
2006年8月30日
摘要:
阅读全文
posted @
2010-02-04 15:30 xnabx 阅读(1607) |
评论 (1) |
编辑 收藏
摘要:
阅读全文
posted @
2010-01-25 11:10 xnabx 阅读(1026) |
评论 (1) |
编辑 收藏
摘要:
阅读全文
posted @
2010-01-21 09:52 xnabx 阅读(1718) |
评论 (0) |
编辑 收藏
摘要:
阅读全文
posted @
2010-01-15 10:10 xnabx 阅读(1404) |
评论 (0) |
编辑 收藏
摘要:
阅读全文
posted @
2010-01-15 09:57 xnabx 阅读(331) |
评论 (0) |
编辑 收藏
摘要:
阅读全文
posted @
2009-12-04 11:45 xnabx 阅读(600) |
评论 (3) |
编辑 收藏
摘要:
阅读全文
posted @
2009-12-03 15:26 xnabx 阅读(307) |
评论 (0) |
编辑 收藏
摘要:
阅读全文
posted @
2009-12-01 16:02 xnabx 阅读(182) |
评论 (0) |
编辑 收藏
摘要:
阅读全文
posted @
2009-12-01 11:05 xnabx 阅读(317) |
评论 (0) |
编辑 收藏
摘要:
阅读全文
posted @
2009-11-10 09:05 xnabx 阅读(755) |
评论 (0) |
编辑 收藏
摘要:
阅读全文
posted @
2009-03-18 14:06 xnabx 阅读(148) |
评论 (0) |
编辑 收藏
摘要:
阅读全文
posted @
2008-10-29 16:34 xnabx 阅读(111) |
评论 (0) |
编辑 收藏
摘要:
阅读全文
posted @
2008-07-30 15:18 xnabx 阅读(236) |
评论 (0) |
编辑 收藏
摘要:
阅读全文
posted @
2008-07-23 11:20 xnabx 阅读(385) |
评论 (0) |
编辑 收藏出处:http://www.blogjava.net/xmatthew/archive/2008/04/14/192450.html
(转)设计一个Tomcat访问日志分析工具
常使用web服务器的朋友大都了解,一般的web server有两部分日志:
一是运行中的日志,它主要记录运行的一些信息,尤其是一些异常错误日志信息
二是访问日志信息,它记录的访问的时间,IP,访问的资料等相关信息。
现在我来和大家介绍一下利用tomcat产生的访问日志数据,我们能做哪些有效的分析数据?
首先是配置tomcat访问日志数据,默认情况下访问日志没有打开,配置的方式如下:
编辑 ${catalina}/conf/server.xml文件.注:${catalina}是tomcat的安装目录
把以下的注释(<!-- -->)去掉即可。
<!--
<Valve className="org.apache.catalina.valves.AccessLogValve"
directory="logs" prefix="localhost_access_log." suffix=".txt"
pattern="common" resolveHosts="false"/>
-->
其中 directory是产生的目录 tomcat安装${catalina}作为当前目录
pattern表示日志生产的格式,common是tomcat提供的一个标准设置格式。其具体的表达式为 %h %l %u %t "%r" %s %b
但本人建议采用以下具体的配置,因为标准配置有一些重要的日志数据无法生。
%h %l %u %t "%r" %s %b %T
具体的日志产生样式说明如下(从官方文档中摘录):
* %a - Remote IP address
* %A - Local IP address
* %b - Bytes sent, excluding HTTP headers, or '-' if zero
* %B - Bytes sent, excluding HTTP headers
* %h - Remote host name (or IP address if resolveHosts is false)
* %H - Request protocol
* %l - Remote logical username from identd (always returns '-')
* %m - Request method (GET, POST, etc.)
* %p - Local port on which this request was received
* %q - Query string (prepended with a '?' if it exists)
* %r - First line of the request (method and request URI)
* %s - HTTP status code of the response
* %S - User session ID
* %t - Date and time, in Common Log Format
* %u - Remote user that was authenticated (if any), else '-'
* %U - Requested URL path
* %v - Local server name
* %D - Time taken to process the request, in millis
* %T - Time taken to process the request, in seconds
There is also support to write information from the cookie, incoming header, the Session or something else in the ServletRequest. It is modeled after the apache syntax:
* %{xxx}i for incoming headers
* %{xxx}c for a specific cookie
* %{xxx}r xxx is an attribute in the ServletRequest
* %{xxx}s xxx is an attribute in the HttpSession
现在我们回头再来看一下下面这个配置 %h %l %u %t "%r" %s %b %T 生产的访问日志数据,我们可以做哪些事?
先看一下,我们能得到的数据有:
* %h 访问的用户IP地址
* %l 访问逻辑用户名,通常返回'-'
* %u 访问验证用户名,通常返回'-'
* %t 访问日时
* %r 访问的方式(post或者是get),访问的资源和使用的http协议版本
* %s 访问返回的http状态
* %b 访问资源返回的流量
* %T 访问所使用的时间
有了这些数据,我们可以根据时间段做以下的分析处理(图片使用jfreechart工具动态生成):
* 独立IP数统计
* 访问请求数统计
* 访问资料文件数统计
* 访问流量统计
* 访问处理响应时间统计
* 统计所有404错误页面
* 统计所有500错误的页面
* 统计访问最频繁页面
* 统计访问处理时间最久页面
* 统计并发访问频率最高的页面

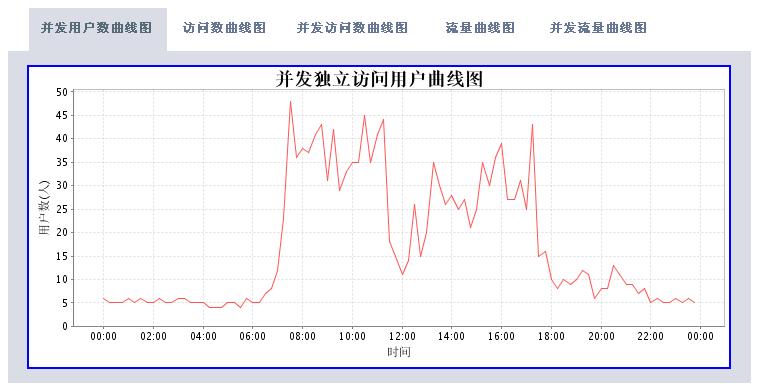
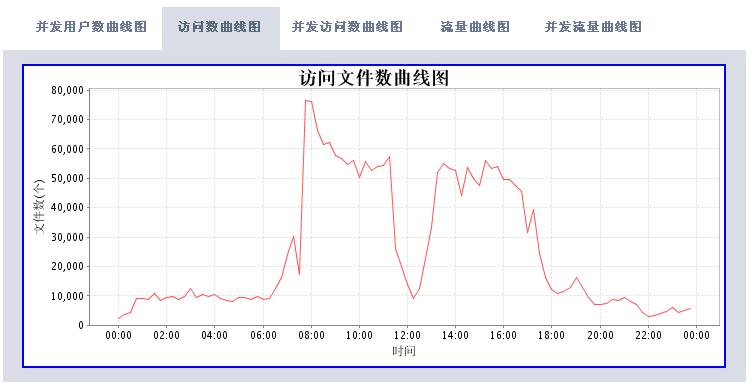
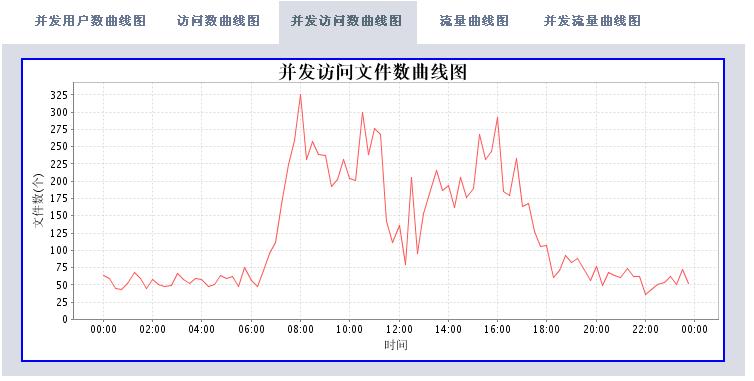
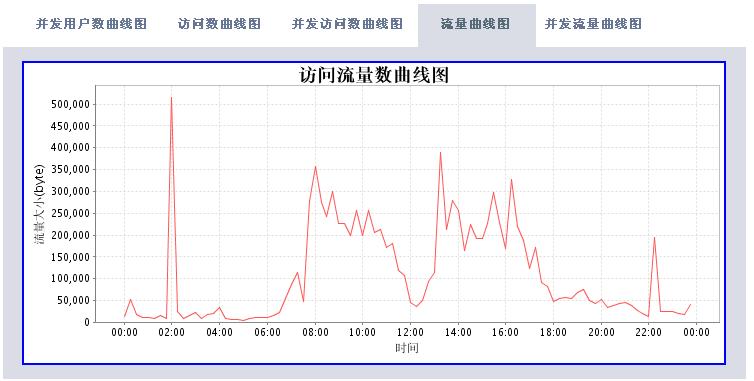
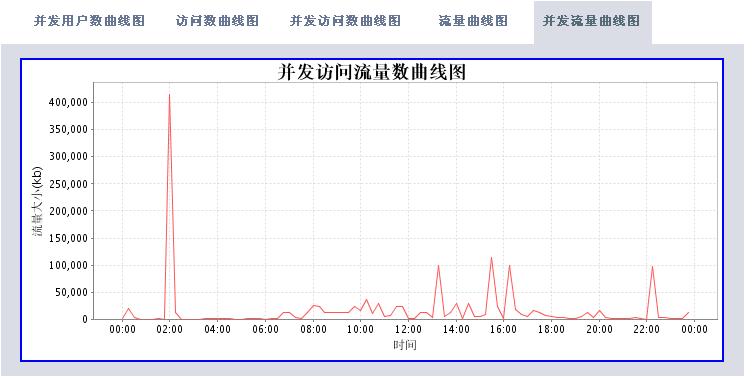

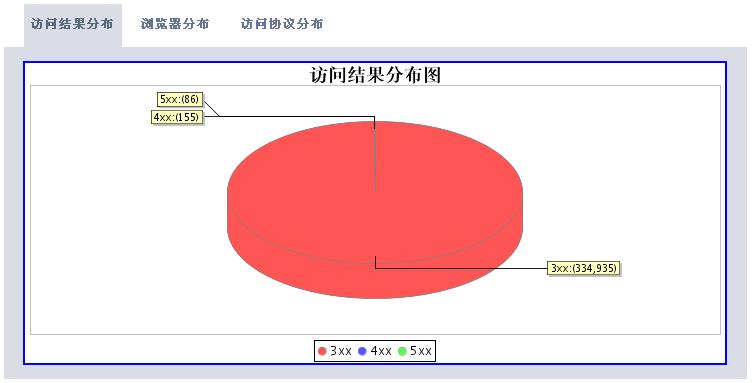
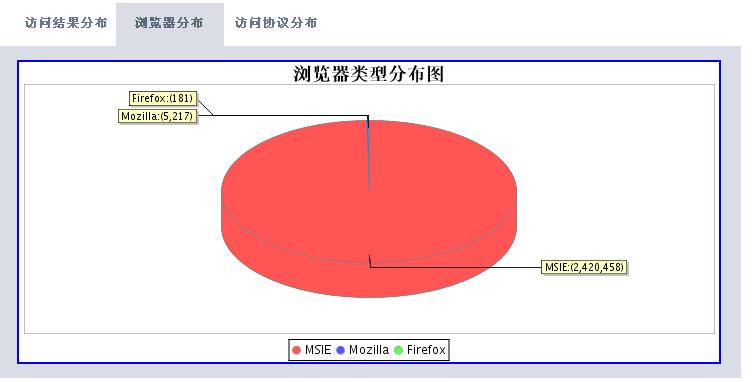
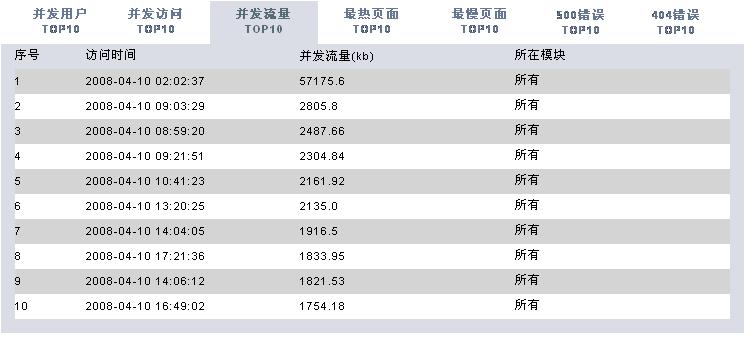

分析工具包括两大部分,一个是后台解释程序,每天执行一次对后台日志数据进行解析后保存到数据库中。
第二个是显示程序,从数据库中查询数据并生成相应的图表信息。
posted @
2008-04-15 12:06 xnabx 阅读(556) |
评论 (0) |
编辑 收藏
摘要:
阅读全文
posted @
2008-04-09 08:50 xnabx 阅读(36) |
评论 (0) |
编辑 收藏
摘要:
阅读全文
posted @
2008-03-19 13:00 xnabx 阅读(184) |
评论 (0) |
编辑 收藏如果你觉得你的Eclipse在启动的时候很慢(比如说超过20秒钟),也许你要调整一下你的Eclipse启动参数了,以下是一些``小贴士'':
1. 检查启动Eclipse的JVM设置。 在Help\About Eclipse SDK\Configuration Detail里面,你可以看到启动Eclipse的JVM。 这个JVM和你在Eclipse中设置的Installed JDK是两回事情。 如果启动Eclipse的JVM还是JDK 1.4的话,那最好改为JDK 5,因为JDK 5的性能比1.4更好。
C:\eclipse\eclipse.exe -vm "C:\Program Files\Java\jdk1.5.0_08\ bin\javaw.exe"
2. 检查Eclipse所使用的heap的大小。 在C:\eclipse目录下有一个配置文件eclipse.ini,其中配置了Eclipse启动的默认heap大小
-vmargs
-Xms40M
-Xmx256M
所以你可以把默认值改为:
-vmargs
-Xms256M
-Xmx512M
当然,也可以这样做,把堆的大小改为256 - 512。
C:\eclipse\eclipse.exe -vm "C:\Program Files\Java\jdk1.5.0_08\ bin\javaw.exe" -vmargs -Xms256M -Xmx512M
3. 其他的启动参数。 如果你有一个双核的CPU,也许可以尝试这个参数:
-XX:+UseParallelGC
让GC可以更快的执行。(只是JDK 5里对GC新增加的参数)
posted @
2007-12-25 10:55 xnabx 阅读(485) |
评论 (0) |
编辑 收藏Java对多线程的支持与同步机制深受大家的喜爱,似乎看起来使用了synchronized关键字就可以轻松地解决多线程共享数据同步问题。到底如何?――还得对synchronized关键字的作用进行深入了解才可定论。
总的说来,synchronized关键字可以作为函数的修饰符,也可作为函数内的语句,也就是平时说的同步方法和同步语句块。如果再细的分类,synchronized可作用于instance变量、object reference(对象引用)、static函数和class literals(类名称字面常量)身上。
在进一步阐述之前,我们需要明确几点:
A.无论synchronized关键字加在方法上还是对象上,它取得的锁都是对象,而不是把一段代码或函数当作锁――而且同步方法很可能还会被其他线程的对象访问。
B.每个对象只有一个锁(lock)与之相关联。
C.实现同步是要很大的系统开销作为代价的,甚至可能造成死锁,所以尽量避免无谓的同步控制。
接着来讨论synchronized用到不同地方对代码产生的影响:
假设P1、P2是同一个类的不同对象,这个类中定义了以下几种情况的同步块或同步方法,P1、P2就都可以调用它们。
1. 把synchronized当作函数修饰符时,示例代码如下:
Public synchronized void methodAAA()
{
//….
}
这也就是同步方法,那这时synchronized锁定的是哪个对象呢?它锁定的是调用这个同步方法对象。也就是说,当一个对象P1在不同的线程中执行这个同步方法时,它们之间会形成互斥,达到同步的效果。但是这个对象所属的Class所产生的另一对象P2却可以任意调用这个被加了synchronized关键字的方法。
上边的示例代码等同于如下代码:
public void methodAAA()
{
synchronized (this) // (1)
{
//…..
}
}
(1)处的this指的是什么呢?它指的就是调用这个方法的对象,如P1。可见同步方法实质是将synchronized作用于object reference。――那个拿到了P1对象锁的线程,才可以调用P1的同步方法,而对P2而言,P1这个锁与它毫不相干,程序也可能在这种情形下摆脱同步机制的控制,造成数据混乱:(
2.同步块,示例代码如下:
public void method3(SomeObject so)
{
synchronized(so)
{
//…..
}
}
这时,锁就是so这个对象,谁拿到这个锁谁就可以运行它所控制的那段代码。当有一个明确的对象作为锁时,就可以这样写程序,但当没有明确的对象作为锁,只是想让一段代码同步时,可以创建一个特殊的instance变量(它得是一个对象)来充当锁:
class Foo implements Runnable
{
private byte[] lock = new byte[0]; // 特殊的instance变量
Public void methodA()
{
synchronized(lock) { //… }
}
//…..
}
注:零长度的byte数组对象创建起来将比任何对象都经济――查看编译后的字节码:生成零长度的byte[]对象只需3条操作码,而Object lock = new Object()则需要7行操作码。
3.将synchronized作用于static 函数,示例代码如下:
Class Foo
{
public synchronized static void methodAAA() // 同步的static 函数
{
//….
}
public void methodBBB()
{
synchronized(Foo.class) // class literal(类名称字面常量)
}
}
代码中的methodBBB()方法是把class literal作为锁的情况,它和同步的static函数产生的效果是一样的,取得的锁很特别,是当前调用这个方法的对象所属的类(Class,而不再是由这个Class产生的某个具体对象了)。
记得在《Effective Java》一书中看到过将 Foo.class和 P1.getClass()用于作同步锁还不一样,不能用P1.getClass()来达到锁这个Class的目的。P1指的是由Foo类产生的对象。
可以推断:如果一个类中定义了一个synchronized的static函数A,也定义了一个synchronized 的instance函数B,那么这个类的同一对象Obj在多线程中分别访问A和B两个方法时,不会构成同步,因为它们的锁都不一样。A方法的锁是Obj这个对象,而B的锁是Obj所属的那个Class。
小结如下:
搞清楚synchronized锁定的是哪个对象,就能帮助我们设计更安全的多线程程序。
还有一些技巧可以让我们对共享资源的同步访问更加安全:
1. 定义private 的instance变量+它的 get方法,而不要定义public/protected的instance变量。如果将变量定义为public,对象在外界可以绕过同步方法的控制而直接取得它,并改动它。这也是JavaBean的标准实现方式之一。
2. 如果instance变量是一个对象,如数组或ArrayList什么的,那上述方法仍然不安全,因为当外界对象通过get方法拿到这个instance对象的引用后,又将其指向另一个对象,那么这个private变量也就变了,岂不是很危险。这个时候就需要将get方法也加上synchronized同步,并且,只返回这个private对象的clone()――这样,调用端得到的就是对象副本的引用了。
posted @
2007-10-11 14:19 xnabx 阅读(263) |
评论 (0) |
编辑 收藏
摘要:
阅读全文
posted @
2007-07-29 09:17 xnabx 阅读(386) |
评论 (0) |
编辑 收藏这几个学习材料非常短小精悍,可清晰快捷的掌握以下几个概念,方便更深入学习
XML tutorial:
http://www.w3schools.com/xml/default.asp
SOAP tutorial:
http://www.w3schools.com/soap/default.asp
WSDL tutorial:
http://www.w3schools.com/wsdl/default.asp
WEB Service tutorial:
http://www.w3schools.com/webservices/default.asp
posted @
2007-07-13 09:00 xnabx 阅读(173) |
评论 (0) |
编辑 收藏类-->对象-->实例
人类是类
某个人是对象
你是实例
实例本身也是对象。
表现出来是这样的
String 类
String str str是对象
String str = "abc"; "abc"是实例,也是对象.
这样也能解释instance of object这种说法 str的实例是"abc"
posted @
2007-07-05 08:47 xnabx 阅读(424) |
评论 (1) |
编辑 收藏
本文主要包括以下几个方面:编码基本知识,java,系统软件,url,工具软件等。
在下面的描述中,将以"中文"两个字为例,经查表可以知道其GB2312编码是"d6d0 cec4",Unicode编码为"4e2d 6587",UTF编码就是"e4b8ad e69687"。注意,这两个字没有iso8859-1编码,但可以用iso8859-1编码来"表示"。
2. 编码基本知识
最早的编码是iso8859-1,和ascii编码相似。但为了方便表示各种各样的语言,逐渐出现了很多标准编码,重要的有如下几个。
2.1. iso8859-1
属于单字节编码,最多能表示的字符范围是0-255,应用于英文系列。比如,字母'a'的编码为0x61=97。
很明显,iso8859-1编码表示的字符范围很窄,无法表示中文字符。但是,由于是单字节编码,和计算机最基础的表示单位一致,所以很多时候,仍旧使用iso8859-1编码来表示。而且在很多协议上,默认使用该编码。比如,虽然"中文"两个字不存在iso8859-1编码,以gb2312编码为例,应该是"d6d0 cec4"两个字符,使用iso8859-1编码的时候则将它拆开为4个字节来表示:"d6 d0 ce c4"(事实上,在进行存储的时候,也是以字节为单位处理的)。而如果是UTF编码,则是6个字节"e4 b8 ad e6 96 87"。很明显,这种表示方法还需要以另一种编码为基础。
2.2. GB2312/GBK
这就是汉子的国标码,专门用来表示汉字,是双字节编码,而英文字母和iso8859-1一致(兼容iso8859-1编码)。其中gbk编码能够用来同时表示繁体字和简体字,而gb2312只能表示简体字,gbk是兼容gb2312编码的。
2.3. unicode
这是最统一的编码,可以用来表示所有语言的字符,而且是定长双字节(也有四字节的)编码,包括英文字母在内。所以可以说它是不兼容iso8859-1编码的,也不兼容任何编码。不过,相对于iso8859-1编码来说,uniocode编码只是在前面增加了一个0字节,比如字母'a'为"00 61"。
需要说明的是,定长编码便于计算机处理(注意GB2312/GBK不是定长编码),而unicode又可以用来表示所有字符,所以在很多软件内部是使用unicode编码来处理的,比如java。
2.4. UTF
考虑到unicode编码不兼容iso8859-1编码,而且容易占用更多的空间:因为对于英文字母,unicode也需要两个字节来表示。所以unicode不便于传输和存储。因此而产生了utf编码,utf编码兼容iso8859-1编码,同时也可以用来表示所有语言的字符,不过,utf编码是不定长编码,每一个字符的长度从1-6个字节不等。另外,utf编码自带简单的校验功能。一般来讲,英文字母都是用一个字节表示,而汉字使用三个字节。
注意,虽然说utf是为了使用更少的空间而使用的,但那只是相对于unicode编码来说,如果已经知道是汉字,则使用GB2312/GBK无疑是最节省的。不过另一方面,值得说明的是,虽然utf编码对汉字使用3个字节,但即使对于汉字网页,utf编码也会比unicode编码节省,因为网页中包含了很多的英文字符。
3. java对字符的处理
在java应用软件中,会有多处涉及到字符集编码,有些地方需要进行正确的设置,有些地方需要进行一定程度的处理。
3.1. getBytes(charset)
这是java字符串处理的一个标准函数,其作用是将字符串所表示的字符按照charset编码,并以字节方式表示。注意字符串在java内存中总是按unicode编码存储的。比如"中文",正常情况下(即没有错误的时候)存储为"4e2d 6587",如果charset为"gbk",则被编码为"d6d0 cec4",然后返回字节"d6 d0 ce c4"。如果charset为"utf8"则最后是"e4 b8 ad e6 96 87"。如果是"iso8859-1",则由于无法编码,最后返回 "3f 3f"(两个问号)。
3.2. new String(charset)
这是java字符串处理的另一个标准函数,和上一个函数的作用相反,将字节数组按照charset编码进行组合识别,最后转换为unicode存储。参考上述getBytes的例子,"gbk" 和"utf8"都可以得出正确的结果"4e2d 6587",但iso8859-1最后变成了"003f 003f"(两个问号)。
因为utf8可以用来表示/编码所有字符,所以new String( str.getBytes( "utf8" ), "utf8" ) === str,即完全可逆。
3.3. setCharacterEncoding()
该函数用来设置http请求或者相应的编码。
对于request,是指提交内容的编码,指定后可以通过getParameter()则直接获得正确的字符串,如果不指定,则默认使用iso8859-1编码,需要进一步处理。参见下述"表单输入"。值得注意的是在执行setCharacterEncoding()之前,不能执行任何getParameter()。java doc上说明:This method must be called prior to reading request parameters or reading input using getReader()。而且,该指定只对POST方法有效,对GET方法无效。分析原因,应该是在执行第一个getParameter()的时候,java将会按照编码分析所有的提交内容,而后续的getParameter()不再进行分析,所以setCharacterEncoding()无效。而对于GET方法提交表单是,提交的内容在URL中,一开始就已经按照编码分析所有的提交内容,setCharacterEncoding()自然就无效。
对于response,则是指定输出内容的编码,同时,该设置会传递给浏览器,告诉浏览器输出内容所采用的编码。
3.4. 处理过程
下面分析两个有代表性的例子,说明java对编码有关问题的处理方法。
3.4.1. 表单输入
User input *(gbk:d6d0 cec4) browser *(gbk:d6d0 cec4) web server iso8859-1(00d6 00d 000ce 00c4) class,需要在class中进行处理:getbytes("iso8859-1")为d6 d0 ce c4,new String("gbk")为d6d0 cec4,内存中以unicode编码则为4e2d 6587。
l 用户输入的编码方式和页面指定的编码有关,也和用户的操作系统有关,所以是不确定的,上例以gbk为例。
l 从browser到web server,可以在表单中指定提交内容时使用的字符集,否则会使用页面指定的编码。而如果在url中直接用?的方式输入参数,则其编码往往是操作系统本身的编码,因为这时和页面无关。上述仍旧以gbk编码为例。
l Web server接收到的是字节流,默认时(getParameter)会以iso8859-1编码处理之,结果是不正确的,所以需要进行处理。但如果预先设置了编码(通过request. setCharacterEncoding ()),则能够直接获取到正确的结果。
l 在页面中指定编码是个好习惯,否则可能失去控制,无法指定正确的编码。
3.4.2. 文件编译
假设文件是gbk编码保存的,而编译有两种编码选择:gbk或者iso8859-1,前者是中文windows的默认编码,后者是linux的默认编码,当然也可以在编译时指定编码。
Jsp *(gbk:d6d0 cec4) java file *(gbk:d6d0 cec4) compiler read uincode(gbk: 4e2d 6587; iso8859-1: 00d6 00d 000ce 00c4) compiler write utf(gbk: e4b8ad e69687; iso8859-1: *) compiled file unicode(gbk: 4e2d 6587; iso8859-1: 00d6 00d 000ce 00c4) class。所以用gbk编码保存,而用iso8859-1编译的结果是不正确的。
class unicode(4e2d 6587) system.out / jsp.out gbk(d6d0 cec4) os console / browser。
l 文件可以以多种编码方式保存,中文windows下,默认为ansi/gbk。
l 编译器读取文件时,需要得到文件的编码,如果未指定,则使用系统默认编码。一般class文件,是以系统默认编码保存的,所以编译不会出问题,但对于jsp文件,如果在中文windows下编辑保存,而部署在英文linux下运行/编译,则会出现问题。所以需要在jsp文件中用pageEncoding指定编码。
l Java编译的时候会转换成统一的unicode编码处理,最后保存的时候再转换为utf编码。
l 当系统输出字符的时候,会按指定编码输出,对于中文windows下,System.out将使用gbk编码,而对于response(浏览器),则使用jsp文件头指定的contentType,或者可以直接为response指定编码。同时,会告诉browser网页的编码。如果未指定,则会使用iso8859-1编码。对于中文,应该为browser指定输出字符串的编码。
l browser显示网页的时候,首先使用response中指定的编码(jsp文件头指定的contentType最终也反映在response上),如果未指定,则会使用网页中meta项指定中的contentType。
3.5. 几处设置
对于web应用程序,和编码有关的设置或者函数如下。
3.5.1. jsp编译
指定文件的存储编码,很明显,该设置应该置于文件的开头。例如:<%@page pageEncoding="GBK"%>。另外,对于一般class文件,可以在编译的时候指定编码。
3.5.2. jsp输出
指定文件输出到browser是使用的编码,该设置也应该置于文件的开头。例如:<%@ page contentType="text/html; charset= GBK" %>。该设置和response.setCharacterEncoding("GBK")等效。
3.5.3. meta设置
指定网页使用的编码,该设置对静态网页尤其有作用。因为静态网页无法采用jsp的设置,而且也无法执行response.setCharacterEncoding()。例如:<META http-equiv="Content-Type" content="text/html; charset=GBK" />
如果同时采用了jsp输出和meta设置两种编码指定方式,则jsp指定的优先。因为jsp指定的直接体现在response中。
需要注意的是,apache有一个设置可以给无编码指定的网页指定编码,该指定等同于jsp的编码指定方式,所以会覆盖静态网页中的meta指定。所以有人建议关闭该设置。
3.5.4. form设置
当浏览器提交表单的时候,可以指定相应的编码。例如:<form accept-charset= "gb2312">。一般不必不使用该设置,浏览器会直接使用网页的编码。
4. 系统软件
下面讨论几个相关的系统软件。
4.1. mysql数据库
很明显,要支持多语言,应该将数据库的编码设置成utf或者unicode,而utf更适合与存储。但是,如果中文数据中包含的英文字母很少,其实unicode更为适合。
数据库的编码可以通过mysql的配置文件设置,例如default-character-set=utf8。还可以在数据库链接URL中设置,例如: useUnicode=true&characterEncoding=UTF-8。注意这两者应该保持一致,在新的sql版本里,在数据库链接URL里可以不进行设置,但也不能是错误的设置。
4.2. apache
appache和编码有关的配置在httpd.conf中,例如AddDefaultCharset UTF-8。如前所述,该功能会将所有静态页面的编码设置为UTF-8,最好关闭该功能。
另外,apache还有单独的模块来处理网页响应头,其中也可能对编码进行设置。
4.3. linux默认编码
这里所说的linux默认编码,是指运行时的环境变量。两个重要的环境变量是LC_ALL和LANG,默认编码会影响到java URLEncode的行为,下面有描述。
建议都设置为"zh_CN.UTF-8"。
4.4. 其它
为了支持中文文件名,linux在加载磁盘时应该指定字符集,例如:mount /dev/hda5 /mnt/hda5/ -t ntfs -o iocharset=gb2312。
另外,如前所述,使用GET方法提交的信息不支持request.setCharacterEncoding(),但可以通过tomcat的配置文件指定字符集,在tomcat的server.xml文件中,形如:<Connector ... URIEncoding="GBK"/>。这种方法将统一设置所有请求,而不能针对具体页面进行设置,也不一定和browser使用的编码相同,所以有时候并不是所期望的。
5. URL地址
URL地址中含有中文字符是很麻烦的,前面描述过使用GET方法提交表单的情况,使用GET方法时,参数就是包含在URL中。
5.1. URL编码
对于URL中的一些特殊字符,浏览器会自动进行编码。这些字符除了"/?&"等外,还包括unicode字符,比如汉子。这时的编码比较特殊。
IE有一个选项"总是使用UTF-8发送URL",当该选项有效时,IE将会对特殊字符进行UTF-8编码,同时进行URL编码。如果改选项无效,则使用默认编码"GBK",并且不进行URL编码。但是,对于URL后面的参数,则总是不进行编码,相当于UTF-8选项无效。比如"中文.html?a=中文",当UTF-8选项有效时,将发送链接"%e4%b8%ad%e6%96%87.html?a=\x4e\x2d\x65\x87";而UTF-8选项无效时,将发送链接"\x4e\x2d\x65\x87.html?a=\x4e\x2d\x65\x87"。注意后者前面的"中文"两个字只有4个字节,而前者却有18个字节,这主要时URL编码的原因。
当web server(tomcat)接收到该链接时,将会进行URL解码,即去掉"%",同时按照ISO8859-1编码(上面已经描述,可以使用URLEncoding来设置成其它编码)识别。上述例子的结果分别是"\ue4\ub8\uad\ue6\u96\u87.html?a=\u4e\u2d\u65\u87"和"\u4e\u2d\u65\u87.html?a=\u4e\u2d\u65\u87",注意前者前面的"中文"两个字恢复成了6个字符。这里用"\u",表示是unicode。
所以,由于客户端设置的不同,相同的链接,在服务器上得到了不同结果。这个问题不少人都遇到,却没有很好的解决办法。所以有的网站会建议用户尝试关闭UTF-8选项。不过,下面会描述一个更好的处理办法。
5.2. rewrite
熟悉的人都知道,apache有一个功能强大的rewrite模块,这里不描述其功能。需要说明的是该模块会自动将URL解码(去除%),即完成上述web server(tomcat)的部分功能。有相关文档介绍说可以使用[NE]参数来关闭该功能,但我试验并未成功,可能是因为版本(我使用的是apache 2.0.54)问题。另外,当参数中含有"?& "等符号的时候,该功能将导致系统得不到正常结果。
rewrite本身似乎完全是采用字节处理的方式,而不考虑字符串的编码,所以不会带来编码问题。
5.3. URLEncode.encode()
这是Java本身提供对的URL编码函数,完成的工作和上述UTF-8选项有效时浏览器所做的工作相似。值得说明的是,java已经不赞成不指定编码来使用该方法(deprecated)。应该在使用的时候增加编码指定。
当不指定编码的时候,该方法使用系统默认编码,这会导致软件运行结果得不确定。比如对于"中文",当系统默认编码为"gb2312"时,结果是"%4e%2d%65%87",而默认编码为"UTF-8",结果却是"%e4%b8%ad%e6%96%87",后续程序将难以处理。另外,这儿说的系统默认编码是由运行tomcat时的环境变量LC_ALL和LANG等决定的,曾经出现过tomcat重启后就出现乱码的问题,最后才郁闷的发现是因为修改修改了这两个环境变量。
建议统一指定为"UTF-8"编码,可能需要修改相应的程序。
5.4. 一个解决方案
上面说起过,因为浏览器设置的不同,对于同一个链接,web server收到的是不同内容,而软件系统有无法知道这中间的区别,所以这一协议目前还存在缺陷。
针对具体问题,不应该侥幸认为所有客户的IE设置都是UTF-8有效的,也不应该粗暴的建议用户修改IE设置,要知道,用户不可能去记住每一个web server的设置。所以,接下来的解决办法就只能是让自己的程序多一点智能:根据内容来分析编码是否UTF-8。
比较幸运的是UTF-8编码相当有规律,所以可以通过分析传输过来的链接内容,来判断是否是正确的UTF-8字符,如果是,则以UTF-8处理之,如果不是,则使用客户默认编码(比如"GBK"),下面是一个判断是否UTF-8的例子,如果你了解相应规律,就容易理解。
public static boolean isValidUtf8(byte[] b,int aMaxCount){
int lLen=b.length,lCharCount=0;
for(int i=0;i<lLen && lCharCount<aMaxCount;++lCharCount){
byte lByte=b[i++];//to fast operation, ++ now, ready for the following for(;;)
if(lByte>=0) continue;//>=0 is normal ascii
if(lByte<(byte)0xc0 || lByte>(byte)0xfd) return false;
int lCount=lByte>(byte)0xfc?5:lByte>(byte)0xf8?4
:lByte>(byte)0xf0?3:lByte>(byte)0xe0?2:1;
if(i+lCount>lLen) return false;
for(int j=0;j<lCount;++j,++i) if(b[i]>=(byte)0xc0) return false;
}
return true;
}
相应地,一个使用上述方法的例子如下:
public static String getUrlParam(String aStr,String aDefaultCharset)
throws UnsupportedEncodingException{
if(aStr==null) return null;
byte[] lBytes=aStr.getBytes("ISO-8859-1");
return new String(lBytes,StringUtil.isValidUtf8(lBytes)?"utf8":aDefaultCharset);
}
不过,该方法也存在缺陷,如下两方面:
l 没有包括对用户默认编码的识别,这可以根据请求信息的语言来判断,但不一定正确,因为我们有时候也会输入一些韩文,或者其他文字。
l 可能会错误判断UTF-8字符,一个例子是"学习"两个字,其GBK编码是" \xd1\xa7\xcf\xb0",如果使用上述isValidUtf8方法判断,将返回true。可以考虑使用更严格的判断方法,不过估计效果不大。
有一个例子可以证明google也遇到了上述问题,而且也采用了和上述相似的处理方法,比如,如果在地址栏中输入"http://www.google.com/search?hl=zh-CN&newwindow=1&q=学习",google将无法正确识别,而其他汉字一般能够正常识别。
最后,应该补充说明一下,如果不使用rewrite规则,或者通过表单提交数据,其实并不一定会遇到上述问题,因为这时可以在提交数据时指定希望的编码。另外,中文文件名确实会带来问题,应该谨慎使用。
6. 其它
下面描述一些和编码有关的其他问题。
6.1. SecureCRT
除了浏览器和控制台与编码有关外,一些客户端也很有关系。比如在使用SecureCRT连接linux时,应该让SecureCRT的显示编码(不同的session,可以有不同的编码设置)和linux的编码环境变量保持一致。否则看到的一些帮助信息,就可能是乱码。
另外,mysql有自己的编码设置,也应该保持和SecureCRT的显示编码一致。否则通过SecureCRT执行sql语句的时候,可能无法处理中文字符,查询结果也会出现乱码。
对于Utf-8文件,很多编辑器(比如记事本)会在文件开头增加三个不可见的标志字节,如果作为mysql的输入文件,则必须要去掉这三个字符。(用linux的vi保存可以去掉这三个字符)。一个有趣的现象是,在中文windows下,创建一个新txt文件,用记事本打开,输入"连通"两个字,保存,再打开,你会发现两个字没了,只留下一个小黑点。
6.2. 过滤器
如果需要统一设置编码,则通过filter进行设置是个不错的选择。在filter class中,可以统一为需要的请求或者回应设置编码。参加上述setCharacterEncoding()。这个类apache已经给出了可以直接使用的例子SetCharacterEncodingFilter。
6.3. POST和GET
很明显,以POST提交信息时,URL有更好的可读性,而且可以方便的使用setCharacterEncoding()来处理字符集问题。但GET方法形成的URL能够更容易表达网页的实际内容,也能够用于收藏。
从统一的角度考虑问题,建议采用GET方法,这要求在程序中获得参数是进行特殊处理,而无法使用setCharacterEncoding()的便利,如果不考虑rewrite,就不存在IE的UTF-8问题,可以考虑通过设置URIEncoding来方便获取URL中的参数。
6.4. 简繁体编码转换
GBK同时包含简体和繁体编码,也就是说同一个字,由于编码不同,在GBK编码下属于两个字。有时候,为了正确取得完整的结果,应该将繁体和简体进行统一。可以考虑将UTF、GBK中的所有繁体字,转换为相应的简体字,BIG5编码的数据,也应该转化成相应的简体字。当然,仍旧以UTF编码存储。
例如,对于"语言 ?言",用UTF表示为"\xE8\xAF\xAD\xE8\xA8\x80 \xE8\xAA\x9E\xE8\xA8\x80",进行简繁体编码转换后应该是两个相同的 "\xE8\xAF\xAD\xE8\xA8\x80>"。
posted @
2006-08-30 17:51 xnabx 阅读(175) |
评论 (0) |
编辑 收藏