|
2014年2月26日
#
嗨心兔是品墨科技自主研发生产的一款智能共享童车,通过物联网和微信+支付宝小程序实行操作,可实现无人值守、智能消毒、自动计费、自动扣费的新型儿童娱乐设备。加盟热线400-6151-556 
市场前景广阔 中国统计局数据显示,截至2018年,我国0-14岁的儿童数量已经达到2.5亿人。2018 年儿童消费市场规模突破4.5 万亿,并以每年20%的速度增长,其中儿童娱乐消费市场的规模突破4600亿元。 当前,80、90后成为了家长群体中的主力军时。他们有较好的经济基础已经对消费升级的追求,这使得育儿支出水涨船高。 目前我国14岁以下的儿童数量较大,儿童消费已占到家庭总支出的3 0 %左右,其中玩具,童装又占据着较高的比例。 根据行业研发报告显示,我国儿童消费规模已经接近4.5万亿元,其中儿童娱乐消费市场的规模突破4600亿元。 中共中央政治局5月31日召开会议,会议指出,进一步优化生育政策,实施一对夫妻可以生育三个子女政策及配套支持措施。我国正处于人口大国向人力资本强国转变的重大战略机遇期,立足国情,“三孩”政策能够最大限度发挥人口对经济社会发展的能动作用。 自二胎政策以来,在人口增长以及产业提升方面,开始有显著的效果的。二孩政策的开放,促使少儿人口数量的逐渐增加,也会为一些儿童产业经济带来相当可观的市场。更别说三孩政策的开放,更会给儿童经济市场带来一个巨大的飞跃。 
新风口 嗨心兔共享童车智能柜,作为新型共享经济的新模式,新风口,大大增加了儿童车的使用选择、节约了购买成本,还大便利了家长带娃,更可以增加孩子公平意识,提升社交乐趣,同时也解决很多用户的痛点: 市场和痛点: 儿童电动车是孩子最不可缺失的用品之一,也是孩子成长过程中最重要的“玩伴”。但是买一台放在家里是非常占地方的,现在的楼价那么高,一台童车占据的面积就差不多一个平方了。按照一二线城市的楼价来计算,家里买一台童车的场地“租金”是相当高的。孩子“喜新厌旧”,玩具车很快就会“失宠”。买过儿童电动车的家长都会反馈,家里买回来的儿童电动车,只玩了两次就不完了, 然后就放在那里了。然后想玩第三的时候,发现因为电池长期没有充电的, 电池就报废了,已经不能再玩了。现在的家长对产品的品质要求都比较高,小孩子也是家里的宝贝,给小孩子买的电动儿童车,而且要买一台质量比较好的电动儿童车,价钱也不低的。现在家庭都是居住在小区内,对于宝妈来说,儿童电动车搬上搬下也是个特别麻烦的事情。 
产品优势和特点: 广东品墨科技科技有限自主研发生产的一款智能共享童车,通过物联网和微信+支付宝小程序实行操作,可实现无人值守、智能消毒、自动计费、自动扣费完美解决了这些问题,项目具备下面几点优势: 优势一:无人值守免人工 传统童车玩乐需要,人工监管,人工收费,场地大了还得多个人看守,而嗨心兔智能设备无需专人值守,自动计费,自动扣费,一个人可管理几十个点。由于传统童车是都是采用定时断电的方式进行计费,这样限制了儿童消费的冲动,影响营业收入。 优势二:占地小租金少 传统童车玩乐有多少车就需要多大的空地存放, 而嗨心兔共享童车智能柜的方式存放,立体空间,一套设备占地还不到1平米。一套设备可以存放2个童车,极大节省了存放的空间。 优势三:还车自动充电 传统童车玩乐专人负责充电,每天随时随地得记着,而嗨心兔采用自助充电,还车和充电一气呵成。不会因为忘记了充电,然后影响了日常的运营。 优势四:防水防盗防嗮 传统童车玩乐不防雨不防盗,要是在户外还得专门找个安全的地方存放,而嗨心兔不但防水,而且防晒,还有设计了安全警报功能,防偷防盗,智能科技呵护你的“摇钱树”。让你轻松的赚取睡后的收入。 优势五:医用级卫生保证 传统童车玩乐轮流使用,基本没有消毒,交叉感染可能性大,而嗨心兔采用医用级消毒灯,—车一消毒,一次一消毒,为儿童健康提供强大保障。 优势六:车型多正版授权 传统童车玩乐只能坐着到处逛, 体验感一般,而嗨心兔全是正版授权的超拉风车辆,包括但是不限于,兰博基尼,法拉利,保时捷,宾利,劳斯莱斯这些,小朋友自驾体验自己操控的乐趣,家长遥控着都感觉有面子。 
关键是选址 公园 公园人流多,而且地方宽敞,也是家里留守老人带孩子爱去的地方。所以对于嗨心兔共享童车来说,公园也是投放场地的重点推荐之一。 商场 商场在共享童车行业中毫无疑问是个优质的投放场地。商场人流大,儿童业态在购物中心的一般占比达到19%或以上,是家庭休闲娱乐的好地方。 小区 在住房压力普遍的现在,特别是在城市,城镇生活的打工人,尺土寸金,很多家庭室内几乎没有孩子骑上童车玩乐的空间。出行的话,又很难放在后备箱中携带,搬来搬去也很是不方便。因此小区作为家庭日常生活的场所,在这里投放共享童车是好地方 广场 广场,是小孩游玩的集中地。广场地域宽阔、无车流,备受群众喜爱,特别是夜晚时有许多父母会带孩子一起散步,人流量越大,生意的机会就多,这也是嗨心兔共享童车投放区域的一大好选择。 
合作伙伴: 选择合作伙伴,如同选择伴侣般重要?首先,价格和成本相对来说,越低越好,这样你就可以尽快偿还成本。第二,要考虑设备的稳定性。要选址产品比较稳定的公司。 最终要是源头厂家合作,要认真调研他们是不是招商公司,假如是招商公司的话,他们只是赚一笔就走了,真正能给提供服务的源头还是厂家,但是你签署合同的是招商公司的话,中间有服务的话,必然也隔了一层,效率必然低下。假如是源头厂家的话,至少如果遇到问题,可以第一时间找到设计制作这个产品的人。他比任何人都清楚哪里容易出现问题,以及如何解决问题。万一找个不专业的公司合作,特别是贴牌的招商公司,售后问题就要经过几层才能解决。不然到时候,你遇到问题一定是疯了。 而广东品墨科技有限公司,是一家以物联网,大数据,人工智能技术为依托的技术和运营推广公司,技术团队由来自汇丰,中国电信,华为,广点通等顶尖企业的资深研发和营销运营团队组成!同时,公司还是腾讯广告的授权的广告服务商,对全国各地的加盟商的广告支持是十分到位的。 
广东品墨科技有限公司,是一家专注于专注于智能设备的研发、生产、推广于一体的企业,我公司自主研发和生成共享童车的控制主板,软件系统,运营后台。旗下的嗨心兔品牌专注于儿童业态的无人智能游乐设备领域,通过整合智能设备和物联网,大数据分析技术,自主研发和设计国内更适应市场需求、更受小朋友喜爱的共享童车智能柜。 全国招商加盟热线:400-6151-556 共享童车源头厂家,品质保证,支持各种物联网系统OEM定制开发
1.wireshark
wireshark安装
#yum install wireshark wireshark-gnome
wireshark使用
#wireshark
2.tcpdump
tcpdump采用命令行方式,它的命令格式为:
tcpdump [ -adeflnNOpqStvx ] [ -c 数量 ] [ -F 文件名 ]
[ -i 网络接口 ] [ -r 文件名] [ -s snaplen ]
[ -T 类型 ] [ -w 文件名 ] [表达式 ]
http://anheng.com.cn/news/24/586.html
(1). tcpdump的选项介绍
http://anheng.com.cn/news/24/586.html
-a 将网络地址和广播地址转变成名字;
-d 将匹配信息包的代码以人们能够理解的汇编格式给出;
-dd 将匹配信息包的代码以c语言程序段的格式给出;
-ddd 将匹配信息包的代码以十进制的形式给出;
-e 在输出行打印出数据链路层的头部信息;
-f 将外部的Internet地址以数字的形式打印出来;
-l 使标准输出变为缓冲行形式;
-n 不把网络地址转换成名字;
-t 在输出的每一行不打印时间戳;
-v 输出一个稍微详细的信息,例如在ip包中可以包括ttl和服务类型的信息;
-vv 输出详细的报文信息;
-c 在收到指定的包的数目后,tcpdump就会停止;
-F 从指定的文件中读取表达式,忽略其它的表达式;
-i 指定监听的网络接口;
-r 从指定的文件中读取包(这些包一般通过-w选项产生);
-w 直接将包写入文件中,并不分析和打印出来;
-T 将监听到的包直接解释为指定的类型的报文,常见的类型有rpc (远程过程调用)和snmp(简单网络管理协议;)
Ethereal和Sniffit两个网络分析工具
PS:tcpdump是一个用于截取网络分组,并输出分组内容的工具,简单说就是数据包抓包工具。tcpdump凭借强大的功能和灵活的截取策略,使其成为Linux系统下用于网络分析和问题排查的首选工具。
tcpdump提供了源代码,公开了接口,因此具备很强的可扩展性,对于网络维护和入侵者都是非常有用的工具。tcpdump存在于基本的Linux系统中,由于它需要将网络界面设置为混杂模式,普通用户不能正常执行,但具备root权限的用户可以直接执行它来获取网络上的信息。因此系统中存在网络分析工具主要不是对本机安全的威胁,而是对网络上的其他计算机的安全存在威胁。
一、概述
顾名思义,tcpdump可以将网络中传送的数据包的“头”完全截获下来提供分析。它支持针对网络层、协议、主机、网络或端口的过滤,并提供and、or、not等逻辑语句来帮助你去掉无用的信息。
# tcpdump -vv
tcpdump: listening on eth0, link-type EN10MB (Ethernet), capture size 96 bytes
11:53:21.444591 IP (tos 0x10, ttl 64, id 19324, offset 0, flags [DF], proto 6, length: 92) asptest.localdomain.ssh > 192.168.228.244.1858: P 3962132600:3962132652(52) ack 2726525936 win 1266
asptest.localdomain.1077 > 192.168.228.153.domain: [bad udp cksum 166e!] 325+ PTR? 244.228.168.192.in-addr.arpa. (46)
11:53:21.446929 IP (tos 0x0, ttl 64, id 42911, offset 0, flags [DF], proto 17, length: 151) 192.168.228.153.domain > asptest.localdomain.1077: 325 NXDomain q: PTR? 244.228.168.192.in-addr.arpa. 0/1/0 ns: 168.192.in-addr.arpa. (123)
11:53:21.447408 IP (tos 0x10, ttl 64, id 19328, offset 0, flags [DF], proto 6, length: 172) asptest.localdomain.ssh > 192.168.228.244.1858: P 168:300(132) ack 1 win 1266
347 packets captured
1474 packets received by filter
745 packets dropped by kernel
不带参数的tcpdump会收集网络中所有的信息包头,数据量巨大,必须过滤。
二、选项介绍
-A 以ASCII格式打印出所有分组,并将链路层的头最小化。
-c 在收到指定的数量的分组后,tcpdump就会停止。
-C 在将一个原始分组写入文件之前,检查文件当前的大小是否超过了参数file_size 中指定的大小。如果超过了指定大小,则关闭当前文件,然后在打开一个新的文件。参数 file_size 的单位是兆字节(是1,000,000字节,而不是1,048,576字节)。
-d 将匹配信息包的代码以人们能够理解的汇编格式给出。
-dd 将匹配信息包的代码以c语言程序段的格式给出。
-ddd 将匹配信息包的代码以十进制的形式给出。
-D 打印出系统中所有可以用tcpdump截包的网络接口。
-e 在输出行打印出数据链路层的头部信息。
-E 用spi@ipaddr algo:secret解密那些以addr作为地址,并且包含了安全参数索引值spi的IPsec ESP分组。
-f 将外部的Internet地址以数字的形式打印出来。
-F 从指定的文件中读取表达式,忽略命令行中给出的表达式。
-i 指定监听的网络接口。
-l 使标准输出变为缓冲行形式,可以把数据导出到文件。
-L 列出网络接口的已知数据链路。
-m 从文件module中导入SMI MIB模块定义。该参数可以被使用多次,以导入多个MIB模块。
-M 如果tcp报文中存在TCP-MD5选项,则需要用secret作为共享的验证码用于验证TCP-MD5选选项摘要(详情可参考RFC 2385)。
-b 在数据-链路层上选择协议,包括ip、arp、rarp、ipx都是这一层的。
-n 不把网络地址转换成名字。
-nn 不进行端口名称的转换。
-N 不输出主机名中的域名部分。例如,‘nic.ddn.mil‘只输出’nic‘。
-t 在输出的每一行不打印时间戳。
-O 不运行分组分组匹配(packet-matching)代码优化程序。
-P 不将网络接口设置成混杂模式。
-q 快速输出。只输出较少的协议信息。
-r 从指定的文件中读取包(这些包一般通过-w选项产生)。
-S 将tcp的序列号以绝对值形式输出,而不是相对值。
-s 从每个分组中读取最开始的snaplen个字节,而不是默认的68个字节。
-T 将监听到的包直接解释为指定的类型的报文,常见的类型有rpc远程过程调用)和snmp(简单网络管理协议;)。
-t 不在每一行中输出时间戳。
-tt 在每一行中输出非格式化的时间戳。
-ttt 输出本行和前面一行之间的时间差。
-tttt 在每一行中输出由date处理的默认格式的时间戳。
-u 输出未解码的NFS句柄。
-v 输出一个稍微详细的信息,例如在ip包中可以包括ttl和服务类型的信息。
-vv 输出详细的报文信息。
-w 直接将分组写入文件中,而不是不分析并打印出来。
三、tcpdump的表达式介绍
表达式是一个正则表达式,tcpdump利用它作为过滤报文的条件,如果一个报文满足表 达式的条件,则这个报文将会被捕获。如果没有给出任何条件,则网络上所有的信息包 将会被截获。
在表达式中一般如下几种类型的关键字:
第一种是关于类型的关键字,主要包括host,net,port,例如 host 210.27.48.2, 指明 210.27.48.2是一台主机,net 202.0.0.0指明202.0.0.0是一个网络地址,port 23 指明端口号是23。如果没有指定类型,缺省的类型是host。
第二种是确定传输方向的关键字,主要包括src,dst,dst or src,dst and src, 这些关键字指明了传输的方向。举例说明,src 210.27.48.2 ,指明ip包中源地址是 210.27.48.2 , dst net 202.0.0.0 指明目的网络地址是202.0.0.0。如果没有指明 方向关键字,则缺省是src or dst关键字。
第三种是协议的关键字,主要包括fddi,ip,arp,rarp,tcp,udp等类型。Fddi指明是在FDDI (分布式光纤数据接口网络)上的特定的网络协议,实际上它是”ether”的别名,fddi和ether 具有类似的源地址和目的地址,所以可以将fddi协议包当作ether的包进行处理和分析。 其他的几个关键字就是指明了监听的包的协议内容。如果没有指定任何协议,则tcpdump 将会 监听所有协议的信息包。
除了这三种类型的关键字之外,其他重要的关键字如下:gateway, broadcast,less, greater, 还有三种逻辑运算,取非运算是 ‘not ‘ ‘! ‘, 与运算是’and’,’&&’;或运算是’or’ ,’||’; 这些关键字可以组合起来构成强大的组合条件来满足人们的需要。
四、输出结果介绍
下面我们介绍几种典型的tcpdump命令的输出信息
(1) 数据链路层头信息
使用命令:
#tcpdump --e host ICE
ICE 是一台装有linux的主机。它的MAC地址是0:90:27:58:AF:1A H219是一台装有Solaris的SUN工作站。它的MAC地址是8:0:20:79:5B:46; 上一条命令的输出结果如下所示:
21:50:12.847509 eth0 < 8:0:20:79:5b:46 0:90:27:58:af:1a ip 60: h219.33357 > ICE. telne t 0:0(0) ack 22535 win 8760 (DF)
21:50:12是显示的时间, 847509是ID号,eth0 <表示从网络接口eth0接收该分组, eth0 >表示从网络接口设备发送分组, 8:0:20:79:5b:46是主机H219的MAC地址, 它表明是从源地址H219发来的分组. 0:90:27:58:af:1a是主机ICE的MAC地址, 表示该分组的目的地址是ICE。 ip 是表明该分组是IP分组,60 是分组的长度, h219.33357 > ICE. telnet 表明该分组是从主机H219的33357端口发往主机ICE的 TELNET(23)端口。 ack 22535 表明对序列号是222535的包进行响应。 win 8760表明发 送窗口的大小是8760。
(2) ARP包的tcpdump输出信息
使用命令:
#tcpdump arp
得到的输出结果是:
22:32:42.802509 eth0 > arp who-has route tell ICE (0:90:27:58:af:1a)
22:32:42.802902 eth0 < arp reply route is-at 0:90:27:12:10:66 (0:90:27:58:af:1a)
22:32:42是时间戳, 802509是ID号, eth0 >表明从主机发出该分组,arp表明是ARP请求包, who-has route tell ICE表明是主机ICE请求主机route的MAC地址。 0:90:27:58:af:1a是主机 ICE的MAC地址。
(3) TCP包的输出信息
用tcpdump捕获的TCP包的一般输出信息是:
src > dst: flags data-seqno ack window urgent options
src > dst:表明从源地址到目的地址, flags是TCP报文中的标志信息,S 是SYN标志, F (FIN), P (PUSH) , R (RST) “.” (没有标记); data-seqno是报文中的数据 的顺序号, ack是下次期望的顺序号, window是接收缓存的窗口大小, urgent表明 报文中是否有紧急指针。 Options是选项。
(4) UDP包的输出信息
用tcpdump捕获的UDP包的一般输出信息是:
route.port1 > ICE.port2: udp lenth
UDP十分简单,上面的输出行表明从主机route的port1端口发出的一个UDP报文 到主机ICE的port2端口,类型是UDP, 包的长度是lenth。
五、举例
(1) 想要截获所有210.27.48.1 的主机收到的和发出的所有的分组:
#tcpdump host 210.27.48.1
(2) 想要截获主机210.27.48.1 和主机210.27.48.2或210.27.48.3的通信,使用命令(注意:括号前的反斜杠是必须的):
#tcpdump host 210.27.48.1 and (210.27.48.2 or 210.27.48.3 )
(3) 如果想要获取主机210.27.48.1除了和主机210.27.48.2之外所有主机通信的ip包,使用命令:
#tcpdump ip host 210.27.48.1 and ! 210.27.48.2
(4) 如果想要获取主机192.168.228.246接收或发出的ssh包,并且不转换主机名使用如下命令:
#tcpdump -nn -n src host 192.168.228.246 and port 22 and tcp
(5) 获取主机192.168.228.246接收或发出的ssh包,并把mac地址也一同显示:
# tcpdump -e src host 192.168.228.246 and port 22 and tcp -n -nn
(6) 过滤的是源主机为192.168.0.1与目的网络为192.168.0.0的报头:
tcpdump src host 192.168.0.1 and dst net 192.168.0.0/24
(7) 过滤源主机物理地址为XXX的报头:
tcpdump ether src 00:50:04:BA:9B and dst……
(为什么ether src后面没有host或者net?物理地址当然不可能有网络喽)。
(8) 过滤源主机192.168.0.1和目的端口不是telnet的报头,并导入到tes.t.txt文件中:
Tcpdump src host 192.168.0.1 and dst port not telnet -l > test.txt
ip icmp arp rarp 和 tcp、udp、icmp这些选项等都要放到第一个参数的位置,用来过滤数据报的类型。
例题:如何使用tcpdump监听来自eth0适配卡且通信协议为port 22,目标来源为192.168.1.100的数据包资料?
答:tcpdump -i eth0 -nn port 22 and src host 192.168.1.100
例题:如何使用tcpdump抓取访问eth0适配卡且访问端口为tcp 9080?
答:tcpdump -i eth0 dst 172.168.70.35 and tcp port 9080
例题:如何使用tcpdump抓取与主机192.168.43.23或着与主机192.168.43.24通信报文,并且显示在控制台上
tcpdump -X -s 1024 -i eth0 host (192.168.43.23 or 192.168.43.24) and host 172.16.70.35
Linux系统出现了性能问题,一般我们可以通过top、iostat、free、vmstat等命令来查看初步定位问题。其中iostat可以给我们提供丰富的IO状态数据。
1. 基本使用 $iostat -d -k 1 10
参数 -d 表示,显示设备(磁盘)使用状态;-k某些使用block为单位的列强制使用Kilobytes为单位;1 10表示,数据显示每隔1秒刷新一次,共显示10次。 $iostat -d -k 1 10
Device: tps kB_read/s kB_wrtn/s kB_read kB_wrtn
sda 39.29 21.14 1.44 441339807 29990031
sda1 0.00 0.00 0.00 1623 523
sda2 1.32 1.43 4.54 29834273 94827104
sda3 6.30 0.85 24.95 17816289 520725244
sda5 0.85 0.46 3.40 9543503 70970116
sda6 0.00 0.00 0.00 550 236
sda7 0.00 0.00 0.00 406 0
sda8 0.00 0.00 0.00 406 0
sda9 0.00 0.00 0.00 406 0
sda10 60.68 18.35 71.43 383002263 1490928140
Device: tps kB_read/s kB_wrtn/s kB_read kB_wrtn
sda 327.55 5159.18 102.04 5056 100
sda1 0.00 0.00 0.00 0 0
tps:该设备每秒的传输次数(Indicate the number of transfers per second that were issued to the device.)。“一次传输”意思是“一次I/O请求”。多个逻辑请求可能会被合并为“一次I/O请求”。“一次传输”请求的大小是未知的。
kB_read/s:每秒从设备(drive expressed)读取的数据量;kB_wrtn/s:每秒向设备(drive expressed)写入的数据量;kB_read:读取的总数据量;kB_wrtn:写入的总数量数据量;这些单位都为Kilobytes。
上面的例子中,我们可以看到磁盘sda以及它的各个分区的统计数据,当时统计的磁盘总TPS是39.29,下面是各个分区的TPS。(因为是瞬间值,所以总TPS并不严格等于各个分区TPS的总和)
2. -x 参数
使用-x参数我们可以获得更多统计信息。 iostat -d -x -k 1 10
Device: rrqm/s wrqm/s r/s w/s rsec/s wsec/s rkB/s wkB/s avgrq-sz avgqu-sz await svctm %util
sda 1.56 28.31 7.80 31.49 42.51 2.92 21.26 1.46 1.16 0.03 0.79 2.62 10.28
Device: rrqm/s wrqm/s r/s w/s rsec/s wsec/s rkB/s wkB/s avgrq-sz avgqu-sz await svctm %util
sda 2.00 20.00 381.00 7.00 12320.00 216.00 6160.00 108.00 32.31 1.75 4.50 2.17 84.20
rrqm/s:每秒这个设备相关的读取请求有多少被Merge了(当系统调用需要读取数据的时候,VFS将请求发到各个FS,如果FS发现不同的读取请求读取的是相同Block的数据,FS会将这个请求合并Merge);wrqm/s:每秒这个设备相关的写入请求有多少被Merge了。
rsec/s:每秒读取的扇区数;wsec/:每秒写入的扇区数。r/s:The number of read requests that were issued to the device per second;w/s:The number of write requests that were issued to the device per second;
await:每一个IO请求的处理的平均时间(单位是微秒毫秒)。这里可以理解为IO的响应时间,一般地系统IO响应时间应该低于5ms,如果大于10ms就比较大了。
%util:在统计时间内所有处理IO时间,除以总共统计时间。例如,如果统计间隔1秒,该设备有0.8秒在处理IO,而0.2秒闲置,那么该设备的%util = 0.8/1 = 80%,所以该参数暗示了设备的繁忙程度。一般地,如果该参数是100%表示设备已经接近满负荷运行了(当然如果是多磁盘,即使%util是100%,因为磁盘的并发能力,所以磁盘使用未必就到了瓶颈)。
3. -c 参数
iostat还可以用来获取cpu部分状态值: iostat -c 1 10
avg-cpu: %user %nice %sys %iowait %idle
1.98 0.00 0.35 11.45 86.22
avg-cpu: %user %nice %sys %iowait %idle
1.62 0.00 0.25 34.46 63.67
4. 常见用法 $iostat -d -k 1 10 #查看TPS和吞吐量信息
iostat -d -x -k 1 10 #查看设备使用率(%util)、响应时间(await)
iostat -c 1 10 #查看cpu状态
5. 实例分析 $$iostat -d -k 1 |grep sda10
Device: tps kB_read/s kB_wrtn/s kB_read kB_wrtn
sda10 60.72 18.95 71.53 395637647 1493241908
sda10 299.02 4266.67 129.41 4352 132
sda10 483.84 4589.90 4117.17 4544 4076
sda10 218.00 3360.00 100.00 3360 100
sda10 546.00 8784.00 124.00 8784 124
sda10 827.00 13232.00 136.00 13232 136
上面看到,磁盘每秒传输次数平均约400;每秒磁盘读取约5MB,写入约1MB。 iostat -d -x -k 1
Device: rrqm/s wrqm/s r/s w/s rsec/s wsec/s rkB/s wkB/s avgrq-sz avgqu-sz await svctm %util
sda 1.56 28.31 7.84 31.50 43.65 3.16 21.82 1.58 1.19 0.03 0.80 2.61 10.29
sda 1.98 24.75 419.80 6.93 13465.35 253.47 6732.67 126.73 32.15 2.00 4.70 2.00 85.25
sda 3.06 41.84 444.90 54.08 14204.08 2048.98 7102.04 1024.49 32.57 2.10 4.21 1.85 92.24
可以看到磁盘的平均响应时间<5ms,磁盘使用率>80。磁盘响应正常,但是已经很繁忙了。
参考文献:
- Linux man iostat
- How Linux iostat computes its results
- Linux iostat
一般对负载均衡的使用是随着网站规模的提升根据不同的阶段来使用不同的技术。具体的应用需求还得具体分析,如果是中小型的Web应用,比如日PV小于1000万,用Nginx就完全可以了;如果机器不少,可以用DNS轮询,LVS所耗费的机器还是比较多的;大型网站或重要的服务,且服务器比较多时,可以考虑用LVS。
AD:
PS:Nginx/LVS/HAProxy是目前使用最广泛的三种负载均衡软件,本人都在多个项目中实施过,参考了一些资料,结合自己的一些使用经验,总结一下。
一般对负载均衡的使用是随着网站规模的提升根据不同的阶段来使用不同的技术。具体的应用需求还得具体分析,如果是中小型的Web应用,比如日PV小于1000万,用Nginx就完全可以了;如果机器不少,可以用DNS轮询,LVS所耗费的机器还是比较多的;大型网站或重要的服务,且服务器比较多时,可以考虑用LVS。
一种是通过硬件来进行进行,常见的硬件有比较昂贵的F5和Array等商用的负载均衡器,它的优点就是有专业的维护团队来对这些服务进行维护、缺点就是花销太大,所以对于规模较小的网络服务来说暂时还没有需要使用;另外一种就是类似于Nginx/LVS/HAProxy的基于Linux的开源免费的负载均衡软件,这些都是通过软件级别来实现,所以费用非常低廉。
目前关于网站架构一般比较合理流行的架构方案:Web前端采用Nginx/HAProxy+Keepalived作负载均衡器;后端采用MySQL数据库一主多从和读写分离,采用LVS+Keepalived的架构。当然要根据项目具体需求制定方案。
下面说说各自的特点和适用场合。
Nginx的优点是:
1、工作在网络的7层之上,可以针对http应用做一些分流的策略,比如针对域名、目录结构,它的正则规则比HAProxy更为强大和灵活,这也是它目前广泛流行的主要原因之一,Nginx单凭这点可利用的场合就远多于LVS了。
2、Nginx对网络稳定性的依赖非常小,理论上能ping通就就能进行负载功能,这个也是它的优势之一;相反LVS对网络稳定性依赖比较大,这点本人深有体会;
3、Nginx安装和配置比较简单,测试起来比较方便,它基本能把错误用日志打印出来。LVS的配置、测试就要花比较长的时间了,LVS对网络依赖比较大。
3、可以承担高负载压力且稳定,在硬件不差的情况下一般能支撑几万次的并发量,负载度比LVS相对小些。
4、Nginx可以通过端口检测到服务器内部的故障,比如根据服务器处理网页返回的状态码、超时等等,并且会把返回错误的请求重新提交到另一个节点,不过其中缺点就是不支持url来检测。比如用户正在上传一个文件,而处理该上传的节点刚好在上传过程中出现故障,Nginx会把上传切到另一台服务器重新处理,而LVS就直接断掉了,如果是上传一个很大的文件或者很重要的文件的话,用户可能会因此而不满。
5、Nginx不仅仅是一款优秀的负载均衡器/反向代理软件,它同时也是功能强大的Web应用服务器。LNMP也是近几年非常流行的web架构,在高流量的环境中稳定性也很好。
6、Nginx现在作为Web反向加速缓存越来越成熟了,速度比传统的Squid服务器更快,可以考虑用其作为反向代理加速器。
7、Nginx可作为中层反向代理使用,这一层面Nginx基本上无对手,唯一可以对比Nginx的就只有lighttpd了,不过lighttpd目前还没有做到Nginx完全的功能,配置也不那么清晰易读,社区资料也远远没Nginx活跃。
8、Nginx也可作为静态网页和图片服务器,这方面的性能也无对手。还有Nginx社区非常活跃,第三方模块也很多。
Nginx的缺点是:
1、Nginx仅能支持http、https和Email协议,这样就在适用范围上面小些,这个是它的缺点。
2、对后端服务器的健康检查,只支持通过端口来检测,不支持通过url来检测。不支持Session的直接保持,但能通过ip_hash来解决。
LVS:使用Linux内核集群实现一个高性能、高可用的负载均衡服务器,它具有很好的可伸缩性(Scalability)、可靠性(Reliability)和可管理性(Manageability)。
LVS的优点是:
1、抗负载能力强、是工作在网络4层之上仅作分发之用,没有流量的产生,这个特点也决定了它在负载均衡软件里的性能最强的,对内存和cpu资源消耗比较低。
2、配置性比较低,这是一个缺点也是一个优点,因为没有可太多配置的东西,所以并不需要太多接触,大大减少了人为出错的几率。
3、工作稳定,因为其本身抗负载能力很强,自身有完整的双机热备方案,如LVS+Keepalived,不过我们在项目实施中用得最多的还是LVS/DR+Keepalived。
4、无流量,LVS只分发请求,而流量并不从它本身出去,这点保证了均衡器IO的性能不会收到大流量的影响。
5、应用范围比较广,因为LVS工作在4层,所以它几乎可以对所有应用做负载均衡,包括http、数据库、在线聊天室等等。
LVS的缺点是:
1、软件本身不支持正则表达式处理,不能做动静分离;而现在许多网站在这方面都有较强的需求,这个是Nginx/HAProxy+Keepalived的优势所在。
2、如果是网站应用比较庞大的话,LVS/DR+Keepalived实施起来就比较复杂了,特别后面有Windows Server的机器的话,如果实施及配置还有维护过程就比较复杂了,相对而言,Nginx/HAProxy+Keepalived就简单多了。
HAProxy的特点是:
1、HAProxy也是支持虚拟主机的。
2、HAProxy的优点能够补充Nginx的一些缺点,比如支持Session的保持,Cookie的引导;同时支持通过获取指定的url来检测后端服务器的状态。
3、HAProxy跟LVS类似,本身就只是一款负载均衡软件;单纯从效率上来讲HAProxy会比Nginx有更出色的负载均衡速度,在并发处理上也是优于Nginx的。
4、HAProxy支持TCP协议的负载均衡转发,可以对MySQL读进行负载均衡,对后端的MySQL节点进行检测和负载均衡,大家可以用LVS+Keepalived对MySQL主从做负载均衡。
5、HAProxy负载均衡策略非常多,HAProxy的负载均衡算法现在具体有如下8种:
① roundrobin,表示简单的轮询,这个不多说,这个是负载均衡基本都具备的;
② static-rr,表示根据权重,建议关注;
③ leastconn,表示最少连接者先处理,建议关注;
④ source,表示根据请求源IP,这个跟Nginx的IP_hash机制类似,我们用其作为解决session问题的一种方法,建议关注;
⑤ ri,表示根据请求的URI;
⑥ rl_param,表示根据请求的URl参数’balance url_param’ requires an URL parameter name;
⑦ hdr(name),表示根据HTTP请求头来锁定每一次HTTP请求;
⑧ rdp-cookie(name),表示根据据cookie(name)来锁定并哈希每一次TCP请求。
Nginx和LVS对比的总结:
1、Nginx工作在网络的7层,所以它可以针对http应用本身来做分流策略,比如针对域名、目录结构等,相比之下LVS并不具备这样的功能,所以Nginx单凭这点可利用的场合就远多于LVS了;但Nginx有用的这些功能使其可调整度要高于LVS,所以经常要去触碰触碰,触碰多了,人为出问题的几率也就会大。
2、Nginx对网络稳定性的依赖较小,理论上只要ping得通,网页访问正常,Nginx就能连得通,这是Nginx的一大优势!Nginx同时还能区分内外网,如果是同时拥有内外网的节点,就相当于单机拥有了备份线路;LVS就比较依赖于网络环境,目前来看服务器在同一网段内并且LVS使用direct方式分流,效果较能得到保证。另外注意,LVS需要向托管商至少申请多一个ip来做Visual IP,貌似是不能用本身的IP来做VIP的。要做好LVS管理员,确实得跟进学习很多有关网络通信方面的知识,就不再是一个HTTP那么简单了。
3、Nginx安装和配置比较简单,测试起来也很方便,因为它基本能把错误用日志打印出来。LVS的安装和配置、测试就要花比较长的时间了;LVS对网络依赖比较大,很多时候不能配置成功都是因为网络问题而不是配置问题,出了问题要解决也相应的会麻烦得多。
4、Nginx也同样能承受很高负载且稳定,但负载度和稳定度差LVS还有几个等级:Nginx处理所有流量所以受限于机器IO和配置;本身的bug也还是难以避免的。
5、Nginx可以检测到服务器内部的故障,比如根据服务器处理网页返回的状态码、超时等等,并且会把返回错误的请求重新提交到另一个节点。目前LVS中 ldirectd也能支持针对服务器内部的情况来监控,但LVS的原理使其不能重发请求。比如用户正在上传一个文件,而处理该上传的节点刚好在上传过程中出现故障,Nginx会把上传切到另一台服务器重新处理,而LVS就直接断掉了,如果是上传一个很大的文件或者很重要的文件的话,用户可能会因此而恼火。
6、Nginx对请求的异步处理可以帮助节点服务器减轻负载,假如使用apache直接对外服务,那么出现很多的窄带链接时apache服务器将会占用大 量内存而不能释放,使用多一个Nginx做apache代理的话,这些窄带链接会被Nginx挡住,apache上就不会堆积过多的请求,这样就减少了相当多的资源占用。这点使用squid也有相同的作用,即使squid本身配置为不缓存,对apache还是有很大帮助的。
7、Nginx能支持http、https和email(email的功能比较少用),LVS所支持的应用在这点上会比Nginx更多。在使用上,一般最前端所采取的策略应是LVS,也就是DNS的指向应为LVS均衡器,LVS的优点令它非常适合做这个任务。重要的ip地址,最好交由LVS托管,比如数据库的 ip、webservice服务器的ip等等,这些ip地址随着时间推移,使用面会越来越大,如果更换ip则故障会接踵而至。所以将这些重要ip交给 LVS托管是最为稳妥的,这样做的唯一缺点是需要的VIP数量会比较多。Nginx可作为LVS节点机器使用,一是可以利用Nginx的功能,二是可以利用Nginx的性能。当然这一层面也可以直接使用squid,squid的功能方面就比Nginx弱不少了,性能上也有所逊色于Nginx。Nginx也可作为中层代理使用,这一层面Nginx基本上无对手,唯一可以撼动Nginx的就只有lighttpd了,不过lighttpd目前还没有能做到 Nginx完全的功能,配置也不那么清晰易读。另外,中层代理的IP也是重要的,所以中层代理也拥有一个VIP和LVS是最完美的方案了。具体的应用还得具体分析,如果是比较小的网站(日PV小于1000万),用Nginx就完全可以了,如果机器也不少,可以用DNS轮询,LVS所耗费的机器还是比较多的;大型网站或者重要的服务,机器不发愁的时候,要多多考虑利用LVS。
现在对网络负载均衡的使用是随着网站规模的提升根据不同的阶段来使用不同的技术:
第一阶段:利用Nginx或HAProxy进行单点的负载均衡,这一阶段服务器规模刚脱离开单服务器、单数据库的模式,需要一定的负载均衡,但是仍然规模较小没有专业的维护团队来进行维护,也没有需要进行大规模的网站部署。这样利用Nginx或HAproxy就是第一选择,此时这些东西上手快, 配置容易,在七层之上利用HTTP协议就可以。这时是第一选择。
第二阶段:随着网络服务进一步扩大,这时单点的Nginx已经不能满足,这时使用LVS或者商用Array就是首要选择,Nginx此时就作为LVS或者Array的节点来使用,具体LVS或Array的是选择是根据公司规模和预算来选择,Array的应用交付功能非常强大,本人在某项目中使用过,性价比也远高于F5,商用首选!但是一般来说这阶段相关人才跟不上业务的提升,所以购买商业负载均衡已经成为了必经之路。
第三阶段:这时网络服务已经成为主流产品,此时随着公司知名度也进一步扩展,相关人才的能力以及数量也随之提升,这时无论从开发适合自身产品的定制,以及降低成本来讲开源的LVS,已经成为首选,这时LVS会成为主流。
最终形成比较理想的基本架构为:Array/LVS — Nginx/Haproxy — Squid/Varnish — AppServer。
原文链接:http://www.ha97.com/5646.html
【编辑推荐】
1、date --help
%% 输出%符号 a literal %
%a 当前域的星期缩写 locale’s abbreviated weekday name (Sun..Sat)
%A 当前域的星期全写 locale’s full weekday name, variable length (Sunday..Saturday)
%b 当前域的月份缩写 locale’s abbreviated month name (Jan..Dec)
%B 当前域的月份全称 locale’s full month name, variable length (January..December)
%c 当前域的默认时间格式 locale’s date and time (Sat Nov 04 12:02:33 EST 1989)
%C n百年 century (year divided by 100 and truncated to an integer) [00-99]
%d 两位的天 day of month (01..31)
%D 短时间格式 date (mm/dd/yy)
%e 短格式天 day of month, blank padded ( 1..31)
%F 文件时间格式 same as %Y-%m-%d
%g the 2-digit year corresponding to the %V week number
%G the 4-digit year corresponding to the %V week number
%h same as %b
%H 24小时制的小时 hour (00..23)
%I 12小时制的小时 hour (01..12)
%j 一年中的第几天 day of year (001..366)
%k 短格式24小时制的小时 hour ( 0..23)
%l 短格式12小时制的小时 hour ( 1..12)
%m 双位月份 month (01..12)
%M 双位分钟 minute (00..59)
%n 换行 a newline
%N 十亿分之一秒 nanoseconds (000000000..999999999)
%p 大写的当前域的上下午指示 locale’s upper case AM or PM indicator (blank in many locales)
%P 小写的当前域的上下午指示 locale’s lower case am or pm indicator (blank in many locales)
%r 12小时制的时间表示(时:分:秒,双位) time, 12-hour (hh:mm:ss [AP]M)
%R 24小时制的时间表示 (时:分,双位)time, 24-hour (hh:mm)
%s 自基础时间 1970-01-01 00:00:00 到当前时刻的秒数 seconds since `00:00:00 1970-01-01 UTC’ (a GNU extension)
%S 双位秒 second (00..60); the 60 is necessary to accommodate a leap second
%t 横向制表位(tab) a horizontal tab
%T 24小时制时间表示 time, 24-hour (hh:mm:ss)
%u 数字表示的星期(从星期一开始 1-7)day of week (1..7); 1 represents Monday
%U 一年中的第几周星期天为开始 week number of year with Sunday as first day of week (00..53)
%V 一年中的第几周星期一为开始 week number of year with Monday as first day of week (01..53)
%w 一周中的第几天 星期天为开始 0-6 day of week (0..6); 0 represents Sunday
%W 一年中的第几周星期一为开始 week number of year with Monday as first day of week (00..53)
%x 本地日期格式 locale’s date representation (mm/dd/yy)
%X 本地时间格式 locale’s time representation (%H:%M:%S)
%y 两位的年 last two digits of year (00..99)
%Y 年 year (1970…)
%z RFC-2822 标准时间格式表示的域 RFC-2822 style numeric timezone (-0500) (a nonstandard extension)
%Z 时间域 time zone (e.g., EDT), or nothing if no time zone is determinable
By default, date pads numeric fields with zeroes. GNU date recognizes
the following modifiers between `%’ and a numeric directive.
`-’ (hyphen) do not pad the field
`_’ (underscore) pad the field with spaces
--------------------------------------------------------------------------------
2、一些用法
1)#以yymmdd的格式输出43天前的当前时刻
date +%Y%m%d --date='43 days ago'
2)# 测试十亿分之一秒
date +’%Y%m%d %H:%M:%S.%N’;date +’%Y%m%d %H:%M:%S.%N’;date +’%Y%m%d %H:%M:%S.%N’;date +’%Y%m%d %H:%M:%S.%N’
3)#创建以当前时间为文件名的目录
mkdir `date +%Y%m%d`
4)#备份以时间做为文件名的
tar -cvf ./htdocs`date +%Y%m%d`.tar ./*
5)#显示时间后跳行,再显示目前日期
date +%T%n%Y%m%d
6)#只显示月份与日数
date +%B%d
7)#获取上周日期(day,month,year,hour)
date -d "-1 week" +%Y%m%d
8)#获取24小时前日期
date --date="-24 hour" +%Y%m%d
9)#shell脚本里面赋给变量值
date_now=`date +%s`
10)#计算执行一段sql脚本的运行时间
TIME_BEGIN=$(date '+%s.%N')
$sqlcli < queries/q1.3.sql 1>> $FILE_RESULT 2>> $FILE_ERROR
TIME_END=$(date '+%s.%N')
TIME_RUN=$(awk 'BEGIN{print '$TIME_END' - '$TIME_BEGIN'}')
11)#编写shell脚本计算离自己生日还有多少天?
read -p "Input your birthday(YYYYmmdd):" date1
m=`date --date="$date1" +%m` #得到生日的月
d=`date --date="$date1" +%d` #得到生日的日
date_now=`date +%s` #得到当前时间的秒值
y=`date +%Y` #得到当前时间的年
birth=`date --date="$y$m$d" +%s` #得到今年的生日日期的秒值
internal=$(($birth-$date_now)) #计算今日到生日日期的间隔时间
if [ "$internal" -lt "0" ]; then #判断今天的生日是否已过
birth=`date --date="$(($y+1))$m$d" +%s` #得到明天的生日日期秒值
internal=$(($birth-$date_now)) #计算今天到下一个生日的间隔时间
fi
echo "There is :$((einternal/60/60/24)) days." #输出结果,秒换算为天
12)#若是不以加号作为开头,则表示要设定时间,而时间格式为 MMDDhhmm[[CC]YY][.ss],
其中 MM 为月份,
DD 为日,
hh 为小时,
mm 为分钟,
CC 为年份前两位数字,
YY 为年份后两位数字,
ss 为秒数
13)
#显示目前的格林威治时间,也叫“世界时”。是英国的标准时间,也是世界各地时间的参考标准。中英两国的标准时差为8个小时,即英国的当地时间比中国的北京时间晚8小时。
date -u
Thu Sep 28 09:32:04 UTC 2006
14)#修改时间
date -s
按字符串方式修改时间
可以只修改日期,不修改时间,输入: date -s 2007-08-03
只修改时间,输入:date -s 14:15:00
同时修改日期时间,注意要加双引号,日期与时间之间有一空格,输入:date -s "2007-08-03 14:15:00"
修改完后,记得输入:clock -w
把系统时间写入CMOS
增加GC相关选项:
-verbose:gc-XX:+UseGCLogFileRotation-XX:NumberOfGCLogFiles=5-XX:GCLogFileSize=512K-XX:+PrintGCDetails-XX:+PrintGCTimeStamps-XX:+PrintGCDateStamps-XX:+PrintTenuringDistribution-XX:+PrintGCApplicationStoppedTime-Xloggc:/var/app/log/Push-server/gc.log
- 如果不能确定所需内存,使用自动jvm自动调优;
- 大致确定所需内存后,使用-Xmx -Xms设置堆大小;
- 观察GC log确定FullGC后剩余堆大小(即为活跃数据大小);
- 整个堆大小宜为老年代活跃数据大小的3-4倍;
- 永久带大小应该比永久带活跃数据大1.2~1.5倍;
- 新生代空间应该为老年代空间活跃数据的1~1.5倍;
- 通过top命令观察栈占用空间、直接内存占用空间,决定所需机器内存大小;
- 新生代大小决定了Minor GC的周期和时长,缩短新生代大小可以减少停顿时长,但是增加了GC频率;在调整新生代大小时,尽量保持老年代大小不变;
- 老年代大小不应该小于活跃数据的1.5倍;新生代空间至少为java堆大小的10%;增加堆大小时,注意不要超过可用物理内存数;
- 从throughput收集器迁移到CMS时,需要将老年代空间增加20%~30%;
- 新生代分为Eden和Survivor两部分,Survivor可以通过
-XX:SurvivorRatio=xx来控制,对应的大小为-Xmn<value>/(ratio+2); - 通过
-XX:MaxTenuringThreshold=<n>来指定晋升阈值(年龄),n为0~15之间; - 期望Survivor空间为剩余总存活对象大小的2倍(age=1;
- 注意调节Survivor大小时,保持Eden大小不变;
- 如果Survivor空间足够大,且对象大部分并未到达老年代,那么就可以将晋升年纪指定的足够大(15)。在Eden与Survivor之间复制和CMS老年代空间压缩之间,我们宁愿选择前者;
- CMS必须能以对象从新生代提升到老年代的同等速度对老年代中的对象进行收集,否则,就会失速;
- 如果观察到'concurrent mode failures',意味着失速已经发生,必须减少
-XX:CMSInitiatingOccupancyFraction=<percent>的值; - 使用上述选项的同时,最好同时使用
-XX:+UseCMSInitiatingOccupancyOnly,强制使用该比例,该比例的大小应该大于老年代占用空间和活跃数据大小之比,一般而言老年代大小*该比例>1.5*老年代活跃数据大小; - 使用
-XX:+ExplicitGCInvokesConcurrentAndUnloadsCloasses可以使用CMS进行显式垃圾回收(System.gc());通过-XX:+DisableExplicitGC关闭显示垃圾回收(慎用); - 使用
-XX:+CMSClassUnloadingEnabled打开永久带垃圾回收,使用-XX:+CMSPermGenSweepingEnabled打开CMS对永久带的扫描;使用-XX:CMSInitiatingPermOccupancyFraction=<perscent>激活回收比例阈值; - 使用
-XX:ParallelGCThreads=<n>控制扫描线程数;使用-XX:+CMSScavengeBeforeRemark强制重新标记前进行一次MinorGC;如果由大量的引用对象或可终结对象要处理,使用-XX:+ParallelRefProcEnabled; - CMS包括Minor GC所带来的开销应该小于10%;
- 如果缺少长时间调优的条件,安全起见,可以使用G1,仅设置如下参数即可:
-d64-Xmx5g-Xms5g-XX:PermSize=100m-XX:MaxPermSize=100m-XX:MaxDirectMemorySize=1g-XX:+UseG1GC-XX:MaxGCPauseMillis=80
G1不必明确设置新生代大小,其自动调优也十分可靠,对于停顿时间往往在长时间运行后可以达到预期效果;对吞吐量优先的应用,可能不是那么明显。
通过traceroute我们可以知道信息从你的计算机到互联网另一端的主机是走的什么路径。当然每次数据包由某一同样的出发点(source)到达某一同样的目的地(destination)走的路径可能会不一样,但基本上来说大部分时候所走的路由是相同的
linux系统中,我们称之为traceroute,在MS Windows中为tracert。 traceroute通过发送小的数据包到目的设备直到其返回,来测量其需要多长时间。一条路径上的每个设备traceroute要测3次。输出结果中包括每次测试的时间(ms)和设备的名称(如有的话)及其IP地址。
在大多数情况下,我们会在linux主机系统下,直接执行命令行:traceroute hostname
而在Windows系统下是执行tracert的命令: tracert hostname
1.命令格式:
traceroute[参数][主机]
2.命令功能:
traceroute指令让你追踪网络数据包的路由途径,预设数据包大小是40Bytes,用户可另行设置。
具体参数格式:traceroute [-dFlnrvx][-f<存活数值>][-g<网关>...][-i<网络界面>][-m<存活数值>][-p<通信端口>][-s<来源地址>][-t<服务类型>][-w<超时秒数>][主机名称或IP地址][数据包大小]
3.命令参数:
-d 使用Socket层级的排错功能。
-f 设置第一个检测数据包的存活数值TTL的大小。
-F 设置勿离断位。
-g 设置来源路由网关,最多可设置8个。
-i 使用指定的网络界面送出数据包。
-I 使用ICMP回应取代UDP资料信息。
-m 设置检测数据包的最大存活数值TTL的大小。
-n 直接使用IP地址而非主机名称。
-p 设置UDP传输协议的通信端口。
-r 忽略普通的Routing Table,直接将数据包送到远端主机上。
-s 设置本地主机送出数据包的IP地址。
-t 设置检测数据包的TOS数值。
-v 详细显示指令的执行过程。
-w 设置等待远端主机回报的时间。
-x 开启或关闭数据包的正确性检验。
4.使用实例:
实例1:traceroute 用法简单、最常用的用法
命令:traceroute www.baidu.com
输出:
[root@localhost ~]# traceroute www.baidu.com
traceroute to www.baidu.com (61.135.169.125), 30 hops max, 40 byte packets
1 192.168.74.2 (192.168.74.2) 2.606 ms 2.771 ms 2.950 ms
2 211.151.56.57 (211.151.56.57) 0.596 ms 0.598 ms 0.591 ms
3 211.151.227.206 (211.151.227.206) 0.546 ms 0.544 ms 0.538 ms
4 210.77.139.145 (210.77.139.145) 0.710 ms 0.748 ms 0.801 ms
5 202.106.42.101 (202.106.42.101) 6.759 ms 6.945 ms 7.107 ms
6 61.148.154.97 (61.148.154.97) 718.908 ms * bt-228-025.bta.net.cn (202.106.228.25) 5.177 ms
7 124.65.58.213 (124.65.58.213) 4.343 ms 4.336 ms 4.367 ms
8 202.106.35.190 (202.106.35.190) 1.795 ms 61.148.156.138 (61.148.156.138) 1.899 ms 1.951 ms
9 * * *
30 * * *
[root@localhost ~]#
说明:
记录按序列号从1开始,每个纪录就是一跳 ,每跳表示一个网关,我们看到每行有三个时间,单位是 ms,其实就是-q的默认参数。探测数据包向每个网关发送三个数据包后,网关响应后返回的时间;如果您用 traceroute -q 4 www.58.com ,表示向每个网关发送4个数据包。
有时我们traceroute 一台主机时,会看到有一些行是以星号表示的。出现这样的情况,可能是防火墙封掉了ICMP的返回信息,所以我们得不到什么相关的数据包返回数据。
有时我们在某一网关处延时比较长,有可能是某台网关比较阻塞,也可能是物理设备本身的原因。当然如果某台DNS出现问题时,不能解析主机名、域名时,也会 有延时长的现象;您可以加-n 参数来避免DNS解析,以IP格式输出数据。
如果在局域网中的不同网段之间,我们可以通过traceroute 来排查问题所在,是主机的问题还是网关的问题。如果我们通过远程来访问某台服务器遇到问题时,我们用到traceroute 追踪数据包所经过的网关,提交IDC服务商,也有助于解决问题;但目前看来在国内解决这样的问题是比较困难的,就是我们发现问题所在,IDC服务商也不可能帮助我们解决。
实例2:跳数设置
命令:traceroute -m 10 www.baidu.com
输出:
[root@localhost ~]# traceroute -m 10 www.baidu.com
traceroute to www.baidu.com (61.135.169.105), 10 hops max, 40 byte packets
1 192.168.74.2 (192.168.74.2) 1.534 ms 1.775 ms 1.961 ms
2 211.151.56.1 (211.151.56.1) 0.508 ms 0.514 ms 0.507 ms
3 211.151.227.206 (211.151.227.206) 0.571 ms 0.558 ms 0.550 ms
4 210.77.139.145 (210.77.139.145) 0.708 ms 0.729 ms 0.785 ms
5 202.106.42.101 (202.106.42.101) 7.978 ms 8.155 ms 8.311 ms
6 bt-228-037.bta.net.cn (202.106.228.37) 772.460 ms bt-228-025.bta.net.cn (202.106.228.25) 2.152 ms 61.148.154.97 (61.148.154.97) 772.107 ms
7 124.65.58.221 (124.65.58.221) 4.875 ms 61.148.146.29 (61.148.146.29) 2.124 ms 124.65.58.221 (124.65.58.221) 4.854 ms
8 123.126.6.198 (123.126.6.198) 2.944 ms 61.148.156.6 (61.148.156.6) 3.505 ms 123.126.6.198 (123.126.6.198) 2.885 ms
9 * * *
10 * * *
[root@localhost ~]#
实例3:显示IP地址,不查主机名
命令:traceroute -n www.baidu.com
输出:
[root@localhost ~]# traceroute -n www.baidu.com
traceroute to www.baidu.com (61.135.169.125), 30 hops max, 40 byte packets
1 211.151.74.2 5.430 ms 5.636 ms 5.802 ms
2 211.151.56.57 0.627 ms 0.625 ms 0.617 ms
3 211.151.227.206 0.575 ms 0.584 ms 0.576 ms
4 210.77.139.145 0.703 ms 0.754 ms 0.806 ms
5 202.106.42.101 23.683 ms 23.869 ms 23.998 ms
6 202.106.228.37 247.101 ms * *
7 61.148.146.29 5.256 ms 124.65.58.213 4.386 ms 4.373 ms
8 202.106.35.190 1.610 ms 61.148.156.138 1.786 ms 61.148.3.34 2.089 ms
9 * * *
30 * * *
[root@localhost ~]# traceroute www.baidu.com
traceroute to www.baidu.com (61.135.169.125), 30 hops max, 40 byte packets
1 211.151.74.2 (211.151.74.2) 4.671 ms 4.865 ms 5.055 ms
2 211.151.56.57 (211.151.56.57) 0.619 ms 0.618 ms 0.612 ms
3 211.151.227.206 (211.151.227.206) 0.620 ms 0.642 ms 0.636 ms
4 210.77.139.145 (210.77.139.145) 0.720 ms 0.772 ms 0.816 ms
5 202.106.42.101 (202.106.42.101) 7.667 ms 7.910 ms 8.012 ms
6 bt-228-025.bta.net.cn (202.106.228.25) 2.965 ms 2.440 ms 61.148.154.97 (61.148.154.97) 431.337 ms
7 124.65.58.213 (124.65.58.213) 5.134 ms 5.124 ms 5.044 ms
8 202.106.35.190 (202.106.35.190) 1.917 ms 2.052 ms 2.059 ms
9 * * *
30 * * *
[root@localhost ~]#
实例4:探测包使用的基本UDP端口设置6888
命令:traceroute -p 6888 www.baidu.com
[root@localhost ~]# traceroute -p 6888 www.baidu.com
traceroute to www.baidu.com (220.181.111.147), 30 hops max, 40 byte packets
1 211.151.74.2 (211.151.74.2) 4.927 ms 5.121 ms 5.298 ms
2 211.151.56.1 (211.151.56.1) 0.500 ms 0.499 ms 0.509 ms
3 211.151.224.90 (211.151.224.90) 0.637 ms 0.631 ms 0.641 ms
4 * * *
5 220.181.70.98 (220.181.70.98) 5.050 ms 5.313 ms 5.596 ms
6 220.181.17.94 (220.181.17.94) 1.665 ms !X * *
[root@localhost ~]#
实例5:把探测包的个数设置为值4
命令:traceroute -q 4 www.baidu.com
[root@localhost ~]# traceroute -q 4 www.baidu.com
traceroute to www.baidu.com (61.135.169.125), 30 hops max, 40 byte packets
1 211.151.74.2 (211.151.74.2) 40.633 ms 40.819 ms 41.004 ms 41.188 ms
2 211.151.56.57 (211.151.56.57) 0.637 ms 0.633 ms 0.627 ms 0.619 ms
3 211.151.227.206 (211.151.227.206) 0.505 ms 0.580 ms 0.571 ms 0.569 ms
4 210.77.139.145 (210.77.139.145) 0.753 ms 0.800 ms 0.853 ms 0.904 ms
5 202.106.42.101 (202.106.42.101) 7.449 ms 7.543 ms 7.738 ms 7.893 ms
6 61.148.154.97 (61.148.154.97) 316.817 ms bt-228-025.bta.net.cn (202.106.228.25) 3.695 ms 3.672 ms *
7 124.65.58.213 (124.65.58.213) 3.056 ms 2.993 ms 2.960 ms 61.148.146.29 (61.148.146.29) 2.837 ms
8 61.148.3.34 (61.148.3.34) 2.179 ms 2.295 ms 2.442 ms 202.106.35.190 (202.106.35.190) 7.136 ms
9 * * * *
30 * * * *
[root@localhost ~]#
实例6:绕过正常的路由表,直接发送到网络相连的主机
命令:traceroute -r www.baidu.com
输出:
[root@localhost ~]# traceroute -r www.baidu.com
traceroute to www.baidu.com (61.135.169.125), 30 hops max, 40 byte packets
connect: 网络不可达
[root@localhost ~]#
实例7:把对外发探测包的等待响应时间设置为3秒
命令:traceroute -w 3 www.baidu.com
输出:
[root@localhost ~]# traceroute -w 3 www.baidu.com
traceroute to www.baidu.com (61.135.169.105), 30 hops max, 40 byte packets
1 211.151.74.2 (211.151.74.2) 2.306 ms 2.469 ms 2.650 ms
2 211.151.56.1 (211.151.56.1) 0.621 ms 0.613 ms 0.603 ms
3 211.151.227.206 (211.151.227.206) 0.557 ms 0.560 ms 0.552 ms
4 210.77.139.145 (210.77.139.145) 0.708 ms 0.761 ms 0.817 ms
5 202.106.42.101 (202.106.42.101) 7.520 ms 7.774 ms 7.902 ms
6 bt-228-025.bta.net.cn (202.106.228.25) 2.890 ms 2.369 ms 61.148.154.97 (61.148.154.97) 471.961 ms
7 124.65.58.221 (124.65.58.221) 4.490 ms 4.483 ms 4.472 ms
8 123.126.6.198 (123.126.6.198) 2.948 ms 61.148.156.6 (61.148.156.6) 7.688 ms 7.756 ms
9 * * *
30 * * *
[root@localhost ~]#
Traceroute的工作原理:
Traceroute最简单的基本用法是:traceroute hostname
Traceroute程序的设计是利用ICMP及IP header的TTL(Time To Live)栏位(field)。首先,traceroute送出一个TTL是1的IP datagram(其实,每次送出的为3个40字节的包,包括源地址,目的地址和包发出的时间标签)到目的地,当路径上的第一个路由器(router)收到这个datagram时,它将TTL减1。此时,TTL变为0了,所以该路由器会将此datagram丢掉,并送回一个「ICMP time exceeded」消息(包括发IP包的源地址,IP包的所有内容及路由器的IP地址),traceroute 收到这个消息后,便知道这个路由器存在于这个路径上,接着traceroute 再送出另一个TTL是2 的datagram,发现第2 个路由器...... traceroute 每次将送出的datagram的TTL 加1来发现另一个路由器,这个重复的动作一直持续到某个datagram 抵达目的地。当datagram到达目的地后,该主机并不会送回ICMP time exceeded消息,因为它已是目的地了,那么traceroute如何得知目的地到达了呢?
Traceroute在送出UDP datagrams到目的地时,它所选择送达的port number 是一个一般应用程序都不会用的号码(30000 以上),所以当此UDP datagram 到达目的地后该主机会送回一个「ICMP port unreachable」的消息,而当traceroute 收到这个消息时,便知道目的地已经到达了。所以traceroute 在Server端也是没有所谓的Daemon 程式。
Traceroute提取发 ICMP TTL到期消息设备的IP地址并作域名解析。每次 ,Traceroute都打印出一系列数据,包括所经过的路由设备的域名及 IP地址,三个包每次来回所花时间。
windows之tracert:
格式:
tracert [-d] [-h maximum_hops] [-j host-list] [-w timeout] target_name
参数说明:
tracert [-d] [-h maximum_hops] [-j computer-list] [-w timeout] target_name
该诊断实用程序通过向目的地发送具有不同生存时间 (TL) 的 Internet 控制信息协议 (CMP) 回应报文,以确定至目的地的路由。路径上的每个路由器都要在转发该 ICMP 回应报文之前将其 TTL 值至少减 1,因此 TTL 是有效的跳转计数。当报文的 TTL 值减少到 0 时,路由器向源系统发回 ICMP 超时信息。通过发送 TTL 为 1 的第一个回应报文并且在随后的发送中每次将 TTL 值加 1,直到目标响应或达到最大 TTL 值,Tracert 可以确定路由。通过检查中间路由器发发回的 ICMP 超时 (ime Exceeded) 信息,可以确定路由器。注意,有些路由器“安静”地丢弃生存时间 (TLS) 过期的报文并且对 tracert 无效。
参数:
-d 指定不对计算机名解析地址。
-h maximum_hops 指定查找目标的跳转的最大数目。
-jcomputer-list 指定在 computer-list 中松散源路由。
-w timeout 等待由 timeout 对每个应答指定的毫秒数。
target_name 目标计算机的名称。
实例:
domain 声明主机的域名。很多程序用到它,如邮件系统;当为没有域名的主机进行DNS 查询时,也要用到。如果没有域名,主机名将被使用,删除所有在第一个点( . )前面的内容。search 它的多个参数指明域名查询顺序。当要查询没有域名的主机,主机将在由search 声明的域中分别查找。domain 和search 不能共存;如果同时存在,后面出现的将会被使用。
下面的说明更清晰
在/etc/resolv.conf 配置文件:domain 和search作用是一样的
domain linpro.no
search linpro.no uio.no ifi.uio.no
domain function:
Had I typed telnet math.uio.no. with the trailing dot, the resolver would have known it was an FQDN and would have looked up math.uio.no at once, without trying to append the specified domain first. Not all applications are tolerant of the trailing dot, though, so it can't always be specified.
search function:
When ssh gram is executed, the resolver first looks for gram.linpro.no, which does not exist; thengram.uio.no, which does not exist, either; and finally gram.ifi.uio.no, which will succeed because it does exist
之前有做过lvs+keepalived来实现高可用。可是现在nginx已经用到了很多公司的web服务器上,并且也表现出优良的性能。
那么在架构中,nginx放在前端用作负载均衡和处理静态页面以及缓存,是一个很重要的位置,必须要保证nginx服务器的高可用,
今天简单介绍下用nginx+keepalived来实现nginx服务器的高可用,即实现故障自动切换。
环境:
主nginx服务器:192.168.2.117
备nginx服务器:192.168.0.170
VIP:192.168.2.114
nginx服务器的安装和配置在此不做介绍,不会的话可以参考:
http://www.linuxyan.com/web-server/6.html
1、keepalived安装(在主和备2台nginx服务器上都安装)
wget http://www.keepalived.org/software/keepalived-1.2.2.tar.gz
tar xzf keepalived-1.2.2.tar.gz
cd keepalived-1.2.2
./configure –prefix=/usr/local/keepalived
make && make install
cp /usr/local/keepalived/etc/rc.d/init.d/keepalived /etc/init.d/
cp /usr/local/keepalived/etc/sysconfig/keepalived /etc/sysconfig/
chmod +x /etc/init.d/keepalived
mkdir /etc/keepalived
ln -s /usr/local/keepalived/sbin/keepalived /usr/sbin/
然后对主nginx服务器的keepalived进行配置
vi /etc/keepalived/keepalived.conf
global_defs {
notification_email {
admin@centos.bz #接收警报的email地址,可以添加多个
}
notification_email_from keepalived@domain.com ###发件人地址
smtp_server 127.0.0.1 ###发送邮件的服务器
smtp_connect_timeout 30 ###超时时间
router_id LVS_DEVEL ####load balancer 的标识 ID,用于email警报
}
vrrp_script chk_http_port {
script “/opt/nginx_pid.sh” ####检测nginx状态的脚本路径
interval 2
weight 2
}
vrrp_instance VI_1 {
state MASTER ############ 辅机为 BACKUP
interface eth0 ####HA 监测网络接口
virtual_router_id 51 #主、备机的 virtual_router_id 必须相同
mcast_src_ip 192.168.2.117 ###本机IP地址
priority 102 ########### 权值要比 back 高
advert_int 1 #主备之间的通告间隔秒数
authentication {
auth_type PASS ###主备切换时的验证
auth_pass 1111
}
track_script {
chk_http_port ### 执行监控的服务
}
virtual_ipaddress {
192.168.2.114 ####vip的地址
}
}
备nginx服务器上配置
global_defs {
notification_email {
admin@centos.bz
}
notification_email_from keepalived@domain.com
smtp_server 127.0.0.1
smtp_connect_timeout 30
router_id LVS_DEVEL
}
vrrp_script chk_http_port {
script “/opt/nginx_pid.sh” ##检测nginx状态的脚本
interval 2
weight 2
}
vrrp_instance VI_1 {
state BACKUP
interface eth0
virtual_router_id 51 #### 保持主从服务器一致
mcast_src_ip 192.168.0.170 ###本机的IP地址
priority 101 ##########权值 要比 master 低。。
advert_int 1
authentication {
auth_type PASS
auth_pass 1111
}
track_script {
chk_http_port ### 执行监控的服务
}
virtual_ipaddress {
192.168.2.114 ###vip的地址
}
}
之后分别在主从服务器建立nginx的监控脚本:
vi /opt/nginx_pid.sh
#!/bin/bash
A=`ps -C nginx –no-header |wc -l`
if [ $A -eq 0 ];then
/usr/local/nginx/sbin/nginx ##这个地方写你nginx命令的路径
sleep 3
if [ `ps -C nginx --no-header |wc -l` -eq 0 ];then
killall keepalived
fi
fi
配置好之后,分别在2台服务器上启动nginx和keepalived
/usr/local/nginx/sbin/nginx -c /usr/local/nginx/conf/nginx.conf
/etc/init.d/keepalived start
在主nginx服务器上执行ip a
[root@localhost ~]# ip a
1: lo: mtu 16436 qdisc noqueue
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: eth0: mtu 1500 qdisc pfifo_fast qlen 1000
link/ether 00:0c:29:58:58:5f brd ff:ff:ff:ff:ff:ff
inet 192.168.2.117/22 brd 192.168.3.255 scope global eth0
inet 192.168.2.114/32 scope global eth0
inet6 fe80::20c:29ff:fe58:585f/64 scope link
valid_lft forever preferred_lft forever
3: sit0: mtu 1480 qdisc noop
link/sit 0.0.0.0 brd 0.0.0.0
可以看到2.114这个vip已经绑定在主nginx服务器上了,这个时候把nginx停掉
[root@localhost ~]# killall nginx
[root@localhost ~]# ps aux |grep nginx
root 9175 0.0 0.3 43268 916 ? Ss 05:45 0:00 nginx: master process /usr/local/nginx/sbin/nginx
nginx 9176 0.0 0.5 43648 1468 ? S 05:45 0:00 nginx: worker process
root 9187 0.0 0.2 61180 716 pts/0 R+ 05:45 0:00 grep nginx
额额,,,怎么停不掉,,,,
注意看监控nginx的脚本,当脚本检测到nginx没有运行的时候,会尝试启动一次,如果启动成功,则不转移vip。如果启动失败,则把keepalived停掉,从机的keepalived会把vip绑定到备nginx服务器上,这个时候就是备nginx的服务器在提供服务了。
为了看下效果,暂且把这个脚本修改一下,不让他尝试启动nginx服务
这个时候把nginx服务停掉,我们用ip a来看下vip是否还在主nginx服务器上绑定着
[root@localhost ~]# ip a
1: lo: mtu 16436 qdisc noqueue
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: eth0: mtu 1500 qdisc pfifo_fast qlen 1000
link/ether 00:0c:29:58:58:5f brd ff:ff:ff:ff:ff:ff
inet 192.168.2.117/22 brd 192.168.3.255 scope global eth0
inet6 fe80::20c:29ff:fe58:585f/64 scope link
valid_lft forever preferred_lft forever
3: sit0: mtu 1480 qdisc noop
link/sit 0.0.0.0 brd 0.0.0.0
可以看到已经没有vip这个地址了
去看备nginx服务器上看vip是否绑定在了上面
[root@localhost etc]# ip a
1: lo: mtu 16436 qdisc noqueue
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: eth0: mtu 1500 qdisc pfifo_fast qlen 1000
link/ether 00:0c:29:34:cc:f9 brd ff:ff:ff:ff:ff:ff
inet 192.168.0.170/22 brd 192.168.1.255 scope global eth0
inet 192.168.2.114/32 scope global eth0
inet6 fe80::20c:29ff:fe34:ccf9/64 scope link
valid_lft forever preferred_lft forever
3: sit0: mtu 1480 qdisc noop
link/sit 0.0.0.0 brd 0.0.0.0
ok,可以看到vip已经绑定在备nginx服务器上了。
对于数据流量过大的网络中,往往单一设备无法承担,需要多台设备进行数据分流,而负载均衡器就是用来将数据分流到多台设备的一个转发器。
目前有许多不同的负载均衡技术用以满足不同的应用需求,如软/硬件负载均衡、本地/全局负载均衡、更高网络层负载均衡,以及链路聚合技术。
我们使用的是软负载均衡器Nginx,而农行用的是F5硬负载均衡器,这里就简单介绍下这两种技术:
a.软件负载均衡解决方案
在一台服务器的操作系统上,安装一个附加软件来实现负载均衡,如Nginx负载均衡(我们管理系统平台使用的也是这款均衡器)。它的优点是基于特定环境、配置简单、使用灵活、成本低廉,可以满足大部分的负载均衡需求。
一、什么是Nginx
Nginx ("engine x") 是一个高性能的 HTTP 和 反向代理 服务器,也是一个 IMAP/POP3/SMTP 代理服务器。 可以说Nginx 是目前使用最为广泛的HTTP软负载均衡器,其将源代码以类BSD许可证的形式发布(商业友好),同时因高效的性能、稳定性、丰富的功能集、示例配置文件和低系统资源的消耗而闻名于业界。像腾讯、淘宝、新浪等大型门户及商业网站都采用Nginx进行HTTP网站的数据分流。
二、Nginx的功能特点
1、工作在网络的7层之上,可以针对http应用做一些分流的策略,比如针对域名、目录结构;
2、Nginx对网络的依赖比较小;
3、Nginx安装和配置比较简单,测试起来比较方便;
4、也可以承担高的负载压力且稳定,一般能支撑超过1万次的并发;
5、Nginx可以通过端口检测到服务器内部的故障,比如根据服务器处理网页返回的状态码、超时等等,www.linuxidc.com 并且会把返回错误的请求重新提交到另一个节点,不过其中缺点就是不支持url来检测;
6、Nginx对请求的异步处理可以帮助节点服务器减轻负载;
7、Nginx能支持http和Email,这样就在适用范围上面小很多;
8、不支持Session的保持、对Big request header的支持不是很好,另外默认的只有Round-robin和IP-hash两种负载均衡算法。
三、Nginx的原理
Nginx采用的是反向代理技术,代理服务器来接受internet上的连接请求,然后将请求转发给内部网络上的服务器,并将从服务器上得到的结果返回给internet上请求连接的客户端,此时代理服务器对外就表现为一个服务器。反向代理负载均衡技术是把将来自internet上的连接请求以反向代理的方式动态地转发给内部网络上的多台服务器进行处理,从而达到负载均衡的目的。
b.硬件负载均衡解决方案
直接在服务器和外部网络间安装负载均衡设备,这种设备我们通常称之为负载均衡器。由于专门的设备完成专门的任务,独立于操作系统,整体性能得到大量提高,加上多样化的负载均衡策略,智能化的流量管理,可达到最佳的负载均衡需求。 一般而言,硬件负载均衡在功能、性能上优于软件方式,不过成本昂贵,比如最常见的就是F5负载均衡器。
什么是F5 BIG-IP
F5负载均衡器是应用交付网络的全球领导者F5 Networks公司提供的一个负载均衡器专用设备,F5 BIG-IP LTM 的官方名称叫做本地流量管理器,可以做4-7层负载均衡,具有负载均衡、应用交换、会话交换、状态监控、智能网络地址转换、通用持续性、响应错误处理、IPv6网关、高级路由、智能端口镜像、SSL加速、智能HTTP压缩、TCP优化、第7层速率整形、内容缓冲、内容转换、连接加速、高速缓存、Cookie加密、选择性内容加密、应用攻击过滤、拒绝服务(DoS)攻击和SYN Flood保护、防火墙—包过滤、包消毒等功能。
以下是F5 BIG-IP用作HTTP负载均衡器的主要功能:
①、F5 BIG-IP提供12种灵活的算法将所有流量均衡的分配到各个服务器,而面对用户,只是一台虚拟服务器。
②、F5 BIG-IP可以确认应用程序能否对请求返回对应的数据。假如F5 BIG-IP后面的某一台服务器发生服务停止、死机等故障,F5会检查出来并将该服务器标识为宕机,从而不将用户的访问请求传送到该台发生故障的服务器上。这样,只要其它的服务器正常,用户的访问就不会受到影响。宕机一旦修复,F5 BIG-IP就会自动查证应用已能对客户请求作出正确响应并恢复向该服务器传送。
③、F5 BIG-IP具有动态Session的会话保持功能。
④、F5 BIG-IP的iRules功能可以做HTTP内容过滤,根据不同的域名、URL,将访问请求传送到不同的服务器。
方案优缺点对比
基于硬件的方式(F5)
优点:能够直接通过智能交换机实现,处理能力更强,而且与系统无关,负载性能强更适用于一大堆设备、大访问量、简单应用
缺点:成本高,除设备价格高昂,而且配置冗余.很难想象后面服务器做一个集群,但最关键的负载均衡设备却是单点配置;无法有效掌握服务器及应用状态.
硬件负载均衡,一般都不管实际系统与应用的状态,而只是从网络层来判断,所以有时候系统处理能力已经不行了,但网络可能还来 得及反应(这种情况非常典型,比如应用服务器后面内存已经占用很多,但还没有彻底不行,如果网络传输量不大就未必在网络层能反映出来)
基于软件的方式(Nginx)
优点:基于系统与应用的负载均衡,能够更好地根据系统与应用的状况来分配负载。这对于复杂应用是很重要的,性价比高,实际上如果几台服务器,用F5之类的硬件产品显得有些浪费,而用软件就要合算得多,因为服务器同时还可以跑应用做集群等。
缺点:负载能力受服务器本身性能的影响,性能越好,负载能力越大。
综述:对我们管理系统应用环境来说,由于负载均衡器本身不需要对数据进行处理,性能瓶颈更多的是在于后台服务器,通常采用软负载均衡器已非常够用且其商业友好的软件源码授权使得我们可以非常灵活的设计,无逢的和我们管理系统平台相结合。
1、首先,bash中0,1,2三个数字分别代表STDIN_FILENO、STDOUT_FILENO、STDERR_FILENO,即标准输入(一般是键盘),标准输出(一般是显示屏,准确的说是用户终端控制台),标准错误(出错信息输出)。
2、输入输出可以重定向,所谓重定向输入就是在命令中指定具体的输入来源,譬如 cat < test.c 将test.c重定向为cat命令的输入源。输出重定向是指定具体的输出目标以替换默认的标准输出,譬如ls > 1.txt将ls的结果从标准输出重定向为1.txt文本。有时候会看到如 ls >> 1.txt这类的写法,> 和 >> 的区别在于:> 用于新建而>>用于追加。即ls > 1.txt会新建一个1.txt文件并且将ls的内容输出到新建的1.txt中,而ls >> 1.txt则用在1.txt已经存在,而我们只是想将ls的内容追加到1.txt文本中的时候。
3、默认输入只有一个(0,STDIN_FILENO),而默认输出有两个(标准输出1 STDOUT_FILENO,标准错误2 STDERR_FILENO)。因此默认情况下,shell输出的错误信息会被输出到2,而普通输出信息会输出到1。但是某些情况下,我们希望在一个终端下看到所有的信息(包括标准输出信息和错误信息),要怎么办呢?
对了,你可以使用我们上面讲到的输出重定向。思路有了,怎么写呢? 非常直观的想法就是2>1(将2重定向到1嘛),行不行呢?试一试就知道了。我们进行以下测试步骤:
1)mkdir test && cd test ; 创建test文件夹并进入test目录
2)touch a.txt b.c c ; 创建a.txt b.c c 三个文件
3)ls > 1 ; 按我们的猜测,这句应该是将ls的结果重定向到标准输出,因此效果和直接ls应该一样。但是实际这句执行后,标准输出中并没有任何信息。
4)ls ; 执行3之后再次ls,则会看到test文件夹中多了一个文件1
5)cat 1 ; 查看文件1的内容,实际结果为:1 a.txt b.c c 可见步骤3中 ls > 1并不是将ls的结果重定向为标准输出,而是将结果重定向到了一个文件1中。即1在此处不被解释为STDOUT_FILENO,而是文件1。
4、到了此时,你应该也能猜到2>&1的用意了。不错,2>&1就是用来将标准错误2重定向到标准输出1中的。此处1前面的&就是为了让bash将1解释成标准输出而不是文件1。至于最后一个&,则是让bash在后台执行。
摘要: https介绍: HTTPS(全称:Hypertext Transfer Protocol over Secure Socket Layer),是以安全为目标的HTTP通道,简单讲是HTTP的安全版。即HTTP下加入SSL层,HTTPS的安全基础是SSL,因此加密的详细内容就需要SSL。 它是一个URI scheme(抽象标识符体系),句法类同http:体系。用于... 阅读全文
1.什么是会话保持?
在大多数电子商务的应用系统或者需要进行用户身份认证的在线系统中,一个客户与服务器经常经过好几次的交互过程才能完成一笔交易或者是一个请求的完成。由于这几次交互过程是密切相关的,服务器在进行这些交互过程的某一个交互步骤时,往往需要了解上一次交互过程的处理结果,或者上几步的交互过程结果,服务器进行下一步操作时就要求所有这些相关的交互过程都由一台服务器完成,而不能被负载均衡器分散到不同的服务器上。
而这一系列的相关的交互过程可能是由客户到服务器的一个连接的多次会话完成,也可能是在客户与服务器之间的多个不同连接里的多次会话完成。不同连接的多次会话,最典型的例子就是基于http的访问,一个客户完成一笔交易可能需多次点击,而一个新的点击产生的请求,可能会重用上一次点击建立起来的连接,也可能是一个新建的连接。
会话保持就是指在负载均衡器上有这么一种机制,可以识别做客户与服务器之间交互过程的关连性,在作负载均衡的同时,还保证一系列相关连的访问请求会保持分配到一台服务器上。
2.F5支持什么样的会话保持方法?
F5 Big-IP支持多种的会话保持方法,其中包括:简单会话保持(源地址会话保持)、HTTP Header的会话保持,基于SSL Session ID的会话保持,i-Rules会话保持以及基于HTTP Cookie的会话保持,此外还有基于SIP ID以及Cache设备的会话保持等,但常用的是简单会话保持,HTTP Header的会话保持以及 HTTP Cookie会话保持以及基于i-Rules的会话保持。
2.1 简单会话保持
简单会话保持也被称为基于源地址的会话保持,是指负载均衡器在作负载均衡时是根据访问请求的源地址作为判断关连会话的依据。对来自同一IP地址的所有访问 请求在作负载均时都会被保持到一台服务器上去。在BIG-IP设备上可以为“同一IP地址”通过网络掩码进行区分,比如可以通过对IP地址 192.168.1.1进行255.255.255.0的网络掩码,这样只要是来自于192.168.1.0/24这个网段的流量BIGIP都可以认为他们是来自于同一个用户,这样就将把来自于192.168.1.0/24网段的流量会话保持到特定的一台服务器上。
简单会话保持里另外一个很重要的参数就是连接超时值,BIGIP会为每一个进行会话保持的会话设定一个时间值,当一个会话上一次完成到这个会话下次再来之前的间隔如果小于这个超时值,BIGIP将会将新的连接进行会话保持,但如果这个间隔大于该超时值,BIGIP将会将新来的连接认为是新的会话然后进行负载平衡。
基于原地址的会话保持实现起来简单,只需要根据数据包三、四层的信息就可以实现,效率也比较高。存在的问题就在于当多个客户是通过代理或地址转换的方式来访问服务器时,由于都分配到同一台服务器上,会导致服务器之间的负载严重失衡。另外一种情况上客户机数量很少,但每个客户机都会产生多个并发访问,对这些并发访问也要求通过负载均衡器分配到多个服器上,这时基于客户端源地址的会话保持方法也会导致负载均衡失效。
2.2 基于Cookie的会话保持
2.2.1 Cookie插入模式:
在Cookie插入模式下,Big-IP将负责插入cookie,后端服务器无需作出任何修改
当客户进行第一次请求时,客户HTTP请求(不带cookie)进入BIG-IP, BIG-IP根据负载平衡算法策略选择后端一台服务器,并将请求发送至该服务器,后端服务器进行HTTP回复(不带cookie)被发回BIGIP,然后 BIG-IP插入cookie,将HTTP回复返回到客户端。当客户请求再次发生时,客户HTTP请求(带有上次BIGIP插入的cookie)进入 BIGIP,然后BIGIP读出cookie里的会话保持数值,将HTTP请求(带有与上面同样的cookie)发到指定的服务器,然后后端服务器进行请求回复,由于服务器并不写入cookie,HTTP回复将不带有cookie,恢复流量再次经过进入BIG-IP时,BIG-IP再次写入更新后的会话保持 cookie。
2.2.2 Cookie 重写模式
当客户进行第一次请求时,客户HTTP请求(不带cookie)进入BIGIP, BIGIP根据负载均衡算法策略选择后端一台服务器,并将请求发送至该服务器,后端服务器进行HTTP回复一个空白的cookie并发回BIGIP,然后BIGIP重新在cookie里写入会话保持数值,将HTTP回复返回到客户端。当客户请求再次发生时,客户HTTP请求(带有上次BIGIP重写的 cookie)进入BIGIP,然后BIGIP读出cookie里的会话保持数值,将HTTP请求(带有与上面同样的cookie)发到指定的服务器,然后后端服务器进行请求回复,HTTP回复里又将带有空的cookie,恢复流量再次经过进入BIGIP时,BIGIP再次写入更新后会话保持数值到该 cookie。
2.2.3 Passive Cookie 模式,服务器使用特定信息来设置cookie。
当客户进行第一次请求时,客户HTTP请求(不带cookie)进入BIGIP, BIGIP根据负载平衡算法策略选择后端一台服务器,并将请求发送至该服务器,后端服务器进行HTTP回复一个cookie并发回BIGIP,然后 BIGIP将带有服务器写的cookie值的HTTP回复返回到客户端。当客户请求再次发生时,客户HTTP请求(带有上次服务器写的cookie)进入 BIGIP,然后BIGIP根据cookie里的会话保持数值,将HTTP请求(带有与上面同样的cookie)发到指定的服务器,然后后端服务器进行请 求回复,HTTP回复里又将带有更新的会话保持cookie,恢复流量再次经过进入BIGIP时,BIGIP将带有该cookie的请求回复给客户端。
2.2.4 Cookie Hash模式:
当客户进行第一次请求时,客户HTTP请求(不带cookie)进入BIGIP, BIGIP根据负载均衡算法策略选择后端一台服务器,并将请求发送至该服务器,后端服务器进行HTTP回复一个cookie并发回BIGIP,然后 BIGIP将带有服务器写的cookie值的HTTP回复返回到客户端。当客户请求再次发生时,客户HTTP请求(带有上次服务器写的cookie)进入 BIGIP,然后BIGIP根据cookie里的一定的某个字节的字节数来决定后台服务器接受请求,将HTTP请求(带有与上面同样的cookie)发到指定的服务器,然后后端服务器进行请求回复,HTTP回复里又将带有更新后的cookie,恢复流量再次经过进入BIGIP时,BIGIP将带有该 cookie的请求回复给客户端。
2.3 SSL Session ID会话保持
在用户的SSL访问系统的环境里,当SSL对话首次建立时,用户与服务器进行首次信息交换以:1}交换安全证书,2)商议加密和压缩方法,3)为每条对话 建立Session ID。由于该Session ID在系统中是一个唯一数值,由此,BIGIP可以应用该数值来进行会话保持。当用户想与该服务器再次建立连接时,BIGIP可以通过会话中的 SSL Session ID识别该用户并进行会话保持。
基于SSL Session ID的会话保持就需要客户浏览器在进行会话的过程中始终保持其SSL Session ID不变,但实际上,微软Internet Explorer被发现在经过特定一段时间后将主动改变SSL Session ID,这就使基于SSL Session ID的会话保持实际应用范围大大缩小。
Linux系统中,有时候普通用户有些事情是不能做的,除非是root用户才能做到。这时就需要用su命令临时切换到root身份来做事了。
su:substitute['sʌbstɪtjuːt]代替 user
su 的语法为:
su [OPTION选项参数] [用户]
-, -l, --login 登录并改变到所切换的用户环境;
-c, --commmand=COMMAND 执行一个命令,然后退出所切换到的用户环境;
用su命令切换用户后,可以用 exit 命令或快捷键[Ctrl+D]可返回原登录用户。
例子:
su 在不加任何参数,默认为切换到root用户,但没有转到root用户家目录下,也就是说这时虽然是切换为root用户了,但并没有改变root登录环境;用户默认的登录环境,可以在/etc/passwd 中查得到,包括家目录,SHELL定义等;
su 加参数 - ,表示默认切换到root用户,并且改变到root用户的环境;
用su是可以切换用户身份,如果每个普通用户都能切换到root身份,如果某个用户不小心泄漏了root的密码,那岂不是系统非常的不安全?没有错,为了改进这个问题,产生了sudo这个命令。使用sudo执行一个root才能执行的命令是可以办到的,但是需要输入密码,这个密码并不是root的密码而是用户自己的密码。默认只有root用户能使用sudo命令,普通用户想要使用sudo,是需要root预先设定的,即,使用visudo命令去编辑相关的配置文件/etc/sudoers。如果没有visudo这个命令,请使用 "yum install -y sudo" 安装。
默认root能够sudo是因为这个文件中有一行” root ALL=(ALL) ALL”
sudo 的适用条件:
由于su对切换到超级权限用户root后,权限的无限制性,所以su并不能担任多个管理员所管理的系统。如果用su来切换到超级用户来管理系统,也不能明 确哪些工作是由哪个管理员进行的操作。特别是对于服务器的管理有多人参与管理时,最好是针对每个管理员的技术特长和管理范围,并且有针对性的下放给权限, 并且约定其使用哪些工具来完成与其相关的工作,这时我们就有必要用到 sudo。
通过sudo,我们能把某些超级权限有针对性的下放,并且不需要普通用户知道root密码,所以sudo 相对于权限无限制性的su来说,还是比较安全的,所以sudo 也能被称为受限制的su ;另外sudo 是需要授权许可的,所以也被称为授权许可的su;
sudo 执行命令的流程:是当前用户切换到root(或其它指定切换到的用户),然后以root(或其它指定的切换到的用户)身份执行命令,执行完成后,直接退回到当前用户;而这些的前提是要通过sudo的配置文件/etc/sudoers来进行授权;
从编写 sudo 配置文件/etc/sudoers开始
sudo的配置文件是/etc/sudoers ,我们可以用他的专用编辑工具visodu ,此工具的好处是在添加规则不太准确时,保存退出时会提示给我们错误信息;配置好后,可以用切换到您授权的用户下,通过sudo -l 来查看哪些命令是可以执行或禁止的;
/etc/sudoers 文件中每行算一个规则,前面带有#号可以当作是说明的内容,并不执行;如果规则很长,一行列不下时,可以用\号来续行,这样看来一个规则也可以拥有多个行;
/etc/sudoers 的规则可分为两类;一类是别名定义,另一类是授权规则;别名定义并不是必须的,但授权规则是必须的;
sudo授权规则(sudoers配置):
授权用户 主机=命令动作
这三个要素缺一不可,但在动作之前也可以指定切换到特定用户下,在这里指定切换的用户要用( )号括起来,如果不需要密码直接运行命令的,应该加NOPASSWD:参数,但这些可以省略;举例说明;
sudoers的缺省配置:
Html代码 收藏代码
#############################################################
# sudoers file.
#
# This file MUST be edited with the 'visudo' command as root.
#
# See the sudoers man page for the details on how to write a sudoers file.
#
# Host alias specification
# User alias specification
# Cmnd alias specification
# Defaults specification
# User privilege specification
root ALL=(ALL) ALL
# Uncomment to allow people in group wheel to run all commands
# %wheel ALL=(ALL) ALL
# Same thing without a password
# %wheel ALL=(ALL) NOPASSWD: ALL
# Samples
# %users ALL=/sbin/mount /cdrom,/sbin/umount /cdrom
# %users localhost=/sbin/shutdown -h now
##################################################################
1. 最简单的配置,让普通用户support具有root的所有权限
执行visudo之后,可以看见缺省只有一条配置:
root ALL=(ALL) ALL
那么你就在下边再加一条配置:
support ALL=(ALL) ALL
这样,普通用户support就能够执行root权限的所有命令
以support用户登录之后,执行:
sudo su -
然后输入support用户自己的密码,就可以切换成root用户了
2. 让普通用户support只能在某几台服务器上,执行root能执行的某些命令
首先需要配置一些Alias,这样在下面配置权限时,会方便一些,不用写大段大段的配置。Alias主要分成4种
Host_Alias
Cmnd_Alias
User_Alias
Runas_Alias
1) 配置Host_Alias:就是主机的列表
Host_Alias HOST_FLAG = hostname1, hostname2, hostname3
2) 配置Cmnd_Alias:就是允许执行的命令的列表,命令前加上!表示不能执行此命令.
命令一定要使用绝对路径,避免其他目录的同名命令被执行,造成安全隐患 ,因此使用的时候也是使用绝对路径!
Cmnd_Alias COMMAND_FLAG = command1, command2, command3 ,!command4
3) 配置User_Alias:就是具有sudo权限的用户的列表
User_Alias USER_FLAG = user1, user2, user3
4) 配置Runas_Alias:就是用户以什么身份执行(例如root,或者oracle)的列表
Runas_Alias RUNAS_FLAG = operator1, operator2, operator3
5) 配置权限
配置权限的格式如下:
USER_FLAG HOST_FLAG=(RUNAS_FLAG) COMMAND_FLAG
如果不需要密码验证的话,则按照这样的格式来配置
USER_FLAG HOST_FLAG=(RUNAS_FLAG) NOPASSWD: COMMAND_FLAG
配置示例:
Html代码 收藏代码
############################################################################
# sudoers file.
#
# This file MUST be edited with the 'visudo' command as root.
#
# See the sudoers man page for the details on how to write a sudoers file.
#
# Host alias specification
Host_Alias EPG = 192.168.1.1, 192.168.1.2
# User alias specification
# Cmnd alias specification
Cmnd_Alias SQUID = /opt/vtbin/squid_refresh, !/sbin/service, /bin/rm
Cmnd_Alias ADMPW = /usr/bin/passwd [A-Za-z]*, !/usr/bin/passwd, !/usr/bin/passwd root
# Defaults specification
# User privilege specification
root ALL=(ALL) ALL
support EPG=(ALL) NOPASSWD: SQUID
support EPG=(ALL) NOPASSWD: ADMPW
# Uncomment to allow people in group wheel to run all commands
# %wheel ALL=(ALL) ALL
# Same thing without a password
# %wheel ALL=(ALL) NOPASSWD: ALL
# Samples
# %users ALL=/sbin/mount /cdrom,/sbin/umount /cdrom
# %users localhost=/sbin/shutdown -h now
###############################################################
摘要: JVM监控与调优
光说不练假把式,学习Java GC机制的目的是为了实用,也就是为了在JVM出现问题时分析原因并解决之。通过学习,我觉得JVM监控与调优主要的着眼点在于如何配置、如何监控、如何优化3点上。下面就将针对这3点进行学习。 (如果您对Java的内存区域划分和内存回收机制尚不明确,那在阅读本文前,请先阅读我的前一篇博客《Java系... 阅读全文
LVS和Nginx都可以用作多机负载的方案,它们各有优缺,在生产环境中需要好好分析实际情况并加以利用。
首先提醒,做技术切不可人云亦云,我云即你云;同时也不可太趋向保守,过于相信旧有方式而等别人来帮你做垫被测试。把所有即时听说到的好东西加以钻研,从而提高自己对技术的认知和水平,乃是一个好习惯。
下面来分析一下两者:
一、lvs的优势:
1、抗负载能力强,因为lvs工作方式的逻辑是非常之简单,而且工作在网络4层仅做请求分发之用,没有流量,所以在效率上基本不需要太过考虑。在我手里的 lvs,仅仅出过一次问题:在并发最高的一小段时间内均衡器出现丢包现象,据分析为网络问题,即网卡或linux2.4内核的承载能力已到上限,内存和 cpu方面基本无消耗。
2、配置性低,这通常是一大劣势,但同时也是一大优势,因为没有太多可配置的选项,所以除了增减服务器,并不需要经常去触碰它,大大减少了人为出错的几率。
3、工作稳定,因为其本身抗负载能力很强,所以稳定性高也是顺理成章,另外各种lvs都有完整的双机热备方案,所以一点不用担心均衡器本身会出什么问题,节点出现故障的话,lvs会自动判别,所以系统整体是非常稳定的。
4、无流量,上面已经有所提及了。lvs仅仅分发请求,而流量并不从它本身出去,所以可以利用它这点来做一些线路分流之用。没有流量同时也保住了均衡器的IO性能不会受到大流量的影响。
5、基本上能支持所有应用,因为lvs工作在4层,所以它可以对几乎所有应用做负载均衡,包括http、数据库、聊天室等等。
另:lvs也不是完全能判别节点故障的,譬如在wlc分配方式下,集群里有一个节点没有配置VIP,会使整个集群不能使用,这时使用wrr分配方式则会丢掉一台机。目前这个问题还在进一步测试中。所以,用lvs也得多多当心为妙。
二、nginx和lvs作对比的结果
1、nginx工作在网络的7层,所以它可以针对http应用本身来做分流策略,比如针对域名、目录结构等,相比之下lvs并不具备这样的功能,所以 nginx单凭这点可利用的场合就远多于lvs了;但nginx有用的这些功能使其可调整度要高于lvs,所以经常要去触碰触碰,由lvs的第2条优点 看,触碰多了,人为出问题的几率也就会大。
2、nginx对网络的依赖较小,理论上只要ping得通,网页访问正常,nginx就能连得通,nginx同时还能区分内外网,如果是同时拥有内外网的 节点,就相当于单机拥有了备份线路;lvs就比较依赖于网络环境,目前来看服务器在同一网段内并且lvs使用direct方式分流,效果较能得到保证。另 外注意,lvs需要向托管商至少申请多一个ip来做Visual IP,貌似是不能用本身的IP来做VIP的。要做好LVS管理员,确实得跟进学习很多有关网络通信方面的知识,就不再是一个HTTP那么简单了。
3、nginx安装和配置比较简单,测试起来也很方便,因为它基本能把错误用日志打印出来。lvs的安装和配置、测试就要花比较长的时间了,因为同上所述,lvs对网络依赖比较大,很多时候不能配置成功都是因为网络问题而不是配置问题,出了问题要解决也相应的会麻烦得多。
4、nginx也同样能承受很高负载且稳定,但负载度和稳定度差lvs还有几个等级:nginx处理所有流量所以受限于机器IO和配置;本身的bug也还是难以避免的;nginx没有现成的双机热备方案,所以跑在单机上还是风险较大,单机上的事情全都很难说。
5、nginx可以检测到服务器内部的故障,比如根据服务器处理网页返回的状态码、超时等等,并且会把返回错误的请求重新提交到另一个节点。目前lvs中 ldirectd也能支持针对服务器内部的情况来监控,但lvs的原理使其不能重发请求。重发请求这点,譬如用户正在上传一个文件,而处理该上传的节点刚 好在上传过程中出现故障,nginx会把上传切到另一台服务器重新处理,而lvs就直接断掉了,如果是上传一个很大的文件或者很重要的文件的话,用户可能 会因此而恼火。
6、nginx对请求的异步处理可以帮助节点服务器减轻负载,假如使用Apache直接对外服务,那么出现很多的窄带链接时apache服务器将会占用大 量内存而不能释放,使用多一个nginx做apache代理的话,这些窄带链接会被nginx挡住,apache上就不会堆积过多的请求,这样就减少了相 当多的内存占用。这点使用squid也有相同的作用,即使squid本身配置为不缓存,对apache还是有很大帮助的。lvs没有这些功能,也就无法能 比较。
7、nginx能支持http和email(email的功能估计比较少人用),lvs所支持的应用在这点上会比nginx更多。
在使用上,一般最前端所采取的策略应是lvs,也就是DNS的指向应为lvs均衡器,lvs的优点令它非常适合做这个任务。
重要的ip地址,最好交由lvs托管,比如数据库的ip、webservice服务器的ip等等,这些ip地址随着时间推移,使用面会越来越大,如果更换ip则故障会接踵而至。所以将这些重要ip交给lvs托管是最为稳妥的,这样做的唯一缺点是需要的VIP数量会比较多。
nginx可作为lvs节点机器使用,一是可以利用nginx的功能,二是可以利用nginx的性能。当然这一层面也可以直接使用squid,squid的功能方面就比nginx弱不少了,性能上也有所逊色于nginx。
nginx也可作为中层代理使用,这一层面nginx基本上无对手,唯一可以撼动nginx的就只有lighttpd了,不过lighttpd目前还没有 能做到nginx完全的功能,配置也不那么清晰易读。另外,中层代理的IP也是重要的,所以中层代理也拥有一个VIP和lvs是最完美的方案了。
nginx也可作为网页静态服务器,不过超出了本文讨论的范畴,简单提一下。
具体的应用还得具体分析,如果是比较小的网站(日PV<1000万),用nginx就完全可以了,如果机器也不少,可以用DNS轮询,lvs所耗费的机器还是比较多的;大型网站或者重要的服务,机器不发愁的时候,要多多考虑利用lvs。
在Linux中常用于判断问题所在的初步定位或性能瓶颈,iostat则给我们提供了丰富的IO状态信息,其他工具还有iotop。
letong@me:~$ sudo iostat
Linux 3.13.0-41-generic (me) 2014年12月18日 _x86_64_ (4 CPU)
avg-cpu: %user %nice %system %iowait %steal %idle
8.92 0.12 2.27 0.65 0.00 88.05
Device: tps kB_read/s kB_wrtn/s kB_read kB_wrtn
sda 5.12 85.24 1.97 586069 13512
sdb 9.51 43.74 112.81 300771 775678
rrqm/s: 每秒进行 merge 的读操作数目。即 delta(rmerge)/s
wrqm/s: 每秒进行 merge 的写操作数目。即 delta(wmerge)/s
r/s: 每秒完成的读 I/O 设备次数。即 delta(rio)/s
w/s: 每秒完成的写 I/O 设备次数。即 delta(wio)/s
rsec/s: 每秒读扇区数。即 delta(rsect)/s
wsec/s: 每秒写扇区数。即 delta(wsect)/s
rkB/s: 每秒读K字节数。是 rsect/s 的一半,因为每扇区大小为512字节。(需要计算)
wkB/s: 每秒写K字节数。是 wsect/s 的一半。(需要计算)
avgrq-sz: 平均每次设备I/O操作的数据大小 (扇区)。delta(rsect+wsect)/delta(rio+wio)
avgqu-sz: 平均I/O队列长度。即 delta(aveq)/s/1000 (因为aveq的单位为毫秒)。
await: 平均每次设备I/O操作的等待时间 (毫秒)。即 delta(ruse+wuse)/delta(rio+wio)
svctm: 平均每次设备I/O操作的服务时间 (毫秒)。即 delta(use)/delta(rio+wio)
%util: 一秒中有百分之多少的时间用于 I/O 操作,或者说一秒中有多少时间 I/O 队列是非空的。即 delta(use)/s/1000 (因为use的单位为毫秒)
常用参数:
-d 1 #每1秒显示1次
-x #显示更详细信息
-c #显示cpu相关
常见用法
iostat -d -k 1 10 #查看TPS和吞吐量信息
iostat -d -x -k 1 10 #查看设备使用率、响应时间
iostat -c 1 10 #查看cpu状态
如果在测试过程中遇到某个进程的CPU利用率过高或者卡死而需要去调试该进程时,可以利用gdb命令生成coredump文件,然后再去调试coredump文件来定位问题。
那么如何使用gdb生成coredump文件呢?其实步骤很简单:
1. 安装好gdb,然后使用命令 'gdb'。(假设需要调试的进程号为 21509)
2. 使用 ‘attach 21590’命令将gdb附加到进程21509上。
3. 使用‘gcore core_name’命令生成coredump文件core_name。
4. 使用‘detach’命令断开连接。
5.使用‘q’命令退出gdb。
此时,在当前目录下就会产生一个名为core_name的coredump文件。下面就可以利用gdb工具来对该coredump文件进行调试了。
linux renice 命令详解 功能说明:调整程序优先级。 语 法:renice [优先等级][-g <程序群组名称>...][-p <程序识别码>...][-u <用户名称>...] 补充说明:renice指令可重新调整程序执行的优先权等级。预设是以程序识别码指定程序调整其优先权,您亦可以指定程序群组或用户名称调整优先权等级,并修改所有隶属于该程序群组或用户的程序的优先权。等级范围从-20--19,只有系统管理者可以改变其他用户程序的优先权,也仅有系统管理者可以设置负数等级。 参 数: -g <程序群组名称> 使用程序群组名称,修改所有隶属于该程序群组的程序的优先权。 -p <程序识别码> 改变该程序的优先权等级,此参数为预设值。 -u <用户名称> 指定用户名称,修改所有隶属于该用户的程序的优先权。 一开始执行程式就立即给予一个特定的 nice 值:用 nice 命令; 调整某个已经存在的 PID 的 nice 值:用 renice 命令。 推荐阅读一:linux进程cpu资源分配命令nice,renice,taskset 进程cpu资源分配就是指进程的优先权(priority)。优先权高的进程有优先执行权利。配置进程优先权对多任务环境的linux很有用,可以改善系统性能。还可以把进程运行到指定的CPU上,这样一来,把不重要的进程安排到某个CPU,可以大大改善系统整体性能。 一、先看系统进程: PR 就是 Priority 的简写,而 NI 是 nice 的简写。这两个值决定了PR的值,PR越小,进程优先权就越高,就越“优先执行”。换算公式为:PR(new) = PR(old) + NI --------------------------------------------------------------------------- 二、修改进程优先级的命令主要有两个:nice,renice 1、一开始执行程序就指定nice值:nice nice -n -5 /usr/local/mysql/bin/mysqld_safe & linux nice 命令详解 功能说明:设置优先权。 语 法:nice [-n <优先等级>][--help][--version][执行指令] 补充说明:nice指令可以改变程序执行的优先权等级。 参 数:-n<优先等级>或-<优先等级>或--adjustment=<优先等级> 设置欲执行的指令的优先权等级。等级的范围从-20-19,其中-20最高,19最低,只有系统管理者可以设置负数的等级。 --help 在线帮助。 --version 显示版本信息。 --------------------------------------------------------------------------- 2.1、调整已存在进程的nice:renice renice -5 -p 5200 #PID为5200的进程nice设为-5 linux renice 命令详解 功能说明:调整优先权。 语 法:renice [优先等级][-g <程序群组名称>...][-p <程序识别码>...][-u <用户名称>...] 补充说明:renice指令可重新调整程序执行的优先权等级。预设是以程序识别码指定程序调整其优先权,您亦可以指定程序群组或用户名称调整优先权等级,并修改所有隶属于该程序群组或用户的程序的优先权。等级范围从-20--19,只有系统管理者可以改变其他用户程序的优先权,也仅有系统管理者可以设置负数等级。 参 数: -g <程序群组名称> 使用程序群组名称,修改所有隶属于该程序群组的程序的优先权。 -p <程序识别码> 改变该程序的优先权等级,此参数为预设值。 -u <用户名称> 指定用户名称,修改所有隶属于该用户的程序的优先权。
性能测试排查定位问题,分析调优过程中,会遇到要分析gc日志,人肉分析gc日志有时比较困难,相关图形化或命令行工具可以有效地帮助辅助分析。
Gc日志参数
通过在tomcat启动脚本中添加相关参数生成gc日志
-verbose.gc开关可显示GC的操作内容。打开它,可以显示最忙和最空闲收集行为发生的时间、收集前后的内存大小、收集需要的时间等。
打开 -xx:+ printGCdetails开关,可以详细了解GC中的变化。
打开 -XX: + PrintGCTimeStamps开关,可以了解这些垃圾收集发生的时间,自JVM启动以后以秒计量。
最后,通过 -xx: + PrintHeapAtGC开关了解堆的更详细的信息。
为了了解新域的情况,可以通过 -XX:=PrintTenuringDistribution开关了解获得使用期的对象权。
-Xloggc:$CATALINA_BASE/logs/gc.loggc日志产生的路径
XX:+PrintGCApplicationStoppedTime//输出GC造成应用暂停的时间
-XX:+PrintGCDateStamps// GC发生的时间信息
Gc日志

日志中显示了gc发生的时间,young区回收情况,整体回收情况,fullGC情况,回收所消耗时间等
常用JVM参数
分析gc日志后,经常需要调整jvm内存相关参数,常用参数如下
-Xms:初始堆大小,默认为物理内存的1/64(<1GB);默认(MinHeapFreeRatio参数可以调整)空余堆内存小于40%时,JVM就会增大堆直到-Xmx的最大限制
-Xmx:最大堆大小,默认(MaxHeapFreeRatio参数可以调整)空余堆内存大于70%时,JVM会减少堆直到-Xms的最小限制
-Xmn:新生代的内存空间大小,注意:此处的大小是(eden+ 2 survivor space)。与jmap -heap中显示的New gen是不同的。整个堆大小=新生代大小+老生代大小+永久代大小。
在保证堆大小不变的情况下,增大新生代后,将会减小老生代大小。此值对系统性能影响较大,Sun官方推荐配置为整个堆的3/8。
-XX:SurvivorRatio:新生代中Eden区域与Survivor区域的容量比值,默认值为8。两个Survivor区与一个Eden区的比值为2:8,一个Survivor区占整个年轻代的1/10。
-Xss:每个线程的堆栈大小。JDK5.0以后每个线程堆栈大小为1M,以前每个线程堆栈大小为256K。应根据应用的线程所需内存大小进行适当调整。在相同物理内存下,减小这个值能生成更多的线程。但是操作系统对一个进程内的线程数还是有限制的,不能无限生成,经验值在3000~5000左右。一般小的应用, 如果栈不是很深, 应该是128k够用的,大的应用建议使用256k。这个选项对性能影响比较大,需要严格的测试。和threadstacksize选项解释很类似,官方文档似乎没有解释,在论坛中有这样一句话:"-Xss is translated in a VM flag named ThreadStackSize”一般设置这个值就可以了。
-XX:PermSize:设置永久代(perm gen)初始值。默认值为物理内存的1/64。
-XX:MaxPermSize:设置持久代最大值。物理内存的1/4。
Gc日志分析工具
(1)GCHisto
http://java.net/projects/gchisto
直接点击gchisto.jar就可以运行,点add载入gc.log
统计了总共gc次数,youngGC次数,FullGC次数,次数的百分比,GC消耗的时间,百分比,平均消耗时间,消耗时间最小最大值等
统计的图形化表示
YoungGC,FullGC不同消耗时间上次数的分布图,勾选可以显示youngGC或fullGC单独的分布情况
整个时间过程详细的gc情况,可以对整个过程进行剖析
(2)GCLogViewer
http://code.google.com/p/gclogviewer/
点击run.bat运行
整个过程gc情况的趋势图,还显示了gc类型,吞吐量,平均gc频率,内存变化趋势等
Tools里还能比较不同gc日志
(3)HPjmeter
获取地址 http://www.hp.com/go/java
参考文档 http://www.javaperformancetuning.com/tools/hpjtune/index.shtml
工具很强大,但只能打开由以下参数生成的GC log,-verbose:gc -Xloggc:gc.log,添加其他参数生成的gc.log无法打开。
(4)GCViewer
http://www.tagtraum.com/gcviewer.html
这个工具用的挺多的,但只能在JDK1.5以下的版本中运行,1.6以后没有对应。
(5)garbagecat
http://code.google.com/a/eclipselabs.org/p/garbagecat/wiki/Documentation
其它监控方法
Jvisualvm动态分析jvm内存情况和gc情况,插件:visualGC

jvisualvm还可以heapdump出对应hprof文件(默认存放路径:监控的服务器/tmp下),利用相关工具,比如HPjmeter可以对其进行分析
grep Full gc.log粗略观察FullGC发生频率
jstat –gcutil [pid] [intervel] [count]
jmap -histo pid可以观测对象的个数和占用空间
jmap -heap pid可以观测jvm配置参数,堆内存各区使用情况
jprofiler,jmap dump出来用MAT分析
如果要分析的dump文件很大的话,就需要很多内存,很容易crash。
所以在启动时,我们应该加上一些参数:Java–Xms512M–Xmx1024M–Xss8M
不同的JVM及其选项会输出不同的日志。
GC 日志
生成下面日志使用的选项: -XX:+PrintGCTimeStamps -XX:+PrintGCDetails -Xloggc:d:/GClogs/tomcat6-gc.log。 4.231: [GC 4.231: [DefNew: 4928K->512K(4928K), 0.0044047 secs] 6835K->3468K(15872K), 0.0045291 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
4.445: [Full GC (System) 4.445: [Tenured: 2956K->3043K(10944K), 0.1869806 secs] 4034K->3043K(15872K), [Perm : 3400K->3400K(12288K)], 0.1870847 secs] [Times: user=0.05 sys=0.00, real=0.19 secs]
最前面的数字 4.231 和 4.445 代表虚拟机启动以来的秒数。
[GC 和 [Full GC 是垃圾回收的停顿类型,而不是区分是新生代还是年老代,如果有 Full 说明发生了 Stop-The-World 。如果是调用 System.gc() 触发的,那么将显示的是 [Full GC (System) 。
接下来的 [DefNew, [Tenured, [Perm 表示 GC 发生的区域,区域的名称与使用的 GC 收集器相关。 Serial 收集器中新生代名为 "Default New Generation",显示的名字为 "[DefNew"。对于ParNew收集器,显示的是 "[ParNew",表示 “Parallel New Generation”。 对于 Parallel Scavenge 收集器,新生代名为 "PSYoungGen"。年老代和永久代也相同,名称都由收集器决定。
方括号内部显示的 “4928K->512K(4928K)” 表示 “GC 前该区域已使用容量 -> GC 后该区域已使用容量 (该区域内存总容量) ”。
再往后的 “0.0044047 secs” 表示该区域GC所用时间,单位是秒。
再往后的 “6835K->3468K(15872K)” 表示 “GC 前Java堆已使用容量 -> GC后Java堆已使用容量 (Java堆总容量)”。
再往后的 “0.0045291 secs” 是Java堆GC所用的总时间。
最后的 “[Times: user=0.00 sys=0.00, real=0.00 secs]” 分别代表 用户态消耗的CPU时间、内核态消耗的CPU时间 和 操作从开始到结束所经过的墙钟时间。墙钟时间包括各种非运算的等待耗时,如IO等待、线程阻塞。CPU时间不包括等待时间,当系统有多核时,多线程操作会叠加这些CPU时间,所以user或sys时间会超过real时间。
堆的分代
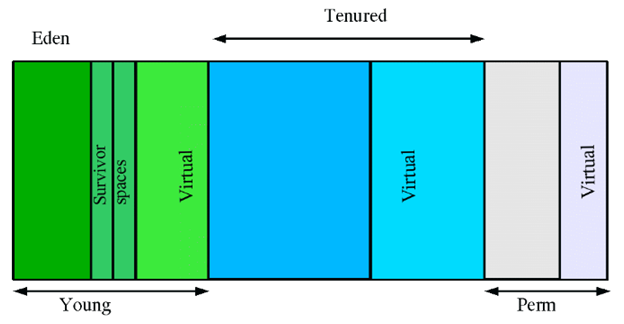
在上图中:
- young区域就是新生代,存放新创建对象;
- tenured是年老代,存放在新生代经历多次垃圾回收后仍存活的对象;
- perm是永生代,存放类定义信息、元数据等信息。
当GC发生在新生代时,称为Minor GC,次收集;当GC发生在年老代时,称为Major GC,主收集。 一般的,Minor GC的发生频率要比Major GC高很多。
摘要: 这个是之前处理过的一个线上问题,处理过程断断续续,经历了两周多的时间,中间各种尝试,总结如下。这篇文章分三部分:
1、问题的场景和处理过程;2、GC的一些理论东西;3、看懂GC的日志
先说一下问题吧
问题场景:线上机器在半夜会推送一个700M左右的数据,这个时候有个数据置换的过程,也就是说有700M*2的数据在heap区域中,线上系统超时比较多,导致了很严重(严重程度就不说了)的问题。
问... 阅读全文
VM性能的快速测试方法
核心提示: 经常有同行问怎么样去做这些性能评测。其实这些性能评测都很简单,任何一个具备Linux基础知识的工程师都可以完成。我们通常使用UnixBench来评估虚拟机CPU性能,mbw来评估内存性能,iozone来评估文件IO性能,iperf来评估网络性能,pgbench来评估数据库性能。在这里我将我自己做性能测试的过程整理一下,供各位同行参考。
中国IDC圈10月30日报道 前段时间陆续发布了一些对公有云服务性能评测的数据。经常有同行问怎么样去做这些性能评测。其实这些性能评测都很简单,任何一个具备Linux基础知识的工程师都可以完成。我们通常使用UnixBench来评估虚拟机CPU性能,mbw来评估内存性能,iozone来评估文件IO性能,iperf来评估网络性能,pgbench来评估数据库性能。在这里我将我自己做性能测试的过程整理一下,供各位同行参考。
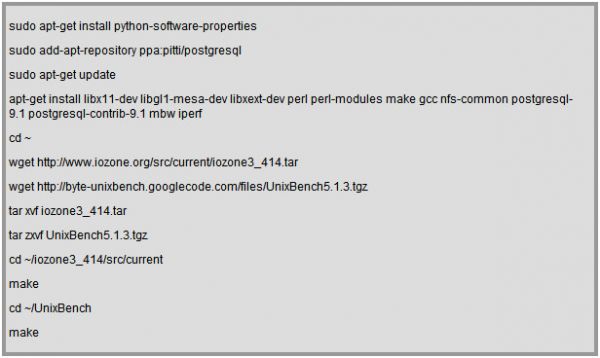
(0)安装必要的软件
假定VM的操作系统是Ubuntu,可以按照如下步骤安装必要的软件:
(1)CPU性能测试
我们使用UnixBench来进行CPU性能测试。UnixBench是一套具有悠久历史的性能测试工具,其测试结果反映的是一台主机的综合性能。从理论上来说UnixBench测试结果与被测试主机的CPU、内存、存储、操作系统都有直接的关系。但是根据我们的观察,对于现代的计算机系统来说,UnixBench测试结果受CPU 处理能力的影响更大一些。因此,在这里我们用UnixBench测试结果来代表虚拟机的vCPU 处理能力。每个UnixBench测试结果包括两个数据,一个是单线程测试结果,另一个是多线程测试结果(虚拟机上有几颗虚拟CPU,就有几个并发的测试线程)。
cd ~/UnixBench
./Run
下面是一个可供参考的测试结果。在这个测试中使用了两台物理机,每台物理机各配置一颗Intel Core i3 540 @ 3.07 GHz (双核四线程),16 GB内存(DDR3 @ 1333 MHz),一块Seagate ST2000DL003-9VT1硬盘(SATA,2TB,5900RPM),运行Ubuntu 10.04 AMD64 Server操作系统,使用的文件系统为ext4,使用的Hypervisor为KVM(qemu-kvm-0.12.3)。我们分别测试了宿主机、磁盘映像以文件格式(RAW格式,没有启用virtio)存储在本地磁盘上的虚拟机、磁盘映像以文件格式(RAW格式,没有启用virtio)存储在NFS上的虚拟机的CPU性能。虚拟机的配置为2 颗vCPU(占用两个物理线程,也就是一个物理核心)和4 GB内存,运行Ubuntu 12.04 AMD64 Server操作系统。在这个测试中没有对操作系统、文件系统、NFS、KVM等等进行任何性能调优。

从如上测试结果可以看出,在没有进行任何性能调优的情况下,在单线程CPU性能方面,宿主机 >> 本地磁盘上的虚拟机 >> NFS服务上的虚拟机;在多线程CPU性能方面,宿主机 >> 本地磁盘上的虚拟机 = NFS服务上的虚拟机。需要注意的是,在多线程测试结果方面,宿主机所占的优势完全是由于宿主机比虚拟机多占用了两个物理线程,也就是一个物理核心。可以认为,在如上所述测试中,物理机和虚拟机的CPU性能基本上是一致的,虚拟化基本上没有导致CPU性能损失。
(2)文件IO性能测试
我们使用iozone来进行文件IO性能测试。iozone性能测试结果表示的是文件IO的吞吐量(KBps),但是通过吞吐量可以估算出IOPS.在如下命令中,我们评估的是以256K为数据块大小对文件进行写、重写、读、重读、随机读、随机写性能测试,在测试过程当中使用/io.tmp作为临时测试文件,该测试文件的大小是4 GB.需要注意的是,命令中所指定的测试文件是带路径的,因此我们可以测试同一虚拟机上不同文件系统的性能。例如我们通过NFS将某一网络共享文件系统挂载到虚拟机的/mnt目录,那么我们可以将该测试文件的路径设定为/mnt/io.tmp.
cd ~/iozone3_414/src/current
./iozone -Mcew -i0 -i1 -i2 -s4g -r256k -f /io.tmp
下面是一个可供参考的测试结果。在这个测试中使用了两台物理机,每台物理机各配置一颗Intel Core i3 540 @ 3.07 GHz (双核四线程),16 GB内存(DDR3 @ 1333 MHz),一块Seagate ST2000DL003-9VT1硬盘(SATA,2TB,5900RPM),运行Ubuntu 10.04 AMD64 Server操作系统,使用的文件系统为ext4,使用的Hypervisor为KVM(qemu-kvm-0.12.3)。我们分别测试了宿主机、NFS、磁盘映像以文件格式(RAW格式,没有启用virtio)存储在本地磁盘上的虚拟机、磁盘映像以文件格式(RAW格式,没有启用virtio)存储在NFS上的虚拟机、以及从虚拟机内部挂载宿主机NFS服务(虚拟网卡启用了virtio)的磁盘IO性能。虚拟机的配置为2 颗vCPU(占用两个物理线程,也就是一个物理核心)和4 GB内存,运行Ubuntu 12.04 AMD64 Server操作系统。在这个测试中没有对操作系统、文件系统、NFS、KVM等等进行任何性能调优。
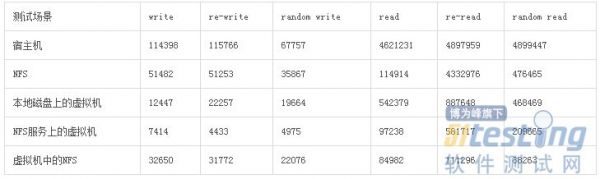
从如上测试结果可以看出,在如上所述特定测试场景中,在文件IO性能方面,宿主机 > NFS > 虚拟机中的NFS > 本地磁盘上的虚拟机 >NFS服务上的虚拟机。值得注意的是,即使是从虚拟机中挂载NFS服务,其文件IO性能也远远超过本地磁盘上的虚拟机。
[特别说明]需要注意的是,当我们说文件(或者磁盘)IO性能的时候,我们指的通常是应用程序(例如iozone)进行文件读写操作时所看到的IO性能。这个性能通常是与系统相关的,包括了多级缓存(磁盘自身的缓存机制、操作系统的缓存机制)的影响,而不仅仅是磁盘本身。利用iozone进行文件IO性能测试时,测试结果与主机的内存大小、测试数据块的大小、测试文件的大小都有很大的关系。如果要全面地描述一个特定系统(CPU、内存、硬盘)的文件IO性能,往往需要对测试数据块的大小和测试文件的大小进行调整,进行一系列类似的测试并对测试结果进行全面分析。本文所提供的仅仅是一个快速测试方法,所提供的测试参数并没有针对任何特定系统进行优化,仅仅是为了说明iozone这个工具的使用方法。如上所述之测试数据,仅仅在如上所述之测试场景下是有效的,并不足以定性地说明任何虚拟化场景下宿主机和虚拟机的文件IO性能差异。建议读者在掌握了iozone这个工具的使用方法的基础上,对被测试对象进行更加全面的测试。(感谢saphires网友的修改建议。)
(3)内存性能测试
我们使用mbw来测试虚拟机的内存性能。mbw通常用来评估用户层应用程序进行内存拷贝操作所能够达到的带宽(MBps)。
mbw 128
下面是一个可供参考的测试结果。在这个测试中使用了两台物理机,每台物理机各配置一颗Intel Core i3 540 @ 3.07 GHz (双核四线程),16 GB内存(DDR3 @ 1333 MHz),一块Seagate ST2000DL003-9VT1硬盘(SATA,2TB,5900RPM),运行Ubuntu 10.04 AMD64 Server操作系统,使用的文件系统为ext4,使用的Hypervisor为KVM(qemu-kvm-0.12.3),虚拟机运行Ubuntu 12.04 AMD64 Server操作系统。我们分别测试了宿主机、磁盘映像以文件格式(RAW格式,没有启用virtio)存储在本地磁盘上的虚拟机、磁盘映像以文件格式(RAW格式,没有启用virtio)存储在NFS上的虚拟机的内存性能。虚拟机的配置为2 颗vCPU(占用两个物理线程,也就是一个物理核心)和4 GB内存。在这个测试中没有对操作系统、文件系统、NFS、KVM等等进行任何性能调优。

从如上测试结果可以看出,在没有进行任何性能调优的情况下,宿主机、本地磁盘上的虚拟机、NFS服务上的虚拟机在内存性能方面基本上是一致的,虚拟化基本上没有导致内存性能损失。
(4)网络带宽测试
我们使用iperf来测试虚拟机之间的网络带宽(Mbps)。测试方法是在一台虚拟机上运行iperf服务端,另外一台虚拟机上运行iperf客户端。假设运行服务端的虚拟机的IP地址是192.168.1.1,运行客户端的虚拟机的IP地址是192.168.1.2.
在服务端执行如下命令:
iperf -s
在客户端执行如下命令:
iperf -c 192.168.1.1
测试完成后,在客户端会显示两台虚拟机之间的网络带宽。
下面是一个可供参考的测试结果。在这个测试中使用了两台物理机,每台物理机各配置一颗Intel Core i3 540 @ 3.07 GHz (双核四线程),16 GB内存(DDR3 @ 1333 MHz),一块Seagate ST2000DL003-9VT1硬盘(SATA,2TB,5900RPM),运行Ubuntu 10.04 AMD64 Server操作系统,使用的文件系统为ext4,使用的Hypervisor为KVM(qemu-kvm-0.12.3)。我们分别测试了宿主机之间、宿主机与虚拟机之间、虚拟机与虚拟机之间的内网带宽。虚拟机的配置为2 颗vCPU(占用两个物理线程,也就是一个物理核心)和4 GB内存。虚拟机的配置为2 颗vCPU(占用两个物理线程,也就是一个物理核心)和4 GB内存,运行Ubuntu 12.04 AMD64 Server操作系统。在这个测试中没有对操作系统、文件系统、NFS、KVM等等进行任何性能调优,但是虚拟机的网卡启用了virtio.
从如上测试结果可以看出,宿主机之间的内网带宽接近内网交换

机的极限。在启用了virtio的情况下,宿主机与虚拟机之间内网带宽有小幅度的性能损失,基本上不会影响数据传输能力;虚拟机与虚拟机之间的内网带宽有接近15%的损失,对数据传输能力影响也不是很大。
(5)数据库性能测试
postgresql是一个著名的开源数据库系统。在MySQL被Sun 公司收购并进一步被Oracle公司收购之后,越来越多的公司正在从MySQL迁移到postgresql.pgbench是一个针对postgresql的性能测试工具,其测试结果接近于TPC-B.pgbench的优点之一在于它能够轻易地进行多线程测试,从而充分利用多核处理器的处理能力。
在虚拟机上以postgres用户登录:
su -l postgres
将/usr/lib/postgresql/9.1/bin加入到路径PATH当中。
创建测试数据库:
createdb pgbench
初始化测试数据库:
pgbench -i -s 16 pgbench
执行单线程测试:
pgbench -t 2000 -c 16 -U postgres pgbench
执行多线程测试,在下面的命令中将N替换为虚拟机的vCPU数量:
pgbench -t 2000 -c 16 -j N -U postgres pgbench
下面是一个可供参考的测试结果。在这个测试中使用了两台物理机,每台物理机各配置一颗Intel Core i3 540 @ 3.07 GHz (双核四线程),16 GB内存(DDR3 @ 1333 MHz),一块Seagate ST2000DL003-9VT1硬盘(SATA,2TB,5900RPM),运行Ubuntu 10.04 AMD64 Server操作系统,使用的文件系统为ext4,使用的Hypervisor为KVM(qemu-kvm-0.12.3),虚拟机运行Ubuntu 12.04 AMD64 Server操作系统。我们分别测试了宿主机、磁盘映像以文件格式(RAW格式,没有启用virtio)存储在本地磁盘上的虚拟机、磁盘映像以文件格式(RAW格式,没有启用virtio)存储在NFS上的虚拟机的数据库性能。虚拟机的配置为2 颗vCPU(占用两个物理线程,也就是一个物理核心)和4 GB内存,运行Ubuntu 12.04 AMD64 Server操作系统。在这个测试中没有对操作系统、文件系统、NFS、KVM等等进行任何性能调优。

从如上测试结果可以看出,在没有进行任何性能调优的情况下,在数据库性能方面,宿主机 >> 本地磁盘上的虚拟机 >> NFS服务上的虚拟机。
本文是参考logstash官方文档实践的笔记,搭建环境和所需组件如下: - Redhat 5.7 64bit / CentOS 5.x
- JDK 1.6.0_45
- logstash 1.3.2 (内带kibana)
- elasticsearch 0.90.10
- redis 2.8.4
搭建的集中式日志分析平台流程如下: elasticsearch1、下载elasticsearch。 wget https://download.elasticsearch.org/elasticsearch/elasticsearch/elasticsearch-0.90.10.tar.gz
2、解压后,进入bin目录。执行如下命令,让elasticsearch以前台方式启动: ./elasticsearch -f
[2014-01-16 16:21:31,825][INFO ][node ] [Saint Elmo] version[0.90.10], pid[32269], build[0a5781f/2014-01-10T10:18:37Z] [2014-01-16 16:21:31,826][INFO ][node ] [Saint Elmo] initializing ... [2014-01-16 16:21:31,836][INFO ][plugins ] [Saint Elmo] loaded [], sites [] [2014-01-16 16:21:35,425][INFO ][node ] [Saint Elmo] initialized [2014-01-16 16:21:35,425][INFO ][node ] [Saint Elmo] starting ... [2014-01-16 16:21:35,578][INFO ][transport ] [Saint Elmo] bound_address {inet[/0.0.0.0:9300]}, publish_address {inet[/10.0.2.15:9300]} Redis1、其安装方式可以参考我的另一篇文章Redis编译安装。 2、进入其bin目录,执行如下命令,使之在控制台输出debug信息: ./redis-server --loglevel verbose
[32470] 16 Jan 16:45:57.330 * The server is now ready to accept connections on port 6379 [32470] 16 Jan 16:45:57.330 - 0 clients connected (0 slaves), 283536 bytes in use logstash日志生成器(shipper)1、新建一个配置文件:shipper.conf,其内容如下: input { stdin { type => "example" } } output { stdout { codec => rubydebug } redis { host => "127.0.0.1" port => 6379 data_type => "list" key => "logstash" } } 2、启动shipper。执行如下命令: java -jar logstash-1.3.2-flatjar.jar agent -f shipper.conf
终端窗口将出现如下提示信息: Using milestone 2 output plugin 'redis'. This plugin should be stable, but if you see strange behavior, please let us know! For more information on plugin milestones, see http://logstash.net/docs/1.3.2/plugin-milestones {:level=>:warn} 然后在终端窗口直接按回车,将出现如下信息: { "message" => "", "@version" => "1", "@timestamp" => "2014-01-16T08:15:19.400Z", "type" => "example", "host" => "redhat" } 这个json信息将发送给redis, 同时redis的终端窗口将出现类似下面的提示信息: [32470] 16 Jan 17:09:23.604 - Accepted 127.0.0.1:44640 [32470] 16 Jan 17:09:27.127 - DB 0: 1 keys (0 volatile) in 4 slots HT. [32470] 16 Jan 17:09:27.127 - 1 clients connected (0 slaves), 304752 bytes in use logstash日志索引器(indexer)1、新建一个配置文件:indexer.conf,其内容如下: input { redis { host => "127.0.0.1" # these settings should match the output of the agent data_type => "list" key => "logstash" # We use the 'json' codec here because we expect to read # json events from redis. codec => json } } output { stdout { debug => true debug_format => "json"} elasticsearch { host => "127.0.0.1" } } 2、启动日志索引器。执行如下命令: java -jar logstash-1.3.2-flatjar.jar agent -f indexer.conf
终端窗口将出现如下提示信息: Using milestone 2 input plugin 'redis'. This plugin should be stable, but if you see strange behavior, please let us know! For more information on plugin milestones, see http://logstash.net/docs/1.3.2/plugin-milestones {:level=>:warn} You are using a deprecated config setting "debug_format" set in stdout. Deprecated settings will continue to work, but are scheduled for removal from logstash in the future. If you have any questions about this, please visit the #logstash channel on freenode irc. {:name=>"debug_format", :plugin=>, :level=>:warn} 索引器从Redis接收到信息,在终端窗口会显示类似如下的信息: {"message":"","@version":"1","@timestamp":"2014-01-16T17:10:03.831+08:00","type":"example","host":"redhat"}{"message":"","@version":"1","@timestamp":"2014-01-16T17:13:20.545+08:00","type":"example","host":"redhat"}{ logstash WEB界面(kibana)1、启动kibana。执行如下命令: java -jar logstash-1.3.2-flatjar.jar web
2、打开浏览器(须支持HTML5),输入地址:http://127.0.0.1:9292/index.html#/dashboard/file/logstash.json。界面效果如下: 参考资料
Fluentd是一个开源收集事件和日志系统,它目前提供150+扩展插件让你存储大数据用于日志搜索,数据分析和存储。 官方地址http://fluentd.org/ 插件地址http://fluentd.org/plugin/ Kibana 是一个为 ElasticSearch 提供日志分析的 Web ui工具,可使用它对日志进行高效的搜索、可视化、分析等各种操作。官方地址http://www.elasticsearch.org/overview/kibana/
elasticsearch 是开源的(Apache2协议),分布式的,RESTful的,构建在Apache Lucene之上的的搜索引擎. 官方地址http://www.elasticsearch.org/overview/ 中文地址 http://es-cn.medcl.net/
具体的工作流程就是利用fluentd 监控并过滤hadoop集群的系统日志,将过滤后的日志内容发给全文搜索服务ElasticSearch, 然后用ElasticSearch结合Kibana 进行自定义搜索web页面展示. 下面开始说部署方法和过程。以下安装步骤在centos 5 64位测试通过 一、 elasticsearch安装部署 elasticsearch 官方提供了几种安装包,适用于windows的zip压缩包,适用于unix/linux的tar.gz压缩包,适用于centos系统的rpm包和ubuntu的deb包。大家可以自己选择安装使用。
因为elasticsearch 需要java环境运行,首先需要安装jdk,安装步骤就省略了。
使用.tar.gz压缩包安装部署的话,先下载压缩包 # wget https://download.elasticsearch.org/elasticsearch/elasticsearch/elasticsearch-0.90.5.tar.gz # tar zxvf elasticsearch-0.90.5.tar.gz ////////////如果是单机部署 # cd elasticsearch-0.90.5 # elasticsearch-0.90.5/bin/elasticsearch -f 就可以启动搜索服务了,查看端口9200是否打开,如果打开说明启动正常。 ////////////////如果是部署集群的话,需要进行配置 例如在192.168.0.1 192.168.0.2 两台服务器部署,两台服务器都安装好jdk,下载elasticsearch 解压缩,然后编辑配置文件 //////////////////////192.168.0.1 服务器编辑文件 vi elasticsearch-0.90.5/config/elasticsearch.yml 删除cluster.name 前面注释,修改集群名称 cluster.name: es_cluster
删除node.name前注释 ,修改节点名称,不修改的话,系统启动后会生成随即node名称。 node.name: "elastic_inst1" node.master: true 设置该节点为主节点
/////////////////////////192.168.0.2 编辑文件 vi elasticsearch-0.90.5/config/elasticsearch.yml 删除cluster.name 前面注释,修改集群名称 cluster.name: es_cluster
删除node.name前注释 ,修改节点名称,不修改的话,系统启动后会生成随即node名称。 node.name: "elastic_inst2" node.master: false 设置该节点为主节点
分别启动两台服务器的服务后,在192.168.0.2的日志中会看到 [elastic_inst2] detected_master [elastic_inst1] 日志信息。说明集群连接成功。
二、安装部署fluentd 在需要监控分析的hadoop集群节点中安装fluentd,安装步骤很简单
curl -L http://toolbelt.treasure-data.com/sh/install-redhat.sh | sh 安装完成后,编辑配置文件# vim /etc/td-agent/td-agent.conf - <source>
- type tail #### tail方式采集日志
- path /var/log/hadoop/mapred/hadoop-mapred-tasktracker-node-128-70.log ### hadoop日志路径
- pos_file /var/log/td-agent/task-access.log.pos
- tag task.mapred
- format /^(?<message>.+(WARN|ERROR).+)$/ #### 收集error 或者warn 日志。
- </source>
-
- <match task.**>
- host 192.168.0.1 ##### <span style="font-family:Arial,Helvetica,sans-serif">elasticsearch 服务器地址</span>
- type elasticsearch
- logstash_format true
- flush_interval 5s
- include_tag_key true
- tag_key mapred
- </match>
# service td-agent start
三、安装部署kibana 3 kibana 3 是使用html 和javascript 开发的web ui前端工具。 下载 wget http://download.elasticsearch.org/kibana/kibana/kibana-latest.zip 解压缩 unzip kibana-latest.zip 安装apache yum -y install httpd cp -r kibana-latest /var/www/html 因为我将kibana3 安装在和elasticsearch同一台服务器中,所以不用修改配置文件 启动apache service httpd start 打开浏览器 http://ip/kibana 就可以看到kibana 界面 初次使用kibana 需要自己定义模块 
前言
持续集成这个概念已经成为软件开发的主流,可以更频繁的进行测试,尽早发现问题并提示。自动化部署就更不用说了,可以加快部署速度,并可以有效减少人为操作的失误。之前一直没有把这个做起来,最近的新项目正好有机会,费了一番功夫总算搞好了,特此记录。 1. 开发环境
我这边建立的标准开发环境如下:
1. Maven做项目管理;
2. Git做代码管理;
3. SpringMVC+Spring+Mybatis搭建的程序框架;
4. Mysql作为数据存储,Druid做连接池;
5. unitils作为测试框架;
6. Hibernate Validator作为数据验证; 7. log4j作为日志输出。
注:其实这套东西非常像Grails,但不敢用太激进的技术和框架,担心招人的问题-_-! 2. Jenkins的部署
Jenkins原名是Hudson,这个渊源这里就不追溯了,网上多得是,但是千万别下错了,官网地址是http://jenkins-ci.org/。建议直接下载最新版本。 这个软件的安装是我见过最简单的了,直接取war包放到tomcat下,启动tomcat即可。相应的工程配置会在~/.jenkins目录中。(当然你根据官网给的那种安装方法也行,只是在debian的那个弄法还要去下载openjdk等等,多下了很多东西,相关配置也按linux目录标准分开的,还要去找。) 另外提醒一下,建议把Jenkins安装在Linux上,这样就不会出现ssh等命令找不到的问题,否则还要想办法去处理。 3. Jenkins的插件
安装好后直接访问“http://yourhost:8080/jenkins”即可进入主界面,点击“系统管理”->“管理插件”,首次进入都是空白的,要等1分钟左右才能看到内容,在后台估计是在做更新或者下载,然后重新再进此界面就能看到内容了。 3.1 Git插件
在“可选插件”中找到“GIT plugin”安装,最下面有个安装完重启的勾选项,选中即可。这里最搞笑的是检测网络是否连通的办法是去尝试打开google,岂不知天朝是打不开的,还好不影响下载。。。 3.2 Email插件
这个事情非常蛋疼,之前测试怎么都发布出来邮件,最后升级了一下默认插件就行了,狂汗。在“可更新”中找到“Mailer Plugin”选中并更新即可。另外如果想有更丰富的邮件内容,就去“可选插件”中安装“Email Extension Plugin”,具体邮件内容配置网上大把可以搜。 3.3 其他插件
默认就装了很多常用插件,比如Maven、Junit等等,如果使用感觉有问题可以尝试升级一下版本,但是没有升级说明,也不知道升级了什么东西。
4. 系统设置
主界面点击“系统管理”->“系统设置”即可进入。重点配置以下内容:
1. Java、Git、Maven的目录位置,确保可以正确找到命令;
2. Jenkins URL,自动生成的,检查一下即可;
3. 邮件的设置。这里注意一下,上面有一个“系统管理员邮件地址”需要填写,另外“Extended E-mail Notification”中填写配置,原来的“邮件配置”就不用再理会了。 5. 项目设置
在主界面直接“新建”,就会有一个新的项目。重点配置以下内容: 1. 源码管理:选择Git,填写“Repository URL”,并加上相应的“Credentials”,其中认证信息用私钥的话干脆直接把私钥内容填上去就行了,省的不知道目录查找规则还不知道出的啥问题。 2. 构建触发器:这个地方要把“Build periodically”和“Poll SCM”都选上,时间格式都填写成一样的即可,比如“H/15 * * * *”,下面会有个具体执行时间的提示,Build动作会自动比Poll延迟3分40秒,这个设定还是很合理的。 3. 构建:增加两个构建步骤,分别是“Execute shell”和“Invoke top-level Maven target”,注意先后顺序,可以拖拽摆放的。脚本执行根据自己需要,比如我需要去修改数据库连接配置,官方建议是自己在工程里面写好脚本,这里直接调用,而不是在这写一个完整的脚本。Maven构建就加上“clean test”即可,就是运行“mvn clean test”的命令。 4. Publish Junit test result report:在测试报告(XML)上加上“**/target/surefire-reports/*.xml”即可,这样就会每次测试完自动找到测试报告,在Jenkins上即可在每个构建结构里面查看到。 5. 邮件通知:在构建后增加“Editable Email Notification”,填写邮件的接受者、内容格式可以直接用全局变量,重点是配置一下发送触发条件。 6. 安全性配置
经过以上配置进行一次构建就会发现,Jenkins可以看到太多内容了,包括pull到的源码,所以非常有必要增加权限控制。进入“系统管理”->“Configure Global Security”中进行如下步骤:
1. 启用安全; 2. Jenkins专有用户数据库,先允许用户注册;
3. 授权策略选择“安全矩阵”,新加一个“admin”的用户,把所有权限都开给admin用户;
4. 在主界面的用户中找到admin,进行配置,设置登陆密码;
5. 先重新登陆测试一下是否admin正常,没有问题就关闭允许用户注册,把匿名用户的所有权限都去掉。 7. 自动化部署
这里我没有让Jenkins每次测试都去部署,一方面是考虑到单元测试基本已经满足需要了,另一方面因为测试太频繁了,一直部署也搞得Stage测试环境要经常重启,反而影响正常的人工测试。所以自己写了个脚本,在必要的时候去运行一下去自动完成整个部署工作。
#!/bin/sh
# update code
git pull
# package
mvn clean
mvn package -Dmaven.test.skip=true
# deploy
WAR=`ls target | grep war`
TOMCAT=/home/test/apache-tomcat-6.0.41
mv target/$WAR $TOMCAT
cd $TOMCAT
# invoke another deploy script
sh deploy-war.sh $WAR webapps 8. 一个非常蛋疼的问题
这个和以上问题都无关,只是极其不解的是这个错误在Windows下不出现,在Linux下打成War也不会出现,只有在Linux下直接执行Maven test就会出错。其实问题的根源就是配置书写不够规范,但是错误出现的不一致性实在让人蛋疼。报错如下:
1 org.apache.ibatis.binding.BindingException: Invalid bound statement (not found): xxx 这个就是Mybatis找不到绑定的类,但是xml是正确打包的,怎么看都是没大问题,并且windows也是对的,最后发现是我在写模糊路径的时候,classpath后面必须要加个*才是标准写法,正确写法如下: <bean class="org.mybatis.spring.mapper.MapperScannerConfigurer">
<property name="basePackage" value="com.gzxitao.demo.*.dao"/>
</bean>
<bean id="sqlSessionFactory" class="org.mybatis.spring.SqlSessionFactoryBean">
<property name="dataSource" ref="dataSource"/>
<property name="configLocation" value="classpath:configuration.xml"/>
<!-- 这里是要扫描多个目录下的文件,必须声明成“classpath*”,否则在某些情况下会报错 -->
<property name="mapperLocations" value="classpath*:com/gzxitao/demo/*/dao/*.xml" />
</bean> Maven权威指南_中文完整版清晰PDF http://www.linuxidc.com/Linux/2014-06/103690.htm Maven 3.1.0 发布,项目构建工具 http://www.linuxidc.com/Linux/2013-07/87403.htm Linux 安装 Maven http://www.linuxidc.com/Linux/2013-05/84489.htm Maven3.0 配置和简单使用 http://www.linuxidc.com/Linux/2013-04/82939.htm Ubuntu下搭建sun-jdk和Maven2 http://www.linuxidc.com/Linux/2012-12/76531.htm Maven使用入门 http://www.linuxidc.com/Linux/2012-11/74354.htm Jenkins的分布式构建及部署——节点 http://www.linuxidc.com/Linux/2015-05/116903.htm Jenkins 的详细介绍:请点这里
Jenkins 的下载地址:请点这里 本文永久更新链接地址:http://www.linuxidc.com/Linux/2015-06/118606.htm
《目录》 一、安装Jenkins 二、配置Jenkins 三、自动编译 四、自动测试 五、自动部署 一、安装Jenkins 地址http://mirrors.jenkins-ci.org/下载适合的Jenkins版本。 Windows最新稳定版的Jenkins地址为:http://mirrors.jenkins-ci.org/windows-stable/jenkins-1.409.1.zip 把Jenkins 1.409.1版解压,把得到的war包直接扔到tomcat下,启动tomcat,Jenkins就安装完毕,是不是很简单啊。 二、配置Jenkins1、打开http://10.3.15.78:8080/jenkins/,第一次进入里面没有数据,我们需要创建job,我们这有2个项目,需要创建2个job。http://10.3.34.163:9890/jenkins/ 2、点击左上角的new job,在new job页面需要选择job的类型,Jenkins支持几种类型,我们选择“构建一个maven2/3项目” 3、点击OK按钮后,进会进入详细配置界面,详细配置界面的配置项很多,不过不用怕,大部分使用默认配置就可以了,下面就说说我们需要修改的几个地方: 3.1)Source Code Management 因为我们使用SVN管理源码,所以这里选择Subversion,并在Repository URL中输入我们的SVN地址: http://10.3.34.163:9880/XXXX/trunk/ 输入SVN库的URL地址后,Jenkins会自动验证地址,并给予提示。 点击红色字体部分的enter credential链接,进入页面 设置好访问SVN库的用户名和密码后,点击OK按钮 设置成功。点击Close按钮,返回之前的Source Code Management页面。此时不再有红色警告信息了。 3.2)配置自动构建的计划,假设我们想让项目中每天12点和晚上8点自动构建一次,只需要在Build Triggers中选择Build periodically,并在Schedule中输入 0 12,20 * * *。 我配置的是每晚8点自动构建 注:Schedule的配置规则是有5个空格隔开的字符组成,从左到右分别代表:分时天月年。*代表所有,0 12,20 * * * 表示“在任何年任何月任何天的12和20点0分”进行构建。 3.3)配置到这里,可能有人发现在Build配置节点,有红色错误信息,提示 Jenkins needs to know where your Maven2 is installed.
Please do so from the system configuration. 是因为Jenkins找不到maven的原因,点击"system configuration",是system configuration的maven配置中添加maven目录就OK。 我设置了JRE 6和MAVEN 3的安装目录。 点击左下角的SAVE按钮,保存设置。 3.4)保存好所有配置后,我们第1个job就算是完成了。 3.5)创建第2个job,配置和上面的配置相同。只需把svn地址改成:http://localhost/svn/Web 三、自动编译在经过上面的配置后,回到Jenkins首页,在首页可以看到刚才添加的2个job 点击某1个job后后面的"Schedule a build"图片手动构建,点击完后,会在左边的Build Queue或者Build Executor Status显示正在构建的任务,在自动构建完后,刷新页面,就可以看到构建结果了,如何某个项目构建失败,点击项目后面的构建数字(从1开始递增)进入项目的"Console Output "可以查看项目构建失败的原因。当然我们也可以配置把构建失败的结果发到邮箱。 到目前为止,1个简单的自动构建环境就搭建好了,很简单吧。
简介awk是一个强大的文本分析工具,相对于grep的查找,sed的编辑,awk在其对数据分析并生成报告时,显得尤为强大。简单来说awk就是把文件逐行的读入,以空格为默认分隔符将每行切片,切开的部分再进行各种分析处理。 awk有3个不同版本: awk、nawk和gawk,未作特别说明,一般指gawk,gawk 是 AWK 的 GNU 版本。 awk其名称得自于它的创始人 Alfred Aho 、Peter Weinberger 和 Brian Kernighan 姓氏的首个字母。实际上 AWK 的确拥有自己的语言: AWK 程序设计语言 , 三位创建者已将它正式定义为“样式扫描和处理语言”。它允许您创建简短的程序,这些程序读取输入文件、为数据排序、处理数据、对输入执行计算以及生成报表,还有无数其他的功能。 使用方法awk '{pattern + action}' {filenames}尽管操作可能会很复杂,但语法总是这样,其中 pattern 表示 AWK 在数据中查找的内容,而 action 是在找到匹配内容时所执行的一系列命令。花括号({})不需要在程序中始终出现,但它们用于根据特定的模式对一系列指令进行分组。 pattern就是要表示的正则表达式,用斜杠括起来。 awk语言的最基本功能是在文件或者字符串中基于指定规则浏览和抽取信息,awk抽取信息后,才能进行其他文本操作。完整的awk脚本通常用来格式化文本文件中的信息。 通常,awk是以文件的一行为处理单位的。awk每接收文件的一行,然后执行相应的命令,来处理文本。 调用awk有三种方式调用awk 1.命令行方式 awk [-F field-separator] 'commands' input-file(s) 其中,commands 是真正awk命令,[-F域分隔符]是可选的。 input-file(s) 是待处理的文件。 在awk中,文件的每一行中,由域分隔符分开的每一项称为一个域。通常,在不指名-F域分隔符的情况下,默认的域分隔符是空格。 2.shell脚本方式 将所有的awk命令插入一个文件,并使awk程序可执行,然后awk命令解释器作为脚本的首行,一遍通过键入脚本名称来调用。 相当于shell脚本首行的:#!/bin/sh 可以换成:#!/bin/awk 3.将所有的awk命令插入一个单独文件,然后调用: awk -f awk-script-file input-file(s) 其中,-f选项加载awk-script-file中的awk脚本,input-file(s)跟上面的是一样的。 本章重点介绍命令行方式。 入门实例假设last -n 5的输出如下 [root@www ~]# last -n 5 <==仅取出前五行 root pts/1 192.168.1.100 Tue Feb 10 11:21 still logged in root pts/1 192.168.1.100 Tue Feb 10 00:46 - 02:28 (01:41) root pts/1 192.168.1.100 Mon Feb 9 11:41 - 18:30 (06:48) dmtsai pts/1 192.168.1.100 Mon Feb 9 11:41 - 11:41 (00:00) root tty1 Fri Sep 5 14:09 - 14:10 (00:01) 如果只是显示最近登录的5个帐号 #last -n 5 | awk '{print $1}'
root
root
root
dmtsai
rootawk工作流程是这样的:读入有'\n'换行符分割的一条记录,然后将记录按指定的域分隔符划分域,填充域,$0则表示所有域,$1表示第一个域,$n表示第n个域。默认域分隔符是"空白键" 或 "[tab]键",所以$1表示登录用户,$3表示登录用户ip,以此类推。 如果只是显示/etc/passwd的账户 #cat /etc/passwd |awk -F ':' '{print $1}' root daemon bin sys这种是awk+action的示例,每行都会执行action{print $1}。 -F指定域分隔符为':'。 如果只是显示/etc/passwd的账户和账户对应的shell,而账户与shell之间以tab键分割 #cat /etc/passwd |awk -F ':' '{print $1"\t"$7}' root /bin/bash daemon /bin/sh bin /bin/sh sys /bin/sh 如果只是显示/etc/passwd的账户和账户对应的shell,而账户与shell之间以逗号分割,而且在所有行添加列名name,shell,在最后一行添加"blue,/bin/nosh"。 cat /etc/passwd |awk -F ':' 'BEGIN {print "name,shell"} {print $1","$7} END {print "blue,/bin/nosh"}' name,shell root,/bin/bash daemon,/bin/sh bin,/bin/sh sys,/bin/sh .... blue,/bin/noshawk工作流程是这样的:先执行BEGING,然后读取文件,读入有/n换行符分割的一条记录,然后将记录按指定的域分隔符划分域,填充域,$0则表示所有域,$1表示第一个域,$n表示第n个域,随后开始执行模式所对应的动作action。接着开始读入第二条记录······直到所有的记录都读完,最后执行END操作。 搜索/etc/passwd有root关键字的所有行 #awk -F: '/root/' /etc/passwd root:x:0:0:root:/root:/bin/bash 这种是pattern的使用示例,匹配了pattern(这里是root)的行才会执行action(没有指定action,默认输出每行的内容)。 搜索支持正则,例如找root开头的: awk -F: '/^root/' /etc/passwd 搜索/etc/passwd有root关键字的所有行,并显示对应的shell # awk -F: '/root/{print $7}' /etc/passwd /bin/bash 这里指定了action{print $7} awk内置变量awk有许多内置变量用来设置环境信息,这些变量可以被改变,下面给出了最常用的一些变量。 ARGC 命令行参数个数 ARGV 命令行参数排列 ENVIRON 支持队列中系统环境变量的使用 FILENAME awk浏览的文件名 FNR 浏览文件的记录数 FS 设置输入域分隔符,等价于命令行 -F选项 NF 浏览记录的域的个数 NR 已读的记录数 OFS 输出域分隔符 ORS 输出记录分隔符 RS 控制记录分隔符 此外,$0变量是指整条记录。$1表示当前行的第一个域,$2表示当前行的第二个域,......以此类推。 统计/etc/passwd:文件名,每行的行号,每行的列数,对应的完整行内容: #awk -F ':' '{print "filename:" FILENAME ",linenumber:" NR ",columns:" NF ",linecontent:"$0}' /etc/passwd filename:/etc/passwd,linenumber:1,columns:7,linecontent:root:x:0:0:root:/root:/bin/bash filename:/etc/passwd,linenumber:2,columns:7,linecontent:daemon:x:1:1:daemon:/usr/sbin:/bin/sh filename:/etc/passwd,linenumber:3,columns:7,linecontent:bin:x:2:2:bin:/bin:/bin/sh filename:/etc/passwd,linenumber:4,columns:7,linecontent:sys:x:3:3:sys:/dev:/bin/sh 使用printf替代print,可以让代码更加简洁,易读 awk -F ':' '{printf("filename:%10s,linenumber:%s,columns:%s,linecontent:%s\n",FILENAME,NR,NF,$0)}' /etc/passwd print和printfawk中同时提供了print和printf两种打印输出的函数。 其中print函数的参数可以是变量、数值或者字符串。字符串必须用双引号引用,参数用逗号分隔。如果没有逗号,参数就串联在一起而无法区分。这里,逗号的作用与输出文件的分隔符的作用是一样的,只是后者是空格而已。 printf函数,其用法和c语言中printf基本相似,可以格式化字符串,输出复杂时,printf更加好用,代码更易懂。 awk编程 变量和赋值 除了awk的内置变量,awk还可以自定义变量。 下面统计/etc/passwd的账户人数 awk '{count++;print $0;} END{print "user count is ", count}' /etc/passwd root:x:0:0:root:/root:/bin/bash ...... user count is 40
count是自定义变量。之前的action{}里都是只有一个print,其实print只是一个语句,而action{}可以有多个语句,以;号隔开。 这里没有初始化count,虽然默认是0,但是妥当的做法还是初始化为0: awk 'BEGIN {count=0;print "[start]user count is ", count} {count=count+1;print $0;} END{print "[end]user count is ", count}' /etc/passwd [start]user count is 0 root:x:0:0:root:/root:/bin/bash ... [end]user count is 40 统计某个文件夹下的文件占用的字节数 ls -l |awk 'BEGIN {size=0;} {size=size+$5;} END{print "[end]size is ", size}'
[end]size is 8657198
如果以M为单位显示: ls -l |awk 'BEGIN {size=0;} {size=size+$5;} END{print "[end]size is ", size/1024/1024,"M"}'
[end]size is 8.25889 M注意,统计不包括文件夹的子目录。 条件语句 awk中的条件语句是从C语言中借鉴来的,见如下声明方式: if (expression) { statement; statement; ... ... } if (expression) { statement; } else { statement2; } if (expression) { statement1; } else if (expression1) { statement2; } else { statement3; } 统计某个文件夹下的文件占用的字节数,过滤4096大小的文件(一般都是文件夹): ls -l |awk 'BEGIN {size=0;print "[start]size is ", size} {if($5!=4096){size=size+$5;}} END{print "[end]size is ", size/1024/1024,"M"}'
[end]size is 8.22339 M 循环语句 awk中的循环语句同样借鉴于C语言,支持while、do/while、for、break、continue,这些关键字的语义和C语言中的语义完全相同。 数组 因为awk中数组的下标可以是数字和字母,数组的下标通常被称为关键字(key)。值和关键字都存储在内部的一张针对key/value应用hash的表格里。由于hash不是顺序存储,因此在显示数组内容时会发现,它们并不是按照你预料的顺序显示出来的。数组和变量一样,都是在使用时自动创建的,awk也同样会自动判断其存储的是数字还是字符串。一般而言,awk中的数组用来从记录中收集信息,可以用于计算总和、统计单词以及跟踪模板被匹配的次数等等。 显示/etc/passwd的账户 awk -F ':' 'BEGIN {count=0;} {name[count] = $1;count++;}; END{for (i = 0; i < NR; i++) print i, name[i]}' /etc/passwd 0 root 1 daemon 2 bin 3 sys 4 sync 5 games ......这里使用for循环遍历数组 awk编程的内容极多,这里只罗列简单常用的用法,更多请参考 http://www.gnu.org/software/gawk/manual/gawk.html
linux tee 命令详解
功能说明:读取标准输入的数据,并将其内容输出成文件。
语法:tee [-ai][--help][--version][文件...]
补充说明:tee指令会从标准输入设备读取数据,将其内容输出到标准输出设备,同时保存成文件。
参数:
-a或--append 附加到既有文件的后面,而非覆盖它.
-i-i或--ignore-interrupts 忽略中断信号。
--help 在线帮助。
--version 显示版本信息。
用途说明在执行Linux命令时,我们可以把输出重定向到文件中,比如 ls >a.txt,这时我们就不能看到输出了,如果我们既想把输出保存到文件中,又想在屏幕上看到输出内容,就可以使用tee命令了。tee命令读取标准输入,把这些内容同时输出到标准输出和(多个)文件中(read from standard input and write to standard output and files. Copy standard input to each FILE, and also to standard output. If a FILE is -, copy again to standard output.)。在info tee中说道:tee命令可以重定向标准输出到多个文件(`tee': Redirect output to multiple files. The `tee' command copies standard input to standard output and also to any files given as arguments. This is useful when you want not only to send some data down a pipe, but also to save a copy.)。要注意的是:在使用管道线时,前一个命令的标准错误输出不会被tee读取。 常用参数格式:tee 只输出到标准输出,因为没有指定文件嘛。 格式:tee file 输出到标准输出的同时,保存到文件file中。如果文件不存在,则创建;如果已经存在,则覆盖之。(If a file being written to does not already exist, it is created. If a file being written to already exists, the data it previously
contained is overwritten unless the `-a' option is used.) 格式:tee -a file 输出到标准输出的同时,追加到文件file中。如果文件不存在,则创建;如果已经存在,就在末尾追加内容,而不是覆盖。 格式:tee - 输出到标准输出两次。(A FILE of `-' causes `tee' to send another copy of input to standard output, but this is typically not that useful as the copies are interleaved.) 格式:tee file1 file2 - 输出到标准输出两次,同时保存到file1和file2中。
一 初级 1)Notepad++ (编辑和查看Perl) 2)Komobo Edit (编辑和执行Perl)
二 高级 A Perl Express
主页:http://www.perl-express.com/ 使用: 很简单
B Eclipse+EPIC+PadWalker a) 下载解压Eclipse b)下载EPIC插件之设置 (help->install new software)
c)下载EPIC插件之下载
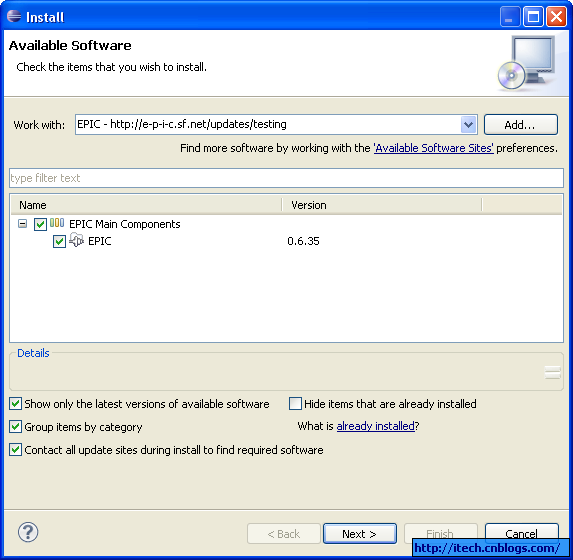
d)EPIC设置(菜单windows->preferences) 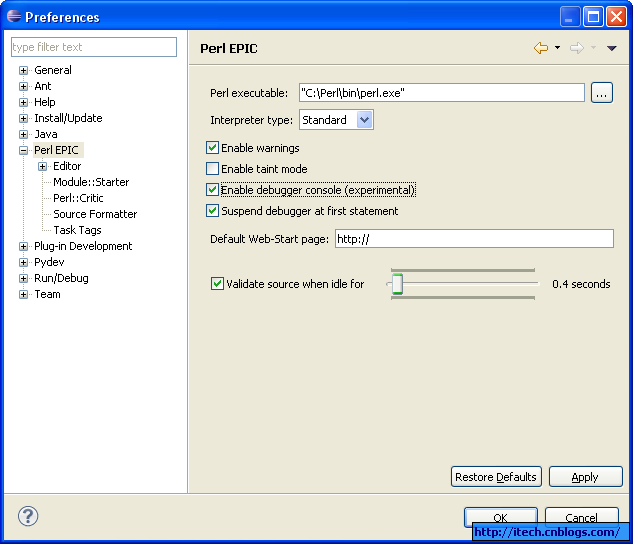
c)下载perl模块PadWalker (用来在debug时显示变量值)
ppm install PadWalker 或cpan> install PadWalker (注意模块名字的大小写)
d)运行和调试perl
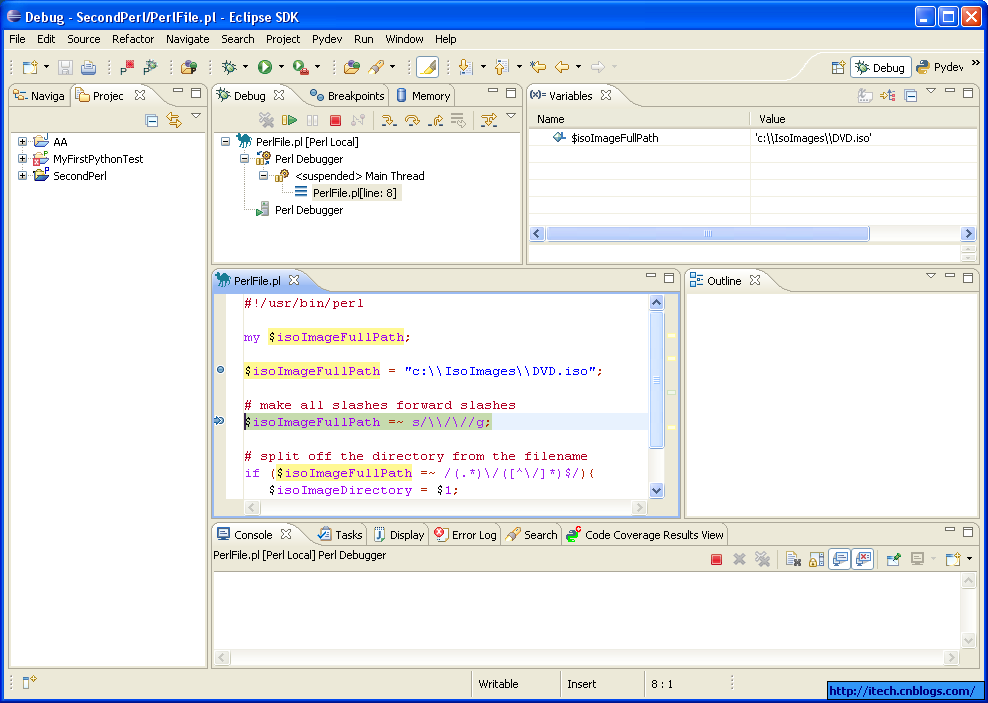 完!
mvn archetype:generate -DgroupId=com.bestpay.support.gd -DartifactId=JBatchReward -DarchetypeArtifactId=maven-archetype-j2ee-simple
看maven-definitive-guide到第五章了,发现maven可以创建不少类型的demo,只要输入:
mvn archetype:create就可以
不过,创建的同时需要archetypeArtifactId这个参数来识别,不过不太清楚有什么类型,只知道默认不填是maven-archetype-quickstart ,web是maven-archetype-webapp
发现有更简单的方法,只要输入mvn archetype:generate
就会将所有可用的类型显示,并且让你自己选,输出如下:
1: internal -> appfuse-basic-jsf (AppFuse archetype for creating a web application with Hibernate, Spring and JSF)
2: internal -> appfuse-basic-spring (AppFuse archetype for creating a web application with Hibernate, Spring and Spring MVC)
3: internal -> appfuse-basic-struts (AppFuse archetype for creating a web application with Hibernate, Spring and Struts 2)
4: internal -> appfuse-basic-tapestry (AppFuse archetype for creating a web application with Hibernate, Spring and Tapestry 4)
5: internal -> appfuse-core (AppFuse archetype for creating a jar application with Hibernate and Spring and XFire)
6: internal -> appfuse-modular-jsf (AppFuse archetype for creating a modular application with Hibernate, Spring and JSF)
7: internal -> appfuse-modular-spring (AppFuse archetype for creating a modular application with Hibernate, Spring and Spring MVC)
8: internal -> appfuse-modular-struts (AppFuse archetype for creating a modular application with Hibernate, Spring and Struts 2)
9: internal -> appfuse-modular-tapestry (AppFuse archetype for creating a modular application with Hibernate, Spring and Tapestry 4)
10: internal -> maven-archetype-j2ee-simple (A simple J2EE Java application)
11: internal -> maven-archetype-marmalade-mojo (A Maven plugin development project using marmalade)
12: internal -> maven-archetype-mojo (A Maven Java plugin development project)
13: internal -> maven-archetype-portlet (A simple portlet application)
14: internal -> maven-archetype-profiles ()
15: internal -> maven-archetype-quickstart ()
16: internal -> maven-archetype-site-simple (A simple site generation project)
17: internal -> maven-archetype-site (A more complex site project)
18: internal -> maven-archetype-webapp (A simple Java web application)
19: internal -> struts2-archetype-starter (A starter Struts 2 application with Sitemesh, DWR, and Spring)
20: internal -> struts2-archetype-blank (A minimal Struts 2 application)
21: internal -> struts2-archetype-portlet (A minimal Struts 2 application that can be deployed as a portlet)
22: internal -> struts2-archetype-dbportlet (A starter Struts 2 portlet that demonstrates a simple CRUD interface with db backing)
23: internal -> struts2-archetype-plugin (A Struts 2 plugin)
24: internal -> shale-archetype-blank (A blank Shale web application with JSF)
25: internal -> maven-adf-archetype (Archetype to ease the burden of creating a new application based with ADF)
26: internal -> data-app (A new Databinder application with sources and resources.)
27: internal -> jini-service-archetype (Archetype for Jini service project creation)
28: internal -> softeu-archetype-seam (JSF+Facelets+Seam Archetype)
29: internal -> softeu-archetype-seam-simple (JSF+Facelets+Seam (no persistence) Archetype)
30: internal -> softeu-archetype-jsf (JSF+Facelets Archetype)
31: internal -> jpa-maven-archetype (JPA application)
32: internal -> spring-osgi-bundle-archetype (Spring-OSGi archetype)
33: internal -> confluence-plugin-archetype (Atlassian Confluence plugin archetype)
34: internal -> maven-archetype-har (Hibernate Archive)
35: internal -> maven-archetype-sar (JBoss Service Archive)
36: internal -> wicket-archetype-quickstart (A simple Apache Wicket project)
- package com.test.dbtest;
-
- import java.sql.CallableStatement;
- import java.sql.Connection;
- import java.sql.DriverManager;
- import java.sql.ResultSet;
- import java.sql.SQLException;
- import java.sql.Statement;
-
- /**Jdbc 连接 Oracle 数据库 简单示例
- *@author wanggq
- *@version 创建时间:2014年3月31日 上午11:00:06
- *类说明
- */
- public class TestO_procedure01 {
-
- public static void main(String[] args) {
- String driver = "oracle.jdbc.driver.OracleDriver";
- String url = "jdbc:Oracle:thin:@localhost:1521:orcl";
- Statement stmt = null;
- ResultSet res = null;
- Connection conn = null;
- CallableStatement proc = null;
- String sql = " select T.REC_NO, T.AIRLINE,T.DEPARTURE,T.ARRIVAL from CDP_MAIN_ORDER t where t.departure=upper('pek')";
-
- try {
- Class.forName(driver);
- conn = DriverManager.getConnection(url, "abc123", "abc123");
- stmt = conn.createStatement();
- res = stmt.executeQuery(sql);
- while(res.next())
- {
- String rec = res.getString("REC_NO");
- String airline = res.getString("AIRLINE");
- String dept = res.getString("DEPARTURE");
- String arr = res.getString("ARRIVAL");
- System.out.println(rec+" "+airline+" "+dept+" "+arr);
- }
-
- } catch (ClassNotFoundException e) {
- // TODO Auto-generated catch block
- e.printStackTrace();
- } catch (SQLException e) {
- // TODO Auto-generated catch block
- e.printStackTrace();
- }
-
-
-
-
- }
-
- }
也可以使用防止SQL注入PreparedStatement方法 - PreparedStatement stmt = null;
- ResultSet res = null;
- Connection conn = null;
- CallableStatement proc = null;
- String sql = " select T.REC_NO, T.AIRLINE,T.DEPARTURE,T.ARRIVAL from CDP_MAIN_ORDER t where t.departure=upper(?)";
-
- try {
- Class.forName(driver);
- conn = DriverManager.getConnection(url, "abc123", "abc123");
- stmt = conn.prepareStatement(sql);
- stmt.setString(1, "pek");
- res = stmt.executeQuery();
摘要: 在windows系统中,windows提供了计划任务这一功能,在控制面板 -> 性能与维护 -> 任务计划, 它的功能就是安排自动运行的任务。 通过'添加任务计划'的一步步引导,则可建立一个定时执行的任务。在linux系统中你可能已经发现了为什么系统常常会自动的进行一些任务?这些任务到底是谁在支配他们工作的?在linux系统如... 阅读全文
我在上传些代码的时候,有时候会遇到“git did not exit cleanly (exit code 128)”错误。通常都是网络原因。 找了网上解决的方法: 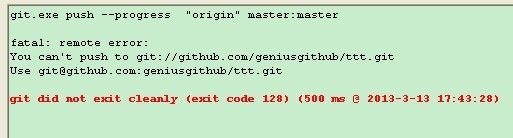
1、鼠标右键 -> TortoiseGit -> Settings -> Network 2、SSH client was pointing to C:\Program Files\TortoiseGit\bin\TortoisePlink.exe 3、Changed path to C:\Program Files (x86)\Git\bin\ssh.exe
jstack用于打印出给定的java进程ID或core file或远程调试服务的Java堆栈信息,如果是在64位机器上,需要指定选项"-J-d64",Windows的jstack使用方式只支持以下的这种方式:
jstack [-l][F] pid
如果java程序崩溃生成core文件,jstack工具可以用来获得core文件的java stack和native stack的信息,从而可以轻松地知道java程序是如何崩溃和在程序何处发生问题。另外,jstack工具还可以附属到正在运行的java程序中,看到当时运行的java程序的java stack和native stack的信息, 如果现在运行的java程序呈现hung的状态,jstack是非常有用的。进程处于hung死状态可以用-F强制打出stack。
dump 文件里,值得关注的线程状态有:
死锁,Deadlock(重点关注)
执行中,Runnable
等待资源,Waiting on condition(重点关注)
等待获取监视器,Waiting on monitor entry(重点关注)
暂停,Suspended
对象等待中,Object.wait() 或 TIMED_WAITING
阻塞,Blocked(重点关注)
停止,Parked 在摘了另一篇博客的三种场景: 实例一:Waiting to lock 和 Blocked "RMI TCP Connection(267865)-172.16.5.25" daemon prio=10 tid=0x00007fd508371000 nid=0x55ae waiting for monitor entry [0x00007fd4f8684000] java.lang.Thread.State: BLOCKED (on object monitor) at org.apache.log4j.Category.callAppenders(Category.java:201) - waiting to lock <0x00000000acf4d0c0> (a org.apache.log4j.Logger) at org.apache.log4j.Category.forcedLog(Category.java:388) at org.apache.log4j.Category.log(Category.java:853) at org.apache.commons.logging.impl.Log4JLogger.warn(Log4JLogger.java:234) at com.tuan.core.common.lang.cache.remote.SpyMemcachedClient.get(SpyMemcachedClient.java:110) 说明:
1)线程状态是 Blocked,阻塞状态。说明线程等待资源超时!
2)“ waiting to lock <0x00000000acf4d0c0>”指,线程在等待给这个 0x00000000acf4d0c0 地址上锁(英文可描述为:trying to obtain 0x00000000acf4d0c0 lock)。
3)在 dump 日志里查找字符串 0x00000000acf4d0c0,发现有大量线程都在等待给这个地址上锁。如果能在日志里找到谁获得了这个锁(如locked < 0x00000000acf4d0c0 >),就可以顺藤摸瓜了。
4)“waiting for monitor entry”说明此线程通过 synchronized(obj) {……} 申请进入了临界区,从而进入了下图1中的“Entry Set”队列,但该 obj 对应的 monitor 被其他线程拥有,所以本线程在 Entry Set 队列中等待。
5)第一行里,"RMI TCP Connection(267865)-172.16.5.25"是 Thread Name 。tid指Java Thread id。nid指native线程的id。prio是线程优先级。[0x00007fd4f8684000]是线程栈起始地址。
实例二:Waiting on condition 和 TIMED_WAITING "RMI TCP Connection(idle)" daemon prio=10 tid=0x00007fd50834e800 nid=0x56b2 waiting on condition [0x00007fd4f1a59000] java.lang.Thread.State: TIMED_WAITING (parking) at sun.misc.Unsafe.park(Native Method) - parking to wait for <0x00000000acd84de8> (a java.util.concurrent.SynchronousQueue$TransferStack) at java.util.concurrent.locks.LockSupport.parkNanos(LockSupport.java:198) at java.util.concurrent.SynchronousQueue$TransferStack.awaitFulfill(SynchronousQueue.java:424) at java.util.concurrent.SynchronousQueue$TransferStack.transfer(SynchronousQueue.java:323) at java.util.concurrent.SynchronousQueue.poll(SynchronousQueue.java:874) at java.util.concurrent.ThreadPoolExecutor.getTask(ThreadPoolExecutor.java:945) at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:907) at java.lang.Thread.run(Thread.java:662) 说明: 1)“TIMED_WAITING (parking)”中的 timed_waiting 指等待状态,但这里指定了时间,到达指定的时间后自动退出等待状态;parking指线程处于挂起中。
2)“waiting on condition”需要与堆栈中的“parking to wait for <0x00000000acd84de8> (a java.util.concurrent.SynchronousQueue$TransferStack)”结合来看。首先,本线程肯定是在等待某个条件的发生,来把自己唤醒。其次,SynchronousQueue 并不是一个队列,只是线程之间移交信息的机制,当我们把一个元素放入到 SynchronousQueue 中时必须有另一个线程正在等待接受移交的任务,因此这就是本线程在等待的条件。
3)别的就看不出来了。
实例三:in Obejct.wait() 和 TIMED_WAITING "RMI RenewClean-[172.16.5.19:28475]" daemon prio=10 tid=0x0000000041428800 nid=0xb09 in Object.wait() [0x00007f34f4bd0000] java.lang.Thread.State: TIMED_WAITING (on object monitor) at java.lang.Object.wait(Native Method) - waiting on <0x00000000aa672478> (a java.lang.ref.ReferenceQueue$Lock) at java.lang.ref.ReferenceQueue.remove(ReferenceQueue.java:118) - locked <0x00000000aa672478> (a java.lang.ref.ReferenceQueue$Lock) at sun.rmi.transport.DGCClient$EndpointEntry$RenewCleanThread.run(DGCClient.java:516) at java.lang.Thread.run(Thread.java:662) 说明: 1)“TIMED_WAITING (on object monitor)”,对于本例而言,是因为本线程调用了 java.lang.Object.wait(long timeout) 而进入等待状态。 2)“Wait Set”中等待的线程状态就是“ in Object.wait() ”。当线程获得了 Monitor,进入了临界区之后,如果发现线程继续运行的条件没有满足,它则调用对象(一般就是被 synchronized 的对象)的 wait() 方法,放弃了 Monitor,进入 “Wait Set”队列。只有当别的线程在该对象上调用了 notify() 或者 notifyAll() ,“ Wait Set”队列中线程才得到机会去竞争,但是只有一个线程获得对象的 Monitor,恢复到运行态。
3)RMI RenewClean 是 DGCClient 的一部分。DGC 指的是 Distributed GC,即分布式垃圾回收。
4)请注意,是先 locked <0x00000000aa672478>,后 waiting on <0x00000000aa672478>,之所以先锁再等同一个对象,请看下面它的代码实现:
static private class Lock { };
private Lock lock = new Lock();
public Reference<? extends T> remove(long timeout)
{
synchronized (lock) {
Reference<? extends T> r = reallyPoll();
if (r != null) return r;
for (;;) {
lock.wait(timeout);
r = reallyPoll();
……
}
}
即,线程的执行中,先用 synchronized 获得了这个对象的 Monitor(对应于 locked <0x00000000aa672478> );当执行到 lock.wait(timeout);,线程就放弃了 Monitor 的所有权,进入“Wait Set”队列(对应于 waiting on <0x00000000aa672478> )。
5)从堆栈信息看,是正在清理 remote references to remote objects ,引用的租约到了,分布式垃圾回收在逐一清理呢。 参考: 命令汇总:http://blog.csdn.net/fenglibing/article/details/6411940
三种实例:http://www.cnblogs.com/zhengyun_ustc/archive/2013/01/06/dumpanalysis.html
1. 如何加大tomcat连接数
在tomcat配置文件server.xml中的<Connector ... />配置中,和连接数相关的参数有:
maxThreads : tomcat起动的最大线程数,即同时处理的任务个数,默认值为200。
minProcessors:最小空闲连接线程数,用于提高系统处理性能,默认值为10 。
maxProcessors:最大连接线程数,即:并发处理的最大请求数,默认值为75 。
acceptCount: 当tomcat起动的线程数达到最大时,接受排队的请求个数,默认值为100。
minSpareThreads :Tomcat初始化时创建的线程数。
maxSpareThreads :一旦创建的线程超过这个值,Tomcat就会关闭不再需要的socket线程。
enableLookups:是否反查域名,取值为:true或false。 缺省值为false,表示使用客户端主机名的DNS解析功能,被ServletRequest.getRemoteHost方法调用。
connectionTimeout:网络连接超时,单位:毫秒。设置为0表示永不超时,这样设置有隐患的。通常可设置为30000毫秒。
其中和最大连接数相关的参数为maxProcessors和acceptCount。如果要加大并发连接数,应同时加大这两个参数。
web server允许的最大连接数还受制于操作系统的内核参数设置,通常Windows是2000个左右,Linux是1000个左右。
Unix中如何设置这些参数,请参阅Unix常用监控和管理命令
tomcat5中的配置示例:
<Connector port="8090" maxHttpHeaderSize="8169" maxThreads="1000" minSpareThreads="75" maxSpareThreads="300" enableLookups="false" redirectPort="8649" acceptCount="100" connectionTimeout="50000" disableUploadTimeout="true" URIEncoding="GBK"/>
<Connector className="org.apache.coyote.tomcat4.CoyoteConnector" port="8080" minProcessors="10" maxProcessors="1024" enableLookups="false" redirectPort="8443" acceptCount="1024" debug="0" connectionTimeout="30000" />
对于其他端口的侦听配置,以此类推。
2. tomcat中如何禁止列目录下的文件
在{tomcat_home}/conf/web.xml中,把listings参数设置成false即可,如下:
<servlet> ... <init-param> <param-name>listings</param-name> <param-value>false</param-value> </init-param> ... </servlet>
3. 如何加大tomcat可以使用的内存
tomcat默认可以使用的内存为128MB,在较大型的应用项目中,这点内存是不够的,需要调大。
Unix下,在文件{tomcat_home}/bin/catalina.sh的前面,增加如下设置:
JAVA_OPTS='-Xms【初始化内存大小】 -Xmx【可以使用的最大内存】' 需要把这个两个参数值调大。
例如: JAVA_OPTS='-Xms256m -Xmx512m' 表示初始化内存为256MB,可以使用的最大内存为512MB 。
export JAVA_HOME='/home/ftpuser/xjSheetHome/java/jdk1.5.0_22/'
JAVA_OPTS="-Xms1500m -Xmx1500m -Xss1024K -XX:PermSize=128m -XX:MaxPermSize=256m -Dfile.encoding=GBK"
参数说明:
-Xms 是指设定程序启动时占用内存大小。一般来讲,大点,程序会启动的 快一点,但是也可能会导致机器暂时间变慢。
-Xmx 是指设定程序运行期间最大可占用的内存大小。如果程序运行需要占 用更多的内存,超出了这个设置值,就会抛出OutOfMemory 异常。
-Xss 是指设定每个线程的堆栈大小。这个就要依据你的程序,看一个线程 大约需要占用多少内存,可能会有多少线程同时运行等。
-XX:PermSize设置非堆内存初始值,默认是物理内存的1/64 。
-XX:MaxPermSize设置最大非堆内存的大小,默认是物理内存的1/4。
<Context path="/Sheet" defaultSessionTimeOut="3600" docBase="/home/user/Sheet" >
<Resource name="jdbc/app" auth="Container"
type="javax.sql.DataSource"
username="SHEET" password="SHEET"
driverClassName="oracle.jdbc.driver.OracleDriver"
url="jdbc:oracle:thin:@136.24.248.106:1521:kf"
maxActive="1000" maxIdle="75"/>
<ResourceLink name="UserTransaction"
global="UserTransaction"
type="javax.transaction.UserTransaction"/>
</Context>
参数说明:
defaultSessionTimeOut:设置会话时间 单位为秒
maxActive : 连接池的最大数据库连接数。设为0表示无限制。
maxIdle :可以同时闲置在连接池中的连接的最大数
maxWait : 最大超时时间,以毫秒计
摘要: 首先先介绍一款知名的网站压力测试工具:webbench.
Webbench能测试处在相同硬件上,不同服务的性能以及不同硬件上同一个服务的运行状况。webbench的标准测试可以向我们展示服务器的两项内容:每分钟相应请求数和每秒钟传输数据量。webbench不但能具有便准静态页面的测试能力,还能对动态页面(ASP,PHP,JAVA,CGI)进 行测试的能力。还有就是他支持对含有SSL的安全网站例如... 阅读全文
1.内存设置(VM参数调优)
(1). Windows环境下,是tomcat解压版(执行startup.bat启动tomcat) ,解决办法:
修改“%TOMCAT_HOME%\bin\catalina.bat”文件,在文件开头增加如下设置:
set JAVA_OPTS=-Xms512m -Xmx512m -XX:PermSize=128M -XX:MaxNewSize=256m -XX:MaxPermSize=512m
备注:一定加在catalina.bat最前面。
(2). Windows环境下,是tomcat安装版(利用windows的系统服务启动tomcat),解决办法:
修改注册表HKEY_LOCAL_MACHINE\SOFTWARE\Apache Software Foundation\Procrun 2.0\Tomcat6\Parameters\JavaOptions
原值为:
-Dcatalina.home=E:\Tomcat 6.0
-Dcatalina.base=E:\Tomcat 6.0
-Djava.endorsed.dirs=E:\Tomcat 6.0\common\endorsed
-Djava.io.tmpdir=E:\Tomcat 6.0\temp
-Djava.util.logging.manager=org.apache.juli.ClassLoaderLogManager
-Djava.util.logging.config.file=E:\Tomcat 6.0\conf\logging.properties
加入:
Xms512m -Xmx512m -XX:PermSize=128M -XX:MaxNewSize=256m -XX:MaxPermSize=512m
重起tomcat服务,设置生效。
(3). Linux环境下, ,解决办法:
修改“%TOMCAT_HOME%\bin\catalina.sh”文件,在文件开头增加如下设置:JAVA_OPTS=’-Xms256m -Xmx512m’
各参数详解:
-Xms:设置JVM初始内存大小(默认是物理内存的1/64)
-Xmx:设置JVM可以使用的最大内存(默认是物理内存的1/4,建议:物理内存80%)
-Xmn:设置JVM最小内存(128-256m就够了,一般不设置)
默认空余堆内存小于 40%时,JVM就会增大堆直到-Xmx的最大限制;空余堆内存大于70%时,JVM会减少堆直到-Xms的最小限制。因此服务器一般设置-Xms、 -Xmx相等以避免在每次GC 后调整堆的大小。
在较大型的应用项目中,默认的内存是不够的,有可能导致系统无法运行。常见的问题是报Tomcat内存溢出错误“java.lang.OutOfMemoryError: Java heap space”,从而导致客户端显示500错误。
-XX:PermSize :为JVM启动时Perm的内存大小
-XX:MaxPermSize :为最大可占用的Perm内存大小(默认为32M)
-XX:MaxNewSize,默认为16M
PermGen space的全称是Permanent Generation space,是指内存的永久保存区域,这块内存主要是被JVM存放Class和Meta信息的,Class在被Loader时就会被放到PermGen space中,它和存放类实例(Instance)的Heap区域不同,GC(Garbage Collection)不会在主程序运行期对PermGen space进行清理,所以如果你的应用中有很CLASS的话,就很可能出现“java.lang.OutOfMemoryError: PermGen space”错误。
对于WEB项目,jvm加载类时,永久域中的对象急剧增加,从而使jvm不断调整永久域大小,为了避免调整),你可以使用更多的参数配置。如果你的WEB APP下都用了大量的第三方jar, 其大小超过了jvm默认的大小,那么就会产生此错误信息了。
其它参数:
-XX:NewSize :默认为2M,此值设大可调大新对象区,减少Full GC次数
-XX:NewRatio :改变新旧空间的比例,意思是新空间的尺寸是旧空间的1/8(默认为8)
-XX:SurvivorRatio :改变Eden对象空间和残存空间的尺寸比例,意思是Eden对象空
间的尺寸比残存空间大survivorRatio+2倍(缺省值是10)
-XX:userParNewGC 可用来设置并行收集【多CPU】
-XX:ParallelGCThreads 可用来增加并行度【多CPU】
-XXUseParallelGC 设置后可以使用并行清除收集器【多CPU】
2.修改tomcat让其支持NIO
修改前:
protocol="HTTP/1.1" connectionTimeout="20000" redirectPort="8443"/>
修改成支持NIO的类型,配置如下 :
protocol="org.apache.coyote.http11.Http11NioProtocol " connectionTimeout="20000" redirectPort="8443" />
3.并发数设置
默认的tomcat配置,并发测试时,可能30个USER上去就当机了。
添加
maxThreads="600" //最大线程数
minSpareThreads="100" //初始化时创建的线程数
maxSpareThreads="500" //一旦线程超过这个值,Tomcat会关闭不需要的socket线程
acceptCount="700"//指定当所有可以使用的处理请求的线程数都被使用时,可以放到
处理队列中的请求数,超过这个数的请求将不予处理
connectionTimeout="20000"
redirectPort="8443" />
或者
name="tomcatThreadPool" namePrefix="catalina-exec-" maxThreads="500" minSpareThreads="400" />
executor="tomcatThreadPool" port="80" protocol="HTTP/1.1" connectionTimeout="20000" enableLookups="false"
redirectPort="8443" URIEncoding="UTF-8" acceptCount="1000" />
4.Java虚拟机调优
应该选择SUN的JVM,在满足项目需要的前提下,尽量选用版本较高的JVM,一般来说高版本产品在速度和效率上比低版本会有改进。 JDK1.4比JDK1.3性能提高了近10%-20%,JDK1.5比JDK1.4性能提高25%-75%。
5.禁用DNS查询
设置enableLookups="false":
enableLookups="false" redirectPort="8443" URIEncoding="UTF-8" acceptCount="1000" />
当web应用程序向要记录客户端的信息时,它也会记录客户端的IP地址或者通过域名服务器查找机器名转换为IP地址。DNS查询需要占用网络,并且包括可能从很多很远的服务器或者不起作用的服务器上去获取对应的IP的过程,这样会消耗一定的时间。为了消除DNS查询对性能的影响我们可以关闭 DNS查询,方式是修改server.xml文件中的enableLookups参数值为false。
6.设置解决乱码问题
URIEncoding="UTF-8" acceptCount="1000" />
二、TOMCAT内存监控
1.设置tomcat的perm size:

2.开启监控
在命令行输入jconsole,在弹出窗口中建立本地端口监控,如下图:
 
使用安装版Tomcat 6.0 ,打开tomcat界面选择java这一项,在java options:
加入
- -Djava.rmi.server.hostname=127.0.0.1
- -Dcom.sun.management.jmxremote.port=8088
- -Dcom.sun.management.jmxremote.ssl=false
- -Dcom.sun.management.jmxremote.authenticate=false
- -Djava.rmi.server.hostname=127.0.0.1
- -Dcom.sun.management.jmxremote.port=8088
- -Dcom.sun.management.jmxremote.ssl=false
- -Dcom.sun.management.jmxremote.authenticate=false
使用jconsole 127.0.0.1:8088可以连接成功,也能看到jvm运行情况,
但此时访问已经部署的应用,却提示“无法显示网页”
今天又研究了一会,猜想了一下是不是这个端口独占的,不能和应用冲突,把Dcom.sun.management.jmxremote.port=8088 改为80, 重启tomcat 果然,应用可以访问。之后去网上看来些相关信息,确实为两个端口,不能占用。
摘要: JDK本身提供了很多方便的JVM性能调优监控工具,除了集成式的VisualVM和jConsole外,还有jps、jstack、jmap、jhat、jstat等小巧的工具,本博客希望能起抛砖引玉之用,让大家能开始对JVM性能调优的常用工具有所了解。 现实企业级Java开发中,有时候我们会碰到下面这些问题:OutOfMemoryError,内存不足内存泄露线程死锁锁争用(Lo... 阅读全文
首先我们先介绍一下为什么要让 Apache 与 Tomcat 之间进行连接。事实上 Tomcat 本身已经提供了 HTTP 服务,该服务默认的端口是 8080,装好 tomcat 后通过 8080 端口可以直接使用 Tomcat 所运行的应用程序,你也可以将该端口改为 80。 既然 Tomcat 本身已经可以提供这样的服务,我们为什么还要引入 Apache 或者其他的一些专门的 HTTP 服务器呢?原因有下面几个: 1. 提升对静态文件的处理性能 2. 利用 Web 服务器来做负载均衡以及容错 3. 无缝的升级应用程序 这三点对一个 web 网站来说是非常之重要的,我们希望我们的网站不仅是速度快,而且要稳定,不能因为某个 Tomcat 宕机或者是升级程序导致用户访问不了,而能完成这几个功能的、最好的 HTTP 服务器也就只有 apache 的 http server 了,它跟 tomcat 的结合是最紧密和可靠的。 接下来我们介绍三种方法将 apache 和 tomcat 整合在一起。 JK这是最常见的方式,你可以在网上找到很多关于配置JK的网页,当然最全的还是其官方所提供的文档。JK 本身有两个版本分别是 1 和 2,目前 1 最新的版本是 1.2.19,而版本 2 早已经废弃了,以后不再有新版本的推出了,所以建议你采用版本 1。 JK 是通过 AJP 协议与 Tomcat 服务器进行通讯的,Tomcat 默认的 AJP Connector 的端口是 8009。JK 本身提供了一个监控以及管理的页面 jkstatus,通过 jkstatus 可以监控 JK 目前的工作状态以及对到 tomcat 的连接进行设置,如下图所示: 图 1:监控以及管理的页面 jkstatus 在这个图中我们可以看到当前JK配了两个连接分别到 8109 和 8209 端口上,目前 s2 这个连接是停止状态,而 s1 这个连接自上次重启后已经处理了 47 万多个请求,流量达到 6.2 个 G,最大的并发数有 13 等等。我们也可以利用 jkstatus 的管理功能来切换 JK 到不同的 Tomcat 上,例如将 s2 启用,并停用 s1,这个在更新应用程序的时候非常有用,而且整个切换过程对用户来说是透明的,也就达到了无缝升级的目的。关于 JK 的配置文章网上已经非常多了,这里我们不再详细的介绍整个配置过程,但我要讲一下配置的思路,只要明白了配置的思路,JK 就是一个非常灵活的组件。 JK 的配置最关键的有三个文件,分别是 httpd.conf
Apache 服务器的配置文件,用来加载 JK 模块以及指定 JK 配置文件信息 workers.properties
到 Tomcat 服务器的连接定义文件 uriworkermap.properties
URI 映射文件,用来指定哪些 URL 由 Tomcat 处理,你也可以直接在 httpd.conf 中配置这些 URI,但是独立这些配置的好处是 JK 模块会定期更新该文件的内容,使得我们修改配置的时候无需重新启动 Apache 服务器。 其中第二、三个配置文件名都可以自定义。下面是一个典型的 httpd.conf 对 JK 的配置 # (httpd.conf) # 加载 mod_jk 模块 LoadModule jk_module modules/mod_jk.so # # Configure mod_jk # JkWorkersFile conf/workers.properties JkMountFile conf/uriworkermap.properties JkLogFile logs/mod_jk.log JkLogLevel warn
接下来我们在 Apache 的 conf 目录下新建两个文件分别是 workers.properties、uriworkermap.properties。这两个文件的内容大概如下 # # workers.properties # # list the workers by name worker.list=DLOG4J, status # localhost server 1 # ------------------------ worker.s1.port=8109 worker.s1.host=localhost worker.s1.type=ajp13 # localhost server 2 # ------------------------ worker.s2.port=8209 worker.s2.host=localhost worker.s2.type=ajp13 worker.s2.stopped=1 worker.DLOG4J.type=lb worker.retries=3 worker.DLOG4J.balanced_workers=s1, s2 worker.DLOG4J.sticky_session=1 worker.status.type=status
以上的 workers.properties 配置就是我们前面那个屏幕抓图的页面所用的配置。首先我们配置了两个类型为 ajp13 的 worker 分别是 s1 和 s2,它们指向同一台服务器上运行在两个不同端口 8109 和 8209 的 Tomcat 上。接下来我们配置了一个类型为 lb(也就是负载均衡的意思)的 worker,它的名字是 DLOG4J,这是一个逻辑的 worker,它用来管理前面配置的两个物理连接 s1 和 s2。最后还配置了一个类型为 status 的 worker,这是用来监控 JK 本身的模块。有了这三个 worker 还不够,我们还需要告诉 JK,哪些 worker 是可用的,所以就有 worker.list = DLOG4J, status 这行配置。 接下来便是 URI 的映射配置了,我们需要指定哪些链接是由 Tomcat 处理的,哪些是由 Apache 直接处理的,看看下面这个文件你就能明白其中配置的意义 /*=DLOG4J /jkstatus=status !/*.gif=DLOG4J !/*.jpg=DLOG4J !/*.png=DLOG4J !/*.css=DLOG4J !/*.js=DLOG4J !/*.htm=DLOG4J !/*.html=DLOG4J
相信你已经明白了一大半了:所有的请求都由 DLOG4J 这个 worker 进行处理,但是有几个例外,/jkstatus 请求由 status 这个 worker 处理。另外这个配置中每一行数据前面的感叹号是什么意思呢?感叹号表示接下来的 URI 不要由 JK 进行处理,也就是 Apache 直接处理所有的图片、css 文件、js 文件以及静态 html 文本文件。 通过对 workers.properties 和 uriworkermap.properties 的配置,可以有各种各样的组合来满足我们前面提出对一个 web 网站的要求。您不妨动手试试! 回页首 http_proxy这是利用 Apache 自带的 mod_proxy 模块使用代理技术来连接 Tomcat。在配置之前请确保是否使用的是 2.2.x 版本的 Apache 服务器。因为 2.2.x 版本对这个模块进行了重写,大大的增强了其功能和稳定性。 http_proxy 模式是基于 HTTP 协议的代理,因此它要求 Tomcat 必须提供 HTTP 服务,也就是说必须启用 Tomcat 的 HTTP Connector。一个最简单的配置如下 ProxyPass /images ! ProxyPass /css ! ProxyPass /js ! ProxyPass / http://localhost:8080/
在这个配置中,我们把所有 http://localhost 的请求代理到 http://localhost:8080/ ,这也就是 Tomcat 的访问地址,除了 images、css、js 几个目录除外。我们同样可以利用 mod_proxy 来做负载均衡,再看看下面这个配置 ProxyPass /images ! ProxyPass /css ! ProxyPass /js ! ProxyPass / balancer://example/ <Proxy balancer://example/> BalancerMember http://server1:8080/ BalancerMember http://server2:8080/ BalancerMember http://server3:8080/ </Proxy>
配置比 JK 简单多了,而且它也可以通过一个页面来监控集群运行的状态,并做一些简单的维护设置。 图 2:监控集群运行状态 回页首 ajp_proxyajp_proxy 连接方式其实跟 http_proxy 方式一样,都是由 mod_proxy 所提供的功能。配置也是一样,只需要把 http:// 换成 ajp:// ,同时连接的是 Tomcat 的 AJP Connector 所在的端口。上面例子的配置可以改为: ProxyPass /images ! ProxyPass /css ! ProxyPass /js ! ProxyPass / balancer://example/ <Proxy balancer://example/> BalancerMember ajp://server1:8080/ BalancerMember ajp://server2:8080/ BalancerMember ajp://server3:8080/ </Proxy>
采用 proxy 的连接方式,需要在 Apache 上加载所需的模块,mod_proxy 相关的模块有 mod_proxy.so、mod_proxy_connect.so、mod_proxy_http.so、mod_proxy_ftp.so、mod_proxy_ajp.so, 其中 mod_proxy_ajp.so 只在 Apache 2.2.x 中才有。如果是采用 http_proxy 方式则需要加载 mod_proxy.so 和 mod_proxy_http.so;如果是 ajp_proxy 则需要加载 mod_proxy.so 和 mod_proxy_ajp.so这两个模块。 回页首 三者比较相对于 JK 的连接方式,后两种在配置上是比较简单的,灵活性方面也一点都不逊色。但就稳定性而言就不像 JK 这样久经考验,毕竟 Apache 2.2.3 推出的时间并不长,采用这种连接方式的网站还不多,因此,如果是应用于关键的互联网网站,还是建议采用 JK 的连接方式。
有段时间没用maven了,最近使用maven下载jar包时速度缓慢,最初以为是自己网速的问题,后来确定是访问maven的central repository端速度缓慢。在网上找到了一个maven repository的中国镜像,速度相当不错。特此收藏。
<mirror>
<id>CN</id>
<name>OSChina Central</name>
<url>http://maven.oschina.net/content/groups/public/</url>
<mirrorOf>central</mirrorOf>
</mirror>
========================================================
OSChina Maven 库使用帮助
==================其他maven仓库镜像==========================
<mirror>
<id>repo2</id>
<mirrorOf>central</mirrorOf>
<name>Human Readable Name for this Mirror.</name>
<url>http://repo2.maven.org/maven2/</url>
</mirror>
<mirror>
<id>net-cn</id>
<mirrorOf>central</mirrorOf>
<name>Human Readable Name for this Mirror.</name>
<url>http://maven.net.cn/content/groups/public/</url>
</mirror>
<mirror>
<id>ui</id>
<mirrorOf>central</mirrorOf>
<name>Human Readable Name for this Mirror.</name>
<url>http://uk.maven.org/maven2/</url>
</mirror>
<mirror>
<id>ibiblio</id>
<mirrorOf>central</mirrorOf>
<name>Human Readable Name for this Mirror.</name>
<url>http://mirrors.ibiblio.org/pub/mirrors/maven2/</url>
</mirror>
<mirror>
<id>jboss-public-repository-group</id>
<mirrorOf>central</mirrorOf>
<name>JBoss Public Repository Group</name>
<url>http://repository.jboss.org/nexus/content/groups/public</url>
</mirror>
<mirror>
<id>JBossJBPM</id>
<mirrorOf>central</mirrorOf>
<name>JBossJBPM Repository</name>
<url>https://repository.jboss.org/nexus/content/repositories/releases/</url>
</mirror>
@import url(http://www.blogjava.net/CuteSoft_Client/CuteEditor/Load.ashx?type=style&file=SyntaxHighlighter.css);@import url(/css/cuteeditor.css);
ed2k://|file|%E4%BC%A0%E6%99%BA%E6%92%AD%E5%AE%A2PHP%E5%9F%B9%E8%AE%AD.%E7%AC%AC%E4%BA%8C%E7%89%88PHP%E8%A7%86%E9%A2%91%E6%95%99%E7%A8%8B.memcached%E6%95%99%E7%A8%8B%E7%AE%80%E4%BB%8B.doc|12288|21dd20b6b1698cde2d3a60558b9cebf5|h=pfwxrfmggemvtxc4p3vnzzzj55k7ynqm|/
ed2k://|file|%E4%BC%A0%E6%99%BA%E6%92%AD%E5%AE%A2PHP%E5%9F%B9%E8%AE%AD.%E7%AC%AC%E4%BA%8C%E7%89%88PHP%E8%A7%86%E9%A2%91%E6%95%99%E7%A8%8B.%E9%9F%A9%E9%A1%BA%E5%B9%B3.%E5%A4%A7%E5%9E%8B%E9%97%A8%E6%88%B7%E7%BD%91%E7%AB%99%E6%A0%B8%E5%BF%83%E6%8A%80%E6%9C%AF-memcachedPPT.zip|994215|2f01ba03d0d09dc44b4b4a1f608169eb|h=myt736l66y4p3ihfuvgaqweigjyjukpx|/
ed2k://|file|%E4%BC%A0%E6%99%BA%E6%92%AD%E5%AE%A2PHP%E5%9F%B9%E8%AE%AD.%E7%AC%AC%E4%BA%8C%E7%89%88PHP%E8%A7%86%E9%A2%91%E6%95%99%E7%A8%8B.%E9%9F%A9%E9%A1%BA%E5%B9%B3.%E5%A4%A7%E5%9E%8B%E9%97%A8%E6%88%B7%E7%BD%91%E7%AB%99%E6%A0%B8%E5%BF%83%E6%8A%80%E6%9C%AF-memcached%E6%BA%90%E7%A0%81.zip|10172|6cc7b73dae59c1d8a7eb18706f8fc7b9|h=5xsecbbhavpglk7yczwvvt2dlhfolete|/
ed2k://|file|%E4%BC%A0%E6%99%BA%E6%92%AD%E5%AE%A2PHP%E5%9F%B9%E8%AE%AD.%E7%AC%AC%E4%BA%8C%E7%89%88PHP%E8%A7%86%E9%A2%91%E6%95%99%E7%A8%8B.%E9%9F%A9%E9%A1%BA%E5%B9%B3.%E5%A4%A7%E5%9E%8B%E9%97%A8%E6%88%B7%E7%BD%91%E7%AB%99%E6%A0%B8%E5%BF%83%E6%8A%80%E6%9C%AF-memcached.%E7%AC%94%E8%AE%B0.zip|328142|6552298f2cc63604b6f7fa873a417869|h=gg3beg7xxtnqoqjbxd3feqdui4axabt6|/
ed2k://|file|%E4%BC%A0%E6%99%BA%E6%92%AD%E5%AE%A2PHP%E5%9F%B9%E8%AE%AD.%E7%AC%AC%E4%BA%8C%E7%89%88PHP%E8%A7%86%E9%A2%91%E6%95%99%E7%A8%8B.%E9%9F%A9%E9%A1%BA%E5%B9%B3.%E5%A4%A7%E5%9E%8B%E9%97%A8%E6%88%B7%E7%BD%91%E7%AB%99%E6%A0%B8%E5%BF%83%E6%8A%80%E6%9C%AF-memcached.%E8%BD%AF%E4%BB%B6%E8%B5%84%E6%96%99.zip|33458096|871b67a5634c9a2caf8d1dd937160df0|h=6epszrrx4vfhnvpmtkzwf5qgux7437gx|/
ed2k://|file|%E4%BC%A0%E6%99%BA%E6%92%AD%E5%AE%A2PHP%E5%9F%B9%E8%AE%AD.%E7%AC%AC%E4%BA%8C%E7%89%88PHP%E8%A7%86%E9%A2%91%E6%95%99%E7%A8%8B.%E9%9F%A9%E9%A1%BA%E5%B9%B3.%E5%A4%A7%E5%9E%8B%E9%97%A8%E6%88%B7%E7%BD%91%E7%AB%99%E6%A0%B8%E5%BF%83%E6%8A%80%E6%9C%AF-memcached01.%E5%8E%9F%E7%90%86%E4%BB%8B%E7%BB%8D.wmv|33671725|93565e481da4e7f8002d2b11910fa00c|h=tx27z622spyvpmvnwi5jnmkoswibfokx|/
ed2k://|file|%E4%BC%A0%E6%99%BA%E6%92%AD%E5%AE%A2PHP%E5%9F%B9%E8%AE%AD.%E7%AC%AC%E4%BA%8C%E7%89%88PHP%E8%A7%86%E9%A2%91%E6%95%99%E7%A8%8B.%E9%9F%A9%E9%A1%BA%E5%B9%B3.%E5%A4%A7%E5%9E%8B%E9%97%A8%E6%88%B7%E7%BD%91%E7%AB%99%E6%A0%B8%E5%BF%83%E6%8A%80%E6%9C%AF-memcached02.%E5%AE%89%E8%A3%85%E6%BC%94%E7%A4%BA.wmv|21819537|ac9f25585c528c75bcc34a84c52d343e|h=vn35qfid546gkrgb5g4xl6p7ciicbm4x|/
ed2k://|file|%E4%BC%A0%E6%99%BA%E6%92%AD%E5%AE%A2PHP%E5%9F%B9%E8%AE%AD.%E7%AC%AC%E4%BA%8C%E7%89%88PHP%E8%A7%86%E9%A2%91%E6%95%99%E7%A8%8B.%E9%9F%A9%E9%A1%BA%E5%B9%B3.%E5%A4%A7%E5%9E%8B%E9%97%A8%E6%88%B7%E7%BD%91%E7%AB%99%E6%A0%B8%E5%BF%83%E6%8A%80%E6%9C%AF-memcached03.telnet%E6%93%8D%E4%BD%9Cmemcached.wmv|56558957|c955905ad064cc0b6f0a56b162045148|h=5ia2w2joekfwrdopy2kst64ijv6gmae6|/
ed2k://|file|%E4%BC%A0%E6%99%BA%E6%92%AD%E5%AE%A2PHP%E5%9F%B9%E8%AE%AD.%E7%AC%AC%E4%BA%8C%E7%89%88PHP%E8%A7%86%E9%A2%91%E6%95%99%E7%A8%8B.%E9%9F%A9%E9%A1%BA%E5%B9%B3.%E5%A4%A7%E5%9E%8B%E9%97%A8%E6%88%B7%E7%BD%91%E7%AB%99%E6%A0%B8%E5%BF%83%E6%8A%80%E6%9C%AF-memcached04.PHP%E6%93%8D%E4%BD%9Cmemcached%28%E4%B8%80%29.wmv|52222153|5a1db437311f8061417794641d30606c|h=x3vxrnxv6dmcyqu5se2gk7eforpfcl5y|/
ed2k://|file|%E4%BC%A0%E6%99%BA%E6%92%AD%E5%AE%A2PHP%E5%9F%B9%E8%AE%AD.%E7%AC%AC%E4%BA%8C%E7%89%88PHP%E8%A7%86%E9%A2%91%E6%95%99%E7%A8%8B.%E9%9F%A9%E9%A1%BA%E5%B9%B3.%E5%A4%A7%E5%9E%8B%E9%97%A8%E6%88%B7%E7%BD%91%E7%AB%99%E6%A0%B8%E5%BF%83%E6%8A%80%E6%9C%AF-memcached05.PHP%E6%93%8D%E4%BD%9Cmemcached%28%E4%BA%8C%29.wmv|40405343|a8969de7049006e9285caa2f70ca2387|h=rosywm4vfzjbijf7hgckirxbzouzrypf|/
ed2k://|file|%E4%BC%A0%E6%99%BA%E6%92%AD%E5%AE%A2PHP%E5%9F%B9%E8%AE%AD.%E7%AC%AC%E4%BA%8C%E7%89%88PHP%E8%A7%86%E9%A2%91%E6%95%99%E7%A8%8B.%E9%9F%A9%E9%A1%BA%E5%B9%B3.%E5%A4%A7%E5%9E%8B%E9%97%A8%E6%88%B7%E7%BD%91%E7%AB%99%E6%A0%B8%E5%BF%83%E6%8A%80%E6%9C%AF-memcached06.PHP%E6%93%8D%E4%BD%9Cmemcached%28%E4%B8%89%29.wmv|40067193|ca146dd6ac27220c9069d45cf75908ac|h=vie3pw4vghyw6vkxkffabc62avzjqazt|/
ed2k://|file|%E4%BC%A0%E6%99%BA%E6%92%AD%E5%AE%A2PHP%E5%9F%B9%E8%AE%AD.%E7%AC%AC%E4%BA%8C%E7%89%88PHP%E8%A7%86%E9%A2%91%E6%95%99%E7%A8%8B.%E9%9F%A9%E9%A1%BA%E5%B9%B3.%E5%A4%A7%E5%9E%8B%E9%97%A8%E6%88%B7%E7%BD%91%E7%AB%99%E6%A0%B8%E5%BF%83%E6%8A%80%E6%9C%AF-memcached07.PHP%E6%93%8D%E4%BD%9Cmemcached%28%E5%9B%9B%29.wmv|40067193|7b7f2b1adc84890c86a11ce9c9616356|h=mfonhchuvmklq4yiy7x522d4knnf2o7q|/
ed2k://|file|%E4%BC%A0%E6%99%BA%E6%92%AD%E5%AE%A2PHP%E5%9F%B9%E8%AE%AD.%E7%AC%AC%E4%BA%8C%E7%89%88PHP%E8%A7%86%E9%A2%91%E6%95%99%E7%A8%8B.%E9%9F%A9%E9%A1%BA%E5%B9%B3.%E5%A4%A7%E5%9E%8B%E9%97%A8%E6%88%B7%E7%BD%91%E7%AB%99%E6%A0%B8%E5%BF%83%E6%8A%80%E6%9C%AF-memcached08.%E5%88%86%E5%B8%83%E5%BC%8Fmemcached.wmv|61955937|4623b853f834b72f422206a9e61cfe56|h=yzzzcrmktvt42do3dnos7nd3mudwf4cs|/
ed2k://|file|%E4%BC%A0%E6%99%BA%E6%92%AD%E5%AE%A2PHP%E5%9F%B9%E8%AE%AD.%E7%AC%AC%E4%BA%8C%E7%89%88PHP%E8%A7%86%E9%A2%91%E6%95%99%E7%A8%8B.%E9%9F%A9%E9%A1%BA%E5%B9%B3.%E5%A4%A7%E5%9E%8B%E9%97%A8%E6%88%B7%E7%BD%91%E7%AB%99%E6%A0%B8%E5%BF%83%E6%8A%80%E6%9C%AF-memcached09.session%E5%85%A5memcached.wmv|92855105|ab19290a975de96197913ae1bcb5c3ee|h=z2wv6s3ta2ao4yikokgigjqmstxa6qim|/
ed2k://|file|%E4%BC%A0%E6%99%BA%E6%92%AD%E5%AE%A2PHP%E5%9F%B9%E8%AE%AD.%E7%AC%AC%E4%BA%8C%E7%89%88PHP%E8%A7%86%E9%A2%91%E6%95%99%E7%A8%8B.%E9%9F%A9%E9%A1%BA%E5%B9%B3.%E5%A4%A7%E5%9E%8B%E9%97%A8%E6%88%B7%E7%BD%91%E7%AB%99%E6%A0%B8%E5%BF%83%E6%8A%80%E6%9C%AF-memcached10.%E5%AE%89%E5%85%A8%E8%AE%A8%E8%AE%BA.wmv|31039265|e82848f5cae1d44774ad17ddd5fe90e5|h=kxxf76z4q5xphf26y64i6wp7wb4zjmqf|/
有关tomcat 6.0如何配置https服务的文章可以参考:http://blog.csdn.net/zhou_zion/article/details/6759171 以下主要讲解如何使用https发起post请求: 参考文档:梁栋前辈的《Java加密与解密的艺术》 [java] view plaincopy import java.io.BufferedReader; import java.io.FileInputStream; import java.io.IOException; import java.io.InputStreamReader; import java.net.MalformedURLException; import java.net.URL; import java.security.GeneralSecurityException; import java.security.KeyStore; import javax.net.ssl.HostnameVerifier; import javax.net.ssl.HttpsURLConnection; import javax.net.ssl.KeyManagerFactory; import javax.net.ssl.SSLContext; import javax.net.ssl.TrustManagerFactory; public class HttpsPost { /** * 获得KeyStore. * @param keyStorePath * 密钥库路径 * @param password * 密码 * @return 密钥库 * @throws Exception */ public static KeyStore getKeyStore(String password, String keyStorePath) throws Exception { // 实例化密钥库 KeyStore ks = KeyStore.getInstance("JKS"); // 获得密钥库文件流 FileInputStream is = new FileInputStream(keyStorePath); // 加载密钥库 ks.load(is, password.toCharArray()); // 关闭密钥库文件流 is.close(); return ks; } /** * 获得SSLSocketFactory. * @param password * 密码 * @param keyStorePath * 密钥库路径 * @param trustStorePath * 信任库路径 * @return SSLSocketFactory * @throws Exception */ public static SSLContext getSSLContext(String password, String keyStorePath, String trustStorePath) throws Exception { // 实例化密钥库 KeyManagerFactory keyManagerFactory = KeyManagerFactory .getInstance(KeyManagerFactory.getDefaultAlgorithm()); // 获得密钥库 KeyStore keyStore = getKeyStore(password, keyStorePath); // 初始化密钥工厂 keyManagerFactory.init(keyStore, password.toCharArray()); // 实例化信任库 TrustManagerFactory trustManagerFactory = TrustManagerFactory .getInstance(TrustManagerFactory.getDefaultAlgorithm()); // 获得信任库 KeyStore trustStore = getKeyStore(password, trustStorePath); // 初始化信任库 trustManagerFactory.init(trustStore); // 实例化SSL上下文 SSLContext ctx = SSLContext.getInstance("TLS"); // 初始化SSL上下文 ctx.init(keyManagerFactory.getKeyManagers(), trustManagerFactory.getTrustManagers(), null); // 获得SSLSocketFactory return ctx; } /** * 初始化HttpsURLConnection. * @param password * 密码 * @param keyStorePath * 密钥库路径 * @param trustStorePath * 信任库路径 * @throws Exception */ public static void initHttpsURLConnection(String password, String keyStorePath, String trustStorePath) throws Exception { // 声明SSL上下文 SSLContext sslContext = null; // 实例化主机名验证接口 HostnameVerifier hnv = new MyHostnameVerifier(); try { sslContext = getSSLContext(password, keyStorePath, trustStorePath); } catch (GeneralSecurityException e) { e.printStackTrace(); } if (sslContext != null) { HttpsURLConnection.setDefaultSSLSocketFactory(sslContext .getSocketFactory()); } HttpsURLConnection.setDefaultHostnameVerifier(hnv); } /** * 发送请求. * @param httpsUrl * 请求的地址 * @param xmlStr * 请求的数据 */ public static void post(String httpsUrl, String xmlStr) { HttpsURLConnection urlCon = null; try { urlCon = (HttpsURLConnection) (new URL(httpsUrl)).openConnection(); urlCon.setDoInput(true); urlCon.setDoOutput(true); urlCon.setRequestMethod("POST"); urlCon.setRequestProperty("Content-Length", String.valueOf(xmlStr.getBytes().length)); urlCon.setUseCaches(false); //设置为gbk可以解决服务器接收时读取的数据中文乱码问题 urlCon.getOutputStream().write(xmlStr.getBytes("gbk")); urlCon.getOutputStream().flush(); urlCon.getOutputStream().close(); BufferedReader in = new BufferedReader(new InputStreamReader( urlCon.getInputStream())); String line; while ((line = in.readLine()) != null) { System.out.println(line); } } catch (MalformedURLException e) { e.printStackTrace(); } catch (IOException e) { e.printStackTrace(); } catch (Exception e) { e.printStackTrace(); } } /** * 测试方法. * @param args * @throws Exception */ public static void main(String[] args) throws Exception { // 密码 String password = "123456"; // 密钥库 String keyStorePath = "tomcat.keystore"; // 信任库 String trustStorePath = "tomcat.keystore"; // 本地起的https服务 String httpsUrl = "https://localhost:8443/service/httpsPost"; // 传输文本 String xmlStr = "<?xml version=\"1.0\" encoding=\"UTF-8\"?><fruitShop><fruits><fruit><kind>萝卜</kind></fruit><fruit><kind>菠萝</kind></fruit></fruits></fruitShop>"; HttpsPost.initHttpsURLConnection(password, keyStorePath, trustStorePath); // 发起请求 HttpsPost.post(httpsUrl, xmlStr); } }
首先,WAS用IBM JSSE,不支持Sun JSSE,有文档说明。
http://www-01.ibm.com/support/docview.wss?uid=swg21418924
然后,你要检查
1) WAS\java\jre\lib\security\java.security, 看看secrity provider list里是否有Sun JSSE
# List of providers and their preference orders (see above):
#
#security.provider.1=com.ibm.crypto.fips.provider.IBMJCEFIPS
security.provider.1=com.ibm.crypto.provider.IBMJCE
security.provider.2=com.ibm.jsse.IBMJSSEProvider
security.provider.3=com.ibm.jsse2.IBMJSSEProvider2
security.provider.4=com.ibm.security.jgss.IBMJGSSProvider
security.provider.5=com.ibm.security.cert.IBMCertPath
security.provider.6=com.ibm.crypto.pkcs11impl.provider.IBMPKCS11Impl
security.provider.7=com.ibm.security.cmskeystore.CMSProvider
security.provider.8=com.ibm.security.jgss.mech.spnego.IBMSPNEGO
security.provider.9=com.ibm.security.sasl.IBMSASL
security.provider.10=com.ibm.xml.crypto.IBMXMLCryptoProvider
security.provider.11=com.ibm.xml.enc.IBMXMLEncProvider
security.provider.12=org.apache.harmony.security.provider.PolicyProvider
2) 类路径里是否有Sun JSSE 的jar包
3)你的代码里是否有调用Sun JSSE provider |
摘要导读:更新20141120: 我始终对修改生产上weblogic上的配置文件这一方法心存担忧(生产上的服务器不允许随便修改,可能会影响到其他应用),所以想使用代码的方式解决此问题,在对方法一失败原因进行了进一步查看,日志打出来的的异常信息为如下: com.sun.net.ssl.internal.www.protocol.https.HttpsURLConnectionOldImpl cannot be cast to javax.net.ssl.HttpsURLConnection 在网上搜索之后,并经过自己的判断,发现我在new URL时传的是com.sun.net.ssl.interna... 我始终对修改生产上weblogic上的配置文件这一方法心存担忧(生产上的服务器不允许随便修改,可能会影响到其他应用),所以想使用代码的方式解决此问题,在对方法一失败原因进行了进一步查看,日志打出来的的异常信息为如下: com.sun.net.ssl.internal.www.protocol.https.HttpsURLConnectionOldImpl cannot be cast to javax.net.ssl.HttpsURLConnection 在网上搜索之后,并经过自己的判断,发现我在new URL时传的是com.sun.net.ssl.internal.www.protocol.https.Handler这个handler,而报错信息是javax.net.ssl这个包下面的,再看我的代码: package java.net.HttpURLConnection;httpURLConnection = (HttpURLConnection) this.url.openConnection(); 这就说明了这两个类不在一个包下面,仔细看了别人的回复,不难发现,这两个类(HttpsURLConnectionOldImpl、HttpsURLConnection)属于不同的包,看到这个贴子最下面(http://bbs.csdn.net/topics/380110416)有一个说明,Handler使用错误,我一看就知道这是问题的关键点,果断修改前面方法一使用的handler: com.sun.net.ssl.internal.www.protocol.https.Handler,改为:sun.net.www.protocol.https.Handler,完整代码如下: this.url =newURL(null, url,newsun.net.www.protocol.https.Handler()); 重新启动后再次进行调试成功,自此证明,方法一也是有效的,不过对于使用别人的API jar包的不是很方便,我现在使用的办法是将别人的代码进行重写,再调用自己写的类解决问题,修改weblogic的配置文件生产上不好修改,只能用代码实现了。 --------------------------------------分割线20141119------------------------------------------ Weblogic问题解决: 在进行调试时,本地(TOMCAT)开发完成,并本地测试通过,但是部署至Weblogic上时,出现以下异常信息: weblogic.net.http.SOAPHttpsURLConnection incompatible with javax.net.ssl.HttpsURLConnection 在网上搜索之后,发现是由于在weblogic上使用HttpsURLConniection时,会默认使用weblogic自己的类weblogic.net.http.SOAPHttpsURLConnection,导致出现问题: http://bbs.csdn.net/topics/380076374 http://luanxiyuan.iteye.com/blog/1808097 http://www.xuebuyuan.com/593657.html 按照上面的贴子找到解决办法: - 1. 按照网上的办法,可以修改代码解决问题,但是由于我们使用的是别人的jar包,不能修改代码,:
URL url = new URL(null,"https://www.etrade.com",new com.sun.net.ssl.internal.www.protocol.https.Handler());// 指定了handler后openConnection()返回了HttpsURLConnection类型对象HttpsURLConnection conn = (HttpsURLConnection) url.openConnection(); - 2. 配置weblogic,在startWeblogic.sh文件中添加参数:-DUseSunHttpHandler=true,我最终添加了一行:MEM_ARGS="${MEM_ARGS} -DUseSunHttpHandler=true"
 以上两个方法,方法一尝试了之后,直接导致weblogic有异常但是没有报错信息,在开发、测试环境无法调查,debug也没用;无奈只能选用第二种方法,配置参数后,成功配置,并测试成功; 总结:方法一我尝试过几种方法,均失败,有用的还是只有第二种方法,如有其他可以使用的方法,欢迎大家推荐
在开发时,有时候可能需要根据不同的环境设置不同的系统参数,我们都知道,在使用java -jar命令时可以使用-D参数来设置运行时的系统变量,同样,在Eclipse中运行java程序时,我们怎么设置该系统变量呢? 另外,如果我们的程序需要输入运行参数,在Eclipse中如何配置? 答案很简单,具体步骤为: 在要运行的类上右键点击Run As-->Run Configurations... 在弹出界面中点击Arguments 
然后弹出如下界面: 1.其中Program arguments栏里可以输入程序运行所需的参数,也就是main方法的参数,如果参数为多个,则用空格分开。 2.VM arguments里接收的是系统变量参数,系统变量输入格式为:-Dargname=argvalue,同样,多个参数之间用空格隔开。另外如果参数值中间有空格,则用引号括起来 
示例程序代码如下: Java代码  - /**
- * ClassName: Main <br/>
- * Function: Eclipse系统变量和运行参数. <br/>
- * date: 2013-8-27 下午04:06:09 <br/>
- *
- * @author chenzhou1025@126.com
- * @version
- */
- public class Main {
- public static void main(String[] args){
- System.out.println("打印所有的参数:");
- if(args.length>0){
- for(int i=0;i<args.length;i++){
- System.out.println("第"+i+"个参数为:"+args[i]);
- }
- }
- System.out.println("打印系统变量:");
- String env = System.getProperty("service.env");
- System.out.println("service.env:"+env);
- String logpath = System.getProperty("logfile.path");
- System.out.println("logfile.path:"+logpath);
- }
- }
运行程序,控制台输出如下: Console代码 - 打印所有的参数:
- 第0个参数为:chenzhou
- 第1个参数为:chenzhou2
- 第2个参数为:chenzhou3
- 打印系统变量:
- service.env:DEV
- logfile.path:E:\u03\project\logs
Mac下面除了用dmg、pkg来安装软件外,比较方便的还有用MacPorts来帮助你安装其他应用程序,跟BSD中的ports道理一样。MacPorts就像apt-get、yum一样,可以快速安装些软件。
下面将MacPorts的安装和使用方法记录在这里以备查。
访问官方网站http://www.macports.org/install.php,这里提供有dmg安装和源码安装两种方式,dmg就多说了,下载MacPorts-1.9.2-10.6-SnowLeopard.dmg,下一步下一步安装即可。
通过Source安装MacPorts
wget http://distfiles.macports.org/MacPorts/MacPorts-1.9.2.tar.gz
tar zxvf MacPorts-1.9.2.tar.gz
cd MacPorts-1.9.2
./configure && make && sudo make install
cd ../
rm -rf MacPorts-1.9.2*
然后将/opt/local/bin和/opt/local/sbin添加到$PATH搜索路径中
编辑/etc/profile文件中,加上
export PATH=/opt/local/bin:$PATH
export PATH=/opt/local/sbin:$PATH
MacPorts使用
更新ports tree和MacPorts版本,强烈推荐第一次运行的时候使用-v参数,显示详细的更新过程。
sudo port -v selfupdate
搜索索引中的软件
port search name
安装新软件
sudo port install name
卸载软件
sudo port uninstall name
查看有更新的软件以及版本
port outdated
升级可以更新的软件
sudo port upgrade outdated
Eclipse的插件需要subclipse需要JavaHL,下面通过MacPorts来安装
sudo port install subversion-javahlbindings
@import url(http://www.blogjava.net/CuteSoft_Client/CuteEditor/Load.ashx?type=style&file=SyntaxHighlighter.css);@import url(/css/cuteeditor.css);
摘要: 这个命令可以以递归的方式下载整站,并可以将下载的页面中的链接转换为本地链接。wget加上参数之后,即可成为相当强大的下载工具。wget -r -p -np -k /var/lcoal/ http://xxx.com/abc/-r, --recursive(递归) ... 阅读全文
EGit released for Supported Version of Eclipse|
| 3.1.0.201310021548-r | N/A | Eclipse 3.8.2/4.2.2 + (Juno) | | 3.0.3.201309161630-r | 4.3.1 (Kepler SR1) | Eclipse 3.8.2/4.2.2 + (Juno) | | 3.0.1.201307141637-r | 4.3.0 (Kepler) | Eclipse 3.8.2/4.2.2 + (Juno) | | 2.3.1.201302201838-r | 3.8.2/4.2.2 (Juno SR2) | Eclipse 3.7.2+ (Indigo) (except EGit Import Support feature, which is optional) | | 2.2.0.201212191850-r | 3.8.1/4.2.1 (Juno SR1) | Eclipse 3.7.2+ (Indigo) (except EGit Import Support feature, which is optional) | | 2.1.0.201209190230-r | 3.8.1/4.2.1 (Juno SR1) | Eclipse 3.5.2+ (Galileo) (except EGit Import Support feature, which is optional) | | 2.0.0.201206130900-r | 3.8/4.2 (Juno) | Eclipse 3.5.2+ (Galileo) (except EGit Import Support feature, which is optional) | | 1.3.0.201202151440-r | 3.7.2 (Indigo SR2) | Eclipse 3.5.2+ (Galileo) | | 1.2.0.201112221803-r | 3.7.2 (Indigo SR2) | Eclipse 3.5.2+ (Galileo) | | 1.1.0.201109151100-r | 3.7.1 (Indigo SR1) | Eclipse 3.5.2+ (Galileo) | | 1.0.0.201106090707-r | 3.7.0 (Indigo) | Eclipse 3.5.2+ (Galileo) |
EGIT下载地址: Release Version p2 repository URL browse p2 repository
一、Eclipse上安装GIT插件EGit
Eclipse的版本eclipse-java-helios-SR2-win32.zip(在Eclipse3.3版本找不到对应的 EGit插件,无法安装)


EGit插件地址:http://download.eclipse.org/egit/updates
OK,随后连续下一步默认安装就可以,安装后进行重启Eclipse
二、在Eclipse中配置EGit
准备工作:需要在https://github.com 上注册账号
Preferences > Team > Git > Configuration

这里的user.name 是你在https://github.com上注册用户名

user.email是你在github上绑定的邮箱。在这里配置user.name即可
三、新建项目,并将代码提交到本地的GIT仓库中
1、新建项目 git_demo,并新建HelloWorld.java类

2、将git_demo项目提交到本地仓库,如下图



到此步,就成功创建GIT仓库。但文件夹处于untracked状态(文件夹中的符号”?”表示),下面我们需要提交代码到本地仓库,如下图



OK,这样代码提交到了本地仓库
四:将本地代码提交到远程的GIT仓库中
准备工作:在https://github.com上创建仓库


点击“Create repository” ,ok,这样在github上的仓库就创建好了。
注意创建好远程仓库后,点击进去,此时可以看到一个HTTP地址,如红线框,这个是你http协议的远程仓库地址

准备工作做好了,那开始将代码提交到远程仓库吧






OK,这样提交远程GIT就完成了,可以在https://github.com核对一下代码是否已经提交

注意的问题
如果是首次提交会第一步:先在本地建立一个一样的仓库,称本地仓库。
第二步:在本地进行commit操作将把更新提交到本地仓库;
第三步: 将服务器端的更新pull到本地仓库进行合并,最后将合并好的本地仓库push到服务器端,这样就进行了一次远程提交。
如果非首次提交同样的道理
第一步:将修改的代码commit操作更新到本地仓库;
第二步:第三步: 将服务器端的更新pull到本地仓库进行合并,最后将合并好的本地仓库push到服务器端
@import url(http://www.blogjava.net/CuteSoft_Client/CuteEditor/Load.ashx?type=style&file=SyntaxHighlighter.css);@import url(/css/cuteeditor.css);
ImageView中XML属性src和background的区别:
background会根据ImageView组件给定的长宽进行拉伸,而src就存放的是原图的大小,不会进行拉伸。src是图片内容(前景),bg是背景,可以同时使用。
此外:scaleType只对src起作用;bg可设置透明度,比如在ImageButton中就可以用android:scaleType控制图片的缩放方式
如上所述,background设置的图片会跟View组件给定的长宽比例进行拉伸。举个例子, 36x36 px的图标放在 xhdpi 文件夹中,在854x480(FWVGA,对应hdpi)环境下,按照
xhdpi : hdpi : mdpi: ldip = 2 : 1.5 : 1 : 0.75
的比例计算,在FWVGA下,图标的实际大小应该是 27x27。
但是当我把它放到一个 layout_width = 96px, layout_height = 75px 的 LinearLayout,布局代码如下:
- <LinearLayout android:gravity="center" android:layout_width="96px" android:layout_height="75px" >
- <ImageButton android:layout_width="wrap_content" android:layout_height="wrap_content" android:background="@drawable/toolbar_bg"/>
- </LinearLayout>
实际情况是,我们得到的ImageButton的大小是 33x27,很明显width被拉伸了,这是我们不想看到的情况。
解决方案一:
代码中动态显式设置ImageButton的layout_width和layout_width,如下
- LinearLayout.LayoutParams layoutParam = new LinearLayout.LayoutParams(27, 27);
- layout.addView(imageButton, layoutParam);
不过,事实上我们并不希望在代码存在“硬编码”的情况。
解决方案二:
在你通过setBackgroundResource()或者在xml设置android:background属性时,将你的background以XML Bitmap的形式定义,如下:
- <?xml version="1.0" encoding="utf-8"?>
- <bitmap xmlns:android="http://schemas.android.com/apk/res/android"
- android:id="@id/toolbar_bg_bmp"
- android:src="@drawable/toolbar_bg"
- android:tileMode="disabled" android:gravity="top" >
- </bitmap>
调用如下:
imageButton.setBackgroundResource(R.drawable.toolbar_bg_bmp)
或者
<ImageButton ... android:background="@drawable/toolbar_bg_bmp" ... />
若背景图片有多种状态,还可参照toolbar_bg_selector.xml:
- <?xml version="1.0" encoding="utf-8"?>
- <selector xmlns:android="http://schemas.android.com/apk/res/android" >
- <item android:state_pressed="true" >
- <bitmap android:src="@drawable/toolbar_bg_sel" android:tileMode="disabled" android:gravity="top" />
- </item>
- <item >
- <bitmap android:src="@drawable/toolbar_bg" android:tileMode="disabled" android:gravity="top" />
- </item>
- </selector>
如此,不管是通过代码方式setBackgroundResource()或XML android:background方式设置背景,均不会产生被拉伸的情况。
@import url(http://www.blogjava.net/CuteSoft_Client/CuteEditor/Load.ashx?type=style&file=SyntaxHighlighter.css);@import url(/css/cuteeditor.css);
在任何浏览器上方便地实现Ajax请求是每一个Ajax框架的初衷。Dojo在这方面无疑提供了非常丰富的支持。除了XMLHttpRequest之外,动态script、iframe、RPC也应有尽有,并且接口统一,使用方便,大多数情况下都只需要一句话就能达到目的,从而免除重复造轮子的麻烦。而且,Dojo一贯追求的概念完整性也在这里有所体现,换句话说,在使用Dojo的Ajax工具的过程中不会感到任何的不自然,相反更容易有触类旁通的感觉,因为API的模式是统一的,而且这里涉及到的某些概念(如Deferred对象)也贯穿在整个Dojo之中。
Dojo的XHR函数
Dojo的XMLHttpRequest函数就叫dojo.xhr,除了把自己取名美元符号之外,这好像是最直接的办法了。它定义在Dojo基本库里,所以不需要额外的require就能使用。它可以实现任何同域内的http请求。不过更常用的是dojo.xhrGet和dojo.xhrPost,它们只不过是对dojo.xhr函数的简单封装;当然根据REST风格,还有dojo.xhrPut和dojo.xhrDelete。
这些函数的参数都很统一。除了dojo.xhr的第一个参数是http方法名之外,所有的dojo.xhr*系列函数都接受同一种散列式的参数,其中包含请求的细节,例如url、是否同步、要传给服务器的内容(可以是普通对象、表单、或者纯文本)、超时设定、返回结果的类型(非常丰富且可扩展)、以及请求成功和失败时的回调。所有dojo.xhr*函数(实际上是所有IO函数)返回值也都一样,都是一个Deferred对象,顾名思义,它能让一些事情延迟发生,从而让API用起来更灵活。
下面的两个例子可能会带来一点直观感受:
dojo.xhrGet({
url: "something.html",
load: function(response, ioArgs){
//用response干一些事
console.log("xhr get success:", response)
return response //必须返回response
},
error: function(response, ioArgs){
console.log("xhr get failed:", response)
return response //必须返回response
}
})
//Deferred对象允许用同步调用的写法写异步调用
var deferredResult = dojo.xhrPost({
url: "something.html",
form: formNode, //Dojo会自动将form转成object
timeout: 3000, //Dojo会保证超时设定的有效性
handleAs: "json" //得到的response将被认为是JSON,并自动转为object
})
//当响应结果可用时再调用回调函数
deferredResult.then(function(response){
console.log("xhr get success:", response)
return response //必须返回response
})
首先解释一下timeout。除了IE8之外,目前大多数XMLHttpRequest对象都没有内置的timeout功能,因此必须用 setTimeout。当同时存在大量请求时,需要为每一个请求设置单独的定时器,这在某些浏览器(主要是IE)会造成严重的性能问题。dojo的做法是只用一个单独的setInterval,定时轮询(间隔50ms)所有还未结束的请求的状态,这样就高效地解决了一切远程请求(包括JSONP和 iframe)的超时问题。
值得一提的还有handleAs参数,通过设置这个参数,可以自动识别服务器的响应内容格式并转换成对象或文本等方便使用的形式。根据文档,它接受如下值:text (默认), json, json-comment-optional, json-comment-filtered, javascript, xml。
而且它还是可扩展的。其实handleAs只是告诉xhr函数去调用哪个格式转换插件,即dojo.contentHandlers对象里的一个方法。例如 dojo.contentHandlers.json就是处理JSON格式的插件。你可以方便地定制自己所需要的格式转换插件,当然,你也可修改现有插件的行为:
dojo.contentHandlers.json = (function(old){
return function(xhr){
var json = old(xhr)
if(json.someSignalFormServer){
doSomthing(json)
delete json.someSignalFormServer
}
return json
}
})(dojo.contentHandlers.json)//一个小技巧,利用传参得到原方法
如果要了解每个参数的细节,可以参考Dojo的文档。
虚拟的参数类
这里特别提一下Dojo在API设计上的两个特点。其一是虚拟的参数类概念:通过利用javascript对象可以灵活扩展的特点,强行规定一个散列参数属于某个类。例如dojo.xhr*系列函数所接受的参数就称为dojo.__XhrArgs。这个类并不存在于实际代码中(不要试图用 instanceof验证它),只停留在概念上,比抽象类还抽象,因此给它加上双下划线前缀(Dojo习惯为抽象类加单下划线前缀)。
这样做看起来没什么意思,但实际上简化了API,因为它使API之间产生了联系,更容易记忆也就更易于使用。这一点在对这种类做继承时更明显。例如 dojo.__XhrArgs继承自dojo.__IoArgs,这是所有IO函数所必须支持的参数集合,同样继承自dojo.__IoArgs的还有 dojo.io.script.__ioArgs和dojo.io.iframe.__ioArgs,分别用于动态脚本请求和iframe请求。子类只向父类添加少量的属性,这样繁多的参数就具有了树形类结构。原本散列式参数是用精确的参数名代替了固定的参数顺序,在增加灵活性和可扩展性的同时,实际上增加了记忆量(毕竟参数名不能拼错),使得API都不像看起来那么好用,有了参数类的设计就缓解了这个问题。
这种参数类的做法在Dojo里随处可见,读源码的话就会发现它们都是被正儿八经地以正常代码形式声明在一种特殊注释格式里的,像这样:
/*=====
dojo.declare("dojo.__XhrArgs", dojo.__IoArgs, {
constructor: function(){
//summary:
//...
//handleAs:
//...
//......
}
})
=====*/
这种格式可以被jsDoc工具自动提取成文档,在文档里这些虚拟出来的类就像真的类一样五脏俱全了。
Deferred对象
另一个API设计特点就是Deferred对象的广泛使用。Dojo里的Deferred是基于MochiKit实现稍加改进而成的,而后者则是受到 python的事件驱动网络工具包Twisted里同名概念的启发。概括来说的话,这个对象的作用就是将异步IO中回调函数的声明位置与调用位置分离,这样在一个异步IO最终完成的地方,开发人员可以简单地说货已经到了,想用的可以来拿了,而不用具体地指出到底该调用哪些回调函数。这样做的好处是让异步IO的写法和同步IO一样(对数据的处理总是在取数据函数的外面,而不是里面),从而简化异步编程。
具体做法是,异步函数总是同步地返回一个代理对象(这就是Deferred对象),可以将它看做你想要的数据的代表,它提供一些方法以添加回调函数,当数据可用时,这些回调函数(可以由很多个)便会按照添加顺序依次执行。如果在取数据过程中出现错误,就会调用所提供的错误处理函数(也可以有很多个);如果想要取消这个异步请求,也可通过Deferred对象的cancel方法完成。
dojo.Deferred的核心方法如下:
then(callback, errback) //添加回调函数
callback(result) //表示异步调用成功完成,触发回调函数
errback(error) //表示异步调用中产生错误,触发错误处理函数
cancel() //取消异步调用
Dojo还提供了一个when方法,使同步的值和异步的Deferred对象在使用时写法一样。例如:
//某个工具函数的实现
var obj = {
getItem: function(){
if(this.item){
return this.item //这里同步地返回数据
}else{
return dojo.xhrGet({ //这里返回的是Deferred对象
url: "toGetItem.html",
load: dojo.hitch(this, function(response){
this.item = response
return response
})
})
}
}
}
//用户代码
dojo.when(obj.getItem(), function(item){
//无论同步异步,使用工具函数getItem的方式都一样
})
在函数闭包的帮助下,Deferred对象的创建和使用变得更为简单,你可以轻易写出一个创建Deferred对象的函数,以同步的写法做异步的事。例如写一个使用store获取数据的函数:
var store = new dojo.data.QueryReadStore({...})
function getData(start, count){
var d = new dojo.Deferred() //初始化一个Deferred对象
store.fetch({
start: start,
count: count,
onComplete: function(items){
//直接取用上层闭包里的Deferred对象
d.callback(items)
}
})
return d //把它当做结果返回
}
用dojo.io.script跨域
dojo.xhr* 只是XmlHttpRequest对象的封装,由于同源策略限制,它不能发跨域请求,要跨域还是需要动态创建script标签。Dojo 没有像JQuery一样把所有东西都封装在一起(JQuery的ajax()方法可以跨域,当然用的是JSONP,所以它不敢把自己称为xhr),而是坚持一个API只干一件事情。毕竟在大部分应用中,同域请求比跨域请求多得多,如果一个应用不需要跨域,就没必要加载相关代码。因此与xhr不同,dojo 的跨域请求组件不在基本库,而在核心库,需要require一下才能使用:
dojo.require("dojo.io.script")
这个包里面基本上只需要用到一个函数:dojo.io.script.get()。它也返回Deferred对象,并接受类型为 dojo.io.script.__ioArgs的散列参数。受益于虚拟参数类,我们不用从头开始学习这个参数,它继承了dojo.__IoArgs,因此和dojo.xhr*系列的参数大同小异。唯一需要注意的是handleAs在这里无效了,代之以jsonp或者checkString。
前者用于实现JSONP协议,其值由服务器端指定,当script标签加载后就按照JSONP协议执行这个函数,然后Dojo会自动介入,负责把真正的数据传给load函数。需要指出的是在Dojo1.4以前,这个参数叫callbackParamName,冗长但意义明确。毕竟Dojo太早了,它成型的时候(2005)JSONP这个词才刚出现不久。现在callbackParamName还是可用的(为了向后兼容),不过处于deprecated状态。
下面的例子从flickr获取feed数据:
dojo.io.script.get({
url: "http://www.flickr.com/services/feeds/photos_public.gne",
jsonp: "jsoncallback", //由flickr指定
content: {format: "json"},
load: function(response){
console.log(response)
return response
},
error: function(response){
console.log(response)
return response
}
})
与jsonp不同,checkString参数专门用于跨域获取javascript代码,它其实是那段跨域脚本里的一个有定义的变量的名字,Dojo会用它来判断跨域代码是否加载完毕,配合前面提到的timeout机制就能实现有效的超时处理。
dojo.io.script.get({
url: "http://......", //某个提供脚本的URL
checkString: "obj",
load: function(response){
//脚本加载完毕,可以直接使用其中的对象了,如obj。
Return response
}
})
用dojo.io.iframe传数据
dojo.io 包里还有一个工具就是iframe,常用于以不刷新页面的方式上传或下载文件。这个很经典的Ajax技巧在Dojo里就是一句 dojo.io.iframe.send({...})。这个函数接受dojo.io.iframe.__ioArgs,相比 dojo.__IoArgs,它只多了一个method参数,用于指定是用GET还是POST(默认)方法发送请求。下面的例子就实现了通过无刷新提交表单来上传文件:
dojo.io.iframe.send({
form: "formNodeId", //某个form元素包含本地文件路径
handleAs: "html", //服务器将返回html页面
load: onSubmitted, //提交成功
error: onSubmitError //提交失败
})
目前send函数的handleAs参数支持html, xml, text, json, 和javascript五种响应格式。除了html和xml之外,使用其他格式有一个比较特别的要求,就是服务端返回的响应必须具有以下格式:
html
head/head
body
textarea真正的响应内容/textarea
/body
/html
这是因为服务器返回的东西是加载在iframe里的,而只有html页面才能在任何浏览器里保证成功加载(有个DOM在,以后取数据也方便)。加一个textarea则可以尽量忠实于原始文本数据的格式,而不会受到html的影响。
试试RPC(远程过程调用)
如果dojo.xhr*函数以及Deferred机制仍然无法避免代码的混乱,那RPC可能就是唯一的选择了。dojo.rpc包提供了基于简单方法描述语言(SMD)的RPC实现。SMD的原理类似于WSDL(Web服务描述语言),不过是基于JSON的,它定义了远程方法的名称、参数等属性,让 Dojo能创建出代理方法以供调用。
Dojo提供了两种方式实现rpc:XHR和JSONP,分别对应dojo.rpc.JsonService类和dojo.rpc.JsonpService类,用户可以根据是否需要跨域各取所需。
一个简单的例子:
var smdObj = {
serviceType: "JSON-RPC",
serviceURL: "http://...."
methods: [
{name: "myFunc", parameters: []}
]
}
var rpc = new dojo.rpc.JsonpService(smdObj) //传入SMD
var result = rpc.myFunc() //直接调用远程方法,返回Deferred对象
dojo.when(result, function(result){
//得到结果
})
SMD还没有一个被广泛认可的官方标准,一直以来都是Dojo社区领导着它的发展,以后这个模块也有可能发生改变,但整个RPC基本的框架会保持稳定。
结语
Ajax请求这个主题太大,本文只能挂一漏万地介绍一点dojo在这方面设计和实现的皮毛,包括基本XHR请求、动态script、iframe请求、以及RPC,并特别强调了几个有Dojo特色的设计,如timeout机制、虚拟参数类、Deferred对象等。
Dojo由Ajax领域的先驱们写就,相信从它的代码中我们一定能学到更多的东西。
String[] str = {}; InternetAddress[] address=new InternetAddress[amount]; for (int i=0;i<str.length;i++){ address[i]=new InternetAddress(str[i]]); } msg.setRecipients(Message.RecipientType.TO,address);
何时我们需要 Dojo 的 build 工具
Dojo 作为一个非常实用的 Ajax 实现框架已经被许多 web2.0 开发人员广泛使用,但使用 Dojo 会导致客户端浏览器需要加载大量的 Dojo 文件,导致应用程序性能下降。解决 Dojo 性能问题的方法之一就是对 Dojo 文件进行定制打包和压缩 ( 提高 Dojo 性能的具体方案请参看“提高基于 Dojo 的 Web 2.0 应用程序的性能”。Dojo 本身已经提供了一套对 Dojo 库文件 ( 自己编写的 Javascript 文件只要符合 Dojo 的规范同样可以进行打包 ) 进行 build 的工具,通过定制库文件和压缩文件的方法来减少浏览器加载文件的时间。
Dojo 的主要库文件 (dojo 包 ) 大小在 1M 左右,dijit 包和 dojox 包大小都在 4M-5M,但我们并不总是需要所有的这些库文件,可以根据开发者自身的需要定制一份 Dojo 库,实际使用的库文件大小往往能大大降低;以笔者目前的开发项目为例,经过定制后实际使用的 Dojo 库文件大小只有 300K 左右。
另外 Dojo 的 build 工具也通过压缩 Javascript 文件的手段来降低浏览器加载文件的时间(该过程中需要使用 ShrinkSafe,有关其详细介绍请参看“http://dojotoolkit.org/docs/shrinksafe”),具体的方法如下:
- 压缩 Javascript 文件,包括:
- 删除所有的空格和空行
- 删除所有的注释
- 将定义变量名用更简短的字符代替
- 将所有打包的的 Javascript 文件的内容合并为一个文件
经过压缩处理,Javascript 文件的大小总体可减少 30%-50%,同时将所有的 Javascript 文件打包成一个文件也减少了浏览器加载时多次开闭文件的负担,从而降低了加载时间。
准备工作
- 到“dojo 下载网站”下载 Dojo 源代码,下载后直接解压即可,设 Dojo 的解压目录为 \dojo(下文中皆用“\dojo”指代 Dojo 文件的解压目录);
- 下载并安装 JDK( 尽量使用 1.5 以上的版本 ),设置 JAVA_HOME 环境变量;
jdk 下载地址:http://java.sun.com/javase/downloads/index.jsp
使用 Dojo 的 build 工具
Dojo 提供的 build 工具位于 \dojo\util\buildsrcipts 下,在 windows 下调用该目录内的 build.bat(linux 下使用 build.sh)文件既可执行 build 工作。
下面是在一个在 windows 下调用 build.bat 的例子:
build profile=base action=release releaseName=myDojo optimize=shrinksafe
该命令中包括了几个最常用的参数,其意义如下:
- action: 指定本次命令的类型,提供的三个值是:clean, release, help;
- releaseName:本次 release 的名字,默认为 dojo;
- optimize:本次 build 中进行优化的方式,一般使用 shrinksafe 既可;
- profile:指定 build 使用的 profile 文件,profile 文件中提供了 build 相关的配置信息,在 \dojo\util\buildsrcipts\profiles 目录下有很多 *.profile.js 文件,我们自定义的 profile 文件也放在这个目录下,例子中“profile=base”表示指定 base.profile.js 作为 build 的参数。
实际上在使用 Dojo 的 build 工具时,关键在于提供的 profile 文件里的内容,在下面的例子中会详细说明 profile 文件的配置方法。
定制 Dojo 文件
Dojo 库中提供了大量的文件供使用者调用,但有的时候我们并不是需要所有的这些文件,此时我们可以使用 Dojo 的 build 工具定制一份个性化的 Dojo 库文件,首先我们需要编写一个 profile 文件来描述我们的需求:
清单 1. profile 文件配置示例 1
/* example.profile.js */
dependencies = {
layers: [ // 可以根据需要制定多个不同的 layer
{
name: "example.js", // 打包生成的 js 文件的名
dependencies: [ // 需要打包的 js 文件列表
"dojo.date",
"dojox.uuid"
]
}
],
prefixes: [ // 设置路径
[ "dijit", "../dijit" ],
[ "dojox", "../dojox" ]
]
}注意:
- dojo.js 是默认被打包的,不需要在 dependencies中声明
- 在 prefixes 设置路径应该是相对 dojo\dojo\dojo.js 的路径,../dijit 实际上是 dojo\dijit
将该文件 (example.profile.js) 放在 \dojo\util\buildsrcipts\profiles 目录下,执行:
build profile=example action=release releaseName=myDojo optimize=shrinksafe build 完成后,会在 \dojo 下生成一个 release 文件夹,如下图所示:
图示 1. build 后释放的文件示意:
因为我们设置了 build 的参数 releaseName=myDojo, 因此 release 下会生成一个 myDojo 文件夹,本次 build 产生的文件都置于该文件夹下。在 \dojo\release\myDojo\dojo\ 目录下,我们可以找到两个文件:example.js 和 example.uncompressed.js,这就是我们需要的打包后的文件,example.uncompressed.js 只是包含了我们指定的所有 dojo 文件,example.js 则在 example.uncompressed.js 基础上又进行了压缩处理。
build 我们自己的 Javascript 文件
对于我们自己编写的 Javascript 文件,我们同样可是借助 Dojo 提供的 build 工具进行压缩和打包,前提是这些 js 文件需要按照 Dojo 相关的的规范编写。打包我们自己的 Javascript 文件与打包 Dojo 文件并没有太大的差别,假设我们有两个 Javascript 文件如下:
清单 2. 假设需要打包的 2 个 Javascript 文件
/* my.example1 */
dojo.provide("my.example1");
dojo.require("my.example2"); // 声明了对 my.example2 的依赖
/*
* this is a js file witch named example1.js
*/
/* my.example2 */
dojo.provide("my.example2");
/*
* this is a js file witch named example2.js
*/在 \dojo 下新建一个文件夹“my”, 将上面的两个文件放在该文件夹下,profile 文件配置如下:
清单 3. profile 文件配置示例 2
/* example.profile.js */
dependencies = {
layers: [
{
name: "example.js",
dependencies: [
"dojo.date",
"dojox.uuid",
"my.example1" // 注意这里我们只声明了 my.example1
]
}
],
prefixes: [
[ "dijit", "../dijit" ],
[ "dojox", "../dojox" ],
[ "my", "../my"] // 刚才新建的 my 文件夹需要在此声明路径
]
}执行:
build.bat profile=example action=release releaseName=myDojo optimize=shrinksafe 请注意,在 profile 文件中,只声明了将 my.example1 进行打包,但在 build 生成的 example.js 中我们会发现 my.example2 中的内容也已经被添加进来了。这是因为在 build 过程中,build 程序在分析 js 文件内容时通过识别一些关键字 ( 例如 dojo.require) 来判断当前文件是否依赖其他的文件,并将这些依赖的文件一同进行打包。因此当 build 程序在 my.example1 中读到 dojo.require("my.example2"); 时,判断出该文件需要依赖另一个文件"my.example2",根据 prefixes 提供的路径 build 程序找到了 my.example2.js 文件,并将该文件的内容添加进来。
按照上面的例子 build 后,我们自己编写的 Javascript 文件会和我们定制 Dojo 的文件合并在一个文件中,我们可能需要独立使用这些自己编写的 Javascript 文件,那么我们修改一下 profile 文件既可:
清单 4. profile 文件配置示例 3
/* example.profile.js */
dependencies = {
layers: [
{ // 这个 layer 用来打包我们定制的 dojo 文件
name: "mydojo.js",
dependencies: [
"dojo.date",
"dojox.uuid"
]
},
{ // 这个 layer 用于打包我们自己的 js 文件
name: "example.js",
dependencies: [
"my.example1"
]
}
],
prefixes: [
[ "dijit", "../dijit" ],
[ "dojox", "../dojox" ],
[ "my", "../my"]
]
}执行:
build.bat profile=example action=release releaseName=myDojo optimize=shrinksafe 这样 build 后在 \dojo\release\myDojo\dojo\ 我们会分别得到 mydojo 和 example 两个 layer 的打包文件:
- mydojo.js 和 mydojo.uncompressed.js:打包的是我们定制的 Dojo 文件
- example.js 和 example.uncompressed.js:打包了我们自己编写 Javascript 文件,我们可以根据需要独立使用他们
需要注意的问题
- 在上面我们已经讲到了 build 程序会按照 dojo.require 等关键字将依赖文件添加进来,因此在每个 layer 的 dependencies 中我们不必列出所有我们需要打包的文件,只需要将一些根文件列出既可 ( 如清单 3 所示 );另外我们也应该确保这些需要打包的文件以及他们所依赖的其他文件所在的路径都在 prefixes 声明注册过,否则 build 程序会因为找不到所需要的文件而失败。
- 上面提到在 build 过程中,会调用 shrinksafe 将 js 文件进行压缩,压缩策略包括将定义的变量名用更为简洁的字符串替代,例如我们定义
”var identifier”,经过压缩处理可能就变成了 ”var _v01”,。如果我们的 Javascript 代码中使用了 eval语句,并且 eval的内容里包含了一些我们定义的变量名,就会导致打包后的文件出现错误而无法使用。例如下面的 Javascript 代码:
var identifier = “”;
eval(“alert(identifier)”); 因为经过压缩后变量名 identifier 被 build 程序以其他的名字替代,因此在执行 eval 方法 , 也就是调用 alert(identifier) 时,会因为无法识别 identifier 而报出 undefined 的错误。
小结
本文站在一个初学者的角度简单地介绍了 Dojo 的 build 工具的使用方法(关键在于 profile 文件的配置),通过以上内容读者应该能够使用该工具进行基本的定制和打包处理,有兴趣的读者可以通过提供的参考资料进行进一步的学习。
1. HTTPS概念 1)简介 HTTPS(全称:Hypertext Transfer Protocol over Secure Socket Layer),是以安全为目标的HTTP通道,简单讲是HTTP的安全版。即HTTP下加入SSL层,HTTPS的安全基础是SSL,因此加密的详细内容就需要SSL。这个系统的最初研发由网景公司进行,提供了身份验证与加密通讯方法,现在它被广泛用于万维网上安全敏感的通讯,例如交易支付方面。 2)HTTPS和HTTP的区别 a. https协议需要到ca申请证书,一般免费证书很少,需要交费。 b. http是超文本传输协议,信息是明文传输;https 则是具有安全性的ssl加密传输协议。 c. http和https使用的是完全不同的连接方式,用的端口也不一样,前者是80,后者是443。 d. http的连接很简单,是无状态的;HTTPS协议是由SSL+HTTP协议构建的可进行加密传输、身份认证的网络协议,比http协议安全。 3)HTTPS的作用 它的主要作用可以分为两种:一种是建立一个信息安全通道,来保证数据传输的安全;另一种就是确认网站的真实性。 a. 一般意义上的https,就是服务器有一个证书。主要目的是保证服务器就是他声称的服务器,这个跟第一点一样;服务端和客户端之间的所有通讯,都是加密的。 b. 具体讲,是客户端产生一个对称的密钥,通过服务器的证书来交换密钥,即一般意义上的握手过程。 c. 接下来所有的信息往来就都是加密的。第三方即使截获,也没有任何意义,因为他没有密钥,当然篡改也就没有什么意义了。 d.少许对客户端有要求的情况下,会要求客户端也必须有一个证书。 这里客户端证书,其实就类似表示个人信息的时候,除了用户名/密码,还有一个CA 认证过的身份。因为个人证书一般来说是别人无法模拟的,所有这样能够更深的确认自己的身份。目前少数个人银行的专业版是这种做法,具体证书可能是拿U盘(即U盾)作为一个备份的载体。 2.SSL简介 1)简介 SSL (Secure Socket Layer)为Netscape所研发,用以保障在Internet上数据传输之安全,利用数据加密(Encryption)技术,可确保数据在网络上之传输过程中不会被截取及窃听。它已被广泛地用于Web浏览器与服务器之间的身份认证和加密数据传输。SSL协议位于TCP/IP协议与各种应用层协议之间,为数据通讯提供安全支持。 2)SSL提供的服务 a.认证用户和服务器,确保数据发送到正确的客户机和服务器 b.加密数据以防止数据中途被窃取 c.维护数据的完整性,确保数据在传输过程中不被改变。 3) SSL协议的握手过程 SSL 协议既用到了公钥加密技术又用到了对称加密技术,对称加密技术虽然比公钥加密技术的速度快,可是公钥加密技术提供了更好的身份认证技术。SSL 的握手协议非常有效的让客户和服务器之间完成相互之间的身份认证,其主要过程如下: ①客户端的浏览器向服务器传送客户端SSL 协议的版本号,加密算法的种类,产生的随机数,以及其他服务器和客户端之间通讯所需要的各种信息。 ②服务器向客户端传送SSL 协议的版本号,加密算法的种类,随机数以及其他相关信息,同时服务器还将向客户端传送自己的证书。 ③客户利用服务器传过来的信息验证服务器的合法性,服务器的合法性包括:证书是否过期,发行服务器证书的CA 是否可靠,发行者证书的公钥能否正确解开服务器证书的“发行者的数字签名”,服务器证书上的域名是否和服务器的实际域名相匹配。如果合法性验证没有通过,通讯将断开;如果合法性验证通过,将继续进行第四步。 ④用户端随机产生一个用于后面通讯的“对称密码”,然后用服务器的公钥(服务器的公钥从步骤②中的服务器的证书中获得)对其加密,然后传给服务器。 ⑤服务器用私钥解密“对称密码”(此处的公钥和私钥是相互关联的,公钥加密的数据只能用私钥解密,私钥只在服务器端保留。详细请参看: http://zh.wikipedia.org/wiki/RSA%E7%AE%97%E6%B3%95),然后用其作为服务器和客户端的“通话密码”加解密通讯。同时在SSL 通讯过程中还要完成数据通讯的完整性,防止数据通讯中的任何变化。 ⑥客户端向服务器端发出信息,指明后面的数据通讯将使用的步骤⑤中的主密码为对称密钥,同时通知服务器客户端的握手过程结束。 ⑦服务器向客户端发出信息,指明后面的数据通讯将使用的步骤⑤中的主密码为对称密钥,同时通知客户端服务器端的握手过程结束。 ⑧SSL 的握手部分结束,SSL 安全通道的数据通讯开始,客户和服务器开始使用相同的对称密钥进行数据通讯,同时进行通讯完整性的检验。  3.配置服务器端证书 为了能实施SSL,一个web服务器对每个接受安全连接的外部接口(IP 地址)必须要有相应的证书(Certificate)。关于这个设计的理论是一个服务器必须提供某种合理的保证以证明这个服务器的主人就是你所认为的那个人。这个证书要陈述与这个网站相关联的公司,以及这个网站的所有者或系统管理员的一些基本联系信息。 这个证书由所有人以密码方式签字,其他人非常难伪造。对于进行电子商务(e-commerce)的网站,或其他身份认证至关重要的任何商业交易,认证书要向大家所熟知的认证权威(Certificate Authority (CA))如VeriSign或Thawte来购买。这样的证书可用电子技术证明属实。实际上,认证权威单位会担保它发出的认证书的真实性,如果你信任发出认证书的认证权威单位的话,你就可以相信这个认证书是有效的。 关于权威证书的申请,请参考:http://www.cnblogs.com/mikespook/archive/2004/12/22/80591.aspx 在许多情况下,认证并不是真正使人担忧的事。系统管理员或许只想要保证被服务器传送和接收的数据是秘密的,不会被连接线上的偷窃者盗窃到。庆幸的是,Java提供相对简单的被称为keytool的命令行工具,可以简单地产生“自己签名”的证书。自己签名的证书只是用户产生的证书,没有正式在大家所熟知的认证权威那里注册过,因此不能确保它的真实性。但却能保证数据传输的安全性。 用Tomcat来配置SSL主要有下面这么两大步骤: 1)生成证书 a. 在命令行下执行: %Java_home%\bin\keytool -genkey -alias tomcat -keyalg RSA 在此命令中,keytool是JDK自带的产生证书的工具。把RSA运算法则作为主要安全运算法则,这保证了与其它服务器和组件的兼容性。 这个命令会在用户的home directory产生一个叫做" .keystore " 的新文件。在执行后,你首先被要求出示keystore密码。Tomcat使用的默认密码是" changeit "(全都是小写字母),如果你愿意,你可以指定你自己的密码。你还需要在server.xml配置文件里指定自己的密码,这在以后会有描述。 b .你会被要求出示关于这个认证书的一般性信息,如公司,联系人名称,等等。这些信息会显示给那些试图访问你程序里安全网页的用户,以确保这里提供的信息与他们期望的相对应。 c.你会被要求出示密钥(key)密码,也就是这个认证书所特有的密码(与其它的储存在同一个keystore文件里的认证书不同)。你必须在这里使用与keystore密码相同的密码。(目前,keytool会提示你按ENTER键会自动帮你做这些)。 如果一切顺利,你现在就拥有了一个可以被你的服务器使用的有认证书的keystore文件。 2) 配置tomcat 第二个大步骤是把secure socket配置在$CATALINA_HOME/conf/server.xml文件里。$CATALINA_HOME代表安装Tomcat的目录。一个例子是SSL连接器的元素被包括在和Tomcat一起安装的缺省server.xml文件里。它看起来象是这样: $CATALINA_HOME/conf/server.xml < -- Define a SSL Coyote HTTP/1.1 Connector on port 8443 -->
< !--
< Connector
port="8443" minProcessors="5" maxProcessors="75"
enableLookups="true" disableUploadTimeout="true"
acceptCount="100" debug="0" scheme="https" secure="true";
clientAuth="false" sslProtocol="TLS"/>
--> Connector元素本身,其默认形式是被注释掉的(commented out),所以需要把它周围的注释标志删除掉。然后,可以根据需要客户化(自己设置)特定的属性。一般需要增加一下keystoreFile和keystorePass两个属性,指定你存放证书的路径(如:keystoreFile="C:/.keystore")和刚才设置的密码(如:keystorePass="123456")。关于其它各种选项的详细信息,可查阅Server Configuration Reference。 在完成这些配置更改后,必须象重新启动Tomcat,然后你就可以通过SSL访问Tomcat支持的任何web应用程序。只不过指令需要像下面这样:https://localhost:8443 4.客户端代码实现 在Java中要访问Https链接时,会用到一个关键类HttpsURLConnection;参见如下实现代码: // 创建URL对象
URL myURL = new URL("https://www.sun.com");
// 创建HttpsURLConnection对象,并设置其SSLSocketFactory对象
HttpsURLConnection httpsConn = (HttpsURLConnection) myURL.openConnection();
// 取得该连接的输入流,以读取响应内容
InputStreamReader insr = new InputStreamReader(httpsConn.getInputStream());
// 读取服务器的响应内容并显示
int respInt = insr.read();
while (respInt != -1) {
System.out.print((char) respInt);
respInt = insr.read();
} 在取得connection的时候和正常浏览器访问一样,仍然会验证服务端的证书是否被信任(权威机构发行或者被权威机构签名);如果服务端证书不被信任,则默认的实现就会有问题,一般来说,用SunJSSE会抛如下异常信息: javax.net.ssl.SSLHandshakeException: sun.security.validator.ValidatorException: PKIX path building
|
failed: sun.security.provider.certpath.SunCertPathBuilderException: unable to find valid certification path to requested target
|
上面提到SunJSSE,JSSE(Java Secure Socket Extension)是实现Internet安全通信的一系列包的集合。它是一个SSL和TLS的纯Java实现,可以透明地提供数据加密、服务器认证、信息完整性等功能,可以使我们像使用普通的套接字一样使用JSSE建立的安全套接字。JSSE是一个开放的标准,不只是Sun公司才能实现一个SunJSSE,事实上其他公司有自己实现的JSSE,然后通过JCA就可以在JVM中使用。 关于JSSE的详细信息参考官网Reference:http://java.sun.com/j2se/1.5.0/docs/guide/security/jsse/JSSERefGuide.html;
以及Java Security Guide:http://java.sun.com/j2se/1.5.0/docs/guide/security/; 在深入了解JSSE之前,需要了解一个有关Java安全的概念:客户端的TrustStore文件。客户端的TrustStore文件中保存着被客户端所信任的服务器的证书信息。客户端在进行SSL连接时,JSSE将根据这个文件中的证书决定是否信任服务器端的证书。在SunJSSE中,有一个信任管理器类负责决定是否信任远端的证书,这个类有如下的处理规则:
1)若系统属性javax.net.sll.trustStore指定了TrustStore文件,那么信任管理器就去jre安装路径下的lib/security/目录中寻找并使用这个文件来检查证书。
2)若该系统属性没有指定TrustStore文件,它就会去jre安装路径下寻找默认的TrustStore文件,这个文件的相对路径为:lib/security/jssecacerts。
3)若jssecacerts不存在,但是cacerts存在(它随J2SDK一起发行,含有数量有限的可信任的基本证书),那么这个默认的TrustStore文件就是lib/security/cacerts。 那遇到这种情况,怎么处理呢?有以下两种方案:
1)按照以上信任管理器的规则,将服务端的公钥导入到jssecacerts,或者是在系统属性中设置要加载的trustStore文件的路径;证书导入可以用如下命令:keytool -import -file src_cer_file –keystore dest_cer_store;至于证书可以通过浏览器导出获得;
2)、实现自己的证书信任管理器类,比如MyX509TrustManager,该类必须实现X509TrustManager接口中的三个method;然后在HttpsURLConnection中加载自定义的类,可以参见如下两个代码片段,其一为自定义证书信任管理器,其二为connect时的代码:  package test;
import java.io.FileInputStream;
import java.security.KeyStore;
import java.security.cert.CertificateException;
import java.security.cert.X509Certificate;
import javax.net.ssl.TrustManager;
import javax.net.ssl.TrustManagerFactory;
import javax.net.ssl.X509TrustManager;
public class MyX509TrustManager implements X509TrustManager {
/*
* The default X509TrustManager returned by SunX509. We'll delegate
* decisions to it, and fall back to the logic in this class if the
* default X509TrustManager doesn't trust it.
*/
X509TrustManager sunJSSEX509TrustManager;
MyX509TrustManager() throws Exception {
// create a "default" JSSE X509TrustManager.
KeyStore ks = KeyStore.getInstance("JKS");
ks.load(new FileInputStream("trustedCerts"),
"passphrase".toCharArray());
TrustManagerFactory tmf =
TrustManagerFactory.getInstance("SunX509", "SunJSSE");
tmf.init(ks);
TrustManager tms [] = tmf.getTrustManagers();
/*
* Iterate over the returned trustmanagers, look
* for an instance of X509TrustManager. If found,
* use that as our "default" trust manager.
*/
for (int i = 0; i < tms.length; i++) {
if (tms[i] instanceof X509TrustManager) {
sunJSSEX509TrustManager = (X509TrustManager) tms[i];
return;
}
}
/*
* Find some other way to initialize, or else we have to fail the
* constructor.
*/
throw new Exception("Couldn't initialize");
}
/*
* Delegate to the default trust manager.
*/
public void checkClientTrusted(X509Certificate[] chain, String authType)
throws CertificateException {
try {
sunJSSEX509TrustManager.checkClientTrusted(chain, authType);
} catch (CertificateException excep) {
// do any special handling here, or rethrow exception.
}
}
/*
* Delegate to the default trust manager.
*/
public void checkServerTrusted(X509Certificate[] chain, String authType)
throws CertificateException {
try {
sunJSSEX509TrustManager.checkServerTrusted(chain, authType);
} catch (CertificateException excep) {
/*
* Possibly pop up a dialog box asking whether to trust the
* cert chain.
*/
}
}
/*
* Merely pass this through.
*/
public X509Certificate[] getAcceptedIssuers() {
return sunJSSEX509TrustManager.getAcceptedIssuers();
}
}
// 创建SSLContext对象,并使用我们指定的信任管理器初始化
TrustManager[] tm = { new MyX509TrustManager() };
SSLContext sslContext = SSLContext.getInstance("SSL", "SunJSSE");
sslContext.init(null, tm, new java.security.SecureRandom());
// 从上述SSLContext对象中得到SSLSocketFactory对象
SSLSocketFactory ssf = sslContext.getSocketFactory();
// 创建URL对象
URL myURL = new URL("https://ebanks.gdb.com.cn/sperbank/perbankLogin.jsp");
// 创建HttpsURLConnection对象,并设置其SSLSocketFactory对象
HttpsURLConnection httpsConn = (HttpsURLConnection) myURL.openConnection();
httpsConn.setSSLSocketFactory(ssf);
// 取得该连接的输入流,以读取响应内容
InputStreamReader insr = new InputStreamReader(httpsConn.getInputStream());
// 读取服务器的响应内容并显示
int respInt = insr.read();
while (respInt != -1) {
System.out.print((char) respInt);
respInt = insr.read();
} 对于以上两种实现方式,各有各的优点,第一种方式不会破坏JSSE的安全性,但是要手工导入证书,如果服务器很多,那每台服务器的JRE都必须做相同的操作;第二种方式灵活性更高,但是要小心实现,否则可能会留下安全隐患; 参考文献: http://baike.baidu.com/view/14121.htm http://zh.wikipedia.org/wiki/RSA%E7%AE%97%E6%B3%95 http://blog.csdn.net/sfdev/article/details/2957240 http://blog.csdn.net/cyberexp2008/article/details/6695691
就是在前台中调用proxy程序的servlet,设置参数servletName和其它参数。代理程序会将该请求发送到目的地址的名称为servletName的servlet中去,并将其它参数作为请求的参数,在得到结果后,将内容原样输出到请求页面。 import java.io.IOException; import java.io.InputStream; import java.io.OutputStream; import java.io.UnsupportedEncodingException; import java.net.HttpURLConnection; import java.net.MalformedURLException; import java.net.URL; import java.net.URLEncoder; import java.util.Iterator; import java.util.Map; import java.util.Map.Entry; import javax.servlet.ServletException; import javax.servlet.http.HttpServlet; import javax.servlet.http.HttpServletRequest; import javax.servlet.http.HttpServletResponse; public class ProxyServlet extends HttpServlet { private String url; /** * 对servlet进行请求处理,并将结果在指定输出流中输出 * * @param os * @param servletName * @param parm * @throws IOException * @throws MalformedURLException */ private void process(HttpServletRequest req, HttpServletResponse resp, String[] target) throws MalformedURLException, IOException { // 取得连接 HttpURLConnection huc = (HttpURLConnection) new URL(url + target[0]) .openConnection(); // 设置连接属性 huc.setDoOutput(true); huc.setRequestMethod("POST"); huc.setUseCaches(false); huc.setInstanceFollowRedirects(true); huc.setRequestProperty("Content-Type", "application/x-www-form-urlencoded"); huc.connect(); // 往目标servlet中提供参数 OutputStream targetOS = huc.getOutputStream(); targetOS.write(target[1].getBytes()); targetOS.flush(); targetOS.close(); // 取得页面输出,并设置页面编码及缓存设置 resp.setContentType(huc.getContentType()); resp.setHeader("Cache-Control", huc.getHeaderField("Cache-Control")); resp.setHeader("Pragma", huc.getHeaderField("Pragma")); resp.setHeader("Expires", huc.getHeaderField("Expires")); OutputStream os = resp.getOutputStream(); // 将目标servlet的输入流直接往页面输出 InputStream targetIS = huc.getInputStream(); int r; while ((r = targetIS.read()) != -1) { os.write(r); } targetIS.close(); os.flush(); os.close(); huc.disconnect(); } /** * 将参数中的目标分离成由目标servlet名称和参数组成的数组 * * @param queryString * @return * @throws UnsupportedEncodingException */ private String[] parse(Map map) throws UnsupportedEncodingException { String[] arr = { "", "" }; Iterator iter = map.entrySet().iterator(); while (iter.hasNext()) { Map.Entry me = (Entry) iter.next(); String[] varr = (String[]) me.getValue(); if ("servletName".equals(me.getKey())) { // 取出servlet名称 arr[0] = varr[0]; } else { // 重新组装参数字符串 for (int i = 0; i < varr.length; i++) { // 参数需要进行转码,实现字符集的统一 arr[1] += "&" + me.getKey() + "=" + URLEncoder.encode(varr[i], "utf-8"); } } } arr[1] = arr[1].replaceAll("^&", ""); return arr; } @Override public void init() throws ServletException { // 设置目标服务器地址 url = this.getInitParameter("url"); if (!url.endsWith("/")) url = url + "/"; } @Override protected void doGet(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException { this.doPost(req, resp); } @Override protected void doPost(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException { String[] target = parse(req.getParameterMap()); process(req, resp, target); } }
现在很多厂商比如,百度、谷歌在调用api接口时早已开始使用json数据。 但是古老的XMLHttpRequest设计时,为了安全性,不能使用跨站数据(就是调用其它的网站的数据) 如果需要访问由远程服务器上一个web服务托管的json数据,则要使用JSONP。 假设,我要进行百度地图坐标转换,这是文档http://developer.baidu.com/map/changeposition.htm 运行示例 http://api.map.baidu.com/geoconv/v1/?coords=114.21892734521,29.575429778924;114.21892734521,29.575429778924&from=1&to=1 浏览器打开得到返回值 (注意当前返回错误,本文只是随便找个例子用来讲解) {"status":22,"message":"param error:to illegal, not support such coord type","result":[]} 那么我们该如何来让我们的页面程序获取这个值呢? 在示例链接中加入 callback=GetValue 然后新建html页面 <!DOCTYPE html> <html xmlns="http://www.w3.org/1999/xhtml"> <head> <meta http-equiv="Content-Type" content="text/html; charset=utf-8"/> <title></title> <script> var getVal; function GetValue(Value) { getVal = Value; alert("ok"); } </script> </head> <body> <script src="http://api.map.baidu.com/geoconv/v1/?coords=114.21892734521,29.575429778924;114.21892734521,29.575429778924&from=1&to=1&callback=GetValue"> </script> </body> </html> !注意html页面中新建的GetValue函数 通过<script>标签调用示例链接产生GetValue值时就会弹窗 然后通过火狐firebug进入控制台查看GetValue的参数传递给getVal的值 Object { status=22, message="param error:to illegal, ...support such coord type", result=[0]}
- package position;
-
- import org.junit.Test;
-
- /**
- * 各地图API坐标系统比较与转换;
- *
- * WGS84坐标系:即地球坐标系,国际上通用的坐标系。设备一般包含GPS芯片或者北斗芯片获取的经纬度为WGS84地理坐标系,谷歌地图采用的是WGS84地理坐标系(中国范围除外);
- *
- * GCJ02坐标系:即火星坐标系,是由中国国家测绘局制订的地理信息系统的坐标系统。由WGS84坐标系经加密后的坐标系。谷歌中国地图和搜搜中国地图采用的是GCJ02地理坐标系;
- *
- * BD09坐标系:即百度坐标系,GCJ02坐标系经加密后的坐标系;
- *
- * 搜狗坐标系、图吧坐标系等,估计也是在GCJ02基础上加密而成的。
- *
- * @author chenhua
- *
- */
- public class PositionUtil
- {
- private static double pi = 3.1415926535897932384626;
- private static double a = 6378245.0;
- private static double ee = 0.00669342162296594323;
-
- @Test
- public void t1()
- {
- // 北斗芯片获取的经纬度为WGS84地理坐标 31.426896,119.496145
-
- Gps gps = new Gps(31.426896, 119.496145);
- System.out.println("gps :" + gps);
-
- Gps gcj = gps84_To_Gcj02(gps.getWgLat(), gps.getWgLon());
- System.out.println("gcj :" + gcj);
-
- Gps star = gcj_To_Gps84(gcj.getWgLat(), gcj.getWgLon());
- System.out.println("star:" + star);
-
- Gps bd = gcj02_To_Bd09(gcj.getWgLat(), gcj.getWgLon());
- System.out.println("bd :" + bd);
-
- Gps gcj2 = bd09_To_Gcj02(bd.getWgLat(), bd.getWgLon());
- System.out.println("gcj :" + gcj2);
-
- }
-
- /**
- * 84 to 火星坐标系 (GCJ-02)
- *
- * World Geodetic System ==> Mars Geodetic System
- *
- * @param lat
- * @param lon
- * @return
- */
- public static Gps gps84_To_Gcj02(double lat, double lon)
- {
- if (outOfChina(lat, lon))
- {
- return null;
- }
- double dLat = transformLat(lon - 105.0, lat - 35.0);
- double dLon = transformLon(lon - 105.0, lat - 35.0);
- double radLat = lat / 180.0 * pi;
- double magic = Math.sin(radLat);
- magic = 1 - ee * magic * magic;
- double sqrtMagic = Math.sqrt(magic);
- dLat = (dLat * 180.0) / ((a * (1 - ee)) / (magic * sqrtMagic) * pi);
- dLon = (dLon * 180.0) / (a / sqrtMagic * Math.cos(radLat) * pi);
- double mgLat = lat + dLat;
- double mgLon = lon + dLon;
-
- return new Gps(mgLat, mgLon);
- }
-
- /**
- * 火星坐标系 (GCJ-02) to 84
- *
- * @param lon
- * @param lat
- * @return
- */
- public Gps gcj_To_Gps84(double lat, double lon)
- {
- Gps gps = transform(lat, lon);
- double lontitude = lon * 2 - gps.getWgLon();
- double latitude = lat * 2 - gps.getWgLat();
-
- return new Gps(latitude, lontitude);
-
- }
-
- /**
- * 火星坐标系 (GCJ-02) 与百度坐标系 (BD-09) 的转换算法
- *
- * 将 GCJ-02 坐标转换成 BD-09 坐标
- *
- * @param gg_lat
- * @param gg_lon
- */
- public static Gps gcj02_To_Bd09(double gg_lat, double gg_lon)
- {
- double x = gg_lon, y = gg_lat;
-
- double z = Math.sqrt(x * x + y * y) + 0.00002 * Math.sin(y * pi);
-
- double theta = Math.atan2(y, x) + 0.000003 * Math.cos(x * pi);
-
- double bd_lon = z * Math.cos(theta) + 0.0065;
-
- double bd_lat = z * Math.sin(theta) + 0.006;
-
- return new Gps(bd_lat, bd_lon);
- }
-
- /**
- * 火星坐标系 (GCJ-02) 与百度坐标系 (BD-09) 的转换算法
- *
- * 将 BD-09 坐标转换成GCJ-02 坐标
- *
- * @param bd_lat
- * @param bd_lon
- * @return
- */
- public static Gps bd09_To_Gcj02(double bd_lat, double bd_lon)
- {
- double x = bd_lon - 0.0065, y = bd_lat - 0.006;
-
- double z = Math.sqrt(x * x + y * y) - 0.00002 * Math.sin(y * pi);
-
- double theta = Math.atan2(y, x) - 0.000003 * Math.cos(x * pi);
-
- double gg_lon = z * Math.cos(theta);
-
- double gg_lat = z * Math.sin(theta);
-
- return new Gps(gg_lat, gg_lon);
- }
-
- private static boolean outOfChina(double lat, double lon)
- {
- if (lon < 72.004 || lon > 137.8347)
- return true;
- if (lat < 0.8293 || lat > 55.8271)
- return true;
- return false;
- }
-
- private Gps transform(double lat, double lon)
- {
- if (outOfChina(lat, lon))
- {
- return new Gps(lat, lon);
- }
- double dLat = transformLat(lon - 105.0, lat - 35.0);
- double dLon = transformLon(lon - 105.0, lat - 35.0);
- double radLat = lat / 180.0 * pi;
- double magic = Math.sin(radLat);
- magic = 1 - ee * magic * magic;
- double sqrtMagic = Math.sqrt(magic);
- dLat = (dLat * 180.0) / ((a * (1 - ee)) / (magic * sqrtMagic) * pi);
- dLon = (dLon * 180.0) / (a / sqrtMagic * Math.cos(radLat) * pi);
- double mgLat = lat + dLat;
- double mgLon = lon + dLon;
-
- return new Gps(mgLat, mgLon);
- }
-
- private static double transformLat(double x, double y)
- {
- double ret = -100.0 + 2.0 * x + 3.0 * y + 0.2 * y * y + 0.1 * x * y + 0.2 * Math.sqrt(Math.abs(x));
- ret += (20.0 * Math.sin(6.0 * x * pi) + 20.0 * Math.sin(2.0 * x * pi)) * 2.0 / 3.0;
- ret += (20.0 * Math.sin(y * pi) + 40.0 * Math.sin(y / 3.0 * pi)) * 2.0 / 3.0;
- ret += (160.0 * Math.sin(y / 12.0 * pi) + 320 * Math.sin(y * pi / 30.0)) * 2.0 / 3.0;
- return ret;
- }
-
- private static double transformLon(double x, double y)
- {
- double ret = 300.0 + x + 2.0 * y + 0.1 * x * x + 0.1 * x * y + 0.1 * Math.sqrt(Math.abs(x));
- ret += (20.0 * Math.sin(6.0 * x * pi) + 20.0 * Math.sin(2.0 * x * pi)) * 2.0 / 3.0;
- ret += (20.0 * Math.sin(x * pi) + 40.0 * Math.sin(x / 3.0 * pi)) * 2.0 / 3.0;
- ret += (150.0 * Math.sin(x / 12.0 * pi) + 300.0 * Math.sin(x / 30.0 * pi)) * 2.0 / 3.0;
- return ret;
- }
-
- }
- package position;
-
- public class Gps
- {
-
- private double wgLat;
- private double wgLon;
-
- public Gps(double wgLat, double wgLon)
- {
- setWgLat(wgLat);
- setWgLon(wgLon);
- }
-
- public double getWgLat()
- {
- return wgLat;
- }
-
- public void setWgLat(double wgLat)
- {
- this.wgLat = wgLat;
- }
-
- public double getWgLon()
- {
- return wgLon;
- }
-
- public void setWgLon(double wgLon)
- {
- this.wgLon = wgLon;
- }
-
- @Override
- public String toString()
- {
- return wgLat + "," + wgLon;
- }
-
- }
摘要: //百度地图的坐标转换,由于百度地图在GCJ02协议的基础上又做了一次处理,变为 BD09协议的坐标,以下是坐标的转化方式,可以方便和其他平台转化jQuery.MapConvert = { x_pi: 3.14159265358979324 * 3000.0 / 180.0, /// <summary... 阅读全文
工作中,使用JAVA的JAXP读取解析XML文件中,就碰到了一件奇件的事。在Web工程中,调试发现JAXP实际使用的是Xerces解析器, 可是,当将工程中的一个小Swing工具,与Web使用一样的jar包,打成一个可执行的jar包时,调试却发现JAXP实际使用的是Crimson 解析器,还会发现解析XML文件时出现错误,经过分析,发现Crimson解析器是Sun公司开发的(实际使用发现Crimson没有Xerces解析器稳定), 打包在JAVA_HOME/lib/dt.jar包中,这个dt.jar被设置在环境变量CLASSPATH中了,当运行可执行的jar包是,JAXP会使用CLASSPATH的解析器, 在Web工程中的War包则不会。 通过阅读JDK源码javax.xml.parsers.FactoryFinder,javax.xml.parsers.SAXParserFactory以及DocumentBuilderFactory发现JDK按照如下顺序:1 系统属性javax.xml.parsers.DocumentBuilderFactory或javax.xml.parsers.SAXParserFactory 2 在jdk-dir/lib/jaxp.properties中设定的javax.xml.parsers.DocumentBuilderFactory或javax.xml.parsers.SAXParserFactory属性 3 运行时jar包中META-INF/services/javax.xml.parsers.DocumentBuilderFactory或javax.xml.parsers.SAXParserFactory文件中设定的值 4. 如果上面的解析器都没有找到,则使用Crimson。如果还没有。。。。。。那报ClassNotFound异常了。 通过JAXP查找解析器的顺序,我们可以使用下面方式来决定,我们使用的实际解析器,
1 在程序中写死实际的解析器
如
javax.xml.parsers.DocumentBuilderFactory factory= new org.apache.crimson.jaxp.DocumentBuilderFactoryImpl();
2 使用JAXP的 DocumentBuilderFactory 工厂类,如
javax.xml.parsers.DocumentBuilderFactory factory= javax.xml.parsers.DocumentBuilderFactory.newInstance();
再通过下面的方式来指定实际的解析器类
方法一:在运行java时,通过设置java -D javax.xml.parsers.DocumentBuilderFactory=new org.apache.crimson.jaxp.DocumentBuilderFactoryImpl
方法二:在程序中调用System.setProperty(“javax.xml.parsers.DocumentBuilderFactory”,” org.apache.crimson.jaxp.DocumentBuilderFactoryImpl”)
来设定实际的XML解析器.
方法三:编写一个jaxp.properties文件,在其中加入如下内容
javax.xml.parsers.DocumentBuilderFactory=org.apache.crimson.jaxp.DocumentBuilderFactoryImpl
再将此文件放入JAVA_HOME/lib/下
方法四:在打jar包下,在目录META-INF/下新建一个services目录,在此目录新建一个文件名为javax.xml.parsers.DocumentBuilderFactory的文件,
文件内容写上实际使用的解析器类,如写org.apache.crimson.jaxp.DocumentBuilderFactoryImpl
通过,上面,我们就可以对JAXP有一个比较深的了解。其实,JAVA中有许多这种思想的做法,这种思想,指的是什么的,就是平台无关性,发展到不依赖于具体的实现。
如我们熟悉的JNDI,JDBC,JAXP等。JNDI是抽像各种目录服务操作的类库,因为目录服务器厂商太多了,如SUN公司的ldapsdk,还有novell公司等等。JDBC是抽像各种数据库
操作的类库,因为数据库厂商也太多了,如ORACLE,SQLSERVER,MYSQL,INFORMIX等等,JAXP就是抽像各种XML解析器和转换器产品的类库,因为XML解析器和转换器产品够多
的了。 访问AIX系统中部署在OC4J中的web 模块的页面时遇到这个错误:
javax.xml.parsers.FactoryConfigurationError: Provider null could not be instantiated:
java.lang.NullPointerException
at javax.xml.parsers.SAXParserFactory.newInstance(Unknown Source)
at org.apache.commons.digester.Digester.getFactory(Digester.java:478)
at org.apache.commons.digester.Digester.getParser(Digester.java:683)
at org.apache.commons.digester.Digester.getXMLReader(Digester.java:891)
at org.apache.commons.digester.Digester.parse(Digester.java:1591)
at org.apache.struts.action.ActionServlet.initServlet(ActionServlet.java:1433)
at org.apache.struts.action.ActionServlet.init(ActionServlet.java:466)
at javax.servlet.GenericServlet.init(GenericServlet.java:256)
at com.evermind[Oracle Containers for J2EE 10g (10.1.3.0.0) ].server.http.HttpApplication.loadServlet(HttpApplication.java:2231)
at com.evermind[Oracle Containers for J2EE 10g (10.1.3.0.0) ].server.http.HttpApplication.findServlet(HttpApplication.java:4617)
……
或者这样的异常:
javax.servlet.jsp.JspException: Can't get definitions factory from context.
at org.apache.struts.taglib.tiles.InsertTag.processDefinitionName(InsertTag.java:583)
at org.apache.struts.taglib.tiles.InsertTag.createTagHandler(InsertTag.java:487)
at org.apache.struts.taglib.tiles.InsertTag.doStartTag(InsertTag.java:451)
at _welcome._jspService(_welcome.java:54)
[SRC:/welcome.jsp:4] ……
而当在Windows环境下部署时就没有问题。 这里是因为IBM的AIX系统使用的是IBM的JDK。而出现这个问题正是因为IBM和SUN的JDK的差异。 具体是因为$JAVA_HOME/jre/lib/jaxp.properties 这个文件。 这个文件以key=value的形式配置和指定实际使用的XML解析器实现类(譬如:javax.xml.parsers.SAXParserFactory=org.apache.xerces.jaxp.SAXParserFactoryImpl)。在XML解析器初始化之前,JDK首先会搜索System的properties寻找解析器的配置项,如果没有则会搜索 $JAVA_HOME/jre/lib 路径下的 jaxp.properties 文件,如果还没有,接下来会在classpath上的.jar包中寻找,仍然没有的话就会使用默认的解析器。 实际上这个文件在SUN的JDK中是不存在的。在找不到文件的情况下,最终将使用默认解析器。在IBM的JDK中存在 jaxp.properties这个文件。但是这个文件中默认所有的配置项是注释掉的,所以在搜索到此处时,不再继续向下搜索,但是由于读取不到配置项,所以会返回null ,于是出现了上文的第一个错误。第二个异常大概是因为访问使用tiles框架的页面时,由于XML解析器初始化出错,所以tiles框架的配置文件也就读取不了了。
一、删除文件或目录CMD命令: rd/s/q 盘符:\某个文件夹 (强制删除文件文件夹和文件夹内所有文件)
del/f/s/q 盘符:\文件名 (强制删除文件,文件名必须加文件后缀名)
XCOPY复制组文件 COPY复制文件 拷贝目录和文件——xcopy 在拷贝单个文件时,可以使用copy命令完成,但当我们要成批拷贝文件,甚至连同子目录一起拷贝时,就要用到xcopy。 一、Xcopy参数介绍 命令格式:XCOPY source [destination] 一堆可选的参数 参数介绍 source 指定要复制的文件。 destination 指定新文件的位置和/或名称。 /A 只复制有存档属性集的文件, 但不改变属性。 /M 只复制有存档属性集的文件, 并关闭存档属性。 /D:m-d-y 复制在指定日期或指定日期以后改变的文件。如果没有提供日期,只复制那些源时间比目标时间新的文件。 /EXCLUDE:file1[+file2][+file3]...
指定含有字符串的文件列表。如果有任何字符串与要被复制的文件的绝对路径相符,那个文件将不会得到复制。 例如,指定如 \obj\ 或 .obj 的字符串会排除目录 obj 下面的所有文件或带有 .obj 扩展名的文件。 /P 创建每个目标文件前提示。 /S 复制目录和子目录,除了空的。 /E 复制目录和子目录,包括空的。 与 /S /E 相同。可以用来修改 /T。 /V 验证每个新文件。 /W 提示您在复制前按键。 /C 即使有错误,也继续复制。 /I 如果目标不存在,又在复制一个以上的文件, 则假定目标一定是一个目录。 /Q 复制时不显示文件名。 /F 复制时显示完整的源和目标文件名。 /L 显示要复制的文件。 /G 允许将没有经过加密的文件复制到不支持加密的目标。 /H 也复制隐藏和系统文件。 /R 改写只读文件。 /T 创建目录结构,但不复制文件。不包括空目录或子目录。/T /E 包括空目录和子目录。 /U 只复制已经存在于目标中的文件。 /K 复制属性。一般的 Xcopy 会重设只读属性。 /N 用生成的短名复制。 /O 复制文件所有权和 ACL 信息。 /X 复制文件审核设置(隐含 /O)。 /Y 禁止提示以确认改写一个现存目标文件。 /-Y 导致提示以确认改写一个现存目标文件。 /Z 用重新启动模式复制网络文件。 二、Xcopy命令实例介绍 ①本机复制文件或文件夹的实例 Xcopy d:\UpdateFiles e:\123 /s /e /y 命令解释:将D盘的UpdateFiles文件夹中包含的所有东西,全部复制到E盘的123文件夹内;/s /e /y 参数说明:在复制文件的同时也复制空目录或子目录,如果目标路径已经有相同文件了,使用覆盖方式而不进行提示。 ②在局域网中的应用实例 Xcopy \\192.168.0.168\UpdateFiles e:\123 /s /e /y 命令解释:将192.168.0.168这台计算机的名称为UpdateFiles的文件夹内的所有东西,全部复制到本机的e:\123 文件夹;参数说明:在复制文件的同时也复制空目录或子目录,如果目标路径已经有相同文件了,使用覆盖方式而不进行提示。
删除一个或数个文件。 一、Del参数介绍
DEL [/P] [/F] [/S] [/Q] [/A[[:]attributes]] names ERASE [/P] [/F] [/S] [/Q] [/A[[:]attributes]] names names 指定一个或数个文件或目录列表。通配符可被用来 删除多个文件。如果指定了一个目录,目录中的所 有文件都会被删除。 /P 删除每一个文件之前提示确认。 /F 强制删除只读文件。 /S 从所有子目录删除指定文件。 /Q 安静模式。删除全局通配符时,不要求确认。 /A 根据属性选择要删除的文件。 attributes R 只读文件 S 系统文件 H 隐藏文件 A 存档文件 - 表示“否”的前缀 如果命令扩展名被启用,DEL 和 ERASE 会如下改变: /S 开关的显示句法会颠倒,即只显示已经 删除的文件,而不显示找不到的文件。
有时候我们需要设置一个alarmmanager事件
但是如果这个事件的时间是凌晨三点 我们不可能等到凌晨三点吧
adb中提供了查看alarmmanager的命令
adb shell dumpsys alarm
通过这命令可以查看被放到定时队列里面的事件 RTC_WAKEUP #1: Alarm{52c2ad84 type 0 com.sina.weibo} type=0 when=+3m1s330ms repeatInterval=0 count=0 operation=PendingIntent{529fa514: PendingIntentRecord{52a7b220 com.sina.weibo broadcastIntent}}
如果我们就可以看到其中一个微博的alarm 如果我们想看他intent的详细信息
就可以用下面这个命令
adb shell dumpsys activity intents
然后找到里面id是52a7b220 的那一段 * PendingIntentRecord{52a7b220 com.sina.weibo broadcastIntent} uid=10073 packageName=com.sina.weibo type=broadcastIntent flags=0x0 requestCode=1383195892 requestResolvedType=null requestIntent=act=AlarmTaskSchedule sent=true canceled=false
1、AlarmManager,顾名思义,就是“提醒”,是Android中常用的一种系统级别的提示服务,在特定的时刻为我们广播一个指定的Intent。简单的说就是我们设定一个时间,然后在该时间到来时,AlarmManager为我们广播一个我们设定的Intent,通常我们使用 PendingIntent,PendingIntent可以理解为Intent的封装包,简单的说就是在Intent上在加个指定的动作。在使用Intent的时候,我们还需要在执行startActivity、startService或sendBroadcast才能使Intent有用。而PendingIntent的话就是将这个动作包含在内了。 定义一个PendingIntent对象。 PendingIntent pi = PendingIntent.getBroadcast(this,0,intent,0); 2、AlarmManager的常用方法有三个: (1)set(int type,long startTime,PendingIntent pi); 该方法用于设置一次性闹钟,第一个参数表示闹钟类型,第二个参数表示闹钟执行时间,第三个参数表示闹钟响应动作。 (2)setRepeating(int type,long startTime,long intervalTime,PendingIntent pi); 该方法用于设置重复闹钟,第一个参数表示闹钟类型,第二个参数表示闹钟首次执行时间,第三个参数表示闹钟两次执行的间隔时间,第三个参数表示闹钟响应动作。 (3)setInexactRepeating(int type,long startTime,long intervalTime,PendingIntent pi); 该方法也用于设置重复闹钟,与第二个方法相似,不过其两个闹钟执行的间隔时间不是固定的而已。 3、三个方法各个参数详悉: (1)int type: 闹钟的类型,常用的有5个值:AlarmManager.ELAPSED_REALTIME、 AlarmManager.ELAPSED_REALTIME_WAKEUP、AlarmManager.RTC、 AlarmManager.RTC_WAKEUP、AlarmManager.POWER_OFF_WAKEUP。 AlarmManager.ELAPSED_REALTIME表示闹钟在手机睡眠状态下不可用,该状态下闹钟使用相对时间(相对于系统启动开始),状态值为3; AlarmManager.ELAPSED_REALTIME_WAKEUP表示闹钟在睡眠状态下会唤醒系统并执行提示功能,该状态下闹钟也使用相对时间,状态值为2; AlarmManager.RTC表示闹钟在睡眠状态下不可用,该状态下闹钟使用绝对时间,即当前系统时间,状态值为1; AlarmManager.RTC_WAKEUP表示闹钟在睡眠状态下会唤醒系统并执行提示功能,该状态下闹钟使用绝对时间,状态值为0; AlarmManager.POWER_OFF_WAKEUP表示闹钟在手机关机状态下也能正常进行提示功能,所以是5个状态中用的最多的状态之一,该状态下闹钟也是用绝对时间,状态值为4;不过本状态好像受SDK版本影响,某些版本并不支持; (2)long startTime: 闹钟的第一次执行时间,以毫秒为单位,可以自定义时间,不过一般使用当前时间。需要注意的是,本属性与第一个属性(type)密切相关,如果第一个参数对 应的闹钟使用的是相对时间(ELAPSED_REALTIME和ELAPSED_REALTIME_WAKEUP),那么本属性就得使用相对时间(相对于 系统启动时间来说),比如当前时间就表示为:SystemClock.elapsedRealtime();如果第一个参数对应的闹钟使用的是绝对时间 (RTC、RTC_WAKEUP、POWER_OFF_WAKEUP),那么本属性就得使用绝对时间,比如当前时间就表示 为:System.currentTimeMillis()。 (3)long intervalTime:对于后两个方法来说,存在本属性,表示两次闹钟执行的间隔时间,也是以毫秒为单位。 (4)PendingIntent pi: 绑定了闹钟的执行动作,比如发送一个广播、给出提示等等。PendingIntent是Intent的封装类。需要注意的是,如果是通过启动服务来实现闹钟提 示的话,PendingIntent对象的获取就应该采用Pending.getService(Context c,int i,Intent intent,int j)方法;如果是通过广播来实现闹钟提示的话,PendingIntent对象的获取就应该采用 PendingIntent.getBroadcast(Context c,int i,Intent intent,int j)方法;如果是采用Activity的方式来实现闹钟提示的话,PendingIntent对象的获取就应该采用 PendingIntent.getActivity(Context c,int i,Intent intent,int j)方法。如果这三种方法错用了的话,虽然不会报错,但是看不到闹钟提示效果。 4.举例说明:定义一个闹钟,5秒钟重复响应。 (1)MainActivity,在onCreate中完成: //创建Intent对象,action为ELITOR_CLOCK,附加信息为字符串“你该打酱油了” Intent intent = new Intent("ELITOR_CLOCK"); intent.putExtra("msg","你该打酱油了"); //定义一个PendingIntent对象,PendingIntent.getBroadcast包含了sendBroadcast的动作。 //也就是发送了action 为"ELITOR_CLOCK"的intent PendingIntent pi = PendingIntent.getBroadcast(this,0,intent,0); //AlarmManager对象,注意这里并不是new一个对象,Alarmmanager为系统级服务 AlarmManager am = (AlarmManager)getSystemService(ALARM_SERVICE); /设置闹钟从当前时间开始,每隔5s执行一次PendingIntent对象pi,注意第一个参数与第二个参数的关系 // 5秒后通过PendingIntent pi对象发送广播 am.setRepeating(AlarmManager.RTC_WAKEUP,System.currentTimeMillis(),5*1000,pi); 那么启动MainActivity之后,由于定义了AlarmManager am,并且调用了am.setRepeating(...)函数,则系统每隔5s将会通过pi启动intent发送广播,其action为ELITOR_CLOCK。所以我们需要在Manifest.xml中注册一个receiver,同时自己定义一个广播接收器类。 (2)定义一个广播接收器类MyReceiver,重写onReceive()函数。 public class MyReceiver extends BroadcastReceiver { @Override public void onReceive(Context context, Intent intent) { // TODO Auto-generated method stub Log.d("MyTag", "onclock......................"); String msg = intent.getStringExtra("msg"); Toast.makeText(context,msg,Toast.LENGTH_SHORT).show(); } } (3)在Manifest.xml中注册广播接收器: <receiver android:name=".MyReceiver"> <intent-filter> <action android:name="ELITOR_CLOCK" /> </intent-filter> </receiver>
当我们从网上下载的原版苹果系统是DMG格式的,要做系统引导必须做成ISO才能做系统盘,所以本文介绍在Windows7下如何来制作苹果系统光盘,各位黑苹果的童鞋要注意了。 准备以下三个东西。 1、苹果OS10.8种子下载 OS X 10.8 正式版种子.torrent 2、 制作光盘工具UltraISO UltraISO破解带注册码.zip 3、7zip http://www.7-zip.org/ 用种子下载整个镜像,是InstallESD.dmg,用7zip打开。  进入 InstallMacOSX.pkg 目录 提取 InstallESD.dmg 这个才是真正的镜像文件。  我们可以改个名字,再进行格式转换。  转换成标准ISO,这个ISO才是我们要的光盘文件,可以来引导安装苹果系统。  介绍完毕,各位想装苹果系统要注意,使用原版苹果系统都要提取转换镜像,适用于OS X 10.7\OS X 10.8.
中文名称:11.28补丁包1.1a Mac OS X Tiger 10.4.3 For x86 PC破解版
英文名称:Mac OS X Tiger 10.4.3 For x86 PC patch
资源类型:ISO
版本:11.28升级补丁包1.1a
地区:大陆
语言:普通话
软件介绍:这个ISO映像已经打好11.28日发布的1.1a补丁包,可以支持8XX板安装。
地址如下:http://www7.rapidupload.com/file.php?filepath=1416
我用以下的方法,已经安装成功,感觉兼容性比以前版本好多了,以及对中文、输入法的支持等,赶快下载体验一下吧
安装简介(如下说明为单硬盘XP(2K/2K3)和MAC共存安装):
VM安装,这个步骤较复杂,只能简说一下,安装方法很多,只能择其一说一下。
用VM(好像5.0以上版本)安装,既可以安装在客户机上,也可以安装在实体机上。
在客户机上安装非常简单,就不说了。
用VM安装在实体机上,网上也已经很多了,就简单说一下。
(1) 在装之前,用PQ8分区大师(最好汉化的)先分出一个6G以上(一般10G以上最好)空白分区,分区切记一定要在扩展分区之前,否则不能安装。
(2) 然后创建主分区:
#在PQ中创建主分区,要选择未格式化的主分区,然后再打开PQ目录下的PTEDIT32.EXE,将要安装MAC的空白分区的类型改为AF(所在分区的第一个框)。
或者#也可以用XP下的DISKPART工具来更改分区类型符(较麻烦),在PQ分出空白分区(1)之后,执行:
DISKPART
SELECT DISK 0(本说明只讲单硬盘,如果为双硬盘的第二个,则为DISK 1)
SELECT PARTITION X(X为你的空白分区号,可用LIST PARTITION 来查看号码)
CREATE partition primary ID=AF
这样就建立了一个分区类型为AF(HFS)的MAC分区了。
(3) 要装上DEAMON TOOL虚拟光驱,将转换好的ISO文件导入虚拟光驱中。
在VM中新建客户机,一路选择其它,内存越大越好,客户机建立后,在配置中删除虚拟硬盘,然后添加硬盘设备,将刚分出的MAC分区选择上。
(4) 之后用记事本打开你的VM虚拟机下的.vmx配置文件,添加一行:paevm=true
之所以这样,是因为10.4.3版的Tiger要求CPU的PAE(Physical Address Extension)支持(用HWINF32可以查看),所以没有PAE的机子还是用VM安装。
(5) 之后启动VM,将DEAMON TOOL的光驱导入VM光驱中,启动安装。
如果出现 "Cannot load /com.apple.Boot.plist"这样的错误信息,可以在启动提示时按F8然后输入:
代码: kernel=mach_kernel.xxx
其中"xxx"对应不同的kernel(只针对下载Maxxuss的kernel)。
进入设置,选择你适合的内核设置,有如下几种内核选择:
mach_kernel (默认): 同 mach_kernel.sse2 一样
mach_kernel.sse2: 支持 SSE2 CPUs, 需 NX/XD CPU 支持(在XP中可以打开控制面板-系统 -高级-数据执行保护,看你的CPU是不是支持DEP,支持DEP就有NX/XD)
mach_kernel.nonx: 支持 SSE2 CPUs, 不需要 NX/XD CPU 支持
mach_kernel.orig: 原来的内核, SSE3 CPUs 带 NX/XD 支持的
(6) 在进入安装界面后,选择上面的disk utility,将要安装的分区(会突显)erase,然后安装就可以了。
之后就可以尽情享受了MAC了。
具体安装方法很多,大家可以用GOOGLE搜索一下!
有些骡友提了很多问题,确实很白
其实我懂的也不是太多,尽能力总结答复一下:
只有是SSE2 或 SSE3的机子,AMD的机子是兼容SSE2/SSE3的,也应该都是可以安装的。
MAC Tiger可以实体安装,也可以用VM模拟安装做客户机,在VM上安装时,要在.vmx配置文件上加上一行 "paevm=true" 。先将ISO文件导入Daemon Tools 虚拟光驱中, 不要用 VMWare CD/DVD 光盘驱动器模拟.
实体刻盘安装,要机子支持PAE,所以还是建议在VM中安装,然后在实体中运行。
这个版本的MAC是至今为止,中文化程度最好的一个,性能的提升也是最好的。
MAC上的软件相当丰富,只要你努力去搜寻,因为MAC机本来是专于多媒体,所以这方面的软件很多。
这个补丁是第一版的,以后还会继续完善,只要能装上,以后升级补丁可以单独下,然后在MAC中打补丁也是一样的。
MAC系统不光是界面好,而且装在PC上启动运行也是相当快的,反正在我的本本上比XP要快,并不是像人所说的,装在PC上很慢。这个补丁包就是可以保证性能的!
|
在英文输入法模式下: 0-9 对应的keyCode是 48-57 在中文输入法模式下: 数字和字母的按键,以及tab键的keyCode为229 回车的回车的 keyCode 为8 以后在JS中少用按键的keyCode来判断数字的输入 直接用String.fromCharCode的方法来获得输入的字符,然后进行正则表达式的判读 找到一种可以屏蔽复制,拖曳的方法,并且只能输入数字,而且使用能让输入法的框消失 - onkeypress="return event.keyCode>=48&&event.keyCode<=57||event.keyCode==46" onpaste="return !clipboardData.getData('text').match(//D/)" ondragenter="return false" style="ime-mode:Disabled"
另外注意,小键盘的onKeyPress 和 onKeyDown的 keyCode是不一样的
Android SDK的tools目录下提供了一个sqlite3.exe工具,这是一个简单的sqlite数据库管理工具。开发者可以方便的使用其对sqlite数据库进行命令行的操作。 程序运行生成的*.db文件一般位于"/data/data/项目名(包括所处包名)/databases/*.db",因此要对数据库文件进行操作需要先找到数据库文件: 1、进入shell 命令 adb shell 2、找到数据库文件 #cd data/data #ls --列出所有项目 #cd project_name --进入所需项目名 #cd databases #ls --列出现寸的数据库文件 3、进入数据库 #sqlite3 test_db --进入所需数据库 会出现类似如下字样: SQLite version 3.6.22 Enter ".help" for instructions Enter SQL statements terminated with a ";" sqlite> 至此,可对数据库进行操作。 4、sqlite常用命令 >.databases --产看当前数据库 >.tables --查看当前数据库中的表 >.help --sqlite3帮助 >.schema --各个表的生成语句
因CooCox用户数及影响力越来越大,CooCox团队也逐渐提高了对软件及代码协议的重视。在收集整理的过程中,一些归纳好的信息和大家分享一下。首先借用有心人士的一张相当直观清晰的图来划分各种协议:开源许可证GPL、BSD、MIT、Mozilla、Apache和LGPL的区别 以下是上述协议的简单介绍:BSD开源协议BSD开源协议是一个给于使用者很大自由的协议。基本上使用者可以”为所欲为”,可以自由的使用,修改源代码,也可以将修改后的代码作为开源或者专有软件再发布。但”为所欲为”的前提当你发布使用了BSD协议的代码,或则以BSD协议代码为基础做二次开发自己的产品时,需要满足三个条件: 如果再发布的产品中包含源代码,则在源代码中必须带有原来代码中的BSD协议。 如果再发布的只是二进制类库/软件,则需要在类库/软件的文档和版权声明中包含原来代码中的BSD协议。 不可以用开源代码的作者/机构名字和原来产品的名字做市场推广。BSD 代码鼓励代码共享,但需要尊重代码作者的著作权。BSD由于允许使用者修改和重新发布代码,也允许使用或在BSD代码上开发商业软件发布和销售,因此是对商业集成很友好的协议。而很多的公司企业在选用开源产品的时候都首选BSD协议,因为可以完全控制这些第三方的代码,在必要的时候可以修改或者二次开发。Apache Licence 2.0Apache Licence是著名的非盈利开源组织Apache采用的协议。该协议和BSD类似,同样鼓励代码共享和尊重原作者的著作权,同样允许代码修改,再发布(作为开源或商业软件)。需要满足的条件也和BSD类似: 需要给代码的用户一份Apache Licence 如果你修改了代码,需要再被修改的文件中说明。 在延伸的代码中(修改和有源代码衍生的代码中)需要带有原来代码中的协议,商标,专利声明和其他原来作者规定需要包含的说明。 如果再发布的产品中包含一个Notice文件,则在Notice文件中需要带有Apache Licence。你可以在Notice中增加自己的许可,但不可以表现为对Apache Licence构成更改。Apache Licence也是对商业应用友好的许可。使用者也可以在需要的时候修改代码来满足需要并作为开源或商业产品发布/销售。GPL我们很熟悉的Linux就是采用了GPL。GPL协议和BSD, Apache Licence等鼓励代码重用的许可很不一样。GPL的出发点是代码的开源/免费使用和引用/修改/衍生代码的开源/免费使用,但不允许修改后和衍生的代码做为闭源的商业软件发布和销售。这也就是为什么我们能用免费的各种linux,包括商业公司的linux和linux上各种各样的由个人,组织,以及商业软件公司开发的免费软件了。GPL协议的主要内容是只要在一个软件中使用(”使用”指类库引用,修改后的代码或者衍生代码)GPL 协议的产品,则该软件产品必须也采用GPL协议,既必须也是开源和免费。这就是所谓的”传染性”。GPL协议的产品作为一个单独的产品使用没有任何问题,还可以享受免费的优势。由于GPL严格要求使用了GPL类库的软件产品必须使用GPL协议,对于使用GPL协议的开源代码,商业软件或者对代码有保密要求的部门就不适合集成/采用作为类库和二次开发的基础。其它细节如再发布的时候需要伴随GPL协议等和BSD/Apache等类似。LGPLLGPL是GPL的一个为主要为类库使用设计的开源协议。和GPL要求任何使用/修改/衍生之GPL类库的的软件必须采用GPL协议不同。LGPL 允许商业软件通过类库引用(link)方式使用LGPL类库而不需要开源商业软件的代码。这使得采用LGPL协议的开源代码可以被商业软件作为类库引用并发布和销售。但是如果修改LGPL协议的代码或者衍生,则所有修改的代码,涉及修改部分的额外代码和衍生的代码都必须采用LGPL协议。因此LGPL协议的开源代码很适合作为第三方类库被商业软件引用,但不适合希望以LGPL协议代码为基础,通过修改和衍生的方式做二次开发的商业软件采用。GPL/LGPL都保障原作者的知识产权,避免有人利用开源代码复制并开发类似的产品MITMIT是和BSD一样宽范的许可协议,作者只想保留版权,而无任何其他了限制.也就是说,你必须在你的发行版里包含原许可协议的声明,无论你是以二进制发布的还是以源代码发布的.MPLMPL是The Mozilla Public License的简写,是1998年初Netscape的 Mozilla小组为其开源软件项目设计的软件许可证。MPL许可证出现的最重要原因就是,Netscape公司认为GPL许可证没有很好地平衡开发者对源代码的需求和他们利用源代码获得的利益。同著名的GPL许可证和BSD许可证相比,MPL在许多权利与义务的约定方面与它们相同(因为都是符合OSIA 认定的开源软件许可证)。但是,相比而言MPL还有以下几个显著的不同之处:◆ MPL虽然要求对于经MPL许可证发布的源代码的修改也要以MPL许可证的方式再许可出来,以保证其他人可以在MPL的条款下共享源代码。但是,在MPL 许可证中对“发布”的定义是“以源代码方式发布的文件”,这就意味着MPL允许一个企业在自己已有的源代码库上加一个接口,除了接口程序的源代码以MPL 许可证的形式对外许可外,源代码库中的源代码就可以不用MPL许可证的方式强制对外许可。这些,就为借鉴别人的源代码用做自己商业软件开发的行为留了一个豁口。◆ MPL许可证第三条第7款中允许被许可人将经过MPL许可证获得的源代码同自己其他类型的代码混合得到自己的软件程序。◆ 对软件专利的态度,MPL许可证不像GPL许可证那样明确表示反对软件专利,但是却明确要求源代码的提供者不能提供已经受专利保护的源代码(除非他本人是专利权人,并书面向公众免费许可这些源代码),也不能在将这些源代码以开放源代码许可证形式许可后再去申请与这些源代码有关的专利。◆ 对源代码的定义而在MPL(1.1版本)许可证中,对源代码的定义是:“源代码指的是对作品进行修改最优先择取的形式,它包括:所有模块的所有源程序,加上有关的接口的定义,加上控制可执行作品的安装和编译的‘原本’(原文为‘Script’),或者不是与初始源代码显著不同的源代码就是被源代码贡献者选择的从公共领域可以得到的程序代码。”◆ MPL许可证第3条有专门的一款是关于对源代码修改进行描述的规定,就是要求所有再发布者都得有一个专门的文件就对源代码程序修改的时间和修改的方式有描述。 以下是上述协议的简单介绍:BSD开源协议BSD开源协议是一个给于使用者很大自由的协议。基本上使用者可以”为所欲为”,可以自由的使用,修改源代码,也可以将修改后的代码作为开源或者专有软件再发布。但”为所欲为”的前提当你发布使用了BSD协议的代码,或则以BSD协议代码为基础做二次开发自己的产品时,需要满足三个条件: 如果再发布的产品中包含源代码,则在源代码中必须带有原来代码中的BSD协议。 如果再发布的只是二进制类库/软件,则需要在类库/软件的文档和版权声明中包含原来代码中的BSD协议。 不可以用开源代码的作者/机构名字和原来产品的名字做市场推广。BSD 代码鼓励代码共享,但需要尊重代码作者的著作权。BSD由于允许使用者修改和重新发布代码,也允许使用或在BSD代码上开发商业软件发布和销售,因此是对商业集成很友好的协议。而很多的公司企业在选用开源产品的时候都首选BSD协议,因为可以完全控制这些第三方的代码,在必要的时候可以修改或者二次开发。Apache Licence 2.0Apache Licence是著名的非盈利开源组织Apache采用的协议。该协议和BSD类似,同样鼓励代码共享和尊重原作者的著作权,同样允许代码修改,再发布(作为开源或商业软件)。需要满足的条件也和BSD类似: 需要给代码的用户一份Apache Licence 如果你修改了代码,需要再被修改的文件中说明。 在延伸的代码中(修改和有源代码衍生的代码中)需要带有原来代码中的协议,商标,专利声明和其他原来作者规定需要包含的说明。 如果再发布的产品中包含一个Notice文件,则在Notice文件中需要带有Apache Licence。你可以在Notice中增加自己的许可,但不可以表现为对Apache Licence构成更改。Apache Licence也是对商业应用友好的许可。使用者也可以在需要的时候修改代码来满足需要并作为开源或商业产品发布/销售。GPL我们很熟悉的Linux就是采用了GPL。GPL协议和BSD, Apache Licence等鼓励代码重用的许可很不一样。GPL的出发点是代码的开源/免费使用和引用/修改/衍生代码的开源/免费使用,但不允许修改后和衍生的代码做为闭源的商业软件发布和销售。这也就是为什么我们能用免费的各种linux,包括商业公司的linux和linux上各种各样的由个人,组织,以及商业软件公司开发的免费软件了。GPL协议的主要内容是只要在一个软件中使用(”使用”指类库引用,修改后的代码或者衍生代码)GPL 协议的产品,则该软件产品必须也采用GPL协议,既必须也是开源和免费。这就是所谓的”传染性”。GPL协议的产品作为一个单独的产品使用没有任何问题,还可以享受免费的优势。由于GPL严格要求使用了GPL类库的软件产品必须使用GPL协议,对于使用GPL协议的开源代码,商业软件或者对代码有保密要求的部门就不适合集成/采用作为类库和二次开发的基础。其它细节如再发布的时候需要伴随GPL协议等和BSD/Apache等类似。LGPLLGPL是GPL的一个为主要为类库使用设计的开源协议。和GPL要求任何使用/修改/衍生之GPL类库的的软件必须采用GPL协议不同。LGPL 允许商业软件通过类库引用(link)方式使用LGPL类库而不需要开源商业软件的代码。这使得采用LGPL协议的开源代码可以被商业软件作为类库引用并发布和销售。但是如果修改LGPL协议的代码或者衍生,则所有修改的代码,涉及修改部分的额外代码和衍生的代码都必须采用LGPL协议。因此LGPL协议的开源代码很适合作为第三方类库被商业软件引用,但不适合希望以LGPL协议代码为基础,通过修改和衍生的方式做二次开发的商业软件采用。GPL/LGPL都保障原作者的知识产权,避免有人利用开源代码复制并开发类似的产品MITMIT是和BSD一样宽范的许可协议,作者只想保留版权,而无任何其他了限制.也就是说,你必须在你的发行版里包含原许可协议的声明,无论你是以二进制发布的还是以源代码发布的.MPLMPL是The Mozilla Public License的简写,是1998年初Netscape的 Mozilla小组为其开源软件项目设计的软件许可证。MPL许可证出现的最重要原因就是,Netscape公司认为GPL许可证没有很好地平衡开发者对源代码的需求和他们利用源代码获得的利益。同著名的GPL许可证和BSD许可证相比,MPL在许多权利与义务的约定方面与它们相同(因为都是符合OSIA 认定的开源软件许可证)。但是,相比而言MPL还有以下几个显著的不同之处:◆ MPL虽然要求对于经MPL许可证发布的源代码的修改也要以MPL许可证的方式再许可出来,以保证其他人可以在MPL的条款下共享源代码。但是,在MPL 许可证中对“发布”的定义是“以源代码方式发布的文件”,这就意味着MPL允许一个企业在自己已有的源代码库上加一个接口,除了接口程序的源代码以MPL 许可证的形式对外许可外,源代码库中的源代码就可以不用MPL许可证的方式强制对外许可。这些,就为借鉴别人的源代码用做自己商业软件开发的行为留了一个豁口。◆ MPL许可证第三条第7款中允许被许可人将经过MPL许可证获得的源代码同自己其他类型的代码混合得到自己的软件程序。◆ 对软件专利的态度,MPL许可证不像GPL许可证那样明确表示反对软件专利,但是却明确要求源代码的提供者不能提供已经受专利保护的源代码(除非他本人是专利权人,并书面向公众免费许可这些源代码),也不能在将这些源代码以开放源代码许可证形式许可后再去申请与这些源代码有关的专利。◆ 对源代码的定义而在MPL(1.1版本)许可证中,对源代码的定义是:“源代码指的是对作品进行修改最优先择取的形式,它包括:所有模块的所有源程序,加上有关的接口的定义,加上控制可执行作品的安装和编译的‘原本’(原文为‘Script’),或者不是与初始源代码显著不同的源代码就是被源代码贡献者选择的从公共领域可以得到的程序代码。”◆ MPL许可证第3条有专门的一款是关于对源代码修改进行描述的规定,就是要求所有再发布者都得有一个专门的文件就对源代码程序修改的时间和修改的方式有描述。
1.Windows 很简单,写出来时为了和linux对比 public void execWindowsCmd(String cmd) throws Exception {
Runtime rt = Runtime.getRuntime();
Process ppp = rt.exec(cmd);
//input
InputStreamReader ir = new InputStreamReader(ppp.getInputStream());
LineNumberReader input = new LineNumberReader(ir); String line;
while ((line = input.readLine()) != null)
com.pub.Log.logger.debug(this.getClass().getClass() + " " +
line); //error
ir = new InputStreamReader(ppp.getErrorStream());
input = new LineNumberReader(ir);
while ((line = input.readLine()) != null)
com.pub.Log.logger.debug(this.getClass().getClass() + " " +
line); ppp.waitFor();
} 2. Linux :首先要确保对于命令,允许Web服务器的用户是否有权限,普通命令和windows没什么区别。Linux管道命令不能这样直接执行,下面是具体实现fang public void execLinuxCmd(String cmd) throws Exception {
Runtime rt = Runtime.getRuntime();
File f = new File(this.fileName + PDU_SHELL);
BufferedWriter bw = new BufferedWriter(new FileWriter(f));
bw.write("#!/bin/bash");
bw.newLine();
bw.write(cmd); //把命令写入一个文本shell文件
bw.flush();
bw.close();
cmd = f.getAbsolutePath(); Process ppp = rt.exec("chmod a+x " + cmd); //授权该shell文件可以执行
ppp.waitFor(); ppp = rt.exec(cmd); //执行shell //input
InputStreamReader ir = new InputStreamReader(ppp.getInputStream());
LineNumberReader input = new LineNumberReader(ir); String line;
while ((line = input.readLine()) != null)
com.pub.Log.logger.debug(this.getClass().getClass() + " " +
line); //error
ir = new InputStreamReader(ppp.getErrorStream());
input = new LineNumberReader(ir);
while ((line = input.readLine()) != null)
com.pub.Log.logger.debug(this.getClass().getClass() + " " +
line); ppp.waitFor(); }
在实际开发中LayoutInflater这个类还是非常有用的,它的作用类似于findViewById()。不同点是LayoutInflater是用来找res/layout/下的xml布局文件,并且实例化;而findViewById()是找xml布局文件下的具体widget控件(如Button、TextView等)。 具体作用: 1、对于一个没有被载入或者想要动态载入的界面,都需要使用LayoutInflater.inflate()来载入; 2、对于一个已经载入的界面,就可以使用Activiyt.findViewById()方法来获得其中的界面元素。 LayoutInflater 是一个抽象类,在文档中如下声明: public abstract class LayoutInflater extends Object 获得 LayoutInflater 实例的三种方式 1. LayoutInflater inflater = getLayoutInflater();//调用Activity的getLayoutInflater() 2. LayoutInflater inflater = LayoutInflater.from(context); 3. LayoutInflater inflater = (LayoutInflater)context.getSystemService (Context.LAYOUT_INFLATER_SERVICE); 其实,这三种方式本质是相同的,从源码中可以看出: getLayoutInflater(): Activity 的 getLayoutInflater() 方法是调用 PhoneWindow 的getLayoutInflater()方法,看一下该源代码: public PhoneWindow(Context context) { super(context); mLayoutInflater = LayoutInflater.from(context); } 可以看出它其实是调用 LayoutInflater.from(context)。 LayoutInflater.from(context): public static LayoutInflater from(Context context) { LayoutInflater LayoutInflater = (LayoutInflater) context.getSystemService (Context.LAYOUT_INFLATER_SERVICE); if (LayoutInflater == null) { throw new AssertionError("LayoutInflater not found."); } return LayoutInflater; } 可以看出它其实调用 context.getSystemService()。 结论:所以这三种方式最终本质是都是调用的Context.getSystemService()。 另外getSystemService()是Android很重要的一个API,它是Activity的一个方法,根据传入的NAME来取得对应的Object,然后转换成相应的服务对象。以下介绍系统相应的服务。 传入的Name 返回的对象 说明 WINDOW_SERVICE WindowManager 管理打开的窗口程序 LAYOUT_INFLATER_SERVICE LayoutInflater 取得xml里定义的view ACTIVITY_SERVICE ActivityManager 管理应用程序的系统状态 POWER_SERVICE PowerManger 电源的服务 ALARM_SERVICE AlarmManager 闹钟的服务 NOTIFICATION_SERVICE NotificationManager 状态栏的服务 KEYGUARD_SERVICE KeyguardManager 键盘锁的服务 LOCATION_SERVICE LocationManager 位置的服务,如GPS SEARCH_SERVICE SearchManager 搜索的服务 VEBRATOR_SERVICE Vebrator 手机震动的服务 CONNECTIVITY_SERVICE Connectivity 网络连接的服务 WIFI_SERVICE WifiManager Wi-Fi服务 TELEPHONY_SERVICE TeleponyManager 电话服务 inflate 方法 通过 sdk 的 api 文档,可以知道该方法有以下几种过载形式,返回值均是 View 对象,如下: public View inflate (int resource, ViewGroup root) public View inflate (XmlPullParser parser, ViewGroup root) public View inflate (XmlPullParser parser, ViewGroup root, boolean attachToRoot) public View inflate (int resource, ViewGroup root, boolean attachToRoot) 示意代码: LayoutInflater inflater = (LayoutInflater)getSystemService(LAYOUT_INFLATER_SERVICE); View view = inflater.inflate(R.layout.custom, (ViewGroup)findViewById(R.id.test)); //EditText editText = (EditText)findViewById(R.id.content);// error EditText editText = (EditText)view.findViewById(R.id.content); 对于上面代码,指定了第二个参数 ViewGroup root,当然你也可以设置为 null 值。 注意: ·inflate 方法与 findViewById 方法不同; ·inflater 是用来找 res/layout 下的 xml 布局文件,并且实例化; ·findViewById() 是找具体 xml 布局文件中的具体 widget 控件(如:Button、TextView 等)。
摘要: 做项目时,感觉android自带的弹出框样式比较丑,很多应用都是自己做的弹出框,这里也试着自己做了一个。废话不说先上图片:实现机制1.先自定义一个弹出框的样式2.自己实现CustomDialog类,继承自Dialog,实现里面方法,在里面加载自定义样式的弹出框;3.使用时,与使用Dialog一样具体代码dialog_normal_layout.xml样式文件[html] view pla... 阅读全文
在LinearLayout中,如果将其定位方向设为横向排列:android:orientation="horizontal",那么这个布局中的控件将自左向右排列。 但有时会有这样的情况:行的左边有两个控制的同时,行的右边也有一个控制。 如图:![]() 这怎么处理呢? 我们可以将右边的控件放在另一个LinearLayout中,同时将其对齐方式设为右对齐:android:gravity="right",还有一点,这个LinearLayout的宽度设为充满父控件: android:layout_width="fill_parent"。这样就行了。 完整的XML代码如下: Xml代码  - <?xml version="1.0" encoding="utf-8"?>
- <LinearLayout xmlns:android="http://schemas.android.com/apk/res/android"
- android:layout_width="fill_parent"
- android:layout_height="fill_parent"
- android:background="@drawable/bg"
- android:orientation="horizontal" >
-
- <TextView
- android:layout_width="wrap_content"
- android:layout_height="wrap_content"
- android:text="左边1" />
-
- <TextView
- android:layout_width="wrap_content"
- android:layout_height="wrap_content"
- android:text="左边2" />
- <!-- 将TextView包在另一个LinearLayout中
- 注意android:layout_width和android:gravity这两个属性
- -->
- <LinearLayout
- android:layout_width="fill_parent"
- android:layout_height="wrap_content"
- android:gravity="right" >
-
- <TextView
- android:layout_width="wrap_content"
- android:layout_height="wrap_content"
- android:layout_marginRight="10dp"
- android:text="右边" />
- </LinearLayout>
-
- </LinearLayout>
摘要: declare-styleable:declare-styleable是给自定义控件添加自定义属性用的。官方的相关内部控件的配置属性文档:http://developer.android.com/reference/android/R.styleable.html如果不知道如何查看源码:点击这里起初,在自定义控件的时候,会要求构造3个方法中的一个或多个,好比我自定义的控件PersonView,[j... 阅读全文
有时候我们不满足于系统控件的外观要改变一些背景,文字颜色等,这些属性可以在代码里更改,随便哪种控件,我们点,后面会出来一大串set开头的方法。但是在代码里这样改来改去还是比较麻烦的,如果同样的控件多了,重复的代码也比较多。控件的这些属性也是可以在xml文件里改的,同样的控件多了,还是会带来代码的重复。这进我们就可以用设置控件样子式的方法了。下面以EditText控件为例来说明如何来设置一个控件的样式,工程序源码可以在后面下载; 第一步建立一个新的工程,在main布局里面建立三个EditText控件。 第二步在工程的res/values文件夹下新建一个xml文件内容如下:
<?xml version="1.0" encoding="utf-8"?>
<resources>
<style name="et1" parent="@android:style/Widget.EditText">
<item name="android:background">#1A4EA4</item>
<item name="android:textColor">#FFF111</item>
</style>
<style name="et2" parent="@android:style/Widget.EditText">
<item name="android:background">#A6C60F</item>
<item name="android:textColor">#EC02C3</item>
</style>
</resources>
<!--
说明:
这里建立了两种样式,从字面意思上可以看出这两中样式分别都更改了背景颜色和文字颜色
,一个控件可以更改的属性有很多,这里只改了两个,要改其它的属性,我们要知道属性的name,
才可以改。那所有的属性的名字在哪呢?找了一番终于找到了,所有的属性的名字在一个attrs.xml
文件里。这个文件存在于:android sdk目录\data\res\values 目录下,找到这个文件以后我们
改某些属性时可以做为查看的资料了。
上面的两个样式中,都有一个parent属性。这就不难理解style是可以继承的。在这里我们继
承的是系统默认的EditText属性,只修改了背景和文字颜色而已。那系统的EditText样式是在哪
定义的呢?找了一番终于也找到了,所有系统控件的样式是在一个style.xml文件中,这个文件也
在上面说的那个目录下。里面我们可以找到Widget.EditText的样式定义。有了它我们也可以查看
某一种控件可以更改哪些样式了。
在设置style时,我们经常用到@和?@表明引用的的资源是在一个项目或是系统框架中定义过
的。?表明引用的资源是在当前的主题定义过的。
上面的设置背景中的值除了可以是颜色的值外,还可以是一个图片的引用哦~~。
-->
第三步我们修改main布局文件中EditText的属性。为了对比,我们将第一个属性将做改变,第二个的style属性设为我们上面建立的name为et1的样式。第三个的style属性设为我们上面建立的name为et2的样式,代码如下: <?xml version="1.0" encoding="utf-8"?>
<LinearLayout xmlns:android="http://schemas.android.com/apk/res/android"
android:layout_width="fill_parent" android:layout_height="fill_parent"
android:orientation="vertical">
<EditText android:layout_width="fill_parent"
android:layout_height="wrap_content" android:text="默认样式" android:id="@+id/et1"></EditText>
<EditText android:layout_width="fill_parent" android:id="@+id/et2"
android:text="自定义样式一" android:layout_height="wrap_content" style="@style/et1"></EditText>
<EditText android:layout_width="fill_parent" android:id="@+id/et3"
android:text="自定义样式二" android:layout_height="wrap_content" style="@style/et2"></EditText>
<Button android:text="改变主题" android:id="@+id/btn1"
android:layout_width="fill_parent" android:layout_height="wrap_content"></Button>
</LinearLayout> 加了一个改变主题的按钮是无效的,下一篇会用到它来设置主题。虽然定义好了style文件,但似乎并不能在java代码里设置,我没有发现像setStyle()这样的方法。所以就不 能在java代码里能过style文件动态改变控件的样式, 不知道哪位仁兄可以解决此问题,特在此求教了。 无图无真相,下面是截图: 
Android中布局的单位很多,如:(dp、sp、px、in、pt、mm) 但是他们之间有什么区别了?又该在什么时候使用了?我想即使是很有经验的开发者有时也会不明白吧。 现在这里介绍一下dp和sp。dp也就是dip。这个和sp基本类似。如果设置表示长度、高度等属性时可以使用dp 或sp。但如果设置字体,需要使用sp。dp是与密度无关,sp除了与密度无关外,还与scale无关。如果屏幕密度为160,这时dp和sp和px是一样的。1dp=1sp=1px,但如果使用px作单位,如果屏幕大小不变(假设还是3.2寸),而屏幕密度变成了320。那么原来TextView的宽度设成160px,在密度为320的3.2寸屏幕里看要比在密度为160的3.2寸屏幕上看短了一半。但如果设置成160dp或160sp的话。系统会自动将width属性值设置成320px的。也就是160 * 320 / 160。其中320 / 160可称为密度比例因子。也就是说,如果使用dp和sp,系统会根据屏幕密度的变化自动进行转换。 px:表示屏幕实际的象素。例如,320*480的屏幕在横向有320个象素,在纵向有480个象素。
in:表示英寸,是屏幕的物理尺寸。每英寸等于2.54厘米。例如,形容手机屏幕大小,经常说,3.2(英)寸、3.5(英)寸、4(英)寸就是指这个单位。这些尺寸是屏幕的对角线长度。如果手机的屏幕是3.2英寸,表示手机的屏幕(可视区域)对角线长度是3.2*2.54 = 8.128厘米。读者可以去量一量自己的手机屏幕,看和实际的尺寸是否一致。
mm:表示毫米,是屏幕的物理尺寸。
pt:表示一个点,是屏幕的物理尺寸。大小为1英寸的1/72。
Windows
修改 C:\Windows\System32\drivers\etc\hosts Linux/Mac
修改 /etc/hosts 在最后添加一行:
74.125.237.1 dl-ssl.google.com 原理就是:我们输入网站时,一般都是通过DNS 域名解析。
但是顺序为:先读取 hosts 文件,是否有对应的IP,若有直接通过此IP访问。没有的话,就通过 DNS 解析到的 IP 访问,但是GOOGLE,在内地是没有服务器的,一般解析不到的。
全球著名投资管理公司Efficient Frontier Advisors联合创始人William Bernstein最近出版了新书,名为 If You Can: How Millennials Can Get Rich Slowly,书中介绍了掌握一些基础金融知识的重要性。 他还在自己的网页上为读者列出了一份投资书单(书单信息来自 华尔街见闻)
这几天这份书单被各大网站所转载 也有热心的坛友发布到了论坛 http://bbs.pinggu.org/thread-3039669-1-1.html http://bbs.pinggu.org/thread-3040268-1-1.html
结合咱论坛自身优势,小冰把书籍下载链接附上 还有几本书下载链接没找到 欢迎大家补充,找到一个链接,奖励50论坛币,如果能上传论坛没有的新的下载文件,奖励100论坛币~~ 咱们一起努力把书单补齐吧~
1. 《漫步华尔街》 A Random Walk Down Wall Street 作者:Burton Malkiel Bernstein荐言:这是一本非常棒的投资初级读本,解释了股票、债券和共同基金的一些基础知识,书中还强调了有效市场的概念。
http://bbs.pinggu.org/thread-935209-1-1.html
2. 《共同基金常识》 Common Sense on Mutual Funds
作者:John Bogle Bernstein荐言:这本书提供了关于共同基金的细节,要多详细就有多详细。John Bogle本人就是投资巨头Vanguard集团的创始人,他的话在这个行业中一直掷地有声。 http://bbs.pinggu.org/thread-563219-1-1.html
3. 《全球投资》 Global Investing
作者:Roger Ibbotson、 Gary Brinson Bernstein荐言:本书介绍了可投资资产的历史,投资者总是会对市场的历史求知若渴,这本书无疑是该类书籍中最好的选择。你能够从这本书中了解到过去200年中的美国股市、过去500年中的黄金价格、过去800年中的利率和通胀等等,该书对外国资产的投资也有详尽介绍。
4. 《有效的投资之道》 What Has Worked in Investing
作者: Tweedy Browne投资公司 Bernstein荐言:这是一个免费的投资小册子,是我见过的价值投资方法中最善于用数据提供论据支持的内容。 http://bbs.pinggu.org/thread-964326-1-1.html
5. The New Finance, the Case Against Efficient Markets
作者:Robert Haugen Bernstein荐言:如果上面那本小册子让你有迷惑为何价值投资在多年之后仍然有效,那么你就可以看看这本书。
6. 《价值平均法》 Value Averaging
作者:Michael Edleson Bernstein荐言:如何在多种多样的资产面前分配你的资金?这本书提供了很有用的指导。
7. 《聪明的投资者》 The Intelligent Investor
作者:Ben Graham Bernstein荐言:这本书非常出名,比起之前的版本《证券分析》更有可读性也更大众化。对于想要购买个股的投资者尤为适用。许多如今的金融大鳄们都从这两本书中得到了启迪。(如果你想读《证券分析》,推荐1934年原版,最近McGraw-Hill出版社有印发) http://bbs.pinggu.org/thread-2864998-1-1.html
8. 《魔鬼来袭》 Devil Take the Hindmost
作者:Edward Chancellor Bernstein荐言:本书讲述了17世纪以来资本市场的泡沫盒泡沫的破裂,可以与Mackay的那本Extraordinary Popular Delusions and the Madness of Crowds相媲美。
9. 《邻家的百万富翁》 The Millionaire Next Door
作者:Thomas Stanley、William Danko Bernstein荐言:如果你是巴菲特,你就不用愁攒不下钱。这本书也是大众投资者了解金融知识的好地方。 http://bbs.pinggu.org/thread-787856-1-1.html
10. 《资产配置》 Asset Allocation
作者:Roger Gibson Bernstein荐言:这本书着重强调了个人资产的质量问题,对于投资热爱者和金融顾问尤为适用。
再分享几个金融学书单~~
高盛推荐金融书单+下载 http://bbs.pinggu.org/thread-2468145-1-1.html http://bbs.pinggu.org/thread-2322467-1-1.html
金融学入门教材推荐+下载
http://bbs.pinggu.org/thread-2917977-1-1.html
金融从业者的必看实务类图书
http://bbs.pinggu.org/thread-1355508-1-1.html
金融从业者的10大必看图书 http://bbs.pinggu.org/thread-1354694-1-1.html
摘要: .同源策略如下:URL说明是否允许通信http://www.a.com/a.jshttp://www.a.com/b.js同一域名下允许http://www.a.com/lab/a.jshttp://www.a.com/script/b.js同一域名下不同文件夹允许http://www.a.com:8000/a.jshttp://www.a.com/b.js同一域名,不同端口不允许http://w... 阅读全文
Dijit 的类文件Dijit 的类也是一个 Dojo 类,所以 Dijit 类的声明和定义也是用 dojo.declare 函数,如清单 10 和清单 13 所示。Dijit 类既然是 Dojo 类,自然也可以继承其它类或被其它类所继承。实际上,一个 Dijit 类区别于其它 Dojo 类最重要的一点是,Dijit 类都直接或间接地继承于类 dijit._Widget,大部分的 Dijit 类通过 mixin 的方式继承类 dijit._Templated,如清单 13 中的 [dijit._Widget,dijit._Templated]。 让我们回过头来看看清单 13,清单 13 中,有一个属性叫 templatePath,从名字就可以看出来,这个属性指定了 template 文件的路径。除了指定 template 文件的路径外,也可以直接把 template 变成一个字符串放到类定义文件中,这种情况下,要用到的属性就是 templateString 了。 除了 templatePath 和 templateString 以外,还有很多扩展点可以根据实际需要重载,这些扩展点覆盖了 dijit 的整个生命周期,具体列举如下: constructor: constructor 会在设置参数之前被调用,可以在这里进行一些初始化的工作。Constructor 结束后,便会开始设置 Dijit 实例的属性值,即把 dijit 标签中定义的属性值赋给 dijit 实例。 postMixInProperties: 如果你在你的 dijit 中重载这个函数,它会在 dijit 展现之前,并且在 dom 节点生成之前被调用。如果你需要在 dijit 展现之前,修改实例的属性,可以在这里实现。 buildRendering: 通常情况下这个函数你不需要去重载,因为 _Templated 为在这里为你做好所有的事情,包括 dom 节点的创建,事情的连接,attach point 的设置。除非你要开发一套完全不一样的模板系统,否则建议你不要重载这个函数。 postCreate: 这个函数会在 dijit 创建之后,子 dijit 创建之前被调用。 startup: 当你需要确保所有的子 dijit 都被创建出来了,你可以调用这个函数。 destroy: 会在 dijit 被销毁时被调用,你可以在这里进行一些资源回收的工作
1、mvn archetype:create -DgroupId=org.david.app -DartifactId=mywebapp -DarchetypeArtifactId=maven-archetype-webapp
2、cd mywebapp
mvn eclipse:eclipse
导入eclipse工程
(或者直接从eclipse中导入maven工程)
3、添加servlet依赖
<dependency>
<groupId>javax.servlet</groupId>
<artifactId>servlet-api</artifactId>
<version>2.5</version>
</dependency>
4、添加源代码目录src/main/java
将源代码放在该目录下。
5、添加jetty插件
<build>
<finalName>mywebapp</finalName>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<configuration>
<source>1.5</source>
<target>1.5</target>
</configuration>
</plugin>
<plugin>
<groupId>org.mortbay.jetty</groupId>
<artifactId>maven-jetty-plugin</artifactId>
</plugin>
</plugins>
</build>
6、用jetty调试(http://www.blogjava.net/alwayscy/archive/2007/06/01/118584.html)
命令行:mvn jetty:run
或者
1、先来配置一个外部工具,来运行JETTY:
选择菜单Run->External Tools->External Tools ...在左边选择Program,再点New:
配置Location为mvn完整命令行。定位到bin下的mvn.bat
选择Working Directory为本项目。
Arguments填写:jetty:run
再点选Enviroment页:加入MAVEN_OPTS变量,值为:
-Xdebug -Xnoagent -Djava.compiler=NONE -Xrunjdwp:transport=dt_socket,address=8080,server=y,suspend=y
其中,如果suspend=n 表示不调试,直接运行。address=8080为端口
然后,点APPLY,再关闭本对话框。
另外注意一点,好像external tool菜单项在java browering的perspective下才会出现。如果在java下看不见,可以切换下试试。
启动jetty
2、调试应用
点选run->debug...
选中左树中的Remote Java Application,再点New。
选择你的项目,关键是要填和之前设置外部工具时相同的端口号。
1.震动 先说简单的,震动提示 第一步,在AndroidManifest.xml 里声明权限 <uses-permissionandroid:name="android.permission.VIBRATE"/> 第二步,获得震动服务并启动 Vibrator vibrator = (Vibrator)activity.getSystemService(Context.VIBRATOR_SERVICE); vibrator.vibrate(newlong[]{300,500},0); 经过以上两步,就启动震动了。上述代码直接在程序中调用就可以了,这个是比较简单的,比大象放冰箱要少一步。Vibrate()的参数网上能查到,看看就知道了。 2.提示铃声 第一步,1.准备一个音频文件比如:beep.ogg。先把音频文件导入到res/raw文件夹下,需要注意的是这个文件下的文件名必须是小写,之后导入即可。 第二步,为activity注册的默认音频通道。这个一般在onCreate()函数中注册即可。 activity.setVolumeControlStream(AudioManager.STREAM_MUSIC); 第三步,检查当前情景模式,确定不要是静音。 第四步,初始化MediaPlayer对象,指定播放的声音通道为 STREAM_MUSIC,这和上面的步骤一致,指向了同一个通道。 MediaPlayer mediaPlayer = new MediaPlayer();//这个我定义了一个成员函数 mediaPlayer.setAudioStreamType(AudioManager.STREAM_MUSIC); 第五步,注册事件。当播放完毕一次后,重新指向流文件的开头,以准备下次播放。 mediaPlayer .setOnCompletionListener(newMediaPlayer.OnCompletionListener() { @Override public voidonCompletion(MediaPlayer player) { player.seekTo(0); } }); 第六步,设定数据源,并准备播放 AssetFileDescriptor file =activity.getResources().openRawResourceFd( R.raw.beep); try{ mediaPlayer.setDataSource(file.getFileDescriptor(), file.getStartOffset(), file.getLength()); file.close(); mediaPlayer.setVolume(BEEP_VOLUME,BEEP_VOLUME); mediaPlayer.prepare(); }catch (IOException ioe) { Log.w(TAG, ioe); mediaPlayer = null; } 第七步,开始播放 mediaPlayer.start(); 经过以上几步,就可以实现手机的铃声了。
1.显示调用方法
- Intent intent=new Intent(this,OtherActivity.class); //方法1
- Intent intent2=new Intent();
- intent2.setClass(this, OtherActivity.class);//方法2
- intent2.setClassName(this, "com.zy.MutiActivity.OtherActivity"); //方法3 此方式可用于打开其它的应用
- intent2.setComponent(new ComponentName(this, OtherActivity.class)); //方法4
- startActivity(intent2);
2.隐式调用方法(只要action、category、data和要跳转到的Activity在AndroidManifest.xml中设置的匹配就OK 3.跳转到另一个Activity后,当返回时能返回数据 - 在跳转的Activity端,调用startActivityForResult(intent2, 1),跳转到下一个Activity,其中第一个参数为传入的意图对象,第二个为设置的请求码;
- 跳转到第二个Activity后,调用setResult(100, intent)方法可返回上一个Activity,其中第一个参数为结果码,第二个为传入的意图对象;
- 在第一个Activity通过onActivityResult()方法获得返回的数据。
PS:有的人安装过程中遇到这个问题this computer meets the reauirements for HAXM,but.... 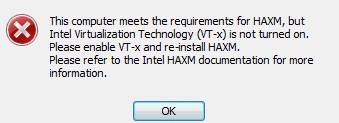
这个问题应该是CPU可能默认没有开Vt,所以得去bios开了再说。进了bios找到virtual technology选项,选择enable即可。
android的模拟器一直以来是它的一大败笔,启动需要很长时间,运行起来也超慢,虽说可以通过创建模拟器时更改参数,但速度还是不理想。所以,以前开发时,一直用真机调试,可它的接口又是那么的脆弱,用不了多久,就接触不良了,这个问题一直困扰很多人。之前发现过一种方法,可以通过WIFI调试,但是需要有无线路由器,而且很多手机对这个支持不太好。前几天同事分享了一种方法(API guid里面有讲),可以让模拟器在X86架构的机器上以原生的速度运行。 方法很简单: 1.通过android sdk manager下载" Intel Hardware Accelerated Execution Manager",下载完成后,在SDK目录中找到下载文件并安装它。 2.通过android sdk manager 下载 “Intel x86 Atom System Image 3.创建Intel x86的模拟器。 下面就可以使用创建的这个x86的模拟器进行调试了,速度非常快,我用的MacBook装的WIN7,启动模拟器只需要几秒,运行APP速度跟我的三星I9001一样流畅,需要注意的是: 1.android sdk tools 至少要R17以上,android sdk API 至少要15 2.自己的电脑要给力,我的模拟器给它分了2G的内存,所以速度特别快。 不上图了,下面是文档地址:http://developer.android.com/tools/devices/emulator.html
首先打开sdk manager,确定有x86的image。如下图 4.2只有ARM的image,所以不好使,还得用4.1.2的(2013年1月31日,4.2版本已有x86的image) 
然后下载一下intelHAXM 
然后进到sdk\extras\intel\Hardware_Accelerated_Execution_Manager去点击exe,一路next安装一下。 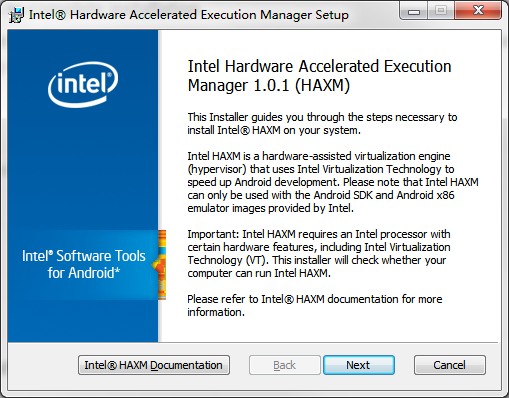
为了确认是否开了,打开命令行 输入 sc query intelhaxm 然后像下面State 是running就对了。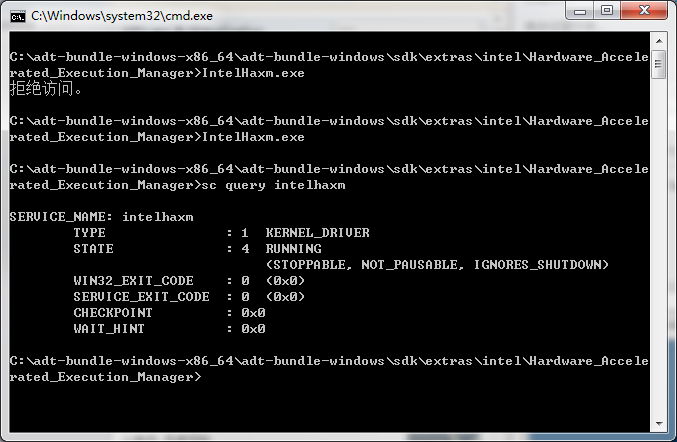
CPU可能默认没有开Vt,所以得去bios开了再说。
然后建立AVD cpu/abi的地方记得选x86的 然后下面的Hardware部分要new一下,搞出来GPU emulation 然后选择yes 
更新了adt到21.0.1后,创建AVD的界面有些不同。如下图,在Emulation Options里要选上Use Host GPU. 
然后就可以了,启动AVD 
显示HAX is working。
用途显示关于卷组的信息。 语法lsvg [ -L ] [ -o ] |[ -n DescriptorPhysicalVolume ] | [ -i ] [ -l | -M | -p ] VolumeGroup ... 描述lsvg 命令显示关于卷组的信息。如果使用 VolumeGroup 参数,只显示那个卷组的信息。如果不使用VolumeGroup 参数,显示所有已定义的卷组名列表。 当来自“设备配置”数据库的信息不可用时,某些字段将会包含一个问号(?)替代丢失的数据。当对命令给出一个逻辑卷标识时,lsvg 命令试图从描述区域获得尽可能多的信息。 注:要确定卷组的主数,请使用 ls -al /dev/VGName 命令。这个命令列出代表卷组的特殊设备文件。卷组主数与特殊的设备文件的主设备号相同。例如,对于名为 ha1vg 的卷组,请输入如下命令:ls -al /dev/ha1vg 该命令返回以下内容: crw-rw---- 1 root system 52, 0 Aug 27 19:57 /dev/ha1vg 在本示例中,卷组主数是 52。 您可以使用基于 Web 的系统管理器(wsm)中的卷应用程序来更改卷组特性。您也可以使用“系统管理接口工具”(SMIT)smit lsvg 快速路径来运行此命令。 标志| -L | 指定不等待获取卷组锁。注:如果要更改卷组,那么使用 -L 标志会带来不可靠的日期。 | | -p | 对于用 VolumeGroup 参数指定的组内的每个物理卷列出以下信息:- Physical volume
- 组内的一个物理卷。
- PVstate
- 物理卷的状态。
- Total PPs
- 物理卷上的物理分区总数。
- Free PPs
- 物理卷上的空闲物理分区数。
- Distribution
- 物理卷的每节中分配的物理分区数:物理卷的外边、外中、正中、内中和内边。
| | -l | 列出由 VolumeGroup 参数指定的组内的每个逻辑卷的以下信息:- LV
- 卷组内的一个逻辑卷。
- Type
- 逻辑卷类型。
- LPs
- 逻辑卷中的逻辑分区数。
- PPs
- 逻辑卷使用的物理分区数。
- PVs
- 逻辑卷使用的物理卷数。
- Logical volume state
- 逻辑卷的状态。Opened/stale 表示逻辑卷是打开的但包含的分区不是当前的。Opened/syncd 表示逻辑卷是打开和同步的。Closed 表示逻辑卷还没有打开。
- Mount point
- 逻辑卷的文件系统安装点(如果适用)。
| | -i | 从标准输入中读取卷组名。 | | -M | 列出物理卷上的每个逻辑卷的以下字段:PVname:PPnum [LVname: LPnum [:Copynum] [PPstate]] - PVname
- 系统指定的物理卷名。
- PPnum
- 物理分区号。物理分区号范围为 1 到 1016。
- LVname
- 分配的物理卷的逻辑卷名。逻辑卷名必须是系统范围内唯一的名称,它可以是 1 到 64 个字符。
- LPnum
- 逻辑分区号。逻辑分区号的范围为 1 到 64000。
- Copynum
- 镜像号。
- PPstate
- 只有在非当前物理卷上的物理分区才显示为旧文件。
| | -n DescriptorPhysicalVolume | 由 DescriptorPhysicalVolume 变量指定描述符区域的访问信息。由于使用 -n 标志访问的信息没有对该逻辑卷进行验证,故这些信息可能不是当前信息。如果不使用 -n 标志,那么物理卷的描述符区域保留着最有效的访问信息,因此显示的信息是当前的。当使用这个标志时,卷组不一定是活动的。 | | -o | 仅列出活动的卷组(那些变化的卷组)。一个活动的卷组是可以使用的卷组。 |
如果不指定任何标志,则显示以下信息: | Volume group | 卷组名。卷组名在系统范围内必须是唯一的并且可以是 1 到 15 个字符。 | | Volume group state | 卷组状态。如果使用 varyonvg 命令激活了卷组,那么卷组状态是active/complete(表明所有物理卷是活动的)或 active/partial(表明某些物理卷不是活动的)。如果没有用 varyonvg 命令激活卷组,那么卷组状态是 inactive。 | | Permission | 访问许可权:只读或读写。 | | Max LVs | 卷组中允许的逻辑卷的最大数目。 | | LVs | 当前在卷组中的逻辑卷数。 | | Open LVs | 当前打开的卷组内的逻辑卷数。 | | Total PVs | 卷组内的物理卷的总数。 | | Active PVs | 当前活动的物理卷数。 | | VG identifier | 卷组标识。 | | PP size | 每个物理分区的大小。 | | Total PPs | 卷组内的物理分区的总数。 | | Free PP | 没有分配的物理分区数。 | | Alloc PPs | 当前分配到逻辑卷的物理分区数。 | | Quorum | 多数需要的物理卷数。 | | VGDS | 卷组内的卷组描述符区域数。 | | Auto-on | 在 IPL 上自动激活(yes 或 no)。 | | Concurrent | 表明卷组状态是“可并发的”或“不可并发的”。 | | Auto-Concurrent | “当前可用”卷组状态是否在并发和非并发方式间自动改变的状态。对于“不可并发的”卷组,缺省值为 Disabled。 | | VG Mode | 卷组方式变化:“并发”或“非并发”。 | | Node ID | 如果卷组在并发节点变化的当前节点的节点标识。 | | Active Nodes | 使卷组变化的其它并发卷组节点的节点标识。 | | Max PPs Per PV | 卷组允许的每个物理卷的物理分区的最大数目。 | | Max PVs | 卷组允许的物理卷的最大数目。 | | LTG size | 卷组的逻辑磁道组大小(千字节数)。 | | BB POLICY | 卷组的坏块重定位策略。 | | SNAPSHOT VG | 如果快照卷组是活动的,则为快照卷组名,否则为快照卷组标识。 | | PRIMARY VG | 如果原始卷组是活动的,则为快照卷组的原始卷组名,否则为原始卷组标识。 |
示例- 要显示所有活动的卷组名,请输入:
lsvg -o
- 要显示系统内的所有卷组名,请输入:
lsvg - 要显示关于 vg02 卷组的信息,请输入:
lsvg vg02 显示卷组 vg02 逻辑分区和物理分区的特性和状态。 - 要显示卷组 vg02 中的所有逻辑卷的名称、特性和状态,请输入:
lsvg -l vg02
文件| /usr/sbin | 包含 lsvg 命令驻留的目录。 |
相关信息chvg 命令、lspv 命令、lslv 命令、varyonvg 命令。 AIX 5L Version 5.2 System Management Concepts: Operating System and Devices 中的 Logical Volume Storge Overview 解释“逻辑卷管理程序”、物理卷、逻辑卷、卷组、组织、确保数据完整性和分配特性。 有关安装基于 Web 的系统管理器的信息,请参阅《AIX 5L V5.2 基于 Web 的系统管理器管理指南》中的『第 2 章:安装基于 Web 的系统管理器』。 AIX 5L Version 5.2 System Management Concepts: Operating System and Devices 中的 System Management Interface Tool(SMIT):Overview 解释结构、主菜单和 SMIT 执行的任务。 VG 卷组 Volume Group (VG) 是计算机上的术语(操作系统的VG概念) 一个VG是由许多物理分区组成的(可能来自多个物理卷或硬盘)。虽然这可能容易让你认为一个VG就是由几个硬盘组成的(例如/dev/hda和/dev/sda),但是更确切的说,它包含由这些硬盘提供的许多PE(物理分区 Physical Extents)。 卷组 = VG (Volume Group) IBM将一组物理卷的集合称为卷组 卷组的操作: 磁盘空间通常在一个卷组内分配 AIX中的所有可用磁盘 - 当作一个组来使用 可以export用于与其它的AIX系统连接 - 高可用性的HACMP 系统的第一个VG 称为rootvg
MongoDB使用手册 一、安装包下载地址 http://www.mongodb.org/downloads 二、服务器端使用 LINUX版本: ①用tar -zxvf mongodb-linux-x86_64-1.2.4.tgz解压开安装包 ②mkdir -p /data/db 创建目录 ③cd /data/db 进入db目录下 然后创建mkdir m_data m_log ④进入mongodb解压目录的bin目录下,用 ./mongod -fork --dbpath=./data/db/m_data/ --logpath=./m_log.log --logappend --port=27017 & 启动服务器。 WINDOW版本: | 执行如下命令启动服务器: mongod --bind_ip 127.0.0.1 --logpath d:\data\logs --logappend --dbpath d:\data\db --directoryperdb –install | 【注:将mongodb安装成服务,装该服务绑定到IP127.0.0.1,日志文件为d:\data\logs,以及添加方式记录。数据目录为d:\data\db。并且每个数据库将储存在一个单独的目录(--directoryperdb)】 三、客户端使用: LINUX版本: 进入MongoDB的bin目录下,使用./mongo进入命令行行下 然后即可进行增删改查等日常操作。 WINDOW版本: 进入mongodb的bin目录下,使用mongo.exe --host IP --port 端口连接到MongoDB服务器上 四、MongDB停止 LINUX版本: 如果在shell窗口下可以直接按“CTRL+C”,如果是作为后台服务使用时,可以先使用 ps -ef |grep mongod查询出服务器的pid,然后使用kill -9 pid 此处的Pid为查询出的pid。 WINDOW版本: 如果在命令窗口下直接按“CTRL+C”,如果是作为系统服务来使用的话,需要到服务管理中停止服务或者在window管理器中终止进程。 五、web版本的统计服务状态 使用http://IP(服务器IP):端口即可 六、语法 1、基本操作 db.AddUser(username,password) 添加用户 db.auth(usrename,password) 设置数据库连接验证 db.cloneDataBase(fromhost) 从目标服务器克隆一个数据库 db.commandHelp(name) returns the help for the command db.copyDatabase(fromdb,todb,fromhost) 复制数据库fromdb---源数据库名称,todb---目标数据库名称,fromhost---源数据库服务器地址 db.createCollection(name,{size:3333,capped:333,max:88888}) 创建一个数据集,相当于一个表 db.currentOp() 取消当前库的当前操作 db.dropDataBase() 删除当前数据库 db.eval(func,args) run code server-side db.getCollection(cname) 取得一个数据集合,同用法:db['cname'] or db.getCollenctionNames() 取得所有数据集合的名称列表 db.getLastError() 返回最后一个错误的提示消息 db.getLastErrorObj() 返回最后一个错误的对象 db.getMongo() 取得当前服务器的连接对象get the server db.getMondo().setSlaveOk() allow this connection to read from then nonmaster membr of a replica pair db.getName() 返回当操作数据库的名称 db.getPrevError() 返回上一个错误对象 db.getProfilingLevel() db.getReplicationInfo() 获得重复的数据 db.getSisterDB(name) get the db at the same server as this onew db.killOp() 停止(杀死)在当前库的当前操作 db.printCollectionStats() 返回当前库的数据集状态 db.printReplicationInfo() db.printSlaveReplicationInfo() db.printShardingStatus() 返回当前数据库是否为共享数据库 db.removeUser(username) 删除用户 db.repairDatabase() 修复当前数据库 db.resetError() db.runCommand(cmdObj) run a database command. if cmdObj is a string, turns it into {cmdObj:1} db.setProfilingLevel(level) 0=off,1=slow,2=all db.shutdownServer() 关闭当前服务程序 db.version() 返回当前程序的版本信息 2、数据集(表)操作 db.test.find({id:10}) 返回test数据集ID=10的数据集 db.test.find({id:10}).count() 返回test数据集ID=10的数据总数 db.test.find({id:10}).limit(2) 返回test数据集ID=10的数据集从第二条开始的数据集 db.test.find({id:10}).skip(8) 返回test数据集ID=10的数据集从0到第八条的数据集 db.test.find({id:10}).limit(2).skip(8) 返回test数据集ID=1=的数据集从第二条到第八条的数据 db.test.find({id:10}).sort() 返回test数据集ID=10的排序数据集 db.test.findOne([query]) 返回符合条件的一条数据 db.test.getDB() 返回此数据集所属的数据库名称 db.test.getIndexes() 返回些数据集的索引信息 db.test.group({key:...,initial:...,reduce:...[,cond:...]}) db.test.mapReduce(mayFunction,reduceFunction,<optional params>) db.test.remove(query) 在数据集中删除一条数据 db.test.renameCollection(newName) 重命名些数据集名称 db.test.save(obj) 往数据集中插入一条数据 db.test.stats() 返回此数据集的状态 db.test.storageSize() 返回此数据集的存储大小 db.test.totalIndexSize() 返回此数据集的索引文件大小 db.test.totalSize() 返回些数据集的总大小 db.test.update(query,object[,upsert_bool]) 在此数据集中更新一条数据 db.test.validate() 验证此数据集 db.test.getShardVersion() 返回数据集共享版本号 3、MongoDB语法与现有关系型数据库SQL语法比较 | MongoDB语法 MySql语法 db.test.find({'name':'foobar'}) <==> select * from test where name='foobar' db.test.find() <==> select * from test db.test.find({'ID':10}).count() <==> select count(*) from test where ID=10 db.test.find().skip(10).limit(20) <==> select * from test limit 10,20 db.test.find({'ID':{$in:[25,35,45]}}) <==> select * from test where ID in (25,35,45) db.test.find().sort({'ID':-1}) <==> select * from test order by ID desc db.test.distinct('name',{'ID':{$lt:20}}) <==> select distinct(name) from test where ID<20 db.test.group({key:{'name':true},cond:{'name':'foo'},reduce:function(obj,prev){prev.msum+=obj.marks;},initial:{msum:0}}) <==> select name,sum(marks) from test group by name db.test.find('this.ID<20',{name:1}) <==> select name from test where ID<20 db.test.insert({'name':'foobar','age':25})<==>insert into test ('name','age') values('foobar',25) db.test.remove({}) <==> delete * from test db.test.remove({'age':20}) <==> delete test where age=20 db.test.remove({'age':{$lt:20}}) <==> elete test where age<20 db.test.remove({'age':{$lte:20}}) <==> delete test where age<=20 db.test.remove({'age':{$gt:20}}) <==> delete test where age>20 db.test.remove({'age':{$gte:20}}) <==> delete test where age>=20 db.test.remove({'age':{$ne:20}}) <==> delete test where age!=20 db.test.update({'name':'foobar'},{$set:{'age':36}}) <==> update test set age=36 where name='foobar' db.test.update({'name':'foobar'},{$inc:{'age':3}}) <==> update test set age=age+3 where name='foobar' | 4、 七、MongoDB主从复制介绍 MongoDB的主从复制其实很简单,就是在运行 主的服务器 上开启mongod进程 时,加入参数--master即可,在运行从的服务 器上开启mongod进程时,加入--slave 和 --source 指定主即可,这样,在主数据 库更新时,数据被复制到从数据库 中
(这里日志 文件 和访问 数据时授权用户暂时不考虑 ) 下面我在单台服务器上开启2 deamon来模拟2台服务器进行主从复制: $ mkdir m_master m_slave $mongodb/bin/mongod --port 28018 --dbpath ~/m_master --master & $mongodb/bin/mongod --port 28019 --dbpath ~/m_slave --slave --source localhost:28018 & 这样主从服务器都已经启动了,可以利用 netstat -an -t 查看28018、28019端口 是否开放 登录主服务器: $ mongodb/bin/mongo --port 28018 MongoDB shell version: 1.2.4- url: test connecting to: 127.0.0.1:28018/test type "help" for help > show dbs admin local test > use test switched to db test > show collections 这里主上的test数据什么表都没有,为空,查看从服 务器同样也是这样 $ mongodb/bin/mongo --port 28019 MongoDB shell version: 1.2.4- url: test connecting to: 127.0.0.1:28019/test type "help" for help > show dbs admin local test > use test switched to db test > show collections 那么现在我们来验证主从数据是否会像想象的那样同步 呢? 我们在主上新建表user > db test >db.createCollection("user"); > show collections system.indexes user > 表 user已经存在了,而且test库中还多了一个system.indexes用来存放索引的表
到从服务器上查看test库: > db test > show collections system.indexes User > db.user.find(); > 从 服务器的test库中user表已经存在,同时我还查了一下user表为空 现在我们再来测试一下,向主服务器test库的user表中插入一条数据 > show collections system.indexes user > db.user.insert({uid:1,name:"Falcon.C",age:25}); > db.user.find(); { "_id" : ObjectId("4b8226a997521a578b7aea38"), "uid" : 1, "name" : "Falcon.C", "age" : 25 } > 这 时我们查看从服务器的test库user表时会多出一条记录来: > db.user.find(); { "_id" : ObjectId("4b8226a997521a578b7aea38"), "uid" : 1, "name" : "Falcon.C", "age" : 25 } > MongoDB 还有 Replica Pairs 和 Master - Master 参考地址:http://www.mongodb.org/display/DOCS/Master+Slave
MongoDB一般情况下都可以支持主主复制,但是在大部分情况下官方不推荐使用 运行 的master - master的准备工作是: 新建存放数据 库文件 的路径 $mkdir mongodata/mm_28050 mongodata/mm_28051 运行mongodb数据库 ,一个端口 为:28050,一个为:28051 $ mongodb/bin/mongod --port 28050 --dbpath ~/mongodata/mm_28050 --master --slave --source localhost:28051 > /dev/null & $ mongodb/bin/mongod --port 28051 --dbpath ~mongodata/mm_28051 --master --slave --source localhost:28050 > /dev/null & 可以通过ps -ef|grep mongod 或 netstat -an -t来检查是否运行功能
测试master - master模式 : $ mongodb/bin/mongo --port 28050 MongoDB shell version: 1.2.4- url: test connecting to: 127.0.0.1:28050/test type "help" for help > show dbs admin local > db test > db.user.insert({_id:1,username:"Falcon.C",age:25,sex:"M"}); > db.user.find(); { "_id" : 1, "username" : "Falcon.C", "age" : 25, "sex" : "M" } > db.user.find(); //在28051端口插入数据后,再来查询,看数据是否同步 { "_id" : 1, "username" : "Falcon.C", "age" : 25, "sex" : "M" } { "_id" : 2, "username" : "NetOne", "age" : 24, "sex" : "F" } > $ mongodb/bin/mongo --port 28051 MongoDB shell version: 1.2.4- url: test connecting to: 127.0.0.1:28051/test type "help" for help > db test > show collections 端口28050已经新建了一个user表并插入了一条数据,这里多出2表 system.indexes user > db.user.find(); //查询表user发现数据已经同步 { "_id" : 1, "username" : "Falcon.C", "age" : 25, "sex" : "M" } > db.user.insert({_id:2,username:"NetOne",age:24,sex:"F"});在此插入数据看数据是否双向同步 > db.user.find(); { "_id" : 1, "username" : "Falcon.C", "age" : 25, "sex" : "M" } { "_id" : 2, "username" : "NetOne", "age" : 24, "sex" : "F" } > 通 过以上开启两终端分别连接到28050、28051端口,分别插入测试数据发现,一切正常,正如我们所想的那样实现数据的双向同步 八、
MongoDB创建数据库完全可以使用use 如下: use mydb; 这样就创建了一个数据库。 这一步很重要如果什么都不操作离开的话 这个库就会被系统删除。 验证------------------------------- 然后使用插入语句: db.user.insert({name:'tompig'}); 在使用下列命令查看 show collections; ---查看‘表’ show dbs ---查看库 如图操作: 
mongodb 删除数据库 use mydb; db.dropDatabase(); mongodb删除表 db.mytable.drop();
摘要: 最后就是下面2个(这两个版本不对就容易出现各种各样的,杂七杂八的问题) 这里我就给出我所采用的版本spring-data-documentspring-data-commons有所改变所有版本必须要对应好下面是jar下载地址 http://www.springsource.org/spring-data/mongodb http://www.springsource.org/s... 阅读全文
db2数据库还原命令 1.备份的数据库(olddb) 与要还原的数据(newdb)名不相同: db2 restore db olddb into newdb; www.2cto.com 2.当前目录下存在多个备份文件.需要指定时间 db2 restore db olddb taken at 20120819175932 into newdb; 3.需要指定备份文件的目录 db2 RESTORE DATABASE olddb FROM "/media/olddb.0.db2inst1.NODE0000.CATN0000.20120819175932.001" TAKEN AT 20120819175932 INTO newdb; 4.需要指定newdb NEWLOGPATH路径 db2 RESTORE DATABASE olddb FROM "/media/olddb.0.db2inst1.NODE0000.CATN0000.20120819175932.001" TAKEN AT 20120819175932 NEWLOGPATH "/opt/log" WITH 2 BUFFERS BUFFER 1024 INTO newdb; 5.需要指定表空间的 1).创建文件夹 mkdir /home/db2inst1/db2space/newdb_sp0; mkdir /home/db2inst1/db2space/newdb_sp1; mkdir /home/db2inst1/db2space/newdb_sp2; mkdir /home/db2inst1/db2space/newdb_sp3; mkdir /home/db2inst1/db2space/newdb_sp4; mkdir /home/db2inst1/db2space/newdb_sp5; mkdir /home/db2inst1/db2space/newdb_sp6; 2).还原命令加入 redirect without rolling forward db2 RESTORE DATABASE olddb FROM "/media/olddb.0.db2inst1.NODE0000.CATN0000.20120819175932.001" TAKEN AT 20120819175932 NEWLOGPATH "/opt/log" WITH 2 BUFFERS BUFFER 1024 INTO newdb redirect without rolling forward; 3).设置表空间目录 SET TABLESPACE CONTAINERS FOR 0 IGNORE ROLLFORWARD CONTAINER OPERATIONS USING (PATH "/home/db2inst1/db2space/newdb_sp0"); SET TABLESPACE CONTAINERS FOR 1 IGNORE ROLLFORWARD CONTAINER OPERATIONS USING (PATH "/home/db2inst1/db2space/newdb_sp1"); SET TABLESPACE CONTAINERS FOR 2 IGNORE ROLLFORWARD CONTAINER OPERATIONS USING (PATH "/home/db2inst1/db2space/newdb_sp2"); SET TABLESPACE CONTAINERS FOR 3 IGNORE ROLLFORWARD CONTAINER OPERATIONS USING (PATH "/home/db2inst1/db2space/newdb_sp3"); SET TABLESPACE CONTAINERS FOR 4 IGNORE ROLLFORWARD CONTAINER OPERATIONS USING (PATH "/home/db2inst1/db2space/newdb_sp4"); SET TABLESPACE CONTAINERS FOR 5 IGNORE ROLLFORWARD CONTAINER OPERATIONS USING (PATH "/home/db2inst1/db2space/newdb_sp5"); SET TABLESPACE CONTAINERS FOR 6 IGNORE ROLLFORWARD CONTAINER OPERATIONS USING (PATH "/home/db2inst1/db2space/newdb_sp6"); 3).还原继续.注意为olddb RESTORE DATABASE olddb CONTINUE; 6.数据库还原退回 db2 restore db 注意为olddb abort 7.还原后如果NEWLOGPATH 需要变更的 db2 UPDATE DB CFG FOR newdb USING NEWLOGPATH /db2/db2inst1/db2logpath db2 UPDATE DB CFG FOR newdb USING LOGFILSIZ 10001 db2 force applications all; db2stop; db2start;
关于怎么写商业策划书的,解读的非常详尽,包括商业策划书的内容、撰写格式、思路等,仅供商业爱好者参考。 
商业策划书的目的很简单,它就是创业者手中的武器,是提供给投资者和一切对创业者的项目感兴趣的人,向他们展现创业的潜力和价值,说服他们对项目进行投资和支持。因此,一份好的商业计划书,要使人读后,对下列问题非常清楚:、 1、公司的商业机会; 2、创立公司,把握这一机会的进程 ; 3、所需要的资源; 4、风险和预期回报; 5、对你采取的行动的建议。 商业计划不是学术论文,它可能面对的是非技术背景但对计划有兴趣的人,比如可能的团队成员,可能的投资人和合作伙伴,供应商,顾客,政策机构等,因此,一份好的商业计划书,应该写得让人明白,避免使用过多的专业词汇,聚焦于特定的策略、目标、计划和行动。商业计划的篇幅要适当,太短,容易让人不相信项目的成功;太长,则会被认为太罗嗦,表达不清楚。适合的篇幅一般为20-40页长(包括附录在内)。 从总体来看,写商业策划的原则是:简明扼要;条理清晰;内容完整;语言通畅易懂;意思表述精确。商业计划书一般包括如下十大部分的内容: 一、执行总结 是商业计划的一到两页的概括。包括: 1、本商业(business)的简单描述(亦即“电梯间陈词”) 2、机会概述 3、目标市场的描述和预测 4、竞争优势 5、经济状况和盈利能力预测 6、团队概述 7、提供的利益 二、产业背景和公司概述 1、详细的市场描述,主要的竞争对手,市场驱动力 2、公司概述应包括详细的产品/服务描述以及它如何满足一个关键的顾客需求。 3、一定要描述你的进入策略和市场开发策略 三、市场调查和分析 这是表明你对市场了解程度的窗口。一定要阐释以下问题: 1、顾客 2、市场容量和趋势 3、竞争和各自的竞争优势 4、估计的市场份额和销售额 5、市场发展的走势(对于新市场而言,这一点相当困难,但一定要力争贴近真实) 四、公司战略 阐释公司如何进行竞争,它包括三个问题 1、营销计划 (定价和分销;广告和提升) 2、规划和开发计划(开发状态和目标;困难和风险) 3、制造和操作计划 (操作周期;设备和改进) 五、总体进度安排 公司的进度安排,包括以下领域的重要事件 1、收入 2、收支平衡点和正现金流 3、市场份额 4、产品开发介绍 5、主要合作伙伴 6、融资 六、关键的风险、问题和假定 1、创业者常常对于公司的假定和将面临的风险不够现实 2、说明你将如何应付风险和问题(紧急计划) 3、在眼光的务实性和对公司的潜力的乐观之间达成仔细的平衡 七、管理团队 1、介绍公司的管理团队。一定要介绍各成员与管理公司有关的教育和工作背景 2、注意管理分工和互补 3、最后,要介绍领导层成员,商业顾问以及主要的投资人和持股情况 八、企业经济状况 介绍公司的财务计划,讨论关键的财务表现驱动因素。一定要讨论如下几个杠杆: 1、毛利和净利 2、盈利能力和持久性 3、固定的、可变的和半可变的成本 4、达到收支平衡所需的月数 5、达到正现金流所需的月数 九、财务预测 1、包括收入报告,平衡报表,前两年为季度报表,前五年为年度报表 2、同一时期的估价现金流分析 3、突出成本控制系统 十、假定公司能够提供的利益 这是你的“卖点”,包括 1、总体的资金需求 2、在这一轮融资中你需要的是哪一级 3、你如何使用这些资金 4、投资人可以得到的回报 5、你还可以讨论可能的投资人退出策略 当你在写商业计划的时候,应该达到下列目标: 1、力求表述清楚简洁。 2、关注市场,用事实说话,因此需展示市场调查和市场容量。 3、解释潜在顾客为什么会掏钱买你的产品或服务。 4、站在顾客的角度考虑问题,提出引导他们进入你的销售体系的策略。 5、在头脑中要形成一个相对比较成熟的投资退出策略。 6、充分说明为什么你和你的团队最合适作这件事。 7、请你的读者做出反馈。 当你做商业计划并向投资者提交时,必须避免下列问题: 1、对产品/服务的前景过分乐观,令人产生不信任感。 2、数据没有说服力,比如拿出一些与产业标准相去甚远的数据。 3、导向是产品或服务,而不是市场。 4、对竞争没有清醒的认识,忽视竞争威胁。 5、选择进入的是一个拥塞的市场,企图后来居上。 6、商业计划显得非常不专业,比如缺乏应有的数据、过分简单或冗长。 7、不是仔细寻求最有可能的投资者,而是滥发材料。
商业策划书形式与内容 目 录 执行概要 ………………………………………………… 第一部分 公司基本情况………………………………… 第二部分 公司管理层…………………………………… 第三部分 产品/服务……………………………………… 第四部分 研究与开发…………………………………… 第五部分 行业及市场情况……………………………… 第六部分 营销策略……………………………………… 第七部分 产品制造……………………………………… 第八部分 管理…………………………………………… 第九部分 融资说明……………………………………… 第十部分 财务计划……………………………………… 第十一部分 风险控制……………………………………… 第十二部分 项目实施进度………………………………… 第十三部分 其它…………………………………………… 备查资料清单…………………………………………………… 1.创办企业的目的?为什么要冒风险,花精力、时间、资源、资金去创办风险企业? 2.创办企业所需的资金?为什么要这么多的钱?为什么投资人值得为此注入资金? 一、怎样写好商业计划书 1.关注产品 2.敢于竞争 3.了解市场 4.表明行动的方针 5.展示你的管理队伍 6.出色的计划摘要 二、商业计划书的内容 1.计划摘要 计划摘要一般要有包括以下内容:公司介绍、主要产品和业务范围、市场概貌、营销策略、销售计划、生产管理计划、管理者及其组织、财务计划、资金需求状况等。 在介绍企业时,首先要说明创办新企业的思路,新思想的形成过程以及企业的目标和发展战略。其次,要交待企业现状、过去的背景和企业的经营范围 企业家的素质对企业的成绩往往起关键性的作用。在这里,企业家应尽量突出自己的优点并表示自己强烈的进取精神,以给投资者留下一个好印象。 在计划摘要中,企业还必须要回答下列问题: (1)企业所处的行业,企业经营的性质和范围; (2)企业主要产品的内容; (3)企业的市场在那里,谁是企业的顾客,他们有哪些需求; (4)企业的合伙人、投资人是谁; (5)企业的竞争对手是谁,竞争对手对企业的发展有何影响。 摘要要尽量简明、生动。特别要详细说明自身企业的不同之处以及企业获取成功的市场因素。 2.产品(服务)介绍 在进行投资项目评估时,投资人最关心的问题之一就是,风险企业的产品、技术或服务能否以及在多大程度上解决现实生活中的问题,或者,风险企业的产品(服务)能否帮助顾客节约开支,增加收入。 (1)顾客希望企业的产品能解决什么问题,顾客能从企业的产品中获得什么好处? (2)企业的产品与竞争对手的产品相比有哪些优缺点,顾客为什么会选择本企业的产品? (3)企业为自己的产品采取了何种保护措施,企业拥有哪些专利、许可证,或与已申请专利的厂家达成了哪些协议? (4)为什么企业的产品定价可以使企业产生足够的利润,为什么用户会大批量地购买企业的产品? (5)企业采用何种方式去改进产品的质量、性能,企业对发展新产品有哪些计划等等。 3.人员及组织结构 有了产品之后,创业者第二步要做的就是结成一支有战斗力的管理队伍。 企业的管理人员应该是互补型的,而且要具有团队精神。 4.市场预测 当企业要开发一种新产品或向新的市场扩展时,首先就要进行市场预测。 市场预测首先要对需求进行预测:市场是否存在对这种产品的需求?需求程度是否可以给企业带来所期望的利益?新的市场规模有多大?需求发展的未来趋向及其状态如何?影响需求都有哪些因素。其次,市场预测还要包括对市场竞争的情况??企业所面对的竞争格局进行分析:市场中主要的竞争者有哪些?是否存在有利于本企业产品的市场空档?本企业预计的市场占有率是多少?本企业进入市场会引起竞争者怎样的反应,这些反应对企业会有什么影响?等等。 在商业计划书中,市场预测应包括以下内容:市场现状综述;竞争厂商概览;目标顾客和目标市场;本企业产品的市场地位;市场区域和特征等等。 5.营销策略 营销是企业经营中最富挑战性的环节,影响营销策略的主要因素有: (1)消费者的特点; (2)产品的特性; (3)企业自身的状况; (4)市场环境方面的因素。最终影响营销策略的则是营销成本和营销效益因素。 在商业计划书中,营销策略应包括以下内容: (1)市场机构和营销渠道的选择; (2)营销队伍和管理; (3)促销计划和广告策略; (4)价格决策。 6.制造计划 商业计划书中的生产制造计划应包括以下内容:产品制造和技术设备现状;新产品投产计划;技术提升和设备更新的要求;质量控制和质量改进计划。 在寻求资金的过程中,为了增大企业在投资前的评估价值,风险企业家应尽量使生产制造计划更加详细、可靠。一般地,生产制造计划应回答以下问题:企业生产制造所需的厂房、设备情况如何;怎样保证新产品在进入规模生产时的稳定性和可靠性;设备的引进和安装情况,谁是供应商;生产线的设计与产品组装是怎样的;供货者的前置期和资源的需求量;生产周期标准的制定以及生产作业计划的编制;物料需求计划及其保证措施;质量控制的方法是怎样的;相关的其他问题。 7.财务规划 财务规划需要花费较多的精力来做具体分析,其中就包括现金流量表,资产负债表以及损益表的制备。流动资金是企业的生命线,因此企业在初创或扩张时,对流动资金需要有预先周详的计划和进行过程中的严格控制;损益表反映的是企业的赢利状况,它是企业在一段时间运作后的经营结果;资产负债表则反映在某一时刻的企业状况,投资者可以用资产负债表中的数据得到的比率指标来衡量企业的经营状况以及可能的投资回报率。 财务规划一般要包括以下内容: (1)商业计划书的条件假设; (2)预计的资产负债表;预计的损益表;现金收支分析;资金的来源和使用。 企业的财务规划应保证和商业计划书的假设相一致。事实上,财务规划和企业的生产计划、人力资源计划、营销计划等都是密不可分的。要完成财务规划,必须要明确下列问题: (1)产品在每一个期间的发出量有多大? (2)什么时候开始产品线扩张? (3)每件产品的生产费用是多少? (4)每件产品的定价是多少? (5)使用什么分销渠道,所预期的成本和利润是多少? (6)需要雇佣那几种类型的人? (7)雇佣何时开始,工资预算是多少?等等 商业策划书的撰写 美国的一位著名风险投资家曾说过,“风险企业邀人投资或加盟,就象向离过婚的女人求婚,而不像和女孩子初恋。双方各有打算,仅靠空口许诺是无济于事的”。商业计划书对那些正在寻求资金的风险企业来说,就是“金钥匙”,决定着投资的成败。对刚开始创业的风险企业来说,商业计划书的作用尤为重要,通过制订商业计划书,把正反理由都书写下来,然后再逐条推敲,会发现原本还在“雏型”的项目已经变得清晰可辨,也更利于风险企业家认识和把握该项目。 商业计划书首先是把计划中要创立的企业推销给了风险企业家自己。其次,商业计划书还能帮助把计划中的风险企业推销给风险投资家,公司商业计划书的主要目的之一就是为了筹集资金。因此,商业计划书必须要说明: (1)创办企业的目的??为什么要冒风险,花精力、时间、资源、资金去创办风险企业? (2)创办企业所需的资金??为什么要这么多的钱?为什么投资人值得为此注入资金? 对已建的风险企业来说,商业计划书可以为企业的发展定下比较具体的方向和重点,从而使员工了解企业的经营目标,并激励他们为共同的目标而努力。更重要的是,它可以使企业的出资者以及供应商、销售商等了解企业的经营状况和经营目标,说服出资者(原有的或新来的)为企业的进一步发展提供资金。正是基于上述理由,商业计划书将是风险企业家所写的商业文件中最主要的一个。那么,如何制订商业计划书呢? 第一部分:摘要 摘要是风险投资者首先看到的部分。通过摘要,风险投资者对你和你的计划书形成第一印象,所以摘要必须形式完美,叙述清楚流畅。 第二部分:公司及未来 这部分要使风险投资者对你公司的几个主要项目及未来的发展战略有一定程度的了解,各专题既要独具特色,又要构成一个相关的整体。 1.概述:只要你提供的公司名称、地址、电话号码、联系人等资料皆清楚无误,则风险投资者将不会提出任何问题。如果可能,可提出行业分类标准,请注意,千万不要给人无法收到的电话号码,如果你不在,应建立接转电话的服务机构或请朋友代转。 2.公司的自然情况:这里,你要力求用最简练的一段话描述公司的业务情况。更重要的是,要用最简短的一句话使风险投资者可以概略认识你的公司。如果你公司已是计算机网络成员,则你对公司的描述应与在计算机中的描述一致,这样,风险投资者可以依据你的行业分类目录概略认识你公司,如果你的文字欠简明扼要,则对方可能要求你解释,以确认你公司所属行业。 3.历史情况:这里,风险投资者主要寻求一个概略性的认识。即使对方已读过公司历史这节,他可能还要求你描述公司的历史,他们欲详细了解过去发生了哪些事件。这节似乎很难确定问题的基本类型,但对方很可能提出与公司特殊历史事件相关的问题。其中一类典型问题可能是:”为什么你人帮了这件事或做了那件事?” 另一类典型问题则可能是:”你公司发展历史上有哪些重要的里程碑?为什么有实现这些历史转折?” 4.公司管理:该部分主要介绍公司的管理情况,领导者及其他对公司业务有关键影响的人。通常,小公司不超过三个关键人物。风险投资对关键人物十分关心。你应该从最高层起,依次介绍,而且注意,关键人物不等于有成就者。主要包括董事和高级职员、关键雇员、管理者之职业道德、薪金等方面。 5.公司未来的发展规划:这里,风险投资者还是寻求有关公司未来可完成的里程碑的信息。他们可能提出涉及及未来关键阶段的问题,其基本问题可能是:”你如何完成计划书规定的关键指标?” 6.唯一性(管理唯一、产品服务唯一或投资基础唯一等):这里,你必须回答的问题是:”本公司独特的原因何在?”这个问题变换说法为:”与世界上所有小公司比较,有哪些因素使你公司兴旺发达?”在公司总体范畴之内,大公司通常优越于小公司,如果认为这条规律有一定道理,那么,在你不得不与大公司竞争时,如何保证你公司必胜?为使风险投资者满意放心,你必须明确提出本公司之不寻常的优势,可以确保成功。如果你只是”此外,我也差不多”式的回答,对方很可能听听睡着了。 7.产品或服务介绍:这里,风险投资者要了解你出售什么,以及市场上需要什么样的产品和满意的服务;他要努力评估你产品的可销售程度和创新程度;他还关心你公司产品处于产品生命周期的哪一阶段。他的问题可能是:”为什么这种产品或服务有实用价值?它为用户提供哪些功能?用户的购买动机是什么”本产品寿命周期如何?何时可能被新产品取低?有无计划出新产品或以现存的产品冲出你的产品市场?这种冲出有利还是有害?你的产品责任是什么?若用户使用你的产品而受到伤害,你要承担哪些责任?你的产品价格受到哪些限制?价格弹性多少?产品耐用性如何?如何进行产品技术改进?在产品生命周期曲线中,你产品处于哪个阶段?” 8.行业情况:这里,风险投资者钭千方百计分析认识你的行业。他的问题可能是:”你在你行业中成功之关键何在?如何保证你公司和产品与你行业协调一致?此外还有一些基本问题,像”你如何了解确认你行业之总销售额与增长速率?你行业基本发展趋势如何?哪些行业变化对你公司盈利水准影响最大?你行业有哪些贸易壁垒?第三者初次进入你所属的行业圈难度如何?与同行其它产品比较,你的产品新颖处何在?本行业销售受哪些季节性因素影响?你的销售范围圈有多广,是地方、地区、全国还是全世界?” 应该注意的是,你所介绍的本行业一定时期内的销售额,不能包括未被你产品占领的领域的销售额。例如:若一个公司只制造微型电脑,则不能说已占领了全部电脑市场。微型电脑市场只是整个电脑市场的一部分,对应的行业只是微电脑市场,而不是全部电脑市场,事实上,目前的微电脑市场已很广阔了。 9.竞争者:这里,风险投资者希望了解:谁是竞争者,其实力如何,有何优势,以及你自身有哪些优势。其典型的问题可能是:”你有哪些超过竞争对手的优势?关于价格、性能、服务和保证措施,你公司与竞争对手优劣如何?竞争对手有哪些超过你的优势?谁是你最主要的竞争对手? 谁是你的行业伙伴?你与谁在高层次基础上竞争?你的产品有无替代品?如果有,谁制造这种产品?其地替代频繁程度怎样?你与竞争对手的价格差异如何?有无竞争对手加入你的行业?如果你打算选择某一市场与竞争对手共享,你的具体措施如何?希望竞争对手如何做出反应?你的竞争对手有股票公开上市的公司吗?” 10.销售策略:这里,风险投资者将集中精力分析研究你的市场行销战略,它希望了解你产品从生产现场最终转到用户手中的全部过程。某些基本问题可能为:” 描述你的产品的分销管道,即说明你产品从生产现场转到最终用户的全过程。你的产品有哪些行销环节?是本公司直接零售,还是通过行业销售网销售?广告在市场行销战略中地位如何?你的基本广告策略是什么?其成本怎样?你的销售对广告的敏感程度怎样?你曾采用过哪些市场渗透策略?现计划采用哪些市场渗透策略?若你的产品和行业进入成熟期计划采用何种市场战略?目前销售难度如何?需要直接推销否?即销售人员是否需要直接对用户叫卖?销售复杂且周期长;还是相当简单且直接推销?购买单件产品费用是高还是低?用户购买产品时是否一定要事前做预算?从与购买者签约到最终销售的时间长短如何?政府对市场交易是否有严格管制?”。 第三部分:投资说明 关于投资,你应该提出自己的融资方案,即对贷款、认股权、优先股、普通股等多种投资形式阐明自己的意见,意见要尽可能具体,使对方全面准确了解己方到底准备采用何种融资方式,并愿意付出多大代价。 第四部分:风险因素 投资者向你公司投资可能会遇到何种风险?你应从政策、经营、资源、财务等各方面加以叙述。在说明过程中,只正面叙述,不做评论性说明,主要包括:经营历史的限制、资源限制、管理经验限制、市场不确定性限制、生产不确定性限制、破产对关键管理者的依赖程度等。 第五部分:投资回报与退身之路 这是投资者非常关心的问题。因为大多数风险投资者并无真正意愿想长期持有公司的股权,而是希望能在条件成熟时“金蝉脱壳”,从而通过股票的增值获取收益。一般来说风险投资者可提出三种投资变现方式,主要包括股票上市,出售公司和买回等。你应指出自己希望采用何种方式。 第六部分:经营分析与预测 该部分主要基于公司历史的经营业绩分析,据以预测未来的经营情况,这里主要应以公司过去财务数据为基础,预测未来经营可能的收入、成本与费用,同时,通过比率分析预测出未来经营效率的高低及经营成果的好坏。 第七部分:财务报告 计划书中应包含你公司当前的财务报告,并附有适当的说明。无论如何,无当前财务报表的计划书是无法让人接受的。一份没有当年财务报告的项目是难以引起风险投资者的兴趣的。 第八部分:财务预测 对公司未来5 年的财务状况进行预测,还需预测以年的资金流量表,以便每个读者能确切了解公司资金流动状态。 第八部分:关于产品的报道、介绍、样品与图片 为增加计划书的说服力,你可以收集一些自己公司的综合介绍文献、搜集行业产品目录、收集某些产品图片等情况等。这些对争取投资均有一定作用,但不宜过多,否则会起喧宾夺主的反作用。需要声明的是,这些只能作为计划书的附件。 总述: 以上介绍的是计划书的全部内容,根据公司及项目的具体情况,可以结合实际情况在此基础上增添或删改,这都是为了满足项目的需要。 后记: 商业地产的策划要从策划的本源上说起,即什么是“策划”。按照中国文字的意思进行理解:策划就是运用谋略和计策去取得一种超出常规的良好结果。如果这个诠释能被接受的话,那么商业地产的策划就易于理解了。 首先商业地产策划是一种智慧的创造,它能在商业地产的开发活动中创造出新的价值;如“海上海”的建筑创意,就使“上实”多收二三斗。如“巴比伦生活”的策划,使得物业的区域价值被凸现出来,“金点子”或者单纯的灵感或创意活动;创建性、系统性、完整性、可导入性,更重要的是可以执行才是策划的本质,它能改变项目,产品的形象市场地位,解决或排除某些商业地产开发过程中某些阻碍和难题。策划不能等同于“包装”,“包装”是策划活动中经常运用的一种常规手段,它只能起到“锦上添花”的作用,如果通过包装手段把不利条件变成有利条件了,那么这种包装行为是有欺诈嫌疑的。 商业地产策划活动没有公式(否则就不是策划了),但有以下几条策划的规律是需要掌据的。一是价值发现,就是要在商业地产的价值挖掘方面要独具慧眼,找出别人没有看到的价值;二是以理服人,商业地产不相信煽情。商业地产是投资性物业,是固化的资本,投资者比消费者理性,过分热炒概念是没有作用的,有用的是完美演绎盈利模式,合理推导要符合商业逻辑,这才是商铺市场乐于接受的引导;三是以品牌策划的手法去策划商业地产;商业地产开发的过程就是这个项目商业品牌树立的过程,有了市场广泛的认可,商业就会繁荣,商业繁荣的结果就是这个商业物业升值或价值兑现快捷。
Nodejs给Javascript赋予了服务端应用的生命,Jquery让Javascript成为浏览中开发的利器。 最近学习了Nodejs的Express3.0的开发框架,本来是按照“node.js开发指南”书中介绍,但“node.js开发指南”讲的是Express2.x的,从Express2.x到Express3.0自己模索中还是走了不少弯路的。写篇文章总结一下。
关于作者目录此文重点介绍Express3.0的开发框架,其中还会涉及到Mongoose,Ejs,Bootstrap等相关内容。 - 建立工程
- 目录结构
- Express3.0配置文件
- Ejs模板使用
- Bootstrap界面框架
- 路由功能
- Session使用
- 页面提示
- 页面访问控制
开发环境:Win7旗舰版 64bit MonogoDB: v2.4.3
Tue May 14 09:24:50.118 [initandlisten] MongoDB starting : pid=1716 port=27017 dbpath=./data 64-bit host=PC201304202140
Tue May 14 09:24:50.119 [initandlisten] db version v2.4.3
Tue May 14 09:24:50.119 [initandlisten] git version: fe1743177a5ea03e91e0052fb5e2cb2945f6d95f
Tue May 14 09:24:50.119 [initandlisten] build info: windows sys.getwindowsversion(major=6, minor=1, build=7601, platform=2, service_pack='Service Pack 1') BOOST_LIB_VERSION=1_49
Tue May 14 09:24:50.119 [initandlisten] allocator: system
Tue May 14 09:24:50.119 [initandlisten] options: { dbpath: "./data" }
Tue May 14 09:24:50.188 [initandlisten] journal dir=./data\journal
Tue May 14 09:24:50.189 [initandlisten] recover : no journal files present, no recovery needed
Tue May 14 09:24:50.441 [initandlisten] preallocateIsFaster=true 3.26
Tue May 14 09:24:50.778 [initandlisten] preallocateIsFaster=true 5.88
Tue May 14 09:24:51.827 [initandlisten] waiting for connections on port 27017
Tue May 14 09:24:51.827 [websvr] admin web console waiting for connections on port 28017
nodejs: v0.10.5, npm 1.2.19 node -v
v0.10.5
npm -v
1.2.19
1. 建立工程进入工程目录
cd D:\workspace\project
全局安装express,express作为命令被安装到了系统中
npm install -g express
查看express版本
express -V
3.2.2
使用express命令创建工程,并支持ejs
D:\workspace\project>express -e nodejs-demo
create : nodejs-demo
create : nodejs-demo/package.json
create : nodejs-demo/app.js
create : nodejs-demo/public
create : nodejs-demo/public/javascripts
create : nodejs-demo/public/images
create : nodejs-demo/public/stylesheets
create : nodejs-demo/public/stylesheets/style.css
create : nodejs-demo/routes
create : nodejs-demo/routes/index.js
create : nodejs-demo/routes/user.js
create : nodejs-demo/views
create : nodejs-demo/views/index.ejs
install dependencies:
$ cd nodejs-demo && npm install
run the app:
$ node app
根据提示,下载依赖包
cd nodejs-demo && npm install
express@3.2.2 node_modules\express
├── methods@0.0.1
├── fresh@0.1.0
├── buffer-crc32@0.2.1
├── range-parser@0.0.4
├── cookie-signature@1.0.1
├── cookie@0.0.5
├── qs@0.6.3
├── commander@0.6.1
├── debug@0.7.2
├── mkdirp@0.3.4
├── send@0.1.0 (mime@1.2.6)
└── connect@2.7.8 (pause@0.0.1, bytes@0.2.0, formidable@1.0.13)
模板项目建立成功,启动模板项目。
D:\workspace\project\nodejs-demo>node app.js
Express server listening on port 3000
本地的3000端口被打开,通过浏览器访问: localhost:3000 通过node启动程序,每次代码修改都需要重新启动。 有一个工具supervisor,每次修改代码后会自动重启,会我们开发省很多的时间。
npm install supervisor
再启动服务
D:\workspace\project\nodejs-demo>supervisor app.js
DEBUG: Running node-supervisor with
DEBUG: program 'app.js'
DEBUG: --watch '.'
DEBUG: --ignore 'undefined'
DEBUG: --extensions 'node|js'
DEBUG: --exec 'node'
DEBUG: Starting child process with 'node app.js'
DEBUG: Watching directory 'D:\workspace\project\nodejs-demo' for changes.
Express server listening on port 3000
2. 目录结构D:\workspace\project\nodejs-demo>dir 2013/05/14 09:42 877 app.js
2013/05/14 09:48 <DIR> node_modules
2013/05/14 09:42 184 package.json
2013/05/14 09:42 <DIR> public
2013/05/14 09:42 <DIR> routes
2013/05/14 09:42 <DIR> views 目录介绍: - node_modules, 存放所有的项目依赖库。(每个项目管理自己的依赖,与Maven,Gradle等不同)
- package.json,项目依赖配置及开发者信息
- app.js,程序启动文件
- public,静态文件(css,js,img)
- routes,路由文件(MVC中的C,controller)
- Views,页面文件(Ejs模板)
3. Express3.0配置文件打开app.js文件
/**
* 模块依赖
*/
var express = require('express')
, routes = require('./routes')
, user = require('./routes/user')
, http = require('http')
, path = require('path');
var app = express();
//环境变量
app.set('port', process.env.PORT || 3000);
app.set('views', __dirname + '/views');
app.set('view engine', 'ejs');
app.use(express.favicon());
app.use(express.logger('dev'));
app.use(express.bodyParser());
app.use(express.methodOverride());
app.use(app.router);
app.use(express.static(path.join(__dirname, 'public')));
// 开发模式
if ('development' == app.get('env')) {
app.use(express.errorHandler());
}
// 路径解析
app.get('/', routes.index);
app.get('/users', user.list);
// 启动及端口
http.createServer(app).listen(app.get('port'), function(){
console.log('Express server listening on port ' + app.get('port'));
});
4. Ejs模板使用让ejs模板文件,使用扩展名为html的文件。 修改:app.js
app.engine('.html', ejs.__express);
app.set('view engine', 'html');// app.set('view engine', 'ejs');
修改后,ejs变量没有定义,supervisor的程序会一直报错
ReferenceError: ejs is not defined
at Object. (D:\workspace\project\nodejs-demo\app.js:17:21)
at Module._compile (module.js:456:26)
at Object.Module._extensions..js (module.js:474:10)
at Module.load (module.js:356:32)
at Function.Module._load (module.js:312:12)
at Function.Module.runMain (module.js:497:10)
at startup (node.js:119:16)
at node.js:901:3
DEBUG: Program node app.js exited with code 8
在app.js中增加ejs变量
var express = require('express')
, routes = require('./routes')
, user = require('./routes/user')
, http = require('http')
, path = require('path')
, ejs = require('ejs');
访问localhost:3000,程序报错
Error: Failed to lookup view "index"
at Function.app.render (D:\workspace\project\nodejs-demo\node_modules\express\lib\application.js:495:17)
at ServerResponse.res.render (D:\workspace\project\nodejs-demo\node_modules\express\lib\response.js:756:7)
at exports.index (D:\workspace\project\nodejs-demo\routes\index.js:7:7)
at callbacks (D:\workspace\project\nodejs-demo\node_modules\express\lib\router\index.js:161:37)
at param (D:\workspace\project\nodejs-demo\node_modules\express\lib\router\index.js:135:11)
at pass (D:\workspace\project\nodejs-demo\node_modules\express\lib\router\index.js:142:5)
at Router._dispatch (D:\workspace\project\nodejs-demo\node_modules\express\lib\router\index.js:170:5)
at Object.router (D:\workspace\project\nodejs-demo\node_modules\express\lib\router\index.js:33:10)
at next (D:\workspace\project\nodejs-demo\node_modules\express\node_modules\connect\lib\proto.js:190:15)
at Object.methodOverride [as handle] (D:\workspace\project\nodejs-demo\node_modules\express\node_modules\connect\lib\middleware\methodOverride.js:37:5)
GET / 500 26ms
重命名:views/indes.ejs 为 views/index.html 访问localhost:3000正确
5. 增加Bootstrap界面框架其实就是把js,css文件复制到项目中对应该的目录里。 包括4个文件: 复制到public/stylesheets目录
bootstrap.min.css
bootstrap-responsive.min.css
复制到public/javascripts目录
bootstrap.min.js
jquery-1.9.1.min.js
接下来,我们把index.html页面切分成3个部分:header.html, index.html, footer.html header.html, 为html页面的头部区域
index.html, 为内容显示区域
footer.html,为页面底部区域 header.html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="utf-8">
<title><%=: title %></title>
<!-- Bootstrap -->
<link href="/stylesheets/bootstrap.min.css" rel="stylesheet" media="screen">
<!-- <link href="css/bootstrap-responsive.min.css" rel="stylesheet" media="screen"> -->
</head>
<body screen_capture_injected="true">
index.html
<% include header.html %>
<h1><%= title %></h1>
<p>Welcome to <%= title %></p>
<% include footer.html %>
注:express3.0时,ejs嵌入其他页面时使用include,express2.x用法不一样。 footer.html
<script src="/javascripts/jquery-1.9.1.min.js"></script>
<script src="/javascripts/bootstrap.min.js"></script>
</body>
</html>
访问localhost:3000正确。 我们已经成功的使用了EJS模板的功能,把公共的头部和底部从页面中分离出来了。 并已经引入了bootstrap界面框架,后面讲到“登陆界面”的时候,就会看到bootstrap界面效果了。
6. 路由功能我们设计一下用户登陆业务需求。 访问路径:/,页面:index.html,不需要登陆,可以直接访问。
访问路径:/home,页面:home.html,必须用户登陆后,才可以访问。
访问路径:/login,页面:login.html,登陆页面,用户名密码输入正确,自动跳转到home.html
访问路径:/logout,页面:无,退出登陆后,自动回到index.html页面
打开app.js文件,在增加路由配置
app.get('/', routes.index);
app.get('/login', routes.login);
app.post('/login', routes.doLogin);
app.get('/logout', routes.logout);
app.get('/home', routes.home);
注:get为get请求,post为post请求,all为所有针对这个路径的请求 我们打开routes/index.js文件,增加对应的方法。
exports.index = function(req, res){
res.render('index', { title: 'Index' });
};
exports.login = function(req, res){
res.render('login', { title: '用户登陆'});
};
exports.doLogin = function(req, res){
var user={
username:'admin',
password:'admin'
}
if(req.body.username===user.username && req.body.password===user.password){
res.redirect('/home');
}
res.redirect('/login');
};
exports.logout = function(req, res){
res.redirect('/');
};
exports.home = function(req, res){
var user={
username:'admin',
password:'admin'
}
res.render('home', { title: 'Home',user: user});
};
创建views/login.html和views/home.html两个文件 login.html
<% include header.html %>
<div class="container-fluid">
<form class="form-horizontal" method="post">
<fieldset>
<legend>用户登陆</legend>
<div class="control-group">
<label class="control-label" for="username">用户名</label>
<div class="controls">
<input type="text" class="input-xlarge" id="username" name="username">
</div>
</div>
<div class="control-group">
<label class="control-label" for="password">密码</label>
<div class="controls">
<input type="password" class="input-xlarge" id="password" name="password">
</div>
</div>
<div class="form-actions">
<button type="submit" class="btn btn-primary">登陆</button>
</div>
</fieldset>
</form>
</div>
<% include footer.html %>
注:使用了bootstrap界面框架,效果还不错吧.
home.html
<% include header.html %>
<h1>Welcome <%= user.username %>, 欢迎登陆!!</h1>
<a claa="btn" href="/logout">退出</a>
<% include footer.html %>
修改index.html,增加登陆链接
index.html
<% include header.html %>
<h1>Welcome to <%= title %></h1>
<p><a href="/login">登陆</a></p>
<% include footer.html %>
路由及页面我们都写好了,快去网站上试试吧。
7. Session使用从刚来的例子上面看,执行exports.doLogin时,如果用户名和密码正确,我们使用redirect方法跳转到的home res.redirect('/home');
执行exports.home时,我们又用render渲染页面,并把user对象传给home.html页面 res.render('home', { title: 'Home',user: user});
为什么不能在doLogin时,就把user对象赋值给session,每个页面就不再传值了。 session这个问题,其实是涉及到服务器的底层处理方式。 像Java的web服务器,是多线程调用模型。每用户请求会打开一个线程,每个线程在内容中维护着用户的状态。 像PHP的web服务器,是交行CGI的程序处理,CGI是无状态的,所以一般用cookie在客户的浏览器是维护用户的状态。但cookie在客户端维护的信息是不够的,所以CGI应用要模仿用户session,就需要在服务器端生成一个session文件存储起来,让原本无状态的CGI应用,通过中间文件的方式,达到session的效果。 Nodejs的web服务器,也是CGI的程序无状态的,与PHP不同的地方在于,单线程应用,所有请求都是异步响应,通过callback方式返回数据。如果我们想保存session数据,也是需要找到一个存储,通过文件存储,redis,Mongdb都可以。 接下来,我将演示如何通过mongodb来保存session,并实现登陆后用户对象传递。 app.js文件
var express = require('express')
, routes = require('./routes')
, user = require('./routes/user')
, http = require('http')
, path = require('path')
, ejs = require('ejs')
, SessionStore = require("session-mongoose")(express);
var store = new SessionStore({
url: "mongodb://localhost/session",
interval: 120000
});
....
app.use(express.favicon());
app.use(express.logger('dev'));
app.use(express.bodyParser());
app.use(express.methodOverride());
app.use(express.cookieParser());
app.use(express.cookieSession({secret : 'fens.me'}));
app.use(express.session({
secret : 'fens.me',
store: store,
cookie: { maxAge: 900000 }
}));
app.use(function(req, res, next){
res.locals.user = req.session.user;
next();
});
app.use(app.router);
app.use(express.static(path.join(__dirname, 'public')));
注:app.js文件有顺序要求,一定要注意!!! 安装session-mongoose依赖库
D:\workspace\project\nodejs-demo>npm install session-mongoose
D:\workspace\project\nodejs-demo\node_modules\session-mongoose\node_modules\mongoose\node_modules\mongodb\node_modules\bson>node "D:\toolkit\nodejs\node_modules\npm\bin\node-gyp-bin\\..\..\node_modules\node-gyp\bin\node-gyp.js" rebuild
C:\Program Files (x86)\MSBuild\Microsoft.Cpp\v4.0\Microsoft.Cpp.InvalidPlatform.Targets(23,7): error MSB8007: 项目“kerberos.vcxproj”的平台无效。平台为“x64”。您会看到此消息的可能原因是,您尝试在没有解决方案文件的情况下生成项目,并且为
oose\node_modules\mongoose\node_modules\mongodb\node_modules\bson\build\bson.vcxproj]
session-mongoose@0.2.2 node_modules\session-mongoose
└── mongoose@3.6.10 (mpath@0.1.1, ms@0.1.0, hooks@0.2.1, sliced@0.0.3, muri@0.3.1, mpromise@0.2.1, mongodb@1.3.3)
安装有错误但是没关系。 访问:http://localhost:3000/login,正常 修改routes/index.js文件 exports.doLogin方法
exports.doLogin = function(req, res){
var user={
username:'admin',
password:'admin'
}
if(req.body.username===user.username && req.body.password===user.password){
req.session.user=user;
return res.redirect('/home');
} else {
return res.redirect('/login');
}
};
exports.logout方法
exports.logout = function(req, res){
req.session.user=null;
res.redirect('/');
};
exports.home方法
exports.home = function(req, res){
res.render('home', { title: 'Home'});
};
这个时候session已经起作用了,exports.home的user显示传值已经被去掉了。 是通过app.js中app.use的res.locals变量,通过框架进行的赋值。
app.use(function(req, res, next){
res.locals.user = req.session.user;
next();
});
注:这个session是express3.0的写法,与express2.x是不一样的。原理是在框架内每次赋值,把我们刚才手动传值的过程,让框架去完成了。
8. 页面提示登陆的大体我们都已经讲完了,最后看一下登陆失败的情况。 我们希望如果用户登陆时,用户名或者密码出错了,会给用户提示,应该如何去实现。 打开app.js的,增加res.locals.message
app.use(function(req, res, next){
res.locals.user = req.session.user;
var err = req.session.error;
delete req.session.error;
res.locals.message = '';
if (err) res.locals.message = '<div class="alert alert-error">' + err + '</div>';
next();
});
修改login.html页面,<%- message %>
<% include header.html %>
<div class="container-fluid">
<form class="form-horizontal" method="post">
<fieldset>
<legend>用户登陆</legend>
<%- message %>
<div class="control-group">
<label class="control-label" for="username">用户名</label>
<div class="controls">
<input type="text" class="input-xlarge" id="username" name="username" value="admin">
</div>
</div>
<div class="control-group">
<label class="control-label" for="password">密码</label>
<div class="controls">
<input type="password" class="input-xlarge" id="password" name="password" value="admin">
</div>
</div>
<div class="form-actions">
<button type="submit" class="btn btn-primary">登陆</button>
</div>
</fieldset>
</form>
</div>
<% include footer.html %>
修改routes/index.js,增加req.session.error
exports.doLogin = function(req, res){
var user={
username:'admin',
password:'admin'
}
if(req.body.username===user.username && req.body.password===user.password){
req.session.user=user;
return res.redirect('/home');
} else {
req.session.error='用户名或密码不正确';
return res.redirect('/login');
}
};
让我们来看看效果: http://localhost:3000/login 输入错误的和密码, 用户名:adminfe,密码:12121 
9. 页面访问控制网站登陆部分按照我们的求已经完成了,但网站并不安全。 localhost:3000/home,页面本来是登陆以后才访问的,现在我们不要登陆,直接在浏览器输入也可访问。 页面报错了,提示<%= user.username %> 变量出错。 GET /home?user==a 500 15ms TypeError: D:\workspace\project\nodejs-demo\views\home.html:2 1| <% include header.html %> >> 2| <h1>Welcome <%= user.username %>, 欢迎登陆!!</h1> 3| <a claa="btn" href="/logout">退出</a> 4| <% include header.html %> Cannot read property 'username' of null at eval (eval at <anonymous> (D:\workspace\project\nodejs-demo\node_modules\ejs\lib\ejs.js: at eval (eval at <anonymous> (D:\workspace\project\nodejs-demo\node_modules\ejs\lib\ejs.js: at D:\workspace\project\nodejs-demo\node_modules\ejs\lib\ejs.js:249:15 at Object.exports.render (D:\workspace\project\nodejs-demo\node_modules\ejs\lib\ejs.js:287: at View.exports.renderFile [as engine] (D:\workspace\project\nodejs-demo\node_modules\ejs\l at View.render (D:\workspace\project\nodejs-demo\node_modules\express\lib\view.js:75:8) at Function.app.render (D:\workspace\project\nodejs-demo\node_modules\express\lib\applicati at ServerResponse.res.render (D:\workspace\project\nodejs-demo\node_modules\express\lib\res at exports.home (D:\workspace\project\nodejs-demo\routes\index.js:36:8) at callbacks (D:\workspace\project\nodejs-demo\node_modules\express\lib\router\index.js:161
这个页面被打开发,因为没有user.username参数。我们避免这样的错误发生。 还记录路由部分里说的get,post,all的作用吗?我现在要回到路由配置中,再做点事情。 修改app.js文件 app.all('/login', notAuthentication); app.get('/login', routes.login); app.post('/login', routes.doLogin); app.get('/logout', authentication); app.get('/logout', routes.logout); app.get('/home', authentication); app.get('/home', routes.home);
访问控制: - / ,谁访问都行,没有任何控制
- /login,用all拦截所有访问/login的请求,先调用authentication,用户登陆检查
- /logout,用get拦截访问/login的请求,先调用notAuthentication,用户不登陆检查
- /home,用get拦截访问/home的请求,先调用Authentication,用户登陆检查
修改app.js文件,增加authentication,notAuthentication两个方法 function authentication(req, res, next) { if (!req.session.user) { req.session.error='请先登陆'; return res.redirect('/login'); } next(); } function notAuthentication(req, res, next) { if (req.session.user) { req.session.error='已登陆'; return res.redirect('/'); } next(); }
配置好后,我们未登陆,直接访问localhost:3000/home时,就会跳到/login页面 
如果你也出现图片显示的内容,那么恭喜你了。 Nodejs使用Express3.0框架的第一步你已经完成了,并且还使用了ejs,bootstrap,mongoose库的使用。 希望此文对大家有所帮助。
从零开始nodejs系列文章,将介绍如何利Javascript做为服务端脚本,通过Nodejs框架web开发。Nodejs框架是基于V8的引擎,是目前速度最快的Javascript引擎。chrome浏览器就基于V8,同时打开20-30个网页都很流畅。Nodejs标准的web开发框架Express,可以帮助我们迅速建立web站点,比起PHP的开发效率更高,而且学习曲线更低。非常适合小型网站,个性化网站,我们自己的Geek网站!! 关于作者 - 张丹(Conan), 程序员Java,R,PHP,Javascript
- weibo:@Conan_Z
- blog: http://blog.fens.me
- email: bsspirit@gmail.com
转载请注明出处:
http://blog.fens.me/nodejs-bower-intro/ 
前言
一个新的web项目开始,我们总是很自然地去下载需要用到的js类库文件,比如jQuery,去官网下载名为jquery-1.10.2.min.js文件,放到我们的项目里。当项目又需要bootstrap的时候,我们会重复刚才的工作,去bootstrap官网下载对应的类库。如果bootstrap所依赖的jQuery并不是1.10.2,而是2.0.3时,我们会再重新下载一个对应版本的jQuery替换原来的。 包管理是个复杂的问题,我们要知道谁依赖谁,还要明确哪个版本依赖哪个版本。这些对于开发人员来说,负担过重了。bower作为一个js依赖管理的工具,提供一种理想包管理方式,借助了npm的一些思想,为我们提供一个舒服的开发环境。 你要还不动起手来试试bower,那你一定不会知道,前端开发是件多么享受的事。 目录 - bower介绍
- bower安装
- bower命令
- bower使用
- 用bower提交自己类库
1. bower介绍Bower 是 twitter 推出的一款包管理工具,基于nodejs的模块化思想,把功能分散到各个模块中,让模块和模块之间存在联系,通过 Bower 来管理模块间的这种联系。 包管理工具一般有以下的功能: - 注册机制:每个包需要确定一个唯一的 ID 使得搜索和下载的时候能够正确匹配,所以包管理工具需要维护注册信息,可以依赖其他平台。
- 文件存储:确定文件存放的位置,下载的时候可以找到,当然这个地址在网络上是可访问的。
- 上传下载:这是工具的主要功能,能提高包使用的便利性。比如想用 jquery 只需要 install 一下就可以了,不用到处找下载。上传并不是必备的,根据文件存储的位置而定,但需要有一定的机制保障。
- 依赖分析:这也是包管理工具主要解决的问题之一,既然包之间是有联系的,那么下载的时候就需要处理他们之间的依赖。下载一个包的时候也需要下载依赖的包。
功能介绍,摘自文章:http://chuo.me/2013/02/twitter-bower.html
2. bower安装bower插件是通过npm, Node.js包管理器安装和管理的. 我的系统环境 - win7 64bit
- Nodejs:v0.10.5
- Npm:1.2.19
~ D:\workspace\javascript>node -v
v0.10.5
~ D:\workspace\javascript>npm -v
1.2.19
在系统中,我们已经安装好了Nodejs和npm。win7安装nodejs请参考文章:Nodejs开发框架Express3.0开发手记–从零开始 安装bower
全局安装bower
~ D:\workspace\javascript>npm install bower -g
新建一个express3的项目nodejs-bower
~ D:\workspace\javascript>express -e nodejs-bower
~ D:\workspace\javascript>cd nodejs-bower && npm install
3. bower命令bower安装后,我们就可以用bower这个命令了。 ~ D:\workspace\javascript\nodejs-bower>bower
Usage:
bower [] []
Commands:
cache Manage bower cache
help Display help information about Bower
home Opens a package homepage into your favorite browser
info Info of a particular package
init Interactively create a bower.json file
install Install a package locally
link Symlink a package folder
list List local packages
lookup Look up a package URL by name
prune Removes local extraneous packages
register Register a package
search Search for a package by name
update Update a local package
uninstall Remove a local package
Options:
-f, --force Makes various commands more forceful
-j, --json Output consumable JSON
-l, --log-level What level of logs to report
-o, --offline Do not hit the network
-q, --quiet Only output important information
-s, --silent Do not output anything, besides errors
-V, --verbose Makes output more verbose
--allow-root Allows running commands as root
See 'bower help ' for more information on a specific command.
Commands,列出了bower支持的各种命令。 - cache:bower缓存管理
- help:显示Bower命令的帮助信息
- home:通过浏览器打开一个包的github发布页
- info:查看包的信息
- init:创建bower.json文件
- install:安装包到项目
- link:在本地bower库建立一个项目链接
- list:列出项目已安装的包
- lookup:根据包名查询包的URL
- prune:删除项目无关的包
- register:注册一个包
- search:搜索包
- update:更新项目的包
- uninstall:删除项目的包
4. bower使用1). 安装jQuery到项目nodejs-bower
~ D:\workspace\javascript\nodejs-bower>bower install jquery
bower jquery#* not-cached git://github.com/components/jquery.git#*
bower jquery#* resolve git://github.com/components/jquery.git#*
bower jquery#* download https://github.com/components/jquery/archive/2.0.3.tar.gz
bower jquery#* extract archive.tar.gz
bower jquery#* resolved git://github.com/components/jquery.git#2.0.3
bower jquery#~2.0.3 install jquery#2.0.3
jquery#2.0.3 bower_components\jquery
通过执行命令,我们可以看到jQuery的最新版本被下载,并安装到项目的bower_components\jquery目录 查看bower_components/jquery目录,发现了3个文件。
~ D:\workspace\javascript\nodejs-bower>ls bower_components/jquery -a
. .. .bower.json component.json jquery.js
同样地,我们的项目还需要d3的类库
~ D:\workspace\javascript\nodejs-bower>bower install d3
bower d3#* not-cached git://github.com/mbostock/d3.git#*
bower d3#* resolve git://github.com/mbostock/d3.git#*
bower d3#* download https://github.com/mbostock/d3/archive/v3.2.8.tar.gz
bower d3#* extract archive.tar.gz
bower d3#* resolved git://github.com/mbostock/d3.git#3.2.8
bower d3#~3.2.8 install d3#3.2.8
d3#3.2.8 bower_components\d3
非常方便,下载并安装完成! 2). 查看项目中已导入的类库
~ D:\workspace\javascript\nodejs-bower>bower list
bower check-new Checking for new versions of the project dependencies..
nodejs-bower#0.0.0 D:\workspace\javascript\nodejs-bower
├── d3#3.2.8
└── jquery#2.0.3
3). 安装bootstrap库,并查看依赖情况
~ D:\workspace\javascript\nodejs-bower>bower install bootstrap
bower bootstrap#* cached git://github.com/twbs/bootstrap.git#3.0.0-rc1
bower bootstrap#* validate 3.0.0-rc1 against git://github.com/twbs/bootstrap.git#*
bower jquery#>= 1.9.0 cached git://github.com/components/jquery.git#2.0.3
bower jquery#>= 1.9.0 validate 2.0.3 against git://github.com/components/jquery.git#>= 1.9.0
bower bootstrap#~3.0.0-rc1 install bootstrap#3.0.0-rc1
bootstrap#3.0.0-rc1 bower_components\bootstrap
└── jquery#2.0.3
~ D:\workspace\javascript\nodejs-bower>bower list
bower check-new Checking for new versions of the project dependencies..
nodejs-bower#0.0.0 D:\workspace\javascript\nodejs-bower
├─┬ bootstrap#3.0.0-rc1 extraneous
│ └── jquery#2.0.3
├── d3#3.2.8
└── jquery#2.0.3
我们发现bootstrap,对jquery是有依赖的。 4). 删除jQuery库,破坏依赖关系
~ D:\workspace\javascript\nodejs-bower>bower uninstall jquery
bower conflict bootstrap depends on jquery
Continue anyway? (y/n) y
bower uninstall jquery
~ D:\workspace\javascript\nodejs-bower>bower list
bower check-new Checking for new versions of the project dependencies..
nodejs-bower#0.0.0 D:\workspace\javascript\nodejs-bower
├─┬ bootstrap#3.0.0-rc1 extraneous
│ └── jquery missing
├── d3#3.2.8
└── jquery missing
5). 安装低版本的jQuery,制造不版本兼容
~ D:\workspace\javascript\nodejs-bower>bower install jquery#1.7.2
bower jquery#~2.0.3 cached git://github.com/components/jquery.git#2.0.3
bower jquery#~2.0.3 validate 2.0.3 against git://github.com/components/jquery.git#~2.0.3
bower jquery#>= 1.9.0 cached git://github.com/components/jquery.git#2.0.3
bower jquery#>= 1.9.0 validate 2.0.3 against git://github.com/components/jquery.git#>= 1.9.0
bower jquery#1.7.2 cached git://github.com/components/jquery.git#1.7.2
bower jquery#1.7.2 validate 1.7.2 against git://github.com/components/jquery.git#1.7.2
Unable to find a suitable version for jquery, please choose one:
1) jquery#1.7.2 which resolved to 1.7.2
2) jquery#~2.0.3 which resolved to 2.0.3 and has nodejs-bower as dependants
3) jquery#>= 1.9.0 which resolved to 2.0.3 and has bootstrap#3.0.0-rc1 as dependants
Prefix the choice with ! to persist it to bower.json
Choice: 1
bower jquery#1.7.2 install jquery#1.7.2
jquery#1.7.2 bower_components\jquery
~ D:\workspace\javascript\nodejs-bower>bower list
bower check-new Checking for new versions of the project dependencies..
nodejs-bower#0.0.0 D:\workspace\javascript\nodejs-bower
├─┬ bootstrap#3.0.0-rc1 extraneous
│ └── jquery#1.7.2 incompatible with >= 1.9.0 (2.0.3 available)
├── d3#3.2.8
└── jquery#1.7.2 incompatible with ~2.0.3 (2.0.3 available)
我们可以清楚的看到bower,很明确的告诉了我们,jquery和bootstrap是不兼容的,强大之处大家应该有所体会。 6).升级jQuery,让版本兼容
~ D:\workspace\javascript\nodejs-bower>bower update jquery
bower jquery#~2.0.3 cached git://github.com/components/jquery.git#2.0.3
bower jquery#~2.0.3 validate 2.0.3 against git://github.com/components/jquery.git#~2.0.3
bower jquery#>= 1.9.0 cached git://github.com/components/jquery.git#2.0.3
bower jquery#>= 1.9.0 validate 2.0.3 against git://github.com/components/jquery.git#>= 1.9.0
bower jquery#~2.0.3 install jquery#2.0.3
jquery#2.0.3 bower_components\jquery
~ D:\workspace\javascript\nodejs-bower>bower list
bower check-new Checking for new versions of the project dependencies..
nodejs-bower#0.0.0 D:\workspace\javascript\nodejs-bower
├─┬ bootstrap#3.0.0-rc1 extraneous
│ └── jquery#2.0.3
├── d3#3.2.8
└── jquery#2.0.3
多么智能,一键搞定,这才是高效的开发。 7). 查看本地bower已经缓存的类库
~ D:\workspace\javascript\nodejs-bower>bower cache list
bootstrap=git://github.com/twbs/bootstrap.git#3.0.0-rc1
d3=git://github.com/mbostock/d3.git#3.2.8
jquery=git://github.com/components/jquery.git#1.7.2
jquery=git://github.com/components/jquery.git#2.0.3
8). 查看D3库信息
~ D:\workspace\javascript\nodejs-bower>bower info d3
d3
Versions:
- 3.2.8
- 3.2.7
- 3.2.6
- 3.2.5
- 3.2.4
- 3.2.3
...
9). 查看dojo库的url
~ D:\workspace\javascript\nodejs-bower>bower lookup dojo
dojo git://github.com/dojo/dojo.git
10). 用浏览器打开dojo的发布主页
~ D:\workspace\javascript\nodejs-bower>bower home dojo
bower dojo#* not-cached git://github.com/dojo/dojo.git#*
bower dojo#* resolve git://github.com/dojo/dojo.git#*
bower dojo#* download https://github.com/dojo/dojo/archive/1.9.1.tar.gz
bower dojo#* extract archive.tar.gz
bower dojo#* resolved git://github.com/dojo/dojo.git#1.9.1
浏览器自动打开:https://github.com/dojo/dojo 11). 查询包含dojo的类库
~ D:\workspace\javascript\nodejs-bower>bower search dojo
Search results:
dojo git://github.com/dojo/dojo.git
dojox git://github.com/dojo/dojox.git
dojo-util git://github.com/dojo/util.git
dojo-bootstrap git://github.com/samvdb/Dojo-Bootstrap
真是方便实用的技术。
5. 用bower提交自己类库1). 生成bower.json配置文件 ~ D:\workspace\javascript\nodejs-bower>bower init bower existing The existing bower.json file will be used and filled in [?] name: nodejs-bower [?] version: 0.0.0 [?] main file: [?] set currently installed components as dependencies? No [?] add commonly ignored files to ignore list? Yes
查看生成的文件bower.json { "name": "nodejs-bower", "version": "0.0.0", "ignore": [ "**/.*", "node_modules", "bower_components", "test", "tests" ], "dependencies": { "d3": "git://github.com/mbostock/d3.git#~3.2.8", "jquery": "git://github.com/components/jquery.git#~2.0.3" } }
2). 在github创建一个资源库:nodejs-bower
3). 本地工程绑定github ~ D:\workspace\javascript\nodejs-bower>git init Initialized empty Git repository in D:/workspace/javascript/nodejs-bower/.git/ ~ D:\workspace\javascript\nodejs-bower>git add . ~ D:\workspace\javascript\nodejs-bower>git commit -m "first commit" # On branch master # # Initial commit # # Untracked files: # (use "git add ..." to include in what will be committed) # # app.js # bower.json # bower_components/ # node_modules/ # package.json # public/ # routes/ # views/ nothing added to commit but untracked files present (use "git add" to track) ~ D:\workspace\javascript\nodejs-bower>git remote add origin https://github.com/bsspirit/nodejs-bower ~ D:\workspace\javascript\nodejs-bower>git push -u origin master Counting objects: 565, done. Delta compression using up to 4 threads. Compressing objects: 100% (516/516), done. Writing objects: 100% (565/565), 803.08 KiB, done. Total 565 (delta 26), reused 0 (delta 0) To https://github.com/bsspirit/nodejs-bower * [new branch] master -> master Branch master set up to track remote branch master from origin.
4). 注册到bower官方类库 ~ D:\workspace\javascript\nodejs-bower>bower register nodejs-bower git@github.com:bsspirit/nodejs-bower.git bower convert Converted git@github.com:bsspirit/nodejs-bower.git to git://github.com/bsspirit/n odejs-bower.git bower nodejs-bower#* resolve git://github.com/bsspirit/nodejs-bower.git#* bower nodejs-bower#* checkout master bower nodejs-bower#* resolved git://github.com/bsspirit/nodejs-bower.git#af3ceaac07 Registering a package will make it visible and installable via the registry (https://bower.herokuapp.com), continue? (y/ n) y bower nodejs-bower register git://github.com/bsspirit/nodejs-bower.git Package nodejs-bower registered successfully! All valid semver tags on git://github.com/bsspirit/nodejs-bower.git will be available as versions. To publish a new version, you just need release a valid semver tag. Run bower info nodejs-bower to list the package versions.
5). 查询我们自己的包 D:\workspace\javascript\nodejs-bower>bower search nodejs-bower Search results: nodejs-bower git://github.com/bsspirit/nodejs-bower.git
6). 安装我们自己的包 D:\workspace\javascript\nodejs-bower>bower install nodejs-bower bower nodejs-bower#* cached git://github.com/bsspirit/nodejs-bower.git#af3ceaac07 bower nodejs-bower#* validate af3ceaac07 against git://github.com/bsspirit/nodejs-bower.git#* bower nodejs-bower#* install nodejs-bower#af3ceaac07 nodejs-bower#af3ceaac07 bower_components\nodejs-bower ├── d3#3.2.8 └── jquery#2.0.3
其实模块化,版本依赖,开发类库,发布类库,安装类库,都是一条命令!还能再简单一点么!快把项目模块化,然后分享给大家吧!!未来是属于开发者的。
Windows平台下的node.js安装 直接去nodejs的官网http://nodejs.org/上下载nodejs安装程序,双击安装就可以了 测试安装是否成功: 在命令行输入 node –v 应该可以查看到当前安装的nodejs版本号 简单的例子 写一段简短的代码,保存为helloworld.js,大致看下nodejs是怎么用的。 如下:该代码主要是创建一个http服务器。 var http = require("http"); http.createServer(function(request, response) { response.writeHead(200, {"Content-Type": "text/html"}); response.write("Hello World!"); response.end(); }).listen(8080); console.log("Server running at http://localhost:8080/"); 打开命令行,转到当前文件所存放的路径下,运行 node helloworld.js命令即可 如果一切正常,可以看到命令行输出:Server running at http://localhost:8080/ 同时,在浏览器输入http://localhost:8080/,可以看到一个写着helloworld的网页。 安装npm npm上有很多优秀的nodejs包,来解决常见的一些问题,比如用node-mysql,就可以方便通过nodejs链接到mysql,进行数据库的操作 在开发过程往往会需要用到其他的包,使用npm就可以下载这些包来供程序调用 a) 如果系统没有安装过Git,可以直接到https://github.com/isaacs/npm下载npm所需要的文件。 b) 如果有Git 可以使用git下载。 git clone --recursive git://github.com/isaacs/npm.git 下载到NPM文件后,命令行首先转到npm所在地址,输入以下代码进行安装。 node cli.js install npm -gf 安装Express Express是nodejs常用的一个框架。 a) 全局安装 npm install express -gd npm install -g express-generator b) 安装在当前文件夹下 npm install express 安装成功后,命令行会提示 npm info ok -g代表安装到NODE_PATH的lib里面,而-d代表把相依性套件也一起安装。如果沒有-g的话会安装目前所在的目录(会建立一个node_modules的文件夹)。 在项目中引用express包 例: var express = require('express'); var app = module.exports = express.createServer(); 如果没有安装过express,那么首先需要在当前项目文件夹下安装一个express 命令行转到当前路径后,运行 npm install express 安装完成后,可以看到当前目录下多了一个【node_modules】文件夹,下有一个【express】文件夹 注:项目中引用的包,都会被安装到【node_modules】文件夹 用express创建项目 在命令行中输入【express 项目名称】,就可以在当前文件夹下创建一个新的项目 如图: 包括以下几个文件: 用此方法,只是创建了一个空的项目框架,和一个简单的实例程序,运行app.js可以查看(还需要在项目文件目录下,安装jade包,方法类似安装express) 参考网站: Node.js基础 http://www.infoq.com/cn/master-nodejs Node.js 入门教程 http://nodebeginner.org/index-zh-cn.html Node.js中文文档 http://cnodejs.org/cman/index.html Express文档 http://expressjs.com/guide.html#routing CNode社区 http://club.cnodejs.org/
Node.js官网有各平台的安装包下载,不想折腾的可以直接下载安装,下面说下windows平台下如何制作绿色版node,以方便迁移。 - 获取node.exe
下载Windows Binary版本,不要下载Windows Installer版本,直接放到H:\nodejs\ - 获取npm(Node Package Manage)
下载最新zip版本,不要下载tgz版本,下载后解压到H:\nodejs\ - 添加环境变量
- NODE_HOME=H:\nodejs
- NODE_PATH=%NODE_HOME%\node_modules
- path增加%NODE_HOME%\
最终得到文件目录结构H:\nodejs\: . ├—— node.exe ├—— npm.cmd └—— node_modules └—— npm 测试一下,出现版本号,说明配置成功: node --version npm --version 至此,绿色版制作完毕,您已经可以正常使用node/npm,也可以迁移到其他机器使用。
下面使用npm命令安装第三方模块,使用方法可以查看: npm -h npm install -h npm help install 默认安装仓库是https://registry.npmjs.org,查找包可以到这里http://search.npmjs.org,一切都很像maven。有两种安装模式可选,参考npm 1.0 Global vs Local installation:
locally
默认是locally模式,安装到当前命令的执行目录。在其他位置执行xxx会报“xxx不是内部或外部命令,也不是可运行的程序”。 npm install xxx globally
-g参数代表全局方式,使用全局模式会安装到H:\nodejs\node_modules\中的xxx下。 npm install xxx -g 你可以重新设置prefix位置,方法有二: - 重新设置prefix的位置:npm config set prefix "H:\hexo"
- 或直接修改 『当前用户』.npmrc 文件,添加prefix = H:\hexo
在 开始研究 java CMS之前,我们先要了解什么是CMS。CMS — Content Management Systems,内容管理系统,简单的说,就是一个帮助进行网站内容管理的系统。CMS通常包含两部分:内容管理程序(Content Management Application ,CMA)和内容发布程序(Content Delivery Application ,CDA),内容管理程序可以帮助网站管理员轻松的实现网站文章的创建、编辑和删除操作,内容发布程序则可以编辑文章并在网站上发布它们。 一 个完整的CMS通常包含一个在线的发布、排版、版本控制,以及列表、搜索、恢复等功能模块。近年来大量涌现的企业网站管理系统,则增加了新闻管 理、使用手册、在线帮助、销售手册等功能。难以避免的,功能强大的CMS往往有着高昂的售价,预算不足的用户很希望找到一款好用且免费的管理系统。现在已 经出现了许多基于java的开源CMS系统,本文挑选了10个最强大、最易用的CMS,向大家做一个简要介绍。1. Alfresco Alfresco是一个开源的企业网站内容管理系统,它提供了文档管理、多人协作、记录管理、知识管理网页内容和图像管理等功能。它使用Spring、 Hibernate、 Lucene 和JSF等最新java技术构建了模块化的系统架构。Alfresco官方网站:http://www.alfresco.com/中文教程:http://blog.csdn.net/alfresco/2. DotCMS DotCMS 是一个开源的企业级内容管理系统,它融入了电子商 务、个性化设置、客户关系管理工具等功能,它可以方便的建立基于各种关系的数据结构和数据库,它可以使用模板快速创建页面,并且提供了一个强大的所见即所 得(WYSIWYG)编辑器。用户可以使用加载外部模块的功能快速的建立Ajax应用、搜索、MP3播放器、幻灯片和相册等功能。DotCMS官方网站http://dotcms.org/中文安装教程http://www.javaeye.com/wiki/topic/2777943. Magnolia Magnolia 是一个老牌的java内容管理系统,目前已经发布了第四版。它的独特之处在于可以定制内容模型,以返回数组形式来搞定各种不确定的 功能。它遵循W3C标准并且在搜索引擎优化上有许多优势。同时它支持java内容仓库( java content repositories , JCR) 的API。Magnolia官方网站http://www.magnolia-cms.com/home.html4. OpenCms 它提供了一套建立和维护网站的方便的工具。在内容建设方面,它拥有一个易于使用的界面和所见即所得编辑器,在网页生成上它使用了一个先进的页面模板。OpenCMS官方网站http://www.opencms.org/opencms/en/index.html中文网站http://www.opencms.cn/6. AtLeap Blandware AtLeap是一个多语种的免费Java内容管理系统,它包含了全文搜索引擎,可以算是一个能让你方便的编写应用的网站框架。Atleap官方网站https://atleap.dev.java.net/7. Fedora Fedora 是“Flexible Extensible Digital Object Repository Architecture”的缩写,并不是Linux发行版Fedora,是一个数字资源管理系统,它可以创建很多类型的数字图书馆、资料库、档案馆系统 等。Fedora官方网站http://www.fedora-commons.org/8. Apache Lenya 这是一个开源的 Java/XML 内容管理系统,提供了版本控制、多站点管理、调度、搜索、所见即所得编辑以及工作流程等功能。Apache Lyenya使用基于模块的Cocoom开源程序框架。Apache Lyenya官方网站http://lenya.apache.org/9. OpenEdit OpenEdit是一个开源的内容管理系统,它旨在建设基于在线数字资产的多媒体网站。它提供在线编辑,动态布局,拼写检查,用户管理器,文件管理器,版本控制和通知工具。同时包含企业级的插件,如电子商务,内容管理,博客,活动日程表,社交网络工具等。OpenEdit官方网站http://www.openedit.org/10. Contelligent这个基于Java的开源解决方案有助于创建和管理个性化网站。它完全遵循J2EE,具有先进的模式,可以方便的添加第三方应用。Contelligent官方网站http://www.contelligent.com/
直接安装安装Sublime text 2插件很方便,可以直接下载安装包解压缩到Packages目录(菜单->preferences->packages)。 使用Package Control组件安装也可以安装package control组件,然后直接在线安装: - 按Ctrl+`调出console(注:安装有QQ输入法的这个快捷键会有冲突的,输入法属性设置-输入法管理-取消热键切换至QQ拼音)
- 粘贴以下代码到底部命令行并回车:
import urllib.request,os; pf = 'Package Control.sublime-package'; ipp = sublime.installed_packages_path(); urllib.request.install_opener( urllib.request.build_opener( urllib.request.ProxyHandler()) ); open(os.path.join(ipp, pf), 'wb').write(urllib.request.urlopen( 'http://sublime.wbond.net/' + pf.replace(' ','%20')).read()) - 重启Sublime Text 3。
- 如果在Perferences->package settings中看到package control这一项,则安装成功。
顺便贴下Sublime Text2 的代码 import urllib2,os; pf='Package Control.sublime-package'; ipp = sublime.installed_packages_path(); os.makedirs( ipp ) if not os.path.exists(ipp) else None; urllib2.install_opener( urllib2.build_opener( urllib2.ProxyHandler( ))); open( os.path.join( ipp, pf), 'wb' ).write( urllib2.urlopen( 'http://sublime.wbond.net/' +pf.replace( ' ','%20' )).read()); print( 'Please restart Sublime Text to finish installation') 如果这种方法不能安装成功,可以到这里下载文件手动安装。 用Package Control安装插件的方法:- 按下Ctrl+Shift+P调出命令面板
- 输入install 调出 Install Package 选项并回车,然后在列表中选中要安装的插件。
不爽的是,有的网络环境可能会不允许访问陌生的网络环境从而设置一道防火墙,而Sublime Text 2貌似无法设置代理,可能就获取不到安装包列表了。
好,方法介绍完了,下面是本文正题,一些有用的Sublime Text 2插件: GBK Encoding Support对应gb2312来说,Sublime Text 2 本生不支持的,我们可以通过Ctrl+Shift+P调出命令面板或Perferences->Package Contro,输入install 调出 Install Package 选项并回车,在输入“GBK Encoding Support”选择开始安装,左下角状态栏有提示安装成功。这时打开gbk编码的文件就不会出现乱码了,如果有需要转成utf-8的可以在File-GBK to UTF8-选择Save with UTF8就偶看了。 这个,不解释了,还不知道ZenCoding的同学强烈推荐去看一下:《Zen Coding: 一种快速编写HTML/CSS代码的方法》。  emmet PS:Zen Coding for Sublime Text 2插件的开发者已经停止了在Github上共享了,现在只有通过Package Control来安装。 如果你离不开jQuery的话,这个必备~~ Prefixr,CSS3 私有前缀自动补全插件,显然也很有用哇  Sublime Prefixr 一个JS代码格式化插件。 一个支持lint语法的插件,可以高亮linter认为有错误的代码行,也支持高亮一些特别的注释,比如“TODO”,这样就可以被快速定位。(IntelliJ IDEA的TODO功能很赞,这个插件虽然比不上,但是也够用了吧)  SublimeLinter 故名思意,占位用,包括一些占位文字和HTML代码片段,实用。 用于代码格式的自动对齐。传说最新版Sublime 已经集成。 
粘贴板历史记录,方便使用复制/剪切的内容。 这是一个代码检测插件。 如果你在用一些公用的或者开源的框架,比如 Normalize.css或者modernizr.js,但是,过了一段时间后,可能该开源库已经更新了,而你没有发现,这个时候可能已经不太适合你的项目了,那么你就要重新折腾一遍或者继续用陈旧的文件。Nettuts Fetch可以让你设置一些需要同步的文件列表,然后保存更新。 
该插件基于Google Closure compiler,自动压缩js文件。 代码自动提示 类似于代码匹配,可以匹配括号,引号等符号内的范围。 
自动转换颜色值,从16进制到HSL格式,快捷键 Ctrl+Shift+U 
将文件编码从GBK转黄成UTF8,快捷键Ctrl+Shift+C 
该插件基本上实现了git的所有功能。 总结好吧,大概就这些,如果你有常用的插件或者扩展,欢迎推荐。Sublime Text 3真是一款一见钟情的编辑器,每次和别人聊到编辑器时必荐的。。。
AngularJS是Google开源的一款JavaScript MVC框架,弥补了HTML在构建应用方面的不足,其通过使用指令(directives)结构来扩展HTML词汇,使开发者可以使用HTML来声明动态内容,从而使得Web开发和测试工作变得更加容易。

AngularJS诞生以来,吸引了大量的目光,也迅速成为了Web开发领域的新宠。本文整理了2013年度一些非常有价值的AngularJS相关教程和资源,如果你想了解AngularJS或正在使用AngularJS,那么这些资源肯定会为你的学习和进阶过程带来帮助。
一、了解AngularJS
二、中文资源
1. 中文系列资源
2. 其他单篇文章
3. 中文书籍
三、英文资源
1. AngularJS入门教程
2. AngularJS指令学习
3. AngularJS应用开发实战
4. AngularJS游戏开发
5. AngularJS工作流程和测试
6. AngularJS书籍
碰到了用java.util.Properties读取中文内容(UTF-8格式)的配置文件,发生中文乱码的现象,
- Properties prop=new Properties();
- prop.load(Client.class.getClassLoader().getResourceAsStream("config.properties"));
习惯性google了一下,网上大多数文章都是让大家用native2ascii.exe转换 这样的解决方案,一开始还差点被懵住了,以为只能使用这样的绕弯子方法。。。
但关键是,太绕了! 如果每次都用native2ascii.exe将中文转换成\uXXXX\uXXXX这样的,麻烦先不说,转换完后的文件完全不可读!!!这基本上是不可忍受的!
(虽然也能用native2ascii.exe转换回来,但同样,麻烦!)
冷静下来后,突然想起来,还是初学java时看过,java.io包中 Reader/Writer和Stream的区别。
(年代久远,具体细节忘记了,大概是:Reader/Write是处理编码文本的,而InputStream/OutputStream只把数据当作2进制流 )
正确解决方案
- Properties prop=new Properties();
- prop.load(new InputStreamReader(Client.class.getClassLoader().getResourceAsStream("config.properties"), "UTF-8"));
其中“UTF-8”,用于明确指定.properties文件的编码格式(不指定则默认使用OS的,这会造成同一份配置文件同一份代码,在linux和windows上、英文windows和中文windows之间的表现都不一致),这个参数应该和具体读取的properties文件的格式匹配。
最近一个项目拿到客户那运行不了。原来我的这个项目要和另一个系统通过http的接口进行通讯。但在客户的生产环境中,那套系统将web应用的登录和Windows Domain的登录结合,做了一个sso单点登录(jcifs实现)。那么我必须要修改我的程序,好自动登录Windows Domain。
通过抓包分析,局域网使用的是NTLM 协议。
当通过浏览器访问被NTLM协议保护的资源的时候,NTLM的认证方式和流程如下: 1: C --> S GET ...
2: C <-- S 401 Unauthorized
WWW-Authenticate: NTLM
3: C --> S GET ...
Authorization: NTLM <base64-encoded type-1-message>
4: C <-- S 401 Unauthorized
WWW-Authenticate: NTLM <base64-encoded type-2-message>
5: C --> S GET ...
Authorization: NTLM <base64-encoded type-3-message>
6: C <-- S 200 Ok
Type-1消息包括机器名、Domain等
Type-2消息包括server发出的NTLM challenge
Type-3消息包括用户名、机器名、Domain、以及两个根据server发出的challenge计算出的response,这里response是基于challenge和当前用户的登录密码计算而得 PS:在第二步时,当浏览器接收到一个401 Unauthorized 的response,会弹出该对话框让用户输入用户名、密码。(ie有可能会自动登录)
我的程序(client)要和另个程序走http接口通讯(server),server再去ad验证域登录

httpclient 实现NTLM验证(当然你也可以自己实现协议)
HttpClient从version 4.1 开始完全支持NTLM authentication protocol(NTLMv1, NTLMv2, and NTLM2 ),文档的原话是“The NTLM authentication scheme is significantly more expensive in terms of computational overhead
and performance impact than the standard Basic and Digest schemes.”
但是使用起来还是非常的方便的。因为 NTLM 连接是有状态的,通常建议使用相对简单的方法触发NTLM 认证,比如GET或 HEAD, 而重用相同的连接来执行代价更大的方法,特别是它们包含请求实体,比如 POST或 PUT。
DefaultHttpClient httpclient = new DefaultHttpClient();
NTCredentials creds = new NTCredentials("user", "pwd",
"myworkstation", "microsoft.com");
httpclient.getCredentialsProvider().setCredentials(AuthScop
.ANY, creds);
HttpHost target = new HttpHost("www.microsoft.com", 80,
"http");
// 保证相同的内容来用于执行逻辑相关的请求
HttpContext localContext = new BasicHttpContext();
// 首先执行简便的方法。这会触发NTLM认证
HttpGet httpget = new HttpGet("/ntlm-protected/info");
HttpResponse response1 = httpclient.execute(target, httpget
localContext);
HttpEntity entity1 = response1.getEntity();
if (entity1 != null) {
entity1.consumeContent();
}
//之后使用相同的内容(和连接)执行开销大的方法。
HttpPost httppost = new HttpPost("/ntlm-protected/form");
httppost.setEntity(new StringEntity("lots and lots of data"))
HttpResponse response2 = httpclient.execute(target, httppost,
localContext);
HttpEntity entity2 = response2.getEntity();
if (entity2 != null) {
entity2.consumeContent();
} import org.apache.commons.httpclient.ProxyHost; import org.apache.http.HttpEntity; import org.apache.http.HttpHost; import org.apache.http.HttpResponse; import org.apache.http.ParseException; import org.apache.http.auth.AuthScope; import org.apache.http.auth.UsernamePasswordCredentials; import org.apache.http.client.ClientProtocolException; import org.apache.http.client.HttpClient; import org.apache.http.client.methods.HttpGet; import org.apache.http.conn.params.ConnRouteParams; import org.apache.http.impl.client.DefaultHttpClient; import org.apache.http.util.EntityUtils;
private HttpClient getHttpClient() {
DefaultHttpClient httpClient = new DefaultHttpClient();
String proxyHost = "";
int proxyPort = 8080;
String userName = "";
String password = "";
httpClient.getCredentialsProvider().setCredentials(
new AuthScope(proxyHost, proxyPort),
new UsernamePasswordCredentials(userName, password));
HttpHost proxy = new HttpHost(proxyHost, proxyPort);
httpClient.getParams().setParameter(ConnRouteParams.DEFAULT_PROXY,
proxy);
return httpClient;
}
1、百度地图API车联网API网址:http://developer.baidu.com/map/carhome.htm
登录http://lbsyun.baidu.com/apiconsole/key?application=key获得密钥
通过坐标取用户位置(反Geocoding)http://api.map.baidu.com/telematics/v2/reverseGeocoding?location=116.305145,39.982368&ak=yourkey
测距http://api.map.baidu.com/telematics/v2/distance?waypoints=118.77147503233,32.054128923368;116.3521416286,39.965780080447&ak=yourkey
获取经纬度http://www.gpsspg.com/maps.htm
天气查询http://api.map.baidu.com/telematics/v2/weather?location=北京&ak=yourkey http://api.map.baidu.com/telematics/v2/weather?location=经度,纬度&ak=yourkey 查询周边商家http://api.map.baidu.com/telematics/v2/local?location=经度,纬度&keyword=类型&ak=yourkey&radius=半径&number=10
导航地图http://developer.baidu.com/map/uri.htm
http://api.map.baidu.com/direction?origin=latlan:34.264642646862,108.95108518068|name:我家&destination=大雁塔&mode=driving®ion=西安&output=html&src=yourCompanyName|yourAppName (mode可以为driving架车、transit公交、walking步行) 2、Google地图API https://developers.google.com/maps/?hl=zh-cn 申请密码https://code.google.com/apis/console
经纬度解析http://maps.googleapis.com/maps/api/geocode/xml?latlng=23.416155105336312,116.6294002532959&sensor=false&language=zh-CN
测距/测时https://developers.google.com/maps/documentation/distancematrix/ http://maps.googleapis.com/maps/api/distancematrix/xml?origins=经度,纬度&destinations=经度,纬度&mode=walking&language=zh-CN&sensor=false (origine起点、destinations终点、sensor感应器是否启动gps、mode包含driving/walking/bicyilng、language语言、avoid避开highways高速tolls收费)
查询周边商家https://developers.google.com/places/ https://developers.google.com/places/documentation/search?hl=zh-CN https://maps.googleapis.com/maps/api/place/search/xml?location=经度,纬度&radius=3000&sensor=false&key=yourkey&keyword=餐馆&language=zh-CN 3、高德地图API http://code.autonavi.com/index 浏览器调用http://code.autonavi.com/URI/browser_guide
接口格式http://mo.amap.com/?from=经度,纬度&to=经度,纬度&type=0&opt=1&dev=1 4、小黄鸡(试用每天只能调100次,30美元/10万次调用) http://developer.simsimi.com/api?lang=zh_CN 试用地址http://sandbox.api.simsimi.com/request.p (参数key密钥、text用户的问题、lc语言中文ch) 5、百度翻译 http://developer.baidu.com/ms/translate 接口http://openapi.baidu.com/public/2.0/bmt/translate (参数from源码语言ch中文、en英文、jp日语、auto自动) http://openapi.baidu.com/public/2.0/bmt/translate?client_id=yourApiKey&q=关键词&from=auto&to=auto 6、快递查询
申请KEY http://www.aikuaidi.cn/api/?type=1 http://www.aikuaidi.cn/rest/?key=参数&order=快递单号&id=快递拼音&ord=排序方式&show= (圆通yuantong/申通shentong/EMSems/韵达yunda/顺丰shunfeng,ord排序asc/desc,show可以为JSON/XML/HTML) 7、每日笑话(不限次数,不用申请KEY) http://api.94qing.com/?type=joke&msg= 8、RSS订阅 http://www.baidu.com/search/rss.html 9、刮刮乐(只是源码地址,需要封装管理程序) http://kuro.tw/scratch.html 10、第三方接口
乐享微信http://www.wxapi.cn/ (收费,不开源)
365微服务http://www.weduty.com (收费,不开源)
宾果科技https://github.com/takura/WeChat4DiscuzX-Binguo (discuz论坛插件、名费、开源)
小I机器人http://www.xiaoi.com (智能聊天,收费,不开源)
V5智能客服http://www.v5kf.com (基础免费、增值收费、不开源)
小九机器人http://www.xiaojo.com (免费、开源)
微擎http://www.we7.cc/ (免费、开源) 11、百度BAE以及新浪SAE
百度BAE http://developer.baidu.com/ (免费创建10个应用,每天200M免费流量,数据库每月1G免费流量,缓存为memcache不免费1.6元/GB/天)
计费 http://developer.baidu.com/dev#/price/charge
新浪SAE http://sae.sina.com.cn/ (免费创建10个应用)
计费 http://sae.sina.com.cn/?m=devcenter&catId=155 12、WAP在线生成 http://siteapp.baidu.com/ 13、百度应用中心 http://r2.mo.baidu.com/webapp_html.php?version=4_0&fn=webpage_flash
微信开放平台
主要面向App开发者 通常前提是拥有成熟的应用程序 之后通过开放平台 将内容分享至朋友圈 发送给某个微信好友.
微信公众平台
强调信息流 既可以向微博一样主要推送内容 也可以像10086一样 根据用户发来的消息进行智能回复 后台可以实现某些功能.
详解:
微信开放平台也即open平台,公众平台即是mp平台,目前open 平台是腾讯移动生活电商团队——微生活在使用,以下是区别。
详解微生活商家后台与公众平台的区别
微信是腾讯近两年崛起的一个新颖的语音沟通工具,随着微信5.0内测版本的发布,扫描二维码、条形码、甚至街景的功能;摇一摇增加了视频功能;公众账号分为企业账号和订阅账号等最新变化的出现,使得微信“横扫一切”“O2O神器”等标签更加流行。而从去年开始流行的“微信扫描二维码 免费获得会员卡”的微生活团队正是腾讯移动生活电商旗下的全新专注生活电子商务与O2O的解决方案提供商,大街小巷铺满商家二维码掀起了全国范围内的微信扫描风潮。据了解微生活有专门的商家后台帮助商家解决CRM会员关系管理、精准营销等问题,与微信的公众平台后台有所区别,一下即是笔者总结的二者的一些区别和联系。
1、 整体概览
5.0之前的微信公众平台媒体属性貌似更强一些,打开微信公众平台第一眼看见的就是实时消息。这里可以看到账号当前增加了多少粉丝、有多少用户留言。其次的重点就是开放接口,微信作为一个大的平台需要给各位开发者以更多的方便,绿色的公众平台API文档方便开发者直接点击进入,高级功能中的开发模式更为开发者提供了广阔的空间。
然而微生活商家后台则没有实时消息这个功能,因为用户的留言都已经被商家的多客服系统处理完毕,这与微生活的泛会员管理与营销平台的定位有很大的关系,时时解决会员的问题,帮助用户完成订单、订位、订房等工作,甚至是陪用户闲聊和调戏,实现用户在移动端的良好体验。总之,微生活商家后台更适合商家去做CRM 管理和会员营销。
从二者的首页中笔者读出一个趋势——大数据管理,对于商家和媒体来说,数据管理必不可少,而从两个平台首页明显的数据折线图来看,二者都focus 在大数据上。
微信开拓了一种语音沟通的新时尚,而腾讯微生活开拓了创新的富媒体会员营销平台,解决企业数据库管理、会员关系管理、会员精准营销等问题,为传统商企打开了进军移动互联网的大门。
2、 首页
微信公众平台功能模块包括:首页、实时消息、用户管理、群发消息、素材管理、设置、高级功能。
打开微信公众平台即可看到实时消息、每日新增订阅人数和每日接收消息数的曲线图表,可以使得用户时时把控每日情况,但是无法看到多日的消息对比。首页右侧是系统公告 ,公众平台接口更新等通知。微信未来要做的是个平台,开放平台,首页的公告是为微信的开发者进行更多的指引。
微生活商家后台功能模块包括:首页、会员、交易、消息、活动、设置 。
打开微生活商家后台首先看到的是会员趋势图,包括新增总量、线下扫码增量、线上传播新增量等分类,这比微信公众平台的的会员增长图坐标要复杂一些。因为微生活会员卡是用户通过打开微信扫描二维码后,获得的一张存在于微信中的虚拟会员卡,而二维码可以存在在海报、桌贴、宣传册等线下物料上,也可以放置在微博、微信、论坛、网站等线上渠道。微生活首页右侧呈现的是今日和昨日的新增会员和交易次数、会员带动交易额。这与微生活致力于成为传统商企精准的泛会员管理与营销平台有着很大的关系,商家人员登录商家后台可以清楚明了的看到自家店面的整体销售情况和会员增长情况,时时把控商机和运营情况。
关于注册公众账号这块不详细介绍
注册完成,审核认证完,就可以开始玩了
1.如何成为开发者?

需要填写接口配置信息,需要自己的服务器资源,一般自己没有服务器,所以可以采用云服务器,例如BAE,SAE,阿里云服务器。这里用BAE
2.打开百度开放云平台官网,注册,登陆,点击开发者服务管理

![\]() 
2.1.点击“创建工程”

填写工程相关信息,应用名称自定义,类型选择java-tomcat,域名唯一,代码管理工具选择svn 到这里,bae应用创建完了.
3.现在来实现TOKEN验证的代码部分
3.1.创建一个Java web工程,我用的是MyEclipse8.5,工程名称为voastudy,点击Finish完成。

3.2.新建一个servlet,这里是CoreServlet,点击Next.

3.3.勾选创建web.xml,以及配置servlet,这里的路径很关键,这是去请求servlet里的方法

3.4.实现验证TOKEN方法,微信公众平台提供的是PHP的实例代码.但其验证本质是一样的,都是要经过排序,sha1加密进行比较。请参考下面的代码。这是CoreServlet.java类.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60 |
package wx.sunl.servlet;
import java.io.IOException;
import java.io.PrintWriter;
import javax.servlet.ServletException;
import javax.servlet.http.HttpServlet;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
import wx.sunl.util.SignUtil;
@SuppressWarnings("serial")
public class CoreServlet extends HttpServlet
{
public CoreServlet() {
super();
}
public void destroy() {
super.destroy();
}
/**
* 验证url和token
*/
public void doGet(HttpServletRequest request, HttpServletResponse response)
throws ServletException, IOException {
String signature = request.getParameter("signature");
String timestamp = request.getParameter("timestamp");
String nonce = request.getParameter("nonce");
String echostr = request.getParameter("echostr");
PrintWriter out = response.getWriter();
if(SignUtil.checkSignature(signature, timestamp, nonce)){
out.print(echostr);
}
out.close();
out = null;
}
/**
*用户向公众平台发信息并自动返回信息
*/
public void doPost(HttpServletRequest request, HttpServletResponse response)
throws ServletException, IOException {
}
public void init() throws ServletException {
}
}
| 其中调用到了SignUtil类的checkSignature方法,下面是SignUtil.java类.注意:其中一个静态属性token的值,在最后一步需要用到来验证的.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75 |
package wx.sunl.util;
import java.security.MessageDigest;
import java.security.NoSuchAlgorithmException;
import java.util.Arrays;
public class SignUtil {
/**
* 与接口配置信息中的 token 要一致,这里赋予什么值,在接口配置信息中的Token就要填写什么值,
* 两边保持一致即可,建议用项目名称、公司名称缩写等,我在这里用的是项目名称weixinface
*/
private static String token = "weixintest";
/**
* 验证签名
* @param signature
* @param timestamp
* @param nonce
* @return
*/
public static boolean checkSignature(String signature, String timestamp, String nonce){
String[] arr = new String[]{token, timestamp, nonce};
Arrays.sort(arr);
StringBuilder content = new StringBuilder();
for(int i = 0; i < arr.length; i++){
content.append(arr[i]);
}
MessageDigest md = null;
String tmpStr = null;
try {
md = MessageDigest.getInstance("SHA-1");
byte[] digest = md.digest(content.toString().getBytes());
tmpStr = byteToStr(digest);
} catch (NoSuchAlgorithmException e) {
e.printStackTrace();
}
content = null;
return tmpStr != null ? tmpStr.equals(signature.toUpperCase()): false;
}
/**
* 将字节数组转换为十六进制字符串
* @param digest
* @return
*/
private static String byteToStr(byte[] digest) {
String strDigest = "";
for(int i = 0; i < digest.length; i++){
strDigest += byteToHexStr(digest[i]);
}
return strDigest;
}
/**
* 将字节转换为十六进制字符串
* @param b
* @return
*/
private static String byteToHexStr(byte b) {
char[] Digit = {'0', '1', '2', '3', '4', '5', '6', '7', '8', '9', 'A', 'B', 'C', 'D', 'E', 'F'};
char[] tempArr = new char[2];
tempArr[0] = Digit[(b >>> 4) & 0X0F];
tempArr[1] = Digit[b & 0X0F];
String s = new String(tempArr);
return s;
}
}
|
4.代码已经写完了,现在来提交代码到svn.如果没有svn客户端工具,那首先下载(svn版本工具)安装。打开svn

4.1.这里的url去百度开放云平台去这里复制

4.2.粘贴url,打开svn,会看到服务器的2个文件

4.3.代码提交到svn 首先删掉root.war

4.4.java web工程打包成war包,取名ROOT.war,然后提交到svn

4.5.然后将这个war包提交到svn

4.6.如果提交成功了,百度开放云平台会检测到有新版本产生,选中应用,点击“发布设置”

4.7.发布新版本

5.发布成功后,测试是否部署成功?
5.1.如果看到这个,离成功只差一步啦。<�喎�"http://www.2cto.com/kf/ware/vc/" target="_blank" class="keylink">vcD4KPHA+PGltZyBzcmM9"http://www.2cto.com/uploadfile/Collfiles/20140510/2014051009050433.jpg" alt="\">
5.5.在域名后边加上请求我们刚刚servlet的请求路径,上边的例子是/CoreServlet,如果报505错误(why?因为那几个参数都是空的),说明部署成功了

6.最后一步,填写Url 和 Token来验证 成为开发者。Url:百度应用的域名+请求servlet的路径例如:http://weixintest11.duapp.com/CoreServlet.Token是在程序中自定义的值(在SignUtil.java中定义)

欢迎吐槽!!!
摘要: Dojo 的这些接口大大简化了我们的 Web 前端开发的复杂度,使得我们能够在更短的时间内实现功能更为丰富的应用。这篇文章将重点介绍 Dojo 的核心接口所带给 Web 开发工程师们的各种便利以及它的一些使用技巧。Dojo 核心接口简介Dojo 的核心接口主要位于 Dojo 的三大库(“dojo”,“dijit”和“dojox”... 阅读全文
Define
先看define。作用是定义一个模块(module)。这个模块可以被require引用,引用了之后就可以使用define里面的东西。一个模块想当然,里面干什么事情,不一定全部自己实现。就像人要coding,除了脑子,也不能没有电脑、键盘。因此,define的第一个参数就是将要用到的其他模块引进来。第二个参数描述这个模块具体干什么,并且给第一个参数中的模块分别起一个朗朗上口的名字。就像下面这段代码描述的样子。 util.js - define([ "dojo/dom"], function(dom) {
- return {
- setRed: function(id){
- dom.byId(id).style.color = "red";
- }
- };
- });
这是一个工具模块,其中一个功能就是把网页上id对应的DOM节点变成红色。当我们要使用它的时候,就可以用require了。 test.jsp - <script>
- require(
- [ "dojo/ready", "test/util" ],
- function(ready, util) {
- ready(function() {
- var id = "selected_text";
- util.setRed(id);
- });
- });
- </script>
Declare
可以看到,上面的模块util作为工具模块,可以在被引用后任意调用其功能。这是无状态的,就好象是一个singleton的对象。但如果我们想定义“类”一样的东西,有状态,可以创建多个对象,就需要在define里用declare。最典型的例子就是dijit下面的诸多UI小控件。 举个很简单的例子,我希望基于dijit.Dialog,创建一个有特殊功能的dialog,每次打开后能把上面的一段text标记为红色。 RedTextDialog.js - define([ "dojo/_base/declare", "dijit/Dialog", "dijit/_WidgetBase",
- "dijit/_TemplatedMixin", "test/util" ], function(declare,
- Dialog, _WidgetBase, _TemplatedMixin, util) {
- return declare("test.RedTextDialog", [ Dialog, _WidgetBase, _TemplatedMixin ], {
- title: "Dialog with Red Text",
-
- onDownloadEnd : function() {
- var id = "selected_text";
- util.setRed(id);
- }
- });
- });
RedTextDialog可以重写dijit.Dialog所有的方法,也可以自创方法、变量,实现自己想要的任意功能。接下来可以用require使用它。 - <script>
- require(
- [ "dojo/ready", "test/RedTextDialog" ],
- function(ready, RedTextDialog) {
- ready(function() {
- var dialog = new RedTextDialog();
- dialog.show();
- });
- });
- </script>
可以看到,每次使用RedTextDialog时,都可以创建一个新的对象实例,因此可以做到互相之间没有关系。 目录结构
为了在test.jsp中调用上述js文件,需要在test.jsp声明js文件的位置。 - <script>
- dojoConfig = {
- isDebug : false,
- parseOnLoad : true,
- async : true,
- packages : [
- {
- name : "test",
- location : "../../js/test"
- }
- ]
- };
- </script>
最后,约定俗成地,一般define类似util的singleton模块,js文件的名字第一个字母小写;而类似RedTextDialog的类模块,第一个字母大写。
spring的 配置文件在启动时,加载的是web-info目录下的applicationContext.xml,
运行时使用的是web-info/classes目录下的applicationContext.xml。
配置web.xml使这2个路径一致:
<context-param>
<param-name>contextConfigLocation</param-name>
<param-value>/WEB-INF/classes/applicationContext.xml</param-value>
</context-param> 多个配置文件的加载
<context-param>
<param-name>contextConfigLocation</param-name>
<param-value>
classpath*:conf/spring/applicationContext_core*.xml,
classpath*:conf/spring/applicationContext_dict*.xml,
classpath*:conf/spring/applicationContext_hibernate.xml,
classpath*:conf/spring/applicationContext_staff*.xml,
classpath*:conf/spring/applicationContext_security.xml
classpath*:conf/spring/applicationContext_modules*.xml
classpath*:conf/spring/applicationContext_cti*.xml
classpath*:conf/spring/applicationContext_apm*.xml
</param-value>
</context-param> contextConfigLocation 参数定义了要装入的 Spring 配置文件。
由于是使用spring mvc来做项目,因此脱离了HttpServletRequest作为参数,不能够直接使用request,要想使用request可以使用下面的方法:
在web点xml中配置一个监听 <listener> <listener-class> org.springframework.web.context.request.RequestContextListener </listener-class> </listener> 之后就可以在程序使用了HttpServletRequest request = ((ServletRequestAttributes)RequestContextHolder.getRequestAttributes()).getRequest();
在xml配置了这个标签后,spring可以自动去扫描base-pack下面或者子包下面的java文件,如果扫描到有@Component @Controller@Service等这些注解的类,则把这些类注册为bean 注意:如果配置了<context:component-scan>那么<context:annotation-config/>标签就可以不用再xml中配置了,因为前者包含了后者。另外<context:annotation-config/>还提供了两个子标签 1. <context:include-filter> 2. <context:exclude-filter> 在说明这两个子标签前,先说一下<context:component-scan>有一个use-default-filters属性,改属性默认为true,这就意味着会扫描指定包下的全部的标有@Component的类,并注册成bean.也就是@Component的子注解@Service,@Reposity等。所以如果仅仅是在配置文件中这么写 <context:component-scan base-package="tv.huan.weisp.web"/> Use-default-filter此时为true那么会对base-package包或者子包下的所有的进行java类进行扫描,并把匹配的java类注册成bean。 可以发现这种扫描的粒度有点太大,如果你只想扫描指定包下面的Controller,该怎么办?此时子标签<context:incluce-filter>就起到了勇武之地。如下所示 <context:component-scan base-package="tv.huan.weisp.web .controller"> <context:include-filter type="annotation" expression="org.springframework.stereotype.Controller"/> </context:component-scan> 这样就会只扫描base-package指定下的有@Controller下的java类,并注册成bean 但是因为use-dafault-filter在上面并没有指定,默认就为true,所以当把上面的配置改成如下所示的时候,就会产生与你期望相悖的结果(注意base-package包值得变化) <context:component-scan base-package="tv.huan.weisp.web "> <context:include-filter type="annotation" expression="org.springframework.stereotype.Controller"/> </context:component-scan> 此时,spring不仅扫描了@Controller,还扫描了指定包所在的子包service包下注解@Service的java类 此时指定的include-filter没有起到作用,只要把use-default-filter设置成false就可以了。这样就可以避免在base-packeage配置多个包名这种不是很优雅的方法来解决这个问题了。 另外在我参与的项目中可以发现在base-package指定的包中有的子包是不含有注解了,所以不用扫描,此时可以指定<context:exclude-filter>来进行过滤,说明此包不需要被扫描。综合以上说明 Use-dafault-filters=”false”的情况下:<context:exclude-filter>指定的不扫描,<context:include-filter>指定的扫描
摘要: 在安装SharePoint 2013 服务器之前,请先了解硬件和软件要求http://technet.microsoft.com/library/cc262485(office.15)?ocid=fwlink#section4Microsoft SharePoint 产品准备工具会为具有内置数据库的单台服务器安装以下必备软件:Web 服务器 (IIS) 角色应用程序服务器角色Microsoft .... 阅读全文
var test= {
$ : function(id){
return document.getElementById(id);
},
addEvent : function(obj,eventType,func){
if(obj.attachEvent){obj.attachEvent("on" + eventType,func);}else{obj.addEventListener(eventType,func,false)}},
delEvent : function(obj,eventType,func){
if(obj.detachEvent){obj.detachEvent("on" + eventType,func)}else{obj.removeEventListener(eventType,func,false)}
}
};
| 字段 | | 允许值 | | 允许的特殊字符 |
秒 |
|
0-59 |
|
, - * / |
分 |
|
0-59 |
|
, - * / |
小时 |
|
0-23 |
|
, - * / |
日期 |
|
1-31 |
|
, - * ? / L W C |
月份 |
|
1-12 或者 JAN-DEC |
|
, - * / |
星期 |
|
1-7 或者 SUN-SAT |
|
, - * ? / L C # |
年(可选) |
|
留空, 1970-2099 |
|
, - * / |
The '*' character is used to specify all values. For example, "*" in the minute field means "every minute".
“*”字符被用来指定所有的值。如:”*“在分钟的字段域里表示“每分钟”。
The '?' character is allowed for the day-of-month and day-of-week fields. It is used to specify 'no specific value'. This is useful when you need to specify something in one of the two fileds, but not the other. See the examples below for clarification.
“?”字符只在日期域和星期域中使用。它被用来指定“非明确的值”。当你需要通过在这两个域中的一个来指定一些东西的时候,它是有用的。看下面的例子你就会明白。
月份中的日期和星期中的日期这两个元素时互斥的一起应该通过设置一个问号(?)来表明不想设置那个字段
The '-' character is used to specify ranges For example "10-12" in the hour field means "the hours 10, 11 and 12".
“-”字符被用来指定一个范围。如:“10-12”在小时域意味着“10点、11点、12点”。
The ',' character is used to specify additional values. For example "MON,WED,FRI" in the day-of-week field means "the days Monday, Wednesday, and Friday".
“,”字符被用来指定另外的值。如:“MON,WED,FRI”在星期域里表示”星期一、星期三、星期五”.
The '/' character is used to specify increments. For example "0/15" in the seconds field means "the seconds 0, 15, 30, and 45". And "5/15" in the seconds field means "the seconds 5, 20, 35, and 50". Specifying '*' before the '/' is equivalent to specifying 0 is the value to start with. Essentially, for each field in the expression, there is a set of numbers that can be turned on or off. For seconds and minutes, the numbers range from 0 to 59. For hours 0 to 23, for days of the month 0 to 31, and for months 1 to 12. The "/" character simply helps you turn on every "nth" value in the given set. Thus "7/6" in the month field only turns on month "7", it does NOT mean every 6th month, please note that subtlety.
The 'L' character is allowed for the day-of-month and day-of-week fields. This character is short-hand for "last", but it has different meaning in each of the two fields. For example, the value "L" in the day-of-month field means "the last day of the month" - day 31 for January, day 28 for February on non-leap years. If used in the day-of-week field by itself, it simply means "7" or "SAT". But if used in the day-of-week field after another value, it means "the last xxx day of the month" - for example "6L" means "the last friday of the month". When using the 'L' option, it is important not to specify lists, or ranges of values, as you'll get confusing results.
L是‘last’的省略写法可以表示day-of-month和day-of-week域,但在两个字段中的意思不同,例如day-of-month域中表示一个月的最后一天,
如果在day-of-week域表示‘7’或者‘SAT’,如果在day-of-week域中前面加上数字,它表示一个月的最后几天,例如‘6L’就表示一个月的最后一个
星期五,
The 'W' character is allowed for the day-of-month field. This character is used to specify the weekday (Monday-Friday) nearest the given day. As an example, if you were to specify "15W" as the value for the day-of-month field, the meaning is: "the nearest weekday to the 15th of the month". So if the 15th is a Saturday, the trigger will fire on Friday the 14th. If the 15th is a Sunday, the trigger will fire on Monday the 16th. If the 15th is a Tuesday, then it will fire on Tuesday the 15th. However if you specify "1W" as the value for day-of-month, and the 1st is a Saturday, the trigger will fire on Monday the 3rd, as it will not 'jump' over the boundary of a month's days. The 'W' character can only be specified when the day-of-month is a single day, not a range or list of days
.
The 'L' and 'W' characters can also be combined for the day-of-month expression to yield 'LW', which translates to "last weekday of the month".
The '#' character is allowed for the day-of-week field. This character is used to specify "the nth" XXX day of the month. For example, the value of "6#3" in the day-of-week field means the third Friday of the month (day 6 = Friday and "#3" = the 3rd one in the month). Other examples: "2#1" = the first Monday of the month and "4#5" = the fifth Wednesday of the month. Note that if you specify "#5" and there is not 5 of the given day-of-week in the month, then no firing will occur that month.
The 'C' character is allowed for the day-of-month and day-of-week fields. This character is short-hand for "calendar". This means values are calculated against the associated calendar, if any. If no calendar is associated, then it is equivalent to having an all-inclusive calendar. A value of "5C" in the day-of-month field means "the first day included by the calendar on or after the 5th". A value of "1C" in the day-of-week field means "the first day included by the calendar on or after sunday".
关于cronExpression的介绍:
字段 允许值 允许的特殊字符
秒 0-59 , - * /
分 0-59 , - * /
小时 0-23 , - * /
日期 1-31 , - * ? / L W C
月份 1-12 或者 JAN-DEC , - * /
星期 1-7 或者 SUN-SAT , - * ? / L C #
年(可选) 留空, 1970-2099 , - * /
表达式意义
"0 0 12 * * ?" 每天中午12点触发
"0 15 10 ? * *" 每天上午10:15触发
"0 15 10 * * ?" 每天上午10:15触发
"0 15 10 * * ? *" 每天上午10:15触发
"0 15 10 * * ? 2005" 2005年的每天上午10:15触发
"0 * 14 * * ?" 在每天下午2点到下午2:59期间的每1分钟触发
"0 0/5 14 * * ?" 在每天下午2点到下午2:55期间的每5分钟触发
"0 0/5 14,18 * * ?" 在每天下午2点到2:55期间和下午6点到6:55期间的每5分钟触发
"0 0-5 14 * * ?" 在每天下午2点到下午2:05期间的每1分钟触发
"0 10,44 14 ? 3 WED" 每年三月的星期三的下午2:10和2:44触发
"0 15 10 ? * MON-FRI" 周一至周五的上午10:15触发
"0 15 10 15 * ?" 每月15日上午10:15触发
"0 15 10 L * ?" 每月最后一日的上午10:15触发
"0 15 10 ? * 6L" 每月的最后一个星期五上午10:15触发
"0 15 10 ? * 6L 2002-2005" 2002年至2005年的每月的最后一个星期五上午10:15触发
"0 15 10 ? * 6#3" 每月的第三个星期五上午10:15触发
每天早上6点
0 6 * * *
每两个小时
0 */2 * * *
晚上11点到早上8点之间每两个小时,早上八点
0 23-7/2,8 * * *
每个月的4号和每个礼拜的礼拜一到礼拜三的早上11点
0 11 4 * 1-3
1月1日早上4点
0 4 1 1 *
quartz的高级特性不仅如此
1 数据库存储
2 集群支持
3 数据库持久化任务,trigger
4 trigger 的停止,运行
5 任务的任意添加
6 比corntrigger 更详尽的任务安排
7 线程的内部数据交换
一个cron表达式有至少6个(也可能7个)有空格分隔的时间元素。
按顺序依次为
1.秒(0~59)
2.分钟(0~59)
3.小时(0~23)
4.天(月)(0~31,但是你需要考虑你月的天数)
5.月(0~11)
6.天(星期)(1~7 1=SUN 或 SUN,MON,TUE,WED,THU,FRI,SAT)
7.年份(1970-2099) 其中每个元素可以是一个值(如6),一个连续区间(9-12),一个间隔时间(8-18/4)(/表示每隔4小时),一个列表(1,3,5),通配符。
由于"月份中的日期"和"星期中的日期"这两个元素互斥的,必须要对其中一个设置?. 0 0 10,14,16 * * ? 每天上午10点,下午2点,4点
0 0/30 9-17 * * ??? 朝九晚五工作时间内每半小时
0 0 12 ? * WED 表示每个星期三中午12点 有些子表达式能包含一些范围或列表
例如:子表达式(天(星期))可以为 “MON-FRI”,“MON,WED,FRI”,“MON-WED,SAT” “*”字符代表所有可能的值
因此,“*”在子表达式(月)里表示每个月的含义,“*”在子表达式(天(星期))表示星期的每一天 “/”字符用来指定数值的增量
例如:在子表达式(分钟)里的“0/15”表示从第0分钟开始,每15分钟 ;
在子表达式(分钟)里的“3/20”表示从第3分钟开始,每20分钟(它和“3,23,43”)的含义一样
“?”字符仅被用于天(月)和天(星期)两个子表达式,表示不指定值
当2个子表达式其中之一被指定了值以后,为了避免冲突,需要将另一个子表达式的值设为“?” “L” 字符仅被用于天(月)和天(星期)两个子表达式,它是单词“last”的缩写 但是它在两个子表达式里的含义是不同的。 在天(月)子表达式中,“L”表示一个月的最后一天 ,
在天(星期)自表达式中,“L”表示一个星期的最后一天,也就是SAT 如果在“L”前有具体的内容,它就具有其他的含义了 例如:“6L”表示这个月的倒数第6天,“FRIL”表示这个月的最后一个星期五 注意:在使用“L”参数时,不要指定列表或范围,因为这会导致问题 ============================================
CronTrigger配置完整格式为: [秒] [分] [小时] [日] [月] [周] [年] | 序号 | 说明 | 是否必填 | 允许填写的值 | 允许的通配符 | | 1 | 秒 | 是 | 0-59 | , - * / | | 2 | 分 | 是 | 0-59 | , - * / | | 3 | 小时 | 是 | 0-23 | , - * / | | 4 | 日 | 是 | 1-31 | , - * ? / L W | | 5 | 月 | 是 | 1-12 or JAN-DEC | , - * / | | 6 | 周 | 是 | 1-7 or SUN-SAT | , - * ? / L # | | 7 | 年 | 否 | empty 或 1970-2099 | , - * / |
通配符说明:
* 表示所有值. 例如:在分的字段上设置 "*",表示每一分钟都会触发。
? 表示不指定值。使用的场景为不需要关心当前设置这个字段的值。例如:要在每月的10号触发一个操作,但不关心是周几,所以需要周位置的那个字段设置为"?" 具体设置为 0 0 0 10 * ?
- 表示区间。例如 在小时上设置 "10-12",表示 10,11,12点都会触发。
, 表示指定多个值,例如在周字段上设置 "MON,WED,FRI" 表示周一,周三和周五触发
/ 用于递增触发。如在秒上面设置"5/15" 表示从5秒开始,每增15秒触发(5,20,35,50)。 在月字段上设置'1/3'所示每月1号开始,每隔三天触发一次。
L 表示最后的意思。在日字段设置上,表示当月的最后一天(依据当前月份,如果是二月还会依据是否是润年[leap]), 在周字段上表示星期六,相当于"7"或"SAT"。如果在"L"前加上数字,则表示该数据的最后一个。例如在周字段上设置"6L"这样的格式,则表示“本月最后一个星期五"
W 表示离指定日期的最近那个工作日(周一至周五). 例如在日字段上设置"15W",表示离每月15号最近的那个工作日触发。如果15号正好是周六,则找最近的周五(14号)触发, 如果15号是周未,则找最近的下周一(16号)触发.如果15号正好在工作日(周一至周五),则就在该天触发。如果指定格式为 "1W",它则表示每月1号往后最近的工作日触发。如果1号正是周六,则将在3号下周一触发。(注,"W"前只能设置具体的数字,不允许区间"-").
# 序号(表示每月的第几个周几),例如在周字段上设置"6#3"表示在每月的第三个周六.注意如果指定"#5",正好第五周没有周六,则不会触发该配置(用在母亲节和父亲节再合适不过了) ;
小提示:
'L'和 'W'可以一组合使用。如果在日字段上设置"LW",则表示在本月的最后一个工作日触发;
周字段的设置,若使用英文字母是不区分大小写的,即MON 与mon相同;
常用示例: | 0 0 12 * * ? | 每天12点触发 | | 0 15 10 ? * * | 每天10点15分触发 | | 0 15 10 * * ? | 每天10点15分触发 | | 0 15 10 * * ? * | 每天10点15分触发 | | 0 15 10 * * ? 2005 | 2005年每天10点15分触发 | | 0 * 14 * * ? | 每天下午的 2点到2点59分每分触发 | | 0 0/5 14 * * ? | 每天下午的 2点到2点59分(整点开始,每隔5分触发) | | 0 0/5 14,18 * * ? | 每天下午的 2点到2点59分、18点到18点59分(整点开始,每隔5分触发) | | 0 0-5 14 * * ? | 每天下午的 2点到2点05分每分触发 | | 0 10,44 14 ? 3 WED | 3月分每周三下午的 2点10分和2点44分触发 | | 0 15 10 ? * MON-FRI | 从周一到周五每天上午的10点15分触发 | | 0 15 10 15 * ? | 每月15号上午10点15分触发 | | 0 15 10 L * ? | 每月最后一天的10点15分触发 | | 0 15 10 ? * 6L | 每月最后一周的星期五的10点15分触发 | | 0 15 10 ? * 6L 2002-2005 | 从2002年到2005年每月最后一周的星期五的10点15分触发 | | 0 15 10 ? * 6#3 | 每月的第三周的星期五开始触发 | | 0 0 12 1/5 * ? | 每月的第一个中午开始每隔5天触发一次 | | 0 11 11 11 11 ? | 每年的11月11号 11点11分触发(光棍节) |
一、ORACLE的启动和关闭
1、在单机环境下
要想启动或关闭ORACLE系统必须首先切换到ORACLE用户,如下
su - oracle
a、启动ORACLE系统
oracle>svrmgrl
SVRMGR>connect internal
SVRMGR>startup
SVRMGR>quit
b、关闭ORACLE系统
oracle>svrmgrl
SVRMGR>connect internal
SVRMGR>shutdown
SVRMGR>quit
启动oracle9i数据库命令:
$ sqlplus /nolog
SQL*Plus: Release 9.2.0.1.0 - Production on Fri Oct 31 13:53:53 2003
Copyright (c) 1982, 2002, Oracle Corporation. All rights reserved.
SQL> connect / as sysdba
Connected to an idle instance.
SQL> startup^C
SQL> startup
ORACLE instance started.
2、在双机环境下
要想启动或关闭ORACLE系统必须首先切换到root用户,如下
su - root
a、启动ORACLE系统
hareg -y oracle
b、关闭ORACLE系统
hareg -n oracle
Oracle数据库有哪几种启动方式
说明:
有以下几种启动方式:
1、startup nomount
非安装启动,这种方式启动下可执行:重建控制文件、重建数据库
读取init.ora文件,启动instance,即启动SGA和后台进程,这种启动只需要init.ora文件。
2、startup mount dbname
安装启动,这种方式启动下可执行:
数据库日志归档、
数据库介质恢复、
使数据文件联机或脱机,
重新定位数据文件、重做日志文件。
执行“nomount”,然后打开控制文件,确认数据文件和联机日志文件的位置,
但此时不对数据文件和日志文件进行校验检查。
3、startup open dbname
先执行“nomount”,然后执行“mount”,再打开包括Redo log文件在内的所有数据库文件,
这种方式下可访问数据库中的数据。
4、startup,等于以下三个命令
startup nomount
alter database mount
alter database open
5、startup restrict
约束方式启动
这种方式能够启动数据库,但只允许具有一定特权的用户访问
非特权用户访问时,会出现以下提示:
ERROR:
ORA-01035: ORACLE 只允许具有 RESTRICTED SESSION 权限的用户使用
6、startup force
强制启动方式
当不能关闭数据库时,可以用startup force来完成数据库的关闭
先关闭数据库,再执行正常启动数据库命令
7、startup pfile=参数文件名
带初始化参数文件的启动方式
先读取参数文件,再按参数文件中的设置启动数据库
例:startup pfile=E:Oracleadminoradbpfileinit.ora
8、startup EXCLUSIVE
二、用户如何有效地利用数据字典
ORACLE的数据字典是数据库的重要组成部分之一,它随着数据库的产生而产生, 随着数据库的变化而变化,
体现为sys用户下的一些表和视图。数据字典名称是大写的英文字符。
数据字典里存有用户信息、用户的权限信息、所有数据对象信息、表的约束条件、统计分析数据库的视图等。
我们不能手工修改数据字典里的信息。
很多时候,一般的ORACLE用户不知道如何有效地利用它。
dictionary 全部数据字典表的名称和解释,它有一个同义词dict
dict_column 全部数据字典表里字段名称和解释
如果我们想查询跟索引有关的数据字典时,可以用下面这条SQL语句:
SQL>select * from dictionary where instr(comments,'index')>0;
如果我们想知道user_indexes表各字段名称的详细含义,可以用下面这条SQL语句:
SQL>select column_name,comments from dict_columns where table_name='USER_INDEXES';
依此类推,就可以轻松知道数据字典的详细名称和解释,不用查看ORACLE的其它文档资料了。
下面按类别列出一些ORACLE用户常用数据字典的查询使用方法。
1、用户
查看当前用户的缺省表空间
SQL>select username,default_tablespace from user_users;
查看当前用户的角色
SQL>select * from user_role_privs;
查看当前用户的系统权限和表级权限
SQL>select * from user_sys_privs;
SQL>select * from user_tab_privs;
2、表
查看用户下所有的表
SQL>select * from user_tables;
查看名称包含log字符的表
SQL>select object_name,object_id from user_objects
where instr(object_name,'LOG')>0;
查看某表的创建时间
SQL>select object_name,created from user_objects where object_name=upper('&table_name');
查看某表的大小
SQL>select sum(bytes)/(1024*1024) as "size(M)" from user_segments
where segment_name=upper('&table_name');
查看放在ORACLE的内存区里的表
SQL>select table_name,cache from user_tables where instr(cache,'Y')>0;
3、索引
查看索引个数和类别
SQL>select index_name,index_type,table_name from user_indexes order by table_name;
查看索引被索引的字段
SQL>select * from user_ind_columns where index_name=upper('&index_name');
查看索引的大小
SQL>select sum(bytes)/(1024*1024) as "size(M)" from user_segments
where segment_name=upper('&index_name');
4、序列号
查看序列号,last_number是当前值
SQL>select * from user_sequences;
5、视图
查看视图的名称
SQL>select view_name from user_views;
查看创建视图的select语句
SQL>set view_name,text_length from user_views;
SQL>set long 2000; 说明:可以根据视图的text_length值设定set long 的大小
SQL>select text from user_views where view_name=upper('&view_name');
6、同义词
查看同义词的名称
SQL>select * from user_synonyms;
7、约束条件
查看某表的约束条件
SQL>select constraint_name, constraint_type,search_condition, r_constraint_name
from user_constraints where table_name = upper('&table_name');
SQL>select c.constraint_name,c.constraint_type,cc.column_name
from user_constraints c,user_cons_columns cc
where c.owner = upper('&table_owner') and c.table_name = upper('&table_name')
and c.owner = cc.owner and c.constraint_name = cc.constraint_name
order by cc.position;
8、存储函数和过程
查看函数和过程的状态
SQL>select object_name,status from user_objects where object_type='FUNCTION';
SQL>select object_name,status from user_objects where object_type='PROCEDURE';
查看函数和过程的源代码
SQL>select text from all_source where owner=user and name=upper('&plsql_name');
三、查看数据库的SQL
1、查看表空间的名称及大小
select t.tablespace_name, round(sum(bytes/(1024*1024)),0) ts_size
from dba_tablespaces t, dba_data_files d
where t.tablespace_name = d.tablespace_name
group by t.tablespace_name;
2、查看表空间物理文件的名称及大小
select tablespace_name, file_id, file_name,
round(bytes/(1024*1024),0) total_space
from dba_data_files
order by tablespace_name;
3、查看回滚段名称及大小
select segment_name, tablespace_name, r.status,
(initial_extent/1024) InitialExtent,(next_extent/1024) NextExtent,
max_extents, v.curext CurExtent
From dba_rollback_segs r, v$rollstat v
Where r.segment_id = v.usn(+)
order by segment_name ;
4、查看控制文件
select name from v$controlfile;
5、查看日志文件
select member from v$logfile;
6、查看表空间的使用情况
select sum(bytes)/(1024*1024) as free_space,tablespace_name
from dba_free_space
group by tablespace_name;
SELECT A.TABLESPACE_NAME,A.BYTES TOTAL,B.BYTES USED, C.BYTES FREE,
(B.BYTES*100)/A.BYTES "% USED",(C.BYTES*100)/A.BYTES "% FREE"
FROM SYS.SM$TS_AVAIL A,SYS.SM$TS_USED B,SYS.SM$TS_FREE C
WHERE A.TABLESPACE_NAME=B.TABLESPACE_NAME AND A.TABLESPACE_NAME=C.TABLESPACE_NAME;
7、查看数据库库对象
select owner, object_type, status, count(*) count# from all_objects group by owner, object_type, status;
8、查看数据库的版本
Select version FROM Product_component_version
Where SUBSTR(PRODUCT,1,6)='Oracle';
9、查看数据库的创建日期和归档方式
Select Created, Log_Mode, Log_Mode From V$Database;
四、ORACLE用户连接的管理
用系统管理员,查看当前数据库有几个用户连接:
SQL> select username,sid,serial# from v$session;
如果要停某个连接用
SQL> alter system kill session 'sid,serial#';
如果这命令不行,找它UNIX的进程数
SQL> select pro.spid from v$session ses,v$process pro where ses.sid=21 and ses.paddr=pro.addr;
说明:21是某个连接的sid数
然后用 kill 命令杀此进程号。
五、SQL*PLUS使用
a、近入SQL*Plus
$sqlplus 用户名/密码
退出SQL*Plus
SQL>exit
b、在sqlplus下得到帮助信息
列出全部SQL命令和SQL*Plus命令
SQL>help
列出某个特定的命令的信息
SQL>help 命令名
c、显示表结构命令DESCRIBE
SQL>DESC 表名
d、SQL*Plus中的编辑命令
显示SQL缓冲区命令
SQL>L
修改SQL命令
首先要将待改正行变为当前行
SQL>n
用CHANGE命令修改内容
SQL>c/旧/新
重新确认是否已正确
SQL>L
使用INPUT命令可以在SQL缓冲区中增加一行或多行
SQL>i
SQL>输入内容
e、调用外部系统编辑器
SQL>edit 文件名
可以使用DEFINE命令设置系统变量EDITOR来改变文本编辑器的类型,在login.sql文件中定义如下一行
DEFINE_EDITOR=vi
f、运行命令文件
SQL>START test
SQL>@test
常用SQL*Plus语句
a、表的创建、修改、删除
创建表的命令格式如下:
create table 表名 (列说明列表);
为基表增加新列命令如下:
ALTER TABLE 表名 ADD (列说明列表)
例:为test表增加一列Age,用来存放年龄
sql>alter table test
add (Age number(3));
修改基表列定义命令如下:
ALTER TABLE 表名
MODIFY (列名 数据类型)
例:将test表中的Count列宽度加长为10个字符
sql>alter atble test
modify (County char(10));
b、将一张表删除语句的格式如下:
DORP TABLE 表名;
例:表删除将同时删除表的数据和表的定义
sql>drop table test
c、表空间的创建、删除
六、ORACLE逻辑备份的SH文件
完全备份的SH文件:exp_comp.sh
rq=` date +"%m%d" `
su - oracle -c "exp system/manager full=y inctype=complete file=/oracle/export/db_comp$rq.dmp"
累计备份的SH文件:exp_cumu.sh
rq=` date +"%m%d" `
su - oracle -c "exp system/manager full=y inctype=cumulative file=/oracle/export/db_cumu$rq.dmp"
增量备份的SH文件: exp_incr.sh
rq=` date +"%m%d" `
su - oracle -c "exp system/manager full=y inctype=incremental file=/oracle/export/db_incr$rq.dmp"
root用户crontab文件
/var/spool/cron/crontabs/root增加以下内容
0 2 1 * * /oracle/exp_comp.sh
30 2 * * 0-5 /oracle/exp_incr.sh
45 2 * * 6 /oracle/exp_cumu.sh
当然这个时间表可以根据不同的需求来改变的,这只是一个例子。
七、ORACLE 常用的SQL语法和数据对象
一.数据控制语句 (DML) 部分
1.INSERT (往数据表里插入记录的语句)
INSERT INTO 表名(字段名1, 字段名2, ……) VALUES ( 值1, 值2, ……);
INSERT INTO 表名(字段名1, 字段名2, ……) SELECT (字段名1, 字段名2, ……) FROM 另外的表名;
字符串类型的字段值必须用单引号括起来, 例如: ’GOOD DAY’
如果字段值里包含单引号’ 需要进行字符串转换, 我们把它替换成两个单引号'.
字符串类型的字段值超过定义的长度会出错, 最好在插入前进行长度校验.
日期字段的字段值可以用当前数据库的系统时间SYSDATE, 精确到秒
或者用字符串转换成日期型函数TO_DATE(‘2001-08-01’,’YYYY-MM-DD’)
TO_DATE()还有很多种日期格式, 可以参看ORACLE DOC.
年-月-日 小时:分钟:秒 的格式YYYY-MM-DD HH24:MI:SS
INSERT时最大可操作的字符串长度小于等于4000个单字节, 如果要插入更长的字符串, 请考虑字段用CLOB类型,
方法借用ORACLE里自带的DBMS_LOB程序包.
INSERT时如果要用到从1开始自动增长的序列号, 应该先建立一个序列号
CREATE SEQUENCE 序列号的名称 (最好是表名+序列号标记) INCREMENT BY 1 START WITH 1
MAXVALUE 99999 CYCLE NOCACHE;
其中最大的值按字段的长度来定, 如果定义的自动增长的序列号 NUMBER(6) , 最大值为999999
INSERT 语句插入这个字段值为: 序列号的名称.NEXTVAL
2.DELETE (删除数据表里记录的语句)
DELETE FROM表名 WHERE 条件;
注意:删除记录并不能释放ORACLE里被占用的数据块表空间. 它只把那些被删除的数据块标成unused.
如果确实要删除一个大表里的全部记录, 可以用 TRUNCATE 命令, 它可以释放占用的数据块表空间
TRUNCATE TABLE 表名;
此操作不可回退.
3.UPDATE (修改数据表里记录的语句)
UPDATE表名 SET 字段名1=值1, 字段名2=值2, …… WHERE 条件;
如果修改的值N没有赋值或定义时, 将把原来的记录内容清为NULL, 最好在修改前进行非空校验;
值N超过定义的长度会出错, 最好在插入前进行长度校验..
注意事项:
A. 以上SQL语句对表都加上了行级锁,
确认完成后, 必须加上事物处理结束的命令 COMMIT 才能正式生效,
否则改变不一定写入数据库里.
如果想撤回这些操作, 可以用命令 ROLLBACK 复原.
B. 在运行INSERT, DELETE 和 UPDATE 语句前最好估算一下可能操作的记录范围,
应该把它限定在较小 (一万条记录) 范围内,. 否则ORACLE处理这个事物用到很大的回退段.
程序响应慢甚至失去响应. 如果记录数上十万以上这些操作, 可以把这些SQL语句分段分次完成,
其间加上COMMIT 确认事物处理.
二.数据定义 (DDL) 部分
1.CREATE (创建表, 索引, 视图, 同义词, 过程, 函数, 数据库链接等)
ORACLE常用的字段类型有
CHAR 固定长度的字符串
VARCHAR2 可变长度的字符串
NUMBER(M,N) 数字型M是位数总长度, N是小数的长度
DATE 日期类型
创建表时要把较小的不为空的字段放在前面, 可能为空的字段放在后面
创建表时可以用中文的字段名, 但最好还是用英文的字段名
创建表时可以给字段加上默认值, 例如 DEFAULT SYSDATE
这样每次插入和修改时, 不用程序操作这个字段都能得到动作的时间
创建表时可以给字段加上约束条件
例如 不允许重复 UNIQUE, 关键字 PRIMARY KEY
2.ALTER (改变表, 索引, 视图等)
改变表的名称
ALTER TABLE 表名1 TO 表名2;
在表的后面增加一个字段
ALTER TABLE表名 ADD 字段名 字段名描述;
修改表里字段的定义描述
ALTER TABLE表名 MODIFY字段名 字段名描述;
给表里的字段加上约束条件
ALTER TABLE 表名 ADD CONSTRAINT 约束名 PRIMARY KEY (字段名);
ALTER TABLE 表名 ADD CONSTRAINT 约束名 UNIQUE (字段名);
把表放在或取出数据库的内存区
ALTER TABLE 表名 CACHE;
ALTER TABLE 表名 NOCACHE;
3.DROP (删除表, 索引, 视图, 同义词, 过程, 函数, 数据库链接等)
删除表和它所有的约束条件
DROP TABLE 表名 CASCADE CONSTRAINTS;
4.TRUNCATE (清空表里的所有记录, 保留表的结构)
TRUNCATE 表名;
三.查询语句 (SELECT) 部分
SELECT字段名1, 字段名2, …… FROM 表名1, [表名2, ……] WHERE 条件;
字段名可以带入函数
例如: COUNT(*), MIN(字段名), MAX(字段名), AVG(字段名), DISTINCT(字段名),
TO_CHAR(DATE字段名,'YYYY-MM-DD HH24:MI:SS')
NVL(EXPR1, EXPR2)函数
解释:
IF EXPR1=NULL
RETURN EXPR2
ELSE
RETURN EXPR1
DECODE(AA﹐V1﹐R1﹐V2﹐R2....)函数
解释:
IF AA=V1 THEN RETURN R1
IF AA=V2 THEN RETURN R2
..…
ELSE
RETURN NULL
LPAD(char1,n,char2)函数
解释:
字符char1按制定的位数n显示,不足的位数用char2字符串替换左边的空位
字段名之间可以进行算术运算
例如: (字段名1*字段名1)/3
查询语句可以嵌套
例如: SELECT …… FROM
(SELECT …… FROM表名1, [表名2, ……] WHERE 条件) WHERE 条件2;
两个查询语句的结果可以做集合操作
例如: 并集UNION(去掉重复记录), 并集UNION ALL(不去掉重复记录), 差集MINUS, 交集INTERSECT
分组查询
SELECT字段名1, 字段名2, …… FROM 表名1, [表名2, ……] GROUP BY字段名1
[HAVING 条件] ;
两个以上表之间的连接查询
SELECT字段名1, 字段名2, …… FROM 表名1, [表名2, ……] WHERE
表名1.字段名 = 表名2. 字段名 [ AND ……] ;
SELECT字段名1, 字段名2, …… FROM 表名1, [表名2, ……] WHERE
表名1.字段名 = 表名2. 字段名(+) [ AND ……] ;
有(+)号的字段位置自动补空值
查询结果集的排序操作, 默认的排序是升序ASC, 降序是DESC
SELECT字段名1, 字段名2, …… FROM 表名1, [表名2, ……]
ORDER BY字段名1, 字段名2 DESC;
字符串模糊比较的方法
INSTR(字段名, ‘字符串’)>0
字段名 LIKE ‘字符串%’ [‘%字符串%’]
每个表都有一个隐含的字段ROWID, 它标记着记录的唯一性.
四.ORACLE里常用的数据对象 (SCHEMA)
1.索引 (INDEX)
CREATE INDEX 索引名ON 表名 ( 字段1, [字段2, ……] ;
ALTER INDEX 索引名 REBUILD;
一个表的索引最好不要超过三个 (特殊的大表除外), 最好用单字段索引, 结合SQL语句的分析执行情况,
也可以建立多字段的组合索引和基于函数的索引
ORACLE8.1.7字符串可以索引的最大长度为1578 单字节
ORACLE8.0.6字符串可以索引的最大长度为758 单字节
2.视图 (VIEW)
CREATE VIEW 视图名AS SELECT …. FROM …..;
ALTER VIEW视图名 COMPILE;
视图仅是一个SQL查询语句, 它可以把表之间复杂的关系简洁化.
3.同义词 (SYNONMY)
CREATE SYNONYM同义词名FOR 表名;
CREATE SYNONYM同义词名FOR 表名@数据库链接名;
4.数据库链接 (DATABASE LINK)
CREATE DATABASE LINK数据库链接名CONNECT TO 用户名 IDENTIFIED BY 密码 USING ‘数据库连接字符串’;
数据库连接字符串可以用NET8 EASY CONFIG或者直接修改TNSNAMES.ORA里定义.
数据库参数global_name=true时要求数据库链接名称跟远端数据库名称一样
数据库全局名称可以用以下命令查出
SELECT * FROM GLOBAL_NAME;
查询远端数据库里的表
SELECT …… FROM 表名@数据库链接名;
五.权限管理 (DCL) 语句
1.GRANT 赋于权限
常用的系统权限集合有以下三个:
CONNECT(基本的连接), RESOURCE(程序开发), DBA(数据库管理)
常用的数据对象权限有以下五个:
ALL ON 数据对象名, SELECT ON 数据对象名, UPDATE ON 数据对象名,
DELETE ON 数据对象名, INSERT ON 数据对象名, ALTER ON 数据对象名
GRANT CONNECT, RESOURCE TO 用户名;
GRANT SELECT ON 表名 TO 用户名;
GRANT SELECT, INSERT, DELETE ON表名 TO 用户名1, 用户名2;
2.REVOKE 回收权限
REVOKE CONNECT, RESOURCE FROM 用户名;
REVOKE SELECT ON 表名 FROM 用户名;
REVOKE SELECT, INSERT, DELETE ON表名 FROM 用户名1, 用户名2;
查询数据库中第63号错误:
select orgaddr,destaddr from sm_histable0116 where error_code='63';
查询数据库中开户用户最大提交和最大下发数: select MSISDN,TCOS,OCOS from ms_usertable;
查询数据库中各种错误代码的总和:
select error_code,count(*) from sm_histable0513 group by error_code order
by error_code;
查询报表数据库中话单统计种类查询。
select sum(Successcount) from tbl_MiddleMt0411 where ServiceType2=111
select sum(successcount),servicetype from tbl_middlemt0411 group by servicetype
J2SDK在目录%JAVA_HOME%/bin提供了密钥库管理工具Keytool,用于管理密钥、证书和证书链。Keytool工具的命令在JavaSE6中已经改变,不过以前的命令仍然支持。Keytool也可以用来管理对称加密算法中的密钥。 最简单的命令是生成一个自签名的证书,并把它放到指定的keystore文件中: keytool -genkey -alias tomcat -keyalg RSA -keystore c:/mykey 如果c:/mykey文件不存在,keytool会生成这个文件。按照命令的提示,回答一系列问题,就生成了数字证书。注意,公共名称(cn)应该是服务器的域名。这样keystore中就存在一个别名为tomcat的实体,它包括公钥、私钥和证书。这个证书是自签名的。 Keytool工具可以从keystore中导出证书,但是不能导出私钥。对于配置apache这样的服务器,就不太方便。这种情况下就完全用OpenSSL吧,上一篇文章《SSL-用OpenSSL生成证书文件》中已经做了介绍。不过keytool对于J2EE AppServer是很有用的,它们就是用keystore存储证书链的。keystore的作用类似于windows存放证书的方式,不过跨平台了,^_^下面用Keytool生成CSR(Certificate Signing Request),并用OpenSSL生成CA签名的证书。
1. 准备
1) 在bin目录下新建目录 demoCA、demoCA/certs、demoCA/certs 、 demoCA/newcerts
2) 在demoCA建立一个空文件 index.txt
3) 在demoCA建立一个文本文件 serial, 没有扩展名,内容是一个合法的16进制数字,例如 0000
4) 配置环境变量PATH,加入%JAVA_HOME%/bin,本文用的JavaSDK1.6
2. 生成CA的自签名证书
openssl req -new -x509 -keyout ca.key -out ca.crt -config openssl.cnf
3. 生成server端证书
1) 生成KeyPair生成密钥对
keytool -genkey -alias tomcat_server -validity 365 -keyalg RSA -keysize 1024 -keypass 123456 -storepass 123456 -keystore server_keystore
输入common name时,要和服务器的域名保持一致。
2) 生成证书签名请求
keytool -certreq -alias tomcat_server -sigalg MD5withRSA -file tomcat_server.csr -keypass 123456 -storepass 123456 -keystore server_keystore
3) 用CA私钥进行签名,也可以到权威机构申请CA签名。
openssl ca -in tomcat_server.csr -out tomcat_server.crt -cert ca.crt -keyfile ca.key -notext -config openssl.cnf
其中-notext表示不要把证书文件的明文内容输出到文件中去,否则在后面用keytool导入到keystore时会出错。
4) 导入信任的CA根证书到keystore
keytool -import -v -trustcacerts -alias my_ca_root -file ca.crt -storepass 123456 -keystore server_keystore
5) 把CA签名后的server端证书导入keystore
keytool -import -v -alias tomcat_server -file tomcat_server.crt -storepass 123456 -keystore server_keystore
6) 查看server端证书
keytool -list -v -keystore server_keystore
可以看到tomcat_server的证书链长度是2
4. 生成client端证书
1) 生成客户端CSR
openssl genrsa -des3 -out tomcat_client.key 1024
openssl req -new -key tomcat_client.key -out tomcat_client.csr -config openssl.cnf
2) 用CA私钥进行签名,也可以到权威机构申请CA签名
openssl ca -in tomcat_client.csr -out tomcat_client.crt -cert ca.crt -keyfile ca.key -notext -config openssl.cnf
3) 生成PKCS12格式证书
openssl pkcs12 -export -inkey tomcat_client.key -in tomcat_client.crt -out tomcat_client.p12
4) 使用Keytool列出pkcs12证书的内容:
keytool -rfc -list -keystore tomcat_client.p12 -storetype pkcs12
1、启动虚拟机 2、我的android sdk在“E:\android\android开发环境\android SDK\platform-tools”把要安装的apk复制到这个根目录(和adb.exe同文件夹)。 2、点击电脑左下角的“开始”按钮,输入cmd然后点击回车打开cmd输入框。 3、 (由于我的Android SDK安装路径为e盘,所以需要定位模拟器platform-tools目录) 在cmd命令提示符中输入E: 回车,如图 第一行, 4、apk名称为zq7.1.1.apk 
这样就安装成功了
摘要: <!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd"> <html xmlns="http:... 阅读全文
摘要: 这篇文章是假设你曾经使用过JavaScript的,所以如果你从没有接触过它,也许你需要先了解下更基础的知识。现在我们开始吧! 模块有多少人在一个文件中写的JS像下面的代码块一样?(注意:我可没有说内嵌在HTML文件中哦):123var someSharedValue = 10;var myFunction = function(){ //do something }var another... 阅读全文
摘要: 引言Java 开发者一般不需要考虑内存释放问题,全交由 GC 去处理。但是在一些生产环境中,JVM 经过长时间运行后,即使是一些很小的未释放的 Java 对象,日积月累也会导致内存资源枯竭,最终使 Java 应用崩溃的问题。本文将就一个 AIX 平台上基于 IBM JDK 开发的 Java 应用内存枯竭的实际案例分析过程,来引领读者理解基于 IBM JDK 的 Java 应用内存泄漏调查方法,以及... 阅读全文
4.到myfaces项目网站http://myfaces.apache.org/,下载与客户应用同一版本的最简单的sample应用myfaces-example-simple-1.1.9.war,在WAS上安装进行测试,页面无法显示,进行第1步更改类加载路径也无法显示。检查myfaces-example-simple-1.1.9.war的lib目录,删除掉xml-apis-1.0.b2.jar和xmlParserAPIs-2.0.2.jar包,运行成功。 5.回到客户应用,删除掉xml-apis-1.0.b2.jar和xmlParserAPIs-2.0.2.jar,更改类加载路径,页面正常显示。 6.如果实际诊断中,能够明确断定是某个类的加载出了问题,可以打开“详细类装入”:选择“应用程序服务器/server1/进程定义/Java虚拟机”,选择“详细类装入”如下图: 
重启WAS之后,在native_stderr.log中,可以看到类的加载信息,例如: class load: org.apache.taglibs.standard.tlv.JstlBaseTLV from: file:/D:/Program/was61/AppServer/profiles/TestProfile/installedApps/wdanNode02Cell/myfaces-example-simple-1_1_9_war.ear/myfaces-example-simple-1.1.9.war/WEB-INF/lib/jstl-1.2.jar 如果还需要类加载的更详细信息,可以在诊断跟踪中设置 *=info: com.ibm.ws.classloader.*=all,具体做法为:登陆管理控制台,左边导航树选择“故障诊断/日志和跟踪”,然后在右面区域选择进程名(单机环境通常为server1)/诊断跟踪,然后选择“更改日志详细信息级别”,设置“*=info: com.ibm.ws.classloader.*=all”,保存。 

重启WAS。在profile_root/logs/server1/trace.log中,就可以看到类加载的详细信息。例如: > loadClass name=com.ibm.isclite.container.collaborator.PortletServletCollaborator … com.ibm.ws.classloader.CompoundClassLoader@3f603f6 Local ClassPath: D:\Program\was61\AppServer\systemApps\isclite.ear\struts.jar; … Delegation Mode: PARENT_FIRST [09-12-31 11:39:18:671 CST] 0000000a CompoundClass < loadClass Exit 需要注意的是,开源项目为应用开发节省了很多工作量,但开发人员使用开源项目时,最好对该开源项目的运行机制、代码,以及要使用的应用服务器类加载机制有较好的理解,以便于错误诊断。
进入 [install directory]/profiles/wp_profile/config/cells/[cell name]/nodes/[node name]/servers/server1/目录; 编辑server.xml,寻找startupTrace Specification元素,将其值改为:*=info:com.ibm.ws.webcontainer.*=all:com.ibm.wsspi.webcontainer.*=all:HTTPChannel=all:GenericBNF=all 重启Websphere,通过浏览器访问一下websphere,然后到websphere的日志目录[install directory]/profiles/wp_profile/logs/server1下,就可以看到跟踪日志文件trace.log
在每个专栏中,支持权威将讨论 IBM Technical Support 的可用于 WebSphere 产品的资源、工具和其他元素,以及一些可以进一步增强您的 IBM 支持体验的技术和新思想。 最新快报 按照惯例,我们将首先提供关于整个 WebSphere® 社区的一些重要新闻: 继续关注与支持相关的各个网站以及本专栏,以获得有关我们所碰到的其他工具的新闻。 接下来让我们继续今天的主题……
回页首 “再多一个工具我就要尖叫了” 我们在与 WebSphere 产品用户进行有关问题确定的交谈时,遇到的一个常见问题是“我现在应该使用哪个工具?”本专栏自从开始以来,已描述了如何以及何时使用许多问题确定工具,但是如果像这样一次一个地介绍工具,跟踪每个可用的工具将会充满了挑战,要确定哪个工具最适合于任何给定的情形就更不用说了。由于更广大的 IBM WebSphere Support 社区是相当动态的工具开发人员社区这一事实,问题变得进一步复杂化,这意味着可用的工具集始终变化不定,针对相似的问题,某一天使用的最佳工具可能在几个月后已经不一样了。 我们的希望在于,本文将为您阐明某些目前可用的主要问题确定工具。您将在下面找到简单的参考表格,其中在单个地方显示了您在与 WebSphere Support 合作时可能遇到的最常见问题确定工具,特别是有关 IBM WebSphere Application Server 和 Java 虚拟机(Java Virtual Machine,JVM)的工具。这些表格并不详尽,所提供的信息在性质上是不完美的——因为在本文发表之后,工具将继续发展改进,并且不同的人将以不同的方式评价各个工具。然而,不管您最终使用的工具是什么,此信息都可作为有价值的初始参考点。如果您碰巧发现这种方法很成功,请告诉我们,以便我们能够为今后的专栏计划定期的更新。
回页首 我们选择的工具 在接触到具体的表格之前,检查一下我们在组合这些信息时使用的指导原则是有帮助的: - 可用性
与 IBM Support 组织直接或间接提供的大多数问题确定资源一样,本文专门集中于可从 IBM 免费获得的工具。这并不是说不存在其他工具;IBM(特别是 Tivoli®)和其他软件供应商提供了各种收费的问题确定工具,您可以使用它们来调查 WebSphere 问题。其中有些工具提供的功能远远超出了这里提到的免费工具的范围。然而,就本文的目的而言,以及为了确保每个人都有访问这些资源的同等能力,这些表格省略了商业化的工具。 - 可访问性
在评估问题确定工具时,IBM 将考虑所有的相关候选工具,而不管这些工具驻留在何处。不过在一般情况下,IBM Support 仅收集 IBM Support Assistant 提供的公共平台中的独立工具(除非存在收集其他工具的技术原因)。IBM Support Assistant 是中央存储库,目前用于查找所有的工具、用于安装和接收现有工具的定期更新,以及用于利用多个工具和其他问题确定功能之间的集成潜力(例如,将工具与诊断收集和 PMR 报告功能联系起来,或者将一个工具的输出作为输入提供给另一个工具,等等)。 - 范围
这里列出的工具仅限于客户和 IBM Support 团队经常用于在活动中帮助分析问题确定构件的工具,而不包括收集问题确定构件或者指导或全面帮助问题确定过程的工具。 - 用于相同用途的多个工具
随着工具的发展和新工具的出现,在最大限度地促进创新的名义下,以及为了鼓励许多感兴趣的工具编写人员做出贡献,必定存在功能上的重叠。因此,您将发现这些表格中有些地方列出了用于同一个目的的多个工具。在这些情况下,将提供有关这些工具之间的重要区别的信息,以帮助您挑选最适合需要的工具。一般情况下,将会有一个工具被标识为主要工具(用粗体字型表示),我们估计它是您在尝试执行特定问题确定任务时最适合首先尝试的工具。然而,如果您具有对另一个工具的特定特征的特殊需要,您也可以使用替代工具。一般来讲,IBM Support 主要致力于对每个领域中指定的主要工具进行增强和支持,并且随着时间的推移,将会尽量把替代工具中有价值的新功能合并到主要工具中。 -
支持 虽然我们希望使新的工具和新的工具功能尽快可用,但这有时意味着在编写它们之后随即“按原样”使它们可用。另一方面,我们认识到许多用户想要并且需要可靠和可信赖的工具IBM WebSphere Support 提供的每个工具与许可协议相关联,许可协议定义了该工具是否受支持的条件。(不得将本文中的任何信息理解为覆盖或取代任何许可协议中提供的信息。)不过在一般情况下: - 通过 IBM Support Assistant 交付但指定为技术预览版的工具以及通过 alphaWorks 交付的工具被认为是“按原样”提供的。如果取得了成功并得到广泛使用,许多起初以这种方式发布的工具(虽然不一定是全部)最终将成为受支持的标准工具。这些工具一般是非常优异的,如果没有更好的替代工具可用,您可以非常舒适地使用它们。
- 通过 IBM Support Assistant 交付并且未指定为技术预览版的工具在其许可协议规定的条款下受到正式支持(由它们的创作者或 IBM WebSphere Support 提供支持)。IBM 一般为受支持的工具提供了帮助和缺陷报告。
- 问题与功能
下面的表格主要按照它们读取的构件类型进行组织。其中也列出了可以使用每种构建分析来确定的问题类型。在调查某个问题时决定如何进行的时候,务必记住这一点。当您需要快速参考的时候,这种以构件为中心的视图通常非常有用;例如,您面对某种特定类型的日志或转储文件,并且您需要快速查找某个可用于分析该文件的工具。然而,以前的“权威支持”专栏用事实证明,要提高效率,问题确定过程应该遵循定义良好的计划,该计划基于问题症状及其可能的根源,并且不执行随机操作或者“只是因为那些构件存在”而分析各个构件。无论是哪种方式,这些表格都应该能够帮助您。 或者,您可能希望利用 IBM Guided Activity Assistant 或以前的专栏中提到的其他某个问题确定指导资源,以帮助您决定何时检查每个构件和使用每个工具可能是最高效的。 下面几个部分中的工具表格将按照它们所用于的构件进行组织: 每个表格后面是每个工具自己的文档中对每个工具的描述,以及每个工具的一般特征的大致细分。
回页首 用于 JVM 生成的信息的工具 此类构件包括: -
Verbose Garbage Collection (verboseGC) 日志也许是最常见的 JVM 诊断类型。它显示了整个 JVM 生存期间,各个垃圾回收周期的顺序。它作为确定问题时的一项初始的辅助工具,常常具有不可估量的价值,用于检测和诊断反常的内存分配问题,例如内存泄漏、碎片,以及与 GC 有关的性能问题等等。 -
线程转储也是一种极为常见的 JVM 诊断类型。线程转储(也称为 javacore)可以根据管理员的请求触发,或者在 JVM 中遇到某种特殊情况时自动触发。线程转储是一个文本文件,其中包含 JVM 状态的关键方面的一个相对较短的快照。该快照最常用的部分是 JVM 中当前活动线程的列表,线程转储也因此而得名。线程转储最常见的用途是诊断 JVM 中出现挂起、变慢、崩溃或 CPU 占用率过高的原因。 -
堆转储是也可由 JVM 生成的另一种形式的转储,可以按需生成,也可以在满足特殊条件时自动生成。通常,堆转储通常是一个非常大的文件,其中包含当前 JVM 堆中所有对象的一个列表。它用于在出现内存不足的情况下执行深入分析。 -
系统堆或核心堆是开销最大的堆,但也是最完整的堆。它是一个巨大的二进制文件,反映了 JVM 进程的全部内容:每一个 Java 对象及其字段、每一个线程、每个内存区域,等等。系统转储的最初用途是在其他类型的转储不足或无法生成时,帮助诊断崩溃、挂起或复杂的内存分配问题。不过,由于系统转储非常完整,它也能用来获取有关 WebSphere Application Server 运行时当前状态的多方面信息,甚至有关在该运行时中执行的应用程序的信息。 这里的有些构件的名称和类型特定于 IBM JDK;其他供应商的 JDK 可能产生相似的文件。有关这些类型的构件的进一步详细信息,请参阅“权威支持”专栏用于实际故障诊断的功能和工具。 表 1. 用于 JVM 生成的信息的工具 工具描述 用于 VerboseGC 分析: -
IBM Monitoring and Diagnostic Tools for Java - Garbage Collection and Memory Visualizer (GCMV)
一个详细的 GC 数据可视化器,用于分析并绘制所有 IBM 详细 GC 日志——Xtgc 输出(并且可扩展到分析和绘制其他形式的输入)。它提供了广泛的详细 GC 数据值的图形显示,并处理 optthruput、optavgpause 和 gencon GC 模式。它具有原始日志、表格式数据和图表视图,并且可以将数据保存到 jpeg 或 .csv 文件(用于导出到电子表格)。 请参阅 IBM Support Assistant 中的完整描述。
输入:verbosegc 日志
输出:图形表示形式、html、jpeg 或 csv 文件
支持:此工具由 IBM 提供支持,目前是用于其所在领域的主要工具。 -
IBM Pattern Modeling and Analysis Tool (PMAT) for Java Garbage Collector
分析 IBM 详细 GC 跟踪,分析 Java 堆使用情况,并基于 Java 堆使用情况的模式建模提供重要配置建议。此工具先于上面的 IBM Monitoring and Diagnostic Tools for Java - Garbage Collection and Memory Visualizer (1),并提供了一个可能相当有用的不同透视图。 请参阅 IBM Support Assistant 或 alphaWorks 中的完整描述。
输入:verbosegc 日志
输出:verbosegc 日志的图形或表格表示形式
其他功能:关于 JVM 参数的一般建议
支持:技术预览版,按原样提供。 -
Diagnostic Tool for Java Garbage Collector
通过读取详细垃圾回收的输出,并产生文本和图形可视化表示形式及相关统计信息,从而帮助检查运行在 JVM 下的应用程序的垃圾回收特征。 请参阅 alphaWorks 中的完整描述。
输入:verbosegc
输出:文本和图形可视化表示形式
支持:按原样提供的工具。 用于 Java 转储/javacore: -
IBM Thread and Monitor Dump Analyzer (TMDA)
分析一个或多个 Java 线程转储或 javacore,并诊断监视器锁和线程活动,以便确定挂起、死锁和资源争用或监视器瓶颈的根源。 请参阅 IBM Support Assistant 或 alphaWorks 中的完整描述。
输入:用于显示相关线程历史记录的单个或多个 javacore
输出:基于 GUI 的视图
其他信息:关于 Analysis of hangs, deadlocks, and resource contention or monitor bottlenecks using IBM Thread and Monitor Dump Analyzer for Java Technology 的网络广播
支持:技术预览版,按原样提供,但是是该领域的主要工具。 -
ThreadAnalyzer
提供 Java 线程转储或 javacore 的分析,例如来自 WebSphere Application Server 的转储或 javacore。可以在不同的级别分析线程使用情况,从高级图形视图开始,然后深入到各个线程的详细记录。如果线程转储中存在任何死锁,ThreadAnalyzer 将检测并报告它们。此工具先于上面的 IBM Thread and Monitor Dump Analyzer 工具 (4),但是其功能已集成到后者之中,后者正在成为该领域的主要工具。 请参阅 IBM Support Assistant 中的完整描述。
输入:Java 线程转储/javacore
输出:线程的图形视图、加载多个线程转储以显示线程历史记录的能力
支持:技术预览版,按原样提供,但是是该领域的主要工具。此工具可能会逐步淘汰;请尽可能使用 IBM Thread and Monitor Dump Analyzer。 用于线程: -
IBM Lock Analyzer for Java
旨在对动态应用程序执行锁分析,以便突出具有可能影响性能的锁争用的线程。此工具由两个包组成: - 第一个包与平台相关,并提供到 JVM 的连接,以便收集有关正在运行的应用程序的锁统计信息。这个包在运行时随同要监视的应用程序一起进行加载。
- 第二个包与平台无关,并提供了图形用户界面。
该图形用户界面连接到平台包,并提供所需的控制和分析以确定性能糟糕的锁。 请参阅 alphaWorks 中的完整描述。
输入:从 JVM 收集的统计信息
输出:锁的图形视图
支持:按原样提供的工具。 用于堆转储: -
Memory Dump Diagnostic for Java (MDD4J)
分析正在运行 WebSphere Application Server 或任何其他独立 Java 应用程序的 JVM 中常见格式的内存转储(堆转储)。内存转储分析旨在确定 Java 堆中可能是内存泄露根源的数据结构。该分析还确定应用程序的 Java 堆占用空间的主要肇事者和它们的所属关系。此工具能够分析从遇到 OutOfMemoryError 问题的生产环境应用程序服务器中获得的非常大的内存转储(将需要 2 GB 或更多的 RAM)。MDD4J 扩展了下面较旧的 IBM HeapAnalyzer (8) 的功能,尽管两个工具的用户界面完全不同。 请参阅 IBM Support Assistant 中的完整描述。
输入:来自虚拟机 (JVM) 的内存转储(堆转储)
输出:交互式报告,其中显示主要的内存泄露可疑之处,以及有关这些泄露的详细信息。
其他功能:操作单个转储。有些版本提供了多个转储的比较分析。
支持:此工具由 IBM 提供支持,目前是用于其所在领域的主要工具。在本文编写之际,IBM Support Assistant 中的最新版本为 Beta 版。 -
HeapAnalyzer
HeapAnalyzer 读取单个 Java 内存转储(堆转储),并使您能够浏览转储以查看其内容。此工具是上面的 Memory Dump Diagnostic for Java (MDD4J) 工具(7) 的前身,后者现在包含前者的大多数功能。当时,HeapAnalyzer 中的原始树浏览功能比在 MDD4J 中更加灵活。另一方面,HeapAnalyzer 缺乏 MDD4J 中的某些更完善的泄露嫌疑检测算法,并且不支持多个转储的比较分析。 请参阅 alphaWorks 中的完整描述。
输入:单个 java 堆转储
输出:可疑对象的图形视图和堆浏览器
支持:按原样提供的工具。 -
HeapRoots
HeapRoots 读取 Java 堆转储文件并提供用于分析数据的命令。这些命令对数据运行算法,或查询有关该数据的信息。HeapRoots 提供了命令行交互式界面,您可以在其中输入命令并获取结果。 请参阅 alphaWorks 中的完整描述。
输入:堆转储文件
输出:可疑对象的图形视图和堆浏览器
支持:按原样提供的工具。 用于系统/核心转储: -
IBM Monitoring and Diagnostic Tools for Java - Dump Analyzer
一个可扩展的工具框架,它读取 IBM JVM 产生的系统转储或核心文件,并针对该转储运行各种各样的分析模块以诊断常见问题,或提供有关该 JVM 和当前运行在该 JVM 中的任何中间件或应用程序的内部状态的深入信息。目前,提供了用于对诸如死锁、挂起、崩溃、内存情况等常见 JVM 问题执行基本分析功能的模块。作为对该基本工具的补充,WebSphere Applicationi Server Modules for Dump Analyzer 提供了附加的模块,可显示 JVM 中的 WebSphere Application Server 运行时的一般状态,以及有关多个 WebSphere Application Server 子系统的详细信息。 请参阅 IBM Support Assistant 中的完整描述。
输入:由 JVM 附带的 jextract 工具进行预处理的格式化系统转储
输出:显示一个报告,其中包含由指定的分析模块提取的信息,还包含有关潜在问题的观察结果的简短摘要,以及一个提供深入信息的详细信息部分。
其他功能:提供交互式模式以手动检查转储的内容。使得用户能够编写自己的新的专门分析模块并将模块添加到该工具。
支持:此工具由 IBM 提供支持,目前是用于其所在领域的主要工具。
回页首 用于日志和跟踪文件的工具 用于这些类型的构件的活动包括: -
日志记录通常用于在日志文件中记录您希望跟踪的重要事件。日志记录用于指示: - 重要的状态更改;例如,当某个服务启动或停止的时候。
- 警告;例如,当您正在写入的磁盘空间不足的时候。
- 错误;例如,当您的代码由于预期的服务不可用而不再能够继续执行的时候。
日志记录通常是始终启用的,因此日志记录代码必须体积相当小,这通常是您应该注意的重要事项。 -
跟踪通常用于记录在调试代码问题时可能有用的任何信息。跟踪通常用于指示调用了哪些方法、向方法传入了哪些数据(或从方法返回了什么值)以及对代码边界之外的其他方法的调用返回了什么数据。跟踪事件体积可能比较大,因此只有在诊断问题时启用。由于跟踪事件的内容极为详细,而且是技术信息,因此经常只对编写应用程序的人有价值。打开跟踪的情况下,应该能够了解在代码中可能出现的任何问题。 表 2. 用于日志和跟踪文件的工具 工具描述 -
Log Analyzer(以及相关的 Symptom Editor)
一个图形用户界面,提供用于浏览、分析和关联多个产品产生的日志的单个联络点。此工具是更广泛的 IBM 自主计算活动的一部分。 请参阅 IBM Support Assistant 中的完整描述。
输入:来自 IBM 和其他供应商推出的许多软件产品的多个日志文件
输出:基于 GUI 的视图和日志文件关联
其他功能:能够保存配置以帮助其他支持工程师进行进一步的分析。提供了配套的 Symptom Editor 工具来创建您自己的症状数据库。
支持:目前是其所在领域的主要工具。 -
Trace Analyzer for WebSphere Application Server
一个高度交互式的实用工具,使您能够详细浏览、检查和搜索 WebSphere Application Server 中的复杂跟踪文件。 请参阅 alphaWorks 中的完整描述。
输入:WebSphere Application Server trace.log;如果启用了高级日志记录,则还支持更多的输入
输出:功能强大的图形视图,带筛选器和搜索视图
其他功能:能够保存配置以帮助其他支持工程师进行进一步的分析
支持:按原样提供,但目前是其所在领域的主要工具。 -
IBM Trace and Request Analyzer for WebSphere Application Server
帮助查找非正常延迟、系统运行缓慢或系统表现为挂起然后又恢复的情况的根源。此工具检查 WebSphere Application Server 和 HTTP 插件中的跟踪文件,通过这些文件确定各个请求,并找出特定操作需要花长时间完成的区域,从而帮助您检查跟踪中的可疑区域,以确定是否存在问题。用户有时将此工具与上面的 Trace Analyzer for WebSphere Application Server (12) 搞混淆,但事实上它们是完全不同的。此工具严格地集中于尽可能自动地找出性能问题和延迟,而 Trace Analyzer 是通用工具,主要用于手动检查跟踪。 请参阅 alphaWorks 中的完整描述。
输入:HTTP 服务器日志 (http_plugin.log) 和 WebSphere Application Server 跟踪日志 (trace.log)
输出:表格分析视图
支持:按原样提供,但目前是其所在领域的主要工具。 -
Database Connection Pool Analyzer for IBM WebSphere Application Server
采用启发式分析引擎来帮助您解决与 Java Database Connectivity (JDBC) 连接池相关的问题,并诊断 JDBC 连接泄露。此工具分析 JDBC 连接池管理器跟踪,并提供以下功能: - JDBC 数据源分析。
- JDBC 连接池配置分析。
- JDBC 连接图表视图。
- getConnection 方法的 Java 堆栈跟踪视图。
有关使用此工具分析连接池问题所需要的 WebSphere Application Server 跟踪设置,请参阅 MustGather 信息。 请参阅 alphaWorks 中的完整描述。
输入:JDBC 跟踪日志
输出:日志的表格和图形分析
支持:按原样提供,但目前是该领域的主要工具。
回页首 用于静态配置文件和相关信息的工具 表 3. 与静态配置相关的文件 工具描述 -
Visual Configuration Explorer (VCE)
提供一种可视化、探索和分析不同来源的配置信息的方法,例如 WebSphere Application Server、WebSphere MQ 和 DB2。此工具允许您: - 比较相同运行时环境的不同快照。
- 创建图表,采用图形格式显示配置信息,包括配置元素之间的主要关系。
- 访问详细的配置属性。
- 在配置内和跨配置搜索属性。
- 比较配置。
- 在不同的产品的配置信息之间建立联系。
- 保存和恢复工作。
- 在问题确定工作中与其他人进行协作。
- 在独立环境或客户机/服务器环境中工作。
请参阅 IBM Support Assistant 中的完整描述。
输入:从 VCE 附带的 VCE 远程收集器工具中产生的 JAR 文件
输出:配置的图形描述。配置的差异报告(保存为 XML 格式)
其他功能:能够保存配置,以帮助其他支持工程师进行进一步的分析。提供了配套的 Symptom Editor 工具来创建您自己的症状数据库。
支持:技术预览版,但它是其所在领域的主要工具。 -
IBM Web Server Plug-in Analyzer for WebSphere Application Server
帮助发现与 WebSphere Application Server 的 HTTP 插件组件相关的潜在问题。此工具同时分析插件配置和对应的跟踪文件,然后应用模式识别算法,以便向用户发出有关可能的不一致性的警报。此工具提供配置和跟踪文件中的 HTTP 返回代码列表、URI 和可用集群的图形表示形式,以及服务器拓扑。 请参阅 alphaWorks 中的完整描述。
输入:WebSphere 插件日志文件 (http_plugin.log) 和 WebSphere Application Server 跟踪文件 (trace.log)。
输出:显示 plugin-cfg.xml 文件和 trace.log 分析中的集群和成员拓扑的可视映射。
支持:按原样提供,但目前是其所在领域中的主要工具。 -
Configuration Validator
此工具是 WebSphere 管理控制台的一部分,它帮助确定和查看 WebSphere Application Server 中的当前配置中存在的问题。 请参阅 WebSphere Application Server 信息中心的完整描述。
输入:操作 WebSphere Application Server 的某个运行实例,可通过管理控制台进行访问。
输出:配置问题的表格视图(单独的错误、警告选项;管理控制台中可用的信息)。
支持:包括为 WebSphere Application Server 的一部分,服从与主产品相同的支持流程。 -
Classloader Viewer
提供 WebSphere Application Server 的某个实例中当前活动的所有类加载器和它们已加载的所有类的详细清单。这可以帮助诊断一系列与类加载相关的问题,例如未能加载所需的类、加载了某个类的意外版本、多个类之间的可见性问题,等等。 请参阅 WebSphere Application Server 信息中心的完整描述。
输入:操作 WebSphere Application Server 的某个运行实例,可通过管理控制台进行访问。
输出:WebSphere Application Server 管理控制台中的树形细分视图;可保存到文件以便以后分析。
支持:包括为 WebSphere Application Server 的一部分,服从与主产品相同的支持流程。 -
Install Verification Utility (IVU)
作为一个在 WebSphere Application Server 中可用的名为“installver”的程序来交付,此程序对构成当前 WebSphere Application Server 安装的文件执行校验和,并将校验和与 WebSphere Application Server 附带或在该工具以前的执行过程中生成的参考文件做比较。此工具帮助检测被破坏的安装,例如,可能安装了修改或修补程序然后却遗忘了。 请参阅 WebSphere Application Server 信息中心的完整描述。
输入:WebSphere Application Server 文件,使用 verifyinstallver.bat 或 .sh 运行该工具。
输出:指示成功的文件检查的消息。
支持:包括为 WebSphere Application Server 的一部分,服从与主产品相同的支持流程。 -
IBM Port Scanning Tool
在产品的安装、配置或激活过程中扫描可用的端口,以帮助防止端口冲突。 请参阅 IBM Support Assistant 中的完整描述。
输入:要检查的端口号范围
输出:列出任何正在使用的端口和任何可能的冲突的报告
支持:技术预览版,但目前是其所在领域的主要工具。
回页首 总结 我们对用于 WebSphere 产品的一些最常遇到的问题确定工具的概述到此就结束了,并提供了一些帮助您确定何时最适合使用每个工具的信息。但愿此信息将帮助您迅速和尽可能高效地启动问题解决任务。请记住,IBM 提供的工具集在不断地发展和增加,因此务必定期检查有关每个工具的最新信息,并从问题确定工作的前沿返回到本专栏以了解更多新闻。
SSL v2的设计顺应经典的公钥基础设施PKI(public key infrastructure)设计,后者认为一个服务器只提供一个服务从而也就只使用一个证书。这意味着服务器可以在TLS启动的早期阶段发送或提交证书,因为它知道它在为哪个域服务。HTTP服务器开启虚拟主机支持后,每个服务器通过相同的地址可以为很多域提供服务。服务器检查每一个请求来决定它在为哪个域服务。这个信息通常从HTTP请求头获得。不幸的是,当设置了TLS加密,服务器在读取HTTP请求里面的域名之前已经向客户端提交了证书,也就是已经为默认域提供了服务。因此,这种为虚拟主机提供安全的简单途径经常导致使用了错误的数字证书,从而导致浏览器对用户发出警告。 以上描述摘自OpenWares。详细了解请到:服务器名字指示SNI(Server Name Indication) 即访问www.buyberry.net会读取到beta.buyberry.net的证书,这样浏览器会报证书错误。 因此需要Server Name Indication (RFC 4366)这个扩展协议来修正。标准apache是支持Name Based SSL VHosts With SNI 。前提需要 OpenSSL 0.9.8f 之后才能支持。但是IHS并不支持这个扩展协议。 只能使用基于端口或者基于IP的虚拟主机来workaround LoadModule ibm_ssl_module modules/mod_ibm_ssl.so Listen 443 Listen 444 NameVirtualHost www.buyberry.net:443 ServerName www.buyberry.net SSLCipherSpec 34 SSLCipherSpec 35 SSLCipherSpec 3A SSLCipherSpec 33 SSLCipherSpec 36 SSLCipherSpec 39 SSLCipherSpec 32 SSLCipherSpec 31 SSLCipherSpec 30 DocumentRoot “/ihs/htdocs” SSLEnable SSLClientAuth none Keyfile “/ihs/sslkey20121227/key.kdb” ErrorLog logs/ssl1_error_log CustomLog logs/ssl1_access_log common env=!image
######################################### NameVirtualHost beta.buyberry.net:444 ServerName beta.buyberry.net SSLCipherSpec 34 SSLCipherSpec 35 SSLCipherSpec 3A SSLCipherSpec 33 SSLCipherSpec 36 SSLCipherSpec 39 SSLCipherSpec 32 SSLCipherSpec 31 SSLCipherSpec 30 DocumentRoot “/ihs/htdocs” SSLEnable SSLClientAuth none Keyfile “/ihs/2012key/2012key.kdb” ErrorLog logs/ssl2_error_log CustomLog logs/ssl2_access_log common env=!image
首先想到的就是dos输出是用系统的默认编码(gbk)的,我文件可是使用UTF-8编写的,肯定会出乱码楼。当时的想法就是在批处理文件中手动设置临时编码来进行输出,可是对这块不了解,百度吧,关键字:dos中设置编码,结果还真的有人遇到了这样的问题,不过是在做 PHP项目中出现的,但是我也一样可以借用,呵呵。原来 系统会有很多的字体代码的,在执行批处理前设置一下就OK了,命令如下: chcp 65001 问题就解决了,65001是UTF-8的代码页,其他如下: MS-DOS为以下国家和语言提供字符集:代码页描述 936 简体中文(默认) 950 繁体中文 65001 UTF-8 1258 越南语 1257 波罗的语 1256 阿拉伯语 1255 希伯来语 1254 土耳其语 1253 希腊语 1252 拉丁 1 字符 (ANSI) 1251 西里尔语 1250 中欧语言 949 朝鲜语 932 日语 874 泰国语 850 多语种 (MS-DOS Latin1) 437 MS-DOS 美国英语 以上就是本次编写批处理命令中遇到的比较特殊的问题,以此记录,以备后用。
注:编写的批处理命令我在顶端空出来一行,才能使 chcp 65001 生效,这应该是和UTF-8文件有无BOM编码格式有关,我选择的是UTF-8有BOM编码格式保存的文件。
Hugepages是从Linux kernal 2.6后被引入的,其目的是使用更大的memory page size以适应越来越大的系统内存,使得oracle SGA这种大内存结构能分配到一个大块(hugepagesize)连续的内存,提高效率.
在Linux下,默认的page size大小为4k。默认的hugepagesize=2M。 我们来看看两者之间有什么区别 1. Page Table大小(小page size 可以节省内存,但提高管理成本page table的规模很大)
Page Table是用来存放虚拟内存也和物理内存页对应关系的内存结构。因为page size较小,所以相应的改内存结构也会比较大。 而Hugepages的常见page size为2M,是4k size的500倍,所以可以大大减小page table的size。 我们来看两个例子: 这是一个没有配置Hugepage的系统,系统内存128G,pagetable大小大约为4G。 cat /proc/meminfo MemTotal: 132086880 kB
PageTables: 4059612 kB 这是配置了Hugepage的系统,系统内存96G, PageTable大小仅为78M MemTotal: 98999880 kB
PageTables: 79916 kB 2. 大大提高了CPU cache中存放的page table所覆盖的内存大小,从而提高了TLB命中率 进程的虚拟内存地址段先连接到page tables然后再连接到物理内存。所以在访问内存时需要先访问page tables得到虚拟内存和物理内存的映射关系,然后再访问物理内存。 CPU cache中有一部分TLB(Translation Lookaside Buffer)用来存放部分page table以提高这种装换的速度。因为page size变大了,所以同样大小的TLB,所覆盖的内存大小也变大了。提高了TBL命中率,也就是提高了地址转换的速度。 3. 使用Hugepages的内存页是不会被交换出去的,永远常驻在内存中,所以也减少了内存也替换的额外开销 下面再说说在数据库服务器上使用Hugepages要注意的几点 1. Hugepages是在分配后就会预留出来的,其大小一定要比服务器上所有实例的SGA总和要大,差一点都不行。 比如说Hugepages设置为90G,oracle SGA为91G,那么oracle在启动的时候就不会使用到这90G的Hugepages。这90G就浪费了。所以在设置Hugepages时要计算SGA的大小,后面会给出一个脚本来计算。 2. 其他进程无法使用Hugepages的内存,所以不要设置太大,稍稍比SGA大一点保证SGA可以使用到hugepages就好了。 3. PGA不会使用Hugepages的内存。所以11g的AMM (Automatic Memory Management,memory_target参数)是不被支持的。而ASMM(Automatic Shared Memory Management, SGA_target参数)是被支持的,这两个不要搞混淆了。 4. 在meminfo中和Hugepage相关的有四项(RHEL5) HugePages_Total: 43000
HugePages_Free: 29493
HugePages_Rsvd: 23550
Hugepagesize: 2048 kB HugePages_Total为所分配的页面数目,和Hugepagesize相乘后得到所分配的内存大小。43000*2/1024大约为84GB
HugePages_Free为从来没有被使用过的Hugepages数目。即使oracle sga已经分配了这部分内存,但是如果没有实际写入,那么看到的还是Free的。这是很容易误解的地方
HugePages_Rsvd为已经被分配预留但是还没有使用的page数目。在Oracle刚刚启动时,大部分内存应该都是Reserved并且Free的,随着oracle SGA的使用,Reserved和Free都会不断的降低 HugePages_Free – HugePages_Rsvd 这部分是没有被使用到的内存,如果没有其他的oracle instance,这部分内存也许永远都不会被使用到,也就是被浪费了。在该系统上有11.5GB的内存被浪费了。 Note: RHEL4上的meminfo有所区别,没有HugePages_Rsvd这一项,并且当oracle instance启动时,所分配的内存就从free list上被移除掉了。也就是启动后HugePages_Free就是没有被SGA用到被浪费的内存。
最后说说如何设置HugePages: 1. 首先计算SGA大小已决定你要使用多少HugePages内存页。 你可以手工计算,如果使用了ASMM可以用SGA_Target/Hugepagesize,否则可以将 db_cache_size,large_pool_size, shared_pool_size,jave_pool_size, streams_pool_size五个部分加起来除以Hugepagesize。 或者可以先将oracle instance都起起来,然后ipcs -m查看共享内存段大小来计算。oracle在401749.1中也提供了一个脚本来帮助计算,脚本如下: #!/bin/bash
#
# hugepages_settings.sh
#
# Linux bash script to compute values for the
# recommended HugePages/HugeTLB configuration
#
# Note: This script does calculation for all shared memory
# segments available when the script is run, no matter it
# is an Oracle RDBMS shared memory segment or not.
#
# This script is provided by Doc ID 401749.1 from My Oracle Support
# http://support.oracle.com
# Welcome text
echo "
This script is provided by Doc ID 401749.1 from My Oracle Support
(http://support.oracle.com) where it is intended to compute values for
the recommended HugePages/HugeTLB configuration for the current shared
memory segments. Before proceeding with the execution please make sure
that:
* Oracle Database instance(s) are up and running
* Oracle Database 11g Automatic Memory Management (AMM) is not setup
(See Doc ID 749851.1)
* The shared memory segments can be listed by command:
# ipcs -m
Press Enter to proceed..."
read
# Check for the kernel version
KERN=`uname -r | awk -F. '{ printf("%d.%d\n",$1,$2); }'`
# Find out the HugePage size
HPG_SZ=`grep Hugepagesize /proc/meminfo | awk '{print $2}'`
# Initialize the counter
NUM_PG=0
# Cumulative number of pages required to handle the running shared memory segments
for SEG_BYTES in `ipcs -m | awk '{print $5}' | grep "[0-9][0-9]*"`
do
MIN_PG=`echo "$SEG_BYTES/($HPG_SZ*1024)" | bc -q`
if [ $MIN_PG -gt 0 ]; then
NUM_PG=`echo "$NUM_PG+$MIN_PG+1" | bc -q`
fi
done
RES_BYTES=`echo "$NUM_PG * $HPG_SZ * 1024" | bc -q`
# An SGA less than 100MB does not make sense
# Bail out if that is the case
if [ $RES_BYTES -lt 100000000 ]; then
echo "***********"
echo "** ERROR **"
echo "***********"
echo "Sorry! There are not enough total of shared memory segments allocated for
HugePages configuration. HugePages can only be used for shared memory segments
that you can list by command:
# ipcs -m
of a size that can match an Oracle Database SGA. Please make sure that:
* Oracle Database instance is up and running
* Oracle Database 11g Automatic Memory Management (AMM) is not configured"
exit 1
fi
# Finish with results
case $KERN in
'2.4') HUGETLB_POOL=`echo "$NUM_PG*$HPG_SZ/1024" | bc -q`;
echo "Recommended setting: vm.hugetlb_pool = $HUGETLB_POOL" ;;
'2.6') echo "Recommended setting: vm.nr_hugepages = $NUM_PG" ;;
*) echo "Unrecognized kernel version $KERN. Exiting." ;;
esac
# End 2. 关闭所有oracle实例 3. 用root设定oracle memlock limit,设置一个较大的数值或者unlimited 在/etc/security/limits.conf最后添加
oracle hard memlock unlimited
oracle soft memlock unlimited 4. 分配hugepages内存 在/etc/sysctl.conf中添加 vm.nr_hugepages = 46000 (step1′s value) 执行sysctl -p使其生效。这时候内存就已经被分配了,可以查看meminfo grep Huge /proc/meminfo HugePages_Total为设定的值大小,HugePages_Free应该和HugePages_Total一样大,HugePages_Rsvd为0. 5. 启动Oracle instance 这时候再次查看meminfo HugePages_Total为设定的值大小不变,HugePages_Free有所降低,HugePages_Rsvd为一个较大的数值(因为刚刚启动时,大部分SGA被分配但是没有被使用到)。 如果Hugepages没有被使用,可能一些memory page被分配为4k大小了,那么需要重启server来设置。 从我们的测试结果看,Hugepages可以提高OLTP系统10%的吞吐量,当然不同的数据库应用结果可能不同,但是总体来说这是一个nice to have的设置。
SoftReference、Weak Reference和PhantomRefrence分析和比较 本文将谈一下对SoftReference(软引用)、WeakReference(弱引用)和PhantomRefrence(虚引用)的理解,这三个类是对heap中java对象的应用,通过这个三个类可以和gc做简单的交互。 强引用: 除了上面提到的三个引用之外,还有一个引用,也就是最长用到的那就是强引用。例如: Object o=new Object();
Object o1=o; |
上面代码中第一句是在heap堆中创建新的Object对象通过o引用这个对象,第二句是通过o建立o1到new Object()这个heap堆中的对象的引用,这两个引用都是强引用.只要存在对heap中对象的引用,gc就不会收集该对象.如果通过如下代码: 如果显式地设置o和o1为null,或超出范围,则gc认为该对象不存在引用,这时就可以收集它了。可以收集并不等于就一会被收集,什么时候收集这要取决于gc的算法,这要就带来很多不确定性。例如你就想指定一个对象,希望下次gc运行时把它收集了,那就没办法了,有了其他的三种引用就可以做到了。其他三种引用在不妨碍gc收集的情况下,可以做简单的交互。 heap中对象有强可及对象、软可及对象、弱可及对象、虚可及对象和不可到达对象。应用的强弱顺序是强、软、弱、和虚。对于对象是属于哪种可及的对象,由他的最强的引用决定。如下: String abc=new String("abc"); //1
SoftReference<String> abcSoftRef=new SoftReference<String>(abc); //2
WeakReference<String> abcWeakRef = new WeakReference<String>(abc); //3
abc=null; //4
abcSoftRef.clear();//5 |
第一行在heap对中创建内容为“abc”的对象,并建立abc到该对象的强引用,该对象是强可及的。 第二行和第三行分别建立对heap中对象的软引用和弱引用,此时heap中的对象仍是强可及的。 第四行之后heap中对象不再是强可及的,变成软可及的。同样第五行执行之后变成弱可及的。 SoftReference(软引用) 软引用是主要用于内存敏感的高速缓存。在jvm报告内存不足之前会清除所有的软引用,这样以来gc就有可能收集软可及的对象,可能解决内存吃紧问题,避免内存溢出。什么时候会被收集取决于gc的算法和gc运行时可用内存的大小。当gc决定要收集软引用是执行以下过程,以上面的abcSoftRef为例: 1、首先将abcSoftRef的referent设置为null,不再引用heap中的new String("abc")对象。 2、将heap中的new String("abc")对象设置为可结束的(finalizable)。 3、当heap中的new String("abc")对象的finalize()方法被运行而且该对象占用的内存被释放, abcSoftRef被添加到它的ReferenceQueue中。 注:对ReferenceQueue软引用和弱引用可以有可无,但是虚引用必须有,参见: | Reference(T paramT, ReferenceQueue<? super T>paramReferenceQueue) |
被 Soft Reference 指到的对象,即使没有任何 Direct Reference,也不会被清除。一直要到 JVM 内存不足且 没有 Direct Reference 时才会清除,SoftReference 是用来设计 object-cache 之用的。如此一来 SoftReference 不但可以把对象 cache 起来,也不会造成内存不足的错误 (OutOfMemoryError)。我觉得 Soft Reference 也适合拿来实作 pooling 的技巧。 A obj = new A();
SoftRefenrence sr = new SoftReference(obj); //引用时
if(sr!=null){
obj = sr.get();
}else{
obj = new A();
sr = new SoftReference(obj);
} |
弱引用 当gc碰到弱可及对象,并释放abcWeakRef的引用,收集该对象。但是gc可能需要对此运用才能找到该弱可及对象。通过如下代码可以了明了的看出它的作用: String abc=new String("abc");
WeakReference<String> abcWeakRef = new WeakReference<String>(abc);
abc=null;
System.out.println("before gc: "+abcWeakRef.get());
System.gc();
System.out.println("after gc: "+abcWeakRef.get()); |
运行结果: before gc: abc
after gc: null gc收集弱可及对象的执行过程和软可及一样,只是gc不会根据内存情况来决定是不是收集该对象。 如果你希望能随时取得某对象的信息,但又不想影响此对象的垃圾收集,那么你应该用 Weak Reference 来记住此对象,而不是用一般的 reference。 A obj = new A(); WeakReference wr = new WeakReference(obj); obj = null; //等待一段时间,obj对象就会被垃圾回收
... if (wr.get()==null) {
System.out.println("obj 已经被清除了 ");
} else {
System.out.println("obj 尚未被清除,其信息是 "+obj.toString());
}
...
} |
在此例中,透过 get() 可以取得此 Reference 的所指到的对象,如果返回值为 null 的话,代表此对象已经被清除。 这类的技巧,在设计 Optimizer 或 Debugger 这类的程序时常会用到,因为这类程序需要取得某对象的信息,但是不可以 影响此对象的垃圾收集。 PhantomRefrence(虚引用) 虚顾名思义就是没有的意思,建立虚引用之后通过get方法返回结果始终为null,通过源代码你会发现,虚引用通向会把引用的对象写进referent,只是get方法返回结果为null。先看一下和gc交互的过程在说一下他的作用。 1 不把referent设置为null,直接把heap中的new String("abc")对象设置为可结束的(finalizable). 2 与软引用和弱引用不同,先把PhantomRefrence对象添加到它的ReferenceQueue中,然后在释放虚可及的对象。 你会发现在收集heap中的new String("abc")对象之前,你就可以做一些其他的事情。通过以下代码可以了解他的作用。 import java.lang.ref.PhantomReference;
import java.lang.ref.Reference;
import java.lang.ref.ReferenceQueue;
import java.lang.reflect.Field;
public class Test {
public static boolean isRun = true;
public static void main(String[] args) throws Exception {
String abc = new String("abc");
System.out.println(abc.getClass() + "@" + abc.hashCode());
final ReferenceQueue referenceQueue = new ReferenceQueue<String>();
new Thread() {
public void run() {
while (isRun) {
Object o = referenceQueue.poll();
if (o != null) {
try {
Field rereferent = Reference.class
.getDeclaredField("referent");
rereferent.setAccessible(true);
Object result = rereferent.get(o);
System.out.println("gc will collect:"
+ result.getClass() + "@"
+ result.hashCode());
} catch (Exception e) {
e.printStackTrace();
}
}
}
}
}.start();
PhantomReference<String> abcWeakRef = new PhantomReference<String>(abc,
referenceQueue);
abc = null;
Thread.currentThread().sleep(3000);
System.gc();
Thread.currentThread().sleep(3000);
isRun = false;
}
} |
结果为: class java.lang.String@96354
gc will collect:class java.lang.String@96354
Red5流媒体服务器简介 Red5是一个采用Java开发开源的Flash流媒体服务器。它支持:把音频(MP3)和视频(FLV)转换成播放流; 录制客户端播放流(只支持FLV);共享对象;现场直播流发布;远程调用。Red5使用RSTP作为流媒体传输协议,在其自带的一些示例中演示了在线录制,flash流媒体播放,在线聊天,视频会议等一些基本功能。 软件环境 既然是Java开发的,自然少不了要安装JDK,这里使用的是JDK6.x版本,Red5用的是0.9.1版本,Red5内嵌了Tomcat6.x服务器。为了测试和使用Red5,需要另外搭建开发环境,开发部署相应的服务端应用,开发IDE为Eclipse3.3.x + MyEclipse6.x(貌似版本有点低了,没办法,刚好电脑上安装程序,不想另外下载了,同时也够用了,哈哈),Web服务器为Tomcat6.x,最后客户端播放器使用Flowplayer3.2.x。以下是Red5和Flowplayer3.2.x下载地址。 Red5下载:http://www.red5.org/downloads/
CuSunPlayer流媒体播放器下载:http://www.CuPlayer.com/CuSunPlayer/ 安装软件与环境配置 1.安装JDK。这里使用的是jdk-6u21-windows-i586.exe,双击按提示安装即可
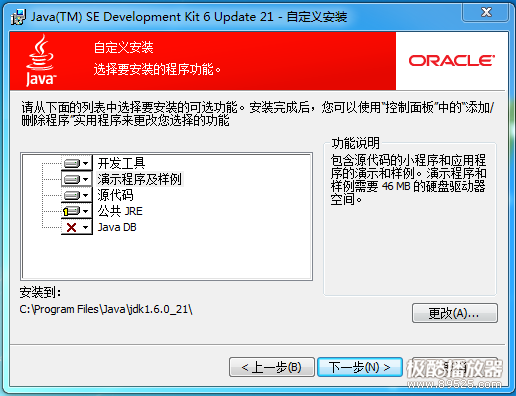
完毕后设置环境变量JAVA_HOME,PATH和CLASSPATH,如何设置环境变量请谷歌或百度 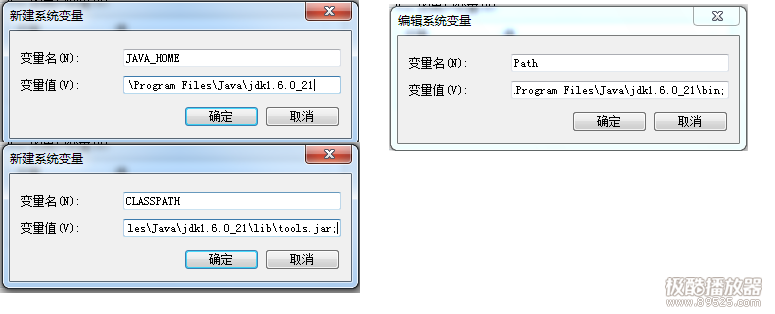
2.安装Red5 因为是Windows环境,这里下载的是setup-Red5-0.9.1.exe。直接双击安装程序安装,安装过程中,需要填写服务器IP地址和端口,由于是本地测试,直接填写127.0.0.1,端口随意,不冲突即可,建议>1024,这里使用5050。安装完之后不要忘记设置RED5_HOME环境变量。 
Red5安装程序会默认把Red5注册为系统服务自动启动,打开系统服务,查看是否服务是否已经存在: 
我们看到服务已安装,但还没有启动,需要我们手动启动一下,选择Red5服务,鼠标右键,选择启动或者重新启动即可。系统界面操作,不赘述。如无意 外,应该可以正常启动。如果启动不了,请检查前面的环境变量设置是否设置完毕并且正确,最后检查Red5的启动日志文件,看看是否有相应的提示信息,日志 文件在Red5主目录下的log目录下,日志文件有多个,查看red5_service.log即可。启动后,打开浏览器,敲入安装Red5时的IP地址 和端口,正常情况下,看到如下信息,说明Red5已经正确安装了。 
这个时候可以点击Install进入下载其官方提供的demo进行研究学习,安装后的demo文件在Red5根目录下的webapps下,如 D:\Red5\webapps。安装操作比较简单,这里不详细介绍,不过要这里要提醒一下,安装完的demo后,需要重新启动一下Red5服务器,重启 操作参考上面的介绍。
3.安装配置开发环境 主要安装配置Eclipse3.3.x + MyEclipse6.x +Tomcat6.x。 Eclipse下载的是eclipse3.3.1.zip,直接解压到D:\Program Files目录下;Tomcat下载apache-tomcat-6.0.36-windows-x86.zip,直接解压到D:\ProgramFiles目录即可;然后安装MyEclipse6.x,这里用的是MyEclipse_6.0.1GA_E3.3.1_Installer.exe,双击按提示安装完毕即可。 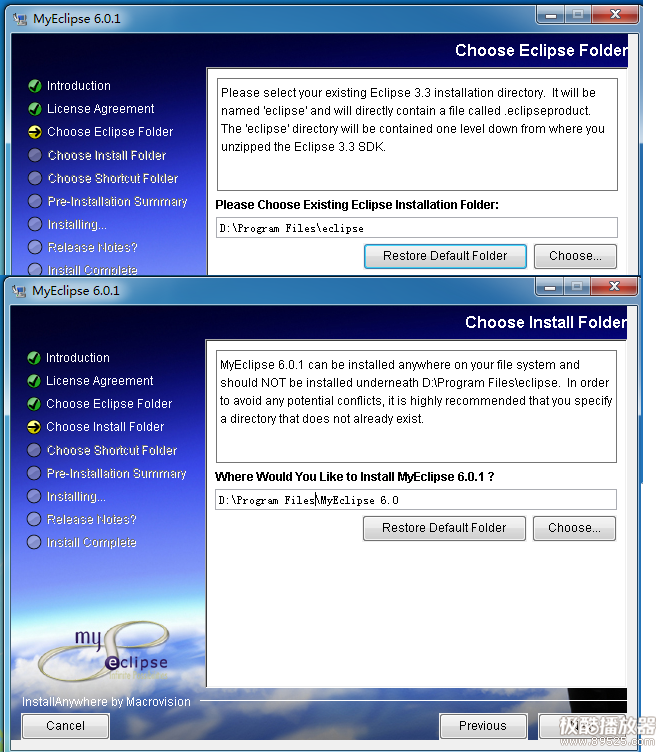
配置Tomcat服务器和默认字符集为UTF-8 
至此,软件的安装与环境配置完成,接下来就是开发和部署我们的流媒体服务器应用以及测试应用了。
信息标注到google地图上(即在google本地商户中心登记您的公司信息和标注地理位置): 第一步:核实是否收录及正确性。 通过google地图(http://ditu.google.cn/)搜索您的公司,核实google地图是否已经收录你的公司信息。如果正确收录则无需再次添加。如果没有收录或者没有正确收录则需要添加或者修改不正确的信息。 第二步:录入公司信息及标注地理位置。 如果要修改已有信息,点击地图中公司信息下的“修改”进入本地商户中心;如果是新增加公司地图标注,则通过http://bendi.google.com/local/add进入。 录入基本信息(公司名称、地址、电话、网址等)、选择公司类别(最多5类)、可选择营业时间、可选择付款方式、可上传多个图片(最多10个)、可加载youtube视频(最多5个)等。如果地图自动标记的位置有误可手动调整。 google本地商户中心信息录入 第三步:验证 录入信息检查无误后进入到验证方式选择界面,验证所需的验证码(5位数字)可以选择电话获取(google自动语音系统拨打您的首选电话)或邮寄信函获取(google给您邮寄信函)。建议选择电话方式,可以在几秒中内获取验证码。(注意需要填写直拨号码而不是总机号码,并在google电话打过来时记录号验证码)。获取验证码后在商户列表页中填入验证码进行验证即可,成功验证后一个小时内您就可以看到贵公司在google地图中展示的效果了,赶快去试试吧。 验证方式选择界面
保存成日志文件形式的时候,大家经常会遇到一个问题:日志文件过大。上百兆的日志文件对 查阅日志信息来说也是一个问题。所以我希望能够每天或每个月产生一个日志文件,这样文件不至于过大。 或者根据日志文件大小来判断,超过规定大小,日志自动增加新文件。 在log4j中这两种方式的实现都很简单,只要在配置文件中设置即可。 一、按照一定时间产生日志文件,配置文件如下: # Set root logger level to ERROR and its only appender to A1. log4j.rootLogger=ERROR,R # R is set to be a DailyRollingFileAppender. log4j.appender.R=org.apache.log4j.DailyRollingFileAppender log4j.appender.R.File=backup.log log4j.appender.R.DatePattern = '.'yyyy-MM-dd log4j.appender.R.layout=org.apache.log4j.PatternLayout log4j.appender.R.layout.ConversionPattern=%-d{yyyy-MM-dd HH:mm:ss} [%c]-[%p] %m%n 以上配置是每天产生一个备份文件。其中备份文件的名字叫backup.log。 具体的效果是这样:当天的日志信息记录在backup.log文件中,前一天的记录在名称为 backup.log.yyyy-mm-dd 的文件中。 类似的,如果需要每月产生一个文件可以修改上面的配置: 将 log4j.appender.R.DatePattern = '.'yyyy-MM-dd 改为 log4j.appender.R.DatePattern = '.'yyyy-MM 二、根据日志文件大小自动产生新日志文件 配置文件内容如下: # Set root logger level to ERROR and its only appender to A1. log4j.rootLogger=ERROR,R # R is set to be a RollingFileAppender. log4j.appender.R=org.apache.log4j.RollingFileAppender log4j.appender.R.File=backup.log #log4j.appender.R.MaxFileSize=100KB # Keep one backup file log4j.appender.R.MaxBackupIndex=1 log4j.appender.R.layout=org.apache.log4j.PatternLayout log4j.appender.R.layout.ConversionPattern=%-d{yyyy-MM-dd HH:mm:ss} [%c]-[%p] %m%n 其中: #日志文件的大小 log4j.appender.R.MaxFileSize=100KB # 保存一个备份文件 log4j.appender.R.MaxBackupIndex=1
SIP5.0以后服务的请求量爆发性增长,因此也暴露了原来没有暴露出来的问题。由于过去一般一个新版本发布周期在一个月左右,因此如果是小的内存泄露,在一个月之内重新发布以后也就看不出任何问题。
因此这阵子除了优化Memcache客户端和SIP框架逻辑以外其他依赖部分以外,对于内存泄露的压力测试也开始实实在在的做起来。经过这次问题的定位和解决以后,大致觉得对于一个大用户量应用要放心的话,那么需要做这么几步。
1. 在GC输出的环境下,大压力下做多天的测试。(可以在 JAVA_OPTS增加-verbose:gc -XX:+PrintGCDetails -XX:+HeapDumpOnOutOfMemoryError)
2. 检查GC输出日志来判断是否有内存泄露。(这部分后面有详细的实例说明)
3. 如果出现内存泄露问题,则使用jprofiler等工具来排查内存泄露点(之所以不一开始使用,因为jprofiler等工具对于压力测试有影响,使得大压力无法上去,也使问题不那么容易暴露)
4. 解决问题,并在重复2步骤。
这里对SIP在jdk1.5和jdk1.6下做压力测试的GC 日志来做一个实际的分析对比,通过对比来大致描述一下如何根据输出情况能够了解应用是否存在内存泄露问题。(这里的内存泄露问题就是在以前blog写过的jdk的concurrent包内LinkedBlockingQueue的poll方法存在比较严重的内存泄露,调用频率越高,内存泄露的越厉害)
两次压力测试都差不多都是两天,测试方案如下:
开始50个并发,每个并发每次请求完毕后休息0.1秒,10分钟后增长50个并发,按此规律增长到500并发。
旧版本SIP是在JDK1.5环境下完成的压力测试,
新版本SIP的JDK版本是1.6,
压力机和以前一样,是10.2.226.40,DELL1950,8CPU,8G内存。
压力机模拟发出对一个需要签名的API不断的调用请求。
看看两个Log的具体内容(内容很多截取部分做分析)
先说一下日志输出的结构:(1.6和1.5略微有一些不同,只是1.6对于时间统计更加细致)
[GC [<collector>: <starting occupancy1> -> <ending occupancy1>, <pause time1> secs] <starting occupancy3> -> <ending occupancy3>, <pause time3> secs]
<collector>GC收集器的名称
<starting occupancy1> 新生代在GC前占用的内存
<ending occupancy1> 新生代在GC后占用的内存
<pause time1> 新生代局部收集时jvm暂停处理的时间
<starting occupancy3> JVM Heap 在GC前占用的内存
<ending occupancy3> JVM Heap 在GC后占用的内存
<pause time3> GC过程中jvm暂停处理的总时间
Jdk1.5 log:
启动时GC输出:
[GC [DefNew: 209792K->4417K(235968K), 0.0201630 secs] 246722K->41347K(498112K), 0.0204050 secs]
[GC [DefNew: 214209K->4381K(235968K), 0.0139200 secs] 251139K->41312K(498112K), 0.0141190 secs]
一句输出:
新生代回收前209792K,回收后4417K,回收数量205375K,Heap总量回收前246722K回收后41347K,回收总量205375K。这就表示100%的收回,没有任何新生代的对象被提升到中生代或者永久区(名字说的不一定准确,只是表达意思)。
第二句输出:
按照分析也就只是有1K内容被提升到中生代。
运行一段时间后:
[GC [DefNew: 210686K->979K(235968K), 0.0257140 secs] 278070K->68379K(498244K), 0.0261820 secs]
[GC [DefNew: 210771K->1129K(235968K), 0.0275160 secs] 278171K->68544K(498244K), 0.0280050 secs]
第一句输出:
新生代回收前210686K,回收后979K,回收数量209707K,Heap总量回收前278070K回收后68379K,回收总量209691K。这就表示有16k没有被回收。
第二句输出:
新生代回收前210771K,回收后1129K,回收数量209642K,Heap总量回收前278171K回收后68544K,回收总量209627K。这就表示有15k没有被回收。
比较一下启动时与现在的新生代占用内存情况和Heap使用情况发现Heap的使用增长很明显,新生代没有增长,而Heap使用总量增长了27M,这就表明可能存在内存泄露,虽然每一次泄露的字节数很少,但是频率很高,大部分泄露的对象都被升级到了中生代或者持久代。
又一段时间后:
[GC [DefNew: 211554K->1913K(235968K), 0.0461130 secs] 350102K->140481K(648160K), 0.0469790 secs]
[GC [DefNew: 211707K->2327K(235968K), 0.0546170 secs] 350275K->140921K(648160K), 0.0555070 secs]
第一句输出:
新生代回收前211554K,回收后1913K,回收数量209641K,Heap总量回收前350102K回收后140481K,回收总量209621K。这就表示有20k没有被回收。
分析到这里就可以看出每一次泄露的内存只有10几K,但是在大压力长时间的测试下,内存泄露还是很明显的,此时Heap已经增长到了140M,较启动时已经增长了100M。同时GC占用的时间越来越长。
后续的现象:
后续观察日志会发现,Full GC的频率越来越高,收集所花费时间也是越来越长。(Full GC定期会执行,同时局部回收不能满足分配需求的情况下也会执行)。
[Full GC [Tenured: 786431K->786431K(786432K), 3.4882390 secs] 1022399K->1022399K(1022400K), [Perm : 36711K->36711K(98304K)], 3.4887920 secs]
java.lang.OutOfMemoryError: Java heap space
Dumping heap to java_pid7720.hprof ...
出现这个语句表示内存真的被消耗完了。
Jdk1.6 log:
启动时GC的输出:
[GC [PSYoungGen: 221697K->31960K(229376K)] 225788K->36051K(491520K), 0.0521830 secs] [Times: user=0.26 sys=0.05, real=0.05 secs]
[GC [PSYoungGen: 228568K->32752K(229376K)] 232659K->37036K(491520K), 0.0408620 secs] [Times: user=0.21 sys=0.02, real=0.04 secs]
第一句输出:
新生代回收前221697K,回收后31960K,回收数量189737K,Heap总量回收前225788K回收后36051K,回收总量189737K。100%被回收。
运行一段时间后输出:
[GC [PSYoungGen: 258944K->2536K(259328K)] 853863K->598135K(997888K), 0.0471620 secs] [Times: user=0.15 sys=0.00, real=0.05 secs]
[GC [PSYoungGen: 259048K->2624K(259328K)] 854647K->598907K(997888K), 0.0462980 secs] [Times: user=0.16 sys=0.02, real=0.04 secs]
第一句输出:
新生代回收前258944K,回收后2536K,回收数量256408K,Heap总量回收前853863K回收后598135K,回收总量255728K。680K没有被回收,但这并不意味着就会产生内存泄露。同时可以看出GC回收时间并没有增加。
在运行一段时间后输出:
[GC [PSYoungGen: 258904K->2488K(259264K)] 969663K->713923K(1045696K), 0.0485140 secs] [Times: user=0.16 sys=0.01, real=0.04 secs]
[GC [PSYoungGen: 258872K->2448K(259328K)] 970307K->714563K(1045760K), 0.0473770 secs] [Times: user=0.16 sys=0.01, real=0.05 secs]
第一句输出:
新生代回收前258904K,回收后2488K,回收数量256416K,Heap总量回收前969663K回收后713923K,回收总量255740K。676K没有被回收,同时总的Heap也有所增加。
此时看起来好像和1.5的状况一样。但是查看了一下Full GC的执行还是400-500次GC执行一次,因此继续观察。
运行一天多以后输出:
[GC [PSYoungGen: 257016K->3304K(257984K)] 1019358K->766310K(1044416K), 0.0567120 secs] [Times: user=0.18 sys=0.01, real=0.06 secs]
[GC [PSYoungGen: 257128K->2920K(258112K)] 1020134K->766622K(1044544K), 0.0549570 secs] [Times: user=0.19 sys=0.00, real=0.05 secs]
可以发现Heap增长趋缓。
运行两天以后输出:
[GC [PSYoungGen: 256936K->3584K(257792K)] 859561K->606969K(1044224K), 0.0565910 secs] [Times: user=0.18 sys=0.01, real=0.06 secs]
[GC [PSYoungGen: 256960K->3368K(257728K)] 860345K->607445K(1044160K), 0.0553780 secs] [Times: user=0.18 sys=0.01, real=0.06 secs]
发现Heap反而减少了,此时可以对内存泄露问题作初步排除了。(其实在jdk1.6环境下用jprofiler来观察,对于concurrent那个内存泄露点的跟踪发现,内存的确还是会不断增长的,不过在一段时间后还是有回收,因此也就可以部分解释前面出现的情况)
总结:
对于GC输出的观察需要分两个维度来看。一个是纵向比较,也就是一次回收对于内存变化的观察。一个是横向比较,对于长时间内存分配占用情况的比较,这部分比较需要较长时间的观察,不能仅仅凭短时间的几个抽样比较,因为对于抽样来说,Full GC前后的区别,运行时长的区别,资源瞬时占用的区别都会影响判断。同时要结合Full GC发生的时间周期,每一次GC收集所耗费的时间作为辅助判断标准。
顺便说一下,Heap的 YoungGen,OldGen,PermGen的设置也是需要注意的,并不是越大越好,越大执行收集的时间越久,但是可能执行Full GC的频率会比较低,因此需要权衡。这些仔细的去了解一下GC的基础设计思想会更有帮助,不过一般用默认的也不错。还有就是可以配置一些特殊的GC,并行,同步等等,充分利用多CPU的资源。
对于GC的优化可以通过现在很多图形工具来做,也可以类似于我这样采用最原始的分析方式,好处就是任何时间任何地点只要知道原理就可以分析无需借助外部工具。原始的总是最好的^_^。
摘要: 1、Java虚拟机运行时的数据区2、常用的内存区域调节参数-Xms:初始堆大小,默认为物理内存的1/64(<1GB);默认(MinHeapFreeRatio参数可以调整)空余堆内存小于40%时,JVM就会增大堆直到-Xmx的最大限制-Xmx:最大堆大小,默认(MaxHeapFreeRatio参数可以调整)空余堆内存大于70%时,JVM会减少堆直到 -Xms的最小限制-Xmn:新生代的内存空间... 阅读全文
性能测试排查定位问题,分析调优过程中,会遇到要分析gc日志,人肉分析gc日志有时比较困难,相关图形化或命令行工具可以有效地帮助辅助分析。 Gc日志参数 通过在tomcat启动脚本中添加相关参数生成gc日志 -verbose.gc开关可显示GC的操作内容。打开它,可以显示最忙和最空闲收集行为发生的时间、收集前后的内存大小、收集需要的时间等。 打开-xx:+ printGCdetails开关,可以详细了解GC中的变化。 打开-XX: + PrintGCTimeStamps开关,可以了解这些垃圾收集发生的时间,自JVM启动以后以秒计量。 最后,通过-xx: + PrintHeapAtGC开关了解堆的更详细的信息。 为了了解新域的情况,可以通过-XX:=PrintTenuringDistribution开关了解获得使用期的对象权。 -Xloggc:$CATALINA_BASE/logs/gc.log gc日志产生的路径 XX:+PrintGCApplicationStoppedTime // 输出GC造成应用暂停的时间 -XX:+PrintGCDateStamps // GC发生的时间信息 Gc日志
日志中显示了gc发生的时间,young区回收情况,整体回收情况,fullGC情况,回收所消耗时间等 常用JVM参数 分析gc日志后,经常需要调整jvm内存相关参数,常用参数如下 -Xms:初始堆大小,默认为物理内存的1/64(<1GB);默认(MinHeapFreeRatio参数可以调整)空余堆内存小于40%时,JVM就会增大堆直到-Xmx的最大限制 -Xmx:最大堆大小,默认(MaxHeapFreeRatio参数可以调整)空余堆内存大于70%时,JVM会减少堆直到 -Xms的最小限制 -Xmn:新生代的内存空间大小,注意:此处的大小是(eden+ 2 survivor space)。与jmap -heap中显示的New gen是不同的。整个堆大小=新生代大小 + 老生代大小 + 永久代大小。
在保证堆大小不变的情况下,增大新生代后,将会减小老生代大小。此值对系统性能影响较大,Sun官方推荐配置为整个堆的3/8。 -XX:SurvivorRatio:新生代中Eden区域与Survivor区域的容量比值,默认值为8。两个Survivor区与一个Eden区的比值为2:8,一个Survivor区占整个年轻代的1/10。 -Xss:每个线程的堆栈大小。JDK5.0以后每个线程堆栈大小为1M,以前每个线程堆栈大小为256K。应根据应用的线程所需内存大小进行适当调整。在相同物理内存下,减小这个值能生成更多的线程。但是操作系统对一个进程内的线程数还是有限制的,不能无限生成,经验值在3000~5000左右。一般小的应用, 如果栈不是很深, 应该是128k够用的,大的应用建议使用256k。这个选项对性能影响比较大,需要严格的测试。和threadstacksize选项解释很类似,官方文档似乎没有解释,在论坛中有这样一句话:"-Xss is translated in a VM flag named ThreadStackSize”一般设置这个值就可以了。 -XX:PermSize:设置永久代(perm gen)初始值。默认值为物理内存的1/64。 -XX:MaxPermSize:设置持久代最大值。物理内存的1/4。 Gc日志分析工具 (1)GCHisto http://java.net/projects/gchisto 直接点击gchisto.jar就可以运行,点add载入gc.log 统计了总共gc次数,youngGC次数,FullGC次数,次数的百分比,GC消耗的时间,百分比,平均消耗时间,消耗时间最小最大值等
统计的图形化表示 YoungGC,FullGC不同消耗时间上次数的分布图,勾选可以显示youngGC或fullGC单独的分布情况 整个时间过程详细的gc情况,可以对整个过程进行剖析 (2)GCLogViewer http://code.google.com/p/gclogviewer/ 点击run.bat运行 整个过程gc情况的趋势图,还显示了gc类型,吞吐量,平均gc频率,内存变化趋势等 Tools里还能比较不同gc日志
(3)HPjmeter 获取地址 http://www.hp.com/go/java
参考文档 http://www.javaperformancetuning.com/tools/hpjtune/index.shtml 工具很强大,但只能打开由以下参数生成的GC log, -verbose:gc -Xloggc:gc.log,添加其他参数生成的gc.log无法打开。 (4)GCViewer http://www.tagtraum.com/gcviewer.html 这个工具用的挺多的,但只能在JDK1.5以下的版本中运行,1.6以后没有对应。 (5)garbagecat http://code.google.com/a/eclipselabs.org/p/garbagecat/wiki/Documentation 其它监控方法 Jvisualvm动态分析jvm内存情况和gc情况,插件:visualGC jvisualvm还可以heapdump出对应hprof文件(默认存放路径:监控的服务器 /tmp下),利用相关工具,比如HPjmeter可以对其进行分析 grep Full gc.log粗略观察FullGC发生频率 jstat –gcutil [pid] [intervel] [count] jmap -histo pid可以观测对象的个数和占用空间
jmap -heap pid可以观测jvm配置参数,堆内存各区使用情况 jprofiler,jmap dump出来用MAT分析 如果要分析的dump文件很大的话,就需要很多内存,很容易crash。 所以在启动时,我们应该加上一些参数: Java –Xms512M –Xmx1024M –Xss8M
如果仍然使用缺省的类加载策略:PARENT_FIRST, 由于BSF自身加载类,导致使用org.eclipse.osgi.framework.internal.core.BundleLoader装载器来装载,在这个装载器级别,似乎发现不了JavaScriptEngine类,实际上JavaScriptEngine和BSFManager同在一个包中。 一个可行的解决方法是,将该baf.jar(JavaScriptEngine类所在jar包)拷贝到jre/lib/ext目录下,则org.eclipse.osgi.framework.internal.core.BundleLoader类装载器一定能找到,因为该JDK加载顺序在org.eclipse.osgi.framework.internal.core.BundleLoader之先。 然而,系统管理员处于安全的考虑,不同意在jre下放置bsf.jar包。看来只得另寻他法。通过阅读下面的文章,理解WAS6.1的加载方式,可知创建应用程序共享库可以解决这一问题。参考:在应用程序服务器级别使用共享库。注意:在应用程序级别使用共享库并不能解决这个问题,如果该类没有使用自己的ClassLoader则应可行。 详细操作步骤: 1、打开WAS6.1控制台,创建共享库 
2、在应用程序服务器级别使用共享库 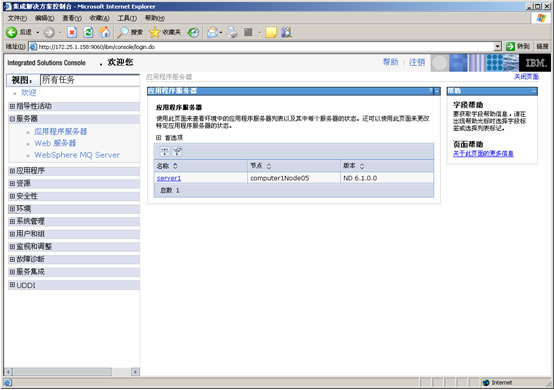
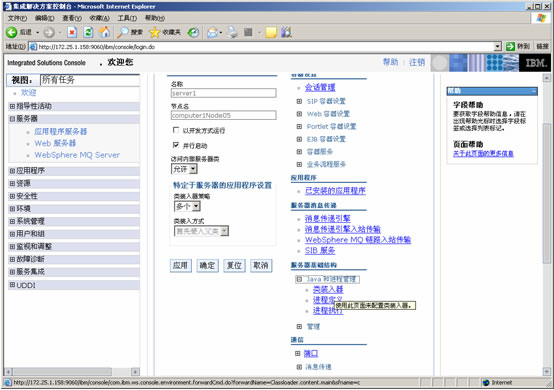
新建类装载器,注意,这里选 类已装入且是先使用应用程序装载器 选项
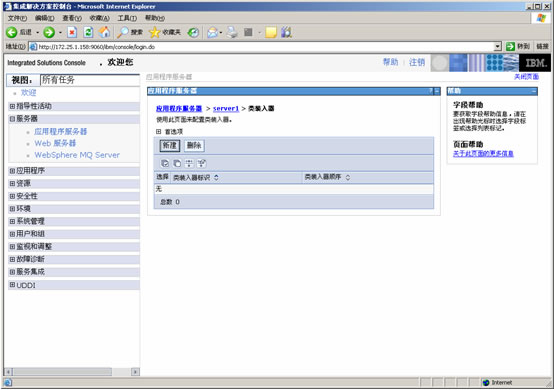
保存
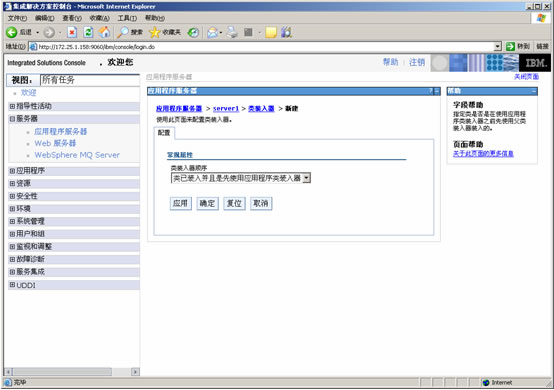
类装载器创建完成
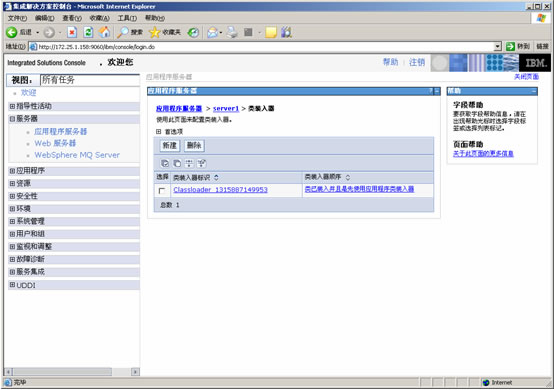 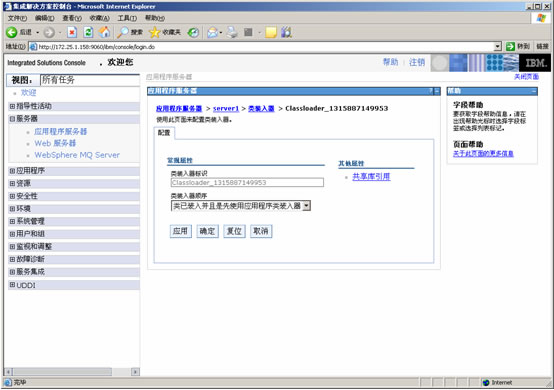
新建共享库的引用
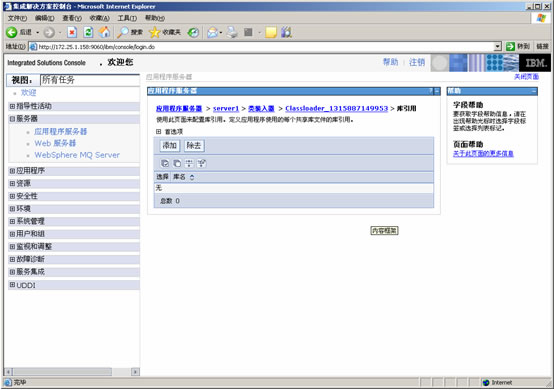
选择已经配置好的共享库
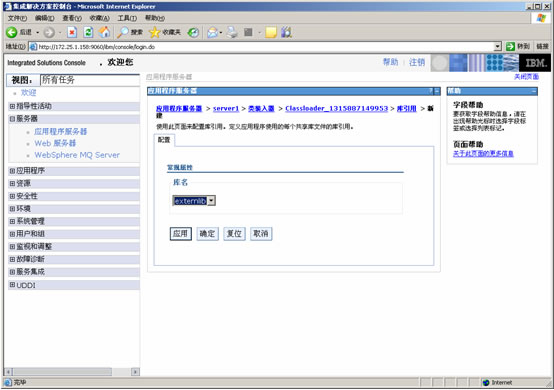
这是配置完的样子
以下为参考文章
-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
理解WAS 6.1的类加载(4)2008-12-3 12.5.2步骤2:添加一个EJB模块和工具JAR 下面,往应用程序中添加一个EJB,它也依赖VersionChecker JAR文件。在此,在EAR的根目录添加一个VersionCheckerV2.jar文件。在这个JAR文件中的VersionChecker类返回了Version 2.0。为了保证扩展类加载中的工具JAR可用,在EJB模块的manifest文件中添加一个引用,如例12-8: 例12-8更新EJB模块的MANIFEST.MF文件 Manifest-Version: 1.0 Class-Path: VersionCheckerV2.jar 现在的结果是:有一个Web模块,在它的WEB-INF/classes目录下面有一个servlet,在WEB-INF/lib目录下面有VersionCheckerV1.jar文件。还有一个EJB模块引用了EAR根目录下面的VersionCheckerV2.jar工具JAR。你期望Web模块装入VersionChecker类文件的版本是什么?是WEB-INF/lib下的Version 1.0还是工具JAR下面的Version 2.0?测试结果如例12-9: 例12-9类加载例2 VersionChecker called from Servlet VersionChecker is v2.0. Loaded bycom.ibm.ws.classloader.CompoundClassLoader@26282628 Local ClassPath: C:\WebSphere\AppServer\profiles\AppSrv02\installedApps\kcgg1d8Node02Cel l\ClassloaderExample.ear\ClassloaderExampleEJB.jar;C:\WebSphere\AppServ er\profiles\AppSrv02\installedApps\kcgg1d8Node02Cell\ClassloaderExample .ear\VersionCheckerV2.jar Delegation Mode: PARENT_FIRST VersionChecker called from EJB VersionChecker is v2.0. Loaded bycom.ibm.ws.classloader.CompoundClassLoader@26282628 Local ClassPath: C:\WebSphere\AppServer\profiles\AppSrv02\installedApps\kcgg1d8Node02Cel l\ClassloaderExample.ear\ClassloaderExampleEJB.jar;C:\WebSphere\AppServ er\profiles\AppSrv02\installedApps\kcgg1d8Node02Cell\ClassloaderExample .ear\VersionCheckerV2.jar Delegation Mode: PARENT_FIRST 正如所看到的,当同时调用EJB模块和Web模块,VersionChecker是Version 2.0。当然,原因是:WAR类加载器将请求委托给了父类加载器而不是他自己,所以工具JAR就被同一个类加载器加载,而无需考虑请求是来自于servlet还是EJB。 12.5.3步骤 3:改变WAR类加载的委托模式 现在是否希望Web模块使用WEB-INF/lib目录下面的VersionCheckerV1.jar文件?为了这个目的,需要先将类加载委托模式从parent first改为parent last。
设置委托模式为PARENT_LAST,使用如下步骤: 1. 在向导栏选择Enterprise Applications; 2. 选择ClassloaderExample应用程序; 3. 在模块部分选择Manage modules ; 4. 选择ClassloaderExampleWeb模块; 5. 将类加载顺序修改成应用程序类加载优先(PARENT_LAST)。记住,这个条目应该称为WAR类加载优先,参见 “类加载/委托模式”; 6. 单击OK. 7. 保存配置; 8. 重新启动应用程序。 WEB-INF/lib下的VersionCheckerV1返回version of 1.0。可以在例12-10中看到: 例12-10类加载例3 VersionChecker called from Servlet VersionChecker is v1.0. Loaded bycom.ibm.ws.classloader.CompoundClassLoader@4d404d40 Local ClassPath: C:\WebSphere\AppServer\profiles\AppSrv02\installedApps\kcgg1d8Node02Cel l\ClassloaderExample.ear\ClassloaderExampleWeb.war\WEB-INF\classes;C:\W ebSphere\AppServer\profiles\AppSrv02\installedApps\kcgg1d8Node02Cell\Cl assloaderExample.ear\ClassloaderExampleWeb.war\WEB-INF\lib\VersionCheck erV1.jar;C:\WebSphere\AppServer\profiles\AppSrv02\installedApps\kcgg1d8 Node02Cell\ClassloaderExample.ear\ClassloaderExampleWeb.war Delegation Mode: PARENT_LAST VersionChecker called from EJB VersionChecker is v2.0. Loaded bycom.ibm.ws.classloader.CompoundClassLoader@37f437f4 Local ClassPath: C:\WebSphere\AppServer\profiles\AppSrv02\installedApps\kcgg1d8Node02Cel l\ClassloaderExample.ear\ClassloaderExampleEJB.jar;C:\WebSphere\AppServ er\profiles\AppSrv02\installedApps \kcgg1d8Node02Cell\ClassloaderExample .ear\VersionCheckerV2.jar Delegation Mode: PARENT_FIRST 如果你使用类加载器的搜索功能,搜索*VersionChecker*,会得到图12-9: 
图12-9类加载查看器搜索功能 例12-11显示源代码 例12-11类加载查看器搜索功能 WAS Module Compound Class Loader (WAR class loader): file: / C: / WebSphere / AppServer / profiles / AppSrv02 / installedApps / kcgg1d8Node02Cell / ClassloaderExample.ear / ClassloaderExampleWeb.war / WEB-INF / lib / VersionCheckerV1.jar WAS Module Jar Class Loader (Application class loader): file: / C: / WebSphere / AppServer / profiles / AppSrv02 / installedApps / kcgg1d8Node02Cell / ClassloaderExample.ear / VersionCheckerV2.jar 12.5.4步骤4:使用共享库共享工具JAR 在此之前,只有一个应用程序使用VersionCheckerV2.jar文件。是否希望多个应用程序能够共享它?当然,你可以在每个EAR文件中把这个文件打包进去。但是如果需要修改这个工具JAR,那需要重新部署所有的应用程序。为了避免这个麻烦,你可以使用共享库全局共享这个JAR文件。 共享库可以定义在单元、节点、应用程序服务器和集群。一旦你定义了共享库,必须将它跟应用程序服务器的类加载器或者单独的Web模块关联起来。根据共享库指派的目的地不同,WebSphere会使用匹配的类加载器加载共享库。 只要愿意,可以定义多个共享库。也可以为应用程序、Web模块或者应用程序服务器指派多个共享库。 在应用程序级别使用共享库 定义一个名为VersionCheckerV2_SharedLib的共享库,并把它跟ClassloaderTest应用程序关联起来,步骤如下: 1. 在管理控制台,选择Environment→Shared Libraries; 2. 选择共享库的作用域,比如单元,单击New; 3. 如图12-10: 
图12-10共享库配置 –Name: 输入VersionCheckerV2_SharedLib; –Class path: 输入类路径中的条目,每个条目之间用回车隔开。如果提供绝对路径,建议是用WebSphere环境变量,比如%FRAMEWORK_JARS%/VersionCheckerV2.jar,确定你已经定义了一个和共享库相同作用域的变量。 –Native library path: 输入JNI代码使用的DLLs和.so文件列表。 4. 单击OK; 5.选择Applications → Enterprise Applications; 6. 选择应用程序ClassloadersExample ; 7. 在引用选项,选择Shared library references ; 8. 在应用程序列选择ClassloaderExample ; 9. 单击Reference shared libraries; 10. 选择VersionCheckerV2_SharedLib,单击>>按钮将选中的移动到Selected列,如下图12-11: 
图12-11指定一个共享库 11.单击OK ; 12.ClassloaderExample应用程序共享库配置窗口如下图12-12: 图12-12将共享库指派给应用程序ClassloaderExample 13.单击OK,保存配置。 如果我们现在从EAR文件的根目录将VersionCheckerV2.jar删除,在EJB模块的manifest文件中也把引用删除,重新启动应用服务器,看到例12-12的结果。记住,Web模块的类加载顺序依然是应用程序类加载优先(PARENT_LAST)。 例12-12类加载例4 VersionChecker called from Servlet VersionChecker is v1.0. Loaded bycom.ibm.ws.classloader.CompoundClassLoader@2e602e60 Local ClassPath: C:\WebSphere\AppServer\profiles\AppSrv02\installedApps\kcgg1d8Node02Cel l\ClassloaderExample.ear\ClassloaderExampleWeb.war\WEB-INF\classes;C:\W ebSphere\AppServer\profiles\AppSrv02\installedApps\kcgg1d8Node02Cell\Cl assloaderExample.ear\ClassloaderExampleWeb.war\WEB-INF\lib\VersionCheck erV1.jar;C:\WebSphere\AppServer\profiles\AppSrv02\installedApps\kcgg1d8
Node02Cell\ClassloaderExample.ear\ClassloaderExampleWeb.war Delegation Mode: PARENT_LAST VersionChecker called from EJB VersionChecker is v2.0. Loaded bycom.ibm.ws.classloader.CompoundClassLoader@19141914 Local ClassPath: C:\WebSphere\AppServer\profiles\AppSrv02\installedApps\kcgg1d8Node02Cel l\ClassloaderExample.ear\ClassloaderExampleEJB.jar;C:\henrik\VersionChe ckerV2.jar Delegation Mode: PARENT_FIRST 正如预料的,由于Web模块的委托模式,当servlet需要VersionChecker类,VersionCheckerV1.jar文件被加载。当EJB需要VersionChecker的类的时候,就会从指向C:\henrik\VersionCheckerV2.jar的共享库中加载它。如果你希望Web模块也使用共享库,只需要将类加载顺序恢复成缺省值,Web模块的类加载是父类加载优先。 在应用程序服务器级别使用共享库 共享库也可以跟应用程序服务器关联起来。在这个服务器上的部署的所有应用程序都能够看到共享库的代码列表。要把共享库跟应用程序服务器关联起来,首先要为应用程序服务器创建一个附加的类加载器,步骤如下: 1. 选择应用程序服务器; 2. 在应用程序基础结构部分,展开Java and Process Management,选择Class loader; 3. 选择New,为这个类加载器选择类加载顺序,父类加载优先(PARENT_FIRST)或者应用程序类加载优先(PARENT_LAST),单击Apply; 4. 单击刚刚创建的类加载器; 5. 单击Shared library references; 6. 单击Add,选择希望跟应用程序服务器关联的库。重复选择操作,将多个库跟这个类加载器关联。比如选择VersionCheckerV2_SharedLib条目; 7. 单击OK; 8. 保存配置; 9. 重新启动应用程序服务器,修改才会生效。 将VersionCheckerV2共享库跟应用程序服务器关联起来,就得到例12-13的结果。 例12-13类加载例5 VersionChecker called from Servlet VersionChecker is v1.0. Loaded bycom.ibm.ws.classloader.CompoundClassLoader@40c240c2 Local ClassPath: C:\WebSphere\AppServer\profiles\AppSrv02\installedApps\kcgg1d8Node02Cel l\ClassloaderExample.ear\ClassloaderExampleWeb.war\WEB-INF\classes;C:\W ebSphere\AppServer\profiles\AppSrv02\installedApps\kcgg1d8Node02Cell\Cl assloaderExample.ear\ClassloaderExampleWeb.war\WEB-INF\lib\VersionCheck erV1.jar;C:\WebSphere\AppServer\profiles\AppSrv02\installedApps\kcgg1d8 Node02Cell\ClassloaderExample.ear\ClassloaderExampleWeb.war VersionChecker called from EJB VersionChecker is v2.0. Loaded bycom.ibm.ws.classloader.ExtJarClassLoader@7dee7dee Local ClassPath: C:\henrik\VersionCheckerV2.jar Delegation Mode: PARENT_FIRST 我们定义的新的名为ExtJarClassLoader类加载器,在EJB模块请求时,它装入VersionCheckerV2.jar文件。由于委托模式,WAR类加载器继续装入自己的version。 12.6类加载器问题诊断 JVM 5.0提供了一些配置,可以让我们查看详细的类装入,比如JVM参数 -verbose:dynload、-Dibm.cl.verbose=<name>。 在实际开发过程中,如果使用不当,会出现很多类加载相关的问题。当遇到类加载问题时,可以查看WAS的相关日志,在日志中出现如下异常,可以认为是类加载器出现了问题: ClassCastException ClassNotFoundException NoClassDefFoundError NoSuchMethodError IllegalArgumentException UnsatisfiedLinkError VerifyError 关于问题诊断,将在下一篇文章《WAS 6.1类加载问题诊断》详细阐述。 总结 本文针对WAS6.1版本,详细介绍了类加载的概念以及如何客户化,并通过几个例子向大家讲述了影响类加载的选项的使用。虽然WAS 6.1允许根据需要修改类加载策略,比如将父类优先改成应用程序优先,但是不推荐这么使用。笔者曾经就遇到因为修改策略,导致应用程序无法启动。原因是WAS中 的组件和应用程序使用的某些类是一致的,加载策略选择不正确,就会导致类加载错误。
<%@ page import="java.security.Provider"%> <%@ page import="java.security.Security"%> <%@ page import="java.util.Set"%> <%@ page import="java.util.Iterator"%> <% Provider[] providers = Security.getProviders(); for (int i = 0; i < providers.length; i++) { Provider provider = providers[i]; %> Provider name: <%=provider.getName()%><br/> Provider information: <%=provider.getInfo()%> <br/> Provider version: <%=provider.getVersion()%><br/> <% Set entries = provider.entrySet(); Iterator iterator = entries.iterator(); while (iterator.hasNext()) { %> Property entry:<%=iterator.next()%><br/><br/><br/> <% } } %>
OA应用程序的性能测试包括了benchmarking test(基准测试),capacity test(容量测试)和soak test(浸泡测试)三个主要测试阶段。
基准测试(Benchmarking Test)
基于SOA的性能测试第一阶段是基准测试,基准测试是用来确定被测应用程序是否存在性能衰退,并且收集可重复性能测试结果以作为性能基准。基准测试的最好方法是每次测试只改变一个参数。基准测试包括了相应时间驱动的测试和吞吐量驱动的测试。
响应时间驱动测试
对于web service的应用程序,其中响应时间定义为发送一个服务请求到收到服务响应的时间间隔。响应时间驱动的测试主要用来测试单个service的性能。首先加一个虚拟用户作为负载量,然后对同一测试用例按照比例的增加并发虚拟用户数,并分别记录下测试结果,最后计算出这些测试结果的平均值作为平均响应时间。
下图为某个web服务在不同并发虚拟用户数下平均响应时间曲线图,由图可看出,平均响应时间随着并发虚拟用户数的增加而增加。在用户数从50到100,平均响应时间开始比较大幅度地增长,此时很有可能某个系统资源出现了瓶颈,当然前提条件是在被测应用程序没有出现错误的情况下。此时可以进行调优,但要保证每次只改动一个参数值,然后再次执行相同测试用例,并与之前的结果进行对比,选取结果最优的参数配置。(图略)
吞吐量驱动测试
吞吐量被定义为在单元时间内能够成功处理的服务请求的数量。吞吐量驱动的测试主要是基于一组连续web服务形成一个或多个测试场景,来测量应用在单位时间内能够处理的事务数量。
这是针对一个业务场景进行的性能测试用例,同样首先加一个虚拟用户作为负载量,然后对同一测试用例按比例的增加并发虚拟用户数,最后记录下不同虚拟用户数下的吞吐量。
下图为不同并发虚拟用户数下吞吐量的曲线图,与响应时间一样,吞吐量也随着并发虚拟用户数的增长而增长,但不同的是吞吐量在达到某一最高点后,再增加并发虚拟用户时吞吐量则保持与最高值接近。这是由于当用户数较少时,单位时间内发出的服务请求较少,所以测出的吞吐量较小,当用户数增加,发出的服务请求增加,所以吞吐量也随之增加,当吞吐量达到最高值表明被测应用在测试的硬件环境下达到处理事务的最高能力。最后同样要做性能调优,以选取最优的吞吐量最大值时的配置情况。(图略)
容量测试(Capacity Test)
容量测试的目标是要看被测应用在一定测试环境下能够达到的最大处理能力。容量测试将模拟更加接近真实用户使用的环境,并且用更为真实的用户负载来测试 SOA应用程序的capacity scale。具体地说,一般容量测试是为了检测在达到一定响应时间或吞吐量的前提下被测应用能够支持的并发用户数。其中容量测试包括了以下几方面内容:
- 定义访问系统的并发虚拟用户数
- 定义虚拟用户的think time,也就是发出两个连续请求之间的时间间隔。
- 用ramp-up run的方式增加负载量进行测试,得到被测应用能够支持的虚拟用户数的范围。
- 在应用支持的用户数地范围内,采用flat run的方式进行测试,以得到更为精确性能结果。
浸泡测试(Soak Test)
Soak test是在一个稳定的并发用户上进行的long run测试,用来测试SOA应用程序的健壮性。通过soak test往往可以发现内存泄露,频繁 GC 等严重性能问题。进行soak test需要注意以下两点:
- Soak test需要在一定适中的用户负载量下进行,最好低于应用支持最大的负载量。
- 在执行long run测试时,采用几种不同用户组,并且每个用户组织性不同的业务流程。
Soak test实际上比较简单的性能测试,测试最好能够运行几天,以真正得到一个健壮的应用。确保应用测试是贴近真实世界,尽量与实际使用情况接近。
|