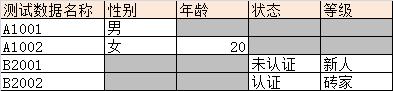
灰色的cell代表在这个场景下,该属性随便取什么值。在这个案例里,我们发现性别和年龄关系密切,而状态和等级关系密切,所以测试数据需要分开设计,我们建立A、B两个模型:
A模型是:
● user.性别 : {"男" , "女" , "不知道"}
● user.年龄 : {"10" , "20" , "30" , "40"}
B模型是:
● user.状态 : {"未认证" , "认证" , "删除" }
● user.等级 : {"新人" , "熟练手" , "砖家" }
每个模型都必须有一个唯一的名称,目的是为了方便测试设计和交流。比如这个Test Suite(一组Test Case的集合)需要使用A模型,那个Test Suite需要B模型。这里的A、B只是一个代号,真实工作中可以根据产品特点重新定义命名规则。
测试数据模型的真正内涵是:把业务逻辑关联最强的数据对象属性聚在一起建立group,并列举出需要的属性值,方便测试用例的设计,更为重要的 是,模型让开发和测试在围绕“测试数据问题”进行讨论的时候,有一个标准。由于模型里面已经封装了很多信息,只要指明模型的名称,交流就变得更加简单了。
当然文章里这个案例的逻辑非常简单,实际工作中并不需要测试数据建模,不过当数据对象比较多时,价值就能体现出来了。比如淘宝的下单,可能就会出现这样的数据模型:
● 商品.价格 : {"",""}
● 卖家.状态 : {"",""}
● 买家.所在地 : {"",""}
● 类目.XXX : {"",""}
复杂的数据模型,可能会有10个以上的数据对象属性。不过我们不能把所有对象属性,都堆在一个模型里,那样没有任何意义,我们需要根据业务逻辑 对属性进行分类,建立不同的模型,比如优惠、运费计算是不同的业务逻辑,因此需要建不同的模型。而围绕优惠这个概念,还会根据不同属性组合关系,建立多个 模型。
我想每个测试场景,需要建立的数据模型并不会很多,2、3个左右。数据模型必须是常用的,这样才有实际意义。时间久了,研发团队每个成员的脑海 里,对于测试数据模型的概念,会越来越深刻,甚至对于模型里的某个Test Case,如果被执行的次数够多的话,也会被大家记住。到时候Test Case也会需要名称,为了方便大家记忆交流。
在实际工作中,开发工程师经常反映,要执行某个Test Case,只修改某个数据对象(比如user)的属性,根本不够,必须要把多个数据对象(比如user、order、item)同时修改,才能完成。这其 实就是一个典型的需求:这个Case需要一个复杂的测试数据模型。
当测试数据模型被大家接受以后,我们就可以围绕模型做一些工具开发,来简化准备测试数据的工作。如果工具只能分别修改某个对象的属性,那么可用 性就不会太好,需要人为进行组合操作。如果工具能以测试数据模型为单元,就可以很快生成数据模型里的某个Test Case,这样会大大简化测试准备工作。
需要说明的是,本文是基于工作现状的推理,这种建模方式仅仅是“原型”,还缺少一些最佳实践。如果本文的论述能引起你的共鸣,欢迎你在自己的产品测试中试一试。