 2013年1月29日
2013年1月29日

Row Key
- 类似于MySQL中的主键,HBase天然自带的,在创建时不需要显示指定。
- HBase不支持条件查询和Order by等查询,读取记录只有三种方式:①. 通过单个Row key访问【速度很快,因为存在着索引机制】②. 给定Row key的range ③. 全表扫描
- Row key按照字典序存储,要充分考虑排序存储这个特性,将经常一起读取的行存储放到一起(位置相关性)。设计方法参见HBase表设计
- 字典序对int排序的结果是1,10,100,11,2,20,21,…,9。要保持整形的自然序,行键必须用0作左填充。
- 行的一次读写是原子操作 (不论一次读写多少列),使得多用户不能并发对同一个行进行更新操作。
Column Family
- 建表时手动指定,包含一个或者多个列
- 列族中的数据都是以二进制的形式保存在hdfs上,没有数据类型
- 增加新的列族:先disable 'users' / alter 'users','info' / enable 'users'。
- 删除列族方式:先disable 'users' / alter 'users',{NAME=>'info',METHOD=>'delete'} / enable 'users'
- 不能重命名列族:通常做法是使用API创建一个有着期望名称的新的列族,然后将数据复制过去,最后再删除旧的列族。
- 每个列族存储在HDFS上的一个单独文件中,空值不会被保存。
- 同一Column Family的Columns会群聚在一个存储文件上,并依Column key排序,因此设计时:读写相关性较高的数据,存在同一列族中。
Column
- 列名在添加数据时动态添加,无需在建表时指定。没有具体的数据类型,以二进制方式存储在HDFS上。
- 设置列值:put 'users','xiaoming','info:age','18'
- 读取列值:get 'users','info:age'
TimeStamp
- 默认值使用系统时间戳,如果应用程序要避免数据时间戳冲突,就必须自己生成具有唯一性的时间戳。
- 每个cell中,不同版本的数据按照时间倒序排列,即最新的数据排在最前面。
- 为了避免数据存在过多版本造成的的管理 (包括存贮和索引)负担,HBase提供了两种数据版本回收方式。一是保存数据的最后n个版本,二是保存最近一段时间内的版本(即设置HColumnDescriptor.setTimeToLive(); 比如最近七天)。用户可以针对每个列族单独进行设置。
Cell
- HBase中通过" tableName + RowKey + ColumnKey "确定的唯一存贮单元称为Cell。
- 每个Cell都保存着同一份数据的多个版本,每个版本通过时间戳Time Stamp来索引。
- Cell的每个值通过4个键唯一索引,tableName + RowKey + ColumnKey + Timestamp => value
存储类型
- TableName 是字符串
- RowKey 和 ColumnFamily 是二进制值(Java 类型 byte[])
- Timestamp 是一个 64 位整数(Java 类型 long)
- Value 是一个字节数组(Java类型 byte[])。
HBase是一种专门为半结构化数据(semistructured)和水平可扩展性(horizontalscalability)设计的数据库。
它把数据存储在表里。在表里,数据按照一个四维坐标系统来组织:行键、列族、列限定符和时间版本。
HBase 是无模式数据库,只需要提前定义列族。它也是无类型数据库,把所有数据不加解释地按照字节数组存储。
有5个基本命令用来访问HBase中的数据,即Get、Put、Delete、Scan 和Increment。
基于非行键值查询HBase的唯一办法是通过带过滤器的扫描Scan。
HBase 不是一个ACID 兼容数据库。但是HBase 提供一些保证,当你的应用系统访问HBase系统时,你可以用其来使你的应用系统的行为更加合理。这些保证具体如下。
1.操作是低级原子不可分的。换句话说,指定行的Put()要么整体成功要么整体失败回到操作开始前的状态,永远不会部分行写入而另一部分没有。这个要素和操作执行的列族的数量无关。
2.行间操作不是原子性的。不能保证所有操作整体成功或者失败。所有单行操作如上一点所述是原子性的。
3.checkAnd*和increment*操作是原子不可分的。
4.对于给定行的多个写操作,总是以每个写操作为整体彼此独立的。这是第一点的延伸。
5.对于给定行的任何Get()操作,返回系统当时所保存的完整行。
6.全表扫描不是对某个时间点表的快照的扫描。如果扫描已经开始,但是在行R 被扫描器对象读出之前,行R 被改变了,那么扫描器读出行R 更新后的版本。但是扫描器读出的数据是一致的,得到行R 更新后的完整行。
当你搭建使用HBase 的应用系统时,这些背景信息是你需要注意的要点。
- 数据模型从逻辑上可以分类为键值存储或有序映射的映射。物理数据模型是基于列族的列式数据库,单个记录以键值形式存储。HBase 把数据记录保存在HFile里,这是一种不能更改的文件格式。因为记录一旦写入就不能修改,新值将保存在新HFile里。在读取数据和数据合并时,数据视图需要在内存中重新衔接。
- HBase Java API 通过HTableInterface 来使用表。表连接可以直接通过构造HTable 实例来建立。使用HTable 实例系统开销大,优选方式是使用HTablePool,因为它可以重复使用连接。表通过HbaseAdmin 、HTableDescriptor 和HColumnDescriptor 类的实例来新建和操作。5 个命令通过相应的命令对象来使用:Get、Put、Delete、Scan 和Increment。命令送到HtableInterface 实例来执行。递增Increment 有另外一种用法,使用HTableInterface.incrementColumnValue()方法。执行Get、Scan 和Increment 命令的结果返回到Result和ResultScanner 对象的实例。一个KeyValue 实例代表一条返回记录。所有这些操作也可以通过HBase Shell 以命令行方式执行。
- 预期的数据访问模式对HBase 的模式设计有很大的影响。理想情况下,HBase 中的表根据预期的模式来组织。行键是HBase 中唯一的全局索引坐标,因此查询经常通过行键扫描实现。复合行键是支持这种扫描的常见做法。行键值经常希望是均衡分布的。诸如MD5 或SHA1 等散列算法通常用来实现这种均衡分布。
HBase简介
HBase – Hadoop Database,是一个高可靠性、高性能、面向列、可伸缩的分布式存储系统,利用HBase技术可在廉价PC Server上搭建起大规模结构化存储集群。
HBase是Google Bigtable的开源实现,类似Google Bigtable利用GFS作为其文件存储系统,HBase利用Hadoop HDFS作为其文件存储系统;Google运行MapReduce来处理Bigtable中的海量数据,HBase同样利用Hadoop MapReduce来处理HBase中的海量数据;Google Bigtable利用 Chubby作为协同服务,HBase利用Zookeeper作为对应。

上图描述了Hadoop EcoSystem中的各层系统,其中HBase位于结构化存储层,Hadoop HDFS为HBase提供了高可靠性的底层存储支持,Hadoop MapReduce为HBase提供了高性能的计算能力,Zookeeper为HBase提供了稳定服务和failover机制。
此外,Pig和Hive还为HBase提供了高层语言支持,使得在HBase上进行数据统计处理变的非常简单。 Sqoop则为HBase提供了方便的RDBMS数据导入功能,使得传统数据库数据向HBase中迁移变的非常方便。
HBase访问接口
1. Native Java API,最常规和高效的访问方式,适合Hadoop MapReduce Job并行批处理HBase表数据
2. HBase Shell,HBase的命令行工具,最简单的接口,适合HBase管理使用
3. Thrift Gateway,利用Thrift序列化技术,支持C++,PHP,Python等多种语言,适合其他异构系统在线访问HBase表数据
4. REST Gateway,支持REST 风格的Http API访问HBase, 解除了语言限制
5. Pig,可以使用Pig Latin流式编程语言来操作HBase中的数据,和Hive类似,本质最终也是编译成MapReduce Job来处理HBase表数据,适合做数据统计
6. Hive,当前Hive的Release版本尚没有加入对HBase的支持,但在下一个版本Hive 0.7.0中将会支持HBase,可以使用类似SQL语言来访问HBase
HBase数据模型
Table & Column Family
Ø Row Key: 行键,Table的主键,Table中的记录按照Row Key排序
Ø Timestamp: 时间戳,每次数据操作对应的时间戳,可以看作是数据的version number
Ø Column Family:列簇,Table在水平方向有一个或者多个Column Family组成,一个Column Family中可以由任意多个Column组成,即Column Family支持动态扩展,无需预先定义Column的数量以及类型,所有Column均以二进制格式存储,用户需要自行进行类型转换。
Table & Region
当Table随着记录数不断增加而变大后,会逐渐分裂成多份splits,成为regions,一个region由[startkey,endkey)表示,不同的region会被Master分配给相应的RegionServer进行管理:

-ROOT- && .META. Table
HBase中有两张特殊的Table,-ROOT-和.META.
Ø .META.:记录了用户表的Region信息,.META.可以有多个regoin
Ø -ROOT-:记录了.META.表的Region信息,-ROOT-只有一个region
Ø Zookeeper中记录了-ROOT-表的location

Client访问用户数据之前需要首先访问zookeeper,然后访问-ROOT-表,接着访问.META.表,最后才能找到用户数据的位置去访问,中间需要多次网络操作,不过client端会做cache缓存。
MapReduce on HBase
在HBase系统上运行批处理运算,最方便和实用的模型依然是MapReduce,如下图:

HBase Table和Region的关系,比较类似HDFS File和Block的关系,HBase提供了配套的TableInputFormat和TableOutputFormat API,可以方便的将HBase Table作为Hadoop MapReduce的Source和Sink,对于MapReduce Job应用开发人员来说,基本不需要关注HBase系统自身的细节。
HBase系统架构

Client
HBase Client使用HBase的RPC机制与HMaster和HRegionServer进行通信,对于管理类操作,Client与HMaster进行RPC;对于数据读写类操作,Client与HRegionServer进行RPC
Zookeeper
Zookeeper Quorum中除了存储了-ROOT-表的地址和HMaster的地址,HRegionServer也会把自己以Ephemeral方式注册到Zookeeper中,使得HMaster可以随时感知到各个HRegionServer的健康状态。此外,Zookeeper也避免了HMaster的单点问题,见下文描述
HMaster
HMaster没有单点问题,HBase中可以启动多个HMaster,通过Zookeeper的Master Election机制保证总有一个Master运行,HMaster在功能上主要负责Table和Region的管理工作:
1. 管理用户对Table的增、删、改、查操作
2. 管理HRegionServer的负载均衡,调整Region分布
3. 在Region Split后,负责新Region的分配
4. 在HRegionServer停机后,负责失效HRegionServer 上的Regions迁移
HRegionServer
HRegionServer主要负责响应用户I/O请求,向HDFS文件系统中读写数据,是HBase中最核心的模块。

HRegionServer内部管理了一系列HRegion对象,每个HRegion对应了Table中的一个Region,HRegion中由多个HStore组成。每个HStore对应了Table中的一个Column Family的存储,可以看出每个Column Family其实就是一个集中的存储单元,因此最好将具备共同IO特性的column放在一个Column Family中,这样最高效。
HStore存储是HBase存储的核心了,其中由两部分组成,一部分是MemStore,一部分是StoreFiles。MemStore是Sorted Memory Buffer,用户写入的数据首先会放入MemStore,当MemStore满了以后会Flush成一个StoreFile(底层实现是HFile),当StoreFile文件数量增长到一定阈值,会触发Compact合并操作,将多个StoreFiles合并成一个StoreFile,合并过程中会进行版本合并和数据删除,因此可以看出HBase其实只有增加数据,所有的更新和删除操作都是在后续的compact过程中进行的,这使得用户的写操作只要进入内存中就可以立即返回,保证了HBase I/O的高性能。当StoreFiles Compact后,会逐步形成越来越大的StoreFile,当单个StoreFile大小超过一定阈值后,会触发Split操作,同时把当前Region Split成2个Region,父Region会下线,新Split出的2个孩子Region会被HMaster分配到相应的HRegionServer上,使得原先1个Region的压力得以分流到2个Region上。下图描述了Compaction和Split的过程:
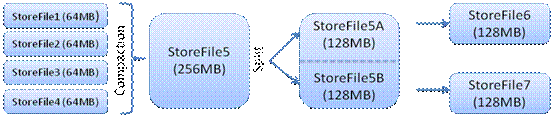
在理解了上述HStore的基本原理后,还必须了解一下HLog的功能,因为上述的HStore在系统正常工作的前提下是没有问题的,但是在分布式系统环境中,无法避免系统出错或者宕机,因此一旦HRegionServer意外退出,MemStore中的内存数据将会丢失,这就需要引入HLog了。每个HRegionServer中都有一个HLog对象,HLog是一个实现Write Ahead Log的类,在每次用户操作写入MemStore的同时,也会写一份数据到HLog文件中(HLog文件格式见后续),HLog文件定期会滚动出新的,并删除旧的文件(已持久化到StoreFile中的数据)。当HRegionServer意外终止后,HMaster会通过Zookeeper感知到,HMaster首先会处理遗留的 HLog文件,将其中不同Region的Log数据进行拆分,分别放到相应region的目录下,然后再将失效的region重新分配,领取 到这些region的HRegionServer在Load Region的过程中,会发现有历史HLog需要处理,因此会Replay HLog中的数据到MemStore中,然后flush到StoreFiles,完成数据恢复。
HBase存储格式
HBase中的所有数据文件都存储在Hadoop HDFS文件系统上,主要包括上述提出的两种文件类型:
1. HFile, HBase中KeyValue数据的存储格式,HFile是Hadoop的二进制格式文件,实际上StoreFile就是对HFile做了轻量级包装,即StoreFile底层就是HFile
2. HLog File,HBase中WAL(Write Ahead Log) 的存储格式,物理上是Hadoop的Sequence File
HFile
下图是HFile的存储格式:
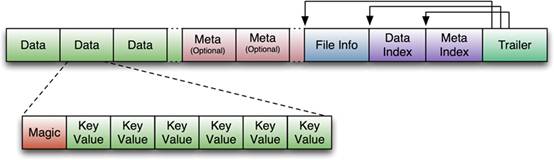
首先HFile文件是不定长的,长度固定的只有其中的两块:Trailer和FileInfo。正如图中所示的,Trailer中有指针指向其他数据块的起始点。File Info中记录了文件的一些Meta信息,例如:AVG_KEY_LEN, AVG_VALUE_LEN, LAST_KEY, COMPARATOR, MAX_SEQ_ID_KEY等。Data Index和Meta Index块记录了每个Data块和Meta块的起始点。
Data Block是HBase I/O的基本单元,为了提高效率,HRegionServer中有基于LRU的Block Cache机制。每个Data块的大小可以在创建一个Table的时候通过参数指定,大号的Block有利于顺序Scan,小号Block利于随机查询。每个Data块除了开头的Magic以外就是一个个KeyValue对拼接而成, Magic内容就是一些随机数字,目的是防止数据损坏。后面会详细介绍每个KeyValue对的内部构造。
HFile里面的每个KeyValue对就是一个简单的byte数组。但是这个byte数组里面包含了很多项,并且有固定的结构。我们来看看里面的具体结构:

开始是两个固定长度的数值,分别表示Key的长度和Value的长度。紧接着是Key,开始是固定长度的数值,表示RowKey的长度,紧接着是RowKey,然后是固定长度的数值,表示Family的长度,然后是Family,接着是Qualifier,然后是两个固定长度的数值,表示Time Stamp和Key Type(Put/Delete)。Value部分没有这么复杂的结构,就是纯粹的二进制数据了。
HLogFile
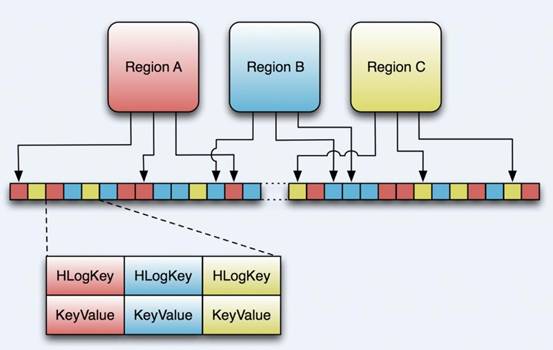
上图中示意了HLog文件的结构,其实HLog文件就是一个普通的Hadoop Sequence File,Sequence File 的Key是HLogKey对象,HLogKey中记录了写入数据的归属信息,除了table和region名字外,同时还包括 sequence number和timestamp,timestamp是“写入时间”,sequence number的起始值为0,或者是最近一次存入文件系统中sequence number。
HLog Sequece File的Value是HBase的KeyValue对象,即对应HFile中的KeyValue,可参见上文描述。
结束
本文对HBase技术在功能和设计上进行了大致的介绍,由于篇幅有限,本文没有过多深入地描述HBase的一些细节技术。目前一淘的存储系统就是基于HBase技术搭建的,后续将介绍“一淘分布式存储系统”,通过实际案例来更多的介绍HBase应用。
Kafka是由LinkedIn开发的一个分布式的消息系统,使用Scala编写,它以可水平扩展和高吞吐率而被广泛使用。目前越来越多的开源分布式处理系统如Cloudera、Apache Storm、Spark都支持与Kafka集成。InfoQ一直在紧密关注Kafka的应用以及发展,“Kafka剖析”专栏将会从架构设计、实现、应用场景、性能等方面深度解析Kafka。
背景介绍
Kafka创建背景
Kafka是一个消息系统,原本开发自LinkedIn,用作LinkedIn的活动流(Activity Stream)和运营数据处理管道(Pipeline)的基础。现在它已被多家不同类型的公司 作为多种类型的数据管道和消息系统使用。
活动流数据是几乎所有站点在对其网站使用情况做报表时都要用到的数据中最常规的部分。活动数据包括页面访问量(Page View)、被查看内容方面的信息以及搜索情况等内容。这种数据通常的处理方式是先把各种活动以日志的形式写入某种文件,然后周期性地对这些文件进行统计分析。运营数据指的是服务器的性能数据(CPU、IO使用率、请求时间、服务日志等等数据)。运营数据的统计方法种类繁多。
近年来,活动和运营数据处理已经成为了网站软件产品特性中一个至关重要的组成部分,这就需要一套稍微更加复杂的基础设施对其提供支持。
Kafka简介
Kafka是一种分布式的,基于发布/订阅的消息系统。主要设计目标如下:
- 以时间复杂度为O(1)的方式提供消息持久化能力,即使对TB级以上数据也能保证常数时间复杂度的访问性能。
- 高吞吐率。即使在非常廉价的商用机器上也能做到单机支持每秒100K条以上消息的传输。
- 支持Kafka Server间的消息分区,及分布式消费,同时保证每个Partition内的消息顺序传输。
- 同时支持离线数据处理和实时数据处理。
- Scale out:支持在线水平扩展。
为何使用消息系统
- 解耦
在项目启动之初来预测将来项目会碰到什么需求,是极其困难的。消息系统在处理过程中间插入了一个隐含的、基于数据的接口层,两边的处理过程都要实现这一接口。这允许你独立的扩展或修改两边的处理过程,只要确保它们遵守同样的接口约束。
- 冗余
有些情况下,处理数据的过程会失败。除非数据被持久化,否则将造成丢失。消息队列把数据进行持久化直到它们已经被完全处理,通过这一方式规避了数据丢失风险。许多消息队列所采用的"插入-获取-删除"范式中,在把一个消息从队列中删除之前,需要你的处理系统明确的指出该消息已经被处理完毕,从而确保你的数据被安全的保存直到你使用完毕。
- 扩展性
因为消息队列解耦了你的处理过程,所以增大消息入队和处理的频率是很容易的,只要另外增加处理过程即可。不需要改变代码、不需要调节参数。扩展就像调大电力按钮一样简单。
- 灵活性 & 峰值处理能力
在访问量剧增的情况下,应用仍然需要继续发挥作用,但是这样的突发流量并不常见;如果为以能处理这类峰值访问为标准来投入资源随时待命无疑是巨大的浪费。使用消息队列能够使关键组件顶住突发的访问压力,而不会因为突发的超负荷的请求而完全崩溃。
- 可恢复性
系统的一部分组件失效时,不会影响到整个系统。消息队列降低了进程间的耦合度,所以即使一个处理消息的进程挂掉,加入队列中的消息仍然可以在系统恢复后被处理。
- 顺序保证
在大多使用场景下,数据处理的顺序都很重要。大部分消息队列本来就是排序的,并且能保证数据会按照特定的顺序来处理。Kafka保证一个Partition内的消息的有序性。
- 缓冲
在任何重要的系统中,都会有需要不同的处理时间的元素。例如,加载一张图片比应用过滤器花费更少的时间。消息队列通过一个缓冲层来帮助任务最高效率的执行———写入队列的处理会尽可能的快速。该缓冲有助于控制和优化数据流经过系统的速度。
- 异步通信
很多时候,用户不想也不需要立即处理消息。消息队列提供了异步处理机制,允许用户把一个消息放入队列,但并不立即处理它。想向队列中放入多少消息就放多少,然后在需要的时候再去处理它们。
常用Message Queue对比
RabbitMQ
RabbitMQ是使用Erlang编写的一个开源的消息队列,本身支持很多的协议:AMQP,XMPP, SMTP, STOMP,也正因如此,它非常重量级,更适合于企业级的开发。同时实现了Broker构架,这意味着消息在发送给客户端时先在中心队列排队。对路由,负载均衡或者数据持久化都有很好的支持。
Redis
Redis是一个基于Key-Value对的NoSQL数据库,开发维护很活跃。虽然它是一个Key-Value数据库存储系统,但它本身支持MQ功能,所以完全可以当做一个轻量级的队列服务来使用。对于RabbitMQ和Redis的入队和出队操作,各执行100万次,每10万次记录一次执行时间。测试数据分为128Bytes、512Bytes、1K和10K四个不同大小的数据。实验表明:入队时,当数据比较小时Redis的性能要高于RabbitMQ,而如果数据大小超过了10K,Redis则慢的无法忍受;出队时,无论数据大小,Redis都表现出非常好的性能,而RabbitMQ的出队性能则远低于Redis。
ZeroMQ
ZeroMQ号称最快的消息队列系统,尤其针对大吞吐量的需求场景。ZeroMQ能够实现RabbitMQ不擅长的高级/复杂的队列,但是开发人员需要自己组合多种技术框架,技术上的复杂度是对这MQ能够应用成功的挑战。ZeroMQ具有一个独特的非中间件的模式,你不需要安装和运行一个消息服务器或中间件,因为你的应用程序将扮演这个服务器角色。你只需要简单的引用ZeroMQ程序库,可以使用NuGet安装,然后你就可以愉快的在应用程序之间发送消息了。但是ZeroMQ仅提供非持久性的队列,也就是说如果宕机,数据将会丢失。其中,Twitter的Storm 0.9.0以前的版本中默认使用ZeroMQ作为数据流的传输(Storm从0.9版本开始同时支持ZeroMQ和Netty作为传输模块)。
ActiveMQ
ActiveMQ是Apache下的一个子项目。 类似于ZeroMQ,它能够以代理人和点对点的技术实现队列。同时类似于RabbitMQ,它少量代码就可以高效地实现高级应用场景。
Kafka/Jafka
Kafka是Apache下的一个子项目,是一个高性能跨语言分布式发布/订阅消息队列系统,而Jafka是在Kafka之上孵化而来的,即Kafka的一个升级版。具有以下特性:快速持久化,可以在O(1)的系统开销下进行消息持久化;高吞吐,在一台普通的服务器上既可以达到10W/s的吞吐速率;完全的分布式系统,Broker、Producer、Consumer都原生自动支持分布式,自动实现负载均衡;支持Hadoop数据并行加载,对于像Hadoop的一样的日志数据和离线分析系统,但又要求实时处理的限制,这是一个可行的解决方案。Kafka通过Hadoop的并行加载机制统一了在线和离线的消息处理。Apache Kafka相对于ActiveMQ是一个非常轻量级的消息系统,除了性能非常好之外,还是一个工作良好的分布式系统。
Kafka架构
Terminology
- Broker
Kafka集群包含一个或多个服务器,这种服务器被称为broker
- Topic
每条发布到Kafka集群的消息都有一个类别,这个类别被称为Topic。(物理上不同Topic的消息分开存储,逻辑上一个Topic的消息虽然保存于一个或多个broker上但用户只需指定消息的Topic即可生产或消费数据而不必关心数据存于何处)
- Partition
Parition是物理上的概念,每个Topic包含一个或多个Partition.
- Producer
负责发布消息到Kafka broker
- Consumer
消息消费者,向Kafka broker读取消息的客户端。
- Consumer Group
每个Consumer属于一个特定的Consumer Group(可为每个Consumer指定group name,若不指定group name则属于默认的group)。
Kafka拓扑结构

如上图所示,一个典型的Kafka集群中包含若干Producer(可以是web前端产生的Page View,或者是服务器日志,系统CPU、Memory等),若干broker(Kafka支持水平扩展,一般broker数量越多,集群吞吐率越高),若干Consumer Group,以及一个Zookeeper集群。Kafka通过Zookeeper管理集群配置,选举leader,以及在Consumer Group发生变化时进行rebalance。Producer使用push模式将消息发布到broker,Consumer使用pull模式从broker订阅并消费消息。
Topic & Partition
Topic在逻辑上可以被认为是一个queue,每条消费都必须指定它的Topic,可以简单理解为必须指明把这条消息放进哪个queue里。为了使得Kafka的吞吐率可以线性提高,物理上把Topic分成一个或多个Partition,每个Partition在物理上对应一个文件夹,该文件夹下存储这个Partition的所有消息和索引文件。若创建topic1和topic2两个topic,且分别有13个和19个分区,则整个集群上会相应会生成共32个文件夹(本文所用集群共8个节点,此处topic1和topic2 replication-factor均为1),如下图所示。

每个日志文件都是一个log entrie序列,每个log entrie包含一个4字节整型数值(值为N+5),1个字节的"magic value",4个字节的CRC校验码,其后跟N个字节的消息体。每条消息都有一个当前Partition下唯一的64字节的offset,它指明了这条消息的起始位置。磁盘上存储的消息格式如下:
message length : 4 bytes (value: 1+4+n) "magic" value : 1 byte crc : 4 bytes payload : n bytes
这个log entries并非由一个文件构成,而是分成多个segment,每个segment以该segment第一条消息的offset命名并以“.kafka”为后缀。另外会有一个索引文件,它标明了每个segment下包含的log entry的offset范围,如下图所示。

因为每条消息都被append到该Partition中,属于顺序写磁盘,因此效率非常高(经验证,顺序写磁盘效率比随机写内存还要高,这是Kafka高吞吐率的一个很重要的保证)。

对于传统的message queue而言,一般会删除已经被消费的消息,而Kafka集群会保留所有的消息,无论其被消费与否。当然,因为磁盘限制,不可能永久保留所有数据(实际上也没必要),因此Kafka提供两种策略删除旧数据。一是基于时间,二是基于Partition文件大小。例如可以通过配置$KAFKA_HOME/config/server.properties,让Kafka删除一周前的数据,也可在Partition文件超过1GB时删除旧数据,配置如下所示。
# The minimum age of a log file to be eligible for deletion log.retention.hours=168 # The maximum size of a log segment file. When this size is reached a new log segment will be created. log.segment.bytes=1073741824 # The interval at which log segments are checked to see if they can be deleted according to the retention policies log.retention.check.interval.ms=300000 # If log.cleaner.enable=true is set the cleaner will be enabled and individual logs can then be marked for log compaction. log.cleaner.enable=false
这里要注意,因为Kafka读取特定消息的时间复杂度为O(1),即与文件大小无关,所以这里删除过期文件与提高Kafka性能无关。选择怎样的删除策略只与磁盘以及具体的需求有关。另外,Kafka会为每一个Consumer Group保留一些metadata信息——当前消费的消息的position,也即offset。这个offset由Consumer控制。正常情况下Consumer会在消费完一条消息后递增该offset。当然,Consumer也可将offset设成一个较小的值,重新消费一些消息。因为offet由Consumer控制,所以Kafka broker是无状态的,它不需要标记哪些消息被哪些消费过,也不需要通过broker去保证同一个Consumer Group只有一个Consumer能消费某一条消息,因此也就不需要锁机制,这也为Kafka的高吞吐率提供了有力保障。
Producer消息路由
Producer发送消息到broker时,会根据Paritition机制选择将其存储到哪一个Partition。如果Partition机制设置合理,所有消息可以均匀分布到不同的Partition里,这样就实现了负载均衡。如果一个Topic对应一个文件,那这个文件所在的机器I/O将会成为这个Topic的性能瓶颈,而有了Partition后,不同的消息可以并行写入不同broker的不同Partition里,极大的提高了吞吐率。可以在$KAFKA_HOME/config/server.properties中通过配置项num.partitions来指定新建Topic的默认Partition数量,也可在创建Topic时通过参数指定,同时也可以在Topic创建之后通过Kafka提供的工具修改。
在发送一条消息时,可以指定这条消息的key,Producer根据这个key和Partition机制来判断应该将这条消息发送到哪个Parition。Paritition机制可以通过指定Producer的paritition. class这一参数来指定,该class必须实现kafka.producer.Partitioner接口。本例中如果key可以被解析为整数则将对应的整数与Partition总数取余,该消息会被发送到该数对应的Partition。(每个Parition都会有个序号,序号从0开始)
import kafka.producer.Partitioner; import kafka.utils.VerifiableProperties; public class JasonPartitioner<T> implements Partitioner { public JasonPartitioner(VerifiableProperties verifiableProperties) {} @Override public int partition(Object key, int numPartitions) { try { int partitionNum = Integer.parseInt((String) key); return Math.abs(Integer.parseInt((String) key) % numPartitions); } catch (Exception e) { return Math.abs(key.hashCode() % numPartitions); } } } 如果将上例中的类作为partition.class,并通过如下代码发送20条消息(key分别为0,1,2,3)至topic3(包含4个Partition)。
public void sendMessage() throws InterruptedException{ for(int i = 1; i <= 5; i++){ List messageList = new ArrayList<KeyedMessage<String, String>>(); for(int j = 0; j < 4; j++){ messageList.add(new KeyedMessage<String, String>("topic2", j+"", "The " + i + " message for key " + j)); } producer.send(messageList); } producer.close(); } 则key相同的消息会被发送并存储到同一个partition里,而且key的序号正好和Partition序号相同。(Partition序号从0开始,本例中的key也从0开始)。下图所示是通过Java程序调用Consumer后打印出的消息列表。

Consumer Group
(本节所有描述都是基于Consumer hight level API而非low level API)。
使用Consumer high level API时,同一Topic的一条消息只能被同一个Consumer Group内的一个Consumer消费,但多个Consumer Group可同时消费这一消息。

这是Kafka用来实现一个Topic消息的广播(发给所有的Consumer)和单播(发给某一个Consumer)的手段。一个Topic可以对应多个Consumer Group。如果需要实现广播,只要每个Consumer有一个独立的Group就可以了。要实现单播只要所有的Consumer在同一个Group里。用Consumer Group还可以将Consumer进行自由的分组而不需要多次发送消息到不同的Topic。
实际上,Kafka的设计理念之一就是同时提供离线处理和实时处理。根据这一特性,可以使用Storm这种实时流处理系统对消息进行实时在线处理,同时使用Hadoop这种批处理系统进行离线处理,还可以同时将数据实时备份到另一个数据中心,只需要保证这三个操作所使用的Consumer属于不同的Consumer Group即可。下图是Kafka在Linkedin的一种简化部署示意图。

下面这个例子更清晰地展示了Kafka Consumer Group的特性。首先创建一个Topic (名为topic1,包含3个Partition),然后创建一个属于group1的Consumer实例,并创建三个属于group2的Consumer实例,最后通过Producer向topic1发送key分别为1,2,3的消息。结果发现属于group1的Consumer收到了所有的这三条消息,同时group2中的3个Consumer分别收到了key为1,2,3的消息。如下图所示。

Push vs. Pull
作为一个消息系统,Kafka遵循了传统的方式,选择由Producer向broker push消息并由Consumer从broker pull消息。一些logging-centric system,比如Facebook的Scribe和Cloudera的Flume,采用push模式。事实上,push模式和pull模式各有优劣。
push模式很难适应消费速率不同的消费者,因为消息发送速率是由broker决定的。push模式的目标是尽可能以最快速度传递消息,但是这样很容易造成Consumer来不及处理消息,典型的表现就是拒绝服务以及网络拥塞。而pull模式则可以根据Consumer的消费能力以适当的速率消费消息。
对于Kafka而言,pull模式更合适。pull模式可简化broker的设计,Consumer可自主控制消费消息的速率,同时Consumer可以自己控制消费方式——即可批量消费也可逐条消费,同时还能选择不同的提交方式从而实现不同的传输语义。
Kafka delivery guarantee
有这么几种可能的delivery guarantee:
- At most once 消息可能会丢,但绝不会重复传输
- At least one 消息绝不会丢,但可能会重复传输
Exactly once 每条消息肯定会被传输一次且仅传输一次,很多时候这是用户所想要的。
当Producer向broker发送消息时,一旦这条消息被commit,因数replication的存在,它就不会丢。但是如果Producer发送数据给broker后,遇到网络问题而造成通信中断,那Producer就无法判断该条消息是否已经commit。虽然Kafka无法确定网络故障期间发生了什么,但是Producer可以生成一种类似于主键的东西,发生故障时幂等性的重试多次,这样就做到了Exactly once。截止到目前(Kafka 0.8.2版本,2015-03-04),这一Feature还并未实现,有希望在Kafka未来的版本中实现。(所以目前默认情况下一条消息从Producer到broker是确保了At least once,可通过设置Producer异步发送实现At most once)。
接下来讨论的是消息从broker到Consumer的delivery guarantee语义。(仅针对Kafka consumer high level API)。Consumer在从broker读取消息后,可以选择commit,该操作会在Zookeeper中保存该Consumer在该Partition中读取的消息的offset。该Consumer下一次再读该Partition时会从下一条开始读取。如未commit,下一次读取的开始位置会跟上一次commit之后的开始位置相同。当然可以将Consumer设置为autocommit,即Consumer一旦读到数据立即自动commit。如果只讨论这一读取消息的过程,那Kafka是确保了Exactly once。但实际使用中应用程序并非在Consumer读取完数据就结束了,而是要进行进一步处理,而数据处理与commit的顺序在很大程度上决定了消息从broker和consumer的delivery guarantee semantic。
读完消息先commit再处理消息。这种模式下,如果Consumer在commit后还没来得及处理消息就crash了,下次重新开始工作后就无法读到刚刚已提交而未处理的消息,这就对应于At most once
读完消息先处理再commit。这种模式下,如果在处理完消息之后commit之前Consumer crash了,下次重新开始工作时还会处理刚刚未commit的消息,实际上该消息已经被处理过了。这就对应于At least once。在很多使用场景下,消息都有一个主键,所以消息的处理往往具有幂等性,即多次处理这一条消息跟只处理一次是等效的,那就可以认为是Exactly once。(笔者认为这种说法比较牵强,毕竟它不是Kafka本身提供的机制,主键本身也并不能完全保证操作的幂等性。而且实际上我们说delivery guarantee 语义是讨论被处理多少次,而非处理结果怎样,因为处理方式多种多样,我们不应该把处理过程的特性——如是否幂等性,当成Kafka本身的Feature)
如果一定要做到Exactly once,就需要协调offset和实际操作的输出。精典的做法是引入两阶段提交。如果能让offset和操作输入存在同一个地方,会更简洁和通用。这种方式可能更好,因为许多输出系统可能不支持两阶段提交。比如,Consumer拿到数据后可能把数据放到HDFS,如果把最新的offset和数据本身一起写到HDFS,那就可以保证数据的输出和offset的更新要么都完成,要么都不完成,间接实现Exactly once。(目前就high level API而言,offset是存于Zookeeper中的,无法存于HDFS,而low level API的offset是由自己去维护的,可以将之存于HDFS中)
总之,Kafka默认保证At least once,并且允许通过设置Producer异步提交来实现At most once。而Exactly once要求与外部存储系统协作,幸运的是Kafka提供的offset可以非常直接非常容易得使用这种方式。
鉴于自己的毕设是与视频检索有关,而在图像和视频检索领域中,D.Lowe和他的“亲儿子”——SIFT( Scale Invariant Feature Transform )算法是不能错过的经典论题,我在之前闲逛过的一个技术博客站点中找到了介绍这一经典算法基本概念的文章,原文地址:http://www.dakaren.com/index.php/archives/639.htm
1、SIFT算法基本概念
Sift是David Lowe于1999年提出的局部特征描述子,可以处理两幅图像之间发生平移、旋转、仿射变换情况下的匹配问题,具有良好的不变性和很强的匹配能力。SIFT算法是一种提取局部特征的算法,也是一种模式识别技术,其基本思想是在尺度空间寻找极值点,提取位置,尺度,旋转不变量,它主要包括两个阶段,一个是Sift特征的生成,即从多幅图像中提取对尺度缩放、旋转、亮度变化无关的特征向量;第二阶段是Sift特征向量的匹配。Sift及其扩展算法已被证实在同类描述子中具有最强的健壮性,目前是国内外研究的热点。
2、SIFT算法的主要特点:
a) SIFT特征是图像的局部特征,其对旋转、尺度缩放、亮度变化保持不变 性,对视角变化、仿射变换、噪声也保持一定程度的稳定性,而对物体运动、遮 挡、噪声等因素也保持较好的可匹配性,从而可以实现差异较大的两幅图像之间 特征的匹配。
b) 独特性(Distinctiveness)好,信息量丰富,适用于在海量特征数据库中进行 快速、准确的匹配,比原有的harris点匹配方式具有更高的匹配准确度。
c) 多量性,即使少数的几个物体也可以产生大量SIFT特征向量。
d) 高速性,经优化的SIFT匹配算法甚至可以达到实时的要求。
e) 可扩展性,可以很方便的与其他形式的特征向量进行联合。
SIFT算法基于图像特征尺度选择的思想,建立图像的多尺度空间,在不同尺度下检测到同一个特征点,确定特征点位置的同时确定其所在尺度,以达到尺度抗缩放的目的。剔除一些对比度较低的点以及边缘响应点,并提取旋转不变特征描述符以达到抗仿射变换的目的。
3、SIFT算法步骤:
1) 构建尺度空间,检测极值点,获得尺度不变性;
2) 特征点过滤并进行精确定位;
3) 为每个关键点指定方向参数
4) 生成关键点的描述子
5) 当两幅图像的Sift特征向量生成以后,下一步就可以采用关键点特征向 量的欧式距离来作为两幅图像中关键点的相似性判定度量。取一幅图中的某个关键点,通过遍历找到另一幅图中的距离最近的两个关键点。在这两个关键点中,如果次近距离除以最近距离小于某个阙值,则判定为一对匹配点。降低这个比例阈值,SIFT匹配点数目会减少,但更加稳定。
4、SIFT算法发展历程:
Sift算子最早是由David.G.Lowe于1999年提出的,当时主要用于对象识别。2004年David.G.Lowe对该算子做了全面的总结及更深入的发展和完善,正式提出了一种基于尺度空间的、对图像缩放、旋转甚至仿射变换保持不变性的图像局部特征描述算子——Sift( Scale Invariant Feature Transform )算子,即尺度不变特征变换。Rob Hess 基于GSL和Opencv编写了相应的C语言程序,后来Y.Ke将其描述子部分用PCA代替直方图的方式,对其进行改进。在Mikolajczyk对包括Sift算子在内的十种局部描述子所做的不变性对比实验中,Sift及其扩展算法已被证实在同类描述子中具有最强的健壮性。
主要文献:
1)David G. Lowe, “Object recognition from local scale-invariant features,” International Conference on Computer Vision, Corfu, Greece 2)David G. Lowe, “Distinctive image features from scale-invariant keypoints,” International Journal of Computer Vision,
3)Y. Ke and R. Sukthankar. PCA-SIFT: A More Distinctive Representation for Local Image Descriptors.Computer Vision and Pattern Recognition, 2004
5、关于局部不变特征
1)局部不变特征的概念
局部不变特征就是由局部邻域所构成的一个图像模式。局部不变特征可以是点集,也可以是边缘集合,或者一些小的图像块集合,甚至是上述集合的复合体。局部不变特征认为图像中总是存在一些特殊的区域,这些区域中的特征比其它图像区域的特征更加稳定,信息含量更高,能够表征图像的内容。局部不变特征的局部是指特征只是图像的局部区域,不变性是指该特征不会因为图像经历了各种变换而发生变化。
2)局部不变特征特点
局部不变特征的种类繁多,适合不同的特征提取场合,各自独立性较强,相互之间可以组合和借鉴。复合类型的局部不变特征可能会增加计算负担,但是能够取得更好的性能。
3)局部不变特征的应用
局部不变特征是一种十分有效的工具,大量研究表明它能够适应各种图像处理的应用场合,特别是在模拟人类视觉系统的物体识别领域,拥有强大的应用性。从直观的人类视觉印象来看,人类视觉对物体的描述也是局部化的,基于局部不变特征的图像识别方法十分接近于人类视觉机理,通过局部化的特征组合,形成对目标物体的整体印象,这就为局部不变特征提取方法提供了生物学上的解释,因此局部不变特征也得到了广泛应用。
4)特征描述符
特征描述符(Featrue Descriptors)指的是检测图像的局部特征(比如边缘、角点、轮廓等),然后根据匹配目标的需要进行特征的组合、变换,以形成易于匹配、稳定性好的特征向量,从而把图像匹配问题转化为特征的匹配问题,进而将特征的匹配问题转化为特征空间特征向量的聚类问题。
5)局部不变特征检测与局部不变特征区域的概念
局部不变特征检测就是从图像中检测出具有某种几何和光学不变性(geometric and photometric invariant)的局部不变特征区域。局部不变特征区域是以特征点(feature point or key point)为中心带有尺度信息的图像局部区域。局部不变特征认为,在大多数的图像中总能找到一些性质特殊的区域,它们可以稳定的提取,并且对各种图像变化具有良好的鲁棒性且包涵更多的图像内容信息。
6、基于局部不变特征的图像处理理论和技术主要包括四个部分:
1)图像尺度空间:图像数据包含大量混杂在一起的特征信息,按照局部不变特征的思想,这些特征信息是归属于不同类型不同属性的目标物体,其位置和控制区域各不相同,不同分布和参数的特征相互叠加和组合,这使得特征提取变得困难,所以需将这些特征进行一定的“分离”操作,将各类特征分散到整个图像数据空间中去,图像尺度空间就是为图像的各种不同类特征分离提供的一种数据表示法。
2)局部不变特征检测:在尺度空间内构造不变特征检测函数,生成对应尺度下的局部不变特征空间,检测其中具有一定特征显著性的局部不变特征区域,并把它作为特征描述的目标区域,确定每个特征的尺度系数,局部不变特征结构的位置和尺度范围。这些局部区域及其包含的信息形成对图像语义结构信息的表示,为进一步的特征描述提供图像内容的结构和范围信息。
3)局部不变特征描述:局部不变特征检测获得的特征仅仅给出了图像内容的结构信息,局部不变特征区域还需要从图像尺度空间表示的数据形式转化特征描述向量。局部不变特征描述就是用局部不变特征描述符(Local feature descriptor)去描述局部不变特征区域,用尽可能相互独立和完备的特征描述数据来表示复杂组合的目标物体,完整详细地描述图像内容,给出图像的语义信息。
4)特征匹配和检索:特征提取的最终目的是使用这些特征来进行目标识别和特征的检索,通过对特征描述空间中的特征数据进行分类、匹配和检索,实现各种图像识别应用。由于其良好的鲁棒性和抗干扰性,使的它作为目标识别中机器学习样本描述的首选特征,图像和视频检索方法也大都采用局部不变特征作为学习和检索的依据。
7、局部不变特征发展方向
目前,局部不变特征主要分为两个发展方向:
1) 结构化的局部不变特征提取模型,也就是特征提取模型分为四个较为清晰的处理模块(上文中有提到)。在局部不变特征检测方面,D.Lowe提出基于扩散方程的尺度不变的SIFT特征检测方法,以及由角点检测发展而来的Multi-scale Harris检测,具有仿射不变性的Harris-Laplace/Affine检测等,目前局部不变特征检测方法逐渐向着检测具有多种不变性和抗干扰性强的局部不变特征的方向发展。局部不变特征描述技术更加广泛,其中以SIFT,GLOH,Steerable Filters,Shape Context,Complex Filters等为主要特征描述符。特征检索和匹配模块一般是面向图像模式识别的具体应用场合,如图像检索,机器学习的样本特征集合,目标识别中的样本特征数据库等,同时在视频的检索领域也获得不错的效果。
2) 模仿人类的视觉系统,通过模仿人类视觉系统的运作原理提出了显著性区域理论。这一理论认为图像中的每个局部区域的重要性和影响范围并非同等重要,即特征不是同等显著的,其主要理论来源是Marr的计算机视觉理论和Treisman的特征整合理论,一般也称为“原子论”。该理论认为视觉的过程开始于对物体的特征性质和简单组成部分的分析,是从局部性
质到大范围性质,图像中的每个局部不变特征的视觉显著性是不同的,所以在局部不变特征的提取和描述时也遵循与人眼视觉注意选择原理相类似的机制(Visual Selective Attention Mechanism)。
8、软件:SIFT Keypoint Detector
该软件是可以在Linux或Windows系统中运行的汇编代码形式的SIFT特征点检测器, 它可以输出特征点和可以匹配到一个简单的ASCII格式文件需要的所有信息。 所提供的MATLAB程序和示例C代码可以读取特征点并根据它们对两幅图片进行匹配。
9、应用前景
SIFT算法是模式识别的一种高效手段,凡模式识别的应用方面都可以运用SIFT算法来改进识别速度。
医学:运动学人体机能研究
仿生学:人工模拟生物
人工智能:智能机器人、智能驾驶
刑侦技术:跟踪
军事用途:敌友识别(战机、战舰、潜艇、雷达跟踪等等)
1、我先要给大家讲一个概念:spring 的多数据源事务,这是民间的说法。官方的说法是:spring 的分布式事务。明白了这个概念,问题就好解决了。
2、分布式事务的应用场景:工程中使用两个及以上数据库中,就要考虑使用分布式事务管理,否则事务不能回滚。
3、现有两种开源的第三方jar支持spring的分布式事务管理,它们分别是:jotm和Atomikos。通过google可以找到下载的链接,其中atomikos的下载需要先填写email信息,再登录email找到链接去下载。下载地址分别:
1、http://jotm.objectweb.org/
2、http://www.atomikos.com/Main/InstallingTransactionsEssentials
我使用的是jotm。
4、基于spring+ibatis的环境下配置jotm的方法很简单。只城要修改spring数据源的配置及事务的配置及可。以下是我的配置,供参考。
-
- <bean id="jotm" class="org.springframework.transaction.jta.JotmFactoryBean">
- <property name="defaultTimeout" value="500000"/>
- </bean>
-
- <bean id="dataSource" class="org.enhydra.jdbc.pool.StandardXAPoolDataSource" destroy-method="shutdown">
- <property name="dataSource">
- <bean class="org.enhydra.jdbc.standard.StandardXADataSource" destroy-method="shutdown">
- <property name="transactionManager" ref="jotm"/>
- <property name="driverName" value="${driverClass}"/>
- <property name="url" value="${jdbcUrl}"/>
- </bean>
- </property>
- <property name="user" value="${user}"/>
- <property name="password" value="${password}"/>
- </bean>
-
- <bean id="dataSourceBbs" class="org.enhydra.jdbc.pool.StandardXAPoolDataSource" destroy-method="shutdown">
- <property name="dataSource">
- <bean class="org.enhydra.jdbc.standard.StandardXADataSource" destroy-method="shutdown">
- <property name="transactionManager" ref="jotm"/>
- <property name="driverName" value="${bbs.driverClass}"/>
- <property name="url" value="${bbs.jdbcUrl}"/>
- </bean>
- </property>
- <property name="user" value="${bbs.user}"/>
- <property name="password" value="${bbs.password}"/>
- </bean>
-
-
- <bean id="myJtaManager" class="org.springframework.transaction.jta.JtaTransactionManager">
- <property name="userTransaction" ref="jotm" />
- </bean>
-
-
- <aop:config>
- <aop:pointcut id="serviceOperation" expression="execution(* com.bohai.service.impl.*.*(..))"/>
- <aop:advisor pointcut-ref="serviceOperation" advice-ref="txAdvice" order="0" />
- </aop:config>
-
-
- <tx:advice id="txAdvice" transaction-manager="myJtaManager">
- <tx:attributes>
- <tx:method name="delete*" propagation="REQUIRED" />
- <tx:method name="save*" propagation="REQUIRED" />
- <tx:method name="update*" propagation="REQUIRED" />
- <tx:method name="*" propagation="REQUIRED" />
- <tx:method name="find*" propagation="SUPPORTS" read-only="true"/>
- <tx:method name="get*" propagation="SUPPORTS" read-only="true"/>
- <tx:method name="fetch*" propagation="SUPPORTS" read-only="true"/>
- <tx:method name="*_noTrans" propagation="NOT_SUPPORTED"/>
- </tx:attributes>
- </tx:advice>
5、jtom 还需要一个配置文件 carol.properties ,内容是:
- # do not use CAROL JNDI wrapper
- carol.start.jndi=false
-
- # do not start a name server
- carol.start.ns=false
-
- # Naming Factory
- carol.jndi.java.naming.factory.url.pkgs=org.apache.naming
文件放在classpath下面,也就是src下面。
6、需要jtom的以下jar:
7、经过测试,配置是成功的。事务可以回滚。
无意中看到张子阳的博客中的这篇文章,个人觉得挺好的就转载过来跟大家分享了,就擅自转载过来跟大家分享了。——靳建通
收入是由什么决定的?
这位员工辞职的原因主要有两个:
- 公司的薪水无法达到他的预期,未来一年在公司的收入前景也不是很明确。
- 想要去做更底层的开发,方向是使用C/C++开发3D图形图像。而我们公司主要是.NET开发。
既然其中的一个原因是薪水无法符合预期,那么首先要搞清楚的就是收入是由什么决定的。
1.积累
首先要说的一点就是:积累。积累就是你在这家公司所创造的价值的积累。
你今天所领的薪水,并不是由你现在所创造的价值所决定的,而是包含了以前一段时期内其他同事所创造的价值。举个例子来说,公司目前排名前三的大客户:客户A、客户B、客户C。
- 客户A是2008年接下来的,现在每年为公司贡献600万。
- 客户B是2009年接下来的,现在每年为公司贡献500万。
- 客户C是2010年接下来的,现在每年为公司贡献350万。
我的年薪是你的两倍还多。可我也承认,我现在所能创造的价值,靳建通和我的能力绝对不可能是你的两倍。可问题是:2008年、2009年、2010年这些年份我都在公司,上面的每一个大客户,都有我的贡献。靳建通而你2012年才新进公司,你并没有之前的积累。所以,新员工入职后,工资相较老员工会低一些是正常的。很多新员工总是认为自己的收入低了,吃亏了,实际上,很多情况下,新员工在加入公司的头一年,公司仅能维持平衡,即新员工创造的价值全当工资发给他了。靳建通直到第二年,有了上一年的积累之后,公司才有所盈余。而加入半年就离职的员工,对公司来说基本上是亏本的。靳建通这也就解释了为什么人员流动特别快的公司活不长,因为人力成本太高。
关于积累,我可以再举几个例子说明一下:
洪小莲,李嘉诚的秘书,几十年来一直追随李嘉诚,她从几千元的工薪族,做到身家上亿的工薪族,享受的是公司成长的回报。这种回报并非是她个人的学识和能力有了大幅的提高而得到的等价交换,很大程度上仅仅是因为她忠诚地待在这趟车上。
杨元庆,联想现在的CEO,研究生毕业后就一直追随柳传志,尽管一开始从事的是他并不很乐意的销售工作,但最终还是坚持了下来。上一次注意到他,是看到一则新闻,标题是“杨元庆自掏2000万奖励一线员工”。
上面只是正面的例子,也有反面的例子:
吴士宏,曾写了一本书叫做《逆风飞扬》,可谓是红极一时。1986年进入IBM,1998年离开IBM,进入微软,担任微软中国公司总经理,1999年进入TCL,2002年离开TCL。之后就离开了公众的视线。我特意去百度搜索靳建通“吴士宏现在在哪里”,没有任何的消息。我想如果她很成功的话,一定还属于“公众人物”,不至于连度娘都不知去向。
跳槽的话显然就要放弃先前的积累。比方说,当你跳槽到另一家公司以后,你曾经做过的系统、曾经服务过的客户仍然在为先前的公司创造着利润,可是跟你已经一毛钱关系都没有了(极少数公司有股票,另当别论)。所以跳槽之前要慎重考虑,跳得不好,有可能越跳越低。
既然新员工相对于老员工来说,收入低一些是正常的,那么老员工工资高也是合情合理的。但是有一些公司,我将其归为“无良公司”,它们会在老员工的收入高到一定程度的时候,将老员工砍掉,然后再招募低廉的新人来承担之前老员工的工作,以赚取更高的利润。我觉得这些都是小聪明,最后的结果就是,聪明能干一些的人,在看出公司的这些伎俩之后果断离职;能力一般的员工,也会把你这里当成培训基地,翅膀硬了就飞了,受损的最后还是公司,实在是得不偿失。还不如厚待老员工,也让新进的员工对未来有一个更好的预期。也有一些人向我抱怨说:“老员工待得久了,干劲都被磨光了,每天都是混日子,还不如新员工,不开他开谁?”。然后我反问他:“激励员工难道不正是你工作的一部分吗?”。这种情况的出现,更多时候,是管理者的责任,而非员工。
最后补充一点:我并不认为老员工工资比新员工高就一定是合理的。当公司对一个新员工开出很高的工资时,其实是出于这样一种期望:他能推动公司进步的更快。而如果他真的这样做到了,公司进步的更快了、收益更高了,可以反哺老员工,从而公司的整体待遇水平都提高了,不是皆大欢喜吗?可能一些老员工并不能明白这些,所以,靳建通当招一个新员工工资水平远高于现有的老员工时,为什么要这样做,最好能让老员工知晓。
2.老板
这个“老板”是宽泛的老板,不一定是公司最大的老板。有的时候,公司比较大,你的职位又比较低,大老板连有没有你这个人都不知道,此时的老板就是你的顶头上司。很多时候,你的收入与他也有着莫大的关系。靳建通
对于我来说,我的原则是:在我的能力范围内,我会为我的员工争取更好的待遇。表面上看,这样做很蠢,花6000块就能雇到一个人,为什么要花8000块?我不是这样认为的,我期望能和我的员工形成这样一种互动:我尽我的能力为你争取好的待遇,你也尽你的努力做好工作。
我不能要求员工“你先把工作做好,我自然会给你好的待遇”。总是要有人先迈出一步,总是要有一方先信任另一方,所以在你什么还没有做的时候,我就先信任你,并且给你尽可能好的待遇,那么我该做的事情都做了,我问心无愧,剩下的,就看你的表现了。
可能有人会想,都这样了怎么还会有人提出辞职?实际上,提出辞职的是一个毕业刚一年的小伙子,1989年生,毕业1年多,我给他的待遇是试用期9000,转正后9500。在给他这个待遇之前,我是进行过一些调研的,我打电话给我的一个表妹,她是西安电子科技大学的研究生(陕西省排名第三的学校,211院校),她和她的同学在今年毕业找工作的时候,多得是6000到8000的工资。所以从这方面来说,我并没有亏待你,而你要求12K的工资,我并不是不愿意给这么多,你的表现也说明了你是个很有潜力的人才。只是受经济环境的影响,今年公司的效益不及往年,要在一定程度上节省开支。其次,你让其他的老员工情何以堪?所以,综合起来,你的要求超出了我的能力范围之外,我无法开口向公司申请提高你的薪水。
3.门槛
除了积累和顶头上司两个决定因素以外,靳建通第三个决定因素就是你从事工作的门槛。为什么餐厅服务员的收入很低?为什么坐在前台收发快递的文员收入很低?因为这些工作的门槛很低,门槛低就意味着你不做有的是人能做,你不做有大批的“后备队伍”在等着做。靳建通由于庞大的后备队伍的竞争,你就无法提高自己的要价。而提升自己所从事工作的门槛,实际上就缩减了竞争者的规模。
程序开发也是一样。如果你想收入高,你就做一些别人做不了,又有市场的。
.NET在程序开发中就属于门槛比较低的一类。个中原因我想大家都懂的,就不在这里赘述了。做.NET不需要你科班出身,或许一点兴趣再加上一点时间,或许一个类似北大青鸟的培训,都可以让你开始从事.NET开发了。你可以不懂指针、不懂数据结构、不懂算法、不懂汇编、不懂很多东西,但照样可以做出一个.NET程序来。而这些人往往又是对薪资的要求没那么高的,这样无形中就拉低了.NET程序员的“身价”。.NET的易学易会,很大程度上是由于它的封装性比较好。底层的东西都屏蔽掉了,你只要知道学习一下命名空间,然后寻找相关的API去调用就好了。记得我们公司曾经开发过一个基于C语言的手持设备程序,没有任何的类库支持,连排序、链表这样.NET中的基本功能,都要自己来实现,更别提内存管理和程序逻辑了,和.NET比起来,门槛就相对高一些了。
所以,如果想收入高一些,那么就去做更高难度的技术工作,这里随便想了几个例子:
- 百度、谷歌的搜索引擎算法。
- 微软、谷歌、苹果的操作系统。
- 网络游戏,例如《征途》的游戏引擎。
- 大型企业的ERP,比方说SAP。
- 软硬结合,比如单片机,电气自动化。
- 以及我这位即将离职的同事说的,3D图形图像。
所以,从这个角度来看,这位同事的辞职是明智的,他很年轻,靳建通有的是机会重新选择自己的道路,所以我也祝愿他能有更好的发展。而这些好赚的钱,就留给我们来做了:-)。
4.平台
接下来要说的一个决定因素是平台。很多程序员觉得30岁就瓶颈了,30岁写程序就到头了,实际上,这只是你的平台比较小罢了。就拿我自己的公司来说,平台就不大,只要是踏踏实实工作过5年的程序员,基本上就能够胜任公司90%的技术工作了,剩下的10%,请教一下其他同事,进行一下技术交流,也完全能够解决。这样就存在一个问题:随着你年龄的增长,你的生活压力越来越大,要求越来越高,可是公司只要5年经验的程序员就够用了。假设市场上5年经验的程序员的平均要求是10K,凭什么要给你15K?你的优势在哪里?如果你没有突破,就会有“30岁写程序就到头了”的感觉。
而如果平台大一些情况就会不一样,比方说,你去了IBM,可能5年的经验不过刚刚入门而已。IBM有一个工程院,其中有5位院士(IBM Fellow)获得过诺贝尔奖,很多人钻研技术都超过20年或者更久。如果你对技术感兴趣,并执着去钻研的话,你可以不断地去挑战和攀登。
当然,你可能没那么好的运气和实力进入IBM,那么其他一些中型的平台也是不错的,比方说阿里巴巴、金蝶、百度、腾讯等等。在这里,至少你有足够的理由和需要再去进行深入学习。因为在这些地方,5年的经验是远远不够的,还需要进一步地学习和努力。
如果你和我一样,不巧没有那么大的平台,此时的选择大概有这么几种:
1. 你可以凭借你在公司的积累(第一节讲过的),过比较安逸的日子。如果比较幸运,押对了宝,公司发展得比较好,收入一样会变得非常可观;如果比较不幸,公司经营的状况不好,那就要承担比较大的风险了。说得难听一点,公司倒闭了你去哪里?你过去的积累已经一文不值,靳建通而你的年龄已经35,水平却相当于只有5年经验。你的竞争力在哪里?
2. 你可以凭自己的努力将现在所在的平台做大,换言之,把自己的小公司做大。这当然是比较积极的做法,也是我一直努力的方向。现在你看到的大公司,不也是从小公司一步一步做起的吗?不过这里还有两个问题:1、有的时候,你的力量在公司中的占比没那么大,你再怎么努力推进的速度也还是有限;2、你缺乏慧眼,选中的公司本身就缺乏长大的资质。我们往往只看到成功了的公司,却忽视了更多在竞争中倒下的公司。
3. 主动选择更大的平台,也就是跳槽了。但是跳槽也是有风险的,尤其是过了30岁的程序员,你在这家公司的收入高,是因为有之前的积累,换一家就没有积累了,等于从新人开始,而大多数的公司,5年经验的程序员就够用了。如果跳得不好,收入还可能越跳越低,如果还有老婆、孩子、房贷,那将面临更大的压力。所以当你想要从一个低的平台向更高的平台跳跃的时候,平时就要做足功夫,认真积累自己的实力。对于我来说,我缺乏大型项目的管理经验,但是没关系,我努力学习考一个PMP没什么问题吧?我缺乏大型软件的架构经验,但是没关系,我把.NET的基础知识和各种设计模式掰开了揉碎了没什么问题吧?我缺乏大型团队的管理经验,但是没关系,每次遇到管理方面的问题我都认真思考仔细总结没什么问题吧?有些人总是抱怨没有机会,运气不好,我想机会总是有的,但只属于有准备的人。
5.行业
我想说的最后一点就是行业。有时候你觉得已经万事俱备了,可是你所处的这个行业本身就属于极低利润率的,你再怎么努力也很难有很高的收入。很多情况下,可能公司也想提高你的待遇,但是由于缺乏利润的支撑,公司也是有心无力。所以,在选择公司,尤其是小公司的时候,要重点考察一下公司所处的行业如何?是不是前景比较好、利润比较高的行业?如果是大公司的话,靳建通这方面的问题就会少一些,因为如果方向有问题,它就无法做成大公司。
行业是有周期性的,可能在一段时期内这个行业好,下一段时期这个行业就不行了。最典型的一个例子就是软盘,我现在的老板在成立这家公司之前是做销售的,他有一个客户,做索尼软盘的,这种软盘我想很多80后都见过。当时生意做得很大,可是当光盘出来以后,软盘的市场是会急剧萎缩的,可是这家公司的领导层居然没有看到,或者是看到了但不愿意转变,像鸵鸟一样在危机来临时把头埋在土里,继续做它的软盘。几年以后,这家公司就倒掉了。
选择行业也不是选择暴利行业就一定好,比方说房地产。资本都是逐利的,当一个行业属于暴利,同时所有人都知道它是暴利的时候,危机就来了。这个危机就是会有大量的社会资源、人力物力投入到这个行业中企图分一杯羹。而全局上又没有一个统一的把控,这个行业究竟需要多少公司才是合适的?最后的结果就是过剩。就好像股票在崩盘时,也许跌到3000点是比较合理也比较正常的位置,靳建通但是由于人们的恐慌,它就跌到1600点了。
感谢阅读,希望这篇文章能给你带来收获。
不是所有一年工作经验的毕业生都有这样的待遇,我主要是看能力,而不是年龄、学历等。特别说明一下,以免误导。
当前很多大型的web系统为了减轻数据库服务器负载,会采用memchached作为缓存系统以提高响应速度。
目录:
- memchached简介
- hash
- 参考资料
memcached是一个开源的高性能分布式内存对象缓存系统。
其实思想还是比较简单的,实现包括server端(memcached开源项目一般只单指server端)和client端两部分:
- server端本质是一个in-memory key-value store,通过在内存中维护一个大的hashmap用来存储小块的任意数据,对外通过统一的简单接口(memcached protocol)来提供操作。
- client端是一个library,负责处理memcached protocol的网络通信细节,与memcached server通信,针对各种语言的不同实现分装了易用的API实现了与不同语言平台的集成。
- web系统则通过client库来使用memcached进行对象缓存。
memcached的分布式主要体现在client端,对于server端,仅仅是部署多个memcached server组成集群,每个server独自维护自己的数据(互相之间没有任何通信),通过daemon监听端口等待client端的请求。
而在client端,通过一致的hash算法,将要存储的数据分布到某个特定的server上进行存储,后续读取查询使用同样的hash算法即可定位。
client端可以采用各种hash算法来定位server:
取模
最简单的hash算法
targetServer = serverList[hash(key) % serverList.size]
直接用key的hash值(计算key的hash值的方法可以自由选择,比如算法CRC32、MD5,甚至本地hash系统,如java的hashcode)模上server总数来定位目标server。这种算法不仅简单,而且具有不错的随机分布特性。
但是问题也很明显,server总数不能轻易变化。因为如果增加/减少memcached server的数量,对原先存储的所有key的后续查询都将定位到别的server上,导致所有的cache都不能被命中而失效。
一致性hash
为了解决这个问题,需要采用一致性hash算法(consistent hash)
相对于取模的算法,一致性hash算法除了计算key的hash值外,还会计算每个server对应的hash值,然后将这些hash值映射到一个有限的值域上(比如0~2^32)。通过寻找hash值大于hash(key)的最小server作为存储该key数据的目标server。如果找不到,则直接把具有最小hash值的server作为目标server。
为了方便理解,可以把这个有限值域理解成一个环,值顺时针递增。

如上图所示,集群中一共有5个memcached server,已通过server的hash值分布到环中。
如果现在有一个写入cache的请求,首先计算x=hash(key),映射到环中,然后从x顺时针查找,把找到的第一个server作为目标server来存储cache,如果超过了2^32仍然找不到,则命中第一个server。比如x的值介于A~B之间,那么命中的server节点应该是B节点

可以看到,通过这种算法,对于同一个key,存储和后续的查询都会定位到同一个memcached server上。
那么它是怎么解决增/删server导致的cache不能命中的问题呢?
假设,现在增加一个server F,如下图

此时,cache不能命中的问题仍然存在,但是只存在于B~F之间的位置(由C变成了F),其他位置(包括F~C)的cache的命中不受影响(删除server的情况类似)。尽管仍然有cache不能命中的存在,但是相对于取模的方式已经大幅减少了不能命中的cache数量。
虚拟节点
但是,这种算法相对于取模方式也有一个缺陷:当server数量很少时,很可能他们在环中的分布不是特别均匀,进而导致cache不能均匀分布到所有的server上。

如图,一共有3台server – 1,2,4。命中4的几率远远高于1和2。
为解决这个问题,需要使用虚拟节点的思想:为每个物理节点(server)在环上分配100~200个点,这样环上的节点较多,就能抑制分布不均匀。
当为cache定位目标server时,如果定位到虚拟节点上,就表示cache真正的存储位置是在该虚拟节点代表的实际物理server上。
另外,如果每个实际server的负载能力不同,可以赋予不同的权重,根据权重分配不同数量的虚拟节点。
源码解析
下面结合一个java的memcached client(gwhalin / Memcached-Java-Client)的源码来看一下consistent hash的实现。
首先看server的分布:
-
- this.consistentBuckets = new TreeMap();
-
- MessageDigest md5 = MD5.get();
-
-
- if ( this.totalWeight for ( int i = 0; i < this.weights.length; i++ )
- this.totalWeight += ( this.weights[i] == null ) ? 1 : this.weights[i];
- } else if ( this.weights == null ) {
- this.totalWeight = this.servers.length;
- }
-
-
- for ( int i = 0; i < servers.length; i++ ) {
-
- int thisWeight = 1;
- if ( this.weights != null && this.weights[i] != null )
- thisWeight = this.weights[i];
-
-
-
-
-
- double factor = Math.floor( ((double)(40 * this.servers.length * thisWeight)) / (double)this.totalWeight );
-
- for ( long j = 0; j < factor; j++ ) {
-
-
-
-
- byte[] d = md5.digest( ( servers[i] + "-" + j ).getBytes() );
-
-
- for ( int h = 0 ; h < 4; h++ ) {
- Long k =
- ((long)(d[3+h*4]&0xFF) << 24)
- | ((long)(d[2+h*4]&0xFF) << 16)
- | ((long)(d[1+h*4]&0xFF) << 8 )
- | ((long)(d[0+h*4]&0xFF));
-
-
- consistentBuckets.put( k, servers[i] );
- }
-
- }
-
- }
// 采用有序map来模拟环
this.consistentBuckets = new TreeMap();
MessageDigest md5 = MD5.get();//用MD5来计算key和server的hash值
// 计算总权重
if ( this.totalWeight for ( int i = 0; i < this.weights.length; i++ )
this.totalWeight += ( this.weights[i] == null ) ? 1 : this.weights[i];
} else if ( this.weights == null ) {
this.totalWeight = this.servers.length;
}
// 为每个server分配虚拟节点
for ( int i = 0; i < servers.length; i++ ) {
// 计算当前server的权重
int thisWeight = 1;
if ( this.weights != null && this.weights[i] != null )
thisWeight = this.weights[i];
// factor用来控制每个server分配的虚拟节点数量
// 权重都相同时,factor=40
// 权重不同时,factor=40*server总数*该server权重所占的百分比
// 总的来说,权重越大,factor越大,可以分配越多的虚拟节点
double factor = Math.floor( ((double)(40 * this.servers.length * thisWeight)) / (double)this.totalWeight );
for ( long j = 0; j < factor; j++ ) {
// 每个server有factor个hash值
// 使用server的域名或IP加上编号来计算hash值
// 比如server - "172.45.155.25:11111"就有factor个数据用来生成hash值:
// 172.45.155.25:11111-1, 172.45.155.25:11111-2, ..., 172.45.155.25:11111-factor
byte[] d = md5.digest( ( servers[i] + "-" + j ).getBytes() );
// 每个hash值生成4个虚拟节点
for ( int h = 0 ; h < 4; h++ ) {
Long k =
((long)(d[3+h*4]&0xFF) << 24)
| ((long)(d[2+h*4]&0xFF) << 16)
| ((long)(d[1+h*4]&0xFF) << 8 )
| ((long)(d[0+h*4]&0xFF));
// 在环上保存节点
consistentBuckets.put( k, servers[i] );
}
}
// 每个server一共分配4*factor个虚拟节点
}
每个server根据权重获得一个虚拟节点数量控制因子factor,然后由services[i]+”-”+i来生成factor个hash值,生成hash值时采用MD5算法。
由于MD5长度是16个字节,正好划分成4段,每段4字节,这样每段就对应一个虚拟节点。linex-liney通过把这一段的4字节拼装成连续的32bit,作为低32位拉升为一个Long。
为key定位cache存储的server:
-
- MessageDigest md5 = MD5.get();
- md5.reset();
- md5.update( key.getBytes() );
- byte[] bKey = md5.digest();
-
-
- long hv = ((long)(bKey[3]&0xFF) << 24) | ((long)(bKey[2]&0xFF) << 16) | ((long)(bKey[1]&0xFF) << 8 ) | (long)(bKey[0]&0xFF);
-
-
- SortedMap tmap = this.consistentBuckets.tailMap( hv );
- return ( tmap.isEmpty() ) ? this.consistentBuckets.firstKey() : tmap.firstKey();
// 用MD5来计算key的hash值
MessageDigest md5 = MD5.get();
md5.reset();
md5.update( key.getBytes() );
byte[] bKey = md5.digest();
// 取MD5值的低32位作为key的hash值
long hv = ((long)(bKey[3]&0xFF) << 24) | ((long)(bKey[2]&0xFF) << 16) | ((long)(bKey[1]&0xFF) << 8 ) | (long)(bKey[0]&0xFF);
// hv的tailMap的第一个虚拟节点对应的即是目标server
SortedMap tmap = this.consistentBuckets.tailMap( hv );
return ( tmap.isEmpty() ) ? this.consistentBuckets.firstKey() : tmap.firstKey();
- 首次提出consistent hash的论文 – “Consistent Hashing and Random Trees: Distributed Caching Protocols for Relieving Hot Spots on the World Wide Web”
- Consistent hashing Wiki – http://en.wikipedia.org/wiki/Consistent_hashing
- Ketama: Consistent Hashing
- memcached开源项目主页
- memcached google code主页
- gwhalin / Memcached-Java-Client主页
一致性 hash 算法( consistent hashing )
张亮
consistent hashing 算法早在 1997 年就在论文 Consistent hashing and random trees 中被提出,目前在 cache 系统中应用越来越广泛;
1 基本场景
比如你有 N 个 cache 服务器(后面简称 cache ),那么如何将一个对象 object 映射到 N 个 cache 上呢,你很可能会采用类似下面的通用方法计算 object 的 hash 值,然后均匀的映射到到 N 个 cache ;
hash(object)%N
一切都运行正常,再考虑如下的两种情况;
1 一个 cache 服务器 m down 掉了(在实际应用中必须要考虑这种情况),这样所有映射到 cache m 的对象都会失效,怎么办,需要把 cache m 从 cache 中移除,这时候 cache 是 N-1 台,映射公式变成了 hash(object)%(N-1) ;
2 由于访问加重,需要添加 cache ,这时候 cache 是 N+1 台,映射公式变成了 hash(object)%(N+1) ;
1 和 2 意味着什么?这意味着突然之间几乎所有的 cache 都失效了。对于服务器而言,这是一场灾难,洪水般的访问都会直接冲向后台服务器;
再来考虑第三个问题,由于硬件能力越来越强,你可能想让后面添加的节点多做点活,显然上面的 hash 算法也做不到。
有什么方法可以改变这个状况呢,这就是 consistent hashing...
2 hash 算法和单调性
Hash 算法的一个衡量指标是单调性( Monotonicity ),定义如下:
单调性是指如果已经有一些内容通过哈希分派到了相应的缓冲中,又有新的缓冲加入到系统中。哈希的结果应能够保证原有已分配的内容可以被映射到新的缓冲中去,而不会被映射到旧的缓冲集合中的其他缓冲区。
容易看到,上面的简单 hash 算法 hash(object)%N 难以满足单调性要求。
3 consistent hashing 算法的原理
consistent hashing 是一种 hash 算法,简单的说,在移除 / 添加一个 cache 时,它能够尽可能小的改变已存在 key 映射关系,尽可能的满足单调性的要求。
下面就来按照 5 个步骤简单讲讲 consistent hashing 算法的基本原理。
3.1 环形hash 空间
考虑通常的 hash 算法都是将 value 映射到一个 32 为的 key 值,也即是 0~2^32-1 次方的数值空间;我们可以将这个空间想象成一个首( 0 )尾( 2^32-1 )相接的圆环,如下面图 1 所示的那样。
图 1 环形 hash 空间
3.2 把对象映射到hash 空间
接下来考虑 4 个对象 object1~object4 ,通过 hash 函数计算出的 hash 值 key 在环上的分布如图 2 所示。
hash(object1) = key1;
… …
hash(object4) = key4;

图 2 4 个对象的 key 值分布
3.3 把cache 映射到hash 空间
Consistent hashing 的基本思想就是将对象和 cache 都映射到同一个 hash 数值空间中,并且使用相同的 hash 算法。
假设当前有 A,B 和 C 共 3 台 cache ,那么其映射结果将如图 3 所示,他们在 hash 空间中,以对应的 hash 值排列。
hash(cache A) = key A;
… …
hash(cache C) = key C;

图 3 cache 和对象的 key 值分布
说到这里,顺便提一下 cache 的 hash 计算,一般的方法可以使用 cache 机器的 IP 地址或者机器名作为 hash 输入。
3.4 把对象映射到cache
现在 cache 和对象都已经通过同一个 hash 算法映射到 hash 数值空间中了,接下来要考虑的就是如何将对象映射到 cache 上面了。
在这个环形空间中,如果沿着顺时针方向从对象的 key 值出发,直到遇见一个 cache ,那么就将该对象存储在这个 cache 上,因为对象和 cache 的 hash 值是固定的,因此这个 cache 必然是唯一和确定的。这样不就找到了对象和 cache 的映射方法了吗?!
依然继续上面的例子(参见图 3 ),那么根据上面的方法,对象 object1 将被存储到 cache A 上; object2 和 object3 对应到 cache C ; object4 对应到 cache B ;
3.5 考察cache 的变动
前面讲过,通过 hash 然后求余的方法带来的最大问题就在于不能满足单调性,当 cache 有所变动时, cache 会失效,进而对后台服务器造成巨大的冲击,现在就来分析分析 consistent hashing 算法。
3.5.1 移除 cache
考虑假设 cache B 挂掉了,根据上面讲到的映射方法,这时受影响的将仅是那些沿 cache B 逆时针遍历直到下一个 cache ( cache C )之间的对象,也即是本来映射到 cache B 上的那些对象。
因此这里仅需要变动对象 object4 ,将其重新映射到 cache C 上即可;参见图 4 。

图 4 Cache B 被移除后的 cache 映射
3.5.2 添加 cache
再考虑添加一台新的 cache D 的情况,假设在这个环形 hash 空间中, cache D 被映射在对象 object2 和 object3 之间。这时受影响的将仅是那些沿 cache D 逆时针遍历直到下一个 cache ( cache B )之间的对象(它们是也本来映射到 cache C 上对象的一部分),将这些对象重新映射到 cache D 上即可。
因此这里仅需要变动对象 object2 ,将其重新映射到 cache D 上;参见图 5 。

图 5 添加 cache D 后的映射关系
4 虚拟节点
考量 Hash 算法的另一个指标是平衡性 (Balance) ,定义如下:
平衡性
平衡性是指哈希的结果能够尽可能分布到所有的缓冲中去,这样可以使得所有的缓冲空间都得到利用。
hash 算法并不是保证绝对的平衡,如果 cache 较少的话,对象并不能被均匀的映射到 cache 上,比如在上面的例子中,仅部署 cache A 和 cache C 的情况下,在 4 个对象中, cache A 仅存储了 object1 ,而 cache C 则存储了 object2 、 object3 和 object4 ;分布是很不均衡的。
为了解决这种情况, consistent hashing 引入了“虚拟节点”的概念,它可以如下定义:
“虚拟节点”( virtual node )是实际节点在 hash 空间的复制品( replica ),一实际个节点对应了若干个“虚拟节点”,这个对应个数也成为“复制个数”,“虚拟节点”在 hash 空间中以 hash 值排列。
仍以仅部署 cache A 和 cache C 的情况为例,在图 4 中我们已经看到, cache 分布并不均匀。现在我们引入虚拟节点,并设置“复制个数”为 2 ,这就意味着一共会存在 4 个“虚拟节点”, cache A1, cache A2 代表了 cache A ; cache C1, cache C2 代表了 cache C ;假设一种比较理想的情况,参见图 6 。

图 6 引入“虚拟节点”后的映射关系
此时,对象到“虚拟节点”的映射关系为:
objec1->cache A2 ; objec2->cache A1 ; objec3->cache C1 ; objec4->cache C2 ;
因此对象 object1 和 object2 都被映射到了 cache A 上,而 object3 和 object4 映射到了 cache C 上;平衡性有了很大提高。
引入“虚拟节点”后,映射关系就从 { 对象 -> 节点 } 转换到了 { 对象 -> 虚拟节点 } 。查询物体所在 cache 时的映射关系如图 7 所示。
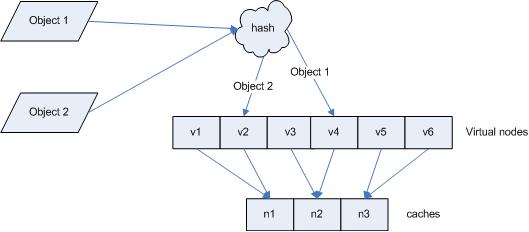
图 7 查询对象所在 cache
“虚拟节点”的 hash 计算可以采用对应节点的 IP 地址加数字后缀的方式。例如假设 cache A 的 IP 地址为 202.168.14.241 。
引入“虚拟节点”前,计算 cache A 的 hash 值:
Hash(“202.168.14.241”);
引入“虚拟节点”后,计算“虚拟节”点 cache A1 和 cache A2 的 hash 值:
Hash(“202.168.14.241#1”); // cache A1
Hash(“202.168.14.241#2”); // cache A2
5 小结
Consistent hashing 的基本原理就是这些,具体的分布性等理论分析应该是很复杂的,不过一般也用不到。
http://weblogs.java.net/blog/2007/11/27/consistent-hashing 上面有一个 java 版本的例子,可以参考。
http://blog.csdn.net/mayongzhan/archive/2009/06/25/4298834.aspx 转载了一个 PHP 版的实现代码。
http://www.codeproject.com/KB/recipes/lib-conhash.aspx C语言版本
一些参考资料地址:
http://portal.acm.org/citation.cfm?id=258660
http://en.wikipedia.org/wiki/Consistent_hashing
http://www.spiteful.com/2008/03/17/programmers-toolbox-part-3-consistent-hashing/
http://weblogs.java.net/blog/2007/11/27/consistent-hashing
http://tech.idv2.com/2008/07/24/memcached-004/
http://blog.csdn.net/mayongzhan/archive/2009/06/25/4298834.aspx