2011年1月11日
前两天休眠后机器非正常关机,重新启动后运行eclipse。悲催的发现eclipse
无法启动了。每次双击启动后,确定完workspace后,显示启动画面,没过一会就进入灰色无响应状态。启动画面始终停留在Loading
workbench状态。反复重启,状态依旧。尝试解决。
搜索了一下,应该是非正常关机导致eclipse工作区的文件状态错误导致。在工作区目录中,有一个.metadata目录,里面是工作区及各插件的信息,删除此目录可以解决问题。
为保险起见,将.metadata改名移动到/tmp目录,再重启eclipse,果然可以正常启动eclipse了,但原来工作区的配置和项目信息也都消失,直接显示的是欢迎界面。
如何恢复原来的project配置呢?尝试对比了当前的.metadata和之前备份的那个目录,发现缺少了很多配置文件。试着一点点恢复一些目录,但效
果不理想。因为不知道哪些文件(目录)可以恢复,哪些恢复会带来问题。将备份的整个目录恢复试试?Eclipse又回到了无法启动的状态了。
怎么办?这时想到启动停止时显示的状态:"Loading workbench",看来和这个workbench插件有关。查看原来的.metadata/.plugins目录,在众多文件夹中
com.collabnet.subversion.merge org.eclipse.search
org.eclipse.compare org.eclipse.team.core
org.eclipse.core.resources org.eclipse.team.cvs.core
org.eclipse.core.runtime org.eclipse.team.ui
org.eclipse.debug.core org.eclipse.ui.ide
org.eclipse.debug.ui org.eclipse.ui.intro
org.eclipse.dltk.core org.eclipse.ui.views.log
org.eclipse.dltk.core.index.sql.h2 org.eclipse.ui.workbench
org.eclipse.dltk.ui org.eclipse.ui.workbench.texteditor
org.eclipse.epp.usagedata.recording org.eclipse.wb.discovery.core
org.eclipse.jdt.core org.eclipse.wst.internet.cache
org.eclipse.jdt.ui org.eclipse.wst.jsdt.core
org.eclipse.ltk.core.refactoring org.eclipse.wst.jsdt.ui
org.eclipse.ltk.ui.refactoring org.eclipse.wst.jsdt.web.core
org.eclipse.m2e.core org.eclipse.wst.sse.ui
org.eclipse.m2e.logback.configuration org.eclipse.wst.validation
org.eclipse.mylyn.bugzilla.core org.eclipse.wst.xml.core
org.eclipse.mylyn.tasks.ui org.tigris.subversion.subclipse.core
org.eclipse.php.core org.tigris.subversion.subclipse.graph
org.eclipse.php.ui org.tigris.subversion.subclipse.ui
发现了两个:
org.eclipse.ui.workbench 和
org.eclipse.ui.workbench.texteditor。
不管三七二十一,删了这两个目录,重新启动eclipse。正常启动且原项目信息正确加载。
最近团队遇到一个案例。看似很小的事情,但仔细研究起来,彻底分析,每一个环节都没做好,细节部分糟糕得一塌糊涂,最后导致一件事情的结果:完全失败。
经常有人在聊起公司的时候问我,你现在最担心的事情有哪些? 我当然会重点提到团队。不过在谈及团队的时候,我又最担心在「细节」问题上做不好。
细节就是竞争力,尤其是对小团队来说,小团队更应该注重细节问题。大一点的公司可以追究责任人,靠流程、靠制度,靠各级评审等等一系列的「成本」来提升细节能力。小一点的公司或者团队怎么办? 恐怕只有依赖每个人的能力和责任心了。
细节也是锻炼人的能力的地方,搞清楚每一个细节,将每一个细节涉及到的背景知识和技能掌握好,能力自然也就会得到提升。继而,着手做更大的事情也不
会手忙脚乱。相反,做不好细节和小事的人,如果总嚷着要做「重要」的事情,做更有「挑战」的事情,这样的事情真的到你面前,真的能接住么?
为什么我们在细节上做不好?
对细节问题不够重视 一件事情到了自己这里,头脑中先入为主认为只是一件小事,是一件简单的事情。这样,当然就不会给予足够的重视。小事不一定不重要,小事不一定意味着做起来就简单。
对事情复杂度缺乏认知 不就是给客户写一封电子邮件么? 不就是用 HTML 写一个页面么? 不就是做一则横幅广告么? 那么,这些事情真的简单么? 为什么别人为客户写的邮件打开率更高? 为什么别人写的页面更容易被搜索引擎收录? 为什么别人做的广告转化率更好? 背后涉及到哪些知识? 不想研究一下么? 不能研究一下么?
对细节缺乏耐心 草草了事,应付了事,遇到问题马马虎虎,轻易得放过了很多可以让自己得到成长的机会。「这问题我没想过」「这事情我没遇到过」「设计稿都改过两次了」... 这类借口在任何一个团队都很常见。
缺少责任心 常常觉得自己这里做不好,还有别人会把关呢。担心什么? 可如果所有人都这么想呢? 「文案是产品经理的事情,关我甚么事?」如果你能对文案也有改进意见,谁说以后你就不能做产品经理做的事情呢?
主观上不认可自己的工作 就给我这么一点钱,要我做这么多工作? 问题是我们如果不多做一点工作,不提升一下自己,又怎么能多一点钱呢?
为什么细节上做不好? 不同人不同的角度还会有不同的看法。不过有一点我能肯定,细节不会决定成败,但做不好细节,一定会失败。
做好细节,百事可作。
mac中自带的jdk并不包含源代码,所以在eclipse中无法查看, 需要到apple上去下载,
https://developer.apple.com/downloads/index.action
Documentation and developer runtime of "Java for OS X 2012-005". Contains JavaDoc, tools documentation, and native framework headers.
目前的版本是:Java for OS X 2012-005 Developer Package
下载下来后,直接安装,默认设置就可以了,然后可以建个link,方便选择。
- sudo -s
- cd /System/Library/Frameworks/JavaVM.framework/Home
- ln -s /Library/Java/JavaVirtualMachines/1.6.0_35-b10-428.jdk/Contents/Home/docs.jar
- ln -s /Library/Java/JavaVirtualMachines/1.6.0_35-b10-428.jdk/Contents/Home/src.jar
- 最后跟windows类似,在eclipse中用command + click点击查看一个类的源码。然后选“add source",选中上面的 src.jar 文件即可
虽然android安装完成后会有一套参考手册,其中包括了api,但是如果在开发过程中能查看android的源码(sdk的源码),将对我们学习android有一定的帮助.毕竟,有时候源码比api文档更能说明问题.
我平常学习android用的2.2版本,从网上下载了2.2的源码(从官方git库下载太麻烦,是从网友共享的源码位置下载的).按照网上的说法,我把
解压后的那一堆文档放在了android-sdk-root\platforms\android-8\sources目录下.不过并没有重启
eclipse.而是通过这种方法来做的-----在eclipse中,鼠标放在一个android提供的类上,按下ctrl键,会打开一个新页面,提示
找不到对应的类的class或者源文件,但这个新页面上有个导入源码的按钮,点击之后选择下载好的source位置,确定后就可以了.
顺便说下我下载android源码的位置:
http://tech.cncms.com/UploadFiles/20101025/androidsdk2.2_sources.zip下载源码到maven仓库: http://search.maven.org/#search|gav|1|g%3A%22com.google.android%22%20AND%20a%3A%22android%22
离开淘宝后,自己创业,产品需要推广,考虑到当今流量最大的聚集在微博上,我们也来做做微博运营,我是一个技术人员,运营对于我来说,从0开始,站在巨人的肩膀上学习,稍稍总结了下。
1. 使用工具:微博第三方插件已经提供了很多功能,适合自己的都用起来,这个我觉得最节省我的时间,其他网上提供的软件都可以使用,重要是适合自己,安全第一。
2. 写工具:有很多个性化需求的时候,如果变相的不能实现,人为处理太慢太花时间,我们现在是小创业团队,很多事情都需要自己做,数据增长慢,在有限的资源下,写工具是非常好的方式,作为技术人员就直接动手写,当然也需要看看性价比。
3.微博定位:
找好本微博的主题,内容一般遵循原则:定制+非定制。定制是指针对你的目标群体来选择内容,要让这部分人感兴趣,非定制:是指那种适合任何粉丝的内容。
例如:我的目标群体是女性,我的定制内容就有美容、护肤、服饰搭配、星座、爱情等女性关注的话题,非定制的有笑话、经典语录、旅游等大众类容。根据内容来 建立话题,如#美容护肤# #开心一笑##XX语录#等等,我就为自己建立了10个左右话题,每天的内容按照话题来制作。
4.主要工作流程:(这个图是转的)

5.常用的微博话题(这个图片也是转的)

6. 关注项目:微博和主动@,评论,私信,群,邀请,勋章,策划产品活动,参与微活动
7.微博运营最重要的是:一段时间需要总结挑选合适的方法执行,没有效果的去除。
如:微博发布时间/数量
我(转,不是我)曾在粉丝超过一万之后就开始研究的我的微博改什么时候发布,每天发布多少。我现在粉丝中做了一个投票:你们一般什么时候织微博。最后有200多人参加, 我大概划分了5个时段,9-12点,12-17点 17-19点 19-22点 22-24点 0-3点,做多选择3个答案,结果出来之后就有个大概了。接下来我用一周的时间从9点—24点之间每1小时发布一条信息。总共16条信息,我就分析每条信 息的转发、回复数量,一周之后我就可以摸清粉丝的上网时间规律。然后我选择哪几个时间段重点维护,并在那几个时间段进一步研究发布数量规律,我又分为每1小时,每0.5小时两个因素来研究发布数量。
JMock是帮助创建mock对象的工具,它基于Java开发,在Java测试与开发环境中有不可比拟的优势,更重要的是,它大大简化了虚拟对象的使用。本文中,通过一个简单的测试用例来说明JMock如何帮助我们实现这种孤立测试。
我们在测试某类时,由于它要与其他类发生联系,因此往往在测试此类的代码中也将与之联系的类也一起测试了。这种测试,将使被测试的类直接依赖于其他类,一旦其他类发生改变,被测试类也随之被迫改变。更重要的是,这些其他类可能尚未经过测试,因此必须先测试这些类,才能测试被测试类。这种情况下,测试驱动开发成为空谈。而如果其他类中也引用了被测试类,我们到底先测试哪一个类?因此,在测试中,如果我们能将被测试类孤立起来,使其完全不依赖于其他类的具体实现,这样,我们就能做到测试先行,先测试哪个类,就先实现哪个类,而不管与之联系的类是否已经实现。
虚拟对象(mock object)就是为此需要而诞生的。它通过JDK中的反射机制,在运行时动态地创建虚拟对象。在测试代码中,我们可以验证这些虚拟对象是否被正确地调用了,也可以在明确的情况下,让其返回特定的假想值。而一旦有了这些虚拟对象提供的服务,被测试类就可以将虚拟对象作为其他与之联系的真实对象的替身,从而轻松地搭建起一个很完美的测试环境。
JMock是帮助创建mock对象的工具,它基于Java开发,在Java测试与开发环境中有不可比拟的优势,更重要的是,它大大简化了虚拟对象的使用。
本文中,通过一个简单的测试用例来说明JMock如何帮助我们实现这种孤立测试。有三个主要的类,User,UserDAO,及UserService。本文中,我们只需测试UserService,准备虚拟UserDAO。对于User,由于本身仅是一个过于简单的POJO,可以不用测试。但如果你是一个完美主义者,也可以使用JMock的虚拟它。在这领域,JMock几乎无所不能。
这里我用到的是:(我用的是maven依赖)
<dependency>
<groupId>org.jmock</groupId>
<artifactId>jmock</artifactId>
<version>2.5.1</version>
</dependency>
<dependency>
<groupId>org.jmock</groupId>
<artifactId>jmock-junit3</artifactId>
<version>2.5.1</version>
</dependency>
在官方的网站上也有的下载。 地址: http://jmock.org/dist/jmock-2.5.1-jars.zip
public class User {
private String name;
public User() {
}
public User(String name) {
this.name = name;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
}
UserDAO负责与数据库打交道,通过数据库保存、获取User的信息。尽管我们可以不用知道JMock如何通过JDK 的反射机制来实现孤立测试,但至少应知道,JDK的反射机制要求这些在运行时创建的动态类必须定义接口。在使用JMock的环境中,由于我们要虚拟 UserDAO,意味着UserDAO必须定义接口
public interface UserDAO {
public User getUser(Long id);
}
public interface UserService {
public void setUserDAO(UserDAO userDAO);
public User getUser(Long id);
}
public class UserServiceImpl implements UserService {
private UserDAO userDAO;
public UserServiceImpl() {
}
public void setUserDAO(UserDAO userDAO) {
this.userDAO = userDAO;
}
public User getUser(Long id) {
return userDAO.getUser(id);
}
}
import org.jmock.Expectations;
import org.jmock.integration.junit3.MockObjectTestCase;
public class UserServiceTest extends MockObjectTestCase {
private UserService userService = new UserServiceImpl();
private UserDAO userDAO = null;
public UserServiceTest(String testName) {
super(testName);
}
protected void setUp() throws Exception {
userDAO = mock(UserDAO.class);
userService.setUserDAO(userDAO);
}
public void testGetUser() {
String name = "lsb";
final User fakeUser = new User(name);
checking(new Expectations(){{
oneOf(userDAO).getUser(1L);
will(returnValue(fakeUser));
}});
User user = userService.getUser(1L);
assertNotNull(user);
assertEquals(name, user.getName());
}
protected void tearDown() throws Exception {
}
}
在开发Android和iPhone应用程序时,我们往往需要从服务器不定的向手 机客户端即时推送各种通知消息,iPhone上已经有了比较简单的和完美的推送通知解决方案,可是Android平台上实现起来却相对比较麻烦,最近利用 几天的时间对Android的推送通知服务进行初步的研究。在Android手机平台上,Google提供了C2DM(Cloudto Device Messaging)服务。
Android Cloud to Device Messaging (C2DM)是一个用来帮助开发者从服务器向Android应用程序发送数据的服务。该服务提供了一个简单的、轻量级的机制,允许服务器可以通知移动应用程序直接与服务器进行通信,以便于从服务器获取应用程序更新和用户数据。C2DM服务负责处理诸如消息排队等事务并向运行于目标设备上的应用程序分发这些消息。
使用C2DM框架的要求
1. 需要Android2.2及以上的系统版本
2. 使用C2DM功能的Android设备上需要设置好Google的账户。
3. C2DM需要依赖于Google官方提供的C2DM服务器,由于国内的网络环境,这个服务经常不可用,如果想要很好的使用,我们的App Server必须也在国外,这个恐怕不是每个开发者都能够实现的
要使用C2DM来进行Push操作,基本上要使用以下6个步骤

(1)注册:Android设备把使用C2DM功能的用户账户(比如android.c2dm.demo@gmail.com)和App名称发送给C2DM服务器。
(2)C2DM服务器会返回一个registration_id值给Android设备,设备需要保存这个registration_id值。
(3)Android设备把获得的registration_id和C2DM功能的用户账户(android.c2dm.demo@gmail.com)发送给自己的服务器,不过一般用户账户信息因为和服务器确定好的,所以不必发送。
这样Android设备就完成了C2DM功能的注册过程,接下来就可以接收C2DM服务器Push过来的消息了。
(4)服务器获得数据。这里图中的例子Chrome To Phone,服务器接收到Chrome浏览器发送的数据。数据也可以是服务器本地产生的。这里的服务器是Google AppEngine(很好的一项服务,可惜在国内被屏了),要换成自己的服务器。服务器还要获取注册使用C2DM功能的用户账户(android.c2dm.demo@gmail.com)的ClientLogin权限Auth。
(5)服务器把要发送的数据和registration_id一起,并且头部带上获取的Auth,使用POST的方式发送给C2DM服务器。
(6)C2DM服务器会以Push的方式把数据发送给对应的Android设备,Android设备只要在程序中按之前和服务器商量好的格式从对应的key中获取数据即可。
转自:
地理位置索引支持是MongoDB的一大亮点,这也是全球最流行的LBS服务foursquare 选择MongoDB的原因之一。我们知道,通常的数据库索引结构是B+ Tree,如何将地理位置转化为可建立B+Tree的形式,下文将为你描述。
首先假设我们将需要索引的整个地图分成16×16的方格,如下图(左下角为坐标0,0 右上角为坐标16,16):

单纯的[x,y]的数据是无法建立索引的,所以MongoDB在建立索引的时候,会根据相应字段的坐标计算一个可以用来做索引的hash值,这个值叫做geohash,下面我们以地图上坐标为[4,6]的点(图中红叉位置)为例。
我们第一步将整个地图分成等大小的四块,如下图:

划分成四块后我们可以定义这四块的值,如下(左下为00,左上为01,右下为10,右上为11):
这样[4,6]点的geohash值目前为 00
然后再将四个小块每一块进行切割,如下:

这时[4,6]点位于右上区域,右上的值为11,这样[4,6]点的geohash值变为:0011
继续往下做两次切分:

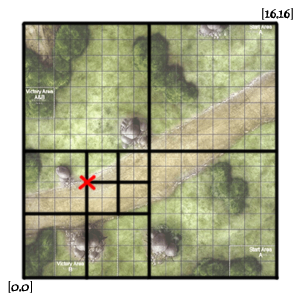
最终得到[4,6]点的geohash值为:00110100
这样我们用这个值来做索引,则地图上点相近的点就可以转化成有相同前缀的geohash值了。
我们可以看到,这个geohash值的精确度是与划分地图的次数成正比的,上例对地图划分了四次。而MongoDB默认是进行26次划分,这个值在建立索引时是可控的。具体建立二维地理位置索引的命令如下:
db.map.ensureIndex({point : "2d"}, {min : 0, max : 16, bits : 4})
其中的bits参数就是划分几次,默认为26次。
摘要: java中的引用分为4种:String Reference, WeakReference, softReference,PhantomReference Strong Reference: 我们平常用的最多的就是强引用了 如:String s = new String("opps");这种形式的引用称为强引用,这种引用有以下几个特点 1.强引用可以直接访问目标对象&...
阅读全文
摘要:
一、对ThreadLocal概术
JDK API 写道:
该类提供了线程局部 (thread-local) 变量。这些变量不同于它们的普通对应物,因为访问某个变量(通过其 get 或 set 方法)的每个线程都有自己的局部变量,它独立于变量的初始...
阅读全文
摘要: 起因:在写java的时候,经常遇到函数需要返回2个值或者3个值,java必须编写一个Object,来封装,但很多应用场景只是临时使用,构建对象感觉杀鸡用宰牛刀,而其他语言有比较好的实现方法。(当然通过指针引用可以解决一部分问题) 如:一般写法:
Code high...
阅读全文
摘要: java.util.concurrent包分成了三个部分,分别是: ...
阅读全文
不复制内容了,可以看戏如下链接,还是有很多值得看的东东,有空看下。~
http://terryblog.blog.51cto.com/1764499/547777
1.找到你的debug.keystore文件所在的路径:
证书的一般路径为:打开eclipse,选择Windows———>Preference———>Android———>Build,其中Default debug keystore的值便是debug.keystore的路径(windows的一般在 C:\Documents and Settings\当前用户\.android下找到debug.keystore)
2.在命令提示符中执行: keytool -list -keystore debug.keystore (keytool是java一个命令,在%java_home%\bin里可以看到)
需要输入密码:android
然后就会得到MD5的值,进入
http://code.google.com/intl/zh-CN/android/add-ons/google-apis/maps-api-signup.html ,根据MD5值获取MAPS API KEY(前提是你必须有一个google账户)
使input组件的绝对位置覆盖select组件的选择框,当select的状态发生改变的时候,使用this.parentNode.nextSibling.value=this.value把select所选择的值赋给input.
<HTML>
<HEAD>
<META http-equiv='Content-Type' content='text/html; charset=gb2312'>
<TITLE>可输入的下拉框</TITLE>
</HEAD>
<BODY >
<div style="position:relative;">
<span style="margin-left:100px;width:18px;overflow:hidden;">
<select style="width:118px;margin-left:-100px" onchange="this.parentNode.nextSibling.value=this.value">
<option value="
www.taobao.com"> taobao </option>
<option value="
www.baidu.com"> soft </option>
<option value="WEB开发者"> WEB开发者 </option>
</select></span><input name="box" style="width:100px;position:absolute;left:0px;">
</div>
</BODY></HTML>
单例创建模式是一个通用的编程习语。和多线程一起使用时,必需使用某种类型的同步。在努力创建更有效的代码时,Java 程序员们创建了双重检查锁定习语,将其和单例创建模式一起使用,从而限制同步代码量。然而,由于一些不太常见的 Java 内存模型细节的原因,并不能保证这个双重检查锁定习语有效。它偶尔会失败,而不是总失败。此外,它失败的原因并不明显,还包含 Java 内存模型的一些隐秘细节。这些事实将导致代码失败,原因是双重检查锁定难于跟踪。在本文余下的部分里,我们将详细介绍双重检查锁定习语,从而理解它在何处失效。
单例创建习语
要理解双重检查锁定习语是从哪里起源的,就必须理解通用单例创建习语,如清单 1 中的阐释:
清单 1. 单例创建习语
import java.util.*;
class Singleton
{
private static Singleton instance;
private Vector v;
private boolean inUse;
private Singleton()
{
v = new Vector();
v.addElement(new Object());
inUse = true;
}
public static Singleton getInstance()
{
if (instance == null) //1
instance = new Singleton(); //2
return instance; //3
}
}
|
此类的设计确保只创建一个 Singleton 对象。构造函数被声明为 private,getInstance() 方法只创建一个对象。这个实现适合于单线程程序。然而,当引入多线程时,就必须通过同步来保护 getInstance() 方法。如果不保护 getInstance() 方法,则可能返回 Singleton 对象的两个不同的实例。假设两个线程并发调用 getInstance() 方法并且按以下顺序执行调用:
- 线程 1 调用
getInstance() 方法并决定 instance 在 //1 处为 null。
- 线程 1 进入
if 代码块,但在执行 //2 处的代码行时被线程 2 预占。
- 线程 2 调用
getInstance() 方法并在 //1 处决定 instance 为 null。
- 线程 2 进入
if 代码块并创建一个新的 Singleton 对象并在 //2 处将变量 instance 分配给这个新对象。
- 线程 2 在 //3 处返回
Singleton 对象引用。
- 线程 2 被线程 1 预占。
- 线程 1 在它停止的地方启动,并执行 //2 代码行,这导致创建另一个
Singleton 对象。
- 线程 1 在 //3 处返回这个对象。
结果是 getInstance() 方法创建了两个 Singleton 对象,而它本该只创建一个对象。通过同步 getInstance() 方法从而在同一时间只允许一个线程执行代码,这个问题得以改正,如清单 2 所示:
清单 2. 线程安全的 getInstance() 方法
public static synchronized Singleton getInstance()
{
if (instance == null) //1
instance = new Singleton(); //2
return instance; //3
}
|
清单 2 中的代码针对多线程访问 getInstance() 方法运行得很好。然而,当分析这段代码时,您会意识到只有在第一次调用方法时才需要同步。由于只有第一次调用执行了 //2 处的代码,而只有此行代码需要同步,因此就无需对后续调用使用同步。所有其他调用用于决定 instance 是非 null 的,并将其返回。多线程能够安全并发地执行除第一次调用外的所有调用。尽管如此,由于该方法是 synchronized 的,需要为该方法的每一次调用付出同步的代价,即使只有第一次调用需要同步。
为使此方法更为有效,一个被称为双重检查锁定的习语就应运而生了。这个想法是为了避免对除第一次调用外的所有调用都实行同步的昂贵代价。同步的代价在不同的 JVM 间是不同的。在早期,代价相当高。随着更高级的 JVM 的出现,同步的代价降低了,但出入 synchronized 方法或块仍然有性能损失。不考虑 JVM 技术的进步,程序员们绝不想不必要地浪费处理时间。
因为只有清单 2 中的 //2 行需要同步,我们可以只将其包装到一个同步块中,如清单 3 所示:
清单 3. getInstance() 方法
public static Singleton getInstance()
{
if (instance == null)
{
synchronized(Singleton.class) {
instance = new Singleton();
}
}
return instance;
}
|
清单 3 中的代码展示了用多线程加以说明的和清单 1 相同的问题。当 instance 为 null 时,两个线程可以并发地进入 if 语句内部。然后,一个线程进入 synchronized 块来初始化 instance,而另一个线程则被阻断。当第一个线程退出 synchronized 块时,等待着的线程进入并创建另一个 Singleton 对象。注意:当第二个线程进入 synchronized 块时,它并没有检查 instance 是否非 null。
双重检查锁定
为处理清单 3 中的问题,我们需要对 instance 进行第二次检查。这就是“双重检查锁定”名称的由来。将双重检查锁定习语应用到清单 3 的结果就是清单 4 。
清单 4. 双重检查锁定示例
public static Singleton getInstance()
{
if (instance == null)
{
synchronized(Singleton.class) { //1
if (instance == null) //2
instance = new Singleton(); //3
}
}
return instance;
}
|
双重检查锁定背后的理论是:在 //2 处的第二次检查使(如清单 3 中那样)创建两个不同的 Singleton 对象成为不可能。假设有下列事件序列:
- 线程 1 进入
getInstance() 方法。
- 由于
instance 为 null,线程 1 在 //1 处进入 synchronized 块。
- 线程 1 被线程 2 预占。
- 线程 2 进入
getInstance() 方法。
- 由于
instance 仍旧为 null,线程 2 试图获取 //1 处的锁。然而,由于线程 1 持有该锁,线程 2 在 //1 处阻塞。
- 线程 2 被线程 1 预占。
- 线程 1 执行,由于在 //2 处实例仍旧为
null,线程 1 还创建一个 Singleton 对象并将其引用赋值给 instance。
- 线程 1 退出
synchronized 块并从 getInstance() 方法返回实例。
- 线程 1 被线程 2 预占。
- 线程 2 获取 //1 处的锁并检查
instance 是否为 null。
- 由于
instance 是非 null 的,并没有创建第二个 Singleton 对象,由线程 1 创建的对象被返回。
双重检查锁定背后的理论是完美的。不幸地是,现实完全不同。双重检查锁定的问题是:并不能保证它会在单处理器或多处理器计算机上顺利运行。
双重检查锁定失败的问题并不归咎于 JVM 中的实现 bug,而是归咎于 Java 平台内存模型。内存模型允许所谓的“无序写入”,这也是这些习语失败的一个主要原因。
无序写入
为解释该问题,需要重新考察上述清单 4 中的 //3 行。此行代码创建了一个 Singleton 对象并初始化变量 instance 来引用此对象。这行代码的问题是:在 Singleton 构造函数体执行之前,变量 instance 可能成为非 null 的。
什么?这一说法可能让您始料未及,但事实确实如此。在解释这个现象如何发生前,请先暂时接受这一事实,我们先来考察一下双重检查锁定是如何被破坏的。假设清单 4 中代码执行以下事件序列:
- 线程 1 进入
getInstance() 方法。
- 由于
instance 为 null,线程 1 在 //1 处进入 synchronized 块。
- 线程 1 前进到 //3 处,但在构造函数执行之前,使实例成为非
null。
- 线程 1 被线程 2 预占。
- 线程 2 检查实例是否为
null。因为实例不为 null,线程 2 将 instance 引用返回给一个构造完整但部分初始化了的 Singleton 对象。
- 线程 2 被线程 1 预占。
- 线程 1 通过运行
Singleton 对象的构造函数并将引用返回给它,来完成对该对象的初始化。
此事件序列发生在线程 2 返回一个尚未执行构造函数的对象的时候。
为展示此事件的发生情况,假设为代码行 instance =new Singleton(); 执行了下列伪代码: instance =new Singleton();
mem = allocate(); //Allocate memory for Singleton object.
instance = mem; //Note that instance is now non-null, but
//has not been initialized.
ctorSingleton(instance); //Invoke constructor for Singleton passing
//instance.
|
这段伪代码不仅是可能的,而且是一些 JIT 编译器上真实发生的。执行的顺序是颠倒的,但鉴于当前的内存模型,这也是允许发生的。JIT 编译器的这一行为使双重检查锁定的问题只不过是一次学术实践而已。
为说明这一情况,假设有清单 5 中的代码。它包含一个剥离版的 getInstance() 方法。我已经删除了“双重检查性”以简化我们对生成的汇编代码(清单 6)的回顾。我们只关心 JIT 编译器如何编译 instance=new Singleton(); 代码。此外,我提供了一个简单的构造函数来明确说明汇编代码中该构造函数的运行情况。
清单 5. 用于演示无序写入的单例类
class Singleton
{
private static Singleton instance;
private boolean inUse;
private int val;
private Singleton()
{
inUse = true;
val = 5;
}
public static Singleton getInstance()
{
if (instance == null)
instance = new Singleton();
return instance;
}
}
|
清单 6 包含由 Sun JDK 1.2.1 JIT 编译器为清单 5 中的 getInstance() 方法体生成的汇编代码。
清单 6. 由清单 5 中的代码生成的汇编代码
;asm code generated for getInstance
054D20B0 mov eax,[049388C8] ;load instance ref
054D20B5 test eax,eax ;test for null
054D20B7 jne 054D20D7
054D20B9 mov eax,14C0988h
054D20BE call 503EF8F0 ;allocate memory
054D20C3 mov [049388C8],eax ;store pointer in
;instance ref. instance
;non-null and ctor
;has not run
054D20C8 mov ecx,dword ptr [eax]
054D20CA mov dword ptr [ecx],1 ;inline ctor - inUse=true;
054D20D0 mov dword ptr [ecx+4],5 ;inline ctor - val=5;
054D20D7 mov ebx,dword ptr ds:[49388C8h]
054D20DD jmp 054D20B0
|
注: 为引用下列说明中的汇编代码行,我将引用指令地址的最后两个值,因为它们都以 054D20 开头。例如,B5 代表 test eax,eax。
汇编代码是通过运行一个在无限循环中调用 getInstance() 方法的测试程序来生成的。程序运行时,请运行 Microsoft Visual C++ 调试器并将其附到表示测试程序的 Java 进程中。然后,中断执行并找到表示该无限循环的汇编代码。
B0 和 B5 处的前两行汇编代码将 instance 引用从内存位置 049388C8 加载至 eax 中,并进行 null 检查。这跟清单 5 中的 getInstance() 方法的第一行代码相对应。第一次调用此方法时,instance 为 null,代码执行到 B9。BE 处的代码为 Singleton 对象从堆中分配内存,并将一个指向该块内存的指针存储到 eax 中。下一行代码,C3,获取 eax 中的指针并将其存储回内存位置为 049388C8 的实例引用。结果是,instance 现在为非 null 并引用一个有效的 Singleton 对象。然而,此对象的构造函数尚未运行,这恰是破坏双重检查锁定的情况。然后,在 C8 行处,instance 指针被解除引用并存储到 ecx。CA 和 D0 行表示内联的构造函数,该构造函数将值 true 和 5 存储到 Singleton 对象。如果此代码在执行 C3 行后且在完成该构造函数前被另一个线程中断,则双重检查锁定就会失败。
不是所有的 JIT 编译器都生成如上代码。一些生成了代码,从而只在构造函数执行后使 instance 成为非 null。针对 Java 技术的 IBM SDK 1.3 版和 Sun JDK 1.3 都生成这样的代码。然而,这并不意味着应该在这些实例中使用双重检查锁定。该习语失败还有一些其他原因。此外,您并不总能知道代码会在哪些 JVM 上运行,而 JIT 编译器总是会发生变化,从而生成破坏此习语的代码。
双重检查锁定:获取两个
考虑到当前的双重检查锁定不起作用,我加入了另一个版本的代码,如清单 7 所示,从而防止您刚才看到的无序写入问题。
清单 7. 解决无序写入问题的尝试
public static Singleton getInstance()
{
if (instance == null)
{
synchronized(Singleton.class) { //1
Singleton inst = instance; //2
if (inst == null)
{
synchronized(Singleton.class) { //3
inst = new Singleton(); //4
}
instance = inst; //5
}
}
}
return instance;
}
|
看着清单 7 中的代码,您应该意识到事情变得有点荒谬。请记住,创建双重检查锁定是为了避免对简单的三行 getInstance() 方法实现同步。清单 7 中的代码变得难于控制。另外,该代码没有解决问题。仔细检查可获悉原因。
此代码试图避免无序写入问题。它试图通过引入局部变量 inst 和第二个 synchronized 块来解决这一问题。该理论实现如下:
- 线程 1 进入
getInstance() 方法。
- 由于
instance 为 null,线程 1 在 //1 处进入第一个 synchronized 块。
- 局部变量
inst 获取 instance 的值,该值在 //2 处为 null。
- 由于
inst 为 null,线程 1 在 //3 处进入第二个 synchronized 块。
- 线程 1 然后开始执行 //4 处的代码,同时使
inst 为非 null,但在 Singleton 的构造函数执行前。(这就是我们刚才看到的无序写入问题。)
- 线程 1 被线程 2 预占。
- 线程 2 进入
getInstance() 方法。
- 由于
instance 为 null,线程 2 试图在 //1 处进入第一个 synchronized 块。由于线程 1 目前持有此锁,线程 2 被阻断。
- 线程 1 然后完成 //4 处的执行。
- 线程 1 然后将一个构造完整的
Singleton 对象在 //5 处赋值给变量 instance,并退出这两个 synchronized 块。
- 线程 1 返回
instance。
- 然后执行线程 2 并在 //2 处将
instance 赋值给 inst。
- 线程 2 发现
instance 为非 null,将其返回。
这里的关键行是 //5。此行应该确保 instance 只为 null 或引用一个构造完整的 Singleton 对象。该问题发生在理论和实际彼此背道而驰的情况下。
由于当前内存模型的定义,清单 7 中的代码无效。Java 语言规范(Java Language Specification,JLS)要求不能将 synchronized 块中的代码移出来。但是,并没有说不能将 synchronized 块外面的代码移入 synchronized 块中。
JIT 编译器会在这里看到一个优化的机会。此优化会删除 //4 和 //5 处的代码,组合并且生成清单 8 中所示的代码。
清单 8. 从清单 7 中优化来的代码。
public static Singleton getInstance()
{
if (instance == null)
{
synchronized(Singleton.class) { //1
Singleton inst = instance; //2
if (inst == null)
{
synchronized(Singleton.class) { //3
//inst = new Singleton(); //4
instance = new Singleton();
}
//instance = inst; //5
}
}
}
return instance;
}
|
如果进行此项优化,您将同样遇到我们之前讨论过的无序写入问题。
用 volatile 声明每一个变量怎么样?
另一个想法是针对变量 inst 以及 instance 使用关键字 volatile。根据 JLS(参见 参考资料),声明成 volatile 的变量被认为是顺序一致的,即,不是重新排序的。但是试图使用 volatile 来修正双重检查锁定的问题,会产生以下两个问题:
- 这里的问题不是有关顺序一致性的,而是代码被移动了,不是重新排序。
- 即使考虑了顺序一致性,大多数的 JVM 也没有正确地实现
volatile。
第二点值得展开讨论。假设有清单 9 中的代码:
清单 9. 使用了 volatile 的顺序一致性
class test
{
private volatile boolean stop = false;
private volatile int num = 0;
public void foo()
{
num = 100; //This can happen second
stop = true; //This can happen first
//...
}
public void bar()
{
if (stop)
num += num; //num can == 0!
}
//...
}
|
根据 JLS,由于 stop 和 num 被声明为 volatile,它们应该顺序一致。这意味着如果 stop 曾经是 true,num 一定曾被设置成 100。尽管如此,因为许多 JVM 没有实现 volatile 的顺序一致性功能,您就不能依赖此行为。因此,如果线程 1 调用 foo 并且线程 2 并发地调用 bar,则线程 1 可能在 num 被设置成为 100 之前将 stop 设置成 true。这将导致线程见到 stop 是 true,而 num 仍被设置成 0。使用 volatile 和 64 位变量的原子数还有另外一些问题,但这已超出了本文的讨论范围。有关此主题的更多信息,请参阅 参考资料。
解决方案
底线就是:无论以何种形式,都不应使用双重检查锁定,因为您不能保证它在任何 JVM 实现上都能顺利运行。JSR-133 是有关内存模型寻址问题的,尽管如此,新的内存模型也不会支持双重检查锁定。因此,您有两种选择:
- 接受如清单 2 中所示的
getInstance() 方法的同步。
- 放弃同步,而使用一个
static 字段。
选择项 2 如清单 10 中所示
清单 10. 使用 static 字段的单例实现
class Singleton
{
private Vector v;
private boolean inUse;
private static Singleton instance = new Singleton();
private Singleton()
{
v = new Vector();
inUse = true;
//...
}
public static Singleton getInstance()
{
return instance;
}
}
|
清单 10 的代码没有使用同步,并且确保调用 static getInstance() 方法时才创建 Singleton。如果您的目标是消除同步,则这将是一个很好的选择。
String 不是不变的
鉴于无序写入和引用在构造函数执行前变成非 null 的问题,您可能会考虑 String 类。假设有下列代码:
private String str;
//...
str = new String("hello");
|
String 类应该是不变的。尽管如此,鉴于我们之前讨论的无序写入问题,那会在这里导致问题吗?答案是肯定的。考虑两个线程访问 String str。一个线程能看见 str 引用一个 String 对象,在该对象中构造函数尚未运行。事实上,清单 11 包含展示这种情况发生的代码。注意,这个代码仅在我测试用的旧版 JVM 上会失败。IBM 1.3 和 Sun 1.3 JVM 都会如期生成不变的 String。
清单 11. 可变 String 的例子
class StringCreator extends Thread
{
MutableString ms;
public StringCreator(MutableString muts)
{
ms = muts;
}
public void run()
{
while(true)
ms.str = new String("hello"); //1
}
}
class StringReader extends Thread
{
MutableString ms;
public StringReader(MutableString muts)
{
ms = muts;
}
public void run()
{
while(true)
{
if (!(ms.str.equals("hello"))) //2
{
System.out.println("String is not immutable!");
break;
}
}
}
}
class MutableString
{
public String str; //3
public static void main(String args[])
{
MutableString ms = new MutableString(); //4
new StringCreator(ms).start(); //5
new StringReader(ms).start(); //6
}
}
|
此代码在 //4 处创建一个 MutableString 类,它包含了一个 String 引用,此引用由 //3 处的两个线程共享。在行 //5 和 //6 处,在两个分开的线程上创建了两个对象 StringCreator 和 StringReader。传入一个 MutableString 对象的引用。StringCreator 类进入到一个无限循环中并且使用值“hello”在 //1 处创建 String 对象。StringReader 也进入到一个无限循环中,并且在 //2 处检查当前的 String 对象的值是不是 “hello”。如果不行,StringReader 线程打印出一条消息并停止。如果 String 类是不变的,则从此程序应当看不到任何输出。如果发生了无序写入问题,则使 StringReader 看到 str 引用的惟一方法绝不是值为“hello”的 String 对象。
在旧版的 JVM 如 Sun JDK 1.2.1 上运行此代码会导致无序写入问题。并因此导致一个非不变的 String。
结束语
为避免单例中代价高昂的同步,程序员非常聪明地发明了双重检查锁定习语。不幸的是,鉴于当前的内存模型的原因,该习语尚未得到广泛使用,就明显成为了一种不安全的编程结构。重定义脆弱的内存模型这一领域的工作正在进行中。尽管如此,即使是在新提议的内存模型中,双重检查锁定也是无效的。对此问题最佳的解决方案是接受同步或者使用一个 static field。
薪水族如何“钱滚钱” 教你用2万赚到1000万
工薪族月薪2000元的理财窍门
在有很多的大学生都是在毕业以后选择留在自己上学的城市,一来对城市有了感情,二来也希望能在大的城市有所
发展,而现在很多大城市劳动力过剩,大学生想找到一个自己喜欢又有较高收入的职位已经变得非常难,很多刚毕业的朋友的月收入都可能徘徊在2000元人民币左右,如果您是这样的情况,让我们来核算一下,如何利用手中的有限资金来进行理财。如果您是单身一人,月收入在2000人民币,又没有其他的奖金分红等收入,那年收入就固定在25000元左右。如何来支配这些钱呢?
生活费占收入30%-40%
首先,你要拿出每个月必须支付的生活费。如房租、水电、通讯费、柴米油盐等,这部分约占收入三分之一。它们是你生活中不可或缺的部分,满足你最基本的物质需求。离开了它们,你就会像鱼儿离开了水一样无法生活,所以无论如何,请你先从收入中抽出这部分,不要动用。
储蓄占收入10%-20%
其次,是自己用来储蓄的部分,约占收入的10%-20%。很多人每次也都会在月初存钱,但是到了月底的时候,往往就变成了泡沫,存进去的大部分又取出来了,而且是不知不觉的,好像凭空消失了一样,总是在自己喜欢的衣饰、杂志、CD或朋友聚会上不加以节制。你要自己提醒自己,起码,你的存储能保证你3个月的基本生活。要知道,现在很多公司动辄减薪裁员。如果你一点储蓄都没有,一旦
工作发生了变动,你将会非常被动。
而且这3个月的收入可以成为你的定心丸,工作实在干得不开心了,忍无可忍无需再忍时,你可以潇洒地对老板说声“拜拜”。想想可以不用受你不喜欢的工作和人的气,是多么开心的事啊。所以,无论如何,请为自己留条退路。
活动资金占收入30%~40%
剩下的这部分钱,约占收入的三分之一。可以根据自己当时的生活目标,侧重地花在不同的地方。譬如“五一”、“十一”可以安排
旅游;服装打折时可以购进自己心仪已久的牌子货;还有平时必不可少的购买CD、朋友聚会的开销。这样花起来心里有数,不会一下子把钱都用完。
最关键的是,即使一发薪水就把这部分用完了,也可当是一次教训,可以惩罚自己一个月内什么都不能再干了(就当是收入全部支出了吧),印象会很深刻而且有效。
除去吃、穿、住、行以及其他的消费外,再怎么节省,估计您现在的状况,一年也只有10000元的积蓄,想来这些都是刚毕业的绝大部分学生所面临的实际情况。如何让钱生钱是大家想得最多的事情,然而,毕竟收入有限,很多想法都不容易实现,
建议处于这个阶段的朋友,最重要的是开源,节流只是我们生活工作的一部分,就像大厦的基层一样。而最重要的是怎样财源滚滚、开源有道,为了达到一个新目标,你必须不断进步以求发展,培养自己的实力以求进步,这才是真正的生财之道。可以安心地发展自己的事业,积累自己的经验,充实自己,使自己不断地提高,才会有好的发展,要相信“机会总是给有准备的人”。
当然,既然有了些许积蓄,也不能让它闲置,我们建议把1万元分为5份,分成5个2000元,分别作出适当的投资安排。这样,家庭不会出现用钱危机,并可以获得最大的收益。
(1)用2000元买国债,这是回报率较高而又很保险的一种投资。
(2)用2000元买保险。以往人们的保险意识很淡薄,实际上购买保险也是一种较好的投资方式,而且保险金不在利息税征收之列。尤其是各寿险公司都推出了两全型险种,增加了有关“权益转换”的条款,即一旦银行利率上升,
客户可在保险公司
出售的险种中进行转换,并获得保险公司给予的一定的价格折扣、免予核保等
优惠政策。
(3)用2000元买股票。这是一种风险最大的投资,当然风险与收益是并存的,只要选择得当,会带来理想的投资回报。除股票外,期货、投资债券等都属这一类。不过,参与这类投资,要求有相应的行业知识和较强的风险意识。
(4)用2000元存定期存款,这是一种几乎没有风险的投资方式,也是未来对家庭生活的一种保障。
(5)用2000元存活期存款,这是为了应急之用。如家里临时急需用钱,有一定数量的活期储蓄存款可解燃眉之急,而且存取又很方便。
这种方法是许多人经过多年尝试后总结出的一套成功的理财经验。当然,各个家庭可以根据不同情况,灵活使用。
正确理财三个观念
建立理财观念一:理财是一件正大光明的事,“你不理财,财不理你”。
建立理财观念二:理财要从现在开始,并长期坚持。
建立理财观念三:理财目的是“梳理财富,增值生活”。
理财四个误区
理财观念误区一:我没财可理;
理财观念误区二:我不需要理财;
理财观念误区三:等我有了钱再理财;
理财观念误区四:会理财不如会挣钱。
理财的五大目标
目标一:获得资产增值;
目标二:保证资金安全;
目标三:防御意外事故;
目标四:保证老有所养;
目标五:提供赡养父母及抚养教育子女的基金。
--------------------精彩阅读推荐--------------------
【500强企业的薪水有多高?】
全球500强大企业的薪水实情大揭密
不一定要是自己的offer letter上的数据,凡是能够确认比较准确的公司薪水都可补充。补充的话最好说明职位、本硕区别、多少个月工资、奖金。宝洁:本7200、研8200、博9700,均14个月,另有交通补助,区域补助等,CBD,marketing每几个月涨20%-30%不定。
【工薪族的你跑赢通胀了吗?】
工薪族理财跑赢通胀 开源节流资产合理配备
龙先生家是典型的工薪阶层。龙先生47岁,是某大型企业的技术师,年收入5.5万元,购买了各类基本保险。太太42岁,是某商场的合同工,年收入4万元,购买了基本的社会保险。两人均在单位吃中午饭,搭班车上下班。儿子16岁,尚在读高中。
【怎样才能钱生钱?】
“阶梯存储”应对利率调整 学三招轻松钱生钱
当前,储蓄依然在居民理财的投资组合中占据着重要地位,但在当前的加息周期内,一些人因缺乏科学的储蓄理财规划而损失利息收入。理财专家建议,进入加息周期,为了使储蓄理财能赚取更多的利息收入,储户应在存款期限、存款金额和存款方式上注意以下几点。
【爷们的脸往哪搁!】
女人太会赚钱也是错? 爷们儿的脸往哪搁
女人财大就气粗?别偏激,妻子赚钱自己也是受益者,所以首先心态放平和些,别太执着于传统的思维和他人的看法。会不会赚钱是女人衡量男人的重要标尺。男人没钱,女人觉得没有面子,不愿提及她的男人;有钱男人不怕提及他女人,无论漂亮与否,只要不给他戴绿帽子。
说起精致,最容易想起的词大概是瓷器了,但这个词用到程序员身上,肯定让很多人觉得摸不着头脑,在详述"精致"这个词以前,还是先来看一个"破窗理论",让我们真正的理解"精致"的概念。
最早的"破窗理论",也称"破窗谬论",源自于一位经济学家黑兹利特(也有人说源于法国19世纪经济学家巴斯夏),用来指出"破坏创造财富"的概念,以彻底地否定凯恩斯主义的政府干预政策。但后来美国斯坦福大学心理学家詹巴斗和犯罪学家凯琳也提出了相应的"破窗理论"。
心理学家詹巴斗进行了一项试验,他把两辆一模一样的汽车分别停放在帕罗阿尔托的中产阶级社区和相对杂乱的布朗克斯街区。对停在布朗克斯街区的那一辆,他摘掉了车牌,并且把顶棚打开,结果不到一天就被人偷走了;而停放在帕罗阿尔托的那一辆,停了一个星期也无人问津。后来,詹巴斗用锤子把这辆车的玻璃敲了个大洞,结果仅仅过了几个小时车就不见了。
而犯罪学家凯琳曾注意到一个问题:在她上班的路旁,有一座非常漂亮的大楼,有一天,她注意到楼上有一窗子的玻璃被打破了,那扇破窗与整座大楼的整洁美丽极不调谐,显得格外的刺眼。又过了一段时间,她惊奇地发现:那扇破窗不但没得到及时的维修,反而又增加了几个带烂玻璃的窗子……这一发现使她的心中忽有所悟:如果有人打坏了一个建筑物的窗户玻璃,而这扇窗户又得不到及时维修的话,别人就可能受到某些暗示性的纵容去打烂更多的玻璃。久而久之,这些破窗户就给人造成一种无序的感觉;其结果是:在这种麻木不仁的氛围中,犯罪就会滋生。这就是凯琳著名的"破窗理论"。
后来的"破窗理论",已经突破原有经济学上的概念,有了新的意义:残缺不全的东西更容易遭受到别人的破坏。前面的汽车和窗户都表明了这一点。
其实作为程序员开发软件也是一样,可能有十种好的方法去写一个功能,一个类,但同时可能会有一百种更快捷但不好的方法去做同样的事情,很多程序员会因为各种原因,如时间压力,工作强度,技术水平等一系列问题选择了后者而非前者。同样的事情还发生在维护和修改阶段,当看到别人的代码写的随意,不好时,那么自然就会沿着别人的方向走下去,结果就是产生出更多不好的代码,这是在代码开发中的一个典型"破窗理论"的体现。
承认一点,现实世界是不完美,特别是开发中,因为时间,精力,能力等各种因素,我们始终是要打破一些窗户,但是却要记住两点:
1.一个月前多打破了一扇窗户,结果一个月就会打破10 扇甚至更多的窗户。
2.如果打破了一扇窗户,就要记住,迟早应该将它补上。
因为各方面的原因,一个程序员也许不能做到精致的代码,但是如果一个程序员不想去做精致的代码,那么又何必选择软件开发呢?
最近有Java解压缩的需求,java.util.zip实在不好用,对中文支持也不行。所以选择了强大的TrueZIP,使用时遇到了一个问题,做个记录。
解压缩代码如下:
ArchiveDetector detector = new DefaultArchiveDetector(ArchiveDetector.ALL,
new Object[] { "zip", new CheckedZip32Driver("GBK") } );
File zipFile = new File("zipFile", detector);
File dst = new File("dst");
// 解压缩
zipFile.copyAllTo(dst);
代码十分简洁,注意这个File是
de.schlichtherle.io.File
不是
java.io.File
当处理完业务要删除这个Zip File时,问题出现了:
这个文件删不掉!!!
把自己的代码检查了好久,确认没问题后,开始从TrueZIP下手,发现它有特殊的地方的,是提示过的:
File file = new File(“archive.zip”); // de.schlichtherle.io.File!
Please do not do this instead:
de.schlichtherle.io.File file = new de.schlichtherle.io.File(“archive.zip”);
This is for the following reasons:
1.Accidentally using java.io.File and de.schlichtherle.io.File instances referring to the same path concurrently will result in erroneous behaviour and may even cause loss of data! Please refer to the section “Third Party Access” in the package Javadoc of de.schlichtherle.io for for full details and workarounds.
2.A de.schlichtherle.io.File subclasses java.io.File and thanks to polymorphism can be used everywhere a java.io.File could be used.
原来两个File不能交叉使用,搞清楚原因了,加这么一句代码搞定。
zipFile.deleteAll();