
退出
分支

合并
扩展图形
随机顺序访问

应用示例
下面以一个在线书店为例,假设我们已经得知以下信息:
● 有4种类型的用户:新用户、已注册用户、供应商、管理员。
● 所有的用户都从主页开始。
● 新用户和已注册用户可以做如下操作:
● 通过标题、作者、关键字搜索图书
● 添加到购物车
● 新用户可以注册成为会员。
● 会员可以登录、修改帐户信息、下订单、查看订单状态
● 管理员和供应商必须从主页登录,然后进入管理页面。
● 管理员可以添加新书、查看订单状态、更改订单状态、取消订单
● 供应商可以查看库存和销售的统计报表。
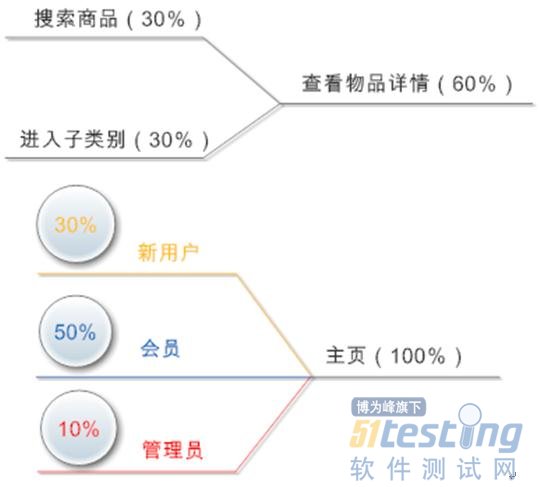
首先为每个类型的用户分别绘制模型图。根据已知数据来制定用户的操作路径、操作比例。
新用户[1]

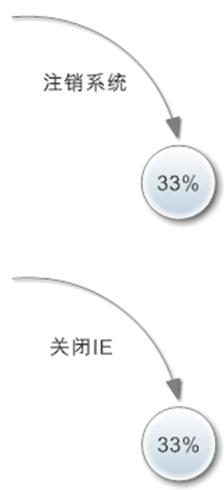
解释:假设有100个新用户,其中33个会进行多次搜索,有5个用户会因为没有找到相关书目而退出系统。其他的95个用户都可以找到所需书目并将其放入购物车中,这时会有20个用户没有创建账号直接退出,其他的75个用户都选择了创建账号。之后有45个用户成功提交了订单,另外30个只是保存了订单。最后有60个用户是通过直接关闭浏览器退出系统的,选择注销的只有15个。
会员
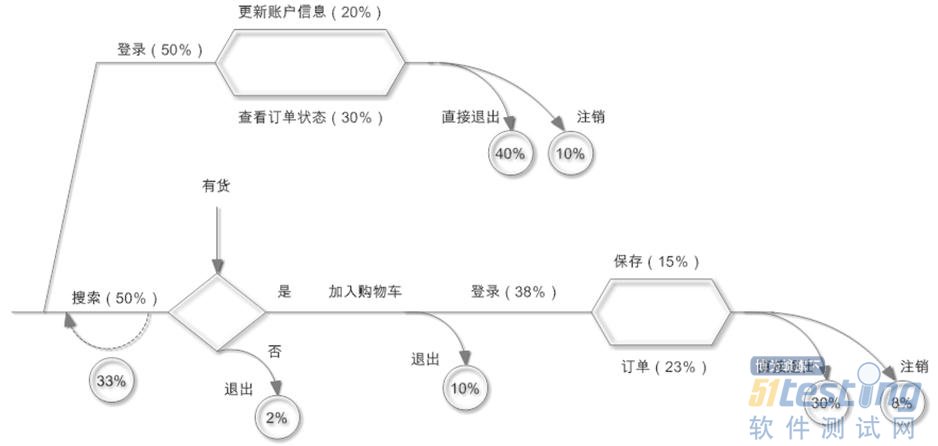
解释:100个会员,有一半是进行买书流程的,还有一半是进入账号进行信息维护和查看订单状态。
管理员

解释:管理员操作都需要从登录管理页面开始,操作最多的是查看订单状态(50%),其中有一半的订单需要修改,增加书目和取消订单都占25%。
供应商
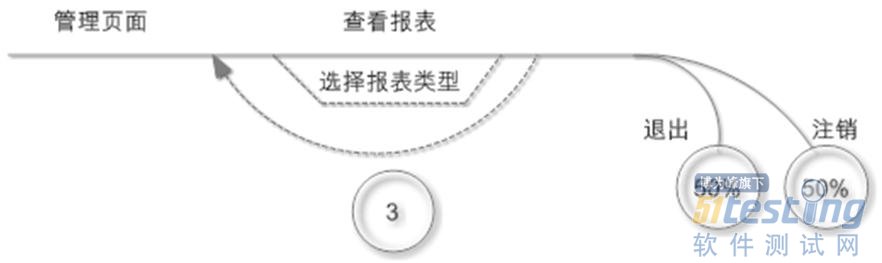
解释:供应商也需要从管理员页面登录。供应商用户只能进行查看报表操作,可以选择多种不同类型的报表进行统计,平均每个用户需要查看3种报表。
确定了各个用户角色的模型后,再根据各用户所占的比例,合并成整体用户群的使用模型。

解释:从整体考虑,新用户占20%,会员70%,管理员4%,供应商6%。不同类型的用户通过不同颜色来标识,所有的用户都需要从主页开始访问系统。此模型反应了系统的整体使用情况,也即测试场景需要模拟的压力。而测试场景中具体要执行的测试脚本,则主要根据各类型用户各自的用户模型来开发。
在绘制出模型图后仍然需要不断的同技术人员、业务人员沟通讨论,找出模型中不合理或者遗漏之处,并逐步完善,直到共同确认。甚至是测试结束后,也需要根据系统实际运行环境来不断调整,为后续的测试提供更准确的模型。
但只依靠模型图仍然不能有效的对压力进行描述,可以发现前文提到的种种基础数据信息目前还未得到使用,如用户操作的间隔时间、页面上需要输入的数据等等。没有模型,这些数据是缺少实用意义的;没有数据,模型图也无法得到应用。
--------------------------------------------------------------------------------
[1]分支百分比的两种表示方式:一是各分支的数值之和等于前一个节点的数值(本文采取的方式),二是各分支的数值之和总等于100%。两种方式各有优点:第一种的图形更直观,对观察者来说每一处的压力大小一目了然。第二种对于脚本的实现者来说更容易,实现测试脚本时无需再次换算,而且如果某一个节点有修改,无需考虑后续节点。