一位朋友说他们正在做EAI的项目,对于EAI,没有接触太深,以前项目中有这一块,却没怎么参与。于是问了一句,"EAI究竟是服务于什么目的"?提起这个名词,在我脑海中蹦出的关键词是诸如实时、总线、消息等,然而,这些似乎只是它的技术特征。
类似的名词包括EII和ETL,ETL是BI项目中必有的部分,也是目前每个项目戏份最重的环节。ETL有一种定义,如"抽取、转换和装载,为了分析的目的,将数据从多种数据源抽取,经过转换、清洗,装载到另一个数据库的过程,包括数据集市和数据仓库,或者是另一个操作型系统",我不知道这是谁的定义,恐怕也恐怕很难有权威的定义。在这个定义中,ETL是广义的,它是数据流动的过程,没有说它究竟是批量的或是实时的。因此,按照这个定义,EAI也就像是ETL。
EAI,全名为企业应用集成,这提升到一个比较高的层面,相比之下,"数据"显得太微观,太底层了。不错,现实的情况是企业的IT环境中,大量不同的系统同时并存,缺乏总体规划。在这种情况下,提出应用集成也是形势所逼。比如联通的经营分析和客户维系挽留系统,缺乏规划的时候,他们就有功能重叠的地方,各自的厂商为了自己的利益,不可能顾及"应该"如何,只是将自己的蛋糕划分得大一些才好。因此,诸如"客户价值模型"这样得东西就会抢来抢去。可能这种交叉应用的存在,才导致人们对应用集成的愿望,他们希望能够统一地看这些不同的应用,就像一个完整的大系统在运行一样。
但显然,如果达到这样的程度,理想的程度,并非一种技术就能搞定。所以,EAI的定义显得比ETL定义更加"虚头八脑",而在实际项目中看来,EAI的主要功能就是数据的集成,在多个应用之间共享数据,联通里面一般管这叫做"交互性"。技术实现上,它更像是CDC(变化数据捕获)+ETL。
至于EII,名称上意思为"企业信息集成",按照数据、信息到知识这个从低到高的层次,EII听起来又比ETL高级一些。然而对它,更加没有深入了解。也不明白它为什么会蹦出这个名词,是和ETL、EAI并列还是有取代他们的意思。从它的定义来看,EII是建立了一个虚拟的数据库,用户向这个虚拟库提交查询,而EII将这种查询物理地分布到各个不同的数据源中,然而返回数据,对于用户来说,他没有意识到这批数据是来自不同应用、不同数据库的。
喔,很酷,不过难度不小,因为这不是技术问题。假设理想的情况下,能够为数据源建立详尽的、一致的元数据,能够有一个引擎实现这种分布式查询,当然可以EII。然而我们不是生活在理想国,为不同的数据源建立一致的元数据几乎是不可能,这涉及到各个系统厂商的管理、系统设计以及维护能力,无法仅仅通过技术手段保证的。所以,EII,我只能暂且将它看作是未来理想。
在建立数据仓库时,
ETL通常都采用批处理的方式,一般来说是每天的夜间进行跑批。
随着数据仓库技术的逐步成熟,企业对数据仓库的时间延迟有了更高的要求,也就出现了目前常说的实时ETL(Real-Time ETL)。实时ETL是数据仓库领域里比较新的一部分内容。
在构建实时ETL架构的数据仓库时,有几种技术可供选择。
1.微批处理(microbatch ETL,MB-ETL)
微批处理的方式和我们通常的ETL处理方式很相似,但是处理的时间间隔要短,例如间隔一个小时处理一次。
2.企业应用集成(Enterprise Application Integration,EAI)
EAI也称为功能整合,通常由中间件来完成数据的交互。而通常的ETL称为数据整合。
对实时性要求非常高的系统,可以考虑使用EAI作为ETL的一个工具,可以提供快捷的数据交互。不过在数据量大时采用EAI工具效率比较差,而且实现起来相对复杂。
3.CTF(Capture, Transform and Flow)
CTF是一类比较新的数据整合工具。它采用的是直接的数据库对数据库的连接方式,可以提供秒级的数据。CTF的缺点是只能进行轻量级的数据整合。通常的处理方式是建立数据准备区,采用CTF工具在源数据库和数据准备区的数据库之间相连接。数据进入数据准备区后再经过其他处理后迁移入数据仓库。
4.EII(Enterprise Information Integration)
EII是另一类比较新的数据整合软件,可以给企业提供实时报表。EII的处理方式和CTF很相似,但是它不将数据迁移入数据准备区或者数据仓库,而是在抽取转换后直接加载到报表中。
在实际建立实时ETL架构的数据仓库时,可以在MB-ETL, EAI, CTF, EII及通常的ETL中作出选择或者进行组合。
Oracle数据库提供了几种不同的数据库启动和关闭方式,本文将详细介绍这些启动和关闭方式之间的区别以及它们各自不同的功能。
一、启动和关闭Oracle数据库
对于大多数Oracle DBA来说,启动和关闭Oracle数据库最常用的方式就是在命令行方式下的Server Manager。从Oracle 8i以后,系统将Server Manager的所有功能都集中到了SQL*Plus中,也就是说从8i以后对于数据库的启动和关闭可以直接通过SQL*Plus来完成,而不再另外需要Server Manager,但系统为了保持向下兼容,依旧保留了Server Manager工具。另外也可通过图形用户工具(GUI)的Oracle Enterprise Manager来完成系统的启动和关闭,图形用户界面Instance Manager非常简单,这里不再详述。
要启动和关闭数据库,必须要以具有Oracle 管理员权限的用户登陆,通常也就是以具有SYSDBA权限的用户登陆。一般我们常用INTERNAL用户来启动和关闭数据库(INTERNAL用户实际上是SYS用户以SYSDBA连接的同义词)。Oracle数据库的新版本将逐步淘汰INTERNAL这个内部用户,所以我们最好还是设置DBA用户具有SYSDBA权限。
二、数据库的启动(STARTUP)
启动一个数据库需要三个步骤:
1、 创建一个Oracle实例(非安装阶段)
2、 由实例安装数据库(安装阶段)
3、 打开数据库(打开阶段)
在Startup命令中,可以通过不同的选项来控制数据库的不同启动步骤。
1、STARTUP NOMOUNT
NONOUNT选项仅仅创建一个Oracle实例。读取init.ora初始化参数文件、启动后台进程、初始化系统全局区(SGA)。Init.ora文件定义了实例的配置,包括内存结构的大小和启动后台进程的数量和类型等。实例名根据Oracle_SID设置,不一定要与打开的数据库名称相同。当实例打开后,系统将显示一个SGA内存结构和大小的列表,如下所示:
SQL> startup nomount
ORACLE 例程已经启动。
Total System Global Area 35431692 bytes
Fixed Size 70924 bytes
Variable Size 18505728 bytes
Database Buffers 16777216 bytes
Redo Buffers 77824 bytes
2、STARTUP MOUNT
该命令创建实例并且安装数据库,但没有打开数据库。Oracle系统读取控制文件中关于数据文件和重作日志文件的内容,但并不打开该文件。这种打开方式常在数据库维护操作中使用,如对数据文件的更名、改变重作日志以及打开归档方式等。在这种打开方式下,除了可以看到SGA系统列表以外,系统还会给出"数据库装载完毕"的提示。
3、STARTUP
该命令完成创建实例、安装实例和打开数据库的所有三个步骤。此时数据库使数据文件和重作日志文件在线,通常还会请求一个或者是多个回滚段。这时系统除了可以看到前面Startup Mount方式下的所有提示外,还会给出一个"数据库已经打开"的提示。此时,数据库系统处于正常工作状态,可以接受用户请求。
如果采用STARTUP NOMOUNT或者是STARTUP MOUNT的数据库打开命令方式,必须采用ALTER DATABASE命令来执行打开数据库的操作。例如,如果你以STARTUP NOMOUNT方式打开数据库,也就是说实例已经创建,但是数据库没有安装和打开。这是必须运行下面的两条命令,数据库才能正确启动。
ALTER DATABASE MOUNT;
ALTER DATABASE OPEN;
而如果以STARTUP MOUNT方式启动数据库,只需要运行下面一条命令即可以打开数据库:
ALTER DATABASE OPEN.
4、其他打开方式
除了前面介绍的三种数据库打开方式选项外,还有另外其他的一些选项。
(1) STARTUP RESTRICT
这种方式下,数据库将被成功打开,但仅仅允许一些特权用户(具有DBA角色的用户)才可以使用数据库。这种方式常用来对数据库进行维护,如数据的导入/导出操作时不希望有其他用户连接到数据库操作数据。
(2) STARTUP FORCE
该命令其实是强行关闭数据库(shutdown abort)和启动数据库(startup)两条命令的一个综合。该命令仅在关闭数据库遇到问题不能关闭数据库时采用。
(3) ALTER DATABASE OPEN READ ONLY;
该命令在创建实例以及安装数据库后,以只读方式打开数据库。对于那些仅仅提供查询功能的产品数据库可以采用这种方式打开。
三、数据库的关闭(SHUTDOWN)
对于数据库的关闭,有四种不同的关闭选项,下面对其进行一一介绍。
1、SHUTDOWN NORMAL
这是数据库关闭SHUTDOWN命令的确省选项。也就是说如果你发出SHUTDOWN这样的命令,也即是SHUTDOWN NORNAL的意思。
发出该命令后,任何新的连接都将再不允许连接到数据库。在数据库关闭之前,Oracle将等待目前连接的所有用户都从数据库中退出后才开始关闭数据库。采用这种方式关闭数据库,在下一次启动时不需要进行任何的实例恢复。但需要注意一点的是,采用这种方式,也许关闭一个数据库需要几天时间,也许更长。
2、SHUTDOWN IMMEDIATE
这是我们常用的一种关闭数据库的方式,想很快地关闭数据库,但又想让数据库干净的关闭,常采用这种方式。
当前正在被Oracle处理的SQL语句立即中断,系统中任何没有提交的事务全部回滚。如果系统中存在一个很长的未提交的事务,采用这种方式关闭数据库也需要一段时间(该事务回滚时间)。系统不等待连接到数据库的所有用户退出系统,强行回滚当前所有的活动事务,然后断开所有的连接用户。
3、SHUTDOWN TRANSACTIONAL
该选项仅在Oracle 8i后才可以使用。该命令常用来计划关闭数据库,它使当前连接到系统且正在活动的事务执行完毕,运行该命令后,任何新的连接和事务都是不允许的。在所有活动的事务完成后,数据库将和SHUTDOWN IMMEDIATE同样的方式关闭数据库。
4、SHUTDOWN ABORT
这是关闭数据库的最后一招,也是在没有任何办法关闭数据库的情况下才不得不采用的方式,一般不要采用。如果下列情况出现时可以考虑采用这种方式关闭数据库。
1、 数据库处于一种非正常工作状态,不能用shutdown normal或者shutdown immediate这样的命令关闭数据库;
2、 需要立即关闭数据库;
3、 在启动数据库实例时遇到问题;
所有正在运行的SQL语句都将立即中止。所有未提交的事务将不回滚。Oracle也不等待目前连接到数据库的用户退出系统。下一次启动数据库时需要实例恢复,因此,下一次启动可能比平时需要更多的时间。
表1可以清楚地看到上述四种不同关闭数据库的区别和联系。
表1 Shutdown数据库不同方式对比表
| 关闭方式 |
A |
I |
T |
N |
| 允许新的连接 |
× |
× |
× |
× |
| 等待直到当前会话中止 |
× |
× |
× |
√ |
| 等待直到当前事务中止 |
× |
× |
√ |
√ |
| 强制CheckPoint,关闭所有文件 |
× |
√ |
√ |
√ |
其中:A-Abort I-Immediate T-Transaction N-Nornal
一 JSP2.0与JSP1.2比较
JSP 2.0是对JSP 1.2的升级,新增功能:
1. Expression Language (我平常都叫EL表达式的)
2. 新增Simple Tag和Tag File
3.web.xml新增<jsp:config>元素
- 特别说明:<jsp-config> 元素主要用来设定JSP相关配置,<jsp-config> 包括<taglib>和<jsp-property-group>子元素。
-
- (1)其中<taglib>以前的Jsp1.2中就有的,taglib主要作用是作为页面taglib标签中的uri和tld文件的一个映射关系
-
- (2)其中<jsp-property-group>是JSP2.0种新增的元素。
- <jsp-property-group> 主要包括8个子元素,它们分别是:
-
- <jsp-property-group>
-
- <description>
- 设定的说明
- </description>
-
- <display-name>设定名称</display-name>
-
- <url-pattern>设定值所影响的范围</url-pattern>
-
- <el-ignored>若为true则不支持EL语法</el-ignored>
-
- <page-encoding>ISO-8859-1</page-encoding>
-
- <scripting-invalid> 若为true则不支持<% scripting%> 语法</scripting-invalid>
-
- <include-prelude>设置JSP网页的抬头,扩展名为.jspf </include-prelude>
-
- <include-coda>设置JSP网页的结尾,扩展名为.jspf</include-coda>
-
- </jsp-property-group>
-
- 例如: 其中抬头程序:
- prelude.jspf
- <br>
- <center>
- 文本内容
- </center>
- <hr>
-
- 结尾程序:
- coda.jspf
- <br>
- <center>
- 文本内容
- </center>
- <hr>
二、Servlet个版本比较
servlet 2.3 新增功能:
2000年10月份出来
Servlet API 2.3中最重大的改变是增加了filters(过滤器)
servlet 2.4 新增功能:
2003年11月份出来
1、web.xml DTD改用了XML Schema;
Servlet 2.3之前的版本使用DTD作为部署描述文件的定义,其web.xml的格式为如下所示:
xml 代码
- <?xml version="1.0" encoding="IS0-8859-1"?>
- <!DOCTYPE web-app
- PUBLIC "-//sunMicrosystems,Inc.//DTD WebApplication 2.3f//EN"
- "http://java.sun.com/j2ee/dtds/web-app_2.3.dtd">
- <web-app>
- .......
- </web-app>
Servlet 2.4版首次使用XML Schema定义作为部署描述文件,这样Web容器更容易校验web.xml语法。同时XML Schema提供了更好的扩充性,其web.xml中的格式如下所示:
xml 代码
- <?xml version="1.0" encoding="UTF-8"?>
- <web-app version="2.4" xmlns="http://java.sun.com/xml/ns/j2ee"
- xmlns:workflow="http://www.workflow.com"
- xmins:xsi="http://www.w3.org/2001/XMLSchema-instance"
- xsi:schemaLocation="http://java.sun.com/xml/ns/j2ee
- http://java.sun.com/xml/ns/j2ee/web-app_2_4.xsd">
- .........
- </web-app>
注意: 改为Schema后主要加强了两项功能:
(1) 元素不依照顺序设定
(2) 更强大的验证机制
主要体现在:
a.检查元素的值是否为合法的值
b.检查元素的值是否为合法的文字字符或者数字字符
c.检查Servlet,Filter,EJB-ref等等元素的名称是否唯一
2.新增Filter四种设定:REQUEST、FORWARD、INCLUDE和ERROR。
3.新增Request Listener、Event和Request Attribute Listener、Enent。
4.取消SingleThreadModel接口。当Servlet实现SingleThreadModel接口时,它能确保同时间内,只能有一个thread执行此Servlet。
5.<welcome-file-list>可以为Servlet。
6.ServletRequest接口新增一些方法。
public String getLocalName()
public String getLocalAddr()
public int getLocalPort()
public int getRemotePort()
Servlet 2.5的新特征
2005年9月发布Servlet 2.5
Servlet2.5一些变化的介绍:
1) 基于最新的J2SE 5.0开发的。
2) 支持annotations 。
3) web.xml中的几处配置更加方便。
4) 去除了少数的限制。
5) 优化了一些实例
servlet的各个版本对监听器的变化有:
(1)servlet2.2和jsp1.1
新增Listener:HttpSessionBindingListener
新增Event: HttpSessionBindingEvent
(2)servlet2.3和jsp1.2
新增Listener:ServletContextListener,ServletContextAttributeListener
,HttpSessionListener,HttpSessionActivationListener,HttpSessionAttributeListener
新增Event: ServletContextEvent,ServletContextAttributeEvent,HttpSessionEvent
(3)servlet2.4和jsp2.0
新增Listener:ServletRequestListener,ServletRequestAttribureListener
新增Event: ServletRequestEvent,ServletRequestAttributeEvent
三、J2EE规范版本比较
1.J2EE的发展
1997年Servlet技术的产生以及紧接着JSP的产生,为Java对抗PHP,ASP等等服务器端语言带来了筹码。1998年,Sun发布了EJB1.0标准,至此J2EE平台的三个核心技术都已经出现。于是,1999年,Sun正式发布了J2EE的第一个版本。并与1999年底发布了J2EE1.2,在2001年发布了J2EE1.3,2003年发布了J2EE1.4。
2.J2EE1.3
J2EE1.3的架构,其中主要包含了Applet容器,Application Client容器,Web容器和EJB容器,并且包含了Web Component,EJB Component,Application Client Component,以JMS,JAAS,JAXP,JDBC,JAF,JavaMail,JTA等等技术做为基础。
1.3中引入了几个值得注意的功能:Java消息服务(定义了JMS的一组API),J2EE连接器技术(定义了扩展J2EE服务到非J2EE应用程序的标准),XML解析器的一组Java API,Servlet2.3,JSP1.2也都进行了性能扩展与优化,全新的CMP组件模型和MDB(消息Bean)。
3.J2EE1.4
J2EE1.4大体上的框架和J2EE1.3是一致的,1.4增加了对Web服务的支持,主要是Web Service,JAX-RPC,SAAJ,JAXR,还对EJB的消息传递机制进行了完善(EJB2.1),部署与管理工具的增强(JMX),以及新版本的Servlet2.4和JSP2.0使得Web应用更加容易。
四、Tomcat版本比较
Tomcat 3.x
servlet2.2和jsp1.1标准
Tomcat 4.x
Servlet 2.3 和 JSP 1.2 版本
Tomcat 5.x
Servlet 2.4或2.5 和 JSP 2.0 版本
五、JDK版本比较
已发行的版本:
版本号 名称 中文名 发布日期
JDK 1.1.4 Sparkler 宝石 1997-09-12
JDK 1.1.5 Pumpkin 南瓜 1997-12-13
JDK 1.1.6 Abigail 阿比盖尔--女子名 1998-04-24
JDK 1.1.7 Brutus 布鲁图--古罗马政治家和将军 1998-09-28
JDK 1.1.8 Chelsea 切尔西--城市名 1999-04-08
J2SE 1.2 Playground 运动场 1998-12-04
J2SE 1.2.1 none 无 1999-03-30
J2SE 1.2.2 Cricket 蟋蟀 1999-07-08
J2SE 1.3 Kestrel 美洲红隼 2000-05-08
J2SE 1.3.1 Ladybird 瓢虫 2001-05-17
J2SE 1.4.0 Merlin 灰背隼 2002-02-13
J2SE 1.4.1 grasshopper 蚱蜢 2002-09-16
J2SE 1.4.2 Mantis 螳螂 2003-06-26
将发行的版本:
J2SE 5.0 (1.5.0) Tiger 老虎 已发布了Beta版本
J2SE 5.1 (1.5.1) Dragonfly 蜻蜓 未发布
J2SE 6.0 (1.6.0) Mustang 野马 未发布
一些网友在Xp下安装了Windows 7(适用于Vista/WS2008)双系统,试用一段时间之后,新鲜过了,就准备卸载掉Windows 7。下面我把我在xp-windows 7双系统中卸载windows 7的方法写下来与大家分享!其中第1-5步网上很多,恕不详述,本文重点讲述第6步,即xp-windows 7(适用于Vista/WS2008)双系统在卸载windows 7后删除xp系统主引导分区的残留文件的详细步骤(注:本方法也即取得对系统文件完全控制的方法)
启动电脑进入Xp系统后按以下步骤操作,
1.插入刻好的 Windows 7 安装光盘(或者用虚拟光驱加载Windows 7镜像)。
2.依次单击“开始”按钮 、“所有程序”、“附件”,右键单击“命令提示符”,然后单击“用管理员帐户运行”。
3.键入 X:"boot"bootsect.exe /nt52 all /force,然后按 Enter。注:X:"代表你的光驱盘符,或者虚拟光驱盘符。
例如,如果 DVD 驱动器号是 F,则键入 F:"boot"bootsect.exe /nt52 ALL /force。
4.弹出 Windows Vista 安装光盘。
5.重新启动计算机。
计算机将使用已安装的以前版本的 Windows 启动。Windows 7系统的启动项不见了,Early Version windows也不见了,只剩下Windows xp的启动项了,基本成功。
6、删除在启动盘中的:
*Boot 文件夹
*Boot.BAK
*bootmgr
*BOOTSECT.BAK
7、格式化windows 7所在的分区,或者修改权限后删除Vista的文件夹。
下面详述第6步即取得对系统文件(夹)完全控制权限的方法:
新的Vista/WS2008/Win 7系统启动与XP等之前系统已经有了很大改变,用一个启动引导程序代替了以前单一的boot.ini文件。删除系统之后,在C盘XP系统分区留下了Boot 文件夹、Boot.BAK、bootmgr和BOOTSECT.BAK一个文件夹,三个文件。其中boot.bak和bootsect.bak很容易删除,剩下的boot文件夹和bootmgr文件删除时,却会提示出错信息。查看了文件和文件夹权限,发现已经被锁定,所以,思路就是通过修改文件夹权限使得当前用户可以正常删除文件。以下即为详细操作步骤:
(1)、首先请用管理员帐户登录XP系统。
(2)、进入我的电脑--工具--文件夹选项--查看,把“使用简单文件共享(推荐)”前面的勾去掉。这样,你才能进入属性里的“安全”选项卡,修改文件和文件夹权限。
删除boot文件夹:
(3)、右键点击boot文件夹--属性--安全--高级。此时,你所有的权限都无法编辑。
(4)、在“所有者”选项卡中,先将文件夹的所有者移交给“Administrators”组,记得选择下面的“替换子容器及对象的所有者”。
(5)、再打开“审核”选项卡,将“用在此显示的那些可以应用到子对象的项目替代所有子对象的审核项目”。点击“添加”按钮,在文本框内输入“administrators”,再点击右侧的“检查名称”,“确定”,进入审核项目权限设置,选择成功和失败都是“完全控制”,“应用”,退出boot文件夹属性。可能会有提示让你配置本地计算机策略,不用管它。
(6)、再次进入boot文件夹属性--安全,你会发现对于当前管理员帐户,你已经可以选择对该文件夹的控制权限了,当然选择允许“完全控制”。另外,你在“组或用户名称”这里还会发现类似S-1-5-80-956008885-3418522649-1831038044-1853292631-2271478464这样的用户,这应该就是原来的vista/ws2008/win7的用户。
(7)、还没完,你还需要再次进入高级--权限选项卡,对于“Administrators”用户组,将下面的两个选项都勾上,目的是将对boot文件夹的权限设置,被所有子文件和文件夹所继承(原来其子文件夹和文件并没有完全继承)。确定,退出。
好了,这回,你终于可以把boot文件夹删除了!
由于操作过程中没想到贴图,只有全部操作完成之后,boot文件夹权限相关信息:
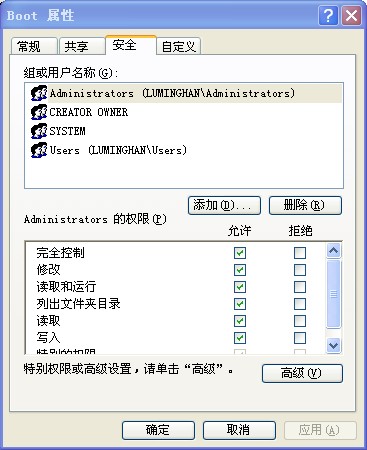
图1 Boot文件夹属性

图2 Boot文件夹权限选项卡

图3 Boot文件夹审核选项卡

图4 Boot文件夹所有者选项卡
删除bootmgr文件:
只需要做删除boot文件夹的(3)、(4)、(5)、(6)步即可,而且由于只有单个文件,简单很多,不再赘述。
总结:其实对于多分区中安装多系统来说,经常会遇到这样的情况。我在以前的本本上装XP和WS2003双系统,WS2003想要查看XP分区music中的音乐文件,也需要夺权,只是没有现在这么麻烦罢了。Anyway,简单来说,就那么几步:添加当前XP管理员用户至审核组以获得审核权限-->夺取文件所有者权限-->删除原所有者-->完全控制,并应用到子文件和文件夹-->删除!
构建一个企业级的应用系统,往往数据库成为最终的一个负载瓶颈,在我们优化完sql语句、优化完应用程序之后,数据库的调优必不可少,下面就基于sql查询的命中率的oracle调优做一个简单的说明。
1.先检验数据库的查询命中率,请执行下面的2组sql语句,并且分别记录修改之前的数值。
第一组sql语句如下:
select 100- (j.value-( a.value+b.value )) /(u.value+v.value-a.value-b.value)*100 as 命中率 from
(select value from v$sysstat where name ='physical reads direct' ) a,
(select value from v$sysstat where name ='physical reads direct (lob)' ) b,
(select value from v$sysstat where name ='physical reads') j,
(select value from v$sysstat where name ='consistent gets') u,
(select value from v$sysstat where name = 'db block gets') v ;
第二组sql语句如下:
select sum(gets) "请求存取数",sum(getmisses) "不命中数" , (1-sum(getmisses)/sum(gets) )*100 "命中率"
from v$rowcache;
2.如果第一组sql语句执行的结果是<90%,则说明需要调整oracle数据库的内存(SGA的大小),第二组sql语句作为一个参照。
一般经验:在 1G 的内存的服务器上,我们能分配给SGA的内存大约为400—500M 。若是2G的内存,大约可以分到1G的内存给 SGA,8G 的内存可以分到5G的内存给SGA。
考虑到数据库服务器的机器内存大小为2G, 可以按照以下脚本执行修改:
【注:请用具有dba权限的用户登录“login as sysdba”登录,可以用pl/sql工具】
--修改前备份一下sqfile
create pfile='d:\oracle\ora9init.ora' from spfile;
--修改共享池大小
alter system set shared_pool_size =256M scope=spfile;
--修改缓冲池大小
alter system set db_cache_size=896M scope=spfile;
--大缓冲池
alter system set large_pool_size=100m scope=spfile;
--修改链接进程数
alter system set processes=1500 scope=spfile;
--会话数
alter system set sessions=900 scope=spfile;
--事务数
alter system set transactions=900 scope=spfile;
--打开游标数
alter system set open_cursors =1000 scope=spfile;
3.用pl/sql工具修改了这些参数之后,需要重启oracle服务。当重启之后再查执行开始的2组sql语句,对比数值的差异。
前言
近来公司技术,研发都在问我关于内存参数如何设置可以优化oracle的性能,所以抽时间整理了这篇文档,以做参考.
目的
希望通过整理此文档,使大家对oracle内存结构有一个全面的了解,并在实际的工作中灵活应用,使oracle的内存性能达到最优配置,提升应用程序反应速度,并进行合理的内存使用.
内容
实例结构
oracle实例=内存结构+进程结构
oracle实例启动的过程,其实就是oracle内存参数设置的值加载到内存中,并启动相应的后台进程进行相关的服务过程。
进程结构
oracle进程=服务器进程+用户进程
几个重要的后台进程:
DBWR:数据写入进程.
LGWR:日志写入进程.
ARCH:归档进程.
CKPT:检查点进程(日志切换;上一个检查点之后,又超过了指定的时间;预定义的日志块写入磁盘;例程关闭,DBA强制产生,表空间offline)
LCKn(0-9):封锁进程.
Dnnn:调度进程.
内存结构(我们重点讲解的)
内存结构=SGA(系统全局区)+PGA(程序全局区)
SGA:是用于存储数据库信息的内存区,该信息为数据库进程所共享。它包含Oracle 服务器的数据和控制信息,它是在Oracle服务器所驻留的计算机的实际内存中得以分配,如果实际内存不够再往虚拟内存中写
我们重点就是设置SGA,理论上SGA可占OS系统物理内存的1/2——1/3
原则:SGA+PGA+OS使用内存<总物理RAM
SGA=((db_block_buffers*blocksize)+(shared_pool_size+large_pool_size+java_pool_size+log_buffers)+1MB
1、SGA系统全局区.(包括以下五个区)
A、数据缓冲区:(db_block_buffers)存储由磁盘数据文件读入的数据。
大小: db_block_buffers*db_block_size
Oracle9i设置数据缓冲区为:Db_cache_size
原则:SGA中主要设置对象,一般为可用内存40%。
B、共享池:(shared_pool_size):数据字典,sql缓冲,pl/sql语法分析.加大可提速度。
原则:SGA中主要设置对象,一般为可用内存10%
C、日志缓冲区:(log_buffer)存储数据库的修改信息.
原则:128K ---- 1M 之间,不应该太大
D 、JAVA池(Java_pool_size)主要用于JAVA语言的开发.
原则:若不使用java,原则上不能小于20M,给30M通常就够了
E、 大池(Large_pool_size) 如果不设置MTS,主要用于数据库备份恢复管理器RMAN。
原则:若不使用MTS,5---- 10M 之间,不应该太大
SGA=. db_block_buffers*db_block_size+ shared_pool_size+ log_buffer+Java_pool+size+large_pool_size
原则: 达到可用内存的55-58%就可以了.
2、PGA程序全局区
PGA:包含单个服务器进程或单个后台进程的数据和控制信息,与几个进程共享的SGA 正相反PGA 是只被一个进程使用的区域,PGA 在创建进程时分配在终止进程时回收.
A、Sort_area_size 用于排序所占内存
B、Hash_area_size 用于散列联接,位图索引
这两个参数在非MTS下都是属于PGA ,不属于SGA,是为每个session单独分配的,在我们的服务器上除了OS + SGA,一定要考虑这两部分
原则:OS 使用内存+SGA+并发执行进程数*(sort_area_size+hash_ara_size+2M) < 0.7*总内存
实例配置
一:物理内存多大
二:操作系统估计需要使用多少内存
三:数据库是使用文件系统还是裸设备
四:有多少并发连接
五:应用是OLTP 类型还是OLAP 类型
基本掌握的原则是, db_block_buffer 通常可以尽可能的大,shared_pool_size 要适度,log_buffer 通常大到几百K到1M就差不多了
A、如果512M RAM 单个CPU db_block_size 是8192 bytes
SGA=0.55*512M=280M左右
建议 shared_pool_size = 50M, db_block_buffer* db_block_size = 200M
具体: shared_pool_size =52428800 #50M
db_block_buffer=25600 #200M
log_buffer = 131072 # 128k (128K*CPU个数)
large_pool_size=7864320 #7.5M
java_pool_size = 20971520 # 20 M
sort_area_size = 524288 # 512k (65k--2M)
sort_area_retained_size = 524288 # MTS 时 sort_area_retained_size = sort_area_size
B、如果1G RAM 单个CPU db_block_size 是8192 bytes
SGA=0.55*1024M=563M左右
建议 shared_pool_size = 100M , db_block_buffer* db_block_size = 400M
具体: shared_pool_size=104857600 #100M
db_block_buffer=51200 #400M
log_buffer = 131072 # 128k (128K*CPU个数)
large_pool_size=15728640 #15M
java_pool_size = 20971520 # 20 M
sort_area_size = 524288 # 512k (65k--2M)
sort_area_retained_size = 524288 # MTS 时 sort_area_retained_size = sort_area_size
C、如果2G 单个CPU db_block_size 是8192 bytes
SGA=0.55*2048M=1126.4M左右
建议 shared_pool_size = 200M , db_block_buffer *db_block_size = 800M
具体: shared_pool_size=209715200 #200M
db_block_buffer=103192 #800M
log_buffer = 131072 # 128k (128K*CPU个数)
large_pool_size= 31457280 #30M
java_pool_size = 20971520 # 20 M
sort_area_size = 524288 # 512k (65k--2M)
sort_area_retained_size = 524288 # MTS 时 sort_area_retained_size = sort_area_size
假定64 bit ORACLE
内存4G
shared_pool_size = 200M , data buffer = 2.5G
内存8G
shared_pool_size = 300M , data buffer = 5G
内存 12G
shared_pool_size = 300M-----800M , data buffer = 8G
参数更改方式
oracle8i:
主要都是通过修改oracle启动参数文件进行相关的配置
参数文件位置:
d:\oracle\admin\DB_Name\pfile\init.ora
按以上修改以上参数值即可。
Oracle9i:
两种方式:第一种是修改oracle启动参数文件后,通过此参数文件再创建服务器参数文件
第二种是直接运行oracle修改命令进行修改。
SQL>alter system set db_cache_size=200M scope=spfile;
SQL>alter system set shared_pool_size=50M scope=spfile;
在Windows系统中的文件压缩工具winrar功能强大,虽然我们都习惯于用gui的winrar,但是
它也能在命令行方式下面使用,这尤其在企图让winrar批量自动压缩解压缩的时候有用。
它自带的帮助也非常的全面,现在从中择出来一些比较常用的总结一下,以免再找的时候比
较头晕
1,最简单的压缩命令:
winrar a asdf.txt.rar asdf.txt
a的意思是进行压缩动作,后面第一个参数是被压缩后的文件名,后缀当然是rar了,最后面
的参数就是要被压缩的文件名
2,最简单的解压缩命令:
winrar e asdf.txt.rar
e的意思是执行解压缩,解压缩的文件是后面这唯一的参数,但是这个e解压缩是把解出来的
文件释放到当前目录下面,与asdf.txt.rar文件并列了,因此,更加实用的是下面的带路径
解压缩。
3,带路径的解压缩命令:
winrar x asdf.rar
x的意思是执行带绝对路径解压动作,这会在当前文件夹下创建一个文件夹asdf,把压缩包
里的文件、文件夹不改动结构释放到文件asdf里面,就像我们在winrar的图形界面下看到的
一样。
4,指定压缩级别压缩:
winrar a -m5 asdf.tr.rar asdf.tr
要被压缩的不再是一个txt文本,而是一个文本格式的十几M的仿真数据文件,希望能够最大
程度的压缩。使用压缩参数-m5。在winrar中,执行操作是不带前导-符号的参数,比如“a
”或“x”,而修饰这种动作的参数,使用带前导符号“-”的参数,比如-m5。其中-m就是
指定压缩级别的参数,压缩级别有如下五级:
-m0 存储 添加到压缩文件时不压缩文件。
-m1 最快 使用最快方式(低压缩)
-m2 较快 使用快速压缩方式
-m3 标准 使用标准(默认)压缩方式
-m4 较好 使用较好压缩方式(较好压缩,但是慢)
-m5 最好 使用最大压缩方式(最好的压缩,但是最慢)
默认的是-m3级别,级别不同,对于大数据量的文本文件压缩后的文件大小有很大的差异
5,指定压缩后删除原文件:
winrar a -m5 -df asdf.tr.rar asdf.tr
用参数-df指定压缩为asdf.tr.rar压缩文件后,删除原文件asdf.tr,也可以是:
winrar m -m5 asdf.tr.rar asdf.tr
这个m的意思是把文件asdf.tr移动入压缩文件asdf.tr.rar中
6,创建自解压文件:
winrar s asdf.tr.rar
在gui界面中,创建自解压文件是有个选项可以直接选择的。而在命令行中,是分为两个步
骤的,第一步是用压缩命令进行压缩:
winrar a -m5 -df asdf.tr.rar asdf.tr
第二步是用s命令把这个压缩文件转化为自解压文件:
winrar s asdf.tr.rar
转化后,生成了自解压文件:asdf.tr.exe
基本上,日常使用这六条就够了
摘要: 第一章 绪论
1.1 论文的选题背景
以往的基于数理统计方法的应用大多都是通过专用程序来实现的,我们知道,大多数的统计分析技术是基于严格的数学理论和高超的应用技巧的,这使得一般的用户很难从容地掌握它。数据挖掘技术是数理统计分析应用的延伸和发展,假如人们利用数据库的方式从被动地查询变成了主动发现知识的话,那么概率论和数理统计可以为我们从数...
阅读全文