|
|
2007年3月23日
使用场景
- 内部网络,无法访问 Docker Hub
- 控制 image 的存储方式和存储位置
- 控制 image 的部署流程
- 内部开发流程需要集成控制 image 的部署和存储
应用逻辑示意图:
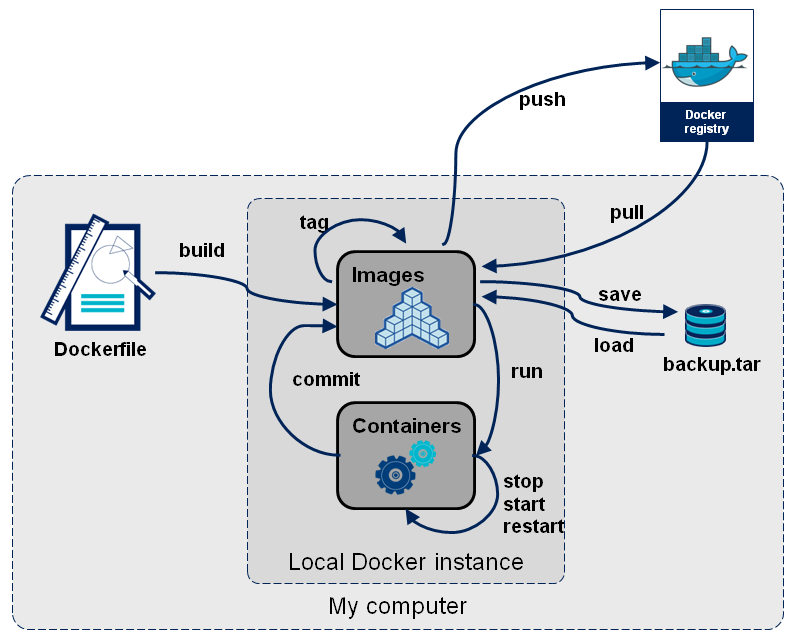  
安装 Registry 服务
概要
Docker Registry 在 docker hub 的名称是 registry。v1 版本的源码地址 github.com/docker/docker-registry 已经废弃,v2 版本源码地址在 github.com/docker/distribution,对应的 API 是 Docker Registry HTTP API V2。
以下安装没有使用 HTTPS 方式,启用 HTTPS 相关的证书配置参考这个文档:
官方文档参考:
最简安装(启动)
docker run -d -p 5000:5000 --name registry registry:2
以上命令未使用用户名密码登录策略。
启用登录密码
生成密码
登录密码可以通过 host 的文件传入,以下命令调用容器的 htpasswd 命令生成密码文件:
mkdir auth
docker run --entrypoint htpasswd registry:2 \
-Bbn <USER_NAME> <PASSWORD> > auth/auth.htpasswd
启用密码
通过 –volume 参数传入密码文件:
docker run -d -p 5000:5000 --restart=always --name registry \
--volume `PWD`/auth:/auth \
--env "REGISTRY_AUTH=htpasswd" \
--env "REGISTRY_AUTH_HTPASSWD_REALM=Registry Realm" \
--env REGISTRY_AUTH_HTPASSWD_PATH=/auth/auth.htpasswd \
registry:2
修改镜像存储
默认镜像数据存储在 Docker Volume 中,可以通过 bind mount 进行修改,参数信息参考 Volume文档。下面的例子将本机目录 PWD/images 绑定到容器的 /var/lib/registry
docker run -d -p 5000:5000 \
--name auth-registry \
-v `PWD`/images:/var/lib/registry \
-e SQLALCHEMY_INDEX_DATABASE=sqlite:////opt/docker-image/docker-registry.db \
-e STORAGE_PATH=/opt/docker-image \
--restart=always \
docker.onestch.com:5000/admin/registry:0.1
默认的存储引擎为本地文件系统,可以修改文件的存储引擎为 Amazon S3 bucket、Google Cloud Platform 或其他引擎,可以通过配置 config.yml 的方式修改存储配置,更多信息参考 Docker Registry 存储配置文档。
停止服务
停止 registry 容器并清理运行数据
docker stop registry && \
docker rm -v registry
验证
查看容器信息
docker ps --no-trunc
查看全部配置信息或部分信息
docker inspect <CONTAINER_ID>
docker inspect <CONTAINER_ID> | grep -C3 -e "Volumes\":"
docker inspect <CONTAINER_ID> | grep -C2 Binds
docker inspect -f '{{ .Mounts }}' <CONTAINER_ID>
查看映射的详细信息
docker volume inspect 4496b0a257b966052ef8d0743014a4f63fc9924251c8de0df0e9c70fde4c45e6
发布镜像
登录服务
如果安装(启动)的 registry 服务需要登录访问时,执行:
docker login <REGISTRY_HOST>:<REGISTRY_PORT>
输入安装时设定的用户名密码。
目标地址
使用 docker tag 设定镜像的目标地址,镜像的目标地址包括三部分
<HOST_NAME>[:<HOST_PORT>]/<IMAGE_NAME>:<IMAGE_VERSION>
例如:repo.company.com:3456/myapp:0.1
发布镜像
发布的镜像文件可以从 docker hub 中 Pull 或者本地使用 Dockerfile build 获得
Pull
docker pull registry
Build
docker build -t docker.onestch.com:5000/admin/registry:0.1 .
首先需要对镜像 tag 设定目标仓库,如果 build 的时候已经设置了目标地址,可以不用进行 tag 操作
docker tag registry:latest docker.onestch.com:5000/admin/registry:0.1
然后 Push
docker push docker.onestch.com:5000/admin/registry:0.1
验证
重新从私有仓库中获取镜像
docker pull localhost:5000/admin/registry:0.1
0.1: Pulling from admin/registry
Digest: sha256:d738e358b6910d3a53c9c7ff7bbb5eac490ab7a9b12ffb4c1c27f2c53aae9275
Status: Image is up to date for localhost:5000/admin/registry:0.1
安装 Registry UI
选择 registry ui,可选的有 atcol/docker-registry-ui、hyper/docker-registry-web、konradkleine/docker-registry-frontend等
安装运行
针对 hyper/docker-registry-web,使用 BASIC 认证,未使用 HTTPS的情况
docker run -it -p 8080:8080 \
--rm \
--name registry-web \
--link auth-registry \
-e REGISTRY_URL=http://auth-registry:5000/v2 \
-e REGISTRY_AUTH_ENABLED=false \
-e REGISTRY_BASIC_AUTH=YWRtaW46MTIzNDU2 \
-e REGISTRY_NAME=docker.onestch.com:5000 hyper/docker-registry-web
命令中 auth-registry 是自定的 registry 镜像。
使用 HTTPS 时需要传入 /config/auth.key 文件,或自定义 config.xml 配置,例如:
docker run -it -p 8080:8080 –name registry-web \
–link auth-registry \
-v $(pwd)/config.yml:/conf/config.yml:ro \
hyper/docker-registry-web
管理界面
建立了 registry 服务后,对 registry 的管理界面在本机的访问地址是http://localhost:8080,一般 ui 服务会和 registry 服务同样运行在私有网络,所以我们可以发布 registry ui 到 registry 服务器再运行。
docker tag docker.io/hyper/docker-registry-web docker.onestch.com:5000/admin/docker-registry-web
docker push docker.onestch.com:5000/admin/docker-registry-web
查看 UI 界面如下图
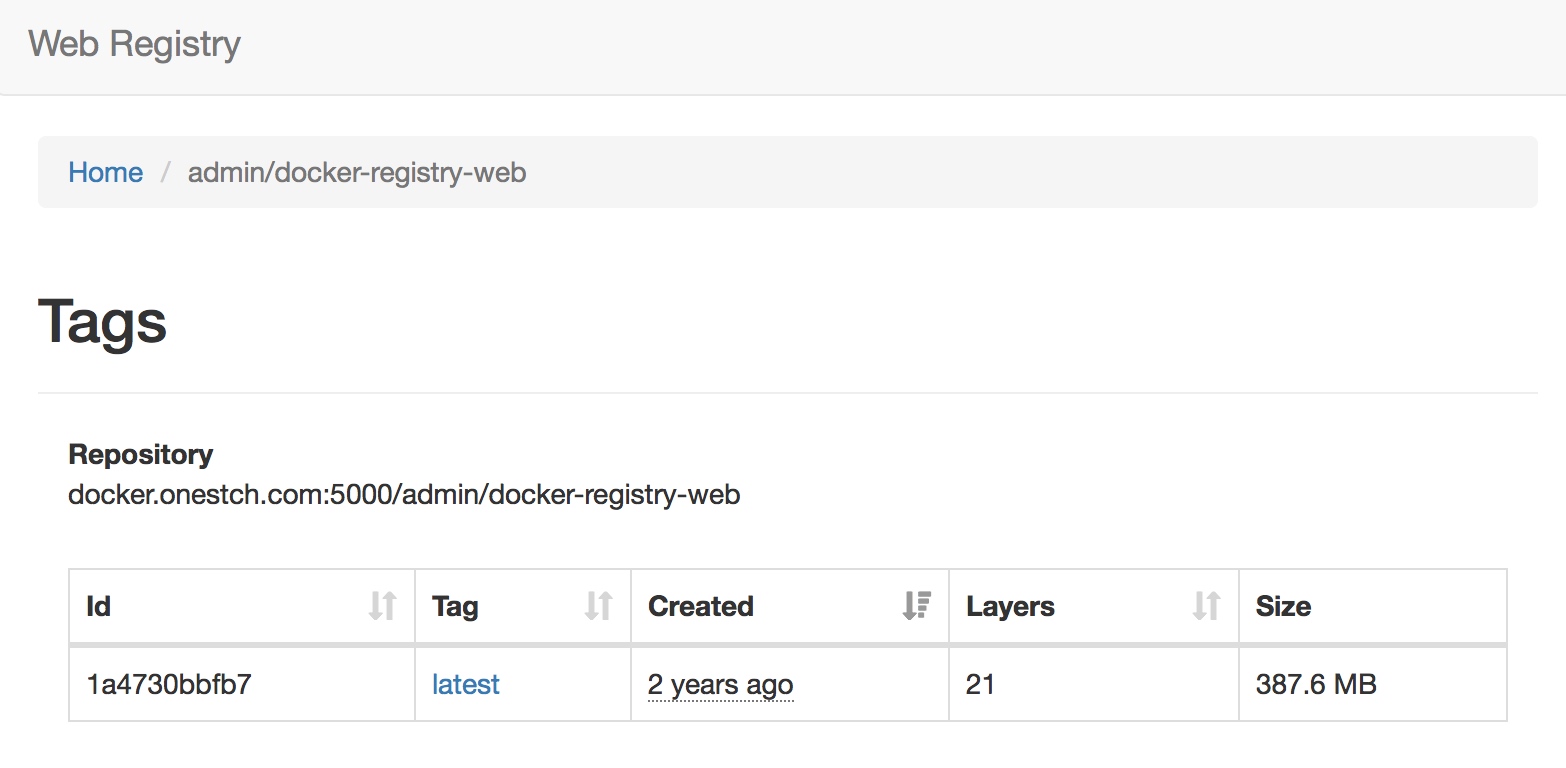  
服务管理
- 启动ZK服务: zkServer.sh start
- 查看ZK状态: zkServer.sh status
- 停止ZK服务: zkServer.sh stop
- 重启ZK服务: zkServer.sh restart
终端操作
使用 zkCli 可以简单的对 ZooKeeper 进行访问,数据创建,数据修改等操作. 连接命令行如下:
zkCli.sh -server 127.0.0.1:2181
命令行工具常用操作:
显示根目录下文件
ls / //查看当前节点数据
ls2 / //查看当前节点数据并能看到更新次数等数据
创建文件, 并设置初始内容:
create /config "test" //创建一个新的节点并设置关联值
create /config “” //创建一个新的空节点
获取文件内容
get /brokers //获取节点内容
修改文件内容
set /zk "zkbak" //对 zk 所关联的字符串进行设置
删除文件
delete /brokers //删除节点
rmr /brokers //删除节点及子节点
四字命令
ZooKeeper 支持某些特定的四字命令字母与其的交互,用来获取服务的当前状态及相关信息。在客户端可以通过 telnet 或 nc 向 ZooKeeper 提交相应的命令。命令行如下:
echo conf | nc 132.37.3.26 26181
ZooKeeper 常用四字命令:
conf
输出相关服务配置的详细信息 cons
列出所有连接到服务器的客户端的完全的连接 / 会话的详细信息。包括“接受 / 发送”的包数量、会话 id 、操作延迟、最后的操作执行等等信息 dump
列出未经处理的会话和临时节点。 envi
输出关于服务环境的详细信息(区别于 conf 命令)。 reqs
列出未经处理的请求 ruok
测试服务是否处于正确状态。如果确实如此,那么服务返回“ imok ”,否则不做任何相应 stat
输出关于性能和连接的客户端的列表。 wchs
列出服务器 watch 的详细信息 wchc
通过 session 列出服务器 watch 的详细信息,它的输出是一个与 watch 相关的会话的列表 wchp
通过路径列出服务器 watch 的详细信息。它输出一个与 session 相关的路径
摘要: JMH简介本文由 ImportNew - hejiani 翻译自 java-performance。JMH是新的microbenchmark(微基准测试)框架(2013年首次发布)。与其他众多框架相比它的特色优势在于,它是由Oracle实现JIT的相同人员开发的。特别是我想提一下Aleksey Shipilev和他优秀的博客文章。JMH可能与最新的Oracle JRE同步,其结果可信度很高。JMH... 阅读全文
如何将 SVN 源码库转换为 Mercurial
首先得安装 Subversion 库函数
wget http://mirrors.hust.edu.cn/apache/subversion/subversion-1.8.8.tar.gz
tar xzf subversion-1.8.8.tar.bz2
cd subversion-1.8.8
subversion-1.8.8 aliang$ ./autogen.sh
buildcheck: checking installation...
buildcheck: autoconf not found.
You need autoconf version 2.59 or newer installed.
brew install autoconf
==> Downloading https://downloads.sf.net/project/machomebrew/Bottles/autoconf-2.69.mavericks.bottle.tar.gz
#################################################### 100.0%
==> Pouring autoconf-2.69.mavericks.bottle.tar.gz
🍺 /usr/local/Cellar/autoconf/2.69: 69 files, 2.0M
./autogen.sh
buildcheck: checking installation...
buildcheck: autoconf version 2.69 (ok)
buildcheck: autoheader version 2.69 (ok)
buildcheck: libtool not found.
You need libtool version 1.4 or newer installed
brew install libtool
Warning: A newer Command Line Tools release is available
Update them from Software Update in the App Store.
==> Downloading https://downloads.sf.net/project/machomebrew/Bottles/libtool-2.4.2.mavericks.bottle.2.tar.gz
##################################################### 100.0%
==> Pouring libtool-2.4.2.mavericks.bottle.2.tar.gz
==> Caveats
In order to prevent conflicts with Apple''s own libtool we have prepended a "g"
so, you have instead: glibtool and glibtoolize.
==> Summary
🍺 /usr/local/Cellar/libtool/2.4.2: 66 files, 2.2M
./autogen.sh
buildcheck: checking installation...
buildcheck: autoconf version 2.69 (ok)
buildcheck: autoheader version 2.69 (ok)
buildcheck: libtool version 2.4.2 (ok)
Copying libtool helper: /usr/local/share/aclocal/libtool.m4
Copying libtool helper: /usr/local/share/aclocal/ltoptions.m4
Copying libtool helper: /usr/local/share/aclocal/ltsugar.m4
Copying libtool helper: /usr/local/share/aclocal/ltversion.m4
Copying libtool helper: /usr/local/share/aclocal/lt~obsolete.m4
Creating build-outputs.mk...
Creating svn_private_config.h.in...
Creating configure...
You can run ./configure now.
Running autogen.sh implies you are a maintainer. You may prefer
to run configure in one of the following ways:
./configure --enable-maintainer-mode
./configure --disable-shared
./configure --enable-maintainer-mode --disable-shared
./configure --disable-optimize --enable-debug
./configure CUSERFLAGS='--flags-for-C' CXXUSERFLAGS='--flags-for-C++'
Note: If you wish to run a Subversion HTTP server, you will need
Apache 2.x. See the INSTALL file for details.
brew install swig
==> Downloading http://downloads.sourceforge.net/project/swig/swig/swig-2.0.11/swig-2.0.11.tar.gz
######################################################################## 100.0%
==> ./configure --prefix=/usr/local/Cellar/swig/2.0.11
==> make
==> make install
🍺 /usr/local/Cellar/swig/2.0.11: 597 files, 6.2M, built in 10.1 minutes
./configure --with-swig=/usr/local/bin/swig
configure: Configuring Subversion 1.8.8
... ...
==================================================================
WARNING: You have chosen to compile Subversion with a different
compiler than the one used to compile Apache.
Current compiler: gcc
Apache's compiler: /Applications/Xcode.app/Contents/Developer/Toolchains/OSX10.9.xctoolchain/usr/bin/cc
This could cause some problems.
==================================================================
... ...
make swig-py
make install
make check-swig-py
sudo make install-swig-py
sudo cp -r /usr/local/lib/svn-python/ /Library/Python/2.7/site-packages/
执行转换命令
mkdir hgpath
cd hgpath
hg init
hg convert -s svn -d hg ${local_path} ./hgpath
注意,这里转换的 SVN 目录只能是仓库目录而不是工作目录
ditaa is a small command-line utility written in Java, that can
convert diagrams drawn using ascii art ('drawings' that contain
characters that resemble lines like | / - ), into proper
bitmap graphics. This is best illustrated by the following
example -- which also illustrates the benefits of using ditaa in
comparison to other methods :) +--------+ +-------+ +-------+
| | --+ ditaa +--> | |
| Text | +-------+ |diagram|
|Document| |!magic!| | |
| {d}| | | | |
+---+----+ +-------+ +-------+
: ^
| Lots of work |
+-------------------------+
| After conversion using ditaa, the above
file becomes:
 |
ditaa interprets ascci art as a series of open and closed
shapes, but it also uses special markup syntax to increase the
possibilities of shapes and symbols that can be rendered. ditaa is open source and free software (free as in free
speech), since it is released under the GPL license. BUT WHY? Does this thing have any real use?There are several reasons why I did this: - Simply for hack value. I wanted to know if/how it could be
done and how easily. - Aesthetic reasons and legacy formats: there are
several old FAQs with ascii diagrams lying out there. At this
time and age ascii diagrams make my eyes hurt due to their
ugliness. ditaa can be used to convert them to something
nicer. Although ditaa would not be able to convert all of them
(due to differences in drawing 'style' in each case), it could
prove useful in the effort of modernising some of those
documents without too much effort. I also know a lot of people
that can make an ascii diagram easily, but when it gets to using
a diagram program, they don't do very well. Maybe this utility
could help them make good-looking diagrams easily/quickly. - Embedding diagrams to text-only formats: There is a
number of formats that are text-based (html, docbook, LaTeX,
programming language comments), but when rendered by other
software (browsers, interpreters, the javadoc tool etc), they
can contain images as part of their content. If ditaa was
intergrated with those tools (and I'm planning to do the javadoc
bit myself soon), then you would have readable/editable diagrams
within the text format itself, something that would make things
much easier. ditaa syntax can currently be embedded to HTML. - Reusability of "code": Suppose you make a diagram in
ascii art and you render it with version 0.6b of ditaa. You keep
the ascii diagram, and then version 0.8 comes out, which
features some new cool effects. You re-render your old diagram
with the new version of ditaa, and it looks better, with zero
effort! In that sense ditaa is a diagram markup language, with
very loose syntax.
Download (((-intro-))) (((-download-))) (((-usage and syntax-))) (((-friends-))) (((-contact-))) The latest version of ditaa can be obtained from its SourceForge project page. You can checkout the code using: svn co https://ditaa.svn.sourceforge.net/svnroot/ditaa ditaa You can also browse the code online.
Usage and syntax
(((-intro-))) (((-download-))) (((-usage and syntax-))) (((-friends-))) (((-contact-))) Command lineYou need the latest Java runtimes (JRE) to use ditaa. The best
anti-aliasing can be achieved using Java 1.5 or higher. To start from the command line, type (where XXX is the version number): java -jar ditaaXXX.jar You will be presented with the command-line options help: -A,--no-antialias Turns anti-aliasing off.
-d,--debug Renders the debug grid over the resulting
image.
-E,--no-separation Prevents the separation of common edges of
shapes. You can see the difference below:
+---------+
| cBLU |
| |
| +----+
| |cPNK|
| | |
+----+----+
|  |  | | Before processing | Common edge
separation (default) | No separation
(with the -E option) |
-e,--encoding <ENCODING> The encoding of the input file.
-h,--html In this case the input is an HTML file. The
contents of the <pre class="textdiagram"> tags
are rendered as diagrams and saved in the
images directory and a new HTML file is
produced with the appropriate <img> tags.
See the HTML section.
--help Prints usage help.
-o,--overwrite If the filename of the destination image
already exists, an alternative name is chosen.
If the overwrite option is selected, the image
file is instead overwriten.
-r,--round-corners Causes all corners to be rendered as round
corners.
-s,--scale <SCALE> A natural number that determines the size of
the rendered image. The units are fractions of
the default size (2.5 renders 1.5 times bigger
than the default).
-S,--no-shadows Turns off the drop-shadow effect.
-t,--tabs <TABS> Tabs are normally interpreted as 8 spaces but
it is possible to change that using this
option. It is not advisable to use tabs in
your diagrams.
-v,--verbose Makes ditaa more verbose.
SyntaxRound cornersIf you use / and \ to connect corners, they are rendered as
round corners: /--+
| |
+--/
|  | | Before processing | Rendered |
ColorColor codes can be used to add color to the diagrams. The
syntax of color codes is cXXX where XXX is a hex number. The first digit of the number
represents the red compoment of the color, the second digit
represents green and the third blue (good ol' RGB). See below for
an example of use of color codes: /----\ /----\
|c33F| |cC02|
| | | |
\----/ \----/
/----\ /----\
|c1FF| |c1AB|
| | | |
\----/ \----/
|  | | Before processing | Rendered |
This can become a bit tedious after a while, so there are (only
some for now) human readable color codes provided: Color codes
/-------------+-------------\
|cRED RED |cBLU BLU |
+-------------+-------------+
|cGRE GRE |cPNK PNK |
+-------------+-------------+
|cBLK BLK |cYEL YEL |
\-------------+-------------/
|  | | Before processing | Rendered |
As you can see above, if a colored shape contains any text, the
color of the text is adjusted according to the underlying
color. If the undelying color is dark, the text color is changed
to white (from the default black). Note that color codes only apply if they are within closed
shapes, and they have no effect anywhere outside. Tagsditaa recognises some tags that change the way a rectangular
shape is rendered. All tags are between { and }. See the table below: | Name | Original | Rendered | Comment |
|---|
| Document | +-----+
|{d} |
| |
| |
+-----+
|  | Symbol representing a document. | | Storage | +-----+
|{s} |
| |
| |
+-----+
|  | Symbol representing a form of storage,
like a
database or a hard disk. | | Input/Output | +-----+
|{io} |
| |
| |
+-----+
|  | Symbol representing input/output. |
Dashed linesAny lines that contain either at least one = (for horizontal
lines) or at least one : (for vertical lines) are rendered as
dashed lines. Only one of those characters can make a whole line
dashed, so this feature "spreads". The rationale behind that is
that you only have to change one character to switch from normal
to dashed (and vice versa), rather than redrawing the whole
line/shape. Special symbols (like document or storage symbols) can
also be dashed. See below: ----+ /----\ +----+
: | | : |
| | | |{s} |
v \-=--+ +----+
|  | | Before processing | Rendered |
Point markersIf * is encountered on a line (but not at the end of the
line), it is rendered as a special marker, called the point
marker (this feature is still experimental). See below: *----*
| | /--*
* * |
| | -*--+
*----*
|  | | Before processing | Rendered |
Text handling(This section is still being written) If the pattern ' o XXXXX' is encountered, where XXXXX is any
text, the 'o' is interpreted and rendered as a bullet point. Note
that there must be a space before the 'o' as well as after it. See
below: /-----------------\
| Things to do |
| cGRE |
| o Cut the grass |
| o Buy jam |
| o Fix car |
| o Make website |
\-----------------/
|  | | Before processing | Rendered |
HTML mode
When ditaa is run using the --html option, the input
is an HTML file. The contents of the <pre
class="textdiagram"> tags are rendered as diagrams and
saved in the images directory and a new HTML file is
produced with the appropriate <img> tags.
If the id parameter is present in the
<pre> tag, its value is used as the filename of the
rendered png. Otherwise a filename of the form
ditaa_diagram_X.png is used, where X is a
number. Similarly, if there is no output filename specified, the
converted html file is named in the form of
xxxx_processed.html, where xxxx is the filename of the
original file.
In this mode, files that exist are not generated again, they
are just skipped. You can force overwrite of the files using the
--overwrite option.
- April 2011
- Posted By Yannick Loriot
- 81 Comments
After an upgrading to Xcode 4, I have been having trouble compiling my own ZXing iOS project. That’s why I decided to explain you how to install easily ZXing with Xcode 4.
First of all (for those who don’t know), ZXing is an open-source library to read the 1D/2D barcodes. This library is available on many platforms such as the iOS, Android, Blackberry, ect. You can find it here: http://code.google.com/p/zxing/.
Before to start, be sure that you have the latest version of ZXing on your computer. If you don’t, you must download it via a SVN client here: http://zxing.googlecode.com/svn/trunk/.
To use ZXing into your project in Xcode 4 follow these steps:

- Firstly go to the “zxing/iphone/ZXingWidget/” and drag and drop the ZXingWidget.xcodeproj file onto your Xcode “Project navigator” sidebar. If a dialog appears uncheck the “Copy items” and verify that the “Reference Type” is “Relative to Project” before clicking “Add”.

- Now we are going to add ZXingWidget as a dependency of your project to allow Xcode to compile it whenever you compile the main project:
- First select your project file in the “Project navigator”.
- Then select the corresponding target.
- After choose the “Build Phases” tab and expand the “Target Dependencies” section.
- Click the “+” (add) button to display a dialog.
- To finish add the “ZXingWidget” target as shown above.

- Now we are going to link the ZXingWidget static library (libZXingWidget.a) to the project:
- Firstly choose the “Build Phases” tab and expand the “Link Binary With Libraries” section.
- Then click the “+” (add) button to display a dialog.
- To finish add the “libZXingWidget.a” which is located in the “Workspace” category as shown above.
- By the way add the following iOS frameworks too:
- AddressBook
- AddressBookUI
- AudioToolbox
- AVFoundation
- CoreMedia
- CoreVideo
- libiconv.dylib

- Then you must configure the header search path of your project to allow Xcode to find the ZXingWidget headers. To do that:
- In the “Project navigator” select the main project (not the target).
- Go to the “Build Settings” tab and search the “Header Search Paths“.
- Double-click on it and add:
- The full path of the “zxing/iphone/ZXingWidget/Classes” directory. Check the “recursive path“.
- The full path of the “zxing/cpp/core/src/” directory. Uncheck the “recursive path“.
Now you just have to import the “ZXingWidgetController.h” and the “QRCodeReader.h” to your project and use them.
Attention: Make sure that the files in which you are using the ZXing headers have the .mm extension because they use c++ library files.
Voilà! Now all should be ok. I hope it’ll help you!

 (33 votes, average: 4.55 out of 5) (33 votes, average: 4.55 out of 5)
http://yannickloriot.com/2011/04/how-to-install-zxing-in-xcode-4/
在Mac下安装MySQL-python一直有问题,不管是用pip还是用setup.py,都是返回如下错误:
sudo python setup.py install
running install
running bdist_egg
running egg_info
writing MySQL_python.egg-info/PKG-INFO
writing top-level names to MySQL_python.egg-info/top_level.txt
writing dependency_links to MySQL_python.egg-info/dependency_links.txt
reading manifest file 'MySQL_python.egg-info/SOURCES.txt'
reading manifest template 'MANIFEST.in'
writing manifest file 'MySQL_python.egg-info/SOURCES.txt'
installing library code to build/bdist.macosx-10.7-x86_64/egg
running install_lib
running build_py
copying MySQLdb/release.py -> build/lib.macosx-10.7-x86_64-2.7/MySQLdb
running build_ext
building '_mysql' extension
/ A p p l i c a t i o n s / X c o d e . a p p / C o n t e n t s / D e v e l o p e r / T o o l c h a i n s / X c o d e D e f a u l t . x c t o o l c h a i n / u s r / b i n / c l a n g - f n o - s t r i c t - a l i a s i n g - f n o - c o m m o n - d y n a m i c - I / u s r / l o c a l / i n c l u d e - I / u s r / l o c a l / o p t / s q l i t e / i n c l u d e - i s y s r o o t / A p p l i c a t i o n s / X c o d e . a p p / C o n t e n t s / D e v e l o p e r / P l a t f o r m s / M a c O S X . p l a t f o r m / D e v e l o p e r / S D K s / M a c O S X 1 0 . 7 . s d k - I / A p p l i c a t i o n s / X c o d e . a p p / C o n t e n t s / D e v e l o p e r / P l a t f o r m s / M a c O S X . p l a t f o r m / D e v e l o p e r / S D K s / M a c O S X 1 0 . 7 . s d k / S y s t e m / L i b r a r y / F r a m e w o r k s / T k . f r a m e w o r k / V e r s i o n s / 8 . 5 / H e a d e r s - D N D E B U G - g - f w r a p v - O 3 - W a l l - W s t r i c t - p r o t o t y p e s -Dversion_info=(1,2,4,'final',1) -D__version__=1.2.4 -I/usr/local/Cellar/mysql/5.6.10/include -I/usr/local/Cellar/python/2.7.5/Frameworks/Python.framework/Versions/2.7/include/python2.7 -c _mysql.c -o build/temp.macosx-10.7-x86_64-2.7/_mysql.o -Os -g -fno-strict-aliasing
unable to execute /: Permission denied
error: command '/' failed with exit status 1
经过Google,发现原来是XCode没有安装Command line Tools的问题,参考:http://sourceforge.net/p/mysql-python/bugs/333/
LVS的特点是:- 抗负载能力强、是工作在网络4层之上仅作分发之用,没有流量的产生,这个特点也决定了它在负载均衡软件里的性能最强的;
- 配置性比较低,这是一个缺点也是一个优点,因为没有可太多配置的东西,所以并不需要太多接触,大大减少了人为出错的几率;
- 工作稳定,自身有完整的双机热备方案,如LVS+Keepalived和LVS+Heartbeat,不过我们在项目实施中用得最多的还是LVS/DR+Keepalived;
- 无流量,保证了均衡器IO的性能不会收到大流量的影响;
- 应用范围比较广,可以对所有应用做负载均衡;
- 软件本身不支持正则处理,不能做动静分离,这个就比较遗憾了;其实现在许多网站在这方面都有较强的需求,这个是Nginx/HAProxy+Keepalived的优势所在。
- 如果是网站应用比较庞大的话,实施LVS/DR+Keepalived起来就比较复杂了,特别后面有Windows Server应用的机器的话,如果实施及配置还有维护过程就比较复杂了,相对而言,Nginx/HAProxy+Keepalived就简单多了。
Nginx的特点是:- 工作在网络的7层之上,可以针对http应用做一些分流的策略,比如针对域名、目录结构,它的正则规则比HAProxy更为强大和灵活,这也是许多朋友喜欢它的原因之一;
- Nginx对网络的依赖非常小,理论上能ping通就就能进行负载功能,这个也是它的优势所在;
- Nginx安装和配置比较简单,测试起来比较方便;
- 也可以承担高的负载压力且稳定,一般能支撑超过几万次的并发量;
- Nginx可以通过端口检测到服务器内部的故障,比如根据服务器处理网页返回的状态码、超时等等,并且会把返回错误的请求重新提交到另一个节点,不过其中缺点就是不支持url来检测;
- N1.ginx仅能支持http和Email,这样就在适用范围上面小很多,这个它的弱势;
- N1.ginx不仅仅是一款优秀的负载均衡器/反向代理软件,它同时也是功能强大的Web应用服务器。LNMP现在也是非常流行的web架构,大有和以前最流行的LAMP架构分庭抗争之势,在高流量的环境中也有很好的效果。
- Nginx现在作为Web反向加速缓存越来越成熟了,很多朋友都已在生产环境下投入生产了,而且反映效果不错,速度比传统的Squid服务器更快,有兴趣的朋友可以考虑用其作为反向代理加速器。
HAProxy的特点是:- HAProxy是支持虚拟主机的,以前有朋友说这个不支持虚拟主机,我这里特此更正一下。
- 能够补充Nginx的一些缺点比如Session的保持,Cookie的引导等工作
- 支持url检测后端的服务器出问题的检测会有很好的帮助。
- 它跟LVS一样,本身仅仅就只是一款负载均衡软件;单纯从效率上来讲HAProxy更会比Nginx有更出色的负载均衡速度,在并发处理上也是优于Nginx的。
- HAProxy可以对Mysql读进行负载均衡,对后端的MySQL节点进行检测和负载均衡,不过在后端的MySQL slaves数量超过10台时性能不如LVS,所以我向大家推荐LVS+Keepalived。
HAProxy的算法现在也越来越多了,具体有如下8种: - roundrobin,表示简单的轮询,这个不多说,这个是负载均衡基本都具备的;
- static-rr,表示根据权重,建议关注;
- leastconn,表示最少连接者先处理,建议关注;
- source,表示根据请求源IP,这个跟Nginx的IP_hash机制类似,我们用其作为解决session问题的一种方法,建议关注;
- ri,表示根据请求的URI;
- rlparam,表示根据请求的URl参数'balance urlparam' requires an URL parameter name;
- hdr(name),表示根据HTTP请求头来锁定每一次HTTP请求;
- rdp-cookie(name),表示根据据cookie(name)来锁定并哈希每一次TCP请求。
下载文件 http://msysgit.googlecode.com/files/PortableGit-1.7.7.1-preview20111027.7z
解压至 D:\JavaSoft\git-1.7.7.1
增加系统环境路径:D:\JavaSoft\git-1.7.7.1\bin;D:\JavaSoft\git-1.7.7.1\cmd;
设置系统属性:
git config --global user.name "your.name"
git config --global user.email git.mail.name@gmail.com
创建密钥:
mkdir /.ssh
ssh-keygen -f D:\JavaSoft\git-1.7.7.1\.ssh\id_rsa -t rsa -C 'git.mail.name@gmail.com' -t rsa
复制 id_rsa.pub 的内容,到github.com增加公钥,然后粘贴保存。
测试:git -v -T git@github.com
Hi your.name! You've successfully authenticated, but GitHub does not provide shell access.
/etc/yum.repos.d/CentOS-Base.repo [base]
name=CentOS-5 - Base
repo=os
baseurl=http://ftp.sjtu.edu.cn/centos/5/os/$basearch/
gpgcheck=1
gpgkey=http://ftp.sjtu.edu.cn/centos/RPM-GPG-KEY-CentOS-5
#released updates
[update]
name=CentOS-5 - Updates
baseurl=http://ftp.sjtu.edu.cn/centos/5/updates/$basearch/
gpgcheck=1
gpgkey=http://ftp.sjtu.edu.cn/centos/RPM-GPG-KEY-CentOS-5
#packages used/produced in the build but not released
[addons]
name=CentOS-5 - Addons
baseurl=http://ftp.sjtu.edu.cn/centos/5/addons/$basearch/
gpgcheck=1
gpgkey=http://ftp.sjtu.edu.cn/centos/RPM-GPG-KEY-CentOS-5
#additional packages that may be useful
[extras]
name=CentOS-5 - Extras
baseurl=http://ftp.sjtu.edu.cn/centos/5/extras/$basearch/
gpgcheck=1
gpgkey=http://ftp.sjtu.edu.cn/centos/RPM-GPG-KEY-CentOS-5
#additional packages that extend functionality of existing packages
[centosplus]
name=CentOS-5 - Plus
baseurl=http://ftp.sjtu.edu.cn/centos/5/centosplus/$basearch/
gpgcheck=1
enabled=0
gpgkey=http://ftp.sjtu.edu.cn/centos/RPM-GPG-KEY-CentOS-5
#contrib - packages by Centos Users
[contrib]
name=CentOS-5 - Contrib
baseurl=http://ftp.sjtu.edu.cn/centos/5/contrib/$basearch/
gpgcheck=1
enabled=0
gpgkey=http://ftp.sjtu.edu.cn/centos/RPM-GPG-KEY-CentOS-5
Dependencies
|
CouchDB
|
Runtime
|
Build
|
|
Spidermonkey
|
Erlang
|
ICU
|
cURL
|
Automake
|
Autoconf
|
|
0.9.x
|
==1.7
|
>=5.6.0
|
>= 3.0
|
>= 7.15.5
|
>= 1.6.3
|
>= 2.59
|
|
0.10.x
|
>=1.7 && <=1.8.0
|
>=5.6.5
|
>= 3.0
|
>= 7.18.0
|
>= 1.6.3
|
>= 2.59
|
|
0.11.x
|
>=1.7
|
>=5.6.5
|
>= 3.0
|
>= 7.18.0
|
>= 1.6.3
|
>= 2.59
|
|
1.0.2
|
>=1.7
|
>=5.6.5
|
>= 3.0
|
>= 7.18.0
|
>= 1.6.3
|
>= 2.59
|
wget http://mirror.centos.org/centos/5/os/x86_64/CentOS/libicu-3.6-5.16.x86_64.rpm
wget http://mirror.centos.org/centos/5/os/x86_64/CentOS/libicu-devel-3.6-5.16.x86_64.rpm
wget http://download.fedora.redhat.com/pub/epel/5/x86_64/js-1.70-8.el5.x86_64.rpm
wget http://download.fedora.redhat.com/pub/epel/5/SRPMS/js-1.70-8.el5.src.rpm
wget http://download.fedora.redhat.com/pub/epel/5/x86_64/js-devel-1.70-8.el5.x86_64.rpm
wget http://curl.haxx.se/download/curl-7.21.6.tar.gz
wget http://labs.renren.com/apache-mirror/couchdb/1.0.2/apache-couchdb-1.0.2.tar.gz
tar -xzf curl-7.21.6.tar.gz
cd curl-7.21.6
./configure --prefix=/usr/local
make
make install
cd ..
rpm -ivh *.rpm
tar -xzf apache-couchdb-1.0.2.tar.gz
cd apache-couchdb-1.0.2
./configure --prefix=/usr/local/couchdb --with-erlang=/usr/lib64/erlang/usr/include
make
make install
cd ..
rm -rf apache-couchdb-1.0.2 curl-7.21.6
/usr/sbin/useradd -r --home /usr/local/couchdb/var/lib/couchdb -M --shell /bin/bash --comment "CouchDB Administrator" couchdb
mkdir -p /var/www/apps/couchdb/data
mkdir -p /var/www/apps/couchdb/view
mkdir -p /usr/local/var/lib/couchdb
mkdir -p /usr/local/var/log
chown -R couchdb: /usr/local/couchdb/var/lib/couchdb /usr/local/couchdb/var/log/couchdb /var/www/apps/couchdb
# [httpd]
# port = 5984
# bind_address = 127.0.0.1 (your binding ip address here)
vi /usr/local/couchdb/etc/couchdb/default.ini
# -A RH-Firewall-1-INPUT -m state --state NEW -m tcp -p tcp --dport 5984 -j ACCEPT
vi /etc/sysconfig/iptables
/sbin/service iptables restart
ln -s /usr/local/couchdb/etc/rc.d/couchdb /etc/init.d/couchdb
/sbin/chkconfig --add couchdb
/sbin/service couchdb start
curl http://localhost{IP}:5984{PORT}/
{"couchdb":"Welcome","version":"1.0.2"}
wget ftp://ftp.univie.ac.at/systems/linux/dag/redhat/el5/en/x86_64/rpmforge/RPMS/rpmforge-release-0.3.6-1.el5.rf.x86_64.rpm
rpm -Uvh
rpmforge-release-0.3.6-1.el5.rf.x86_64.rpm
yum install mercurial
软件开发者面试百问
作者 Jurgen Appelo译者 李剑 发布于 2009年1月20日 上午2时2分
1月13日,著名博客作者Jurgen Appelo写了一篇博文:“软件开发者面试百问”。该文甚受读者欢迎,15日便登上了delicious,Popurls.com,Reddit的首页。InfoQ中文站在得到作者许可之后,将其全文翻译为中文,希望可以对国内读者有所助益。
以下为文章全文:
想雇到搞软件开发的聪明人可不容易。万一一不小心,就会搞到一堆低能大狒狒。我去年就碰到这种事了。你肯定不想这样吧。听我的,没错。在树上开站立会议门都没有。
问点有难度的问题能帮你把聪明人跟狒狒们分开。我决定把我自己整理出来的软件开发者面试百问发出来,希望能帮到你们的忙。
这个列表涵盖了软件开发知识体系中定义的大多数知识域。当然,如果你只想找出类拔萃的程序员,便只需涉及结构、算法、数据结构、测试这几个话题。如果想雇架构师,也可以只考虑需求、功能设计、技术设计这些地方。
不过不管你怎么做,都要牢记一点:
这里大多数问题的答案都没有对错之分!
你可以把我的这些问题作为引子,展开讨论。例如下面有个问题是使用静态方法或是单例的缘由。如果那个面试的就此展开长篇大论,那他很有可能是个聪明能干的家伙!如果他一脸茫然的看着你,发出这种声音,很明显这就是只狒狒了。同样,想知道一个数是不是2的乘方也有很多方法,不过要是面试的人想用mod运算符,嗯……你知道我的意思吧。(你不知道也没关系,来根香蕉?)
需求
1. 你能给出一些非功能性(或者质量)需求的例子么?
2. 如果客户需要高性能、使用极其方便而又高度安全,你会给他什么建议?
3. 你能给出一些用来描述需求的不同技术么?它们各自适用于什么场景?
4. 需求跟踪是什么意思?什么是向前追溯,什么是向后追溯?
5. 你喜欢用什么工具跟踪需求?
6. 你怎么看待需求变化?它是好是坏?给出你的理由。
7. 你怎样研究需求,发现需求?有哪些资源可以用到?
8. 你怎么给需求制定优先级?有哪些技术?
9. 在需求过程中,用户、客户、开发人员各自的职责是什么?
10. 你怎么对待不完整或是令人费解的需求?
功能设计
1. 在功能设计中有哪些隐喻?给出几个成功的例子。
2. 如果有些功能的执行时间很长,怎么能让用户感觉不到太长的等待?
3. 如果用户必须要在一个很小的区域内,从一个常常的列表中选择多个条目,你会用什么控件?
4. 有哪些方法可以保证数据项的完整?
5. 建立系统原型有哪些技术?
6. 应用程序怎样建立对用户行为的预期?给出一些例子。
7. 如何入手设计一组数量庞大而又复杂的特性,你能举出一些设计思路吗?
8. 有一个列表,其中有10个元素,每个元素都有20个字段可以编辑,你怎样设计这种情况?如果是1000个元素,每个元素有3个字段呢?
9. 用不同的颜色对一段文本中的文字标记高亮,这种做法有什么问题?
10. Web环境和Windows环境各有些什么限制?
技术设计
1. 什么是低耦合和高聚合?封装原则又是什么意思?
2. 在Web应用中,你怎样避免几个人编辑同一段数据所造成的冲突?
3. 你知道设计模式吗?你用过哪些设计模式?在什么场合下用的?
4. 是否了解什么是无状态的业务层?长事务如何与之相适应?
5. 在搭建一个架构,或是技术设计时,你用过几种图?
6. 在N层架构中都有哪些层?它们各自的职责是什么?
7. 有哪些方法可以确保架构中数据的正确和健壮?
8. 面向对象设计和面向组件设计有哪些不同之处?
9. 怎样在数据库中对用户授权、用户配置、权限管理这几项功能建模?
10. 怎样按照等级制度给动物王国(包括各种物种和各自的行为)建模?
结构
1. 你怎样保证你的代码可以处理各种错误事件?
2. 解释一下什么是测试驱动开发,举出极限编程中的一些原则。
3. 看别人代码的时候,你最关心什么地方?
4. 什么时候使用抽象类,什么时候使用接口?
5. 除了IDE以外,你还喜欢哪些必不可少的工具?
6. 你怎么保证代码执行速度快,而又不出问题?
7. 什么时候用多态,什么时候用委派?
8. 什么时候使用带有静态成员的类,什么时候使用单例?
9. 你在代码里面怎么提前处理需求的变化?给一些例子。
10. 描述一下实现一段代码的过程,从需求到最终交付。
算法
1. 怎样知道一个数字是不是2的乘方?怎样判断一个数是不是奇数?
2. 怎样找出链表中间的元素?
3. 怎样改变10,000个静态HTML页面中所有电话号码的格式?
4. 举出一个你所用过的递归的例子。
5. 在哈希表和排序后的列表中找一个元素,哪个查找速度最快?
6. 不管是书、杂志还是网络,你从中所学到的最后一点算法知识是什么?
7. 怎样把字符串反转?你能不用临时的字符串么?
8. 你愿意用什么类型的语言来编写复杂的算法?
9. 有一个数组,里面是从1到1,000,000的整数,其中有一个数字出现了两次,你怎么找出那个重复的数字?
10. 你知道“旅行商问题(Traveling Salesman Problem)”么?
数据结构
1. 怎样在内存中实现伦敦地铁的结构?
2. 怎样以最有效的方式在数据库中存储颜色值?
3. 队列和堆栈区别是什么?
4. 用堆或者堆栈存储数据的区别是什么?
5. 怎样在数据库中存储N维向量?
6. 你倾向于用哪种类型的语言编写复杂的数据结构?
7. 21的二进制值是什么?十六制值呢?
8. 不管是书、杂志还是网络,你从中所学到的最后一点数据结构的知识是什么?
9. 怎样在XML文档中存储足球比赛结果(包括队伍和比分)?
10. 有哪些文本格式可以保存Unicode字符?
测试
1. 什么是回归测试?怎样知道新引入的变化没有给现有的功能造成破坏?
2. 如果业务层和数据层之间有依赖关系,你该怎么写单元测试?
3. 你用哪些工具测试代码质量?
4. 在产品部署之后,你最常碰到的是什么类型的问题?
5. 什么是代码覆盖率?有多少种代码覆盖率?
6. 功能测试和探索性测试的区别是什么?你怎么对网站进行测试?
7. 测试栈、测试用例、测试计划,这三者之间的区别是什么?你怎么组织测试?
8. 要对电子商务网站做冒烟测试,你会做哪些类型的测试?
9. 客户在验收测试中会发现不满意的东西,怎样减少这种情况的发生?
10. 你去年在测试和质量保证方面学到了哪些东西?
维护
1. 你用哪些工具在维护阶段对产品进行监控?
2. 要想对一个正在产品环境中被使用的产品进行升级,该注意哪些重要事项?
3. 如果在一个庞大的文件中有错误,而代码又无法逐步跟踪,你怎么找出错误?
4. 你怎样保证代码中的变化不会影响产品的其他部分?
5. 你怎样为产品编写技术文档?
6. 你用过哪些方式保证软件产品容易维护?
7. 怎样在产品运行的环境中进行系统调试?
8. 什么是负载均衡?负载均衡的方式有哪些种?
9. 为什么在应用程序的生命周期中,软件维护费用所占的份额最高?
10. re-engineering和reverse engineering的区别是什么?
配置管理
1. 你知道配置管理中基线的含义么?怎样把项目中某个重要的时刻冻结?
2. 你一般会把哪些东西纳入版本控制?
3. 怎样可以保证团队中每个人都知道谁改变了哪些东西?
4. Tag和Branch的区别是什么?在什么情况下该使用tag,什么时候用branch?
5. 怎样管理技术文档——如产品架构文档——的变化?
6. 你用什么侗剧管理项目中所有数字信息的状态?你最喜欢哪种工具?
7. 如果客户想要对一款已经发布的产品做出变动,你怎么处理?
8. 版本管理和发布管理有什么差异?
9. 对文本文件的变化和二进制文件的变化进行管理,这二者有什么不同?
10. 同时处理多个变更请求,或是同时进行增量开发和维护,这种事情你怎么看待?
项目管理
1. 范围、时间、成本,这三项中哪些是可以由客户控制的?
2. 谁该对项目中所要付出的一切做出估算?谁有权设置最后期限?
3. 减少交付的次数,或是减少每个每个交付中的工作量,你喜欢哪种做法?
4. 你喜欢用哪种图来跟踪项目进度?
5. 迭代和增量的区别在哪里?
6. 试着解释一下风险管理中用到的实践。风险该如何管理?
7. 你喜欢任务分解还是滚动式计划?
8. 你需要哪些东西帮助你判断项目是否符合时间要求,在预算范围内运作?
9. DSDM、Prince2、Scrum,这三者之间有哪些区别?
10. 如果客户想要的东西太多,你在范围和时间上怎样跟他达成一致呢?
Powered by ScribeFire.
From: http://blogs.sun.com/andreas/entry/no_more_unable_to_find
Some of you may be familiar with the (not very user friendly) exception
message
javax.net.ssl.SSLHandshakeException:
sun.security.validator.ValidatorException:
PKIX path building failed:
sun.security.provider.certpath.SunCertPathBuilderException:
unable to
find valid certification path to requested target
when trying to open an SSL connection to a host using JSSE.
What this usually means is that the server is using a test certificate
(possibly generated using keytool) rather than a certificate from a well
known commercial Certification Authority such as
Verisign or
GoDaddy. Web browsers display
warning dialogs in this case, but since JSSE cannot assume an
interactive user is present it just throws an exception by default.
Certificate validation is a very important part of SSL security, but I
am not writing this entry to explain the details. If you are interested,
you can start by reading the
Wikipedia
blurb. I am writing this entry to show a simple way to talk to that
host with the test certificate, if you really want to.
Basically, you want to add the server's certificate to the KeyStore with
your trusted certificates. There are any number of ways to achieve
that, but a simple solution is to compile and run the
attached
program as
java InstallCert hostname, for example
% java InstallCert ecc.fedora.redhat.com
Loading KeyStore /usr/jdk/instances/jdk1
.5.0
/jre/lib/security/cacerts
Opening connection to ecc.fedora.redhat.com:
443
Starting SSL handshake
javax.net.ssl.SSLHandshakeException: sun.security.validator.ValidatorException: PKIX path building failed:
sun.security.provider.certpath.SunCertPathBuilderException: unable to find valid certification path to requested target
at com.sun.net.ssl.internal.ssl.Alerts.getSSLException(Alerts.java:
150
)
at com.sun.net.ssl.internal.ssl.SSLSocketImpl.fatal(SSLSocketImpl.java:
1476
)
at com.sun.net.ssl.internal.ssl.Handshaker.fatalSE(Handshaker.java:
174
)
at com.sun.net.ssl.internal.ssl.Handshaker.fatalSE(Handshaker.java:
168
)
at com.sun.net.ssl.internal.ssl.ClientHandshaker.serverCertificate(ClientHandshaker.java:
846
)
at com.sun.net.ssl.internal.ssl.ClientHandshaker.processMessage(ClientHandshaker.java:
106
)
at com.sun.net.ssl.internal.ssl.Handshaker.processLoop(Handshaker.java:
495
)
at com.sun.net.ssl.internal.ssl.Handshaker.process_record(Handshaker.java:
433
)
at com.sun.net.ssl.internal.ssl.SSLSocketImpl.readRecord(SSLSocketImpl.java:
815
)
at com.sun.net.ssl.internal.ssl.SSLSocketImpl.performInitialHandshake(SSLSocketImpl.java:
1025
)
at com.sun.net.ssl.internal.ssl.SSLSocketImpl.startHandshake(SSLSocketImpl.java:
1038
)
at InstallCert.main(InstallCert.java:
63
)
Caused by: sun.security.validator.ValidatorException: PKIX path building failed: sun.security.provider.certpath.SunCertPathBuilderException:
unable to find valid certification path to requested target
at sun.security.validator.PKIXValidator.doBuild(PKIXValidator.java:
221
)
at sun.security.validator.PKIXValidator.engineValidate(PKIXValidator.java:
145
)
at sun.security.validator.Validator.validate(Validator.java:
203
)
at com.sun.net.ssl.internal.ssl.X509TrustManagerImpl.checkServerTrusted(X509TrustManagerImpl.java:
172
)
at InstallCert$SavingTrustManager.checkServerTrusted(InstallCert.java:
158
)
at com.sun.net.ssl.internal.ssl.JsseX509TrustManager.checkServerTrusted(SSLContextImpl.java:
320
)
at com.sun.net.ssl.internal.ssl.ClientHandshaker.serverCertificate(ClientHandshaker.java:
839
)
7
more
Caused by: sun.security.provider.certpath.SunCertPathBuilderException: unable to find valid certification path to requested target
at sun.security.provider.certpath.SunCertPathBuilder.engineBuild(SunCertPathBuilder.java:
236
)
at java.security.cert.CertPathBuilder.build(CertPathBuilder.java:
194
)
at sun.security.validator.PKIXValidator.doBuild(PKIXValidator.java:
216
)
13
more
Server sent
2
certificate(s):
1
Subject CN
=
ecc.fedora.redhat.com
,
O
=
example.com
,
C
=
US
Issuer CN
=
Certificate Shack
,
O
=
example.com
,
C
=
US
sha1 2e 7f
76
9b
52
91
09
2e 5d 8f 6b
61
39
2d 5e
06
e4 d8 e9 c7
md5 dd d1 a8
03
d7 6c 4b
11
a7 3d
74
28
89
d0
67
54
2
Subject CN
=
Certificate Shack
,
O
=
example.com
,
C
=
US
Issuer CN
=
Certificate Shack
,
O
=
example.com
,
C
=
US
sha1 fb
58
a7
03
c4 4e 3b 0e e3 2c
40
2f
87
64
13
4d df e1 a1 a6
md5
72
a0
95
43
7e
41
88
18
ae 2f 6d
98
01
2c
89
68
Enter certificate to add to trusted keystore or 'q' to quit:
[
1
]
What happened was that the program opened a connection to the specified
host and started an SSL handshake. It printed the exception stack trace
of the error that occured and shows you the certificates used by the
server. Now it prompts you for the certificate you want to add to your
trusted KeyStore. You should only do this if you are sure that
this is the certificate of the trusted host you want to connect to.
You may want to check the MD5 and SHA1 certificate fingerprints against
a fingerprint generated on the server (e.g. using keytool) to make sure
it is the correct certificate.
If you've changed your mind, enter 'q'. If you really want to add the
certificate, enter '1'. (You could also add a CA certificate by entering
a different certificate, but you usually don't want to do that'). Once
you have made your choice, the program will print the following:
... Added certificate to keystore 'jssecacerts' using alias 'ecc.fedora.redhat.com-1'
It displayed the complete certificate and then added it to a Java
KeyStore 'jssecacerts' in the current directory. To use it in your
program, either configure JSSE to use it as its trust store (as
explained in the
documentation)
or copy it into your $JAVA_HOME/jre/lib/security
directory. If you want all Java applications to recognize the
certificate as trusted and not just JSSE, you could also overwrite the cacerts
file in that directory.
After all that, JSSE will be able to complete a handshake with the host,
which you can verify by running the program again:
% java InstallCert ecc.fedora.redhat.com Loading KeyStore jssecacerts
Opening connection to ecc.fedora.redhat.com:443
Starting SSL handshake
No errors, certificate is already trusted Server sent 2 certificate(s): 1 []
Enter certificate to add to trusted keystore or 'q' to quit: [1] q KeyStore not changed
以前试过在Ant下使用Proguard,感觉挺简单的,使用Maven后,明显复杂多了,复杂不在Proguard,而在proguard-maven-plugin。 配置如下: <plugin>
<groupId>com.pyx4me</groupId>
<artifactId>proguard-maven-plugin</artifactId>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>proguard</goal>
</goals>
</execution>
</executions>
<configuration>
<obfuscate>true</obfuscate>
<proguardInclude>${basedir}/proguard.pro</proguardInclude>
<libs>
<lib>${java.home}/lib/rt.jar</lib>
<lib>${java.home}/lib/jsse.jar</lib>
<lib>${java.home}/lib/jce.jar</lib>
</libs>
</configuration>
</plugin>
出现异常:
[proguard] Obfuscating
[proguard] Printing mapping to [D:\cces\linker\target\proguard_map.txt]
[proguard] Preverifying
[proguard] Unexpected error while performing partial evaluation:
[proguard] Class = [net/sicross/tms/service/cces/SearchFlightOrderDetailService]
[proguard] Method = [getRouteDetail(Ljava/util/Map;)Ljava/util/List;]
[proguard] Exception = [java.lang.IllegalArgumentException] (Can't find common super class of [java/util/List] and [java/lang/StringBuffer])
[proguard] Unexpected error while preverifying:
[proguard] Class = [net/sicross/tms/service/cces/SearchFlightOrderDetailService] [proguard] Method = [getRouteDetail(Ljava/util/Map;)Ljava/util/List;]
[proguard] Exception = [java.lang.IllegalArgumentException] (Can't find common super class of [java/util/List] and [java/lang/StringBuffer])
[proguard] java.lang.IllegalArgumentException: Can't find common super class of [java/util/List] and [java/lang/StringBuffer]
[proguard] at proguard.evaluation.value.ReferenceValue.generalize(ReferenceValue.java:330)
[proguard] at proguard.evaluation.value.ReferenceValue.generalize(ReferenceValue.java:467)
[proguard] at proguard.evaluation.Variables.generalize(Variables.java:137)
[proguard] at proguard.evaluation.TracedVariables.generalize(TracedVariables.java:140)
[proguard] at proguard.optimize.evaluation.PartialEvaluator.evaluateInstructionBlock(PartialEvaluator.java:637)
根据异常,先是怀疑有什么jre的包没有导入,增加了另外几个也不行。在怀疑是jdk编译版本的问题,因为输出目标jdk版本是1.6的,在proguard-maven-plugin的configuration中增加下面的配置也没有。 <options>
<option>-target 1.6</option>
</options> 最后,将maven的target=1.6改为1.5后,异常消失。
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<version>2.0.2</version>
<artifactId>maven-compiler-plugin</artifactId>
<configuration>
<source>1.5</source>
<target>1.6</target>
<encoding>UTF-8</encoding>
</configuration>
</plugin>
Powered by ScribeFire.
Red Hat 9 2.4.20-8
Fedora Core 4 2.6.11-1.1369_FC4
Fedora Core 5 2.6.15-1.2054_FC5
Fedora Core 6 2.6.18-1.2798.fc6
Fedora 7 2.6.21-1.3194.fc7
Fedora 8 2.6.23.1-42.fc8
Ubuntu 7.10 2.6.22-14-generic
RedHat as4.0 2.6.9-11.EL
CentOS 5.1 2.6.18
CentOS 5.2 2.6.18
系统
# uname -a # 查看内核/操作系统/CPU信息
# head -n 1 /etc/issue # 查看操作系统版本
# cat /proc/cpuinfo # 查看CPU信息
# hostname # 查看计算机名
# lspci -tv # 列出所有PCI设备
# lsusb -tv # 列出所有USB设备
# lsmod # 列出加载的内核模块
# env # 查看环境变量
资源
# free -m # 查看内存使用量和交换区使用量
# df -h # 查看各分区使用情况
# du -sh # 查看指定目录的大小
# grep MemTotal /proc/meminfo # 查看内存总量
# grep MemFree /proc/meminfo # 查看空闲内存量
# uptime # 查看系统运行时间、用户数、负载
# cat /proc/loadavg # 查看系统负载
磁盘和分区
# mount | column -t # 查看挂接的分区状态
# fdisk -l # 查看所有分区
# swapon -s # 查看所有交换分区
# hdparm -i /dev/hda # 查看磁盘参数(仅适用于IDE设备)
# dmesg | grep IDE # 查看启动时IDE设备检测状况
网络
# ifconfig # 查看所有网络接口的属性
# iptables -L # 查看防火墙设置
# route -n # 查看路由表
# netstat -lntp # 查看所有监听端口
# netstat -antp # 查看所有已经建立的连接
# netstat -s # 查看网络统计信息
进程
# ps -ef # 查看所有进程
# top # 实时显示进程状态
用户
# w # 查看活动用户
# id # 查看指定用户信息
# last # 查看用户登录日志
# cut -d: -f1 /etc/passwd # 查看系统所有用户
# cut -d: -f1 /etc/group # 查看系统所有组
# crontab -l # 查看当前用户的计划任务
服务
# chkconfig --list # 列出所有系统服务
# chkconfig --list | grep on # 列出所有启动的系统服务
程序
# rpm -qa # 查看所有安装的软件包
编写:Leaf Zhou
EMAIL:leaf_zhou_8@hotmail.com
TCP是英文Transport Control Protocol的缩写。从字面理解,就是传输控制协议。因此,TCP是一种控制协议,他本身不能用来传输数据,它需要通过网络层的IP协议来进行实际数据的传输。这也就是我们常常看到,TCP/IP和TCP/UDP总是同时出现的原因。因此,也可以理解为TCP是很多的不同的协议组成,实际上是一个协议组。提供可靠的主机到主机层数据传输控制协议。这里要先强调一下,传输控制协议是OSI网络的第四层的叫法,TCP传输控制协议是TCP/IP传输的6个基本协议的一种。TCP是一种可靠的面向连接的传送服务。它在
一、TCP概述
TCP是英文Transport Control Protocol的缩写。从字面理解,就是传输控制协议。因此,TCP是一种控制协议,他本身不能用来传输数据,它需要通过网络层的IP协议来进行实际数据的传输。这也就是我们常常看到,TCP/IP和TCP/UDP总是同时出现的原因。因此,也可以理解为TCP是很多的不同的协议组成,实际上是一个协议组。提供可靠的主机到主机层数据传输控制协议。这里要先强调一下,传输控制协议是OSI网络的第四层的叫法,TCP传输控制协议是TCP/IP传输的6个基本协议的一种。TCP是一种可靠的面向连接的传送服务。它在传送数据时是分段进行的,主机交换数据必须先建立一个会话。它用比特流通信,即数据被作为无结构的字节流进行传输,没有数据边界。通过每个TCP传输的字段指定顺序号,以获得可靠性。是在OSI参考模型中的第四层,TCP是使用IP的网间互联功能而提供可靠的数据传输,IP不停的把报文放到网络上,而TCP是负责确信报文到达。在协同IP的操作中TCP负责:握手过程、报文管理、流量控制、错误检测和处理(控制),可以根据一定的编号顺序对非正常顺序的报文给予从新排列顺序。关于TCP的RFC文档有RFC793、RFC791、RFC1700。
二、TCP连接的建立
建立一个TCP连接,需要下面的步骤:
(1)服务器端通过listen来准备接受外来的连接,称为被动打开(passive open)。
(2) 客户端通过connect进行连接服务器,称为主动打开(active open)。在这个操作中,客户端需要发送一个同步数据报(SYN),用来通知服务器端开始发送数据的初始序列号。通常情况下,同步数据报不携带数据,它只包含一个IP头部、一个TCP头部和本次通信所使用的TCP的选项。
(3)服务器端必须对客户端发来的同步数据报SYN进行确认,同时自己也要发送一个同步数据报(SYN),它包含客户端发送数据的初始序列号。服务器端对在同一连接中发送的数据初始序号和对客户端发送的确认信息(ACK),都放在一个数据报中,一起发送给客户端。
(4)客户端也必须发送确认服务器端的同步数据报(SYN)。
由上面的步骤来看,建立一个TCP连接,至少需要服务器端和客户端进行三个分组数据的交换,因此,称之为TCP的三路握手(three-way handshake)。
客户端 服务器端
connect() accept()
---> SYN S ----->
<--- SYN C
,
ACK S+
1
<---
---> ACK C+
1
----->
第一次进行分组数据交换的过程中,分组数据中可能包含着本次通信中可能的TCP选项。这些选项有:
(1) 最大分组(MSS)选项。TCP发送的SYN中带有这个选项,用来告诉对方它的最大分组数据的大小MSS(Maximum Segment Size),即它能接收的每个TCP分组数据中的最大数据量。这个选项可以通过TCP_MAXSEG套接口选项获取与设置这个TCP选项。
(2) 窗口大小选项。这是TCP能提供流量控制的主要手段。TCP连接的每一方都有固定大小的缓冲空间,TCP的接收端只允许另一端发送接收端缓冲区所能接纳的数据。这将防止较快主机致使较慢主机的缓冲区溢出。TCP双方能够通知对方的最大窗口大小是64K(65535 bytes),因为TCP头部相应的标识字段值只用了16位来表示。每个套接口都有一个发送缓冲区和一个接收缓冲区,接收缓冲区被TCP和UDP用来将接收到的数据一直保存到由应用进程来读取。对于TCP,TCP通告另一端的窗口大小。 TCP套接口接收缓冲区不可能溢出,因为对方不允许发出超过所通告窗口大小的数据。这就是TCP的流量控制,如果对方无视窗口大小而发出了超过窗口大小的数据,则接收方TCP将丢弃它;而对于UDP,当套接口接收缓冲区放不下接收到的数据报时,此数据报就被丢弃。UDP是没有流量控制的,快的发送者可以很容易地就淹没慢的接收者,导致接收方的UDP丢弃数据报,使数据发生丢失。
(3)时间戳选项。时间戳选项使发送方在每个报文段中放置一个时间戳值。接收方在确认中返回这个数值,从而允许发送方为每一个收到的ACK计算RTT。
三、TCP连接的终止
终止TCP连接
TCP用三个分组数据建立一个连接,但要终止一个连接则通常需要需要四个分组数据。过程如下:
(1)先调用close的进程,称为主动关闭(active close)。这一端的TCP先发送一个FIN分组数据,告诉对方,数据发送完毕。
(2)接收到FIN分组数据的一端执行被动关闭(passive close),同时,发送对这个FIN的确认ACK分组数据给对方。确认序号为收到的序号加1。FIN分组数据的接收意味着在当前的连接上,再也不会收到额外的数据。
(3)接收到FIN分组数据的一端的应用进程,将调用close关闭自己的套接口,同时TCP 会发送一个FIN分组数据给另一端。
(4)收到这个FIN的分组数据,即执行主动关闭的一端对这个FIN分组数据进行确认。发回确认ACK分组数据,并将确认序号设置为收到序号加1
在这个过程中,执行被动关闭的一方可以把确认对方FIN分组数据的ACK分组数据和自己要发送的FIN分组数据可以放到一个分组数据中。TCP的连接终止的过程如下:
客户端 服务器端
close() close()
---> FIN S ----->
<--- ACK S+
1
<---
<--- FIN C <---
---> FIN C+
1
--->
四、TCP连的状态 TCP的连接的建立和终止,基本上已经清楚了,那么在这个过程中,是如何知道这个连接正处在什么状态呢?方法当然是有的,我们先运行如下命令,看看返回的结果: [root@linux81 leaf]# netstat -an
Active Internet connections (servers and established)
Proto Recv-Q Send-Q Local Address Foreign Address State
tcp 0 0 0.0.0.0:3306 0.0.0.0:* LISTEN
tcp 0 0 0.0.0.0:139 0.0.0.0:* LISTEN
tcp 0 0 0.0.0.0:21 0.0.0.0:* LISTEN
tcp 0 0 0.0.0.0:22 0.0.0.0:* LISTEN
tcp 0 0 0.0.0.0:23 0.0.0.0:* LISTEN
tcp 0 0 192.168.253.81:139 192.168.253.35:1201 ESTABLISHED
tcp 0 272 192.168.253.81:22 192.168.253.59:1776 ESTABLISHED
udp 0 0 192.168.253.81:137 0.0.0.0:*
udp 0 0 0.0.0.0:137 0.0.0.0:*
udp 0 0 192.168.253.81:138 0.0.0.0:*
udp 0 0 0.0.0.0:138 0.0.0.0:*
udp 0 0 127.0.0.1:36260 0.0.0.0:* 在上面的返回结果中,State一列,就是说明连接的当前状态。
TCP的连接状态有:
(01)CLOSED
(02)LISTEN 被动打开
(03)SYN_RCVD
(04)SYN_SEND
(05)ESTABLISHED 数据传送状态
(06)CLOSE_WAIT
(07)LAST_ACK 被动关闭
(08)FIN_WAIT_1
(09)FIN_WAIT_2
(10)CLOSING
(11)TIME_WAIT TCP连接状态转换示意图如下所示:
+---------+ ---------\ active OPEN
| CLOSED | \ -----------
+---------+<---------\ \ create TCB
| ^ \ \ snd SYN
passive OPEN | | CLOSE \ \
------------ | | ---------- \ \
create TCB | | delete TCB \ \
V | \ \
+---------+ CLOSE | \
| LISTEN | ---------- | |
+---------+ delete TCB | |
rcv SYN | | SEND | |
----------- | | ------- | V
+---------+ snd SYN,ACK / \ snd SYN +---------+
| |<----------------- ------------------>| |
| SYN | rcv SYN | SYN |
| RCVD |<-----------------------------------------------| SENT |
| | snd ACK | |
| |------------------ -------------------| |
+---------+ rcv ACK of SYN \ / rcv SYN,ACK +---------+
| -------------- | | -----------
| x | | snd ACK
| V V
| CLOSE +---------+
| ------- | ESTAB |
| snd FIN +---------+
| CLOSE | | rcv FIN
V ------- | | -------
+---------+ snd FIN / \ snd ACK +---------+
| FIN |<----------------- ------------------>| CLOSE |
| WAIT-1 |------------------ | WAIT |
+---------+ rcv FIN \ +---------+
| rcv ACK of FIN ------- | CLOSE |
| -------------- snd ACK | ------- |
V x V snd FIN V
+---------+ +---------+ +---------+
|FINWAIT-2| | CLOSING | | LAST-ACK|
+---------+ +---------+ +---------+
| rcv ACK of FIN | rcv ACK of FIN |
| rcv FIN -------------- | Timeout=2MSL -------------- |
| ------- x V ------------ x V
\ snd ACK +---------+delete TCB +---------+
------------------------>|TIME WAIT|------------------>| CLOSED |
+---------+ +---------+
TCP Connection State Diagram 从上面的图表中,可以做出如下总结:
服务器端的正常状态转换过程如下:
CLOSED --> LISTEN --> SYN_RCVD --> ESTABLISHED --> CLOSE_WAIT --> LAST_ACK --> CLOSED
客户端的正常状态转换过程如下:
CLOSED --> SYN_SENT --> ESTABLISHED --> FIN_WAIT_1 --> FIN_WAIT_2 --> TIME_WAIT --> CLOSED
从上面的连接状态转换中可以看出,从ESTABLISHED状态的转换有两种,对于客户端和服务器端来说,是一样的,即当收到FIN数据报之前,主动关闭,则转换成FIN_WAIT_1;如果因为收到FIN数据报,而引起的被动关闭,则转换成CLOSE_WAIT状态。
Install: yum grouplist sudo yum groupinstall "X Window System" "GNOME Desktop Environment" or sudo mount /dev/cdrom /media/cdrom sudo yum --disablerepo=\* --enablerepo=c5-media groupinstall "X Window System" "GNOME Desktop Environment"
Error:
Missing Dependency: libgaim.so.0 is needed by package nautilus-sendto more detail: https://bugzilla.redhat.com/show_bug.cgi?id=250403
Resolved: wget http://mirror.centos.org/centos/5/os/i386/CentOS/nautilus-sendto-0.7-5.fc6.i386.rpm ~
sudo rpm -Uvh --nodeps ~/nautilus-sendto-0.7-5.fc6.i386.rpm repeat install.
Creating A Local Yum Repository (CentOS)
摘自: www.howtoforge.com
Author & Content of this howto, Tim Haselaars (http://www.trinix.be)
Sometimes it can be handy to set up your own repository to prevent from downloading the remote repository over and over again. This tutorial shows how to create a CentOS mirror for your local network. If you have to install multiple systems in your local network then all needed packages can be downloaded over the fast LAN connection, thus saving your internet bandwidth.
Create the Directories:
mkdir -pv /var/www/html/centos/{base,updates}
The Base Repository
Copy the RPMs from the CDs/DVD to /var/www/html/centos/base.
Create the base repository headers:
createrepo /var/www/html/centos/base
The Updates Repository
Select an rsync mirror for updates: check out this list of aviable mirrors: Centos OS Mirror list and these are identified with rsync.
For example: rsync://ftp.belnet.be/packages/centos/
The mirrors share a common structure for updates. Simply append /updates//.
Rsync to create the updates-released repository:
rsync -avrt rsync://ftp.belnet.be/packages/centos/5.0/updates/i386 \ --exclude=debug/ /var/www/html/centos/updates
This will create a complete update repository at /var/www/html/centos/updates/i386. The repodata directory will be created with all of the headers.
Next I would advise to setup a cron job to run the rsync (above). In this manner your repository is kept updated and only new updates and headers will be downloaded to your repository.
Yum Configuration
Edit yum.conf:
vi /etc/yum.repos.d/CentOS-Base.repo
[base]
name=CentOS-$releasever - Base
baseurl=http://192.168.*.*/centos/$releasever/os/$basearch/
#mirrorlist=http://mirrorlist.centos.org/?release=$releasever&arch=$basearch&repo=os
#baseurl=http://mirror.centos.org/centos/$releasever/os/$basearch/
gpgcheck=1
gpgkey=http://mirror.centos.org/centos/RPM-GPG-KEY-CentOS-5
#released updates
[update]
name=CentOS-$releasever - Updates
baseurl=http://192.168.*.*/centos/$releasever/updates/$basearch/
#mirrorlist=http://mirrorlist.centos.org/?release=$releasever&arch=$basearch&repo=updates
#baseurl=http://mirror.centos.org/centos/$releasever/updates/$basearch/
gpgcheck=1
gpgkey=http://mirror.centos.org/centos/RPM-GPG-KEY-CentOS-5
That's it.
Powered by ScribeFire.
Linux设置DNS和主机名
操作过程
配置文件位于:
/etc/sysconfig/network-scripts/ifcfg-eth0
DEVICE=eth0
ONBOOT=yes
BOOTPROTO=static
IPADDR=192.168.0.3
NETMASK=255.255.255.0
GATEWAY=192.168.0.1
使IP地址生效:
/sbin/ifdown eth0 /sbin/ifup eth0
配置dns解析
echo "nameserver 211.98.1.28">> /etc/resolv.conf
通知网关更新信息:
/etc/init.d/network restart
DNS 简介
DNS就是Domain Name System,它能够把形如www.21php.com这样的域名转换为211.152.50.35这样的IP地址;没有DNS,浏览21php.com 这个网站时,就必须用211.152.50.35这么难记的数字来访问。提供DNS服务的就是DNS服务器。DNS服务器可以分为三种,高速缓存服务器 (Cache-only server)、主服务器(Primary Name server)、辅助服务器(Second Name Server)。 DNS的详细原理、工作流程、术语、概念,限于篇幅,这里就不说了。可以阅读专门的文章,如DNS-HOWTO加以了解。
配置主DNS服务器
首先我们做以下假设:
- A服务器为21php.com的主域名服务器,其IP地址为11.0.0.1
- B服务器为21php.com的辅助域名服务器,其IP地址为11.0.0.2;
下面我们配置服务器11.0.0.1为 21PHP.COM 的主 DNS 服务器。Linux下的dns功能是通过bind软件实现的。bind软件安装后,会产生几个固有文件,分为两类,一类是配置文件在 /etc 目录下,一类是dns记录文件在 /var/named 目录下。加上其他相关文件,共同设置dns服务器。下面是所有和dns设置相关文件的列表与说明。
位于/etc目录下的有:
- hosts
- host.conf
- resolv.conf
- named.boot
- named.conf
具体说明:
-
hosts
定义了主机名和ip地址的对应,其中也有将要运行dns这台电脑的ip地址和主机名。内容:
127.0.0.1 localhost.localdomain localhost
-
host.conf “order hosts bind”语句,指定了对主机名的解析顺序是先到hosts中查找,然后到dns服务器的记录里查找。 “multi on”则是允许一个主机名对应多个ip地址。内容:
order hosts, bind
multi on
nospoof on
-
“resolv.conf”
“nameserver 10.0.0.211”指定了dns服务器的地址。注意,这个文件对普通非dns服务器的电脑(非windows的系统;Windows系统是在“网络属性”中设置这项的)来说,是必不可少的。你如果没有设置本机为dns服务器,你又要能够解析域名,就必须指定一个dns服务器的地址。你可以最多写上三个地址,作为前一个失败时的候选dns服务器。“domain zrs.com”指定默认的域。内容:
domain 21php.com
nameserver 11.0.0.1
-
named.boot
文件是早期版本的bind软件使用的配置文件,现在新版本中已经让位于“named.conf”。named.conf是 dns 服务器配置的核心文件。
下面我们一段一段的来解说。
# named.conf - configuration for bind #
# Generated automatically by bindconf, alchemist et al.
controls {
inet 127.0.0.1 allow {
localhost;
} keys {
rndckey;
};
};
include "/etc/rndc.key";
options {
directory "/var/named/";
};
zone "." {
type hint;
file "named.ca";
};
zone "0.0.127.in-addr.arpa" {
type master;
file "0.0.127.in-addr.arpa.zone";
};
zone "localhost" {
type master;
file "localhost.zone";
};
zone "21php.com" {
type master; notify yes; file "21php.com";
};
上文中#为注释符号, 其他各行含义如下:
diretory /var/named
指定named从 /var/named 目录下读取DNS数据文件,这个目录用户可自行指定并创建,指定后所有的DNS数据文件都存放在此目录下;
zone "." { type hint; file "named.ca"; };
指定named从 named.ca 文件中获得Internet的顶层“根”服务器地址 。
zone "0.0.127.in-addr.arpa" {
type master;
file "0.0.127.in-addr.arpa.zone";
};
指定named作为127.0.0网段地址转换主服务器,named.local文件中包含了127.0.0.*形式的地址到域名的转换数据(127.0.0网段地址是局域网接口的内部 loopback地址);
zone "localhost" { type master; file "localhost.zone"; };
指定包含localhost的DNS文件数据存放在/var/named/localhost.zone中;
zone "21php.com" { type master; notify yes; file "21php.com.zone"; };
以上语句表明域21php.com的DNS数据存放在/var/named/目录下的21php.com.zone中;用文本编辑器打开/var/named/21php.com.zone,其内容如下:
$TTL 86400
@ IN SOA @ root.localhost ( 2 ; serial 28800 ; refresh 7200 ; retry 604800 ; expire 86400 ; ttl )
@ IN NS localhost
www IN A 11.0.0.233
www2 IN A 11.0.0.23
forum IN A 11.0.0.10
@ IN MX 5 mail.21php.com.
该文件的前部分是相应的参数设置,此部分不需要改动,后面的部分就是具体的DNS数据;例如:
www IN A 11.0.0.233 # 将www.21php.com 解析到地址11.0.0.233;
www2 IN A 11.0.0.23 # 将www2.21php.com 解析到地址11.0.0.23;
club IN A 11.0.0.10 # 将club.21php.com 解析到地址11.0.0.10;
配置辅助DNS服务器
辅助DNS服务器,可从主服务器中转移一整套域信息。区文件是从主服务器中转移出来的,并作为本地磁盘文件存储在辅助服务器中。在辅助服务器中有域信息的完整拷贝,所以也可以可以回答对该域的查询。这部分的配置内容如下:
zone "21php.com" IN {
type slave;
file "21php.com.zone";
masters {
11.0.0.1;
};
};
可以看到,和主DNS服务器不同地方就是:“type”改为了“slave”,然后指明了主DNS服务器的地址masters { 11.0.0.1; };。DNS服务启动时,就会自动连接11.0.0.1,读取21php.com域的信息,然后保存到本机的21php.com.zone文件里。
测试DNS服务器
改动过DNS的相应文件,用“ndc restart”命令重新启动服务,在redhat 7.1以上版本中使用命令:
/etc/rc.d/init.d/named restart
或者
/etc/rc.d/init.d/named reload
使改动生效。
要测试DNS,可以找一台客户机,把它的DNS地址设成新建立的DNS服务器地址,然后试试上网,收信,下载等。也可以使用nslookup命令:运行nslookup,输入要查询的主机名,看是否返回正确的ip地址,在redhat 7.1以上版本中推荐使用dig命令。
yum install yum-downloadonly yum install xxx--downloadonly --downloaddir=/home/dev
/etc/sysconfig/network
包括主机基本网络信息,用于系统启动#该文件用来指定服务器上的网络配置信息
NETWORK
=
yes/no 网络是否被配置
FORWARD_IPV4
=
yes/no 是否开启IP转发功能
HOSTNAME
=
<hostname> <hostname>表示服务器的主机名
GAREWAY
=
<address> <address>表示网络网关的IP地址
GAREWAYDEV
=
<device> <device>表示网关的设备名,如:eth0
####示例:
1 #该文件用来指定服务器上的网络配置信息
2 NETWORK=yes/no 网络是否被配置
3 FORWARD_IPV4=yes/no 是否开启IP转发功能
4 HOSTNAME=<hostname> <hostname>表示服务器的主机名
5 GAREWAY=<address> <address>表示网络网关的IP地址
6 GAREWAYDEV=<device> <device>表示网关的设备名,如:eth0
/etc/sysconfig/network-script/
此目录下是系统启动最初始化网络的信息
系统网络设备的配置文件保存在/etc/sysconfig/network-scripts目录下,ifcfg-eth0包含第一块网卡的配置信息,ifcfg-eth1包含第二块网卡的配置信息。在启动时,系统通过读取这个配置文件决定某个网卡是否启动和如何配置。/etc/sysconfig /network-scripts/ifcfg-eth0文件示例:
DEVICE
=
eth0
IPADDR
=
192.168.0.2
NETMASK
=
255.255.255.0
BROADCAST
=
192.168.0.255
ONBOOT
=
yes
BOOTPROTO
=
none
GATEWAY=
192.168.0.1
若希望手工修改网络地址或增加新的网络连接,可以通过修改对应的文件ifcfg-<interface-name>或创建新的文件来实现。
DEVICE
=
<name> <name>表示物理设备的名字
IPADDR
=
<address> <address>表示赋给该网卡的IP地址
NETMASK
=
<mask> <mask>表示子网掩码
BROADCAST
=
<address> <address>表示广播地址
ONBOOT
=
yes/no 启动时是否激活该卡
BOOTPROTO
=
none none:无须启动协议
bootp:使用bootp协议
dhcp:使用dhcp协议
GATEWAY
=
<address> <address>表示默认网关
MACADDR
=
<MAC-address><MAC-address>表示指定一个MAC地址
USERCTL
=
yes/no 是否允许非root用户控制该设备
/etc/xinetd.conf 定义了由超级进程XINETD启动的网络服务
/etc/protocols 设定了主机使用的协议以及各个协议的协议号
/etc/services 设定了主机的不同端口的网络服务 /etc/resolv.conf文件
文件/etc/resolv.conf配置DNS客户端,它包含了DNS服务器地址和域名搜索配置,每一行应包含一个关键字和一个或多个的由空格隔开的参数。例子文件:
search winxp.com
nameserver
192.168.0.1
nameserver
192.168.0.2
search winxp.com:表示当提供了一个不包括完全域名的主机名时,在该主机名后添加wuxp.com的后缀;
nameserver:表示解析域名时使用该地址指定的主机为域名服务器。
其中域名服务器是按照文件中出现的顺序来查询的。因此,应该首先给出最可靠的服务器。目前,至多支持三个名字服务器。
/etc/hosts文件
当机器启动时,在可以查询DNS以前,机器需要查询一些主机名到IP地址的匹配。这些匹配信息存放在/etc/hosts文件中。在没有域名服务器情况下,系统上的所有网络程序都通过查询该文件来解析对应于某个主机名的IP地址。
下面是一个/etc/hosts文件的示例:
127.0.0.1 Localhost server.winxp.com
192.168.0.3 station1.winxp.com
#### 使用ifconfig命令配置并查看网络接口情况
#配置eth0的IP,同时激活设备
ifconfig eth0
192.168.168.119
netmask
255.255.255.0
up
//配置eth0别名设备 eth0:
1
的IP,并添加路由
ifconfig eth0:
1
192.168.168.110
route add –host
192.168.168.110
dev eth0:
1
//激活(禁用)设备
ifconfig eth0:
1
up(down)
//查看所有(指定)网络接口配置
ifconfig (eth0)
#### 使用route 命令配置路由表
#添加到主机路由
route add –host
192.168.168.110
dev eth0:
1
route add –host
192.168.168.119
gw
192.168.168.1
#添加到网络的路由
route add –net IP netmask MASK eth0
route add –net IP netmask MASK gw ${IP}
route add –net IP/
24
eth1
#添加默认网关
route add default gw ${IP}
#删除路由
route del –host
192.168.168.110
dev eth0:
1
####常用命令
traceroute
[
URL
]
ping
[
URL
]
#显示网络接口状态信息
netstat –I
#显示所有监控的服务器的Socket和正在使用Socket的程序信息
netstat –lpe
#显示内核路由表信息
netstat –r
netstat –nr
#显示TCP/UDP传输协议的连接状态
netstat –t
netstat –u
#更改主机名
hostname myhost
#查询系统支持的字符集
locale -a
#设置系统字符集(在 /etc/sysconfig/i18n文件中)
export LANG=zh_CN.GBK / LANG=en_US.UTF-8
#查看ARP缓存
arp
#添加
arp –s IP MAC
#删除
arp –d IP
#### 运行级别与网络服务
#查看当前运行级别
runlevel
#运行级别的切换
init
telinit
top
1.作用
top命令用来显示执行中的程序进程,使用权限是所有用户。
2.格式
top [-] [d delay] [q] [c] [S] [s] [i] [n]
3.主要参数
d:指定更新的间隔,以秒计算。
q:没有任何延迟的更新。如果使用者有超级用户,则top命令将会以最高的优先序执行。
c:显示进程完整的路径与名称。
S:累积模式,会将己完成或消失的子行程的CPU时间累积起来。
s:安全模式。
i:不显示任何闲置(Idle)或无用(Zombie)的行程。
n:显示更新的次数,完成后将会退出top。

图1 top命令的显示
在图1中,第一行表示的项目依次为当前时间、系统启动时间、当前系统登录用户数目、平均负载。第二行显示的是所有启动的进程、目前运行的、挂起(Sleeping)的和无用(Zombie)的进程。第三行显示的是目前CPU的使用情况,包括系统占用的比例、用户使用比例、闲置(Idle)比例。第四行显示物理内存的使用情况,包括总的可以使用的内存、已用内存、空闲内存、缓冲区占用的内存。第五行显示交换分区使用情况,包括总的交换分区、使用的、空闲的和用于高速缓存的大小。第六行显示的项目最多,下面列出了详细解释。
PID(Process ID):进程标示号。
USER:进程所有者的用户名。
PR:进程的优先级别。
NI:进程的优先级别数值。
VIRT:进程占用的虚拟内存值。
RES:进程占用的物理内存值。
SHR:进程使用的共享内存值。
S:进程的状态,其中S表示休眠,R表示正在运行,Z表示僵死状态,N表示该进程优先值是负数。
%CPU:该进程占用的CPU使用率。
%MEM:该进程占用的物理内存和总内存的百分比。
TIME+:该进程启动后占用的总的CPU时间。
Command:进程启动的启动命令名称,如果这一行显示不下,进程会有一个完整的命令行。
top命令使用过程中,还可以使用一些交互的命令来完成其它参数的功能。这些命令是通过快捷键启动的。
<空格>:立刻刷新。
P:根据CPU使用大小进行排序。
T:根据时间、累计时间排序。
q:退出top命令。
m:切换显示内存信息。
t:切换显示进程和CPU状态信息。
c:切换显示命令名称和完整命令行。
M:根据使用内存大小进行排序。
W:将当前设置写入~/.toprc文件中。这是写top配置文件的推荐方法。
可以看到,top命令是一个功能十分强大的监控系统的工具,对于系统管理员而言尤其重要。但是,它的缺点是会消耗很多系统资源。
更多的请看:http://www.QQread.com/windows/2003/index.Html
free
1.作用
free命令用来显示内存的使用情况,使用权限是所有用户。
2.格式
free [-b-k-m] [-o] [-s delay] [-t] [-V]
3.主要参数
-b -k -m:分别以字节(KB、MB)为单位显示内存使用情况。
-s delay:显示每隔多少秒数来显示一次内存使用情况。
-t:显示内存总和列。
-o:不显示缓冲区调节列。
4.应用实例
free命令是用来查看内存使用情况的主要命令。和top命令相比,它的优点是使用简单,并且只占用很少的系统资源。通过-S参数可以使用free命令不间断地监视有多少内存在使用,这样可以把它当作一个方便实时监控器。
#free -b -s5
使用这个命令后终端会连续不断地报告内存使用情况(以字节为单位),每5秒更新一次。

更多的请看:http://www.qqread.com/windows/2003/index.html
uptime 命令
我曾经看到资料上讲,load avarage <3 系统良好,大于5 则有严重的性能问题。注意,这个值还应当除以CPU数目。
如果load avarage=8 ,CPU=3,8/3=2.666,2.66这个值表示系统状态良好
大于5也不一定是严重性能问题,有可能是的确主机提供的服务超过了他能够提供的能力,需要扩容了。要具体看看。

".*"="application/octet-stream"
".001"="application/x-001"
".301"="application/x-301"
".323"="text/h323"
".906"="application/x-906"
".907"="drawing/907"
".a11"="application/x-a11"
".acp"="audio/x-mei-aac"
".ai"="application/postscript"
".aif"="audio/aiff"
".aifc"="audio/aiff"
".aiff"="audio/aiff"
".anv"="application/x-anv"
".asa"="text/asa"
".asf"="video/x-ms-asf"
".asp"="text/asp"
".asx"="video/x-ms-asf"
".au"="audio/basic"
".avi"="video/avi"
".awf"="application/vnd.adobe.workflow"
".biz"="text/xml"
".bmp"="application/x-bmp"
".bot"="application/x-bot"
".c4t"="application/x-c4t"
".c90"="application/x-c90"
".cal"="application/x-cals"
".cat"="application/vnd.ms-pki.seccat"
".cdf"="application/x-netcdf"
".cdr"="application/x-cdr"
".cel"="application/x-cel"
".cer"="application/x-x509-ca-cert"
".cg4"="application/x-g4"
".cgm"="application/x-cgm"
".cit"="application/x-cit"
".class"="java/*"
".cml"="text/xml"
".cmp"="application/x-cmp"
".cmx"="application/x-cmx"
".cot"="application/x-cot"
".crl"="application/pkix-crl"
".crt"="application/x-x509-ca-cert"
".csi"="application/x-csi"
".css"="text/css"
".cut"="application/x-cut"
".dbf"="application/x-dbf"
".dbm"="application/x-dbm"
".dbx"="application/x-dbx"
".dcd"="text/xml"
".dcx"="application/x-dcx"
".der"="application/x-x509-ca-cert"
".dgn"="application/x-dgn"
".dib"="application/x-dib"
".dll"="application/x-msdownload"
".doc"="application/msword"
".dot"="application/msword"
".drw"="application/x-drw"
".dtd"="text/xml"
".dwf"="Model/vnd.dwf"
".dwf"="application/x-dwf"
".dwg"="application/x-dwg"
".dxb"="application/x-dxb"
".dxf"="application/x-dxf"
".edn"="application/vnd.adobe.edn"
".emf"="application/x-emf"
".eml"="message/rfc822"
".ent"="text/xml"
".epi"="application/x-epi"
".eps"="application/x-ps"
".eps"="application/postscript"
".etd"="application/x-ebx"
".exe"="application/x-msdownload"
".fax"="image/fax"
".fdf"="application/vnd.fdf"
".fif"="application/fractals"
".fo"="text/xml"
".frm"="application/x-frm"
".g4"="application/x-g4"
".gbr"="application/x-gbr"
".gcd"="application/x-gcd"
".gif"="image/gif"
".gl2"="application/x-gl2"
".gp4"="application/x-gp4"
".hgl"="application/x-hgl"
".hmr"="application/x-hmr"
".hpg"="application/x-hpgl"
".hpl"="application/x-hpl"
".hqx"="application/mac-binhex40"
".hrf"="application/x-hrf"
".hta"="application/hta"
".htc"="text/x-component"
".htm"="text/html"
".html"="text/html"
".htt"="text/webviewhtml"
".htx"="text/html"
".icb"="application/x-icb"
".ico"="image/x-icon"
".ico"="application/x-ico"
".iff"="application/x-iff"
".ig4"="application/x-g4"
".igs"="application/x-igs"
".iii"="application/x-iphone"
".img"="application/x-img"
".ins"="application/x-internet-signup"
".isp"="application/x-internet-signup"
".IVF"="video/x-ivf"
".java"="java/*"
".jfif"="image/jpeg"
".jpe"="image/jpeg"
".jpe"="application/x-jpe"
".jpeg"="image/jpeg"
".jpg"="image/jpeg"
".jpg"="application/x-jpg"
".js"="application/x-javascript"
".jsp"="text/html"
".la1"="audio/x-liquid-file"
".lar"="application/x-laplayer-reg"
".latex"="application/x-latex"
".lavs"="audio/x-liquid-secure"
".lbm"="application/x-lbm"
".lmsff"="audio/x-la-lms"
".ls"="application/x-javascript"
".ltr"="application/x-ltr"
".m1v"="video/x-mpeg"
".m2v"="video/x-mpeg"
".m3u"="audio/mpegurl"
".m4e"="video/mpeg4"
".mac"="application/x-mac"
".man"="application/x-troff-man"
".math"="text/xml"
".mdb"="application/msaccess"
".mdb"="application/x-mdb"
".mfp"="application/x-shockwave-flash"
".mht"="message/rfc822"
".mhtml"="message/rfc822"
".mi"="application/x-mi"
".mid"="audio/mid"
".midi"="audio/mid"
".mil"="application/x-mil"
".mml"="text/xml"
".mnd"="audio/x-musicnet-download"
".mns"="audio/x-musicnet-stream"
".mocha"="application/x-javascript"
".movie"="video/x-sgi-movie"
".mp1"="audio/mp1"
".mp2"="audio/mp2"
".mp2v"="video/mpeg"
".mp3"="audio/mp3"
".mp4"="video/mpeg4"
".mpa"="video/x-mpg"
".mpd"="application/vnd.ms-project"
".mpe"="video/x-mpeg"
".mpeg"="video/mpg"
".mpg"="video/mpg"
".mpga"="audio/rn-mpeg"
".mpp"="application/vnd.ms-project"
".mps"="video/x-mpeg"
".mpt"="application/vnd.ms-project"
".mpv"="video/mpg"
".mpv2"="video/mpeg"
".mpw"="application/vnd.ms-project"
".mpx"="application/vnd.ms-project"
".mtx"="text/xml"
".mxp"="application/x-mmxp"
".net"="image/pnetvue"
".nrf"="application/x-nrf"
".nws"="message/rfc822"
".odc"="text/x-ms-odc"
".out"="application/x-out"
".p10"="application/pkcs10"
".p12"="application/x-pkcs12"
".p7b"="application/x-pkcs7-certificates"
".p7c"="application/pkcs7-mime"
".p7m"="application/pkcs7-mime"
".p7r"="application/x-pkcs7-certreqresp"
".p7s"="application/pkcs7-signature"
".pc5"="application/x-pc5"
".pci"="application/x-pci"
".pcl"="application/x-pcl"
".pcx"="application/x-pcx"
".pdf"="application/pdf"
".pdf"="application/pdf"
".pdx"="application/vnd.adobe.pdx"
".pfx"="application/x-pkcs12"
".pgl"="application/x-pgl"
".pic"="application/x-pic"
".pko"="application/vnd.ms-pki.pko"
".pl"="application/x-perl"
".plg"="text/html"
".pls"="audio/scpls"
".plt"="application/x-plt"
".png"="image/png"
".png"="application/x-png"
".pot"="application/vnd.ms-powerpoint"
".ppa"="application/vnd.ms-powerpoint"
".ppm"="application/x-ppm"
".pps"="application/vnd.ms-powerpoint"
".ppt"="application/vnd.ms-powerpoint"
".ppt"="application/x-ppt"
".pr"="application/x-pr"
".prf"="application/pics-rules"
".prn"="application/x-prn"
".prt"="application/x-prt"
".ps"="application/x-ps"
".ps"="application/postscript"
".ptn"="application/x-ptn"
".pwz"="application/vnd.ms-powerpoint"
".r3t"="text/vnd.rn-realtext3d"
".ra"="audio/vnd.rn-realaudio"
".ram"="audio/x-pn-realaudio"
".ras"="application/x-ras"
".rat"="application/rat-file"
".rdf"="text/xml"
".rec"="application/vnd.rn-recording"
".red"="application/x-red"
".rgb"="application/x-rgb"
".rjs"="application/vnd.rn-realsystem-rjs"
".rjt"="application/vnd.rn-realsystem-rjt"
".rlc"="application/x-rlc"
".rle"="application/x-rle"
".rm"="application/vnd.rn-realmedia"
".rmf"="application/vnd.adobe.rmf"
".rmi"="audio/mid"
".rmj"="application/vnd.rn-realsystem-rmj"
".rmm"="audio/x-pn-realaudio"
".rmp"="application/vnd.rn-rn_music_package"
".rms"="application/vnd.rn-realmedia-secure"
".rmvb"="application/vnd.rn-realmedia-vbr"
".rmx"="application/vnd.rn-realsystem-rmx"
".rnx"="application/vnd.rn-realplayer"
".rp"="image/vnd.rn-realpix"
".rpm"="audio/x-pn-realaudio-plugin"
".rsml"="application/vnd.rn-rsml"
".rt"="text/vnd.rn-realtext"
".rtf"="application/msword"
".rtf"="application/x-rtf"
".rv"="video/vnd.rn-realvideo"
".sam"="application/x-sam"
".sat"="application/x-sat"
".sdp"="application/sdp"
".sdw"="application/x-sdw"
".sit"="application/x-stuffit"
".slb"="application/x-slb"
".sld"="application/x-sld"
".slk"="drawing/x-slk"
".smi"="application/smil"
".smil"="application/smil"
".smk"="application/x-smk"
".snd"="audio/basic"
".sol"="text/plain"
".sor"="text/plain"
".spc"="application/x-pkcs7-certificates"
".spl"="application/futuresplash"
".spp"="text/xml"
".ssm"="application/streamingmedia"
".sst"="application/vnd.ms-pki.certstore"
".stl"="application/vnd.ms-pki.stl"
".stm"="text/html"
".sty"="application/x-sty"
".svg"="text/xml"
".swf"="application/x-shockwave-flash"
".tdf"="application/x-tdf"
".tg4"="application/x-tg4"
".tga"="application/x-tga"
".tif"="image/tiff"
".tif"="application/x-tif"
".tiff"="image/tiff"
".tld"="text/xml"
".top"="drawing/x-top"
".torrent"="application/x-bittorrent"
".tsd"="text/xml"
".txt"="text/plain"
".uin"="application/x-icq"
".uls"="text/iuls"
".vcf"="text/x-vcard"
".vda"="application/x-vda"
".vdx"="application/vnd.visio"
".vml"="text/xml"
".vpg"="application/x-vpeg005"
".vsd"="application/vnd.visio"
".vsd"="application/x-vsd"
".vss"="application/vnd.visio"
".vst"="application/vnd.visio"
".vst"="application/x-vst"
".vsw"="application/vnd.visio"
".vsx"="application/vnd.visio"
".vtx"="application/vnd.visio"
".vxml"="text/xml"
".wav"="audio/wav"
".wax"="audio/x-ms-wax"
".wb1"="application/x-wb1"
".wb2"="application/x-wb2"
".wb3"="application/x-wb3"
".wbmp"="image/vnd.wap.wbmp"
".wiz"="application/msword"
".wk3"="application/x-wk3"
".wk4"="application/x-wk4"
".wkq"="application/x-wkq"
".wks"="application/x-wks"
".wm"="video/x-ms-wm"
".wma"="audio/x-ms-wma"
".wmd"="application/x-ms-wmd"
".wmf"="application/x-wmf"
".wml"="text/vnd.wap.wml"
".wmv"="video/x-ms-wmv"
".wmx"="video/x-ms-wmx"
".wmz"="application/x-ms-wmz"
".wp6"="application/x-wp6"
".wpd"="application/x-wpd"
".wpg"="application/x-wpg"
".wpl"="application/vnd.ms-wpl"
".wq1"="application/x-wq1"
".wr1"="application/x-wr1"
".wri"="application/x-wri"
".wrk"="application/x-wrk"
".ws"="application/x-ws"
".ws2"="application/x-ws"
".wsc"="text/scriptlet"
".wsdl"="text/xml"
".wvx"="video/x-ms-wvx"
".xdp"="application/vnd.adobe.xdp"
".xdr"="text/xml"
".xfd"="application/vnd.adobe.xfd"
".xfdf"="application/vnd.adobe.xfdf"
".xhtml"="text/html"
".xls"="application/vnd.ms-excel"
".xls"="application/x-xls"
".xlw"="application/x-xlw"
".xml"="text/xml"
".xpl"="audio/scpls"
".xq"="text/xml"
".xql"="text/xml"
".xquery"="text/xml"
".xsd"="text/xml"
".xsl"="text/xml"
".xslt"="text/xml"
".xwd"="application/x-xwd"
".x_b"="application/x-x_b"
".x_t"="application/x-x_t"
关于设置路径变量
1> cd(a).
C:/Erlang5.6.4/erl5.6.4/usr
ok
2> cd("D:/Work/sp/apps").
D:/Work/sp/apps
ok
还可以直接在user.home目录中建立.erlang文件,在文件中加入自定义搜索路径:
io:format(
"
Custom search path added.~n~n
"
).
code:add_patha(
"
.
"
).
code:add_pathz(
"
/Erlang5.6.4/erlyweb-0.7.1/ebin
"
).
code:add_pathz(
"
/Yaws-1.77/include
"
).
开发准备
在开发前,首先我们要做一些环境准备,这样你可以快速进入这个场景。首先你要安装好IntelliJ IDEA,这里我推荐大家使用IntelliJ IDEA 7.0 M2,你可以通过http://www.jetbrains.com/idea下载。IntelliJ IDEA安装完毕后,你需要安装一个插件开发包,主要用于IntelliJ IDEA的插件开发。下载地址和IntelliJ IDEA相同。 这个开发包包含以下内容:IntelliJ IDEA的Open API和源码,以及一些插件的源码(IntelliJ IDEA的插件源码都在 http://svn.jetbrains.org/idea/Trunk,这些都是你编写插件的很好样例)。当然没有这个插件开发包你可以开发插件,不过我强烈推荐下载这个开发包。开发部下载完毕后,你需要将其解压到IntelliJ IDEA的安装目录下,这样IntelliJ IDEA的SDK创建会很简单。这里要注意一点,插件开发包的版本最好和IntelliJ IDEA的版本相对应。关于IntelliJ IDEA的SDK准备,你可以参考这篇文章:建立IntelliJ IDEA插件开发环境 。
接下来我们启动IntelliJ IDEA来创建一个IntelliJ IDEA SDK,这是开发插件的基础。启动IDEA,打开设置面板,选择”Project Settings",在弹出的对话框中安装下图进行IntelliJ IDEA SDK设置:
这里要有一个注意事项:默认的情况下,新创建的SDK并会将idea.jar包含到classpath中,由于IntelliJ IDEA的Open API不能完全满足你需要的功能,你的插件可能会用到IDEA未公布的API,所以这里建议你检查一下idea.jar文件是否已经被包含,如果没有被包含,请加入这个jar文件。
IntelliJ IDEA的SDK已经被创建了,它是开发插件的基础包。在这里我相对这些jar文件进行一些描述,已方便我们以后的代码编写,毕竟我们代码是要引用其他的开发包的,如果IDEA已经提供,我们就没有必要在找第三方的jar包啦。在$IDEA_HOME/lib下有以下文件需要提一下:
commons-codec-1.3.jar:这个是进行编码转换的开发包,是Apache Commons一个比较重要的开发包; http://commons.apache.org/codec
commons-collections.jar: Java Collection扩展框架,对Collection处理更加方便,也是Apache Commons一个比较重要的开发包; http://commons.apache.org/collections/
j2ee.jar和javaee.jar:J2EE开发包,这个不用说啦; http://java.sun.com/javaee/5/docs/api/
jdom.jar:XML开发包; http://www.jdom.org
trove4j.jar: java.util.Collections的一个实现,更加快速、轻量; http://trove4j.sourceforge.net/
velocity.jar: Velocity模板引擎; http://velocity.apache.org
xmlrpc-2.0.jar: xml-rpc的开发包; http://ws.apache.org/xmlrpc/
xstream.jar: xml/object映射框架; http://xstream.codehaus.org/
了解一下这些开发包,可能对后续的开发有不少的帮助。
下面就让我们开始创建一个项目并进行插件开发。首先我们要创建一个项目,这里个人有一个建议:建立一个空的项目,然后添加多个plugin module,这样在一个项目中可以包含多个plugin module,主要的好处就是你可以添加一些参考的插件,这对编写一个新的插件会帮助不少。
项目创建后,我们需要添加一个plugin module。只需打开"File" -> "Add Module"然后选择"plugin module"就可以啦,请将module的SDK设置为上面我们创建的IDEA SDK。到这里插件开发的项目就创建完毕啦,你可以开发你的插件啦。

IntelliJ IDEA的IoC介绍
当你看到这一章节时,你估计会骂我鸡婆。IoC,这个还要你来告诉我,我用SpringFramework已经很久啦。但我还是要说一下。IDEA整个组件结构是基于PicoContainer(http://www.picocontainer.org)的,PicoContainer是一个高效的嵌入式的DI容器。如果你有时间的话,我建议你花5分钟浏览一下PicoContainer,然后回到这篇文档来。
PicoContainer是有层次结构的,就是一个container可以包含子container,子容器可以访问父容器中的组件,而各个子容器直接是独立的。在IDEA中,主要有三种container:Application, Project和Module,分别包含不同的组件。application container包含多个project container,project container可以包含多个module container,如下图:

这样各个project container是独立的,都可以访问application container中的组件;module container也是独立的,可以访问所属project container和application container中的组件。这个图是我们后面理解application component, project component, module component和extension point等等的基础。
PicoContainer的组件注入主要有两种方式:构造注入和Setter注入,但是在IDEA中,目前Setter注入还不支持,全部是构造注入,关于构造注入,PicoContainer推荐最好使用一个构造函数,这点也在IDEA中需要明确。如果你的组件需要引用其他的组件或资源,你最好在组件的构造函数中指定,PicoContainer会帮助你完成资源引用和初始化。
IDEA的这些容器中包含些什么? 当然首先是各种component,还有就是一些服务,容器中不仅仅是component,还有相关为组件服务的资源,在后面我们也会涉及到对容器中服务资源的讲述。
如果访问这些容器中的组件?在IDEA中,访问application container中的组件可以通过ApplicationManager.getInstance().getComponent(Class T)来进行。通用获得project对象后,你可以访问project容器中的组件;获取module对象后,你可以访问module容器的组件。有了容器后,如何能获取指定的组件?有以下几种方式: 1. 组件ID,组件提供的组件标识符号,可以通过标识符来访问。如果组件没有标识符号,我们称之为匿名组件。 2. 组件的interface类。如果一个组件的是通过interface向外服务的,那么我们可以通过interface来获取对应的组件。如果 interface的实现为多个组件,就会获得多个组件。
如果让我的组件被注册到这些容器中? 在IDEA中,有三种组件: Application Component, Project Component和Module Component。不用的组件需要继承不同接口,分别为Application Component, ProjectComponent和ModuleComponent,如果你的组件继承了某一接口,将会自动放置到某一容器中,不需要你手动去注册。
组件既然要交给容器去管理,这就牵涉到生命周期的概念,对于Application Component来说,initComponent负责初始化,disposeComponent负责资源清理。对ProjectComponent来说,除了initComponent和disposeComponent,还增加了projectOpened 和projectClosed,这个意思还比较容易理解,就是一个挂钩(hook)。组件一旦被激活,就开始发挥它的作用啦。
组件的行为可能需要设置,如设置不同的参数组件的特性就不一样。如何给组件设置参数?当然可以让组件自身去做,去找一个文件,当文件修改后重新加载。在IDEA中,你不需要这么做,你只需让组件继承Configurable接口,IDEA会将在设置面板中添加一个设置选项,让你设置这个组件的参数,当然包括运行期的,这个好像和JMX相像。 :)
组件的参数设置完毕啦,当容器关闭后,组件带的这些参数需要保存在一个地方,这样当容器重新启动后,组件仍然能向以前一样工作,不然你又得重新设置一下。同样的道理,你可以自己设定逻辑,保存到某一个地方,然后在加载起来。如果IDEA提供了一个 JDOMExternalizable接口,只要实现接口并添加少量的代码,IDEA就会完成component的参数保存和读取的任务。在最新的 IDEA 7.0中,采取了另外一种保存机制,这个我们会在后面进行说明。
讲到这里,你可能会问,有没有一种方面来声明Component? 这是有的,那就是extension point。extension point是组件的简化方式,它的主要功能是数据信息扩展,它们不需要继承component接口,同时也没有组件标识符号,只需要在 plugin.xml声明就可以,在声明的时候你需要指名是何种类型的组件。下面会有更详细的介绍。
PicoContainer是IDEA基础,因为我们编写的组件都是由容器初始化的,而且组件直接的相互依赖也是有容器完成,所有了解一下PicoContainer还是很有必要的,对插件编写和IDEA的机制都非常有好处。
Extension Points
前面讲解了一下extions point,这里想再细化一下。Extension point的主要作用是数据信息扩展和事件监听,也就是一个插件注册了某一extension point,其他插件可以通过extension point为该插件提供数据信息或触发事件逻辑,从而达到影响上一插件中的组件的一些行为。最典型的就是gotoSymbolContributor,我们在各个插件中通过gotoSymbolContributor的声明,提供插件自己的symbol信息给IDEA,这样在按下 Ctrl+Shift+Alt+N时,插件提供的symbol信息就会被提示出来,当然你可以利用这种机制实现其他功能,监听也是一种实现。从用户的角度来看,就是在某些方面,原先的插件功能增加啦。那么如何声明一个extension point呢。这个很简单,只要建立一个Java Integerace,然后在plugin.xml进行什么就可以啦,代码如下:
<extensionPoint name="resourceBundleManager" interface="com.intellij.lang.properties.psi.ResourceBundleManager" area="IDEA_PROJECT"/>
前面说过,extension point是组件的简化方式,这里的area是指组件的类型,如果不指定就是ApplicationComponent,IDEA_PROJECT表示 ProjectComponent,MODULE_PROJECT表示ModuleComponent。声明完成后,我们需要在插件中访问 extension point去获取数据,代码如下:
Object[] extensions = Extensions.getExtensions("plugin_id.testExtPoint");
这里字符串中的plugin_id表示plugin的id(在xml文件中),testExtPoint就是extension point的name。还有一种就是提供ExtensionPointName,这个可以参考一下Open API,也非常简单。这里返回一个数组,因为可能多个其他插件使用该extension point为该插件提供数据。接下来就是在其他插件应用该extension point啦,三个步骤:
1 首先依赖该插件: <depends>reliant_plugin_id</depends>
2 创建extension point的interface的实现,java编码即可
3 extension point引用声明,xmlns的值就是所依赖的plugin的id。代码如下:
<extensions xmlns="reliant_plugin_id">
<testExtPoint implementation="com.foobar.test.impl.Extender"/>
</extensions>
通过这种方式,可以实现插件直接的数据供给,提示原有插件的功能,一个好的插件,如果能定义好一下扩展点,方便其他插件进行扩充,将是非常有益的。
事实上IDEA核心就提供了非常多的extension point,这里你可以扩展IDEA的功能。关于这些扩展点的元信息,请参考:$IDEA_HOME/lib/resources.jar文件的/META-INF/plugin.xml文件。
Plugin的结构介绍
我们应该进入正题啦。Plugin的主要功能扩展IDE的功能,前面我们讲述了IDEA整体结构是基于容器的,那么要扩展IDEA的功能,唯一的方法就是想容器中添加组件,新添加的组件包含自身的一些功能,同时和其他组件进行交互(修改一些参数和特性等),影响其他组件的行为,从而达到功能的扩展目的。那么一个插件中,应该会包含application component, project component和module component。由于还要和用户进行交换,插件还提供了action,也就是和用户进行交换的操作,所以插件的主要内容就是component和 action。这里顺便还聊一句,component是由容器管理的,那么action可不可以也由容器管理呢?这样在action中引用 component将更加方便。目前action还不是由容器管理的,这个主要是由历史原因决定的,不少action的代码还不能转移到容器中管理,不过 IDEA正在做一些工作,相信以后action也可以由容器进行管理。
下面我们要开始插件编写啦。首先我们要设定一下插件的基本信息。插件需要有一个唯一标识符,有一个版本号(便于升级)还有就是适用的IDEA版本。这三项应该说是必需的,其他就是插件的额外信息,如描述,changeLog,作者等等,在plugin.xml设定就可以啦。
完成设定后,我们就需要向插件中添加内容啦。创建Component和Action非常简单,只要通过new group就可以创建。图例如下:
这里我们可能还要啰嗦一下,就是关于plugin的目录结构。插件开发包中有一个plugin structure的html文档,已经讲述的非常清楚,这里只是重复一下。一个plugin通常包含plugin.xml,相关的class和引用的第三方jar文件。如何组织这些文件,我推荐以下的结构:插件目录下的lib文件夹保存第三方jar文件(如果没有引用第三方jar,可以没有该目录),classes目录包含插件的代码,META-INF包含 plugin.xml文件,结构如下:

使用Maven管理插件项目
Maven实际上已经成为Java项目管理的规范,当然这里我们也希望IDEA的插件开发也能通过Maven管理起来。Maven并不难,但是针对 IDEA的插件项目主要有以下问题,可能导致管理有一定的难度:1. IDEA并不是都使用Javac进行代码编译。如果你使用了IDEA的UI Designer,那么你得使用Javac2才能编译这些代码; 2. 开发插件需要的IDEA的jar文件在repo1.maven.org/maven2中没有,你可能需要自己设定repository的位置;3. IDEA的插件需要装配,这个可能是一些web项目,jar项目不具有的。基于这些原因,我想给一个相对标准的pom.xml文件和插件项目的目录结构,目录结构如下图:
这个目录和标准Maven项目是一致的,不过有一点就是我们将plugin.xml文件放置在src/main/resources目录下,最好形成这样的标准,这对后续的plugin打包分发有帮助。
回到pom.xml文件,其实只需注意一下,IDEA插件开发需要的jar包都在 http://mevenide.codehaus.org/m2-repository/, 所以我们需要设置一下项目的repository的位置。由于还使用了codehaus的一些Maven插件,所以还有设置一下plugin repository的为位置。下面就是设置build plugin,能保证插件项目中的代码能被正确编译,主要就是IDEA的UI Designer的文件编译,其他的和标准的Maven编译选项一致。接下来就是设置dependency,由于插件开发需要的jar包不少都包括在 IDEA SDK(前面我们讲述过),所有这些dependency的scope设置为provided即可。如果你引用的是IntelliJ IDEA本身的jar包,那可能还有注意一点:由于IDEA的jar包包括正式版本号和编译版本号,所以你可能还有给dependency设置 classifier,这个值就是IDEA的编译版本号,一个典型的dependency声明如下:
<dependency>
<groupId>com.intellij.idea</groupId>
<artifactId>openapi</artifactId>
<version>7.0</version>
<scope>provided</scope>
<classifier>${idea_build_number}</classifier>
</dependency>
因为牵涉到插件要发布出去,所以我们还是需要设置一下如何将插件打包。在Maven中这称之为Assembly,是通过Assembly plugin完成。我们只需要创建Assembly的描述文件,然后在设置一下Assembly插件的配置,最后咨询mvn assembly:assembly就可以啦。一个IDEA插件项目典型的Assembly的描述文件如下所示:
<?xml version="1.0" encoding="utf-8" ?>
<assembly xmlns="http://maven.apache.org/xsd/assembly" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/xsd/assemblyhttp://maven.apache.org/xsd/assembly-1.1.0-SNAPSHOT.xsd">
<id/>
<formats>
<format>zip</format>
</formats>
<includeBaseDirectory>false</includeBaseDirectory>
<dependencySets>
<dependencySet>
<outputDirectory>/gmail-plugin/lib</outputDirectory>
<unpack>false</unpack>
<scope>runtime</scope>
<includes>
<include>org.intellij:gmail-plugin</include>
<include>net.sf:jgmail</include>
<include>commons-httpclient:commons-httpclient</include>
<include>commons-logging:commons-logging</include>
</includes>
</dependencySet>
</dependencySets>
</assembly>
在Assembly中出现的artifact,如commons-httpclient需要能在pom.xml中解析得到(只要commons- httpclient处于dependency中就可以),这样我们就可以将IDEA的插件打包成zip文件,这样就可以发布,现在你只要将登录到 http://plugins.intellij.net,然后上传这个zip文件,你的发布就完成啦。
IntelliJ IDEA TestCase
个人对TDD还是比较推崇的,所以在没有进行开发前,还是先介绍一下如何进行测试。在com.intellij.testFramework包下包含各种 TestCase,你可以进行相关的单元测试。下面我们先看一下IDEA是如何运行TestCase的。IntelliJ IDEA在运行IDEA的TestCase时,会加载当前编辑的插件,这样就会模拟出一个IDEA运行的真实环境,这样你就可以进行各种测试。在实际的开发中,我们经常会PsiFile,VirtualFile等Java类,在plugin的内容组织方面,也主要是Action,Inspection 等,IDEA的test framework都提供了这些TestCase,很方便地测试这些类和组件。IdeaTestCase、LightIdeaTestCase、 PsiTestCase以及InspectionTestCase等都提供很便捷的方式来测试你编写的代码。当然IDEA还没有提供非常全面的测试方案来测试任何代码,这个可能对TestCase设计编写要求会比较高,应该绝大多数情况下,你要自己觉得怎样去编写Unit Test。对于新的插件开发人员,个人建议还是TestCase加Debug合并使用,毕竟这方面的知识我们还是比较欠缺点。参考一下别人编写的 TestCase可能会提升我们编写TestCase的水平。如何使用IDEA test framework提供的TestCase,这个很简单,只要继承响应的TestCase,然后编写代码就可以啦,没有任何特殊的要求。不要害怕,编写几个TestCase,你就有感觉啦。最后说一句,IDETalk插件的Unit Test写的不错,大家可以参考一下,而且IDETalk的作者Kirill Maximov也写了不是关于IDEA下Unit Test的文章。
开发场景
1 开发一个读写文件的Action:
IDEA的设计思路是多线程读单线程写的模式,而且在AnAction中是不能进行写操作的,如果你要在Action中进行写操作,你需要创建一个 Runnable对象,然后交给 ApplicationManager.getApplication().runWriteAction(runnable)去执行。
2 Editor Action:
editor action主要用于操作当前编辑窗口中的内容,通常需要给editor action设置一个EditorWriteActionHandler来完成对editor的操作。EditorModificationUtil提供了不少方法,可以加快开发。如果向想获取光标处的PsiElement对象,需要设置PsiFile的 getElementByOffset(offset)来获取。如果你想进行相关的插入操作,你可能需要创建指定的PsiElement,这个时候 PsiElementFactory可能会帮你不少忙,你可以参考一下PsiElementFactory API,看是否有你需要的东西。
3 Intention Action:
intention action简单地说就是意图操作,IDEA会根据光标所在的位置,进行相关检查,然后提示可以进行相关的操作。intention action需要继承IntentionAction类,需要提供family name(ID标识)和description(显示名称)。在IntentionAction类中,isAvailable判断当前Intention Action是否有效,invoke表示你选择该intention action后执行的动作。PsiElement element = file.findElementAt(editor.getCaretModel().getOffset()); 这个语句用来获取当前光标处的PsiElement。intention action还需要注意的一点,就是我们要在源码根目录建立一个intentionDescriptions的目录,然后在依据family name建立一个子目录,最后添加三个文件:description.html、before.xxx.templates和 after.xxx.template,xxx可以为某一种类型文件的扩展名。如下图所示:

最后,我们需要将这个action进行注册,action通常要归属于某一类别。注册有两种方式:代码和声明。代码为:IntentionManager.getInstance().registerIntentionAndMetaData(new FirstIntentionAction(), "category"); 声明方式需要在plugin.xml中指定,代码如下:
<intentionAction>
<className>com.foobar.FirstIntentionAction</className>
<category>category</category>
</intentionAction>
4 Inspection action创建
inspection action就是代码审查action,它可以检查发现代码潜在的错误。如果你留意一下右下角的侦探头像,他就是代码审查员,负责调用各种 inspection action,完成对代码的审查。如果发现潜在的问题,就会给你一个解决方案,你可以选择该方案进行问题修复。在IDEA设置面板中的“Errors”选项,其实就是inspection action的集合,目前IDEA 7.0大概包含800+个inspection action,审查代码的各个方面,对代码质量的提升有很大的帮助。
言归正传,如果编写一个这样的action。首先我们创建一个新的inspection action,它需要实现LocalInspectionTool类。Inspection action需要提供short name(ID标识),display name(显示名)和group display name(所在的组名), 这样inspection action可以更好地显示。和Intention Action一样,我们需要在源码目录下建立一个inspectionDescription的目录,然后依据short name创建一个html文档,将该inspection的功能进行描述。图例如下:

LocalInspectionTool默认是检查Java文件的,如果你想让LocalInspectionTool审查其他文件,你需要重写 LocalInspectionTool类的buildVisitor方法,来审查特定的类型的PsiElement,你可以参考一下 LocalInpsectionTool的源码。前面我们讲到inspection action会提供一个解决问题的方案,在IDEA中这叫QuickFix。当我们检查到一个错误时,我们需要创建一个问题描述,如果有必要的话,需要创建一个quick fix来完成问题修复。注册一个问题,通常提供这四个参数:可能存在错误的PsiElement、警告级别、描述和quickfix。这个可以通过 InspectionManager进行审查问题创建。
目前,我们的Inspection Action已经完成啦,如何注册inspection action? 和intention action的注册一样,有两种方式:代码和extension point。代码方式:需要创建一个application component,然后继承InspectionToolProvider,只要实现InspectionToolProvider的 getInspectionClasses()方法即可。 extension point:同intention action不一样的是,我们要创建一个类,继承InspectionToolProvider,这个类不必要继承 ApplicationComponent,然后实现InspectionToolProvider的getInspectionClasses(),最后在plugin.xml文件中进行声明,如下:
<inspectionToolProvider implementation="com.intellij.psi.css.CssInspectionsLoader"/>
从理论上来说,IDEA是将inspectionToolProvider最为一个application component对待。
5. Annotator创建
annotator顾名思义标注,就是给相关的PsiElement加上标识,这个标识涉及到高亮显示、装订栏(装订栏添加图标标识)等等,annotator主要用于标识一些信息。编写annotator,我们需要创建一个类,继承Annotator,然后根据psiElement来判断是否要给element添加标识,主要是和Annotation打交到。最后,我们需要在plugin.xml中进行annotator申明,如下:
<annotator language="JAVA" annotatorClass="cn.org.intellij.webx.ScreenAnnotator"/>
6. 设置组件属性和状态保存
前面我们讲过如何保存组件的状态,在这里我们讲述一下IDEA 7.0中的实现方法,可能有点不一样。想要设置一个组件的状态,你需要继承Configurable,这样在设置面板中就会出现一个选项,你可以进行相关的操作。接下来我们需要将设置的状态保存起来,这是我们需要创建另外一个类,专门用于保存设置,我们可以称之为Settings类,这个Settings 类需要PersistentStateComponent类,负责信息的保存和读取。信息的读取是通过一个@State的annotation来设置的。到这里,我们就可以理解啦,一个类用于接收参数设定,一个类用于参数保存和读取,由于该类包含相关参数,所以它就是一个Service,通常将参数进行封装,对外提供服务,代码很简单。接下来就是在plugin.xml中进行声明,我们可以参考一下Ruby插件中的例子:
<projectConfigurable implementation="com.intellij.openapi.roots.ui.configuration.ProjectStructureConfigurable"/>
<projectService serviceInterface="org.jetbrains.plugins.ruby.settings.RProjectSettings" serviceImplementation="org.jetbrains.plugins.ruby.settings.RProjectSettings"/>
下面是@State的描述:
@State(
name = YourPluginConfiguration.COMPONENT_NAME,
storages = {@Storage(id = "your_id", file = "$PROJECT_FILE$")}
)
在这个例子中我们使用了$PROJECT_FILE$宏,你可以根据组件的类型不同设置不同的宏,如下:
- application-level components (ApplicationComponent): $APP_CONFIG$, $OPTIONS$;
- project-level components (ProjectComponent): $PROJECT_FILE$, $WORKSPACE_FILE$, $PROJECT_CONFIG_DIR$;
- module-level components (ModuleComponent): $MODULE_FILE$
7. gotoClassContributor
在IDEA中,我们通常会按下Ctrl+N或Ctrl+All+Shift+N去寻找类或symbol,如果你想扩展各个功能,如在struts中,查找某一个action的声明,这个时候我们需要扩展这一功能。这个时候我们只需创建一个类,让其继承ChooseByNameContributor,实现 ChooseByNameContributor的方法就可以。接下来就是在plugin.xml中进行声明,可以参考Struts, Ruby的插件:
<gotoSymbolContributor implementation="org.jetbrains.plugins.ruby.ruby.gotoByName.RubySymbolContributor"/>
Virtual File, Document 和Psi File
在IDEA中,我想对文本的操作可能就是这三个在发挥作用,这三者都可以对文件的内容进行更改。
Virtual File是IDEA的统一文件系统,就向Java的IO一样,我们可以称之为VFS(虚拟文件系统)。有了Virtual File,我们不在需要和传统的文件打交到,取而代之的是VFS。我们对VFS的各种操作,会映射到传统的文件系统上。IDEA中的所有和文件相关的操作都是通过Virtual File进行,这些操作和传统的文件操作差不多,不过更加简单。
Document其实就是Virtual File的内容的字符序列,所以对Document的各种操作都是基于普通文本的。Document的可操作的方法并不多,主要是Document是基于字符序列的,操作起来难度有点大。事实上我们对Document的使用也比较少,通常都是一些信息的简单获取。
Psi File这个是结构化的文件内容呈现,这样我们通过操作结构化的对象,从而达到操作文件内容的目的。这些结构化的对象通常通过一种编程语言来体现,在 IDEA中,就是Java对象,这样我们操作就更加简单。这里我不知道这个例子是否合适,JDom是用Java对象来体现xml文档,这里PsiFile 就是用Java语言来体现各种文件内容。讲到这里可能大家还没有体验PsiFile的好处,我们举一个例子来说明。现在有一个Java文件,那么我们就可以构建一个PsiJavaFile对象,通过该对象,我们可以了解该java文件的一些信息,如package 名称,import语句列表,包含的class。假设我们获取了PsiJavaFile的一个PsiClass对象,我们就可以了解该Java类的各种信息,如名称、注释和包含的函数等等。在这里我们可以更改PsiClass的名称、注释等等,这些修改马上就会反映到文件的内容中。试想一下,如果这一切通过文本分析完成,那将是多么复杂的工作,有了Psi File,这一切就简单啦,操作对象比操作文件内容要可靠简单的多。关于PSI,请参考一些IntelliJ IDEA的插件开发文档,同时我们推荐Psi Viewer这个插件,你可以对IDEA处理内容做更好地理解。如果你想写出好的插件的话,你需要对PSI有较深的理解,虽然我写的很少,但是它的重要性却相当高。
数据关联结构
其实这节不知道如何写?章节的名称也怪怪的。我们都知道IDEA的代码提示、代码导航和代码重构非常强大,这背后的是什么样的数据结构来支撑这些特性。在 IDEA中,通过一种Reference机制可以将很多的事情关联起来。回到上一节所说的,在IDEA中,我们对文件的内容操作,通常都是通过 PsiFile完成的。PsiFile中最小的元素就是PsiElement,由于PSI的设计合理,所以可以将PsiElement进行关联,这样可以实现很多的特性。举一个例子来说吧。 <bean id="personManager" class="com.foobar.PersonManagerImpl"/>这是一个简单xml元素,但是在这个云素中,我们知道class的属性值(XmlAttributeValue, PsiElemnt的子类)是和Java Class类进行关联的。如果我们将将XmlAttributeValue和PsiClass(Java类的Psi结构类型)关联起来,那么我们就可以实现代码提示,导航和重构(当类名更改会更新xml的属性值),这个关联的过程就是Reference的实现。我们通过特定的Reference将这两者关联进行实现,然后进行注册声明,那么我们这种关联就建立起来,我们就会体会到其中的便捷。IDEA包含特定的索引结构,你可以想象一下,项目中文件的内容都存在着一定的关联关系,最后形成一个很大的网来维护这些关联。在IDEA启动时,会花不少的时间来建立索引,来形成这些关联关系,相信大家在打开项目都能体验到这一点。如果建立这些关联关系,有很多中实现方式,主要是PsiReference和ReferenceProvidersRegistry。 PsiReference顾名思义就是建立PsiElement直接的关联,ReferenceProvidersRegistry则完成这些关联的注册和管理。关于这些方面的内容写起来比较琐碎,如果你实现了某一关联,代码提示、导航、重构等都能很好的工作,对你的工作效率提升有很大的帮助。
前面介绍了基本原理,下面我们看一下如何实现常用的几种关联方式。我们前面讲述了PsiReference,但是这里还有一个 PsiReferenceProvider要介绍一下,其实就是对PsiReference的一个封装,因为 ReferenceProvidersRegistry进行注册的时候,只接受PsiReferenceProvider。 PsiReferenceProvider很简单,只需要将指定的PsiReference实例返回即可。 ReferenceProvidersRegistry的对象实例可以通过 ReferenceProvidersRegistry registry = ReferenceProvidersRegistry.getInstance(project); 接下来注册的代码可以在project component初始化的时候完成。下面让我们进行几个样例吧:
1. xml tag的属性值和某一PsiElement进行关联:这种情形很常见,如xmlTag的属性值和java class关联,xmlTag的属性值和java class field关联等等。如果实现这个关联呢。首先我们要找到指定的属性值,通常我们通过三个参数就可以确定: xml的namspace, tag名称和属性名,有了这三个值,我们就可以确定该属性值,下面就是和某一reference provider关联。代码如下:
String[] attributeNames=...;
String tagName=...;
NamespaceFilter namespaceFilter=...;
PsiReferenceProvider referenceProvider=...;
registry.registerXmlAttributeValueReferenceProvider(attributeNames, new ScopeFilter(new ParentElementFilter(new AndFilter(new ClassFilter(XmlTag.class), new AndFilter(new OrFilter(new TextFilter(tagName)), namespaceFilter)), 2)), referenceProvider);
如果你说,这个xml没有namespace,你可能需要根据改xml的特征写一个filter,完成定位的需要。你可以将上述的namespaceFilter替换为你需要的filter即可。
2. xml tag的文本值和某一PsiElement关联: 由于IDEA并没有提供类似 registerXmlAttributeValueReferenceProvider这样的函数,这样xml tag的文本值就没法通过直接api的方式进行。IDEA提供了这样的一个方式: registry.registerReferenceProvider(filter, XmlTag.class, psiReferenceProvider); 你只需要设定filter即可。另外你可以通过registry.registerXmlTagReferenceProvider()也可以进行注册。
3. 字符串和某一PsiElement关联:这种情形也很多,如context.getBean(""),和xml中的bean tag关联,这里的字符串作为函数的参数,有了实际的意义,可能就会和某一个PsiElement关联。这个关联注册很简单, registry.registerReferenceProvider(filter, PsiLiteralExpression.class, psiReferenceProvider); PsiLiteralExpression.class是文本的代表。这里要注意的是,一定要设置好filter,否则会很其他的代码带来问题。关于字符串和PsiElement关联还要注意一点就是PsiReference的isSoft一定要设置为false,因为IDEA中字符串的默认提示是 property key,还有是classpath中的路径,如果isSoft为false,那么其他的提示将不会出现。
上面的三个是比较常见的。说到这里,因为是要建立关联,必定涉及到更加字符串查找指定的PsiElement。在IDEA中我们可以通过 PsiManager,PsiShortNamesCache和PsiSearchHelper能完成不少的工作。如果还有问题的话,请参考 PsiElement和PsiRecursiveElementVisitor完成查找工作。
基于xml的框架插件开发指南
这一章节可以说有实际的意义,毕竟xml在各种框架中的应用还是毕竟广的(尽管annotation已经替代部分xml的功能)。IntelliJ IDEA提供一个文档主要介绍在IntelliJ IDEA下如何通过DOM方式进行xml操作(http://www.jetbrains.com/idea/documentation/dom-rp.html),这个章节可以说作为中文说明和补充。我不想就细节和大家沟通,主要说的是一个步骤:
1. 创建各种Dom Element及其直接关系,这个在IDEA DOM的文档中有描述。这里我们说一下,根节点需要继承CommonDomModelRootElement,普通节点需要继承 CommonDomModelElement,最好给每一个Dom Element创建对应的实现类,主要是为了扩展。对于实现类,根节点需要实现RootBaseImpl,普通节点实现BaseImpl。
2. 首先我们创建一个DOM File Descriptor,进行Dom File注册,让IDEA能在某一类型的xml和Dom直接进行映射。DomFileDescription提供一个isMyFile()方法,可以帮助我们确定xml文件是否是Dom要求的。接下来在plugin.xml中进行声明: <dom.fileDescription implementation="org.intellij.ibatis.IbatisConfigurationFileDescription"/>
3. 如果有必要的话,给Dom Element创建各种converter;
4. 创建DomModel和DomModelFactory:xml文件是提供基础信息的基石,如果我们想访问xml文件中的信息,可以通过统一的接口去访问,这个就是DomModel和DomModelFactory。DomModel负责和Dom Element之间交互,对外提供服务。而DomModelFactory则创建DomModel,DomModelFacotory能够处理各种情况,准确构建DomModel;
5. 这样我们就完成XML的基本处理。在实际的开发我们可能要参考这些类: DomManager, DomElement, DomUtil, 这些类都在com.intellij.util.xml包下,建议看一下。
6. 总的来说,DOM的操作要比之间操作XmlFile和XmlTag要简单很多,如果你的插件中牵涉到xml操作,考虑一下IDEA DOM是非常有必要的。
Custom Language Plugin
写这节的目的有两点:1. 开发中可能需要各种语言; 2. IntelliJ IDEA中支持语言注入,你编写的这一功能可能被应用到各种地方,提升效率。由于Custom Language Plugin牵涉到很多的内容,如果你对这方面感兴趣,可以先参考一下 http://www.jetbrains.com/idea/plugins/developing_custom_language_plugins.html,了解一下基本原理和自定义语言插件的功能。这里还要说一下就是关于JFlex,通常你需要了解这个工具,它是词法分析器,和IDEA能结合的很好,同时 IDEA也提供了JFlex Plugin,你可以进行JFlex相关的试验。关于这部分内容,在后续我还会更新,主要是想通过一个具体的例子来说明。
代码提示相关
如果你想在编辑窗口实现代码提示,通常有三种方式: PsiReference,CompletionData和LookupManager,其中PsiReference,CompletionData是系统直接调用的,而LookupManager需要你手动触发的。PsiReference前面已经介绍过,就是通过PsiElement之间相互关联来进行的。CompletionData则是和某一种语言管理起来,在调用代码提示时会触发这段代码,从而达到提示的目的。LookupManager就完全手动编码方式,就是手动触发一个代码提示框,只不过LookupManager帮你做了很多,而不用关心很多的细节。
Inspection Action和Intention Action编写注意事项
在进行Inspection讲解之前,让我看一下Inpsection的结构:

在此结构中,我们可以看到一个Inspection需要一个Visitor去访问某一起始点下的各个子PsiElement,在遍历各个 PsiElement的过程中,当发现问题时注册问题描述(ProblemDescription),如果该问题有对应的QuickFix,则将该问题描述和QuickFix关联起来。Inspection的机制如下:
1. Inspection Manager调用某一Inspection来审查某一PsiElement
2. Inpsection会调用visitor去访问该PsiElement的各个子PsiElement
3. 在访问各个子PsiElement时,如果发现了问题,这创建对应的问题描述,如果该问题包含对应的QuickFix,则进行关联
4. 当用户调用quickfix时,触发quickfix的执行
在实际的编码中,我们看一下BaseInspection的结构:

通常一个Inspection只会关注一种问题,基于这个原则,所有错误提示应该是一样的,所以BaseInspection需要你提供一个统一的问题描述。对应同一个问题的解决方法,当然可能有一种或多种,所以BaseInspection提供了buildFix和BuildFixes,你只需要实现一个即可。最后是Visitor的创建,BaseInspection引入了BaseInspectionVisitor,顾名思义就是专门为 inspection做的的visitor,包含了针对Inspecitond的常用方法。Visitor同时包含ProlemsHolder和 Inspection对象,这样在发现问题的时候,马上可以将问题和该inspection对应的解决方法关联起来。这里还有一个 InspectionGadgetsFix,这个类没有太多的解释,主要目的就是去做一些判定,是否可以进行QuickFix操作等。通过这种结构调整,流程和代码就简单了很多,你创建Inspection就容易多啦。
同样的原理可用在Intention Action上,在Intention Action中,首先通过一个predicate来进行匹配判断,如果匹配后又专门的处理逻辑进行操作,完成intention action。
FAQ
Q: 插件中的图片大小有哪些要求?
A: 在菜单栏中出现的图片要是是16x16的png图片;在设置面板中出现的图片要求是48x48的png图片。这些图片通常都是要求透明的,如果你不知道怎么制作透明的png图片的话,你可以通过ImageMagick提供的命令行行进行操作: >convert -transparent white logo.png logo_1.png
Q: 如何创建Live Template的自定义function?
A: 在Open API里没有涉及到这个方面,你需要参考一下Macro和MacroFactory,Macro是自定义函数的接口,MacroFactory完成注册,你可以参考一下CapitalizeMacro的实现,在Web Service插件中也有例子。
Q: 如何访问剪切板?
A:你可以通过CopyPasteManager进行访问,下面是一个想剪切板添加内容的例子。
CopyPasteManager copyPasteManager = CopyPasteManager.getInstance ();
copyPasteManager.setContents (new StringSelection ("the character string which we would like to copy appointment"));
参考资源
这里我不想列出几篇文档,这些文档只能起到扫盲的作用,如果你想开发插件,从扫盲版毕业是远不够的。个人的建议,多看别人的插件,多看论坛的帖子,多看API,多实践。
IntelliJ IDEA官方论坛: http://www.intellij.net/forums
Jira for Open API:http://www.jetbrains.net/jira/secure/IssueNavigator.jspa?reset=true&mode=hide&pid=10132&component=10366
插件的源码库: http://svn.jetbrains.org/idea/Trunk
现在不少项目都在Google Code上安家啦,你可以去Google Code上搜索关于IDEA的插件,然后了解他人的想法和代码,对自己的帮助会很大。
安装了几次老是启动有问题: The service did not start due to the following error: Unable to connect to the repository isaservice on database jamax.. Check the log for more information.  node01 node01
或者 The service did not start due to the following error: DataBase error: [IBM][CLI Driver][LU62SPM] SQL30070N 不支持 "Unsupported function for SPMDB connect" 命令。 SQLSTATE=58014 sqlstate = 40003 Database driver error... Function Name : Execute SQL Stmt : VALUES CURRENT TIMESTAMP DB2 Fatal Error.. Check the log for more information.
node01 node01
日志:  DOM_10079 Unable to start service [isaservice] on any node specified for the service. DOM_10079 Unable to start service [isaservice] on any node specified for the service.
DOM_10055 Unable to start service process [isaservice] on node [node01].
SPC_10013 Process for service isaservice failed to start.原来怀疑是安装的问题,后来才发现是因为元数据库和源数据的连接错误地设置成同一个数据库,造成元数据库损坏造成的。出错后试了几种办法都不行,只能重新再装,原来的元数据就没法用了,这是一个很严重的后果!正确的做法应该如下(本机): 1. 设置元数据仓库:  Database URL 格式是HOST_NAME:PORT_NAME,如果用的是默认端口那么只需要填HOST_NAME就可以了。 Database user ID: 填一个有管理员权限的用户(sys好像不行,可以用system) Database service name: 填全局数据库名, 对应下面的SERVICE_NAME file:tnsnames.ora
INFORMAT =
(DESCRIPTION =
(ADDRESS = (PROTOCOL = TCP)(HOST = jamax)(PORT = 1521))
(CONNECT_DATA =
(SERVER = DEDICATED)
(SERVICE_NAME = informatic.jamax)
)
) 2. 新建源数据库的知识库(Repository )配置。  这里2的数据库配置应该是连接源数据库的,如果设置为1的配置就会出错。
当使用了DataSourceTransactionManager后,使用同一个DataSource的JdbcTemplate也在事务中了吗?
还是使用了从这个dataSourceTransactionManager.getDataSource()的jdbcTemplate才在事务里?不明白。
/**
* 在同一事务中执行,当抛出异常时会自动回滚事务,操作成功后自动提交事务
*/
public int[] batchExc(final List lists) {
//这个txManager是DataSourceTransactionManager
TransactionTemplate tt = new TransactionTemplate(txManager);
return (int[]) tt.execute(
new TransactionCallback() {
public Object doInTransaction(TransactionStatus status) {
if (!lists.isEmpty()) {
log.info(" === 开始事务 === ");
String[] sqls = new String[lists.size() - 1];
for (int i = 0; i < lists.size(); i++) {
sqls[i] = (String) lists.get(i);
log.info(sqls[i]);
}
log.info(" === 结束事务 === ");
//这个jdbcTemplate不用设置DataSource就可以实现在事务中
return jdbcTemplate.getJdbcOperations().batchUpdate(sqls);
} else {
return new int[0];
}
}
});
}
继续跟踪。。。 Powered by ScribeFire.
在Spring中,使用PropertyPlaceholderConfigurer可以在XML配置文件中加入外部属性文件,例如: <bean id="propertyConfigurer"
class="org.springframework.beans.factory.config.PropertyPlaceholderConfigurer">
<property name="location" value="classpath:config/jdoserver.properties"/>
</bean>
但是好像在属性文件定义中却不支持多个属性文件的定义,比如不能这样用config/*.properties。
经过查看源码,发现可以使用locations属性定义多个配置文件: <property name="locations">
<list>
<value>classpath:config/maxid.properties</value>
<value>classpath:config/jdoserver.properties</value>
</list>
</property>
使用外部属性后如下: <bean id="dataSource" class="org.springframework.jdbc.datasource.DriverManagerDataSource">
<property name="driverClassName" value="${jdbc.agent.driver}"/>
<property name="url" value="${jdbc.agent.main.url}"/>
</bean>
上面的例子是采用Spring DriverManagerDataSource包装VJDBC Connection的用法,没有提供连接池功能,只能作作简单的单机连接。
代码示例: int a = 32;
System.out.println("二进制: "+Integer.toBinaryString(a));
System.out.println("十六进制: "+Integer.toHexString(a));
System.out.println("八进制: "+Integer.toOctalString(a));
System.out.println("十二进制: "+Integer.toString(month, 12));
String s="66";
System.out.println(Integer.toString(Integer.parseInt(s,12), 6));
可以使用一个变量或字段记录几个复合状态:
int a = 1;
System.out.println(a);
System.out.println("Integer.toBinaryString(a)=" +
Integer.toBinaryString(a));
System.out.println("Integer.toHexString(a)=" + Integer.toHexString(a));
System.out.println("Integer.toOctalString(a)=" +
Integer.toOctalString(a));
a = 2;
System.out.println(a);
System.out.println("Integer.toBinaryString(a)=" +
Integer.toBinaryString(a));
System.out.println("Integer.toHexString(a)=" + Integer.toHexString(a));
System.out.println("Integer.toOctalString(a)=" +
Integer.toOctalString(a));
a = 4;
System.out.println(a);
System.out.println("Integer.toBinaryString(a)=" +
Integer.toBinaryString(a));
System.out.println("Integer.toHexString(a)=" + Integer.toHexString(a));
System.out.println("Integer.toOctalString(a)=" +
Integer.toOctalString(a));
a = 8;
System.out.println(a);
System.out.println("Integer.toBinaryString(a)=" +
Integer.toBinaryString(a));
System.out.println("Integer.toHexString(a)=" + Integer.toHexString(a));
System.out.println("Integer.toOctalString(a)=" +
Integer.toOctalString(a));
int b = 1 | 2 | 4 | 8;
System.out.println("1 | 2 | 4 | 8 = " + b);
int b1 = 4;
System.out.println(b1 + " is In " + b + " ? " + ((b1 & b) == b1) );
来源: 网奇
设置服务器端的 JVM:JAVA_OPTS="-server -Xms3000m -Xmx3000m -Xss512k"
-server:一定要作为第一个参数,在多个CPU时性能佳
-Xms:初始Heap大小,使用的最小内存
-Xmx:java heap最大值,使用的最大内存
上面两个值一般设置为同样的大小。
-Xss:每个线程的Stack大小
-verbose:gc 现实垃圾收集信息
-Xloggc:gc.log 指定垃圾收集日志文件
刚刚了解到的一些参数(待实践测试)
-Xmn:young generation的heap大小,一般设置为Xmx的3、4分之一
-XX:+UseParNewGC :缩短minor收集的时间
-XX:+UseConcMarkSweepGC :缩短major收集的时间
提示:此选项在Heap Size 比较大而且Major收集时间较长的情况下使用更合适
根据网上的一些资料,按照如下步骤
- 首先将Subversion安装目录bin\下面的两个文件:mod_authz_svn.so和mod_dav_svn.so复制到Apache安装目录modules\目录下。
- 找到Apache安装目录下的conf目录,用文本编辑器打开httpd.conf,找到一下两行:
#LoadModule dav_module modules/mod_dav.so
#LoadModule dav_fs_module modules/mod_dav_fs.so
将每行前面的注释符"#"去掉。再在所有LoadModule语句的最后添加一下几行:
#SVN
LoadModule dav_svn_module modules/mod_dav_svn.so
LoadModule authz_svn_module modules/mod_authz_svn.so
<Location /svn>
DAV svn
SVNParentPath "E:/svnrepos"
</Location>
但是使用启动测试一直有错,返回
Syntax error on line 143 of C:\apache\conf\httpd.conf: API module structure 'dav_svn_module' in file C:\apache\modules\mod_dav_svn.so is garbled - perhaps this is not an Apache module DSO?
Apache could not be started
后来再看资料,好像是SVN1.4.3提供的so文件只支持APACHE2.0,并不支持2.2版本的,除非重新编译。好在已经有人解决了,下载了一个支持APACHE2.2的,但却是SVN1.3.2的,死马当活马医了,放到SVN1.4中居然也可以,hoho~~。我是把所有和SVN有关的文件(含动态连接库文件)全部放在了APACHE安装目录的svn目录里,配置文件如下:
LoadModule dav_svn_module svn/mod_dav_svn_1.3.so
LoadModule authz_svn_module svn/mod_authz_svn_1.3.so
<Location /svn>
DAV svn
SVNParentPath "E:/svnrepos"
</Location>
Technorati : SVN APACHE
今天试了个XML和JavaBean转换的软件JOX,之前一直有这样的需求,但比较来比较去还是这个比较简单实用。我想除非我有WS的需求,否则象JIBX和APACHE 的WS工具对我来说都是重量级的。
先看看输出结果:
<?
xml version="1.0" encoding="ISO-8859-1"
?>
<
ApproxItem
java-class
="com.greatwall.csi.np.model.ApproxItem"
>
<
expose
java-class
="java.lang.Double"
>
0.23
</
expose
>
<
list
java-class
="com.greatwall.csi.np.model.ApproxInfo"
>
<
IDno
>
bbb
</
IDno
>
<
birth
java-class
="java.lang.Integer"
>
222
</
birth
>
</
list
>
<
map
java-class
="java.util.HashMap"
>
<
dd
java-class
="com.greatwall.csi.np.model.ApproxInfo"
>
<
IDno
>
bbb
</
IDno
>
<
birth
java-class
="java.lang.Integer"
>
222
</
birth
>
</
dd
>
<
ss
java-class
="com.greatwall.csi.np.model.ApproxInfo"
>
<
IDno
>
bbb
</
IDno
>
<
birth
java-class
="java.lang.Integer"
>
222
</
birth
>
</
ss
>
</
map
>
<
month
java-class
="java.lang.Integer"
>
3923
</
month
>
</
ApproxItem
>
在看看原来的JavaBean:
package
com.greatwall.csi.np.model;
import
java.util.ArrayList;
import
java.util.HashMap;
public
class
ApproxItem {
public
int
getMonth() {
return
month;
}
public
void
setMonth(
int
month) {
this
.month
=
month;
}
public
double
getExpose() {
return
expose;
}
public
void
setExpose(
double
expose) {
this
.expose
=
expose;
}
public
ArrayList getList() {
return
list;
}
public
HashMap getMap() {
return
map;
}
public
void
setList(ArrayList list) {
this
.list
=
list;
}
public
void
setMap(HashMap map) {
this
.map
=
map;
}
private
int
month;
private
double
expose;
private
ArrayList list;
private
HashMap map;
}
处理结果是令人满意的。实现过程如下:
public
class
JOXUtils {
/**
* Retrieves a bean object for the
* received XML and matching bean class
*/
public
static
Object fromXML(String xml, Class className) {
ByteArrayInputStream xmlData
=
new
ByteArrayInputStream(xml.getBytes());
JOXBeanInputStream joxIn
=
new
JOXBeanInputStream(xmlData);
try
{
return
(Object) joxIn.readObject(className);
}
catch
(IOException exc) {
exc.printStackTrace();
return
null
;
}
finally
{
try
{
xmlData.close();
joxIn.close();
}
catch
(Exception e) {
e.printStackTrace();
}
}
}
/**
* Returns an XML document String for the received bean
*/
public
static
String toXML(Object bean) {
ByteArrayOutputStream xmlData
=
new
ByteArrayOutputStream();
JOXBeanOutputStream joxOut
=
new
JOXBeanOutputStream(xmlData);
try
{
joxOut.writeObject(beanName(bean), bean);
return
xmlData.toString();
}
catch
(IOException exc) {
exc.printStackTrace();
return
null
;
}
finally
{
try
{
xmlData.close();
joxOut.close();
}
catch
(Exception e) {
e.printStackTrace();
}
}
}
/**
* Find out the bean class name
*/
private
static
String beanName(Object bean) {
String fullClassName
=
bean.getClass().getName();
String classNameTemp
=
fullClassName.substring(
fullClassName.lastIndexOf(
"
.
"
)
+
1
,
fullClassName.length()
);
return
classNameTemp.substring(
0
,
1
)
+
classNameTemp.substring(
1
);
}
public
static
void
main(String[] args) {
ApproxItem approxItem
=
new
ApproxItem();
approxItem.setMonth(
3923
);
approxItem.setExpose(
0.23
);
approxItem.setMap(
new
HashMap());
ApproxInfo approxInfo
=
new
ApproxInfo();
approxInfo.setBirth(
111
);
approxInfo.setIDno(
"
aaa
"
);
approxItem.getMap().put(
"
ss
"
, approxInfo);
approxInfo.setBirth(
222
);
approxInfo.setIDno(
"
bbb
"
);
approxItem.getMap().put(
"
dd
"
, approxInfo);
approxItem.setList(
new
ArrayList(
1
));
approxItem.getList().add(approxInfo);
System.out.println(
"
JOXUtils.toXML(approxItem)=
"
);
System.out.println(JOXUtils.toXML(approxItem));
}
Wutka Consulting还提供了一个比较有趣的工具,Java2DTD,自从使用JDO做持久层框架,我就一直想找一个这样的工具,因为JDO的映射文件并没有将全部的JavaBean类描述到.jdo文件,所以在编程环境下一直无法获取所有的实体类和字段的一个描述情况。废话少说,马上试一下。运行时需要3个包文件:beantodtd,需要转换的实体classes,dtdparser。 java -cp beantodtd-1.0;classes;d:/policy38/lib/dtdparser121.jar; BeanToDTD \n
-mixed com.greatwall.csi.bs.model.PersonBase -mixed参数是指定按JavaBean中的变量名生成属性,还有些其它的参数,可以控制大小写和连字符号等。另外由于我用的实体是JDO增强过的class文件,所以classpath还需要加上JDO实现的包。
运行的结果有少少无奈,因为对于JavaBean中List这样的容器字段类型,无法让它识别出对象的类型,只能生成类似<!ELEMENT pension ANY>这样的描述,如果在一个什么配置文件中可以设置的话那就更好了。 另外还有一个DTD解析工具,可以解析DTD文件,目前还不知道有什么其它用途,使用如下方法可以解析后输出控制台: java -classpath d:/policy38/lib/dtdparser121.jar com.wutka.dtd.Tokenize code.dtd
资源: http://www.wutka.com/download.html
错误信息:
警告: 最后一个参数使用了不准确的变量类型的 varargs 方法的非 varargs 调用;
[javac] 对于 varargs 调用,应使用 java.lang.Object
[javac] 对于非 varargs 调用,应使用 java.lang.Object[],这样也可以抑制此警告
程序是一样的,在jdk1.4下可以编译通过,但在1.5就不行。上网查了一下,解决办法:
Method method
=
cls.getMethod(
"
hashCode
"
,
new
Class[
0
]);
//
编译通过
Method method
=
cls.getMethod(
"
hashCode
"
,
null
);
//
编译失败
allMethod[i].invoke(dbInstance,
new
Object[]{});
//
编译通过
allMethod[i].invoke(dbInstance,
null
);
//
编译失败
|