在CMMI四五级的软件公司中,建立过程性能模型是一个重点也是一个难点工作,很多公司无法建立过程性能模型,为什么呢?
1)数据不准
比如:
? 对于评审的会议,评审的参与人有的是来学习的,在统计人数、工作量时就不应该统计在内。
? 有的数据当时没有采集,而是靠时候回忆采集上来的。
? 有的代码行数不是通过工具统计上来的,而是靠人估计估计出来的。
2)过程不稳定
过程不稳定的原因可以细分为:
i)过程太大
比如:对于整个项目的工期偏差率建立回归分析模型,由于影响因子太多,每个因子都有影响,但是影响都不是很大,这样对于采集数据的要求,过程的稳定性等要求很高,很难建立起回归方程,因此此时需要划分项目的阶段建立每个阶段工期偏差率模型或者不去细致的分析影响因子,而是建立蒙特卡罗的模拟模型,或者分不同类型的项目建立回归方程。
ii)过程定义不稳定
在过程定义中定义的不够细致,对于过程成功的要点没有定义清楚,比如:
对于评审的流程,为了保证评审过程的稳定,应该要求:
● 评审的时长不能超过2小时。
● QA跟着每次评审控制会议不要过多讨论。
● 会议开始是要声明规则。
● 评审会与讨论会要分开。
iii)过程执行不稳定
在流程定义中有要求,但是实际执行时没有做到位,比如:
● 开评审会的时候进行了大量的讨论比如设计的评审会,所以会议的工作量、会议的时长都不准。在设计会议上讨论了设计方案的合理性。
● 会议的时间超过了2个小时,4个小时的评审会议,后边的2个小时效率很低的。
● 会议的主持人在会议上没有讨论的现象进行控制。
iv)过程的输入不稳定
不同的项目在执行过程时,投入差别太大,过程执行的前提条件不稳定,导致过程的输出也会不稳定。比如:测试过程投入的单位工作量,有的项目投入的多,有的项目投入少,而如果这些输入没有被识别出来作为因子的话,则方程就无法建立起来。
3)影响因子(X)识别不全
● 在识别对于Y的影响因子时没有识别出来关键的影响因子,比如测试过程的单位规模的测试工作量等;
● 识别了关键影响因子但是不好量化表达,采集数据有难度,比如人员的技术水平;
● 采集了关键因子的度量数据,但是数据不全,缺少样本点;
影响因子的识别需要经验识别,也需要统计的假设检验,也可以进行实验设计。
4)对于大过程建模,影响因子太多,每个因子相关性都不大
如果是对于大的过程建模,则可能存在如下的问题:
● 影响因子多,每个因子的相关性都不是很大;
● 影响因子多,采集数据有难度,对每个数据都要求很准确;
● 影响因子之间彼此有交互叠加的作用,有相关性,建模困难。
5)样本量太少
样本量太少,增加或删除一个样本对回归的结果影响很明显,则规律不具有典型性。比如,在下图中如果删除右上角的一个点,则两个变量之间就没有相关性了,如果删除了右下的2个点则两个变量之间就是相关的。之所以出现这种现象就是样本点太少而导致的。
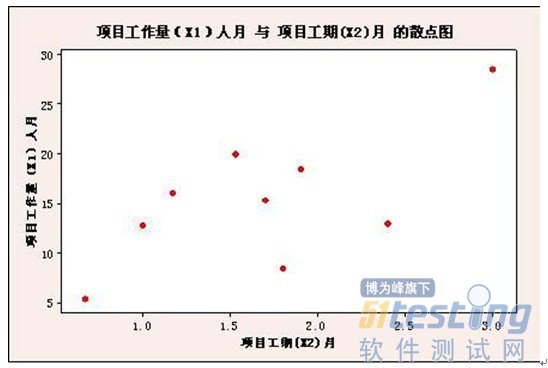
6)样本不随机
比如有2个变量X1,X2与Y都应该是正相关的,但是在实际中存在的数据却是:
| | 正相关 | 正相关 |
| Y | x1 | x2 |
| 中 | 大 | 小 |
| 中 | 小 | 大 |
此时如果对这些类型的数据进行分析,则表现出来Y与X1,X2是不相关的。
以测试过程为例,我们的经验与常识:
假设或常识1:高水平的测试人员找出的BUG多, 低水平的测试人员找出的BUG少。
假设或常识2:高水平的开发人员犯的错误应该少,低水平的开发人员犯的错误应该多。
我们的实际数据:
在实践中常常采用的策略:
策略1:关键的模块应该由高水平的开发人员进行开发,非关键的模块由低水平的开发人员进行开发。
策略2:高水平的测试人员要测关键的模块,低水平的测试人员测试非关键的模块。
如果是这样,对于测试过程做了度量以后,数据无法证明假设1和2的成立。
以上六个原因就是最常见的原因,这些原因在实际中克服起来并非那么容易,这也是为什么4-5级需要比较长的实施周期的原因。