
Facebook发布了Jest,一个开源的、基于Jasmine框架的JavaScript单元
测试工具。
Jest源于Facebook两年前的构想,用于快速、可靠地测试Web聊天应用。它吸引了公司内部的兴趣,Facebook的一名软件工程师Jeff Morrison半年前又重拾这个项目,改善它的性能,并将其开源。
在最基础层面,Jest被设计用于快速、简单地编写地道的JavaScript测试。Jest自动模拟require()返回的CommonJS模块,并提供了包括内置的测试环境Dom API支持、合理的默认值、预处理代码和默认执行并行测试在内的特性。通过在并行进程中同时运行测试,Jest让测试更快地结束。
Morrison说:
Jest的目标是减少开始测试一个项目所要花费的时间和认知负荷,因此它提供了大部分你需要的现成工具:快速的命令行接口、Mock工具集以及它的自动模块Mock系统。
此外,如果你在寻找隔离工具例如Mock库,大部分其它工具将让你在测试中(甚至经常在你的主代码中)写一些不尽如人意的样板代码,以使其生效。
我们已经在Facebook亲眼看到花更多的时间用于开发你的应用是多么重要(相对于花时间去准备开发你的应用),而这就是Jest关注并正在解决的问题。
Jest与Jasmine框架的区别是在后者之上增加了一些层。最值得注意的是,运行测试时,Jest会自动模拟依赖。Jest自动为每个依赖的模块生成Mock,并默认提供这些Mock,这样就可以很容易地隔离模块的依赖。Morrison说对于新测试,默认会进行隔离,开发人员现在也能够“完全控制”需要隔离多少模块。每个测试都可以指明哪些模块应该或者不应该Mock。
关于自动化Mock,Facebook的文档有进一步的说明:
实际上,Jest在测试环境中执行自己的require()函数。Jest的自定义require()函数加载真正的模块,检查它是什么样子,然后基于它所看到的创建一个Mock版本并返回。也就是说,Jest将给你一个与真实模块具有相同形状的对象,但它模拟每一个Export值而不是实际的值。
尽管Jest引入了自动化Mock,需要注意的是,开发者仍然可以使用jest.mock()和jest.dontMock()控制哪些应该或者不应该进行Mock。
来自社区的反应绝大部分都很正面。在Hacker News,用户Cthulu说:
看起来很有趣:我们现在的AngularJS项目的测试套件越来越慢,部分原因是逐渐增加的测试,但主要的性能瓶颈是:
没有并行,即使测试套件全部是独立的;
DOM测试,导致大量的GC暂停;
(可能是)PhantomJS启动和初始化(未度量)。
我已经做了简单的优化,将我的那些测试分成两半,开两个终端运行(开发时和持续测试中),但它看来有点玄。
直接应对依赖注入和AngularJS,Facebook说:“Jest使用不同的方法来达到相同的结果。”对于Angular,依赖作为参数进行传递,因此测试很容易写。然而,Facebook指出,为了Angular中函数的可测性,开发者必须遵循其特定模式,将其传递给Angular的依赖注入框架。Jest的解决方案略有不同:
Jest也能以Angular相同的方式Mock依赖,但它使用CommonJS,而不是构建一个特定的模块加载器。这让你能够测试任何使用CommonJS的现有代码,不需要重度重构以使其兼容其它模块系统。
用户Caiob认同关于Jest的乐观情绪,他也是这种依赖注入方法的拥护者,他说:“Facebook能够提升像Jasmine这样的现有/熟悉的工具,这非常棒。并且,我喜欢他们处理CommonJS模块的方式。”
Morrison说,通过Jest,Facebook希望开始这样一种趋势,让测试变得更简单,让开发者有更多时间开发应用。读者如果想参与这个项目,可以检出Github库并发送Pull请求,或者在Freenode加入#jestjs。
一. 说明
本讲解是在Windows2003 sp1操作系统下进行Bugzillal环境的搭建,其他
操作系统和各使用软件间的版本兼容没有进行
测试,如遇到问题可以大家共同讨论
学习。
二. 操作系统及使用软件
ActivePerl-5.8.8.817-MSWin32-x86-257965.msi
Mysql 4.1.19
Bugzilla-2.20.2
这里用到的软件在同目录software文件夹下
三. 正式开始搭建环境
推荐更改以下所有软件的默认安装路径,不要放在系统盘。此处我将安装主目录设在 D盘下,本文下面的路径均为此路径,自行安装更改为其他路径后请配置时也作相应修改。
还要说一下,在win下搭建
bugzilla确实太难了,因为本来就不是为
工作在win下而设计的,bugzilla也是在最近几个版本才加强了对win的支持。
3.1 安装IIS
我们这里是使用IIS发布bugzilla,Win2003默认不安装iis,所以我们需要首先在Win组件中安装,这个比较简单我就不详细说了。
控制面板-〉添加删除程序—〉添加删除win组件-〉应用程序服务器-〉IIS。勾选上点击下一步即可。
3.2 安装ActivePerl
我这里安装的是ActivePerl-5.8.8.817-MSWin32-x86-257965.msi。修改安装路径为:D:\usr\(根据国际习惯,也可以自己修改)。
3.3 安装mysql数据库
这个比较简单,双击安装程序,选择Custom安装,最好更改安装路径。之后就是安装。
安装过程中会让你注册帐号,我选择跳过。安装完成后选择配置mysql
选择standard configuration即可,如果想更为详细的配置可以选择detail,这里我们就不详细讲了。
点击next进入安装
数据库服务配置,制定服务的名字,是否以后可以通过命令行操作mysql,我们都勾选安装
再点击next进入帐户设置,必须为root用户设置一个密码,建议使用比较强壮的密码。
next后就可以点击execute来执行刚才你所做的设置了。
mysql安装全部完成。
3.4 Mysql的配置:
打开mysql的command line client
输入之前设置好的root密码,创建数据库bugs,用户bugs,密码为空。并赋予这个用户一定的权限。(因为bugzilla配置文件中默认是数据库bugs,用户bugs,密码为空,所以我们在这里设置好后往下进行就会较方便了。)
创建数据库:
mysql>create database bugs;
创建用户并赋予权限:
mysql> GRANT SELECT,INSERT,UPDATE,DELETE,INDEX, ALTER,CREATE,DROP,REFERENCES,LOCK TABLES,CREATE TEMPORARY TABLES ON bugs.* TObugs@localhostIDENTIFIED BY '';
刷新一下:
mysql> FLUSH PRIVILEGES;
mysql的设置就完成了。
3.5 安装bugzilla
将bugzilla 2.20.1文件夹所有文件全部拷贝到D:\bugzilla\下。在 开始-〉程序-〉运行 中输入CMD,进入D:\bugzilla目录下,运行 perl checksetup.pl 检查bugzilla安装所需模块是否都已找到,默认情况下是需要安装许多模块的,不用着急,这里我已经把所需模块都放到software文件夹下了:bugzilla-bundle.zip。解压缩这个zip包,放到D盘下,打开CMD,定位到这里,运行ppm,在ppm>下依次输入并回车:
install AppConfig.ppd install DBI.ppd install GD.ppd install GDTextUtil.ppd install MailTools.ppd install PatchReader.ppd install Template-Toolkit.ppd install TimeDate.ppd install Chart.ppd install DBD-mysql.ppd install GDGraph.ppd install MIME-tools.ppd |
即可安装完所有模块(中间可能某一个模块会提示安装失败,这时请安装完其他模块后再重新安装失败的模块) 。
再从命令行到D:\bugzilla\下运行 perl checksetup.pl,检查是否需要的模块都已经安装并找到了。是的话则会在目录下生成一个localconfig文件,这个文件是bugzilla运行时的配置文件。打开这个文件我们只需看一下用户名和密码那块是否和我们在mysql中设置的一样即可。
再次运行 perl checksetup.pl 会生成bugzilla需要的模版和数据库中的表。
输入exchange服务器(这个不要输入错误,因为bugzilla以后很多的操作都是需要发送邮件的,比如新建一个account后初始密码是发送到你的邮箱里的)。接着会让你输入管理员的邮箱地址,名字,密码
确认输入后即完成bugzilla的安装了。
再次输入perl checksetup.pl 确认数据库已经连接正常。修改D:\bugzilla\目录下所有cgi文件,去掉第一行的最后一个字符T。可以使用UE中“在多文件里替换”功能。
3.6 配置IIS发布bugzilla
打开IIS管理器,在默认网站下新建一个虚拟目录 ,名称为bugzilla(怎样发布你可以根据自己的需要来设置,这里我就先说我是怎样设置的,大概原理都一样),勾选虚拟目录的权限为“写入”(这个比较重要,不然后面的汉化无法设置),路径定位到D:\bugzilla\
在iis上右键选择“默认网站”-〉“属性”,点击“主目录”下面的“配置”,“添加”对cgi扩展名的解析
在“文档”中添加默认主页:index.cgi,并移到上面。
在web服务扩展中开启对perl的支持
好了,打开IE,在地址栏中输入http://127.0.0.1/bugzilla(因为我是设置为默认网站下的一个虚拟目录,所以要多加一个/bugzilla)察看一下吧,应该出现bugzilla的主页了吧
汉化比较简单,将汉化包(建议使用UTF8的那个)解压缩到bugzilla\template\下,文件夹更名为cn(里面默认有一个en,解压缩后注意查看一下结构是否一样),使用管理员账户登录bugzilla,点击 Parameters(系统参数设置)链接,将 languages 一项的值改为 cn,保存即可,回过头来看看你的bugzilla变成中文了吧。如果考虑到安全问题,我们可以在把IIS中的“写入”权限去掉。
如果服务器是在域中,则还需要在IIS的属性-〉目录安全性-〉身份验证和访问控制 中勾选“集成Windows身份验证”,这样管理员在bugzilla中所作的修改才能生效。
3.7 注意事项:
在将bugzilla汉化完成后还需作一些调整:
<Buzilla安装目录>\template\cn\default\list\table.html.tmpl。
将其中的 "bug_status" => { maxlength => 4 } , 改为 "bug_status" => { maxlength => 16 } ; "resolution" => { maxlength => 4 } 改为"resolution" => { maxlength => 16 } , 即将这两栏的长度由4改为16。存盘退出
为保证向后兼容,按照Bugzilla官方的建议,2.20版Bugzilla的汉化文件全部存为 UTF-8 格式。将 <Bugzilla安装目录>\Bugzilla\CGI.pm 的第55行改为 $self->charset('UTF-8')
打开 系统设置(Parameters), 找到 newchangedmail:一项, 将该项下文本框里面的 Subject: [Bug %bugid%] %summary% 改为 Subject: [Bug %bugid%] 吧, 或改为 Subject: Attention [Bug %bugid%] ---总之避开 %summary% 这个变量里面的汉字
四. 总结:
Bugzilla的测试环境搭建与安装全部讲述完毕,由于时间原因我没有对不同版本间的兼容性作试验,且这几种开源软件不同版本可能会有较大的变化,所以如果使用不同环境搭建时遇到问题,就只能大家一块来讨论解决了。
之前已经搭建了
测试需要的环境,也
学习了locateelements的方法,下面我们就来创建第一个简单的
自动化测试用例。
测试场景如下:
2.在搜索框输入关键字搜索,比如:webdriverautomationtesting
3.点击百度一下button
4.验证搜索结果是否包含输入的关键字
用例自动化测试代码实例如下:
packagecom.example.tests; importorg.openqa.selenium.By; importorg.openqa.selenium.WebDriver; importorg.openqa.selenium.firefox.FirefoxDriver; importorg.testng.Assert; importorg.testng.annotations.AfterMethod; importorg.testng.annotations.BeforeMethod; importorg.testng.annotations.Test; publicclassBaiDuSearchTest{ privateWebDriverdriver; privateStringbaseUrl; @BeforeMethod publicvoidsetUp()throwsException{ //LaunchFirefoxbrowser driver=newFirefoxDriver(); baseUrl="http://www.baidu.com"; } @Test publicvoidbaiDuSearchTest()throwsException{ StringexResult="WebDriverautomationtesting"; //Open百度homepage driver.get(baseUrl); //Locatesearchboxandinputsearchkeyword driver.findElement(By.id("kw1")).sendKeys("WebDriverautomationtesting"); //Click百度一下button driver.findElement(By.id("su1")).click(); //在结果页面找到第一个link并验证搜索关键字显示在链接中 StringactResult=driver.findElement(By.id("1")).getText(); Assert.assertTrue(actResult.contains(exResult)); } @AfterMethod publicvoidtearDown()throwsException{ driver.quit(); } } |
然后直接右击该
java文件选择runasTestNGtest,然后可以查看自动化
测试用例的执行了。
最简单的一个测试用例就到这里了。是不是很easy?
自动装箱和拆箱问题是Java中一个老生常谈的问题了,今天我们就来一些看一下装箱和拆箱中的若干问题。本文先讲述装箱和拆箱最基本的东西,再来看一下
面试笔试中经常遇到的与装箱、拆箱相关的问题。
一.什么是装箱?什么是拆箱?
在前面的
文章中提到,Java为每种基本数据类型都提供了对应的包装器类型,至于为什么会为每种基本数据类型提供包装器类型在此不进行阐述,有兴趣的朋友可以查阅相关资料。在Java SE5之前,如果要生成一个数值为10的Integer对象,必须这样进行:
Integer i = new Integer(10);
而在从Java SE5开始就提供了自动装箱的特性,如果要生成一个数值为10的Integer对象,只需要这样就可以了:
Integer i = 10;
这个过程中会自动根据数值创建对应的 Integer对象,这就是装箱。
那什么是拆箱呢?顾名思义,跟装箱对应,就是自动将包装器类型转换为基本数据类型:
Integer i = 10; //装箱
int n = i; //拆箱
简单一点说,装箱就是 自动将基本数据类型转换为包装器类型;拆箱就是 自动将包装器类型转换为基本数据类型。
下表是基本数据类型对应的包装器类型:
int(4字节)Integer
byte(1字节)Byte
short(2字节)Short
long(8字节)Long
float(4字节)Float
double(8字节)Double
char(2字节)Character
boolean(未定)Boolean
二.装箱和拆箱是如何实现的
上一小节了解装箱的基本概念之后,这一小节来了解一下装箱和拆箱是如何实现的。
我们就以Interger类为例,下面看一段代码:
public class Main { public static void main(String[] args) { Integer i = 10; int n = i; } } |
反编译class文件之后得到如下内容:
从反编译得到的字节码内容可以看出,在装箱的时候自动调用的是Integer的valueOf(int)方法。而在拆箱的时候自动调用的是Integer的intValue方法。
其他的也类似,比如Double、Character,不相信的朋友可以自己手动尝试一下。
因此可以用一句话总结装箱和拆箱的实现过程:
装箱过程是通过调用包装器的valueOf方法实现的,而拆箱过程是通过调用包装器的 xxxValue方法实现的。(xxx代表对应的基本数据类型)。
三.面试中相关的问题
虽然大多数人对装箱和拆箱的概念都清楚,但是在面试和笔试中遇到了与装箱和拆箱的问题却不一定会答得上来。下面列举一些常见的与装箱/拆箱有关的面试题。
1.下面这段代码的输出结果是什么?
public class Main { public static void main(String[] args) { Integer i1 = 100; Integer i2 = 100; Integer i3 = 200; Integer i4 = 200; System.out.println(i1==i2); System.out.println(i3==i4); } } |
也许有些朋友会说都会输出false,或者也有朋友会说都会输出true。但是事实上输出结果是:
为什么会出现这样的结果?输出结果表明i1和i2指向的是同一个对象,而i3和i4指向的是不同的对象。此时只需一看源码便知究竟,下面这段代码是Integer的valueOf方法的具体实现:
而其中IntegerCache类的实现为:
从这2段代码可以看出,在通过valueOf方法创建Integer对象的时候,如果数值在[-128,127]之间,便返回指向IntegerCache.cache中已经存在的对象的引用;否则创建一个新的Integer对象。
上面的代码中i1和i2的数值为100,因此会直接从cache中取已经存在的对象,所以i1和i2指向的是同一个对象,而i3和i4则是分别指向不同的对象。
2.下面这段代码的输出结果是什么?
public class Main { public static void main(String[] args) { Double i1 = 100.0; Double i2 = 100.0; Double i3 = 200.0; Double i4 = 200.0; System.out.println(i1==i2); System.out.println(i3==i4); } } |
也许有的朋友会认为跟上面一道题目的输出结果相同,但是事实上却不是。实际输出结果为:
View Code
至于具体为什么,读者可以去查看Double类的valueOf的实现。
在这里只解释一下为什么Double类的valueOf方法会采用与Integer类的valueOf方法不同的实现。很简单:在某个范围内的整型数值的个数是有限的,而浮点数却不是。
注意,Integer、Short、Byte、Character、Long这几个类的valueOf方法的实现是类似的。
Double、Float的valueOf方法的实现是类似的。
3.下面这段代码输出结果是什么:
public class Main { public static void main(String[] args) { Boolean i1 = false; Boolean i2 = false; Boolean i3 = true; Boolean i4 = true; System.out.println(i1==i2); System.out.println(i3==i4); } } |
输出结果是:
至于为什么是这个结果,同样地,看了Boolean类的源码也会一目了然。下面是Boolean的valueOf方法的具体实现:
而其中的 TRUE 和FALSE又是什么呢?在Boolean中定义了2个静态成员属性:
至此,大家应该明白了为何上面输出的结果都是true了。
4.谈谈Integer i = new Integer(xxx)和Integer i =xxx;这两种方式的区别。
当然,这个题目属于比较宽泛类型的。但是要点一定要答上,我总结一下主要有以下这两点区别:
1)第一种方式不会触发自动装箱的过程;而第二种方式会触发;
2)在执行效率和资源占用上的区别。第二种方式的执行效率和资源占用在一般性情况下要优于第一种情况(注意这并不是绝对的)。
5.下面程序的输出结果是什么?
public class Main { public static void main(String[] args) { Integer a = 1; Integer b = 2; Integer c = 3; Integer d = 3; Integer e = 321; Integer f = 321; Long g = 3L; Long h = 2L; System.out.println(c==d); System.out.println(e==f); System.out.println(c==(a+b)); System.out.println(c.equals(a+b)); System.out.println(g==(a+b)); System.out.println(g.equals(a+b)); System.out.println(g.equals(a+h)); } } |
先别看输出结果,读者自己想一下这段代码的输出结果是什么。这里面需要注意的是:当 "=="运算符的两个操作数都是 包装器类型的引用,则是比较指向的是否是同一个对象,而如果其中有一个操作数是表达式(即包含算术运算)则比较的是数值(即会触发自动拆箱的过程)。另外,对于包装器类型,equals方法并不会进行类型转换。明白了这2点之后,上面的输出结果便一目了然:
第一个和第二个输出结果没有什么疑问。第三句由于 a+b包含了算术运算,因此会触发自动拆箱过程(会调用intValue方法),因此它们比较的是数值是否相等。而对于c.equals(a+b)会先触发自动拆箱过程,再触发自动装箱过程,也就是说a+b,会先各自调用intValue方法,得到了加法运算后的数值之后,便调用Integer.valueOf方法,再进行equals比较。同理对于后面的也是这样,不过要注意倒数第二个和最后一个输出的结果(如果数值是int类型的,装箱过程调用的是Integer.valueOf;如果是long类型的,装箱调用的Long.valueOf方法)。
如果对上面的具体执行过程有疑问,可以尝试获取反编译的字节码内容进行查看。
Why Automation Testing
现在似乎大家都一致认同一个项目应该有足够多的
测试来保证功能的正常运作,而且这些此处的‘测试’特指
自动化测试;并且大多数人会认为如果还有哪个项目依然采用人工测试来保证代码的正确性的话,那简直是太落后了,太不可思议了。
但是在我现在的项目里,之前大部分的情况下我们还是在使用手动测试,项目依然在每周一次井然有序的上线着。当然有部分原因是因为项目业务和技术上的特殊性,但是这开始让我思考:我们究竟为什么要进行自动化?什么情况下该进行自动化?自动化测试使用与所有的测试场景吗?
我认为自动化测试对我们的项目之所以重要,有几点原因:
Automated Software Testing Saves Time
我们的项目现在以每周一次的频率上线,由于项目本身的特殊性,每次上线后就要进行一次大规模的手动测试来保证不会break任何已有功能。这样的测试每周一次的重复着,测试的内容也毫无变化,这消耗了团队成员大部分的时间和精力。所以引入自动化测试之后我们就能够运行自动化测试来完成这些重复性的
工作,节省了时间和不必要的劳动。
Team Morale Improves
并不是说如果没有测试我们就对自己的代码没有了信心。但是无论多么厉害的程序员都没有办法保证自己的代码能够100%毫无差错的运行,尤其是当这些代码需要和一个已有的项目结合起来运作的时候。当我们的代码和别的项目结合的时候,我们有时会担心我们的代码能够单独的运作,但是却会在集成后破坏一些原有的功能。特别是在这种情况确实发生过之后,这样的担心又会被进一步放大。自动化运行的测试能够在一定程度上保证我们的代码是按照我们的期待运作的,这就加强了开发人员对自己的代码的信心。并且这种信心不是出于程序员对自己的代码的欣赏,而是自己的代码能够真的经受检验后正常运作。同时,这样的信心也来自于自动化测试带来的第三个好处:
正是因为自动化测试可以覆盖到更多的人工测试需要花大量时间精力才能覆盖到的测试范围和深度,我们才能知道我们的代码在一定程度上已经能够经受住考验了,才能对自己的代码更有信心的继续后续的集成和开发。
Selenium是一个自动化浏览器的工具,常被用来做
web应用的自动化测试。它与其他的测试工具相比优势主要在于:
Selenium 测试直接在浏览器中运行,就像真实用户所做的一样。
Selenium webdriver可以运行在各种不同的
操作系统的众多浏览器平台上:
Internet Explorer 6, 7, 8, 9 - 32 and 64-bit where applicable Firefox 3.0, 3.5, 3.6, 4.0, 5.0, 6, 7 Opera 11.5+ HtmlUnit 2.9 Android – 2.3+ for phones and tablets (devices & emulators) iOS 3+ for phones (devices & emulators) and 3.2+ for tablets (devices & emulators) |
另外,selenium提供多种编程语言支持:
Java, Javascript,
Ruby, PHP, Python, Perl , C#。
在这么多的语言支持中,为什么我们选择了python呢?
首先,python是一门非常容易入门的面向对象的脚本语言。我在开始写python+selenium之前完全没有python的编程经验,但是由于它的语法相当简单,并且表意和英语十分接近,因此让人能在简单的
学习之后就快速的上手。
另外,作为一门脚本语言,相较于java来说就有了天生的优势:解释执行。这就意味着我写了几行代码,只需要一行命令就可以快速的运行起来看到结果,而不像Java那样需要漫长的编译打包等过程。完成同样的功能,python只需要一个py文件和一行命令,而java则需要整整一个project,然后编译打包发布等等。就算使用maven,也要进行很多相关的配置,过程相当麻烦。
在将python与selenium结合起来写functional test时,只需要在机器上配置好python的环境,下载selenium(easy_install selenium),编写测试代码,然后一句简单的命令:python xxx.py 就可以将测试代码运行起来。
How to Write Test Code
首先,我们需要将selenium webdriver的依赖加入我们的测试代码中:
from selenium import webdriver
webdriver组件包含了所有的WebDriver的实现,这样我们就可以使用selenium webdriver为我们提供的浏览器交互等强大的功能了。
driver = web driver.Firefox()
driver.get("http://www.google.com")
创建一个Firefox WebDriver的实例,driver.get方法将打开方法参数中给出的URL所指向的网页。这行代码将会等到指向的目标页面完全加载后才会把控制还给后续的代码。
得到了我们想要打开的页面后,我们就可以对网页进行一些基础的判断:
assert "Google" in driver.title
这个断言会判断网页的html <title>标签中是否包含“Google”这个字符串。这种断言很常见,可以用来判断打开的是否是我们期待的页面。
之后,在目标页面上,我们可以进一步的定位到每一个页面元素,与这些元素进行交互来模仿用户操作,测试元素的行为是否和我们预期的相符:
searchInput = driver.find_element_by_id("lst-ib") searchInput.send_keys("selenium") searchBtn = driver.find_element_by_name("btnK") searchBtn.click() |
WebDriver提供了多种的定位到元素的方法:
click()与send_keys()都是selenium.webdriver.common.action_chains.ActionChains中提供的与元素交互的方法。click()模拟了对一个元素的点击,send_keys()模拟了向一个元素输入一些键盘输入。其他的交互方法可以查看API。
最后,在完成了页面操作之后我们可以使用driver.close()或是driver.quit()来退出。这两者的区别是:close只关闭一个tab,quit则是关闭整个浏览器。
A Simple Demo
上面的代码严格来说并不像我们常常写的测试代码,它只是打开了一个网页并做了一些简单的操作而已。我们可以使用python提供的标准unittest库来把它写得更符合我们的测试代码的风格。使用unittest库后,我们能在terminal中看到测试报告。
import unittest from selenium import webdriver class GooglePageTest(unittest.TestCase): def setUp(self): self.driver = webdriver.Firefox() def test_click_all_links_on_page(self): driver = self.driver driver.get("http://www.google.com") length = len(driver.find_elements_by_tag_name("a")) for i in range(0,length): links = driver.find_elements_by_tag_name("a") if links[i].is_displayed(): links[i].click() driver.back() self.assertIn("Google" or "YouTube",driver.title) def tearDown(self): self.driver.close() if __name__ == "__main__": unittest.main() |
这段代码首先引入了unittest组件,然后使用我们熟悉的test case的风格写了一个测试用例,测试了Google主页上面的所有<a>标签点击,对每个打开的页面检查title中是否含有期待的关键字。测试结束后将自动关闭浏览器,并且在terminal中可以看到测试报告。
数据库查询不外乎4个步骤,1、建立连接。2、输入查询代码。3、建立查询并取出数据。4、关闭连接。
php连接mssql数据库有几个注意事项,尤其mssql的多个版本、32位、64位都有区别。
首先,php.ini文件中;extension=php_pdo_mssql.dll ;extension=php_pdo_odbc.dll 前面的分号去掉,对应的使哪种方式连接mssql。注意要重启服务使其生效。
一、建立连接
1、odbc
首先,在php程序所在的服务器设置odbc。这里32位和64位
操作系统有区别。32位的从控制面板中管理工具中的数据源(odbc)直接建立就可以了,64位的要运行C:\Windows\SysWOW64\odbcad32.exe
从这里面设置。注意:上面只的是数据库服务器为32为的,数据源设置服务器为32位和64位两种的情况。只要两个服务器建立的数据源位数一致就好。
下面是odbc建立连接代码。
$con = odbc_connect('odbc名称','用户名','密码');
2、连接mssql2000
$con = mssql_connect('数据库地址','用户名','密码');
3、连接mssql2008
$connectionInfo = array("UID"=>用户名,"PWD"=>密码,"Database"=>"数据库名称");
$con = sqlsrv_connect( 数据库地址,$connectionInfo);
二、输入查询代码
这个都一样,可以直接写入,也可以从mssql中验证好后复制过来。简单点说就是把一个sql语句赋值给一个变量。
类似下面代码
$query = "SELECT top 12 * 数据库名称 order by id desc";
三、建立查询并取出数据
1、odbc
$result = odbc_do($con,$query);
while(odbc_fetch_row($result))
{
$变量名称 = odbc_result($result, "字段名称");
}
2、连接mssql2000
$result = mssql_query($con, $query);
while($row =mssql_fetch_array($result))
{
$变量名称 = $row["字段名称"];
}
3、连接mssql2008
$result = sqlsrv_query($con, $query);
while($row = sqlsrv_fetch_array($result))
{
$变量名称 = $row["字段名称"];
}
在php5.3及以后的版本中不附带sqlsrv库了。所以要从
微软这里下载。
四、关闭连接
这个没有什么区别,分别是odbc_close();和mssql_close()和sqlsrv_close();
最后体会:php连接mssql比连接mssql的函数少了一些,但是也够用了。具体函数可以参考php官方手册或者oschina的php中文文档。
Tcpcopy传统架构在产品中实践遇到一些问题,要理解和解决问题深入了解Tcpcopy两种的架构的原理是必须的。当了解的越多就发现它不仅仅是一个工具,而需要掌握不仅仅是简单的几个使用命令。
Tcpcopy传统架构与新架构最大的区别:传统架构的intercept进程与
测试服务器在同一台机器上,新架构的intercept进程从测试服务器上offload出来,单独部署在辅助服务器上。下面分别对两种结构的原理详细介绍。
传统架构
Tcpcopy
传统架构下,在线机器上面抓取请求数据包,默认采用raw socket input 接口。raw socket(原始套接字)可以接收本机网卡上的数据帧或者数据包,可监听网络的流量和分析。可以通过3种方式创建这类socket ,这里只详细讲tcpcopy使用的函数。Raw_socket的原理和其它使用方式,可参考 http://blog.sina.com.cn/s/blog_9599e95101010w2g.html
抓包函数:int sock = socket(AF_INET,SOCK_RAW,IPPROTO_TCP)。 第一个参数表示协议簇, AF_INET 代表TCP/IP协议。第二个参数表示SOCKET类型。第三个参数表协议类型。该套接字可以接收协议类型为tcp(也可以设置其它协议类型)发往本机的IP数据包,不能收到非发往本机IP的数据包(IP软过滤会丢弃这些不是发往本机的数据包)。Tcpcopy利用Raw Socket只抓进来的包,而不能收到从本机发送出去的数据包这一特点,实现抓包的功能。系统在IP层会检查有没有进程创建这种类型的raw socket,如果有,这个包就会被复制一份并发送到这个socket的缓冲区,Tcpcopy就是通过这种方式来复制访问流量的。
在发包前,调用函数sock = socket(AF_INET, SOCK_RAW,IPPROTO_RAW),并且设置setsockopt(sock, IPPROTO_IP, IP_HDRINCL, &n, sizeof(n)),这样IP数据包头部就可以由用户自己编写(在不设置这个选项的情况下,IP协议会自动填充IP数据包的首部),Tcpcopy利用此函数将数据包的目的IP和端口改为测试机的IP和端口,如下:tcp_header->dest = remote_port;
ip_header->daddr = remote_ip;最后调用sendto函数发送包到测试前端机:
send_len = sendto(sock,(char *)ip_header,tot_len,0,(struct sockaddr *)&toaddr,sizeof(toaddr));
Intercept
测试机上Intercept进程主要完成的是对复制请求的响应包进行处理。复制的请求到达测试机经应用程序处理后的响应包如果不经处理,将会返回给线上客户端。Tcpcopy传统架构的使用需要Iptable这一工具辅助实现对响应包的处理。
modprobe ip_queue
iptables -I OUTPUT -p tcp –sport 2080 -j QUEUE
以上iptable命令,表示OUTPUT链从2080端口发出的包在IP层会被匹配发往目标QUEUE,而QUEUE是由ip_queue模块实现(http://bbs.chinaunix.net/thread-1941806-1-1.shtml).因此在使用iptable命令前,内核需要使用modprobbe命令加载ip_queue模块。有了以上两个步骤, 所有匹配到iptable命令的报文将会调用IP Queue模块的相关函数。
Tcpcopy服务器端的Intercept进程用如下方式创建Netlink socket:
int sock = socket(AF_NETLINK,SOCK_RAW,NETLINK_FIREWALL);
Netlink详细介绍http://linux.chinaunix.net/techdoc/beginner/2008/11/12/1044982.shtml。
NETLINK_FIREWALL协议有三种消息类型:IPQM_MODE,IPQM_PACKET,IPQM_VERDICT.其中内核通过IPQM_PACKET消息将刚才截获的返回结果包发送到Inercept。Intercept给内核发送一个IPQM_VERDICT消息告诉内核对这个包的裁决结果(DROP,ACCEPT)。Tcpcopy通过这样的办法将测试机上应用返回的结果截获丢弃,并由Intercept返回一个Ip header。 Tcpcopy利用这个特点保留了一个允许访问的ip列表,因为默认情况下访问测试前端机上应用服务所得到的结果会在IP层被drop掉,造成在2080端口上无法访问应用服务。有了这个白名单,即使是设置了iptables规则,在白名单内的机器上也是可以正常访问测试前端机上的应用服务的。
新架构
Tcpcopy
新架构的Tcpcopy进程的实现与旧架构相比差别不大,在线机器上面抓请求数据包默认采用raw socket input 接口,增加了采用pcap 接口抓包的功能。Libpcap是Packet Capture Libray的英文缩写,即数据包捕获函数库。该库提供的C函数接口用于捕捉经过指定网络接口的数据包,该接口应该是被设为混杂模式。常用的抓包软件Tcpdump就是在Libpcap的基础上开发而成的。Libpcap提供的接口函数实现和封装了与数据包截获有关的过程,工作原理不赘述,详细可参考http://www.cnblogs.com/coder2012/archive/2013/04/13/3012390.html。根据使用手册上的描述,新架构一般推荐使用Pcap抓包,安装命令如下:
./configure --enable-advanced --enable-pcap
make
make install
新架构和传统架构一样,默认使用Raw socket output 接口发包,采用Raw Socket命令发包命令如下: ./tcpcopy -x 80-测试机IP:测试机应用端口 -s 服务服务器IP -i eth0 。其中-i参数指定pcap从哪个网卡抓取请求包。
此外,新架构还支持通过pcap_inject(编译时候增加--enable-dlinject)来发包。使用pcap_inject发包有两点好处:1.可以避开在线机器在IP层的防火墙设置,因为tcpcopy进程复制过来的包源IP还是线上客户端的IP,在线机器上可能会被直接扔掉,在不能改变防火墙设置的情况下,采用pacp_inject直接从数据链路层发包,可以避开IP层复杂的防火墙设置;2.在压力比较大的场合推荐使用pcap_inject 来发包,根据测试结果来看合理利用pcap_inject 来发包可提高30%的性能(详见使用手册),但是pcap_inject发包需要知道数据包从在线机器发出下一跳的网卡地址,这需要使用tcpdump工具抓包获取.
Pcap发包命令:sudo ./tcpcopy -x 在线端口号@在线机器的出口网卡地址-测试机器的IP地址:测试机器的端口@下一跳网卡地址 -s 运行intercept的机器IP地址 -o 出口网卡设备 -i 抓包网卡设备。
测试服务器
新架构测试机部署上,需要更改其路由设置,目的是将测试应用程序的响应包路由到辅助测试服务器。以外网应用为例如下:
删除测试服务器的外网IP的默认路由
route del default gw 原外网网关IP
添加辅助测试服务器IP作为测试服务器的默认路由
route add default gw 辅助服务器的外网IP
这里的意思就是说,在测试服务器返回给客户端的响应走默认网关-辅助服务器的外网IP,但这台机器其实并没有开启路由模式,所以这些响应包到了辅助测试机后,会在ip层被drop掉,这样internet进程就可以在辅助测试服务器的数据链路层抓到这些响应包
辅助服务器
辅助服务器主要是用于捕获测试服务器转发过来的响应包,辅助服务器要确保没有开启路由模式cat /proc/sys/net/ipv4/ip_forward,为0表示没有开启。辅助服务器上采用的也是pcap抓取响应包,安装命令如下:
./configure --enable-advanced --enable-pcap
make
make install
辅助服务器intercept进程通过pcap抓取测试机应用程序的响应包,将头部抽取后发送给线上的tcpcopy进程,完成一次请求的复制。
小结:
Tcpcopy两种架构都是通过巧妙地应用一些网络工具和包实现其复制转发的功能,传统架构rawsocket+iptable+netlink,新架构pacp+route,通过对其深入的了解也拓展了许多网络知识,在之后遇到一些问题也可以比较清楚明白的去解释和分析。
对比两种架构的原理和实践中遇到的问题可以得出,传统架构更容易实施,但是由于它借助于linux的IP_QUEUE模块,其性能完全依赖于系统,在压力较大时性能表现较差;而新架构将测试机和辅助服务器分离开来,性能有所提升,但是在部署实施受硬件条件制约,比如测试机和辅助测试服务器需在一个网段等,同时需要用到的网络知识更多。在使用时,结合条件选择合适的架构。
相关文章:
Why Automation Testing
现在似乎大家都一致认同一个项目应该有足够多的
测试来保证功能的正常运作,而且这些此处的‘测试’特指
自动化测试;并且大多数人会认为如果还有哪个项目依然采用人工测试来保证代码的正确性的话,那简直是太落后了,太不可思议了。
但是在我现在的项目里,之前大部分的情况下我们还是在使用手动测试,项目依然在每周一次井然有序的上线着。当然有部分原因是因为项目业务和技术上的特殊性,但是这开始让我思考:我们究竟为什么要进行自动化?什么情况下该进行自动化?自动化测试使用与所有的测试场景吗?
我认为自动化测试对我们的项目之所以重要,有几点原因:
Automated Software Testing Saves Time
我们的项目现在以每周一次的频率上线,由于项目本身的特殊性,每次上线后就要进行一次大规模的手动测试来保证不会break任何已有功能。这样的测试每周一次的重复着,测试的内容也毫无变化,这消耗了团队成员大部分的时间和精力。所以引入自动化测试之后我们就能够运行自动化测试来完成这些重复性的
工作,节省了时间和不必要的劳动。
Team Morale Improves
并不是说如果没有测试我们就对自己的代码没有了信心。但是无论多么厉害的程序员都没有办法保证自己的代码能够100%毫无差错的运行,尤其是当这些代码需要和一个已有的项目结合起来运作的时候。当我们的代码和别的项目结合的时候,我们有时会担心我们的代码能够单独的运作,但是却会在集成后破坏一些原有的功能。特别是在这种情况确实发生过之后,这样的担心又会被进一步放大。自动化运行的测试能够在一定程度上保证我们的代码是按照我们的期待运作的,这就加强了开发人员对自己的代码的信心。并且这种信心不是出于程序员对自己的代码的欣赏,而是自己的代码能够真的经受检验后正常运作。同时,这样的信心也来自于自动化测试带来的第三个好处:
正是因为自动化测试可以覆盖到更多的人工测试需要花大量时间精力才能覆盖到的测试范围和深度,我们才能知道我们的代码在一定程度上已经能够经受住考验了,才能对自己的代码更有信心的继续后续的集成和开发。
Selenium是一个自动化浏览器的工具,常被用来做
web应用的自动化测试。它与其他的测试工具相比优势主要在于:
Selenium 测试直接在浏览器中运行,就像真实用户所做的一样。
Selenium webdriver可以运行在各种不同的
操作系统的众多浏览器平台上:
Internet Explorer 6, 7, 8, 9 - 32 and 64-bit where applicable Firefox 3.0, 3.5, 3.6, 4.0, 5.0, 6, 7 Opera 11.5+ HtmlUnit 2.9 Android – 2.3+ for phones and tablets (devices & emulators) iOS 3+ for phones (devices & emulators) and 3.2+ for tablets (devices & emulators) |
另外,selenium提供多种编程语言支持:
Java, Javascript,
Ruby, PHP, Python, Perl , C#。
在这么多的语言支持中,为什么我们选择了python呢?
首先,python是一门非常容易入门的面向对象的脚本语言。我在开始写python+selenium之前完全没有python的编程经验,但是由于它的语法相当简单,并且表意和英语十分接近,因此让人能在简单的
学习之后就快速的上手。
另外,作为一门脚本语言,相较于java来说就有了天生的优势:解释执行。这就意味着我写了几行代码,只需要一行命令就可以快速的运行起来看到结果,而不像Java那样需要漫长的编译打包等过程。完成同样的功能,python只需要一个py文件和一行命令,而java则需要整整一个project,然后编译打包发布等等。就算使用maven,也要进行很多相关的配置,过程相当麻烦。
在将python与selenium结合起来写functional test时,只需要在机器上配置好python的环境,下载selenium(easy_install selenium),编写测试代码,然后一句简单的命令:python xxx.py 就可以将测试代码运行起来。
How to Write Test Code
首先,我们需要将selenium webdriver的依赖加入我们的测试代码中:
from selenium import webdriver
webdriver组件包含了所有的WebDriver的实现,这样我们就可以使用selenium webdriver为我们提供的浏览器交互等强大的功能了。
driver = web driver.Firefox()
driver.get("http://www.google.com")
创建一个Firefox WebDriver的实例,driver.get方法将打开方法参数中给出的URL所指向的网页。这行代码将会等到指向的目标页面完全加载后才会把控制还给后续的代码。
得到了我们想要打开的页面后,我们就可以对网页进行一些基础的判断:
assert "Google" in driver.title
这个断言会判断网页的html <title>标签中是否包含“Google”这个字符串。这种断言很常见,可以用来判断打开的是否是我们期待的页面。
之后,在目标页面上,我们可以进一步的定位到每一个页面元素,与这些元素进行交互来模仿用户操作,测试元素的行为是否和我们预期的相符:
searchInput = driver.find_element_by_id("lst-ib") searchInput.send_keys("selenium") searchBtn = driver.find_element_by_name("btnK") searchBtn.click() |
WebDriver提供了多种的定位到元素的方法:
click()与send_keys()都是selenium.webdriver.common.action_chains.ActionChains中提供的与元素交互的方法。click()模拟了对一个元素的点击,send_keys()模拟了向一个元素输入一些键盘输入。其他的交互方法可以查看API。
最后,在完成了页面操作之后我们可以使用driver.close()或是driver.quit()来退出。这两者的区别是:close只关闭一个tab,quit则是关闭整个浏览器。
A Simple Demo
上面的代码严格来说并不像我们常常写的测试代码,它只是打开了一个网页并做了一些简单的操作而已。我们可以使用python提供的标准unittest库来把它写得更符合我们的测试代码的风格。使用unittest库后,我们能在terminal中看到测试报告。
import unittest from selenium import webdriver class GooglePageTest(unittest.TestCase): def setUp(self): self.driver = webdriver.Firefox() def test_click_all_links_on_page(self): driver = self.driver driver.get("http://www.google.com") length = len(driver.find_elements_by_tag_name("a")) for i in range(0,length): links = driver.find_elements_by_tag_name("a") if links[i].is_displayed(): links[i].click() driver.back() self.assertIn("Google" or "YouTube",driver.title) def tearDown(self): self.driver.close() if __name__ == "__main__": unittest.main() |
这段代码首先引入了unittest组件,然后使用我们熟悉的test case的风格写了一个测试用例,测试了Google主页上面的所有<a>标签点击,对每个打开的页面检查title中是否含有期待的关键字。测试结束后将自动关闭浏览器,并且在terminal中可以看到测试报告。
软件测试这个职业,相信大家都很熟悉了,只是传统的手工测试大家比较多见,觉得测试就是小case了,不就是拿着设备用手指点来点去吗?或者拿着鼠标在屏幕上不断点击吗?真有大家想象得那么简单吗?点击这事,也要知道你要怎么点,点了这个,下一个要点哪个?也要经过整体的规划的是吧!
其实测试就是一项有计划有活动,所有计划,就是要做很多准备
工作的,比如:写测试计划,
测试用例,测试用例又分很多种了。下面简单对android手机客户端测试做个全面的测试介绍。见下图。
自
谷歌提出云计算概念之后,大数据领域的发展就逐渐加速日新月异,云计算具体到实例,可以归纳为调度、均衡、容错、监控、运维等一整套操作海量数据的方案。有别于传统小规模或孤立体系产品,云计算生态圈存在错综复杂的系统级别关联,并行其中的不同架构和模块流转于超大规模的分布式软硬体资源中,很难划分出明显的界限。对于这样的产品体系,传统领域的
测试方案要么逐渐失效,要么作用域缩减到仅能覆盖体系末端。为了保证大数据平台的可靠性、稳定性和高性能,亟需构建一套与之相匹配的测试体系来衡量产品是否合格。
存在的问题
业界在大数据测试领域的探索始终没有停止过,以hadoop生态圈为例,与之相关的各类
测试工具自成一体,例如Hadoop本身通过mock出MiniCluster(包括MR和HDFS)用来为开发代码做功能验证,DFSIO/Slive等用来做压力和
性能测试;HBase则通过一系列模拟随机/顺序读写相关的工具来做性能测试。而我们自己的ODPS则通过HiveUT来完成功能覆盖和有限的性能验证。仔细梳理这些工具不难发现存在一些问题,列举如下:
1.这些独立的测试工具和体系很难被其他产品复用,比如说验证hadoop功能的MiniCluster上是不能搭建HBase的,也不能跑Hive。MR输出的默认Counters很难在HBase的测试调优中发挥作用。
2.各种工具之间对比性较差,例如DFSIO和Slive的输出结果几乎没有什么关联性;还有的时候同一个工具测不同版本,判断耗时、资源占用状况几乎相同,实际上某些第三方指标出现了变化,工具却不能很好的反映出来。
3.各种工具自身的运行效率无评判标准,被测目标无第三方监控依据。缺乏系统的绘制性能趋势图的能力。
4.传承性不够,跨产品使用的可能性较小,例如HBase的测试中,很少对HDFS的性能做一个预判,原因是相关的人员缺乏对HDFS体系的了解,对其工具可起到的测试作用缺乏理解。
5.工具易用性较差,几乎所有类似独立体系工具由于想在广度上覆盖尽量多的应用场景,因此使用了大量的参数用于配合用户不同的测试目的。
6.此类工具往往依赖产品自身架构来进行相关测试,缺乏完全独立于产品本身的第三方验证方式,如果产品相关联部分发生了变动,要么造成基于老版本的工具失效,要么可能会影响到测试结果的准确性。
诸如以上所述的问题,几乎存在于大数据测试领域的每一个角落,对于阿里数据平台的相关产品来说,随着时间的推移规模的扩大和业务的日渐繁忙,测试上的这些缺陷越来越无法容忍,构建一套与之匹配的分布式测试框架体系就成为了必经之路。为了构造这样一个测试体系,分布式测试框架与集群管理(DST)于2012年初应声而出,从雏形开始一步步构造成为如今拥有数十个页面、数万次构建、数千测试场景和报告,既可以应对复杂业务场景,也可以满足小版本单一功能快速集测需求的
自动化测试框架体系。
历史溯源
解决上述存在的问题,构造与之匹配的测试体系,就要从分布式测试框架与集群管理(DST)的历史说起,因为DST的发展过程恰恰正是解决上述问题的轨迹。以下是里程碑级别事件的时间线:
2012年1月,DST开始立项,第一行代码提交版本控制
2012年3月,场景管理(用于构造
测试用例)和实验室管理(用于调度执行测试)制作完成
2012年4月,指标配置器和指标计算模板配置功能完成
2012年5月,第一次执行从场景到调度,如今可供查阅这份古老的测试报告:隐藏
2012年5月,ganglia监控数据导入HBase成功,可供查阅第一份有监控数据的测试报告:隐藏
2012年7月,生成集测报告功能上线,最古老的一份集测报告:隐藏
2012年7月底,三线(BI线、广告线、搜索线)回归纳入DST调度体系,首次实现业务线自动化回归
2012年8月,实现基线对比功能,多个版本测试结果可自动进行趋势对比
2012年11月,数据魔方业务线回归纳入DST调度体系(由于对比工具的复杂性导致纳入体系的难度很大)
2013年1月,DST接入Kelude体系使用kelude接口进行用户认证管理和通知等功能
2013年2月,实现测试报告评审体系,通过工具引导流程,迫使测试报告必须通过开发、运维、测试的三方会审
2013年上半年,随着云梯1跨机房项目启动,DST最高接受超过7000台机器的平均每台150多个监控指标的同时导入
2013年3月,
配置管理上线,海量测试资源首次实现图形化调度管理
2013年12月,优化监控指标查询系统,将分级查询耗时优化到秒级查询耗时
2014年2月,集群管理上线,用户可以自由分配测试资源组装自己的测试集群,其中云梯1产品更实现了一键自动化部署
综上所述,最终构造成功的体系与架构可以从下面几张图来看:
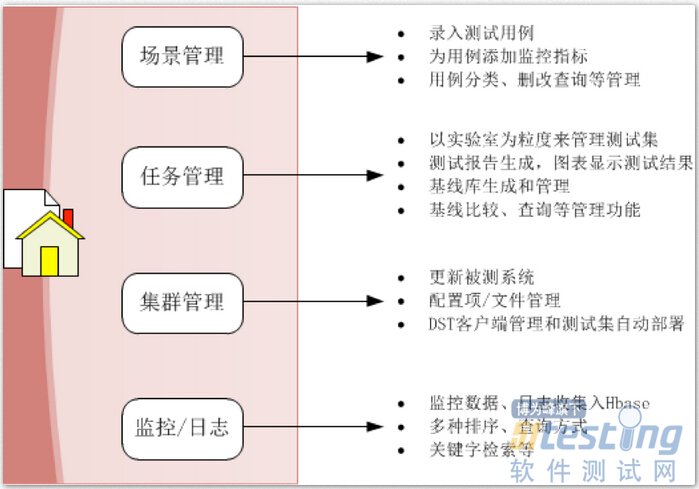
图:DST的构成
图:DST的体系架构
图:工具引导过程
问题的解决
回到我们刚才提到的6个问题上,DST通过场景管理促使用例复用和使用便利程度得以提升,通过监控体系的创新和改进,促使海量监控数据得到有效的管理和查询。此外,由第三方监控构成的性能评价系统能够排除产品本身的干扰,可以更客观的反应性能结果。
DST在大数据分布式测试上有三个优点:
1.分布式调度器。调度器采用总分的形式,由console调度多个agent执行测试代码,这样可以模拟出大并发产生的压力。好处是测试代码独立于被测目标,可以防止受被测目标的干扰,且测试代码的分发和结果的收集合并过程都由框架自动化实现,免去用户自行做分布式测试时候对测试结果收集整理的烦恼。
2.海量监控数据收集展示。DST将数据存储到HBase中,利用HBase的高效率和高容量保证了超过7000台机器的海量监控数据可以实时容纳到DST系统中。数据经过压缩整理,进一步提高了展示速度。业界在2013年2月左右出现一个开源产品OpenTSDB,有点类似这套系统。不同的是,OpenTSDB并没有利用在大数据监控领域使用广泛的成熟产品ganglia来收集监控数据,虽然在数据存储和性能效率方面更好一些,但是并不适用云梯1产品线的测试。
3.集群管理实现动态测试资源调整。云计算最大的特点是集群和计算资源的动态伸缩,对于测试来说,为了获得不同规模下的性能数据,需要不断调整测试资源的大小,而每一次调整过程通过人工去实现都非常繁琐。DST通过集群管理实现了自动化调整测试资源,图形界面使得配置更加直观,测试资源的利用率状况也可以一目了然。此外,用户独占互斥锁的存在也避免了同一个资源被其他测试目标污染,有效保证测试的可靠性。
DST在设计成功后,于2013年初引入其他非大数据产品中,依托高度自由的框架体系,帮助用户在不同的产品中构建复杂的测试场景。
图:2014年4月新建实验室与调度次数分布
分布式测试体系架构成功后,DST进入了产品推广阶段,我们认为DST更适用于以下测试场景:
1.被测目标是一个后端服务。无论是独立单机还是多机集群,通过简单的一键部署监控工具后,被测目标就将被纳入DST监控体系。同时,可以通过简单地配置将JMX端口监听起来,用于收集JVM的各项指标信息。
2.性能、压力和稳定性测试。这些场景往往测试耗时较长,人工值守存在很大的困难,对结果数据的分析也比较困难。接入DST系统后,除了实现无人值守,自动报警通知用户之外。当监控数据的量也比较大的时候,通过指标模板的自动化计算更方便阅读和查找问题。稳定性测试更是可以揉入多个实验室,通过不同工作机的调度实现非常复杂且真实的用户实际使用场景。
3.需要高效利用测试资源的产品。集群管理使得用户间沟通成本大大降低,测试资源的利用状况一目了然,每日报表更可以看到哪些产品的测试更为繁忙。
4.多机联合制造负载。被测目标需要足够大的压力才能得出准确的测试结果,而且测试场景构造复杂,通过LR之类工具实现,要么难度太大,要么根本不能实现。DST通过分布式调度器,将测试代码自动分发,并实现结果的收集整理。而最关键的是,整套runner完全可以由用户自行编码订制,自由度与方便性并存。
5.有指标监控需求的产品。监控体系纳入后,结果更加准确,有利于对被测目标的精致观察。
6.存在大数据工具的复用和传承需求。由于DST中已经积累了数千个测试场景,因此用户在接入相关产品时便可以利用已有的测试场景来验证被测目标。例如,当Hive接入测试时,可以通过Hadoop的基准测试判断环境是否已经完备,发现bug时也更方便定位是Hive还是Hadoop上的问题。
前景展望
DST架构体系的建成并非一蹴而就,期间经历了复杂的论证、摸索、重构和优化。其中仅监控收集一块,由于完全是创新的产品,在多次摸索中推翻了数种方案,对其进行的优化更是持续数月。在DST推进的过程中,业务测试的需求成为其改进优化的第一源动力。例如早期云梯1由于监控数据存储在mysql中,导致100台机器的监控数据仅需两三周就可以撑爆mysql服务器,而每次测试报告的生成往往耗时达数小时。这一切在DST系统中,由于采用海量存储的缘故,得以缩短到秒级展现。此外,由于调度的自动化,收集体系的自动化,测试环境运维的自动化,促使云梯1回归集测从长达月余,缩短到最快4天以内。
对于DST来说,目前将会跟随项目脚步,逐步实现对云梯2相关的性能、压力和稳定性测试的需求。未来的工作集中于三个方向,一个是纳入神农监控体系,实现调度执行与神农监控数据的对应关系;第二个是指标的收集整理,云梯2相关指标数量巨大,理清这些将会方便用户的测试目的性;第三个是构造各种测试场景,用于对云梯2进行多角度的验证。
分布式测试体系的构建依然任重而道远,以数据为己任,为数据的流转,计算的调度保驾护航是这套体系的价值所在。能跟随这个世界级规模的海量数据平台前行,见证这一切,既是人生之幸,也是责任之所在。