本文由cxuan分享,原题“原来这才是 Socket”,有修订。
1、引言
本系列文章前面那些主要讲解的是计算机网络的理论基础,但对于即时通讯IM这方面的应用层开发者来说,跟计算机网络打道的其实是各种API接口。
本篇文章就来聊一下网络应用程序员最熟悉的Socket这个东西,抛开生涩的计算机网络理论,从应用层的角度来理解到底什么是Socket。
对于 Socket 的认识,本文将从以下几个方面着手介绍:
- 1)Socket 是什么;
- 2)Socket 是如何创建的;
- 3)Socket 是如何连接的;
- 4)Socket 是如何收发数据的;
- 5)Socket 是如何断开连接的;
- 6)Socket 套接字的删除等。
特别说明:本文中提到的“Socket”、“网络套接字”、“套接字”,如无特殊指明,指的都是同一个东西哦。
2、Socket 是什么
一个数据包经由应用程序产生,进入到协议栈中进行各种报文头的包装,然后操作系统调用网卡驱动程序指挥硬件,把数据发送到对端主机。
整个过程的大体的图示如下:
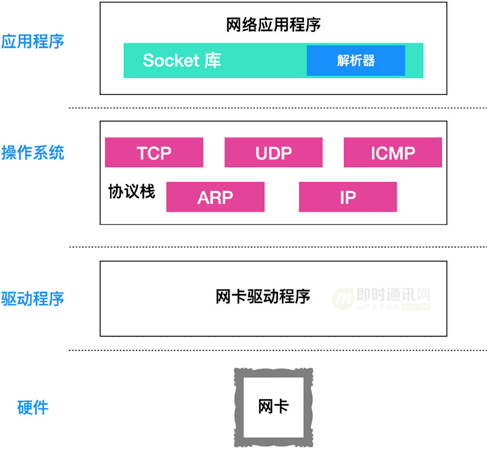
我们大家知道,协议栈其实是位于操作系统中的一些协议的堆叠,这些协议包括 TCP、UDP、ARP、ICMP、IP等。
通常某个协议的设计都是为了解决特定问题的,比如:
- 1)TCP 的设计就负责安全可靠的传输数据;
- 2)UDP 设计就是报文小,传输效率高;
- 3)ARP 的设计是能够通过 IP 地址查询物理(Mac)地址;
- 4)ICMP 的设计目的是返回错误报文给主机;
- 5)IP 设计的目的是为了实现大规模主机的互联互通。
应用程序比如浏览器、电子邮件、文件传输服务器等产生的数据,会通过传输层协议进行传输。而应用程序是不会和传输层直接建立联系的,而是有一个能够连接应用层和传输层之间的套件,这个套件就是 Socket。
在上面这幅图中,应用程序包含 Socket 和解析器,解析器的作用就是向 DNS 服务器发起查询,查询目标 IP 地址(关于DNS请见《理论联系实际,全方位深入理解DNS》)。
应用程序的下面:就是操作系统内部,操作系统内部包括协议栈,协议栈是一系列协议的堆叠。
操作系统下面:就是网卡驱动程序,网卡驱动程序负责控制网卡硬件,驱动程序驱动网卡硬件完成收发工作。
在操作系统内部有一块用于存放控制信息的存储空间,这块存储空间记录了用于控制通信的控制信息。其实这些控制信息就是 Socket 的实体,或者说存放控制信息的内存空间就是Socket的实体。
这里大家有可能不太清楚所以然,所以我用了一下 netstat 命令来给大伙看一下Socket是啥玩意。
我们在 Windows 的命令提示符中输入:
netstat-ano
# netstat 用于显示Socket内容 , -ano 是可选选项
# a 不仅显示正在通信的Socket,还显示包括尚未开始通信等状态的所有Socket
# n 显示 IP 地址和端口号
# o 显示Socket的程序 PID
我的计算机会出现下面结果:
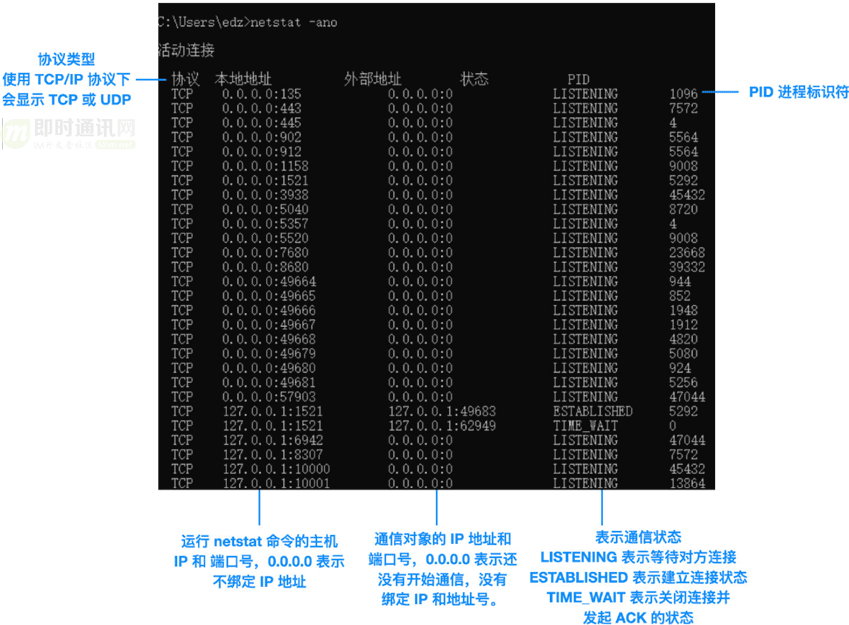
如上图所示:
- 1)每一行都相当于一个Socket;
- 2)每一列也被称为一个元组。
所以,一个Socket就是五元组:
- 1)协议;
- 2)本地地址;
- 3)外部地址;
- 4)状态;
- 5)PID。
PS:有的时候也被叫做四元组,四元组不包括协议。
我们来解读一下上图中的数据,比如图中的第一行:
1)它的协议就是 TCP,本地地址和远程地址都是 0.0.0.0(这表示通信还没有开始,IP 地址暂时还未确定)。
2)而本地端口已知是 135,但是远程端口还未知,此时的状态是 LISTENING(LISTENING 表示应用程序已经打开,正在等待与远程主机建立连接。关于各种状态之间的转换,大家可以阅读《通俗易懂-深入理解TCP协议(上):理论基础》)。
3)最后一个元组是 PID,即进程标识符,PID 就像我们的身份证号码,能够精确定位唯一的进程。
3、Socket 是如何创建的
通过上节的讲解,现在你可能对 Socket 有了一个基本的认识,先喝口水,休息一下,让我们继续探究 Socket。
现在我有个问题,Socket 是如何创建的呢?
Socket 是和应用程序一起创建的。
应用程序中有一个 socket 组件,在应用程序启动时,会调用 socket 申请创建Socket,协议栈会根据应用程序的申请创建Socket:首先分配一个Socket所需的内存空间,这一步相当于是为控制信息准备一个容器,但只有容器并没有实际作用,所以你还需要向容器中放入控制信息;如果你不申请创建Socket所需要的内存空间,你创建的控制信息也没有地方存放,所以分配内存空间,放入控制信息缺一不可。至此Socket的创建就已经完成了。
Socket创建完成后,会返回一个Socket描述符给应用程序,这个描述符相当于是区分不同Socket的号码牌。根据这个描述符,应用程序在委托协议栈收发数据时就需要提供这个描述符。
4、Socket 是如何连接的
Socket创建完成后,最终还是为数据收发服务的。但是,在数据收发之前,还需要进行一步“连接”(术语就是 connect),建立连接有一整套过程。
这个“连接”并不是真实的连接(用一根水管插在两个电脑之间?不是你想的这样。。。)。
实际上这个“连接”是应用程序通过 TCP/IP 协议标准从一个主机通过网络介质传输到另一个主机的过程。
Socket刚刚创建完成后,还没有数据,也不知道通信对象。
在这种状态下:即使你让客户端应用程序委托协议栈发送数据,它也不知道发送到哪里。所以浏览器需要根据网址来查询服务器的 IP 地址(做这项工作的协议是 DNS),查询到目标主机后,再把目标主机的 IP 告诉协议栈。至此,客户端这边就准备好了。
在服务器上:与客户端一样也需要创建Socket,但是同样的它也不知道通信对象是谁,所以我们需要让客户端向服务器告知客户端的必要信息:IP 地址和端口号。
现在通信双方建立连接的必要信息已经具备,可以开始“连接”过程了。
首先:客户端应用程序需要调用 Socket 库中的 connect 方法,提供 socket 描述符和服务器 IP 地址、端口号。
以下是connect的伪码调用:
connect(<描述符>、<服务器IP地址和端口号>)
这些信息会传递给协议栈中的 TCP 模块,TCP 模块会对请求报文进行封装,再传递给 IP 模块,进行 IP 报文头的封装,然后传递给物理层,进行帧头封装。
之后通过网络介质传递给服务器,服务器上会对帧头、IP 模块、TCP 模块的报文头进行解析,从而找到对应的Socket。
Socket收到请求后,会写入相应的信息,并且把状态改为正在连接。
请求过程完成后:服务器的 TCP 模块会返回响应,这个过程和客户端是一样的(如果大家不太清楚报文头的封装过程,可以阅读《快速理解TCP协议一篇就够》)。
在一个完整的请求和响应过程中,控制信息起到非常关键的作用:
- 1)SYN 就是同步的缩写,客户端会首先发送 SYN 数据包,请求服务端建立连接;
- 2)ACK 就是相应的意思,它是对发送 SYN 数据包的响应;
- 3)FIN 是终止的意思,它表示客户端/服务器想要终止连接。
由于网络环境的复杂多变,经常会存在数据包丢失的情况,所以双方通信时需要相互确认对方的数据包是否已经到达,而判断的标准就是 ACK 的值。
上面的文字不够生动,动画可以更好的说明这个过程:
(PS:这个“连接”的详细理论知识,可以阅读《理论经典:TCP协议的3次握手与4次挥手过程详解》、《跟着动画来学TCP三次握手和四次挥手》,这里不再赘述。)
当所有建立连接的报文都能够正常收发之后,此时套接字就已经进入可收发状态了,此时可以认为用一根管理把两个套接字连接了起来。当然,实际上并不存在这个管子。建立连接之后,协议栈的连接操作就结束了,也就是说 connect 已经执行完毕,控制流程被交回给应用程序。
另外:如果你对Socket代码更熟悉的话,可以先读读这篇《手把手教你写基于TCP的Socket长连接》。
5、Socket 是如何收发数据的
当控制流程上节中的连接过程回到应用程序之后,接下来就会直接进入数据收发阶段。
数据收发操作是从应用程序调用 write 将要发送的数据交给协议栈开始的,协议栈收到数据之后执行发送操作。
协议栈不会关心应用程序传输过来的是什么数据,因为这些数据最终都会转换为二进制序列,协议栈在收到数据之后并不会马上把数据发送出去,而是会将数据放在发送缓冲区,再等待应用程序发送下一条数据。
为什么收到数据包不会直接发送出去,而是放在缓冲区中呢?
因为只要一旦收到数据就会发送,就有可能发送大量的小数据包,导致网络效率下降(所以协议栈需要将数据积攒到一定数量才能将其发送出去)。
至于协议栈会向缓冲区放多少数据,这个不同版本和种类的操作系统有不同的说法。
不过,所有的操作系统都会遵循下面这几个标准:
1)第一个判断要素:是每个网络包能够容纳的数据长度,判断的标准是 MTU,它表示的是一个网络包的最大长度。最大长度包含头部,所以如果单论数据区的话,就会用 MTU - 包头长度,由此的出来的最大数据长度被称为 MSS。

2)另一个判断标准:是时间,当应用程序产生的数据比较少,协议栈向缓冲区放置数据效率不高时,如果每次都等到 MSS 再发送的话,可能因为等待时间太长造成延迟。在这种情况下,即使数据长度没有到达 MSS,也应该把数据发送出去。
但协议栈并没有告诉我们怎样平衡这两个因素,如果数据长度优先,那么效率有可能比较低;如果时间优先,那又会降低网络的效率。
经过了一段时间。。。。。。

假设我们使用的是长度有限法则:此时缓冲区已满,协议栈要发送数据了,协议栈刚要把数据发送出去,却发现无法一次性传输这么大数据量(相对的)的数据,那怎么办呢?
在这种情况下,发送缓冲区中的数据就会超过 MSS 的长度,发送缓冲区中的数据会以 MSS 大小为一个数据包进行拆分,拆分出来的每块数据都会加上 TCP,IP,以太网头部,然后被放进单独的网络包中。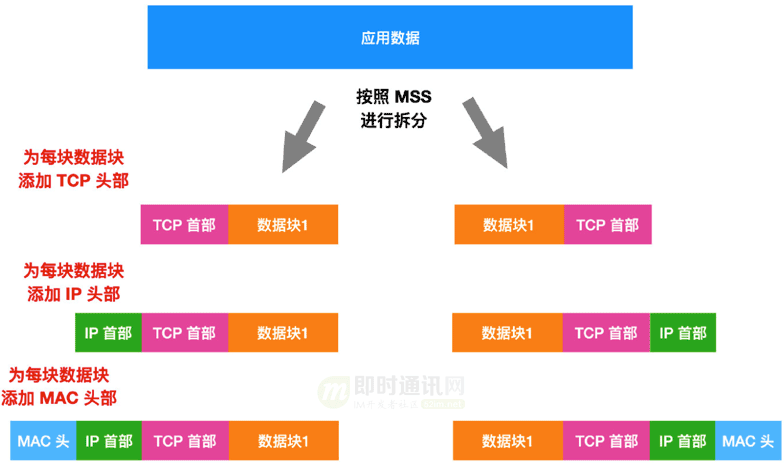
到现在,网络包已经准备好发往服务器了,但是数据发送操作还没有结束,因为服务器还未确认是否已经收到网络包。因此在客户端发送数据包之后,还需要服务器进行确认。
TCP 模块在拆分数据时,会计算出网络包偏移量,这个偏移量就是相对于数据从头开始计算的第几个字节,并将算好的字节数写在 TCP 头部,TCP 模块还会生成一个网络包的序号(SYN),这个序号是唯一的,这个序号就是用来让服务器进行确认的。
服务器会对客户端发送过来的数据包进行确认,确认无误之后,服务器会生成一个序号和确认号(ACK)并一起发送给客户端,客户端确认之后再发送确认号给服务器。
我们来看一下实际的工作过程:

首先:客户端在连接时需要计算出序号初始值,并将这个值发送给服务器。
接下来:服务器通过这个初始值计算出确认号并返回给客户端(初始值在通信过程中有可能会丢弃,因此当服务器收到初始值后需要返回确认号用于确认)。
同时:服务器也需要计算出从服务器到客户端方向的序号初始值,并将这个值发送给客户端。然后,客户端也需要根据服务器发来的初始值计算出确认号发送给服务器。
至此:连接建立完成,接下来就可以进入数据收发阶段了。
数据收发阶段中,通信双方可以同时发送请求和响应,双方也可以同时对请求进行确认。
请求 - 确认机制非常强大:通过这一机制,我们可以确认接收方有没有收到某个包,如果没有收到则重新发送,这样一来,但凡网络中出现的任何错误,我们都可以即使发现并补救。
上面的文字不够生动,动画可以更好的理解请求 - 确认机制:
网卡、集线器、路由器(见《史上最通俗的集线器、交换机、路由器功能原理入门》)都没有错误补救机制,一旦检测到错误就会直接丢弃数据包,应用程序也没有这种机制,起作用的只是 TCP/IP 模块。
由于网络环境复杂多变,所以数据包会存在丢失情况,因此发送序号和确认号也存在一定规则,TCP 会通过窗口管理确认号,我们这篇文章不再赘述,大家可以阅读《通俗易懂-深入理解TCP协议(下):RTT、滑动窗口、拥塞处理》来寻找答案。
PS:另一篇《我们在读写Socket时,究竟在读写什么?》中用动画详细说明了这个过程,有兴趣可以读一读。
6、Socket 是如何断开连接的
当通信双方不再需要收发数据时,需要断开连接。不同的应用程序断开连接的时机不同。
以 Web 为例:浏览器向 Web 服务器发送请求消息,Web 服务器再返回响应消息,这时收发数据就全部结束了,服务器可能会首先发起断开响应,当然客户端也有可能会首先发起(谁先断开连接是应用程序做出的判断),与协议栈无关。
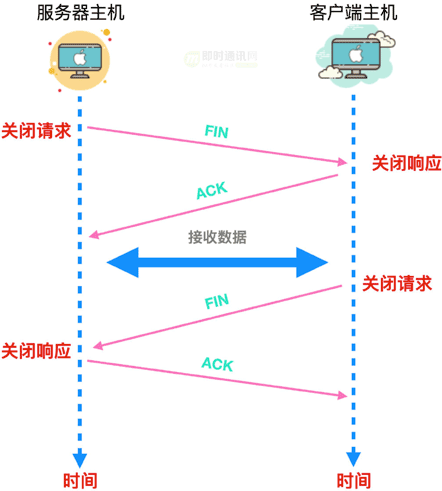
无论哪一方发起断开连接的请求,都会调用 Socket 库的 close 程序。
我们以服务器断开连接为例:服务器发起断开连接请求,协议栈会生成断开连接的 TCP 头部,其实就是设置 FIN 位,然后委托 IP 模块向客户端发送数据,与此同时,服务器的Socket会记录下断开连接的相关信息。
收到服务器发来 FIN 请求后:客户端协议栈会将Socket标记为断开连接状态,然后,客户端会向服务器返回一个确认号,这是断开连接的第一步,在这一步之后,应用程序还会调用 read 来读取数据。等到服务器数据发送完成后,协议栈会通知客户端应用程序数据已经接收完毕。
只要收到服务器返回的所有数据,客户端就会调用 close 程序来结束收发操作,这时客户端会生成一个 FIN 发送给服务器,一段时间后服务器返回 ACK 号。至此,客户端和服务器的通信就结束了。
上面的文字不够生动,动画可以更好的说明这个过程:
PS:断开连接的详细理论知识,可以阅读《理论经典:TCP协议的3次握手与4次挥手过程详解》、《跟着动画来学TCP三次握手和四次挥手》,这里不再赘述。
7、Socket的删除
上述通信过程完成后,用来通信的Socket就不再会使用了,此时我们就可以删除这个Socket了。
不过,这时候Socket不会马上删除,而是等过一段时间再删除。
等待这段时间是为了防止误操作,最常见的误操作就是客户端返回的确认号丢失,至于等待多长时间,和数据包重传的方式有关,这里我们就深入展开讨论了。
关于Socket操作的全过程,如果从系统的角度来看,可能会更深入一些,建议可以深入阅读张彦飞的《深入操作系统,从内核理解网络包的接收过程(Linux篇)》一文。
8、系列文章
本文是系列文章中的第14篇,本系列文章的大纲如下:
[1] 网络编程懒人入门(一):快速理解网络通信协议(上篇)
[2] 网络编程懒人入门(二):快速理解网络通信协议(下篇)
[3] 网络编程懒人入门(三):快速理解TCP协议一篇就够
[4] 网络编程懒人入门(四):快速理解TCP和UDP的差异
[5] 网络编程懒人入门(五):快速理解为什么说UDP有时比TCP更有优势
[6] 网络编程懒人入门(六):史上最通俗的集线器、交换机、路由器功能原理入门
[7] 网络编程懒人入门(七):深入浅出,全面理解HTTP协议
[8] 网络编程懒人入门(八):手把手教你写基于TCP的Socket长连接
[9] 网络编程懒人入门(九):通俗讲解,有了IP地址,为何还要用MAC地址?
[10] 网络编程懒人入门(十):一泡尿的时间,快速读懂QUIC协议
[11] 网络编程懒人入门(十一):一文读懂什么是IPv6
[12] 网络编程懒人入门(十二):快速读懂Http/3协议,一篇就够!
[13] 网络编程懒人入门(十三):一泡尿的时间,快速搞懂TCP和UDP的区别
[14] 网络编程懒人入门(十四):到底什么是Socket?一文即懂!(* 本文)
9、参考资料
[1] TCP/IP详解 - 第17章·TCP:传输控制协议
[2] TCP/IP详解 - 第18章·TCP连接的建立与终止
[3] TCP/IP详解 - 第21章·TCP的超时与重传
[4] 快速理解网络通信协议(上篇)
[5] 快速理解网络通信协议(下篇)
[6] 面视必备,史上最通俗计算机网络分层详解
[7] 假如你来设计网络,会怎么做?
[8] 假如你来设计TCP协议,会怎么做?
[10] 浅析TCP协议中的疑难杂症(下篇)
[11] 关闭TCP连接时为什么会TIME_WAIT、CLOSE_WAIT
[12] 从底层入手,深度分析TCP连接耗时的秘密
(本文已同步发布于:http://www.52im.net/thread-3821-1-1.html)