本文由腾讯技术团队peter分享,原题“腾讯网关TGW架构演进之路”,下文进行了排版和内容优化等。
1、引言
TGW全称Tencent Gateway,是一套实现多网统一接入,支持自动负载均衡的系统, 是公司有10+年历史的网关,因此TGW也被称为公司公网的桥头堡。
本文从腾讯公网TGW网关系统的应用场景、背景需求讲起,重点解析了从山海1.0架构到山海2.0架构需要解决的问题和架构规划与设计实现,以及对于未来TGW山海网关的发展和演进方向。

技术交流:
2、专题目录
本文是专题系列文章的第11篇,总目录如下:
- 《长连接网关技术专题(一):京东京麦的生产级TCP网关技术实践总结》
- 《长连接网关技术专题(二):知乎千万级并发的高性能长连接网关技术实践》
- 《长连接网关技术专题(三):手淘亿级移动端接入层网关的技术演进之路》
- 《长连接网关技术专题(四):爱奇艺WebSocket实时推送网关技术实践》
- 《长连接网关技术专题(五):喜马拉雅自研亿级API网关技术实践》
- 《长连接网关技术专题(六):石墨文档单机50万WebSocket长连接架构实践》
- 《长连接网关技术专题(七):小米小爱单机120万长连接接入层的架构演进》
- 《长连接网关技术专题(八):B站基于微服务的API网关从0到1的演进之路》
- 《长连接网关技术专题(九):去哪儿网酒店高性能业务网关技术实践》
- 《长连接网关技术专题(十):百度基于Go的千万级统一长连接服务架构实践》
- 《长连接网关技术专题(十一):揭秘腾讯公网TGW网关系统的技术架构演进》(* 本文)
3、TGW网关系统的重要性
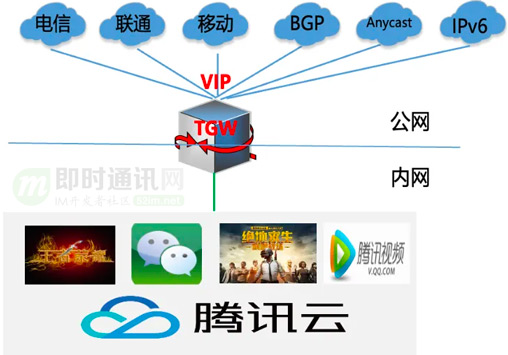
TGW全称Tencent Gateway,是一套实现多网统一接入、支持自动负载均衡的系统, 是公司有10+年历史的网关,因此TGW也被称为公司公网的桥头堡。它对外连接了各大运营商并支撑公有云上EIP、CLB等产品功能,对内提供了公网网络的接入功能,如为游戏、微信等业务提供公网接入服务。
TGW主要有两大产品:
- 1)弹性EIP(比如购买一台虚拟机CVM或是一个NAT实例后,通过EIP连通外网);
- 2)四层CLB。
四层CLB一般分为内网CLB和外网CLB:
- 1)内网CLB是在vpc内创建一个CLB实例,把多个CVM服务挂在了内网CLB上,为后端RS提供负载均衡的能力;
- 2)外网CLB面对的是公网侧负载均衡的需求。
当在内部部署CLB集群时,可分为IPV4或者IPV6两大类,根据物理网络类型又细分为BGP和三网两类。三网指这些IP地址是静态的,不像BGP一样能够在多个运营商之间同时进行广播。
以上就是四层TGW产品及功能,山海网关在原有产品基础上做了网络架构方面的演进。
4、Region EIP的引入
具体介绍下EIP和CLB两个产品。
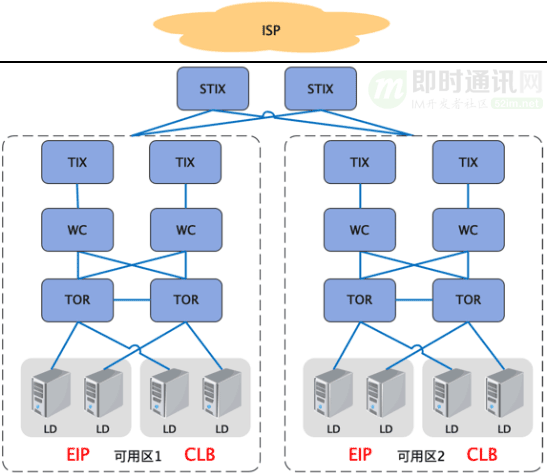
过去CLB和EIP使用不同的IP地址池,导致资源池上的隔离问题。使得我们无法把EIP地址绑定到公有云CLB实例上。
例如:一个创业公司最初只购买一台虚拟机并挂载一个公网EIP来提供服务。随着用户量的增长,如果想将这个EIP地址迁移到一个公网CLB实例上,在原有架构下是无法实现这种迁移的。
此外:EIP和CLB部署在每个机房,因此在每个机房都需要建立EIP出口。但是各个机房的公网出口之间缺无法相互容灾。
所以这种情形下,我们确定了产品的目标:
- 1)希望将所有公网出口整合到一到两个机房之内,以避免重复建设,节省成本;
- 2)通过将出口集中,我们可以将对应的网关服务器也进行集中,进而提高设备的利用率;
- 3)通过这样的布局可实现跨机房的容灾方案。
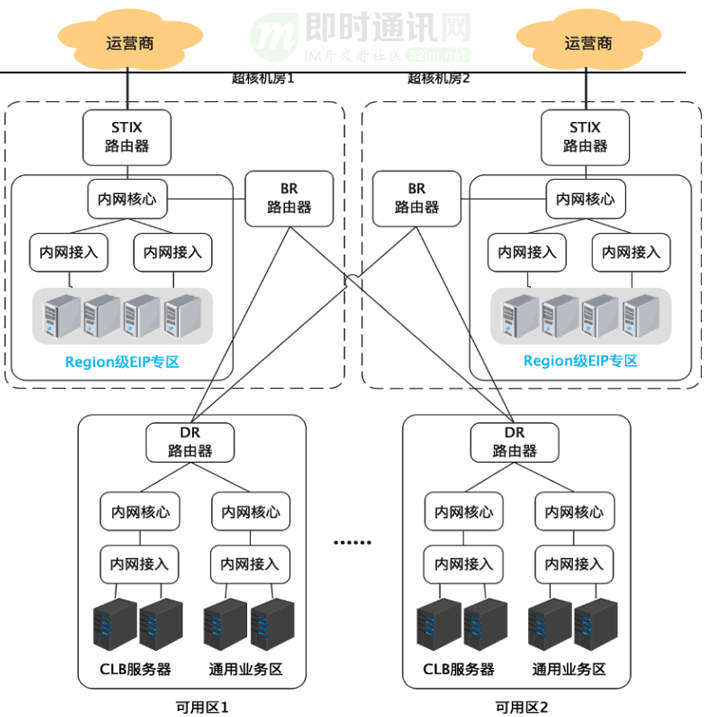
因此:最早的Region EIP(REIP)计划应运而生。
以北京这类大型region为例的:我们将EIP专区建设到位于两个城市的超核机房。这两个机房通常会放置物理网络的交换设备,并为各自设立了一个REIP专区。在REIP专区内部署Region EIP集群。为了实现跨AZ容灾,两个机房的集群之间借助大小网段实现互相备份容灾的能力。一旦其中一个机房的集群发生故障或出现网络问题,另一个机房的集群可以立即承担起容灾任务。
同时:因为新的Region EIP的网络架构跟原来的网络架构不一样,通过网络架构升级以及机型升级,我们能够把单台Region EIP的性能做到原有单台EIP性能的5倍。这样我们通过容量的提升进一步提升了设备利用率,在完成全量Region EIP后,设备数量会从3000+台缩减至700+台。同时原有的CLB集群还保留在各个机房不变,这些CLB集群的外网接入能力由Region EIP承担。
5、公网CLB的演进
5.1概述
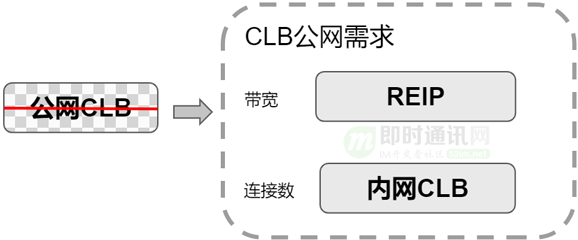
公网CLB最早是有公网接入能力的。引入到Region EIP之后,当初设想是公网CLB不再演进,尽量让存量用户迁移到另外一种形式,上层是Region EIP,下层是内网CLB。用户先买一个内网CLB,如果需要对公网提供服务就再买一个弹性EIP,把EIP跟内网CLB绑定在一起,提供CLB公网的能力,替代原有的公网CLB,这是最早公网CLB的替代方案。
两个方案的区别是:原有公网CLB,用户仅看到一个CLB实例。新的模式下,用户看到的是两个实例:一个EIP+一个内网CLB,两个实例都可以独立运营管理。这就是我们最早的两层架构设想,想把公网CLB跟外网解耦。
但是,真正去跟用户或产品交流时,这个想法遇到了比较大的挑战:
1)用户体验的改变:以前公网CLB用户看到是一个实例,但是现在用户看到两个实例,必然会给用户带来一些适配工作。比如用户进行创建、管理实例时,API不一样了。以前使用通过自动化脚本创建公网CLB实例的,现在脚本还要改变去适配新的API。
2)用户习惯改变:以前用户习惯在一个实例下,点击页面,就能够查看流量、链接数等监控信息。现在EIP流量需要到REIP查看,而链接数还需在CLB产品上看。
3)存量客户无法迁移:原来客户买的公网CLB实例,是无法直接无感知迁移到内网CLB+REIP这种新形式的。
在这些挑战下,这个替代方案没能真正落地。结合用户的要求,我们最终跟产品定下的策略是:公网CLB保持不变。原有的公网CLB继续保留,同时如果用户新增的公网CLB需求,也要继续支持。
5.2公网CLB模型
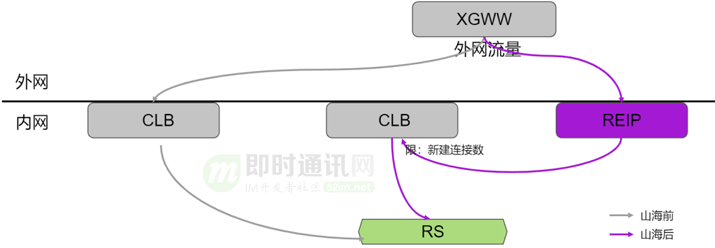
那么,公网CLB到底怎么演变?
我们的初衷并不是把公网CLB这个产品摒弃掉,而是要收敛公网入口。所以我们针对这个初始需求,提出了上面这个两级架构模型。
首先:用REIP将公网流量先引进来,再将这个流量通过隧道报文的形式转发给原有的公网CLB集群,这样公网CLB不需要原有外网接入的能力,不需要再跟外网打交道,可以演变成只在机房内部的集群;同时因为公网CLB的流量都会经过REIP,REIP自然也就是公网CLB的流量入口。从而达到我们最初收敛公网入口的目的。这样的架构升级,可实现用户无感知。架构升级切换过程中,用户在访问公网CLB,不会出现卡顿或者重连的现象。
这个架构模型也有一定的局限性的。公网CLB实例只能承载公网的流量,无法像上文提到的两层RERP+CLB那样,内外网随时进行转化。REIP+CLB实例中的CLB既承载内网侧CLB的流量,又承载公网侧CLB的流量。
6、山海架构 1.0
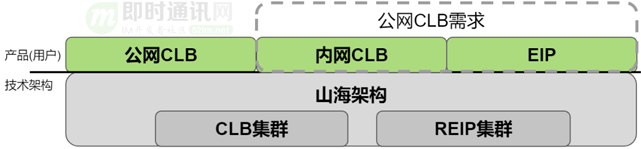
借助这个两级架构模型,我们能够把公网CLB保留下来,并且通过REIP把公网入口收敛。
进一步思考并完善,我们提出了下面的想法:跟产品进行解耦。
以前我们一个地区上线公网CLB产品,底层就要搭建有一个公网CLB的集群去支持。用户需要内网CLB服务,就要对应搭建个内网CLB的集群。底层集群类型跟产品是强耦合,有IPv4/IPv6, 公网/内网、BGP/三网组合出的多个产品形态。
这种模式在小地域部署,因为产品业务的流量小,集群利用率低,就会造成很大的成本压力。
为了应对这种小带宽低成本的诉求,我们将CLB+REIP的模型进一步抽象,引入山海架构:我们只建设CLB和REIP两类集群。通过这两类集群上的不同实例组合,满足多个产品形态的要求。从而实现产品形态和底层物理网络集群类型解耦。
解耦合的方式是:CLB和REIP通过不同的实例类型,组合出不同的产品形态。
山海架构在TGW内部做闭环,不涉及到产品侧和用户侧的改动。整个过程升级,对产品侧不做任何接口上的更新。因为产品侧的API接口保持不变,对用户侧就可以做到完全无感知。在产品侧保持不变,就需要我们在内部管控,识别接入用户实例是哪种形态的产品,拆分成不同形式的CLB和REIP的实例。其他的相关功能的比如流量统计、限速等模块也都要适配不同的产品形态,通过模块的适配,做到山海架构对上层产品侧应用的透明。
山海架构1.0归纳起来有两个重点:收敛公网入口和集群类型归一。
1)REIP:部署在城核机房,同时承载的是CLB和REIP两类产品的公网流量。之前EIP,在物理网络上有BGP+三网、v4/v6等多种集群类型。REIP借助vlan的隔离支持,把所有的网络类型都集中到一种REIP集群上来,我们称之为全通集群。在物理网络层面实现网络类型的归一, 然后再通过软件层的适配,实现REIP支持多通类型的网络接入能力。
2)CLB:在山海两级架构下,REIP集群处理公网侧的各种场景组合,CLB集群通过隧道与REIP处理公网流量。之前一个机房如果要把所有的产品能力支持起来,大概有7种集群类型。现在CLB集群可以用一种集群类型来支持所有的产品的公网CLB产品,以及内网CLB产品的能力。我们把三网+BGP以及内外网还有V4V6等集群类型都用一种类型来支持,山海架构完全落地后,开区的最小服务器数量可以降低到8台服务器,来承载所有的EIP和CLB产品需求。
归纳起来一句话:对于用户来说,产品形态没有改变,用户使用习惯也没有改变。而在底层,我们把集群类型收敛到一个CLB集群和一个REIP集群上。
7、山海架构1.0限速技术
在山海架构演进中,有许多技术点,本文选取限速技术进行分享。

首先Region EIP支持三网。以前BGP跟三网分开独立支持,山海网关统一用Region EIP支持。Region EIP本身的网络架构分成两个机房,每个机房放4台TGW设备,每个EIP只会走左边或者右边。一个EIP进来的流量经过上面这层交换机时,经过了ECMP分流,然后分到了4台设备上。这样对每个EIP其实是采用了分布式限速。
限速有两个要求:
- 1)精确性,限速上下浮动要小,要限得准;
- 2)要有容灾能力。
限速最极端的精准就是把它放到单点上去做限速,但是单点限速就会面临单点故障和容灾的问题。在X86服务器上,使用的是分布式限速,一个EIP均分到4台服务器上,每五秒钟做一次流量的的汇总统计,通过流量比例计算将这个EIP的带宽配额,重新分配并分发到4台设备上,以此来实现集群上的限速。在单台设备上,也是没隔一段时间,就重新计算配额并分配到每个CPU核上,我们目前用的是300毫秒周期。
需要说明的是:在限速的实现上,业务有多重实现方式,我们了解到有的实现的是静态分配,比如120兆的带宽,4台设备,我们每台设备分40M(三分之一)的带宽。1/3而不是1/4的带宽,目的是防止某一台设备断了之后,用户总带宽不达标,影响用户体验。在单台设备上限速,也有另外一种实现方式,大小桶。比如限速1M的带宽,那么每个核第一次取回100K或者200K配额。后续报文处理时候,先消耗上次取回的配额,如果带宽配额消耗光了,再重新取。周期调整跟大小桶这两种实现方式各有优缺点。从资源消耗来说,300毫秒周期的资源消耗相对会更少一些,两者大概有10%左右的性能偏差。
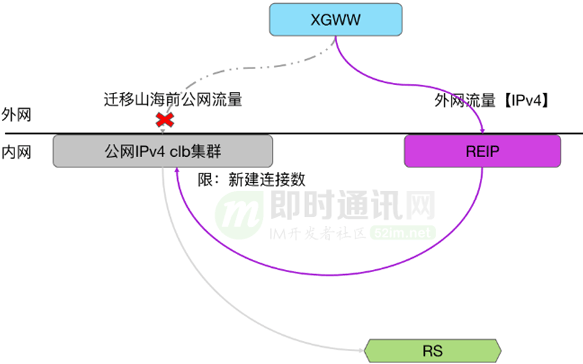
限速上另一诉求:小带宽的限速的精准限速。
大带宽比如100兆,分到每个核上相对富裕。小带宽如一M带宽,一秒钟100k字节等,分到四台机器再分到几十个核上,每个核都可能不到一个大报,这时候再去做精准限速就会非常困难,因为既然要提前分配资源,资源那么少,分配到单核上,可能一个包都过不去,但凡有一个报文过去了,又可能超了。所以在小带宽限速时,我们把它退化成类似于单点限速的模式。由于入方向带宽最小也是100兆,因此保持原有的分布式限速不变。只对出方向小带宽,使用单点限速。方案是这样的:
每台REIP有自己一个独享的内网地址,只有这台服务器故障时候,这个地址的流量才被分发到其他三台服务器。
入方向流量被分到四台REIP服务器后,REIP处理完通过tunnel转发给母机。隧道的外层源地址,只使用其中一台REIP服务器的独享的IP地址。每个外网IP地址在挂载到集群下管理时候,就确定下来了。
母机在接受到网关发过去的流量,解析外层报文地址,并记录在本地会话表里,我们称之为母机的自学习能力。当母机侧转发出方向报文时,就只会使用本地学习并记录的外层地址去封装隧道。这样出方向的流量,就回到单台TGW设备上,实现了单点限速。
独享的内网地址本身是有容灾能力:
- 1)当其服务器故障了,流量就被分散到集群其他服务器,放弃单点限速;
- 2)当服务器被修复上线后,又可以重新变成精准的单点限速。
这样保证小带宽精准限速的同时,又避免了单点故障。
在限速过程中,还有一个问题,因为CLB集群原来的限速是在CLB集群上自己做的,引入山海之后,REIP上有限速能力,那么公网CLB的限速要不要挪到REIP上?
我们经过多次讨论, 最终还是维持**这个限速在公网CLB上不变。
这里有几种场景考量:
1)内外网攻击:如果我们把它放到REIP上,这里可以扛住外网的攻击,但同时内网的攻击我们是防不住的,因为公网CLB上没有限速后,流量内网的攻击就会先把CLB上压过载,导致丢包,影响业务的稳定性。
2)有效流量的准确统计:原有架构下,从公网流量首先到达CLB,我们需要检查公网CLB上与port对应的服务是否已配置规则并启用。如果没有启用,则将报文直接丢弃且不记录为公网CLB的带宽使用量。山海架构下,如果先经过Region EIP限速,这类无服务访问流量(如恶意攻击和垃圾流量)也将占用限速资源。尽管这部分限速流量会送达至CLB集群,但由于缺乏相应服务支持,它们最终还是将被丢弃。结果导致用户带宽不及预期。比如用户购买10M带宽,实际有效运行的仅有8M流量,而其余2M被无服务流量占用了。
3)多重限速的影响:还有一个这个场景中,当Region EIP实施带宽限速后,这些流量最终可能进入公网CLB。然而,由于CLB的规格限制,例如新建连接数或并发连接数已达到上限,部分数据包可能会被丢弃。这些丢失的数据包已经消耗了购买的公网带宽,从而导致用户观察到的公网CLB流量带宽未达到预期。因此,我们保留公网CLB限速功能不变,仅进行引流调整。
8、山海架构1.0的优势
CLB产品及REIP产品,在使用山海1.0之后的几点优势。
1)CLB产品本身支持热迁移,扩容到山海热迁移,不会引起用户的断流,有助于运维做用户产品升级迭代。这方面有个典型案例,比如某台设备坏了或者发现某台设备上有问题,需要把流量迁走的时候,我们可以不用中断用户的流量的。我们了解到,以前有的竞品,因为热迁移做的不是特别完善,在设备出现问题或者是需要升级版本的时候,常选择低峰期做升级。
2)EIP在做限速的时候,在出方向时是小带宽,可以做到比较精准的限速。好处是用户做压测或测试的时,带宽不会抖动影响自己的业务的稳定性。
3)高低优先级限速。用户买一些比较小的比如10M带宽或者5M带宽,用来服务本身业务,同时也会ssh或者远程桌面登录EIP;因为一起我们是做无差别的限速丢包的话,这样会造成它本身的控制流量,如远程桌面的流量也会被丢包,造成登录的卡顿。用户需要在不超限速的前提下,优先保证远程桌面不卡,然后再提供其他的下载服务。我们把流量根据端口进行区分,比如22端口或者是远程桌面的3389端口的流量,标记为高优先级。在做限速时,只要高优先流量不超限速,就全部放行。当高优先级流量再叠加上低优先级的流量超限速时,把低优先级的流量丢掉,这样ssh访问服务器的时候能够非常顺畅。
4)山海架构上线后,基于vip粒度的调度,可以让调度更加灵活。比如原来一个集群为了节省路由条目,我们按照一个网段发路由,不是每个VIP都发路由的。山海两级架构之后,没有了这个限制,就可以按照VIP,把CLB实例调度到不同CLB集群。这样如果用户需要一个特别大规格的VIP的时候,我们可用一个集群的能力去扛用户一个VIP,从而满足超大规格实例的诉求。当然真实使用产品时,很少有客户把上百G的流量用一个VIP来承载。用户出于容灾考虑,通常不会把所有的鸡蛋放到一个篮子里。
9、山海架构 2.0
9.1概述
如前所述:山海 1.0 主要目标是整合公共网络并将所有公网出口集中在城市核心机房内。至于剩余的 CLB 群集,我们会继续将其保存在原有各机房的专区里。这是因为网关设备有其与服务器不同的网络诉求,例如普通服务器不能提供发布动态路由,并通过动态路由引流处理业务流量。
再比如:网关专区的收敛比1:1,而服务器虽然带宽也是100G, 但其收敛比率往往小于1:1。
在这种情况下,我们不能简单地将 CLB 网关群集群平移放置到服务器区。因此,CLB 网关群集通常在构建每个机房时,预先规划并预留相应的网关专区。机房建设起来后,如业务量小,又会因预留资源空置造成浪费。目前专区闲置机位也是一笔较大的费用。
同时,还有一种临时扩容的需求场景,例如VIP大客户,临时会有大流量的转发需求,这时常态运营水位没法满足需要,需要调配设备做集群扩容。如果本机房的设备不够还需要跨机房搬迁,搬迁周期比较长,对我们运营压力会很大。
所以,我们希望通过山海2.0能把专区建设的空置率降下来,同时提升弹性,能够低成本的快速扩缩容。
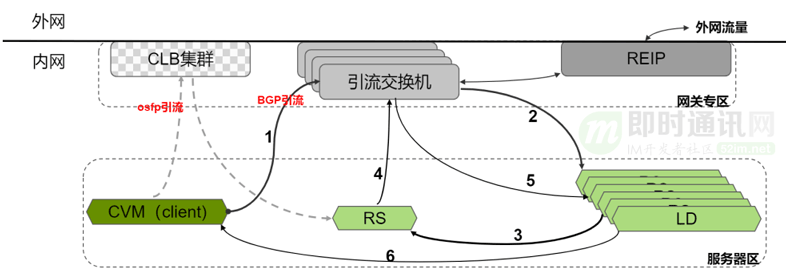
9.2引流交换机
在山海 2.0里,我们采用了“引流交换机”。在每个机房的建设时,我们可以放置两组共四台引流交换机。
考虑到单个交换机的容量可以达到 1 T 以上,有四台交换机工作,一个机房能够承受大约 4T~ 6T 的流量峰值。这意味着后续无需再额外扩容,一次性的建设和布局就可以满足长期的需求。相比于 CLB 群集占用的机位空间,四台交换机所需的机位显著减少。
我们把原来CLB集群对外声明路由的能力放到了引流交换机上,把CLB服务器用用通用服务器区的设备来代替。考虑收敛比和容灾,不会把一个集群放到一两个机架上,会相对分散些,更不会把整个机架全部再用成CLB集群。这样CLB集群不再单独建设网关专区,引流交换机把路由声明发出去,通过隧道跟CLB设备转发流量。
9.3山海2.0的变化
我们以内网CLB为例,原来一台虚拟机访问CLB集群,CLB集群把它的流量转到对应的RS。
引入交换机之后,其进出两个方向都会有变化:入方向(访问LB方向),虚拟机的流量先被引流到了引流交换机,交换机把报文做一次封装,然后发送给对应的服务器,进行负载均衡转换。最后处理后的结果,被转发给真正的RS。原来的两跳访问变成了现在的三跳。同样反方向流量返回时,RS的流量先回到引流交换机,然后被分发到对应的LD设备上。LD处理完之后,再把报文直接转到client虚拟机上。借助引流交换机的中转,我们就能够让负载均衡的专区设备的放到普通的服务器区里。
另外:这里的CLB服务器,可以跟其他的网关包括母机复用一些相同机型的服务器,当需要扩容时,就可以使用通用服务器。而不像以前CLB既有自己独立的机型,又对服务器的物理位置有要求。有了引流交换机跟LD之间是做隧道传输,LD具体的物理位置就没有像原来一样有硬性的要求。这样CLB可以通过通用服务器区域,调配服务器。
最后一项是:原有跟REIP类似的,CLB设备做路由通告时,也是按照网段通告,有引流交换机之后,我们可以在引流交换机上去做细粒度的调度,一个VIP或是几个vip放到一个集群。还可以在引流交换机上做更细粒度的调度,如IP+port这样的五元组的粒度的调度。
10、未来展望
目前网关设备最重要也是最大的一个方向就是做高性能、硬件卸载。依赖硬件来实现高性能的转发。
网关设备分为有状态和无状态两种:
- 1)无状态设备就像IP转换一样,只要依据规则,任何时刻来了报文,转换出来的形式都是固定的;
- 2)有状态设备是需要记录TCP、 UDP状态,记录转发到后端设备,当不同的时间转发即使相同的类型的流量,它转发的目的地也不一样,转换的格式也可能不一样。
硬件卸载在有状态和无状态时,基本上用到的设备都是DPU和交换机,用到的介质几乎都是FPGA。
FPGA和ASIC本质上是一个东西,无论友商还是我们自己内部研发,更多的是FPGA上做功能,并小规模的灰度上线验证,一旦稳定下来,就转化成批量的ASIC,以此来降低成本。
DPU和交换机在无状态设备上,交换机相对更有优势,因为无状态设备对容量的要求相对小些,像EIP网关以及内部无状态的网关大多用交换机形态实现。DPU目前更多的用在母机侧,做有状态类的网络处理。当然, 采用DPU不仅仅局限网络诉求,还有存储安全等其他需求。去年英特尔宣布已不再进行交换机tf芯片的演进迭代,大家对交换机的质疑会增大。
所以,也衍化了另一种方案:在一台额外的服务器中插入 DPU 网卡以实现卸载功能。
但不同方案有不同的优缺点:
1)使用交换机的最大优势在于其强大的交换性能(可达 1T或几个T及更高),可支持很大的接入容量。但是,交换机仅能是一个底座,若要扩展容量仍需依赖 FPGA 技术。
2) DPU 的优点则包括成熟的产业链、庞大的产量以及稳定的供应保障;此外,由于 DPU 在母机侧已被广泛验证和采用,许多功能的实现都相对固定。
这是两种方案各自的优缺点。
在两个产品运用负载均衡状态的交换上,业内不同的厂家也有不同的玩法,有的是交换机,有的是DPU。当前,无论是交换机还是 DPU,都依赖FPGA(ASIC)来做大容量的会话管理,同时越来越多的设备或多或少的支持P4。在 X86 上进行编程时,通常选择 DPDK。
相较之下:使用 P4 进行编程的门槛较低。P4 编写一般功能需求的代码非常简单快捷,只需一两周时间即可完成,甚至对于熟练者来说,可以在几个小时就开发出一个小功能。虽然充分发挥硬件的性能,P4类芯片还需要进行很深入细节的研究,但P4还是大大降低了数据面编程的门槛,特别是在高性能转发的需求方面。
另一个特点是:小型化。大家过去比较关注数据中心和海量数据的优化问题,随着业务发展,逐步转向降低运营成本和提高效率的场景,开设小型站点。这类小型站点,是典型的“麻雀虽小,五脏俱全”,希望用尽量少的设备成本来满足各种功能需求。所以我们将设备设计为具有较小规格的产品系列,并在易用性上进行改进,通过集群合并、虚拟机等承担更多的任务负载。这样在业务规模和流量不大,也能以较少的资源应对较高的功能性需求。一旦业务规模扩大,我们可将这些小型站点升级为传统的数据中心级物理设备。
以上未来网关两个主要的方向。
11、相关资料
[1] IPv6技术详解:基本概念、应用现状、技术实践(上篇)
[2] 网络编程入门从未如此简单(三):什么是IPv6?漫画式图文,一篇即懂!
[3] 网络编程懒人入门(十五):外行也能读懂的网络硬件设备功能原理速成
[4] 脑残式网络编程入门(六):什么是公网IP和内网IP?NAT转换又是什么鬼?
[5] 脑残式网络编程入门(七):面视必备,史上最通俗计算机网络分层详解
[6] 以网游服务端的网络接入层设计为例,理解实时通信的技术挑战
[7] 百度统一socket长连接组件从0到1的技术实践
[8] 淘宝移动端统一网络库的架构演进和弱网优化技术实践
[9] 百度APP移动端网络深度优化实践分享(二):网络连接优化篇
[10] 新手入门:零基础理解大型分布式架构的演进历史、技术原理、最佳实践
[11] 一套高可用、易伸缩、高并发的IM群聊、单聊架构方案设计实践
(本文已同步发布于:http://www.52im.net/thread-4641-1-1.html)