新写了一个Java并发程序设计教程, 用于公司内部培训的,和2007年写的那个相比,内容更翔实一些。
内容列表
1、使用线程的经验:设置名称、响应中断、使用ThreadLocal
2、Executor :ExecutorService和Future ☆ ☆ ☆
3、阻塞队列 : put和take、offer和poll、drainTo
4、线程间的协调手段:lock、condition、wait、notify、notifyAll ☆ ☆ ☆
5、Lock-free: atomic、concurrentMap.putIfAbsent、CopyOnWriteArrayList ☆ ☆ ☆
6、关于锁使用的经验介绍
7、并发流程控制手段:CountDownlatch、Barrier
8、定时器: ScheduledExecutorService、大规模定时器TimerWheel
9、并发三大定律:Amdahl、Gustafson、Sun-Ni
10、神人和图书
11、业界发展情况: GPGPU、OpenCL
12、复习题
下载地址:
http://files.cnblogs.com/jobs/Java%e5%b9%b6%e5%8f%91%e7%a8%8b%e5%ba%8f%e8%ae%be%e8%ae%a1%e6%95%99%e7%a8%8b.pdf
欢迎看了之后写反馈给我。
博客园的文章地址:
http://www.cnblogs.com/jobs/archive/2010/07/29/1788156.html
Google云计算AppEngine
Java版刚刚推出来的时候,我就申请了该服务。该服务的申请需要提供手机号码验证,GOOGLE很牛B,能够发送全球的手机短信。申请的帐号放了很久,
前段时间学习OpenID,需要作一个范例,于是就在Google
AppEngine上作,作的过程发现其不能使用线程,导致HttpClient组件无法工作,于是我修改了OpenID4Java的实现,全部使用
URLConnection来实现。最终程序部署成功了,网址 http://cogito-study.appspot.com,欢迎大家测试使用。
我来说一下我对Google AppEngine Java版本的使用感受吧。
1、
Google AppEngine
Java版本,具备基本功能,但是由于缺乏一些重要的功能,例如线程,没有线程,很多库无法使用,例如我上面提到的HttpClient不能使用。
Google提供一个类的白名单http://code.google.com/intl/zh-CN/appengine/docs/java
/jrewhitelist.html,大多数需要使用的类都有,javax.xml.crypto不再其中,使得我要部署一个SAML2的实现时玩不
转。
2、Google
AppEngine提供了一个DataStore,使用JDO访问数据,其查询语言支持GQL。基本功能是具备的,但是也是存在很大的局限性,最多返回
1000行数据,COUNT(*)也是最多返回1000行。这个限制使得很多应用要跑在其上,会很麻烦。
3、部署很简单,在Eclipse中使用Google提供的插件,输入帐号密码就可以部署了,太简单了。但我使用的过程中,经常出现某些时段无法部署的情况,通常遇到这种情况,多尝试几次或者过段时间再尝试就好了。
4、管理界面简洁方便,功能基本完备。包括性能监控、数据管理、日志、计费等都有。
总结
Google的AppEngine Java版本已经具备了基本功能,可以部署简单应用了,但是由于其功能不够完备,目前大多数应用要部署在其上,都会要做相当大的修改或者无法实现。
我在Google AppEngine上部署了一个Java应用(OpenID测试)
http://cogito-study.appspot.com
Google Apps不支持线程,所用到的库openid4java需要创建线程(因为HttpClient),我修改了openid4java的实现,使得其支持Google App Engine。
部署在Google App Engine上的应用可以应用任何OpenID Provider登陆,包括Google、Yahoo、MSN等。
你可以通过这个测试网站了解OpenID
最近花了较多时间学习单点登陆以及相关的安全技术,做一个简单的总结,发表我的一些看法。抛砖引玉,希望各位朋友参与讨论。
单点登陆,鸟语原文为Single Sign-On,缩写为SSO。别以为单点登陆是很时髦高深的技术,相反单点登陆是很古老的技术,例如1980年kerberos v4发布,一直发展至今,被Windows、Mac OS X、Linux等流行的操作系统所采用,是为应用最广泛的单点登陆技术。
kerberos适用于局域网,十分成熟。互联网发展之后,多个网站需要统一认证,业界需要适合互联网的单点登陆技术,也就是WEB SSO。2002年,微软提出了passport服务,由微软统一提供帐号和认证服务,理所当然,大家都不愿意受制于微软,但是很认同微软提出WEB SSO理念,于是产生了Liberty Alliance,另外指定一套标准,这套标准发展起来就是SAML,目前SAML的版本是SAML V2,属于OASIS的标准。
--------------
SAML
SAML,鸟语全名为Security Assertion Markup Language,弥漫着学院派的腐尸味道,缩写十分怪异,令人望而生畏。计算机行业,向来崇尚时髦,SAML这一名称使得其较少受到大众程序员的关注。
SAML的标准制定者,来自SUN、BEA、IBM、RSA、AOL、Boeing等大公司,制定技术规范相当专业有水准,系统分层合理,抽象了几个概念把整个系统描述得很清楚,使用流行技术XML Schema来描述协议,使用到了XML-Sign和XML Encrypt等较为前缘XML安全技术。
SAML的基本部分包括Protocol、Bingding、Profile、Metadata、AuthenticationContext。其中Protocol是交互消息的格式,例如AuthnRuequest/Response(认证请求/响应)的消息对。Bingding是指协议所采用的传输方式,例如使用HTTP Redirect或HTTP POST或SOAP的方式传输Protocol中所定义的消息。Profile是系统角色间交互消息的各种场景,例如Web Single Sign-ON是一种Profile、Single Sign-Out也是一种Profile、身份联邦也是一种Profile。各个参与方所提供的服务的描述信息为metadata。系统的认证方法通常是千差万别的,AuthenticationContext是SAML中定义的认证扩展点,可以是最普通的User Password认证,也可以是kerberos认证,也可以是电信常用的RADIUS,或者是动态密码卡。
SAML在Java企业应用中,得到广泛支持,IBM、BEA、ORACLE、SUN的Java应用服务器都提供了SAML的支持,曾经有人说,SAML就是如同JDBC一样,将会是使系统集成的准入证。SAML有很多开源实现,包括SUN公司的Open SSO,不幸的是,这些开源实现都不够好,或者相当糟糕,如果我们需要支持SAML协议,可能需要在开源的版本上裁剪或者另行开发。
SAML考虑了Web SSO,也考虑了传统的SSO集成,包括Kerberos和LDAP的集成,其中Attributed扩展机制以及相关规范,使得SAML拥有良好的扩展性,很好集成传统协议和支持新协议。
SAML是一个定义良好的规范,概念清晰,分层合理,扩展性良好,一切都很棒,但是有一点不好,就是曲高和寡!
-------------
OpenID
有一些互联网公司,拥有众多很多帐号,很牛B,例如GOOGLE、YAHOO、Facebook,希望别人的系统使用它们的帐号登陆。他们希望一种足够简单的WEB SSO规范,于是选择一种草根网络协议OpenID。OpenID,名字取得好,顾名思义,一看就知道它是干嘛的。国内也有它的Fans,例如豆瓣网。openID的确足够简单,但是协议本身是不完善,可能需要一些补充协议才能够满足业务需求。例如GOOGLE采用OpenID + OAuth。目前支持OpenID有Yahoo、Google、Windows Live,还有号称要支持OpenID的Facebook。目前Yahoo和Google宣称对OpenID的支持,但是其实是有限制的,Yahoo的OpenID只有少数合作伙伴才能获得其属性,Google也只有在其Google Apps中才能获得账号的Attribute。用户账号毕竟是一个互联网公司的最宝贵资源,希望他们完全分享账号是不可能的。
Open ID和SAML两种规范,都将会减少系统间交互的成本,我们提供Open API时,应该支持其中一种或者或两种规范。
--------------
OAuth
oAuth涉及到3大块的交互和通信。1. 用户,2. 拥有用户资料/资源的服务器A,3. 求资源的服务器B,。
oAuth的典型应用场景(senario)
以前,用户在 拥有资源 的的网站A有一大堆东西;现在用户发现了一个新的网站B,比较好玩,但是这个新的网站B想调用 拥有资源的网站A的数据。
用户在 求资源的网站B 上,点击一个URL,跳转到 拥有 资源的网站A。
拥有资源的网站A提示:你需要把资源分享给B网站吗?Yes/No。
用户点击 Yes,拥有资源的网站A 给 求资源的网站B 临时/永久 开一个通道,然后 求资源的网站 就可以来 拥有资源的网站 抓取所需的信息了。
(参考资料:http://initiative.yo2.cn/archives/633801)
(摘抄)
--------------
内部系统间集成使用LDAP、Kerberos,外部系统集成使用SAML或者OpenID + OAuth,这是一种建议的模式。
------------
PAM
人们寻找一种方案:一方面,将鉴别功能从应用中独立出来,单独进行模块化设计,实现和维护;另一方面,为这些鉴别模块建立标准 API,以便各应用程序能方便的使用它们提供的各种功能;同时,鉴别机制对其上层用户(包括应用程序和最终用户)是透明的。直到 1995 年,SUN 的研究人员提出了一种满足以上需求的方案--插件式鉴别模块(PAM)机制并首次在其操作系统 Solaris 2.3 上部分实现。插件式鉴别模块(PAM)机制采用模块化设计和插件功能,使得我们可以轻易地在应用程序中插入新的鉴别模块或替换原先的组件,而不必对应用程序做任何修改,从而使软件的定制、维持和升级更加轻松--因为鉴别机制与应用程序之间相对独立。应用程序可以通过 PAM API 方便的使用 PAM 提供的各种鉴别功能,而不必了解太多的底层细节。此外,PAM的易用性也较强,主要表现在它对上层屏蔽了鉴别的具体细节,所以用户不必被迫学习各种各样的鉴别方式,也不必记住多个口令;又由于它实现了多鉴别机制的集成问题,所以单个程序可以轻易集成多种鉴别机制如 Kerberos 鉴别机制和 Diffie - Hellman 鉴别机制等,但用户仍可以用同一个口令登录而感觉不到采取了各种不同鉴别方法。PAM 后来被标准化为 X/Open UNIX® 标准化流程(在 X/Open 单点登录服务(XSSO)架构中)的一部分。(摘抄)
如果我们设计一个认证系统,PAM是应该参考借鉴的。
-------------
JAAS
Java Authentication Authorization Service(JAAS,Java验证和授权API)提供了灵活和可伸缩的机制来保证客户端或服务器端的Java程序。Java早期的安全框架强调的是通过验证代码的来源和作者,保护用户避免受到下载下来的代码的攻击。JAAS强调的是通过验证谁在运行代码以及他/她的权限来保护系统面受用户的攻击。它让你能够将一些标准的安全机制,例如Solaris NIS(网络信息服务)、Windows NT、LDAP(轻量目录存取协议),Kerberos等通过一种通用的,可配置的方式集成到系统中。在客户端使用JAAS很简单。在服务器端使用JAAS时情况要复杂一些。(摘抄)
-------------
Spring Security,Spring框架大名鼎鼎,Spring Security属于SpringFramework旗下的一个子项目,源自acegi 1.x发展起来。很多人项目应用了spring security,但我个人看来,spring security绝对不算是一个设计良好的安全框架。其设计感觉就是一个小项目的安全认证实践罢了。
-------------
CAS
应用最广的开源单点登陆实现了,其实现模仿Kerberos的一些概念,例如KDC、TGS等等,都是来自于Kerberos。CAS对SAML和OpenID协议支持得不够好。个人感觉类似Kerberos的机制在互联网中可能过于复杂了。我感觉单纯的ticket机制,过于局限于基于加密解密的安全了,感觉上SAML的Assertion概念更好,Assertion可以包括认证、授权以及属性信息。
-------------

--------------------------
09博客园纪念T恤
新闻:
Wordpress发布实时RSS技术 推动实时网络发展
网站导航:
博客园首页 个人主页 新闻 社区 博问 闪存 找找看
现在很多开源项目在使用LOG的时候做了不好的示范--在基类中实例化的方式使用LOG,而不是静态变量。
例如:
class Base {
private final Log LOG = LogFactory.getLog(this.getClass());
}
class Derived {
public void foo() {
if (LOG.isDebugEnabled()) LOG.debug("foo");
}
}
这种用法,当类被继承的时候,LOG就完全乱了。spring、struts都有这样的问题。
正确的使用方式应该是直接静态化声明LOG。
例如:
class DerivedA {
private final static Log LOG = LogFactory.getLog(DerivedA.class);
}

--------------------------
盛大招聘.Net开发工程师
经典好书:.NET框架程序设计(修订版)
新闻:
2008年最精彩科技图片:电流运动模拟图居首
导航:
博客园首页 知识库 新闻 招聘 社区 小组 博问 网摘 找找看
文章来源:
http://www.cnblogs.com/jobs/archive/2009/01/05/1368894.html
Eclipse包含很多插件,插件之间有复杂的依赖关系,如果使用单独下载安装的方式,容易遗失部分需要依赖的插件。
在Ecliipse的Software Update功能中安装插件,能够解决插件依赖的问题,但是在Eclipse 3.4之前的版本,Software Update不能够多线程同时下载,遇到网速较慢的更新站点时,需要漫长的等待,有时候安装一个插件,需要数个小时,甚至更久。
在Eclipse 3.4之后,Software Update有了很大的改变,可以多线程下载了,但是不能手工选择镜像,它会笨笨的选择一些很慢的站点,效果变得更差了,下载速度时快时慢,但是经常都比以前手工选择镜像要慢。经常选择一些只有数百B速度的下载站点,令人抓狂!
所以说,Eclipse 3.4的Software Update功能依然令失望。
期待数年,终于盼来了新版的Software Update功能,但是新版的更差了,哎。。。
摘要: 我们在开发中,经常需要遍历一个目录下的所有文件,常用的办法就是使用一个函数递归遍历是常用的办法。但是递归函数的缺点就是扩展不方便,当然你对这个函数加入一个参数FileHandler,这样扩展性稍好一些,但是仍然不够好,比如说,不能根据遍历的需要中途停止遍历,加入Filter等等。我实现了一个FileIterator,使得遍历一个目录下的文件如何遍历一个集合中的元素一般操作。
阅读全文
http://openjdk.java.net/上的Announcements:
2008/04/28
New Project approved: More New I/O APIs for the Java
Platform
包括内容:
- 4313887 New
I/O: Improved filesystem interface
- 4640544 New
I/O: Complete socket-channel functionality
- 4607272 New
I/O: Support asynchronous I/O
让人期待太久太久了,终于来了,Java在大规模并发、高性能方面又进一步,JSR 203应该会在JDK 7中实现,届时随着JDK 7的发布,将会有更多的基础软件使用Java实现,而且有极好的性能。
在磁盘I/O和网络大规模并发I/O方面都会得到更好的性能。
可以预见受益的程序:
1、WEB服务器 Tomcat、Jetty等,在Windows下,Java将可以使用IOCP,而不是现在nio所用的select,网络并发性能将会得到大幅度提升。在Linux下则应该改变不多,毕竟linux现在并发最好性能的网络I/O EPOLL,JDK 6.0 nio的缺省实现就是epoll。
2、数据库应用程序。如Derby、Berkeley DB Java Edition等使用Java实现的数据库,性能将会得到更好的提升,有望能够诞生和Oracle、SQL Server一样强大的100% Pure Java的数据库系统。
3、其他网络应用程序。例如DNS、LDAP等,随着MINA之类的框架更强大和JDK的原生支持,将会越来越多的服务器程序使用Java实现。
在新项目中,除了一些框架所依赖的配置文件使用XML外,基本没有使用XML。JSON基本替代了原来XML在程序内的位置。在以前,我们不愿意使用一种私有的格式,于是选择了XML。选择XML的理由,可能是大家都用它,所以我们也用它。
XML 是一种很好的技术,但是目前的情况来看,XML被滥用了,SOAP是XML被滥用的一种典型,程序内部的表示使用XML也是滥用的一种典型。看到的一种情况,一个对象toString使用XML格式输出,导致日志文件十分罗嗦,调试时,在watch窗口中看到一大堆<tag>。
在新项目中,认真考虑这种情况,找到了另外一种选择,那就是JSON。选择JSON的理由很充分:
1、JSON的解释性能要比XML要好,要简洁紧凑。
2、可读性要比XML好。JSON本身就是JavaScript的语法,和程序员的思维,而非文档编写的思维。
3、JavaScript原生支持,客户端浏览器不需要为此使用额外的解释器,在web环境中使用特别合适。
在java中使用json,目前需要注意一些情况:
1、目前开源的JSON-LIB代码质量不好,最好是在此基础之上修改一个版本,或者自己重新开发一个版本。
2、使用new Date的方式替代JSON-LIB中的{year:2007, month:12, ....}之类的方式
3、JSON-LIB中,object的propertyName在输出的时候,都带上"",例如{"name": "温少"}, 其中name是的双引号是不必要的,在输出时应该判断,不需要的就是就不加上"",减少网络流量。
4、JSON的解释器中,应该支持简单的表达式,例如new Date()、new Date(2939234723)之类的,这使得JSON的表达能力会更强一些。
5、JSON应该分两种,一种只支持简单格式,类似开源的JSON-LIB,一种是通过JavaScript解释器来实现的。后者在程序中传输数据时,能够得到更强大的表达能力,但是也会导致安全问题,需要慎重使用。
1、
XP中的结对编程。XP编程中,有一些思想总结的很好,例如测试驱动,但又有极度的荒唐的就是结对编程。结对编程是我看到过的最荒唐最可笑的软件工程方
法,两倍的投入,一半的产出,可谓事倍功半。以前看结对编程只是觉得荒唐可笑,后来看了李安的电影《断背山》,觉得以“断背”来形容结对编程最适合了,结
对编程简直就是专门为“男同志”们度身定做的软件工程方法,你想一对“男同志”,每天手牵手背靠背进行“结对编程”,是多么“浪漫有趣”的事情。不过这只
对“男同志”们的浪漫有趣,对工作本身一点也不有趣!
--------------
2、JDO投票闹剧(2004-2005)。
一个通过黑客式静态AOP方式旁门左道实现的持久化技术JDO,竟然会被一些人追捧,这本身就是一个很荒唐的事情了。在JCP的投票中,JDO被否决了,
这一点也不奇怪,奇怪的是投票结果出来之后的闹剧。一些人以“政治阴谋论”来说事,说JDO不被通过,是因为政治原因,而非技术原因,这个荒唐的理由竟然
被社区的很多人相信了,一片声讨,JCP迫于压力,重新投票,通过了JDO相关的JSR。但是JDO并没有因此有一点点起色,一直沉沦至今。JDO通过静
态AOP(enhance)的方式使得代码无法调试,就单这一点,就足以使JDO永远无法流行。
这件事情很明确表明两点:1)、不要相信一些技术作家的判断力;2)、普通的大众没有判断能力,会人云亦云。
当年荒唐的文章选录:
《程序员》2005年第2期 http://blog.csdn.net/gigix/archive/2005/01/21/262163.aspx
---------------
竟
然64个annotation,没有分类,放在同一个package下,同一个package(javax.persistance)还有其他java文
件,共有88个java文件。不看内容本身,单从表面,都觉得这是混乱不堪的事情。这是那个猪头的杰作?glassfish上下载的源码中,这些java
文件似乎都没有author,估计也不好意思把名字放出来见人吧!
------
觉得对象关系存储方面一直没有突破,也没有好的产品出来,其中一个原因,就是从没有过优秀的工程师投身过这个领域。关系数据库为什么能够一直坚守领地,成为绝大多数商业应用的基石,其中一个原因就是有过大量的精英投身于此,包括两个图灵奖获得者。
关
系数据库,为了描述关系,创造一门SQL语言,将关系一些操作,例如投影(select)、选择(where)、分组(group
by)等等,抽象得形象易懂,功能强大。对于数据的操作,SQL语言是最强大,也是最方便的,也是最易于使用的。一些非程序员的IT从业人员,非计算机专
业的人员都能够熟练掌握SQL。
OO和Relational都是伟大的技术,从计算机最高荣誉奖可以看出这两个技术的伟大。OO的图灵奖获得者是三个,Relational的图灵奖获得者是两个。
面向对象技术自1967年simula引进以来,所想披靡,93年-98年从C++开始流行,然后到Java,成为主流编程技术。Relational没有OO那么辉煌,但是在数据存储方面的地位固如磐石,长期占据绝对的地位。
曾
经OO技术涉足于数据存储领域,但终究没有成功。面向对象数据库的变现总是差强人意,面向对象的方式操作数据,总是不如使用关系那么方便,那么灵活,那么
易于使用,那么好的性能。于是人们在数据存储和处理方面,不在青睐面向对象技术,而是仍然使用关系方式,使用SQL语言,使用关系运算操作数据。面向对象
数据库成了昙花一现的东西,并且可能永远都不会再流行了。
OO成了主流编程技术,Relational占据了绝对的数据存储地位,这两大技术需要交互,需要桥接,这需要OR-Mapping。Relational虽然好,但我们也要与时俱进,所以也需要OR-Mapping。
但
是,做OR-Mapping时,不积极吸取relational方式对数据处理的灵活性、方便性、简单性,而只强调Relational和对象之间的的
Mapping,试图以面向对象的方式操作数据,这是错误的方向。以前的EJB、现在Hibernate、JPA都犯了同样的错误,试图以更面向对象的方
式操作数据,从而导致复杂混乱的模型,这也是JPA的现状吧。例如user.getGroup(),目前的ORM试图以纯OO的方式操作数据,所引起的
LazyLoad、n+1等问题,使得事情变得复杂而且混乱不堪。
一些开发人员,去学习Hibernate,不学习SQL,有人提倡,只需要了解面向对象编程技术,不需要了解关系技术,亦属于本末倒置。需求人员都会用的SQL语言,对数据操作最方便最简单最强大的SQL语言,竟然成了令人生畏的纸老虎,可笑啊。
-------------
以下是过去的一些业界浮躁不理智:
1、面向对象数据库。曾被热衷而吹捧,面向对象数据库的变现总是差强人意,面向对象的方式操作数据,总是不如使用关系那么方便,那么灵活,那么易于使用,那么好的性能。于是人们在数据存储和处
理方面,不在青睐面向对象技术,而是仍然使用关系方式,使用SQL语言,使用关系运算操作数据。面向对象数据库成了昙花一现的东西,并且可能永远都不会再
流行了。
2、
JDO投票闹剧。2004-2005年,JDO的JSR在JCP投票被否决的,无聊者在Java社区以及媒体发起闹事,阴谋论其为政治谋杀,几大公司是的
迫于形象,重新投票使得JDO被通过,但JDO这种静态AOP叫雕虫小计式技术,不单开发过程不方便,而且会使得"enhance"之后的代码不可调试。
这完全是对开发者不友好的技术,没有前途的技术,竟然会有人为它在JCP投票不通过鸣不平。这件事情使得我更坚信一点,不要相信那些技术编辑的判断力。
3、
AOP。也是最近这几年流行的一个名词了。起了一个和OOP相似的名字,但是和伟大的OOP相比,它完全不算是什么。AOP只是一种很小很小的技巧而已,
静态的AOP是黑客式的插入代码,会导致代码不可调试,动态的AOP能力有限,AOP最常被引用例子“日志AOP”是不合适,有用的日志通常是精心设计
的,AOP方式的日志在生产环境中基本上是不可用。OO这么多年,这么为伟大,人们总是希望自己能做点什么和伟大的OO相比,于是命名为AOP,这是一个
可笑的名字,前些年还有人谈论面向对象的未来是面向事实,也是同样的可笑。AOP有价值,但它是一种小技巧,和名字不般配。
--------------
目前在流行,但是可能是不理智的技术:
1、hibernate之类的ORM,试图以面向对象方式操作数据,和面向对象数据库一样,重蹈覆辙。
2、Ruby,一个小脚本语言,只是因为动态类型、mixin之类的功能,还没有被证明有生产力,有效益可用的脚本语言,就被媒体吹到天上去。Ruby有价值,但是最终结果会离大家的期待相差甚远。
中国最大的在线记账及商务管理平台—金蝶“友商网”(www.youshang.com)正式上线!请立刻体验!
摘要: 本文描述一种ID生成算法
阅读全文
摘要: 本文介绍流行的非阻塞算法关键思想Compare And Set在数据库开发中的应用
阅读全文
由于在实际工作中使用到了mina,所以一直关注其mail-list。
最近mina的mail-list讨论的一个问题,就是提供的manual close connector,这个问题可害惨我了。
原来的Connector,无论是SocketConnector或者VmPipeConnector,都是没有提供close方法的,而且不会自动释放。
原来做得一个网络程序客户端,每次重新创建的时候,都会new SocketConnector,可是,SocketConnector不会被GC回收的,所使用的线程和内存都不会自动释放,这个程序在服务器断开时会重连,于是,当服务器重启或者网络中断时,内存泄漏就产生了,程序慢慢的占用更多的内存,直至崩溃!
解决此问题的办法就是,要么使用Singleton,要么使用即将发布的1.1.3!

使用maven2一段时间了,我基本把我自己能够迁移的project都转换为maven2 project,以下是我的一点感想。
(原作者温少,转载请注明)
乱世盼英雄
现在的软件开发,比过去的软件开发要复杂得多。包括在参与开发的人数、代码规模、复杂的需求、依赖包的复杂性、使用到更多的技术、多个项目之间的复杂依赖关系。
现在的开发人员,要掌握的技术要比过去的开发人员要多,不是现在的开发人员比以前的开发人员本身更优秀,而是拥有更多的资料、更多的学习机会、更多更大规模的时间,同时软件行业也在发展。说一句题外话,老程序员,如果不与时俱进,靠老本,是无法和新一代程序员竞争的,当然,老程序员,拥有更多的经验,掌握新技术的速度更快,这又是另外一回事。
开发人员掌握的技术更复杂了,项目用得的技术自然也是更复杂,例如一个web项目,可能使用到很多技术,面向对象、泛型、or-mapping、依赖注入(spring-framework)、全文检索(lucene)、数据库、集群、工作流、web service等等。
由于使用了多种技术,这些技术可能是JDK提供的,也可能是第三方开源组织提供的,或者不同的商业公司提供的。
于是出现了一个新的难题,就是包依赖复杂性。以前,你很难想象你的代码依赖数十个不同开源组织、商业公司提供的库。例如,我们经常使用的log4j、junit、easymock、ibatis、springframework,每个组件都有悠久的历史,存在不同的版本,他们之间版本还有依赖关系。
项目依赖的复杂性,经常的,一个较大部门有10-30个项目是常事,项目之间有不同版本的依赖关系,部门与部门之间的项目也存在复杂的版本依赖关系。
Eclipse本身提供Project的依赖,但是简单的依赖显然解决不了问题。例如Project B依赖Project A,Project A依赖第三方的jar包abc-1.0.jar,那么需要在两个项目的lib下都存放abc-1.0.jar,这产生冗余,当Project数量多起来,这个冗余就产生了管理问题,如果需要将abc-1.0.jar升级为abc-1.1.jar,则需要在两个Project中同时修改,如果Project数量达到10个以上,而且是不同项目组维护的项目,这个就是非常麻烦的事情。而且Project A修改依赖,为啥需要Project B也作相应的修改呢?
需要解决此问题,就需要在Project A的包中描述其依赖库的信息,例如在META-INFO记录所以来的abc-1.0.jar等。Eclipse的plug-in拥有类似的方案,但是这样一来,就使得开发Project B的项目组,需要把Project A的代码从源代码库中check out出来。在依赖链末端的项目组是很惨的。
由于Project数量众多,关系复杂,dailybuild的ant脚本编写成了很麻烦的事情,使用Project依赖的方式,更加使得编写dailybuild ant script是非常痛苦的事情。
当然也可以不使用project依赖的方式,而使用artifact lib的依赖方式,但是artifact lib的依赖方式,就是同时修改多个project,互相调试时带来了痛苦。
在以前,我们面临这些问题时,唯一的感觉就是,这事情TMD的太麻烦,几乎是失控了。
maven的出现,解决这种问题看到了希望。maven出现的原因就是,现在的开发管理复杂度达到了一定程序,需要专门的开发管理工具,这样的工具需要涵盖开发的各个阶段,包括工程建立、配置依赖管理、编译、测试、产生分析报告、部署、产生制品等阶段。目前,各个阶段的工具都存在,但是不是集成的,对使用带来了很大麻烦。maven集成了这些工具,提高了统一的环境,使得使用更简单。
现在maven非常流行了,apache上所有java project都已经build by maven,其他跟进的开源项目非常多,例如mule、hibernat等等,商业公司也很多在采用,sun公司提供有maven2 repository。
现在,2007年,如果你还没采用maven project,你可能需要思考一下,是否你使用了不恰当的方式管理的代码,或者你落伍了?
maven的一些常用任务
compile 编译代码
test 运行单元测试
package 打包代码
site 产生报告,例如java doc、junit的通过率报告和覆盖率报告、findbugs的分析报告等等。
assembly 使用需求产生assembly,例如把生成一个程序目录,包括bin、config、lib、logs,把依赖包放在lib中。
deploy 部署制品到repository中。
这些都是常用的任务,在以前编写脚本很麻烦,现在在maven中,一切都是很简单,需要仔细设置时功能又强大到令人惊叹,例如site的fml,assembly。
maven资源库
maven官方提供了一个常用lib的资源库,包括apache的所有java项目,开源常用的基本都能够找到,例如mule、c3p0、easymock、hibernate、springframework、json等等,版本齐全,任你挑选。
可以部署本地资源库代理提高下载速度。使用maven proxy。
maven体系结构
maven使用plug-in的体系,使用很好的自动更新策略,本身用到的jar都是lazy download的,可以指定download的repository。这样,初始下载的maven是一个很小的程序,使用的时候从本地的资源库或者本地代理资源库高速下载lib。maven的插件体系,充分利用了internet的资源丰富和局域网的高速带宽,使用本地repository时,可以享受到每秒钟数M的下载速度,感觉就是,人生真是美妙!
elcipse的plug-in体系,就不是那么好用了,我们使用eclipse的find and install功能下载或者更新插件时,慢如蜗牛,依赖缺失时的烦恼,更新一个plug-in,可能耗费你数个小时,第三方的plug-in的下载服务器可能更慢,例如subversive的plugin-in,有一次我花了两天还没下载好,只好使用下载工具下载好,copy到plug-in目录下。此时,我们总是感叹,人生总是有很多烦恼事啊!
相比之下,高下立判!在此我不是说eclipse的plug-in体系结构设计不好,eclipse的插件体系非常优秀,但是还有很大改进空间!

在beep4j上作了一些修改,并且在此之上实现了一个基于BEEP协议的服务器框架。
BEEP协议提供了Session、Channel、Greeting、Profile、Frame等概念,这些基础概念之上,很容易进行更高级的应用层协议设计。
BEEP协议的特征和能力
长连接
对等通讯
请求\应答式交互
在一个Session中创建多个独立的传输通道(Channel)
在一个通道中进行多个异步请求(滑动窗口)
可以使用不同的消息编码方式,包括二进制、文本、XML等,类似SMTP的MIME,使得可以在高效的二进制、易懂的文本之间作出选择。
这是一个在传输层和应用层之间的协议,应用场景很广泛,RFC标准化,官方网站为http://www.beepcore.org/。很多公司都有相应的支持,包括IBM。在不同语言下都是相应的实现,包括C、Java、Python、Ruby、JavaScript Beep client等等。
关于ContentType和Codec
在Java程序之间通讯,前期可能不希望作更多的协议编码、解码工作,使用spring bean xml格式传输是一种方式。
在一些对效率不是特别高,又不喜欢使用机器友好的XML的场景,可以使用JSON的编码方式。
在一些对效率要求很高的场景,ASN.1或者自定义的二进制编码格式。
甚至使用土土的序列化编码方式

匆忙写成,以后会慢慢补充
请用力一击中等规模的并发程序设计
http://www.cnblogs.com/Files/jobs/2007-5-9-concurrent-ppt.rar2007-5-10修改版(带参考文档)
http://www.cnblogs.com/Files/jobs/2007-5-10-concurrent-ppt.rar
2007年4月刊《程序员》,专题为“多核时下的软件开发”。《程序员》并非阳春白雪,它面向大众程序员。面向大众的《程序员》介绍多核、并发,也意味着并发程序设计的开始进入中国大众程序员的视野。
并发程序设计,在很多的书籍或者文章中,都会提到他的一个特点,复杂。这个特性,也导致了在以往并发程序设计只为高级程序员所专用。
复杂度并非事物的固有属性,并发程序设计的复杂,是我们主观认为。我们认为并发程序设计复杂,是因为我们还没有掌握一些使其简单化、清晰化的方法。当我们掌握相关方法,研究彻底,并发就会变得简单。这个过程已经开始了。
以
往,我们需要直接使用一些低级并发概念来构造系统,不断发明轮子,容易出错,难以调试,这种的并发程序设计当然复杂,因此也只能为高级程序员所专用。如此
环境,就如同Dijkstra给我们带来结构化程序设计之前的世界一般。很幸运的是,一些软件业的先驱们,已经抽象出一些概念,能够使得并发程序设计简单
化,清晰化。例如Future、Lock-free思想等。
在主流编程语言中,Java走在最前头,理念领先,提供了实用的库。在
Java SE
5.0中就提供了util.concurent包,包括了Future、Executor、BlockingQueue等,一系列lock-free的数
据结构,例如ConcurrentMap。包括并发流程控制工具类:CountDownLatch、CycliBarrier。还有精巧好用的
DelayQueue(参考我之前写过的文章http:
//www.cnblogs.com/jobs/archive/2007/04/27/730255.html)。使用这些概念以及提供的模式,能够使
得编写并发程序简单化。
C++中,Herb Sutter在Visual C++中加入了很多支持并发的语法特性,包括atomic、future等。boost的线程库开始引入了第一个高级概念barrier。
Windows
平台本身提供了功能强大的并发API,包括WaitForSingle系列,WaitForMulti系列,Auto和Manual模式的Event等
等。.NET平台基本没有任何自有的并发库和工具类,完全是Windows
API的简单封装。可以这么说,.NET的类库没有为并发作任何事情,完全吃Windows API的老本。
如同Herb Sutter认为,我们很幸运处于并经历这个软件大变革(并发)。并发进入主流这个过程将会延续数年,Herb Sutter认为是2007-2012。
参考我以前写的一篇文章(Herb Sutter的一些观点 http://www.cnblogs.com/jobs/archive/2006/11/12/558078.html)
类
似的场景也有,早期面向对象技术,也只为少数高级程序员所掌握,现在刚入门的程序员都能说上一大通。数据结构算法也是,早期只为少数优秀程序员所掌握,但
现在主流的开发环境中就包括了主要的数据结构和算法,会用的人一把一把,会用List、Hashtable、快速排序一点也不酷。并发程序设计也一样,将
不再是阳春白雪!
面向对象技术在最初在Simula语言中引进,顾名思义,最初朴素的面向对象思想就是模拟,在程序中模拟真实世界。这种
“模拟”,使得程序的组织清晰化,简单化。但真实世界是充满着并发。真实世界的并发要比虚拟环境中的并发要复杂的多,但是人们轻松应付,由此,我们有足够
的理由相信,并发程序设计将不会是一种复杂难掌握的技术。
我们谈一下实际的场景吧。我们在开发中,有如下场景
a) 关闭空闲连接。服务器中,有很多客户端的连接,空闲一段时间之后需要关闭之。
b) 缓存。缓存中的对象,超过了空闲时间,需要从缓存中移出。
c) 任务超时处理。在网络协议滑动窗口请求应答式交互时,处理超时未响应的请求。
一种笨笨的办法就是,使用一个后台线程,遍历所有对象,挨个检查。这种笨笨的办法简单好用,但是对象数量过多时,可能存在性能问题,检查间隔时间不好设置,间隔时间过大,影响精确度,多小则存在效率问题。而且做不到按超时的时间顺序处理。
这场景,使用DelayQueue最适合了。
DelayQueue
是java.util.concurrent中提供的一个很有意思的类。很巧妙,非常棒!但是java doc和Java SE
5.0的source中都没有提供Sample。我最初在阅读ScheduledThreadPoolExecutor源码时,发现DelayQueue
的妙用。随后在实际工作中,应用在session超时管理,网络应答通讯协议的请求超时处理。
本文将会对DelayQueue做一个介绍,然后列举应用场景。并且提供一个Delayed接口的实现和Sample代码。
DelayQueue是一个BlockingQueue,其特化的参数是Delayed。(不了解BlockingQueue的同学,先去了解BlockingQueue再看本文)
Delayed扩展了Comparable接口,比较的基准为延时的时间值,Delayed接口的实现类getDelay的返回值应为固定值(final)。DelayQueue内部是使用
PriorityQueue实现的。
DelayQueue = BlockingQueue + PriorityQueue + Delayed
DelayQueue的关键元素BlockingQueue、PriorityQueue、Delayed。可以这么说,DelayQueue是一个使用优先队列(PriorityQueue)实现的BlockingQueue,
优先队列的比较基准值是时间。他们的基本定义如下
public interface Comparable<T> {
public int compareTo(T o);
}
public interface Delayed extends Comparable<Delayed> {
long getDelay(TimeUnit unit);
}
public class DelayQueue<E extends Delayed> implements BlockingQueue<E> {
private final PriorityQueue<E> q = new PriorityQueue<E>();
}
DelayQueue内部的实现使用了一个优先队列。当调用DelayQueue的offer方法时,把Delayed对象加入到优先队列q中。如下:
public boolean offer(E e) {
final ReentrantLock lock = this.lock;
lock.lock();
try {
E first = q.peek();
q.offer(e);
if (first == null || e.compareTo(first) < 0)
available.signalAll();
return true;
} finally {
lock.unlock();
}
}
DelayQueue的take方法,把优先队列q的first拿出来(peek),如果没有达到延时阀值,则进行await处理。如下:
public E take() throws InterruptedException {
final ReentrantLock lock = this.lock;
lock.lockInterruptibly();
try {
for (;;) {
E first = q.peek();
if (first == null) {
available.await();
} else {
long delay = first.getDelay(TimeUnit.NANOSECONDS);
if (delay > 0) {
long tl = available.awaitNanos(delay);
} else {
E x = q.poll();
assert x != null;
if (q.size() != 0)
available.signalAll(); // wake up other takers
return x;
}
}
}
} finally {
lock.unlock();
}
}
-------------------
以下是Sample,是一个缓存的简单实现。共包括三个类Pair、DelayItem、Cache。如下:
public class Pair<K, V> {
public K first;
public V second;
public Pair() {}
public Pair(K first, V second) {
this.first = first;
this.second = second;
}
}
--------------
以下是Delayed的实现
import java.util.concurrent.Delayed;
import java.util.concurrent.TimeUnit;
import java.util.concurrent.atomic.AtomicLong;
public class DelayItem<T> implements Delayed {
/** Base of nanosecond timings, to avoid wrapping */
private static final long NANO_ORIGIN = System.nanoTime();
/**
* Returns nanosecond time offset by origin
*/
final static long now() {
return System.nanoTime() - NANO_ORIGIN;
}
/**
* Sequence number to break scheduling ties, and in turn to guarantee FIFO order among tied
* entries.
*/
private static final AtomicLong sequencer = new AtomicLong(0);
/** Sequence number to break ties FIFO */
private final long sequenceNumber;
/** The time the task is enabled to execute in nanoTime units */
private final long time;
private final T item;
public DelayItem(T submit, long timeout) {
this.time = now() + timeout;
this.item = submit;
this.sequenceNumber = sequencer.getAndIncrement();
}
public T getItem() {
return this.item;
}
public long getDelay(TimeUnit unit) {
long d = unit.convert(time - now(), TimeUnit.NANOSECONDS);
return d;
}
public int compareTo(Delayed other) {
if (other == this) // compare zero ONLY if same object
return 0;
if (other instanceof DelayItem) {
DelayItem x = (DelayItem) other;
long diff = time - x.time;
if (diff < 0)
return -1;
else if (diff > 0)
return 1;
else if (sequenceNumber < x.sequenceNumber)
return -1;
else
return 1;
}
long d = (getDelay(TimeUnit.NANOSECONDS) - other.getDelay(TimeUnit.NANOSECONDS));
return (d == 0) ? 0 : ((d < 0) ? -1 : 1);
}
}
以下是Cache的实现,包括了put和get方法,还包括了可执行的main函数。
import java.util.concurrent.ConcurrentHashMap;
import java.util.concurrent.ConcurrentMap;
import java.util.concurrent.DelayQueue;
import java.util.concurrent.TimeUnit;
import java.util.logging.Level;
import java.util.logging.Logger;
public class Cache<K, V> {
private static final Logger LOG = Logger.getLogger(Cache.class.getName());
private ConcurrentMap<K, V> cacheObjMap = new ConcurrentHashMap<K, V>();
private DelayQueue<DelayItem<Pair<K, V>>> q = new DelayQueue<DelayItem<Pair<K, V>>>();
private Thread daemonThread;
public Cache() {
Runnable daemonTask = new Runnable() {
public void run() {
daemonCheck();
}
};
daemonThread = new Thread(daemonTask);
daemonThread.setDaemon(true);
daemonThread.setName("Cache Daemon");
daemonThread.start();
}
private void daemonCheck() {
if (LOG.isLoggable(Level.INFO))
LOG.info("cache service started.");
for (;;) {
try {
DelayItem<Pair<K, V>> delayItem = q.take();
if (delayItem != null) {
// 超时对象处理
Pair<K, V> pair = delayItem.getItem();
cacheObjMap.remove(pair.first, pair.second); // compare and remove
}
} catch (InterruptedException e) {
if (LOG.isLoggable(Level.SEVERE))
LOG.log(Level.SEVERE, e.getMessage(), e);
break;
}
}
if (LOG.isLoggable(Level.INFO))
LOG.info("cache service stopped.");
}
// 添加缓存对象
public void put(K key, V value, long time, TimeUnit unit) {
V oldValue = cacheObjMap.put(key, value);
if (oldValue != null)
q.remove(key);
long nanoTime = TimeUnit.NANOSECONDS.convert(time, unit);
q.put(new DelayItem<Pair<K, V>>(new Pair<K, V>(key, value), nanoTime));
}
public V get(K key) {
return cacheObjMap.get(key);
}
// 测试入口函数
public static void main(String[] args) throws Exception {
Cache<Integer, String> cache = new Cache<Integer, String>();
cache.put(1, "aaaa", 3, TimeUnit.SECONDS);
Thread.sleep(1000 * 2);
{
String str = cache.get(1);
System.out.println(str);
}
Thread.sleep(1000 * 2);
{
String str = cache.get(1);
System.out.println(str);
}
}
}
运行Sample,main函数执行的结果是输出两行,第一行为aaa,第二行为null。
china-pub购书网址:http://www.china-pub.com/computers/common/info.asp?id=34017
1、总体感受
a) 这本书主要介绍的是intel平台下的多核程序设计技术,Windows介绍较多,Linux介绍较少,Java更少。作者是Intel公司的平台架构师,我们知道wintel联盟,书中的内容如此分布也是正常。
b) 此书让我懂得了很多硬件方面的并行知识。
c)
此书介绍Windows API中和并发相关的部分,很详尽,比Jeffrey
Richter的《Windows核心编成》有深度多了,也精辟多了。显然《多核程序设计》作者属于有经验的工程师,Jeffrey
Richter只是一个写手,两者没有可比性。不过这方面的知识偶早已涉猎,当作复习一遍罢了。
d) 此书偏向底层,硬件和操作系统层面。更高层面的技术介绍较少。
e) 第一次了解OpenMP技术的一些细节。以前只听说,也没查过任何相关资料,在此书中看到了相关部分,挺有意思的,感觉那些语法很有趣。Herb Sutter也是要在语法方面动手。反正我在有了一个粗浅认识之后,觉得很有意思。
-------------------------
2、并发流程控制
Fence
在Java
中对应的是java.util.concurrent.CountDownLatch。最初接触CountDownLatch的时候,由于其实现很简单,
当时觉得是一个可有可无的工具类。但后来在不同的场景多次使用,发现很有用。在此书中再次发现类似的Fence,用于在共享存储多处理器或者多核环境中,
确保存储操作的一致性。我猜这属于业界并发流控制的典型手段了。
Barrier
在Java中对应的是java.util.concurrent.CyclicBarrier。在应用程序中,一个场景就是和定时器结合使用,countDown、await、reset,做定时定量批量处理。
我猜这也属于业界并发流程控制的典型手段了。
(CountDownLatch和CycliBarrier的实现代码都很简单,但很有用,他们都属于并发流程控制的典型手段)
-------------------------
3、非阻塞算法
InterLocked在Java中对应的是java.util.concurrent.atomic.xxx
书中提到了cache行乒乓球现象导致的性能问题,提高了非阻塞算法的复杂性问题。
关于性能问题,developerworks上有一片文章,有测试数据:
《Java 理论与实践: 流行的原子》 (http://www.ibm.com/developerworks/cn/java/j-jtp11234/index.html)
文章中的测试数据表明,直接使用atomic在1个和2个处理器时是最好的,4个处理器以上,使用java.util.concurrent.locks.ReentrantLock性能更好。
java.util.concurrent包,提供了很多高级的概念,隐藏了非阻塞算法带来的复杂度,其底层框架达到了最佳性能。
-------------------------
4、任务分解、数据分解以及数据流分解
此书中明确提出了这三个概念,很有用,让我在这方面的知识概念清晰化了。
任务分解
Java
中的Executor,提供了任务分解的手段和模式。任务分解提交给Executor执行。java.util.concurrent中提供了
Future,用于任务提交者和Executor之间的协调。Future是一种很好的手段,在很多涉及并发的库都提供。例如C++网络并发库中提供了
Future,Herb Sutter要在Visual C++中引入Future。
数据分解
数据分解的手段很多也很常见。
Java中,提供了一种高级的数据分解协同模式java.util.concurrent.Exchanger这个类。早在Java SE
5.0时,Exchanger只支持2Parties,Java SE 6.0支持n
parties。偶想象过一些很酷的应用场景,写过模拟测试,但一直没有机会用于实际开发中。
数据流分解
书中提到了众多周知的producer/consumer问题。
其实java.util.concurrent.Exchanger类,既有数据分解,又有数据流分解,exchanger中的producer和consumer的角色会互换的,很有意思。
-------------------------
5、作为Java程序员的思考
Java SE 5.0之后,提供了util.concurrent包,功能齐全,性能卓越,非常优秀。从此书来看,业界流行的流程控制手段和并发程序设计方法一个不落。我们应该感谢伟大的Doug Lea,他为我们带了一个如此完美的并发库!
一旦方案想清楚,剩余部分的工作效率瓶颈就在于你的手速了。最近一直看起点中文网上的《师士传说》,主角叶重一个强项就是手速。
最基本的就是盲打。不会盲打的通常属于“编码低能儿”。身边也有不会盲打的朋友,他们通常都有一个问题,就是眼高手低,说说还行,动手就不行。当然他们能够在IT研发领域还混得很好,是因为在其他方面拥有优秀的能力。
熟练掌握快捷键是关键。键盘和鼠标之间通常有较大的距离,手经常在键盘和鼠标之间移动,会降低效率,也容易导致疲劳,用鼠标过多,也容易导致龌龊的鼠标手。解决这个问题的办法,就是纯键盘操作,其实很多IDE的快捷键功能强大,足以让你纯键盘操作,高效率编码。
我比较熟悉的IDE是Eclipse,就以Eclispse来说吧。
Eclipse的keys列表中,属于Eclipse本身有180多个快捷键,要提高编码速度,就应该熟练使用其中绝大多数。
练习的办法:
1、在Windows/Preferences/General/keys中,使用Export,把快捷键导出,导出的格式是csv格式,Windows下可以用Excel直接打开,Linux下可以用OpenOffice打开,打开时选择分隔符为“,”。
2、挨个练习使用。每天练习一部分,反复练习,坚持一段时间。
3、开始的时候,把鼠标放到一个不方便使用的角落,尽量不要让自己用鼠标。
4、快捷键的组合使用需要加强训练。在不同场景下,认真考虑用怎样的组合快捷键最高效。
如此坚持一段时间之后,编码的过程会很流畅,速度就会大大提高。
这是一个很老的问题了,经常在论坛上看到,很多人也写了相关的文章。我在这方面拥有较多的经验,我也谈一下我的看法吧。
我曾经实现过金蝶EAS BOS的多数据支持引擎,脚本引擎,也作过O-R Mapping的预研工作,曾经对多个O-R Mapping产品做过研究。
C++、Java、C#都源自Algol,这系列语言也称为Imperative语言,中文翻译为命令式语言。命令式语言建立在冯*诺依曼体系结构上,程序员必须处理变量管理、变量复制。这样的结果是增加了执行的效率,但带来了程序开发的艰苦。
LISP、Schema、Haskell等语言属于函数式语言,函数式语言基于数学函数,不使用变量或者赋值语句产生结果,使用函数的应用、条件表示和递归作为执行控制。函数式语言是更高级的程序设计语言,和命令式语言相比,编写更少的代码,更高的开发效率,这是函数式语言的明确有点。很多编程技术都首先应用于函数式语言,例如范型、垃圾收集等。很多函数式语言都增加了一些命令式语言的特征,增加效率和易用性。
SQL语言是一个领域专用语言,专门用于处理关系数据。他具备一些函数式语言的特征,在处理关系数据方面非常直观和简介。在处理选择、投影、聚合、排序等等操作方面,显然比在Java或者C#中要方便得多。SQL也是易学易用。很多非程序员都掌握SQL,在金蝶,大多需求人员都熟练掌握SQL。SQL的解释需要损耗一定的性能,在对性能极端要求的情况下,通常不使用关系数据库。例如Google Account采用Berkeley DB等。
现在关系数据库已经发展很成熟,数据库的一些技术发展得很好,包括事务等,其中一些从数据库中发展起来的技术,还应用到操作系统中了。在前些年面向对象技术狂热的时候,作了很多面向对象数据库的研究,但是都没有取得较大的成功。在主流的关系数据库中,大多都包括了面向对象的支持,例如Oracle、Sybase,都具备了很丰富的面向对象功能,但是很少任用。
现在有人跟我说起db4o这样的数据库,我认为db4o不会取得成功,因为他在错误的方向发展。
现在关系数据库最流行,最流行的应用开发语言包括Java、C#等,都是面向对象命令式语言。开发语言需要访问关系数据库,需要转换,转换的过程比较繁琐,于是就诞生了O-R Mapping技术。这是一种妥协的结果,面向对象技术在数据库领域无法取得成功,在面向对象开发语言中,就需要一种对象-关系映射技术。我相信,这种妥协产生的技术,会越来越流行。
我也认为,这是一个正确的选择。就如高级语言不会尝试取代汇编,无论高级语言有多好,最多在其上增加抽象层。例如Java使用bytecode、C#使用IL这样,使用一种抽象层,而不是尝试取代汇编。
O-R Mapping技术除了简单映射之外,需要一种OQL,混合SQL和面向对象特征,提供映射方便的同时,保留关系数据库提供的强大功能。例如聚合、排序等关系运算必须在OQL中提供。由于程序中的返回结果,有时不需要映射成对象,所以OQL必须提供另外一种功能,数据查询。很多O-R Mappping产品都提供了基于对象的OQL和基于数据的OQL。
这导致包括三个部分:
1、应用程序使用OQL
2、O-R Mapping解释或者编译OQL
3、对象数据库负责数据处理
如果O-R Mapping使用解释的方式处理OQL,则会包括产生SQL、组装对象等操作。效率通常都不会很好,现在的O-R Mapping产品基本都是基于解释的方式处理。
如果O-R Mapping使用编译的方式,可以优化产生SQL,动态创建SQL存储过程,减少SQL交互的过程,能够获得很好的性能,可以做到比绝
大多数人直接使用SQL性能都要好。我曾经做过一个实验性的实现,取得很好的效果,可惜由于种种原因,没有继续下去。
我认为,下一代的O-R Mapping产品,都将会采用编译的方式,因为在很多情形下,特别是复杂对象的处理方面,可以有大幅度的性能提升,在某些场景下,可以数倍甚至数十倍的性能提升。
一直不是很看好Hibernate,因为其主要作者gavin对编译技术不了解,2.x版本的HQL语法很搞笑,实现也是很搞笑的,简单的文本替换,看到让人目瞪口呆。3.0之后加入了HQL的AST(抽象语法树),但这不是他本人的做的,其他爱好者加入进来,3.1还是没有很好融合进来。之后的版本我就没有继续关注了。
我觉得O-R Mapping完全就是一种编译技术,不懂编译技术的人去作这件事清总会有些不妥。这不单是Hibernate的问题,也是其他O-R Mapping产品的问题。
我的观点:
1、Java、C#、C++等语言在处理关系数据方面没有优势。SQL是关系数据处理的领域专用语言(DSL),更适合处理关系数据,提供强大的功能。
2、关系数据是主流,希望应用开发人员使用O-R Mapping,而不懂关系数据库,这是不现实的。
3、O-R Mapping技术还有很大发展空间,以后在功能、性能等方面都会有重大提升,最终成熟。

文章来源:
http://www.cnblogs.com/jobs/archive/2007/04/23/723297.html
在操作系统中,有两种不同的方法提供线程支持:用户层的用户线程,或内核层的内核线程。
其中用户线程在内核之上支持,并在用户层通过线程库来实现。不需要用户态/核心态切换,速度快。操作系统内核不知道多线程的存在,因此一个线程阻塞将使得整个进程(包括它的所有线程)阻塞。由于这里的处理器时间片分配是以进程为基本单位,所以每个线程执行的时间相对减少。
内核线程由操作系统直接支持。由操作系统内核创建、调度和管理。内核维护进程及线程的上下文信息以及线程切换。一个内核线程由于I/O操作而阻塞,不会影响其它线程的运行。
Java线程的实现是怎样的呢?我们通过SUN Java 6的源码了解其在Windows和Linux下的实现。
在Windows下的实现,os_win32.cpp中
// Allocate and initialize a new OSThread
bool os::create_thread(Thread* thread, ThreadType thr_type, size_t stack_size) {
unsigned thread_id;
// Allocate the OSThread object
OSThread* osthread = new OSThread(NULL, NULL);
if (osthread == NULL) {
return false;
}
// Initial state is ALLOCATED but not INITIALIZED
{
MutexLockerEx ml(thread->SR_lock(), Mutex::_no_safepoint_check_flag);
osthread->set_state(ALLOCATED);
}
// Initialize support for Java interrupts
HANDLE interrupt_event = CreateEvent(NULL, true, false, NULL);
if (interrupt_event == NULL) {
delete osthread;
return NULL;
}
osthread->set_interrupt_event(interrupt_event);
osthread->set_interrupted(false);
thread->set_osthread(osthread);
if (stack_size == 0) {
switch (thr_type) {
case os::java_thread:
// Java threads use ThreadStackSize which default value can be changed with the flag -Xss
if (JavaThread::stack_size_at_create() > 0)
stack_size = JavaThread::stack_size_at_create();
break;
case os::compiler_thread:
if (CompilerThreadStackSize > 0) {
stack_size = (size_t)(CompilerThreadStackSize * K);
break;
} // else fall through:
// use VMThreadStackSize if CompilerThreadStackSize is not defined
case os::vm_thread:
case os::pgc_thread:
case os::cgc_thread:
case os::watcher_thread:
if (VMThreadStackSize > 0) stack_size = (size_t)(VMThreadStackSize * K);
break;
}
}
// Create the Win32 thread
//
// Contrary to what MSDN document says, "stack_size" in _beginthreadex()
// does not specify stack size. Instead, it specifies the size of
// initially committed space. The stack size is determined by
// PE header in the executable. If the committed "stack_size" is larger
// than default value in the PE header, the stack is rounded up to the
// nearest multiple of 1MB. For example if the launcher has default
// stack size of 320k, specifying any size less than 320k does not
// affect the actual stack size at all, it only affects the initial
// commitment. On the other hand, specifying 'stack_size' larger than
// default value may cause significant increase in memory usage, because
// not only the stack space will be rounded up to MB, but also the
// entire space is committed upfront.
//
// Finally Windows XP added a new flag 'STACK_SIZE_PARAM_IS_A_RESERVATION'
// for CreateThread() that can treat 'stack_size' as stack size. However we
// are not supposed to call CreateThread() directly according to MSDN
// document because JVM uses C runtime library. The good news is that the
// flag appears to work with _beginthredex() as well.
#ifndef STACK_SIZE_PARAM_IS_A_RESERVATION
#define STACK_SIZE_PARAM_IS_A_RESERVATION (0x10000)
#endif
HANDLE thread_handle =
(HANDLE)_beginthreadex(NULL,
(unsigned)stack_size,
(unsigned (__stdcall *)(void*)) java_start,
thread,
CREATE_SUSPENDED | STACK_SIZE_PARAM_IS_A_RESERVATION,
&thread_id);
if (thread_handle == NULL) {
// perhaps STACK_SIZE_PARAM_IS_A_RESERVATION is not supported, try again
// without the flag.
thread_handle =
(HANDLE)_beginthreadex(NULL,
(unsigned)stack_size,
(unsigned (__stdcall *)(void*)) java_start,
thread,
CREATE_SUSPENDED,
&thread_id);
}
if (thread_handle == NULL) {
// Need to clean up stuff we've allocated so far
CloseHandle(osthread->interrupt_event());
thread->set_osthread(NULL);
delete osthread;
return NULL;
}
Atomic::inc_ptr((intptr_t*)&os::win32::_os_thread_count);
// Store info on the Win32 thread into the OSThread
osthread->set_thread_handle(thread_handle);
osthread->set_thread_id(thread_id);
// Initial thread state is INITIALIZED, not SUSPENDED
{
MutexLockerEx ml(thread->SR_lock(), Mutex::_no_safepoint_check_flag);
osthread->set_state(INITIALIZED);
}
// The thread is returned suspended (in state INITIALIZED), and is started higher up in the call chain
return true;
}
可以看出,SUN JVM在Windows下的实现,使用_beginthreadex来创建线程,注释中也说明了为什么不用“Window编程书籍推荐使用”的CreateThread函数。由此看出,Java线程在Window下的实现是使用内核线程。
而在Linux下又是怎样的呢?
在os_linux.cpp文件中的代码摘录如下:
# include <pthread.h>
bool os::create_thread(Thread* thread, ThreadType thr_type, size_t stack_size) {
assert(thread->osthread() == NULL, "caller responsible");
// Allocate the OSThread object
OSThread* osthread = new OSThread(NULL, NULL);
if (osthread == NULL) {
return false;
}
// set the correct thread state
osthread->set_thread_type(thr_type);
// Initial state is ALLOCATED but not INITIALIZED
osthread->set_state(ALLOCATED);
thread->set_osthread(osthread);
// init thread attributes
pthread_attr_t attr;
pthread_attr_init(&attr);
pthread_attr_setdetachstate(&attr, PTHREAD_CREATE_DETACHED);
// stack size
if (os::Linux::supports_variable_stack_size()) {
// calculate stack size if it's not specified by caller
if (stack_size == 0) {
stack_size = os::Linux::default_stack_size(thr_type);
switch (thr_type) {
case os::java_thread:
// Java threads use ThreadStackSize which default value can be changed with the flag -Xss
if (JavaThread::stack_size_at_create() > 0) stack_size = JavaThread::stack_size_at_create();
break;
case os::compiler_thread:
if (CompilerThreadStackSize > 0) {
stack_size = (size_t)(CompilerThreadStackSize * K);
break;
} // else fall through:
// use VMThreadStackSize if CompilerThreadStackSize is not defined
case os::vm_thread:
case os::pgc_thread:
case os::cgc_thread:
case os::watcher_thread:
if (VMThreadStackSize > 0) stack_size = (size_t)(VMThreadStackSize * K);
break;
}
}
stack_size = MAX2(stack_size, os::Linux::min_stack_allowed);
pthread_attr_setstacksize(&attr, stack_size);
} else {
// let pthread_create() pick the default value.
}
// glibc guard page
pthread_attr_setguardsize(&attr, os::Linux::default_guard_size(thr_type));
ThreadState state;
{
// Serialize thread creation if we are running with fixed stack LinuxThreads
bool lock = os::Linux::is_LinuxThreads() && !os::Linux::is_floating_stack();
if (lock) {
os::Linux::createThread_lock()->lock_without_safepoint_check();
}
pthread_t tid;
int ret = pthread_create(&tid, &attr, (void* (*)(void*)) java_start, thread);
pthread_attr_destroy(&attr);
if (ret != 0) {
if (PrintMiscellaneous && (Verbose || WizardMode)) {
perror("pthread_create()");
}
// Need to clean up stuff we've allocated so far
thread->set_osthread(NULL);
delete osthread;
if (lock) os::Linux::createThread_lock()->unlock();
return false;
}
// Store pthread info into the OSThread
osthread->set_pthread_id(tid);
// Wait until child thread is either initialized or aborted
{
Monitor* sync_with_child = osthread->startThread_lock();
MutexLockerEx ml(sync_with_child, Mutex::_no_safepoint_check_flag);
while ((state = osthread->get_state()) == ALLOCATED) {
sync_with_child->wait(Mutex::_no_safepoint_check_flag);
}
}
if (lock) {
os::Linux::createThread_lock()->unlock();
}
}
// Aborted due to thread limit being reached
if (state == ZOMBIE) {
thread->set_osthread(NULL);
delete osthread;
return false;
}
// The thread is returned suspended (in state INITIALIZED),
// and is started higher up in the call chain
assert(state == INITIALIZED, "race condition");
return true;
}
Java在Linux下的线程的创建,使用了pthread线程库,而pthread就是一个用户线程库,因此结论是,Java在Linux下是使用用户线程实现的。

MessageDigest的选择好多,包括MD2、MD4、MD5、SHA-1、SHA-256、RIPEMD128、RIPEMD160等等。我们如何选择呢?
选择考虑在两个方面:安全、速度。
MD2很安全,但是速度极慢,一般不用。
速度方面,最快的是MD4,MD5比SHA-1快
速度排名:MD4 > MD5 > RIPEMD-128 > SHA-1 > REPEMD-160
按照《应用密码学手册》提供的表格数据为:
MD4 长度 128 相对速度 1
MD5 长度 128 相对速度 0.68
REPEMD-128 长度 128 相对速度 0.39
SHA-1 长度 160 相对速度 0.29
REPEMD-160 长度 160 相对速度 0.24
我亲自测试的结果和《应用密码学手册》提供的数据接近。
MD4已经很早证明有缺陷,很少使用,最流行的是MD5和SHA-1,但MD5和SHA1也被王小云找到碰撞,证实不安全。
传说SHA-1比MD5要安全,但是SHA-1有美国国家安全局的背景,有人怀疑这个算法背后有不可告人的秘密,我也是阴谋论者之一,倾向选择MD5而不是SHA-1。王小云找到SHA-1碰撞之后,可以说传说的谣言破灭了,而且MD5速度要比SHA-1快差不多一倍,没有什么理由选择SHA-1。
----------------------------------
在Java的现实环境中是怎样?
在SUN的JCE实现中,只提供了MD2、MD5、SHA-1,SHA-256等常用的MessageDigest算法。
开源的JCE实现bouncycastle则提供了众多的实现,包括MD整个系列,SHA整个系列,RIPEMD整个系列。
很多的开源项目都带一个bcprov-jdk14.jar的包,可以说bouncycastle应用很广泛。SUN公司的一些项目也用了bouncycastle,例如JXTA。
但实际上,SUN的实现包括了MD4,但你需要这样使用:
MessageDigest md = sun.security.provider.MD4.getInstance();
但是,JDK带实现性能要比bouncycastle性能好得多,相差速度通常超过一倍以上,我测试过MD5、SHA1和MD4,其性能差别都是类似,一倍多。
比较的结论:
bouncycastle开源免费,提供算法多,但速度较慢
SUN JCE提供的实现,包括了流行常用算法,速度很快,同类型算法比bouncycastle要快一倍以上。
----------------------------------
结论:
又要安全又要速度,选择MD5
追求安全,不在意速度,相信传说,不相信阴谋论,选择SHA系列
追求速度,安全次之,可以选择MD4。
----------------------------------
现实例子:
emule采用MD4和SHA-1两种结合使用
apache之类的技术网站,提供下载的文件,同时提供一个校验文件.md5


不是使用每连接一线程的技术,而是使用多路复用技术。
作了一个分配算法。第一个HTTP Request返回取得ContentLength之后,如果使用多个连接下载,则需要一个分配算法,分配每个Request所对应的Range。分配的部分可能是一个连续的块,例如bytes=100-999,也可能是一些碎块,例如bytes=500-600,700-800,850-999。为此,我做了一个数据结构,其提供的功能类似java.util.BitSet,也支持and、or等操作。
实现了对ContentType为multipart/bytes的HTTP Message Body的解释。如果发送HTTP Request,Range为多个不连续的部分,返回的HTTP Message,就会是multipart,每个part都会包括一个Head和一个Body,需要一个解析器。
下一步就是把HTTP下载加入P2P下载中!

最近编码更流畅了。原因包括:
1) 绝大多数时候纯键盘操作,Eclipse 200多个快捷键,我熟练使用绝大部分,编码的过程,如同行云流水般。
2)掌握了更多的解决问题的办法,有了更广的知识面,编码时,信手拈来。最近一年里,掌握了很多知识,包括并发、网络、操作系统等等方面的知识。
3)组织代码的能力更强了,最近对于大型复杂的程序,组织代码的能力更强了,组织程序的能力包括,更好的结构,更好的扩展性,可测试性,可管理性等等。
a) 在编码的过程中,使得更多的模块可以单独于整个环境独立测试
b) 精心处理过的LOG,使得代码更容易跟踪,排错。
c) 复杂的模块,附带监控管理界面,使得排错和优化都更为方便。
d) 使用制作状态转换表的手段,清晰化复杂的状态处理。在前些年设计/实现工作流引擎时,就开始使用状态转换表描述状态机,但现在面临的状态机复杂。

贴图的实现方式为:
1、把剪切板中的图片存在本地的SendingImages目录,存放的格式使用PNG,当然可以其他格式,但是PNG格式更小。
2、使用MD5算法产生一个ImageID。当然可以使用SHA1等其他算法
3、把imageID发送remote peer
4、当remote peer收到imageID时,检查本地ReceivedImage目录,如果已经存在,显示图片,不存在则发送一个RequestImage请求,并在聊天记录中显示一个等待信息(为一个GIF动画)。
5、本地Peer收到RequestImage请求之后,发送图片数据。如果图片大于64K,则分块发送。
6、remote peer收到图像数据之后,进行校验,看是否正确。
7、校验通过后,把图片在聊天面板上显示(替换等待图片)
预定义表情的实现很简单,自定义表情的实现和贴图实现一致,只是少了从剪贴板保存图片的过程。

上一篇博客写了我一些关于P2P下载以及平台的思考,有这样的思考,是因为我正在做一件这样的事情。
我介绍一下我正在做的事情吧:
1、基于JXTA,我崇拜Bill Joy,学习JXTA就是因为我崇拜他,之后觉得这个技术很棒。但是JXTA存在一些用户不友好的地方,包括JXTA的ConfigDialog和DialogAuthenticator是十分用户不友好的,我重写了这些部分。虽然是一些无关痛痒的地方,但是可以改变用户体验,提高用户友好性。
2、简单的插件机制,我做了一个简单的插件系统,Application启动之后挨个装载服务,UI也是服务之一,UI也是基于插件的,在微内核框架流行的今天,使用一个简单的插件机制似乎不是太好,等过一段时间之后考虑使用osgi替代之。
3、提供了两个功能,聊天和文件共享下载。这两个功能分别表现为两个JXTA的Service。
4、聊天功能。目前还比较简单,只实现了不带格式的文本聊天,但是我随后会加入带格式的文本聊天,也将会加入类似腾讯QQ那样的贴图支持,自定义表情支持,腾讯QQ的实现很巧妙,但并不困难。四月初的版本就有可能实现之。
5、共享和下载。目前实现了文件和文件夹的共享。其中包括了高级智能错误检测(AICH)等。传输协议参考了BT和emule的协议。在界面中还实现对DragAndDrop支持,从Windows Explore中拖一个文件到目录共享的面板,即开始共享该文件。
6、存储信息采用apache的Derby数据库。我很喜欢Berkeley DB,Berkely DB高效简洁,但是License不开放。我最终还是采用Derby了,采用Derby将会带来一系列好处,SQL支持、JDBC支持等等,License无限制等等。扩展的应用基于其上也十分方便。由于我曾经开发过多数据库支持引擎KSQL,在KSQL上增加支持Derby的翻译是很容易的事情。如此一来,可能存储引擎部分,将有可能扩展到KSQL目前所支持的多种数据库,包括严格测试过的Oracle、DB2、MS SQL Server,还有经过简单测试支持Sybase、PostgreSQL、MySQL。
7、最近的JXTA Java SE 2.5版本,使用了nio来管理连接,也就说,使用了多路复用的技术,使得每个Peer创建大量连接成为可能,例如Windows下默认最大的多路复用支持1024个连接。而Linux下,java nio是使用epoll实现的,并发性能将更好,这对于聚合点来说很重要。普通的Peer部署在Linux下可能较少,但是聚合点部署在Linux完全是可能的。
8、使用Swing做界面,使用Java 6 SE的Swing,做了系统托盘Tray的支持等等。由于Swing的UI设计工具很不稳定,最终完全手工编写UI部分代码,虽然辛苦,但是代码简洁,不同UI Designer生成的那样。
9、我期望4月初发布一个版本,提供一个基本可用的版本。
10、我是从1月初开始学习JXTA的,到现在还不满3个月,其中还包括过年回家休息等等,玩游戏沉迷等等,但总的来说,我对这个学习速度很满意。不过其中感觉最爽的是,在这个过程中,编码时,基本纯键盘操作,不用鼠标,如行云流水一边,十分流畅,工作效率高,人也舒服。

1、使用多路复用或者异步I/O模型,这本是服务器段常用的技术,但在P2P应用,每台机器既是服务器,又是客户端,共享了一个十分受欢迎的文件,可能会有很多希望连接者,或者你下载一个受欢迎文件时,可能搜索到数百上千的Peer,此时就很有必要采用多路复用或者异步I/O技术,降低应用程序所占用的资源。
2、支持传统的协议,包括HTTP和FTP,其实这两种技术能够和P2P网络集成,其中一种办法就是,在提供下载地址的同时提供一个种子文件下载,例如服务器中提供了ABC.rar文件,同时提供一个ABC.rar.md5文件允许下载,这样P2P下载工具下载时,通过md5在P2P网络中搜索更多的资源,这样客户能够获得更好的速度,服务器端也可能降低下载的网络流量。
3、流行的P2P网络协议支持,包括BT和emule,这两种都是公开协议了,都有开源的实现,可以参考并重写,要支持并不困难。
4、健壮性。如同emule一样,将文件分块(piece)的同时,把每一块摘要一个piece_ID,将所有的piece_ID再摘要成一个总的ID,成为AICH。其实这也是一种很简单的技术,实现起来并不困难,做法可以多种多样。
5、对大型局域网有特别支持。现实中,存在很多大型的局域网,局域网之间的拥有高速的带宽。对局域网的特别支持办法也有很多的,例如,类似BT那样,在局域网里建立一个Tracker Server。若是基于JXTA,可以在局域网里部署聚合点(Rendezvous)
6、支持P2P目录共享,现在流行的P2P下载工具,都不支持以目录为单位实现P2P共享和下载。其实支持P2P目录共享也不困难,在提供共享时,提供一个目录结构信息就可以了。目录结构信息dir_info可以这样记录:子文件或子目录路径 偏移量 长度。当然把目录压缩然后提供下载也是可以的,不过这样会浪费共享者的磁盘空间。目录共享,要考虑共享之后文件进行修改,添加新文件等事情,使用dir_info能够更好解决这种问题。
7、关于通告。一个P2P共享资源(包括文件和目录),应该包括三个ID:content_id、aich_id、dir_info_id。其中content_id是整个资源的摘要,aich_id是每块id进行摘要产生的id,dir_info_id是dir_info的摘要id。
content_id可用资源搜索,建议采用MD5摘要产生,因为现在很多网上提供下载的文件,都提供一个.md5后缀的校验文件。
aich_id用于校验和智能恢复
dir_info_id。如果计算content_id时,dir_info独立计算,则需要提供dir_info_id,用于校验dir_info。理论上dir_info可以作为content的一部分,但是我觉得dir_info独立计算会带来很多好处。
8、关于传输。资源的传输,应该包括三部分,hashset的传输、dir_info的传输、内容数据的传输。内容传输是分块传输的,我觉得采用BT的默认值256K一块挺好的。每一块(piece)摘要计算一个piece_id,所有的piece_id放在一起,就是一个hashset,hashset这个名字不大好,不直观,但既然emule协议是这样会说,我也这样说好了。dir_info是可选的,文件共享不带dir_info。
9、P2P下载技术的应用范围应该扩展,程序的安装更新都应该加入P2P的支持,将会大大提高程序的用户体验。
10、P2P的平台应该具备良好的扩展性。当我们构建起一个庞大的P2P平台时,不单单只是在其上共享文件,有很多应用可以部署在其上,包括现在很流行的P2P视频,分布式计算等等。即时通讯也是可以构建在P2P网络上的。面对众多的应用需求,我们需要一个具备良好扩展性的协议,不应该像BT和emule那样,除了下载,别无它用。可能基于JXTA是一种较好的选择。
11、安全。P2P网络应该支持安全特性,一些团体,一些企业,需要限定范围内共享资源。例如NASA的卫星数据共享项目SAXTA,采用JXTA,就是因为JXTA支持安全特性。我想很多的P2P应用场景,都需要安全,例如,企业只希望内部员工之间实现P2P资源共享等等。

1、通用的唯一ID,使用MD5或者SHA1等摘要算法。
2、需要引入类似emule AICH机制,防止恶意客户端捣乱,或者用户修改数据之后,无意上传错误数据。
3、引入文件结构。描述文件在整个共享内容中的位置,整个共享项包括那些文件等等。
4、总共的ID应该包括:唯一ID、AICH_ID、文件结构摘要三个。如果使用JXTA的方式,需要在ContentAdv中包括这三个ID。
5、如果采用类似BT种子文件的方式,可以把三个ID、AICH_HashSet、FILE_LIST_INFO全部放在一起。
在做一个基于JXTA的实现,当然支持目录P2P共享的,已经实现的差不多了,自我感觉很酷!!

jxta.org上也有一个资源共享的项目,jxta-cm,但是这个项目作的不够好。
我重新设计了传输协议,参考了BT的传输协议。
存储本地信息,不像jxta-cm那样简单,序列化一个本地磁盘文件,而是引入了Derby数据库。我本想用Berkeley DB的,我很喜欢Berkeley DB,但是由于版权协议的问题,不得不放弃了。
当然与jxta-cm还有其他很多地方不同,包括一边下载一边上传等等。
今天文件传输测试成功了,随后将会进行更多的测试,保证稳定。
希望4月1日能够出一个愚人节版本。

Java SE 6.0的改变包括了ClassFile格式的改变。
新的版本的ClassFile中major_version为0x0032,也就是50。
Java SE 6 : 0x0032 (用自己写的ClassFileParser分析过证实)
Java SE 5 : 0x0031 (用自己写的ClassFileParser分析过证实)
JDK 1.4 : (未经证实是0x0030)
JDK 1.3 : (未经证实是0x002F)
JDK 1.2 : 0x002E
JDK 1.1 : 0x002D
每次JDK大版本升级,ClassFile格式都改变,然后版本加1。
6.0增加了StackMapTable的Attribute。
要提一下三个byte code处理库:
ObjectWeb ASM
Apache BCEL
sourceforge SERP
ASM目前版本为3.0。其2.1版本开始支持StackMapTableAttribute。
其中ASM 2.1支持StackMapTableAttribute,BCEL 5.2似乎只支持JDK 1.3,SERP 1.12只支持JDK 5.0。
Aapche BCEL支持JDK 1.3,是从代码中猜测的,没有从文档中看到,但其中5.2版本的ClassParser的确是不支持StackMapTable Attribute,其代码中的StackMap和Java SE 6.0的StackMapTable Attribute没有任何关系。BCEL中的对象和ClassFile中的各项对应,用于学习分析方便。
ASM号称更小,速度更快。现在流行的Eclipse插件bytecode outline也是其中的子项目。
ASM可以直接cvs访问,提供的代码是一个Eclipse Project,十分方便,我很喜欢!
http://forge.objectweb.org/projects/asm/
在规范4.10.1中的这一段话有些疑问:
If the class file version number is 51.0 or above, then neither the jsr opcode or the jsr_w opcode may appear in the code array.
class file version number is 51.0 or above,什么意思?Java SE 6.0编译出俩的结果应该是50.x,这是怎么回事?
规范是一个186页的PDF,没有文档大纲,看晕了
这是6.0之前的poll模型。
solaris\native\sun\nio\ch\SocketChannelImpl.c
JNIEXPORT jint JNICALL
Java_sun_nio_ch_SocketChannelImpl_checkConnect(JNIEnv *env, jobject this,
jobject fdo, jboolean block,
jboolean ready)
{
int error = 0;
int n = sizeof(int);
jint fd = fdval(env, fdo);
int result = 0;
struct pollfd poller;
poller.revents = 1;
if (!ready) {
poller.fd = fd;
poller.events = POLLOUT;
poller.revents = 0;
result = poll(&poller, 1, block ? -1 : 0);
if (result < 0) {
JNU_ThrowIOExceptionWithLastError(env, "Poll failed");
return IOS_THROWN;
}
if (!block && (result == 0))
return IOS_UNAVAILABLE;
}
if (poller.revents) {
errno = 0;
result = getsockopt(fd, SOL_SOCKET, SO_ERROR, &error, &n);
if (result < 0) {
handleSocketError(env, errno);
return JNI_FALSE;
} else if (error) {
handleSocketError(env, error);
return JNI_FALSE;
}
return 1;
}
return 0;
}
6.0缺省的模型是使用epoll
E:\Java\jdk-6-rc-src\j2se\src\solaris\native\sun\nio\ch\EPollArrayWrapper.c
JNIEXPORT void JNICALL
Java_sun_nio_ch_EPollArrayWrapper_init(JNIEnv *env, jclass this)
{
epoll_create_func = (epoll_create_t) dlsym(RTLD_DEFAULT, "epoll_create");
epoll_ctl_func = (epoll_ctl_t) dlsym(RTLD_DEFAULT, "epoll_ctl");
epoll_wait_func = (epoll_wait_t) dlsym(RTLD_DEFAULT, "epoll_wait");
if ((epoll_create_func == NULL) || (epoll_ctl_func == NULL) ||
(epoll_wait_func == NULL)) {
JNU_ThrowInternalError(env, "unable to get address of epoll functions, pre-2.6 kernel?");
}
}
具体程序的流程我还是不够清楚,还有待进一步深入了解。
java 1.4提供了nio,也就是之前我的一片博客中所说的multiplexed non-blocking I/O。这种模型比阻塞模型的并发性能要好一些,Java很多的网络应用都因此重写了底层模块,包括Tomcat、Jetty等等,也出现了基于nio的框架mina、国产的cindy等等。
java nio带来的影响是巨大的,得到了很多拥护和赞赏。
不过有一些是谣言,例如windows下的实现是Windows中并发性能最好的I/O模型IOCP,但事实上是这样么?
JDK 6.0 RC版提供了源码下载,下载路径:
http://www.java.net/download/jdk6/jdk-6-rc-src-b104-jrl-01_nov_2006.jar我们看最终Windows的实现:
j2se\src\windows\native\sun\nio\ch\WindowsSelectorImpl.c
82行开始:

 /**//* Call select */
/**//* Call select */
 if ((result = select(0 , &readfds, &writefds, &exceptfds, tv))
if ((result = select(0 , &readfds, &writefds, &exceptfds, tv))
== SOCKET_ERROR)  {
{

 /**//* Bad error - this should not happen frequently */
/**//* Bad error - this should not happen frequently */
/**//* Iterate over sockets and call select() on each separately */
 FD_SET errreadfds, errwritefds, errexceptfds;
FD_SET errreadfds, errwritefds, errexceptfds;
readfds.fd_count = 0;
writefds.fd_count = 0;
exceptfds.fd_count = 0;
for (i = 0; i < numfds; i++) {
/**//* prepare select structures for the i-th socket */
errreadfds.fd_count = 0;
errwritefds.fd_count = 0;
if (fds[i].events & POLLIN) {
errreadfds.fd_array[0] = fds[i].fd;
errreadfds.fd_count = 1;
 }
}
if (fds[i].events & (POLLOUT | POLLCONN)) {
errwritefds.fd_array[0] = fds[i].fd;
errwritefds.fd_count = 1;
}
errexceptfds.fd_array[0] = fds[i].fd;
errexceptfds.fd_count = 1;
/**//* call select on the i-th socket */
if (select(0, &errreadfds, &errwritefds, &errexceptfds, &zerotime)
== SOCKET_ERROR) {
/**//* This socket causes an error. Add it to exceptfds set */
exceptfds.fd_array[exceptfds.fd_count] = fds[i].fd;
exceptfds.fd_count++;
} else {
/**//* This socket does not cause an error. Process result */
if (errreadfds.fd_count == 1) {
readfds.fd_array[readfds.fd_count] = fds[i].fd;
readfds.fd_count++;
}
if (errwritefds.fd_count == 1) {
writefds.fd_array[writefds.fd_count] = fds[i].fd;
writefds.fd_count++;
}
if (errexceptfds.fd_count == 1) {
exceptfds.fd_array[exceptfds.fd_count] = fds[i].fd;
exceptfds.fd_count++;
}
}
}
 }
} 这就是广泛应用在Winsock中使用的select模型,也众所周知,并发性能不是很好。而且FD_SETSIZE不能超过Windows下层提供者的限制,这个限制通常是1024。也就是说Windows下,JDK的nio模型,不能超过1024个连接,这个跟我之前做的测试结果相似。
而且,如果FD_SETSIZE很大的话,例如是1000,调用select之前,必须设置1000个socket,返回之后又必须检查这1000个socket。
也就说,Windows下使用SUN JDK java的nio,并不能提高很好的并发性能。
回顾一下Unix的5种I/O模型
1、阻塞I/O
2、非阻塞I/O
3、I/O复用(select、poll、linux 2.6种改进的epoll)
4、信号驱动IO(SIGIO)
5、异步I/O(POSIX的aio_系列函数)
同步I/O和异步IO
POSIX把这两个术语定义如下:
同步I/O操作导致请求进程阻塞,直至操作完成
异步I/O操作不导致请求阻塞。
根据上述定义,前四种I/O模型都是同步I/O,第5种才是异步I/O。
select不允许多于一个的线程在同一个描述符集上等待。这使得反应式模型不适用于高性能应用,因为它没有有效地利用硬件的并行性。
异步I/O通常能够提高更好的性能,windows的iocp通过内核线程调度,也能提供很好的并发性能,但不是真正的异步。
Java nio和多路复用
java 1.4 nio提供的select,这是一种多路复用I/O(multiplexed non-blocking I/O)模型,底层是使用select或者poll。I/O复用就是,阻塞在select或者poll系统调用的某一个之上,而不是阻塞在真正的I/O系统调用之上。JDK 5.0 update 9和JDK 6.0在linux下支持使用epoll,可以提高并发idle connection的性能(
http://blogs.sun.com/alanb/entry/epoll)。
以前看到有人猜测Windows下nio使用了IOCP,那应该是错的,毕竟IOCP不是多路复用I/O模型。从JavaOne 2006的幻灯片来看,aio才会使用IOCP来实现的。
Java aio和JSR 203
2003年,就有了JSR 203(
http://jcp.org/en/jsr/detail?id=203),但是一直没有实现。
终于,JSR 203的spec lead说,将会在Java SE 7.0中完成JSR 203,Java SE 6.0已经是RC,很快正式版就会发布,然后就是Java SE 7.0,估计我们不需要等太久了。
http://blogs.sun.com/alanb/entry/what_is_happening_with_jsrasynchronous I/O对于Java的影响,将不会低于当年JDK 1.4 nio引入multiplexed non-blocking I/O的影响,很多的Java应用都会重写。如同Linux 2.6支持AIO,DB2、Oracle数据库都会发布新版本,说支持使用AIO,性能提高多少多少云云(主要是AIO的文件操作部分)。
对asynchronous I/O的支持,Java程序就能够支撑大并发网络应用了,在IO模型方面,对于C/C++等语言不再存在“C/C++能做,但是Java不能做的事情”。
这个是Java One 2006上的幻灯片。
http://blogs.sun.com/roller/resources/alanb/bof0895.pdf提到了:
需要新的channel types支持异步I/O模型
使用Native机制,例如Windows IO Completion ports。
文章:
http://blogs.sun.com/alanb/entry/epoll
JDK 6.0 nio支持epoll,对并发idle connection会有大幅度的性能提升,这就是很多网络服务器应用程序需要的。
One of the updates in build 59 of
Mustang
(Java
TM SE 6)
is that the New I/O
Selector
implementation will use the
epoll event notification
facility when running on the Linux 2.6 kernel.
JDK 5.0 update 9也支持了。
The epoll SelectorProvider will be included in 5.0 update 9. To enable
it requires setting the system property
java.nio.channels.spi.SelectorProvider to the value
sun.nio.ch.EPollSelectorProvider.
5种IO模型:
阻塞IO
非阻塞IO
多路复用
信号驱动IO
异步IO
最好性能的还是异步IO,目前Java只能支持到多路复用一级,期待着以后Java 7.0/8.0支持异步IO,6.0是没有希望了。
买了个新硬盘安装ubuntu,把所有的工作迁移到linux下进行。
没感到什么不方便的,毕竟最常用的工具是Eclipse、Firefox、UltraEdit。UltraEdit在linux下的替代品为vi和gedit,一切都好。
听音乐的播放器要比windows下要差一些,也没关系,将就着用。
字体有些难看,也能用,可以将就。
开发环境,在Ubuntu下配置ACE、boost等库的环境是在太方便的,比windows下方便多了。
唯一的缺陷就是系统不稳定,用linux作服务器是很稳定的,但是linux的桌面系统稳定性就比较差劲了,仿佛回到
windows 98的那种年代,系统经常死机。
总之,了系统不稳定之外,一切都好。

文章来源:
http://www.cnblogs.com/jobs/archive/2006/10/25/538989.html
一直以来,都是使用两种即时通讯工具QQ和MSN,最近越来越讨厌MSN,而觉得QQ越作越好。
1、MSN是明文传输数据,偷窥、监听都是极为简单的事情。查看别人MSN是某些网管的乐趣,而且是普遍的现象。
2、MSN任何时候的聊天数据都是明文经过服务器的,这个动机非常值得怀疑。明文传输而且通过服务器,为了使得海量监听更有效率?
3、MSN在贴图、群方面功能缺乏,聊天记录没有等等,不好用,不方便。
4、骚扰很多,一些交友网站的骚扰烦死人。
5、MSN的语音传输效果很差,而且经常建立不了连接。
6、文件传输很慢。
QQ虽然也不是极好,但比MSN还是强一些。
1、QQ聊天数据传输是使用TEA加密的,虽然并不是非常高强度的加密,但至少是经过加密的。
2、QQ聊天数据,双方都在线的时候,不经过服务器。如果对方不在线,聊天记录经过服务器,会受到监听审查。但比MSN要好一些。
3、QQ功能比MSN完备,使用方便。
这两种工具的官方版本都是广告一大堆,解决办法就是使用第三方的客户端。例如lumaQQ、gaim来替代他。
在中文世界中,越来越多人使用QQ,包括一些海外的朋友,终有一天在中文世界里,MSN就如ICQ一样,微不足道,这是一个可以预见的趋势,我也将很乐见看到这个结果。
因为还有一些朋友只使用MSN,现在只能是少用MSN,最终将会不再使用MSN。

文章来源:
http://www.cnblogs.com/jobs/archive/2006/11/08/553714.html
Herb Sutter的观点
Herb Sutter最近的一篇文章中如是说:“90年代,我们到处跟人叫讲,什么是对象,什么是虚函数,现在我们到处跟人说,什么是主动对象,什么是Future”,他还说,结构编程、面向对象,现在该轮到并发和并行了。
记得在去年,Herb Sutter就写文章预示并发时代的到来,主要是因为CPU的主频将不再会有以前那样的增长速度,而将迎来多核时代。程序将是靠并发来提高运行效率。
JDK 1.5 Concurrent包
在传统的多线程程序中,经常会有:
创建线程
wait\notify
重新发明轮子,例如BlockingQueue、Lock、Semaphore这样的基本工具类。
不恰当的抽象,会导致难以承受的复杂度,代码错误多,常犯死锁、lost notify之类,也很容易导致性能低下。我也有过这样的经历,失败的教训刻骨铭心。
JDK 1.5 util.concurrent包提供了一系列工具类,其中一些类的使用,代表一些观念的转变,更好的抽象,优雅的设计模式,会使多线程程序具有良好的结构。
使
用Excector、ScheduleExecutorService、Future、BlockingQueue等类搭建起来的程序,会使得多线程程序
有很清晰明了的结构。其中的差别,似乎就象以前“非结构化程序设计”到“结构化程序设计”那样的转变,现在我们使用Future等设计模式,起到了同样好
的效果。
结构化程序设计,使用if/else、while、do...while、for、switch等结构,把程序组织的清晰易懂,更容易掌握,更少出错。
Executor、Future、Concurrent Collection等工具类、模式,使得并发程序结构清晰化/模式化,更容易掌握,更少出错,也更高效。
随着多核CPU的普及,摩尔定律逐步失效,并发程序设计将会是程序员要求掌握的基本技巧,就如同现在程序员要求掌握面向对象一样。
有几个文档值得一看的:
javaone的幻灯片
http://developers.sun.com/learning/javaoneonline/2005/coreplatform/TS-3423.pdf
http://developers.sun.com/learning/javaoneonline/2005/coreplatform/TS-5807.pdf
Doug Lea的文章
http://gee.cs.oswego.edu/dl/papers/aqs.pdf
上面的文档只能给你一个介绍,最好的办法还是通读一遍JDK 1.5 utilconcurrent包的源码,然后在实践中,改变观念,积累经验。
并发和网络编程
网
络中,存在中心服务器,不同机器的交互,并发和异步是常见行为。网络中的服务器,需要相应大量的并发,这种并发通常会是极端的并发,操作系统提供一些特别
的API,例如select模型,poll,windows的完成端口等等。JDK在1.4之后支持nio,主要也是针对大并发的支持。
C++的框架ACE,提供了跨平台的线程、进程、Future等API,并且提供了Reactor、Proactor等框架,使得能够容易编写跨平台的并发网络服务器。
ACE框架的一个思想就是,使用ACE和模式消除复杂性。这一点和JDK 1.5 concurrent包提供的高级设计模式类的意图是一致的。
在《C++网络编程》卷1和卷2中讲述了一些模式,例如Half Sync/Aysnc vs Leader/Follow模式。这是ACE开发过程中的一些研究成果,我们查找ACE相关资料时,会发现一些关于并发方面的论文。ACE也提供了Future。
我才运用ACE作了一些简单的应用,了解还不够深入,不过觉得JDK concurrent包在并发设计模式方面,比ACE走到更远。
今天,你使用Future了吗?

文章来源:
http://www.cnblogs.com/jobs/archive/2006/11/10/556063.html
并发程序设计的领域,有三个牛人
Doug Lea (Java util.concurrent)
Douglas C. Schmidt (ACE、POSA2)
Herb Sutter (C++/CLI concurrent)
Doug Lea

util.concurrent包的作者,JSR166规范的制定。图书著作《Concurrent Programming in Java:
Design Principles and Patterns》。在JDK
1.6的源码中,还看到他修改的代码(例如重写Exchanger,修正N parters时死锁的问题)。随着JDK
1.5、1.6的普及推广,他的思想,他的作品,都将产生极大的影响。
Douglas C. Schmidt

他创造了ACE,一个流行开源跨平台的C++网络框架。他的图书著作:
《C++ Network Programming: Mastering Complexity Using ACE and Patterns》
《C++ Network Programming: Systematic Reuse with ACE and Frameworks》
《Pattern-Oriented Software Architecture: Patterns for Concurrent & Networked Objects》
他的成果:
Leader/Follow模式
ACE Reacotr
ACE Proactor
虽然ACE中也包括Acitve Object、Future等,他的书中也讲述了基于事件/基于任务的模型,但这些并非他的创造。
Douglas C. Schmidt的成果是网络、并发、跨平台。
Douglas C. Schmidt创造辉煌的时刻已经过去了。
Herb Sutter

ISO C++标准委员会主席,微软C++/CLI首席架构师,Exceptional三卷书的作者,目前领导微软的concur
Project。从2005年开始,他一直发表一些预告并发时代来临的文章。2005年,他代表Microsoft参加OOPSLA,主题就是关于C++
/CLI的并发。Herb Sutter是我极为敬仰的牛人!
他的网站:
http://www.gotw.ca/

文章来源:
http://www.cnblogs.com/jobs/archive/2006/11/10/556470.html
C++领域的知名人物
Bjarne Stoustrup 一代宗师,发明了C++,并且作了第一个实现,把面向对象技术带入主流,丰功伟业啊。
Herb Sutter 大师 (IOS/ANSI C++标准委员会秘书,目前领导微软的Concur Porject,推动并发进入主流,有成为宗师的潜力)
Andrei Alexandrescu 牛人 (经典著作《Modern C++ Design Generic Programming and Design Patterns Applied》)
Lippman 牛人 (宝刀已老)
Scott Meyers (著名讲师,自吹为C++领域权威,著作为Effetive C++系列)
侯捷 (著名译者,翻译的书质量不错,但他写的书千万别买)
上面的排名分先后.
Herb Sutter
我最佩服的人之一,他写的Exceptional C++系列三卷书,他的网站www.gotw.ca,OOPSLA上的演讲,他在微软的C++/CLI、Concur Projec等,最近两年所写的关于并发的一些列文章,都是非常非常的棒,偶像啊!!

有胡子的照片比较帅一些。
Bjarne Stoustrup
他来过中国,以前的照片是有胡子的,好酷,最近他网站的照片胡子刮干净了,难道是为了显得年轻一些么?

Lippman


很明显,他已经老了。
Scott Meyers

这就那个说自己是C++领域权威的家伙(真的是吗?)

文章来源:
http://www.cnblogs.com/jobs/archive/2006/11/11/557511.html
昨天就开始看这个PPT,看了几遍,对并发的前景有了更多的理解。
http://irbseminars.intel-research.net/HerbSutter.pdf可以从他的网站上下载视频版本。
过去30年,主流软件开发一直忽略了并发。但是现在,并发时代要来了,因为我们的新电脑是并发的,软件开发将会迎来巨变。
现在买的电脑,是双核的,明年就会是4核,然后就是8核,16核,32核……,都是之后几年的事情,一切都不遥远!

很多服务器程序准备好了(也不完全是吧),而客户端程序还没有。

算法的时间复杂度改变了

盲人摸象

技术发展史
|
|
出现 |
进入主流 |
|
GUIs |
1973 (Xerox Alto) |
~1984-89 (Mac)
~1990-95 (Win3.x) |
|
Objects |
1967 (Simula) |
~1993-98 (C++, Java) |
|
Garbage Collection |
1958 (Lisp) |
~1995-2000 (Java) |
|
Generic Types |
1967 (Strachey) |
~198x (US DoD, Ada) ~1995-2000 (C++) |
|
Concurrency |
1964 (CDC 6600) |
~2007-12 (est.) |
他的PPT中还讲述了Acitve Object、Future、Atomic之类的,VC提供特别语法支持。这也是老生常谈的咚咚了。

文章来源:
http://www.cnblogs.com/jobs/archive/2006/11/12/558078.html
一般来说,Exchanger都是一个Consumer,一个producer,在适当的时候互相交换,这样可以避免锁。
我想到Exchanger N parties的一种用法。如下:
最初N个都是producer,达到一定条件之后,进行交换。根据交换的结果重新确定角色,决定自己是consumer还是producer。
这样做的结果是,最初所有都是producer,之后一部分转变成consumer。并且由于consumer以及producer的速度不一样,而能够自动适应调整。
要注意的是,JDK 1.5中的Exchanger只支持2 parties,N parties时,N > 2会导致死锁。JDK 1.6中,Exchanger重写了,没有这个问题。
在JDK 1.5中要这样用的话,可以把JDK 1.6中Exchanger源码抄过来就是了。

文章来源:
http://www.cnblogs.com/jobs/archive/2006/11/12/558626.html
java.util.concurrent中的ExecutorCompletionService,其实现的是CompletionService接口。
我对ExecutorCompletionService存在一个疑问,在其实现中,task是被执行之后,才把futureTask加入到completionQueue,既然如此,不如直接把Result加入到completionQueue中了。这个行为没什么差别的。对这个类的设计存在一些怀疑,我认为其task方法,似乎返回值是V更合适。
原来是这样的:
Future<V> take() throws InterruptedException;
Future<V> poll();
觉得也许应该改称这样:
V take() throws InterruptedException;
V poll();

文章来源:
http://www.cnblogs.com/jobs/archive/2006/11/13/559609.html
客户端程序应用
无意发现的一个类
 package javax.swing;
package javax.swing;

 public abstract class SwingWorker<T, V> implements RunnableFuture<T>
public abstract class SwingWorker<T, V> implements RunnableFuture<T>  { }
{ }
也就是,一些并发相发的设计模式,已经应用在客户端程序设计中。
我没有对swing关注更多,只是觉得预想中的趋势开始出现了。
Exchanger
重写了,支持N parties。
RunnableFuture
这是理所当然的事情,Executor使用之后,FutureTask这个东西常用,兼有Runnable和Future,所以出现一个RunnableFuture是理所当然。
ConcurrentNavigableMap
一些系列的派生类,例如ConcurrentSkipListMap等等,还没用过,大概就是一个并发支持的SortedMap了。

文章来源:
http://www.cnblogs.com/jobs/archive/2006/11/14/559859.html
应该来说,util.concurrent包中提供的atomic,包括两部分:
1、atomic值对象,例如AtomicInteger、AtomicLong等。常用作计数器。
2、AtomicReference
3、一些内部使用Lock提供的compareAndSet操作。例如ConcurrentHashMap的putIfAbsent。
.NET中也提供了类似的功能,InterLocked类提供着完全的能力。
这是一种思想,提供原子操作,把两个以上的操作合并,使得调用者不需要使用Lock,使得程序结构变得简单,减少出错的可能,包括减少死锁发生的可能,程序也因此获得更好的性能。
将会有更多的数据结构支持atomic操作,JDK 1.5提供了支持atomic操作的ConcurrentMap、JDK 1.6提供了支持atomic的ConcurrentNavigableMap。
如同Herb Sutter预测的那样,并发技术将进入主流,这个过程会持续数年。

文章来源:
http://www.cnblogs.com/jobs/archive/2006/11/14/560416.html
原来用不上,只是因为没学好,所以需要重新学习。

文章来源:
http://jobs.cnblogs.com/archive/2006/03/28/360548.html
1、还没有找到快速返回整个BDB Database数据的办法。类似关系数据库中的SELECT * FROM T
2、还没有找到使用索引进行快速分组的办法。类似关系数据库中的SELECT F1, COUNT(*) FROM T GROUP BY F1 HAVING COUNT() > 1
以上的两个问题,我都有了能够正确返回结果的方案,但是还没有快速返回结果的办法。我估计还是需要认真阅读BDB源码之后才能解决。
2006年4月4,我已经找到原来测试返回整个DBD Database数据效率低的原因,是因为使用SerialBinding的原因。全部改成TupleBinding,速度快了很多,速度是SQL Server的三倍。(返回56444行记录)
最近也加入了My SQL的性能测试,事实上My SQL在查询时的速度不如SQL Server。特别作Group by的时候,性能很差的。

文章来源:
http://jobs.cnblogs.com/archive/2006/03/30/362272.html
之前就想为Berkeley DB写一个SQL前端+JDBC Driver。真的动手去做了,发现并不是很困难。不用花两天就可以写一个支持最简单SELECT、INSERT、CREATE TABLE语句的前端了。还包括一个可以运行的JDBC Driver。虽然要完善还需要做大量的工作,但是可以肯定的是,并不是一件困难的事情。
突然有点轻视MySQL,MySQL也是基于别人的引擎,不过也是如此吧了。
也许是我无知,无知者无畏!

文章来源:
http://jobs.cnblogs.com/archive/2006/04/14/375637.html
XP所强调大多观点我都是十分认同并且应用在实际工作中,包括作Code Review、测试驱动等等。
但对于其中的结对编程,向来是冷眼相对,没看出这是什么好主意。
看了电影《断背山》之后,更是觉得,结对编程,也许是两个男人在一起交流感情的好方式吧。

文章来源:
http://jobs.cnblogs.com/archive/2006/04/23/382824.html
今天重新阅读罗素《西方哲学史》下卷关于卢梭的部分。
卢梭早年曾当过一个贵妇的男仆,那贵妇死去时,发现卢梭有一个贵妇的纽扣,其实是他偷来的。卢梭一口咬定是某个他喜欢的女仆送给他的,结果那个女仆受到了处罚。卢梭说:“从来没有比在这个残酷时刻邪恶更远离我了;当我控告那可怜的姑娘时,说来矛盾,却是实情:我对她的爱情是我所干的事的原因。她浮现在我的心头,于是我把罪过推给了第一个出现的对象。”
在卢梭道德观中,这是一个以“善感性”替代一切平常道德的好实例。卢梭认为他永远有这一副温情心肠,然而温情心肠却从未阻碍他对最好的朋友有卑鄙行动。
在我们周围,也有很多人,有一副温情心肠,有善感性,被人认为是好人,或者纯朴、或者善良的人,但这并不会妨碍他们对自己的朋友或者亲人有卑鄙的行动。

文章来源:
http://jobs.cnblogs.com/archive/2006/04/24/383110.html
CMPP和SMPP协议比较
并非同类型协议
CMPP和SMPP都是短信协议中的一种,但它们不是同一类型的协议。SMPP和ESME和SMC(短信中心)之间的协议,而CMPP是SP和中国移动ISMG之间的通讯协议。
以下是CMPP 3.0文档中的图示。

与CMPP对应的协议有,联通的SGIP协议,中国电信的SMGP协议,网通的CNGP协议。
作为SP,只需要了解CMPP,不需要了解SMPP。
最新版本和兼容
SMPP协议是一个国际标准,有SMS论坛制定,官方网址为smsforum.net,截至2006年7月2日,最新版本是5.0。曾经流行的版本是3.3、3.4。SMPP协议向后兼容的。
CMPP最新版本似乎是3.0。现在(2006年7月),大多数还是使用CMPP 2.0。CMPP协议没有做到向后兼容,3.0的文档本身也没有讲到兼容的问题,甚至认为,协议制定者压根没想过要兼容。CMPP
3.0没做到向后兼容导致了一个问题,就是SP无法平滑升级。
PDU格式
PDU是协议数据单元的缩写,SMPP和CMPP都使用最先一个4位的长度标志整个PDU的长度。

SMPP是一个国际标准,不同的SMC的是实现可能要增加特定参数,为了具备更好的扩展性,SMPP 3.4以上版本,增加了可选参数,在5.0中,可选参数叫做TLVTable。
CMPP是中国移动定义的其内部ISMG之间、ISMG与SP之间的通讯标准,涉及一些具体的计费信息,但没有可选参数。
在SMPP中,消息头包括4部分:PDU长度、Command_Id、Command_Status、Sequence_Id。其中Command_Status字段,只在回应消息中使用,存在冗余。
CMPP中,消息头部包括3部分:PDU长度、Command_Id、Sequence_Id。个人认为,CMPP中的消息头,不包括Command_Status,似乎更好一些。
消息传输模式
SMPP和CMPP都支持异步传输,CMPP中,建议异步传输的窗口大小为16。
CMPP使用一个连接发送短信息和接收短信息。
SMPP支持多种的连接,其中TX类型的连接,只能发送短信息,RX类型的连接只能接收短信息,TRX类型的连接支持接收和发送短信息。
SMPP 3.4中,消息传输模式分三中:Store And Forward、Datagram、Forward。分别用在大吞吐量、可靠性保证等不同的应用场合。
CMPP没有规定其消息传输的模式,根据实际使用的情况看来,华为的网关的消息传输模式类似SMPP协议中规定的Datagram模式。

文章来源:
http://jobs.cnblogs.com/archive/2006/07/02/440902.html
刘小枫在北师大的开讲座讲尼采如是说,人类写东西并不仅仅想要人懂,也肯定想要人不懂。
理所当然,人类写的东西,也包括代码!

文章来源:
http://jobs.cnblogs.com/archive/2006/07/03/441087.html
GSM 03.40规范(TP-06 1999-12-15 7.4.0)中规定了SME对于超长短信的合并处理。规范制定至今,已经超过6年,绝大多数正在使用的手机,都支持这一功能。
CMPP协议中,CMPP_SUBMIT_MESSAGE中有两个字段pk_total和pk_numer,恰看起来,这就是发送超长短信的设置参数,其实不然,这两个参数的设置,应该是没有用处。
发送超长短信,需要做两件事情:设置TP_udhi的值设置为1,在消息正文中增加协议头。协议后可以两种格式,分别是长度为6和长度为7的协议头。格式如下:
6位协议头格式:05 00 03 XX MM NN
byte 1 : 05, 表示剩余协议头的长度
byte 2 : 00, 这个值在GSM 03.40规范9.2.3.24.1中规定,表示随后的这批超长短信的标识位长度为1(格式中的XX值)。
byte 3 : 03, 这个值表示剩下短信标识的长度
byte 4 : XX,这批短信的唯一标志,事实上,SME(手机或者SP)把消息合并完之后,就重新记录,所以这个标志是否唯一并不是很重要。
byte 5 : MM, 这批短信的数量。如果一个超长短信总共5条,这里的值就是5。
byte 6 : NN, 这批短信的数量。如果当前短信是这批短信中的第一条的值是1,第二条的值是2。
7位的协议头格式:06 08 04 XX XX MM NN
byte 1 : 06, 表示剩余协议头的长度
byte 2 : 08, 这个值在GSM 03.40规范9.2.3.24.1中规定,表示随后的这批超长短信的标识位长度为2(格式中的XX值)。
byte 3 : 04, 这个值表示剩下短信标识的长度
byte 4-5 : XX XX,这批短信的唯一标志,事实上,SME(手机或者SP)把消息合并完之后,就重新记录,所以这个标志是否唯一并不是很重要。
byte 6 : MM, 这批短信的数量。如果一个超长短信总共5条,这里的值就是5。
byte 7 : NN, 这批短信的数量。如果当前短信是这批短信中的第一条的值是1,第二条的值是2。
发送的短信这么处理,接受短信反过来就可以了。上述内容,在CMPP协议以及多款手机上经过测试验证。

文章来源:
http://jobs.cnblogs.com/archive/2006/07/07/445584.html
之前就想为Berkeley DB写一个SQL前端+JDBC Driver。真的动手去做了,发现并不是很困难。不用花两天就可以写一个支持最简单SELECT、INSERT、CREATE TABLE语句的前端了。还包括一个可以运行的JDBC Driver。虽然要完善还需要做大量的工作,但是可以肯定的是,并不是一件困难的事情。
突然有点轻视MySQL,MySQL也是基于别人的引擎,不过也是如此吧了。
也许是我无知,无知者无畏!
文章来源:
http://jobs.cnblogs.com/archive/2006/04/14/375637.html
1、整表查询
把整个表数据列出来,不知道为什么,BerkerlyDB 比 SQL Server还慢,没理由的,可能我没用好。
2、getByPrimaryKey
33606条数据的表,共19个字段的情况下:BerkerlyDB的性能要比SQL Server快10倍左右。(SQL Server数据库也是部署在本机)
33606条数据的表,共2个字段的情况:BerkerlyDB的性能要比SQL Server快500倍左右。(SQL Server数据库也是部署在本机)
(待继续补充中)
3、使用索引。
33606条数据的表,共19个字段的情况下,返回两条记录,使用字符串索引:BerkerlyDB的性能要比SQL Server快50~100倍左右。(SQL Server数据库也是部署在本机)
4、插入数据
插入2000条输入到数据表,共19个字段。SQL Server使用JDBC的executeBatch,每批1000条。Berkerly DB使用comiteNoSync的方法提交每次插入的数据。BerkerlyDB大约比SQL Server要快10~20倍。

文章来源:
http://jobs.cnblogs.com/archive/2006/03/29/361406.html
1、易于学习
2、支持主流数据库,包括MS SQL Server 2000、Oracle 9i、DB 2 7、Sybase、My SQL 5.0。应该有良好的支持多数据库方式,而不是现在一些流行O-R Mapping多数据库支持方式那么笨拙。
3、包括数据查询和对象查询。明确区分两种查询,他们对应的OQL功能应该有所不同。
4、能够处理复杂对象。例如多层一对多包含关系。评注,现在流行的O-R Mapping引擎处理复杂对象都不好,包括Hibernate 3.0。
5、有较为完整的DSL。不单应该包括用于运行时数据处理的OQL,还应该包括定义期的语言。
6、不完整装载。
7、对Event-Driven模型有良好的支持,并且支持请求合并
8、O-R Mapping应该更像一个“编译器”和“执行引擎”的组合,这个编译器输入是OQL,编译时使用各种技巧进行优化,编译的中间结果可以存储,可以生成存储过程。甚至可以根据执行过程的统计信息,采用不同的优化手段,调整最终的执行计划。
9、应该有良好的性能
我认为,一个实现良好O-R Mapping引擎,可以运用大量的优化技巧,其中一些优化技巧,是相当多开发人员都不掌握的,还有一些优化技巧,使用起来比较复杂,开发人员为了兼顾开发效率,不予以使用的。所以,一个实现良好O-R Mapping引擎,应该能够比大多数开发者直接使用JDBC要快。

文章来源:
http://jobs.cnblogs.com/archive/2006/01/13/317007.html
有朋友问过我,怎样学习多线程编程,我总结了一下,列了一下知识点:
1、synchronized
2、Runnable、Thread、Thread.sleep、Thread.yield、Thread.join
3、wait、notify、notifyAll(注意其中锁的获得和释放)
4、Mutex、Semaphore
5、BlockingQueue (十分有用,必须掌握)
6、ThreadPool
7、ExecutorService
8、Future (十分重要,必须掌握)
9、ReadWriteLock
10、Lock、condition。这是很多线程库都包含的内容,概念和synchronized、object.wait、object.notify那套咚咚类似,不过是通过库的方式展现,更加灵活。
、死锁、哲学家就餐问题
12、TSL汇编指令、JDK 1.5中的compareAndSet(java.uti.concurrent.atomic)、Windows API中的InterLock
13、工作线程+请求队列的应用
14、用户线程、内核线程,fork时用户线程问题 (很多Unix和早期的Linux不支持内核线程)
15、Windows Thread API,特色API:WaitForMultiObject
相关的书籍有:
《JAVA多线程设计模式》 结城浩 中国铁道出版社 (这本书讲得很清楚形象,十分适合初学者阅读)
JAVA并发编程—设计原则与模式(第二版) Doug Lea 中国电力出版社 (不可以不看,同时要配合阅读util.concurrent包的源码或者JDK 1.5的源码)
《JAVA线程编程》 Paul Hyde 人民邮电出版社 (我觉得这本书也不错)
《POSIX多线程程序设计》 David R.Butenhof 中国电力出版社
《WINDOWS核心编程》 Jeffrey Richter 机械工业出版社
《UNIX系统编程》 Kay A.Robbins, Steve Robbins 机械工业出版社
《现代操作系统》 Andrew S.Tanenbaum 机械工业出版社
《UNIX 网络编程(第二版)第2卷:进程间通信》W.Richard Stevens 北京科海电子出版社

文章来源:
http://jobs.cnblogs.com/archive/2006/01/09/313535.html
Apache的BCEL库,文档很少,例子也很简单。动态构建类的工作,要求的只是并不是熟练使用BCEL类库本身,而是要对java的class结构了解。我对java的pcode也不熟悉,但是我曾经做过大量的.NET的反编译工作,两者类似,所以我用BCEL也不觉得困难。
我提供一个例子,这里例子是使用BCEL创建类的实例,而不是使用反射。
如下:
IFactory.java
public interface IFactory {
public Object newInstance();
} FileClassLoader.java
import java.io.ByteArrayOutputStream;
import java.io.File;
import java.io.FileInputStream;
import java.io.IOException;
public class FileClassLoader extends ClassLoader {
public FileClassLoader() {
super();
}
public FileClassLoader(ClassLoader parent) {
super(parent);
}
public Class getClass(String className, String filePath) {
FileInputStream fileInputStream = null;
byte[] data = null;
try {
fileInputStream = new FileInputStream(new File(filePath));
ByteArrayOutputStream byteArrayOutputStream = new ByteArrayOutputStream();
int ch = 0;
while ((ch = fileInputStream.read()) != -1) {
byteArrayOutputStream.write(ch);
}
data = byteArrayOutputStream.toByteArray();
return defineClass(className, data, 0, data.length);
} catch (IOException e) {
e.printStackTrace();
throw new Error(e.getMessage(), e);
}
}
} buildFactory方法:
public static IFactory buildFactory(String procductClassName)
throws Exception {
InstructionList il = new InstructionList();
String className = "HelloWorld";
ClassGen class_gen = new ClassGen(className, "java.lang.Object",
"", Constants.ACC_PUBLIC | Constants.ACC_SUPER, null);
ConstantPoolGen cons_pool = class_gen.getConstantPool();
class_gen.addInterface(IFactory.class.getName());
InstructionFactory il_factory = new InstructionFactory(class_gen);
// 创建构造函数
{
String methodName = "";
Type returnType = Type.VOID;
Type[] arg_Types = new Type[] {};
String[] arg_names = new String[] {};
MethodGen method_gen = new MethodGen(Constants.ACC_PUBLIC,
returnType, arg_Types, arg_names, methodName, className,
il, cons_pool);
// super();
il.append(InstructionFactory.createLoad(Type.OBJECT, 0));
il.append(il_factory.createInvoke("java.lang.Object", "",
Type.VOID, new Type[0], Constants.INVOKESPECIAL));
il.append(InstructionFactory.createReturn(Type.VOID));
method_gen.setMaxStack();
class_gen.addMethod(method_gen.getMethod());
il.dispose(); // Reuse instruction handles of list
}
{
String methodName = "newInstance";
Type returnType = Type.OBJECT;
Type[] arg_Types = new Type[] {};
String[] arg_names = new String[] {};
MethodGen method_gen = new MethodGen(Constants.ACC_PUBLIC,
returnType, arg_Types, arg_names, methodName, className,
il, cons_pool);
il.append(il_factory.createNew(procductClassName));
il.append(InstructionConstants.DUP);
il.append(il_factory.createInvoke(procductClassName, "",
Type.VOID, new Type[0], Constants.INVOKESPECIAL));
il.append(InstructionFactory.createReturn(Type.OBJECT));
method_gen.setMaxStack();
class_gen.addMethod(method_gen.getMethod());
il.dispose(); // Reuse instruction handles of list
}
// 保存到文件中
JavaClass clazz = class_gen.getJavaClass();
String path = "e:\\temp\\" + className + ".class";
class_gen.getJavaClass().dump(path);
// 使用ClassLoader装载class
FileClassLoader classLoader = new FileClassLoader();
Class factoryClass = classLoader.getClass(className, path);
Object newInst = factoryClass.newInstance();
return (IFactory) newInst;
} 测试用例:
String className = "java.lang.Object";
IFactory factory = buildFactory(className);
Object inst = factory.newInstance();
在密码学里,有一种理想的加密方案,叫做一次一密乱码本(one-time pad)。
one-time pad的算法有以下要求:
1、密钥必须随机产生
2、密钥不能重复使用
3、密钥和密文的长度是一样的。
one-time pad是最安全的加密算法,双方一旦安全交换了密钥,之后交换信息的过程就是绝对安全的啦。这种算法一直在一些要求高度机密的场合使用,据说美国和前苏联之间的热线电话、前苏联的间谍都是使用One-time pad的方式加密的。不管超级计算机工作多久,也不管多少人,用什么方法和技术,具有多大的计算能力,都不可能破解。
一次一密的一种实现方式,如下:
public class OneTimePadUtil {

 public static byte[] xor(byte[] bytes, byte[] keyBytes) {
public static byte[] xor(byte[] bytes, byte[] keyBytes) {
if (keyBytes.length != bytes.length) {
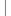 throw new IllegalArgumentException();
throw new IllegalArgumentException();
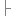 }
}
byte[] resultBytes = new byte[bytes.length];
for (int i = 0; i < resultBytes.length; ++i) {
resultBytes[i] = (byte) (keyBytes[i] ^ bytes[i]);
}
return resultBytes;
}
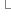 }
} 使用例子:
String plainText = "温少";
String keyText = "密码";
byte[] plainBytes = plainText.getBytes();
byte[] keyBytes = keyText.getBytes();
assert plainBytes.length == keyBytes.length;
//加密
byte[] cipherBytes = OneTimePadUtil.xor(plainBytes, keyBytes);
//解密
byte[] cipherPlainBytes = OneTimePadUtil.xor(cipherBytes, keyBytes);
这是最简单的加密算法,但也是最安全的机密算法。前天和朋友讨论到了这个问题,所以写了这篇文章。

我在阅读JDK 1.5中java.util.concurrent的源码时,对atomic下的一大堆atomic对象感到迷惑,google一把,得到一些有用的信息,与大家分享:
http://www-900.ibm.com/developerWorks/cn/java/j-jtp11234/index.shtml

文章来源:
http://www.cnblogs.com/jobs/archive/2005/03/08/114711.html
真的很棒,推荐大家去看一看!!
http://www.cnblogs.com/Files/jobs/1.rar

文章来源:
http://www.cnblogs.com/jobs/archive/2005/03/18/121437.html
由于DES不再安全,现在都流行使用AES加密算法替代DES,Rijndael是AES的实现。
我从网上找到了很多Rijndael的java实现代码,我用了其中的一个,并且写了一个工具类,使得更方便使用它。
http://www.cnblogs.com/Files/jobs/Rijndael.rar
Rijndael_Util.java是我写的,使用方法如下:
import mit.Rijndael.Rijndael_Util;
String strKey = "欲练神功挥刀子宫";
String plainText = "葵花宝典";
String cipherText = Rijndael_Util.encode(strKey, plainText);
System.out.println(cipherText);
System.out.println(Rijndael_Util.decode(strKey, plainText);
由于Rijindael的算法要求每次加密的数据必须是一个block,blockSize可以是16、24或者32。因此,当需要加密一个byte数组paintBytes时,如果byte数组plainBytes的长度不为blockSize的倍数,则需要补位。此时,就需要一个数值来保留明文byte数组的长度。最初我是用四个byte来保存plainBytes的长度,然后直接放在密文byte数组cipherBytes的最前面。但是我考虑到把直接把明文的长度暴露出来,不是很好,于是,就做了一个处理。
当blockSize为16或者24时,而且plainBytes的长度不为blockSize的倍数,最后一个block的blockSize使用一个长度为blckSize+8的byte数组lastBlockBytes来保存,这样,最后一个block的长度就比普通的block长8个byte,这个8个byte的前4位用来保存plainBytes的长度。
当blockSize为32时,则最后一个block拆为两个block,一个block的长度为16,一个block的长度为24,这样一来,又有多余的8位来保存plainBytes的长度了。
把int变为四个byte和把四个byte读回一个int的实现如下:
public final static void putInt(int val, byte[] bytes, int offSet) {
bytes[offSet] = (byte) (val >> 24);
bytes[offSet + 1] = (byte) (val >> 16);
bytes[offSet + 2] = (byte) (val >> 8);
bytes[offSet + 3] = (byte) val;
}
public final static int getInt(byte[] bytes, int offSet) {
return ((bytes[offSet + 0] & 0xff) << 24)
| ((bytes[offSet + 1]) << 16)
| ((bytes[offSet + 2] & 0xff) << 8)
| ((bytes[offSet + 3] & 0xff) << 0);
}
.NET的朋友注意,java中的byte是带符号,而c#中的byte是无符号的。
以前,由于很少写低级的代码,所以对位运算不够熟悉,最初是,把一个int拆成4个byte的算法自己写,但是觉得不够好,后来和flier_lu交流后,flier_lu建议我看java.nio中的ByteBuffer的实现,可能会有收获。我查看后java.nio.Bytes类后,发现了java.nio.Bits的实现比我做的更好一些。java.nio.Bits是一个内部类,不是public,我们不能调用它,但是可以参考他的源码实现。
在这个过程中,我和以往的感觉一样,一个基础类库,开放源码对于使用者会有很大帮助。
最近有人对.NET的前途提出质疑,有人说到关键点上来了:.NET是一个相当封闭的平台。微软对于公开基础类库的源码,在走倒退的道路。以前微软的基础类库MFC是可以查看源码的,你甚至可以调试源码,但是微软提供.NET的基础类库而是不开放源代码的,虽然你可以通过Reflectro或者Mono了解一些基础类库的源码,但这个不能够确定你通过这些途径得到的源码和你正在使用的是一致的。
从.NET转向Java快两年了,越来越对Java的前途充满希望,也很多人一样,对微软的.NET越来越失望。

文章来源:
http://www.cnblogs.com/jobs/archive/2005/03/20/122208.html
jdk 1.5中中,引入了concurrent包,非常棒,在阅读源码时发现其文档的一个小虫,如下:
java.util.concurrent.Semaphore源码中,26行,有如下示例代码:
private static final MAX_AVAILABLE = 100;
应该为:
private static final int MAX_AVAILABLE = 100;
这只是文档中Sample代码的错误,嘻嘻……
我吃饱没事干了??

最近试用了几个数据库
1、MySQL的最新版本mysql-5.0.2-alpha非常不稳定。如果你查询了系统表,例如执行show columns之类的语句,会导致整个数据库崩溃。值得一提的是,MySQL的管理工具和安装配置都有了较大的进步。
2、HSQL,这是一个纯Java的数据库,性能很不错,可以嵌入到程序内部,可以作为一个进程内的数据库,感觉很棒。HSQL是开源的,文档作的不够好,一些系统表的使用,需要直接查看其JDBC Driver实现的源码才得知。
http://sourceforge.net/projects/hsqldb/
3、SQLite,我用了一下,感觉也不错,不过我认为,对于Java开发人员,使用Sqlite就不如直接使用HSQL。Sqlite是使用C开发的数据库,在Java中也可以通过JNI来实现进程内使用(sqlite网站提供了windows平台的dll下载),但是这样,你的程序安装配置就麻烦了。

文章来源:
http://www.cnblogs.com/jobs/archive/2005/02/24/108362.html
架构师?一定是开发人员的职业发展方向吗?
两年前,也很希望自己能够成为一个软件架构设计师。后来,慢慢就失去了兴趣,甚至很不喜欢架构师这个词。
架构师通常是,最大程度利用现有成熟的技术完成产品目标。但在我看来,这意味着妥协,抑制创新,而我恰恰是,一个凭激情和冲动来完成一些挑战性任务,以对现有产品在性能、功能进行大幅度改进的一个人。
架构师通常协调不同的人的设计,达成一种妥协,一种平衡又或取舍。尽管架构师通常对产品的发展,对项目的成功能够起很大的作用,但是,我想在未来的几年内,我还有能力创造的时候,不会刻意要自己成为一个架构师。
我所认识的要做架构师或职位是架构师的人,大多数没有什么技术创新,也没有什么突出成就,所以觉得这个词很虚。认为他们没有什么突出成就,是从一个技术狂热爱好者的角度来看的。注意,我无意贬低他们的工作成果,我承认,从产品方面来看,他们起的作用很大。
我更佩服一些有激情的程序员,也就是老一辈的黑客。例如Dennis Richie和Ken Thompson,他们创造了Unix,C语言,Linus Trovalds创造了Linux。我们会称这些顶级的程序员为大师,称很多优秀的程序员为黑客(不是那种发动网络攻击的黑客)。他们凭激情创造一切,不为常规所约束,是真正的程序员。
我要说明的是,架构师不是程序员,它是更像项目经理的一种角色,充担很多协调性的工作。
我是一个程序员,渴望能够成为一个优秀的程序员,有所创造,我不希望成为一个架构师!这就是我在新年里的职业发展定位。。。

文章来源:
http://www.cnblogs.com/jobs/archive/2005/01/06/87100.html
微软的技术专家Don Box最近在一篇BLOG中提出了对2005年IT技术前景的预测,包括:
Windows平台上的其他非微软浏览器将超越FireFox
Sun公司将拥抱Eclipse
SOA的鼓吹将走到尽头,软件业会找出另一个“大词”来加以鼓吹
Intel和/或AMD会发布6GHZ主频的CPU
BEA不会被收购
尽管有很多新技术发布,微软PDC2005还是会令人失望
Miguel de Icaza会离开Novell加盟Google
苹果会发布Mac OS X媒体中心版本
XML Query、语意web和WS-*不会有任何重大突破
Robert Scoble会登上一份全美重要杂志的封面
我对其中部分十分认同:
1、SOA的鼓吹将走到尽头,软件业会找出另一个“大词”来加以鼓吹
尽管有我十分尊敬的前辈在鼓吹SOA,但似乎他们都没有足够的理由,让我觉得SOA是一件值得注意的事情。我甚至觉得SOA没有任何实质的内容。
2、尽管有很多新技术发布,微软PDC2005还是会令人失望
我估计微软将要发布的一些技术,都不是新技术,都是一些在.NET一种模拟实现。
3、Sun公司将拥抱Eclipse
Eclipse做的实在太好了,比Visual Studio .NET要好得多。SUN自己的IDE连Visual Sutdio .NET也超不过,不如接受Eclipse。。。

文章来源:
http://www.cnblogs.com/jobs/archive/2005/01/01/85167.html
23日出的。不知道RC2有什么改进,我现在机器上安装的是RC1版本,用得好好的,正是版本不出来之前,就不更换了。
PostgreSQL的文档做得不够好。我还不知道8.0比7.0有哪些增强的功能列表 

文章来源:
http://www.cnblogs.com/jobs/archive/2004/12/25/81711.html
我已经不止一次听人说O-R Mapping的技术已经很成熟了,事情真的是这样的吗?
以前我跟人说,我要优化现有的O-R Mapping引擎,提高速度,朋友告诉我,O-R Mapping是一种很成熟的技术了,没什么好研究的。我没有反驳,当我找到更好的方法把现有的O-R Mapping优化,提高数倍的性能后,另外一个朋友知道这件事后,跟我说,O-R Mapping是一个很成熟的技术,你能够提高数倍的速度,原来的设计一定很烂。
在我看来,他们的想法都不正确。O-R Mapping一直以来存在一个难题,就是速度,这个问题没有解决之前,就不能说O-R Mapping的技术已经成熟了。O-R Mapping还存在另一个问题,就是使用的方便性。Entity Bean在性能和易用性方面都做得很差,Hibernate也做得不好,听说TopLink性能不错,但应该也不会太好。我看过TopLink的一些例子,觉得其接口不直观。
现在O-R Mapping的产品处于战国时代,群雄无首。用徐少春的话来说,所有的都是小猴子,还没有出现一个大金刚,。。。
我希望能够在这个方面有所突破,最终造就一个大金刚!!

文章来源:
http://www.cnblogs.com/jobs/archive/2004/12/24/81643.html
Hibernate 3作了一些改进,改进了一些原来很显而易见的缺点。例如加了抽象语法树,但是在Hibernate 3.0 Beta1中,感觉还是有些不大成熟。从代码可以看出,Hibernate 3.0 Beta1的HQL AST使用了antlr,我向来不大喜欢这种使用yacc、antlr等生成的文法分析和AST。
ast部分的代码是josh提供的,看来gavin并不熟悉文法分析等编译技术,ast是否能够很好发挥作用,现在还难说...
在ObjectSpaces中,提出了两种查询分类:Object Query和Data Query。这种提法很好的,Object Space的一些思路是很好的,可惜这个项目不知道为什么取消了。
我认为HQL,抽象得不好,他引入了一种无需写连接条件的连接NATURAL JOIN,其实连接条件在元数据中描述了。我认为这种做法是很不好的!

文章来源:
http://www.cnblogs.com/jobs/archive/2004/12/23/80812.html