有机会做了一次
性能测试工作,主要是预研性质的工作。开发人员有必要再提交给测试做性能测试之前,做一次比较粗糙的性能测试工作。
1)走通性能测试流程,从造数据到测试,可以走通,方可交由测试同学。毕竟开发(相对性能测试人员而非功能测试)对业务逻辑更了解一些。
2)测试一些显而易见的bug;
3)建立性能方面的信心;
4)可在测试的同学做完测试以后做一个对比,不至于偏离太过离谱。
参照测试部门的意见,我把这次的性能测试总结了如下几个步骤:
1、测试目标和范围:根据需要满足的非功能需求,确定上线功能点哪些需要测试。测试性能、稳定性、最大压力。
2、测试方案准备:包括施压方式,环境配置,环境依赖,资源监控,整理方案文档。
3、环境准备:准备压力测试环境,一般是压力测试机配置,压力测试数据库配置。
4、数据准备:根据线上预估数据,对数据库数据进行准备和模拟。
5、测试准备:包括需要编写的程序,如其他系统间依赖可写mock程序。另外编写jmeter的测试计划等。尝试测试,并确保一个请求或处理过程能顺利通过。
6、进行测试:通过客户端施压服务器,监控器各方面资源利用。
7、进行测试分析总结:写测试报告。TPS,吞吐量,CPU占比等。对异常现象记录,如内存溢出等。
8、根据测试报告对程序进行优化或重构。
做技术还是有做技术的天性,我们开发最关心的也就是5-8的步骤。我们的应用主要以hessian接口的形式向外面暴露,另外的就是任务在后台处理接口推送过来的数据。所以,我们的测试主要集中在接口测试和任务测试。比一般网页的性能测试更简单一些。
我们选用的施压客户端是开源的jmeter,文档较为丰富,且操作极为方便,扩展性好。服务器端性能监控工具,均采用linux的shell命令和jvm自带的工具或命令。jvm的工具已经够强大了,测试团队也是利用linux的命令采集服务器端资源,然后把消息发送到自己编写的一些资源监控工具上,其实都是利用了原生的shell命令和jvm命令来周期性采集并绘图的。
JMeter没有现成的sampler施压hessian的接口,所以我们需要利用它极具扩展性的java请 求sampler来施压hessian接口。我们查看jmeter安装目录下的lib>ext下可以发现其他多种类型的sampler。其他的种类 都可以由javasampler来实现。我们只需要继承org.apache.jmeter.protocol.java.sampler. AbstractJavaSamplerClient该类,在runTest方法中调用hessian接口,并封装返回值即可。然后把工程打成jar包, 放到jmeter安装目录下的lib>ext下。启动jemter,在利用javasampler就可以定为到我们编写的扩展测试程序了。
在压力测试过程中,包括两部分的资源检测,jvm的资源占用。一般利用jdk自带工具集
1、jps
常用的几个参数:
-l输出java应用程序的mainclass的完整包
-q仅显示pid,不显示其它任何相关信息
-m输出传递给main方法的参数
-v输出传递给JVM的参数。在诊断JVM相关问题的时候,这个参数可以查看JVM相关参数的设置
2、jstat-JavaVirtualMachineStatisticsMonitoringTool
jstat[Options]vmid[interval][count]
Options--选项,我们一般使用-gcutil查看gc情况还有其他选项如:
-class-compiler-gc-gccapacity-gccause-gcnew-gcnewcapacity-gcold-gcoldcapacity-gcpermcapacity-gcutil-printcompilation
vmid--VM的进程号,即当前运行的java进程号
interval--间隔时间,单位为毫秒
count--打印次数,如果缺省则打印无数次
-----------------------------------------------jstat-gcutil[pid]输出解释
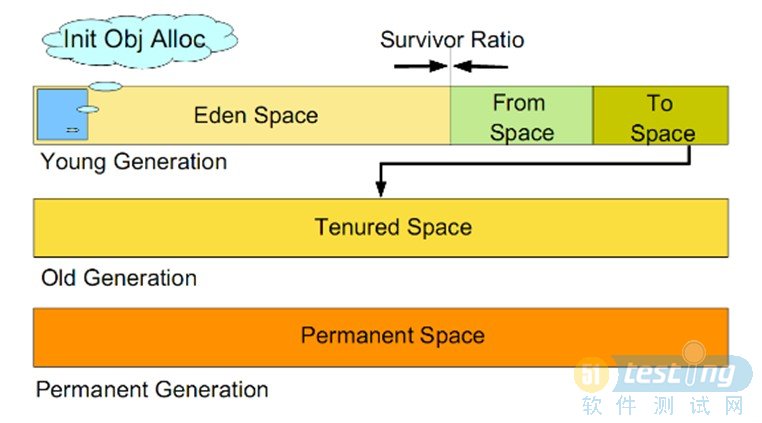
S0--Heap上的Survivorspace0区已使用空间的百分比
S1--Heap上的Survivorspace1区已使用空间的百分比
E--Heap上的Edenspace区已使用空间的百分比
O--Heap上的Oldspace区已使用空间的百分比
P--Permspace区已使用空间的百分比
YGC--从应用程序启动到采样时发生YoungGC的次数
YGCT--从应用程序启动到采样时YoungGC所用的时间(单位秒)
FGC--从应用程序启动到采样时发生FullGC的次数
FGCT--从应用程序启动到采样时FullGC所用的时间(单位秒)
GCT--从应用程序启动到采样时用于垃圾回收的总时间(单位秒)
3、jhat-JavaHeapAnalysisTool用于内存快照文件的分析,当然还有很多类似工具
4、jstatd-VirtualMachinejstatDaemon
5、jinfo-ConfigurationInfo
6、jvisualvm-JavaVirtualMachineMonitoring,Troubleshooting,andProfilingTool
7、jconsole-JavaMonitoringandManagementConsole
8、jmap-MemoryMapjvm内存分析工具,得到最普遍的使用。
jmap-histo<pid>b。log输出内存类占用,对比各时段的内存类,可方便知道回收情况和占用情况。
jmap-dump:format=b,file=heap。dump<pid>输出内存快照,可用许多开源工具分析内存快照。
jprofile太耗内存,如果静态分析能得出结论的可避免使用
9、jstack-StackTrace打印线程的堆栈跟踪信息
10、btrace-sun提供的检测工具,很好很强大,用于检测函数耗时等,微浸入。
而服务器端的资源监控多用Linux的shell命令如:top,free,vmstat,iostat,uptime等,详细用法不累述。
本次测试过程中遇到的几个误区和犯的错误:
1、jmeter关于线程组的线程数和ramp-up值的设置,如果设置ramp-up为1秒,线程数为10,我错误的理解为这就是一秒内的请求量。其实是jmeter一秒内启动了10个线程,这10个线程分别发送请求,知道服务器端返回后,再次发送。
这个错误的理解直接导致我们的一个异步接口(接口把数据保存在一个无上限queue中,另外起线程来消费)在压力测试过程中,被压垮,以为是内存泄露问题,其实只是我们的服务器没能力处理这样一个数据量。
2、在一个日志处理模块中的生产和消费者模型中,产生的线程过多。后经过配置修改了消费者和生产者的比例。但是在定位问题时,产生很多困难,因为不知道是什么线程出现这么多。程序中所有的线程必须命名才方便工具的观察,需要开发中规范和定义好。
3、对于任务类型的性能测试没有返回值,我们怎么观察任务处理一条记录的时间,或单位时间内处理记录的条数呢?开发 人员习惯在源代码中去修改,并做trace,更好的方法是采用btrace工具来跟踪方法的进出。它在监控方法的耗时,查看某些方法的参数值,监控内存使 用情况等一系列场合中使用。
4、开发错误的理解org。springframework。scheduling。concurrent。 ThreadPoolTaskExecutor类的corePoolSize和maxPoolSize和queueCapacity三者的关系。原以为 corePoolSize是启动时变初始化的核心线程数,如果还有任务需要执行,那么就会新建线程到线程池中,直到达到最大maxPoolSize的大 小。然后放不下的任务才浸入queueCapacity中存储。而实际情况确是:任务到达corePoolSize之后,就放入 queueCapacity的queue中了。造成我们的配置错误,引起串行的任务执行。
的确在开发功能测试中没有发现的问题,通过性能测试暴露了出来。除了这些bug之外,我们还确认了我们接口的性能,任务的性能和稳定性。