日子在一个项目中用到了iText,稍有收获,便总结于此,以供他人所需。
iText是一个比较底层的pdf库,很多项目的pdf操作都是以它为基础的。像spring,以及另一个比较有名的报表工具jasperreports。简单的pdf报表输出用它比较合适,比较复杂的话使用起来就比较困难了,你要手工编写太多的代码。
比较好的是iText网站上提供相当多的示例代码,比较容易入门。我这里只说一些在它的文档里并没有直接讲到的东西。
1 关于Document
Document的几种构造函数:
public Document();
public Document(Rectangle pageSize);
public Document(Rectangle pageSize,
int marginLeft,
int marginRight,
int marginTop,
int marginBottom);
下面两种比较有用,如果是你想定义纸张大小和边缘的时候。对于Margin,iText上提到“You can also change the margins while you are adding content. Note that the changes will only be noticed on the NEXT page. If you want the margins mirrored (odd and even pages), you can do this with this method: setMarginMirroring(true). ”不过,对于table似乎并不好使。table并不会了理会你设定的margin,如果想改变它的magin还是需要去改变它的宽度(setWidth)。
2 pdf表单
使用PdfStamper是可以填充pdf表单的,这样就给出了一种很好的报表生成思路。
word制作报表样式-->acrobat转pdf-->itext填充数据-->输出pdf
这做非常简单,因为可以比较容易的控制pdf的样式。我对于Java的报表工具了解的并不多,不过在jasperreports,即使用GUI工具做一个样式比较复杂的报表也不是怎么容易。比如有那种斜线的表头,比较花哨的嵌套表格。这样的情况还是比较多见的,客户不会关系你实现起来是否困难。不过想要使用这种方式也有不足的地方。首先是acrobat把word转化成pdf的时候,格式总是保持不好,特别的是字体。然后是文件的体积这样生成的pdf会比直接用iText生成的pdf文件大很多,acrobat在pdf里加入了太多无用的信息。初次使用iText填充Adobe Designer生成的pdf表单时会有点小麻烦。在Designer中设计了一个name的text文本框的绑定名为name。照着iText中例子使用使用PdfStamper的setField方法去这样写form.setField("name", "XXXX");并不会成功。原因是Adobe Designer生成的表单名都是具有层次的,它可能是这个样子form1[0].#subform[0].name[0]。不过我们可以用一个方法把它们列出来,只要做一次就知道结构了,可以使用类似下面的代码:
PdfReader reader = new PdfReader("form.pdf");
PdfStamper stamp = new PdfStamper(reader, new FileOutputStream("registered_flat.pdf"));
AcroFields form = stamp.getAcroFields();
for (Iterator it = form.getFields().keySet().iterator(); it
.hasNext();) {
System.out.println(it.next());
}
如果直接用iText编程生成的表单就不会有这样的问题,设定的什么名字就是什么名字。
3 表单元素
pdf并不像html那样具有良好清晰的结构,而是一个有层次的文档类型。在它的maillist里,作者说明了iText虽然可以操作现存的pdf文件但是没办法去还原它的结构的。没办法像html一样,能从一个pdf文件获得一个清晰的“源文件”的。关于层次,可以从iText上得到详细的讲述,获取去看看pdf规范。表单和普通文本是不在一个层上的。没办法适用对待文本表各一样把它们简单的add进Document对象。获取一个cb直接去用绝对定位的方法可以加入表单元素,不过很多的时候因为排版并不能那么简单的去做。就是在html中布局一样可以使用表格定位。想把一个表单元素加入cell,要借助cell的setCellEvent方法。以一个checkbox为例。新建一个类CheckBoxForm,实现PdfPCellEvent接口。需要实现一个cellLayout的方法。
public void cellLayout(PdfPCell cell, Rectangle position, PdfContentByte[] canvases)
position可以好好利用,它包含当前cell的位置信息,你可以用它来确定自己checkbox的位置。
position.top()-position.bottom()就能得到高position.right()-position.left()可以得到长,如果需要这两个值得花可以如此计算。下面的代码就是定义一个宽度为a的checkbox的rectangle 。它在cell中水平居中,垂直也居中。
float bo = (position.top()-position.bottom()-a)/2;
float ao = (position.right()-position.left()-a)/2;
Rectangle rectangle = new Rectangle(position.left() + ao, position
.bottom() + bo, position.left() +ao+ a, position.bottom()+ bo + a);
然后把它加入Document
RadioCheckField tf = new RadioCheckField(writer, rectangle, fieldname,
"f");
tf.setCheckType(RadioCheckField.TYPE_SQUARE);
tf.setBorderWidth(1);
tf.setBorderColor(Color.black);
tf.setBackgroundColor(Color.white);
try {
PdfFormField field = tf.getCheckField();
writer.addAnnotation(field);
} catch (IOException e) {
e.printStackTrace();
} catch (DocumentException e) {
e.printStackTrace();
}
其它的元素与此类似。
4 PdfPTable和Table
说不上哪种更好用,有时候不能不使用PdfPTable。可惜它只有setColspan方法,没有setRowspan。嵌套的时候也有区别,PdfPTable是用addcell()加入嵌套表的,table则有一个更明了的方法insertTable()。PdfPTable想进行设置border之类的操作要先获得一个默认cell,
pdfPTableName.getDefaultCell().setBorder(Rectangle.NO_BORDER);//设置无框的表
另外在PdfPTable中,一些修饰属性会因为设置的时机不正确而没有效果。如,适用cell的构造函数加入了文本,在cell的setVerticalAlignment()fangfa去设定垂直对齐方式就不会有效。还有一个有意思的不同是table默认外边框是加粗的,而PdfPTable则一样粗细。
5 字体
iText的例子有很多足够用,给出一些pdf的字体名称和编码,如果想使用内嵌字体的话。
语言 PDF 字体名
简体中文 STSong-Light
繁体中文 MHei-Medium
MSung-Light
日语 HeiseiKakuGo-W5
HeiseiMin-W3
韩语 HYGoThic-Medium
HYSMyeongJo-Medium
字符集 编码
简体中文 UniGB-UCS2-H
UniGB-UCS2-V
繁体中文 UniCNS-UCS2-H
UniCNS-UCS2-V
日语 UniJIS-UCS2-H
UniJIS-UCS2-V
UniJIS-UCS2-HW-H
UniJIS-UCS2-HW-V
韩语 UniKS-UCS2-H
UniKS-UCS2-H
必须要有Asian的包才可以用,也可以使用TrueType字体。
ps:因为隔了一段时间了,所以有些现在一时也想不起来了,也可能会有理解的错误。另外,适用iText的时候自己最好抽象一下,可能会省不少力气。
前言:本文不是专门讲述Web Service技术的,读者在阅读本文之前需要具备一定的SOAP和Web Service知识基础,同时对Weblogic Server的使用也应该熟悉。如果要自己动手实践本文的例子,就需要安装Weblogic Server 81,尽管本文是以weblogic server 81为测试环境,但是针对weblogic server 7下也是差不多的。本文只是起个抛砖引玉的作用,如果想深入研究Web Service的开发,还需要参考、学习相关的资料,包括Weblogic Service的相关文档。
一、概述
在JBuilder中也支持开发基于weblogic的web service,不过实际上在JBuilder下开发web service也是基于ant任务来生成和构造web service的。但是,当初笔者在一个项目中使用JBuilder下自动生成构造ant脚本生成的web service时碰到了一个问题,通过JBuilder生成的web service,如果你的web service调用接口中存在一个或者多个String类型参数的时候,在生成的wsdl文件中对该接口的参数命名不会按照你的后端组件对应方法中参数的名字,而是以string、string0、string1…等形式命名的。而在那个项目中需要在Delphi环境中调用web service,问题就出现了,string在Delphi中是关键词,产生了冲突,不能进行调用。于是笔者决定采用自编写ant脚本的方式来生成和构造web service来解决前面所述Delphi调用的问题。
BEA Weblogic提供了一些Ant任务,用来帮助开发者生成、构造一个Web服务的重要部件,(例如:序列化类、客户端jar支持库、以及web-services.xml描述文件),并且把一个Weblogic Web 服务的所有部分打包成一个可部署的EAR文件。
BEA Weblogic所提供的Web服务Ant任务,支持从实现了Web Service接口的普通JAVA源文件和EJB jar生成Web Service部件,也支持从WSDL描述文件生成,同时支持基于http/https传输协议和JMS传输协议的Web Service。在这一节我们只讲述通过基于一个普通JAVA类作为后端组件来实现的Web Service,传输协议使用http(基于https的方式将在后述关于Web Service安全的部分讲述)。
二、使用Weblogic ant工具生成Web Service
我们先建立D:\wls_ws_demo的工作目录,在此目录下分别建立src、build、ddfiles、webapp、test目录。具体用途后文会涉及到。
首先我们编写一个实现了两个Web Service接口的普通JAVA类:
package com.wnetw.ws.demo;
public class HelloWorldWS{
public String sayHello(){
return "Hello World!";
}
public String welcome(String name){
return "Hello " + name + ",Welcome to WebService!";
}
}
上面两个方法就不需要解释了,很简单。把此类按封装包一致的路径放置在src目录下。
下面是本示例中ant脚本文件内的属性设置:
<property name="build.compiler" value="modern"/>
<property name="src.dir" value="src"/>
<property name="build.dir" value="build"/>
<property name="war.file" value="${build.dir}/
applications/HelloWorldWS.war" />
<property name="ear.file" value="${build.dir}/
applications/HelloWorldWS.ear" />
<property name="clients.lib" value="${build.dir}/
clientslib/HelloWorldWS_clients.jar"/>
<property name="bea.home" value="D:/bea"/>
<property name="wls.dir" value="${bea.home}/weblogic81/server"/>
<property name="wlslib.dir" value="${wls.dir}/lib"/>
<property name="wlsext.dir" value="${wls.dir}/ext"/>
<property name="namespace" value="http://www.wnetw.com/demo/"/>
<path id="classpath">
<dirset dir="${build.dir}/classes">
<include name="**"/>
</dirset>
<fileset dir="${wlslib.dir}">
<include name="**/weblogic.jar"/>
<include name="**/webservices.jar"/>
</fileset>
</path>
<property name="javac.fork" value="no"/>
<property name="javac.debug" value="no"/>
<property name="javac.optimize" value="on"/>
<property name="javac.listfiles" value="yes"/>
<property name="javac.failonerror" value="yes"/>
上面的属性应该不是很难理解,关键的是对于bea weblogic server安装目录和构造生成文件的路径说明,其次是对classpath的设置,需要用到的两个weblogic库是weblogic.jar和webservices.jar。
接着我们看看我们在本节中使用的Weblogic提供的Ant任务:
1、source2wsdd
source2wsdd Ant任务最基本的功能是根据我们编写的普通JAVA类源文件生成一个Web Service所必需的两个部件:web-services.xml和.wsdl描述文件。
下面是针对上面HelloWorldWS.java对应的Ant脚本:
<target name="genwsdd">
<source2wsdd javaSource="${src.dir}/com/wnetw/ws/
demo/HelloWorldWS.java"
ddFile="${build.dir}/wsddfiles/web-services.xml"
wsdlFile="${build.dir}/wsddfiles/HelloWorldWS.wsdl"
serviceURI="/HelloWorldWS">
<classpath refid="classpath"/>
</source2wsdd>
</target>
属性说明
javaSource:指定web service的实现后端组件,这里是普通JAVA类com.wnetw.ws.demo HelloWorldWS.java。注意属性里面是对源文件目录路径设置,而不是包路径。
ddFile:生成的web service部署描述符文件web-services.xml的存放路径。
wsdlFile:生成的.wsdl文件存放的路径和名字。
serviceURI:客户应用程序调用此Web服务的URL中的Web Service URI部分。注意:必须以“/”开头。例如:/ HelloWorldWS 。同时这个URI属性也会成为生成的web-services.xml 部署描述符文件中<web-service>元素的uri属性。
例如:本机访问本web service例子的url是http://localhost:7001/ WSDemo/ HelloWorldWS
上面的serviceURI属性就指定了上述url中的/ HelloWorldWS这一部分。
2、clientgen
clientgen可以用来生成JAVA环境下客户端应用调用一个Web Service客户端jar支持库。可以通过wsdl文件来生成,也可以通过一个包含web service实现的ear文件来生成。
下面是clientgen ant任务的脚本示例:
<target name="genclient">
<clientgen wsdl="${build.dir}/wsddfiles/HelloWorldWS.wsdl"
packageName="com.wnetw.ws.demo.client"
clientJar="${clients.lib}"
keepGenerated="false">
<classpath refid="classpath"/>
</clientgen>
</target>
这里采用从前面source2wsdd任务生成的wsdl文件来生成客户端jar支持库。通过wsdl属性指定。
3、war
这是ant提供的标准任务,这里与其他普通的war包有一点区别是,需要把web-services.xml文件打包到war中去。
说明:需要准备web.xml,后面对于安全设置的时候还需要weblogic.xml文件,这里先都打包进去,这些文件都需要提前编辑准备好:
---Web.xml---
<!DOCTYPE web-app PUBLIC "-//Sun Microsystems, Inc.//DTD Web
Application 2.3//EN" "http://java.sun.com/dtd/web-app_2_3.dtd">
<web-app>
<mime-mapping>
<extension>wsdl</extension>
<mime-type>text/xml</mime-type>
</mime-mapping>
</web-app>
---weblogic.xml---
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE weblogic-web-app PUBLIC "-//BEA Systems, Inc.//DTD Web
Application 7.0//EN" "http://www.bea.com/servers/wls700
/dtd/weblogic700-web-jar.dtd">
<weblogic-web-app>
</weblogic-web-app>
这个文件没设置,在后面关于安全的处理里面需要这里配置角色映射。
下面是war ant脚本示例:
<target name="genwar">
<war destfile="${war.file}" webxml="webapp/WEB-INF/web.xml">
<classes dir="${build.dir}/classes"/>
<webinf dir="${build.dir}/wsddfiles">
<include name="web-services.xml"/>
</webinf>
<webinf dir="webapp/WEB-INF">
<include name="weblogic.xml"/>
</webinf>
</war>
</target>
4、ear
这也是ant标准任务,需要注意的是必须提前编写application.xml文件,下面针对本文例子的application.xml文件:
<!DOCTYPE application PUBLIC '-//Sun Microsystems, Inc.//DTD J2EE
Application 1.3//EN' 'http://java.sun.com/dtd/application_1_3.dtd'>
<application>
<display-name></display-name>
<module>
<web>
<web-uri>HelloWorldWS.war</web-uri>
<context-root>WSDemo</context-root>
</web>
</module>
</application>
说明:context-root元素指定此Web Service所在Web应用的应用根。
例如:本机访问本web service例子的url是http://localhost:7001/
WSDemo/ HelloWorldWS
上面的context-root元素就指定了上述url中的WSDemo这一部分。
下面是本文例子的ear ant任务脚本:
<target name="genear">
<ear destfile="${ear.file}" appxml="ddfiles/application.xml">
<fileset dir="${build.dir}/applications" includes="*.war"/>
</ear>
</target>
核心的ant任务说明完了,下面是完整的ant脚本文件:
--- build_wls_all.xml---
<project name="wls_ws_demo" default="all" basedir=".">
<property name="build.compiler" value="modern"/>
<property name="src.dir" value="src"/>
<property name="build.dir" value="build"/>
<property name="war.file" value="${build.dir}/applications/
HelloWorldWS.war" />
<property name="ear.file" value="${build.dir}/applications/
HelloWorldWS.ear" />
<property name="clients.lib" value="${build.dir}/clientslib/
HelloWorldWS_clients.jar"/>
<property name="bea.home" value="D:/bea"/>
<property name="wls.dir" value="${bea.home}/weblogic81/server"/>
<property name="wlslib.dir" value="${wls.dir}/lib"/>
<property name="wlsext.dir" value="${wls.dir}/ext"/>
<property name="namespace" value="http://www.wnetw.com/demo/"/>
<path id="classpath">
<dirset dir="${build.dir}/classes">
<include name="**"/>
</dirset>
<fileset dir="${wlslib.dir}">
<include name="**/weblogic.jar"/>
<include name="**/webservices.jar"/>
</fileset>
</path>
<property name="javac.fork" value="no"/>
<property name="javac.debug" value="no"/>
<property name="javac.optimize" value="on"/>
<property name="javac.listfiles" value="yes"/>
<property name="javac.failonerror" value="yes"/>
<target name="all" depends="clean,mdir,compile,genwsdd,
genclient,genwar,genear"/>
<target name="clean">
<delete dir="${build.dir}"/>
</target>
<target name="mdir">
<mkdir dir="${build.dir}"/>
<mkdir dir="${build.dir}/classes"/>
<mkdir dir="${build.dir}/applications"/>
<mkdir dir="${build.dir}/clientslib"/>
<mkdir dir="${build.dir}/wsddfiles"/>
</target>
<target name="compile">
<javac encoding="GBK" srcdir="${src.dir}" destdir=
"${build.dir}/classes">
<classpath refid="classpath"/>
</javac>
</target>
<target name="genwsdd">
<source2wsdd javaSource="${src.dir}/com/wnetw/ws/
demo/HelloWorldWS.java"
ddFile="${build.dir}/wsddfiles/web-services.xml"
wsdlFile="${build.dir}/wsddfiles/HelloWorldWS.wsdl"
serviceURI="/HelloWorldWS">
<classpath refid="classpath"/>
</source2wsdd>
</target>
<target name="genclient">
<clientgen wsdl="${build.dir}/wsddfiles/HelloWorldWS.wsdl"
packageName="com.wnetw.ws.demo.client"
clientJar="${clients.lib}"
keepGenerated="false">
<classpath refid="classpath"/>
</clientgen>
</target>
<target name="genwar">
<war destfile="${war.file}" webxml="webapp/WEB-INF/web.xml">
<classes dir="${build.dir}/classes"/>
<webinf dir="${build.dir}/wsddfiles">
<include name="web-services.xml"/>
</webinf>
<webinf dir="webapp/WEB-INF">
<include name="weblogic.xml"/>
</webinf>
</war>
</target>
<target name="genear">
<ear destfile="${ear.file}" appxml="ddfiles/application.xml">
<fileset dir="${build.dir}/applications" includes="*.war"/>
</ear>
</target>
</project>
运行ant生成Web Service:
打开命令行窗口,转到工作目录D:\wls_ws_demo下,在此目录下先运行D:\bea\weblogic81\server\bin\setWLSEnv.cmd(此cmd文件具体路径与你的weblogic platform81实际安装目录相关)进行环境设置,然后运行:D:\bea\weblogic81\server\bin\ant.bat -buildfile build_wls_all.xml。
运行结束,出现“BUILD SUCCESSFUL”,那就代表OK了。转到工作目录下的build目录,你就会看到HelloWorldWS.ear这个文件。
三、测试Web Service
本节将讲述对前一节里生成的Web Service HelloWorldWS进行测试。
启动Weblogic Server,进入Weblogic Server控制台,在Deployments->Applications下部署上节生成的HelloWorldWS.ear。
1、通过Weblogic自动生成的测试主页测试
部署成功后,在浏览器中输入http://localhost:7001/WSDemo/HelloWorldWS访问Weblogic Server默认生成的上述HelloWorldWS Web Service的测试主页。
如下图:

图上列出了HelloWorldWS Web Service上的两个方法:welcome和sayHello。
点击welcome连接进入wecome方法的测试页,如下图:

在上述页面输入“老Z”,提交后就会看到如下图页面:

测试的结果跟上节中的HelloWorldWS.java实现此方法的结果是一样的。测试sayHello方法跟上面过程一样。
在测试主页中还能看到在JAVA环境下,基于clientgen ant任务生成的jar客户端stub支持库调用此HelloWorldWS Web服务的代码示例。
2、使用JAVA程序调用Web Service
下面实际编写一个java测试程序来调用上述Web Service。
--- HelloWorldWSTest.java ---
import com.wnetw.was.demo.client.*;
public class HelloWorldWSTest {
public static void main(String[] args){
try{
HelloWorldWS_Impl ws = new HelloWorldWS_Impl("http://localhost:7001
/WSDemo/HelloWorldWS?WSDL");
HelloWorldWSPort port = ws.getHelloWorldWSPort();
System.out.println(port.welcome(“老Z”));
}catch(Exception e){
e.printStackTrace();
System.out.println(e);
}
}
}
编译、运行上述测试程序的时候首先需要weblogic客户端webservice支持库webserviceclient.jar,还需要前面clientgen ant任务生成的jar客户端stub支持库HelloWorldWS_clients.jar。在下面的编译、运行测试程序的ant脚本中可以看到在classpath中引入了上述两个jar。
编译、运行测试程序的ant脚本如下:
<project name="wls_ws_demo" default="all" basedir=".">
<property name="build.compiler" value="modern"/>
<property name="bea.home" value="D:/bea"/>
<property name="wls.dir" value="${bea.home}/weblogic81/server"/>
<property name="wlslib.dir" value="${wls.dir}/lib"/>
<property name="wlsext.dir" value="${wls.dir}/ext"/>
<path id="classpath">
<fileset dir="${wlslib.dir}">
<include name="**/webserviceclient.jar"/>
</fileset>
<fileset dir="build/clientslib">
<include name="**/HelloWorldWS_clients.jar"/>
</fileset>
<pathelement path="test"/>
</path>
<property name="javac.fork" value="no"/>
<property name="javac.debug" value="no"/>
<property name="javac.optimize" value="on"/>
<property name="javac.listfiles" value="yes"/>
<property name="javac.failonerror" value="yes"/>
<target name="all" depends="compile,run"/>
<target name="compile">
<javac encoding="GBK" srcdir="test" destdir="test">
<classpath refid="classpath"/>
</javac>
</target>
<target name="run">
<java classname="HelloWorldWSTest">
<classpath refid="classpath"/>
</java>
</target>
</project>
运行上述ant脚本后,如果成功的话,应该得到类似下图结果:

3、在VB下调用Web Service
下面我在VB环境下来调用下这个Web Service,笔者使用的是Visual Basic 6.0,要在VB下调用Web Service需要先安装Microsoft SOAP toolkit。
新建一个VB工程,然后把Microsoft Soap Type Library引用进来,如下图:

新建一个form1,添加一个按钮command1,在form1源代码窗口中整个拷贝如下代码:
Dim soap As MSSOAPLib.SoapClient
Private Sub Command1_Click()
MsgBox soap.sayHello()
MsgBox soap.welcome("老Z")
If Err <> 0 Then
MsgBox "Web Service调用失败: " + Err.Description
End If
End Sub
Private Sub Form_Load()
Set soap = New MSSOAPLib.SoapClient
On Error Resume Next
Call soap.mssoapinit("http://localhost:7001/WSDemo/HelloWorldWS?WSDL")
If Err <> 0 Then
MsgBox "初始化SOAP失败: " + Err.Description
End If
End Sub
然后运行工程,点击窗口上的按钮就开始调用前面部署的Web Service(确保Weblogic Server在运行中),成功的话会得到如下图的两个MessageBox:


四、使用非内建数据类型
前面例子中的Web Service方法中使用的参数和返回值都是String,类似String,int等数据类型是属于Weblogic web service所支持的内建类型,关于Weblogic web service所支持的内建数据类型请参见:http://e-docs.bea.com/wls/docs81/webserv/implement.html#1054236
所支持的XML非内建类型请参见:
http://e-docs.bea.com/wls/docs81/webserv/assemble.html#1060805
所支持的Java非内建数据类型请参见:
http://e-docs.bea.com/wls/docs81/webserv/assemble.html#1068595
WebLogic Server能够对内建数据类型进行XML与Java表示之间的转换。但是,如果你在web service操作中使用了非内建数据类型,那么你必须提供以下信息,以确保weblogic server能够正确地进行转换。
- 用于处理数据的Java表示与XML之间的转换的序列化类;
- 包含了数据类型Java表示的Java类;
- 数据类型的XML Schema表示;
- web-services.xml部署描述文件中的数据类型映射信息。
Weblogic Server中带有servicegen和autotype Atn任务,这两个任务通过对web service的无状态EJB或者Java类后端组件的内省,从而自动生成上述部件。上述Ant任务能够处理许多非内建数据类型,所以大多数的开发者并不需要手工生成上述的部件。
有时,你可能也需要手工去创建非内建数据类型部件。因为你的数据类型可能很复杂,以致Ant任务不能正确生成前述部件。你也可能想要自己控制数据在XML和Java表示之间的转换过程,而不依赖Weblogic Server所使用的缺省转换程序。
本节将演示在Weblogic web service中如何处理非内建(自定义)的数据类型。
我们先编写一个数值Bean类UserInfo,如下:
package com.wnetw.ws.demo;
import java.util.*;
public class UserInfo{
private Integer userid;
private String username;
private String sex;
private Date birthday;
private int level;
private double salary;
private telcodes list;
public UserInfo(){}
public Integer getUserid(){
return userid;
}
public void setUserid(Integer userid){
this.userid = userid;
}
public String getUsername(){
return username;
}
public void setUsername(String username){
this.username = username;
}
public String getSex(){
return sex;
}
public void setSex(String sex){
this.sex = sex;
}
public Date getBirthday(){
return birthday;
}
public void setBirthday(Date birthday){
this.birthday = birthday;
}
public int getLevel(){
return level;
}
public void setLevel(int level){
this.level = level;
}
public double getSalary(){
return salary;
}
public void setSalary(double salary){
this.salary = salary;
}
public List getTelcodes(){
return telcodes;
}
public void setTelcodes (List telcodes){
this. telcodes = telcodes;
}
}
在前文中的后端组件类HelloWorldWS.java中增加一个方法:
public UserInfo getUserInfo(Integer userid){
UserInfo userinfo = new UserInfo();
userinfo.setUserid(userid);
userinfo.setUsername("李泽林");
userinfo.setSex("男");
userinfo.setBirthday(new Date());
userinfo.setLevel(2);
userinfo.setSalary(1000.51);
List telcodes = new ArrayList();
telcodes.add("123");
telcodes.add("321");
userinfo.setTelcodes (telcodes);
return userinfo;
}
在这个方法里,返回值是UserInfo,这是我们前面定义的数值Bean,由于这是非内建类型,而且也不属于受支持的非内建类型,所以需要我们必须自己来处理XML和UserInfo Java表示数据类型之间的转换。
在本文的例子中,我们使用Weblogic Server的autotype任务来做这件事情。我们先在build目录建一个autotype目录,然后在前文中ant完整脚本中的compile任务之后增加下述脚本:
<target name="gentypeinfo">
<autotype javatypes="com.wnetw.ws.demo.UserInfo"
targetNamespace="${namespace}"
packageName="com.wnetw.ws.demo"
destDir="${build.dir}/autotype"
keepGenerated="true">
<classpath refid="classpath"/>
</autotype>
<copy todir="${build.dir}/classes">
<fileset dir="${build.dir}/autotype">
<include name="**/*.class"/>
</fileset>
</copy>
</target> autotype Ant任务有几个常用属性,下面简要说明下:
javatypes:需要进行类型转换的非内建(自定义)数据类型java类,注意取值是全限定类名,不需要带上java或者class扩展名。如果存在多个这样的数据类型类,用逗号“,”隔开;
targetNamespace:在对数据类型映射到XML的时候使用的命名空间;
packageName:生成的序列化相关类的封装包;
destDir:生成的序列化相关类存放的目录;
keepGenerated:是否保留中间java源文件,取值为:true或者false。
关于autotype任务的详细信息请参考:
http://e-docs.bea.com/wls/docs81/webserv/anttasks.html#1080062
上述ant任务成功运行后就会生成build/autotype/目录下生成types.xml文件以及按包封装的数据转换类的源文件和class文件。
由于增加了自定义数据类型,所以我们还得更新source2wsdd任务脚本,以下是增加了自定义数据类型处理后的source2wsdd任务脚本:
<target name="genwsdd">
<source2wsdd javaSource="${src.dir}/com/wnetw/ws/demo/HelloWorldWS.java"
typesInfo="${build.dir}/autotype/types.xml"
ddFile="${build.dir}/wsddfiles/web-services.xml"
wsdlFile="${build.dir}/wsddfiles/HelloWorldWS.wsdl"
serviceURI="/HelloWorldWS">
<classpath refid="classpath"/>
</source2wsdd>
</target>
跟以前的脚本相比,增加了typesInfo属性来指定自定义数据类型的XML描述文件。
增加了对自定义数据类型支持后的完整脚本请参考本文代码下载文件。
按照第一节所述方法运行ant脚本build_wls_all.xml后,再部署build\applications\目录下的HelloWorldWS.ear。就可以按照以前说的方法进行测试了。
这一次在Weblogic Server自动生成的web service测试主页:
http://localhost:7001/WSDemo/HelloWorldWS
可以发现多了一个叫getUserInfo的方法连接,进入此方法的调用测试页面,调用此方法后就可以看到此web service方法的调用结果,以下是结果截图:

从调用测试结果页面可以看到,这一次的Return Value是:
com.wnetw.ws.demo.UserInfo@82d235
这正是我们的web service方法返回值类型类型的一个对象,图中的下面也以SOAP消息的形式描述了调用的输入和返回结果。
我们接着修改测试类HelloWorldWSTest.java,如以下:
import com.wnetw.ws.demo.client.*;
import com.wnetw.ws.demo.UserInfo;
public class HelloWorldWSTest {
public static void main(String[] args){
try{
HelloWorldWS_Impl ws = new HelloWorldWS_Impl("http://localhost:7001
/WSDemo/HelloWorldWS?WSDL");
HelloWorldWSPort port = ws.getHelloWorldWSPort();
System.out.println(port.sayHello());
System.out.println(port.welcome("老Z"));
System.out.println("开始测试自定义数据类型的返回值。。。");
UserInfo info = port.getUserInfo(100);
System.out.println(info);
System.out.println(info.getUsername());
}catch(Exception e){
e.printStackTrace();
System.out.println(e);
}
}
}
看看以下代码好像有点问题,UserInfo info = port.getUserInfo(123);我们在HelloWorldWS.java类中定义的对应方法是getUserInfo(Integer userid),参数是Integer的,但是上述测试类代码中却使用int类型,这是正确的。我们可以把clientgen任务中的keepGenerated属性设为true,把自动生成的java源代码保留下来,build成功后,我们打开build\clientslib目录下HelloWorldWS_clients.jar文件中的com.wnetw.ws.demo.client.HelloWorldWSPor.java源文件,可以看到如下代码:
package com.wnetw.ws.demo.client;
/**
* Generated interface, do not edit.
*
* This stub interface was generated by weblogic
* webservice stub gen on Sat Sep 17 16:11:21 CST 2005 */
public interface HelloWorldWSPort extends java.rmi.Remote{
/**
* welcome
*/
public java.lang.String welcome(java.lang.String name)
throws java.rmi.RemoteException ;
/**
* sayHello
*/
public java.lang.String sayHello()
throws java.rmi.RemoteException ;
/**
* getUserInfo
*/
public com.wnetw.ws.demo.UserInfo getUserInfo(int userid)
throws java.rmi.RemoteException ;
} 其中的getUserInfo(int userid)方法是使用int参数的!如果你使用Integer类型参数,反而会编译通不过!只能认为这是weblogic server ant任务对数据类型映射的具体实现了,如果你仔细看了本节前面所述对java内建数据类型的支持列表,那么也是好理解的,因为java数据类型到XML Schema数据类型映射中,java中的int和java.lang.Integer都映射到了int。所以web service服务端接收到的SOAP消息中只会是XML Schema int类型,无法区分客户端使用的会是int或者java.lang.Integer,所以在ant工具根据wsdl文件自动生成客户端支持类的时候就只能使用int了,没法区分int或者java.lang.Integer。这是个有意思的问题^-^一不小心也许会在你工作中浪费不必要的时间。当然如果有必要,你完全可以手动修改、甚至完全自己来生成客户端支持库和数据类型转换类。不过嘛,除了出于研究和特殊情况外这是没有必要的。
我们接着看看HelloWorldWS_clients.jar中还有什么东西,发现有个language_builtins这样的包,从包名也许你能猜到这是干什么的,是对java语言内建数据类型处理的包,此包下面是util包,里面有ListCodec.class类。看看我们的UserInfo类,里面使用了List类,这个包里面的类正是用来处理java.util.List数据类型的,java.util.List属于Weblogic server web service所支持的非内建数据类型,也就是说不需要通过autotype明确来标志生成相关的数据转换类和类型信息。但是,java.util.List又有别于int、java.lang.String等wls web service所支持的内建类型,对于java.util.List等受支持的非内建类型由ant任务自动生动相关数据类型处理信息,不需要手工干预。对比来看,int、java.lang.String等wls web service所支持的内建类型是直接映射,不需要数据类型转换相关类。Java.util.List最终映射成了XML Shema SOAP Array类型。其他类型请参考:http://e-docs.bea.com/wls/docs81/webserv/assemble.html#1068595
运行修改后的build_wls_test.xml脚本,成功的话应该得到如下图类似结果:

增加了自定义数据类型后,VB测试客户端的处理也得增加一些处理来测试返回值为UserInfo的web service方法,如下面代码:
Set Nodes = soap.getUserInfo(100)
MsgBox Nodes(0).nodeName + ":" + Nodes(0).Text
MsgBox Nodes(1).nodeName + ":" + Nodes(1).Text
MsgBox Nodes(2).nodeName + ":" + Nodes(2).xml
MsgBox Nodes(3).nodeName + ":" + Nodes(3).Text
MsgBox Nodes(4).nodeName + ":" + Nodes(4).Text
MsgBox Nodes(5).nodeName + ":" + Nodes(5).Text
MsgBox Nodes(6).nodeName
完整VB测试客户端代码请见本文附带下载代码。
五、配置Web Service安全
Weblogic Web Service包括三种不同概念的安全设置:
- 消息层安全:对SOAP消息中数据的数字签名或者加密;
- 传输层安全:使用SSL来保证客户应用与Web Service之间连接的安全性;
- 访问控制:指定何种用户、组、角色被允许访问该Web Service。
在这里我们主要针对访问控制概念上的安全处理。
Weblogic Web Service最终是作为一个标准的J2EE ear打包文件提供进行部署的,其中包含了一个war包,也就是说web service是以web应用的形式提供并部署的,这从前面的章节就可以看出。
所以,针对web service的访问控制安全处理与J2EE中对于Web资源的访问控制处理是一样的。具体的说就是对特定Web资源增加安全约束。具体配置就是通过在Web应用部署描述符web.xml增加相应的元素:需要进行安全约束的资源集合、授权访问的角色列表、对用户数据的安全约束、角色映射等信息。
在这里,我们需要对前面用到的web.xml文件进行修改,如下所示:
<!DOCTYPE web-app PUBLIC "-//Sun Microsystems, Inc.//DTD Web
Application 2.3//EN" "http://java.sun.com/dtd/web-app_2_3.dtd">
<web-app>
<mime-mapping>
<extension>wsdl</extension>
<mime-type>text/xml</mime-type>
</mime-mapping>
<security-constraint>
<display-name>SecurityConstraint</display-name>
<web-resource-collection>
<web-resource-name>HelloWorldWS</web-resource-name>
<url-pattern>/*</url-pattern>
<http-method>GET</http-method>
<http-method>POST</http-method>
</web-resource-collection>
<auth-constraint>
<role-name>testrole</role-name>
</auth-constraint>
</security-constraint>
<security-role>
<role-name>testrole</role-name>
</security-role>
</web-app>
然后运行ant构造脚本,部署ear。部署成功后,你会在weblogic server运行命令行窗口中看到如下类似信息:
<2005-9-24 下午22时03分45秒 CST> <Warning> <HTTP> <BEA-101304>
<Webapp: ServletC
ontext(id=11680063,name=WSDemo,context-path=/WSDemo),
the role: testrole defined
in web.xml has not been mapped to principals in
security-role-assignment in web
logic.xml. Will use the rolename itself as the principal-name.>
这是因为没有进行角色映射,所以直接使用角色名作为用户名了。这只是一个警告信息,没有关系。后面将会讲述怎么进行角色映射。
然后进入weblogic server Console,新建一个名叫testrole的用户。接着在左侧目录树中一次展开Deployments-Applications- HelloWorldWS- WSDemo,在WSDemo节点上鼠标右击,选择Define Security Policy…


在Policy Condition项选择User name of the caller,点击增加,在接着出现的窗口中填入testrole,OK之后,点击上图页面中的Apply。接下来就可以跟以前一样测试了。
浏览器中输入http://localhost:7001/WSDemo/HelloWorldWS,这个时候会弹出来一个登陆框,如下图:

现在可以看到,访问控制起作用了。输入testrole以及拟增加用户的时候指定的密码后,就能进入到和以前一样的测试主页了。
上面那种使用角色名和用户名对应的方式显示在实际应用中是不方便的,因为具体会有什么样的用户会访问此web service在构建时是不确定的。我们可以使用角色映射的方式来避免这个问题。
进行角色映射需要在weblogic.xml文件中配置,下面我将对testrole映射到一个group,weblogic.xml文件如下所示:
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE weblogic-web-app PUBLIC "-//BEA Systems, Inc.//DTD Web
Application 7.0//EN" "http://www.bea.com/servers/wls700/dtd
/weblogic700-web-jar.dtd">
<weblogic-web-app>
<security-role-assignment>
<role-name>testrole</role-name>
<principal-name>test_group</principal-name>
</security-role-assignment>
</weblogic-web-app>
在web.xml文件中指定的授权访问角色testrole映射到了test_group,也就是说test_group组中的所有用户都有权访问。这样一来用户授权和实现就解耦了。
使用ant脚本重新构建,然后部署ear。接着进入weblogic server console,删除testrole用户,新建test_group组,新建一个叫test_user的用户,并指派给test_group组。接着按照前面一样Define Security Policy,这一次在Policy Condition部分选择Caller is member of the group,然后点Add进入授权group指定页面,输入test_group,点增加-点OK,回到Define Security Policy主页面,点击Apply就好了。
然后我们在浏览中进入http://localhost:7001/WSDemo/HelloWorldWS,弹出登陆框,这一次我们可以使用test_group中的任何成员用户来登陆了,前面例子是test_user。这样在以后,需要分配新的用户授权访问此Web Service的时候就知需要在Cosole在test_group中增加一个成员就行了,不需要重新构建web service了。
加入了访问控制后,在调用web service的时候就需要提供授权凭证了,下面是需要增加的代码信息:
- JAVA客户
HelloWorldWS_Impl ws = new HelloWorldWS_Impl("http://localhost:7001/WSDemo/HelloWorldWS?WSDL");
HelloWorldWSPort port = ws.getHelloWorldWSPort("test_user","test_user");
改成
HelloWorldWS_Impl ws = new HelloWorldWS_Impl();
//因为加入了访问控制,所以对于http://localhost:7001/WSDemo/HelloWorldWS?WSDL的访问也需授权,所以我们使用缺省构建器,这样就会使用客户端支持库jar中的静态wsdl文件了。
HelloWorldWSPort port = ws.getHelloWorldWSPort(“test_user”, “test_user”);
//后面的参数是test_user的密码,根据你具体的密码更改
- VB客户端
Call soap.mssoapinit("HelloWorldWS.wsdl")
‘由于http://localhost:7001/WSDemo/HelloWorldWS?WSDL需要授权访问,所以我们把脚本生成的HelloWorldWS.wsdl文件直接拷贝到VB项目目录下,使用这个静态文件来初始化soap对象。
‘后面增加下属代码
soap.ConnectorProperty("AuthUser") = "test_user"
soap.ConnectorProperty("AuthPassword") = "test_user"
在我们运行上述两个测试程序的时候会发现调用不成功。原因接下来进行说明。
我们打开工作目录中下build\wsddfiles这个目录中的HelloWorldWS.wsdl这个文件,在最后可以看到下面的service元素内容,如下:
<service name="HelloWorldWS">
<port name="HelloWorldWSPort"
binding="tns:HelloWorldWSPort">
<soap:address location="http://pls.set.the.end.point.address/">
</soap:address>
</port>
</service>
问题就出在这里,soap:address节点的location属性有问题,因为客户端soap初始化后,会使用这个URL来调用本wsdl中描述的web service操作,显然这个地址与我们部署的实际地址是不一样的。所以我们把location属性改为我们部署的web service实际访问URL:
http://localhost:7001/WSDemo/HelloWorldWS。这就是上述两个测试程序不能正确运行的原因。
笔者也没有找到如何在生成web service部件时设置此正确属性的方法,正是因为需要修改上述wsdl文件属性,所以我们需要把build脚本分成两部分来执行,先生成相关部件,然后修改wsdl文件的上述属性,最后才进行打包和客户端支持库的生成,把build_wls_all.xml分开成了build_wls_1.xml和build_wls_2.xml两个build脚本文件。在运行完后build_wls_1.xml修改上述属性,然后运行build_wls_2.xml即可。
部署成功后,就可以测试上面两个调用例子了,注意把修改好的wsdl文件拷贝到VB项目目录中去。
如果在web.xml中<security-constraint>元素里加入下述项目
<user-data-constraint>
<transport-guarantee>CONFIDENTIAL</transport-guarantee>
</user-data-constraint> 那就会强制要求客户端使用https进行访问,其他更多信息请参考J2EE中Web应用安全方面的资料。
六、杂项设置
本节要说的实际也是安全性方面的问题,只不过和一般的安全性概念不一样,这里讲的是针对在生产部署环境下的考虑。
1、定制主页
在生产环境下,一般是不允许公开web service默认主页的。其次由于通过主页:
http://localhost:7001/WSDemo/HelloWorldWS?WSDL
访问的wsdl描述符文件是动态生成,同时加入了访问控制安全约束后,客户程序访问此文件也存在问题,所以通常在生产环境下将禁止访问web service默认主页以及动态wsdl文件,可以使用专门的静态web站点来提供必要的信息,以及通过静态web站点来发布wsdl。
要禁用默认主页以及wsdl文件,需要在web-services.xml描述符文件中进行设置。如下所示在web-service节点中加入下面两个属性:
exposeWSDL="False"
exposeHomePage="False"
修改后类似下面示例:
。。。
<web-services>
<web-service name="HelloWorldWS"
targetNamespace="http://tempuri.org/"
uri="/HelloWorldWS"
exposeWSDL="False"
exposeHomePage="False">
。。。
这个修改也需要在运行build_wls_1.xml之后进行修改,才能保证应用打包部署后使得此设置生效。
在禁止了默认主页和WSDL文件后,为了保证web service更新后不需要更新客户程序的文件,所以最好建立一个静态web站点来发布web service,也就是发布wsdl文件。在用于发布wsdl的web应用中需要在web.xml中加入以下的Mime类型映射:
<mime-mapping>
<extension>wsdl</extension>
<mime-type>text/xml</mime-type>
</mime-mapping>
2、启用https协议
除了上一节中在web.xml中加入
<user-data-constraint>
<transport-guarantee>CONFIDENTIAL</transport-guarantee>
</user-data-constraint>
来启用https通讯协议外,还可以在通过在web-service.xml文件中,在web-service(注意不是web-services)节点中加入下面属性:
protocol="https"
上述属性能保证客户端必须使用https来访问本web service。
七、结束语
本文只是针对很小的一方面来讲述基于weblogic ant任务开发web service的,只是起个抛砖引玉的作用。其次,通过本文你也能了解到web service的本质过程,无论通过什么工具来开发,本质上都是生成基础部件,然后打包。如果需要全面了解weblogic server web service开发方面的知识请参考bea文档:
http://e-docs.bea.com/wls/docs81/webservices.html
同时本文使用的环境是window 2000 server和weblogic platform8.1英文版。
本文示例项目代码可从以下地址下载:
http://www.wnetw.com/jclub_resources/technology/attachfiles/wls_ws_demo.rar