本文由爱奇艺技术团队分享,作者isno,原题“爱奇艺海外App的网络优化实践”,下文进行了排版和内容优化等。
1、引言
做海外市场,特别目标是面向全球的用户,网络的重要性不言而喻。试想一个移动端应用,比如即时通讯IM,聊天消息的本质就是人跟人在说话,一条消息从发送到接受需要10秒的时间,这恐怕会让用户崩溃,随之就是被无情地卸载,开拓海外市场那就是做梦了。
本次分享的文章内容,基于爱奇艺面向全球用户推出的国际版,在海外跨国网络环境复杂的前提下,针对性地做了一系列弱网优化实践,取得了不错的效果,在此总结分享我们的一些做法和优化思路,希望对你有所帮助。
总结下来,跨国弱网优化实践的几个核心就是:
- 1)能不请求网络就不请求;
- 2)请求的链接目标 0-RTT;
- 3)请求的内容越小越好。
正文内容我们将逐个技术点展开了分享。
2、系列文章
本文是系列文章中的第 3 篇,本系列文章的大纲如下:
- 《移动端IM开发者必读(一):通俗易懂,理解移动网络的“弱”和“慢”》
- 《移动端IM开发者必读(二):史上最全移动弱网络优化方法总结》
- 《移动端IM开发者必读(三):爱奇艺移动端跨国弱网通信的优化实践》(* 本文)
如果您是IM开发初学者,强烈建议首先阅读《新手入门一篇就够:从零开发移动端IM》。
3、 跨国弱网样本摸底
在 App 初期版本内增加请求链路的采样。样本数足够的情况下,可以清楚你要推广的市场是怎样的环境。样本数据让我们清楚发现了各个国家、地区网络的问题,在大规模宣传和投入前,做好 App 的基础工作非常重要。
海外用户至海外数据中心的网络延迟(这是监测节点数据,用户端延迟更高):
海外主要国家、地区移动网络情况:
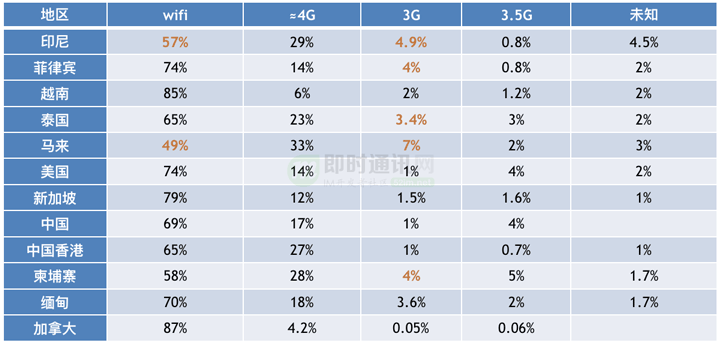
在调研阶段,我们发现了以下问题比较明显,切实影响我们的运营及 App 体验。
这些问题主要是:
- 1)运营商劫持严重,DNS 劫持、HTTP 劫持;
- 2)移动端网络复杂 ,东南亚的网络基础建设还待改善;
- 3)低端 Android 机有一定的占比,数量级别影响决策;
- 4)国际网络用户端到服务器的延迟高。
在初期阶段,技术工作的核心是解决以上问题,为后续的运营做好基础建设。因为业务接口大部分为 HTTP 形式,就开始围绕 HTTPS 进行针对性改进。
一个HTTPS请求阶段分析:

一个 HTTPS 在第一请求会有 5 个 RTT:
1RTT(DNS)+ 1RTT(TCP 握手)+ 2RTT(TLS1.2)+ 1RTT(HTTP 链接)
如果以端到服务 50ms 延迟为例:
一个 HTTPS 的接口延迟 = 350ms = 50*5+ 100ms(服务端)
如果目标是一个非国内用户,打开首页需要 1.1s, 这个时间显然有点长。
下面开始进行技术改进的正文,以下是概括技术性优化的关键点:
4、基础链路的改进优化
4.1DNS 优化调整
DNS 的解析改为 HTTPDNS,DNS 的改进上线后观察初始连接请求提升 17% 的效率。
目的主要是:
- 1)解决域名劫持问题 (东南亚地区回传的数据显示有不少劫持);
- 2)解决 LocalDNS 非就近分配问题;
- 3)结合业务可以做解析预热。
4.2传输层的优化调整
MTU 的问题 :
- 1)Client 端和 Server 端不同的 MTU 值会导致丢包率过高。AWS 某些场景实例默认巨型帧:MTU 是 9001,但接收端默认 1500,这时候就会出现一些丢包的现象;
- 2)如果你用了多个云商服务,用 VPN 组网,IP隧道封装的数据临界 1500,又会造成丢包、包重传问题;
- 3)最严重的情况:部分网络封杀 ICMP 协议,导致 MTU 无法自动协商。
TCP 拥塞控制优化:
拥塞窗口 CongWin 是未接收到接收端确认情况下连续发送的字节数; 。CongWin 是动态调整,取决于带宽和延迟的积,比如 100MB 的带宽 100ms 的延迟环境。
时延带宽积 = 100Mbps*100ms = (100/8)*(100/1000) = 1.25MB
理论上 CongWin 窗口可以最大化到 1.25MB。CentOS 默认CongWin = 20*MSS,在 29KB 左右,离上限 1.26MB 差太多了,默认值上调TCP的启动会更快。
TCP 快速打开 (TCP Fast Open:TFO):
TCP 的 keepalive 下依然会有链接断掉重建的情况,TFO 是针对这种情况的优化。
TFO 的原理机制:
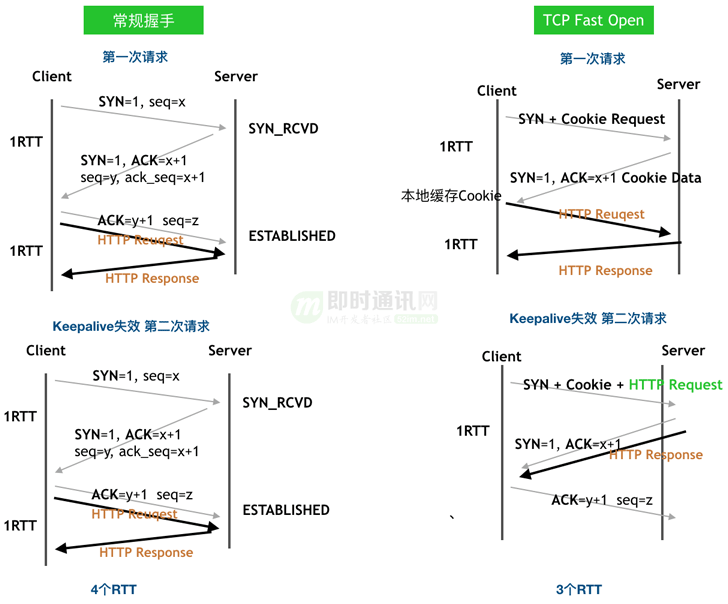
在我们观察中开启 TFO 机制,海外业务一个 RTT 通常时间在 100ms 以上,HTTP 请求效率提升了 12% 左右。
5、应用层的改进优化
5.1HTTP 的优化
HTTP1.1 有个 keep-alive 作用是复用 TCP 链接,减少新建的消耗,对于浏览器的业务比较适用,但对于移动端这种时间分散的请求,大部分请求还是新建连接。
HTTP1.1 的串行机制有头部阻塞的问题。
5.2SSL 层优化
尽量升级到 TLS1.3(微信的TLS1.3实践:《微信新一代通信安全解决方案:基于TLS1.3的MMTLS详解》),利用 Pre-shared Key 机制,开启 ssl_early_data 可以进一步优化 “0-RTT ”,如果无法升级 TLS 版本,优化密钥算法为 ECDHE,运算速度快,握手的消息往返由 2-RTT 减少到 1-RTT,能达到与 TLS1.3 类似的效果。
TLS 版本的区别:

TLS1.3 经过优化后,一个 HTTP 请求由之前的 4 个 RTT 减少为 3 个 RTT。
5.3升级 HTTP2.0
几个重要的改进点:
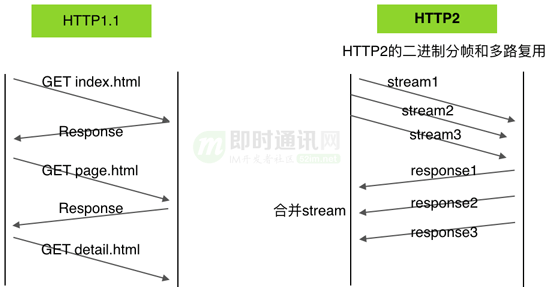
多路复用:
在 HTTP/2 中,两个非常重要的概念:帧(frame)和流(stream)。帧代表着最小的数据单位,每个帧会标识出该帧属于哪个流,流也就是多个帧组成的数据流。多路复用,就是在一个 TCP 连接中可以存在多条流。这些改进可以避免 HTTP 队头阻塞问题,提高传输性能。
头部压缩:
开发人员如果不注意对 header 内容的控制,会造成 header 内容失控的现象,客户端极容易存储一个非常大的 Cookie。
HTTP2 的分帧传输机制:
5.4边缘节点动态加速
这个是非常有效的方式。
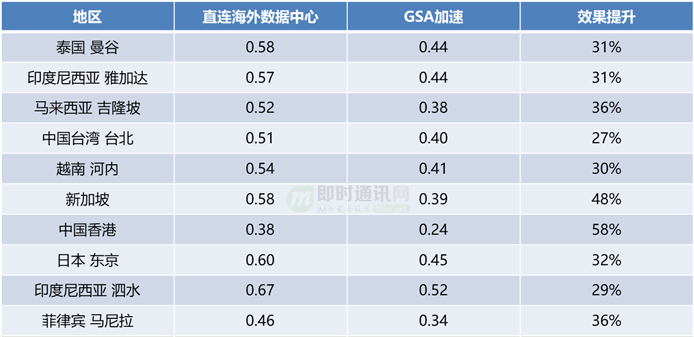
尽可能离用户最近,利用边缘节点对路由、链路进行优化,提高动态服务的效率。相较于直连模式,使用动态加速后,P90 的接口延迟效率提升了 60%。
爱奇艺海外动态加速的效果提升(请求时间为秒):
5.5启用兜底机制
对于失败的请求,启用兜底的协议 QUIC 或者 kcp。
客户端的失败率在 3% 左右,对这部分请求使用 UDP 协议兜底尝试,在我们的观察成功率提升了 45%。
6、传输内容的优化
6.1应用 Brotli
因为预置了字典,在同等级别的压缩率下,对比 gzip 至少提升了 17% 的压缩比,接口平均的 Content-Size 由 30KB,降至 18KB。
6.2接口由 JSON 改为 Google Protobuf
应用 Protobuf 的重要原因是解析效率比 JSON 至少高四五倍,在节点深度和数据量大的情况下更明显。
但注意 Protobuf 内部的 varint 压缩,只对小于 128 的数字进行可变长压缩。实际效果不大,生产环境如果数据量大,外层的压缩如 gzip 不可少。
PS:关于Protobuf的资料,可以进一步阅读《IM通讯协议专题学习》。
6.3图片格式升级为 WebP
在应用 WebP 的同时,降低海报图片的质量,实践看海报的 quality 设置为 85% 肉眼难以分辨,相对同质量的 JPEG 或者 PNG ,可以最大减小 45% 的体积。
应用效果明显。App 打开首页图片的加载提升肉眼可见。
7、业务层面的优化改进
7.1减少不必要请求:
一些通用内容,如导航、频道,通常由运营人员主动更新。
如下图:增加一个启动阶段请求的接口,里面放入内容更新的时间戳,与本地 cache 的时间戳有差异,则异步请求更新。
7.2区别用户网络,适应不同的策略
具体作法是:
- 1)对于视频,非 WiFi 默认启播码率为 360P;
- 2)对于海报,后端接口提供两种质量的 Url,WiFi 高质,4G 低质。
7.3更多的业务优化
增加请求重试、调整 HTTP 的超时时间,请求缓存等等 这些可以根据业务的需求进行调整。
8、本文小结
爱奇艺海外版APP经过一系列细节优化,用户体验持续上升。用户接口延迟、客户端失败率、视频播放成功率一系列的关键指标得到很大的改善。这也助力爱奇艺在东南亚多个国家的应用市场排名升至 TOP 1。
另外 App 优化、Server 延迟优化、产品体验的改进,这一系列只有相辅相成才可以最大化提升用户体验。
9、参考资料
[1] TCP/IP详解 - 第17章·TCP:传输控制协议
[2] 网络编程懒人入门(三):快速理解TCP协议一篇就够
[3] 新手入门一篇就够:从零开发移动端IM
[4] 现代移动端网络短连接的优化手段总结:请求速度、弱网适应、安全保障
[5] 全面了解移动端DNS域名劫持等杂症:技术原理、问题根源、解决方案等
[6] 美图App的移动端DNS优化实践:HTTPS请求耗时减小近半
[7] 百度APP移动端网络深度优化实践分享(一):DNS优化篇
[8] 百度APP移动端网络深度优化实践分享(二):网络连接优化篇
[9] 百度APP移动端网络深度优化实践分享(三):移动端弱网优化篇
[10] 爱奇艺移动端网络优化实践分享:网络请求成功率优化篇
[11] 美团点评的移动端网络优化实践:大幅提升连接成功率、速度等
[12] 淘宝移动端统一网络库的架构演进和弱网优化技术实践
[13] 谈谈移动端 IM 开发中登录请求的优化
[14] 移动端IM开发需要面对的技术问题(含通信协议选择)
[15] 简述移动端IM开发的那些坑:架构设计、通信协议和客户端
[16] 微信对网络影响的技术试验及分析(论文全文)
[17] 腾讯原创分享(二):如何大幅压缩移动网络下APP的流量消耗(上篇)
[18] IM开发者的零基础通信技术入门(十二):上网卡顿?网络掉线?一文即懂!
[19] 微信新一代通信安全解决方案:基于TLS1.3的MMTLS详解
[20] IM通讯协议专题学习(一):Protobuf从入门到精通,一篇就够!
(本文已同步发布于:http://www.52im.net/thread-4669-1-1.html)