
这是一个典型的Bug跟踪过程,设计者笃信只有完整的检查才会保证修改一个Bug的时候不会产生另外一个Bug。但是现实好像总是跟他作对,Bug返回率一直居高不下。于是设计者修订了流程,增加了几个步骤。他希望问题能够通过复查被发现出来。但是增加了流程以后Bug返回率反而提高了。
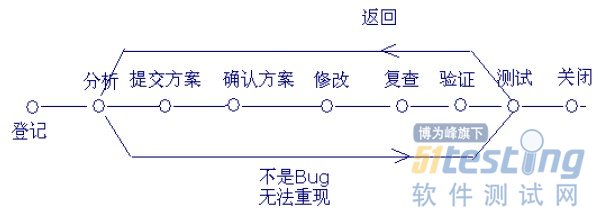
“这是人的问题!”流程设计者认为。
这不是人的问题,这是流程的问题。我说。
另外一个团队,并没有采用这样的模型,Bug返回率却很低,而且修改的时间明显的要短于前一个团队。他们采用的是这个流程:
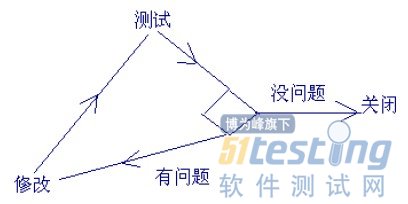
这个流程和前一个流程的最大区别在于测试是自动进行的,而且由开发团队自己进行管理。这是开发团队的内部流程,由测试团队提出的Bug,将会被首先整理成一组测试用例来进行复现,自动测试中的代码可以自由修改,所以,问题定位要快的多,并且修改了代码以后,可以马上对测试用例进行回归测试。很快就可以知道是否修改完毕。并且,对于有影响的模块,由于已经有了大量的测试用例,可以全部回归,从而避免了因为影响性分析不充分而造成的Bug返回,所以大大的降低了Bug的返回率。
我们为一家大型电信公司做咨询的时候,他们采用了比图1更加复杂的流程,还有上传修改代码和确认的过程,但是效果没有得到改善,而且所耗时间更长。在采用了我们帮助其完善的新流程以后,Bug修改时间和效果上都得到了大大的改善。
注:Bug返回率是指,开发团队将修改后的代码提交给测试团队以后,测试团队验证Bug修改状况,对于没有修改正确的Bug返回到开发团队的情况称作返回。返回个数占修改个数的比例称作Bug返回率。