最近关注Hadoop,因此也顺便关注了一下Hadoop相关的项目。HBASE就是基于Hadoop的一个开源项目,也是对Google的BigTable的一种实现。
BigTable是什么?Google的Paper对其作了充分的说明。字面上看就是一张大表,其实和我们想象的传统数据库的表还是有些差别的。松散数据可以说是介于Map Entry(key & value)和DB Row之间的一种数据。在我使用Memcache的时候,有时候的需求是需要存储的不仅仅是简单的一个key对应一个value,可能我需要类似于数据库表结构中多属性的存储,但是又不会有传统数据库表结构中那么多关联关系的需求,其实这类数据就是所谓的松散数据。BigTable最浅显来看就是一张很大的表,表的属性可以根据需求去动态增加,但是又没有表与表之间关联查询的需求。
互联网应用有一个最大的特点,就是速度,功能再强大,速度慢,还是会被舍弃。因此在大访问量的网站都采取前后的缓存来提升性能和响应时间。对于Map Entry类型的数据,集中式分布式Cache都有很多选择,对于传统的关系型数据,从MySQL到Oracle都给了很好的支持,唯有松散数据这类数据,采用前后两种解决方案都不能最大化它的处理能力。因此BigTable才有了它用武之地。
HBASE作为Apache的开源项目,也是出于起步阶段,因为其实它所依赖的Hadoop也不能说已经到了成熟阶段,所以都有很大的发展空间,这也为我们这些开源爱好者提供了更多空间去贡献。这里主要会谈到HBASE的框架设计方面的知识和它的一些特点,不论是否采用HBASE去解决工作中的问题,一种好的流程设计总会给开发者和架构设计者带来一些思想上的火花。
HBASE设计介绍
数据模型
HBASE中的每一张表,就是所谓的BigTable。BigTable会存储一系列的行记录,行记录有三个基本类型的定义:Row Key,Time Stamp,Column。Row Key是行在BigTable中的唯一标识,Time Stamp是每次数据操作对应关联的时间戳,可以看作类似于SVN的版本,Column定义为:<family>:<label>,通过这两部分可以唯一的指定一个数据的存储列,family的定义和修改需要对HBASE作类似于DB的DDL操作,而对于label的使用,则不需要定义直接可以使用,这也为动态定制列提供了一种手段。family另一个作用其实在于物理存储优化读写操作,同family的数据物理上保存的会比较临近,因此在业务设计的过程中可以利用这个特性。
看一下逻辑数据模型:
|
Row Key
|
Time Stamp
|
Column "contents:"
|
Column "anchor:"
|
Column "mime:"
|
|
"com.cnn.www"
|
t9
|
|
"anchor:cnnsi.com"
|
"CNN"
|
|
|
t8
|
|
"anchor:my.look.ca"
|
"CNN.com"
|
|
|
t6
|
"<html>..."
|
|
|
"text/html"
|
|
t5
|
"<html>..."
|
|
|
|
|
t3
|
"<html>..."
|
|
|
|
上表中有一列,列的唯一标识为com.cnn.www,每一次逻辑修改都有一个timestamp关联对应,一共有四个列定义:<contents:>,<anchor:cnnsi.com>,<anchor:my.look.ca>,<mime:>。如果用传统的概念来将BigTable作解释,那么BigTable可以看作一个DB Schema,每一个Row就是一个表,Row key就是表名,这个表根据列的不同可以划分为多个版本,同时每个版本的操作都会有时间戳关联到操作的行。
再看一下HBASE的物理数据模型:
|
Row Key
|
Time Stamp
|
Column "contents:"
|
|
"com.cnn.www"
|
t6
|
"<html>..."
|
|
t5
|
"<html>..."
|
|
t3
|
"<html>..."
|
|
Row Key
|
Time Stamp
|
Column "anchor:"
|
|
"com.cnn.www"
|
t9
|
"anchor:cnnsi.com"
|
"CNN"
|
|
t8
|
"anchor:my.look.ca"
|
"CNN.com"
|
|
Row Key
|
Time Stamp
|
Column "mime:"
|
|
"com.cnn.www"
|
t6
|
"text/html"
|
物理数据模型其实就是将逻辑模型中的一个Row分割成为根据Column family存储的物理模型。
对于BigTable的数据模型操作的时候,会锁定Row,并保证Row的原子操作。
框架结构及流程
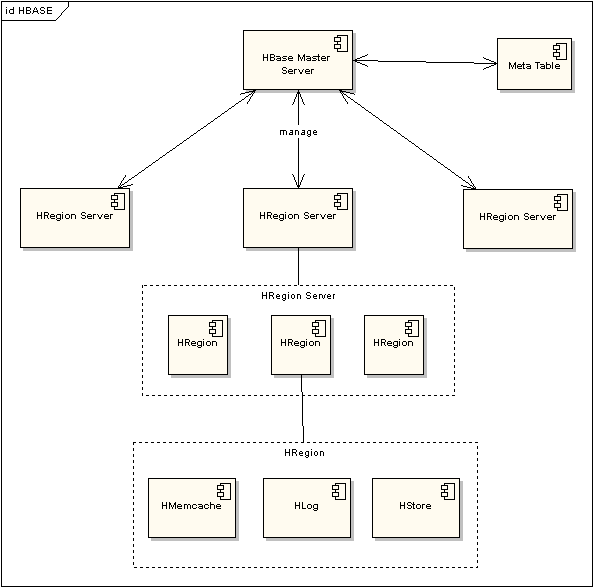
图1 框架结构图
HBASE依托于Hadoop的HDFS作为存储基础,因此结构也很类似于Hadoop的Master-Slave模式,Hbase Master Server 负责管理所有的HRegion Server,但Hbase Master Server本身并不存储HBASE中的任何数据。HBASE逻辑上的Table被定义成为一个Region存储在某一台HRegion Server上,HRegion Server与Region的对应关系是一对多的关系。每一个HRegion在物理上会被分为三个部分:Hmemcache、Hlog、HStore,分别代表了缓存,日志,持久层。通过一次更新流程来看一下这三部分的作用:
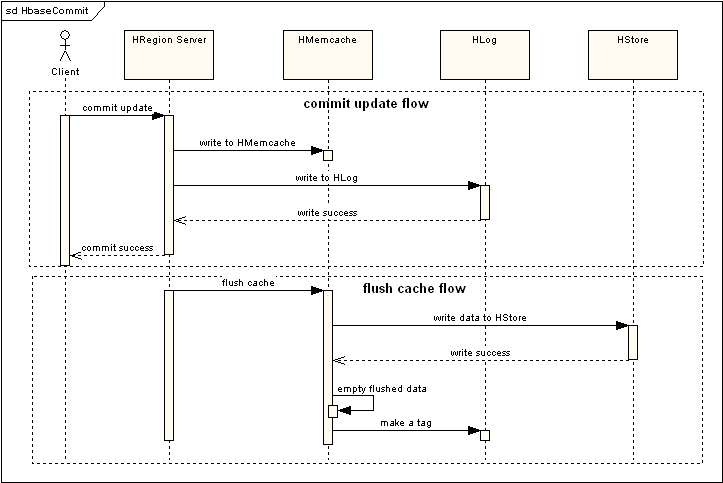
图2 提交更新以及刷新Cache流程
由流程可以看出,提交更新操作将会写入到两部分实体中,HMemcache和Hlog中,HMemcache就是为了提高效率在内存中建立缓存,保证了部分最近操作过的数据能够快速的被读取和修改,Hlog是作为同步Hmemcache和Hstore的事务日志,在HRegion Server周期性的发起Flush Cache命令的时候,就会将Hmemcache中的数据持久化到Hstore中,同时会清空Hmemecache中的数据,这里采用的是比较简单的策略来做数据缓存和同步,复杂一些其实可以参照java的垃圾收集机制来做。
在读取Region信息的时候,优先读取HMemcache中的内容,如果未取到再去读取Hstore中的数据。
几个细节:
1. 由于每一次Flash Cache,就会产生一个Hstore File,在Hstore中存储的文件会越来越多,对性能也会产生一定影响,因此达到设置文件数量阀值的时候就会Merge这些文件为一个大文件。
2. Cache大小的设置以及flush的时间间隔设置需要考虑内存消耗以及对性能的影响。
3. HRegion Server每次重新启动的时候会将Hlog中没有被Flush到Hstore中的数据再次载入到Hmemcache,因此Hmemcache过大对于启动的速度也有直接影响。
4. Hstore File中存储数据采用B-tree的算法,因此也支持了前面提到对于Column同Family数据操作的快速定位获取。
5. HRegion可以Merge也可以被Split,根据HRegion的大小决定。不过在做这些操作的时候HRegion都会被锁定不可使用。
6. Hbase Master Server通过Meta-info Table来获取HRegion Server的信息以及Region的信息,Meta最顶部的一个Region是虚拟的一个叫做Root Region,通过Root Region可以找到下面各个实际的Region。
7. 客户端通过Hbase Master Server获得了Region所在的Region Server,然后就直接和Region Server进行交互,而对于Region Server相互之间不通信,只和Hbase Master Server交互,受到Master Server的监控和管理。
后话
对HBase还没有怎么使用,仅仅只是看了wiki去了解了一下结构和作用,暂时还没有需要使用的场景,不过对于各种开源项目的设计有所了解,对自己的框架结构设计也会有很多帮助,因此分享一下。