四、需求分析→数据库设计
从这开始,就真正进入项目实战啦。先说点体会,我刚开始接触编程的时候,都是编写一些小东西,往往都是半天或者一天什么的就编完了,那时候根本没想过做程序之前还要有需求分析。经过快两年的学习, 接触的都是比较大的系统,才明白没有需求分析的程序都太业余了,没有任何技术含量。对于一个系统来说,如果需求分析不到位,那么将有灾难性的后果,从这节 的小标题就能看出,需求是数据库设计的基石,需求定了,数据库基本上就定了,数据库定了,程序的基本功能也就定了。我们以一个简单的学生管理系统为例子, 来分析一下需求。分析需求地球人一般都是用UML图,啥是UML图呢,就是一种把程序用图形表示的标准,它可以表示需求、程序流程、程序模块、程序功能等 等,可以说,UML图画完了,程序基本上就出来了,目前比较好的画UML的工具是Rational rose,不多说啦,剩下的就交给google了。本系统的需求非常简单,就是老师可以添加、删除、修改学生记录,学生的记录包括:学号、年级、班级、姓名、性别、年龄、备注(这些就是字段)。根据这些叙述,我们可以画出UML用例图(用例图就是用来分析需求的):
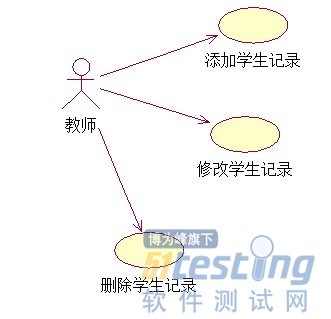
根据需求分析我们就可以设计数据库了,非常“简单”嘛,需要一个表就行了,把它命名为student表,里边添加刚刚提的那些字段就可以了。注意,数据 库中的一切,包括:数据库名、表名、字段名、存储过程等等,都要用英文,不可以出现中文,因为咱是专业菜鸟,不走业余路。接着往下看,教你如何创建数据 库。
作为专业教程,俺不会教你用鼠标建立数据库,咱们要用T-SQL语句建立数据库,也就是写数据库脚本。这样建立数据库,相当于留了个备份,无论到哪,只要有SQL环境,直接执行一下脚本数据就建好了,非常方便快捷,就算是第一次写脚本,也比用鼠标建立数据库快。在大型系统开发时,脚本还可以作为数据库维护的依据,非常有用。那么怎样写呢,打开SQL server 2005 Management Studio,输入帐号密码登录平台,然后点一下左上角的"新建查询"就可以打开查询分析器了,我们可以在这输入任何SQL语句。
第一步先创建数据库,我先把创建数据库的标准格式给大家:
create database studentManager
On primary
(
name=student_data,
filename='E:\SQL Server2008 SQLFULL_CHS\Microsoft SQL Server\MSSQL10.MSSQLSERVER\MSSQL\DATA\student_data.mdf',
size=3,
maxsize=unlimited,
filegrowth=1
)
Log on
(name=student_log,
filename='E:\SQL Server2008 SQLFULL_CHS\Microsoft SQL Server\MSSQL10.MSSQLSERVER\MSSQL\DATA\student_log.ldf',
size=1,
maxsize=20, |
相信看着这个很多人都蒙了,简单说一下,其实这么多代码,也就第一句最重要,意思是创建一个名字叫studentManager的数据库。On primary下边的是对数据库的一些初始设置,比如:路径、初始大小、增量等等。Log on下边的是对数据库日志的 设置,也是那么几项。很明确的告诉大家,除非是特殊需求,否则我们没必要管那么多,默认的就够咱们用了,创建数据库就一句话:create database studentManager,输入完后点一下工具栏上的“执行”,就搞定啦。数据库建完了,就该在数据库里建表了,还是先给出代码:
--指定数据库
use t_studentManager;
--创建t_student表
create table t_student
(
number varchar(20) PRIMARY KEY, --PRIMARY KEY 是主键约束
grade varchar(10) NOT NULL, --NOT NULL是非空约束
class varchar(10) NOT NULL,
[name] varchar(20) NOT NULL, --name属于sql保留字,所以用方括号括起来
sex varchar(1) NOT NULL CHECK(sex in ('男','女')), --CHECK约束,意思是性别字段只能是男或女。
age int NOT NULL,
remark varchar(100),
addTime datetime DEFAULT(getdate())--默认值约束,getdate()获取服务器时间
);
给大家解释一下,刚刚我们创建完数据库,在这要引用一下,也就是use,这样才可以在指定数据库中建表。
create table当然就是建表的意思了,在表名前最好加一个“t_”,表示是表(table),这样容易区分,而且专业。括号里的就是这个表中的字段,格式是: 字段名类型 约束,注意每个字段写完后边都要加逗号(最后一个就不用加啦),表示分隔。举这个例子,约束用的还是比较全的,重点说说约束。约束可是数据库中相当重要的 东西,它保证了数据库的安全和稳定,同时也保证了数据完整性。约束主要有6种,分别是:NOT NULL约束(非空约束)、PRIMARY KEY约束(主键约束)、FOREIGN KEY约束(外键约束)、UNIQUE约束(唯一约束)、CHECK约束(检查约束)、DEFAULT约束(默认值约束)。这些约束可以用在任何字段的后 边,一个字段也可以有多个约束,用空格分隔即可,比如上边的sex字段,就同时使用了非空约束和检查约束。当然,有些约束只能用一次,比如主键约束。我只 是提了一下这些常用约束,大家了解我的目的就达到了,以后具体用到,再去google,就怕你不知道有这些约束。在查询分析器中执行这段代码,表就建立好 了,提示一下:SQL查询分析器可以选中执行,也就是你选中那些代码就执行那些代码,建表的时候注意不要再次执行建数据库的语句哦。
五、优化数据库。
数据库设计是程序的根基,也是一门艺术。上一节我们设计的数据库,太随意了,什么都没有考虑,作为专业菜鸟,这样是不行的。
优化数据库,先要了解数据库设计三范式,简单说下:
1、第一范式:是指数据库表的每一列都是不可分割的基本数据项,同一列中不能有多个值,即实体中的某个属性不能有多个值或者不能有重复的属性。
2、第二范式:第二范式需要确保数据库表中的每一列都和主键相关,而不能只与主键的某一部分相关(主要针对联合主键而言)。
3、第三范式:第三范式需要确保数据表中的每一列数据都和主键直接相关,而不能间接相关。
这三个范式大致的意思就是:数据库中表的职责要单一,依赖关系明确,尽量减少数据库数据冗余。从网上查,可以查到很多个人理解,我在这也不理解 了,核心思想就是我刚刚说的。我首先声明,三范式只是一个整体的指导思想,并不可能完全遵从,有时候数据冗余未必是坏事,要考虑实际情况。
很明显,刚刚我们设计的数据库不符合三范式的要求。在此表中学生应该依赖的是学号,而我们冒昧的把班级、年级也放在了这里,学生当然也应该依赖 于班级、年级。这样一来,表就乱了,造成的直接后果就是数据不完整,比如我们由于失误,插入了一个年级是100的学生,而根本就没有100这个班级。这样 还有个比较大的问题就是数据冗余,因为我们每插入一个学生,不得不记录一次班级、年级,造成大量无用数据。所以我们要改,要把一个表拆成三个,分别是:年 级表、班级表、学生表。这样一来,数据库就显得漂亮多了。刚刚是一个表,我们还应付得过来,现在三个表,记不住了怎么办?别急,刚刚提到了UML图,它可 以用来设计数据库。在程序设计过程中,数据库中的每一个表,都会在程序中映射成一个类,而表中的每一个字段,都是类中的一个属性,它们的类型是一致的,我 们管他叫做实体类(可以提前google一下三层架构哦),这时我们可以借助于UML中的类图画出数据库的结构。如下图:
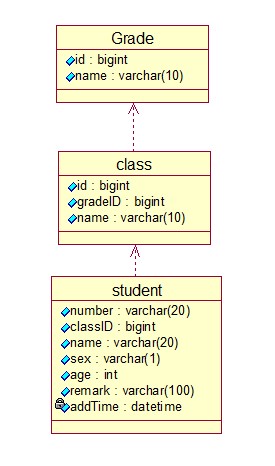
通过UML类图,清晰的描述了表之间的关系。所以,在大型项目开发中,必须借助工具设计数据库,展示数据库的结构和关系,这样我们才能优化、改进 数据库,数据库不是一下就能设计成功的,往往要根据需求的理解而发生变动。很多童鞋可能会问为什么用实体类,我只说一句话:用实体类便于在程序中对数据库 进行操作,实体类是对数据的打包,便于数据传递。剩下的就要去google啦~不多说。这下我们的数据库设计算是完工了,删掉原来的数据库,对照这UML 实体类图写优化后的数据库脚本,代码如下:
| --创建数据库
create database studentManager; --指定数据库
use t_studentManager; --创建年级表
create table t_grade
(
id bigint IDENTITY(1,1) PRIMARY KEY,
[name] varchar(10) NOT NULL
); --创建班级表
create table t_class
(
id bigint IDENTITY(1,1) PRIMARY KEY,
gradeID bigint NOT NULL,
[name] varchar(10) NOT NULL,
CONSTRAINT FK_class_gradeID FOREIGN KEY(gradeID) REFERENCES t_grade(id) --外键约束
); --创建t_student表
create table t_student
(
number varchar(20) PRIMARY KEY, --PRIMARY KEY 是主键约束
classID bigint NOT NULL,
[name] varchar(20) NOT NULL, --name属于sql保留字,所以用方括号括起来
sex varchar(1) NOT NULL CHECK(sex in ('男','女')), --CHECK约束,意思是性别字段只能是男或女。
age int NOT NULL,
remark varchar(100),
addTime datetime DEFAULT(getdate()),--默认值约束,getdate()获取服务器时间
CONSTRAINT FK_student_classID FOREIGN KEY(classID) REFERENCES t_class(id) --外键约束
); |
在讲代码之前,必须先说什么是外键约束,外键约束就是:A表的某个字段用到了B表的主键字段,那么A表中的这个字段就叫外键,A、B两个表间的 约束关系就叫外键约束。A表的外键字段必须依赖于B表的主键字段,如果向A表外键字段中添加一个B表主键字段中不存在的数据,那么将失败。外键约束保证了 数据的完整性和合理性。
这段代码,我还是要重点说说约束,与上一次创建表不同的是,不仅仅是表多了,而且最后多了外键约束,CONSTRAINT是创建一个约束,后边 接约束名;FOREIGN KEY代表该约束是外键约束,括号里写字段名,代表这个字段是外键;REFERENCES是参考的意思,也就是参考哪个表里的哪个字段,也就是主键在哪, 后边接"表名(字段名)"。其实我是故意把它写在最后的边的,外键约束也是约束,完全可以放在字段定义的最后边,也就是NOT NULL那个位置上,我这样写是想告诉大家还有另一种写法,所有的约束都可以类似这样写,就是换个位置,我现在提出来避免大家以后见到发蒙。需要注意的 是,创建表的括号里,无论是写约束还是写字段,都要用逗号分隔,千万别忘了。