背景:
某电信项目中采用HBase来存储用户终端明细数据,供前台页面即时查询。HBase无可置疑拥有其优势,但其本身只对rowkey支持毫秒级的快速检索,对于多字段的组合查询却无能为力。针对HBase的多条件查询也有多种方案,但是这些方案要么太复杂,要么效率太低,本文只对基于Solr的HBase多条件查询方案进行测试和验证。
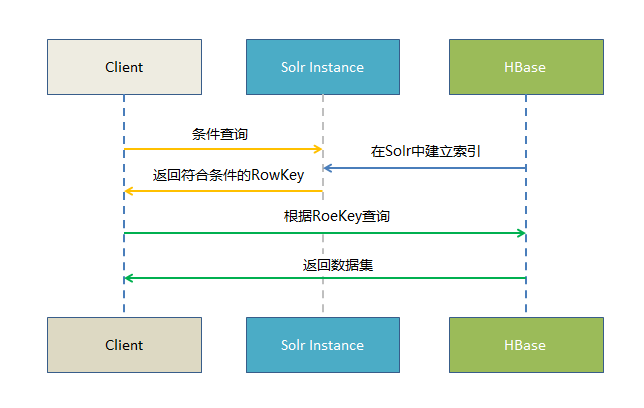
原理:
基于Solr的HBase多条件查询原理很简单,将HBase表中涉及条件过滤的字段和rowkey在Solr中建立索引,通过Solr的多条件查询快速获得符合过滤条件的rowkey值,拿到这些rowkey之后在HBASE中通过指定rowkey进行查询。
测试环境:
solr 4.0.0版本,使用其自带的jetty服务端容器,单节点;
hbase-0.94.2-cdh4.2.1,10台Lunux服务器组成的HBase集群。
HBase中2512万条数据172个字段;
Solr索引HBase中的100万条数据;
测试结果:
1、100万条数据在Solr中对8个字段建立索引。在Solr中最多8个过滤条件获取51316条数据的rowkey值,基本在57-80毫秒。根据Solr返回的rowkey值在HBase表中获取所有51316条数据12个字段值,耗时基本在15秒;
2、数据量同上,过滤条件同上,采用Solr分页查询,每次获取20条数据,Solr获得20个rowkey值耗时4-10毫秒,拿到Solr传入的rowkey值在HBase中获取对应20条12个字段的数据,耗时6毫秒。
以下列出测试环境的搭建、以及相关代码实现过程。
一、Solr环境的搭建
因为初衷只是测试Solr的使用,Solr的运行环境也只是用了其自带的jetty,而非大多人用的Tomcat;没有搭建Solr集群,只是一个单一的Solr服务端,也没有任何参数调优。
1)在Apache网站上下载Solr 4:http://lucene.apache.org/solr/downloads.html,我们这里下载的是“apache-solr-4.0.0.tgz”;
2)在当前目录解压Solr压缩包:
-xvzf apache-solr-..tgz
3)修改Solr的配置文件schema.xml,添加我们需要索引的多个字段(配置文件位于“/opt/apache-solr-4.0.0/example/solr/collection1/conf/”)
<field name="rowkey" type="string" indexed="true" stored="true" required="true" multiValued="false" /> <field name="time" type="string" indexed="true" stored="true" required="false" multiValued="false" /> <field name="tebid" type="string" indexed="true" stored="true" required="false" multiValued="false" /> <field name="tetid" type="string" indexed="true" stored="true" required="false" multiValued="false" /> <field name="puid" type="string" indexed="true" stored="true" required="false" multiValued="false" /> <field name="mgcvid" type="string" indexed="true" stored="true" required="false" multiValued="false" /> <field name="mtcvid" type="string" indexed="true" stored="true" required="false" multiValued="false" /> <field name="smaid" type="string" indexed="true" stored="true" required="false" multiValued="false" /> <field name="mtlkid" type="string" indexed="true" stored="true" required="false" multiValued="false" />
另外关键的一点是修改原有的uniqueKey,本文设置HBase表的rowkey字段为Solr索引的uniqueKey:
<uniqueKey>rowkey</uniqueKey>
type 参数代表索引数据类型,我这里将type全部设置为string是为了避免异常类型的数据导致索引建立失败,正常情况下应该根据实际字段类型设置,比如整型字段设置为int,更加有利于索引的建立和检索;
indexed 参数代表此字段是否建立索引,根据实际情况设置,建议不参与条件过滤的字段一律设置为false;
stored 参数代表是否存储此字段的值,建议根据实际需求只将需要获取值的字段设置为true,以免浪费存储,比如我们的场景只需要获取rowkey,那么只需把rowkey字段设置为true即可,其他字段全部设置flase;
required 参数代表此字段是否必需,如果数据源某个字段可能存在空值,那么此属性必需设置为false,不然Solr会抛出异常;
multiValued 参数代表此字段是否允许有多个值,通常都设置为false,根据实际需求可设置为true。
4)我们使用Solr自带的example来作为运行环境,定位到example目录,启动服务监听:
cd /opt/apache-solr-4.0.0/example java -jar ./start.jar
如果启动成功,可以通过浏览器打开此页面:http://192.168.1.10:8983/solr/
二、读取HBase源表的数据,在Solr中建立索引
一种方案是通过HBase的普通API获取数据建立索引,此方案的缺点是效率较低每秒只能处理100多条数据(或许可以通过多线程提高效率):
package com.ultrapower.hbase.solrhbase;import java.io.IOException;import org.apache.hadoop.conf.Configuration;import org.apache.hadoop.hbase.HBaseConfiguration;import org.apache.hadoop.hbase.KeyValue;import org.apache.hadoop.hbase.client.HTable;import org.apache.hadoop.hbase.client.Result;import org.apache.hadoop.hbase.client.ResultScanner;import org.apache.hadoop.hbase.client.Scan;import org.apache.hadoop.hbase.util.Bytes;import org.apache.solr.client.solrj.SolrServerException;import org.apache.solr.client.solrj.impl.HttpSolrServer;import org.apache.solr.common.SolrInputDocument;public class SolrIndexer { /** * @param args * @throws IOException * @throws SolrServerException */ public static void main(String[] args) throws IOException, SolrServerException { final Configuration conf; HttpSolrServer solrServer = new HttpSolrServer( "http://192.168.1.10:8983/solr"); // 因为服务端是用的Solr自带的jetty容器,默认端口号是8983 conf = HBaseConfiguration.create(); HTable table = new HTable(conf, "hb_app_xxxxxx"); // 这里指定HBase表名称 Scan scan = new Scan(); scan.addFamily(Bytes.toBytes("d")); // 这里指定HBase表的列族 scan.setCaching(500); scan.setCacheBlocks(false); ResultScanner ss = table.getScanner(scan); System.out.println("start ..."); int i = 0; try { for (Result r : ss) { SolrInputDocument solrDoc = new SolrInputDocument(); solrDoc.addField("rowkey", new String(r.getRow())); for (KeyValue kv : r.raw()) { String fieldName = new String(kv.getQualifier()); String fieldValue = new String(kv.getValue()); if (fieldName.equalsIgnoreCase("time") || fieldName.equalsIgnoreCase("tebid") || fieldName.equalsIgnoreCase("tetid") || fieldName.equalsIgnoreCase("puid") || fieldName.equalsIgnoreCase("mgcvid") || fieldName.equalsIgnoreCase("mtcvid") || fieldName.equalsIgnoreCase("smaid") || fieldName.equalsIgnoreCase("mtlkid")) { solrDoc.addField(fieldName, fieldValue); } } solrServer.add(solrDoc); solrServer.commit(true, true, true); i = i + 1; System.out.println("已经成功处理 " + i + " 条数据"); } ss.close(); table.close(); System.out.println("done !"); } catch (IOException e) { } finally { ss.close(); table.close(); System.out.println("erro !"); } } }另外一种方案是用到HBase的Mapreduce框架,分布式并行执行效率特别高,处理1000万条数据仅需5分钟,但是这种高并发需要对Solr服务器进行配置调优,不然会抛出服务器无法响应的异常:
Error: org.apache.solr.common.SolrException: Server at http://192.168.1.10:8983/solr returned non ok status:503, message:Service Unavailable
MapReduce入口程序:
package com.ultrapower.hbase.solrhbase;import java.io.IOException;import java.net.URISyntaxException;import org.apache.hadoop.conf.Configuration;import org.apache.hadoop.hbase.HBaseConfiguration;import org.apache.hadoop.hbase.client.Scan;import org.apache.hadoop.hbase.mapreduce.TableMapReduceUtil;import org.apache.hadoop.hbase.util.Bytes;import org.apache.hadoop.mapreduce.Job;import org.apache.hadoop.mapreduce.lib.output.NullOutputFormat;public class SolrHBaseIndexer { private static void usage() { System.err.println("输入参数: <配置文件路径> <起始行> <结束行>"); System.exit(1); } private static Configuration conf; public static void main(String[] args) throws IOException, InterruptedException, ClassNotFoundException, URISyntaxException { if (args.length == 0 || args.length > 3) { usage(); } createHBaseConfiguration(args[0]); ConfigProperties tutorialProperties = new ConfigProperties(args[0]); String tbName = tutorialProperties.getHBTbName(); String tbFamily = tutorialProperties.getHBFamily(); Job job = new Job(conf, "SolrHBaseIndexer"); job.setJarByClass(SolrHBaseIndexer.class); Scan scan = new Scan(); if (args.length == 3) { scan.setStartRow(Bytes.toBytes(args[1])); scan.setStopRow(Bytes.toBytes(args[2])); } scan.addFamily(Bytes.toBytes(tbFamily)); scan.setCaching(500); // 设置缓存数据量来提高效率 scan.setCacheBlocks(false); // 创建Map任务 TableMapReduceUtil.initTableMapperJob(tbName, scan, SolrHBaseIndexerMapper.class, null, null, job); // 不需要输出 job.setOutputFormatClass(NullOutputFormat.class); // job.setNumReduceTasks(0); System.exit(job.waitForCompletion(true) ? 0 : 1); } /** * 从配置文件读取并设置HBase配置信息 * * @param propsLocation * @return */ private static void createHBaseConfiguration(String propsLocation) { ConfigProperties tutorialProperties = new ConfigProperties( propsLocation); conf = HBaseConfiguration.create(); conf.set("hbase.zookeeper.quorum", tutorialProperties.getZKQuorum()); conf.set("hbase.zookeeper.property.clientPort", tutorialProperties.getZKPort()); conf.set("hbase.master", tutorialProperties.getHBMaster()); conf.set("hbase.rootdir", tutorialProperties.getHBrootDir()); conf.set("solr.server", tutorialProperties.getSolrServer()); } }对应的Mapper:
package com.ultrapower.hbase.solrhbase;import java.io.IOException;import org.apache.hadoop.conf.Configuration;import org.apache.hadoop.hbase.KeyValue;import org.apache.hadoop.hbase.client.Result;import org.apache.hadoop.hbase.io.ImmutableBytesWritable;import org.apache.hadoop.hbase.mapreduce.TableMapper;import org.apache.hadoop.io.Text;import org.apache.solr.client.solrj.SolrServerException;import org.apache.solr.client.solrj.impl.HttpSolrServer;import org.apache.solr.common.SolrInputDocument;public class SolrHBaseIndexerMapper extends TableMapper<Text, Text> { public void map(ImmutableBytesWritable key, Result hbaseResult, Context context) throws InterruptedException, IOException { Configuration conf = context.getConfiguration(); HttpSolrServer solrServer = new HttpSolrServer(conf.get("solr.server")); solrServer.setDefaultMaxConnectionsPerHost(100); solrServer.setMaxTotalConnections(1000); solrServer.setSoTimeout(20000); solrServer.setConnectionTimeout(20000); SolrInputDocument solrDoc = new SolrInputDocument(); try { solrDoc.addField("rowkey", new String(hbaseResult.getRow())); for (KeyValue rowQualifierAndValue : hbaseResult.list()) { String fieldName = new String( rowQualifierAndValue.getQualifier()); String fieldValue = new String(rowQualifierAndValue.getValue()); if (fieldName.equalsIgnoreCase("time") || fieldName.equalsIgnoreCase("tebid") || fieldName.equalsIgnoreCase("tetid") || fieldName.equalsIgnoreCase("puid") || fieldName.equalsIgnoreCase("mgcvid") || fieldName.equalsIgnoreCase("mtcvid") || fieldName.equalsIgnoreCase("smaid") || fieldName.equalsIgnoreCase("mtlkid")) { solrDoc.addField(fieldName, fieldValue); } } solrServer.add(solrDoc); solrServer.commit(true, true, true); } catch (SolrServerException e) { System.err.println("更新Solr索引异常:" + new String(hbaseResult.getRow())); } } }读取参数配置文件的辅助类:
package com.ultrapower.hbase.solrhbase;import java.io.File;import java.io.FileReader;import java.io.IOException;import java.util.Properties;public class ConfigProperties { private static Properties props; private String HBASE_ZOOKEEPER_QUORUM; private String HBASE_ZOOKEEPER_PROPERTY_CLIENT_PORT; private String HBASE_MASTER; private String HBASE_ROOTDIR; private String DFS_NAME_DIR; private String DFS_DATA_DIR; private String FS_DEFAULT_NAME; private String SOLR_SERVER; // Solr服务器地址 private String HBASE_TABLE_NAME; // 需要建立Solr索引的HBase表名称 private String HBASE_TABLE_FAMILY; // HBase表的列族 public ConfigProperties(String propLocation) { props = new Properties(); try { File file = new File(propLocation); System.out.println("从以下位置加载配置文件: " + file.getAbsolutePath()); FileReader is = new FileReader(file); props.load(is); HBASE_ZOOKEEPER_QUORUM = props.getProperty("HBASE_ZOOKEEPER_QUORUM"); HBASE_ZOOKEEPER_PROPERTY_CLIENT_PORT = props.getProperty("HBASE_ZOOKEEPER_PROPERTY_CLIENT_PORT"); HBASE_MASTER = props.getProperty("HBASE_MASTER"); HBASE_ROOTDIR = props.getProperty("HBASE_ROOTDIR"); DFS_NAME_DIR = props.getProperty("DFS_NAME_DIR"); DFS_DATA_DIR = props.getProperty("DFS_DATA_DIR"); FS_DEFAULT_NAME = props.getProperty("FS_DEFAULT_NAME"); SOLR_SERVER = props.getProperty("SOLR_SERVER"); HBASE_TABLE_NAME = props.getProperty("HBASE_TABLE_NAME"); HBASE_TABLE_FAMILY = props.getProperty("HBASE_TABLE_FAMILY"); } catch (IOException e) { throw new RuntimeException("加载配置文件出错"); } catch (NullPointerException e) { throw new RuntimeException("文件不存在"); } } public String getZKQuorum() { return HBASE_ZOOKEEPER_QUORUM; } public String getZKPort() { return HBASE_ZOOKEEPER_PROPERTY_CLIENT_PORT; } public String getHBMaster() { return HBASE_MASTER; } public String getHBrootDir() { return HBASE_ROOTDIR; } public String getDFSnameDir() { return DFS_NAME_DIR; } public String getDFSdataDir() { return DFS_DATA_DIR; } public String getFSdefaultName() { return FS_DEFAULT_NAME; } public String getSolrServer() { return SOLR_SERVER; } public String getHBTbName() { return HBASE_TABLE_NAME; } public String getHBFamily() { return HBASE_TABLE_FAMILY; } }参数配置文件“config.properties”:
HBASE_ZOOKEEPER_QUORUM=slave-1,slave-2,slave-3,slave-4,slave-5HBASE_ZOOKEEPER_PROPERTY_CLIENT_PORT=2181HBASE_MASTER=master-1:60000HBASE_ROOTDIR=hdfs:///hbaseDFS_NAME_DIR=/opt/data/dfs/name DFS_DATA_DIR=/opt/data/d0/dfs2/data FS_DEFAULT_NAME=hdfs://192.168.1.10:9000SOLR_SERVER=http://192.168.1.10:8983/solrHBASE_TABLE_NAME=hb_app_m_user_te HBASE_TABLE_FAMILY=d
三、结合Solr进行HBase数据的多条件查询:
可以通过web页面操作Solr索引,
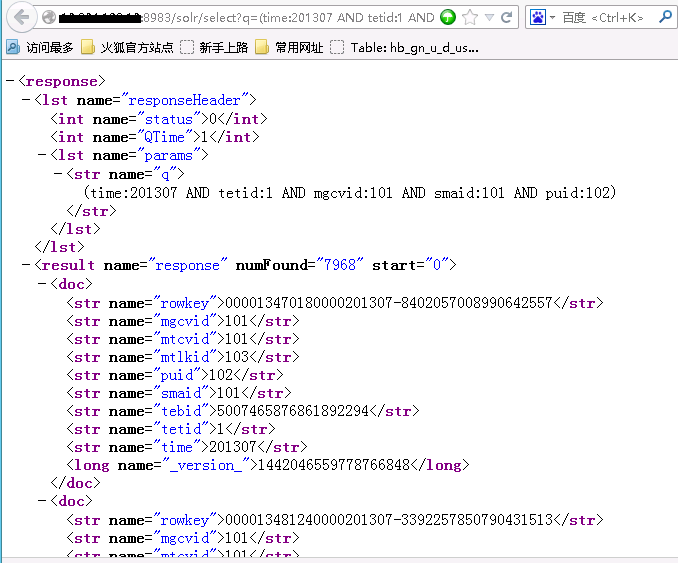
查询:
http://192.168.1.10:8983/solr/select?(time:201307 AND tetid:1 AND mgcvid:101 AND smaid:101 AND puid:102)
删除所有索引:
http://192.168.1.10:8983/solr/update/?stream.body=<delete><query>*:*</query></delete>&stream.contentType=text/xml;charset=utf-8&commit=true
通过java客户端结合Solr查询HBase数据:
package com.ultrapower.hbase.solrhbase;import java.io.IOException;import java.nio.ByteBuffer;import java.util.ArrayList;import java.util.List;import org.apache.hadoop.conf.Configuration;import org.apache.hadoop.hbase.HBaseConfiguration;import org.apache.hadoop.hbase.client.Get;import org.apache.hadoop.hbase.client.HTable;import org.apache.hadoop.hbase.client.Result;import org.apache.hadoop.hbase.util.Bytes;import org.apache.solr.client.solrj.SolrQuery;import org.apache.solr.client.solrj.SolrServer;import org.apache.solr.client.solrj.SolrServerException;import org.apache.solr.client.solrj.impl.HttpSolrServer;import org.apache.solr.client.solrj.response.QueryResponse;import org.apache.solr.common.SolrDocument;import org.apache.solr.common.SolrDocumentList;public class QueryData { /** * @param args * @throws SolrServerException * @throws IOException */ public static void main(String[] args) throws SolrServerException, IOException { final Configuration conf; conf = HBaseConfiguration.create(); HTable table = new HTable(conf, "hb_app_m_user_te"); Get get = null; List<Get> list = new ArrayList<Get>(); String url = "http://192.168.1.10:8983/solr"; SolrServer server = new HttpSolrServer(url); SolrQuery query = new SolrQuery("time:201307 AND tetid:1 AND mgcvid:101 AND smaid:101 AND puid:102"); query.setStart(0); //数据起始行,分页用 query.setRows(10); //返回记录数,分页用 QueryResponse response = server.query(query); SolrDocumentList docs = response.getResults(); System.out.println("文档个数:" + docs.getNumFound()); //数据总条数也可轻易获取 System.out.println("查询时间:" + response.getQTime()); for (SolrDocument doc : docs) { get = new Get(Bytes.toBytes((String) doc.getFieldValue("rowkey"))); list.add(get); } Result[] res = table.get(list); byte[] bt1 = null; byte[] bt2 = null; byte[] bt3 = null; byte[] bt4 = null; String str1 = null; String str2 = null; String str3 = null; String str4 = null; for (Result rs : res) { bt1 = rs.getValue("d".getBytes(), "3mpon".getBytes()); bt2 = rs.getValue("d".getBytes(), "3mponid".getBytes()); bt3 = rs.getValue("d".getBytes(), "amarpu".getBytes()); bt4 = rs.getValue("d".getBytes(), "amarpuid".getBytes()); if (bt1 != null && bt1.length>0) {str1 = new String(bt1);} else {str1 = "无数据";} //对空值进行new String的话会抛出异常 if (bt2 != null && bt2.length>0) {str2 = new String(bt2);} else {str2 = "无数据";} if (bt3 != null && bt3.length>0) {str3 = new String(bt3);} else {str3 = "无数据";} if (bt4 != null && bt4.length>0) {str4 = new String(bt4);} else {str4 = "无数据";} System.out.print(new String(rs.getRow()) + " "); System.out.print(str1 + "|"); System.out.print(str2 + "|"); System.out.print(str3 + "|"); System.out.println(str4 + "|"); } table.close(); } }小结:
通过测试发现,结合Solr索引可以很好的实现HBase的多条件查询,同时还能解决其两个难点:分页查询、数据总量统计。
实际场景中大多都是分页查询,分页查询返回的数据量很少,采用此种方案完全可以达到前端页面毫秒级的实时响应;若有大批量的数据交互,比如涉及到数据导出,实际上效率也是很高,十万数据仅耗时10秒。
另外,如果真的将Solr纳入使用,Solr以及HBase端都可以不断进行优化,比如可以搭建Solr集群,甚至可以采用SolrCloud基于hadoop的分布式索引服务。
总之,HBase不能多条件过滤查询的先天性缺陷,在Solr的配合之下可以得到较好的弥补,难怪诸如新蛋科技、国美电商、苏宁电商等互联网公司以及众多游戏公司,都使用Solr来支持快速查询。
----end