|
|
2011年4月18日
这个问题很多小伙伴都遇到了,网上搜罗了半天也没找到太好、太完美的解决办法,有人说是因为安装IE11时联网了,导致自动打了补丁,这个补丁可以自动检查IE主页是否损坏,可以通过卸载相应的补丁解决,我同时又找到了另外一个通过修改hosts文件的方法,貌似目前解决了我的问题,修改方法如下:
使用记事本打开 C:\Windows\System32\drivers\etc\hosts 文件,在最下面追加一行:
127.0.0.1 ieonline.microsoft.com
将JDK中BIN文件夹下的 msvcr71.dll 这个文件复制到 TOMCAT 中的 BIN 下
有段日子没做记录了,这段日子一直在排雷(前人埋下的隐患代码,或者直接说bug),今天这个雷让我排了将近大半天,因为是正式上线的系统,只能看后台日志,不能调试,打印出的异常信息不完整,种种的条件不充分,导致问题很难定位。标题上的两个异常,第一个一看就明白是插入的数值大于数据库字段长度,第二个多是因为Number类型的字段导致,比如精度不足。我们的这次问题原因是程序员在做除法运算时没有对除数进行非零判断,导致计算出来的数值非法,插入数据库失败,请看代码:
  public static void main(String[] args) public static void main(String[] args)  { {
 double a = 10; double a = 10;
double b = 0;
double c = 0;
double m = a/c;
double n = b/c;
System.out.println(m);
System.out.println(n);
 } }
经过计算后,m和n的值分别是多少?没在实际开发中遇到的可能不知道,或者你有个好习惯不会出现这样的bug,请看结果:
 Infinity Infinity
NaN
被除数非零,除数为零做除法的结果是字符串“Infinity”,翻译成中文就是“无限”,你的中学数学老师可能说过;
被除数为零,除数为零做触发的结果是字符串“NaN”,即不是有效的数字。
就是这个“Infinity”花费了我一小天的时间才定位。下面详述问题定位的方法。
异常1:ORA-01438: value larger than specified precision allowed for this column
了解点数据库的打眼一看就知道插入的数值超过了表字段长度,但你知道是哪个表哪个字段吗?我不知道,于是网上查阅了下,Oracle数据库服务器在Linux上。
命令行登陆到数据库所在服务器,进入Oracle的安装目录,假设是/opt/oracle/
进入到如下目录:/opt/oracle/admin/实例名/udump
中间的数据库实例名根据实际情况修改,udump目录下会有一堆的.trc文件,这些文件记录了所有操作当前数据库出现异常的堆栈信息。为了定位问题,我将该目录下的所有.trc文件都删除了(当然,删除之前把udump目录整个备份了),再进行一次系统的业务操作,查看一下udump目录,发现立刻生成一个新 的.trc文件,打开查看(内容片段):
Oracle Database 10g Enterprise Edition Release 10.2.0.4.0 - 64bit Production
With the Partitioning, Real Application Clusters, OLAP, Data Mining
and Real Application Testing options
ORACLE_HOME = /u01/app/oracle/product/10.2/db_1
System name: AIX
Node name: gsdj1
Release: 1
Version: 6
Machine: 00CFD4644C00
Instance name: bjwd1
Redo thread mounted by this instance: 1
Oracle process number: 132
Unix process pid: 48300280, image: oracle@gsdj1
*** SERVICE NAME:(bjwd) 2014-03-28 16:48:05.683
*** SESSION ID:(2969.43961) 2014-03-28 16:48:05.683
*** 2014-03-28 16:48:05.683
ksedmp: internal or fatal error
ORA-01438: value larger than specified precision allowed for this column
Current SQL statement for this session:
insert into CP_TEMP_STOCKTRAN (APPLY_ID, ALIEN, CER_TYPE, CER_NO, TRANS_AM, TRANS_AM_PR, TRANS_TYPE, TRANS_DATE, ENDORSOR, BLIC_TYPE, ALIEN_ID, ENDORSOR_ID, STOCKTRAN_ID) values (:1, :2, :3, :4, :5, :6, :7, :8, :9, :10, :11, :12, :13)
黄色背景红色字体的SQL就是罪魁祸首,这仅仅能定位发生问题的数据库表,字段还得自己排查。异常1让我定位到了这里,这时想起了异常2。
异常2: Could not synchronize database state with session
之前也搜索过这个异常,多数是由于Number类型的字段导致。冷静的思考一下,平常我们在做表设计时,会把文字类型的字段设置大一些,Number类型的精度也会根据实际业务进行设计,但往往Number类型的字段最容易出问题:
1、如果将非Number值插入该字段,比如字符串
2、如果插入的数值精度过多,如字段设计Number(10,2),也就是最大支持8为整数和两位小数,要插入34.121313就会失败
根据表名定位到hibernate的映射文件以及实体类,再从业务功能入口(一个action方法)搜索,终于定位到一个业务接口做了该实体类的保存代码,定位到了那个字段,定位到了做除法没有判断除数是否为0。
源机器:192.168.1.1 备份机器:192.168.1.2 前提条件: 1、两台机器的网络是连通的 2、两台机器必须同时安装了SVN服务器 假设: 源机器上需要同步的库名为autoSync,访问地址为:svn://192.168.1.1/autoSync,对其具备读写权限的账户:sync/sync 备份机器配置: 1、创建与源机器库名相同的空库 # 假设备份机器的SVN根目录建立在 /home/backup/svn/repository下
svnadmin create /home/backup/svn/repository/autoSync 2、配置备份机器上的autoSync 分别修改conf下的svnserve.conf、passwd、authz,根据实际情况配置,假设创建了用户sync/sync,对库autoSync具备读写权限,配置方法略,配置完成后启动SVN服务 3、创建并修改pre-revprop-change文件 cd /home/backup/svn/repository/autoSync/hooks
cp pre-revprop-change.tmpl pre-revprop-change
vi pre-revprop-change 将文件末尾的“exit 1”修改为“exit 0”即可,保存退出 REPOS="$1"
REV="$2"
USER="$3"
PROPNAME="$4"
ACTION="$5"
if [ "$ACTION" = "M" -a "$PROPNAME" = "svn:log" ]; then exit 0; fi
echo "Changing revision properties other than svn:log is prohibited" >&2
exit 0
增加可执行权限 chmod 755 pre-revprop-change 4、初始化 命令: svnsync init --username 用户名 --password 密码 备份机器库URL 源机器库URL 说明: 用户名和密码是对源机器SVN库具备读写权限的SVN用户 示例: svnsync init --username sync --password sync svn://192.168.1.2/autoSync svn://192.168.1.1/autoSync 5、首次同步 首次同步即为一次全备份过程,在此期间请停止客户端段源机器哦一切操作(提交代码等) 命令: svnsync sync 备份机器库URL 示例: svnsync sync svn://192.168.1.2/autoSync 源机器配置 6、增量自动同步配置 创建并修改post-commit文件 # 假设源机器的SVN根目录建立在 /home/svn/repository下
cd /home/svn/repository/autoSync/hooks
cp post-commit.tmpl post-commit
vi post-commit 在文件末尾追加:svnsync sync --non-interactive 备份机器库URL --username 用户名 --password 密码 说明: 用户名和密码是对备份机器SVN库具备读写权限的SVN用户 示例: svnsync sync --non-interactive svn://192.168.1.2/autoSync --username sync --password sync 7、术语 配置完成,今后客户端再向SVN(192.168.1.1)提交文件时,会自动触发源机器(192.168.1.1)向备份机器(192.168.1.2)提交更新 8、版本库UUID一致性 首先查看源机器库的UUID,假设得到的是:fcdcbee9-6be3-4575-8d4a-681ec15ad8e0 svnlook uuid svn://192.168.1.1/autoSync 更新备份机器库的UUID为源机器库的UUID svnadmin setuuid svn://192.168.1.2/autoSync fcdcbee9-6be3-4575-8d4a-681ec15ad8e0
本文记录的安装步骤是基于基本安装后的Debian,启动后漆黑一片,只有命令行,采用在线安装方式,因此配置中国的镜像软件源能提高软件的下载速度,首先配置软件源。备份源文件# cp /etc/apt/sources.list /etc/apt/sources.list.bak
编辑源文件# nano /etc/apt/sources.list
注释掉本地光盘源这一行,注释后如:# deb cdrom:[Debian GNU/Linux 6.0.7 _Squeeze_ - Official amd64 NETINST Binary-1 20130223-18:50]/ squeeze main取消下面两行官方源前面的注释deb http://security.debian.org/ squeeze/updates maindeb-src http://security.debian.org/ squeeze/updates main追加163的镜像源地址deb http://mirrors.163.com/debian/ squeeze main non-free contrib deb http://mirrors.163.com/debian/ squeeze-proposed-updates main contrib non-free deb http://mirrors.163.com/debian-security/ squeeze/updates main contrib non-free deb-src http://mirrors.163.com/debian/ squeeze main non-free contrib deb-src http://mirrors.163.com/debian/ squeeze-proposed-updates main contrib non-free deb-src http://mirrors.163.com/debian-security/ squeeze/updates main contrib non-free deb http://ftp.sjtu.edu.cn/debian/ squeeze main non-free contrib deb http://ftp.sjtu.edu.cn/debian/ squeeze-proposed-updates main contrib non-free deb http://ftp.sjtu.edu.cn/debian-security/ squeeze/updates main contrib non-free deb-src http://ftp.sjtu.edu.cn/debian/ squeeze main non-free contrib deb-src http://ftp.sjtu.edu.cn/debian/ squeeze-proposed-updates main contrib non-free deb-src http://ftp.sjtu.edu.cn/debian-security/ squeeze/updates main contrib non-free保存修改# ctrl + o 回车退出# ctrl + x更新源# apt-get update更新系统# apt-get upgrade安装SVN服务器# apt-get install subversion subversion-tools安装完成后可以运行命令查看SVN服务器版本信息# svnserve --version配置SVN首先创建版本库的根目录,如位置:/home/svn/repository,所有项目都将在该目录下创建相应子文件夹# mkdir –p /home/svn/repository创建项目版本库test(仅为演示)# svnadmin create /home/svn/repository/test
修改SVN配置文件
nano /home/svn/repository/test/conf/svnserve.conf
以下为文件内容:
### This file controls the configuration of the svnserve daemon, if you
### use it to allow access to this repository. (If you only allow
### access through http: and/or file: URLs, then this file is
### irrelevant.) ### Visit http://subversion.tigris.org/ for more information. [general]
### These options control access to the repository for unauthenticated
### and authenticated users. Valid values are "write", "read",
### and "none". The sample settings below are the defaults
# 未授权配置为禁止访问none,已授权配置为可以读写write
anon-access = none
auth-access = write
### The password-db option controls the location of the password
### database file. Unless you specify a path starting with a /,
### the file's location is relative to the directory containing
### this configuration file.
### If SASL is enabled (see below), this file will NOT be used.
### Uncomment the line below to use the default password file.
# 用户数据库文件,配置授权用户,当前使用的文件是和svnserve.conf在相同目录下的passwd文件,也可以指定其他绝对路径文件,如:/home/svn/passwd
password-db = passwd
### The authz-db option controls the location of the authorization
### rules for path-based access control. Unless you specify a path
### starting with a /, the file's location is relative to the the
### directory containing this file. If you don't specify an
### authz-db, no path-based access control is done.
### Uncomment the line below to use the default authorization file.
# 授权文件,配置如同用户配置
authz-db = authz
### This option specifies the authentication realm of the repository.
### If two repositories have the same authentication realm, they should
### have the same password database, and vice versa. The default realm
### is repository's uuid.
# realm = My First Repository [sasl]
### This option specifies whether you want to use the Cyrus SASL
### library for authentication. Default is false.
### This section will be ignored if svnserve is not built with Cyrus
### SASL support; to check, run 'svnserve --version' and look for a line
### reading 'Cyrus SASL authentication is available.'
# use-sasl = true
### These options specify the desired strength of the security layer
### that you want SASL to provide. 0 means no encryption, 1 means
### integrity-checking only, values larger than 1 are correlated
### to the effective key length for encryption (e.g. 128 means 128-bit
### encryption). The values below are the defaults.
# min-encryption = 0
# max-encryption = 256
保存
# ctrl + o 回车
退出
# ctrl + x
配置用户
# nano passwd 以下为文件内容:
### This file is an example password file for svnserve.
### Its format is similar to that of svnserve.conf. As shown in the
### example below it contains one section labelled [users].
### The name and password for each user follow, one account per line. [users]
# harry = harryssecret
# sally = sallyssecret
IceWee = IceWee 增加用户IceWee,密码也为IceWee,=号两侧需要有空格,保存(ctrl + o 回车)退出(ctrl + x)
配置访问权限
# nano authz 以下为文件内容:
### This file is an example authorization file for svnserve.
### Its format is identical to that of mod_authz_svn authorization
### files.
### As shown below each section defines authorizations for the path and
### (optional) repository specified by the section name.
### The authorizations follow. An authorization line can refer to:
### - a single user,
### - a group of users defined in a special [groups] section,
### - an alias defined in a special [aliases] section,
### - all authenticated users, using the '$authenticated' token,
### - only anonymous users, using the '$anonymous' token,
### - anyone, using the '*' wildcard.
###
### A match can be inverted by prefixing the rule with '~'. Rules can
### grant read ('r') access, read-write ('rw') access, or no access
### (''). [aliases]
# joe = /C=XZ/ST=Dessert/L=Snake City/O=Snake Oil, Ltd./OU=Research Institute/CN=Joe Average [groups]
# harry_and_sally = harry,sally
# harry_sally_and_joe = harry,sally,&joe
developers = IceWee # [/foo/bar]
# harry = rw
# &joe = r
# * = # [repository:/baz/fuz]
# @harry_and_sally = rw
# * = r [/]
* = r
IceWee = rw
@developers = rw [/tags]
IceWee = rw 默认所有用户可读取根,IceWee可以读写根。可以分别对子目录进行授权,如上的tags目录,IceWee具有读写权限,以及IceWee所在的组developers也具备读写权限。
启动SVN服务器
# svnserve -d -r /home/svn/repository
-d含义为后台运行(daemon),-r指定的根目录,如访问test应该使用这样的地址 svn://hostname:port/test
停止SVN服务
# killall svnserve
备份还原命令,与oracle的备份有些类似
导出
# svnadmin dump /home/svn/repository/test > /home/bak/test.dump
导入
# svnadmin load /home/svn/repository/demo < /home/bak/demo.dump
导入前提:
必须先创建要导入版本库目录,如上的demo,则需要做以下操作
# svnadmin create /home/svn/respository/demo
修改svnserve.conf、passwd、authz等文件,前面已介绍
2013年12月10日
---------------------------
冒泡排序
  void bubble(int[] array) { void bubble(int[] array) {
 boolean swaped = true; boolean swaped = true;
  for (int t = 1; t < array.length && swaped; t++) { for (int t = 1; t < array.length && swaped; t++) {
swaped = false;
for (int i = 0; i < array.length - t; i++) {
if (array[i] > array[i + 1]) {
int temp = array[i];
array[i] = array[i + 1];
array[i + 1] = temp;
swaped = true;
 } }
}
}
 } }
2013年11月26日
---------------------------
1、String的split方法
平常总是这样用,String str = "a,b,c,d,e"; String[] arr = str.split(",");
其实还可以这样用,String lan = "Java;C#?C++:C"; String si = lan.split("[;?:]"); 返回的是字符串数组{"Java", "C#", "C++", "C"}
2013年11月21日
---------------------------
1、Java对象池知多少?
示例:String s1 = "abc"; String s2 = "abc"; s1 == s2 返回ture还是false?只要不是new出来的都先从对象池中读取,因此结果为true,两个变量指向的是同一块内存空间地址。
Java除了String类使用了对象池以外,还有5个基本类型的封装类:Byte、Short、Integer、Long和Character,例如:Integer inA = 20; Integer inB = 20; 那么 inA == inB 的结果为true,其他类与此相同,不做示例。
特别注意:
(1)浮点型的两个封装类Float和Double并没有参与对象池;
(2)整形封装类(Byte、Short、Integer和Long)只有数值小于或等于127时才使用对象池,例如:Integer x = 128; Integer y = 128; x == y的结果为false。
2、Java变量命名规范
A. String #name = "Joe";
B. int $age = 30;
C. Double _height = 174.4;
D. float ~temp = 37.6;
以上A到D,哪个无法通过编译?答案是A和D,因为Java变量名只允许字母、下划线(_)、美元符($)开头,那么 int _ = 30; String $$ = "I DO";可以吗?答案是完全可以,但很少有人这样定义变量名,虽然没有违法命名规范,但最后我估计程序员自己都会被自己绕晕。
3、0和1能标识布尔值吗?
int flag = 0;
if (flag) {
System.out.print("error");
}
error会打印吗?不会,因为根本就不会编译通过,编译器会提示flag是int类型而不是boolean类型,如果你会有这种想法可能之前学过C,C总的0和1可以标识布尔的。
4、静态导入
例:
ClassA.java
 package bing.test.sub1; package bing.test.sub1;
public class ClassA {
public static final int MAX_INT = Integer.MAX_VALUE;
}
ClassB.java
package bing.test.sub2;
import static bing.test.sub1.ClassA.MAX_INT;
public class ClassB {
public static void main(String[] args) {
System.out.println(MAX_INT);
}
}
输出:2147483647。不仅仅可以静态导入其他类的静态属性还可以导入静态方法,这些特性在实际开发中很少见。
Apache Commons的FTPClient局域网上传文件速度本应该很快的,但却在实际开发中发现上传一个文件蜗牛速度,都是因为调用了如下API: ftpClient.storeFile(fileName, inputStream) 原因是因为默认缓冲区大小是1024,也就是1K,当然慢了,在调用上传API之前重新修改以下默认设置即可,如将缓冲区改为10M,API: ftpClient.setBufferSize(1024 * 1024 * 10)
第一步,查询锁表信息 --查询被锁住的数据库对象
select object_name, machine, s.sid, s.serial#
from v$locked_object l, dba_objects o, v$session s
where l.object_id = o.object_id
and l.session_id = s.sid; 第二步,杀死数据库会话 --杀死数据库会话
alter system kill session '207,707'; -- 207为SID, 707为SERIAL# 第三步,如果第二步无法杀死会话,报ORA-00031,那么只能杀死UNIX/LINUX系统进程了 --查询当前操作的系统进程ID
select spid, osuser, s.program
from v$session s, v$process p
where s.paddr = p.addr
and s.sid = 207; -- 207为SID 第四步,根据查询到的系统PID,杀掉进程 kill -9 24664 // 24664为UNIX/LINUX系统进程ID
摘要: 备用。Code highlighting produced by Actipro CodeHighlighter (freeware)http://www.CodeHighlighter.com/-->import java.io.BufferedReader;import java.io.IOException;import java.io.InputStream;... 阅读全文
项目开发组建立后一般要统一开发环境,一般是指开发环境,开发工具的版本和设置,其中编码设置是个较为重要的部分,其重要性不言而喻。以下为eclipse编码设置方法(将默认编码改为UTF-8为例):
1.工作空间的编码(这样以后新建的文件也是新设置的编码格式)
eclipse->window->preferences->General->workspaceTypes->Other->UTF-8->OK
2.工程的编码
Project->Properties->General->Resource->Other->UTF-8->OK
3.某类文件的编码
eclipse->window->preferences->General->Content Types->右侧找到需要修改的文件的类型(如JAVA,JSP等)->在下面的Default encoding,输入框中输入UTF-8->点击Update->OK
4、单个文件的编码
在包资源管理器视图,右键点击文件->属性,改变文本文件编码格式为UTF-8
进来的看官使用的是win7吧?!是64位的吧!?安装了eclipse的subclipse插件了吧!每次用到SVN插件时都会弹出如下的对话框,虽然不影响使用但是很不爽是不是啊?LZ也是一个有丁点儿强迫症的人,我想干掉这个弹出框! 稍后上图,服务器估计挂了!! 解决方法: Window-Preferences-Team-SVN,在SVN接口的下拉框可以看到,默认选择的是JavaHL(JNI) Not Available,手动更改为SVNKit(Pure Java) SVNKit v1.3.5.7406,OK,enjoy it!
错误提示框: 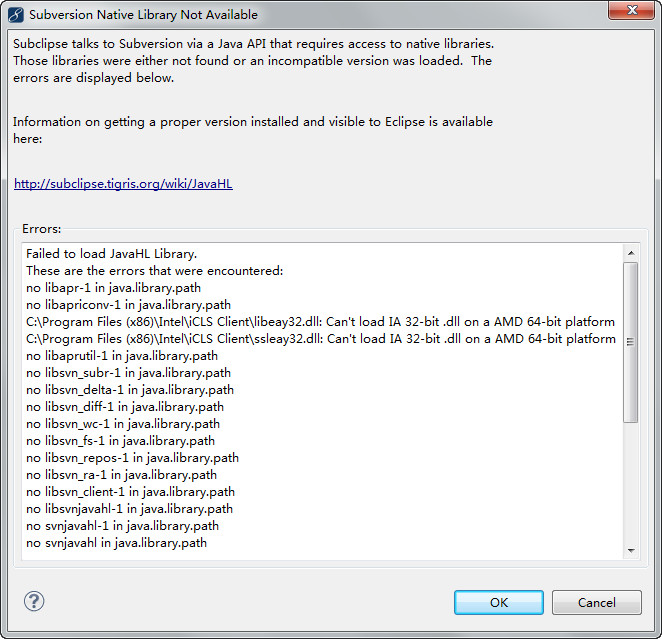 修改前: 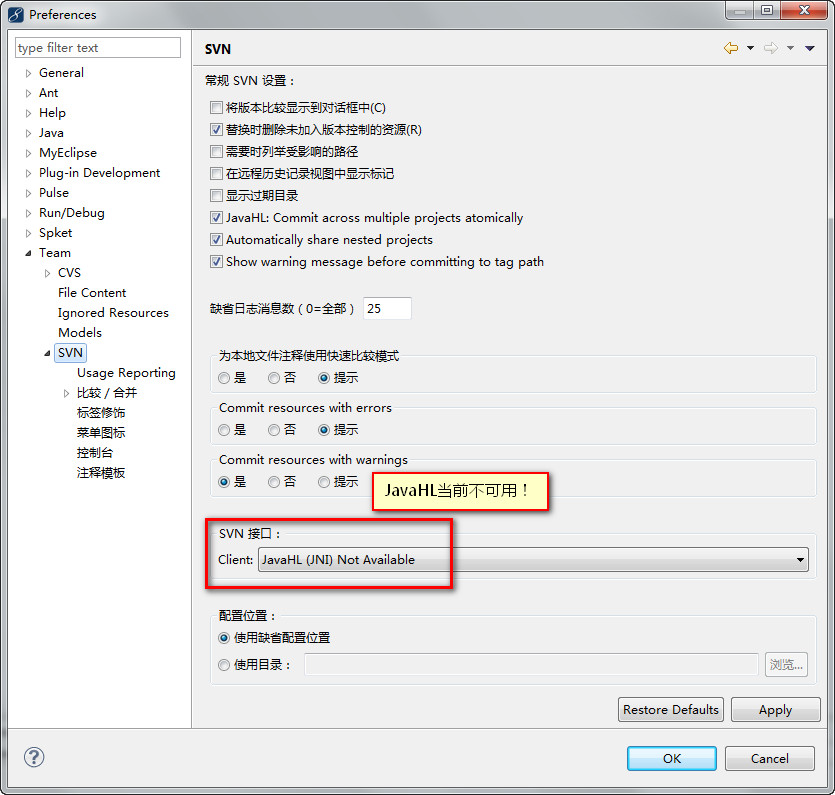 修改后: 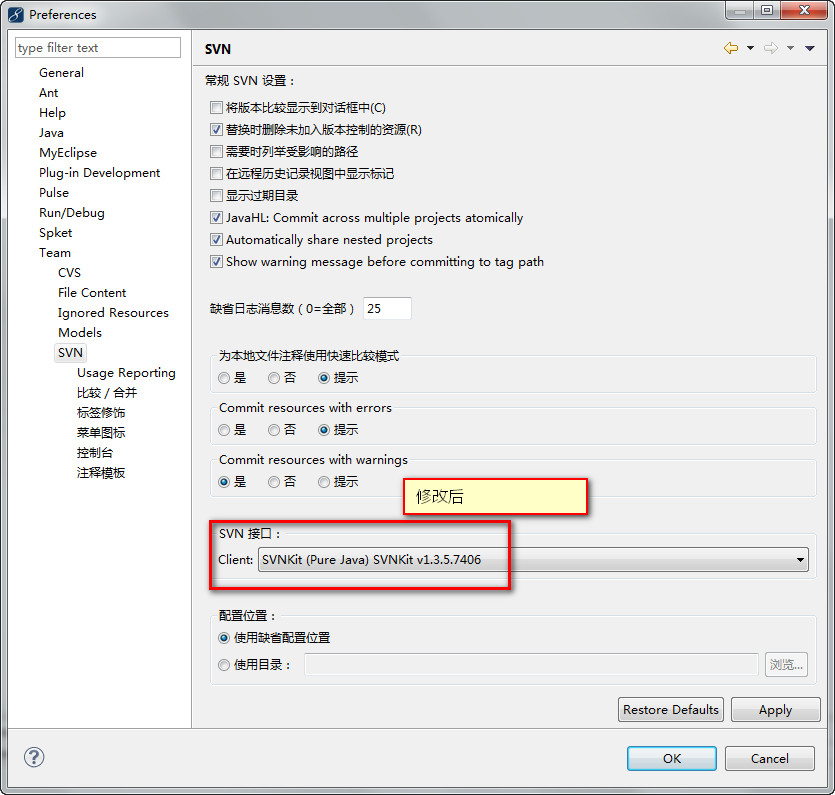
一、Redhat上VNC Server配置
本文以当前Linux系统未安装VNC服务器为基本,如果已安装请跳过第1节!
前提:
1.连接到互联网,将使用yum在线安装VNC服务器
2. 确认 SSH 在运行
1.安装 TigerVNC Server # yum search tigervnc-server
返回大概如下内容:
tigervnc-server.x86_64 : A TigerVNC Server
tigervnc-server-applet.noarch : Java TigerVNC Viewer applet for TigerVNC Server
tigervnc-server-module.x86._64 : TigerVNC Mode to Xorg
...
第一行即是我们要安装的VNS服务器,第二行是客户端,执行
# yum install tigervnc-server.x86_64
回车后会有一次安装确认,输入y后回车即可安装,安装完毕后返回到命令行输入光标,执行
# vncserver
会提示输入验证密码,至少6位,该密码是客户端连接时用到的。
2.配置图形界面
修改配置文件,激活图形界面,执行命令:
# vi /root/.vnc/xstartup
注释掉这行
#twm & // 注释该行
末尾增加一行
gnome-session & // 增加该行
保存退出
3.启动VNC服务
执行命令
# /etc/init.d/vncserver start 或 # service vncserver start
启动后提示:
Starting VNC server: no displays configured [FAILED]
解决方法:
执行命令
# vim /etc/sysconfig/vncservers
修改最后两行如:
VNCSERVERS="1:root"
VNCSERVERARGS[1]="-geometry 1024x768"
说明:
第一行为服务配置,当前只配置了一个VNC服务,使用用户root启动,如果还需要使用其他用户登陆,可以修改VNCSERVERS的值如:“1:root 2:tiger”(tiger为系统另一存在用户)。第二行可以注释,是配置窗口分辨率的,需要去掉后面的-localhost
VNC Server随系统自动启动
执行命令
# sudo chkconfig --level 345 vncserver on
4.停止VNC服务
执行命令
# /etc/init.d/vncserver stop 或 # service vncserver stop
二、Windows借助VNC Viewer访问Linux
首先安装RealVNC,从互联网下载获得
开始 - Run VNC Viewer,输入IP地址,后面的:1代表使用root用户登陆,在RH上配置的1:root,如果想使用其他用户登陆则调整冒号后的数字即可,密码就是先前配置的。
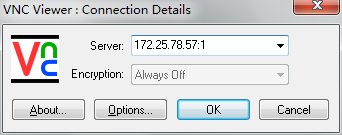
解决连接不上问题的方法
执行命令,查看VNC监听的端口是什么,在防火墙中开放端口即可
# netstat -ntupl|grep vnc
返回列表如:
1. tcp 0 0 0.0.0.0:5901 0.0.0.0:* LISTEN 4411/Xvnc
2. tcp 0 0 0.0.0.0:6001 0.0.0.0:* LISTEN 4411/Xvnc
3. tcp 0 0 :::6001 :::* LISTEN 4411/Xvnc
修改防火墙配置文件,开放5901端口即可
# vi /etc/sysconfig/iptables
可以复制22端口一行,黏贴修改即可,重新启动防火墙服务
# service iptables restart
基本信息
操作系统:CentOS Release 6.3 (Final)
内核版本:Kernel Linux 2.6.32-279.el6.x86_64
JDK版本:Oracle ®Java SE Development Kit 7u15 (1.7.0_15-b03)
JBoss版本:JBoss Application Server 7.1.1
安装包: jdk-7u15-linux-x64.rpm、jboss-as-7.1.1.Final.zip
安装准备
上传安装文件
将JDK和JBoss安装文件(先解压成目录)上传到服务器,目录随意,如:/home/下
开始安装
JDK安装
使用root登陆系统,打开命令行窗口,先为安装文件授权 # chmod 755 jdk-7u15-linux-x64.rpm
执行安装
# rpm -ivh jdk-7u15-linux-x64.rpm
自动安装到目录 /usr/java 下
JDK配置
Root登陆执行 # vi /etc/profile
增加下面内容
JAVA_HOME=/usr/java/jdk1.7.0_15
CLASSPATH=.:$JAVA_HOME/lib:$JAVA_HOME/jre/lib
PATH=$JAVA_HOME/bin:$PATH
保存退出,执行如下命令立即生效以上环境配置
# source /etc/profile
JDK版本检测,执行:
# java – version 返回JDK版本信息
JBoss安装
JBoss为绿色版本,不需要安装,解压即可使用,和Tomcat一样,下面将JBoss目录移动到一个相对规范的位置,Root登陆执行 # mv /home/jboss-as-7.1.1.Final /usr/jboss-as-7.1.1.Final
OK,安装完毕,配置一下环境变量,执行
# vi /etc/profile
增加下面内容
JBOSS_HOME=/usr/jboss-as-7.1.1.Final
启动服务
# /usr/jboss-as-7.1.1.Final/bin/standalone.sh 访问,在浏览器地址栏中输入:http://127.0.0.1:8080,出现欢迎界面,证明启动成功!
停止服务
可以在启动终端窗口按键 CTRL + C,即可完全停止JBoss服务
局域网访问
http://xxx.xx.xx.xxx:8080是不能访问的,如果想让局域网内的其他机器访问必须要修改JBoss配置,方法如下:
编辑jboss-as-7.1.1.Final\standalone\configuration\standalone.xml,找到 <interface name="public">
<inet-address value="${jboss.bind.address:127.0.0.1}"/>
</interface>
将127.0.0.1修改为JBoss所在机器的IP地址即可,但是依旧无法访问,是因为Linux防火墙没有开放8080端口,执行:
# vi /etc/sysconfig/iptables
发现有一行
-A INPUT -m state --state NEW -m tcp -p tcp --dport 22 -j ACCEPT
复制它把22改成8080追加该行后面保存退出!
创建管理员用户 # ./add-user.sh What type of user do you wish to add?
a) Management User (mgmt-users.properties)
b) Application User (application-users.properties)
(a): 回车 Enter the details of the new user to add.
Realm (ManagementRealm) : //回车,默认
Username : // 管理员用户名,如:admin
Password : // 管理员密码,如:jboss
Re-enter Password : // 重复密码
管理员控制台访问
http://127.0.0.1:9990/console
如果也想在其他局域网机器上访问管理员控制台,防火墙需要开放端口9990,修改standalone.xml
<interface name="management">
<inet-address value="${jboss.bind.address.management:127.0.0.1}"/>
</interface>
同样将127.0.0.1修改为JBoss所在机器的IP地址
1、先用system和密码登陆SQLPLUS(如果不能直接以sys登陆到sqlplus的话),进入到sql*plus之后,可以通过conn /as sysdba转变为sysdba身份连接到数据库
2、开始修改编码
shutdown immediate; // 停止oracle服务以及监听。如果服务停止,这部可省略
startup mount;
alter system enable restricted session;
alter system set job_queue_processes=0; // 初始化设置job
alter database open;
alter database character set internal_use utf8; //设置编码 (alter database character set internal_use ZHS16GBK;)(alter database character set internal_use WE8ISO8859P1;)
shutdown immediate; // 关闭
startup; // 重启
至此编码已经设置完成。
此问题一般发生在Myeclipse 保存文件并自动部署时候。
Errors occurred during the build.
Errors running builder 'DeploymentBuilder' on project '项目名'.
java.lang.NullPointerException
有一种产生此错误的原因是因为此项目不不是由myeclipse创建的。
所以你需要检查.project 文件。
并且添加 <nature>com.genuitec.eclipse.j2eedt.core.webnature</nature>
然后重新打开项目。
摘要: SSL——Secure Sockets Layer双向认证(个人理解):客户端认证:客户端通过浏览器访问某一网站时,如果该网站为HTTPS网站,浏览器会自动检测系统中是否存在该网站的信任证书,如果没有信任证书,浏览器一般会拒绝访问,IE会有一个继续访问的链接,但地址栏是红色,给予用户警示作用,即客户端验证服务端并不是强制性的,可以没有服务端的信任证书,当然是否继续访问完全取... 阅读全文
摘要: 之前使用到了NIO的FileChannel做文件快速阅读,后来发现存在一个巨大的BUG,使用它会一直不释放文件句柄,即生成MD5的文件不能操作(移动或删除等),这个BUG网上吵得沸沸扬扬,至今没有解决,毕竟是SUN的BUG,解铃还需系铃人啊!咱只好乖乖的使用文件分块读取的方法,这种方式要求生成MD5和验证的时候得使用相同的缓存大小。MD5Utils.javaCode highlighting pr... 阅读全文
摘要: 实际开发中可能会用到压缩或解压缩,底层借助于apache的zip,依赖jar文件:ant-1.7.1.jarZipUtilsTester.javaCode highlighting produced by Actipro CodeHighlighter (freeware)http://www.CodeHighlighter.com/-->public static void&... 阅读全文
摘要: 本文中的Base64Utils.java在其他随笔中已经贴出。Java证书生成命令如下,不做过多解释,可先到网上查询下资料,本文仅提供工具类代码:把生成的密钥库和证书都放到类的同包下。Code highlighting produced by Actipro CodeHighlighter (freeware)http://www.CodeHighlighter.com/-->keytool&nb... 阅读全文
摘要: 该工具类中用到了BASE64,需要借助第三方类库:javabase64-1.3.1.jar注意:RSA加密明文最大长度117字节,解密要求密文最大长度为128字节,所以在加密和解密的过程中需要分块进行。RSA加密对明文的长度是有限制的,如果加密数据过大会抛出如下异常:Code highlighting produced by Actipro CodeHighlighter (freeware)ht... 阅读全文
摘要: 之前写了DES加解密,AES几乎与之相同,不同的是底层key的位数而已,不过这些对于我们使用者都是透明的。AESUtils.javaCode highlighting produced by Actipro CodeHighlighter (freeware)http://www.CodeHighlighter.com/-->package demo.security;import&nb... 阅读全文
摘要: 本工具类经过测试可用,之前写的没有使用CipherInputStream和CipherOutputStream,生成的加密文件与源文件大小不一致,加密时没有问题,解密时总是抛出如下异常:Code highlighting produced by Actipro CodeHighlighter (freeware)http://www.CodeHighlighter.com/-->Exception... 阅读全文
之前开发的环境为:
JDK5/TOMCAT5.5
现在的开发环境为:
JDK6/TOMCAT5.5
登陆地图界面地图无法加载,IE左下角黄色警告,点开显示“dojo未定义”,GG,BD了一晚上,真是众说纷纭,各有各的情况,直到见到了JDK版本这一说我恍然大悟,我的环境确实变了,迅速装上了JDK5,登陆地图,OK。。。
className.class.getResourceAsStream :
一: 要加载的文件和.class文件在同一目录下,例如:com.x.y 下有类Test.class ,同时有资源文件config.properties 那么,应该有如下代码: //前面没有“/”代表当前类的目录 InputStream is1 = Test.class.getResourceAsStream("config.properties");
System.out.println(is1);// 不为null 第二:在Test.class目录的子目录下,例如:com.x.y 下有类Test.class ,同时在 com.x.y.prop目录下有资源文件config.properties 那么,应该有如下代码: //前面没有“/”代表当前类的目录 InputStream is2 = Test.class.getResourceAsStream("prop/config.properties");
System.out.println(is2);//不为null 第三:不在同目录下,也不在子目录下,例如:com.x.y 下有类Test.class ,同时在 com.m.n 目录下有资源文件config.properties 那么,应该有如下代码: //前面有“/”,代表了工程的根目录 InputStream is3 = Test.class.getResourceAsStream("/com/m/n/config.properties"); System.out.println(is3);//不为null ClassLoader.getSystemResourceAsStream : 和className.class.getResourceAsStream 的第三种取得的路径一样,但少了“/” InputStream is4 = ClassLoader.getSystemResourceAsStream("properties/PayManagment_Config.properties");
System.out.println(is4);//不为null
在安装有些软件的时候,会向注册表中写入大量信息,但长度却超出了注册表的默认限值,此时就会报改错,如图:

错误信息和实际原因简直风马牛不相及,你可能会困惑许久。解决方法:
开始-运行,输入:regedit,确定后打开注册表编辑器
修改注册表:
HKEY_LOCAL_MACHINE\System\CurrentControlSet\Control
Key: RegistrySizeLimit
Type: REG_DWORD
Value: ffffffff (4294967295)
如果在注册表中没有找到RegistrySizeLimit 键,可以通过在“HKEY_LOCAL_MACHINE\System\CurrentControlSet\Control”右面窗口中新建RegistrySizeLimit的DWORD键值,并设该值为ffffffff

原文出自【雪的痕迹】原文地址:http://www.java3z.com/cwbwebhome/article/article8/852.htmljava做的系统给人的印象是什么?占内存!说道这句话就会有N多人站出来为java辩护,并举出一堆的性能测试报告来证明这一点。其实从理论上来讲java做的系统并不比其他语言开发出来的系统更占用内存,那么为什么却有这么N多理由来证明它确实占内存呢?两个字,陋习。(1)别用new Boolean()
在很多场景中Boolean类型是必须的,比如JDBC中boolean类型的set与get都是通过Boolean封装传递的,大部分ORM也是用Boolean来封装boolean类型的,比如:ps.setBoolean("isClosed",new Boolean(true));ps.setBoolean("isClosed",new Boolean(isClosed));ps.setBoolean("isClosed",new Boolean(i==3));通常这些系统中构造的Boolean实例的个数是相当多的,所以系统中充满了大量Boolean实例小对象,这是相当消耗内存的。Boolean类实际上只要两个实例就够了,一个true的实例,一个false的实例。Boolean类提供两了个静态变量:public static final Boolean TRUE = new Boolean(true);public static final Boolean FALSE = new Boolean(false);需要的时候只要取这两个变量就可以了,比如:ps.setBoolean("isClosed",Boolean.TRUE);那么象2、3句那样要根据一个boolean变量来创建一个Boolean怎么办呢?可以使用Boolean提供的静态方法: Boolean.valueOf()比如:ps.setBoolean("isClosed",Boolean.valueOf(isClosed));ps.setBoolean("isClosed",Boolean.valueOf(i==3));因为valueOf的内部实现是:return (b ? TRUE : FALSE);所以可以节省大量内存。相信如果Java规范直接把Boolean的构造函数规定成private,就再也不会出现这种情况了。(2)别用new Integer
和Boolean类似,java开发中使用Integer封装int的场合也非常多,并且通常用int表示的数值通常都非常小。SUN SDK中对Integer的实例化进行了优化,Integer类缓存了-128到127这256个状态的Integer,如果使用Integer.valueOf(int i),传入的int范围正好在此内,就返回静态实例。这样如果我们使用Integer.valueOf代替new Integer的话也将大大降低内存的占用。如果您的系统要在不同的SDK(比如IBM SDK)中使用的话,那么可以自己做了工具类封装一下,比如IntegerUtils.valueOf(),这样就可以在任何SDK中都可以使用这种特性。(3)用StringBuffer代替字符串相加
这个我就不多讲了,因为已经被人讲过N次了。我只想将一个不是笑话的笑话,我在看国内某“著名”java开发的WEB系统的源码中,竟然发现其中大量的使用字符串相加,一个拼装SQL语句的方法中竟然最多构造了将近100个string实例。无语中!(4)过滥使用哈希表
有一定开发经验的开发人员经常会使用hash表(hash表在JDK中的一个实现就是HashMap)来缓存一些数据,从而提高系统的运行速度。比如使用HashMap缓存一些物料信息、人员信息等基础资料,这在提高系统速度的同时也加大了系统的内存占用,特别是当缓存的资料比较多的时候。其实我们可以使用操作系统中的缓存的概念来解决这个问题,也就是给被缓存的分配一个一定大小的缓存容器,按照一定的算法淘汰不需要继续缓存的对象,这样一方面会因为进行了对象缓存而提高了系统的运行效率,同时由于缓存容器不是无限制扩大,从而也减少了系统的内存占用。现在有很多开源的缓存实现项目,比如ehcache、oscache等,这些项目都实现了FIFO、MRU等常见的缓存算法。(5)避免过深的类层次结构和过深的方法调用
因为这两者都是非常占用内存的(特别是方法调用更是堆栈空间的消耗大户)。(6)变量只有在用到它的时候才定义和实例化。
(7)尽量避免使用static变量
类内私有常量可以用final来代替。 java内存管理的思想(主要来源于thinking in java)
Java内存管理特点
Java一个最大的优点就是取消了指针,由垃圾收集器来自动管理内存的回收。程序员不需要通过调用函数来释放内存。
1、Java的内存管理就是对象的分配和释放问题。
在Java中,程序员需要通过关键字new为每个对象申请内存空间
(基本类型除外),所有的对象都在堆
(Heap)中分配空间。
对象的释放是由GC决定和执行的。
在Java中,内存的分配是由程序完成的,而内存的释放是由GC完成的,这种收支两条线的方法简化了程序员的工作。但也加重了JVM的工作。这也是Java程序运行速度较慢的原因之一。
GC释放空间方法:
监控每一个对象的运行状态,包括对象的申请、引用、被引用、赋值等。当该对象不再被引用时,释放对象。
2、内存管理结构
Java使用有向图的方式进行内存管理,对于程序的每一个时刻,我们都有一个有向图表示JVM的内存分配情况。
将对象考虑为有向图的顶点,将引用关系考虑为图的有向边,有向边从引用者指向被引对象。另外,每个线程对象可以作为一个图的起始顶点,例如大多程序从main进程开始执行,那么该图就是以main进程顶点开始的一棵根树。在这个有向图中,根顶点可达的对象都是有效对象,GC将不回收这些对象。如果某个对象 (连通子图)与这个根顶点不可达(注意,该图为有向图),那么我们认为这个(这些)对象不再被引用,可以被GC回收。 3、使用有向图方式管理内存的优缺点
Java使用有向图的方式进行内存管理,可以消除引用循环的问题,例如有三个对象,相互引用,只要它们和根进程不可达的,那么GC也是可以回收它们的。
这种方式的优点是管理内存的精度很高,但是效率较低。
++:
另外一种常用的内存管理技术是使用计数器,例如COM模型采用计数器方式管理构件,它与有向图相比,精度行低(很难处理循环引用的问题),但执行效率很高。
★ Java的内存泄露
Java虽然由GC来回收内存,但也是存在泄露问题的,只是比C++小一点。
1、与C++的比较
c++所有对象的分配和回收都需要由用户来管理。即需要管理点,也需要管理边。若存在不可达的点,无法回收分配给那个点的内存,导致内存泄露。存在无用的对象引用,自然也会导致内存泄露。
Java由GC来管理内存回收,GC将回收不可达的对象占用的内存空间。所以,Java需要考虑的内存泄露问题主要是那些被引用但无用的对象——即指要管理边就可以。被引用但无用的对象,程序引用了该对象,但后续不会再使用它。它占用的内存空间就浪费了。
如果存在对象的引用,这个对象就被定义为“活动的”,同时不会被释放。
2、Java内存泄露处理
处理Java的内存泄露问题:确认该对象不再会被使用。
典型的做法——
把对象数据成员设为null
从集合中移除该对象
注意,当局部变量不需要时,不需明显的设为null,因为一个方法执行完毕时,这些引用会自动被清理。
例子:
List myList=new ArrayList();
for (int i=1;i<100; i++) {
Object o=new
Object();
myList.add(o);
o=null;
}
//此时,所有的Object对象都没有被释放,因为变量myList引用这些对象。
当myList后来不再用到,将之设为null,释放所有它引用的对象。之后GC便会回收这些对象占用的内存。
★ 对GC操作
对GC的操作并不一定能达到管理内存的效果。
GC对于程序员来说基本是透明的,不可见的。我们只有几个函数可以访问GC,例如运行GC的函数System.gc(),System.。
但是根据Java语言规范定义,
System.gc()函数不保证JVM的垃圾收集器一定会执行。因为,不同的JVM实现者可能使用不同的算法管理GC。通常,GC的线程的优先级别较低。 JVM调用GC的策略有很多种,有的是内存使用到达一定程度时,GC才开始工作,也有定时执行的,有的是平缓执行GC,有的是中断式执行GC。但通常来说,我们不需要关心这些。除非在一些特定的场合,GC的执行影响应用程序的性能,例如对于基于Web的实时系统,如网络游戏等,用户不希望GC突然中断应用程序执行而进行垃圾回收,那么我们需要调整GC的参数,让GC能够通过平缓的方式释放内存,例如将垃圾回收分解为一系列的小步骤执行,Sun提供的HotSpot
JVM就支持这一特性。
★ 内存泄露检测
市场上已有几种专业检查Java内存泄漏的工具,它们的基本工作原理大同小异,都是通过监测Java程序运行时,所有对象的申请、释放等动作,将内存管理的所有信息进行统计、分析、可视化。开发人员将根据这些信息判断程序是否有内存泄漏问题。这些工具包括Optimizeit
Profiler,JProbe Profiler,JinSight , Rational 公司的Purify等。
在运行过程中,我们可以随时观察内存的使用情况,通过这种方式,我们可以很快找到那些长期不被释放,并且不再使用的对象。我们通过检查这些对象的生存周期,确认其是否为内存泄露。
★ 软引用
特点:只有当内存不够的时候才回收这类内存,同时又保证在Java抛出OutOfMemory异常之前,被设置为null。
保证最大限度的使用内存而不引起OutOfMemory异常。
在某些时候对软引用的使用会降低应用的运行效率与性能,例如:应用软引用的对象的初始化过程较为耗时,或者对象的状态在程序的运行过程中发生了变化,都会给重新创建对象与初始化对象带来不同程度的麻烦。
用途:
可以用于实现一些常用资源的缓存,实现Cache的功能
处理一些占用内存大而且声明周期较长,但使用并不频繁的对象时应尽量应用该技术
★ java程序设计中有关内存管理的经验
1.最基本的建议是尽早释放无用对象的引用。如:...
A a = new A();
//应用a对象
a = null; //当使用对象a之后主动将其设置为空
….
注:如果a 是方法的返回值,不要做这样的处理,否则你从该方法中得到的返回值永远为空,而且这种错误不易被发现、排除
2.尽量少用finalize函数。它会加大GC的工作量。
3.如果需要使用经常用到的图片,可以使用soft应用类型。它尽可能把图片保存在内存中
4.注意集合数据类型,包括数组、树、图、链表等数据结构,这些数据结构对GC来说,回收更为复杂。
5.尽量避免在类的默认构造器中创建、初始化大量的对象,防止在调用其自类的构造器时造成不必要的内存资源浪费
6.尽量避免强制系统做垃圾内8.尽量做远程方法调用类应用开发时使用瞬间值变量,除非远程调用端需要获取该瞬间值变量的值。
9.尽量在合适的场景下使用对象池技术以提高系统性能。存的回收,增长系统做垃圾回收的最终时间
7.尽量避免显式申请数组空间
上个礼拜卸了ArcIMS装上了ArcGIS Server9.3,感觉使用起来比ArcIMS简单了,安装也比较简单,除了选择下安装目录外一直是下一步。
ESRI公司不是想把一切都WEB化嘛!就是桌面能做的WEB也可以!所以安装后有个定向到ArcGIS Server Manager的网页链接,点击后即可发布地图服务。
但是我安装后怎么都进不去,当然要注意的一点是你用什么帐号登陆?默认的管理员帐号是arcgismanager,密码是你在安装Post Install的时候指定的,没错,就是它,可死活就是进不去呢?先搁下。有人喜欢用管理员帐号登陆,那么没问题,你只需要将当前登陆的管理员或其他用户添加到agsadmin和agsusers两个用户组中即可。当你登陆到Windows操作系统的时候发现增加了这三个用户,看起来很不爽,你根本不会用他们登陆操作系统,那么这里有个隐藏账户的注册表文件,你可以复制下来保存成“任意名称.reg”,双击运行即可
系统登陆界面中隐藏某账户
Windows Registry Editor Version 5.00
[HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\Windows NT\CurrentVersion\Winlogon\SpecialAccounts\UserList] "arcgismanager"=dword:00000000
[HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\Windows NT\CurrentVersion\Winlogon\SpecialAccounts\UserList] "ArcGISSOC"=dword:00000000
[HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\Windows NT\CurrentVersion\Winlogon\SpecialAccounts\UserList] "ArcGISSOM"=dword:00000000
言归正传,为啥我用arcgismanager/密码 登陆不进去了呢?密码我明明记得,或者我用系统管理员(前提是已经将管理员加入了那两个用户组中)登陆也不行?我左思右想,终于想到了,之前查过资料,网上有人说需要关闭防火墙,我突然想起该事来!怎么早没想起?!害得我卸载重装了一遍还是不行!没文化真可怕,记忆力差咱就多写博客吧!大脑不行,咱用文字记录!
摘要: 前言:
我们都知道Java可以将二进制程序打包成可执行jar文件,双击这个jar和双击exe效果是一样一样的,但感觉还是不同。其实将java程序打包成exe也需要这个可执行jar文件。
阅读全文
FlexBuilder3.0(FB3)插件的安装要求系统中已经存在eclipse,就像当初的MyEclipse一样(MyEclipse5.5-),现在MyEclipse强大了,直接All In One了,把eclipse吃到肚子里了,所以再不用咱们选eclipse目录了,后话。。。eclipse版本要求3.2、3.3或3.4,所以为了能够顺利安装FlexBuilder3.0(FB3),事先要做的是解压一个eclipse(3.2、3.3或3.4)到任意目录,完成FlexBuilder3.0(FB3)的安装
如FlexBuilder3.0(FB3)安装在了如下目录:
E:\Program Files\Adobe\Flex Builder 3 Plug-in
到该目录下将eclipse目录拷贝到MyEclipse的dropins目录下,我的目录结构:D:\Program Files\MyEclipse\MyEclipse 9\dropins,之后将eclipse重命名,如FlexBuilder3,启动MyEclipse就有FlexBuilder3的支持了
MyEclipse好像从7开始装插件的方式就变了,多了个dropins目录,你可以随意将下载下来的eclipse插件放到该目录下,移除也简单
网上的通过代码将插件的.jar文件都追加到bundles.info文件中,我觉得不够清晰,个人感觉将插件拷贝到dropins目录下的方式比较低碳环保
ORA-12516: TNS: 监听程序找不到符合协议堆栈要求的可用处理程
以前没有遇到过这个错误,一般常见的就是ORA-12514,这个错误是第一次遇到,我们是用SSH框架的,数据库链接由spring来管理,所以不担心连接不能及时释放的问题。但是现在数据库不只是我们做web的在使用,还有做通讯的同事,今天上午突然发现PL/SQL连不上数据库了,报的就是这个错误。
网上查找资料发现出现这个问题是由于Oracle的会话数不够导致的,使用命令“show parameter processes;”,返回
NAME TYPE VALUE
----------------------------------- ------------- ------------
aq_tm_processes integer 0
db_writer_processes integer 1
gcs_server_processes integer 0
job_queue_processes integer 10
log_archive_max_processes integer 2
processes integer 150
可见当前最大连接数是150,于是我到数据库服务器使用DBA登陆,结果也登陆不上,报错ORA-12520,看来问题很严重啊!我查看了listener.log,发现有个IP创建了很多的链接,最终锁定问题原因,就是因为同事没有及时释放连接导致连接数不够。解决此法最好是程序上注意,使用后及时释放,如果你写的是循环,那就很危险了。也可以修改最大连接数,如果服务器能顶得住。
在网页中使用自定义右键菜单,实现上皆为使用javascript禁用浏览器默认的右键菜单,然后在网页中响应鼠标右键事件,弹出自定义的菜单。
类似右键菜单的组件网上很多。一般而言,改变浏览器的默认菜单应当慎用,这会使多数用户感到不习惯。但是在企业Web应用中,用户的使用环境更加可控,在这种应用中使用自定义右键菜单会更加适合。
以下列举几款比较成熟的jQuery右键菜单插件,我们将逐一介绍,请读者自行比较,并根据自己的需求选择。
原文直通车
摘要: 经常用谷歌百度的人会觉得他们自动提示下拉框很酷,而且用来起很方便。最近由于业务需求,我们也需要这样的功能,网络上搜刮了一下,但却遇不到自己满意的,于是决定取长补短,自己重构。由于平常很少写类似控件或小工具的脚本,顶多写点简单的校验脚本,所以写了这个东东花费了我3天时间,当然3天也不全是一直扑到它身上,毕竟还有其他的工作,通过这次练习,自己对protype的熟悉又更近了一步。 阅读全文
摘要:
最近使用PD比较频繁,也被PD给搞的焦头烂额,网上好的东西还是比较多的,摘了点留作备用。
sql语句中表名与字段名前的引号去除:
打开cdm的情况下,进入Tools-Model Options-Naming Convention,把Name和Code的标签的Charcter case选项设置成Uppercase或者Lowercase,只要不是Mixed Case就行!
或者选择Database->Edit current database->Script->Sql->Format,有一项CaseSensitivityUsingQuote,它的 comment为“Determines if the case sensitivity for identifiers is managed using double quotes”,表示是否适用双引号来规定标识符的大小写, 可以看到右边的values默认值为“YES”,改为“No”即可!
或者在打开pdm的情况下,进入Tools-Model 阅读全文
实际开发中,如果用的是Oracle数据库,那么备份还原数据库的命令会经常用到
DOS环境下(开始-运行-CMD),在命令行输入,exp 用户名/密码@数据库连接名 owner=用户名 file="盘符:\文件名.dmp" log="盘符:\日志文件名.log",日志可选,回车即可。
导出/备份命令:
exp admin/password@orcl owner=admin file="D:\orcl.dmp" log="D:\orcl.log"
其中admin和password是连接到orcl数据库的登录名和密码,orcl是通过数据库工具建立的数据库连接时取的别名,file和log用于导出文件的数据存储和日志存储,由自己指定任意名。
导入/还原命令:
imp admin/password@orcl file="D:\orcl.dmp" log="D:\orcl.log" fromuser=other touser=admin
摘要: 由于工作需要,今天要在电脑上安装SQL Server 2005。以往的项目都是使用Oracle,MS的数据库还真的没怎么用过,安装Oracle已经轻车熟路,但装SQL Server好像还有点小麻烦,所以记录下来,以留备用。
-------------------------------------------------------------------------------------------------
操作系统:Microsoft Windows 7 旗舰版(32位)
数据库版本:SQL Server 2005 简体中文开发板
数据库下载链接:http://222.132.81.146/rj/cs_sql_2005_dev_all_dvd.rar
文件解压密码:www.mofang.net
---------------------------------------------------------------------------------------- 阅读全文
话不多说,请看代码!/**//** left (outer) join */
/**//** Standard SQL Syntax */
select * from a left outer join b on a.id = b.id;
/**//** Oracle SQL Syntax */
select * from a, b where a.id = b.id(+);
/**//** right (outer) join */
/**//** Standard SQL Syntax */
select * from a right outer join b on a.id = b.id;
/**//** Oracle SQL Syntax */
select * from a, b where a.id(+) = b.id;
/**//** (inner) join */
/**//** Standard SQL Syntax */
select * from a inner join b on a.id = b.id;
/**//** Oracle SQL Syntax */
select * from a, b where a.id = b.id;
/**//** (full) join */
/**//** Standard SQL Syntax */
select * from a full join b on a.id = b.id;
/**//** Oracle SQL Syntax */
select * from a, b where a.id = b.id(+) union select * from a, b where a.id(+) = b.id;
|