ICTCLAS初步分词包括:1)原子切分;2)找出原子之间所有可能的组词方案;3)N-最短路径中文词语粗分三步。
例如:“他说的确实在理”这句话。
1)原子切分的目的是完成单个汉字的切分。经过原子切分后变成“始##始/他/说/的/确/实/在/理/末##末”。
2)然后根据“词库字典”找出所有原子之间所有可能的组词方案。经过词库检索后,该句话变为“始##始/他/说/的/的确/确/确实/实/实在/在/在理/末##末”。
3)N-最短路径中文词语粗分。下面的过程就比较复杂了,首先我们要找出这些词之间所有可能的两两组合的距离(这需要检索BigramDict.dct词典库)。对于上面的案例而言,得到的BiGraph结果如下:
row: 0, col: 1, eWeight: 3.37, nPOS: 1, sWord:始##始@他
row: 1, col: 2, eWeight: 2.25, nPOS: 0, sWord:他@说
row: 2, col: 3, eWeight: 4.05, nPOS: 0, sWord:说@的
row: 2, col: 4, eWeight: 7.11, nPOS: 0, sWord:说@的确
row: 3, col: 5, eWeight: 4.10, nPOS: 0, sWord:的@确
row: 3, col: 6, eWeight: 4.10, nPOS: 0, sWord:的@确实
row: 4, col: 7, eWeight: 11.49, nPOS: 25600, sWord:的确@实
row: 5, col: 7, eWeight: 11.63, nPOS: 0, sWord:确@实
row: 4, col: 8, eWeight: 11.49, nPOS: 25600, sWord:的确@实在
row: 5, col: 8, eWeight: 11.63, nPOS: 0, sWord:确@实在
row: 6, col: 9, eWeight: 3.92, nPOS: 0, sWord:确实@在
row: 7, col: 9, eWeight: 10.98, nPOS: 0, sWord:实@在
row: 6, col: 10, eWeight: 10.97, nPOS: 0, sWord:确实@在理
row: 7, col: 10, eWeight: 10.98, nPOS: 0, sWord:实@在理
row: 8, col: 11, eWeight: 11.17, nPOS: 0, sWord:实在@理
row: 9, col: 11, eWeight: 5.62, nPOS: 0, sWord:在@理
row: 10, col: 12, eWeight: 14.30, nPOS: 24832, sWord:在理@末##末
row: 11, col: 12, eWeight: 11.95, nPOS: 0, sWord:理@末##末
可以从上表中可以看出“的@确实”的距离为4.10,而“的确@实”间的距离为11.49,这说明“的@确实”的组合可能性要大一些。不过这只是一面之词,究竟如何组词需要放到整句话的环境下通盘考虑,达到整体最优。这就是N最短路径需要完成的工作。
在求最短路径前我们需要将上表换一个角度观察,其实上表可以等价的表述成如下图所示的“有向图”:
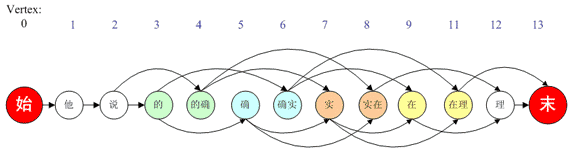
上表中词与词的组合(例如“的@确实”)在该图中对应一条边(由节点“的”到节点“确实”),其路径长度就是上表中的eWeight值。这样一来,求最优分词方案就成了求整体最短路径。
由于是初次切分,为了提高后续优化质量,这里求的是N最短路径,即路径长度由小到大排序后的前N种长度的所有路径。对于上面案例,我们假设N=2,那么求解得到的路径有2条(注意也可能比两条多,关于这点我 将在后续专门介绍NShortPath时再说):
路径(1):
0, 1, 2, 3, 6, 9, 11, 12, 13
始##始 / 他 / 说 / 的 / 确实 / 在 / 理 / 末##末
路径(2):
0, 1, 2, 3, 6, 10, 12, 13
始##始 / 他 / 说 / 的 / 确实 / 在理 / 末##末
如果要想真正搞清楚上述过程,必须对下面的数据结构以及它的几种不同的表述方式有个透彻的了解。
DynamicArray是什么?其实它的本质是一个经过排序的链表。为了表达的更明白些,我们不妨看下面这张图:

(图一)
上面这张图是一个按照index值进行了排序的链表,当插入新结点时必须确保index值的有序性。DynamicArray类完成的功能基本上与上面这个链表差不多,只是排序规则不是index,而是row和col两个数据,如下图:

(图二)
大家可以看到,这个有序链表的排序规则是先按row排序,row相同的按照col排序。当然排序规则是可以改变的,如果先按col排,再按row排,则上面的链表必须表述成:

(图三)
原有ICTCLAS实现时,在一个类里面综合考虑了row先排序和col先排序的两种情况,这在SharpICTCLAS中做了很大调整,将DynamicArray类作为父类提供一些基础操作,同时设计了RowFirstDynamicArray和ColumnFirstDynamicArray类作为子类提供专门的方法,这使得代码变得清晰多了(有关DynamicArray的实现我在下一篇文章中再做介绍)。
在本文最前面给出的案例中,根据“词库字典”找出所有原子字间的组词方案,其结果为“始##始/他/说/的/的确/确/确实/实/实在/在/在理/末##末”,而内容就是靠一个RowFirstDynamicArray存储的,如下:
row: 0, col: 1, eWeight: 329805.00, nPOS: 1, sWord:始##始
row: 1, col: 2, eWeight: 19823.00, nPOS: 0, sWord:他
row: 2, col: 3, eWeight: 17649.00, nPOS: 0, sWord:说
row: 3, col: 4, eWeight: 358156.00, nPOS: 0, sWord:的
row: 3, col: 5, eWeight: 210.00, nPOS: 25600, sWord:的确
row: 4, col: 5, eWeight: 181.00, nPOS: 0, sWord:确
row: 4, col: 6, eWeight: 361.00, nPOS: 0, sWord:确实
row: 5, col: 6, eWeight: 357.00, nPOS: 0, sWord:实
row: 5, col: 7, eWeight: 295.00, nPOS: 0, sWord:实在
row: 6, col: 7, eWeight: 78484.00, nPOS: 0, sWord:在
row: 6, col: 8, eWeight: 3.00, nPOS: 24832, sWord:在理
row: 7, col: 8, eWeight: 129.00, nPOS: 0, sWord:理
row: 8, col: 9, eWeight:2079997.00, nPOS: 4, sWord:末##末
如果根据RowFirstDynamicArray中row和col的坐标信息将DynamicArray放到一个二维表格中的话,我们就得到了DynamicArray的二维图表表示。如下图所示:

(图四)
在这张图中,行和列有一个非常有意思的关系:col为 n 的列中所有词可以与row为 n 的所有行中的词进行组合。例如“的确”这个词,它的col = 5,需要和它计算平滑值的有两个,分别是row = 5的两个词:“实”和“实在”。
如果将所有行与列之间词与词之间的关系找到,我们就可以得到另外一个ColumnFirstDynamicArray,如本文第一张表中内容所示。将该ColumnFirstDynamicArray的内容放到另外一个二维表中就得到如下图所示内容:
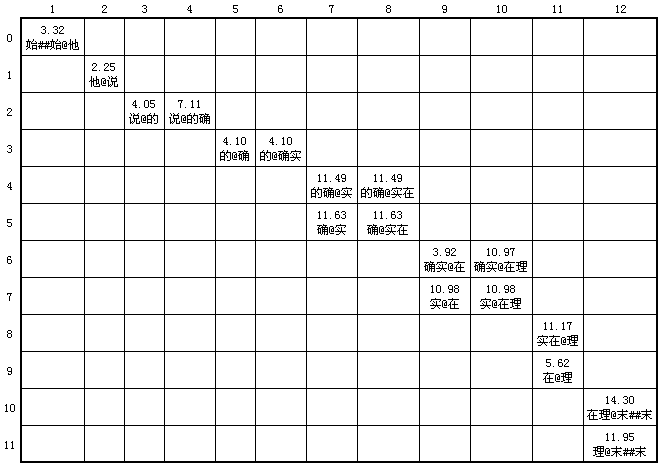
(图五)
- ColumnFirstDynamicArray的有向图表示
上面这张表可以和一张有向图所对应,就如前文所说,词与词的组合(例如“的@确实”)在该图中对应一条边(由节点“的”到节点“确实”),其路径长度就是上表中的eWeight值,如下图所示:
剩下的事情就是针对该图求解N最短路径了,这将在后续文章中介绍。
ICTCLAS的初步分词是一个比较复杂的过程,涉及的数据结构、数据表示以及相关算法都颇有难度。在SharpICTCLAS中,对原有C++代码做了比较多的更改,重新设计了DynamicArray类与NShortPath方法,在牺牲有限性能的同时力争大幅度简化代码的复杂度,提高可读性。
有关SharpICTCLAS中DynamicArray类的实现以及在代码可读性与性能之间的权衡将在下一篇文章中加以介绍。
来源:http://www.cnblogs.com/zhenyulu/category/85598.html