1.理解DOM——很详尽的DOM入门资料
https://www6.software.ibm.com/developerworks/cn/education/xml/x-udom/section2.html
http://www.cnblogs.com/huangyu/articles/33572.html
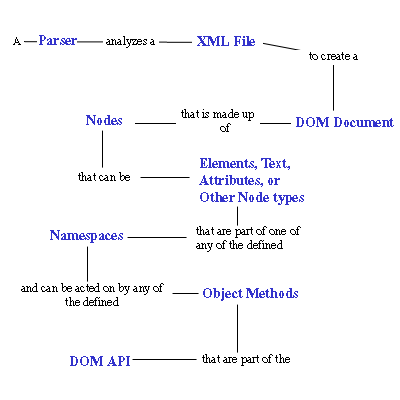
DOM路标图
2.理解SAX
https://www6.software.ibm.com/developerworks/cn/education/xml/x-usax/index.html
http://www.cnblogs.com/huangyu/archive/2004/08/16/33934.html
SAX 是什么?
用于读取和操作 XML 文件的标准是文档对象模型(Document Object Model,DOM)。遗憾的是,DOM 方法涉及读取整个文件并将该文件存储在一个树结构中,而这样可能是低效的、缓慢的,并且很消耗资源。
一种替代技术就是 Simple API for XML,或称为 SAX。SAX 允许您在读取文档时处理它,从而不必等待整个文档被存储之后才采取操作。
SAX 是由 XML-DEV 邮件列表的成员开发的,现在对应的 Java 版本是 SourceForge 项目(请参阅 参考资料)。该项目的目的是为 XML 的使用提供一种更自然的手段 —— 换句话说,也就是不涉及 DOM 所必需的开销和概念跳跃。
项目的成果是一个基于事件 的 API。解析器向一个事件处理程序发送事件,比如元素的开始和结束,而事件处理程序则处理该信息。然后应用程序才能够处理该数据。原始的文档仍然保持原样,但是 SAX 提供了操作数据的手段,因此数据可以用于另一个进程或文档。
SAX 没有官方的标准机构,由万维网联盟(Wide Web Consortium,W3C)或其他官方机构维护,但它是 XML 社区事实上的标准。
SAX 处理涉及以下步骤:
- 创建一个事件处理程序。
- 创建 SAX 解析器。
- 向解析器分配事件处理程序。
- 解析文档,同时向事件处理程序发送每个事件。
基于事件的处理的优点和缺点
这种处理的优点非常类似于流媒体的优点。分析能够立即开始,而不是等待所有的数据被处理。而且,由于应用程序只是在读取数据时检查数据,因此不需要将数据存储在内存中。这对于大型文档来说是个巨大的优点。事实上,应用程序甚至不必解析整个文档;它可以在某个条件得到满足时停止解析。一般来说,SAX 还比它的替代者 DOM 快许多。
另一方面,由于应用程序没有以任何方式存储数据,使用 SAX 来更改数据或在数据流中往后移是不可能的。
SAX 和 DOM 不是相互排斥的,记住这点很重要。您可以使用 DOM 来创建 SAX 事件流,也可以使用 SAX 来创建 DOM 树。事实上,用于创建 DOM 树的大多数解析器实际上都使用 SAX 来完成这个任务!
3.DW上的相关资源
http://www.ibm.com/developerworks/cn/xml/
4.使用Xpath提高基于DOM的XML处理效率
http://www.ibm.com/developerworks/cn/xml/x-domjava/index.shtml