存储我们要讲两点内容:
实存管理:
存储我们只需要了解三种分配方法即 可:单一连续分配、固定分区分配、可变分区分配;其实我们经常讲对于一些不好区分的概念,我们画个表,把他们放在一起来进行对比,那么通过对比来理解,那 真的是太爽了;所以呢,我们也画个表,把这几个概念放在一起来进行区分和理解,看图:

这样一对比,我们就能看的出来,只有可变分区分配的空间是可变的;然后另外两个分配是静态的。其实顾名思义也就差不多能理解的差不多,没有难度的,我们再深入一点来了解:看几个图:
单一连续分配:

我们可以看得出来,把整个内存区画为一个区。它同一时间在内存当中只能装入一个程序,只能用于单用户、单任务的执行操作。
固定分区分配:

这个跟单一连续有相似之处,就是内存分配的还是比较固定了;但是这个分配还有自己的特点,就是把内存分为几个块,比如是:10K、22K、32K;那么 就会有可能能运行三个程序,当三个程序占用内存在这三个区域内的时候,我们就能运行。把这个分区给定死了,所以一旦有比这些区域要大的程序要运行,那么就 完蛋了,虽然总内存够用,但是也不能运行,因为分区分的太死了。
可变分区:
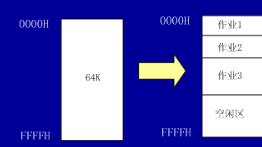
打个比方:有三个过程,一开始和单一连续分配是一样的,然后当有程序要运行的时候,就给该程序分配匹配的空间,当用完之后,释放出来之后,又能拼凑成一个空白的区域,回到最初的状态,特别灵活。
我们继续对可变分区分配方式进行探讨:
最佳适应法:选 择等于或最接近需求的内存自由区进行分配。这种方法可以减少碎片,但同时也可能带来更多小得无法再用的碎片。但是这个还算有弊端的,这个我们应该怎么理解 呢?比如我们有一个6K的空间,然后分配一个5K的空间给一个程序运行,那么剩余的1K一般来说就没法利用了,因为一般很少有1K的程序要运行,所以这个 1K就成了碎片了,那么循环下来的话,就有很多碎片产生了。但是相对来说,这个分配方法还算是挺好的。
首次适应法:首次就是寻找第一个可用的,可用就是寻找大于等于作业需求的内存的自由区分配给作业。这个的好处就是缩短查找时间。
最差适应法:选择整个主存中最大的内存自由区。比如我有一个5K的程序要运行,然后内存中最大的自由区是64K,那么一样把64K分配给5K的程序运行,然后剩下的59K自由区还能继续利用起来。
循环首次适应算法:不在每次都是从头开始分配,而是连续向下匹配。我们画个图来理解:
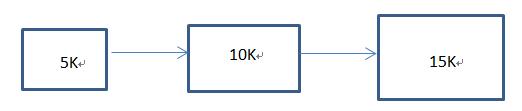
比如我们的内存是这么个分配,那么我们现在有个作业需要12K内存占用,我们就从5K、10K、15K连续查找合适 的,当找到15K的时候,我们就分配给12K,那么当我们剩余的3K的时候,刚好有一个程序是3K的需要分配内容来运行,要是我们按照首次适应法来进行分 配,因为首次适应法是每次都是从头开始的,所以我们就找到5K的区域,就把5K分配了;但是要是我们按照循环首次适应的话,我们是连续分配的,这样我们就 能刚好把剩余的3K分配给这个程序了;这就是首次和循环首次的区别;我这么讲应该没有问题了吧。
虚存管理:
页式存储存储管理:
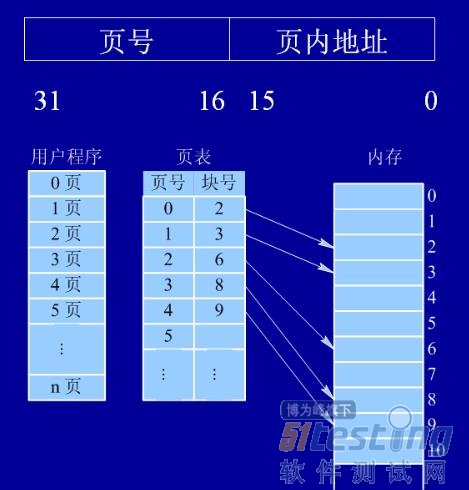
通过用户程序和内存的分块,用户程序分为n个页面,页表起记录的作用。接下来我们看地址转换图:
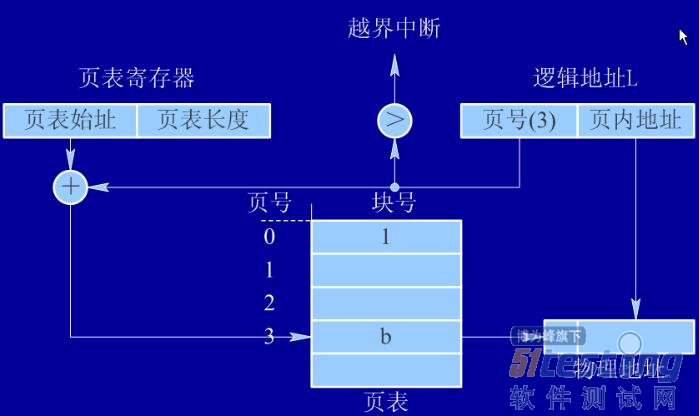
这个就是我们的地址转换器,我们想看这个是怎么个工作的,那么我们来看个例子,我们分析例子来进行理解:

我们设定页面大小为4K,图中的逻辑地址用十进制表示:我们来求a:
我们的过程应该是这样的,我们的逻辑地址是8644(十进制的),那么转换成二进制的为:10 0001 1100 0100;我们得知页面为4K=2的12次方,所以页内地址就为12位,所以a的后半部分为10 0001 1100 0100的后12位,为0001 1100 0100,那么剩下的最高两位为页号:10,转换成十进制为2,然后找出物理块号为8,8转换成二进制位1000,所以物理快号页内偏移拼合得1000 0001 1100 0100,化为十进制得33220。
其实只要我们懂得了这个过程,那么剩下的就是进制的转换了,不难。
段式存储组织
从用户出发,将一个程序分成几个块:

我们有页式存储的基础,这个就不在胯下,只是段的大小有点大。
我们再看看地址转换:

这个算法跟咱们的页式存储是一样的。大家动手试试。
存储讲起来挺有意思,我理解也许会有偏差,希望大家多多指正,不胜感激~