2009年11月1日
#
APACHE是一个web服务器环境程序 启用他可以作为web服务器使用 不过只支持静态网页 如(asp,php,cgi,jsp)等动态网页的就不行
如果要在APACHE环境下运行jsp 的话就需要一个解释器来执行jsp网页 而这个jsp解释器就是TOMCAT, 为什么还要JDK呢?因为jsp需要连接数据库的话 就要jdk来提供连接数据库的驱程,所以要运行jsp的web服务器平台就需要APACHE+TOMCAT+JDK
整合的好处是:
如果客户端请求的是静态页面,则只需要Apache服务器响应请求
如果客户端请求动态页面,则是Tomcat服务器响应请求
因为jsp是服务器端解释代码的,这样整合就可以减少Tomcat的服务开销
============================几种常见的服务器===============================
① Microsoft IIS
Microsoft的Web服务器产品为Internet Information Server (IIS), IIS 是允许在公共Intranet或Internet上发布信息的Web服务器。IIS是目前最流行的Web服务器产品之一,很多著名的网站都是建立在IIS的平台上。IIS提供了一个图形界面的管理工具,称为 Internet服务管理器,可用于监视配置和控制Internet服务。
IIS是一种Web服务组件,其中包括Web服务器、FTP服务器、NNTP服务器和SMTP服务器,分别用于网页浏览、文件传输、新闻服务和邮件发送等方面,它使得在网络(包括互联网和局域网)上发布信息成了一件很容易的事。它提供ISAPI(Intranet Server API)作为扩展Web服务器功能的编程接口;同时,它还提供一个Internet数据库连接器,可以实现对数据库的查询和更新。
② IBM WebSphere
WebSphere Application Server 是一种功能完善、开放的Web应用程序服务器,是IBM电子商务计划的核心部分,它是基于 Java 的应用环境,用于建立、部署和管理 Internet 和 Intranet Web 应用程序。 这一整套产品进行了扩展,以适应 Web 应用程序服务器的需要,范围从简单到高级直到企业级。
WebSphere 针对以 Web 为中心的开发人员,他们都是在基本 HTTP服务器和 CGI 编程技术上成长起来的。IBM 将提供 WebSphere 产品系列,通过提供综合资源、可重复使用的组件、功能强大并易于使用的工具、以及支持 HTTP 和 IIOP 通信的可伸缩运行时环境,来帮助这些用户从简单的 Web 应用程序转移到电子商务世界。
③ BEA WebLogic Server
是一种多功能、基于标准的web应用服务器,为企业构建自己的应用提供了坚实的基础。各种应用开发、部署所有关键性的任务,无论是集成各种系统和数据库,还是提交服务、跨 Internet 协作,起始点都是 BEA WebLogic Server。由于 它具有全面的功能、对开放标准的遵从性、多层架构、支持基于组件的开发,基于 Internet 的企业都选择它来开发、部署最佳的应用。
BEA WebLogic Server 在使应用服务器成为企业应用架构的基础方面继续处于领先地位。BEA WebLogic Server 为构建集成化的企业级应用提供了稳固的基础,它们以 Internet 的容量和速度,在连网的企业之间共享信息、提交服务,实现协作自动化。BEA WebLogic Server 的遵从 J2EE 、面向服务的架构,以及丰富的工具集支持,便于实现业务逻辑、数据和表达的分离,提供开发和部署各种业务驱动应用所必需的底层核心功能。
④ IPlanet Application Server
作为Sun与Netscape联盟产物的iPlanet公司生产的iPlanet Application Server 满足最新J2EE规范的要求。它是一种完整的WEB服务器应用解决方案,它允许企业以便捷的方式,开发、部署和管理关键任务 Internet 应用。该解决方案集高性能、高度可伸缩和高度可用性于一体,可以支持大量的具有多种客户机类型与数据源的事务。
iPlanet Application Server的基本核心服务包括事务监控器、多负载平衡选项、对集群和故障转移全面的支持、集成的XML 解析器和可扩展格式语言转换(XLST)引擎以及对国际化的全面支持。iPlanet Application Server 企业版所提供的全部特性和功能,并得益于J2EE系统构架,拥有更好的商业工作流程管理工具和应用集成功能。
⑤Oracle IAS
Oracle iAS的英文全称是Oracle Internet Application Server,即Internet应用服务器,Oracle iAS是基于Java的应用服务器,通过与Oracle 数据库等产品的结合,Oracle iAS能够满足Internet应用对可靠性、可用性和可伸缩性的要求。
Oracle iAS最大的优势是其集成性和通用性,它是一个集成的、通用的中间件产品。在集成性方面,Oracle iAS将业界最流行的HTTP服务器Apache集成到系统中,集成了Apache的Oracle iAS通信服务层可以处理多种客户请求,包括来自Web浏览器、胖客户端和手持设备的请求,并且根据请求的具体内容,将它们分发给不同的应用服务进行处理。在通用性方面,Oracle iAS支持各种业界标准,包括 JavaBeans、CORBA、Servlets以及XML标准等,这种对标准的全面支持使得用户很容易将在其他系统平台上开发的应用移植到Oracle平台上。
⑥ Apache
Apache源于NCSAhttpd服务器,经过多次修改,成为世界上最流行的Web服务器软件之一。Apache是自由软件,所以不断有人来为它开发新的功能、新的特性、修改原来的缺陷。Apache的特点是简单、速度快、性能稳定,并可做代理服务器来使用。本来它只用于小型或试验Internet网络,后来逐步扩充到各种Unix系统中,尤其对Linux的支持相当完美。
Apache是以进程为基础的结构,进程要比线程消耗更多的系统开支,不太适合于多处理器环境,因此,在一个Apache Web站点扩容时,通常是增加服务器或扩充群集节点而不是增加处理器。到目前为止Apache仍然是世界上用的最多的Web服务器,世界上很多著名的网站都是Apache的产物,它的成功之处主要在于它的源代码开放、有一支开放的开发队伍、支持跨平台的应用(可以运行在几乎所有的Unix、Windows、Linux系统平台上)以及它的可移植性等方面。
⑦ Tomcat
Tomcat是一个开放源代码、运行servlet和JSP Web应用软件的基于Java的Web应用软件容器。Tomcat Server是根据servlet和JSP规范进行执行的,因此我们就可以说Tomcat Server也实行了Apache-Jakarta规范且比绝大多数商业应用软件服务器要好。
Tomcat是Java Servlet 2.2和JavaServer Pages 1.1技术的标准实现,是基于Apache许可证下开发的自由软件。Tomcat是完全重写的Servlet API 2.2和JSP 1.1兼容的Servlet/JSP容器。Tomcat使用了JServ的一些代码,特别是Apache服务适配器。随着Catalina Servlet引擎的出现,Tomcat第四版号的性能得到提升,使得它成为一个值得考虑的Servlet/JSP容器,因此目前许多WEB服务器都是采用Tomcat。
web服务器和应用服务器得区别
通俗的讲,Web服务器传送(serves)页面使浏览器可以浏览,然而应用程序服务器提供的是客户端应用程序可以调用(call)的方法(methods)。确切一点,你可以说:Web服务器专门处理HTTP请求(request),但是应用程序服务器是通过很多协议来为应用程序提供(serves)商业逻辑(business logic)。
下面让我们来细细道来:
Web服务器(Web Server)
Web服务器可以解析(handles)HTTP协议。当Web服务器接收到一个HTTP请求(request),会返回一个HTTP响应(response),例如送回一个HTML页面。为了处理一个请求(request),Web服务器可以响应(response)一个静态页面或图片,进行页面跳转(redirect),或者把动态响应(dynamic response)的产生委托(delegate)给一些其它的程序例如CGI脚本,JSP(JavaServer Pages)脚本,servlets,ASP(Active Server Pages)脚本,服务器端(server-side)JavaScript,或者一些其它的服务器端(server-side)技术。无论它们(译者注:脚本)的目的如何,这些服务器端(server-side)的程序通常产生一个HTML的响应(response)来让浏览器可以浏览。
要知道,Web服务器的代理模型(delegation model)非常简单。当一个请求(request)被送到Web服务器里来时,它只单纯的把请求(request)传递给可以很好的处理请求(request)的程序(译者注:服务器端脚本)。Web服务器仅仅提供一个可以执行服务器端(server-side)程序和返回(程序所产生的)响应(response)的环境,而不会超出职能范围。服务器端(server-side)程序通常具有事务处理(transaction processing),数据库连接(database connectivity)和消息(messaging)等功能。
虽然Web服务器不支持事务处理或数据库连接池,但它可以配置(employ)各种策略(strategies)来实现容错性(fault tolerance)和可扩展性(scalability),例如负载平衡(load balancing),缓冲(caching)。集群特征(clustering—features)经常被误认为仅仅是应用程序服务器专有的特征。
应用程序服务器(The Application Server)
根据我们的定义,作为应用程序服务器,它通过各种协议,可以包括HTTP,把商业逻辑暴露给(expose)客户端应用程序。Web服务器主要是处理向浏览器发送HTML以供浏览,而应用程序服务器提供访问商业逻辑的途径以供客户端应用程序使用。应用程序使用此商业逻辑就象你调用对象的一个方法(或过程语言中的一个函数)一样。
应用程序服务器的客户端(包含有图形用户界面(GUI)的)可能会运行在一台PC、一个Web服务器或者甚至是其它的应用程序服务器上。在应用程序服务器与其客户端之间来回穿梭(traveling)的信息不仅仅局限于简单的显示标记。相反,这种信息就是程序逻辑(program logic)。 正是由于这种逻辑取得了(takes)数据和方法调用(calls)的形式而不是静态HTML,所以客户端才可以随心所欲的使用这种被暴露的商业逻辑。
在大多数情形下,应用程序服务器是通过组件(component)的应用程序接口(API)把商业逻辑暴露(expose)(给客户端应用程序)的,例如基于J2EE(Java 2 Platform, Enterprise Edition)应用程序服务器的EJB(Enterprise JavaBean)组件模型。此外,应用程序服务器可以管理自己的资源,例如看大门的工作(gate-keeping duties)包括安全(security),事务处理(transaction processing),资源池(resource pooling), 和消息(messaging)。就象Web服务器一样,应用程序服务器配置了多种可扩展(scalability)和容错(fault tolerance)技术。
一个例子
例如,设想一个在线商店(网站)提供实时定价(real-time pricing)和有效性(availability)信息。这个站点(site)很可能会提供一个表单(form)让你来选择产品。当你提交查询(query)后,网站会进行查找(lookup)并把结果内嵌在HTML页面中返回。网站可以有很多种方式来实现这种功能。我要介绍一个不使用应用程序服务器的情景和一个使用应用程序服务器的情景。观察一下这两中情景的不同会有助于你了解应用程序服务器的功能。
情景1:不带应用程序服务器的Web服务器
在此种情景下,一个Web服务器独立提供在线商店的功能。Web服务器获得你的请求(request),然后发送给服务器端(server-side)可以处理请求(request)的程序。此程序从数据库或文本文件(flat file,译者注:flat file是指没有特殊格式的非二进制的文件,如properties和XML文件等)中查找定价信息。一旦找到,服务器端(server-side)程序把结果信息表示成(formulate)HTML形式,最后Web服务器把会它发送到你的Web浏览器。
简而言之,Web服务器只是简单的通过响应(response)HTML页面来处理HTTP请求(request)。
情景2:带应用程序服务器的Web服务器
情景2和情景1相同的是Web服务器还是把响应(response)的产生委托(delegates)给脚本(译者注:服务器端(server-side)程序)。然而,你可以把查找定价的商业逻辑(business logic)放到应用程序服务器上。由于这种变化,此脚本只是简单的调用应用程序服务器的查找服务(lookup service),而不是已经知道如何查找数据然后表示为(formulate)一个响应(response)。 这时当该脚本程序产生HTML响应(response)时就可以使用该服务的返回结果了。
在此情景中,应用程序服务器提供(serves)了用于查询产品的定价信息的商业逻辑。(服务器的)这种功能(functionality)没有指出有关显示和客户端如何使用此信息的细节,相反客户端和应用程序服务器只是来回传送数据。当有客户端调用应用程序服务器的查找服务(lookup service)时,此服务只是简单的查找并返回结果给客户端。
通过从响应产生(response-generating)HTML的代码中分离出来,在应用程序之中该定价(查找)逻辑的可重用性更强了。其他的客户端,例如收款机,也可以调用同样的服务(service)来作为一个店员给客户结帐。相反,在情景1中的定价查找服务是不可重用的因为信息内嵌在HTML页中了。
总而言之,在情景2的模型中,在Web服务器通过回应HTML页面来处理HTTP请求(request),而应用程序服务器则是通过处理定价和有效性(availability)请求(request)来提供应用程序逻辑的。
警告(Caveats)
现在,XML Web Services已经使应用程序服务器和Web服务器的界线混淆了。通过传送一个XML有效载荷(payload)给服务器,Web服务器现在可以处理数据和响应(response)的能力与以前的应用程序服务器同样多了。
另外,现在大多数应用程序服务器也包含了Web服务器,这就意味着可以把Web服务器当作是应用程序服务器的一个子集(subset)。虽然应用程序服务器包含了Web服务器的功能,但是开发者很少把应用程序服务器部署(deploy)成这种功能(capacity)(译者注:这种功能是指既有应用程序服务器的功能又有Web服务器的功能)。相反,如果需要,他们通常会把Web服务器独立配置,和应用程序服务器一前一后。这种功能的分离有助于提高性能(简单的Web请求(request)就不会影响应用程序服务器了),分开配置(专门的Web服务器,集群(clustering)等等),而且给最佳产品的选取留有余地。
2009年10月21日
#
下面的这个简单的 Java 程序完成四项不相关的任务。这样的程序有单个控制线程,控制在这四个任务之间线性地移动。此外,因为所需的资源 ? 打印机、磁盘、数据库和显示屏 — 由于硬件和软件的限制都有内在的潜伏时间,所以每项任务都包含明显的等待时间。因此,程序在访问数据库之前必须等待打印机完成打印文件的任务,等等。如果您正在等待程序的完成,则这是对计算资源和您的时间的一种拙劣使用。改进此程序的一种方法是使它成为多线程的。
四项不相关的任务
class myclass {
static public void main(String args[]) {
print_a_file();
manipulate_another_file();
access_database();
draw_picture_on_screen();
}
}
多个进程
在大多数操作系统中都可以创建多个进程。当一个程序启动时,它可以为即将开始的每项任务创建一个进程,并允许它们同时运行。当一个程序因等待网络访问或用户输入而被阻塞时,另一个程序还可以运行,这样就增加了资源利用率。但是,按照这种方式创建每个进程要付出一定的代价:设置一个进程要占用相当一部分处理器时间和内存资源。而且,大多数操作系统不允许进程访问其他进程的内存空间。因此,进程间的通信很不方便,并且也不会将它自己提供给容易的编程模型。
线程
线程也称为轻型进程 (LWP)。因为线程只能在单个进程的作用域内活动,所以创建线程比创建进程要廉价得多。这样,因为线程允许协作和数据交换,并且在计算资源方面非常廉价,所以线程比进程更可取。线程需要操作系统的支持,因此不是所有的机器都提供线程。Java 编程语言,作为相当新的一种语言,已将线程支持与语言本身合为一体,这样就对线程提供了强健的支持。
使用 Java 编程语言实现线程
Java编程语言使多线程如此简单有效,以致于某些程序员说它实际上是自然的。尽管在 Java 中使用线程比在其他语言中要容易得多,仍然有一些概念需要掌握。要记住的一件重要的事情是 main() 函数也是一个线程,并可用来做有用的工作。程序员只有在需要多个线程时才需要创建新的线程。
Thread 类
下面的代码说明了它的用法:
创建两个新线程
import java.util.*;
class TimePrinter extends Thread {
int pauseTime;
String name;
public TimePrinter(int x, String n) {
pauseTime = x;
name = n;
}
public void run() {
while(true) {
try {
System.out.println(name + “:” + new
Date(System.currentTimeMillis()));
Thread.sleep(pauseTime);
} catch(Exception e) {
System.out.println(e);
}
}
}
static public void main(String args[]) {
TimePrinter tp1 = new TimePrinter(1000, “Fast Guy”);
tp1.start();
TimePrinter tp2 = new TimePrinter(3000, “Slow Guy”);
tp2.start();
}
}
在本例中,我们可以看到一个简单的程序,它按两个不同的时间间隔(1 秒和 3 秒)在屏幕上显示当前时间。这是通过创建两个新线程来完成的,包括 main() 共三个线程。但是,因为有时要作为线程运行的类可能已经是某个类层次的一部分,所以就不能再按这种机制创建线程。虽然在同一个类中可以实现任意数量的接口,但 Java 编程语言只允许一个类有一个父类。同时,某些程序员避免从 Thread 类导出,因为它强加了类层次。对于这种情况,就要 runnable 接口。
Runnable 接口
此接口只有一个函数,run(),此函数必须由实现了此接口的类实现。但是,就运行这个类而论,其语义与前一个示例稍有不同。我们可以用 runnable 接口改写前一个示例。(不同的部分用黑体表示。)
创建两个新线程而不强加类层次
import java.util.*;
class TimePrinter implements Runnable {
int pauseTime;
String name;
public TimePrinter(int x, String n) {
pauseTime = x;
name = n;
}
public void run() {
while(true) {
try {
System.out.println(name + “:” + new
Date(System.currentTimeMillis()));
Thread.sleep(pauseTime);
} catch(Exception e) {
System.out.println(e);
}
}
}
static public void main(String args[]) {
Thread t1 = new Thread(new TimePrinter(1000, “Fast Guy”));
t1.start();
Thread t2 = new Thread(new TimePrinter(3000, “Slow Guy”));
t2.start();
}
}
请注意,当使用 runnable 接口时,您不能直接创建所需类的对象并运行它; 必须从 Thread 类的一个实例内部运行它。许多程序员更喜欢 runnable 接口,因为从 Thread 类继承会强加类层次。
synchronized 关键字
到目前为止,我们看到的示例都只是以非常简单的方式来利用线程。只有最小的数据流,而且不会出现两个线程访问同一个对象的情况。但是,在大多数有用的程序中,线程之间通常有信息流。试考虑一个金融应用程序,它有一个 Account 对象,如下例中所示:
一个银行中的多项活动
public class Account {
String holderName;
float amount;
public Account(String name, float amt) {
holderName = name;
amount = amt;
}
public void deposit(float amt) {
amount += amt;
}
public void withdraw(float amt) {
amount -= amt;
}
public float checkBalance() {
return amount;
}
}
在此代码样例中潜伏着一个错误。如果此类用于单线程应用程序,不会有任何问题。但是,在多线程应用程序的情况中,不同的线程就有可能同时访问同一个 Account 对象,比如说一个联合帐户的所有者在不同的 ATM 上同时进行访问。在这种情况下,存入和支出就可能以这样的方式发生:一个事务被另一个事务覆盖。这种情况将是灾难性的。但是,Java 编程语言提供了一种简单的机制来防止发生这种覆盖。每个对象在运行时都有一个关联的锁。这个锁可通过为方法添加关键字 synchronized 来获得。这样,修订过的 Account 对象(如下所示)将不会遭受像数据损坏这样的错误:
对一个银行中的多项活动进行同步处理
public class Account {
String holderName;
float amount;
public Account(String name, float amt) {
holderName = name;
amount = amt;
}
public synchronized void deposit(float amt) {
amount += amt;
}
public synchronized void withdraw(float amt) {
amount -= amt;
}
public float checkBalance() {
return amount;
}
}
deposit() 和 withdraw() 函数都需要这个锁来进行操作,所以当一个函数运行时,另一个函数就被阻塞。请注意, checkBalance() 未作更改,它严格是一个读函数。因为 checkBalance() 未作同步处理,所以任何其他方法都不会阻塞它,它也不会阻塞任何其他方法,不管那些方法是否进行了同步处理。
Java 编程语言中的高级多线程支持
线程组
线程是被个别创建的,但可以将它们归类到线程组中,以便于调试和监视。只能在创建线程的同时将它与一个线程组相关联。在使用大量线程的程序中,使用线程组组织线程可能很有帮助。可以将它们看作是计算机上的目录和文件结构。
线程间发信
当线程在继续执行前需要等待一个条件时,仅有 synchronized 关键字是不够的。虽然 synchronized 关键字阻止并发更新一个对象,但它没有实现线程间发信。Object 类为此提供了三个函数:wait()、notify() 和 notifyAll()。以全球气候预测程序为例。这些程序通过将地球分为许多单元,在每个循环中,每个单元的计算都是隔离进行的,直到这些值趋于稳定,然后相邻单元之间就会交换一些数据。所以,从本质上讲,在每个循环中各个线程都必须等待所有线程完成各自的任务以后才能进入下一个循环。这个模型称为屏蔽同步,下例说明了这个模型:
屏蔽同步
public class BSync {
int totalThreads;
int currentThreads;
public BSync(int x) {
totalThreads = x;
currentThreads = 0;
}
public synchronized void waitForAll() {
currentThreads++;
if(currentThreads < totalThreads) {
try {
wait();
} catch (Exception e) {}
}
else {
currentThreads = 0;
notifyAll();
}
}
}
当对一个线程调用 wait() 时,该线程就被有效阻塞,只到另一个线程对同一个对象调用 notify() 或 notifyAll() 为止。因此,在前一个示例中,不同的线程在完成它们的工作以后将调用 waitForAll() 函数,最后一个线程将触发 notifyAll() 函数,该函数将释放所有的线程。第三个函数 notify() 只通知一个正在等待的线程,当对每次只能由一个线程使用的资源进行访问限制时,这个函数很有用。但是,不可能预知哪个线程会获得这个通知,因为这取决于 Java 虚拟机 (JVM) 调度算法。
将 CPU 让给另一个线程
当线程放弃某个稀有的资源(如数据库连接或网络端口)时,它可能调用 yield() 函数临时降低自己的优先级,以便某个其他线程能够运行。
守护线程
有两类线程:用户线程和守护线程。用户线程是那些完成有用工作的线程。 守护线程是那些仅提供辅助功能的线程。Thread 类提供了 setDaemon() 函数。Java 程序将运行到所有用户线程终止,然后它将破坏所有的守护线程。在 Java 虚拟机 (JVM) 中,即使在 main 结束以后,如果另一个用户线程仍在运行,则程序仍然可以继续运行。
避免不提倡使用的方法
不提倡使用的方法是为支持向后兼容性而保留的那些方法,它们在以后的版本中可能出现,也可能不出现。Java 多线程支持在版本 1.1 和版本 1.2 中做了重大修订,stop()、suspend() 和 resume() 函数已不提倡使用。这些函数在 JVM 中可能引入微妙的错误。虽然函数名可能听起来很诱人,但请抵制诱惑不要使用它们。
调试线程化的程序
在线程化的程序中,可能发生的某些常见而讨厌的情况是死锁、活锁、内存损坏和资源耗尽。
死锁
死锁可能是多线程程序最常见的问题。当一个线程需要一个资源而另一个线程持有该资源的锁时,就会发生死锁。这种情况通常很难检测。但是,解决方案却相当好:在所有的线程中按相同的次序获取所有资源锁。例如,如果有四个资源 ?A、B、C 和 D ? 并且一个线程可能要获取四个资源中任何一个资源的锁,则请确保在获取对 B 的锁之前首先获取对 A 的锁,依此类推。如果“线程 1”希望获取对 B 和 C 的锁,而“线程 2”获取了 A、C 和 D 的锁,则这一技术可能导致阻塞,但它永远不会在这四个锁上造成死锁。
活锁
当一个线程忙于接受新任务以致它永远没有机会完成任何任务时,就会发生活锁。这个线程最终将超出缓冲区并导致程序崩溃。试想一个秘书需要录入一封信,但她一直在忙于接电话,所以这封信永远不会被录入。
内存损坏
如果明智地使用 synchronized 关键字,则完全可以避免内存错误这种气死人的问题。
资源耗尽
某些系统资源是有限的,如文件描述符。多线程程序可能耗尽资源,因为每个线程都可能希望有一个这样的资源。如果线程数相当大,或者某个资源的侯选线程数远远超过了可用的资源数,则最好使用资源池。一个最好的示例是数据库连接池。只要线程需要使用一个数据库连接,它就从池中取出一个,使用以后再将它返回池中。资源池也称为 资源库。
调试大量的线程
有时一个程序因为有大量的线程在运行而极难调试。在这种情况下,下面的这个类可能会派上用场:
public class Probe extends Thread {
public Probe() {}
public void run() {
while(true) {
Thread[] x = new Thread[100];
Thread.enumerate(x);
for(int i=0; i<100; i++) {
Thread t = x[i];
if(t == null)
break;
else
System.out.println(t.getName() + “\t” + t.getPriority()
+ “\t” + t.isAlive() + “\t” + t.isDaemon());
}
}
}
}
限制线程优先级和调度
Java 线程模型涉及可以动态更改的线程优先级。本质上,线程的优先级是从 1 到 10 之间的一个数字,数字越大表明任务越紧急。JVM 标准首先调用优先级较高的线程,然后才调用优先级较低的线程。但是,该标准对具有相同优先级的线程的处理是随机的。如何处理这些线程取决于基层的操作系统策略。在某些情况下,优先级相同的线程分时运行; 在另一些情况下,线程将一直运行到结束。请记住,Java 支持 10 个优先级,基层操作系统支持的优先级可能要少得多,这样会造成一些混乱。因此,只能将优先级作为一种很粗略的工具使用。最后的控制可以通过明智地使用 yield() 函数来完成。通常情况下,请不要依靠线程优先级来控制线程的状态。
2009年10月17日
#
第一范式
定义:如果关系R 中所有属性的值域都是单纯域,那么关系模式R是第一范式的
那么符合第一模式的特点就有
1)有主关键字
2)主键不能为空,
3)主键不能重复,
4)字段不可以再分
例如:
StudyNo | Name | Sex | Contact
20040901 john Male Email:kkkk@ee.net,phone:222456
20040901 mary famale email:kkk@fff.net phone:123455
以上的表就不符合,第一范式:主键重复(实际中数据库不允许重复的),而且Contact字段可以再分
所以变更为正确的是
StudyNo | Name | Sex | Email | Phone
20040901 john Male kkkk@ee.net 222456
20040902 mary famale kkk@fff.net 123455
第二范式:
定义:如果关系模式R是第一范式的,而且关系中每一个非主属性不部分依赖于主键,称R是第二范式的。
所以第二范式的主要任务就是
满足第一范式的前提下,消除部分函数依赖。
StudyNo | Name | Sex | Email | Phone | ClassNo | ClassAddress
01 john Male kkkk@ee.net 222456 200401 A楼2
02 mary famale kkk@fff.net 123455 200402 A楼3
这个表完全满足于第一范式,
主键由StudyNo和ClassNo组成,这样才能定位到指定行
但是,ClassAddress部分依赖于关键字(ClassNo-〉ClassAddress),
所以要变为两个表
表一
StudyNo | Name | Sex | Email | Phone | ClassNo
01 john Male kkkk@ee.net 222456 200401
02 mary famale kkk@fff.net 123455 200402
表二
ClassNo | ClassAddress
200401 A楼2
200402 A楼3
第三范式:
满足第二范式的前提下,消除传递依赖。
例:
StudyNo | Name | Sex | Email | bounsLevel | bouns
20040901 john Male kkkk@ee.net 优秀 $1000
20040902 mary famale kkk@fff.net 良 $600
这个完全满足了第二范式,但是bounsLevel和bouns存在传递依赖
更改为:
StudyNo | Name | Sex | Email | bouunsNo
20040901 john Male kkkk@ee.net 1
20040902 mary famale kkk@fff.net 2
bounsNo | bounsLevel | bouns
1 优秀 $1000
2 良 $600
这里我比较喜欢用bounsNo作为主键,
基于两个原因
1)不要用字符作为主键。可能有人说:如果我的等级一开始就用数值就代替呢?
2)但是如果等级名称更改了,不叫 1,2 ,3或优、良,这样就可以方便更改,所以我一般优先使用与业务无关的字段作为关键字。
一般满足前三个范式就可以避免数据冗余。
第四范式:
主要任务:满足第三范式的前提下,消除多值依赖
product | agent | factory
Car A1 F1
Bus A1 F2
Car A2 F2
在这里,Car的定位,必须由 agent 和 Factory才能得到(所以主键由agent和factory组成),可以通过 product依赖了agent和factory两个属性
所以正确的是
表1 表2:
product | agent factory | product
Car A1 F1 Car
Bus A1 F2 Car
Car A2 F2 Bus
第五范式:
定义: 如果关系模式R中的每一个连接依赖, 都是由R的候选键所蕴含, 称R是第五范式的
看到定义,就知道是要消除连接依赖,并且必须保证数据完整
例子
A | B | C
a1 b1 c1
a2 b1 c2
a1 b2 c1
a2 b2 c2
如果要定位到特定行,必须三个属性都为关键字。
所以关系要变为 三个关系,分别是A 和B,B和C ,C和A
如下:
表1 表2 表3
A | B B | C C | A
a1 b1 b1 c1 c1 a1
a1 b2 b1 c2 c1 a2
数据库范式是数据库设计中必不可少的知识,没有对范式的理解,就无法设计出高效率、优雅的数据库。甚至设计出错误的数据库。而想要理解并掌握范式却并不是那 么容易。教科书中一般以关系代数的方法来解释数据库范式。这样做虽然能够十分准确的表达数据库范式,但比较抽象,不太直观,不便于理解,更难以记忆。
一、基础概念
- 实体:现实世界中客观存在并可以被区别的事物。比如“一个学生”、“一本书”、“一门课”等等。值得强调的是这里所说的“事物”不仅仅是看得见摸得着的“东西”,它也可以是虚拟的,不如说“老师与学校的关系”。
- 属性:教科书上解释为:“实体所具有的某一特性”,由此可见,属性一开始是个逻辑概念,比如说,“性别”是“人”的一个属性。在关系数据库中,属性又是个物理概念,属性可以看作是“表的一列”。
- 元组:表中的一行就是一个元组。
- 分量:元组的某个属性值。在一个关系数据库中,它是一个操作原子,即关系数据库在做任何操作的时候,属性是“不可分的”。否则就不是关系数据库了。
- 码:表中可以唯一确定一个元组的某个属性(或者属性组),如果这样的码有不止一个,那么大家都叫候选码,我们从候选码中挑一个出来做老大,它就叫主码。
- 全码:如果一个码包含了所有的属性,这个码就是全码。
- 主属性:一个属性只要在任何一个候选码中出现过,这个属性就是主属性。
- 非主属性:与上面相反,没有在任何候选码中出现过,这个属性就是非主属性。
- 外码:一个属性(或属性组),它不是码,但是它别的表的码,它就是外码。
二、6个范式
好了,上面已经介绍了我们掌握范式所需要的全部基础概念,下面我们就来讲范式。首先要明白,范式的包含关系。一个数据库设计如果符合第二范式,一定也符合第一范式。如果符合第三范式,一定也符合第二范式…
第一范式(1NF):属性不可分。
在前面我们已经介绍了
属性值的概念,我们说,它是“不可分的”。而第一范式要求属性也不可分。那么它和属性值不可分有什么区别呢?给一个例子:
| name |
tel |
age |
| 大宝 |
13612345678 |
22 |
| 小明 |
13988776655 |
010-1234567 |
21 |
Ps:这个表中,属性值“分”了。
| name |
tel |
age |
| 手机 |
座机 |
| 大宝 |
13612345678 |
021-9876543 |
22 |
| 小明 |
13988776655 |
010-1234567 |
21 |
Ps:这个表中,属性 “分”了。
这两种情况都不满足第一范式。不满足第一范式的数据库,不是关系数据库!所以,我们在任何关系数据库管理系统中,做不出这样的“表”来。
第二范式(2NF):符合1NF,并且,
非主属性完全依赖于码。
听起来好像很神秘,其实真的没什么。
一 个候选码中的主属性也可能是好几个。如果一个主属性,它不能单独做为一个候选码,那么它也不能确定任何一个非主属性。给一个反例:我们考虑一个小学的教务 管理系统,学生上课指定一个老师,一本教材,一个教室,一个时间,大家都上课去吧,没有问题。那么数据库怎么设计?(学生上课表)
| 学生 |
课程 |
老师 |
老师职称 |
教材 |
教室 |
上课时间 |
| 小明 |
一年级语文(上) |
大宝 |
副教授 |
《小学语文1》 |
101 |
14:30 |
一个学生上一门课,一定在特定某个教室。所以有(学生,课程)->教室
一个学生上一门课,一定是特定某个老师教。所以有(学生,课程)->老师
一个学生上一门课,他老师的职称可以确定。所以有(学生,课程)->老师职称
一个学生上一门课,一定是特定某个教材。所以有(学生,课程)->教材
一个学生上一门课,一定在特定时间。所以有(学生,课程)->上课时间
因此(学生,课程)是一个码。
然而,一个课程,一定指定了某个教材,一年级语文肯定用的是《小学语文1》,那么就有课程->教材。(学生,课程)是个码,课程却决定了教材,这就叫做不完全依赖,或者说部分依赖。出现这样的情况,就不满足第二范式!
有什么不好吗?你可以想想:
1、校长要新增加一门课程叫“微积分”,教材是《大学数学》,怎么办?学生还没选课,而学生又是主属性,主属性不能空,课程怎么记录呢,教材记到哪呢? ……郁闷了吧?
(插入异常)
2、下学期没学生学一年级语文(上)了,学一年级语文(下)去了,那么表中将不存在一年级语文(上),也就没了《小学语文1》。这时候,校长问:一年级语文(上)用的什么教材啊?……郁闷了吧?
(删除异常)
3、校长说:一年级语文(上)换教材,换成《大学语文》。有10000个学生选了这么课,改动好大啊!改累死了……郁闷了吧?
(修改异常)
那应该怎么解决呢?投影分解,将一个表分解成两个或若干个表
| 学生 |
课程 |
老师 |
老师职称 |
教室 |
上课时间 |
| 小明 |
一年级语文(上) |
大宝 |
副教授 |
101 |
14:30 |
学生上课表新
课程的表
第三范式(3NF):符合2NF,并且,
消除传递依赖
上面的“学生上课表新”符合2NF,可以这样验证:两个主属性单独使用,不用确定其它四个非主属性的任何一个。但是它有传递依赖!
在哪呢?问题就出在“老师”和“老师职称”这里。一个老师一定能确定一个老师职称。
有什么问题吗?想想:
1、老师升级了,变教授了,要改数据库,表中有N条,改了N次……
(修改异常)
2、没人选这个老师的课了,老师的职称也没了记录……
(删除异常)
3、新来一个老师,还没分配教什么课,他的职称记到哪?……
(插入异常)
那应该怎么解决呢?和上面一样,投影分解:
| 学生 |
课程 |
老师 |
教室 |
上课时间 |
| 小明 |
一年级语文(上) |
大宝 |
101 |
14:30 |
BC范式(BCNF):符合3NF,并且,
主属性不依赖于主属性
若关系模式属于第一范式,且每个属性都不传递依赖于键码,则R属于BC范式。
通常
BC范式的条件有多种等价的表述:每个非平凡依赖的左边必须包含键码;每个决定因素必须包含键码。
BC范式既检查非主属性,又检查主属性。当只检查非主属性时,就成了第三范式。满足BC范式的关系都必然满足第三范式。
还可以这么说:
若一个关系达到了第三范式,并且它只有一个候选码,或者它的每个候选码都是单属性,则该关系自然达到BC范式。
一般,一个数据库设计符合3NF或BCNF就可以了。在BC范式以上还有第四范式、第五范式。
第四范式:要求把同一表内的多对多关系删除。
第五范式:从最终结构重新建立原始结构。
2009年9月16日
#
关键字: editplus
原文出自:http://www.cnblogs.com/JustinYoung/archive/2008/01/14/editplus-skills.html
除了windows操作系统,EditPlus可以说是我最经常使用的软件了。无论是编写xhtml页面,还是css、js文件,甚至随笔记记这样的事情,我都会使用EditPlus(现在使用的是EditPlus2.31英文版),感觉它不仅功能强大,更难得的是:绿色、轻量级、启动速度快、稳定性高……反正,我个人是爱死她了
在使用中,我个人也总结了一些使用经验。可能作为高手的你,看来只是”相当肤浅”,但是没有关系,因为我相信,只要把知识共享出来,总能帮助到一些还在进步中的朋友。下面就让我们来开始配置出符合你自己使用习惯的EditPlus吧!
一边阅读,一边动手吧!
为了达到更好的效果,请你先下载我打包的这个 EditPlus压缩包文件(压缩包文件为绿色的EditPlus2.31英文版,含自动完成文件,高亮语法文件和剪切板代码片断文件,这些文件在解压目录下的”yzyFile”目录下),这样就可以一边看着这篇文章,一边亲自动手,从而达到更好的效果了。
设置EditPlus的配置文件路径
因为EditPlus是可以绿色使用的(直接解压那个EditPlus压缩包文件即可直接使用,不用安装),所以,当我们对EditPlus进行一系列的配置以后,保存下这些配置文件。以后当我们重装系统,或者换台电脑使用的时候,只要重新加载一下那些配置文件,以前的配置就都重新回来了,很是方便。所以,在讲其他配置和技巧之前,我们先设置好EditPlus的配置文件路径。
打开EditPlus → 【Tools】→ 【INI File Directory…】 → 在弹出的对话框中设置配置文件的保存位置(压缩包内的配置保存文件在解压目录下的”yzyFile\INIFiles”目录下)。这里你可能要重新设置一下目录,因为,我喜欢把EditPlus放在”D:\GreenSoft\EditPlus 2″下(把所有的绿色软件装在一个目录下,每次重装系统的时候,可以直接把绿色软件拷回去,就能直接使用了,从而避免了每次都安装那么多软件)。所以,就请你重新设置一下,根据你的习惯,把配置文件存放在某个目录下吧。
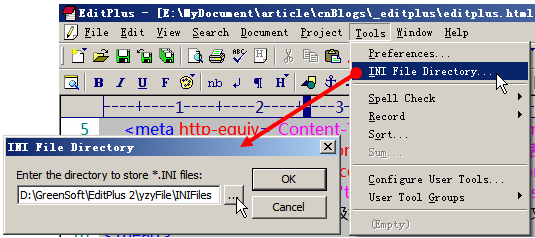
图1:设置EditPlus的配置文件保存路径
保护视力,从EditPlus做起
“最近眼睛好痛呀!”、”靠~眼睛简直要瞎了!”……不知道作为程序员的你是否也经常抱怨这样的事情,每天对着电脑看,的确对视力的伤害很大,所以能不能采取一些措施来为眼睛减减压呢?我在EditPlus里面是这样做的(因为EditPlus是我最长使用的工具,所以以EditPlus为例)–编辑区的背景设为灰色而不是默认的白色,使用较大字号的字体。效果如下图所示:
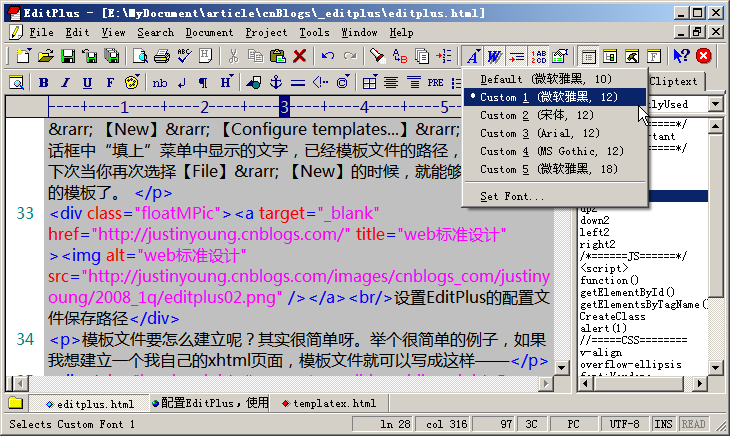
图2:灰色的背景,12号的雅黑字体,构造”爱眼”环境你可以这样设置EditPlus编辑环境的背景颜色和字体。菜单【Tools】→ 【Preperences】→ 【General】→ 【fonts】和【colors】。需要说明一下的是:可以设置多种fonts,这样就可以很方便地切换fonts了(参看图2所示),这招对日企这样的朋友很方便哦。中文的字体设置几个,日文的字体设置几个,出现乱码的时候,切换一下字体就可以了。
图3:设置EditPlus的字体和颜色
配置文件模板,告别重复的体力劳动
设置好EditPlus的配置文件,就让我们开始EditPlus的使用技巧吧。第一个技巧当然就是和”新建”有关的啦。如果我们经常建立一种文件,而这种文件总会包含一些重复的文字或者代码的话,我们就可以建立模板,然后通过模板建立文件。从而摆脱每次都要重复的体力劳动。
我们就从建立一个属于自己的xhtml文件开始吧。菜单【File】→ 【New】→ 【Configure templates…】→ 在打开的对话框中”填上”菜单中显示的文字,已经模板文件的路径,就可以了。下次当你再次选择【File】→ 【New】的时候,就能够看到你建立的模板了。
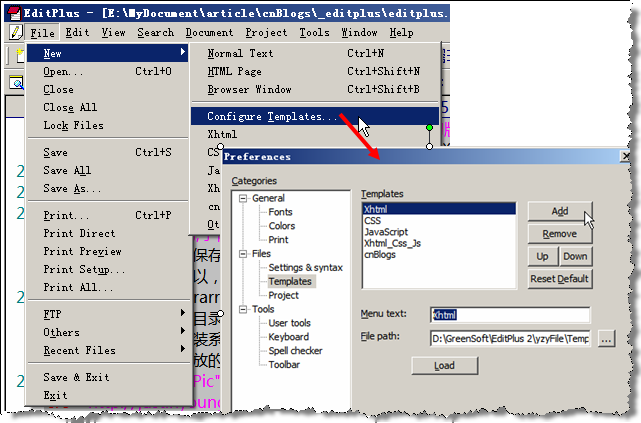
图4:EditPlus中建立自己的模板模板文件要怎么建立呢?其实很简单呀。举个很简单的例子,如果我想建立一个我自己的xhtml页面,模板文件就可以写成这样–
1 <!DOCTYPE html public ”-//W3C//DTD XHTML 1.0 Transitional//EN” ”http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd”>
<!DOCTYPE html public ”-//W3C//DTD XHTML 1.0 Transitional//EN” ”http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd”>
2<html xmlns=”http://www.w3.org/1999/xhtml”>
3<head>
4 <meta http-equiv=”Content-Type” content=”text/html; charset=utf-8″ />
5 <meta name=”Keywords” content=”YES!B/S!,JustinYoung,web标准设计” />
6 <meta name=”Description” content=”This page is from http://Justinyoung.cnblogs.com” />
7 <title>简单的XHTML页面</title>
8</head>
9<body>
10^!
11</body>
12</html>显然里面的Keywords和Description,意见title的内容都已经变成我常用的了。还有一点,请大家注意第10行的”^!”标签。这个标签在EditPlus中表示光标所在位置。显然,这里的意思就是:当你用这个模板建立一个新的文件的时候,光标就会自动停留在<body>和</body>之间,从而方便你的直接输入。
关于模板文件再说两句:
1:在我提供的那个 EditPlus压缩包文件中,模板文件存放在解压目录下的”\yzyFile\Templates”文件夹下。
2:我们知道使用快捷键”Ctrl + Shift + N”可以快速的建立一个html页面,而这个可以快速的建立html的模板,位于EditPlus目录下的,文件名为”templatex.html”。你可以通过修改这个模板文件,来达到你个性化html页面的目的。
顺手的侧边栏
如果你看不到侧边栏,可以使用快捷键(Alt + Shift + 1)。侧边栏包含了”快速目录路径”和”快速剪贴板”功能。”快速目录路径”就不说了,重点来说说”快速剪贴板”功能吧。其实说白了,就是一个地方,这个地方可以存放一些代码片断、常用文言等等文字。当你需要这些文字的时候,只要双击,就可以方便的添加到光标所在位置了。默认情况下会有一些html,css代码,但是,说实话,我是不太经常使用那些东西的,那么多,找到都累死了。所以,我喜欢建立一个自己最常用的”剪贴板”库,因为是自己建的,所以用着就会比较顺手了。
你可以通过这种方式来建立自己的”剪贴板”库文件。在Cliptext侧边栏上的下拉列表框上点击右键 → 新建 → 填写文件名和显示标题→ 在新建的空白侧边栏上点击右键 → 新建 → 填入显示文本和代码即可。
关于”剪贴板”库文件再说两句:
1:在我提供的那个 EditPlus压缩包文件中”剪贴板”库文件存放在解压目录下的”\yzyFile\CliptextLibrary”文件夹下。
2:你可以通过直接编辑,解压目录下的”\yzyFile\CliptextLibrary”文件夹下的”剪贴板”库文件,来快速的建立自己的常用代码库(用EditPlus就可以打开,格式看一下就懂了。编辑好以后要重新”Reload”一下,或者重新启动一下才能刷新哦)。
3:侧边栏可以放在左边,也可以放在右面。设置的方法是:在侧边栏点击鼠标右键 → 选择【Location】菜单内的left或者right。
华丽的自动完成功能
<ul>
<li><a href=”" mce_href=”" title=”"></a></li>
<li><a href=”" mce_href=”" title=”"></a></li>
<li><a href=”" mce_href=”" title=”"></a></li>
<li><a href=”" mce_href=”" title=”"></a></li>
<li><a href=”" mce_href=”" title=”"></a></li>
</ul>可以说是俺最喜欢的功能了。想象一下,作为一个经常制作网页的人来所,当你打一个”ua”字,然后按下空格,编辑器里面就出现了右边的代码,而且鼠标就停留在第一个href的双引号之间。那是多么愉快的事情。这就是EditPlus的自动完成功能,使用EditPlus的自动完成功能将会极大的提高你的工作效率。而且我们可以根据不同的文件类型,建立不同的”自动完成”,例如,如果是xhtml文件,打”b”+ 空格”,就是 <strong></strong>,而在css文件中,”b”+ 空格”,就是 “border:1px solid red;”。非常的人性化。
你可以通过这样的设置,来使用EditPlus的自动完成功能。【Tools】→【Preperences】→ 【Files】→ 【Settings & syntax】 → 在【File types】中设置一下文件类型,然后再【Auto completion】中选择自动完成文件即可(如果你使用的是我那个 EditPlus压缩包文件,请注意调整这里的自动完成文件的路径)。自动完成文件我们可以自己进行编辑,这里我举个简单的例子,展开下面的代码,这个便是我css文件自动完成的文件内容,以第11行的”#T=bor”为例,它的意思就是如果输入bor然后按空格,就在光标所在位置插入”border:1px solid red;”
关于”自动完成”文件再说两句:
1:在我提供的那个 EditPlus压缩包文件中”自动完成”文件存放在解压目录下的”\yzyFile\AutoCompletion”文件夹下。
2:你可以通过直接编辑,解压目录下的”\yzyFile\AutoCompletion”文件夹下的EditPlus自动完成文件,来快速的建立自己的EditPlus自动完成文件。
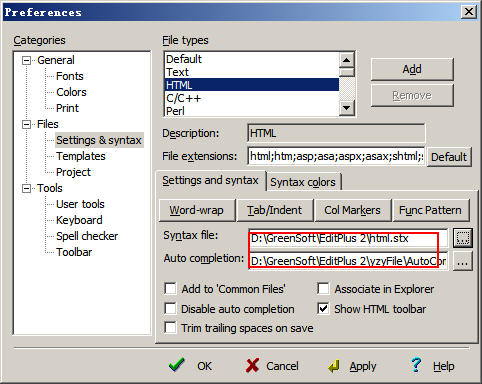
图5:”自动完成”和”高亮语法”设置对话框
彩色的文件,高亮语法文件
很多的开发工具都有语法高亮显示功能,EditPlus虽小,但是也有这个功能哦。设置方法可以参考图片5所示。和”自动完成”功能一样,只要为不同的文件类型指定”高亮语法”文件即可。css、html等常用的文件类型,EditPlus已经自带了高亮语法文件。如果自带的高亮语法文件没有你需要的,你可以去EditPlus官方网站的文件下载频道去看看,来自全球各地的朋友,贡献了很多的不同文件类型的高亮语法文件。可以很方便地免费下载到。
这里就稍微列举一下比较常用的EditPlus的高亮语法文件,更多的请到EditPlus的官方网站下载,EditPlus的官方地址为: http://www.editplus.com/files.html
EditPlus正则表达式
EditPlus中的查找(替换)功能,支持正则表达式。使用正则表达式可以极大的提高查找(替换)的强悍程度。因为正则表达式这东西不是一句话就能说完的,而且偏离此篇文章主题,所以这里只列举几个常用的例子。对此有兴趣的可以参考正则表达式资料,或者在EditPlus的help中”Regular Expression”关键字进行索引查找。
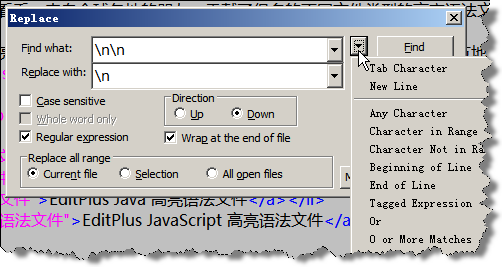
图6:在查找(替换)对话框中使用正则表达式使用正则表达式进行查找(替换)的方法如上图所示,选择查找(替换)对话框中”Regular Expression”前面checkbox。点击查找(替换)文本框后的”倒三角”可以选择常用的正则表达式。
正则表达式实例
| 需求说明 |
正则表达式写法 |
备注 |
| 替换指定内容(以abc为例)到行尾 |
abc.* |
“.”表示匹配任意字符;”*”表示匹配0次或更多 |
| 给所有的数字加上引号 |
查找[0-9]替换为”\0″ |
\0表示正则表达式匹配的对象 |
| 删除空白行 |
查找\n\n 替换为\n |
把连续的2个换行符,替换成一个换行符 |
矩形选区
看到这个词,好像是说图像处理工具,其实非也,不管是VS还是EditPlus,其实都是支持矩形选区的。这对处理一些形如:去掉文章前端行号的情况有特效,矩形全区的选取方式就是按住Alt键,然后用鼠标划矩形选区(如图7所示)。需要注意到是在”自动换行”的情况下,是不能使用”矩形选区”的。你可以使用Ctrl+Shift +W来切换”自动换行”或者”不自动换行”视图。
图7:在EditPlus中选取矩形选区(注意红色框内的”自动换行图标”)
提高工作效率,EditPlus 快捷键的使用
如果一个来你们公司面试程序员,连Ctrl + C 和Ctrl + V 都不用,而是使用”选中文本”→ 鼠标右键 → 【复制】,然后再鼠标右键→ 【粘贴】。你会不会录用他呢?(你还别笑,以前我们公司还真面试过一个这样的,所谓的”精通asp.net”的程序员)。所以熟练的使用软件的快捷键,不仅仅能够极大的提高工作效率,也从一个侧面表现出一个人对此软件的使用能力。EditPlus同样也有很多的快捷键,下面是一些我经常使用的EditPlus特有的快捷键(Ctrl +C 、Ctrl+H这样的通用快捷键就不介绍了),略举一二,更多的请参看文章《EditPlus快捷键》
| 以浏览器模式预览文件 |
Ctrl + B |
| 开始编辑”以浏览器模式预览的文件” |
Ctrl + E |
| 新建html文件 |
Ctrl+Shift+N |
| 新建浏览器窗口(类似于在EditPlus中打开ie) |
Ctrl+Shift+B |
| 选中的字母切换为小写 |
Ctrl+L |
| 选中的字母切换为大写 |
Ctrl+U |
| 选中的词组首字母大写 |
Ctrl+Shift+U |
| 复制选定文本并追加到剪贴板中 |
Ctrl+Shift+C |
| 剪切选定文本并追加到剪贴板中 |
Ctrl+Shift+X |
| 创建当前行的副本 |
Ctrl+J |
| 复制上一行的一个字符到当前行 |
Ctrl+- |
| 剪切选定文本并追加到剪贴板中 |
Ctrl+Shift+X |
| 合并选定行 |
Ctrl+Shift+J |
| 反转选定文本的大小写 |
Ctrl+K |
| 开始/结束选择区域 |
Alt+Shift+B |
| 选择当前行 |
Ctrl+R |
| 全屏模式开/关 |
Ctrl+K |
| 显示或隐藏标尺 |
Alt+Shift+R |
| 显示或隐藏制表符与空格 |
Alt+Shift+I |
| 显示函数列表 |
Ctrl+F11 |
| 转到当前文档的指定行 |
Ctrl + G |
| 设置或清除当前行的标记 |
F9 |
| 转到下一个标记位置 |
F4 |
| 转到上一个标记位置 |
Shift+F4 |
| 清除当前文档中的所有标记 |
Ctrl+Shift+F9 |
| 搜索一对匹配的括号 |
Ctrl+] |
| 搜索一对匹配的括号并选择该文本 |
Ctrl+Shift+] |
| 切换当前文档的自动换行功能 |
Ctrl+Shift+W |
| 编辑当前 HTML 页面的源文件 |
Ctrl+E |
2009年9月1日
#
2009年7月24日
#
常用的类有BufferedReader,
Scanner。
实例程序:
一,利用 Scanner 实现从键盘读入integer或float 型数据
import
java.util.*;
//import
java.io.*;
class Abc
{
public static
void main(String args[])
{
Scanner in=new
Scanner(System.in); //使用Scanner类定义对象
System.out.println("please input a float number");
float
a=in.nextFloat(); //接收float型数据
System.out.println(a);
System.out.println("please input a integer number");
int
b=in.nextInt(); //接收整形数据
System.out.println(b);
}
}
二,利用 BufferedReader实现从键盘读入字符串并写进文件abc.txt中
import java.io.*;
public class
Test1
{
public static
void main(String[] args) throws IOException
{
BufferedReader buf = new
BufferedReader (new
InputStreamReader(System.in));
BufferedWriter buff = new
BufferedWriter(new FileWriter("abc.txt"));
String str = buf.readLine();
while(!str.equals("exit"))
{
buff.write(str);
buff.newLine();
str = buf.readLine();
}
buf.close();
buff.close();
}
}
关于JDK1.5 Scanner类的说明
Scanner是SDK1.5新增的一个类,可是使用该类创建一个对象.
Scanner reader=new Scanner(System.in);
然后reader对象调用下列方法(函数),读取用户在命令行输入的各种数据类型:
next.Byte(),nextDouble(),nextFloat,nextInt(),nextLine(),nextLong(),nextShot()
使用nextLine()方法输入行中可能包含空格.如果读取的是一个单词,则可调用
.next()方法
2009年7月15日
#
Java语言细节
Java作为一门优秀的面向对象的程序设计语言,正在被越来越多的人使用。本文试图列出作者在实际开发中碰到的一些Java语言的容易被人忽视的细节,希望能给正在学习Java语言的人有所帮助。
1,位移运算越界怎么处理
考察下面的代码输出结果是多少?
int a=5;
System.out.println(a<<33);
按照常理推测,把a左移33位应该将a的所有有效位都移出去了,那剩下的都是零啊,所以输出结果应该是0才对啊,可是执行后发现输出结果是10,为什么
呢?因为Java语言对位移运算作了优化处理,Java语言对a<<b转化为a<<(b%32)来处理,所以当要移位的位数b超
过32时,实际上移位的位数是b%32的值,那么上面的代码中a<<33相当于a<<1,所以输出结果是10。
2,可以让i!=i吗?
当你看到这个命题的时候一定会以为我疯了,或者Java语言疯了。这看起来是绝对不可能的,一个数怎么可能不等于它自己呢?或许就真的是Java语言疯了,不信看下面的代码输出什么?
double i=0.0/0.0;
if(i==i){
System.out.println("Yes i==i");
}else{
System.out.println("No i!=i");
}
上面的代码输出"No i!=i",为什么会这样呢?关键在0.0/0.0这个值,在IEEE
754浮点算术规则里保留了一个特殊的值用来表示一个不是数字的数量。这个值就是NaN("Not a
Number"的缩写),对于所有没有良好定义的浮点计算都将得到这个值,比如:0.0/0.0;其实我们还可以直接使用Double.NaN来得到这个
值。在IEEE 754规范里面规定NaN不等于任何值,包括它自己。所以就有了i!=i的代码。
3,怎样的equals才安全?
我们都知道在Java规范里定义了equals方法覆盖的5大原则:reflexive(反身性),symmetric(对称性),transitive(传递性),consistent(一致性),non-null(非空性)。那么考察下面的代码:
public class Student{
private String name;
private int age;
public Student(String name,int age){
this.name=name;
this.age=age;
}
public boolean equals(Object obj){
if(obj instanceof Student){
Student s=(Student)obj;
if(s.name.equals(this.name) && s.age==this.age){
return true;
}
}
return super.equals(obj);
}
}
你认为上面的代码equals方法的覆盖安全吗?表面看起来好像没什么问题,这样写也确实满足了以上的五大原则。但其实这样的覆盖并不很安全,假如
Student类还有一个子类CollegeStudent,如果我拿一个Student对象和一个CollegeStudent对象equals,只要
这两个对象有相同的name和age,它们就会被认为相等,但实际上它们是两个不同类型的对象啊。问题就出在instanceof这个运算符上,因为这个
运算符是向下兼容的,也就是说一个CollegeStudent对象也被认为是一个Student的实例。怎样去解决这个问题呢?那就只有不用
instanceof运算符,而使用对象的getClass()方法来判断两个对象是否属于同一种类型,例如,将上面的equals()方法修改为:
public boolean equals(Object obj){
if(obj.getClass()==Student.class){
Student s=(Student)obj;
if(s.name.equals(this.name) && s.age==this.age){
return true;
}
}
return super.equals(obj);
}
这样才能保证obj对象一定是Student的实例,而不会是Student的任何子类的实例。
4,浅复制与深复制
1)浅复制与深复制概念
⑴浅复制(浅克隆)
被复制对象的所有变量都含有与原来的对象相同的值,而所有的对其他对象的引用仍然指向原来的对象。换言之,浅复制仅仅复制所考虑的对象,而不复制它所引用的对象。
⑵深复制(深克隆)
被复制对象的所有变量都含有与原来的对象相同的值,除去那些引用其他对象的变量。那些引用其他对象的变量将指向被复制过的新对象,而不再是原有的那些被引用的对象。换言之,深复制把要复制的对象所引用的对象都复制了一遍。
2)Java的clone()方法
⑴clone方法将对象复制了一份并返回给调用者。一般而言,clone()方法满足:
①对任何的对象x,都有x.clone() !=x//克隆对象与原对象不是同一个对象
②对任何的对象x,都有x.clone().getClass()= =x.getClass()//克隆对象与原对象的类型一样
③如果对象x的equals()方法定义恰当,那么x.clone().equals(x)应该成立。
⑵Java中对象的克隆
①为了获取对象的一份拷贝,我们可以利用Object类的clone()方法。
②在派生类中覆盖基类的clone()方法,并声明为public。
③在派生类的clone()方法中,调用super.clone()。
④在派生类中实现Cloneable接口。
请看如下代码:
class Student implements Cloneable{
String name;
int age;
Student(String name,int age){
this.name=name;
this.age=age;
}
public Object clone(){
Object obj=null;
try{
obj=(Student)super.clone();
//Object中的clone()识别出你要复制的是哪一个对象。
}
catch(CloneNotSupportedException e){
e.printStackTrace();
}
return obj;
}
}
public static void main(String[] args){
Student s1=new Student("zhangsan",18);
Student s2=(Student)s1.clone();
s2.name="lisi";
s2.age=20;
System.out.println("name="+s1.name+","+"age="+s1.age);//修改学生2
//后,不影响学生1的值。
}
说明:
①为什么我们在派生类中覆盖Object的clone()方法时,一定要调用super.clone()呢?在运行时刻,Object中的clone()
识别出你要复制的是哪一个对象,然后为此对象分配空间,并进行对象的复制,将原始对象的内容一一复制到新对象的存储空间中。
②继承自java.lang.Object类的clone()方法是浅复制。以下代码可以证明之。
class Teacher{
String name;
int age;
Teacher(String name,int age){
this.name=name;
this.age=age;
}
}
class Student implements Cloneable{
String name;
int age;
Teacher t;//学生1和学生2的引用值都是一样的。
Student(String name,int age,Teacher t){
this.name=name;
this.age=age;
this.t=t;
}
public Object clone(){
Student stu=null;
try{
stu=(Student)super.clone();
}catch(CloneNotSupportedException e){
e.printStackTrace();
}
stu.t=(Teacher)t.clone();
return stu;
}
public static void main(String[] args){
Teacher t=new Teacher("tangliang",30);
Student s1=new Student("zhangsan",18,t);
Student s2=(Student)s1.clone();
s2.t.name="tony";
s2.t.age=40;
System.out.println("name="+s1.t.name+","+"age="+s1.t.age);
//学生1的老师成为tony,age为40。
}
}
那应该如何实现深层次的克隆,即修改s2的老师不会影响s1的老师?代码改进如下。
class Teacher implements Cloneable{
String name;
int age;
Teacher(String name,int age){
this.name=name;
this.age=age;
}
public Object clone(){
Object obj=null;
try{
obj=super.clone();
}catch(CloneNotSupportedException e){
e.printStackTrace();
}
return obj;
}
}
class Student implements Cloneable{
String name;
int age;
Teacher t;
Student(String name,int age,Teacher t){
this.name=name;
this.age=age;
this.t=t;
}
public Object clone(){
Student stu=null;
try{
stu=(Student)super.clone();
}catch(CloneNotSupportedException e){
e.printStackTrace();
}
stu.t=(Teacher)t.clone();
return stu;
}
}
public static void main(String[] args){
Teacher t=new Teacher("tangliang",30);
Student s1=new Student("zhangsan",18,t);
Student s2=(Student)s1.clone();
s2.t.name="tony";
s2.t.age=40;
System.out.println("name="+s1.t.name+","+"age="+s1.t.age);
//学生1的老师不改变。
}
3)利用串行化来做深复制
把对象写到流里的过程是串行化(Serilization)过程,Java程序员又非常形象地称为“冷冻”或者“腌咸菜(picking)”过程;而把对
象从流中读出来的并行化(Deserialization)过程则叫做“解冻”或者“回鲜(depicking)”过程。应当指出的是,写在流里的是对象
的一个拷贝,而原对象仍然存在于JVM里面,因此“腌成咸菜”的只是对象的一个拷贝,Java咸菜还可以回鲜。
在Java语言里深复制一个对象,常常可以先使对象实现Serializable接口,然后把对象(实际上只是对象的一个拷贝)写到一个流里(腌成咸菜),再从流里读出来(把咸菜回鲜),便可以重建对象。
如下为深复制源代码。
public Object deepClone(){
//将对象写到流里
ByteArrayOutoutStream bo=new ByteArrayOutputStream();
ObjectOutputStream oo=new ObjectOutputStream(bo);
oo.writeObject(this);
//从流里读出来
ByteArrayInputStream bi=new ByteArrayInputStream(bo.toByteArray());
ObjectInputStream oi=new ObjectInputStream(bi);
return(oi.readObject());
}
这样做的前提是对象以及对象内部所有引用到的对象都是可串行化的,否则,就需要仔细考察那些不可串行化的对象可否设成transient,从而将之排除在复制过程之外。上例代码改进如下。
class Teacher implements Serializable{
String name;
int age;
Teacher(String name,int age){
this.name=name;
this.age=age;
}
}
class Student implements Serializable
{
String name;//常量对象。
int age;
Teacher t;//学生1和学生2的引用值都是一样的。
Student(String name,int age,Teacher t){
this.name=name;
this.age=age;
this.p=p;
}
public Object deepClone() throws IOException,
OptionalDataException,ClassNotFoundException
{
//将对象写到流里
ByteArrayOutoutStream bo=new ByteArrayOutputStream();
ObjectOutputStream oo=new ObjectOutputStream(bo);
oo.writeObject(this);
//从流里读出来
ByteArrayInputStream bi=new ByteArrayInputStream(bo.toByteArray());
ObjectInputStream oi=new ObjectInputStream(bi);
return(oi.readObject());
}
}
public static void main(String[] args){
Teacher t=new Teacher("tangliang",30);
Student s1=new Student("zhangsan",18,t);
Student s2=(Student)s1.deepClone();
s2.t.name="tony";
s2.t.age=40;
System.out.println("name="+s1.t.name+","+"age="+s1.t.age);
//学生1的老师不改变。
}
5,String类和对象池 我们知道得到String对象有两种办法: String str1="hello"; String str2=new
String("hello");
这两种创建String对象的方法有什么差异吗?当然有差异,差异就在于第一种方法在对象池中拿对象,第二种方法直接生成新的对象。在JDK5.0里面,
Java虚拟机在启动的时候会实例化9个对象池,这9个对象池分别用来存储8种基本类型的包装类对象和String对象。当我们在程序中直接用双引号括起
来一个字符串时,JVM就到String的对象池里面去找看是否有一个值相同的对象,如果有,就拿现成的对象,如果没有就在对象池里面创建一个对象,并返
回。所以我们发现下面的代码输出true: String str1="hello"; String str2="hello";
System.out.println(str1==str2);
这说明str1和str2指向同一个对象,因为它们都是在对象池中拿到的,而下面的代码输出为false: String str3="hello"
String str4=new String("hello"); System.out.println(str3==str4);
因为在任何情况下,只要你去new一个String对象那都是创建了新的对象。
与此类似的,在JDK5.0里面8种基本类型的包装类也有这样的差异: Integer i1=5;//在对象池中拿 Integer i2
=5;//所以i1==i2 Integer i3=new Integer(5);//重新创建新对象,所以i2!=i3
对象池的存在是为了避免频繁的创建和销毁对象而影响系统性能,那我们自己写的类是否也可以使用对象池呢?当然可以,考察以下代码: class
Student{ private String name; private int age; private static HashSet pool=new HashSet();//对象池
public Student(String name,int age){
this.name=name;
this.age=age;
}
//使用对象池来得到对象的方法
public static Student newInstance(String name,int age){
//循环遍历对象池
for(Student stu:pool){
if(stu.name.equals(name) && stu.age==age){
return stu;
}
}
//如果找不到值相同的Student对象,则创建一个Student对象
//并把它加到对象池中然后返回该对象。
Student stu=new Student(name,age);
pool.add(stu);
return stu;
}
}
public class Test{
public static void main(String[] args){
Student stu1=Student.newInstance("tangliang",30);//对象池中拿
Student stu2=Student.newInstance("tangliang",30);//所以stu1==stu2
Student stu3=new Student("tangliang",30);//重新创建,所以stu1!=stu3
System.out.println(stu1==stu2);
System.out.println(stu1==stu3);
}
}
6,2.0-1.1==0.9吗? 考察下面的代码: double a=2.0,b=1.1,c=0.9; if(a-b==c){
System.out.println("YES!"); }else{ System.out.println("NO!"); }
以上代码输出的结果是多少呢?你认为是“YES!”吗?那么,很遗憾的告诉你,不对,Java语言再一次cheat了你,以上代码会输出“NO!”。为什
么会这样呢?其实这是由实型数据的存储方式决定的。我们知道实型数据在内存空间中是近似存储的,所以2.0-1.1的结果不是0.9,而是
0.88888888889。所以在做实型数据是否相等的判断时要非常的谨慎。一般来说,我们不建议在代码中直接判断两个实型数据是否相等,如果一定要比
较是否相等的话我们也采用以下方式来判断: if(Math.abs(a-b)<1e-5){ //相等 }else{ //不相等 }
上面的代码判断a与b之差的绝对值是否小于一个足够小的数字,如果是,则认为a与b相等,否则,不相等。
7,判断奇数 以下的方法判断某个整数是否是奇数,考察是否正确: public boolean isOdd(int n){ return
(n%2==1); }
很多人认为上面的代码没问题,但实际上这段代码隐藏着一个非常大的BUG,当n的值是正整数时,以上的代码能够得到正确结果,但当n的值是负整数时,以上
方法不能做出正确判断。例如,当n=-3时,以上方法返回false。因为根据Java语言规范的定义,Java语言里的求余运算符(%)得到的结果与运
算符左边的值符号相同,所以,-3%2的结果是-1,而不是1。那么上面的方法正确的写法应该是: public boolean isOdd(int
n){ return (n%2!=0); }
8,拓宽数值类型会造成精度丢失吗?
Java语言的8种基本数据类型中7种都可以看作是数值类型,我们知道对于数值类型的转换有一个规律:从窄范围转化成宽范围能够自动类型转换,反之则必须
强制转换。请看下图:
byte-->short-->int-->long-->float-->double
char-->int
我们把顺箭头方向的转化叫做拓宽类型,逆箭头方向的转化叫做窄化类型。一般我们认为因为顺箭头方向的转化不会有数据和精度的丢失,所以Java语言允许自
动转化,而逆箭头方向的转化可能会造成数据和精度的丢失,所以Java语言要求程序员在程序中明确这种转化,也就是强制转换。那么拓宽类型就一定不会造成
数据和精度丢失吗?请看下面代码:
int i=2000000000;
int num=0;
for(float f=i;f
9,i=i+1和i+=1完全等价吗?
可能有很多程序员认为i+=1只是i=i+1的简写方式,其实不然,它们一个使用简单赋值运算,一个使用复合赋值运算,而简单赋值运算和复合赋值运算的最
大差别就在于:复合赋值运算符会自动地将运算结果转型为其左操作数的类型。看看以下的两种写法,你就知道它们的差别在哪儿了:
(1) byte i=5;
i+=1;
(2) byte i=5;
i=i+1;
第一种写法编译没问题,而第二种写法却编译通不过。原因就在于,当使用复合赋值运算符进行操作时,即使右边算出的结果是int类型,系统也会将其值转化为
左边的byte类型,而使用简单赋值运算时没有这样的优待,系统会认为将i+1的值赋给i是将int类型赋给byte,所以要求强制转换。理解了这一点
后,我们再来看一个例子:
byte b=120;
b+=20;
System.out.println("b="+b);
说到这里你应该明白了,上例中输出b的值不是140,而是-116。因为120+20的值已经超出了一个byte表示的范围,而当我们使用复合赋值运
算时系统会自动作类型的转化,将140强转成byte,所以得到是-116。由此可见,在使用复合赋值运算符时还得小心,因为这种类型转换是在不知不觉中
进行的,所以得到的结果就有可能和你的预想不一样。
下面引用由zhangyue在 2007/09/01 09:07pm 发表的内容:
唐老师:
long类型为什么能自动转换成float类型啊!!
long是64bits;
float是32bits;
...
long
能自动转换为float,但这种转换会造成精度的丢失,float中只保留了原来long类型的低24位的数据。这是Java语言中三种基本类型的自动转
换会造成精度丢失的情况之一,另两种情况是int-->float 和long-->double,详情请参考:
8,拓宽数值类型会造成精度丢失吗?
下面引用由plastrio在 2007/09/01 09:08am 发表的内容:
请教个问题 您给我们0703讲线程时 有段课堂代码为什么 用synchronized(Object obj) 锁代码块而不是一般教程上讲的 synchronized(this)
当两个线程在运行时this不代表同一个对象时就不能用synchronized(this)来锁。必须定义一个唯一的公共对象来声明,如:synchronized(obj)
例如:
public class ThreadTest{
public static void main(String[] args){
Thread t1=new Thread(new ThreadA());
Thread t2=new Thread(new ThreadA());//两个线程对应两个不同的ThreadA对象。
t1.start();
t2.start();
}
}
class ThreadA implements Runnable{
static int i=0;
static Object obj=new Object();
public run(){
while(i<20){
synchronized(obj){//两个线程在执行时所引用的this不是同一个对象,所以写this就不能达到锁的目的。
System.out.println(i);
i++;
}
}
}
}
在java语言中,位移操作共分三种,左位移(<<),右位移(>>)和无符号右位移(>>>)。如果将位移
运算表示为公式的话,即n operator
s。其中,operator表示上述的三种位移操作之一;n和s表示操作数,必须是可以转化成int类型的,否则出现运行时错误。n是原始数值,s表示位
移距离。该公式的含义是n按照operator运算符含义位移s位。位移的距离使用掩码32(类似于子网掩码),即位移距离总是在0~31之间,超出这个
范围的位移距离(包括负数)会被转化在这个范围里。也就是说真正的位移距离是n%32,所以唐老师的位移距离33实际上是1。n<<s的结果
(无论是否溢出)总是等价于n与2的n%32次幂的乘积。在唐老师的例子里面,位移距离是33%32即1,2的1次幂是2,5与2的乘积是10.所以最终
结果是10。对于右位移操作n<<s的结果(无论是否溢出)总是等价于n与2的n%32次幂的商。(以上内容参考java规范15.9)
2009年6月15日
#
抽象类
抽象类与接口紧密相关。然接口又比抽象类更抽象,这主要体现在它们的差别上:1)类可以实现无限个接口,但仅能从一个抽象(或任何其他类型)类继承,从抽象类派生的类仍可实现接口,从而得出接口是用来解决多重继承问题的。2)抽象类当中可以存在非抽象的方法,可接口不能且它里面的方法只是一个声明必须用public来修饰没有具体实现的方法。3)抽象类中的成员变量可以被不同的修饰符来修饰,可接口中的成员变量默认的都是静态常量(static final)。4)这一点也是最重要的一点本质的一点"抽象类是对象的抽象,然接口是一种行为规范"。
以上是它们本身的异同,下面再来从实际应用讲讲它们的异同!
不同之处:
1、定义
抽象类表示该类中可能已经有一些方法的具体定义,但是接口就仅仅只能定义各个方法的界面(方法名,参数列表,返回类型),并不关心具体细节。
1、用法
1)在继承抽象类时,必须覆盖该类中的每一个抽象方法,而每个已实现的方法必须和抽象类中指定的方法一样,接收相同数目和类型的参数,具有同样的返回值,这一点与接口相同。
2)当父类已有实际功能的方法时,该方法在子类中可以不必实现,直接引用的方法,子类也可以重写该父类的方法(继承的概念)。
3)而实现 (implement)一个接口(interface)的时候,是一定要实现接口中所定义的所有方法,而不可遗漏任何一个。
4)另外,抽象类不能产生对象的,但可以由它的实现类来声明对象。
有鉴于此,在实现接口时,我们也常写一个抽象类,来实现接口中的某些子类所需的通用方法,接着在编写各个子类时,即可继承该抽象类来使用,省去在每个都要实现通用的方法的困扰。
多态(Polymorphism)按字面的意思就是“多种形状”。引用Charlie Calverts对多态的描述——多态性是允许你将父对象设置成为和一个或更多的他的子对象相等的技术,赋值之后,父对象就可以根据当前赋值给它的子对象的特性以不同的方式运作(摘自“Delphi4 编程技术内幕”)。简单的说,就是一句话:允许将子类类型的指针赋值给父类类型的指针。多态性在Object Pascal和C++中都是通过虚函数(Virtual Function) 实现的。
多态性是允许将父对象设置成为和一个或多个它的子对象相等的技术,比如Parent:=Child; 多态性使得能够利用同一类(基类)类型的指针来引用不同类的对象,以及根据所引用对象的不同,以不同的方式执行相同的操作.
多态的作用:把不同的子类对象都当作父类来看,可以屏蔽不同子类对象之间的差异,写出通用的代码,做出通用的编程,以适应需求的不断变化。
赋值之后,父对象就可以根据当前赋值给它的子对象的特性以不同的方式运作。也就是说,父亲的行为像儿子,而不是儿子的行为像父亲。
举个例子:从一个基类中派生,响应一个虚命令,产生不同的结果。
比如从某个基类继承出多个对象,其基类有一个虚方法Tdoit,然后其子类也有这个方法,但行为不同,然后这些子对象中的任何一个可以附给其基类的对象,这样其基类的对象就可以执行不同的操作了。实际上你是在通过其基类来访问其子对象的,你要做的就是一个赋值操作。
使用继承性的结果就是可以创建一个类的家族,在认识这个类的家族时,就是把导出类的对象 当作基类的的对象,这种认识又叫作upcasting。这样认识的重要性在于:我们可以只针对基类写出一段程序,但它可以适 应于这个类的家族,因为编译器会自动就找出合适的对象来执行操作。这种现象又称为多态性。而实现多态性的手段又叫称动态绑定(dynamic binding)。
简单的说,建立一个父类的变量,它的内容可以是这个父类的,也可以是它的子类的,当子类拥有和父类同样的函数,当使用这个变量调用这个函数的时候,定义这个变量的类,也就是父类,里的同名函数将被调用,当在父类里的这个函数前加virtual关键字,那么子类的同名函数将被调用
class A {
public:
A() {}
virtual void foo() {
cout << "This is A." << endl;
}
};
class B : public A {
public:
B() {}
void foo() {
cout << "This is B." << endl;
}
};
int main(int argc, char* argv[]) {
A *a = new B();
a->foo();
return 0;
}
这将显示:
This is B.
如果把virtual去掉,将显示:
This is A.
前面的多态实现使用抽象类,并定义了虚方法.
“继承”(Inheritance)是面向对象软件技术当中的一个概念,例如在java语言中,java语言中不支持多重继承,是通过接口实现多重继承的功能。如果一个类A继承自另一个类B,就把这个A称为"B的子类",而把B称为"A的父类"。继承可以使得子类具有父类的各种属性和方法,而不需要再次编写相同的代码。在令子类继承父类的同时,可以重新定义某些属性,并重写某些方法,即覆盖父类的原有属性和方法,使其获得与父类不同的功能。尽管子类包括父类的所有成员,它不能访问父类中被声明成private 的成员 ...
继承是指一个对象直接使用另一对象的属性和方法。事实上,我们遇到的很多实体都有继承的含义。例如,若把汽车看成一个实体,它可以分成多个子实体,如:卡车、公共汽车等。这些子实体都具有汽车的特性,因此,汽车是它们的"父亲",而这些子实体则是汽车的"孩子"。
继承的目的:实现代码重用
派生类声明:
class 派生类名:继承方式 基类名
{
新增成员声明;
};
三种继承方式
公有继承 public (原封不动)
保护继承 protected (折中)
私有继承 private (化公为私)
继承方式影响子类的访问权限:
派生类成员对基类成员的访问权限
通过派生类对象对基类成员的访问权限
同类事物具有共同性,在同类事物中,每个事物又具有其特殊性。运用抽象的原则舍弃对象的特殊性,抽取其共同性,则得到一个适应于一批对象的类,这便是基类(父类),而把具有特殊性的类称为派生类(子类),派生类的对象拥有其基类的全部或部分属性与方法,称作派生类对基类的继承。
1、我们先建立基类BaseClass.class,然后再从该类派生新类InherienceTest,展示从基类派生的方法(Methord)及基类构造函数的执行。
package InherienceTest.BaseClass;//package 后能被继承,不过不能执行
public class BaseClass
{
public BaseClass(){
System.out.println("I’m the Constructor Function in BaseClass!");
}
protected static void FuncTest(){
System.out.println("This is a Function Test in BaseClass!");//Static Methord
}
public static void main(String[] args){
FuncTest();
System.out.println("This is the BaseClass!");
System.out.println(new java.util.Date());
}
};
import InherienceTest.BaseClass.BaseClass;//相当于路径:path & InherienceTest\BaseClass\BaseClass.class
public class
InherienceTest extends BaseClass//注意:public主类名必须和文件名相同
{
//基类不能和派生类在同一目录下面。
public static void main(String[] args)
//main函数必须是pulic static
{
InherienceTest xx=new InherienceTest();//构造函数被执行
xx.FuncTest();
//调用继承的方法
System.out.println("Hello World!");
}
}
枚举的确是一个类,在JDK1.4及以前,没有enum这个用法,那时候都是使用类来建立的,在《Java编程思想》中介绍了一类写法(详见第三版的章节8.1.3群组常量);JDK5以后,enum被引入,本质上就是一个类,所以可以被继承,总体思路和第三版这个写法类似,只是换了个名字(《Java编程思想》第四版第19章专门讲这个)
Enum作为Sun全新引进的一个关键字,看起来很象是特殊的class, 它也可以有自己的变量,可以定义自己的方法,可以实现一个或者多个接口。 当我们在声明一个enum类型时,我们应该注意到enum类型有如下的一些特征。
枚举类型的本质:定义枚举类型就是定义一个类别,只不过很多细节由编译器帮您完成了,所以在某些程度上,enum关键字的作用就像是class或interface。
当您使用"enum"定义枚举类型时,实质上您定义出来的类型继承自java.lang.Enum类型,而每个枚举的成员其实就是您定义的枚举类型的一个个实例(instance),它们都是 public static final型的成员。不可更改它们,可直接使用。
1.它不能有public的构造函数,这样做可以保证客户代码没有办法新建一个enum的实例。
2.所有枚举值都是public , static , final的。注意这一点只是针对于枚举值,我们可以和在普通类里面定义 变量一样定义其它任何类型的非枚举变量,这些变量可以用任何你想用的修饰符。
3.Enum默认实现了java.lang.Comparable接口。
4.Enum覆载了了toString方法,因此我们如果调用Color.Blue.toString()默认返回字符串”Blue”.
5.Enum提供了一个valueOf方法,这个方法和toString方法是相对应的。调用valueOf(“Blue”)将返回Color.Blue.因此我们在自己重写toString方法的时候就要注意到这一点,一把来说应该相对应地重写valueOf方法。
6.Enum还提供了values方法,这个方法使你能够方便的遍历所有的枚举值。
7.Enum还有一个oridinal的方法,这个方法返回枚举值在枚举类种的顺序,这个顺序根据枚举值声明的顺序而定,这里Color.Red.ordinal()返回0。
了解了这些基本特性,我们来看看如何使用它们。
1.遍历所有有枚举值. 知道了有values方法,我们可以轻车熟路地用ForEach循环来遍历了枚举值了。
for (Color c: Color.values())
System.out.println(“find value:” + c);
2.在enum中定义方法和变量,比如我们可以为Color增加一个方法随机返回一个颜色。
public enum Color {
Red,
Green,
Blue;
/*
*定义一个变量表示枚举值的数目。
*(我有点奇怪为什么sun没有给enum直接提供一个size方法).
*/
private static int number = Color.values().length ;
/**
* 随机返回一个枚举值
@return a random enum value.
*/
public static Color getRandomColor(){
long random = System.currentTimeMillis() % number;
switch ((int) random){
case 0:
return Color.Red;
case 1:
return Color.Green;
case 2:
return Color.Blue;
default : return Color.Red;
}
}
}
可以看出这在枚举类型里定义变量和方法和在普通类里面定义方法和变量没有什么区别。唯一要注意的只是变量和方法定义必须放在所有枚举值定义的后面,否则编译器会给出一个错误。
3.覆载(Override)toString, valueOf方法
前面我们已经知道enum提供了toString,valueOf等方法,很多时候我们都需要覆载默认的toString方法,那么对于enum我们怎么做呢。其实这和覆载一个普通class的toString方法没有什么区别。
….
public String toString(){
switch (this){
case Red:
return "Color.Red";
case Green:
return "Color.Green";
case Blue:
return "Color.Blue";
default:
return "Unknow Color";
}
}
….
这时我们可以看到,此时再用前面的遍历代码打印出来的是
Color.Red
Color.Green
Color.Blue
而不是
Red
Green
Blue.
可以看到toString确实是被覆载了。一般来说在覆载toString的时候我们同时也应该覆载valueOf方法,以保持它们相互的一致性。
4.使用构造函数
虽然enum不可以有public的构造函数,但是我们还是可以定义private的构造函数,在enum内部使用。还是用Color这个例子。
public enum Color {
Red("This is Red"),
Green("This is Green"),
Blue("This is Blue");
private String desc;
Color(String desc){
this.desc = desc;
}
public String getDesc(){
return this.desc;
}
}
这里我们为每一个颜色提供了一个说明信息, 然后定义了一个构造函数接受这个说明信息。
要注意这里构造函数不能为public或者protected, 从而保证构造函数只能在内部使用,客户代码不能new一个枚举值的实例出来。这也是完全符合情理的,因为我们知道枚举值是public static final的常量而已。
5.实现特定的接口
我们已经知道enum可以定义变量和方法,它要实现一个接口也和普通class实现一个接口一样,这里就不作示例了。
6.定义枚举值自己的方法。
前面我们看到可以为enum定义一些方法,其实我们甚至可以为每一个枚举值定义方法。这样,我们前面覆载 toString的例子可以被改写成这样。
public enum Color {
Red {
public String toString(){
return "Color.Red";
}
},
Green {
public String toString(){
return "Color.Green";
}
},
Blue{
public String toString(){
return "Color.Blue";
}
};
}
从逻辑上来说这样比原先提供一个“全局“的toString方法要清晰一些。
总的来说,enum作为一个全新定义的类型,是希望能够帮助程序员写出的代码更加简单易懂,个
人觉得一般也不需要过多的使用enum的一些高级特性,否则就和简单易懂的初衷想违背了。
【转载】
一、理解多线程 多线程是这样一种机制,它允许在程序中并发执行多个指令流,每个指令流都称为一个线程,彼此间互相独立。
线程又称为轻量级进程,它和进程一样拥有独立的执行控制,由
操作系统负责调度,区别在于线程没有独立的存储空间,而是和所属进程中的其它线程共享一个存储空间,这使得线程间的通信远较进程简单。
多个线程的执行是并发的,也就是在逻辑上“同时”,而不管是否是物理上的“同时”。如果系统只有一个CPU,那么真正的“同时”是不可能的,但是由于CPU的速度非常快,用户感觉不到其中的区别,因此我们也不用关心它,只需要设想各个线程是同时执行即可。
多线程和传统的单线程在程序设计上最大的区别在于,由于各个线程的控制流彼此独立,使得各个线程之间的代码是乱序执行的,由此带来的线程调度,同步等问题,将在以后探讨。
二、在Java中实现多线程
我们不妨设想,为了创建一个新的线程,我们需要做些什么?很显然,我们必须指明这个线程所要执行的代码,而这就是在Java中实现多线程我们所需要做的一切!
真是神奇!Java是如何做到这一点的?通过类!作为一个完全面向对象的语言,Java提供了类java.lang.Thread来方便多线程编程,这个类提供了大量的方法来方便我们控制自己的各个线程,我们以后的讨论都将围绕这个类进行。
那么如何提供给 Java 我们要线程执行的代码呢?让我们来看一看 Thread 类。Thread 类最重要的方法是run(),它为Thread类的方法start()所调用,提供我们的线程所要执行的代码。为了指定我们自己的代码,只需要覆盖它!
方法一:继承 Thread 类,覆盖方法 run(),我们在创建的 Thread 类的子类中重写 run() ,加入线程所要执行的代码即可。下面是一个例子:
public class MyThread extends Thread
{
int count= 1, number;
public MyThread(int num)
{
number = num;
System.out.println
("创建线程 " + number);
}
public void run() {
while(true) {
System.out.println
("线程 " + number + ":计数 " + count);
if(++count== 6) return;
}
}
public static void main(String args[])
{
for(int i = 0;
i 〈 5; i++) new MyThread(i+1).start();
}
}
这种方法简单明了,符合大家的习惯,但是,它也有一个很大的缺点,那就是如果我们的类已经从一个类继承(如小程序必须继承自 Applet 类),则无法再继承 Thread 类,这时如果我们又不想建立一个新的类,应该怎么办呢?
我们不妨来探索一种新的方法:我们不创建Thread类的子类,而是直接使用它,那么我们只能将我们的方法作为参数传递给 Thread 类的实例,有点类似回调函数。但是 Java 没有指针,我们只能传递一个包含这个方法的类的实例。
那么如何限制这个类必须包含这一方法呢?当然是使用接口!(虽然抽象类也可满足,但是需要继承,而我们之所以要采用这种新方法,不就是为了避免继承带来的限制吗?)
Java 提供了接口 java.lang.Runnable 来支持这种方法。
方法二:实现 Runnable 接口
Runnable接口只有一个方法run(),我们声明自己的类实现Runnable接口并提供这一方法,将我们的线程代码写入其中,就完成了这一部分的任务。但是Runnable接口并没有任何对线程的支持,我们还必须创建Thread类的实例,这一点通过Thread类的构造函数public Thread(Runnable target);来实现。下面是一个例子:
public class MyThread implements Runnable
{
int count= 1, number;
public MyThread(int num)
{
number = num;
System.out.println("创建线程 " + number);
}
public void run()
{
while(true)
{
System.out.println
("线程 " + number + ":计数 " + count);
if(++count== 6) return;
}
}
public static void main(String args[])
{
for(int i = 0; i 〈 5;
i++) new Thread(new MyThread(i+1)).start();
}
}
严格地说,创建Thread子类的实例也是可行的,但是必须注意的是,该子类必须没有覆盖 Thread 类的 run 方法,否则该线程执行的将是子类的 run 方法,而不是我们用以实现Runnable 接口的类的 run 方法,对此大家不妨试验一下。
使用 Runnable 接口来实现多线程使得我们能够在一个类中包容所有的代码,有利于封装,它的缺点在于,我们只能使用一套代码,若想创建多个线程并使各个线程执行不同的代码,则仍必须额外创建类,如果这样的话,在大多数情况下也许还不如直接用多个类分别继承 Thread 来得紧凑。
综上所述,两种方法各有千秋,大家可以灵活运用。
下面让我们一起来研究一下多线程使用中的一些问题。
三、线程的四种状态
1. 新状态:线程已被创建但尚未执行(start() 尚未被调用)。
2. 可执行状态:线程可以执行,虽然不一定正在执行。CPU 时间随时可能被分配给该线程,从而使得它执行。
3. 死亡状态:正常情况下 run() 返回使得线程死亡。调用 stop()或 destroy() 亦有同样效果,但是不被推荐,前者会产生异常,后者是强制终止,不会释放锁。
4. 阻塞状态:线程不会被分配 CPU 时间,无法执行。
四、线程的优先级
线程的优先级代表该线程的重要程度,当有多个线程同时处于可执行状态并等待获得 CPU 时间时,线程调度系统根据各个线程的优先级来决定给谁分配 CPU 时间,优先级高的线程有更大的机会获得 CPU 时间,优先级低的线程也不是没有机会,只是机会要小一些罢了。
你可以调用 Thread 类的方法 getPriority() 和 setPriority()来存取线程的优先级,线程的优先级界于1(MIN_PRIORITY)和10(MAX_PRIORITY)之间,缺省是5(NORM_PRIORITY)。
五、线程的同步
由于同一进程的多个线程共享同一片存储空间,在带来方便的同时,也带来了访问冲突这个严重的问题。Java语言提供了专门机制以解决这种冲突,有效避免了同一个数据对象被多个线程同时访问。
由于我们可以通过 private 关键字来保证数据对象只能被方法访问,所以我们只需针对方法提出一套机制,这套机制就是 synchronized 关键字,它包括两种用法:synchronized 方法和 synchronized 块。
1. synchronized 方法:通过在方法声明中加入 synchronized关键字来声明 synchronized 方法。如:
public synchronized void accessVal(int newVal);
synchronized 方法控制对类成员变量的访问:每个类实例对应一把锁,每个 synchronized 方法都必须获得调用该方法的类实例的锁方能执行,否则所属线程阻塞,方法一旦执行,就独占该锁,直到从该方法返回时才将锁释放,此后被阻塞的线程方能获得该锁,重新进入可执行状态。
这种机制确保了同一时刻对于每一个类实例,其所有声明为 synchronized 的成员函数中至多只有一个处于可执行状态(因为至多只有一个能够获得该类实例对应的锁),从而有效避免了类成员变量的访问冲突(只要所有可能访问类成员变量的方法均被声明为 synchronized)。
在 Java 中,不光是类实例,每一个类也对应一把锁,这样我们也可将类的静态成员函数声明为 synchronized ,以控制其对类的静态成员变量的访问。
synchronized 方法的缺陷:若将一个大的方法声明为synchronized 将会大大影响效率,典型地,若将线程类的方法 run() 声明为 synchronized ,由于在线程的整个生命期内它一直在运行,因此将导致它对本类任何 synchronized 方法的调用都永远不会成功。当然我们可以通过将访问类成员变量的代码放到专门的方法中,将其声明为 synchronized ,并在主方法中调用来解决这一问题,但是 Java 为我们提供了更好的解决办法,那就是 synchronized 块。
2. synchronized 块:通过 synchronized关键字来声明synchronized 块。语法如下:
synchronized(syncObject)
{
//允许访问控制的代码
}
synchronized 块是这样一个代码块,其中的代码必须获得对象 syncObject (如前所述,可以是类实例或类)的锁方能执行,具体机制同前所述。由于可以针对任意代码块,且可任意指定上锁的对象,故灵活性较高。
六、线程的阻塞
为了解决对共享存储区的访问冲突,Java 引入了同步机制,现在让我们来考察多个线程对共享资源的访问,显然同步机制已经不够了,因为在任意时刻所要求的资源不一定已经准备好了被访问,反过来,同一时刻准备好了的资源也可能不止一个。为了解决这种情况下的访问控制问题,Java 引入了对阻塞机制的支持。
阻塞指的是暂停一个线程的执行以等待某个条件发生(如某资源就绪),学过操作系统的同学对它一定已经很熟悉了。Java 提供了大量方法来支持阻塞,下面让我们逐一分析。
1. sleep() 方法:sleep() 允许 指定以毫秒为单位的一段时间作为参数,它使得线程在指定的时间内进入阻塞状态,不能得到CPU 时间,指定的时间一过,线程重新进入可执行状态。典型地,sleep() 被用在等待某个资源就绪的情形:测试发现条件不满足后,让线程阻塞一段时间后重新测试,直到条件满足为止。
2. suspend() 和 resume() 方法:两个方法配套使用,suspend()使得线程进入阻塞状态,并且不会自动恢复,必须其对应的resume() 被调用,才能使得线程重新进入可执行状态。典型地,suspend() 和 resume() 被用在等待另一个线程产生的结果的情形:测试发现结果还没有产生后,让线程阻塞,另一个线程产生了结果后,调用 resume() 使其恢复。
3. yield() 方法:yield() 使得线程放弃当前分得的 CPU 时间,但是不使线程阻塞,即线程仍处于可执行状态,随时可能再次分得 CPU 时间。调用 yield() 的效果等价于调度程序认为该线程已执行了足够的时间从而转到另一个线程。
4. wait() 和 notify() 方法:两个方法配套使用,wait() 使得线程进入阻塞状态,它有两种形式,一种允许 指定以毫秒为单位的一段时间作为参数,另一种没有参数,前者当对应的 notify() 被调用或者超出指定时间时线程重新进入可执行状态,后者则必须对应的 notify() 被调用。
初看起来它们与 suspend() 和 resume() 方法对没有什么分别,但是事实上它们是截然不同的。区别的核心在于,前面叙述的所有方法,阻塞时都不会释放占用的锁(如果占用了的话),而这一对方法则相反。
上述的核心区别导致了一系列的细节上的区别。
首先,前面叙述的所有方法都隶属于 Thread 类,但是这一对却直接隶属于 Object 类,也就是说,所有对象都拥有这一对方法。初看起来这十分不可思议,但是实际上却是很自然的,因为这一对方法阻塞时要释放占用的锁,而锁是任何对象都具有的,调用任意对象的 wait() 方法导致线程阻塞,并且该对象上的锁被释放。
而调用 任意对象的notify()方法则导致因调用该对象的 wait() 方法而阻塞的线程中随机选择的一个解除阻塞(但要等到获得锁后才真正可执行)。
其次,前面叙述的所有方法都可在任何位置调用,但是这一对方法却必须在 synchronized 方法或块中调用,理由也很简单,只有在synchronized 方法或块中当前线程才占有锁,才有锁可以释放。
同样的道理,调用这一对方法的对象上的锁必须为当前线程所拥有,这样才有锁可以释放。因此,这一对方法调用必须放置在这样的 synchronized 方法或块中,该方法或块的上锁对象就是调用这一对方法的对象。若不满足这一条件,则程序虽然仍能编译,但在运行时会出现IllegalMonitorStateException 异常。
wait() 和 notify() 方法的上述特性决定了它们经常和synchronized 方法或块一起使用,将它们和操作系统的进程间通信机制作一个比较就会发现它们的相似性:synchronized方法或块提供了类似于操作系统原语的功能,它们的执行不会受到多线程机制的干扰,而这一对方法则相当于 block 和wakeup 原语(这一对方法均声明为 synchronized)。
它们的结合使得我们可以实现操作系统上一系列精妙的进程间通信的算法(如信号量算法),并用于解决各种复杂的线程间通信问题。关于 wait() 和 notify() 方法最后再说明两点:
第一:调用 notify() 方法导致解除阻塞的线程是从因调用该对象的 wait() 方法而阻塞的线程中随机选取的,我们无法预料哪一个线程将会被选择,所以编程时要特别小心,避免因这种不确定性而产生问题。
第二:除了 notify(),还有一个方法 notifyAll() 也可起到类似作用,唯一的区别在于,调用 notifyAll() 方法将把因调用该对象的 wait() 方法而阻塞的所有线程一次性全部解除阻塞。当然,只有获得锁的那一个线程才能进入可执行状态。
谈到阻塞,就不能不谈一谈死锁,略一分析就能发现,suspend() 方法和不指定超时期限的 wait() 方法的调用都可能产生死锁。遗憾的是,Java 并不在语言级别上支持死锁的避免,我们在编程中必须小心地避免死锁。
以上我们对 Java 中实现线程阻塞的各种方法作了一番分析,我们重点分析了 wait() 和 notify()方法,因为它们的功能最强大,使用也最灵活,但是这也导致了它们的效率较低,较容易出错。实际使用中我们应该灵活使用各种方法,以便更好地达到我们的目的。
七、守护线程
守护线程是一类特殊的线程,它和普通线程的区别在于它并不是应用程序的核心部分,当一个应用程序的所有非守护线程终止运行时,即使仍然有守护线程在运行,应用程序也将终止,反之,只要有一个非守护线程在运行,应用程序就不会终止。守护线程一般被用于在后台为其它线程提供服务。
可以通过调用方法 isDaemon() 来判断一个线程是否是守护线程,也可以调用方法 setDaemon() 来将一个线程设为守护线程。
八、线程组
线程组是一个 Java 特有的概念,在 Java 中,线程组是类ThreadGroup 的对象,每个线程都隶属于唯一一个线程组,这个线程组在线程创建时指定并在线程的整个生命期内都不能更改。
你可以通过调用包含 ThreadGroup 类型参数的 Thread 类构造函数来指定线程属的线程组,若没有指定,则线程缺省地隶属于名为 system 的系统线程组。
在 Java 中,除了预建的系统线程组外,所有线程组都必须显式创建。在 Java 中,除系统线程组外的每个线程组又隶属于另一个线程组,你可以在创建线程组时指定其所隶属的线程组,若没有指定,则缺省地隶属于系统线程组。这样,所有线程组组成了一棵以系统线程组为根的树。
Java 允许我们对一个线程组中的所有线程同时进行操作,比如我们可以通过调用线程组的相应方法来设置其中所有线程的优先级,也可以启动或阻塞其中的所有线程。
Java 的线程组机制的另一个重要作用是线程安全。线程组机制允许我们通过分组来区分有不同安全特性的线程,对不同组的线程进行不同的处理,还可以通过线程组的分层结构来支持不对等安全措施的采用。
Java 的 ThreadGroup 类提供了大量的方法来方便我们对线程组树中的每一个线程组以及线程组中的每一个线程进行操作。
九、总结
在本文中,我们讲述了 Java 多线程编程的方方面面,包括创建线程,以及对多个线程进行调度、管理。我们深刻认识到了多线程编程的复杂性,以及线程切换开销带来的多线程程序的低效性,这也促使我们认真地思考一个问题:我们是否需要多线程?何时需要多线程?
多线程的核心在于多个代码块并发执行,本质特点在于各代码块之间的代码是乱序执行的。我们的程序是否需要多线程,就是要看这是否也是它的内在特点。
假如我们的程序根本不要求多个代码块并发执行,那自然不需要使用多线程;假如我们的程序虽然要求多个代码块并发执行,但是却不要求乱序,则我们完全可以用一个循环来简单高效地实现,也不需要使用多线程;只有当它完全符合多线程的特点时,多线程机制对线程间通信和线程管理的强大支持才能有用武之地,这时使用多线程才是值得的。
一、继承可以打破父类原有的封装
class Body
{ String name;
public Body(String name)
{this.name=name;}
}
class ChildBody extends Body
{
private int age;
}
public class Test
{ public static void main(String[] args)
{
Body Tom=new ChildBody();
}
}
看看这段代码,有没有问题呢?能不能通过编译呢?
父类,没有错误。子类继承了父类,并添加了私有成员变量age
看似没有错误。
编译错误,没有找到0参数的构造函数Body()
这是为什么呢? 咱们没有调用Body()呀
只是直接调用的ChildBody()构造函数,而这个应该是由编译器提供的呀?
为什么这次它没有提供呢?傻了吗?
可是
究竟为什么呢?困惑中
其实 ,事实不像看到的那样
1 类如果没构造方法,编译器会尝试给创建一个默认的
2 但是子类构造方法要用父类的构造方法来初始化其父类的东西
3 这时候,编译器就疑惑了,不能帮你合成了
需要你显示的来写构造方法
所以看出一个问题:
继承虽然提高代码复用,但是子类的编写者需要了解父类的设计细节,因此,继承某种程度上
打破了封装
我们对子类做一下修改,
class ChildBody extends Body
{
private int age;
public ChildBody(String name){
super(name);
}
}
而现在就应该可以通过编译了
我的分析是
我们用了super()句子,就是调用了父类的构造方法
而父类的此构造方法,则要调用它自己的父类无参构造函数
大家知道类Body 隐式的继承于Object
也就是说,调用了Object的无参构造函数
自然是可以成功编译了
2009年6月7日
#
摘要: 美国信息交换标准代码
American Standard Code for Information Interchange, ASCII )
在计算机中,所有的数据在存储和运算时都要使用二进制数表示(因为计算机用高电平和低电平分别表示1和0),例如,象a、b、c、d这样的52个字母(...
阅读全文
最近开始学习java语言,大家推荐初学者最好不要用eclipse,因为eclipse太过于集成会,很多代码能过自动生成,对初学者来说就不太适合,那么给大家推荐一下EditPlus这个文本编辑器,刚开始安装好后,对于EditPlsu的java配置里面的参数设置看似简单,但是又是有容易忘记,我就犯过类似的错误,所以整理了一下java的配置,希望大家参考。
准备工作:1:安装jdk,我的是jdk6.0的,我直接装在的了C盘根目录。2:设置系统变量,我的电脑>属性>高级>环境变量>系统变量>path值在最后添加
;C:\jdk6.0\bin(注意要有c前面的分号)。
Editplus的java环境的所有配置见图:
首先打开EditPlus,依次点击“工具(Tools)”; “配置用户工具...”进入用户工具设置,选择“组和工具条目”中的“Group 1”,点击面板右边的“组名称...”按钮,将文本Group1”修改成“Java工具”,点击“添加工具”按钮,选择应用程序,
然后就是修改属性:
配置编辑环境:

配置运行环境:

配置.jar文件运行环境(可以不用配置):

完毕!
JAVA环境配置大全
我刚学习java的时候也被各种环境配置搞得头晕脑胀,现在把自己平时用到的整理一下,希望给大家一些帮助。比较简单,希望大家能看懂。(最好按照我的顺序装,如果大家觉得网上看费事,我把文档传到网上供大家下载^_^)
安装JDK
从java.sun.com/">;http://java.sun.com/下载jdk-1_5_0_04-windows-i586-p.exe
安装到指定路径,我选择D:jdk1.5.0
配置环境变量:
JAVA_HOME: D:jdk1.5.0
PATH: D:jdk1.5.0\bin;
CLASSPATH: .;D:jdk1.5.0lib ools.jar;D:jdk1.5.0jrelib t.jar;
安装WTK
从java.sun.com/">;http://java.sun.com/下载j2me_wireless_toolkit-2_2-windows.exe
安装到指定路径,我选择D:WTK22
安装Eclipse
从http://www.eclipse.org/下载eclipse-SDK-3.0.1-win32.zip和
NLpack-eclipse-SDK-3.0.x-win32.zip(语言包)
解压缩eclipse-SDK-3.0.1-win32.zip即可,我的路径:D:MyDevelopToolseclipse
解压缩NLpack-eclipse-SDK-3.0.x-win32.zip,得到features和plugins两个文件夹,把里面的文件分别拷入eclipse中相应的目录下即可
安装Tomcat
从http://jakarta.apache.org/下载jakarta-tomcat-5.5.9.zip
解压缩jakarta-tomcat-5.5.9.zip即可
配置环境变量:
Tomcat_Home: D:MyDevelopTools omcat-5.5.9
PATH: D:MyDevelopTools omcat-5.5.9;
在eclipse中配置J2ME开发环境:
安装eclipseme:
从http://www.eclipseme.org/下载eclipseme.feature_0.9.4_site.zip
在eclipse中选择帮助-〉软件更新-〉查找并安装-〉搜索要安装的新功能部件-〉新建已归档的站点
选择eclipseme.feature_0.9.4_site.zip,打开-〉选择eclipseme.feature_0.9.4_site.zip,剩下的一直下一步就可以了。安装完成会在窗口-〉首选项中出现J2ME
修改JAVA-〉调试:
选中JAVA-〉调试,把暂挂执行的前两项点去,通信中的调试器超时改为15000
配置WTK
窗口-〉首选项-〉J2ME-〉Platform Components
右键单击对话框右侧的Wireless Toolkit,选择Add Wireless Toolkit,
选择WTK安装目录,eclipse会自动匹配。
在eclipse中配置J2EE开发环境(Tomcat5.5.9):
安装EMF-RunTime:
从http://www.eclipseme.org/下载emf-sdo-runtime-2.0.1.zip
解压缩emf-sdo-runtime-2.0.1.zip,得到features和plugins两个文件夹,把里面的文件分别拷入eclipse中相应的目录下即可。
安装Lomboz:
从http://forge.objectweb.org下载org.objectweb.lomboz_3.0.1.N20050106.zip解压缩org.objectweb.lomboz_3.0.1.N20050106.zip,得到features和plugins两个文件夹,把里面的文件分别拷入eclipse中相应的目录下。如果在窗口-〉首选项中有Lomboz选项就安装正确,如果没有,在D:eclipseconfiguration下删除org.eclipse.update这个文件夹,再重起eclipse就可以了。
配置Lomboz:
在D:eclipsepluginscom.objectlearn.jdt.j2ee_3.0.1servers下新建一个文件tomcat559.server,里面的内容从tomcat50x.server全部复制过来,把name="Apache Tomcat v5.0.x"替换成name="Apache Tomcat v5.5.9",然后把所有的
“${serverRootDirectory}/bin;${serverRootDirectory}/common/endorsed”替换成
“${serverRootDirectory}/common/endorsed”就可以了。然后进入eclipse,窗口-〉首选项-〉Lomboz,把JDK Tools.jar改为:D:jdk1.5.0lib ools.jar,窗口-〉首选项-〉Lomboz-〉Server Definitions,在Server types中选择Tomcat5.5.9在Application Server Directory和Classpath Variable的路径改为D:/MyDevelopTools/tomcat-5.5.9先应用,再确定就可以了。
2009年5月3日
#
JAVA中静态数组与动态数组
前面我们学习的数组都是静态数组,其实在很多的时候,静态数组根本不能满足我们编程的实际需要,比方说我需要在程序运行过程中动态的向数组中添加数据,这时我们的静态数组大小是固定的,显然就不能添加数据,要动态添加数据必须要用到动态数组,动态数组中的各个元素类型也是一致的,不过这种类型已经是用一个非常大的类型来揽括—Object类型。
Object类是JAVA.LANG包中的顶层超类。所有的类型都可以与Object类型兼容,所以我们可以将任何Object类型添加至属于Object类型的数组中,能添加Object类型的的集合有ArrayList、Vector及LinkedList,它们对数据的存放形式仿造于数组,属于集合类,下面是他们的特点:
特点一、容量扩充性
从内部实现机制来讲ArrayList和Vector都是使用Objec的数组形式来存储的。当你向这两种类型中增加元素的时候,如果元素的数目超出了内部数组目前的长度它们都需要扩展内部数组的长度,Vector缺省情况下自动增长原来一倍的数组长度,ArrayList是原来的50%,所以最后你获得的这个集合所占的空间总是比你实际需要的要大。所以如果你要在集合中保存大量的数据那么使用Vector有一些优势,因为你可以通过设置集合的初始化大小来避免不必要的资源开销。
特点二、同步性
ArrayList,LinkedList是不同步的,而Vestor是的。所以如果要求线程安全的话,可以使用ArrayList或LinkedList,可以节省为同步而耗费开销。但在多线程的情况下,有时候就不得不使用Vector了。当然,也可以通过一些办法包装ArrayList,LinkedList,使他们也达到同步,但效率可能会有所降低。
特点三、数据操作效率
ArrayList和Vector中,从指定的位置(用index)检索一个对象,或在集合的末尾插入、删除一个对象的时间是一样的,可表示为O(1)。但是,如果在集合的其他位置增加或移除元素那么花费的时间会呈线形增长:O(n-i),其中n代表集合中元素的个数,i代表元素增加或移除元素的索引位置。为什么会这样呢?以为在进行上述操作的时候集合中第i和第i个元素之后的所有元素都要执行(n-i)个对象的位移操作。
LinkedList中,在插入、删除集合中任何位置的元素所花费的时间都是一样的—O(1),但它在索引一个元素的时候比较慢,为O(i),其中i是索引的位置。
所以,如果只是查找特定位置的元素或只在集合的末端增加、移除元素,那么使用Vector或ArrayList都可以。如果是对其它指定位置的插入、删除操作,最好选择LinkedList
ArrayList 和Vector是采用数组方式存储数据,此数组元素数大于实际存储的数据以便增加和插入元素,都允许直接序号索引元素,但是插入数据要设计到数组元素移动等内存操作,所以索引数据快插入数据慢,Vector由于使用了synchronized方法(线程安全)所以性能上比ArrayList要差,LinkedList使用双向链表实现存储,按序号索引数据需要进行向前或向后遍历,但是插入数据时只需要记录本项的前后项即可,所以插入数度较快。