
2012年2月29日
https://www.jianshu.com/p/ebf2e5b34aad
posted @
2018-11-18 16:56 Seraphi 阅读(182) |
评论 (0) |
编辑 收藏
今天换了Macbook pro来写毕业论文,发现有一大堆中文相关的问题导致编译错误。经过一晚上的研究,终于解决。主要有以下要点:
1. 由于MacTex对CTex的支持并不如TexLive那么好,在用pkuthss 1.7.3模板写论文的时候,首先需要对pkuthss.cls文件进行修改:
需要将原来的\LoadClass[hyperref, cs4size, fntef, fancyhdr]{ctexbook}[2011/03/11]一行改为如下形式:
\LoadClass[fontset = windowsold,cs4size,UTF8,fancyhdr,hyperref,fntef,openany]{ctexbook}[2011/03/11]
2.在进行上述改动后,发现还是不行。提示simhei.ttf, simsong.ttc, simfang.ttf找不到。这个时候,需要将上述三种字体超链接到tex的目录下。
具体方法如下:
(1)在tex对应的下列目录建立Chinese文件夹:/usr/local/texlive/2016/texmf-dist/fonts/truetype/
(2)将SimHei SimSong Fangsong三种字体超链接到上述目录。这三种字体可以在/Library/Fonts/Microsoft中找到,注意的是放到tex下时,文件名需要小写,黑体和仿宋后缀名为.ttf,宋体为.ttc
(3)sudo texhash
3.再编译的时候发现已经可以了!Yeah~~~
posted @
2017-02-28 22:13 Seraphi 阅读(558) |
评论 (0) |
编辑 收藏I have successfully run your code after doing the following two steps:
Download GLPK from
http://sourceforge.net/projects/winglpk/files/latest/download (as mentioned by oyvind)
- Unzip it into (for example) :
C:\glpk_is_here\ Add GLPK binaries to your system path before running python C:\>set PATH=%PATH%;C:\glpk_is_here\glpk-4.55\w64
Using the same cmd window from (3), use python/ipython to run your code:
C:\>ipython your_code.py
See the results Out[4]: 2.0
Good luck.
posted @
2016-05-27 14:25 Seraphi 阅读(686) |
评论 (0) |
编辑 收藏原贴:http://www.cnblogs.com/ajunForNet/archive/2012/09/12/2682063.html
组长说在内网部署一个论坛,这可难不倒我,装个Discuz嘛。
部署环境就一台普通的PC,四核i3,Windows7。这就开搞了。
准备工作
系统是Windows 7 专业版,自带IIS7.5(家庭版不带)。IIS7开始带了FastCgi,对PHP支持好了许多,所以也不必装Apache啦。
下载 PHP 5.4、 MySQL 5.5 以及Discuz X2。
对于IIS7 FastCgi,我们应当选择VC9编译的线程安全的版本。
安装PHP
解压PHP,我给的路径是C:\PHP,大伙儿随意
把php.ini-production改名为php.ini(用于开发环境的话,就改那个development)
修改扩展路径
extension_dir = "./ext"
启用MySQL扩展(即去掉分号)
extension=php_MySQL.dll
修改时区
date.timezone=Asia/Shanghai
完了可以尝试在命令行中执行以下PHP:
cd C:\PHP
php -v
可以看到php的版本信息,如果把dll文件不存在的扩展打开了的话,会有提示。
配置IIS
IIS容易对付,不过先得把确保这几项已经装上:

1、添加模块映射
启动IIS管理器,对服务器设置“处理程序映射”,”添加模块映射“:
(图)
注意,设置可执行文件路径的时候,要选择exe。

2、添加index.php为默认文档
对服务器设置“默认文档”,添加index.php
3、创建新站点
接着在创建一个新的站点,并创建一个目录存放你的网站,C:\Forum
主机名填你想要绑定的域名,对于一台服务器上有多个网站的情况,域名几乎是必须的。
当然啦,内网的话,就改hosts随便弄个上去吧。
4、设置程序池
去应用程序池,设置刚才创建的站点对应的程序池,把.Net framework版本设成无托管代码。
重启IIS,在网站目录下放一个index.php,内容很简单:
<?php phpinfo(); ?>
访问网站,设置无误的话应该能看到PHP的系统信息。
安装MySQL
安装MySQL挺容易的,按照Discuz给出的教程就可以了。
因为我下的是UTF8版本的Discuz,所以在选择字符编码那一步选的UTF8。
至于改数据库目录以及移动那个dll,看上去完全没那个必要,我也就没弄。
安装Discuz
最烦的都搞定了,最后把安装包里upload里面的东西都复制到网站目录下,
访问网站下的install目录就能看到安装界面
剩下的不用说了吧···
得记得安装完了以后,进UCenter->全局->域名设置->应用域名,把论坛的域名给设好了,
否则论坛首页就是个500
Over.
posted @
2013-03-11 11:09 Seraphi 阅读(606) |
评论 (0) |
编辑 收藏
nohup + 命令 + & 后台运行程序(连接服务器时,运行程序)
posted @
2013-03-06 10:38 Seraphi 阅读(265) |
评论 (0) |
编辑 收藏
摘要: LaTeX( LATEX,音译“拉泰赫”)是一种基于TeX的排版系统,由 美国 计算机学家 莱斯利·兰伯特(Leslie Lamport)在20世纪80年代初期开发,利用这种格式,即使使用者没有排版和程序设计的知识也可以充分发挥由TeX所提供的强大功能,能在几天,甚至几小时内生成很多具有书籍质量的印刷品。 你可以在...
阅读全文
posted @
2013-02-16 13:51 Seraphi 阅读(289) |
评论 (0) |
编辑 收藏Python正则
初学Python,对Python的文字处理能力有很深的印象,除了str对象自带的一些方法外,就是正则表达式这个强大的模块了。但是对于初学者来说,要用好这个功能还是有点难度
,我花了好长时间才摸出了点门道。由于我记性不好,很容易就忘事,所以还是写下来比较好一些,同时也可以加深印象,整理思路。
由于我是初学,所以肯定会有些错误,还望高手不吝赐教,指出我的错误。
1 Python正则式的基本用法
Python的正则表达式的模块是‘re’,它的基本语法规则就是指定一个字符序列,比如你要在一个字符串s=’123abc456’中查找字符串’abc’,只要这样写:
>>> import re
>>> s='123abc456eabc789'
>>> re.findall(r’abc’,s)
结果就是:
['abc', 'abc']
这里用到的函数”findall(rule , target [,flag] )” 是个比较直观的函数,就是在目标字符串中查找符合规则的字符串。第一个参数是规则,第二个参数是目标字符串,后面
还可以跟一个规则选项(选项功能将在compile函数的说明中详细说明)。返回结果结果是一个列表,中间存放的是符合规则的字符串。如果没有符合规则的字符串被找到,就返
回一个空列表。
为什么要用r’ ..‘字符串(raw字符串)?由于正则式的规则也是由一个字符串定义的,而在正则式中大量使用转义字符’/’,如果不用raw字符串,则在需要写一个’/’的地
方,你必须得写成’//’,那么在要从目标字符串中匹配一个’/’的时候,你就得写上4个’/’成为’////’!这当然很麻烦,也不直观,所以一般都使用r’’来定义规则字符
串。当然,某些情况下,可能不用raw字符串比较好。
以上是个最简单的例子。当然实际中这么简单的用法几乎没有意义。为了实现复杂的规则查找,re规定了若干语法规则。它们分为这么几类:
功能字符: ‘.’ ‘*’ ‘+’ ‘|’ ‘?’ ‘^’ ‘$’ ‘/’等,它们有特殊的功能含义。特别是’/’字符,它是转义引导符号,跟在它后面的字符一般有特殊的含义。
规则分界符: ‘[‘ ‘]’ ‘(’ ‘)’ ‘{‘ ‘}’等,也就是几种括号了。
预定义转义字符集:“/d” “/w” “/s” 等等,它们是以字符’/’开头,后面接一个特定字符的形式,用来指示一个预定义好的含义。
其它特殊功能字符:’#’ ‘!’ ‘:’ ‘-‘等,它们只在特定的情况下表示特殊的含义,比如(?# …)就表示一个注释,里面的内容会被忽略。
下面来一个一个的说明这些规则的含义,不过说明的顺序并不是按照上面的顺序来的,而是我认为由浅入深,由基本到复杂的顺序来编排的。同时为了直观,在说明的过程中尽量
多举些例子以方便理解。
1.1基本规则
‘[‘ ‘]’字符集合设定符
首先说明一下字符集合设定的方法。由一对方括号括起来的字符,表明一个字符集合,能够匹配包含在其中的任意一个字符。比如[abc123],表明字符’a’ ‘b’ ‘c’ ‘1’
‘2’ ‘3’都符合它的要求。可以被匹配。
在’[‘ ‘]’中还可以通过’-‘ 减号来指定一个字符集合的范围,比如可以用[a-zA-Z]来指定所以英文字母的大小写,因为英文字母是按照从小到大的顺序来排的。你不可以
把大小的顺序颠倒了,比如写成[z-a]就不对了。
如果在’[‘ ‘]’里面的开头写一个‘^’ 号,则表示取非,即在括号里的字符都不匹配。如[^a-zA-Z]表明不匹配所有英文字母。但是如果‘^’不在开头,则它就不再是表示
取非,而表示其本身,如[a-z^A-Z]表明匹配所有的英文字母和字符’^’。
‘|’ 或规则
将两个规则并列起来,以‘|’连接,表示只要满足其中之一就可以匹配。比如
[a-zA-Z]|[0-9]表示满足数字或字母就可以匹配,这个规则等价于[a-zA-Z0-9]
注意:关于’|’要注意两点:
第一, 它在’[‘ ‘]’之中不再表示或,而表示他本身的字符。如果要在’[‘ ‘]’外面表示一个’|’字符,必须用反斜杠引导,即’/|’ ;
第二, 它的有效范围是它两边的整条规则,比如‘dog|cat’匹配的是‘dog’和’cat’,而不是’g’和’c’。如果想限定它的有效范围,必需使用一个无捕获组‘
(?: )’包起来。比如要匹配‘I have a dog’或’I have a cat’,需要写成r’I have a (?:dog|cat)’,而不能写成r’I have a dog|cat’
例
>>> s = ‘I have a dog , I have a cat’
>>> re.findall( r’I have a (?:dog|cat)’ , s )
['I have a dog', 'I have a cat'] #正如我们所要的
下面再看看不用无捕获组会是什么后果:
>>> re.findall( r’I have a dog|cat’ , s )
['I have a dog', 'cat'] #它将’I have a dog’和’cat’当成两个规则了
至于无捕获组的使用,后面将仔细说明。这里先跳过。
‘.’ 匹配所有字符
匹配除换行符’/n’外的所有字符。如果使用了’S’选项,匹配包括’/n’的所有字符。
例:
>>> s=’123 /n456 /n789’
>>> findall(r‘.+’,s)
['123', '456', '789']
>>> re.findall(r‘.+’ , s , re.S)
['123/n456/n789']
‘^’和’$’匹配字符串开头和结尾
注意’^’不能在‘[ ]’中,否则含意就发生变化,具体请看上面的’[‘ ‘]’说明。在多行模式下,它们可以匹配每一行的行首和行尾。具体请看后面compile函数说明的’M
’选项部分
‘/d’匹配数字
这是一个以’/’开头的转义字符,’/d’表示匹配一个数字,即等价于[0-9]
‘/D’匹配非数字
这个是上面的反集,即匹配一个非数字的字符,等价于[^0-9]。注意它们的大小写。下面我们还将看到Python的正则规则中很多转义字符的大小写形式,代表互补的关系。这样很
好记。
‘/w’匹配字母和数字
匹配所有的英文字母和数字,即等价于[a-zA-Z0-9]。
‘/W’匹配非英文字母和数字
即’/w’的补集,等价于[^a-zA-Z0-9]。
‘/s’匹配间隔符
即匹配空格符、制表符、回车符等表示分隔意义的字符,它等价于[ /t/r/n/f/v]。(注意最前面有个空格)
‘/S’匹配非间隔符
即间隔符的补集,等价于[^ /t/r/n/f/v]
‘/A’匹配字符串开头
匹配字符串的开头。它和’^’的区别是,’/A’只匹配整个字符串的开头,即使在’M’模式下,它也不会匹配其它行的很首。
‘/Z’匹配字符串结尾
匹配字符串的结尾。它和’$’的区别是,’/Z’只匹配整个字符串的结尾,即使在’M’模式下,它也不会匹配其它各行的行尾。
例:
>>> s= '12 34/n56 78/n90'
>>> re.findall( r'^/d+' , s , re.M ) #匹配位于行首的数字
['12', '56', '90']
>>> re.findall( r’/A/d+’, s , re.M ) #匹配位于字符串开头的数字
['12']
>>> re.findall( r'/d+$' , s , re.M ) #匹配位于行尾的数字
['34', '78', '90']
>>> re.findall( r’/d+/Z’ , s , re.M ) #匹配位于字符串尾的数字
['90']
‘/b’匹配单词边界
它匹配一个单词的边界,比如空格等,不过它是一个‘0’长度字符,它匹配完的字符串不会包括那个分界的字符。而如果用’/s’来匹配的话,则匹配出的字符串中会包含那个
分界符。
例:
>>> s = 'abc abcde bc bcd'
>>> re.findall( r’/bbc/b’ , s ) #匹配一个单独的单词‘bc’ ,而当它是其它单词的一部分的时候不匹配
['bc'] #只找到了那个单独的’bc’
>>> re.findall( r’/sbc/s’ , s ) #匹配一个单独的单词‘bc’
[' bc '] #只找到那个单独的’bc’,不过注意前后有两个空格,可能有点看不清楚
‘/B’匹配非边界
和’/b’相反,它只匹配非边界的字符。它同样是个0长度字符。
接上例:
>>> re.findall( r’/Bbc/w+’ , s ) #匹配包含’bc’但不以’bc’为开头的单词
['bcde'] #成功匹配了’abcde’中的’bcde’,而没有匹配’bcd’
‘(?:)’无捕获组
当你要将一部分规则作为一个整体对它进行某些操作,比如指定其重复次数时,你需要将这部分规则用’(?:’ ‘)’把它包围起来,而不能仅仅只用一对括号,那样将得到绝对
出人意料的结果。
例:匹配字符串中重复的’ab’
>>> s=’ababab abbabb aabaab’
>>> re.findall( r’/b(?:ab)+/b’ , s )
['ababab']
如果仅使用一对括号,看看会是什么结果:
>>> re.findall( r’/b(ab)+/b’ , s )
['ab']
这是因为如果只使用一对括号,那么这就成为了一个组(group)。组的使用比较复杂,将在后面详细讲解。
‘(?# )’注释
Python允许你在正则表达式中写入注释,在’(?#’ ‘)’之间的内容将被忽略。
(?iLmsux) 编译选项指定
Python的正则式可以指定一些选项,这个选项可以写在findall或compile的参数中,也可以写在正则式里,成为正则式的一部分。这在某些情况下会便利一些。具体的选项含义请
看后面的compile函数的说明。
此处编译选项’i’等价于IGNORECASE ,L 等价于 LOCAL ,m 等价于 MULTILINE,s等价于 DOTALL ,u等价于UNICODE , x 等价于 VERBOSE。
请注意它们的大小写。在使用时可以只指定一部分,比如只指定忽略大小写,可写为‘(?i)’,要同时忽略大小写并使用多行模式,可以写为‘(?im)’。
另外要注意选项的有效范围是整条规则,即写在规则的任何地方,选项都会对全部整条正则式有效。
1.2重复
正则式需要匹配不定长的字符串,那就一定需要表示重复的指示符。Python的正则式表示重复的功能很丰富灵活。重复规则的一般的形式是在一条字符规则后面紧跟一个表示重复
次数的规则,已表明需要重复前面的规则一定的次数。重复规则有:
‘*’ 0或多次匹配
表示匹配前面的规则0次或多次。
‘+’ 1次或多次匹配
表示匹配前面的规则至少1次,可以多次匹配
例:匹配以下字符串中的前一部分是字母,后一部分是数字或没有的变量名字
>>> s = ‘ aaa bbb111 cc22cc 33dd ‘
>>> re.findall( r’/b[a-z]+/d*/b’ , s ) #必须至少1个字母开头,以连续数字结尾或没有数字
['aaa', 'bbb111']
注意上例中规则前后加了表示单词边界的’/b’指示符,如果不加的话结果就会变成:
>>> re.findall( r’[a-z]+/d*’ , s )
['aaa', 'bbb111', 'cc22', 'cc', 'dd'] #把单词给拆开了
大多数情况下这不是我们期望的结果。
‘?’ 0或1次匹配
只匹配前面的规则0次或1次。
例,匹配一个数字,这个数字可以是一个整数,也可以是一个科学计数法记录的数字,比如123和10e3都是正确的数字。
>>> s = ‘ 123 10e3 20e4e4 30ee5 ‘
>>> re.findall( r’ /b/d+[eE]?/d*/b’ , s )
['123', '10e3']
它正确匹配了123和10e3,正是我们期望的。注意前后的’/b’的使用,否则将得到不期望的结果。
1.2.1 精确匹配和最小匹配
Python正则式还可以精确指定匹配的次数。指定的方式是
‘{m}’ 精确匹配m次
‘{m,n}’ 匹配最少m次,最多n次。(n>m)
如果你只想指定一个最少次数或只指定一个最多次数,你可以把另外一个参数空起来。比如你想指定最少3次,可以写成{3,}(注意那个逗号),同样如果只想指定最大为5次,可
以写成{,5},也可以写成{0,5}。
例寻找下面字符串中
a:3位数
b: 2位数到4位数
c: 5位数以上的数
d: 4位数以下的数
>>> s= ‘ 1 22 333 4444 55555 666666 ‘
>>> re.findall( r’/b/d{3}/b’ , s ) # a:3位数
['333']
>>> re.findall( r’/b/d{2,4}/b’ , s ) # b: 2位数到4位数
['22', '333', '4444']
>>> re.findall( r’/b/d{5,}/b’, s ) # c: 5位数以上的数
['55555', '666666']
>>> re.findall( r’/b/d{1,4}/b’ , s ) # 4位数以下的数
['1', '22', '333', '4444']
‘*?’ ‘+?’ ‘??’最小匹配
‘*’ ‘+’ ‘?’通常都是尽可能多的匹配字符。有时候我们希望它尽可能少的匹配。比如一个c语言的注释‘/* part 1 */ /* part 2 */’,如果使用最大规则:
>>> s =r ‘/* part 1 */ code /* part 2 */’
>>> re.findall( r’//*.*/*/’ , s )
[‘/* part 1 */ code /* part 2 */’]
结果把整个字符串都包括进去了。如果把规则改写成
>>> re.findall( r’//*.*?/*/’ , s ) #在*后面加上?,表示尽可能少的匹配
['/* part 1 */', '/* part 2 */']
结果正确的匹配出了注释里的内容
1.3 前向界定与后向界定
有时候需要匹配一个跟在特定内容后面的或者在特定内容前面的字符串,Python提供一个简便的前向界定和后向界定功能,或者叫前导指定和跟从指定功能。它们是:
‘(?<=…)’前向界定
括号中’…’代表你希望匹配的字符串的前面应该出现的字符串。
‘(?=…)’ 后向界定
括号中的’…’代表你希望匹配的字符串后面应该出现的字符串。
例:你希望找出c语言的注释中的内容,它们是包含在’/*’和’*/’之间,不过你并不希望匹配的结果把’/*’和’*/’也包括进来,那么你可以这样用:
>>> s=r’/* comment 1 */ code /* comment 2 */’
>>> re.findall( r’(?<=//*).+?(?=/*/)’ , s )
[' comment 1 ', ' comment 2 ']
注意这里我们仍然使用了最小匹配,以避免把整个字符串给匹配进去了。
要注意的是,前向界定括号中的表达式必须是常值,也即你不可以在前向界定的括号里写正则式。比如你如果在下面的字符串中想找到被字母夹在中间的数字,你不可以用前向界
定:
例:
>>> s = ‘aaa111aaa , bbb222 , 333ccc ‘
>>> re.findall( r’(?<=[a-z]+)/d+(?=[a-z]+)' , s ) #错误的用法
它会给出一个错误信息:
error: look-behind requires fixed-width pattern
不过如果你只要找出后面接着有字母的数字,你可以在后向界定写正则式:
>>> re.findall( r’/d+(?=[a-z]+)’, s )
['111', '333']
如果你一定要匹配包夹在字母中间的数字,你可以使用组(group)的方式
>>> re.findall (r'[a-z]+(/d+)[a-z]+' , s )
['111']
组的使用将在后面详细讲解。
除了前向界定前向界定和后向界定外,还有前向非界定和后向非界定,它的写法为:
‘(?<!...)’前向非界定
只有当你希望的字符串前面不是’…’的内容时才匹配
‘(?!...)’后向非界定
只有当你希望的字符串后面不跟着’…’内容时才匹配。
接上例,希望匹配后面不跟着字母的数字
>>> re.findall( r’/d+(?!/w+)’ , s )
['222']
注意这里我们使用了/w而不是像上面那样用[a-z],因为如果这样写的话,结果会是:
>>> re.findall( r’/d+(?![a-z]+)’ , s )
['11', '222', '33']
这和我们期望的似乎有点不一样。它的原因,是因为’111’和’222’中的前两个数字也是满足这个要求的。因此可看出,正则式的使用还是要相当小心的,因为我开始就是这样
写的,看到结果后才明白过来。不过Python试验起来很方便,这也是脚本语言的一大优点,可以一步一步的试验,快速得到结果,而不用经过烦琐的编译、链接过程。也因此学习
Python就要多试,跌跌撞撞的走过来,虽然曲折,却也很有乐趣。
1.4组的基本知识
上面我们已经看过了Python的正则式的很多基本用法。不过如果仅仅是上面那些规则的话,还是有很多情况下会非常麻烦,比如上面在讲前向界定和后向界定时,取夹在字母中间
的数字的例子。用前面讲过的规则都很难达到目的,但是用了组以后就很简单了。
‘(‘’)’ 无命名组
最基本的组是由一对圆括号括起来的正则式。比如上面匹配包夹在字母中间的数字的例子中使用的(/d+),我们再回顾一下这个例子:
>>> s = ‘aaa111aaa , bbb222 , 333ccc ‘
>>> re.findall (r'[a-z]+(/d+)[a-z]+' , s )
['111']
可以看到findall函数只返回了包含在’()’中的内容,而虽然前面和后面的内容都匹配成功了,却并不包含在结果中。
除了最基本的形式外,我们还可以给组起个名字,它的形式是
‘(?P<name>…)’命名组
‘(?P’代表这是一个Python的语法扩展’<…>’里面是你给这个组起的名字,比如你可以给一个全部由数字组成的组叫做’num’,它的形式就是’(?P<num>/d+)’。起了名字之
后,我们就可以在后面的正则式中通过名字调用这个组,它的形式是
‘(?P=name)’调用已匹配的命名组
要注意,再次调用的这个组是已被匹配的组,也就是说它里面的内容是和前面命名组里的内容是一样的。
我们可以看更多的例子:请注意下面这个字符串各子串的特点。
>>> s='aaa111aaa,bbb222,333ccc,444ddd444,555eee666,fff777ggg'
我们看看下面的正则式会返回什么样的结果:
>>> re.findall( r'([a-z]+)/d+([a-z]+)' , s ) #找出中间夹有数字的字母
[('aaa', 'aaa'), ('fff', 'ggg')]
>>> re.findall( r '(?P<g1>[a-z]+)/d+(?P=g1)' , s ) #找出被中间夹有数字的前后同样的字母
['aaa']
>>> re.findall( r'[a-z]+(/d+)([a-z]+)' , s ) #找出前面有字母引导,中间是数字,后面是字母的字符串中的中间的数字和后面的字母
[('111', 'aaa'), ('777', 'ggg')]
我们可以通过命名组的名字在后面调用已匹配的命名组,不过名字也不是必需的。
‘/number’ 通过序号调用已匹配的组
正则式中的每个组都有一个序号,序号是按组从左到右,从1开始的数字,你可以通过下面的形式来调用已匹配的组
比如上面找出被中间夹有数字的前后同样的字母的例子,也可以写成:
>>> re.findall( r’([a-z]+)/d+/1’ , s )
['aaa']
结果是一样的。
我们再看一个例子
>>> s='111aaa222aaa111 , 333bbb444bb33'
>>> re.findall( r'(/d+)([a-z]+)(/d+)(/2)(/1)' , s ) #找出完全对称的数字-字母-数字-字母-数字中的数字和字母
[('111', 'aaa', '222', 'aaa', '111')]
Python2.4以后的re模块,还加入了一个新的条件匹配功能
‘(?(id/name)yes-pattern|no-pattern)’ 判断指定组是否已匹配,执行相应的规则
这个规则的含义是,如果id/name指定的组在前面匹配成功了,则执行yes-pattern的正则式,否则执行no-pattern的正则式。
举个例子,比如要匹配一些形如usr@mail的邮箱地址,不过有的写成< usr@mail >即用一对<>括起来,有点则没有,要匹配这两种情况,可以这样写
>>> s='<usr1@mail1> usr2@maill2'
>>> re.findall( r'(<)?/s*(/w+@/w+)/s*(?(1)>)' , s )
[('<', 'usr1@mail1'), ('', 'usr2@maill2')]
不过如果目标字符串如下
>>> s='<usr1@mail1> usr2@maill2 <usr3@mail3 usr4@mail4> < usr5@mail5 '
而你想得到要么由一对<>包围起来的一个邮件地址,要么得到一个没有被<>包围起来的地址,但不想得到一对<>中间包围的多个地址或不完整的<>中的地址,那么使用这个式子并
不能得到你想要的结果
>>> re.findall( r'(<)?/s*(/w+@/w+)/s*(?(1)>)' , s )
[('<', 'usr1@mail1'), ('', 'usr2@maill2'), ('', 'usr3@mail3'), ('', 'usr4@mail4'), ('', 'usr5@mail5')]
它仍然找到了所有的邮件地址。
想要实现这个功能,单纯的使用findall有点吃力,需要使用其它的一些函数,比如match或search函数,再配合一些控制功能。这部分的内容将在下面详细讲解。
小结:以上基本上讲述了Python正则式的语法规则。虽然大部分语法规则看上去都很简单,可是稍不注意,仍然会得到与期望大相径庭的结果,所以要写好正则式,需要仔细的体
会正则式规则的含义后不同规则之间细微的差别。
详细的了解了规则后,再配合后面就要介绍的功能函数,就能最大的发挥正则式的威力了。
2 re模块的基本函数
在上面的说明中,我们已经对re模块的基本函数‘findall’很熟悉了。当然如果光有findall的话,很多功能是不能实现的。下面开始介绍一下re模块其它的常用基本函数。灵活
搭配使用这些函数,才能充分发挥Python正则式的强大功能。
首先还是说下老熟人findall函数吧
findall(rule , target [,flag] )
在目标字符串中查找符合规则的字符串。
第一个参数是规则,第二个参数是目标字符串,后面还可以跟一个规则选项(选项功能将在compile函数的说明中详细说明)。
返回结果结果是一个列表,中间存放的是符合规则的字符串。如果没有符合规则的字符串被找到,就返回一个空列表。
2.1使用compile加速
compile( rule [,flag] )
将正则规则编译成一个Pattern对象,以供接下来使用。
第一个参数是规则式,第二个参数是规则选项。
返回一个Pattern对象
直接使用findall ( rule , target )的方式来匹配字符串,一次两次没什么,如果是多次使用的话,由于正则引擎每次都要把规则解释一遍,而规则的解释又是相当费时间的,
所以这样的效率就很低了。如果要多次使用同一规则来进行匹配的话,可以使用re.compile函数来将规则预编译,使用编译过返回的Regular Expression Object或叫做Pattern对
象来进行查找。
例
>>> s='111,222,aaa,bbb,ccc333,444ddd'
>>> rule=r’/b/d+/b’
>>> compiled_rule=re.compile(rule)
>>> compiled_rule.findall(s)
['111', '222']
可见使用compile过的规则使用和未编译的使用很相似。compile函数还可以指定一些规则标志,来指定一些特殊选项。多个选项之间用’|’(位或)连接起来。
I IGNORECASE 忽略大小写区别。
L LOCAL 字符集本地化。这个功能是为了支持多语言版本的字符集使用环境的,比如在转义符/w,在英文环境下,它代表[a-zA-Z0-9],即所以英文字符和数字。如果在一个法
语环境下使用,缺省设置下,不能匹配"é"或"ç"。加上这L选项和就可以匹配了。不过这个对于中文环境似乎没有什么用,它仍然不能匹配中文字符。
M MULTILINE 多行匹配。在这个模式下’^’(代表字符串开头)和’$’(代表字符串结尾)将能够匹配多行的情况,成为行首和行尾标记。比如
>>> s=’123 456/n789 012/n345 678’
>>> rc=re.compile(r’^/d+’) #匹配一个位于开头的数字,没有使用M选项
>>> rc.findall(s)
['123'] #结果只能找到位于第一个行首的’123’
>>> rcm=re.compile(r’^/d+’,re.M) #使用M选项
>>> rcm.findall(s)
['123', '789', '345'] #找到了三个行首的数字
同样,对于’$’来说,没有使用M选项,它将匹配最后一个行尾的数字,即’678’,加上以后,就能匹配三个行尾的数字456 012和678了.
>>> rc=re.compile(r’/d+$’)
>>> rcm=re.compile(r’/d+$’,re.M)
>>> rc.findall(s)
['678']
>>> rcm.findall(s)
['456', '012', '678']
S DOTALL ‘.’号将匹配所有的字符。缺省情况下’.’匹配除换行符’/n’外的所有字符,使用这一选项以后,’.’就能匹配包括’/n’的任何字符了。
U UNICODE /w,/W,/b,/B,/d,/D,/s和/S都将使用Unicode。
X VERBOSE 这个选项忽略规则表达式中的空白,并允许使用’#’来引导一个注释。这样可以让你把规则写得更美观些。比如你可以把规则
>>> rc = re.compile(r"/d+|[a-zA-Z]+") #匹配一个数字或者单词
使用X选项写成:
>>> rc = re.compile(r""" # start a rule/d+ # number| [a-zA-Z]+ # word""", re.VERBOSE)在这个模式下,如果你想匹配一个空格,你必须
用'/ '的形式('/'后面跟一个空格)
2.2 match与search
match( rule , targetString [,flag] )
search( rule , targetString [,flag] )
(注:re的match与search函数同compile过的Pattern对象的match与search函数的参数是不一样的。Pattern对象的match与search函数更为强大,是真正最常用的函数)
按照规则在目标字符串中进行匹配。
第一个参数是正则规则,第二个是目标字符串,第三个是选项(同compile函数的选项)
返回:若成功返回一个Match对象,失败无返回
findall虽然很直观,但是在进行更复杂的操作时,就有些力不从心了。此时更多的使用的是match和search函数。他们的参数和findall是一样的,都是:
match( rule , targetString [,flag] )
search( rule , targetString [,flag] )
不过它们的返回不是一个简单的字符串列表,而是一个MatchObject(如果匹配成功的话).。通过操作这个matchObject,我们可以得到更多的信息。
需要注意的是,如果匹配不成功,它们则返回一个NoneType。所以在对匹配完的结果进行操作之前,你必需先判断一下是否匹配成功了,比如:
>>> m=re.match( rule , target )
>>> if m: #必需先判断是否成功
doSomethin
这两个函数唯一的区别是:match从字符串的开头开始匹配,如果开头位置没有匹配成功,就算失败了;而search会跳过开头,继续向后寻找是否有匹配的字符串。针对不同的需
要,可以灵活使用这两个函数。
关于match返回的MatchObject如果使用的问题,是Python正则式的精髓所在,它与组的使用密切相关。我将在下一部分详细讲解,这里只举个最简单的例子:
例:
>>> s= 'Tom:9527 , Sharry:0003'
>>> m=re.match( r'(?P<name>/w+):(?P<num>/d+)' , s )
>>> m.group()
'Tom:9527'
>>> m.groups()
('Tom', '9527')
>>> m.group(‘name’)
'Tom'
>>> m.group(‘num’)
'9527'
2.3 finditer
finditer( rule , target [,flag] )
参数同findall
返回一个迭代器
finditer函数和findall函数的区别是,findall返回所有匹配的字符串,并存为一个列表,而finditer则并不直接返回这些字符串,而是返回一个迭代器。关于迭代器,解释起来
有点复杂,还是看看例子把:
>>> s=’111 222 333 444’
>>> for i in re.finditer(r’/d+’ , s ):
print i.group(),i.span() #打印每次得到的字符串和起始结束位置
结果是
111 (0, 3)
222 (4, 7)
333 (8, 11)
444 (12, 15)
简单的说吧,就是finditer返回了一个可调用的对象,使用for i in finditer()的形式,可以一个一个的得到匹配返回的Match对象。这在对每次返回的对象进行比较复杂的操作
时比较有用。
2.4字符串的替换和修改
re模块还提供了对字符串的替换和修改函数,他们比字符串对象提供的函数功能要强大一些。这几个函数是
sub ( rule , replace , target [,count] )
subn(rule , replace , target [,count] )
在目标字符串中规格规则查找匹配的字符串,再把它们替换成指定的字符串。你可以指定一个最多替换次数,否则将替换所有的匹配到的字符串。
第一个参数是正则规则,第二个参数是指定的用来替换的字符串,第三个参数是目标字符串,第四个参数是最多替换次数。
这两个函数的唯一区别是返回值。
sub返回一个被替换的字符串
sub返回一个元组,第一个元素是被替换的字符串,第二个元素是一个数字,表明产生了多少次替换。
例,将下面字符串中的’dog’全部替换成’cat’
>>> s=’ I have a dog , you have a dog , he have a dog ‘
>>> re.sub( r’dog’ , ‘cat’ , s )
' I have a cat , you have a cat , he have a cat '
如果我们只想替换前面两个,则
>>> re.sub( r’dog’ , ‘cat’ , s , 2 )
' I have a cat , you have a cat , he have a dog '
或者我们想知道发生了多少次替换,则可以使用subn
>>> re.subn( r’dog’ , ‘cat’ , s )
(' I have a cat , you have a cat , he have a cat ', 3)
split( rule , target [,maxsplit] )
切片函数。使用指定的正则规则在目标字符串中查找匹配的字符串,用它们作为分界,把字符串切片。
第一个参数是正则规则,第二个参数是目标字符串,第三个参数是最多切片次数
返回一个被切完的子字符串的列表
这个函数和str对象提供的split函数很相似。举个例子,我们想把上例中的字符串被’,’分割开,同时要去掉逗号前后的空格
>>> s=’ I have a dog , you have a dog , he have a dog ‘
>>> re.split( ‘/s*,/s*’ , s )
[' I have a dog', 'you have a dog', 'he have a dog ']
结果很好。如果使用str对象的split函数,则由于我们不知道’,’两边会有多少个空格,而不得不对结果再进行一次处理。
escape( string )
这是个功能比较古怪的函数,它的作用是将字符串中的non-alphanumerics字符(我已不知道该怎么翻译比较好了)用反义字符的形式显示出来。有时候你可能希望在正则式中匹
配一个字符串,不过里面含有很多re使用的符号,你要一个一个的修改写法实在有点麻烦,你可以使用这个函数,
例在目标字符串s中匹配’(*+?)’这个子字符串
>>> s= ‘111 222 (*+?) 333’
>>> rule= re.escape( r’(*+?)’ )
>>> print rule
/(/*/+/?/)
>>> re.findall( rule , s )
['(*+?)']
3 更深入的了解re的组与对象
前面对Python正则式的组进行了一些简单的介绍,由于还没有介绍到match对象,而组又是和match对象密切相关的,所以必须将它们结合起来介绍才能充分地说明它们的用途。
不过再详细介绍它们之前,我觉得有必要先介绍一下将规则编译后的生成的patter对象
3.1编译后的Pattern对象
将一个正则式,使用compile函数编译,不仅是为了提高匹配的速度,同时还能使用一些附加的功能。编译后的结果生成一个Pattern对象,这个对象里面有很多函数,他们看起来
和re模块的函数非常象,它同样有findall , match , search ,finditer , sub , subn , split这些函数,只不过它们的参数有些小小的不同。一般说来,re模块函数的第一个
参数,即正则规则不再需要了,应为规则就包含在Pattern对象中了,编译选项也不再需要了,因为已经被编译过了。因此re模块中函数的这两个参数的位置,就被后面的参数取
代了。
findall , match , search和finditer这几个函数的参数是一样的,除了少了规则和选项两个参数外,它们又加入了另外两个参数,它们是:查找开始位置和查找结束位置,也就
是说,现在你可以指定查找的区间,除去你不感兴趣的区间。它们现在的参数形式是:
findall ( targetString [, startPos [,endPos] ] )
finditer ( targetString [, startPos [,endPos] ] )
match ( targetString [, startPos [,endPos] ] )
search ( targetString [, startPos [,endPos] ] )
这些函数的使用和re模块的同名函数使用完全一样。所以就不多介绍了。
除了和re模块的函数同样的函数外,Pattern对象还多了些东西,它们是:
flags 查询编译时的选项
pattern查询编译时的规则
groupindex规则里的组
这几个不是函数,而是一个值。它们提供你一些规则的信息。比如下面这个例子
>>> p=re.compile( r'(?P<word>/b[a-z]+/b)|(?P<num>/b/d+/b)|(?P<id>/b[a-z_]+/w*/b)' , re.I )
>>> p.flags
2
>>> p.pattern
'(?P<word>//b[a-z]+//b)|(?P<num>//b//d+//b)|(?P<id>//b[a-z_]+//w*//b)'
>>> p.groupindex
{'num': 2, 'word': 1, 'id': 3}
我们来分析一下这个例子:这个正则式是匹配单词、或数字、或一个由字母或’_’开头,后面接字母或数字的一个ID。我们给这三种情况的规则都包入了一个命名组,分别命名
为’word’ , ‘num’和‘id’。我们规定大小写不敏感,所以使用了编译选项‘I’。
编译以后返回的对象为p,通过p.flag我们可以查看编译时的选项,不过它显示的不是’I’,而是一个数值2。其实re.I是一个整数,2就是它的值。我们可以查看一下:
>>> re.I
2
>>> re.L
4
>>> re.M
8
…
每个选项都是一个数值。
通过p.pattern可以查看被编译的规则是什么。使用print的话会更好看一些
>>> print p.pattern
(?P<word>/b[a-z]+/b)|(?P<num>/b/d+/b)|(?P<id>/b[a-z_]+/w*/b)
看,和我们输入的一样。
接下来的p.groupindex则是一个字典,它包含了规则中的所有命名组。字典的key是名字,values是组的序号。由于字典是以名字作为key,所以一个无命名的组不会出现在这里。
3.2组与Match对象
组与Match对象是Python正则式的重点。只有掌握了组和Match对象的使用,才算是真正学会了Python正则式。
3.2.1 组的名字与序号
正则式中的每个组都有一个序号,它是按定义时从左到右的顺序从1开始编号的。其实,re的正则式还有一个0号组,它就是整个正则式本身。
我们来看个例子
>>> p=re.compile( r’(?P<name>[a-z]+)/s+(?P<age>/d+)/s+(?P<tel>/d+).*’ , re.I )
>>> p.groupindex
{'age': 2, 'tel': 3, 'name': 1}
>>> s=’Tom 24 88888888 <=’
>>> m=p.search(s)
>>> m.groups() #看看匹配的各组的情况
('Tom', '24', '8888888')
>>> m.group(‘name’) #使用组名获取匹配的字符串
‘Tom’
>>> m.group( 1 ) #使用组序号获取匹配的字符串,同使用组名的效果一样
>>> m.group(0) # 0组里面是什么呢?
'Tom 24 88888888 <='
原来0组就是整个正则式,包括没有被包围到组里面的内容。当获取0组的时候,你可以不写这个参数。m.group(0)和m.group()的效果是一样的:
>>> m.group()
'Tom 24 88888888 <='
接下来看看更多的Match对象的方法,看看我们能做些什么。
3.2.2 Match对象的方法
group([index|id]) 获取匹配的组,缺省返回组0,也就是全部值
groups() 返回全部的组
groupdict() 返回以组名为key,匹配的内容为values的字典
接上例:
>>> m.groupindex()
{'age': '24', 'tel': '88888888', 'name': 'Tom'}
start( [group] ) 获取匹配的组的开始位置
end( [group] ) 获取匹配的组的结束位置
span( [group] ) 获取匹配的组的(开始,结束)位置
expand( template )根据一个模版用找到的内容替换模版里的相应位置
这个功能比较有趣,它根据一个模版来用匹配到的内容替换模版中的相应位置,组成一个新的字符串返回。它使用/g<index|name>或/index来指示一个组。
接上例
>>> m.expand(r'name is /g<1> , age is /g<age> , tel is /3')
'name is Tom , age is 24 , tel is 88888888'
除了以上这些函数外,Match对象还有些属性
pos 搜索开始的位置参数
endpos 搜索结束的位置参数
这两个是使用findall或match等函数时,传入的参数。在上面这个例子里,我们没有指定开始和结束位置,那么缺省的开始位置就是0,结束位置就是最后。
>>> m.pos
0
>>> m.endpos
19
lastindex 最后匹配的组的序号
>>> m.lastindex
3
lastgroup 最后匹配的组名
>>> m.lastgroup
'tel'
re 产生这个匹配的Pattern对象,可以认为是个逆引用
>>> m.re.pattern
'(?P<name>[a-z]+)//s+(?P<age>//d+)//s+(?P<tel>//d+).*'
得到了产生这个匹配的规则
string 匹配的目标字符串
>>> m.string
'Tom 24 88888888 <='
转自:
http://hi.baidu.com/yangdaming1983/item/e6a8146255a5442169105b91posted @
2013-02-11 16:28 Seraphi 阅读(302) |
评论 (0) |
编辑 收藏
摘要: 1 概述1.1 什么是捕获组捕获组就是把正则表达式中子表达式匹配的内容,保存到内存中以数字编号或显式命名的组里,方便后面引用。当然,这种引用既可以是在正则表达式内部,也可以是在正则表达式外部。捕获组有两种形式,一种是普通捕获组,另一种是命名捕获组,...
阅读全文
posted @
2013-02-11 16:26 Seraphi 阅读(1971) |
评论 (0) |
编辑 收藏Python读写文件
1.open
使用open打开文件后一定要记得调用文件对象的close()方法。比如可以用try/finally语句来确保最后能关闭文件。
file_object = open('thefile.txt')
try:
all_the_text = file_object.read( )
finally:
file_object.close( )
注:不能把open语句放在try块里,因为当打开文件出现异常时,文件对象file_object无法执行close()方法。
2.读文件
读文本文件
input = open('data', 'r')
#第二个参数默认为r
input = open('data')
读二进制文件
input = open('data', 'rb')
读取所有内容
file_object = open('thefile.txt')
try:
all_the_text = file_object.read( )
finally:
file_object.close( )
读固定字节
file_object = open('abinfile', 'rb')
try:
while True:
chunk = file_object.read(100)
if not chunk:
break
do_something_with(chunk)
finally:
file_object.close( )
读每行
list_of_all_the_lines = file_object.readlines( )
如果文件是文本文件,还可以直接遍历文件对象获取每行:
for line in file_object:
process line
3.写文件
写文本文件
output = open('data', 'w')
写二进制文件
output = open('data', 'wb')
追加写文件
output = open('data', 'w+')
写数据
file_object = open('thefile.txt', 'w')
file_object.write(all_the_text)
file_object.close( )
写入多行
file_object.writelines(list_of_text_strings)
注意,调用writelines写入多行在性能上会比使用write一次性写入要高。
在处理日志文件的时候,常常会遇到这样的情况:日志文件巨大,不可能一次性把整个文件读入到内存中进行处理,例如需要在一台物理内存为 2GB 的机器上处理一个 2GB 的日志文件,我们可能希望每次只处理其中 200MB 的内容。
在 Python 中,内置的 File 对象直接提供了一个 readlines(sizehint) 函数来完成这样的事情。以下面的代码为例:
file = open('test.log', 'r')sizehint = 209715200 # 200Mposition = 0lines = file.readlines(sizehint)while not file.tell() - position < 0: position = file.tell() lines = file.readlines(sizehint)
每次调用 readlines(sizehint) 函数,会返回大约 200MB 的数据,而且所返回的必然都是完整的行数据,大多数情况下,返回的数据的字节数会稍微比 sizehint 指定的值大一点(除最后一次调用 readlines(sizehint) 函数的时候)。通常情况下,Python 会自动将用户指定的 sizehint 的值调整成内部缓存大小的整数倍。
file在python是一个特殊的类型,它用于在python程序中对外部的文件进行操作。在python中一切都是对象,file也不例外,file有file的方法和属性。下面先来看如何创建一个file对象:
file(name[, mode[, buffering]])
file()函数用于创建一个file对象,它有一个别名叫open(),可能更形象一些,它们是内置函数。来看看它的参数。它参数都是以字符串的形式传递的。name是文件的名字。
mode是打开的模式,可选的值为r w a U,分别代表读(默认) 写 添加支持各种换行符的模式。用w或a模式打开文件的话,如果文件不存在,那么就自动创建。此外,用w模式打开一个已经存在的文件时,原有文件的内容会被清空,因为一开始文件的操作的标记是在文件的开头的,这时候进行写操作,无疑会把原有的内容给抹掉。由于历史的原因,换行符在不同的系统中有不同模式,比如在 unix中是一个\n,而在windows中是‘\r\n’,用U模式打开文件,就是支持所有的换行模式,也就说‘\r’ '\n' '\r\n'都可表示换行,会有一个tuple用来存贮这个文件中用到过的换行符。不过,虽说换行有多种模式,读到python中统一用\n代替。在模式字符的后面,还可以加上+ b t这两种标识,分别表示可以对文件同时进行读写操作和用二进制模式、文本模式(默认)打开文件。
buffering如果为0表示不进行缓冲;如果为1表示进行“行缓冲“;如果是一个大于1的数表示缓冲区的大小,应该是以字节为单位的。
file对象有自己的属性和方法。先来看看file的属性。
closed #标记文件是否已经关闭,由close()改写
encoding #文件编码
mode #打开模式
name #文件名
newlines #文件中用到的换行模式,是一个tuple
softspace #boolean型,一般为0,据说用于print
file的读写方法:
F.read([size]) #size为读取的长度,以byte为单位
F.readline([size])
#读一行,如果定义了size,有可能返回的只是一行的一部分
F.readlines([size])
#把文件每一行作为一个list的一个成员,并返回这个list。其实它的内部是通过循环调用readline()来实现的。如果提供size参数,size是表示读取内容的总长,也就是说可能只读到文件的一部分。
F.write(str)
#把str写到文件中,write()并不会在str后加上一个换行符
F.writelines(seq)
#把seq的内容全部写到文件中。这个函数也只是忠实地写入,不会在每行后面加上任何东西。
file的其他方法:
F.close()
#关闭文件。python会在一个文件不用后自动关闭文件,不过这一功能没有保证,最好还是养成自己关闭的习惯。如果一个文件在关闭后还对其进行操作会产生ValueError
F.flush()
#把缓冲区的内容写入硬盘
F.fileno()
#返回一个长整型的”文件标签“
F.isatty()
#文件是否是一个终端设备文件(unix系统中的)
F.tell()
#返回文件操作标记的当前位置,以文件的开头为原点
F.next()
#返回下一行,并将文件操作标记位移到下一行。把一个file用于for ... in file这样的语句时,就是调用next()函数来实现遍历的。
F.seek(offset[,whence])
#将文件打操作标记移到offset的位置。这个offset一般是相对于文件的开头来计算的,一般为正数。但如果提供了whence参数就不一定了,whence可以为0表示从头开始计算,1表示以当前位置为原点计算。2表示以文件末尾为原点进行计算。需要注意,如果文件以a或a+的模式打开,每次进行写操作时,文件操作标记会自动返回到文件末尾。
F.truncate([size])
#把文件裁成规定的大小,默认的是裁到当前文件操作标记的位置。如果size比文件的大小还要大,依据系统的不同可能是不改变文件,也可能是用0把文件补到相应的大小,也可能是以一些随机的内容加上去。
本文来自CSDN博客,转载请标明出处:http://blog.csdn.net/adupt/archive/2009/08/11/4435615.aspx
posted @
2013-02-10 23:31 Seraphi 阅读(1336) |
评论 (0) |
编辑 收藏
posted @
2013-02-02 16:01 Seraphi 阅读(397) |
评论 (0) |
编辑 收藏linux 下的iconv命令可以把Windows默认GBK编码的文件转成Linux下用的UTF-8编码。
Example: $ iconv -f GBK -t UTF-8 file_name -o file_name
1. 安装命令行版的texlive: sudo apt-get install texlive-full
2. 安装一个比较有帮助性的编辑器: sudo apt-get install texmaker
3. 安装中文环境: sudo apt-get install latex-cjk-all
A useful webiste http://chixi.an.blog.163.com/blog/static/29359272201262952120729/
To install/upgrade to TeX Live 2012:
- Open a terminal with Ctrl+Alt+T
Add the texlive-backports PPA by typing the below (enter your password when prompted):
sudo apt-add-repository ppa:texlive-backports/ppa
Then type:
sudo apt-get update
Installation:
If you are installing TeX Live for the first time, type:
sudo apt-get install texlive
If you already have TeX Live installed and are upgrading, type:
sudo apt-get upgrade
Warning: this will also upgrade all other packages on your Ubuntu system for which upgrades are available. If you do not wish to do this, please use the previous sudo apt-get install texliveinstead.
转自:http://blog.csdn.net/lsg32/article/details/8058491
posted @
2013-02-02 15:27 Seraphi 阅读(296) |
评论 (0) |
编辑 收藏
在新版本的UBUNTU里不支持WINDOWS的wubi安装,要用如下方式:
Ubuntu 12.04 wubi的安装
一、在12.04里,在Windows内安装那个选项被禁用了,只能通过以下指令开启,X为光驱盘符:
代码:
X:\wubi.exe --force-wubi
posted @
2013-02-01 12:27 Seraphi 阅读(268) |
评论 (0) |
编辑 收藏
1、学会latex
2、熟练python
3、NLP相关知识,主要是gibbs sampling;以及这学期所学到的东西
4、Deep learning
5、改论文
6、加强算法方面的练习
posted @
2013-01-17 00:24 Seraphi 阅读(194) |
评论 (0) |
编辑 收藏【招聘须知】 Facebook正在全球招聘,对中国顶尖大学的Engineering专业学生尤其欢迎。 具体职位信息可以在https://www.facebook.com/careers上找到,申请的时候一般都是选 择Software Engineer (University Recruiting),Facebook的制度是并不预先定向你去 哪个组。在入职的第一个月统一进行培训,培训结束的两周后进行统一的Team Selectio n,每个组的大Manager过来将自己的组做的东西,你可以和感兴趣的组聊,双向选择后最 终决定去哪里。所以是很自由的文化,决定你去哪里的最重要的是Potential,而不是你 已经在这个area的experience,这也是FB的文化,希望培养每个Engineer成为多面手,对 任何问题的Fast learner。 【基本要求】 专业不限要求有限,可以分成两个类,看看你符合哪一类 1. 第一类: - ACM/ICPC 区域银牌以上,或者在大型比赛上得过不错的名次(前15%),这里大型比赛 指包括NOIP, NOI, APOI,省级选拔赛,Topcoder, Google Code Jam, 百度之星,有道难 题等等 - 在以下公司有过实习经验:Google, Microsoft Research Asia, Hulu, EMC/VMware, Microstrategy (这些公司只是在经验范围内实习生非常靠谱,并没有对其他公司不尊重 的意思,只是接触的不多而已,见谅) - 本科成绩年级前10%,核心课程算法,数据结构,C++,离散,组合数学等等绝大部分为 优秀 - 顶级会议上发表一二作论文,顶级会议的定义是专业领域内公认的大会,例如IR/ML领 域的SIGIR, ICML, WWW, ICDM等等 以上符合任意一条的话,请联系我 2. 第二类: - <Crack the Coding Interview> 从头到尾详细阅读并且做完所有的例题和习题 - www.leetcode.com 全部做完所有的题 符合以上所有条件的,请联系我,附上代码 PS: CTCI书课后有答案,leetcode网上有不错的人做了发表,比如 https://github.com/zwxxx/LeetCode https://github.com/anson627/leetcode 做的时候请不要参考,做完以后可以和参考答案对比改进,直接抄答案是没有意义的,答 案只是帮你提高的工具。对于代码的要求是,写的块,风格简洁,易于理解 【联系方式】 请发邮件到邮箱zhangchitc@gmail.com,附上简单的自我介绍,并著名是符合上述哪些要 求,如果第二类请用zip压缩包打包代码附在附件中 BTW: 第一类满足的话最终还是要将第二类里面的材料全部做了的。。。。 【面试过程】 职位都是美国总部,不排除可能外派海外Site,不过基本应该都是前者。在推荐以后一 周之内应该总部会安排工程师使用skype进行2到3轮电话面试,通过以后提供机票到美国 进行onsite面试。3到5轮不等。基本都是算法面试,在白板上写程序。全程英文,不需要 英语标准考试成绩,但是对基本的听力和口语要求比较高,要能自由和工程师进行交流, 语法有问题的可以完全不用担心 住宿和交通费用全包。 【注意事项】 - 理论上是可以推实习的,不过对中国学生来讲实习不是很现实,本科生太忙,研究生完 全2、3个月在外面导师应该说不过去 - 基本没有deadline,全年都可以联系我,但是考虑到大陆学生过去的H1B签证申请,如 果拿到offer需要在每年4月前递交申请,所以最晚开始面试应该是2月,越快申请越好 - 因为FB在中国没有公开的招聘渠道,所以请不要传播本帖(虽然知道基本是白说,但是 希望至少本校的同学不要传播出去)招聘的细节我不能说太多,接触以后可以聊 - 满足条件就请大胆申请,在整个过程中我都可以为大家提供帮助和建议。根据HR的反馈 来看本人的推荐还是挺靠谱的,目前为止有7位同学通过我的推荐成功拿到了offer,目测 很快在一周之内会达到10个
posted @
2013-01-11 00:24 Seraphi 阅读(2348) |
评论 (2) |
编辑 收藏Windows Registry Editor Version 5.00
[HKEY_CLASSES_ROOT\CLSID\{B416D21B-3B22-B6D4-BBD3-BBD452DB3D5B}]
@="Internet Explorer"
"InfoTip"="@C:\\WINDOWS\\system32\\zh-CN\\ieframe.dll.mui,-881"
"LocalizedString"="@C:\\WINDOWS\\system32\\zh-CN\\ieframe.dll.mui,-880"
[HKEY_CLASSES_ROOT\CLSID\{B416D21B-3B22-B6D4-BBD3-BBD452DB3D5B}\DefaultIcon]
@="C:\\Program Files\\Internet Explorer\\iexplore.exe,-32528"
[HKEY_CLASSES_ROOT\CLSID\{B416D21B-3B22-B6D4-BBD3-BBD452DB3D5B}\Shell\NoAddOns]
@="在没有加载项的情况下启动"
[HKEY_CLASSES_ROOT\CLSID\{B416D21B-3B22-B6D4-BBD3-BBD452DB3D5B}\Shell\NoAddOns\Command]
@="C:\\Program Files\\Internet Explorer\\iexplore.exe about:NoAdd-ons"
[HKEY_CLASSES_ROOT\CLSID\{B416D21B-3B22-B6D4-BBD3-BBD452DB3D5B}\Shell\Open]
@="打开(O)"
[HKEY_CLASSES_ROOT\CLSID\{B416D21B-3B22-B6D4-BBD3-BBD452DB3D5B}\Shell\Open\Command]
@="C:\\Program Files\\Internet Explorer\\iexplore.exe"
[HKEY_CLASSES_ROOT\CLSID\{B416D21B-3B22-B6D4-BBD3-BBD452DB3D5B}\Shell\属性(R)]
@=""
[HKEY_CLASSES_ROOT\CLSID\{B416D21B-3B22-B6D4-BBD3-BBD452DB3D5B}\Shell\属性(R)\Command]
@="Rundll32.exe Shell32.dll,Control_RunDLL Inetcpl.cpl"
[HKEY_CLASSES_ROOT\CLSID\{B416D21B-3B22-B6D4-BBD3-BBD452DB3D5B}\ShellFolder]
@=""
"Attributes"=dword:00000010
"HideFolderVerbs"=""
"WantsParseDisplayName"=""
"HideOnDesktopPerUser"=""
@="C:\\WINDOWS\\system32\\ieframe.dll,-190"
"HideAsDeletePerUser"=""
Windows Registry Editor Version 5.00
[HKEY_CURRENT_USER\Software\Microsoft\Windows\CurrentVersion\Explorer\CLSID\{B416D21B-3B22-B6D4-BBD3-BBD452DB3D5B}]
@="Internet Explorer"
Windows Registry Editor Version 5.00
[HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\Windows\CurrentVersion\Explorer\Desktop\NameSpace\{B416D21B-3B22-B6D4-BBD3-BBD452DB3D5B}]
@="Windows Media"
posted @
2013-01-06 15:13 Seraphi 阅读(185) |
评论 (0) |
编辑 收藏set tags=tags;
set backspace=indent,eol,start
set shiftwidth=4
set tabstop=4
set expandtab
set encoding=utf8
set fileencodings=utf8,gbk
set nocompatible "去掉讨厌的有关vim一致性模式,避免以前版本的一些bug和局限.
set number "显示行号.
set background=dark "背景颜色暗色.(我觉得不错,保护眼睛.)
syntax on "语法高亮显示.(这个肯定是要的.)
set history=50 "设置命令历史记录为50条.
set autoindent "使用自动对起,也就是把当前行的对起格式应用到下一行.
set smartindent "依据上面的对起格式,智能的选择对起方式,对于类似C语言编.
set tabstop=4 "设置tab键为4个空格.
set shiftwidth=4 "设置当行之间交错时使用4个空格
set showmatch "设置匹配模式,类似当输入一个左括号时会匹配相应的那个右括号
set incsearch
"搜索选项.(比如,键入"/bo",光标自动找到第一个"bo"所在的位置.)hi Comment ctermfg=darkmagenta
hi String ctermfg=darkred
hi Number ctermfg=darkblue
"是否生成一个备份文件.(备份的文件名为原文件名加“~“后缀
"(我不喜欢这个备份设置,一般注释掉.)
"if has(“vms.
" set nobackup
"else
" set backup
"endif
关于注释字体颜色的修改,可以参考:http://blog.csdn.net/a670449625/article/details/48051249
posted @
2012-11-09 19:44 Seraphi 阅读(231) |
评论 (0) |
编辑 收藏http://www.coli.uni-saarland.de/~csporled/page.php?id=tools
这个站点列举出了几乎所有NLP和IR领域能够直接使用的好用的工具包~
posted @
2012-10-29 10:25 Seraphi 阅读(347) |
评论 (0) |
编辑 收藏转载自:cool shell,作者:陈皓
From:http://coolshell.cn/articles/7992.html
先说明一下,我不希望本文变成语言争论贴。希望下面的文章能让我们客观理性地了解C++这个语言。(另,我觉得技术争论不要停留在非黑即白的二元价值观上,这样争论无非就是比谁的嗓门大,比哪一方的观点强,毫无价值。我们应该多看看技术是怎么演进的,怎么取舍的。)
事由
 周五的时候,我在我的微博上发了一个贴说了一下一个网友给我发来的C++程序的规范和内存管理写的不是很好(后来我删除了,因为当事人要求),我并非批判,只是想说明其实程序员是需要一些“疫苗”的,并以此想开一个“程序员疫苗的网站”,结果,@简悦云风同学直接回复到:“不要用 C++ 直接用 C , 就没那么多坑了。”就把这个事带入了语言之争。
周五的时候,我在我的微博上发了一个贴说了一下一个网友给我发来的C++程序的规范和内存管理写的不是很好(后来我删除了,因为当事人要求),我并非批判,只是想说明其实程序员是需要一些“疫苗”的,并以此想开一个“程序员疫苗的网站”,结果,@简悦云风同学直接回复到:“不要用 C++ 直接用 C , 就没那么多坑了。”就把这个事带入了语言之争。
我又发了一条微博:
@左耳朵耗子  : 说C++比C的坑更多的人我可以理解,但理性地思考一下。C语言的坑也不少啊,如果说C语言有90个坑,那么C++就是100个坑(另,我看很多人都把C语言上的坑也归到了C++上来),但是C++你得到的东西更多,封装,多态,继承扩展,泛型编程,智能指针,……,你得到了500%东西,但却只多了10%的坑,多值啊。
: 说C++比C的坑更多的人我可以理解,但理性地思考一下。C语言的坑也不少啊,如果说C语言有90个坑,那么C++就是100个坑(另,我看很多人都把C语言上的坑也归到了C++上来),但是C++你得到的东西更多,封装,多态,继承扩展,泛型编程,智能指针,……,你得到了500%东西,但却只多了10%的坑,多值啊。
结果引来了更多的回复(只节选了一些言论):
- @淘宝褚霸也在微博里说:“自从5年前果断扔掉C++,改用了ansi c后,我的生活质量大大提升,没有各种坑坑我。”
- @Laruence在其微博里说: “我确实用不到, C语言灵活运用struct, 可以很好的满足这些需求.//@左耳朵耗子: 封装,继承,多态,模板,智能指针,这也用不到?这也学院派?//@Laruence: 问题是, 这些东西我都用不到… C语言是工程师搞的, C++是学院派搞的”
那么,C++的坑真的多么?我还请大家理性地思考一下。
C++真的比C差吗?
我们先来看一个图——《各种程序员的嘴脏的对比》,从这个图上看,C程序员比C++的程序员在注释中使用fuck的字眼多一倍。这说明了什么?我个人觉得这说明C程序员没有C++程序员淡定。

不要太纠结上图,只是轻松一下,我没那么无聊,让我们来看点真正的论据。
相信用过C++的程序员知道,C++的很多特性主要就是解决C语言中的各种不完美和缺陷:(注:C89、C99中许多的改进正是从C++中所引进的)
- 用const/inline/template代替了宏,解决了C语言中宏的各种坑。
- 用const的类型解决了很多C语言中变量值莫名改变的问题。
- 用引用代替指针,解决了C语言中指针的各种坑。这个在Java里得到彻底地体现。
- 用强类型检查和四种转型,解决了C语言中乱转型的各种坑。
- 用封装(构造,析构,拷贝构造,赋值重载)解决了C语言中各种复制一个结构体(struct)或是一个数据结构(link, hashtable, list, array等)中浅拷贝的内存问题的各种坑。
- 用封装让你可以在成员变量加入getter/setter,而不会像C一样只有文件级的封装。
- 用函数重载、函数默认参数,解决了C中扩展一个函数搞出来像func2()之类的ugly的东西。
- 用继承多态和RTTI解决了C中乱转struct指针和使用函数指针的诸多让代码ugly的问题。
- 用RAII,智能指针的方式,解决了C语言中因为出现需要释放资源的那些非常ugly的代码的问题。
- 用OO和GP解决各种C语言中用函数指针,对指针乱转型,及一大砣if-else搞出来的ugly的泛型。
(注意:上面我没有提重载运算符和异常,前者写出来的代码并不易读和易维护(参看《
恐怖的C++语言》后面的那个示例),坑也多,后者并不成熟(相对于Java的异常),但是我们需要知道try-catch这种方式比传统的不断地判断函数返回值和errno形成的大量的if-else在代码可读性上要好很多)
上述的这些东西填了不知有多少的C语言编程和维护的坑。少用指针,多用引用,试试autoptr,用用封装,继承,多态和函数重载…… 你面对的坑只会比C少,不会多。
C++的坑有多少?
C++的坑真的不多,如果你能花两到三周的时候读一下《Effecitve C++》里的那50多个条款,你就知道C++里的坑并不多,而且,有很多条款告诉我们C++是怎么解决C的坑的。然后,你可以读读《Exceptional C++》和《More Exceptional C++》,你可以了解一下C++各种问题的解决方法和一些常见的经典错误。
当然,C++在解决了很多C语的坑的同时,也因为OO和泛型又引入了一些坑。消一些,加一些,我个人感觉上总体上只比C多10%左右吧。但是你有了开发速度更快,代码更易读,更易维护的500%的利益。
另外,不可否认的是,C++中的代码出了错误,有时候很难搞,而且似乎用C++的人会觉得C++更容易出错?我觉得主要是下面几个原因:
- C和C++都没学好,大多数人用C++写C,所以,C的坑和C++的坑合并了。
- C++太灵活了,想怎么搞就怎么搞,所以,各种不经意地滥用和乱搞。
另外,C++的编译对标准C++的实现各异,支持地也千差万别,所以会有一些比较奇怪的问题,但是如果你一般用用C++的封装,继承,多态,以及namespace,const, refernece, inline, templete, overloap, autoptr,还有一些OO 模式,并不会出现奇怪的问题。
而对于STL中的各种坑,我觉得是程序员们还对GP(泛型编程)理解得还不够,STL是泛型编程的顶级实践!属于是大师级的作品,一般人很难理解。必需承认STL写出来的代码和编译错误的确相当复杂晦涩,太难懂了。这也是C++的一个诟病。
这和Linus说的一样 —— “C++是一门很恐怖的语言,而比它更恐怖的是很多不合格的程序员在使用着它”。注意我飘红了“很多不合格的程序员”!
我觉得C++并不适合初级程序员使用,C++只适合高级程序员使用(参看《21天学好C++》和《C++学习自信心曲线》),正如《Why C++》中说的,C++适合那些对开发维护效率和系统性能同时关注的高级程序员使用。
这就好像飞机一样,开飞机很难,开飞机要注意的东西太多太多,对驾驶员的要求很高,但你不能说飞机这个工具很烂,开飞机的坑太多。(注:我这里并不是说C++是飞机,C是汽车,C++和C的差距,比飞机到汽车的差距少太多太多,这里主要是类比,我们对待C++语言的心态!)
C++的初衷
理解C++设计的最佳读本是《C++演化和设计》,在这本书中Stroustrup说了些事:
1)Stroustrup对C是非常欣赏,实际上早期C++许多的工作是对于C的强化和净化,并把完全兼容C作为强制性要求。C89、C99中许多的改进正是从C++中所引进。可见,Stroustrup对C语言的贡献非常之大。今天不管你对C++怎么看,C++的确扩展和进化了C,对C造成了深远的影响。
2)Stroustrup对于C的抱怨主要来源于两个方面——在C++兼容C的过程中遇到了不少设计实现上的麻烦;以及守旧的K&R C程序员对Stroustrup的批评。很多人说C++的恶梦就是要去兼容于C,这并不无道理(Java就干的比C++彻底得多),但这并不是Stroustrup考虑的,Stroustrup一边在使尽浑身解数来兼容C,另一方面在拼命地优化C。
3)Stroustrup在书中直接说,C++最大的竞争对手正是C,他的目的就是——C能做到的,C++也必须做到,而且要做的更好。大家觉得是不是做到了?有多少做到了,有多少还没有做到?
4)对于同时关注的运行效率和开发效率的程序员,Stroustrup多次强调C++的目标是——“在保证效率与C语言相当的情况下,加强程序的组织性;能保证同样功能的程序,C++更短小”,这正是浅封装的核心思想。而不是过渡设计的OO。(参看:面向对象是个骗局)
5)这本书中举了很多例子来回应那些批评C++有运行性能问题的人。C++在其第二个版本中,引入了虚函数机制,这是C++效率最大的瓶颈了,但我个人认为虚函数就是多了一次加法运算,但让我们的代码能有更好的组织,极大增加了程序的阅读和降底了维护成本。(注:Lippman的《深入探索C++对象模型》也说明了C++不比C的程序在运行性能低。Bruce的《Think in C++》也说C++和C的性能相差只有5%)
6)这本书中还讲了一些C++的痛苦的取舍,印象最深的就是多重继承,提出,拿掉,再被提出,反复很多次,大家在得与失中不断地辩论和取舍。这个过程让我最大的收获是——a) 对于任何一种设计都有好有坏,都只能偏重一方,b) 完全否定式的批评是不好的心态,好的心态应该是建设性地批评。
我对C++的感情
我先说说我学C++的经历。
我毕业时,是直接从C跳过C++学Java的,但是学Java的时候,不知道为什么Java要设计成这样,只好回头看C++,结果学C++的时候又有很多不懂,又只得回头看C,最后发现,C -> C++ -> Java的过程,就是C++填C的坑,Java填C++的坑的过程。
注,下面这些东西可以看到Java在填C/C++坑:
- Java彻底废弃了指针(指针这个东西,绝对让这个社会有几百亿的损失),使用引用。
- Java用GC解决了C++的各种内存问题的诟病,当然也带来了GC的问题,不过功大于过。
- Java对异常的支持比C++更严格,让编程更方便了。
- Java没有像C++那样的template/macro/函数对象/操作符重载,泛型太晦涩,用OO更容易一些。
- Java改进了C++的构造、析构、拷贝构造、赋值。
- Java对完全抛弃了C/C++这种面向过程的编程方式,并废弃了多重继承,更OO(如:用接口来代替多重继承)
- Java比较彻底地解决了C/C++自称多年的跨平台技术。
- Java的反射机制把这个语言提升了一个高度,在这个上面可以构建各种高级用法。
- C/C++没有一些比较好的类库,比如UI,线程 ,I/O,字符串处理等。(C++0x补充了一些)
- 等等……
当然时代还在前进,这个演变的过程还在C#和Go上体现着。不过我学习了C -> C++ -> Java这个填坑演进的过程,让我明白了很多东西:
- 我明白了OO是怎么一回事,重要的是明白了OO的封装,继承,和多态是怎么实现的。(参看我以前写过的《C++虚函数表解析》和《C++对象内存布局》)
- 我明白了STL的泛型编程和Java的各种花哨的技术是怎么一回事,以及那些很花哨的编程方法和技术。
- 我明白了C,C++,Java的各中坑,这就好像玩火一样,我知道怎么玩火不会烧身了。
我从这个学习过程中得到的最大的收获不是语言本身,而是各式各样的编程技术和方法,和技术的演进的过程,这比语言本身更重要!(在这个角度上学习,你看到的不是一个又一个的坑,你看到的是——各式各样让你可以爬得更高的梯子)
我对C++的感情有三个过程:先是喜欢地要死,然后是恨地要死,现在的又爱又恨,爱的是这个语言,恨的是很多不合格的人在滥用和凌辱它。
C++的未来
C++语言发展大概可以分为三个阶段(摘自Wikipedia):
- 第一阶段从80年代到1995年。这一阶段C++语言基本上是传统类型上的面向对象语言,并且凭借著接近C语言的效率,在工业界使用的开发语言中占据了相当大份额;
- 第二阶段从1995年到2000年,这一阶段由于标准模板库(STL)和后来的Boost等程式库的出现,泛型程式设计在C++中占据了越来越多的比重性。当然,同时由于Java、C#等语言的出现和硬件价格的大规模下降,C++受到了一定的冲击;
- 第三阶段从2000年至今,由于以Loki、MPL等程式库为代表的产生式编程和模板元编程的出现,C++出现了发展历史上又一个新的高峰,这些新技术的出现以及和原有技术的融合,使C++已经成为当今主流程式设计语言中最复杂的一员。
在《Why C++? 王者归来》中说了 ,性能主要就是要省电,省电就是省钱,在数据中心还不明显,在手机上就更明显了,这就是为什么Android 支持C++的原因。所以,在NB的电池或是能源出现之前,如果你需要注重程序的运行性能和开发效率,并更关注程序的运性能,那么,应该首选 C++。这就是iOS开发也支持C++的原因。
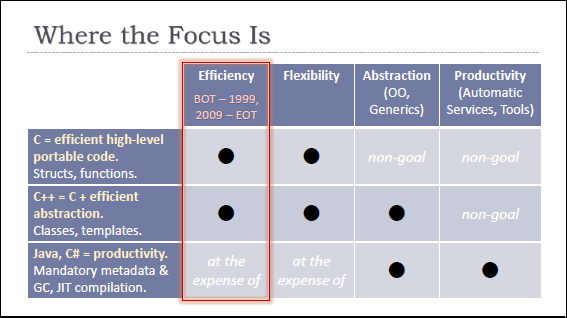
今天的C++11中不但有更多更不错的东西,而且,还填了更多原来C++的坑。(参看:C++11 Wiki,C++ 11的主要特性)
总结
- 是那些不合格的、想对编程速成的程序员让C++变得坑多。
最后,非常感谢能和“@简悦云风”,“@淘宝诸霸”,“@Laruence”一起讨论这个问题!无论你们的观点怎么样,我都和你们“在一起”,嘿嘿嘿……
(全文完)
posted @
2012-08-06 12:58 Seraphi 阅读(476) |
评论 (0) |
编辑 收藏转载Cool Shell,作者:陈皓
From:http://coolshell.cn/articles/2250.html
下面是一个《Teach Yourself C++ in 21 Days》的流程图,请各位程序员同仁认真领会。如果有必要,你可以查看这个图书以作参照:http://www.china-pub.com/27043

看完上面这个图片,我在想,我学习C++有12年了,好像C++也没有学得特别懂,看到STL和泛型,还是很头大。不过,我应该去考虑研究量子物理和生物化学,这样,我才能重返98年杀掉还在大学的我,然后达到21天搞定C++的目标。另外,得要特别提醒刚刚开始学习C++的朋友,第21天的时候,小心被人杀害。呵呵。
当然,上面只是一个恶搞此类图片,学习一门技术,需要你很长的时间,正如图片中的第三图和第四图所示,你需要用十年的时间去不断在尝试,并在错误中总结经验教训,以及在项目开发中通过与别人相互沟通互相学习来历练自己。你才能算得上是真正学会。
这里有篇文章叫《Teach Yourself Programming in Ten Years》,网上有人翻译了一下,不过原文已被更新了,我把网上的译文转载并更新如下:
用十年来学编程
Peter Norvig
为什么每个人都急不可耐?
走进任何一家书店,你会看见《Teach Yourself Java in 7 Days》(7天Java无师自通)的旁边是一长排看不到尽头的类似书籍,它们要教会你Visual Basic、Windows、Internet等等,而只需要几天甚至几小时。我在
Amazon.com上进行了如下
搜索:
结论是,要么是人们非常急于学会计算机,要么就是不知道为什么计算机惊人地简单,比任何东西都容易学会。没有一本书是要在几天里教会人们欣赏贝多芬或者量子物理学,甚至怎样给狗打扮。在《
How to Design Programs》这本书里说“
Bad programming is easy. Idiots can learn it in 21 days, even if they are dummies.” (坏的程序是很容易的,就算他们是笨蛋白痴都可以在21天内学会。)
- 学会:在3天时间里,你不够时间写一些有意义的程序,并从它们的失败与成功中学习。你不够时间跟一些有经验的程序员一起工作,你不会知道在C++那样的环境中是什么滋味。简而言之,没有足够的时间让你学到很多东西。所以这些书谈论的只是表面上的精通,而非深入的理解。如Alexander Pope(英国诗人、作家,1688-1744)所言,一知半解是危险的(a little learning is a dangerous thing)
- C++:在3天时间里你可以学会C++的语法(如果你已经会一门类似的语言),但你无法学到多少如何运用这些语法。简而言之,如果你是,比如说一个Basic程序员,你可以学会用C++语法写出Basic风格的程序,但你学不到C++真正的优点(和缺点)。那关键在哪里?Alan Perlis(ACM第一任主席,图灵奖得主,1922-1990)曾经说过:“如果一门语言不能影响你对编程的想法,那它就不值得去学”。另一种观点是,有时候你不得不学一点C++(更可能是javascript和Flash Flex之类)的皮毛,因为你需要接触现有的工具,用来完成特定的任务。但此时你不是在学习如何编程,你是在学习如何完成任务。
- 3天:不幸的是,这是不够的,正如下一节所言。
10年学编程
在这三个小组中的每一个人基本上都是从相同的时间开始练习的(在五岁的时候)。在开始的几年里,每个人都是每周练习2-3个小时。但是在八岁的时候,练习的强度开始显现差异。在这个班中水平最牛的人开始比别人练习得更多——在九岁的时候每周练习6个小时,十二岁的时候,每周8个小时,十四岁的时候每周16个小时,并在成长过程中练习得越来越多,到20岁的时候,其每周练习可超过30个小时。到了20岁,这些优秀者在其生命中练习音乐总共超过 10,000 小时。与之对比,其它人只平均有8,000小时,而未来只能留校当老师的人仅仅是4,000 小时。
所以,这也许需要10,000 小时,并不是十年,但这是一个magic number。Samuel Johnson(英国诗人)认为10 年还是不够的:“任何领域的卓越成就都只能通过一生的努力来获得;稍低一点的代价也换不来。”(Excellence in any department can be attained only by the labor of a lifetime; it is not to be purchased at a lesser price.) 乔叟(Chaucer,英国诗人,1340-1400)也抱怨说:“生命如此短暂,掌握技艺却要如此长久。”(the lyf so short, the craft so long to lerne.)
下面是我在编程这个行当里获得成功的处方:
- 对编程感兴趣,因为乐趣而去编程。确定始终都能保持足够的乐趣,以致你能够将10年时间投入其中。
- 跟其他程序员交谈;阅读其他程序。这比任何书籍或训练课程都更重要。
- 编程。最好的学习是从实践中学习。用更加技术性的语言来讲,“个体在特定领域最高水平的表现不是作为长期的经验的结果而自动获得的,但即使是非常富有经验的个体也可以通过刻意的努力而提高其表现水平。”(p. 366),而且“最有效的学习要求为特定个体制定适当难度的任务,有意义的反馈,以及重复及改正错误的机会。”(p. 20-21)《Cognition in Practice: Mind, Mathematics, and Culture in Everyday Life》(在实践中认知:心智、数学和日常生活的文化)是关于这个观点的一本有趣的参考书。
- 如果你愿意,在大学里花上4年时间(或者再花几年读研究生)。这能让你获得一些工作的入门资格,还能让你对此领域有更深入的理解,但如果你不喜欢进学校,(作出一点牺牲)你在工作中也同样能获得类似的经验。在任何情况下,单从书本上学习都是不够的。“计算机科学的教育不会让任何人成为内行的程序员,正如研究画笔和颜料不会让任何人成为内行的画家”, Eric Raymond,《The New Hacker’s Dictionary》(新黑客字典)的作者如是说。我曾经雇用过的最优秀的程序员之一仅有高中学历;但他创造出了许多伟大的软件(XEmacs, Mozilla),甚至有讨论他本人的新闻组,而且股票期权让他达到我无法企及的富有程度(译注:指Jamie Zawinski,Xemacs和Netscape的作者)。
- 跟别的程序员一起完成项目。在一些项目中成为最好的程序员;在其他一些项目中当最差的一个。当你是最好的程序员时,你要测试自己领导项目的能力,并通过你的洞见鼓舞其他人。当你是最差的时候,你学习高手们在做些什么,以及他们不喜欢做什么(因为他们让你帮他们做那些事)。
- 接手别的程序员完成项目。用心理解别人编写的程序。看看在没有最初的程序员在场的时候理解和修改程序需要些什么。想一想怎样设计你的程序才能让别人接手维护你的程序时更容易一些。
- 学会至少半打编程语言。包括一门支持类抽象(class abstraction)的语言(如Java或C++),一门支持函数抽象(functional abstraction)的语言(如Lisp或ML),一门支持句法抽象(syntactic abstraction)的语言(如Lisp),一门支持说明性规约(declarative specification)的语言(如Prolog或C++模版),一门支持协程(coroutine)的语言(如Icon或Scheme),以及一门支持并行处理(parallelism)的语言(如Sisal)。
- 记住在“计算机科学”这个词组里包含“计算机”这个词。了解你的计算机执行一条指令要多长时间,从内存中取一个word要多长时间(包括缓存命中和未命中的情况),从磁盘上读取连续的数据要多长时间,定位到磁盘上的新位置又要多长时间。(答案在这里)
- 尝试参与到一项语言标准化工作中。可以是ANSI C++委员会,也可以是决定自己团队的编码风格到底采用2个空格的缩进还是4个。不论是哪一种,你都可以学到在这门语言中到底人们喜欢些什么,他们有多喜欢,甚至有可能稍微了解为什么他们会有这样的感觉。
- 拥有尽快从语言标准化工作中抽身的良好判断力。
抱着这些想法,我很怀疑从书上到底能学到多少东西。在我第一个孩子出生前,我读完了所有“怎样……”的书,却仍然感到自己是个茫无头绪的新手。30个月后,我第二个孩子出生的时候,我重新拿起那些书来复习了吗?不。相反,我依靠我自己的经验,结果比专家写的几千页东西更有用更靠得住。
Fred Brooks在他的短文《No Silver Bullets》(没有银弹)中确立了如何发现杰出的软件设计者的三步规划:
- 尽早系统地识别出最好的设计者群体。
- 指派一个事业上的导师负责有潜质的对象的发展,小心地帮他保持职业生涯的履历。
- 让成长中的设计师们有机会互相影响,互相激励。
这实际上是假定了有些人本身就具有成为杰出设计师的必要潜质;要做的只是引导他们前进。Alan Perlis说得更简洁:“每个人都可以被教授如何雕塑;而对米开朗基罗来说,能教给他的倒是怎样能够不去雕塑。杰出的程序员也一样”。
所以尽管去买那些Java书;你很可能会从中找到些用处。但你的生活,或者你作为程序员的真正的专业技术,并不会因此在24小时、24天甚至24个月内发生真正的变化。
(全文完)
posted @
2012-08-06 12:56 Seraphi 阅读(366) |
评论 (0) |
编辑 收藏
注:如果看不到图片,请右键图片获得图片地址,然后在浏览中访问图片地址即可~
1.去下载LINUX上使用的BIN文件,去www.java.sun.com,最终会到ORACLE网站上去,因为SUN被收购了嘛,下载JDK,名称为jdk-6u22-linux-i586.bin,然后去www.eclipse.org,下载eclipse,笔者下载的是JAVA EE版的,文件名称为eclipse-jee-helios-SR1-linux-gtk.tar.gz,因为这个工具多,比较适合WEB等开发。路径


2.本人的文件目录放在/home/heroguo/下载,使用tar命令解压(这个具体可以去查找资料或者tar -help)eclipse,会生成eclipse文件夹。mv到/home文件夹。
3、安装JDK,使用终端,运行下载下来的jdk-6u22-linux-i586.bin。
第一步,将目录CD到/home/heroguo/下载。
第二步,使用命令./jdk-6u22-linux-i586.bin,等待中,直到完成。完成后,会在当前目录下生成一个JDK1.6.0_22的文件夹。
第三步,使用mv命令将JDK1.6.0_22到/home文件夹。
4.环境变量
用文本编辑器打开/etc/profile
·在profile文件末尾加入:
export JAVA_HOME=/usr/share/jdk1.6.0_14
export PATH=$JAVA_HOME/bin:$PATH
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
注意:千万不要范和笔者一样的错,狂晕,写PATH的时候,前面的$PATH 没有写,导致PATH路径下所有位置被覆盖,包括写命令都得打完整路径,汗死!!路径之间用:隔开
这一步很重要:重启ubuntu,在终端中输入java –version,查看版本号

看到上面按要求1.6.0_22证明JDK被正确安装了
5.用终端将当前目录CD为 /home/heroguo/eclipse,使用命令./eclipse,可以看到eclipse开始运行了。

弹出eclipse工作目录设置,OK基本JAVA开发环境也搞定了。

进行WEB开发,再去下个TOMCAT,由于TOMCAT7 刚出来,所以选择了TOMCAT6,方法和WINDOWS上一样的,就不再赘述了,哈哈,休息哈去!
转贴:原文链接:
http://blog.csdn.net/guoleimail/article/details/5960244
posted @
2012-05-10 12:09 Seraphi 阅读(1034) |
评论 (1) |
编辑 收藏怎样做研究(一)
几年前,我写了一套胶片,题目是《怎样做研究》,多次在实验室内部给学生们做报告,也曾对外讲过一次,听众反应良好。也有网友读过这套胶片,给我来信称有所收获。然而,胶片中的文字毕竟只是提纲携领,无法充分阐述我的想法,为此,借周末一点闲暇,把《怎样做研究》写成一篇文章,与师友切磋。
什么是科学
科学是分科的学问,客观地说,是起源于西方的。中国只有经验科学,典型的如中医。我的母亲是学中医的,我从小就对中医耳濡目染,生了病,妈妈就会请他的老师来,一贴小药下去,我的病就好了。因此,我对中医一直是很信服的。然而,近些年来,中医多受批评,发展也越来越缓慢,究其原因,中医不是科学,或者说只是经验科学,而非实证科学。中药的成分以及生化功效不曾用实验进行深入的分析,望闻问切的诊断方法完全凭经验而无法量化,阴阳五行的理论似是而非,祖传秘方的传承方式与知识共享的现代思维背道而驰。因此,尽管中医有诊治的整体观和方剂的个性化两大优点,但其停留于经验层面,而迟迟不能进入科学的殿堂,因此在现代社会中的发展必然步履维艰。
中医不是科学,那到底什么是科学呢?科学(自然科学)是人们用来认识和改造自然世界的思维武器,科学研究可以分为基础研究(理论研究)和应用研究(技术研发)。
基础研究
万事万物皆有其规律,掌握并且利用这些规律就能够为人类造福,这些规律是隐蔽在纷繁复杂的现象背后的,要识破大自然的奥秘,读懂上帝的天书,非要下一番深入观察和探究的功夫不可。以揭示规律为目的的研究活动属于基础研究,从事这些活动的学者是科学家。规律不是被创造出来的,而是早已存在的,人们只有认识规律的权利,而没有创造规律的可能。
从根本上讲,推动基础研究的也是人们在生产生活中的一些实际需要,但是随着基础研究的深入,理论已经成为一个庞大的体系,理论研究早已开始按照它自有的逻辑独立发展,而不必时时刻刻联系实际需要,比如著名的歌德巴赫猜想,可能在百年之后,发现其有重大的应用价值,但是目前到底有什么用,谁也说不清楚。理论的价值在今天这个非常讲求短期功利的社会中常常被忽视,现在有一种倾向认为只有产生实际经济效益的科研工作才有价值,这种极端化的观点显然是错误的,我们必须承认并高度尊重理论研究者的成就。
理论研究的直接动力是科学家的好奇心,以及他们对科学荣誉的渴望。越是单纯的科学家越有希望发现真理,他们的科学探索有点像迷宫探宝或者海边拾贝,伟大的科学家都是没有丧失童趣的人,他们在实验室里是宁静而愉快的,他们是乐此不疲的,很多在常人看来难以忍受的寂寞在他们看来却是一种幸福。越是找不到答案,越是激发探索的热情,在一次次的失败中积累着烦闷与紧张,在终于取得突破后兴奋异常。与此同时,也必须承认科学荣誉也是激励科学家们前进的重要动力,只要别把荣誉看得高于真理,货真价实的荣誉仍然是值得追求的。
理论上的突破对应用研究产生持续不断的推动力,在模式识别领域,神经网络、支持向量机、条件随机域等等机器学习技术不断出现,每当一项理论出现,应用研究者们争相将其应用于自己的研究课题中,于是基于神经网络、基于支持向量机、基于条件随机域的某某研究就成为一个标准的论文题目。首先把某项理论应用于某个实际课题的研究工作应该说还是具有一定的创新性的,毕竟用一个新的思路、新的模型去观察了一个旧的课题,HMM在语音识别上的成功应用就是一例。有人比喻说,理论工具仿佛是锤子,实际课题好比是钉子,一个新的锤子被打造出来,大家都借用过来砸一砸自己手头的钉子,确属常理。不过,需要注意的事,如果拿一个硕大无比的汽锤去砸一个纤细的大头针就荒诞可笑了,不注意思考问题与理论的适配关系而盲目跟风的事情在学术界也是司空见惯,比如我们就曾用HMM试图解决词义消歧的问题,而每个多义词的词义跟它前后一两个词并没有紧密的关系,因此词义消歧貌似和词性标注一样属于线性序列标注问题,其实是有根本差别的。
应用研究
我们是搞计算机的,计算机是一门应用科学,应用科学是由应用驱动的。时至今日,数学定理和物理学定律似乎已经被先哲们发现的差不多了,因此整个科学界中纯粹搞理论研究的人越来越少,很多大学教授都和工业界有着密切的联系,很多大企业也开办企业研究院,这些导致应用科学的研究如火如荼。最近,国家863设立了一个"中文为核心的多语言信息处理"重点项目,总经费7000万,这在多年前的大陆语言处理界完全是不可想象的。
应用驱动,也可以说是市场驱动。市场是一个精灵古怪的家伙,搞应用研究的人如果对市场的未来没有一个基本准确地判断,往往会导致选题上的偏差。二十年前,国内一些研究者开始研究汉字手写输入技术,开始人们觉得从键盘输入汉字很困难,手写输入一定有前途,但是很快,拼音输入法大面积普及,而且拼音输入的速度远比在手写板上输入汉字快得多,于是汉字手写输入套件根本卖不动,前景黯淡。有人开始犹豫,有人开始转向搞印刷体汉字识别等,但忽然有一天,集成了手写功能的商务通大量热销,人们忽然发现原来在手持设备上由于键盘太小,输入不便,给手写功能留下了很大的应用空间。一直专注于手写识别的汉王公司也借着商务通的热销而把多年的科研成果成功地产业化了。再举一个例子:5年前,我认为以图像为输入的图像检索没有什么应用价值,问这些技术的倡导者,他们也只说能够在数码相册中可以找到一些应用,但近来听了微软一些学者们的演讲,他们提到可以用手机拍下一个植物的图片,传回服务器,在大量植物图片库中检索,找到最相似的植物,并给出植物的名称,特点等。哈哈,这对于我这个五谷不分的人来说实在是太有帮助了,可见对于一项技术是否有用实在要仔细思考,不要早下断言。
技术和市场是一个互动的关系,有人认为技术严格地从用户的现实需求出发,这个观点总的来说没有错,但是忽视了技术创造需求的一面。大多数用户往往并不了解技术发展到了什么程度,他们提不出需求来,这时技术专家们需要把技术和产品做出来给人们看,刺激、引领用户的需求,比如数码相机,5年前我想大多数用户和我一样并没有淘汰胶卷相机的强烈要求,但当数码相机进入市场后,人人都意识到:原来我需要这个东东。
在市场与技术的互动中,总的来说,还是市场在引导和拉动技术的发展。市场需要的是产品,产品往往集成了多项技术,因此一项被市场接受的产品能够推动多项技术的进步。比如搜索引擎,它拉动了自然语言处理、并行计算、海量存储设备、数据挖掘等等多项技术的发展。最近中国计算机学会设立了王选奖,在中国真正有市场眼光,能够发明一项技术,拉动一个行业的计算机专家,王选是第一人。怎样根据市场选择研究方向,设计产品,调整技术形态,我在后面还有详细阐述。
科学技术的力量
科学技术的力量是巨大的,爱因斯坦给出的公式E=M*C2,C是光速啊,质量乘以光速的平方,这是多么巨大的能量啊,爱因斯坦的理论直接导致了原子能的利用与开发。基因图谱的发现以及后基因组时代对基因图谱的深入分析必将为人类征服疾病提供一条崭新的解决道路,通过对损坏的基因进行修复,将使无数患者得以康复,无数家庭重拾幸福。互联网的发明,把全世界连为一体,过不了多久,石头里也会嵌入芯片,在这个世界上有生命的、无生命的各种物质之间都可能进行通讯,人们的生活面貌已经彻底改变了。
当然,科学也是双刃剑:原子弹爆炸了,核战争始终威胁着人类;在对基因组这套上帝给出生命密码没有全面理解以前,任何盲动都可能导致基因污染,以至于玩火自焚;互联网上的虚拟生存让人们感到更加孤独。
怎样做研究(二)
研究的层次
研究是分层次的,很多大科学家在晚年登上了最高层,比如钱学森在80年代倡导思维科学,他对整个科学技术体系进行了重新分类。在中国的大学里,分为一级学科,二级学科等,我就处在计算机科学技术一级学科下面的计算机应用技术二级学科下。二级学科的带头人称为学科带头人,二级学科下面一个研究方向的带头人称为学术带头人,我就被指定为学术带头人。
我的研究方向是信息检索,信息检索下面又有子方向,比如文本检索、文本挖掘、跨语言检索、跨媒体检索等,子方向下面设立具体的科研课题,比如文本挖掘中的多文档自动文摘课题,针对一项课题又有不同的解决办法,基于事件抽取与集成的多文档文摘就是利用一种具体的解决问题的方法。
总结来说,就是6个层级:
A. 一级学科
B. 二级学科
C. 研究方向
D. 子方向
E. 课题
F. 基于某种方法对课题进行的具体研究
君子思不出其位,我是学术带头人,因此主要在思考C类的问题,也就是和信息检索相关的问题。一个学院的院长通常会思考A类的课题,学科带头人或者说是一个博士点的点长是要考虑B类问题的。一个人对相关的方向或学科有所了解,对自己的研究工作是很有好处的,只有看清了整体的学科面貌,才能知道自己处在那个位置上,自己未来的方向在哪里。我在读博士以及在微软做副研究员的时候,只看到E类问题,想到最多的是F类问题,因此你让我提一个新方向,让我对一项技术进行预测,我茫然无知。后来担任院长助理,负责学院的成果转化,需要了解学院里各个方向的发展状态,使我的视野开阔了一些。尽管我凡事不求甚解,但是喜欢总结归纳,因此对信息检索与其它学科的关系有了更多地认识,这对后来的选题很有帮助,特别是在应用研究方面,心里比较有底。
学科好比一棵大树的树根,研究方向如同树干,具体的课题就是枝叶了。和学科中各个方向都相关的研究课题是最基础的研究课题,比如在人工智能中,各类机器学习算法是图像识别、语音识别和语言理解等各个方向都离不开的,机器学习技术提高一步,好比树根抬高了一寸,各项应用技术也都跟着进步,因此越是基础的研究,越会对业界产生较大较深远的影响力。不过,基础研究的突破比较难,而在某个应用课题上不考虑一般情况,只考虑具体需要,成功的可能性大。枝叶上的课题做多了,经过合并同类项,就会发现比较共性的基础课题,比如我们在做问答系统、多文档文摘、例句检索等课题时发现复述(paraphrasing)是一个共性的问题,于是把复述单拿出来展开专门的研究,如此,可以越做越深。
学者的层次
研究有层次,学者也有层次,大致可以分为:
A. 大家(剑客):提出问题
B. 专家(侠客):解决问题
C. 学徒:修修补补
D. 抄袭者:抄来抄去
E. 搞伪科学的人:弄虚作假
A类是大家,站得高,看得远,他们往往能够前瞻性地提出某个学科领域中的若干重大问题,最著名的是希尔伯特的23个问题,对数学界影响深远。提出问题其实也是解决问题的一种方式,只不过他们是在很高的层面解决问题,类似一个软件系统分析员,他把一个复杂的工程问题分解为若干个有机联系的子问题,然后宣布只要这几个子问题解决了,整个大问题也就解决了。至于这几个子问题到底怎样解决,或者说相应的子系统到底怎样开发,他就不管了。胡乱地提问题并不难,小孩子也会向大人提出各种各样有趣的问题,有的大人也答不出来,问题的关键在于在适当的时候提出适合当前学术发展阶段的关键性课题,这绝对不是一般人能够做到的,这是需要具有对整个领域全面深入的理解才行的。
B类是专家,是在某个研究方向上有专长的人,他们沿着大家指出的方向探索前进,提出全新的方法体系来解决问题。比如在机器翻译领域中,日本长尾真教授提出了基于实例的机器翻译方法,从一个全新的视角看待机器翻译问题。专家经验丰富,能够自由地驾驭课题,稳步地推动课题的进展。
C类是学徒,就是我们这些普通的研究人员了,这部分人的注意力在具体的课题上。学徒们还没有宏大的视野,没有捕捉全局战略要点的本事,也还没有在一个研究方向上提出原创性的解决之道,他们跟在拓荒者后面捡拾麦穗,他们负责对科学大厦修修补补。他们一会儿听说了一个新的机器学习方法,赶紧在自己的课题上试一下;一会儿发现了一个以前忽略了的新的特征,立即想方设法把这个特征提取出来;一会儿为了参加一个技术评测,耐心地调一调系统参数;一会儿为了发表一篇论文构造出一个试验来。我们每天的研究活动差不多都是在这样进行的,很多时候在原地打转转。
我这样描述学徒们的工作情景丝毫没有贬低的意味,在达到专家的水平,证悟研究真谛以前,跌跌撞撞、浑浑沌沌是在所难免的。只要遵守诚信之道,不抄袭,不造假,点点滴滴的贡献对科学界也是有帮助的。从更高的要求看,学徒的目标应该是成为专家,应该时常静下心来想一想,自己的工作是否有价值,是否有新意,揣摩一下大家们、专家们到底是怎样思考问题的,在不断地反思与实践中向上迈进。
D类学者根本算不上学者,他们为了评职称等目的,对别人的论文进行抄袭拼凑,他们是思想的窃贼,对学术界毫无贡献可言。
E类学者不仅仅是做贼了,他编造伪科学,毁坏科学界在公众中的形象,他们是科学界的公敌。
以上的分类也只是为了讨论的方便,在各类之间并没有明确的界限,我只是依次谈出我心中做学问的境界而已。
在人类已知的世界和未知的世界之间有一条动态边界,科学家就站在这条边界上,他们是挑战未知世界的勇士,他们每向前迈出一步,就意味着整个人类的已知世界向前拓展了一步,由此足见科学工作的艰难和科学家的伟大。
研究又好比爬山,一座座山峰如同一个个研究领域,大家已登峰造极,一览众山小,把东南西北各条山路上的沟沟坎坎,把此山与他山之间的距离关系看得清清楚楚。隔行如隔山,隔行不隔道,在一个领域做到顶尖的学者已入化境,一通百通,你把另一个领域的问题讲给他听,他往往也能够很快地抓到要害。专家已到半山腰,看不到山的全貌,但是他找到了一条通往山顶的道路,并一步一步地向上攀登着。学徒还没有进入山门,他们一会儿仰望山顶,一会儿看看山腰,在山脚下绕来绕去找不到门径,费力不少,却并没有缩短与山顶的距离。
怎样做研究(三)
怎样选题
前文曾提到科学研究的层次,并分了6个层级。此处所说的选题指的是从C到E三个层次上的选择问题,即:C. 研究方向、D. 子方向、E. 课题。选择研究方向是实验室(Lab)主任们需要重点思考的事情,选择子方向是研究小组(Group)的组长们需要重点思考的事情,选择课题是研究生们需要重点思考的事情。
选择太多,很容易让人困惑,要想理出一个头绪来,需要一些基本的原则。微软的许峰雄来访时谈到了他选择课题的三个标准:有足够的兴趣,能成为世界第一,能赚钱。(!)兴趣,这个原则是非常重要的,我赞同,获得国家最高科技奖的"黄土之父"刘东生院士是搞地球环境科学的,经常在野外作业,按常人推断,这该是多么枯燥艰苦的工作啊,但他说:"枯燥?不!因为经常有新发现,其中的乐趣难以形容"。我坚信任何一个成功的科学家的直接工作动源都是兴趣,而不是意志。(2)成为世界第一,不容易,但是应该作为一种判断标准,如果某个领域已经非常成熟,很难有什么创新了,或者大牛云集,已经打破头了,则应该有所回避。(3)赚钱,许峰雄是在工业研究院中工作,比较注重实用,因此他强调了"赚钱",我是在工科大学里工作,也比较偏重应用,因此是赞同"能赚钱"这个标准的。不过,"能赚钱"不等于立即赚钱,5年、10年,20年后能够赚钱的研究课题都是值得关注的。
谈谈我选择课题的一些体会:
1、 要有实际需求
一个课题必须有实际需求,可能是现实的需求,也可能是潜在的需求;可能是直接的需求,也可能是间接的需求,总之是的的确确被人们所需要的。据个反例,比如自动文摘,自动文摘是我的博士论文课题,但是实际应用需求始终不清楚,自动文摘的结果用于编辑出版,质量肯定无法保证,用于帮助人们快速浏览资料吧, Google提供的包含查询词的简单的Snippet就起到了这个作用,因此,至今基于全文分析的单文档自动文摘到底用到哪里,仍然不清楚,这方面的研究已经有50多年的历史了,仍然是不死不活,总是找不到应用就无法得到政府和企业界的持续性支持,以往的付出成为鸡肋。我觉得单自动文摘不是一个好课题,目前阶段多文档文摘,或者说对某个题目的自动综述分析是非常好的题目。
2、 有较大的未知空间
以手写体汉字识别为例,市场上已经大面积应用了,在研究上就不宜再展开。
3、 与自己以往的工作有关联
如果你觉得自己的研究领域太窄,或者竞争对手太多,或者自己缺乏兴趣,则可以适当扩展研究方向,但最好是相关性地扩展,比如从自然语言处理(NLP)扩展到信息检索(IR),IR要用到NLP的技术,这种扩展是从底层技术到应用系统的扩展,很自然。再比如从图片检索扩展到视频检索,只是处理对象有变化,很多原有的技术优势仍然能够发挥。如果跳跃性太大,比如搞NLP,忽然发现做数据挖掘有前途,于是单纯地转向数据库中数据挖掘,和文本处理完全脱节,这种做法一方面无法发挥既有的技术积累,另一方面也让同行感觉你不够专注,不容易得到认可。最要命的是有的人根本就没有自己的方向,什么课题都敢接,这样的人可以一时间让人觉得风风火火,经费也很充足,但过不了多久就会摔落下去,因为缺乏积累,学术形象不清,公鸡下蛋,干了自己不擅长的事情,在学术圈还怎么混?
4、 有可能得到国家的支持
对于资深学者,他选定一个课题后,可以写出立项建议,去说服政府或军方支持他的工作,从而填补国家空白,成为国内这个方向的先驱。哈工大的杨孝宗老师借鉴 CMU在wearable computing方面的研究成果,在国内率先提出穿戴计算机的概念,坚持多年,就获得了军方的认可。对于刚出道的年轻人,无力直接影响政府,那只有自己预先判定一个几年后可能成为热点的方向,先走一步,做出一些成绩来,等到大气候适宜的时候,由于他已经取得了一定的成果,也有可能被认可为这个领域的先行者,得到国家的支持。
课题的类型
对一个课题的类型要有一个判断,是研究型的还是开发型的,如果是研究型的,要组织博士生们来攻关,鼓励大家大胆尝试,提出创见;如果是开发型的,要更多地召集硕士生们来做,强调利用一切现有的技术手段把技术或系统做到实用可靠。这两者要分的比较清楚,既不能通过各种打补丁的方法,或者说一大堆小技巧来对付研究型的课题,因为那样是做不出突破性进展的,也不能在开发类课题上总是异想天开,尝试还很不成熟的技术。
如果是研究型课题,还要区别是基础研究还是应用研究,基础研究的结果不能直接被用户使用,类似重工业,应用研究的结果最终用户直接就能够用上,类似轻工业。对于基础研究,可以抛开具体应用的约束,专注于一些科学原理技术原理的突破。对于应用研究,则需要考虑用户的需求。
课题还有长期(long term)和短期(short term)之分,长期研究的课题往往难度大,研究结果难以预料,短期项目则比较好预测,可以速战速决。
怎样做研究(四)
在一个具体的题目上作研究,应该遵从怎样的程序呢?我觉得可以概括为"螺旋式深入",也就是在"阅读","思考","实验","写作",再阅读。。。这四个阶段的时间分配可以根据实际情况灵活调整,刚进入课题的研究生阅读调研花费的时间要多一些,而在一个课题上已经开展了一两年工作的人则可能增量式地阅读资料,阅读时间自然比起步时少一些。专门用于思考、设计、推演的时间可能并不多,但思考是渗透在其它三个阶段中不断进行的,因此总的思考时间并不少。实验中编程的时间应该尽可能短,用更多的时间进行实验数据的分析。写作是常常被中国的研究生忽略的环节,写作的时间要足够长。收集资料,了解别人的工作,找出问题所在,针对性地提出自己的创意,用实验验证自己创意的正确性,总结归纳,撰写论文,发现新的问题,再收集资料,如此反复,这是研究活动的大致流程。
怎样阅读资料
收集资料、阅读资料是从事研究工作的第一步,但是如何收集、阅读资料却很有学问,初学者如果没有得到足够的指导,常常走很多弯路。
1、 阅读重要的论文
目前互联网上的信息量太大了,对每一条信息的重要性、可靠性的判断是一个人采集信息的关键环节。如果判断一篇论文是否重要呢?GoogleScholar给出的引用数是一个有效指标,很多学者都引用的文章往往就是有价值的论文。有的同学觉得看中文论文容易,于是把自己能够查到的中文论文一网打尽,反复阅读,但是很多发表在三流刊物上为了评职晋级而炮制的论文完全没有阅读的价值,白白耽误了时间。即使是英文论文,国外一样有滥竽充数的文章,这样的论文引用数肯定低,用引用数可能很容易地把这样的论文淘汰掉。
计算机领域的顶级会议论文非常重要,在NLP领域有ACL,在IR领域有SIGIR,在机器翻译领域有MT Summit,这些顶级会议的论文质量很高,内容很新,应该高度关注。期刊上的论文是一个作者或机构一个阶段的研究成果的总结,通常质量较高,但由于审稿及编辑出版的周期很长,因此内容不够新,适当关注即可。NLP领域的CL,机器翻译中的MT,信息检索领域的IP&M和JASIST等都是很好的期刊。进入一个领域,必须立即了解该领域有哪些顶级的国际会议和国际期刊。
2、以作者为线索理清脉络
阅读论文一定要注意论文的作者是谁,研究机构是哪里,以作者为线索理一理就会发现全世界搞你这个方向的也就那么几个、十几个研究机构、研究者,以后就跟踪这些人的研究工作即可,还能够发现该作者的研究工作的演进脉络。如果拿到一篇文章就读,读完了也不知道作者是谁,时间长了,就会感到晕头晕脑,不知道从哪个期刊或会议上就会冒出一篇相关文章来,让你防不胜防。
3、 阅读最新的论文
学术发展很快,要集中尽力阅读近5年,特别是近3年的论文,对于5年前的论文,只看引用率最高的经典文章即可。
4、 抓住论文的要害
读完一篇论文必须了解哪些关键内容呢?我觉得应该包括以下方面:作者为什么要做这项工作?要解决的是一个什么问题?作者在解决问题时遇到了怎样的困难?为了解决他的困难他提出了什么样的解决办法?试验结果是否可能真的证明他的方法好,数据是否充分,有没有和别人的工作,别的方法进行对比?你认为他的方法是否新颖,你从中学到了什么?该方法有哪些不足,你是否立即有了新的改进方案?如果有立即记录下来。带着上述问题,抓住要点,做好记录,一篇长文就会像庖丁解牛一样轰然倒下。
5、 批判式阅读
真理越辩越明,我们读的是一篇学术论文,不是《圣经》,不能带着崇敬的心理去阅读,要像一个审稿人那样带着批判挑剔的心理阅读论文,在阅读中不断地找出论文中的问题,选题上的,方法上的,实验上的,表述上的,并不断地通过积极独立的思考给出自己认为见解。只有这样,资料才能够为你所用,而不会成为你的包袱。有的同学读资料,越读越丧失信心,发现别人做得太好了,自己的想法都被别人做完了,资料全读完了,自己也准备换课题了,这是失败的读法。
中国的研究生要有信心,不要被国外所谓的名家吓住。中国的科研水平在快速提高,科研人员的素质也在快速提高。一位美籍华裔企业家在一篇文章中写道:"可不幸的是,除了很少顶尖学校的博士外,大部分博士所做的研究课题都是陈旧或者没有意义的。"不知道顶尖高校的含义是什么,但是我觉得我们的研究生要对自己的国家有信心,对自己的学校有信心,对自己的倒是有信心,对自己有信心。只要我们掌握正确的研究方法,广泛阅读国外最新的研究成果,大胆尝试自己人为正确的方法,充分释放我们的聪明才智,我们就丝毫不用对国外的研究工作顶礼膜拜。在科学研究上,欧美人从内心里是瞧不起我们亚洲人,我们中国人的,以至于欧美归来的学者们也以欧美为样板来评估我们教育科研体制,只要和美国不一样就是大错特错了,中国高校的教师们都是在误人子弟。我奉劝每一位研究生建立不崇拜权威,不崇拜欧美,只服从真理的独立思维模式,大胆质疑大胆批判,只有这样才能不死于他人之言下,才能有活脱脱的自己。
posted @
2012-04-13 19:08 Seraphi 阅读(348) |
评论 (0) |
编辑 收藏
用途:对我来说,学习HMM是为了对以后的词性或概念标注打下理论基础
符号说明:
S:表示状态集合。
S=[S
1,S
2,S
3....]。其中S
i表示第i个状态(第i种状态)
Q:表示系统实际的状态序列,
Q=[q
1,q
2,....,q
T]。q1表示t=1时,系统所处的状态,如:q
1=S
3表示t=1时刻,系统状态为S
3。
1.离散马尔可夫过程
(1)定义:一个系统,在任一时刻t,可能处于N个不同状态S
1,S
2...S
N中的某一个。系统变化服从某种统计规律。如果系统状态序列满足下列无后效的条件,则称(q
t,t
≥1)为离散的马尔可夫过程。
P[q
t+1=S
j|q
t=S
i,q
t-1=S
k,...]=P[q
t+1=S
j|q
t=S
i]
可见系统将来的状态仅与现在所处状态有关,与过去无关,这种情况称之为“无后效”。
如果进一步有P[q
t+1=S
j|q
t=S
i]与时刻t无关,则称相应的马尔可夫过程是齐决的或是时齐的,引入记号:
a
ij=P[q
t+1=S
j|q
t=S
i],1
≤i,j≤N
注:这里有人也称aij为Si→Sj的发射概率,也称转移概率。
(2)初始概率分布: πi=P[q1=Si], 1≤i,j≤N
k步转移概率:
aij(k)=P[qt+k=Sj|qt=Si]
当k=1时,aij(k)=aij(1)=aij
(3)切普曼—柯尔莫哥洛夫公式(Chapman-Kolmogorol)

2.隐马尔可夫模型
当状态本身是不可观察,从而得到隐马尔可夫模型(HMM)。值得一提的是,隐马尔可夫模型(HMM)包含了双重随机过程:一是系统状态变化的过程,即前面所述的马尔可夫过程,另一个是由状态决定观察的随机过程。
举例:碗、球模型
假设N只碗,每个碗中放着数量与比例均不同的各种色彩的球,不同的彩色球为M。先随机选一个碗,再从碗中随机拿一个球,报告球的颜色得到一个观察O1,然后将球放回到碗中,继续这个过程,得到一系列观察O=O1O2O3...OT
在这个模型中,碗(状态)是不可观察的,只有球的颜色是可观察的。这里引入M,指不同观察值的数目 。所有不同观察值记为V={V1,V2,....VM}。
对于第一种随机过程(选碗),时齐马尔可夫过程的转移概率矩阵:A={aij},初始分布:π=(πi)
对于第二种随机过程,有多项分布B={bj(k)},其中
bj(k)=P[时刻t时观察值为Vk|qt=Sj]
给定一组N,M,A,B和π后,一个HMM即确定了,为紧缩起见,今后将用λ=(A,B,π)表示一个HMM。
3.HMM中三个基本问题
问题1:
给定一个观察序列O=O1O2...OT和一个模型λ=(A,B,π),如何有效计算P(O|λ),即给定模型λ的条件下,观察序列O的概率。
问题1是一个计算概率的问题,也可以看成一个评估给定的模型能否很好地拟合给定的观察的问题。
解法:
(1)前向算法:
定义αt(i)=P(O1O2....Ot,qt=Si|λ)
αt可用递推算法完成计算:
①初始化:α1(i)= πibi(O1)
②递推:
③终止:
(2)后向算法:
定义βt(i)=P(Ot+1,Ot+2,...,OT|qt=Si,λ)
βt可用递推算法计算:
①初始化:βT(i)=1
②递推:
③终止:
问题2:
给定一个观察序列O=O1O2...OT和一个模型λ=(A,B,π),如何选择一个相应状态Q=q1q2...qT使得在某种意义下,它能最好地说明观察序列O。
两个准则:
准则1:对每个时刻t,逐个选取状态qt使
γt(i)=P(qt=Si|O,λ)=max
其中:

求出γ
t(i)后,问题2便迎刃而解。
准则2(应用最为广泛):综合选取一个状态序列
Q=q
1q
2....q
T使P(
Q|
O,
λ)=max
对于P(
Q|
O,
λ)=P(
Q,
O|
λ)/P(
O|
λ)
而分母P(
O|λ)与
Q无关,因此等价于P(
Q,
O|
λ)=max。
对于全局最优问题,使用动态规划方法,这就是Viterbi算法。
定义

基于HMM特性,

因为我们同样关心q
1q
2...q
T的序列,因此引入

整个递推算法(Viterbi算法)描述如下:
①初始化
δ1(i)=πibi(O1)
φ1(i)=0
②递推
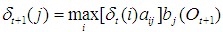

③终止

④回溯最佳路径
q
t*=
φt+1(qt+1*)
将其应用到词性自动标注中。在自动标注中,每个词是可观察的,一个词串W=w1w2....wT即相当这里的一个观察序列O=O1O2...OT。不可观察的状态相当于词性或概念标记,即状态序列Q=q1q2....qT相当于上一节中的一个标记序列。
可以看出准则1相当于词级评价,准则2相当于句子级评价。
问题3.
如何修正模型参数λ=(A,B,π)使P(O|
λ)=max。
问题3是最困难的,至少也没有很好的解法。可参考的方法有基于均值修正的迭代方法等。
参考文献:
[1] 吴立德: 大规模中文文本处理[M]. 复旦大学出版社,1993.
posted @
2012-03-07 13:56 Seraphi 阅读(1333) |
评论 (0) |
编辑 收藏
1.马尔可夫
2.GBDT,随机森林
3.SVD,LDA等理论
4.上述理论的工具使用
5.网络可视化工具的调研
暂时就想到这些,到时候再补充~
posted @
2012-02-29 10:16 Seraphi 阅读(252) |
评论 (0) |
编辑 收藏