3.5 Exchange TiP v2——将TiP迁移到Windows Azure云端
虽然第一个版本的服务毫无疑问地已经为公司带来了收益,并且是度量和改进在线服务的主要工具,但是我们有一个大胆的计划,那就是处理当前服务存在的问题,并使它具有更大的价值。第一个版本中最需要处理的3个问题是:
将执行移到公司网络之外,来处理雷德蒙德地区的代理防火墙问题。
将测试执行的频率增加到5分钟一次或者更少时间。
将覆盖扩展到所有的数据库可用性组(Database Availability Group, DAG)和邮箱数据库。
我们考虑了几种方法来解决上述这些问题,如表3-4所示。
虽然我们还想维持现有测试执行用具的简单易操作性,但很显然的是,没有任何潜在可用的环境能够支持它。同时,与用具相关的所有报告、失效调查和工作流对于复合结果并不是非常有效,这使我们得出了一个结论:必须为测试更换执行夹具(harness)。最后我们决定将TiP基础设施移到具有平台优势的Windows Azure上面的运行。最值得骄傲的是,因为我们设计测试架构的方式,所以移动到另一个平台的时候不需要修改(事实上,我们只需要简单地将测试移到新的夹具,而不需要重新编译)。
表3-4 TiP框架潜在执行环境中的决策矩阵
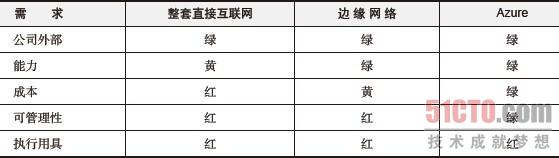
将TiP框架从测试实验室移到产品中,正是采用了TiP中将测试基础设施从实验室移到数据中心的思想。在这种情况下,我们进驻云端并构建了一个可扩展的、灵活的TiP服务。
图3-5中的框架以插图的形式说明了现在是如何执行产品测试的。通过使用Windows Azure,我们不仅具有了覆盖现有标度单位的能力,还具有了对之前无法预期的新场景进行模拟的功能(比如,在提交给客户之前,即便没有成千上万的用户,仍然可以对数百个用户并发地使用产品进行模拟)。随着时间的推移,这个框架当然会不断演进来满足日益增长的需求。
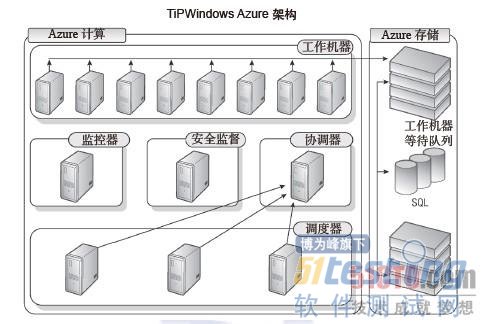
图3-5 Exchange TiP第二个版本的系统拓扑结构
3.6 我们的心得
TiP测试使我们可以找出数据中心上线过程中引入的问题和有时在产品中客户还没发现的问题。随着时间的推移,还可以让我们找出潜在问题、性能和总体功能表现的非常有趣的发展趋势。
3.6.1 合作方服务相关的问题
对TiP测试至关重要的一个组成部分就是:找出我们所依赖的并在其上进行构建的与合作方服务相关的问题。我们的服务,与几乎所有其他云端服务一样,依赖于许多特定领域相关的不同服务。例如,我们依赖Windows Live ID来提供专门的身份验证层。又如,命名空间管理和提供是依赖于在线域名服务的。在找出上面这些通过别的方面无法捕获的依赖问题方面,我们的测试是非常有帮助的。
3.6.2 云端监视的挑战性
Exchange作为服务很独特的一个方面是它的目标客户是IT专业人员,他们在升级到新的服务时总是非常谨慎,而且很多大客户都定制了一些写在Exchange顶层的产品。此外,有一些客户在混合模式下运行,而另一个客户仅仅只在公司的Exchange Servers中运行,也有一些是在云端运行的。在处理单个云端中版本的一些值得注意的、更持久的变化方面,标准监控解决方案设计得并不是很好。TiP测试在流经系统时,其版本和配置变化使我们能更好地在异构的云端测量和保证质量。这些挑战对于很多云端服务来说是非典型的,如Bing、Facebook、Twitter, 更多的是使用同构的和松耦合的服务架构来获取连续的部署模型。
尽管如此,我们的服务是分层的,且依赖于比Exchange团队更快速的发布周期。网络本身就是随着新的Firmware版本和访问控制列表(Access Control List, ACL)的改变而不断更新的一个层。当那些层发生灾难性的改变时,由监控服务(如Gomez 和Keynote)提供的黑盒方法会向运营中心发出警报,但是对于间歇型或边缘情况却不会发出警报。TiP使我们可以在这些依赖问题变成灾难性问题之前深入分析并捕获它们。在某些情况下,我们甚至可以在合作方服务升级过程中捕获问题,这样就可以提醒他们将这些变更进行回滚。
3.6.3 在线TiP测试所发现的一些问题
以下是通过TiP测试在产品中找到问题的一些样例:
都柏林(爱尔兰共和国的首都)的服务提供的一个队列挂起了,但是监控器并没有检测到。
检测到服务提供的延迟。
TiP检测到了Hotmail运行中断,Exchange团队可以暂停并等待Hotmail的修复。
Live ID运行中断影响了Exchange Cloud的客户;Live ID的运营需要进一步加强。
TellMe, 一个可以将电话在我们的系统和手机交换器(Quest/Verizon负责的地上通信线和T-Mobile的移动电话)之间转换的VoIP网关系统,需要对最终用户连接场景的运行中断进行监控。TiP是找出集成试点测试中所使用的电话号码故障的唯一方法。
也常用TiP测试来鉴定发生随时间不断流逝的间歇失效的根本原因(随着时间流逝出现故障的百分比,而不仅仅只是在单个事故中出现故障)。
3.6.4 聚集处理结果中的“噪声”
我们学到了很多关于对一个实时服务如何执行测试的知识。学到的第一点就是,这种自动化的运行并不简单。例如,因为是在公司防火墙后面运行的,所以只好按照雷德蒙德的代理服务器的路线来发送请求。这些代理服务器并非旨在拥有这种用途,所以导致了有时会出现请求丢失、主机查找失败和其他奇怪的网络故障等。这很快导致了第二种实现方法的出现,即在产品系统中运行自动化测试时,重要的不是个体的通过或者失败的结果,而是随着时间推移,这些结果的聚集体。聚集可以帮助识别一个问题是持久中断问题还是仅仅只是一次网络故障,因此可以将噪声级减少到足够低,这能对服务安全性进行更精确的提高。同时还可以帮助预测未来的发展趋势,而只通过简单地适时看一看统计结果是无法做到这些的。
【小窍门】
对细节过程进行监控是非常重要的,但留意总体趋势也同样重要。
当你注意到测试一个小时运行一次的时候,上述最后一点(关于噪声消减)就变得十分重要。这一频率受到测试执行框架上的内置假设的影响,即关于测试通过之后怎么配置(比如,假设每一个测试运行执行都必须出现在一个新部署的机器上)和关于测试本身是如何执行的。我们发现那些假设因为很多原因存在一些漏洞。
它们一个小时运行一次的另外一个原因是担心消耗太多的生产力。我们发现一个服务必须要留出一些额外的设备来支持实时网站监控、使用过程中的高峰和低谷、拒绝服务攻击和成长。如果以一个增长的频率,比如每5分钟一次,在每个产品簇中运行一个自动化功能测试集合来对服务的边缘进行检测,那么运行的这项服务的时间就太密集了,需要增加设备。但事实上,对许多IT组织来说,采购和安置专用硬件的成本太高,以至于他们觉得准备额外设备留作备用是很不可思议的。然而,随着转移到进行云计算并具有了对电脑和存储资源的动态增长能力,很多组织都能负担得起通过一些合理的额外设备构建一个服务以用于在线测试。
3.6.5 易犯的错误
我们得到的一个教训就是,测试自动化比由外到内的基本监控更完整,并且由于这些测试的质量不错,团队很快就想将TiP系统作为一个加强的监控解决方案。但问题是,我们不可能对频率为1小时的测试进行适时的反应,因为收集足够的样本来分析一个问题是否真的需要花费的太长时间。另一种办法是在测试中实施重试逻辑(retry logic),这样有可能进一步降低通过率并有可能因为瞬态问题而给你提供假阳性的结果(例如,因节流机制而引起发送信息失败)。
我们得到的第二个教训是,当处理横向扩展的产品系统时,如果没有一个类似的自动化测试横向验证策略,就有可能导致一种虚假的安全感。在最初的实施过程中,我们为每一个规模化单元的每个人创建了单个邮箱账户集合,问题是,规模化单元还有进一步的粒度分割,因为它们是由多服务器、可用组织和其他最初未说明的资源组成的。事实上,这意味着每个站点只能覆盖一个可用的组织或者邮箱数据库。这会导致事故不被基础设施所捕获的情形,因为规模化单元受到影响的那部分并不是我们所覆盖的那部分。
除了作为回归测试的金丝雀之外,TiP测试像我们的系统一样,应该将其当作更健壮的持续改进项目(continuous improvement project,CIP)中的一员来对待。与大多数CIP一样,高层管理人员的参与和带动是成功的关键。管理人员与团队的同心协力将保证工程团队获得支持以改善产品服务、弥补TiP和整个监控解决方案中其他元素(单服务器并且由外到内)的空缺。
3.7 总结
在线测试在这个快节奏的在线服务领域中是很有必要的,测试实验室中的自动化测试应该扩展到产品中去,因为没有哪一个服务是封闭的孤岛,持续执行那些贯穿和验证主要端到端(end-to-end)场景的测试用例,这将会增强简单的单服务器(SCOM)或由外而内(Gomez or Keynote)可用性监控。持续回归测试具有类似监视器的作用,可以针对服务运行中断向产品服务团队发出警报,而且该方法对于早期鉴定非用户影响的间歇性bug特别有用。
虽然本案例研究是基于Exchange的,但测试自动化的趋势,尤其是丰富自动化场景,在微软服务团队中发展非常迅速。同时,在产品云端运行这些解决方案的趋势也越来越受到关注。我们期待通过自动化测试来加强监视作用的这类活动会,在整个微软延续下去。
【小窍门】
在云端进行测试可能是你将来工作的一部分,从本章作者的这些经历中学习知识吧!
3.8 致谢
感谢Keith Stobie 和Andy Tischaefer的同行审校,并感谢Karen Johnston对本章进行审稿。
(连载完)
相关链接:
自动化测试最佳实践 连载一
自动化测试最佳实践 连载二
自动化测试最佳实践 连载三
自动化测试最佳实践 连载四
自动化测试最佳实践 连载五
自动化测试最佳实践 连载六
自动化测试最佳实践 连载七