大家使用多线程无非是为了提高性能,但如果多线程使用不当,不但性能提升不明显,而且会使得资源消耗更大。下面列举一下可能会造成多线程性能问题的点:
下面分别解析以上性能隐患
死锁
关于死锁,我们在学习操作系统的时候就知道它产生的原因和危害,这里就不从原理上去累述了,可以从下面的代码和图示重温一下死锁产生的原因:
- public class LeftRightDeadlock {
- private final Object left = new Object();
- private final Object right = new Object();
- public void leftRight() {
- synchronized (left) {
- synchronized (right) {
- doSomething();
- }
- }
- }
- public void rightLeft() {
- synchronized (right) {
- synchronized (left) {
- doSomethingElse();
- }
- }
- }
- }

预防和处理死锁的方法:
1)尽量不要在释放锁之前竞争其他锁
一般可以通过细化同步方法来实现,只在真正需要保护共享资源的地方去拿锁,并尽快释放锁,这样可以有效降低在同步方法里调用其他同步方法的情况
2)顺序索取锁资源
如果实在无法避免嵌套索取锁资源,则需要制定一个索取锁资源的策略,先规划好有哪些锁,然后各个线程按照一个顺序去索取,不要出现上面那个例子中不同顺序,这样就会有潜在的死锁问题
3)尝试定时锁
Java 5提供了更灵活的锁工具,可以显式地索取和释放锁。那么在索取锁的时候可以设定一个超时时间,如果超过这个时间还没索取到锁,则不会继续堵塞而是放弃此次任务,示例代码如下:
- public boolean trySendOnSharedLine(String message,
- long timeout, TimeUnit unit)
- throws InterruptedException {
- long nanosToLock = unit.toNanos(timeout)
- - estimatedNanosToSend(message);
- if (!lock.tryLock(nanosToLock, NANOSECONDS))
- return false;
- try {
- return sendOnSharedLine(message);
- } finally {
- lock.unlock();
- }
- }
这样可以有效打破死锁条件。
4)检查死锁
JVM采用thread dump的方式来识别死锁的方式,可以通过操作系统的命令来向JVM发送thread dump的信号,这样可以查询哪些线程死锁。
过多串行化
用多线程实际上就是想并行地做事情,但这些事情由于某些依赖性必须串行工作,导致很多环节得串行化,这实际上很局限系统的可扩展性,就算加CPU加线程,但性能却没有线性增长。有个Amdahl定理可以说明这个问题:
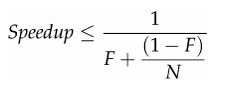
其中,F是串行化比例,N是处理器数量,由上可知,只有尽可能减少串行化,才能最大化地提高可扩展能力。降低串行化的关键就是降低锁竞争,当很多并行任务挂在锁的获取上,就是串行化的表现
过多锁竞争
过多锁竞争的危害是不言而喻的,那么看看有哪些办法来降低锁竞争
1)缩小锁的范围
前面也谈到这一点,尽量缩小锁保护的范围,快进快出,因此尽量不要直接在方法上使用synchronized关键字,而只是在真正需要线程安全保护的地方使用
2)减小锁的粒度
Java 5提供了显式锁后,可以更为灵活的来保护共享变量。synchronized关键字(用在方法上)是默认把整个对象作为锁,实际上很多时候没有必要用这么大一个锁,这会导致这个类所有synchronized都得串行执行。可以根据真正需要保护的共享变量作为锁,也可以使用更为精细的策略,目的就是要在真正需要串行的时候串行,举一个例子:
- public class StripedMap {
- // Synchronization policy: buckets[n] guarded by locks[n%N_LOCKS]
- private static final int N_LOCKS = 16;
- private final Node[] buckets;
- private final Object[] locks;
- private static class Node { ... }
- public StripedMap(int numBuckets) {
- buckets = new Node[numBuckets];
- locks = new Object[N_LOCKS];
- for (int i = 0; i < N_LOCKS; i++)
- locks[i] = new Object();
- }
- private final int hash(Object key) {
- return Math.abs(key.hashCode() % buckets.length);
- }
- public Object get(Object key) {
- int hash = hash(key);
- synchronized (locks[hash % N_LOCKS]) {
- for (Node m = buckets[hash]; m != null; m = m.next)
- if (m.key.equals(key))
- return m.value;
- }
- return null;
- }
- public void clear() {
- for (int i = 0; i < buckets.length; i++) {
- synchronized (locks[i % N_LOCKS]) {
- buckets[i] = null;
- }
- }
- }
- ...
- }
上面这个例子是通过hash算法来把存取的值所对应的hash值来作为锁,这样就只需要对hash值相同的对象存取串行化,而不是像HashTable那样对任何对象任何操作都串行化。
3)减少共享资源的依赖
共享资源是竞争锁的源头,在多线程开发中尽量减少对共享资源的依赖,比如对象池的技术应该慎重考虑,新的JVM对新建对象以做了足够的优化,性能非常好,如果用对象池不但不能提高多少性能,反而会因为锁竞争导致降低线程的可并发性。
4)使用读写分离锁来替换独占锁
Java 5提供了一个读写分离锁(ReadWriteLock)来实现读-读并发,读-写串行,写-写串行的特性。这种方式更进一步提高了可并发性,因为有些场景大部分是读操作,因此没必要串行工作。关于ReadWriteLock的具体使用可以参加一下示例:
- public class ReadWriteMap<K,V> {
- private final Map<K,V> map;
- private final ReadWriteLock lock = new ReentrantReadWriteLock();
- private final Lock r = lock.readLock();
- private final Lock w = lock.writeLock();
- public ReadWriteMap(Map<K,V> map) {
- this.map = map;
- }
- public V put(K key, V value) {
- w.lock();
- try {
- return map.put(key, value);
- } finally {
- w.unlock();
- }
- }
- // Do the same for remove(), putAll(), clear()
- public V get(Object key) {
- r.lock();
- try {
- return map.get(key);
- } finally {
- r.unlock();
- }
- }
- // Do the same for other read-only Map methods
- }
切换上下文
线程比较多的时候,操作系统切换线程上下文的性能消耗是不能忽略的,在构建高性能web之路------web服务器长连接 可以看出在进程切换上的代价,当然线程会更轻量一些,不过道理是类似的
内存同步
当使用到synchronized、volatile或Lock的时候,都会为了保证可见性导致更多的内存同步,这就无法享受到JMM结构带来了性能优化。