扩展性与硬件
随着系统的膨胀,硬件的可扩展性体现在增加资源,提高性能的能力上,如添加更多的处理器、内存等。
扩展性与软件
扩展性要求软件能够有效地利用硬件的能力,软件的设计应该支持并行计算。对于数据库引擎,这意味着服务器组件必须支持多线程计算,允许操作系统在所有处理器核心上执行并行任务调度。不仅如此,数据库引擎必须提供有效的方法,以在多核上分解工作负荷。举个例子,如果数据库只使用四个线程,那么它在四核处理器和八核处理器上允许,并不能体现出性能差异。
分布式设计
数据库引擎分割工作流,以充分利用硬件的能力并非易事,不是所有的数据库管理系统都能很好地支持并行计算。不仅仅是数据库引擎,数据库和其它系统资源都必须进行分割,以解决相互依赖性关系。因此,整个系统需要一个分布式设计。
例如,大多数数据库以B树架构存储索引。B树使得索引可以快速地定位数据,高效地插入、删除数据,但这需要保持“平衡”,即B树的树架构必须具有相同层级的叶节点。一个简单的插入或删除操作都可能打破这种平衡。这导致在多核、多线程之间B树的管理与共享非常困难。多个线程会频繁抢夺B树的根节点,这会导致性能瓶颈。
最小化共享资源
最小化共享资源的数量是扩展性的重要话题。最小化共享资源可以使不同的线程运行在不同的核心之上,而无需等待其它线程释放共享资源。如果线程缺乏独立性,即便增加处理器,性能也会大打折扣。
这个概念可以通过数据库管理系统RDM予以体现。RDM对分布式数据库有非常智能的支持,允许应用在不同的硬件之上进行数据的分布式计算,并能在不同的线程、进程之间尽可能地减少竞争。
多版本并发控制与同时访问
对同一数据的并发读写访问非常重要,多版本并发控制(MVCC)允许对同一数据进行并发读写访问,而不必阻塞线程或进程。MVCC可以让读进程在写进程访问数据之前访问数据的镜像,通过这种方式,保证了读写进程的并行操作。
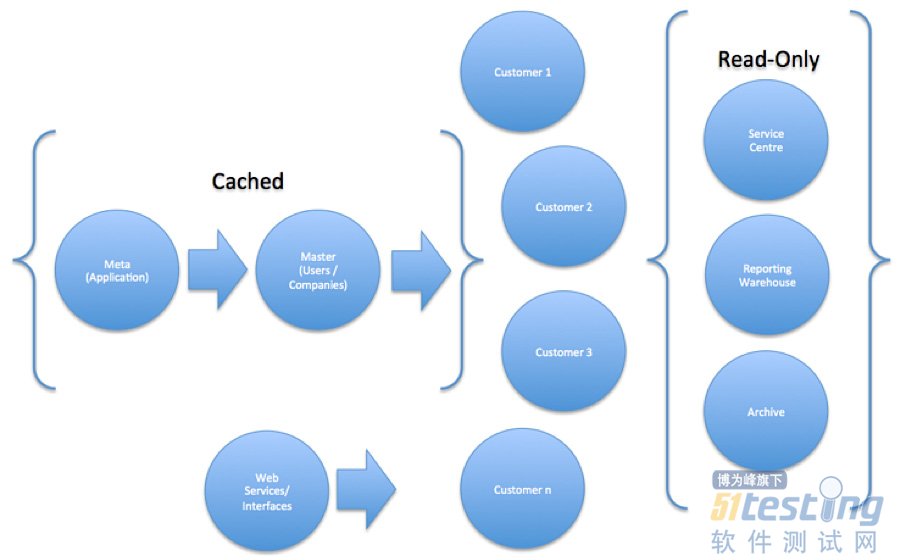
数据复制:高效的分布式技术
数据复制通过将主数据库复制为多个只读副本,成为了一种提高扩展性的有效途径。这样,远程服务器的处理器也可以读取和本地数据一致的副本,非常有助于降低访问主数据库的并发进程数目。
总结
简而言之,一个高度扩展性的分布式数据库架构应具备如下特性:
1、轻量级服务器的进程不应占用过多的CPU时间,而应通过我们的多个处理器并行运行多个实例。
2、客户端应用可连接多台服务器并从中提取数据。
3、通过数据复制技术,客户端应用可以从主数据库或从数据库中检索数据。