|
#
这几天自己琢磨起来javascript,以前都是看看没有实战过,现在觉得实战起来果然错误多多,以后要不断总结错误,关键可以减少调试时间,菜鸟啊: 1.js通常有一个地方错误了, 下边的函数都不会再继续执行啦(本来觉得很正常的事,但是...) 2.为什么open()请求服务器的时候,请求的servlet后边要加一个参数变化,告知服务器这是一个新的请求???否则在IE8中请求失败
var bojingNum = 0; //定义一个变量用来存储xmlHttpRequest对象
var xmlHttp= null; //该函数用于创建一个xmlHttpRequest对象
function createXMLHttpRequest() { if (window.ActiveXObject) //ActiveXObject这个对象是IE浏览器提供的控件,所以有的网银只支持这样的控件的IE浏览器
{ xmlHttp = new ActiveXObject("Microsoft.XMLHTTP"); //IE浏览器生成的对象
} else if (window.XMLHttpRequest) //除了IE外的其他浏览器
{ xmlHttp = new XMLHttpRequest(); } } //这是一个通过ajax刷新统计图的方法
function autoFlush() { //创建日期变量时间变量
var tempTime = new Date(); var tempParameter = tempTime.getTime(); //创建一个xmlHttpRequest对象
createXMLHttpRequest(); if(xmlHttp!= null) { //这里放置一个时间参数是为了让服务器知道这是一个新的请求
xmlHttp.open("GET", "SerialDataSvt?tmd="+tempParameter); //将状态触发器绑定到一个函数
xmlHttp.onreadystatechange=processor; //请求发送
xmlHttp.send( null); } } //处理从服务器返回的xml文档
function processor() { //定义一个变量用于存储从服务器返回的结果
var result; if(xmlHttp.readyState==4) //如果响应完成
{ if(xmlHttp.status==200) //如果返回成功
{ //取出服务器返回的xml文档的所有counter标签的子节点
result = xmlHttp.responseXML.getElementsByTagName("data"); //alert(result);
//解析xml中的数据并更新统计图状态
for( var i = 0 ; i < result.length; i++) { //用于统计数据更新统计图片状态
var id =result[i].getAttribute("id"); //alert(id);
var dir =result[i].getAttribute("dir"); //alert(dir);
var datas =xmlHttp.responseXML.getElementsByTagName("dataContent")[0].childNodes[0].nodeValue; var addTime =xmlHttp.responseXML.getElementsByTagName("addTime")[0].childNodes[0].nodeValue; if(datas.substring(17,18)=="1") { document.getElementById("yujing"+(i+1)).innerHTML="<embed src='video/wartgroud.mp3' type=audio/x-ms-wma autostart='true' loop='true'>报警中  </embed> "; document.getElementById("yujingPic"+(i+1)).style.display = 'block'; bojingNum++; document.getElementById("yujingNum"+(i+1)).innerHTML="预警次数:"+bojingNum; } else { document.getElementById("yujing"+(i+1)).innerHTML="暂无报警 "; document.getElementById("yujingPic"+(i+1)).style.display = 'none'; } document.getElementById("n_nodeID"+i).innerHTML= id+dir; document.getElementById("n_nodeData"+i).innerHTML= datas; document.getElementById("n_nodeTime"+i).innerHTML= addTime; document.getElementById("s_nodeID"+i).innerHTML= id+dir; document.getElementById("s_nodeData"+i).innerHTML= datas; document.getElementById("s_nodeTime"+i).innerHTML= addTime; document.getElementById("e_nodeID"+i).innerHTML= id+dir; document.getElementById("e_nodeData"+i).innerHTML= datas; document.getElementById("e_nodeTime"+i).innerHTML= addTime; document.getElementById("w_nodeID"+i).innerHTML= id+dir; document.getElementById("w_nodeData"+i).innerHTML= datas; document.getElementById("w_nodeTime"+i).innerHTML= addTime; } } } } //每隔一秒就执行一次autoFlush方法
setInterval(autoFlush, 2000);
昨天看到C#群里有人问一个投票功能如何实现... 我对此很感兴趣,为了练习一下,就有了以下代码。 投票功能使用jQuery实现..纯html代码...数据通过json字符串传递,通过 eval转换为json对象 投票功能分为: 1.设置投票内容: 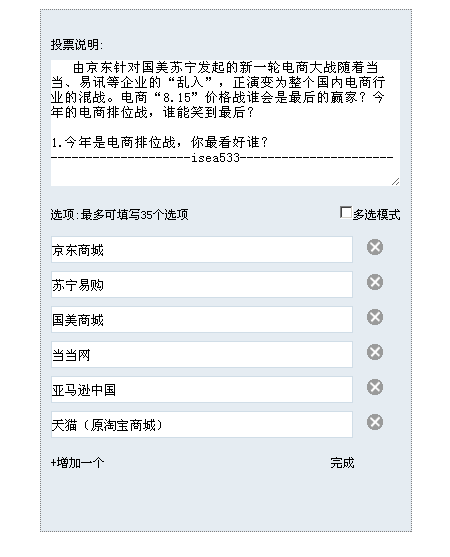
2.投票: 
3.投票结果: 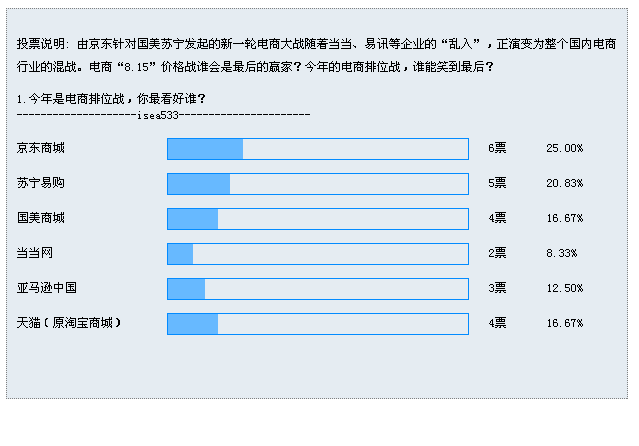
文件列表: 
传值:
{
info: " 由京东针对国美苏宁发起的新一轮电商大战随着当当、易讯等企业的“乱入”,正演变为整个国内电商行业的混战。电商“8.15”价格战谁会是最后的赢家?今年的电商排位战,谁能笑到最后?<br/><br/>1.今年是电商排位战,你最看好谁?<br/>--------------------isea533----------------------",
choices: [{
name: "choice0",
value: "京东商城",
num: 6,
percent: 0.25
},
{
name: "choice1",
value: "苏宁易购",
num: 5,
percent: 0.20833333333333334
},
{
name: "choice2",
value: "国美商城",
num: 4,
percent: 0.16666666666666666
},
{
name: "choice3",
value: "当当网",
num: 2,
percent: 0.08333333333333333
},
{
name: "choice4",
value: "亚马逊中国",
num: 3,
percent: 0.125
},
{
name: "choice5",
value: "天猫(原淘宝商城)",
num: 4,
percent: 0.16666666666666666
}]
}
jQuery对象初始化的传参方式包括:
1.$(DOMElement)
2.$('<h1>...</h1>'), $('#id'), $('.class') 传入字符串, 这是最常见的形式, 这种传参数经常也传入第二个参数context指定上下文,其中context参数可以为$(...), DOMElement
3.$(function() {}); <===> $(document).ready(function() { });
4.$({selector : '.class', context : context}) <===> $('.class', context)
jQuery.fn = jQuery.prototype = {
constructor: jQuery,
init: function( selector, context, rootjQuery ) {
var match, elem, ret, doc;
// 处理$(""), $(null), $(undefined), $(false)这几种参数,直接返回this
if ( !selector ) {
return this;
}
// 当传参selector为DOM结点时,将context置为selector
if ( selector.nodeType ) {
this.context = this[0] = selector;
this.length = 1;
return this;
}
// Handle HTML strings
// 当传入的selector参数为字符串时,
if ( typeof selector === "string" ) {
if ( selector.charAt(0) === "<" && selector.charAt( selector.length - 1 ) === ">" && selector.length >= 3 ) {
// Assume that strings that start and end with <> are HTML and skip the regex check
match = [ null, selector, null ];
} else {
match = rquickExpr.exec( selector );
}
// Match html or make sure no context is specified for #id
if ( match && (match[1] || !context) ) {
// HANDLE: $(html) -> $(array)
if ( match[1] ) {
context = context instanceof jQuery ? context[0] : context;
doc = ( context && context.nodeType ? context.ownerDocument || context : document );
// scripts is true for back-compat
selector = jQuery.parseHTML( match[1], doc, true );
if ( rsingleTag.test( match[1] ) && jQuery.isPlainObject( context ) ) {
this.attr.call( selector, context, true );
}
return jQuery.merge( this, selector );
// HANDLE: $(#id)
} else {
elem = document.getElementById( match[2] );
// Check parentNode to catch when Blackberry 4.6 returns
// nodes that are no longer in the document #6963
if ( elem && elem.parentNode ) {
// Handle the case where IE and Opera return items
// by name instead of ID
if ( elem.id !== match[2] ) {
return rootjQuery.find( selector );
}
// Otherwise, we inject the element directly into the jQuery object
this.length = 1;
this[0] = elem;
}
this.context = document;
this.selector = selector;
return this;
}
// HANDLE: $(expr, $(...))
} else if ( !context || context.jquery ) {
return ( context || rootjQuery ).find( selector );
// HANDLE: $(expr, context)
// (which is just equivalent to: $(context).find(expr)
} else {
return this.constructor( context ).find( selector );
}
// HANDLE: $(function)
// Shortcut for document ready
// 当selector为function时相当于$(document).ready(selector);
} else if ( jQuery.isFunction( selector ) ) {
return rootjQuery.ready( selector );
}
// 当selector参数为{selector:'#id', context:document}之类时,重置属性selector和context
if ( selector.selector !== undefined ) {
this.selector = selector.selector;
this.context = selector.context;
}
return jQuery.makeArray( selector, this );
}
};
最近项目任务繁重,更新博客会较慢,不过有时间希望可以把自己的积累分享出来。 JavaScript正则实战(会根据最近写的不断更新) 1、javascript 正则对象替换创建 和用法: /pattern/flags 先简单案例学习认识下replace能干什么 正则表达式构造函数: new RegExp("pattern"[,"flags"]); 正则表达式替换变量函数:stringObj.replace(RegExp,replace Text); 参数说明:
pattern -- 一个正则表达式文本
flags -- 如果存在,将是以下值:
g: 全局匹配
i: 忽略大小写
gi: 以上组合
//下面的例子用来获取url的两个参数,并返回urlRewrite之前的真实Url
var reg=new RegExp("(http://www.qidian.com/BookReader/)(\\d+),(\\d+).aspx","gmi");
var url="http://www.qidian.com/BookReader/1017141,20361055.aspx";
//方式一,最简单常用的方式
var rep=url.replace(reg,"$1ShowBook.aspx?bookId=$2&chapterId=$3");
alert(rep);
//方式二 ,采用固定参数的回调函数
var rep2=url.replace(reg,function(m,p1,p2,p3){return p1+"ShowBook.aspx?bookId="+p3+"&chapterId="+p3});
alert(rep2);
//方式三,采用非固定参数的回调函数
var rep3=url.replace(reg,function(){var args=arguments; return args[1]+"ShowBook.aspx?bookId="+args[2]+"&chapterId="+args[3];});
alert(rep3);
//方法四
//方式四和方法三很类似, 除了返回替换后的字符串外,还可以单独获取参数
var bookId;
var chapterId;
function capText()
{
var args=arguments;
bookId=args[2];
chapterId=args[3];
return args[1]+"ShowBook.aspx?bookId="+args[2]+"&chapterId="+args[3];
}
var rep4=url.replace(reg,capText);
alert(rep4);
alert(bookId);
alert(chapterId);
//使用test方法获取分组
var reg3=new RegExp("(http://www.qidian.com/BookReader/)(\\d+),(\\d+).aspx","gmi");
reg3.test("http://www.qidian.com/BookReader/1017141,20361055.aspx");
//获取三个分组
alert(RegExp.$1);
alert(RegExp.$2);
alert(RegExp.$3);
2、 学习最常用的 test exec match search replace split 6个方法 1) test 检查指定的字符串是否存在
var data = “123123″;
var reCat = /123/gi;
alert(reCat.test(data)); //true
//检查字符是否存在 g 继续往下走 i 不区分大小写 2) exec 返回查询值
var data = “123123,213,12312,312,3,Cat,cat,dsfsdfs,”;
var reCat = /cat/i;
alert(reCat.exec(data)); //Cat 3)match 得到查询数组
var data = “123123,213,12312,312,3,Cat,cat,dsfsdfs,”;
var reCat = /cat/gi;
var arrMactches = data.match(reCat)
for (var i=0;i < arrMactches.length ; i++)
{
alert(arrMactches[i]); //Cat cat
} 4) search 返回搜索位置 类似于indexof
var data = “123123,213,12312,312,3,Cat,cat,dsfsdfs,”;
var reCat = /cat/gi;
alert(data.search(reCat)); //23 5) replace 替换字符 利用正则替换
var data = “123123,213,12312,312,3,Cat,cat,dsfsdfs,”;
var reCat = /cat/gi;
alert(data.replace(reCat,”libinqq”)); 6)split 利用正则分割数组
var data = “123123,213,12312,312,3,Cat,cat,dsfsdfs,”;
var reCat = /\,/;
var arrdata = data.split(reCat);
for (var i = 0; i < arrdata.length; i++)
{
alert(arrdata[i]);
} 3、常用表达式收集:"^\\d+$" //非负整数(正整数 + 0)
"^[0-9]*[1-9][0-9]*$" //正整数
"^((-\\d+)|(0+))$" //非正整数(负整数 + 0)
"^-[0-9]*[1-9][0-9]*$" //负整数
"^-?\\d+$" //整数
"^\\d+(\\.\\d+)?$" //非负浮点数(正浮点数 + 0)
"^(([0-9]+\\.[0-9]*[1-9][0-9]*)|([0-9]*[1-9][0-9]*\\.[0-9]+)|([0-9]*[1-9][0-9]*))$"
//正浮点数
"^((-\\d+(\\.\\d+)?)|(0+(\\.0+)?))$" //非正浮点数(负浮点数 + 0)
"^(-(([0-9]+\\.[0-9]*[1-9][0-9]*)|([0-9]*[1-9][0-9]*\\.[0-9]+)|([0-9]*[1-9][0-9]*)))$"
//负浮点数
"^(-?\\d+)(\\.\\d+)?$" //浮点数
"^[A-Za-z]+$" //由26个英文字母组成的字符串
"^[A-Z]+$" //由26个英文字母的大写组成的字符串
"^[a-z]+$" //由26个英文字母的小写组成的字符串
"^[A-Za-z0-9]+$" //由数字和26个英文字母组成的字符串
"^\\w+$" //由数字、26个英文字母或者下划线组成的字符串
"^[\\w-]+(\\.[\\w-]+)*@[\\w-]+(\\.[\\w-]+)+$" //email地址
"^[a-zA-z]+://(\\w+(-\\w+)*)(\\.(\\w+(-\\w+)*))*(\\?\\S*)?$" //url
"^[A-Za-z0-9_]*$"。
============================================正则表达式基础知识============================================== ^ 匹配一个输入或一行的开头,/^a/匹配"an A",而不匹配"An a"
$ 匹配一个输入或一行的结尾,/a$/匹配"An a",而不匹配"an A"
* 匹配前面元字符0次或多次,/ba*/将匹配b,ba,baa,baaa
+ 匹配前面元字符1次或多次,/ba+/将匹配ba,baa,baaa
? 匹配前面元字符0次或1次,/ba?/将匹配b,ba
(x) 匹配x保存x在名为$1...$9的变量中
x|y 匹配x或y
{n} 精确匹配n次
{n,} 匹配n次以上
{n,m} 匹配n-m次
[xyz] 字符集(character set),匹配这个集合中的任一一个字符(或元字符)
[^xyz] 不匹配这个集合中的任何一个字符
[\b] 匹配一个退格符
\b 匹配一个单词的边界
\B 匹配一个单词的非边界
\cX 这儿,X是一个控制符,/\cM/匹配Ctrl-M
\d 匹配一个字数字符,/\d/ = /[0-9]/
\D 匹配一个非字数字符,/\D/ = /[^0-9]/
\n 匹配一个换行符
\r 匹配一个回车符
\s 匹配一个空白字符,包括\n,\r,\f,\t,\v等
\S 匹配一个非空白字符,等于/[^\n\f\r\t\v]/
\t 匹配一个制表符
\v 匹配一个重直制表符
\w 匹配一个可以组成单词的字符(alphanumeric,这是我的意译,含数字),包括下划线,如[\w]匹配"$5.98"中的5,等于[a-zA-Z0-9]
\W 匹配一个不可以组成单词的字符,如[\W]匹配"$5.98"中的$,等于[^a-zA-Z0-9]。
在浏览网页时,经常会看到分页显示的页面。如果想把大量的数据提供给浏览者,分页显示是个非常实用的方法。分页显示数据能够帮助浏览者更好地查看信息,能够有条理的显示信息。
在传统的web技术中,分页显示的相关操作都是在服务器端进行的,服务器端获取客户端的请求分页,并根据请求页数获取指定的结果集。最后把结果集中的数据返回到客户端,这时返回结果中不但包含了数据,还可能包含了数据的显示样式。客户端的每一次数据更新,都会重新打开一个网页,如果网页中包含了很多html元素,就会造成网页打开速度较慢的情况。
为了显示部分数据,而需要加载整个页面的数据,显得有点得不偿失。使用Ajax技术可以很好的弥补这些问题,服务器端只传输数据库表中的数据,客户端获取这些数据只更新局部内容,与数据无关的其他元素保持不变。
现在创建一个实例,以演示使用Ajax技术实现数据的分页显示。该实例的代码实现分为服务器端和客户端。
1,准备工作
我们这里使用Mysql数据库,我在shop数据库中创建了一张mobileshop表,这张表有两个字段name,model。
打开记事本,输入下列代码:
<%@ page language="java" import="java.util.*,java.sql.*,java.io.*" pageEncoding="GBK"%>
<%
class DBManager{
String userName="root";
String password="123456";
Connection conn=null;
Statement stmt=null;
String url="jdbc:mysql://localhost:3306/shop";
ResultSet rst;
public DBManager(String sql){
try {
Class.forName("com.mysql.jdbc.Driver");
conn=DriverManager.getConnection(url,userName,password);
stmt=conn.createStatement();
rst=stmt.executeQuery(sql);
} catch (Exception e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
public ResultSet getResultSet(){
return rst;
}
}
%> 将上述代码保存为Conn.jsp,用于返回查询结果集。 2,服务器端代码
在本实例中,服务器端代码具有获取客户端请求页数和产生指定记录集的功能。打开记事本,输入下列代码:
<%@ page contentType="text/html; charset=utf-8" import="java.sql.*" errorPage="" %>
<%@ include file="Conn.jsp" %>
<%@ page import="java.util.*" %>
<%@ page import="java.io.*" %>
<%
try
{
ResultSet rs=new DBManager("select name,model from mobileshop").getResultSet();
int intPageSize; //一页显示的记录数
int intRowCount; //记录的总数
int intPageCount; //总页数
int intPage; //待显示的页码
String strPage;
int i;
intPageSize=2; //设置一页显示的记录数
strPage=request.getParameter("page"); //取得待显示的页码
if(strPage==null) //判断strPage是否等于null,如果是,则显示第一页数据
{
intPage=1;
}else{
intPage=java.lang.Integer.parseInt(strPage); //将字符串转化为整形
}
if(intPage<1)
{
intPage=1;
}
//获取记录总数
rs.last();
intRowCount=rs.getRow();
//计算总页数
intPageCount=(intRowCount+intPageSize-1)/intPageSize;
//调整显示的页码
if(intPage>intPageCount) intPage=intPageCount;
if(intPageCount>0)
{
//将记录指针定位到待显示页的第一条记录上
rs.absolute((intPage-1)*intPageSize+1);
}
//下面用于显示数据
i=0;
StringBuffer content=new StringBuffer("");
response.setContentType("text/xml");
response.setHeader("Cache-Control","no-cache");
content.append("<?xml version=\"1.0\" encoding=\"UTF-8\" ?>");
content.append("<contents>");
while(i<intPageSize && !rs.isAfterLast())
{
String name=rs.getString("name");
String email=rs.getString("model");
content.append("<content>");
content.append("<name>"+ name +"</name>");
content.append("<model>"+email+"</model>");
content.append("</content>");
rs.next();
i++;
}
content.append("</contents>");
System.out.print(content);
out.print(content);
}
catch(Exception e)
{
e.printStackTrace();
}
%>
网页自动刷新功能在web网站上已经屡见不鲜了,如即时新闻信息,股票信息等,都需要不断获取最新信息。在传统的web实现方式中,想要实现类似的效果,必须进行整个页面的刷新,在网络速度受到一定限制的情况下,这种因为一个局部变动而牵动整个页面的处理方式显得有些得不偿失。Ajax技术的出现很好的解决了这个问题,利用Ajax技术可以实现网页的局部刷新,只更新指定的数据,并不更新其他的数据。
现在创建一个实例,以演示网页的自动刷新功能,该实例模拟火车侯票大厅的显示字幕。 1,服务器端代码
该实例服务器端代码的功能比较简单,即产生一个随机数,并以XML文件形式返回给客户端。打开记事本,输入下列代码:
<%@ page contentType="text/html; charset=gb2312" %>
<%
response.setContentType("text/xml; charset=UTF-8");//设置输出信息的格式及字符集
response.setHeader("Cache-Control","no-cache");
out.println("<response>");
for(int i=0;i<2;i++){
out.println("<name>"+(int)(Math.random()*10)+"</name>");
out.println("<count>" +(int)(Math.random()*100)+ "</count>");
}
out.println("</response>");
out.close();
%>
保存上述代码,名称为auto.jsp。在该文件中,使用java.lang包中的Math类,产生一个随机数。
2,客户端代码
本实例客户端代码主要利用服务器端返回的数字,指定显示样式。打开记事本,输入下列代码
<%@ page language="java" import="java.util.*" pageEncoding="GBK"%>
<head>
<META http-equiv=Content-Type content="text/html; charset=gb2312">
</head>
<script language="javascript">
var XMLHttpReq;
//创建XMLHttpRequest对象
function createXMLHttpRequest() {
if(window.XMLHttpRequest) { //Mozilla 浏览器
XMLHttpReq = new XMLHttpRequest();
}
else if (window.ActiveXObject) { // IE浏览器
try {
XMLHttpReq = new ActiveXObject("Msxml2.XMLHTTP");
} catch (e) {
try {
XMLHttpReq = new ActiveXObject("Microsoft.XMLHTTP");
} catch (e) {}
}
}
}
//发送请求函数
function sendRequest() {
createXMLHttpRequest();
var url = "auto.jsp";
XMLHttpReq.open("GET", url, true);
XMLHttpReq.onreadystatechange = processResponse;//指定响应函数
XMLHttpReq.send(null); // 发送请求
}
// 处理返回信息函数
function processResponse() {
if (XMLHttpReq.readyState == 4) { // 判断对象状态
if (XMLHttpReq.status == 200) { // 信息已经成功返回,开始处理信息
DisplayHot();
setTimeout("sendRequest()", 1000);
} else { //页面不正常
window.alert("您所请求的页面有异常。");
}
}
}
function DisplayHot() {
var name = XMLHttpReq.responseXML.getElementsByTagName("name")[0].firstChild.nodeValue;
var count = XMLHttpReq.responseXML.getElementsByTagName("count")[0].firstChild.nodeValue;
document.getElementById("cheh").innerHTML = "T-"+name+"次列车";
document.getElementById("price").innerHTML = count+"元";
}
</script>
<body onload =sendRequest()>
<table style="BORDER-COLLAPSE: collapse" borderColor=#5555555 cellSpacing=0 cellPadding=0 width=200 border=0>
<TR>
<TD align=middle bgColor=#abc2d0 height=19 colspan="2"><B>开往北京的列车</B> </TD>
</TR>
<tr>
<td height="20"> 车号:</td>
<td height="20" id="cheh"> </td>
</tr>
<tr>
<td height="20"> 价格:</td>
<td height="20" id="price"> </td>
</tr>
</table>
</body>
将上述代码保存,名称为autoRefresh.jsp。在该文件中,createXMLHttpRequest()函数用于创建异步调用对象;sendRequest()函数用于发送请求到客户端;processResponse()函数用于处理服务器端的响应,在处理过程中调用DisplayHot()函数设定数据的显示样式。其中,setTimeout(“sendRequest()”,1000)函数的含义为每隔1秒的时间调用sendRequest()函数,该函数在Ajax页面刷新中起了一个主导作用。DisplayHot()函数主要用于从服务器端返回的XML文件进行解析,并获取返回数据,显示在当前页面。
机房收费系统完成了已经有很长一段时间了,本以为就此结束了。可是,前几天突然要求对其进行验收了。 开始的时候,感觉验收就验收没什么。可是,有小道消息称,做的不好的有可能重构。如果是因为当初的设计思路或者是逻辑错误而重构,那无话可说,必须要重构。但是如果是因为一些注释、UML图、命名规范等而重构,都会让大家笑话。 于是,在前面人验收的时候,后面的人都在讨论验收人员的侧重点。然后大家在修改自己的收费系统。 通过这次验收,虽然我没有被要求重构,但是,在验收过程中还是出现了很多的问题,验收人员也给提出了很多的宝贵意见。 首先就是出现的问题。 命名不规范。尤其是参数的命名,当初以为参数只是使用在某一个方法或者函数中,不会和其他的类、函数产生关系,不用太在意它的命名。可是,这种代码只适合与自己看,其他人看你的代码就会感觉不舒服,同时给人一种外行的感觉。 注释不全。虽说对于类、方法和函数都做了注释,但是,不是很完整。例如,所有的remarks都是空着的。通过验收人员的讲解,理解了它的作用,记录版本号,编写时间以及修改时间。还有就是,对于注释的代码,不要删除,而应该保留并完整写明修改人,以及修改的时间。虽说是个人版的,但对于注释,都是被删除了。 文档不全。当时做收费系统的时候,只写了需求、概要、数据库设计以及详细设计文档。其他的则没有写。当初就是由于惰性的原因吧,感觉写文档太枯燥了,就急于编写代码了,当系统实现之后,就以为系统实现了就行了,至于其他文档就算了吧。 对UML图理解不深。当初在画UML图的时候,对用例图理解的不是太深,以至于我的用例图中的用例都是窗体。在验收过程中,自己都不禁问自己,当初是怎么想的呢?怎么会出现那种用例图呢? 再说一些个别人出现的问题吧(也算是给自己提个醒) 文档、数据库没了。在做完机房收费系统到现在有很长的时间了,有的同学重装了系统。有的没有提前把数据库中的数据备份,导致现在没有了原先的数据。而文档,有的是在第一遍的基础上修改的,原先的也没有备份。导致现在的文档是合作版的时候,自己第三次修改的文档,前两次的文档都没了。 UML图不知道哪一个是最新版本。有的同学UML图画了好几遍,但是在文件保存的时候,没有注意到命名,没有表明版本号。以至于寻找的时候花费了很长时间,有的甚至就找不到了。 应该说,通过这次验收,让我们认识到了当初所做的系统存在着很大的不足。这次要求我们都要补全文档、注释,规范命名等等,让我们长了一个记性。对我们来说没有坏处。同时通过这次验收,也让我们认识到,文件备份、管理、保存的重要性。在以后大家都会记住这次的验收来提醒自己。
为了检查八期分层重要阶段学习成果,老师,七期全体成员参与验收工作。 在提高班,四年的学习中,分了几个重要的模块。其中在重要的关键的方向性的学习上是需要把控的,是需要及时检验以及验收的。 在验收八期学习的过程中,不仅发现他们的问题,同时也发现自己的问题。 验收工作,不仅是验收他们,同时也是验收自己对此知识点掌握的情况。 首先说一下验收过程中,八期普遍存在的问题。 1. 对文档的认识不够,导致文档与程序不对应。 包图与程序集的对应,这个没意识到。命名是其中一方面,还有就是其中包图中的每条线的作用,意义,以及在代码中体现。 2. UML认识不够,需要进步学习。 UML中的共九种图,常用的像用例图,类图,对象图,时序图,包图,活动图,状态图这几种,每种图的符号以及画法掌握不够。并且对每种图的概念以及适合什么场景有所欠缺。并且图中的关系需要进步掌握。比如用例之间的包含关系、扩展关系等,还有UML中的五种关系以及在代码中的体现。 3. 对分层的认识不够,导致假隔离真耦合。 不仅仅把程序分成了UI,BLL,DAL,但是最主要的是各个层之间的隔离。比如因为DAL生成的路径的原因,导致了明明UI与DAL隔离,却因为路径问题而再次耦合,结果确是一种假隔离真耦合。还有就是BLL,DAL引入UI中的某个包,导致了后面与前面分层再次耦合。 4. 规范问题。命名规范,注释规范。 5. 对文档中的内容理解不到位,导致人云亦云。 常写的几种需求说明书,概要说明书,详细说明书。对其中的内容不了解,不知道文档中应该写什么。也不知道那些图应该放在那个文档中。导致了结果,每个文档中都有重复的东西。 6. 项目驱动未做到。 大家着急开发,忽略文档。在开发过程中,文档一直没有起到任何作用,所以对文档没有深度认识。 八期出现的问题,确实可以理解。当时的七期,也翻过如此的错误。这毕竟是八期第一次的个人版。做到这种程度,已经是相当好了。当初的七期,几乎每人重构了三四遍。对这个分层,文档才有了今天的理解以及重视。 然后说一下验收过程中,自己的收获问题。 1. 发言沟通交流。通过这次发言机会,锻炼与他人沟通,交流。 2. 在验收他们的过程中,进一步考验自己的对过去知识点的理解。 提问他们,促进他们的思考,同时与自己所学的知识进行比对,补充自己的欠缺。 其中有个学生的包图,自己也理解错了,对工厂模式,抽象工厂模式,反射,以及接口,多态这些应用有了进一步认识。 3. 对某个知识点的问题学习。 其中有个学生用了单例模式。单利模式的作用,以及好处都是可以理解的,但是当时的他利用的嵌套类实现的单例模式,对嵌套类,静态块有了进一步认识。 另一个是错误处理。Trycatch,throw,throws知识点的学习。 4. 对文档中的内容进一步补充。 全体七期发言,正好补充自己对文档的认识不足的问题。 5. 验收中记录下自己的不懂的问题。 对UML中活动图,状态图,构件图,部署图的概念理解,但是画出某一个图,无法确定对与错,说明自己对这方面欠缺。 6. 再次加深文档的问题。规范问题。 当把问题提给八期的学生时,同时也在提给自己。严格要求自己,以专业程序猿的身份要求自己。各种文档,代码规范化。 验收别人,也在验收自己。抓住一切可以提升自己的机会。
两步
(1)date 042612492005
(2)hwclock -w
第一步的意思是设置时间,设置完了可以用date命令查看对不对...注意是月日时分年
第二步的意思是写入主板的rtc芯片..
=======================================
su -c 'date -s 月/日/年'
su -c 'date -s 时:分:秒'
=======================================
了解Linux的时钟
由于Linux时钟和Windows时钟从概念的分类、使用到设置都有很大的不同,所以,搞清楚Linux时钟的工作方式与设置操作,不仅对于Linux初学者有着重大意义,而且对于使用Linux服务器的用户来说尤为重要。
Linux时钟的分类
Windows 时钟大家可能十分熟悉了,Linux时钟在概念上类似Windows时钟显示当前系统时间,但在时钟分类和设置上却和Windows大相径庭。和 Windows不同的是,Linux将时钟分为系统时钟(System Clock)和硬件(Real Time Clock,简称RTC)时钟两种。系统时间是指当前Linux Kernel中的时钟,而硬件时钟则是主板上由电池供电的那个主板硬件时钟,这个时钟可以在BIOS的“Standard BIOS Feture”项中进行设置。
既然Linux有两个时钟系统,那么大家所使用的Linux默认使用哪种时钟系统呢?会不回出现两种系统时钟冲突的情况呢?这些疑问和担心不无道理。首先,Linux并没有默认哪个时钟系统。当Linux启动时,硬件时钟会去读取系统时钟的设置,然后系统时钟就会独立于硬件运作。
从Linux启动过程来看,系统时钟和硬件时钟不会发生冲突,但Linux中的所有命令(包括函数)都是采用的系统时钟设置。不仅如此,系统时钟和硬件时钟还可以采用异步方式,见图1所示,即系统时间和硬件时间可以不同。这样做的好处对于普通用户意义不大,但对于Linux网络管理员却有很大的用处。例如,要将一个很大的网络中(跨越若干时区)的服务器同步,假如位于美国纽约的Linux服务器和北京的 Linux服务器,其中一台服务器无须改变硬件时钟而只需临时设置一个系统时间,如要将北京服务器上的时间设置为纽约时间,两台服务器完成文件的同步后,再与原来的时钟同步一下即可。这样系统和硬件时钟就提供了更为灵活的操作。
设置Linux的时钟
在 Linux中,用于时钟查看和设置的命令主要有date、hwclock和clock。其中,clock和hwclock用法相近,只不过clock命令除了支持x86硬件体系外,还支持Alpha硬件体系。由于目前绝大多数用户使用x86硬件体系,所以可以视这两个命令为一个命令来学习。
1.在虚拟终端中使用date命令来查看和设置系统时间
查看系统时钟的操作:
# date
设置系统时钟的操作:
# date 091713272003.30
通用的设置格式:
# date 月日时分年.秒
2.使用hwclock或clock命令查看和设置硬件时钟
查看硬件时钟的操作:
# hwclock --show 或
# clock --show
2003年09月17日 星期三 13时24分11秒 -0.482735 seconds
设置硬件时钟的操作:
# hwclock --set --date="09/17/2003 13:26:00"
或者
# clock --set --date="09/17/2003 13:26:00"
通用的设置格式:hwclock/clock --set --date=“月/日/年 时:分:秒”。
3.同步系统时钟和硬件时钟
Linux系统(笔者使用的是Red Hat 8.0,其它系统没有做过实验)默认重启后,硬件时钟和系统时钟同步。如果不大方便重新启动的话(服务器通常很少重启),使用clock或hwclock命令来同步系统时钟和硬件时钟。
硬件时钟与系统时钟同步:
# hwclock --hctosys
或者
# clock --hctosys
上面命令中,--hctosys表示Hardware Clock to SYStem clock。
系统时钟和硬件时钟同步:
# hwclock --systohc
或者
# clock --systohc
使用图形化系统设置工具设置时间
对于初学者来,笔者推荐使用图形化的时钟设置工具,如Red Hat 8.0中的日期与时间设置工具,可以在虚拟终端中键“redhat-config-time”命令,或者选择“K选单/系统设置/日期与时间”来启动日期时间设置工具。使用该工具不必考虑系统时间和硬件时间,只需从该对话框中设置日期时间,可同时设置、修改系统时钟和硬件时钟。
Internet同步时钟设置
在Windows XP日期与时间设置中有一项与Internet同步的功能,有了这项功能只要上网便可得到十分准确的时间。Red Hat 8.0也提供了这样的功能,在日期与时间设置工具对话框中的下部,有一个“启用网络时间协议”的选项,将该项选中就可以使用网络时间协议来同步Linux 系统时钟。选中该项后,其下面的服务器下拉列表框就变为可用状态,可从中选择一个时间服务器作为远程时间服务器。然后单击确定按钮,便可连接所设定的时间服务器,并与之同步时间。
关于网络校时: ntpdate
基本上,网络校时需要两个步骤:
1. 由 time.stdtime.gov.tw 取得最新的时间,并实时更新 Linux 系统时间;
2. 更改 BIOS 的时间。
[root @test root]# ntpdate time.stdtime.gov.tw
[root @test root]# clock –w
描述
tar 程序用于储存或展开 tar 存档文件。存档文件可放在磁盘中 ,也可以存为普通文件。 tar是需要参数的,可选的参数是A、c、d、r、t、u、x,您在使用tar时必须首先为 tar 指定至少一个参数;然后,您必须指定要处理的文件或目录。如果指定一个目录则该目录下的所有子目录都将被加入存档。
应用举例: 1)展开 abc.tar.gz 使用命令: tar xvzf abc.tar.gz 展开 abc.tar 使用命令: tar xvf abc.tar 2)将当前目录下的 man 目录及其子目录存成存档 man.tar tar cf man.tar ./man
参数说明
运行tar时必须要有下列参数中的至少一个才可运行 -A, --catenate, --concatenate
将一存档与已有的存档合并
-c, --create
建立新的存档
-d, --diff, --compare
比较存档与当前文件的不同之处
--delete
从存档中删除
-r, --append
附加到存档结尾
-t, --list
列出存档中文件的目录
-u, --update
仅将较新的文件附加到存档中
-x, --extract, --get
从存档展开文件 其他参数 --atime-preserve
不改变转储文件的存取时间 -b, --block-size N
指定块大小为 Nx512 字节(缺省时 N=20) -B, --read-full-blocks
读取时重组块(???!!!) -C, --directory DIR 转到指定的目录 --checkpoint
读取存档时显示目录名 -f, --file [HOSTNAME:]F
指定存档或设备 (缺省为 /dev/rmt0) --force-local
强制使用本地存档,即使存在克隆 -F, --info-script F --new-volume-script F
在每个磁盘结尾使用脚本 F (隐含 -M) -G, --incremental
建立老 GNU 格式的备份 -g, --listed-incremental F
建立新 GNU 格式的备份 -h, --dereference
不转储动态链接,转储动态链接指向的文件。 -i, --ignore-zeros
忽略存档中的 0 字节块(通常意味着文件结束) --ignore-failed-read
在不可读文件中作 0 标记后再退出??? -k, --keep-old-files
保存现有文件;从存档中展开时不进行覆盖 -K, --starting-file F
从存档文件 F 开始 -l, --one-file-system
在本地文件系统中创建存档 -L, --tape-length N
在写入 N*1024 个字节后暂停,等待更换磁盘 -m, --modification-time
当从一个档案中恢复文件时,不使用新的时间标签 -M, --multi-volume
建立多卷存档,以便在几个磁盘中存放 -N, --after-date DATE, --newer DATE
仅存储时间较新的文件 -o, --old-archive, --portability
以 V7 格式存档,不用 ANSI 格式 -O, --to-stdout
将文件展开到标准输出 -p, --same-permissions, --preserve-permissions
展开所有保护信息 -P, --absolute-paths
不要从文件名中去除 '/' --preserve
like -p -s
与 -p -s 相似 -R, --record-number
显示信息时同时显示存档中的记录数 --remove-files
建立存档后删除源文件 -s, --same-order, --preserve-order
???
--same-owner
展开以后使所有文件属于同一所有者 -S, --sparse
高效处理 -T, --files-from F
从文件中得到要展开或要创建的文件名 --null
读取空结束的文件名,使 -C 失效 --totals
显示用 --create 参数写入的总字节数 -v, --verbose
详细显示处理的文件 -V, --label NAME
为存档指定卷标 --version
显示 tar 程序的版本号 -w, --interactive, --confirmation
每个操作都要求确认 -W, --verify
写入存档后进行校验 --exclude FILE
不把指定文件包含在内 -X, --exclude-from FILE
从指定文件中读入不想包含的文件的列表 -y, --bzip2, --bunzip2
用 bzip2 对存档压缩或解压 -Z, --compress, --uncompress
用 compress 对存档压缩或解压 -z, --gzip, --ungzip
用 gzip 对存档压缩或解压 --use-compress-program PROG
用 PROG 对存档压缩或解压 ( PROG 需能接受 -d 参数) --block-compress
为便于磁盘存储,按块记录存档 -[0-7][lmh]
指定驱动器和密度[高中低]
|