北北 发表于 2006-8-21 20:46:15
前言:
半年前我对正则表达式产生了兴趣,在网上查找过不少资料,看过不少的教程,最后在使用一个正则表达式工具RegexBuddy时发现他的教程写的非常好,可以说是我目前见过最好的正则表达式教程。于是一直想把他翻译过来。这个愿望直到这个五一长假才得以实现,结果就有了这篇文章。关于本文的名字,使用“深入浅出”似乎已经太俗。但是通读原文以后,觉得只有用“深入浅出”才能准确的表达出该教程给我的感受,所以也就不能免俗了。
本文是Jan Goyvaerts为RegexBuddy写的教程的译文,版权归原作者所有,欢迎转载。但是为了尊重原作者和译者的劳动,请注明出处!谢谢!
1.什么是正则表达式
基本说来,正则表达式是一种用来描述一定数量文本的模式。Regex代表Regular Express。本文将用<<regex>>来表示一段具体的正则表达式。
一段文本就是最基本的模式,简单的匹配相同的文本。
2.不同的正则表达式引擎
正则表达式引擎是一种可以处理正则表达式的软件。通常,引擎是更大的应用程序的一部分。在软件世界,不同的正则表达式并不互相兼容。本教程会集中讨论Perl 5 类型的引擎,因为这种引擎是应用最广泛的引擎。同时我们也会提到一些和其他引擎的区别。许多近代的引擎都很类似,但不完全一样。例如.NET正则库,JDK正则包。
3.文字符号
最基本的正则表达式由单个文字符号组成。如<<a>>,它将匹配字符串中第一次出现的字符“a”。如对字符串“Jack is a boy”。“J”后的“a”将被匹配。而第二个“a”将不会被匹配。
正则表达式也可以匹配第二个“a”,这必须是你告诉正则表达式引擎从第一次匹配的地方开始搜索。在文本编辑器中,你可以使用“查找下一个”。在编程语言中,会有一个函数可以使你从前一次匹配的位置开始继续向后搜索。
类似的,<<cat>>会匹配“About cats and dogs”中的“cat”。这等于是告诉正则表达式引擎,找到一个<<c>>,紧跟一个<<a>>,再跟一个<<t>>。
要注意,正则表达式引擎缺省是大小写敏感的。除非你告诉引擎忽略大小写,否则<<cat>>不会匹配“Cat”。
· 特殊字符
对于文字字符,有11个字符被保留作特殊用途。他们是:
[ ] \ ^ $ . | ? * + ( )
这些特殊字符也被称作元字符。
如果你想在正则表达式中将这些字符用作文本字符,你需要用反斜杠“\”对其进行换码 (escape)。例如你想匹配“1+1=2”,正确的表达式为<<1\+1=2>>.
需要注意的是,<<1+1=2>>也是有效的正则表达式。但它不会匹配“1+1=2”,而会匹配“123+111=234”中的“111=2”。因为“+”在这里表示特殊含义(重复1次到多次)。
在编程语言中,要注意,一些特殊的字符会先被编译器处理,然后再传递给正则引擎。因此正则表达式<<1\+2=2>>在C++中要写成“1\\+1=2”。为了匹配“C:\temp”,你要用正则表达式<<C:\\temp>>。而在C++中,正则表达式则变成了“C:\\\\temp”。
·不可显示字符
可以使用特殊字符序列来代表某些不可显示字符:
<<\t>>代表Tab(0x09)
<<\r>>代表回车符(0x0D)
<<\n>>代表换行符(0x0A)
要注意的是Windows中文本文件使用“\r\n”来结束一行而Unix使用“\n”。
4.正则表达式引擎的内部工作机制
知道正则表达式引擎是如何工作的有助于你很快理解为何某个正则表达式不像你期望的那样工作。
有两种类型的引擎:文本导向(text-directed)的引擎和正则导向(regex-directed)的引擎。Jeffrey Friedl把他们称作DFA和NFA引擎。本文谈到的是正则导向的引擎。这是因为一些非常有用的特性,如“惰性”量词(lazy quantifiers)和反向引用(backreferences),只能在正则导向的引擎中实现。所以毫不意外这种引擎是目前最流行的引擎。
你可以轻易分辨出所使用的引擎是文本导向还是正则导向。如果反向引用或“惰性”量词被实现,则可以肯定你使用的引擎是正则导向的。你可以作如下测试:将正则表达式<<regex|regex not>>应用到字符串“regex not”。如果匹配的结果是regex,则引擎是正则导向的。如果结果是regex not,则是文本导向的。因为正则导向的引擎是“猴急”的,它会很急切的进行表功,报告它找到的第一个匹配 。
·正则导向的引擎总是返回最左边的匹配
这是需要你理解的很重要的一点:即使以后有可能发现一个“更好”的匹配,正则导向的引擎也总是返回最左边的匹配。
当把<<cat>>应用到“He captured a catfish for his cat”,引擎先比较<<c>>和“H”,结果失败了。于是引擎再比较<<c>>和“e”,也失败了。直到第四个字符,<<c>>匹配了“c”。<<a>>匹配了第五个字符。到第六个字符<<t>>没能匹配“p”,也失败了。引擎再继续从第五个字符重新检查匹配性。直到第十五个字符开始,<<cat>>匹配上了“catfish”中的“cat”,正则表达式引擎急切的返回第一个匹配的结果,而不会再继续查找是否有其他更好的匹配。
5.字符集
字符集是由一对方括号“[]”括起来的字符集合。使用字符集,你可以告诉正则表达式引擎仅仅匹配多个字符中的一个。如果你想匹配一个“a”或一个“e”,使用<<[ae]>>。你可以使用<<gr[ae]y>>匹配gray或grey。这在你不确定你要搜索的字符是采用美国英语还是英国英语时特别有用。相反,<<gr[ae]y>>将不会匹配graay或graey。字符集中的字符顺序并没有什么关系,结果都是相同的。
你可以使用连字符“-”定义一个字符范围作为字符集。<<[0-9]>>匹配0到9之间的单个数字。你可以使用不止一个范围。<<[0-9a-fA-F] >>匹配单个的十六进制数字,并且大小写不敏感。你也可以结合范围定义与单个字符定义。<<[0-9a-fxA-FX]>>匹配一个十六进制数字或字母X。再次强调一下,字符和范围定义的先后顺序对结果没有影响。
·字符集的一些应用
查找一个可能有拼写错误的单词,比如<<sep[ae]r[ae]te>> 或 <<li[cs]en[cs]e>>。
查找程序语言的标识符,<<A-Za-z_][A-Za-z_0-9]*>>。(*表示重复0或多次)
查找C风格的十六进制数<<0[xX][A-Fa-f0-9]+>>。(+表示重复一次或多次)
·取反字符集
在左方括号“[”后面紧跟一个尖括号“^”,将会对字符集取反。结果是字符集将匹配任何不在方括号中的字符。不像“.”,取反字符集是可以匹配回车换行符的。
需要记住的很重要的一点是,取反字符集必须要匹配一个字符。<<q[^u]>>并不意味着:匹配一个q,后面没有u跟着。它意味着:匹配一个q,后面跟着一个不是u的字符。所以它不会匹配“Iraq”中的q,而会匹配“Iraq is a country”中的q和一个空格符。事实上,空格符是匹配中的一部分,因为它是一个“不是u的字符”。
如果你只想匹配一个q,条件是q后面有一个不是u的字符,我们可以用后面将讲到的向前查看来解决。
·字符集中的元字符
需要注意的是,在字符集中只有4个 字符具有特殊含义。它们是:“] \ ^ -”。“]”代表字符集定义的结束;“\”代表转义;“^”代表取反;“-”代表范围定义。其他常见的元字符在字符集定义内部都是正常字符,不需要转义。例如,要搜索星号*或加号+,你可以用<<[+*]>>。当然,如果你对那些通常的元字符进行转义,你的正则表达式一样会工作得很好,但是这会降低可读性。
在字符集定义中为了将反斜杠“\”作为一个文字字符而非特殊含义的字符,你需要用另一个反斜杠对它进行转义。<<[\\x]>>将会匹配一个反斜杠和一个X。“]^-”都可以用反斜杠进行转义,或者将他们放在一个不可能使用到他们特殊含义的位置。我们推荐后者,因为这样可以增加可读性。比如对于字符“^”,将它放在除了左括号“[”后面的位置,使用的都是文字字符含义而非取反含义。如<<[x^]>>会匹配一个x或^。<<[]x]>>会匹配一个“]”或“x”。<<[-x]>>或<<[x-]>>都会匹配一个“-”或“x”。
·字符集的简写
因为一些字符集非常常用,所以有一些简写方式。
<<\d>>代表<<[0-9]>>;
<<\w>>代表单词字符。这个是随正则表达式实现的不同而有些差异。绝大多数的正则表达式实现的单词字符集都包含了<<A-Za-z0-9_]>>。
<<\s>>代表“白字符”。这个也是和不同的实现有关的。在绝大多数的实现中,都包含了空格符和Tab符,以及回车换行符<<\r\n>>。
字符集的缩写形式可以用在方括号之内或之外。<<\s\d>>匹配一个白字符后面紧跟一个数字。<<[\s\d]>>匹配单个白字符或数字。<<[\da-fA-F]>>将匹配一个十六进制数字。
取反字符集的简写
<<[\S]>> = <<[^\s]>>
<<[\W]>> = <<[^\w]>>
<<[\D]>> = <<[^\d]>>
·字符集的重复
如果你用“?*+”操作符来重复一个字符集,你将会重复整个字符集。而不仅是它匹配的那个字符。正则表达式<<[0-9]+>>会匹配837以及222。
如果你仅仅想重复被匹配的那个字符,可以用向后引用达到目的。我们以后将讲到向后引用。
6.使用?*或+ 进行重复
?:告诉引擎匹配前导字符0次或一次。事实上是表示前导字符是可选的。
+:告诉引擎匹配前导字符1次或多次
*:告诉引擎匹配前导字符0次或多次
<[A-Za-z][A-Za-z0-9]*>匹配没有属性的HTML标签,“<”以及“>”是文字符号。第一个字符集匹配一个字母,第二个字符集匹配一个字母或数字。
我们似乎也可以用<[A-Za-z0-9]+>。但是它会匹配<1>。但是这个正则表达式在你知道你要搜索的字符串不包含类似的无效标签时还是足够有效的。
·限制性重复
许多现代的正则表达式实现,都允许你定义对一个字符重复多少次。词法是:{min,max}。min和max都是非负整数。如果逗号有而max被忽略了,则max没有限制。如果逗号和max都被忽略了,则重复min次。
因此{0,}和*一样,{1,}和+ 的作用一样。
你可以用<<\b[1-9][0-9]{3}\b>>匹配1000~9999之间的数字(“\b”表示单词边界)。<<\b[1-9][0-9]{2,4}\b>>匹配一个在100~99999之间的数字。
·注意贪婪性
假设你想用一个正则表达式匹配一个HTML标签。你知道输入将会是一个有效的HTML文件,因此正则表达式不需要排除那些无效的标签。所以如果是在两个尖括号之间的内容,就应该是一个HTML标签。
许多正则表达式的新手会首先想到用正则表达式<< <.+> >>,他们会很惊讶的发现,对于测试字符串,“This is a <EM>first</EM> test”,你可能期望会返回<EM>,然后继续进行匹配的时候,返回</EM>。
但事实是不会。正则表达式将会匹配“<EM>first</EM>”。很显然这不是我们想要的结果。原因在于“+”是贪婪的。也就是说,“+”会导致正则表达式引擎试图尽可能的重复前导字符。只有当这种重复会引起整个正则表达式匹配失败的情况下,引擎会进行回溯。也就是说,它会放弃最后一次的“重复”,然后处理正则表达式余下的部分。
和“+”类似,“?*”的重复也是贪婪的。
·深入正则表达式引擎内部
让我们来看看正则引擎如何匹配前面的例子。第一个记号是“<”,这是一个文字符号。第二个符号是“.”,匹配了字符“E”,然后“+”一直可以匹配其余的字符,直到一行的结束。然后到了换行符,匹配失败(“.”不匹配换行符)。于是引擎开始对下一个正则表达式符号进行匹配。也即试图匹配“>”。到目前为止,“<.+”已经匹配了“<EM>first</EM> test”。引擎会试图将“>”与换行符进行匹配,结果失败了。于是引擎进行回溯。结果是现在“<.+”匹配“<EM>first</EM> tes”。于是引擎将“>”与“t”进行匹配。显然还是会失败。这个过程继续,直到“<.+”匹配“<EM>first</EM”,“>”与“>”匹配。于是引擎找到了一个匹配“<EM>first</EM>”。记住,正则导向的引擎是“急切的”,所以它会急着报告它找到的第一个匹配。而不是继续回溯,即使可能会有更好的匹配,例如“<EM>”。所以我们可以看到,由于“+”的贪婪性,使得正则表达式引擎返回了一个最左边的最长的匹配。
·用懒惰性取代贪婪性
一个用于修正以上问题的可能方案是用“+”的惰性代替贪婪性。你可以在“+”后面紧跟一个问号“?”来达到这一点。“*”,“{}”和“?”表示的重复也可以用这个方案。因此在上面的例子中我们可以使用“<.+?>”。让我们再来看看正则表达式引擎的处理过程。
再一次,正则表达式记号“<”会匹配字符串的第一个“<”。下一个正则记号是“.”。这次是一个懒惰的“+”来重复上一个字符。这告诉正则引擎,尽可能少的重复上一个字符。因此引擎匹配“.”和字符“E”,然后用“>”匹配“M”,结果失败了。引擎会进行回溯,和上一个例子不同,因为是惰性重复,所以引擎是扩展惰性重复而不是减少,于是“<.+”现在被扩展为“<EM”。引擎继续匹配下一个记号“>”。这次得到了一个成功匹配。引擎于是报告“<EM>”是一个成功的匹配。整个过程大致如此。
·惰性扩展的一个替代方案
我们还有一个更好的替代方案。可以用一个贪婪重复与一个取反字符集:“<[^>]+>”。之所以说这是一个更好的方案在于使用惰性重复时,引擎会在找到一个成功匹配前对每一个字符进行回溯。而使用取反字符集则不需要进行回溯。
最后要记住的是,本教程仅仅谈到的是正则导向的引擎。文本导向的引擎是不回溯的。但是同时他们也不支持惰性重复操作。
7.使用“.”匹配几乎任意字符
在正则表达式中,“.”是最常用的符号之一。不幸的是,它也是最容易被误用的符号之一。
“.”匹配一个单个的字符而不用关心被匹配的字符是什么。唯一的例外是新行符。在本教程中谈到的引擎,缺省情况下都是不匹配新行符的。因此在缺省情况下,“.”等于是字符集[^\n\r](Window)或[^\n]( Unix)的简写。
这个例外是因为历史的原因。因为早期使用正则表达式的工具是基于行的。它们都是一行一行的读入一个文件,将正则表达式分别应用到每一行上去。在这些工具中,字符串是不包含新行符的。因此“.”也就从不匹配新行符。
现代的工具和语言能够将正则表达式应用到很大的字符串甚至整个文件上去。本教程讨论的所有正则表达式实现都提供一个选项,可以使“.”匹配所有的字符,包括新行符。在RegexBuddy, EditPad Pro或PowerGREP等工具中,你可以简单的选中“点号匹配新行符”。在Perl中,“.”可以匹配新行符的模式被称作“单行模式”。很不幸,这是一个很容易混淆的名词。因为还有所谓“多行模式”。多行模式只影响行首行尾的锚定(anchor),而单行模式只影响“.”。
其他语言和正则表达式库也采用了Perl的术语定义。当在.NET Framework中使用正则表达式类时,你可以用类似下面的语句来激活单行模式:Regex.Match(“string”,”regex”,RegexOptions.SingleLine)
·保守的使用点号“.”
点号可以说是最强大的元字符。它允许你偷懒:用一个点号,就能匹配几乎所有的字符。但是问题在于,它也常常会匹配不该匹配的字符。
我会以一个简单的例子来说明。让我们看看如何匹配一个具有“mm/dd/yy”格式的日期,但是我们想允许用户来选择分隔符。很快能想到的一个方案是<<\d\d.\d\d.\d\d>>。看上去它能匹配日期“02/12/03”。问题在于02512703也会被认为是一个有效的日期。
<<\d\d[-/.]\d\d[-/.]\d\d>>看上去是一个好一点的解决方案。记住点号在一个字符集里不是元字符。这个方案远不够完善,它会匹配“99/99/99”。而<<[0-1]\d[-/.][0-3]\d[-/.]\d\d>>又更进一步。尽管他也会匹配“19/39/99”。你想要你的正则表达式达到如何完美的程度取决于你想达到什么样的目的。如果你想校验用户输入,则需要尽可能的完美。如果你只是想分析一个已知的源,并且我们知道没有错误的数据,用一个比较好的正则表达式来匹配你想要搜寻的字符就已经足够。
8.字符串开始和结束的锚定
锚定和一般的正则表达式符号不同,它不匹配任何字符。相反,他们匹配的是字符之前或之后的位置。“^”匹配一行字符串第一个字符前的位置。<<^a>>将会匹配字符串“abc”中的a。<<^b>>将不会匹配“abc”中的任何字符。
类似的,$匹配字符串中最后一个字符的后面的位置。所以<<c$>>匹配“abc”中的c。
·锚定的应用
在编程语言中校验用户输入时,使用锚定是非常重要的。如果你想校验用户的输入为整数,用<<^\d+$>>。
用户输入中,常常会有多余的前导空格或结束空格。你可以用<<^\s*>>和<<\s*$>>来匹配前导空格或结束空格。
·使用“^”和“$”作为行的开始和结束锚定
如果你有一个包含了多行的字符串。例如:“first line\n\rsecond line”(其中\n\r表示一个新行符)。常常需要对每行分别处理而不是整个字符串。因此,几乎所有的正则表达式引擎都提供一个选项,可以扩展这两种锚定的含义。“^”可以匹配字串的开始位置(在f之前),以及每一个新行符的后面位置(在\n\r和s之间)。类似的,$会匹配字串的结束位置(最后一个e之后),以及每个新行符的前面(在e与\n\r之间)。
在.NET中,当你使用如下代码时,将会定义锚定匹配每一个新行符的前面和后面位置:Regex.Match("string", "regex", RegexOptions.Multiline)
应用:string str = Regex.Replace(Original, "^", "> ", RegexOptions.Multiline)--将会在每行的行首插入“> ”。
· 绝对锚定
<<\A>>只匹配整个字符串的开始位置,<<\Z>>只匹配整个字符串的结束位置。即使你使用了“多行模式”,<<\A>>和<<\Z>>也从不匹配新行符。
即使\Z和$只匹配字符串的结束位置,仍然有一个例外的情况。如果字符串以新行符结束,则\Z和$将会匹配新行符前面的位置,而不是整个字符串的最后面。这个“改进”是由Perl引进的,然后被许多的正则表达式实现所遵循,包括Java,.NET等。如果应用<<^[a-z]+$>>到“joe\n”,则匹配结果是“joe”而不是“joe\n”。
radic 发表于 2006-12-15 12:24:05
作者:Radic 来源:sun
评论数:5 点击数:592 投票总得分:6 投票总人次:2
关键字:Java;安全编码
摘要:
本文是来自Sun官方站点的一篇关于如何编写安全的Java代码的指南,开发者在编写一般代码时,可以参照本文的指南
本文是来自Sun官方站点的一篇关于如何编写安全的Java代码的指南,开发者在编写一般代码时,可以参照本文的指南:
• 静态字段
• 缩小作用域
• 公共方法和字段
• 保护包
• equals方法
• 如果可能使对象不可改变
• 不要返回指向包含敏感数据的内部数组的引用
• 不要直接存储用户提供的数组
• 序列化
• 原生函数
• 清除敏感信息静态字段• 避免使用非final的公共静态变量
应尽可能地避免使用非final公共静态变量,因为无法判断代码有无权限改变这些变量值。
• 一般地,应谨慎使用易变的静态状态,因为这可能导致设想中相互独立的子系统之间发生不可预知的交互。
缩小作用域作为一个惯例,尽可能缩小方法和字段的作用域。检查包访问权限的成员能否改成私有的,保护类型的成员可否改成包访问权限的或者私有的,等等。
公共方法/字段避免使用公共变量,而是使用访问器方法访问这些变量。用这种方式,如果需要,可能增加集中安全控制。
对于任何公共方法,如果它们能够访问或修改任何敏感内部状态,务必使它们包含安全控制。
参考如下代码段,该代码段中不可信任代码可能设置TimeZone的值:
private static TimeZone defaultZone = null;
public static synchronized void setDefault(TimeZone zone)
{
defaultZone = zone;
}
保护包有时需要在全局防止包被不可信任代码访问,本节描述了一些防护技术:
• 防止包注入:如果不可信任代码想要访问类的包保护成员,可以尝试在被攻击的包内定义自己的新类用以获取这些成员的访问权。防止这类攻击的方式有两种:
1. 通过向java.security.properties文件中加入如下文字防止包内被注入恶意类。
...
package.definition=Package#1 [,Package#2,...,Package#n]
...
这会导致当试图在包内定义新类时类装载器的defineClass方法会抛出异常,除非赋予代码一下权限:
...
RuntimePermission("defineClassInPackage."+package)
...
2. 另一种方式是通过将包内的类加入到封装的Jar文件里。
(参看http://java.sun.com/j2se/sdk/1.2/docs/guide/extensions/spec.html)
通过使用这种技巧,代码无法获得扩展包的权限,因此也无须修改java.security.properties文件。
• 防止包访问:通过限制包访问并仅赋予特定代码访问权限防止不可信任代码对包成员的访问。通过向java.security.properties文件中加入如下文字可以达到这一目的:
...
package.access=Package#1 [,Package#2,...,Package#n]
...
这会导致当试图在包内定义新类时类装载器的defineClass方法会抛出异常,除非赋予代码一下权限:
...
RuntimePermission("defineClassInPackage."+package)
...
如果可能使对象不可改变如果可能,使对象不可改变。如果不可能,使得它们可以被克隆并返回一个副本。如果返回的对象是数组、向量或哈希表等,牢记这些对象不能被改变,调用者修改这些对象的内容可能导致安全漏洞。此外,因为不用上锁,不可改变性能够提高并发性。参考Clear sensitive information了解该惯例的例外情况。
不要返回指向包含敏感数据的内部数组的引用该惯例仅仅是不可变惯例的变型,在这儿提出是因为常常在这里犯错。即使数组中包含不可变的对象(如字符串),也要返回一个副本这样调用者不能修改数组中的字符串。不要传回一个数组,而是数组的拷贝。
不要直接在用户提供的数组里存储该惯例仅仅是不可变惯例的另一个变型。使用对象数组的构造器和方法,比如说PubicKey数组,应当在将数组存储到内部之前克隆数组,而不是直接将数组引用赋给同样类型的内部变量。缺少这个警惕,用户对外部数组做得任何变动(在使用讨论中的构造器创建对象后)可能意外地更改对象的内部状态,即使该对象可能是无法改变的
序列化当对对象序列化时,直到它被反序列化,它不在Java运行时环境的控制之下,因此也不在Java平台提供的安全控制范围内。
在实现Serializable时务必将以下事宜牢记在心:
• transient
在包含系统资源的直接句柄和相对地址空间信息的字段前使用transient关键字。 如果资源,如文件句柄,不被声明为transient,该对象在序列化状态下可能会被修改,从而使得被反序列化后获取对资源的不当访问。
• 特定类的序列化/反序列化方法
为了确保反序列化对象不包含违反一些不变量集合的状态,类应该定义自己的反序列化方法并使用ObjectInputValidation接口验证这些变量。
如果一个类定义了自己的序列化方法,它就不能向任何DataInput/DataOuput方法传递内部数组。所有的DataInput/DataOuput方法都能被重写。注意默认序列化不会向DataInput/DataOuput字节数组方法暴露私有字节数组字段。
如果Serializable类直接向DataOutput(write(byte [] b))方法传递了一个私有数组,那么黑客可以创建ObjectOutputStream的子类并覆盖write(byte [] b)方法,这样他可以访问并修改私有数组。下面示例说明了这个问题。
你的类:
public class YourClass implements Serializable {
private byte [] internalArray;
....
private synchronized void writeObject(ObjectOutputStream stream) {
...
stream.write(internalArray);
...
}
}黑客代码
public class HackerObjectOutputStream extends ObjectOutputStream{
public void write (byte [] b) {
Modify b
}
}
...
YourClass yc = new YourClass();
...
HackerObjectOutputStream hoos = new HackerObjectOutputStream();
hoos.writeObject(yc);• 字节流加密
保护虚拟机外的字节流的另一方式是对序列化包产生的流进行加密。字节流加密防止解码或读取被序列化的对象的私有状态。如果决定加密,应该管理好密钥,密钥的存放地点以及将密钥交付给反序列化程序的方式等。
• 需要提防的其他事宜
如果不可信任代码无法创建对象,务必确保不可信任代码也不能反序列化对象。切记对对象反序列化是创建对象的另一途径。
比如说,如果一个applet创建了一个frame,在该frame上创建了警告标签。如果该frame被另一应用程序序列化并被一个applet反序列化,务必使该frame出现时带有同一个警告标签。
原生方法应从以下几个方面检查原生方法:
• 它们返回什么
• 它们需要什么参数
• 它们是否绕过了安全检查
• 它们是否是公共的,私有的等
• 它们是否包含能绕过包边界的方法调用,从而绕过包保护
清除敏感信息当保存敏感信息时,如机密,尽量保存在如数组这样的可变数据类型中,而不是保存在字符串这样的不可变对象中,这样使得敏感信息可以尽早显式地被清除。不要指望Java平台的自动垃圾回收来做这种清除,因为回收器可能不会清除这段内存,或者很久后才会回收。尽早清除信息使得来自虚拟机外部的堆检查攻击变得困难。
关注beanaction时,查到的资料,顺便做个备份
多数IT 组织都必须解决三个主要问题:1.帮助组织减少成本 2.增加并且保持客户 3.加快业务效率。完成这些问题一般都需要实现对多个业务系统的数据和业务逻辑的无缝访问,也就是说,要实施系统集成工程,以便联结业务流程、实现数据的访问与共享。
JpetStore 4.0是ibatis的最新示例程序,基于Struts MVC框架(注:非传统Struts开发模式),以ibatis作为持久化层。该示例程序设计优雅,层次清晰,可以学习以及作为一个高效率的编程模型参考。本文是在其基础上,采用Spring对其中间层(业务层)进行改造。使开发量进一步减少,同时又拥有了Spring的一些好处…
1. 前言
JpetStore 4.0是ibatis的最新示例程序。ibatis是开源的持久层产品,包含SQL Maps 2.0 和 Data Access Objects 2.0 框架。JpetStore示例程序很好的展示了如何利用ibatis来开发一个典型的J2EE web应用程序。JpetStore有如下特点:
- ibatis数据层
- POJO业务层
- POJO领域类
- Struts MVC
- JSP 表示层
以下是本文用到的关键技术介绍,本文假设您已经对Struts,SpringFramewok,ibatis有一定的了解,如果不是,请首先查阅附录中的参考资料。
- Struts 是目前Java Web MVC框架中不争的王者。经过长达五年的发展,Struts已经逐渐成长为一个稳定、成熟的框架,并且占有了MVC框架中最大的市场份额。但是Struts某些技术特性上已经落后于新兴的MVC框架。面对Spring MVC、Webwork2 这些设计更精密,扩展性更强的框架,Struts受到了前所未有的挑战。但站在产品开发的角度而言,Struts仍然是最稳妥的选择。本文的原型例子JpetStore 4.0就是基于Struts开发的,但是不拘泥于Struts的传统固定用法,例如只用了一个自定义Action类,并且在form bean类的定义上也是开创性的,令人耳目一新,稍后将具体剖析一下。
- Spring Framework 实际上是Expert One-on-One J2EE Design and Development 一书中所阐述的设计思想的具体实现。Spring Framework的功能非常多。包含AOP、ORM、DAO、Context、Web、MVC等几个部分组成。Web、MVC暂不用考虑,JpetStore 4.0用的是更成熟的Struts和JSP;DAO由于目前Hibernate、JDO、ibatis的流行,也不考虑,JpetStore 4.0用的就是ibatis。因此最需要用的是AOP、ORM、Context。Context中,最重要的是Beanfactory,它能将接口与实现分开,非常强大。目前AOP应用最成熟的还是在事务管理上。
- ibatis 是一个功能强大实用的SQL Map工具,不同于其他ORM工具(如hibernate),它是将SQL语句映射成Java对象,而对于ORM工具,它的SQL语句是根据映射定义生成的。ibatis 以SQL开发的工作量和数据库移植性上的让步,为系统设计提供了更大的自由空间。有ibatis代码生成的工具,可以根据DDL自动生成ibatis代码,能减少很多工作量。
2. JpetStore简述
2.1. 背景
最初是Sun公司的J2EE petstore,其最主要目的是用于学习J2EE,但是其缺点也很明显,就是过度设计了。接着Oracle用J2EE petstore来比较各应用服务器的性能。微软推出了基于.Net平台的 Pet shop,用于竞争J2EE petstore。而JpetStore则是经过改良的基于struts的轻便框架J2EE web应用程序,相比来说,JpetStore设计和架构更优良,各层定义清晰,使用了很多最佳实践和模式,避免了很多"反模式",如使用存储过程,在java代码中嵌入SQL语句,把HTML存储在数据库中等等。最新版本是JpetStore 4.0。
2.2. JpetStore开发运行环境的建立
1、开发环境
- Java SDK 1.4.2
- Apache Tomcat 4.1.31
- Eclipse-SDK-3.0.1-win32
- HSQLDB 1.7.2
2、Eclipse插件
- EMF SDK 2.0.1:Eclipse建模框架,lomboz插件需要,可以使用runtime版本。
- lomboz 3.0:J2EE插件,用来在Eclipse中开发J2EE应用程序
- Spring IDE 1.0.3:Spring Bean配置管理插件
- xmlbuddy_2.0.10:编辑XML,用免费版功能即可
- tomcatPluginV3:tomcat管理插件
- Properties Editor:编辑java的属性文件,并可以预览以及自动存盘为Unicode格式。免去了手工或者ANT调用native2ascii的麻烦。
3、示例源程序
- ibatis示例程序JpetStore 4.0 http://www.ibatis.com/jpetstore/jpetstore.html
- 改造后的源程序(+spring)(源码链接)
2.3. 架构
图1 JpetStore架构图
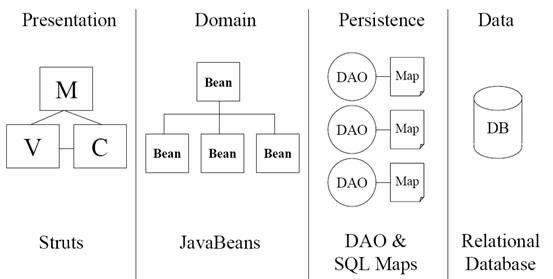
图1 是JPetStore架构图,更详细的内容请参见JPetStore的白皮书。参照这个架构图,让我们稍微剖析一下源代码,得出JpetStore 4.0的具体实现图(见图2),思路一下子就豁然开朗了。前言中提到的非传统的struts开发模式,关键就在struts Action类和form bean类上。
struts Action类只有一个:BeanAction。没错,确实是一个!与传统的struts编程方式很不同。再仔细研究BeanAction类,发现它其实是一个通用类,利用反射原理,根据URL来决定调用formbean的哪个方法。BeanAction大大简化了struts的编程模式,降低了对struts的依赖(与struts以及WEB容器有关的几个类都放在com.ibatis.struts包下,其它的类都可以直接复用)。利用这种模式,我们会很容易的把它移植到新的框架如JSF,spring。
这样重心就转移到form bean上了,它已经不是普通意义上的form bean了。查看源代码,可以看到它不仅仅有数据和校验/重置方法,而且已经具有了行为,从这个意义上来说,它更像一个BO(Business Object)。这就是前文讲到的,BeanAction类利用反射原理,根据URL来决定调用form bean的哪个方法(行为)。form bean的这些方法的签名很简单,例如:
public String myActionMethod() {
//..work
return "success";
}
|
方法的返回值直接就是字符串,对应的是forward的名称,而不再是ActionForward对象,创建ActionForward对象的任务已经由BeanAction类代劳了。
另外,程序还提供了ActionContext工具类,该工具类封装了request 、response、form parameters、request attributes、session attributes和 application attributes中的数据存取操作,简单而线程安全,form bean类使用该工具类可以进一步从表现层框架解耦。
在这里需要特别指出的是,BeanAction类是对struts扩展的一个有益尝试,虽然提供了非常好的应用开发模式,但是它还非常新,一直在发展中。
图2 JpetStore 4.0具体实现
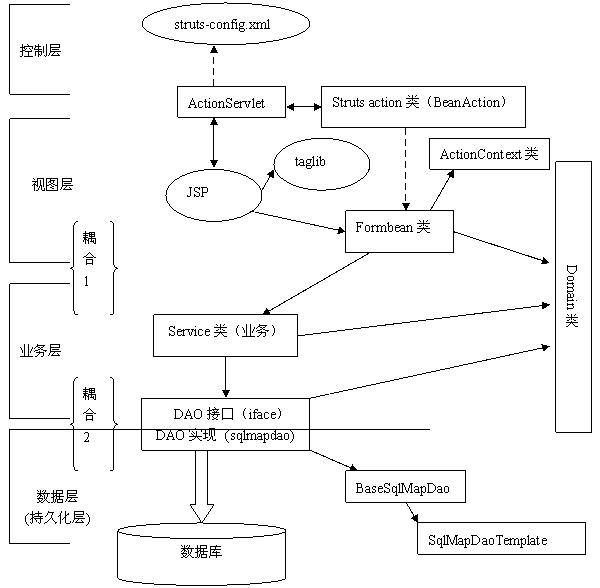
2.4. 代码剖析
下面就让我们开始进一步分析JpetStore4.0的源代码,为下面的改造铺路。
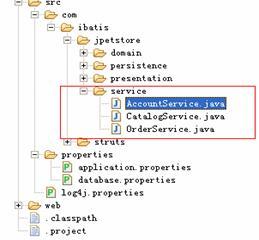
- BeanAction.java是唯一一个Struts action类,位于com.ibatis.struts包下。正如上文所言,它是一个通用的控制类,利用反射机制,把控制转移到form bean的某个方法来处理。详细处理过程参考其源代码,简单明晰。
-
Form bean类位于com.ibatis.jpetstore.presentation包下,命名规则为***Bean。Form bean类全部继承于BaseBean类,而BaseBean类实际继承于ActionForm,因此,Form bean类就是Struts的 ActionForm,Form bean类的属性数据就由struts框架自动填充。而实际上,JpetStore4.0扩展了struts中ActionForm的应用: Form bean类还具有行为,更像一个BO,其行为(方法)由BeanAction根据配置(struts-config.xml)的URL来调用。虽然如此,我们还是把Form bean类定位于表现层。
Struts-config.xml的配置里有3种映射方式,来告诉BeanAction把控制转到哪个form bean对象的哪个方法来处理。
以这个请求连接为例http://localhost/jpetstore4/shop/viewOrder.do
1. URL Pattern
<action path="/shop/viewOrder" type="com.ibatis.struts.BeanAction"
name="orderBean" scope="session"
validate="false">
<forward name="success" path="/order/ViewOrder.jsp"/>
</action>
|
此种方式表示,控制将被转发到"orderBean"这个form bean对象 的"viewOrder"方法(行为)来处理。方法名取"path"参数的以"/"分隔的最后一部分。
2. Method Parameter
<action path="/shop/viewOrder" type="com.ibatis.struts.BeanAction"
name="orderBean" parameter="viewOrder" scope="session"
validate="false">
<forward name="success" path="/order/ViewOrder.jsp"/>
</action>
|
此种方式表示,控制将被转发到"orderBean"这个form bean对象的"viewOrder"方法(行为)来处理。配置中的"parameter"参数表示form bean类上的方法。"parameter"参数优先于"path"参数。
3. No Method call
<action path="/shop/viewOrder" type="com.ibatis.struts.BeanAction"
name="orderBean" parameter="*" scope="session"
validate="false">
<forward name="success" path="/order/ViewOrder.jsp"/>
</action>
|
此种方式表示,form bean上没有任何方法被调用。如果存在"name"属性,则struts把表单参数等数据填充到form bean对象后,把控制转发到"success"。否则,如果name为空,则直接转发控制到"success"。
这就相当于struts内置的org.apache.struts.actions.ForwardAction的功能
<action path="/shop/viewOrder" type="org.apache.struts.actions.ForwardAction"
parameter="/order/ViewOrder.jsp " scope="session" validate="false">
</action>
|
- Service类位于com.ibatis.jpetstore.service包下,属于业务层。这些类封装了业务以及相应的事务控制。Service类由form bean类来调用。
- com.ibatis.jpetstore.persistence.iface包下的类是DAO接口,属于业务层,其屏蔽了底层的数据库操作,供具体的Service类来调用。DaoConfig类是工具类(DAO工厂类),Service类通过DaoConfig类来获得相应的DAO接口,而不用关心底层的具体数据库操作,实现了如图2中{耦合2}的解耦。
- com.ibatis.jpetstore.persistence.sqlmapdao包下的类是对应DAO接口的具体实现,在JpetStore4.0中采用了ibatis来实现ORM。这些实现类继承BaseSqlMapDao类,而BaseSqlMapDao类则继承ibatis DAO 框架中的SqlMapDaoTemplate类。ibatis的配置文件存放在com.ibatis.jpetstore.persistence.sqlmapdao.sql目录下。这些类和配置文件位于数据层
- Domain类位于com.ibatis.jpetstore.domain包下,是普通的javabean。在这里用作数据传输对象(DTO),贯穿视图层、业务层和数据层,用于在不同层之间传输数据。
剩下的部分就比较简单了,请看具体的源代码,非常清晰。
2.5. 需要改造的地方
JpetStore4.0的关键就在struts Action类和form bean类上,这也是其精华之一(虽然该实现方式是试验性,待扩充和验证),在此次改造中我们要保留下来,即控制层一点不变,表现层获取相应业务类的方式变了(要加载spring环境),其它保持不变。要特别关注的改动是业务层和持久层,幸运的是JpetStore4.0设计非常好,需要改动的地方非常少,而且由模式可循,如下:
1. 业务层和数据层用Spring BeanFactory机制管理。
2. 业务层的事务由spring 的aop通过声明来完成。
3. 表现层(form bean)获取业务类的方法改由自定义工厂类来实现(加载spring环境)。
3. JPetStore的改造
3.1. 改造后的架构
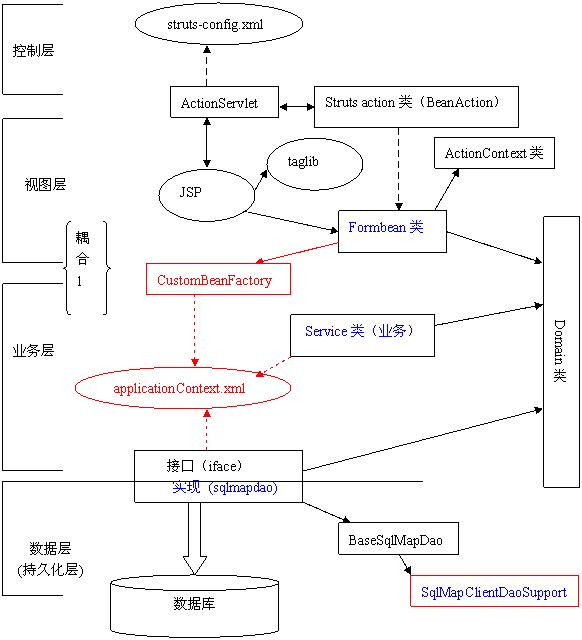
其中红色部分是要增加的部分,蓝色部分是要修改的部分。下面就让我们逐一剖析。
3.2. Spring Context的加载
为了在Struts中加载Spring Context,一般会在struts-config.xml的最后添加如下部分:
<plug-in className="org.springframework.web.struts.ContextLoaderPlugIn">
<set-property property="contextConfigLocation"
value="/WEB-INF/applicationContext.xml" />
</plug-in>
|
Spring在设计时就充分考虑到了与Struts的协同工作,通过内置的Struts Plug-in在两者之间提供了良好的结合点。但是,因为在这里我们一点也不改动JPetStore的控制层(这是JpetStore4.0的精华之一),所以本文不准备采用此方式来加载ApplicationContext。我们利用的是spring framework 的BeanFactory机制,采用自定义的工具类(bean工厂类)来加载spring的配置文件,从中可以看出Spring有多灵活,它提供了各种不同的方式来使用其不同的部分/层次,您只需要用你想用的,不需要的部分可以不用。
具体的来说,就是在com.ibatis.spring包下创建CustomBeanFactory类,spring的配置文件applicationContext.xml也放在这个目录下。以下就是该类的全部代码,很简单:
public final class CustomBeanFactory {
static XmlBeanFactory factory = null;
static {
Resource is = new
InputStreamResource( CustomBeanFactory.class.getResourceAsStream("applicationContext.xml"));
factory = new XmlBeanFactory(is);
}
public static Object getBean(String beanName){
return factory.getBean(beanName);
}
}
|
实际上就是封装了Spring 的XMLBeanFactory而已,并且Spring的配置文件只需要加载一次,以后就可以直接用CustomBeanFactory.getBean("someBean")来获得需要的对象了(例如someBean),而不需要知道具体的类。CustomBeanFactory类用于{耦合1}的解耦。
CustomBeanFactory类在本文中只用于表现层的form bean对象获得service类的对象,因为我们没有把form bean对象配置在applicationContext.xml中。但是,为什么不把表现层的form bean类也配置起来呢,这样就用不着这CustomBeanFactory个类了,Spring会帮助我们创建需要的一切?问题的答案就在于form bean类是struts的ActionForm类!如果大家熟悉struts,就会知道ActionForm类是struts自动创建的:在一次请求中,struts判断,如果ActionForm实例不存在,就创建一个ActionForm对象,把客户提交的表单数据保存到ActionForm对象中。因此formbean类的对象就不能由spring来创建,但是service类以及数据层的DAO类可以,所以只有他们在spring中配置。
所以,很自然的,我们就创建了CustomBeanFactory类,在表现层来衔接struts和spring。就这么简单,实现了另一种方式的{耦合一}的解耦。
3.3. 表现层
上 面分析到,struts和spring是在表现层衔接起来的,那么表现层就要做稍微的更改,即所需要的service类的对象创建上。以表现层的AccountBean类为例:
原来的源代码如下
private static final AccountService accountService = AccountService.getInstance();
private static final CatalogService catalogService = CatalogService.getInstance();
|
改造后的源代码如下
private static final AccountService accountService = (AccountService)CustomBeanFactory.getBean("AccountService");
private static final CatalogService catalogService = (CatalogService)CustomBeanFactory.getBean("CatalogService");
|
其他的几个presentation类以同样方式改造。这样,表现层就完成了。关于表现层的其它部分如JSP等一概不动。也许您会说,没有看出什么特别之处的好处啊?你还是额外实现了一个工厂类。别着急,帷幕刚刚开启,spring是在表现层引入,但您发没发现:
- presentation类仅仅面向service类的接口编程,具体"AccountService"是哪个实现类,presentation类不知道,是在spring的配置文件里配置。(本例中,为了最大限度的保持原来的代码不作变化,没有抽象出接口)。Spring鼓励面向接口编程,因为是如此的方便和自然,当然您也可以不这么做。
- CustomBeanFactory这个工厂类为什么会如此简单,因为其直接使用了Spring的BeanFactory。Spring从其核心而言,是一个DI容器,其设计哲学是提供一种无侵入式的高扩展性的框架。为了实现这个目标,Spring 大量引入了Java 的Reflection机制,通过动态调用的方式避免硬编码方式的约束,并在此基础上建立了其核心组件BeanFactory,以此作为其依赖注入机制的实现基础。org.springframework.beans包中包括了这些核心组件的实现类,核心中的核心为BeanWrapper和BeanFactory类。
3.4. 持久层
在讨论业务层之前,我们先看一下持久层,如下图所示:
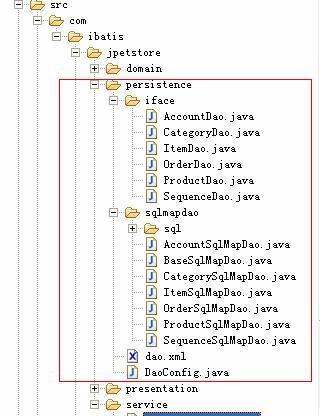
在上文中,我们把iface包下的DAO接口归为业务层,在这里不需要做修改。ibatis的sql配置文件也不需要改。要改的是DAO实现类,并在spring的配置文件中配置起来。
1、修改基类
所有的DAO实现类都继承于BaseSqlMapDao类。修改BaseSqlMapDao类如下:
public class BaseSqlMapDao extends SqlMapClientDaoSupport {
protected static final int PAGE_SIZE = 4;
protected SqlMapClientTemplate smcTemplate = this.getSqlMapClientTemplate();
public BaseSqlMapDao() {
}
}
|
使BaseSqlMapDao类改为继承于Spring提供的SqlMapClientDaoSupport类,并定义了一个保护属性smcTemplate,其类型为SqlMapClientTemplate。关于SqlMapClientTemplate类的详细说明请参照附录中的"Spring中文参考手册"
2、修改DAO实现类
所有的DAO实现类还是继承于BaseSqlMapDao类,实现相应的DAO接口,但其相应的DAO操作委托SqlMapClientTemplate来执行,以AccountSqlMapDao类为例,部分代码如下:
public List getUsernameList() {
return smcTemplate.queryForList("getUsernameList", null);
}
public Account getAccount(String username, String password) {
Account account = new Account();
account.setUsername(username);
account.setPassword(password);
return (Account) smcTemplate.queryForObject("getAccountByUsernameAndPassword", account);
}
public void insertAccount(Account account) {
smcTemplate.update("insertAccount", account);
smcTemplate.update("insertProfile", account);
smcTemplate.update("insertSignon", account);
}
|
就这么简单,所有函数的签名都是一样的,只需要查找替换就可以了!
3、除去工厂类以及相应的配置文件
除去DaoConfig.java这个DAO工厂类和相应的配置文件dao.xml,因为DAO的获取现在要用spring来管理。
4、DAO在Spring中的配置(applicationContext.xml)
<bean id="dataSource"
class="org.springframework.jdbc.datasource.DriverManagerDataSource">
<property name="driverClassName">
<value>org.hsqldb.jdbcDriver</value>
</property>
<property name="url">
<value>jdbc:hsqldb:hsql://localhost/xdb</value>
</property>
<property name="username">
<value>sa</value>
</property>
<property name="password">
<value></value>
</property>
</bean>
<!-- ibatis sqlMapClient config -->
<bean id="sqlMapClient"
class="org.springframework.orm.ibatis.SqlMapClientFactoryBean">
<property name="configLocation">
<value>
classpath:com\ibatis\jpetstore\persistence\sqlmapdao\sql\sql-map-config.xml
</value>
</property>
<property name="dataSource">
<ref bean="dataSource"/>
</property>
</bean>
<!-- Transactions -->
<bean id="TransactionManager"
class="org.springframework.jdbc.datasource.DataSourceTransactionManager">
<property name="dataSource">
<ref bean="dataSource"/>
</property>
</bean>
<!-- persistence layer -->
<bean id="AccountDao"
class="com.ibatis.jpetstore.persistence.sqlmapdao.AccountSqlMapDao">
<property name="sqlMapClient">
<ref local="sqlMapClient"/>
</property>
</bean>
|
具体的语法请参照附录中的"Spring中文参考手册"。在这里只简单解释一下:
1. 我们首先创建一个数据源dataSource,在这里配置的是hsqldb数据库。如果是ORACLE数据库,driverClassName的值是"oracle.jdbc.driver.OracleDriver",URL的值类似于"jdbc:oracle:thin:@wugfMobile:1521:cdcf"。数据源现在由spring来管理,那么现在我们就可以去掉properties目录下database.properties这个配置文件了;还有不要忘记修改sql-map-config.xml,去掉<properties resource="properties/database.properties"/>对它的引用。
2. sqlMapClient节点。这个是针对ibatis SqlMap的SqlMapClientFactoryBean配置。实际上配置了一个sqlMapClient的创建工厂类。configLocation属性配置了ibatis映射文件的名称。dataSource属性指向了使用的数据源,这样所有使用sqlMapClient的DAO都默认使用了该数据源,除非在DAO的配置中另外显式指定。
3. TransactionManager节点。定义了事务,使用的是DataSourceTransactionManager。
4. 下面就可以定义DAO节点了,如AccountDao,它的实现类是com.ibatis.jpetstore.persistence.sqlmapdao.AccountSqlMapDao,使用的SQL配置从sqlMapClient中读取,数据库连接没有特别列出,那么就是默认使用sqlMapClient配置的数据源datasource。
这样,我们就把持久层改造完了,其他的DAO配置类似于AccountDao。怎么样?简单吧。这次有接口了:) AccountDao接口->AccountSqlMapDao实现。
3.5. 业务层
业务层的位置以及相关类,如下图所示:
在这个例子中只有3个业务类,我们以OrderService类为例来改造,这个类是最复杂的,其中涉及了事务。
1、在ApplicationContext配置文件中增加bean的配置:
<bean id="OrderService"
class="org.springframework.transaction.interceptor.TransactionProxyFactoryBean">
<property name="transactionManager">
<ref local="TransactionManager"></ref>
</property>
<property name="target">
<bean class="com.ibatis.jpetstore.service.OrderService">
<property name="itemDao">
<ref bean="ItemDao"/>
</property>
<property name="orderDao">
<ref bean="OrderDao"/>
</property>
<property name="sequenceDao">
<ref bean="SequenceDao"/>
</property>
</bean>
</property>
<property name="transactionAttributes">
<props>
<prop key="insert*">PROPAGATION_REQUIRED</prop>
</props>
</property>
</bean>
|
定义了一个OrderService,还是很容易懂的。为了简单起见,使用了嵌套bean,其实现类是com.ibatis.jpetstore.service.OrderService,分别引用了ItemDao,OrderDao,SequenceDao。该bean的insert*实现了事务管理(AOP方式)。TransactionProxyFactoryBean自动创建一个事务advisor, 该advisor包括一个基于事务属性的pointcut,因此只有事务性的方法被拦截。
2、业务类的修改
以OrderService为例:
public class OrderService {
/* Private Fields */
private ItemDao itemDao;
private OrderDao orderDao;
private SequenceDao sequenceDao;
/* Constructors */
public OrderService() {
}
/**
* @param itemDao 要设置的 itemDao。
*/
public final void setItemDao(ItemDao itemDao) {
this.itemDao = itemDao;
}
/**
* @param orderDao 要设置的 orderDao。
*/
public final void setOrderDao(OrderDao orderDao) {
this.orderDao = orderDao;
}
/**
* @param sequenceDao 要设置的 sequenceDao。
*/
public final void setSequenceDao(SequenceDao sequenceDao) {
this.sequenceDao = sequenceDao;
}
//剩下的部分
…….
}
|
红色部分为修改部分。Spring采用的是Type2的设置依赖注入,所以我们只需要定义属性和相应的设值函数就可以了,ItemDao,OrderDao,SequenceDao的值由spring在运行期间注入。构造函数就可以为空了,另外也不需要自己编写代码处理事务了(事务在配置中声明),daoManager.startTransaction();等与事务相关的语句也可以去掉了。和原来的代码比较一下,是不是处理精简了很多!可以更关注业务的实现。
4. 结束语
ibatis是一个功能强大实用的SQL Map工具,可以直接控制SQL,为系统设计提供了更大的自由空间。其提供的最新示例程序JpetStore 4.0,设计优雅,应用了迄今为止很多最佳实践和设计模式,非常适于学习以及在此基础上创建轻量级的J2EE WEB应用程序。JpetStore 4.0是基于struts的,本文在此基础上,最大程度保持了原有设计的精华以及最小的代码改动量,在业务层和持久化层引入了Spring。在您阅读了本文以及改造后的源代码后,会深切的感受到Spring带来的种种好处:自然的面向接口的编程,业务对象的依赖注入,一致的数据存取框架和声明式的事务处理,统一的配置文件…更重要的是Spring既是全面的又是模块化的,Spring有分层的体系结构,这意味着您能选择仅仅使用它任何一个独立的部分,就像本文,而它的架构又是内部一致。
Lucene 是基于 Java 的全文信息检索包,它目前是 Apache Jakarta 家族下面的一个开源项目。在这篇文章中,我们首先来看如何利用 Lucene 实现高级搜索功能,然后学习如何利用 Lucene 来创建一个健壮的 Web 搜索应用程序。
在本篇文章中,你会学习到如何利用 Lucene 实现高级搜索功能以及如何利用 Lucene 来创建 Web 搜索应用程序。通过这些学习,你就可以利用 Lucene 来创建自己的搜索应用程序。
架构概览
通常一个 Web 搜索引擎的架构分为前端和后端两部分,就像图一中所示。在前端流程中,用户在搜索引擎提供的界面中输入要搜索的关键词,这里提到的用户界面一般是一个带有输入框的 Web 页面,然后应用程序将搜索的关键词解析成搜索引擎可以理解的形式,并在索引文件上进行搜索操作。在排序后,搜索引擎返回搜索结果给用户。在后端流程中,网络爬虫或者机器人从因特网上获取 Web 页面,然后索引子系统解析这些 Web 页面并存入索引文件中。如果你想利用 Lucene 来创建一个 Web 搜索应用程序,那么它的架构也和上面所描述的类似,就如图一中所示。
Figure 1. Web 搜索引擎架构

利用 Lucene 实现高级搜索
Lucene 支持多种形式的高级搜索,我们在这一部分中会进行探讨,然后我会使用 Lucene 的 API 来演示如何实现这些高级搜索功能。
布尔操作符
大多数的搜索引擎都会提供布尔操作符让用户可以组合查询,典型的布尔操作符有 AND, OR, NOT。Lucene 支持 5 种布尔操作符,分别是 AND, OR, NOT, 加(+), 减(-)。接下来我会讲述每个操作符的用法。
-
OR: 如果你要搜索含有字符 A 或者 B 的文档,那么就需要使用 OR 操作符。需要记住的是,如果你只是简单的用空格将两个关键词分割开,其实在搜索的时候搜索引擎会自动在两个关键词之间加上 OR 操作符。例如,“Java OR Lucene” 和 “Java Lucene” 都是搜索含有 Java 或者含有 Lucene 的文档。
-
AND: 如果你需要搜索包含一个以上关键词的文档,那么就需要使用 AND 操作符。例如,“Java AND Lucene” 返回所有既包含 Java 又包含 Lucene 的文档。
-
NOT: Not 操作符使得包含紧跟在 NOT 后面的关键词的文档不会被返回。例如,如果你想搜索所有含有 Java 但不含有 Lucene 的文档,你可以使用查询语句 “Java NOT Lucene”。但是你不能只对一个搜索词使用这个操作符,比如,查询语句 “NOT Java” 不会返回任何结果。
-
加号(+): 这个操作符的作用和 AND 差不多,但它只对紧跟着它的一个搜索词起作用。例如,如果你想搜索一定包含 Java,但不一定包含 Lucene 的文档,就可以使用查询语句“+Java Lucene”。
-
减号(-): 这个操作符的功能和 NOT 一样,查询语句 “Java -Lucene” 返回所有包含 Java 但不包含 Lucene 的文档。
接下来我们看一下如何利用 Lucene 提供的 API 来实现布尔查询。清单1 显示了如果利用布尔操作符进行查询的过程。
清单1:使用布尔操作符
//Test boolean operator
public void testOperator(String indexDirectory) throws Exception{
Directory dir = FSDirectory.getDirectory(indexDirectory,false);
IndexSearcher indexSearcher = new IndexSearcher(dir);
String[] searchWords = {"Java AND Lucene", "Java NOT Lucene", "Java OR Lucene",
"+Java +Lucene", "+Java -Lucene"};
Analyzer language = new StandardAnalyzer();
Query query;
for(int i = 0; i < searchWords.length; i++){
query = QueryParser.parse(searchWords[i], "title", language);
Hits results = indexSearcher.search(query);
System.out.println(results.length() + "search results for query " + searchWords[i]);
}
}
|
域搜索(Field Search)
Lucene 支持域搜索,你可以指定一次查询是在哪些域(Field)上进行。例如,如果索引的文档包含两个域,Title 和 Content,你就可以使用查询 “Title: Lucene AND Content: Java” 来返回所有在 Title 域上包含 Lucene 并且在 Content 域上包含 Java 的文档。清单 2 显示了如何利用 Lucene 的 API 来实现域搜索。
清单2:实现域搜索
//Test field search
public void testFieldSearch(String indexDirectory) throws Exception{
Directory dir = FSDirectory.getDirectory(indexDirectory,false);
IndexSearcher indexSearcher = new IndexSearcher(dir);
String searchWords = "title:Lucene AND content:Java";
Analyzer language = new StandardAnalyzer();
Query query = QueryParser.parse(searchWords, "title", language);
Hits results = indexSearcher.search(query);
System.out.println(results.length() + "search results for query " + searchWords);
}
|
通配符搜索(Wildcard Search)
Lucene 支持两种通配符:问号(?)和星号(*)。你可以使用问号(?)来进行单字符的通配符查询,或者利用星号(*)进行多字符的通配符查询。例如,如果你想搜索 tiny 或者 tony,你就可以使用查询语句 “t?ny”;如果你想查询 Teach, Teacher 和 Teaching,你就可以使用查询语句 “Teach*”。清单3 显示了通配符查询的过程。
清单3:进行通配符查询
//Test wildcard search
public void testWildcardSearch(String indexDirectory)throws Exception{
Directory dir = FSDirectory.getDirectory(indexDirectory,false);
IndexSearcher indexSearcher = new IndexSearcher(dir);
String[] searchWords = {"tex*", "tex?", "?ex*"};
Query query;
for(int i = 0; i < searchWords.length; i++){
query = new WildcardQuery(new Term("title",searchWords[i]));
Hits results = indexSearcher.search(query);
System.out.println(results.length() + "search results for query " + searchWords[i]);
}
}
|
模糊查询
Lucene 提供的模糊查询基于编辑距离算法(Edit distance algorithm)。你可以在搜索词的尾部加上字符 ~ 来进行模糊查询。例如,查询语句 “think~” 返回所有包含和 think 类似的关键词的文档。清单 4 显示了如果利用 Lucene 的 API 进行模糊查询的代码。
清单4:实现模糊查询
//Test fuzzy search
public void testFuzzySearch(String indexDirectory)throws Exception{
Directory dir = FSDirectory.getDirectory(indexDirectory,false);
IndexSearcher indexSearcher = new IndexSearcher(dir);
String[] searchWords = {"text", "funny"};
Query query;
for(int i = 0; i < searchWords.length; i++){
query = new FuzzyQuery(new Term("title",searchWords[i]));
Hits results = indexSearcher.search(query);
System.out.println(results.length() + "search results for query " + searchWords[i]);
}
}
|
范围搜索(Range Search)
范围搜索匹配某个域上的值在一定范围的文档。例如,查询 “age:[18 TO 35]” 返回所有 age 域上的值在 18 到 35 之间的文档。清单5显示了利用 Lucene 的 API 进行返回搜索的过程。
清单5:测试范围搜索
//Test range search
public void testRangeSearch(String indexDirectory)throws Exception{
Directory dir = FSDirectory.getDirectory(indexDirectory,false);
IndexSearcher indexSearcher = new IndexSearcher(dir);
Term begin = new Term("birthDay","20000101");
Term end = new Term("birthDay","20060606");
Query query = new RangeQuery(begin,end,true);
Hits results = indexSearcher.search(query);
System.out.println(results.length() + "search results is returned");
}
|
在 Web 应用程序中集成 Lucene
接下来我们开发一个 Web 应用程序利用 Lucene 来检索存放在文件服务器上的 HTML 文档。在开始之前,需要准备如下环境:
- Eclipse 集成开发环境
- Tomcat 5.0
- Lucene Library
- JDK 1.5
这个例子使用 Eclipse 进行 Web 应用程序的开发,最终这个 Web 应用程序跑在 Tomcat 5.0 上面。在准备好开发所必需的环境之后,我们接下来进行 Web 应用程序的开发。
1、创建一个动态 Web 项目
- 在 Eclipse 里面,选择 File > New > Project,然后再弹出的窗口中选择动态 Web 项目,如图二所示。
图二:创建动态Web项目

- 在创建好动态 Web 项目之后,你会看到创建好的项目的结构,如图三所示,项目的名称为 sample.dw.paper.lucene。
图三:动态 Web 项目的结构

2. 设计 Web 项目的架构
在我们的设计中,把该系统分成如下四个子系统:
-
用户接口: 这个子系统提供用户界面使用户可以向 Web 应用程序服务器提交搜索请求,然后搜索结果通过用户接口来显示出来。我们用一个名为 search.jsp 的页面来实现该子系统。
-
请求管理器: 这个子系统管理从客户端发送过来的搜索请求并把搜索请求分发到搜索子系统中。最后搜索结果从搜索子系统返回并最终发送到用户接口子系统。我们使用一个 Servlet 来实现这个子系统。
-
搜索子系统: 这个子系统负责在索引文件上进行搜索并把搜索结构传递给请求管理器。我们使用 Lucene 提供的 API 来实现该子系统。
-
索引子系统: 这个子系统用来为 HTML 页面来创建索引。我们使用 Lucene 的 API 以及 Lucene 提供的一个 HTML 解析器来创建该子系统。
图4
显示了我们设计的详细信息,我们将用户接口子系统放到 webContent 目录下面。你会看到一个名为 search.jsp 的页面在这个文件夹里面。请求管理子系统在包 sample.dw.paper.lucene.servlet 下面,类 SearchController 负责功能的实现。搜索子系统放在包 sample.dw.paper.lucene.search 当中,它包含了两个类,SearchManager 和 SearchResultBean,第一个类用来实现搜索功能,第二个类用来描述搜索结果的结构。索引子系统放在包 sample.dw.paper.lucene.index 当中。类 IndexManager 负责为 HTML 文件创建索引。该子系统利用包 sample.dw.paper.lucene.util 里面的类 HTMLDocParser 提供的方法 getTitle 和 getContent 来对 HTML 页面进行解析。
图四:项目的架构设计

3. 子系统的实现
在分析了系统的架构设计之后,我们接下来看系统实现的详细信息。
-
用户接口: 这个子系统有一个名为 search.jsp 的 JSP 文件来实现,这个 JSP 页面包含两个部分。第一部分提供了一个用户接口去向 Web 应用程序服务器提交搜索请求,如图5所示。注意到这里的搜索请求发送到了一个名为 SearchController 的 Servlet 上面。Servlet 的名字和具体实现的类的对应关系在 web.xml 里面指定。
图5:向Web服务器提交搜索请求

这个JSP的第二部分负责显示搜索结果给用户,如图6所示:
图6:显示搜索结果

-
请求管理器: 一个名为
SearchController 的 servlet 用来实现该子系统。清单6给出了这个类的源代码。
清单6:请求管理器的实现
package sample.dw.paper.lucene.servlet;
import java.io.IOException;
import java.util.List;
import javax.servlet.RequestDispatcher;
import javax.servlet.ServletException;
import javax.servlet.http.HttpServlet;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
import sample.dw.paper.lucene.search.SearchManager;
/**
* This servlet is used to deal with the search request
* and return the search results to the client
*/
public class SearchController extends HttpServlet{
private static final long serialVersionUID = 1L;
public void doPost(HttpServletRequest request, HttpServletResponse response)
throws IOException, ServletException{
String searchWord = request.getParameter("searchWord");
SearchManager searchManager = new SearchManager(searchWord);
List searchResult = null;
searchResult = searchManager.search();
RequestDispatcher dispatcher = request.getRequestDispatcher("search.jsp");
request.setAttribute("searchResult",searchResult);
dispatcher.forward(request, response);
}
public void doGet(HttpServletRequest request, HttpServletResponse response)
throws IOException, ServletException{
doPost(request, response);
}
}
|
在清单6中,doPost 方法从客户端获取搜索词并创建类 SearchManager 的一个实例,其中类 SearchManager 在搜索子系统中进行了定义。然后,SearchManager 的方法 search 会被调用。最后搜索结果被返回到客户端。
-
搜索子系统: 在这个子系统中,我们定义了两个类:
SearchManager 和 SearchResultBean。第一个类用来实现搜索功能,第二个类是个JavaBean,用来描述搜索结果的结构。清单7给出了类 SearchManager 的源代码。
清单7:搜索功能的实现
package sample.dw.paper.lucene.search;
import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
import org.apache.lucene.analysis.Analyzer;
import org.apache.lucene.analysis.standard.StandardAnalyzer;
import org.apache.lucene.queryParser.ParseException;
import org.apache.lucene.queryParser.QueryParser;
import org.apache.lucene.search.Hits;
import org.apache.lucene.search.IndexSearcher;
import org.apache.lucene.search.Query;
import sample.dw.paper.lucene.index.IndexManager;
/**
* This class is used to search the
* Lucene index and return search results
*/
public class SearchManager {
private String searchWord;
private IndexManager indexManager;
private Analyzer analyzer;
public SearchManager(String searchWord){
this.searchWord = searchWord;
this.indexManager = new IndexManager();
this.analyzer = new StandardAnalyzer();
}
/**
* do search
*/
public List search(){
List searchResult = new ArrayList();
if(false == indexManager.ifIndexExist()){
try {
if(false == indexManager.createIndex()){
return searchResult;
}
} catch (IOException e) {
e.printStackTrace();
return searchResult;
}
}
IndexSearcher indexSearcher = null;
try{
indexSearcher = new IndexSearcher(indexManager.getIndexDir());
}catch(IOException ioe){
ioe.printStackTrace();
}
QueryParser queryParser = new QueryParser("content",analyzer);
Query query = null;
try {
query = queryParser.parse(searchWord);
} catch (ParseException e) {
e.printStackTrace();
}
if(null != query >> null != indexSearcher){
try {
Hits hits = indexSearcher.search(query);
for(int i = 0; i < hits.length(); i ++){
SearchResultBean resultBean = new SearchResultBean();
resultBean.setHtmlPath(hits.doc(i).get("path"));
resultBean.setHtmlTitle(hits.doc(i).get("title"));
searchResult.add(resultBean);
}
} catch (IOException e) {
e.printStackTrace();
}
}
return searchResult;
}
}
|
在清单7中,注意到在这个类里面有三个私有属性。第一个是 searchWord,代表了来自客户端的搜索词。第二个是 indexManager,代表了在索引子系统中定义的类 IndexManager 的一个实例。第三个是 analyzer,代表了用来解析搜索词的解析器。现在我们把注意力放在方法 search 上面。这个方法首先检查索引文件是否已经存在,如果已经存在,那么就在已经存在的索引上进行检索,如果不存在,那么首先调用类 IndexManager 提供的方法来创建索引,然后在新创建的索引上进行检索。搜索结果返回后,这个方法从搜索结果中提取出需要的属性并为每个搜索结果生成类 SearchResultBean 的一个实例。最后这些 SearchResultBean 的实例被放到一个列表里面并返回给请求管理器。
在类 SearchResultBean 中,含有两个属性,分别是 htmlPath 和 htmlTitle,以及这个两个属性的 get 和 set 方法。这也意味着我们的搜索结果包含两个属性:htmlPath 和 htmlTitle,其中 htmlPath 代表了 HTML 文件的路径,htmlTitle 代表了 HTML 文件的标题。
-
索引子系统: 类
IndexManager 用来实现这个子系统。清单8 给出了这个类的源代码。
清单8:索引子系统的实现
package sample.dw.paper.lucene.index;
import java.io.File;
import java.io.IOException;
import java.io.Reader;
import org.apache.lucene.analysis.Analyzer;
import org.apache.lucene.analysis.standard.StandardAnalyzer;
import org.apache.lucene.document.Document;
import org.apache.lucene.document.Field;
import org.apache.lucene.index.IndexWriter;
import org.apache.lucene.store.Directory;
import org.apache.lucene.store.FSDirectory;
import sample.dw.paper.lucene.util.HTMLDocParser;
/**
* This class is used to create an index for HTML files
*
*/
public class IndexManager {
//the directory that stores HTML files
private final String dataDir = "c:\\dataDir";
//the directory that is used to store a Lucene index
private final String indexDir = "c:\\indexDir";
/**
* create index
*/
public boolean createIndex() throws IOException{
if(true == ifIndexExist()){
return true;
}
File dir = new File(dataDir);
if(!dir.exists()){
return false;
}
File[] htmls = dir.listFiles();
Directory fsDirectory = FSDirectory.getDirectory(indexDir, true);
Analyzer analyzer = new StandardAnalyzer();
IndexWriter indexWriter = new IndexWriter(fsDirectory, analyzer, true);
for(int i = 0; i < htmls.length; i++){
String htmlPath = htmls[i].getAbsolutePath();
if(htmlPath.endsWith(".html") || htmlPath.endsWith(".htm")){
addDocument(htmlPath, indexWriter);
}
}
indexWriter.optimize();
indexWriter.close();
return true;
}
/**
* Add one document to the Lucene index
*/
public void addDocument(String htmlPath, IndexWriter indexWriter){
HTMLDocParser htmlParser = new HTMLDocParser(htmlPath);
String path = htmlParser.getPath();
String title = htmlParser.getTitle();
Reader content = htmlParser.getContent();
Document document = new Document();
document.add(new Field("path",path,Field.Store.YES,Field.Index.NO));
document.add(new Field("title",title,Field.Store.YES,Field.Index.TOKENIZED));
document.add(new Field("content",content));
try {
indexWriter.addDocument(document);
} catch (IOException e) {
e.printStackTrace();
}
}
/**
* judge if the index exists already
*/
public boolean ifIndexExist(){
File directory = new File(indexDir);
if(0 < directory.listFiles().length){
return true;
}else{
return false;
}
}
public String getDataDir(){
return this.dataDir;
}
public String getIndexDir(){
return this.indexDir;
}
}
|
这个类包含两个私有属性,分别是 dataDir 和 indexDir。dataDir 代表存放等待进行索引的 HTML 页面的路径,indexDir 代表了存放 Lucene 索引文件的路径。类 IndexManager 提供了三个方法,分别是 createIndex, addDocument 和 ifIndexExist。如果索引不存在的话,你可以使用方法 createIndex 去创建一个新的索引,用方法 addDocument 去向一个索引上添加文档。在我们的场景中,一个文档就是一个 HTML 页面。方法 addDocument 会调用由类 HTMLDocParser 提供的方法对 HTML 文档进行解析。你可以使用最后一个方法 ifIndexExist 来判断 Lucene 的索引是否已经存在。
现在我们来看一下放在包 sample.dw.paper.lucene.util 里面的类 HTMLDocParser。这个类用来从 HTML 文件中提取出文本信息。这个类包含三个方法,分别是 getContent,getTitle 和 getPath。第一个方法返回去除了 HTML 标记的文本内容,第二个方法返回 HTML 文件的标题,最后一个方法返回 HTML 文件的路径。清单9 给出了这个类的源代码。
清单9:HTML 解析器
package sample.dw.paper.lucene.util;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.IOException;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.io.Reader;
import java.io.UnsupportedEncodingException;
import org.apache.lucene.demo.html.HTMLParser;
public class HTMLDocParser {
private String htmlPath;
private HTMLParser htmlParser;
public HTMLDocParser(String htmlPath){
this.htmlPath = htmlPath;
initHtmlParser();
}
private void initHtmlParser(){
InputStream inputStream = null;
try {
inputStream = new FileInputStream(htmlPath);
} catch (FileNotFoundException e) {
e.printStackTrace();
}
if(null != inputStream){
try {
htmlParser = new HTMLParser(new InputStreamReader(inputStream, "utf-8"));
} catch (UnsupportedEncodingException e) {
e.printStackTrace();
}
}
}
public String getTitle(){
if(null != htmlParser){
try {
return htmlParser.getTitle();
} catch (IOException e) {
e.printStackTrace();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
return "";
}
public Reader getContent(){
if(null != htmlParser){
try {
return htmlParser.getReader();
} catch (IOException e) {
e.printStackTrace();
}
}
return null;
}
public String getPath(){
return this.htmlPath;
}
}
|
5.在 Tomcat 5.0 上运行应用程序
现在我们可以在 Tomcat 5.0 上运行开发好的应用程序。
- 右键单击 search.jsp,然后选择 Run as > Run on Server,如图7所示。
图7:配置 Tomcat 5.0

- 在弹出的窗口中,选择 Tomcat v5.0 Server 作为目标 Web 应用程序服务器,然后点击 Next,如图8 所示:
图8:选择 Tomcat 5.0

- 现在需要指定用来运行 Web 应用程序的 Apache Tomcat 5.0 以及 JRE 的路径。这里你所选择的 JRE 的版本必须和你用来编译 Java 文件的 JRE 的版本一致。配置好之后,点击 Finish。如 图9 所示。
图9:完成Tomcat 5.0的配置

- 配置好之后,Tomcat 会自动运行,并且会对 search.jsp 进行编译并显示给用户。如 图10 所示。
图10:用户界面

- 在输入框中输入关键词 “information” 然后单击 Search 按钮。然后这个页面上会显示出搜索结果来,如 图11 所示。
图11:搜索结果

- 单击搜索结果的第一个链接,页面上就会显示出所链接到的页面的内容。如 图12 所示.
图12:详细信息

现在我们已经成功的完成了示例项目的开发,并成功的用Lucene实现了搜索和索引功能。你可以下载这个项目的源代码(下载)。
总结
Lucene 提供了灵活的接口使我们更加方便的设计我们的 Web 搜索应用程序。如果你想在你的应用程序中加入搜索功能,那么 Lucene 是一个很好的选择。在设计你的下一个带有搜索功能的应用程序的时候可以考虑使用 Lucene 来提供搜索功能。
使用Windows操作系统的朋友对Excel(电子表格)一定不会陌生,但是要使用Java语言来操纵Excel文件并不是一件容易的事。在Web应用日益盛行的今天,通过Web来操作Excel文件的需求越来越强烈,目前较为流行的操作是在JSP或Servlet 中创建一个CSV (comma separated values)文件,并将这个文件以MIME,text/csv类型返回给浏览器,接着浏览器调用Excel并且显示CSV文件。这样只是说可以访问到Excel文件,但是还不能真正的操纵Excel文件,本文将给大家一个惊喜,向大家介绍一个开放源码项目,Java Excel API,使用它大家就可以方便地操纵Excel文件了。
JAVA EXCEL API简介
Java Excel是一开放源码项目,通过它Java开发人员可以读取Excel文件的内容、创建新的Excel文件、更新已经存在的Excel文件。使用该API非Windows操作系统也可以通过纯Java应用来处理Excel数据表。因为是使用Java编写的,所以我们在Web应用中可以通过JSP、Servlet来调用API实现对Excel数据表的访问。
现在发布的稳定版本是V2.0,提供以下功能:
从Excel 95、97、2000等格式的文件中读取数据;
读取Excel公式(可以读取Excel 97以后的公式);
生成Excel数据表(格式为Excel 97);
支持字体、数字、日期的格式化;
支持单元格的阴影操作,以及颜色操作;
修改已经存在的数据表;
现在还不支持以下功能,但不久就会提供了:
不能够读取图表信息;
可以读,但是不能生成公式,任何类型公式最后的计算值都可以读出;
应用示例
1 从Excel文件读取数据表
Java Excel API既可以从本地文件系统的一个文件(.xls),也可以从输入流中读取Excel数据表。读取Excel数据表的第一步是创建Workbook(术语:工作薄),下面的代码片段举例说明了应该如何操作:(完整代码见ExcelReading.java)
import java.io.*;
import jxl.*;
… … … …
try
{
//构建Workbook对象, 只读Workbook对象
//直接从本地文件创建Workbook
//从输入流创建Workbook
InputStream is = new FileInputStream(sourcefile);
jxl.Workbook rwb = Workbook.getWorkbook(is);
}
catch (Exception e)
{
e.printStackTrace();
}
一旦创建了Workbook,我们就可以通过它来访问Excel Sheet(术语:工作表)。参考下面的代码片段:
//获取第一张Sheet表
Sheet rs = rwb.getSheet(0);
我们既可能通过Sheet的名称来访问它,也可以通过下标来访问它。如果通过下标来访问的话,要注意的一点是下标从0开始,就像数组一样。
一旦得到了Sheet,我们就可以通过它来访问Excel Cell(术语:单元格)。参考下面的代码片段:
//获取第一行,第一列的值
Cell c00 = rs.getCell(0, 0);
String strc00 = c00.getContents();
//获取第一行,第二列的值
Cell c10 = rs.getCell(1, 0);
String strc10 = c10.getContents();
//获取第二行,第二列的值
Cell c11 = rs.getCell(1, 1);
String strc11 = c11.getContents();
System.out.println("Cell(0, 0)" + " value : " + strc00 + "; type : " + c00.getType());
System.out.println("Cell(1, 0)" + " value : " + strc10 + "; type : " + c10.getType());
System.out.println("Cell(1, 1)" + " value : " + strc11 + "; type : " + c11.getType());
如果仅仅是取得Cell的值,我们可以方便地通过getContents()方法,它可以将任何类型的Cell值都作为一个字符串返回。示例代码中Cell(0, 0)是文本型,Cell(1, 0)是数字型,Cell(1,1)是日期型,通过getContents(),三种类型的返回值都是字符型。
如果有需要知道Cell内容的确切类型,API也提供了一系列的方法。参考下面的代码片段:
String strc00 = null;
double strc10 = 0.00;
Date strc11 = null;
Cell c00 = rs.getCell(0, 0);
Cell c10 = rs.getCell(1, 0);
Cell c11 = rs.getCell(1, 1);
if(c00.getType() == CellType.LABEL)
{
LabelCell labelc00 = (LabelCell)c00;
strc00 = labelc00.getString();
}
if(c10.getType() == CellType.NUMBER)
{
NmberCell numc10 = (NumberCell)c10;
strc10 = numc10.getValue();
}
if(c11.getType() == CellType.DATE)
{
DateCell datec11 = (DateCell)c11;
strc11 = datec11.getDate();
}
System.out.println("Cell(0, 0)" + " value : " + strc00 + "; type : " + c00.getType());
System.out.println("Cell(1, 0)" + " value : " + strc10 + "; type : " + c10.getType());
System.out.println("Cell(1, 1)" + " value : " + strc11 + "; type : " + c11.getType());
在得到Cell对象后,通过getType()方法可以获得该单元格的类型,然后与API提供的基本类型相匹配,强制转换成相应的类型,最后调用相应的取值方法getXXX(),就可以得到确定类型的值。API提供了以下基本类型,与Excel的数据格式相对应,如下图所示:
每种类型的具体意义,请参见Java Excel API Document。
当你完成对Excel电子表格数据的处理后,一定要使用close()方法来关闭先前创建的对象,以释放读取数据表的过程中所占用的内存空间,在读取大量数据时显得尤为重要。参考如下代码片段:
//操作完成时,关闭对象,释放占用的内存空间
rwb.close();
Java Excel API提供了许多访问Excel数据表的方法,在这里我只简要地介绍几个常用的方法,其它的方法请参考附录中的Java Excel API Document。
Workbook类提供的方法
1. int getNumberOfSheets()
获得工作薄(Workbook)中工作表(Sheet)的个数,示例:
jxl.Workbook rwb = jxl.Workbook.getWorkbook(new File(sourcefile));
int sheets = rwb.getNumberOfSheets();
2. Sheet[] getSheets()
返回工作薄(Workbook)中工作表(Sheet)对象数组,示例:
jxl.Workbook rwb = jxl.Workbook.getWorkbook(new File(sourcefile));
Sheet[] sheets = rwb.getSheets();
3. String getVersion()
返回正在使用的API的版本号,好像是没什么太大的作用。
jxl.Workbook rwb = jxl.Workbook.getWorkbook(new File(sourcefile));
String apiVersion = rwb.getVersion();
Sheet接口提供的方法
1) String getName()
获取Sheet的名称,示例:
jxl.Workbook rwb = jxl.Workbook.getWorkbook(new File(sourcefile));
jxl.Sheet rs = rwb.getSheet(0);
String sheetName = rs.getName();
2) int getColumns()
获取Sheet表中所包含的总列数,示例:
jxl.Workbook rwb = jxl.Workbook.getWorkbook(new File(sourcefile));
jxl.Sheet rs = rwb.getSheet(0);
int rsColumns = rs.getColumns();
3) Cell[] getColumn(int column)
获取某一列的所有单元格,返回的是单元格对象数组,示例:
jxl.Workbook rwb = jxl.Workbook.getWorkbook(new File(sourcefile));
jxl.Sheet rs = rwb.getSheet(0);
Cell[] cell = rs.getColumn(0);
4) int getRows()
获取Sheet表中所包含的总行数,示例:
jxl.Workbook rwb = jxl.Workbook.getWorkbook(new File(sourcefile));
jxl.Sheet rs = rwb.getSheet(0);
int rsRows = rs.getRows();
5) Cell[] getRow(int row)
获取某一行的所有单元格,返回的是单元格对象数组,示例子:
jxl.Workbook rwb = jxl.Workbook.getWorkbook(new File(sourcefile));
jxl.Sheet rs = rwb.getSheet(0);
Cell[] cell = rs.getRow(0);
6) Cell getCell(int column, int row)
获取指定单元格的对象引用,需要注意的是它的两个参数,第一个是列数,第二个是行数,这与通常的行、列组合有些不同。
jxl.Workbook rwb = jxl.Workbook.getWorkbook(new File(sourcefile));
jxl.Sheet rs = rwb.getSheet(0);
Cell cell = rs.getCell(0, 0);
2 生成新的Excel工作薄
下面的代码主要是向大家介绍如何生成简单的Excel工作表,在这里单元格的内容是不带任何修饰的(如:字体,颜色等等),所有的内容都作为字符串写入。(完整代码见ExcelWriting.java)
与读取Excel工作表相似,首先要使用Workbook类的工厂方法创建一个可写入的工作薄(Workbook)对象,这里要注意的是,只能通过API提供的工厂方法来创建Workbook,而不能使用WritableWorkbook的构造函数,因为类WritableWorkbook的构造函数为protected类型。示例代码片段如下:
import java.io.*;
import jxl.*;
import jxl.write.*;
… … … …
try
{
//构建Workbook对象, 只读Workbook对象
//Method 1:创建可写入的Excel工作薄
jxl.write.WritableWorkbook wwb = Workbook.createWorkbook(new File(targetfile));
//Method 2:将WritableWorkbook直接写入到输出流
/*
OutputStream os = new FileOutputStream(targetfile);
jxl.write.WritableWorkbook wwb = Workbook.createWorkbook(os);
*/
}
catch (Exception e)
{
e.printStackTrace();
}
API提供了两种方式来处理可写入的输出流,一种是直接生成本地文件,如果文件名不带全路径的话,缺省的文件会定位在当前目录,如果文件名带有全路径的话,则生成的Excel文件则会定位在相应的目录;另外一种是将Excel对象直接写入到输出流,例如:用户通过浏览器来访问Web服务器,如果HTTP头设置正确的话,浏览器自动调用客户端的Excel应用程序,来显示动态生成的Excel电子表格。
接下来就是要创建工作表,创建工作表的方法与创建工作薄的方法几乎一样,同样是通过工厂模式方法获得相应的对象,该方法需要两个参数,一个是工作表的名称,另一个是工作表在工作薄中的位置,参考下面的代码片段:
//创建Excel工作表
jxl.write.WritableSheet ws = wwb.createSheet("Test Sheet 1", 0);
"这锅也支好了,材料也准备齐全了,可以开始下锅了!",现在要做的只是实例化API所提供的Excel基本数据类型,并将它们添加到工作表中就可以了,参考下面的代码片段:
//1.添加Label对象
jxl.write.Label labelC = new jxl.write.Label(0, 0, "This is a Label cell");
ws.addCell(labelC);
//添加带有字型Formatting的对象
jxl.write.WritableFont wf = new jxl.write.WritableFont(WritableFont.TIMES, 18, WritableFont.BOLD, true);
jxl.write.WritableCellFormat wcfF = new jxl.write.WritableCellFormat(wf);
jxl.write.Label labelCF = new jxl.write.Label(1, 0, "This is a Label Cell", wcfF);
ws.addCell(labelCF);
//添加带有字体颜色Formatting的对象
jxl.write.WritableFont wfc = new jxl.write.WritableFont(WritableFont.ARIAL, 10, WritableFont.NO_BOLD, false,
Underlinestyle.NO_UNDERLINE, jxl.format.Colour.RED);
jxl.write.WritableCellFormat wcfFC = new jxl.write.WritableCellFormat(wfc);
jxl.write.Label labelCFC = new jxl.write.Label(1, 0, "This is a Label Cell", wcfFC);
ws.addCell(labelCF);
//2.添加Number对象
jxl.write.Number labelN = new jxl.write.Number(0, 1, 3.1415926);
ws.addCell(labelN);
//添加带有formatting的Number对象
jxl.write.NumberFormat nf = new jxl.write.NumberFormat("#.##");
jxl.write.WritableCellFormat wcfN = new jxl.write.WritableCellFormat(nf);
jxl.write.Number labelNF = new jxl.write.Number(1, 1, 3.1415926, wcfN);
ws.addCell(labelNF);
//3.添加Boolean对象
jxl.write.Boolean labelB = new jxl.write.Boolean(0, 2, false);
ws.addCell(labelB);
//4.添加DateTime对象
jxl.write.DateTime labelDT = new jxl.write.DateTime(0, 3, new java.util.Date());
ws.addCell(labelDT);
//添加带有formatting的DateFormat对象
jxl.write.DateFormat df = new jxl.write.DateFormat("dd MM yyyy hh:mm:ss");
jxl.write.WritableCellFormat wcfDF = new jxl.write.WritableCellFormat(df);
jxl.write.DateTime labelDTF = new jxl.write.DateTime(1, 3, new java.util.Date(), wcfDF);
ws.addCell(labelDTF);
这里有两点大家要引起大家的注意。第一点,在构造单元格时,单元格在工作表中的位置就已经确定了。一旦创建后,单元格的位置是不能够变更的,尽管单元格的内容是可以改变的。第二点,单元格的定位是按照下面这样的规律(column, row),而且下标都是从0开始,例如,A1被存储在(0, 0),B1被存储在(1, 0)。
最后,不要忘记关闭打开的Excel工作薄对象,以释放占用的内存,参见下面的代码片段:
//写入Exel工作表
wwb.write();
//关闭Excel工作薄对象
wwb.close();
这可能与读取Excel文件的操作有少少不同,在关闭Excel对象之前,你必须要先调用write()方法,因为先前的操作都是存储在缓存中的,所以要通过该方法将操作的内容保存在文件中。如果你先关闭了Excel对象,那么只能得到一张空的工作薄了。
3 拷贝、更新Excel工作薄
接下来简要介绍一下如何更新一个已经存在的工作薄,主要是下面二步操作,第一步是构造只读的Excel工作薄,第二步是利用已经创建的Excel工作薄创建新的可写入的Excel工作薄,参考下面的代码片段:(完整代码见ExcelModifying.java)
//创建只读的Excel工作薄的对象
jxl.Workbook rw = jxl.Workbook.getWorkbook(new File(sourcefile));
//创建可写入的Excel工作薄对象
jxl.write.WritableWorkbook wwb = Workbook.createWorkbook(new File(targetfile), rw);
//读取第一张工作表
jxl.write.WritableSheet ws = wwb.getSheet(0);
//获得第一个单元格对象
jxl.write.WritableCell wc = ws.getWritableCell(0, 0);
//判断单元格的类型, 做出相应的转化
if(wc.getType() == CellType.LABEL)
{
Label l = (Label)wc;
l.setString("The value has been modified.");
}
//写入Excel对象
wwb.write();
//关闭可写入的Excel对象
wwb.close();
//关闭只读的Excel对象
rw.close();
之所以使用这种方式构建Excel对象,完全是因为效率的原因,因为上面的示例才是API的主要应用。为了提高性能,在读取工作表时,与数据相关的一些输出信息,所有的格式信息,如:字体、颜色等等,是不被处理的,因为我们的目的是获得行数据的值,既使没有了修饰,也不会对行数据的值产生什么影响。唯一的不利之处就是,在内存中会同时保存两个同样的工作表,这样当工作表体积比较大时,会占用相当大的内存,但现在好像内存的大小并不是什么关键因素了。
一旦获得了可写入的工作表对象,我们就可以对单元格对象进行更新的操作了,在这里我们不必调用API提供的add()方法,因为单元格已经于工作表当中,所以我们只需要调用相应的setXXX()方法,就可以完成更新的操作了。
尽单元格原有的格式化修饰是不能去掉的,我们还是可以将新的单元格修饰加上去,以使单元格的内容以不同的形式表现。
新生成的工作表对象是可写入的,我们除了更新原有的单元格外,还可以添加新的单元格到工作表中,这与示例2的操作是完全一样的。
最后,不要忘记调用write()方法,将更新的内容写入到文件中,然后关闭工作薄对象,这里有两个工作薄对象要关闭,一个是只读的,另外一个是可写入的。
以上摘自IBM网站
[原创文章,转载请保留或注明出处:http://www.regexlab.com/zh/encoding.htm]
级别:中级
摘要:本文介绍了字符与编码的发展过程,相关概念的正确理解。举例说明了一些实际应用中,编码的实现方法。然后,本文讲述了通常对字符与编码的几种误解,由于这些误解而导致乱码产生的原因,以及消除乱码的办法。本文的内容涵盖了“中文问题”,“乱码问题”。
掌握编码问题的关键是正确地理解相关概念,编码所涉及的技术其实是很简单的。因此,阅读本文时需要慢读多想,多思考。
引言
“字符与编码”是一个被经常讨论的话题。即使这样,时常出现的乱码仍然困扰着大家。虽然我们有很多的办法可以用来消除乱码,但我们并不一定理解这些办法的内在原理。而有的乱码产生的原因,实际上由于底层代码本身有问题所导致的。因此,不仅是初学者会对字符编码感到模糊,有的底层开发人员同样对字符编码缺乏准确的理解。
1. 编码问题的由来,相关概念的理解
1.1 字符与编码的发展
从计算机对多国语言的支持角度看,大致可以分为三个阶段:
| |
系统内码
|
说明
|
系统
|
| 阶段一 |
ASCII |
计算机刚开始只支持英语,其它语言不能够在计算机上存储和显示。 |
英文 DOS |
| 阶段二 |
ANSI编码
(本地化) |
为使计算机支持更多语言,通常使用 0x80~0xFF 范围的 2 个字节来表示 1 个字符。比如:汉字 '中' 在中文操作系统中,使用 [0xD6,0xD0] 这两个字节存储。
不同的国家和地区制定了不同的标准,由此产生了 GB2312, BIG5, JIS 等各自的编码标准。这些使用 2 个字节来代表一个字符的各种汉字延伸编码方式,称为 ANSI 编码。在简体中文系统下,ANSI 编码代表 GB2312 编码,在日文操作系统下,ANSI 编码代表 JIS 编码。
不同 ANSI 编码之间互不兼容,当信息在国际间交流时,无法将属于两种语言的文字,存储在同一段 ANSI 编码的文本中。 |
中文 DOS,中文 Windows 95/98,日文 Windows 95/98 |
| 阶段三 |
UNICODE
(国际化) |
为了使国际间信息交流更加方便,国际组织制定了 UNICODE 字符集,为各种语言中的每一个字符设定了统一并且唯一的数字编号,以满足跨语言、跨平台进行文本转换、处理的要求。 |
Windows NT/2000/XP,Linux,Java |
字符串在内存中的存放方法:
在 ASCII 阶段,单字节字符串使用一个字节存放一个字符(SBCS)。比如,"Bob123" 在内存中为:
| 42 |
6F |
62 |
31 |
32 |
33 |
00 |

|
|
|
|
|
|
|
| B |
o |
b |
1 |
2 |
3 |
\0 |
在使用 ANSI 编码支持多种语言阶段,每个字符使用一个字节或多个字节来表示(MBCS),因此,这种方式存放的字符也被称作多字节字符。比如,"中文123" 在中文 Windows 95 内存中为7个字节,每个汉字占2个字节,每个英文和数字字符占1个字节:
| D6 |
D0 |
CE |
C4 |
31 |
32 |
33 |
00 |
|
|
|
|
|
|
|
| 中 |
文 |
1 |
2 |
3 |
\0 |
在 UNICODE 被采用之后,计算机存放字符串时,改为存放每个字符在 UNICODE 字符集中的序号。目前计算机一般使用 2 个字节(16 位)来存放一个序号(DBCS),因此,这种方式存放的字符也被称作宽字节字符。比如,字符串 "中文123" 在 Windows 2000 下,内存中实际存放的是 5 个序号:
| 2D |
4E |
87 |
65 |
31 |
00 |
32 |
00 |
33 |
00 |
00 |
00 |
← 在 x86 CPU 中,低字节在前
|
|
|
|
|
|
|
|
|
| 中 |
文 |
1 |
2 |
3 |
\0 |
|
一共占 10 个字节。
1.2 字符,字节,字符串
理解编码的关键,是要把字符的概念和字节的概念理解准确。这两个概念容易混淆,我们在此做一下区分:
| |
概念描述
|
举例
|
| 字符 |
人们使用的记号,抽象意义上的一个符号。 |
'1', '中', 'a', '$', '¥', …… |
| 字节 |
计算机中存储数据的单元,一个8位的二进制数,是一个很具体的存储空间。 |
0x01, 0x45, 0xFA, …… |
ANSI
字符串 |
在内存中,如果“字符”是以 ANSI 编码形式存在的,一个字符可能使用一个字节或多个字节来表示,那么我们称这种字符串为 ANSI 字符串或者多字节字符串。 |
"中文123"
(占7字节) |
UNICODE
字符串 |
在内存中,如果“字符”是以在 UNICODE 中的序号存在的,那么我们称这种字符串为 UNICODE 字符串或者宽字节字符串。 |
L"中文123"
(占10字节) |
由于不同 ANSI 编码所规定的标准是不相同的,因此,对于一个给定的多字节字符串,我们必须知道它采用的是哪一种编码规则,才能够知道它包含了哪些“字符”。而对于 UNICODE 字符串来说,不管在什么环境下,它所代表的“字符”内容总是不变的。
1.3 字符集与编码
各个国家和地区所制定的不同 ANSI 编码标准中,都只规定了各自语言所需的“字符”。比如:汉字标准(GB2312)中没有规定韩国语字符怎样存储。这些 ANSI 编码标准所规定的内容包含两层含义:
- 使用哪些字符。也就是说哪些汉字,字母和符号会被收入标准中。所包含“字符”的集合就叫做“字符集”。
- 规定每个“字符”分别用一个字节还是多个字节存储,用哪些字节来存储,这个规定就叫做“编码”。
各个国家和地区在制定编码标准的时候,“字符的集合”和“编码”一般都是同时制定的。因此,平常我们所说的“字符集”,比如:GB2312, GBK, JIS 等,除了有“字符的集合”这层含义外,同时也包含了“编码”的含义。
“UNICODE 字符集”包含了各种语言中使用到的所有“字符”。用来给 UNICODE 字符集编码的标准有很多种,比如:UTF-8, UTF-7, UTF-16, UnicodeLittle, UnicodeBig 等。
1.4 常用的编码简介
简单介绍一下常用的编码规则,为后边的章节做一个准备。在这里,我们根据编码规则的特点,把所有的编码分成三类:
|
分类
|
编码标准
|
说明
|
| 单字节字符编码 |
ISO-8859-1 |
最简单的编码规则,每一个字节直接作为一个 UNICODE 字符。比如,[0xD6, 0xD0] 这两个字节,通过 iso-8859-1 转化为字符串时,将直接得到 [0x00D6, 0x00D0] 两个 UNICODE 字符,即 "ÖÐ"。
反之,将 UNICODE 字符串通过 iso-8859-1 转化为字节串时,只能正常转化 0~255 范围的字符。 |
| ANSI 编码 |
GB2312,
BIG5,
Shift_JIS,
ISO-8859-2 …… |
把 UNICODE 字符串通过 ANSI 编码转化为“字节串”时,根据各自编码的规定,一个 UNICODE 字符可能转化成一个字节或多个字节。
反之,将字节串转化成字符串时,也可能多个字节转化成一个字符。比如,[0xD6, 0xD0] 这两个字节,通过 GB2312 转化为字符串时,将得到 [0x4E2D] 一个字符,即 '中' 字。
“ANSI 编码”的特点:
1. 这些“ANSI 编码标准”都只能处理各自语言范围之内的 UNICODE 字符。
2. “UNICODE 字符”与“转换出来的字节”之间的关系是人为规定的。 |
| UNICODE 编码 |
UTF-8,
UTF-16, UnicodeBig …… |
与“ANSI 编码”类似的,把字符串通过 UNICODE 编码转化成“字节串”时,一个 UNICODE 字符可能转化成一个字节或多个字节。
与“ANSI 编码”不同的是:
1. 这些“UNICODE 编码”能够处理所有的 UNICODE 字符。
2. “UNICODE 字符”与“转换出来的字节”之间是可以通过计算得到的。 |
我们实际上没有必要去深究每一种编码具体把某一个字符编码成了哪几个字节,我们只需要知道“编码”的概念就是把“字符”转化成“字节”就可以了。对于“UNICODE 编码”,由于它们是可以通过计算得到的,因此,在特殊的场合,我们可以去了解某一种“UNICODE 编码”是怎样的规则。
2. 字符与编码在程序中的实现
2.1 程序中的字符与字节
在 C++ 和 Java 中,用来代表“字符”和“字节”的数据类型,以及进行编码的方法:
|
类型或操作
|
C++
|
Java
|
| 字符 |
wchar_t |
char |
| 字节 |
char |
byte |
| ANSI 字符串 |
char[] |
byte[] |
| UNICODE 字符串 |
wchar_t[] |
String |
| 字节串→字符串 |
mbstowcs(), MultiByteToWideChar() |
string = new String(bytes, "encoding") |
| 字符串→字节串 |
wcstombs(), WideCharToMultiByte() |
bytes = string.getBytes("encoding") |
以上需要注意几点:
- Java 中的 char 代表一个“UNICODE 字符(宽字节字符)”,而 C++ 中的 char 代表一个字节。
- MultiByteToWideChar() 和 WideCharToMultiByte() 是 Windows API 函数。
2.2 C++ 中相关实现方法
声明一段字符串常量:
// ANSI 字符串,内容长度 7 字节
char
sz[20] = "中文123";
// UNICODE 字符串,内容长度 5 个 wchar_t(10 字节)
wchar_t wsz[20] = L"\x4E2D\x6587\x0031\x0032\x0033"; |
UNICODE 字符串的 I/O 操作,字符与字节的转换操作:
// 运行时设定当前 ANSI 编码,VC 格式
setlocale(LC_ALL, ".936");
// GCC 中格式
setlocale(LC_ALL, "zh_CN.GBK");
// Visual C++ 中使用小写 %s,按照 setlocale 指定编码输出到文件
// GCC 中使用大写 %S
fwprintf(fp, L"%s\n", wsz);
// 把 UNICODE 字符串按照 setlocale 指定的编码转换成字节
wcstombs(sz, wsz, 20);
// 把字节串按照 setlocale 指定的编码转换成 UNICODE 字符串
mbstowcs(wsz, sz, 20); |
在 Visual C++ 中,UNICODE 字符串常量有更简单的表示方法。如果源程序的编码与当前默认 ANSI 编码不符,则需要使用 #pragma setlocale,告诉编译器源程序使用的编码:
// 如果源程序的编码与当前默认 ANSI 编码不一致,
// 则需要此行,编译时用来指明当前源程序使用的编码
#pragma setlocale
(".936")
// UNICODE 字符串常量,内容长度 10 字节
wchar_t wsz[20] = L"中文123"; |
以上需要注意 #pragma setlocale 与 setlocale(LC_ALL, "") 的作用是不同的,#pragma setlocale 在编译时起作用,setlocale() 在运行时起作用。
2.3 Java 中相关实现方法
字符串类 String 中的内容是 UNICODE 字符串:
// Java 代码,直接写中文
String
string = "中文123";
// 得到长度为 5,因为是 5 个字符
System.out.println(string.length()); |
字符串 I/O 操作,字符与字节转换操作。在 Java 包 java.io.* 中,以“Stream”结尾的类一般是用来操作“字节串”的类,以“Reader”,“Writer”结尾的类一般是用来操作“字符串”的类。
// 字符串与字节串间相互转化
// 按照 GB2312 得到字节(得到多字节字符串)
byte
[] bytes = string.getBytes("GB2312");
// 从字节按照 GB2312 得到 UNICODE 字符串
string = newString(bytes, "GB2312");
// 要将 String 按照某种编码写入文本文件,有两种方法:
// 第一种办法:用 Stream 类写入已经按照指定编码转化好的字节串
OutputStream os = new FileOutputStream("1.txt");
os.write(bytes);
os.close();
// 第二种办法:构造指定编码的 Writer 来写入字符串
Writer ow = new OutputStreamWriter(new FileOutputStream("2.txt"), "GB2312");
ow.write(string);
ow.close();
/* 最后得到的 1.txt 和 2.txt 都是 7 个字节 */ |
如果 java 的源程序编码与当前默认 ANSI 编码不符,则在编译的时候,需要指明一下源程序的编码。比如:
| E:\>javac -encoding BIG5 Hello.java |
以上需要注意区分源程序的编码与 I/O 操作的编码,前者是在编译时起作用,后者是在运行时起作用。
3. 几种误解,以及乱码产生的原因和解决办法
3.1 容易产生的误解
| |
对编码的误解
|
| 误解一 |
在将“字节串”转化成“UNICODE 字符串”时,比如在读取文本文件时,或者通过网络传输文本时,容易将“字节串”简单地作为单字节字符串,采用每“一个字节”就是“一个字符”的方法进行转化。
而实际上,在非英文的环境中,应该将“字节串”作为 ANSI 字符串,采用适当的编码来得到 UNICODE 字符串,有可能“多个字节”才能得到“一个字符”。
通常,一直在英文环境下做开发的程序员们,容易有这种误解。 |
| 误解二 |
在 DOS,Windows 98 等非 UNICODE 环境下,字符串都是以 ANSI 编码的字节形式存在的。这种以字节形式存在的字符串,必须知道是哪种编码才能被正确地使用。这使我们形成了一个惯性思维:“字符串的编码”。
当 UNICODE 被支持后,Java 中的 String 是以字符的“序号”来存储的,不是以“某种编码的字节”来存储的,因此已经不存在“字符串的编码”这个概念了。只有在“字符串”与“字节串”转化时,或者,将一个“字节串”当成一个 ANSI 字符串时,才有编码的概念。
不少的人都有这个误解。 |
第一种误解,往往是导致乱码产生的原因。第二种误解,往往导致本来容易纠正的乱码问题变得更复杂。
在这里,我们可以看到,其中所讲的“误解一”,即采用每“一个字节”就是“一个字符”的转化方法,实际上也就等同于采用 iso-8859-1 进行转化。因此,我们常常使用 bytes = string.getBytes("iso-8859-1") 来进行逆向操作,得到原始的“字节串”。然后再使用正确的 ANSI 编码,比如 string = new String(bytes, "GB2312"),来得到正确的“UNICODE 字符串”。
3.2 非 UNICODE 程序在不同语言环境间移植时的乱码
非 UNICODE 程序中的字符串,都是以某种 ANSI 编码形式存在的。如果程序运行时的语言环境与开发时的语言环境不同,将会导致 ANSI 字符串的显示失败。
比如,在日文环境下开发的非 UNICODE 的日文程序界面,拿到中文环境下运行时,界面上将显示乱码。如果这个日文程序界面改为采用 UNICODE 来记录字符串,那么当在中文环境下运行时,界面上将可以显示正常的日文。
由于客观原因,有时候我们必须在中文操作系统下运行非 UNICODE 的日文软件,这时我们可以采用一些工具,比如,南极星,AppLocale 等,暂时的模拟不同的语言环境。
3.3 网页提交字符串
当页面中的表单提交字符串时,首先把字符串按照当前页面的编码,转化成字节串。然后再将每个字节转化成 "%XX" 的格式提交到 Web 服务器。比如,一个编码为 GB2312 的页面,提交 "中" 这个字符串时,提交给服务器的内容为 "%D6%D0"。
在服务器端,Web 服务器把收到的 "%D6%D0" 转化成 [0xD6, 0xD0] 两个字节,然后再根据 GB2312 编码规则得到 "中" 字。
在 Tomcat 服务器中,request.getParameter() 得到乱码时,常常是因为前面提到的“误解一”造成的。默认情况下,当提交 "%D6%D0" 给 Tomcat 服务器时,request.getParameter() 将返回 [0x00D6, 0x00D0] 两个 UNICODE 字符,而不是返回一个 "中" 字符。因此,我们需要使用 bytes = string.getBytes("iso-8859-1") 得到原始的字节串,再用 string = new String(bytes, "GB2312") 重新得到正确的字符串 "中"。
3.4 从数据库读取字符串
通过数据库客户端(比如 ODBC 或 JDBC)从数据库服务器中读取字符串时,客户端需要从服务器获知所使用的 ANSI 编码。当数据库服务器发送字节流给客户端时,客户端负责将字节流按照正确的编码转化成 UNICODE 字符串。
如果从数据库读取字符串时得到乱码,而数据库中存放的数据又是正确的,那么往往还是因为前面提到的“误解一”造成的。解决的办法还是通过 string = new String( string.getBytes("iso-8859-1"), "GB2312") 的方法,重新得到原始的字节串,再重新使用正确的编码转化成字符串。
3.5 电子邮件中的字符串
当一段 Text 或者 HTML 通过电子邮件传送时,发送的内容首先通过一种指定的字符编码转化成“字节串”,然后再把“字节串”通过一种指定的传输编码(Content-Transfer-Encoding)进行转化得到另一串“字节串”。比如,打开一封电子邮件源代码,可以看到类似的内容:
Content-Type: text/plain;
charset="gb2312"
Content-Transfer-Encoding: base64
sbG+qcrQuqO17cf4yee74bGjz9W7+b3wudzA7dbQ0MQNCg0KvPKzxqO6uqO17cnnsaPW0NDEDQoNCg== |
最常用的 Content-Transfer-Encoding 有 Base64 和 Quoted-Printable 两种。在对二进制文件或者中文文本进行转化时,Base64 得到的“字节串”比 Quoted-Printable 更短。在对英文文本进行转化时,Quoted-Printable 得到的“字节串”比 Base64 更短。
邮件的标题,用了一种更简短的格式来标注“字符编码”和“传输编码”。比如,标题内容为 "中",则在邮件源代码中表示为:
// 正确的标题格式
Subject: =?GB2312?B?1tA=?= |
其中,
- 第一个“=?”与“?”中间的部分指定了字符编码,在这个例子中指定的是 GB2312。
- “?”与“?”中间的“B”代表 Base64。如果是“Q”则代表 Quoted-Printable。
- 最后“?”与“?=”之间的部分,就是经过 GB2312 转化成字节串,再经过 Base64 转化后的标题内容。
如果“传输编码”改为 Quoted-Printable,同样,如果标题内容为 "中":
// 正确的标题格式
Subject: =?GB2312?Q?=D6=D0?= |
如果阅读邮件时出现乱码,一般是因为“字符编码”或“传输编码”指定有误,或者是没有指定。比如,有的发邮件组件在发送邮件时,标题 "中":
// 错误的标题格式
Subject: =?ISO-8859-1?Q?=D6=D0?= |
这样的表示,实际上是明确指明了标题为 [0x00D6, 0x00D0],即 "ÖÐ",而不是 "中"。
4. 几种错误理解的纠正
误解:“ISO-8859-1 是国际编码?”
非也。iso-8859-1 只是单字节字符集中最简单的一种,也就是“字节编号”与“UNICODE 字符编号”一致的那种编码规则。当我们要把一个“字节串”转化成“字符串”,而又不知道它是哪一种 ANSI 编码时,先暂时地把“每一个字节”作为“一个字符”进行转化,不会造成信息丢失。然后再使用 bytes = string.getBytes("iso-8859-1") 的方法可恢复到原始的字节串。
误解:“Java 中,怎样知道某个字符串的内码?”
Java 中,字符串类 java.lang.String 处理的是 UNICODE 字符串,不是 ANSI 字符串。我们只需要把字符串作为“抽象的符号的串”来看待。因此不存在字符串的内码的问题。