本文主要作为优化查询性能的一些知识储备,感觉知识点有些散,不知道起啥名字好,独立成文又没有达到把每个点都说透彻那样的高度,且就当做创建合理索引的一个楔子把。本文对实际应用没有太大的指导意义,但可以加深我们对SQL Server理解,夯实我们的基本功,就像小说里面的武功一样,没有足够的内功基础,给你再好的秘籍你也成不了武林高手。
序言
写这篇文章时表示鸭梨很大,主要是对SQL Server的认识很有限,远远不足把这个话题说清楚,不过还是鼓起勇气写出来,也算作自己对索引认识的一个总结。索引这潭水太深了,应用场景不同,所建立的索引在有些情况下运行良好,有些情况下可能完全无效。而对于索引理解、认识层次不同,怎样建才比较合理的也是众说分云,用万金油的说法就是没有最合理的只有最合适的。一般来说最懂数据库的当属DBA,不过DBA却不懂业务,一般除了一些核心业务模块表建立及索引维护有DBA完成外,大多数情况下索引、SQL维护都是有开发人员完成的,因此我们通常认为的索引建立、优化都是有开发人员完成的(并不是我无视DBA,事实就是这个情况),可能有人疑惑了,DBA不维护索引、不写SQL那他们都干嘛吃去了,这个俺还真不知道,不过DBA很忙、很累我是知道的,估计、可能、大概会做以下事情:数据库并发、分发复制、性能监控、数据迁移、备份、日常维护、索引、SQL调优等等,DBA童鞋别喷我,我是真的不知道,DBA童鞋们可以留言告诉我下哈。
下面简单说一些暂时想到的对使用索引影响较大的几个注意点
页是SQL Server存储数据的基本单位,大小为8KB。
请一定要记住,页是SQL Server进行数据读写的最小I/O单位,而不是行。SQL Server中一个页大小为8KB,每8个页形成一个区,每页8KB,其中页头占用96个字节,页尾的行指示器占用2个字节,还有几个保留字节,也就是一个页8192个字节,能用了存储数据的实际约8000个字节,8000个字节一般可以存储很多行数据。即便SQL Server只访问一行数据,它也要把整个页加载到缓存并从缓存读取数据,我们通常所说的开销主要就是I/O开销,这点不少人都没有清醒的认知。
认识窄索引
很多书籍和文章都写过索引要使用窄索引,窄索引是个什么东东呢,大白话就是把索引建在字节长度比较小的列上,比如int占用4个字节,bigint占用8个字节,char(20)占用20个字节nchar(20)最占用40个字节,那么int 相对于bigint来说就是窄了(占用字节数更少),bigint比char(20)也要窄,char(20)和nchar(20)相比要窄(nchar(20)每个字符占用2个字节)。
明白了啥是窄索引我们来说下为什么要使用窄索引,我们知道数据存储和读取的最小单位是页,一个页8K大小,当使用比较窄的列做索引列时,每个页能存储的数据就更多,以int和bigint为例,一个8K的页大约能存储8*1024/4(int 4个字节)=2048(实际值要比这个数字小)条数据,使用bigint大约能存储8*1024/8(bigint为8个字节)=1024(实际值要比这个数字小)条数据,也就是说索引列的长度也小,每个页能存储的数据也就越多,反过来说就是存储索引所需要的页数也就越少,页数少了进行索引查找时需要检索的页自然也就少了,检索页数少了IO开销也就随之减少,查询效率自然也就高了。
认识索引的二叉树级数
SQL Server中所有的索引都是平衡二叉树结构,平衡树的意思是所有叶子节点到根节点的距离都相同,SQL Server进行索引查找时总是从索引的根节点开始,并从根跳到下一级的相应页,并继续从一个级别跳到下一个级别,直到达把可以查找键的叶子页。所有叶级节点到底跟的距离都是相同的,这意味着一次查找操作在叶读取上的成本正好是页的级数。索引级数大多为2级到4级,2级索引大约包含几千行,3级索引大约4 000 000行,4级索引能容纳约4 000 000 000 行,这点上聚集索引和非聚集索引上是一样的。一般来说对于小表来说索引通常只有2级,对于大表通常包含3级或4级。
索引级数也就意味着一次索引查找的最小开销,比如我们建立一个User表
CREATE TABLE Users
(
UserID INT IDENTITY,
UserName nvarchar(50),
Age INT,
Gender BIT,
CreateTime DateTime
) --在UserID列上创建聚集索引 IX_UserID
CREATE UNIQUE CLUSTERED INDEX IX_UserID ON dbo.Users(UserID)
--插入示例数据
insert into Users(UserName,Age,Gender,CreateTime)
select N'Bob',20,1,'2012-5-1'
union all
select N'Jack',23,0,'2012-5-2'
union all
select N'Robert',28,1,'2012-5-3'
union all
select N'Janet',40,0,'2012-5-9'
union all
select N'Michael',22,1,'2012-5-2'
union all
select N'Laura',16,1,'2012-5-1'
union all
select N'Anne',36,1,'2012-5-7' |
我们执行查询
| SELECT * FROM dbo.Users WHERE UserID=1 |
可以看到输出信息为
(1 行受影响)
表 'Users'。扫描计数 0,逻辑读取 2 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。 |
当表数据量增多至几千条时,执行上述查询逻辑读依然为2,当数据量到达百万级别时逻辑读会变成3,当到达千万、亿级别时,逻辑读就会变成4,有兴趣的童鞋可以亲自去试验下。
认识书签查找的开销
当使用非聚集索引时,若查询条件没有实现索引覆盖就会形成书签查找,那么一次书签查找的开销是多少呢?答案是不一定,一般为1到4次逻辑读,对于堆表(无聚集索引的表)来说,一次书签查找只需要一次逻辑读,对于非堆表(有聚集索引的表)来说一次书签查找的逻辑读次数为聚集索引的级数,在索引结构我们简单说了下大多数聚集索引的级数为2-4级,也就是说对于非堆表来说一次逻辑读的开销为2-4次逻辑读,下面我们做具体测试
创建非聚集索引 IX_UserName
| CREATE INDEX IX_UserName ON dbo.Users(UserName) |
执行查询
| SELECT UserID,UserName FROM dbo.Users WITH(INDEX(IX_UserName))WHERE UserName =('Bob') |
由于我们的查询实现了索引覆盖,没有书签查找,获取一条数据需要2次逻辑读

(1 行受影响)
表 'Users'。扫描计数 1,逻辑读取 2 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。 (1 行受影响) |
修改查询,返回列中增加CreateTime,这样就无法实现索引覆盖
| SELECT UserID,UserName,CreateTime FROM dbo.Users WITH(INDEX(IX_UserName))WHERE UserName =('Bob') |
可以看到这时发生了书签查找,同样返回一条数据,逻辑读达到了4次(索引查找2次,书签查找2次),由于我们的表Users为非堆表,故一次书签查找需要2次(聚集索引IS_UserID的级数为2)逻辑读
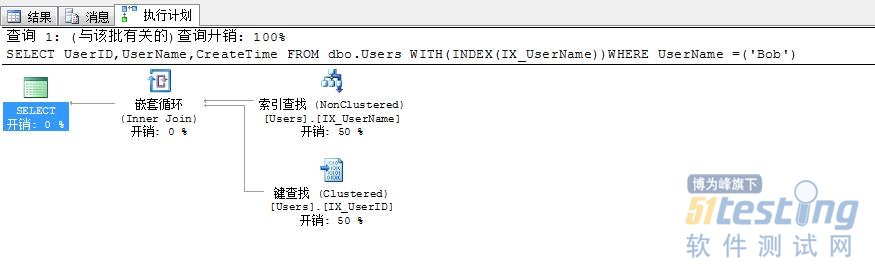
(1 行受影响)
表 'Users'。扫描计数 1,逻辑读取 4 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。 (1 行受影响) |
然后我们继续测试堆表的书签查找开销,删除表Users的聚集索引IX_UserID,使其变为堆表
| DROP INDEX IX_UserID ON dbo.Users |
再次执行我们的查询,可以看到逻辑读变成了3次(索引查找2次,书签查找1次),想想为什么堆表的书签查找次数少呢?
| SELECT UserID,UserName,CreateTime FROM dbo.Users WITH(INDEX(IX_UserName))WHERE UserName =('Bob') |
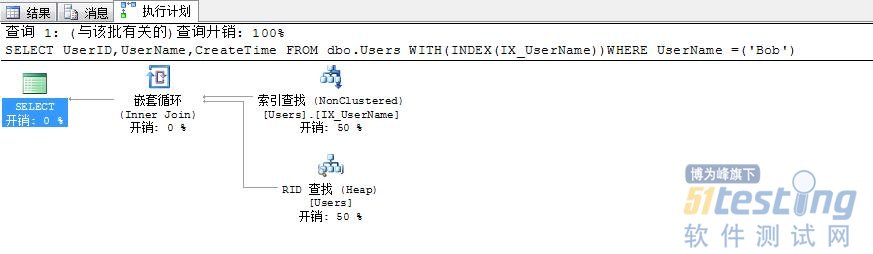
(1 行受影响)
表 'Users'。扫描计数 1,逻辑读取 3 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。 (1 行受影响) |
使用索引时的随机读
嗯,关于随机读我现在也有些迷糊,只是大概的知道发生随即读时即便需要的数据就存在同一页上,也会发生多次读取,而不是一次拿到整页数据后进行筛选。当进行where in查找或发生书签查找时,一定会使用随机读
首先我们看看聚集索引的随即读表现
--创建聚集索引IX_UserID
CREATE UNIQUE CLUSTERED INDEX IX_UserID ON dbo.Users(UserID) |
执行如下查询,可以发现在聚集索引上面使用where in时不管有没有找到记录都会进行聚集索引查找,而且查找次数固定为where in里面的条件数*索引级数,不知道为什么明明索引扫描有着更高的效率,查询优化器还是选择聚集索引查找,有知道的朋友还请告知下哈
--这个聚集索引扫描,返回记录7条,逻辑读2次
SELECT * FROM dbo.Users
--这个聚集索引查找,返回记录3条,逻辑读2次
SELECT * FROM dbo.Users WHERE UserID<=2
--这个聚集索引查找,返回记录3条,逻辑读6次
SELECT * FROM dbo.Users WHERE UserID IN(1,2)
--这个聚集索引查找,返回记录0条,逻辑读6次
SELECT * FROM dbo.Users WHERE UserID IN(10,20,22) |

(7 行受影响)
表 'Users'。扫描计数 1,逻辑读取 2 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。 (1 行受影响) (3 行受影响)
表 'Users'。扫描计数 1,逻辑读取 2 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。 (1 行受影响) (3 行受影响)
表 'Users'。扫描计数 3,逻辑读取 6 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。 (1 行受影响) (0 行受影响)
表 'Users'。扫描计数 3,逻辑读取 6 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。 (1 行受影响) |
我们再来看下非聚集索引的随机读,当然我这里为了演示特意使用了索引提示,实际应用中没事千万别加索引提示,当使用非聚集索引时查询优化器发现使用索引后效率更低时会放弃索引转为使用表扫描,我们这个例子中若去掉索引提示的话使用表扫描仅需要2次逻辑读就可以完成查询,这里仅仅是为了演示
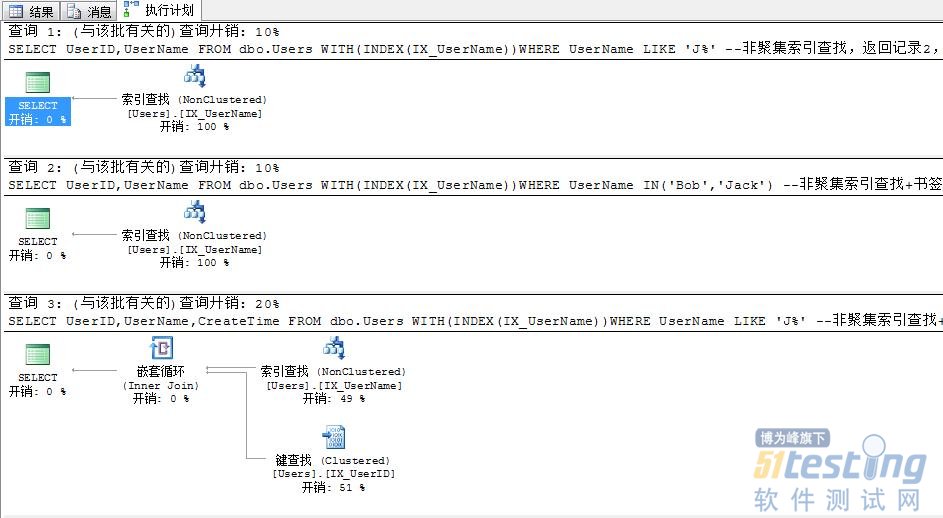
--非聚集索引查找,返回记录2,逻辑读2
SELECT UserID,UserName FROM dbo.Users WITH(INDEX(IX_UserName))WHERE UserName LIKE 'J%'
--非聚集索引查找,返回记录2,逻辑读4
SELECT UserID,UserName FROM dbo.Users WITH(INDEX(IX_UserName))WHERE UserName IN('Bob','Jack') --非聚集索引查找+书签查找,返回记录2,逻辑读6
SELECT UserID,UserName,CreateTime FROM dbo.Users WITH(INDEX(IX_UserName))WHERE UserName LIKE 'J%' --非聚集索引查找+书签查找,返回记录0,逻辑读2(索引查找2*1+书签查找2*0)
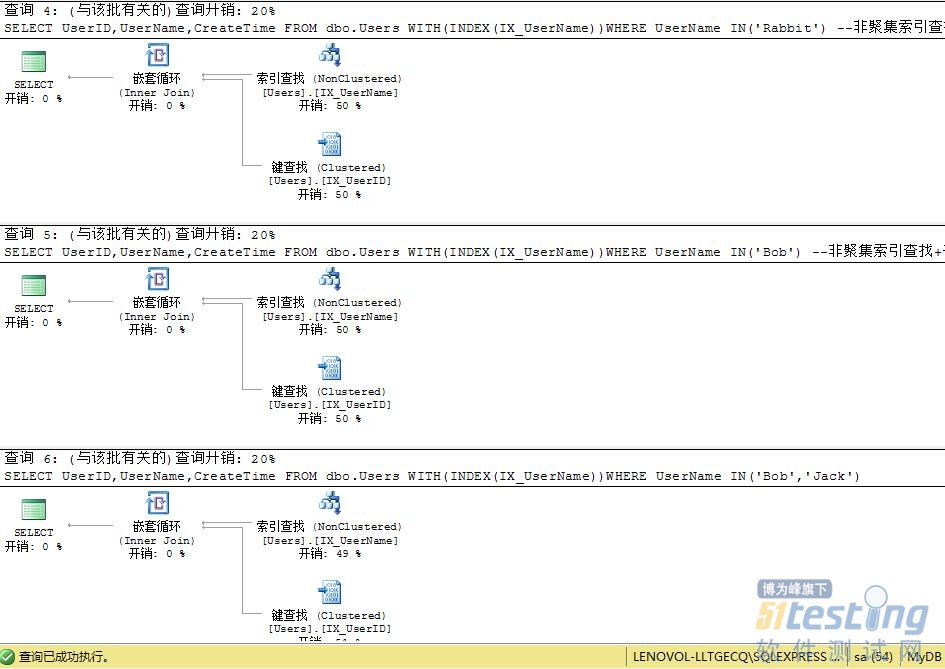
SELECT UserID,UserName,CreateTime FROM dbo.Users WITH(INDEX(IX_UserName))WHERE UserName IN('Rabbit')
--非聚集索引查找+书签查找,返回记录1,逻辑读4(索引查找2*1+书签查找2*1)
SELECT UserID,UserName,CreateTime FROM dbo.Users WITH(INDEX(IX_UserName))WHERE UserName IN('Bob')
--非聚集索引查找+书签查找,返回记录2,逻辑读8(索引查找2*2+书签查找2*2)
SELECT UserID,UserName,CreateTime FROM dbo.Users WITH(INDEX(IX_UserName))WHERE UserName IN('Bob','Jack') |
(2 行受影响)
表 'Users'。扫描计数 1,逻辑读取 2 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。 (1 行受影响) (2 行受影响)
表 'Users'。扫描计数 2,逻辑读取 4 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。 (1 行受影响) (2 行受影响)
表 'Users'。扫描计数 1,逻辑读取 6 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。 (1 行受影响) (0 行受影响)
表 'Worktable'。扫描计数 0,逻辑读取 0 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。
表 'Users'。扫描计数 1,逻辑读取 2 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。 (1 行受影响) (1 行受影响)
表 'Users'。扫描计数 1,逻辑读取 4 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。 (1 行受影响) (2 行受影响)
表 'Users'。扫描计数 2,逻辑读取 8 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。 (1 行受影响) |
总结:
认识书索引的查找开销、书签查找的开销、随机读的影响对我们具体创建索引和编写SQL有着积极的影响,毕竟对查询的的认识更加清楚了,我们在写索引和SQL时候才有更有针对性,最起码我们又知道了一个尽量不适用where in的理由,为什么要尽量规避书签查找,聚集索引查找不见得就一定高效,顺便留个问题:聚集索引扫描和非聚集索引扫描哪个有着更高的效率,什么情况下会发生非聚集索引扫描?
嗯,暂且写到这里,还是脑子里的墨水太少了,写点东西就感觉脑子里空荡荡的......
原文出自:http://www.cnblogs.com/lzrabbit/archive/2012/06/11/2517963.html