
2012年6月25日
Linux中JDK1.6的安装和配置方法
一、安装
创建安装目录,在/usr/java下建立安装路径,并将文件考到该路径下:
# mkdir /usr/java
1、jdk-6u11-linux-i586.bin 这个是自解压的文件,在linux上安装如下:
# chmod 755 jdk-6u11-linux-i586.bin
# ./jdk-6u11-linux-i586.bin (注意,这个步骤一定要在jdk-6u11-linux-i586.bin所在目录下)
在按提示输入yes后,jdk被解压。
出现一行字:Do you aggree to the above license terms? [yes or no]
安装程序在问您是否愿意遵守刚才看过的许可协议。当然要同意了,输入"y" 或 "yes" 回车。
2、若是用jdk-6u11-linux-i586-rpm.bin 这个也是一个自解压文件,不过解压后的文件是jdk-6u11-linux-i586-rpm 包,执行rpm命令装到linux上就可以了。安装如下:
#chmod 755 ./jdk-6u11-linux-i586-rpm
# ./jdk-6u11-linux-i586-rpm .bin
# rpm -ivh jdk-6u11-linux-i586-rpm
出现一行字:Do you aggree to the above license terms? [yes or no]
安装程序在问您是否愿意遵守刚才看过的许可协议。当然要同意了,输入"y" 或 "yes" 回车。
安装软件会将JDK自动安装到 /usr/java/目录下。
二、配置
#vi /etc/profile
在里面添加如下内容
export JAVA_HOME=/usr/java/jdk1.6.0_27
export JAVA_BIN=/usr/java/jdk1.6.0_27/bin
export PATH=$PATH:$JAVA_HOME/bin
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export JAVA_HOME JAVA_BIN PATH CLASSPATH
让/etc/profile文件修改后立即生效 ,可以使用如下命令:
# . /etc/profile
注意: . 和 /etc/profile 有空格.
重启测试
java -version
set 查看环境变量
pwd 显示当前位置
posted @
2014-04-25 17:26 hoojo 阅读(398) |
评论 (0) |
编辑 收藏samba文件共享服务可以让linux和linux系统、linux和windows系统之间共享文件
服务查询
默认情况下,Linux系统在默认安装中已经安装了Samba服务包的一部分,为了对整个过程有一个完整的了解,在此先将这部分卸载掉。使用命令
rpm -qa | grep samba,默认情况下可以查询到两个已经存在的包:
samba-client-xxx-xxx
samba-common-xxx.xxx
卸载Samba
用rpm -e 将两个包卸载掉。对于samba-common-xxx.xxx,因为与其它rpm包之间存在依赖关系,所以必须加参数-f和--nodeps,-f是指强制,--nodeps是指不检查依赖关系,具体完整命令为:
rpm -e samba-common-xxx -f --nodeps
rpm -e samba-client-xxx -f –nodeps
挂在镜像文件
因为安装samba你需要下载对应的安装包,一般系统盘就有这些软件,所以可以直接挂载上去
mount -o loop /home/rhel-server-6.2-x86_64-dvd.iso /media/OS
这样就将系统盘挂载到指定的OS目录了,在OS目录下的Packages下有很多安装包可以使用。
安装Samba
用以下命令安装:
rpm -ivh samba-xxx.rpm -f --nodeps
rpm -ivh samba-client-xxx.rpm -f --nodeps
rpm -ivh samba-common-xxx.rpm -f --nodeps
安装完成后,使用命令rpm -qa | grep samba进行查询,发现搭建samba服务器所依赖的所有服务器都已经安装好了即可。
安装完成后配置/etc/samba/smb.conf配置文件,你可以备份原来的配置,把下面的配置覆盖当前配置即可:
[global]
workgroup=takecar
netbios name=Linux-108.12
server string=Linux Samba Server TestServer
#security=share
security=user
map to guest=Bad User
[takecar]
path=/opt/takecar
writable=yes
browseable=yes
guest ok=yes
以上就是配置匿名用户共享目录/opt/takecar
其中writable是写入权限、browseable是浏览权限、guest是贵宾用户
建立相应目录并授权
[root@localhost ~]# mkdir -p /opt/linuxsir
[root@localhost ~]# id nobody
uid=99(nobody) gid=99(nobody) groups=99(nobody)
[root@localhost ~]# chown -R nobody:nobody /opt/linuxsir
注释:关于授权nobody,我们先用id命令查看了nobody用户的信息,发现他的用户组也是nobody,我们要以这个为准。有些系统nobody用户组并非是nobody ;
启动smbd和nmbd服务器
[root@localhost ~]# smbd
[root@localhost ~]# nmbd
关闭和查询服务
pkill smbd
pkill nmbd
pgrep smbd
pgrep nmbd
如果启动后不能访问可能是防火墙原因,关闭防火墙
service iptables stop
chkconfig iptables off
设置服务开机启动 ntsysv命令可以进入图形界面设置,如果windows不能建立linux的共享目录可能是window中的某个服务原因。
可以在运行输入 secpol.msc命令 进入本地策略/安全选项, 设置
直接用进程杀死程序
ps -ef|grep smb
kill -9 pid #pid 为相应的进程号
#直接查看指定端口的进程pid
netstat -anp|grep 9217
posted @
2014-04-25 17:24 hoojo 阅读(487) |
评论 (0) |
编辑 收藏
摘要: oracle job有定时执行的功能,可以在指定的时间点或每天的某个时间点自行执行任务。 一、查询系统中的job,可以查询视图 --相关视图select * from dba_jobs;select * from all_jobs;select * from user_jobs;-- 查询字段描述/*字段(列) 类型 描述JOB ...
阅读全文
posted @
2013-11-21 10:55 hoojo 阅读(2845) |
评论 (2) |
编辑 收藏
// 方式一:
double f = 3.1516;
BigDecimal b = new BigDecimal(f);
double f1 = b.setScale(2, BigDecimal.ROUND_HALF_UP).doubleValue();
// 方式二:
new java.text.DecimalFormat("#.00").format(3.1415926);// #.00 表示两位小数 #.0000四位小数 以此类推…
// 方式三:
double d = 3.1415926;
String result = String.format("%.2f", d);// %.2f %. 表示 小数点前任意位数 2 表示两位小数 格式后的结果为f 表示浮点型。
//方法四:
Math.round(5.2644555 * 100) * 0.01d;
//String.format("%0" + 15 + "d", 23) 23不足15为就在前面补0posted @
2013-11-15 15:13 hoojo 阅读(674) |
评论 (0) |
编辑 收藏在使用cxf实现webservice时,经常碰到的问题就是如果在服务端,修改了一个接口的签名实现,如增加一个字段,或者删除一个字段。在这种情况下,在默认的配置中,就会报以下的错误信息:
org.apache.cxf.interceptor.Fault: Unmarshalling Error: unexpected element . Expected elements are
这种错误即客户端使用的传输对象与服务端接收的参数的字段不匹配。但如果,每次修改服务端的实现,都需要更新客户端时,就会出现一些问题,如在某些情况下,客户端的更新是不可能的事(如不在自己掌握之内,或者服务不能随便更新,或者其它计划时)。
如果避免这种问题,其实也很简单,就是禁用cxf中的字段信息验证,如果禁用掉此验证,就不再会对相应的字段信息进行验证,同时没有的字段也会自动的忽略。整个解决只需要增加以下的一行配置即可,在cxf.xml(spring集成文件)中增加以下配置项:
<cxf:properties>
<entry key="set-jaxb-validation-event-handler" value="false"/>
</cxf:properties>
这样,即会禁用掉所有cxf的数据验证,在大多数情况下,这可以满足我们的要求(除非你有其它和cxf集成的数据验证要求)。
转载请标明出处:i flym
本文地址:http://www.iflym.com/index.php/code/201307310001.html
posted @
2013-11-12 13:45 hoojo 阅读(961) |
评论 (0) |
编辑 收藏
摘要: 副标题:利用ant脚本 自动构建svn增量/全量 系统程序升级包 首先请允许我这样说,作为开发或测试,你一定要具备这种本领。你可以手动打包、部署你的工程,但这不是最好的方法。最好的方式就是全自动化的方式。开发人员提交了代码后,可以自动构建、打包、部署到测试环境。测试通过后进入到模拟环境或是直接发布的生产环境,这个过程可以是全自动的。但这个自动化的方式有一些公司用到了,但也有很多公司还不知道,他们...
阅读全文
posted @
2013-11-05 09:01 hoojo 阅读(17070) |
评论 (2) |
编辑 收藏ant 命令行方式执行build javac编译class出现 泛型无法转换 无法确定 <X>X 的类型参数;对于上限为 X,java.lang.Object 的类型变量 X,不存在唯一最大实例
解决方法:
需要用到eclipse的jdt来编译class,不能再使用javac的默认编译方式。
在eclipse或MyEclipse的eclipse/plugin目录中找到org.eclipse.jdt.core_3.5.2.v_981_R35x.jar里面找到jdtCompilerAdapter.jar
还有
org.eclipse.jdt.compiler.tool_1.0.100.v_972_R35x.jar
org.eclipse.jdt.core_3.5.2.v_981_R35x.jar
org.eclipse.jdt.debug.ui_3.4.1.v20090811_r351.jar
jdtCompilerAdapter.jar
并拷贝到ant_home/lib下。
在ant的build.xml脚本中加入
<property name="build.compiler" value="org.eclipse.jdt.core.JDTCompilerAdapter"/>
<javac nowarn="false" debug="true" debuglevel="source,lines,vars" destdir="${dist.path}/classes" source="1.6" target="1.6" encoding="utf-8" fork="true" memoryMaximumSize="512m" includeantruntime="false">
或者
<javac compiler="org.eclipse.jdt.core.JDTCompilerAdapter" nowarn="false" debug="true" debuglevel="source,lines,vars" destdir="${dist.path}/classes" source="1.6" target="1.6" encoding="utf-8" fork="true" memoryMaximumSize="512m" includeantruntime="false"/>
如果是用eclipse运行ant脚本,在右键菜单选择从RUN as Ant 启动build.xml时,在对话框中 选择Runtime jRE:run in the same JRE as workspace.

记得要引入上面需要的几个jar包
posted @
2013-10-31 14:10 hoojo 阅读(5033) |
评论 (2) |
编辑 收藏
摘要: 一、摘要 上两篇文章分别介绍了Spring3.3 整合 Hibernate3、MyBatis3.2 配置多数据源/动态切换数据源 方法 和 Spring3 整合Hibernate3.5 动态切换SessionFactory (切换数据库方言),这篇文章将介绍Spring整合Mybatis 如何完成SqlSessionFactory的动态切换的。并且会简单的介绍下MyBatis整合Spring中的...
阅读全文
posted @
2013-10-22 10:27 hoojo 阅读(17021) |
评论 (3) |
编辑 收藏
摘要: 一、缘由 上一篇文章Spring3.3 整合 Hibernate3、MyBatis3.2 配置多数据源/动态切换数据源 方法介绍到了怎么样在Sping、MyBatis、Hibernate整合的应用中动态切换DataSource数据源的方法,但最终遗留下一个问题:不能切换数据库方言。数据库方言可能在当前应用的架构中意义不是很大,但是如果单纯用MyBatis或Hibernate做数据库持久化操作,还...
阅读全文
posted @
2013-10-18 12:13 hoojo 阅读(8128) |
评论 (8) |
编辑 收藏
摘要: 一、开篇 这里整合分别采用了Hibernate和MyBatis两大持久层框架,Hibernate主要完成增删改功能和一些单一的对象查询功能,MyBatis主要负责查询功能。所以在出来数据库方言的时候基本上没有什么问题,但唯一可能出现问题的就是在hibernate做添加操作生成主键策略的时候。因为我们都知道hibernate的数据库本地方言会针对不同的数据库采用不同的主键生成策略。 所以针对这一问...
阅读全文
posted @
2013-10-12 10:53 hoojo 阅读(12397) |
评论 (5) |
编辑 收藏
摘要: 基于HTTP的长连接,是一种通过长轮询方式实现"服务器推"的技术,它弥补了HTTP简单的请求应答模式的不足,极大地增强了程序的实时性和交互性。 一、什么是长连接、长轮询? 用通俗易懂的话来说,就是客户端不停的向服务器发送请求以获取最新的数据信息。这里的“不停”其实是有停止的,只是我们人眼无法分辨是否停止,它只是一种快速的停下然后又立即开始连接而已。 二、长连接...
阅读全文
posted @
2013-09-26 14:41 hoojo 阅读(7208) |
评论 (2) |
编辑 收藏
UML是一种通用的建模语言,其表达能力相当的强,不仅可以用于软件系统的建模,而且可用于业务建模以及其它非软件系统建模。UML综合了各种面向对象方法与表示法的优点,至提出之日起就受到了广泛的重视并得到了工业界的支持。
本章将按视图、模型元素、图以及公共机制依次介绍UML的构造和基本元素,以使得读者对UML有一个总体了解,其具体细节将在后续章节中详细描述。
画图工具:eDraw、jude


欢迎大家继续支持和关注我的博客:
http://hoojo.cnblogs.com
http://blog.csdn.net/IBM_hoojo
也欢迎大家和我交流、探讨IT方面的知识。
email:hoojo_@126.com
如果你觉得本文不错的话,请你点击屏幕右下方的 。如果你以后会用到这篇文章的或觉得以后要重新翻阅的话,你可以点击屏幕右下角的
。如果你以后会用到这篇文章的或觉得以后要重新翻阅的话,你可以点击屏幕右下角的 。如果你觉得我的博文不错或是想在第一时间看到我的动态的话,你可以点击屏幕右下角
。如果你觉得我的博文不错或是想在第一时间看到我的动态的话,你可以点击屏幕右下角 。如果你想说点什么的话,你可以点击屏幕右下方的
。如果你想说点什么的话,你可以点击屏幕右下方的 。如果你都点过了,那真的太谢谢你了,兄弟太支持了。此时,或许你可以点击
。如果你都点过了,那真的太谢谢你了,兄弟太支持了。此时,或许你可以点击 按钮,然后看看博文的导航继续浏览其他文章。
按钮,然后看看博文的导航继续浏览其他文章。
1. UML的组成
UML由视图(View)、图(Diagram)、模型元素(Model Element)和通用机制(General Mechanism)等几个部分组成。
a) 视图(View): 是表达系统的某一方面的特征的UML建模元素的子集,由多个图构成,是在某一个抽象层上,对系统的抽象表示。
b) 图(Diagram): 是模型元素集的图形表示,通常是由弧(关系)和顶点(其他模型元素)相互连接构成的。
c) 模型元素(Model Element):代表面向对象中的类、对象、消息和关系等概念,是构成图的最基本的常用概念。
d) 通用机制(General Mechanism):用于表示其他信息,比如注释、模型元素的语义等。另外,UML还提供扩展机制,使UML语言能够适应一个特殊的方法(或过程),或扩充至一个组织或用户。

2. UML视图的分类
UML是用来描述模型的,用模型来描述系统的机构或静态特征,以及行为或动态特征。从不同的视角为系统构架建模,形成系统的不同视图。

(1) 用例视图(Use Case View),强调从用户的角度看到的或需要的系统功能,是被称为参与者的外部用户所能观察到的系统功能的模型图。
(2) 逻辑视图(Logical View),展现系统的静态或结构组成及特征,也称为结构模型视图(Structural Model View)或静态视图(Static View)。
(3) 并发视图(Concurrent View),体现了系统的动态或行为特征,也称为行为模型视图(Behavioral Model View)或动态视图(Dynamic View)。
(4) 组件视图(Component View),体现了系统实现的结构和行为特征,也称为实现模型视图(Implementation Model View)。
(5) 配置视图(Deployment View),体现了系统实现环境的结构和行为特征,也称为环境模型视图(Environment Model View)或物理视图(Physical View)。
视图是由图组成的,UML提供9种不同的图:

(1) 用例图(Use Case Diagram),描述系统功能;
(2) 类图(Class Diagram),描述系统的静态结构;
(3) 对象图(Object Diagram),描述系统在某个时刻的静态结构;
(4) 组件图(Component Diagram),描述了实现系统的元素的组织;
(5) 配置图(Deployment Diagram),描述了环境元素的配置,并把实现系统的元素映射到配置上;
(6) 状态图(State Diagram),描述了系统元素的状态条件和响应;
(7) 时序图(Sequence Diagram),按时间顺序描述系统元素间的交互;
(8) 协作图(Collaboration Diagram),按照时间和空间顺序描述系统元素间的交互和它们之间的关系;
(9) 活动图(Activity Diagram),描述了系统元素的活动;
建模方法由建模语言和建模过程两部分构成。其中建模语言是用来表述设计方法的表示法,建模过程是对设计中所应采取的步骤的描述。UML是一种建模语言,它在很大程度上独立于建模过程。在实际建模中,建模人员最好把UML用于以用案驱动的、以体系机构为中心的、迭代的和渐增式的开发过程中。
一般而言,软件系统的体系结构给出了软件系统的组织、组成系统的构造元素及其接口的选择、系统的行为和体系结构风格等信息。也就是说,它不仅关心系统的结构和行为等功能性需求,而且也涉及系统的性能、易理解性、易复用性等非功能性需求。如下图所示,UML利用用户模型视图、结构模型视图、行为模型视图、实现模型视图和环境模型视图来描述软件系统的体系结构。
根据它们在不同架构视图的应用,可以把9种图分成:

(1) 用户模型视图:用例图;
(2) 结构模型视图:类图和对象;
(3) 行为模型视图:状态图、时序图、协作图和活动图(动态图);
(4) 实现模型视图:组件图;
(5) 环境模型视图:配置图。
用户模型视图由专门描述最终用户、分析人员和测试人员看到的系统行为的用案组成,它实际上是从用户角度来描述系统应该具有的功能。用户模型视图所描述的系统功能依靠外部用户或者另外一个系统来激活,为用户或者另一系统提供服务,从而实现用户或另一系统与系统的交互。系统实现的最终目标是提供用户模型视图中所描述的功能。在UML中,用户模型视图是由用案图组成。
结构模型视图描述组成系统的类、对象以及它们之间的关系等静态结构,用来支持系统的功能需求,即描述系统内部功能是如何设计的。结构模型视图由类图和对象图构成,主要供设计人员和开发人员使用。
行为模型视图主要用来描述形成系统并发与同步机制的线程和进程,其关注的重点是系统的性能、易伸缩性和系统的吞吐量等非功能性需求。行为模型视图利用并发来描述资源的高效使用、并行执行和处理异步事件。除了讲系统划分为并发执行的控制线程之外,行为模型还必须处理通信和这些线程及进程之间的同步问题。行为模型视图主要供系统开发人员和系统集成人员使用,它由序列图、协作图、状态图和活动图组成。
实现模型视图用来描述系统的实现模块它们之间的依赖关系以及资源分配情况。这种视图主要用于系统的配置管理,它是由一些独立的构件组成的。实现模型视图由构件图组成。其中构件是代码模块,不同类型的代码模块形成不同的构件。实现模型视图主要供开发人员使用。
环境模型视图用来描述物理系统的硬件拓扑结构。例如,系统中的计算机和设备的分布情况以及它们之间的连接方式,其中计算机和设备统称为节点。在UML中环境模型视图是由部署图来表示的。系统部署图描述了系统构件在节点上的分布情况,即用来描述软件构件到物理节点的映射。部署图主要供开发人员、系统集成人员和测试人员使用。
上面每一种视图反映了系统的一个特定方面,不同人员可以单独的使用其中每一种视图,从而可以关注特定的体系结构问题。但在通常情况下,由于系统的最终目标是提供用户模型视图中描述的功能以及其它一些非功能性需求,因此,用户模型视图是其它视图的核心基础,其它视图的构造都依赖与用户模型视图中所描述的类容。
细心的读者已经发现,每一种UML图都是由多个图组成的,每一种图都是体系结构某个侧面的表示,各种图实际上是一致的,所有的图在一起组成了系统的完整视图。如下图所示,UML中总共提供了用案图、类图、对象图、序列图、协作图、状态图、活动图、构建图和部署图9种图。根据它们描述的是系统的静态结构还是动态行为,可以将它们分为静态图和动态图两类。再进一步介绍这9中UML图时,先了解下什么是模型元素:

3. UML的建模机制
UML有两套建模机制:静态建模机制和动态建模机制。静态建模机制包括用例图、类图、对象图、包、组件图和配置图。动态建模机制包括状态图、时序图、协作图、活动图。
(1) 用例图:用例的可视化工具,它提供计算机系统的高层次的用户视图,表示以外部活动者的角度来看系统将是怎样使用的。
用例图(用案图)是用于描述一组用案,参与者以及它们之间的连接关系。一个用案图描述了一组动作序列,每一个序列表示系统的外部设施(系统的参与者)与系统本身的交互。从一个特定参与者的角度看,一个用案完成对其有价值的工作。如图2.5所示,用案图仅仅是从参与者使用系统的角度来描述系统中的信息,即站在系统外部查看系统应该具有什么功能,而并不描述该功能在软件内部是如何实现的。用案可以应用于整个系统,也可以应用于系统的一个部分,包括子系统、单个的类或者接口。通常,用案不仅代表这些元素所期望的行为,而且还可以把这些元素用作开发过程中测试用案的基础。
用例图包括以下3方面内容:
(a) 用例(Use Case)
(b) 参与者(Actor)
(c) 依赖、泛化和关联关系
用例图示例:

(2) 类图:描述类、接口、协作以及它们之间关系的图。
类图是用于描述一组类、接口、协作以及它们之间的静态关系。在面向对象系统的建模中,类图是最为常用的图,它用来阐明系统的静态结构。事实上类是对一组具有相同属性、操作、关系和语义的对象的描述,其中对类的属性和操作进行描述时的一个最重要的细节就是它的可见性。
类可以以多种形式连接,例如关联、泛化、依赖和实现等。一个典型的系统中通常有若干个类图。一个类图不一定要包含系统中所有的类,一个类可以加到几个类图中。
类图示例:

(3) 对象图:表示在某一时间上一组对象以及它们之间的关系的图。对象图可以被看做是类图在系统某一时刻的实例。
对象图是类图的实例,用来描述特定运行时刻一组对象之间的关系。也就是说,对象用于描述交互的静态部分,它由参与协作的有关对象组成。但不包括在对象之间传递的任何消息。
在创建对象图时,建模人员并不需要用单个的对象图来描述系统中的每一个对象。事实上,绝大多数系统中都会包含成百上千的对象。用对象来描述系统的所有对象以及它们之间的关系一般是不太现实的。因此,建模人员可以选择所感兴趣的对象极其之间的关系来描述。
对象图中所使用的符号和类图中使用的符号几乎完全相同,区别仅在于对象图的对象名带有下划线,而且类与类之间关系的所有的实例都要画出来。

(4) 组件图:描述软件组件以及组件之间的关系,组件本身是代码的物理模块,组件图则显示了代码的结构。
组件图(构件图)是用于描述一组构件之间的组织和依赖关系,用于建模系统的静态实现视图。构件可以是可执行程序集、库、表、文件和文档等,它包含了逻辑类或者逻辑类的实现信息,因此结构模型视图和实现模型视图之间存在映射关系。
构建图中也可以包括包或子系统,它们都是用于将模型元素组成较大的组块。
组件图例图:

(5) 配置图:描述系统硬件的物理拓扑结构以及在此结构上执行的软件。配置图可以显示计算节点的拓扑结构和通信路径、结点上运行的软件组件、软件组件包含的逻辑单元(对象、类)等。配置图常常用于帮助理解分布式系统。
配置图(部署图)用来描述系统运行是进行处理的节点以及在节点上活动的构件的配置。部署图用来对系统的环境模型视图进行建模。在大多数情况下,部署图用来描述系统硬件的扩普结构。
在UML中,建模人员可以用类图来描述系统的静态结构,可以用序列图、协作图、状态图、活动图来描述系统的动态行为,而用部署图来描述软件所执行所需的处理器和设备的拓扑结构。

(6) 状态图:通过类对象的生命周期建立模型来描述对象随时间变化的动态行为。
状态图实际上是一种由状态、变迁、事件和活动组成的状态机。状态图描述从状态到状态的控制流,常用于系统的动态特性建模。在大多数情况下,它用来对反应型对象的行为建模。
在UML中,状态图可以用来对一个对象按事件排序的行为建模。一个状态图是强调从状态到状态的控制流的状态机的简单表示。一般而言,状态图是对类所描述的设施的补充说明,它描述了类的所有对象可能具有的状态以及引起状态变化的事件。

(7) 时序图:交互图描述了一个交互,它由一组对象和它们之间的关系组成,并且还包括在对象间传递的信息。交互图表达对象之间的交互,是描述一组对象如何协作完成某个行为的模型化工具。
序列图和协作图统称为交互图。其中,序列图用来描述对象之间消息发送的先后次序,阐明对象之间的交互过程以及在系统执行过程中的某一具体时刻将会发生什么事件。序列图是一种强调时间顺序的交互图,其中对象沿横轴方向排列,消息沿纵轴方向排列。
![Product-seq[6]](http://www.blogjava.net/images/blogjava_net/hoojo/WindowsLiveWriter/UMLUML_E9F6/Product-seq%5B6%5D_thumb.png "Product-seq[6]")
序列图中的对象生命线是一条垂直的虚线,它表示一个对象在一段时间内存在。由于序列图中大多数对象都存在于整个交互过程中,因此这些对象全部排列在图的顶部,它们的生命线从图的顶部画到图的底部。每个对象的下方有一个矩形条,它与对象的生命线重叠,它表示该对象的控制焦点。序列图中的消息可以有序号,但由于这种图上的消息已经从纵轴上按时间顺序排序,因此消息序号通常予以省略。
(8) 协作图:包含类元角色和关联角色,而不仅仅是类元和关联。协作图强调参加交互的各对象的组织。协作图只对相互间有交互作用的对象和这些对象间的关系建模,而忽略了其他对象和关联。协作图也是一种交互图,它强调收发消息的对象的组织结构。
协作图和序列图是协作的,它们可以互相转换。在多数情况下,协作图主要对单调的、顺序的控制流建模,但它也可以用来对包括迭代和分支在内的复杂控制流进行建模。
一般而言,建模人员可以创建多个协作图,其中一些是主要的,另外一些是可选择的路径或者异常条件。建模人员可以用包来组织这些协作图,并给每个图起一个合适的名字,以便与其它图区别开。

(9) 活动图:用于展现参与行为的类的活动或动作。
活动图是状态图的一种特殊情况,其中几乎所有或大多数状态都处于活动状态,而且几乎所有或者大多数变迁都是由源状态中活动的完成触发的。活动图本质上是一种流程图,它描述了从活动到活动的控制流。
可以把活动图看作是新样的交互图,但交互图观察的是传递消息的对象,而活动图观察到的是对象之间传送的消息。尽管两者在语义上的区别很细微,但它们使用不同的方式来看系统的。

如果你觉得本文不错的话,请你点击屏幕右下方的 。如果你以后会用到这篇文章的或觉得以后要重新翻阅的话,你可以点击屏幕右下角的 。如果你觉得我的博文不错或是想在第一时间看到我的动态的话,你可以点击屏幕右下角 。如果你想说点什么的话,你可以点击屏幕右下方的 。如果你都点过了,那真的太谢谢你了,兄弟太支持了。此时,或许你可以点击 按钮,然后看看博文的导航继续浏览其他文章。
最后,欢迎大家继续支持和关注我的博客:
http://hoojo.cnblogs.com
http://blog.csdn.net/IBM_hoojo
也欢迎大家和我交流、探讨IT方面的知识。
posted @
2013-08-30 16:52 hoojo 阅读(2283) |
评论 (2) |
编辑 收藏
摘要: 在flex组件中嵌入html代码,可以利用flex iframe。这个在很多时候会用到的,有时候flex必须得这样做,如果你不这样做还真不行…… flex而且可以和html进行JavaScript交互操作,flex调用到html中的JavaScript方法以及获取调用后的返回值。 1、flex iframe下载地址:https://github.com/downloads/flex...
阅读全文
posted @
2013-08-15 15:58 hoojo 阅读(5879) |
评论 (2) |
编辑 收藏一、UML中的六大关系
在UML类图中,常见的有以下几种关系: 泛化(Generalization), 实现(Realization),关联(Association),聚合(Aggregation),组合(Composition),依赖(Dependency)。

1.1、 继承关系—泛化(Generalization)
指的是一个类(称为子类、子接口)继承另外的一个类(称为父类、父接口)的功能,并可以增加它自己的新功能的能力,继承是类与类或者接口与接口之间最常见的关系;在Java中用extends关键字。

【泛化关系】是一种继承关系,表示一般与特殊的关系,它指定了子类如何特化父类的所有特征和行为。例如:猫头鹰是鸟的一种,即有鸟的特性也有猫头鹰的共性。
【箭头指向】带三角箭头的实线,箭头指向父类。
【描述】上图中的类bird有嘴、翅膀、羽毛等属性。会飞、会唧唧喳喳的叫,那么就有这些方法。而猫头鹰有大眼睛和捕捉老鼠的本领,这则是自身的特性。
1.2、 实现关系(Realization)
指的是一个class类实现interface接口(可以是多个)的功能;实现是类与接口之间最常见的关系;在Java中此类关系通过关键字implements明确标识。

【实现关系】是一种类与接口的关系,表示类是接口所有特征和行为的实现.
【箭头指向】带三角箭头的虚线,箭头指向接口。
【描述】上图中IFly是一个接口,接口中有时间、速度等常量,还有一个fly方法。FlyImpl继承了这个IFly接口后,需要实现fly方法,同时实现类也可以拥有自己的属性和方法。
1.3、 依赖(Dependency)
可以简单的理解,就是一个类A使用到了另一个类B,而这种使用关系是具有偶然性的、临时性的、非常弱的,但是B类的变化会影响到A;比如某人要过河,需要借用一条船,此时人与船之间的关系就是依赖;表现在代码层面,为类B作为参数、属性被类A在某个method方法中使用;

【依赖关系】是一种使用的关系,即一个类的实现需要另一个类的协助,所以要尽量不使用双向的互相依赖。
【代码表现】局部变量、方法的参数或者对静态方法的调用
【箭头及指向】带箭头的虚线,指向被使用者
【描述】Bird类中有一个setFly方法,它需要使用者用到IFly接口的实现,那么这种关系就是依赖关系。
1.4、 关联
他体现的是两个类、或者类与接口之间语义级别的一种强依赖关系,比如我和我的朋友;这种关系比依赖更强、不存在依赖关系的偶然性、关系也不是临时性的,一般是长期性的,而且双方的关系一般是平等的、关联可以是单向、双向的;表现在代码层面,为被关联类B以类属性的形式出现在关联类A中,也可能是关联类A引用了一个类型为被关联类B的全局变量;

【关联关系】是一种拥有的关系,它使一个类知道另一个类的属性和方法;如:老师与学生,丈夫与妻子关联可以是双向的,也可以是单向的。双向的关联可以有两个箭头或者没有箭头,单向的关联有一个箭头。
【代码体现】成员变量
【箭头及指向】带普通箭头的实心线,指向被拥有者
【描述】在Bird类中有一个IFly类型的fly属性,需要提供IFly的接口实现。Bird对象会利用IFly接口的实现完成fly方法。
1.4.1、双向关联
双方都知道对方的存在,都可以调用对方的公共属性、方法。

【关联关系】双方都有关联的关系,通过自身对对方关联的属性来访问对方的属性和方法。
【代码体现】成员变量
【箭头及指向】用不带箭头的实线连接双方
【描述】在中国一个妻子只能嫁给一个丈夫,一个丈夫也只能取一个妻子。
1.4.2、自身关联
自己关联自己,这种情况比较少出现但是也有用到。

【自关联关系】双方都有关联的关系,通过自身对自身关联的属性引用来访问对方的属性和方法。
【代码体现】成员变量
【箭头及指向】用带普通箭头的实线连接自己
【描述】在盗梦空间中,演员需要在梦中再造梦,这种梦中梦的情况跟上图描述很符合。
1.5、 聚合(Aggregation)
聚合是关联关系的一种特例,他体现的是整体与部分、拥有的关系,即has-a的关系,此时整体与部分之间是可分离的,他们可以具有各自的生命周期,部分可以属于多个整体对象,也可以为多个整体对象共享;比如计算机与CPU、公司与员工的关系等;表现在代码层面,和关联关系是一致的,只能从语义级别来区分;

【聚合关系】是整体与部分的关系,且部分可以离开整体而单独存在。如车和轮胎是整体和部分的关系,轮胎离开车仍然可以存在。聚合关系是关联关系的一种,是强的关联关系;关联和聚合在语法上无法区分,必须考察具体的逻辑关系。
【代码体现】成员变量
【箭头及指向】带空心菱形的实心线,菱形指向整体
【描述】birdChild一只鸟有很多鸟宝宝,所以自引用。鸟有很多不同数量和颜色的羽毛,所以引用关系是0~*。
1.6、 组合(Composition)
组合也是关联关系的一种特例,他体现的是一种contains-a的关系,这种关系比聚合更强,也称为强聚合;他同样体现整体与部分间的关系,但此时整体与部分是不可分的,整体的生命周期结束也就意味着部分的生命周期结束;比如你和你的大脑;表现在代码层面,和关联关系是一致的,只能从语义级别来区分;

【组合关系】是整体与部分的关系,但部分不能离开整体而单独存在。如公司和部门是整体和部分的关系,没有公司就不存在部门。组合关系是关联关系的一种,是比聚合关系还要强的关系,它要求普通的聚合关系中代表整体的对象负责代表部分的对象的生命周期。
【代码体现】成员变量
【箭头及指向】带实心菱形的实线,菱形指向整体
【描述】一个学校由多个班级组成,班级离开学校也就不存在、而学校离开班级也不成立。像这种不可分离的关系就需要用组合。
综合示例

对于继承、实现这两种关系没多少疑问,他们体现的是一种类与类、或者类与接口间的纵向关系;其他的四者关系则体现的是类与类、或者类与接口间的引用、横向关系,是比较难区分的,有很多事物间的关系要想准备定位是很难的,前面也提到,这几种关系都是语义级别的,所以从代码层面并不能完全区分各种关系;但总的来说,后几种关系所表现的强弱程度依次为:泛化 = 实现 > 组合 > 聚合 > 关联 > 依赖。
posted @
2013-08-01 16:17 hoojo 阅读(2451) |
评论 (5) |
编辑 收藏异常信息如下:
org.springframework.beans.ConversionNotSupportedException: Failed to convert property value of type 'java.util.Date' to required type 'java.sql.Timestamp' for property 'wfsj'; nested exception is java.lang.IllegalStateException: Cannot convert value of type [java.util.Date] to required type [java.sql.Timestamp] for property 'wfsj': no matching editors or conversion strategy found
at org.springframework.beans.BeanWrapperImpl.convertIfNecessary(BeanWrapperImpl.java:463)
at org.springframework.beans.BeanWrapperImpl.convertForProperty(BeanWrapperImpl.java:494)
at org.springframework.beans.BeanWrapperImpl.setPropertyValue(BeanWrapperImpl.java:1097)
at org.springframework.beans.BeanWrapperImpl.setPropertyValue(BeanWrapperImpl.java:882)
at org.springframework.flex.core.io.SpringPropertyProxy.setValue(SpringPropertyProxy.java:182)
at flex.messaging.io.amf.Amf3Input.readScriptObject(Amf3Input.java:438)
at flex.messaging.io.amf.Amf3Input.readObjectValue(Amf3Input.java:152)
at flex.messaging.io.amf.Amf3Input.readObject(Amf3Input.java:130)
at flex.messaging.io.amf.Amf3Input.readArray(Amf3Input.java:358)
…………
at flex.messaging.io.amf.AmfMessageDeserializer.readObject(AmfMessageDeserializer.java:227)
at flex.messaging.io.amf.AmfMessageDeserializer.readBody(AmfMessageDeserializer.java:206)
at flex.messaging.io.amf.AmfMessageDeserializer.readMessage(AmfMessageDeserializer.java:126)
at flex.messaging.endpoints.amf.SerializationFilter.invoke(SerializationFilter.java:145)
at flex.messaging.endpoints.BaseHTTPEndpoint.service(BaseHTTPEndpoint.java:291)
at flex.messaging.endpoints.AMFEndpoint$$EnhancerByCGLIB$$6f090fa2.service(<generated>)
at org.springframework.flex.servlet.MessageBrokerHandlerAdapter.handle(MessageBrokerHandlerAdapter.java:109)
…………
Caused by: java.lang.IllegalStateException: Cannot convert value of type [java.util.Date] to required type [java.sql.Timestamp] for property 'wfsj': no matching editors or conversion strategy found
at org.springframework.beans.TypeConverterDelegate.convertIfNecessary(TypeConverterDelegate.java:264)
at org.springframework.beans.BeanWrapperImpl.convertIfNecessary(BeanWrapperImpl.java:448)
... 59 more
看异常信息大概知道属性wfsj这个字段,不能完成java.util.Date 到 java.sql.Timestamp 日期时间戳的转换。后面还有提示, 没有找到匹配的conversion或editor。
conversion 在Spring中转换对象属性会用到,而editor和converter 以及formatter也是在转换对象(String –> Date, String –> Timestamp),从字符串到对象,从对象到字符串的时候会经常用到。
解决方法:
<bean id="customConfigProcessor" class="com.jp.tic.framework.flex.converter.CustomAmfConversionServiceConfigProcessor"/>
<flex:message-broker services-config-path="/WEB-INF/flex/services-config.xml">
<flex:exception-translator ref="flexExceptionTranslator" />
<flex:config-processor ref="configProcessor"/>
<flex:config-processor ref="customConfigProcessor"/>
<!--<flex:message-interceptor ref="flexMessageInterceptor" />
<flex:message-interceptor ref="loginMessageInterceptor" />-->
</flex:message-broker>
为message-broker对象注入CustomAmfConversionServiceConfigProcessor对象,CustomAmfConversionServiceConfigProcessor是继承AbstractAmfConversionServiceConfigProcessor对象。
AbstractAmfConversionServiceConfigProcessor对象中提供了对各个类型转换serialization/deserialization的方法。
package com.jp.tic.framework.flex.converter;
import java.util.HashSet;
import java.util.Set;
import org.springframework.flex.core.io.AbstractAmfConversionServiceConfigProcessor;
/**
* <b>function:</b> 自定义AMF转换服务
* @author hoojo
* @createDate 2013-7-17 下午01:35:12
* @file CustomAmfConversionServiceConfigProcessor.java
* @package com.jp.tic.framework.flex.converter
* @project JTZHJK-Server
* @blog http://blog.csdn.net/IBM_hoojo
* @email hoojo_@126.com
* @version 1.0
*/
public class CustomAmfConversionServiceConfigProcessor extends AbstractAmfConversionServiceConfigProcessor {
private static Set<Class<?>> classes = new HashSet<Class<?>>();
@Override
protected Set<Class<?>> findTypesToRegister() { return classes;
}
}
如果你还需要添加更多自己的转化服务,那么你需要给CustomAmfConversionServiceConfigProcessor 注入conversionService对象。
<!-- 添加配置类型转换器、转换服务 -->
<bean id="conversionService" class="org.springframework.format.support.FormattingConversionServiceFactoryBean">
<property name="converters">
<list>
<bean class="com.jp.tic.framework.mvc.convert.StringToTimestampConverter"/>
<bean class="com.jp.tic.framework.mvc.convert.DateToTimestampConverter"/>
</list>
</property>
<property name="formatters">
<list>
<bean class="com.jp.tic.framework.mvc.formatter.SimpleDateTimeFormatAnnotationFormatterFactory"/>
<bean class="com.jp.tic.framework.mvc.formatter.TimestampFormatterFactory"/>
</list>
</property>
</bean>
<bean id="customConfigProcessor" class="com.jp.tic.framework.flex.converter.CustomAmfConversionServiceConfigProcessor">
<property name="conversionService" ref="conversionService"/>
</bean>
posted @
2013-07-17 17:18 hoojo 阅读(4823) |
评论 (0) |
编辑 收藏
摘要: 一、 概述与介绍 ActiveMQ 是Apache出品,最流行的、功能强大的即时通讯和集成模式的开源服务器。ActiveMQ 是一个完全支持JMS1.1和J2EE 1.4规范的 JMS Provider实现。提供客户端支持跨语言和协议,带有易于在充分支持JMS 1.1和1.4使用J2EE企业集成模式和许多先进的功能。 二、 特性 1、 多种语言和协议编写客户端。语言: Java...
阅读全文
posted @
2013-06-27 09:09 hoojo 阅读(8723) |
评论 (2) |
编辑 收藏
摘要: 一、概述 ant 是一个将软件编译、测试、部署等步骤联系在一起加以自动化的一个工具,大多用于Java环境中的软件开发。在实际软件开发中,有很多地方可以用到ant。 开发环境: System:Windows JDK:1.6+ IDE:eclipse ant:1.9.1 Email:hoojo_@126.com Blog:http://blog.csdn....
阅读全文
posted @
2013-06-14 13:07 hoojo 阅读(7516) |
评论 (2) |
编辑 收藏 Eclipse下的Java反编译插件:Eclipse Class Decompiler,整合了目前最好的2个Java反编译工具Jad和JD-Core,并且和Eclipse Class Viewer无缝集成,能够很方便的使用本插件查看类库源码,以及采用本插件进行Debug调试。
转载自:http://bbs.csdn.net/topics/390263414
Eclipse Class Decompiler插件: http://download.csdn.net/detail/ibm_hoojo/5250263
下载后,解压可以看到如下目录,复制所有文件粘贴到你的eclipse或MyEclipse的目录:D:\MyEclipse 6.5\myeclipse\eclipse下,选择覆盖即可。然后重新启动eclipse。

下图为Eclipse Class Decompiler的首选项页面,可以选择缺省的反编译器工具,并进行反编译器的基本设置。缺省的反编译工具为JD-Core,JD-Core更为先进一些,支持泛型、Enum、注解等JDK1.5以后才有的新语法。
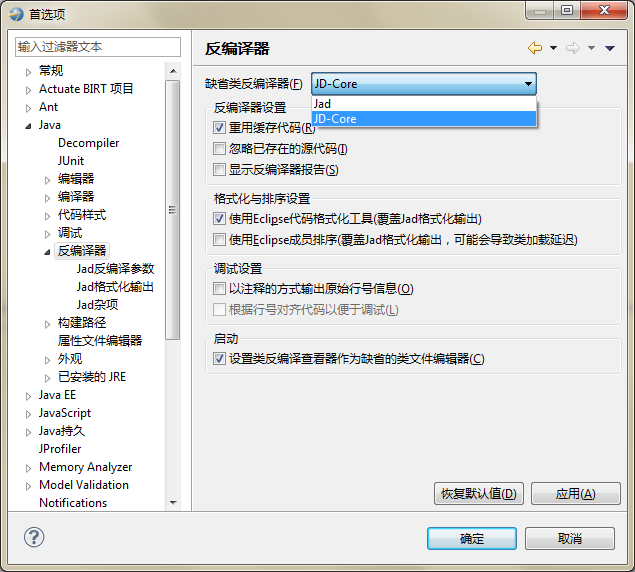
首选项配置选项:
1.重用缓存代码:只会反编译一次,以后每次打开该类文件,都显示的是缓存的反编译代码。
2.忽略已存在的源代码:若未选中,则查看Class文件是否已绑定了Java源代码,如果已绑定,则显示Java源代码,如果未绑定,则反编译Class文件。若选中此项,则忽略已绑定的Java源代码,显示反编译结果。
3.显示反编译器报告:显示反编译器反编译后生成的数据报告及异常信息。
4.使用Eclipse代码格式化工具:使用Eclipse格式化工具对反编译结果重新格式化排版,反编译整个Jar包时,此操作会消耗一些时间。
5.使用Eclipse成员排序:使用Eclipse成员排序对反编译结果重新格式化排版,反编译整个Jar包时,此操作会消耗大量时间。
6.以注释方式输出原始行号信息:如果Class文件包含原始行号信息,则会将行号信息以注释的方式打印到反编译结果中。
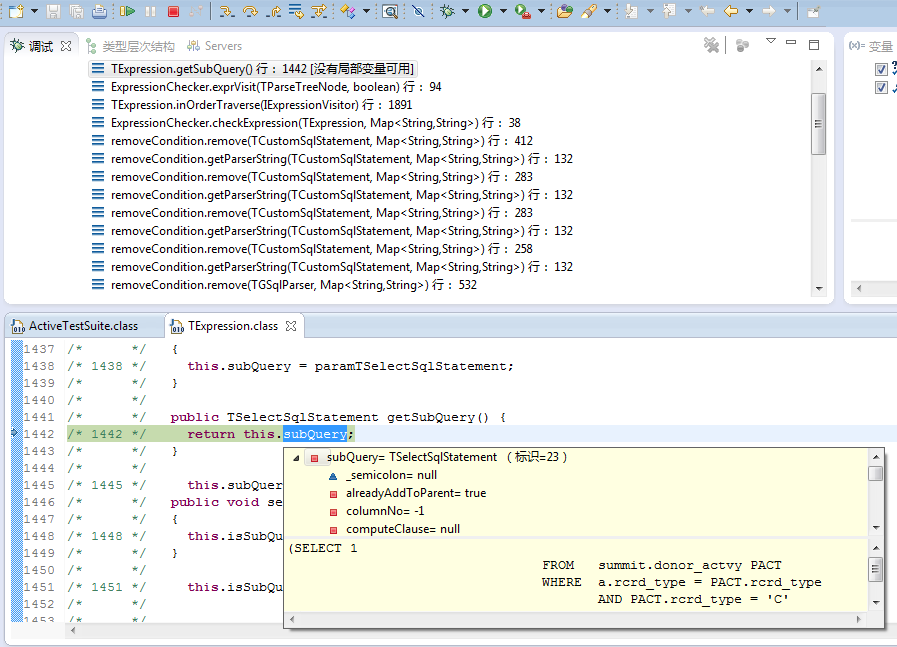
7.根据行号对齐源代码以便于调试:若选中该项,插件会采用AST工具分析反编译结果,并根据行号信息调整代码顺序,以便于Debug过程中的单步跟踪调试。
8.设置类反编译查看器作为缺省的类文件编辑器:默认为选中,将忽略Eclipse自带的Class Viewer,每次Eclipse启动后,默认使用本插件提供的类查看器打开Class文件。
插件提供了系统菜单,工具栏,当打开了插件提供的类反编译查看器后,会激活菜单和工具栏选项,可以方便的进行首选项配置,切换反编译工具重新反编译,以及导出反编译结果。
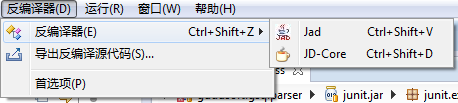

类反编译查看器右键菜单包含了Eclipse自带类查看器右键菜单的全部选项,并增加了一个“导出反编译源代码”菜单项。
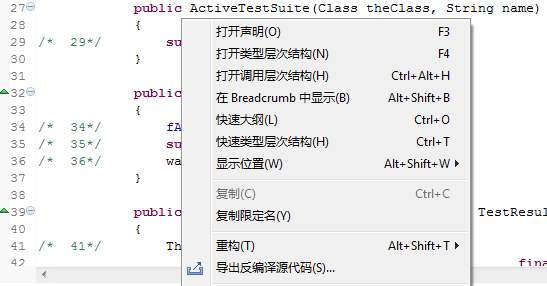
打开项目路径下的Class文件,如果设置类反编译查看器为缺省的查看器,直接双击Class文件即可,如果没有设置为缺省查看器,可以使用右键菜单进行查看。
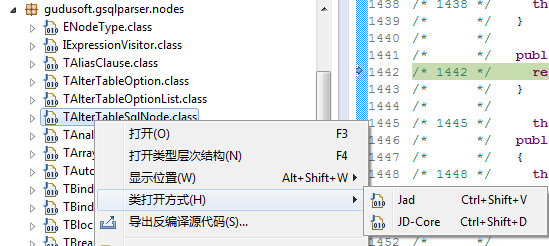
Eclipse Class Decompiler插件也提供了反编译整个Jar文件或者Java包的反编译。该操作支持Package Explorer对包显示布局的操作,如果是平铺模式布局,则导出的源代码不包含子包,如果是层级模式布局,则导出选中的包及其所有的子包。
Debug调试:可以在首选项选中对齐行号进行单步跟踪调试,和普通的包含源代码时的调试操作完全一致,同样的也可以设置断点进行跟踪。
转载:http://bbs.csdn.net/topics/390263414
posted @
2013-04-12 15:29 hoojo 阅读(1128) |
评论 (0) |
编辑 收藏
摘要: 上一篇文章介绍到怎么在自己的Java环境中搭建openfire插件开发的环境,同时介绍到怎样一步步简单的开发openfire插件。一步步很详细的介绍到简单插件开发,带Servlet的插件的开发、带JSP页面插件的开发,以及怎么样将开发好的插件打包、部署到openfire服务器。 如果你没有看上一篇文章的话,请你还是看看。http://www.cnblogs.com/hoojo/ar...
阅读全文
posted @
2013-03-29 11:03 hoojo 阅读(8654) |
评论 (0) |
编辑 收藏
摘要: 这篇是简单插件开发,下篇聊天记录插件。 开发环境: System:Windows WebBrowser:IE6+、Firefox3+ JavaEE Server:tomcat5.0.2.8、tomcat6 IDE:eclipse、MyEclipse 8 开发依赖库: Jdk1.6、jasper-compiler.jar、jasper-runtime.jar、openfire.jar...
阅读全文
posted @
2013-03-07 11:25 hoojo 阅读(10398) |
评论 (1) |
编辑 收藏 本人是做Java开发的,在程序开发中会经常使用到OpenSource开源框架,这些框架大多都灵活、简单、易用、方便。而且开源框架一般会提供一些基本的配置,如我们常用的框架就有Hibernate要配置对象实体到数据库的映射;Spring要配置bean的管理及其对象、属性的注入;Struts要配置Action对象和返回的资源路径;MyBatis要配置CRUD(增删改查)的相关SQL语句。这些配置你不能省略,必须得有,没有程序也不会自动添加。我们也是极可能的简化这些配置,不管怎么样简化但这些配置是不能省略,虽然这些框架给我们开发程序都提供了很大方面上的便利。
但有时候你是否有纠结这么样的一个问题:到底是用XML配置?还是用Annotation注解配置?或是用XML和Annotation混合配置?
首先看看两种配置的优缺点比较
XML它是无可代替的超文本标记语言,可读性、传输性好,它还具有一下优点:
1、可读性、传输性好:XML可扩展标记语言,最大的优势在于开发者能够为软件量身定制适用的标记,使代码可读性大大提升。
2、灵活性、易用性、扩展性、移植性好:利用XML配置能使软件更具扩展性。如Spring将class间的依赖配置在XML中,最大限度地提升应用的可扩展性。同样,如果是基于接口注入方式,可以随便切换接口实现类进行注入即可。
3、验证机制:具有成熟的验证机制确保程序正确性。利用Schema或DTD可以对XML的正确性进行验证,避免了非法的配置导致应用程序出错。
4、修改配置而无需变动现有程序、无需重新编译。
虽然XML有如此多的好处,但它也不是万能的,XML也有自身的缺点:
1、开发友好性支持:需要解析工具或类库的支持。如果你的XML配置需要用到XML的提示或是解析编译,需要用到Schema或DTD进行验证。
2、性能影响:解析XML势必会影响应用程序性能,占用系统资源。至少你会用到一些解析XML的技术去解析节点元素内容。
3、维护性高:配置文件过多导致管理变得困难。
4、编译期无法对其配置项的正确性进行验证,或要查错只能在运行期。如Spring Bean配置了一个错误的类路径class。
5、IDE 无法验证配置项的正确性无能为力。如Spring注入一个错误的对象或属性。
6、查错变得困难。往往配置的一个手误导致莫名其妙的错误。
7、开发人员不得不同时维护代码和配置文件,开发效率变得低下。
8、配置项与代码间存在潜规则,改变了任何一方都有可能影响另外一方。
让我们来看看Annotation的优点
1、保存在class文件中,降低维护成本。
2、无需工具支持,无需解析。
3、编译期即可验证正确性,查错变得容易,虽然有部分错误需要在运行期间才能看到。
4、配置简单、简约,提升开发效率。
同样Annotation也不是万能的,它也有很多缺点
1、若要对配置项进行修改,不得不修改Java文件,重新编译打包应用。
2、配置项编码在Java文件中,可扩展性差、移植性性低。
那到底用什么样的配置呢,在这里我谈谈我个人的看法:
1、在开发期间我们用Annotation注解,这样在一定程度上不仅可以省去对XML配置文件的维护,而且大大的提高了开发效率,缩短了开发周期。
2、开发后期,项目功能完成,我们可以将Annotation配置转换为XML配置,禁用Annotation即可。这样做的理由是如果项目上线,我们需要修改相关代码的配置,直接改XML、properties配置文件即可。这样就不需要开发人员找到相应的代码修改源代码、重新编译打包发布。而xml的配置是可以直接修改的,不需要重新编译,只需重启下你的服务器即可。
如果这样是不是即利用到框架给我们提供的Annotation注解,也利用到了XML配置。充分的发挥了开源框架给我们提供的技术应用。
3、混合模式,Annotation和XML相互运用。需要动态配置、后期经常性修改的就用XML配置,如果是不怎么修改的就用Annotation。或许这种混合模式更适合我们,你觉得呢?O(∩_∩)O~
posted @
2012-10-31 12:44 hoojo 阅读(2527) |
评论 (2) |
编辑 收藏1. 全文检索系统与Lucene简介
1.1 什么是全文检索与全文检索系统
全文检索是指计算机索引程序通过扫描文章中的每一个词,对每一个词建立一个索引,指明该词在文章中出现的次数和位置,当用户查询时,检索程序就根据事先建立的索引进行查找,并将查找的结果反馈给用户的检索方式。这个过程类似于通过字典中的检索字表查字的过程。
全文检索的方法主要分为按字检索和按词检索两种。按字检索是指对于文章中的每一个字都建立索引,检索时将词分解为字的组合。对于各种不同的语言而言,字有不同的含义,比如英文中字与词实际上是合一的,而中文中字与词有很大分别。按词检索指对文章中的词,即语义单位建立索引,检索时按词检索,并且可以处理同义项等。英文等西方文字由于按照空白切分词,因此实现上与按字处理类似,添加同义处理也很容易。中文等东方文字则需要切分字词,以达到按词索引的目的,关于这方面的问题,是当前全文检索技术尤其是中文全文检索技术中的难点,在此不做详述。
全文检索系统是按照全文检索理论建立起来的用于提供全文检索服务的软件系统。一般来说,全文检索需要具备建立索引和提供查询的基本功能,此外现代的全文检索系统还需要具有方便的用户接口、面向WWW[1]的开发接口、二次应用开发接口等等。功能上,全文检索系统核心具有建立索引、处理查询返回结果集、增加索引、优化索引结构等等功能,外围则由各种不同应用具有的功能组成。结构上,全文检索系统核心具有索引引擎、查询引擎、文本分析引擎、对外接口等等,加上各种外围应用系统等等共同构成了全文检索系统。图1.1展示了上述全文检索系统的结构与功能。

在上图中,我们看到:全文检索系统中最为关键的部分是全文检索引擎,各种应用程序都需要建立在这个引擎之上。一个全文检索应用的优异程度,根本上由全文检索引擎来决定。因此提升全文检索引擎的效率即是我们提升全文检索应用的根本。另一个方面,一个优异的全文检索引擎,在做到效率优化的同时,还需要具有开放的体系结构,以方便程序员对整个系统进行优化改造,或者是添加原有系统没有的功能。比如在当今多语言处理的环境下,有时需要给全文检索系统添加处理某种语言或者文本格式的功能,比如在英文系统中添加中文处理功能,在纯文本系统中添加XML或者HTML格式的文本处理功能,系统的开放性和扩充性就十分的重要。
1.2 什么是Lucene
Lucene是apache软件基金会jakarta项目组的一个子项目,是一个开放源代码的全文检索引擎工具包,即它不是一个完整的全文检索引擎,而是一个全文检索引擎的架构,提供了完整的查询引擎和索引引擎,部分文本分析引擎(英文与德文两种西方语言)。Lucene的目的是为软件开发人员提供一个简单易用的工具包,以方便的在目标系统中实现全文检索的功能,或者是以此为基础建立起完整的全文检索引擎。
Lucene的原作者是Doug Cutting,他是一位资深全文索引/检索专家,曾经是V-Twin搜索引擎的主要开发者,后在Excite担任高级系统架构设计师,目前从事于一些Internet底层架构的研究。早先发布在作者自己的http://www.lucene.com/,后来发布在SourceForge,2001年年底成为apache软件基金会jakarta的一个子项目:http://jakarta.apache.org/lucene/。
1.3 Lucene的应用、特点及优势
作为一个开放源代码项目,Lucene从问世之后,引发了开放源代码社群的巨大反响,程序员们不仅使用它构建具体的全文检索应用,而且将之集成到各种系统软件中去,以及构建Web应用,甚至某些商业软件也采用了Lucene作为其内部全文检索子系统的核心。apache软件基金会的网站使用了Lucene作为全文检索的引擎,IBM的开源软件eclipse的2.1版本中也采用了Lucene作为帮助子系统的全文索引引擎,相应的IBM的商业软件Web Sphere中也采用了Lucene。Lucene以其开放源代码的特性、优异的索引结构、良好的系统架构获得了越来越多的应用。
Lucene作为一个全文检索引擎,其具有如下突出的优点:
(1)索引文件格式独立于应用平台。Lucene定义了一套以8位字节为基础的索引文件格式,使得兼容系统或者不同平台的应用能够共享建立的索引文件。
(2)在传统全文检索引擎的倒排索引的基础上,实现了分块索引,能够针对新的文件建立小文件索引,提升索引速度。然后通过与原有索引的合并,达到优化的目的。
(3)优秀的面向对象的系统架构,使得对于Lucene扩展的学习难度降低,方便扩充新功能。
(4)设计了独立于语言和文件格式的文本分析接口,索引器通过接受Token流完成索引文件的创立,用户扩展新的语言和文件格式,只需要实现文本分析的接口。
(5)已经默认实现了一套强大的查询引擎,用户无需自己编写代码即使系统可获得强大的查询能力,Lucene的查询实现中默认实现了布尔操作、模糊查询(Fuzzy Search)、分组查询等等。
面对已经存在的商业全文检索引擎,Lucene也具有相当的优势:
首先,它的开发源代码发行方式(遵守Apache Software License),在此基础上程序员不仅仅可以充分的利用Lucene所提供的强大功能,而且可以深入细致的学习到全文检索引擎制作技术和面相对象编程的实践,进而在此基础上根据应用的实际情况编写出更好的更适合当前应用的全文检索引擎。在这一点上,商业软件的灵活性远远不及Lucene。其次,Lucene秉承了开放源代码一贯的架构优良的优势,设计了一个合理而极具扩充能力的面向对象架构,程序员可以在Lucene的基础上扩充各种功能,比如扩充中文处理能力,从文本扩充到HTML、PDF等等文本格式的处理,编写这些扩展的功能不仅仅不复杂,而且由于Lucene恰当合理的对系统设备做了程序上的抽象,扩展的功能也能轻易的达到跨平台的能力。最后,转移到apache软件基金会后,借助于apache软件基金会的网络平台,程序员可以方便的和开发者、其它程序员交流,促成资源的共享,甚至直接获得已经编写完备的扩充功能。最后,虽然Lucene使用Java语言写成,但是开放源代码社区的程序员正在不懈的将之使用各种传统语言实现(例如.net framework),在遵守Lucene索引文件格式的基础上,使得Lucene能够运行在各种各样的平台上,系统管理员可以根据当前的平台适合的语言来合理的选。
2. Lucene系统结构分析
2.1 系统结构组织
Lucene作为一个优秀的全文检索引擎,其系统结构具有强烈的面向对象特征。首先是定义了一个与平台无关的索引文件格式,其次通过抽象将系统的核心组成部分设计为抽象类,具体的平台实现部分设计为抽象类的实现,此外与具体平台相关的部分比如文件存储也封装为类,经过层层的面向对象式的处理,最终达成了一个低耦合高效率,容易二次开发的检索引擎系统。
以下将讨论Lucene系统的结构组织,并给出系统结构与源码组织图:

从图中我们清楚的看到,Lucene的系统由基础结构封装、索引核心、对外接口三大部分组成。其中直接操作索引文件的索引核心又是系统的重点。Lucene的将所有源码分为了7个模块(在java语言中以包即package来表示),各个模块所属的系统部分也如上图所示。需要说明的是org.apache.lucene.queryPaser是做为org.apache.lucene.search的语法解析器存在,不被系统之外实际调用,因此这里没有当作对外接口看待,而是将之独立出来。
从面象对象的观点来考察,Lucene应用了最基本的一条程序设计准则:引入额外的抽象层以降低耦合性。首先,引入对索引文件的操作org.apache.lucene.store的封装,然后将索引部分的实现建立在(org.apache.lucene.index)其之上,完成对索引核心的抽象。在索引核心的基础上开始设计对外的接口org.apache.lucene.search与org.apache.lucene.analysis。在每一个局部细节上,比如某些常用的数据结构与算法上,Lucene也充分的应用了这一条准则。在高度的面向对象理论的支撑下,使得Lucene的实现容易理解,易于扩展。
Lucene在系统结构上的另一个特点表现为其引入了传统的客户端服务器结构以外的的应用结构。Lucene可以作为一个运行库被包含进入应用本身中去,而不是做为一个单独的索引服务器存在。这自然和Lucene开放源代码的特征分不开,但是也体现了Lucene在编写上的本来意图:提供一个全文索引引擎的架构,而不是实现。
2.2 数据流分析
了解数据流分析的重要性:
理解Lucene系统结构的另一个方式是去探讨其中数据流的走向,并以此摸清楚Lucene系统内部的调用时序。在此基础上,我们能够更加深入的理解Lucene的系统结构组织,以方便以后在Lucene系统上的开发工作。这部分的分析,是深入Lucene系统的钥匙,也是进行重写的基础。
Lucene系统中的主要的数据流以及它们之间的关系图:

图2.2很好的表明了Lucene在内部的数据流组织情况,并且沿着数据流的方向我们也可以对与Lucene内部的执行时序有一个清楚的了解。现在将图中的涉及到的流的类型与各个逻辑对应系统的相关部分的关系说明一下。
图中共存在4种数据流,分别是文本流、token流、字节流与查询语句对象流。文本流表示了对于索引目标和交互控制的抽象,即用文本流表示了将要索引的文件,用文本流向用户输出信息;在实际的实现中,Lucene中的文本流采用了UCS-2作为编码,以达到适应多种语言文字的处理的目的。Token流是Lucene内部所使用的概念,是对传统文字中的词的概念的抽象,也是Lucene在建立索引时直接处理的最小单位;简单的讲Token就是一个词和所在域值的组合,后面在叙述文件格式时也将继续涉及到token,这里不详细展开。字节流则是对文件抽象的直接操作的体现,通过固定长度的字节(Lucene定义为8比特位长,后面文件格式将详细叙述)流的处理,将文件操作解脱出来,也做到了与平台文件系统的无关性。查询语句对象流则是仅仅在查询语句解析时用到的概念,它对查询语句抽象,通过类的继承结构反映查询语句的结构,将之传送到查找逻辑来进行查找的操作。
图中的涉及到了多种逻辑,基本上直接对应于系统某一模块,但是也有跨模块调用的问题发生,这是因为Lucene的重用程度非常好,因此很多实现直接调用了以前的工作成果,这在某种程度上其实是加强了模块耦合性,但是也是为了避免系统的过于庞大和不必要的重复设计的一种折衷体现。词法分析逻辑对应于org.apache.lucene.analysis部分。查询语句语法分析逻辑对应于org.apache.lucene.queryParser部分,并且调用了org.apache.lucene.analysis的代码。查询结束之后向评分排序逻辑输出token流,继而由评分排序逻辑处理之后给出文本流的结果,这一部分的实现也包含在了org.apache.lucene.search中。索引构建逻辑对应于org.apache.lucene.index部分。索引查找逻辑则主要是org.apache.lucene.search,但是也大量的使用了org.apache.lucene.index部分的代码和接口定义。存储抽象对应于org.apache.lucene.store。没有提到的模块则是做为系统公共基础设施存在。
2.3 基于Lucene的应用开发
首先,我们需要的是按照目标语言的词法结构来构建相应的词法分析逻辑,实现Lucene在org.apache.lucene.analysis中定义的接口,为Lucene提供目标系统所使用的语言处理能力。Lucene默认的已经实现了英文和德文的简单词法分析逻辑(按照空格分词,并去除常用的语法词,如英语中的is,am,are等等)。在这里,主要需要参考实现的接口在org.apache.lucene.analysis中的Analyzer.java和Tokenizer.java中定义,Lucene提供了很多英文规范的实现样本,也可以做为实现时候的参考资料。其次,需要按照被索引的文件的格式来提供相应的文本分析逻辑,这里是指除开词法分析之外的部分,比如HTML文件,通常需要把其中的内容按照所属于域分门别类加入索引,这就需要从org.apache.lucene.document中定义的类document继承,定义自己的HTMLDocument类,然后就可以将之交给org.apache.lucene.index模块来写入索引文件。完成了这两步之后,Lucene全文检索引擎就基本上完备了。这个过程可以用下图表示:

下面是使用java语言开发,Lucene系统能够方便的嵌入到整个系统中去,作为一个API集来调用。这个过程十分简单,以下便是一个示例程序,配合注释理解起来很容易。

2.4 Lucene索引文件格式
首先在Lucene的文件格式中,以字节为基础,定义了如下的数据类型:
表 3.1 Lucene文件格式中定义的数据类型
| 数据类型 | 所占字节长度(字节) | 说明 |
| Byte | 1 | 基本数据类型,其他数据类型以此为基础定义 |
| UInt32 | 4 | 32位无符号整数,高位优先 |
| UInt64 | 8 | 64位无符号整数,高位优先 |
| VInt | 不定,最少1字节 | 动态长度整数,每字节的最高位表明还剩多少字节,每字节的低七位表明整数的值,高位优先。可以认为值可以为无限大。其示例如下 | 值 | 字节1 | 字节2 | 字节3 | | 0 | 00000000 | | | | 1 | 00000001 | | | | 2 | 00000010 | | | | 127 | 01111111 | | | | 128 | 10000000 | 00000001 | | | 129 | 10000001 | 00000001 | | | 130 | 10000010 | 00000001 | | | 16383 | 10000000 | 10000000 | 00000001 | | 16384 | 10000001 | 10000000 | 00000001 | | 16385 | 10000010 | 10000000 | 00000001 | |
| Chars | 不定,最少1字节 | 采用UTF-8编码[20]的Unicode字符序列 |
| String | 不定,最少2字节 | 由VInt和Chars组成的字符串类型,VInt表示Chars的长度,Chars则表示了String的值 |
以上的数据类型就是Lucene索引文件格式中用到的全部数据类型,由于它们都以字节为基础定义而来,因此保证了是平台无关,这也是Lucene索引文件格式平台无关的主要原因。接下来我们看看Lucene索引文件的概念组成和结构组成。

以上就是Lucene的索引文件的概念结构。Lucene索引index由若干段(segment)组成,每一段由若干的文档(document)组成,每一个文档由若干的域(field)组成,每一个域由若干的项(term)组成。项是最小的索引概念单位,它直接代表了一个字符串以及其在文件中的位置、出现次数等信息。域是一个关联的元组,由一个域名和一个域值组成,域名是一个字串,域值是一个项,比如将“标题”和实际标题的项组成的域。文档是提取了某个文件中的所有信息之后的结果,这些组成了段,或者称为一个子索引。子索引可以组合为索引,也可以合并为一个新的包含了所有合并项内部元素的子索引。我们可以清楚的看出,Lucene的索引结构在概念上即为传统的倒排索引结构。
从概念上映射到结构中,索引被处理为一个目录(文件夹),其中含有的所有文件即为其内容,这些文件按照所属的段不同分组存放,同组的文件拥有相同的文件名,不同的扩展名。此外还有三个文件,分别用来保存所有的段的记录、保存已删除文件的记录和控制读写的同步,它们分别是segments,deletable和lock文件,都没有扩展名。每个段包含一组文件,它们的文件扩展名不同,但是文件名均为记录在文件segments中段的名字。让我们看如下的结构图3.2:

每个段的文件中,主要记录了两大类的信息:域集合与项集合。这两个集合中所含有的文件在图3.2中均有表明。由于索引信息是静态存储的,域集合与项集合中的文件组采用了一种类似的存储办法:一个小型的索引文件,运行时载入内存;一个对应于索引文件的实际信息文件,可以按照索引中指示的偏移量随机访问;索引文件与信息文件在记录的排列顺序上存在隐式的对应关系,即索引文件中按照“索引项1、索引项2…”排列,则信息文件则也按照“信息项1、信息项2…”排列。比如在图3.2所示文件中,segment1.fdx与segment1.fdt之间,segment1.tii与segment1.tis、segment1.prx、segment1.frq之间,都存在这样的组织关系。而域集合与项集合之间则通过域的在域记录文件(比如segment1.fnm)中所记录的域记录号维持对应关系,在图3.2中segment1.fdx与segment1.tii中就是通过这种方式保持联系。这样,域集合和项集合不仅仅联系起来,而且其中的文件之间也相互联系起来。此外,标准化因子文件和被删除文档文件则提供了一些程序内部的辅助设施(标准化因子用在评分排序机制中,被删除文档是一种伪删除手段)。这样,整个段的索引信息就通过这些文档有机的组成。
2.5 一些公用的基础类
基础结构封装,或者基础类,由org.apache.lucene.util和org.apache.lucene.document两个包组成,前者定义了一些常量和优化过的常用的数据结构和算法,后者则是对于文档(document)和域(field)概念的一个类定义。以下我们用列表的方式来分析这些封装类,指出其要点;
表 3.2 基础类包org.apache.lucene.util
| 类 | 说明 |
| Arrays | 一个关于数组的排序方法的静态类,提供了优化的基于快排序的排序方法sort |
| BitVector | C/C++语言中位域的java实现品,但是加入了序列化能力 |
| Constants | 常量静态类,定义了一些常量 |
| PriorityQueue | 一个优先队列的抽象类,用于后面实现各种具体的优先队列,提供常数时间内的最小元素访问能力,内部实现机制是哈析表和堆排序算法 |
表 3.3 基础类包org.apache.lucene.document
| 类 | 说明 |
| Document | 是文档概念的一个实现类,每个文档包含了一个域表(fieldList),并提供了一些实用的方法,比如多种添加域的方法、返回域表的迭代器的方法 |
| Field | 是域概念的一个实现类,每个域包含了一个域名和一个值,以及一些相关的属性 |
| DateField | 提供了一些辅助方法的静态类,这些方法将java中Date和Time数据类型和String相互转化 |
org.apache.lucene.store包:存储抽象是唯一能够直接对索引文件存取的包,因此其主要目的是抽象出和平台文件系统无关的存储抽象,提供诸如目录服务(增、删文件)、输入流和输出流。在分析其实现之前,首先我们看一下UML图;

图 3.3 存储抽象实现UML图(一)

图 3.4 存储抽象实现UML图(二)

图 3.4 存储抽象实现UML图(三)
图3.2到3.4展示了整个org.apache.lucene.store中主要的继承体系。共有三个抽象类定义:Directory、InputStream和OutputStrem,构成了一个完整的基于抽象文件系统的存取体系结构,在此基础上,实作出了两个实现品:(FSDirectory,FSInputStream,FSOutputStream)和(RAMDirectory,RAMInputStream和RAMOutputStream)。前者是以实际的文件系统做为基础实现的,后者则是建立在内存中的虚拟文件系统。前者主要用来永久的保存索引文件,后者的作用则在于索引操作时是在内存中建立小的索引,然后一次性的输出合并到文件中去,这一点我们在后面的索引逻辑部分能够看到。此外,还定以了org.apache.lucene.store.lock和org.apache.lucene.store.with两个辅助内部实现的类用在实现Directory方法的makeLock的时候,以在锁定索引读写之前来让客户程序做一些准备工作。
(FSDirectory,FSInputStream,FSOutputStream)的内部实现依托于java语言中的io类库,只是简单的做了一个外部逻辑的包装。这当然要归功于java语言所提供的跨平台特性,同时也带了一些隐患:文件存取的效率提升需要依耐于文件类库的优化。如果需要继续优化文件存取的效率,应该还提供一个文件与目录的抽象,以根据各种文件系统或者文件类型来提供一个优化的机会。当然,这是应用开发者所不需要关系的问题。
(RAMDirectory,RAMInputStream和RAMOutputStream)的内部实现就比较直接了,直接采用了虚拟的文件RAMFile类(定义于文件RAMDirectory.java中)来表示文件,目录则看作一个String与RAMFile对应的关联数组。RAMFile中采用数组来表示文件的存储空间。在此的基础上,完成各项操作的实现,就形成了基于内存的虚拟文件系统。因为在实际使用时,并不会牵涉到很大字节数量的文件,因此这种设计是简单直接的,也是高效率的。
3. Lucene索引构建逻辑模块分析
3.1对象体系与UML图
1. 项(Term)
项(Term):包括概念所实际涉及的类、永久化类。项(Term)所表示的是一个字符串,它拥有域、频数和位置信息等等属性。因此,Lucene中设计了两个类来表示这个概念,如下图

图 4.1 UML图(-)
上图中,有意的突出了类Term和TermInfo中的数据成员,因为它反映了对于项(Term)这个概念的具体表示。同时上图中也同时列出了用于永久化项(Term)的代理类TermInfosWriter和TermInfosReader,它们完成永久化的功能,需要注意的是,TermInfosReader内部使用了数组indexTerms和indexInfos来存储一系列项;而TermInfosWriter则是一个类似于链表的结构,通过一个other指向下一个TermInfosWriter,每一个TermInfosWriter只负责本身那个lastTerm和lastTi的永久化工作。这是一个设计上的技巧,通过批量读取(或者称为缓冲的方式)来获得读入时候的效率优化;而通过一个链表式的、各负其责的方式,来获得写出时候的设计简化。
项(term)这部分的设计中,还有一些重要的接口和类:

图 4.2 UML图(二)
图4.2中,我们看到三个类:TermEnum、TermDocs与TermPositions,第一个是抽象类,后两个都是接口。TermEnum的设计主要用在后面Segment和Document等等的实现中,以提供枚举其中每一个项(Term)的能力。TermDocs是一个接口,用来继承以提供返回<document, frequency>值对的能力,通过这个接口就可以获得某个项(Term)在某个文档中出现的频数。TermPositions则是在TermDocs上的扩展,将项(Term)在文档中的位置信息也表示出来。TermDocs(TermPositions)接口的使用方式类似于java中的Enumration接口,即通过next方法跳转,通过doc,freq等方法获得当前的属性值。
2. 域(Field)
由于Field的基本概念在org.apache.lucene.document中已经做了定义,因此在这部分主要是针对项文件(.fnm文件、.fdx文件、.fdt文件)所需要的信息再来设计一些类。

图 4.3 UML图(三)
图 4.3中展示的,就是表示与域(Field)所关联的属性信息的类。其中isIndexed表示的这个域的值是否被索引过,即值是否被分词然后索引;另外两个属性所表示的意思则很明显:一个是域的名字,一个是域的编号。
关于域表和存取逻辑的UML图:

FieldInfos即为域表的概念表示,内部采用了冗余的方式以获取在通过域的编号访问或者通过域的名字来访问时候的高效率。FieldsReader与FieldsWriter则分别是写出和读入的代理类。在功能和实现上,这两个类都比较简单。
3. 文档(document)
文档(document)同样也是在org.apache.lucene.document中定义过的结构。由于对于这部分比较重要,我们也来看看其UML图:

图 4.5 UML图(五)
在图4.5中我们看到,Document的设计基本上沿用了链表的处理方法。左边的Document类作为一个数据外包类,用来提供对于内部结构DocumentFieldList的增加删除访问操作等等。DocumentFieldList才是实际上的数据存储单位,它用了链表的处理方法,直接指向一个当前的Field对象和下一个DocumentFieldList对象,这个与前面的类似。为了能够逐个访问链表中的节点,还设计了DocumentFieldEnumeration枚举类。

图 4.6 UML图(六)
实际上定义于org.apache.lucene.index中的有关于Document的就是永久化的代理类。在图4.6中给出了其UML图。需要说明的是为什么没有出现读入的方法:这个方法已经隐含在图4.5中Document类中的add方法中了,结合图2.4中的程序代码段,我们就能够清楚的理解这种设计。
4. 段(segment)
段(Segment)这一部分设计的比较特殊,在实现简单的对象结构之上,还特意的设计了用于段之间合并的类。接下来,我们仍然采取对照UML分析的方式逐个叙述。接下来我们看Lucene中如何表示段这个概念。

图 4.7 UML图(七)
Lucene定义了一个类SegmentInfo用来表示每一个段(Segment)的信息,包括名字(name)、含有的文档的数目(docCount)和段所位于的目录的位置(dir)。根据索引文件中的段的意义,有了这三点,就能唯一确定一个段了。SegmentInfos这个类则是用来表示一个段的链表(从标准的java.util.Vector继承而来),实际上,也就是索引(index)的意思了。需要注意的是,这里并没有在SegmentInfo中安插一个文档(document)的链表。这样做的原因牵涉到Lucene内部对于文档(相当于一个被索引文件)的处理;Lucene内部采用了赋予文档编号,给域赋值的方式来处理文档,即加入的文档顺次编号,以后用文档号表示文档,而路径信息,文件名字等等在以后索引查找需要的属性,都作为域存储下来;因此SegmentInfo中并没有另外存储一个文档(document)的链表,对于这些的写出和读入,则交给了永久化的代理类来做。

图 4.8 UML图(八)
图4.8给出了负责段(segment)的读入操作的代理类,而负责段(segment)的写出操作也同样没有定义,这些操作都直接实现在了类IndexWriter类中。段的操作同样采用了之前的数组或者说是缓冲的处理方式。
针对前面项(term)那部分定义的几个接口,段(segment)这部分也需要做相应的接口实现,因为提供直接遍历访问段中的各个项的能力对于检索来说,无疑是十分重要的。即这部分的设计,实际上都是在为了检索在服务。

图 4.9 UML图(九)

图 4.10 UML图(十)
图4.9和图4.10分别展示了前面项(term)那里定义的接口是如何在这里通过继承实现的。Lucene在处理这部分的时候,也是分成两部分(Segment与Segments开头的类)来实现,而且很合理的运用了数组的技法,以及注意了继承重用。但是细化到局部,终归是比较简单的按照语义来获得结果而已了。
Lucene为了兼顾建立索引时的效率和读取索引查找的速度,引入了分小段建立索引的方式,即每一次批量建立索引时,先在内存中的虚拟文件系统中为每一个文档单独建立一个段,然后在输出的时候将这些段合并之后输出成为索引文件,这时仅仅存在一个段。多次建立的索引后,如果想优化索引文件,也可采取合并段的方法,将索引中的段合并成为一个段。我们来看一下在IndexWriter类中相应的方法的实现,来了解一下这中建立索引的实现。

在mergeSegments函数中,将用到几个重要的类结构,它们记录了合并时候的一些重要信息,完成合并时候的工作。接下来,我们来看这几个类的UML图:

图 4.12 UML图(十一)
从图4.12中,我们看到Lucene设计一个类SegmentMergeInfo用来保存每一个被合并的段的信息,也保存能够访问其内部的接口句柄,也就是说合并时的操作使用这个类作为对被合并的段的操作代理。类SegmentMergeQueue则设计为org.apache.lucene.util.PriorityQueue的子类,做为SegmentMergeInfo的容器类,而且附带能够自动排序。SegmentMerger是主要进行操作的类,主要完成合并各个数据项的问题。
5. IndexReader类与IndexWirter类
最后剩下的,就是整个索引逻辑部分的使用接口类了。外界通过这两个类以及文档(document)类的构造函数调用之,比如图2.4中的代码示例所示。下面我们来看一下这部分最后两个类的UML图:

图 4.13 UML图(十二)
IndexWriter的设计与IndexReader的设计很不相同,前者是一个实现类,而后者是一个抽象类,带有没有实现的接口。IndexWriter的主要作用就是接收新加入的文档(document),然后在内部为之生成相应的小段,最后再合并并向索引文件中输出,图4.11中已经给出了一些实现的代码。由于Lucene在面向对象上封装的努力,通过各个构造函数就已经完成了对于各个概念的构造过程,剩下部分的代码主要是依据各个数组或者是链表中的信息,逐个逐个的将信息写出到相应的文件中去了。IndexReader部分则只是做了接口设计,没有具体的实现,这个和本部分所完成的主要功能有关:索引构建逻辑。设计这个抽象类的目的是,预先完成一些函数,为以后的检索(search)部分的各种形式的IndexReader铺平道路,也是利用了在同一个包内可以方便访问其它类的保护变量这个java语言的限制。
3.2 数据流逻辑
从宏观上明白一个系统的设计,理清楚其中的运行规律,最好的方式应该是通过数据流图。在分析了各个位于索引构建逻辑部分的类的设计之后,我们接下来就通过分析数据流图的方式来总结一下。但是由于之前提到的原因:索引读入部分在这一部分并没有完全实现,所以我们在数据流图中主要给出的是索引构建的数据流图。

对于图4.14中所描述的内容,结合Lucene源代码中的一些文件看,能够加深理解。准备阶段可以参考demo文件夹中的org.apache.lucene.demo.IndexFiles类和java文件夹中的org.apache.lucene.document文件包。索引构建阶段的主要源码位于java文件夹中org.apache.lucene.index.IndexWriter类,因此这部分可以结合这个类的实现来看。至于内存文件系统,比较复杂,但是这时的逻辑相对简单,因此也不难理解。
上面的数据流图十分清楚的勾画除了整个索引构建逻辑这部分的设计:通过层层嵌套的类结构,在构建时候即分步骤有计划的生成了索引结构,将之存储到内存中的文件系统中,然后通过对内存中的文件系统优化合并输出到实际的文件系统中。
本文是在我2010年学习Lucene的时候在互联网上摘抄整理而来,当时是在一家电子商务公司做商品检索需要用到Lucene,所以就研究了下。这篇文章也是在当时在网络上阅读Lucene相关知识整理而来的。
posted @
2012-09-06 09:34 hoojo 阅读(3495) |
评论 (0) |
编辑 收藏什么是全文检索与全文检索系统?
全文检索是指计算机索引程序通过扫描文章中的每一个词,对每一个词建立一个索引,指明该词在文章中出现的次数和位置,当用户查询时,检索程序就根据事先建立的索引进行查找,并将查找的结果反馈给用户的检索方式。这个过程类似于通过字典中的检索字表查字的过程。
全文检索的方法主要分为按字检索和按词检索两种。按字检索是指对于文章中的每一个字都建立索引,检索时将词分解为字的组合。对于各种不同的语言而言,字有不同的含义,比如英文中字与词实际上是合一的,而中文中字与词有很大分别。按词检索指对文章中的词,即语义单位建立索引,检索时按词检索,并且可以处理同义项等。
全文检索系统是按照全文检索理论建立起来的用于提供全文检索服务的软件系统。一般来说,全文检索需要具备建立索引和提供查询的基本功能,此外现代的全文检索系统还需要具有方便的用户接口、面向WWW[1]的开发接口、二次应用开发接口等等。功能上,全文检索系统核心具有建立索引、处理查询返回结果集、增加索引、优化索引结构等等功能,外围则由各种不同应用具有的功能组成。结构上,全文检索系统核心具有索引引擎、查询引擎、文本分析引擎、对外接口等等,加上各种外围应用系统等等共同构成了全文检索系统。
什么是Lucene?
Lucene是apache软件基金会jakarta项目组的一个子项目,是一个开放源代码的全文检索引擎工具包,即它不是一个完整的全文检索引擎,而是一个全文检索引擎的架构,提供了完整的查询引擎和索引引擎,部分文本分析引擎(英文与德文两种西方语言)。Lucene的目的是为软件开发人员提供一个简单易用的工具包,以方便的在目标系统中实现全文检索的功能,或者是以此为基础建立起完整的全文检索引擎。
Lucene的原作者是Doug Cutting,他是一位资深全文索引/检索专家,曾经是V-Twin搜索引擎的主要开发者,后在Excite担任高级系统架构设计师,目前从事于一些Internet底层架构的研究。早先发布在作者自己的http://www.lucene.com/,后来发布在SourceForge,2001年年底成为apache软件基金会jakarta的一个子项目:http://jakarta.apache.org/lucene/。
Lucene作为一个全文检索引擎,其具有如下突出的优点:
(1)索引文件格式独立于应用平台。Lucene定义了一套以8位字节为基础的索引文件格式,使得兼容系统或者不同平台的应用能够共享建立的索引文件。
(2)在传统全文检索引擎的倒排索引的基础上,实现了分块索引,能够针对新的文件建立小文件索引,提升索引速度。然后通过与原有索引的合并,达到优化的目的。
(3)优秀的面向对象的系统架构,使得对于Lucene扩展的学习难度降低,方便扩充新功能。
(4)设计了独立于语言和文件格式的文本分析接口,索引器通过接受Token流完成索引文件的创立,用户扩展新的语言和文件格式,只需要实现文本分析的接口。
(5)已经默认实现了一套强大的查询引擎,用户无需自己编写代码即使系统可获得强大的查询能力,Lucene的查询实现中默认实现了布尔操作、模糊查询(Fuzzy Search)、分组查询等等。
面对已经存在的商业全文检索引擎,Lucene也具有相当的优势:
首先,它的开发源代码发行方式(遵守Apache Software License),在此基础上程序员不仅仅可以充分的利用Lucene所提供的强大功能,而且可以深入细致的学习到全文检索引擎制作技术和面相对象编程的实践,进而在此基础上根据应用的实际情况编写出更好的更适合当前应用的全文检索引擎。在这一点上,商业软件的灵活性远远不及Lucene。
其次,Lucene秉承了开放源代码一贯的架构优良的优势,设计了一个合理而极具扩充能力的面向对象架构,程序员可以在Lucene的基础上扩充各种功能,比如扩充中文处理能力,从文本扩充到HTML、PDF等等文本格式的处理,编写这些扩展的功能不仅仅不复杂,而且由于Lucene恰当合理的对系统设备做了程序上的抽象,扩展的功能也能轻易的达到跨平台的能力。
最后,转移到apache软件基金会后,借助于apache软件基金会的网络平台,程序员可以方便的和开发者、其它程序员交流,促成资源的共享,甚至直接获得已经编写完备的扩充功能。最后,虽然Lucene使用Java语言写成,但是开放源代码社区的程序员正在不懈的将之使用各种传统语言实现(例如.net framework),在遵守Lucene索引文件格式的基础上,使得Lucene能够运行在各种各样的平台上,系统管理员可以根据当前的平台适合的语言来合理的选。
索引和搜索的关系
索引是现代搜索引擎的核心,建立索引的过程就是把源数据处理成非常方便查询的索引文件的过程。为什么索引这么重要呢,试想你现在要在大量的文档中搜索含有某个关键词的文档,那么如果不建立索引的话你就需要把这些文档顺序的读入内存,然后检查这个文章中是不是含有要查找的关键词,这样的话就会耗费非常多的时间,想想搜索引擎可是在毫秒级的时间内查找出要搜索的结果的。这就是由于建立了索引的原因,你可以把索引想象成这样一种数据结构,他能够使你快速的随机访问存储在索引中的关键词,进而找到该关键词所关联的文档。Lucene 采用的是一种称为反向索引(inverted index)的机制。反向索引就是说我们维护了一个词/短语表,对于这个表中的每个词/短语,都有一个链表描述了有哪些文档包含了这个词/短语。这样在用户输入查询条件的时候,就能非常快的得到搜索结果。我们将在本系列文章的第二部分详细介绍 Lucene 的索引机制,由于 Lucene 提供了简单易用的 API,所以即使读者刚开始对全文本进行索引的机制并不太了解,也可以非常容易的使用 Lucene 对你的文档实现索引。
对文档建立好索引后,就可以在这些索引上面进行搜索了。搜索引擎首先会对搜索的关键词进行解析,然后再在建立好的索引上面进行查找,最终返回和用户输入的关键词相关联的文档。
Lucene 软件包分析
Package: org.apache.lucene.document
这个包提供了一些为封装要索引的文档所需要的类,比如 Document, Field。这样,每一个文档最终被封装成了一个 Document 对象。
Package: org.apache.lucene.analysis
这个包主要功能是对文档进行分词,因为文档在建立索引之前必须要进行分词,所以这个包的作用可以看成是为建立索引做准备工作。
Package: org.apache.lucene.index
这个包提供了一些类来协助创建索引以及对创建好的索引进行更新。这里面有两个基础的类:IndexWriter 和 IndexReader,其中 IndexWriter 是用来创建索引并添加文档到索引中的,IndexReader 是用来删除索引中的文档的。
Package: org.apache.lucene.search
这个包提供了对在建立好的索引上进行搜索所需要的类。比如 IndexSearcher 和 Hits, IndexSearcher 定义了在指定的索引上进行搜索的方法,Hits 用来保存搜索得到的结果
| Lucene包结构功能表 |
| 包名 | 功能 |
| org.apache.lucene.analysis | 语言分析器,主要用于的切词,支持中文主要是扩展此类 |
| org.apache.lucene.document | 索引存储时的文档结构管理,类似于关系型数据库的表结构 |
| org.apache.lucene.index | 索引管理,包括索引建立、删除等 |
| org.apache.lucene.queryParser | 查询分析器,实现查询关键词间的运算,如与、或、非等 |
| org.apache.lucene.search | 检索管理,根据查询条件,检索得到结果 |
| org.apache.lucene.store | 数据存储管理,主要包括一些底层的I/O操作 |
| org.apache.lucene.util | 一些公用类 |
一个简单的搜索应用程序
假设我们的电脑的目录中含有很多文本文档,我们需要查找哪些文档含有某个关键词。为了实现这种功能,我们首先利用
Lucene 对这个目录中的文档建立索引,然后在建立好的索引中搜索我们所要查找的文档。通过这个例子读者会对如何利用
Lucene 构建自己的搜索应用程序有个比较清楚的认识。
建立索引
为了对文档进行索引,Lucene 提供了五个基础的类,他们分别是 Document, Field, IndexWriter, Analyzer, Directory。下面我们分别介绍一下这五个类的用途:
Document
Document 是用来描述文档的,这里的文档可以指一个 HTML 页面,一封电子邮件,或者是一个文本文件。一个 Document 对象由多个 Field 对象组成的。可以把一个 Document 对象想象成数据库中的一个记录,而每个 Field 对象就是记录的一个字段。
| 接口名 | 备注 |
| add(Field field) | 添加一个字段(Field)到Document中 |
| String get(String name) | 从文档中获得一个字段对应的文本 |
| Field getField(String name) | 由字段名获得字段值 |
| Field[] getFields(String name) | 由字段名获得字段值的集 |
Field
Field 对象是用来描述一个文档的某个属性的,比如一封电子邮件的标题和内容可以用两个 Field 对象分别描述。
即上文所说的“字段”,它是Document的片段section。
Field的构造函数:
Field(String name, String string, boolean store, boolean index, boolean token)。
Indexed:如果字段是Indexed的,表示这个字段是可检索的。
Stored:如果字段是Stored的,表示这个字段的值可以从检索结果中得到。
Tokenized:如果一个字段是Tokenized的,表示它是有经过Analyzer转变后成为一个tokens序列,在这个转变过程tokenization中,Analyzer提取出需要进行索引的文本,而剔除一些冗余的词句(例如:a,the,they等,详见org.apache.lucene.analysis.StopAnalyzer.ENGLISH_STOP_WORDS和org.apache.lucene.analysis.standard.StandardAnalyzer(String[] stopWords)的API)。Token是索引时候的基本单元,代表一个被索引的词,例如一个英文单词,或者一个汉字。因此,所有包含中文的文本都必须是Tokenized的。
Analyzer
在一个文档被索引之前,首先需要对文档内容进行分词处理,这部分工作就是由 Analyzer 来做的。Analyzer 类是一个抽象类,它有多个实现。针对不同的语言和应用需要选择适合的 Analyzer。Analyzer 把分词后的内容交给 IndexWriter 来建立索引。
| 接口名 | 备注 |
| addDocument(Document doc) | 索引添加一个文档 |
| addIndexes(Directory[] dirs) | 将目录中已存在索引添加到这个索引 |
| addIndexes(IndexReader[] readers) | 将提供的索引添加到这个索引 |
| optimize() | 合并索引并优化 |
| close() | 关闭 |
IndexWriter
IndexWriter 是 Lucene 用来创建索引的一个核心的类,他的作用是把一个个的 Document 对象加到索引中来。
Directory
这个类代表了 Lucene 的索引的存储的位置,这是一个抽象类,它目前有两个实现,第一个是 FSDirectory,它表示一个存储在文件系统中的索引的位置。第二个是 RAMDirectory,它表示一个存储在内存当中的索引的位置。
熟悉了建立索引所需要的这些类后,我们就开始对某个目录下面的文本文件建立索引了,给出了对某个目录下的文本文件建立索引的源代码。
public class TextFileIndexer { public static void main(String[] args) throws Exception { // fileDir is the directory that contains the text files to be indexed
File fileDir = new File("C:\\index");
// indexDir is the directory that hosts Lucene's index files
File indexDir = new File("C:\\luceneIndex"); Analyzer luceneAnalyzer = new StandardAnalyzer(Version.LUCENE_30);
IndexWriter indexWriter = new IndexWriter(FSDirectory.open(indexDir), luceneAnalyzer, true, IndexWriter.MaxFieldLength.LIMITED);
File[] textFiles = fileDir.listFiles();
long startTime = new Date().getTime();
// Add documents to the index
for (int i = 0; i < textFiles.length; i++) { if (textFiles[i].isFile() && textFiles[i].getName().endsWith(".txt")) { System.out.println("File " + textFiles[i].getCanonicalPath() + " is being indexed"); Reader textReader = new FileReader(textFiles[i]);
Document document = new Document();
document.add(new Field("content", textReader)); document.add(new Field("path", textFiles[i].getPath(), Field.Store.YES, Field.Index.ANALYZED_NO_NORMS)); indexWriter.addDocument(document);
}
}
indexWriter.optimize();
indexWriter.close();
long endTime = new Date().getTime();
System.out.println("It took " + (endTime - startTime) + " milliseconds to create an index for the files in the directory " + fileDir.getPath()); }
}
我们注意到类 IndexWriter 的构造函数需要三个参数,第一个参数指定了所创建的索引要存放的位置,他可以是一个 File 对象,也可以是一个 FSDirectory 对象或者 RAMDirectory 对象。第二个参数指定了 Analyzer 类的一个实现,也就是指定这个索引是用哪个分词器对文挡内容进行分词。第三个参数是一个布尔型的变量,如果为 true 的话就代表创建一个新的索引,为 false 的话就代表在原来索引的基础上进行操作。接着程序遍历了目录下面的所有文本文档,并为每一个文本文档创建了一个 Document 对象。然后把文本文档的两个属性:路径和内容加入到了两个 Field 对象中,接着在把这两个 Field 对象加入到 Document 对象中,最后把这个文档用 IndexWriter 类的 add 方法加入到索引中去。这样我们便完成了索引的创建。接下来我们进入在建立好的索引上进行搜索的部分。
搜索文档
Query
这是一个抽象类,他有多个实现,比如TermQuery, BooleanQuery, PrefixQuery. 这个类的目的是把用户输入的查询字符串封装成Lucene能够识别的Query。
Term
Term是搜索的基本单位,一个Term对象有两个String类型的域组成。生成一个Term对象可以有如下一条语句来完成:Term term = new Term(“fieldName”,”queryWord”); 其中第一个参数代表了要在文档的哪一个Field上进行查找,第二个参数代表了要查询的关键词。
TermQuery
TermQuery是抽象类Query的一个子类,它同时也是Lucene支持的最为基本的一个查询类。生成一个TermQuery对象由如下语句完成: TermQuery termQuery = new TermQuery(new Term(“fieldName”,”queryWord”)); 它的构造函数只接受一个参数,那就是一个Term对象。
IndexSearcher
IndexSearcher是用来在建立好的索引上进行搜索的。它只能以只读的方式打开一个索引,所以可以有多个IndexSearcher的实例在一个索引上进行操作。
Hits
Hits是用来保存搜索的结果的。
介绍完这些搜索所必须的类之后,我们就开始在之前所建立的索引上进行搜索了,清单2给出了完成搜索功能所需要的代码。
如何添加一个文档到索引文
|
Document document = new Document();
document.add(new Field("content",textReader));
document.add(new Field("path",textFiles[i].getPath(), Field.Store.YES, Field.Index.ANALYZED_NO_NORMS));
indexWriter.addDocument(document);
//最后不要忘记了关闭
indexWriter.close(); |
首先第一行创建了类 Document 的一个实例,它由一个或者多个的域(Field)组成。你可以把这个类想象成代表了一个实际的文档,比如一个 HTML 页面,一个 PDF 文档,或者一个文本文件。而类 Document 中的域一般就是实际文档的一些属性。比如对于一个 HTML 页面,它的域可能包括标题,内容,URL 等。我们可以用不同类型的 Field 来控制文档的哪些内容应该索引,哪些内容应该存储。如果想获取更多的关于 Lucene 的域的信息,可以参考 Lucene 的帮助文档。代码的第二行和第三行为文档添加了两个域,每个域包含两个属性,分别是域的名字和域的内容。在我们的例子中两个域的名字分别是"content"和"path"。分别存储了我们需要索引的文本文件的内容和路径。最后一行把准备好的文档添加到了索引当中。
从索引中删除文档
类IndexReader负责从一个已经存在的索引中删除文档。
|
File indexDir = new File("C:\\luceneIndex");
IndexReader ir = IndexReader.open(indexDir);
ir.delete(1);
ir.delete(new Term("path","C:\\file_to_index\lucene.txt"));
ir.close(); |
第二行用静态方法 IndexReader.open(indexDir) 初始化了类 IndexReader 的一个实例,这个方法的参数指定了索引的存储路径。类 IndexReader 提供了两种方法去删除一个文档,如程序中的第三行和第四行所示。第三行利用文档的编号来删除文档。每个文档都有一个系统自动生成的编号。第四行删除了路径为"C:\\file_to_index\lucene.txt"的文档。你可以通过指定文件路径来方便的删除一个文档。值得注意的是虽然利用上述代码删除文档使得该文档不能被检索到,但是并没有物理上删除该文档。Lucene 只是通过一个后缀名为 .delete 的文件来标记哪些文档已经被删除。既然没有物理上删除,我们可以方便的把这些标记为删除的文档恢复过来,如清单 3 所示,首先打开一个索引,然后调用方法 ir.undeleteAll() 来完成恢复工作。
恢复已删除文档
|
File indexDir = new File("C:\\luceneIndex");
IndexReader ir = IndexReader.open(indexDir);
ir.undeleteAll();
ir.close(); |
如何物理上删除文档
|
File indexDir = new File("C:\\luceneIndex");
Analyzer luceneAnalyzer = new StandardAnalyzer();
IndexWriter indexWriter = new IndexWriter(indexDir,luceneAnalyzer,false);
indexWriter.optimize();
indexWriter.close(); |
第三行创建了类 IndexWriter 的一个实例,并且打开了一个已经存在的索引。第 4 行对索引进行清理,清理过程中将把所有标记为删除的文档物理删除。
提高索引性能
利用 Lucene,在创建索引的工程中你可以充分利用机器的硬件资源来提高索引的效率。当你需要索引大量的文件时,你会注意到索引过程的瓶颈是在往磁盘上写索引文件的过程中。为了解决这个问题, Lucene 在内存中持有一块缓冲区。但我们如何控制 Lucene 的缓冲区呢?幸运的是,Lucene 的类 IndexWriter 提供了三个参数用来调整缓冲区的大小以及往磁盘上写索引文件的频率。
1.合并因子(mergeFactor)
这个参数决定了在 Lucene 的一个索引块中可以存放多少文档以及把磁盘上的索引块合并成一个大的索引块的频率。比如,如果合并因子的值是 10,那么当内存中的文档数达到 10 的时候所有的文档都必须写到磁盘上的一个新的索引块中。并且,如果磁盘上的索引块的隔数达到 10 的话,这 10 个索引块会被合并成一个新的索引块。这个参数的默认值是 10,如果需要索引的文档数非常多的话这个值将是非常不合适的。对批处理的索引来讲,为这个参数赋一个比较大的值会得到比较好的索引效果。
2.最小合并文档数
这个参数也会影响索引的性能。它决定了内存中的文档数至少达到多少才能将它们写回磁盘。这个参数的默认值是10,如果你有足够的内存,那么将这个值尽量设的比较大一些将会显著的提高索引性能。
3.最大合并文档数
这个参数决定了一个索引块中的最大的文档数。它的默认值是 Integer.MAX_VALUE,将这个参数设置为比较大的值可以提高索引效率和检索速度,由于该参数的默认值是整型的最大值,所以我们一般不需要改动这个参数。
|
int mergeFactor = 10;
int minMergeDocs = 10;
int maxMergeDocs = Integer.MAX_VALUE;
IndexWriter indexWriter = new IndexWriter(indexDir,luceneAnalyzer,true);
indexWriter.mergeFactor = mergeFactor;
indexWriter.minMergeDocs = minMergeDocs;
indexWriter.maxMergeDocs = maxMergeDocs; |
下面我们来看一下这三个参数取不同的值对索引时间的影响,注意参数值的不同和索引之间的关系。我们为这个实验准备了 10000 个测试文档。表 1 显示了测试结果。
表1:测试结果

通过表 1,你可以清楚地看到三个参数对索引时间的影响。在实践中,你会经常的改变合并因子和最小合并文档数的值来提高索引性能。只要你有足够大的内存,你可以为合并因子和最小合并文档数这两个参数赋尽量大的值以提高索引效率,另外我们一般无需更改最大合并文档数这个参数的值,因为系统已经默认将它设置成了最大。
posted @
2012-09-05 12:21 hoojo 阅读(2210) |
评论 (0) |
编辑 收藏 -- 死锁查询语句
SELECT bs.username "Blocking User", bs.username "DB User",
ws.username "Waiting User", bs.SID "SID", ws.SID "WSID",
bs.serial# "Serial#", bs.sql_address "address",
bs.sql_hash_value "Sql hash", bs.program "Blocking App",
ws.program "Waiting App", bs.machine "Blocking Machine",
ws.machine "Waiting Machine", bs.osuser "Blocking OS User",
ws.osuser "Waiting OS User", bs.serial# "Serial#",
ws.serial# "WSerial#",
DECODE (wk.TYPE,
'MR', 'Media Recovery',
'RT', 'Redo Thread',
'UN', 'USER Name',
'TX', 'Transaction',
'TM', 'DML',
'UL', 'PL/SQL USER LOCK',
'DX', 'Distributed Xaction',
'CF', 'Control FILE',
'IS', 'Instance State',
'FS', 'FILE SET',
'IR', 'Instance Recovery',
'ST', 'Disk SPACE Transaction',
'TS', 'Temp Segment',
'IV', 'Library Cache Invalidation',
'LS', 'LOG START OR Switch',
'RW', 'ROW Wait',
'SQ', 'Sequence Number',
'TE', 'Extend TABLE',
'TT', 'Temp TABLE',
wk.TYPE
) lock_type,
DECODE (hk.lmode,
0, 'None',
1, 'NULL',
2, 'ROW-S (SS)',
3, 'ROW-X (SX)',
4, 'SHARE',
5, 'S/ROW-X (SSX)',
6, 'EXCLUSIVE',
TO_CHAR (hk.lmode)
) mode_held,
DECODE (wk.request,
0, 'None',
1, 'NULL',
2, 'ROW-S (SS)',
3, 'ROW-X (SX)',
4, 'SHARE',
5, 'S/ROW-X (SSX)',
6, 'EXCLUSIVE',
TO_CHAR (wk.request)
) mode_requested,
TO_CHAR (hk.id1) lock_id1, TO_CHAR (hk.id2) lock_id2,
DECODE
(hk.BLOCK,
0, 'NOT Blocking', /**//* Not blocking any other processes */
1, 'Blocking', /**//* This lock blocks other processes */
2, 'Global', /**//* This lock is global, so we can't tell */
TO_CHAR (hk.BLOCK)
) blocking_others
FROM v$lock hk, v$session bs, v$lock wk, v$session ws
WHERE hk.BLOCK = 1
AND hk.lmode != 0
AND hk.lmode != 1
AND wk.request != 0
AND wk.TYPE(+) = hk.TYPE
AND wk.id1(+) = hk.id1
AND wk.id2(+) = hk.id2
AND hk.SID = bs.SID(+)
AND wk.SID = ws.SID(+)
AND (bs.username IS NOT NULL)
AND (bs.username <> 'SYSTEM')
AND (bs.username <> 'SYS')
ORDER BY 1;
查询发生死锁的select语句
select sql_text from v$sql where hash_value in (
select sql_hash_value from v$session where sid in (select session_id from v$locked_object)
)
关于数据库死锁的检查方法
一、数据库死锁的现象
程序在执行的过程中,点击确定或保存按钮,程序没有响应,也没有出现报错。
二、死锁的原理
当对于数据库某个表的某一列做更新或删除等操作,执行完毕后该条语句不提
交,另一条对于这一列数据做更新操作的语句在执行的时候就会处于等待状态,
此时的现象是这条语句一直在执行,但一直没有执行成功,也没有报错。
三、死锁的定位方法
通过检查数据库表,能够检查出是哪一条语句被死锁,产生死锁的机器是哪一台。
1)用dba用户执行以下语句
select username,lockwait,status,machine,program from v$session where sid
in (select session_id from v$locked_object)
如果有输出的结果,则说明有死锁,且能看到死锁的机器是哪一台。字段说明:
Username:死锁语句所用的数据库用户;
Lockwait:死锁的状态,如果有内容表示被死锁。
Status: 状态,active表示被死锁
Machine: 死锁语句所在的机器。
Program: 产生死锁的语句主要来自哪个应用程序。
2)用dba用户执行以下语句,可以查看到被死锁的语句
select sql_text from v$sql where hash_value in
(select sql_hash_value from v$session where sid in
(select session_id from v$locked_object))
四、死锁的解决方法
一般情况下,只要将产生死锁的语句提交就可以了,但是在实际的执行过程中。用户可
能不知道产生死锁的语句是哪一句。可以将程序关闭并重新启动就可以了。
经常在Oracle的使用过程中碰到这个问题,所以也总结了一点解决方法。
1)查找死锁的进程:
sqlplus "/as sysdba" (sys/change_on_install)
SELECT s.username,l.OBJECT_ID,l.SESSION_ID,s.SERIAL#,l.ORACLE_USERNAME,l.OS_USER_NAME,l.PROCESS
FROM V$LOCKED_OBJECT l,V$SESSION S
WHERE l.SESSION_ID=S.SID;
2)kill掉这个死锁的进程:
alter system kill session ‘sid,serial#’; (其中sid=l.session_id)
3)如果还不能解决:
select pro.spid from v$session ses, v$process pro where ses.sid=XX and ses.paddr=pro.addr;
其中sid用死锁的sid替换:
exit
ps -ef|grep spid
其中spid是这个进程的进程号,kill掉这个Oracle进程。
转自:http://sungang-82.iteye.com/blog/310781
posted @
2012-08-31 16:24 hoojo 阅读(33374) |
评论 (0) |
编辑 收藏 处理oracle sql 语句in子句中(where id in (1, 2, ..., 1000, 1001)),如果子句中超过1000项就会报错。
这主要是oracle考虑性能问题做的限制。如果要解决次问题,可以用 where id (1, 2, ..., 1000) or id (1001, ...)
/**
* <b>function:</b> 处理oracle sql 语句in子句中(where id in (1, 2, ..., 1000, 1001)),如果子句中超过1000项就会报错。
* 这主要是oracle考虑性能问题做的限制。如果要解决次问题,可以用 where id (1, 2, ..., 1000) or id (1001, ...)
* @author hoojo
* @createDate 2012-8-31 下午02:36:03
* @param ids in语句中的集合对象
* @param count in语句中出现的条件个数
* @param field in语句对应的数据库查询字段
* @return 返回 field in (...) or field in (...) 字符串
*/
private String getOracleSQLIn(List<?> ids, int count, String field) { count = Math.min(count, 1000);
int len = ids.size();
int size = len % count;
if (size == 0) { size = len / count;
} else { size = (len / count) + 1;
}
StringBuilder builder = new StringBuilder();
for (int i = 0; i < size; i++) { int fromIndex = i * count;
int toIndex = Math.min(fromIndex + count, len);
//System.out.println(ids.subList(fromIndex, toIndex));
String productId = StringUtils.defaultIfEmpty(StringUtils.join(ids.subList(fromIndex, toIndex), "','"), "");
if (i != 0) { builder.append(" or "); }
builder.append(field).append(" in ('").append(productId).append("')"); }
return StringUtils.defaultIfEmpty(builder.toString(), field + " in ('')");}
posted @
2012-08-31 14:51 hoojo 阅读(5020) |
评论 (0) |
编辑 收藏
摘要: 这篇文章主要介绍用JavaScript和jQuery、HTML、CSS以及用第三方聊天JavaScript(jsjac)框架构建一个BS Web的聊天应用程序。此程序可以和所有连接到Openfire服务器的应用进行通信、发送消息。如果要运行本程序还需要一个聊天服务器Openfire, 以及需要用到Http方式和Openfire通信的第三方库(JabberHTTPBind)。 JabberHTTPB...
阅读全文
posted @
2012-08-13 09:39 hoojo 阅读(7395) |
评论 (2) |
编辑 收藏
摘要: 开发环境: System:Windows JavaSDK:1.6 IDE:eclipse、MyEclipse 6.6 开发依赖库: Jdk1.4+、mina-core-2.0.4.jar、slf4j-api-1.5.11.jar、slf4j-log4j12-1.5.11.jar Email:hoojo_@126.com Blog:http://blog.csdn.net/IBM_ho...
阅读全文
posted @
2012-08-01 10:23 hoojo 阅读(30271) |
评论 (19) |
编辑 收藏这个解决方法已经定制下来很久了,上一段时间比较忙,没有时间整这些东西。最近稍微好些,不怎么加班。所以抽空总结下,同时也分享给大家,也算是给大家一个借鉴吧!或许这并不是最好的解决方案,但只要能满足当前需求的最好方案也算是最好的解决方案,谁说不是呢!O(∩_∩)O~
我们采用的方案如下:
先看图

上图的流程大致上是这样的:
手机端向PC端发送聊天内容
1、手机端程序通过Socket连接服务器端的ServerSocket
2、然后服务器端根据手机Mobile客户端发送过来统一规范的报文或聊天内容,进行解析
3、然后将解析的内容,再用smack框架转发到openfire服务器
4、最后由openfire服务器向客户端(BS、CS、PhoneClient)程序发送聊天信息。这里的客户端可以是pc上的浏览器,pc上的桌面应用,手机应用等
5、PC客户端BS程序(用http bind方式监听)的长连接监听到openfire服务器发送过来的数据,直接在页面中显示
同样,PC客户端向手机端发送聊天内容
1、PC客户端(BS)可以直接用http bind(xmpp 提供的http请求的长连接方式)直接向openfire服务器发送聊天数据;
2、然后openfire服务器接收到聊天内容的时候,这时候socket服务器中的smack框架中有一个聊天内容的监听器
3、监听到PC端向openfire发送的内容后,会用socket的流向手机端发送我们定义好的报文或是聊天内容
4、手机端的socket会不停的轮询(可以模拟心跳式长连接的方式),判断是否有消息到达,如果有则显示
而普通的聊天程序的流程则是客户端发送信息到openfire服务器,openfire服务器再将消息转发给其他客户端。他们省去了socket服务器这部分,那我们为什么要加上socket服务器这部分呢?
我们这样做也是有自己的道理的:
首先,如果让手机端自己实现向openfire服务器发送程序的代码,那工作量是相当大的。因为每个手机平台使用的语言都不同,每个平台都需要实现向openfire服务器发送聊天信息的报文。这其实就是在做重复的工作,而且每个平台实现向手机端发送报文信息的技术会让每个手机端的开发人员都要学会一套和openfire交互的代码。这势必会重复工作、重复相同业务的代码。所以,把这些代码放在一个tcp/ip的socket中转服务器进行统一发送,这也是有好处的。
其次,把所以发送消息在报文在socket服务器完成,可以对业务进行一个统一的处理、消息过滤。
手机端被否决的解决方案,供参考
手机端用http长连接的方式,这个是不行的
其一、手机的移动网络不稳定,长连接会经常断掉,当然你可以自动进行重连
其二、长连接一直连接在服务器上,占用服务器资源。当然你可以使用心跳式长连接或是轮询方式
其三、手机端一直连接服务器会使用手机端用户的网络带宽流量(流量不是免费的,客户会怎么想)
其四、手机端一直连着服务器,对手机的电量也有消耗(现在智能机解决电量也是一个问题)
posted @
2012-07-31 15:16 hoojo 阅读(2023) |
评论 (0) |
编辑 收藏
摘要: 这篇文章是承接之前CXF整合Spring的这个项目示例的延伸,所以有很大一部分都是一样的。关于发布CXF WebServer和Spring整合CXF这里就不再多加赘述了。如果你对Spring整合CXF WebService不了解,具体你可以参看这两篇文章: http://www.cnblogs.com/hoojo/archive/2011/03/30/1999563.html http://www...
阅读全文
posted @
2012-07-23 16:58 hoojo 阅读(6231) |
评论 (0) |
编辑 收藏
摘要: 开发环境: System:Windows JavaEE Server:tomcat5.0.2.8、tomcat6 JavaSDK: jdk6+ IDE:eclipse、MyEclipse 6.6 开发依赖库: JDK6、 JavaEE5、ehcache-core-2.5.2.jar Email:hoojo_@126.com Blog:http://blog.csdn....
阅读全文
posted @
2012-07-19 16:33 hoojo 阅读(3277) |
评论 (0) |
编辑 收藏在CXF2版本中,整合Spring3发布CXF WebService就更加简单了。因为Spring 3提供了annotation注解,而CXF2发布WebService已经不像之前版本的配置那样(参考老版本发布WebService系列文章:http://www.cnblogs.com/hoojo/archive/2011/03/30/1999563.html),现在发布一个WebService可以直接从Spring的IoC容器中拿到一个对象,发布成WebService服务。当然发布WebService的配置有了些小小的变动,具体请往下看。
在老版本中发布一个WebService,配置applicationContext-server.xml文件中添加如下配置如下:
jaxws:server的发布方式
<bean id="userServiceBean" class="com.hoo.service.ComplexUserService"/>
<bean id="inMessageInterceptor" class="com.hoo.interceptor.MessageInterceptor">
<constructor-arg value="receive"/>
</bean>
<bean id="outLoggingInterceptor" class="org.apache.cxf.interceptor.LoggingOutInterceptor"/>
<!-- 注意下面的address,这里的address的名称就是访问的WebService的name -->
<jaxws:server id="userService" serviceClass="com.hoo.service.IComplexUserService" address="/Users">
<jaxws:serviceBean>
<!-- 要暴露的 bean 的引用 -->
<ref bean="userServiceBean"/>
</jaxws:serviceBean>
<jaxws:inInterceptors>
<ref bean="inMessageInterceptor"/>
</jaxws:inInterceptors>
<jaxws:outInterceptors>
<ref bean="outLoggingInterceptor"/>
</jaxws:outInterceptors>
</jaxws:server>
jaxws:endpoint的发布方式
<!-- com.hoo.service.ComplexUserService是com.hoo.service.IComplexUserService接口的实现, 这种方法应该不能从Ioc中引用对象 -->
<jaxws:endpoint id="userService2" implementor="com.hoo.service.ComplexUserService" address="/Users">
<jaxws:inInterceptors>
<ref bean="inMessageInterceptor"/>
</jaxws:inInterceptors>
<jaxws:outInterceptors>
<ref bean="outLoggingInterceptor"/>
</jaxws:outInterceptors>
</jaxws:endpoint>
而在2.x新版本中,发布Ioc容器中的对象为一个WebService的方法
<bean id="userServiceBean" class="com.hoo.service.ComplexUserService"/>
<bean id="inMessageInterceptor" class="com.hoo.interceptor.MessageInterceptor">
<constructor-arg value="receive"/>
</bean>
<bean id="outLoggingInterceptor" class="org.apache.cxf.interceptor.LoggingOutInterceptor"/>
<!-- 注意下面的address,这里的address的名称就是访问的WebService的name;#userServiceBean是直接引用Ioc容器中的Bean对象 -->
<jaxws:server id="userService" serviceBean="#userServiceBean" address="/Users">
<jaxws:inInterceptors>
<ref bean="inMessageInterceptor"/>
</jaxws:inInterceptors>
<jaxws:outInterceptors>
<ref bean="outLoggingInterceptor"/>
</jaxws:outInterceptors>
</jaxws:server>
<!-- 或者这种方式,在老版本中这个是不能引用Ioc容器中的对象,但在2.x中可以直接用#id或#name的方式发布服务 -->
<jaxws:endpoint id="userService2" implementor="#userServiceBean" address="/Users">
<jaxws:inInterceptors>
<ref bean="inMessageInterceptor"/>
</jaxws:inInterceptors>
<jaxws:outInterceptors>
<ref bean="outLoggingInterceptor"/>
</jaxws:outInterceptors>
</jaxws:endpoint>
CXF发布WebService官方参考:http://cxf.apache.org/docs/writing-a-service-with-spring.html
posted @
2012-07-13 17:47 hoojo 阅读(3957) |
评论 (0) |
编辑 收藏在xmpp协议通信中,用smack框架登录非本地openfire服务器的时候,出现javax.net.ssl.SSLException: Received fatal alert: internal_error异常信息。原因是登录他网openfire服务器出现登录延时(在没有成功链接到openfire服务器),然后就进行登录login操作的时候,就会出现这个异常。
解决办法
1、在链接openfire服务器后,线程休眠一段时间,再进行登录login操作。
……
connection.connect();
Thread.sleep(3000);
connection.login(user, pass);
……
2、设置setPacketReplyTimeout参数
......
SmackConfiguration.setPacketReplyTimeout(PACKET_REPLY_TIMEOUT);
config = new ConnectionConfiguration(SERVER, PORT);
......
注意:如果设置了休眠时间或setPacketReplyTimeout参数后还是出现错误,请讲时间设置再大些看看
参考官方解答:http://community.igniterealtime.org/message/206443#206443
posted @
2012-07-12 16:49 hoojo 阅读(4018) |
评论 (1) |
编辑 收藏 前一篇http://www.blogjava.net/hoojo/archive/2012/07/12/382852.html介绍了Ehcache整合Spring缓存,使用页面、对象缓存;这里将介绍在Hibernate中使用查询缓存、一级缓存、二级缓存,整合Spring在HibernateTemplate中使用查询缓存。
EhCache是Hibernate的二级缓存技术之一,可以把查询出来的数据存储在内存或者磁盘,节省下次同样查询语句再次查询数据库,大幅减轻数据库压力;
EhCache的使用注意点
当用Hibernate的方式修改表数据(save,update,delete等等),这时EhCache会自动把缓存中关于此表的所有缓存全部删除掉(这样能达到同步)。但对于数据经常修改的表来说,可能就失去缓存的意义了(不能减轻数据库压力);
在比较少更新表数据的情况下,EhCache一般要使用在比较少执行write操作的表(包括update,insert,delete等)[Hibernate的二级缓存也都是这样];对并发要求不是很严格的情况下,两台机子中的缓存是不能实时同步的;
首先要在hibernate.cfg.xml配置文件中添加配置,在hibernate.cfg.xml中的mapping标签上面加以下内容:
<!-- Hibernate 3.3 and higher -->
<!--
<property name="hibernate.cache.region.factory_class">net.sf.ehcache.hibernate.EhCacheRegionFactory</property>
<property name="hibernate.cache.region.factory_class">net.sf.ehcache.hibernate.SingletonEhCacheRegionFactory</property>
-->
<!-- hibernate3.0-3.2 cache config-->
<!--
<property name="hibernate.cache.region.factory_class">net.sf.ehcache.hibernate.EhCacheProvider</property>
-->
<property name="hibernate.cache.provider_class">net.sf.ehcache.hibernate.SingletonEhCacheProvider</property>
<!-- Enable Second-Level Cache and Query Cache Settings -->
<property name="hibernate.cache.use_second_level_cache">true</property>
<property name="hibernate.cache.use_query_cache">true</property>
如果你是整合在spring配置文件中,那么你得配置你的applicationContext.xml中相关SessionFactory的配置
<prop key="hibernate.cache.use_query_cache">true</prop>
<prop key="hibernate.cache.use_second_level_cache">true</prop>
<prop key="hibernate.cache.provider_class">org.hibernate.cache.EhCacheProvider</prop>
然后在hibernate.cfg.xml配置文件中加入使用缓存的属性
<!-- class-cache config -->
<class-cache class="com.hoo.hibernate.entity.User" usage="read-write" />
当然你也可以在User.hbm.xml映射文件需要Cache的配置class节点下,加入类似如下格式信息:
<class name="com.hoo.hibernate.entity.User" table="USER" lazy="false">
<cache usage="transactional|read-write|nonstrict-read-write|read-only" />
注意:cache节点元素应紧跟class元素
关于选择缓存策略依据:
ehcache不支持transactional,其他三种可以支持。
read- only:无需修改, 可以对其进行只读缓存,注意:在此策略下,如果直接修改数据库,即使能够看到前台显示效果,但是将对象修改至cache中会报error,cache不会发生作用。另:删除记录会报错,因为不能在read-only模式的对象从cache中删除。
read-write:需要更新数据,那么使用读/写缓存比较合适,前提:数据库不可以为serializable transaction isolation level(序列化事务隔离级别)
nonstrict-read-write:只偶尔需要更新数据(也就是说,两个事务同时更新同一记录的情况很不常见),也不需要十分严格的事务隔离,那么比较适合使用非严格读/写缓存策略。
如果你使用的注解方式,没有User.hbm.xml,那么你也可以用注解方式配置缓存
@Cache(usage = CacheConcurrencyStrategy.READ_WRITE)
public class User implements Serializable {}
在Dao层使用cache,代码如下
Session s = HibernateSessionFactory.getSession();
Criteria c = s.createCriteria(User.class);
c.setCacheable(true);//这句必须要有
System.out.println("第一次读取");List<User> users = c.list();
System.out.println(users.size());
HibernateSessionFactory.closeSession();
s = HibernateSessionFactory.getSession();
c = s.createCriteria(User.class);
c.setCacheable(true);//这句必须要有
System.out.println("第二次读取");users = c.list();
System.out.println(users.size());
HibernateSessionFactory.closeSession();
你会发现第二次查询没有打印sql语句,而是直接使用缓存中的对象。
如果你的Hibernate和Spring整合在一起,那么你可以用HibernateTemplate来设置cache
getHibernateTemplate().setCacheQueries(true);
return getHibernateTemplate().find("from User");
当你整合Spring时,如果你的HibernateTemplate模板配置在Spring的Ioc容器中,那么你可以这样启用query cache
<bean id="hibernateTemplate" class="org.springframework.orm.hibernate3.HibernateTemplate">
<property name="sessionFactory">
<ref bean="sessionFactory" />
</property>
<property name="cacheQueries">
<value>true</value>
</property>
</bean>
此后,你在dao模块中注入sessionFactory的地方都注入hibernateTemplate即可。
以上讲到的都是Spring和Hibernate的配置,下面主要结合上面使用的ehcache,来完成ehcache.xml的配置。如果你没有配置ehcache,默认情况下使用defaultCache的配置。
<cache name="com.hoo.hibernate.entity.User" maxElementsInMemory="10000" eternal="false" timeToIdleSeconds="300" timeToLiveSeconds="600" overflowToDisk="true" />
<!--
hbm文件查找cache方法名的策略:如果不指定hbm文件中的region="ehcache.xml中的name的属性值",则使用name名为com.hoo.hibernate.entity.User的cache,如果不存在与类名匹配的cache名称,则用 defaultCache。
如果User包含set集合,则需要另行指定其cache
例如User包含citySet集合,则需要
添加如下配置到ehcache.xml中
-->
<cache name="com.hoo.hibernate.entity.citySet"
maxElementsInMemory="10000" eternal="false" timeToIdleSeconds="300"
timeToLiveSeconds="600" overflowToDisk="true" />
如果你使用了Hibernate的查询缓存,需要在ehcache.xml中加入下面的配置
<cache name="org.hibernate.cache.UpdateTimestampsCache"
maxElementsInMemory="5000"
eternal="true"
overflowToDisk="true" />
<cache name="org.hibernate.cache.StandardQueryCache"
maxElementsInMemory="10000"
eternal="false"
timeToLiveSeconds="120"
overflowToDisk="true" />
调试时候使用log4j的log4j.logger.org.hibernate.cache=debug,更方便看到ehcache的操作过程,主要用于调试过程,实际应用发布时候,请注释掉,以免影响性能。
使用ehcache,打印sql语句是正常的,因为query cache设置为true将会创建两个缓存区域:一个用于保存查询结果集 (org.hibernate.cache.StandardQueryCache); 另一个则用于保存最近查询的一系列表的时间戳(org.hibernate.cache.UpdateTimestampsCache)。请注意:在查询缓存中,它并不缓存结果集中所包含的实体的确切状态;它只缓存这些实体的标识符属性的值、以及各值类型的结果。需要将打印sql语句与最近的cache内 容相比较,将不同之处修改到cache中,所以查询缓存通常会和二级缓存一起使用。
posted @
2012-07-12 10:48 hoojo 阅读(9254) |
评论 (0) |
编辑 收藏
摘要: Ehcache在很多项目中都出现过,用法也比较简单。一般的加些配置就可以了,而且Ehcache可以对页面、对象、数据进行缓存,同时支持集群/分布式缓存。如果整合Spring、Hibernate也非常的简单,Spring对Ehcache的支持也非常好。EHCache支持内存和磁盘的缓存,支持LRU、LFU和FIFO多种淘汰算法,支持分布式的Cache,可以作为Hibernate的缓存插件。同时它也能...
阅读全文
posted @
2012-07-12 10:15 hoojo 阅读(5032) |
评论 (0) |
编辑 收藏
摘要: 在文章开始,请你了解和熟悉openfire方面的相关知识,这样对你理解下面代码以及下面代码的用途有很好的了解。同时,你可能需要安装一个简单的CS聊天工具,来测试你的代码是否成功的在openfire服务器上建立会话链接,并成功的向在线用户发送聊天消息。 必须了解:http://www.cnblogs.com/hoojo/archive/2012/05/17/2506769.html http://w...
阅读全文
posted @
2012-06-25 17:41 hoojo 阅读(9724) |
评论 (2) |
编辑 收藏